Embed Size (px)
Citation preview

CRYPTANALYSIS USING RECONFIGURABLEHARDWARE CLUSTERS FOR
HIGH-PERFORMANCE COMPUTING
DISSERTATION
zur Erlangung des Grades eines Doktor-Ingenieursder Fakultät für Elektrotechnik und Informationstechnik
an der Ruhr-Universität Bochum
by Ralf ZimmermannBochum, June 2015

Copyright c© 2015 by Ralf Zimmermann. All rights reserved.Printed in Germany.

To my beloved wife, Heike.


Ralf ZimmermannPlace of birth: Cologne, Germany
Author’s contact information:[email protected]
www.rub.de
Thesis Advisor: Prof. Dr.-Ing. Christof PaarRuhr-Universität Bochum, Germany
Secondary Referee: Prof. Dr. Tanja LangeTechnische Universiteit Eindhoven, Netherlands
Thesis submitted: June 10th, 2015Thesis defense: July 13th, 2015Last revision: March 16, 2016
v

vi

viii

Abstract
Today, we share our thoughts, habits, and acquaintances in social networks at every step we takein our lives and use network-based services like smart grid, home automation, and the Internetof Things. As the connectivity and data-flow between sensors and networks grows, we rely moreand more on cryptographic primitives to prevent misuse of services, protect data, and ensuredata integrity, authenticity, and confidentiality — given that the primitives remain secure as longas the data is considered useful. History shows the need for well-performed cryptanalysis notonly on the theoretical level but also by utilizing state-of-the-art technology: By applying thebest implementation of suitable attacks to cutting-edge hardware, we derive upper bounds onthe security level of cryptographic algorithms. This allows us to suggest adjustments of securityparameters or to exchange primitives at an early stage.
The focus of this thesis is an analysis of the effects of hardware acceleration using clustersof reconfigurable devices for cryptanalytical tasks and security evaluations of practical attacks.As not all tasks are equally suitable for hardware implementations, this thesis covers differentareas of cryptography and cryptanalysis in four major projects, i. e., algebraic attacks on streamciphers, post-quantum cryptography, password search, and elliptic curve cryptography:
The first project, Dynamic Cube Attack on the Grain-128 Stream Cipher, introduces a newtype of algebraic attack, based on an improved version of cube testers, against the Grain-128stream cipher and required special-purpose hardware for the attack verification. The secondproject covers Password Search against Key Derivation Functions and evaluates the security oftwo of the current standards in password-based key derivation: PBKDF2 and bcrypt. We analyzethe effects of special-purpose hardware for both low-power attacks and well-funded, powerfuladversaries. In the third project, Elliptic Curve Discrete Logarithm Problem on sect113r2, wetarget the ECDL computation on the sect113r2 elliptic curve, which is a non-broken SECGstandard binary elliptic curve. We implemented Pollard’s rho algorithm in combination withthe negation-map technique on FPGAs to increase the efficiency of the random walk, which hasnot been done before. The last part consists of the project Information Set Decoding againstMcEliece, in which we designed the first hardware-accelerated implementation of an InformationSet Decoding attack against the code-based cryptosystem McEliece. We present a proof-of-concept implementation of ISD on reconfigurable devices and discuss the benefits and restrictionsof our hardware approach to provide a solid basis for upcoming hardware implementations.
The results of the projects show that special-purpose hardware is a very important platformto accelerate cryptanalytic tasks and — even though the speed gain heavily depends on thealgorithm and the choice of the hardware platform — that it plays a key role for practicalattacks and security evaluations of new cryptographic primitives. Thus, a lot of effort is spentto decrease the effects of massively parallelized and energy-efficient attack implementations.
ix

Abstract
Keywords
Cryptanaysis, Reconfigurable Hardware, FPGA, Cluster, High-Performance Computation, Im-plementation.
x

Kurzfassung
Hochleistungsrechner aus rekonfigurierbarer Hardware fürAnwendungen in der Kryptoanalyse
Heutzutage haben wir uns angewöhnt, zu jedem Zeitpunkt unsere Gedanken, Gewohnheiten undBekanntschaften in sozialen Netzwerken zu teilen. Hierzu nutzen wir netzwerkbasierte Dienstewie das intelligente Stromnetz, ferngesteuerte Haustechnik oder das Internet der Dinge. Imgleichen Maße, in dem die Verbindung zwischen Mensch und Netzwerk sowie der Datenfluss an-steigen, wächst die Bedeutung eines verlässlichen Schutzes vor Datenmissbrauch. Dazu vertrauenwir auf kryptographische Primitive, die wir zum Schutz von Datenintegrität, -authentizität und-vertrauenswürdigkeit einsetzen. Diese Primitive müssen dabei so lange als sicher gelten, wie dieDaten potenziell Verwendung finden können. Die Geschichte hat gezeigt, dass Kryptoanalysenicht nur eine theoretische Bedeutung hat, sondern auch unter Berücksichtigung des aktuellenStandes der Technik erfolgen muss. Durch die Verwendung optimaler Angriffe in Kombinationmit der modernsten Hardware lässt sich das Sicherheitsniveau kryptographischer Algorithmennach oben abschätzen. Dadurch können frühzeitig Anpassungen an die Sicherheitsparameteroder der Austausch von Algorithmen vorgeschlagen werden.Der Fokus dieser Arbeit liegt in der Analyse der Einflüsse der Verwendung von Hardwarebe-
schleunigung durch Hochleistungsrechner aus rekonfigurierbarer Hardware für die Anwendungenin der Kryptoanalyse. Zudem werden die daraus resultierenden Auswirkung auf die Sicherheits-abschätzungen untersucht. Da nicht alle kryptographischen Primitive gleichermaßen für eineHardwareimplementierung geeignet sind, werden in dieser Arbeit vier Projekte aus verschiedenenTeilgebieten der Kryptologie, insbesondere aus dem Bereich der Stromchiffren, effizienter Pass-wortsuche, Elliptischen-Kurven-Kryptographie und Post-Quantum Kryptographie dargestellt:Im ersten Projekt wird ein neuer algebraischer Angriff, der auf einer verbesserten Version der
Cube Tester basiert, gegen die Stromchiffre Grain-128 beschrieben. Die Validierung des Angriffsunter Verwendung eines Simulationsalgorithmuses erfordert darauf spezialisierte Hardware, daein Software-Ansatz nicht effizient genug ist. Das zweite Projekt beschäftigt sich mit der effi-zienten Passwortsuche gegen Schlüsselableitungsfunktionen und untersucht die Sicherheit vonzwei der derzeitigen Standards in der Passwortableitung: PBKDF2 und bcrypt. Dabei werdendie Auswirkungen von spezialisierter Hardware für energieeffiziente Angriffe und Kontrahen-ten mit entsprechenden finanziellen Mitteln analysiert. In dem dritten Projekt geht es um dieBerechnung des diskreten Logarithmus auf der elliptischen Kurve sect113r2, die eine bislangnicht gebrochene Binärkurve der SECG Standardkurven über dem F2113 ist. Dabei wurde derparallele Pollard’s Rho Algorithmus zum ersten Mal in Hardware in Kombination mit der Ne-gation Map Technik implementiert, um die Effizienz der Random Walk Iteration zu erhöhen.Der letzte Abschnitt handelt von der ersten hardwarebeschleunigten Implementierung eines In-formation Set Decoding Angriffs auf das Post-Quantum Kryptographieverfahren McEliece. DieProof-of-Concept Implementierung dient dabei als Grundlage für die Diskussion der Vorteile
xi

Kurzfassung
und Einschränkungen durch den Hardware-Entwurf, die signifikante Unterschiede in der Wahlder Parameter und Optimierungen nach sich ziehen.Die Resultate der Projekte zeigen, dass in den verschiedenen Bereichen der Kryptoanalyse
der Einsatz von Hardwarebeschleunigung unterschiedliche große Auswirkungen mit sich bringt.Dennoch rücken Hochleistungsrechner und hochparallele Implementierungen immer stärker inden Fokus der Sicherheitsforscher, da die relativen Kosten für die Durchführung von Angriffenimmer attraktiver werden. Dementsprechend wird inzwischen bei der Definition neuer krypto-graphischer Primitive viel Wert auf Maßnahmen gegen Vorteile eines Angreifers durch massiveParallelisierung und energie-effiziente Implementierungen gelegt.
Schlagworte
Kryptoanalyse, Rekonfigurierbare Hardware, FPGA, Hochleistungsrechner, Hochgeschwindig-keitsberechnungen, Implementierung.
xii

Acknowledgements
This thesis is the result of the last 5 years, which I spent at the Chair for Embedded Securityat the Ruhr-University Bochum, at conferences, workshops and summer schools all around theworld, and by commuting far more than 100 000 km on countless (usually delayed) trains betweenMainz and Bochum. Here, I would like to express my gratitude and thank those, who made allof this possible and enjoyable.First and foremost, I would like to thank my family for all of the support throughout the years
and thank my wife, Heike, in particular, who managed to act as a counterbalance and marriedme in spite of my unrealistic years-to-graduate estimation, the long long-distance relationship,and the work I brought home frequently to ruin her plans for our weekends. Thank you for allyour support, your faith, and your love.Coming back to academia, I am very grateful to my supervisor, Christof Paar. Aside from the
scientific guidance, helpful advices, and the contribution of research ideas, you always managedto motivate and encourage me. Thank you very much! I would also like to thank my thesiscommittee, especially Tanja Lange, who provided me with advices and suggestions whenever Imet her.I am very grateful for the wonderful working atmosphere at our chair and want to thank
my colleagues and friends. Special thanks go out to my long-time office-mate, Schnufff, whotaught me countless lessons such as the value of gigantic coffee cups, the fine art of well-timedprocrastination, and the efficiency of working as/with a programming rubber duck team-mate.Furthermore, I would like to thank Nicolas Sendrier, Peter Schwabe and Bo-Yin Yang for
providing me with the opportunity of research stays, Christiane Peters for her endless effortsexplaining code-based cryptography (and the attempts at keeping skepticism out of her voice),and my co-authors (in alphabetic order) for the joint research work: Daniel J. Bernstein, ItaiDinur, Markus Dürmuth, Susanne Engels, Tim Güneysu, Stefan Heyse, Markus Kasper, TanjaLange, Ruben Niederhagen, Peter Schwabe, Adi Shamir, Friedrich Wiemer, Tolga Yalcin.A very big “thank you” goes to those (un)lucky enough to proof-read my thesis in the various
stages of writing: Ruben Niederhagen, my wife1, Erik Krupicka, Christian Kison, and SonjaMenges.Last but not least, I want to thank our team assistant, Irmgard Kühn, who manages so many
of the administrative tasks, keeps it off our backs, and always has a warm smile and a friendlyword when a deadline is near. . .
1In for a penny, in for a pound!
xiii

xiv

Table of Contents
Imprint . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vPreface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . viiiAbstract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ixKurzfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiAcknowledgements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiii
I Preliminaries 1
1 Introduction 3
2 High-Performance Computation Platforms 92.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2 General-Purpose Computing on Graphics Processing Units . . . . . . . . . . . . . 102.3 Application-Specific Integrated Circuits . . . . . . . . . . . . . . . . . . . . . . . 132.4 Field-Programmable Gate-Arrays . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
II Cryptanalysis using Reconfigurable Hardware 19
3 Dynamic Cube Attack on the Grain-128 Stream Cipher 213.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.2 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.1 The Grain Stream Cipher Family . . . . . . . . . . . . . . . . . . . . . . . 223.2.2 Cube Testers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 233.2.3 Dynamic Cube Attacks . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3 A New Approach for Attacking Grain-128 . . . . . . . . . . . . . . . . . . . . . . 253.4 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.4.1 Analysis of the Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . 293.4.2 Hardware Layout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333.4.3 Software Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343.4.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4 Password Search against Key-Derivation Functions 394.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
xv

Table of Contents
4.2 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414.2.1 Password Security . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 424.2.2 Password-Based Key Derivation . . . . . . . . . . . . . . . . . . . . . . . . 434.2.3 Processing Platforms for Password Cracking . . . . . . . . . . . . . . . . . 45
4.3 Attack Implementation: PBKDF2 (TrueCrypt) . . . . . . . . . . . . . . . . . . . 464.3.1 GPU Attack Implementation . . . . . . . . . . . . . . . . . . . . . . . . . 484.3.2 FPGA Attack Implementation . . . . . . . . . . . . . . . . . . . . . . . . 494.3.3 Performance Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 524.3.4 Search Space and Success Rate of an Attack . . . . . . . . . . . . . . . . . 53
4.4 Attack Implementation: bcrypt (OpenBSD) . . . . . . . . . . . . . . . . . . . . . 544.4.1 FPGA Attack Implementation . . . . . . . . . . . . . . . . . . . . . . . . 554.4.2 Performance Results and Comparison . . . . . . . . . . . . . . . . . . . . 57
4.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5 Elliptic Curve Discrete Logarithm Problem (ECDLP) on a Binary Elliptic Curve 635.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 635.2 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
5.2.1 Discrete Logarithm Problem . . . . . . . . . . . . . . . . . . . . . . . . . . 655.2.2 Binary Field Arithmetic . . . . . . . . . . . . . . . . . . . . . . . . . . . . 655.2.3 Elliptic Curves . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
5.3 Attack Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 705.3.1 Target Curve . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 715.3.2 Non-Negating Walk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 725.3.3 Walks modulo negation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 725.3.4 Expected runtime . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 735.3.5 Hardware Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
5.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 775.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
6 Information Set Decoding (ISD) against McEliece 816.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 816.2 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
6.2.1 Code-Based Cryptography . . . . . . . . . . . . . . . . . . . . . . . . . . . 826.2.2 The McEliece Public-Key Cryptosystem . . . . . . . . . . . . . . . . . . . 836.2.3 The Niederreiter Public-Key Cryptosystem . . . . . . . . . . . . . . . . . 836.2.4 Information Set Decoding (ISD) . . . . . . . . . . . . . . . . . . . . . . . 83
6.3 Attack Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 846.3.1 Modifications and Design Considerations . . . . . . . . . . . . . . . . . . . 856.3.2 Hardware/Software Implementation . . . . . . . . . . . . . . . . . . . . . 87
6.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 906.4.1 Runtime Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 906.4.2 Optimal Parameters . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 916.4.3 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
6.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
7 Conclusion and Future Work 95
xvi

Table of Contents
III Appendix 99
A Additional Content 101A.1 Algorithms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101A.2 Tables and Figures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102A.3 Listings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
Bibliography 109
List of Abbreviations 123
List of Figures 125
List of Tables 128
List of Algorithms 129
About the Author 133
Publications 135
Conferences and Workshops 137
xvii

xviii

Part I
Preliminaries
1


Chapter 1
Introduction
Thinking back two decades, we were skeptical about emerging online services like online-banking,which promised that the transactions are as secure as the classical bank-transfers. Nevertheless,we noticed the benefit and comfort for daily life and became more comfortable about beingconnected and accessing the internet from our homes. Soon, the high demand for fast and always-available access to the internet created new fields of research and economy. In the following years,new types of data acquisition hardware were added and today, we are constantly accessinginformation from surrounding networks and share information in return.These changes in our behavior demanded rapid improvements in our infrastructure: While
we used personal computers for work and did access the internet before, the advances in mobiletelecommunication technology and high-performance mobile devices provide us with the tools touse online services not only occasionally but constantly: Today, we share our thoughts, habits,and acquaintances in social networks at every step we take in our lives. Navigation systemscompute routes not only based on offline maps, they frequently query live-data from the sur-rounding users to locate possible traffic jams. Using home automation, we are able to accessinformation about our home, e. g., the room temperature or the state of our stove, and changethem without being physically near the house. Following the idea of the Internet of Things, wecreate an information-based network, where objects communicate without human interactionand slowly replace the need of powerful, centralized computers in our lives. To achieve this,we can query information from additional sensors, microcontrollers or radio-frequency identi-fication (RFID) chips built into common, non-electronic devices. A prominent example is the“smart fridge”, which notifies the user that certain products are empty and may automaticallyorder the missing products online. A different, much more subtle area, where we start broad-casting information, is the vehicle-to-vehicle communication: The ultimate goal is to removethe human-error component and increase road safety. To achieve this, we add new technol-ogy like camera-based pedestrian collision detection systems and let our vehicle communicatewith its surrounding vehicles and back-end servers. This allows computers to predict dangeroussituations and initiate evasive actions.But these advances and innovations come at the cost of new risks and threats on different
severity-levels: We need to cope with dishonest members in the networks or our surroundings,trying to misuse the information we share. A good example of such attempts are the improvedphishing attacks: Well-built clones of payment or other e-commerce websites, which trick victimsto enter name, address and credit card information, which we encounter almost on a daily basis.These attacks aim at identity theft or credit card fraud, following a criminal intent. On theother hand, we encounter highly advanced malware, which poses a threat on a different level asit opens backdoors for multiple purposes from industrial espionage to mass-surveillance.
3

Chapter 1 Introduction
Since the revelations of Edward Snowden starting in 2013, the public view on global, unfilteredmass-surveillance changed from science fiction of the paranoid to currently practiced technol-ogy [Gre14]. The documents released to the public1 — and the corresponding information ongovernmental surveillance programs — reflect the downside of our global, free-for-all network:The possibility of automated information extraction from multiple sources covering almost allaspects of daily life leads to high-quality profiling via data collection. This type of data acqui-sition is very dangerous, as people freely share a lot of seemingly unconnected information withtheir friends on social networks: Their thoughts, discussions on news or recent events, pictures,and locations. Linking these with emails, voice mails, instant messenger communication, andbank transactions shows the potential of information collection and espionage.In order to live with these risks of information misuse, we adjusted the way we look at digital
data: While we trusted others to respect the privacy and property before, we now considerstorage and transportation of digital media as insecure and compromised. This leads to acompletely different point of view on security and countermeasures: Everything we store ortransfer via public networks needs additional security, which is usually gained by thoughtful useof cryptographic primitives. These algorithms and protocols may prevent misuse of services,protect data and ensure data integrity, authenticity and confidentiality.
Cryptography Cryptanalysis
DESAES
Blowfish
GrainRC4
Salsa
MD5SHA
WhirlpoolRipeMD
Protocols
bcryptscrypt
PBKDF2
Classical ImplementationContext-based
Algebraic
DifferentialBrute-Force
Linear
Social Engineering
Passwords
PINs
Cryptology
RSAECCMcEliece
Hash / KDFAsymmetric Symmetric
Figure 1.1: An overview on cryptology and the subfields cryptography and cryptanalysis. Notethat the classification does not cover all aspects of the fields and the algorithms andtypes mentioned are given as examples.
While the idea of simply applying some form of cryptography to solve the security and privacyissues is very tempting, we need to understand the different parts of cryptology, the derivedsecurity definitions, and the intended use-cases. Figure 1.1 shows that the science of cryptologyis split into two areas: cryptography and cryptanalysis.The area of cryptography covers the art of building cryptographic primitives, which belong
to different classes of algorithms and protocols: Asymmetric and symmetric ciphers convertmeaningful messages (called plaintext) into random-looking sequences (called ciphertext) usinga secret key, which is required to revert the transformation. While asymmetric or public-keycryptography uses different keys for the sender and intended recipient, symmetric ciphers requirethe same key for encryption and decryption. Other classes cover cryptographic hash functions,
1Archived at the Electronic Frontier Foundation https://www.eff.org/nsa-spying (visited April 2015)
4

message authentication codes, key-derivation functions, and protocols, e. g., key-exchange orzero-knowledge protocols. From the end-user’s perspective, cryptography offers a wide varietyof secure algorithms in combination with the intended use-case, requirements, and securityparameters.This creates the tight link with the field of cryptanalysis, which focuses on the analysis of these
cryptographic primitives and their structure, develops different methods to attack them, findssecurity weaknesses or proves if an algorithm is secure under certain assumptions. The crucialpart is the definition of a secure algorithm: In [Sch95], Schneier states that “an algorithm isunconditionally secure if, no matter how much ciphertext a cryptanalyst has, there is not enoughinformation to recover the plaintext. [..] only a one-time pad is unbreakable given infiniteresources. All other cryptosystems are breakable in a ciphertext-only attack, simply by tryingevery possible key one by one and checking whether the resulting plaintext is meaningful. Thisis called a brute-force attack.” In practice, we use such brute-force or exhaustive key-searchattacks only if no better approach exists or if we are able to limit the keyspace. Nevertheless,this will break every algorithm — given a good verification, e. g., a known plaintext-ciphertextpair, and enough time and resources.In the area of provable secure cryptography, a formal description of the adversary model is
required and followed by a formal proof of security. Given the resources and assumptions aboutthe adversary follows that the hardness assumptions of the system hold true. While this is aformal approach, the practical security may be different: The adversary model must match thereal adversary’s abilities including future advancements and include every restriction imposedon the surrounding interfaces, e. g., physical access, network interfaces or allowed informationleakage. Even given a very detailed model, there is still the risk that the engineers implementingthese schemes will skip the conditions of the formal proof and rely on the security reduction towork in any case. The different views on theoretical and practical security lead to controversialviews on provable security in cryptography [KM07, Gol06, KM06, Dam07, Men12].Going back to the generic case (as we do not cover provable secure cryptography in this
thesis), we can derive from the existence of brute-force attacks that modern cryptography isat best computationally secure. This means that the algorithms or their underlying hardnessproblems withstand all practical attacks within the lifetime of the secret against the best knownattacks considering both the state-of-the-art and in the time to come technology and resources,e. g., memory and storage capabilities, power consumption and supply, computational power, orthe adversary budget.Apart from the advances in technology in terms of more powerful and cheaper processors, com-
putationally secure algorithms suffer from an always-existing threat: A major break-through inscience may enhance existing or even create new fields in cryptanalysis, e. g., the public devel-opment of differential cryptanalysis in 1990 [BS90] or the practical importance of timing attacks[Koc96] for side-channel analysis, and/or completely break the underlying security problems.Once large quantum computers are available, this will be the case for most of the commonlyused public-key cryptosystems, as they are based on the Discrete Logarithm Problem (DLP) orthe integer factoring problem: Shor’s algorithm on a quantum computer [Sho97] solves thesemathematical problems efficiently. While quantum computers with these abilities do not yetexist, researchers have been working in this field for more than three decades. During the lastyears, large companies and research institutes started investing heavily into quantum comput-ing, e. g., IBM announced a US$ 3 billion budget in July 2014 for computing and chip material
5

Chapter 1 Introduction
research covering quantum computers. In addition, intelligence agencies such as the NationalSecurity Agency (NSA) also research on quantum computers secretly: According to the docu-ments made public by Edward Snowden on January 2nd, 20142, parts of the US$ 79.7 millionproject “Penetrating Hard Targets” covers research in quantum computing.These developments show the need for well-performed cryptanalysis both on the theoretical
level as well as with state-of-the-art technology: By using the best implementation of suitableattacks on cutting-edge hardware, we can derive upper bounds on the security level of crypto-graphic algorithms and suggest upgrading the security parameters or abandoning algorithms forspecific tasks.
Context of the Thesis: We know from the history of cryptanalysis that the impact of up-coming technologies is a critical aspect to consider. Special-purpose hardware, i. e., dedicatedcomputing devices optimized for a single task, have a long tradition in code-breaking, includingattacks against the Enigma cipher during World War II [Bud00]. If we review the history ofthe more recent Data Encryption Standard (DES), which was published in 1975 with a call forcomments and standardized in 1977, the 64-bit key (limited to 256 different key combinations)seemed safe for decades to come. Nevertheless, in the same year, Diffie and Helman consideredDES broken [DH77] using a theoretical special-purpose hardware attack. They estimated thecosts of the machine at about US$ 20 million at the time of writing, but predicted the costs ofthe same machine to drop towards US$ 200 000 within 10 years and suggested using 128-bit keysto withstand such attacks. While their predictions were deemed unrealistic and the DES was notofficially completely broken within that time-span, the algorithm was successfully attacked in1997 with a distributed software-attack. In 1998, a machine based on Application Specific Inte-grated Circuits (ASICs) with the name Deep Crack — consisting of 1856 DES-Chips dedicatedto brute-forcing DES keys — needed 4.5 days on average to recover the key at a one-time costof about US$ 250 000 [Fou98]. Eight years later, the Cost-Optimized Parallel Code Breaker andAnalyzer (COPACOBANA) — based on Field Programmable Gate Arrays (FPGAs) — brokeDES in 6.4 days on average with an investment of only US$ 10 000 [KPP+06].These results indicate that special-purpose hardware is useful in cryptanalysis, especially when
the number of operations is in the range of 250 to 264 operations. In case of a lower complexity,central processing unit (CPU) clusters are sufficient, e. g., in case of the linear cryptanalysisattack against DES [Mat94], which required 243 DES evaluations. Nevertheless, even if the com-plexity of an attack exceeds 264 operations, the feasibility depends on the budget and attackingtarget: [BCC+13] presented an efficient solver for polynomial systems over F2 and concludedthat a system with 80 variables (280 operations) should not be considered secure with the currentcomputing technology.Usually, the overall cost of large-scale attacks on cryptographic functions — and thus the
feasibility of the attack — is dominated by the power costs. For this reason, specialized hard-ware achieves excellent results due to its low power consumption, especially when compared togeneral-purpose architectures. This makes special-purpose hardware very attractive for crypt-analysis [GKN+08, GPPS08, GNR08, ZGP10, GKN+13].
2cf. https://www.eff.org/nsa-spying/nsadocs (visited April 2015)
6

The focus of this thesis is an analysis of the effects of hardware acceleration using differentFPGA families and FPGA clusters (like the COPACOBANA and its successor, the RIVYERA)for cryptanalytical tasks and security evaluations of cryptosystems.
Research Contribution: As not all problems seem equally suitable for hardware implementa-tions, this thesis covers different areas of cryptography, i. e., algebraic attacks, post-quantumcryptography, password search, and elliptic curve cryptography in four major projects:
Dynamic Cube Attack on the Grain-128 Stream Cipher: This chapter introduces a new typeof algebraic attack on the stream cipher Grain-128, which is based on an improved versionof cube testers [ADMS09]. With the removal of previously existing restrictions on the key,the required computational power exceeded the capabilities, the simulation algorithm requireda highly-optimized hardware design instead of a software implementation. The project wascompleted in 2011 as a joint work with Itai Dinur, Tim Güneysu, Christof Paar and Adi Shamir.The results were published in [DGP+11] with the focus on the theoretical aspects, whereas theimplementation details were published in [DGP+12].In the context of this project, my contribution was the analysis of the reference software
implementation, the development of an optimized hardware architecture together with a multi-threaded Linux hardware/software co-design running on the RIVYERA-S3 FPGA cluster toverify the efficiency of the new attack and evaluate different parameter sets.
Password Search against Key Derivation Functions: This project evaluates the strength of differ-ent Password-Based Key Derivation Functions (PBKDFs) against dedicated hardware attacks.In 2012, we completed the first project — an evaluation of PBKDF2 using TrueCrypt, an opensource full disk encryption (FDE) software and the standard for Windows FDE at that time,as the target. This was a joint work with Markus Dürmuth, Tim Güneysu, Markus Kasper,Christoph Paar and Tolga Yalcin and was published in [DGK+12]. The second project con-centrated on an FPGA implementation of bcrypt, one of the two major Key Derivation Func-tions (KDFs) besides Password-Based Key Derivation Function 2 (PBKDF2). This was a jointwork together with Friedrich Wiemer and was published in [WZ14] end of 2014.In the scope of both projects, my main contribution was the implementation of the KDFs
and the resulting optimization on FPGAs. In addition, we analyzed the success rate and powerconsumption of different attack types, focusing on low-power password hashing using the recentXilinx Zynq FPGA as well as on massive parallelization with the RIVYERA-S3 FPGA cluster.In both projects, we implemented the fastest known attack against the chosen key-derivationfunctions available at that time.
Elliptic Curve Discrete Logarithm Problem (ECDLP) on a Binary Elliptic Curve: In this project,the focus changes towards public-key cryptosystems and the first hardware-implementation ofthe parallel Pollard’s rho algorithm using negation-map in hardware. The target of the attackis the Standards for Efficient Cryptography Group (SECG) standard curve sect113r2. Thisbinary elliptic curve was deprecated in 2005 but resisted all attacks until March 2015 [WW15],when Wenger et al. independently implemented an attack on the same curve. The researchproject started in 2013 as a joint work with Tanja Lange and Daniel J. Bernstein. Duringthe project time, Peter Schwabe, Susanne Engels and Ruben Niederhagen joint, and the first
7

Chapter 1 Introduction
implementation was published as the master thesis of Susanne Engels. Ruben Niederhagen iscurrently implementing a modified design to improve the published results.In this project, I designed the FPGA implementation together with Susanne Engels and
optimized the implementation afterwards. I implemented the basic negation-map and changedthe design to work on the RIVYERA-S6 cluster.
ISD against the McEliece Cryptosystem: In the scope of Post-Quantum Cryptography, we exper-imented with the design of a hardware-accelerated implementation of an ISD attack against code-based cryptosystems like McEliece or Niederreiter. We showed that hardware-support requiressignificantly different implementation and optimization approaches than Lee and Brickel [LB88],Leon [Leo88], Stern [Ste88], or Bernstein et al. [BLP11a], May et al. [MMT11] and Beckeret al. [BJMM12]. This project was a joint work with Stefan Heyse and Christof Paar, which wefinished in 2014 and published the results in [HZP14].This project consisted of two parts. The first part was an analysis of the existing algorithms
and the improvements published during the last years with the goal of mapping the CPU-based algorithms to hardware. The second part contained the modification of the algorithmand implementation as a hardware/software co-design. I contributed to the first part and wasworking on the hardware design and optimization targeting the RIVYERA-S6 FPGA cluster.
In the context of these projects, the thesis evaluates if — and to which degree — special-purpose hardware and the available choices of such hardware platforms are suitable for cryptan-alytic computation that pose a threat to currently established cryptosystems. In this context,we consider different adversaries and give an overview of potential risks.
Structure: The thesis is divided into two parts, followed by an appendix. Part I consists of thepreliminaries, covering both the introduction and motivation to the task of high-performancecomputation (HPC) in cryptanalysis in Chapter 1 and information on different HPC platformsavailable and used throughout this thesis in Chapter 2. Please note that due to the amount ofdifferent areas touched by the four projects, the background in these chapters is not suitable as aself-contained introduction into the different areas: It does not include in-depth details, e. g., themathematical background of code-based cryptography, and instead focuses on the required infor-mation to understand the concepts and design decisions of the project-related implementations.Part II presents the four different projects in detail. We start with an algebraic attack on
the stream cipher Grain-128 in Chapter 3 and review different methods to derive cryptographickey material from human-entered passwords and implement attacks on the PBKDF2 and bcryptalgorithm in Chapter 4. The second half of the projects covers public-key cryptography: Chapter5 contains an attack on the ECDLP of a 113-bit binary elliptic curve, while Chapter 6 covers thefirst hardware implementation of an ISD attack on the post-quantum cryptosystems McElieceand Niederreiter. The thesis concludes with suggestions for future work and closing remarks inChapter 7.
8

Chapter 2
High-Performance Computation Platforms
In this chapter, we consider different hardware platforms usable for cryptanalysis anddiscuss their strengths and weaknesses. We start with general-purpose platforms,i. e., standard CPUs, and continue with more specialized hardware, i. e., GraphicsProcessing Units (GPUs), Application Specific Integrated Circuits (ASICs), and FieldProgrammable Gate Arrays (FPGAs).
Contents of this Chapter2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2 General-Purpose Computing on Graphics Processing Units . . . . . . . . . 10
2.3 Application-Specific Integrated Circuits . . . . . . . . . . . . . . . . . . . . . 13
2.4 Field-Programmable Gate-Arrays . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.1 Introduction
With the definition of computational security and the feasibility of an attack, benchmarkingthe runtime of an attack implementation using state-of-the-art technology and predicting theimpact of architectural changes in technology are essential elements of the security evaluation.The most common source of computational power is general-purpose hardware like the CPU
of modern desktop systems. Those processors offer a wide variety of instructions to implementdifferent programs and algorithms. We can see from the processor manuals of Intel1 and AMD2
that the processor instruction sets were constantly modified and extended over the years. Thesemodifications include the architecture re-design from register sizes of 16-bit to 32-bit to 64-bitas well as special instruction extensions like floating-point unit, SSE instructions, or the recentAES-NI addition to support Advanced Encryption Standard (AES) computations. With thesein mind, we map algorithms to the architecture and optimize the implementation with specialinstructions, e. g., the fused-multiply-add instruction.A major advantage of general-purpose hardware is the common availability and thus smaller
upfront-costs compared to customized, problem-specific solutions. In addition, when we im-plement algorithms on CPUs, we have multiple programming languages and both open source
1cf. http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
2cf. http://developer.amd.com/resources/documentation-articles/developer-guides-manuals
9

Chapter 2 High-Performance Computation Platforms
as well as commercially supported tool-chains available to choose from. This leads to a goodacceptance of the platform and a small time-to-market.Multiple projects already exist, which utilize idle CPU resources in a distributed-computing
approach: They split large, difficult problems into small chunks, which are then assigned andsolved by computer nodes. BOINC3 is a prominent example for such a distributed computationnetwork in science.A more dedicated and efficient approach are high-performance computation (HPC) supercom-
puters and supercomputer centers like the Jülich Supercomputing Centre (JSC)4, which hostsJUQUEEN, a 458 752 core super-computer with a peak performance of 5 872 Tflops/s. In theTOP500 Supercompter List5 of November 2014, JUQUEEN reached the 8th place. The current1st place holds Tianhe-2 (MilkyWay-2) with 3 120 000 cores and a peak performance of 54 902Tflops/s. Of course, the workload generated from public projects is divided between many dif-ferent (scientific) problems instead of full-time cryptographic attacks. Still, the military usessupercomputers for this purpose, e. g., as part of the National Security Agency (NSA)’s Longhaulsystem6.Nevertheless, massive computational power requires thoughtful implementation with paral-
lelization in mind in order to fully unlock its potential and use the resources efficiently. Inthe context of a single computational node, i. e., a single CPU, and a very specific task, i. e., acryptanalytic algorithm, we usually require only a small subset of the capabilities in terms ofinstructions and available registers. This leads to two observations: First, parts of the hardwareare unused (in the context of a given algorithm). This may cover both wasted area as well aswasted power, as the chip is not utilized optimally; second, the architecture may become a limit-ing factor, e. g., the number of available registers or chip-internal structures and mechanisms likepipelining, branch-prediction, and caches for highly-parallel tasks or incompatible register-sizeslike 32- or 64-bit registers for large-integer arithmetic.
To improve the overall usage of the available hardware and increase the performance of veryspecific implementations, we move from general-purpose to special-purpose hardware. In thefollowing sections, we will introduce two different implementation targets: Using GPUs forgeneral-purpose computations as well as FPGAs together with the more specialized ASICs.
2.2 General-Purpose Computing on Graphics Processing Units
With the invention of dedicated Graphics Processing Units (GPUs) and the broad availabilitytoday, we have access to a high-performance, special-purpose hardware co-processor for the CPU:It highly improves the speed of the specific task of transforming vertices to pixels, which wasinitially done by the CPU. When GPUs emerged, they used (with small exceptions) a definedfixed-function Application Programming Interface (API). These functions directly mapped todedicated hardware inside the GPUs, going through the fixed-function pipeline, i. e., Vertexcontrol and conversion, transform and lighting, triangle setup, rasterization, shading, and the
3cf. http://boinc.berkeley.edu4cf. http://www.fz-juelich.de/ias/jsc/EN/5cf. http://www.top500.org/lists6cf. http://www.spiegel.de/international/germany/inside-the-nsa-s-war-on-internet-security-
a-1010361.html
10

2.2 General-Purpose Computing on Graphics Processing Units
frame buffer interface. This provided programmers with easy-to-use, task-driven functions anddid not require special knowledge of the underlying hardware, still with graphics processing asthe main task.Shader-based GPUs changed the approach and provided more direct access to the rendering
pipeline: Using a special shading language, the developers were able to write programs executablein the shading transform and lighting stage. With this access to more generic instructions, thefixed-function API was mostly used for backwards compatibility.This change also opened the specialized hardware for non-graphic computations, which is
referred to as General-Purpose Computing on Graphics Processing Units (GPGPU). Withinthe last decade, the field of HPC using GPUs slowly became a new target of the major GPUmanufacturers, i. e., AMD (formerly ATI) and NVIDIA, and programmers have access to well-documented APIs and new hardware architectures optimized for parallel computation.There are two major standards for heterogeneous, parallel computing on GPUs: NVIDIA’s
CUDA7 and the OpenCL8. Depending on the target environment, CUDA may be a betterchoice for NVIDIA-only systems, as the development and support of the architecture and driversis maintained by the same company. Nevertheless, using OpenCL is officially supported byNVIDIA: The support is included with the GPU drivers and they offer NVIDIA OpenCL SDKsamples9 for Windows, Linux and Mac.In this thesis, we used an NVIDIA GPU programmed in CUDA in the Password Search
project (cf. Section 4.3.1), as those were the available out-of-the-box GPU clusters at that time.Please note that GPU architectures are rapidly changing, e. g., the NVIDIA Maxwell generationimproved on-chip boolean logic computation. Thus, a detailed review is beyond the scope ofthis introduction. We focus on the CUDA terminology and the Tesla GPUs.
CUDA Terminology and Code Execution Basics CUDA and its compiler use a subset of theC programming language with GPU extensions. The language defines two models, which areimportant to maximize the efficiency of GPU acceleration: A programming model and a memorymodel.The device code is compiled as kernels and while multiple kernels may be queued, only one
kernel runs at a time with many threads executing its code in parallel. Comparing GPU andCPU kernels, the GPU model uses thousands of parallel threads for efficient computation andperforms the creation and switching of threads with minimal overhead. Threads of the samekernel are combined into blocks, which are grouped into a grid. The threads inside each blockhave access to a per-block shared memory and can use this memory for thread-interaction withinthe block. CUDA also provides block-wide thread-synchronization mechanisms. The schedulingscheme of CUDA is independent of the actual hardware. To achieve this, it provides a multi-dimensional indexing theme: Blocks inside a grid have either one or two dimensions, whilethreads inside a block may have either one, two or three dimensions to identify them. Theoverall dimensions are parameters of the CPU code launching the kernel. When the GPU startsa kernel, it assigns the blocks to Streaming Multiprocessors (SMs). Each SM consists of registers,caches, warp schedulers and cores for integer and floating point operations. A warp is a fixed-sizechunk (recent GPUs use a warp size of 32) of the pending blocks, where all threads inside the
7cf. http://developer.nvidia.com/category/zone/cuda-zone8cf. http://www.khronos.org/opencl9cf. http://developer.nvidia.com/opencl
11

Chapter 2 High-Performance Computation Platforms
warp execute the same instruction on the hardware. Thus, a warp executes Single Instruction,Multiple Data (SIMD) vector operations. The schedulers change contexts between the threadsand issue the next instruction. Please note that due to the SIMD operations, all threads perwarp either execute the same instruction or diverging threads skip the execution, i. e., in case ofdifferent branches.CUDA defines different types of memories usable on the GPU: A long latency, large global
memory, which is used to transfer data between the host and the GPU. The global memorymay be accessed from all threads. Access to the per-block shared memory is faster than theglobal memory. For the smallest latency, the threads use their local registers, though theseregisters are very limited in their number. While the general rule is to avoid accessing the globalmemory when possible, the GPU contains a latency-hiding mechanism: In case a high-latencyinstruction is executed, the warp scheduler may execute additional warps in the meantime. Thislatency-hiding improves the performance drastically: It is possible for the GPU to completelyhide the delay if there are enough other instructions on a SM.
NVIDIA Tesla C207010 : In Chapter 4, we used a very specific GPU: The Tesla C2070,which was released in Q3 2010. The device consists of 14 SMs with 32 computing cores each.Therefore, this architecture provides 14 × 32 = 448 dedicated cores within a single GPU. Interms of bandwidth and computational power, the card achieves a memory transfer rate of 144GBps and the cores are clocked at 1.15 GHz, reaching a single-precision floating point peakperformance of up to 1.03 Tflops/s. Comparing this to a modern CPU of the same time, the2011 Intel i7 98011, the 3.6 GHz chip achieves about 86 Gflops/s.
Limitations of GPU Programming: As mentioned before, we use CUDA as the API to workon the graphic processor and thus, the code may be used on different NVIDIA devices. Nev-ertheless, we can optimize the code for the target architecture of the specific GPU model andincrease the efficiency. To achieve the best results, we need to know the limitations posed by thearchitecture and how to deal with them. The following considerations are derived from the TeslaC2070 device itself: The maximum number of blocks per SM is restricted to 8 with a maximumnumber of 1 536 assigned threads. As each SM contains 32 768×32-bit registers and 49 152 bytesof shared memory, this restricts the number of parallel threads depending on the resource usageper thread: A design using all of the 1 536 threads in parallel is limited to at most 21 registersand 32 bytes of shared memory. These restrictions influence the performance of the design: Ifthe kernel requires more registers, additional variables are stored in global memory, which has asignificantly higher latency compared to the registers. If the per-block shared memory limit iscritical, the number of threads per block decreases and the warp scheduler may fail to hide highlatencies.
In comparison to standard CPUs, GPUs offer a very high number of parallel cores per devicewith comparable clock frequencies, combined with a fast memory-architecture and latency-hidingmechanisms. The main drawbacks are the considerably higher power consumption of GPUs and
10cf. C2070 Datasheet: http://www.nvidia.com/docs/IO/43395/NV_DS_Tesla_C2050_C2070_jul10_lores.pdf
11cf. http://download.intel.com/support/processors/corei7/sb/core_i7-900_d.pdf
12

2.3 Application-Specific Integrated Circuits
the architectural and device-specific restrictions, which have a direct impact on the suitabilityof the device as a target platform for a specific algorithm.
2.3 Application-Specific Integrated Circuits
Application Specific Integrated Circuits (ASICs) are hardware chips dedicated to exactly onespecific task and contain a static circuit. GPUs started as specialized (co-)processors, i. e., theyhad a very specific task without general-purpose processing. Today, GPUs are fast, general-purpose multi-core platforms with special instructions for graphic processing programmed inhigh-level programming languages or assembler.ASICs on the other hand are not programmable, as they are designed as integrated circuits:
This means that the target algorithm is transformed to a combination of logical functions andstorage elements and then implemented with standard-cell libraries. Usually, such a chip containsvolatile storage elements, e. g., flip-flops, latches or SRAM, non-volatile memory (if requiredfor the task), Input/Output (I/O) pins, i. e., to communicate with the outside world, and thealgorithm-specific control logic, e. g., designed as a Finite-State Machine (FSM). The completeabsence of general-purpose features or generic APIs leads to very straight-forward, small, andfast designs.This changes the implementation approaches and restrictions compared to CPUs and GPUs:
While there are still limitations derived from the available chip-area, cell libraries, and celltechnologies, the designer creates an algorithm-specific architecture, e. g., by defining the numberof available registers, their sizes and distribution, or builds specialized co-processors. Thesecreate an optimal basis for the specific target algorithm, for example by providing unusualregister sizes like 81-bit registers in case the target requires it.Such dedicated chips outperform any other implementation, as they use exactly the area the
circuit requires and waste no power for additional tasks: Compared to CPUs or GPUs, thedesign will only perform essential operations in every clock cycle, as there is no overhead forbranch predictions, context switches, instruction pipelines or latency-hiding.Though this approach provides the best possible performance and — when produced in high
quantities — low unit costs, the development process is much more complex than programmingin software: Before the design is built, the designer needs to carefully verify the correctness ofthe circuit, usually by building several prototypes, testing them in the target environment, anditeratively optimizing the design. In addition to the complexity, the upfront cost for the toolchainlicenses and the different standard cell-libraries (depending on the technology) as well as thecosts to produce the prototypes make hardware design less attractive for rapid prototyping.
2.4 Field-Programmable Gate-Arrays
Field Programmable Gate Arrays (FPGAs) combine the performance and inherent, true par-allelism of a gate-level hardware implementation with the flexibility, simple development, andreconfigurability of a software-based approach. Compared to the ASIC, it provides reconfigurablelogic in hardware. Using these, the FPGA is programmed and may be reprogrammed to work ona different algorithm and allows reuse of the same hardware. These reconfigurable logic consistsof logical building blocks, I/O pins, and — depending on the device — include additional fea-
13

Chapter 2 High-Performance Computation Platforms
tures such as multiple clock domains or dedicated hard blocks, e. g., dedicated memory blocks,PowerPC cores, high-speed transceivers, or signal processing cores.The designer builds upon these resources and creates a chip with an application-specific ar-
chitecture. Two major programming languages exist to implement on FPGAs: Verilog andVery High Speed Integrated Circuit (VHSIC) Hardware Description Language (VHDL). Thedeveloper builds hardware modules using these languages and describes the hardware eitherin structural or behavioral models and combines those using signals and wires. The toolchainstarts with a synthesis stage, where the design is transformed from a high-level language tothe register-transfer level and identifies logic macros, e. g., a multi-input XOR. Afterwards,the translate and map stage breaks these information down to the underlying structure of thetarget device using the logical resources and delay information of the specific FPGA. In thelast stage, the place and route, the tools physically place the logic on the chip, optimize thison-chip placement and reduce the signal routes. Please note that in contrast to software im-plementations, which execute low-level instructions with the clock frequency the CPU or GPUprovides, a clock-synchronous hardware design of an algorithm updates the full circuit in everyclock cycle. Thus, the signal routes have a direct impact on the maximum clock frequency ofthe design: The longest route a signal travels in one clock cycle from a source register to thedestination register defines the critical path, which defines the maximum clock frequency. Thedesigner needs to carefully optimize the critical path and thus the on-chip routing. Please notethat the automatic, probabilistic optimization is usually not sufficient and manual optimizationis required.As this design process and even more the optimization steps require several iterations,
FPGAs provide a very interesting rapid-prototyping, low cost approach: Implementations ben-efit from the implicit parallelization (parallel circuits truly work in parallel) and the low power-consumption of hardware implementations in combination with the flexibility of reusing thesame chip for different approaches or multiple algorithms.
FPGA layout: The FPGA-specific building blocks and naming conventions depend on theFPGA vendor. While there exist many different vendors, two large companies take up about 90%of the market share: Altera and Xilinx12. The FPGA clusters we are using throughout this thesisare successors of the Cost-Optimized Parallel Code Breaker and Analyzer (COPACOBANA)[KPP+06]. This cluster was built in 2006 by two groups from the Universities of Bochum and Kielusing 120 Xilinx Spartan-3 1000 FPGAs. It demonstrated the potential of low-cost reconfigurablehardware for cryptanalysis with a brute-force attack on DES for less than US$ 10 000. Since 2007,SciEngines GmbH13 produces and supports the cluster and its successors.We continue with the description of the internal building blocks with respect to the Xilinx
devices and toolchain. Most of the FPGA area is occupied with a generic structure consistingof Configurable Logic Blocks (CLBs) and Interconnects. Figure 2.1 shows the layout of a smallXilinx Spartan-6 device, the XC6SLX16-CSG324-2C. The blue area covering most of the deviceare the CLBs. Each CLB comprises a fixed number of slices. The number of slices per CLB andthe exact content of a slice depend on the target FPGA. All slices contain a basic structure, whileseveral slices contain additional features. The basic layout of a slice contains Look-Up Tables(LUTs) to implement boolean functions, multiplexers to select signals, and Flip Flops (FFs) as
12cf. http://investor.xilinx.com, Key Documentation: Investor Factsheet (April 2015)13cf. http://www.sciengines.com
14

2.4 Field-Programmable Gate-Arrays
storage elements. In addition to the CLBs, the small Spartan-6 also contains 8 independentclock regions and two types of dedicated hard cores: Two rows of Block RAM (BRAM) (pink)and two rows of Digital Signal Processing (DSP) cores.
Figure 2.1: Exemplary picture of an FPGA layout of a Xilinx XC6SLX16 FPGA. Most of thedevice’s area provides CLBs (blue). The I/O pins are located outside, surroundingthe programmable area. The FPGA contains 8 independent clock domain regions.This small device contains two types of hard cores, physically distributed in columns:BRAM (pink) and DSP cores (cyan).
As mentioned before, FPGA optimizations are tightly linked to the target device. It is veryimportant to know the exact type, structure, and available elements, as we cannot easily reusedesigns previously optimized for one architecture. A good example are the dedicated hard cores,as they are physically distributed over the chip area. In our example, we have two columnsof memory cores, which pose an area-restriction on the logic, which processes the input andoutput data. A different FPGA might use four smaller columns, which may not change the totalmemory but has an effect — negative or positive — on the placement and the signal routing.While we can create generic implementations, these designs will most likely not utilize the full
potential of all available hardware structures. In the worst case, the implementation results in
15

Chapter 2 High-Performance Computation Platforms
an over-mapping of the physical resources and does not fit within the hardware at all, e. g., ifthe new target provides less memory or not enough logical resources. Change from a smallerto a larger device is less problematic, but usually requires manual, device-specific changes toincrease the performance.
We will now briefly discuss the different FPGAs clusters used in this thesis and provide ashort overview of their features and the devices they utilize.
RIVYERA-S3: The first successor of the COPACOBANA, called SciEngines RIVYERA S3-5000 [GPPS09], is populated with 128 Spartan-3 XC3S5000 FPGAs, each tightly coupled with32MB of Dynamic Random Access Memory (DRAM) memory for direct access from the fabric.Each of these FPGAs provides a set of logic resources consisting of 33 280 slices and 104 BRAMs.These slices are the core of the reconfigurable hardware, as they allow the implementation ofcomplex boolean functions in reconfigurable hardware. The Spartan-3 Series uses slices, whichcontain two 4-input LUTs and two FFs each. The XC3S5000 does not contain any DSP coresfor fast integer arithmetic, which are only part of specific Spartan-3A and more recent FPGAs.
XC3S5000-1XC3S5000-2XC3S5000-8
FPGA
CTL
Module 16XC3S5000-1XC3S5000-2
XC3S5000-8
FPGA
CTL
Module 2XC3S5000-1XC3S5000-2
XC3S5000-8
FPGA
CTL
Module 1
Ring Bus
BackplaneCorei7 920
PC
Ie
Ethernet
Host PC
External Data
Figure 2.2: Architecture of the RIVYERA-S3 cluster system.
Figure 2.2 provides an overview of the architecture of the RIVYERA special-purpose cluster:Eight FPGAs are soldered on individual card modules that are plugged into a backplane, whichimplements a global systolic ring-bus for high-performance communication. The internal ring-bus is further connected via Peripheral Component Interconnect (PCI) Express to a host CPU— an Intel Core i7 based PC — which is installed in the same 19" housing of the cluster. Apartfrom the change of the FPGA from the smaller Spartan-3 1000 FPGAs of the COPACOBANAto the largest Spartan-3 FPGAs, the new bus system is the most important addition to thecluster. More complex cryptanalytic designs like [ZGP10] were slowed down considerably dueto the interface-bottleneck.
16

2.4 Field-Programmable Gate-Arrays
RIVYERA-S6 The second generation of the SciEngines RIVYERA cluster featured the morerecent Spartan-6 XC6SLX150 FPGAs and increased the optional DRAM to 2 GB. This clusterexists in multiple versions: We use a small prototyping variant with 8 FPGAs, called FORMICA,and have access to two 64 FPGA versions. The most notable difference to the RIVYERA-S3firmware is the ability to simulate the design including the full API, which drastically reducesthe debugging time.Apart from the improvements for the designer, implementations benefit from the new version
of the Spartan FPGAs: The devices contain 23 038 slices, 268 × 18-Kb BRAMs and 180 DSPcores. Please note that in contrast to the Spartan-3, each slice now features four 6-input LUTsand 8 FFs and the CLB layout changed: The Spartan-6 uses three different types of slices,distributing the additional slice features differently. With these changes, the half-equippedSpartan-6 clusters outperform the fully-equipped RIVYERA-S3 cluster even with the lowernumber of FPGAs available in our machines.
Xilinx Virtex-6 and Series-7 FPGAs The FPGAs of the latest generation were not availablein large clusters during the implementation time of the projects. As the Virtex-Family containsthe high-performance FPGAs, we use an Virtex-6 evaluation board for runtime estimations inChapter 6 and two members of the 7th series in Section 4.4: The low-cost Xilinx zedboard andthe high-performance Xilinx VC707 Evaluation Kit.The FPGA on the zedboard is a Zynq-7000 XC7Z020. It is located in the low-power low-cost
segment. The device consists of a dual-core ARM Cortex A9 CPU, while the fabric area and re-sources are comparable to an Xilinx Artix-7 FPGA. The zedboard allows easy access to the logicinside the fabric and memory modules via direct memory access. It provides several interfaces,e. g., AXI4, AXI4-Stream, AXI4-Lite, or Xillybus and is a good choice for hardware/softwareco-designs and provides a self-contained system.The Virtex-7 on the other hand offers a five times larger fabric area and seven times more
memory cores at the cost of more power consumption and a higher device price. In the contextof HPC, this allows the implementation of fully-unrolled designs previously limited by the areaconstraints.
17

18

Part II
Cryptanalysis using ReconfigurableHardware
19


Chapter 3
Dynamic Cube Attack on the Grain-128Stream Cipher
This chapter introduces a new type of algebraic attack on the stream cipher Grain-128, which is based on an improved version of cube testers [ADMS09]. With theremoval of previously existing restrictions on the key, the required computationalpower exceeded the capabilities. The simulation algorithm required a highly-optimizedhardware design instead of a software implementation. The project was completed in2011 as a joint work with Itai Dinur, Tim Güneysu, Christof Paar, and Adi Shamir.The results were published in [DGP+11] with the focus on the theoretical aspects,whereas the implementation details were published in [DGP+12]. The content of thischapter is based on both papers and structured as follows:
Contents of this Chapter3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.2 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.3 A New Approach for Attacking Grain-128 . . . . . . . . . . . . . . . . . . . 253.4 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Contribution: In the context of this project, my contribution was the analysis ofthe reference software implementation and the development of an optimized hardwarearchitecture. This included a multi-threaded Linux hardware/software co-design run-ning on the RIVYERA-S3 FPGA cluster to verify the efficiency of the new attackand to evaluate different parameter sets.
3.1 Introduction
The algorithm Grain-128 [HJMM06] belongs to the class of stream ciphers. It is the 128-bitvariant of the Grain scheme, which was selected by the eSTREAM project in 2008 as one of thethree recommended hardware-efficient stream ciphers.Considering the different attacks on Grain-128 published at the time of the project, related-
key attacks on the full cipher were presented in [LJSH08] and — by using a sliding property —
21

Chapter 3 Dynamic Cube Attack on the Grain-128 Stream Cipher
[CKP08] improved exhaustive search by a factor of two. The only single-key attacks substantiallyfaster than exhaustive search either attacked a reduced number of rounds [EJT07, FKM08,ADMS09, KMNP10, Sta10] or a specific class of weak keys [DS11] with dynamic cube attacks.The attack on this particular subset of weak keys — containing the 2−10 fraction of keys, inwhich ten specific key bits are all zero — is faster than exhaustive search by a factor of about215. For the remaining 0.999 fraction of keys, there is no known attack faster than exhaustivesearch.In this work, we verify an improved scheme called Dynamic Cube Attack, which is based on
cube distinguishers. It introduces dynamic variables and — with their help — removes all ofthe restrictions previously applied to the key. This proves to be challenging, as a large numberof iterations and evaluations is necessary: With the increased dimension parameter of 50, eachevaluation works on 250 output bits of Grain-128 after the initial setup-phase of the cipher.This becomes infeasible on the previously used CPU clusters, as they lack the computationalpower to verify the correctness of the attack algorithm. To solve this issue, we exploit thehardware-oriented and highly parallel implementation properties of the algorithm and use aspecial-purpose hardware instead of a software implementation.At the time of the project, we had access to a RIVYERA-S3 with 128 Spartan-3 FPGAs.
We defined two different project goals: Foremost, we wanted to verify the attack algorithm. Inaddition, in case the massive parallelization leads to enough computational power, we aimedat testing the effect of different parameter sets. Those sets were derived from the previouspublications and our secondary goal was to experimentally tweak them and increase the overallefficiency of the attack.
3.2 Background
In this section, we will introduce the required background information and reference to moredetailed descriptions. We start with the target algorithm, Grain-128, and continue with cubetesters and dynamic cube attacks as introduced in [ADMS09] and [DS11], respectively.
3.2.1 The Grain Stream Cipher Family
Grain is a family of stream ciphers submitted and revised during the ECRYPT II - eSTREAMproject. The strengthened version Grain v1 was recommended in 2008 as one of the hardware-efficient stream ciphers. The ciphers were introduced by Hell et al. in 2006 and updated duringthe following years in two variants: Grain uses an 80-bit key [HJM07] and Grain-128 a 128-bitkey [HJMM06]. By construction, Grain-128 is a very small and efficient stream cipher, whichtargets highly constrained hardware environments. It uses only a minimum of resources in termsof chip area and power consumption: The basic components are a 128-bit Linear Feedback ShiftRegister (LFSR) and a 128-bit Nonlinear Feedback Shift Register (NFSR).The feedback functions of the LFSR and NFSR are defined as si and bi, respectively, with
si+128 = si + si+7 + si+38 + si+70 + si+81 + si+96
bi+128 = si + bi + bi+26 + bi+56 + bi+91 + bi+96 + bi+3bi+67 + bi+11bi+13 +
bi+17bi+18 + bi+27bi+59 + bi+40bi+48 + bi+61bi+65 + bi+68bi+84.
22

3.2 Background
The corresponding output function of the cipher is
zi =∑j∈A
bi+j + h(x) + si+93
where A = {2, 15, 36, 45, 64, 73, 89}and h(x) = x0x1 + x2x3 + x4x5 + x6x7 + x0x4x8.
Per definition, the remaining variables xi, 0 ≤ i ≤ 8 correspond to the tap positions: bi+12, si+8,si+13, si+20, bi+95, si+42, si+60, si+79 and si+95.
Figure 3.1: Overview on the Grain-128 initialization function as needed for Cube Attacks. Thisfunction consists mainly of a linear and a non-linear feedback shift register, both ofwidth 128 bits. The figure is derived from [CKP08].
Figure 3.1 shows the initialization setup of the algorithm and gives an overview of the im-plementation aspects in hardware. Grain-128 is initialized with a 128-bit key and with a 96-bitInitialization Vector (IV), which are loaded into the NFSR and LFSR, respectively. The remain-ing 32 LFSR bits are initialized with ’1’. The state is then clocked through 256 initializationrounds without producing an output, feeding the output back into the input of both registers.
3.2.2 Cube Testers
In almost any cryptographic scheme, each output bit can be described by a multivariate masterpolynomial p(x1, .., xn, v1, .., vm) over GF(2) of secret variables xi (key bits) and public variablesvj (plaintext bits in block ciphers and Message Authentication Codes (MACs), IV bits in streamciphers). This polynomial is usually too large to write down or to manipulate in an explicit way,but its values can be evaluated by running the cryptographic algorithm as a black box. Thecryptanalyst is able to tweak this master polynomial by assigning chosen values to the publicvariables (which result in multiple derived polynomials), but in single-key attacks he cannotmodify the secret variables.To simplify our notation, we ignore the distinction between public and private variables for
the rest of this subsection. Given a multivariate master polynomial with n variables p(x1, .., xn)over GF(2) in algebraic normal form (ANF) and a term tI containing variables from an index
23

Chapter 3 Dynamic Cube Attack on the Grain-128 Stream Cipher
subset I that are multiplied together, the polynomial can be written as the sum of terms whichare supersets of I and terms that miss at least one variable from I:
p(x1, .., xn) ≡ tI · pS(I) + q(x1, .., xn)
pS(I) is called the superpoly of I in p. Compared to p, the algebraic degree of the superpoly isreduced by at least the number of variables in tI and its number of terms is smaller.Cube testers [ADMS09] are related to high order differential attacks [Lai94]. The basic idea
behind them is that the symbolic sum over GF(2) of all the derived polynomials — obtainedfrom the master polynomial by assigning all the possible 0/1 values to the subset of variablesin the term tI — is exactly pS(I), which is the superpoly of tI in p(x1, .., xn). This simplifiedpolynomial is more likely to exhibit non-random properties than the original polynomial P .Cube testers work by evaluating superpolys of carefully selected terms tI , which are products
of public variables, and trying to distinguish them from a random function. One of the naturalproperties that can be tested is balance: A random function is expected to contain as manyzeros as ones in its truth table. A superpoly that has a strongly unbalanced truth table canthus be used to distinguish the cryptosystem from a random polynomial by testing whether thesum of output values over an appropriate boolean cube evaluates as often to one as to zero (asa function of the public bits, which are not summed over).
3.2.3 Dynamic Cube Attacks
Dynamic Cube Attacks exploit distinguishers obtained from cube testers to recover some secretkey bits. This is reminiscent of the way that distinguishers are used in differential attacks torecover the last subkey in an iterated cryptosystem. In static cube testers (and other relatedattacks such as the original cube attack [DS09] and AIDA [Vie07]), the values of all the publicvariables that are not summed over are fixed to a constant (usually zero) and thus they are calledstatic variables. However, in dynamic cube attacks, the values of some of the public variables,which are not part of the cube, are not fixed. Instead, a function is assigned to each of thesevariables (called dynamic variables) that depends on some of the cube public variables as wellas on some private variables. Each such function is carefully chosen in order to simplify theresulting superpoly and thus to amplify the expected bias (or the non-randomness in general)of the cube tester.The basic steps of the attack are briefly summarized below. For more details we refer to
[DS11], where the notion of dynamic cube attacks was introduced.
Preprocessing Phase: We first choose some polynomials that we want to set to zero at all thevertices of the cube and show how to nullify them by setting certain dynamic variables toappropriate expressions in terms of the other public and secret variables. To minimize thenumber of evaluations of the cryptosystem, we choose a big cube of dimension d and a setof subcubes to sum over during the online phase. We usually choose the subcubes of thehighest dimension (namely d and d − 1), which are the most likely to give a biased sum.We then determine a set of e expressions in the private variables that need to be guessedby the attacker in order to calculate the values of the dynamic variables during the cubesummations.
Online Phase: The online phase of the attack has two steps that are described in the following.
24

3.3 A New Approach for Attacking Grain-128
Step 1: The first step also consists of two substeps:
(1) For each possible vector of values for the e secret expressions, sum the outputbits modulo 2 over the subcubes chosen during preprocessing with the dynamicvariables set accordingly and obtain a list of sums (one bit per subcube).
(2) Given the list of sums, calculate its score by measuring the non-randomness inthe subcube sums. The output of this step is a sequence of lists sorted from thelowest score to the highest (in our notation the list with the lowest score has thelargest bias and is thus the most likely to be correct in our attack).
Given that the dimension of our big cube is d, the complexity of summing over all itssubcubes is bounded by d2d (using the Moebius transform [Jou09]). Assuming thatwe have to guess the values of e secret expressions in order to determine the values ofthe dynamic variables, the complexity of this step is bounded by d2d+e bit operations.Assuming that we have y dynamic variables, both the data and memory complexitiesare bounded by 2d+y (since it is sufficient to obtain an output bit for every possiblevertex of the cube and for every possible value of the dynamic variables).
Step 2: Given the sorted guess score list, we determine the most likely values for the secretexpressions, for a subset of the secret expressions, or for the entire key. The specificdetails of this step vary according to the attack.
Partial Simulation Phase: The complexity of executing online step 1 of the attack for a singlekey is d2d+e bit operations and 2d+y cipher executions. In the case of Grain-128, thesecomplexities are too high and thus we have to experimentally verify our attack with asimpler procedure. Our solution is to calculate the cube summations in online step 1 onlyfor the correct guess of the e secret expressions. We then calculate the score of the correctguess and estimate its expected position g in the sorted list of score values by assumingthat incorrect guesses will make the scheme behave as a random function. Consequently, ifthe cube sums for the correct guess detect a property that is satisfied by a random cipherwith probability p, we estimate that the location of the correct guess in the sorted list willbe g ≈ max{p× 2e, 1} as justified in [DS11].
3.3 A New Approach for Attacking Grain-128
Please note that Itai Dinur and Adi Shamir constructed the new attack, which is the basis forthe implementation and the experiments in the following sections.The starting point of our new attack on Grain-128 is the weak-key attack described in [DS11].
Both our new attack and [DS11] use only the first output bit of Grain-128 (with index i = 257).The output function of the cipher is a multivariate polynomial of degree 3 in the state and itsonly term of degree 3 is bi+12bi+95si+95. Since this term is likely to contribute the most to thehigh degree terms in the output polynomial, we try to nullify it. Since bi+12 is the state bitthat is calculated at the earliest stage of the initialization steps (compared to bi+95 and si+95),it should be the least complicated to nullify. However, after many initialization steps, the ANFof bi+12 becomes very complicated and it does not seem possible to nullify it in a direct way.Instead, the idea in [DS11] is to simplify (and not nullify) bi+12bi+95si+95 by nullifying bi−21(which participated in the most significant terms of bi+12, bi+95 and si+95). The ANF of the
25

Chapter 3 Dynamic Cube Attack on the Grain-128 Stream Cipher
earlier bi−21 is much easier to analyze compared to the one of bi+12, but it is still very complex.The solution adopted in [DS11] was to assume that 10 specific key bits are set to 0. This leadsto a weak-key attack on Grain-128, which can only attack a particular fraction of 0.001 of thekeys.In order to attack a significant portion of all the possible keys, we use a different approach,
which nullifies state bits produced at an earlier stage of the encryption process. This approachweakens the resistance of the output of Grain-128 to cube testers, but in a more indirect way.In fact, the output function is a higher degree polynomial, which can be more resistant to cubetesters compared to [DS11] and forces us to slightly increase the dimension d from 46 to 50. Onthe other hand, since we choose to nullify state bits that are produced at an earlier stage of theencryption process, their ANF is relatively simple and thus the number of secret expressions ethat we need to guess is reduced from 61 to 39. Since the complexity of the attack is proportionalto d2d+e, the smaller value of e more than compensates for the slightly larger value of d. Our newstrategy thus yields not only an attack, which has a significant probability of success for all thekeys rather than an attack on a particular subset of weak keys, but also a better improvementfactor over exhaustive search (details are given at the end of this section).In the new attack, we decided to nullify bi−54. This simplifies the ANF of the output function
in two ways: It nullifies the ANF of the most significant term of bi−21 (the only term of degree 3),which has a large influence on the ANF of the output. In addition, setting bi−54 to zero nullifiesthe most significant terms of bi+62 and si+62, simplifying their ANF. This simplifies the ANFof the most significant terms of bi+95 and si+95, both participating in the most significant termof the output function. In addition to nullifying bi−54, we nullify the most significant term ofbi+12 (which has a large influence on the ANF of the output, as described in the first paragraphof this section), bi−104bi−21si−21, by nullifying bi−104.
Table 3.1: Parameter set for the attack on the full Grain-128, given output bit 257.Cube Indexes {0,2,4,11,12,13,16,19,21,23,24,27,29,33,35,37,38,41,43,44,46, 47,49,52,53,54,55,
57,58,59,61,63,65,66,67,69,72,75,76,78,79,81,82,84,85,87,89,90,92,93}Dynamic Variables {31,3,5,6,8,9,10,15,7,25,42,83,1}State Bits Nullified {b159, b131, b133, b134, b136, b137, b138, b145, s135, b153, b170, b176, b203}
The parameter set we used for the new attack is given in Table 3.1. Most of the dynamicvariables are used in order to simplify the ANF of bi−54 = b203 so that we can nullify it using onemore dynamic variable with acceptable complexity. We now describe in detail how to perform theonline phase of the attack given this parameter set. Before executing these steps, the followingpreparation steps are necessary to determine the list of e secret expressions in the key variables,which we have to guess during the actual attack.
Preprocessing Phase
(1) Assign values to the dynamic variables given in Table 3.1. This is a very simple process,which is described in Appendix B of [DS11]. Since the symbolic values of the dynamicvariables contain hundreds of terms, we do not list them here, but rather refer to theprocess that calculates their values.
26

3.3 A New Approach for Attacking Grain-128
(2) Given the symbolic form of a dynamic variable, look for all the terms, which are combi-nations of variables from the big cube.
(3) Rewrite the symbolic form as a sum of these terms, each one multiplied by an expressioncontaining only secret variables.
(4) Add the expressions of secret variables to the set of expressions that need to be guessed.Do not add expressions, whose value can be deduced from the values of the expressionsalready contained in the set.
When we prepare the attack, we initially get 50 secret expressions. However, after removing11 expressions — which are dependent on the rest — the number of expressions that need to beguessed is reduced to 39. We are now ready to execute the online phase of the attack:
Online Phase
(1) Obtain the first output bit produced by Grain-128 after the full 256 initialization stepswith the fixed secret key, all the possible values of the variables of the big cube, and thedynamic variables given in Table 3.1. The remaining public variables are set to zero. Thedimension of the big cube is 50 and we have 13 dynamic variables. Thus, the total amountof data and memory required is 250+13 = 263 bits.
(2) We have 239 possible guesses for the secret expressions. Allocate a guess score array of 239
entries (an entry per guess). For each possible value (guess) of the secret expressions:
a) Plug the values of these expressions into the dynamic variables, which thus becomea function of the cube variables, but not of the secret variables.
b) Our big cube in Table 3.1 is of dimension 50. Allocate an array of 250 bit entries. Foreach possible assignment to the cube variables:
i. Calculate the values of the dynamic variables and obtain the corresponding out-put bit of Grain-128 from the data.
ii. Copy the value of the output bit to the array entry, whose index corresponds tothe assignment of the cube variables.
c) Given the 250-bit array, sum over all the entry values that correspond to the 51subcubes of the big cube, which are of dimension 49 and 50. When summing over49-dimensional cubes, keep the cube variable that is not summed over to zero. Thisstep gives a list of 51 bits (subcube sums).
d) Given the 51 sums, calculate the score of the guess by measuring the fraction of bits,which are equal to 1. Copy the score to the appropriate entry in the guess score arrayand continue to the next guess (step 2). If no more guesses remain, go to the nextstep.
(3) Sort the 239 guess scores from the lowest to the highest score.
To justify step 2.c, we note that the largest biases are likely to be created by the largest cubesand thus we only use cubes of dimension 50 and 49. To justify step 2.d, we note that the cubesummations tend to yield sparse superpolys, which are all biased towards 0, and thus we can
27

Chapter 3 Dynamic Cube Attack on the Grain-128 Stream Cipher
use the number of zeros as a measure of non-randomness. The big cube in the parameter setis of dimension 50, which has 16 times more vertices than the cube used in [DS11] to attackthe weak key set. The total complexity of the algorithm above is about 50 × 250+39 < 295 bitoperations. It is dominated by step 2.c, which is performed once for each of the 239 possiblesecret expression guesses.Given the sorted guess array, which is the output of online step 1, we are now ready to perform
online step 2 of the attack, which recovers the secret key without going through the difficult stepof solving the large system of polynomial equations. In order to optimize this step, we analyzethe symbolic form of the secret expressions: Out of the 39 expressions (denoted by s1, s2, ..., s39),20 contain only a single key bit (denoted by s1, s2, ..., s20). Moreover, 18 out of the remaining39 − 20 = 19 expressions (denoted by s21, s22, ..., s38) are linear combinations of key bits orcan be made linear by fixing the values of 45 more key bits. Thus, we define the following fewsets of linear expressions: Set 1 contains the 20 secret key bits s1, s2, ..., s20. Set 2 containsthe 45 key bits, whose choice simplifies s21, s22, ..., s38 into linear expressions. Set 3 containsthe 18 linear expressions of s21, s22, ..., s38 after plugging in the values of the 20 + 45 = 65 keybits of the first two sets. Note that the set itself depends on the values of the key bits in thefirst two sets. Altogether, the first three sets contain 20 + 45 + 18 = 83 singletons or linearexpressions. Set 4 contains 128− 83 = 45 linearly independent expressions, which form a basisto the complementary subspace spanned by the first three sets. Note that given the 128 valuesof all the expressions contained in the 4 sets, it is easy to calculate the 128-bit key.
Key-Recovery Phase: Our attack exploits the relatively simple form of 38 out of the 39 secretexpressions in order to recover the key using basic linear algebra. Consider the guesses from thelowest score to the highest. For each guess:
(1) Obtain the value of the key bits of set 1: s1, s2, ..., s20.
(2) For each possible value of the 45 key bits of set 2:
a) Plug in the (current) values of the key bits from sets 1 and 2 to the expressions ofs21, s22, ..., s38 and obtain set 3.
b) Obtain the values of the linear expressions of set 3 from the guess.
c) From the first 3 sets, obtain the 45 linear expressions of set 4 using Gaussian Elimi-nation.
d) For all possible values of the 45 linear expressions of set 4 (iterated using Gray Codingto simplify the transitions between values):
i. Given the values of the expressions of the 4 sets, derive the secret key.
ii. Run Grain-128 with the derived key and compare the result to a given (known)key stream. If there is equality, return the full key.
This algorithm contains 2 nested loops and is performed g times, where g is the expectedposition of the correct guess in the sorted guess array. The outer loop (step 2) is performed 245
times per guess with an inner loop of 245 iterations (step 2.d) The outer loop contains linearalgebra (step 2.c), whose complexity is clearly negligible compared to 245 cipher evaluations ofthe inner loop.
28

3.4 Implementation
In the inner loop, we need to derive the 128-bit key in step 2.d.i. In general, this is done bymultiplying a 128×128 matrix with a 128-bit vector that corresponds to the values of the linearexpressions. However, note that 65 key bits (of sets 1 and 2) are already known. Moreover, sincewe iterate the values of set 4 using Gray Coding (i. e., we flip the value of a single expressionper iteration), we only need to perform the multiplication once and then calculate the differencefrom the previous iteration by adding a single vector to the previous value of the key. Thisoptimization requires a few dozen bit operations, which is negligible compared to running Grain-128 in step 2.d.ii, as this step requires at least 1 000 bit operations. Thus, the complexity ofthe exhaustive search per guess is about 245+45 = 290 cipher executions, which implies that thetotal complexity the algorithm is about g × 290.The attack is worse than exhaustive search if we have to try all the 239 possible values of g and
thus, it is crucial to provide strong experimental evidence that g is relatively small for a largefraction of keys. In order to estimate g, we executed the online part of the attack by calculatingthe score for the correct guess of the 39 expression values. Then, we estimate how likely such abias is for incorrect guesses if we assume that they behave as random functions.
3.4 Implementation
In this section, we will describe the implementation — both in hardware and software — of theattack simulation from Section 3.3 for correct guesses to provide experimental evidence of theattack properties.We start with a stripped-down version of the simulation algorithm and outline the program
workflow in Section 3.4.1, discuss the hardware layout and the software design in Section 3.4.2and Section 3.4.3, and present the implementation results in Section 3.4.4.
3.4.1 Analysis of the Algorithm
Before we start with the implementation, we review the simulation algorithm shown in Algorithm12 in the appendix. It was derived from a simplified version of step 2 of the online phase as theinitial basis of the software implementation and is only performed for the correct key.Algorithm 1 describes the simulation algorithm with respect to an implementation in hard-
ware. To simplify the description, we use the function getBit(int, pos), returning the bit atposition pos of the integer int, and setBit(int, pos, val), setting the bit at position pos ofinteger int to val.All input arguments are included in the parameter set in Table 3.1. Please keep in mind
that — while the parameters are provided by the table — the attack is also an experimentalverification of this parameter set. Thus, it is important that the implementation should beflexible enough to allow changes and pose as few restrictions as possible to these values. Thealgorithm will compute the cube sum of d+ 1 bits, i. e., of size 51 bits with our parameters.First, we select the key, for which we simulate the attack or verify the attack properties.
Afterwards, we need to choose the polynomials, which nullify certain state bits and reset the IVto a default value. In the loop starting at line 5, we iterate over all 2d combinations. Each time,we modify the IV by spreading the current iteration value over the cube positions (line 7) andevaluate the polynomials — boolean functions depending on these changing positions — andstore the resulting bit per function at the dynamic variable positions (line 10). Now that the IV
29

Chapter 3 Dynamic Cube Attack on the Grain-128 Stream Cipher
Algorithm 1 Dynamic Cube Attack Simulation (Algorithm 12), Optimized for ImplementationInput: 96 bit integer baseIV, cube dimension d, cube C = {C0, . . . , Cd} with 0 ≤ Ci < 96 ∀Ci ∈ C, number of
polynomials m, dynamic variable indices D = {D0, . . . , Dm} with 0 ≤ Di < 96 ∀Di ∈ D, state bit indicesS = {S0, . . . , Sm} with 0 ≤ Si < 96 ∀Si ∈ S.
Output: (d+ 1) bit cubesum s1: IV ← baseIV2: s← 0.
Key Selection3: Choose random 128 bit key K.4: Choose key-dependent polynomials Pj(X) nullifying state bits Sj .
Computation5: for i← 0 to 2d − 1 do6: for j ← 0 to d− 1 do7: setBit(IV, Cj , getBit(i, j))8: end for9: for j ← 0 to m− 1 do10: setBit(IV, Dj , Pj(i))11: end for12: ks← first bit of Grain-128(IV, K) keystream13: if ks = 1 then14: s← s⊕ (1|not(i))15: end if16: end for17: return s.
is prepared, we run a full initialization (256 rounds) of Grain-128 (line 12) and — in case thefirst keystream bit is not zero — we XOR the current sum with the inverse of the d bit iterationcount, prefixed by a 1 (line 14).
Choose random keyRead parameters Update worker cube
Evaluate polynomials and
update dynamic variablesUpdate worksum Compute Grain-128
2d times
Figure 3.2: Cube Attack — Program-flow for cube dimension d.
Now that we analyzed the algorithm itself, we need to think about the overall implementationin a hardware/software scope. Figure 3.2 describes the basic workflow, which uses a parameterset as input, e. g., the cube dimension, the cube itself, a base IV, and the number of keys toattack: The program selects a random key to attack and divides the big cube into smaller workercubes and distributes them to worker threads running in parallel. Please note that for simplicitythe figure shows only one worker. If 2w workers are used in parallel, the iterations per workerare reduced from 2d to 2d−w.
30

3.4 Implementation
The darker nodes and the bold path show the steps of each independent thread: As eachworker iterates over a distinct subset of the cube, it evaluates polynomials on the worker cube(dynamic variables) and updates the IV input to Grain-128. Using this generated IV and therandom key, it computes the output of Grain-128 after the initialization phase. With this output,the thread updates an intermediate value — the worker sum — and starts the next iteration.In the end, the software combines all worker sums, evaluates the result and may chose a newrandom key to start again.We can see that the algorithm is split into three parts: First, we manipulate the worker cube
positions and derive an IV from it. Then, we compute the output of the Grain-128 stream cipherusing the given key, data, and derived IV. Before we start the next iteration, the worksum isupdated.
Grain-128: The second part is straight-forward and is the most computationally expensivetask. It concerns only the Grain implementation: With a cube of dimension d, the attack onone key computes the first output bit of Grain-128 2d times. As we already need 250 iterationswith the current parameter set, it is necessary to implement Grain-128 as efficiently as possiblein order to speed up the attack.Taking a closer look at the design of the stream cipher (see Section 3.2.1), it yields much
potential for an efficient hardware implementation: It consists mainly of two shift registers andsome additional logic. Using bit-slicing techniques on CPUs increases the efficiency but is not asefficient as a small and fast FPGA implementation as proposed by Aumasson et al. [ADH+09]when implementing cube testers on Grain-128.
IV Generation: To create an independent worker, the implementation also needs to includethe IV generation. This process takes the default IV and modifies d + m bits, which is easilydone in software by storing the generated IV as an array and accessing the positions directly.Changing the parameters to compute larger cube dimensions d > d or to allow more than mpolynomials poses no problem either.Considering a possible hardware implementation, this increases the complexity a lot. In
contrast to the software design, we cannot create a generic layout, which reads the parameterset: We need multiplexers for all IV bits to allow dynamic choices and even more multiplexersto allow all possible combinations of boolean functions to support all possible polynomials.As this problem seems very easy in software and difficult in hardware, a software approach
of the IV generation seems more reasonable at first glance. In combination with the hardwareimplementation of Grain-128, this leads to a significant communication overhead to supply manyhardware workers with IVs every few clock cycles. This negates the effect of the simplicity of asoftware implementation.In order to compute the cipher, we need a key and an IV. The value of the key varies, as it
is chosen at random. The IV, on the other hand, is modified in each iteration. To estimate theeffort of building a fully independent worker in hardware, we need to know how many dynamicinputs we have to consider in the IV generation process: Without restrictions, the modificationsare very inefficient in hardware.The IV is a 96-bit value, where each bit is set according to one out of three input sources.
Figure 3.3 shows the multiplexer design for a given index i in hardware: The current IV bitreceives the value either from the base IV position (light grey) provided by the parameter set,
31

Chapter 3 Dynamic Cube Attack on the Grain-128 Stream Cipher
0 1 2
base(i)
0...
d-w-1
cnt(0)
cnt(d-1)
iv(i)
0...
m-1
p0
pm-1
Figure 3.3: Necessary Multiplexers for each IV bit (without optimizations) of a worker withworker cube size d−w and m different polynomials. This is an (m+ d−w+ 1)-to-1bit multiplexer, i. e., with the current parameter set a (64−w)-to-1 bit multiplexer.
from a part of the current counter spread across the worker cube (grey), or from a dynamicvariable (dark grey). As the choice used for each bit changes not only with the parameter set,but also when assigning partial cubes to different workers, this input to the IV bit is not fixedand cannot be precomputed efficiently. Thus, we need to create an (m + d − w + 1)-to-1 bitmultiplexer for each bit, resulting in 96×(64−w)-to-1 bit multiplexers for our current parameterset.The first two input sources are both restricted and can be realized by simple multiplexers in
hardware. The dynamic variable on the other hand stores the result of a polynomial evaluation.Please note that the polynomials used in this step are not pre-defined polynomials, as theyare derived at runtime (cf. Algorithm 1, line 4) and depend on the input key. Thus, a generichardware implementation must realize every possible boolean function over the worker cubes.Even with tight restrictions, i. e., a maximum number of terms per monomial and monomialsper polynomial, it is impossible to provide such a reconfigurable structure in hardware. As aconsequence, a fully dynamic approach leads to extremely large multiplexers and thus to veryhigh area consumption on the FPGA, which is prohibitively slow. Another approach would beto utilize the complete area of an FPGA for massive parallel Grain-128 computations withoutadditional logic. In this case, the communication between the host and the FPGA will be thebottleneck of the system and the parallel cores on the FPGA will idle. Therefore, we need tochoose a different strategy to implement this part in hardware, which is described in the Section3.4.2.
Worksum update: At the end of one iteration, the worksum is modified. To simplify the syn-chronization between the different threads, each worker updates a local intermediate value. Inorder to generate (d+1)-bit intermediate values from the (d−w)-bit sums, we prefix the numbernot only by a constant ’1’ but also with the w-bit number of the worker thread. Please notethat in the actual implementation, we do not use (d+ 1)-bit XOR operations: If the number ofXORs is even, we need to prefix the constant, otherwise, we need to prefix zeros. Thus, a simple1-bit value is sufficient to choose between these two values. When all workers are finished, the
32

3.4 Implementation
final result is computed using an XOR operation over all results.
Overall, the complexity of the algebraic attack is too high for a single machine and a clusterof some kind is necessary. As the most cost-intensive operation concerns the 2d computations ofthe 256-step Grain initialization, an efficient hardware implementation is bound to outperformbit-sliced CPU implementations.Thus, we decided to implement and experimentally verify the complex attack on dedicated
reconfigurable hardware using the RIVYERA-S3 special-purpose hardware cluster, as describedin Section 2.4. For the following design decisions, we remark that this cluster provides 128Spartan-3 FPGAs, which are tightly connected to an integrated server system powered by anIntel Core i7 920 with 8 logical CPU cores. This allows us to utilize dedicated hardware and usea multi-core architecture for the software part.
3.4.2 Hardware Layout
In this section, we give an overview of the hardware implementation. As the total number ofiterations for one attack (for the correct guess of the 39 secret expression values) is 2d, thenumber of workers for an optimal setup should be a power of two to decrease control logic andcommunication overhead.
Cube
Attack
System
Partial
cubesum
(System)
Worker
Worker
Worker
Worker
7
Grain-128
Grain-128
Grain-128worksum
control
IV generator
partial cube sum
d-11 d-11
d-11d
FPGA number
FPGA
number
Figure 3.4: FPGA Implementation of the online phase for cube dimension d.
Figure 3.4 shows the top level overview. Each of the 128 Spartan-3 5000 FPGAs features16 independent workers and each of these workers consists of its own IV generator to controlmultiple Grain-128 instances.As it is possible to execute more than one initialization step per clock cycle in parallel, we
look at the implementation results to find the most suitable time-/area trade-off for the cipherimplementation.Table 3.2 shows the synthesis results of our Grain implementation. [ADH+09] used 25 parallel
steps, which is the maximum number of supported parallel steps without additional overhead,on the large Virtex-5 LX330 FPGA. Analyzing the critical path in our full design, we see that
33

Chapter 3 Dynamic Cube Attack on the Grain-128 Stream Cipher
Table 3.2: Synthesis results of Grain-128 implementation on the Spartan-3 5000 FPGA withdifferent numbers of parallel steps per clock cycle.
Parallel Steps 20 21 22 23 24 25
Clock Cycles (Init) 256 128 64 32 16 8Max. Frequency (MHz) 227 226 236 234 178 159FPGA Resources (Slices) 165 170 197 239 311 418Flip Flops 278 285 310 339 393 3714 input LUTs 288 297 345 420 583 804
the impact of the cipher implementation is negligible regardless of the choice of parallel stepsand we can optimize the area consumption instead.The IV generator requires three clock cycles per IV. If we use 25 parallel steps in the Grain
instance and add another clock cycle to process the output and relax the routing, we end witha total of nine clock cycles per cipher computation. Thus, we can provide three Grain instanceswith one IV generator and keep them working all the time. The results of the cipher instancesare gathered in the worksum control, which updates the worker-based partial cubesum. TheFPGA computes a system-wide partial cubesum from all of the worker-based sums and returnsit upon request.As mentioned before, it is not possible to create an unrestricted IV generation on the FPGA.
To circumvent this problem, we locally fix certain values per key. This enables us to reducethe complexity of the system, as dynamic inputs are converted to constants. The drawback isthat we need to generate the different FPGA code depending on the parameter set and — moreimportantly — on the key we wish to attack.By looking at the discussion on the dynamic input to the IV generation, we see that by fixing
the parameter set, we already gain an advantage on the iteration over the cube itself: By sortingthese positions and a smart distribution among the FPGAs, we reduce the complexity of thefirst part of the IV generation. By setting the base IV constant, we can optimize the designautomatically and with the constant key, we remove the need to transfer any data to the FPGAsafter programming them.Nevertheless, the most important unknowns are the key-dependent polynomials. While we do
have some restrictions from the way these polynomials (consisting of and and XOR operations)are generated, we cannot forecast the impact of them: Remember that we use 13 differentboolean functions in this parameter set. Each of these can have up to 50 monomials, whereevery monomial can — in theory — use all d positions of the cube. Luckily, on average, mostpolynomials depend on less than 5 variables.
3.4.3 Software Design
Now that we described the FPGA design and the need of key-dependent configurations, we willdiscuss the details of the software side of the attack. In order to successfully implement and runthe attack on the RIVYERA cluster and benefit from its massive computing power, we proposethe following implementation. Figure 3.5 shows the design of the modified attack.The software design runs on the integrated CPU on the FPGA cluster. It is split into two
parts: We use all but one core of the i7 CPU to generate attack specific bitstreams — the
34

3.4 Implementation
Choose random key and
generate VHDL constants
Read parameters
Generate FPGA bitstream
Queue bitstream
for RIVYERA
Wait for next bitstream
Program RIVYERA and
wait for results
Store results
Try differen
t strategies
Figure 3.5: Cube Attack Implementation utilizing the workflow from Figure 3.2 on the integratedCPU of the RIVYERA FPGA cluster.
configuration files for the FPGAs — in parallel in preparation of the computation on the FPGAcluster. Each of these generated designs configures the RIVYERA for a complete attack on onerandom key. As soon as one bitstream was generated and waits in the queue, the remainingcore programs all 128 FPGAs with it, starts the attack, waits for the computation to finish,and fetches the results. With the partial cubesums per FPGA, the software computes the finalresult and evaluates the attack on the chosen key to measure the effectiveness of the attack.
In contrast to the first approach, which uses the generic structure realizable in software andneeded a lot of communication, we generate custom VHDL code containing constant settings andfixed boolean functions of the polynomials derived from the parameter set and the provided key.Building specific configuration files for each attack setup allows us to implement as many fullyfunctional, independent, parallel workers as possible without the area consumption of complexcontrol structures. In addition, this allows us to strip down the communication interface anddata paths to a minimum: Only a single 7-bit parameter is required to separate the workspaceof all 128 FPGAs, to start the computation and finally receive a d-bit return value. This
35

Chapter 3 Dynamic Cube Attack on the Grain-128 Stream Cipher
efficiently circumvents all of the problems and overhead of a generic hardware design at the costof rerunning the FPGA design flow for each parameter/key pair.Please note that in this approach the host software modifies a basic design by hard-coding
conditions and adjusting internal bus and memory sizes for each attack. We optimized thisbasic layout as much as possible for average sized boolean functions, but the different choicesof the polynomial functions lead to different combinatorial logic paths and routing decisions,which is bound to change the critical path in the hardware design. As the clock frequency isdirectly linked to the critical path, we implemented different design strategies as well as multiplefallback options. These modify the clock frequency constraints in order to prevent parameter/keypairs from resulting in an invalid hardware configurations. As a consequence, the fallback path inFigure 3.5 tries different design strategies automatically if the generated reports indicate failuresduring the process or timing violations after the analysis phase.
3.4.4 Results
In this section, we present the results of our implementation. The hardware results are basedon Xilinx ISE Foundation 13 for synthesis and place and route. We compiled the software partusing the GNU Compiler Collection (GCC) 4.1.2 and the OpenMP library for multi-threadingand ran the tests on the i7 920 CPU integrated in the RIVYERA cluster.The hardware design was used to test different parameter sets and chose the most promising
set. The resulting attack system for the online phase — consisting of the software and theRIVYERA cluster — uses 16 workers per FPGA and 128 FPGAs on the cluster in parallel.Therefore, the number of Grain computations per worker is reduced to 2d−11, i. e., 239 withthe current cube dimension. The design ensures that each key can be attacked at the highestpossible clock frequency, while it tries to keep the building time per configuration moderate.
Table 3.3: Strategy Overview for the automated build process. The strategies are sorted fromtop to bottom. In the worst case, all 16 combinations may be executed.
Global Settings Worker Clock (MHz)2.4× Input Clk 1202.2× Input Clk 1102.0× Input Clk 100RIVYERA Input Clk 50Map Settings Placer Effort Placer Extra Effort Register Duplication Cover ModeSpeed Normal None On SpeedArea High Normal Off AreaPlace and Route Settings Overall Effort Placer Effort Router Effort Extra EffortFast Build High Normal Normal NoneHigh Effort High High High Normal
Table 3.3 explains the different strategies in more detail: Each row represents one choice ofsettings, while the three setting groups represent the impact on the subsequent build process.The design is synthesized with one of the four clock frequency settings. When the build processreaches the mapping stage, it first tries the speed optimized settings and runs the fast placeand route. In case this fails, it tries the high effort place and route setting. If this also fails,
36

3.5 Conclusion
it tries the Area settings for the mapping and may fall back to a lower clock frequency setting,repeating the complete build process.As the user clock frequency of the Spartan-3 RIVYERA architecture is 50 MHz, the Xilinx
Tools will easily analyze the paths for a scaling factor 1.0 and 2.0. We noticed that the successrate for the 125 MHz design (2.5 times the input clock frequency) was too low and removed thissetting due to the high impact on the building time.
Table 3.4: Results of the generation process for cubes of dimension 46, 47 and 50. The durationis the time required for the RIVYERA cluster to complete the online phase. The Per-centage row gives the percentage of configurations built with the given clock frequencyout of the total number of configurations built with cubes of the same dimension.
Cube Dimension d 46 47 50Clock Frequency (MHz) 100 110 120 120 110 120Configurations Built 1 7 8 6 60 93Percentage 6.25 43.75 50 100 39.2 60.8Online Phase Duration 17.2 min 15.6 min 14.3 min 28.6 min 4h 10 min 3h 49 min
Table 3.4 lists the experimental results of the generation process and the distribution of theconfigurations with respect to the different clock frequencies. It shows that the impact of theunknown parameters is not predictable and that fallback strategies are necessary. Please notethat the new attack tries to generate configurations for multiple keys in parallel. This process— if several strategies are tried — may require more than 6 hours before the first configurationbecomes available. Smaller cube dimensions, i. e., all cube dimensions lower than 48, result invery fast online phase and should be neglected, as the building time will exceed the duration ofthe attack in hardware. Further note that the duration of the attack increases exponentially ind, e. g., assuming 100 MHz as achievable for larger cube dimensions, d = 53 needs 1.5 days andd = 54 needs 3 days.
3.5 Conclusion
In this project, we presented a new and improved variant of an attack on the Grain-128 streamcipher. It is the first attack which is considerably faster than exhaustive search and — unlikeprevious attacks — makes no assumptions on the secret key.Cube attacks and testers are notoriously difficult to analyze mathematically. While previous
implementations with lower cube dimensions were successfully tested using CPU clusters, theevaluation of the new attack was limited by the restrictions of the CPU implementation. Inorder to experimentally test the attack, find and validate suitable parameters, and to verifythe complexity of the attack, we required a different implementation approach: Due to itshigh complexity and hardware-oriented nature, the attack was developed and verified using theRIVYERA-S3 hardware cluster. Our design makes use of both the integrated i7 CPU and the128 FPGAs and heavily relies on the reconfigurability of the cluster system.We performed this simulation for 107 randomly chosen keys, out of which 8 gave a very
significant bias in which at least 50 of the 51 cubes sums were zero. This is expected to occurin a random function with probability p < 2−45. We estimate that for about 7.5% of the keys,
37

Chapter 3 Dynamic Cube Attack on the Grain-128 Stream Cipher
g ≈ max{2−45 × 239, 1} = 1 and thus, the correct guess of the 39 secret expressions will bethe first in the sorted score list (additional keys among those we tested showed smaller biasesand a larger g). The complexity of online step 2 of the attack is thus expected to be about 290
cipher executions, which dominates the complexity of the attack (the complexity of online step1 is about 295 bit operations, which we estimate as 295−10 = 285 cipher executions). This givesan improvement factor of 238 over the 2128 complexity of exhaustive search for a non-negligiblefraction of keys, which is significantly better than the improvement factor of 215 announcedin [DS11] for the small subset of weak keys considered in that attack. We note that for mostadditional keys there is a continuous trade-off between the fraction of keys that we can attackand the complexity of the attack on these keys.Apart from the verification of the attack, this is the first published implementation of a
complex analytical attack (compared to exhaustive search) successful against a full-size cipherusing special-purpose hardware. It also uses the reconfigurable nature of the hardware to supplythe necessary flexibility, while still aiming for optimized results.
38

Chapter 4
Password Search against Key-DerivationFunctions
This chapter considers the strength of different Password-Based Key DerivationFunctions (PBKDFs) against dedicated hardware attacks. In 2012, we completedthe first project — an evaluation of PBKDF2 using TrueCrypt, an open source fulldisk encryption (FDE) software, and the (at that time) standard for Windows FDE,as the target. This was a joint work with Markus Dürmuth, Tim Güneysu, MarkusKasper, Christoph Paar, and Tolga Yalcin and was published in [DGK+12].The second project concentrated on an FPGA implementation of bcrypt, one of thetwo major Key Derivation Functions (KDFs) besides Password-Based Key Deriva-tion Function 2 (PBKDF2). This was a joint work together with Friedrich Wiemerand was published in [WZ14] end of 2014. The content of this chapter is based onboth papers and structured as follows:
Contents of this Chapter4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394.2 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414.3 Attack Implementation: PBKDF2 (TrueCrypt) . . . . . . . . . . . . . . . . 464.4 Attack Implementation: bcrypt (OpenBSD) . . . . . . . . . . . . . . . . . . 544.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
Contribution: In the scope of both projects, my main contribution was the imple-mentation of the KDFs and the resulting optimization on FPGAs. In addition, weanalyzed the success rate and power consumption of different attack types, focusingon low-power password hashing using the recent Xilinx Zynq FPGA as well as onmassive parallelization with the RIVYERA-S3 FPGA cluster. In both projects, weimplemented the fastest known attack against the chosen key-derivation functionsavailable at that time.
4.1 Introduction
In the modern world, we constantly use online services in daily life. As a consequence, we provideinformation to the corresponding service providers, e. g., financial services, email providers, or
39

Chapter 4 Password Search against Key-Derivation Functions
social networks. To prevent abuse like identity theft, we encounter access-control mechanisms atevery step we take. Although it is one of the oldest mechanisms, password authentication is stillone of the most frequently used authentication methods on the internet even with the emergingadvanced login-procedures, e. g., single sign-on or two-factor authentications, and it will be inthe foreseeable future.Alternative technologies such as security-tokens and biometric identification exist but have a
number of drawbacks that prevent their wide-spread use outside of specific realms: Using theexample of security tokens, they require a well-established management infrastructure, which isa demanding task for internet-wide services with millions of users. Tokens can be lost and a stan-dardized interface is required to use them on every possible computing device including desktopcomputers, mobile phones, tablet PCs, or smart TVs. Biometric identification systems requireextra hardware to read the biometrics. In addition, false-rejects cause user annoyance, and manybiometrics are not suitable secrets, as demonstrated for commercial unlocking mechanisms likeApple TouchID1.Passwords on the other hand are highly portable, easy to understand by users, and relatively
easy to manage for the administrators. Still, there are a number of problems with passwords:Arguably, the most delicate aspect is the trade-off between choosing a strong password versusa human memorable password. Various studies and recommendations have been publishedpresenting the imminent threat of insufficiently strong passwords chosen by humans for securitysystems [BK95, NS05, WAdMG09]).To authenticate users for online services, their passwords are stored on the corresponding
authentication servers. As a consequence, an attack on these password databases followed by aleak of the information poses a very high threat to the users. In case the passwords are storedin plain text, this authentication method is a single point of failure, as it efficiently rendersall additional security means useless. Examples of password leaks are the eBay2 or Adobe3
password leaks, where several million passwords were stolen.To prevent these attacks or at least raise the barrier of abuse, the authentication data must
be protected on the server. Instead of storing the password as plaint text, a cryptographichash of the password is kept. In this case, a successful attacker has to recover the passwordsfrom the stored value, which should be — in theory — infeasible due to the properties ofthe cryptographic hash function. Nevertheless, guessing attacks are the most efficient method ofattacking passwords, and studies indicate that a substantial number of passwords can be guessedwith moderately fast hardware [Wik12].To prevent time-memory trade-off techniques like rainbow tables, the password is combined
with a randomly chosen salt and the tuple
(s, h) = (salt, hash(salt, password))
is stored. Improvements to exhaustive password searches with the aim to determine weak pass-words exist. As passwords are often generated from a specific character set, e. g., using dig-its, upper- and lower-case characters, and may be length-restricted, e. g., allowing six to eightcharacters, the search space may be reduced considerably. This enables password recovery by
1cf. http://www.ccc.de/en/updates/2013/ccc-breaks-apple-touchid2cf. http://www.ebayinc.com/in_the_news/story/ebay-inc-ask-ebay-users-change-passwords3cf. https://adobe.cynic.al/
40

4.2 Background
brute-force or dictionary attacks. Recently, more advanced methods, e. g., probabilistic context-free grammars [WAdMG09] or Markov models [NS05, CCDP13] were analyzed to improve thepassword guesses and the success rate and thus reduce the number of necessary guesses.Apart from the generation of suitable password candidates, the implementation has a high
impact on the success. On general-purpose CPUs, generic tools like John the Ripper (JtR)4 ortarget-specific tools like TrueCrack5 — addressing a specific algorithm, in this case TrueCryptvolumes — use algorithmic optimizations to gain a speedup when testing multiple passwords. Tofurther improve efficiency, not only the CPU may be used: Modern GPUs feature a large amountof parallel processing cores at high clock-frequencies in combination with large memory. As aprominent example, oclHashCat6 utilizes this platform for high-performance hash computations.The major problem remains that hash functions are very fast to evaluate and thus enable
fast attacks. Password-hashing functions address this issue. These functions map a password tokey material for further usage and explicitly slow down the computation time by making heavyuse of the available resources: The computation should be fast enough to validate an honestuser, but render password guessing infeasible. One key idea to prevent future improvements inarchitectures from breaking the efficiency of these function are flexible cost parameters. Theseadjust the function in terms of time and/or memory complexity.The only standardized Password-Based Key Derivation Function is PBKDF2, which replaced
the previous PBKDF1 and is part of the Public-Key Cryptography Standard (PKCS), publishedin the Request for Comments #2898 [IET00]. Non-standardized alternatives are bcrypt [PM99]and scrypt [Per09]. While the three functions are considered secure to use, each has its ownset of advantages and disadvantages. This led to the Password Hashing Competition (PHC)7 in2014, which aims at providing well-analyzed alternatives. Another purpose is the discussion ofnew ideas and different security models with respect to the impact of special-purpose hardwarelike modern GPUs, ASICs, or FPGAs.The remaining chapter is structured as follows: Section 4.2 discusses the problems and algo-
rithms required for the attack implementations. The attacks are split into two parts: Section 4.3describes the implementation of cluster-based password-search against PBKDF2 in the contextof the TrueCrypt FDE Software, followed by Section 4.4 with the details on the hardware-accelerated, low-power password-search against bcrypt. The chapter closes with the conclusionin Section 4.5.
4.2 Background
In this section, we introduce the background information required for the attack implementa-tions. We start with a short discussion of the general problem of password security (cf. Section4.2.1, then introduce the two target PBKDFs (cf. Section 4.2.2) and end with the related workin the context of processing platforms for password cracking (cf. Section 4.2.3).
4cf. http://www.openwall.com/john5cf. http://code.google.com/p/truecrack6cf. http://hashcat.net/oclhashcat7cf. https://password-hashing.net/
41

Chapter 4 Password Search against Key-Derivation Functions
4.2.1 Password Security
The widely accepted best practice for password storage on authentication servers enforces theuse of a salted cryptographic hash h := H(salt , pwd). In an offline attack on passwords, anattacker has access to the value h and tries to recover the password pwd . Another case is theonline guessing attack, where the attacker is restricted to a login prompt or similar mechanism,which may keep track of and restrict the number of guesses and apply a penalty on brute-forceattempts. In the following, we focus on offline attacks only.The basis of attacking password-based systems is the assumption that user-generated pass-
words usually consist of a pattern or specific structure, e. g., a composition of words from asource language and numbers or special characters. This leads to the conclusion that — withknowledge of the structure — an attacker may use a very effective shortcut to brute-forcing.Consequently, guessing attacks, are very efficient: The attacker first guesses a password candi-
date, computes the hash function, and compares the output to the stored value. This has been re-alized early and password guessing has been deployed for a long time [BK95, Wu99, ZH99, KI99].In a dictionary attack, the attacker obtained a list of words that are likely to appear in
passwords. These lists range from simple language dictionaries to person-specific lists gatheredvia social engineering. The attacker may use additional mangling rules, e. g., appending specialcharacters at the end or using transformations like leetspeak. Pentesting tools such as JtRimplement dictionary attacks and already include large dictionaries of common passwords, oftengrouped for different languages to better meet specific target requirements.More recent work by Weir et al. [WAdMG09] is a generalization of the idea of mangling
rules: Patterns that constitute extended mangling rules are extracted from real-world passwordsusing probabilistic grammars, which are context-free grammars with probabilities associatedto production rules. Then, these structures are used to generate passwords, based on thesestructures and a dictionary as before.Another efficient way to guess passwords, first proposed in [NS05], is based on Markov models.
These are based on the observation that in human-generated passwords — as well as in naturallanguages — adjacent letters are not independently chosen. They follow certain regularities,e. g., the 2-gram th is much more likely than tm. In other words, the letter following a t is morelikely an h than an m. In an n-gram Markov model, the probability of the next character ismodeled in a string based on a prefix of length n − 1. Hence, for a given string c1, . . . , cm, wewrite
P (c1, . . . , cm) = P (c1, . . . , cn−1) ·m∏i=n
P (ci|ci−n+1, . . . , ci−1).
To work with probabilistic models, we need a training phase and an attack phase. In thetraining phase, the model derives the conditional probabilities from leaked plaintext passwordlists, e. g., the RockYou password list, available password dictionaries, or from plain Englishtext. In the attack phase, the algorithm generates password candidates that follow the Markovmodel and defines and applies pattern-filters specifically linked to the context of passwords toincrease the success probability of the guess. An example for such a pattern is that the numericpart of alpha-numeric passwords is likely to be at the end of the password, i. e., as in password1.Another way to speed up the guessing step uses rainbow-tables [Hel80, Oec03]. An imple-
mentation of rainbow-tables in hardware is studied in [MBPV06]. As the use of KDFs preventsrainbow-tables, we do not focus on this aspect in the rest of the chapter.
42

4.2 Background
A final problem, which is closely related to password guessing, is the estimation of the strengthof a given password. This is of high importance for the operator of a service to ensure a certainlevel of security. In the beginning, password cracking was used to identify weak passwords[MT79]. Later, so-called pro-active password checkers followed [Spa92, Kle90, BK95, BDP06]and online services like The Password Meter8 compute a hardness score of a given password.However, most pro-active password checkers use simple rule-sets to determine password strengthand thus do not reflect the real-world password strength [WACS10, KSK+11, CDP12]. Morerecently, Schechter et al. [SHM10] classified password strength by counting the number of times acertain password is present in the password database. Also, Markov models seem to be promisingpredictors of password strength [CDP12].
4.2.2 Password-Based Key Derivation
To reduce the chances of password guessing against a single hash function output, the passwordhash is typically generated using special password-hashing functions.With the release of PKCS #5 v2.0 and RFC2898 [IET00], a standard for password key deriva-
tion schemes based on a pseudo-random function (PRF) with variable output key size has beenestablished. The specified Password-Based Key Derivation Function 2 (PBKDF2) has beenwidely employed in many security-related systems, such as TrueCrypt 9, OpenDocument En-cryption of OpenOffice 10, and Counter Mode with Cipher Block Chaining Message Authentica-tion Code Protocol (CCMP) of Wi-Fi Protected Access 2 (WPA2) [IEE07]. The PRF typicallyinvolves an Hash-based Message Authentication Code (HMAC) construction based on a crypto-graphic hash function that can be freely chosen by the designer. In addition to the password, thePBKDF2 requires a salt S, a parameter for the desired output key length kLen, and an iterationcounter value c that specifies the number of repeated invocations of the PRF.Out of the other two widely used KDFs bcrypt and scrypt, the latter builds upon PBKDF2. In
this chapter, we focus on PBKDF2 and bcrypt and refer to [DK14] for a comparison of passwordguessing attacks on FPGAs and GPUs including scrypt.
PBKDF2
The PBKDF2 takes a predefined PRF 11 and requires four inputs to generate the output keykout with
kout = PBKDF2PRF(Pwd, S, c, kLen),
where Pwd is the password, S the salt, c the iteration counter, and kLen the desired key outputlength.Algorithm 2 shows the PBKDF2 pseudo-code. The main concept is to repeatedly use a PRF
to generate intermediate values and increase the computation time. In order to generate anarbitrary output length from a limited-length hash function, the computation may be repeatedwith a different counter value to compute more key-material.As all intermediate values are used, we are able to tweak the time needed for the computation
by adjusting the value of the iteration count c. This has a direct influence on the possible attacks:8cf. http://www.passwordmeter.com9http://www.truecrypt.org
10http://docs.oasis-open.org/office/v1.2/OpenDocument-v1.2-part3.html11As mentioned before, this is typically an HMAC construction
43

Chapter 4 Password Search against Key-Derivation Functions
Algorithm 2 Pseudo-code of PBKDF2 as specified in [IET00, 5.2]Input: Pseudo-random function PRF of output length hLen, intended output length dkLen,
password P , salt S, iteration count cOutput: derived key dk consisting of l =
⌈dkLenhLen
⌉blocks Ti
1: for i = 1 to l do2: U1 ← PRF(P , S || i) . i encoded in 4 byte (most significant byte first)3: Ux ← U1
4: for j = 2 to c do5: Uj ← PRF(P , Uj−1)6: Ux ← Ux ⊕ Uj
7: end for8: Ti ← Ux
9: end for10: return dk← T1 || . . . ||Tn
If we select an adequately high number of iterations, the time per password guess increases andrenders generic attacks, i. e., simple brute-force attacks, less effective.In practice, common values for the iteration count range between the recommended minimum
of 1 000 [IET00, 4.2] and 4 000 iterations. Please note that PBKDF2 does not specify the pseudo-random function. The RFC suggests the use of an HMAC construction [IET00, B.1] but doesnot limit it to specific hash functions. For example, in our target TrueCrypt, we are free tochoose between HMAC using RIPEMD-160, SHA-512, and Whirlpool.
bcrypt
Provos and Mazières published the bcrypt hash function [PM99] in 1999, which is at its corea cost-parameterized, modified version of the Blowfish encryption algorithm [Sch93]. The keyconcepts are a tunable cost parameter and the pseudo-random access of a 4 KByte memory.bcrypt is used as the default password hash in OpenBSD since version 2.1 [PM99]. Additionally,it is the default password hash in current versions of Ruby on Rails and PHP.bcrypt uses the parameters cost, a 128-bit salt, and a 448-bit key as input. The key contains
the password, which may be up to 56 bytes including a terminating zero byte in case of an ASCIIstring. The number of executed loop iterations is exponential in the cost parameter as definedin the EksBlowfishSetup-Algorithm:The computation is divided into two phases: First, Algorithm 3 (EksBlowfishSetup) ini-
tializes the internal state, which has the highest impact on the total runtime. Afterwards,Algorithm 4 (bcrypt) encrypts a fixed value repeatedly using this state.In its structure, bcrypt makes heavy use of the Blowfish encryption function inside the
ExpandKey calls. Blowfish (cf. [Sch93]) is a standard 16-round Feistel network, which usesSBoxes and subkeys determinded by the current state. Its blocksize is 64-bit and during everyround, an f-function is evaluated: It uses the 32-bit input as four 8-bit addresses for the SBoxesand computes (S0(a) + S1(b))⊕ S2(c) + S3(d).EksBlowfishSetup is a modified version of the Blowfish key schedule. It computes a state,
which consists of 18 32-bit subkeys and four SBoxes, each 256 × 32 bits in size and used later in
44

4.2 Background
Algorithm 3 EksBlowfishSetupInput: cost, 128-bit salt, key (up to 56 bytes)Output: updated state1: state ← InitState()2: state ← ExpandKey(state, salt, key)3: loop 2cost times4: state ← ExpandKey(state, 0, salt)5: state ← ExpandKey(state, 0, key)6: end loop7: return state
Algorithm 4 bcryptInput: cost, 128-bit salt, key (up to 56 bytes)Output: password-hash1: state ← EksBlowfishSetup(cost, salt, key)2: ctext ← “OrpheanBeholderScryDoubt”3: loop 64 times4: ctext ← EncryptECB(state, ctext)5: end loop6: return Concatenate(cost, salt, ctext)
the encryption process. The state is initially filled with the digits of π before an ExpandKey stepis performed: After adding the input key to the subkeys, this step successively uses the currentstate to encrypt blocks of its salt parameter and updates it with the resulting ciphertext. In thisprocess, ExpandKey computes 521 Blowfish encryptions. If the salt is fixed to zero, the functionresembles the standard Blowfish key schedule. An important detail is that the input key is onlyused during the very first part of the ExpandKey steps. bcrypt finally uses EncryptECB, whichis effectively a Blowfish encryption.
4.2.3 Processing Platforms for Password Cracking
We will now briefly discuss the related work on different password cracking platforms withrespect to our two target algorithms. We start with a generic view and then move to TrueCryptfor PBKDF2 and in the end focus on bcrypt.The simplest and most commonly used platform for breaking passwords is the personal com-
puter, as implementing password cracking on a general-purpose CPU is straightforward. How-ever, due to the versatility of their architecture, CPUs usually do not achieve an optimal cost-performance ratio for a specific application. As an example, there are a number of cracking toolsfor TrueCrypt compiled for x86 CPUs, but only few go beyond re-using the original TrueCryptcode. An example is TrueCrack12, which reports 15 passwords/sec on an Intel Core-i7 920,2.67GHz.Other processing platforms exceeded the performance (and cost-performance ratio) of conven-
tional CPUs for specific applications such as password cracking: Modern GPUs combine a large12cf. http://code.google.com/p/truecrack, 2012
45

Chapter 4 Password Search against Key-Derivation Functions
number of parallel processor cores, which allow highly parallel applications using programmingmodels such as OpenCL or CUDA. Their usefulness for password cracking was demonstrated inparticular by the Lightning Hash Cracker developed by ElcomSoft13, which achieves — for sim-ple Message-Digest Algorithm 5 (MD5)-hashed password lists — a throughput rate of up to 680million passwords per second using an NVIDIA 9800GTX2. Further work like IGHASHGPU14
and [Sch10] report similarly impressive numbers with about 230 million SHA-1 (pure) hashoperations per second on an NVIDIA 260GTX GPU. TrueCrack reports 330 passwords persecond (pps) on an NVIDIA GeForce GTX470, the press release of Passware Kit 10.115 reports2 500 pps, and [Bel09] stated that ElcomSoft software cracks 52 400 pps on a Tesla S1070 with4 GPUs for WPA-PSK, which essentially is PBKDF2 using only SHA-1.Another cost-effective platform for processing parallel applications is Sony’s PlayStation
3 (PS3), which internally uses an IBM Cell Broadband Engine (Cell) processor. The processorcontains a general-purpose CPU and seven streaming processors with a 128-bit SIMD architec-ture. Bevand [Bev08] presented a Unix crypt password cracker based on this processor. However,the Cell processor is slightly outdated in comparison to recent GPU and FPGA devices. Thus,we did not include the Cell processor in our tests.Another way to tackle the large number of computations for password cracking efficiently is the
deployment of special-purpose hardware. Moving applications into hardware usually providessignificant savings in terms of power consumption and provides a boost in performance at thesame time, since operations can be specifically tailored for the target application and potentiallybe highly parallelized. Given that password guessing is amenable to special-purpose hardwarearchitectures and is highly parallelizable, FPGAs are a promising platform for password cracking.While FPGAs were not used to implement PBKDF2 before, this platform has been targeted
for bcrypt: With the goal of benchmarking energy-efficient password cracking, [Mal13] providedseveral implementations of bcrypt on low-power devices, including an FPGA implementation inDecember 2013. Malvoni et al. used the Xilinx zedboard (cf. Section 2.4), which combines anARM processor and an FPGA, and split the workload on both platforms: The FPGA computesthe time-consuming cost-loop of the algorithm while the ARM manages the setup and post-processing. They reported up to 780 pps for a cost parameter of 5 and identified the highlyunbalanced resource usage as a drawback of the design. In August 2014, [MDK14] presented anew design, improving the performance to 4 571 pps for the same device and parameter, usingthe ARM only for JtR to generate candidates and to transfer initialization values to the FPGA.When they further optimized performance, the zedboard became unstable with heat and voltageproblems. Due to these issues, they also report higher theoretical performance numbers of 8 122pps (derived from cost 12) and 7 044 pps (simulated using the larger Zynq 7045 FPGA).
4.3 Attack Implementation: PBKDF2 (TrueCrypt)
In this chapter, we motivate and discuss the implementations of a fast password guessing attackagainst PBKDF2 on GPUs and FPGAs. In our evaluation, we have targeted TrueCrypt. It is a
13cf. http://www.elcomsoft.com/lhc.html (visited 2011-11-16)14cf. http://www.golubev.com/hashgpu.htm (visited 2011-11-16)15cf. http://www.prnewswire.com/news-releases/passware-kit-100-cracks-rar-and-truecrypt-
encryption-in-record-time-99539629.html (visited 2011-11-16)
46

4.3 Attack Implementation: PBKDF2 (TrueCrypt)
free open-source FDE software using PBKDF2 with fixed sizes of 512 bits for the password andsalt.For consistency, we consider recent TrueCrypt versions, starting with Version 5.0 (released
February 5, 2008). Since then, TrueCrypt uses AES-256, Serpent, and Twofish in XEX-basedtweaked-codebook mode with ciphertext stealing (XTS) mode as block ciphers and generatesthe keys using either RIPEMD-160, SHA-512, or Whirlpool as supported hash functions. Thenumber of required HMAC iterations are 2 000, 1 000, and 1 000, respectively and the corre-sponding number of hash computations are 4 003, 2 002, and 4 002. The variation in the numberof hash executions is due to the input block sizes of each hash function.TrueCrypt supports different block-cipher algorithms and combinations of these algorithms.
In the best case for the attacker — when only one encryption algorithm is used — we require 512key bits of key material. In the worst case, the key material increases to 1 536 bits. As TrueCryptdoes not store any information about the algorithms used in its header, the verification processrequires the decryption of a specific sector using all combinations of block ciphers and keyderivation algorithms.
H H H
H H H
H H H
H H H
999x / 1999x
Hinit
Hinit
Hinit
Hinit
PW XOR 0x36..36
PW XOR 0x36..36
PW XOR 0x5C..5C
PW XOR 0x5C..5C
Salt CNT|Padding
Padding
Padding
Padding
Figure 4.1: An abstract view of the PBKDF2 scheme employed in TrueCrypt. Each box denotesone iteration of the hash compression function. Two rows together map to oneexecution of an HMAC.
Figure 4.1 shows a simplified block diagram of the PBKDF2 scheme used in TrueCrypt: TheHMAC algorithm is repeatedly chained such that the outputs of all HMAC computations add tothe derived key. If the desired output key length is larger than the output of the hash function,this scheme repeats multiple times with different counter value CNT. Depending on the input andoutput length, two cases should be distinguished: If the input length of the hash function H issmaller than its output plus the padding rule, then the HMAC construction requires at least six
47

Chapter 4 Password Search against Key-Derivation Functions
computations of H. This is the case for Whirlpool. Otherwise, each HMAC result requires fourcalls to H, i. e., in the cases of RIPEMD-160 and SHA-512.As the password in each chain of the HMAC computations is the same, the result of the
leftmost compression functions — corresponding to the hash of the password xor 0x36..36 or0x5C..5C, respectively — will not change. Thus, we can compute the values once and reusethem for all subsequent HMAC computations using the same password. Furthermore, the saltvalue never changes during the complete attack and we can reuse the hashed salt for the HMACchains using different counter values. These two observations reduce the required number ofcomputations for a password evaluation to one half and one third for an HMAC with four andsix invocations of the compression function, respectively.
4.3.1 GPU Attack Implementation
This section provides details about the GPU implementation. Please note that this implemen-tation was mainly done by Markus Kasper and is provided in a shortened version for the sakeof completeness. For the full details, we refer to [DGK+12].For the experiments, we used a machine equipped with four Tesla C2070 GPUs by NVIDIA
(cf. Section 2.2). To implement the PBKDF2, we decided to aim at an implementation thatavoids high-latency access of the main GPU memory by using only fast registers and sharedmemory. The other major strategy was to avoid redundant computation as detailed in Sec-tion 4.3. In the following, we briefly provide the implementation-specific algorithm details as anoverview of the functions RIPEMD-160, SHA-512, and Whirlpool.
RIPEMD-160: The state of the RIPEMD hash function has a size of 320 bit, which is dividedinto a left and a right part, each consisting of five 32 bit values. Both parts can be processedindependently. For this reason, we decided to let two threads team up to process the hashcomputation of one key candidate. The kernel uses an overall of 40 registers and 5 376 bytes ofshared memory (64 passwords * (16 registers for inputs + 5 registers for outputs) * 4 bytes per32-bit value) and runs with 128 threads per block. This allows 6 blocks in parallel per SM anda total of 5 376 passwords that can be processed in parallel on each GPU.
SHA-512: The state of SHA-512 consists of eight 64 bit values. Compared to the RIPEMD-160state, this complicates the computation of the compression function in two ways: The native 32-bit architecture is not optimal for the computations and the number of registers and large amountof shared memory necessary to store all internal values generate additional latency. For thisreason, our SHA-512 implementation uses only 64 threads per block and compiles to 63 registersper thread and 4 096 bytes of shared memory per block. Please note that 63 registers per threadare the upper bound the hardware can handle and the implementation results in an additionalspill of used variables into the slow device memory. As with the RIPEMD implementation, thiskernel also processes 5 376 passwords in parallel.
Whirlpool: The state of Whirlpool is of the same size as in the case of SHA-512, which againleads to high register usage. We designed the Whirlpool hash function with a table-lookupimplementation using eight (256 × 32)-bit lookup-tables stored in shared memory. We employ128 threads per block, each using the maximum of 63 registers. The shared memory usage of
48

4.3 Attack Implementation: PBKDF2 (TrueCrypt)
each block is 16 384 bytes per block and only 4 blocks will run in parallel on each SM. Each blockprocesses 128 passwords, such that we achieve 7 168 passwords that are processed in parallel.
Wrapper Implementation
We use a host system powered by two Intel Xeon X5660 six-core CPUs at 2.8GHz with enabledHyperthreading and AES New Instructions (AES-NI) instruction support. It is equipped withfour Tesla C2070 GPUs connected by full PCI Express (PCIe) 2.0 16x lanes. We use CUDAVersion 4.1 and the CUDA developer driver 286.19 for Windows 7 (x64). The host systemgenerates the passwords in a single thread, writing them to a memory buffer. We schedulepasswords in chunks of size 21 504, i. e., 14 · 6 · 4 = 336 blocks for RIPEMD-160 and SHA-512and 14 ·6 ·2 = 168 blocks for Whirlpool. We selected the block numbers to be small multiples ofthe maximum number of concurrent blocks on the GPU for all implemented kernels. This way,the GPU hardware should always be fully occupied with respect to the number of scheduledblocks for maximum performance. The derived key material is copied back to the host memoryto test for the correct decryption of the TrueCrypt header.As the host system is idle during the GPU computations, the password verification (which
is much less computationally expensive) can be hidden within the kernel execution time of theGPU computations. For our experiments, the implementation on the host system reuses largeparts of the cryptographic primitives from the original TrueCrypt implementation sources.To overlap memory copies between host and GPU with computations, we employed four
streams per GPU. Furthermore each stream alternately uses four sets of password and resultbuffers. This way the GPU can process the next password chunk without having to wait forthe host to finish checking the latest generated key material. The implementation is capable ofgenerating both 1 536 bits and 512 bits of key material for a password and an HMAC candidatefunction, matching the worst case in the TrueCrypt specification.
4.3.2 FPGA Attack Implementation
In our FPGA-based attack on TrueCrypt, we implemented the PBKDF2 scheme on theRIVYERA-S3 cluster, balancing the different parts of the algorithm in terms of area and speed.In accordance with the goal of the PBKDF2 algorithm to derive a key using a hash functionand perform encryption/decryption afterwards, sufficient key material has to be generated byrunning the hash function n times. An optimal strategy is to connect several copies of a hashfunction in a pipelined design in order to get the highest possible throughput. However, thehigh number of iterations n (1 000 to 4 000) makes this approach impossible.The three hash functions used by TrueCrypt need a different number of clock cycles to com-
plete processing and also have different critical paths, resulting in different processing times.Partitioning parts of an FPGA between these three hash functions would result in a slower andmore complex design. Therefore, we chose to implement individual systems for each hash func-tion used and distribute them among multiple FPGAs. This also adds flexibility to implementhigher percentage of a favored algorithm, e. g., in case the used algorithm is known or has ahigher probability.
49

Chapter 4 Password Search against Key-Derivation Functions
FIFO
REG
FIFO
PBKDF2
RAM
Twofish
Serpent
AES
3264
64
64 32PBKDF2
PBKDF2PBKDF2
Figure 4.2: Top-Level view of the FPGA design featuring dedicated PBKDF2 cores and — op-tionally — on-chip verification using all block cipher combinations.
Implementing the KDF
The Password-Based Key Derivation Function 2 relies on repeated executions of a hash functionin HMAC construction, where the result of each HMAC is accumulated starting with an initialall-zero key, until the final key is derived at the end of all HMAC runs. The inputs to thePBKDF2 are the password and a salt (see 4.2.2). The lengths of the password, salt, and thenumber of HMAC runs depend on the specific implementation.We designed three independent single-iteration cores, one for each of the three target hash
functions, optimized for time-area product. The other important parameter is the number ofkey bits that can be generated by each PBKDF2 module. It is equal to the predefined messagedigest size of the incorporated hash function, which is 512 bits for both SHA-512 and Whirlpool,but only 160-bits for RIPEMD-160. This means that while three instances of either SHA-512or Whirlpool cores are sufficient to supply the worst case of 1536-bits key (required for Twofish,AES, and Serpent combination), the same can be accomplish with ten instances of the RIPEMD-160-based PBKDF2 core, making it the most critical part of the whole design.Implementing for FPGAs, the predefined topology of resources is the most limiting and hence
the most important factor. It is imperative to come up with a balanced design that uses bothregisters and BRAMs to the highest possible ratio while losing minimum cycles for additionalRandom Access Memory (RAM) access. For this purpose, the initial values, constants, andhash results are stored in the BRAMs, while registers are utilized for storage of internal iterationvariables within each hash function in all our hash cores. As mentioned above, we have developedthree different FPGA designs — each targeting one hash function as shown in Figure 4.2 — anddistributed them among the 128 FPGAs on the RIVYERA cluster.The design uses a 64-to-32 bit input First In First Out (FIFO) queue to split the data from
the RIVYERA bus to the local bus architecture and switch between the system clock domainand the computation clock domain. All PBKDF2 units are initialized using the salt from theTrueCrypt header and the password candidates are distributed among the available units. Afterreceiving a password, each unit immediately starts processing. As soon as a unit finishes itsexecution, its result is written into a dedicated memory, where the optional cipher blocks canaccess it and perform the on-chip test phase. An additional 64-bit register stores all informationon the current FPGA operations, which the host application can access at any time. Since using
50

4.3 Attack Implementation: PBKDF2 (TrueCrypt)
area for a dedicated on-chip test is not suitable for all hash functions, the option to write thederived keys back to the host PC for offline key tests is also supported in order to save resourcesfor more on-chip key derivation units.The password list, generated by a password derivation program, is transmitted by a host
program (running on the Core i7 in the RIVYERA) to the FPGAs using the PCIe architecture.Each of the three PBKDF2 units implements the scheme in Figure 4.1 with minor differences.The basic idea is to first hash the password XORed with inner padding as well as the passwordXORed with the outer padding and store the two results in memory as they will be repeatedlyused during further iterations as initial values of the hash function. The next step is to hashthe combination of salt and key number (which is 1 ≤ n ≤ 3 for SHA-512 and Whirlpool and1 ≤ n ≤ 10 for RIPEMD-160) in order to obtain the input value for the next run of the hashcore. In all of the following runs, the output of the previous run is the input data, and one ofthe two stored password hash results (in alternating order) is the initial value. The output ofevery second hash run (chaining variable) is accumulated (starting with all zero value) to get thefinal derived key. In the following paragraphs, we present the specific details for each differentalgorithm.
RIPEMD-160: The RIPEMD-160 based PBKDF2 core uses a 512-bit input message and hashesit by mixing with a 160-bit chaining variable, which is updated in 80 rounds. After the updatefinishes, the chaining variable is added to the previous hash value. The internal round function issimilar to that of SHA-1. However, the RIPEMD round function has two parallel paths, whichstore the results in two parallel 160-bit registers. The final hash result is stored in BRAMs.At the end of each round, the previous hash result — read from the RAM in 32-bit words —is added to the corresponding word of the update value from the current hash run and thenwritten back into the memory. While this causes additional cycles, it saves more than 160-bit ofregisters and 128-bit of adders, resulting in further time-area product optimization. The totalcycle count for each hash run is 95 cycles, in comparison to the ideal case of 80 cycles.The RIPEMD-160 core is run twice for the SALT and key number due to its 512-bits input
block size. Since the total number of key iterations is defined as 2 000 for RIPEMD-160, thisresults in a total of (5 + 1 999 · 2) · 95 = 380 285 cycles for key derivation per core, each of whichoccupies 1 032 slices (461 FFs, 1 764 LUTs) on a Xilinx Spartan-3 FPGA.
SHA-512: Each SHA-512 PBKDF2 core operates on 1 024-bit message blocks and generatesa 512-bit message digest. The intermediate hash values and the internal chaining variables areprocessed on a 32-bit datapath, which is not only compatible with the existing 32-bit BRAMs,but also minimizes delay paths. The only drawback is the number of cycles per hashing, which is200 instead of the ideal case of 80. However, this time-area product optimization is well justifiedwith an increase in the achievable frequency and a corresponding reduction in area.Each SHA-512 based key derivation requires 1 000 PBKDF2 iterations, which correspond to
a total number of (4 + 999 · 2) · 200 = 400 400 cycles for key derivation per SHA-512 PBKDF2core, each of which occupies 1 001 slices (897 FFs, 1 500 LUTs) on a Xilinx Spartan-3 FPGA.
Whirlpool: The structure of Whirlpool significantly differs from the structures of the other twocores. It not only generates a 512-bit message digest, but also processes 512-bit message blocks.The internal structure of Whirlpool resembles a block cipher with two identical datapaths in
51

Chapter 4 Password Search against Key-Derivation Functions
parallel; one as key expansion module, the other as message processing module. The internalstructures of each path are identical. However, the key expansion module uses hash input togenerate round keys, while the message processing module uses message inputs together withround keys to generate the next state of the hash.Each iteration computes the Whirlpool hash function four times due to its equal input and
output blocksize. We implemented a word-serial implementation, processing the hash (key) in64-bit chunks. This considerably reduces the overall area and needs 9 cycles per round for 11rounds in per computation. In total, the Whirlpool PBKDF2 core needs (6+999·4)·99 = 396 198cycles for the full key derivation and occupies 6 013 slices (1 131 FFs, 10 878 LUTs) on a XilinxSpartan-3 FPGA.
4.3.3 Performance Results
In this section, we will present the performance results for the experiments and compare thetwo platforms: GPUs and FPGAs. We measured the performance for each of the three hashfunctions and distinguish between the worst case (i. e., 1 526 bit of key material) and the best case(i. e., 512 bit of key material) of TrueCrypt’s password derivation. The latter case correspondsto a single encryption algorithm, e. g., AES-256 in XTS mode, while the first one correspondsto a cascade of all three ciphers.
Table 4.1: Implementation Results of PBKDF2 on 4 Tesla C2070 GPUs
Hash RIPEMD SHA-512 WhirlpoolRIPEMD
RIPEMD SHA-512 WhirlpoolRIPEMD
SHA-512 SHA-512Whirlpool Whirlpool
Key length 1536 bit 512 bitpps (max) 29 330 35 246 16 980 8 268 72 786 105 351 50 686 23 366pps (w/ I/O) 27 591 29 892 12 153 6 585 51 661 54 874 36 103 19 627
GPU Implementation Table 4.1 contains the performance results for each of the hash algo-rithms. In addition, we provide the performance of the implementation when calculating allthree PBKDF2 variants for each password. These values clearly show that the implementationsscale linearly: The performance boost for the smaller key sizes corresponds to the difference inthe number of blocks that need to be hashed to derive the desired output lengths, i. e., 4 vs. 10rounds for RIPEMD and 1 vs. 3 rounds for SHA-512 and Whirlpool.When deriving 1 536 bit of key material per password for each of the three hash algorithms
RIPEMD-160, Whirlpool, and SHA-512, our fastest implementation using a hardcoded salt wasable to derive the key material at 8 268 pps, i. e., about 714 million passwords per day (ppd) and21.4 billion passwords per month (ppm). Using only the TrueCrypt default settings of RIPEMD-160 and AES-256 in XTS mode, i. e., 512 bit of key material are generated, the performanceboosts to 72 786 pps, 6.29 billion ppd and 188 billion ppm.Our fully implemented TrueCrypt cracker tool consists of the password generator, the key
derivation and the decryption of the header data to verify the material. Unfortunately, thisimplementation suffers from a performance drop due to post-processing of key material on thehost. We observed a maximum speed limit of around 55 000 pps, which is the speed of thepassword generator we used in our experiment. This limitation can be leveled by further opti-mizations. For the sake of completeness, we also provide the performance figures of the full tool.
52

4.3 Attack Implementation: PBKDF2 (TrueCrypt)
Please note that our numbers, as all specific implementations, may only provide a lower bound:Implementations using other GPU architectures or further optimized code are likely to improvethe results.
FPGA Implementation In the case of the FPGA-based password search, we use differentFPGA configurations for the best case (single block cipher) and the worst case (cascade of allthree block ciphers).
Table 4.2: Implementation results and performance numbers of PBKDF2 on the RIVYERAcluster (Place & Route) without on-chip verification. Please note that the numbersreflect the worst-case and uses the lowest clock frequency valid for all designs insteadof target-optimized designs.
Hash RIPEMD SHA-512 Whirlpool RIPEMD SHA-512 WhirlpoolClock cycles per PBKDF2 380 285 400 400 396 198 380 285 400 400 396 198Key length 1536 bit 512 bitPBKDF2 units 4 11 3 9 32 15Hash cores per PBKDF2 10 3 3 4 1 1FPGA resources (Slices) 29 753 31 773 18 380 28 227 31 943 29 528FPGA resources (%) 89% 95% 55% 84% 95% 88%pps per FPGA 386 957 265 828 2 784 1 325pps on the RIVYERA 41 104 122 496 33 920 105 984 356 352 169 600
Table 4.2 shows the place and route results. With respect to a single instance, the RIPEMDdesign derives 368 pps for 1 536 bit output and up to 828 pps for 512 bit output on a single FPGA,respectively. This scales to 47 104 and 105 984 pps on the full 128 FPGA cluster, taking onlythis hash algorithm into account. The SHA-512 implementation is slightly faster and computes957 and 2 784 pps per FPGA, respectively, and achieves a throughput of 122 496 and 356 352pps for the 512 and 1 536 bit case on RIVYERA, correspondingly.Even though the current Whirlpool implementation does not utilize the complete FPGA logic
optimally due to the PBKDF2 block size, it is more than 50% faster than the RIPEMD schemefor 512 bit. In order to test all three hash functions for TrueCrypt, we utilize the full RIVYERAsequentially, as the reprogramming time is negligible. As with the GPU implementation, thebottleneck in our experiments was also the host-based password generation and the throughputdrops slightly due to offline verification. Hence, with the remaining logic on the FPGA, we builtan on-chip verification as the number of clock cycles necessary to perform a key derivation islarge compared to the number of cycles required to compute the ciphers. With this approach,all cores of the host CPU can produce password candidates in order to minimize this bottleneck.
4.3.4 Search Space and Success Rate of an Attack
In order to determine the actual influence of the number of guessed passwords from the lastsection, we calculated the percentage of passwords an attack can break on average with thatnumber of guesses. To this end, we use an implementation of a Markov-based password guesser.As training set used to derive the Markov model, we used a random selection of 90% of theRockYou password list. The test set consists of the remaining 10% of the RockYou list — stillmore than 3 million passwords.Figure 4.3 shows the fraction of passwords guessed correctly (y-axis) for a given number of
guesses made (x-axis). These results were obtained by running the password generator indepen-
53
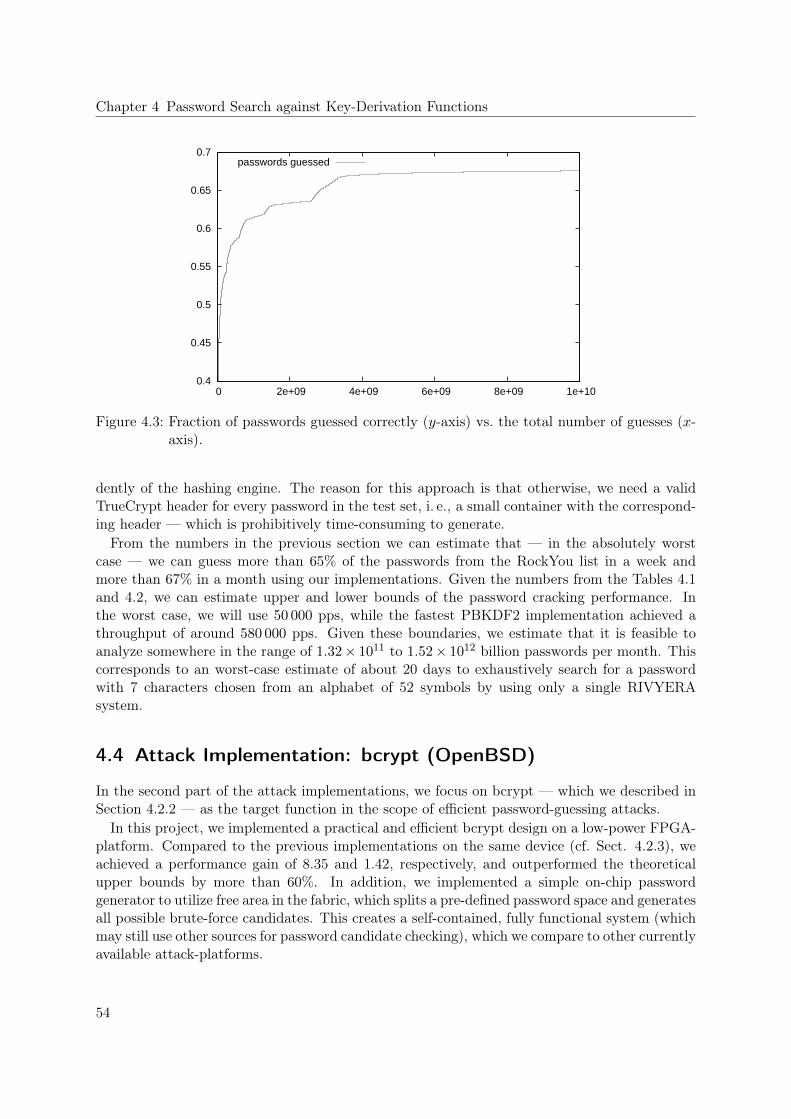
Chapter 4 Password Search against Key-Derivation Functions
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0 2e+09 4e+09 6e+09 8e+09 1e+10
passwords guessed
Figure 4.3: Fraction of passwords guessed correctly (y-axis) vs. the total number of guesses (x-axis).
dently of the hashing engine. The reason for this approach is that otherwise, we need a validTrueCrypt header for every password in the test set, i. e., a small container with the correspond-ing header — which is prohibitively time-consuming to generate.From the numbers in the previous section we can estimate that — in the absolutely worst
case — we can guess more than 65% of the passwords from the RockYou list in a week andmore than 67% in a month using our implementations. Given the numbers from the Tables 4.1and 4.2, we can estimate upper and lower bounds of the password cracking performance. Inthe worst case, we will use 50 000 pps, while the fastest PBKDF2 implementation achieved athroughput of around 580 000 pps. Given these boundaries, we estimate that it is feasible toanalyze somewhere in the range of 1.32× 1011 to 1.52× 1012 billion passwords per month. Thiscorresponds to an worst-case estimate of about 20 days to exhaustively search for a passwordwith 7 characters chosen from an alphabet of 52 symbols by using only a single RIVYERAsystem.
4.4 Attack Implementation: bcrypt (OpenBSD)
In the second part of the attack implementations, we focus on bcrypt — which we described inSection 4.2.2 — as the target function in the scope of efficient password-guessing attacks.In this project, we implemented a practical and efficient bcrypt design on a low-power FPGA-
platform. Compared to the previous implementations on the same device (cf. Sect. 4.2.3), weachieved a performance gain of 8.35 and 1.42, respectively, and outperformed the theoreticalupper bounds by more than 60%. In addition, we implemented a simple on-chip passwordgenerator to utilize free area in the fabric, which splits a pre-defined password space and generatesall possible brute-force candidates. This creates a self-contained, fully functional system (whichmay still use other sources for password candidate checking), which we compare to other currentlyavailable attack-platforms.
54

4.4 Attack Implementation: bcrypt (OpenBSD)
4.4.1 FPGA Attack Implementation
In this section, we describe our FPGA implementation of a multi-core bcrypt attack, capableof both on-chip password generation and offline dictionary attacks. We start with the generaldesign decisions, the results of an early version of our design and discuss the choices we madeto improve the overall design.An efficient implementation should result in a balanced usage of the available dedicated hard-
ware and fabric resources and maximize the number of parallel instances on the device. In thecase of bcrypt, using one dual-port BRAM hardcore to store two SBoxes saves LUT resources,results in high clock frequencies and relaxes the routing without creating wait-states. To increasethe utilization of the memory, we focused on shared memory access without adding clock cyclesto the main computation. In the final design, one bcrypt core occupies three BRAM blocks withtwo additional global memory resources for the initialization values. This leads to an upperbound of 46 cores per zedboard (ignoring any extra BRAM usage of the interface).Considering a brute-force attack to benchmark the capabilities of the FPGA, the interface can
be minimalistic. We use a bus-system with minimal bandwidth capacity, resulting in a smallon-chip area footprint. For this scenario, we chose the following setup: During start-up, the hosttransfers a 128-bit target salt and a 192-bit target hash to the FPGA. These values are kept intwo registers to allow access during the whole computation time. After filling the registers, allbcrypt cores start to work in parallel. The password candidates are generated on-chip. Afterthe attack has finished, a successful candidate is transferred back to the host.Our earlier design was built out of fully independent bcrypt cores. Each core contained its own
password register as well as the memory for the initialization values. This effectively removedall cross-dependencies and resulted in very short routing delays and thus high clock frequencies.Due to Blowfish’s simple Feistel structure, only a small amount of combinatoric logic was neededsince the main work is done via BRAM lookups. Nevertheless, storing the password in fabricconsumes far too much area and resulted in an unbalanced implementation. However, the timingresults indicated that more than 100 MHz should be possible.In order to reduce the area footprint, we tried to share resources and analyzed the algorithm
for registers that are not constantly accessed by all cores. We first removed the initializationmemory and used the free register resources to implement a pipeline and buffer the signals suchthat the critical path was unaffected by the change. Due to the required memory access andthe dual port properties, we also combined four bcrypt cores with one password generator andpassword memory. These quad-cores can schedule password accesses with negligible overhead.These changes reduced the area consumption by roughly 20% at the cost of one additional
BRAM resource per quad-core. Figure 4.4 shows the resulting design using multiple paralleland independent quad-cores. Every bcrypt core starts its operation with the initialization ofthe 256 SBox entries. Within this timeslot, the password generator produces four new passwordcandidates and writes them into the password memory. By using the dual-port structure of thememory, two bcrypt cores access their passwords in parallel. While these first two cores use theBRAM, the second pair of cores is stalled. This leads to a delay of 19 clock cycles between bothpairs.The bcrypt core spends most of the time within Blowfish encryptions, as these are used 512
times during the ExpandKey and 3 times during the EncryptECB steps. Thus, optimizing theBlowfish core heavily improves the overall performance. A naïve implementation needs two clock
55

Chapter 4 Password Search against Key-Derivation Functions
bcryptquad core
bcryptquad core
bcryptquad core
bcryptquad core
bcryptquad core
bcryptquad core
Salt R
egiste
rH
ash
Registe
r
Inte
rface
bcryptquad core
bcryptquad core
bcryptquad core
bcryptquad core
bcryptcore
bcryptcore
bcryptcore
bcryptcore
PasswordGenerator
PasswordMemory
quad core
50
MH
z
10
0 M
Hz
Figure 4.4: Schematic Top-Level view of FPGA implementation. The design uses multiple clock-domains: A slower interface clock and a faster bcrypt clock. Each quad-core accessesthe salt- and hash registers and consists of a dedicated password memory, four bcryptcores and a password generator.
cycles per Blowfish round: One to calculate the input of the f-function — and thus the addressesto the SBox entries — and one to compute the XOR operation on the f-function output and thesubkey.Figure 4.5a shows the standard Blowfish Feistel round. We moved the XORs along the data-
path, changing the round boundaries. This delay allows us to prefetch the subkeys from thememory and resolve data-access dependencies to reduce the cycle count to one per round.The resulting Blowfish core is depicted in Figure 4.5b. All of the three XOR operations — the
f-function’s output and the subkeys PA and PB — are computed in every round, removing allmultiplexers from the design. Please note that this modification changes the Blowfish algorithm,as it leads to invalid intermediate values. To counter this behavior, we use the reset of the BRAMoutput registers to suppress any invalid results of the XOR operations during the computation.This design leads to a very minimalistic control logic and thus a very small Blowfish design interms of area. Concerning the critical path, the maximum delay comes from the path from theSBox through the evaluation of the f-function.We have roughly a fourth of the available slices left once we reach the limit of available
memory blocks. With the remaining resources, we build an on-chip password generation circuit:In its simplest form, this is very efficient on-chip, as it only requires a small amount of logicalresources.Figure 4.6 provides a schematic overview: For each password byte, one counter and one
register store the current state. The initialization value differs for each core and determinesthe search space. The logic always generates two subsequent passwords and enumerates overall possible combinations for a given character set and maximum password length. When thestate has been updated correctly, it is mapped into ASCII representation and written into thepassword memory. The generation process finishes during the 256 initialization clock cycles,leaving enough time to buffer the signals and ensure a low amount of levels-of-logic.
56

4.4 Attack Implementation: bcrypt (OpenBSD)
PiS0S1S2S3
f
Lefti Righti
Lefti+1 Righti+1
(a) Note that the final XOR operation maybe moved along the datapath. By delay-ing it to the next round, we can resolvedata dependencies and compute one Blow-fish round in one clock cycle more effi-ciently.
0 1addrcntrst
Left Right
01 addrcntrst
din
PAPBfsbox
addr
dout(b) The computation of the delayed f-function
is integrated into the left half and the resultof the modified datapath forms the memoryaddress for the next f-function.
Figure 4.5: An overview of the highly sequential datapath inferred by the Feistel-structure ofone Blowfish round in comparison to the implementation realized on the FPGA.
Please note that with this design, even a slow and simple interface capable of sending 320bits and a start flag can use the system for brute-force attacks. A more complex interface —capable of fast data-transfer or even direct memory access of the BRAM cores — easily enablesdictionary attacks, as new passwords are transferred directly into the password memory duringthe long bcrypt computation. The on-chip password generation may be removed or modified towork in a hybrid mode.
4.4.2 Performance Results and Comparison
In this section, we present the results of our implementation. We used Xilinx ISE 14.7 and — ifneeded Xilinx Vivado 2014.1 — during the design flow and verified the design both in simulationand on the zedboard after Place and Route.
Table 4.3: Resource utilization of design and submodules.LUT FF Slice BRAM
Overall 64.8% 13.06% 93.29% 95.71%Quad-core 2 777 720 801 13Single core 617 132 197 3Blowfish core 354 64 71 0Password Generator 216 205 81 0
Table 4.3 provides the post place-and-route results of the full design on the zedboard. Weimplemented the design using ten parallel bcrypt quad-cores and a Xillybus interface. The designachieves a clock frequency of 100 MHz. The optimizations from Section 4.4.1 reduced the LUTconsumption to roughly 600 LUTs, the amount of BRAMs to 3.25 per single core. Therefore,
57

Chapter 4 Password Search against Key-Derivation Functions
Cnt c
Reg c
nc
nc
c
c
R_CE(0)
C_CE(0)
Cnt c
Reg c
R_CE(1)
C_CE(1)
Cnt c
Reg c
R_CE(n-1)
C_CE(n-1)
int2asc
int2asc
8 32
shiftreg
8 32
shiftreg
doutA
doutB
sel
Figure 4.6: Schematic view of the password generation. The counter and registers in the upperhalf store the actual state of the generator. The mapping to ASCII characters isdone by multiplexer. It uses a cyclic output for bcrypt and generates two passwordsin parallel.
we can fit ten quad-cores — and thus 40 single cores — on a zedboard, including the on-chippassword generation.The bcrypt cores need a constant number of c cycles for the hash generation, in detail:
cReset = 1
cDelay = 19
cbf = 18
ckey xor = 19
cInit = 256
cPipeline = n, (n = 2)
cupdateP = 9 · (cbf)cupdateSBox = 512 · (cbf)
cExpandKey = ckey xor + cupP + cupSBox = 9 397
cEncryptECB = 3 · 64 · (cbf − 1) = 3 264
Following these values, one bcrypt hashing needs
cbcrypt = cReset + cPipeline + cInit + cDelay+
(1 + 2cost+1 · cExpandKey) + cEncryptECB
= 12 939 + 2cost+1 · 9 397
cycles to finish. This leads to a total of 614 347 cycles per password (cost 5) and 76 993 163 (cost12), respectively.In order to compare the design with other architectures, especially with the previous results
on the zedboard, we measured the power consumption of the board during a running attack.We used hashcat and oclHashcat to benchmark a Xeon E3-1240 CPU (4 [email protected] GHz) anda GTX 750 Ti (Maxwell architecture), respectively, as representatives for the classes of CPUsand GPUs.Furthermore, we synthesized our quad-core architecture on the Virtex 7 XC7VX485T FPGA,
which is available on the VC707 development board, and estimated the number of available cores
58

4.4 Attack Implementation: bcrypt (OpenBSD)
Table 4.4: Comparison of multiple implementations and platforms considering full system powerconsumption.
cost parameter 5 cost parameter 12HashesSecond
HashesWatt Second
HashesSecond
HashesWatt Second Power (W) Price (US$ )
zedboard 6 511 1 550.23 51.95 12.37 4.2 319Virtex-7 51 437 2 571.84 410.43 20.52 20.0 3 495
Xeon E3-1240 6 210 20.70 50.00 0.17 300.0 262GTX 750 Ti 1 920 6.40 15.00 0.05 300.0 120
[MDK14] Epiphany 16 1 207 132.64 9.64 1.06 9.1 149[MDK14] zedboard 4 571 682.24 64.83 9.68 6.7 319
with respect to the area a new interface may occupy. We assume a worst-case upper bound of20W as the power consumption for the full evaluation board. For the CPU and the GPU attack,we also consider the complete system. While there are smaller power supplies available, weconsider a 300W power supply, which is the recommended minimum for the GPU to run stable.
Xeon E3-1240∗ GTX 750 Ti∗ zedboardVirtex-7
(estimated)[MDK14]
Epiphany 16[MDK14]zedboard
100
101
102
103
104
105 HsHWs
Figure 4.7: Comparison of different implementations for cost parameter 5. Left bars (red) showthe hashes-per-seconds rate, right bars (green) the hashes-per-watt-seconds rate.Results with ∗ were measured with (ocl)Hashcat. The axial scale is logarithmic.
Table 4.4 compares the different implementation platforms for cost parameter of 5 and 12.For better comparison, Figure 4.7 shows the performance and efficiency graphically only forthe first case. Our zedboard implementation outperforms the previous implementation from[MDK14] by a factor of 1.42, computing 6 511 pps at a measured power consumption of only4.2W compared to the 6.7W of the previous implementation. Thus, this implementation alsoyields a better power efficiency of 1 550 pps per watt, which is more than twice as efficient asthe previous implementation. The CPU attack on a Xeon processor computes 5% less pps ata significantly higher power consumption. Even considering only the power consumption of theCPU itself of 80W, the efficiency of the zedboard is still about 20 times higher. The estimatedVirtex-7 design shows that the high-performance board is a decent alternative to the zedboard:
59

Chapter 4 Password Search against Key-Derivation Functions
it outperforms all other platforms with 51 437 pps and has a very high power-efficiency rating.The drawback is the high price of US$ 3 495 for the development board.To analyze the full costs of an attack, including the necessary power consumption (at the
price of 10.08 cents per kWh16), we consider two different scenarios. The first uses the fairly lowcost parameter of 5 for a simple brute-force attack on passwords of length 8 with 62 differentcharacters and requires the runtime to be at most 1 month. We chose the considerably low costparameter for comparison with the related work, as it is typically used for bcrypt benchmarks.However, this value is insecure for practical applications, where a common choice seems tobe 12, which is also used in the related work. Thus, we use this more reasonable parameterin the second setting. Here, the adversary uses more sophisticated attacks and aims for areduction of the number of necessary password guesses and for a reduced runtime of one day percracked password: We consider an adversary with access to meaningful, target-specific, customdictionaries and derivation rules — for example generated through social engineering.In Section 4.3.4, we trained the Markov model on a random subset of 90% from the leaked
RockYou passwords to attack the remaining 10% and estimated that 4 · 109 guesses are neededfor about 67% chance of success. We use this as a basis for the computational power.
5 10 15 20 25 30 35 40 45 50
5
7
10
15
20
Number of attacked passwords
Total
costsin
US$
1000000
break-evenCPU∗
GPU∗
CPU+GPU∗
Virtex-7zedboard[MDK14] Epiphany[MDK14] zedboard
Figure 4.8: Total costs in millions USD for attacking n passwords of length 8 from a set of 62characters using logarithmic scale. Each attack finishes within one month. Both theacquisition costs for the required amount of devices and the total power costs whereconsidered.
Figure 4.8 shows the costs of running brute-force attacks in the first scenario. To achievethe requested number of password tests in one month, we need 13 564 single CPUs, 43 872GPUs, 10 361 CPUs + GPUs, 12 999 zedboards or 1 645 Virtex-7 boards. The figure showsthe total costs considering acquisition costs (fixed cost) and the power consumption. It revealsthe infeasibility of CPUs for attacking password hashes and even more clearly the efficiency ofspecial-purpose devices. Even high-performance FPGAs like the Virtex-7 are more profitableafter only a few password recoveries than a combination of CPUs and GPUs.
16Taken from the “Independent Statistics & Analysis U.S. Energy Information Administration”, average retailprice of electricity United States all sectors. http://www.eia.gov/electricity/data/browser
60

4.5 Conclusion
20 40 60 80 100 120 140 160 180 200
7
10
15
20
30
40
Number of attacked passwords
Total
costsin
US$
1000
break-evenCPU∗
GPU∗
CPU+GPU∗
Virtex-7zedboard[MDK14] Epiphany[MDK14] zedboard
Figure 4.9: Total costs in thousands USD for attacking n passwords of length 8 from a set of62 characters using a cost parameter of 12 (which is commonly recommended) usinglogarithmic scale. Each attack finishes within one day, with a dictionary attackwhere 65% are covered (4 · 109 Tests).
Figure 4.9 shows the costs of attacking multiple passwords in the second scenario. Here, weneed 30 CPUs, 102 GPUs, 23 CPUs + GPUs, 38 zedboards or 4 Virtex-7 boards. Even thoughwe consider a much higher cost parameter and require a runtime of one day per password, theattack is considerably less expensive due to the better derivation of password candidates.With the higher cost parameter our current zedboard implementation does not yield similar
good results and thus [MDK14] implementation is currently better suited for this attack whenmounted on a zedboard: Their implementation can conceal an interface bottleneck due to theinitialization of the bcrypt cores. As our implementation does not suffer from this bottleneck ingeneral, we can run several cores on a bigger FPGA without negative consequences. Please notethat the Virtex-7 — after amortizing its acquisition costs — outperforms every other platform(reaching the break-even point with [MDK14] zedboard after attacking about 1 500 passwords).
4.5 Conclusion
In this chapter, we examined the feasibility of extensive password-guessing using hardware ac-celeration and implemented guessing-attacks for two of the three major key-derivation functionsused in practice: PBKDF2 and bcrypt. While carefully chosen passwords are essential to pro-tect systems relying on password-based authentication, key-derivation functions should renderpassword guessing attempts useless.In the case of PBKDF2, even though it was specifically designed to prevent simple brute-force
attacks, we showed that parallel hardware platforms are capable to search through a significantnumber of passwords per second (356,352 pps for SHA-512 case). We tested our experiments withTrueCrypt as the target platform, using a Markov-based password candidate generation. Ourresults indicate that GPU clusters have a better cost/performance ratio than FPGAs, mainlydue to the low prices of the wide-spread use of GPUs.
61

Chapter 4 Password Search against Key-Derivation Functions
In the second part of this chapter, we presented a highly optimized bcrypt implementation onFPGAs. We used a quad-core structure to achieve an optimal resource utilization and gained aspeed-up of 42% and — due to lower power consumption — increased power-efficiency by 127%compared to the previous results on the same device. In the design we presented, the criticalpath is still within the Blowfish core, resulting in a moderate clock-frequency of 100 MHz. Apossible improvement would be a pipeline of the encryption within a quad-core, interleavingthe computations of the core. This may help shortening the critical path, allowing higher clockfrequencies and more bcrypt cores running in parallel due to the shared resources.We showed that it is possible to utilize the remaining fabric area to implement a small on-chip
password generation, which is adaptable and may be combined with a dictionary attack, e. g., forprefix and suffix modifications. These possibilities should be evaluated and further analyzed,as the password generation has a high impact on the success rate. Even more important, usingonly off-chip password generation, i. e., by using a CPU to generate passwords and transfer themto the FPGA, introduces two potential bottlenecks: The software implementation itself and thedata bus. With the combination of off-chip creation and on-chip modification, it should bepossible to reduce the risk of these bottlenecks even in large and highly parallelized clusters: Wecan use the password generator construction for simple mangling rules and relax the interfaceor dedicate several cores to brute-force attacks, while others work on a dictionary. This leads tomore possible trade-offs in terms of interface speed vs. area consumption.Analyzing the security of the two key derivation functions, we notice that both use a pa-
rameter to determine the cost of an attack: The iteration counter c for PBKDF2 and costfor bcrypt. While PBKDF2 uses excessive hash computation suitable for GPU parallelization,bcrypt requires more memory in favor of FPGAs.Due to the advancements in technology outlined by Moore’s law, we do not consider it sufficient
for a secure system to use a constant number of iterations throughout the entire lifetime ofan application or a secure system. We therefore recommend to replace this constant with adynamic variable that is stored in each respective application instance and which is adjusted overtime according to technological scaling effects. The parameter should be lower-bounded by thecomputational resources of the least-capable target platform of the application. Note, however,that even recent “low-end” processing devices (e. g., smart phones) often provide powerful multi-core ARM processors performing at more than 1 GHz.To validate our bcrypt experiments and derive a cost-estimation for different attack scenarios,
we considered modern versions of CPUs as well as GPUs and benchmarked the (ocl)Hashcatbcrypt implementation on these platforms. We compared the total costs of low-power andhigh-performance devices in two scenarios: Simple brute-force with a fixed runtime of 1 month(cost 5) and an advanced attack with a timeframe of 1 day (cost 12). In both cases, the highpower consumption of CPUs and GPUs renders large-scale attacks infeasible, while our FPGAimplementation not only outperforms these devices but also requires significantly less power.
62

Chapter 5
Elliptic Curve Discrete Logarithm Problem(ECDLP) on a Binary Elliptic Curve
In this chapter, the focus changes towards public-key cryptosystems and the firsthardware-implementation of the parallel Pollard’s rho algorithm using negation-mapin hardware. The target of the attack is the Standards for Efficient CryptographyGroup (SECG) standard curve sect113r2. This binary elliptic curve was deprecatedin 2005 but resisted all attacks as of today. In February 2015, Wenger et al. inde-pendently implemented an attack on the curve sect113r1, which is a slightly smallercurve.The research project started in 2013 as a joined work with Tanja Lange and DanielJ. Bernstein. During the project time, Peter Schwabe, Susanne Engels, and RubenNiederhagen joined, and the first implementation was published as the master thesisof Susanne Engels [Eng14]. Ruben Niederhagen is currently implementing a modifieddesign to improve the published results.
Contents of this Chapter5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 635.2 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 645.3 Attack Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 705.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 775.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
Contribution: In this project, I designed the FPGA implementation together withSusanne Engels and optimized the implementation afterwards. I implemented thebasic negation-map and changed the design to work on the RIVYERA-S6 cluster.
5.1 Introduction
In the area of public-key cryptography, Elliptic Curve Cryptography (ECC) plays an importantrole as small and efficient cryptographic algorithms. In contrast to other asymmetric cryptosys-tems like RSA, ECC requires significantly smaller key-sizes to achieve comparable security levels.This makes it a viable choice for constrained devices. A prominent example in Germany are
63

Chapter 5 Elliptic Curve Discrete Logarithm Problem (ECDLP) on a Binary Elliptic Curve
the new German passports, where ECC is used for authentication. It is also used in internetprotocols such as the Transport Layer Security (TLS) [IET06] or the Secure Shell (SSH) [IET09]protocols.Cryptanalysts strife to analyze the security of the Elliptic Curve Discrete Logarithm Problem
(ECDLP). In November 1997, Certicom presented the first ECC Challenge1. It contains apre-exercise and two challenge levels. The exercise contains a 79-bit, an 89-bit and a 97-bitchallenge, which were solved between 1997 and 1999. The first challenge level contains a 109-bitand a 131-bit challenge, while the second level is comprised of a 163-bit, a 191-bit, a 239-bit,and a 359-bit challenge. As of 2014, only the 109-bit challenge has been solved over prime fieldsand binary fields. The most complex, currently running challenge is the ECC2K-130 [BBB+09].Refer to [Nie12] for detailed information of a GPU and Cell implementation of the attack.There have been successful attacks on other ECDLP challenges: The largest ECDLP over
prime fields was successfully attacked in 2012 [BKK+09], the largest ECDLP over a Koblitz-Curve was recently solved in 2014 [WW14]. When this project started, the largest ECDLPover non-Koblitz binary curves was the ECC2-109 challenge of 2004. In February 2015, Wengeret al. published a successful attack on the sect113-r1 Certicom curve in [WW15], which is aslightly smaller curve than our target in this chapter.The main goal of this project was to implement and execute an attack on the largest non-
Koblitz binary curve within the scope of reconfigurable hardware using the state-of-the-art tech-niques available today. Previously, in 2006, Bulens et al. presented a special-purpose hard-ware design with results for the curve ECC2-79 and estimations for ECC2-163 [BdDQ06]. In[dDBQ07], de Dormale et al. provided more details on the power consumption, performance,and runtime. They estimated that — using a COPACOBANA cluster with 120 Spartan-3 1000FPGAs — their design can solve an ECDLP over GF(2113) in six months.The second goal was to include a hardware implementation of the negation map technique in
the random walk. This was previously done in software only, as it requires additional arithmeticoperations and a more complex control flow. Due to the controversial views on the usefulness ina hardware implementation, our goal was the implementation and verification of said technique.The remaining chapter is structured as follows: Section 5.2 briefly introduces the background
on elliptic curves. The target curve, design decisions, and implementation details are discussedin Section 5.3.5, followed by the results in Section 5.4. The chapter ends with the conclusion inSection 5.5.
5.2 Background
In this section, we discuss the background required for the implementation of our attack. Itis based on [HMV04, ACD+06], to which we refer for more detailed information. Please notethat the target curve is defined over a binary field and we restrict most of the background tothe applicable arithmetic only. We start with the definition of the Discrete Logarithm Problem(DLP) and an overview of the required binary field arithmetic, followed by a brief introductionto elliptic curves, the ECDLP and Pollard’s rho algorithm.
1cf. http://www.certicom.com/index.php/the-certicom-ecc-challenge
64

5.2 Background
5.2.1 Discrete Logarithm Problem
The Discrete Logarithm Problem (DLP) is defined as follows: Given a finite cyclic group Z∗pof order p − 1, a primitive element α ∈ Z∗p, and another element β ∈ Z∗p, find 1 ≤ x ≤ p − 1such as αx ≡ β (mod p). The DLP is used in different cryptographic algorithms, such as theDiffie-Hellman Key Exchange or the ElGamal Encryption Scheme. The security is linked to thegroup order and thus the prime p, which must be large in order to obtain a secure system. ForElGamal, the currently recommended bit-length of the prime p is 2048 bits (note that p − 1must have a large prime factor as well).The Generalized Discrete Logarithm Problem (GDLP) removes the restriction to Z∗p and is
defined as follows: Given a finite cyclic group (G, ◦) with G ={α, α2, · · · , α|G|
}, α generator,
and β ∈ G, find x ∈ G with β = α ◦ α ◦ α · · · ◦ α =
{αx, if ◦ multiplicativexα, if ◦ additive
.
5.2.2 Binary Field Arithmetic
We recall the finite field arithmetic applicable for the target curve, which is defined over a binaryfield F2m . The elements of this field are binary polynomials of degree at most m− 1, i. e.,
a(z) =
m−1∑i=0
aizi
with each ai ∈ F2. We store the field elements by grouping the m coefficients as an m-bit vectorand keep in mind that the elements are not integers but polynomials.We require different field operations to work with the target curve, i. e., modular addition,
multiplication, squaring and inversion in F2m with respect to a given irreducible binary polyno-mial f(z) of degree m.
Addition
As the field elements represent binary polynomials with coefficients from F2, the addition inF2m is a component-wise applied XOR operation. As we store the elements as m-bit vectors, wecompute
c = a⊕ b
with a, b ∈ F2m . In the context of an FPGA implementation, the overhead and area consumptionof this operation is negligible.
Multiplication
Since the FPGA does not provide native binary field multiplication, the implementation of thefield multiplication is more complex compared to the addition. We can choose from differentpolynomial multiplication algorithms, e. g., bit-serial, digit-serial, left-to-right or right-to-leftcomb, or Karatsuba multiplication. In this project, we implemented a digit-serial multiplier andthe recursive Karatsuba multiplication [KO63] and compared the resource utilization and theeffects on the overall design.
65

Chapter 5 Elliptic Curve Discrete Logarithm Problem (ECDLP) on a Binary Elliptic Curve
Algorithm 5 Digit-Serial Multiplier in F2m
Input:Digitsize k, irreducible polynomial f(z)A(z) =
∑m−1i=0 aiz
i ∈ F2m [z]
B(z) =∑l−1
i=0 bizki ∈ F2m [z] represented using k-bit digits bi
Output:C(z) = A(z) ·B(z)
1: C(z)← 0, A(z)← A(z)2: for i← 0 to l − 1 do3: C(z)← C(z) + bi · A(z)4: A(z)← zk · A(z) mod f(z)5: end for
Digit-Serial Multiplication: Algorithm 5 shows the digit-serial multiplication. In every step ofthe main loop, it processes k bits in parallel. Please note that the parameter k is used to modifythe time/area consumption in the implementation.
Algorithm 6 Recursive Karatsuba Multiplication in F2m
Input:Recursion parameter k ≤ m, assume k even for simplicity.Irreducible polynomial f(z)A(z) =
∑k−1i=0 aiz
i ∈ F2m [z]
B(z) =∑k−1
i=0 bizi ∈ F2m [z]
Output:C(z) = A(z) ·B(z)
1: if k = 1 then2: return C(z) = A(z) ·B(z) = a0b03: end if
4: Preparation5: k ←
⌈k2
⌉6: A(z) = zkA1 +A0
7: B(z) = zkB1 +B0
Recursive Multiplication8: A = A1 +A0
9: B = B1 +B0
10: r0 = KARATSUBA(k, A0, B0)11: r1 = KARATSUBA(k, A, B)12: r2 = KARATSUBA(k, A1, B1)
13: return C(z) = z2kr2 + zk(r1 + r0 + r2) + r0 mod f(z)
Karatsuba Multiplication: The Karatsuba multiplication, shown in Algorithm 6, is a divideand conquer algorithm. It splits the input into two equally-sized halves (using a zero-padding forodd degree) and recursively computes the intermediate multiplications using these smaller parts.As with the digit-serial multiplication, we are not fixed in terms of the time/area consumptionof the Karatsuba implementation: Instead of completely unrolling the multiplication (end of
66

5.2 Background
recursion condition k = 1), we can stop at earlier stages and compute the remaining multiplica-tions using a different algorithm. Please note that Karatsuba requires a certain bit-range to beefficient and that k = 1 is used for simplicity of the exposition only.
Squaring
Squaring of a binary polynomial in standard representation is a very fast and efficient operationcompared to the multiplication. Given a polynomial a(z) ∈ F2m , a(z) = am−1z
m−1 + · · · +a2z
2 + a1z + a0, the resulting polynomial of degree 2m of the square operation is a(z)2 =am−1z
2m−2 + · · ·+ a2z4 + a1z
2 + a0.
Algorithm 7 Squaring with Subsequent Reduction in F2m
Input:Irreducible polynomial f(z)A(z) =
∑m−1i=0 aiz
i ∈ F2m [z]Output:
B(z) = A(z)2 mod f(z)
1: B(z) =∑2m−1
i=0 bizi ∈ F22m [z] . Use temporary 2m-bit element
2: for i← 0 to m− 1 do . Insert a ’0’ between consecutive bits3: b2i ← ai
4: b2i+1 ← 05: end for6: return B(z) mod f(z) . Modular reduction of the result
Algorithm 7 describes the square operation with a subsequent reduction step. As every bitin the m-bit element represents a coefficient, this operation is very efficient in hardware byassigning the source bits to the appropriate index positions of the target register.
Inversion
The modular inversion is the most time consuming operation of the required finite field arith-metic. Instead of using a generic algorithm like the extended Euclidean algorithm, we use anoptimal addition chain for the specific field of interest: This chain computes an inverse elementusing 8 multiplications, 128 squarings and two temporary registers. The addition chain is listedin Table A.1 in the appendix.
Reduction
[HMV04] lists multiple algorithms to perform the reduction of finite field elements for differentunderlying register architectures, starting with reduction of one bit at a time. Recall thatreduction requires an irreducible polynomial and — depending on the binary field used — thereexists either a pentanomial or a trinomial. In the scope of this project, we use the trinomialf(z) = z113 + z9 + 1.
5.2.3 Elliptic Curves
An elliptic curve E over a general field F is defined by
E(F) := {(x, y) | y2 + a1xy + a3y = x3 + a2x2 + a4x+ a6} (5.1)
67

Chapter 5 Elliptic Curve Discrete Logarithm Problem (ECDLP) on a Binary Elliptic Curve
for some coefficients ai ∈ F, i = 1 . . . 6 with discriminant ∆ 6= 0, where
∆ := −d22d8 − 8d34 − 27d26 + 9d2d4d6
d2 = a21 + 4a2
d4 = 2a4 + a1a3
d6 = a23 + 4a6
d8 = a21 + 4a2a6 − a1a3a4 + a2a23 − a24
As known from the algebra, the discriminant of an algebraic equation relates to the numberand form of solutions. The assumption ∆ 6= 0 is an important requirement for elliptic curvesthat implies non-singularity.
Order of the Elliptic Curve: We call |E(Fq)| the order of an elliptic curve E over the finitefield Fq. A simple but naive way for finding the number of elements is testing and countingall x ∈ Fq, for which some y ∈ Fq exists such that Equation 5.1 is satisfied. Hasse’s theoremapproximates the order of an elliptic curve E over Fq as
q + 1− 2√q ≤ |E(Fq)| ≤ q + 1 + 2
√q.
For large order q of the finite field, this theorem yields the asymptotic estimate |E(Fq)| ≈ q asthe order of elliptic curves. Finding the exact number of points is important for elliptic curvecryptosystems depending on the ECDLP.
Elliptic Curves Arithmetic: We will now introduce a group addition of points on elliptic curves,motivated by the geometric construction of the addition + in E(Fq) in three steps, followed bythe algebraic definition. Please note that we handle the cases P 6= Q (Figure 5.1a) and P = Q(Figure 5.1b) separately.
(a) P 6= Q (b) P = Q
Figure 5.1: Geometric construction of the point addition and point doubling on an elliptic curve.
(1) (Define line G): G =
{through P and Q if P 6= Q
tangent line through P if P = Q,
68

5.2 Background
(2) (Define point S of intersection): S ∈ G ∩ E(Fp), S 6∈ {P,Q},
(3) (Define point R of reflection): R of S by reflection on the x axis.
Note that if there is no point of intersection between the line and the curve, S := R := O is thepoint of infinity. The arithmetic formulas for the group law depend on the choice of coordinatesand the field on which the curve is defined. Our target curve is an ordinary curve defined overF2113 and we only consider elliptic curves E(F2m) for the remainder of the project.We consider the curve in short Weierstraß form defined by
E(F2m) : {(x, y) | y2 + xy = x3 + ax2 + b}.
Given P = (x1, y1) ∈ E(F2m), Q = (x2, y2) ∈ E(F2m), the result R = P +Q = (x3, y3) ∈ E(F2m)of the point addition (P 6= ±Q) and the point doubling P = Q 6= −Q (P 6= −P ) is defined as
x3 = λ2 + λ+ x1 + x2 + a
y3 = λ(x1 + x3) + x3 + y1, where
λ =
y1+y2x1+x2
if point doubling
x21+y1x1
if point addition.
If we take the complexity of the underlying field operations into account and re-consider thepoint operations on the elliptic curve, we notice that the point addition and point doubling bothrequire one inversion and two multiplications, which dominate the computational effort, as theyare significantly more expensive in terms of time and area consumption than the addition orsquaring.
Negative Point: Please note that the corresponding negative point of P = (x1, y1) ∈ E(F2m)with P + (−P ) = O has the coordinates (−P ) = (x1, x1 + y1). For binary curves, this is a veryefficient computation, requiring negligible hardware resources.
Elliptic Curve Discrete Logarithm Problem: The Elliptic Curve Discrete Logarithm Problem(ECDLP) applies the GDLP to elliptic curves. As the points on the curve (including the pointof infinity) have cyclic subgroups, the ECDLP is defined as follows: Given an elliptic curve E, apoint P , and another element Q ∈ 〈P 〉, find the integer k such that P+P+P+· · ·+P = kP = Q.The complexity is linked to the order of P , which is typically close to q. Thus, the key-lengthis significantly smaller compared to other public key systems like ElGamal or RSA for the samesecurity level: Typically, the RSA key-size of 2 048 bits is compared with the elliptic curvekey-size of 224 bits.
Pollard’s Rho: In this project, we implement Pollard’s rho algorithm, invented by John Pollardin 1978 [Pol78], relying on the birthday paradox. To solve the ECDLP and recover k fromkP = Q with a given base point P ∈ E of order ` and Q ∈ 〈P 〉, we iteratively construct linear
69

Chapter 5 Elliptic Curve Discrete Logarithm Problem (ECDLP) on a Binary Elliptic Curve
combinations until we find two distinct linear combinations aP + bQ and a′P + b′Q of the samepoint, i. e., aP + bQ = a′P + b′Q and solve
aP + bQ = a′P + b′Q
aP + bkP = a′P + b′kP
(a− a′)P = (b− b′)kPk = (a− a′)/(b− b′) (mod `)
for arbitrary coefficients a, a′, b, b′, which are integers. Instead of randomly choosing the coef-ficients, Pollard’s rho algorithm uses a pseudo-random iteration function to compute the nextpoint from the previous point. While this random walk is a deterministic computation, it be-haves randomly with respect to the underlying structure. Once a collision is found, the walkperiodically reaches the collision, leading to the ρ figure: The first non-colliding iterations forma line, followed by a cycle.
An example for such a random walk is the point addition of the current point with a randomlyselected point taken from a precomputed set of points. As we need a deterministic but randomlybehaving iteration function, we can derive the index of the precomputed point from the currentpoint.
5.3 Attack Implementation
Our attack uses the parallel version of Pollard’s rho algorithm [vOW99] by van Oorschot andWiener to compute the discrete logarithm of Q to the base P . This algorithm works in aclient-server approach.
Each client, which is an FPGA worker in our case, receives as input a point R0. This is aknown linear combination in P and Q, i. e., R0 = a0P + b0Q. From this input point, it startsa pseudo-random walk, where each step depends only on the coordinates of the current pointRi and preserves knowledge about the linear combination in P and Q. The walk ends whenit reaches a so-called distinguished point Rd, where the property of being distinguished is aproperty of the coordinates of the point. This distinguished point is then reported to a servertogether with information that allows the server to obtain ad and bd.
The server searches through incoming points until it finds a collision, i. e., two walks thatended up in the same distinguished point. With very high probability, two such walks producedifferent linear combinations in P and Q, so we have Rd = ad1P + bd1Q and Rd = ad2P + bd2Q.At this point, we can compute the discrete logarithm.
In the following, we describe the target curve and the construction of our iteration function.We start with a simple version, which does not make use of the negation map, and then modifythis walk to perform iterations modulo negation. We discuss the expected runtime of the attackand give details of the hardware/software implementation.
70

5.3 Attack Implementation
5.3.1 Target Curve
The SECG curve sect113r2 is defined over F2113∼= F2[z]/(z
113 + z9 + 1) by an equation of theform E : y2 + xy = x3 + ax2 + b and the basepoint P = (xP , yP ), where
a = 0x0689918DBEC7E5A0DD6DFC0AA55C7,
b = 0x95E9A9EC9B297BD4BF36E059184F,
xP = 0x1A57A6A7B26CA5EF52FCDB8164797, andyP = 0xB3ADC94ED1FE674C06E695BABA1D.
using hexadecimal representation for elements of F2113 , i. e., taking the coefficients in the binaryrepresentation of the integer as coefficients of the powers of z, with the least significant bit corre-sponding to the power of z0. The order of P is ` = 5 192 296 858 534 827 702 972 497 909 952 403,which is prime. The order of the curve |E(F2113)| equals 2`.It is possible to transform the elliptic curve to an isomorphic one by a map of the form
x′ = c2x+u, y′ = c3y+dx+v. This does not change the general shape of the curve (the highestterms are still y2, x3, and xy) but allows mapping to more efficient representations. The securityamong isomorphic curves is identical, the DLP can be transformed using the same equations.Curve arithmetic depends on the value of a and for fields of odd extension degree, it is alwayspossible to choose a ∈ {0, 1}. It is unclear why this optimization was not applied in SECG butwe will use it in the cryptanalysis.In the case of sect113r2, we can transform the curve to have a = 1. The map uses a field
element t satisfying t2 + t + a + 1 = 0 so that (xP , yP + txP ) is on y2 + xy = x3 + x2 + b forevery (xP , yP ) on E because
(yP + txP )2 + xP (yP + txP ) = y2P + xP yP + (t2x2P + tx2P )
= x3P + ax2P + b+ (t2 + t)x2P = x3P + x2P + b.
This means that the base point gets transformed to (xP , y′P ) with
y′P = 0x1F31AF1A5DABE43F02EE96630D57D.
All curves of the form y2 +xy = x3 +x2 + b have a co-factor of 2, with (0,√b) being a point of
order 2. Varying b varies the group order but the term x2 means that there is no point of order4. Essentially, all integer orders within the Hasse interval [2113 +1−2 ·2113/2, 2113 +1+2 ·2113/2]that are congruent to 2 modulo 4 are attainable by changing b within F2113 .Cryptographic applications work in the subgroup of order `. Because ` is odd, 2 is invertible
modulo `, so there exists an s with 2s ≡ 1 mod ` and a point R in this subgroup is the double ofsR. Seroussi showed in [Ser98] that points (x, y) which are doubles of other points satisfy thatTr(x) = Tr(a). For F2113
∼= F2[z]/(z113 + z9 + 1) one can easily prove using Newton’s identities
that Tr(zi) = 0 for 1 ≤ i ≤ 112 and, of course, Tr(1) = 1. Note that the trace is additive,so here Tr(x) = Tr(
∑112i=0 xiz
i) =∑112
i=0 xiTr(zi) = x0. This implies that for our curve havinga = 1, each point in the subgroup of order ` has Tr(x) = 1 = x0, i. e., the least significant bit inthe representation of x is 1.
71

Chapter 5 Elliptic Curve Discrete Logarithm Problem (ECDLP) on a Binary Elliptic Curve
5.3.2 Non-Negating Walk
Our iteration function follows the standard approach of an additive walk, e. g., as described in[Tes01], with some improvements following [BLS11]. We precompute a table (T0, . . . , Tn−1) ofrandom multiples of the base point P ; our implementation uses n = 1 024. Note that descriptionsoften request these steps to be combinations of P and Q but Q is a multiple of P itself, so takingrandom multiples of P has the same effect and makes the step function independent of the targetdiscrete logarithm. This means the design including the precomputed points can be synthesizedfor the FPGA and then be used to break multiple discrete logarithms. Inputs to the iterationfunction are random multiples of the target point Q. Our iteration function f is defined as
Ri+1 = f(Ri) = Ri + TI(Ri),
where I(Ri) takes the coefficients of z10, z9, . . . , z1 of the x-coordinate of Ri, interpreted as aninteger. We ignored the coefficient of z0 because it is 1 for all points (see Section 5.3.1) andchose the next 10 most significant bits in order to avoid overlaps with the distinguished pointproperty.After each iteration, we check whether we have reached a distinguished point. We call a point
distinguished when the 30 most significant bits of the x-coordinate are zero. If the point is adistinguished point, it is marked as valid output. Otherwise, the iteration proceeds.In the literature, there are two different approaches of how to continue after a distinguished
point has been found. The traditional approach is to report the point and the linear combinationleading to it and then to simply continue with the random walk. This approach has been used,for example, in [Har98], [BKK+09], [BKM09], and most recently in a paper this year by Wengerand Wolfger [WW14]. The disadvantage of this approach is that the iteration function needs toupdate the coefficients of the linear combination of P and Q. In our case, this would mean thatthe FPGAs not only have to perform arithmetic in F2113 but also big-integer arithmetic modulothe 113-bit group order `.A more efficient approach was suggested in [BBB+09] and [BLS11]: Once a distinguished
point has been found, the walk stops and reports the distinguished point. The processor thenstarts with a fresh input point. This means that all walks have about the same length, in thiscase about 230 steps. The walks do not compute the counters for the multiples of P and Q andinstead only remember the initial multiple of Q. The server stores this initial multiple (in theform of a seed) and the resulting distinguished point. After a collision between distinguishedpoints has been found, we can simply recompute the two colliding walks and this time computethe multiples of P . We wrote a non-optimized software implementation based on the NTLlibrary for this task, which took time on the scale of an hour to recompute the length-230 walksand solve the DLP once a collision occurred.
5.3.3 Walks modulo negation
We improve the simple non-negating walk described above by computing iterations modulo theefficiently computable negation map. This improvement halves the search space of Pollard’s rhoand thus gives a theoretic speedup of
√2. The use of the negation map has been an issue of
debate, see [BKL10] for arguments against and [BLS11] for an implementation that achievesessentially the predicted speedup.
72

5.3 Attack Implementation
Changing the walk to work modulo the negation map requires two changes. First, we have tomap {P,−P} to a well-defined representative. We denote this representative |P | and decided topick the point with the lexicographically smaller y coordinate. After each step of the iterationfunction, we compare the y-coordinate of the reached point Ri to the y-coordinate of −Ri andthen proceed our iteration with the point with the lexicographically smaller y-coordinate. Thisrequires one field addition and one comparison.Second, we need a mechanism to escape so-called fruitless cycles. These mini-cycles stem from
the combination of additive walks and walks defined modulo negation. The most basic and mostfrequent case of a fruitless cycle is a 2-cycle. Such a cycle occurs whenever I(Ri) = I(Ri+1) andRi+1 = |(Ri + TI(Ri))| = −(Ri + TI(Ri)). In this case, Ri+2 is again Ri and the walk is caughtin a cycle consisting of Ri and Ri+1. The probability of this to occur is 1/(2n), where n is thenumber of precomputed points. There also exist larger fruitless cycles of lengths 4, 6, 8, etc., butthe frequency of those is much lower.We follow the approach by Bernstein, Lange, and Schwabe in [BLS11] to handle fruitless cycles
but adjust it to our low-area implementation environment. Specifically, instead of frequentlychecking for cycles of length 2 and less frequently for cycles of length 12, we only use thecheck for 12-cycles at about the same frequency as detecting 2-cycles to ensure that not toomuch time is wasted on these. Large counters most conveniently handle powers of 2, so withn = 1 024, we perform 32 iterations, store the point, perform 12 more iterations, compare to thestored point, double to escape a cycle (see below), conditionally use the result of the doublingdepending on the comparison, and repeat. This means that 44 additions and 1 doubling handle44 iterations, and the occasional 2-cycle (occurring about once every 2 048 iterations) wastes atmost 44 iterations. For comparison, the analysis in [BLS11] says that it is optimal to check for2-cycles after 2
√n = 64 iterations, but there is a wide range of iteration counts, for which the
efficiency is within a small fraction of a percent of this optimum.In the detection and escape of fruitless cycles, we define min{P1, P2} as the point with the
lexicographically smaller x-coordinate. The advantage of using the x-coordinate instead of the y-coordinate is that min can be computed before the y-coordinate is known; we can thus computemin and the y-coordinate in parallel. Furthermore, using the lexicographical ordering meansthat if the cycle contains a distinguished point it will be found as the min. At the entry ofa cycle check, we store the x-coordinate of the entry point Pi in xentry; this will be used forcomparison to detect whether Pi+12 is the same as the entry point (and we are in a cycle).To escape the cycle we use the minimum over all points encountered in the cycle. To this endwe define Pmin = Pi at the entry of the check and then update Pmin = min{Pmin, Pi+j} whenreaching Pi+j , 1 ≤ j ≤ 11. After 12 steps, we compare xentry and x(Pi+12). If they are equal, weare in a fruitless cycle and need to escape it. We define Pi+13 = Pi+12 if no cycle was encounteredand Pi+13 = 2Pmin otherwise. To streamline the computation, we compute 2Pmin in any caseand mask the result of Pi+13.We use the same criteria for a distinguished point (30 zeros) and the same table of precomputed
steps as described in the previous section.
5.3.4 Expected runtime
For the sect113r2 curve the expected number of group operations to break the DLP is roughly256. Each walk takes about 230 steps to reach a distinguished point and so we expect about 226
73

Chapter 5 Elliptic Curve Discrete Logarithm Problem (ECDLP) on a Binary Elliptic Curve
distinguished points before we find a collision. This amount of data poses no problem for thehost PC and for the I/O part of the hardware. For larger Discrete Logarithm (DL) computationsa less frequent property needs to be chosen. A benefit of relatively short walks is that they areeasily recomputed on a PC, which we use for finding the DL after a collision of distinguishedpoints occurs. This also helped in verifying that the FPGA code computed the same walks as asoftware implementation.
5.3.5 Hardware Implementation
In this section, we present our hardware implementation. In contrast to [WW14], we use inde-pendent Pollard rho cores with multiple cores per FPGA. This ensures that it is possible to usethe implementation even on smaller FPGAs, where a fully unrolled implementation exceeds thearea-restrictions, and have a better scalability of the implementation.We chose the Xilinx Spartan-6 LX150 as our target device, as we have access to two different
RIVYERA-S6 clusters using this FPGA: An 8-FPGA machine for rapid prototyping and a64-FPGA machine. Both use a PCIexpress interface to transfer data to and from the chips.
BRAMQ
BRAMT''
BRAMP
BRAMT'
BRAMaddrP
Pre-AddMultiplier
BRAMNM
SQ SQ SQ
cmp cmpcmp cmp
Post-Add
SQ SQ SQ
Figure 5.2: Layout of one independent Pollard Rho core: It contains two pipelines as well as thenecessary BRAM cores for the intermediate results and the precomputed points.
Figure 5.2 shows the design of one core. It consists of three main components: A series ofmemory cores (grey) to store all intermediate values for the point operations, the fruitless cyclechecks, and the precomputed steps. The other two components are two parallel pipelines. Theupper part (dark grey) is a pipelined comparator for two 113-bit values, which computes botha ≤ b and a == b. The second pipeline realizes the main computation (light grey). It includesa pre- and post adder, two pipelined multi-square modules and the modular multiplicationmodule. With this layout and by making use of the dual-port property of the BRAM cores,we implemented a pipelined, self-contained ECDLP core. It computes point additions, pointdoublings, and checks for fruitless cycles and distinguished points.Even though post-synthesis results are not very meaningful in terms of maximum clock fre-
quency, timing analysis, or even the implementation possibility2, it gives a first estimation ofthe area usage on the FPGA. To reflect this, we only include the percentage of the area usedfor synthesis figures.
2Please note that an FPGA contains different types of slices with different features. Achieving synthesisresults of less than 100% slices is not sufficient to ensure that the design is implementable.
74

5.3 Attack Implementation
Table 5.1: Pipeline stages and area of multiplier after synthesis on a Spartan-6 LX150 FPGA.
(a) Digit-serial multiplier
Digitsize Stages Slice FF Slice LUTs1 113 13% 14%2 57 7% 10%3 38 4% 9%4 29 3% 8%5 23 2% 8%6 19 2% 8%7 17 2% 7%8 15 1% 7%9 13 1% 7%
(b) Karatsuba multiplier
Depth Stages Slice FF Slice LUTs1 58 10% 11%2 31 8% 9%3 18 6% 7%4 12 5% 6%5 9 5% 6%6 8 5% 6%
We implemented two different multiplication schemes to evaluate the impact of the Karatsubamultiplication on the total design. Tables 5.1a and 5.1b contain the area estimations and — moreimportantly — the pipeline delay for a simple digit-serial schoolbook multiplier and a Karatsubamultiplier in combination with the schoolbook multiplication at the lowest level, respectively3.Both contain the modular reduction step and are adjustable in terms of area and pipeline stagesby changing the digitsize (digit-serial multiplier) and the recursion depth (Karatsuba multiplier).The digit-serial multiplier leads to a highly unbalanced LUT-FF ratio, whereas the Karatsuba
multiplier results in a much more balanced implementation. In addition, the automaticallyderived number of pipeline stages to keep the routing relaxed during the place-and-route stagehas a huge impact on the total area of the core: The necessary pipeline registers are up to 113-bitwide, so their number should be as low as possible without restricting the routing. In the finaldesign, we use the Karatsuba multiplication with 6 levels.The full pipeline has a length of 20 stages, combining the memory delay, multiplication, and
multiple-squaring pipeline. Thus, all operations are computed for 20 points in a row. In total,the point addition needs 11 clock cycles to complete, while the point doubling after the fruitlesscycle check needs 14 clock cycles. This includes the checks for the distinguished point propertyand the negation map control logic.
Table 5.2: Area usage depending on the number of parallel cores. These results are post-synthesisestimations.
Cores Slices Slice FF Slice LUTs1 24% 10% 14%2 39% 18% 24%3 57% 25% 34%4 69% 32% 44%5 81% 40% 54%6 91% 47% 64%
3Please note that the use the schoolbook multiplication in combination with Karatsuba is not optimal and canbe improved, i. e., by using optimized multipliers on the lowest level, cf. High-speed cryptography in characteristic2: Minimum number of bit operations for multiplication (https://binary.cr.yp.to/m.html).
75

Chapter 5 Elliptic Curve Discrete Logarithm Problem (ECDLP) on a Binary Elliptic Curve
Table 5.3: Tradeoffs for different lookup-table sizes (PA means point addition, FC meansfruitless-cycle check), selected value is bold face.
log2n Memory PAs between FC cycles/PA FC slowdown overall speedup2 1 kB 2 12.00 9.09% 32.33%3 2 kB 3 11.93 8.48% 32.94%4 4 kB 4 11.88 7.95% 33.47%5 8 kB 6 11.78 7.07% 34.35%6 15 kB 8 11.70 6.36% 35.06%7 29 kB 12 11.58 5.30% 36.12%8 57 kB 16 11.50 4.55% 36.88%9 113 kB 24 11.39 3.54% 37.89%
10 226 kB 32 11.32 2.89% 38.53%11 452 kB 48 11.23 2.12% 39.30%12 904 kB 64 11.18 1.67% 39.75%13 1 808 kB 96 11.13 1.18% 40.24%14 3 616 kB 128 11.10 0.91% 40.51%15 7 232 kB 192 11.07 0.62% 40.80%16 14 464 kB 256 11.05 0.47% 40.95%17 28 928 kB 384 11.04 0.32% 41.10%18 57 856 kB 512 11.03 0.24% 41.18%19 115 712 kB 768 11.02 0.16% 41.26%20 231 424 kB 1 024 11.01 0.12% 41.30%
Table 5.2 shows the area usage after synthesis. It suggests that 5 to 6 cores seem reasonablefor the Spartan-6 LX150 FPGA. Using this estimation, we implemented multi-core designs usingthe full toolchain. We obtained a valid design with a clock frequency of 100 MHz for the fulldesign using 5 and 6 parallel cores. However, when testing the design on different clusters, weachieved non-deterministic results due to a bug in the host interface. We gradually decreasedthe number of parallel cores and verified the computed distinguished points and noticed that— depending on the machine — 3 or 4 parallel cores compute the correct test set of 10 000distinguished points and continued the rest of the tests with a 2-core version to verify the resultsand estimations.Another design parameter is the size of the lookup table containing the precomputed multiples
of P . A larger lookup table has the advantage that fruitless cycles become less frequent and theiteration function performs more iterations before checking for fruitless cycles. The disadvantageis the memory requirement. Storing the tables in several small BRAM cores, which are physicallyfixed on the FPGA, has an impact on the routing due to the limited choices in physical resources.Table 5.3 displays how different choices of log2 n (the number of lookup-index bits and thus thememory address bus width) influences memory consumption, the number of point additionsbetween fruitless cycle checks, the slowdown from fruitless cycle checks, and the overall speedupcompared to a walk which does not use the negation map at all.For small choices of n, the slowdown due to the cycle check significantly reduces the negation
speedup. As expected, larger values of n lead to higher overall speedup but even for very largetable sizes, the speedup does not exceed 41%. We chose n = 1 024 as the number of precomputedpoints because the required storage easily fits the available BRAM resources and the speedupgained from doubling the memory is not worth the additional resources.
76

5.4 Results
5.4 Results
The obvious way to verify the performance and functionality of our implementation is to repeatthe following procedure many times: Generate a random point Q on the curve sect113r2, usethe implementation to find k such that Q = kP , take notes on how much time the computationtook, and check that in fact Q = kP .The reason for repeating this procedure many times is that the performance is a random
variable. Checking the performance of a single DL computation would obviously be inadequateas a verification tool. For example, if the claimed average DL time is T while the observedtime of a single DL computation is 2.3T , then it could be that this particular computation wasmoderately unlucky, or it could be that the claim was highly inaccurate.There are two reasons that more efficient verification procedures are important. First, even
though a single DL computation is feasible, performing many DL computations would be quiteexpensive. Second, and more importantly, verification is not merely something to carry out inretrospect: It provides essential feedback during the exploration of the design space. Below, wedescribe the verification steps that we took for our final implementation, but there were alsomany rounds of similar verification steps for earlier versions of the implementation.Running hundreds or thousands of walks (a tiny fraction of a complete sect113r2 DL com-
putation; recall that we expect orders of magnitude more distinguished points for our selectedparameters) produces reasonably robust statistics regarding the number of iterations requiredto find a distinguished point and regarding the time used for each iteration. However, it doesnot provide any evidence regarding the number of distinguished points required to compute aDL. A recurring theme of several recent papers is that standard heuristics overestimate therandomness of DL walks and thus underestimate the number of distinguished points required;see, e. g., the correction factors in [BBB+09, Appendix B] and the further correction factors in[BL12, Section 4].To efficiently verify performance including walk randomness and successful DL computation,
we adapt the following observation from Bernstein, Lange, and Schwabe [BLS11, Section 6]. Thefastest available Elliptic Curve Discrete Logarithm (ECDL) algorithms use the fastest availableformulas for adding affine points. Those are independent of some of the curve coefficients:Specifically, [BLS11] used formulas that are independent of b in y2 = x3 − 3x + b, and we useformulas that are independent of b in y2 + xy = x3 + ax2 + b. Thus, the same algorithmswork without change for points (and precomputed tables) on other curves obtained by varyingb. Searching many curves finds curves with different sizes of prime-order subgroups, allowingtests of exactly the same ECDL algorithms at different scales.For example, applying an isomorphism to sect113r2 to obtain a = 1 as described ear-
lier, and then changing b to 10010111, produces a curve with a subgroup of prime order1 862 589 870 449 786 557 ≈ 260.7. This group is large enough to carry out reasonably largeexperiments without distractions such as frequent self-colliding walks and, at the same time, issmall enough for experiments to complete quickly.We performed 512 DL computations on this curve, in each case using 20 bits to define dis-
tinguished points. These computations used a total of 609 930 walks, producing 609 928 dis-tinguished points and 2 walks that did not find distinguished points (presumably because theyentered fruitless cycles of length 8, but we did not check). The average number of walks perDL was slightly over 1 191. For comparison, the predicted average is
√π`/4/220 ≈ 1 153 for
77

Chapter 5 Elliptic Curve Discrete Logarithm Problem (ECDLP) on a Binary Elliptic Curve
` = 1 862 589 870 449 786 557, and the predicted standard deviation is on the same scale as thepredicted average. The gap between 1 191 and 1 153 is unsurprising for 512 experiments. Eachcomputation successfully produced a verified discrete logarithm.We defined the first DL computation to use seed 0, 1, 2, . . . until finding a collision between
seed s and a previous seed. The second DL computation uses seeds s + 1, s + 2, . . . untilfinding a collision within those seeds; etc. We post-processed seeds with AES before multiplyingthem by Q, so (if AES is strong) choosing consecutive seeds is indistinguishable from choosingindependent uniform random 128-bit scalars.The advantage of choosing consecutive seeds is that, without knowing in advance which seeds
would be used in each computation, we simply provided a large enough batch of seeds 0, 1, 2, . . .to our FPGAs. Retroactively attaching each seed to the correct computation was a simple matterof sorting the resulting distinguished points in order of seeds and then scanning for collisions.Here, the sorting step is important: If we had scanned for collisions using the order of pointsoutput by the FPGAs, then we would have incorrectly biased the initial computations towardsshort walks.We also carried out various experiments with
� a group of size 2 149 433 571 795 004 101 539 ≈ 270.86 with b = 110,
� a group of size 2 608 103 394 926 752 635 062 767 ≈ 281.1 with b = 100111, and
� a group of size 1 534 122 330 555 159 121 115 288 777 ≈ 290.3 with b = 10000111.
The percentage of walks that did not find distinguished points remained tiny across the 60-to-90-bit range. We spot-checked walks against a separate software implementation, verifiedcorrectness of 16 DL computations for the 70-bit group, and verified correctness of 1 DL com-putation for the 80-bit group.We used 8 FPGAs for these small-scale experiments, running 2 cores on each FPGA. These
16 cores each ran 44 iterations per 498 cycles at 100MHz, for a total of slightly over 141 mil-lion iterations per second, but also had considerable input/output overhead when distinguishedpoints were defined by a small number of bits. For 15-bit distinguished points we observed 310points per second, an order of magnitude slower than 16 · 44 · 108/(498 · 215) ≈ 4314 points persecond. For 20-bit distinguished points we observed 75 points per second, about 1.8× slowerthan 16 ·44 ·108/(498 ·220) ≈ 135 points per second. For 25-bit distinguished points we observed3.8 points per second, about 1.1× slower than 16 · 44 · 108/(498 · 225) ≈ 4.2 points per second.Note that not all of this gap is from input/output overhead: Some iterations are spent in fruitlesscycles before those cycles are detected.
5.5 Conclusion
In this project, we designed an implementation of the parallel Pollard rho method, solving theelliptic curve discrete logarithm on the curve sect113-r2. We use the RIVYERA Spartan-6 cluster and thus fit the implementation of multiple worker cores on the low-power SpartanFPGAs.While these Field Programmable Gate Array are from the low-power segment and cannot
compete with the large and powerful Virtex-6 or Virtex-7 devices, we show that even those
78

5.5 Conclusion
FPGAs can compute a significant number of point operations. As the design is scalable andself-optimizing (within reasonable parameters), we can adjust it to optimally use the area andpower of the Virtex-Field Programmable Gate Array.We tested the design with different multiplication algorithms and noticed that Karatsuba
multiplication achieves a better LUT-FF balance than the digit-serial multiplication. Our im-plementation of the negation map using 1 024 precomputed points leads to an overall speedupof 38.52% compared to a normal design without significant overhead.We noticed a bottleneck in the communication for small DLs but can mitigate its effects by
choosing an appropriate distinguished point criterion. For the design, which targets the 113-bitDL of the sect113-r2 curve, we chose 30-bit distinguished points to minimize the I/O overhead.When we finished the testing phase of the design, we noticed stability problems with different
RIVYERA clusters. In October 2014, Ruben Niederhagen joined the project and solved several ofthe previously known issues, i. e., he fixed the host interface bug, redesigned parts of the core andimplemented the optimized multiplication at the lowest level of the Karatsuba multiplication.With these improvements, the number of cores available per FPGA increased the number ofcores from 4 stable cores to 7, exceeding the previous estimation of 6 parallel cores.In February 2015, Wenger et al. published their independent research on the sect113r1 curve
in [WW15]. They use the Kintex-7 FPGAs and designed their ECC Breaker implementation asa fully unrolled, fully pipelined iteration function. Please note that they successfully computedthe discrete logarithm of that curve.
79

80

Chapter 6
Information Set Decoding (ISD) againstMcEliece
In the scope of Post-Quantum Cryptography, we designed a hardware-acceleratedimplementation of an ISD attack against code-based cryptosystems like McElieceor Niederreiter. We show that hardware approaches require significantly differentimplementation and optimization than the approaches by Lee and Brickel [LB88],Leon [Leo88], Stern [Ste88], or Bernstein et al. [BLP11a], May et al. [MMT11]and Becker et al. [BJMM12]. This project was a joint work with Stefan Heyse andChristof Paar. We finished it in 2014 and published the results in [HZP14]. Thecontent of this chapter is based on the paper and structured as follows:
Contents of this Chapter6.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 816.2 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 826.3 Attack Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 846.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 906.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
Contribution: This project consisted of two parts. The first part was an analysis ofthe existing algorithms and the improvements published during the last years with thegoal of mapping the CPU-based algorithms to hardware. The second part containedthe modification of the algorithm and the implementation as a hardware/software co-design. I contributed to the first part and was working on the hardware design andthe optimization targeting the RIVYERA-S6 FPGA cluster.
6.1 Introduction
Most of the currently deployed asymmetric cryptosystems work on the basis of either the discretelogarithm or the integer factorization problem as the underlying mathematical problem. Shor’sAlgorithm [Sho97] in combination with upcoming advances in quantum computing poses a severethreat to these primitives.The McEliece cryptosystem — introduced by McEliece in 1978 [McE78] — is one of the
alternative cryptosystems unaffected by the known weaknesses against quantum computers. Like
81

Chapter 6 Information Set Decoding (ISD) against McEliece
most other systems, its key size needs to be doubled to withstand Grover’s algorithm [HV08,OS08]. The same holds for Niederreiter’s variant [Nie86], proposed in 1986. The best knownattacks on these promising code-based cryptosystems are decoding-attacks based on InformationSet Decoding (ISD) [Pra62, LB88, Leo88, Ste88, BLP11a, MMT11, BJMM12].So far, all proposed ISD-variants and the single public implementation we are aware of [BLP08]
optimize the attack-parameters for CPU-based software implementations. As code-based sys-tems mature over time, it is important to know if and how these attacks scale when using notonly CPUs but incorporating also dedicated hardware accelerators. This allows a more realisticestimation of the true attacking costs and attack efficiency than the analysis of an algorithm’sasymptotic behavior.The base field of most proposed code-based systems is F2, which makes it suitable for hardware
implementations. The authors of [BLP11b] published a wide range of challenges [BLP13] —including binary codes, which we target in this work with a hardware attack.The remaining chapter is structured as follows: In Section 6.2, we briefly cover the neces-
sary background regarding code-based cryptosystems and introduce the basic ISD-variants. Wepresent different optimization strategies and hardware restrictions as well as our implementationin Section 6.3 and end with a discussion of the results and conclusions in Sections 6.4 and 6.5.
6.2 Background
In this section, we briefly discuss the background required for the remainder of this work.We start with a very short introduction into code-based cryptography including McEliece,Niederreiter and Information Set Decoding. For more detailed information, we refer to[OS08, Pet11, Hey13].
6.2.1 Code-Based Cryptography
Definition 1 Let Fq denote a finite field of q elements and Fnq a vector space of n tuples over
Fq. An [n,k]-linear code C is a k-dimensional vector subspace of Fnq . The elements of C are
called codewords.
Definition 2 The Hamming distance (HD) d(x, y) between two vectors x, y ∈ Fnq is defined to
be the number of positions at which corresponding symbols xi, yi, ∀1 ≤ i ≤ n are different. TheHamming weight (HW) wt(x) of a vector x ∈ Fn
q is defined as Hamming distance d(x, 0) betweenx and the zero-vector.
Definition 3 A matrix G ∈ Fk×nq is called generator matrix for an [n,k]-code C if its rows form
a basis for C such that C = {x ·G | x ∈ Fkq}. In general there are many generator matrices for a
code. An information set of C is a set of coordinates corresponding to any k linearly independentcolumns of G while the remaining n− k columns of G form the redundancy set of C.
If G is of the form [Ik|Q], where Ik is the k× k identity matrix, then the first k columns of Gform an information set for C. Such a generator matrix G is said to be in standard (systematic)form.
82

6.2 Background
Definition 4 For any [n,k]-code C there exists a matrix H ∈ F(n−k)×nq with (n−k) independent
rows such that C = {y ∈ Fnq | H · yT = 0}. Such a matrix H is called parity-check matrix for C.
In general, there are several possible parity-check matrices for C.
6.2.2 The McEliece Public-Key Cryptosystem
The secret key of the McEliece cryptosystem consists of a linear code C over Fq of length n anddimension k capable of correcting w errors. A generator matrix G, an n × n permutation P ,and an invertible k × k matrix S are randomly generated and form the secret key. The publickey consists of the k × n matrix G = SGP and the error weight w. A message m of length k isencrypted as y = mG+e, where e has Hamming weight w. The decryption works by computingyP−1 = mSG+ eP−1 and using a decoding algorithm for C to find mS and finally m.
6.2.3 The Niederreiter Public-Key Cryptosystem
The secret key of the Niederreiter cryptosystem consists of a linear code C over Fq of length nand dimension k capable of correcting w errors. A parity check matrix H, an n×n permutationP , and an invertible (n−k)× (n−k) matrix S are randomly generated and form the secret key.The public key is the (n − k) × n matrix H = SHP and the error weight w. To encrypt, themessage m of length n and Hamming weight w is encrypted as y = HmT. To decrypt, computeS−1y = HPmT and use a decoding algorithm for C to find PmT and finally m.
6.2.4 Information Set Decoding (ISD)
Information set decoding was introduced by Prange in [Pra62]. Attacks based on this approachare the best known algorithms, which do not rely on any specific structure in the code. This isthe case for code-based cryptography, i. e., an attacker deals with a random-looking code withouta known structure. In its simplest form, an attacker tries to find a subset of generator matrixcolumns that is error-free and where the submatrix composed by this subset is invertible. Themessage can then be recovered by multiplying the code-word by the inverse of this submatrix.Several improvements of the attack were published, including [LB88] (Lee and Brickel), [Leo88](Leon), [Ste88] (Stern), and recently [BLP11a] (Bernstein et al.), [MMT11] (May et al.) and[BJMM12] (Becker et al.).To the best of our knowledge, the latest and only publicly available implementation is [BLP08].
The authors presented an improved attack based on Stern’s variant that breaks the originallyproposed parameters (a binary (1 024, 524) Goppa code with 50 errors added) of the McEliecesystem. The attack ran for the equivalent of 1 400 days on a single 2.4 GHz Core2 Quad CPUor 7 days on a cluster of 200 CPUs.We now give a short introduction into the classical ISD-variants based on [OS08]. Given a
word y = c+e with c ∈ C, the basic idea is to find a word e with Hamming weight of e ≤ w. TheISD-algorithms differ in the assumption on the distribution of 1s in e. If a given matrix G doesnot successfully find a solution, the matrix is randomized, swapping columns and converting theresult back into reduced row-echelon form by Gauss-Jordan elimination. As each of these columnswaps also transforms the positions of the error vector e, there is a chance that it now matchesthe assumed distribution. The trade-off is between the success probability of one iteration ofAlgorithm 8 (or, in other words, the number of required randomizations) and the cost of a single
83

Chapter 6 Information Set Decoding (ISD) against McEliece
Algorithm 8 Information set decoding for parameter pInput: k × n matrix G, Integer wOutput: a non-zero codeword c of weight ≤ w1: repeat2: pick a n× n permutation P .3: compute G′ = UGP = (Ik|R) (w.l.o.g we assume the first k positions from an information
set, else re-randomize).4: compute all the sums s of ≤ p rows of G′
5: until Hamming weight of s ≤ w − p6: return s
Table 6.1: Weight profile of the codewords searched for by the different algorithms. Numbers inboxes are Hamming weight of the tuples. Derived from [OS08].
n←−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−→Prange w
k←−−−−−−−−−−−−−−−−−→ n− k←−−−−−−−−−−−−−−−−−−−−→Lee-Brickel p w − p
l←−−−−−−−→ n− k − l←−−−−−−−−−−−−−−→Leon p 0 w − p
Stern p/2 p/2 0 w − p
iteration of this algorithm. Table 6.1 gives an overview on the differences in the weight profilefor four selected ISD variants. Stern’s algorithm is special as it allows a collision search in thetwo p/2 sized windows by a birthday attack technique.The recent improvements from [MMT11] and [BJMM12] extend this technique but are out
of scope of this work because they introduce large tables highly unsuitable for hardware im-plementations. Please note that Table 1 on page 4 in [MMT11] shows the time and memorycomplexities of the different ISD-variants.
6.3 Attack Implementation
In this section, we discuss the attack implementation, starting with the modifications neces-sary for the hardware-based attack. We review the main differences to a pure software attack,the limitations posed by the hardware and the implemented techniques to circumvent theserestrictions.
84

6.3 Attack Implementation
6.3.1 Modifications and Design Considerations
The previous publications focused on software implementations of the algorithm and differentasymptotic improvements, e. g., time-memory trade-offs. In this context, the reasoning for de-sign and parameter choices is based on CPU architectures. Since this is the first hardwareimplementation of an attack, we need to figure out the best starting point in terms of the ISDvariant and tweak the parameters for the underlying hardware platforms. It is important tokeep in mind that we are mostly restricted by the memory consumption of the matrices andthat this is a hard limitation on FPGAs. Thus, we cannot precompute collision tables of severalgigabytes to speed up the attack.We evaluated the choices of parameters of the attacks for hardware suitability. As starting
point, we chose Stern’s ISD variant without the requirement of splitting the p-sized windowsinto two equal-sized halves. The main problem we identified in this process for a hardwareimplementation were the l-bit collision-search proposed in [Ste88] and the different choices forsplitting p into p1 and p2 to gain the most from this search. To take advantage of the birthday-likeattack strategy, while reducing the memory consumption at the same time to a hardware friendlylevel, we developed a hashtable-like memory structure called collision memory (CMEM). Pleasenote that this construction fixes p1 = 1 and thus p2 = p− 1.
H =
1 0 · · · 0 0 1 0 1 0 10 1 0 0 0 0 1 0 1 0
0 0. . . 0 1 0 1 1 1 0
0 0 0 1 0 1 1 0 1 10 0 0 0 1 0 1 0 0 10 0 0 0 1 1 0 1 0 1
ID
n− k − l
n− k − l
ZEROl
HK1
k1
CMEM
HK2
k2
w − p p1 p2
Figure 6.1: Splitting of the public key into memory segments. The values under the arrows belowthe matrix denote the assumed Hamming weight distribution of the error e.
Before we explain the different hardware modules required for an ISD-attack, we need todefine the parts of the matrix we use in each step. Figure 6.1 shows the full matrix includingthe identity part and the notation we use: The last k2 columns of the matrix of n− k bits eachform the submatrix HK2, where the enumerator computes all sums of p2 = p − 1 columns. Inthe middle, k1 columns form HK1 of n−k− l bits each. CMEM contains all information aboutthe integer representation of the remaining lower l bits of these k1 columns.
Enumerator
The most expensive step in the attacks is the computation of the(k2p2
)sums of p2 columns each.
In case of a software implementation, the n−k bits per column usually do not match the registersize of CPUs. Thus, multiple operations per addition are required to update all of the involvedregisters. To reduce the overhead, only the sum of the lower l bits is computed, which fitsthe register size of the CPU. In case of a collision with the p1-sums from the first part of the
85

Chapter 6 Information Set Decoding (ISD) against McEliece
columns, the remaining bits are used to compute the sum and check for the final HW. Pleasenote that at this stage, early-abort techniques usually reduce the number of times the full checkis computed [BLP08]Please note that in a hardware implementation, we can perform the full (n− k)-bit addition
of two columns in one clock cycle in hardware regardless of the parameter sizes — as long as weare able to store the full matrix on the FPGA. This allows us to perform the full iteration onthe FPGA without further post-computations, e. g., to sum up remaining bits.There is another advantage: Instead of computing the sums from scratch for each intermediate
step, we can modify the previous sum (of p2 columns) by utilizing a gray-code approach: Weadd one new column and remove one old column in one step. That way, we keep the number ofp2 columns in the sum constant and minimize the effort - given that this enumeration processis fast enough.
Collision search
As outlined before, the collision search is tricky in hardware. The approach of using a largeprecomputed table is not possible within the restricted device. We use a CMEM construction,consisting of 2l× (dlog2(k1)e+ 1) bits, which prepares the relevant information for fast access inhardware: For a given l-bit integer, we can find out (a) if at least one of the k1 columns containsthis bit sequence in the last l positions, (b) how many matches exist, and (c) the position ofthese columns in the memory — all within one clock cycle.In order to remove additional wait cycles and minimize the memory consumption, we generate
the part denoted as CMEM in Figure 6.1 in two steps during the matrix generation. First, wesort the k1 columns according to the integer representation of the last l bits. Please note thatthe cost for the column swaps are negligible, as the matrix is stored in column representation.Afterwards, we generate the 2l elements of the new structure: For index i, the Most SignificantBit (MSB) of CMEM [i] is set only if the integer was present in the k1 columns. In this case,the remaining l bits contain the position of its first occurrence. Otherwise, these l bits are notinterpreted.
Example: In the following example, we use l = 3, k1 = 6. Each line represents a step in thegeneration process: (1) contains the integer representation of the last l = 3 bits of the k1 = 6columns, while (2) consists of the sorted column list and (3) of the (larger) memory content ofCMEM .
1 [ 0, 1, 0, 4, 3, 6 ]2 [ 0, 0, 1, 3, 4, 6 ]3 [ 1|0, 1|2, 0|3, 1|3, 1|4, 0|5, 1|5, 0|6 ]
When checking for a collision with i, we simply check the MSB of CMEM [i]. As we areable to use two ports simultaneously, we can directly derive the number of collisions from thesubtraction of CMEM [i + 1] − CMEM [i] and only need one multiplexer for the special casei = k1 − 1. The base address is provided by the last l bits of CMEM [i].
86

6.3 Attack Implementation
Determining Hamming Weight
For all collisions found by the collision search, a column from HK1 is added to the current sum,which has been computed from the columns of HK2. Afterwards, the Hamming weight of theresult is compared to w − p.The Hamming weight check in hardware needs to be a fully pipelined adder-tree, automatically
generated for the target FPGA: The size of the internal look-up tables is used as a parameterduring this process. More recent FPGAs with 6-input LUTs can benefit from this.
6.3.2 Hardware/Software Implementation
In this section, we will present our hardware-implementation of the modified attack and startwith an algorithmic description of the attack before we describe the software and hardware partsin more detail.The hardware design was carefully build to work on different types of FPGAs— in this case the
Xilinx Spartan-3, Spartan-6, and Virtex-6 Familiy — and to integrate well into the RIVYERAFPGA cluster. Algorithm 9 describes the combination of the FPGA and the host-CPU for pre-and post-processing: The iteration on the FPGAs is computed in parallel to the generation stepon the CPU, which may utilize multiple parallel cores for matrix randomization.
Algorithm 9 Modified HW/SW algorithmInput:
Challenge Parameters: n, k, w, public key matrix, ciphertextAttack Parameters: FPGA bitstream, #FPGAs, #cores, p, l, k1
Output:Valid solution to the challenge.
1: Program all available FPGAs with the provided bitstream2: repeat3: for all hardware cores do4: Randomize matrix5: Generate collision memory6: Store HK1, HK2, CMEM in datastream7: Store permutation8: end for9: Evaluate FPGA success flag of previous iteration10: if success then11: Read columns of successful FPGA12: else13: Burst-Transfer datastream to FPGAs14: FPGAs: compute iteration on all datasets in parallel15: end if16: until success flag is set17: Recover solution of challenge.
Software Part
As mentioned in Section 6.3.1, the complete randomization step is done in software. After thechallenge file and actual attack parameter are read, it generates as many data sets as hardware
87

Chapter 6 Information Set Decoding (ISD) against McEliece
cores are allocated. The CPU computation uses the OpenMP library to parallelize the tasks:Each thread uses the original public key matrix and processes it as described in Algorithm 10.
Algorithm 10 Randomization StepInput: Public key matrix, r=#columns to swapOutput: Randomized matrix in reduced row echelon form1: while less than r columns swapped do2: Choose a column i from the identity part at random3: Choose a random column j from the redundant part, but ensure that the bit at position (i, j) is one.4: Swap columns i and j5: Eliminate by optimized Gauss-Jordan6: end while7: Construct the collision memory(CMEM)8: Store HK1, HK2 and CMEM in memory.
As the FPGA expects the data in columns, the matrix is also organized in columns in memory.Thus, pointer swaps reflect the column swaps. The Gauss-Jordan elimination is optimized takingadvantage of the following facts: Only one column in the identity part has changed and the pivotbit in this column is ’1’ by definition. Therefore, only this column is important during eliminationand only the k+l rightmost bits of each row must be added to other rows, as the leftmost n−k−lbits (except the pivot column) remain unchanged.The performed column swaps during randomization and CMEM construction are stored in a
separate memory. This is necessary in order to recover the actual matrix, on which the successfulFPGA core was working, because the randomized matrices are not stored. Once an FPGA sendsback the p1 = 1 column from CMEM and the p2 columns from the enumerator, the low weightword is recomputed locally after applying all previous permutations to the original matrix,followed by a Gauss-Jordan elimination. In a final step, the remaining w − p bits (set to 1 inthe plaintext) are recovered.
Hardware Part
It is not possible to generate an optimized design inherently suitable for all matrices. Thus, theISD attack requires a flexible hardware design, in which we trade potential manually-achievedoptimizations for a more generic design. This allows us to generate custom configurations forevery parameter set with a close to optimal configuration in terms of area utilization and thenumber of parallel cores. These parameters are included into the source code as a configurationpackage and define constants used throughout the design. Thus, we can adjust the parametersvery easily and automatically create valid bitstreams for the challenges.The basic layout is the same for all FPGA types. We use a fast interface to read incoming data,
distribute it to multiple ISD-cores and initialize the local memory cores. After this initialization,all ISD-cores compute the iteration steps in parallel.The iteration step consists of three major parts: The gray-code enumeration, the collision
search and the Hamming weight computation. Algorithm 11 describes the iteration process ofeach core on the FPGA. First, the different memories are initialized from the transferred data.Afterwards, the columns from the enumeration step provide the intermediate sum, which is usedin the collision-check step. If a collision is found on the lower l bits, the corresponding columnfrom HK1 is added to the sum and the Hamming weight is computed.
88

6.3 Attack Implementation
Algorithm 11 Iteration Step in HardwareInput: Memory content for HK1, HK2, CMEM , Parameters n, k, l, w, p2, k1, k2Output: On success: 1 column index from HK1, p2 column indices from HK2
1: Initialize HK1: (k1 × (n− k − l))-bit memory (BRAM)2: Initialize HK2: (k2 × (n− k)-bit memory (BRAM)3: Initialize CMEM : (2l × (dlog2 k1e+ 1))-bit memory BRAM or LUT)4: while (not enumeration_done) and (not successful) do5: Enumerate columns in HK2 and update sum6: for all collisions of sum (last l-bit) in CMEM do7: Update sum (upper part) with column from HK1
8: if HW(sum) = w − p2 − 1 then9: Set success flag and column indices10: Set done flag and terminate11: end if12: end for13: end while
Enumeration Step: For the enumeration process, we implemented a generic, optimized,constant-weight gray-code enumerator as described in Section 6.3.1. It starts with the initialstate of [0, 1, . . . , p2 − 1] and keeps track of the columns used to build the current column-sum.Aside from the internal state necessary to recover the solutions, it provides the memory corewith two addresses to modify the sum. With this setup, we can compute a new valid sum of p2columns in exactly one clock cycle. The timing is independent of the parameters, even thoughthe area consumption is determined by the p2 registers of log2 k2 bits. The enumerator is auto-matically adjusted to these parameters and always provides the optimal implementation for thegiven FPGA and challenge.
Collision Search: After the enumerator provides a sum of p2 columns from HK2, we check thelower l bits for collisions with CMEM for valid candidates. Due to the memory restrictionson FPGAs, we keep the parameter l smaller than in software-oriented attacks. If storage indistributed memory (in contrast to a BRAM memory core) requires only small area, we auto-matically evaluate if an additional core may be placed when using LUTs instead of BRAMs andconfigure the design accordingly.The additional logic surrounding the memory triggers the Hamming weight check in case a
match was found and provides the column addresses to access HK1.
Hamming Weight Computation: The final part of the implementation is the computation ofthe Hamming weight. To speed up the process at a minimal delay, we split the resulting (n−k−l)-bit word into an adder-tree of depth log2(n − k − l) − 1 and compute the Hamming weight ofthe different parts in parallel. These intermediate results are merged afterwards with a delayequal to the depth of the tree. The circuit is automatically generated from the parameters anduses multiple registers as pipeline steps, i. e., we can start a new Hamming weight computationin each clock cycle.
Pipeline and Routing: To maximize the effect of the hardware attack, the design is built asa fully pipelined implementation: All modules work independently and store the intermediatevalues in registers.
89

Chapter 6 Information Set Decoding (ISD) against McEliece
enumHK2
Memory
HK1
Memory
sum
CMEM
HWcheck
Figure 6.2: Overview of the different modules inside one iteration core.
Figure 6.2 illustrates this pipeline structure. Every memory block provides an implicit pipelinestage and the HW check is automatically pipelined. The figure also shows that the single mostimportant resource for the attack is the on-chip memory.Due to the large amount of free area in terms of fabric logic (i. e., not memory hardcores),
the routing of the design is not as difficult as an area-intensive design. In theory, we could alsouse parts of the free logic resources as memory in addition to the dedicated memory cores. Thiscomplicates the automated generation process and does not guarantee a successful build for allparameters. Thus, we did not utilize these resources and used them to relax the routing process.
6.4 Results
In this section, we present the results of our analysis. The hardware results are based on XilinxISE Foundation 14 for synthesis and place and route. We compiled the software part using GCC4.1.21 and the OpenMP library for multi-threading and ran the tests on the host CPU of theRIVYERA cluster.
6.4.1 Runtime Analysis
Based on the partition of the public key matrix (see Figure 6.1 with p1 = 1) and the distributionof errors necessary for a successful attack, the number of expected iterations is
#it =
⌈ (nw
)(k1p1
)×(k2p2
)×(n−k−lw−p
)⌉.As the hardware layout is very straight-forward and is fully pipelined, we can determine the
number of cycles per iteration as
#c = cenum + cpipe + cpopcount + ccollision
with
1Please note that the version is due to the Long Term Support (LTS) system and mentioned only for com-pleteness. While better compiler optimizations may increase software speed, the speed-up for the overall hardwareattack is negligible.
90

6.4 Results
cenum =
(k2p2
)cpipe = 4
cpopcount = log2 (n− k − l)− 1
ccollision =cenum
2l× 1
#mcols
Each operation for one iteration is computed in exactly one clock cycle. Due to the pipelineddesign, every clock cycle generates an iteration result after an initial, constant pipeline delay.We almost achieve an equal running time for all iterations with one exception: The only part,which may vary from iteration to iteration, is the collision search. If we find more than onecandidate using CMEM , we need to process them before continuing with the next enumerationstep. Thus, we need to add the expected number of multiple column candidates to the totalnumber of clock cycles. We can estimate this expected number of collisions inside CMEM —which is the number of multiple column candidates to test — as
#mcols = k1 × (1− (1− 1
2l)k1−1).
6.4.2 Optimal Parameters
We will now motivate the choice of optimal parameters for selected challenges taken from [BLP13]and provide the expected number of iterations on different FPGA families: The Xilinx Spartan-3, Spartan-6 and Virtex-6. The first two are integrated into the RIVYERA framework, whichfeatures 128 Spartan-3 5000 (RIVYERA-S3) and 64 Spartan-6 LX150 (RIVYERA-S6) FPGAs,respectively. During the tests with the RIVYERA framework, we noticed that the transfer timeof the randomized data exceeds the generation time.To measure the impact of the transfer speed on the overall performance, we added a sin-
gle Virtex-6 LX240T evaluation board offering PCIe interface including Direct Memory Ac-cess (DMA) transfer. The PCIe engine based on [WA10, Aye09, Xil10a, Xil10b] is, dependingon the data block size, capable of transferring at 0.014Mbps, 181Mbps, 792Mbps, 1412Mbps,2791Mbps for block sizes of 128 byte, 100Kbyte, 500Kbyte, 1Mbyte, 4Mbyte, respectively.2 Weuse a Sage script to generate the optimal parameters for all challenges and provide the scriptonline3 and in the appendix as Listing A.1.Table 6.2 contains the results for the selected challenges. Given the bottleneck of the data
transfer time, the script optimizes the parameters l, p and k1 in such a way that the iterationstep requires approximately as much time as transferring the data to all cores. The number ofcores per FPGA depends on the challenge and the available memory and takes the area andmemory consumption of the data transfer interface into account.As the challenges from [BLP13] are sorted according to their public key size, we selected four
challenges as examples. These are the binary field challenges with public key sizes of 5Kbyte,2As only a single device was available and a completely different interface must be used, the actual attack
was not performed using this device.3For the script and the output, cf. http://fs.emsec.rub.de/isd
91

Chapter 6 Information Set Decoding (ISD) against McEliece
Table 6.2: Optimal Parameter Set for selected Challenges.C1 C2 C3 C4
Riv
yera
-S3
clock frequency (MHz) 75data transfer rate (Mbps) 240
cores/FPGA 12 5 2 1p 5 4 4 4l 7 7 9 11k1 113 127 511 1424k2 164 438 630 691
#cycles / iterations (log2)1 24.79 23.73 25.31 25.71
#expected iterations (log2) 10.58 29.53 55.76 94.32
Riv
yera
-S6
clock frequency (MHz) 125data transfer rate (Mbps) 640
cores/FPGA 32 15 7 2p 5 4 4 4l 7 7 9 11k1 126 127 502 1525k2 151 438 639 590
#cycles / iterations (log2)1 24.31 23.73 25.37 25.02
#expected iterations (log2) 10.9 29.53 55.72 94.90
Vir
tex-
62
clock frequency (MHz) 250data transfer rate (Mbps) up to 2 791
cores/FPGA 43 21 14 6p 3 3 3 3l 6 8 10 11k1 63 204 642 1578k2 213 362 500 537
#cycles / iterations (log2)1 7.72 6.55 8.58 9.50
#expected iterations (log2) 13.82 33.40 59.95 94.961 Please note that the number of cycles is the total cycle count to perform #cores × #FPGAsiterations, as they start after receiving data and finish all iterations within the transfer time frameof the other FPGAs.
2 As the data transfer rate is significantly higher for the Virtex-6 device, the Sage script does notoptimize correctly as it neglects the — in this case — relevant pre-processing time in software andassumes zero delay.
20KByte, 62Kbyte and 168Kbyte. The last two correspond roughly to 80 and 128 bit symmetricsecurity, respectively [BLP08]. The related parameters of the challenges C1 to C4 are given inTable A.2 in the appendix.
6.4.3 Discussion
In addition to the hardware/software design, we also implemented the complete algorithm insoftware to generate testvectors and to compare the runtime of the FPGA version against theCPU implementation on a CPU cluster for small challenges. As the algorithm operates on fullcolumns, the software version behaves significantly slower than the FPGA implementation andoptimized software implementations: Usually, only small parts of the columns (fitting into nativeregister sizes) are added up during the collision search. Afterwards — for the candidates foundin the previous step — the sum is updated on additional register-sized parts and the Hamming
92

6.5 Conclusion
weight is checked, making use of early-abort techniques to increase the speed. This makes acomparison of the algorithm difficult, as neither the parameters nor the assumptions on thedistribution target asymptotic behavior.The FPGA implementation is very fast on small challenges. Please note that one hardware
iteration includes the iteration step for all cores on all FPGAs in parallel, as the parameterstake the full transfer time into account. Nevertheless, for larger challenges, the implementationperforms less well: The memory requirements for the matrices reduce the number of parallel coresdrastically and thus remove the advantage of the dedicated hardware. This makes a softwareattack with a large amount of memory the better choice, as it also has the advantage of largercollision tables.To circumvent these problems, we can also implement trade-offs in hardware as described for
software implementations. To increase the number of parallel cores, we can store smaller partsof the columns, which better fit the BRAM cores and utilize the early-abort techniques. Thedrawback is that this approach further increases the I/O communication, as a post-processingstep per iteration is necessary to check all candidates off-chip. As the communication was thebottleneck in our implementation, we did not implement this approach.A different approach and a way to minimize the I/O communication might be to generate
the randomization on-chip. While the column swaps are easy to implement in one clock cycle,we need more algorithms on the device: We need both a pseudo-random number generatorto identify the columns to swap and also a dedicated Gauss-Jordan elimination and also addcontrol logic to the design so that we are able to reuse them by sequentially updating the cores.In addition, this approach will require the storage of the full matrix on the FPGA.While these are restrictions posed by the hardware/software approach and the underlying
FPGA structure, a different evaluation should cover another hardware platform for ISD attacks:Recent GPUs combine a large number of parallel cores at high clock frequency and large memory.Even though the memory structure imposes restrictions, an optimized GPU implementation mayprove superior to both CPUs and FPGAs. This is especially true when attacking non-binarycodes, which are not optimal for FPGAs.
6.5 Conclusion
We presented the first hardware implementation of ISD-attacks on binary McEliece challenges.Our results show that it is possible to create optimized hardware, mapping the ideas from pre-viously available software approaches into the hardware domain. We circumvented the memoryrestrictions of the small FPGA, where the excessive time-memory trade-off previously prohibitedimplementations, and verified the results in simulation and with an unoptimized version runningon the FPGA cluster.While software attacks benefit from the huge amount of available memory, CPUs are not
inherently suited for the underlying operations, e. g., as the columns exceed the register sizesand the precomputed lookup tables exceed the CPU cache. Nevertheless, a lot of effort wasalready spent into improvements of these software attacks, which currently remain superior forlarge challenges.We showed that the strength of a fully pipelined hardware implementation — the computation
of all operations including memory access per iteration in exactly one clock cycle — does not leadto the expected massive parallelism, e. g., as hardware clusters have done in case of DES, and
93

Chapter 6 Information Set Decoding (ISD) against McEliece
does not weaken the security of code-based cryptography dramatically: The benefit is restrictednot only by the data bus latency but — far more importantly — by the memory requirementsof the attacks.These results should be considered as a proof-of-concept and the basis for upcoming hard-
ware/software attacks, trying different implementation approaches and evaluating other algo-rithmic choices. We discussed the benefits and drawbacks of potential techniques for on-chipimplementation of the ISD-attacks and stressed the need of an optimized GPU implementationfor a better security analysis.
94

Chapter 7
Conclusion and Future Work
In the course of this thesis, we dedicated our research efforts to the hardware accelerationof cryptanalytic implementations using special-purpose hardware clusters for high-performancecomputing. We covered different fields of cryptography in four major projects as summarizedbelow:
CubeAttacks on Grain-128In Chapter 3, we presented a new and improved variant of an attack on the stream cipher Grain-128. It was the first attack, which is considerably faster than exhaustive search and — unlikeprevious attacks — makes no assumptions on the secret key. To achieve these improvements, thecube dimension was increased and the verification of the attack required a more powerful imple-mentation than the previous software running on CPU clusters. We successfully implementedthe optimized simulation algorithm on the RIVYERA-S3 FPGA cluster and experimentallyverified the attack.These results of the CubeAttack show that an efficient utilization of an FPGA cluster is a
very powerful tool for cryptanalysis, which benefits from reconfigurable, self-optimizing designs.In this case, the software program generates target-specific VHDL source-code and uses theXilinx toolchain for automated bitstream generation in parallel to the iteration computation onthe hardware-cluster. This is especially useful for algorithms, where a generic approach is toocomplex, as dedicated bitstreams may significantly simplify and balance the design.In case of the CubeAttack simulation algorithm, the FPGA design was not possible without
such simplifications and the complexity of the algorithm required the performance of a special-purpose implementation.
Password Search against Key-Derivation FunctionsIn Chapter 4, we implemented an efficient, hardware-accelerated password search against two ofthe current standards in password-based key derivation, PBKDF2 and bcrypt. We implementeda cluster attack against the TrueCrypt FDE, compared it to a GPU cluster implementation, andapproximated the possible searchable key-space using these attacks. In the second project, wedesigned a low-power attack against bcrypt, outperforming the currently available implementa-tions on the same hardware. In addition, we derived the costs of password attacks including theupfront cost and the power consumption from our results.The password search project showed that the sequential design of PBKDF2 in combination
with HMAC constructions performs better on GPUs, while the FPGA implementation of bcryptoutperforms CPUs and GPUs. Interestingly, the overall costs for an attack (when using fast andpower-efficient hardware implementations) are not as high as expected for reasonable parameters.
95

Chapter 7 Conclusion and Future Work
This is a limitation inherited from password-based key derivation functions: Even assuming atask-specific KDF stronger than PBKDF2 or bcrypt (which is the aim of the currently runningPassword Hashing Competition), we still achieve a significant coverage of the password searchspace due to limited selection criteria of typical human-chosen passwords.It is important to understand that KDF parameters used in practice need frequent re-
evaluation to withstand state-of-the-art implementations, as they balance user-friendliness (timeto check a valid password request) and security (time to delay an attacker’s guess). Further-more, it is necessary to combine strong passwords with additional credentials, e. g., cryptographichardware-tokens, to counter the typically limited password selection criteria. These steps areimportant to withstand the advances in technology and intelligent password guessing attacks.
Elliptic Curve Discrete Logarithm Problem on the sect113r2 Binary CurveIn Chapter 5, we implemented an attack on the SECG standard curve sect113r2 using aparallel Pollard’s rho design on the low-power Spartan-6 FPGAs. The design implements theunderlying arithmetic, is scalable, works on different FPGA families, and is incorporated into theRIVYERA-S6 cluster. Our design was the first FPGA implementation including the negationmap technique. By using 1 024 precomputed points, this provides a speedup of 38.52% comparedto a normal design without significant overhead.For binary elliptic curves and the underlying arithmetic, FPGA are a perfect choice. Recently,
Wenger et al. published independent research results on similar curves using larger FPGAs.Both results suggest that the technological advancements in reconfigurable hardware have ahigh impact on the success rate of attacks on cryptographic primitives.In the scope of this project, future work should cover using small clusters utilizing the latest
high-performance FPGA instead of large clusters using low-power FPGAs. Even with a slightlyhigher power-consumption, the high-performance FPGAs may help solving the ECC2K-130challenge.
Information Set Decoding against McElieceIn Chapter 6, we designed the first hardware implementation of an ISD attack against code-basedcryptosystems like McEliece or Niederreiter. While the recent research focused on asymptoticimprovements in the context of software designs, we presented a proof-of-concept implementationusing low cost Spartan-3 and Spartan-6 FPGAs and provided estimations for high-performanceVirtex-6 devices. As the utilization of constrained hardware requires different choices of param-eters and optimization techniques than a software approach (as the large precomputed tables ofsoftware-based time-memory tradeoffs exceed the device constraints), we discuss the drawbacksand advantages of our solution.In light of this project, the implementation must be considered as the basis for ongoing
research. We identified the memory consumption of the large matrix as the main problemmitigating the effects of our FPGA implementation: We used the internal BRAM, which isat most 4 824 Kb on the largest Spartan-6 device. The RIVYERA-S3 cluster offers 32 MB ofDRAM per FPGA, the RIVYERA-S6 up to 2 GB. Given the performance estimations1 of up to3.2 GB/s, this memory is suitable for matrix storage.
1cf. http://www.sciengines.com/products/computers-and-clusters/rivyera-s6-lx150.html
96

Overall CommentsThe results of the projects show that special-purpose hardware is a very important platform toaccelerate cryptanalytic tasks and plays a key role for practical attacks and security evaluationsof new cryptographic primitives. Recent examples are the NIST SHA-3 and the PHC candidateevaluation processes, in which the reduction of the effects from massive parallelization for attacksplay a critical role in the security evaluation.Nevertheless, FPGAs are not always the hardware platform of choice and the speedup (com-
pared to CPU implementations) heavily depends on the target algorithm and the memory re-quirements. As both GPUs and FPGAs offer architectures for high-speed implementation withdifferent restrictions, these two platforms are currently the main target for cryptanalytic imple-mentations.When it comes to the long-term application of attacks, adversaries benefit from using low-
power special-purpose hardware2: In the password guessing project, we analyzed the costs ofattacking bcrypt-derived passwords using CPUs, GPUs, and FPGAs given a fixed number ofpasswords to test within a predefined time. The results reflect that the power consumption is themain cost factor. Thus, not the total number of computations per second but the computationsper second per Watt is the critical metric, which is often in favor of low-power circuits comparedto the high-performance GPUs.However, please note that the development of optimized FPGA designs is in most cases not as
straightforward as programming CPU or GPU implementations. With the recent developmentsin hardware/software co-design, e. g., the combination of ARM processors and FPGAs and theIntel Acquisition of Altera3, this may change in the future.
2Considering an adversary without unlimited, free power supply.3cf. http://intelacquiresaltera.transactionannouncement.com
97

98

Part III
Appendix
99


Appendix A
Additional Content
This chapter contains additional information, which are not mandatory in order to understandthe implementations and discussions throughout the thesis. Nevertheless, they may pose aninteresting addition to some readers.
A.1 Algorithms
Algorithm 12 [Section 3.4.1] The original Dynamic Cube Attack Simulation AlgorithmInput:
128-bit key K.Expressions e1, ..., e13 and the corresponding indexes of the dynamic variable i1, ..., i13.Big cube C = (c1, ..., c50) containing the indexes of the 50 cube variables.
Output: The score of K.1: S ← (0, ..., 0) . the 51 cube boolean sums, where S[51] is the sum of the big cube2: IV ← (0, ..., 0) . as the initial 96-bit IV3: for j ← 1 to 13 do4: ej ← eval(ej ,K) . Plug the value of the secret key into the expression5: end for6: for all cube indexes CV from 0 to 250 do7: for j ← 1 to 50 do8: IV [cj ]← CV [j] . Update IV with the value of the cube variable9: end for10: for j ← 1 to 13 do11: IV [ij ]← eval(ej , IV ) . Update IV with the evaluation of the dynamic variable12: end for13: b← Grain-128(IV,K) . Calculate the first output bit of Grain-12814: for j ← 1 to 50 do15: if CV [j] = 0 then16: S[j]← S[j] + b (mod 2) . Update cube sum17: end if18: end for19: S[51]← S[51] + b (mod 2)20: end for21: HW ← 022: for j ← 1 to 51 do23: if S[j] = 0 then24: HW ← HW + 1.25: end if26: end for27: return HW/51
101

Appendix A Additional Content
A.2 Tables and Figures
Table A.1: [Section 5.2.2] Addition Chain to compute the multiplicative inverse by means ofFermat’s Little Theorem. Table based on [Eng14].
Exponentiation Computation Squarings Multiplications
x20 a ← a 0 0x21 b ← a2 1 0x22 a ← b2 2 0
x23 − x21 b ← a · b 2 1
x24 − x22 a ← b2 3 1x25 − x23 a ← a2 4 1x25 − x21 b ← a · b 4 2
x26 − x22 a ← b2 5 2x27 − x23 a ← a2 6 2x28 − x24 a ← a2 7 2x29 − x25 a ← a2 8 2x29 − x21 b ← a · b 8 3
x210 − x22 a ← b2 9 3x211 − x23 a ← a2 10 3
. . . . . . . . . . . .x217 − x29 a ← a2 16 3x217 − x21 b ← a · b 16 4
x218 − x22 a ← b2 17 4x219 − x23 a ← a2 18 4
. . . . . . . . . . . .x233 − x217 a ← a2 32 4x233 − x21 c ← a · b 32 5
x234 − x22 a ← c2 33 5x235 − x23 a ← a2 34 5
. . . . . . . . . . . .x265 − x233 a ← a2 64 5x265 − x21 a ← a · c 64 6
x266 − x22 a ← a2 65 6. . . . . . . . . . . .
x297 − x233 a ← a2 96 6x297 − x21 a ← a · c 96 7
x298 − x22 a ← a2 97 7. . . . . . . . . . . .
x2113 − x217 a ← a2 112 7x2113 − x21 a ← a · b 112 8
102

A.3 Listings
Table A.2: [Section 6.4] Parameters of C1 to C4
C1 C2 C3 C4
n 414 848 1572 2752k 270 558 1132 2104w 16 29 40 54
A.3 Listings
Listing A.1: Section 6.4 Sage script to generate optimal parameters for all Wild McEliece chal-lenges with respect to our FPGA implementation.
1 def log2(x):2 return log(x)/log (2.)34 # parameter sets generated from challenges5 # layout is [[ filename , n, k, w ], ..]6 params = [[’5-9-414-0-16.txt’, 414, 270, 16], [’6-9-442-0-20.txt’, 442, 262,
20], [’7-9-482-0-21.txt’, 482, 293, 21], [’9-9-498-0-23.txt’, 498, 291, 23],[’10-10-620 -0 -19.txt’, 620, 430, 19], [’11-10-618 -0 -23.txt’, 618, 388, 23],[’12-10-638 -0 -24.txt’, 638, 398, 24], [’13-10-710 -0 -21.txt’, 710, 500, 21],[’14-10-726 -0 -22.txt’, 726, 506, 22], [’15-10-722 -0 -26.txt’, 722, 462, 26],[’16-10-786 -0 -24.txt’, 786, 546, 24], [’17-10-794 -0 -26.txt’, 794, 534, 26],[’18-10-812 -0 -27.txt’, 812, 542, 27], [’19-10-830 -0 -28.txt’, 830, 550, 28],[’20-10-848 -0 -29.txt’, 848, 558, 29], [’21-10-862 -0 -31.txt’, 862, 552, 31],[’22-10-884 -0 -31.txt’, 884, 574, 31], [’23-10-942 -0 -27.txt’, 942, 672, 27],[’24-10-998 -0 -27.txt’, 998, 728, 27], [’25-10-940 -0 -34.txt’, 940, 600, 34],[’26-10-962 -0 -34.txt’, 962, 622, 34], [’27-10-996 -0 -32.txt’, 996, 676, 32],[’28 -10 -1002 -0 -35. txt’, 1002, 652, 35], [’32-10 -996-0 -37.txt’, 996, 626,
37], [’34 -11 -1208 -0 -28. txt’, 1208, 900, 28], [’36 -11 -1222 -0 -29. txt’, 1222,903, 29], [’38 -11 -1250 -0 -31. txt’, 1250, 909, 31], [’40 -11 -1252 -0 -33. txt’,1252, 889, 33], [’42 -11 -1348 -0 -31. txt’, 1348, 1007, 31], [’44 -11 -1304 -0 -36.txt’, 1304, 908, 36], [’46 -11 -1332 -0 -36. txt’, 1332, 936, 36], [’48 -11 -1404 -0 -35. txt’, 1404, 1019, 35], [’50 -11 -1406 -0 -37. txt’, 1406, 999,37], [’52 -11 -1412 -0 -39. txt’, 1412, 983, 39], [’54 -11 -1532 -0 -35. txt’, 1532,1147, 35], [’56 -11 -1510 -0 -38. txt’, 1510, 1092, 38], [’58 -11 -1502 -0 -41. txt’,1502, 1051, 41], [’60 -11 -1530 -0 -41. txt’, 1530, 1079, 41], [’62 -11 -1572 -0 -40.txt’, 1572, 1132, 40], [’64 -11 -1668 -0 -38. txt’, 1668, 1250, 38], [’68 -11 -1662 -0 -42. txt’, 1662, 1200, 42], [’72 -11 -1682 -0 -45. txt’, 1682, 1187,45], [’76 -11 -1716 -0 -47. txt’, 1716, 1199, 47], [’80 -11 -1850 -0 -42. txt’, 1850,1388, 42], [’84 -11 -1950 -0 -42. txt’, 1950, 1488, 42], [’88 -11 -1972 -0 -44. txt’,1972, 1488, 44], [’92 -11 -1918 -0 -49. txt’, 1918, 1379, 49], [’96 -11 -1950 -0 -51.txt’, 1950, 1389, 51], [’100 -11 -1994 -0 -52. txt’, 1994, 1422, 52], [’104 -11 -1990 -0 -55. txt’, 1990, 1385, 55], [’108 -11 -2010 -0 -59. txt’, 2010, 1361,59], [’112 -11 -2014 -0 -63. txt’, 2014, 1321, 63], [’128 -11 -2008 -0 -65. txt’,
2008, 1293, 65], [’136 -12 -2386 -0 -53. txt’, 2386, 1750, 53], [’144 -12 -2558 -0 -50. txt’, 2558, 1958, 50], [’152 -12 -2644 -0 -51. txt’, 2644, 2032,51], [’160 -12 -2564 -0 -58. txt’, 2564, 1868, 58], [’168 -12 -2752 -0 -54. txt’,
2752, 2104, 54], [’176 -12 -2744 -0 -59. txt’, 2744, 2036, 59], [’184 -12 -2728 -0 -64. txt’, 2728, 1960, 64], [’192 -12 -2920 -0 -59. txt’, 2920, 2212,59], [’bigtest.txt’, 2920, 2212, 59], [’medium2test.txt’, 482, 293, 21], [’
medium3test.txt’, 482, 293, 21], [’mediumtest.txt’, 200, 140, 6], [’smalltest.txt’, 50, 26, 3], [’test.txt’, 414, 270, 16]]
103

Appendix A Additional Content
78 ##### global settings for the attack #####9
10 ## FPGA constants ##11 #12 #_fpga_name = [ "XC3S5000 -4", "XC6SLX150 -3", "XC6VLX240T -3", "XC6VSX475T -2"
]13 _fpga_name = [ "XC3S5000 -4", "XC6SLX150 -3", "XC6VLX240T -3" ]14 _fpgas = [ 128, 64, 1, 1 ]15 _clk_freq = [ 75, 125, 250, 200 ]16 _lut_size = [ 4, 6, 6, 6 ]17 _api_bram = [ 8, 14, 130, 130 ]18 _api_mbps = [ float (30*8) , float (80*8) , float (2791) , float (2791) ]19 _bram_max = [ 104, 536, 832, 2128 ]20 _bram_free = [i - j for i, j in zip(_bram_max , _api_bram)]21 _bram_sp_align = [ [[16384 , 1], [8192 , 2], [4096, 4], [2048, 8], [2048 , 9],
[1024, 16], [1024 , 18], [512, 32], [512, 36], [256, 72]], [[8192 , 1], [4096 ,2], [2048 , 4], [1024 , 9], [1024, 8], [512, 16], [512, 18], [256, 32], [256,36]], [[16384 , 1], [8192 , 2], [4096, 4], [2048, 9], [1024 , 18], [512, 36]],[[16384 , 1], [8192, 2], [4096, 4], [2048 , 9], [1024, 18], [512, 36]] ]
22 _bram_dp_align = [ [[16384 , 1], [8192 , 2], [4096, 4], [2048, 8], [2048 , 9],[1024, 16], [1024 , 18], [512, 32], [512, 36]], [[8192 , 1], [4096, 2], [2048 ,4], [1024 , 9], [1024 , 8], [512, 16], [512, 18]], [[16384 , 1], [8192 , 2],
[4096, 4], [2048 , 9], [1024 , 18]], [[16384 , 1], [8192, 2], [4096, 4], [2048 ,9], [1024 , 18]] ]
2324 # RIVYERA constants25 time_alloc = 1.43 # time in seconds for
allocation of the machine26 time_program = 0.16 # time in seconds for
programming of all FPGAs27 time_startup = time_alloc + time_program # setup time at the beginning2829 ###### functions ######3031 # compute number of brams from memory and output width32 def map2bram(entries , output_width , need_dualport):33 # [ brams , alignment ]34 best=3 * [infinity]3536 # choose correct alignment options37 if need_dualport:38 align = bram_dp_align39 dp_str = "true"40 else:41 align = bram_sp_align42 dp_str = "false"4344 # print "entries = {0:d}, output_width = {1:d}, dual -port = {2:s}". format(
entries , output_width , dp_str)4546 # find best possible mapping47 for mapping in align:4849 bram_count = ceil(entries/mapping [0]) * ceil(output_width/mapping [1])
104

A.3 Listings
50 # print "trying: {0:d}x{1:d} => {2:d}". format(mapping [0], mapping [1],bram_count)
5152 if best [0] > bram_count:53 best [0] = bram_count54 best [2] = mapping5556 # get number of luts for the memory (distributed ram usage only)57 data_size = max(ceil(log2(entries))-lut_size , 0)58 best [1] = 2**( data_size) * output_width5960 # return best mapping61 return best6263 # generate dumer parameters with memory transfer and initial setup time64 def fpga_dumer_memtransfer(n,k,w):65 local_best =[ infinity] + 19*[ -1]66 # print "[runtime , p1 , p2, l, k1 , k2 , cores , mem/c, bram/c, lut/c, trans/c,
bram/f, lut/f, trans/r, time/f, time/t, time/r, it/t, cyc/it , runs]"67 for p in range(2, max_p):68 p1 = 169 p2 = p-p17071 # test possible values for l (indicating collision memory data width)72 # l must be at least 2 (!)73 # l must not exceed 16 (memory alignment)74 for l in range(2, 18):7576 # pre -compute n-k-l choose w-p and log2(n-k-l)77 #print n, k, l, w, p, n-k-l, w-p78 binomial_nkl_wp = binomial(n-k-l,w-p)79 log2_nkl = log2(n-k-l)8081 # k1 must not exceed 2^l (estimated number of collisions)82 # k1 must not exceed k+l-p2 (otherwise , k2 < p2 which is not possible)83 # k1 should not exceed (3!) ^(1/3) * (2^(l))^(2/3)84 k1max=min (2^l, k+l-p2)8586 # we search for the best combination of k1 | k287 for k1 in range(3, k1max):8889 # compute k290 k2=k+l-k19192 #print "k1 =", k1 , "k2 =", k2, "l =", l9394 #### memory consumption ####95 # width_xxx : memory layout: [x, y] -> x times y-bit96 # memory_xxx : memory in bits needed to store data perfectly97 # bram_xxx : estimated number of BRAM cores needed to store data98 # lut_xxx : estimated number of LUTs needed to store data99 # mapping_xxx : best result of map2bram100 # transfer_xxx : 64-bit words needed to transfer data from host101102 ## CMEM ##
105

Appendix A Additional Content
103 width_cmem = [ 2**l, l+1 ]104 memory_cmem = width_cmem [0] * width_cmem [1]105 transfer_cmem = 2**(l-2) # l < 16 --> always transfer 4 elements per
64 bit word106 mapping_cmem = map2bram(width_cmem [0], width_cmem [1], false)107 bram_cmem = mapping_cmem [0]108 lut_cmem = mapping_cmem [1]109110 # debug output111 # print "CMEM memory: {0:d}x{1:d}, {2:d} bits -> {3:d} BRAMs or {4:d}
LUTs , needs {5:d} 64-bit words". format(width_cmem [0], width_cmem [1],memory_cmem , bram_cmem , lut_cmem , transfer_cmem)
112113 ## HK1 ##114 width_hk1 = [ k1, n-k-l ]115 memory_hk1 = width_hk1 [0] * width_hk1 [1]116 transfer_hk1 = ceil(width_hk1 [1] / 64) * width_hk1 [0]117 mapping_hk1 = map2bram(width_hk1 [0], width_hk1 [1], true)118 bram_hk1 = mapping_hk1 [0]119 lut_hk1 = mapping_hk1 [1]120 # print "HK1 memory: {0:d}x{1:d}, {2:d} bits -> {3:d} BRAMs or {4:d}
LUTs , needs {5:d} 64-bit words". format(width_hk1 [0], width_hk1 [1],memory_hk1 , bram_hk1 , lut_hk1 , transfer_hk1)
121122 ## HK2 ##123 width_hk2 = [ k2, n-k ]124 memory_hk2 = width_hk2 [0] * width_hk2 [1]125 transfer_hk2 = ceil(width_hk2 [1] / 64) * width_hk2 [0]126 mapping_hk2 = map2bram(width_hk2 [0], width_hk2 [1], true)127 bram_hk2 = mapping_hk2 [0]128 lut_hk2 = mapping_hk2 [1]129 # print "HK2 memory: {0:d}x{1:d}, {2:d} bits -> {3:d} BRAMs or {4:d}
LUTs , needs {5:d} 64-bit words". format(width_hk2 [0], width_hk2 [1],memory_hk2 , bram_hk2 , lut_hk2 , transfer_hk2)
130131 # total memory132 memory_core = memory_cmem + memory_hk1 + memory_hk2133 transfer_core = transfer_cmem + transfer_hk1 + transfer_hk2134135 # choose to build the cores either with distributed or bram resources
for CMEM136 bram_core_lut = bram_hk1 + bram_hk2137 bram_core_full= bram_core_lut + bram_cmem138 cores_no_cmem = floor(bram_free / bram_core_lut)139 cores_full = floor(bram_free / bram_core_full)140141 # default: use BRAM142 cores = cores_full143 lut_core = 0144 bram_core = bram_core_full145146 # does LUT usage make sense?147 if cores_no_cmem > cores_full:148 # if so, prevent very high LUT usage149 # and overwrite defaults
106

A.3 Listings
150 if cores_no_cmem * lut_cmem < 16000:151 cores = cores_no_cmem152 lut_core = lut_cmem153 bram_core = bram_core_lut154155 # FPGA usage156 bram_fpga = bram_core * cores + api_bram157 lut_fpga = lut_core * cores158159 # only continue if we can fit at least one core on the FPGA ...160 if cores > 0:161162 ### total memory ###163 cores_total = cores * fpgas164 memory_total = memory_core * cores_total165 transfer_total= transfer_core * cores_total166 #print "cores:", cores_total , "memory =", memory_total , "transfer =",
transfer_total167168 #### iterations and expected cycles ####169 # cycles to finish computation on all FPGAs in parallel170 cycles_enumerator = binomial(k2, p2)171 cycles_pipeline = 4172 cycles_popcount = log2_nkl -1173 # note: if we need an additional clock cycle when testing more than
one collision174 # we175 collisions_in_cmem = k1 * (1 - (1 - 1/(2**l))**(k1 -1))176 cycles_cmem = round(( cycles_enumerator / (2**l)) * (1 /
collisions_in_cmem))177 cycles_per_iteration = ceil(cycles_enumerator + cycles_pipeline +
cycles_popcount + cycles_cmem)178 # total number of iterations to find a solution179 total_iterations=ceil( const_bin_nw / ( binomial(k1 ,p1) * binomial(
k2 ,p2) * binomial_nkl_wp ) )180181 # expected total runs off full machine182 total_expected_runs = ceil( total_iterations / cores_total )183184 ### runtime ###185 # iteration time and transfer time186 time_fpga = float(cycles_per_iteration / cps)187 time_transfer = float(transfer_total * 64 / api_mbps_div)188189 # as FPGAs run in parallel to the transfer (ring bus), optimize them
against each other190 time_run = max(time_fpga , time_transfer)191192 # total runtime193 runtime = time_startup + (total_expected_runs * time_run)194195 # check if the result is better than the previous best result196 if runtime < local_best [0]:197 local_best =[runtime , p1 , p2 , l, k1, k2 , cores , memory_core ,
bram_core , lut_core , transfer_core , bram_fpga , lut_fpga ,
107

Appendix A Additional Content
transfer_total , time_fpga , time_transfer , time_run ,total_iterations , cycles_per_iteration , total_expected_runs]
198199 # return best result200 return local_best201202203 # compute results for all parameter sets204205 # we can loop later on...206 for fpga_type in range(len(_fpga_name)):207208 # set correct values for the selected FPGA209 fpga_name = _fpga_name[fpga_type ]. rjust (10)210 fpgas = _fpgas[fpga_type]211 clk_freq = _clk_freq[fpga_type]212 cps = clk_freq * (10**6)213 api_bram = _api_bram[fpga_type]214 api_mbps = _api_mbps[fpga_type]215 api_mbps_div = api_mbps * (2**20)216 lut_size = _lut_size[fpga_type]217 bram_max = _bram_max[fpga_type]218 bram_free = _bram_free[fpga_type]219 bram_sp_align = _bram_sp_align[fpga_type]220 bram_dp_align = _bram_dp_align[fpga_type]221222 print "Begin of generation for for device", fpga_name223224 for i in range(len(params)):225 par = params[i]226 print "-------------------------------------"227 print "Parameter", i+1, "/", len(params), "taken from ", par [0]228 n = par [1]229 k = par [2]230 w = par [3]231 max_p = min(6, w) # restrict maximum value of p232 const_bin_nw = binomial(n,w) # precompute n choose w233234 best=fpga_dumer_memtransfer(n,k,w)235 # print best236237 if best [0] == infinity:238 print "\nNo valid configuration found.. probably needs too much memory
for the BRAM approach!"239 else:240 # format values241 runtime = best [0]242 p1 = best [1]243 p2 = best [2]244 l = best [3]245 k1 = best [4]246 k2 = best [5]247 cores = best [6]248 mem_core = best [7]249 bram_core = best [8]
108

A.3 Listings
250 lut_core = best [9]251 transfer_core = best [10]252 bram_fpga = best [11]253 lut_fpga = best [12]254 transfer_total = best [13]255 time_fpga = best [14]256 time_transfer = best [15]257 time_run = best [16]258 total_it = best [17]259 cycles_per_it = best [18]260 total_exp_runs = best [19]261262 # split runtime in d/h/m/s263 tmp = ceil(runtime)264 runtime_s = tmp % 60265 tmp = (tmp -runtime_s)/60266 runtime_m = tmp % 60267 tmp = (tmp -runtime_m)/60268 runtime_h = tmp % 24269 tmp = (tmp -runtime_h)/24270 runtime_d = tmp % 365271 tmp = (tmp -runtime_d)/365272 runtime_y = round(tmp)273274 print "\nOptimal parameters for a COLLISION ATTACK (memory transfer) are:
"275 print "{0:s} Parameters: {1:2d} cores per FPGA , {2:3d} FPGAs , {3:.3f} s
setup time , {4:.2f} Mbps transfer , {5:d} MHz clk freq".format(fpga_name , cores , fpgas , float(time_startup), float(api_mbps),clk_freq)
276 print " Challenge Parameters: n = {0:d}, k = {1:d}, w = {2:d}".format(n,k,w)
277 print " Attack Parameters: p = {0:d}, p1 = {1:d}, p2 = {2:d}, l = {3:d}, k1 = {4:d}, k2 = {5:d}".format(p1+p2, p1, p2 , l, k1, k2)
278 print " Core Details : bram = {0:d}, lut = {1:d} ({2:d} bitsstored data), {3:d} 64-bit words transferred".format(bram_core ,lut_core , mem_core , transfer_core)
279 print " FPGA Details : bram = {0:d}, lut = {1:d}, {2:d} 64-bitwords transferred".format(bram_fpga , lut_fpga , transfer_total)
280 print " Time / Run : {0:.3f} s (transfer), {1:.3f} s (computation), {2:.3f} s (total)".format(float(time_transfer), float(time_fpga), float(time_run))
281 print " Expected Duration : 2^({0:03.2f}) iterations expected ,2^({1:03.2f}) cycles per {2:d} iterations".format(float(log2(total_it)), float(log2(cycles_per_it)), cores*fpgas)
282 print " Attack Duration : 2^({0:03.2f}) expected runs in {1:d} y, {2:d} d, {3:d} h, {4:d} m, {5:d} s".format(float(log2(total_exp_runs)),runtime_y , runtime_d , runtime_h , runtime_m , runtime_s)
283 #284 #print "EOF"
109

110

Bibliography
[ACD+06] Roberto Avanzi, Henri Cohen, Christophe Doche, Gerhard Frey, Tanja Lange, KimNguyen, and Frederik Vercauteren. Handbook of elliptic and hyperelliptic curvecryptography. Discrete Mathematics and its Applications (Boca Raton). Chapman& Hall/CRC, Boca Raton, FL, 2006.
[ADH+09] Jean-Philippe Aumasson, Itai Dinur, Luca Henzen, Willi Meier, and Adi Shamir.Efficient FPGA Implementations of High-Dimensional Cube Testers on the StreamCipher Grain-128. Workshop on Special-purpose Hardware for Attacking Crypto-graphic Systems – SHARCS, September 2009.
[ADMS09] Jean-Philippe Aumasson, Itai Dinur, Willi Meier, and Adi Shamir. Cube Testersand Key Recovery Attacks on Reduced-Round MD6 and Trivium. In Orr Dunkel-man, editor, Fast Software Encryption, 16th International Workshop, FSE 2009,Leuven, Belgium, February 22-25, 2009, Revised Selected Papers, volume 5665 ofLecture Notes in Computer Science, pages 1–22. Springer, 2009.
[Aye09] John Ayer, Jr. Using the Memory Endpoint Test Driver (MET) with the Pro-grammed Input/Output Example Design for PCI Express Endpoint Cores. Xilinx,xapp1022 v2.0 edition, November 2009.
[BBB+09] Daniel V. Bailey, Lejla Batina, Daniel J. Bernstein, Peter Birkner, Joppe W. Bos,Hsieh-Chung Chen, Chen-Mou Cheng, Gauthier Van Damme, Giacomo de Meule-naer, Luis J. Dominguez Perez, Junfeng Fan, Tim Güneysu, Frank K. Gürkaynak,Thorsten Kleinjung, Tanja Lange, Nele Mentens, Ruben Niederhagen, ChristofPaar, Francesco Regazzoni, Peter Schwabe, Leif Uhsadel, Anthony Van Her-rewege, and Bo-Yin Yang. Breaking ECC2K-130. IACR Cryptology ePrint Archive,2009:541, 2009.
[BCC+13] Charles Bouillaguet, Chen-Mou Cheng, Tung Chou, Ruben Niederhagen, and Bo-Yin Yang. Fast Exhaustive Search for Quadratic Systems in F2 on FPGAs. In TanjaLange, Kristin E. Lauter, and Petr Lisonek, editors, Selected Areas in Cryptography- SAC 2013 - 20th International Conference, Burnaby, BC, Canada, August 14-16,2013, Revised Selected Papers, volume 8282 of Lecture Notes in Computer Science,pages 205–222. Springer, 2013.
[BD08] Johannes Buchmann and Jintai Ding, editors. Post-Quantum Cryptography, Sec-ond International Workshop, PQCrypto 2008, Cincinnati, OH, USA, October17-19, 2008, Proceedings, volume 5299 of Lecture Notes in Computer Science.Springer, 2008.
111

Bibliography
[BdDQ06] Philippe Bulens, Guerric Meurice de Dormale, and Jean-Jacques Quisquater.Hardware for Collision Search on Elliptic Curve over GF (2m). Workshop onSpecial-purpose Hardware for Attacking Cryptographic Systems – SHARCS, April2006.
[BDP06] William E. Burr, Donna F. Dodson, and W. Timothy Polk. Electronic Authenti-cation Guideline: NIST Special Publication 800-63, 2006.
[Bel09] Andrey Belenko. GPU Assisted Password Cracking, April 2009. Pre-sented at TROOPERS’09, http://www.troopers.de/events/troopers09/230_gpu-assisted_password_cracking/.
[Bev08] Marc Bevand. Breaking UNIX crypt() on the PlayStation 3, September 2008.Presented at ToorCon 10, San Diego, CA, USA, http://www.zorinaq.com/talks/breaking-unix-crypt.pdf.
[BJMM12] Anja Becker, Antoine Joux, Alexander May, and Alexander Meurer. DecodingRandom Binary Linear Codes in 2n/20: How 1 + 1 = 0 Improves Information SetDecoding. In Pointcheval and Johansson [PJ12], pages 520–536.
[BK95] Matt Bishop and Daniel V. Klein. Improving system security via proactive pass-word checking. Computers & Security, 14(3):233–249, 1995.
[BKK+09] Joppe W. Bos, Marcelo E. Kaihara, Thorsten Kleinjung, Arjen K. Lenstra, andPeter L. Montgomery. PlayStation 3 computing breaks 260 barrier; 112-bit primeECDLP solved, 2009.
[BKL10] Joppe W. Bos, Thorsten Kleinjung, and Arjen K. Lenstra. On the Use of theNegation Map in the Pollard Rho Method. In Guillaume Hanrot, François Morain,and Emmanuel Thomé, editors, Algorithmic Number Theory, 9th InternationalSymposium, ANTS-IX, Nancy, France, July 19-23, 2010. Proceedings, volume 6197of Lecture Notes in Computer Science, pages 66–82. Springer, 2010.
[BKM09] Joppe W. Bos, Marcelo E. Kaihara, and Peter L. Montgomery. Pollard rho on thePlayStation 3. Workshop on Special-purpose Hardware for Attacking CryptographicSystems – SHARCS, pages 30–50, September 2009.
[BL12] Daniel J. Bernstein and Tanja Lange. Two grumpy giants and a baby. In Everett W.Howe and Kiran S. Kedlaya, editors, Algorithmic Number Theory, 10th Interna-tional Symposium, ANTS-X, San Diego, CA, USA, July 9-13, 2012. Proceedings,volume 1 of Open Book Series, pages 87–111. Mathematical Sciences Publishers,2012.
[BLP08] Daniel J. Bernstein, Tanja Lange, and Christiane Peters. Attacking and Defendingthe McEliece Cryptosystem. In Buchmann and Ding [BD08], pages 31–46.
[BLP11a] Daniel J. Bernstein, Tanja Lange, and Christiane Peters. Smaller decoding expo-nents: Ball-collision decoding. In Phillip Rogaway, editor, Advances in Cryptology- CRYPTO 2011 - 31st Annual Cryptology Conference, Santa Barbara, CA, USA,
112

Bibliography
August 14-18, 2011. Proceedings, volume 6841 of Lecture Notes in Computer Sci-ence, pages 743–760. Springer, 2011.
[BLP11b] Daniel J. Bernstein, Tanja Lange, and Christiane Peters. Wild McEliece. InProceedings of the 17th international conference on Selected areas in cryptography,SAC’10, pages 143–158, Berlin, Heidelberg, 2011. Springer-Verlag.
[BLP13] Daniel J. Bernstein, Tanja Lange, and Christiane Peters. Cryptanalytic challengesfor wild McEliece. http://pqcrypto.org/wild-challenges.html, June 2013.
[BLS11] Daniel J. Bernstein, Tanja Lange, and Peter Schwabe. On the Correct Use of theNegation Map in the Pollard Rho Method. In Dario Catalano, Nelly Fazio, RosarioGennaro, and Antonio Nicolosi, editors, Public Key Cryptography - PKC 2011 -14th International Conference on Practice and Theory in Public Key Cryptography,Taormina, Italy, March 6-9, 2011. Proceedings, volume 6571 of Lecture Notes inComputer Science, pages 128–146. Springer, 2011.
[BS90] Eli Biham and Adi Shamir. Differential Cryptanalysis of DES-like Cryptosys-tems. In Alfred Menezes and Scott A. Vanstone, editors, Advances in Cryptology -CRYPTO ’90, 10th Annual International Cryptology Conference, Santa Barbara,California, USA, August 11-15, 1990, Proceedings, volume 537 of Lecture Notes inComputer Science, pages 2–21. Springer, 1990.
[Bud00] Stephen Budiansky. Battle of wits: the complete story of codebreaking in WorldWar II. Free Press, 2000.
[CCDP13] Claude Castelluccia, Abdelberi Chaabane, Markus Dürmuth, and Daniele Perito.OMEN: An improved password cracker leveraging personal information. Availableas arXiv:1304.6584, 2013.
[CDP12] Claude Castelluccia, Markus Dürmuth, and Daniele Perito. Adaptive Password-Strength Meters from Markov Models. In 19th Annual Network and DistributedSystem Security Symposium, NDSS 2012, San Diego, California, USA, February5-8, 2012. The Internet Society, 2012.
[CKP08] Christophe De Cannière, Özgül Küçük, and Bart Preneel. Analysis of Grain’sInitialization Algorithm. In Vaudenay [Vau08], pages 276–289.
[Dam07] Ivan Damgård. A "proof-reading" of Some Issues in Cryptography. In Lars Arge,Christian Cachin, Tomasz Jurdzinski, and Andrzej Tarlecki, editors, Automata,Languages and Programming, 34th International Colloquium, ICALP 2007, Wro-claw, Poland, July 9-13, 2007, Proceedings, volume 4596 of Lecture Notes in Com-puter Science, pages 2–11. Springer, 2007.
[dDBQ07] Guerric Meurice de Dormale, Philippe Bulens, and Jean-Jacques Quisquater. Col-lision Search for Elliptic Curve Discrete Logarithm over GF(2m) with FPGA.In Pascal Paillier and Ingrid Verbauwhede, editors, Cryptographic Hardware andEmbedded Systems - CHES 2007, 9th International Workshop, Vienna, Austria,September 10-13, 2007, Proceedings, volume 4727 of Lecture Notes in ComputerScience, pages 378–393. Springer, 2007.
113

Bibliography
[DGK+12] Markus Dürmuth, Tim Güneysu, Markus Kasper, Christof Paar, Tolga Yalçin, andRalf Zimmermann. Evaluation of Standardized Password-Based Key Derivationagainst Parallel Processing Platforms. In Sara Foresti, Moti Yung, and Fabio Mar-tinelli, editors, Computer Security - ESORICS 2012 - 17th European Symposiumon Research in Computer Security, Pisa, Italy, September 10-12, 2012. Proceed-ings, volume 7459 of Lecture Notes in Computer Science, pages 716–733. Springer,2012.
[DGP+11] Itai Dinur, Tim Güneysu, Christof Paar, Adi Shamir, and Ralf Zimmermann. AnExperimentally Verified Attack on Full Grain-128 Using Dedicated ReconfigurableHardware. In Lee and Wang [LW11], pages 327–343.
[DGP+12] Itai Dinur, Tim Güneysu, Christof Paar, Adi Shamir, and Ralf Zimmermann.Experimentally Verifying a Complex Algebraic Attack on the Grain-128 CipherUsing Dedicated Reconfigurable Hardware. Workshop on Special-purpose Hardwarefor Attacking Cryptographic Systems – SHARCS, March 2012.
[DH77] Whitfield Diffie and Martin E. Hellman. Special Feature Exhaustive Cryptanalysisof the NBS Data Encryption Standard. Computer, 10(6):74–84, June 1977.
[DK14] Markus Dürmuth and Thorsten Kranz. On Password Guessing with GPUs andFPGAs. In Stig F. Mjølsnes, editor, Technology and Practice of Passwords -International Conference on Passwords, PASSWORDS’14, Trondheim, Norway,December 8-10, 2014, Revised Selected Papers, volume 9393 of Lecture Notes inComputer Science, pages 19–38. Springer, 2014.
[DS09] Itai Dinur and Adi Shamir. Cube Attacks on Tweakable Black Box Polynomials.In Antoine Joux, editor, Advances in Cryptology - EUROCRYPT 2009, 28th An-nual International Conference on the Theory and Applications of CryptographicTechniques, Cologne, Germany, April 26-30, 2009. Proceedings, volume 5479 ofLecture Notes in Computer Science, pages 278–299. Springer, 2009.
[DS11] Itai Dinur and Adi Shamir. Breaking Grain-128 with Dynamic Cube Attacks. InAntoine Joux, editor, Fast Software Encryption - 18th International Workshop,FSE 2011, Lyngby, Denmark, February 13-16, 2011, Revised Selected Papers, vol-ume 6733 of Lecture Notes in Computer Science, pages 167–187. Springer, 2011.
[EJT07] Håkan Englund, Thomas Johansson, and Meltem Sönmez Turan. A Frameworkfor Chosen IV Statistical Analysis of Stream Ciphers. In K. Srinathan, C. PanduRangan, and Moti Yung, editors, Progress in Cryptology - INDOCRYPT 2007,8th International Conference on Cryptology in India, Chennai, India, December9-13, 2007, Proceedings, volume 4859 of Lecture Notes in Computer Science, pages268–281. Springer, 2007.
[Eng14] Susanne Engels. Breaking ecc2-113: Efficient Implementation of an OptimizedAttack on a Reconfigurable Hardware Cluster. Master Thesis, Ruhr-UniversityBochum, 2014.
114

Bibliography
[FKM08] Simon Fischer, Shahram Khazaei, and Willi Meier. Chosen IV Statistical Analysisfor Key Recovery Attacks on Stream Ciphers. In Vaudenay [Vau08], pages 236–245.
[Fou98] Electronic Frontier Foundation. Cracking DES: Secrets of Encryption Research,Wiretap Politics and Chip Design. O’Reilly & Associates, Inc., Sebastopol, CA,USA, 1998.
[GKN+08] Tim Güneysu, Timo Kasper, Martin Novotný, Christof Paar, and Andy Rupp.Cryptanalysis with COPACOBANA. IEEE Trans. Computers, 57(11):1498–1513,2008.
[GKN+13] Tim Güneysu, Timo Kasper, Martin Novotný, Christof Paar, Lars Wienbrandt,and Ralf Zimmermann. High-Performance Cryptanalysis on RIVYERA and CO-PACOBANA Computing Systems. In Wim Vanderbauwhede and Khaled Benkrid,editors, High-Performance Computing Using FPGAs, pages 335–366. Springer NewYork, 2013.
[GNR08] Timo Gendrullis, Martin Novotný, and Andy Rupp. A Real-World Attack Break-ing A5/1 within Hours. In Elisabeth Oswald and Pankaj Rohatgi, editors, Crypto-graphic Hardware and Embedded Systems - CHES 2008, 10th International Work-shop, Washington, D.C., USA, August 10-13, 2008. Proceedings, volume 5154 ofLecture Notes in Computer Science, pages 266–282. Springer, 2008.
[Gol06] Oded Goldreich. On Post-Modern Cryptography. IACR Cryptology ePrint Archive,2006:461, 2006.
[GPPS08] Tim Güneysu, Christof Paar, Gerd Pfeiffer, and Manfred Schimmler. EnhancingCOPACOBANA for advanced applications in cryptography and cryptanalysis. InFPL 2008, International Conference on Field Programmable Logic and Applica-tions, Heidelberg, Germany, 8-10 September 2008, pages 675–678. IEEE, 2008.
[GPPS09] Tim Güneysu, Gerd Pfeiffer, Christof Paar, and Manfred Schimmler. Three Yearsof Evolution: Cryptanalysis with COPACOBANA Special-Purpose Hardware forAttacking Cryptographic Systems. Workshop on Special-purpose Hardware forAttacking Cryptographic Systems – SHARCS, 2009.
[Gre14] Glenn Greenwald. No Place to Hide: Edward Snowden, the NSA, and the U.S.Surveillance State. Metropolitan Books/Henry Holt, New York, NY, 2014.
[Har98] Robert J. Harley. Solution to Certicom’s ECC2K-95 problem (email message),1998.
[Hel80] Martin E. Hellman. A cryptanalytic time-memory trade-off. IEEE Transactionson Information Theory, 26(4):401–406, 1980.
[Hey13] Stefan Heyse. Post Quantum Cryptography: Implementing Alternative Public KeySchemes on Embedded Devices — Preparing for the Rise of Quantum Computers.PhD thesis, Ruhr-University Bochum, 2013.
115

Bibliography
[HJM07] Martin Hell, Thomas Johansson, and Willi Meier. Grain - A Stream Cipher forConstrained Environments. International Journal of Wireless and Mobile Com-puting, 2(1):86–93, May 2007.
[HJMM06] Martin Hell, Thomas Johansson, Er Maximov, and Willi Meier. A Stream CipherProposal: Grain-128. In Information Theory, 2006 IEEE International Symposiumon, pages 1614 –1618, july 2006.
[HMV04] Darrel Hankerson, Alfred Menezes, and Scott Vanstone. Guide to elliptic curvecryptography. Springer Professional Computing. New York, 2004.
[HV08] Sean Hallgren and Ulrich Vollmer. Quantum Computing. In Buchmann and Ding[BD08], pages 15–34.
[HZP14] Stefan Heyse, Ralf Zimmermann, and Christof Paar. Attacking Code-Based Cryp-tosystems with Information Set Decoding Using Special-Purpose Hardware. InMichele Mosca, editor, Post-Quantum Cryptography - 6th International Workshop,PQCrypto 2014, Waterloo, ON, Canada, October 1-3, 2014. Proceedings, volume8772 of Lecture Notes in Computer Science, pages 126–141. Springer, 2014.
[IEE07] IEEE Standard for Information Technology 802.11 - Telecommunications and In-formation Exchange Between Systems - Local and Metropolitan Area Networks -Specific Requirements - Part 11: Wireless LAN Medium Access Control (MAC)and Physical Layer (PHY), 2007. http://standards.ieee.org/getieee802/download/802.11-2007.pdf.
[IET00] PKCS #5: Password-Based Cryptography Specification Version 2.0, Sept. 2000.http://tools.ietf.org/html/rfc2898.
[IET06] Elliptic Curve Cryptography (ECC) Cipher Suites for Transport Layer Security(TLS), May. 2006. http://tools.ietf.org/html/rfc4492.
[IET09] Elliptic Curve Algorithm Integration in the Secure Shell Transport Layer, Dec.2009. http://tools.ietf.org/html/rfc5656.
[Jou09] Antoine Joux. Algorithmic Cryptanalysis. Chapman & Hall/CRC, 2009.
[KI99] Gershon Kedem and Yuriko Ishihara. Brute Force Attack on UNIX Passwords withSIMD Computer. In G. Winfield Treese, editor, Proceedings of the 8th USENIX Se-curity Symposium, Washington, D.C., August 23-26, 1999. USENIX Association,1999.
[Kle90] Daniel Klein. Foiling the Cracker: a Survey of, and Improvements to, PasswordSecurity. In USENIX, editor, UNIX Security II Symposium, August 27–28, 1990.Portland, Oregon, pages 101–106. USENIX, aug 1990.
[KM06] Neal Koblitz and Alfred Menezes. Another Look at "Provable Security". II. InRana Barua and Tanja Lange, editors, Progress in Cryptology - INDOCRYPT
116

Bibliography
2006, 7th International Conference on Cryptology in India, Kolkata, India, Decem-ber 11-13, 2006, Proceedings, volume 4329 of Lecture Notes in Computer Science,pages 148–175. Springer, 2006.
[KM07] Neal Koblitz and Alfred Menezes. Another Look at "Provable Security". J. Cryp-tology, 20(1):3–37, 2007.
[KMNP10] Simon Knellwolf, Willi Meier, and María Naya-Plasencia. Conditional DifferentialCryptanalysis of NLFSR-Based Cryptosystems. In Masayuki Abe, editor, Ad-vances in Cryptology - ASIACRYPT 2010 - 16th International Conference on theTheory and Application of Cryptology and Information Security, Singapore, De-cember 5-9, 2010. Proceedings, volume 6477 of Lecture Notes in Computer Science,pages 130–145. Springer, 2010.
[KO63] Anatolii Karatsuba and Yuri Ofman. Multiplication of Multidigit Numbers onAutomata. Soviet Physics-Doklady, 7:595–596, 1963.
[Koc96] Paul C. Kocher. Timing Attacks on Implementations of Diffie-Hellman, RSA, DSS,and Other Systems. In Neal Koblitz, editor, Advances in Cryptology - CRYPTO’96, 16th Annual International Cryptology Conference, Santa Barbara, California,USA, August 18-22, 1996, Proceedings, volume 1109 of Lecture Notes in ComputerScience, pages 104–113. Springer, 1996.
[KPP+06] Sandeep S. Kumar, Christof Paar, Jan Pelzl, Gerd Pfeiffer, and Manfred Schimm-ler. Breaking Ciphers with COPACOBANA - A Cost-Optimized Parallel CodeBreaker. In Louis Goubin and Mitsuru Matsui, editors, Cryptographic Hardwareand Embedded Systems - CHES 2006, 8th International Workshop, Yokohama,Japan, October 10-13, 2006, Proceedings, volume 4249 of Lecture Notes in Com-puter Science, pages 101–118. Springer, 2006.
[KSK+11] Saranga Komanduri, Richard Shay, Patrick Gage Kelley, Michelle L. Mazurek,Lujo Bauer, Nicolas Christin, Lorrie Faith Cranor, and Serge Egelman. Of Pass-words and People: Measuring the Effect of Password-Composition Policies. InDesney S. Tan, Saleema Amershi, Bo Begole, Wendy A. Kellogg, and Manas Tun-gare, editors, Proceedings of the International Conference on Human Factors inComputing Systems, CHI 2011, Vancouver, BC, Canada, May 7-12, 2011, pages2595–2604. ACM, 2011.
[Lai94] Xuejia Lai. Higher Order Derivatives and Differential Cryptanalysis. In Richard E.Blahut, Daniel J. Costello, Jr., Ueli Maurer, and Thomas Mittelholzer, editors,Communication and Cryptography: Two Sides of One Tapestry, pages 227–233.Springer, 1994.
[LB88] Pil Joong Lee and Ernest F. Brickell. An Observation on the Security of McEliece’sPublic-Key Cryptosystem. In Christoph G. Günther, editor, Advances in Cryp-tology - EUROCRYPT ’88, Workshop on the Theory and Application of of Cryp-tographic Techniques, Davos, Switzerland, May 25-27, 1988, Proceedings, volume330 of Lecture Notes in Computer Science, pages 275–280. Springer, 1988.
117

Bibliography
[Leo88] Jeffrey S. Leon. A Probabilistic Algorithm for Computing Minimum Weightsof Large Error-correcting Codes. IEEE Transactions on Information Theory,34(5):1354–1359, 1988.
[LJSH08] Yuseop Lee, Kitae Jeong, Jaechul Sung, and Seokhie Hong. Related-Key ChosenIV Attacks on Grain-v1 and Grain-128. In Yi Mu, Willy Susilo, and JenniferSeberry, editors, Information Security and Privacy, 13th Australasian Conference,ACISP 2008, Wollongong, Australia, July 7-9, 2008, Proceedings, volume 5107 ofLecture Notes in Computer Science, pages 321–335. Springer, 2008.
[LW11] Dong Hoon Lee and Xiaoyun Wang, editors. Advances in Cryptology - ASI-ACRYPT 2011 - 17th International Conference on the Theory and Applicationof Cryptology and Information Security, Seoul, South Korea, December 4-8, 2011.Proceedings, volume 7073 of Lecture Notes in Computer Science. Springer, 2011.
[Mal13] Katja Malvoni. Energy-efficient bcrypt cracking, Dec 2013. Presen-tation held at PasswordCon Bergen, 2013. Slides online at: http://www.openwall.com/presentations/Passwords13-Energy-Efficient-Cracking/Passwords13-Energy-Efficient-Cracking.pdf.
[Mat94] Mitsuru Matsui. The First Experimental Cryptanalysis of the Data EncryptionStandard. In Yvo Desmedt, editor, Advances in Cryptology - CRYPTO ’94, 14thAnnual International Cryptology Conference, Santa Barbara, California, USA, Au-gust 21-25, 1994, Proceedings, volume 839 of Lecture Notes in Computer Science,pages 1–11. Springer, 1994.
[MBPV06] Nele Mentens, Lejla Batina, Bart Preneel, and Ingrid Verbauwhede. Time-MemoryTrade-Off Attack on FPGA Platforms: UNIX Password Cracking. In Koen Bertels,João M. P. Cardoso, and Stamatis Vassiliadis, editors, Reconfigurable Computing:Architectures and Applications, Second International Workshop, ARC 2006, Delft,The Netherlands, March 1-3, 2006, Revised Selected Papers, volume 3985 of LectureNotes in Computer Science, pages 323–334. Springer, 2006.
[McE78] Robert J. McEliece. A Public-key Cryptosystem Based on Algebraic Coding The-ory. Technical report, Jet Propulsion Lab Deep Space Network Progress report,1978.
[MDK14] Katja Malvoni, Solar Designer, and Josip Knezovic. Are Your Passwords Safe:Energy-Efficient Bcrypt Cracking with Low-Cost Parallel Hardware. In SergeyBratus and Felix F. X. Lindner, editors, 8th USENIX Workshop on OffensiveTechnologies, WOOT ’14, San Diego, CA, USA, August 19, 2014. USENIX Asso-ciation, 2014.
[Men12] Alfred Menezes. Another Look at Provable Security. In Pointcheval and Johansson[PJ12], page 8.
[MMT11] Alexander May, Alexander Meurer, and Enrico Thomae. Decoding Random LinearCodes in O(20.054n). In Lee and Wang [LW11], pages 107–124.
118

Bibliography
[MT79] Robert Morris and Ken Thompson. Password Security - A Case History. Commun.ACM, 22(11):594–597, 1979.
[Nie86] H. Niederreiter. Knapsack-type Cryptosystems and Algebraic Coding Theory.Problems Control Inform. Theory/Problemy Upravlen. Teor. Inform., 15(2):159–166, 1986.
[Nie12] Ruben Niederhagen. Parallel Cryptanalysis. PhD thesis, Eindhoven University ofTechnology, 2012. http://polycephaly.org/thesis/index.shtml.
[NS05] Arvind Narayanan and Vitaly Shmatikov. Fast dictionary attacks on passwordsusing time-space tradeoff. In Vijay Atluri, Catherine Meadows, and Ari Juels, edi-tors, Proceedings of the 12th ACM Conference on Computer and CommunicationsSecurity, CCS 2005, Alexandria, VA, USA, November 7-11, 2005, pages 364–372.ACM, 2005.
[Oec03] Philippe Oechslin. Making a Faster Cryptanalytic Time-Memory Trade-Off. InDan Boneh, editor, Advances in Cryptology - CRYPTO 2003, 23rd Annual Inter-national Cryptology Conference, Santa Barbara, California, USA, August 17-21,2003, Proceedings, volume 2729 of Lecture Notes in Computer Science, pages 617–630. Springer, 2003.
[OS08] Raphael Overbeck and Nicolas Sendrier. Code-based Cryptogrpahy. In Buchmannand Ding [BD08], pages 95–145.
[Per09] Colin Percival. Stronger Key Derivation via Sequential Memory-Hard Func-tions. Presentation at BSDCan’09. Available online at http://www.tarsnap.com/scrypt/scrypt.pdf, 2009.
[Pet11] Christiane Pascale Peters. Curves, Codes, and Cryptography. PhD thesis, Tech-nische Universiteit Eindhoven, 2011.
[PJ12] David Pointcheval and Thomas Johansson, editors. Advances in Cryptology - EU-ROCRYPT 2012 - 31st Annual International Conference on the Theory and Ap-plications of Cryptographic Techniques, Cambridge, UK, April 15-19, 2012. Pro-ceedings, volume 7237 of Lecture Notes in Computer Science. Springer, 2012.
[PM99] Niels Provos and David Mazières. A Future-Adaptable Password Scheme. InProceedings of the FREENIX Track: 1999 USENIX Annual Technical Conference,June 6-11, 1999, Monterey, California, USA, pages 81–91. USENIX, 1999.
[Pol78] John M. Pollard. Monte Carlo methods for index computation mod p. Mathematicsof Computation, 32:918–924, 1978.
[Pra62] Eugene Prange. The Use of Information Sets in Decoding Cyclic Codes. IRETransactions on Information Theory, 8(5):5–9, 1962.
[Sch93] Bruce Schneier. Description of a New Variable-Length Key, 64-bit Block Cipher(Blowfish). In Ross J. Anderson, editor, Fast Software Encryption, Cambridge
119

Bibliography
Security Workshop, Cambridge, UK, December 9-11, 1993, Proceedings, volume809 of Lecture Notes in Computer Science, pages 191–204. Springer, 1993.
[Sch95] Bruce Schneier. Applied cryptography (2nd ed.): protocols, algorithms, and sourcecode in C. John Wiley & Sons, Inc., New York, NY, USA, 1995.
[Sch10] Marc Schober. Efficient Password and Key recovery using Graphic Cards. Master’sthesis, Ruhr-University Bochum, 2010.
[Ser98] Gadiel Seroussi. Compact Representation of Elliptic Curve Points over F2n . Tech-nical report, HP Labs Technical Reports, 1998.
[SHM10] Stuart E. Schechter, Cormac Herley, and Michael Mitzenmacher. Popularity IsEverything: A New Approach to Protecting Passwords from Statistical-GuessingAttacks. In Wietse Venema, editor, 5th USENIX Workshop on Hot Topics in Secu-rity, HotSec’10, Washington, D.C., USA, August 10, 2010. USENIX Association,2010.
[Sho97] Peter W. Shor. Polynomial-Time Algorithms for Prime Factorization and Dis-crete Logarithms on a Quantum Computer. SIAM J. Comput., 26(5):1484–1509,October 1997.
[Spa92] Eugene Spafford. Observations on Reusable Password Choices. In USENIX, editor,UNIX Security III Symposium, September 14–17, 1992. Baltimore, MD, pages 299–312. USENIX, sep 1992.
[Sta10] Paul Stankovski. Greedy Distinguishers and Nonrandomness Detectors. In GuangGong and Kishan Chand Gupta, editors, Progress in Cryptology - INDOCRYPT2010 - 11th International Conference on Cryptology in India, Hyderabad, India,December 12-15, 2010. Proceedings, volume 6498 of Lecture Notes in ComputerScience, pages 210–226. Springer, 2010.
[Ste88] Jacques Stern. A Method for Finding Codewords of Small Weight. In Gérard D.Cohen and Jacques Wolfmann, editors, Coding Theory and Applications, 3rd In-ternational Colloquium, Toulon, France, November 2-4, 1988, Proceedings, volume388 of Lecture Notes in Computer Science, pages 106–113. Springer, 1988.
[Tes01] Edlyn Teske. On random walks for Pollard’s rho method. Math. Comput.,70(234):809–825, 2001.
[Vau08] Serge Vaudenay, editor. Progress in Cryptology - AFRICACRYPT 2008, First In-ternational Conference on Cryptology in Africa, Casablanca, Morocco, June 11-14,2008. Proceedings, volume 5023 of Lecture Notes in Computer Science. Springer,2008.
[Vie07] Michael Vielhaber. Breaking ONE.FIVIUM by AIDA an Algebraic IV DifferentialAttack. IACR Cryptology ePrint Archive, 2007:413, 2007.
[vOW99] Paul C. van Oorschot and Michael J. Wiener. Parallel Collision Search with Crypt-analytic Applications. J. Cryptology, 12(1):1–28, 1999.
120

Bibliography
[WA10] Jake Wiltgen and John Ayer. Bus Master DMA Performance Demonstration Ref-erence Design for the Xilinx Endpoint PCI Express Solutions. Xilinx, xapp1052edition, September 2010.
[WACS10] Matt Weir, Sudhir Aggarwal, Michael P. Collins, and Henry Stern. Testing metricsfor password creation policies by attacking large sets of revealed passwords. InEhab Al-Shaer, Angelos D. Keromytis, and Vitaly Shmatikov, editors, Proceedingsof the 17th ACM Conference on Computer and Communications Security, CCS2010, Chicago, Illinois, USA, October 4-8, 2010, pages 162–175. ACM, 2010.
[WAdMG09] Matt Weir, Sudhir Aggarwal, Breno de Medeiros, and Bill Glodek. PasswordCracking Using Probabilistic Context-Free Grammars. In 30th IEEE Symposiumon Security and Privacy (S&P 2009), 17-20 May 2009, Oakland, California, USA,pages 391–405. IEEE Computer Society, 2009.
[Wik12] Openwall Community Wiki. John the Ripper benchmarks, April 2012. http://openwall.info/wiki/john/benchmarks.
[Wu99] Thomas D. Wu. A Real-World Analysis of Kerberos Password Security. In Pro-ceedings of the Network and Distributed System Security Symposium, NDSS 1999,San Diego, California, USA. The Internet Society, 1999.
[WW14] Erich Wenger and Paul Wolfger. Solving the Discrete Logarithm of a 113-BitKoblitz Curve with an FPGA Cluster. In Antoine Joux and Amr M. Youssef, edi-tors, Selected Areas in Cryptography - SAC 2014 - 21st International Conference,Montreal, QC, Canada, August 14-15, 2014, Revised Selected Papers, volume 8781of Lecture Notes in Computer Science, pages 363–379. Springer, 2014.
[WW15] Erich Wenger and Paul Wolfger. Harder, Better, Faster, Stronger - Elliptic CurveDiscrete Logarithm Computations on FPGAs. Cryptology ePrint Archive, Report2015/143, 2015. http://eprint.iacr.org/.
[WZ14] Friedrich Wiemer and Ralf Zimmermann. High-speed implementation of bcryptpassword search using special-purpose hardware. In 2014 International Confer-ence on ReConFigurable Computing and FPGAs, ReConFig14, Cancun, Mexico,December 8-10, 2014, pages 1–6. IEEE, 2014.
[Xil10a] Xilinx. Bus Master DMA Performance Demonstration Reference Design for theXilinx Endpoint PCI Virtex-6, Virtex-5, Spartan-6 and Spartan-3 FPGA FamiliesBus Master DMA Performance Demonstration Reference Design for the XilinxEndpoint PCI, 2010.
[Xil10b] Xilinx. Virtex-6 FPGA Integrated Block for PCI Express, ug517 v5.0 edition, April2010.
[ZGP10] Ralf Zimmermann, Tim Güneysu, and Christof Paar. High-Performance IntegerFactoring with Reconfigurable Devices. In International Conference on Field Pro-grammable Logic and Applications, FPL 2010, August 31 2010 - September 2,2010, Milano, Italy, pages 83–88. IEEE, 2010.
121

Bibliography
[ZH99] Moshe Zviran and William J. Haga. Password Security: An Empirical Study. J.of Management Information Systems, 15(4):161–186, 1999.
122

List of Abbreviations
AES Advanced Encryption Standard
AES-NI AES New Instructions
ANF algebraic normal form
API Application Programming Interface
AXI Advaned eXtensible Interace Bus
ASCII American Standard Code for Information Interchange
ASIC Application Specific Integrated Circuit
BRAM Block RAM
CLB Configurable Logic Block
CCMP Counter Mode with Cipher Block Chaining Message Authentication Code Protocol
Cell Cell Broadband Engine
COPACOBANA Cost-Optimized Parallel Code Breaker and Analyzer
CPU central processing unit
CUDA Compute Unified Device Architecture
DES Data Encryption Standard
DL Discrete Logarithm
DLP Discrete Logarithm Problem
DMA Direct Memory Access
DRAM Dynamic Random Access Memory
DSP Digital Signal Processing
ECC Elliptic Curve Cryptography
ECDL Elliptic Curve Discrete Logarithm
ECDLP Elliptic Curve Discrete Logarithm Problem
FDE full disk encryption
FF Flip Flop
FIFO First In First Out (memory)
123

Abbreviations
FPGA Field Programmable Gate Array
FSM Finite-State Machine
GCC GNU Compiler Collection
GDLP Generalized Discrete Logarithm Problem
GPGPU General-Purpose Computing on Graphics Processing Units
GPU Graphics Processing Unit
HD Hamming distance
HMAC Hash-based Message Authentication Code
HPC high-performance computation
HW Hamming weight
I/O Input/Output
ISD Information Set Decoding
IV Initialization Vector
JSC Jülich Supercomputing Centre
JtR John the Ripper
KDF Key Derivation Function
LFSR Linear Feedback Shift Register
LTS Long Term Support
LUT Look-Up Table
MAC Message Authentication Code
MD5 Message-Digest Algorithm 5
MSB Most Significant Bit
NSA National Security Agency
NIST National Institute of Standards and Technology
NFSR Nonlinear Feedback Shift Register
OpenCL Open Computing Language
PBKDF Password-Based Key Derivation Function
PBKDF2 Password-Based Key Derivation Function 2
PCI Peripheral Component Interconnect
PCIe PCI Express
PHC Password Hashing Competition
124

Abbreviations
PKCS Public-Key Cryptography Standard
ppd passwords per day
ppm passwords per month
pps passwords per second
PRF pseudo-random function
PS3 PlayStation 3
RAM Random Access Memory
RFID radio-frequency identification
RFC Request for Comments
RIPEMD RACE Integrity Primitives Evaluation Message Digest
RSA Rivest, Shamir and Adleman
SECG Standards for Efficient Cryptography Group
SHA Secure Hash Algorithm
SIMD Single Instruction, Multiple Data
SM Streaming Multiprocessor
SSH Secure Shell
TLS Transport Layer Security
VHDL VHSIC Hardware Description Language
VHSIC Very High Speed Integrated Circuit
WPA2 Wi-Fi Protected Access 2
XOR Exclusive OR
XEX XOR-encrypt-XOR
XTS XEX-based tweaked-codebook mode with ciphertext stealing
125

126

List of Figures
1.1 An overview on cryptology and the subfields cryptography and cryptanalysis.Note that the classification does not cover all aspects of the fields and the algo-rithms and types mentioned are given as examples. . . . . . . . . . . . . . . . . 4
2.1 Exemplary picture of an FPGA layout of a Xilinx XC6SLX16 FPGA. Mostof the device’s area provides CLBs (blue). The I/O pins are located outside,surrounding the programmable area. The FPGA contains 8 independent clockdomain regions. This small device contains two types of hard cores, physicallydistributed in columns: BRAM (pink) and DSP cores (cyan). . . . . . . . . . . . 15
2.2 Architecture of the RIVYERA-S3 cluster system. . . . . . . . . . . . . . . . . . . 16
3.1 Overview on the Grain-128 initialization function as needed for Cube Attacks.This function consists mainly of a linear and a non-linear feedback shift register,both of width 128 bits. The figure is derived from [CKP08]. . . . . . . . . . . . . 23
3.2 Cube Attack — Program-flow for cube dimension d. . . . . . . . . . . . . . . . . 303.3 Necessary Multiplexers for each IV bit (without optimizations) of a worker with
worker cube size d−w andm different polynomials. This is an (m+d−w+1)-to-1bit multiplexer, i. e., with the current parameter set a (64−w)-to-1 bit multiplexer. 32
3.4 FPGA Implementation of the online phase for cube dimension d. . . . . . . . . . 333.5 Cube Attack Implementation utilizing the workflow from Figure 3.2 on the inte-
grated CPU of the RIVYERA FPGA cluster. . . . . . . . . . . . . . . . . . . . . 35
4.1 An abstract view of the PBKDF2 scheme employed in TrueCrypt. Each boxdenotes one iteration of the hash compression function. Two rows together mapto one execution of an HMAC. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.2 Top-Level view of the FPGA design featuring dedicated PBKDF2 cores and —optionally — on-chip verification using all block cipher combinations. . . . . . . 50
4.3 Fraction of passwords guessed correctly (y-axis) vs. the total number of guesses(x-axis). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.4 Schematic Top-Level view of FPGA implementation. The design uses multipleclock-domains: A slower interface clock and a faster bcrypt clock. Each quad-coreaccesses the salt- and hash registers and consists of a dedicated password memory,four bcrypt cores and a password generator. . . . . . . . . . . . . . . . . . . . . 56
4.5 An overview of the highly sequential datapath inferred by the Feistel-structure ofone Blowfish round in comparison to the implementation realized on the FPGA. 57
4.6 Schematic view of the password generation. The counter and registers in the upperhalf store the actual state of the generator. The mapping to ASCII charactersis done by multiplexer. It uses a cyclic output for bcrypt and generates twopasswords in parallel. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
127

List of Figures
4.7 Comparison of different implementations for cost parameter 5. Left bars (red)show the hashes-per-seconds rate, right bars (green) the hashes-per-watt-secondsrate. Results with ∗ were measured with (ocl)Hashcat. The axial scale is loga-rithmic. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.8 Total costs in millions USD for attacking n passwords of length 8 from a set of 62characters using logarithmic scale. Each attack finishes within one month. Boththe acquisition costs for the required amount of devices and the total power costswhere considered. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.9 Total costs in thousands USD for attacking n passwords of length 8 from a setof 62 characters using a cost parameter of 12 (which is commonly recommended)using logarithmic scale. Each attack finishes within one day, with a dictionaryattack where 65% are covered (4 · 109 Tests). . . . . . . . . . . . . . . . . . . . . 61
5.1 Geometric construction of the point addition and point doubling on an ellipticcurve. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.2 Layout of one independent Pollard Rho core: It contains two pipelines as wellas the necessary BRAM cores for the intermediate results and the precomputedpoints. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
6.1 Splitting of the public key into memory segments. The values under the arrowsbelow the matrix denote the assumed Hamming weight distribution of the error e. 85
6.2 Overview of the different modules inside one iteration core. . . . . . . . . . . . . 90
128

List of Tables
3.1 Parameter set for the attack on the full Grain-128, given output bit 257. . . . . . 263.2 Synthesis results of Grain-128 implementation on the Spartan-3 5000 FPGA with
different numbers of parallel steps per clock cycle. . . . . . . . . . . . . . . . . . 343.3 Strategy Overview for the automated build process. The strategies are sorted
from top to bottom. In the worst case, all 16 combinations may be executed. . . 363.4 Results of the generation process for cubes of dimension 46, 47 and 50. The
duration is the time required for the RIVYERA cluster to complete the onlinephase. The Percentage row gives the percentage of configurations built with thegiven clock frequency out of the total number of configurations built with cubesof the same dimension. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.1 Implementation Results of PBKDF2 on 4 Tesla C2070 GPUs . . . . . . . . . . . 524.2 Implementation results and performance numbers of PBKDF2 on the RIVYERA
cluster (Place & Route) without on-chip verification. Please note that the num-bers reflect the worst-case and uses the lowest clock frequency valid for all designsinstead of target-optimized designs. . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.3 Resource utilization of design and submodules. . . . . . . . . . . . . . . . . . . . 574.4 Comparison of multiple implementations and platforms considering full system
power consumption. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.1 Pipeline stages and area of multiplier after synthesis on a Spartan-6 LX150 FPGA. 755.2 Area usage depending on the number of parallel cores. These results are post-
synthesis estimations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 755.3 Tradeoffs for different lookup-table sizes (PA means point addition, FC means
fruitless-cycle check), selected value is bold face. . . . . . . . . . . . . . . . . . . 76
6.1 Weight profile of the codewords searched for by the different algorithms. Numbersin boxes are Hamming weight of the tuples. Derived from [OS08]. . . . . . . . . 84
6.2 Optimal Parameter Set for selected Challenges. . . . . . . . . . . . . . . . . . . . 92
A.1 [Section 5.2.2] Addition Chain to compute the multiplicative inverse by means ofFermat’s Little Theorem. Table based on [Eng14]. . . . . . . . . . . . . . . . . . 102
A.2 [Section 6.4] Parameters of C1 to C4 . . . . . . . . . . . . . . . . . . . . . . . . . 103
129

130

List of Algorithms
1 Dynamic Cube Attack Simulation (Algorithm 12), Optimized for Implementation 302 Pseudo-code of PBKDF2 as specified in [IET00, 5.2] . . . . . . . . . . . . . . . . 443 EksBlowfishSetup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454 bcrypt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 455 Digit-Serial Multiplier in F2m . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 666 Recursive Karatsuba Multiplication in F2m . . . . . . . . . . . . . . . . . . . . . . 667 Squaring with Subsequent Reduction in F2m . . . . . . . . . . . . . . . . . . . . . 678 Information set decoding for parameter p . . . . . . . . . . . . . . . . . . . . . . 849 Modified HW/SW algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8710 Randomization Step . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8811 Iteration Step in Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8912 [Section 3.4.1] The original Dynamic Cube Attack Simulation Algorithm . . . . . 101
131

132

About the Author
Personal Data
Name Ralf Christian ZimmermannAddress Chair for Embedded Security
ID 2/627Universitätsstr. 15044801 Bochum, Germany
E-Mail [email protected] of Birth January 23rd, 1983Place of Birth Cologne, Germany
Short CV
2010–2015 PhD studies, Chair for Embedded Security, Ruhr-University Bochum2003–2009 Student in Computer Science, Technische Universität Braunschweig
Diploma Thesis: Optimized Implementation of the Elliptic Curve Factorization Methodon a Highly Parallelized Hardware ClusterFinal Grade: 1.16
2002 Abitur, Gaußschule, Gymnasium am Löwenwall, Braunschweig
133

134

Publications
Peer-Reviewed Conferences and Workshops
2014 Wiemer, Zimmermann: High-Speed Implementation of bcrypt Password Search usingSpecial-Purpose HardwareReConFig 2014 - International Conference on ReConFigurable Computing and FPGAs
2014 Heyse, Zimmermann, Paar: Attacking Code-Based Cryptosystems with Information SetDecoding Using Special-Purpose HardwarePQCrypto 2014 - 6th International Workshop on Post-Quantum Cryptography
2013 Dürmuth, Güneysu, Kasper, Paar, Yalcin, Zimmermann: Evaluation of StandardizedPassword-Based Key Derivation against Parallel Processing PlatformsESORICS - 18th European Symposium on Research in Computer Security
2012 Dinur, Güneysu, Paar, Shamir, Zimmermann: Experimentally Verifying a Complex Al-gebraic Attack on the Grain-128 Cipher Using Dedicated Reconfigurable HardwareSHARCS’12 - 5th Workshop on Special-Purpose Hardware for Attacking CryptographicSystems
2011 Dinur, Güneysu, Paar, Shamir, Zimmermann: An Experimentally Verified Attack onFull Grain-128 Using Dedicated Reconfigurable HardwareASIACRYPT - 17th Annual International Conference on the Theory and Application ofCryptology and Information Security
2010 Zimmermann, Güneysu, Paar: High-Performance Integer Factoring with ReconfigurableDevicesFPL2010 - 20th International Conference on Field Programmable Logic and Applications
Other Publications
2014 Wiemer, Zimmermann: Speed and Area-Optimized Password Search of bcrypt on FP-GAsCryptArchi - 12th International Workshop on Cryptographic Architectures Embedded inReconfigurable Devices
2011 Zimmermann, Güneysu, Paar: High-Performance Integer Factorization with Reconfig-urable DevicesCryptArchi - 9th International Workshop on Cryptographic Architectures Embedded in Re-configurable Devices
135

Publications
Book Chapters
2013 Güneysu, Kasper, Novotný, Paar, Zimmermann: High-Performance Cryptanalysis onRIVYERA and COPACOBANA Computing Systemsin “High-Performance Computing Using FPGAs”, Springer VerlagISBN: 978-1-4614-1790-3
Invited Talks
2014 ecc2-113 — FPGAs vs BinärkurvenElliptic Curve Cryptography Brainpool — Bonn, Germany
2012 Problem-Adapted, High-Performance Computation Platforms for Cryptanalysis — WhenGeneric Is Not Good EnoughECRYPT II Summer School on Tools — Mykonos, Greece
2011 Cryptanalysis on Special Hardware — Optimized Implementation of the Elliptic CurveMethodElliptic Curve Cryptography Brainpool — Bonn, Germany
2010 Optimized Implementation of the Elliptic Curve Factoriztation Method on a Highly Par-allelized Hardware ClusterCAST Förderpreis IT-Sicherheit — Darmstadt, Germany
136

Conferences and Workshops
Research Visits
Apr 2014 Radboud University Nijmegen, NetherlandsDigital Security Group
Nov 2012 INRIA Rocquencour, FranceÉquipe-projet SECRET
Jul 2012 Academia Sinica, TaiwanInstitute of Information Science
Participation in Selected Conferences & Workshops
2014 PQCrypto’14 (Waterloo, CA)2014 CryptArchi’14 (Annecy, France)2014 Security in Times of Surveillance (Eindhoven, Netherlands)2014 ECC Brainpool’14 (Bonn, Germany)2013 CCS’13 (Berlin, Germany)2013 CHES’13 (Santa Barbara, USA)2013 Crypto’13 (Santa Barbara, USA)2013 CryptArchi’13 (Frejus, France)2012 CHES’12 (Leuven, Belgium)2012 ECRYPT II Summer School on Tools (Mykonos, Greece)2012 NIST Third SHA-3 Candidate Conference (Washington, D.C., USA)2012 FSE’12 (Washington, D.C., USA)2012 SHARCS’12 (Washington, D.C., USA)2011 AsiaCrypt’11 (Seoul, South Korea)2011 CryptArchi’11 (Bochum, Germany)2011 ECC Brainpool’11 (Bonn, Germany)2010 CAST Workshop (IT-Sicherheit) (Darmstadt, Germany)2010 FPL’10 (Milano, Italy)2010 CHES’10 (Santa Barbara, USA)2010 Crypto’10 (Santa Barbara, USA)2010 ECC Brainpool’10 (Bonn, Germany)
137






























