Embed Size (px)
Citation preview

2
POS Tagging Problem Given a sentence W1…Wn and a tagset of lexical
categories, find the most likely tag C1..Cn for each word in the sentence
Note that many of the words may have unambiguous tags
ExampleSecretariat/NNP is/VBZ expected/VBN to/TO race/VB
tomorrow/NNPeople/NNS continue/VBP to/TO inquire/VB the/DT reason/NN
for/IN the/DT race/NN for/IN outer/JJ space/NN But enough words are either ambiguous or
unknown that it’s a nontrivial task

3
More details of the problem
How ambiguous? Most words in English have only one Brown Corpus tag
Unambiguous (1 tag) 35,340 word types Ambiguous (2- 7 tags) 4,100 word types = 11.5%
7 tags: 1 word type “still” But many of the most common words are ambiguous
Over 40% of Brown corpus tokens are ambiguous Obvious strategies may be suggested based on intuition
to/TO race/VB the/DT race/NN will/MD race/VB
This leads to hand-crafted rule-based POS tagging (J&M, 8.4) Sentences can also contain unknown words for which tags
have to be guessed: Secretariat/NNP is/VBZ

4
POS tagging methods First, we’ll look at how POS-annotated corpora
are constructed Then, we’ll narrow in on various POS tagging
methods, which rely on POS-annotated corpora Supervised learning: use POS-annotated corpora as
training material HMMs, TBL, Maximum Entropy, MBL
Unsupervised learning: use training material which is unannotated
HMMs, TBL

5
Constructing POS-annotated corpora
By examining how POS-annotated corpora are created, we will understand the task even better
Basic steps 1. Tokenize the corpus 2. Design a tagset, along with guidelines 3. Apply the tagset to the text
Knowing what issues the corpus annotators had to deal with in hand-tagging tells us the kind of issues we’ll have to deal with in automatic tagging

6
1. Tokenize the corpus The corpus is first segmented into sentences And then each sentence is tokenized into
unique tokens (words) Punctuation usually split off
Figuring out sentence-ending periods vs. abbreviatory periods is not always easy, etc.
Can become tricky: Proper nouns and other multi-word units: one token or
separate tokens? e.g., Jimmy James, in spite of Contractions often split into separate words: can’t
can n’t (because these are two different POSs) Hyphenations sometimes split, sometimes kept
together

7
Some other preprocessing issues
Should other word form information be included? Lemma: the base, or root, form of a word. So, cat and cats
have the same lemma, cat. Sometimes, words are lemmatized by stemming, other
times by morphological analysis, using a dictionary & morphological rules
Sometimes it makes a big difference – roughly vs. rough Fold case or not (usually folded)?
The the THE Mark versus mark One may need, however, to regenerate the original case
when presenting it to the user

8
2. Design the Tagset It is not obvious what the parts of speech are in any
language, so a tagset has to be designed. Criteria:
External: what do we need to capture the linguistic properties of the text?
Internal: what distinctions can be made reliably in a text? Some tagsets are compositional: each character in
the tag has a particular meaning: e.g., Vr3s-f = verb-present-3rd-singular-<undefined_for_case>-female
What do you do with multi-token words, e.g. in terms of?

9
Example English Part-of-Speech Tagsets
Brown corpus - 87 tags Allows compound tags
“I'm” tagged as PPSS+BEM PPSS for "non-3rd person nominative personal pronoun" and
BEM for "am, 'm“ Others have derived their work from Brown
Corpus LOB Corpus: 135 tags Lancaster UCREL Group: 165 tags London-Lund Corpus: 197 tags. BNC – 61 tags (C5) PTB – 45 tags
Other languages have developed other tagsets

10
PTB Tagset (36 main tags + punctuation tags)

11
Typical Problem Cases Certain tagging distinctions are particularly
problematic For example, in the Penn Treebank (PTB), tagging
systems do not consistently get the following tags correct:
NN vs NNP vs JJ, e.g., Fantastic somewhat ill-defined distinctions
RP vs RB vs IN, e.g., off pseudo-semantic distinctions
VBD vs VBN vs JJ, e.g., hated non-local distinctions
(Often, the annotators get these wrong, as well, but that’s another story …)

12
Tagging Guidelines The tagset should be clearly documented and
explained, with a “case law” of what to do in problematic cases
If you don’t do this, you will have problems in applying the tagset to the text
If you have good documentation, you can have high interannotator agreement and a corpus of high quality.

13
3. Apply Tagset to Text: PTB Tagging Process
1. Tagset developed 2. Automatic tagging by rule-based and statistical POS
taggers, error rates of 2-6%. 3. Human correction using a text editor
Takes under a month for humans to learn this (at 15 hours a week), and annotation speeds after a month exceed 3,000 words/hour
Inter-annotator disagreement (4 annotators, eight 2000-word docs) was 7.2% for the tagging task and 4.1% for the correcting task
Benefit of post-editing: Manual tagging took about 2X as long as correcting, with about 2X the inter-annotator disagreement rate and error rate that was about 50% higher

14
POS Tagging Methods Two basic ideas to build from:
Establishing a simple baseline with unigrams Hand-coded rules
Machine learning techniques: Supervised learning techniques Unsupervised learning techniques

15
A Simple Strategy for POS Tagging
Choose the most likely tag for each ambiguous word, independent of previous words
i.e., assign each token the POS category it occurred as most often in the training set
E.g., race – which POS is more likely in a corpus?
This strategy gives you 90% accuracy in controlled tests
So, this “unigram baseline” must always be compared against

16
Example of the Simple Strategy
Which POS is more likely in a corpus (1,273,000 tokens)?
NN VB Totalrace 400 600 1000
P(NN|race) = P(race&NN) / P(race) by the definition of conditional probability
P(race) 1000/1,273,000 = .0008 P(race&NN) 400/1,273,000 =.0003 P(race&VB) 600/1,273,000 = .0005
And so we obtain: P(NN|race) = P(race&NN)/P(race) = .0003/.0008 =.4 P(VB|race) = P(race&VB)/P(race) = .0004/.0008 = .6

17
Hand-coded rules Two-stage system:
Dictionary assigns all possible tags to a word Rules winnow down the list to a single tag (or
sometimes, multiple tags are left, if it cannot be determined)
Can also use some probabilistic information These systems can be highly effective, but
they of course take time to write the rules. We’ll see an example later of trying to automatically
learn the rules (transformation-based learning)

18
Hand-coded Rules: ENGTWOL System
Uses 56,000-word lexicon which lists parts-of-speech for each word
Uses 1,100 rules for pos-disambiguationADV-that ruleGiven input “that” (ADV/PRON/DET/COMP)If (+1 A/ADV/QUANT) #next word is adj, adverb, or quantifier (+2 SENT_LIM) #and following which is a sentence boundary (NOT -1 SVOC/A) #and the previous word is not a verb like #consider which allows adjs as object
complementsThen eliminate non-ADV tagsElse eliminate ADV tag

19
Machine Learning Machines can learn from examples Learning can be supervised or unsupervised Given training data, machines analyze the data,
and learn rules which generalize to new examples Can be sub-symbolic (rule may be a mathematical
function) e.g., neural nets Or it can be symbolic (rules are in a representation that
is similar to representation used for hand-coded rules) In general, machine learning approaches allow for
more tuning to the needs of a corpus, and can be reused across corpora

20
Ways of learning Supervised learning:
A machine learner learns the patterns found in an annotated corpus
Unsupervised learning: A machine learner learns the patterns found in an
unannotated corpus Often uses another database of knowledge, e.g., a
dictionary of possible tags Techniques used in supervised learning can be
adapted to unsupervised learning, as we will see.

21
HMMs: A Probabilistic Approach
What you want to do is find the “best sequence” of POS tags T=T1..Tn for a sentence W=W1..Wn.
(Here T1 is pos_tag(W1)).find a sequence of POS tags T
that maximizes P(T|W) Using Bayes’ Rule, we can say
P(T|W) = P(W|T)*P(T)/P(W) We want to find the value of T
which maximizes the RHS denominator can be discarded (it’s the same for every T)
Find T which maximizes P(W|T) * P(T)
Example: He will race Possible sequences:
He/PP will/MD race/NN He/PP will/NN race/NN He/PP will/MD race/VB He/PP will/NN race/VB
W = W1 W2 W3 = He will race
T = T1 T2 T3 Choices:
T= PP MD NN T= PP NN NN T = PP MD VB T = PP NN VB

22
N-gram Models POS problem formulation
Given a sequence of words, find a sequence of categories that maximizes P(T1..Tn| W1…Wn)
i.e., that maximizes P(W1…Wn | T1…Tn) * P(T1..Tn) (by Bayes’ Rule)
Chain Rule of probability: P(W|T) = i=1, n P(Wi|W1…Wi-1T1…Ti)
prob. of this word based on previous words & tagsP(T) = i=1, n P(Ti|W1…WiT1…Ti-1)
prob. of this tag based on previous words & tags
But we don’t have sufficient data for this, and we would likely overfit the data, so we make some assumptions to simplify the problem …

23
Independence Assumptions
Assume that current event is based only on previous n-1 events (i.e., for bigram model, based on previous event)
P(T1….Tn) i=1, n P(Ti| Ti-1) assumes that the event of a POS tag occurring is independent
of the event of any other POS tag occurring, except for the immediately previous POS tag
From a linguistic standpoint, this seems an unreasonable assumption, due to long-distance dependencies
P(W1….Wn | T1….Tn) i=1, n P(Wi| Ti) assumes that the event of a word appearing in a category is
independent of the event of any surrounding word or tag, except for the tag at this position.

24
Hidden Markov Models Linguists know both these assumptions are
incorrect! But, nevertheless, statistical approaches based
on these assumptions work pretty well for part-of-speech tagging
In particular, one called a Hidden Markov Model (HMM)
Very widely used in both POS-tagging and speech recognition, among other problems
A Markov model, or Markov chain, is just a weighted Finite State Automaton

25
POS Tagging Based on Bigrams
Problem: Find T which maximizes P(W | T) * P(T) Here W=W1..Wn and T=T1..Tn
Using the bigram model, we get: Transition probabilities (prob. of transitioning from one
state/tag to another): P(T1….Tn) i=1, n P(Ti|Ti-1)
Emission probabilities (prob. of emitting a word at a given state):
P(W1….Wn | T1….Tn) i=1, n P(Wi| Ti)
So, we want to find the value of T1..Tn which maximizes:i=1, n P(Wi| Ti) * P(Ti| Ti-1)
26
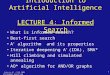
Using POS bigram probabilities: transitions
P(T1….Tn) i=1, n P(Ti|Ti-1)
Example: He will race Choices for T=T1..T3
T= PRP MD NN T= PRP NN NN T = PRP MD VB T = PRP NN NN
POS bigram probs from training corpus can be used for P(T)
P(PRP-MD-NN)=1*.8*.4 =.32
C|R MD NN VB PRP
MD .4 .6
NN .3 .7
PRP .8 .2 1
POS bigram probs
PRP
MDNN
VBNN
.4
.6.3
.7
.8
.2
1

27
HMMs = Weighted FSAs Nodes (or states): tag options Edges: Each edge from a node has a (transition)
probability to another state The sum of transition probabilities of all edges going out
from a node is 1
The probability of a path is the product of the probabilities of the edges along the path.
Why multiply? Because of the assumption of independence (Markov assumption).
The probability of a string is the sum of the probabilities of all the paths for the string.
Why add? Because we are considering the union of all interpretations.
A string that isn’t accepted has probability zero.

28
Hidden Markov Models Why the word “hidden”? Called “hidden” because one cannot tell what
state the model is in for a given sequence of words.
e.g., will could be generated from NN state, or from MD state, with different probabilities.
That is, looking at the words will not tell you directly what tag state you’re in.
29
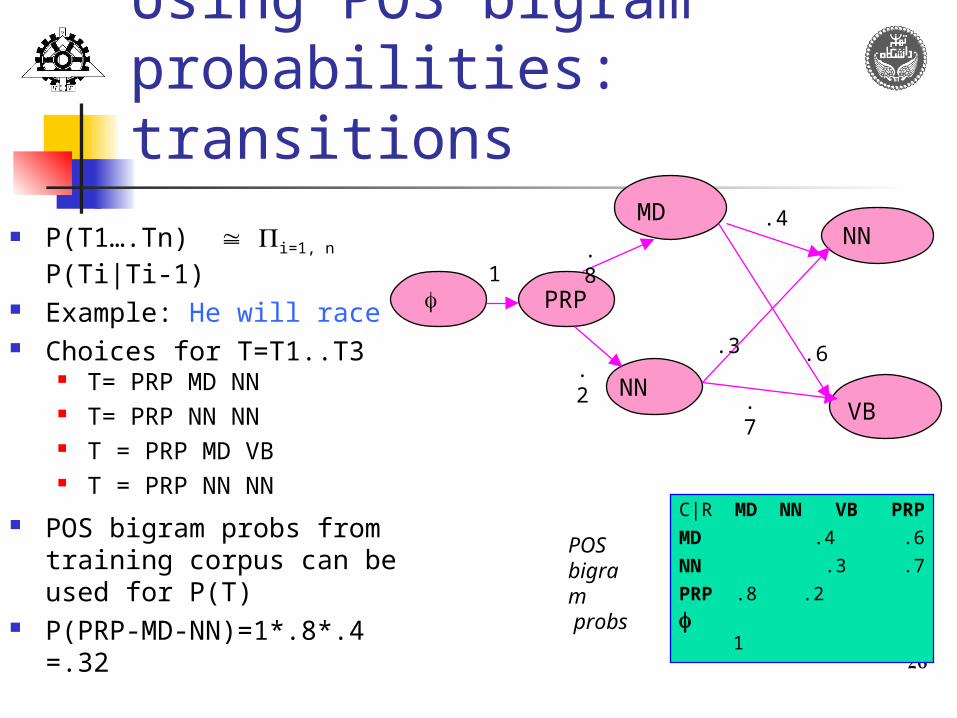
Factoring in lexical generation probabilities
From the training corpus, we need to find the Ti which maximizesi=1, n P(Wi| Ti) * P(Ti| Ti-1)
So, we’ll need to factor the lexical generation (emission) probabilities, somehow:
MD NN VB PRP
he 0 0 0 1
will .8 .2 0 0
race 0 .4 .6 0
lexical generation probs
PRP
MDNN
VBNN
.4
.6.3
.7
.8
.2
1
+A B
D
F
C E
30
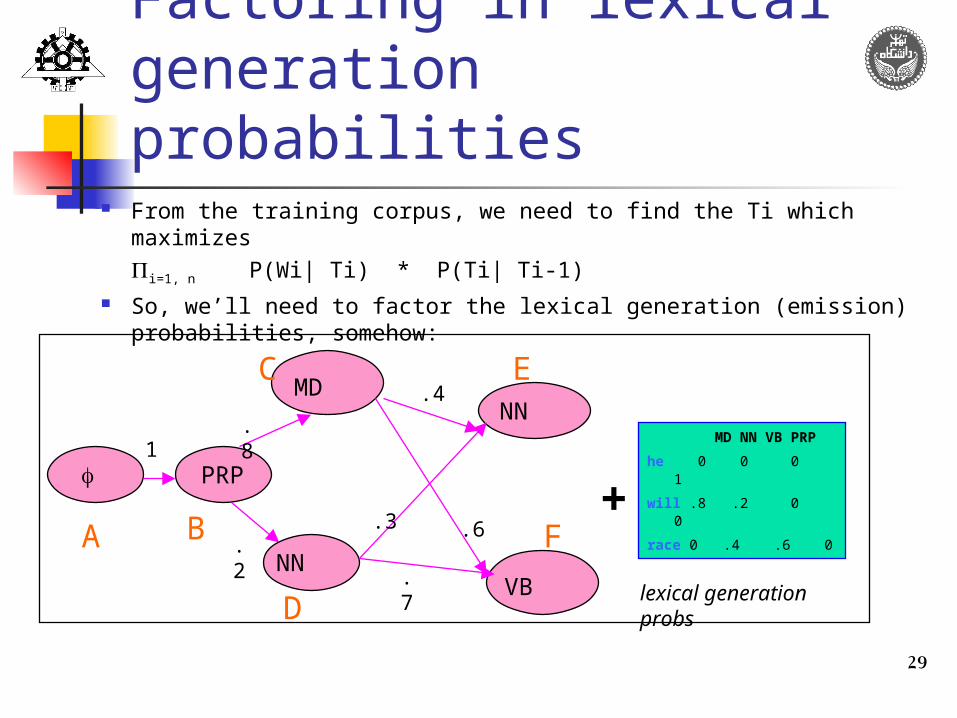
Adding emission probabilities
he|PRP .3
will|MD.8
race|NN.4
race|VB.6
will|NN .2
.4
.6.3
.7
.8
.2
<s>| 1
MD NN VB PRP
he 0 0 0 .3
will .8 .2 0 0
race 0 .4 .6 0
lexical generation probs
C|R MD NN VB PRP
MD .4 .6
NN .3 .7
PP .8 .2 1
pos bigram probs
Like a weighted FSA, except that there are output
probabilities associated with each node.

31
Dynamic Programming In order to find the most likely sequence of
categories for a sequence of words, we don’t need to enumerate all possible sequences of categories.
Because of the Markov assumption, if you keep track of the most likely sequence found so far for each possible ending category, you can ignore all the other less likely sequences.
i.e., multiple edges coming into a state, but only keep the value of the most likely path
This is another use of dynamic programming The algorithm to do this is called the Viterbi
algorithm.

32
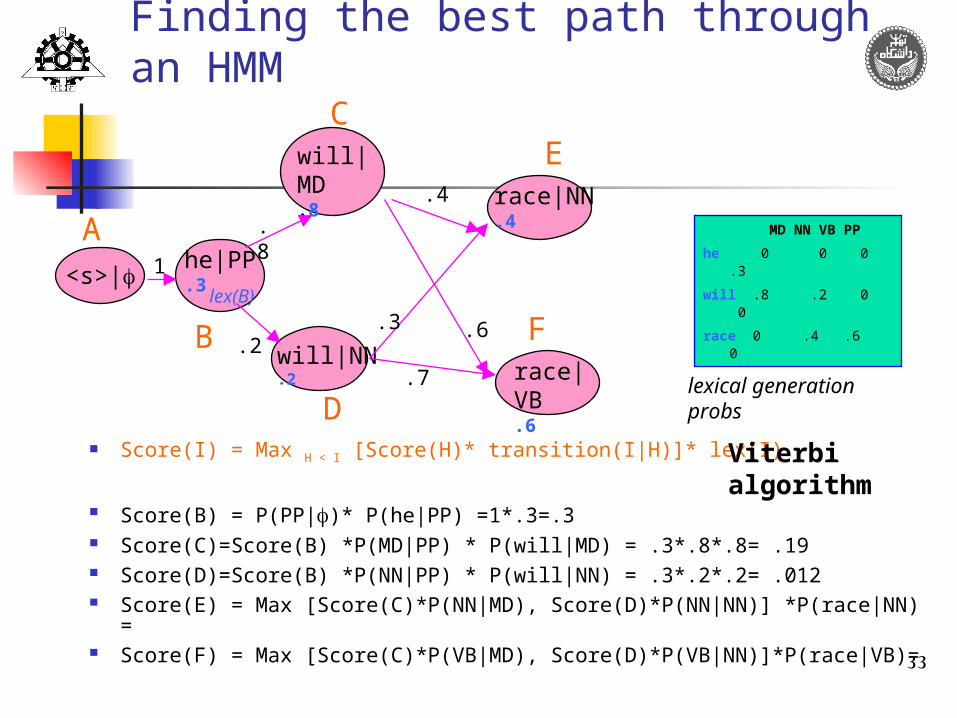
The Viterbi algorithm Assume we’re at state I in the HMM Obtain
the probability of each previous state H1…Hm the transition probabilities of H1-I, …, Hm-I the emission probability for word w at I
Multiple the probabilities for each new path: P(H1,I) = Score(H1)*P(I|H1)*P(w|I) …
One of these states (H1…Hm) will give the highest probability
Only keep the highest probability when using I for the next state
33
Finding the best path through an HMM
Score(I) = Max H < I [Score(H)* transition(I|H)]* lex(I)
Score(B) = P(PP|)* P(he|PP) =1*.3=.3 Score(C)=Score(B) *P(MD|PP) * P(will|MD) = .3*.8*.8= .19 Score(D)=Score(B) *P(NN|PP) * P(will|NN) = .3*.2*.2= .012 Score(E) = Max [Score(C)*P(NN|MD), Score(D)*P(NN|NN)] *P(race|NN) = Score(F) = Max [Score(C)*P(VB|MD), Score(D)*P(VB|NN)]*P(race|VB)=
he|PP.3
will|MD.8
race|NN.4
race|VB.6
will|NN.2
.4
.6.3
.7
.8
.2
<s>| 1
MD NN VB PP
he 0 0 0 .3
will .8 .2 0 0
race 0 .4 .6 0
lexical generation probs
A
C
B
D
E
Flex(B)
Viterbialgorithm

34
Smoothing Lexical generation probabilities will lack
observations for low-frequency and unknown words
Most systems do one of the following Smooth the counts
E.g., add a small number to unseen data (to zero counts). For example, assume a bigram not seen in the data has a very small probability, e.g., .0001.
Use lots more data (but you’ll still need to smooth) Group items into classes, thus increasing class frequency
e.g., group words into ambiguity classes, based on their set of tags. For counting, all words in an ambiguity class are treated as variants of the same ‘word’

35
2. TBL: A Symbolic Learning Method
HMMs are subsymbolic – they don’t give you rules that you can inspect
A method called error-driven Transformation-Based Learning (TBL) (Brill algorithm) can be used for symbolic learning
The rules (actually, a sequence of rules) are learned from an annotated corpus
Performs at least as accurately as other statistical approaches
Has better treatment of context compared to HMMs rules which use the next (or previous) POS
HMMs just use P(Ci| Ci-1) or P(Ci| Ci-2,Ci-1) rules which use the previous (next) word
HMMs just use P(Wi|Ci)

36
Brill Algorithm (Overview) Assume you are given a
training corpus G (for gold standard)
First, create a tag-free version V of it
Notes: As the algorithm proceeds,
each successive rule becomes narrower (covering fewer examples, i.e., changing fewer tags), but also potentially more accurate
Some later rules may change tags changed by earlier rules
1. First label every word token in V with most likely tag for that word type from G. If this ‘initial state annotator’ is perfect, you’re done!
2. Then consider every possible transformational rule, selecting the one that leads to the most improvement in V using G to measure the error
3. Retag V based on this rule4. Go back to 2, until there is
no significant improvement in accuracy over previous iteration

37
Rule Templates Brill’s method learns transformations which fit
different templates Change tag X to tag Y when previous word is W
NN VB when previous word = to Change tag X to tag Y when next tag is Z
NN NNP when next tag = NNP Change tag X to tag Y when previous 1st, 2nd, or 3rd word is
W VBP VB when one of previous 3 words = has
The learning process is guided by a small number of templates (e.g., 26) to learn specific rules from the corpus
Note how these rules sort of match linguistic intuition

38
Error-driven method How does one learn the rules? The TBL method is error-driven
The rule which is learned on a given iteration is the one which reduces the error rate of the corpus the most, e.g.:
Rule 1 fixes 50 errors but introduces 25 more net decrease is 25
Rule 2 fixes 45 errors but introduces 15 more net decrease is 30
Choose rule 2 in this case We set a stopping criterion, or threshold once
we stop reducing the error rate by a big enough margin, learning is stopped

39
Brill Algorithm (More Detailed)
1. Label every word token with its most likely tag (based on lexical generation probabilities).
2. List the positions of tagging errors and their counts, by comparing with “truth” (T)
3. For each error position, consider each instantiation I of X, Y, and Z in Rule template. If Y=T, increment improvements[I], else increment errors[I].
4. Pick the I which results in the greatest error reduction, and add to output
e.g., VB NN PREV1OR2TAG DT improves 98 errors, but produces 18 new errors, so net decrease of 80 errors
5. Apply that I to corpus 6. Go to 2, unless stopping
criterion is reached
Most likely tag:
P(NN|race) = .98
P(VB|race) = .02
Is/VBZ expected/VBN to/TO race/NN tomorrow/NN
Rule template: Change a word from tag X to tag Y when previous tag is Z
Rule Instantiation for above example: NN VB
PREV1OR2TAG TO
Applying this rule yields:
Is/VBZ expected/VBN to/TO race/VB tomorrow/NN
40
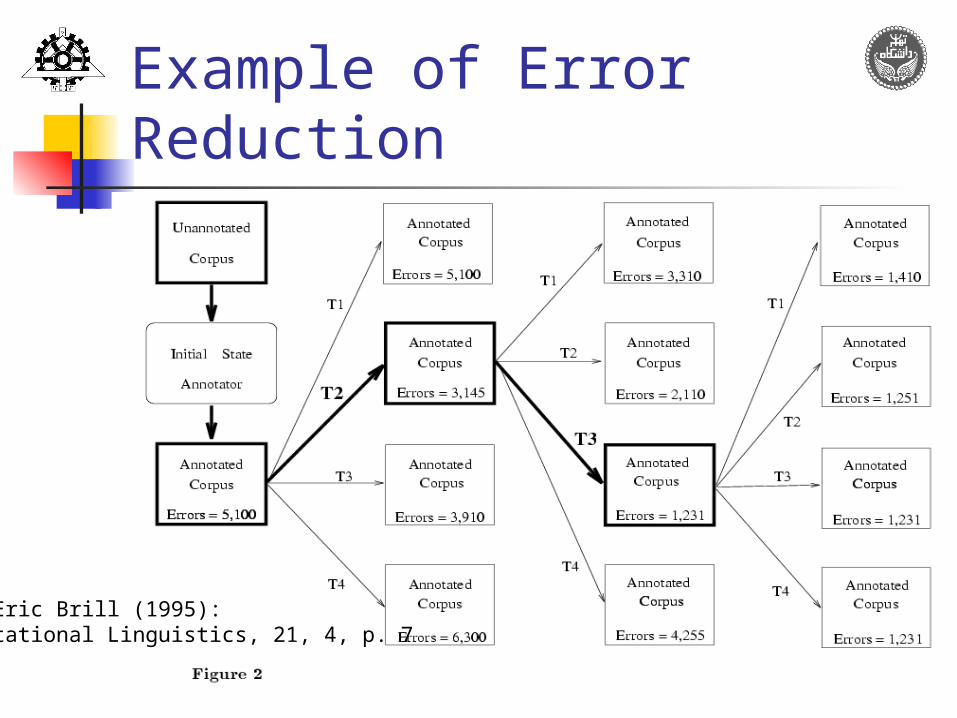
Example of Error Reduction
From Eric Brill (1995):Computational Linguistics, 21, 4, p. 7

41
Rule ordering One rule is learned with every pass through the
corpus The set of final rules is what the final output is Unlike HMMs, such a representation allows a linguist
to look through and make more sense of the rules Thus, the rules are learned iteratively and must
be applied in an iterative fashion. At one stage, it may make sense to change NN to VB
after to But at a later stage, it may make sense to change VB
back to NN in the same context, e.g., if the current word is school

42
Example of Learned Rule Sequence
1. NN VB PREVTAG TO to/TO race/NN->VB
2. VBP VB PREV1OR20R3TAG MD might/MD vanish/VBP-> VB
3. NN VB PREV1OR2TAG MD might/MD not/MD reply/NN -> VB
4. VB NN PREV1OR2TAG DT the/DT great/JJ feast/VB->NN
5. VBD VBN PREV1OR20R3TAG VBZ He/PP was/VBZ killed/VBD->VBN by/IN Chapman/NNP

43
Handling Unknown Words Can also use the Brill
method to learn how to tag unknown words
Instead of using surrounding words and tags, use affix info, capitalization, etc.
Guess NNP if capitalized, NN otherwise.
Or use the tag most common for words ending in the last 3 letters.
etc. TBL has also been applied
to some parsing tasks
Example Learned Rule Sequence for Unknown Words

44
Insights on TBL TBL takes a long time to train, but is relatively
fast at tagging once the rules are learned The rules in the sequence may be decomposed
into non-interacting subsets, i.e., only focus on VB tagging (need to only look at rules which affect it)
In cases where the data is sparse, the initial guess needs to be weak enough to allow for learning
Rules become increasingly specific as you go down the sequence.
However, the more specific rules don’t overfit because they cover just a few cases

45
3. Maximum Entropy Maximum entropy: model what you know as best you
can, remain uncertain about the rest Set up some features, similar to Brill’s templates When tagging, the number of features which are true
determines the probability of a tag in a particular context
Make your probability model match the training data as well as it can, i.e., if an example matches features we’ve seen, we know exactly what to do
But the probability model also maximizes the entropy = uncertainty … so, we are noncommittal to anything not seen in the training data
E.g. MXPOST

46
4. Decision Tree Tagging Each tagging decision can be viewed as a
series of questions Each question should make a maximal division in the
data, i.e., ask a question which gives you the most information at that point
Different metrics can be used here Each question becomes more specific as you go down
the tree Training consists of constructing a decision tree Tagging consists of using the decision tree to
give us transition probabilities … and the rest plays out like an HMM

47
Decision Tree example
Tag-1 = JJ?
YES NO
A tree for nouns:
Tag-2 = DT?YES NO
NN = .85JJ = .14…
…
…

48
5. Memory-Based Learning (MBL)
Each corpus position is just a bundle of features Word t-1 t-2 …
Training simply stores every corpus position in memory
i.e., there is no generalization in training Tagging consists of finding the case in memory
which best matches the situation we are trying to tag
Use different metrics to determine how similar two items are

49
Other techniques Neural networks Conditional random fields A network of linear functions
Basically, whatever techniques are being used in machine learning are appropriate techniques to try with POS tagging

50
Unsupervised learning Unsupervised learning:
Use an unannotated corpus for training data Instead, will have to use another database of
knowledge, such as a dictionary of possible tags Unsupervised learning use the same general
techniques as supervised, but there are differences
Advantage is that there is more unannotated data to learn from
And annotated data isn’t always available

51
Unsupervised Learning #1: HMMs
We still want to use transition (P(ti|ti-1)) and emission (P(w|t)) probabilities, but how do we obtain them?
During training, the values of the states (i.e., the tags) are unknown, or hidden
Start by using a dictionary, to at least estimate the emission probability
Using the forward-backward algorithm, iteratively derive better probability estimates
The best tag may change with each iteration Stop when probability of the sequence of words
has been (locally) maximized

52
Forward-Backward Algorithm
The Forward-Backward (or Baum-Welch) Algorithm for POS tagging works roughly as follows:
1. Initialize all parameters (forward and backward probability estimates)
2. Calculate new probabilities A. Re-estimate the probability for a given word in the sentence
from the forward and backward probabilities B. Use that to re-estimate the forward and backward parameters
3. Terminate when a local maximum for the string is reached NB: The initial probabilities for words are based on
dictionaries … which you probably need tagged text to obtain

53
Unsupervised Learning #2: TBL
With TBL, we want to learn rules of patterns, but how can we learn the rules if there’s no annotated data?
Main idea: look at the distribution of unambiguous words to guide the disambiguation of ambiguous words
Example: the can, where can can be a noun, modal, or verb
Let’s take unambiguous words from dictionary and count their occurrences after the
the elephant the guardian
Conclusion: immediately after the, nouns are more common than verbs or modals

54
Unsupervised TBL Initial state annotator
Supervised: assign random tag to each word Unsupervised: for each word, list all tags in
dictionary
The templates change accordingly … Transformation template:
Change tag of word to tag Y if the previous (next) tag (word) is Z, where is a set of 1 or more tags
Don’t change any other tags

55
Error Reduction in Unsupervised Method
Let a rule to change to Y in context C be represented as Rule(, Y, C).
Rule1: {VB, MD, NN} NN PREVWORD the Rule2: {VB, MD, NN} VB PREVWORD the
Idea: since annotated data isn’t available, score rules so as to
prefer those where Y appears much more frequently in the context C than all others in
frequency is measured by counting unambiguously tagged words so, prefer {VB, MD, NN} NN PREVWORD the
to {VB, MD, NN} VB PREVWORD the
since dict-unambiguous nouns are more common in a corpus after the than dict-unambiguous verbs

56
Using weakly supervised methods
Can mix supervised and unsupervised to improve performance. For the TBL tagging:
Use the unsupervised method for the initial state tagger
Use the supervised method to adjust the tags Advantage of using weakly supervised over
just supervised: Lots of training data available for unsupervised part Less training data available for supervised part

57
Voting Taggers A more recent technique which seems to improve
performance is to set up a system of tagger voting. Train multiple taggers on a corpus and learn not only
about individual performance, but how they interact Can vote in different ways
Each tagger gets a fraction of the vote For certain tagging decisions, one tagger is always right
Works best when the taggers are looking at different, or complementary, information
Intuition: if taggers A, B, and C are all looking at different info and two of them agree, that’s better than the one that disagrees

58
Unknown words One thing we haven’t addressed yet is the fact
that all taggers have to deal with unknown words. Words in the testing data which were not in the training
data The handling of unknown words can have a big
impact on performance Some different general methods:
Train an unknown word learner on affix information and/or other features (e.g., is the word capitalized?)
Use information about the distribution of tags in the training data

59
Ambiguity classes Another way that POS tagging methods have
been improved is by grouping words together in classes
Words are grouped together if they have the same set of possible tags
Can calculate new probabilities based on these classes
This can help if a word occurs very rarely but other members in its class are more frequent

60
Summary: POS tagging Part-of-speech tagging can use
Hand-crafted rules based on inspecting a corpus Machine Learning-based approaches based on corpus
statistics Machine Learning-based approaches using rules derived
automatically from a corpus And almost any other Machine Learning technique you can
think of When Machine Learning is used, it can be
Supervised (using an annotated corpus) Unsupervised (using an unannotated corpus)
Combinations of different methods often improve performance