Embed Size (px)
Citation preview

1
Channel Hardening and Favorable Propagation inCell-Free Massive MIMO with Stochastic Geometry
Zheng Chen and Emil Björnson
Abstract—Cell-Free (CF) Massive MIMO is an alternativetopology for Massive MIMO networks, where a large numberof single-antenna access points (APs) are distributed over thecoverage area. There are no cells but all users are jointly servedby the APs using network MIMO methods. In prior work, ithas been claimed that CF Massive MIMO inherits the basicproperties of cellular Massive MIMO, namely channel hardeningand favorable propagation. In this paper, we evaluate if one canrely on these properties when having a realistic stochastic APdeployment. Our results show that the level of channel hardeningdepends strongly on the propagation environment and there isgenerally little hardening, except when the pathloss exponentis small. We further show that using 5–10 antennas per AP,instead of one, we can greatly improve the hardening. The level offavorable propagation is affected by the propagation environmentand by the distance between the users, where only spatially wellseparated users exhibit favorable propagation. The conclusionis that we cannot rely on channel hardening and favorablepropagation when analyzing and designing CF Massive MIMOnetworks, but we need to use achievable rate expressions andresource allocation schemes that work well in the absence ofthese properties. Some options are described in this paper.
Index terms— Cell-Free Massive MIMO, channel harden-ing, favorable propagation, achievable rates, stochastic geom-etry.
I. INTRODUCTION
The throughput of conventional cellular networks is limitedby the uncoordinated inter-cell interference. To mitigate thisinterference, Shamai and Zaidel introduced the co-processingconcept in 2001 [2], which is more commonly known asnetwork multiple-input multiple-output (MIMO) [3]. The keyidea is to let all access points (APs) in the network jointlyserve all users, in downlink as well as uplink, thereby turninginterference into useful signals [4]. Despite the great theoreti-cal potential, the 3GPP LTE standardization of this technologyfailed to provide any remarkable gains [5].
Two practical issues with network MIMO are to achievescalable channel acquisition and sharing of data between APs.The former can be solved by utilizing only local channel stateinformation (CSI) at each AP [6], which refers to knowledgeof the channels between the AP and the users. These channelscan be estimated by exploiting uplink pilot transmission andchannel reciprocity in time-division duplex (TDD) systems,
Z. Chen and E. Björnson are with the Department of Electrical Engineering(ISY), Linköping University, Linköping, Sweden (email: [email protected],[email protected]). A part of this work will appear in Globecom Work-shops 2017 [1].
This work was supported in part by ELLIIT, CENIIT, and the SwedishFoundation for Strategic Research.
thus making TDD a key enabler for network MIMO. User-centric clustering, where all APs reasonably close to a usertransmit signals to it, is key to reduce the data sharingoverhead [7]. These concepts are not easily incorporated intoLTE, which relies on codebook-based channel acquisition andnetwork-centric AP clustering.
The network MIMO concept has recently reappeared underthe name Cell-Free (CF) Massive MIMO [8], [9], whichrefers to a network with a massive number of geographicallydistributed single-antenna APs that jointly serve a smallernumber of users. In particular, it has been presented as abetter option for providing coverage than using uncoordinatedsmall cells [10]. The CF concept is fundamentally the sameas in the network MIMO paper [6], where the APs performjoint transmission with access to data to every user but onlylocal CSI. The main novelty introduced by CF Massive MIMOis the capacity analysis that takes practical pilot allocationand imperfect CSI into account [10], [11], using similarmethodology as in the cellular Massive MIMO literature [12].
Conventional cellular Massive MIMO systems consist ofnon-cooperating APs equipped with a massive number of co-located antennas. Such systems deliver high spectral efficiencyby utilizing the channel hardening and favorable propa-gation phenomena [12]. Channel hardening means that thebeamforming turns the fading multi-antenna channel into annearly deterministic scalar channel [13]. Favorable propagationmeans that the users’ channel vectors are almost orthogonal[14]. These are both consequences of the law of large numbers.
CF Massive MIMO is essentially a single-cell MassiveMIMO system with antennas distributed over a wide geo-graphical area, which makes the joint channel from the APsto a user strongly spatially correlated—some APs are closerto the user than others. The capacity of Massive MIMO withspatial correlation and imperfect CSI has been analyzed in[15]–[17], among others, but with channel models that providechannel hardening and favorable propagation. It is claimed in[10] that the outstanding aspect of CF Massive MIMO is thatit can also utilize these phenomena, but this has not been fullydemonstrated so far. Hence, it is not clear if the known MassiveMIMO capacity lower bounds are useful in the CF context or ifthey underestimate the achievable performance. For example,[18] derived a new downlink capacity lower bound for thecase when the precoded channels are estimated using downlinkpilots. That bound provides larger values than the commonbound that estimates the precoded channels by relying onchannel hardening, but it is unclear whether this indicates theneed for downlink pilots and/or the lack of channel hardeningin the CF Massive MIMO setup.
arX
iv:1
710.
0039
5v1
[cs
.IT
] 1
Oct
201
7

2
This paper aims at answering the following open questions:• Can we observe channel hardening and favorable propa-
gation in CF Massive MIMO with single-antenna APs?• Is it more beneficial to deploy more antennas on few
APs or more APs with few antennas, in order to achievea reasonable degree of channel hardening and favorablepropagation?
• Are there any other important factors that affect theconditions of these two properties?
• Which capacity bounds in conventional cellular MassiveMIMO are appropriate to use in CF Massive MIMO?
In order to answer these questions, we model the AP dis-tribution by a homogeneous Poisson Point Process (PPP),where each AP is equipped with N ≥ 1 of antennas. Unlikethe conventional regular grid model for the base stationdeployment, the stochastic point process model consideredin this work can capture the irregular and semi-random APdeployment in real networks [19], [20]. First, conditioningon a specific network realization with APs located at fixedlocations and a reference user point at the origin, we definethe channel hardening and favorable propagation criteria asfunctions of the AP-user distances. Then, we examine thespatially averaged percentage/probability of randomly locatedusers that satisfy these criteria. The separation of the random-ness caused by small-scale fading and the spatial locations ofAPs allows us to study the statistical performance of large-scale CF Massive MIMO network with time-scale separation.It is similar to the concept of meta distribution proposed in[21], where the difference mainly lies in the definition of thestudied performance metrics.
Our analysis is carried out by considering different numberof antennas per AP and different non-singular pathloss mod-els: the single-slope model with different pathloss exponents[22], [23] and the multi-slope model [10]. Compared to theconference paper [1], which focuses on the channel hardeningaspect of CF Massive MIMO, in this paper, we provide thor-ough investigation for both channel hardening and favorablepropagation, based on which we give insights into the selectionof achievable rate expressions in CF Massive MIMO.
The remainder of this paper is organized as follows. InSection II we describe the CF Massive MIMO network model,including the AP distribution and the channel models. Next,Section III analyzes the channel hardening and Section IVanalyzes the favorable propagation in CF Massive MIMO.Section V considers different capacity lower bounds fromcellular Massive MIMO and demonstrates which ones areuseful in CF systems. Section VI concludes this paper.
II. SYSTEM MODEL
We consider a CF Massive MIMO system in a finite-sized network region A. The APs are distributed on the two-dimensional Euclidean plane according to a homogeneous PPPΦA with intensity λA, measured by per m2. [24]. Each AP isequipped with N ≥ 1 antennas, which is a generalization of theN = 1 CF Massive MIMO considered in prior works [8]–[11].All the APs are connected to a central processing unit (CPU)through backhaul, and the CPU codes and decodes the data
CPU
gm,k
APm
UEk
Fig. 1. Cell-Free Massive System. Here, each AP can be equipped with eithersingle or multiple antennas.
signals; see Fig. 1 for an illustration. Different to a small-cell network, all the APs are coordinated to serve all userssimultaneously using the same frequency-time resources. Thenumber of users and their locations are generated by anotherindependent point process. Denote by L the number of APsin a specific realization of the PPP ΦA, we have that L is aPoisson random variable (RV) with mean value
E[L] = λAS(A), (1)
where S(A) denotes the area of the network region A. Let Mdenote the total number of antennas existing in A, then wehave M = LN and E[M] = NλAS(A).
Given the user distribution, we assume that there are Kusers in a specific network realization, where K � M . Whenthe AP density is much larger than the user density, theboundary effect caused by the finite-size network region isweak, i.e., users located at the network boundary are stilllikely to have nearby dominant APs that makes their receivedsignal distribution similar to network-center users. Considera typical user at the origin, the spatially averaged networkstatistics seen at this typical user can represent the averagenetwork performance seen by randomly located users in thenetwork. Denote by gk the M × 1 channel vector between allthe antennas and the typical user (labeled as user k), the m-thelement gm,k is modeled by
gm,k =√
l(dm,k)hm,k, (2)
where hm,k represents the small-scale fading and l(dm,k)represents the distance-dependent pathloss and it is a functionof the distance dm,k between the m-th antenna and the userk. Since every N antennas are co-located at the same AP, wehave d(i−1)·N+1,k = d(i−1)·N+2,k = . . . = di ·N,k , for i = 1, . . . , L.
We assume independent Rayleigh fading from each antennato the typical user, which means that {hm,k} are independentlyand identically distributed (i.i.d.) CN(0, 1) RVs. In the firstpart of this paper, we consider a non-singular pathloss modell(r) = min(1, r−α), where r is the antenna-user distance and

3
α > 1 is the pathloss exponent.1 A three-slope pathloss modelwill also be studied in Section III-D.
Note that we do not include shadow fading in our analysis.With the commonly used log-normal shadowing model, therandom shadowing coefficients from randomly located APsdo not have any fundamental impact on the channel gaindistribution. Therefore, the inclusion of shadowing coefficientswould not change the general trends observed in this paper.
A. Main Advantage of CF Massive MIMO
Similar to other distributed antenna systems, the mainadvantage of CF Massive MIMO is the macro-diversity; that is,reduced distance between a user and its nearest APs. This canbe demonstrated by analyzing the distribution of the squarednorm of the channel vector,
‖gk ‖2 =M∑m=1|hm,k |2l(dm,k), (3)
which we refer to as the channel gain. Here, M depends oneach realization of the PPP ΦA.
Each AP is equipped with N antennas and therefore thesum of the small-scale fading coefficients of its N co-locatedantennas is a RV following a Gamma(N, 1) distribution, whichhas mean N and variance N . We define the distance vectorr = [r1, . . . , rL]T , where each element ri denotes the distancefrom the i-th AP to the typical user at the origin. Thus, thesquared norm in (3) can be written as
‖gk ‖2 =∑i∈ΦA
Hil(ri), (4)
where Hi =i ·N∑
m=(i−1)·N+1|hm,k |2 ∼ Gamma(N, 1) and ri =
d(i−1)·N+1,k = . . . = di ·N,k for i = 1, . . . , L.Note that there are two sources of randomness in (4):{Hi} and ΦA. When studying the channel distribution for arandomly located user, it is natural to consider the distributionof ‖gk ‖2 with respect to both sources of randomness. Fromprior studies on the application of stochastic geometry inwireless networks, it is well known that the sum of the receivedpower from randomly distributed nodes is described by a shotnoise process. The mean and variance of ‖gk ‖2 averagingover the spatial distribution of the antennas are known forthe unbounded and bounded pathloss models [23]. For ourconsidered pathloss model l(r) = min(1, r−α), in a finitenetwork region with radius ρ centered around the typical user,we have
E[‖gk ‖2
]=
{NλAπ
(1 + 2(1−ρ2−α)
α−2
)if α , 2
NλAπ (1 + 2 ln(ρ)) if α = 2(5)
Var[‖gk ‖2
]= (N2 + N)λAπ
(1 +
1 − ρ2−2α
α − 1
). (6)
Proof: See Appendix A.
1Note that the unbounded pathloss model l(r) = r−α is not appropriatewhen analyzing CF Massive MIMO with stochastic geometry, because theantennas can then be arbitrarily close to the user, which might result inunrealistically high power gain when using the unbounded pathloss model.
When α > 2, ‖gk ‖2 is guaranteed to have finite mean evenwith infinite network size, i.e., ρ → ∞. When 1 < α < 2,‖gk ‖2 increases unboundedly when the network size grows.
It is particularly interesting to study the case when theantenna density µ = NλA is fixed. We then observe thatthe mean channel gain in (5) is the same, irrespective ofwhether there is a high density of single-antenna APs ora smaller density of multi-antenna APs. The variance is,however, proportional to (N2 + N)λA = (N + 1)µ and thusgrows with N .
-70 -60 -50 -40 -30 -20 -10 0 10 20
||g||2 [dB]
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
CD
F
N=1N=10N=100
Fig. 2. The CDF of the squared norm of the channel vector ‖gk ‖2 to userk with respect to small-scale fading and PPP realizations. The number ofantennas per AP is N = {1, 10, 100}. The antenna density is fixed µ =NλA = 0.001/m2 (103/km2).
Fig. 2 shows the cumulative distribution function (CDF)of ‖gk ‖2, with respective to random spatial locations andsmall-scale fading realizations. We consider µ = 103/km2 anddifferent numbers of antennas per AP: N ∈ {1, 10, 100}. Notethat the horizontal axis is shown in decibel, thus a few usersare very close to an AP and have large values of ‖gk ‖2 whilethe majority have substantially smaller values. The long-tailedexponential distribution of the small-scale fading |hm,k |2 hasa strong impact on the CDF, but also the AP density makes adifference. The larger N is, the longer tail the distribution has;at the 95%-likely point, N = 1 achieves a 12 dB higher valuethan N = 100. The reason behind the increasing tail with N isthat Var[‖gk ‖2] is proportional to (N +1), as described above.A practical interpretation is that having higher AP densityreduces the average distance between the APs and this macro-diversity reduces the risk that a randomly located user has largedistances to all of its closest APs. This observation evinces akey motivation of CF Massive MIMO with N = 1 and highAP density, in terms of providing more uniform coverage tousers at random locations than a conventional cellular MassiveMIMO deployment with N = 100 and a low AP density.
From [23] and [25], it is known that a Gamma distributionprovides a good approximation of the interference distributionin a Poisson random field with non-singular pathloss. Here, theexpression of ‖gk ‖2 coincides with the definition of interfer-ence power in [23] and [25]. Thus, the Gamma distribution canbe used to approximate the distribution of ‖gk ‖2. The detailsare omitted since it is outside the scope of this work.

4
B. Conditional Channel Distribution at Fixed Location
The previous analysis characterized the channel gain dis-tribution that a user will observe when moving around in alarge network. Once the APs are deployed, for a user at afixed location (e.g., located in a room), the small-scale fadingvaries over time but the large-scale fading from the APs to theuser remains the same. Conditioning on a specific networkrealization of ΦA, assuming that there are L APs in thenetwork, the distances between the APs and the typical userare basically fixed. The conditional distribution of the channelstatistics with respect to the small-scale fading distributionis essential for performance evaluation (e.g., computing theergodic capacity) of CF Massive MIMO networks with a fixedtopology and users at fixed but random locations.
With single-antenna APs, i.e., N = 1, the total number ofantennas M is equal to the number of APs L. As a resultof the exponentially distributed small-scale fading coefficient|hm,k |2, the conditional distribution of the channel gain ‖gk ‖2in (3) follows a Hypoexponential distribution, denoted byHypo(l(r1)−1, . . . , l(rL)−1), which is usually a long-tailed dis-tribution when the coefficients l(ri) are distinct [26].
With N > 1 antennas per AP, the channel gain ‖gk ‖2is given by (4) where Hi ∼ Gamma(N, 1). As a result, theconditional distribution of the channel gain from the i-th APis Hil(ri) ∼ Gamma(N, l(ri)) for i = 1, . . . , L. Due to the sumof independent Gamma RVs with different scale parameters,the mean and variance of ‖gk ‖2 conditioning on the distancevector r are
E[‖gk ‖2
��� r]= N
L∑i=1
l(ri) (7)
Var[‖gk ‖2
��� r]= N
L∑i=1
l2(ri). (8)
The exact conditional probability density function (PDF) of‖gk ‖2 can be computed using the approach in [27] and theexact expression is available in [28, Eq. (6)]. By looking at(7) and (8), it is unclear how the channel gain behaves; forexample, if it is the mean value or the channel variations thatgrow faster.
In cellular Massive MIMO with M co-located antennas,conditioning on a specific location of the user, denote by β =E[‖gk ‖2 |r]/M the pathloss from the M co-located antennasto the user. The squared norm of the channel gain ‖gk ‖2 thenfollows a Gamma(M, β)-distribution, with mean value βM andstandard deviation β
√M . When M increases, the distribution
approaches a normal distribution and is (relatively speaking)concentrated around the mean since it grows faster than thestandard deviation. The different channel gain distributions inCF and cellular Massive MIMO highlight the fundamentaldifference between the channel statistics of these two typesof networks. In the remainder of this paper, we will proceedto investigate if in a CF Massive MIMO network, we couldobserve the classical Massive MIMO phenomena, namelychannel hardening and favorable propagation.
III. MEASURE OF CHANNEL HARDENING
In cellular Massive MIMO, when the number of antennasgrows, the channel between the AP and the user behavesas almost deterministic. This property of is called channelhardening. Conditioning on a specific network realization withdistance vector r = [r1, . . . , rL]T , channel hardening appearsin CF Massive MIMO when the following condition holds:
‖gk ‖2
E[‖gk ‖2 |r
] → 1 as M →∞, (9)
where ‖gk ‖2 =L∑i=1
Hil(ri) is the channel gain from the L APs
to the typical user. One way to prove channel hardening (withconvergence2 in (9) in mean square sense) is to show that thechannel gain variation
Var
[‖gk ‖2
E[‖gk ‖2 |r
] ����r] = Var[‖gk ‖2 |r
](E
[‖gk ‖2 |r
] )2 → 0 as M →∞.
(10)For a large wireless network, studying the channel statistics
at a specific location is of limited interest and the results cannotbe generalized to users at other arbitrary locations. To quantifythe channel gain variation for users at arbitrary locations, wedefine the following channel hardening measure:
pθ = P
Var
[‖gk ‖2
��� r]
(E
[‖gk ‖2
��� r] )2 ≤ θ
. (11)
This is the CDF ofVar[‖gk ‖2 |r](E[‖gk ‖2 |r])2
given a certain threshold θ.
Here, the probability is obtained over different network realiza-tions that generate different distance vector r. As mentionedin Section II, the spatially averaged probability pθ providesthe percentage of randomly located users that experienceVar[‖gk ‖2 |r](E[‖gk ‖2 |r])2
smaller or equal to θ. Notice that pθ = 1 implies
that all users have channel gain variations that are smaller thanθ. The ideal case is p0 = 1 where the variance is zero for allusers. When the threshold θ is small enough, the larger pθis, with higher possibility we observe channel hardening forusers at arbitrary locations.
A. Necessary Conditions for Channel Hardening
With N ≥ 1 antennas per AP, from (7) and (8), the channelhardening measure in (11) can be written as
pθ = P
N
∑Li=1 l2(ri)(
N∑L
i=1 l(ri))2 ≤ θ
= P
∑Li=1 l2(ri)
N(∑L
i=1 l(ri))2 ≤ θ
.(12)
Since N appears in the denominator, for a given θ, pθ alwaysincreases with N . This implies that regardless of the APdensity, having more antennas per AP always helps the channelto harden. In the following, we fix the number of antennas Nper AP and study the impact that the AP density λA has onthe channel hardening criterion.
2Note that convergence in mean square implies convergence in probability.

5
For a given network realization with L APs, by definingY1 =
∑Li=1 l(ri), Y2 =
∑Li=1 l2(ri), and
Xch =Y2
NY21=
∑Li=1 l2(ri)
N(∑L
i=1 l(ri))2 , (13)
we can write the channel hardening measure as
pθ = P [Xch ≤ θ] . (14)
The exact of distribution of Xch is difficult to analyze even withthe joint PDF of ri , i = 1, . . . , L. One objective of this work isto provide intuitive insights into the relation between channelhardening and the AP density. Specifically, if pθ should ap-proach 1 when the AP density λA increases, we need Xch → 0when λA → ∞. Since Y2
1 = Y2 +∑L
i=1 l(ri)∑L
j=1, j,i l(rj),it follows that Y2 and Y2
1 are highly correlated. Though thedistributions of Y2 and Y2
1 are not trivial to obtain, their meanand variance can be obtained by Campbell’s theorem as inSection II-A. For the non-singular pathloss model l(r) =min(1, r−α), in a network region with radius ρ, we have
E [Y1] ={
λAπ(1 + 2(1−ρ2−α)
α−2
)if α , 2
λAπ(1 + 2 ln(ρ)) if α = 2(15)
Var [Y1] = λAπ(1 +
1 − ρ2−2α
α − 1
). (16)
Then, using E[Y21 ] = Var[Y1] + (E[Y1])2, we obtain
E[Y2
1]=
λAπ
(α−ρ2−2α
α−1 + λAπ(α−2ρ2−α
α−2
)2)
if α , 2
λAπ(α−ρ2−2α
α−1 + λAπ (1 + 2 ln(ρ))2)
if α = 2.(17)
For Y2 =∑L
i=1 l2(ri), using again Campbell’s theorem, we have
E[Y2] = λAπα − ρ2−2α
α − 1= Var[Y1]. (18)
From the above results, we make the following observations:
• Y2 scales proportionally to λA;• The higher order element of Y2
1 scales proportionally toλ2A;
• When the pathloss is bounded, both Y2 and Y21 have finite
mean, which increase with λA.
Given these observations, one intuitive conclusion is that whenλA increases, Y2
NY21→ 0, which implies E[Y2]
NE[Y21 ]→ 0. In other
words, if E[Y2]NE[Y2
1 ]does not converge to zero when λA increases,
adding more APs will not help the channel to harden. Wecontinue to investigate this necessary condition for channelhardening below.
When the network region grows infinity large, i.e., ρ→∞,depending on the pathloss exponent, we have the followingcases:
1) α > 2: As the network radius ρ→∞, we have ρ2−2α →0 and ρ2−α → 0, which implies
E[Y2
1]→ λAπ
(α
α − 1+ λAπ
( α
α − 2
)2), (19)
E[Y2] → λAπα
α − 1, (20)
E[Y2]NE
[Y2
1] → 1/N
1 + λAπ α(α−1)(α−2)2
. (21)
With small N , in order to have E[Y2]NE[Y2
1 ]approaching 0, the AP
density should satisfy λAαπ(α−1)(α−2)2 � 1. Since the AP density is
measured in APs per m2, the condition for channel hardeningis only satisfied if λA ∼ 1 AP/m2, which is a rather unrealisticcondition in practice.
2) α = 2: This case behaves as in a free-space propagationenvironment. As ρ→∞, we have ln(ρ) → ∞ and ρ2−2α → 0,which implies
E[Y2] → λAπα
α − 1, (22)
E[Y2]NE
[Y2
1] � 1/N
1 + λAπ(1 + 2 ln(ρ))2 α−1α
→ 0, (23)
where the operator � means that the difference between theexpressions vanishes asymptotically. From (23), we observethat channel hardening is achieved as the network radiusincreases.
3) 1 < α < 2: One example of this case is the indoornear field propagation. With ρ→∞, we have ρ2−α →∞ andρ2−2α → 0, which implies
E[Y2]NE
[Y2
1] � 1/N
1 + λAπ 4ρ4−2α
(2−α)2α−1α
→ 0. (24)
From the above equations, we see that E[Y2]NE[Y2
1 ]decreases
rapidly with λA and ρ when α ≤ 2. When the network regiongrows infinitely large, E[Y2]
NE[Y21 ]
will eventually approach 0. Thissuggests that with smaller pathloss exponents, e.g., free-spacepropagation and indoor near field propagation, it is morelikely to observe channel hardening in CF Massive MIMO.With the two-ray ground-reflection pathloss model and α = 4[29], the convergence to channel hardening only happens withimpractically high antenna density.
In order to validate our analytical predictions, we presentin Fig. 3 the simulated pθ (i.e., the CDF of Xch) for differentAP densities, obtained with pathloss exponents α ∈ {3.76, 2}.Note that in this figure we only consider N = 1. We havechosen large values of λA in order to see the behavior ofpθ when λA → ∞. Fig. 3 shows that with α = 3.76, for agiven threshold θ, the channel hardening measure pθ doesnot change much with the AP intensity, unless we reachλA = 105/km2 (0.1/m2). However, having λA > 103/km2 isprobably practically unreasonable. With α = 2, the conver-gence of the channel hardening measure pθ to one becomesmore obvious when the AP density grows, which indicatesthat the probability to observe channel hardening at randomlocations is fairly large.

6
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Threshold
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1p
A=105/km2, =2
A=103/km2, =2
A=102/km2, =2
A=105/km2, =3.76
A=103/km2, =3.76
A=102/km2, =3.76
Fig. 3. The CDF of Xch, with pathloss exponent α ∈ {3.76, 2}. Thenetwork radius is ρ = 0.5 km and N = 1. The AP density is λA ∈{102, 103, 105 }/km2, which is equivalent to {10−4, 10−3, 0.1}/m2.
Property 1. Increasing the number of antennas per AP in CFMassive MIMO always helps the channel to harden. With oneantenna per AP, increasing the AP density does not lead tochannel hardening when using typical pathloss exponents andAP densities. In a propagation environment with a very smallpathloss exponent, α ≤ 2, the channel hardening criterion hashigher chance to be satisfied as the AP density increases.
B. More Antennas on Few APs or More APs with FewAntennas?
When the antenna density µ = NλA is fixed, whether tochoose larger N with smaller AP density λA or vice versa toachieve a high level of channel hardening can be inferred from(21) for α > 2. We can rewrite (21) as
E[Y2]NE
[Y2
1] = 1
N + NλAπα(α−1)(α−2)2
=1
N + µπ α(α−1)(α−2)2
. (25)
Since the denominator contains N plus a constant term forfixed µ, we will clearly obtain more channel hardening byhaving more antennas on fewer APs if we have a limitednumber of antennas to deploy.3 For α ≤ 2, we can get thesame observations from (23) and (24). Note that the strongerhardening comes at the price of less macro diversity.
In Fig. 4, we present pθ (i.e., the CDF of Xch) for differentλA and N while keeping the overall antenna density fixed atµ = NλA = 103/km2 (10−3/m2). This figure confirms ourprediction from (25) that having multiple antennas per APwill substantially help the channel to harden, and the level ofchannel hardening clearly increases with N . The curve N = 50can be interpreted as a cellular Massive MIMO system, dueto the massive number of antennas per AP. The largest gainsoccur when going from N = 1 to N = 5 (or to N = 10), thuswe can achieve reasonable strong channel hardening withinthe scope of CF Massive MIMO if each AP is equipped with
3This result was obtained with uncorrelated fading between the user andthe antennas on an AP. If there instead is spatially correlated fading, due toinsufficient scattering around the AP, this will slightly reduce the hardening,but more antennas will still be beneficial.
an array of 5-10 antennas. With a smaller pathloss exponent,the required number of antennas per AP to achieve reasonablystrong channel hardening is also smaller.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Threshold
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p N=50, A=20/km2
N=20, A=50/km2
N=10, A=100/km 2
N=5, A=200/km 2
N=1, A=1000/km 2
Fig. 4. The CDF of Xch with pathloss exponent α = 3.76 and network radiusρ = 0.5 km. The antenna density is µ = NλA = 1000/km2 (10−3/m2).
C. Distance vs. Number of Antennas
With higher AP density, the average number of antennas ina certain area is larger, thus the distances from the nearestAPs to the user are generally smaller—this is the macrodiversity effect. The effect of larger AP density on the channelhardening criteria can be related to the reduced distance and/orthe increased antenna number. To understand whether thedistance or the number of antennas plays the dominant role,we now examine the impact of the AP density while assumingthat the typical user is only served by the Mc nearest antennas,where Mc is usually much smaller than the total antennanumber M in the network region. Here, we focus only onthe case with a single antenna per AP. Thus, the Mc nearestantennas represent also the Mc nearest APs.
From existing results on the distance distribution inPoisson networks, the joint PDF of the distances r =
[r1, r2, . . . , rMc ]T from the Mc nearest antennas to the typicaluser is fr(x1, . . . , xMc ) = e−πλAx
2Mc (2πλA)Mc , for 0 < x1 <
. . . < xMc < ∞ [30]. To avoid the dependence betweenthe distribution of the Mc distance variables, we consideran approximately equivalent case where a fixed number Mc
antennas are uniformly and independently distributed in a diskB(0, R) centered at the typical user at the origin. Here, R is anaverage radius determined by the equivalent antenna density,i.e., R =
√Mc
πλA.
As a result of the i.i.d. uniform distribution, the joint PDFof the Mc points within B(0, R) is
fr(x1, . . . , xMc ) =Mc∏i=1
2xiR2 (26)
for x1, . . . , xMc ∈ [0, R]. Then we have
E [Xch] ≈∫ R
0· · ·
∫ R
0
Mc∑m=1
l2(rm)(Mc∑m=1
l(rm))2
Mc∏i=1
2xiR2 dx1 · · · dxMc . (27)
Here, the approximation comes from two parts:
7
• Mc � M , i.e., we consider that only the Mc nearest APscontribute to the majority of the channel gain and Mc isusually much smaller than M;
• Our assumption on having Mc antennas uniformly dis-tributed on B(0,
√Mc
πλA) is an approximation of the real
joint distance distribution of the Mc nearest antennas.
500 1000 1500 2000 2500 3000 3500 4000 4500 5000
AP Density A
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Mea
n Va
lue
of X
ch
=3.76, Mc=10, Approximation=3.76, Mc=10, Simulation=3.76, Mc=M, Simulation=2, Mc=10, Approximation=2, Mc=10, Simulation=2, Mc=M, Simulation
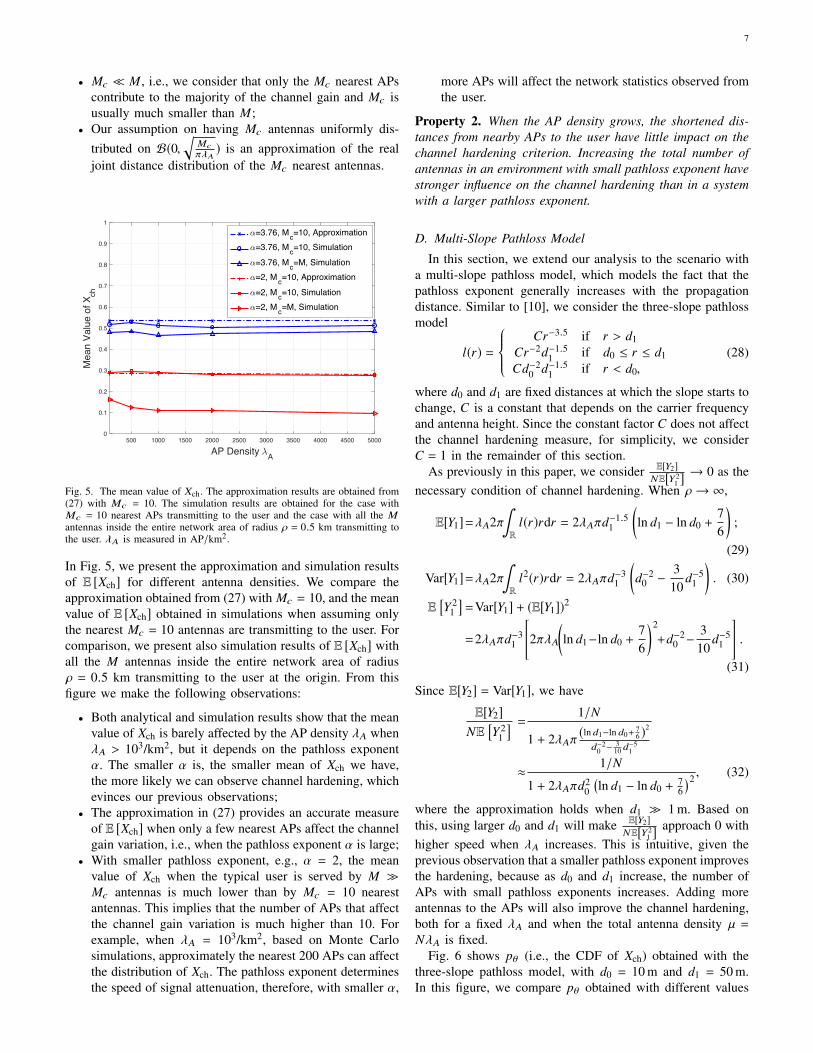
Fig. 5. The mean value of Xch. The approximation results are obtained from(27) with Mc = 10. The simulation results are obtained for the case withMc = 10 nearest APs transmitting to the user and the case with all the Mantennas inside the entire network area of radius ρ = 0.5 km transmitting tothe user. λA is measured in AP/km2.
In Fig. 5, we present the approximation and simulation resultsof E [Xch] for different antenna densities. We compare theapproximation obtained from (27) with Mc = 10, and the meanvalue of E [Xch] obtained in simulations when assuming onlythe nearest Mc = 10 antennas are transmitting to the user. Forcomparison, we present also simulation results of E [Xch] withall the M antennas inside the entire network area of radiusρ = 0.5 km transmitting to the user at the origin. From thisfigure we make the following observations:
• Both analytical and simulation results show that the meanvalue of Xch is barely affected by the AP density λA whenλA > 103/km2, but it depends on the pathloss exponentα. The smaller α is, the smaller mean of Xch we have,the more likely we can observe channel hardening, whichevinces our previous observations;
• The approximation in (27) provides an accurate measureof E [Xch] when only a few nearest APs affect the channelgain variation, i.e., when the pathloss exponent α is large;
• With smaller pathloss exponent, e.g., α = 2, the meanvalue of Xch when the typical user is served by M �Mc antennas is much lower than by Mc = 10 nearestantennas. This implies that the number of APs that affectthe channel gain variation is much higher than 10. Forexample, when λA = 103/km2, based on Monte Carlosimulations, approximately the nearest 200 APs can affectthe distribution of Xch. The pathloss exponent determinesthe speed of signal attenuation, therefore, with smaller α,
more APs will affect the network statistics observed fromthe user.
Property 2. When the AP density grows, the shortened dis-tances from nearby APs to the user have little impact on thechannel hardening criterion. Increasing the total number ofantennas in an environment with small pathloss exponent havestronger influence on the channel hardening than in a systemwith a larger pathloss exponent.
D. Multi-Slope Pathloss Model
In this section, we extend our analysis to the scenario witha multi-slope pathloss model, which models the fact that thepathloss exponent generally increases with the propagationdistance. Similar to [10], we consider the three-slope pathlossmodel
l(r) =
Cr−3.5 if r > d1Cr−2d−1.5
1 if d0 ≤ r ≤ d1Cd−2
0 d−1.51 if r < d0,
(28)
where d0 and d1 are fixed distances at which the slope starts tochange, C is a constant that depends on the carrier frequencyand antenna height. Since the constant factor C does not affectthe channel hardening measure, for simplicity, we considerC = 1 in the remainder of this section.
As previously in this paper, we consider E[Y2]NE[Y2
1 ]→ 0 as the
necessary condition of channel hardening. When ρ→∞,
E[Y1]=λA2π∫R
l(r)rdr = 2λAπd−1.51
(ln d1 − ln d0 +
76
);
(29)
Var[Y1]=λA2π∫R
l2(r)rdr = 2λAπd−31
(d−2
0 −310
d−51
). (30)
E[Y2
1]=Var[Y1] + (E[Y1])2
=2λAπd−31
[2πλA
(ln d1−ln d0 +
76
)2+d−2
0 −310
d−51
].
(31)
Since E[Y2] = Var[Y1], we have
E[Y2]NE
[Y2
1] = 1/N
1 + 2λAπ(ln d1−ln d0+
76 )2
d−20 −
310 d
−51
≈ 1/N1 + 2λAπd2
0(ln d1 − ln d0 +
76)2 , (32)
where the approximation holds when d1 � 1 m. Based onthis, using larger d0 and d1 will make E[Y2]
NE[Y21 ]
approach 0 withhigher speed when λA increases. This is intuitive, given theprevious observation that a smaller pathloss exponent improvesthe hardening, because as d0 and d1 increase, the number ofAPs with small pathloss exponents increases. Adding moreantennas to the APs will also improve the channel hardening,both for a fixed λA and when the total antenna density µ =NλA is fixed.
Fig. 6 shows pθ (i.e., the CDF of Xch) obtained with thethree-slope pathloss model, with d0 = 10 m and d1 = 50 m.In this figure, we compare pθ obtained with different values

8
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Threshold
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1p A=200/km 2, N=10
A=100/km 2, N=10
A=50/km 2, N=10
A=2000/km2, N=1
A=1000/km2, N=1
A=500/km 2,N=1
Fig. 6. The CDF of Xch with the three-slope pathloss model. d0 = 10 m andd1 = 50 m. The total antenna density is µ = NλA = {500, 1000, 2000}/km2.
of the AP density λA for N = 1 and N = 10 antennas perAP. First, with N = 1, when the antenna density increases,the increase of pθ is substantial, and more influential than theresults in Fig. 3 and Fig. 4 with the one-slope model. Second,comparing the results obtained with N = 1 and N = 10, we seethat the number of antennas per AP plays a more importantrole than increasing the AP density in helping the channelto harden, in terms of achieving a small Xch with practicallyreasonable AP density values.
Property 3. With the three-slope pathloss model, due tothe small pathloss exponent of the propagation environmentnearby the user, the channel gain variance declines rather fastwith the AP density compared to the mean value. Furthermore,having large number of antennas per AP can guarantee smallchannel variation, which makes the channel hardening easierto achieve.
IV. FAVORABLE PROPAGATION
In this section, we define and analyze the favorable propa-gation conditions in CF Massive MIMO networks. Similar tothe previous section, we will consider both conventional CFnetworks with single-antenna APs and a generalization withmultiple antennas per AP.
Recall that the channel vector from the M antennas to theuser k is gk = [g1,k, . . . , gM,k]T , where the m-th elementis gm,k =
√l(dm,k)hm,k . To have favorable propagation, the
channel vectors between the BS and the user terminals shouldbe orthogonal, which means
gHk gj =
{0 if k , j
‖gk ‖2 , 0 if k = j . (33)
When this condition is satisfied, each user can get the samecommunication performance as if it is alone in the network[31]. In practice, this condition is not fully satisfied, but can beapproximately achieved when the number of antennas growsto infinity, in which case the channels are said to provideasymptotically favorable propagation. To be more specific, in
CF Massive MIMO, the asymptotically favorable propagationcondition can be defined as follows:
gHk
gj√E
[‖gk ‖2 |dk
]E
[‖gj ‖2 |dj
] −→ 0, when M →∞, k , j .
(34)Here, we have conditioned on a specific network realiza-tion with distance vectors dk = [d1,k, . . . , dM,k]T and dj =
[d1, j, . . . , dM, j]T , and each element dm,k represents the dis-tance from the m-th antenna to the user k. Recall thatevery N antennas are co-located at the same AP, we haved(i−1)·N+1,k = . . . = di ·N,k for i = 1, . . . , L.
Different from cellular Massive MIMO with co-locatedantennas, the large-scale fading coefficients from each antennain CF Massive MIMO to a user are different, which can beviewed as a type of spatial channel correlation. Thus, we have
gHk gj =
M∑m=1
√l(dm,k)l(dm, j)h∗m,khm, j (35)
and√E
[‖gk ‖2 |dk
]E
[‖gj ‖2 |dj
]=
√√√M∑m=1
l(dm,k)M∑m=1
l(dm, j).
(36)Since {hm,k} are i.i.d. CN(0, 1) RVs, we have
E[h∗m,khm, j
]=
{0 if k , j1 if k = j (37)
and it follows that
E
gHk
gj√E
[‖gk ‖2 |dk
]E
[‖gj ‖2 |dj
] �����dk, dj
={
0 if k , j1 if k = j .
(38)With this mean value, the convergence in (34) holds (in meansquare sense and in probability) if the variance of the left-handside goes asymptotically to zero. Using (35) and (36), we have
Var
gHk
gj√E
[‖gk ‖2 |dk
]E
[‖gj ‖2 |dj
] �����dk, dj
(39)
=
NL∑i=1
l(di ·N,k)l(di ·N, j)
N2L∑i=1
l(di ·N,k)L∑i=1
l(di ·N, j)(40)
≤ L
N L2(
1L
L∑i=1
l(di ·N,k)) (
1L
L∑i=1
l(di ·N, j)) . (41)
As the AP density λA grows, L increases. 1L
L∑i=1
l(di ·N,k) will
approach E[l(di ·N,k)] > 0, which is a positive value that onlydepends on the network size and the pathloss model. Thus,(40) is upper-bounded by a positive value that decreases as1/L when L increases. When L → ∞, the variance of thechannel orthogonality will approach 0. Combined with (38),we can prove that the asymptotically favorable propagationcondition defined in (34) holds for CF Massive MIMO.

9
For finite L, we use (40) to define the channel orthogonalitymetric
Xfp =
L∑i=1
l(di ·N,k)l(di ·N, j)
NL∑i=1
l(di ·N,k)L∑i=1
l(di ·N, j)(42)
and consider the probability that two users at random locationshave Xfp no larger than a threshold γ:
pγ = P[Xfp ≤ γ]. (43)
Clearly, in order to have asymptotically favorable propagation,when the antenna density grows, pγ should approach one forany γ ≥ 0. For practical purposes, it is desirable that pγ islarge for values of the threshold γ that are close to zero. In thefollowing, we will analyze how the antenna density, the inter-user distance, and the pathloss exponent affects the channelorthogonality.
A. Impact of Antenna Density on Channel Orthogonality
The impact of the antenna density µ = NλA will be analyzedin two cases: fixed λA with different N or fixed N withdifferent λA. As mentioned above, Xfp is inversely proportionalto N when L is fixed, so increasing N always helps thechannels to become more orthogonal. In the other case, whenL increases, the denominator of Xfp grows almost as L2,while the numerator increases almost linearly with L. Knowingthat L is a Poisson RV with mean value proportional to λA,consequently, Xfp should scale roughly inversely proportionalto λA, which evinces that for a given γ, pγ will grow with theAP density λA. Combining the two cases, we can see that bothlarger N and larger AP density λA can help the channel to offermore favorable propagation. Fig. 7 presents the CDF of thechannel orthogonality metric Xfp with different λA and N . Bycomparing the results obtained with λA = {500, 100}/km2 andN = {1, 5} (marked with circle, left triangle and plus sign), wevalidate that both increasing λA and increasing N can improvethe channel orthogonality.
B. More Antennas on Few APs or More APs with FewAntennas?
From (42), we see that the value of Xfp is always upper-bounded by 1
N . When the antenna density µ = NλA is fixed,increasing N means smaller λA. As the result, the averagenumber of APs within close distance to the user will be less.Thus, it is hard to predict whether it is more beneficial to havemore antennas on few APs or more APs with few antennas.
In Fig. 7, we present the CDF of Xfp when fixing the totalantenna density NλA = 500/km2. We see that increasing Ndoes not necessarily lead to higher or lower pγ for a givenvalue of γ. We also observe that when choosing sufficientlylarge N , e.g., N ≥ 20, the channel orthogonality metricXfp becomes very small. In other words, sufficiently large Nwill help the channels to different users to be asymptoticallyorthogonal.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Threshold
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p
A=25/km 2, N=20
A=50/km 2, N=10
A=100/km 2, N=5
A=500/km 2, N=1
A=100/km 2, N=1
Fig. 7. The CDF of Xfp. Pathloss exponent α = 3.76. Network radius ρ = 0.5km. For the first four curves (marked with upward triangle, cross, circle andleft triangle), the antenna density is µ = NλA = 500/km2 (5× 10−4/m2). Thedistance between user j and user k is 70 m.
C. Impact of Inter-User Distance on Channel Orthogonality
From (34), it is obvious that the distance between two usersaffects the variance of each term
√l(dm,k)l(dm, j)h∗m,khm, j .
When two users are far apart, their channel vectors are morelikely to be orthogonal with smaller variance. This resultcomes from the fact that l(dm,k)l(dm, j) for all m = 1, . . . , Mwill become much smaller when the distance lk, j between userk and user j is large. In addition,
∑Mm=1 l(dm,k)
∑Mm=1 l(dm, j)
will not vary much with the inter-user distance lk, j when M isfixed. Therefore, Xfp becomes smaller when the distance lk, jincreases.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Threshold
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p
A=200/km 2, lk,j=212m
A=100/km 2,lk,j=212m
A=50/km 2,lk,j=212m
A=200/km 2, lk,j=70m
A=100/km 2, lk,j=70m
A=50/km 2, lk,j=70m
Fig. 8. The CDF of Xfp with different λA and different inter-user distancesld, j , N = 1, and pathloss exponent α = 3.76.
In Fig. 8, we present pγ for different AP densities λA ∈{50, 100, 200} APs/km2, N = 1, and inter-user distances lk, j ∈{70, 212}m. First, it is shown that with larger λA, the varianceof the orthogonality metric Xfp is smaller. Second, when thedistance between two users is larger, they are more likely tohave nearly orthogonal channels. This observation showcasesthe importance of serving spatially separated users in order toensure near channel orthogonality.
D. Impact of Pathloss Exponent on Channel Orthogonality
When the number of antennas M and their locations arefixed, we consider two extreme cases: user k and user j are

10
very close or extremely far from each other. Since Xch coin-cides with Xfp in the special case when di ·N,k ' di ·N, j for allm = 1, . . . , M , we infer from Section III that smaller pathlossexponent will also lead to smaller Xfp. In the other extremecase, when the two users are far apart, in the denominator ofXfp,
∑Li=1 l(di ·N, j) is almost independent of
∑Li=1 l(di ·N,k), and
both terms increase much faster than the numerator, especiallywhen α is small. Combining these two extreme cases, weexpect that smaller pathloss exponent would help the channelsto become asymptotically orthogonal when M is sufficientlylarge.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Threshold
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
p
=2=3=4
Fig. 9. The CDF of Xfp with different pathloss exponent α ∈ {2, 3, 4},N = 1, and the inter-user distance lk, j = 70 m.
Fig. 9 shows pγ obtained with pathloss exponents α ∈{2, 3, 4}, N = 1, and an inter-user distance of lk, j = 70 m. Thefigure shows that with smaller α the channels become moreorthogonal, which is line with our prediction from above. Ifwe would instead use the three-slope pathloss model in (28),APs close to the user (distance smaller than d1) will havepathloss exponent α ≤ 2, and users at larger distances havepathloss exponent 3.5. Therefore, compared to the single-slopenon-singular pathloss model l(r) = min(r−3.76, 1), the channelsbetween two users will in the average be more orthogonal.
Summarizing the above analysis and observations, we havethe following conclusions.
Property 4. Increasing the antenna density by increasing ei-ther the AP density or the number of antennas per AP can bothhelp the user channels to offer favorable propagation. Smallerpathloss also helps the channels to become asymptoticallyorthogonal. The larger the distance between two users, themore likely their channels will be nearly orthogonal.
V. CAPACITY BOUNDS FOR CELL-FREE MASSIVE MIMO
A key conclusion from the previous sections is that CFMassive MIMO systems exhibit little channel hardening, ascompared to cellular Massive MIMO. Hence, although CFMassive MIMO is equivalent to a single-cell Massive MIMOsystem with strong spatial channel correlation, we must becareful when reusing results from the Massive MIMO lit-erature. In particular, capacity bounds that were derived byrelying on channel hardening can potentially be very loosewhen applied to CF systems. In this section, we explain whichcapacity lower bounds are suitable for CF systems.
Consider a CF Massive MIMO system with M single-antenna APs and K users, which are assigned mutually or-thogonal pilot sequences. The transmission is divided intocoherence intervals of τc samples, whereof τp are used foruplink pilot signaling and K ≤ τp ≤ τc . The channels aremodeled as in previous sections: gk ∼ CN(0,Bk), whereBk = diag(β1,k, . . . , βM,k) and βm,k = l(rm,k). Each user trans-mits its orthogonal pilot sequence. User k uses the transmitpowers ρk and pk for pilot and data, respectively. Since theelements in gk are independent, it is optimal to estimate themseparately at the receiving antenna. The MMSE estimate ofgm,k is
gm,k =
√τpρk βm,k
τpρk βm,k + 1(√τρkgm,k + wm,k
), (44)
where wm,k ∼ CN(0, 1) is i.i.d. additive noise. If we denoteby γm,k
4=E
[|gm,k |2
]the mean square of the MMSE estimate
of gm,k , then it follows from (44) that
γm,k =τρk β
2m,k
τρk βm,k + 1. (45)
We will now compare different achievable rate expressions foruplink and downlink when using maximum ratio (MR) pro-cessing, which is commonly assumed in CF Massive MIMOsince it can be implemented distributively. The expressions arelower bounds on the capacity, thus we should use the one thatgives the largest value the accurately predict the achievableperformance.
A. Uplink Achievable Rate
During the uplink data transmission, all K users simultane-ously transmit to the M APs. When using MR, an achievablerate (i.e., a lower bound on the capacity) of user k is
RUatFu,k = log2
©«1 +
pk
(M∑m=1
γm,k
)2
K∑j=1
pj
M∑m=1
γm,k βm, j +M∑m=1
γm,k
ª®®®®¬, (46)
which was used for CF Massive MIMO in [10]. This boundis derived based on the use and then forget (UatF) principle[12], where the channel estimates are used for MR but then“forgotten” and channel hardening is utilized to obtain asimple closed-form expression. Note that RUatF
u,k is a specialcase of the general expression in [32] for correlated single-cell Massive MIMO systems that apply MR processing. Al-ternatively, the achievable rate expression in [16] for spatiallycorrelated channels can be used:
Ru,k
= E
log2
©«pk |aH
kgk |2
K∑j,k
pj |aHk
gj |2 + aHk
( K∑j=1
pj(Bj − Γ j) + IM)ak
ª®®®®¬,
(47)

11
0 1 2 3 4 5 6 7 8
Per-user rate [bit/s/Hz]
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
CD
F
Perfect CSIGeneral rateUatF rate
Fig. 10. The CDF of the uplink achievable rates obtained with the UatFbound, the general bound, and the rate with perfect CSI. M = 100, N = 1,K = 20, τp = 20.
0 1 2 3 4 5 6 7 8 9 10
Per-user rate [bit/s/Hz]
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
CD
F
Perfect CSIGeneral rateUatF rate
Fig. 11. Same as Fig. 10. M = 100, N = 5, K = 20, τp = 20.
TABLE ISIMULATION SETUP
Parameters ValuesM , K , τp , τc 100, 20, 20, 500
d0, d1 10 m, 50 mCarrier frequency f 1.9 GHz
Antenna height hAP , hu 1.5 m, 1.65 mUplink pilot power ρk , data power pk 100 mW, 100 mW
Downlink power per UE q 100 mW
where gk = [g1,k, . . . , gM,k]T , Γ j = diag(γ1, j, . . . , γM, j), andak is the combining vector, which is ak = gk for MR. Thisgeneral bound does not rely on channel hardening.
In Fig. 10 and Fig. 11, we compare the uplink achievablerates obtained with (46) and (47), and also the rate with perfectCSI (obtained from (47) by letting ρk → ∞). The simulationis performed in a network area of 1 km ×1 km. K = 20 usersare randomly and uniformly distributed in the network region,and we have τp = K . The total number of antennas is M =100. The results in Fig. 10 are obtained with L = 100 single-antenna APs and those in Fig. 11 are obtained with L = 20 APswith N = 5 antennas per AP. All the APs are independentlyand uniformly distributed in the network region. The lengthof the coherence block is τc = 500. The large-scale fadingcoefficients between the antennas and the users are generatedfrom 300 different PPP realizations. The three-slope pathlossmodel in (28) is used with d0 = 10 m and d1 = 50 m. The
constant factor C (dB) is given by
C =105 + 46.3 + 33.9 log 10( f ) − 13.82 log 10(hAP)− (1.1 log 10( f ) − 0.7)hu + (1.56 log 10( f ) − 0.8),
(48)
where f is the carrier frequency, hAP and hu are the APand user antenna height, respectively [10]. The simulationparameters are summarized in Table I. Fig. 10 and Fig. 11show the CDFs of the user rates for random distances betweenthe L APs and the K users. The general rate expression in(47) provides almost identical rates to the perfect CSI case,which indicates that the estimation errors to the closest APsare negligible. In contrast, the UatF rate in (46) is a muchlooser bound on the capacity, particularly for the users thatsupport the highest data rates. Some users get almost twicethe rate when using the general expression. This is due to thelack of channel hardening for users that are close to only afew APs. Hence, a general guideline is to only use (47) forachievable rates in CF Massive MIMO with single-antennaAPs. An important observation from Fig. 10 and Fig. 11 is that,with multiple antennas per AP, e.g., N = 5, the differencesbetween the UatF bound and the perfect CSI case becomessmaller, particularly for the users that support the smallestrates. This comes from the fact that having multiple antennasper AP gives better channel hardening, as we have seen inSection III. However, the average rate reduces when goingfrom many single-antenna APs to fewer multi-antenna APs,so it is not obvious what is the better choice in practice.
B. Downlink Achievable Rate
In the downlink of Massive MIMO, it is popular to use rateexpressions where the only CSI available at the user is thechannel statistics. When there is channel hardening, one canachieve rates similar to the uplink. If MR precoding is used,then one can use the rate expression for spatially correlatedfading from [16] and obtain the achievable rate
RUatFd,k = log2
©«1 +
(M∑m=1
√pm,kγm,k
)2
K∑k′=1
M∑m=1
pm,k′βm,k + 1
ª®®®®¬(49)
for user k, where pm,k is the average transmit power allocatedto user k by AP m. This type of expression was used for CFMassive MIMO in [10], using a slightly different notation. Wecall this the UatF rate since we use the received signals fordetection, but “forget” to use them for blind estimation of theinstantaneous channel realizations.
Suppose ak is the precoding vector (including power al-location) assigned to user k. To avoid relying on channelhardening, user k can estimate its instantaneous channel afterprecoding, aH
kgk , from the collection of τd received downlink

12
signals in the current coherence block. By following a similarapproach as in [33, Lemma 3], we obtain the achievable rate
Rd,k =
E
log2
©«|aH
kgk |2
K∑j,k|aH
j gk |2 + 1
ª®®®®¬− 1τd
K∑j=1
log2
(1 + τdVar[aH
j gk]).
(50)
The first term in (50) is the rate with perfect CSI and the sec-ond term is a penalty term from imperfect channel estimationat the user. Note that the latter term vanishes as τd → ∞,thus this general rate expression is a good lower bound whenthe channels change slowly. The rate with MR precoding isobtained by setting ak =
[g1,k
√p1,kγ1,k
. . . gM,k√
pM,k
γM,k
]T .
0 1 2 3 4 5 6
Per-user rate [bit/s/Hz]
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
CD
F
Perfect CSIGeneral rateUatF rate
Fig. 12. The CDF of the downlink achievable rates obtained with the UatFbound, the general bound, and the rate with perfect CSI. M = 100, N = 1,K = 20, τp = 20.
In Fig. 12, we compare the downlink achievable ratesobtained with (49) and (50), and also the rate with perfectCSI at user (obtained from (50) by letting τd → ∞). Thesimulation parameters are summarized in Table I, which arethe same as in Section V-A for the uplink. The downlink powerpm,k is given by
pm,k =q · γm,kE[‖gk ‖2]
= qγm,k
M∑m′=1
γm′,k
, (51)
where q is the downlink power allocated to each user k, whichis chosen as 100 mW in the simulations. By doing so, we haveE[‖ak ‖2] = q, which is the same for all users. Fig. 12 showsthe CDFs of the user rates for random antenna-user distances.As in the uplink, there is a substantial gap between the ratesachieved by perfect CSI curve and the UatF rate. The curvefor the general rate in (50) is in the middle, which impliesthat the users should estimate their downlink channels and notrely on channel hardening in CF Massive MIMO. It is unclearwhether the gap from the perfect CSI curve is due to limiteddownlink estimation quality or is an artifact from the capacitybounding technique that lead to (50). In any case, there isa need to further study the achievable downlink rates in CFMassive MIMO.
VI. CONCLUSION
In this work, we provided thorough investigation of thechannel hardening and favorable propagation phenomena inCF Massive MIMO systems from a stochastic geometry per-spective. By studying the channel distribution from stochasti-cally distributed APs with either single or multiple antennasper AP, we characterized the channel gain distribution, basedon which we examined the conditions of channel hardeningand favorable propagation. Our results showed that whether thechannel hardens with increasing number of antennas stronglydepends on the propagation environment and pathloss model,but one should generally not expect much hardening. However,one can improve the hardening by deploying multiple antennasper AP. There are several factors that can help the channel toprovide favorable propagation, such as smaller pathloss expo-nent, higher antenna density, and spatially separated users withlarger distances. Well separated users will generally exhibitfavorable propagation since they are mainly communicatingwith different subsets of the APs.
A main implication of this work is that one should notrely on channel hardening and favorable propagation whencomputing the achievable rates in CF Massive MIMO, becausethis could lead to a great underestimation of the achievableperformance. There is a good uplink rate expression forspatially correlated Massive MIMO systems that can be used.Further development of downlink rate expressions is neededto fully understand the achievable downlink performance inCF Massive MIMO.
APPENDIX
A. Proof of (5) and (6)
Recall Campbell’s theorem as follows [23]. If f (x) :Rd → [0,+∞] is a measurable function and Φ is a station-ary/homogeneous PPP with density λ, then
E
[∑x∈Φ
f (x)]= λ
∫Rd
f (x)dx. (52)
Since ΦA is a two-dimensional homogeneous PPP, for a finitenetwork region with radius ρ, we have
E[‖gk ‖2
]= E
[ ∑i∈ΦA
Hil(ri)]
= E [Hi] · λA∫B(0,ρ)
l(‖x‖)dx.
= λA · E [Hi] 2π∫ ρ
0l(r)rdr . (53)
Note that l(r) = min(1, r−α) and E [Hi] = N as a result of theGamma distribution, thus
E[‖gk ‖2
]= NλA2π
(∫ 1
0rdr +
∫ ρ
1r1−αdr
). (54)
Depending on the value of α, we have
E[‖gk ‖2
]=
{NλAπ
(1 + 2(1−ρ2−α)
α−2
)if α , 2
NλAπ (1 + 2 ln ρ) if α = 2(55)

13
From [23], we have the expression for the variance
Var
[∑x∈Φ
f (x)]= λ
∫Rd
f (x)2dx. (56)
Since Hi ∼ Gamma(N, 1), we have E[H2i
]= (E [Hi])2 +
Var[H2i
]= N2 + N , thus
Var[‖gk ‖2
]= λA · E
[H2i
]2π
∫ ρ
0l2(r)rdr
= (N2 + N)λA2π(∫ 1
0rdr +
∫ ∞
1r1−2αdr
)= (N2 + N)λAπ
(1 +
1α − 1
(1 − ρ2−2α
)). (57)
Note that (57) will have a different form when α = 1, whichis unlikely to happen in a real propagation environment. Thus,this case is not discussed here.
REFERENCES
[1] Z. Chen and E. Björnson, “Can we rely on channel hardening in cell-freeMassive MIMO?” accepted in IEEE GLOBECOM Workshops, 2017.
[2] S. Shamai and B. M. Zaidel, “Enhancing the cellular downlink capacityvia co-processing at the transmitting end,” in Proc. IEEE VTC-Spring,vol. 3, 2001, pp. 1745–1749.
[3] S. Venkatesan, A. Lozano, and R. Valenzuela, “Network MIMO: Over-coming intercell interference in indoor wireless systems,” in Proc. IEEEACSSC, 2007, pp. 83–87.
[4] D. Gesbert, S. Hanly, H. Huang, S. Shamai, O. Simeone, and W. Yu,“Multi-cell MIMO cooperative networks: A new look at interference,”IEEE J. Sel. Areas Commun., vol. 28, no. 9, pp. 1380–1408, 2010.
[5] A. Osseiran, J. F. Monserrat, and P. Marsch, 5G Mobile and WirelessCommunications Technology. Cambridge University Press, 2016, ch.9, Coordinated Multi-Point Transmission in 5G.
[6] E. Björnson, R. Zakhour, D. Gesbert, and B. Ottersten, “Cooperativemulticell precoding: Rate region characterization and distributed strate-gies with instantaneous and statistical CSI,” IEEE Trans. Signal Process.,vol. 58, no. 8, pp. 4298–4310, 2010.
[7] E. Björnson, N. Jaldén, M. Bengtsson, and B. Ottersten, “Optimalityproperties, distributed strategies, and measurement-based evaluationof coordinated multicell OFDMA transmission,” IEEE Trans. SignalProcess., vol. 59, no. 12, pp. 6086–6101, 2011.
[8] H. Q. Ngo, A. E. Ashikhmin, H. Yang, E. G. Larsson, and T. L. Marzetta,“Cell-free Massive MIMO: Uniformly great service for everyone,” inProc. IEEE SPAWC, 2015.
[9] E. Nayebi, A. Ashikhmin, T. L. Marzetta, and H. Yang, “Cell-freeMassive MIMO systems,” in Proc. Asilomar, 2015.
[10] H. Q. Ngo, A. Ashikhmin, H. Yang, E. G. Larsson, and T. L. Marzetta,“Cell-free Massive MIMO versus small cells,” IEEE Trans. WirelessCommun., vol. 16, no. 3, pp. 1834–1850, 2017.
[11] E. Nayebi, A. Ashikhmin, T. L. Marzetta, H. Yang, and B. D. Rao,“Precoding and power optimization in cell-free Massive MIMO sys-tems,” IEEE Trans. Wireless Commun., vol. 16, no. 7, pp. 4445–4459,2017.
[12] T. L. Marzetta, E. G. Larsson, H. Yang, and H. Q. Ngo, Fundamentalsof Massive MIMO. Cambridge University Press, 2016.
[13] H. Q. Ngo and E. Larsson, “No downlink pilots are needed in TDDMassive MIMO,” IEEE Transactions on Wireless Communications,vol. 16, no. 5, pp. 2921–2935, May 2017.
[14] H. Q. Ngo, E. G. Larsson, and T. L. Marzetta, “Aspects of favorablepropagation in Massive MIMO,” in European Signal Processing Con-ference (EUSIPCO), September 2014, pp. 76–80.
[15] H. Huh, G. Caire, H. Papadopoulos, and S. Ramprashad, “Achieving“massive MIMO” spectral efficiency with a not-so-large number ofantennas,” IEEE Trans. Wireless Commun., vol. 11, no. 9, pp. 3226–3239, 2012.
[16] J. Hoydis, S. ten Brink, and M. Debbah, “Massive MIMO in the UL/DLof cellular networks: How many antennas do we need?” IEEE J. Sel.Areas Commun., vol. 31, no. 2, pp. 160–171, 2013.
[17] H. Yin, D. Gesbert, M. Filippou, and Y. Liu, “A coordinated approachto channel estimation in large-scale multiple-antenna systems,” IEEE J.Sel. Areas Commun., vol. 31, no. 2, pp. 264–273, 2013.
[18] G. Interdonato, H. Q. Ngo, E. G. Larsson, and P. Frenger, “How muchdo downlink pilots improve cell-free Massive MIMO?” in Proc. IEEEGLOBECOM, 2016.
[19] W. Lu and M. Di Renzo, “Stochastic geometry modeling of cellularnetworks: Analysis, simulation and experimental validation,” in ACMInternational Conference on Modeling, Analysis and Simulation ofWireless and Mobile Systems, November 2015, pp. 179–188.
[20] J. G. Andrews, F. Baccelli, and R. K. Ganti, “A tractable approachto coverage and rate in cellular networks,” IEEE Transactions onCommunications, vol. 59, no. 11, pp. 3122–3134, November 2011.
[21] M. Haenggi, “The meta distribution of the SIR in Poisson bipolar andcellular networks,” IEEE Transactions on Wireless Communications,vol. 15, no. 4, pp. 2577–2589, April 2016.
[22] R. K. Ganti and M. Haenggi, “Interference in ad hoc networks withgeneral motion-invariant node distributions,” in IEEE InternationalSymposium on Information Theory, July 2008, pp. 1–5.
[23] M. Haenggi, R. K. Ganti et al., “Interference in large wireless networks,”Foundations and Trends R© in Networking, vol. 3, no. 2, pp. 127–248,2009.
[24] M. Haenggi, Stochastic geometry for wireless networks. CambridgeUniversity Press, 2012.
[25] M. Kountouris and N. Pappas, “Approximating the interference distribu-tion in large wireless networks,” in International Symposium on WirelessCommunications Systems (ISWCS), August 2014, pp. 80–84.
[26] K. Smaili, T. Kadri, and S. Kadry, “Hypoexponential distribution withdifferent parameters,” Applied mathematics, vol. 4, no. 04, p. 624, 2013.
[27] S. V. Amari and R. B. Misra, “Closed-from expressions for distributionof sum of exponential random variables,” IEEE Trans. Rel., vol. 46,no. 4, pp. 519–522, 1997.
[28] E. Björnson, D. Hammarwall, and B. Ottersten, “Exploiting quantizedchannel norm feedback through conditional statistics in arbitrarily cor-related MIMO systems,” IEEE Trans. Signal Process., vol. 57, no. 10,pp. 4027–4041, 2009.
[29] A. Goldsmith, Wireless Communications. Cambridge University Press,2005.
[30] D. Moltchanov, “Distance distributions in random networks,” Ad HocNetworks, vol. 10, no. 6, pp. 1146–1166, 2012.
[31] F. Rusek, D. Persson, B. Lau, E. Larsson, T. Marzetta, O. Edfors, andF. Tufvesson, “Scaling up MIMO: Opportunities and challenges withvery large arrays,” IEEE Signal Process. Mag., vol. 30, no. 1, pp. 40–60, 2013.
[32] E. Björnson, L. Sanguinetti, and M. Debbah, “Massive MIMO withimperfect channel covariance information,” in Proc. ASILOMAR, 2016.
[33] G. Caire, “On the ergodic rate lower bounds with applications to MassiveMIMO,” CoRR, vol. abs/1705.03577, 2017.
![Tensile Properties and Work Hardening Behaviour of Alloy 6016 in …icaa-conference.net/ICAA12/pdf/P109.pdf · 2016-06-02 · age hardening response [1]. It is unclear, however, how](https://img.pdfslide.us/doc/110x75/5ebcbcfc504d091dd447e7f6/tensile-properties-and-work-hardening-behaviour-of-alloy-6016-in-icaa-2016-06-02.jpg)




























