Embed Size (px)
Citation preview

C-Store: How Different are Column-Stores and Row-Stores?
Jianlin FengSchool of SoftwareSUN YAT-SEN UNIVERSITYMay. 8, 2009
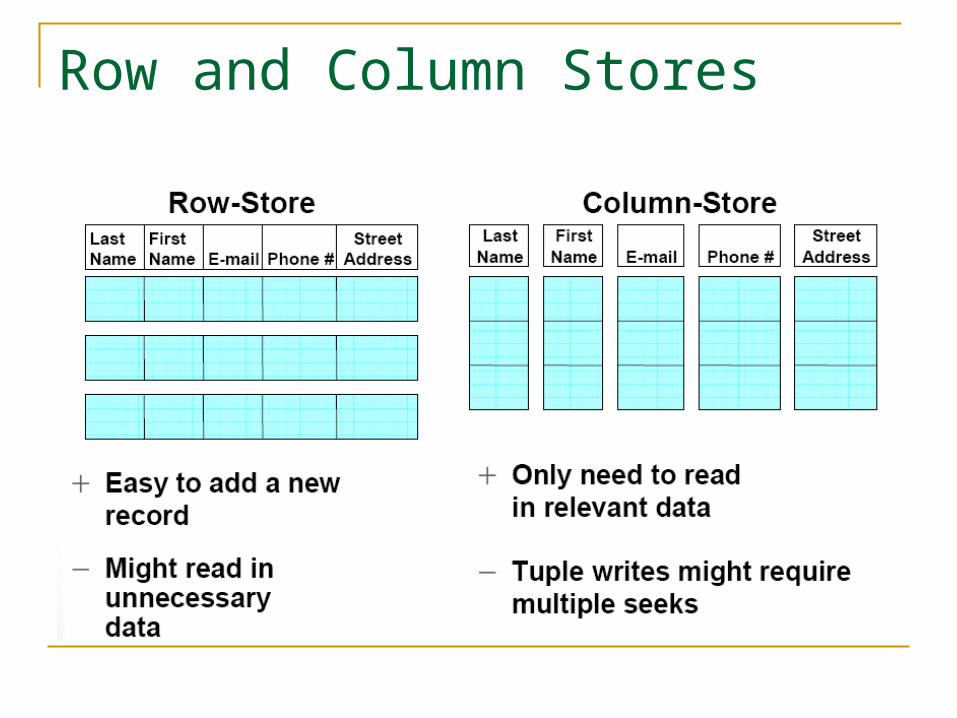
Row and Column Stores

Limitation of Current Comparison Assuming a row store does not use any colu
mn-oriented physical design. Columns of the same logical tuple is traditionally s
tored together.
In fact it is possible to simulate a column store in a row store.

Simulating a Column Store in a Row Store Vertical Partitioning Indexing Every Column Materialized views C-Tables
Vertical Partitioning + Run-Length Encoding

Simulation 1: Vertical Partitioning Each column makes its own table
N columns result in N tables, each table stores (tuple-id, attr) pairs.
Need to do tuple reconstruction In C-store, columns are sorted in the same order.
In MonetDB, base columns are kept in insertion order, updates only happen to cracker columns.
In this “simulation” scenario, an integer “tuple-id” column is associated to each column. Use hash join on “tuple-id” column to reconstruct tuples.

Two Problems of Vertical Partitioning 1. It requires the “tuple-id” column to be explici
tly stored in each column. Waste space and disk bandwidth.
2. Most row-stores store a relatively large header on every tuple further waste space.

Tuple Header
A tuple header provides metadata about the tuple.
For example, in Postgres, each tuple contains a 27 bytes header including information such as
Insert transaction timestamp. Number of attributes in the tuple. NULL flags Length of tuple header

Tuple Header in a Column Store A column-store puts tuple header in separate
columns Some information in the tuple header can be
removed For example, in MonetDB, each logical column st
ores (key, attr) pairs. Hence, the number of attributes is always 2. And there is no need for NULL flags, say we simpl
y don’t store the tuple with NULL value.

Simulation 2: Indexing Every Column Base relations are stored using a standard, ro
w-oriented physical design.
And an additional secondary B-Tree is built on every column of every table. Join columns on tuple-id.
This approach answers queries by reading values directly from the indexes.

One Problems of Indexing Every Column If a column has no predicate on it, this approach req
uires its index to be scanned to extract the needed values.
One optimization is to create indexes with composite keys
SELECT AVG(salary) FROM emp WHERE age > 40;
If we have a composite index with an (age, salary) key, we can answer this query directly from the index.

Simulation 3: Materialized Views For every query in the benchmark workload,
create an optimal set of materialized views. Involve only the columns needed to answer queries.
Do not pre-join columns from different tables in these materialized views.
Problem of materialized views. It requires query workload to be known in advance.

Comparison Results by Abadi et al. (SIGMOD’2008) Using a simplified version of TPC-H called th
e Star Schema Benchmark (SSBM).
Major Results: None of the three attemps to simulate a column st
ore in a row store are particularly effective. The Materialized View approach is the best The Vertical Partitioning approach is the moderate The Indexing Every Column approach is the worst.

Relevant Factors for Successful Simulation For successfully simulating a column store in
a row store, we may have to Store tuple headers separately Use virtual tuple-id to do tuple reconstruction (i.e.,
joins). Maintain heap files (for base relations) in guarante
ed position order.
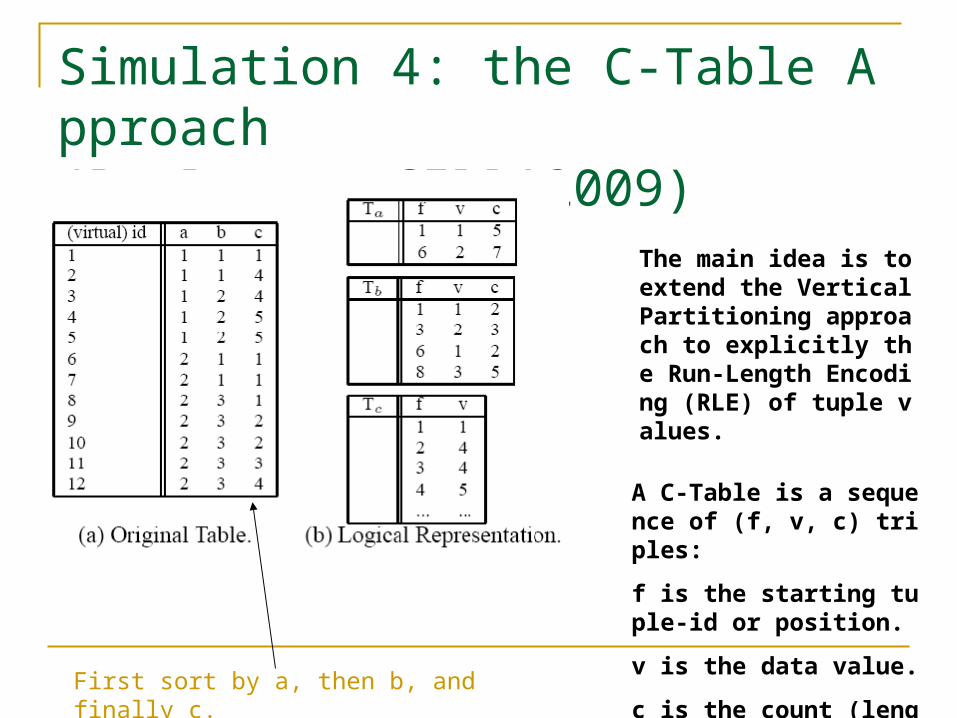
Simulation 4: the C-Table Approach(By Bruno, CIDR’2009)
The main idea is to extend the Vertical Partitioning approach to explicitly the Run-Length Encoding (RLE) of tuple values.
A C-Table is a sequence of (f, v, c) triples:
f is the starting tuple-id or position.
v is the data value.
c is the count (length).First sort by a, then b, and finally c.

An Interesting Property of C-Table For any pair of tuples t1 and t2, possibly on different
c-tables, the range [f1, f1 + c1 -1] and [f2, f2 + c2 -1] do not partially
overlap, i.e., they are either disjoint, or the one associated with the c
olumn deeper in the sort order is included in the other.
This property allows us to use specific query rewriting to combine information from different c-tables to answer queries.
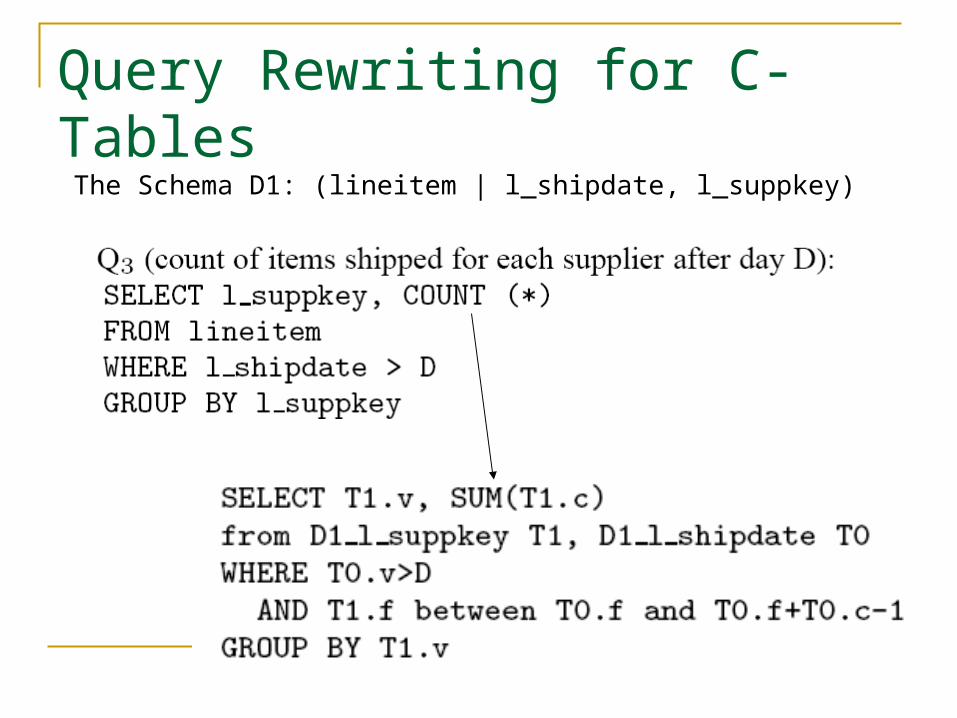
Query Rewriting for C-Tables
The Schema D1: (lineitem | l_shipdate, l_suppkey)

Comparison Results by Bruno. (CIDR’2009) Using TPC-H. Using for comparison a loose lower bound on any
column store implementation Manually compute how many pages in disk need to be read
by any column store execution plan, And measure the time taken to just read the pages.
Results: The C-Table approach can compete with column stores.
Vision: Row-stores should be able to incorporate column specific
optimizations.

Column-Specific Optimizations Late materialization
Construct tuples as late as possible. Block iteration
Multiple-tuples-at-a-time Column-specific compression
Run-Length Encoding Invisible join on star schema (New)
Like semi-join in distributed DBMS.
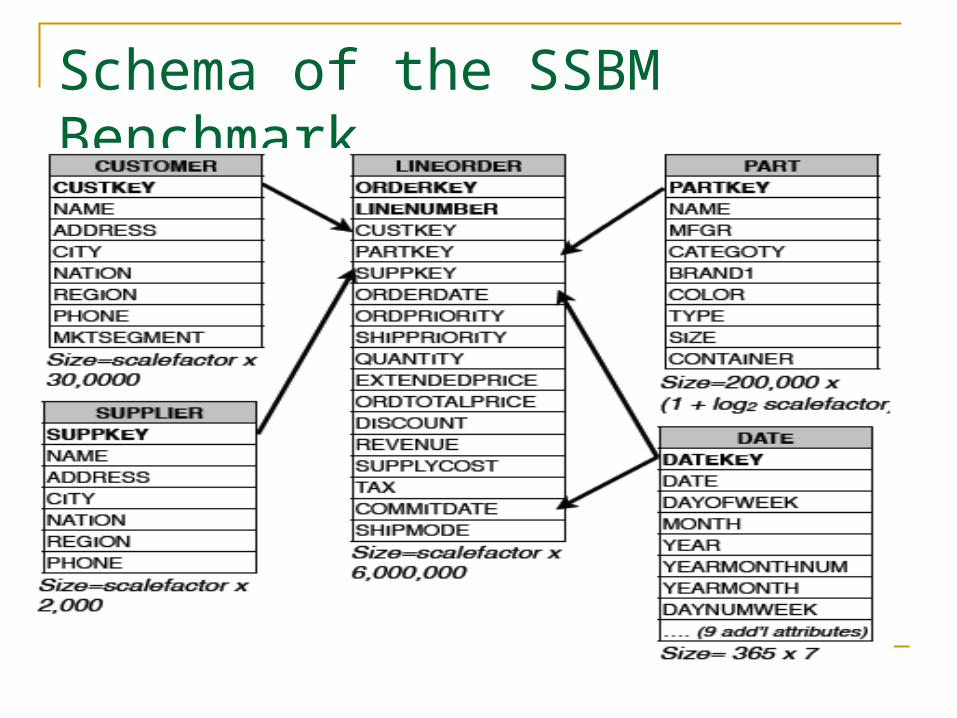
Schema of the SSBM Benchmark

An Example Query for Illustrating Invisible Join
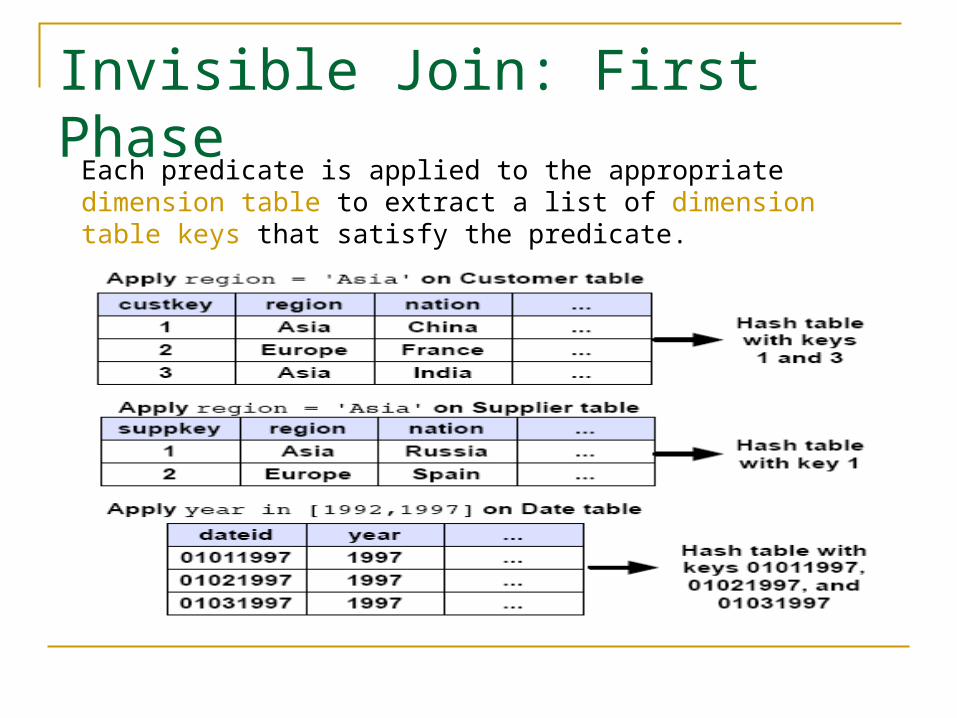
Invisible Join: First Phase
Each predicate is applied to the appropriate dimension table to extract a list of dimension table keys that satisfy the predicate.
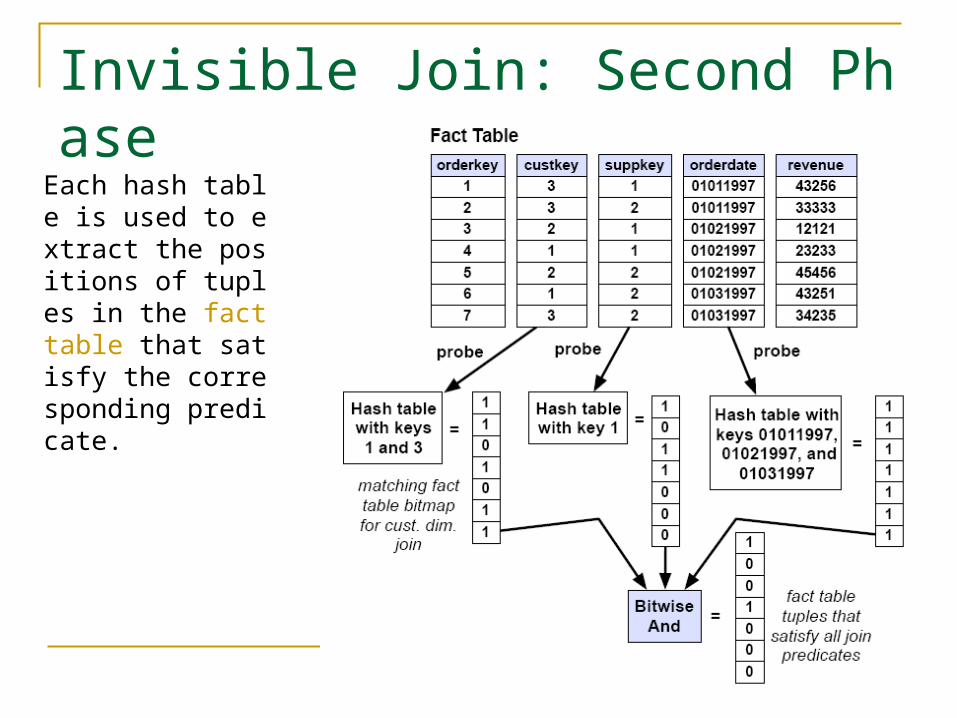
Invisible Join: Second Phase
Each hash table is used to extract the positions of tuples in the fact table that satisfy the corresponding predicate.
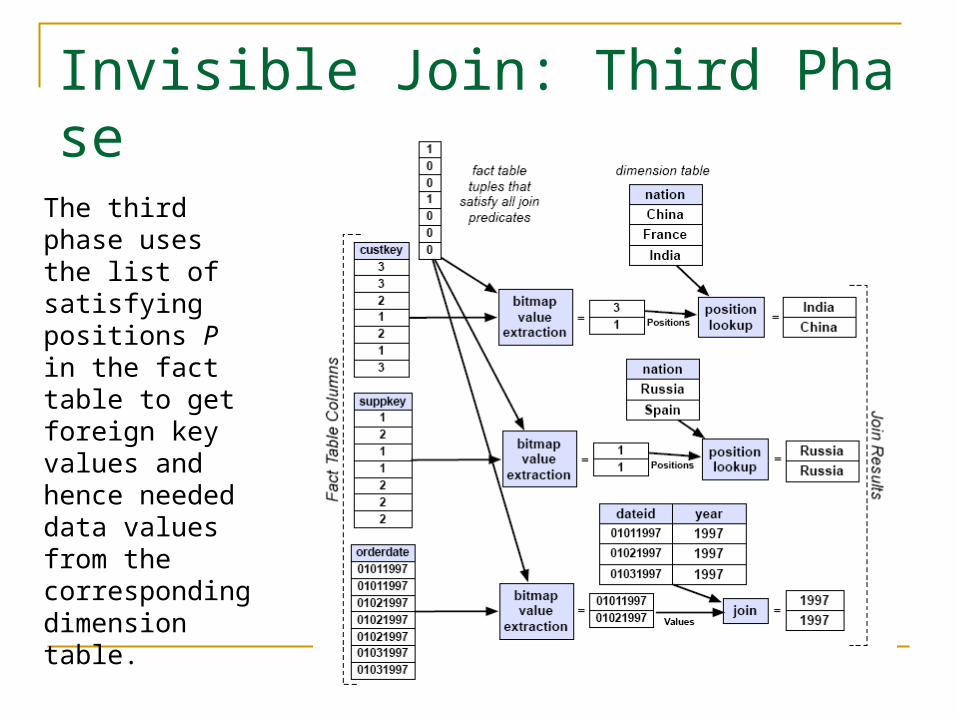
Invisible Join: Third Phase
The third phase uses the list of satisfying positions P in the fact table to get foreign key values and hence needed data values from the corresponding dimension table.

Which Column-Specific Optimization is most significant? Late materialization
Improves performance by a factor of 3. Block iteration
Improves performance by 5% - 50%. Column-specific compression
Improves performance by a factor of 2 on average Improves performance by a factor of 10 on queries that acc
ess sorted data. Invisible join on star schema
Improves performance by 50% - 70%.

Open Question
Building a complete row-store that can transform into a column-store on workloads where column-stores perform well.

References
Daniel J. Abadi, Samuel R. Madden, and Nabil Hachem. Column-Stores vs. Row-Stores: How Different Are They Really?. In SIGMOD, 2008.
Allison L. Holloway, David J. DeWitt. Read-optimized databases, in depth. In VLDB, 2008.
N Bruno. Teaching an Old Elephant New Tricks. In CIDR’2009.





























