Embed Size (px)
Citation preview

Bayesian Networks
Graphical ModelsGraphical Models
Siamak Ravanbakhsh Winter 2018
Learning objectivesLearning objectives
what is a Bayesian network?factorizationconditional independencies
how to read it from the graphequivalent class of Bayesian networks
how are they related?

Representing distributionsRepresenting distributions
give a large number of random variables X , … ,X1 n
how to represent
number of parameters exponential in n (curse of dimensionality)
need to leverage some structure in P
P (X , … ,X )1 n

IndependenceIndependence & representation & representation
for discrete domains
representation ofexponential in n:
P (X = x , … ,x ) = θ1 n i ,…,i1 n
V al(X ) = {1, … ,D} ∀ii
O(D }n

IndependenceIndependence & representation & representation
X ⊥ X ∀i, ji j
for discrete domains
representation ofexponential in n:
P (X = x , … ,x ) = P (X = x ) = θ1d
nd ∏i i i
d ∏i i,d
P (X = x , … ,x ) = θ1 n i ,…,i1 n
assuming independence
linear-sized representation:
a particular assignment (d) in discrete domain
V al(X ) = {1, … ,D} ∀ii
O(D }n

IndependenceIndependence & representation & representation
X ⊥ X ∀i, ji j
for discrete domains
representation ofexponential in n:
P (X = x , … ,x ) = P (X = x ) = θ1d
nd ∏i i i
d ∏i i,d
P (X = x , … ,x ) = θ1 n i ,…,i1 n
assuming independence
linear-sized representation:
a particular assignment (d) in discrete domain
independence assumption is too restrictive
V al(X ) = {1, … ,D} ∀ii
O(D }n

Independence and representationIndependence and representation
For a Gaussian distribution:
from quadratic
to a linear-sized representation
P (X = x , … ,x ) = exp − (x − μ )1 n ∏i √ 2πσi2
1 ( 2σi2
1i i
2)
P (X = x , … ,x ) = exp − (x− μ) Σ (x− μ)1 n √ ∣2πΣ∣ 1 ( 2
1 T −1 )n x n matrix

Using the Using the chain rulechain rule
P (X) = P (X )P (X ∣ X ) …P (X ∣ X , … ,X )1 2 1 n 1 n−1
pick an ordering of the variables

Using the Using the chain rulechain rule
parameterize each termdoes it compress the representation?
P (X) = P (X )P (X ∣ X ) …P (X ∣ X , … ,X )1 2 1 n 1 n−1
original #params D − 1n
pick an ordering of the variables

Using the Using the chain rulechain rule
parameterize each termdoes it compress the representation?
P (X) = P (X )P (X ∣ X ) …P (X ∣ X , … ,X )1 2 1 n 1 n−1
original #params D − 1n
new #params (D − 1) + (D − D) + … + (D − D ) = D − 12 n n−1 n
pick an ordering of the variables
P (X )1 P (X ∣ X )2 1 P (X ∣ X , … ,X )n 1 n−1

Using the Using the chain rulechain rule
P (X) = P (X )P (X ∣ X ) …P (X ∣ X , … ,X )1 2 1 n 1 n−1
simplify the conditionals
flexible compression of P
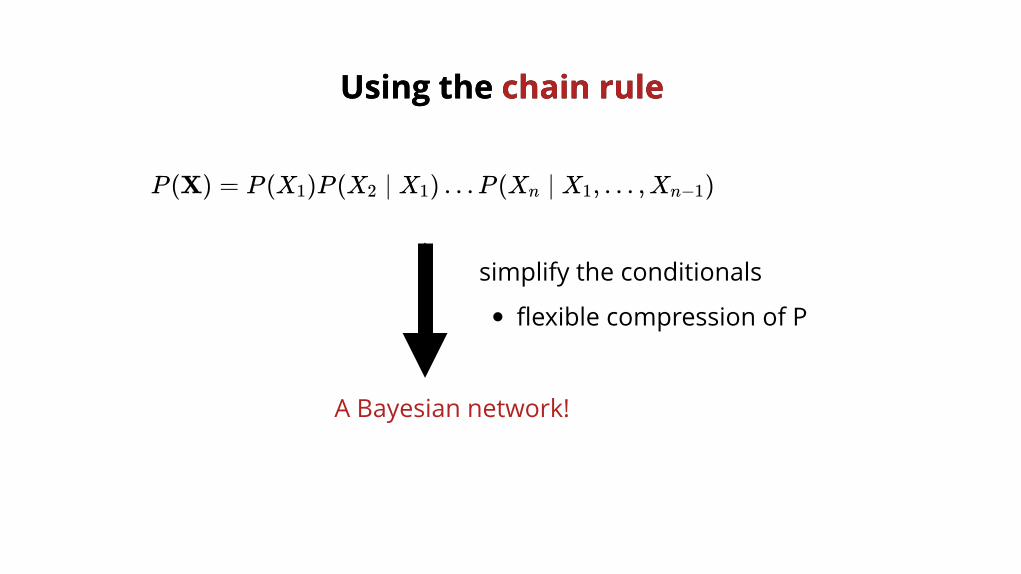
Using the Using the chain rulechain rule
P (X) = P (X )P (X ∣ X ) …P (X ∣ X , … ,X )1 2 1 n 1 n−1
simplify the conditionals
flexible compression of P
A Bayesian network!
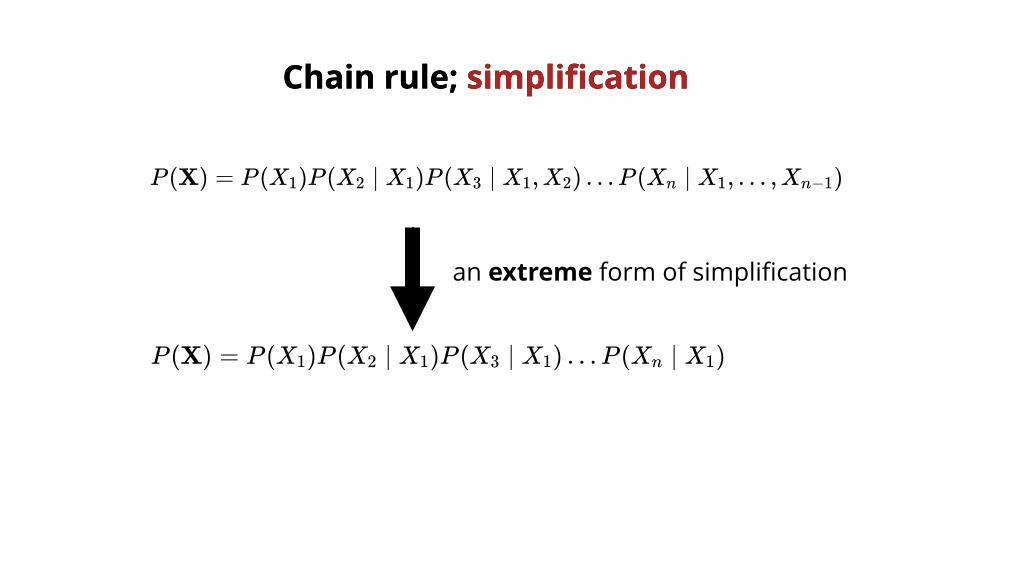
Chain rule; Chain rule; simplificationsimplification
P (X) = P (X )P (X ∣ X )P (X ∣ X ,X ) …P (X ∣ X , … ,X )1 2 1 3 1 2 n 1 n−1
an extreme form of simplification
P (X) = P (X )P (X ∣ X )P (X ∣ X ) …P (X ∣ X )1 2 1 3 1 n 1

Chain rule; Chain rule; simplificationsimplification
P (X) = P (X )P (X ∣ X )P (X ∣ X ,X ) …P (X ∣ X , … ,X )1 2 1 3 1 2 n 1 n−1
an extreme form of simplification
P (X) = P (X )P (X ∣ X )P (X ∣ X ) …P (X ∣ X )1 2 1 3 1 n 1
# params (D − 1) + (n − 1)(D − D)2
O(nD )2 instead of O(D )n

Idiot BayesIdiot Bayes

OrOr naive Bayes naive Bayes
P (class,X) = P (class)P (X ∣ class)P (X ∣ class) …P (X ∣ class)2 3 n
independence assumption: X ⊥ X ∣ classi −i
for classification (use Bayes rule)
P (class ∣ X) ∝ P (class)P (X ∣ class)P (X ∣ class) …P (X ∣ class)2 3 n
Example: medical diagnosis (what if two symptoms are correlated?)
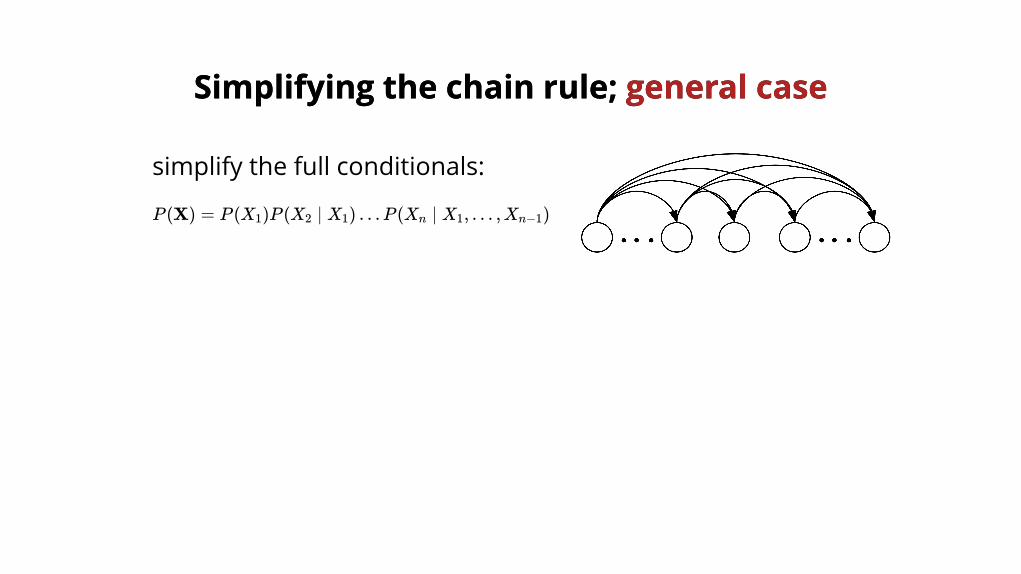
Simplifying the chain rule; Simplifying the chain rule; general casegeneral case
P (X) = P (X )P (X ∣ X ) …P (X ∣ X , … ,X )1 2 1 n 1 n−1
simplify the full conditionals:
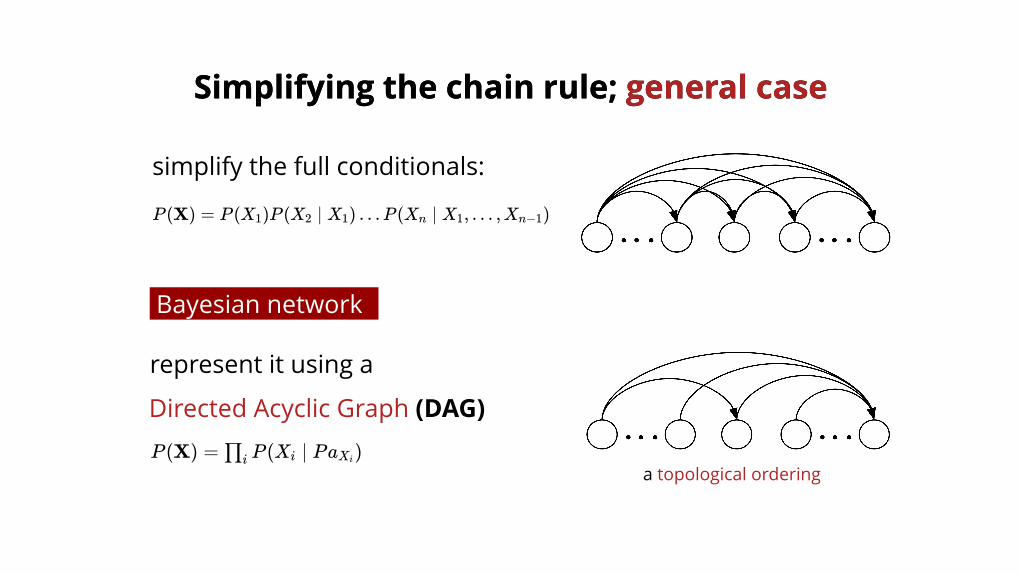
Directed Acyclic Graph (DAG)
Simplifying the chain rule; Simplifying the chain rule; general casegeneral case
P (X) = P (X )P (X ∣ X ) …P (X ∣ X , … ,X )1 2 1 n 1 n−1
simplify the full conditionals:
represent it using a
P (X) = P (X ∣ Pa )∏i i Xi
Bayesian network
a topological ordering

identifying a DAGhas a topological ordering?no directed path from a node to itself?
DAG; DAG; identificationidentification
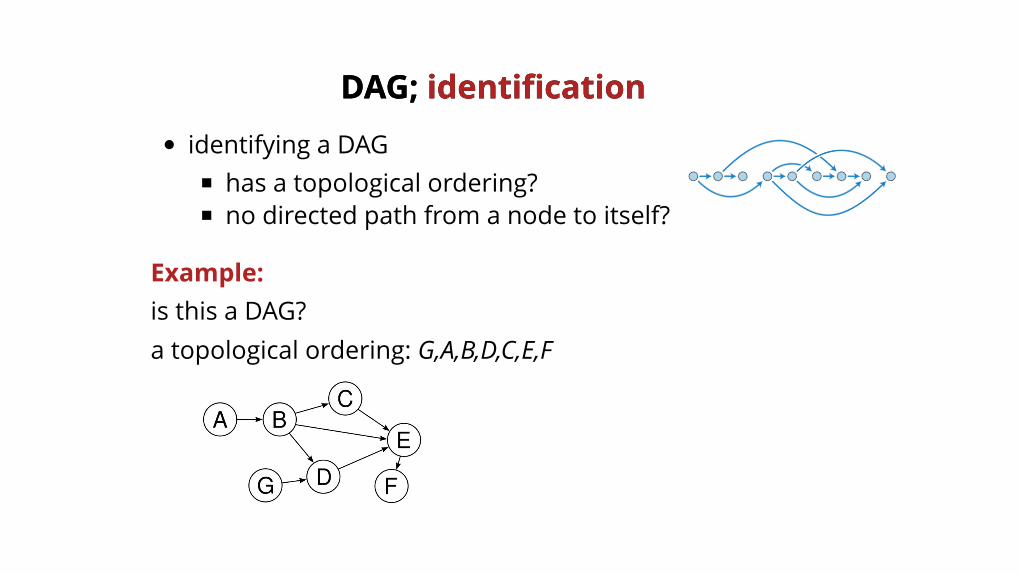
identifying a DAGhas a topological ordering?no directed path from a node to itself?
Example:is this a DAG?a topological ordering: G,A,B,D,C,E,F
DAG; DAG; identificationidentification
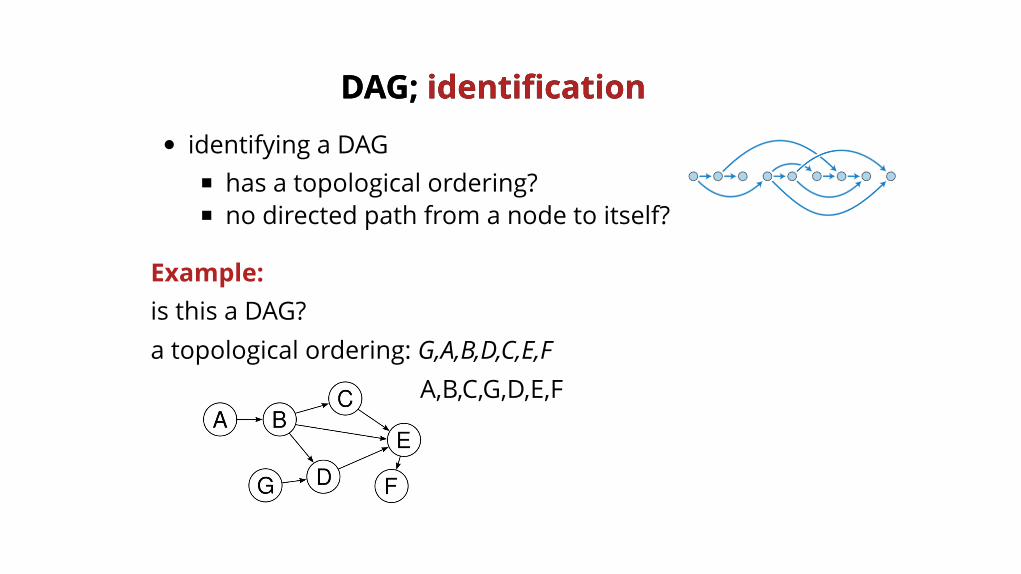
identifying a DAGhas a topological ordering?no directed path from a node to itself?
Example:is this a DAG?a topological ordering: G,A,B,D,C,E,F
DAG; DAG; identificationidentification
A,B,C,G,D,E,F
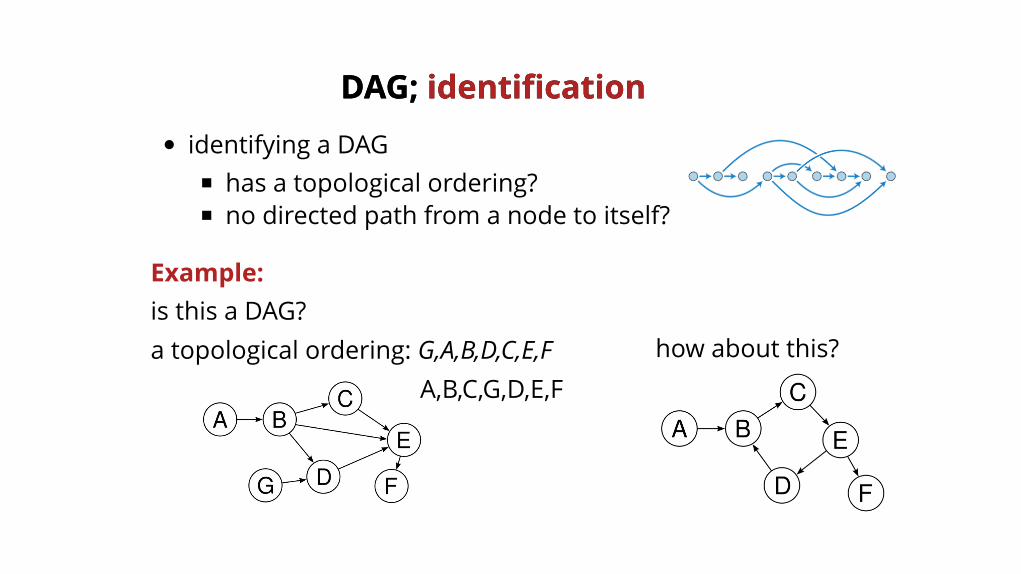
identifying a DAGhas a topological ordering?no directed path from a node to itself?
Example:is this a DAG?a topological ordering: G,A,B,D,C,E,F how about this?
DAG; DAG; identificationidentification
A,B,C,G,D,E,F
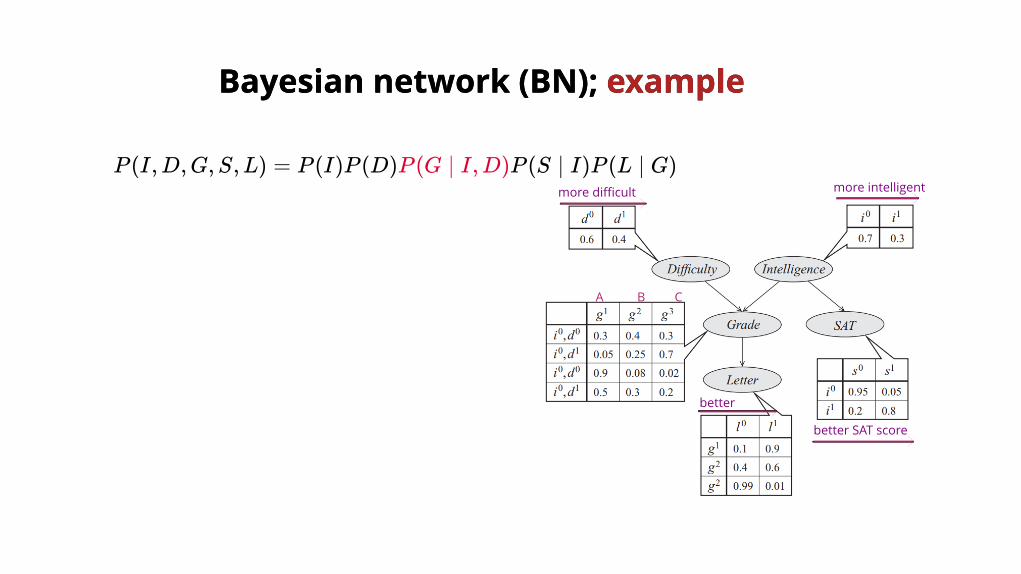
Bayesian network (BN); Bayesian network (BN); exampleexample
P (I,D,G,S,L) = P (I)P (D)P (G ∣ I,D)P (S ∣ I)P (L ∣ G)more intelligent
A B C
better SAT score
more difficult
better
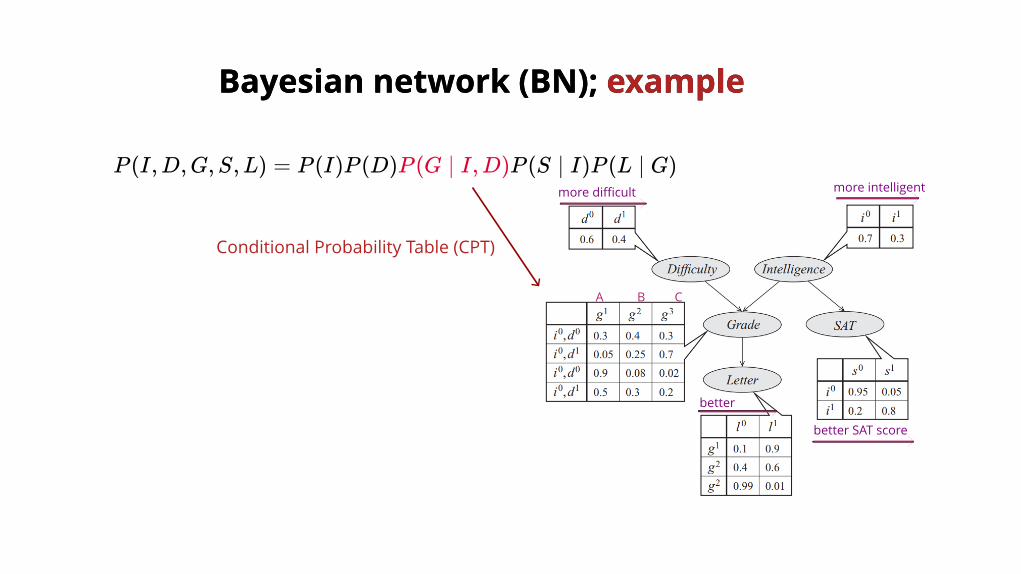
Bayesian network (BN); Bayesian network (BN); exampleexample
P (I,D,G,S,L) = P (I)P (D)P (G ∣ I,D)P (S ∣ I)P (L ∣ G)
Conditional Probability Table (CPT)
more intelligent
A B C
better SAT score
more difficult
better
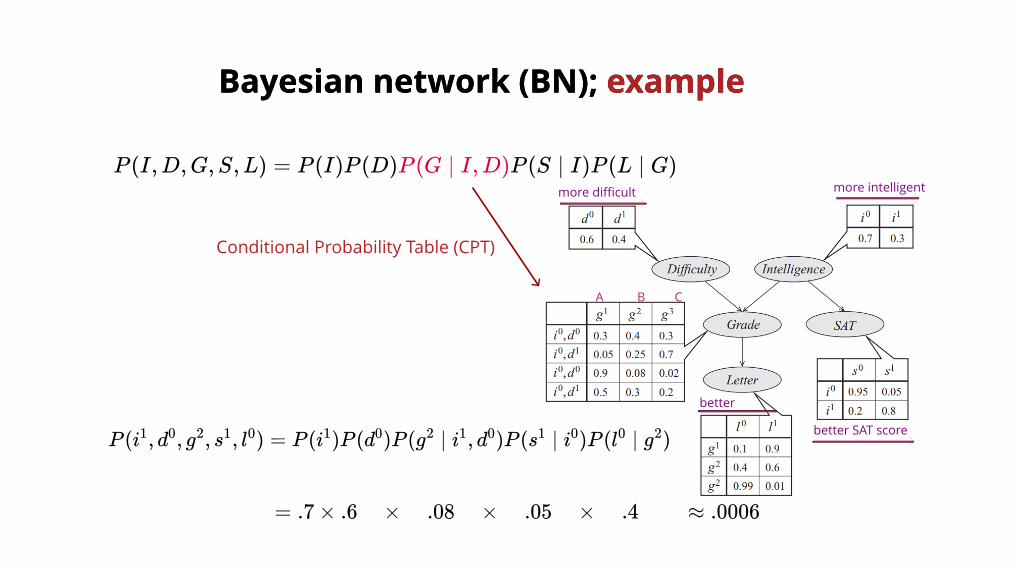
Bayesian network (BN); Bayesian network (BN); exampleexample
P (I,D,G,S,L) = P (I)P (D)P (G ∣ I,D)P (S ∣ I)P (L ∣ G)
P (i , d , g , s , l ) = P (i )P (d )P (g ∣ i , d )P (s ∣ i )P (l ∣ g )1 0 2 1 0 1 0 2 1 0 1 0 0 2
Conditional Probability Table (CPT)
more intelligent
A B C
better SAT score
more difficult
better
= .7 × .6 × .08 × .05 × .4 ≈ .0006
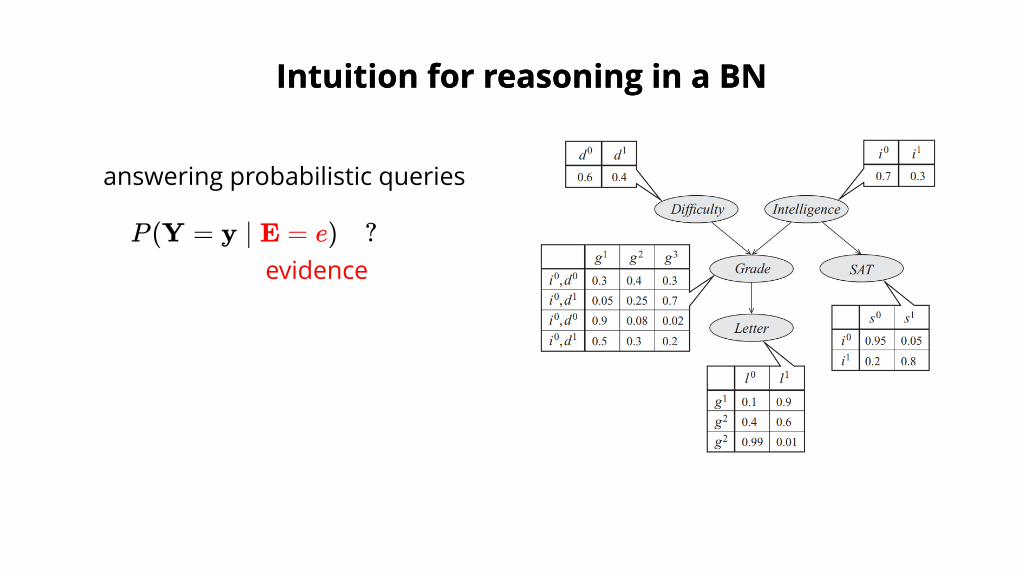
answering probabilistic queries
P (Y = y ∣ E = e) ?evidence
Intuition for reasoning in a BNIntuition for reasoning in a BN
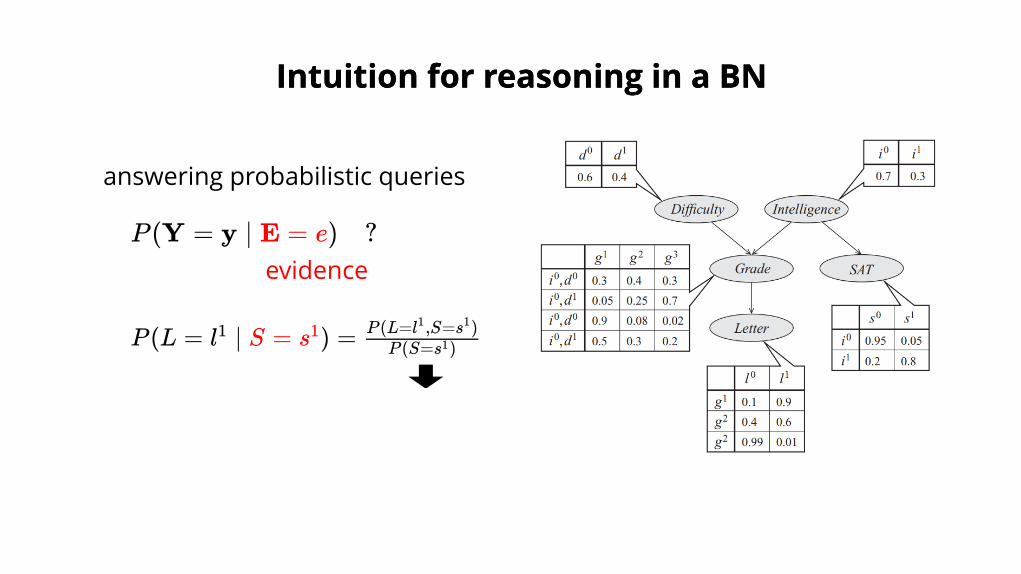
answering probabilistic queries
P (Y = y ∣ E = e) ?evidence
Intuition for reasoning in a BNIntuition for reasoning in a BN
P (L = l ∣ S = s ) =1 1P (S=s )1
P (L=l ,S=s )1 1
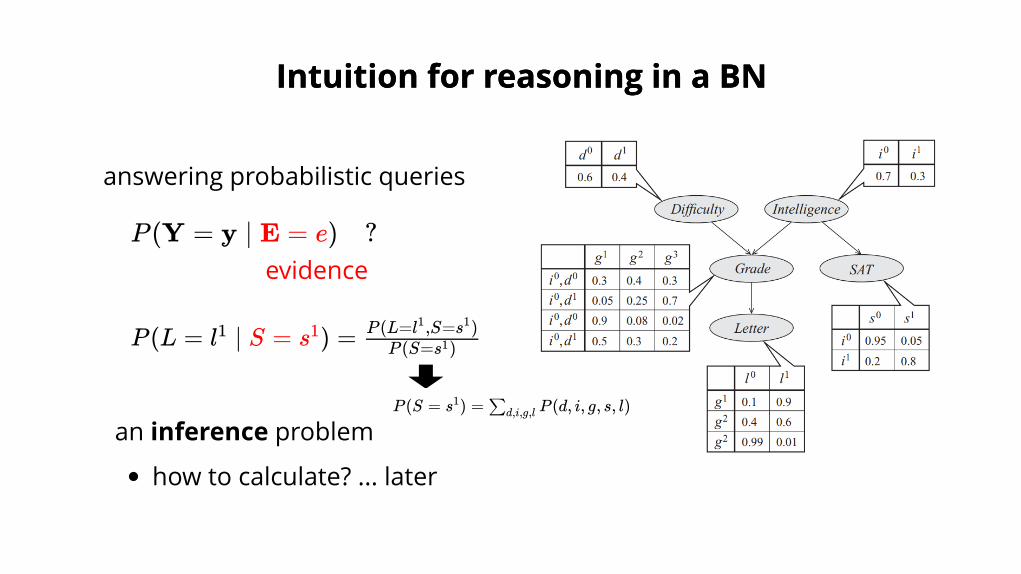
answering probabilistic queries
P (Y = y ∣ E = e) ?evidence
an inference problem
how to calculate? ... later
Intuition for reasoning in a BNIntuition for reasoning in a BN
P (L = l ∣ S = s ) =1 1P (S=s )1
P (L=l ,S=s )1 1
P (S = s ) = P (d, i, g, s, l)1 ∑d,i,g,l
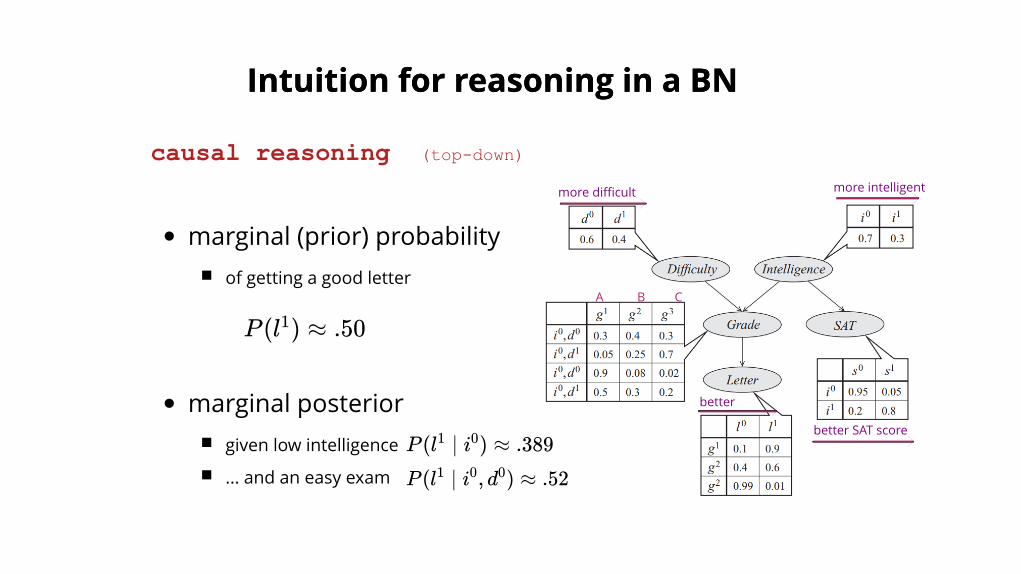
marginal (prior) probabilityof getting a good letter
marginal posteriorgiven low intelligence
... and an easy exam
causal reasoning (topdown)
P (l ) ≈ .501
P (l ∣ i ) ≈ .3891 0
P (l ∣ i , d ) ≈ .521 0 0
Intuition for reasoning in a BNIntuition for reasoning in a BN
more intelligent
A B C
better SAT score
more difficult
better
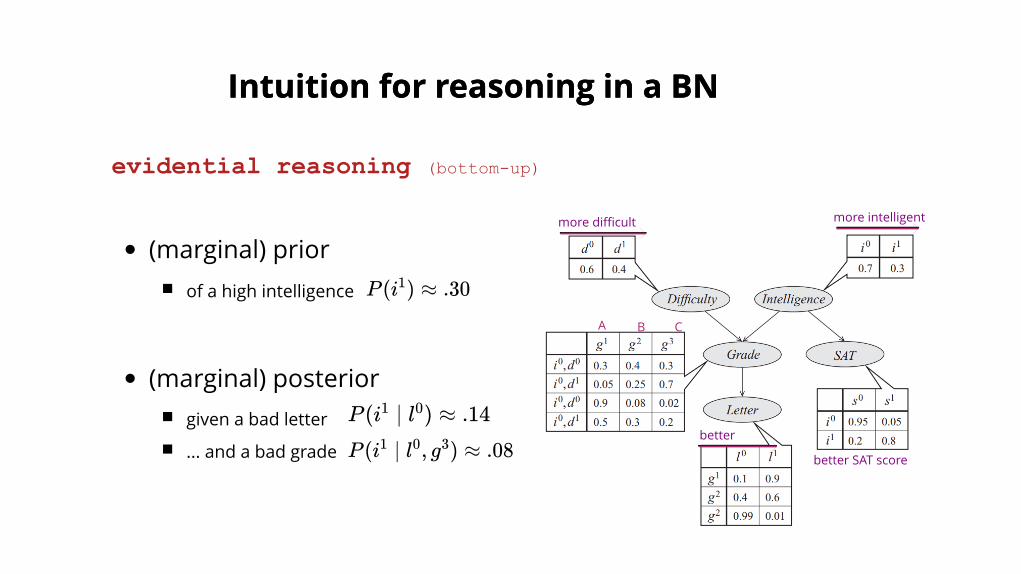
(marginal) priorof a high intelligence
(marginal) posteriorgiven a bad letter
... and a bad grade
evidential reasoning (bottomup)
P (i ) ≈ .301
P (i ∣ l ) ≈ .141 0
P (i ∣ l , g ) ≈ .081 0 3
Intuition for reasoning in a BNIntuition for reasoning in a BN
more intelligent
A B C
better SAT score
more difficult
better

priorof a high intelligence
posteriorgiven a bad letter
... and a bad grade
a difficult exam explains away the grade
Explaining away (vstructure)
P (i ) ≈ .301
P (i ∣ l ) ≈ .141 0
P (i ∣ l , g ) ≈ .081 0 3
Intuition for Reasoning in BNIntuition for Reasoning in BN
P (i ∣ l , g , d ) ≈ .111 0 3 1
more intelligent
A B C
better SAT score
more difficult
better

DAG; DAG; semanticssemantics
associating P with a DAG:
factorization of the joint probability:
conditional independencies in P from the DAG
P (X) = P (X ∣ Pa )∏i i Xi
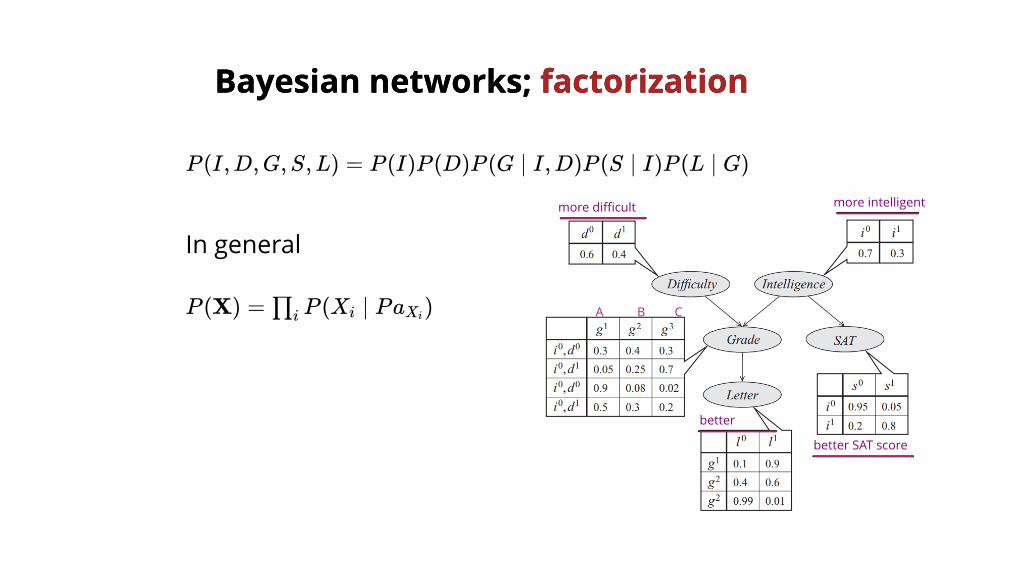
Bayesian networks; Bayesian networks; factorizationfactorization
P (I,D,G,S,L) = P (I)P (D)P (G ∣ I,D)P (S ∣ I)P (L ∣ G)
more intelligent
A B C
better SAT score
more difficult
better
P (X) = P (X ∣ Pa )∏i i Xi
In general
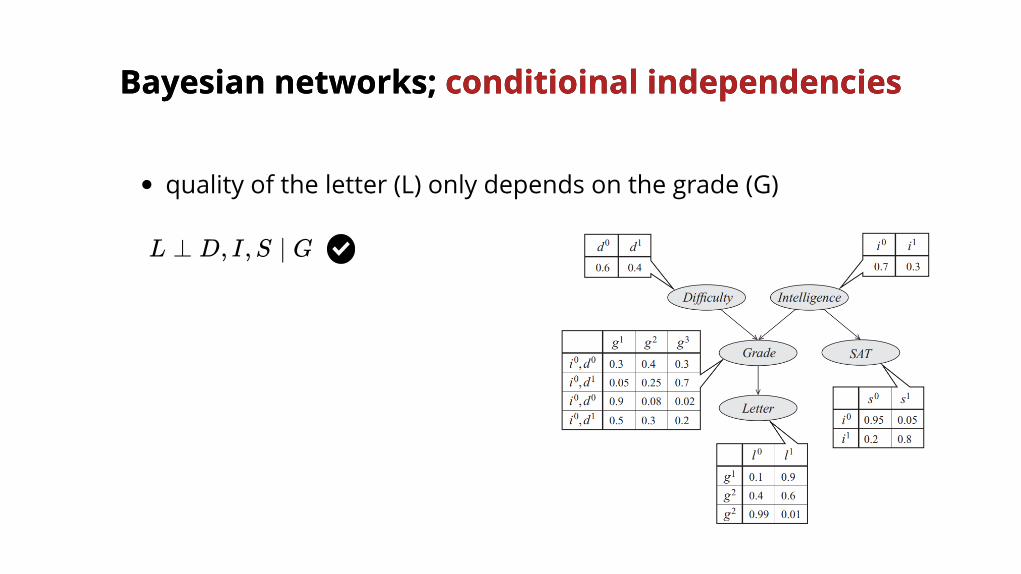
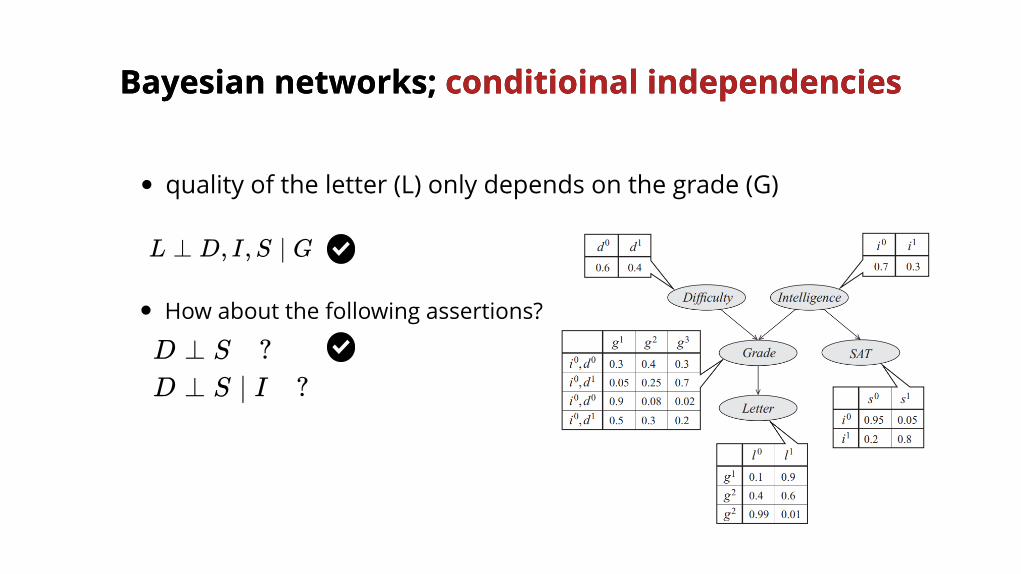
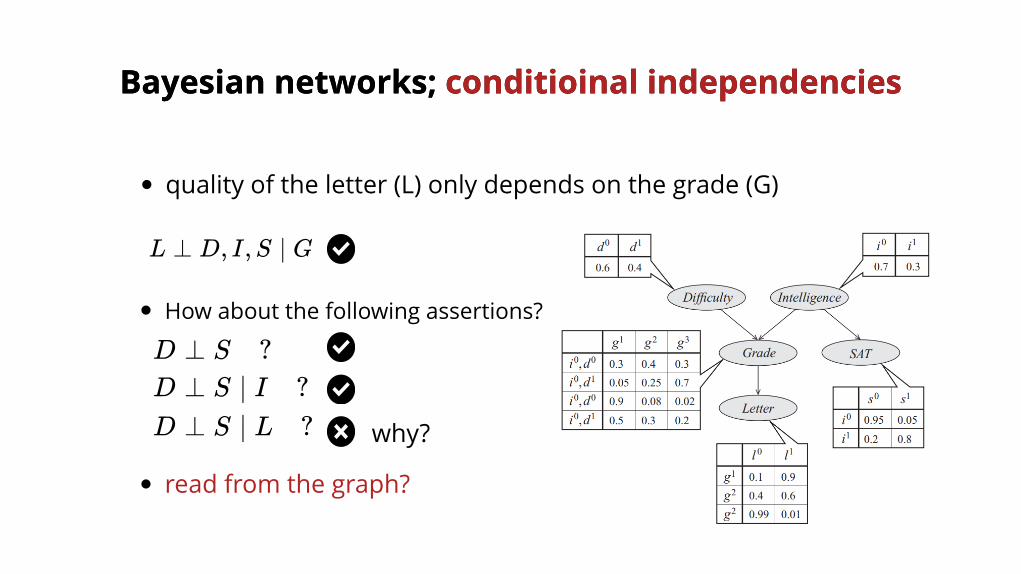
L ⊥ D, I,S ∣ G
quality of the letter (L) only depends on the grade (G)
Bayesian networks;Bayesian networks; conditioinal independencies conditioinal independencies
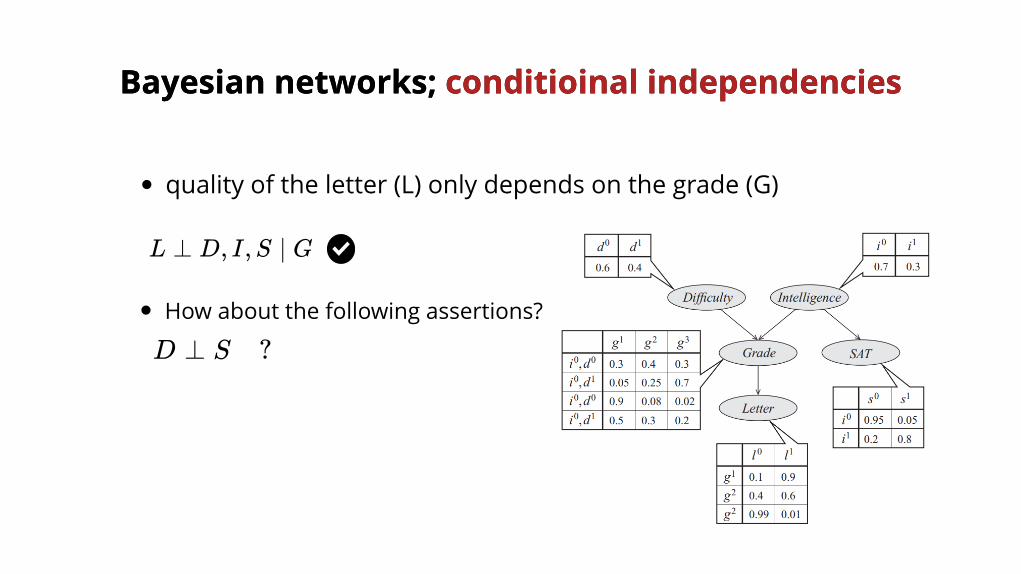
L ⊥ D, I,S ∣ G
D ⊥ S ?
quality of the letter (L) only depends on the grade (G)
How about the following assertions?
Bayesian networks;Bayesian networks; conditioinal independencies conditioinal independencies
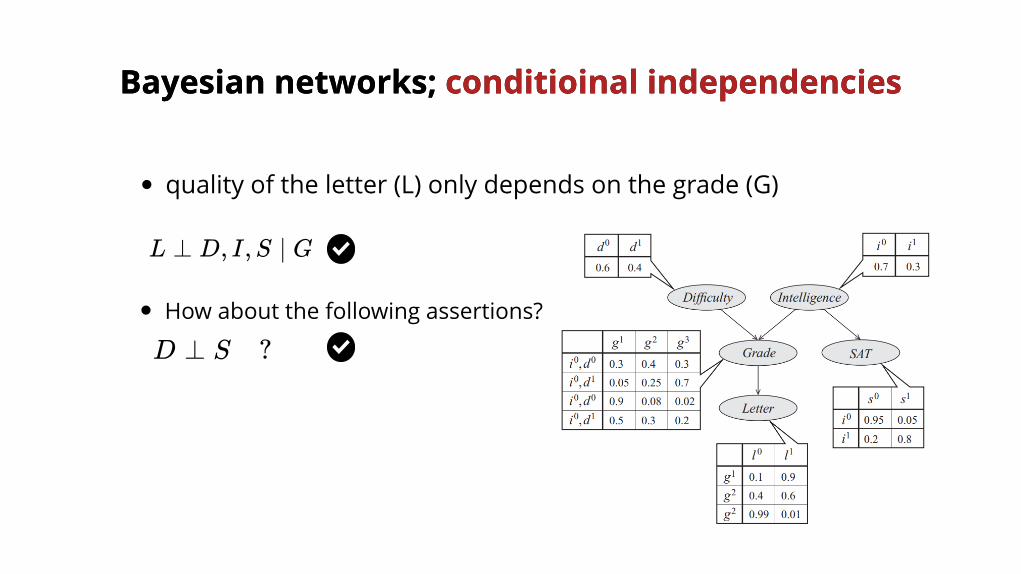
L ⊥ D, I,S ∣ G
D ⊥ S ?
quality of the letter (L) only depends on the grade (G)
How about the following assertions?
Bayesian networks;Bayesian networks; conditioinal independencies conditioinal independencies
L ⊥ D, I,S ∣ G
D ⊥ S ?D ⊥ S ∣ I ?
quality of the letter (L) only depends on the grade (G)
How about the following assertions?
Bayesian networks;Bayesian networks; conditioinal independencies conditioinal independencies
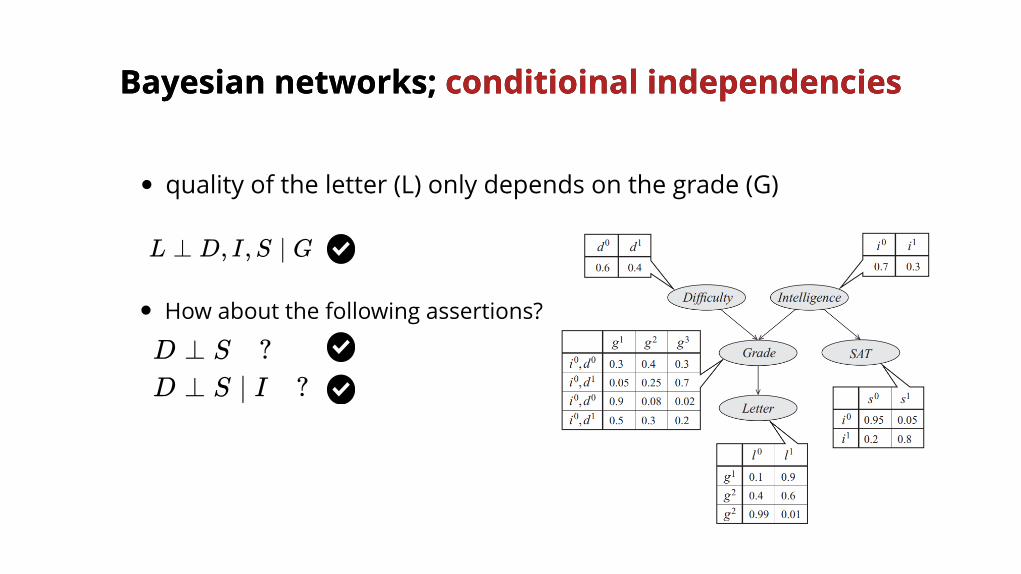
L ⊥ D, I,S ∣ G
D ⊥ S ?D ⊥ S ∣ I ?
quality of the letter (L) only depends on the grade (G)
How about the following assertions?
Bayesian networks;Bayesian networks; conditioinal independencies conditioinal independencies
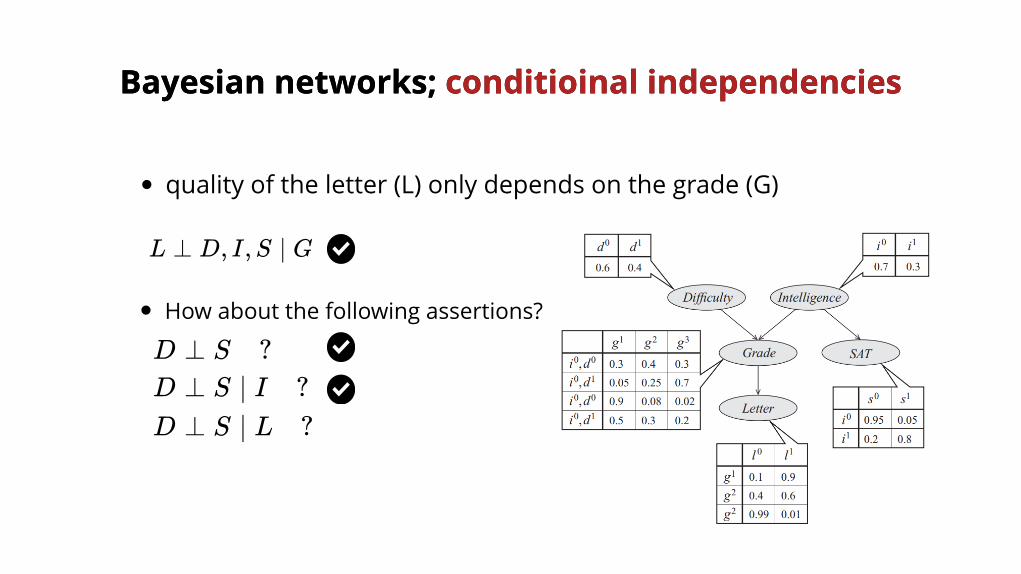
L ⊥ D, I,S ∣ G
D ⊥ S ?D ⊥ S ∣ I ?
quality of the letter (L) only depends on the grade (G)
How about the following assertions?
D ⊥ S ∣ L ?
Bayesian networks;Bayesian networks; conditioinal independencies conditioinal independencies
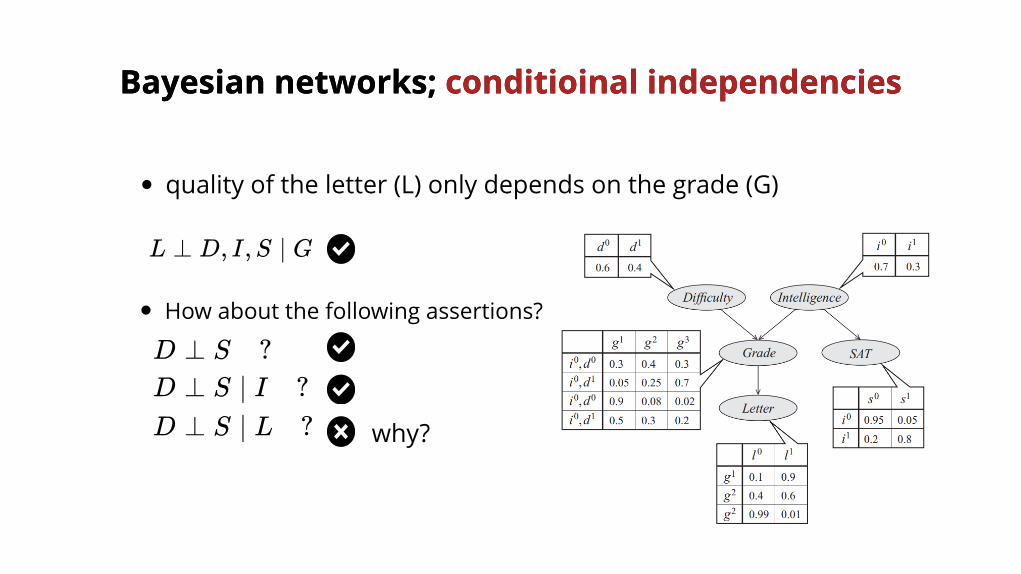
L ⊥ D, I,S ∣ G
D ⊥ S ?D ⊥ S ∣ I ?
quality of the letter (L) only depends on the grade (G)
How about the following assertions?
D ⊥ S ∣ L ?
Bayesian networks;Bayesian networks; conditioinal independencies conditioinal independencies
why?
L ⊥ D, I,S ∣ G
D ⊥ S ?D ⊥ S ∣ I ?
quality of the letter (L) only depends on the grade (G)
How about the following assertions?
D ⊥ S ∣ L ?
Bayesian networks;Bayesian networks; conditioinal independencies conditioinal independencies
read from the graph?
why?

Conditional independencies (CI); Conditional independencies (CI); notationnotation
1. set of all CIs of the distribution P
2. set of local CIs from the graph (DAG)
3. set of all (global) CIs from the graph
I(P )
I (G)ℓ
I(G)

LocalLocal conditional independencies (conditional independencies (CICIs)s)
X ⊥ NonDescendents ∣ Parentsi Xi Xifor any node Xi
A ⊥ G ∣ ∅
B ⊥ G ∣ A
C ⊥ G,D,A ∣ B
G ⊥ A,B,C
D ⊥ A,C ∣ B,G
E ⊥ A,G ∣ B,C,DF ⊥ A,B,C,D,G ∣ E
graph G
I (G) = {ℓ
}
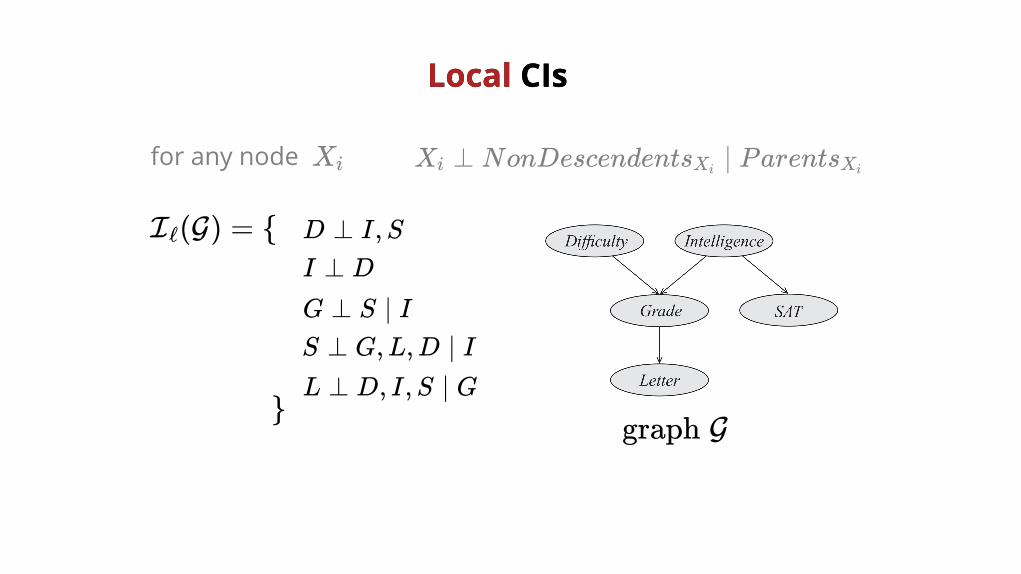
LocalLocal CIs CIs
X ⊥ NonDescendents ∣ Parentsi Xi Xifor any node Xi
D ⊥ I,SI ⊥ D
G ⊥ S ∣ IS ⊥ G,L,D ∣ I
L ⊥ D, I,S ∣ G
graph G
I (G) = {ℓ
}

use the factorized form
Local CIsLocal CIs from factorizationfrom factorization
P (X) = P (X ∣ Pa )∏i i Xi
P (X ,NonDesc ∣ Pa ) = P (X ∣ Pa )P (NonDesc ∣ Pa )i Xi Xi i Xi Xi Xi
to show
X ⊥ NonDesc ∣ Pai Xi Xiwhich means
∀Xi

S ⊥ G ∣ I P (D, I,G,S,L) = P (D)P (I)P (G ∣ D, I)P (S ∣ I)P (L ∣ G)
Local CIsLocal CIs from factorization; from factorization; example example
given

S ⊥ G ∣ I P (D, I,G,S,L) = P (D)P (I)P (G ∣ D, I)P (S ∣ I)P (L ∣ G)
P (G,S ∣ I) = =P (D,I,G,S,L)∑d,g,s,l
P (D,I,G,S,L)∑d,l
Local CIsLocal CIs from factorization; from factorization; example example
given
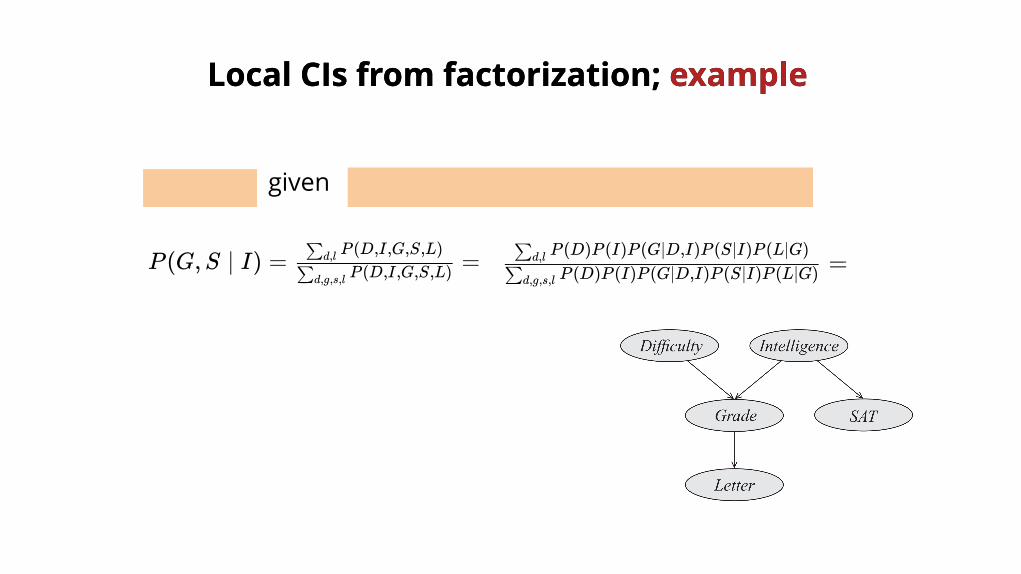
S ⊥ G ∣ I P (D, I,G,S,L) = P (D)P (I)P (G ∣ D, I)P (S ∣ I)P (L ∣ G)
=P (D)P (I)P (G∣D,I)P (S∣I)P (L∣G)∑d,g,s,l
P (D)P (I)P (G∣D,I)P (S∣I)P (L∣G)∑d,lP (G,S ∣ I) = =P (D,I,G,S,L)∑d,g,s,l
P (D,I,G,S,L)∑d,l
Local CIsLocal CIs from factorization; from factorization; example example
given
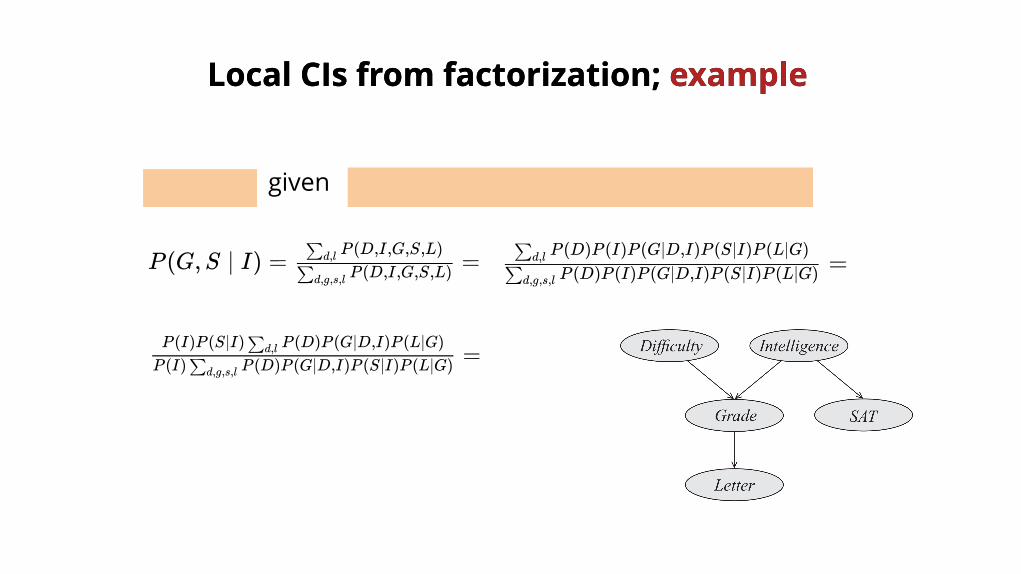
S ⊥ G ∣ I P (D, I,G,S,L) = P (D)P (I)P (G ∣ D, I)P (S ∣ I)P (L ∣ G)
=P (D)P (I)P (G∣D,I)P (S∣I)P (L∣G)∑d,g,s,l
P (D)P (I)P (G∣D,I)P (S∣I)P (L∣G)∑d,lP (G,S ∣ I) = =P (D,I,G,S,L)∑d,g,s,l
P (D,I,G,S,L)∑d,l
=P (I) P (D)P (G∣D,I)P (S∣I)P (L∣G)∑d,g,s,l
P (I)P (S∣I) P (D)P (G∣D,I)P (L∣G)∑d,l
Local CIsLocal CIs from factorization; from factorization; example example
given
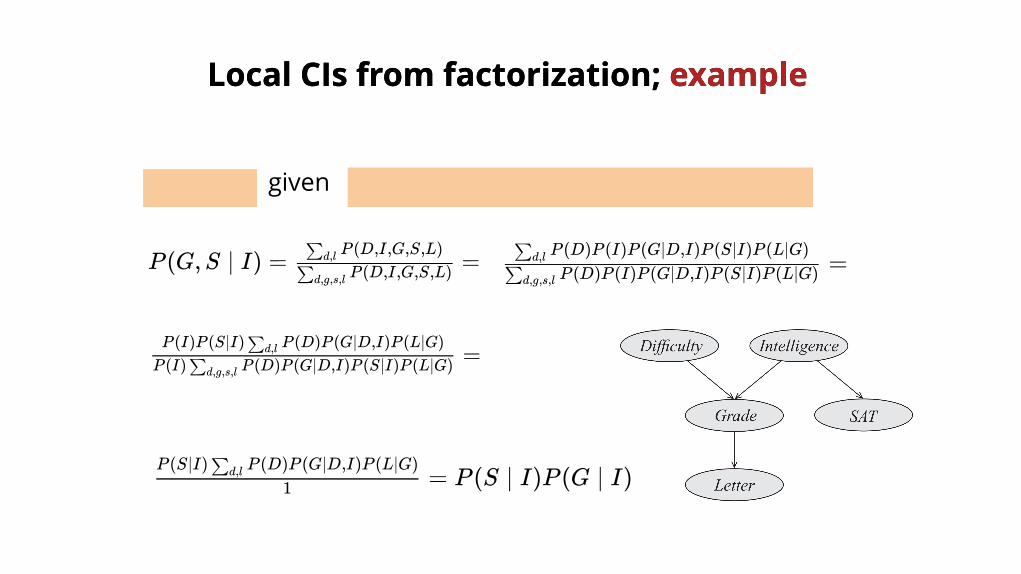
S ⊥ G ∣ I P (D, I,G,S,L) = P (D)P (I)P (G ∣ D, I)P (S ∣ I)P (L ∣ G)
=P (D)P (I)P (G∣D,I)P (S∣I)P (L∣G)∑d,g,s,l
P (D)P (I)P (G∣D,I)P (S∣I)P (L∣G)∑d,lP (G,S ∣ I) = =P (D,I,G,S,L)∑d,g,s,l
P (D,I,G,S,L)∑d,l
=P (I) P (D)P (G∣D,I)P (S∣I)P (L∣G)∑d,g,s,l
P (I)P (S∣I) P (D)P (G∣D,I)P (L∣G)∑d,l
= P (S ∣ I)P (G ∣ I)1P (S∣I) P (D)P (G∣D,I)P (L∣G)∑d,l
Local CIsLocal CIs from factorization; from factorization; example example
given
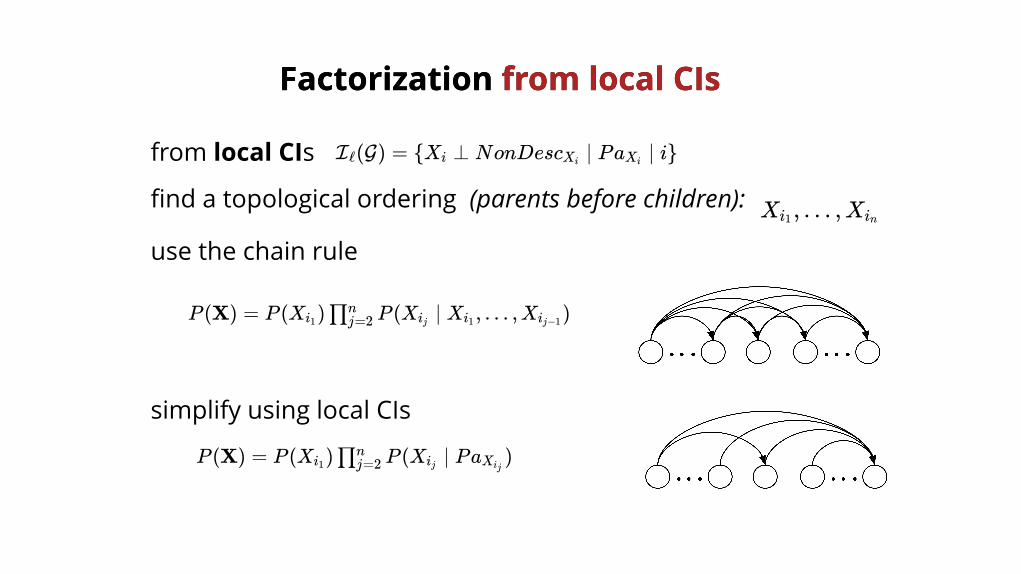
FactorizationFactorization from local CIsfrom local CIs
from local CIs I (G) = {X ⊥ NonDesc ∣ Pa ∣ i}ℓ i Xi Xi
find a topological ordering (parents before children):
use the chain rule
simplify using local CIs
X , … ,Xi1 in
P (X) = P (X ) P (X ∣ X , … ,X )i1 ∏j=2n
ij i1 ij−1
P (X) = P (X ) P (X ∣ Pa )i1 ∏j=2n
ij Xij
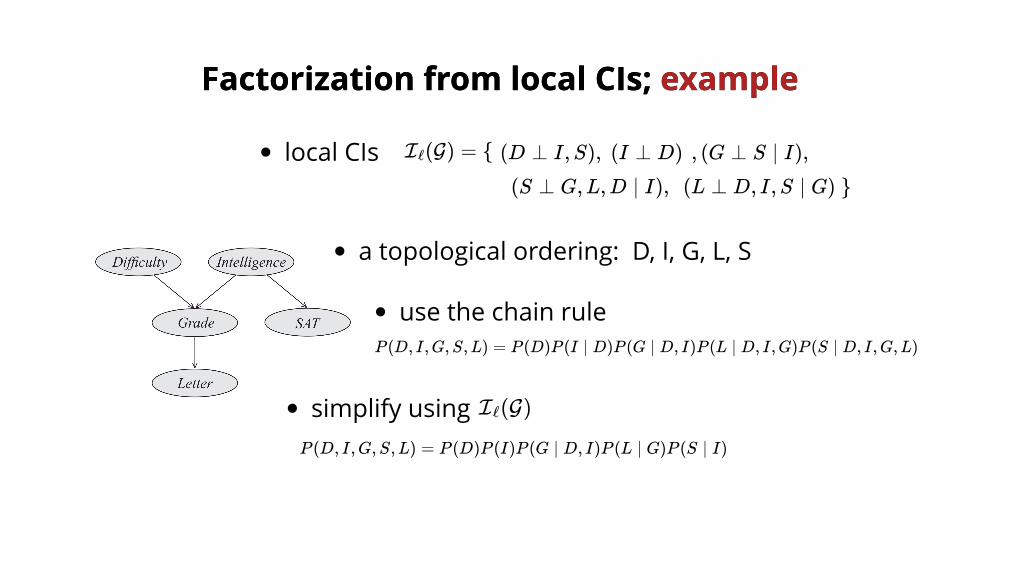
FactorizationFactorization from local CIs;from local CIs; example example
local CIs (D ⊥ I,S), (I ⊥ D) , (G ⊥ S ∣ I),
(S ⊥ G,L,D ∣ I), (L ⊥ D, I,S ∣ G)
I (G) = {ℓ
}
P (D, I,G,S,L) = P (D)P (I ∣ D)P (G ∣ D, I)P (L ∣ D, I,G)P (S ∣ D, I,G,L)
a topological ordering: D, I, G, L, S
I (G)ℓ
P (D, I,G,S,L) = P (D)P (I)P (G ∣ D, I)P (L ∣ G)P (S ∣ I)
use the chain rule
simplify using

Factorization local CIsFactorization local CIs
P factorizes according to G
P (X) = P (X ∣ Pa )∏i i Xi
G
⇔
⇔ holds in PI (G)ℓ

Factorization local CIsFactorization local CIs
P factorizes according to G I (G) ⊆ I(P )ℓ
P (X) = P (X ∣ Pa )∏i i Xi
G
⇔
⇔ holds in PI (G)ℓ

Factorization local CIsFactorization local CIs
P factorizes according to G I (G) ⊆ I(P )ℓ
P (X) = P (X ∣ Pa )∏i i Xi
G
⇔
is an I-map for PG
it does not mislead usabout independencies in P
⇔ holds in PI (G)ℓ
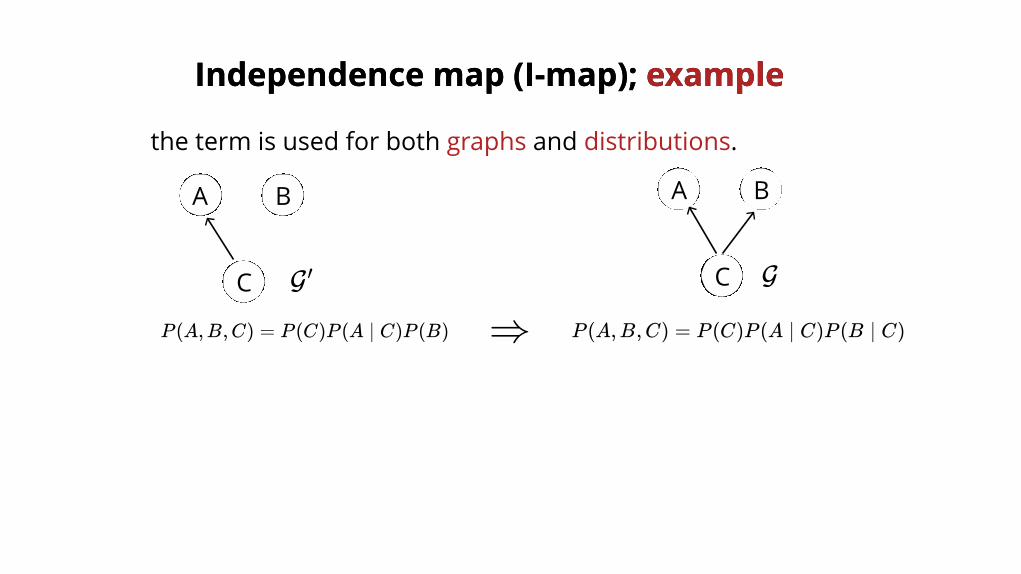
Independence map (I-map); Independence map (I-map); exampleexample
GG ′
A B
C
A B
C
P (A,B,C) = P (C)P (A ∣ C)P (B ∣ C)P (A,B,C) = P (C)P (A ∣ C)P (B)
the term is used for both graphs and distributions.
⇒
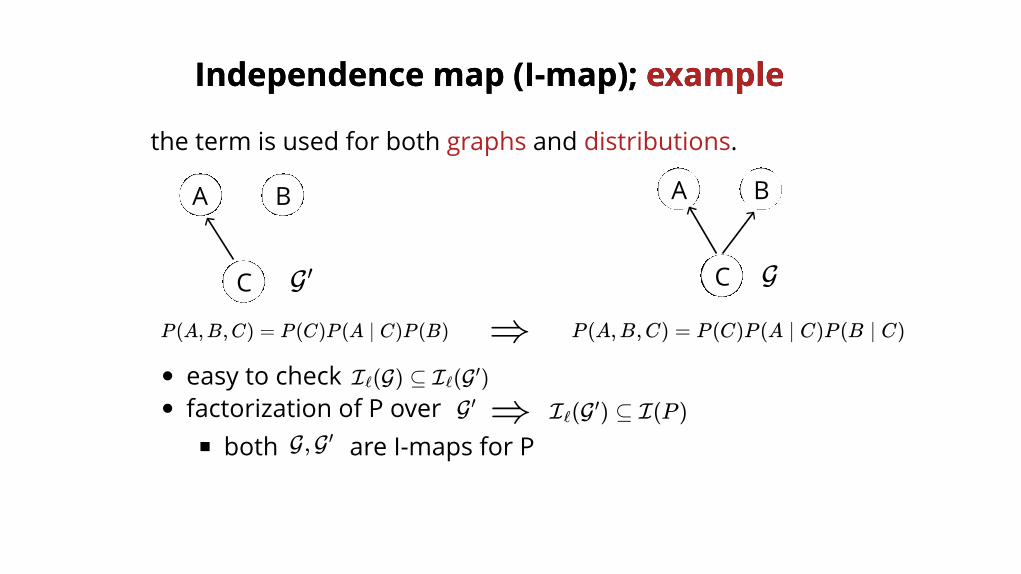
easy to checkfactorization of P over
both are I-maps for P
Independence map (I-map); Independence map (I-map); exampleexample
I (G ) ⊆ I(P )ℓ′G ′
GG ′
I (G) ⊆ I (G )ℓ ℓ′
A B
C
A B
C
P (A,B,C) = P (C)P (A ∣ C)P (B ∣ C)P (A,B,C) = P (C)P (A ∣ C)P (B)
⇒G,G ′
the term is used for both graphs and distributions.
⇒
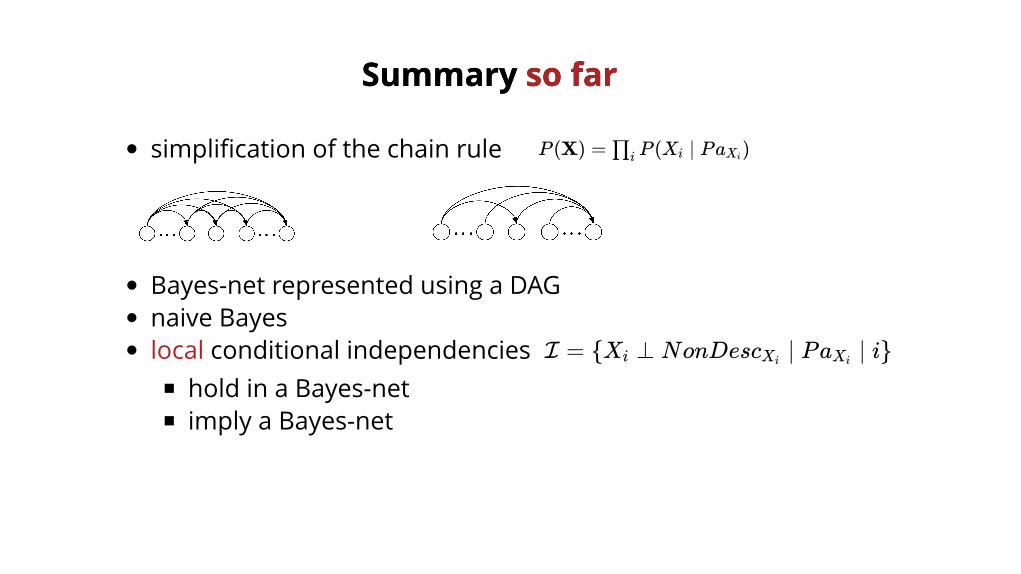
Summary Summary so farso far
simplification of the chain rule P (X) = P (X ∣ Pa )∏i i Xi
Bayes-net represented using a DAGnaive Bayeslocal conditional independencies
hold in a Bayes-netimply a Bayes-net
I = {X ⊥ NonDesc ∣ Pa ∣ i}i Xi Xi

GlobalGlobal CIs CIs from the graphfrom the graph
for any subset of vars X, Y and Z, we can ask X ⊥ Y ∣ Z?
global CI: the set of all such CIs

GlobalGlobal CIs CIs from the graphfrom the graph
factorized form of P global CIs I (G) ⊆ I(G) ⊆ I(P )ℓ⇒
for any subset of vars X, Y and Z, we can ask X ⊥ Y ∣ Z?
global CI: the set of all such CIs

GlobalGlobal CIs CIs from the graphfrom the graph
factorized form of P global CIs I (G) ⊆ I(G) ⊆ I(P )ℓ⇒
algorithm: directed separation (D-separation)
C ⊥ D ∣ B,F ?
for any subset of vars X, Y and Z, we can ask X ⊥ Y ∣ Z?
global CI: the set of all such CIs
Example:
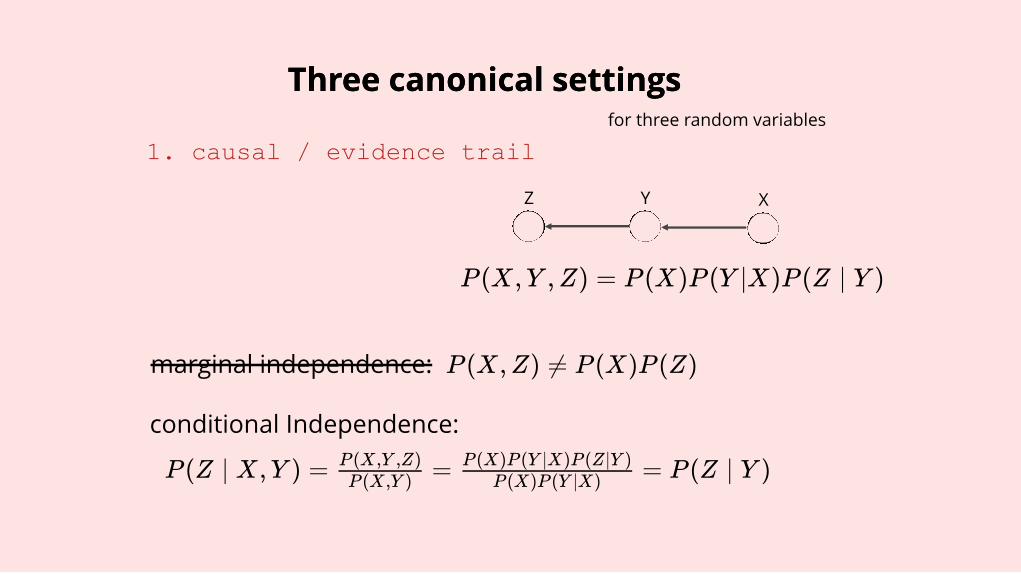
Three canonical settingsThree canonical settings
1. causal / evidence trail
P (X,Y ,Z) = P (X)P (Y ∣X)P (Z ∣ Y )
P (Z ∣ X,Y ) = = = P (Z ∣ Y )P (X,Y )
P (X,Y ,Z)P (X)P (Y ∣X)
P (X)P (Y ∣X)P (Z∣Y )
conditional Independence:
marginal independence: P (X,Z) ≠ P (X)P (Z)
XYZ
for three random variables
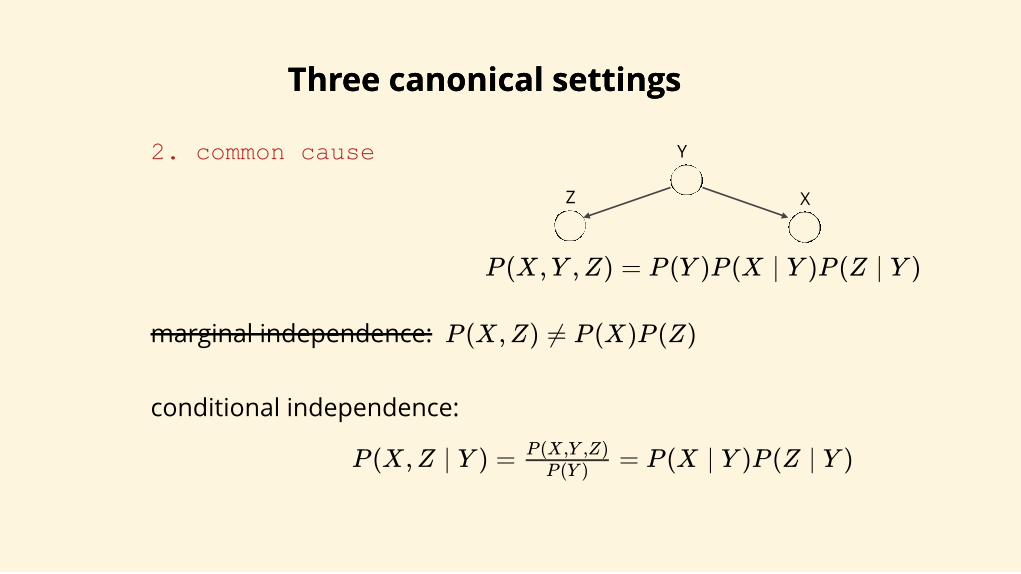
Three canonical settingsThree canonical settings
2. common cause
P (X,Y ,Z) = P (Y )P (X ∣ Y )P (Z ∣ Y )
P (X,Z ∣ Y ) = = P (X ∣ Y )P (Z ∣ Y )P (Y )
P (X,Y ,Z)
conditional independence:
marginal independence: P (X,Z) ≠ P (X)P (Z)
X
Y
Z
Three canonical settingsThree canonical settings
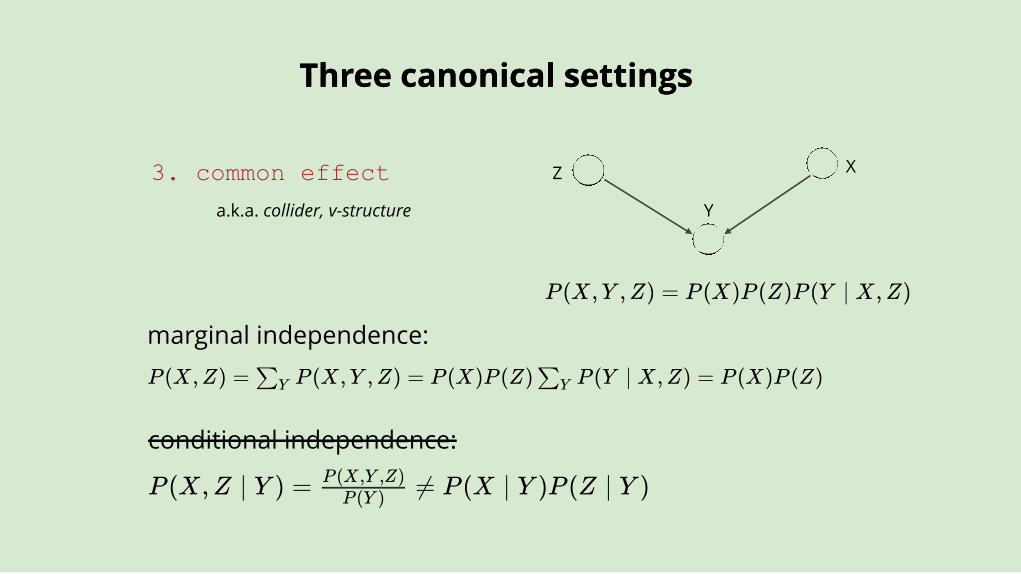
3. common effect
P (X,Y ,Z) = P (X)P (Z)P (Y ∣ X,Z)
P (X,Z ∣ Y ) = ≠ P (X ∣ Y )P (Z ∣ Y )P (Y )
P (X,Y ,Z)
conditional independence:
marginal independence:P (X,Z) = P (X,Y ,Z) = P (X)P (Z) P (Y ∣ X,Z) = P (X)P (Z)∑Y ∑Y
X
Y
Z
a.k.a. collider, v-structure
Three canonical settingsThree canonical settings
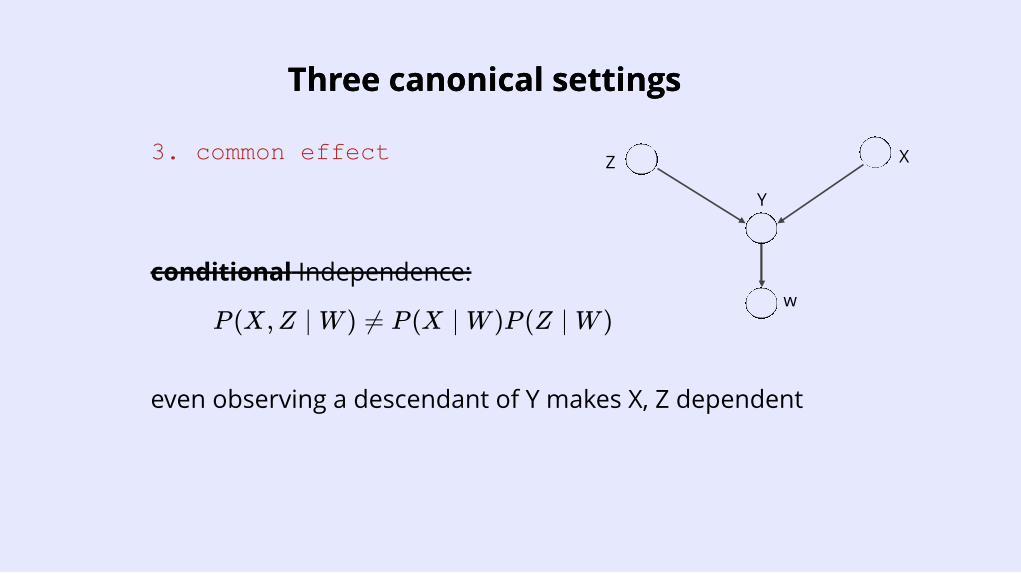
3. common effect
P (X,Z ∣ W ) ≠ P (X ∣ W )P (Z ∣ W )
conditional Independence:w
even observing a descendant of Y makes X, Z dependent
X
Y
Z
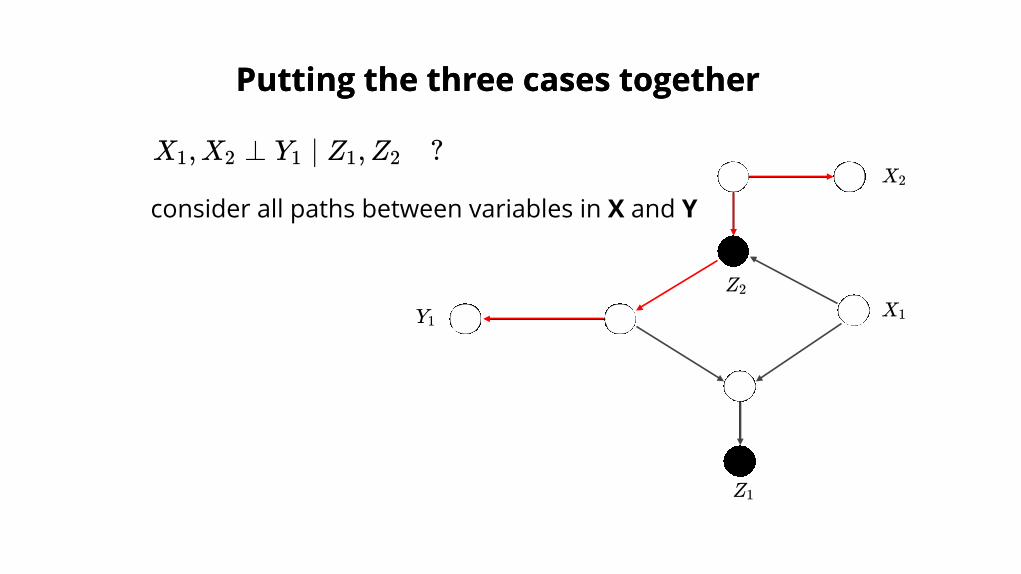
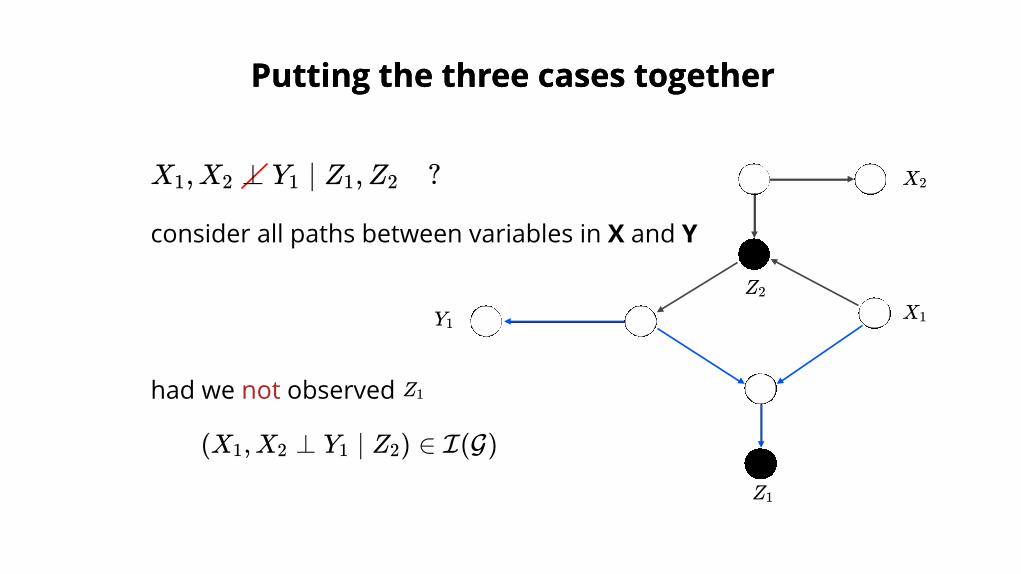
Putting the three cases togetherPutting the three cases together
consider all paths between variables in X and Y
X ,X ⊥ Y ∣ Z ,Z ?1 2 1 1 2
X1
X2
Y1
Z1
Z2
X1
X2
Y1
Z1
Z2
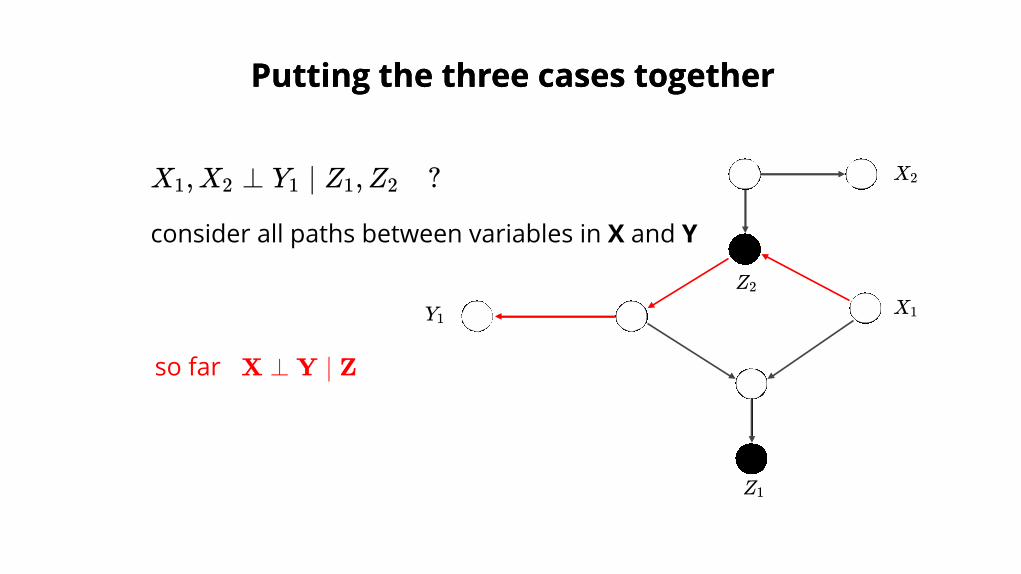
so far X ⊥ Y ∣ Z
consider all paths between variables in X and Y
X ,X ⊥ Y ∣ Z ,Z ?1 2 1 1 2
Putting the three cases togetherPutting the three cases together
X1
X2
Y1
Z1
Z2
consider all paths between variables in X and Y
X ,X ⊥ Y ∣ Z ,Z ?1 2 1 1 2
Putting the three cases togetherPutting the three cases together
had we not observed Z1
(X ,X ⊥ Y ∣ Z ) ∈ I(G)1 2 1 2
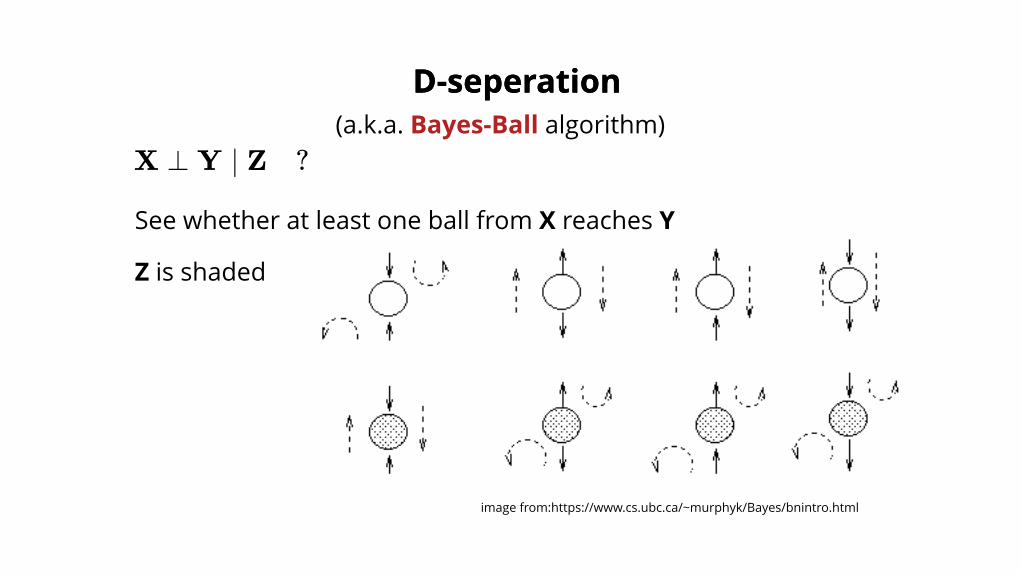
(a.k.a. Bayes-Ball algorithm)
See whether at least one ball from X reaches Y
X ⊥ Y ∣ Z ?
image from:https://www.cs.ubc.ca/~murphyk/Bayes/bnintro.html
Z is shaded
D-seperationD-seperation

D-separation; D-separation; algorithmalgorithm
input: graph G and X, Y, Z
output: mark the variables in Z and all of their ancestors in Gbreadth-first-search starting from X
stop any trail that reaches a blocked node
a node in Y is reached?
X ⊥ Y ∣ Z ?
unmarked middle of a collider (V-structure)
in Z otherwise
Linear time complexity
D-separation D-separation quizquiz
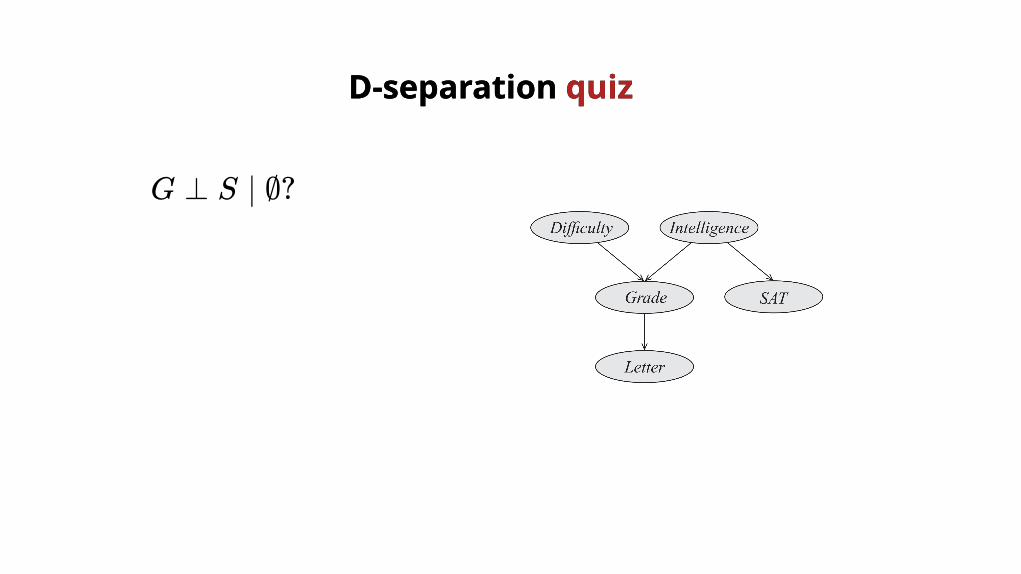
D-separation D-separation quizquiz
G ⊥ S ∣ ∅?
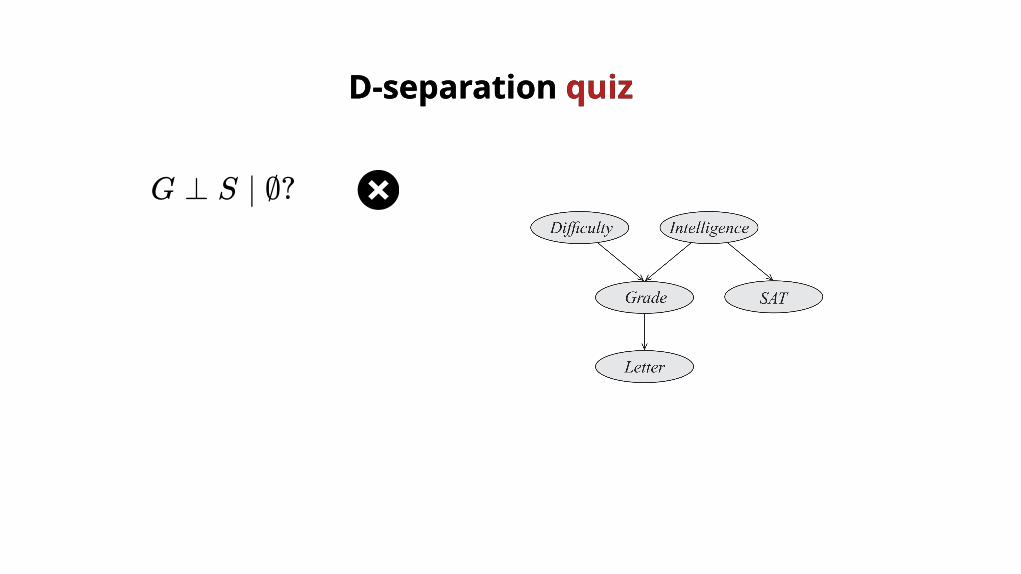
D-separation D-separation quizquiz
G ⊥ S ∣ ∅?
D-separation D-separation quizquiz
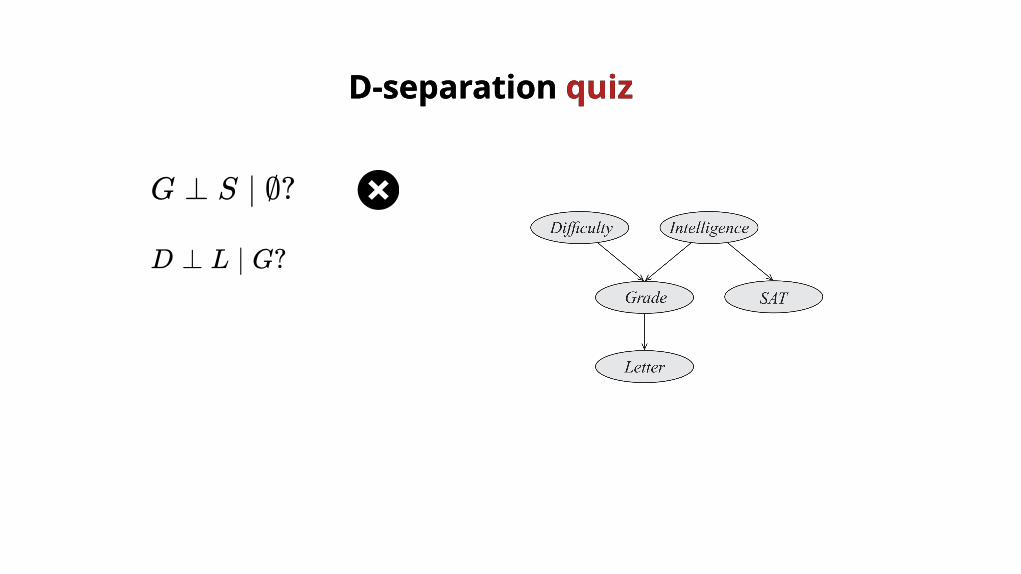
G ⊥ S ∣ ∅?
D ⊥ L ∣ G?
D-separation D-separation quizquiz
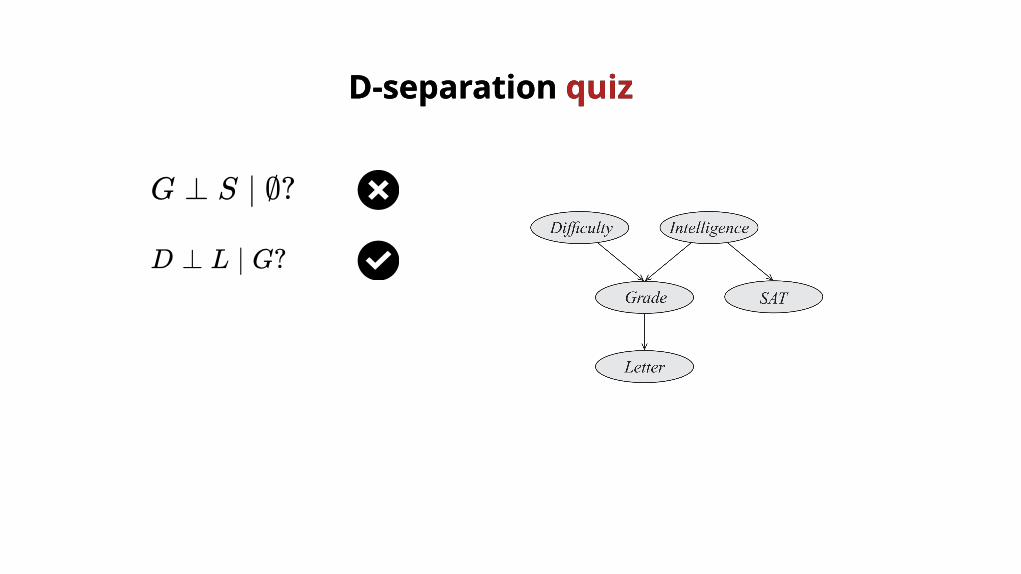
G ⊥ S ∣ ∅?
D ⊥ L ∣ G?
D-separation D-separation quizquiz
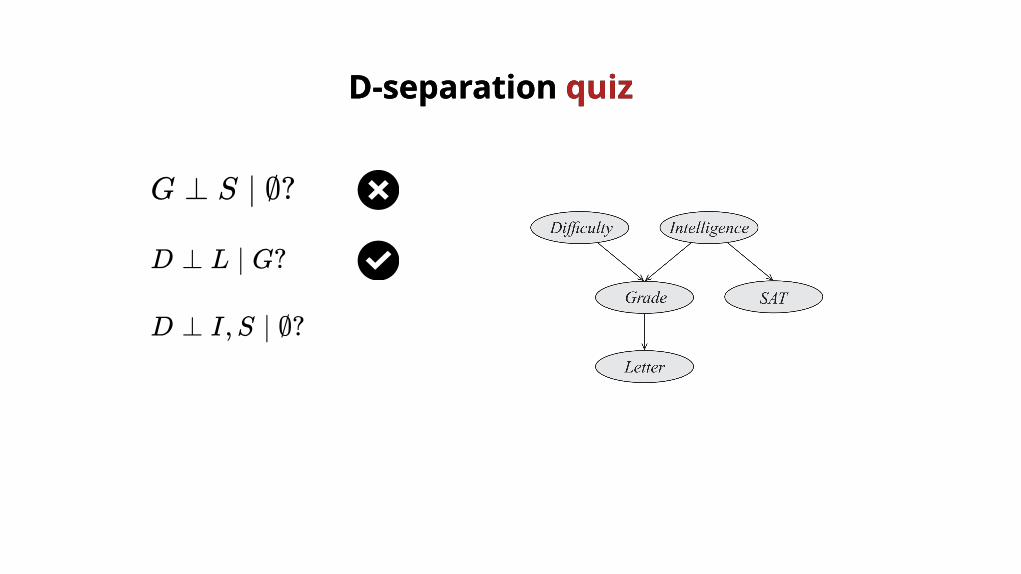
G ⊥ S ∣ ∅?
D ⊥ L ∣ G?
D ⊥ I,S ∣ ∅?
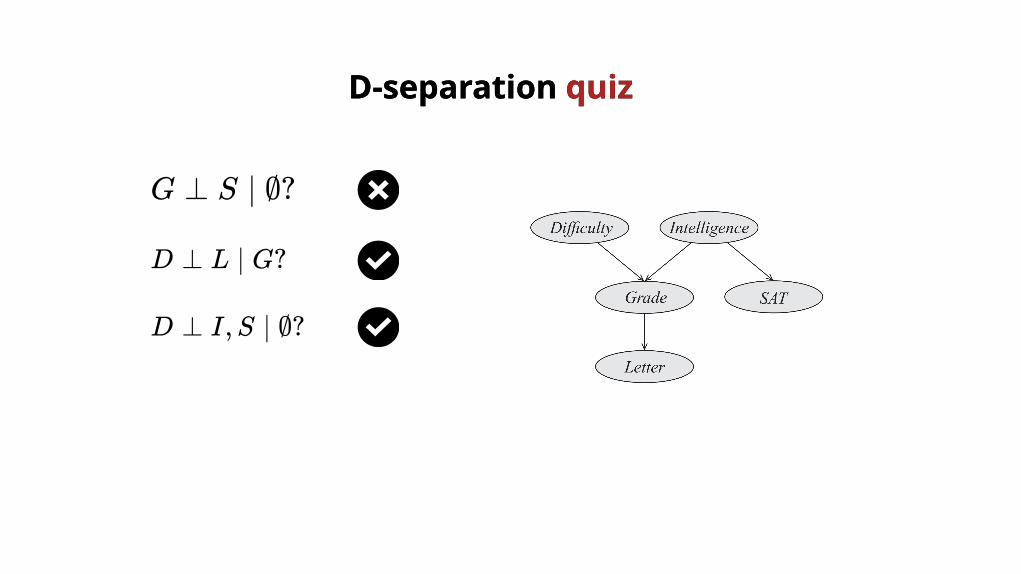
D-separation D-separation quizquiz
G ⊥ S ∣ ∅?
D ⊥ L ∣ G?
D ⊥ I,S ∣ ∅?
D-separation D-separation quizquiz
G ⊥ S ∣ ∅?
D ⊥ L ∣ G?
D ⊥ I,S ∣ ∅?
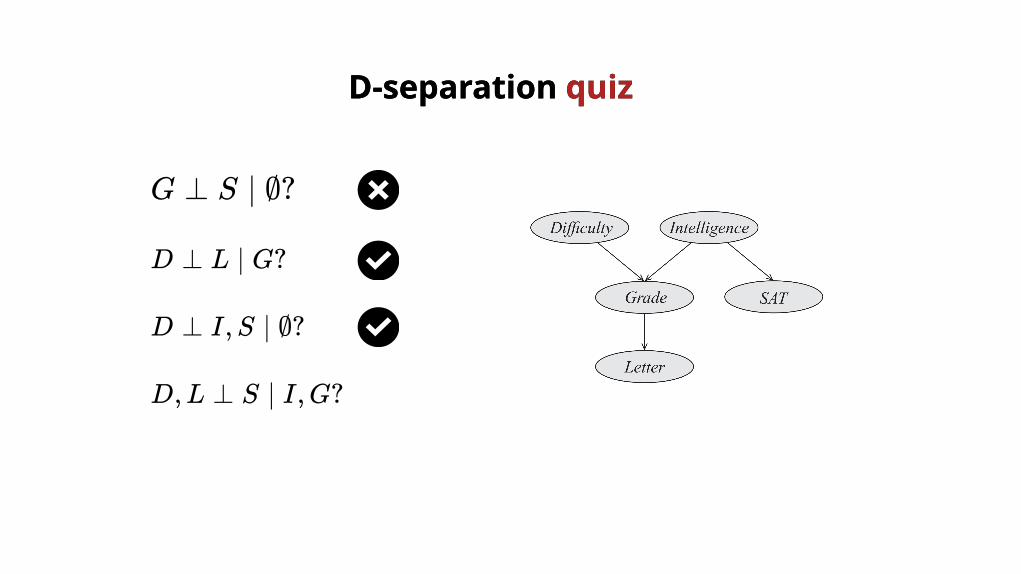
D,L ⊥ S ∣ I,G?
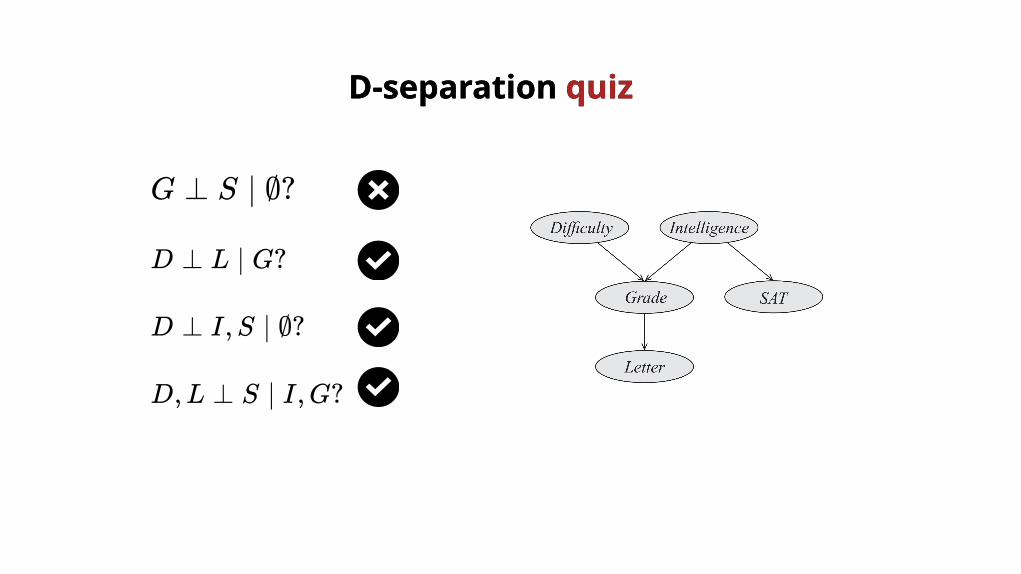
D-separation D-separation quizquiz
G ⊥ S ∣ ∅?
D ⊥ L ∣ G?
D ⊥ I,S ∣ ∅?
D,L ⊥ S ∣ I,G?
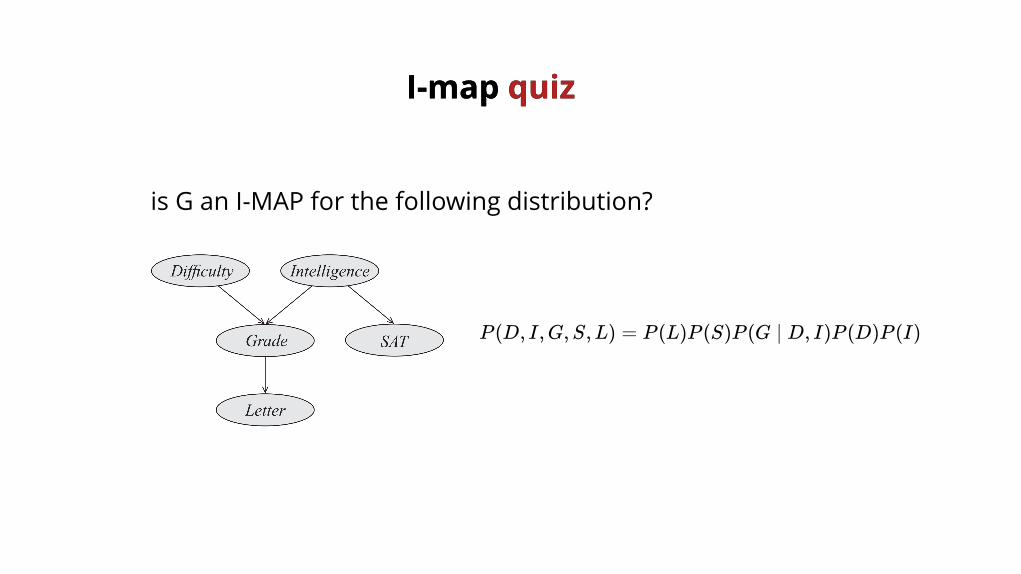
I-map I-map quizquiz
is G an I-MAP for the following distribution?
P (D, I,G,S,L) = P (L)P (S)P (G ∣ D, I)P (D)P (I)
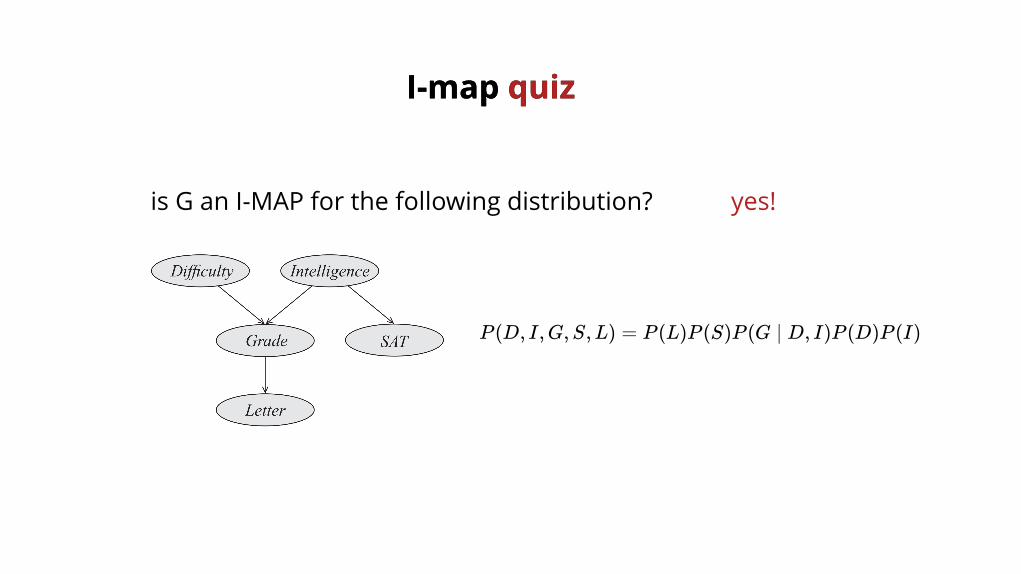
I-map I-map quizquiz
is G an I-MAP for the following distribution?
P (D, I,G,S,L) = P (L)P (S)P (G ∣ D, I)P (D)P (I)
yes!

conditional independencies of the distributioninferred from the graph
local CI:global CI: D-separation
Summary Summary so farso far
graph and distribution are combined:
factorization of the distributionaccording to the graph
X ⊥ NonDescendents ∣ Parentsi Xi Xi
P (X) = P (X ∣ Pa )∏i i Xi
G

Summary Summary so farso far
factorization of the distributionlocal conditional independenciesglobal conditional independencies
identify the samefamily of distributions
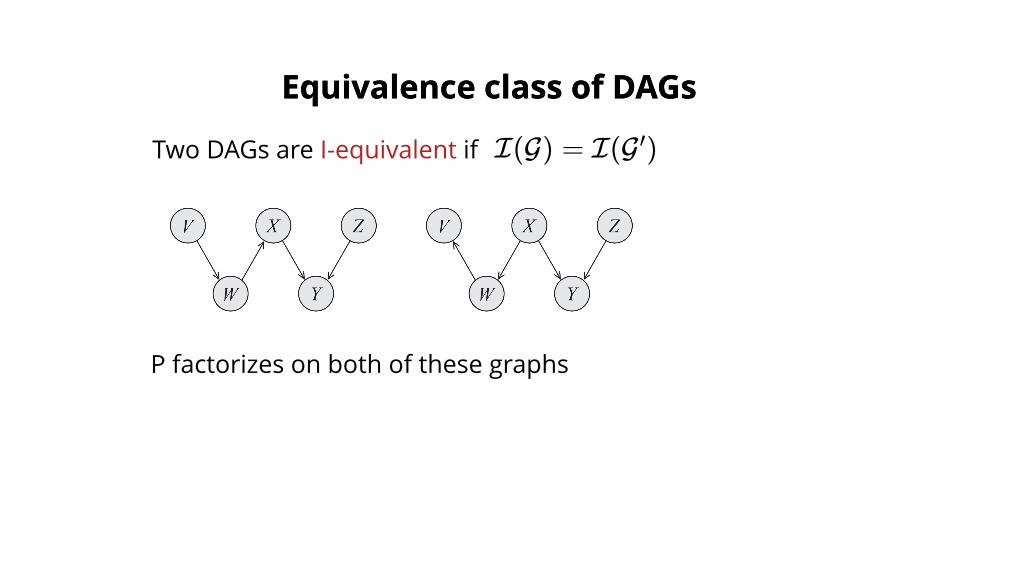
Equivalence class of DAGsEquivalence class of DAGs
Two DAGs are I-equivalent if I(G) = I(G )′
P factorizes on both of these graphs
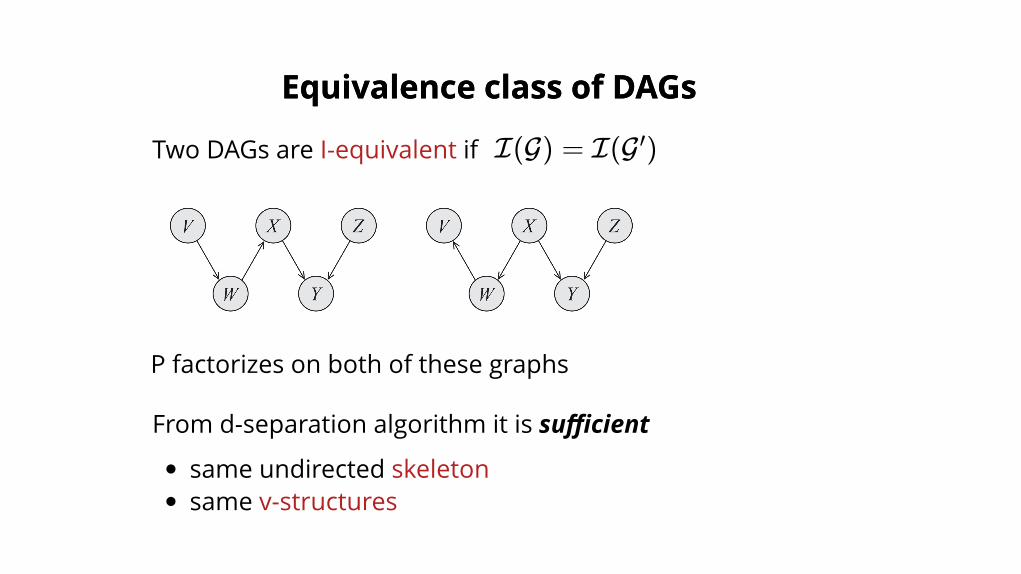
Equivalence class of DAGsEquivalence class of DAGs
Two DAGs are I-equivalent if I(G) = I(G )′
From d-separation algorithm it is sufficient
same undirected skeletonsame v-structures
P factorizes on both of these graphs
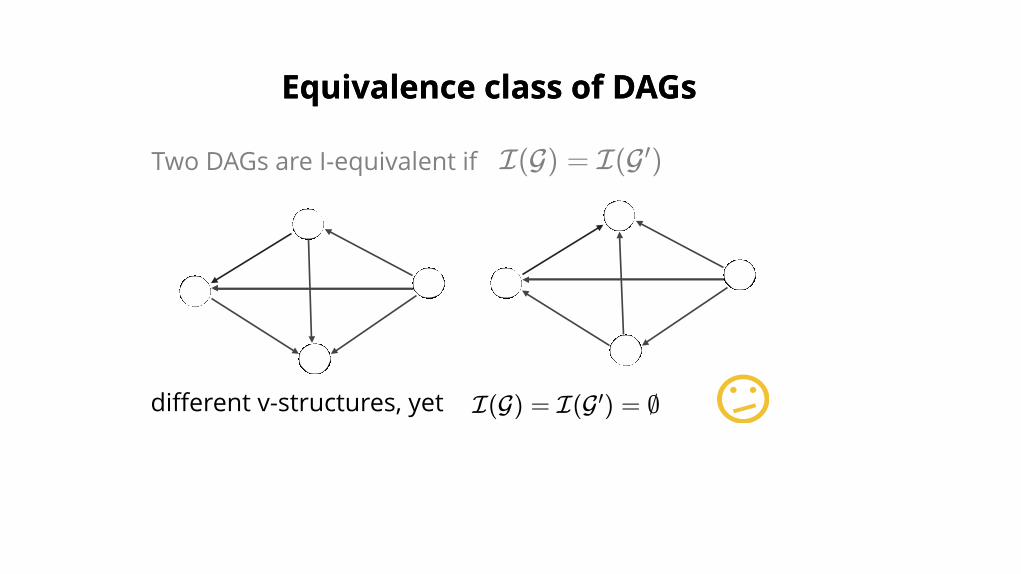
Equivalence class of DAGsEquivalence class of DAGs
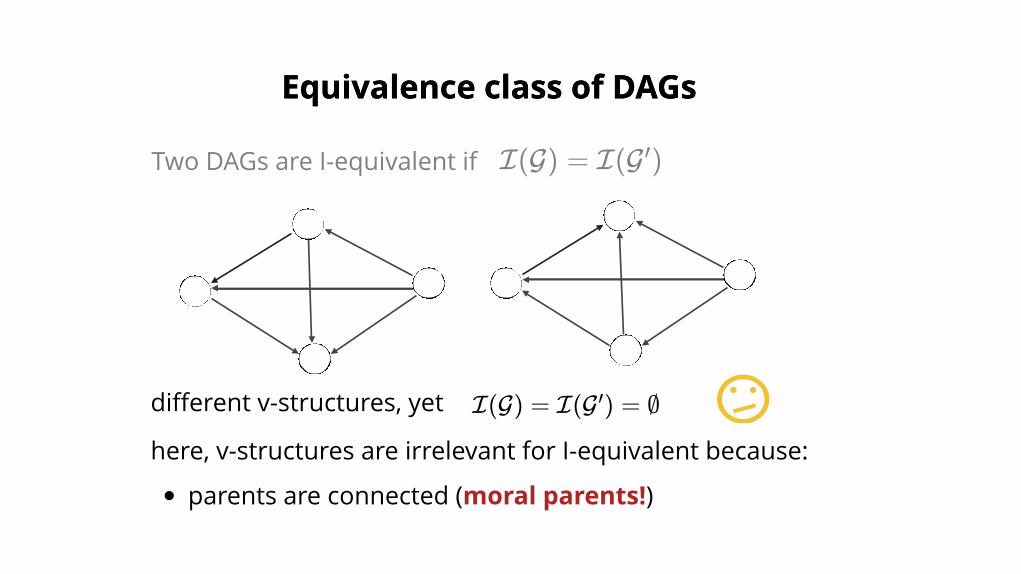
Two DAGs are I-equivalent if I(G) = I(G )′
different v-structures, yet I(G) = I(G ) = ∅′
Equivalence class of DAGsEquivalence class of DAGs
Two DAGs are I-equivalent if I(G) = I(G )′
different v-structures, yet I(G) = I(G ) = ∅′
here, v-structures are irrelevant for I-equivalent because:
parents are connected (moral parents!)
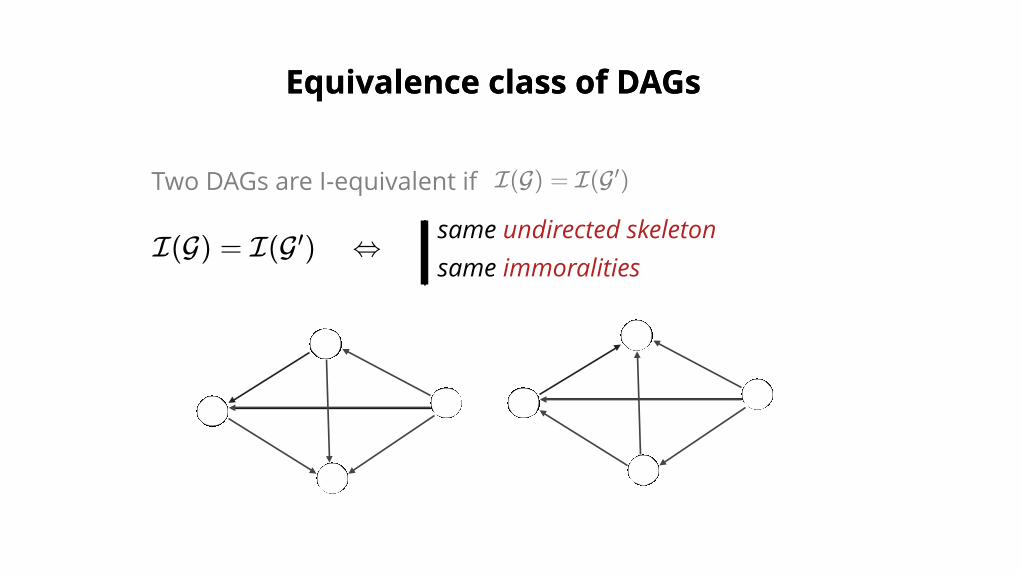
Equivalence class of DAGsEquivalence class of DAGs
Two DAGs are I-equivalent if I(G) = I(G )′
I(G) = I(G ) ⇔′ same undirected skeletonsame immoralities
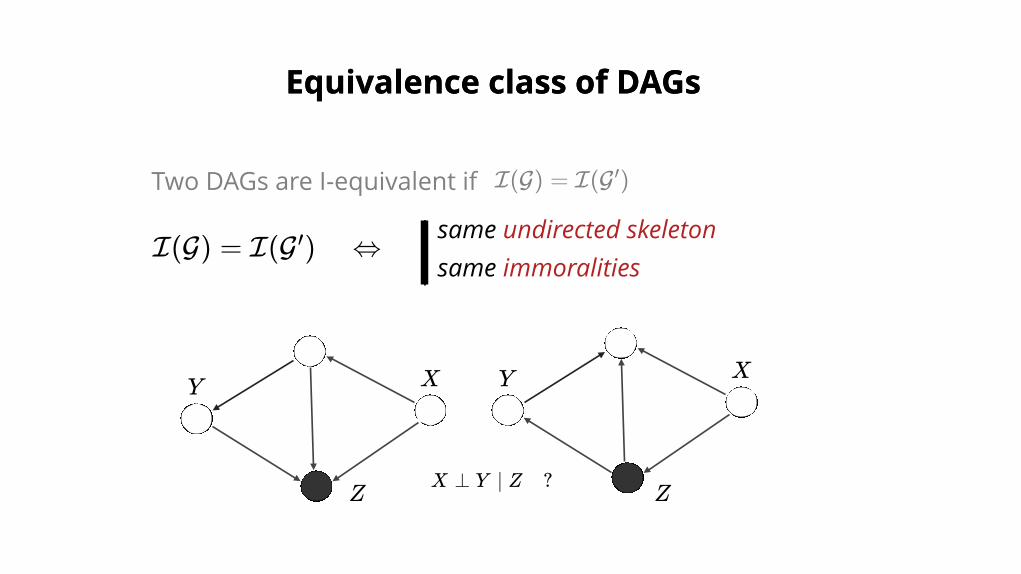
Equivalence class of DAGsEquivalence class of DAGs
Two DAGs are I-equivalent if I(G) = I(G )′
I(G) = I(G ) ⇔′ same undirected skeletonsame immoralities
X ⊥ Y ∣ Z ?ZZ
XXY Y
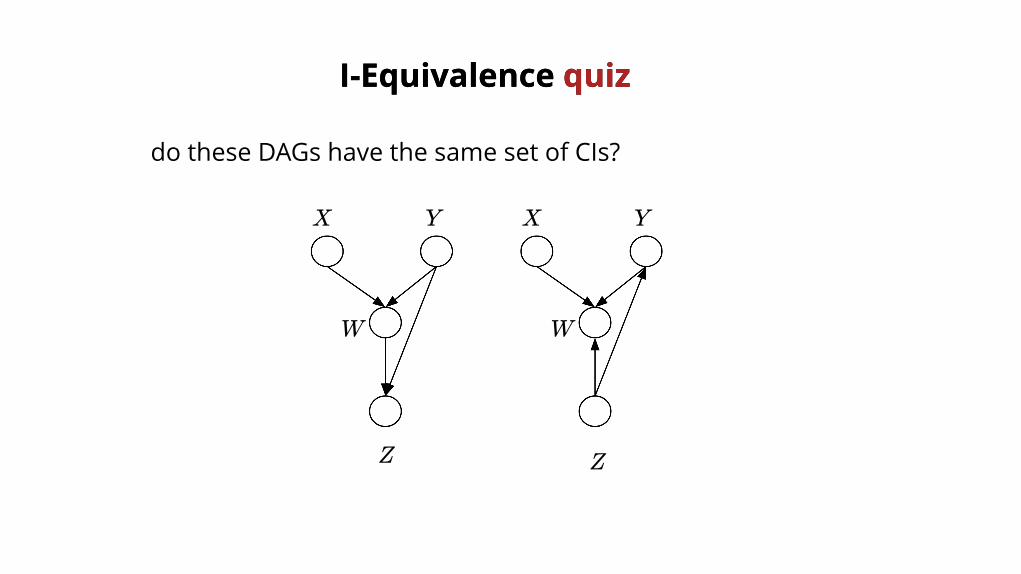
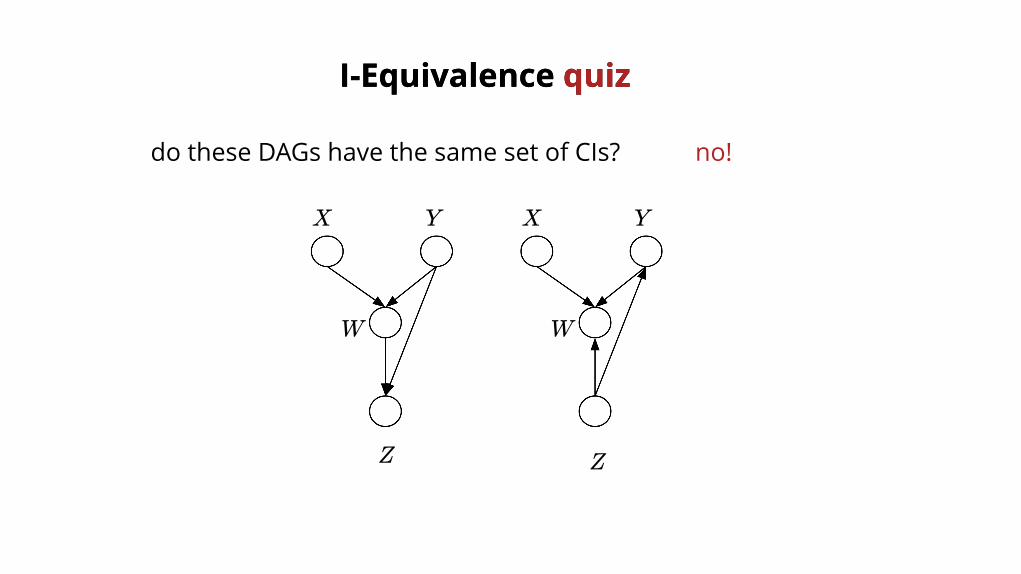
I-Equivalence I-Equivalence quizquiz
do these DAGs have the same set of CIs?
X X YY
Z Z
W W
I-Equivalence I-Equivalence quizquiz
do these DAGs have the same set of CIs? no!
X X YY
Z Z
W W
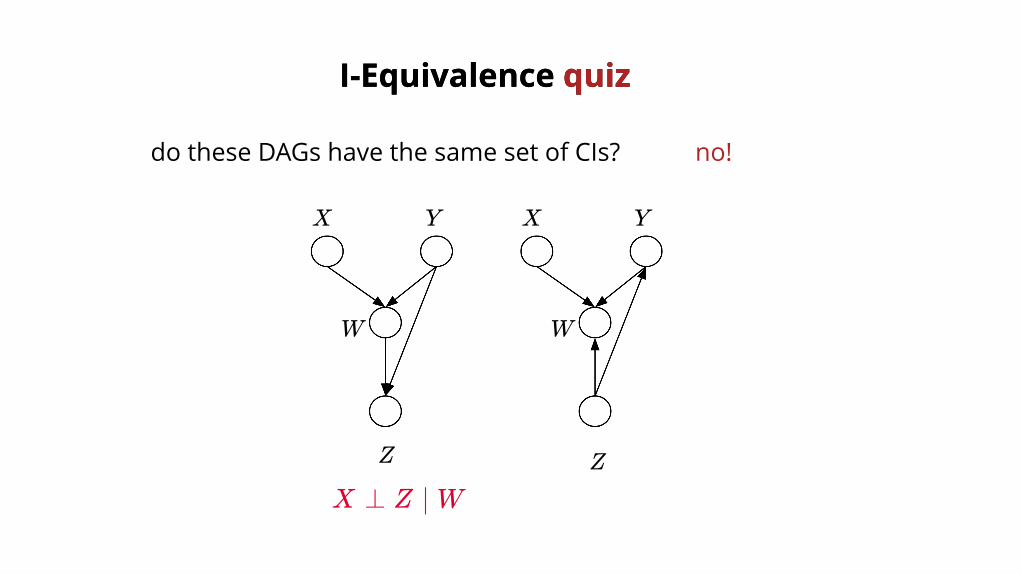
I-Equivalence I-Equivalence quizquiz
do these DAGs have the same set of CIs? no!
X X YY
Z Z
W W
X ⊥ Z ∣ W

MinimalMinimal I-map I-map G is minimal I-map for P:
G is an I-map for P:removing any edge destroys this property
P (X,Y ,Z,W ) = P (X ∣ Y ,Z)P (W )P (Y ∣ Z)P (Z) Example:
I(G) ⊆ I(P )
which graph G to use for P?
X X X
Z Z ZY Y Y
WWW
IMAP
X
Z Y
W
min. IMAP min. IMAP NOT an IMAP

Minimal I-map Minimal I-map from CIfrom CI
input: or an oracle; an orderingoutput: a minimal I-map G for i=1...n
find minimal s.t.set
which graph G to use for P?
I(P ) X , … ,X1 n
(X ⊥ X , … ,X −U ∣ U)i 1 i−1U ⊆ {X , … ,X }1 i−1
X1 XnXi
Pa ← UXi X ⊥ NonDesc ∣ Pai Xi Xi

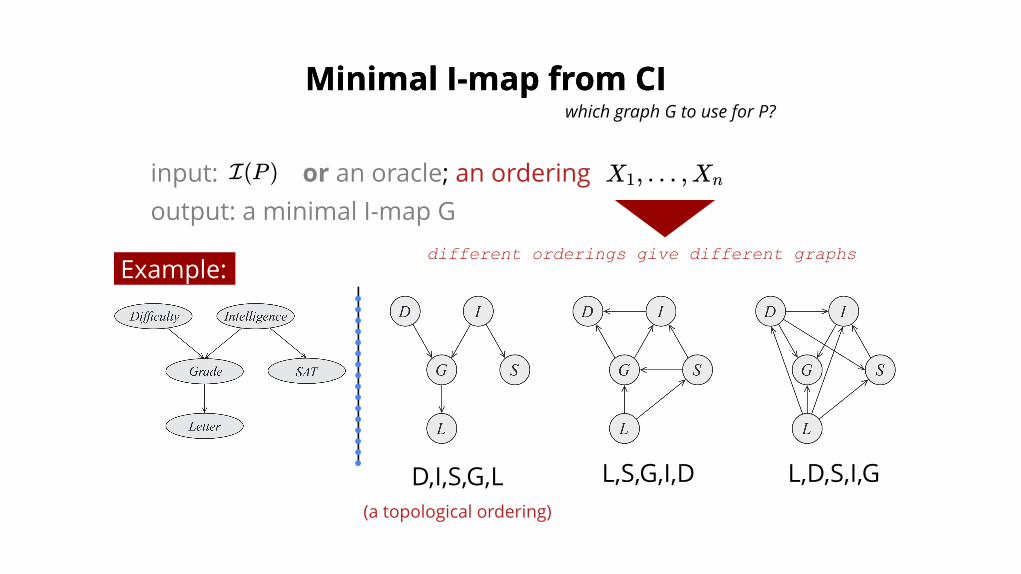
Minimal I-map from CIMinimal I-map from CI
input: or an oracle; an orderingoutput: a minimal I-map G
which graph G to use for P?
I(P ) X , … ,X1 n
different orderings give different graphs
Minimal I-map from CIMinimal I-map from CI
input: or an oracle; an orderingoutput: a minimal I-map G
which graph G to use for P?
I(P ) X , … ,X1 n
different orderings give different graphs Example:
D,I,S,G,L(a topological ordering)
L,S,G,I,D L,D,S,I,G
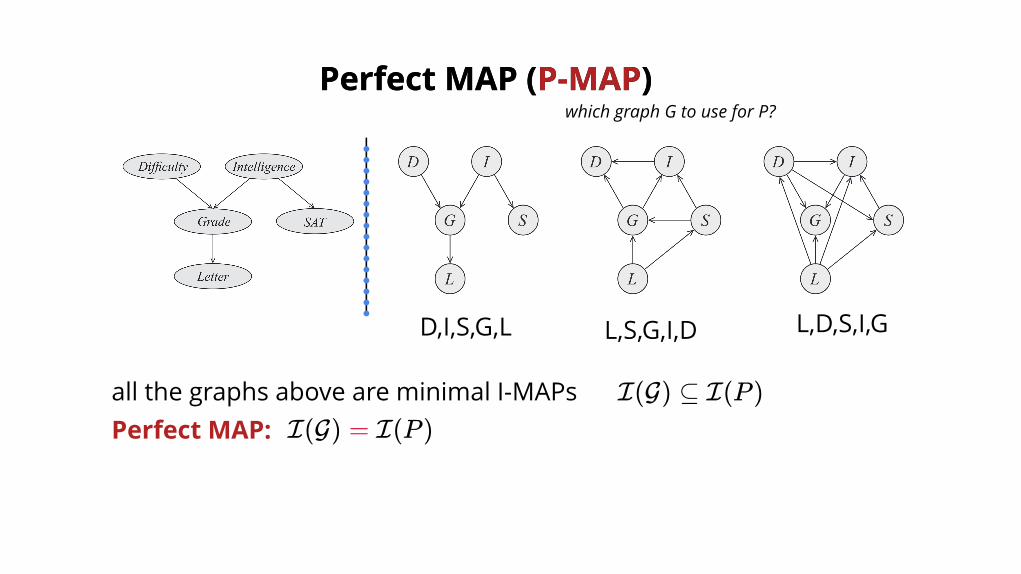
Perfect MAP (Perfect MAP (P-MAPP-MAP))which graph G to use for P?
D,I,S,G,L L,S,G,I,D L,D,S,I,G
all the graphs above are minimal I-MAPsPerfect MAP:
I(G) ⊆ I(P )I(G) = I(P )

Perfect map (Perfect map (P-mapP-map))which graph G to use for P?
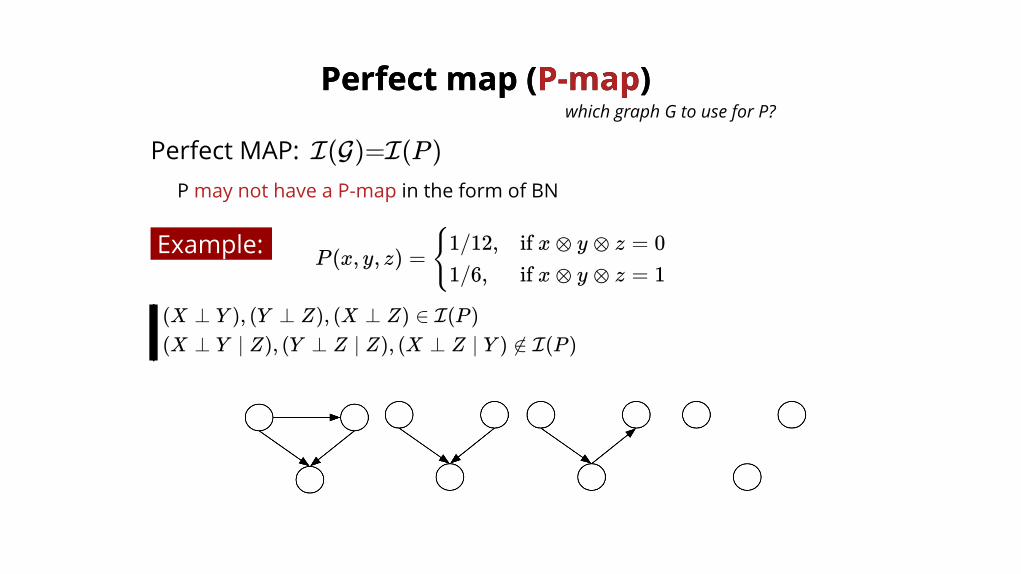
Perfect MAP: I(G)=I(P )P may not have a P-map in the form of BN
Perfect map (Perfect map (P-mapP-map))which graph G to use for P?
Perfect MAP: I(G)=I(P )P may not have a P-map in the form of BN
Example:P (x, y, z) = {1/12,
1/6,if x ⊗ y ⊗ z = 0if x ⊗ y ⊗ z = 1
(X ⊥ Y ), (Y ⊥ Z), (X ⊥ Z) ∈ I(P )(X ⊥ Y ∣ Z), (Y ⊥ Z ∣ Z), (X ⊥ Z ∣ Y ) ∉ I(P )
Perfect map (Perfect map (P-mapP-map))which graph G to use for P?
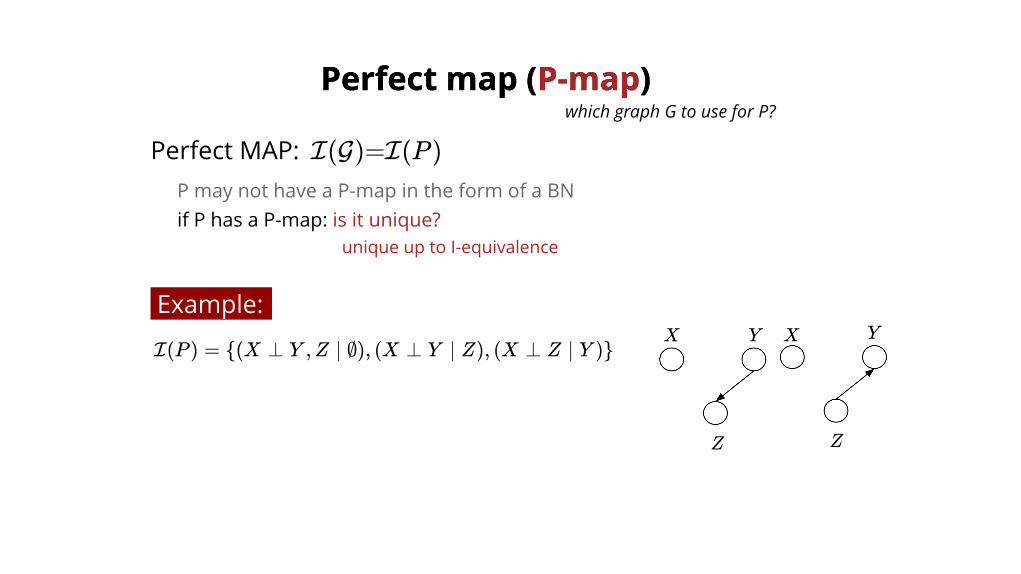
Perfect MAP: I(G)=I(P )P may not have a P-map in the form of a BNif P has a P-map: is it unique?
Example:
I(P ) = {(X ⊥ Y ,Z ∣ ∅), (X ⊥ Y ∣ Z), (X ⊥ Z ∣ Y )}X XY Y
ZZ
unique up to I-equivalence
Perfect map (Perfect map (P-mapP-map))which graph G to use for P?
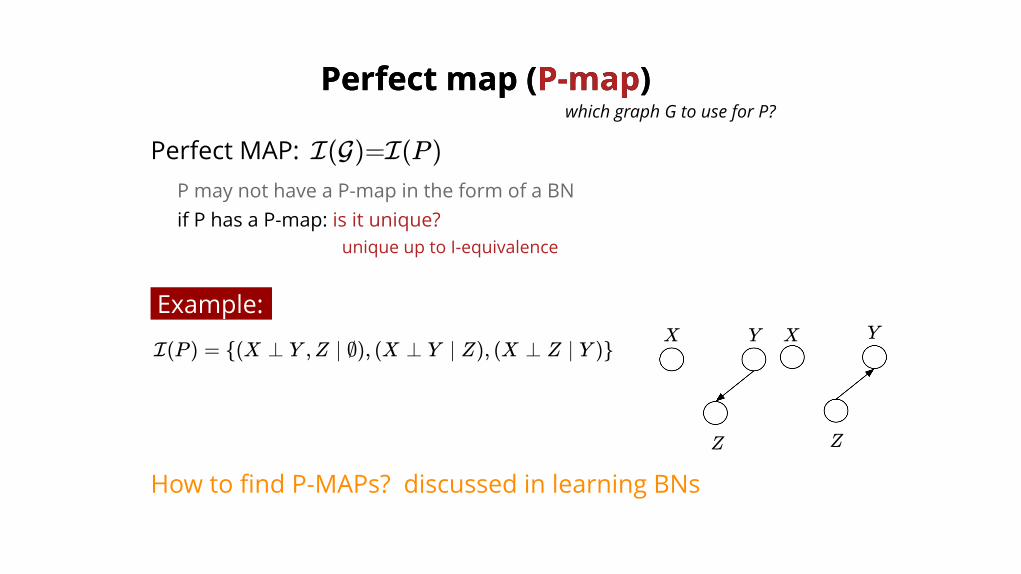
Perfect MAP: I(G)=I(P )P may not have a P-map in the form of a BNif P has a P-map: is it unique?
Example:
I(P ) = {(X ⊥ Y ,Z ∣ ∅), (X ⊥ Y ∣ Z), (X ⊥ Z ∣ Y )}X XY Y
ZZ
How to find P-MAPs? discussed in learning BNs
unique up to I-equivalence
SummarySummary
factorization of the dist.local CIsglobal CIs
can be represented using an equivalent class of graphs:
alternative factorizationdifferent local CIssame global CIs
identify the samefamily of distributions





























