Embed Size (px)
Citation preview

1? 1998 Morgan Kaufmann Publishers
Capítulo 6
Permission is granted to copy and distribute this material for educational purposes only, provided that the complete bibliographic citation and following credit line is included: "Copyright 1998 Morgan Kaufmann Publishers." Permission is granted to alter and distribute this material provided that the following credit line is included: "Adapted from Computer Organization and Design: The Hardware/Software Interface, 2nd Edition David A. Patterson, John L. Hennessy Morgan Kaufmann, 2nd ed., 1997, ISBN 1558604286 Copyright 1998 Morgan Kaufmann Publishers."
This material may not be copied or distributed for commercial purposes without express written permission of the copyright holder.
Lecture slides created by Michael Wahl in English
Tradução: Christian Lyra Gomes
Revisão e alterações: Wagner M. N. Zola
2? 1998 Morgan Kaufmann Publishers
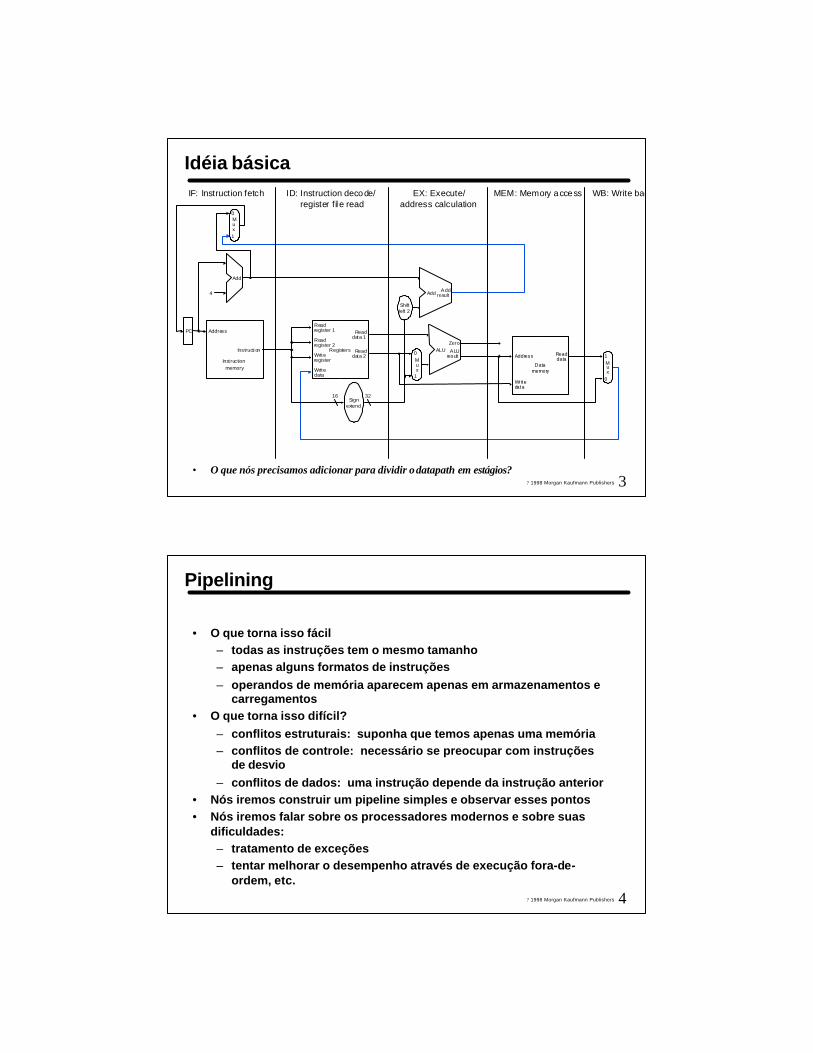
Idéia básica
T im e76 P M 8 9 1 0 1 1 1 2 1 2 A M
A
B
C
D
T im e76 P M 8 9 1 0 1 1 1 2 1 2 A M
A
B
C
D
T a s ko r d e r
T a s ko r d e r
3? 1998 Morgan Kaufmann Publishers
Idéia básica
• O que nós precisamos adicionar para dividir o datapath em estágios?
Inst ructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Instructi on
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
ReaddataAddress
Datamemory
1
ALUresult
Mux
ALUZero
IF: Instruction fetch ID: Instruction decode/register file read
EX: Execute/address calculation
MEM: Memory access WB: Write bac
4? 1998 Morgan Kaufmann Publishers
Pipelining
• O que torna isso fácil– todas as instruções tem o mesmo tamanho– apenas alguns formatos de instruções– operandos de memória aparecem apenas em armazenamentos e
carregamentos• O que torna isso difícil?
– conflitos estruturais: suponha que temos apenas uma memória– conflitos de controle: necessário se preocupar com instruções
de desvio– conflitos de dados: uma instrução depende da instrução anterior
• Nós iremos construir um pipeline simples e observar esses pontos• Nós iremos falar sobre os processadores modernos e sobre suas
dificuldades:– tratamento de exceções– tentar melhorar o desempenho através de execução fora-de-
ordem, etc.

5? 1998 Morgan Kaufmann Publishers
Pipelining
• Melhorando o desempenho através do aumento da vazão de instruções
•
A aceleração ideal é igual ao número de estágios do pipeline. Nós conseguimos alcançar isso?
Instructionfe tch
R eg AL U Dat aaccess
R eg
8 nsInstruction
fe tch R eg ALU D ataa ccess R eg
8 nsI nstru ction
fet ch
8 ns
Time
lw $1, 100($0)
lw $2, 200($0)
lw $3, 300($0)
2 4 6 8 10 12 14 16 18
2 4 6 8 10 12 14
...
Programexec utionorder(in ins truct ions)
I nstructionfet ch R eg ALU D ata
a cce ss Re g
Ti me
lw $1, 1 00($0)
lw $2, 2 00($0)
lw $3, 3 00($0)
2 nsI nstruction
fetch R eg ALUD ata
a cce ss Re g
2 nsIn structio n
fetch R eg ALU D ataa cce ss Re g
2 ns 2 ns 2 ns 2 ns 2 ns
Programex ec utionorder(in in struc tions)
6? 1998 Morgan Kaufmann Publishers
Pipeline Hazards (azares? Conflitos?)
• “Hazards” Estruturais– Hardware não consegue acomodar certas combinações de instruções no
mesmo ciclo de relógio, porque algumas delas iriam necessitar us ar uma parte do hardware simultaneamente (i.e. Necessidade de duplicar algumas unidades do hardware)
• “Hazards”de controle– Seria necessario tomar alguma decisão de “como executar” um estágio,
baseado em um resultado de outro estagio.– Ex: paradas (stall) em desvios (jumps)
• “Hazards de dados”– Dado de uma instrução depende de resultado (dado gerado) em instrução
anterior (i.e. Estagio posterior do pipeline)
•

7? 1998 Morgan Kaufmann Publishers
Conflitos de controle em desvios (jump stalls)
• Solução 1: – processador sempre espera até saber para onde será o desvio– Busca da próxima instrução é sempre atrasada de alguns ciclos– Atraso que se dá à busca da proxima instrução é chamado de parada
(stall) ou bolha (bubble)– Esta solução, no MIPS, pode ser feita com atrazo de um ciclo apenas; em
outros processadores atraso pode ser maior.
• Exemplo 6.4:
•
Instructionfetch
Reg ALUData
accessReg
Time
beq $1, $2, 40
add $4, $5, $6
lw $3, 300($0)4 ns
Instructionfetch
Reg ALU Dataaccess
Reg2ns
Instructionfetch
Reg ALUData
accessReg
2ns
2 4 6 8 10 12 14 16Programexecutionorder(in instructions)
8? 1998 Morgan Kaufmann Publishers
Solução de conflitos de controle em desvios . Predição de desvios.
• Solução 2:
– Esta soluçao é chamada de “Predição de desvios”– Na verdade, processador apenas assume:
• (a) que o desvio não vai ocorrer e então busca a próxima instrução na sequência.
• (b) que o desvio vai ocorrer e então busca a próxima instrução cujo endereço de destino do desvio foi especificado.
• Caso o que foi “assumido” não esteja correto processador tem de “invalidar” a proxima instrução já buscada/começada
– Isso fica equivalente a uma bolha
• Veja figura a seguir
•

9? 1998 Morgan Kaufmann Publishers
Ins truc tionfetch
Reg ALUData
acc essR eg
Time
beq $1, $2 , 40
add $4, $5 , $6
lw $3, 300($0)
Instruct ionfetc h Reg ALU
Dataacc ess Reg
2 ns
Instruct ionfetc h Reg ALU
Dataacc ess Reg
2 ns
Programexecutionorder(in instructions)
Inst ruc tionfetch
R eg ALUData
ac cessR eg
Time
beq $1, $2 , 40
add $4, $5 ,$6
or $7 , $8, $9
Instruc tionfetch
Reg ALUData
ac cessR eg
2 4 6 8 10 12 14
2 4 6 8 10 12 14
In struc tionfetch Reg ALU
Dataacc es s Reg
2 ns
4 ns
bub ble bubble b ubble bubble bu bble
Programexecutionorder( in instructions)
Solução de conflitos de controle em desvios . Predição de desvios. Figura 6.5, Assumindo que desvio não ocorrerá
Caso o desvio não ocorra, bolha é gerada (instrução buscada é não continua)
Ocorre ou não
Instruction
fetch
Instruction Decode
10? 1998 Morgan Kaufmann Publishers
Predição de desvios mais sofisticada.
– Prevê que desvio será tomado em alguns casos (predict as taken),
prevê que desvio NÃO será tomado em outros casos (predict as not taken)
– “Predição” pode ser estática ou dinâmica
? Predição Estática:
• jump do fim de um “do ... While”
• Se é um jump condicional “de volta”, ... muitas vezes ocorre, processador pode assumir sempre “predict taken” nesses casos.
• jumps condicionais “para frente” são sempre preditos como “not taken”
• Esse esquema é rígido (estático) não casa com a natureza dinâmica dos desvios condicionais
? Predição Dinâmica:
• Cada desvio condicional é “predito”de acordo com histórico recente de como ocorreram seus desvios
• Mais difícil de implementar
• Mais preciso (acerta cerca de 90% dos casos)

11? 1998 Morgan Kaufmann Publishers
Solução de conflitos de controle em desvios . Desvios atrazados. (Delayed branches) Exemplo 6.6
• Processador sempre atraza execuçao do jump em 1 clock• Compilador pode preencher proxima instrução com “nop” ou com
outra instrução útil.• Compilador consegue preencher de maneira “útil” em 50% dos
casos (tipicamente).
Instructionfetch Reg ALU
Dataaccess Reg
Time
beq $1, $2, 40
add $4, $5, $6
lw $3, 300($0)
Instructionfetch
Reg ALUData
accessReg
2 ns
Instructionfetch
Reg ALUData
accessReg
2 ns
2 4 6 8 10 12 14
2 ns
(Delayed branch slot)
Programexecutionorder(in instructions)
12? 1998 Morgan Kaufmann Publishers
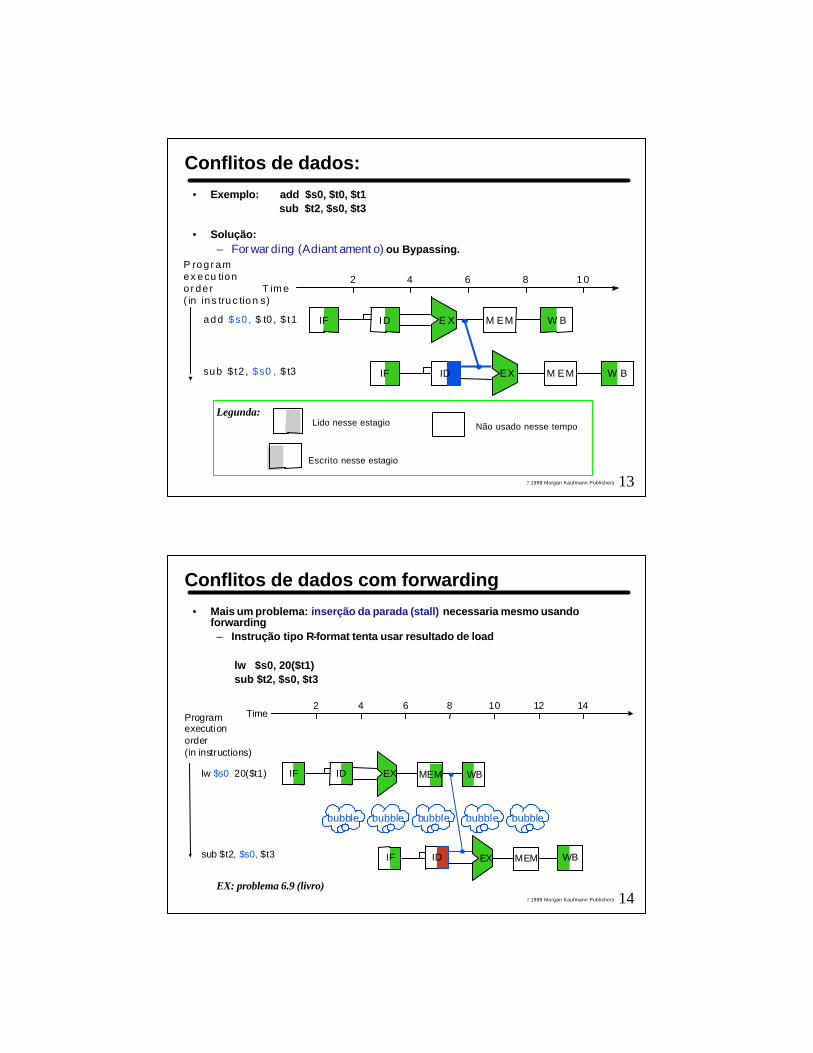
Conflitos de dados:
• Exemplo: add $s0, $t0, $t1 sub $t2, $s0, $t3
• Solução:
– Forwarding (Adiantamento) ou Bypassing.
13? 1998 Morgan Kaufmann Publishers
Conflitos de dados:
• Exemplo: add $s0, $t0, $t1 sub $t2, $s0, $t3
• Solução:– Forwarding (Adiantamento) ou Bypassing.
Legunda:
add $s0 , $ t0 , $ t1
sub $ t2 , $s0 , $ t3
P rog r amex ecu tiono r de r( in ins truc tion s)
IF ID W BE X
IF ID M EMEX
T im e2 4 6 8 10
M EM
W BM EM
Lido nesse estagio
Escrito nesse estagio
Não usado nesse tempo
14? 1998 Morgan Kaufmann Publishers
Conflitos de dados com forwarding
• Mais um problema: inserção da parada (stall) necessaria mesmo usando forwarding – Instrução tipo R-format tenta usar resultado de load
lw $s0, 20($t1)sub $t2, $s0, $t3
EX: problema 6.9 (livro)
Time2 4 6 8 10 12 14
lw $s0, 20($t1)
sub $t2, $s0, $t3
Programexecutionorder(in instructions)
IF ID WBMEMEX
IF ID WBMEMEX
bubble bubble bubble bubble bubble

15? 1998 Morgan Kaufmann Publishers
Conflitos de dados com forwarding
Solução no MIPS original:“Delayed loads” – processador evita ciclo de parada (bolha) no pipeline,requerendo que: “todas as intruções que seguem um load devem ser
seguidas por outra que não usa o valor lido”
16? 1998 Morgan Kaufmann Publishers
Representando Graficamente os Pipelines
• Pode ajudar respondendo questões como:– Quantos ciclos são necessários para executar esse código?– O que a ULA estará fazendo durante o ciclo 4?– Usar essa representação nos ajuda a entender os datapaths
IM Reg DM Reg
IM Reg DM Reg
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6
Time (in clock cycles)
lw $10, 20($1)
Programexecutionorder(in instructions)
sub $11, $2, $3
ALU
ALU
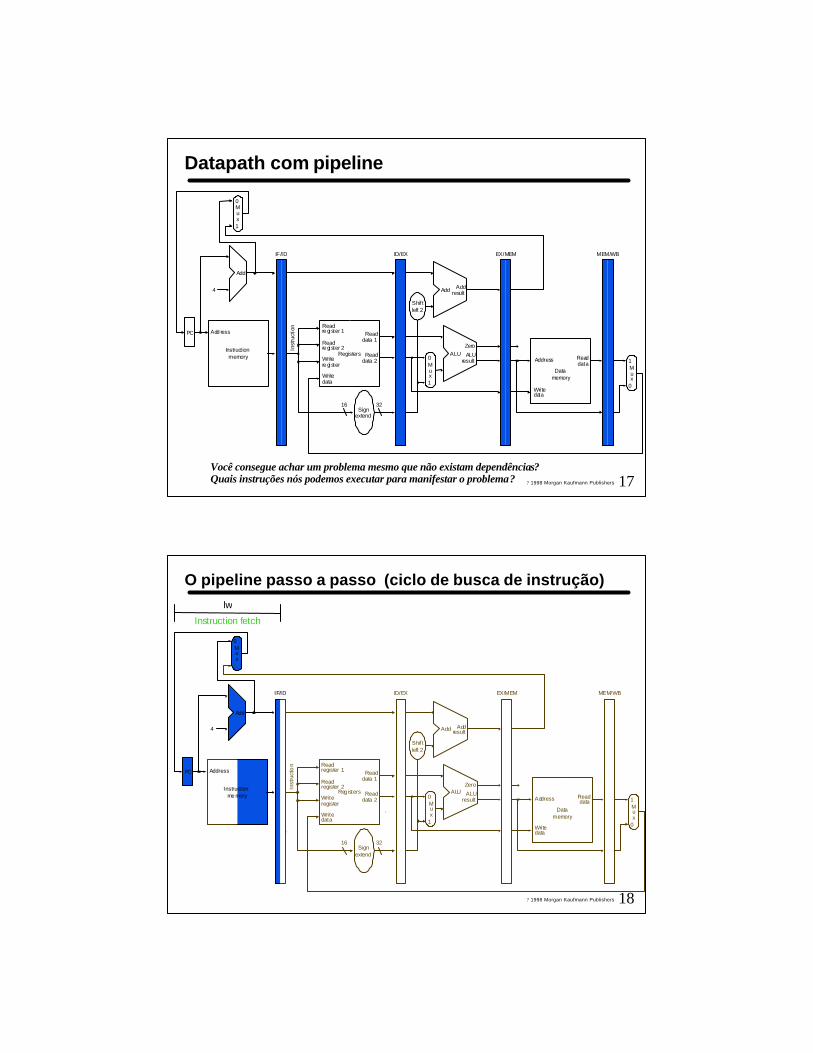
17? 1998 Morgan Kaufmann Publishers
Datapath com pipeline
Você consegue achar um problema mesmo que não existam dependências?Quais instruções nós podemos executar para manifestar o problema?
Instructionmemory
Add ress
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM MEM/WB
Mux
0
1
Add
PC
0Wri tedata
Mux
1Registers
Readdata 1
Readdata 2
Readre gister 1
Readre gister 2
16Sign
extend
Writere gi ster
Writedata
Readdata
1
ALUresult
Mux
ALUZero
ID/EX
Datamemory
Address
18? 1998 Morgan Kaufmann Publishers
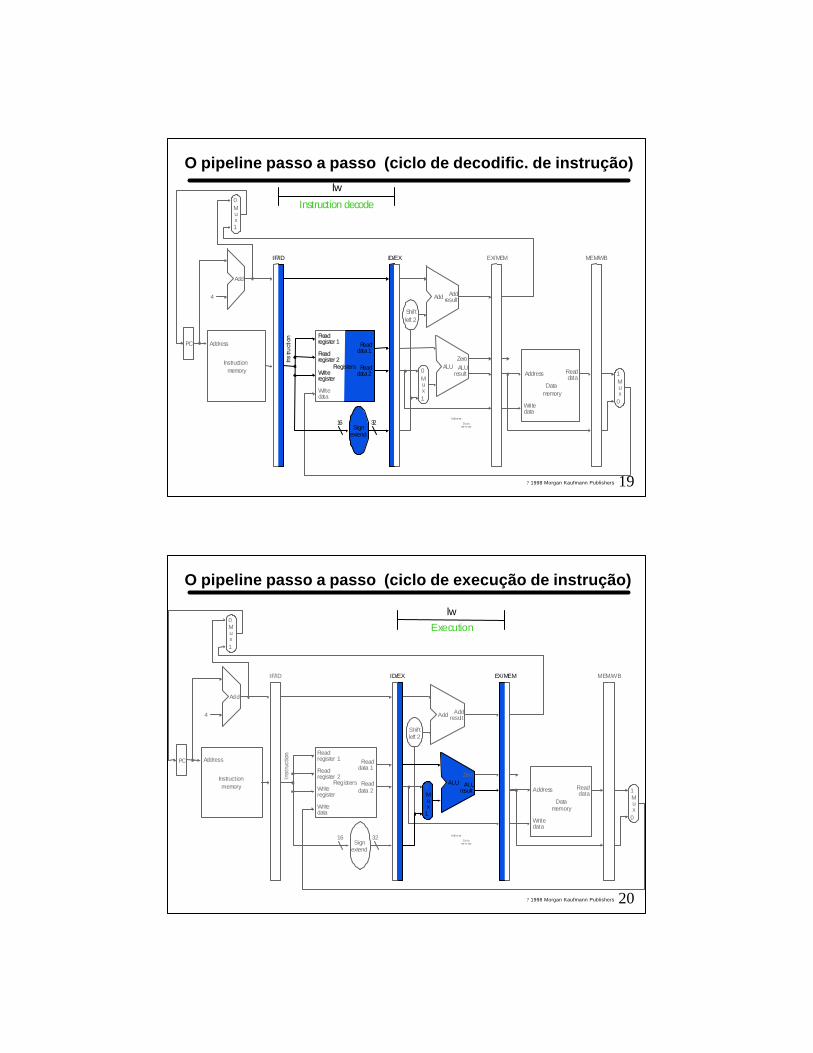
O pipeline passo a passo (ciclo de busca de instrução)
i
i
Instructionme mory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM MEM/WB
Mux
0
1
Add
PC
0Wri tedata
Mux
1Reg isters
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
1
ALUresult
Mux
ALUZero
ID/EX
Instruction fetch
lw
Address
Datamemory
19? 1998 Morgan Kaufmann Publishers
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Ins
truct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Wri tedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Instruction decode
lw
Address
Datamemory
O pipeline passo a passo (ciclo de decodific. de instrução)
Address
Datamem ory
20? 1998 Morgan Kaufmann Publishers
O pipeline passo a passo (ciclo de execução de instrução)
Address
Datamem ory
Instructionmemory
Address
4
32
0
Add Addresul t
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Execution
lw
Address
Datamemory
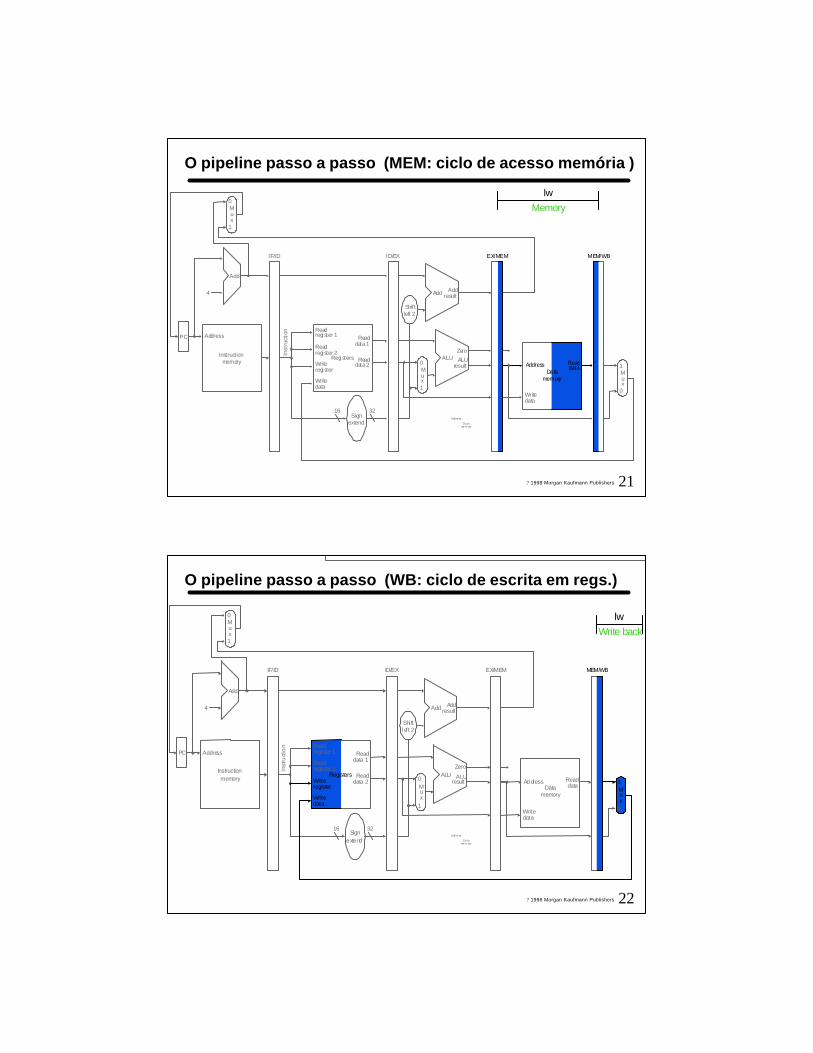
21? 1998 Morgan Kaufmann Publishers
O pipeline passo a passo (MEM: ciclo de acesso memória )
Address
Datamem ory
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
Da tamemory
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Memorylw
Address
22? 1998 Morgan Kaufmann Publishers
Instructionmemory
Address
4
32
0
Add Addresult
Shi ftleft 2
Inst
ruct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writedata
ReaddataData
memory
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Write backlw
Writeregister
Address
O pipeline passo a passo (WB: ciclo de escrita em regs.)
Address
Datamem ory
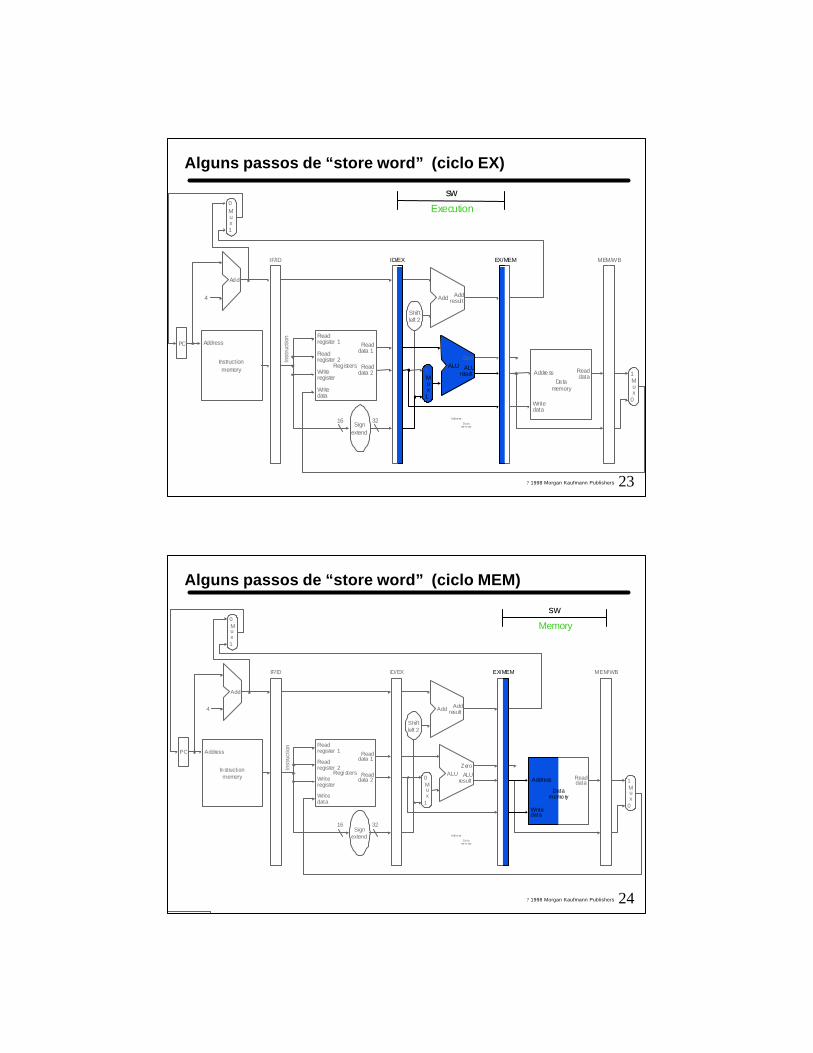
23? 1998 Morgan Kaufmann Publishers
Alguns passos de “store word” (ciclo EX)
Address
Datamem ory
Instructionmemory
Address
4
32
0
Add Addresul t
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
Datamemory
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Execution
sw
Address
24? 1998 Morgan Kaufmann Publishers
Alguns passos de “store word” (ciclo MEM)
Address
Datamem ory
In structionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
Datamemo ry
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Memory
sw
Address
sw
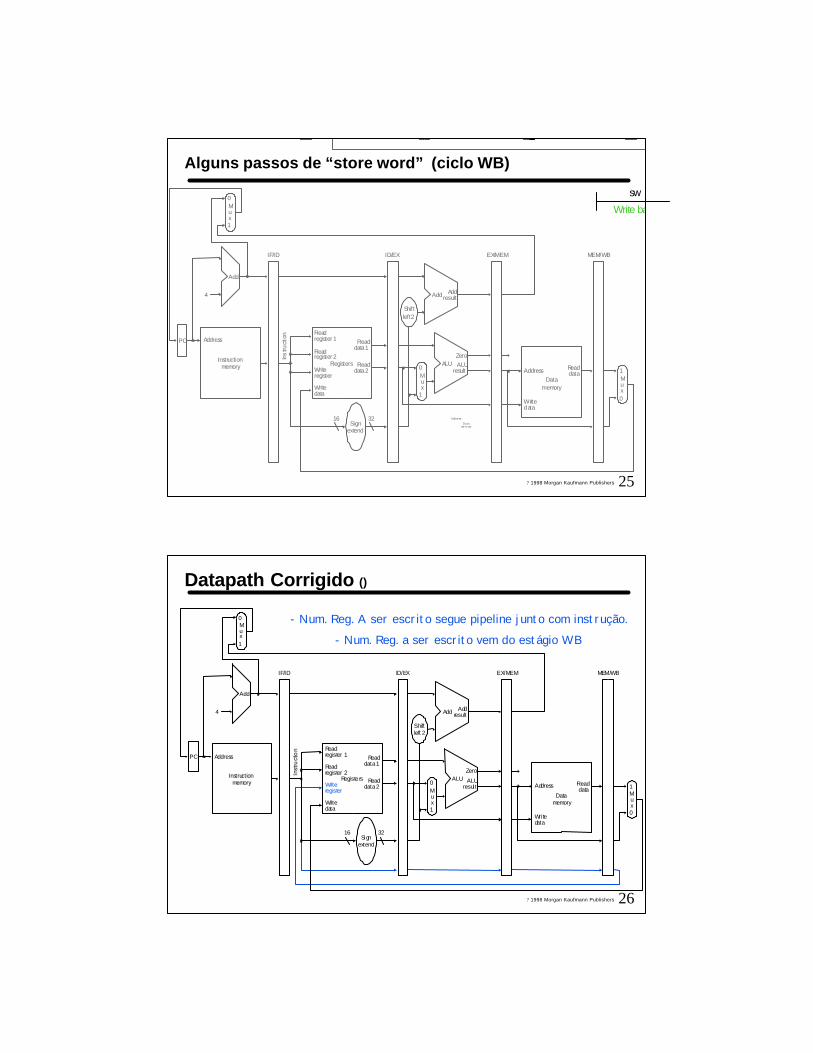
25? 1998 Morgan Kaufmann Publishers
Alguns passos de “store word” (ciclo WB)
Address
Datamem ory
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Ins
truct
ion
IF/ID EX/MEM
Mux
0
1
Add
PC
0
Address
Writedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
Datamemory
1
ALUresult
Mux
ALUZero
ID/EX MEM/WB
Write ba
sw
26? 1998 Morgan Kaufmann Publishers
Datapath Corrigido ()
Instructionmemory
Address
4
32
0
Add Addresult
Shiftleft 2
Inst
ruct
ion
IF/ID EX/MEM MEM/WB
Mux
0
1
Add
PC
0
Address
Wri tedata
Mux
1Registers
Readdata 1
Readdata 2
Readregister 1
Readregister 2
16Sign
extend
Writeregister
Writedata
Readdata
Datamemory
1
ALUresul t
Mux
ALUZero
ID/EX
- Num. Reg. A ser escrito segue pipeline junto com instrução.
- Num. Reg. a ser escrito vem do estágio WB
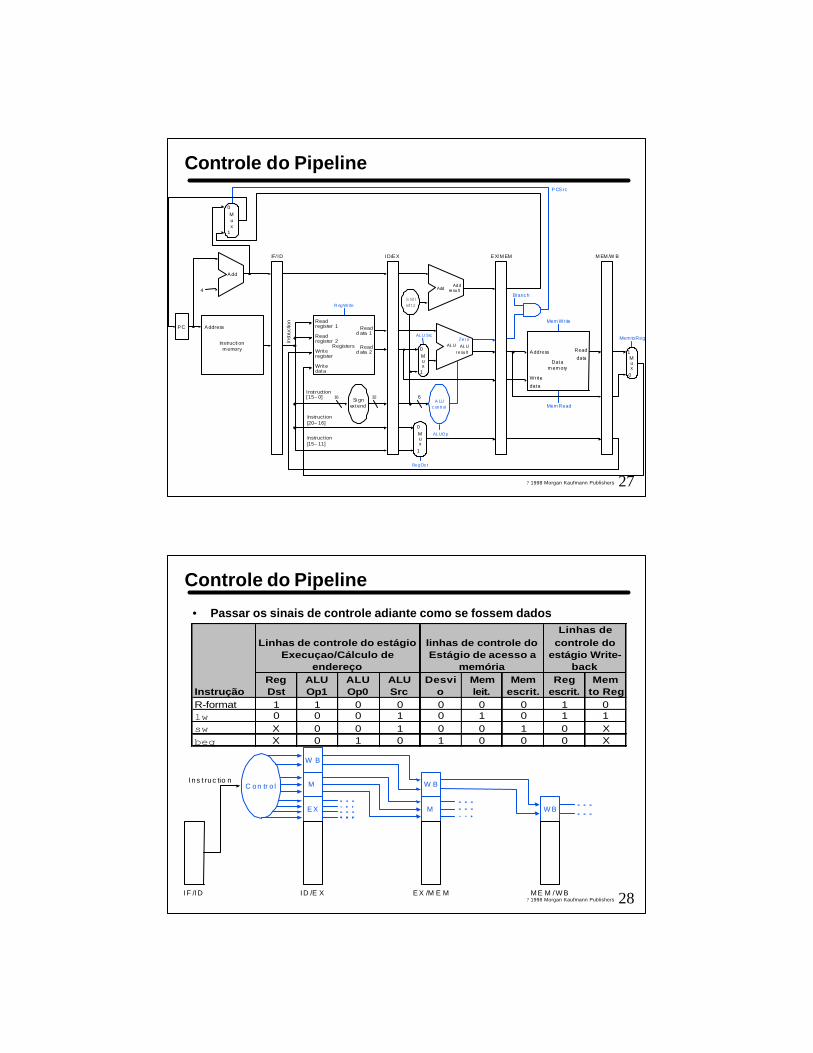
27? 1998 Morgan Kaufmann Publishers
Controle do Pipeline
PC
Instructi onm emory
Address
Inst
ruct
ion
Instruct ion[20– 16]
Mem toReg
ALUOp
Branch
RegDs t
ALU Src
4
16 32Inst ruct ion[15– 0]
0
0RegistersWriteregister
Writedata
Readd ata 1
Readd ata 2
Readregister 1
Readregister 2
Si gnextend
Mux
1Write
data
Read
data Mux
1
A LUc on trol
R egWr ite
Mem Read
Instruct ion[15– 11]
6
IF/ ID ID/EX EX/M EM M EM /W B
Mem Write
Address
Datam em ory
PCSrc
Zero
AddAdd
resu lt
S hif tlef t 2
ALUresu lt
ALUZero
Add
0
1
Mux
0
1
Mux
28? 1998 Morgan Kaufmann Publishers
• Passar os sinais de controle adiante como se fossem dados
Controle do Pipeline
Linhas de controle do estágio Execuçao/Cálculo de
endereço
linhas de controle do Estágio de acesso a
memória
Linhas de controle do
estágio Write-back
InstruçãoReg Dst
ALU Op1
ALU Op0
ALU Src
Desvio
Mem leit.
Mem escrit.
Reg escrit.
Mem to Reg
R-format 1 1 0 0 0 0 0 1 0lw 0 0 0 1 0 1 0 1 1sw X 0 0 1 0 0 1 0 Xbeq X 0 1 0 1 0 0 0 X
C on tr o l
E X
M
W B
M
W B
W B
IF /ID ID /E X E X /M E M ME M /W B
Ins t ruc tio n
29? 1998 Morgan Kaufmann Publishers
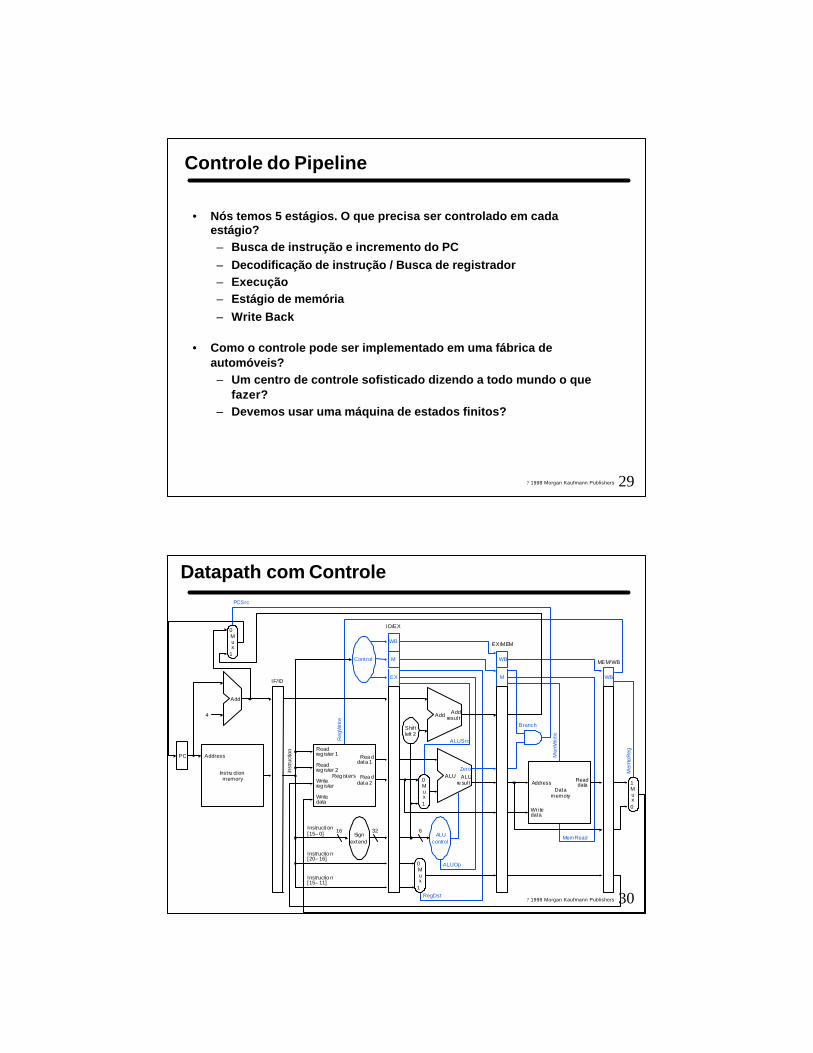
• Nós temos 5 estágios. O que precisa ser controlado em cada estágio?– Busca de instrução e incremento do PC– Decodificação de instrução / Busca de registrador– Execução– Estágio de memória– Write Back
• Como o controle pode ser implementado em uma fábrica de automóveis?– Um centro de controle sofisticado dizendo a todo mundo o que
fazer?– Devemos usar uma máquina de estados finitos?
Controle do Pipeline
30? 1998 Morgan Kaufmann Publishers
Datapath com Controle
PC
Instru ct ionmemory
Inst
ruct
ion
Add
Instructio n[20– 16]
Mem
toR
eg
ALUOp
Branch
RegDst
ALUSrc
4
16 32Instructi on[15– 0]
0
0
Mux
0
1
Add Addresul t
Reg istersWritereg ister
Writedata
Rea ddata 1
Rea ddata 2
Readreg ister 1
Readreg ister 2
Signextend
Mux1
ALUre sul t
Zero
Wri tedata
Readdata
Mux
1
ALUcontrol
Shif tleft 2
Reg
Writ
e
MemRead
Control
ALU
Instructio n[15– 11]
6
EX
M
WB
M
WB
WBIF/ID
PCSrc
ID/EX
EX/MEM
MEM/WB
Mux
0
1
Mem
Writ
e
AddressData
memory
Address

31? 1998 Morgan Kaufmann Publishers
• Problema de iniciar a próxima instrução sem a primeira ter terminado– dependências que “se deslocam para trás no tempo” são
conflitos de dados
Dependências
I M R e g
I M R e g
C C 1 C C 2 C C 3 C C 4 C C 5 C C 6
Ti m e ( in c loc k cyc le s)
s u b $ 2 , $ 1 , $ 3
P ro g ra me x e cu tio no rd e r( in i ns tru ct io ns )
a n d $ 1 2 , $ 2 , $ 5
IM R e g D M R e g
IM D M R e g
IM D M R e g
C C 7 C C 8 C C 9
1 0 10 1 0 1 0 1 0 / – 2 0 – 2 0 – 2 0 – 2 0 – 2 0
o r $1 3 , $ 6 , $ 2
a d d $ 1 4 , $ 2 , $ 2
s w $ 1 5 , 1 0 0($ 2 )
V alu e of reg is te r $ 2 :
D M R e g
R e g
R e g
R e g
D M
32? 1998 Morgan Kaufmann Publishers
• Fazer com que o compilador garanta que não haverá conflitos• Onde nós devemos inserir os “nops” ?
sub $2, $1, $3and $12, $2, $5or $13, $6, $2add $14, $2, $2sw $15, 100($2)
• Problema: isso realmente nos atrasa!
Solução por Software

33? 1998 Morgan Kaufmann Publishers
• Usar resultados temporários, não esperar que eles sejam escritos– banco de registrados de adiantamento para lidar com
escritas/leituras do mesmo registrador– adiantamento de ULA
Adiantamento
E se esse $2 fosse $13?
I M R e g
IM R e g
C C 1 C C 2 C C 3 C C 4 C C 5 C C 6
T im e ( in c lo ck cycle s)
s ub $2 , $1 , $ 3
P ro g ra me xe c utio n o rde r( in in stru ct ion s)
a n d $ 12 , $ 2, $ 5
I M R eg D M R e g
IM D M R e g
I M D M R e g
C C 7 C C 8 C C 9
10 1 0 1 0 1 0 1 0 /– 20 – 2 0 – 2 0 – 2 0 – 2 0
o r $ 1 3 , $ 6 , $2
a d d $ 14 , $ 2, $ 2
s w $ 1 5, 1 0 0($ 2 )
Va lu e o f re g iste r $ 2 :
D M R e g
R e g
R e g
R e g
X X X – 20 X X X X XV alu e o f EX /M E M :X X X X – 2 0 X X X XV a lu e o f M EM /W B :
D M
34? 1998 Morgan Kaufmann Publishers
• Leitura de palavra ainda pode causar um conflito:– uma instrução tenta ler um registrador após uma instrução de leitura que
escreva neste mesmo registrador.
• Logo, precisamos de uma unidade de detecção de conflito que “par alise” a instrução de leitura
Nem sempre pode-se Adiantar
Reg
IM
R eg
R eg
IM
C C 1 C C 2 CC 3 CC 4 C C 5 C C 6
T ime (in c lock c yc les )
lw $2, 20($1)
Pro gra mex ecu tionorder(in ins truct ions )
and $4, $2, $5
IM R eg D M Reg
IM D M Reg
IM D M Reg
C C 7 CC 8 CC 9
or $8, $2, $6
add $9, $4, $2
s lt $1, $6, $7
DM R eg
Reg
R eg
D M

35? 1998 Morgan Kaufmann Publishers
Adiantamento
PC Instructionmemory
Registers
Mux
Mux
Control
ALU
EX
M
WB
M
WB
WB
ID/EX
EX/MEM
MEM/WB
Datamemory
Mux
Forwardingunit
IF/IDIn
stru
ctio
n
Mux
RdEX/MEM.RegisterRd
MEM/WB.RegisterRd
Rt
Rt
Rs
IF/ID.RegisterRd
IF/ID.RegisterRt
IF/ID.RegisterRt
IF/ID.RegisterRs
RR#1
RR#2
RW#
Data in
Fw A
Fw BDois bits
cada
36? 1998 Morgan Kaufmann Publishers
paralisando
• Nós podemos paralisar o pipeline mantendo uma instrução no mesmo estágio
lw $2, 20($1)
Programexecutionorder(in instructions)
and $4, $2, $5
or $8, $2, $6
add $9, $4, $2
slt $1, $6, $7
Reg
IM
Reg
Reg
IM DM
CC 1 CC 2 CC 3 CC 4 CC 5 CC 6Time (in clock cycles)
IM Reg DM RegIM
IM DM Reg
IM DM Reg
CC 7 CC 8 CC 9 CC 10
DM Reg
RegReg
Reg
bubble

37? 1998 Morgan Kaufmann Publishers
Unidade de Detecção de Conflitos• Paralisando ao deixar que uma instrução que não escreve nada
prosseguir
PC Instructionmemory
Registers
Mux
Mux
Mux
Control
ALU
EX
M
WB
M
WB
WB
ID/EX
EX/MEM
MEM/WB
Datamemory
Mux
Hazarddetection
unit
Forwardingunit
0
Mux
IF/ID
Inst
ruct
ion
ID/EX.MemRead
IF/ID
Writ
e
PC
Writ
e
ID/EX.RegisterRt
IF/ID.RegisterRd
IF/ID.RegisterRtIF/ID.RegisterRtIF/ID.RegisterRs
RtRs
Rd
RtEX/MEM.RegisterRd
MEM/WB.RegisterRd
Condição unica de parada: Ver item 6.5 livroParadaconseguida não
deixando escrita nesses regs.
38? 1998 Morgan Kaufmann Publishers
• Quando decidimos por desviar, outras instruções podem estar no pipeline !
• Nós estamos predizendo “desvio não tomado”– precisamos adicionar hardware para descartar as instruções se
estivermos errados
Conflitos de Desvios
Reg
Reg
CC 1
Time (in clock cycles)
40 beq $1 , $3, 7
Programexecutionorder(in instructions)
IM Reg
IM DM
IM DM
IM DM
DM
DM Reg
Reg Reg
Reg
Reg
RegIM
44 and $12, $2, $5
48 or $13, $6, $2
52 add $14, $2, $2
72 lw $4, 50($7)
CC 2 CC 3 CC 4 CC 5 CC 6 CC 7 CC 8 CC 9
Reg
Não otimizado !
(detectado somente no
estágio MEM)

39? 1998 Morgan Kaufmann Publishers
Descartando Instruções
PC Instru ctionmemory
4
Registers
Mux
Mux
Mux
ALU
EX
M
WB
M
WB
WB
ID/EX
0
EX/MEM
MEM/WB
Datamemory
Mux
Hazarddetection
uni t
Fo rwardingunit
IF.Flush
IF/ID
Signe xtend
Control
Mux
=
Sh iftleft 2
Mux
Otimizado !-detectado no estágio ID
- um nop inserido automáticamente (IF.Flush zera reg IF/ID)
40? 1998 Morgan Kaufmann Publishers
Melhorando o Desempenho
• Tentar e evitar paralisar! Exemplo, re-ordene essas instruções:
lw $t0, 0($t1)lw $t2, 4($t1)sw $t2, 0($t1)sw $t0, 4($t1)
• Adicione um “slot de atraso de desvio”– a próxima instrução após o desvio é sempre executada– depende do compilador preencher esse slot com algo útil
• Superscalar: inicia mais de uma instrução no mesmo ciclo

41? 1998 Morgan Kaufmann Publishers
Escalonamento Dinâmico
• O hardware desempenha o “escalonamento”
– hardware tenta encontrar instruções para executar– execução fora de ordem é possível
– execução especulativa e predição dinâmica de desvio
• Todos os processadores modernos são bastante complicados
– DEC Alpha 21264: pipeline de 9 estágios, lança 6 instruções– PowerPC and Pentium : tabela de histórico de desvio
– tecnologia do compilador importa






















![Macacos-Prego (Cebus apella) Resolvem Problemas de ... · bem diferente dos demais trabalhos citados que buscam outros aspectos, como a discriminação condicional [13], a predição](https://img.pdfslide.us/doc/110x75/5be6162f09d3f247448c7c8f/macacos-prego-cebus-apella-resolvem-problemas-de-bem-diferente-dos-demais.jpg)






