Embed Size (px)
Citation preview

CASS-MT Review: 6-Apr-2011Task 3: Semantic Databases on the XMT
PNNL: David Haglin, Bob Adolf, Sinan al-Saffar, Cliff JoslynCray: David Mizell
SNL: Eric Goodman, Edward Jimenez, Greg Mackey
1

HPC applied to Semantic Graph Databases
2
Result Set
• Expressing queries as a graph• SPARQL• SGD as an Appliance (Front end)
User Interface
• Billion Triple size datasets• Extant Ontological Scaling• Motif Analysis
Analysis
• Dictionary Encoding• Materialized Inference• Paging graph portions / dictionary
Data Storage &Manipulation
• Search Processing Approach• Query Optimization• On-the-fly Inferencing
Search / Query

Outline
Introduction (David Haglin)AccomplishmentsFocus this review: Query Search Process
OWL Rules, Subgraph Isomorphism, Sprinkle-SPARQL (Eric Goodman)Generic Forward-Inferencing Capability(David Mizell)Graph Analysis and Extant Ontology (Sinan al-Saffar)What next? (David Haglin)

Accomplishments
Accepted Papers:Eric Goodman, Edward Jimenez, David Mizell, Sinan al-Saffar, Bob Adolf, and David Haglin. “High-performance Computing Applied to Semantic Databases”. Extended Semantic Web Conference (ESWC 2011), May 2011. (23% acceptance rate)
Submissions:Cliff Joslyn, Bob Adolf, Sinan al-Saffar, John Feo, Eric Goodman, David Haglin, Greg Mackey, and David Mizell. “High Performance Descriptive Semantic Analysis of Semantic Graph Databases”. Workshop on High-Performance Computing for the Semantic Web, ESWC 2011, May 2011.Sinan al-Saffar, Cliff Joslyn, Alan Chappell. “Extant Ontological Scaling and Descriptive Semantics for Semantic Structure Discovery in Large Graph Datasets.” IEEE/WIC/ACM International Conference on Web Intelligence.
Workshops Organized:HPCSW – Most of task 3 personnel on program committee.Complex Query Workshop – scheduled for April 25/26 in Seattle, WA
Hybrid Database Planning Technical Meeting:Battelle Seattle Research Center, February 2011UW (Howe, Shaw), PNNL (CASS/SDB and TAI), SNL

Sandia is a multiprogram laboratory operated by Sandia Corporation, a Lockheed Martin Company,for the United States Department of Energy’s National Nuclear Security Administration
under contract DE-AC04-94AL85000.
CASS-MT Quarterly ReviewTask 3: Semantic Databases on the XMT
Eric GoodmanEdward Jimenez
Greg Mackey
Update April 2011
Sprinkle SPARQL
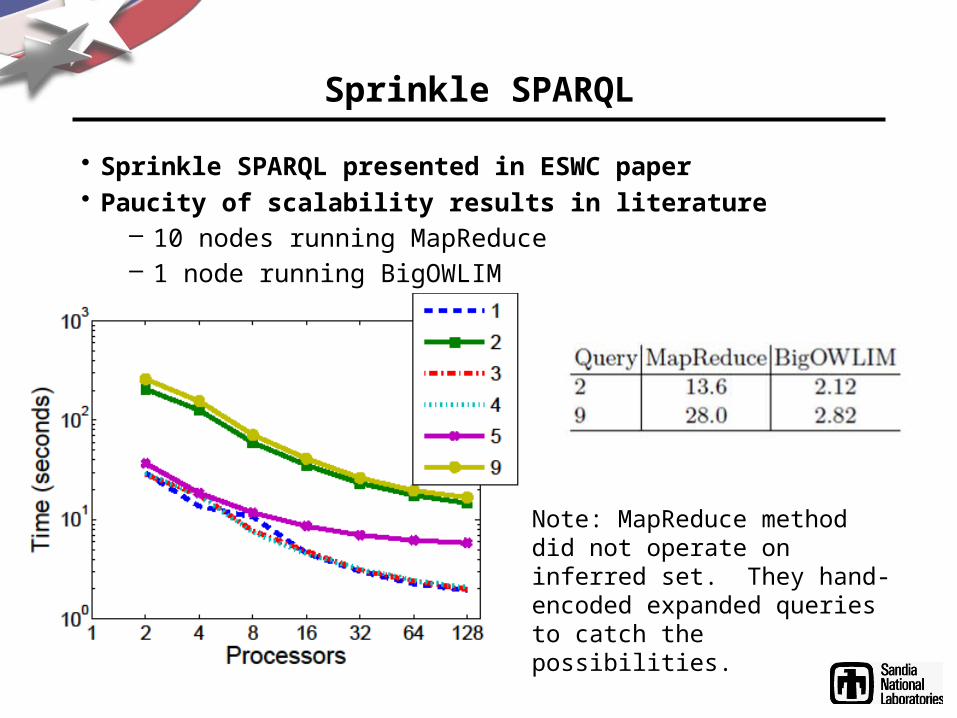
• Sprinkle SPARQL presented in ESWC paper• Paucity of scalability results in literature
– 10 nodes running MapReduce– 1 node running BigOWLIM
Note: MapReduce method did not operate on inferred set. They hand-encoded expanded queries to catch the possibilities.
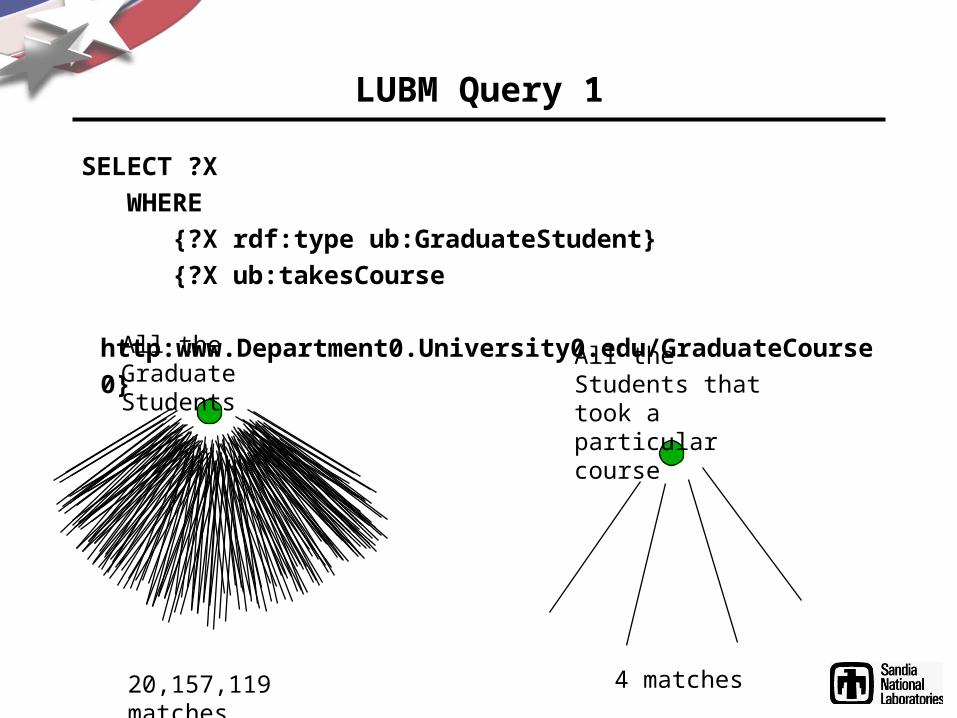
LUBM Query 1
SELECT ?X
WHERE
{?X rdf:type ub:GraduateStudent}
{?X ub:takesCourse
http:www.Department0.University0.edu/GraduateCourse0}All the Graduate Students
All the Students that took a particular course
20,157,119 matches 4 matches

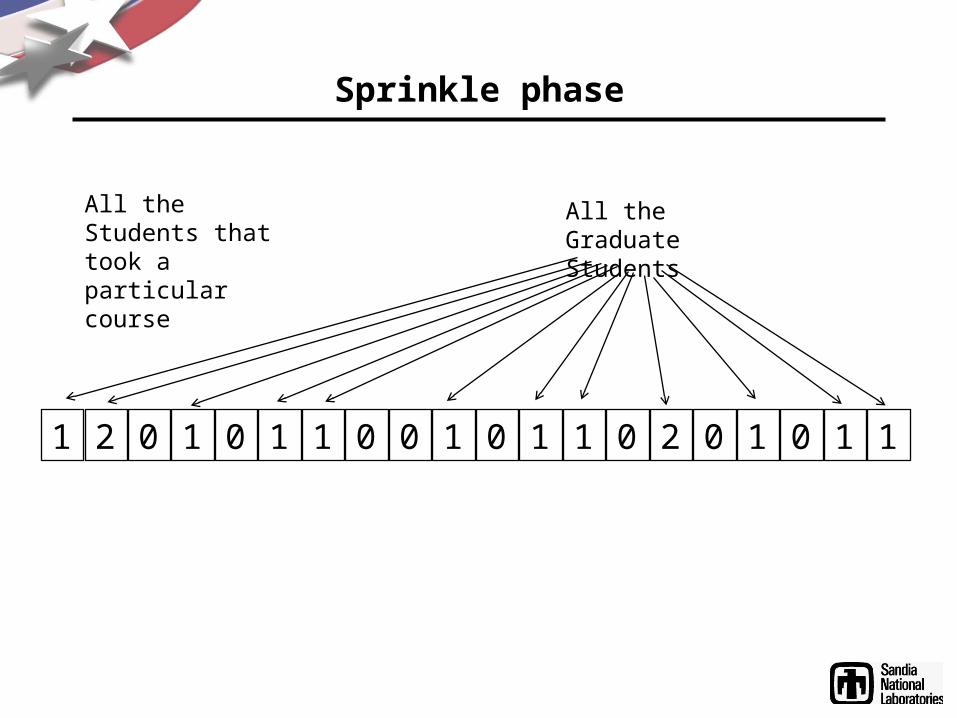
Sprinkle phase
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
• Create an array the same size as the order of the graph for each
variable in each BGP• Process each BGP
– If node fulfills constraint of BGP, increment counter in associated array for the variable
• The point: Constrain the problem before we start joining

Sprinkle phase
0
All the Students that took a particular course
1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0
Sprinkle phase
1
All the Students that took a particular course
2 0 1 0 1 1 0 0 1 0 1 1 0 2 0 1 0 1 1
All the Graduate Students

Future Query Work
• Spinkle-SPARQL– In-depth analysis– More discriminating use of Sprinkle
• Comparison to other approaches– MTGL subgraph isomorphism algorithm– Approach from Bob Adolf and David Haglin– Array-based method from David Mizell for SC10 demo

Inference Work
• Multimap data structure• OWL Horst rules
– rdfp4: Transitivity– rdfp8: InverseOf– rdfp12: Equivalent Classes– rdfp15: SomeValuesFrom– These are the set of rules required for LUBM

Multimaps
• A mapping between keys and multiple values• Comes up often in RDFS/OWL inferencing
– Class hierarchies– Property hierarchies– SameAs relationships– Indices to find triples with certain subjects, predicates, or objects
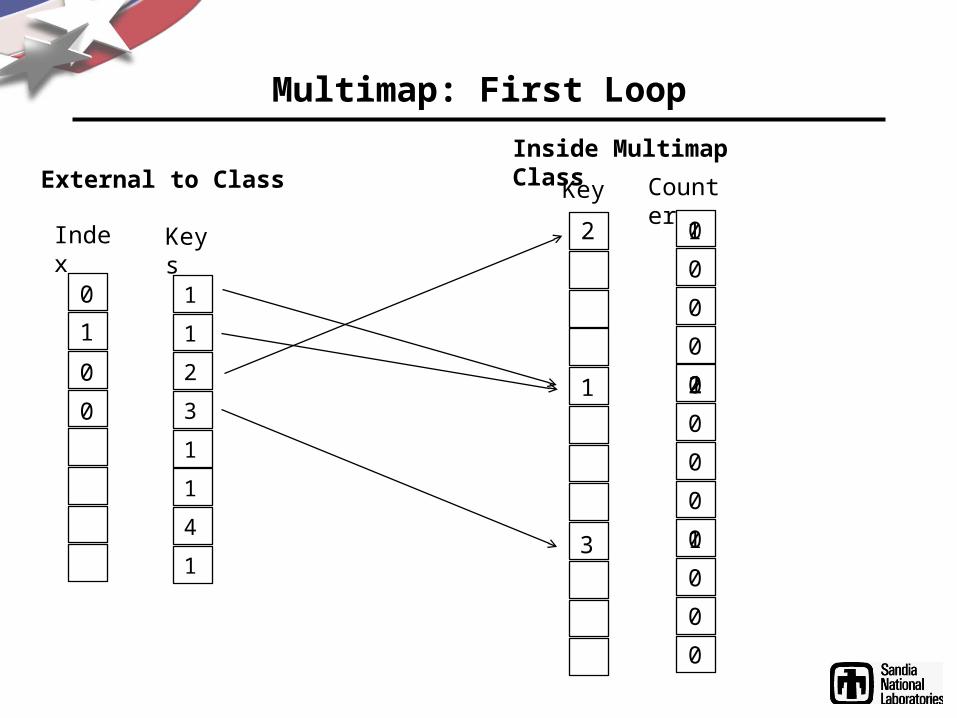
Multimap: First Loop
1
1
2
3
1
1
4
1
KeysIndex
CounterKeyExternal to ClassInside Multimap Class
0
0
0
0
0
0
0
0
0
0
0
0
1 12
2 1
3 1
0
1
0
0

Multimap: First Loop
1
1
2
3
1
1
4
1
KeysIndex
CounterKeyExternal to ClassInside Multimap Class
0
1
0
0
0
1
0
0
0
1
5
0
1
2
3
0
1
0
0
4
2
3
0
4
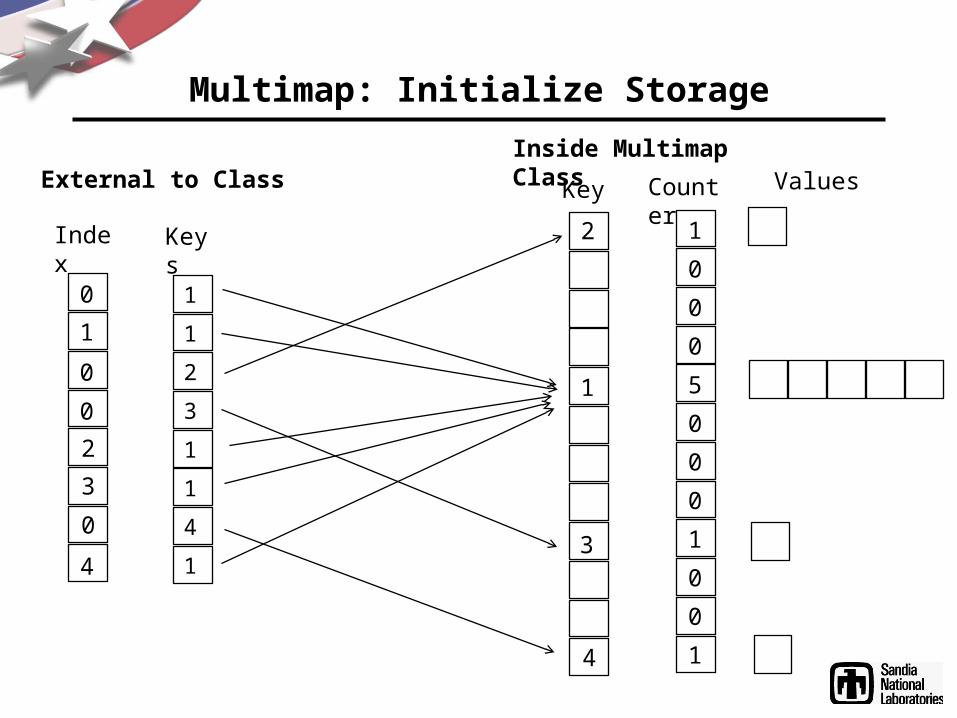
Multimap: Initialize Storage
1
1
2
3
1
1
4
1
KeysIndex
CounterKeyExternal to ClassInside Multimap Class
0
1
0
0
0
1
0
0
0
1
5
0
1
2
3
0
1
0
0
4
2
3
0
4
Values
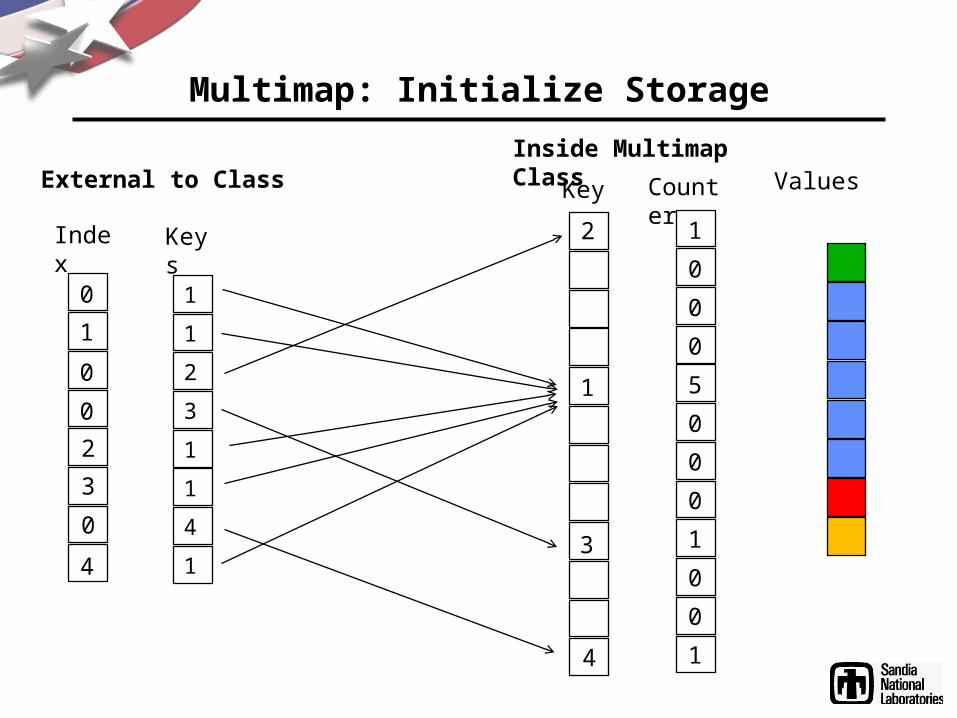
Multimap: Initialize Storage
1
1
2
3
1
1
4
1
KeysIndex
CounterKeyExternal to ClassInside Multimap Class
0
1
0
0
0
1
0
0
0
1
5
0
1
2
3
0
1
0
0
4
2
3
0
4
Values

Results
• Data set: ~5B Zipfian Integers– Value was “1” for each key
• Total time at 128 Processors– Old Method:
• 23.5 seconds• 208e6 inserts/second
– New Method: • 11.5 seconds• 422e6 inserts/second
• Comparison to hashing– 5.5 seconds– 878e6 inserts/second
• Speedup from 2 to 128 (ideal 64x)– Old: 37x– New: 53x
Note: Had to grab class member variables and pass them back in to get good scaling.
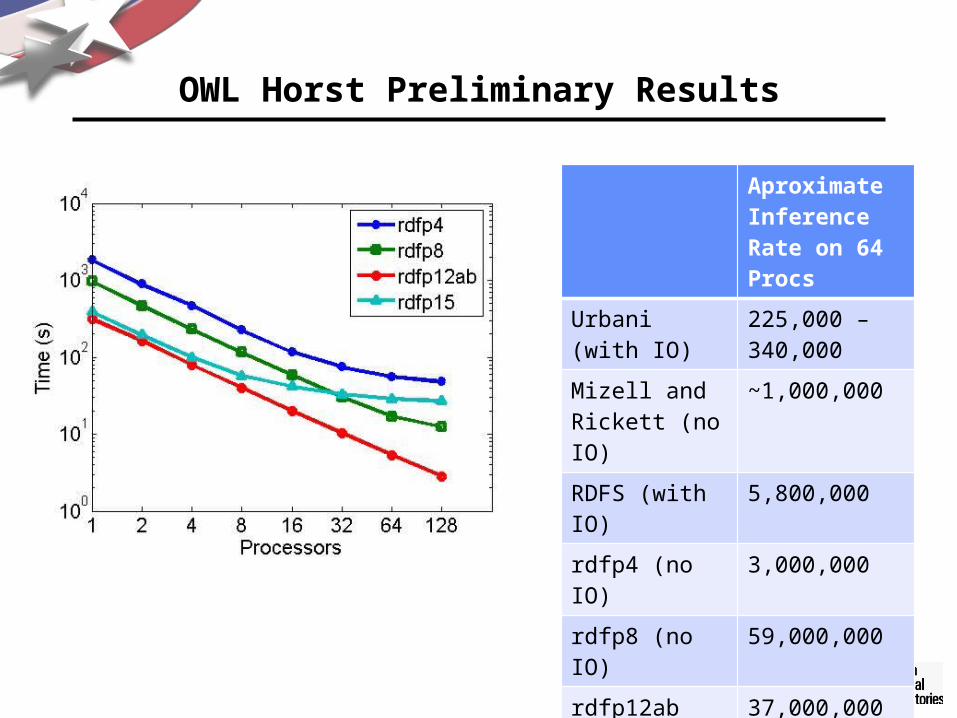
OWL Horst Preliminary Results
Aproximate Inference Rate on 64 Procs
Urbani (with IO) 225,000 – 340,000
Mizell and Rickett (no IO)
~1,000,000
RDFS (with IO) 5,800,000
rdfp4 (no IO) 3,000,000
rdfp8 (no IO) 59,000,000
rdfp12ab (no IO) 37,000,000
rdfp15 (no IO) 8,700,000

Future Inference Work
• Compare with Chris Rickett and David Mizell’s strategy• Prepare submission for ISWC 2011 (June deadline)• Move to on-the-fly inference

Towards a Generic Forward-Inferencing Capability for Semantic Database Ontologies
David Mizell, Cray Inc.
working with
Chris Rickett, Cray Inc.Eric Goodman, Sandia
Sinan al-Saffar, PNNL Lake Union

The Main Idea
Develop an automated or semi-automated process for extracting the ontology from an RDF triples database translating the ontological rules into a simple syntax, eg Jena Rules using the translation to perform forward (later backward) inferencing on
the database

Forward Inferencing: Computing the "Closure" of an Ontology on an RDF Triples Dataset
…( ?x is-a Cray-employee ) -> ( ?x has-a cell-phone )…( Cray-employee subset-of US-citizen )…
…( David is-a Cray-employee )……( Shoaib is-a Cray-employee )……
New, inferred triples:
Ontology rules
Triples database
( David has-a cell-phone )( Shoaib has-a cell-phone )( David is-a US-citizen )( Shoaib is-a US-citizen )
Get applied to…
…(also called “materialization”)

Take each rule( ?x is-a Cray-employee ) -> ( ?x has-a cell-phone )
Search the database for triples that match the left-hand side of the rule( ?x is-a Cray-employee )( David is-a Cray-employee )
Add the new triple(s) to the database corresponding to the right-hand side( David has-a cell-phone )
(worst case) repeat until you reach a fixed-point
The Forward Inferencing Process
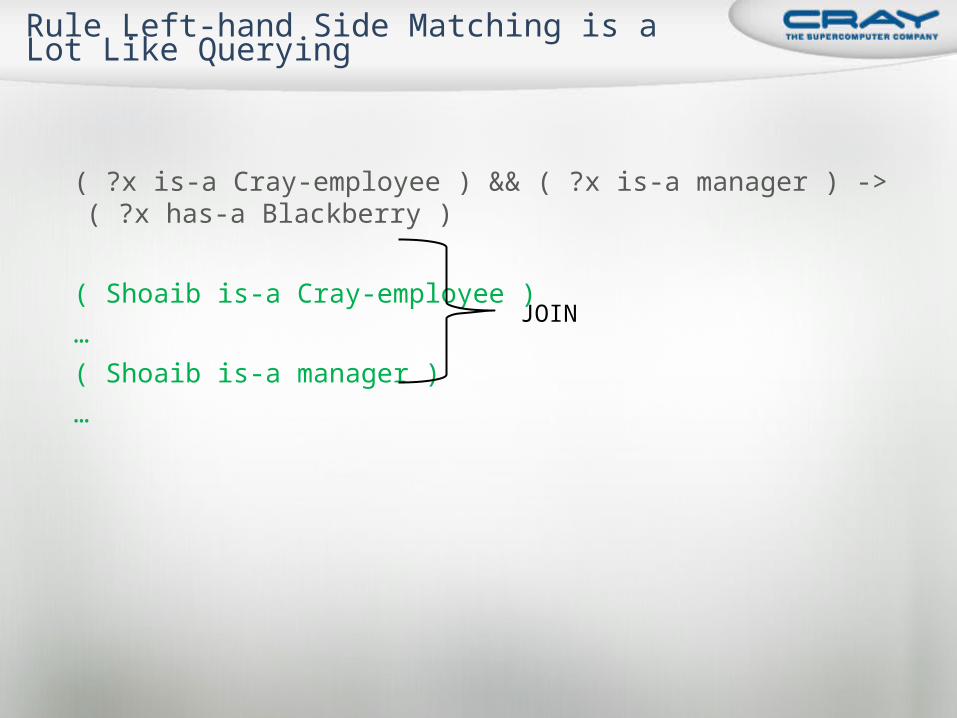
( ?x is-a Cray-employee ) && ( ?x is-a manager ) -> ( ?x has-a Blackberry )
( Shoaib is-a Cray-employee ) … ( Shoaib is-a manager ) …
Rule Left-hand Side Matching is a Lot Like Querying
JOIN

Goodman and Mizell, “Scalable In-Memory Closure on Billions of Triples,” International Workshop on Scalable Semantic Web Knowledge Bases, at the International Semantic Web Conference, Shanghai, Nov. 2010
RDFS is a standard ontology with 13 rules. 6 of these have 2 triple patterns on the left-hand side (require join-like processing). We only used those.
Wrote 6 functions with the same overall structure: Search the database for matches to the left-hand side Add the implied triples
Eric cleverly scheduled the application of these functions to avoid fixpoint iteration
What Eric Goodman and I (mostly Eric) Did Last Year
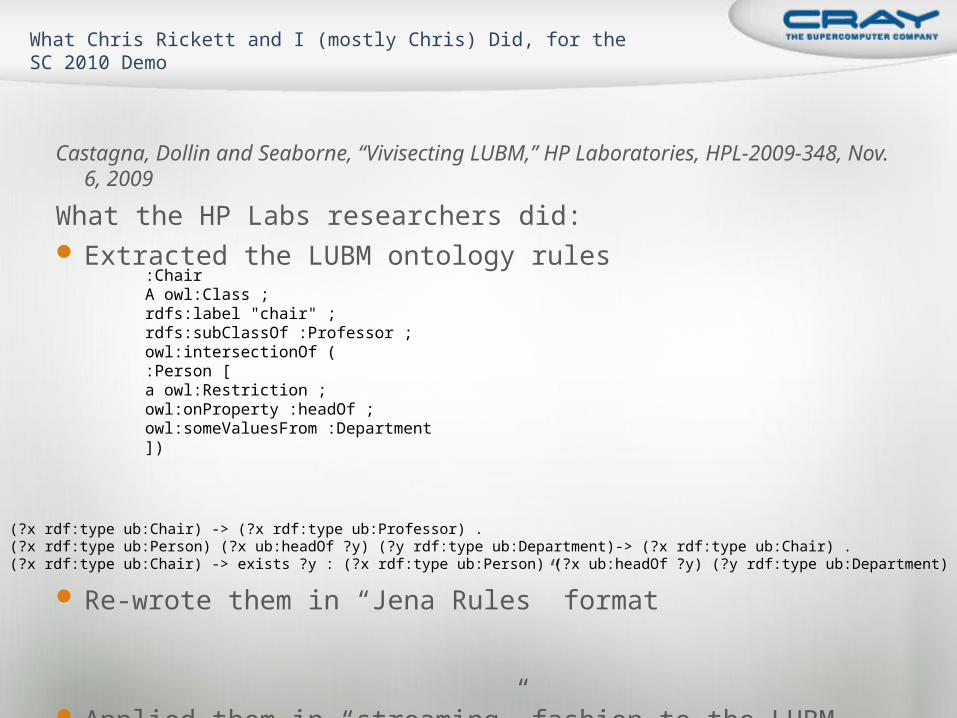
Castagna, Dollin and Seaborne, “Vivisecting LUBM,” HP Laboratories, HPL-2009-348, Nov. 6, 2009
What the HP Labs researchers did: Extracted the LUBM ontology rules
Re-wrote them in “Jena Rules” format
Applied them in “streaming” fashion to the LUBM database
What Chris Rickett and I (mostly Chris) Did, for the SC 2010 Demo
:ChairA owl:Class ;rdfs:label "chair" ;rdfs:subClassOf :Professor ;owl:intersectionOf (:Person [a owl:Restriction ;owl:onProperty :headOf ;owl:someValuesFrom :Department])
(?x rdf:type ub:Chair) -> (?x rdf:type ub:Professor) .(?x rdf:type ub:Person) (?x ub:headOf ?y) (?y rdf:type ub:Department)-> (?x rdf:type ub:Chair) .(?x rdf:type ub:Chair) -> exists ?y : (?x rdf:type ub:Person) (?x ub:headOf ?y) (?y rdf:type ub:Department) .

Grabbed their Jena-formatted rules from the paper’s appendix
Chris wrote a parser for the rules, converted them to triples-pattern (integer) data structure (using Eric Goodman’s “dictionary”)
Iterated through the rules until no new triples were added Recently, I tuned the inferencer by substituting a hash table specialized to
integer triples (written by Eric Goodman) – used for duplicate elimination Time on LUBM8000, 1.1B triples before, 1.7B after (just inferencing, no
I/O): 350 sec/128p; 185 sec/256p 148 sec/512p
What Chris Rickett and I (mostly Chris) Did (2)
(?x rdf:type ub:Course) -> (?x rdf:type ub:Work) .(?x rdf:type ub:Research) -> (?x rdf:type ub:Work) .(?x rdf:type ub:GraduateCourse) -> (?x rdf:type ub:Course) (?x rdf:type ub:Work) .(?x rdf:type ub:UndergraduateStudent) -> (?x rdf:type ub:Student) .(?x rdf:type ub:ResearchAssistant) -> (?x rdf:type ub:Student) .(?x rdf:type ub:GraduateStudent) -> (?x rdf:type ub:Person) .(?x rdf:type ub:Faculty) -> (?x rdf:type ub:Employee) .(?x rdf:type ub:Professor) -> (?x rdf:type ub:Faculty) (?x rdf:type ub:Employee) .(?x rdf:type ub:AssistantProfessor) -> (?x rdf:type ub:Professor) (?x rdf:type ub:Faculty)(?x rdf:type ub:Employee) .(?x rdf:type ub:AssociateProfessor) -> (?x rdf:type ub:Professor) (?x rdf:type ub:Faculty)(?x rdf:type ub:Employee) .(?x rdf:type ub:Dean) -> (?x rdf:type ub:Professor) (?x rdf:type ub:Faculty) (?x rdf:type ub:Employee) .(?x rdf:type ub:FullProfessor) -> (?x rdf:type ub:Professor) (?x rdf:type ub:Faculty) (?x rdf:type ub:Employee) .(?x rdf:type ub:Chair) -> (?x rdf:type ub:Professor) (?x rdf:type ub:Faculty) (?x rdf:type ub:Employee) .…
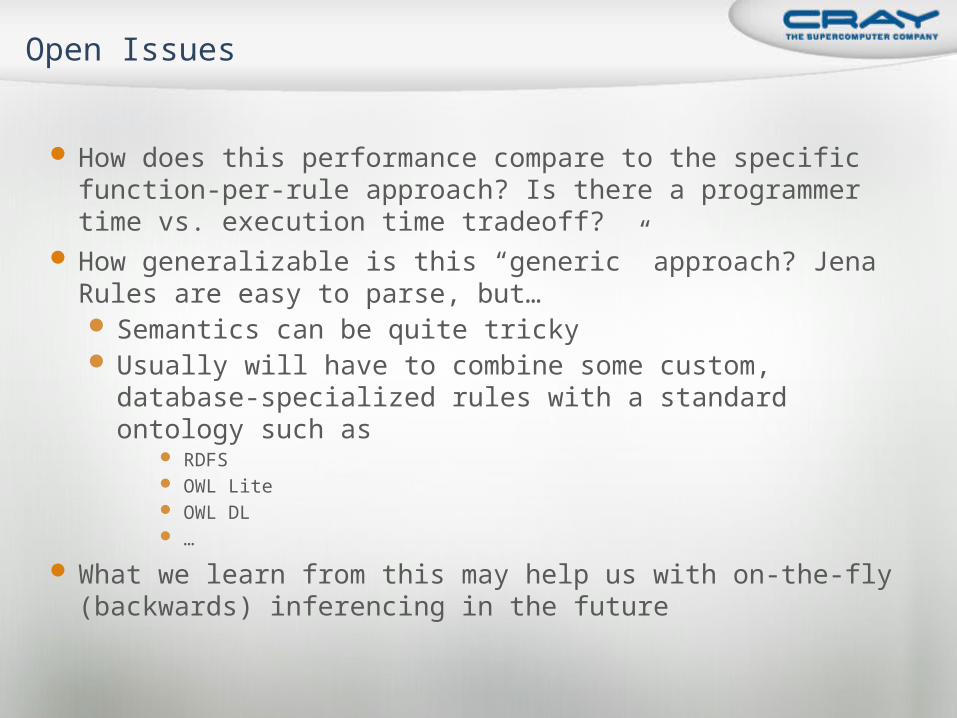
How does this performance compare to the specific function-per-rule approach? Is there a programmer time vs. execution time tradeoff?
How generalizable is this “generic” approach? Jena Rules are easy to parse, but… Semantics can be quite tricky Usually will have to combine some custom, database-specialized rules
with a standard ontology such as RDFS OWL Lite OWL DL …
What we learn from this may help us with on-the-fly (backwards) inferencing in the future
Open Issues


Graph Analysis and Extant Ontology
31
Sinan al-Saffar, Cliff Joslyn

Informing the Design of a Future Database Engine
Similarly to relational databases, in order to optimize any future graph database engine, we need to understand:
Graph Content and Structure
Queries and Inference
Why? Because these influence the data structure and algorithms of choice to achieve efficient time and space utilization
This has to happen in both: The overall design,
And as a dynamic query optimization component

Graph-O-Scope
We built a set of functions that compute statistical measures to help us understand the contents of semantic graphs
The intention is to re-implement these functions in an API that is to be used from within a dynamic query optimization module
Some of the Statistics:Edge and nodes counts and graph density
Literal, blank, and URI counts with break-downs by subjects/object
Predicate and class distributions
Counts of reification and ontological components
In-degree / out-degree dist
Connected component
sameAs cliques

What is in the graph?Question: How can we “understand” a 2 billion edge graph?
We looked at three large datasets:
BTC is a result of a semantic web crawl Uniprot is a ten year, primary bioinformatics referenceLUBM is a synthetic dataset
Dataset # Edges
BTC2010 1.4 b
UNIPROT 2.04 b
LUBM8K 1.07 b

Reification
Original Reification
BTC2010 1.4b 24.21m
UNIPROT 2.04b 554.86m
LUBM8K 1.07b 0
Discovery: A good chunk of the data is refied
Design: Make database a hybrid
Primary Statement
Annotation
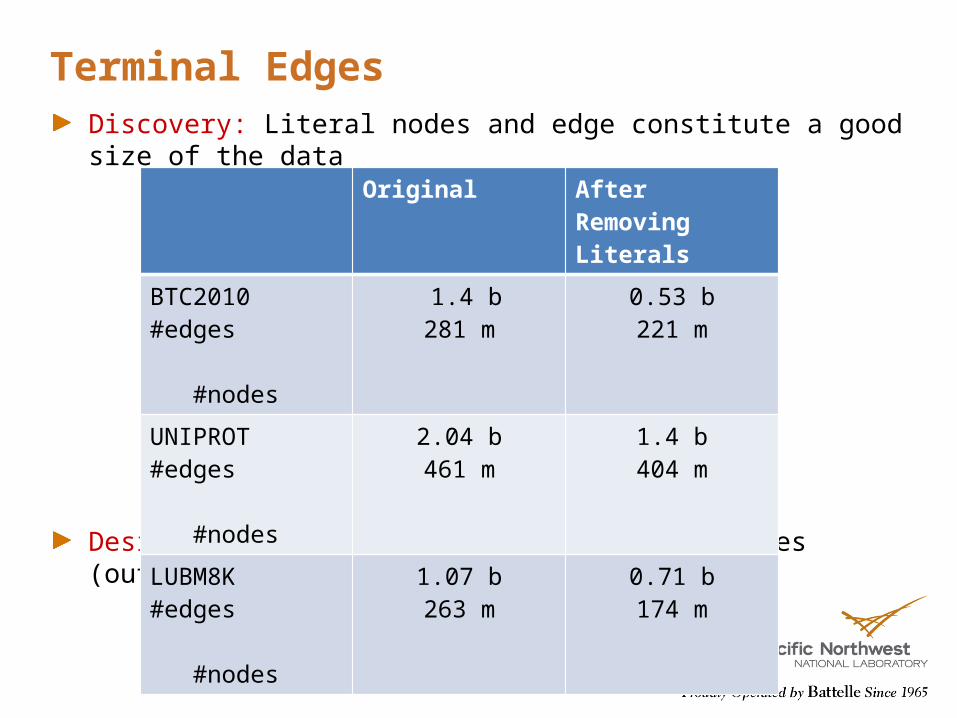
Terminal EdgesDiscovery: Literal nodes and edge constitute a good size of the data
Design: Implement literals as node properties (outside the graph)
Original After Removing Literals
BTC2010 #edges #nodes
1.4 b281 m
0.53 b221 m
UNIPROT #edges #nodes
2.04 b461 m
1.4 b404 m
LUBM8K #edges #nodes
1.07 b263 m
0.71 b174 m
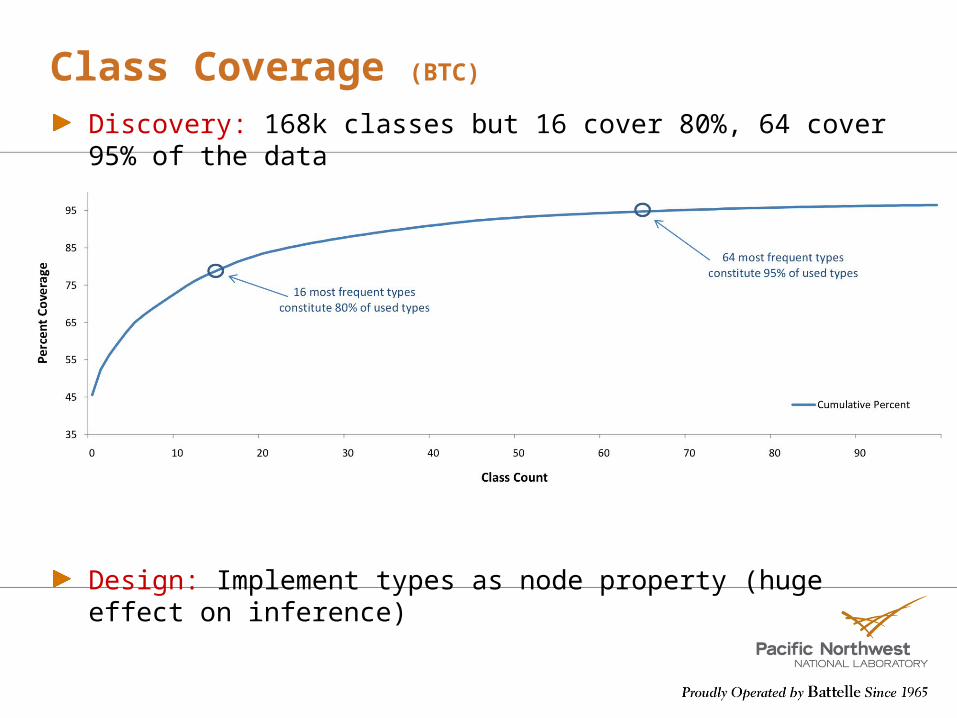
Class Coverage (BTC)
Discovery: 168k classes but 16 cover 80%, 64 cover 95% of the data
Design: Implement types as node property (huge effect on inference)

Predicate Coverage (BTC)
Discovery: 95k different predicates but 64 cover 86% of the data
Design: optimize graph data structure for a small range of edge labels

UniProt Extant Ontology I
A 243-edge graph as a statistical representation of the present semantic structures in 2b-edge Uniprot graph
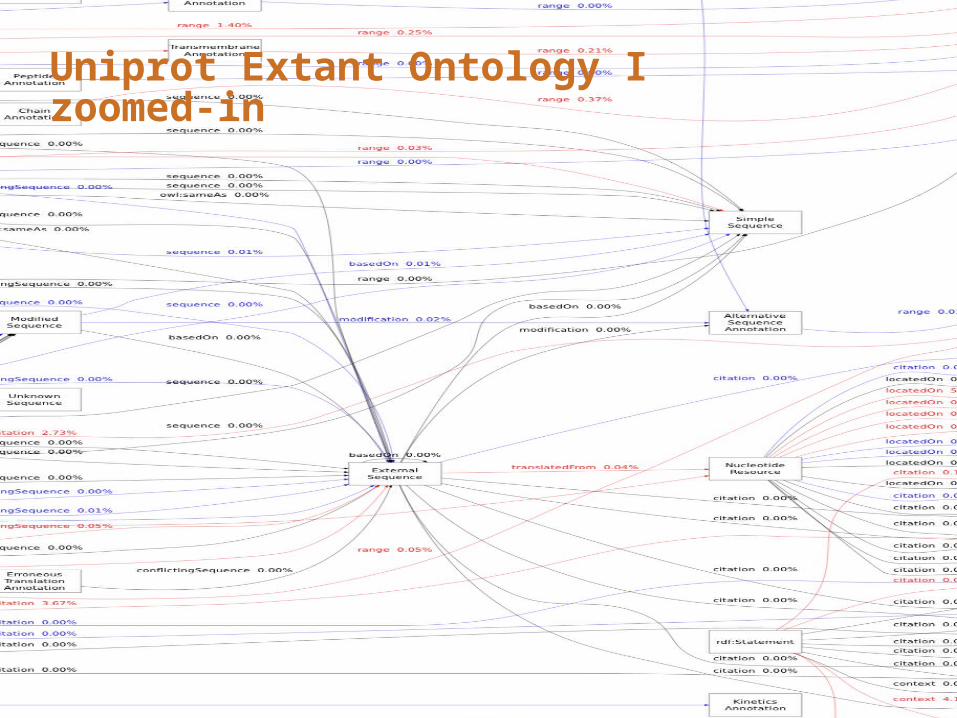
Uniprot Extant Ontology I zoomed-in
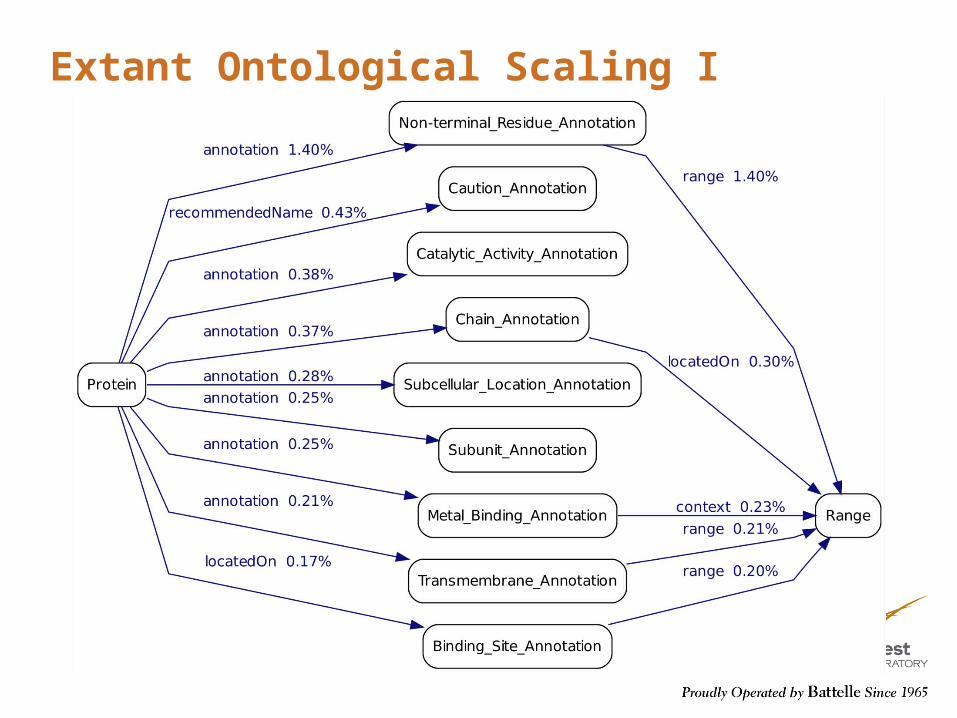
Extant Ontological Scaling I
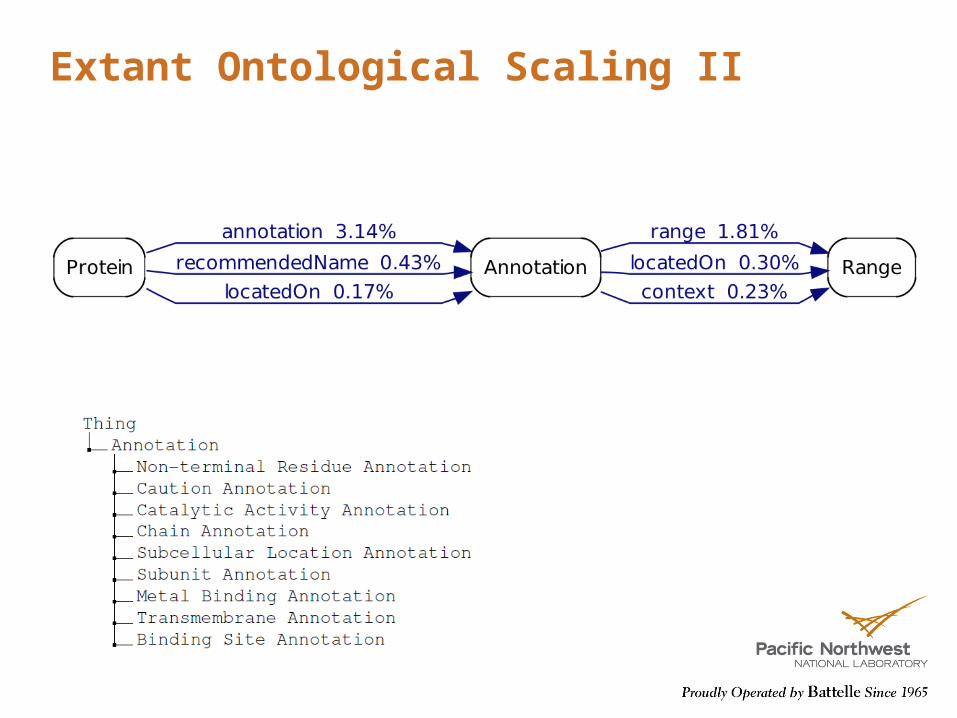
Extant Ontological Scaling II
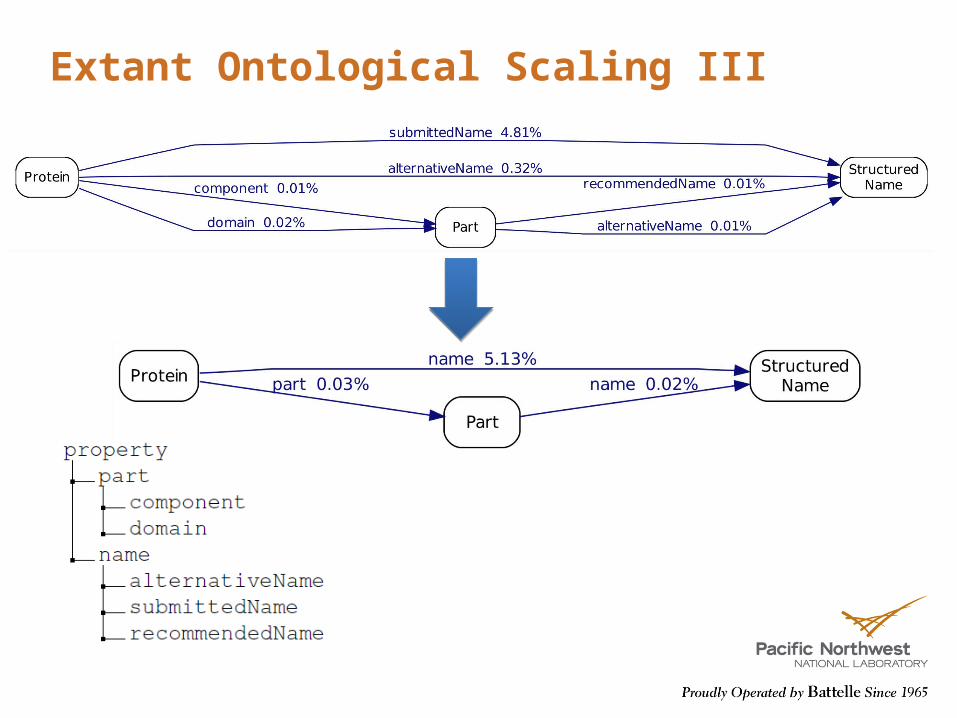
Extant Ontological Scaling III
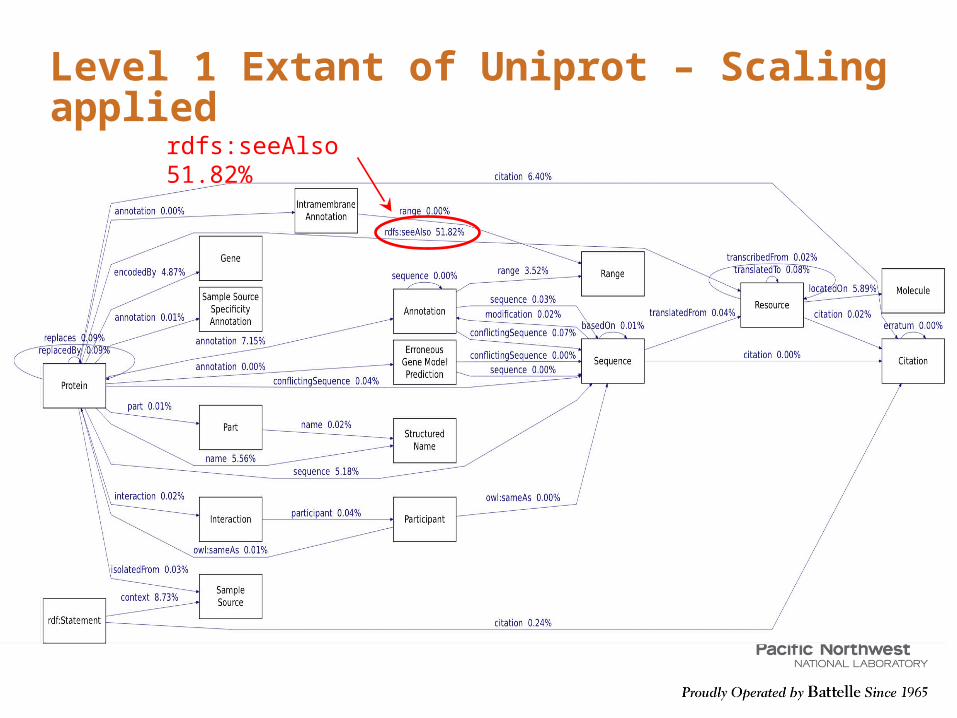
Level 1 Extant of Uniprot – Scaling applied
rdfs:seeAlso 51.82%

Future Work: specific directionsContinue working with Larry Holder (WSU) to find common ground on frequent subgraph mining and semantic database query
Work with Bill Howe on query language and hybrid search strategies
Expand our collaboration with Task 1.
Support Task 16 (Mayo)
Engage with Bioinformatics domain to find/build interestingly large and complex Bio dataset (i.e., more complex than uniprot)
Find collections of complex queries
Continue work on search engine comparison:Array-based
Subgraph-isomorphism (MTGL)
Sprinkle-SPARQL
Explore query optimization strategies
Extend study of larger path types (n=4,5) and/or non-linear motifs





![C. André Christie-Mizell, Ph.D. - Amazon S3 · C. André Christie-Mizell: Page 2 PUBLICATIONS [Peer-reviewed articles (*current or former graduate student)]: Christie-Mizell, C](https://img.pdfslide.us/doc/110x75/5f0451cf7e708231d40d6442/c-andr-christie-mizell-phd-amazon-s3-c-andr-christie-mizell-page-2-publications.jpg)






















