Embed Size (px)
Citation preview

Bayesian Learning, Part 1 of (probably)
4Reading: Bishop Ch. 1.2, 1.5, 2.3

Administrivia•Office hours tomorrow moved:
•noon-2:00
•Thesis defense announcement:
•Sergey Plis, Improving the information derived from human brain mapping experiments.
•Application of ML/statistical techniques to analysis of MEG neuroimaging data
•Feb 21, 9:00-11:00 AM
•FEC 141; everybody welcome

Yesterday, today, and...•Last time:
•Finish up SVMs
•This time:
•HW3
• Intro to statistical/generative modeling
•Statistical decision theory
•The Bayesian viewpoint
•Discussion of R1

Homework (proj) 3•Data sets:
•MNIST Database of handwritten digits:• http://yann.lecun.com/exdb/mnist/
•One other (forthcoming)
•Algorithms:
•Decision tree: http://www.cs.waikato.ac.nz/ml/weka/
•Linear LSE classifier (roll your own)
•SVM (ditto, and compare to Weka’s)
•Gaussian kernel; poly degree 4, 10, 20; sigmoid
•Question: which algorithm is better on these data sets? Why? Prove it.

HW 3 additional details•Due: Tues Mar 6, 2007, beginning of class
•2 weeks from today -- many office hours between now and then
•Feel free to talk to each other, but write your own code
•Must code LSE, SVM yourself; can use pre-packaged DT•Use a QP library/solver for SVM (e.g.,
Matlab’s quadprog() function)•Hint: QPs are sloooow for large data;
probably want to sub-sample data set.•Q’: what effect does this have?
•Extra credit: roll your own DT

ML trivia of the day...•Which data mining techniques [have] you used
in a successfully deployed application?
htt
p:/
/w
ww
.kdnu
gg
ets
.com
/

Assumptions•“Assume makes an a** out of U and ME”...
•Bull****
•Assumptions are unavoidable
• It is not possible to have an assumption-free learning algorithm
•Must always have some assumption about how the data works
•Makes learning faster, more accurate, more robust

Example assumptions
•Decision tree:
•Axis orthogonality
• Impurity-based splitting
•Greedy search ok
•Accuracy (0/1 loss) objective function

Example assumptions
•Linear discriminant (hyperplane classifier) via MSE:
•Data is linearly separable
•Squared-error cost

Example assumptions
•Support vector machines
•Data is (close to) linearly separable...
• ... in some high-dimensional projection of input space
• Interesting nonlinearities can be captured by kernel functions
•Max margin objective function

Specifying assumptions•Bayesian learning assumes:
•Data were generated by some stochastic process
•Can write down (some) mathematical form for that process
•CDF/PDF/PMF
•Mathematical form needs to be parameterized
•Have some “prior beliefs” about those params

Specifying assumptions•Makes strong assumptions about form
(distribution) of data
•Essentially, an attempt to make assumptions explicit and to divorce them from learning algorithm
• In practice, not a single learning algorithm, but a recipe for generating problem-specific algs.
•Will work well to the extent that these assumptions are right

Example•F={height, weight}
•Ω={male, female}
•Q1: Any guesses about individual distributions of height/weight by class?
•What probability function (PDF)?
•Q2: What about the joint distribution?
•Q3: What about the means of each?
•Reasonable guess for the upper/lower bounds on the means?

Some actual data*
* Actual synthesized data, anyway...

General idea
•Find probability distribution that describes classes of data
•Find decision surface in terms of those probability distributions

H/W data as PDFs

Or, if you prefer...

General idea
•Find probability distribution that describes classes of data
•Find decision surface in terms of those probability distributions
•What would be a good rule?

5 minutes of math
•Bayesian decision rule: Bayes optimality
•Want to pick the class that minimizes expected cost
•Simplest case: cost==misclassification
•Expected cost == expected misclassification rate

5 minutes of math
•Expectation only defined w.r.t. a probability distribution:
•Posterior probability of class i given data x:
• Interpreted as: chance that the real class is , given that the observed data is x

5 minutes of math•Expected cost is then:
•cost of getting it wrong * prob of getting it wrong
• integrated over all possible outcomes (true classes)
•More formally:
Cost of classifying a class j thing as a class i

5 minutes of math•Expected cost is then:
•cost of getting it wrong * prob of getting it wrong
• integrated over all possible outcomes (true classes)
•More formally:
•Want to pick that minimizes this

5 minutes of math•For 0/1 cost, reduces to:

5 minutes of math•For 0/1 cost, reduces to:
•To minimize, pick the that minimizes:
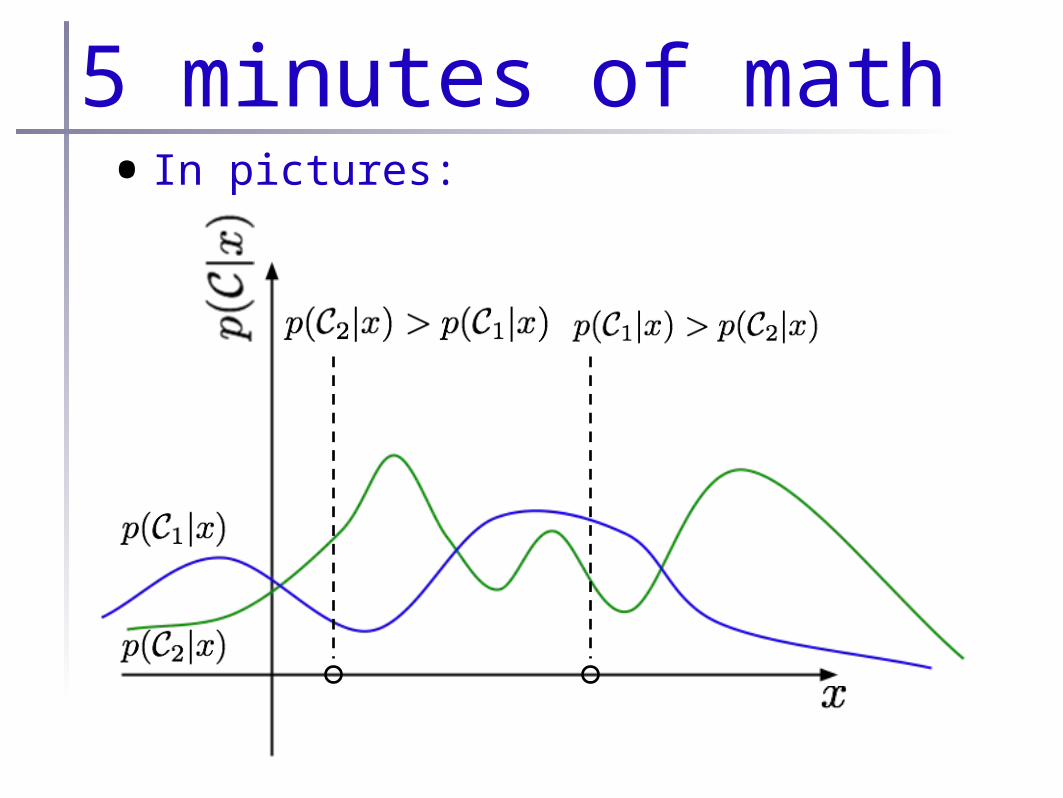
5 minutes of math• In pictures:

5 minutes of math• In pictures:

5 minutes of math•These thresholds are called the Bayes
decision thresholds
•The corresponding cost (err rate) is called the Bayes optimal cost
A real-worldexample:





























