Embed Size (px)
Citation preview

AWS Database Migration ServiceBenutzerhandbuch
API-Version API Version 2016-01-01

AWS Database Migration Service Benutzerhandbuch
AWS Database Migration Service: BenutzerhandbuchCopyright © 2020 Amazon Web Services, Inc. and/or its affiliates. All rights reserved.
Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's,in any manner that is likely to cause confusion among customers, or in any manner that disparages or discreditsAmazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may notbe affiliated with, connected to, or sponsored by Amazon.

AWS Database Migration Service Benutzerhandbuch
Table of ContentsWas ist AWS Database Migration Service? ............................................................................................ 1
Von AWS DMS durchgeführte Migrationsaufgaben .......................................................................... 1Wie AWS DMS auf unterster Ebene funktioniert ............................................................................. 2
Funktionsweise von AWS DMS ............................................................................................................ 4Allgemeine Übersicht über AWS DMS ........................................................................................... 4Komponenten ............................................................................................................................. 5Quellen .................................................................................................................................... 11Ziele ....................................................................................................................................... 13Mit anderen AWS-Services ......................................................................................................... 15
Unterstützung für AWS CloudFormation ............................................................................... 15Erstellen eines ARN .......................................................................................................... 15
Einrichten ........................................................................................................................................ 18Anmelden bei AWS ................................................................................................................... 18Erstellen eines IAM-Benutzers .................................................................................................... 18Planen der Migration für AWS Database Migration Service .............................................................. 20
Erste Schritte ................................................................................................................................... 22Starten einer Datenbankmigration ................................................................................................ 22Schritt 1: Begrüßungsseite ......................................................................................................... 23Schritt 2: Erstellen einer Replikations-Instance ............................................................................... 23Schritt 3: Geben Sie Quell- und Zielendpunkte an .......................................................................... 28Schritt 4: Erstellen einer Migrationsaufgabe ................................................................................... 33Überwachen Ihrer Aufgabe ......................................................................................................... 37
Sicherheit ........................................................................................................................................ 38Datenschutz ............................................................................................................................. 39
Datenverschlüsselung ........................................................................................................ 40Richtlinie für den Datenverkehr zwischen Netzwerken ............................................................. 41
Identity and Access Management ................................................................................................ 41Zielgruppe ........................................................................................................................ 41Authentifizieren mit Identitäten ............................................................................................ 42Verwalten des Zugriffs mit Richtlinien ................................................................................... 44Funktionsweise von AWS Database Migration Service mit IAM ................................................. 46Beispiele für identitätsbasierte Richtlinien ............................................................................. 50Beispiele für eine ressourcenbasierte Richtlinie ..................................................................... 56Fehlersuche ..................................................................................................................... 60
Protokollieren und überwachen ................................................................................................... 62Compliance-Validierung .............................................................................................................. 63Ausfallsicherheit ........................................................................................................................ 64Sicherheit der Infrastruktur ......................................................................................................... 65Erforderliche IAM-Berechtigungen ................................................................................................ 65IAM-Rollen für die CLI und API ................................................................................................... 68Differenzierte Zugriffskontrolle ..................................................................................................... 72
Verwenden von Ressourcennamen für die Zugriffskontrolle ..................................................... 72Steuern des Zugriffs mit Tags ............................................................................................. 74
Festlegen eines Verschlüsselungsschlüssels ................................................................................. 79Netzwerksicherheit .................................................................................................................... 81Verwenden von SSL ................................................................................................................. 82
Einschränkungen bei der Verwendung von SSL mit AWS DMS ................................................ 83Verwalten von Zertifikaten .................................................................................................. 84Aktivieren von SSL für einen MySQL-kompatiblen, PostgreSQL- oder SQL Server-Endpunkt ......... 84SSL-Unterstützung für einen Oracle-Endpunkt ....................................................................... 86
Ändern des Datenbankpassworts ................................................................................................ 91Limits .............................................................................................................................................. 92
Limits für AWS Database Migration Service .................................................................................. 92Replikations-Instance ......................................................................................................................... 93
API-Version API Version 2016-01-01iii

AWS Database Migration Service Benutzerhandbuch
Replikations-Instances im Detail .................................................................................................. 94Öffentliche und private Replikations-Instances ............................................................................... 96AWS DMS-Wartung .................................................................................................................. 96
AWS DMS-Wartungsfenster ................................................................................................ 97Versionen der Replikations-Engine .............................................................................................. 99
Veralten einer Replikations-Engine-Version ......................................................................... 100Aktualisieren der Engine-Version der Replikations-Instance .................................................... 100
Einrichten eines Netzwerks für eine Replikations-Instance ............................................................. 103Netzwerkkonfigurationen für die Datenbankmigration ............................................................ 103Erstellen einer Replikationssubnetzgruppe .......................................................................... 108
Festlegen eines Verschlüsselungsschlüssels ............................................................................... 110Erstellen einer Replikations-Instance .......................................................................................... 110Ändern einer Replikations-Instance ........................................................................................... 115Neustarten einer Replikations-Instance ...................................................................................... 118Löschen einer Replikations-Instance ......................................................................................... 120Unterstützte DDL-Anweisungen ................................................................................................. 121
Endpunkte ...................................................................................................................................... 122Quellen für die Datenmigration .................................................................................................. 122
Verwenden von Oracle als Quelle ...................................................................................... 124Verwenden von SQL Server als Quelle .............................................................................. 151Verwenden einer Azure SQL-Datenbank als Quelle .............................................................. 164Verwenden von PostgreSQL als Quelle .............................................................................. 164Verwenden von MySQL als Quelle .................................................................................... 183Verwenden von SAP ASE als Quelle ................................................................................. 191Verwenden von MongoDB als Quelle ................................................................................. 196Verwenden von Amazon S3 als Quelle ............................................................................... 201Verwenden von IBM Db2 LUW als Quelle ........................................................................... 207
Ziele für die Datenmigration ...................................................................................................... 211Verwenden von Oracle als Ziel ......................................................................................... 213Verwenden von SQL Server als Ziel .................................................................................. 219Verwenden von PostgreSQL als Ziel .................................................................................. 222Verwenden von MySQL als Ziel ........................................................................................ 226Verwenden von Amazon Redshift als Ziel ........................................................................... 231Verwenden von SAP ASE als Ziel ..................................................................................... 243Verwenden von Amazon S3 als Ziel .................................................................................. 245Verwenden von Amazon DynamoDB als Ziel ....................................................................... 271Verwenden von Amazon Kinesis Data Streams als Ziel ......................................................... 285Verwendung von Apache Kafka als Ziel .............................................................................. 296Verwenden von Amazon Elasticsearch Service als Ziel ......................................................... 306Verwenden von Amazon DocumentDB als Ziel .................................................................... 310
Erstellen der Quell- und Zielendpunkte ....................................................................................... 324Aufgaben ....................................................................................................................................... 329
Erstellen eines Aufgabenbewertungsberichts ............................................................................... 331Erstellen einer Aufgabe ............................................................................................................ 333
Aufgabeneinstellungen ..................................................................................................... 340Einrichten der LOB-Unterstützung ...................................................................................... 361Erstellen mehrerer Aufgaben ............................................................................................. 362
Fortlaufende Replikationsaufgaben ............................................................................................. 363Starten der Replikation von einem CDC-Startpunkt aus ......................................................... 364Durchführen der bidirektionalen Replikation ......................................................................... 367
Ändern einer Aufgabe .............................................................................................................. 369Erneutes Laden von Tabellen während einer Aufgabe ................................................................... 370
AWS Management Console .............................................................................................. 370Tabellenzuweisung .................................................................................................................. 372
Festlegen der Tabellenauswahl und Transformationen durch Tabellenzuweisungen über dieKonsole ......................................................................................................................... 372Festlegen der Tabellenauswahl und Transformationen durch Tabellenzuweisungen mit JSON ..... 377
API-Version API Version 2016-01-01iv

AWS Database Migration Service Benutzerhandbuch
Überwachen von Aufgaben ............................................................................................................... 421Aufgabenstatus ....................................................................................................................... 421Tabellenstatus während der Aufgaben ........................................................................................ 422Überwachen von Replikationsaufgaben mit Amazon CloudWatch .................................................... 423Metriken von Data Migration Service .......................................................................................... 425
Metriken zur Replikations-Instance ..................................................................................... 426Metriken für die Replikationsaufgabe .................................................................................. 427
Verwalten von AWS DMS-Protokollen ........................................................................................ 429Protokollieren von AWS DMS-API-Aufrufen mit AWS CloudTrail ..................................................... 430
AWS DMS-Informationen in CloudTrail ............................................................................... 430Grundlagen zu AWS DMS-Protokolldateieinträgen ................................................................ 431
Validieren von Aufgaben .................................................................................................................. 434Replikationsaufgaben-Statistiken ................................................................................................ 435Erneutes Validieren von Tabellen während einer Aufgabe .............................................................. 437
AWS Management Console .............................................................................................. 437Fehlersuche ............................................................................................................................ 437Einschränkungen ..................................................................................................................... 438
Markieren von Ressourcen ............................................................................................................... 440API ....................................................................................................................................... 441
Arbeiten mit Ereignissen und Benachrichtigungen ................................................................................ 443Ereigniskategorien und Ereignismeldungen in AWS DMS .............................................................. 444Abonnieren von AWS DMS-Ereignisbenachrichtigungen ................................................................ 446
AWS Management Console .............................................................................................. 447AWS DMS-API ............................................................................................................... 447
Migrieren von großen Datenspeichern mit Snowball Edge ...................................................................... 448Prozessübersicht ..................................................................................................................... 449Voraussetzungen ..................................................................................................................... 450Checkliste für die Migration ...................................................................................................... 450Schrittweise Anleitungen ........................................................................................................... 452
Schritt 1: Erstellen eines Snowball Edge-Auftrags ................................................................. 452Schritt 2: Herunterladen und Installieren von AWS Schema Conversion Tool (AWS SCT) ............ 452Schritt 3: Entsperren des Snowball Edge-Geräts .................................................................. 452Schritt 4: Konfigurieren des DMS-Agent-Hosts mit ODBC-Treibern .......................................... 454Schritt 5: Installieren des DMS-Agenten .............................................................................. 456Schritt 6: Erstellen eines neuen AWS SCT-Projekts .............................................................. 458Schritt 7: Konfigurieren von AWS SCT zur Verwendung der Snowball Edge-Appliance ................ 459Schritt 8: Registrieren des DMS-Agenten in AWS SCT .......................................................... 462Schritt 9: Erstellen einer lokalen und DMS-Aufgabe .............................................................. 463Schritt 10: Ausführen und Überwachen der Aufgabe in SCT ................................................... 467
Einschränkungen ..................................................................................................................... 469Fehlerbehebung .............................................................................................................................. 470
Langsame Ausführung von Migrationsaufgaben ........................................................................... 470Aufgabenstatusleiste bewegt sich nicht ....................................................................................... 471Fehlende Fremdschlüssel und sekundäre Indizes ......................................................................... 471Probleme mit Amazon RDS-Verbindungen .................................................................................. 471
Fehlermeldung: Incorrect thread connection string: incorrect thread value 0 ............................. 472Netzwerkprobleme ................................................................................................................... 472CDC nach vollständigem Ladevorgang hängen geblieben .............................................................. 472Fehler durch Primärschlüsselverletzung beim Neustarten einer Aufgabe ........................................... 473Erstes Laden des Schemas fehlgeschlagen ................................................................................ 473Aufgaben mit unbekanntem Fehler fehlgeschlagen ....................................................................... 473Bei erneutem Laden der Aufgabe werden Tabellen von Beginn an geladen ...................................... 473Anzahl der Tabellen pro Aufgabe .............................................................................................. 473Aufgaben schlagen fehl, wenn der Primärschlüssel in der LOB-Spalte erstellt wird ............................. 474Doppelte Datensätzen in der Zieltabelle ohne Primärschlüssel ........................................................ 474Quellendpunkte im reservierten IP-Bereich .................................................................................. 474Behebung von Oracle-spezifischen Problemen ............................................................................ 474
API-Version API Version 2016-01-01v

AWS Database Migration Service Benutzerhandbuch
Abrufen von Daten aus Ansichten ...................................................................................... 475Migrieren von LOBs aus Oracle 12c .................................................................................. 475Wechseln zwischen Oracle LogMiner und Binary Reader ...................................................... 475Fehler: Oracle CDC angehalten 122301 Oracle CDC maximale Wiederholversuche überschritten . 476Automatisches Hinzufügen der zusätzlichen Protokollierung zu einem Oracle-Quellendpunkt ........ 476Nicht erfasste LOB-Änderungen ........................................................................................ 476Fehler: ORA-12899: Wert zu groß für Spalte <Spaltenname> ................................................. 477Datentyp NUMBER wird nicht richtig interpretiert .................................................................. 477
Behebung von MySQL-spezifischen Problemen ........................................................................... 477CDC-Aufgabe schlägt für Amazon RDS-DB-Instance-Endpunkt aufgrund deaktivierter binärerProtokollierung fehl .......................................................................................................... 477Verbindungen mit einer MySQL-Ziel-Instance werden während einer Aufgabe getrennt ............... 478Hinzufügen von Autocommit zu einem MySQL-kompatiblen Endpunkt ...................................... 478Deaktivieren von Fremdschlüsseln auf einem MySQL-kompatiblen Zielendpunkt ........................ 479Zeichen ersetzt durch Fragezeichen ................................................................................... 479"Bad event"-Protokolleinträge ............................................................................................ 479Change Data Capture (CDC) mit MySQL 5.5 ....................................................................... 479Erhöhen der Aufbewahrungszeit für binäre Protokolle für Amazon RDS-DB-Instances ................. 479Protokollmeldung: Einige Änderungen von der Quelldatenbank hatten bei Anwendung auf dieZieldatenbank keine Auswirkungen. ................................................................................... 480Fehler: Bezeichner zu lang ............................................................................................... 480Fehler: Felddatenumwandlung schlägt aufgrund nicht unterstützten Zeichensatzes fehl ............... 480Fehler: Codeseite 1252 zu UTF8 [120112] Eine Felddatenkonvertierung ist fehlgeschlagen ......... 481
Behebung von PostgreSQL-spezifischen Problemen ..................................................................... 481Verkürzte JSON-Datentypen ............................................................................................. 481Spalten eines benutzerdefinierten Datentyps werden nicht korrekt migriert ................................ 482Fehler: Kein Schema zum Erstellen ausgewählt ................................................................... 482Lösch- und Aktualisierungsvorgänge für eine Tabelle werden nicht mit CDC repliziert ................. 482Truncate-Anweisungen werden nicht ordnungsgemäß verteilt ................................................. 482Verhindern, dass PostgreSQL DDL erfasst .......................................................................... 483Auswahl des Schemas, in dem Datenbankobjekte für die DDL-Erfassung erstellt werden ............. 483Oracle-Tabellen fehlen nach Migration zu PostgreSQL .......................................................... 483Für Aufgabe, die Ansicht als Quelle verwendet, wurden keine Zeilen kopiert ............................. 483
Behebung von Problemen im Zusammenhang mit Microsoft SQL Server .......................................... 483Spezielle Berechtigungen für AWS DMS-Benutzerkonto für die Verwendung von CDC ................ 484Fehler bei Erfassung von Änderungen für SQL Server-Datenbank ........................................... 484Fehlende Identitätsspalten ................................................................................................ 484Fehler: SQL Server unterstützt keine Publikationen .............................................................. 484Änderungen werden im Ziel nicht angezeigt ........................................................................ 484Uneinheitliche Tabelle, die über Partitionen hinweg zugeordnet ist .......................................... 485
Behebung von Amazon Redshift-spezifischen Problemen .............................................................. 485Laden in einen Amazon Redshift-Cluster in einer anderen Region als die AWS DMS-Replikations-Instance ....................................................................................................... 486Fehler: Beziehung "attrep_apply_exceptions" bereits vorhanden .............................................. 486Fehler mit Tabellen, deren Name mit "awsdms_changes" beginnt ........................................... 486Anzeigen von Tabellen in Clustern mit Namen wie "dms.awsdms_changes000000000XXXX" ....... 486Berechtigungen für die Verwendung mit Amazon Redshift erforderlich ..................................... 486
Behebung von Amazon Aurora MySQL-spezifischen Problemen ..................................................... 487Fehler: CHARACTER SET UTF8-Felder beendet durch ',' umschlossen von '"' Zeilen beendetdurch '\n' ........................................................................................................................ 487
Bewährte Methoden ......................................................................................................................... 488Verbessern der Leistung .......................................................................................................... 488Bestimmen der Größe einer Replikations-Instance ........................................................................ 490Reduzieren des Workloads Ihrer Quelldatenbank ......................................................................... 491Verwenden des Aufgabenprotokolls ........................................................................................... 491Schemakonvertierung ............................................................................................................... 492Migrieren von Binary Large Objects (LOBs) ............................................................................... 492
API-Version API Version 2016-01-01vi

AWS Database Migration Service Benutzerhandbuch
Verwenden des begrenzten LOB-Modus ............................................................................ 492Fortlaufende Replikation ........................................................................................................... 493Ändern des Benutzers und des Schemas für ein Oracle-Ziel ......................................................... 493Ändern von Tabellen- und Index-Tabellenräumen für ein Oracle-Ziel ............................................... 494Verbessern der Leistung beim Migrieren umfangreicher Tabellen ................................................... 495Verwenden Ihres eigenen On-Premise-Nameservers ................................................................... 495
Referenz ........................................................................................................................................ 499AWS DMS-Datentypen ............................................................................................................. 499
Versionshinweise ............................................................................................................................. 501Versionshinweise zu AWS DMS 3.3.2 ........................................................................................ 501Versionshinweise zu AWS DMS 3.3.1 ........................................................................................ 502AWS DMS 3.3.0 – Versionshinweise .......................................................................................... 505AWS DMS 3.1.4 – Versionshinweise .......................................................................................... 506AWS DMS 3.1.3 – Versionshinweise .......................................................................................... 508AWS DMS 3.1.2 – Versionshinweise .......................................................................................... 509AWS DMS 3.1.1 – Versionshinweise .......................................................................................... 510AWS DMS 2.4.5 – Versionshinweise .......................................................................................... 512AWS DMS 2.4.4 – Versionshinweise .......................................................................................... 513AWS DMS 2.4.3 – Versionshinweise .......................................................................................... 515AWS DMS 2.4.2 – Versionshinweise .......................................................................................... 516AWS DMS 2.4.1 – Versionshinweise .......................................................................................... 517AWS DMS 2.4.0 – Versionshinweise .......................................................................................... 519AWS DMS 2.3.0 – Versionshinweise .......................................................................................... 520
Dokumentverlauf ............................................................................................................................. 523Frühere Aktualisierungen .......................................................................................................... 523
AWS-Glossar .................................................................................................................................. 526
API-Version API Version 2016-01-01vii

AWS Database Migration Service BenutzerhandbuchVon AWS DMS durchgeführte Migrationsaufgaben
Was ist AWS Database MigrationService?
AWS Database Migration Service (AWS DMS) ist ein Cloud-Service, der die Migration von relationalenDatenbanken, Data Warehouses, NoSQL-Datenbanken und anderen Arten von Datenspeichern erleichtert.Sie können AWS DMS verwenden, um Ihre Daten in die AWS Cloud, zwischen lokalen Instances (übereine AWS Cloud-Einrichtung) oder zwischen Kombinationen aus Cloud und lokalen Einrichtungen zumigrieren.
Mit AWS DMS können Sie einmalige Migrationen durchführen und laufende Änderungen replizieren, umQuellen und Ziele synchron zu halten. Wenn Sie Datenbank-Engines ändern möchten, können Sie mitdem AWS Schema Conversion Tool (AWS SCT) Ihr Datenbankschema auf die neue Plattform übertragen.Anschließend migrieren Sie die Daten mit AWS DMS. Da AWS DMS Teil der AWS Cloud ist, profitieren Sievon der Kosteneffizienz, Schnelligkeit, Sicherheit und Flexibilität, die AWS-Services bieten.
Weitere Informationen dazu, welche AWS-Regionen AWS DMS unterstützen, finden Sie unter Arbeitenmit einer AWS DMS-Replikations-Instance (p. 93) Weitere Informationen über die Kosten derDatenbankmigration finden Sie auf der Seite mit den Preisen für AWS Database Migration Service.
Von AWS DMS durchgeführte MigrationsaufgabenAWS DMS übernimmt viele der schwierigen oder langwierigen Aufgaben, die mit einem Migrationsprojektverbunden sind:
• Bei einer herkömmlichen Lösung müssen Sie Kapazitätsanalysen durchführen, Hardware und Softwarebeschaffen, Systeme installieren und verwalten sowie die Installation testen und debuggen. AWS DMSverwaltet die Bereitstellung, Verwaltung und Überwachung aller für die Migration benötigten Hard- undSoftwarekomponenten automatisch. Ihre Migration kann innerhalb weniger Minuten nach dem Start desAWS DMS-Konfigurationsprozesses abgeschlossen werden.
• Mit AWS DMS können Sie Ihre Migrationsressourcen nach Bedarf nach oben (oder unten) skalieren,um sie an Ihren tatsächlichen Workload anzupassen. Wenn Sie beispielsweise feststellen, dass Siezusätzlichen Speicherplatz benötigen, können Sie den zugewiesenen Speicherplatz problemlos erhöhenund die Migration in der Regel innerhalb von Minuten erneut starten. Wenn Sie andererseits feststellen,dass Sie nicht die gesamte Ressourcenkapazität, die Sie konfiguriert haben, nutzen, können Sie dieSpeicherplatzgröße ganz einfach reduzieren, um Ihrem tatsächlichen Workload gerecht zu werden.
• AWS DMS verwendet ein Servicemodell mit nutzungsabhängiger Abrechnung. Im Gegensatz zuherkömmlichen Lizenzmodellen mit Vorabkosten für die Anschaffung und laufenden Unterhaltungskostenzahlen Sie nur für AWS DMS-Ressourcen, die Sie nutzen.
• AWS DMS verwaltet automatisch die gesamte Infrastruktur, die Ihren Migrationsserver unterstützt,einschließlich Hardware und Software, Software-Patching und Fehlerberichten.
• AWS DMS bietet ein automatisches Failover. Wenn Ihr primärer Replikationsserver aus irgendeinemGrund ausfällt, übernimmt ein Backup-Replikationsserver, ohne dass der Dienst unterbrochen wird.
• AWS DMS kann Sie dabei unterstützen, auf eine moderne, vielleicht kostengünstigere Datenbank-Engine umzusteigen, als die, die Sie gerade betreiben. Beispielsweise kann AWS DMS Ihnen helfen,die Vorteile der verwalteten Datenbankservices zu nutzen, die von Amazon RDS oder Amazon Aurorabereitgestellt werden. Es kann Sie auch dabei unterstützen, auf den verwalteten Data-Warehouse-Service von Amazon Redshift auf NoSQL-Plattformen wie Amazon DynamoDB oder auf kostengünstige
API-Version API Version 2016-01-011

AWS Database Migration Service BenutzerhandbuchWie AWS DMS auf unterster Ebene funktioniert
Speicherplattformen wie Amazon Simple Storage Service (Amazon S3) umzusteigen. Umgekehrtunterstützt AWS DMS auch den Prozess, wenn Sie sich von der alten Infrastruktur verabschieden, aberweiterhin die gleiche Datenbank-Engine verwenden wollen.
• AWS DMS unterstützt nahezu alle gängigen DBMS-Engines als Datenquellen, einschließlich Oracle,Microsoft SQL Server, MySQL, MariaDB, PostgreSQL, Db2 LUW, SAP, MongoDB und Amazon Aurora.
• AWS DMS bietet ein breites Spektrum an verfügbaren Ziel-Engines, darunter Oracle, Microsoft SQLServer, PostgreSQL, MySQL, Amazon Redshift, SAP ASE, Amazon S3 und Amazon DynamoDB.
• Sie können von jeder der unterstützten Datenquellen auf jedes der unterstützten Datenziele migrieren.AWS DMS unterstützt vollständig heterogene Datenmigrationen zwischen den unterstützten Engines.
• AWS DMS sorgt für eine sichere Datenmigration. Daten im Ruhezustand werden mit der AWS KeyManagement Service (AWS KMS)-Verschlüsselung verschlüsselt. Während der Migration können SieSecure Socket Layers (SSL) verwenden, um Ihre übertragenen Daten auf dem Weg von der Quelle zumZiel zu verschlüsseln.
Wie AWS DMS auf unterster Ebene funktioniertAuf unterster Ebene ist AWS DMS ein Server in der AWS Cloud, auf dem Replikationssoftware ausgeführtwird. Sie legen eine Quell- und eine Zielverbindung an, um AWS DMS mitzuteilen, wohin es extrahierenund laden soll. Dann planen Sie eine Aufgabe, die auf diesem Server ausgeführt wird, um Ihre Daten zuverschieben. AWS DMS legt die Tabellen und die dazugehörigen Primärschlüssel an, falls diese nichtbereits im Ziel existieren. Sie können die Zieltabellen vorab manuell anlegen, wenn Sie dies wünschen.Oder Sie können AWS SCT verwenden, um einige oder alle Zieltabellen, Indizes, Ansichten, Auslöser usw.anzulegen.
Das folgende Diagramm veranschaulicht den AWS DMS-Prozess.
Ausführen des gesamten AWS DMS-Prozesses
1. Um ein Migrationsprojekt zu starten, ermitteln Sie Ihre Quell- und Zieldatenspeicher. DieseDatenspeicher können sich auf einer der vorstehend genannten Daten-Engines befinden.
2. Konfigurieren Sie sowohl für die Quelle als auch für das Ziel Endpunkte innerhalb von AWS DMS,die die Verbindungsinformationen zu den Datenbanken angeben. Die Endpunkte verwenden dieentsprechenden ODBC-Treiber, um mit Ihrer Quelle und Ihrem Ziel zu kommunizieren.
3. Stellen Sie eine Replikations-Instance bereit, bei dem es sich um einen Server handelt, den AWS DMSautomatisch mit Replikations-Software konfiguriert.
4. Legen Sie eine Replikationsaufgabe an, die die zu migrierenden Ist-Datentabellen und dieanzuwendenden Datentransformationsregeln festlegt. AWS DMS verwaltet die Ausführung derReplikationsaufgabe und teilt Ihnen den Status des Migrationsprozesses mit.
API-Version API Version 2016-01-012

AWS Database Migration Service BenutzerhandbuchWie AWS DMS auf unterster Ebene funktioniert
Für weitere Informationen siehe:
• Falls AWS DMS für Sie neu ist, Sie aber mit anderen AWS-Services vertraut sind, beginnen Sie mitFunktionsweise von AWS Database Migration Service (p. 4). Dieser Abschnitt befasst sich mit denSchlüsselkomponenten von AWS DMS und dem Gesamtprozess der Einrichtung und Durchführung einerMigration.
• Wenn Sie die Datenbank-Engines wechseln möchten, kann das AWS Schema Conversion Tool Ihrbestehendes Datenbankschema, einschließlich Tabellen, Indizes und der meisten Anwendungscodes, indie Zielplattform konvertieren.
• Informationen zu dazugehörigen AWS-Diensten, die Sie möglicherweise für die Planung IhrerMigrationsstrategie benötigen, finden Sie unter AWS Cloud-Produkte.
• Amazon Web Services bietet eine Reihe von Datenbankdiensten an. Um zu erfahren, welcher Service fürIhre Umgebung am besten geeignet ist, lesen Sie Ausführen von Datenbanken in AWS.
• Einen Überblick über alle AWS-Produkte finden Sie unter Was ist Cloud Computing?
API-Version API Version 2016-01-013

AWS Database Migration Service BenutzerhandbuchAllgemeine Übersicht über AWS DMS
Funktionsweise von AWS DatabaseMigration Service
AWS Database Migration Service (AWS DMS) ist ein Webservice, mit dem Sie Daten aus einemQuelldatenspeicher in einen Zieldatenspeicher migrieren können. Diese beiden Datenspeicher werdenals Endpunkte bezeichnet. Sie können zwischen den Quell- und Zielendpunkten migrieren, die diegleiche Datenbank-Engine verwenden, wie z. B. von einer Oracle-Datenbank in eine Oracle-Datenbank.Außerdem können Sie zwischen Quell- und Zielendpunkten migrieren, die verschiedene Datenbank-Engines verwenden, wie z. B. von einer Oracle-Datenbank in eine PostgreSQL-Datenbank. Die einzigeAnforderung für die Verwendung von AWS DMS besteht darin, dass sich einer Ihrer Endpunkte in einemAWS-Service befinden muss. Sie können mit AWS DMS keine Migration von einer On-Premise-Datenbankzu einer anderen On-Premise-Datenbank durchführen.
Weitere Informationen über die Kosten der Datenbankmigration finden Sie auf der Seite mit den Preisen fürAWS Database Migration Service.
Gehen Sie die folgenden Themen durch, um AWS DMS besser zu verstehen.
Themen• Allgemeine Übersicht über AWS DMS (p. 4)• AWS DMS-Komponenten (p. 5)• Quellen für AWS DMS (p. 11)• Ziele für AWS DMS (p. 13)• Verwenden von AWS DMS mit anderen AWS-Services (p. 15)
Allgemeine Übersicht über AWS DMSZur Durchführung einer Datenbankmigration verbindet sich AWS DMS mit dem Quelldatenspeicher,liest die Quelldaten und formatiert die Daten für die Verwendung durch den Zieldatenspeicher.Anschließend werden die Daten in der Zieldatenspeicher geladen. Die meisten dieser Vorgänge werdenim Arbeitsspeicher ausgeführt, wenn auch umfangreiche Transaktionen eventuell auf Festplatte gepuffertwerden. Zwischengespeicherte Transaktionen und Protokolldateien werden ebenfalls auf Festplattegeschrieben.
Im Allgemeinen führen Sie mit AWS DMS die folgenden Tätigkeiten aus:
• Erstellen eines Replikationsservers.• Erstellen der Quell- und Zielendpunkte, die über Verbindungsinformationen zu Ihren Datenspeichern
verfügen.• Erstellen Sie eine oder mehrere Migrationsaufgaben zum Migrieren von Daten zwischen den Quell- und
Zieldatenspeichern.
Eine Aufgabe kann aus drei Hauptphasen bestehen:
• Das vollständige Laden von vorhandenen Daten• Die Anwendung der zwischengespeicherten Änderungen
API-Version API Version 2016-01-014

AWS Database Migration Service BenutzerhandbuchKomponenten
• Fortlaufende Replikation
Während eines vollständigen Migrationsladevorgangs, bei dem vorhandene Daten von der Quelle zumZiel verschoben werden, lädt AWS DMS Daten aus Tabellen des Quelldatenspeichers in Tabellendes Zieldatenspeichers. Während des vollständigen Ladevorgangs werden alle Änderungen an denTabellen, die gerade geladen werden, auf dem Replikationsserver im Cache gespeichert. Dies sind diezwischengespeicherten Änderungen. Beachten Sie, dass AWS DMS erst dann Änderungen an einerbestimmen Tabelle erfasst, wenn der vollständige Ladevorgang für diese Tabelle gestartet wurde. Mitanderen Worten: Die Änderungserfassung beginnt für jede einzelne Tabelle zu einem jeweils anderenZeitpunkt.
Wenn der vollständige Ladevorgang für eine bestimmte Tabelle abgeschlossen ist, beginnt AWS DMSsofort mit der Anwendung der zwischengespeicherten Änderungen für diese Tabelle. Wenn alle Tabellengeladen wurden, beginnt AWS DMS, Änderungen als Transaktionen für die laufende Replikationsphasezu erfassen. Nachdem AWS DMS alle zwischengespeicherten Änderungen angewendet hat, sind dieTabellen transaktionskonsistent. An diesem Punkt geht AWS DMS zur laufenden Replikationsphase überund wendet Änderungen als Transaktionen an.
Zu Beginn der laufenden Replikationsphase führt ein Rückstand bei den Transaktionen im Allgemeinenzu einer Verzögerung zwischen der Quell- und Zieldatenbank. Schließlich erreicht die Migration abereinen stabilen Zustand, nachdem dieser Transaktionsrückstand abgearbeitet wurde. An diesem Punktkönnen Sie Ihre Anwendungen herunterfahren und zulassen, dass alle verbleibenden Transaktionen aufdie Zieldatenbank angewendet werden. Wenn Sie Ihre Anwendungen dann starten, verweisen sie auf dieZieldatenbank.
AWS DMS erstellt die für die Migration erforderlichen Zielschemaobjekte. Allerdings geht AWS DMShierbei minimalistisch vor und erstellt nur die Objekte, die für eine effiziente Migration der Daten erforderlichsind. Anders ausgedrückt: AWS DMS erstellt Tabellen, Primärschlüssel und in einigen Fällen eindeutigeIndizes, jedoch keine Objekte, die für eine effiziente Migration der Daten von der Quelle nicht erforderlichsind. So erstellt DMS z. B. keine sekundären Indizes, Nicht-Primärschlüssel-Beschränkungen oderDatenstandardwerte.
Bei einer Migration migrieren Sie in der Regel das Quellschema vollständig oder nahezu vollständig.Wenn Sie eine homogene Migration (zwischen zwei Datenbanken desselben Engine-Typs) durchführen,migrieren Sie das Schema unter Verwendung der nativen Tools Ihrer Engine, um das Schema selbst, ohneirgendwelche Daten, zu exportieren und zu importieren.
Wenn die Migration heterogen ist (zwischen zwei Datenbanken mit verschiedenen Engine-Typen), könnenSie das AWS Schema Conversion Tool (AWS SCT) verwenden, das ein vollständiges Zielschema fürSie erstellt. Wenn Sie das Tool verwenden, müssen alle Abhängigkeiten zwischen den Tabellen wie z. B.Fremdschlüsseleinschränkungen während des vollständigen Ladevorgangs und der Anwendung derzwischengespeicherten Änderungen deaktiviert werden. Wenn die Leistung beeinträchtigt ist, entfernenoder deaktivieren Sie sekundäre Indizes während der Migration. Weitere Informationen zum AWS SCTfinden Sie unter AWS Schema Conversion Tool in der AWS SCT-Dokumentation.
AWS DMS-KomponentenDieser Abschnitt beschreibt die internen Komponenten von AWS DMS und wie diese zusammenarbeiten,um Ihre Datenmigration durchzuführen. Das Verständnis der zugrunde liegenden Komponenten von AWSDMS kann Ihnen helfen, Daten effizienter zu migrieren und einen besseren Einblick bei der Fehlersucheund -behebung zu erhalten.
Eine AWS DMS-Migration besteht aus drei Komponenten: einer Replikations-Instance, Quell- und Ziel-Endpunkten und einer Replikationsaufgabe. Sie erstellen eine AWS DMS-Migration, indem Sie dieerforderliche Replikations-Instance sowie die erforderlichen Endpunkte und Aufgaben in einer AWS-Regionerstellen.
API-Version API Version 2016-01-015
AWS Database Migration Service BenutzerhandbuchKomponenten
Replikations-Instance
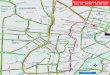
Grundsätzlich ist eine AWS DMS-Replikations-Instance einfach eine verwaltete Amazon ElasticCompute Cloud(Amazon EC2)-Instance, die eine oder mehrere Replikationsaufgaben hostet.
Die folgende Abbildung zeigt ein Beispiel für eine Replikations-Instance mit mehreren zugehörigenReplikationsaufgaben.
Eine einzelne Replikations-Instance kann eine oder mehrere Replikationsaufgaben hosten, abhängigvon den Eigenschaften Ihrer Migration und der Kapazität des Replikationsservers. AWS DMS bieteteine Vielzahl von Replikations-Instances. Dadurch können Sie die optimale Konfiguration für IhrenAnwendungsfall auswählen. Weitere detaillierte Informationen über die verschiedenen Klassen von
API-Version API Version 2016-01-016

AWS Database Migration Service BenutzerhandbuchKomponenten
Replikations-Instances finden Sie unter Auswahl der geeigneten AWS DMS-Replikations-Instance fürIhre Migration (p. 94).
AWS DMS erstellt die Replikations-Instance auf einer Amazon EC2-Instance. Einige derkleineren Instance-Klassen reichen für das Testen des Service oder für kleine Migrationen aus.Wenn Ihre Migration eine große Anzahl von Tabellen umfasst oder Sie mehrere gleichzeitigeReplikationsaufgaben ausführen möchten, sollten Sie in Betracht ziehen, eine der größeren Instanceszu verwenden. Wir empfehlen diese Vorgehensweise, da AWS DMS eine erhebliche Menge anArbeitsspeicher und CPU-Leistung verbraucht.
Abhängig von der Klasse der Amazon EC2-Instance, die Sie auswählen, umfasst Ihre Replikations-Instance entweder 50 GB oder 100 GB Datenspeicher. Dieser Umfang ist normalerweise ausreichendfür die meisten Kunden. Wenn Ihre Migration jedoch große Transaktionen oder eine große Menge anDatenänderungen beinhaltet, sollten Sie die Basisspeicherzuordnung erhöhen. Change Data Capture(CDC) kann dazu führen, dass Daten auf die Festplatte geschrieben werden, je nachdem, wie schnelldas Ziel die Änderungen schreiben kann.
AWS DMS kann eine hohe Verfügbarkeit und Failover-Support durch eine Multi-AZ-Bereitstellungbieten. Bei einer Multi-AZ-Bereitstellung sorgt AWS DMS für die automatische Bereitstellung undVerwaltung eines Standby-Replikats der Replikations-Instance in einer anderen Availability Zone. Dieprimäre Replikations-Instance wird auf das Standby-Replikat repliziert. Wenn die primäre Replikations-Instance ausfällt oder nicht mehr reagiert, nimmt der Standby-Modus alle laufenden Tasks mitminimaler Unterbrechung wieder auf. Da die primäre Replikations-Instance ihren Status ständig in denStandby-Modus repliziert, verursacht die Multi-AZ-Bereitstellung einen gewissen Leistungs-Overhead.
Weitere detaillierte Informationen zur AWS DMS-Replikations-Instance finden Sie unter Arbeiten miteiner AWS DMS-Replikations-Instance (p. 93).
Endpunkte
AWS DMS verwendet einen Endpunkt für den Zugriff auf Ihren Quell- oder Zieldatenspeicher. Diespezifischen Verbindungsinformationen sind je nach Datenspeicher unterschiedlich, aber in der Regelgeben Sie beim Anlegen eines Endpunkts die folgenden Informationen an.• Endpunkttyp – Quelle oder Ziel• Engine-Typ – Typ der Datenbank-Engine, z. B. Oracle oder PostgreSQL.• Servername – Servername oder IP-Adresse, die AWS DMS erreichen kann.• Port – Portnummer für die Datenbankserver-Verbindungen• Verschlüsselung – Secure Socket Layer (SSL)-Modus, wenn SSL zum Verschlüsseln der
Verbindung verwendet wird.• Anmeldeinformationen – Benutzername und Passwort für ein Konto mit den erforderlichen
Zugriffsrechten.
Wenn Sie einen Endpunkt mit der AWS DMS-Konsole erstellen, müssen Sie die Endpunktverbindungtesten. Der Test muss erfolgreich abgeschlossen werden, bevor Sie den Endpunkt in einer DMS-Aufgabe nutzen können. Wie die Verbindungsinformationen sind auch die spezifischen Prüfkriterienfür verschiedene Engine-Typen unterschiedlich. Im Allgemeinen überprüft AWS DMS, ob dieDatenbank unter dem angegebenen Servernamen und Port vorhanden ist, und ob die mitgeliefertenAnmeldeinformationen verwendet werden können, um eine Verbindung zur Datenbank mit den für eineMigration erforderlichen Berechtigungen herzustellen. Wenn der Verbindungstest erfolgreich ist, lädtAWS DMS Schemainformationen herunter, die später während der Aufgabenkonfiguration verwendetwerden sollen, und speichert sie. Schemainformationen können beispielsweise Tabellendefinitionen,Primärschlüsseldefinitionen und eindeutige Schlüsseldefinitionen beinhalten.
Mehrere Replikationsaufgaben können einen einzelnen Endpunkt verwenden. Beispielsweise könntenSie zwei logisch getrennte Anwendungen auf derselben Quelldatenbank hosten, die Sie separatmigrieren möchten. In diesem Fall erstellen Sie zwei Replikationsaufgaben, eine für jede Gruppe vonAnwendungstabellen. Sie können denselben AWS DMS-Endpunkt in beiden Aufgaben verwenden.
API-Version API Version 2016-01-017

AWS Database Migration Service BenutzerhandbuchKomponenten
Sie können das Verhalten eines Endpunkts unter Verwendung von zusätzlichen Verbindungsattributenanpassen. Zusätzliche Verbindungsattribute können verschiedene Verhaltensweisen kontrollieren,wie z. B. Protokollierungsdetail, Dateigröße und andere Parameter. Jeder Datenspeicher-Engine-Typ stellt andere zusätzlichen Verbindungsattribute bereit. Sie finden die spezifischen, zusätzlichenVerbindungsattribute für jeden Datenspeicher im Quell- oder Ziel-Abschnitt für den jeweiligenDatenspeicher. Eine Liste unterstützter Quell- und Zieldatenspeicher finden Sie unter Quellen für AWSDMS (p. 11) und Ziele für AWS DMS (p. 13).
Weitere Informationen zu AWS DMS-Endpunkten finden Sie unter Arbeiten mit AWS DMS-Endpunkten (p. 122).
Replikationsaufgaben
Sie verwenden eine AWS DMS-Replikations-Aufgabe zum Verschieben einer Reihe von Daten vomQuellendpunkt zum Zielendpunkt. Das Erstellen einer Replikations-Aufgabe ist der letzte Schritt, dieSie durchführen müssen, bevor Sie eine Migration beginnen.
Beim Erstellen einer Replikationsaufgabe geben Sie die folgenden Aufgabeneinstellungen an:• Replikations-Instance – die Instance, die die Aufgabe hostet und ausführt• Quellendpunkt• Zielendpunkt• Die Optionen für den Migrationstyp sind nachfolgend aufgeführt. Eine vollständige Erläuterung der
Migrationsoptionen finden Sie unter Erstellen einer Aufgabe (p. 333).• Volllast (Migrieren vorhandener Daten) – Wenn Sie sich einen Ausfall leisten können, der
ausreichend lange dauert, um Ihre vorhandenen Daten zu kopieren, eignet sich diese Option sehrgut. Bei dieser Option werden die Daten einfach aus Ihrer Quelldatenbank in Ihre Zieldatenbankmigriert. Tabellen werden erstellt, wenn dies erforderlich ist.
• Volllast + CDC (Migrieren vorhandener Daten und Replizieren fortlaufender Änderungen) –Diese Option führt einen vollständigen Datenladevorgang durch und erfasst dabei Änderungenin der Quelle. Nachdem der vollständige Ladevorgang abgeschlossen ist, werden dieerfassten Änderungen auf die Zieldatenbank angewendet. Am Ende erreicht die Anwendungder Änderungen einen stabilen Zustand. An diesem Punkt können Sie Ihre Anwendungenherunterfahren. Die verbleibenden Änderungen werden an das Ziel weitergeleitet. Starten Siedann Ihre Anwendungen erneut, die nun auf das Ziel verweisen.
• Nur CDC (Replizieren nur von Datenänderungen) – Manchmal ist es effizienter, vorhandene Datenmithilfe einer anderen Methode als AWS DMS zu kopieren. Bei einer homogenen Migration kannes z. B. eventuell effizienter sein, beim Laden der Massendaten native Export-/Import-Tools zuverwenden. In diesem Fall können Sie mit AWS DMS dann mit der Replikation von Änderungenbeginnen, wenn Sie den Massenladevorgang starten, und dafür sorgen, dass die Quell- undZieldatenbanken synchron sind.
• Die Optionen des Vorbereitungsmodus für die Zieltabelle werden nachfolgend aufgeführt. Einevollständige Erläuterung der Zieltabellenmodi finden Sie unter Erstellen einer Aufgabe (p. 333).• Do nothing (Keine Aktion) – In diesem Modus geht AWS DMS davon aus, dass die Zieltabellen auf
dem Ziel vorab erstellt wurden.• Drop tables on target (Tabellen auf dem Ziel löschen) – AWS DMS löscht die Zieltabellen und
erstellt sie neu.• Truncate (Verkürzen) – Wenn Sie Tabellen in der Zieldatenbank erstellt haben, kürzt AWS DMS
diese, bevor die Migration gestartet wird. Wenn keine Tabellen vorhanden sind und Sie dieseOption auswählen, erstellt AWS DMS alle fehlenden Tabellen.
• Die Optionen des LOB-Modus werden nachfolgend aufgeführt. Eine vollständige Erläuterung derLOB-Modi finden Sie unter Festlegen von LOB-Support für Quelldatenbanken in einer AWS DMS-Aufgabe (p. 361).• Don't include LOB columns (Keine LOB-Spalten einschließen) – Die LOB-Spalten sind von der
Migration ausgeschlossen.API-Version API Version 2016-01-01
8

AWS Database Migration Service BenutzerhandbuchKomponenten
• Full LOB mode (Vollständiger LOB-Modus) – Die LOBs werden vollständig migriert, unabhängigvon ihrer Größe. AWS DMS migriert LOBs stückweise in Blöcken, die vom Parameter Max LOBsize (Maximale LOB-Größe) gesteuert werden. Dieser Modus ist langsamer als der Modus"Limited LOB".
• Limited LOB mode (Eingeschränkter LOB-Modus) – Die LOBs werden auf den Wert des Max LOBSize-Parameters gekürzt. Dieser Modus ist schneller als der Modus "Full LOB".
• Tabellenzuweisungen – gibt an, welche Tabellen migriert werden und auf welche Weise.Weitere Informationen finden Sie unter Verwenden der Tabellenzuweisung zum Angeben vonAufgabeneinstellungen (p. 372).
• Die Datentransformationen werden nachfolgend aufgeführt. Weitere Informationen zuDatentransformationen finden Sie unter Festlegen der Tabellenauswahl und Transformationendurch Tabellenzuweisungen mit JSON (p. 377).• Ändern von Schema-, Tabellen- und Spaltennamen• Ändern von Tabellenraumnamen (für Oracle-Zielendpunkte)• Definieren von primären Schlüsseln und eindeutigen Indizes auf dem Ziel.
• Datenvalidierung• Amazon CloudWatch-Protokollierung
Unter Verwendung der Aufgabe migrieren Sie Daten vom Quell- zum Zielendpunkt. DieAufgabenverarbeitung erfolgt auf der Replikations-Instance. Sie geben an, welche Tabellenund Schemas für die Migration verwendet werden sollen. Zudem legen Sie eine spezielleVerarbeitung, z. B. die Protokollierung von Anforderungen, die Steuerung von Tabellendaten und dieFehlerbehandlung, fest.
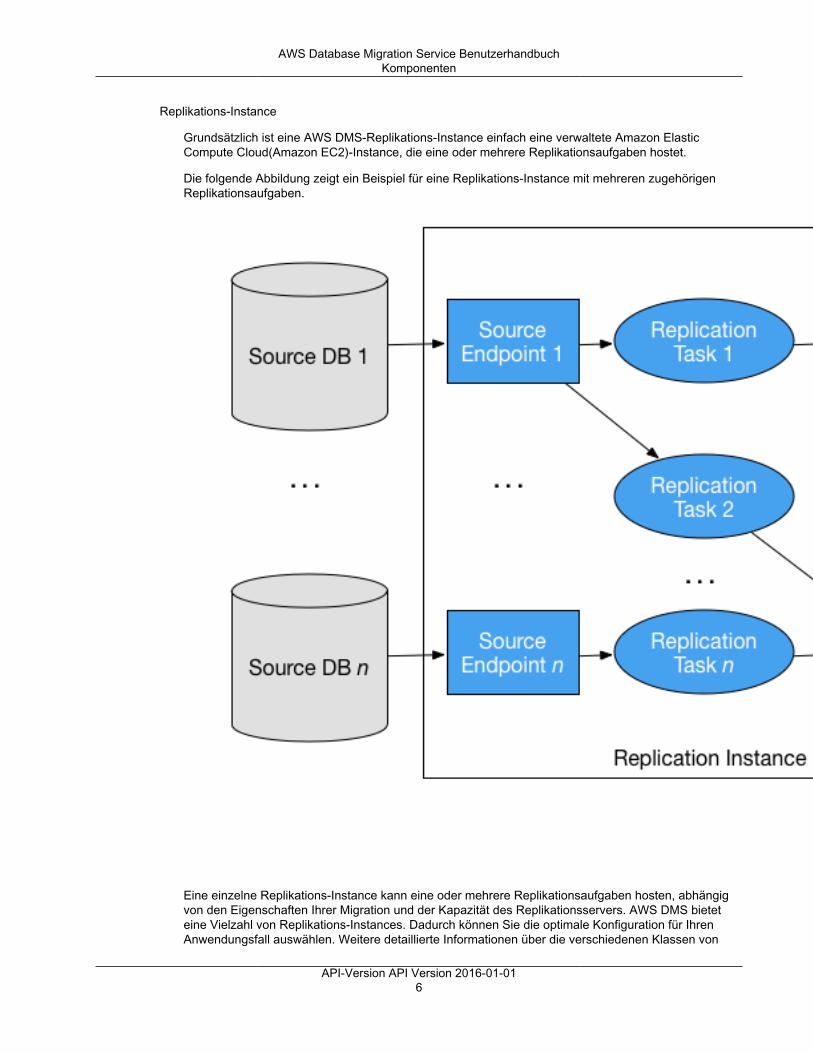
Grundsätzlich erfüllt eine AWS DMS-Replikationsaufgabe zwei unterschiedliche Funktionen, wie in derfolgenden Abbildung dargestellt:
API-Version API Version 2016-01-019
AWS Database Migration Service BenutzerhandbuchKomponenten
Der Volllastprozess ist einfach zu verstehen. Die Daten werden komplett aus der Quelle extrahiertund direkt in das Ziel geladen. Sie können die Anzahl der zu extrahierenden und parallel zu ladendenTabellen auf der AWS DMS-Konsole unter Advanced Settings (Erweiterte Einstellungen) angeben.
Weitere Informationen zu AWS DMS-Aufgaben finden Sie unter Arbeiten mit AWS DMS-Aufgaben (p. 329).
Fortlaufende Replikation oder CDC (Change Data Capture)
Sie können eine AWS DMS-Aufgabe auch zum Erfassen fortlaufender Änderungen amQuelldatenspeicher verwenden, während Sie Ihre Daten zu einem Ziel migrieren. Der Prozess der
API-Version API Version 2016-01-0110

AWS Database Migration Service BenutzerhandbuchQuellen
Änderungserfassung, den AWS DMS beim Replizieren von fortlaufenden Änderungen von einemQuellendpunkt verwendet, erfasst Änderungen an den Datenbankprotokollen mithilfe der nativen APIder Datenbank-Engine.
Im CDC-Prozess ist die Replikationsaufgabe darauf ausgelegt, Änderungen von der Quelle zum Ziel zustreamen, wobei In-Memory-Puffer verwendet werden, um Daten während des Transports zu halten.Wenn die In-Memory-Puffer aus irgendeinem Grund erschöpft sind, lässt die Replikationsaufgabeanstehende Änderungen in den Change Cache auf der Festplatte überlaufen. Dies kann z. B. der Fallsein, wenn AWS DMS Änderungen aus der Quelle schneller erfasst, als sie auf das Ziel angewendetwerden können. In diesem Fall überschreitet die Ziellatenz der Aufgabe die Quelllatenz der Aufgabe.
Dies können Sie überprüfen, indem Sie auf der AWS DMS-Konsole zu Ihrer Aufgabe navigierenund die Registerkarte „Task Monitoring (Aufgabenüberwachung)“ öffnen. Die DiagrammeCDCLatencyTarget und CDCLatencySource sind unten auf der Seite gezeigt. Wenn Sie eine Aufgabehaben, die eine Ziellatenz anzeigt, dann ist es wahrscheinlich, dass eine Abstimmung auf dem Ziel-Endpunkt erforderlich ist, um die Anwendungsrate zu erhöhen.
Die Replikationsaufgabe verwendet auch Speicher für Task-Protokolle, wie oben beschrieben. Der fürIhre Replikations-Instance vorkonfigurierte Speicherplatz reicht in der Regel für die Protokollierung undübergelaufene Änderungen aus. Wenn Sie zusätzlichen Speicherplatz benötigen, z. B. wenn Sie beider Untersuchung eines Migrationsproblems ein detailliertes Debugging verwenden, können Sie dieReplikations-Instance modifizieren, um mehr Speicherplatz zuzuordnen.
Schema- und Codemigration
AWS DMS führt keine Schema- oder Codekonvertierung durch. Sie können Tools wie Oracle SQLDeveloper, MySQL Workbench oder pgAdmin III verwenden, um Ihr Schema zu verschieben, sofernQuelle und Ziel die gleiche Datenbank-Engine sind. Wenn Sie ein vorhandenes Schema in eine andereDatenbank-Engine konvertieren möchten, können Sie AWS SCT verwenden. Dieses Tool kann einZielschema erstellen, aber auch ein ganzes Schema generieren und erstellen, wie Tabellen, Indizes,Ansichten und so weiter. Sie können AWS SCT auch nutzen, um PL/SQL oder TSQL in PgSQL undandere Formate umzuwandeln. Weitere Informationen zu AWS SCT finden Sie unter AWS SchemaConversion Tool.
Wann immer dies möglich ist, versucht AWS DMS, das Zielschema für Sie zu erstellen. Es kannvorkommen, dass AWS DMS das Schema nicht erstellen kann, beispielsweise erstellt AWS DMS ausSicherheitsgründen kein Oracle-Zielschema. Für MySQL-Datenbank-Ziele können Sie zusätzlicheVerbindungsattribute verwenden, damit DMS alle Objekte in die angegebene Datenbank unddas angegebene Schema migriert. Oder Sie können diese Attribute verwenden, damit DMS jedeDatenbank und jedes Schema für Sie erstellt, wenn es das Schema in der Quelle findet.
Quellen für AWS DMSSie können die folgenden Datenspeicher als Quellendpunkte für die Datenmigration mit AWS DMSverwenden.
Lokale und EC2-Instance-Datenbanken
• Oracle-Versionen 10.2 und höher (für Versionen 10.x), 11g und bis zu 12.2, 18c und 19c für die EditionenEnterprise, Standard, Standard One und Standard Two
Note
• Unterstützung für Oracle-Version 19c als Quelle ist in den AWS DMS-Versionen 3.3.2 undhöher verfügbar.
• Unterstützung für Oracle-Version 18c als Quelle ist in den AWS DMS-Versionen 3.3.1 undhöher verfügbar.
API-Version API Version 2016-01-0111

AWS Database Migration Service BenutzerhandbuchQuellen
• Microsoft SQL Server-Versionen 2005, 2008, 2008R2, 2012, 2014, 2016, 2017 und 2019 für dieEditionen Enterprise, Standard, Workgroup und Developer. Die Web und Express Edition werden nichtunterstützt.
Note
Unterstützung für Microsoft SQL Server Version 2019 als Quelle ist in den AWS DMS-Versionen3.3.2 und höher verfügbar.
• MySQL-Versionen 5.5, 5.6 und 5.7.• MariaDB (unterstützt als MySQL-kompatible Datenquelle), Versionen 10.0.24 bis 10.0.28, 10.1, 10.2 und
10.3.
Note
Unterstützung für MariaDB als Quelle ist in allen AWS DMS-Versionen verfügbar, in denenMySQL unterstützt wird.
• PostgreSQL-Version 9.4 und höher (für Versionen 9.x), 10.x und 11.x.
Note
Die PostgreSQL-Versionen 11.x werden als Quelle nur in den AWS DMS-Versionen 3.3.1 undhöher unterstützt. Sie können die PostgreSQL-Versionen 9.4 und höher (für Versionen 9.x) und10.x als Quelle in jeder beliebigen DMS-Version verwenden.
• MongoDB-Versionen 2.6.x und 3.x und höher.• SAP Adaptive Server Enterprise (ASE)-Versionen 12.5, 15, 15.5, 15.7, 16 und höher.• IBM Db2 für Linux-, UNIX- und Windows (Db2 LUW)-Versionen:
• Version 9.7, alle Fix Packs werden unterstützt.• Version 10.1, alle Fix Packs werden unterstützt.• Version 10.5, alle Fix Packs außer Fix Pack 5 werden unterstützt.
Microsoft Azure
• Azure SQL Database.
Amazon RDS-Instance-Datenbanken und Amazon Simple Storage Service (Amazon S3)
• Oracle-Versionen 10.2 und höher (für Versionen 10.x), 11g (Versionen 11.2.0.3.v1 und höher) und bis zu12.2, 18c und 19c für die Editionen Enterprise, Standard, Standard One und Standard Two.
Note
• Unterstützung für Oracle-Version 19c als Quelle ist in den AWS DMS-Versionen 3.3.2 undhöher verfügbar.
• Unterstützung für Oracle-Version 18c als Quelle ist in den AWS DMS-Versionen 3.3.1 undhöher verfügbar.
• Microsoft SQL Server-Versionen 2008R2, 2012, 2014, 2016, 2017 und 2019 für die Editionen Enterprise,Standard, Workgroup und Developer. Die Web und Express Edition werden nicht unterstützt.
Note
Unterstützung für Microsoft SQL Server Version 2019 als Quelle ist in den AWS DMS-Versionen3.3.2 und höher verfügbar.
• MySQL-Versionen 5.5, 5.6 und 5.7.• MariaDB (unterstützt als MySQL-kompatible Datenquelle), Versionen 10.0.24 bis 10.0.28, 10.1, 10.2 und
10.3. API-Version API Version 2016-01-0112

AWS Database Migration Service BenutzerhandbuchZiele
Note
Unterstützung für MariaDB als Quelle ist in allen AWS DMS-Versionen verfügbar, in denenMySQL unterstützt wird.
• PostgreSQL-Version 9.4 und höher (für Versionen 9.x), 10.x und 11.x. Change Data Capture (CDC)wird nur für die Versionen 9.4.9, 9.5.4 und höher sowie für 10.x und 11.x unterstützt. Der Parameterrds.logical_replication, der für CDC erforderlich ist, wird nur in diesen Versionen und höherunterstützt.
Note
Die PostgreSQL-Versionen 11.x werden als Quelle nur in den AWS DMS-Versionen 3.3.1 undhöher unterstützt. Sie können die PostgreSQL-Versionen 9.4 und höher (für Versionen 9.x) und10.x als Quelle in jeder beliebigen DMS-Version verwenden.
• Amazon Aurora mit MySQL-Kompatibilität (unterstützt als MySQL-kompatible Datenquelle).• Amazon Aurora mit PostgreSQL-Kompatibilität (unterstützt als PostgreSQL-kompatible Datenquelle).• Amazon S3 aus.
Ziele für AWS DMSSie können die folgenden Datenspeicher als Zielendpunkte für die Datenmigration mit AWS DMSverwenden.
Lokale und Amazon EC2-Instance-Datenbanken
• Oracle Versionen 10g, 11g, 12c, 18c und 19c für die Editionen Enterprise, Standard, Standard One undStandard Two.
Note
• Unterstützung für Oracle-Version 19c als Ziel ist in den AWS DMS-Versionen 3.3.2 und höherverfügbar.
• Unterstützung für Oracle-Version 18c als Ziel ist in den AWS DMS-Versionen 3.3.1 und höherverfügbar.
• Microsoft SQL Server-Versionen 2005, 2008, 2008R2, 2012, 2014, 2016, 2017 und 2019 für dieEditionen Enterprise, Standard, Workgroup und Developer. Die Web und Express Edition werden nichtunterstützt.
Note
Unterstützung für Microsoft SQL Server Version 2019 als Ziel ist in den AWS DMS-Versionen3.3.2 und höher verfügbar.
• MySQL-Versionen 5.5, 5.6 und 5.7.• MariaDB (unterstützt als MySQL-kompatibles Datenziel), Versionen 10.0.24 bis 10.0.28, 10.1, 10.2 und
10.3.
Note
Unterstützung für MariaDB als Ziel ist in allen AWS DMS-Versionen verfügbar, in denen MySQLunterstützt wird.
• PostgreSQL-Version 9.4 und höher (für Versionen 9.x), 10.x und 11.x.
API-Version API Version 2016-01-0113

AWS Database Migration Service BenutzerhandbuchZiele
Note
Die PostgreSQL-Versionen 11.x werden nur in den AWS DMS-Versionen 3.3.1 und höher alsZiel unterstützt. Sie können die PostgreSQL-Versionen 9.4 und höher (für Versionen 9.x) und10.x als Ziel in jeder beliebigen DMS-Version verwenden.
• SAP Adaptive Server Enterprise (ASE)-Versionen 15, 15.5, 15.7, 16 und höher.
Amazon RDS-Instance-Datenbanken, Amazon Redshift, Amazon DynamoDB, Amazon S3,Amazon Elasticsearch Service, Amazon Kinesis Data Streams und Amazon DocumentDB
• Oracle-Versionen 11g (Versionen 11.2.0.3.v1 und höher), 12c, 18c und 19c für die Editionen Enterprise,Standard, Standard One und Standard Two.
Note
• Unterstützung für Oracle-Version 19c als Ziel ist in den AWS DMS-Versionen 3.3.2 und höherverfügbar.
• Unterstützung für Oracle-Version 18c als Ziel ist in den AWS DMS-Versionen 3.3.1 und höherverfügbar.
• Microsoft SQL Server-Versionen 2008R2, 2012, 2014, 2016, 2017 und 2019 für die Editionen Enterprise,Standard, Workgroup und Developer. Die Web und Express Edition werden nicht unterstützt.
Note
Unterstützung für Microsoft SQL Server Version 2019 als Ziel ist in den AWS DMS-Versionen3.3.2 und höher verfügbar.
• MySQL-Versionen 5.5, 5.6 und 5.7• MariaDB (unterstützt als MySQL-kompatibles Datenziel), Versionen 10.0.24 bis 10.0.28, 10.1, 10.2 und
10.3.
Note
Unterstützung für MariaDB als Ziel ist in allen AWS DMS-Versionen verfügbar, in denen MySQLunterstützt wird.
• PostgreSQL-Version 9.4 und höher (für Versionen 9.x), 10.x und 11.x.
Note
Die PostgreSQL-Versionen 11.x werden nur in den AWS DMS-Versionen 3.3.1 und höher alsZiel unterstützt. Sie können die PostgreSQL-Versionen 9.4 und höher (für Versionen 9.x) und10.x als Ziel in jeder beliebigen DMS-Version verwenden.
• Amazon Aurora mit MySQL-Kompatibilität aus.• Amazon Aurora mit PostgreSQL-Kompatibilität aus.• Amazon Redshift aus.• Amazon S3 aus.• Amazon DynamoDB aus.• Amazon Elasticsearch Service aus.• Amazon Kinesis Data Streams aus.• Apache Kafka – Amazon Managed Streaming for Apache Kafka (Amazon MSK) und selbstverwaltetes
Apache Kafka.• Amazon DocumentDB (mit MongoDB-Kompatibilität) aus.
API-Version API Version 2016-01-0114

AWS Database Migration Service BenutzerhandbuchMit anderen AWS-Services
Verwenden von AWS DMS mit anderen AWS-Services
Sie können AWS DMS mit verschiedenen anderen AWS-Services verwenden:
• Sie können eine Amazon Amazon EC2-Instance oder eine Amazon RDS-DB-Instance als Ziel für eineDatenmigration verwenden.
• Sie können das AWS Schema Conversion Tool (AWS SCT) verwenden, um Quell-Schema und SQL-Code in ein gleichwertiges Zielschema und gleichwertigen SQL-Code zu konvertieren.
• Sie können Amazon S3 als Speicherort für Ihre Daten oder als Zwischenschritt bei der Migration großerDatenmengen verwenden.
• Sie können AWS CloudFormation verwenden, um Ihre AWS-Ressourcen für die Verwaltung oderBereitstellung der Infrastruktur einzurichten. Beispielsweise können Sie AWS DMS-Ressourcen wieReplikations-Instances, Aufgaben, Zertifikate und Endpunkte bereitstellen. Sie erstellen eine Vorlage, inder alle gewünschten AWS-Ressourcen beschrieben werden. AWS CloudFormation übernimmt dann dieBereitstellung und Konfiguration dieser Ressourcen für Sie.
AWS DMS-Unterstützung für AWS CloudFormationSie können AWS DMS-Ressourcen mithilfe von AWS CloudFormation bereitstellen. AWS CloudFormationist ein Service, der Ihnen hilft, Ihre AWS-Ressourcen für die Verwaltung oder Bereitstellung IhrerInfrastruktur zu modellieren und einzurichten. Beispielsweise können Sie AWS DMS-Ressourcen wieReplikations-Instances, Aufgaben, Zertifikate und Endpunkte bereitstellen. Sie erstellen eine Vorlage, inder alle gewünschten AWS-Ressourcen beschrieben werden. AWS CloudFormation übernimmt dann dieBereitstellung und Konfiguration dieser Ressourcen für Sie.
Als Entwickler oder Systemadministrator können Sie Sammlungen dieser Ressourcen erstellen undverwalten, die Sie dann für wiederkehrende Migrationsaufgaben oder die Bereitstellung von Ressourcenfür Ihre Organisation verwenden können. Weitere Informationen zu AWS CloudFormation finden Sie unterAWS CloudFormation-Konzepte im AWS CloudFormation Benutzerhandbuch.
AWS DMS unterstützt das Erstellen der folgenden AWS DMS-Ressourcen mit AWS CloudFormation:
• AWS::DMS::Certificate• AWS::DMS::Endpoint• AWS::DMS::EventSubscription• AWS::DMS::ReplicationInstance• AWS::DMS::ReplicationSubnetGroup• AWS::DMS::ReplicationTask
Erstellen eines Amazon-Ressourcennamens (ARN) fürAWS DMSWenn Sie die AWS CLI- oder AWS DMS-API verwenden, um die Datenbankmigration zu automatisieren,arbeiten Sie mit Amazon-Ressourcennamen (ARNs). Jede Ressource, die in Amazon Web Services erstelltwird, wird durch einen ARN identifiziert, bei dem es sich um einen eindeutigen Bezeichner handelt. WennSie die AWS CLI- oder die AWS DMS-API zur Einrichtung der Datenbankmigration verwenden, müssen Sieden ARN der Ressource angeben, mit der Sie arbeiten möchten.
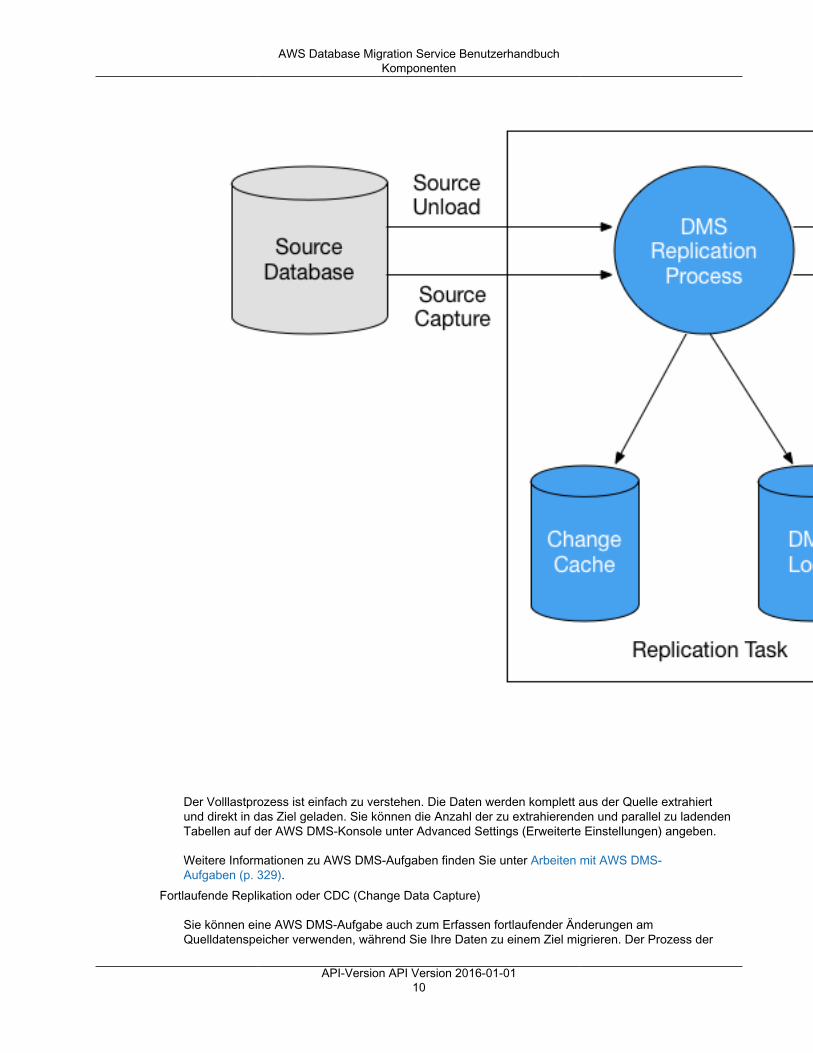
Ein ARN für eine AWS DMS-Ressource verwendet die folgende Syntax:
API-Version API Version 2016-01-0115
AWS Database Migration Service BenutzerhandbuchErstellen eines ARN
arn:aws:dms:<region>:<account number>:<resourcetype>:<resourcename>
In dieser Syntax gilt Folgendes:
• <region> ist die ID der AWS-Region, in der die AWS DMS-Ressource erstellt wurde, etwa us-west-2.
Die folgende Tabelle zeigt die Namen der AWS-Regionen sowie die Werte, die Sie beim Erstellen einesARN verwenden sollten.
Region Name
Region Asien-Pazifik (Tokio) ap-northeast-1
Region Asien-Pazifik (Seoul) ap-northeast-2
Region Asien-Pazifik (Mumbai) ap-south-1
Region Asien-Pazifik (Singapur) ap-southeast-1
Region Asien-Pazifik (Sydney) ap-southeast-2
Region Kanada (Zentral) ca-central-1
Region China (Peking) cn-north-1
Region „China (Ningxia)“ cn-northwest-1
Region Europa (Stockholm) eu-north-1
Region EU (Frankfurt) eu-central-1
Region Europa (Irland) eu-west-1
Region EU (London) eu-west-2
Region EU (Paris) eu-west-3
Region Südamerika (São Paulo) sa-east-1
Region USA Ost (N.-Virginia) us-east-1
Region USA Ost (Ohio) us-east-2
Region USA West (Nordkalifornien) us-west-1
Region USA West (Oregon) us-west-2
• <account number> ist Ihre Kontonummer ohne Bindestriche. Um Ihre Kontonummer zu finden, meldenSie sich bei Ihrem AWS-Konto unter http://aws.amazon.com an und wählen Sie My Account/Console(Eigenes Konto/Konsole) und dann My Account (Eigenes Konto).
• <resourcetype> ist der Typ der AWS DMS-Ressource.
In der folgenden Tabelle sind die Ressourcentypen aufgeführt, die Sie beim Erstellen eines ARN für einebestimmte AWS DMS-Ressource verwenden sollten.
AWS DMS-Ressourcentyp
ARN-Format
Replikations-Instance arn:aws:dms:<region>: <account>:rep: <resourcename>
API-Version API Version 2016-01-0116
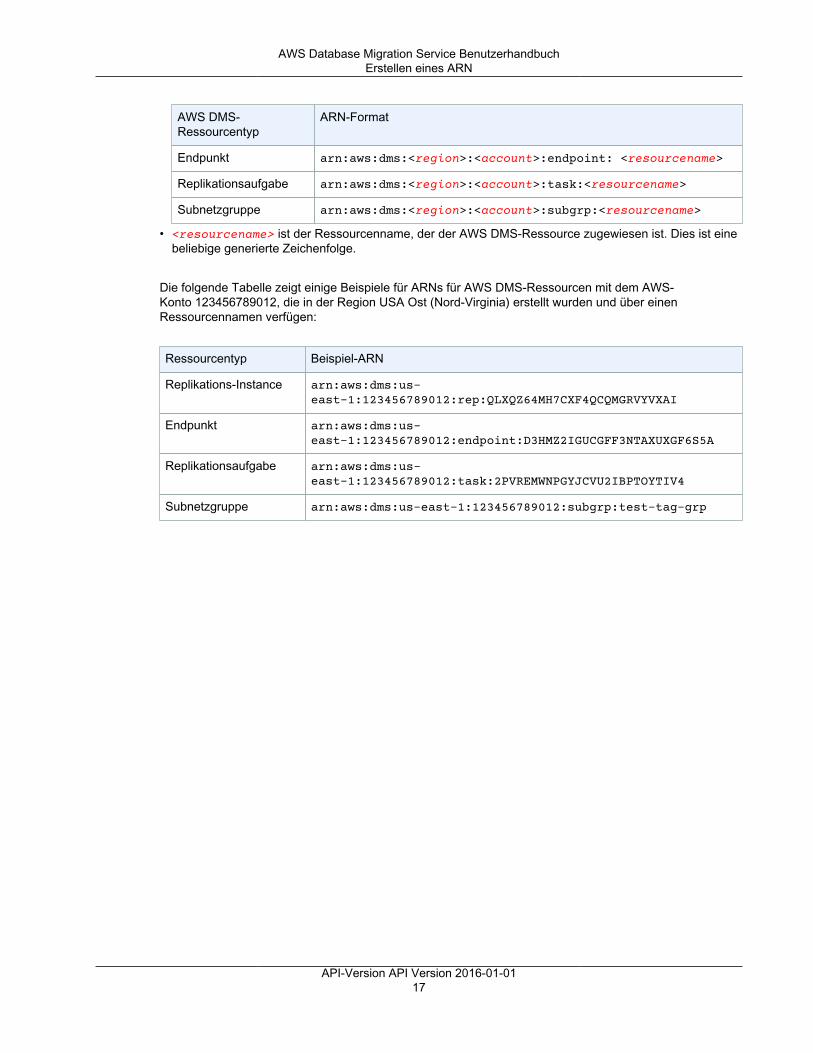
AWS Database Migration Service BenutzerhandbuchErstellen eines ARN
AWS DMS-Ressourcentyp
ARN-Format
Endpunkt arn:aws:dms:<region>:<account>:endpoint: <resourcename>
Replikationsaufgabe arn:aws:dms:<region>:<account>:task:<resourcename>
Subnetzgruppe arn:aws:dms:<region>:<account>:subgrp:<resourcename>
• <resourcename> ist der Ressourcenname, der der AWS DMS-Ressource zugewiesen ist. Dies ist einebeliebige generierte Zeichenfolge.
Die folgende Tabelle zeigt einige Beispiele für ARNs für AWS DMS-Ressourcen mit dem AWS-Konto 123456789012, die in der Region USA Ost (Nord-Virginia) erstellt wurden und über einenRessourcennamen verfügen:
Ressourcentyp Beispiel-ARN
Replikations-Instance arn:aws:dms:us-east-1:123456789012:rep:QLXQZ64MH7CXF4QCQMGRVYVXAI
Endpunkt arn:aws:dms:us-east-1:123456789012:endpoint:D3HMZ2IGUCGFF3NTAXUXGF6S5A
Replikationsaufgabe arn:aws:dms:us-east-1:123456789012:task:2PVREMWNPGYJCVU2IBPTOYTIV4
Subnetzgruppe arn:aws:dms:us-east-1:123456789012:subgrp:test-tag-grp
API-Version API Version 2016-01-0117

AWS Database Migration Service BenutzerhandbuchAnmelden bei AWS
Einrichten für AWS DatabaseMigration Service
Bevor Sie AWS Database Migration Service (AWS DMS) zum ersten Mal verwenden, führen Sie diefolgenden Schritte aus:
1. Anmelden bei AWS (p. 18)2. Erstellen eines IAM-Benutzers (p. 18)3. Planen der Migration für AWS Database Migration Service (p. 20)
Anmelden bei AWSBei der Registrierung für Amazon Web Services (AWS) wird Ihr AWS-Konto automatisch für alle Dienste inAWS einschließlich AWS DMS registriert. Berechnet werden Ihnen aber nur die Services, die Sie nutzen.
Mit AWS DMS zahlen Sie nur für die Ressourcen, die Sie wirklich nutzen. Die erstellte AWS DMS-Replikations-Instance ist aktiv (sie wird nicht in einer Sandbox ausgeführt). Es fallen die standardmäßigenAWS DMS-Nutzungsgebühren für die Instance an, bis Sie sie beenden. Weitere Informationen über AWSDMS-Nutzungsgebühren finden Sie auf der AWS DMS-Produktseite. Wenn Sie ein AWS-Neukunde sind,können Sie kostenfrei bei AWS DMS einsteigen. Weitere Informationen finden Sie unter KostenlosesNutzungskontingent für AWS.
Wenn Sie Ihr AWS-Konto schließen, werden alle AWS DMS-Ressourcen und Konfigurationen, die IhremKonto zugeordnet sind, nach zwei Tagen gelöscht. Zu diesen Ressourcen gehören alle Replikations-Instances, Quell- und Ziel-Endpunktkonfiguration, Replikationsaufgaben und SSL-Zertifikate. Wenn Sie sichnach zwei Tagen wieder für AWS DMS entscheiden, legen Sie die benötigten Ressourcen neu an.
Wenn Sie bereits ein AWS-Konto haben, wechseln Sie zur nächsten Aufgabe.
Wenn Sie kein AWS-Konto haben, führen Sie die folgenden Schritte zum Erstellen eines Kontos durch.
Um sich für AWS anzumelden:
1. Öffnen Sie https://aws.amazon.com/ und wählen Sie Create an AWS Account aus.2. Folgen Sie den Onlineanweisungen.
Notieren Sie Ihre AWS-Kontonummer. Sie benötigen sie im nächsten Schritt.
Erstellen eines IAM-BenutzersWenn Sie auf Services wie AWS DMS in AWS zugreifen, müssen Sie Anmeldeinformationen eingeben.So kann der Service bestimmen, ob Sie über die Berechtigung für den Zugriff auf dessen Ressourcenverfügen. Für die Konsole müssen Sie Ihr Passwort eingeben. Sie können für Ihr AWS-KontoZugriffsschlüssel erstellen, um auf die Befehlszeilenschnittstelle oder API zuzugreifen. Wir empfehlenjedoch nicht, dass Sie für den Zugriff auf AWS die Anmeldeinformationen für Ihr AWS-Konto verwenden.
API-Version API Version 2016-01-0118

AWS Database Migration Service BenutzerhandbuchErstellen eines IAM-Benutzers
Wir empfehlen, stattdessen AWS Identity and Access Management (IAM) zu verwenden. Erstellen Sieeinen IAM-Benutzer, und fügen Sie den Benutzer einer IAM-Gruppe mit Administrator-Berechtigungenhinzu, oder/und gewähren Sie diesem Benutzer Administrator-Berechtigungen. Sie können dann mit einerspeziellen URL und den Anmeldeinformationen für den IAM-Benutzer auf AWS zugreifen.
Wenn Sie sich zwar bei AWS angemeldet, aber für sich selbst keinen IAM-Benutzer erstellt haben, könnenSie mithilfe der IAM-Konsole einen Benutzer erstellen.
So erstellen Sie einen Administratorbenutzer für sich selbst und fügen ihn einerAdministratorengruppe hinzu (Konsole)
1. Verwenden Sie die E-Mail-Adresse des und das Passwort für Ihr AWS-Konto für die Anmeldung alsStammbenutzer des AWS-Kontos bei der IAM-Konsole unter https://console.aws.amazon.com/iam/.
Note
Wir empfehlen ausdrücklich, die bewährten Verfahren mithilfe des AdministratorIAM-Benutzers unten zu verwenden und die Anmeldeinformationen des Stammbenutzers aneinem sicheren Ort abzulegen. Melden Sie sich als Stammbenutzer an, um einige Konto- undService-Verwaltungsaufgaben durchzuführen.
2. Wählen Sie im Navigationsbereich Users und dann Add User aus.3. Geben Sie unter Benutzername Administrator als Benutzernamen ein.4. Aktivieren Sie das Kontrollkästchen neben AWS Management Console access (Konsolenzugriff).
Wählen Sie dann Custom password (Benutzerdefiniertes Passwort) aus und geben Sie danach Ihrneues Passwort in das Textfeld ein.
5. (Optional) Standardmäßig erfordert AWS, dass der neue Benutzer bei der ersten Anmeldung ein neuesPasswort erstellt. Sie können das Kontrollkästchen neben User must create a new password at nextsign-in (Benutzer muss bei der nächsten Anmeldung ein neues Passwort erstellen) deaktivieren, umdem neuen Benutzer zu ermöglichen, sein Kennwort nach der Anmeldung zurückzusetzen.
6. Wählen Sie Next: Permissions aus.7. Wählen Sie unter Set permissions (Berechtigungen festlegen) die Option Add user to group (Benutzer
der Gruppe hinzufügen) aus.8. Wählen Sie Create group (Gruppe erstellen) aus.9. Geben Sie im Dialogfeld Create group (Gruppe erstellen) unter Group name (Gruppenname)
Administrators ein.10. Wählen Sie Filter policies (Richtlinien filtern) und anschließend AWS-managed job function (AWS-
verwaltete Auftragsfunktion) aus, um den Tabelleninhalt zu filtern.11. Aktivieren Sie in der Richtlinienliste das Kontrollkästchen AdministratorAccess. Wählen Sie dann
Create group aus.
Note
Sie müssen den Zugriff der IAM-Benutzer und -Rollen auf die Fakturierung aktivieren, bevorSie die AdministratorAccess-Berechtigungen verwenden können, um auf die AWS Billingand Cost Management-Konsole zuzugreifen. Befolgen Sie hierzu die Anweisungen in Schritt 1des Tutorials zum Delegieren des Zugriffs auf die Abrechnungskonsole.
12. Kehren Sie zur Gruppenliste zurück und aktivieren Sie das Kontrollkästchen der neuen Gruppe.Möglicherweise müssen Sie Refresh auswählen, damit die Gruppe in der Liste angezeigt wird.
13. Wählen Sie Weiter: Tags aus.14. (Optional) Fügen Sie dem Benutzer Metadaten hinzu, indem Sie Tags als Schlüssel-Wert-Paare
anfügen. Weitere Informationen zur Verwendung von Tags in IAM finden Sie unter Tagging von IAM-Entitäten im IAM-Benutzerhandbuch.
15. Wählen Sie Next: Review aus, damit die Liste der Gruppenmitgliedschaften angezeigt wird, die demneuen Benutzer hinzugefügt werden soll. Wenn Sie bereit sind, fortzufahren, wählen Sie Create user(Benutzer erstellen) aus.
API-Version API Version 2016-01-0119

AWS Database Migration Service BenutzerhandbuchPlanen der Migration für AWS Database Migration Service
Mit diesen Schritten können Sie weitere Gruppen und Benutzer erstellen und Ihren Benutzern Zugriffauf Ihre AWS-Kontoressourcen gewähren. Weitere Informationen dazu, wie Sie die Berechtigungeneines Benutzers auf bestimmte AWS-Ressourcen mithilfe von Richtlinien beschränken, finden Sie unterZugriffsverwaltung und Beispielrichtlinien.
Um sich als diesen neuen IAM-Benutzer anzumelden, melden Sie sich aus der AWS-Konsole ab undverwenden dann die folgende URL, wobei your_aws_account_id ohne Bindestriche Ihre AWS-Kontonummer darstellt (wenn beispielsweise Ihre AWS-Kontonummer 1234-5678-9012 lautet, ist IhreAWS-Konto-ID 123456789012):
https://your_aws_account_id.signin.aws.amazon.com/console/
Geben Sie den IAM-Benutzernamen und das von Ihnen soeben erstellte Passwort ein. Nachdem Sie sichangemeldet haben, wird in der Navigationsleiste „your_user_name @ your_aws_account_id“ angezeigt.
Wenn Sie nicht möchten, dass die URL für Ihre Anmeldeseite Ihre AWS-Konto-ID enthält, können Sie einenKonto-Alias erstellen. Wählen Sie im IAM-Dashboard Customize (Anpassen) aus und geben Sie einen Aliasein, beispielsweise Ihren Firmennamen. Nach dem Erstellen eines Konto-Alias verwenden Sie die folgendeURL, um sich anzumelden.
https://your_account_alias.signin.aws.amazon.com/console/
Öffnen Sie die IAM-Konsole, um den Anmeldelink für IAM-Benutzer in Ihrem Konto zu prüfen. Sie findenden Link auf dem Dashboard unter AWS Account Alias (AWS-Konto-Alias).
Planen der Migration für AWS Database MigrationService
Beim Planen einer Datenbankmigration mit AWS Database Migration Service sollten Sie Folgendesbeachten:
• Sie müssen ein Netzwerk konfigurieren, das Ihre Quell- und Zieldatenbanken mit einer AWS DMS-Replikations-Instance verbindet. Dies kann so einfach sein wie das Herstellen einer Verbindungzwischen zwei AWS-Ressourcen in der gleichen VPC als Replikations-Instance, oder eine komplexereKonfiguration erfordern, wie etwa beim Verbinden einer lokalen Datenbank mit einer Amazon RDS-DB-Instance über VPN. Weitere Informationen finden Sie unter Netzwerkkonfigurationen für dieDatenbankmigration (p. 103)
• Quell- und Ziel-Endpunkte – Sie müssen wissen, welche Informationen und Tabellen in derQuelldatenbank zur Zieldatenbank migriert werden müssen. AWS DMS unterstützt eine grundlegendeSchemamigration, einschließlich der Erstellung von Tabellen und primären Schlüsseln. Allerdingserstellt AWS DMS nicht automatisch sekundäre Indizes, Fremdschlüssel, Benutzerkonten und so weiterin der Zieldatenbank. Beachten Sie, dass Sie je nach Quell- und Ziel-Datenbank-Engine zusätzlicheProtokollierung einrichten oder andere Einstellungen für eine Quell- oder Zieldatenbank ändern müssen.Weitere Informationen finden Sie in den Abschnitten Quellen für die Datenmigration (p. 122) und Zielefür die Datenmigration (p. 211).
• Schema/Code-Migration – AWS DMS führt keine Schema- oder Code-Umwandlung aus. Sie können IhrSchema mithilfe von Tools wie Oracle SQL Developer, MySQL Workbench oder pgAdmin III umwandeln.Wenn Sie ein vorhandenes Schema in eine andere Datenbank-Engine konvertieren möchten, könnenSie das AWS Schema Conversion Tool verwenden. Dieses Tool kann ein Zielschema erstellen, aberauch ein ganzes Schema generieren und erstellen, wie Tabellen, Indizes, Ansichten und so weiter. Siekönnen das Tool auch verwenden, um PL/SQL oder TSQL in PgSQL und andere Formate umzuwandeln.Weitere Informationen zu diesem Tool finden Sie unter AWS Schema Conversion Tool.
API-Version API Version 2016-01-0120

AWS Database Migration Service BenutzerhandbuchPlanen der Migration für AWS Database Migration Service
• Nicht unterstützte Datentypen – Einige Quelldatentypen müssen in die äquivalenten Datentypen für dieZieldatenbank konvertiert werden. Weitere Informationen über unterstützte Datentypen finden Sie imQuell- oder Zielabschnitt für Ihren Datenspeicher.
API-Version API Version 2016-01-0121

AWS Database Migration Service BenutzerhandbuchStarten einer Datenbankmigration
Erste Schritte mit AWS DatabaseMigration Service
AWS Database Migration Service (AWS DMS) unterstützt Sie bei der einfachen und sicheren Migrationzu AWS. Sie können Ihre Daten von und zu den gängigsten kommerziellen und Open-Source-Datenbanken migrieren, wie z. B. Oracle, MySQL und PostgreSQL. Der Service unterstützt sowohlhomogene Migrationen (z. B. Oracle zu Oracle) als auch heterogene Migrationen mit verschiedenenDatenbankplattformen (z. B. Oracle zu PostgreSQL oder MySQL zu Oracle).
Weitere Informationen über die Kosten der Datenbankmigration mithilfe der AWS Database MigrationService finden Sie unter AWS Database Migration Service – Preise.
Themen• Starten einer Datenbankmigration mit AWS Database Migration Service (p. 22)• Schritt 1: Begrüßungsseite (p. 23)• Schritt 2: Erstellen einer Replikations-Instance (p. 23)• Schritt 3: Geben Sie Quell- und Zielendpunkte an (p. 28)• Schritt 4: Erstellen einer Migrationsaufgabe (p. 33)• Überwachen Ihrer Aufgabe (p. 37)
Starten einer Datenbankmigration mit AWSDatabase Migration Service
Es gibt verschiedene Möglichkeiten, wie Sie mit einer Datenbankmigration beginnen können. Sie könnenden Assistenten der AWS DMS-Konsole auswählen, der Sie durch die einzelnen Schritte des Prozessesführt. Alternativ können Sie jeden Schritt auch ausführen, indem Sie die entsprechende Aufgabe imNavigationsbereich wählen. Sie können auch die AWS-CLI verwenden. Informationen zur Verwendung derCLI mit AWS DMS finden Sie unter AWS-CLI für AWS-DMS.
Um den Assistenten zu verwenden, wählen Sie Getting started (Erste Schritte) im Navigationsbereichder AWS DMS-Konsole aus. Mithilfe des Assistenten können Sie Ihre erste Datenmigration erstellen.Den Anweisungen des Assistenten folgend weisen Sie eine Replikations-Instance zu, die alleMigrationsprozesse durchführt, geben Sie eine Quell- und eine Zieldatenbank an und erstellen dann eineAufgabe bzw. mehrere Aufgaben, um festzulegen, welche Tabellen und Replikationsprozesse verwendetwerden sollen. AWS DMS erstellt dann Ihre Replikations-Instance und führt die dazugehörigen Aufgabenauf die zu migrierenden Daten aus.
Sie können die einzelnen Komponenten einer AWS DMS-Datenbankmigration auch erstellen, indem Sie dieentsprechenden Elemente im Navigationsbereich auswählen. Für eine Datenbankmigration müssen Sie diefolgenden Schritte ausführen:
• Ausführen der Aufgaben unter Einrichten für AWS Database Migration Service (p. 18)• Zuweisen einer Replikations-Instance, die alle Migrationsprozesse durchführt• Angeben eines Quell- und Zieldatenbankendpunkts
API-Version API Version 2016-01-0122

AWS Database Migration Service BenutzerhandbuchSchritt 1: Begrüßungsseite
• Erstellen einer oder mehrerer Aufgaben, um festzulegen, welche Tabellen und Replikationsprozesseverwendet werden sollen
Schritt 1: BegrüßungsseiteWenn Sie Ihre Datenbankmigration mithilfe des Assistenten der AWS DMS-Konsole starten, sehen Sie dieBegrüßungsseite, auf der der Prozess der Datenbankmigration mit AWS DMS erläutert wird.
So starten Sie eine Datenbankmigration von der Begrüßungsseite der Konsole
• Wählen Sie Next.
Schritt 2: Erstellen einer Replikations-InstanceIhre erste Aufgabe bei der Migration einer Datenbank besteht darin, eine Replikations-Instance mitgenügend Speicherplatz und der nötigen Rechenleistung für die Durchführung der zugewiesenen Aufgabenzu erstellen und die Daten von der Quelldatenbank zur Zieldatenbank zu migrieren. Die erforderlicheGröße dieser Instance hängt von der Menge der Daten ab, die Sie migrieren müssen, sowie von denAufgaben, die die Instance ausführen muss. Weitere Informationen zu Replikations-Instances finden Sieunter Arbeiten mit einer AWS DMS-Replikations-Instance (p. 93).
Im folgenden Verfahren wird davon ausgegangen, dass Sie den Assistenten der AWS DMS-Konsolegewählt haben. Sie können diesen Schritt auch ausführen, indem Sie Replication instances (Replikations-Instances) im Navigationsbereich der AWS DMS-Konsole und dann Create replication instance(Replikations-Instance erstellen) auswählen.
API-Version API Version 2016-01-0123

AWS Database Migration Service BenutzerhandbuchSchritt 2: Erstellen einer Replikations-Instance
So erstellen Sie eine Replikations-Instance über die AWS-Konsole
1. Klicken Sie im Navigationsbereich auf Replication instances.2. Wählen Sie Create Replication Instance aus.3. Legen Sie auf der Seite Create replication instance die Angaben zur Replikations-Instance fest. In der
folgenden Tabelle sind die Einstellungen beschrieben.
Option Vorgehensweise
Name Geben Sie einen Namen für die Replikations-Instance an,der aus bis zu 63 druckbaren ASCII-Zeichen (ohne /, “ und@) besteht. Das erste Zeichen muss ein Buchstabe sein,und der Name darf nicht mit einem Bindestrich enden. DerName sollte für Ihr Konto für die gewählte Region eindeutigsein. Sie können zu dem Namen noch weitere Angabenmachen, z. B. die Region und Aufgabe, die Sie ausführen,beispielsweise west2-mysql2mysql-instance1.
Beschreibung Geben Sie eine kurze Beschreibung für die Replikations-Instance an.
Instance class (Instance-Klasse) Wählen Sie eine Instance-Klasse mit der benötigtenKonfiguration für die Migration aus. Beachten Sie,dass die Instance über ausreichend Speicherplatz,Netzwerkkapazität und Rechenleistung verfügen muss,um Ihre Migration erfolgreich abzuschließen. WeitereInformationen dazu, wie Sie herausfinden, welcheInstance-Klasse sich am besten für Ihre Migration eignet,
API-Version API Version 2016-01-0124
AWS Database Migration Service BenutzerhandbuchSchritt 2: Erstellen einer Replikations-Instance
Option Vorgehensweisefinden Sie unter Arbeiten mit einer AWS DMS-Replikations-Instance (p. 93).
Replication engine version (Version derReplikations-Engine)
Standardmäßig wird die Replikations-Instance mit derneuesten Version der AWS DMS-Replikations-Engine-Software ausgeführt. Wir empfehlen, dass Sie dieseStandardeinstellung übernehmen. Sie können jedoch beiBedarf eine vorherige Engine-Version auswählen.
VPC Wählen Sie die Amazon Virtual Private Cloud (AmazonVPC) aus, die Sie verwenden möchten. Wenn sich dieQuell- oder Zieldatenbank innerhalb einer VPC befindet,wählen Sie diese VPC aus. Wenn sich Ihre Quell- undZieldatenbank in verschiedenen VPCs befinden, stellen Siesicher, dass sie sich in öffentlichen Subnetzen befindenund öffentlich zugänglich sind, und wählen Sie dann dieVPC aus, in der die Replikations-Instance abgelegt werdensoll. Die Replikations-Instance muss auf die Daten in derQuell-VPC zugreifen können. Wenn sich weder die Quell-noch die Zieldatenbank in einer VPC befinden, wählen Sieeine VPC aus, in der die Replikations-Instance abgelegtwerden soll.
Multi-AZ Verwenden Sie diesen optionalen Parameter zum Erstelleneines Standby-Replikats Ihrer Replikations-Instance ineiner anderen Availability Zone, um Failover-Unterstützungzu bieten. Wenn Sie Change Data Capture (CDC) oder diefortlaufende Replikation verwenden möchten, sollten Siediese Option aktivieren.
Publicly accessible (Öffentlichzugänglich)
Wählen Sie diese Option, wenn Sie möchten, dass dieReplikations-Instance über das Internet zugänglich ist.
4. Wählen Sie die Registerkarte Advanced (Erweitert) aus (siehe unten), um ggf. Werte für Netzwerk-und Verschlüsselungseinstellungen festzulegen. In der folgenden Tabelle sind die Einstellungenbeschrieben.
API-Version API Version 2016-01-0125
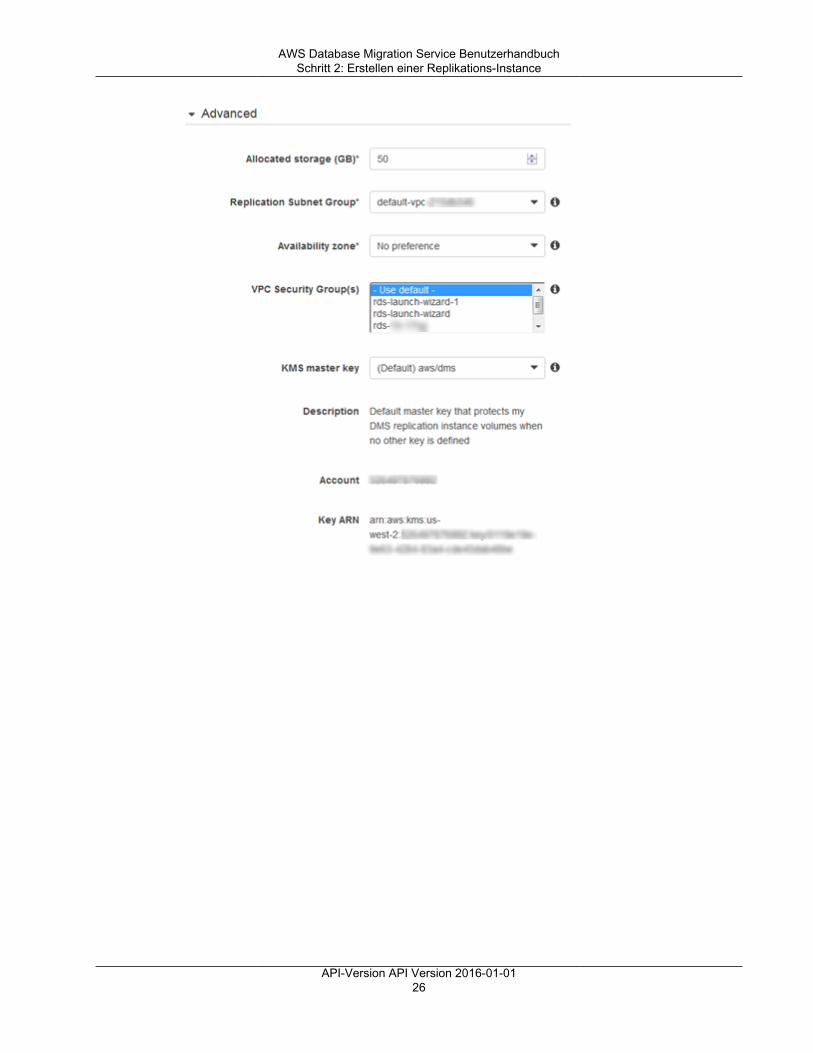
AWS Database Migration Service BenutzerhandbuchSchritt 2: Erstellen einer Replikations-Instance
API-Version API Version 2016-01-0126
AWS Database Migration Service BenutzerhandbuchSchritt 2: Erstellen einer Replikations-Instance
Option Vorgehensweise
Allocated storage (GB) (ZugewiesenerSpeicher (GB())
Speicherplatz wird in erster Linie von Protokolldateienund zwischengespeicherten Transaktionen belegt. Für diezwischengespeicherten Transaktionen wird Speicherplatznur verwendet, wenn die zwischengespeichertenTransaktionen auf Festplatte geschrieben werden müssen.Daher verbraucht AWS DMS nicht viel Speicherplatz. Esgibt jedoch folgende Ausnahmen:
• Sehr große Tabellen, bei der viele Transaktionengeladen werden. Das Laden einer großen Tabellekann einige Zeit in Anspruch nehmen, sodasszwischengespeicherte Transaktionen eher während desLadens einer großen Tabelle auf Festplatte geschriebenwerden.
• Aufgaben, die so konfiguriert sind, dass sie vor demLaden zwischengespeicherter Transaktionen angehaltenwerden. In diesem Fall werden alle Transaktionenzwischengespeichert, bis der vollständige Ladevorgangfür alle Tabellen abgeschlossen ist. Bei dieserKonfiguration kann durch die zwischengespeichertenTransaktionen recht viel Speicherplatz beanspruchtwerden.
• Aufgaben, die mit Tabellen konfiguriert sind, die inAmazon Redshift geladen werden. Diese Konfigurationist jedoch kein Problem, wenn Amazon Aurora das Zielist.
In den meisten Fällen reicht die standardmäßigzugewiesene Speichermenge aus. Es ist allerdings immersinnvoll, auf speicherbezogene Metriken zu achten undden Speicherplatz zu erhöhen, wenn Sie feststellen, dassmehr Speicherplatz verbraucht wird, als standardmäßigzugewiesen ist.
Replication Subnet Group Wählen Sie die Replikationssubnetzgruppe inder von Ihnen ausgewählten VPC aus, in der dieReplikations-Instance erstellt werden soll. Wenn sichIhre Quelldatenbank in einer VPC befindet, wählen Siedie Subnetzgruppe, die die Quelldatenbank enthält, alsSpeicherort für Ihre Replikations-Instance aus. WeitereInformationen zu Replikationssubnetzgruppen finden Sieunter Erstellen einer Replikationssubnetzgruppe (p. 108).
Availability Zone Wählen Sie die Availability Zone aus, in der sich IhreQuelldatenbank befindet.
VPC Security group(s) (VPC-Sicherheitsgruppe(n))
Die Replikations-Instance wird in einer VPC erstellt. Wennsich Ihre Quelldatenbank in einer VPC befindet, wählenSie die VPC-Sicherheitsgruppe aus, die Zugriff auf die DB-Instance bietet, in der die Datenbank gespeichert ist.
API-Version API Version 2016-01-0127

AWS Database Migration Service BenutzerhandbuchSchritt 3: Geben Sie Quell- und Zielendpunkte an
Option Vorgehensweise
KMS-Masterschlüssels Wählen Sie den Verschlüsselungsschlüssel aus, derzum Verschlüsseln der Replikationsspeicher- undVerbindungsinformationen verwendet werden soll. WennSie (Default) aws/dms auswählen, wird der mit IhremKonto und Ihrer Region verknüpfte AWS Key ManagementService (AWS-KMS)-Schlüssel verwendet. EineBeschreibung und die Kontonummer werden angezeigt,zusammen mit den Schlüssel-ARN. Weitere Informationenzur Verwendung des Verschlüsselungsschlüssels findenSie unter Einrichten eines Verschlüsselungsschlüssels undAngeben von AWS KMS-Berechtigungen (p. 79).
5. Geben Sie die Maintenance-Einstellungen an. In der folgenden Tabelle sind die Einstellungenbeschrieben. Weitere Informationen zu den Wartungseinstellungen finden Sie unter AWS DMS-Wartungsfenster (p. 97)
Option Vorgehensweise
Automatisches Unterversion-Upgrade Wählen Sie diese Option, damit kleinere Engine-Aktualisierungen innerhalb des Wartungsfenstersautomatisch auf die Replikations-Instance angewendetwerden.
Maintenance window(Wartungsfenster)
Wählen Sie einen wöchentlichen Zeitraum, in demSystemwartungen durchgeführt werden können, in UTC(Universal Coordinated Time) aus.
Standard: ein 30-minütiges Fenster, das zufällig auseinem 8-Stunden-Zeitblock pro Region an einem zufälligenWochentag ausgewählt wird.
6. Wählen Sie Create replication instance aus.
Schritt 3: Geben Sie Quell- und Zielendpunkte anWährend die Replikations-Instance erstellt wird, können Sie die Quell- und Zieldatenspeicher angeben.Die Quell- und Zieldatenspeicher können sich auf einer Amazon EC2-Instance (Amazon Elastic ComputeCloud), einer Amazon RDS-DB-Instance (Amazon Relational Database Service) oder einer lokalenDatenbank befinden.
API-Version API Version 2016-01-0128

AWS Database Migration Service BenutzerhandbuchSchritt 3: Geben Sie Quell- und Zielendpunkte an
Im folgenden Verfahren wird davon ausgegangen, dass Sie den Assistenten der AWS DMS-Konsolegewählt haben. Sie können diesen Schritt auch ausführen, indem Sie Endpoints (Endpunkte) imNavigationsbereich der AWS DMS-Konsole und anschließend Create endpoint (Endpunkt erstellen)auswählen. Wenn Sie den Assistenten der Konsole verwenden, werden die Quell- und Zielendpunkteauf der gleichen Seite erstellt. Wenn Sie den Assistenten nicht verwenden, erstellen Sie die einzelnenEndpunkte separat voneinander.
So geben Sie die Quell- oder Zieldatenbankendpunkte mit der AWS-Konsole an
1. Geben Sie auf der Seite Connect source and target database endpoints die Verbindungsinformationenfür die Quell- oder Zieldatenbank an. In der folgenden Tabelle sind die Einstellungen beschrieben.
API-Version API Version 2016-01-0129
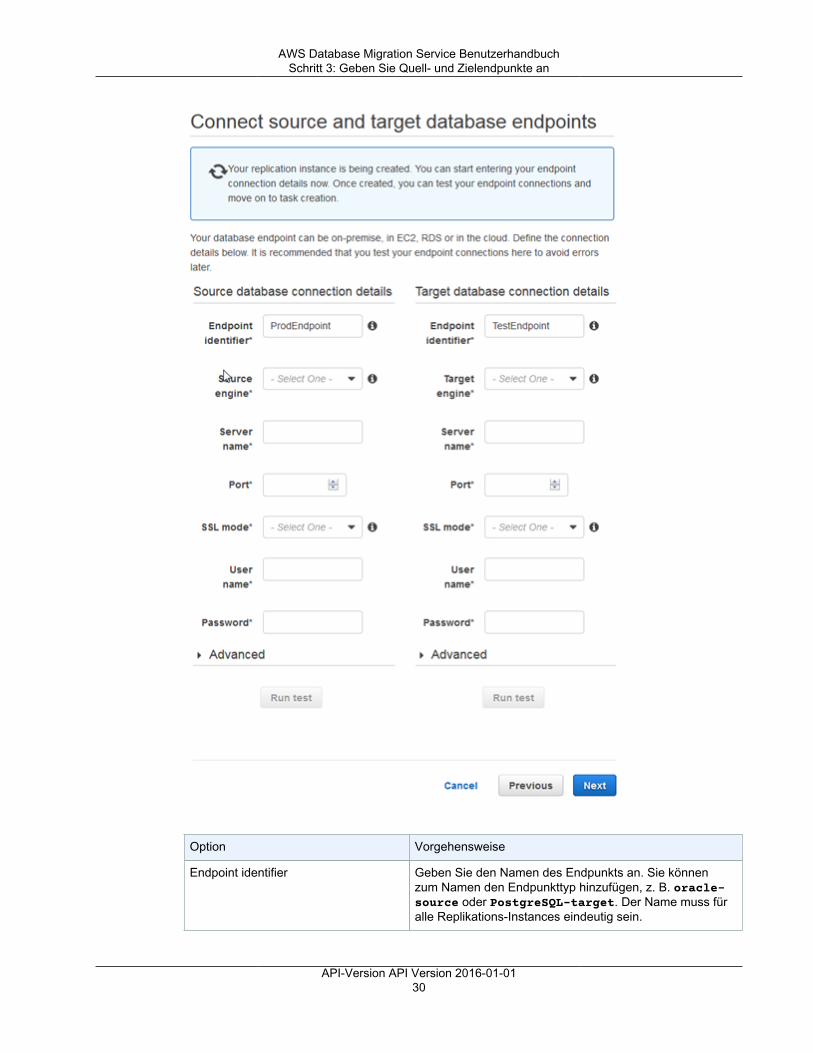
AWS Database Migration Service BenutzerhandbuchSchritt 3: Geben Sie Quell- und Zielendpunkte an
Option Vorgehensweise
Endpoint identifier Geben Sie den Namen des Endpunkts an. Sie könnenzum Namen den Endpunkttyp hinzufügen, z. B. oracle-source oder PostgreSQL-target. Der Name muss füralle Replikations-Instances eindeutig sein.
API-Version API Version 2016-01-0130
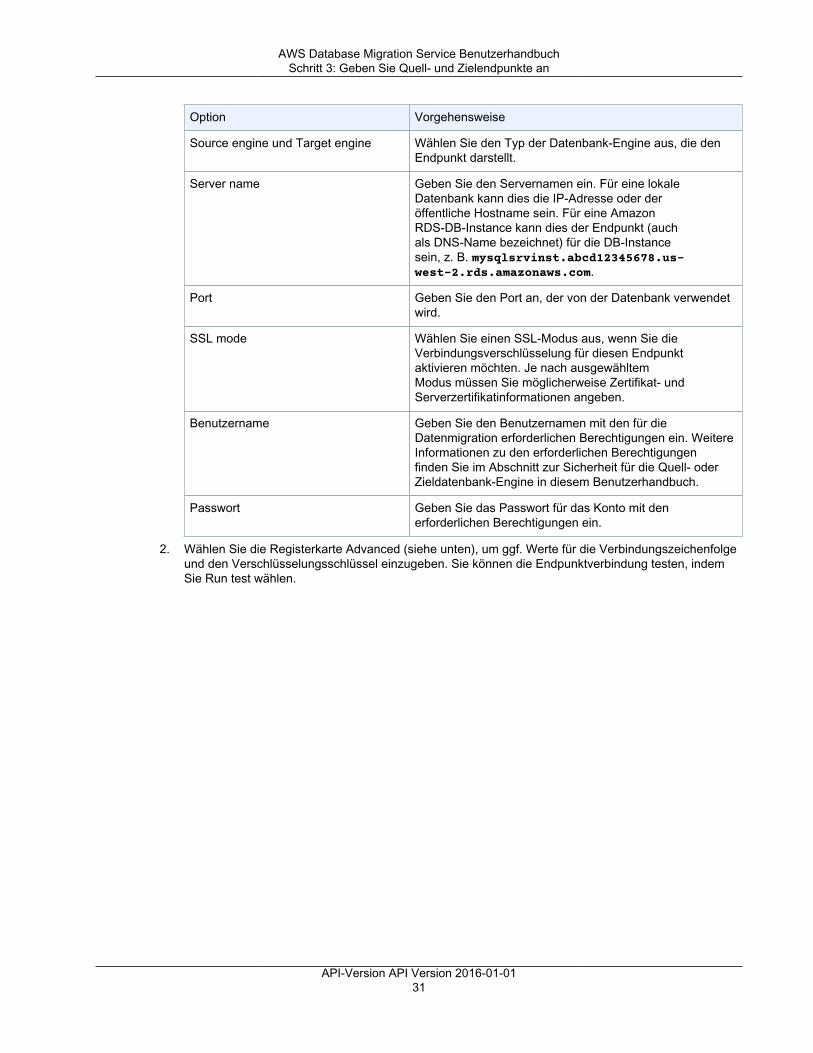
AWS Database Migration Service BenutzerhandbuchSchritt 3: Geben Sie Quell- und Zielendpunkte an
Option Vorgehensweise
Source engine und Target engine Wählen Sie den Typ der Datenbank-Engine aus, die denEndpunkt darstellt.
Server name Geben Sie den Servernamen ein. Für eine lokaleDatenbank kann dies die IP-Adresse oder deröffentliche Hostname sein. Für eine AmazonRDS-DB-Instance kann dies der Endpunkt (auchals DNS-Name bezeichnet) für die DB-Instancesein, z. B. mysqlsrvinst.abcd12345678.us-west-2.rds.amazonaws.com.
Port Geben Sie den Port an, der von der Datenbank verwendetwird.
SSL mode Wählen Sie einen SSL-Modus aus, wenn Sie dieVerbindungsverschlüsselung für diesen Endpunktaktivieren möchten. Je nach ausgewähltemModus müssen Sie möglicherweise Zertifikat- undServerzertifikatinformationen angeben.
Benutzername Geben Sie den Benutzernamen mit den für dieDatenmigration erforderlichen Berechtigungen ein. WeitereInformationen zu den erforderlichen Berechtigungenfinden Sie im Abschnitt zur Sicherheit für die Quell- oderZieldatenbank-Engine in diesem Benutzerhandbuch.
Passwort Geben Sie das Passwort für das Konto mit denerforderlichen Berechtigungen ein.
2. Wählen Sie die Registerkarte Advanced (siehe unten), um ggf. Werte für die Verbindungszeichenfolgeund den Verschlüsselungsschlüssel einzugeben. Sie können die Endpunktverbindung testen, indemSie Run test wählen.
API-Version API Version 2016-01-0131
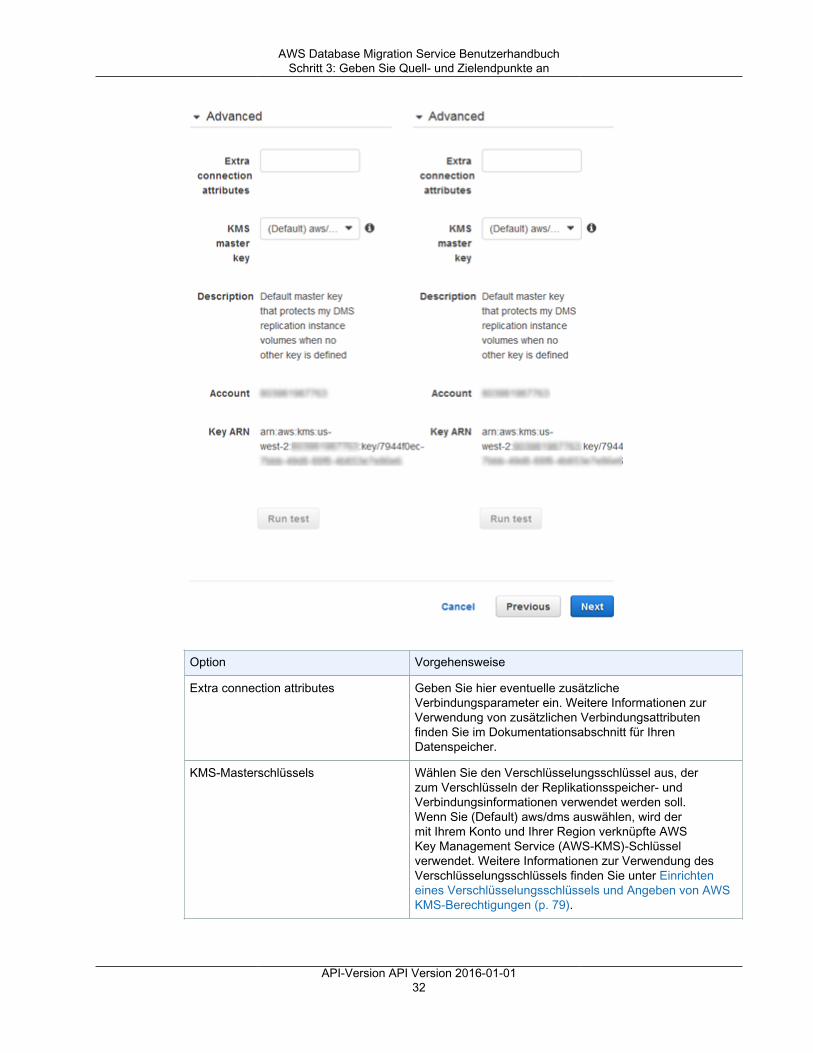
AWS Database Migration Service BenutzerhandbuchSchritt 3: Geben Sie Quell- und Zielendpunkte an
Option Vorgehensweise
Extra connection attributes Geben Sie hier eventuelle zusätzlicheVerbindungsparameter ein. Weitere Informationen zurVerwendung von zusätzlichen Verbindungsattributenfinden Sie im Dokumentationsabschnitt für IhrenDatenspeicher.
KMS-Masterschlüssels Wählen Sie den Verschlüsselungsschlüssel aus, derzum Verschlüsseln der Replikationsspeicher- undVerbindungsinformationen verwendet werden soll.Wenn Sie (Default) aws/dms auswählen, wird dermit Ihrem Konto und Ihrer Region verknüpfte AWSKey Management Service (AWS-KMS)-Schlüsselverwendet. Weitere Informationen zur Verwendung desVerschlüsselungsschlüssels finden Sie unter Einrichteneines Verschlüsselungsschlüssels und Angeben von AWSKMS-Berechtigungen (p. 79).
API-Version API Version 2016-01-0132
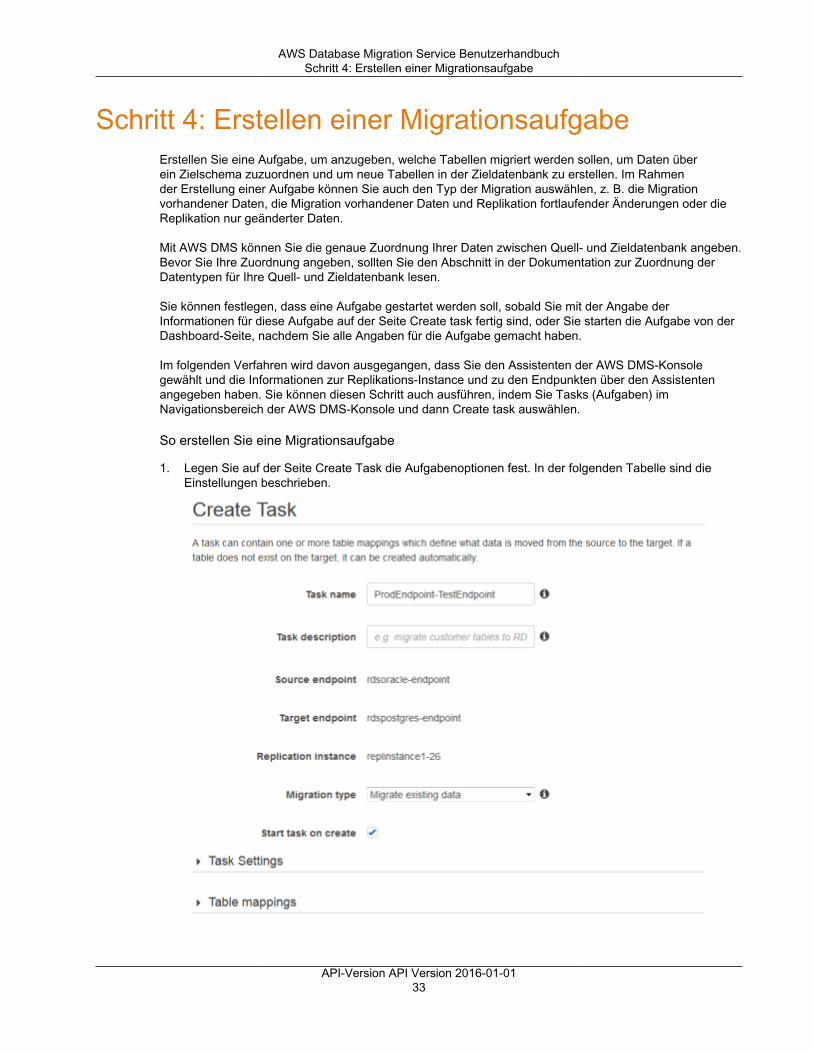
AWS Database Migration Service BenutzerhandbuchSchritt 4: Erstellen einer Migrationsaufgabe
Schritt 4: Erstellen einer MigrationsaufgabeErstellen Sie eine Aufgabe, um anzugeben, welche Tabellen migriert werden sollen, um Daten überein Zielschema zuzuordnen und um neue Tabellen in der Zieldatenbank zu erstellen. Im Rahmender Erstellung einer Aufgabe können Sie auch den Typ der Migration auswählen, z. B. die Migrationvorhandener Daten, die Migration vorhandener Daten und Replikation fortlaufender Änderungen oder dieReplikation nur geänderter Daten.
Mit AWS DMS können Sie die genaue Zuordnung Ihrer Daten zwischen Quell- und Zieldatenbank angeben.Bevor Sie Ihre Zuordnung angeben, sollten Sie den Abschnitt in der Dokumentation zur Zuordnung derDatentypen für Ihre Quell- und Zieldatenbank lesen.
Sie können festlegen, dass eine Aufgabe gestartet werden soll, sobald Sie mit der Angabe derInformationen für diese Aufgabe auf der Seite Create task fertig sind, oder Sie starten die Aufgabe von derDashboard-Seite, nachdem Sie alle Angaben für die Aufgabe gemacht haben.
Im folgenden Verfahren wird davon ausgegangen, dass Sie den Assistenten der AWS DMS-Konsolegewählt und die Informationen zur Replikations-Instance und zu den Endpunkten über den Assistentenangegeben haben. Sie können diesen Schritt auch ausführen, indem Sie Tasks (Aufgaben) imNavigationsbereich der AWS DMS-Konsole und dann Create task auswählen.
So erstellen Sie eine Migrationsaufgabe
1. Legen Sie auf der Seite Create Task die Aufgabenoptionen fest. In der folgenden Tabelle sind dieEinstellungen beschrieben.
API-Version API Version 2016-01-0133
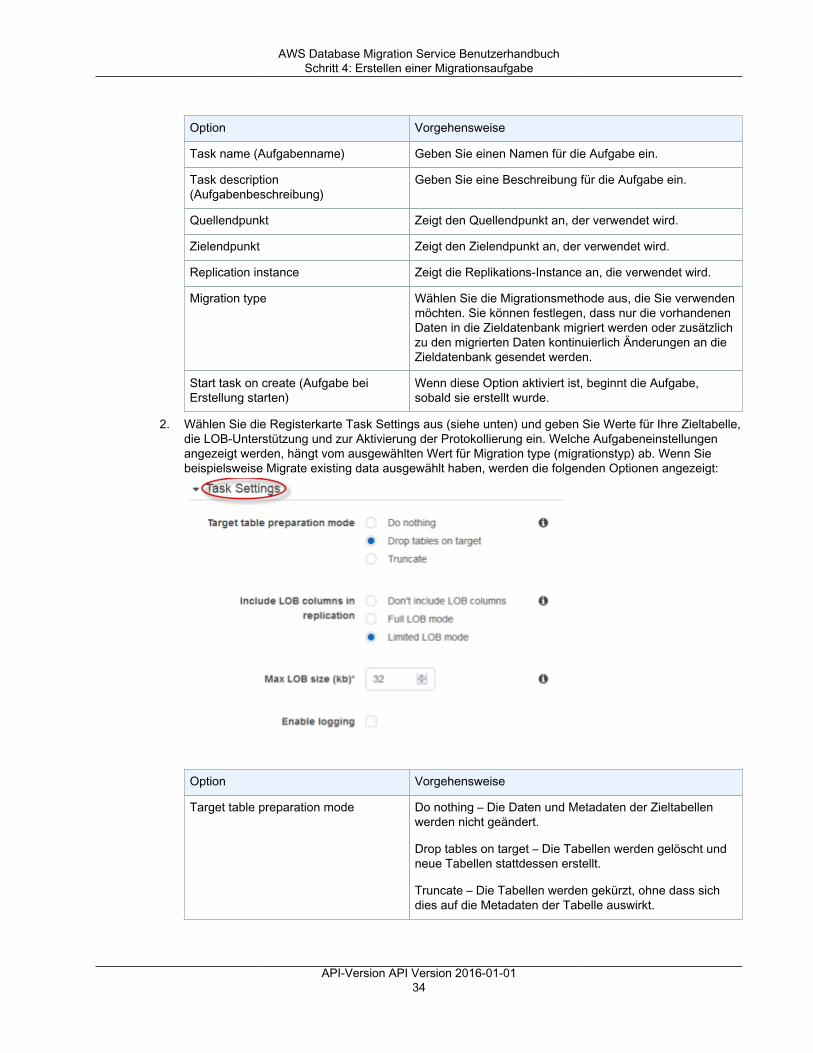
AWS Database Migration Service BenutzerhandbuchSchritt 4: Erstellen einer Migrationsaufgabe
Option Vorgehensweise
Task name (Aufgabenname) Geben Sie einen Namen für die Aufgabe ein.
Task description(Aufgabenbeschreibung)
Geben Sie eine Beschreibung für die Aufgabe ein.
Quellendpunkt Zeigt den Quellendpunkt an, der verwendet wird.
Zielendpunkt Zeigt den Zielendpunkt an, der verwendet wird.
Replication instance Zeigt die Replikations-Instance an, die verwendet wird.
Migration type Wählen Sie die Migrationsmethode aus, die Sie verwendenmöchten. Sie können festlegen, dass nur die vorhandenenDaten in die Zieldatenbank migriert werden oder zusätzlichzu den migrierten Daten kontinuierlich Änderungen an dieZieldatenbank gesendet werden.
Start task on create (Aufgabe beiErstellung starten)
Wenn diese Option aktiviert ist, beginnt die Aufgabe,sobald sie erstellt wurde.
2. Wählen Sie die Registerkarte Task Settings aus (siehe unten) und geben Sie Werte für Ihre Zieltabelle,die LOB-Unterstützung und zur Aktivierung der Protokollierung ein. Welche Aufgabeneinstellungenangezeigt werden, hängt vom ausgewählten Wert für Migration type (migrationstyp) ab. Wenn Siebeispielsweise Migrate existing data ausgewählt haben, werden die folgenden Optionen angezeigt:
Option Vorgehensweise
Target table preparation mode Do nothing – Die Daten und Metadaten der Zieltabellenwerden nicht geändert.
Drop tables on target – Die Tabellen werden gelöscht undneue Tabellen stattdessen erstellt.
Truncate – Die Tabellen werden gekürzt, ohne dass sichdies auf die Metadaten der Tabelle auswirkt.
API-Version API Version 2016-01-0134

AWS Database Migration Service BenutzerhandbuchSchritt 4: Erstellen einer Migrationsaufgabe
Option Vorgehensweise
Include LOB columns in replication Don't include LOB columns – Die LOB-Spalten sind vonder Migration ausgeschlossen.
Full LOB mode – Die LOBs werden vollständig migriert,unabhängig von ihrer Größe. LOBs werden stückweise inBlöcken migriert, je nach LOB-Blockgröße. Diese Methodeist langsamer als der Modus "Limited LOB Mode".
Limited LOB mode (Limitierter LOB-Modus) – Die LOBswerden auf die maximale LOB-Größe gekürzt. DieseMethode ist schneller als der Modus "Full LOB Mode".
Max LOB size (kb) Im Limited LOB Mode werden LOB-Spalten, die den Wertunter Max LOB Size überschreiten, auf die angegebenemaximale LOB-Größe gekürzt.
Enable logging (Protokollierungaktivieren)
Aktiviert die Protokollierung von Amazon CloudWatch.
Wenn Sie beispielsweise Migrate existing data and replicate (Vorhandene Daten migrieren undreplizieren) für Migration type (Migrationstyp) ausgewählt haben, werden die folgenden Optionenangezeigt:
API-Version API Version 2016-01-0135
AWS Database Migration Service BenutzerhandbuchSchritt 4: Erstellen einer Migrationsaufgabe
Option Vorgehensweise
Target table preparation mode Do nothing – Die Daten und Metadaten der Zieltabellenwerden nicht geändert.
Drop tables on target – Die Tabellen werden gelöscht undneue Tabellen stattdessen erstellt.
Truncate – Die Tabellen werden gekürzt, ohne dass sichdies auf die Metadaten der Tabelle auswirkt.
Stop task after full load completes Don't stop – Aufgabe nicht anhalten, zwischengespeicherteÄnderungen sofort anwenden und Vorgang fortsetzen.
Stop before applying cached changes – Die Aufgabe vorAnwendung der zwischengespeicherten Änderungenanhalten. So können Sie sekundäre Indizes hinzufügen,was die Anwendung von Änderungen möglicherweisebeschleunigt.
Stop after applying cached changes – Die Aufgabe nachAnwendung der zwischengespeicherten Änderungenanhalten. Dies ermöglicht Ihnen das Hinzufügen vonFremdschlüsseln, Auslösern usw., wenn Sie "TransactionalApply" (Transaktional anwenden) verwenden.
Include LOB columns in replication Don't include LOB columns – Die LOB-Spalten sind vonder Migration ausgeschlossen.
Full LOB mode – Die LOBs werden vollständig migriert,unabhängig von ihrer Größe. LOBs werden stückweise inBlöcken migriert, je nach LOB-Blockgröße. Diese Methodeist langsamer als der Modus "Limited LOB Mode".
Limited LOB mode (Limitierter LOB-Modus) – Die LOBswerden auf die maximale LOB-Größe gekürzt. DieseMethode ist schneller als der Modus "Full LOB Mode".
Max LOB size (kb) Im Limited LOB Mode werden LOB-Spalten, die den Wertunter Max LOB Size überschreiten, auf die angegebenemaximale LOB-Größe gekürzt.
Enable logging (Protokollierungaktivieren)
Aktiviert die Protokollierung von Amazon CloudWatch.
3. Wählen Sie die Registerkarte Table mappings (Tabellenzuweisungen) (siehe unten), um Werte für dieSchemazuweisung und Zuweisungsmethode festzulegen. Wenn Sie Custom wählen, können Sie dasZielschema und die Tabellenwerte angeben. Weitere Informationen zur Tabellenzuweisung finden Sieunter Verwenden der Tabellenzuweisung zum Angeben von Aufgabeneinstellungen (p. 372).
API-Version API Version 2016-01-0136
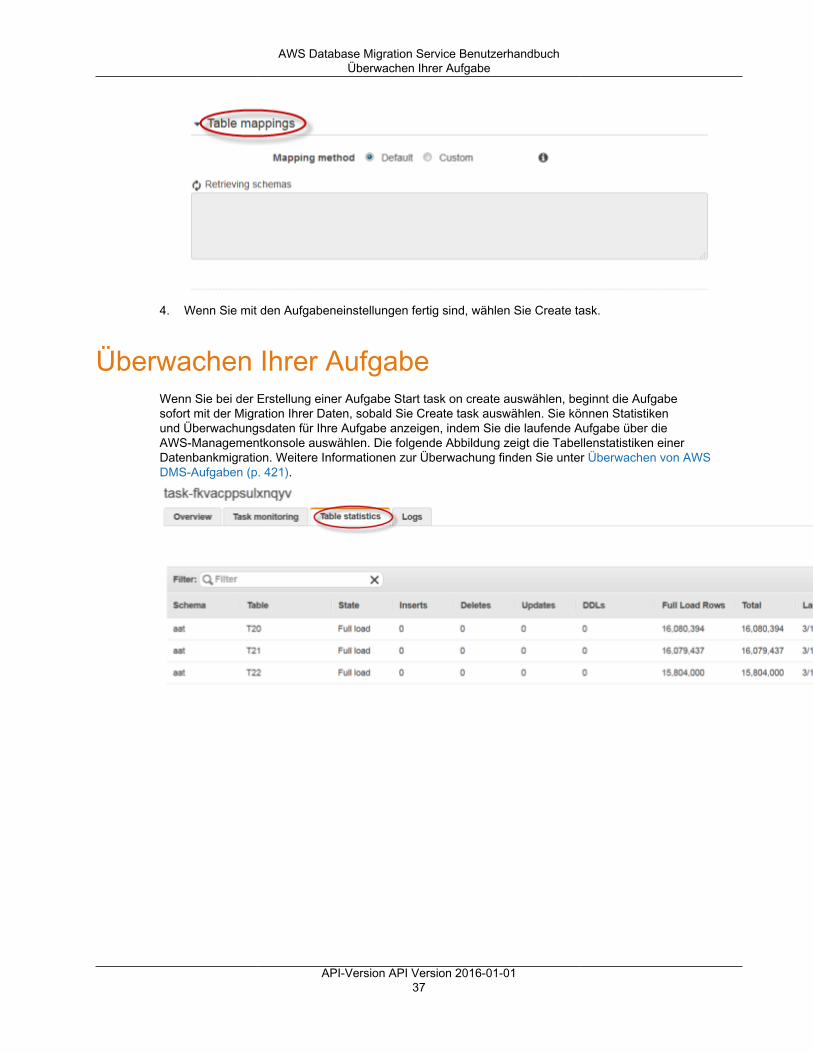
AWS Database Migration Service BenutzerhandbuchÜberwachen Ihrer Aufgabe
4. Wenn Sie mit den Aufgabeneinstellungen fertig sind, wählen Sie Create task.
Überwachen Ihrer AufgabeWenn Sie bei der Erstellung einer Aufgabe Start task on create auswählen, beginnt die Aufgabesofort mit der Migration Ihrer Daten, sobald Sie Create task auswählen. Sie können Statistikenund Überwachungsdaten für Ihre Aufgabe anzeigen, indem Sie die laufende Aufgabe über dieAWS-Managementkonsole auswählen. Die folgende Abbildung zeigt die Tabellenstatistiken einerDatenbankmigration. Weitere Informationen zur Überwachung finden Sie unter Überwachen von AWSDMS-Aufgaben (p. 421).
API-Version API Version 2016-01-0137

AWS Database Migration Service Benutzerhandbuch
Sicherheit in AWS DatabaseMigration Service
Cloud-Sicherheit hat bei AWS höchste Priorität. Als AWS-Kunde profitieren Sie von einer Rechenzentrums-und Netzwerkarchitektur, die eingerichtet wurde, um die Anforderungen der anspruchsvollstenOrganisationen in puncto Sicherheit zu erfüllen.
Sicherheit ist eine übergreifende Verantwortlichkeit zwischen AWS und Ihnen. Im Modell derübergreifenden Verantwortlichkeit wird Folgendes mit „Sicherheit der Cloud“ bzw. „Sicherheit in der Cloud“umschrieben:
• Sicherheit der Cloud selbst – AWS ist dafür verantwortlich, die Infrastruktur zu schützen, mit der AWS-Services in der AWS- Cloud ausgeführt werden. AWS stellt Ihnen außerdem Services bereit, die Siesicher nutzen können. Auditoren von Drittanbietern testen und überprüfen die Effektivität unsererSicherheitsmaßnahmen im Rahmen der AWS-Compliance-Programme regelmäßig. Informationen zuden Compliance-Programmen, die für AWS DMS gelten, finden Sie unter Vom Compliance-Programmabgedeckte AWS-Services.
• Sicherheit in der Cloud in – Ihr Verantwortungsumfang wird durch den AWS-Service bestimmt, den Sieverwenden. In Ihre Verantwortung fallen außerdem weitere Faktoren, wie z. B. die Vertraulichkeit derDaten, die Anforderungen Ihrer Organisation sowie geltende Gesetze und Vorschriften.
In dieser Dokumentation wird erläutert, wie das Modell der übergreifenden Verantwortlichkeit bei derVerwendung von AWS DMS zum Tragen kommt. Die folgenden Themen zeigen, wie Sie AWS DMS zurErfüllung Ihrer Sicherheits- und Compliance-Ziele konfigurieren können. Sie erfahren außerdem, wie Sieandere AWS-Services verwenden, um Ihre AWS DMS-Ressourcen zu überwachen und zu schützen.
Sie können den Zugriff auf Ihre AWS DMS-Ressourcen und Ihre Datenbanken (DBs) verwalten. DieMethode, die Sie zum Verwalten des Zugriffs verwenden, hängt von der Replikationsaufgabe ab, die Siemit AWS DMS ausführen müssen:
• Verwenden Sie AWS Identity and Access Management (IAM) -Richtlinien, um Berechtigungenzuzuweisen, die bestimmen, wer AWS DMS-Ressourcen verwalten darf. AWS DMS erfordert, dassSie über die entsprechenden Berechtigungen verfügen, wenn Sie sich als IAM-Benutzer anmelden.Beispielsweise können Sie IAM verwenden, um zu bestimmen, wer DB-Instances und Cluster erstellen,beschreiben, ändern und löschen, Ressourcen markieren oder Sicherheitsgruppen ändern darf. WeitereInformationen zu IAM und seiner Verwendung mit AWS DMS finden Sie unter Identity and AccessManagement für AWS Database Migration Service (p. 41).
• AWS DMS verwendet Secure Sockets Layer (SSL) für Ihre Endpunktverbindungen mit Transport LayerSecurity (TLS). Weitere Informationen zur Verwendung von SSL/TLS mit AWS DMS finden Sie unterVerwenden von SSL mit AWS Database Migration Service (p. 82).
• AWS DMS verwendet AWS Key Management Service (AWS KMS)-Verschlüsselungsschlüssel, um denvon Ihrer Replikations-Instance verwendeten Speicher und deren Endpunktverbindungsinformationenzu verschlüsseln. AWS DMS verwendet auch AWS KMS-Verschlüsselungsschlüssel, um IhreZieldaten im Ruhezustand für Amazon S3- und Amazon Redshift-Zielendpunkte zu sichern. WeitereInformationen finden Sie unter Einrichten eines Verschlüsselungsschlüssels und Angeben von AWSKMS-Berechtigungen (p. 79).
• AWS DMS erstellt Ihre Replikations-Instance immer in einer Virtual Private Cloud (VPC)basierend auf dem Amazon Virtual Private Cloud(Amazon VPC)-Service für die größtmöglicheNetzwerkzugriffskontrolle. Verwenden Sie für Ihre DB-Instances und Instance-Cluster dieselbe VPC wieIhre Replikations-Instance oder zusätzliche VPCs, um diese Zugriffskontrolle zu erreichen. Jeder von
API-Version API Version 2016-01-0138

AWS Database Migration Service BenutzerhandbuchDatenschutz
Ihnen verwendete Amazon VPC muss einer Sicherheitsgruppe zugeordnet sein, die Regeln enthält, mitdenen der gesamte Datenverkehr auf allen Ports die VPC verlassen kann. Dieser Ansatz ermöglicht dieKommunikation von der Replikations-Instance zu Ihren Quell- und Zieldatenbankendpunkten, sofern aufdiesen Endpunkten korrekte Eingangsregeln aktiviert sind.
Weitere Hinweise zu verfügbaren Netzwerkkonfigurationen für AWS DMS finden Sie unter Einrichteneines Netzwerks für eine Replikations-Instance (p. 103). Weitere Informationen zum Erstellen einer DB-Instance oder eines Instance-Clusters in einer VPC finden Sie in der Dokumentation zur Sicherheits- undClusterverwaltung für Ihre Amazon-Datenbanken unter AWS-Dokumentation. Weitere Hinweise zu vonAWS DMS unterstützten Netzwerkkonfigurationen finden Sie unter Einrichten eines Netzwerks für eineReplikations-Instance (p. 103).
• Um Datenbankmigrationsprotokolle anzuzeigen, benötigen Sie die entsprechenden Amazon CloudWatchLogs-Berechtigungen für die verwendete IAM-Rolle. Weitere Informationen zur Protokollierung für AWSDMS finden Sie unter Überwachen von Replikationsaufgaben mit Amazon CloudWatch (p. 423).
Themen• Datenschutz in AWS Database Migration Service (p. 39)• Identity and Access Management für AWS Database Migration Service (p. 41)• Protokollierung und Überwachung in AWS Database Migration Service (p. 62)• Compliance-Validierung für AWS Database Migration Service (p. 63)• Ausfallsicherheit in AWS Database Migration Service (p. 64)• Infrastruktursicherheit in AWS Database Migration Service (p. 65)• Erforderliche IAM-Berechtigungen zur Verwendung von AWS DMS (p. 65)• Erstellen der IAM-Rollen für die Verwendung mit der AWS CLI- und AWS DMS-API (p. 68)• Differenzierte Zugriffskontrolle mit Ressourcennamen und Ressourcen-Tags (p. 72)• Einrichten eines Verschlüsselungsschlüssels und Angeben von AWS KMS-Berechtigungen (p. 79)• Netzwerksicherheit für AWS Database Migration Service (p. 81)• Verwenden von SSL mit AWS Database Migration Service (p. 82)• Ändern des Datenbankpassworts (p. 91)
Datenschutz in AWS Database Migration ServiceAWS DMS entspricht dem AWS-Modell der übergreifenden Verantwortlichkeit, das Richtlinien undLeitfäden für den Datenschutz umfasst. AWS ist für den Schutz der globalen Infrastruktur verantwortlich,die alle AWS-Services ausführt. AWS behält die Kontrolle über die in der Infrastruktur gehostetenDaten, einschließlich Sicherheitskonfigurationskontrollen für die Handhabung von Kundeninhalten undpersonenbezogenen Daten. AWS-Kunden und AWS Partner Network (APN)-Partner agieren entweder alsDatenverantwortliche oder Datenverarbeiter und sind für alle personenbezogenen Daten verantwortlich, diesie in der AWS-Cloud platzieren.
Für den Datenschutz empfehlen wir, dass Sie AWS-Kontoanmeldeinformationen schützen und Prinzipalemit AWS Identity and Access Management (IAM) einrichten. Auf diese Weise erhält jeder Benutzer nur dieBerechtigungen, die zum Durchführen seiner Aufgaben erforderlich sind. Außerdem sollten Sie die Datenmit folgenden Methoden schützen:
• Verwenden Sie für jedes Konto die Multi-Factor Authentication (MFA).• Verwenden Sie SSL/TLS für die Kommunikation mit AWS-Ressourcen.• Richten Sie die API und die Protokollierung von Benutzeraktivitäten mit AWS CloudTrail ein.• Verwenden Sie AWS-Verschlüsselungslösungen zusammen mit allen Standardsicherheitskontrollen in
AWS-Services.
API-Version API Version 2016-01-0139

AWS Database Migration Service BenutzerhandbuchDatenverschlüsselung
• Verwenden Sie erweiterte verwaltete Sicherheits-Services wie Amazon Macie, um Unterstützung bei derErkennung und beim Schutz von persönlichen Daten zu erhalten, die in Amazon S3 gespeichert sind.
Wir empfehlen dringend, in Freitextfeldern einer Datenbank keine sensiblen, identifizierenden Informationenwie Kontonummern von Kunden einzugeben. Diese Empfehlung gilt insbesondere, wenn Sie mit AWS-Datenbankservices arbeiten, die als AWS DMS-Quellendpunkte von der Konsole, der API, AWS CLIoder AWS-SDKs verwendet werden. Alle Daten, die Sie in diese Datenbankservices eingeben, werdenmöglicherweise in Diagnoseprotokolle aufgenommen. Wenn Sie eine URL für einen externen Serverbereitstellen, schließen Sie keine Anmeldeinformationen zur Validierung Ihrer Anfrage an den betreffendenServer in die URL ein.
Weitere Informationen zum Datenschutz enthält der Blog-Beitrag AWS Shared Responsibility Model andGDPR im AWS-Sicherheitsblog.
DatenverschlüsselungSie können die Verschlüsselung für Datenressourcen unterstützter AWS DMS-Zielendpunkte aktivieren.AWS DMS verschlüsselt auch Verbindungen zu AWS DMS und zwischen AWS DMS und allen seinenQuell- und Zielendpunkten. Darüber hinaus können Sie die Schlüssel verwalten, die AWS DMS und dieunterstützten Zielendpunkte verwenden, um diese Verschlüsselung zu aktivieren.
Themen• Verschlüsselung im Ruhezustand (p. 40)• Verschlüsselung während der Übertragung (p. 40)• Schlüsselverwaltung (p. 41)
Verschlüsselung im RuhezustandAWS DMS unterstützt die Verschlüsselung im Ruhezustand, indem Sie den serverseitigenVerschlüsselungsmodus angeben können, in dem Sie die replizierten Daten zu Amazon S3übertragen möchten, bevor sie auf unterstützte AWS DMS-Zielendpunkte kopiert werden. Siekönnen diesen Verschlüsselungsmodus angeben, indem Sie das zusätzliche encryptionMode-Verbindungsattribut für den Endpunkt festlegen. Wenn diese encryptionMode-Einstellung den KMS-Schlüsselverschlüsselungsmodus angibt, können Sie auch benutzerdefinierte KMS-Schlüssel speziell zumVerschlüsseln der Zieldaten für die folgenden AWS DMS-Zielendpunkte erstellen:
• Amazon Redshift – Weitere Informationen zum Einstellen von encryptionMode finden Sieunter Zusätzliche Verbindungsattribute bei der Verwendung von Amazon Redshift als Zielfür AWS DMS (p. 239). Weitere Hinweise zum Erstellen eines benutzerdefinierten KMS-Verschlüsselungsschlüssels finden Sie unter Erstellen und Verwenden von AWS KMS-Schlüsseln für dieVerschlüsselung von Amazon Redshift-Zieldaten (p. 234).
• Amazon S3 – Weitere Informationen zum Einstellen von encryptionMode finden Sie unter ZusätzlicheVerbindungsattribute bei der Verwendung von Amazon S3 als Ziel für AWS DMS (p. 260). WeitereHinweise zum Erstellen eines benutzerdefinierten KMS-Verschlüsselungsschlüssels finden Sie unterErstellen von AWS KMS-Schlüsseln zum Verschlüsseln von Amazon S3-Zielobjekten (p. 254).
Verschlüsselung während der ÜbertragungAWS DMS unterstützt die Verschlüsselung während der Übertragung, indem sichergestellt wird, dassdie replizierten Daten sicher vom Quellendpunkt zum Zielendpunkt verschoben werden. Dazu gehörtdas Verschlüsseln eines S3-Buckets auf der Replikations-Instance, die Ihre Replikationsaufgabe fürZwischenspeicher verwendet, wenn die Daten durch die Replikationspipeline verschoben werden. ZumVerschlüsseln von Aufgabenverbindungen zu Quell- und Zielendpunkten verwendet AWS DMS Secure
API-Version API Version 2016-01-0140

AWS Database Migration Service BenutzerhandbuchRichtlinie für den Datenverkehr zwischen Netzwerken
Socket Layer (SSL) mit Transport Layer Security (TLS). Durch die Verschlüsselung von Verbindungenzu beiden Endpunkten stellt AWS DMS sicher, dass Ihre Daten sicher sind, wenn sie sowohl vomQuellendpunkt zur Replikationsaufgabe als auch von der Aufgabe zum Zielendpunkt verschoben werden.Weitere Informationen zur Verwendung von SSL/TLS mit AWS DMS finden Sie unter Verwenden von SSLmit AWS Database Migration Service (p. 82).
AWS DMS unterstützt sowohl Standard- als auch benutzerdefinierte Schlüssel, um sowohlZwischenreplikationsspeicher als auch Verbindungsinformationen zu verschlüsseln. Sieverwalten diese Schlüssel mit AWS KMS. Weitere Informationen finden Sie unter Einrichten einesVerschlüsselungsschlüssels und Angeben von AWS KMS-Berechtigungen (p. 79).
SchlüsselverwaltungAWS DMS unterstützt Standard- oder benutzerdefinierte Schlüssel zum Verschlüsseln desReplikationsspeichers, der Verbindungsinformationen und des Zieldatenspeichers für bestimmteZielendpunkte. Sie verwalten diese Schlüssel mit AWS KMS. Weitere Informationen finden Sie unterEinrichten eines Verschlüsselungsschlüssels und Angeben von AWS KMS-Berechtigungen (p. 79).
Richtlinie für den Datenverkehr zwischen NetzwerkenVerbindungen werden mit einem Schutz zwischen AWS DMS-Quell- und Zielendpunkten in derselbenAWS-Region bereitgestellt, unabhängig davon, ob sie On-Premise oder als Teil eines AWS-Services in derCloud ausgeführt werden. (Mindestens ein Endpunkt, eine Quelle oder ein Ziel muss als Teil eines AWS-Services in der Cloud ausgeführt werden.) Dieser Schutz gilt, unabhängig davon, ob diese Komponentendieselbe Virtual Private Cloud (VPC) verwenden oder in separaten VPCs existieren, wenn sich die VPCsalle in derselben AWS-Region befinden. Weitere Hinweise zu den unterstützten Netzwerkkonfigurationenfür AWS DMS finden Sie unter Einrichten eines Netzwerks für eine Replikations-Instance (p. 103).Weitere Hinweise zu Sicherheitsüberlegungen bei der Verwendung dieser Netzwerkkonfigurationen findenSie unter Netzwerksicherheit für AWS Database Migration Service (p. 81).
Identity and Access Management für AWSDatabase Migration Service
AWS Identity and Access Management (IAM) ist ein AWS-Service, der Administratoren bei der sicherenKontrolle des Zugriffs auf AWS-Ressourcen unterstützt. IAM-Administratoren steuern, wer zur Verwendungvon AWS DMS-Ressourcen authentifiziert (angemeldet) und autorisiert (berechtigt) werden kann. IAM istein AWS-Service, den Sie ohne zusätzliche Kosten nutzen können.
Themen• Zielgruppe (p. 41)• Authentifizieren mit Identitäten (p. 42)• Verwalten des Zugriffs mit Richtlinien (p. 44)• Funktionsweise von AWS Database Migration Service mit IAM (p. 46)• Beispiele für identitätsbasierte AWS Database Migration Service-Richtlinien (p. 50)• Beispiele für eine ressourcenbasierte Richtlinie für AWS KMS (p. 56)• Fehlerbehebung bei AWS Database Migration Service-Identität und -Zugriff (p. 60)
ZielgruppeWie Sie AWS Identity and Access Management (IAM) verwenden, unterscheidet sich je nach Ihrer Arbeit inAWS DMS.
API-Version API Version 2016-01-0141

AWS Database Migration Service BenutzerhandbuchAuthentifizieren mit Identitäten
Service-Benutzer – Wenn Sie den AWS DMS-Service verwenden, stellt Ihnen Ihr Administrator dieerforderlichen Anmeldeinformationen und Berechtigungen bereit. Wenn Sie für Ihre Arbeit weitere AWSDMS-Funktionen ausführen, benötigen Sie möglicherweise zusätzliche Berechtigungen. Wenn Sie dieFunktionsweise der Zugriffskontrolle verstehen, kann Ihnen dies helfen, die richtigen Berechtigungen vonIhrem Administrator anzufordern. Unter Fehlerbehebung bei AWS Database Migration Service-Identität und-Zugriff (p. 60) finden Sie nützliche Informationen für den Fall, dass Sie keinen Zugriff auf eine Funktionin AWS DMS haben.
Service-Administrator – Wenn Sie in Ihrem Unternehmen die Verantwortung für AWS DMS-Ressourcenhaben, haben Sie wahrscheinlich vollständigen Zugriff auf AWS DMS. Ihre Aufgabe besteht darin, dieAWS DMS-Funktionen und -Ressourcen festzulegen, auf die Mitarbeiter zugreifen können sollten. Siemüssen anschließend bei Ihrem IAM-Administrator entsprechende Änderungen für die BerechtigungenIhrer Service-Benutzer anfordern. Lesen Sie die Informationen auf dieser Seite, um die Grundkonzepte vonIAM zu verstehen. Weitere Informationen dazu, wie Ihr Unternehmen IAM mit AWS DMS verwenden kann,finden Sie unter Funktionsweise von AWS Database Migration Service mit IAM (p. 46).
IAM Administrator – Wenn Sie als IAM-Administrator fungieren, sollten Sie Einzelheiten dazu kennen, wieSie Richtlinien zur Verwaltung des Zugriffs auf AWS DMS verfassen können. Beispiele für identitätsbasierteAWS DMS-Richtlinien, die Sie in IAM verwenden können, finden Sie unter Beispiele für identitätsbasierteAWS Database Migration Service-Richtlinien (p. 50).
Authentifizieren mit IdentitätenDie Authentifizierung ist die Art und Weise, wie Sie sich mit Ihren Anmeldeinformationen bei AWSanmelden. Weitere Informationen zum Anmelden über die AWS Management Console finden Sie unter DieIAM-Konsole und -Anmeldeseite im IAM-Benutzerhandbuch.
Sie müssen als Stammbenutzer des AWS-Kontos, als IAM-Benutzer oder durch Übernahme einer IAM-Rolle authentifiziert (bei AWS angemeldet) sein. Sie können auch die Single-Sign-on-AuthentifizierungIhres Unternehmens verwenden oder sich sogar über Google oder Facebook anmelden. In diesen Fällenhat Ihr Administrator vorher einen Identitätsverbund unter verwendung von IAM-Rollen eingerichtet. WennSie mit Anmeldeinformationen eines anderen Unternehmens auf AWS zugreifen, nehmen Sie indirekt eineRolle an.
Verwenden Sie zur direkten Anmeldung bei AWS Management Console Ihr Kennwort mit Ihrer Root-Benutzer-E-Mail-Adresse oder Ihrem IAM-Benutzernamen. Sie können auf AWS programmgesteuertoder mit Ihren Root-Benutzer- oder IAM-Benutzerzugriffsschlüsseln zugreifen. AWS stellt SDK- undBefehlszeilen-Tools bereit, mit denen Ihre Anforderung anhand Ihrer Anmeldeinformationen kryptografischsigniert wird. Wenn Sie keine AWS-Tools verwenden, müssen Sie die Anforderung selbst signieren.Hierzu verwenden Sie Signature Version 4, ein Protokoll für die Authentifizierung eingehender API-Anforderungen. Weitere Informationen zur Authentifizierung von Anfragen finden Sie unter SignatureVersion 4-Signaturprozess im AWS General Reference.
Unabhängig von der von Ihnen verwendeten Authentifizierungsmethode müssen Sie möglicherweise auchzusätzliche Sicherheitsinformationen angeben. AWS empfiehlt beispielsweise die Verwendung von Multi-Factor Authentication (MFA), um die Sicherheit Ihres Kontos zu verbessern. Weitere Informationen findenSie unter Verwenden der Multi-Factor Authentication (MFA) in AWS im IAM-Benutzerhandbuch.
Stammbenutzer des AWS-KontosWenn Sie ein AWS-Konto neu erstellen, enthält es zunächst nur eine einzelne Anmeldeidentität, die überVollzugriff auf sämtliche AWS-Services und -Ressourcen im Konto verfügt. Diese Identität wird als Root-Benutzer des AWS-Kontos bezeichnet. Um auf es zuzugreifen, müssen Sie sich mit der E-Mail-Adresseund dem Passwort anmelden, die zur Erstellung des Kontos verwendet wurden. Wir raten ausdrücklichdavon ab, den Root-Benutzer für Alltagsaufgaben einschließlich administrativen Aufgaben zu verwenden.Bleiben Sie stattdessen bei der bewährten Methode, den Root-Benutzer nur zu verwenden, um Ihrenersten IAM-Benutzer zu erstellen. Anschließend legen Sie die Anmeldedaten für den Root-Benutzer
API-Version API Version 2016-01-0142

AWS Database Migration Service BenutzerhandbuchAuthentifizieren mit Identitäten
an einem sicheren Ort ab und verwenden ihn nur, um einige Konto- und Service-Verwaltungsaufgabendurchzuführen.
IAM-Benutzer und -GruppenEin IAM-Benutzer ist eine Entität in Ihrem AWS-Konto mit bestimmten Berechtigungen für eine einzelnePerson oder eine einzelne Anwendung. Ein IAM-Benutzer kann langfristige Anmeldeinformationen wieBenutzername und Kennwort oder einen Satz von Zugriffsschlüsseln haben. Informationen zum Generierenvon Zugriffsschlüsseln finden Sie unter Verwalten von Zugriffsschlüsseln für IAM-Benutzer im IAM-Benutzerhandbuch. Achten Sie beim Generieren von Zugriffsschlüsseln für einen IAM-Benutzer darauf,dass Sie das Schlüsselpaar anzeigen und sicher speichern. Sie können den geheimen Zugriffsschlüsselspäter nicht wiederherstellen. Stattdessen müssen Sie ein neues Zugriffsschlüsselpaar generieren.
Ein IAM-Gruppe ist eine Identität, die eine Sammlung von IAM.Benutzern angibt. Sie können sich nichtals Gruppe anmelden. Mithilfe von Gruppen können Sie Berechtigungen für mehrere Benutzer gleichzeitigangeben. Gruppen vereinfachen die Verwaltung von Berechtigungen, wenn es zahlreiche Benutzer gibt.Sie könnten beispielsweise einer Gruppe mit dem Namen IAMAdmins Berechtigungen zum Verwalten vonIAM-Ressourcen erteilen.
Benutzer unterscheiden sich von Rollen. Ein Benutzer ist einer einzigen Person oder Anwendung eindeutigzugeordnet. Eine Rolle kann von allen Personen angenommen werden, die sie benötigen. Benutzerbesitzen permanente langfristige Anmeldeinformationen. Rollen stellen temporäre Anmeldeinformationenbereit. Weitere Informationen finden Sie unter Erstellen eines IAM-Benutzers (anstelle einer Rolle) im IAM-Benutzerhandbuch.
IAM-RollenEine IAMRolle ist eine Entität in Ihrem AWS-Konto mit spezifischen Berechtigungen. Sie ist einem IAM-Benutzer vergleichbar, jedoch nicht mit einer bestimmten Person verknüpft. Sie können eine AWSManagement Console-Rolle vorübergehend in der IAM annehmen, indem Sie Rollen wechseln. Siekönnen eine Rolle annehmen, indem Sie eine AWS CLI- oder AWS-API-Operation aufrufen oder einebenutzerdefinierte URL verwenden. Weitere Informationen zu Methoden für die Verwendung von Rollenfinden Sie unter Verwenden von IAM-Rollen im IAM-Benutzerhandbuch.
IAM-Rollen mit temporären Anmeldeinformationen sind in folgenden Situationen hilfreich:
• Temporäre IAM-Benutzerberechtigungen – Ein IAM-Benutzer kann eine IAM-Rolle annehmen, umvorübergehend andere Berechtigungen für eine bestimmte Aufgabe zu erhalten.
• Zugriff für verbundene Benutzer –Statt einen IAM-Benutzer zu erstellen, können Sie vorhandeneIdentitäten von AWS Directory Service, aus Ihrem Unternehmens-Benutzerverzeichnis oder von einemWeb-Identitätsanbieter verwenden. Diese werden als verbundene Benutzer bezeichnet. AWS weisteinem verbundenen Benutzer eine Rolle zu, wenn der Zugriff über einen Identitätsanbieter angefordertwird. Weitere Informationen zu verbundenen Benutzern finden Sie unter Verbundene Benutzer undRollen im IAM-Benutzerhandbuch.
• Kontenübergreifender Zugriff–: Sie können eine IAM-Rolle verwenden, um einem vertrauenswürdigenPrinzipal in einem anderen Konto den Zugriff auf Ressourcen in Ihrem Konto zu ermöglichen. Rollensind die primäre Möglichkeit, um kontoübergreifenden Zugriff zu gewähren. In einigen AWS-Serviceskönnen Sie jedoch eine Richtlinie direkt an eine Ressource anfügen (anstatt eine Rolle als Proxyzu verwenden). Informationen zu den Unterschieden zwischen Rollen und ressourcenbasiertenRichtlinien für den kontenübergreifenden Zugriff finden Sie unter So unterscheiden sich IAM-Rollen vonressourcenbasierten Richtlinien im IAM-Benutzerhandbuch.
• AWS-Service-Zugriff –Eine Servicerolle ist eine IAM-Rolle, die ein Service übernimmt, um Aktionenin Ihrem Konto für Sie auszuführen. Beim Einrichten einiger AWS-Serviceumgebungen müssen Sieeine Rolle für den zu übernehmenden Service definieren. Diese Servicerolle muss alle für den Serviceerforderlichen Berechtigungen für den Zugriff auf die AWS-Ressourcen, die erforderlich sind, enthalten.Servicerollen unterscheiden sich von Service zu Service, aber viele erlauben Ihnen, Ihre Berechtigungenauszuwählen, solange Sie die dokumentierten Anforderungen für diesen Service erfüllen. Service-Rollen
API-Version API Version 2016-01-0143

AWS Database Migration Service BenutzerhandbuchVerwalten des Zugriffs mit Richtlinien
bieten nur Zugriff innerhalb Ihres Kontos und können nicht genutzt werden, um Zugriff auf Services inanderen Konten zu erteilen. Sie können eine Servicerolle in IAM erstellen, ändern und löschen. Siekönnen beispielsweise eine Rolle erstellen, mit der Amazon Redshift in Ihrem Namen auf einen AmazonS3-Bucket zugreifen und Daten aus diesem Bucket in einen Amazon Redshift-Cluster laden kann.Weitere Informationen finden Sie unter Erstellen einer Rolle zum Delegieren von Berechtigungen aneinen AWS-Service im IAM-Benutzerhandbuch.
• Auf Amazon EC2 ausgeführte Anwendungen – Sie können eine IAM-Rolle nutzen, um temporäreAnmeldeinformationen für Anwendungen zu verwalten, die auf einer EC2-Instance ausgeführtwerden und AWS CLI- oder AWS-API-Anforderungen durchführen. Das ist empfehlenswerter alsZugriffsschlüssel innerhalb der EC2 Instance zu speichern. Erstellen Sie ein Instance-Profil, das an dieInstance angefügt ist, um eine AWS-Rolle einer EC2-Instance zuzuweisen und die Rolle für sämtlicheAnwendungen der Instance bereitzustellen. Ein Instance-Profil enthält die Rolle und ermöglicht, dassProgramme, die in der EC2-Instance ausgeführt werden, temporäre Anmeldeinformationen erhalten.Weitere Informationen finden Sie unter Verwenden einer IAM-Rolle zum Erteilen von Berechtigungen fürAnwendungen, die auf Amazon EC2-Instances ausgeführt werden im IAM-Benutzerhandbuch.
Informationen dazu, wann Sie IAM-Rollen verwenden sollten, finden Sie unter Wann Sie eine IAM-Rolle(statt eines Benutzers) erstellen sollten im IAM-Benutzerhandbuch.
Verwalten des Zugriffs mit RichtlinienFür die Zugriffssteuerung in AWS erstellen Sie Richtlinien und weisen sie den IAM-Identitäten oderAWS-Ressourcen zu. Eine Richtlinie ist ein Objekt in AWS, das, wenn es einer Identität oder Ressourcezugeordnet wird, deren Berechtigungen definiert. AWS wertet diese Richtlinien aus, wenn eine Entität(Root-Benutzer, IAM-Benutzer oder IAM-Rolle) eine Anforderung stellt. Berechtigungen in den Richtlinienbestimmen, ob die Anforderung zugelassen oder abgelehnt wird. Die meisten Richtlinien werden inAWS als JSON-Dokumente gespeichert. Weitere Informationen zu Struktur und Inhalten von JSON-Richtliniendokumenten finden Sie unter Übersicht über JSON-Richtlinien im IAM-Benutzerhandbuch.
Ein IAM-Administrator kann mithilfe von Richtlinien die Benutzer, die auf AWS-Ressourcen zugreifenkönnen, und die Aktionen, die diese für diese Ressourcen ausführen dürfen, angeben. Eine IAM-Entität (Benutzer oder Rolle) besitzt zunächst keine Berechtigungen. Anders ausgedrückt, könnenBenutzer standardmäßig keine Aktionen ausführen und nicht einmal ihr Kennwort ändern. Um einemBenutzer die Berechtigung für eine Aktion zu erteilen, muss ein Administrator einem Benutzer eineBerechtigungsrichtlinie zuweisen. Alternativ kann der Administrator den Benutzer zu einer Gruppehinzufügen, die über die gewünschten Berechtigungen verfügt. Wenn ein Administrator einer GruppeBerechtigungen erteilt, erhalten alle Benutzer in dieser Gruppe diese Berechtigungen.
IAM-Richtlinien definieren Berechtigungen für eine Aktion unabhängig von der Methode, die Sie zurAusführung der Aktion verwenden. Angenommen, es gibt eine Richtlinie, die Berechtigungen für dieiam:GetRole-Aktion erteilt. Ein Benutzer mit dieser Richtlinie kann Benutzer informationen über die AWSManagement Console, die AWS CLI oder die AWS-API abrufen.
Identitätsbasierte RichtlinienIdentitätsbasierte Richtlinien sind JSON-Berechtigungsrichtliniendokumente, die Sie einem Prinzipal (odereiner Identität) anfügen können, wie z. B.IAM-Benutzer, -Rollen oder -Gruppen. Diese Richtlinien steuern,welche Aktionen diese Identität für welche Ressourcen und unter welchen Bedingungen ausführen kann.Informationen zum Erstellen identitätsbasierter Richtlinien finden Sie unter Erstellen von IAM-Richtlinien imIAM-Benutzerhandbuch.
Identitätsbasierte Richtlinien können weiter als Inline-Richtlinien oder verwaltete Richtlinien kategorisiertwerden. Inline-Richtlinien sind direkt in einen einzelnen Benutzer, eine einzelne Gruppe oder eine einzelneRolle eingebettet. Verwaltete Richtlinien sind eigenständige Richtlinien, die Sie mehreren Benutzern,Gruppen und Rollen in Ihrem AWS-Konto anfügen können. Verwaltete Richtlinien umfassen von AWSverwaltete und von Kunden verwaltete Richtlinien. Informationen dazu, wie Sie zwischen einer verwalteten
API-Version API Version 2016-01-0144

AWS Database Migration Service BenutzerhandbuchVerwalten des Zugriffs mit Richtlinien
Richtlinie und einer Inline-Richtlinie wählen, finden Sie unter Wählen zwischen verwalteten und Inline-Richtlinien im IAM-Benutzerhandbuch.
Ressourcenbasierte RichtlinienRessourcenbasierte Richtlinien sind JSON-Richtliniendokumente, die Sie an eine Ressource wie z. B.einen Amazon S3-Bucket anfügen. Serviceadministratoren können mit diesen Richtlinien festlegen,welche Aktionen ein angegebener Prinzipal (Kontomitglied, Benutzer oder Rolle) für diese Ressourcedurchführen kann, und unter welchen Bedingungen dies möglich ist. Ressourcenbasierte Richtlinien sindInline-Richtlinien. Es gibt keine verwalteten ressourcenbasierte Richtlinien.
Zugriffskontrolllisten (ACLs)Zugriffskontrolllisten (ACLs) sind ein Richtlinientyp, mit dem gesteuert wird, welche Prinzipale(Kontomitglieder, Benutzer oder Rollen) die Berechtigung für den Zugriff auf eine Ressource haben. ACLssind ähnlich wie ressourcenbasierte Richtlinien, obwohl sie das JSON-Richtliniendokumentformat nichtverwenden. Amazon S3, AWS WAF und Amazon VPC sind Beispiele für Services, die ACLs unterstützen.Weitere Informationen zu ACLs finden Sie unter Zugriffskontrollliste (ACL) – Übersicht im Amazon SimpleStorage Service-Entwicklerhandbuch.
Weitere RichtlinientypenAWS unterstützt zusätzliche, weniger häufig verwendete Richtlinientypen. Diese Richtlinientypen könnendie maximalen Berechtigungen festlegen, die Ihnen von den häufiger verwendeten Richtlinientypen erteiltwerden können.
• Berechtigungsgrenzen – Eine Berechtigungsgrenze ist eine erweiterte Funktion, mit der Sie diemaximalen Berechtigungen festlegen können, die eine identitätsbasierte Richtlinie einer IAM-Entität(IAM-Benutzer oder Rolle) erteilen kann. Sie können eine Berechtigungsgrenze für eine Entität festlegen.Die resultierenden Berechtigungen sind eine Schnittmenge der identitätsbasierten Richtlinien derEntität und ihrer Berechtigungsgrenzen. Ressourcenbasierte Richtlinien, die den Benutzer oder dieRolle im Feld Principal angeben, werden nicht durch Berechtigungsgrenzen eingeschränkt. Eineexplizite Zugriffsverweigerung in einer dieser Richtlinien setzt eine Zugriffserlaubnis außer Kraft. WeitereInformationen zu Berechtigungsgrenzen finden Sie unter Berechtigungsgrenzen für IAM-Entitäten imIAM-Benutzerhandbuch.
• Service-Kontrollrichtlinien (Service Control Policies, SCPs) – SCPs sind JSON-Richtlinien, die diemaximalen Berechtigungen für eine Organisation oder Organisationseinheit (Organization Unit,OU) in AWS Organizations angeben. AWS Organizations ist ein Service für die Gruppierung undzentrale Verwaltung der AWS-Konten Ihres Unternehmens. Wenn Sie innerhalb einer Organisationalle Funktionen aktivieren, können Sie Service-Kontrollrichtlinien (SCPs) auf alle oder einzelne IhrerKonten anwenden. SCPs schränken Berechtigungen für Entitäten in Mitgliedskonten einschließlich desjeweiligen Stammbenutzer des AWS-Kontos ein. Weitere Informationen zu Organisationen und SCPsfinden Sie unter Funktionsweise von SCPs im AWS Organizations-Benutzerhandbuch.
• Sitzungsrichtlinien – Sitzungsrichtlinien sind erweiterte Richtlinien, die Sie als Parameter übergeben,wenn Sie eine temporäre Sitzung für eine Rolle oder einen verbundenen Benutzer programmgesteuerterstellen. Die resultierenden Sitzungsberechtigungen sind eine Schnittmenge der auf der Identität desBenutzers oder der Rolle basierenden Richtlinien und der Sitzungsrichtlinien. Berechtigungen könnenauch aus einer ressourcenbasierten Richtlinie stammen. Eine explizite Zugriffsverweigerung in einerdieser Richtlinien setzt eine Zugriffserlaubnis außer Kraft. Weitere Informationen finden Sie unterSitzungsrichtlinien im IAM-Benutzerhandbuch.
Mehrere RichtlinientypenWenn mehrere auf eine Anforderung mehrere Richtlinientypen angewendet werden können, sind dieentsprechenden Berechtigungen komplizierter. Informationen dazu, wie AWS die Zuässigkeit einer
API-Version API Version 2016-01-0145

AWS Database Migration Service BenutzerhandbuchFunktionsweise von AWS Database
Migration Service mit IAM
Anforderung ermittelt, wenn mehrere Richtlinientypen beteiligt sind, finden Sie unter Logik für dieRichtlinienauswertung im IAM-Benutzerhandbuch.
Funktionsweise von AWS Database Migration Servicemit IAMBevor Sie IAM zum Verwalten des Zugriffs auf AWS DMS verwenden, sollten Sie verstehen, welcheIAM-Funktionen für die Verwendung mit AWS DMS verfügbar sind. Eine Übersicht darüber, wie AWSDMS und andere AWS-Services mit IAM funktionieren, finden Sie unter AWS-Services IAM im IAM-Benutzerhandbuch.
Themen• Identitätsbasierte AWS DMS-Richtlinien (p. 46)• AWS DMSRessourcenbasierte Richtlinien (p. 48)• Autorisierung auf der Basis von AWS DMS-Tags (p. 49)• IAM-Rollen für AWS DMS (p. 49)
Identitätsbasierte AWS DMS-RichtlinienMit identitätsbasierten IAM-Richtlinien können Sie angeben, welche Aktionen und Ressourcen zugelassenoder abgelehnt werden. Darüber hinaus können Sie die Bedingungen festlegen, unter denen Aktionenzugelassen oder abgelehnt werden. AWS DMS unterstützt bestimmte Aktionen, Ressourcen undBedingungsschlüssel. Informationen zu sämtlichen Elementen, die Sie in einer JSON-Richtlinie verwenden,finden Sie in der IAM-Referenz für JSON-Richtlinienelemente im IAM-Benutzerhandbuch.
AktionenDas Element Action einer identitätsbasierten IAM-Richtlinie beschreibt die spezifischen Aktionen,die von der Richtlinie zugelassen oder abgelehnt werden. Richtlinienaktionen haben normalerweisedenselben Namen wie die zugehörige AWS-API-Operation. Die Aktion wird in einer Richtlinie verwendet,um Berechtigungen zur Durchführung der zugehörigen Aktion zu gewähren.
Richtlinienaktionen in AWS DMS verwenden das folgende Präfix vor der Aktion: dms:. Um jemandembeispielsweise die Berechtigung zum Erstellen einer Replikationsaufgabe mithilfe der AWS DMS-API-Operation CreateReplicationTask zu erteilen, fügen Sie die dms:CreateReplicationTask-Aktionin seine Richtlinie ein. Richtlinienanweisungen müssen ein Action- oder NotAction-Element enthalten.AWS DMS definiert seinen eigenen Satz an Aktionen, die Aufgaben beschreiben, die Sie mit diesemService durchführen können.
Um mehrere Aktionen in einer einzigen Anweisung anzugeben, trennen Sie sie folgendermaßen durchKommas.
"Action": [ "dms:action1", "dms:action2"
Sie können auch Platzhalter verwenden, um mehrere Aktionen anzugeben. Beispielsweise können Sie alleAktionen festlegen, die mit dem Wort Describe beginnen, einschließlich der folgenden Aktion:
"Action": "dms:Describe*"
Die Liste der AWS DMS-Aktionen finden Sie unter Von AWS Database Migration Service definierteAktionen im IAM-Benutzerhandbuch.
API-Version API Version 2016-01-0146

AWS Database Migration Service BenutzerhandbuchFunktionsweise von AWS Database
Migration Service mit IAM
Ressourcen
Das Element Resource gibt die Objekte an, auf die die Aktion angewendet wird. Anweisungen müssenentweder ein Resource- oder ein NotResource-Element enthalten. Sie geben eine Ressource unterVerwendung eines ARN oder eines Platzhalters (*) an, um anzugeben, dass die Anweisung für alleRessourcen gilt.
AWS DMS arbeitet mit den folgenden Ressourcen:
• Zertifikate• Endpunkte• Ereignisabonnements• Replikations-Instances• Replikations-Subnetzgruppen (Sicherheit)• Replikationsaufgaben
Die Ressource(n), die für AWS DMS erforderlich sind, hängen von der Aktion oder den Aktionen ab, die Sieaufrufen. Sie benötigen eine Richtlinie, die diese Aktionen für die zugeordnete Ressource oder Ressourcenzulässt, die von den Ressourcen-ARNs angegeben werden.
Beispielsweise weist eine AWS DMS-Endpunktressource den folgenden ARN auf:
arn:${Partition}:dms:${Region}:${Account}:endpoint/${InstanceId}
Weitere Informationen zum Format von ARNs finden Sie unter Amazon-Ressourcennamen (ARNs) undAWS-Service-Namen.
Um beispielsweise die 1A2B3C4D5E6F7G8H9I0J1K2L3M-Endpunkt-Instance für die use-east-2-Regionin Ihrer Anweisung anzugeben, verwenden Sie den folgenden ARN.
"Resource": "arn:aws:dms:us-east-2:987654321098:endpoint/1A2B3C4D5E6F7G8H9I0J1K2L3M"
Um alle Endpunkte anzugeben, die zu einem bestimmten Konto gehören, verwenden Sie den Platzhalter(*):
"Resource": "arn:aws:dms:us-east-2:987654321098:endpoint/*"
Einige AWS DMS-Aktionen, z. B. zum Erstellen von Ressourcen, können auf bestimmten Ressourcen nichtausgeführt werden. In diesen Fällen müssen Sie den Platzhalter (*) verwenden.
"Resource": "*"
Bei einigen AWS DMS-API-Aktionen sind mehrere Ressourcen beteiligt. Beispielsweisestartet StartReplicationTask eine Replikationsaufgabe und verbindet sie mit zweiDatenbankendpunktressourcen, einer Quelle und einem Ziel, so dass ein IAM-Benutzer Berechtigungenzum Lesen des Quellendpunkts und zum Schreiben auf den Zielendpunkt haben muss. Um mehrereRessourcen in einer einzigen Anweisung anzugeben, trennen Sie die ARNs durch Kommata voneinander.
"Resource": [ "resource1", "resource2" ]
API-Version API Version 2016-01-0147

AWS Database Migration Service BenutzerhandbuchFunktionsweise von AWS Database
Migration Service mit IAM
Weitere Informationen zum Steuern des Zugriffs auf AWS DMS-Ressourcen mithilfe von Richtlinien findenSie unter ??? (p. 72). Informationen, dazu, wie Sie die Liste der AWS DMS-Ressourcentypen und ihrerARNs anzeigen, finden Sie unter Von AWS Database Migration Service definierte Ressourcen im IAM-Benutzerhandbuch. Informationen dazu, mit welchen Aktionen Sie den ARN der einzelnen Ressourcenangeben können, finden Sie unter Von AWS Database Migration Service definierte Aktionen.
Bedingungsschlüssel.
Mithilfe des Elements Condition(oder des Blocks Condition) können Sie die Bedingungen angeben,unter denen eine Anweisung wirksam ist. Das Element Condition ist optional. Sie können bedingteAusdrücke erstellen, die Bedingungsoperatoren verwenden, z. B. ist gleich oder kleiner als, damit dieBedingung in der Richtlinie mit Werten in der Anforderung übereinstimmt.
Wenn Sie mehrere Condition-Elemente in einer Anweisung oder mehrere Schlüssel in einem einzelnenCondition-Element angeben, wertet AWS diese mittels einer logischen AND-Operation aus. Wenn Siemehrere Werte für einen einzelnen Bedingungsschlüssel angeben, wertet AWS die Bedingung mittelseiner logischen OR-Operation aus. Alle Bedingungen müssen erfüllt werden, bevor die Berechtigungen derAnweisung gewährt werden.
Sie können auch Platzhaltervariablen verwenden, wenn Sie Bedingungen angeben. Beispielsweise könnenSie einem IAM-Benutzer die Berechtigung für den Zugriff auf eine Ressource nur dann gewähren, wennsie mit dessen IAM-Benutzernamen gekennzeichnet ist. Weitere Informationen finden Sie unter IAMRichtlinienelemente: Variablen und Tags im IAM-Benutzerhandbuch.
AWS DMS definiert einen eigenen Satz von Bedingungsschlüsseln und unterstützt auch einige globalenBedingungsschlüssel. Die Liste aller globalen AWS-Bedingungsschlüssel finden Sie unter Globale AWS-Bedingungskontextschlüssel im IAM-Benutzerhandbuch.
AWS DMS definiert eine Reihe von Standard-Tags, die Sie in seinen Bedingungsschlüsseln verwendenkönnen, und ermöglicht Ihnen auch, eigene benutzerdefinierte Tags zu definieren. Weitere Informationenfinden Sie unter Steuern des Zugriffs mit Tags (p. 74).
Die Liste der AWS DMS-Bedingungsschlüssel finden Sie unter Bedingungsschlüssel für AWS DatabaseMigration Service im IAM-Benutzerhandbuch. Informationen dazu, mit welchen Aktionen und RessourcenSie einen Bedingungsschlüssel verwenden können, finden Sie unter Von AWS Database Migration Servicedefinierte Aktionen und Von AWS Database Migration Service definierte Ressourcen.
Beispiele
Beispiele für identitätsbasierte AWS DMS-Richtlinien finden Sie unter Beispiele für identitätsbasierte AWSDatabase Migration Service-Richtlinien (p. 50).
AWS DMSRessourcenbasierte RichtlinienRessourcenbasierte Richtlinien sind JSON-Richtliniendokumente, die angeben, welche Aktionen einspezifizierter Prinzipal für eine bestimmte AWS DMS-Ressource ausführen kann, und unter welchenBedingungen dies möglich ist. AWS DMS unterstützt ressourcenbasierte Berechtigungsrichtlinien fürAWS KMS-Verschlüsselungsschlüssel, die Sie erstellen, um Daten zu verschlüsseln, die auf unterstützteZielendpunkte migriert werden. Die unterstützten Ziel-Endpunkte enthalten Amazon Redshift und AmazonS3. Mithilfe ressourcenbasierter Richtlinien können Sie anderen Konten für jeden Zielendpunkt dieBerechtigung zur Verwendung dieser Verschlüsselungsschlüssel erteilen.
Um kontoübergreifenden Zugriff zu ermöglichen, können Sie ein gesamtes Konto oder IAM-Entitätenin einem anderen Konto als Prinzipal in einer ressourcenbasierten Richtlinie angeben. Durch das
API-Version API Version 2016-01-0148

AWS Database Migration Service BenutzerhandbuchFunktionsweise von AWS Database
Migration Service mit IAM
Hinzufügen eines kontoübergreifenden Prinzipals zu einer ressourcenbasierten Richtlinie ist nur die halbeVertrauensbeziehung eingerichtet. Wenn sich das Prinzipal und die Ressource in verschiedenen AWS-Konten befinden, müssen Sie auch der Prinzipal-Entität die Berechtigung für den Zugriff auf die Ressourceerteilen. Sie erteilen Berechtigungen, indem Sie der Entität eine identitätsbasierte Richtlinie anfügen.Wenn jedoch eine ressourcenbasierte Richtlinie Zugriff auf einen Prinzipal in demselben Konto gewährt,ist keine zusätzliche identitätsbasierte Richtlinie erforderlich. Weitere Informationen finden Sie unter Sounterscheiden sich IAM-Rollen von ressourcenbasierten Richtlinien im IAM-Benutzerhandbuch.
Der AWS DMS-Service unterstützt nur eine Art ressourcenbasierter Richtlinien, die als Schlüsselrichtliniebezeichnet wird und einem AWS KMS-Verschlüsselungsschlüssel angefügt ist. Diese Richtlinie legt fest,welche Prinzipal-Entitäten (Konten, Benutzer, Rollen und verbundene Benutzer) migrierte Daten auf demunterstützten Zielendpunkt verschlüsseln können.
Informationen zum Anfügen einer ressourcenbasierten Richtlinie an einen Verschlüsselungsschlüssel, denSie für die unterstützten Zielendpunkte erstellen, finden Sie unter Erstellen und Verwenden von AWS KMS-Schlüsseln für die Verschlüsselung von Amazon Redshift-Zieldaten (p. 234) und Erstellen von AWS KMS-Schlüsseln zum Verschlüsseln von Amazon S3-Zielobjekten (p. 254).
Beispiele
Beispiele für ressourcenbasierte AWS DMS-Richtlinien finden Sie unter Beispiele für eineressourcenbasierte Richtlinie für AWS KMS (p. 56).
Autorisierung auf der Basis von AWS DMS-TagsSie können Tags an AWS DMS-Ressourcen anfügen oder Tags in einer Anforderung an AWSDMS übergeben. Um den Zugriff basierend auf Tags zu steuern, geben Sie Tag-Informationen imBedingungselement einer Richtlinie mithilfe des Bedingungsschlüssels dms:ResourceTag/key-name,aws:RequestTag/key-name oder aws:TagKeys an. AWS DMS definiert eine Reihe von Standard-Tags, die Sie in den Bedingungsschlüsseln verwenden können, und ermöglicht Ihnen auch, eigenebenutzerdefinierte Tags zu definieren. Weitere Informationen finden Sie unter Steuern des Zugriffs mitTags (p. 74).
Eine identitätsbasierte Beispielrichtlinie, die den Zugriff auf eine Ressource auf Tags beschränkt, finden Sieunter Zugriff auf AWS DMS-Ressourcen basierend auf Tags (p. 56).
IAM-Rollen für AWS DMSEine IAM-Rolle ist eine Entität in Ihrem AWS-Konto mit spezifischen Berechtigungen.
Verwenden temporärer Anmeldeinformationen mit AWS DMS
Sie können temporäre Anmeldeinformationen verwenden, um sich über einen Verbund anzumelden,eine IAM-Rolle anzunehmen oder eine kontenübergreifende Rolle anzunehmen. TemporäreSicherheitsanmeldeinformationen erhalten Sie durch Aufrufen von AWS STS-API-Operationen wieAssumeRole oder GetFederationToken.
AWS DMS unterstützt die Verwendung temporärer Anmeldeinformationen.
Serviceverknüpfte Rollen
Serviceverknüpfte Rollen erlauben AWS-Services den Zugriff auf Ressourcen in anderen Services, umeine Aktion in Ihrem Auftrag auszuführen. Serviceverknüpfte Rollen werden in Ihrem IAM-Konto angezeigtund gehören zum Service. Ein IAM-Administrator kann die Berechtigungen für serviceverknüpfte Rollenanzeigen, aber nicht bearbeiten.
API-Version API Version 2016-01-0149

AWS Database Migration Service BenutzerhandbuchBeispiele für identitätsbasierte Richtlinien
AWS DMS unterstützt keine serviceverknüpften Rollen.
Servicerollen
Diese Funktion ermöglicht einem Service das Annehmen einer Servicerolle in Ihrem Namen. DieseRolle gewährt dem Service Zugriff auf Ressourcen in anderen Services, um eine Aktion in Ihrem Namenauszuführen. Servicerollen werden in Ihrem IAM-Konto angezeigt und gehören zum Konto. Dies bedeutet,dass ein IAM-Administrator die Berechtigungen für diese Rolle ändern kann. Dies kann jedoch dieFunktionalität des Services beeinträchtigen.
AWS DMS unterstützt zwei Arten von Servicerollen, die Sie erstellen müssen, um bestimmte Quell- oderZielendpunkte zu verwenden:
• Rollen mit Berechtigungen für den Zugriff von AWS DMS auf die folgenden Quell- und Zielendpunkte(oder deren Ressourcen):• Amazon DynamoDB als Ziel – Weitere Informationen finden Sie unter Voraussetzungen für die
Verwendung von DynamoDB als Ziel für AWS Database Migration Service (p. 273).• Elasticsearch als Ziel – Weitere Informationen finden Sie unter Voraussetzungen für die Verwendung
von Amazon Elasticsearch Service als Ziel für AWS Database Migration Service (p. 308).• Amazon Kinesis als Ziel – Weitere Informationen finden Sie unter Voraussetzungen für die
Verwendung eines Kinesis-Daten-Streams als Ziel für AWS Database Migration Service (p. 291).• Amazon Redshift als Ziel – Sie müssen die angegebene Rolle nur zum Erstellen eines
benutzerdefinierten KMS-Verschlüsselungsschlüssels zum Verschlüsseln der Zieldaten oderzum Angeben eines benutzerdefinierten S3-Buckets für Zwischenaufgabenspeicher erstellen.Weitere Informationen finden Sie unter Erstellen und Verwenden von AWS KMS-Schlüsselnfür die Verschlüsselung von Amazon Redshift-Zieldaten (p. 234) oder Amazon S3-Bucket-Einstellungen (p. 238).
• Amazon S3 als Quelle oder als Ziel – Weitere Informationen finden Sie unter Voraussetzungen fürdie Verwendung von Amazon S3 als Quelle für AWS DMS (p. 205) oder Voraussetzungen für dieVerwendung von Amazon S3 als Ziel (p. 246).
Um beispielsweise Daten von einem S3-Quellendpunkt zu lesen oder Daten an einen S3-Zielendpunktzu übertragen, müssen Sie eine Servicerolle als Voraussetzung für den Zugriff auf S3 für jede dieserEndpunktoperationen erstellen.
• Rollen mit erforderlichen Berechtigungen für die Verwendung der AWS CLI- und AWS DMS-API – ZweiIAM-Rollen, die Sie erstellen müssen, sind dms-vpc-role und dms-cloudwatch-logs-role. WennSie Amazon Redshift als Zieldatenbank verwenden, müssen Sie Ihrem AWS-Konto auch die IAM-Rolledms-access-for-endpoint hinzufügen. Weitere Informationen finden Sie unter Erstellen der IAM-Rollen für die Verwendung mit der AWS CLI- und AWS DMS-API (p. 68).
Auswählen einer IAM-Rolle in AWS DMS
Wenn Sie die AWS CLI- oder die AWS DMS-API für Ihre Datenbankmigration verwenden, müssen SieIhrem AWS-Konto bestimmte IAM-Rollen hinzufügen, bevor Sie die Funktionen von AWS DMS verwendenkönnen. Zwei dieser Optionen sind dms-vpc-role und dms-cloudwatch-logs-role. Wenn SieAmazon Redshift als Zieldatenbank verwenden, müssen Sie Ihrem AWS-Konto auch die IAM-Rolle dms-access-for-endpoint hinzufügen. Weitere Informationen finden Sie unter Erstellen der IAM-Rollen fürdie Verwendung mit der AWS CLI- und AWS DMS-API (p. 68).
Beispiele für identitätsbasierte AWS DatabaseMigration Service-RichtlinienIAM-Benutzer besitzen keine Berechtigungen zum Erstellen oder Ändern von AWS DMS-Ressourcen. Siekönnen auch keine Aufgaben mithilfe der AWS Management Console, AWS CLI oder AWS-API ausführen.
API-Version API Version 2016-01-0150

AWS Database Migration Service BenutzerhandbuchBeispiele für identitätsbasierte Richtlinien
Ein IAM-Administrator muss IAM-Richtlinien erstellen, die Benutzern und Rollen die Berechtigung zumAusführen bestimmter API-Operationen für die angegebenen Ressourcen gewähren, die diese benötigen.Der Administrator muss diese Richtlinien anschließend den IAM-Benutzern oder -Gruppen anfügen, diediese Berechtigungen benötigen.
Informationen dazu, wie Sie unter Verwendung dieser beispielhaften JSON-Richtliniendokumente eineidentitätsbasierte IAM-Richtlinie erstellen, finden Sie unter Erstellen von Richtlinien auf der JSON-Registerkarte im IAM-Benutzerhandbuch.
Themen• Bewährte Methoden für Richtlinien (p. 51)• Verwenden der AWS DMS-Konsole (p. 51)• Gewähren der Berechtigung zur Anzeige der eigenen Berechtigungen für Benutzer (p. 54)• Zugriff auf einen einzelnen Amazon S3-Bucket (p. 55)• Zugriff auf AWS DMS-Ressourcen basierend auf Tags (p. 56)
Bewährte Methoden für RichtlinienIdentitätsbasierte Richtlinien sind sehr leistungsfähig. Sie können festlegen, ob jemand AWS DMS-Ressourcen in Ihrem Konto erstellen oder löschen oder auf sie zugreifen kann.. Dies kann zusätzlicheKosten für Ihr AWS-Konto verursachen. Befolgen Sie beim Erstellen oder Bearbeiten identitätsbasierterRichtlinien die folgenden Anleitungen und Empfehlungen:
• Verwenden Sie zum Einstieg von AWS verwaltete Richtlinien – Um schnell mit der Verwendung von AWSDMS zu beginnen, verwenden Sie von AWS verwaltete Richtlinien, um Ihren Mitarbeitern die von ihnenbenötigten Berechtigungen zu gewähren. Diese Richtlinien sind bereits in Ihrem Konto verfügbar undwerden von AWS gewartet und aktualisiert. Weitere Informationen finden Sie unter Erste Schritte zurVerwendung von Berechtigungen mit von AWS verwalteten Richtlinien im IAM-Benutzerhandbuch.
• Gewähren Sie die geringstmöglichen Berechtigungen – Gewähren Sie beim Erstellen benutzerdefinierterRichtlinien nur die Berechtigungen, die zum Ausführen einer Aufgabe erforderlich sind. Beginnen Sie miteinem Mindestsatz von Berechtigungen und gewähren Sie zusätzliche Berechtigungen wie erforderlich.Dies ist sicherer, als mit Berechtigungen zu beginnen, die zu weit gefasst sind, und dann später zuversuchen, sie zu begrenzen. Weitere Informationen finden Sie unter Gewähren der geringstmöglichenBerechtigungen im IAM-Benutzerhandbuch.
• Aktivieren Sie für sensible Vorgänge MFA – Fordern Sie von IAM-Benutzern die Verwendung vonMulti-Factor Authentication (MFA), um zusätzliche Sicherheit beim Zugriff auf sensible Ressourcenoder API-Operationen zu bieten. Weitere Informationen finden Sie unter Verwenden von Multi-FactorAuthentication (MFA) in AWS im IAM-Benutzerhandbuch.
• Verwenden Sie Richtlinienbedingungen, um zusätzliche Sicherheit zu bieten – Definieren Sie dieBedingungen, unter denen Ihre identitätsbasierten Richtlinien den Zugriff auf eine Ressource zulassen,soweit praktikabel. Beispielsweise können Sie Bedingungen schreiben, die eine Reihe von zulässigenIP-Adressen festlegen, von denen eine Anforderung stammen muss. Sie können auch Bedingungenschreiben, die Anforderungen nur innerhalb eines bestimmten Datums- oder Zeitbereichs zulassenoder die Verwendung von SSL oder MFA fordern. Weitere Informationen finden Sie unter IAM-JSON-Richtlinienelemente: Bedingung im IAM-Benutzerhandbuch.
Verwenden der AWS DMS-KonsoleMit der folgenden Richtlinie erhalten Sie Zugriff auf AWS DMS, einschließlich der AWS DMS- Konsole, undgibt auch Berechtigungen für bestimmte Aktionen an, die von anderen Amazon-Diensten wie Amazon EC2benötigt werden.
API-Version API Version 2016-01-0151

AWS Database Migration Service BenutzerhandbuchBeispiele für identitätsbasierte Richtlinien
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "dms:*", "Resource": "*" }, { "Effect": "Allow", "Action": [ "kms:ListAliases", "kms:DescribeKey" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "iam:GetRole", "iam:PassRole", "iam:CreateRole", "iam:AttachRolePolicy" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ec2:DescribeVpcs", "ec2:DescribeInternetGateways", "ec2:DescribeAvailabilityZones", "ec2:DescribeSubnets", "ec2:DescribeSecurityGroups", "ec2:ModifyNetworkInterfaceAttribute", "ec2:CreateNetworkInterface", "ec2:DeleteNetworkInterface" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "cloudwatch:Get*", "cloudwatch:List*" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "logs:DescribeLogGroups", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogEvents" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "redshift:Describe*", "redshift:ModifyClusterIamRoles" ], "Resource": "*" }
API-Version API Version 2016-01-0152

AWS Database Migration Service BenutzerhandbuchBeispiele für identitätsbasierte Richtlinien
]}
Eine Aufschlüsselung dieser Berechtigungen kann Ihnen helfen, besser zu verstehen, warum alle für dieVerwendung der Konsole erforderlichen Berechtigungen erforderlich sind.
Der folgende Abschnitt ist erforderlich, damit die Benutzer berechtigt sind, ihre verfügbaren AWS KMS-Schlüssel und den Alias für die Anzeige in der Konsole aufzulisten. Dieser Eintrag ist nicht erforderlich,wenn Sie den Amazon-Ressourcennamen (ARN) für den KMS-Schlüssel kennen und nur die AWSCommand Line Interface (AWS CLI) verwenden.
{ "Effect": "Allow", "Action": [ "kms:ListAliases", "kms:DescribeKey" ], "Resource": "*" }
Der folgende Abschnitt ist für bestimmte Endpunkttypen erforderlich, die die Übergabe eines Rollen-ARN mit dem Endpunkt erfordern. Wenn darüber hinaus die erforderlichen AWS DMS-Rollen nicht voraberstellt werden, ist das Erstellen der Rolle über die AWS DMS-Konsole möglich. Wenn alle Rollen vorabkonfiguriert werden, muss dies innerhalb von iam:GetRole und iam:PassRole geschehen. WeitereInformationen zu Rollen finden Sie unter Erstellen der IAM-Rollen für die Verwendung mit der AWS CLI-und AWS DMS-API (p. 68).
{ "Effect": "Allow", "Action": [ "iam:GetRole", "iam:PassRole", "iam:CreateRole", "iam:AttachRolePolicy" ], "Resource": "*" }
Der folgende Abschnitt ist erforderlich, da AWS DMS die Amazon EC2-Instance erstellen und das Netzwerkfür die erstellte Replikations-Instance konfigurieren muss. Diese Ressourcen sind im Konto des Kundenvorhanden, deshalb muss es möglich sein, diese Aktionen im Namen des Kunden auszuführen.
{ "Effect": "Allow", "Action": [ "ec2:DescribeVpcs", "ec2:DescribeInternetGateways", "ec2:DescribeAvailabilityZones", "ec2:DescribeSubnets", "ec2:DescribeSecurityGroups", "ec2:ModifyNetworkInterfaceAttribute", "ec2:CreateNetworkInterface", "ec2:DeleteNetworkInterface" ], "Resource": "*" }
Der folgende Abschnitt ist erforderlich, damit der Benutzer Replikations-Instance-Metriken anzeigen kann.
API-Version API Version 2016-01-0153

AWS Database Migration Service BenutzerhandbuchBeispiele für identitätsbasierte Richtlinien
{ "Effect": "Allow", "Action": [ "cloudwatch:Get*", "cloudwatch:List*" ], "Resource": "*" }
Dieser Abschnitt ist erforderlich, damit der Benutzer Replikationsprotokolle anzeigen kann.
{ "Effect": "Allow", "Action": [ "logs:DescribeLogGroups", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogEvents" ], "Resource": "*" }
Der folgende Abschnitt ist erforderlich, wenn Amazon Redshift als Ziel verwendet wird. AWS DMS kanndamit überprüfen, ob der Amazon Redshift-Cluster korrekt für AWS DMS eingerichtet wurde.
{ "Effect": "Allow", "Action": [ "redshift:Describe*", "redshift:ModifyClusterIamRoles" ], "Resource": "*" }
Die AWS DMS-Konsole erstellt mehrere Rollen, die Ihrem AWS-Konto automatisch angefügt werden, wennSie die AWS DMS-Konsole verwenden. Wenn Sie die AWS Command Line Interface (AWS CLI)- oder dieAWS DMS-API für Ihre Migration verwenden, müssen Sie diese Rollen Ihrem Konto hinzufügen. WeitereInformationen zum Hinzufügen dieser Rollen finden Sie unter Erstellen der IAM-Rollen für die Verwendungmit der AWS CLI- und AWS DMS-API (p. 68).
Weitere Informationen zu den Anforderungen für die Verwendung dieser Richtlinie für den Zugriff auf AWSDMS finden Sie unter Erforderliche IAM-Berechtigungen zur Verwendung von AWS DMS (p. 65)
Gewähren der Berechtigung zur Anzeige der eigenenBerechtigungen für BenutzerIn diesem Beispiel wird gezeigt, wie Sie eine Richtlinie erstellen, die IAM-Benutzern die Berechtigung zumAnzeigen der Inline-Richtlinien und verwalteten Richtlinien gewährt, die ihrer Benutzeridentität angefügtsind. Diese Richtlinie enthält Berechtigungen für die Ausführung dieser Aktion auf der Konsole oder für dieprogrammgesteuerte Ausführung über die AWS CLI oder die AWS-API.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ViewOwnUserInfo", "Effect": "Allow",
API-Version API Version 2016-01-0154

AWS Database Migration Service BenutzerhandbuchBeispiele für identitätsbasierte Richtlinien
"Action": [ "iam:GetUserPolicy", "iam:ListGroupsForUser", "iam:ListAttachedUserPolicies", "iam:ListUserPolicies", "iam:GetUser" ], "Resource": ["arn:aws:iam::*:user/${aws:username}"] }, { "Sid": "NavigateInConsole", "Effect": "Allow", "Action": [ "iam:GetGroupPolicy", "iam:GetPolicyVersion", "iam:GetPolicy", "iam:ListAttachedGroupPolicies", "iam:ListGroupPolicies", "iam:ListPolicyVersions", "iam:ListPolicies", "iam:ListUsers" ], "Resource": "*" } ]}
Zugriff auf einen einzelnen Amazon S3-BucketAWS DMS verwendet Amazon S3-Buckets als Zwischenspeicher für die Datenbankmigration. In derRegel verwaltet AWS DMS Standard-S3-Buckets für diesen Zweck. In bestimmten Fällen, insbesonderewenn Sie die AWS CLI- oder die AWS DMS-API verwenden, ermöglicht AWS DMS, dass Sie stattdessenIhren eigenen S3-Bucket angeben. Sie können beispielsweise einen eigenen S3-Bucket für die Migrationvon Daten zu einem Amazon Redshift-Zielendpunkt angeben. In diesem Fall müssen Sie eine Rolle mitBerechtigungen basierend auf der von Amazon verwalteten AmazonDMSRedshiftS3Role-Richtlinieerstellen.
Das folgende Beispiel zeigt eine Version der AmazonDMSRedshiftS3Role-Richtlinie. Diese ermöglichtAWS DMS, einem IAM-Benutzer in Ihrem AWS-Konto Zugriff auf einen Ihrer Amazon S3-Buckets zugewähren. Außerdem kann der Benutzer Objekte hinzufügen, aktualisieren und löschen.
Zusätzlich zum Erteilen der Berechtigungen s3:PutObject, s3:GetObject und s3:DeleteObjectfür den Benutzer, gewährt die Richtlinie die Berechtigungen s3:ListAllMyBuckets,s3:GetBucketLocation und s3:ListBucket. Dies sind die zusätzlichen Berechtigungen, die vonder Konsole benötigt werden. Andere Berechtigungen ermöglichen AWS DMS das Verwalten des Bucket-Lebenszyklus. Außerdem ist die s3:GetObjectAcl-Aktion erforderlich, um Objekte kopieren zu können.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:CreateBucket", "s3:ListBucket", "s3:DeleteBucket", "s3:GetBucketLocation", "s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:GetObjectVersion",
API-Version API Version 2016-01-0155

AWS Database Migration Service BenutzerhandbuchBeispiele für eine ressourcenbasierte Richtlinie
"s3:GetBucketPolicy", "s3:PutBucketPolicy", "s3:GetBucketAcl", "s3:PutBucketVersioning", "s3:GetBucketVersioning", "s3:PutLifecycleConfiguration", "s3:GetLifecycleConfiguration", "s3:DeleteBucketPolicy" ], "Resource": "arn:aws:s3:::dms-*" } ]}
Weitere Informationen zum Erstellen einer Rolle auf der Grundlage dieser Richtlinie finden Sie unterAmazon S3-Bucket-Einstellungen (p. 238).
Zugriff auf AWS DMS-Ressourcen basierend auf TagsSie können in Ihrer identitätsbasierten Richtlinie für die Steuerung des Zugriffs auf AWS DMS-Ressourcenauf der Basis von Tags Bedingungen verwenden. In diesem Beispiel wird gezeigt, wie Sie eine Richtlinieerstellen können, die den Zugriff auf alle AWS DMS-Endpunkte ermöglicht. Die Berechtigung wird jedochnur gewährt, wenn der Wert des Endpunktdatenbank-Tags Owner der Name des Benutzers ist.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "dms:*", "Resource": "arn:aws:dms:*:*:endpoint/*", "Condition": { "StringEquals": {"dms:endpoint-tag/Owner": "${aws:username}"} } } ]}
Sie können diese Richtlinie den IAM-Benutzern in Ihrem Konto zuweisen. Wenn ein Benutzer mit demNamen richard-roe versucht, auf einen AWS DMS-Endpunkt zuzugreifen, muss die Endpunktdatenbankmit Owner=richard-roe oder owner=richard-roe gekennzeichnet sein. Andernfalls wird diesemBenutzer der Zugriff verweigert. Der Tag-Schlüssel Owner der Bedingung stimmt sowohl mit Ownerals auch mit owner überein, da die Namen von Bedingungsschlüsseln nicht zwischen Groß- undKleinschreibung unterscheiden. Weitere Informationen finden Sie unter IAM-JSON-Richtlinienelemente:Bedingung im IAM-Benutzerhandbuch.
Beispiele für eine ressourcenbasierte Richtlinie fürAWS KMSAWS DMS erlaubt das Erstellen benutzerdefinierter AWS KMS-Verschlüsselungsschlüssel, um unterstützteZielendpunktdaten zu verschlüsseln. Informationen zum Erstellen und Anfügen einer Schlüsselrichtliniean den Verschlüsselungsschlüssel, den Sie für die unterstützte Verschlüsselung von Zieldaten erstellen,finden Sie unter Erstellen und Verwenden von AWS KMS-Schlüsseln für die Verschlüsselung von AmazonRedshift-Zieldaten (p. 234) und Erstellen von AWS KMS-Schlüsseln zum Verschlüsseln von Amazon S3-Zielobjekten (p. 254).
Themen
API-Version API Version 2016-01-0156

AWS Database Migration Service BenutzerhandbuchBeispiele für eine ressourcenbasierte Richtlinie
• Eine Richtlinie für einen benutzerdefinierten AWS KMS-Verschlüsselungsschlüssel zum Verschlüsselnvon Amazon Redshift-Zieldaten (p. 57)
• Eine Richtlinie für einen benutzerdefinierten AWS KMS-Verschlüsselungsschlüssel zum Verschlüsselnvon Amazon S3-Zieldaten (p. 58)
Eine Richtlinie für einen benutzerdefinierten AWS KMS-Verschlüsselungsschlüssel zum Verschlüsseln von AmazonRedshift-ZieldatenDas folgende Beispiel zeigt den JSON für die Schlüsselrichtlinie, die für einen AWS KMS-Verschlüsselungsschlüssel erstellt wurde, den Sie zum Verschlüsseln von Amazon Redshift-Zieldatenerstellen.
{ "Id": "key-consolepolicy-3", "Version": "2012-10-17", "Statement": [ { "Sid": "Enable IAM User Permissions", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::987654321098:root" ] }, "Action": "kms:*", "Resource": "*" }, { "Sid": "Allow access for Key Administrators", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::987654321098:role/Admin" ] }, "Action": [ "kms:Create*", "kms:Describe*", "kms:Enable*", "kms:List*", "kms:Put*", "kms:Update*", "kms:Revoke*", "kms:Disable*", "kms:Get*", "kms:Delete*", "kms:TagResource", "kms:UntagResource", "kms:ScheduleKeyDeletion", "kms:CancelKeyDeletion" ], "Resource": "*" }, { "Sid": "Allow use of the key", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::987654321098:role/DMS-Redshift-endpoint-access-role" ]
API-Version API Version 2016-01-0157

AWS Database Migration Service BenutzerhandbuchBeispiele für eine ressourcenbasierte Richtlinie
}, "Action": [ "kms:Encrypt", "kms:Decrypt", "kms:ReEncrypt*", "kms:GenerateDataKey*", "kms:DescribeKey" ], "Resource": "*" }, { "Sid": "Allow attachment of persistent resources", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::987654321098:role/DMS-Redshift-endpoint-access-role" ] }, "Action": [ "kms:CreateGrant", "kms:ListGrants", "kms:RevokeGrant" ], "Resource": "*", "Condition": { "Bool": { "kms:GrantIsForAWSResource": true } } } ]}
Hier können Sie sehen, wo die Schlüsselrichtlinie auf die Rolle für den Zugriff auf Amazon Redshift-Zielendpunktdaten verweist, die Sie vor dem Erstellen des Schlüssels erstellt haben. Im Beispiel ist diesDMS-Redshift-endpoint-access-role. Sie können auch die verschiedenen Schlüsselaktionensehen, die für die verschiedenen Prinzipale (Benutzer und Rollen) zulässig sind. Beispielsweise kann jederBenutzer mit DMS-Redshift-endpoint-access-role die Zieldaten verschlüsseln, entschlüsseln undneu verschlüsseln. Ein solcher Benutzer kann auch Datenschlüssel für den Export generieren, um dieDaten außerhalb von AWS KMS zu verschlüsseln. Sie können auch detaillierte Informationen über einenKundenmasterschlüssel (CMK) zurückgeben, z. B. den gerade erstellten Schlüssel. Darüber hinaus kannein solcher Benutzer Anhänge an AWS-Ressourcen verwalten, z. B. den Zielendpunkt.
Eine Richtlinie für einen benutzerdefinierten AWS KMS-Verschlüsselungsschlüssel zum Verschlüsseln von Amazon S3-ZieldatenDas folgende Beispiel zeigt den JSON für die Schlüsselrichtlinie, die für einen AWS KMS-Verschlüsselungsschlüssel erstellt wurde, den Sie zum Verschlüsseln von Amazon S3-Zieldaten erstellen.
{ "Id": "key-consolepolicy-3", "Version": "2012-10-17", "Statement": [ { "Sid": "Enable IAM User Permissions", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::987654321098:root"
API-Version API Version 2016-01-0158

AWS Database Migration Service BenutzerhandbuchBeispiele für eine ressourcenbasierte Richtlinie
] }, "Action": "kms:*", "Resource": "*" }, { "Sid": "Allow access for Key Administrators", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::987654321098:role/Admin" ] }, "Action": [ "kms:Create*", "kms:Describe*", "kms:Enable*", "kms:List*", "kms:Put*", "kms:Update*", "kms:Revoke*", "kms:Disable*", "kms:Get*", "kms:Delete*", "kms:TagResource", "kms:UntagResource", "kms:ScheduleKeyDeletion", "kms:CancelKeyDeletion" ], "Resource": "*" }, { "Sid": "Allow use of the key", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::987654321098:role/DMS-S3-endpoint-access-role" ] }, "Action": [ "kms:Encrypt", "kms:Decrypt", "kms:ReEncrypt*", "kms:GenerateDataKey*", "kms:DescribeKey" ], "Resource": "*" }, { "Sid": "Allow attachment of persistent resources", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::987654321098:role/DMS-S3-endpoint-access-role" ] }, "Action": [ "kms:CreateGrant", "kms:ListGrants", "kms:RevokeGrant" ], "Resource": "*", "Condition": { "Bool": { "kms:GrantIsForAWSResource": true }
API-Version API Version 2016-01-0159

AWS Database Migration Service BenutzerhandbuchFehlersuche
} } ]
Hier können Sie sehen, wo die Schlüsselrichtlinie auf die Rolle für den Zugriff auf Amazon S3-Zielendpunktdaten verweist, die Sie vor dem Erstellen des Schlüssels erstellt haben. Im Beispiel ist diesDMS-S3-endpoint-access-role. Sie können auch die verschiedenen Schlüsselaktionen sehen, diefür die verschiedenen Prinzipale (Benutzer und Rollen) zulässig sind. Beispielsweise kann jeder Benutzermit DMS-S3-endpoint-access-role die Zieldaten verschlüsseln, entschlüsseln und neu verschlüsseln.Ein solcher Benutzer kann auch Datenschlüssel für den Export generieren, um die Daten außerhalb vonAWS KMS zu verschlüsseln. Sie können auch detaillierte Informationen über einen Kundenmasterschlüssel(CMK) zurückgeben, z. B. den gerade erstellten Schlüssel. Darüber hinaus kann ein solcher BenutzerAnhänge an AWS-Ressourcen verwalten, z. B. den Zielendpunkt.
Fehlerbehebung bei AWS Database Migration Service-Identität und -ZugriffVerwenden Sie die folgenden Informationen, um häufige Probleme zu diagnostizieren und zu beheben, diebeim Arbeiten mit AWS DMS und IAM auftreten könnten.
Themen• Ich bin nicht autorisiert, eine Aktion in AWS DMS auszuführen (p. 60)• Ich bin nicht zur Ausführung von iam:PassRole autorisiert (p. 60)• Ich möchte meine Zugriffsschlüssel anzeigen (p. 61)• Ich bin Administrator und möchte anderen den Zugriff auf AWS DMS ermöglichen (p. 61)• Ich möchte Personen außerhalb meines AWS-Kontos Zugriff auf meine AWS DMS-Ressourcen
gewähren (p. 61)
Ich bin nicht autorisiert, eine Aktion in AWS DMS auszuführenWenn die AWS Management Console Ihnen mitteilt, dass Sie nicht zur Ausführung einer Aktion autorisiertsind, müssen Sie sich an Ihren Administrator wenden, um Unterstützung zu erhalten. Ihr Administrator istdie Person, die Ihnen Ihren Benutzernamen und Ihr Passwort bereitgestellt hat.
Der folgende Beispielfehler tritt auf, wenn der mateojackson IAM-Benutzer versucht, die Konsolezum Anzeigen von Details zu einem AWS DMS-Endpunkt zu verwenden, aber keine dms:DescribeEndpoint-Berechtigungen hat.
User: arn:aws:iam::123456789012:user/mateojackson is not authorized to perform: dms:DescribeEndpoint on resource: my-postgresql-target
In diesem Fall bittet Mateo seinen Administrator, seine Richtlinien zu aktualisieren, um ihm den Zugriffauf die my-postgresql-target-Endpunktressource mit der dms:DescribeEndpoint-Aktion zuermöglichen.
Ich bin nicht zur Ausführung von iam:PassRole autorisiertWenn Sie die Fehlermeldung erhalten, dass Sie nicht zur Ausführung der Aktion iam:PassRole autorisiertsind, müssen Sie sich an Ihren Administrator wenden, um Unterstützung zu erhalten. Ihr Administrator istdie Person, die Ihnen Ihren Benutzernamen und Ihr Passwort bereitgestellt hat. Bitten Sie diese Person umdie Aktualisierung Ihrer Richtlinien, um eine Rolle an AWS DMS übergeben zu können.
API-Version API Version 2016-01-0160

AWS Database Migration Service BenutzerhandbuchFehlersuche
Einige AWS-Services gewähren Ihnen die Berechtigung zur Übergabe einer vorhandenen Rolle an diesenService, statt eine neue Service-Rolle oder serviceverknüpfte Rolle erstellen zu müssen. Hierfür benötigenSie Berechtigungen zur Übergabe der Rolle an den Service.
Der folgende Beispielfehler tritt auf, wenn ein IAM-Benutzer mit dem Namen marymajor versucht, dieKonsole zu verwenden, um eine Aktion in AWS DMS auszuführen. Um die Aktion ausführen zu können,müssen dem Service jedoch von einer Service-Rolle Berechtigungen gewährt werden. Mary besitzt keineBerechtigungen für die Übergabe der Rolle an den Service.
User: arn:aws:iam::123456789012:user/marymajor is not authorized to perform: iam:PassRole
In diesem Fall bittet Mary ihren Administrator um die Aktualisierung ihrer Richtlinien, um die Aktioniam:PassRole ausführen zu können.
Ich möchte meine Zugriffsschlüssel anzeigenNachdem Sie Ihre IAM-Benutzerzugriffsschlüssel erstellt haben, können Sie Ihre Zugriffsschlüssel-IDjederzeit anzeigen. Sie können Ihren geheimen Zugriffsschlüssel jedoch nicht erneut anzeigen. Wenn Sieden geheimen Zugriffsschlüssel verlieren, müssen Sie ein neues Zugriffsschlüsselpaar erstellen.
Zugriffsschlüssel bestehen aus zwei Teilen: einer Zugriffsschlüssel-ID (z. B. AKIAIOSFODNN7EXAMPLE)und einem geheimen Zugriffsschlüssel (z. B. wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY).Ähnlich wie bei Benutzernamen und Passwörtern müssen Sie die Zugriffsschlüssel-ID und den geheimenZugriffsschlüssel zusammen verwenden, um Ihre Anfragen zu authentifizieren. Verwalten Sie IhreZugriffsschlüssel so sicher wie Ihren Benutzernamen und Ihr Passwort.
Important
Stellen Sie Ihre Zugriffsschlüssel keinen Dritten bereit, auch nicht, wenn Sie Hilfe bei der Suchenach Ihrer kanonischen Benutzer-ID benötigen. Wenn Sie dies tun, gewähren Sie anderenPersonen möglicherweise den permanenten Zugriff auf Ihr Konto.
Während der Erstellung eines Zugriffsschlüsselpaars werden Sie aufgefordert, die Zugriffsschlüssel-ID und den geheimen Zugriffsschlüssel an einem sicheren Speicherort zu speichern. Der geheimeZugriffsschlüssel ist nur zu dem Zeitpunkt verfügbar, an dem Sie ihn erstellen. Wenn Sie Ihren geheimenZugriffsschlüssel verlieren, müssen Sie Ihrem IAM-Benutzer neue Zugriffsschlüssel hinzufügen. Sie könnenmaximal zwei Zugriffsschlüssel besitzen. Wenn Sie bereits zwei Zugriffschlüssel besitzen, müssen Sie einSchlüsselpaar löschen, bevor Sie ein neues erstellen. Anweisungen hierfür finden Sie unter Verwalten vonZugriffsschlüsseln im IAM-Benutzerhandbuch.
Ich bin Administrator und möchte anderen den Zugriff auf AWSDMS ermöglichenUm anderen Personen oder einer Anwendung Zugriff auf AWS DMS zu gewähren, müssen Sie eineIAM-Entität (Benutzer oder Rolle) für die Person oder Anwendung erstellen, die Zugriff benötigt. Dieseverwendet dann die Anmeldeinformationen für diese Entität, um auf AWS zuzugreifen. Anschließendmüssen Sie der Entität eine Richtlinie anfügen, die dieser die korrekten Berechtigungen in AWS DMSgewährt.
Informationen zum Einstieg finden Sie unter Erstellen Ihrer ersten delegierten IAM-Benutzer und -Gruppenim IAM-Benutzerhandbuch.
Ich möchte Personen außerhalb meines AWS-Kontos Zugriff aufmeine AWS DMS-Ressourcen gewährenSie können eine Rolle erstellen, die Benutzer in anderen Konten oder Personen außerhalb IhrerOrganisation für den Zugriff auf Ihre Ressourcen verwenden können. Sie können angeben, welchen
API-Version API Version 2016-01-0161

AWS Database Migration Service BenutzerhandbuchProtokollieren und überwachen
Personen vertraut werden darf, damit diese die Rolle übernehmen können. Im Fall von Services, dieressourcenbasierte Richtlinien oder Zugriffskontrolllisten (Access Control Lists, ACLs) verwenden, könnenSie diese Richtlinien verwenden, um Personen Zugriff auf Ihre Ressourcen zu gewähren.
Weitere Informationen finden Sie hier:
• Informationen dazu, ob AWS DMS diese Funktionen unterstützt, finden Sie unter Funktionsweise vonAWS Database Migration Service mit IAM (p. 46).
• Informationen zum gewähren des Zugriffs auf Ihre Ressourcen für alle Ihre AWS-Konten finden Sieunter Gewähren des Zugriffs für einen IAM-Benutzer in einem anderen Ihrer AWS-Konten im IAM-Benutzerhandbuch.
• Informationen dazu, wie Sie AWS-Konten Dritter Zugriff auf Ihre Ressourcen bereitstellen, finden Sieunter Gewähren von Zugriff auf AWS-Konten Dritter im IAM-Benutzerhandbuch.
• Informationen dazu, wie Sie über einen Identitätsverbund Zugriff gewähren, finden Sie unter Gewährenvon Zugriff für extern authentifizierte Benutzer (Identitätsverbund) im IAM-Benutzerhandbuch.
• Informationen zum Unterschied zwischen der Verwendung von Rollen und ressourcenbasiertenRichtlinien für den kontenübergreifenden Zugriff finden Sie unter So unterscheiden sich IAM-Rollen vonressourcenbasierten Richtlinien im IAM-Benutzerhandbuch.
Protokollierung und Überwachung in AWSDatabase Migration Service
Die Überwachung ist ein wichtiger Teil der Aufrechterhaltung der Zuverlässigkeit, Verfügbarkeit undLeistung von AWS DMS und Ihrer AWS-Lösungen. Sie sollten Überwachungsdaten von allen Teilen IhrerAWS-Lösung erfassen, damit Sie einen Multi-Point-Fehler leichter debuggen können, wenn ein solcherauftritt. AWS bietet verschiedene Tools zur Überwachung von AWS DMS-Aufgaben und -Ressourcen undzur Reaktion auf potenzielle Vorfälle.
AWS DMS-Ereignisse und Benachrichtigungen
AWS DMS verwendet Amazon Simple Notification Service (Amazon SNS), um Benachrichtigungenbereitzustellen, wenn ein AWS DMS-Ereignis eintritt, z. B. das Erstellen oder Löschen einerReplikations-Instance. AWS DMS gruppiert Ereignisse in Kategorien, die Sie abonnieren können,so dass Sie benachrichtigt werden, wenn ein Ereignis in einer bestimmten Kategorie eintritt. WennSie beispielsweise die Kategorie "Erstellung" für eine bestimmte Replikations-Instance abonnieren,werden Sie benachrichtigt, sobald ein erstellungsbezogenes Ereignis auftritt, das sich auf IhreReplikations-Instance auswirkt. Sie können mit diesen Benachrichtigungen in einem beliebigen Formatarbeiten, das von Amazon SNS für eine AWS-Region unterstützt wird, z. B. eine E-Mail-Nachricht,eine Textnachricht oder ein Anruf an einen HTTP-Endpunkt. Weitere Informationen finden Sie unterArbeiten mit Ereignissen und Benachrichtigungen in AWS Database Migration Service (p. 443)
Aufgabenstatus
Sie können den Fortschritt einer Aufgabe überwachen, indem Sie den Aufgabenstatus überprüfenund die Steuerungstabelle der Aufgabe überwachen. Der Aufgabenstatus gibt den Zustand einerAWS DMS-Aufgabe und die zugehörigen Ressourcen an. Er enthält Hinweise dazu, ob die Aufgabeerstellt, gestartet, ausgeführt oder gestoppt wird. Er enthält auch den aktuellen Status der Tabellen,die die Aufgabe migriert, z. B. wenn eine vollständige Last einer Tabelle begonnen hat oder geradeausgeführt wird, sowie Details wie die Anzahl der aufgetretenen Einfügungen, Löschungen undAktualisierungen für die Tabelle. Weitere Informationen zum Überwachen des Zustands von Aufgaben-und Aufgabenressourcen finden Sie unter Aufgabenstatus (p. 421) und Tabellenstatus während derAufgaben (p. 422). Weitere Informationen zu Steuerungstabellen finden Sie unter Einstellungen derKontrolltabelle für Aufgaben (p. 346).
API-Version API Version 2016-01-0162

AWS Database Migration Service BenutzerhandbuchCompliance-Validierung
Amazon CloudWatch-Alarme und Protokolle
Mithilfe von Amazon CloudWatch-Alarmen überwachen Sie eine oder mehrere Aufgaben-Metrikenüber einen von Ihnen angegebenen Zeitraum. Wenn die Metrik einen bestimmten Schwellenwertüberschreitet, wird eine Benachrichtigung an ein Amazon SNS-Thema gesendet. CloudWatch-Alarme rufen keine Aktionen auf, weil sie einen besonderen Status aufweisen. Vielmehr muss derZustand geändert und für eine bestimmte Anzahl von Perioden beibehalten werden. AWS DMSverwendet auch CloudWatch, um Aufgabeninformationen während des Migrationsprozesses zuprotokollieren. Sie können die AWS CLI- oder die AWS DMS-API verwenden, um Informationen zu denAufgabenprotokollen anzuzeigen. Weitere Informationen zur Verwendung von CloudWatch mit AWSDMS finden Sie unter Überwachen von Replikationsaufgaben mit Amazon CloudWatch (p. 423).Weitere Informationen zur Überwachung von AWS DMS-Metriken finden Sie unter Metriken von DataMigration Service (p. 425). Weitere Hinweise zum Verwenden von AWS DMS-Aufgabenprotokollenfinden Sie unter Verwalten von AWS DMS-Aufgabenprotokollen (p. 429).
AWS CloudTrail-Protokolle
AWS DMS ist in AWS CloudTrail integriert, einen Service, der die Aktionen eines Benutzers, einerIAM-Rolle oder eines AWS-Service in AWS DMS aufzeichnet. CloudTrail erfasst alle API-Aufrufe fürAWS DMS als Ereignisse, einschließlich Aufrufen von der AWS DMS-Konsole und von Code-Aufrufenan die AWS DMS-API-Operationen. Wenn Sie einen Trail erstellen, können Sie die kontinuierlicheBereitstellung von CloudTrail-Ereignissen an einen Amazon S3-Bucket, einschließlich Ereignissen fürAWS DMS, aktivieren. Auch wenn Sie keinen Trail konfigurieren, können Sie die neuesten Ereignissein der CloudTrail-Konsole in Event history (Ereignisverlauf) anzeigen. Mit den von CloudTrailgesammelten Informationen können Sie die an AWS DMS gestellte Anfrage, die IP-Adresse, von derdie Anfrage gestellt wurde, den Initiator der Anfrage, den Zeitpunkt der Anfrage und weitere Angabenbestimmen. Weitere Informationen finden Sie unter Protokollieren von AWS DMS-API-Aufrufen mitAWS CloudTrail (p. 430).
Datenbankprotokolle
Sie können Datenbankprotokolle für Ihre Aufgabenendpunkte mithilfe der AWS Management Console-,AWS CLI- oder der API für Ihren AWS-Datenbankservice anzeigen, herunterladen und überwachen.Weitere Informationen finden Sie in der Dokumentation zu Ihrem Datenbankservice unter AWS-Dokumentation.
Compliance-Validierung für AWS DatabaseMigration Service
Externe Auditoren bewerten im Rahmen verschiedener AWS-Compliance-Programme die Sicherheit undCompliance von AWS Database Migration Service. Dazu gehören die folgenden Programme:
• SOC• PCI• ISO• FedRAMP• DoD CC SRG• HIPAA BAA• MTCS• CS• K-ISMS• ENS High
API-Version API Version 2016-01-0163

AWS Database Migration Service BenutzerhandbuchAusfallsicherheit
• OSPAR• HITRUST CSF
Eine Liste der AWS-Services im Bereich bestimmter Compliance-Programme finden Sie unter AWS-Services im Bereich nach Compliance-Programm. Allgemeine Informationen finden Sie unter AWS-Compliance-Programme.
Die Auditberichte von Drittanbietern lassen sich mit AWS Artifact herunterladen. Weitere Informationenfinden Sie unter Herunterladen von Berichten in AWS Artifact.
Ihre Verantwortung in Bezug auf die Compliance bei der Verwendung von AWS DMS ergibt sich aus derVertraulichkeit der Daten, den Compliance-Zielen des Unternehmens sowie den einschlägigen Gesetzenund Vorschriften. AWS stellt die folgenden Ressourcen zur Sicherstellung der Compliance bereit:
• Kurzanleitungen für Sicherheit und Compliance – In diesen Bereitstellungsleitfäden finden Sie wichtigeÜberlegungen zur Architektur sowie die einzelnen Schritte zur Bereitstellung von sicherheits- undCompliance-orientierten Basisumgebungen in AWS.
• Whitepaper zur Erstellung einer Architektur mit HIPAA-konformer Sicherheit und Compliance – DiesesWhitepaper beschreibt, wie Unternehmen mithilfe von AWS HIPAA-konforme Anwendungen erstellen.
• AWS-Compliance-Ressourcen – Diese Arbeitsbücher und Leitfäden könnten für Ihre Branche und IhrenStandort interessant sein.
• AWS Config: Dieser AWS-Service bewertet, zu welchem Grad die Konfiguration Ihrer Ressourcen deninternen Vorgehensweisen, Branchenrichtlinien und Vorschriften entspricht.
• AWS Security Hub: Dieser AWS-Service liefert einen umfassenden Überblick über den Sicherheitsstatusin AWS. So können Sie die Compliance mit den Sicherheitsstandards in der Branche und den bewährtenMethoden abgleichen.
Ausfallsicherheit in AWS Database MigrationService
Im Zentrum der globalen AWS-Infrastruktur stehen die AWS-Regionen und -Availability Zones(Verfügbarkeitszonen, AZs). AWS-Regionen stellen mehrere physisch getrennte und isolierte AvailabilityZones bereit, die über hoch redundante Netzwerke mit niedriger Latenz und hohen Durchsätzen verbundensind. Mithilfe von Availability Zones können Sie Anwendungen und Datenbanken erstellen und ausführen,die automatisch Failover zwischen Availability Zones ausführen, ohne dass es zu Unterbrechungenkommt. Availability Zones sind besser hoch verfügbar, fehlertoleranter und skalierbarer als herkömmlicheInfrastrukturen mit einem oder mehreren Rechenzentren.
Weitere Informationen über AWS-Regionen und -Availability Zones finden Sie unter Globale AWS-Infrastruktur.
Neben der globalen AWS-Infrastruktur bietet AWS DMS Hochverfügbarkeit und Failover-Unterstützung füreine Replikations-Instance mit einer Multi-AZ-Bereitstellung, wenn Sie die Multi-AZ-Option wählen.
Bei einer Multi-AZ-Bereitstellung sorgt AWS DMS für die automatische Bereitstellung und Verwaltung einesStandby-Replikats der Replikations-Instance in einer anderen Availability Zone. Die primäre Replikations-Instance wird auf das Standby-Replikat repliziert. Wenn die primäre Replikations-Instance ausfällt odernicht mehr reagiert, nimmt der Standby-Modus alle laufenden Tasks mit minimaler Unterbrechung wiederauf. Da die primäre Replikations-Instance ihren Status ständig in den Standby-Modus repliziert, verursachtdie Multi-AZ-Bereitstellung einen gewissen Leistungs-Overhead.
Weitere Informationen zum Arbeiten mit Multi-AZ-Bereitstellungen finden Sie unter Arbeiten mit einer AWSDMS-Replikations-Instance (p. 93).
API-Version API Version 2016-01-0164

AWS Database Migration Service BenutzerhandbuchSicherheit der Infrastruktur
Infrastruktursicherheit in AWS Database MigrationService
Als verwalteter Service ist AWS Database Migration Service durch die globalen Verfahren zurGewährleistung der Netzwerksicherheit von AWS geschützt, die im Whitepaper Amazon Web Services:Overview of Security Processes (Übersicht über die Sicherheitsprozesse) beschrieben werden.
Sie verwenden von AWS veröffentlichte API-Aufrufe, um über das Netzwerk auf AWS DMS zuzugreifen.Clients müssen Transport Layer Security (TLS) 1.0 oder höher unterstützen. Clients müssen außerdemCipher Suites mit PFS (Perfect Forward Secrecy) wie DHE (Ephemeral Diffie-Hellman) oder ECDHE(Elliptic Curve Ephemeral Diffie-Hellman) unterstützen. Die meisten modernen Systemen wie Java 7 undhöher unterstützen diese Modi.
Darüber hinaus müssen Anfragen mit einer Zugriffsschlüssel-ID und einem geheimen Zugriffsschlüsselsigniert sein, der mit einem AWS Identity and Access Management(IAM)-Prinzipal verknüpft ist. Alternativkönnen Sie mit AWS Security Token Service (AWS STS) temporäre Sicherheitsanmeldeinformationenerstellen, um Anfragen zu signieren.
Diese API-Operationen lassen sich von einem beliebigen Netzwerkstandort aus aufrufen. Da AWS DMSjedoch ressourcenbasierte Zugriffsrichtlinien unterstützt, kann es zu Einschränkungen bezüglich der Quell-IP-Adresse kommen. Sie können auch AWS DMS-Richtlinien verwenden, um den Zugriff von bestimmtenAmazon VPC-Endpunkten oder bestimmten Virtual Private Clouds (VPCs) aus zu steuern. Hierdurchwird der Netzwerkzugriff auf eine bestimmte AWS DMS-Ressource effektiv eingeschränkt, sodass erausschließlich über eine bestimmte VPC innerhalb des AWS-Netzwerks ausgeführt werden kann.
Weitere Hinweise zum Verwenden von ressourcenbasierten Zugriffsrichtlinien mit AWS DMS, mitBeispielen, finden Sie unter Differenzierte Zugriffskontrolle mit Ressourcennamen und Ressourcen-Tags (p. 72).
Erforderliche IAM-Berechtigungen zur Verwendungvon AWS DMS
Sie verwenden bestimmte IAM-Berechtigungen und IAM-Rollen zur Verwendung von AWS DMS. Wenn Sieals IAM-Benutzer angemeldet sind und AWS DMS verwenden möchten, muss Ihr Kontoadministrator demIAM-Benutzer, der Gruppe oder Rolle, den bzw. die Sie für die Ausführung von AWS DMS verwenden, diein diesem Abschnitt beschriebene Richtlinie anfügen. Weitere Informationen zu IAM-Berechtigungen findenSie im IAM-Benutzerhandbuch.
Mit der folgenden Richtlinie erhalten Sie Zugriff auf AWS DMS sowie Berechtigungen für bestimmteerforderliche Aktionen von anderen Amazon-Services wie AWS KMS, IAM, Amazon EC2 und AmazonCloudWatch. CloudWatch überwacht Ihre AWS DMS-Migration in Echtzeit und erfasst und verfolgtMetriken, die den Fortschritt Ihrer Migration anzeigen. Sie können CloudWatch-Protokolle verwenden, umProbleme mit einer Aufgabe zu debuggen.
Note
Mittels Tags können Sie den Zugriff auf AWS DMS-Ressourcen weiter einschränken. WeitereInformationen zum Einschränken des Zugriffs auf AWS DMS-Ressourcen mithilfe von Tags findenSie unter Differenzierte Zugriffskontrolle mit Ressourcennamen und Ressourcen-Tags (p. 72).
{
API-Version API Version 2016-01-0165

AWS Database Migration Service BenutzerhandbuchErforderliche IAM-Berechtigungen
"Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "dms:*", "Resource": "*" }, { "Effect": "Allow", "Action": [ "kms:ListAliases", "kms:DescribeKey" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "iam:GetRole", "iam:PassRole", "iam:CreateRole", "iam:AttachRolePolicy" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ec2:DescribeVpcs", "ec2:DescribeInternetGateways", "ec2:DescribeAvailabilityZones", "ec2:DescribeSubnets", "ec2:DescribeSecurityGroups", "ec2:ModifyNetworkInterfaceAttribute", "ec2:CreateNetworkInterface", "ec2:DeleteNetworkInterface" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "cloudwatch:Get*", "cloudwatch:List*" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "logs:DescribeLogGroups", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogEvents" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "redshift:Describe*", "redshift:ModifyClusterIamRoles" ], "Resource": "*" } ]
API-Version API Version 2016-01-0166

AWS Database Migration Service BenutzerhandbuchErforderliche IAM-Berechtigungen
}
Eine Aufschlüsselung dieser Berechtigungen hilft Ihnen zu verstehen, warum die einzelnen Berechtigungennötig sind.
Der folgende Abschnitt ist erforderlich, damit der Benutzer berechtigt ist, AWS DMS-API-Operationenaufzurufen.
{ "Effect": "Allow", "Action": "dms:*", "Resource": "*"}
Der folgende Abschnitt ist erforderlich, damit die Benutzer berechtigt sind, ihre verfügbaren AWS KMS-Schlüssel und den Alias für die Anzeige in der Konsole aufzulisten. Dieser Eintrag ist nicht erforderlich,wenn Sie den Amazon-Ressourcennamen (ARN) für den KMS-Schlüssel kennen und nur die AWSCommand Line Interface (AWS CLI) verwenden.
{ "Effect": "Allow", "Action": [ "kms:ListAliases", "kms:DescribeKey" ], "Resource": "*" }
Der folgende Abschnitt ist für bestimmte Endpunkttypen erforderlich, die die Übergabe eines IAM-Rollen-ARN mit dem Endpunkt erfordern. Wenn darüber hinaus die erforderlichen AWS DMS-Rollen nicht voraberstellt werden, ist das Erstellen der Rolle über die AWS DMS-Konsole möglich. Wenn alle Rollen vorabkonfiguriert werden, sind nur iam:GetRole und iam:PassRole erforderlich. Weitere Informationen zuRollen finden Sie unter Erstellen der IAM-Rollen für die Verwendung mit der AWS CLI- und AWS DMS-API (p. 68).
{ "Effect": "Allow", "Action": [ "iam:GetRole", "iam:PassRole", "iam:CreateRole", "iam:AttachRolePolicy" ], "Resource": "*" }
Der folgende Abschnitt ist erforderlich, da AWS DMS die Amazon EC2-Instance erstellen und das Netzwerkfür die erstellte Replikations-Instance konfigurieren muss. Diese Ressourcen sind im Konto des Kundenvorhanden, deshalb muss es möglich sein, diese Aktionen im Namen des Kunden auszuführen.
{ "Effect": "Allow", "Action": [ "ec2:DescribeVpcs", "ec2:DescribeInternetGateways", "ec2:DescribeAvailabilityZones", "ec2:DescribeSubnets",
API-Version API Version 2016-01-0167

AWS Database Migration Service BenutzerhandbuchIAM-Rollen für die CLI und API
"ec2:DescribeSecurityGroups", "ec2:ModifyNetworkInterfaceAttribute", "ec2:CreateNetworkInterface", "ec2:DeleteNetworkInterface" ], "Resource": "*" }
Der folgende Abschnitt ist erforderlich, damit der Benutzer Replikations-Instance-Metriken anzeigen kann.
{ "Effect": "Allow", "Action": [ "cloudwatch:Get*", "cloudwatch:List*" ], "Resource": "*" }
Dieser Abschnitt ist erforderlich, damit der Benutzer Replikationsprotokolle anzeigen kann.
{ "Effect": "Allow", "Action": [ "logs:DescribeLogGroups", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogEvents" ], "Resource": "*" }
Der folgende Abschnitt ist erforderlich, wenn Amazon Redshift als Ziel verwendet wird. AWS DMS kanndamit überprüfen, ob der Amazon Redshift-Cluster korrekt für AWS DMS eingerichtet wurde.
{ "Effect": "Allow", "Action": [ "redshift:Describe*", "redshift:ModifyClusterIamRoles" ], "Resource": "*" }
Die AWS DMS-Konsole erstellt mehrere Rollen, die Ihrem AWS-Konto automatisch angefügt werden, wennSie die AWS DMS-Konsole verwenden. Wenn Sie die AWS Command Line Interface(AWS CLI)- oder dieAWS DMS-API für Ihre Migration verwenden, müssen Sie diese Rollen Ihrem Konto hinzufügen. WeitereInformationen zum Hinzufügen dieser Rollen finden Sie unter Erstellen der IAM-Rollen für die Verwendungmit der AWS CLI- und AWS DMS-API (p. 68).
Erstellen der IAM-Rollen für die Verwendung mit derAWS CLI- und AWS DMS-API
Wenn Sie die AWS CLI- oder die AWS DMS-API für Ihre Datenbankmigration verwenden, müssen SieIhrem AWS-Konto drei IAM-Rollen hinzufügen, bevor Sie die Funktionen von AWS DMS verwenden
API-Version API Version 2016-01-0168

AWS Database Migration Service BenutzerhandbuchIAM-Rollen für die CLI und API
können. Zwei dieser Optionen sind dms-vpc-role und dms-cloudwatch-logs-role. Wenn SieAmazon Redshift als Zieldatenbank verwenden, müssen Sie Ihrem AWS-Konto auch die IAM-Rolle dms-access-for-endpoint hinzufügen.
Aktualisierungen zu verwalteten Richtlinien erfolgen automatisch. Wenn Sie eine benutzerdefinierteRichtlinie mit den IAM-Rollen verwenden, stellen Sie sicher, dass Sie regelmäßig überprüfen, obAktualisierungen für die verwaltete Richtlinie in dieser Dokumentation vorliegen. Sie können die Details derverwalteten Richtlinie anzeigen, indem Sie eine Kombination der Befehle get-policy und get-policy-version verwenden.
Der folgende get-policy-Befehl ruft beispielsweise Informationen über die angegebene IAM-Rolle ab.
aws iam get-policy --policy-arn arn:aws:iam::aws:policy/service-role/AmazonDMSVPCManagementRole
Die von dem Befehl zurückgegebenen Informationen sind wie folgt.
{ "Policy": { "PolicyName": "AmazonDMSVPCManagementRole", "Description": "Provides access to manage VPC settings for AWS managed customer configurations", "CreateDate": "2015-11-18T16:33:19Z", "AttachmentCount": 1, "IsAttachable": true, "PolicyId": "ANPAJHKIGMBQI4AEFFSYO", "DefaultVersionId": "v3", "Path": "/service-role/", "Arn": "arn:aws:iam::aws:policy/service-role/AmazonDMSVPCManagementRole", "UpdateDate": "2016-05-23T16:29:57Z" }}
Mit dem folgenden get-policy-version-Befehl werden IAM-Richtlinieninformationen abgerufen.
aws iam get-policy-version --policy-arn arn:aws:iam::aws:policy/service-role/AmazonDMSVPCManagementRole --version-id v3
Die von dem Befehl zurückgegebenen Informationen sind wie folgt.
{ "PolicyVersion": { "CreateDate": "2016-05-23T16:29:57Z", "VersionId": "v3", "Document": { "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:CreateNetworkInterface", "ec2:DescribeAvailabilityZones", "ec2:DescribeInternetGateways",
API-Version API Version 2016-01-0169

AWS Database Migration Service BenutzerhandbuchIAM-Rollen für die CLI und API
"ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeVpcs", "ec2:DeleteNetworkInterface", "ec2:ModifyNetworkInterfaceAttribute" ], "Resource": "*", "Effect": "Allow" } ] }, "IsDefaultVersion": true }}
Sie können dieselben Befehle verwenden, um Informationen über AmazonDMSCloudWatchLogsRole unddie AmazonDMSRedshiftS3Role-verwaltete Richtlinie abrufen.
Note
Wenn Sie die AWS DMS-Konsole für die Migration Ihrer Datenbank verwenden, werden dieseRollen Ihrem AWS-Konto automatisch hinzugefügt.
Mit den folgenden Verfahren werden die IAM-Rollen dms-vpc-role, dms-cloudwatch-logs-role unddms-access-for-endpoint erstellt.
So erstellen Sie die IAM-Rolle dms-vpc-role für die Verwendung mit der AWS CLI- oder der AWSDMS-API:
1. Erstellen Sie eine JSON-Datei mit der folgenden IAM-Richtlinie. Weisen Sie der JSON-Datei dieBezeichnung dmsAssumeRolePolicyDocument.json zu.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "dms.amazonaws.com" }, "Action": "sts:AssumeRole" } ]}
Erstellen Sie die Rolle über die AWS CLI mithilfe des folgenden Befehls.
aws iam create-role --role-name dms-vpc-role --assume-role-policy-document file://dmsAssumeRolePolicyDocument.json
2. Fügen Sie die Richtlinie AmazonDMSVPCManagementRole mithilfe des folgenden Befehls an dms-vpc-role an.
aws iam attach-role-policy --role-name dms-vpc-role --policy-arn arn:aws:iam::aws:policy/service-role/AmazonDMSVPCManagementRole
API-Version API Version 2016-01-0170

AWS Database Migration Service BenutzerhandbuchIAM-Rollen für die CLI und API
So erstellen Sie die IAM-Rolle dms-cloudwatch-logs-role für die Verwendung mit der AWS CLI-oder der AWS DMS-API:
1. Erstellen Sie eine JSON-Datei mit der folgenden IAM-Richtlinie. Weisen Sie der JSON-Datei dieBezeichnung dmsAssumeRolePolicyDocument2.json zu.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "dms.amazonaws.com" }, "Action": "sts:AssumeRole" } ]}
Erstellen Sie die Rolle über die AWS CLI mithilfe des folgenden Befehls.
aws iam create-role --role-name dms-cloudwatch-logs-role --assume-role-policy-document file://dmsAssumeRolePolicyDocument2.json
2. Fügen Sie die Richtlinie AmazonDMSCloudWatchLogsRole mithilfe des folgenden Befehls an dms-cloudwatch-logs-role an.
aws iam attach-role-policy --role-name dms-cloudwatch-logs-role --policy-arn arn:aws:iam::aws:policy/service-role/AmazonDMSCloudWatchLogsRole
Wenn Sie Amazon Redshift als Zieldatenbank verwenden, müssen Sie die IAM-Rolle dms-access-for-endpoint erstellen, um den Zugriff auf Amazon S3 bereitzustellen.
So erstellen Sie die IAM-Rolle DMS-access-for-endpoint zur Verwendung mit Amazon Redshift alsZieldatenbank
1. Erstellen Sie eine JSON-Datei mit der folgenden IAM-Richtlinie. Weisen Sie der JSON-Datei dieBezeichnung dmsAssumeRolePolicyDocument3.json zu.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "1", "Effect": "Allow", "Principal": { "Service": "dms.amazonaws.com" }, "Action": "sts:AssumeRole"
API-Version API Version 2016-01-0171

AWS Database Migration Service BenutzerhandbuchDifferenzierte Zugriffskontrolle
}, { "Sid": "2", "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ]}
2. Erstellen Sie die Rolle über die AWS CLI mithilfe des folgenden Befehls.
aws iam create-role --role-name dms-access-for-endpoint --assume-role-policy-document file://dmsAssumeRolePolicyDocument3.json
3. Fügen Sie die Richtlinie AmazonDMSRedshiftS3Role mithilfe des folgenden Befehls an die Rolledms-access-for-endpoint an.
aws iam attach-role-policy --role-name dms-access-for-endpoint \ --policy-arn arn:aws:iam::aws:policy/service-role/AmazonDMSRedshiftS3Role
Sie sollten jetzt die IAM-Richtlinien zur Verfügung haben, um die AWS CLI- oder AWS DMS-API zuverwenden.
Differenzierte Zugriffskontrolle mitRessourcennamen und Ressourcen-Tags
Sie können Ressourcennamen und Ressourcen-Tags basierend auf Amazon-Ressourcennamen (ARNs)verwenden, um den Zugriff auf AWS DMS-Ressourcen zu verwalten. Dazu definieren Sie erlaubte Aktionenoder schließen Bedingungsanweisungen in IAM-Richtlinien ein.
Verwenden von Ressourcennamen für dieZugriffskontrolleSie können ein IAM-Benutzerkonto erstellen und eine Richtlinie basierend auf dem ARN der AWS DMS-Ressource zuweisen.
Mit der folgenden Richtlinie wird der Zugriff auf die AWS DMS-Replikations-Instance mit dem ARNarn:aws:dms:us-east-1:152683116:rep:DOH67ZTOXGLIXMIHKITV verweigert:
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "dms:*"
API-Version API Version 2016-01-0172

AWS Database Migration Service BenutzerhandbuchVerwenden von Ressourcennamen für die Zugriffskontrolle
], "Effect": "Deny", "Resource": "arn:aws:dms:us-east-1:152683116:rep:DOH67ZTOXGLIXMIHKITV" } ]}
Bei diesem Beispiel würden bei Geltung der Richtlinie die folgenden Befehle fehschlagen:
$ aws dms delete-replication-instance --replication-instance-arn "arn:aws:dms:us-east-1:152683116:rep:DOH67ZTOXGLIXMIHKITV"
A client error (AccessDeniedException) occurred when calling the DeleteReplicationInstance operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:DeleteReplicationInstance on resource: arn:aws:dms:us-east-1:152683116:rep:DOH67ZTOXGLIXMIHKITV
$ aws dms modify-replication-instance --replication-instance-arn "arn:aws:dms:us-east-1:152683116:rep:DOH67ZTOXGLIXMIHKITV"
A client error (AccessDeniedException) occurred when calling the ModifyReplicationInstance operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:ModifyReplicationInstance on resource: arn:aws:dms:us-east-1:152683116:rep:DOH67ZTOXGLIXMIHKITV
Sie können auch IAM-Richtlinien angeben, die den Zugriff auf AWS DMS-Endpunkte undReplikationsaufgaben einschränken.
Mit der folgenden Richtlinie wird der Zugriff auf einen AWS DMS-Endpunkt mithilfe des ARN des Endpunktseingeschränkt:
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "dms:*" ], "Effect": "Deny", "Resource": "arn:aws:dms:us-east-1:152683116:endpoint:D6E37YBXTNHOA6XRQSZCUGX" } ]}
Hier würden beispielsweise die folgenden Befehle fehlschlagen, wenn die Richtlinie, die den ARN desEndpunkts verwendet, gelten würde:
$ aws dms delete-endpoint --endpoint-arn "arn:aws:dms:us-east-1:152683116:endpoint:D6E37YBXTNHOA6XRQSZCUGX"
A client error (AccessDeniedException) occurred when calling the DeleteEndpoint operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:DeleteEndpoint on resource: arn:aws:dms:us-east-1:152683116:endpoint:D6E37YBXTNHOA6XRQSZCUGX
API-Version API Version 2016-01-0173

AWS Database Migration Service BenutzerhandbuchSteuern des Zugriffs mit Tags
$ aws dms modify-endpoint --endpoint-arn "arn:aws:dms:us-east-1:152683116:endpoint:D6E37YBXTNHOA6XRQSZCUGX"
A client error (AccessDeniedException) occurred when calling the ModifyEndpoint operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:ModifyEndpoint on resource: arn:aws:dms:us-east-1:152683116:endpoint:D6E37YBXTNHOA6XRQSZCUGX
Mit der folgenden Richtlinie wird der Zugriff auf eine AWS DMS-Aufgabe mithilfe des ARN der Aufgabeeingeschränkt:
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "dms:*" ], "Effect": "Deny", "Resource": "arn:aws:dms:us-east-1:152683116:task:UO3YR4N47DXH3ATT4YMWOIT" } ]}
Hier würden beispielsweise die folgenden Befehle fehlschlagen, wenn die Richtlinie, die den ARN derAufgabe verwendet, gelten würde.
$ aws dms delete-replication-task --replication-task-arn "arn:aws:dms:us-east-1:152683116:task:UO3YR4N47DXH3ATT4YMWOIT"
A client error (AccessDeniedException) occurred when calling the DeleteReplicationTask operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:DeleteReplicationTask on resource: arn:aws:dms:us-east-1:152683116:task:UO3YR4N47DXH3ATT4YMWOIT
Steuern des Zugriffs mit TagsAWS DMS definiert eine Reihe allgemeiner Schlüssel-Wert-Paare, die in benutzerdefinierten Richtlinienohne zusätzliche Tagging-Anforderungen verfügbar sind. Weitere Informationen über das Markieren mitTags von AWS DMS-Ressourcen finden Sie unter Taggen von Ressourcen in AWS Database MigrationService (p. 440).
Die folgende Liste enthält die Standard-Tags für die Verwendung mit AWS DMS:
• aws:CurrentTime – Stellt das Datum und die Uhrzeit der Anforderung dar, sodass eine Beschränkungdes Zugriffs basierend auf zeitlichen Kriterien möglich ist.
• aws:EpochTime – Dieses Tag ähnelt dem obigen aws:CurrentTime-Tag, mit der Ausnahme, dass dieaktuelle Zeit in Form der verstrichenen Sekunden seit der Unix-Epoche dargestellt wird.
• aws:MultiFactorAuthPresent – Hierbei handelt es sich um ein boolesches Tag, das angibt, ob dieAnforderung mit Multi-Factor Authentication signiert wurde.
• aws:MultiFactorAuthAge – Bietet Zugriff auf das Alter des Tokens der Multi-Factor Authentication (inSekunden).
API-Version API Version 2016-01-0174

AWS Database Migration Service BenutzerhandbuchSteuern des Zugriffs mit Tags
• aws:principaltype – bietet Zugriff auf den Prinzipaltyp (Benutzer, Konto, verbundener Benutzer usw.) fürdie aktuelle Anforderung.
• aws:SourceIp – Stellt die Quell-IP-Adresse für den Benutzer dar, der die Anforderung ausgibt.• aws:UserAgent – Bietet Informationen über die Client-Anwendung, die eine Ressource angefordert hat.• aws:userid – Bietet Zugriff auf die ID des Benutzers, der die Anforderung ausgibt.• aws:username – Bietet Zugriff auf den Namen des Benutzers, der die Anforderung ausgibt.• dms:InstanceClass – Bietet Zugriff auf die Datenverarbeitungsgröße der/s Replikations-Instance-Hosts.• dms:StorageSize – Bietet Zugriff auf die Speichergröße (in GB).
Sie können auch eigene Tags definieren. Benutzerdefinierte Tags sind einfache Schlüssel-Wert-Paare,die im AWS Tagging Service persistent sind. Sie können diese zu AWS DMS-Ressourcen hinzufügen,einschließlich Replikations-Instances, Endpunkte und Aufgaben. Diese Tags werden durch das Verwendenvon "konditionalen" IAM-Anweisungen in Richtlinien abgestimmt. Der Verweis auf diese Tags erfolgt mittelseines spezifischen konditionalen Tags. Die Tag-Schlüssel weisen das Präfix "dms", den Ressourcentyp unddas "tag"-Präfix auf. Im Folgenden sehen Sie das Tag-Format.
dms:{resource type}-tag/{tag key}={tag value}
Angenommen, Sie möchten eine Richtlinie definieren, durch die ein API-Aufruf nur dann erfolgreichdurchgeführt werden kann, wenn eine Replikations-Instance das Tag "stage=production" enthält. Diefolgende Bedingungsanweisung stimmt mit einer Ressource mit dem angegebenen Tag überein.
"Condition":{ "streq": { "dms:rep-tag/stage":"production" }}
Sie fügen das folgende Tag zu einer Replikations-Instance hinzu, die mit dieser Richtlinienbedingungübereinstimmt.
stage production
Zusätzlich zu bereits zu den AWS DMS-Ressourcen hinzugefügten Tags können Richtlinien auch erstelltwerden, um die Tag-Schlüssel und -Werte zu begrenzen, die auf eine bestimmte Ressource angewendetwerden können. In diesem Fall ist das Tag-Präfix "req".
Mit der folgenden Richtlinienanweisung werden die Tags auf eine bestimmte Liste zulässiger Wertebeschränkt, die ein Benutzer einer bestimmten Ressource zuweisen kann.
"Condition":{ "streq": { "dms:rep-tag/stage": [ "production", "development", "testing" ] }}
Die folgenden Richtlinienbeispiele beschränken den Zugriff auf eine AWS DMS-Ressource basierend aufRessourcen-Tags.
API-Version API Version 2016-01-0175

AWS Database Migration Service BenutzerhandbuchSteuern des Zugriffs mit Tags
Die folgende Richtlinie beschränkt den Zugriff auf eine Replikations-Instance, bei der der Tag-Wert"Desktop" und der Tag-Schlüssel "Env" ist:
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "dms:*" ], "Effect": "Deny", "Resource": "*", "Condition": { "StringEquals": { "dms:rep-tag/Env": [ "Desktop" ] } } } ]}
Die folgenden Befehle können erfolgreich ausgeführt werden oder schlagen fehl. Dies hängt von der IAM-Richtlinie ab, die den Zugriff einschränkt, wenn der Tag-Wert "Desktop" und der Tag-Schlüssel "Env" ist.
$ aws dms list-tags-for-resource --resource-name arn:aws:dms:us-east-1:152683116:rep:46DHOU7JOJYOJXWDOZNFEN --endpoint-url http://localhost:8000 { "TagList": [ { "Value": "Desktop", "Key": "Env" } ]}
$ aws dms delete-replication-instance --replication-instance-arn "arn:aws:dms:us-east-1:152683116:rep:46DHOU7JOJYOJXWDOZNFEN"A client error (AccessDeniedException) occurred when calling the DeleteReplicationInstance operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:DeleteReplicationInstance on resource: arn:aws:dms:us-east-1:152683116:rep:46DHOU7JOJYOJXWDOZNFEN
$ aws dms modify-replication-instance --replication-instance-arn "arn:aws:dms:us-east-1:152683116:rep:46DHOU7JOJYOJXWDOZNFEN"
A client error (AccessDeniedException) occurred when calling the ModifyReplicationInstance operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:ModifyReplicationInstance on resource: arn:aws:dms:us-east-1:152683116:rep:46DHOU7JOJYOJXWDOZNFEN
$ aws dms add-tags-to-resource --resource-name arn:aws:dms:us-east-1:152683116:rep:46DHOU7JOJYOJXWDOZNFEN --tags Key=CostCenter,Value=1234
A client error (AccessDeniedException) occurred when calling the AddTagsToResource operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:AddTagsToResource on resource: arn:aws:dms:us-east-1:152683116:rep:46DHOU7JOJYOJXWDOZNFEN
API-Version API Version 2016-01-0176

AWS Database Migration Service BenutzerhandbuchSteuern des Zugriffs mit Tags
$ aws dms remove-tags-from-resource --resource-name arn:aws:dms:us-east-1:152683116:rep:46DHOU7JOJYOJXWDOZNFEN --tag-keys Env
A client error (AccessDeniedException) occurred when calling the RemoveTagsFromResource operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:RemoveTagsFromResource on resource: arn:aws:dms:us-east-1:152683116:rep:46DHOU7JOJYOJXWDOZNFEN
Die folgende Richtlinie beschränkt den Zugriff auf einen AWS DMS-Endpunkt, bei dem der Tag-Wert„Desktop“ und der Tag-Schlüssel „Env“ ist.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "dms:*" ], "Effect": "Deny", "Resource": "*", "Condition": { "StringEquals": { "dms:endpoint-tag/Env": [ "Desktop" ] } } } ]}
Die folgenden Befehle können erfolgreich ausgeführt werden oder schlagen fehl. Dies hängt von der IAM-Richtlinie ab, die den Zugriff einschränkt, wenn der Tag-Wert "Desktop" und der Tag-Schlüssel "Env" ist.
$ aws dms list-tags-for-resource --resource-name arn:aws:dms:us-east-1:152683116:endpoint:J2YCZPNGOLFY52344IZWA6I{ "TagList": [ { "Value": "Desktop", "Key": "Env" } ]}
$ aws dms delete-endpoint --endpoint-arn "arn:aws:dms:us-east-1:152683116:endpoint:J2YCZPNGOLFY52344IZWA6I"
A client error (AccessDeniedException) occurred when calling the DeleteEndpoint operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:DeleteEndpoint on resource: arn:aws:dms:us-east-1:152683116:endpoint:J2YCZPNGOLFY52344IZWA6I
$ aws dms modify-endpoint --endpoint-arn "arn:aws:dms:us-east-1:152683116:endpoint:J2YCZPNGOLFY52344IZWA6I"
A client error (AccessDeniedException) occurred when calling the ModifyEndpoint
API-Version API Version 2016-01-0177

AWS Database Migration Service BenutzerhandbuchSteuern des Zugriffs mit Tags
operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:ModifyEndpoint on resource: arn:aws:dms:us-east-1:152683116:endpoint:J2YCZPNGOLFY52344IZWA6I
$ aws dms add-tags-to-resource --resource-name arn:aws:dms:us-east-1:152683116:endpoint:J2YCZPNGOLFY52344IZWA6I --tags Key=CostCenter,Value=1234
A client error (AccessDeniedException) occurred when calling the AddTagsToResource operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:AddTagsToResource on resource: arn:aws:dms:us-east-1:152683116:endpoint:J2YCZPNGOLFY52344IZWA6I
$ aws dms remove-tags-from-resource --resource-name arn:aws:dms:us-east-1:152683116:endpoint:J2YCZPNGOLFY52344IZWA6I --tag-keys Env
A client error (AccessDeniedException) occurred when calling the RemoveTagsFromResource operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:RemoveTagsFromResource on resource: arn:aws:dms:us-east-1:152683116:endpoint:J2YCZPNGOLFY52344IZWA6I
Die folgende Richtlinie beschränkt den Zugriff auf eine Replikationsaufgabe, bei der der Tag-Wert"Desktop" und der Tag-Schlüssel "Env" ist.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "dms:*" ], "Effect": "Deny", "Resource": "*", "Condition": { "StringEquals": { "dms:task-tag/Env": [ "Desktop" ] } } } ]}
Die folgenden Befehle können erfolgreich ausgeführt werden oder schlagen fehl. Dies hängt von der IAM-Richtlinie ab, die den Zugriff einschränkt, wenn der Tag-Wert "Desktop" und der Tag-Schlüssel "Env" ist.
$ aws dms list-tags-for-resource --resource-name arn:aws:dms:us-east-1:152683116:task:RB7N24J2XBUPS3RFABZTG3{ "TagList": [ { "Value": "Desktop", "Key": "Env" } ]}
API-Version API Version 2016-01-0178

AWS Database Migration Service BenutzerhandbuchFestlegen eines Verschlüsselungsschlüssels
$ aws dms delete-replication-task --replication-task-arn "arn:aws:dms:us-east-1:152683116:task:RB7N24J2XBUPS3RFABZTG3"
A client error (AccessDeniedException) occurred when calling the DeleteReplicationTask operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:DeleteReplicationTask on resource: arn:aws:dms:us-east-1:152683116:task:RB7N24J2XBUPS3RFABZTG3
$ aws dms add-tags-to-resource --resource-name arn:aws:dms:us-east-1:152683116:task:RB7N24J2XBUPS3RFABZTG3 --tags Key=CostCenter,Value=1234
A client error (AccessDeniedException) occurred when calling the AddTagsToResource operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:AddTagsToResource on resource: arn:aws:dms:us-east-1:152683116:task:RB7N24J2XBUPS3RFABZTG3
$ aws dms remove-tags-from-resource --resource-name arn:aws:dms:us-east-1:152683116:task:RB7N24J2XBUPS3RFABZTG3 --tag-keys Env
A client error (AccessDeniedException) occurred when calling the RemoveTagsFromResource operation: User: arn:aws:iam::152683116:user/dmstestusr is not authorized to perform: dms:RemoveTagsFromResource on resource: arn:aws:dms:us-east-1:152683116:task:RB7N24J2XBUPS3RFABZTG3
Einrichten eines Verschlüsselungsschlüssels undAngeben von AWS KMS-Berechtigungen
AWS DMS verschlüsselt den von einer Replikations-Instance verwendeten Speicher und dieVerbindungsinformationen für den Endpunkt. Um den von einer Replikations-Instance verwendetenSpeicher zu verschlüsseln, verwendet AWS DMS einen AWS Key Management Service(AWS KMS)-Schlüssel, der nur für Ihr AWS-Konto gültig ist. Sie können diesen Schlüssel mit AWS KMS anzeigenund verwalten. Sie können den Standard-AWS KMS-Schlüssel in Ihrem Konto (aws/dms) verwendenoder einen benutzerdefinierten AWS KMS-Schlüssel erstellen. Wenn Sie bereits über einen AWS KMS-Schlüssel verfügen, können Sie auch diesen für die Verschlüsselung verwenden.
Note
Jeder benutzerdefinierte oder vorhandene AWS KMS-Schlüssel, den Sie alsVerschlüsselungsschlüssel verwenden, muss ein symmetrischer Schlüssel sein. AWS DMSunterstützt die Verwendung asymmetrischer Verschlüsselungsschlüssel nicht. WeitereInformationen zu symmetrischen und asymmetrischen Verschlüsselungsschlüsseln findenSie https://docs.aws.amazon.com/kms/latest/developerguide/symmetric-asymmetric.html imEntwicklerhandbuch zum AWS Key Management Service.
Der Standard-AWS KMS-Schlüssel (aws/dms) wird erstellt, wenn Sie zum ersten Mal eine Replikations-Instance starten und keinen benutzerdefinierten AWS KMS-Masterschlüssel aus dem Bereich Advanced(Erweitert) der Seite Create Replication Instance (Replikations-Instance erstellen) ausgewählt haben. WennSie den Standard-AWS KMS-Schlüssel verwenden, müssen Sie dem IAM-Benutzerkonto, das Sie fürdie Migration verwenden, nur die Berechtigungen kms:ListAliases und kms:DescribeKey erteilen.Weitere Informationen zum Verwenden des Standard-AWS KMS-Schlüssels finden Sie unter ErforderlicheIAM-Berechtigungen zur Verwendung von AWS DMS (p. 65).
Um einen benutzerdefinierten AWS KMS-Schlüssel zu verwenden, weisen Sie Berechtigungen für denbenutzerdefinierten AWS KMS-Schlüssel mithilfe einer der folgenden Optionen zu:
API-Version API Version 2016-01-0179

AWS Database Migration Service BenutzerhandbuchFestlegen eines Verschlüsselungsschlüssels
• Fügen Sie das IAM-Benutzerkonto, das für die Migration verwendet wird, als Schlüsseladministratoroder Schlüsselbenutzer für den benutzerdefinierten AWS KMS-Schlüssel hinzu. Auf diese Weise wirdsichergestellt, dass dem IAM-Benutzerkonto die erforderlichen AWS KMS-Berechtigungen erteilt werden.Diese Aktion besteht zusätzlich zu den IAM-Berechtigungen, die Sie dem IAM-Benutzerkonto für dieNutzung von AWS DMS erteilen müssen. Weitere Informationen zum Erteilen von Berechtigungen füreinen Schlüsselbenutzer finden Sie unter Gestattet Schlüsselbenutzern die Verwendung des CMK imAWS Key Management Service Developer Guide.
• Wenn Sie das IAM-Benutzerkonto nicht als Schlüsseladministrator oder Schlüsselbenutzer für Ihrenbenutzerdefinierten AWS KMS-Schlüssel hinzufügen möchten, dann fügen Sie folgende zusätzlicheBerechtigungen zu den IAM-Berechtigungen hinzu, die Sie dem IAM-Benutzerkonto für die Nutzung vonAWS DMS erteilen müssen.
{ "Effect": "Allow", "Action": [ "kms:ListAliases", "kms:DescribeKey", "kms:CreateGrant", "kms:Encrypt", "kms:ReEncrypt*" ], "Resource": "*" },
AWS DMS funktioniert auch mit AWS KMS-Schlüsselaliassen. Weitere Informationen zum Erstellen Ihrereigenen AWS KMS-Schlüssel und zum Gewähren des Zugriffs auf einen AWS KMS-Schlüssel für Benutzerfinden Sie im Entwicklerhandbuch für KMS.
Wenn Sie keine AWS KMS-Schlüsselkennung angeben, verwendet AWS DMS IhrenStandardverschlüsselungsschlüssel. AWS KMS erstellt den Standardverschlüsselungsschlüsselfür AWS DMS für Ihr AWS-Konto. Ihr AWS-Konto verfügt für jede AWS-Region über einen anderenStandardverschlüsselungsschlüssel.
Verwenden Sie zur Verwaltung der AWS KMS-Schlüssel für die Verschlüsselung Ihrer AWS DMS-Ressourcen den AWS Key Management Service. AWS KMS kombiniert sichere, hoch verfügbare Hard-und Software, um ein System für die Schlüsselverwaltung bereitzustellen, das für die Cloud skaliert ist. MitAWS KMS können Sie Verschlüsselungsschlüssel erstellen und Richtlinien definieren, die steuern, wiediese Schlüssel verwendet werden können.
Sie finden AWS KMS im folgenden AWS Management Console
1. Melden Sie sich bei der AWS Management Console an und öffnen Sie die AWS Key ManagementService(AWS KMS)-Konsole unter https://console.aws.amazon.com/kms.
2. Um die AWS-Region zu ändern, verwenden Sie die Regionenauswahl in der oberen rechten Ecke derSeite.
3. Wählen Sie eine der folgenden Optionen, um mit AWS KMS-Schlüsseln zu arbeiten:
• Zum Anzeigen der Schlüssel in Ihrem Konto, die AWS für Sie erstellt und verwaltet, wählen Sie imNavigationsbereich AWS managed keys (Von AWS verwaltete Schlüssel) aus.
• Zum Anzeigen der Schlüssel in Ihrem Konto, die Sie erstellen und verwalten, wählen Sie imNavigationsbereich Customer managed keys (Vom Kunden verwaltete Schlüssel) aus.
AWS KMS unterstützt AWS CloudTrail, so dass Sie die Schlüsselverwendung prüfen und sicherstellenkönnen, dass die Schlüssel korrekt verwendet werden. Ihre AWS KMS-Schlüssel können in Kombination
API-Version API Version 2016-01-0180

AWS Database Migration Service BenutzerhandbuchNetzwerksicherheit
mit AWS DMS und unterstützten AWS-Services wie Amazon RDS, Amazon S3, Amazon Redshift undAmazon EBS verwendet werden.
Sie können auch benutzerdefinierte AWS KMS-Schlüssel speziell zum Verschlüsseln von Zieldaten für diefolgenden AWS DMS-Endpunkte erstellen:
• Amazon Redshift – Weitere Informationen finden Sie unter Erstellen und Verwenden von AWS KMS-Schlüsseln für die Verschlüsselung von Amazon Redshift-Zieldaten (p. 234).
• Amazon S3 – Weitere Informationen finden Sie unter Erstellen von AWS KMS-Schlüsseln zumVerschlüsseln von Amazon S3-Zielobjekten (p. 254).
Nachdem Sie Ihre AWS DMS-Ressourcen mit einem AWS KMS-Schlüssel erstellt haben, können Sie denVerschlüsselungsschlüssel für diese Ressourcen nicht mehr ändern. Stellen Sie sicher, die Anforderungenfür Ihre Verschlüsselungsschlüssel zu definieren, bevor Sie Ihre AWS DMS-Ressourcen erstellen.
Netzwerksicherheit für AWS Database MigrationService
Die Sicherheitsanforderungen für das Netzwerk, das Sie erstellen, wenn Sie AWS Database MigrationService verwenden, hängen davon ab, wie Sie das Netzwerk konfigurieren. Die allgemeinen Regeln zurNetzwerksicherheit für AWS DMS lauten wie folgt:
• Die Replikations-Instance muss Zugriff auf die Quell- und Zielendpunkte haben. Die Sicherheitsgruppefür die Replikations-Instance muss Netzwerk-ACLs oder Regeln haben, die den Ausgang von derInstance über den Datenbankport zu den Datenbankendpunkten erlauben.
• Datenbankendpunkte müssen Netzwerk-ACLs und Sicherheitsgruppenregeln beinhalten, dieeingehenden Zugriff von der Replikations-Instance erlauben. Sie können dies mithilfe derSicherheitsgruppe der Replikations-Instance, der privaten IP-Adresse, der öffentlichen IP-Adresse oderder öffentlichen Adresse des NAT-Gateways erreichen, je nach Konfiguration.
• Wenn Ihr Netzwerk einen VPN-Tunnel verwendet, muss die Amazon EC2-Instance, die als NAT-Gateway fungiert, eine Sicherheitsgruppe mit Regeln verwenden, die der Replikations-Instance erlauben,Datenverkehr durch sie zu senden.
Standardmäßig hat die VPC-Sicherheitsgruppe, die von der AWS DMS-Replikations-Instance verwendetwird, Regeln, die den Ausgang zu 0.0.0.0/0 auf allen Ports erlauben. Wenn Sie diese Sicherheitsgruppeändern oder Ihre eigene Sicherheitsgruppe Egress verwenden, muss der Ausgang mindestens zu denQuell- und Zielendpunkten auf den jeweiligen Datenbankports zugelassen werden.
Die Netzwerkkonfigurationen, die Sie für die Datenbankmigration verwenden können, erfordern spezifischeSicherheitsüberlegungen:
• Konfiguration mit allen Datenbankmigrationskomponenten in einer VPC (p. 103) — DieSicherheitsgruppe, die von den Endpunkten verwendet wird, muss den Eingang über den Datenbankportvon der Replikations-Instance erlauben. Stellen Sie sicher, dass die von der Replikations-Instanceverwendete Sicherheitsgruppe Eingang zu den Endpunkten hat, oder Sie können eine Regel in der vonden Endpunkten verwendeten Sicherheitsgruppe erstellen, die der privaten IP-Adresse der Replikations-Instance den Zugriff erlaubt.
• Konfiguration mit zwei VPCs (p. 104) — Die Sicherheitsgruppe, die von der Replikations-Instanceverwendet wird, muss eine Regel für den VPC-Bereich und den DB-Port auf der Datenbank haben.
• Konfiguration eines Netzwerks zu einer VPC über AWS Direct Connect oder VPN (p. 104) — einVPN-Tunnel, der Datenverkehr durch einen Tunnel aus der VPC in ein lokales VPN erlaubt. Bei dieser
API-Version API Version 2016-01-0181

AWS Database Migration Service BenutzerhandbuchVerwenden von SSL
Konfiguration enthält das VPC eine Routing-Regel, die Datenverkehr, der für eine IP-Adresse oder einenIP-Bereich bestimmt ist, zu einem Host sendet, der den Datenverkehr aus der VPC in das lokale VPNleiten kann. In diesem Fall verfügt der NAT-Host über eigene Sicherheitsgruppeneinstellungen, die denDatenverkehr von der privaten IP-Adresse oder Sicherheitsgruppe der Replikations-Instance zur NAT-Instance zulassen muss.
• Konfiguration eines Netzwerks zu einer VPC über das Internet (p. 105) — Die VPC-Sicherheitsgruppemuss Routing-Regeln enthalten, die den nicht für die VPC bestimmten Datenverkehr an das Internet-Gateway sendet. In dieser Konfiguration scheint es, dass die Verbindung zum Endpunkt von deröffentlichen IP-Adresse auf der Replikations-Instance kommt.
• Konfiguration mit einer Amazon RDS-DB-Instance, die sich nicht in einer VPC befindet, zu einer DB-Instance in einer VPC über ClassicLink (p. 105) — Wenn die Amazon RDS-Quell- oder Ziel-DB-Instance sich nicht in einem VPC befindet und keine Sicherheitsgruppe mit der VPC teilt, in der sich dieReplikations-Instance befindet, können Sie einen Proxy-Server einrichten und ClassicLink verwenden,um die Quell- und Zieldatenbanken zu verbinden.
• Der Quellendpunkt befindet sich außerhalb der von der Replikations-Instance verwendeten VPC undverwendet NAT-Gateway – Sie können ein NAT-Gateway (Network Address Translation) mit einereinzelnen Elastic IP-Adresse konfigurieren, die an eine einzelne Elastic Network-Schnittstelle gebundenist. Diese Elastic Network-Schnittstelle empfängt dann eine NAT-Kennung (nat- # # # # #). Wenn dieVPC eine Standardroute zu diesem NAT-Gateway anstatt zum Internet-Gateway enthält, scheint dieReplikations-Instance den Datenbankendpunkt mit der öffentlichen IP-Adresse des Internet-Gatewayszu kontaktieren. In diesem Fall muss der Eingang zum Datenbankendpunkt außerhalb der VPC denEingang von der NAT-Adresse anstatt von der öffentlichen IP-Adresse der Replikations-Instanceerlauben.
Verwenden von SSL mit AWS Database MigrationService
Sie können Verbindungen für Quell- und Zielendpunkte mithilfe von SSL (Secure Sockets Layer)verschlüsseln. Um dies zu tun, können Sie mithilfe der AWS DMS-Managementkonsole oder der AWSDMS-API ein Zertifikat einem Endpunkt zuweisen. Sie können mithilfe der AWS DMS-Konsole auch IhreZertifikate verwalten.
Nicht alle Datenbanken verwenden SSL auf die gleiche Weise. Amazon Aurora mit MySQL-Kompatibilitätverwendet den Servernamen, den Endpunkt der primären Instance im Cluster, als Endpunkt für SSL. EinAmazon Redshift-Endpunkt verwendet bereits eine SSL-Verbindung und erfordert nicht die Einrichtungeiner SSL-Verbindung durch AWS DMS. Ein Oracle-Endpunkt erfordert zusätzliche Schritte. WeitereInformationen finden Sie unter SSL-Unterstützung für einen Oracle-Endpunkt (p. 86).
Themen• Einschränkungen bei der Verwendung von SSL mit AWS DMS (p. 83)• Verwalten von Zertifikaten (p. 84)• Aktivieren von SSL für einen MySQL-kompatiblen, PostgreSQL- oder SQL Server-Endpunkt (p. 84)• SSL-Unterstützung für einen Oracle-Endpunkt (p. 86)
Um ein Zertifikat einem Endpunkt zuzuweisen, geben Sie das Stammzertifikat oder die Kette derZertifikate von Zwischenzertifizierungsstellen an, die zu dem Stammzertifikat führen (als Zertifikat-Paket), mit dem das Server-SSL-Zertifikat signiert wurde, das auf dem Endpunkt bereitgestellt ist.Zertifikate werden nur als PEM-formatierte X.509-Dateien akzeptiert. Wenn Sie ein Zertifikat importieren,erhalten Sie einen ARN (Amazon Resource Name), mit dem Sie dieses Zertifikat für einen Endpunktangeben können. Wenn Sie Amazon RDS verwenden, können Sie die Stammzertifizierungsstelle und dasZertifikatbündel herunterladen, die in der von Amazon RDS gehosteten rds-combined-ca-bundle.pem-
API-Version API Version 2016-01-0182
AWS Database Migration Service BenutzerhandbuchEinschränkungen bei der
Verwendung von SSL mit AWS DMS
Datei bereitgestellt werden. Weitere Informationen zum Herunterladen dieser Datei finden Sie unterVerwenden von SSL/TLS für die Verschlüsselung einer Verbindung zu einer DB-Instance im Amazon RDS-Benutzerhandbuch.
Sie können verschiedene SSL-Modi für die Überprüfung des SSL-Zertifikats auswählen.
• none – Die Verbindung ist nicht verschlüsselt. Diese Option ist nicht sicher, erfordert jedoch wenigerAufwand.
• require – Die Verbindung ist mit SSL (TLS) verschlüsselt, es wird aber keine CA-Verifizierungdurchgeführt. Diese Option ist sicherer und erfordert mehr Aufwand.
• verify-ca – Die Verbindung ist verschlüsselt. Diese Option ist sicherer und erfordert mehr Aufwand. DieseOption überprüft das Serverzertifikat.
• verify-full – Die Verbindung ist verschlüsselt. Diese Option ist sicherer und erfordert mehr Aufwand. DieseOption überprüft das Serverzertifikat und prüft, ob der Server-Hostname dem Hostnamen-Attribut für dasZertifikat entspricht.
Nicht alle SSL-Modi funktionieren mit allen Datenbankendpunkten. Die folgende Tabelle zeigt, welche SSL-Modi für jede Datenbank-Engine unterstützt werden.
DB-Engine Keine require verify-ca verify-full
MySQL/MariaDB/Amazon Aurora MySQL
Standard Nicht unterstützt Unterstützt Unterstützt
Microsoft SQL Server Standard Unterstützt Nicht unterstützt Unterstützt
PostgreSQL Standard Unterstützt Unterstützt Unterstützt
Amazon Redshift Standard SSL nichtaktiviert
SSL nichtaktiviert
SSL nichtaktiviert
Oracle Standard Nicht unterstützt Unterstützt Nicht unterstützt
SAP ASE Standard SSL nichtaktiviert
SSL nichtaktiviert
Unterstützt
MongoDB Standard Unterstützt Nicht unterstützt Unterstützt
Db2 LUW Standard Nicht unterstützt Unterstützt Nicht unterstützt
Einschränkungen bei der Verwendung von SSL mitAWS DMSIm Folgenden werden Einschränkungen bei der Verwendung von SSL mit AWS DMS aufgeführt:
• SSL-Verbindungen zu Amazon Redshift-Zielendpunkten werden nicht unterstützt. AWS DMS verwendeteinen Amazon S3-Bucket, um Daten in die Amazon Redshift-Datenbank zu übertragen. DieseÜbertragung ist standardmäßig von Amazon Redshift verschlüsselt.
• SQL-Timeouts können auftreten, wenn CDC Aufgaben (Change Data Capture) mit SSL-fähigenOracle-Endpunkten durchgeführt werden. Wenn dieses Problem auftritt, wobei CDC-Zähler nicht dieerwarteten Zahlen anzeigen, legen Sie den Parameter MinimumTransactionSize aus dem AbschnittChangeProcessingTuning der Aufgabeneinstellungen auf einen niedrigeren Wert fest. Sie könnenmit einem Wert von 100 beginnen. Weitere Informationen zum Parameter MinimumTransactionSizeerhalten Sie unter Einstellungen für die Optimierung der Verarbeitung von Änderungen (p. 350).
API-Version API Version 2016-01-0183
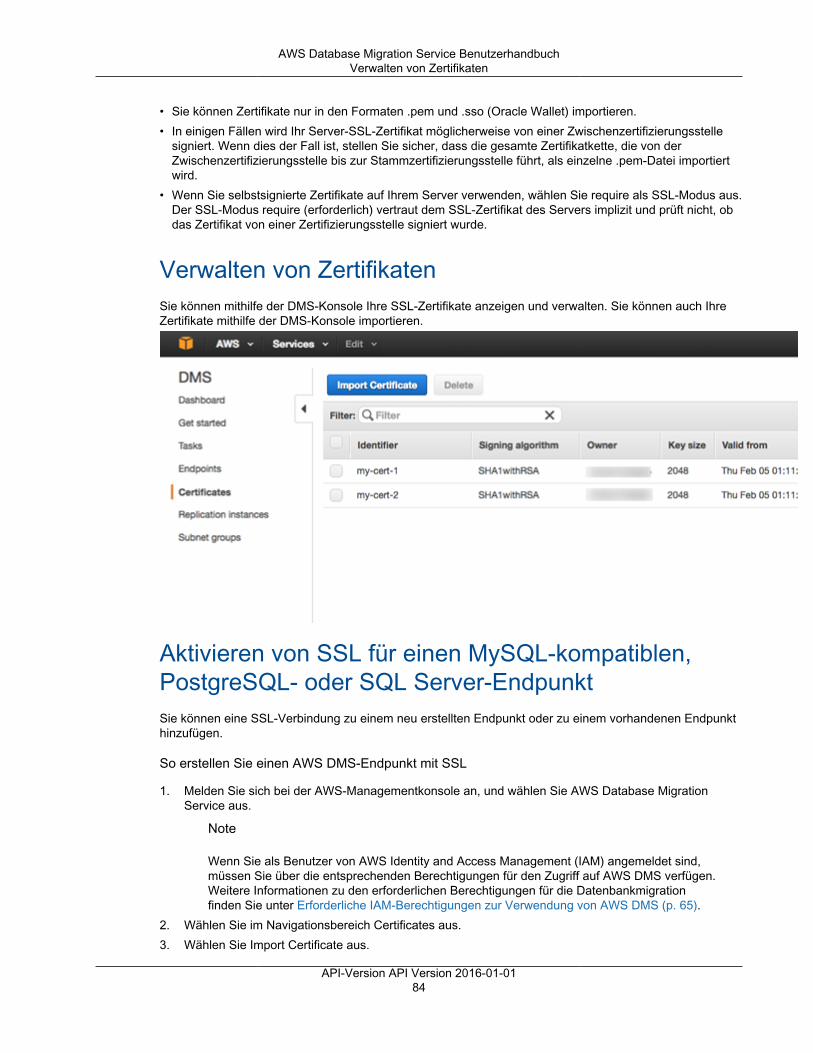
AWS Database Migration Service BenutzerhandbuchVerwalten von Zertifikaten
• Sie können Zertifikate nur in den Formaten .pem und .sso (Oracle Wallet) importieren.• In einigen Fällen wird Ihr Server-SSL-Zertifikat möglicherweise von einer Zwischenzertifizierungsstelle
signiert. Wenn dies der Fall ist, stellen Sie sicher, dass die gesamte Zertifikatkette, die von derZwischenzertifizierungsstelle bis zur Stammzertifizierungsstelle führt, als einzelne .pem-Datei importiertwird.
• Wenn Sie selbstsignierte Zertifikate auf Ihrem Server verwenden, wählen Sie require als SSL-Modus aus.Der SSL-Modus require (erforderlich) vertraut dem SSL-Zertifikat des Servers implizit und prüft nicht, obdas Zertifikat von einer Zertifizierungsstelle signiert wurde.
Verwalten von ZertifikatenSie können mithilfe der DMS-Konsole Ihre SSL-Zertifikate anzeigen und verwalten. Sie können auch IhreZertifikate mithilfe der DMS-Konsole importieren.
Aktivieren von SSL für einen MySQL-kompatiblen,PostgreSQL- oder SQL Server-EndpunktSie können eine SSL-Verbindung zu einem neu erstellten Endpunkt oder zu einem vorhandenen Endpunkthinzufügen.
So erstellen Sie einen AWS DMS-Endpunkt mit SSL
1. Melden Sie sich bei der AWS-Managementkonsole an, und wählen Sie AWS Database MigrationService aus.
Note
Wenn Sie als Benutzer von AWS Identity and Access Management (IAM) angemeldet sind,müssen Sie über die entsprechenden Berechtigungen für den Zugriff auf AWS DMS verfügen.Weitere Informationen zu den erforderlichen Berechtigungen für die Datenbankmigrationfinden Sie unter Erforderliche IAM-Berechtigungen zur Verwendung von AWS DMS (p. 65).
2. Wählen Sie im Navigationsbereich Certificates aus.3. Wählen Sie Import Certificate aus.
API-Version API Version 2016-01-0184

AWS Database Migration Service BenutzerhandbuchAktivieren von SSL für einen MySQL-kompatiblen,
PostgreSQL- oder SQL Server-Endpunkt
4. Laden Sie das Zertifikat hoch, das Sie zur Verschlüsselung der Verbindung zu einem Endpunktverwenden möchten.
Note
Sie können auch ein Zertifikat mithilfe der AWS DMS-Konsole hochladen, wenn Sie einenEndpunkt erstellen oder ändern, indem Sie Add new CA certificate (Neues CA-Zertifikathinzufügen) auf der Seite Create database endpoint (Datenbank-Endpunkt erstellen)auswählen.
5. Erstellen Sie einen Endpunkt wie beschrieben unter Schritt 3: Geben Sie Quell- und Zielendpunktean (p. 28)
So ändern Sie einen vorhandenen AWS DMS-Endpunkt für die Verwendung von SSL:
1. Melden Sie sich bei der AWS-Managementkonsole an, und wählen Sie AWS Database MigrationService aus.
Note
Wenn Sie als Benutzer von AWS Identity and Access Management (IAM) angemeldet sind,müssen Sie über die entsprechenden Berechtigungen für den Zugriff auf AWS DMS verfügen.Weitere Informationen zu den erforderlichen Berechtigungen für die Datenbankmigrationfinden Sie unter Erforderliche IAM-Berechtigungen zur Verwendung von AWS DMS (p. 65).
2. Wählen Sie im Navigationsbereich Certificates aus.3. Wählen Sie Import Certificate aus.4. Laden Sie das Zertifikat hoch, das Sie zur Verschlüsselung der Verbindung zu einem Endpunkt
verwenden möchten.
Note
Sie können auch ein Zertifikat mithilfe der AWS DMS-Konsole hochladen, wenn Sie einenEndpunkt erstellen oder ändern, indem Sie Add new CA certificate (Neues CA-Zertifikathinzufügen) auf der Seite Create database endpoint (Datenbank-Endpunkt erstellen)auswählen.
5. Wählen Sie im Navigationsbereich die Option Endpoints aus. Wählen Sie dann den Endpunkt aus, denSie ändern möchten, und klicken Sie auf Modify.
6. Wählen Sie einen Wert für den SSL-Modus.
Wenn Sie den Modus verify-ca oder verify-full wählen, geben Sie das Zertifikat an, das Sie für das CAcertificate (Zertifizierungsstellenzertifikat) verwenden möchten (siehe unten).
API-Version API Version 2016-01-0185
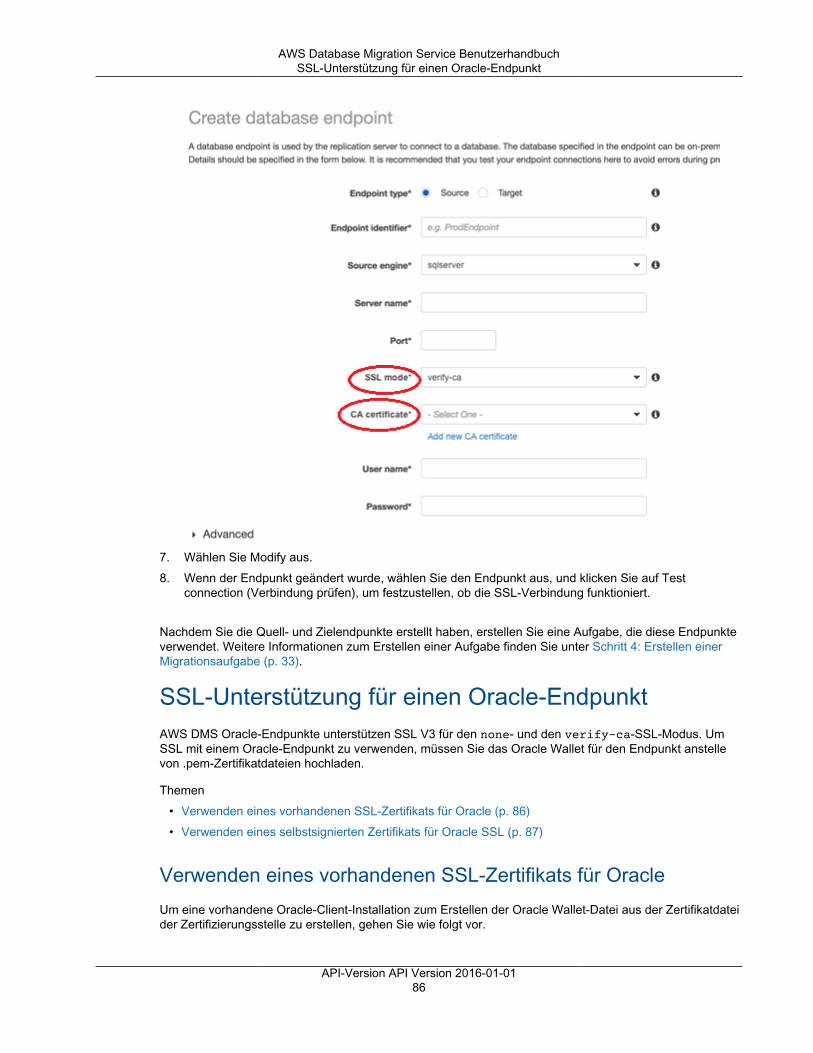
AWS Database Migration Service BenutzerhandbuchSSL-Unterstützung für einen Oracle-Endpunkt
7. Wählen Sie Modify aus.8. Wenn der Endpunkt geändert wurde, wählen Sie den Endpunkt aus, und klicken Sie auf Test
connection (Verbindung prüfen), um festzustellen, ob die SSL-Verbindung funktioniert.
Nachdem Sie die Quell- und Zielendpunkte erstellt haben, erstellen Sie eine Aufgabe, die diese Endpunkteverwendet. Weitere Informationen zum Erstellen einer Aufgabe finden Sie unter Schritt 4: Erstellen einerMigrationsaufgabe (p. 33).
SSL-Unterstützung für einen Oracle-EndpunktAWS DMS Oracle-Endpunkte unterstützen SSL V3 für den none- und den verify-ca-SSL-Modus. UmSSL mit einem Oracle-Endpunkt zu verwenden, müssen Sie das Oracle Wallet für den Endpunkt anstellevon .pem-Zertifikatdateien hochladen.
Themen• Verwenden eines vorhandenen SSL-Zertifikats für Oracle (p. 86)• Verwenden eines selbstsignierten Zertifikats für Oracle SSL (p. 87)
Verwenden eines vorhandenen SSL-Zertifikats für OracleUm eine vorhandene Oracle-Client-Installation zum Erstellen der Oracle Wallet-Datei aus der Zertifikatdateider Zertifizierungsstelle zu erstellen, gehen Sie wie folgt vor.
API-Version API Version 2016-01-0186

AWS Database Migration Service BenutzerhandbuchSSL-Unterstützung für einen Oracle-Endpunkt
So verwenden Sie eine vorhandene Oracle-Client-Installation für Oracle-SSL mit AWS DMS:
1. Legen Sie die Systemvariable ORACLE_HOME auf den Pfad Ihres dbhome_1-Verzeichnisses fest,indem Sie den folgenden Befehl ausführen:
prompt>export ORACLE_HOME=/home/user/app/user/product/12.1.0/dbhome_1
2. Hängen Sie $ORACLE_HOME/lib an die Systemvariable LD_LIBRARY_PATH an.
prompt>export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$ORACLE_HOME/lib
3. Erstellen Sie ein Oracle Wallet-Verzeichnis unter $ORACLE_HOME/ssl_wallet.
prompt>mkdir $ORACLE_HOME/ssl_wallet
4. Legen Sie die CA-Zertifikatdatei .pem im Verzeichnis ssl_wallet ab. Wenn Sie Amazon RDSverwenden, können Sie die von Amazon RDS gehostete Stammzertifikatdatei rds-ca-2015-root.pem der Zertifizierungsstelle herunterladen. Weitere Informationen zum Herunterladen dieserDatei finden Sie unter Verwenden von SSL/TLS für die Verschlüsselung einer Verbindung zu einer DB-Instance im Amazon RDS-Benutzerhandbuch.
5. Führen Sie die folgenden Befehle zur Oracle Wallet-Erstellung aus.
prompt>orapki wallet create -wallet $ORACLE_HOME/ssl_wallet -auto_login_only
prompt>orapki wallet add -wallet $ORACLE_HOME/ssl_wallet -trusted_cert –cert $ORACLE_HOME/ssl_wallet/ca-cert.pem -auto_login_only
Wenn Sie die vorherigen Schritte ausgeführt haben, können Sie die Wallet-Datei mit der ImportCertificate-API importieren, indem Sie den Parameter "certificate-wallet" angeben. Sie können das importierte Wallet-Zertifikat dann verwenden, wenn Sie verify-ca als SSL-Modus beim Erstellen oder Ändern Ihres Oracle-Endpunkts auswählen.
Note
Oracle Wallets sind Binärdateien. AWS DMS akzeptiert diese Dateien ohne Änderung.
Verwenden eines selbstsignierten Zertifikats für Oracle SSLUm ein selbstsigniertes Zertifikat für Oracle SSL zu verwenden, gehen Sie wie folgt vor.
So verwenden Sie ein selbstsigniertes Zertifikat für Oracle SSL mit AWS DMS:
1. Erstellen Sie ein Verzeichnis für die Arbeit mit dem selbstsignierten Zertifikat.
mkdir <SELF_SIGNED_CERT_DIRECTORY>
2. Wechseln Sie in das Verzeichnis, das Sie im vorherigen Schritt erstellt haben.
API-Version API Version 2016-01-0187

AWS Database Migration Service BenutzerhandbuchSSL-Unterstützung für einen Oracle-Endpunkt
cd <SELF_SIGNED_CERT_DIRECTORY>
3. Erstellen Sie einen Stammschlüssel.
openssl genrsa -out self-rootCA.key 2048
4. Signieren Sie selbst ein Stammzertifikat mithilfe des Stammschlüssels, den Sie im vorherigen Schritterstellt haben.
openssl req -x509 -new -nodes -key self-rootCA.key -sha256 -days 1024 -out self-rootCA.pem
5. Erstellen Sie ein Oracle Wallet-Verzeichnis für die Oracle-Datenbank.
mkdir $ORACLE_HOME/self_signed_ssl_wallet
6. Erstellen Sie ein neues Oracle Wallet.
orapki wallet create -wallet $ORACLE_HOME/self_signed_ssl_wallet -pwd <password> -auto_login_local
7. Fügen Sie das Stammzertifikat dem Oracle Wallet hinzu.
orapki wallet add -wallet $ORACLE_HOME/self_signed_ssl_wallet -trusted_cert -cert self-rootCA.pem -pwd <password>
8. Listen Sie den Inhalt des Oracle Wallet auf. Die Liste sollte das Stammzertifikat enthalten.
orapki wallet display -wallet $ORACLE_HOME/self_signed_ssl_wallet
9. Generieren Sie die CSR (Certificate Signing Request) mithilfe des ORAPKI-Dienstprogramms.
orapki wallet add -wallet $ORACLE_HOME/self_signed_ssl_wallet -dn "CN=dms" -keysize 2048 -sign_alg sha256 -pwd <password>
10. Führen Sie den folgenden Befehl aus.
openssl pkcs12 -in $ORACLE_HOME/self_signed_ssl_wallet/ewallet.p12 -nodes -out nonoracle_wallet.pem
11. Legen Sie "dms" als allgemeinen Namen fest.
openssl req -new -key nonoracle_wallet.pem -out certrequest.csr
12. Rufen Sie die Zertifikatsignatur ab.
openssl req -noout -text -in certrequest.csr | grep -i signature
13. Wenn die Ausgabe von Schritt 12 sha1WithRSAEncryption oder sha256WithRSAEncryption ist, führenSie den folgenden Code aus.
openssl x509 -req -in certrequest.csr -CA self-rootCA.pem-CAkey self-rootCA.key -CAcreateserial-out certrequest.crt -days 365 -sha256
14. Wenn die Ausgabe aus Schritt 12 md5WithRSAEncryption ist, führen Sie den folgenden Code aus.
API-Version API Version 2016-01-0188

AWS Database Migration Service BenutzerhandbuchSSL-Unterstützung für einen Oracle-Endpunkt
openssl x509 -req -in certrequest.csr -CA self-rootCA.pem -CAkey self-rootCA.key -CAcreateserial -out certrequest.crt -days 365 -sha256
15. Fügen Sie das Zertifikat dem Wallet hinzu.
orapki wallet add -wallet $ORACLE_HOME/self_signed_ssl_wallet -user_cert -cert certrequest.crt -pwd <password>
16. Konfigurieren Sie die Datei sqlnet.ora ($ORACLE_HOME/network/admin/sqlnet.ora).
WALLET_LOCATION = (SOURCE = (METHOD = FILE) (METHOD_DATA = (DIRECTORY = <ORACLE_HOME>/self_signed_ssl_wallet) ) )
SQLNET.AUTHENTICATION_SERVICES = (NONE)SSL_VERSION = 1.0SSL_CLIENT_AUTHENTICATION = FALSESSL_CIPHER_SUITES = (SSL_RSA_WITH_AES_256_CBC_SHA)
17. Beenden Sie den Oracle Listener.
lsnrctl stop
18. Fügen Sie in der Datei listener.ora Einträge für SSL hinzu (($ORACLE_HOME/network/admin/listener.ora).
SSL_CLIENT_AUTHENTICATION = FALSEWALLET_LOCATION = (SOURCE = (METHOD = FILE) (METHOD_DATA = (DIRECTORY = <ORACLE_HOME>/self_signed_ssl_wallet) ) )
SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (GLOBAL_DBNAME = <SID>) (ORACLE_HOME = <ORACLE_HOME>) (SID_NAME = <SID>) ) )
LISTENER = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = localhost.localdomain)(PORT = 1521)) (ADDRESS = (PROTOCOL = TCPS)(HOST = localhost.localdomain)(PORT = 1522)) (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521)) ) )
19. Konfigurieren Sie die Datei tnsnames.ora ($ORACLE_HOME/network/admin/tnsnames.ora).
<SID>=
API-Version API Version 2016-01-0189

AWS Database Migration Service BenutzerhandbuchSSL-Unterstützung für einen Oracle-Endpunkt
(DESCRIPTION= (ADDRESS_LIST = (ADDRESS=(PROTOCOL = TCP)(HOST = localhost.localdomain)(PORT = 1521)) ) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = <SID>) ))
<SID>_ssl=(DESCRIPTION= (ADDRESS_LIST = (ADDRESS=(PROTOCOL = TCPS)(HOST = localhost.localdomain)(PORT = 1522)) ) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = <SID>) ))
20. Starten Sie den Oracle Listener neu.
lsnrctl start
21. Zeigen Sie den Status des Oracle Listener an.
lsnrctl status
22. Testen Sie die SSL-Verbindung zu der Datenbank von "localhost" mithilfe von sqlplus und dem SSL-Eintrag "tnsnames".
sqlplus -L <ORACLE_USER>@<SID>_ssl
23. Überprüfen Sie, dass Sie sich erfolgreich mithilfe von SSL verbunden haben.
SELECT SYS_CONTEXT('USERENV', 'network_protocol') FROM DUAL;
SYS_CONTEXT('USERENV','NETWORK_PROTOCOL')--------------------------------------------------------------------------------tcps
24. Wechseln Sie zu dem Verzeichnis mit dem selbstsignierten Zertifikat.
cd <SELF_SIGNED_CERT_DIRECTORY>
25. Erstellen Sie ein neues Client-Oracle Wallet, das AWS DMS verwenden wird.
orapki wallet create -wallet ./ -auto_login_only
26. Fügen Sie das selbstsignierte Stammzertifikat dem Oracle Wallet hinzu.
orapki wallet add -wallet ./ -trusted_cert -cert rootCA.pem -auto_login_only
27. Listen Sie den Inhalt des Oracle Wallet auf, das AWS DMS verwenden wird. Die Liste sollte dasselbstsignierte Stammzertifikat enthalten.
orapki wallet display -wallet ./
28. Laden Sie das Oracle Wallet, das Sie gerade erstellt haben, zu AWS DMS hoch.
API-Version API Version 2016-01-0190

AWS Database Migration Service BenutzerhandbuchÄndern des Datenbankpassworts
Ändern des DatenbankpasswortsIn den meisten Fällen lässt sich das Datenbankpasswort für Ihren Quell- oder Zielendpunkt einfachändern. Falls Sie das Datenbankpasswort für einen Endpunkt ändern müssen, den Sie gegenwärtig ineiner Migrations- oder Replikationsaufgabe verwenden, ist der Prozess etwas komplexer. Das folgendeVerfahren zeigt, wie Sie dies tun können.
So ändern Sie das Datenbankpasswort für einen Endpunkt in einer Migrations- oderReplikationsaufgabe
1. Melden Sie sich bei der AWS-Managementkonsole an, und wählen Sie AWS DMS aus. Wenn Sie alsBenutzer von AWS Identity and Access Management (IAM) angemeldet sind, müssen Sie über dieentsprechenden Berechtigungen für den Zugriff auf AWS DMS verfügen. Weitere Informationen zu denerforderlichen Berechtigungen finden Sie unter Erforderliche IAM-Berechtigungen zur Verwendung vonAWS DMS (p. 65).
2. Wählen Sie im Navigationsbereich Tasks aus.3. Wählen Sie die Aufgabe aus, die den Endpunkt verwendet, für den Sie das Datenbankpasswort ändern
möchten, und klicken Sie dann auf Stop.4. Während die Aufgabe beendet wird, können Sie das Passwort der Datenbank für den Endpunkt
mithilfe der nativen Tools ändern, die Sie für die Arbeit mit der Datenbank verwenden.5. Kehren Sie zur DMS Management Console zurück und wählen Sie im Navigationsbereich Endpoints
aus.6. Wählen Sie den Endpunkt für die Datenbank aus, für die Sie das Passwort geändert haben, und
klicken Sie dann auf Modify.7. Geben Sie das neue Passwort in das Feld Password ein und wählen Sie Modify aus.8. Wählen Sie im Navigationsbereich Tasks aus.9. Wählen Sie die Aufgabe aus, die Sie zuvor gestoppt haben, und wählen Sie Start/Resume aus.10. Wählen Sie entweder Start oder Resume aus, je nachdem, wie Sie mit der Aufgabe fortfahren
möchten, und wählen Sie dann Start task aus.
API-Version API Version 2016-01-0191

AWS Database Migration Service BenutzerhandbuchLimits für AWS Database Migration Service
Limits für AWS Database MigrationService
Im Folgenden finden Sie die Ressourcen-Limits und Benennungseinschränkungen für AWS DatabaseMigration Service (AWS DMS).
Die maximale Größe einer Datenbank, die von AWS DMS migriert werden kann, hängt von derQuellumgebung, der Verteilung von Daten in der Quelldatenbank und der Auslastung des Quellsystemsab. Ob Ihr System für AWS DMS geeignet ist, können Sie am besten feststellen, indem Sie es testen.Beginnen Sie langsam, damit Sie sich mit der Konfiguration vertraut machen können. Fügen Sie danneinige komplexe Objekte hinzu und führen Sie abschließend einen vollständigen Ladevorgang als Test aus.
Limits für AWS Database Migration ServiceFür jedes AWS-Konto gelten regionsbasierte Limits in Bezug auf die Anzahl der AWS DMS-Ressourcen,die erstellt werden können. Sobald eine Größenbeschränkung für eine Ressource erreicht wurde, schlagenzusätzliche Aufrufe zum Erstellen dieser Ressource mit einer Ausnahme fehl.
In der folgenden Tabelle werden die AWS DMS-Ressourcen und ihre Limits pro Region aufgelistet.
Ressource Standardlimit
Replikations-Instances 20
Gesamtspeichermenge für eine Replikations-Instance 10 TB
Ereignisabonnements 20
Replikations-Subnetzgruppen 20
Subnetze pro Replikations-Subnetzgruppe 20
Endpunkte 100
Aufgaben 200
Endpunkte pro Instance 20
Note
• Die maximale Speicherkapazität von 10 TB gilt für die DMS-Replikations-Instance. DieserSpeicher dient zum Zwischenspeichern von Änderungen, falls das Ziel nicht mit der Quellemithalten kann, sowie zum Speichern von Protokollinformationen.
• Die Speichergröße von Quell- und Zielendpunkten kann 10 TB überschreiten.
API-Version API Version 2016-01-0192

AWS Database Migration Service Benutzerhandbuch
Arbeiten mit einer AWS DMS-Replikations-Instance
Wenn Sie eine AWS DMS-Replikations-Instance erstellen, erstellt AWS DMS die Replikations-Instanceauf einer Amazon Elastic Compute Cloud (Amazon EC2)-Instance in einer VPC, die auf dem AmazonVirtual Private Cloud (Amazon VPC)-Service basiert. Sie verwenden diese Replikations-Instance für dieDurchführung Ihrer Datenbankmigration. Die Replikations-Instance bietet hohe Verfügbarkeit und Failover-Support über eine Multi-AZ-Bereitstellung bei Auswahl der Option Multi-AZ.
Bei einer Multi-AZ-Bereitstellung sorgt AWS DMS für die automatische Bereitstellung und Verwaltungeines synchronen Standby-Replikats der Replikations-Instance in einer anderen Availability Zone. Dieprimäre Replikations-Instance wird über die Availability Zones synchron auf das Standby-Replikat repliziert.Dieser Ansatz sorgt für Datenredundanz, vermeidet das Einfrieren von E/A-Vorgängen und minimiertLatenzspitzen.
AWS DMS nutzt eine Replikations-Instance für die Verbindung mit Ihrem Quelldatenspeicher, zum Lesender Quelldaten und zum Formatieren der Daten für die Verwendung durch den Zieldatenspeicher. EineReplikations-Instance lädt zudem die Daten in den Ziel-Datenspeicher. Der Großteil dieser Verarbeitungerfolgt im Arbeitsspeicher. Allerdings werden umfangreiche Transaktionen ggf. auf Festplatte gepuffert.Zwischengespeicherte Transaktionen und Protokolldateien werden ebenfalls auf Festplatte geschrieben.
Sie haben folgende Möglichkeiten, um eine AWS DMS-Replikations-Instance in den folgenden AWS-Regionen zu erstellen.
Region Name
Region Asien-Pazifik (Tokio) ap-northeast-1
Region Asien-Pazifik (Seoul) ap-northeast-2
Region Asien-Pazifik (Mumbai) ap-south-1
Region Asien-Pazifik (Singapur) ap-southeast-1
Region Asien-Pazifik (Sydney) ap-southeast-2
Region Kanada (Zentral) ca-central-1
Region China (Peking) cn-north-1
Region „China (Ningxia)“ cn-northwest-1
Region Europa (Stockholm) eu-north-1
API-Version API Version 2016-01-0193

AWS Database Migration Service BenutzerhandbuchReplikations-Instances im Detail
Region Name
Region EU (Frankfurt) eu-central-1
Region Europa (Irland) eu-west-1
Region EU (London) eu-west-2
Region EU (Paris) eu-west-3
Region Südamerika (São Paulo) sa-east-1
Region USA Ost (N.-Virginia) us-east-1
Region USA Ost (Ohio) us-east-2
Region USA West (Nordkalifornien) us-west-1
Region USA West (Oregon) us-west-2
AWS DMS unterstützt eine besondere AWS-Region mit der Bezeichnung "AWS GovCloud (USA)",die entwickelt wurde, damit US-Regierungsbehörden und Kunden vertrauliche Workloads in die Cloudverschieben können. AWS GovCloud (USA) erfüllt die spezifischen regulatorischen und Compliance-Anforderungen der US-Regierung. Weitere Informationen zu AWS GovCloud (USA) finden Sie unter Wasist AWS GovCloud (USA)?.
In den folgenden Abschnitten erhalten Sie weitere Informationen zu Replikations-Instances.
Themen• Auswahl der geeigneten AWS DMS-Replikations-Instance für Ihre Migration (p. 94)• Öffentliche und private Replikations-Instances (p. 96)• AWS DMS-Wartung (p. 96)• Arbeiten mit Versionen der Replikations-Engine (p. 99)• Einrichten eines Netzwerks für eine Replikations-Instance (p. 103)• Festlegen eines Verschlüsselungsschlüssels für eine Replikations-Instance (p. 110)• Erstellen einer Replikations-Instance (p. 110)• Ändern einer Replikations-Instance (p. 115)• Neustarten einer Replikations-Instance (p. 118)• Löschen einer Replikations-Instance (p. 120)• Von AWS DMS unterstützte DDL-Anweisungen (p. 121)
Auswahl der geeigneten AWS DMS-Replikations-Instance für Ihre Migration
AWS DMS erstellt die Replikations-Instance auf einer Amazon Elastic Compute Cloud (AmazonEC2)-Instance. AWS DMS unterstützt derzeit die T2-, C4- und R4-Amazon EC2-Instance-Klassen fürReplikations-Instances:
• Die T2-Instance-Klassen sind kostengünstige Standard-Instances, die eine erweiterbare CPU-Basisleistung bieten. Sie eignen sich für die Entwicklung, Konfiguration und das Testen Ihres Datenbank-Migrationsprozesses. Sie eigenen sich auch gut für periodische Datenmigrationsaufgaben, die von derCPU-Burst-Fähigkeit profitieren können.
API-Version API Version 2016-01-0194

AWS Database Migration Service BenutzerhandbuchReplikations-Instances im Detail
• Die C4-Instance-Klassen wurden für höchste Prozessorleistung für rechenintensive Workloadskonzipiert. Sie ermöglichen wesentlich mehr Pakete pro Sekunde (PPS), weniger Netzwerk-Jitter undeine niedrigere Netzwerklatenz. AWS DMS kann CPU-intensiv sein, insbesondere bei heterogenenMigrationen und Replikationen wie der Migration von Oracle nach PostgreSQL. C4-Instances könneneine gute Wahl für diese Situationen sein.
• Die R4-Instance-Klassen sind speicheroptimiert für speicherintensive Workloads Laufende Migrationenoder Replikationen von Transaktionssystemen mit hohem Durchsatz unter Verwendung von DMSkönnen zeitweise große Mengen an CPU und Speicher verbrauchen. R4-Instances verfügen über mehrArbeitsspeicher pro vCPU.
Jede Replikations-Instance verfügt über eine spezifische Konfiguration für Arbeitsspeicher und vCPU. Diefolgende Tabelle zeigt die Konfiguration für die einzelnen Replikations-Instance-Typen. Informationen zuPreisen finden Sie auf der Seite mit den Preisen für den AWS Database Migration Service.
Replikations-Instance-Typ vCPU Speicher (GB)
Allgemeine Zwecke
dms.t2.micro 1 1
dms.t2.small 1 2
dms.t2.medium 2 4
dms.t2.large 2 8
Für Datenverarbeitung optimiert
dms.c4.large 2 3,75
dms.c4.xlarge 4 7,5
dms.c4.2xlarge 8 15
dms.c4.4xlarge 16 30
RAM-optimiert
dms.r4.large 2 15,25
dms.r4.xlarge 4 30,5
dms.r4.2xlarge 8 61
dms.r4.4xlarge 16 122
dms.r4.8xlarge 32 244
Um festzustellen, welche Replikations-Instance-Klasse für Ihre Migration am besten geeignet ist, werfenwir einen Blick auf den Change Data Capture (CDC)-Prozess, den die AWS DMS-Replikations-Instanceverwendet.
Nehmen wir an, Sie führen eine Volllast plus CDC-Aufgabe (Bulk Load plus laufende Replikation) aus. Indiesem Fall hat die Aufgabe ein eigenes SQLite-Repository, um Metadaten und andere Informationen zuspeichern. Bevor AWS DMS eine Volllast startet, finden diese Schritte statt:
• AWS DMS beginnt mit der Erfassung der Änderungen für die Tabellen, die es aus demTransaktionsprotokoll der Quell-Engine migriert (wir bezeichnen sie als zwischengespeichertenÄnderungen). Nachdem das vollständige Laden abgeschlossen ist, werden diese zwischengespeicherten
API-Version API Version 2016-01-0195

AWS Database Migration Service BenutzerhandbuchÖffentliche und private Replikations-Instances
Änderungen gesammelt und auf das Ziel angewendet. Abhängig von der Menge derzwischengespeicherten Änderungen können diese Änderungen direkt aus dem Arbeitsspeicherangewendet werden, wo sie zuerst bis zu einem festen Schwellenwert gesammelt werden. Alternativkönnen sie auch von der Festplatte aus angewendet werden, wohin Änderungen geschrieben werden,wenn sie nicht im Arbeitsspeicher gehalten werden können.
• Nachdem die im Cache gespeicherten Änderungen übernommen wurden, startet AWS DMSstandardmäßig eine transaktionale Anwendung auf der Ziel-Instance.
Während der Phase angewendeter zwischengespeicherter Änderungen und der Phase laufenderReplikationen verwendet AWS DMS zwei Stream-Puffer für ein- bzw. ausgehende Daten. AWS DMS nutztaußerdem eine wichtige Komponente, als Sorter bezeichnet, wobei es sich um einen weiteren Speicher-Puffer handelt. Im Folgenden sind zwei wichtige Anwendungen der Sorter-Komponente beschrieben (esgibt noch andere):
• Er verfolgt alle Transaktionen und stellt sicher, dass er nur relevante Transaktionen in denAusgangspuffer weiterleitet.
• Es stellt sicher, dass Transaktionen in der gleichen Commit-Reihenfolge wie auf der Quelle weitergeleitetwerden.
Wie Sie sehen, haben wir drei wichtige Speicherpuffer in dieser Architektur für CDC in AWS DMS. Wenneiner dieser Puffer unter Speicherdruck steht, kann es bei der Migration zu Leistungsproblemen kommen,die zu Ausfällen führen können.
Wenn Sie hohe Workloads mit einer hohen Anzahl von Transaktionen pro Sekunde (TPS) in dieseArchitektur einbinden, finden Sie möglicherweise den zusätzlichen Speicher nützlich, der von R4-Instanceszur Verfügung gestellt wird. Sie können R4-Instances verwenden, um eine große Anzahl von Transaktionenim Speicher zu halten und Speicherdruckprobleme bei laufenden Replikationen zu vermeiden.
Öffentliche und private Replikations-InstancesSie können festlegen, ob eine Replikations-Instance eine öffentliche oder private IP-Adresse hat, die vonder Instance verwendet wird, um eine Verbindung mit der Quell- und Zieldatenbank herzustellen.
Eine private Replikations-Instance verfügt über eine private IP-Adresse, auf die Sie von außerhalb desReplikationsnetzwerks nicht zugreifen können. Eine Replikations-Instance sollte eine private IP-Adressehaben, wenn sich sowohl die Quell- als auch die Zieldatenbank in demselben Netzwerk befinden, das mitder VPC der Replikations-Instance über ein VPN, AWS Direct Connect oder VPC Peering verbunden ist.
Eine VPC Peering-Verbindung ist eine Netzwerkverbindung zwischen zwei VPCs. Sie ermöglicht dieWeiterleitung über die privaten IP-Adressen jeder VPC, als befänden sie sich im selben Netzwerk. WeitereInformationen zu VPC Peering finden Sie unter VPC Peering im Benutzerhandbuch zu Amazon VPC.
AWS DMS-WartungIn regelmäßigen Abständen führt AWS DMS Wartungsarbeiten für AWS DMS-Ressourcen durch. ZurWartung gehören in der Regel Aktualisierungen der Replikations-Instance oder des Betriebssystemsder Replikations-Instance. Sie können den Zeitraum für Ihr Wartungsfenster verwalten und sich dieWartungsaktualisierungen über die AWS CLI- oder die AWS DMS-API anschauen. Die AWS DMS-Konsolewird für diese Aufgaben derzeit nicht unterstützt.
Für die Wartungsaufgaben muss AWS DMS Ihre Replikations-Instance für kurze Zeit offline schalten. Zuden Wartungsaufgaben, für die eine Ressource offline sein muss, gehört z. B. das Einspielen von Patchesfür das Betriebssystem oder die Instance. Das erforderliche Patching wird automatisch und nur für Patches
API-Version API Version 2016-01-0196

AWS Database Migration Service BenutzerhandbuchAWS DMS-Wartungsfenster
eingeplant, die die Sicherheit und Instance-Zuverlässigkeit betreffen. Das Patching erfolgt nicht so häufig(in der Regel ein- oder zweimal im Jahr) und nimmt selten mehr als einen Bruchteil Ihres Wartungsfenstersin Anspruch. Sie können kleinere Updates automatisch aktualisieren, indem Sie die Konsolenoption Autominor version upgrade (Automatisches Unterversion-Upgrade) auswählen.
AWS DMS-WartungsfensterJede AWS DMS-Replikations-Instance verfügt über ein wöchentliches Wartungsfenster, während dem alleverfügbaren Systemänderungen angewendet werden. Sie können sich das Wartungsfenster als Möglichkeitvorstellen, zu kontrollieren, wann Änderungen und Software-Patches auftreten.
Wenn AWS DMS bestimmt, dass die Wartung während einer bestimmten Woche erforderlich ist, erfolgtsie innerhalb des von Ihnen bei der Erstellung der Replikations-Instance festgelegten 30-minütigenWartungsfensters. AWS DMS schließt die meisten Wartungsaktivitäten innerhalb des von Ihnenfestgelegten 30-minütigen Wartungsfensters ab. Allerdings können größere Änderungen mehr Zeit inAnspruch nehmen.
Das von Ihnen bei der Erstellung der Replikations-Instance festgelegte 30-minütige Wartungsfensterwird aus einem 8-Stunden-Zeitraum für jede AWS-Region zugewiesen. Falls Sie bei der Erstellung IhrerReplikations-Instance keinen bevorzugten Wartungszeitraum angeben, weist Ihnen AWS DMS einenZeitraum an einem zufällig ausgewählten Wochentag zu. Für eine Replikations-Instance, die eine Multi-AZ-Bereitstellung verwendet, könnte ein Failover für die Wartung erforderlich sein.
In der folgenden Tabelle sind die Wartungsfenster für jede AWS-Region aufgeführt, die AWS DMSunterstützt.
Region Zeitblock
Region Asien-Pazifik(Sydney)
12:00–20:00 UTC
Region Asien-Pazifik (Tokio) 13:00–21:00 UTC
Region Asien-Pazifik(Mumbai)
17:30–01:30 UTC
Region Asien-Pazifik (Seoul) 13:00–21:00 UTC
Region Asien-Pazifik(Singapur)
14:00–22:00 UTC
Region Kanada (Zentral) 06:29–14:29 UTC
Region China (Peking) 06:00–14:00 UTC
Region „China (Ningxia)“ 06:00–14:00 UTC
Region Europa (Stockholm) 23:00–07:00 UTC
Region Europa (Frankfurt) 23:00–07:00 UTC
Region Europa (Irland) 22:00–06:00 UTC
Region Europa (London) 06:00–14:00 UTC
Region Europa (Paris) 23:00–07:00 UTC
Region Südamerika (SãoPaulo)
00:00–08:00 UTC
API-Version API Version 2016-01-0197

AWS Database Migration Service BenutzerhandbuchAWS DMS-Wartungsfenster
Region Zeitblock
Region USA Ost (N.-Virginia) 03:00–11:00 UTC
Region USA Ost (Ohio) 03:00–11:00 UTC
Region USA West(Nordkalifornien)
06:00–14:00 UTC
Region USA West (Oregon) 06:00–14:00 UTC
AWS GovCloud (US-West) 06:00–14:00 UTC
Auswirkungen der Wartung auf vorhandene MigrationsaufgabenWenn eine AWS DMS-Migrationsaufgabe auf einer Instance ausgeführt wird, treten die folgendenEreignisse auf, wenn ein Patch angewendet wird:
• Wenn die Tabellen in der Migrationsaufgabe sich in der laufenden Änderungsphase der Replikation(CDC) befinden, pausiert AWS DMS die Aufgabe für einen Moment, während der Patch angewendetwird. Die Migration wird dann an der Stelle fortgesetzt, an der sie unterbrochen wurde, als der Patchangewendet wurde.
• Falls AWS DMS eine Tabelle migriert, wenn der Patch angewendet wird, startet AWS DMS die Migrationfür die Tabelle neu.
Ändern der Einstellung des WartungsfenstersSie können den Zeitraum des Wartungsfensters über die AWS Management Console, die AWS CLI oderdie AWS DMS-API ändern.
Ändern der Einstellung des Wartungsfensters mit der AWS-Konsole
Sie können den Zeitraum des Wartungsfensters über die AWS Management Console ändern.
So ändern Sie das bevorzugte Wartungsfenster mit der AWS-Konsole
1. Melden Sie sich bei der AWS Management Console an und wählen Sie AWS DMS aus.2. Wählen Sie im Navigationsbereich Replication instances (Replikations-Instances) aus.3. Wählen Sie die Replikations-Instance aus, die Sie ändern möchten, und wählen Sie Modify aus.4. Erweitern Sie den Abschnitt Maintenance (Wartung) und wählen Sie Datum und Uhrzeit Ihres
Wartungsfensters aus.
API-Version API Version 2016-01-0198

AWS Database Migration Service BenutzerhandbuchVersionen der Replikations-Engine
5. Wählen Sie Apply changes immediately aus.6. Wählen Sie Modify aus.
Ändern der Einstellung des Wartungsfensters mithilfe der CLI
Verwenden Sie den AWS CLI modify-replication-instance-Befehl mit den folgenden Parametern,um den bevorzugten Wartungszeitraum anzuzeigen.
• --replication-instance-identifier
• --preferred-maintenance-window
Example
Im folgenden AWS CLI-Beispiel wird das Wartungsfenster auf dienstags von 4:00–4:30 Uhr UTC festgelegt.
aws dms modify-replication-instance \--replication-instance-identifier myrepinstance \--preferred-maintenance-window Tue:04:00-Tue:04:30
Ändern der Einstellung des Wartungsfensters mithilfe der API
Verwenden Sie die AWS DMS-API-Aktion ModifyReplicationInstance mit den folgendenParametern, um den bevorzugten Wartungszeitraum einzustellen.
• ReplicationInstanceIdentifier = myrepinstance
• PreferredMaintenanceWindow = Tue:04:00-Tue:04:30
Example
Im folgenden Codebeispiel wird das Wartungsfenster auf dienstags von 4:00–4:30 Uhr UTC festgelegt.
https://dms.us-west-2.amazonaws.com/?Action=ModifyReplicationInstance&DBInstanceIdentifier=myrepinstance&PreferredMaintenanceWindow=Tue:04:00-Tue:04:30&SignatureMethod=HmacSHA256&SignatureVersion=4&Version=2014-09-01&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIADQKE4SARGYLE/20140425/us-east-1/dms/aws4_request&X-Amz-Date=20140425T192732Z&X-Amz-SignedHeaders=content-type;host;user-agent;x-amz-content-sha256;x-amz-date&X-Amz-Signature=1dc9dd716f4855e9bdf188c70f1cf9f6251b070b68b81103b59ec70c3e7854b3
Arbeiten mit Versionen der Replikations-EngineDie Replikations-Engine ist die Kern-AWS DMS-Software, die auf Ihrer Replikations-Instanceausgeführt wird und die die Migration der Aufgaben durchführt, die Sie angeben. AWS veröffentlichtregelmäßig neue Versionen der AWS DMS-Replikations-Engine-Software mit neuen Funktionen undLeistungsverbesserungen. Jede Version der Replikations-Engine-Software verfügt über eine eigeneVersionsnummer, um sie von anderen Versionen zu unterscheiden.
Wenn Sie eine neue Replikations-Instance starten, führt sie die neueste AWS DMS-Engine-Version aus,es sei denn, Sie legen etwas Anderes fest. Weitere Informationen finden Sie unter Arbeiten mit einer AWSDMS-Replikations-Instance (p. 93).
API-Version API Version 2016-01-0199

AWS Database Migration Service BenutzerhandbuchVeralten einer Replikations-Engine-Version
Wenn Sie eine Replikations-Instance besitzen, die derzeit ausgeführt wird, können Sie ein Upgrade aufeine neuere Version der Engine vornehmen. (AWS DMS unterstützt keine Downgrades der Engine-Version.) Weitere Informationen, einschließlich einer Liste der Replikations-Engine-Versionen, finden Sie imfolgenden Abschnitt.
Veralten einer Replikations-Engine-VersionGelegentlich stuft AWS DMS ältere Versionen der Replikations-Engine als veraltet ein. Ab dem 2. April2018 deaktiviert AWS DMS die Erstellung einer neuen Instance der Replikations-Engine-Version 1.9.0.Diese Version wurde in AWS DMS ursprünglich unterstützt (Stand vom 15. März 2016) und wurde seitdemdurch neue Versionen mit verbesserter Funktionalität, Sicherheit und Zuverlässigkeit ersetzt.
Ab dem 5. August 2018 um 0:00 Uhr UTC werden alle DMS-Instances mit der Version 1.9.0 derReplikations-Engine während des für jede Instance festgelegten Wartungsfensters automatisch auf dieneueste verfügbare Version aktualisiert. Wir empfehlen Ihnen, Ihre Instances vorher an einem für Siegünstigen Zeitpunkt zu aktualisieren.
Sie können ein Upgrade Ihrer Replikations-Instance initiieren, indem Sie die Anweisungen im folgendenAbschnitt, Aktualisieren der Engine-Version der Replikations-Instance (p. 100), befolgen.
Bei Migrationsaufgaben, die ausgeführt werden, wenn Sie sich für ein Upgrade der Replikations-Engineentscheiden, werden Tabellen, die sich zum Zeitpunkt des Upgrades in der Volllast-Phase befinden, nachAbschluss des Upgrades von Anfang an neu geladen. Die Replikation für alle anderen Tabellen solltenach Abschluss des Upgrades ohne Unterbrechung fortgesetzt werden. Wir empfehlen, alle aktuellenMigrationsaufgaben auf der neuesten verfügbaren Version der AWS DMS-Replikations-Instance zu testen,bevor Sie die Instances von Version 1.9.0 aktualisieren.
Aktualisieren der Engine-Version der Replikations-InstanceAWS veröffentlicht regelmäßig neue Versionen der AWS DMS-Replikations-Engine-Software mit neuenFunktionen und Leistungsverbesserungen. Im Folgenden finden Sie eine Zusammenfassung derverfügbaren AWS DMS-Engine-Versionen.
Version Versionsübersicht
3.3.x • Versionshinweise zu AWS Database Migration Service (AWS DMS)3.3.2 (p. 501)
• Versionshinweise zu AWS Database Migration Service (AWS DMS)3.3.1 (p. 502)
• AWS Database Migration Service (AWS DMS) 3.3.0 Beta –Versionshinweise (p. 505)
3.1.x • AWS Database Migration Service (AWS DMS) 3.1.3 –Versionshinweise (p. 508)
• AWS Database Migration Service (AWS DMS) 3.1.2 –Versionshinweise (p. 509)
• AWS Database Migration Service (AWS DMS) 3.1.1 –Versionshinweise (p. 510)
2.4.x • AWS Database Migration Service (AWS DMS) 2.4.5 –Versionshinweise (p. 512)
• AWS Database Migration Service (AWS DMS) 2.4.4 –Versionshinweise (p. 513)
API-Version API Version 2016-01-01100
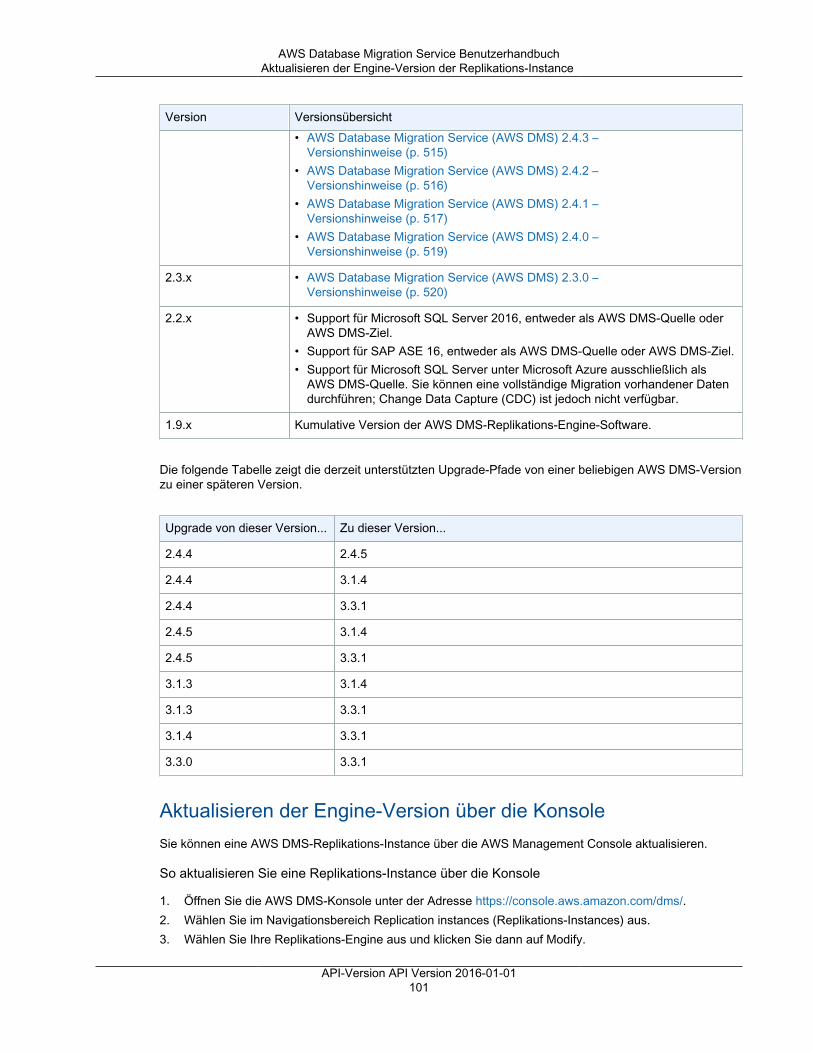
AWS Database Migration Service BenutzerhandbuchAktualisieren der Engine-Version der Replikations-Instance
Version Versionsübersicht• AWS Database Migration Service (AWS DMS) 2.4.3 –
Versionshinweise (p. 515)• AWS Database Migration Service (AWS DMS) 2.4.2 –
Versionshinweise (p. 516)• AWS Database Migration Service (AWS DMS) 2.4.1 –
Versionshinweise (p. 517)• AWS Database Migration Service (AWS DMS) 2.4.0 –
Versionshinweise (p. 519)
2.3.x • AWS Database Migration Service (AWS DMS) 2.3.0 –Versionshinweise (p. 520)
2.2.x • Support für Microsoft SQL Server 2016, entweder als AWS DMS-Quelle oderAWS DMS-Ziel.
• Support für SAP ASE 16, entweder als AWS DMS-Quelle oder AWS DMS-Ziel.• Support für Microsoft SQL Server unter Microsoft Azure ausschließlich als
AWS DMS-Quelle. Sie können eine vollständige Migration vorhandener Datendurchführen; Change Data Capture (CDC) ist jedoch nicht verfügbar.
1.9.x Kumulative Version der AWS DMS-Replikations-Engine-Software.
Die folgende Tabelle zeigt die derzeit unterstützten Upgrade-Pfade von einer beliebigen AWS DMS-Versionzu einer späteren Version.
Upgrade von dieser Version... Zu dieser Version...
2.4.4 2.4.5
2.4.4 3.1.4
2.4.4 3.3.1
2.4.5 3.1.4
2.4.5 3.3.1
3.1.3 3.1.4
3.1.3 3.3.1
3.1.4 3.3.1
3.3.0 3.3.1
Aktualisieren der Engine-Version über die KonsoleSie können eine AWS DMS-Replikations-Instance über die AWS Management Console aktualisieren.
So aktualisieren Sie eine Replikations-Instance über die Konsole
1. Öffnen Sie die AWS DMS-Konsole unter der Adresse https://console.aws.amazon.com/dms/.2. Wählen Sie im Navigationsbereich Replication instances (Replikations-Instances) aus.3. Wählen Sie Ihre Replikations-Engine aus und klicken Sie dann auf Modify.
API-Version API Version 2016-01-01101

AWS Database Migration Service BenutzerhandbuchAktualisieren der Engine-Version der Replikations-Instance
4. Wählen Sie im Feld Replication engine version (Version der Replikations-Engine) die Versionsnummeraus, die Sie ändern möchten, und klicken Sie anschließend auf Modify (Ändern).
Note
Das Aktualisieren der Replikations-Instance dauert einige Minuten. Sobald die Instance bereit ist,ändert sich ihr Status zu available.
Aktualisieren der Engine-Version über die CLISie können eine AWS DMS-Replikations-Instance über die AWS CLI folgendermaßen aktualisieren.
So aktualisieren Sie eine Replikations-Instance über die AWS CLI
1. Bestimmen Sie den Amazon-Ressourcennamen (ARN) Ihrer Replikations-Instance anhand desfolgenden Befehls.
aws dms describe-replication-instances \--query "ReplicationInstances[*].[ReplicationInstanceIdentifier,ReplicationInstanceArn,ReplicationInstanceClass]"
Beachten Sie in der Ausgabe den ARN für die Replikations-Instance,die Sie aktualisieren möchten, beispielsweise: arn:aws:dms:us-east-1:123456789012:rep:6EFQQO6U6EDPRCPKLNPL2SCEEY
2. Bestimmen Sie, welche Replikations-Instance-Versionen verfügbar sind, anhand des folgendenBefehls.
aws dms describe-orderable-replication-instances \--query "OrderableReplicationInstances[*].[ReplicationInstanceClass,EngineVersion]"
Beachten Sie in der Ausgabe die Engine-Versionsnummer oder -nummern, die für Ihre Replikations-Instance-Klasse verfügbar sind. Sie sollten diese Informationen in der Ausgabe von Schritt 1 sehen.
3. Aktualisieren Sie die Replikations-Instance anhand des folgenden Befehls.
aws dms modify-replication-instance \--replication-instance-arn arn \--engine-version n.n.n
Ersetzen Sie arn im vorausgehenden Befehl mit dem tatsächlichen Replikations-Instance-ARN ausdem vorherigen Schritt.
Ersetzen Sie n.n.n mit der gewünschten Engine-Versionsnummer, beispielsweise: 2.2.1
Note
Das Aktualisieren der Replikations-Instance dauert einige Minuten. Sie können den Replikations-Instance-Status mit dem folgenden Befehl anzeigen.
aws dms describe-replication-instances \--query "ReplicationInstances[*].[ReplicationInstanceIdentifier,ReplicationInstanceStatus]"
Sobald die Replikations-Instance bereit ist, ändert sich ihr Status zu available.
API-Version API Version 2016-01-01102

AWS Database Migration Service BenutzerhandbuchEinrichten eines Netzwerks für eine Replikations-Instance
Einrichten eines Netzwerks für eine Replikations-Instance
AWS DMS erstellt die Replikations-Instance immer in einer VPC, die auf Amazon Virtual Private Cloud(Amazon VPC) basiert. Geben Sie die VPC an, in der sich Ihre Replikations-Instance befindet. Sie könnenIhre Standard-VPC für Ihr Konto und Ihre AWS-Region verwenden oder eine neue VPC erstellen. Die VPCmuss über zwei Subnetze in mindestens einer Availability Zone verfügen.
Die Elastic Network-Schnittstelle (ENI), die der Replikations-Instance in Ihrer VPC zugeteilt ist, muss miteiner Sicherheitsgruppe verknüpft sein, deren Regeln es zulassen, dass der gesamte Datenverkehr aufallen Ports die VPC verlassen dürfen. Dieser Ansatz ermöglicht die Kommunikation von der Replikations-Instance zu Ihren Quell- und Zieldatenbankendpunkten, sofern auf den Endpunkten die richtigenAusgangsregeln aktiviert sind. Wir empfehlen, die Standardeinstellungen für die Endpunkte zu verwenden.Diese erlauben ausgehenden Zugriff auf allen Ports für alle Adressen.
Die Quell- und Zielendpunkte greifen auf die Replikations-Instance zu, die sich in der VPC befindet,indem sie sich entweder mit der VPC verbinden oder sich selbst innerhalb der VPC befinden. DieDatenbankendpunkte müssen Netzwerk-Zugriffskontrolllisten (ACLs) und Sicherheitsgruppenregeln(falls zutreffend) enthalten, die eingehenden Zugriff von der Replikations-Instance erlauben. Je nachNetzwerkkonfiguration können Sie die VPC-Sicherheitsgruppe der Replikations-Instance, die privateoder öffentliche IP-Adresse der Replikations-Instance oder die öffentliche IP-Adresse des NAT-Gatewaysverwenden. Diese Verbindungen bilden ein Netzwerk, das Sie für die Datenmigration nutzen.
Netzwerkkonfigurationen für die DatenbankmigrationMit AWS Database Migration Service können Sie verschiedene Netzwerkkonfigurationen verwenden. ImFolgenden werden einige häufige Konfigurationen für ein Netzwerk erörtert, die für die Datenbankmigrationverwendet werden.
Themen• Konfiguration mit allen Datenbankmigrationskomponenten in einer VPC (p. 103)• Konfiguration mit zwei VPCs (p. 104)• Konfiguration eines Netzwerks zu einer VPC über AWS Direct Connect oder VPN (p. 104)• Konfiguration eines Netzwerks zu einer VPC über das Internet (p. 105)• Konfiguration mit einer Amazon RDS-DB-Instance, die sich nicht in einer VPC befindet, zu einer DB-
Instance in einer VPC über ClassicLink (p. 105)
Konfiguration mit allen Datenbankmigrationskomponenten ineiner VPCDie einfachste Netzwerkkonfiguration für die Datenbankmigration besteht darin, dass sich Quellendpunkt,Replikations-Instance und Zielendpunkt alle in derselben VPC befinden. Diese Konfiguration eignet sich,wenn sich Ihre Quell- und Zielendpunkte auf einer Amazon RDS-DB-Instance oder einer Amazon EC2-Instance befinden.
Die folgende Abbildung zeigt eine Konfiguration, bei der sich eine Datenbank auf einer Amazon EC2-Instance mit der Replikations-Instance verbindet und die Daten zu einer Amazon RDS-DB-Instance migriertwerden.
API-Version API Version 2016-01-01103

AWS Database Migration Service BenutzerhandbuchNetzwerkkonfigurationen für die Datenbankmigration
Die VPC-Sicherheitsgruppe, die in dieser Konfiguration verwendet wird, muss eingehenden Zugriff amDatenbank-Port von der Replikations-Instance erlauben. Dazu müssen Sie sicherstellen, dass die von derReplikations-Instance verwendete Sicherheitsgruppe eingehenden Zugriff zu den Endpunkten erlaubt, oderdie private IP-Adresse der Replikations-Instance explizit zulassen.
Konfiguration mit zwei VPCsWenn sich Ihre Quell- und Zielendpunkte in verschiedenen VPCs befinden, können Sie Ihre Replikations-Instance in einer der VPCs erstellen und die beiden VPCs dann über VPC Peering verknüpfen.
Eine VPC Peering-Verbindung ist eine Netzwerkverbindung zwischen zwei VPCs. Sie ermöglicht dieWeiterleitung über die privaten IP-Adressen jeder VPC, als befänden sie sich im selben Netzwerk. Wirempfehlen, diese Methode zum Verbinden von VPCs innerhalb einer AWS-Region zu verwenden. Siekönnen VPC-Peering-Verbindungen zwischen Ihren eigenen VPCs oder mit einer VPC in einem anderenAWS-Konto innerhalb derselben AWS-Region herstellen. Weitere Informationen zu VPC Peering finden Sieunter VPC Peering im Benutzerhandbuch zu Amazon VPC.
Die folgende Abbildung zeigt eine Beispielkonfiguration unter Verwendung von VPC-Peering. Hier wirddie Quell-Datenbank auf einer Amazon EC2-Instance in einer VPC über VPC-Peering mit einer VPCverbunden. Diese VPC enthält die Replikations-Instance und die Zieldatenbank auf einer Amazon RDS-DB-Instance.
Die VPC-Sicherheitsgruppen, die in dieser Konfiguration verwendet werden, müssen eingehenden Zugriffam Datenbank-Port von der Replikations-Instance erlauben.
Konfiguration eines Netzwerks zu einer VPC über AWS DirectConnect oder VPNFür Remote-Netzwerke stehen für die Verbindung mit einer VPC mehrere Optionen zur Verfügung, z.B. AWS Direct Connect oder eine Software- oder Hardware-VPN-Verbindung. Diese Optionen werdenoft verwendet, um lokale Services zu integrieren, wie beispielsweise Überwachung, Authentifizierung,Sicherheit, Daten oder andere Systeme, indem ein internes Netzwerk in die AWS Cloud erweitert wird. Mitdieser Art von Netzwerkerweiterung können Sie problemlos eine Verbindung mit durch AWS gehostetenRessourcen wie einer VPC herstellen.
Die folgende Abbildung zeigt eine Konfiguration, bei der der Quellendpunkt eine lokale Datenbank ineinem firmeneigenen Rechenzentrum ist. Er wird über AWS Direct Connect oder ein VPN mit einer VPCverbunden, die die Replikations-Instance und eine Zieldatenbank auf einer Amazon RDS-DB-Instanceenthält.
API-Version API Version 2016-01-01104

AWS Database Migration Service BenutzerhandbuchNetzwerkkonfigurationen für die Datenbankmigration
Bei dieser Konfiguration muss die VPC-Sicherheitsgruppe eine Weiterleitungsregel enthalten, die den füreine bestimmte IP-Adresse oder einen IP-Bereich vorgesehenen Datenverkehr an einen Host sendet.Dieser Host muss dazu in der Lage sein, den von der VPC kommenden Datenverkehr in ein lokales VPNweiterzuleiten. In diesem Fall verfügt der NAT-Host über eigene Sicherheitsgruppeneinstellungen, die denDatenverkehr von der privaten IP-Adresse oder Sicherheitsgruppe der Replikations-Instance zur NAT-Instance zulassen muss.
Konfiguration eines Netzwerks zu einer VPC über das InternetWenn Sie weder ein VPN noch AWS Direct Connect für die Verbindung mit AWS-Ressourcen verwenden,können Sie das Internet nutzen, um eine Datenbank zu einer Amazon EC2-Instance oder Amazon RDS-DB-Instance zu migrieren. Diese Konfiguration umfasst eine öffentliche Replikations-Instance in einer VPCmit einem Internet-Gateway, das den Zielendpunkt und die Replikations-Instance enthält.
Informationen zum Anfügen eines Internet-Gateways zu Ihrer VPC finden Sie unter Anfügen eines Internet-Gateways im Benutzerhandbuch zu Amazon VPC.
Die VPC-Sicherheitsgruppe muss Routing-Regeln enthalten, die den nicht für die VPC bestimmtenDatenverkehr standardmäßig an das Internet-Gateway senden. Bei dieser Konfiguration stammt dieVerbindung mit dem Endpunkt scheinbar von der öffentlichen IP-Adresse der Replikations-Instance undnicht von der privaten IP-Adresse.
Konfiguration mit einer Amazon RDS-DB-Instance, die sich nichtin einer VPC befindet, zu einer DB-Instance in einer VPC überClassicLinkSie können ClassicLink in Verbindung mit einem Proxy-Server verwenden, um eine Amazon RDS-DB-Instance, die sich nicht in einer VPC befindet, mit einem AWS DMS-Replikationsserver und einer DB-Instance innerhalb einer VPC zu verbinden.
ClassicLink ermöglicht es Ihnen, eine EC2-Classic-DB-Instance mit einer VPC in Ihrem Konto innerhalbderselben AWS-Region zu verknüpfen. Nachdem Sie die Verknüpfung erstellt haben, kann die DB-Quell-Instance mit der Replikations-Instance in der VPC über ihre privaten IP-Adressen kommunizieren.
Da die Replikations-Instance in der VPC nicht direkt auf die Quell-DB-Instance auf der EC2-Classic-Plattform mithilfe von ClassicLink zugreifen kann, müssen Sie einen Proxy-Server verwenden. Der Proxy-Server verbindet die Quell-DB-Instance mit der VPC, die die Replikations-Instance und Ziel-DB-Instanceenthält. Der Proxy-Server verwendet ClassicLink zum Verbinden mit der VPC. Die Port-Weiterleitungauf dem Proxy-Server ermöglicht die Kommunikation zwischen der Quell-DB-Instance und der Ziel-DB-Instance in der VPC.
API-Version API Version 2016-01-01105

AWS Database Migration Service BenutzerhandbuchNetzwerkkonfigurationen für die Datenbankmigration
Verwenden von ClassicLink mit AWS Database Migration Service
Sie können ClassicLink in Verbindung mit einem Proxy-Server verwenden, um eine Amazon RDS-DB-Instance, die sich nicht in einer VPC befindet, mit einem AWS DMS-Replikationsserver und einer DB-Instance innerhalb einer VPC zu verbinden.
Das folgende Verfahren zeigt, wie Sie ClassicLink nutzen, um eine Amazon RDS-DB-Quell-Instance, diesich nicht in einer VPC befindet, mit einer VPC zu verbinden, die eine AWS DMS-Replikations-Instance undeine DB-Ziel-Instance enthält.
• Erstellen Sie eine AWS DMS-Replikations-Instance in einer VPC. (Alle Replikations-Instances werden ineiner VPC erstellt).
• Verknüpfen Sie eine VPC-Sicherheitsgruppe mit der Replikations-Instance und der DB-Ziel-Instance.Wenn zwei Instances gemeinsam eine VPC-Sicherheitsgruppe verwenden, können sie standardmäßigmiteinander kommunizieren.
• Richten Sie einen Proxy-Server auf einer EC2-Classic-Instance ein.• Erstellen Sie mit ClassicLink eine Verbindung zwischen dem Proxy-Server und der VPC.• Erstellen Sie AWS DMS-Endpunkte für die Quell- und die Zieldatenbank.• Erstellen Sie eine AWS DMS-Aufgabe.
So verwenden Sie ClassicLink, um eine Datenbank auf einer DB-Instance außerhalb einer VPC zueiner Datenbank auf einer DB-Instance innerhalb einer VPC zu migrieren
1. Schritt 1: Erstellen einer AWS DMS-Replikations-Instance
So erstellen Sie eine AWS DMS-Replikations-Instance und weisen eine VPC-Sicherheitsgruppe zu:
a. Melden Sie sich bei der AWS-Managementkonsole an und wählen Sie AWS DatabaseMigration Service aus. Wenn Sie als Benutzer von AWS Identity and Access Management(IAM) angemeldet sind, müssen Sie über die entsprechenden Berechtigungen für den Zugriffauf AWS DMS verfügen. Weitere Informationen zu den erforderlichen Berechtigungen für dieDatenbankmigration finden Sie unter Erforderliche IAM-Berechtigungen zur Verwendung von AWSDMS (p. 65).
b. Wählen Sie auf der Seite Dashboard Replication Instance (Replikations-Instance). Befolgen Siedie Anweisungen unter Schritt 2: Erstellen einer Replikations-Instance (p. 23) zum Erstellen einerReplikations-Instance.
c. Öffnen Sie nach dem Erstellen der AWS DMS-Replikations-Instance die EC2-Service-Konsole.Wählen Sie im Navigationsbereich Network Interfaces aus.
d. Wählen Sie DMSNetworkInterface und anschließend Change Security Groups(Sicherheitsgruppen ändern) aus dem Menü Actions (Aktionen) aus.
e. Wählen Sie die Sicherheitsgruppe aus, die Sie für die Replikations-Instance und die DB-Ziel-Instance verwenden möchten.
2. Schritt 2: Verknüpfen der Sicherheitsgruppe aus dem letzten Schritt mit der DB-Ziel-Instance
So verknüpfen Sie eine Sicherheitsgruppe mit einer DB-Instance
API-Version API Version 2016-01-01106

AWS Database Migration Service BenutzerhandbuchNetzwerkkonfigurationen für die Datenbankmigration
a. Öffnen Sie die Amazon RDS-Konsole. Wählen Sie im Navigationsbereich Instances aus.b. Wählen Sie die DB-Ziel-Instance aus: Wählen Sie unter Instance Actions Modify aus.c. Wählen Sie für den Parameter Security Group die Sicherheitsgruppe aus, die Sie im vorherigen
Schritt verwendet haben.d. Wählen Sie Continue (Fortsetzen) und dann Modify DB Instance (DB-Instance ändern) aus.
3. Schritt 3: Einrichten eines Proxy-Servers auf einer EC2-Classic-Instance mit NGINX. Verwenden Sieein AMI Ihrer Wahl, um eine EC2-Classic-Instance zu starten. Das folgende Beispiel basiert auf AMIUbuntu Server 14.04 LTS (HVM).
So richten Sie einen Proxy-Server auf einer EC2-Classic-Instance ein
a. Stellen Sie eine Verbindung mit der EC2-Classic-Instance her und installieren Sie NGINX mithilfeder folgenden Befehle:
Prompt> sudo apt-get updatePrompt> sudo wget http://nginx.org/download/nginx-1.9.12.tar.gzPrompt> sudo tar -xvzf nginx-1.9.12.tar.gz Prompt> cd nginx-1.9.12Prompt> sudo apt-get install build-essentialPrompt> sudo apt-get install libpcre3 libpcre3-devPrompt> sudo apt-get install zlib1g-devPrompt> sudo ./configure --with-streamPrompt> sudo makePrompt> sudo make install
b. Bearbeiten Sie die NGINX-Daemon-Datei "/etc/init/nginx.conf" unter Verwendung des folgendenCodes:
# /etc/init/nginx.conf – Upstart file
description "nginx http daemon"author "email"
start on (filesystem and net-device-up IFACE=lo)stop on runlevel [!2345]
env DAEMON=/usr/local/nginx/sbin/nginxenv PID=/usr/local/nginx/logs/nginx.pid
expect forkrespawnrespawn limit 10 5
pre-start script $DAEMON -t if [ $? -ne 0 ] then exit $? fiend script
exec $DAEMON
c. Erstellen Sie eine NGINX-Konfigurationsdatei unter "/usr/local/nginx/conf/nginx.conf". Fügen Sie inder Konfigurationsdatei Folgendes hinzu:
API-Version API Version 2016-01-01107

AWS Database Migration Service BenutzerhandbuchErstellen einer Replikationssubnetzgruppe
# /usr/local/nginx/conf/nginx.conf - NGINX configuration file
worker_processes 1;
events { worker_connections 1024;}
stream { server { listen <DB instance port number>;proxy_pass <DB instance identifier>:<DB instance port number>; }}
d. Starten Sie von der Befehlszeile NGINX mithilfe der folgenden Befehle:
Prompt> sudo initctl reload-configurationPrompt> sudo initctl list | grep nginxPrompt> sudo initctl start nginx
4. Schritt 4: Erstellen einer ClassicLink-Verbindung zwischen dem Proxy-Server und der Ziel-VPC, die dieDB-Ziel-Instance und die Replikations-Instance enthält
Verwenden von ClassicLink zum Verbinden des Proxy-Servers mit der Ziel-VPC
a. Öffnen Sie die EC2-Konsole und wählen Sie die EC2-Classic-Instance aus, auf der der Proxy-Server ausgeführt wird.
b. Wählen Sie ClassicLink unter Actions (Aktionen) aus und dann Link to VPC (Mit VPC verknüpfen).c. Wählen Sie die Sicherheitsgruppe aus, die Sie zuvor in diesem Verfahren verwendet haben.d. Wählen Sie Link to VPC (Mit VPC verknüpfen) aus.
5. Schritt 5: Erstellen von AWS DMS-Endpunkten mit dem Verfahren unter Schritt 3: Geben Sie Quell-und Zielendpunkte an (p. 28). Sie müssen den internen EC2-DNS-Hostnamen des Proxy-Servers alsServernamen verwenden, wenn Sie den Quellendpunkt angeben.
6. Schritt 6: Erstellen einer AWS DMS-Aufgabe mit dem Verfahren unter Schritt 4: Erstellen einerMigrationsaufgabe (p. 33)
Erstellen einer ReplikationssubnetzgruppeAls Teil des für die Datenbankmigration zu verwendenden Netzwerks müssen Sie angeben, welcheSubnetze in Ihrer Amazon Virtual Private Cloud (Amazon VPC) verwendet werden sollen. Ein Subnetz istein IP-Adressbereich in Ihrer VPC in einer bestimmten Availability Zone. Diese Subnetze können unter denAvailability Zones der AWS-Region, in der sich Ihre VPC befindet, verteilt werden.
Sie erstellen eine Replikations-Instance in einem Subnetz, das Sie auswählen. Sie können über die AWSDMS-Konsole festlegen, welches Subnetz ein Quell- oder Zielendpunkt verwenden soll.
Sie erstellen eine Replikationssubnetzgruppe, um zu definieren, welche Subnetze verwendet werden. Siemüssen mindestens ein Subnetz in zwei verschiedenen Availability Zones angeben.
So erstellen Sie eine Replikationssubnetzgruppe
1. Melden Sie sich bei der AWS Management Console an und wählen Sie AWS Database MigrationService aus. Wenn Sie als Benutzer von AWS Identity and Access Management (IAM) angemeldet
API-Version API Version 2016-01-01108
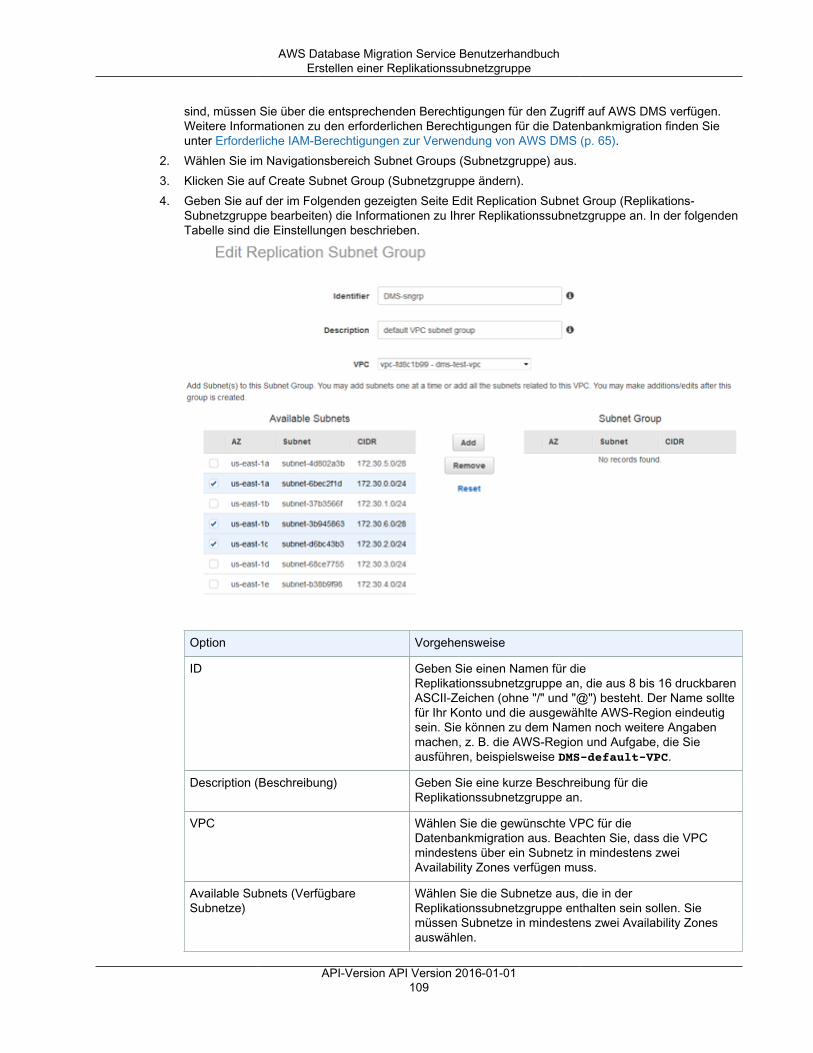
AWS Database Migration Service BenutzerhandbuchErstellen einer Replikationssubnetzgruppe
sind, müssen Sie über die entsprechenden Berechtigungen für den Zugriff auf AWS DMS verfügen.Weitere Informationen zu den erforderlichen Berechtigungen für die Datenbankmigration finden Sieunter Erforderliche IAM-Berechtigungen zur Verwendung von AWS DMS (p. 65).
2. Wählen Sie im Navigationsbereich Subnet Groups (Subnetzgruppe) aus.3. Klicken Sie auf Create Subnet Group (Subnetzgruppe ändern).4. Geben Sie auf der im Folgenden gezeigten Seite Edit Replication Subnet Group (Replikations-
Subnetzgruppe bearbeiten) die Informationen zu Ihrer Replikationssubnetzgruppe an. In der folgendenTabelle sind die Einstellungen beschrieben.
Option Vorgehensweise
ID Geben Sie einen Namen für dieReplikationssubnetzgruppe an, die aus 8 bis 16 druckbarenASCII-Zeichen (ohne "/" und "@") besteht. Der Name solltefür Ihr Konto und die ausgewählte AWS-Region eindeutigsein. Sie können zu dem Namen noch weitere Angabenmachen, z. B. die AWS-Region und Aufgabe, die Sieausführen, beispielsweise DMS-default-VPC.
Description (Beschreibung) Geben Sie eine kurze Beschreibung für dieReplikationssubnetzgruppe an.
VPC Wählen Sie die gewünschte VPC für dieDatenbankmigration aus. Beachten Sie, dass die VPCmindestens über ein Subnetz in mindestens zweiAvailability Zones verfügen muss.
Available Subnets (VerfügbareSubnetze)
Wählen Sie die Subnetze aus, die in derReplikationssubnetzgruppe enthalten sein sollen. Siemüssen Subnetze in mindestens zwei Availability Zonesauswählen.
API-Version API Version 2016-01-01109

AWS Database Migration Service BenutzerhandbuchFestlegen eines Verschlüsselungsschlüssels
5. Wählen Sie Add (Hinzufügen) aus, um die Subnetze zur Replikationssubnetzgruppe hinzuzufügen.6. Wählen Sie Create aus.
Festlegen eines Verschlüsselungsschlüssels füreine Replikations-Instance
AWS DMS verschlüsselt den von einer Replikations-Instance verwendeten Speicher und dieVerbindungsinformationen für den Endpunkt. Um den von einer Replikations-Instance verwendetenSpeicher zu verschlüsseln, verwendet AWS DMS einen Hauptschlüssel, der nur für Ihr AWS-Kontogültig ist. Sie können diesen Masterschlüssel mit AWS Key Management Service (AWS KMS) anzeigenund verwalten. Sie können den Standardhauptschlüssel in Ihrem Konto (aws/dms) oder einenbenutzerdefinierten Hauptschlüssel, den Sie erstellen, verwenden. Wenn Sie bereits über einen AWS KMS-Verschlüsselungsschlüssel verfügen, können Sie auch diesen für die Verschlüsselung verwenden.
Sie können Ihren eigenen Verschlüsselungsschlüssel angeben, indem Sie eine KMS-Schlüsselkennungzur Verschlüsselung Ihrer AWS DMS-Ressourcen bereitstellen. Wenn Sie Ihren eigenenVerschlüsselungsschlüssel angeben, muss das Benutzerkonto, mit dem die Datenbankmigrationdurchgeführt wird, Zugriff auf diesen Schlüssel haben. Weitere Informationen zum Erstellen eigenerVerschlüsselungsschlüssel und zum Erteilen von Zugriffsrechten auf einen Verschlüsselungsschlüssel fürBenutzer finden Sie im Entwicklerhandbuch für AWS KMS.
Wenn Sie keine KMS-Schlüsselkennung angeben, verwendet AWS DMS IhrenStandardverschlüsselungsschlüssel. KMS erstellt den Standardverschlüsselungsschlüssel fürAWS DMS für Ihr AWS-Konto. Ihr AWS-Konto verfügt für jede AWS-Region über einen anderenStandardverschlüsselungsschlüssel.
Die für die Verschlüsselung der AWS DMS-Ressourcen verwendeten Schlüssel verwalten Sie mit KMS.Sie finden KMS in der AWS Management Console, indem Sie Identity & Access Management (Identitätund Zugriffsverwaltung) auf der Startseite der Konsole und anschließend im Navigationsbereich EncryptionKeys (Verschlüsselungsschlüssel) auswählen.
KMS kombiniert sichere, hoch verfügbare Hard- und Software, um ein System für die Schlüsselverwaltungbereitzustellen, das für die Cloud skaliert ist. Mit KMS können Sie Verschlüsselungsschlüssel erstellenund Richtlinien definieren, die steuern, wie diese Schlüssel verwendet werden können. KMS unterstütztAWS CloudTrail, sodass Sie die Schlüsselverwendung prüfen und sicherstellen können, dass die Schlüsselkorrekt verwendet werden. Ihre KMS-Schlüssel können in Kombination mit AWS DMS und unterstütztenAWS-Services, wie z. B. Amazon RDS, Amazon S3, Amazon Elastic Block Store (Amazon EBS) undAmazon Redshift, verwendet werden.
Nach der Erstellung Ihrer AWS DMS-Ressourcen mit einem bestimmten Verschlüsselungsschlüsselkönnen Sie diesen Verschlüsselungsschlüssel für diese Ressourcen nicht mehr ändern. Stellen Sie sicher,die Anforderungen für Ihre Verschlüsselungsschlüssel zu definieren, bevor Sie Ihre AWS DMS-Ressourcenerstellen.
Erstellen einer Replikations-InstanceIhre erste Aufgabe bei der Migration einer Datenbank besteht darin, eine Replikations-Instance mitgenügend Speicherplatz und der nötigen Rechenleistung für die Durchführung der zugewiesenen Aufgabenzu erstellen und die Daten von der Quelldatenbank zur Zieldatenbank zu migrieren. Die erforderlicheGröße dieser Instance hängt von der Menge der Daten ab, die Sie migrieren müssen, sowie von denAufgaben, die die Instance ausführen muss. Weitere Informationen zu Replikations-Instances finden Sieunter Arbeiten mit einer AWS DMS-Replikations-Instance (p. 93).
API-Version API Version 2016-01-01110
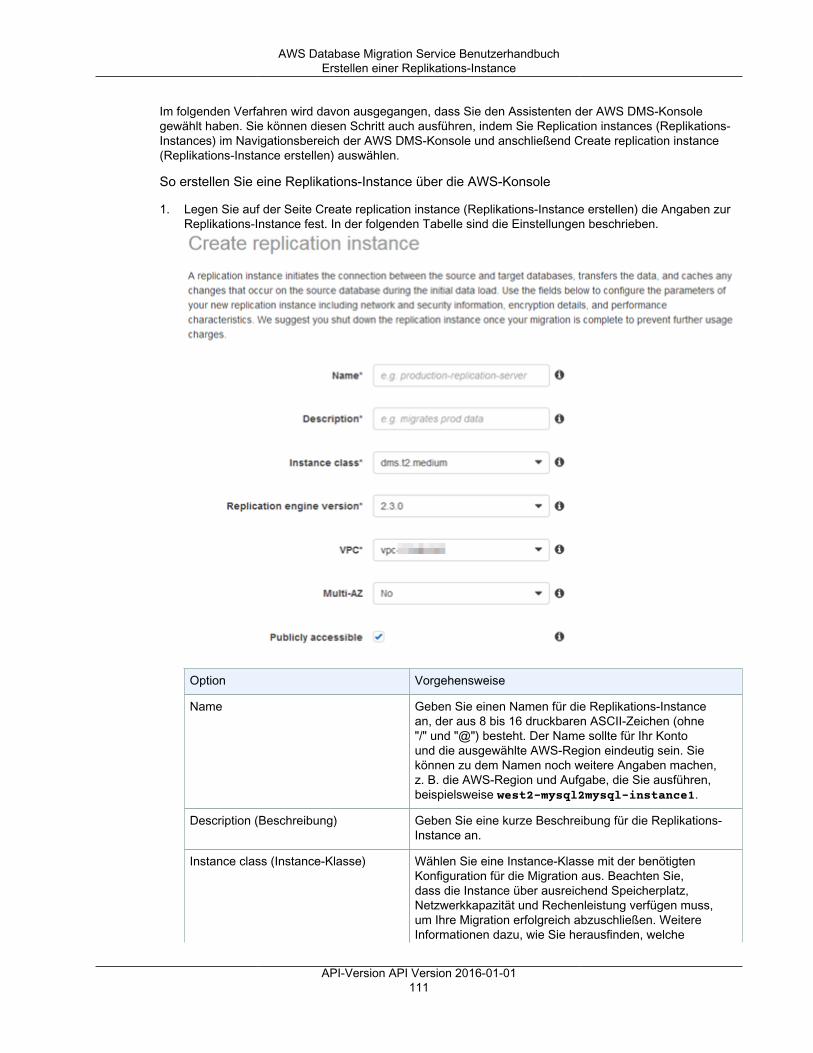
AWS Database Migration Service BenutzerhandbuchErstellen einer Replikations-Instance
Im folgenden Verfahren wird davon ausgegangen, dass Sie den Assistenten der AWS DMS-Konsolegewählt haben. Sie können diesen Schritt auch ausführen, indem Sie Replication instances (Replikations-Instances) im Navigationsbereich der AWS DMS-Konsole und anschließend Create replication instance(Replikations-Instance erstellen) auswählen.
So erstellen Sie eine Replikations-Instance über die AWS-Konsole
1. Legen Sie auf der Seite Create replication instance (Replikations-Instance erstellen) die Angaben zurReplikations-Instance fest. In der folgenden Tabelle sind die Einstellungen beschrieben.
Option Vorgehensweise
Name Geben Sie einen Namen für die Replikations-Instancean, der aus 8 bis 16 druckbaren ASCII-Zeichen (ohne"/" und "@") besteht. Der Name sollte für Ihr Kontound die ausgewählte AWS-Region eindeutig sein. Siekönnen zu dem Namen noch weitere Angaben machen,z. B. die AWS-Region und Aufgabe, die Sie ausführen,beispielsweise west2-mysql2mysql-instance1.
Description (Beschreibung) Geben Sie eine kurze Beschreibung für die Replikations-Instance an.
Instance class (Instance-Klasse) Wählen Sie eine Instance-Klasse mit der benötigtenKonfiguration für die Migration aus. Beachten Sie,dass die Instance über ausreichend Speicherplatz,Netzwerkkapazität und Rechenleistung verfügen muss,um Ihre Migration erfolgreich abzuschließen. WeitereInformationen dazu, wie Sie herausfinden, welche
API-Version API Version 2016-01-01111
AWS Database Migration Service BenutzerhandbuchErstellen einer Replikations-Instance
Option VorgehensweiseInstance-Klasse sich am besten für Ihre Migration eignet,finden Sie unter Arbeiten mit einer AWS DMS-Replikations-Instance (p. 93).
Replication engine version (Version derReplikations-Engine)
Standardmäßig wird die Replikations-Instance mit derneuesten Version der AWS DMS-Replikations-Engine-Software ausgeführt. Wir empfehlen, dass Sie dieseStandardeinstellung übernehmen. Sie können jedoch beiBedarf eine vorherige Engine-Version auswählen.
VPC Wählen Sie die Amazon Virtual Private Cloud (AmazonVPC) aus, die Sie verwenden möchten. Wenn sich dieQuell- oder Zieldatenbank innerhalb einer VPC befindet,wählen Sie diese VPC aus. Wenn sich Ihre Quell- undZieldatenbank in verschiedenen VPCs befinden, stellen Siesicher, dass sie sich in öffentlichen Subnetzen befindenund öffentlich zugänglich sind, und wählen Sie dann dieVPC aus, in der die Replikations-Instance abgelegt werdensoll. Die Replikations-Instance muss auf die Daten in derQuell-VPC zugreifen können. Wenn sich weder die Quell-noch die Zieldatenbank in einer VPC befinden, wählen Sieeine VPC aus, in der die Replikations-Instance abgelegtwerden soll.
Multi-AZ Verwenden Sie diesen optionalen Parameter zum Erstelleneines Standby-Replikats Ihrer Replikations-Instance ineiner anderen Availability Zone, um Failover-Unterstützungzu bieten. Wenn Sie Change Data Capture (CDC) oder diefortlaufende Replikation verwenden möchten, sollten Siediese Option aktivieren.
Publicly accessible (Öffentlichzugänglich)
Wählen Sie diese Option, wenn Sie möchten, dass dieReplikations-Instance über das Internet zugänglich ist.
2. Wählen Sie die Registerkarte Advanced (Erweitert) aus (siehe unten), um ggf. Werte für Netzwerk-und Verschlüsselungseinstellungen festzulegen. In der folgenden Tabelle sind die Einstellungenbeschrieben.
API-Version API Version 2016-01-01112
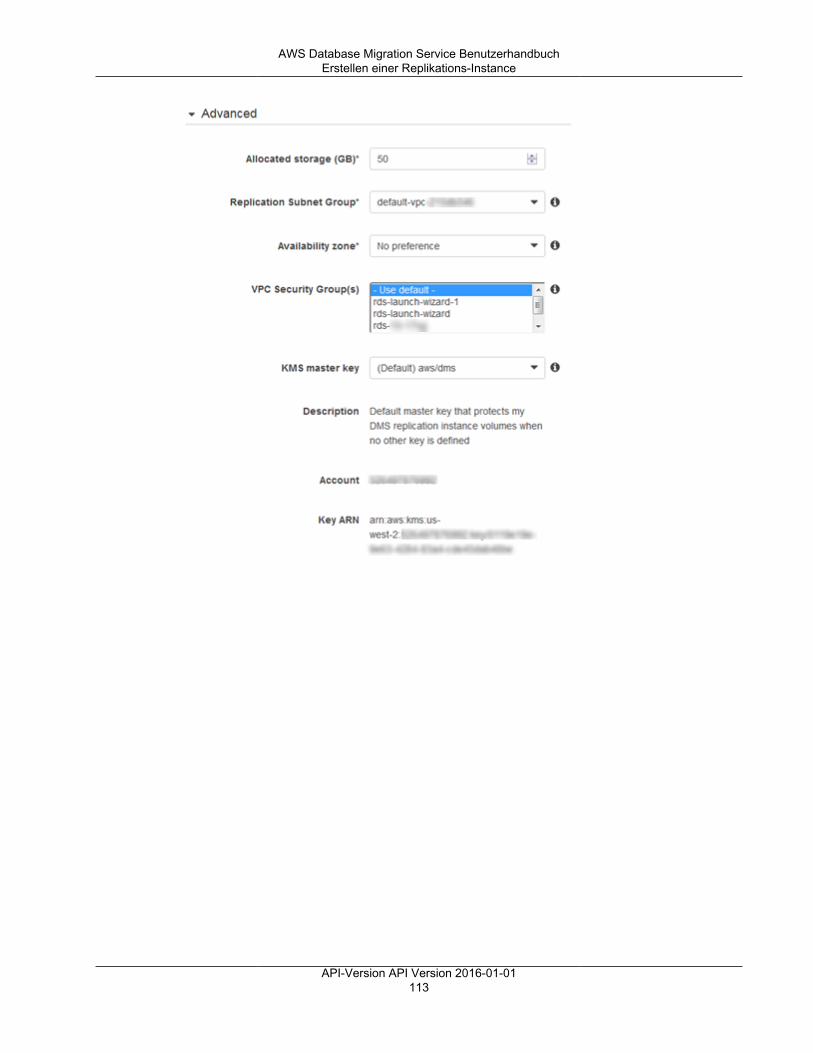
AWS Database Migration Service BenutzerhandbuchErstellen einer Replikations-Instance
API-Version API Version 2016-01-01113
AWS Database Migration Service BenutzerhandbuchErstellen einer Replikations-Instance
Option Vorgehensweise
Allocated storage (GB) (ZugewiesenerSpeicher (GB())
Speicherplatz wird in erster Linie von Protokolldateienund zwischengespeicherten Transaktionen belegt. Für diezwischengespeicherten Transaktionen wird Speicherplatznur verwendet, wenn die zwischengespeichertenTransaktionen auf Festplatte geschrieben werden müssen.Daher verbraucht AWS DMS nicht viel Speicherplatz. Esgibt jedoch folgende Ausnahmen:
• Sehr große Tabellen, bei der viele Transaktionengeladen werden. Das Laden einer großen Tabellekann einige Zeit in Anspruch nehmen, sodasszwischengespeicherte Transaktionen eher während desLadens einer großen Tabelle auf Festplatte geschriebenwerden.
• Aufgaben, die so konfiguriert sind, dass sie vor demLaden zwischengespeicherter Transaktionen angehaltenwerden. In diesem Fall werden alle Transaktionenzwischengespeichert, bis der vollständige Ladevorgangfür alle Tabellen abgeschlossen ist. Bei dieserKonfiguration kann durch die zwischengespeichertenTransaktionen recht viel Speicherplatz beanspruchtwerden.
• Aufgaben, die mit Tabellen konfiguriert sind, die inAmazon Redshift geladen werden. Diese Konfigurationist jedoch kein Problem, wenn Amazon Aurora das Zielist.
In den meisten Fällen reicht die standardmäßigzugewiesene Speichermenge aus. Es ist allerdings immersinnvoll, auf speicherbezogene Metriken zu achten undden Speicherplatz zu erhöhen, wenn Sie feststellen, dassmehr Speicherplatz verbraucht wird, als standardmäßigzugewiesen ist.
Replication Subnet Group(Replikations-Subnetzgruppe)
Wählen Sie die Replikationssubnetzgruppe inder von Ihnen ausgewählten VPC aus, in der dieReplikations-Instance erstellt werden soll. Wenn sichIhre Quelldatenbank in einer VPC befindet, wählen Siedie Subnetzgruppe, die die Quelldatenbank enthält, alsSpeicherort für Ihre Replikations-Instance aus. WeitereInformationen zu Replikationssubnetzgruppen finden Sieunter Erstellen einer Replikationssubnetzgruppe (p. 108).
Availability Zone Wählen Sie die Availability Zone aus, in der sich IhreQuelldatenbank befindet.
VPC Security group(s) (VPC-Sicherheitsgruppe(n))
Die Replikations-Instance wird in einer VPC erstellt. Wennsich Ihre Quelldatenbank in einer VPC befindet, wählenSie die VPC-Sicherheitsgruppe aus, die Zugriff auf die DB-Instance bietet, in der die Datenbank gespeichert ist.
API-Version API Version 2016-01-01114
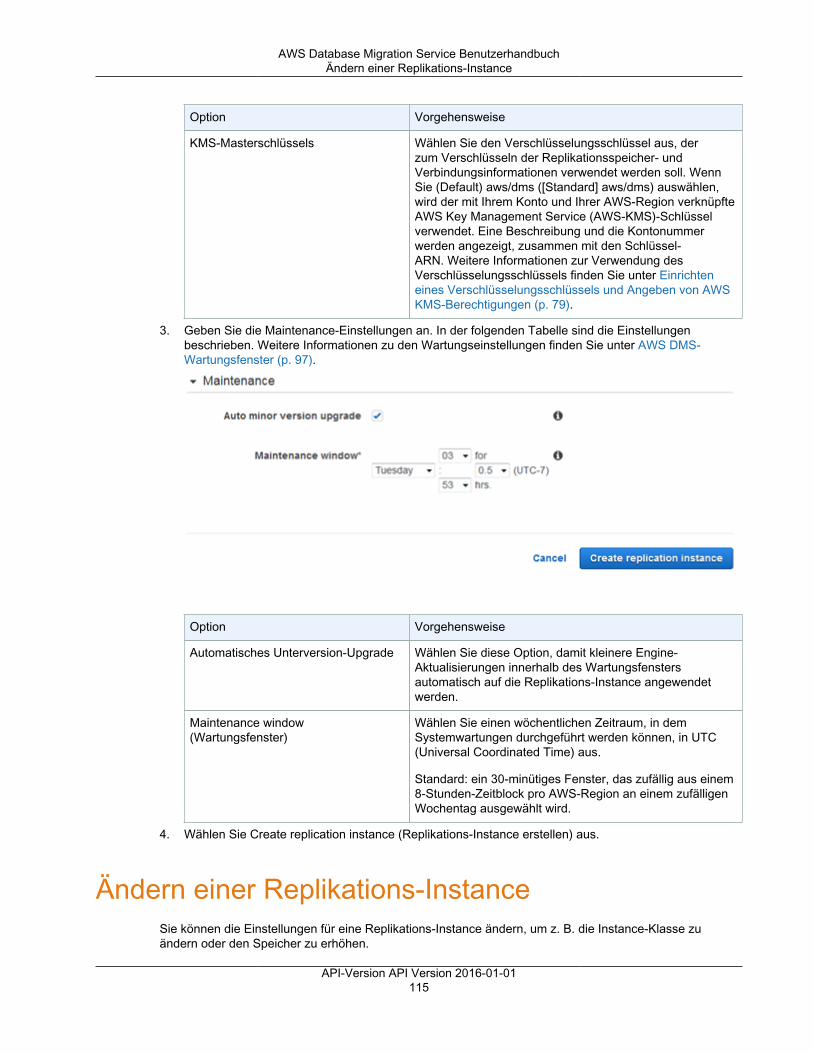
AWS Database Migration Service BenutzerhandbuchÄndern einer Replikations-Instance
Option Vorgehensweise
KMS-Masterschlüssels Wählen Sie den Verschlüsselungsschlüssel aus, derzum Verschlüsseln der Replikationsspeicher- undVerbindungsinformationen verwendet werden soll. WennSie (Default) aws/dms ([Standard] aws/dms) auswählen,wird der mit Ihrem Konto und Ihrer AWS-Region verknüpfteAWS Key Management Service (AWS-KMS)-Schlüsselverwendet. Eine Beschreibung und die Kontonummerwerden angezeigt, zusammen mit den Schlüssel-ARN. Weitere Informationen zur Verwendung desVerschlüsselungsschlüssels finden Sie unter Einrichteneines Verschlüsselungsschlüssels und Angeben von AWSKMS-Berechtigungen (p. 79).
3. Geben Sie die Maintenance-Einstellungen an. In der folgenden Tabelle sind die Einstellungenbeschrieben. Weitere Informationen zu den Wartungseinstellungen finden Sie unter AWS DMS-Wartungsfenster (p. 97).
Option Vorgehensweise
Automatisches Unterversion-Upgrade Wählen Sie diese Option, damit kleinere Engine-Aktualisierungen innerhalb des Wartungsfenstersautomatisch auf die Replikations-Instance angewendetwerden.
Maintenance window(Wartungsfenster)
Wählen Sie einen wöchentlichen Zeitraum, in demSystemwartungen durchgeführt werden können, in UTC(Universal Coordinated Time) aus.
Standard: ein 30-minütiges Fenster, das zufällig aus einem8-Stunden-Zeitblock pro AWS-Region an einem zufälligenWochentag ausgewählt wird.
4. Wählen Sie Create replication instance (Replikations-Instance erstellen) aus.
Ändern einer Replikations-InstanceSie können die Einstellungen für eine Replikations-Instance ändern, um z. B. die Instance-Klasse zuändern oder den Speicher zu erhöhen.
API-Version API Version 2016-01-01115

AWS Database Migration Service BenutzerhandbuchÄndern einer Replikations-Instance
Wenn Sie eine Replikations-Instance ändern, können Sie die Änderungen sofort anwenden. Wählen Siedie Option Apply changes immediately (Änderungen sofort übernehmen) in der AWS Management Consoleunter Verwendung des --apply-immediately-Parameters aus, wenn Sie die AWS-CLI aufrufen, oderSie setzen den ApplyImmediately-Parameter auf true, wenn Sie die AWS-DMS-API verwenden.
Wenn Sie sich entscheiden die Änderungen nicht sofort zu übernehmen, werden die Änderungen in derWarteschlange für ausstehende Änderungen aufgenommen. Während des nächsten Wartungsfensters,werden alle ausstehenden Änderungen in der Warteschlange angewandt.
Note
Wenn Sie sich entscheiden die Änderungen sofort zu übernehmen, werden alle Änderungenin der auch alle ausstehenden Änderungen in der Warteschlange übernommen. Wenn eineder ausstehenden Änderungen eine Ausfallzeit erfordert, kann die Auswahl von Apply changesimmediately (Änderungen sofort übernehmen) einen unerwarteten Ausfall verursachen.
So ändern Sie eine Replikations-Instance über die AWS-Konsole
1. Melden Sie sich bei der AWS Management Console an und wählen Sie AWS DMS aus.2. Wählen Sie im Navigationsbereich Replication instances (Replikations-Instances) aus.3. Wählen Sie die Replikations-Instance aus, die Sie ändern möchten. Die folgende Tabelle beschreibt
die Änderungen, die Sie vornehmen können.
Option Vorgehensweise
Name Sie können den Namen der Replikations-Instance ändern.Geben Sie einen Namen für die Replikations-Instancean, der aus 8 bis 16 druckbaren ASCII-Zeichen (ohne"/" und "@") besteht. Der Name sollte für Ihr Kontound die ausgewählte AWS-Region eindeutig sein. Siekönnen zu dem Namen noch weitere Angaben machen,z. B. die AWS-Region und Aufgabe, die Sie ausführen,beispielsweise west2-mysql2mysql-instance1.
Instance class (Instance-Klasse) Sie können die Instance-Klasse ändern. Wählen Sieeine Instance-Klasse mit der benötigten Konfigurationfür die Migration aus. Das Ändern der Instance-Klassebewirkt, dass die Replikations-Instance neu gestartetwird. Dieser Neustart erfolgt während des nächstenWartungsfensters oder sofort, wenn Sie die Option Applychanges immediately (Änderungen sofort anwenden)auswählen.
Weitere Informationen dazu, wie Sie herausfinden, welcheInstance-Klasse sich am besten für Ihre Migration eignet,finden Sie unter Arbeiten mit einer AWS DMS-Replikations-Instance (p. 93).
Replication engine version (Version derReplikations-Engine)
Sie können ein Upgrade für die Engine-Versiondurchführen, die von der Replikations-Instance verwendetwird. Das Upgraden der Replikations-Engine-Version führtzum Herunterfahren der Replikations-Instance, währendsie auf eine neue Version aktualisiert wird.
Multi-AZ Sie können diese Option ändern, um ein Standby-ReplikatIhrer Replikations-Instance in einer anderen AvailabilityZone für eine Failover-Unterstützung zu erstellen, oderdiese Option entfernen. Wenn Sie Change Data Capture
API-Version API Version 2016-01-01116
AWS Database Migration Service BenutzerhandbuchÄndern einer Replikations-Instance
Option Vorgehensweise(CDC), fortlaufende Replikation, verwenden möchten,sollten Sie diese Option aktivieren.
Allocated storage (GB) (ZugewiesenerSpeicher (GB())
Speicherplatz wird in erster Linie von Protokolldateienund zwischengespeicherten Transaktionen belegt. Für diezwischengespeicherten Transaktionen wird Speicherplatznur verwendet, wenn die zwischengespeichertenTransaktionen auf Festplatte geschrieben werden müssen.Daher verbraucht AWS DMS nicht viel Speicherplatz. Esgibt jedoch folgende Ausnahmen:
• Sehr große Tabellen, bei der viele Transaktionengeladen werden. Das Laden einer großen Tabellekann einige Zeit in Anspruch nehmen, sodasszwischengespeicherte Transaktionen eher während desLadens einer großen Tabelle auf Festplatte geschriebenwerden.
• Aufgaben, die so konfiguriert sind, dass sie vor demLaden zwischengespeicherter Transaktionen angehaltenwerden. In diesem Fall werden alle Transaktionenzwischengespeichert, bis der vollständige Ladevorgangfür alle Tabellen abgeschlossen ist. Bei dieserKonfiguration kann durch die zwischengespeichertenTransaktionen recht viel Speicherplatz beanspruchtwerden.
• Aufgaben, die mit Tabellen konfiguriert sind, die inAmazon Redshift geladen werden. Diese Konfigurationist jedoch kein Problem, wenn Amazon Aurora das Zielist.
In den meisten Fällen reicht die standardmäßigzugewiesene Speichermenge aus. Es ist allerdings immersinnvoll, auf speicherbezogene Metriken zu achten undden Speicherplatz zu erhöhen, wenn Sie feststellen, dassmehr Speicherplatz verbraucht wird, als standardmäßigzugewiesen ist.
VPC Security group(s) (VPC-Sicherheitsgruppe(n))
Die Replikations-Instance wird in einer VPC erstellt. Wennsich Ihre Quelldatenbank in einer VPC befindet, wählenSie die VPC-Sicherheitsgruppe aus, die Zugriff auf die DB-Instance bietet, in der die Datenbank gespeichert ist.
Automatisches Unterversion-Upgrade Wählen Sie diese Option für eine automatischeAnwendung kleinerer Upgrades der Engine auf dieReplikations-Instance während des Wartungsfensters odersofort, wenn Sie die Option Apply changes immediately(Änderungen sofort anwenden) auswählen.
Maintenance window(Wartungsfenster)
Wählen Sie einen wöchentlichen Zeitraum, in demSystemwartungen durchgeführt werden können, in UTC(Universal Coordinated Time) aus.
Standard: ein 30-minütiges Fenster, das zufällig aus einem8-Stunden-Zeitblock pro AWS-Region an einem zufälligenWochentag ausgewählt wird.
API-Version API Version 2016-01-01117

AWS Database Migration Service BenutzerhandbuchNeustarten einer Replikations-Instance
Option Vorgehensweise
Apply changes immediately(Änderungen sofort anwenden)
Wählen Sie diese Option, um alle durchgeführtenÄnderungen sofort anzuwenden. Abhängig von dengewählten Einstellungen könnte die Auswahl dieser Optionzu einem sofortigen Neustart der Replikations-Instanceführen.
Neustarten einer Replikations-InstanceSie können eine AWS DMS-Replikations-Instance neu starten, um die Replikations-Engine neu zu starten.Ein Neustart führt zu einem kurzzeitigen Ausfall der Replikations-Instance, bei dem der Instance-Status aufNeustarten gesetzt wird. Wenn die AWS DMS-Instance für Multi-AZ konfiguriert ist, kann der Neustart miteinem Failover durchgeführt werden. Ein AWS DMS-Ereignis wird nach abgeschlossenem Neustart erstellt.
Wenn Ihre AWS DMS-Instance eine Multi-AZ-Bereitstellung ist, können Sie ein Failover aus einer AWSAvailability Zone zu einer anderen erzwingen, wenn Sie einen Neustart durchführen. Wenn Sie ein FailoverIhrer AWS DMS-Instance erzwingen, wechselt AWS DMS automatisch zu einer Standby-Instance in eineranderen Availability Zone. Ein Neustart mit Failover ist vorteilhaft, wenn Sie einen Ausfall einer AWS DMS-Instance zu Testzwecken simulieren möchten.
Wenn bei einem Neustart Migrationsaufgaben auf der Replikations-Instance ausgeführt werden, gibt eskeinen Datenverlust und die Aufgabe wird wieder aufgenommen, sobald der Neustart abgeschlossenist. Befinden sich die Tabellen der Migrationsaufgabe in der Mitte einer Massenlade-Phase (Full-Load-Phase), so startet DMS die Migration für diese Tabellen von Anfang an neu. Wenn sich Tabellen in derMigrationsaufgabe in der laufenden Replikationsphase befinden, wird die Aufgabe nach Abschluss desNeustarts wieder aufgenommen.
Sie können Ihre AWS DMS-Replikations-Instance nicht neu starten, wenn deren Status nicht Available(Verfügbar) ist. Ihre AWS DMS-Instance kann aus mehreren Gründen nicht verfügbar sein, zum Beispielaufgrund einer zuvor angeforderten Änderung oder einer Aktion im Wartungsfenster. Die Zeit, die benötigtwird, um eine AWS DMS-Replikations-Instance neu zu starten, ist in der Regel gering (unter 5 Minuten).
Neustart einer Replikations-Instance über die AWS-KonsoleZum Neustart einer Replikations-Instance verwenden Sie die AWS-Konsole.
So starten Sie eine Replikations-Instance über die AWS-Konsole neu
1. Melden Sie sich bei der AWS Management Console an und wählen Sie AWS DMS aus.2. Wählen Sie im Navigationsbereich Replication instances (Replikations-Instances) aus.3. Wählen Sie die Replikations-Instance aus, die Sie neustarten möchten.4. Wählen Sie Reboot.5. Wählen Sie im Dialogfeld Reboot replication instance (Replikations-Instance neu starten) die Option
Reboot With Failover? (Neustart mit Failover?), wenn Sie Ihre Replikations-Instance für die Multi-AZ-Bereitstellung konfiguriert haben und möchten, dass ein Failover in einer anderen AWS AvailabilityZone durchgeführt wird.
6. Wählen Sie Reboot.
Neustart einer Replikations-Instance mithilfe der CLIUm eine Replikations-Instance neu zu starten, verwenden Sie den AWS CLI-Befehl reboot-replication-instance mit dem folgenden Parameter:
API-Version API Version 2016-01-01118
AWS Database Migration Service BenutzerhandbuchNeustarten einer Replikations-Instance
• --replication-instance-arn
Example Beispiel für einen einfachen Neustart
Im folgenden AWS CLI-Beispiel wird eine Replikations-Instance neu gestartet.
aws dms reboot-replication-instance \--replication-instance-arn arnofmyrepinstance
Example Beispiel für einen einfachen Neustart mit Failover
Im folgenden AWS CLI-Beispiel wird eine Replikations-Instance mit Failover neu gestartet.
aws dms reboot-replication-instance \--replication-instance-arn arnofmyrepinstance \--force-failover
Neustart einer Replikations-Instance mithilfe der APIUm eine Replikations-Instance neu zu starten, verwenden Sie die AWS DMS-API-AktionRebootReplicationInstance mit den folgenden Parametern:
• ReplicationInstanceArn = arnofmyrepinstance
Example Beispiel für einen einfachen Neustart
Im folgenden Code-Beispiel wird eine Replikations-Instance neu gestartet.
https://dms.us-west-2.amazonaws.com/?Action=RebootReplicationInstance&DBInstanceArn=arnofmyrepinstance&SignatureMethod=HmacSHA256&SignatureVersion=4&Version=2014-09-01&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIADQKE4SARGYLE/20140425/us-east-1/dms/aws4_request&X-Amz-Date=20140425T192732Z&X-Amz-SignedHeaders=content-type;host;user-agent;x-amz-content-sha256;x-amz-date&X-Amz-Signature=1dc9dd716f4855e9bdf188c70f1cf9f6251b070b68b81103b59ec70c3e7854b3
Example Beispiel für einen einfachen Neustart mit Failover
Mit dem folgenden Code-Beispiel wird eine Replikations-Instance neu gestartet und ein Failover in eineranderen AWS Availability Zone durchgeführt.
https://dms.us-west-2.amazonaws.com/?Action=RebootReplicationInstance&DBInstanceArn=arnofmyrepinstance&ForceFailover=true&SignatureMethod=HmacSHA256&SignatureVersion=4&Version=2014-09-01&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIADQKE4SARGYLE/20140425/us-east-1/dms/aws4_request&X-Amz-Date=20140425T192732Z&X-Amz-SignedHeaders=content-type;host;user-agent;x-amz-content-sha256;x-amz-date
API-Version API Version 2016-01-01119

AWS Database Migration Service BenutzerhandbuchLöschen einer Replikations-Instance
&X-Amz-Signature=1dc9dd716f4855e9bdf188c70f1cf9f6251b070b68b81103b59ec70c3e7854b3
Löschen einer Replikations-InstanceSie können eine AWS DMS-Replikations-Instance löschen, wenn Sie sie nicht mehr verwenden. Wenn SieMigrationsaufgaben haben, die die Replikations-Instance verwenden, müssen Sie die Aufgaben stoppenund löschen, bevor Sie die Replikations-Instance löschen.
Wenn Sie Ihr AWS-Konto schließen, werden alle AWS DMS-Ressourcen und Konfigurationen, die IhremKonto zugeordnet sind, nach zwei Tagen gelöscht. Zu diesen Ressourcen gehören alle Replikations-Instances, Quell- und Ziel-Endpunktkonfiguration, Replikationsaufgaben und SSL-Zertifikate. Wenn Sie sichnach zwei Tagen wieder für AWS DMS entscheiden, legen Sie die benötigten Ressourcen neu an.
Löschen einer Replikations-Instance über die AWS-KonsoleZum Löschen einer Replikations-Instance verwenden Sie die AWS-Konsole.
Löschen einer Replikations-Instance unter Verwendung der AWS-Konsole
1. Melden Sie sich bei der AWS Management Console an und wählen Sie AWS DMS aus.2. Wählen Sie im Navigationsbereich Replication instances (Replikations-Instances) aus.3. Wählen Sie die Replikations-Instance aus, die Sie löschen möchten.4. Wählen Sie Delete.5. Wählen Sie im Dialogfeld (Bestätigung) Delete (Löschen) aus.
Löschen einer Replikations-Instance über die CLIUm eine Replikations-Instance zu löschen, verwenden Sie den AWS CLI-Befehl delete-replication-instance mit dem folgenden Parameter:
• --replication-instance-arn
Example Beispiel für das Löschen
Im folgenden AWS CLI-Beispiel wird eine Replikations-Instance gelöscht.
aws dms delete-replication-instance \--replication-instance-arn <arnofmyrepinstance>
Löschen einer Replikations-Instance über die APIUm eine Replikations-Instance zu löschen, verwenden Sie die AWS DMS-API-AktionDeleteReplicationInstance mit den folgenden Parametern:
• ReplicationInstanceArn = <arnofmyrepinstance>
Example Beispiel für das Löschen
Im folgenden Codebeispiel wird eine Replikations-Instance gelöscht.
https://dms.us-west-2.amazonaws.com/
API-Version API Version 2016-01-01120

AWS Database Migration Service BenutzerhandbuchUnterstützte DDL-Anweisungen
?Action=DeleteReplicationInstance&DBInstanceArn=arnofmyrepinstance&SignatureMethod=HmacSHA256&SignatureVersion=4&Version=2014-09-01&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIADQKE4SARGYLE/20140425/us-east-1/dms/aws4_request&X-Amz-Date=20140425T192732Z&X-Amz-SignedHeaders=content-type;host;user-agent;x-amz-content-sha256;x-amz-date&X-Amz-Signature=1dc9dd716f4855e9bdf188c70f1cf9f6251b070b68b81103b59ec70c3e7854b3
Von AWS DMS unterstützte DDL-AnweisungenSie können DDL-Anweisungen (Data Definition Language) auf der Quelledatenbank während desMigrationsprozesses ausführen. Diese Anweisungen werden vom Replikationsserver in der Zieldatenbankrepliziert.
Unterstützte DDL-Anweisungen:
• Create table• Drop table• Rename table• Add column• Drop column• Rename column• Change column data type
Weitere Informationen dazu, welche DDL-Anweisungen für eine bestimmte Quelle unterstützt werden,finden Sie in dem Abschnitt mit der Beschreibung der Quelle.
API-Version API Version 2016-01-01121

AWS Database Migration Service BenutzerhandbuchQuellen für die Datenmigration
Arbeiten mit AWS DMS-EndpunktenEin Endpunkt stellt eine Verbindung, einen Datenspeichertyp sowie Standortinformationen zu IhremDatenspeicher bereit. AWS Database Migration Service verwendet diese Informationen, um eineVerbindung mit einem Datenspeicher herzustellen und Daten von einem Quellendpunkt zu einemZielendpunkt zu migrieren. Über zusätzliche Verbindungsattribute können Sie weitere Verbindungsattributefür einen Endpunkt angeben. Diese Attribute können die Protokollierung, die Dateigröße und andereParameter steuern. Weitere Informationen zu zusätzlichen Verbindungsattributen finden Sie imDokumentationsabschnitt zu Ihrem Datenspeicher.
In den folgenden Abschnitten erhalten Sie weitere Informationen zu Endpunkten.
Themen• Quellen für die Datenmigration (p. 122)• Ziele für die Datenmigration (p. 211)• Erstellen der Quell- und Zielendpunkte (p. 324)
Quellen für die DatenmigrationAWS Database Migration Service (AWS DMS) kann viele der gängigen Datenbank-Engines als Quelle fürdie Datenreplikation verwenden. Bei der Datenbankquelle kann es sich um eine selbstverwaltete Engine,die auf einer Amazon EC2-Instance ausgeführt wird, oder um eine lokale Datenbank handeln. Alternativkann sich die Datenquelle auch in einem von Amazon verwalteten Service, wie z. B. Amazon RDS oderAmazon S3 befinden.
Zulässige Quellen für AWS DMS sind u. a.:
Lokale und Amazon EC2-Instance-Datenbanken
• Oracle-Versionen 10.2 und höher (für Versionen 10.x), 11g und bis zu 12.2, 18c und 19c für die EditionenEnterprise, Standard, Standard One und Standard Two.
Note
• Unterstützung für Oracle-Version 19c als Quelle ist in den AWS DMS-Versionen 3.3.2 undhöher verfügbar.
• Unterstützung für Oracle-Version 18c als Quelle ist in den AWS DMS-Versionen 3.3.1 undhöher verfügbar.
• Microsoft SQL Server-Versionen 2005, 2008, 2008R2, 2012, 2014, 2016, 2017 und 2019. Die EditionenEnterprise, Standard, Workgroup und Developer werden unterstützt. Die Web und Express Editionwerden von AWS DMS nicht unterstützt.
Note
Unterstützung für Microsoft SQL Server Version 2019 als Quelle ist in den AWS DMS-Versionen3.3.2 und höher verfügbar.
• MySQL-Versionen 5.5, 5.6 und 5.7.• MariaDB (unterstützt als MySQL-kompatible Datenquelle), Versionen 10.0.24 bis 10.0.28, 10.1, 10.2 und
10.3.Note
Unterstützung für MariaDB als Quelle ist in allen AWS DMS-Versionen verfügbar, in denenMySQL unterstützt wird.
API-Version API Version 2016-01-01122

AWS Database Migration Service BenutzerhandbuchQuellen für die Datenmigration
• PostgreSQL-Version 9.4 und höher (für Versionen 9.x), 10.x und 11.x.
Note
Die PostgreSQL-Versionen 11.x werden als Quelle nur in den AWS DMS-Versionen 3.3.1 undhöher unterstützt. Sie können die PostgreSQL-Versionen 9.4 und höher (für Versionen 9.x) und10.x als Quelle in jeder beliebigen DMS-Version verwenden.
• SAP Adaptive Server Enterprise (ASE)-Versionen 12.5.3 oder höher, 15, 15.5, 15.7, 16 und höher.• MongoDB-Versionen 2.6.x und 3.x und höher.• IBM Db2 für Linux-, UNIX- und Windows (Db2 LUW)-Versionen:
• Version 9.7, alle Fix Packs werden unterstützt.• Version 10.1, alle Fix Packs werden unterstützt.• Version 10.5, alle Fix Packs außer Fix Pack 5 werden unterstützt.• Version 11.1, alle Fix Packs werden unterstützt.
Microsoft Azure
• AWS DMS unterstützt den vollständigen Datenladevorgang, wenn Azure SQL-Datenbank als Quelleunterstützt wird. Change Data Capture (CDC) wird nicht unterstützt.
Amazon RDS-Instance-Datenbanken
• Oracle-Versionen 10.2 und höher (für Versionen 10.x), 11g (Versionen 11.2.0.3.v1 und höher) und bis zu12.2, 18c und 19c für die Editionen Enterprise, Standard, Standard One und Standard Two.
Note
• Unterstützung für Oracle-Version 19c als Quelle ist in den AWS DMS-Versionen 3.3.2 undhöher verfügbar.
• Unterstützung für Oracle-Version 18c als Quelle ist in den AWS DMS-Versionen 3.3.1 undhöher verfügbar.
• Microsoft SQL Server-Versionen 2008R2, 2012, 2014, 2016, 2017 und 2019. Die Editionen Enterpriseund Standard werden unterstützt. CDC wird für alle Versionen der Enterprise-Edition unterstützt. CDCwird nur für die Standard-Edition der Version 2016 SP1 und höher unterstützt. Die Editionen Web,Workgroup, Developer und Express werden von AWS DMS nicht unterstützt.
Note
Unterstützung für Microsoft SQL Server Version 2019 als Quelle ist in den AWS DMS-Versionen3.3.2 und höher verfügbar.
• MySQL-Versionen 5.5, 5.6 und 5.7. Änderungsdatenerfassung (CDC) wird nicht unterstützt für MySQL5.5 oder früher. CDC wird für die MySQL-Versionen 5.6 und 5.7 unterstützt.
• PostgreSQL-Version 9.4 und höher (für Versionen 9.x), 10.x und 11.x. Change Data Capture (CDC)wird nur für die Versionen 9.4.9, 9.5.4 und höher sowie für 10.x und 11.x unterstützt. Der Parameterrds.logical_replication, der für CDC erforderlich ist, wird nur in diesen Versionen und höherunterstützt.
Note
Die PostgreSQL-Versionen 11.x werden als Quelle nur in den AWS DMS-Versionen 3.3.1 undhöher unterstützt. Sie können die PostgreSQL-Versionen 9.4 und höher (für Versionen 9.x) und10.x als Quelle in jeder beliebigen DMS-Version verwenden.
• MariaDB (unterstützt als MySQL-kompatible Datenquelle), Versionen 10.0.24 bis 10.0.28, 10.1, 10.2 und10.3.
API-Version API Version 2016-01-01123

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Note
Unterstützung für MariaDB als Quelle ist in allen AWS DMS-Versionen verfügbar, in denenMySQL unterstützt wird.
• Amazon Aurora mit MySQL-Kompatibilität aus.• Amazon Aurora mit PostgreSQL-Kompatibilität (10.6 und höher).
Amazon S3
• AWS DMS unterstützt den vollständigen Datenladevorgang und Change Data Capture (CDC), wennAmazon S3 als Quelle verwendet wird.
Themen• Verwenden einer Oracle-Datenbank als Quelle für AWS DMS (p. 124)• Verwenden einer Microsoft SQL Server-Datenbank als Quelle für AWS DMS (p. 151)• Verwenden einer Microsoft Azure SQL-Datenbank als Quelle für AWS DMS (p. 164)• Verwenden einer PostgreSQL-Datenbank als Quelle für AWS DMS (p. 164)• Verwenden einer MySQL-kompatiblen Datenbank als Quelle für AWS DMS (p. 183)• Verwenden einer SAP ASE-Datenbank als Quelle für AWS DMS (p. 191)• Verwenden von MongoDB als Quelle für AWS DMS (p. 196)• Verwenden von Amazon S3 als Quelle für AWS DMS (p. 201)• Verwenden von IBM Db2 für Linux, Unix und Windows-Datenbank (Db2 LUW) als Quelle für AWS
DMS (p. 207)
Verwenden einer Oracle-Datenbank als Quelle fürAWS DMSSie können Daten von einer oder vielen Oracle-Datenbanken mithilfe von AWS DMS migrieren. Miteiner Oracle-Datenbank als Quelle können Sie Daten zu einer der anderen von AWS DMS unterstütztenZieldatenbanken migrieren.
DMS unterstützt die folgenden Oracle-Datenbank-Editionen:
• Oracle Enterprise Edition• Oracle Standard Edition• Oracle Express Edition• Oracle Personal Edition
Für selbstverwaltete Oracle-Datenbanken als Quellen unterstützt AWS DMS alle Oracle-Datenbank-Editionen der Versionen 10.2 und höher, 11g und bis zu 12.2, 18c und 19c. Für von Amazon verwalteteOracle-Datenbanken, die über Amazon RDS bereitgestellt werden, unterstützt AWS DMS alle Oracle-Datenbank-Editionen der Versionen 11g (Versionen 11.2.0.3.v1 und höher) und bis zu 12.2, 18c und 19c.
Note
• Unterstützung für Oracle-Version 19c als Quelle ist in den AWS DMS-Versionen 3.3.2 und höherverfügbar.
API-Version API Version 2016-01-01124

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
• Unterstützung für Oracle-Version 18c als Quelle ist in den AWS DMS-Versionen 3.3.1 und höherverfügbar.
Sie können Secure Sockets Layer (SSL) verwenden, um Verbindungen zwischen Ihrem Oracle-Endpunktund der Replikations-Instance zu verschlüsseln. Weitere Informationen zur Verwendung von SSL mit einemOracle-Endpunkt finden Sie unter Verwenden von SSL mit AWS Database Migration Service (p. 82). AWSDMS unterstützt auch die Verwendung von Oracle Transparent Data Encryption (TDE) zum Verschlüsselnvon Daten, die sich in der Quelldatenbank befinden. Weitere Informationen zur Verwendung von OracleTDE mit einem Oracle-Quellendpunkt finden Sie unter Unterstützte Verschlüsselungsmethoden für dieVerwendung von Oracle als Quelle für AWS DMS (p. 137).
Die Schritte zum Konfigurieren einer Oracle-Datenbank als AWS DMS-Quelle sind wie folgt:
1. Wenn eine Aufgabe nur für CDC oder eine Aufgabe für den vollständigen Ladevorgang plus CDC erstelltwerden soll, müssen Sie zur Erfassung der Datenänderungen entweder Oracle LogMiner oder AWSDMS Binary Reader verwenden. Über die Auswahl von LogMiner oder Binary Reader legen Sie einigeder nachfolgenden Berechtigungs- und Konfigurationsschritte fest. Einen Vergleich von LogMiner undBinary Reader finden Sie im folgenden Abschnitt.
2. Erstellen Sie einen Oracle-Benutzer mit den entsprechenden Berechtigungen für AWS DMS. Bei einerAufgabe nur für einen vollständigen Ladevorgang ist keine weitere Konfiguration erforderlich.
3. Erstellen Sie einen DMS-Endpunkt, der der gewählten Konfiguration entspricht.
Weitere Informationen zum Arbeiten mit Oracle-Datenbanken und AWS DMS finden Sie in den folgendenAbschnitten.
Themen• Verwenden von Oracle LogMiner oder AWS DMS Binary Reader für CDC (Change Data
Capture) (p. 125)• Verwenden einer selbstverwalteten Oracle-Datenbank als Quelle für AWS DMS (p. 128)• Verwenden einer von Amazon verwalteten Oracle-Datenbank als Quelle für AWS DMS (p. 133)• Einschränkungen bei der Verwendung von Oracle als Quelle für AWS DMS (p. 136)• Unterstützte Verschlüsselungsmethoden für die Verwendung von Oracle als Quelle für AWS
DMS (p. 137)• Unterstützte Komprimierungsmethoden für die Verwendung von Oracle als Quelle für AWS
DMS (p. 139)• Replizieren verschachtelter Tabellen mit Oracle als Quelle für AWS DMS (p. 140)• Zusätzliche Verbindungsattribute bei der Verwendung von Oracle als Quelle für AWS DMS (p. 142)• Quelldatentypen für Oracle (p. 148)
Verwenden von Oracle LogMiner oder AWS DMS Binary Readerfür CDC (Change Data Capture)Oracle bietet zwei Methoden für das Lesen der Wiederholungsprotokolle bei der Änderungsverarbeitung:Oracle LogMiner und AWS DMS Binary Reader. LogMiner ist eine Oracle-API zum Lesen der Online-Wiederholungsprotokolldateien und der archivierten Wiederholungsprotokolldateien. Binary Reader ist eineAWS DMS-native Methode, mit der Wiederherstellungsprotokolldateien im Raw-Format direkt gelesen undanalysiert werden können.
Standardmäßig verwendet AWS DMS Oracle LogMiner für CDC (Change Data Capture).
Die Verwendung von LogMiner mit AWS DMS bietet folgende Vorteile:
API-Version API Version 2016-01-01125

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
• LogMiner unterstützt die meisten Oracle-Optionen, wie z. B. Verschlüsselungsoptionen undKomprimierungsoptionen. Binary Reader unterstützt nicht alle Oracle-Optionen, insbesondere dieKomprimierung und die meisten Optionen für die Verschlüsselung.
• LogMiner bietet eine einfachere Konfiguration, insbesondere im Vergleich zur Einrichtung desDirektzugriffs von Binary Reader bzw. wenn sich die Wiederholungsprotokolle von Oracle ASM(Automatic Storage Management) verwaltet werden.
• LogMiner unterstützt die folgenden Hybrid Columnar Compression (HCC)-Typen sowohl für dieReplikation mit vollständigem Ladevorgang als auch für die fortlaufende Replikation (CDC):• QUERY HIGH• ARCHIVE HIGH• ARCHIVE LOW• QUERY LOW
Binary Reader unterstützt den Komprimierungstyp QUERY LOW nur für Replikationen mit vollständigemLadevorgang (und nicht für fortlaufende (CDC-) Replikationen).
• LogMiner unterstützt Tabellen-Cluster zur Verwendung durch AWS DMS. Bei Binary Reader ist das nichtder Fall.
Die Verwendung von Binary Reader anstelle von LogMiner mit AWS DMS bietet u.a. die folgenden Vorteile:
• Für Migrationen mit einer hohen Anzahl von Änderungen hat LogMiner möglicherweise E/A- oder CPU-Auswirkungen auf den Computer, der die Oracle-Quelldatenbank hostet. Mit Binary Reader ist dieWahrscheinlichkeit einer E/A- oder CPU-Leistungsbeeinträchtigung geringer, da die Archivprotokolle aufdie Replikations-Instance kopiert und dort im Detail untersucht werden.
• Für Migrationen mit einer hohen Anzahl von Änderungen ist die CDC-Leistung in der Regel wesentlichbesser, wenn Binary Reader statt Oracle LogMiner verwendet wird.
• Binary Reader unterstützt CDC für LOBs in Oracle Version 12c. LogMiner tut dies nicht.• Binary Reader unterstützt die folgenden HCC-Komprimierungstypen sowohl für vollständige
Ladevorgänge als auch für die fortlaufende Replikation (CDC):• QUERY HIGH• ARCHIVE HIGH• ARCHIVE LOW
Der Komprimierungstyp QUERY LOW wird nur für Migrationen mit vollständigem Ladevorgangunterstützt.
Im Allgemeinen, verwenden Sie Oracle LogMiner für die Migration Ihrer Oracle-Datenbank, es sei denn, esliegt eine der folgenden Situationen vor:
• Sie müssen mehrere Migrationsaufgaben auf der Oracle-Quelldatenbank ausführen.• Der Umfang der Änderungen oder des Wiederholungsprotokolls in der Oracle-Quelldatenbank ist hoch
oder Sie haben Änderungen und verwenden auch ASM.• Ihr Workload enthält UPDATE-Anweisungen, mit denen nur LOB (Large Object)-Spalten aktualisiert
werden. Verwenden Sie in diesem Fall Binary Reader. Diese UPDATE-Anweisungen werden von OracleLogMiner nicht unterstützt.
• Sie migrieren LOB-Spalten von Oracle 12c. Bei Oracle 12c unterstützt LogMiner keine LOB-Spalten.Verwenden Sie in diesem Fall daher Binary Reader.
Note
Sie müssen eine Aufgabe neu starten, wenn Sie zwischen der Verwendung von Oracle LogMinerund AWS DMS Binary Reader wechseln, um Change Data Capture (CDC) durchzuführen.
API-Version API Version 2016-01-01126

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Konfiguration für CDC (Change Data Capture) auf einer Oracle-QuelldatenbankWenn Sie Oracle als Quellendpunkt entweder für einen vollständigen Ladevorgang und CDC (ChangeData Capture) oder nur für CDC nutzen, müssen Sie zusätzliche Verbindungsattribute angeben. Mitdiesen Attributen wird festgelegt, ob der Zugriff auf die Transaktionsprotokolle über Binary Reader erfolgensoll. Diese zusätzlichen Verbindungsattribute geben Sie beim Erstellen des Quellendpunkts an. WennSie mehrere Verbindungsattributeinstellungen verwenden, trennen Sie diese durch Semikola und ohnezusätzliche Leerräume voneinander (z. B. oneSetting;thenAnother).
LogMiner wird standardmäßig verwendet, sodass Sie dies nicht explizit angeben müssen. Um BinaryReader für den Zugriff auf die Transaktionsprotokolle zu verwenden, fügen Sie die folgenden zusätzlichenVerbindungsattribute hinzu.
useLogMinerReader=N;useBfile=Y;
Note
Sie können einen CDC-Ladevorgang für einen Amazon RDS for Oracle als Quellinstancekonfigurieren, indem Sie den Binary Reader nur für Oracle-Versionen 11.2.0.4.v11 und höher und12.1.0.2.v7 verwenden. Verwenden Sie für eine Amazon RDS für Oracle-Version 12.2 oder 18c-Instance AWS DMS-Version 3.3.1. Weitere Informationen finden Sie unter Verwenden einer vonAmazon verwalteten Oracle-Datenbank als Quelle für AWS DMS (p. 133).
In AWS DMS Versionen vor 3.x, in denen die Oracle-Quelldatenbank Oracle ASM verwendet, erfordert dieVerwendung des Binary Reader zusätzliche Attribute. Stellen Sie außerdem sicher, dass Sie Attribute fürden ASM-Benutzernamen und die ASM-Serveradresse angeben. Beim Erstellen des Quellendpunkts mussder Anforderungsparameter Password beide Passwörter angeben: das Oracle-Quellendpunkt-Passwortund das ASM-Passwort.
Verwenden Sie das folgende Format für die zusätzlichen Verbindungsattribute, um auf einen Serverzuzugreifen, der ASm mit Binary Reader zuzugreifen.
useLogMinerReader=N;useBfile=Y;asm_user=asm_username;asm_server=RAC_server_ip_address:port_number/+ASM;
Setzen Sie den Password-Anforderungsparameter des Quellendpunkts sowohl auf das Oracle-Benutzerpasswort als auch das ASM-Passwort (durch ein Komma getrennt) wie nachfolgend dargestellt:
oracle_user_password,asm_user_password
In den AWS DMS-Versionen ab 3.x, in denen die Oracle-Quelle ASM verwendet, können Sie mitHochleistungsoptionen im Binary Reader für die Transaktionsverarbeitung in großem Umfangarbeiten. In diesem Fall unterstützt die Replikations-Instance diese Hochleistungsoptionen. Zudiesen Optionen gehören zusätzliche Verbindungsattribute, um die Anzahl der parallelen Threads(parallelASMReadThreads) und die Anzahl der Read-Ahead-Puffer (readAheadBlocks) anzugeben.Das gemeinsame Festlegen dieser Attribute kann die Leistung eines CDC-Ladevorgangs unterVerwendung von ASM erheblich verbessern. Die nachfolgend gezeigten Einstellungen liefern guteErgebnisse für die meisten ASM-Konfigurationen.
useLogMinerReader=N;useBfile=Y;parallelASMReadThreads=6;readAheadBlocks=150000;
Weitere Hinweise zu Werten, die zusätzliche Verbindungsattribute unterstützen, finden Sie unterZusätzliche Verbindungsattribute bei der Verwendung von Oracle als Quelle für AWS DMS (p. 142).
API-Version API Version 2016-01-01127

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Die Leistung eines CDC-Ladevorgangs unter Verwendung von ASM hängt zudem von anderenEinstellungen ab, die von Ihnen festgelegt werden. Zu diesen Einstellungen gehören Ihre zusätzlichenAWS DMS-Verbindungsattribute sowie die SQL-Einstellungen für die Konfiguration der Oracle-Quellekonfiguriert wurde. Wenn Sie die AWS DMS-Versionen ab 2.4.x verwenden, gelten die oben genanntenLeistungsparameter nicht. Zu diesen AWS DMS-Versions vgl. den Post How to Migrate from OracleASM to AWS using AWS DMS (Migration von Oracle ASM zu AWS) im AWS Database-Blog für weitereInformationen zur Verwendung von ASM mit Ihrem Oracle-Quellendpunkt.
Verwenden einer selbstverwalteten Oracle-Datenbank als Quellefür AWS DMSEine selbstverwaltete Datenbank wird von Ihnen konfiguriert und kontrolliert. Dabei kann es sich um eineOn-Premise-Datenbank-Instance oder um eine Datenbank auf Amazon EC2 handeln. In den folgendenAbschnitten finden Sie Informationen zu den entsprechenden Berechtigungen und Konfigurationen, die beiVerwendung einer selbstverwalteten Oracle-Datenbank mit AWS DMS eingerichtet werden müssen.
Erforderliche Benutzerkontoberechtigungen zum Verwenden einerselbstverwalteten Oracle-Quelle für AWS DMSUm eine Oracle-Datenbank als Quelle in AWS DMS zu verwenden, erteilen Sie dem Oracle-Benutzer, derin den Oracle-Endpunkt-Verbindungseinstellungen angegeben ist, die folgenden Berechtigungen.
Note
Wenn Sie Berechtigungen erteilen, verwenden Sie den tatsächlichen Namen der Objekte und nichtdie Synonyme dafür. Verwenden Sie beispielsweise V_$OBJECT einschließlich des Unterstrichs,nicht V$OBJECT ohne Unterstrich.
• SELECT ANY TRANSACTION
• SELECT on V_$ARCHIVED_LOG
• SELECT on V_$LOG
• SELECT on V_$LOGFILE
• SELECT on V_$DATABASE
• SELECT on V_$THREAD
• SELECT on V_$PARAMETER
• SELECT on V_$NLS_PARAMETERS
• SELECT on V_$TIMEZONE_NAMES
• SELECT on V_$TRANSACTION
• SELECT on ALL_INDEXES
• SELECT on ALL_OBJECTS
• SELECT on DBA_OBJECTS – Erforderlich, wenn die Oracle-Version älter als 11.2.0.3 ist.
Erteilen Sie für jede replizierte Tabelle die folgende zusätzliche Berechtigung, wenn Sie eine bestimmteTabellenliste verwenden.
SELECT on any-replicated-table;
Erteilen Sie die folgende zusätzliche Berechtigung, wenn Sie ein Muster für die Tabellenliste verwenden.
SELECT ANY TABLE;
Erteilen Sie die folgende zusätzliche Berechtigung für jede replizierte Tabelle, wenn AWS DMS zusätzlicheProtokollierung automatisch hinzufügt (Standardverhalten) und Sie eine bestimmte Tabellenliste
API-Version API Version 2016-01-01128

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
verwenden. Informationen zum Deaktivieren der zusätzlichen Protokollierung finden Sie unter ZusätzlicheVerbindungsattribute bei der Verwendung von Oracle als Quelle für AWS DMS (p. 142).
ALTER on any-replicated-table;;
Erteilen Sie die folgende zusätzliche Berechtigung, wenn AWS DMS die zusätzliche Protokollierungautomatisch hinzufügt (Standardverhalten). Informationen zum Deaktivieren der zusätzlichenProtokollierung finden Sie unter Zusätzliche Verbindungsattribute bei der Verwendung von Oracle alsQuelle für AWS DMS (p. 142).
ALTER ANY TABLE;
Wenn Sie auf eine Oracle-Standby-Datenbank zugreifen, erteilen Sie die folgende Berechtigung.
SELECT on V$STANDBY_LOG;
Kontenberechtigungen, die erforderlich sind, wenn Oracle LogMiner für den Zugriffauf die Wiederholungsprotokolle verwendet wirdUm mit Oracle LogMiner auf die Wiederholungsprotokolle zuzugreifen, erteilen Sie dem Oracle-Benutzer,der in den Oracle-Endpunkt-Verbindungseinstellungen angegeben ist, die folgenden Berechtigungen:
• CREATE SESSION
• EXECUTE on DBMS_LOGMNR
• SELECT on V_$LOGMNR_LOGS
• SELECT on V_$LOGMNR_CONTENTS
• GRANT LOGMINING – Nur erforderlich, wenn die Oracle-Version 12c oder höher ist.
Kontoberechtigungen, die erforderlich sind, wenn Sie AWS DMS Binary Readerfür den Zugriff auf die Wiederholungsprotokolle verwendenUm mit dem AWS DMS Binary Reader auf die Wiederholungsprotokolle zuzugreifen, erteilen Sie demOracle-Benutzer, der in den Oracle-Endpunkt-Verbindungseinstellungen angegeben ist, die folgendenBerechtigungen:
• CREATE SESSION
• SELECT on v_$transportable_platform – Erteilen Sie diese Berechtigung, wenn dieWiederholungsprotokolle in Oracle Automatic Storage Management (ASM) gespeichert sind und AWSDMS von ASM aus darauf zugreift.
• CREATE ANY DIRECTORY – Erteilen Sie diese Berechtigung, um AWS DMS in bestimmten Fällenden Zugriff auf die Oracle BFILE-Lesedatei zu ermöglichen. Dieser Zugriff ist erforderlich, wenn dieReplikations-Instance keinen Zugriff auf die Wiederholungsprotokolle auf Dateiebene hat und dieWiederholungsprotokolle sich auf Nicht-ASM-Speicher befinden.
• EXECUTE on DBMS_FILE_TRANSFER package – Erteilen Sie diese Berechtigung zur Kopie derWiederholungsprotokolle in einen temporären Ordner mithilfe der CopyToTempFolder-Methode.
• EXECUTE on DBMS_FILE_GROUP
Binary Reader arbeitet mit Oracle-Dateimerkmalen, zu denen Oracle-Verzeichnisse gehören.Jedes Oracle-Verzeichnisobjekt enthält den Namen des Ordners, der die zu verarbeitendenWiederholungsprotokolldateien enthält. Diese Oracle-Verzeichnisse sind nicht auf Dateisystemebenerepräsentiert. Stattdessen handelt es sich um logische Verzeichnisse, die auf Oracle-Datenbankebeneerstellt werden. Sie können sie in der Oracle ALL_DIRECTORIES-Ansicht anzeigen.
API-Version API Version 2016-01-01129

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Wenn Sie möchten, dass AWS DMS diese Oracle-Verzeichnisse erstellt, erteilen Sie die zuvor angegebeneCREATE ANY DIRECTORY-Berechtigung. AWS DMS erstellt die Verzeichnisnamen mit dem DMS_-Präfix.Wenn Sie die CREATE ANY DIRECTORY-Berechtigung nicht erteilen, erstellen Sie die entsprechendenVerzeichnisse manuell. In einigen Fällen ist bei der manuellen Erstellung der Oracle-Verzeichnisse der imOracle-Quellendpunkt angegebene Oracle-Benutzer nicht der Benutzer, der diese Verzeichnisse erstellthat. In diesen Fällen erteilen Sie auch die READ on DIRECTORY-Berechtigung.
Wenn sich der Oracle-Quellendpunkt im Active Dataguard Standby (ADG) befindet, lesen Sie den EintragHow to Use Binary Reader with ADG (Verwenden von Binary Reader mit ADG) im AWS Database-Blog.
In einigen Fällen können Sie möglicherweise Oracle Managed Files (OMF) zum Speichern derProtokolle verwenden. Oder Ihr Quellendpunkt befindet sich in ADG und die Berechtigung CREATE ANYDIRECTORY kann nicht erteilt werden. In diesen Fällen erstellen Sie die Verzeichnisse mit allen möglichenProtokollspeicherorten manuell, bevor Sie die AWS DMS-Replikationsaufgabe starten. Wenn AWS DMSnicht das erwartete vorangestellte Verzeichnis findet, wird die Aufgabe beendet. Weiterhin löscht AWSDMS nicht die Einträge, die es in der ALL_DIRECTORIES-Ansicht erstellt hat, löschen Sie diese dahermanuell.
Kontoberechtigungen, die erforderlich sind, wenn Binary Reader mit OracleAutomatic Storage Management (ASM) verwendet wirdUm mit Binary Reader auf die Wiederholungslogs in Automatic Storage Management (ASM) zuzugreifen,erteilen Sie dem Oracle-Benutzer, der in den Oracle-Endpunkt-Verbindungseinstellungen angegeben ist,die folgenden Berechtigungen:
• SELECT ON v_$transportable_platform
• SYSASM – Um mit Oracle 11g Release 2 (Version 11.2.0.2) und höher auf das ASM-Konto zuzugreifen,erteilen Sie dem Oracle-Endpunktbenutzer die SYSASM-Berechtigung. Bei älteren unterstützten Oracle-Versionen reicht es normalerweise aus, dem Oracle-Endpunktbenutzer die SYSDBA-Berechtigung zuerteilen.
Sie können den ASM-Kontozugriff validieren, indem Sie eine Eingabeaufforderung öffnen und eine derfolgenden Anweisungen aufrufen, je nach Ihrer zuvor angegebenen Oracle-Version.
Wenn Sie die SYSDBA-Berechtigung benötigen, verwenden Sie Folgendes.
sqlplus asmuser/asmpassword@+asmserver as sysdba
Wenn Sie die SYSASM-Berechtigung benötigen, verwenden Sie Folgendes.
sqlplus asmuser/asmpassword@+asmserver as sysasm
Konfigurieren einer selbstverwalteten Oracle-Quelle für die Replikation mit AWSDMSNachfolgend werden Konfigurationsanforderungen für die Verwendung einer selbstverwalteten Oracle-Datenbank als Quelle in AWS DMS aufgeführt.
• Stellen Sie den Oracle-Kontozugriff für den AWS DMS-Benutzer bereit. Weitere Informationen finden Sieunter Bereitstellen des Zugriffs auf Oracle-Konten (p. 131)
• Stellen Sie für Protokolle den ARCHIVELOG-Modus ein. Weitere Informationen finden Sie unter Einstellender Protokolle auf den ARCHIVELOG-Modus (p. 131)
Sie können Oracle in zwei verschiedenen Modi ausführen: dem ARCHIVELOG-Modus und demNOARCHIVELOG-Modus. Um die Oracle-Protokolle mit AWS DMS zu verwenden, führen Sie dieDatenbank im ARCHIVELOG-Modus aus.
API-Version API Version 2016-01-01130

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
• Richten Sie die zusätzliche Protokollierung ein und überprüfen Sie sie.
Sie können die zusätzliche Protokollierung automatisch mit zusätzlichen Verbindungsattributenfür den Oracle-Quellendpunkt einrichten. Weitere Informationen finden Sie unter ZusätzlicheVerbindungsattribute bei der Verwendung von Oracle als Quelle für AWS DMS (p. 142). Wenn Siediese zusätzlichen Verbindungsattribute nicht einstellen, können Sie die zusätzliche Protokollierungmit einem feinkörnigeren Konzept einrichten. Weitere Informationen finden Sie unter Überprüfen undEinrichten der zusätzlichen Protokollierung (p. 131)
Bereitstellen des Zugriffs auf Oracle-Konten
So stellen Sie dem AWS DMS-Benutzer den Oracle-Kontozugriff bereit:
• Stellen Sie sicher, dass der AWS DMS-Benutzer über Lese-/Schreibberechtigungen für die Oracle-Datenbank verfügt. Informationen zum Einrichten des Zugriffs auf das Oracle-Konto finden Sie unterErforderliche Benutzerkontoberechtigungen zum Verwenden einer selbstverwalteten Oracle-Quelle fürAWS DMS (p. 128).
Einstellen der Protokolle auf den ARCHIVELOG-Modus
So stellen Sie Protokolle auf den ARCHIVELOG-Modus ein:
• Führen Sie den folgenden Befehl aus.
ALTER database ARCHIVELOG;
Note
Wenn sich Ihre Oracle-Datenbank-Instance auf Amazon RDS befindet, führen Sie einenanderen Befehl aus. Weitere Informationen finden Sie unterVerwenden einer von Amazonverwalteten Oracle-Datenbank als Quelle für AWS DMS (p. 133).
Sie können auch die zusätzliche Protokollierung einrichten und überprüfen, wie nachfolgend beschrieben.
Überprüfen und Einrichten der zusätzlichen Protokollierung
Um die zusätzliche Protokollierung einzurichten, führen Sie die folgenden Schritte aus, die weiter unten indiesem Abschnitt näher beschrieben werden:
1. Prüfen Sie, ob die zusätzliche Protokollierung für die Datenbank aktiviert ist:2. Prüfen Sie, ob die erforderliche zusätzliche Protokollierung für jede Tabelle aktiviert ist.3. Wenn ein Filter oder eine Transformation für eine Tabelle definiert ist, aktivieren Sie die zusätzliche
Protokollierung nach Bedarf.
So überprüfen und aktivieren Sie ggf. die zusätzliche Protokollierung für die Datenbank:
1. Führen Sie die folgende Beispielabfrage aus, um zu überprüfen, ob die aktuelle Version der Oracle-Datenbank von AWS DMS unterstützt wird. Wenn die Abfrage fehlerfrei ausgeführt wird, wird diezurückgegebene Datenbankversion unterstützt.
SELECT name, value, description FROM v$parameter WHERE name = 'compatible';
Hier sind name, value und description Spalten irgendwo in der Datenbank, die auf der Grundlagedes Wertes von name abgefragt werden. Als Teil der Abfrage überprüft eine AWS DMS-Aufgabe
API-Version API Version 2016-01-01131

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
den Wert von v$parameter anhand der zurückgegebenen Version der Oracle-Datenbank. Wenneine Übereinstimmung vorliegt, wird die Abfrage fehlerfrei ausgeführt und AWS DMS unterstütztdiese Version der Datenbank. Wenn keine Übereinstimmung vorliegt, löst die Abfrage einen Fehleraus und AWS DMS unterstützt diese Version der Datenbank nicht. Konvertieren Sie in diesemFall zunächst die Oracle-Datenbank in eine AWS DMS-unterstützte Version, um mit der Migrationfortzufahren. Beginnen Sie dann erneut mit der Konfiguration der Datenbank, wie unter Konfiguriereneiner selbstverwalteten Oracle-Quelle für die Replikation mit AWS DMS (p. 130) beschrieben.
2. Führen Sie die folgende Abfrage aus, um zu überprüfen, ob die zusätzliche Protokollierung fürdie Datenbank aktiviert ist. Wenn das zurückgegebene Ergebnis YES oder IMPLICIT ist, ist diezusätzliche Protokollierung für die Datenbank aktiviert.
SELECT supplemental_log_data_min FROM v$database;
3. Aktivieren Sie ggf. die zusätzliche Protokollierung für die Datenbank, indem Sie den folgenden Befehlausführen.
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
Note
Wenn sich Ihre Oracle-Datenbank-Instance auf Amazon RDS befindet, führen Sie einenanderen Befehl aus. Weitere Informationen finden Sie unterVerwenden einer von Amazonverwalteten Oracle-Datenbank als Quelle für AWS DMS (p. 133).
So überprüfen Sie, ob die erforderliche zusätzliche Protokollierung für jede Datenbanktabelleaktiviert ist:
• Führen Sie eine der folgenden Aufgaben aus:
• Wenn ein Primärschlüssel vorhanden ist, fügen Sie die zusätzliche Protokollierung für denPrimärschlüssel hinzu. Dazu können Sie entweder das Format für die Hinzufügung der zusätzlichenProtokollierung zum Primärschlüssel verwenden oder die zusätzliche Protokollierung auf denPrimärschlüsselspalten hinzufügen.
• Wenn kein Primärschlüssel vorhanden ist, führen Sie einen der folgenden Schritte aus:• Wenn kein Primärschlüssel vorhanden ist und die Tabelle über einen einzigen eindeutigen Index
verfügt, müssen alle Spalten des eindeutigen Index dem zusätzlichen Protokoll hinzugefügtwerden.
Die Verwendung von SUPPLEMENTAL LOG DATA (UNIQUE INDEX) COLUMNS fügt die Spaltendes eindeutigen Index dem Protokoll nicht hinzu.
• Wenn kein Primärschlüssel vorhanden ist und die Tabelle mehrere eindeutige Indizes enthält,fügen Sie dem zusätzlichen Protokoll alle Spalten für den eindeutigen Index hinzu, den AWSDMS auswählt. AWS DMS wählt den ersten eindeutigen Index aus einer alphabetisch aufsteigendsortierten Liste aus.
• Wenn kein Primärschlüssel vorhanden ist und kein eindeutiger Index vorhanden ist, fügen Sie diezusätzliche Protokollierung für alle Spalten hinzu.
Durch Verwendung von SUPPLEMENTAL LOG DATA (UNIQUE INDEX) COLUMNS werden dieSpalten des ausgewählten eindeutigen Index nicht dem Protokoll hinzugefügt.
Note
In einigen Fällen sind der Primärschlüssel oder der eindeutige Index der Zieltabelle und derPrimärschlüssel oder der eindeutige Index der Quelltabelle unterschiedlich. Fügen sie in solchenAPI-Version API Version 2016-01-01
132

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Fällen die zusätzliche Protokollierung manuell für die Spalten der Quelltabelle hinzu, die denPrimärschlüssel oder den eindeutigen Index der Zieltabelle darstellen.Wenn Sie den Primärschlüssel der Zieltabelle ändern, sollten Sie die zusätzliche Protokollierungfür die Spalten des eindeutigen Zielindex hinzufügen, anstatt für die Spalten des Primärschlüsselsoder des eindeutigen Index der Quelle.
Wenn für eine Tabelle ein Filter oder eine Transformation definiert ist, müssen Sie möglicherweise diezusätzliche Protokollierung aktivieren. Einige Überlegungen dazu:
• Wenn der Tabelle die zusätzliche ALL COLUMNS-Protokollierung hinzugefügt wurde, muss keinezusätzliche Protokollierung hinzugefügt werden.
• Wenn die Tabelle über einen eindeutigen Index oder einen Primärschlüssel verfügt, fügen Sie diezusätzliche Protokollierung für jede Spalte hinzu, die von einem Filter oder einer Transformationbetroffen ist, aber nur, wenn sich diese Spalten von dem Primärschlüssel oder eindeutigen Indexspaltenunterscheiden.
• Wenn eine Transformation nur eine Spalte verwendet, fügen Sie diese Spalte nicht einer zusätzlichenProtokollierungsgruppe hinzu. Fügen Sie für eine Transformation A+B beispielsweise die zusätzlicheProtokollierung für beide Spalten, A und B, hinzu. Fügen Sie jedoch für eine Transformationsubstring(A,10) jedoch keine zusätzliche Protokollierung für Spalte A hinzu.
• Eine Methode zum Einrichten der zusätzlichen Protokollierung sowohl für Primärschlüssel als auchfür eindeutige Indexspalten und andere bestimmte Spalten, die gefiltert oder transformiert werden,besteht darin, zusätzliche USER_LOG_GROUP-Protokollierung hinzuzufügen. Fügen Sie diese zusätzlicheUSER_LOG_GROUP-Protokollierung sowohl für die Primärschlüssel/eindeutigen Indexspalten, als auch fürdie anderen spezifischen Spalten hinzu, die gefiltert oder transformiert werden.
Wenn Sie beispielsweise eine Tabelle mit dem Namen TEST.LOGGING mit dem Primärschlüssel IDund einem Filter nach der Spalte NAME replizieren möchten, können Sie einen Befehl wie den folgendenausführen, um die zusätzliche Protokollierung der Protokollgruppe zu erstellen.
ALTER TABLE TEST.LOGGING ADD SUPPLEMENTAL LOG GROUP TEST_LOG_GROUP (KEY, ADDRESS) ALWAYS;
In diesem Beispiel ist die NAME-Spalte eine Komponente von ADDRESS.
Verwenden einer von Amazon verwalteten Oracle-Datenbank alsQuelle für AWS DMSEine von Amazon verwaltete Datenbank ist in einem Amazon-Service wie z. B. Amazon RDS, AmazonAurora oder Amazon S3 enthalten. In den folgenden Abschnitten finden Sie die entsprechendenBerechtigungen und Konfigurationen, die bei Verwendung einer von Amazon verwalteten Oracle-Datenbank mit AWS DMS eingerichtet werden müssen.
Erforderliche Benutzerkontoberechtigungen zum Verwenden einer von Amazonverwalteten Oracle-Quelle für AWS DMSVerwenden Sie zum Erteilen von Berechtigungen für Oracle-Datenbanken auf Amazon RDS diegespeicherte Prozedur rdsadmin.rdsadmin_util.grant_sys_object. Weitere Informationen findenSie unter Erteilen von SELECT- oder EXECUTE-Berechtigungen für SYS-Objekte.
Erteilen Sie dem AWS DMS-Benutzerkonto folgende Berechtigungen für den Zugriff auf den Oracle-Quellendpunkt:
GRANT SELECT ANY TABLE to dms_user;GRANT SELECT on ALL_VIEWS to dms_user;GRANT SELECT ANY TRANSACTION to dms_user;GRANT SELECT on DBA_TABLESPACES to dms_user;
API-Version API Version 2016-01-01133

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
GRANT SELECT on ALL_TAB_PARTITIONS to dms_user;GRANT SELECT on ALL_INDEXES to dms_user;GRANT SELECT on ALL_OBJECTS to dms_user;GRANT SELECT on ALL_TABLES to dms_user;GRANT SELECT on ALL_USERS to dms_user;GRANT SELECT on ALL_CATALOG to dms_user;GRANT SELECT on ALL_CONSTRAINTS to dms_user;GRANT SELECT on ALL_CONS_COLUMNS to dms_user;GRANT SELECT on ALL_TAB_COLS to dms_user;GRANT SELECT on ALL_IND_COLUMNS to dms_user;GRANT SELECT on ALL_LOG_GROUPS to dms_user;GRANT LOGMINING TO dms_user;GRANT READ ON DIRECTORY ONLINELOG_DIR TO dms_user; (for Binary Reader)GRANT READ ON DIRECTORY ARCHIVELOG_DIR TO dms_user; (for Binary Reader)
Führen Sie außerdem folgende Schritte aus:
exec rdsadmin.rdsadmin_util.grant_sys_object('V_$ARCHIVED_LOG','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('V_$LOG','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('V_$LOGFILE','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('V_$DATABASE','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('V_$THREAD','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('V_$PARAMETER','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('V_$NLS_PARAMETERS','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('V_$TIMEZONE_NAMES','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('V_$TRANSACTION','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('DBA_REGISTRY','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('OBJ$','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('ALL_ENCRYPTED_COLUMNS','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('V_$LOGMNR_LOGS','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('V_$LOGMNR_CONTENTS','dms_user','SELECT');exec rdsadmin.rdsadmin_util.grant_sys_object('DBMS_LOGMNR','dms_user','EXECUTE');exec rdsadmin.rdsadmin_util.grant_sys_object('REGISTRY$SQLPATCH', 'MKTEST', 'SELECT'); (as of AWS DMS versions 3.3.1 and later)exec rdsadmin.rdsadmin_util.grant_sys_object('V_$STANDBY_LOG', 'MKTEST', 'SELECT'); (for RDS Active Dataguard Standby (ADG))
Konfigurieren einer von Amazon verwalteten Oracle-Quelle für AWS DMSBevor Sie eine von Amazon verwaltete Oracle-Datenbank als Quelle für AWS DMS verwenden, führen Siedie folgenden Aufgaben für die Oracle-Datenbank aus:
• Richten Sie die zusätzliche Protokollierung ein.• Aktivieren Sie automatische Sicherungen.• Richten Sie die Archivierung ein. Wenn Sie die Wiederholungsprotokolle für Ihr Amazon RDS für Ihre
Oracle DB-Instance archivieren, kann AWS DMS die Protokollinformationen mit Oracle LogMiner oderBinary Reader abrufen.
Jeder der vorhergehenden Schritte wird im Folgenden ausführlicher beschrieben.
So richten Sie die zusätzliche Protokollierung ein:
1. Führen Sie den folgenden Befehl aus.
exec rdsadmin.rdsadmin_util.alter_supplemental_logging('ADD');
2. (Optional) Ändern Sie die zusätzlichen Protokollierungsattribute nach Bedarf mithilfe der folgendenBefehle.
exec rdsadmin.rdsadmin_util.alter_supplemental_logging('ADD','ALL');
API-Version API Version 2016-01-01134

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
exec rdsadmin.rdsadmin_util.alter_supplemental_logging('DROP','PRIMARY KEY');
So aktivieren Sie automatische Sicherungen:
1. Melden Sie sich bei der AWS Management Console an und öffnen Sie die Amazon RDS-Konsole unterhttps://console.aws.amazon.com/rds/.
2. Setzen Sie im Abschnitt Management Settings (Verwaltungseinstellungen) für Ihre Amazon RDS-Oracle-Datenbank-Instance die Option Enabled Automated Backups (Automatische Sicherungenaktiviert) auf Yes (Ja).
So richten Sie die Archivierung ein:
1. Führen Sie den rdsadmin.rdsadmin_util.set_configuration Befehl aus, um die Archivierungeinzurichten.
Führen Sie beispielsweise den folgenden Befehl aus, um die archivierten Wiederholungsprotokolle 24Stunden lang beizubehalten.
exec rdsadmin.rdsadmin_util.set_configuration('archivelog retention hours',24);
2. Stellen Sie sicher, dass Ihr Speicherplatz für die archivierten Wiederholungsprotokolle in demangegebenen Zeitraum ausreicht.
Konfigurieren von Change Data Capture (CDC) für eine Amazon RDS for Oracle-Quelle für AWS DMS
Sie können AWS DMS so konfigurieren, dass eine Amazon RDS for Oracle-Instance als Quelle für CDCverwendet wird.
Um Oracle LogMiner verwenden zu können, sind die minimal erforderlichen Benutzerkontoberechtigungenausreichend. Weitere Informationen finden Sie unter Erforderliche Benutzerkontoberechtigungen zumVerwenden einer von Amazon verwalteten Oracle-Quelle für AWS DMS (p. 133).
Um AWS DMS Binary Reader zu verwenden, geben Sie je nach AWS DMS-Version zusätzlicheEinstellungen und zusätzliche Verbindungsattribute für den Oracle-Quellendpunkt an. Informationen zuden Amazon RDS-Oracle-Versionen 11g und 12.1 finden Sie im Beitrag AWS DMS now supports BinaryReader for Amazon RDS for Oracle and Oracle Standby as a source (AWS DMS unterstützt jetzt BinaryReader für Amazon RDS for Oracle und Oracle Standby als Quelle) im AWS Database-Blog.
Für AWS DMS-Versionen ab 3.3.1 ist Binary Reader-Unterstützung in Amazon RDS Oracle-Versionen 12.2und 18c verfügbar.
So konfigurieren Sie CDC mit dem AWS DMS Binary Reader:
1. Melden Sie sich als Master-Benutzer bei Ihrer Amazon RDS-Oracle-Quelldatenbank an.2. Führen Sie die folgenden gespeicherten Prozeduren aus, um die Verzeichnisse auf Serverebene zu
erstellen. Weitere Informationen finden Sie unter Zugreifen auf Transaktionsprotokolle im AmazonRDS-Benutzerhandbuch.
exec rdsadmin.rdsadmin_master_util.create_archivelog_dir;exec rdsadmin.rdsadmin_master_util.create_onlinelog_dir;
3. Legen Sie die folgenden zusätzlichen Verbindungsattribute auf dem Amazon RDS-Oracle-Quellendpunkt fest. Verwenden Sie keine Leerzeichen, wenn Sie mehrere Attributeinstellungen durchSemikolon (;) trennen.
API-Version API Version 2016-01-01135

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
useLogminerReader=N;useBfile=Y
Note
Verwenden Sie keine Leerzeichen nach den Semikolon als Trennzeichen (;) für mehrereEinstellungen (zum Beispiel oneSetting;thenAnother).
Einschränkungen bei der Verwendung von Oracle als Quelle fürAWS DMSDie folgenden Einschränkungen gelten, wenn Sie eine Oracle-Datenbank als Quelle für AWS DMSverwenden:
• AWS DMS unterstützt keine langen Objektnamen (über 30 Byte).• AWS DMS unterstützt keine funktionsbasierten Indizes.• Wenn Sie die zusätzliche Protokollierung verwenden und Transformationen für eine der Spalten
durchführen, stellen Sie sicher, dass die zusätzliche Protokollierung für alle Felder und Spalten aktiviertist.
• AWS DMS unterstützt keine Multi-Tenant-Container-Datenbanken (CDB).• AWS DMS unterstützt keine verzögerten Einschränkungen.• AWS DMS unterstützt die rename table table-name to new-table-name-Syntax für die Oracle-
Versionen 11 und höher.• AWS DMS repliziert keine Datenänderungen, die sich aus Partitions- oder Unterpartitionsoperationen
(ADD, DROP, EXCHANGE und TRUNCATE) ergeben. Solche Aktualisierungen können während derReplikation folgende Fehler verursachen:• Bei ADD-Operationen können Aktualisierungen und Löschungen für die hinzugefügten Daten die
Warnung „0 rows affected (0 Zeilen betroffen)“ auslösen.• Für DROP- und TRUNCATE-Operationen können neue Einfügungen „Duplicates (Duplikate)“-Fehler
verursachen.• EXCHANGE-Operationen können sowohl eine Warnung „0 rows affected (0 Zeilen betroffen)“, als auch
„Duplicates (Duplikate)“-Fehler auslösen.
Um Änderungen zu replizieren, die sich aus Partitions- oder Unterpartitionsoperationen ergeben,laden Sie die betreffenden Tabellen neu. Nach dem Hinzufügen einer neuen leeren Partition werdenOperationen für die neu hinzugefügten Tabellen wie gewohnt auf das Ziel repliziert.
• AWS DMS unterstützt Datenänderungen auf dem Ziel, die sich aus der Ausführung der CREATE TABLEAS-Anweisung auf der Quelle ergeben, mit Ausnahme von Oracle bereitgestellter Datentypen wie z. B.XMLType.
• Wenn Sie den LOB-Modus mit eingeschränkter Größe aktivieren, repliziert AWS DMS LOBs aus derOracle-Quelle als NULL-Werte auf dem Ziel.
• AWS DMS erfasst keine vom Oracle DBMS_REDEFINITION-Paket vorgenommenen Änderungen, z. B.die Tabellenmetadaten und das OBJECT_ID-Feld.
• AWS DMS ordnet leere BLOB- und CLOB-Spalten zu NULL auf dem Ziel zu.• Beim Erfassen von Änderungen mit Oracle 11 LogMiner geht eine Aktualisierung einer CLOB-Spalte mit
einer Zeichenfolgenlänge von mehr als 1982 verloren und das Ziel wird nicht aktualisiert.• Während des Change Data Capture (CDC)-Vorgangs unterstützt AWS DMS keine
Stapelaktualisierungen von numerischen Spalten, die als Primärschlüssel definiert sind.• AWS DMS unterstützt bestimmte UPDATE-Befehle nicht. Das folgende Beispiel ist ein nicht unterstützterUPDATE-Befehl.
API-Version API Version 2016-01-01136

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
UPDATE TEST_TABLE SET KEY=KEY+1;
Hier ist TEST_TABLE der Tabellenname und KEY ist eine numerische Spalte, die als Primärschlüsseldefiniert ist.
• AWS DMS kürzt alle Daten in LONG- oder LONG RAW-Spalten, die länger als 64 KB sind.• AWS DMS repliziert keine Tabellen, deren Namen Apostrophe enthalten.• AWS DMS unterstützt CDC für dynamische Ansichten nicht.• Wenn Sie AWS DMS Binary Reader verwenden, um auf die Wiederholungsprotokolle zuzugreifen,
unterstützt AWS DMS CDC für indexorganisierte Tabellen mit einem Überlaufsegment nicht.• Wenn Sie Oracle LogMiner verwenden, um auf die Wiederholungsprotokolle zuzugreifen, gelten für AWS
DMS die folgenden Einschränkungen:• Nur für Oracle 12 repliziert AWS DMS keine Änderungen an LOB-Spalten.• Für alle Oracle-Versionen repliziert AWS DMS nicht das Ergebnis von UPDATE-Operationen aufXMLTYPE- und LOB-Spalten.
• AWS DMS repliziert keine Ergebnisse der DDL-Anweisung ALTER TABLE ADD column data_typeDEFAULT <default_value>. Anstatt <default_value> auf das Ziel zu replizieren, wird die neueSpalte auf NULL gesetzt. Ein solches Ergebnis kann selbst dann auftreten, wenn die DDL-Anweisung,die die neue Spalte hinzugefügt hat, in einer vorherigen Aufgabe ausgeführt wurde.
Wenn die neue Spalte löschbar ist, aktualisiert Oracle alle Tabellenzeilen, bevor die DDL selbstprotokolliert wird. Infolgedessen erfasst AWS DMS die Änderungen, aktualisiert das Ziel jedoch nicht.Wenn die neue Spalte auf NULL gesetzt ist, wird eine Meldung „0 rows affected (Null Zeilen betroffen)“ausgelöst, wenn die Zieltabelle keinen Primärschlüssel oder eindeutigen Index aufweist.
• AWS DMS unterstützt keine Verbindungen zu einer Pluggable Database (PDB) mit Oracle LogMiner.Um eine Verbindung mit einer PDB herzustellen, greifen Sie mit dem Binary Reader auf dieWiederholungsprotokolle zu.
• Wenn Sie Binary Reader verwenden, gelten für AWS DMS die folgenden Einschränkungen:• Es unterstützt keine Tabellencluster.• Es unterstützt nur SHRINK SPACE-Operationen auf Tabellenebene. Diese Ebene umfasst die
vollständige Tabelle, Partitionen und Unterpartitionen.• Es unterstützt keine Änderungen an indexorganisierten Tabellen mit Schlüsselkomprimierung.
• AWS DMS unterstützt keine transparente Datenverschlüsselung (TDE), wenn Binary Reader mit einerAmazon RDS-Oracle-Quelle verwendet wird.
• AWS DMS unterstützt keine Verbindungen zu einer Amazon RDS-Oracle-Quelle mit einem OracleAutomatic Storage Management (ASM)-Proxy.
• AWS DMS unterstützt keine virtuellen Spalten.• AWS DMS unterstützt nicht den ROWID-Datentyp oder materialisierte Ansichten basierend auf einerROWID-Spalte.
• AWS DMS lädt oder erfasst keine globalen temporären Tabellen.
Unterstützte Verschlüsselungsmethoden für die Verwendung vonOracle als Quelle für AWS DMSIn der folgenden Tabelle finden Sie die TDE (Transparent Data Encryption)-Methoden, die AWS DMS beider Arbeit mit einer Oracle-Quelldatenbank unterstützt.
Note
AWS DMS unterstützt derzeit nicht die Verwendung von Oracle TDE in einer Oracle-Datenbankder Version 19c.
API-Version API Version 2016-01-01137
AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Zugriffsmethode fürWiederholungsprotokolle
TDE Tablespace TDE Column
Oracle LogMiner Ja Ja
Binary Reader Ja Ja (AWS DMS-Version 3.x undhöher)
Ab Version 3.x unterstützt AWS DMS Oracle TDE (sowohl in der Spalte als auch im Tablespace) beiVerwendung von Binary Reader. Geben Sie die relevanten Verschlüsselungsschlüssel mit AWS DMSals Teil des für den Oracle-Quellendpunkt angegebenen Password (Passwort)-Feldwerts frei. WeitereInformationen finden Sie in den folgenden Absätzen.
Um den richtigen Verschlüsselungsschlüssel oder die richtigen Schlüssel für die TDE-Tablespace-Verschlüsselung oder die TDE-Spaltenverschlüsselung anzugeben, suchen Sie den entsprechendenEintrag in Oracle Wallet, der den oder die Schlüssel enthält. Nachdem Sie die entsprechenden Einträgegefunden haben, kopieren Sie alle Einträge und deren Werte, fügen Sie dann jeden Eintrag in dasFeld Names (Namen) und jeden Eintragswert in das Feld Values (Werte) ein. Trennen Sie mehrereEintragsnamen und Werte in den entsprechenden Feldern durch Kommata.
Um mehrere Werte zu kopieren und einzufügen, kopieren Sie jeden Eintrag in einen Texteditor wieNotepad++ und stellen Sie sicher, dass die Werte durch ein Komma getrennt werden. Kopieren Sie dieZeichenfolge, die die durch Kommata getrennten Werte enthält, aus dem Texteditor, und fügen Sie siein das Feld Values (Werte) ein. Um mehrere Einträge zu kopieren und einzufügen, müssen Sie keinenZwischentexteditor verwenden. Stattdessen können Sie die Einträge direkt in das Feld Names (Namen)einfügen und dann jeden Eintrag durch ein Komma trennen.
Um Oracle Wallet-Einträge abzurufen, versuchen Sie Folgendes:
• Wenn der ENCRYPTION_WALLET_LOCATION-Parameter in der sqlnet.ora-Datei definiert ist,verwenden Sie das Wallet aus dem durch diesen Parameter definierten Verzeichnis.
• Wenn der WALLET_LOCATION-Parameter in der sqlnet.ora-Datei definiert ist, verwenden Sie dasWallet aus dem durch diesen Parameter definierten Verzeichnis.
• In anderen Fällen verwenden Sie das Wallet am Standarddatenbankspeicherort.
Note
In jedem Fall sollte der Wallet-Name ewallet.p12 sein.• Verwenden Sie die -list-Option im Oracle mkstore-Dienstprogramm, um den/dieORACLE.SECURITY.DB/TS.ENCRYPTION.SUFFIX-Eintragsnamen wie folgt zu bestimmen.
mkstore –wrl full-wallet-name -list
• Wenn Sie wissen, welche Einträge zum Verschlüsseln der Wiederholungsprotokolle verwendet werden,wählen Sie zuerst den oder die Eintragsnamen aus. Verwenden Sie dann die -viewEntry-Option imOracle mkstore-Dienstprogramm, um jeden Eintragswert wie folgt zu bestimmen.
mkstore –wrl full-wallet-name -viewEntry entry-name
• Wenn Sie nicht wissen, welcher Eintrag zum Verschlüsseln der Wiederholungsprotokolle verwendetwird, können Sie mehrere DB- oder TS-Einträge auswählen und deren Werte wie oben beschriebenbestimmen. Kopieren Sie dann die Eintragsnamen und -werte und fügen Sie sie in die Felder Names(Namen) und Values (Werte) ein, wie zuvor beschrieben. Wenn die angegebenen Einträge nicht korrektsind, schlägt die Aufgabe fehl und die Fehlermeldung enthält den korrekten Eintragsnamen.
• Wenn DBA den Eintrag ändert, während die Aufgabe ausgeführt wird, schlägt die Aufgabe fehl und dieFehlermeldung enthält den neuen Eintragsnamen. Fügen Sie den neuen Eintrag (Name und Wert) zu
API-Version API Version 2016-01-01138

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
den bereits angegebenen Einträgen hinzu und setzen Sie dann die Aufgabe fort. Weitere Informationenzum Hinzufügen eines neuen Eintrags zum Fortsetzen der Aufgabe finden Sie im folgenden Verfahren.
So fügen Sie einen neuen Eintrag hinzu, um eine Aufgabe fortzusetzen:
1. Rufen Sie den Oracle Wallet-Benutzernamen und das Passwort für TDE ab, die für die zu migrierendeTabelle verwendet werden:
a. Führen Sie in der Oracle-Datenbank die folgende Abfrage aus, um OBJECT_ID für einenbestimmten Besitzer und Tabellennamen zurückzugeben.
SELECT OBJECT_ID FROM ALL_OBJECTS WHERE OWNER='table-owner' ANDOBJECT_NAME='table-name' AND OBJECT_TYPE='TABLE';
b. Verwenden Sie den abgerufenen OBJECT_ID-Wert in der folgenden Abfrage, um den relevantenMasterschlüssel zurückzugeben.
SELECT MKEYID FROM SYS.ENC$ WHERE OBJ#=OBJECT_ID;
c. Wählen Sie den Schlüsselwert aus dem Oracle Wallet wie folgt.
mkstore –wrl full-wallet-name -viewEntry entry-name
2. Kopieren Sie den Masterschlüsseleintrag in das Feld Names (Namen) und dessen Wert in das FeldValues (Werte).
3. Nachdem Sie diese Details abgerufen haben, geben Sie den Masterschlüsselnamen auf dem Oracle-Quellendpunkt an, indem Sie das zusätzliche securityDbEncryptionName-Verbindungsattributverwenden. Beispielsweise können Sie den Namen des Masterschlüssels auf den folgenden Wertfestlegen.
securityDbEncryptionName=ORACLE.SECURITY.DB.ENCRYPTION.Adg8m2dhkU/0v/m5QUaaNJEAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
Geben Sie das zugehörige Passwort für diesen Masterschlüssel im Feld Password (Passwort) für denOracle-Quellendpunkt ein. Verwenden Sie die folgende Reihenfolge, um die entsprechenden durchKommata getrennten Passwortwerte zu formatieren. Hier ist TDE_Password das Passwort, das demMasterschlüssel zugeordnet ist.
Oracle_db_password,ASM_Password,TDE_Password
Geben Sie die Passwortwerte in dieser Reihenfolge an, unabhängig von Ihrer Oracle-Datenbankkonfiguration. Wenn Sie beispielsweise TDE verwenden, aber Ihre Oracle-DatenbankASM nicht verwendet, geben Sie die relevanten Passwortwerte in der folgenden Reihenfolge, durchKommata getrennt, an.
Oracle_db_password,,TDE_Password
Unterstützte Komprimierungsmethoden für die Verwendung vonOracle als Quelle für AWS DMSIn der folgenden Tabelle sehen Sie, welche Komprimierungsmethoden AWS DMS bei der Arbeit mit einerOracle-Quelldatenbank unterstützt. Wie die Tabelle zeigt, hängt die Komprimierungsunterstützung sowohl
API-Version API Version 2016-01-01139
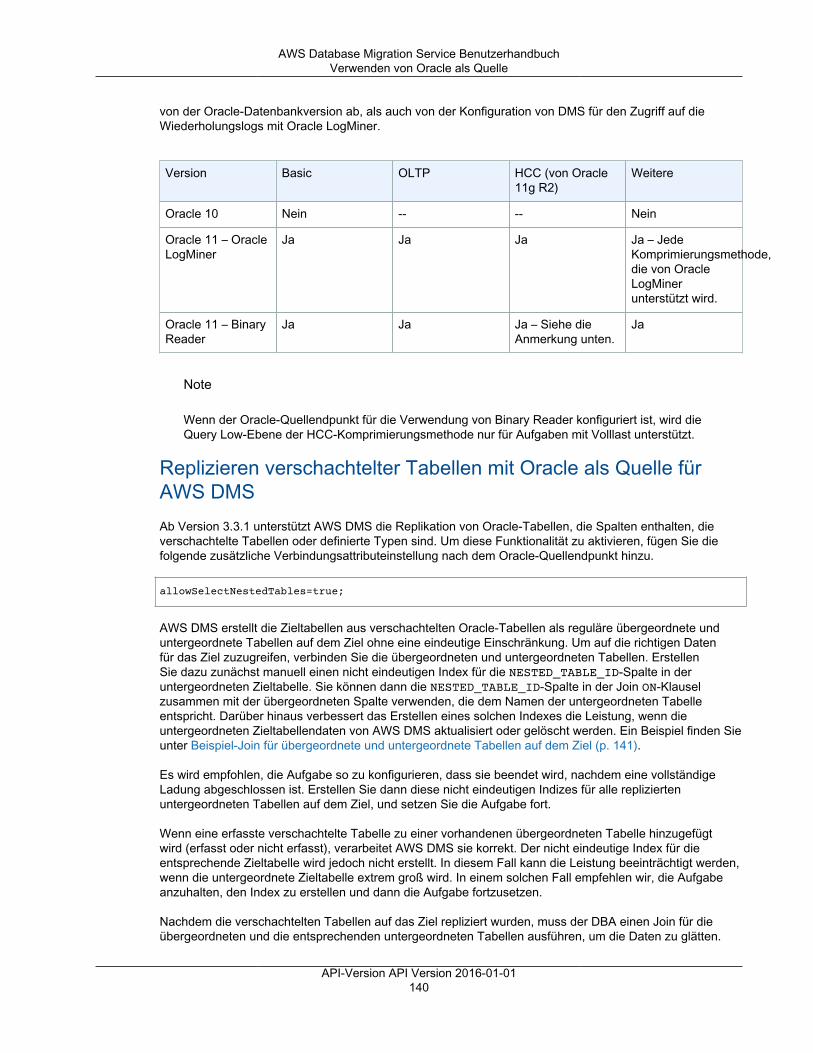
AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
von der Oracle-Datenbankversion ab, als auch von der Konfiguration von DMS für den Zugriff auf dieWiederholungslogs mit Oracle LogMiner.
Version Basic OLTP HCC (von Oracle11g R2)
Weitere
Oracle 10 Nein -- -- Nein
Oracle 11 – OracleLogMiner
Ja Ja Ja Ja – JedeKomprimierungsmethode,die von OracleLogMinerunterstützt wird.
Oracle 11 – BinaryReader
Ja Ja Ja – Siehe dieAnmerkung unten.
Ja
Note
Wenn der Oracle-Quellendpunkt für die Verwendung von Binary Reader konfiguriert ist, wird dieQuery Low-Ebene der HCC-Komprimierungsmethode nur für Aufgaben mit Volllast unterstützt.
Replizieren verschachtelter Tabellen mit Oracle als Quelle fürAWS DMSAb Version 3.3.1 unterstützt AWS DMS die Replikation von Oracle-Tabellen, die Spalten enthalten, dieverschachtelte Tabellen oder definierte Typen sind. Um diese Funktionalität zu aktivieren, fügen Sie diefolgende zusätzliche Verbindungsattributeinstellung nach dem Oracle-Quellendpunkt hinzu.
allowSelectNestedTables=true;
AWS DMS erstellt die Zieltabellen aus verschachtelten Oracle-Tabellen als reguläre übergeordnete unduntergeordnete Tabellen auf dem Ziel ohne eine eindeutige Einschränkung. Um auf die richtigen Datenfür das Ziel zuzugreifen, verbinden Sie die übergeordneten und untergeordneten Tabellen. ErstellenSie dazu zunächst manuell einen nicht eindeutigen Index für die NESTED_TABLE_ID-Spalte in deruntergeordneten Zieltabelle. Sie können dann die NESTED_TABLE_ID-Spalte in der Join ON-Klauselzusammen mit der übergeordneten Spalte verwenden, die dem Namen der untergeordneten Tabelleentspricht. Darüber hinaus verbessert das Erstellen eines solchen Indexes die Leistung, wenn dieuntergeordneten Zieltabellendaten von AWS DMS aktualisiert oder gelöscht werden. Ein Beispiel finden Sieunter Beispiel-Join für übergeordnete und untergeordnete Tabellen auf dem Ziel (p. 141).
Es wird empfohlen, die Aufgabe so zu konfigurieren, dass sie beendet wird, nachdem eine vollständigeLadung abgeschlossen ist. Erstellen Sie dann diese nicht eindeutigen Indizes für alle repliziertenuntergeordneten Tabellen auf dem Ziel, und setzen Sie die Aufgabe fort.
Wenn eine erfasste verschachtelte Tabelle zu einer vorhandenen übergeordneten Tabelle hinzugefügtwird (erfasst oder nicht erfasst), verarbeitet AWS DMS sie korrekt. Der nicht eindeutige Index für dieentsprechende Zieltabelle wird jedoch nicht erstellt. In diesem Fall kann die Leistung beeinträchtigt werden,wenn die untergeordnete Zieltabelle extrem groß wird. In einem solchen Fall empfehlen wir, die Aufgabeanzuhalten, den Index zu erstellen und dann die Aufgabe fortzusetzen.
Nachdem die verschachtelten Tabellen auf das Ziel repliziert wurden, muss der DBA einen Join für dieübergeordneten und die entsprechenden untergeordneten Tabellen ausführen, um die Daten zu glätten.
API-Version API Version 2016-01-01140

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Voraussetzungen für die Replikation von verschachtelten Oracle-Tabellen alsQuelleStellen Sie sicher, dass Sie die übergeordneten Tabellen für alle replizierten verschachtelten Tabellenreplizieren. Fügen Sie sowohl die übergeordneten Tabellen (die Tabellen, die die verschachtelteTabellenspalte enthalten), als auch die untergeordneten (d. h. verschachtelten) Tabellen in die AWS DMS-Tabellenzuweisungen ein.
Unterstützte verschachtelte Oracle-Tabellentypen als QuelleAWS DMS unterstützt die folgenden verschachtelten Oracle-Tabellentypen als Quelle:
• Datentyp• Benutzerdefiniertes Objekt
Einschränkungen der AWS DMS-Unterstützung für verschachtelte Oracle-Tabellen als QuelleAWS DMS hat folgende Einschränkungen bei seiner Unterstützung von verschachtelten Oracle-Tabellenals Quelle:
• AWS DMS unterstützt nur eine Ebene der Tabellenverschachtelung.• Die AWS DMS-Tabellenzuweisung überprüft nicht, ob sowohl die übergeordnete(n) als auch die
untergeordnete(n) Tabelle(n) zur Replikation ausgewählt sind. Dies bedeutet, dass es möglich ist,eine übergeordnete Tabelle ohne untergeordnete Tabelle oder eine untergeordnete Tabelle ohneübergeordnete Tabelle auszuwählen.
Wie AWS DMS verschachtelte Oracle-Tabellen als Quelle repliziertAWS DMS repliziert übergeordnete und verschachtelte Tabellen wie folgt auf das Ziel:
• AWS DMS erstellt die übergeordnete Tabelle, die mit der Quelle identisch ist. Anschließend definiert esdie verschachtelte Spalte im übergeordneten Element als RAW(16) und schließt eine Referenz zu denverschachtelten Tabellen des übergeordneten Elements in seiner NESTED_TABLE_ID-Spalte ein.
• AWS DMS erstellt die untergeordnete Tabelle, die mit der verschachtelten Quelle identisch ist, jedochmit einer zusätzlichen Spalte mit dem Namen NESTED_TABLE_ID. Diese Spalte hat denselben Typund denselben Wert wie die entsprechende übergeordnete verschachtelte Spalte und auch dieselbeBedeutung.
Beispiel-Join für übergeordnete und untergeordnete Tabellen auf dem ZielUm die übergeordnete Tabelle zu glätten, führen Sie einen Join zwischen der übergeordneten und deruntergeordneten Tabelle aus, wie im folgenden Beispiel gezeigt:
1. Erstellen Sie die Type-Tabelle.
CREATE OR REPLACE TYPE NESTED_TEST_T AS TABLE OF VARCHAR(50);
2. Erstellen Sie die übergeordnete Tabelle mit einer Spalte des Typs NESTED_TEST_T, wie oben definiert.
CREATE TABLE NESTED_PARENT_TEST (ID NUMBER(10,0) PRIMARY KEY, NAME NESTED_TEST_T) NESTED TABLE NAME STORE AS NAME_KEY;
3. Glätten Sie die Tabelle NESTED_PARENT_TEST mit einem Join mit der untergeordneten TabelleNAME_KEY, wobei CHILD.NESTED_TABLE_ID mit PARENT.NAME übereinstimmt.
API-Version API Version 2016-01-01141

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
SELECT … FROM NESTED_PARENT_TEST PARENT, NAME_KEY CHILD WHERE CHILD.NESTED_TABLE_ID = PARENT.NAME;
Zusätzliche Verbindungsattribute bei der Verwendung von Oracleals Quelle für AWS DMSSie können zusätzliche Verbindungsattribute verwenden, um Ihre Oracle-Quelle zu konfigurieren.Sie geben diese Einstellungen beim Erstellen des Quellendpunkts an. Wenn Sie mehrereVerbindungsattributeinstellungen verwenden, trennen Sie diese durch Semikola und ohne zusätzlicheLeerräume voneinander (z. B. oneSetting;thenAnother).
Die folgende Tabelle zeigt die zusätzlichen Verbindungsattribute, die Sie verwenden können, um eineOracle-Datenbank als Quelle für AWS DMS zu konfigurieren.
Name Beschreibung
addSupplementalLogging Konfigurieren Sie dieses Attribut so, dass für die Oracle-Datenbank die zusätzliche Protokollierung auf Tabellenebeneeingerichtet wird. Mit diesem Attribut wird die zusätzlicheProtokollierung PRIMARY KEY für alle Tabellen aktiviert, diefür eine Migrationsaufgabe ausgewählt sind.
Standardwert: N
Zulässige Werte: Y/N
Beispiel: addSupplementalLogging=Y;
Note
Wenn Sie diese Option verwenden, müssenSie dennoch die zusätzliche Protokollierung aufDatenbankebene wie zuvor erläutert aktivieren.
additionalArchivedLogDestId Legen Sie dieses Attribut mit archivedLogDestId in einerprimären/Standby-Einrichtung fest. Mit diesem Attribut ist beieinem Failover nützlich. In diesem Fall muss AWS DMS dasZiel kennen, von dem archivierte Wiederherstellungsprotokollezum Auslesen der Änderungen abgerufen werden sollen. Dasliegt daran, dass die vorherige primäre Instance nach demFailover nun zur Standby-Instance wurde.
allowSelectNestedTables Setzen Sie dieses Attribut auf „true“, um die Replikation vonOracle-Tabellen zu aktivieren, die Spalten enthalten, dieverschachtelte Tabellen oder definierte Typen sind. WeitereInformationen finden Sie unter Replizieren verschachtelterTabellen mit Oracle als Quelle für AWS DMS (p. 140).
Standardwert: false
Zulässige Werte: true/false
Beispiel: allowSelectNestedTables=true;
useLogminerReader Legen Sie für dieses Attribut "Y" fest, um Änderungen mit demDienstprogramm LogMiner (Standardprogramm) zu erfassen.
API-Version API Version 2016-01-01142
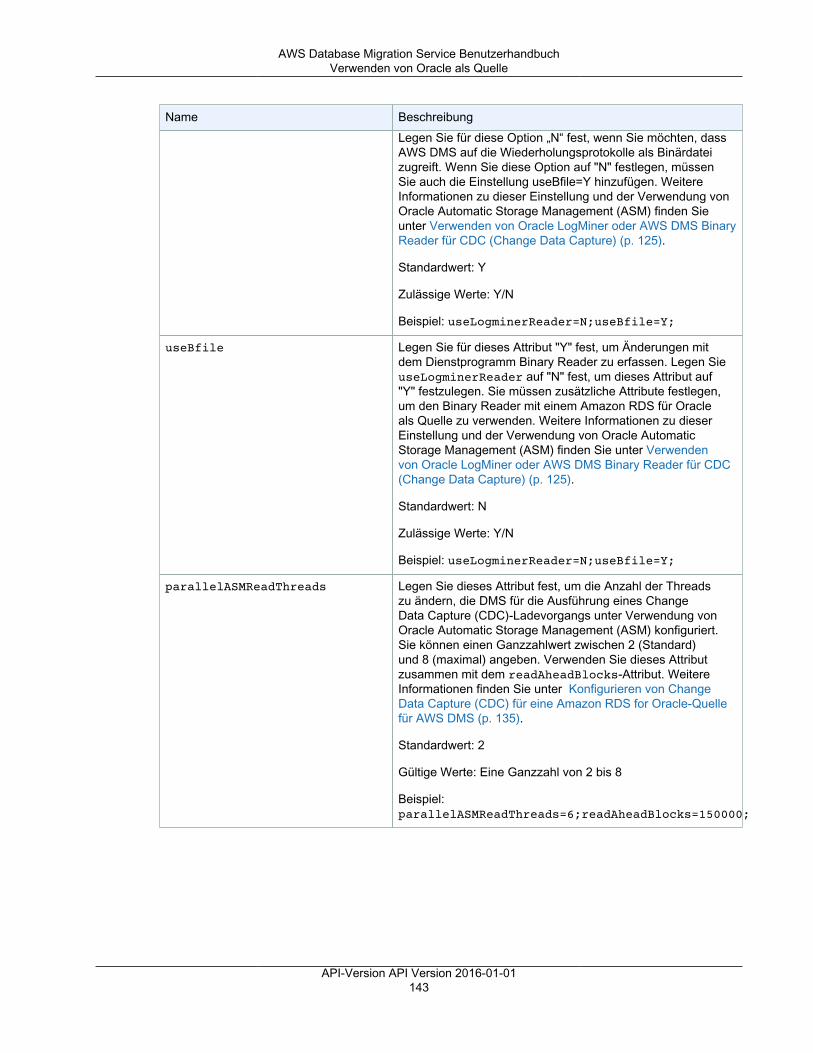
AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Name BeschreibungLegen Sie für diese Option „N“ fest, wenn Sie möchten, dassAWS DMS auf die Wiederholungsprotokolle als Binärdateizugreift. Wenn Sie diese Option auf "N" festlegen, müssenSie auch die Einstellung useBfile=Y hinzufügen. WeitereInformationen zu dieser Einstellung und der Verwendung vonOracle Automatic Storage Management (ASM) finden Sieunter Verwenden von Oracle LogMiner oder AWS DMS BinaryReader für CDC (Change Data Capture) (p. 125).
Standardwert: Y
Zulässige Werte: Y/N
Beispiel: useLogminerReader=N;useBfile=Y;
useBfile Legen Sie für dieses Attribut "Y" fest, um Änderungen mitdem Dienstprogramm Binary Reader zu erfassen. Legen SieuseLogminerReader auf "N" fest, um dieses Attribut auf"Y" festzulegen. Sie müssen zusätzliche Attribute festlegen,um den Binary Reader mit einem Amazon RDS für Oracleals Quelle zu verwenden. Weitere Informationen zu dieserEinstellung und der Verwendung von Oracle AutomaticStorage Management (ASM) finden Sie unter Verwendenvon Oracle LogMiner oder AWS DMS Binary Reader für CDC(Change Data Capture) (p. 125).
Standardwert: N
Zulässige Werte: Y/N
Beispiel: useLogminerReader=N;useBfile=Y;
parallelASMReadThreads Legen Sie dieses Attribut fest, um die Anzahl der Threadszu ändern, die DMS für die Ausführung eines ChangeData Capture (CDC)-Ladevorgangs unter Verwendung vonOracle Automatic Storage Management (ASM) konfiguriert.Sie können einen Ganzzahlwert zwischen 2 (Standard)und 8 (maximal) angeben. Verwenden Sie dieses Attributzusammen mit dem readAheadBlocks-Attribut. WeitereInformationen finden Sie unter Konfigurieren von ChangeData Capture (CDC) für eine Amazon RDS for Oracle-Quellefür AWS DMS (p. 135).
Standardwert: 2
Gültige Werte: Eine Ganzzahl von 2 bis 8
Beispiel:parallelASMReadThreads=6;readAheadBlocks=150000;
API-Version API Version 2016-01-01143
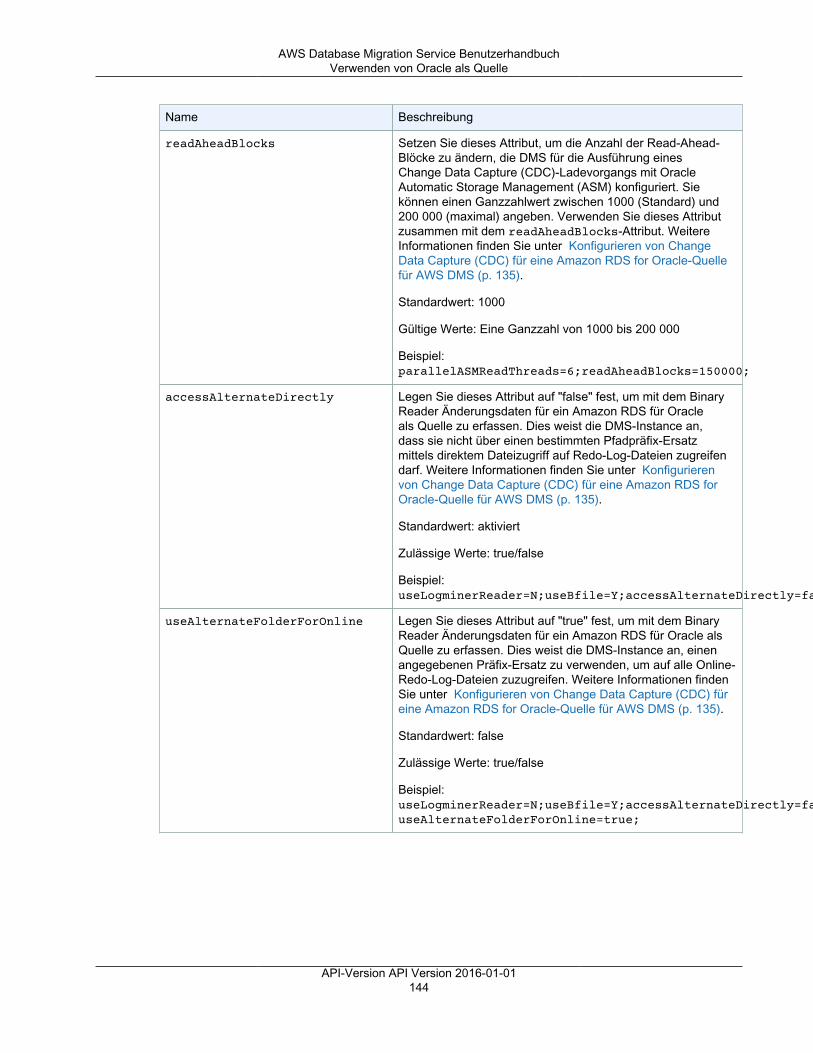
AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Name Beschreibung
readAheadBlocks Setzen Sie dieses Attribut, um die Anzahl der Read-Ahead-Blöcke zu ändern, die DMS für die Ausführung einesChange Data Capture (CDC)-Ladevorgangs mit OracleAutomatic Storage Management (ASM) konfiguriert. Siekönnen einen Ganzzahlwert zwischen 1000 (Standard) und200 000 (maximal) angeben. Verwenden Sie dieses Attributzusammen mit dem readAheadBlocks-Attribut. WeitereInformationen finden Sie unter Konfigurieren von ChangeData Capture (CDC) für eine Amazon RDS for Oracle-Quellefür AWS DMS (p. 135).
Standardwert: 1000
Gültige Werte: Eine Ganzzahl von 1000 bis 200 000
Beispiel:parallelASMReadThreads=6;readAheadBlocks=150000;
accessAlternateDirectly Legen Sie dieses Attribut auf "false" fest, um mit dem BinaryReader Änderungsdaten für ein Amazon RDS für Oracleals Quelle zu erfassen. Dies weist die DMS-Instance an,dass sie nicht über einen bestimmten Pfadpräfix-Ersatzmittels direktem Dateizugriff auf Redo-Log-Dateien zugreifendarf. Weitere Informationen finden Sie unter Konfigurierenvon Change Data Capture (CDC) für eine Amazon RDS forOracle-Quelle für AWS DMS (p. 135).
Standardwert: aktiviert
Zulässige Werte: true/false
Beispiel:useLogminerReader=N;useBfile=Y;accessAlternateDirectly=false;
useAlternateFolderForOnline Legen Sie dieses Attribut auf "true" fest, um mit dem BinaryReader Änderungsdaten für ein Amazon RDS für Oracle alsQuelle zu erfassen. Dies weist die DMS-Instance an, einenangegebenen Präfix-Ersatz zu verwenden, um auf alle Online-Redo-Log-Dateien zuzugreifen. Weitere Informationen findenSie unter Konfigurieren von Change Data Capture (CDC) füreine Amazon RDS for Oracle-Quelle für AWS DMS (p. 135).
Standardwert: false
Zulässige Werte: true/false
Beispiel:useLogminerReader=N;useBfile=Y;accessAlternateDirectly=false;useAlternateFolderForOnline=true;
API-Version API Version 2016-01-01144
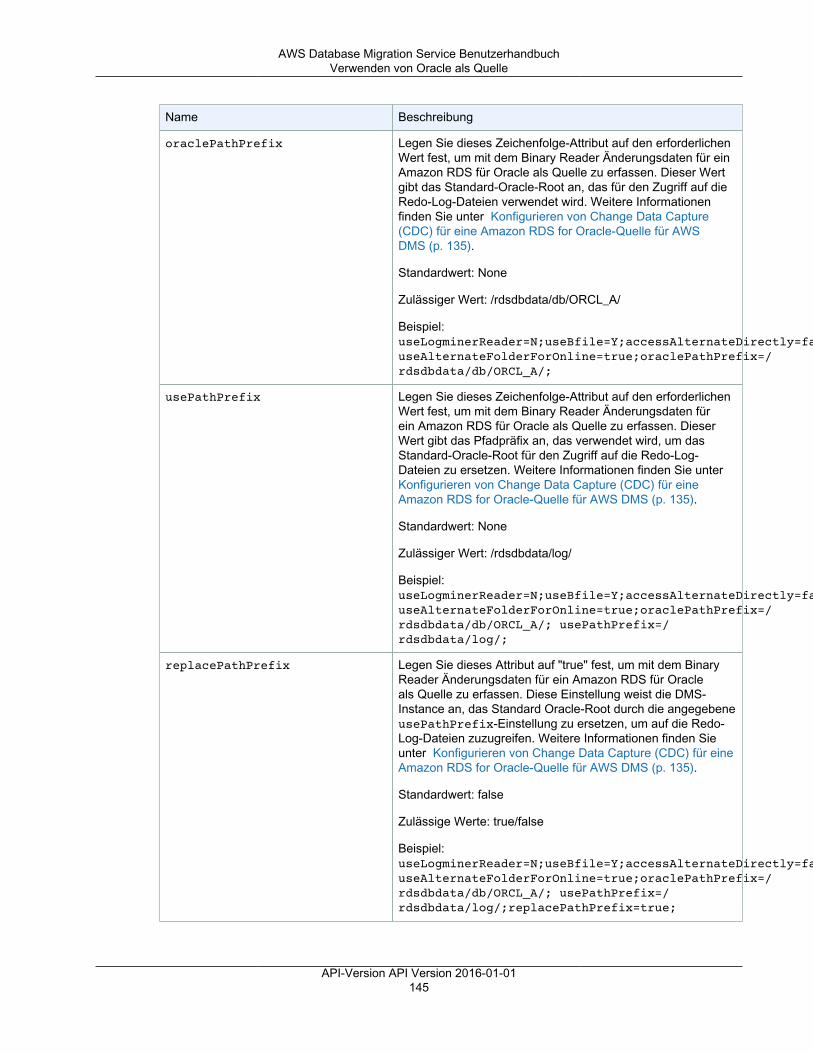
AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Name Beschreibung
oraclePathPrefix Legen Sie dieses Zeichenfolge-Attribut auf den erforderlichenWert fest, um mit dem Binary Reader Änderungsdaten für einAmazon RDS für Oracle als Quelle zu erfassen. Dieser Wertgibt das Standard-Oracle-Root an, das für den Zugriff auf dieRedo-Log-Dateien verwendet wird. Weitere Informationenfinden Sie unter Konfigurieren von Change Data Capture(CDC) für eine Amazon RDS for Oracle-Quelle für AWSDMS (p. 135).
Standardwert: None
Zulässiger Wert: /rdsdbdata/db/ORCL_A/
Beispiel:useLogminerReader=N;useBfile=Y;accessAlternateDirectly=false;useAlternateFolderForOnline=true;oraclePathPrefix=/rdsdbdata/db/ORCL_A/;
usePathPrefix Legen Sie dieses Zeichenfolge-Attribut auf den erforderlichenWert fest, um mit dem Binary Reader Änderungsdaten fürein Amazon RDS für Oracle als Quelle zu erfassen. DieserWert gibt das Pfadpräfix an, das verwendet wird, um dasStandard-Oracle-Root für den Zugriff auf die Redo-Log-Dateien zu ersetzen. Weitere Informationen finden Sie unter Konfigurieren von Change Data Capture (CDC) für eineAmazon RDS for Oracle-Quelle für AWS DMS (p. 135).
Standardwert: None
Zulässiger Wert: /rdsdbdata/log/
Beispiel:useLogminerReader=N;useBfile=Y;accessAlternateDirectly=false;useAlternateFolderForOnline=true;oraclePathPrefix=/rdsdbdata/db/ORCL_A/; usePathPrefix=/rdsdbdata/log/;
replacePathPrefix Legen Sie dieses Attribut auf "true" fest, um mit dem BinaryReader Änderungsdaten für ein Amazon RDS für Oracleals Quelle zu erfassen. Diese Einstellung weist die DMS-Instance an, das Standard Oracle-Root durch die angegebeneusePathPrefix-Einstellung zu ersetzen, um auf die Redo-Log-Dateien zuzugreifen. Weitere Informationen finden Sieunter Konfigurieren von Change Data Capture (CDC) für eineAmazon RDS for Oracle-Quelle für AWS DMS (p. 135).
Standardwert: false
Zulässige Werte: true/false
Beispiel:useLogminerReader=N;useBfile=Y;accessAlternateDirectly=false;useAlternateFolderForOnline=true;oraclePathPrefix=/rdsdbdata/db/ORCL_A/; usePathPrefix=/rdsdbdata/log/;replacePathPrefix=true;
API-Version API Version 2016-01-01145
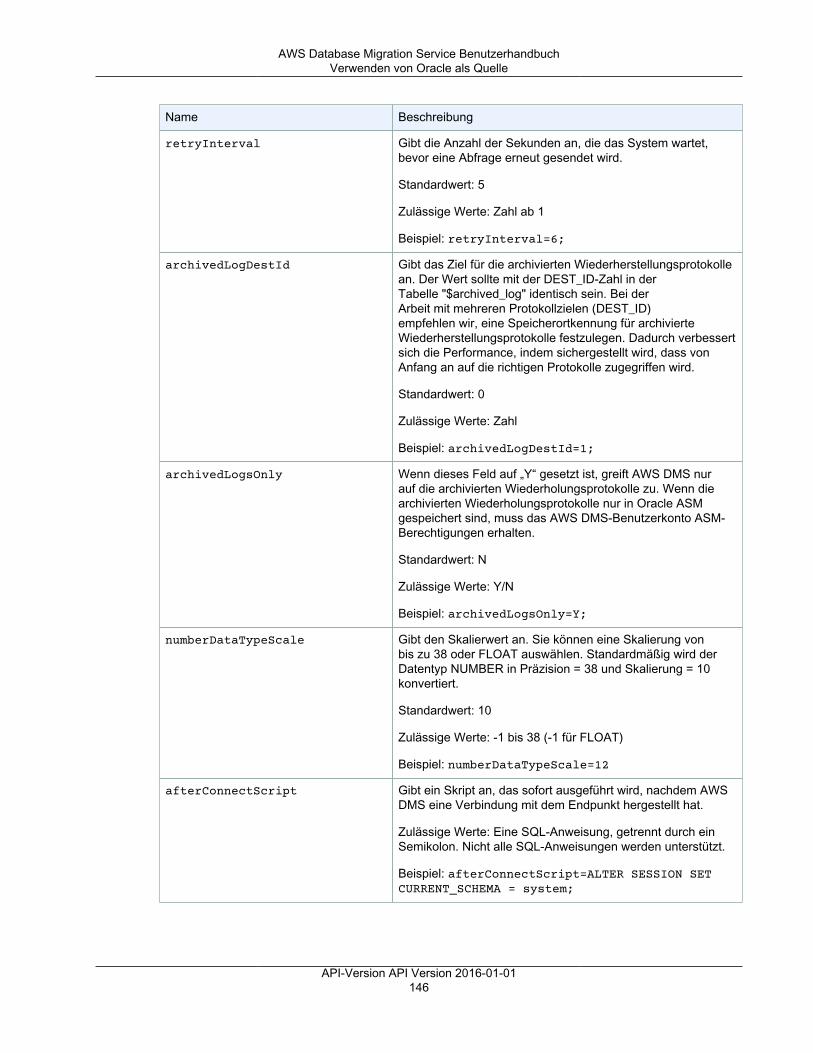
AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Name Beschreibung
retryInterval Gibt die Anzahl der Sekunden an, die das System wartet,bevor eine Abfrage erneut gesendet wird.
Standardwert: 5
Zulässige Werte: Zahl ab 1
Beispiel: retryInterval=6;
archivedLogDestId Gibt das Ziel für die archivierten Wiederherstellungsprotokollean. Der Wert sollte mit der DEST_ID-Zahl in derTabelle "$archived_log" identisch sein. Bei derArbeit mit mehreren Protokollzielen (DEST_ID)empfehlen wir, eine Speicherortkennung für archivierteWiederherstellungsprotokolle festzulegen. Dadurch verbessertsich die Performance, indem sichergestellt wird, dass vonAnfang an auf die richtigen Protokolle zugegriffen wird.
Standardwert: 0
Zulässige Werte: Zahl
Beispiel: archivedLogDestId=1;
archivedLogsOnly Wenn dieses Feld auf „Y“ gesetzt ist, greift AWS DMS nurauf die archivierten Wiederholungsprotokolle zu. Wenn diearchivierten Wiederholungsprotokolle nur in Oracle ASMgespeichert sind, muss das AWS DMS-Benutzerkonto ASM-Berechtigungen erhalten.
Standardwert: N
Zulässige Werte: Y/N
Beispiel: archivedLogsOnly=Y;
numberDataTypeScale Gibt den Skalierwert an. Sie können eine Skalierung vonbis zu 38 oder FLOAT auswählen. Standardmäßig wird derDatentyp NUMBER in Präzision = 38 und Skalierung = 10konvertiert.
Standardwert: 10
Zulässige Werte: -1 bis 38 (-1 für FLOAT)
Beispiel: numberDataTypeScale=12
afterConnectScript Gibt ein Skript an, das sofort ausgeführt wird, nachdem AWSDMS eine Verbindung mit dem Endpunkt hergestellt hat.
Zulässige Werte: Eine SQL-Anweisung, getrennt durch einSemikolon. Nicht alle SQL-Anweisungen werden unterstützt.
Beispiel: afterConnectScript=ALTER SESSION SETCURRENT_SCHEMA = system;
API-Version API Version 2016-01-01146
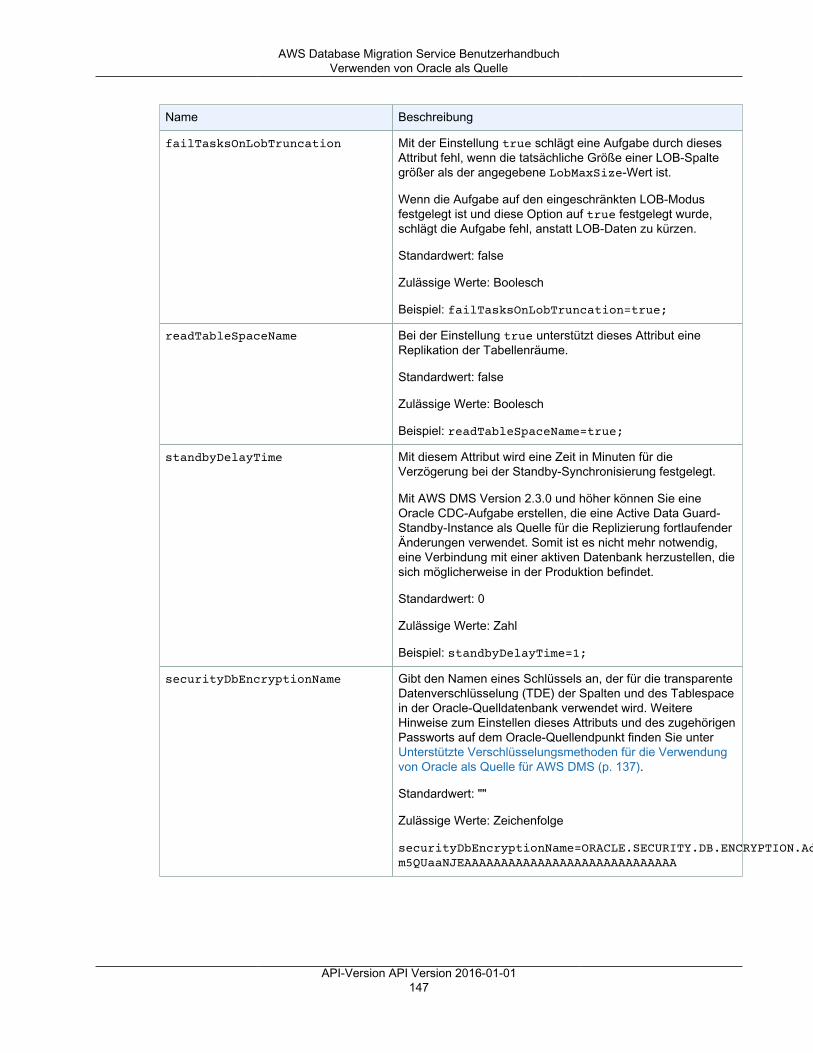
AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Name Beschreibung
failTasksOnLobTruncation Mit der Einstellung true schlägt eine Aufgabe durch diesesAttribut fehl, wenn die tatsächliche Größe einer LOB-Spaltegrößer als der angegebene LobMaxSize-Wert ist.
Wenn die Aufgabe auf den eingeschränkten LOB-Modusfestgelegt ist und diese Option auf true festgelegt wurde,schlägt die Aufgabe fehl, anstatt LOB-Daten zu kürzen.
Standardwert: false
Zulässige Werte: Boolesch
Beispiel: failTasksOnLobTruncation=true;
readTableSpaceName Bei der Einstellung true unterstützt dieses Attribut eineReplikation der Tabellenräume.
Standardwert: false
Zulässige Werte: Boolesch
Beispiel: readTableSpaceName=true;
standbyDelayTime Mit diesem Attribut wird eine Zeit in Minuten für dieVerzögerung bei der Standby-Synchronisierung festgelegt.
Mit AWS DMS Version 2.3.0 und höher können Sie eineOracle CDC-Aufgabe erstellen, die eine Active Data Guard-Standby-Instance als Quelle für die Replizierung fortlaufenderÄnderungen verwendet. Somit ist es nicht mehr notwendig,eine Verbindung mit einer aktiven Datenbank herzustellen, diesich möglicherweise in der Produktion befindet.
Standardwert: 0
Zulässige Werte: Zahl
Beispiel: standbyDelayTime=1;
securityDbEncryptionName Gibt den Namen eines Schlüssels an, der für die transparenteDatenverschlüsselung (TDE) der Spalten und des Tablespacein der Oracle-Quelldatenbank verwendet wird. WeitereHinweise zum Einstellen dieses Attributs und des zugehörigenPassworts auf dem Oracle-Quellendpunkt finden Sie unterUnterstützte Verschlüsselungsmethoden für die Verwendungvon Oracle als Quelle für AWS DMS (p. 137).
Standardwert: ""
Zulässige Werte: Zeichenfolge
securityDbEncryptionName=ORACLE.SECURITY.DB.ENCRYPTION.Adg8m2dhkU/0v/m5QUaaNJEAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
API-Version API Version 2016-01-01147
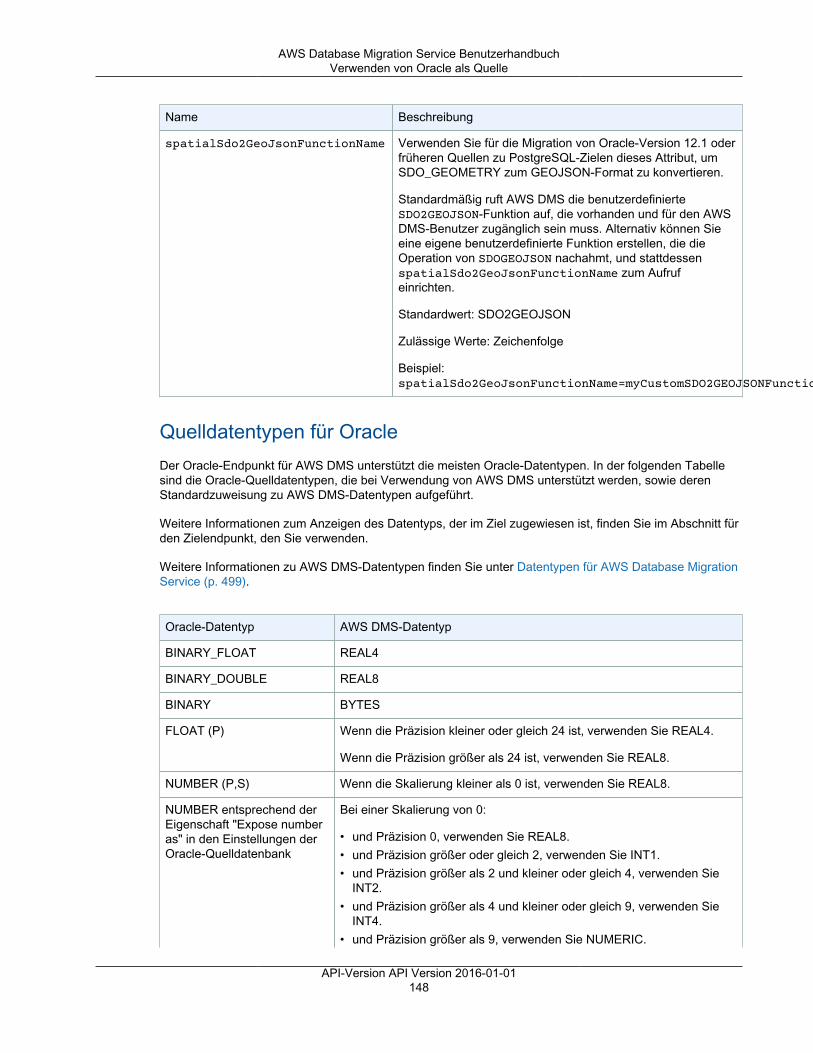
AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Name Beschreibung
spatialSdo2GeoJsonFunctionName Verwenden Sie für die Migration von Oracle-Version 12.1 oderfrüheren Quellen zu PostgreSQL-Zielen dieses Attribut, umSDO_GEOMETRY zum GEOJSON-Format zu konvertieren.
Standardmäßig ruft AWS DMS die benutzerdefinierteSDO2GEOJSON-Funktion auf, die vorhanden und für den AWSDMS-Benutzer zugänglich sein muss. Alternativ können Sieeine eigene benutzerdefinierte Funktion erstellen, die dieOperation von SDOGEOJSON nachahmt, und stattdessenspatialSdo2GeoJsonFunctionName zum Aufrufeinrichten.
Standardwert: SDO2GEOJSON
Zulässige Werte: Zeichenfolge
Beispiel:spatialSdo2GeoJsonFunctionName=myCustomSDO2GEOJSONFunction;
Quelldatentypen für OracleDer Oracle-Endpunkt für AWS DMS unterstützt die meisten Oracle-Datentypen. In der folgenden Tabellesind die Oracle-Quelldatentypen, die bei Verwendung von AWS DMS unterstützt werden, sowie derenStandardzuweisung zu AWS DMS-Datentypen aufgeführt.
Weitere Informationen zum Anzeigen des Datentyps, der im Ziel zugewiesen ist, finden Sie im Abschnitt fürden Zielendpunkt, den Sie verwenden.
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
Oracle-Datentyp AWS DMS-Datentyp
BINARY_FLOAT REAL4
BINARY_DOUBLE REAL8
BINARY BYTES
FLOAT (P) Wenn die Präzision kleiner oder gleich 24 ist, verwenden Sie REAL4.
Wenn die Präzision größer als 24 ist, verwenden Sie REAL8.
NUMBER (P,S) Wenn die Skalierung kleiner als 0 ist, verwenden Sie REAL8.
NUMBER entsprechend derEigenschaft "Expose numberas" in den Einstellungen derOracle-Quelldatenbank
Bei einer Skalierung von 0:
• und Präzision 0, verwenden Sie REAL8.• und Präzision größer oder gleich 2, verwenden Sie INT1.• und Präzision größer als 2 und kleiner oder gleich 4, verwenden Sie
INT2.• und Präzision größer als 4 und kleiner oder gleich 9, verwenden Sie
INT4.• und Präzision größer als 9, verwenden Sie NUMERIC.
API-Version API Version 2016-01-01148
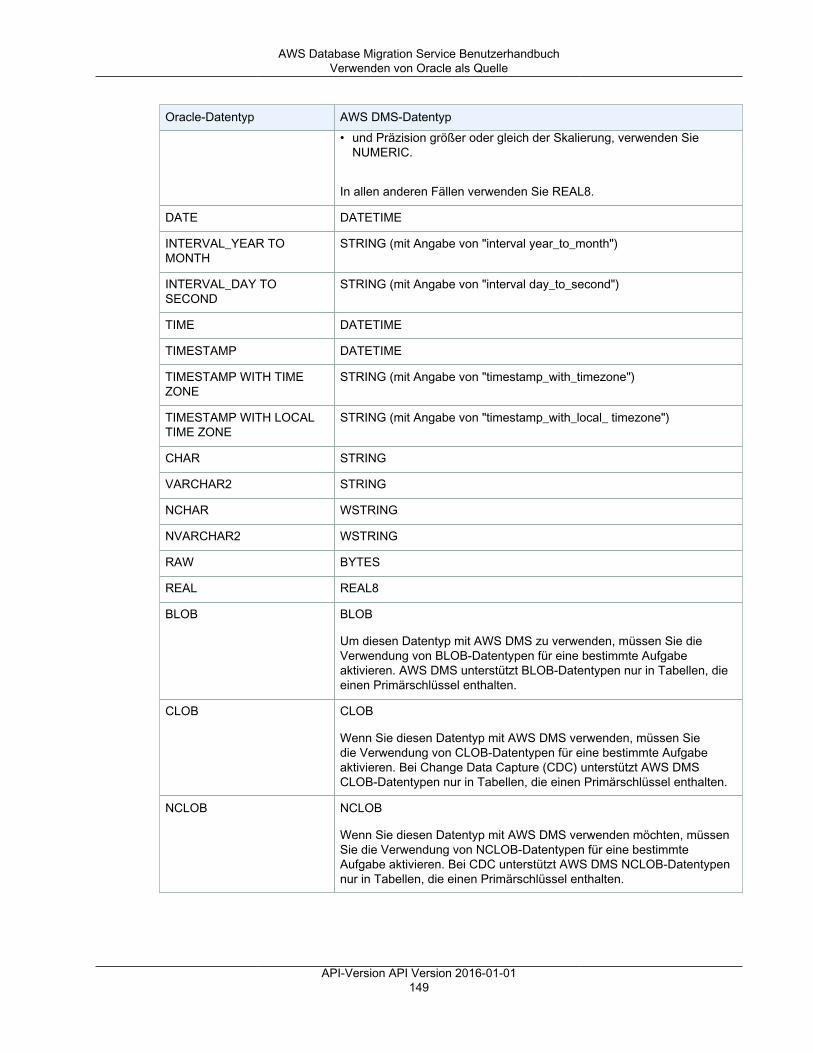
AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Oracle-Datentyp AWS DMS-Datentyp• und Präzision größer oder gleich der Skalierung, verwenden Sie
NUMERIC.
In allen anderen Fällen verwenden Sie REAL8.
DATE DATETIME
INTERVAL_YEAR TOMONTH
STRING (mit Angabe von "interval year_to_month")
INTERVAL_DAY TOSECOND
STRING (mit Angabe von "interval day_to_second")
TIME DATETIME
TIMESTAMP DATETIME
TIMESTAMP WITH TIMEZONE
STRING (mit Angabe von "timestamp_with_timezone")
TIMESTAMP WITH LOCALTIME ZONE
STRING (mit Angabe von "timestamp_with_local_ timezone")
CHAR STRING
VARCHAR2 STRING
NCHAR WSTRING
NVARCHAR2 WSTRING
RAW BYTES
REAL REAL8
BLOB BLOB
Um diesen Datentyp mit AWS DMS zu verwenden, müssen Sie dieVerwendung von BLOB-Datentypen für eine bestimmte Aufgabeaktivieren. AWS DMS unterstützt BLOB-Datentypen nur in Tabellen, dieeinen Primärschlüssel enthalten.
CLOB CLOB
Wenn Sie diesen Datentyp mit AWS DMS verwenden, müssen Siedie Verwendung von CLOB-Datentypen für eine bestimmte Aufgabeaktivieren. Bei Change Data Capture (CDC) unterstützt AWS DMSCLOB-Datentypen nur in Tabellen, die einen Primärschlüssel enthalten.
NCLOB NCLOB
Wenn Sie diesen Datentyp mit AWS DMS verwenden möchten, müssenSie die Verwendung von NCLOB-Datentypen für eine bestimmteAufgabe aktivieren. Bei CDC unterstützt AWS DMS NCLOB-Datentypennur in Tabellen, die einen Primärschlüssel enthalten.
API-Version API Version 2016-01-01149
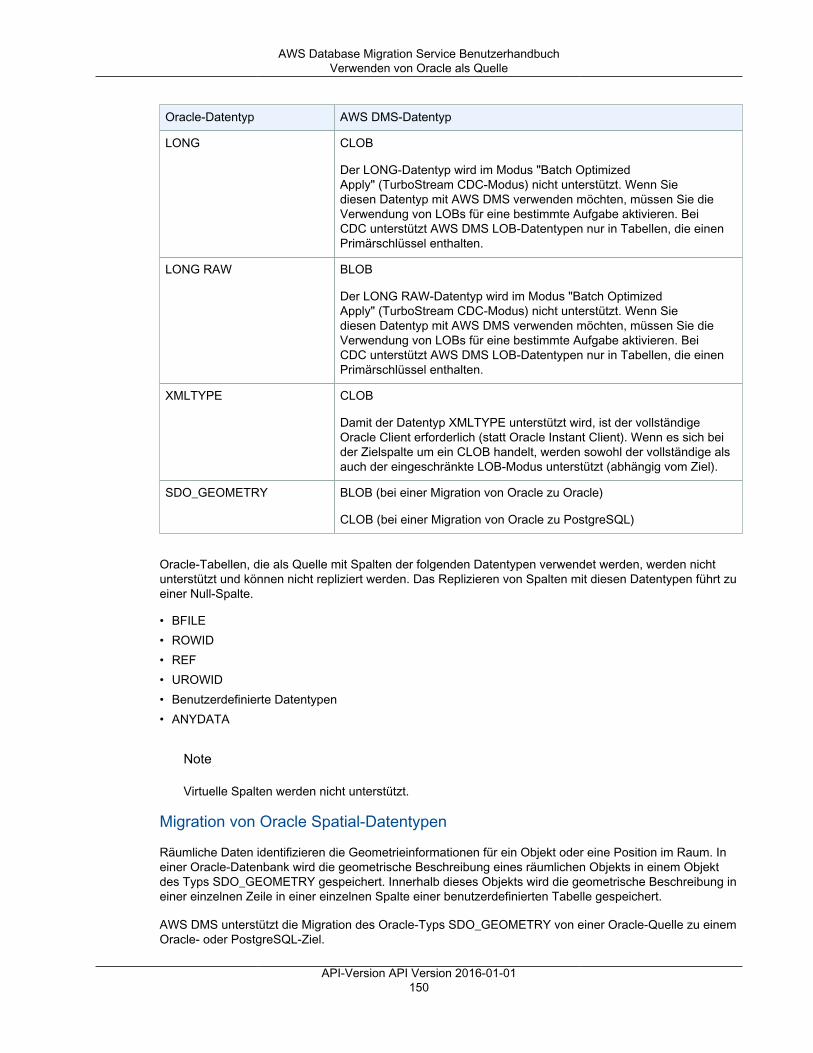
AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Quelle
Oracle-Datentyp AWS DMS-Datentyp
LONG CLOB
Der LONG-Datentyp wird im Modus "Batch OptimizedApply" (TurboStream CDC-Modus) nicht unterstützt. Wenn Siediesen Datentyp mit AWS DMS verwenden möchten, müssen Sie dieVerwendung von LOBs für eine bestimmte Aufgabe aktivieren. BeiCDC unterstützt AWS DMS LOB-Datentypen nur in Tabellen, die einenPrimärschlüssel enthalten.
LONG RAW BLOB
Der LONG RAW-Datentyp wird im Modus "Batch OptimizedApply" (TurboStream CDC-Modus) nicht unterstützt. Wenn Siediesen Datentyp mit AWS DMS verwenden möchten, müssen Sie dieVerwendung von LOBs für eine bestimmte Aufgabe aktivieren. BeiCDC unterstützt AWS DMS LOB-Datentypen nur in Tabellen, die einenPrimärschlüssel enthalten.
XMLTYPE CLOB
Damit der Datentyp XMLTYPE unterstützt wird, ist der vollständigeOracle Client erforderlich (statt Oracle Instant Client). Wenn es sich beider Zielspalte um ein CLOB handelt, werden sowohl der vollständige alsauch der eingeschränkte LOB-Modus unterstützt (abhängig vom Ziel).
SDO_GEOMETRY BLOB (bei einer Migration von Oracle zu Oracle)
CLOB (bei einer Migration von Oracle zu PostgreSQL)
Oracle-Tabellen, die als Quelle mit Spalten der folgenden Datentypen verwendet werden, werden nichtunterstützt und können nicht repliziert werden. Das Replizieren von Spalten mit diesen Datentypen führt zueiner Null-Spalte.
• BFILE• ROWID• REF• UROWID• Benutzerdefinierte Datentypen• ANYDATA
Note
Virtuelle Spalten werden nicht unterstützt.
Migration von Oracle Spatial-Datentypen
Räumliche Daten identifizieren die Geometrieinformationen für ein Objekt oder eine Position im Raum. Ineiner Oracle-Datenbank wird die geometrische Beschreibung eines räumlichen Objekts in einem Objektdes Typs SDO_GEOMETRY gespeichert. Innerhalb dieses Objekts wird die geometrische Beschreibung ineiner einzelnen Zeile in einer einzelnen Spalte einer benutzerdefinierten Tabelle gespeichert.
AWS DMS unterstützt die Migration des Oracle-Typs SDO_GEOMETRY von einer Oracle-Quelle zu einemOracle- oder PostgreSQL-Ziel.
API-Version API Version 2016-01-01150

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
Berücksichtigen Sie beim Migrieren von räumlichen Oracle-Datentypen mit AWS DMS die folgendenÜberlegungen:
• Stellen Sie bei der Migration zu einem Oracle-Ziel sicher, dass USER_SDO_GEOM_METADATA-Einträge, die Typinformationen enthalten, manuell übertragen werden.
• Beim Migrieren von einem Oracle-Quellendpunkt zu einem PostgreSQL-Zielendpunkt erstellt AWS DMSZielspalten. Diese Spalten verfügen über Standardgeometrie- und Geographie-Typinformationen miteiner 2D-Dimension und einer Raumbezugskennung (SRID) gleich Null (0). Ein Beispiel ist <GEOMETRY,2, 0>.
• Konvertieren Sie bei der Migration von Oracle-Version 12.1- oder früheren Quellen zu PostgreSQL-Zielen SDO_GEOMETRY-Objekte mithilfe der SDO2GEOJSON_Funktion oder des zusätzlichenVerbindungsattributs spatialSdo2GeoJsonFunctionName. Weitere Informationen finden Sie unterZusätzliche Verbindungsattribute bei der Verwendung von Oracle als Quelle für AWS DMS (p. 142).
Verwenden einer Microsoft SQL Server-Datenbank alsQuelle für AWS DMSSie können Daten von einer oder von vielen Microsoft SQL Server-Datenbanken mithilfe von AWS DMSmigrieren. Mit einer SQL Server-Datenbank als Quelle können Sie Daten zu einer anderen SQL Server-Datenbank oder einer der anderen von AWS DMS unterstützten Datenbanken migrieren.
AWS DMS unterstützt, als Quelle, die Microsoft SQL Server-Versionen 2005, 2008, 2008R2, 2012, 2014,2016, 2017 und 2019, On-Premise- und Amazon EC2-Instance-Datenbanken. Unterstützt werden dieEditionen Enterprise, Standard, Workgroup, Developer und Web. Die fortlaufende Replikation (CDC) wirdfür alle Versionen von Enterprise Edition und Standard Edition Version 2016 SP1 und höher unterstützt.
AWS DMS unterstützt, als Quelle, Amazon RDS-DB-Instance-Datenbanken für die SQL Server-Versionen 2008R2, 2012, 2014, 2016, 2017 und 2019. Die Editionen Enterprise und Standard werdenunterstützt. Die fortlaufende Replikation (CDC) wird für alle Versionen von Enterprise Edition und StandardEdition Version 2016 SP1 und höher unterstützt.
Note
Unterstützung für Microsoft SQL Server Version 2019 als Quelle ist in den AWS DMS-Versionen3.3.2 und höher verfügbar.
Die SQL Server-Quelldatenbank kann auf einem beliebigen Computer in Ihrem Netzwerk installiert sein. EinSQL Server-Konto mit den entsprechenden Zugriffsberechtigungen für die Quelldatenbank für den Typ derausgewählten Aufgabe ist für die Verwendung mit AWS DMS erforderlich.
AWS DMS unterstützt die Datenmigration von benannten SQL Server-Instances. Beim Erstellen desQuellendpunkts können Sie folgende Notation für den Servernamen verwenden.
IPAddress\InstanceName
Im folgenden Beispiel wird ein korrekter Servername für den Quellendpunkt angegeben. Der erste Teil desNamens ist die IP-Adresse des Servers und der zweite Teil ist der Name der SQL Server-Instance (hier"SQLTest").
10.0.0.25\SQLTest
Rufen Sie außerdem die Portnummer ab, auf die Ihre benannte Instance von SQL Server wartet, undverwenden Sie sie, um Ihren AWS DMS-Quellendpunkt zu konfigurieren.
API-Version API Version 2016-01-01151

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
Note
Port 1433 ist der Standard für Microsoft SQL Server. Dynamische Ports, die sich jedes Maländern, wenn SQL Server gestartet wird, und bestimmte statische Portnummern, die verwendetwerden, um eine Verbindung mit SQL Server über eine Firewall herzustellen, werden jedochebenfalls häufig verwendet. Sie sollten also die tatsächliche Portnummer Ihrer benannten Instancevon SQL Server kennen, wenn Sie den AWS DMS-Quellendpunkt erstellen.
Sie können SSL verwenden, um Verbindungen zwischen Ihrem SQL Server-Endpunkt und derReplikations-Instance zu verschlüsseln. Weitere Informationen zur Verwendung von SSL mit einem SQLServer-Endpunkt finden Sie unter Verwenden von SSL mit AWS Database Migration Service (p. 82).
Um Änderungen von einer SQL Server-Quelldatenbank zu erfassen, muss die Datenbank für vollständigeSicherungen konfiguriert sein und die Edition muss entweder Enterprise, Developer oder Standard sein.
Weitere Informationen zur Arbeit mit SQL Server-Quelldatenbanken und AWS DMS finden Sie in denfolgenden Themen.
Themen• Einschränkungen bei der Verwendung von SQL Server als Quelle für AWS DMS (p. 152)• Verwenden der fortlaufenden Replikation (CDC) von einer SQL Server-Quelle (p. 154)• Unterstützte Kompressionsmethoden (p. 159)• Arbeiten mit SQL Server AlwaysOn-Verfügbarkeitsgruppen (p. 159)• Konfigurieren einer SQL Server-Datenbank als Replikationsquelle für AWS DMS (p. 159)• Zusätzliche Verbindungsattribute bei der Verwendung von SQL Server als Quelle für AWS
DMS (p. 160)• Quelldatentypen für SQL Server (p. 161)
Einschränkungen bei der Verwendung von SQL Server als Quellefür AWS DMSDie folgenden Einschränkungen gelten, wenn Sie eine SQL Server-Datenbank als Quelle für AWS DMSverwenden:
• Sie können keine SQL Server-Datenbank als AWS DMS-Quelle verwenden, wenn SQL Server ChangeTracking (CT) auf der Datenbank aktiviert ist.
Note
Diese Einschränkung gilt nicht mehr in den AWS DMS-Versionen 3.3.1 und höher.• Die Identitätseigenschaft für eine Spalte wird nicht zu einer Spalte in der Zieldatenbank migriert.• In AWS DMS-Engine-Versionen vor Version 2.4.x werden Änderungen an Zeilen mit mehr als 8.000 Byte
an Informationen, einschließlich Header und Zuweisungsinformationen, nicht ordnungsgemäßverarbeitet. Dies liegt an Beschränkungen der SQL Server TLOG-Puffergröße. Verwenden Sie dieaktuelle AWS DMS-Version, um dieses Problem zu vermeiden.
• Der SQL Server-Endpunkt unterstützt die Verwendung von Sparse-Tabellen nicht.• Windows-Authentifizierung wird nicht unterstützt.• Änderungen an berechneten Feldern in einem SQL Server werden nicht repliziert.• Temporäre Tabellen werden nicht unterstützt.• SQL Server-Partition-Switching wird nicht unterstützt.• Ein gruppierter Index in der Quelle wird als nicht gruppierter Index im Ziel erstellt.• Mithilfe der Dienstprogramme WRITETEXT und UPDATETEXT erfasst AWS DMS keine Ereignisse, die
auf die Quelldatenbank angewendet werden.
API-Version API Version 2016-01-01152

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
• Das folgende DML-Muster (Data Manipulation Language) wird nicht unterstützt:
SELECT * INTO new_table FROM existing_table
• Bei der Verwendung von SQL Server als Quelle wird die Verschlüsselung auf Spaltenebene nichtunterstützt.
• Aufgrund eines bekannten Problems mit SQL Server 2008 und 2008 R2 unterstützt AWS DMS keinePrüfungen auf Serverebene auf SQL Server 2008 und SQL Server 2008 R2 als Quellen. Die Ausführungdes folgenden Befehls führt beispielsweise dazu, dass AWS DMS fehlschlägt.
USE [master]GO ALTER SERVER AUDIT [my_audit_test-20140710] WITH (STATE=on)GO
• Bei der Verwendung von SQL Server als Quelle werden Geometriespalten im Full-LOB-Modusnicht unterstützt. Verwenden Sie stattdessen den eingeschränkten LOB-Modus, oder legen Sie dieInlineLobMaxSize-Aufgabeneinstellung so fest, dass der Inline-LOB-Modus verwendet wird.
• Eine sekundäre SQL Server-Datenbank wird nicht als Quelldatenbank unterstützt.• Wenn Sie eine Microsoft SQL Server-Quelldatenbank in einer Replikationsaufgabe verwenden, werden
die SQL Server Replication Publisher-Definitionen nicht entfernt, wenn Sie die Aufgabe entfernen. EinMicrosoft SQL Server-Systemadministrator muss diese Definitionen von Microsoft SQL Server löschen.
• Das Replizieren von Daten aus indizierten Ansichten wird nicht unterstützt.• Das Umbenennen von Tabellen mit sp_rename wird nicht unterstützt (z. B. sp_rename'Sales.SalesRegion', 'SalesReg;)
• Das Umbenennen von Spalten mit sp_rename wird nicht unterstützt (z. B. sp_rename'Sales.Sales.Region', 'RegID', 'COLUMN';)
• TRUNCATE-Ereignisse werden nicht erfasst.
Beim Zugriff auf die Sicherungstransaktionsprotokolle gelten die folgenden Einschränkungen:
• Verschlüsselte Sicherungen werden nicht unterstützt.• Sicherungen, die unter einer URL oder unter Windows Azure gespeichert sind, werden nicht unterstützt.
Beim Zugriff auf die Sicherungstransaktionsprotokolle auf Dateiebene gelten die folgendenEinschränkungen:
• Die Sicherungstransaktionsprotokolle müssen sich in einem freigegebenen Ordner mit denentsprechenden Berechtigungen und Zugriffsrechten befinden.
• Der Zugriff auf aktive Transaktionsprotokolle erfolgt über die Microsoft SQL Server-API (und nicht aufDateiebene).
• AWS DMS und Microsoft SQL Server-Computer müssen sich in derselben Domäne befinden.• Komprimierte Sicherungstransaktionsprotokolle werden nicht unterstützt.• Transparente Datenverschlüsselung (TDE) wird nicht unterstützt. Beachten Sie, dass beim Zugriff auf
die Sicherungstransaktionsprotokolle mit der nativen Funktionalität von SQL Server (ohne Zugriff aufDateiebene) TDE-Verschlüsselung unterstützt wird
• UNIX-Plattformen werden nicht unterstützt.• Das Lesen der Sicherungsprotokolle aus mehreren Stripes wird nicht unterstützt.• Microsoft SQL Server-Sicherung auf mehrere Datenträger wird nicht unterstützt.
API-Version API Version 2016-01-01153

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
• Wenn Sie einen Wert in räumliche SQL Server-Datentypen (GEOGRAPHY und GEOMETRY) einfügen,können Sie entweder die Eigenschaft SRID (Spatial Reference System Identifier) ignorieren oder eineandere Zahl angeben. Beim Replizieren von Tabellen mit räumlichen Datentypen ersetzt AWS DMS dieSRID durch die Standard-SRID (0 für GEOMETRY und 4326 für GEOGRAPHY).
• Wenn Ihre Datenbank nicht für MS-REPLICATION oder MS-CDC konfiguriert ist, können Sie dennochTabellen erfassen, die keinen Primärschlüssel haben, es werden aber nur INSERT/DELETE DML-Ereignisse erfasst. Die Ereignisse UPDATE und TRUNCATE TABLE werden ignoriert.
• Columnstore-Indizes werden nicht unterstützt.• Speicheroptimierte Tabellen (unter Verwendung von In-Memory OLTP) werden nicht unterstützt.• Wenn Sie eine Tabelle mit einem Primärschlüssel replizieren, der aus mehreren Spalten besteht, wird
das Aktualisieren der Primärschlüsselspalten während der Volllast nicht unterstützt.• Verzögerte Haltbarkeit wird nicht unterstützt.
Verwenden der fortlaufenden Replikation (CDC) von einer SQLServer-QuelleSie können die fortlaufende Replikation (Change Data Capture, CDC) für eine selbstverwaltete SQLServer-Datenbank lokal oder auf Amazon EC2 oder für eine von Amazon verwalteten Datenbank aufAmazon RDS verwenden.
AWS DMS unterstützt die fortlaufende Replikation für die folgenden SQL Server-Konfigurationen:
• Für SQL Server-Quell-Instances, die lokal oder auf Amazon EC2 existieren, unterstützt AWS DMS dielaufende Replikation für SQL Server Enterprise Edition, Standard Edition Version 2016 SP1 und höhersowie Developer Edition.
• Bei SQL Server-Quell-Instances, die auf Amazon RDS ausgeführt werden, unterstützt AWS DMS diefortlaufende Replikation für SQL Server Enterprise bis SQL Server 2016 SP1. Über diese Version hinausunterstützt AWS DMS CDC sowohl für SQL Server Enterprise- als auch für Standard-Editionen.
Wenn Sie möchten, dass AWS DMS die fortlaufende Replikation automatisch einrichtet, muss das AWSDMS-Benutzerkonto, über das Sie die Verbindung zur Quelldatenbank herstellen, die feste sysadmin-Serverrolle aufweisen. Falls Sie dem verwendeten Benutzerkonto nicht die feste sysadmin-Serverrollezuweisen möchten, können Sie die fortlaufende Replikation trotzdem nutzen. Dazu führen Sie dienachfolgend beschriebenen manuellen Schritte aus.
Die folgenden Anforderungen gelten speziell für die Verwendung der fortlaufenden Replikation mit einerSQL Server-Datenbank als Quelle für AWS DMS:
• SQL Server muss für vollständige Sicherungen konfiguriert werden und vor Beginn der Datenreplikationmuss eine Sicherung ausgeführt werden.
• Das Wiederherstellungsmodell muss auf Bulk logged (Massenprotokollierung) oder Full (Vollständig)eingestellt sein.
• Die SQL Server-Sicherung auf mehrere Datenträger wird nicht unterstützt. Wenn die Sicherung sodefiniert ist, dass die Datenbanksicherung auf mehrere Dateien über verschiedene Festplatten zuschreiben ist, kann AWS DMS die Daten nicht lesen und die AWS DMS-Aufgabe schlägt fehl.
• Beachten Sie bei selbstverwalteten SQL Server-Quellen, dass SQL Server Replication Publisher-Definitionen für die Quelldatenbank, die in einer DMS CDC-Aufgabe verwendet werden, nicht beimEntfernen der Aufgabe mit entfernt werden. Bei selbstverwalteten Quellen muss ein SQL Server-Systemadministrator diese Definitionen aus SQL Server löschen.
• Während CDC muss AWS DMS auf Sicherungen des SQL Server-Transaktionsprotokollszugreifen, um Änderungen zu lesen. AWS DMS unterstützt nicht die Verwendung von SQL Server-Transaktionsprotokollsicherungen, die mithilfe der Sicherungssoftware von Drittanbietern erstellt wurden.
API-Version API Version 2016-01-01154

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
• Beachten Sie bei selbstverwalteten SQL Server-Quellen, dass SQL Server Änderungen an neu erstelltenTabellen erst erfasst, nachdem diese veröffentlicht wurden. Wenn Tabellen einer SQL Server-Quellehinzugefügt werden, verwaltet AWS DMS die Erstellung der Veröffentlichung. Dieser Vorgang kannallerdings einige Minuten dauern. Während dieser Verzögerung vorgenommene Operationen in neuerstellten Tabellen werden nicht erfasst oder in der Zieldatenbank repliziert.
• AWS DMS Change Data Capture erfordert, dass die vollständige Protokollierung in SQL Server aktiviertwird. Um die vollständige Protokollierung in SQL Server zu aktivieren, müssen Sie entweder MS-REPLICATION oder CHANGE DATA CAPTURE (CDC) einschalten.
• Das tlog von SQL Server lässt sich erst wiederverwenden, nachdem die Änderungen verarbeitet wurden.• CDC-Vorgänge werden auf speicheroptimierten Tabellen nicht unterstützt. Diese Einschränkung gilt für
SQL Server 2014 (als die Funktion erstmals eingeführt wurde) und höher.
Erfassen von Datenänderungen für SQL Server
Für eine selbstverwaltete SQL Server-Quelle verwendet AWS DMS Folgendes:
• MS-Replikation – um Änderungen für Tabellen mit Primärschlüsseln zu erfassen. Sie können diesautomatisch konfigurieren, indem Sie dem Benutzer des AWS DMS-Endpunkts Sysadmin-Privilegien aufder SQL-Server-Quell-Instance erteilen. Alternativ können Sie die in diesem Abschnitt beschriebenenSchritte ausführen, um die Quelle vorzubereiten und einen Nicht-Sysadmin-Benutzer für den AWS DMS-Endpunkt zu verwenden.
• MS-CDC – um Änderungen für Tabellen ohne Primärschlüssel zu erfassen. MS-CDC muss aufDatenbankebene und für alle Tabellen einzeln aktiviert werden.
Für eine SQL Server-Quelle, die auf Amazon RDS läuft, verwendet AWS DMS MS-CDC, um Änderungenfür Tabellen mit oder ohne Primärschlüssel zu erfassen. MS-CDC muss auf Datenbankebene und für alleTabellen einzeln mit den gespeicherten Amazon RDS-spezifischen Prozeduren aktiviert werden, die indiesem Abschnitt beschrieben werden.
Es gibt mehrere Möglichkeiten, wie Sie eine SQL Server-Datenbank für die fortlaufende Replikation (CDC)verwenden können:
• Einrichten der fortlaufenden Replikation mit der Sysadmin-Rolle. (Dies gilt ausschließlich fürselbstverwaltete SQL Server-Quellen.)
• Einrichten der fortlaufenden Replikation ohne Verwendung der Sysadmin-Rolle. (Dies gilt ausschließlichfür selbstverwaltete SQL Server-Quellen.)
• Einrichten der fortlaufenden Replikation auf einer Amazon RDS für SQL Server DB-Instance.
Einrichten der fortlaufenden Replikation mit der Sysadmin-Rolle
Bei Tabellen mit Primärschlüsseln kann AWS DMS die benötigten Artefakte in der Quelle konfigurieren. BeiTabellen ohne Primärschlüssel müssen Sie MS-CDC einrichten.
Zunächst aktivieren Sie MS-CDC für die Datenbank, indem Sie den folgenden Befehl ausführen.Verwenden Sie ein Konto, dem die Sysadmin-Rolle zugewiesen ist.
use [DBname]EXEC sys.sp_cdc_enable_db
Als Nächstes aktivieren Sie MS-CDC für jede Quelltabelle, indem Sie den folgenden Befehl ausführen.
EXECUTE sys.sp_cdc_enable_table @source_schema = N'MySchema', @source_name =N'MyTable', @role_name = NULL;
API-Version API Version 2016-01-01155

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
Weitere Informationen zum Einrichten von MS-CDC für bestimmte Tabellen finden Sie in der SQL Server-Dokumentation.
Einrichten der fortlaufenden Replikation ohne Zuweisung der Sysadmin-Rolle
Sie können die fortlaufende Replikation für eine SQL Server-Datenbankquelle einrichten, für die dasBenutzerkonto keine Sysadmin-Berechtigungen benötigt.
Note
Sie können dieses Verfahren durchführen, während die DMS-Aufgabe ausgeführt wird. Wenndie DMS-Aufgabe angehalten wird, können Sie diesen Vorgang nur ausführen, wenn keineTransaktionsprotokoll- oder Datenbanksicherungen durchgeführt werden. Dies liegt daran,dass SQL Server die SYSADMIN-Berechtigung benötigt, um die Sicherung für die LSN Positionabzufragen.
So richten Sie eine SQL Server-Datenbankquelle für die fortlaufende Replikation ohneVerwendung der Sysadmin-Rolle ein
1. Erstellen Sie unter Verwendung von SQL Server Management Studio (SSMS) ein neues SQL Server-Konto mit Passwort-Authentifizierung. In diesem Beispiel verwenden wir ein Konto mit dem Namendmstest.
2. Wählen Sie im Abschnitt User Mappings (Benutzer-Zuweisung) von SSMS die MSDB- und MASTER-Datenbanken aus (die öffentliche Berechtigung erteilen) und weisen Sie der Datenbank, die Sie für diefortlaufende Replikation verwenden möchten, die Rolle DB_OWNER zu.
3. Öffnen Sie das Kontextmenü (rechte Maustaste) für das neue Konto, wählen Sie Security (Sicherheit)aus und erteilen Sie explizit die "Connect SQL"-Berechtigung.
4. Führen Sie die folgenden Befehle zum Erteilen der Berechtigungen aus.
GRANT SELECT ON FN_DBLOG TO dmstest;GRANT VIEW SERVER STATE TO dmstest;use msdb;GRANT EXECUTE ON MSDB.DBO.SP_STOP_JOB TO dmstest;GRANT EXECUTE ON MSDB.DBO.SP_START_JOB TO dmstest;GRANT SELECT ON MSDB.DBO.BACKUPSET TO dmstest;GRANT SELECT ON MSDB.DBO.BACKUPMEDIAFAMILY TO dmstest;GRANT SELECT ON MSDB.DBO.BACKUPFILE TO dmstest;
5. Öffnen Sie in SSMS das Kontextmenü (rechte Maustaste) für den Ordner Replikation und wählenSie die Option Configure Distribution (Verteilung konfigurieren). Führen Sie alle Standardschritte ausund konfigurieren Sie diese SQL Server-Instance für die Verteilung. Unter Datenbanken wird eineVerteilungsdatenbank angelegt.
6. Gehen Sie wie folgt vor, um eine Veröffentlichung zu erstellen.7. Erstellen Sie unter Verwendung des von Ihnen erstellten Benutzerkontos eine neue AWS DMS-
Aufgabe mit SQL Server als Quellendpunkt.
Note
Die Schritte dieser Anleitung gelten nur für Tabellen mit Primärschlüsseln. Sie müssen MS-CDCnoch für Tabellen ohne Primärschlüssel aktivieren.
Erstellen einer SQL Server-Veröffentlichung für die laufende Replikation
Zur Verwendung von CDC mit SQL Server müssen Sie eine Veröffentlichung für jede Tabelle erstellen, diean der laufenden Replikation beteiligt ist.
API-Version API Version 2016-01-01156

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
So erstellen Sie eine Veröffentlichung für die laufende SQL Server-Replikation
1. Melden Sie sich unter Verwendung des SYSADMIN-Benutzerkonto bei SSMS an.2. Erweitern Sie Replication (Replikation).3. Öffnen Sie das Kontextmenü (rechte Maustaste) für Local Publications (Lokale Veröffentlichungen).4. Wählen Sie im New Publication Wizard (Assistent für neue Veröffentlichungen) Next (Weiter).5. Wählen Sie die Datenbank, in der Sie die Veröffentlichung erstellen möchten.6. Wählen Sie Transactional publication (Transaktionale Veröffentlichung) und anschließend Next
(Weiter) aus.7. Erweitern Sie Tables (Tabellen) und wählen Sie die Tabellen mit PK (auch die Tabellen, die Sie
veröffentlichen möchten) aus. Wählen Sie Next.8. Klicken Sie auf Next (Weiter) und anschließend auf Next (Weiter), da Sie keinen Filter oder Snapshot-
Agent erstellen müssen.9. Wählen Sie Security Settings (Sicherheitseinstellungen) und wählen Sie Run under the SQL Server
Agent service account (Unter dem SQL Server Agent-Servicekonto ausführen). Wählen Sie fürdie Verbindung des Herausgebers unbedingt By impersonating the process account (Durch dieVerkörperung des Prozesskontos) wählen. Klicken Sie auf OK.
10. Wählen Sie Next (weiter).11. Wählen Sie Create the publication (Die Veröffentlichung erstellen).12. Geben Sie einen Namen für die Veröffentlichung im folgenden Format an:
AR_PUBLICATION_000DBID.
Sie können der Veröffentlichung beispielsweise den Namen AR_PUBLICATION_00018 geben.Sie können auch die DB_ID-Funktion in SQL Server verwenden. Weitere Informationen zur DB_ID-Funktion finden Sie in der SQL Server-Dokumentation.
Einrichten der fortlaufenden Replikation auf einem Amazon RDS für SQL ServerDB-Instance
Amazon RDS für SQL Server unterstützt MS-CDC für alle Versionen von Amazon RDS für SQL ServerEnterprise-Editionen bis SQL Server 2016 SP1. Standardeditionen von SQL Server 2016 SP1 und höherunterstützen MS-CDC für Amazon RDS für SQL Server.
Im Gegensatz zu selbstverwalteten SQL Server-Quellen unterstützt Amazon RDS für SQL Server keineMS-Replikation. Daher muss AWS DMS MS-CDC für Tabellen mit oder ohne Primärschlüssel verwenden.
Amazon RDS vergibt keine Sysadmin-Berechtigungen für das Einrichten von Replikationsartefakten, dieAWS DMS für laufende Änderungen in einer SQL-Server-Quell-Instance verwendet. Sie müssen MS-CDC auf der Amazon RDS-Instance mithilfe der Berechtigungen für den Hauptbenutzer in der folgendenProzedur aktivieren.
So aktivieren Sie MS-CDC auf einer RDS für SQL Server DB-Instance
1. Führen Sie die folgende Abfrage auf Datenbankebene aus.
exec msdb.dbo.rds_cdc_enable_db 'DB_name'
2. Führen Sie die folgende Abfrage für jede Tabelle mit einem Primärschlüssel aus, um MS-CDC zuaktivieren.
exec sys.sp_cdc_enable_table
API-Version API Version 2016-01-01157

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
@source_schema = N'schema_name',@source_name = N'table_name',@role_name = NULL,@supports_net_changes = 1GO
Führen Sie die folgende Abfrage für jede Tabelle mit eindeutigen Schlüsseln, aber ohnePrimärschlüssel aus, um MS-CDC zu aktivieren.
exec sys.sp_cdc_enable_table@source_schema = N'schema_name',@source_name = N'table_name',@index_name = N'unique_index_name'@role_name = NULL,@supports_net_changes = 1GO
Führen Sie die folgende Abfrage für jede Tabelle ohne Primärschlüssel oder eindeutige Schlüssel aus,um MS-CDC zu aktivieren.
exec sys.sp_cdc_enable_table@source_schema = N'schema_name',@source_name = N'table_name',@role_name = NULLGO
3. Stellen Sie mit dem folgenden Befehl den Aufbewahrungszeitraum für Änderungen ein, die in derQuelle verfügbar sein sollen.
use dbnameEXEC sys.sp_cdc_change_job @job_type = 'capture' ,@pollinginterval = 3599exec sp_cdc_start_job 'capture'
Der Parameter @pollinginterval wird in Sekunden mit einer maximalen Länge von 3599gemessen. Dies bedeutet, dass das Transaktionsprotokoll Änderungen für 3599 Sekunden (fast eineStunde) behält, wenn @pollinginterval = 3599. Die Prozedur exec sp_cdc_start_job'capture' initiiert die Einstellungen.
Wahrung des Aufbewahrungszeitraums während einer AWS DMS-Replikationsaufgabe
Wenn eine AWS DMS-Replikationsaufgabe, die laufende Änderungen an der SQL Server-Quelle erfasst,länger als eine Stunde angehalten wird, gehen Sie folgendermaßen vor:
1. Halten Sie die Aufgabe an, indem Sie die Transaktionsprotokolle (TLogs) mit diesem Befehl kürzen:
exec sp_cdc_stop_job 'capture'
2. Navigieren Sie zu Ihrer Aufgabe in der AWS DMS-Konsole und setzen Sie die Aufgabe wieder fort.3. Öffnen Sie die Registerkarte „Monitoring (Überwachung)“ in der AWS DMS-Konsole und überprüfen
Sie die Metrik CDClatencySource.4. Sobald die CDClatencySource-Metrik gleich 0 (Null) ist und dort bleibt, starten Sie die Aufgabe neu,
indem Sie die TLogs mit dem folgenden Befehl kürzen:
exec sp_cdc_start_job 'capture'
API-Version API Version 2016-01-01158
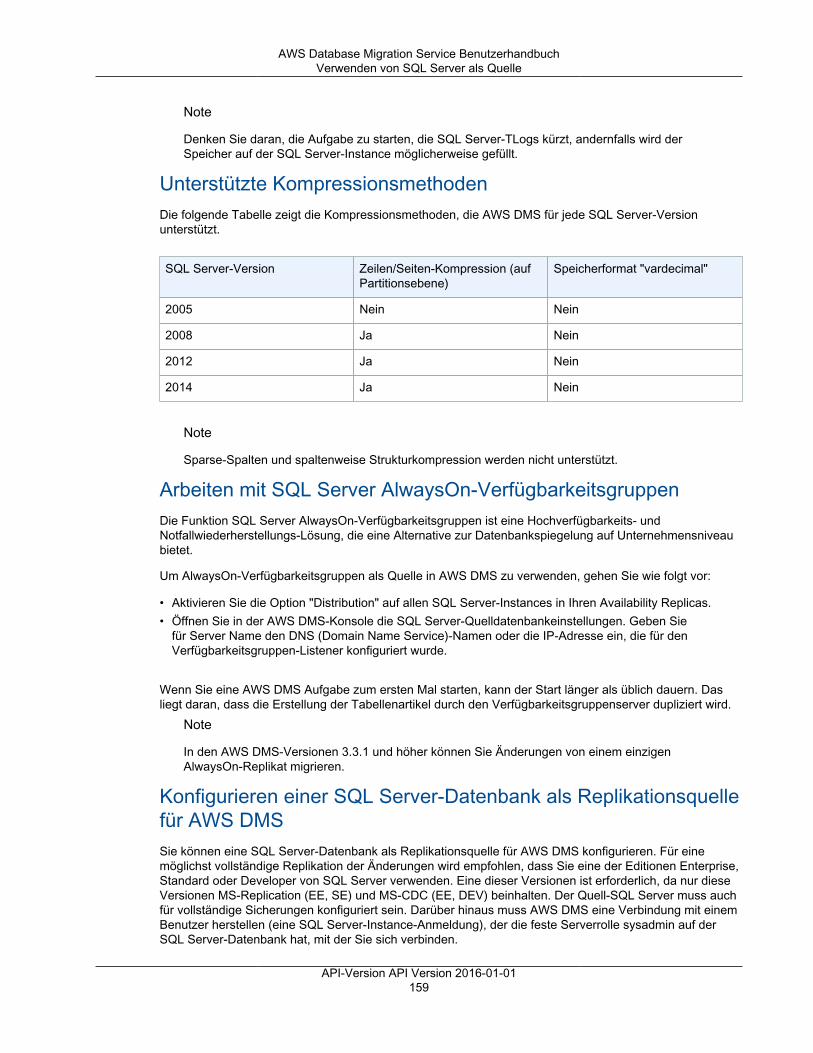
AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
Note
Denken Sie daran, die Aufgabe zu starten, die SQL Server-TLogs kürzt, andernfalls wird derSpeicher auf der SQL Server-Instance möglicherweise gefüllt.
Unterstützte KompressionsmethodenDie folgende Tabelle zeigt die Kompressionsmethoden, die AWS DMS für jede SQL Server-Versionunterstützt.
SQL Server-Version Zeilen/Seiten-Kompression (aufPartitionsebene)
Speicherformat "vardecimal"
2005 Nein Nein
2008 Ja Nein
2012 Ja Nein
2014 Ja Nein
Note
Sparse-Spalten und spaltenweise Strukturkompression werden nicht unterstützt.
Arbeiten mit SQL Server AlwaysOn-VerfügbarkeitsgruppenDie Funktion SQL Server AlwaysOn-Verfügbarkeitsgruppen ist eine Hochverfügbarkeits- undNotfallwiederherstellungs-Lösung, die eine Alternative zur Datenbankspiegelung auf Unternehmensniveaubietet.
Um AlwaysOn-Verfügbarkeitsgruppen als Quelle in AWS DMS zu verwenden, gehen Sie wie folgt vor:
• Aktivieren Sie die Option "Distribution" auf allen SQL Server-Instances in Ihren Availability Replicas.• Öffnen Sie in der AWS DMS-Konsole die SQL Server-Quelldatenbankeinstellungen. Geben Sie
für Server Name den DNS (Domain Name Service)-Namen oder die IP-Adresse ein, die für denVerfügbarkeitsgruppen-Listener konfiguriert wurde.
Wenn Sie eine AWS DMS Aufgabe zum ersten Mal starten, kann der Start länger als üblich dauern. Dasliegt daran, dass die Erstellung der Tabellenartikel durch den Verfügbarkeitsgruppenserver dupliziert wird.
Note
In den AWS DMS-Versionen 3.3.1 und höher können Sie Änderungen von einem einzigenAlwaysOn-Replikat migrieren.
Konfigurieren einer SQL Server-Datenbank als Replikationsquellefür AWS DMSSie können eine SQL Server-Datenbank als Replikationsquelle für AWS DMS konfigurieren. Für einemöglichst vollständige Replikation der Änderungen wird empfohlen, dass Sie eine der Editionen Enterprise,Standard oder Developer von SQL Server verwenden. Eine dieser Versionen ist erforderlich, da nur dieseVersionen MS-Replication (EE, SE) und MS-CDC (EE, DEV) beinhalten. Der Quell-SQL Server muss auchfür vollständige Sicherungen konfiguriert sein. Darüber hinaus muss AWS DMS eine Verbindung mit einemBenutzer herstellen (eine SQL Server-Instance-Anmeldung), der die feste Serverrolle sysadmin auf derSQL Server-Datenbank hat, mit der Sie sich verbinden.
API-Version API Version 2016-01-01159

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
Zusätzliche Verbindungsattribute bei der Verwendung von SQLServer als Quelle für AWS DMSSie können zusätzliche Verbindungsattribute verwenden, um Ihr SQL Server-Quelle zu konfigurieren.Sie geben diese Einstellungen beim Erstellen des Quellendpunkts an. Wenn Sie mehrereVerbindungsattributeinstellungen verwenden, trennen Sie diese durch Semikola und ohne zusätzlicheLeerräume voneinander (z. B. oneSetting;thenAnother).
Die folgende Tabelle zeigt die zusätzlichen Verbindungsattribute, die Sie verwenden können, wenn SQLServer die Quelle ist:
Name Beschreibung
safeguardPolicy Um eine optimale Leistung zu erreichen, versuchtAWS DMS, alle ungelesenen Änderungen vom aktivenTransaktionsprotokoll (TLOG) zu erfassen. Manchmalenthält das aktive TLOG jedoch aufgrund von Kürzungennicht alle ungelesenen Änderungen. Wenn dies der Fall ist,greift AWS DMS auf das Sicherungsprotokoll zu, um diefehlenden Änderungen zu erfassen. Um die Notwendigkeitzu minimieren, auf das Sicherungsprotokoll zuzugreifen,vermeidet AWS DMS Kürzungen mit einer der folgendenMethoden:
1. Start transactions in the database (Transaktionen inder Datenbank starten): Dies ist die Standardmethode.Wenn diese Methode verwendet wird, verhindert AWS DMSKürzungen im TLOG durch Nachahmung einer Transaktionin der Datenbank. Solange eine Transaktion offen ist, werdenÄnderungen, die nach Beginn der Transaktion erscheinen,nicht gekürzt. Wenn Sie Microsoft Replication in IhrerDatenbank aktivieren müssen, müssen Sie diese Methodewählen.
2. Exclusively use sp_repldone within a single task(Ausschließlich sp_repldone innerhalb einer einzigenAufgabe verwenden): Bei dieser Methode liest AWS DMSdie Änderungen und markiert die TLOG-Transaktionendann mit sp_repldone als bereit für die Kürzung. Obwohl beidieser Methode keine Transaktionsaktivitäten involviert sind,kann sie nur verwendet werden, wenn Microsoft Replicationnicht ausgeführt wird. Wenn Sie diese Methode verwenden,kann außerdem nur eine AWS DMS-Aufgabe zu einemgegebenen Zeitpunkt auf die Datenbank zugreifen. WennSie also parallele AWS DMS-Aufgaben für die gleicheDatenbank ausführen müssen, verwenden Sie daher dieStandardmethode.
Standardwert:RELY_ON_SQL_SERVER_REPLICATION_AGENT
Zulässige Werte: {EXCLUSIVE_AUTOMATIC_TRUNCATION,RELY_ON_SQL_SERVER_REPLICATION_AGENT}
Beispiel:safeguardPolicy=RELY_ON_SQL_SERVER_REPLICATION_AGENT;
API-Version API Version 2016-01-01160

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
Name Beschreibung
readBackupOnly Wenn der Parameter auf Y gesetzt ist, liest AWS DMSwährend der laufenden Replikation nur Änderungen ausSicherungen des Transaktionsprotokolls und nicht ausder aktiven Transaktionsprotokolldatei. Wenn Sie diesenParameter auf Y festlegen, können Sie steuern, wie starkdie aktive Transaktionsprotokolldatei beim vollständigenLaden und fortlaufenden Replikationsaufgaben wächst. Dieskann bei fortlaufender Replikation jedoch zu einer gewissenQuelllatenz führen.
Gültige Werte: N oder Y. Der Standardwert ist N.
Beispiel: readBackupOnly=Y;
Quelldatentypen für SQL ServerEine Datenmigration, bei der SQL Server als Quelle für AWS DMS verwendet wird, unterstützt diemeisten SQL Server-Datentypen. In der folgenden Tabelle sind die SQL Server-Quelldatentypen, diebei Verwendung von AWS DMS unterstützt werden, sowie deren Standardzuweisung von AWS DMS-Datentypen aufgeführt.
Weitere Informationen zum Anzeigen des Datentyps, der im Ziel zugewiesen ist, finden Sie im Abschnitt fürden Zielendpunkt, den Sie verwenden.
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
SQL Server-Datentyp AWS DMS-Datentypen
BIGINT INT8
BIT BOOLEAN
DECIMAL NUMERIC
INT INT4
MONEY NUMERIC
NUMERIC (p,s) NUMERIC
SMALLINT INT2
SMALLMONEY NUMERIC
TINYINT UINT1
REAL REAL4
FLOAT REAL8
DATETIME DATETIME
DATETIME2 (SQL Server 2008 und höher) DATETIME
SMALLDATETIME DATETIME
API-Version API Version 2016-01-01161
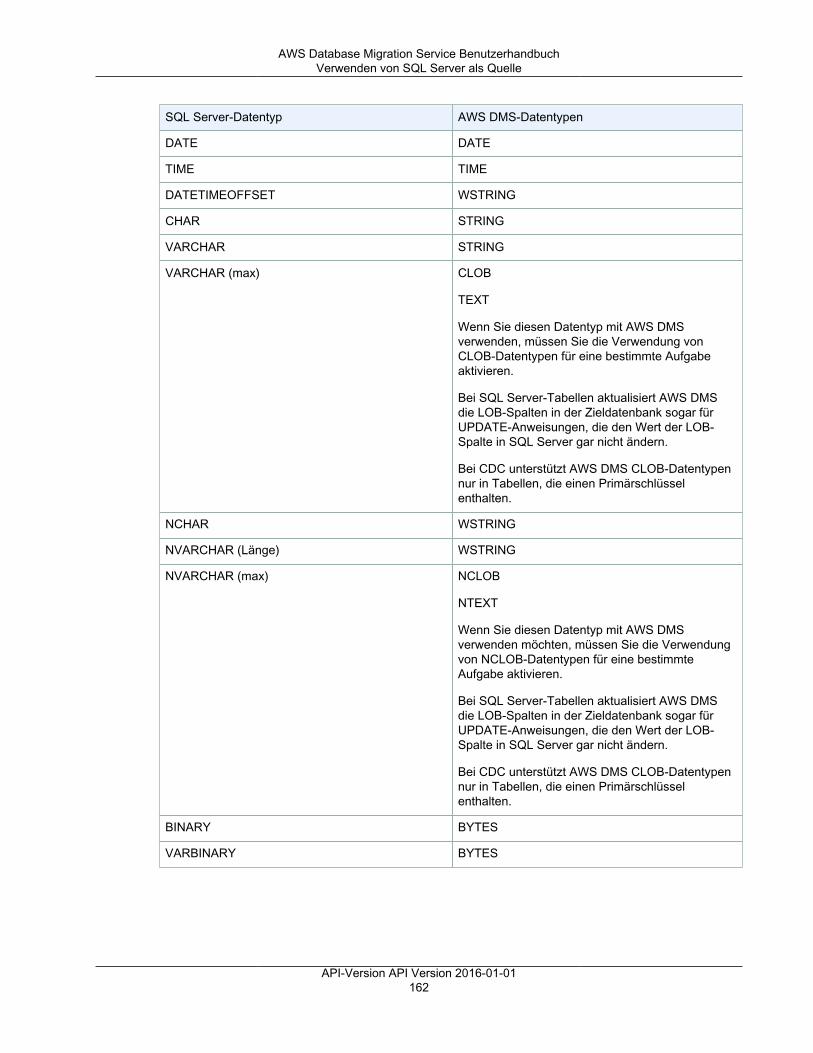
AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
SQL Server-Datentyp AWS DMS-Datentypen
DATE DATE
TIME TIME
DATETIMEOFFSET WSTRING
CHAR STRING
VARCHAR STRING
VARCHAR (max) CLOB
TEXT
Wenn Sie diesen Datentyp mit AWS DMSverwenden, müssen Sie die Verwendung vonCLOB-Datentypen für eine bestimmte Aufgabeaktivieren.
Bei SQL Server-Tabellen aktualisiert AWS DMSdie LOB-Spalten in der Zieldatenbank sogar fürUPDATE-Anweisungen, die den Wert der LOB-Spalte in SQL Server gar nicht ändern.
Bei CDC unterstützt AWS DMS CLOB-Datentypennur in Tabellen, die einen Primärschlüsselenthalten.
NCHAR WSTRING
NVARCHAR (Länge) WSTRING
NVARCHAR (max) NCLOB
NTEXT
Wenn Sie diesen Datentyp mit AWS DMSverwenden möchten, müssen Sie die Verwendungvon NCLOB-Datentypen für eine bestimmteAufgabe aktivieren.
Bei SQL Server-Tabellen aktualisiert AWS DMSdie LOB-Spalten in der Zieldatenbank sogar fürUPDATE-Anweisungen, die den Wert der LOB-Spalte in SQL Server gar nicht ändern.
Bei CDC unterstützt AWS DMS CLOB-Datentypennur in Tabellen, die einen Primärschlüsselenthalten.
BINARY BYTES
VARBINARY BYTES
API-Version API Version 2016-01-01162
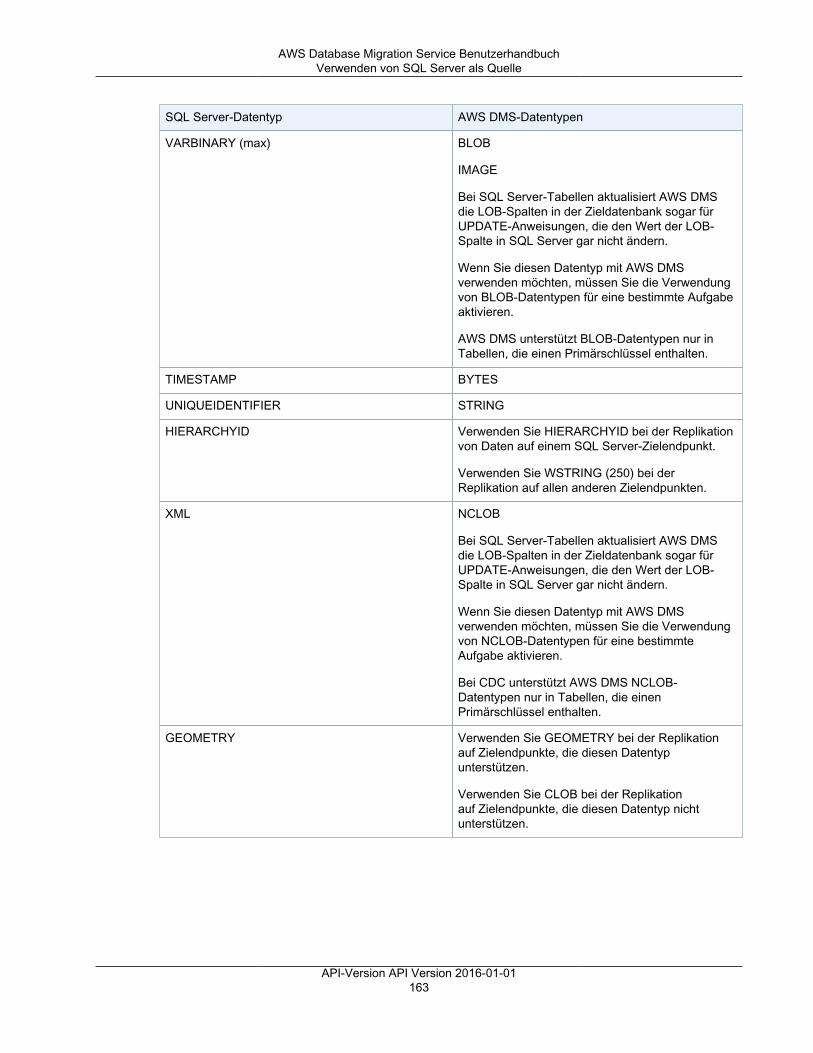
AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Quelle
SQL Server-Datentyp AWS DMS-Datentypen
VARBINARY (max) BLOB
IMAGE
Bei SQL Server-Tabellen aktualisiert AWS DMSdie LOB-Spalten in der Zieldatenbank sogar fürUPDATE-Anweisungen, die den Wert der LOB-Spalte in SQL Server gar nicht ändern.
Wenn Sie diesen Datentyp mit AWS DMSverwenden möchten, müssen Sie die Verwendungvon BLOB-Datentypen für eine bestimmte Aufgabeaktivieren.
AWS DMS unterstützt BLOB-Datentypen nur inTabellen, die einen Primärschlüssel enthalten.
TIMESTAMP BYTES
UNIQUEIDENTIFIER STRING
HIERARCHYID Verwenden Sie HIERARCHYID bei der Replikationvon Daten auf einem SQL Server-Zielendpunkt.
Verwenden Sie WSTRING (250) bei derReplikation auf allen anderen Zielendpunkten.
XML NCLOB
Bei SQL Server-Tabellen aktualisiert AWS DMSdie LOB-Spalten in der Zieldatenbank sogar fürUPDATE-Anweisungen, die den Wert der LOB-Spalte in SQL Server gar nicht ändern.
Wenn Sie diesen Datentyp mit AWS DMSverwenden möchten, müssen Sie die Verwendungvon NCLOB-Datentypen für eine bestimmteAufgabe aktivieren.
Bei CDC unterstützt AWS DMS NCLOB-Datentypen nur in Tabellen, die einenPrimärschlüssel enthalten.
GEOMETRY Verwenden Sie GEOMETRY bei der Replikationauf Zielendpunkte, die diesen Datentypunterstützen.
Verwenden Sie CLOB bei der Replikationauf Zielendpunkte, die diesen Datentyp nichtunterstützen.
API-Version API Version 2016-01-01163

AWS Database Migration Service BenutzerhandbuchVerwenden einer Azure SQL-Datenbank als Quelle
SQL Server-Datentyp AWS DMS-Datentypen
GEOGRAPHY Verwenden Sie GEOGRAPHY bei der Replikationauf Zielendpunkte, die diesen Datentypunterstützen.
Verwenden Sie CLOB bei der Replikationauf Zielendpunkte, die diesen Datentyp nichtunterstützen.
AWS DMS unterstützt keine Tabellen, die Felder mit den folgenden Datentypen enthalten:
• CURSOR• SQL_VARIANT• TABLE
Note
Benutzerdefinierte Datentypen werden abhängig von dem Typ, auf dem sie basieren, unterstützt.Beispielsweise wird ein benutzerdefinierter Datentyp basierend auf DATETIME als DatentypDATETIME verarbeitet.
Verwenden einer Microsoft Azure SQL-Datenbank alsQuelle für AWS DMSMit AWS DMS können Sie eine Microsoft Azure SQL-Datenbank ähnlich als Quelle verwenden wie SQLServer. AWS DMS unterstützt dieselben aufgelisteten Datenbankversionen als Quelle wie für SQL Server,der lokal oder auf einer Amazon EC2-Instance ausgeführt wird.
Weitere Informationen finden Sie unter Verwenden einer Microsoft SQL Server-Datenbank als Quelle fürAWS DMS (p. 151).
Note
AWS DMS unterstützt keine Change Data Capture-Operationen (CDC) mit einer Azure SQL-Datenbank.
Verwenden einer PostgreSQL-Datenbank als Quellefür AWS DMSSie können Daten von einer oder vielen PostgreSQL-Datenbanken mithilfe von AWS DMS migrieren.Mit einer PostgreSQL-Datenbank als Quelle können Sie Daten entweder zu einer anderen PostgreSQL-Datenbank oder einer der anderen unterstützten Datenbanken migrieren. AWS DMS unterstützt diePostgreSQL-Datenbankversionen 9.4 und höher (für Versionen 9.x), 10.x und 11.x als Quelle für dieseArten von Datenbanken:
• Lokale Datenbanken• Datenbanken auf einer EC2-Instance• Datenbanken auf einer Amazon RDS-DB-Instance• Datenbanken auf einer Amazon Aurora-DB-Instance mit PostgreSQL-Kompatibilität
API-Version API Version 2016-01-01164

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
Note
• AWS DMS funktioniert weder als Quelle noch als Ziel mit Amazon RDS for PostgreSQL 10.4oder Amazon Aurora (PostgreSQL 10.4).
• Die PostgreSQL-Versionen 11.x werden als Quelle nur in den AWS DMS-Versionen 3.3.1 undhöher unterstützt. Sie können die PostgreSQL-Versionen 9.4 und höher (Versionen 9.x) und10.x als Quelle in jeder beliebigen DMS-Version verwenden.
• Die PostgreSQL-Versionen 10.x weisen im Vergleich zu früheren Versionen zahlreicheÄnderungen bei Funktions- und Ordnernamen auf.
In einigen Fällen verwenden Sie möglicherweise eine PostgreSQL-Version 10.x-Datenbank alsQuelle und eine AWS DMS-Version vor 3.3.1. In diesen Fällen finden Sie hier Verwenden vonPostgreSQL-Version 10.x als Quelle für AWS DMS (p. 176) Informationen zur VorbereitungIhrer Datenbank als Quelle für AWS DMS.
Note
Wenn Sie eine PostgreSQL 10.x-Datenbank als Quelle mit AWS DMS-Versionen ab3.3.1 verwenden, führen Sie diese Vorbereitungen nicht für 10.x-Quelldatenbankenaus, die für frühere AWS DMS-Versionen erforderlich sind.
In der folgenden Tabelle finden Sie eine Zusammenfassung der Anforderungen an die AWS DMS-Versionen für die Verwendung der unterstützten PostgreSQL-Quellversionen.
PostgreSQL-Quellversion Zu verwendende AWS DMS-Version
9.x Verwenden Sie eine beliebige verfügbare AWSDMS-Version.
10.x Wenn Sie eine AWS DMS-Version vor 3.3.1verwenden, bereiten Sie die PostgreSQL-Quellemithilfe der Wrapper-Funktionen vor, die unterVerwenden von PostgreSQL-Version 10.x alsQuelle für AWS DMS (p. 176) beschrieben sind.
Wenn Sie eine AWS DMS-Version ab 3.3.1verwenden, erstellen Sie diese Wrapper-Funktionen nicht. Sie können die PostgreSQL-Quelle ohne zusätzliche Vorbereitung verwenden.
11.x Verwenden Sie AWS DMS-Version 3.3.1.
Sie können SSL verwenden, um Verbindungen zwischen Ihrem PostgreSQL-Endpunkt und derReplikations-Instance zu verschlüsseln. Weitere Informationen zur Verwendung von SSL mit einemPostgreSQL-Endpunkt finden Sie unter Verwenden von SSL mit AWS Database Migration Service (p. 82).
Bei einer homogenen Migration von einer PostgreSQL-Datenbank zu einer PostgreSQL-Datenbank aufAWS gilt Folgendes:
• JSONB-Spalten auf der Quelle werden zu JSONB-Spalten auf dem Ziel migriert.• JSON-Spalten werden zu JSON-Spalten auf dem Ziel migriert.• HSTORE-Spalten werden zu HSTORE-Spalten auf dem Ziel migriert.
Bei einer heterogenen Migration mit PostgreSQL als Quelle und einer anderen Datenbank-Engine als Zielist die Situation anders. In einem solchen Fall werden JSONB-, JSON- und HSTORE-Spalten in den AWS
API-Version API Version 2016-01-01165

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
DMS-Zwischentyp NCLOB konvertiert und anschließend in den entsprechenden NCLOB-Spaltentyp aufdem Ziel übertragen. Dabei werden JSONB-Daten von AWS DMS als LOB-Spalte behandelt. Während derMigrationsphase des vollständigen Ladevorgangs muss die Zielspalte nullwertfähig sein.
AWS DMS unterstützt CDC (Change Data Capture) für PostgreSQL-Tabellen mit Primärschlüsseln. Wenneine Tabelle keinen Primärschlüssel hat, enthalten die Write-Ahead-Protokolle (WAL) kein Vorher-Imageder Datenbankzeile und AWS DMS kann die Tabelle nicht aktualisieren.
AWS DMS unterstützt CDC auf Amazon RDS-PostgreSQL-Datenbanken, wenn die DB-Instance sokonfiguriert ist, dass sie logische Replikation verwendet. Amazon RDS unterstützt die logische Replikationfür eine PostgreSQL-DB-Instance der Version 9.4.9 und höher sowie 9.5.4 und höher. Amazon RDSunterstützt darüber hinaus die logische Replikation für eine Amazon Aurora-DB-Instance mit den Versionen2.2.0 und 2.2.1 mit PostgreSQL-10.6-Kompatibilität.
Weitere Informationen zum Arbeiten mit PostgreSQL-Datenbanken und AWS DMS finden Sie in denfolgenden Abschnitten.
Themen• Migrieren von PostgreSQL auf PostgreSQL mit AWS DMS (p. 166)• Voraussetzungen für die Verwendung einer PostgreSQL-Datenbank als Quelle für AWS
DMS (p. 169)• Sicherheitsanforderungen bei Verwendung einer PostgreSQL-Datenbank als Quelle für AWS
DMS (p. 170)• Einschränkungen bei der Verwendung einer PostgreSQL-Datenbank als Quelle für AWS
DMS (p. 171)• Einrichten einer Amazon RDS PostgreSQL-DB-Instance als Quelle (p. 172)• Entfernen von AWS DMS-Artefakten aus einer PostgreSQL-Quelldatenbank (p. 176)• Zusätzliche Konfigurationseinstellungen bei der Verwendung einer PostgreSQL-Datenbank als Quelle
für AWS DMS (p. 176)• Verwenden von PostgreSQL-Version 10.x als Quelle für AWS DMS (p. 176)• Zusätzliche Verbindungsattribute bei der Verwendung von PostgreSQL als Quelle für AWS
DMS (p. 178)• Quelldatentypen für PostgreSQL (p. 180)
Migrieren von PostgreSQL auf PostgreSQL mit AWS DMSFür eine heterogene Migration, bei der Sie von einer anderen Datenbank-Engine als PostgreSQL auf einePostgreSQL-Datenbank migrieren, eignet sich AWS DMS fast immer als Migrationstool. Wenn Sie jedocheine homogene Migration durchführen möchten, bei der Sie aus einer PostgreSQL-Datenbank auf einePostgreSQL-Datenbank migrieren, können native Tools effektiver sein.
Unter den folgenden Bedingungen empfehlen wir Ihnen die Verwendung von nativen PostgreSQL-Datenbank-Migrationstools wie pg_dump:
• Sie möchten eine homogene Migration durchführen, bei der die PostgreSQL-Ausgangsdatenbank aufeine PostgreSQL-Zieldatenbank migriert werden soll.
• Sie möchten eine komplette Datenbank migrieren.• Die nativen Tools erlauben Ihnen, Ihre Daten mit einer minimalen Ausfallzeit zu migrieren.
Das Dienstprogramm pg_dump verwendet den Befehl COPY, um ein Schema sowie eine Daten-Dumpdateieiner PostgreSQL-Datenbank zu erstellen. Das durch pg_dump erzeugte Dump-Skript lädt Daten in eineDatenbank mit demselben Namen und erstellt die Tabellen, Indizes und Fremdschlüssel. Sie könnenden Befehl pg_restore und den Parameter -d verwenden, um die Daten in einer Datenbank mit einemanderen Namen wiederherzustellen.
API-Version API Version 2016-01-01166
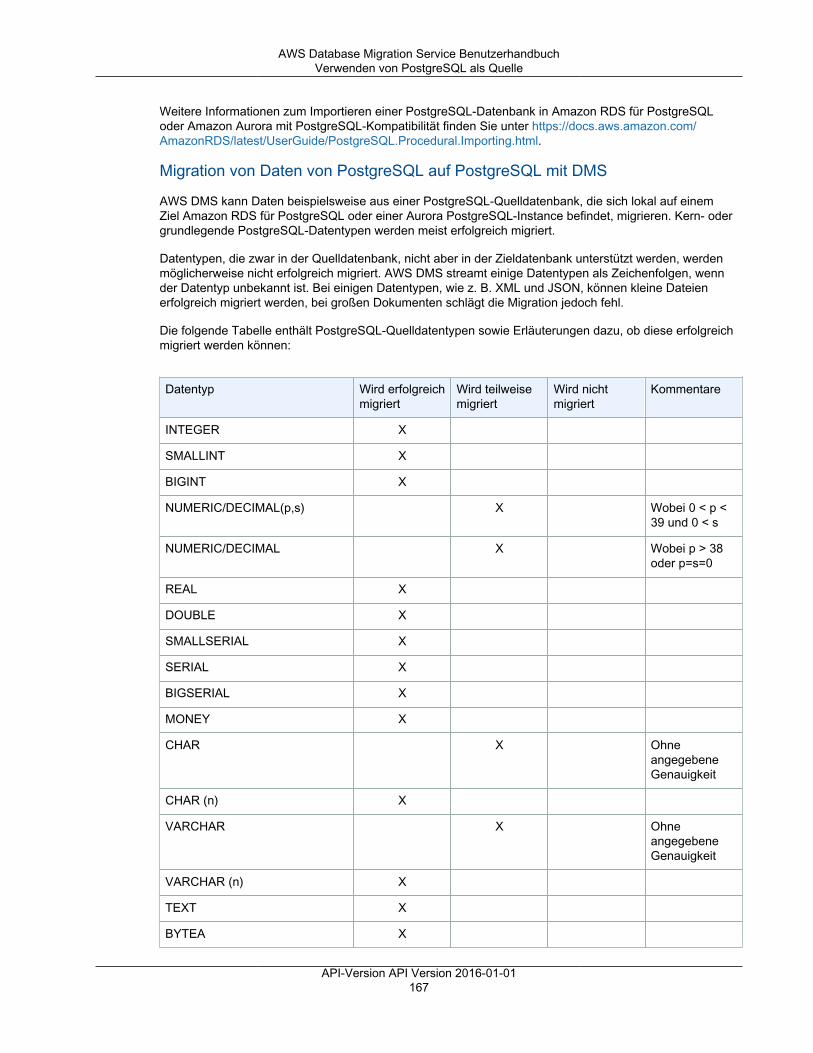
AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
Weitere Informationen zum Importieren einer PostgreSQL-Datenbank in Amazon RDS für PostgreSQLoder Amazon Aurora mit PostgreSQL-Kompatibilität finden Sie unter https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/PostgreSQL.Procedural.Importing.html.
Migration von Daten von PostgreSQL auf PostgreSQL mit DMS
AWS DMS kann Daten beispielsweise aus einer PostgreSQL-Quelldatenbank, die sich lokal auf einemZiel Amazon RDS für PostgreSQL oder einer Aurora PostgreSQL-Instance befindet, migrieren. Kern- odergrundlegende PostgreSQL-Datentypen werden meist erfolgreich migriert.
Datentypen, die zwar in der Quelldatenbank, nicht aber in der Zieldatenbank unterstützt werden, werdenmöglicherweise nicht erfolgreich migriert. AWS DMS streamt einige Datentypen als Zeichenfolgen, wennder Datentyp unbekannt ist. Bei einigen Datentypen, wie z. B. XML und JSON, können kleine Dateienerfolgreich migriert werden, bei großen Dokumenten schlägt die Migration jedoch fehl.
Die folgende Tabelle enthält PostgreSQL-Quelldatentypen sowie Erläuterungen dazu, ob diese erfolgreichmigriert werden können:
Datentyp Wird erfolgreichmigriert
Wird teilweisemigriert
Wird nichtmigriert
Kommentare
INTEGER X
SMALLINT X
BIGINT X
NUMERIC/DECIMAL(p,s) X Wobei 0 < p <39 und 0 < s
NUMERIC/DECIMAL X Wobei p > 38oder p=s=0
REAL X
DOUBLE X
SMALLSERIAL X
SERIAL X
BIGSERIAL X
MONEY X
CHAR X OhneangegebeneGenauigkeit
CHAR (n) X
VARCHAR X OhneangegebeneGenauigkeit
VARCHAR (n) X
TEXT X
BYTEA X
API-Version API Version 2016-01-01167
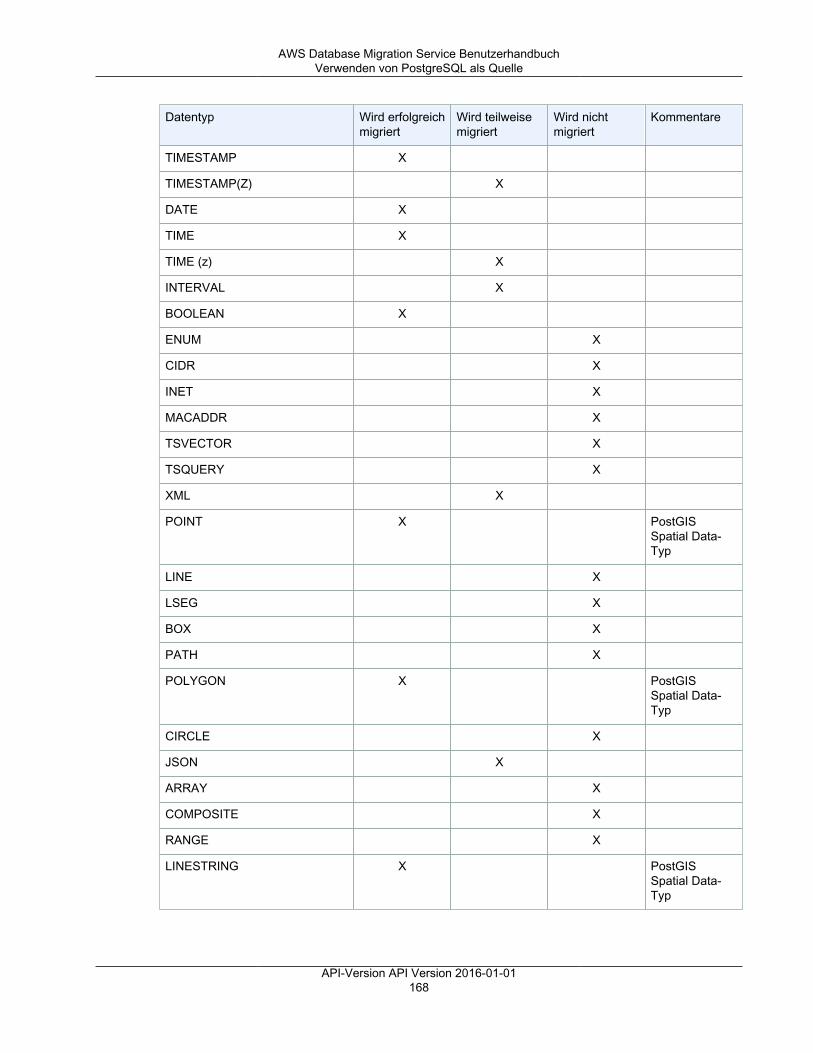
AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
Datentyp Wird erfolgreichmigriert
Wird teilweisemigriert
Wird nichtmigriert
Kommentare
TIMESTAMP X
TIMESTAMP(Z) X
DATE X
TIME X
TIME (z) X
INTERVAL X
BOOLEAN X
ENUM X
CIDR X
INET X
MACADDR X
TSVECTOR X
TSQUERY X
XML X
POINT X PostGISSpatial Data-Typ
LINE X
LSEG X
BOX X
PATH X
POLYGON X PostGISSpatial Data-Typ
CIRCLE X
JSON X
ARRAY X
COMPOSITE X
RANGE X
LINESTRING X PostGISSpatial Data-Typ
API-Version API Version 2016-01-01168
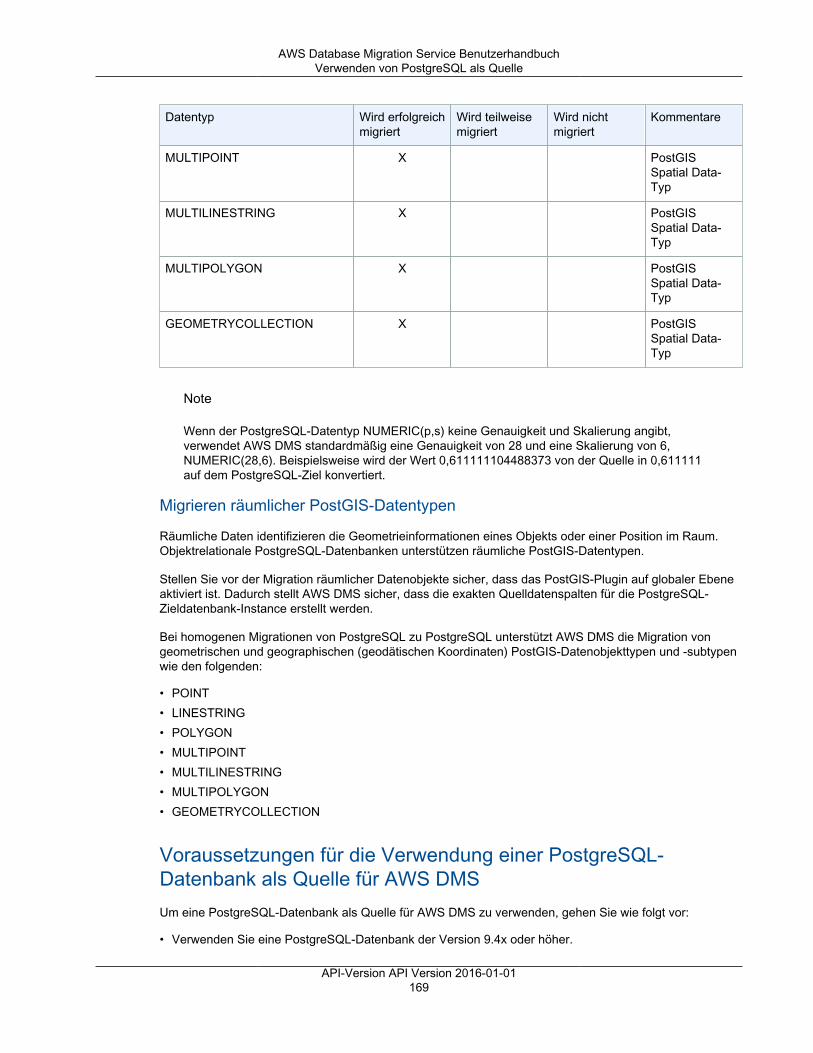
AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
Datentyp Wird erfolgreichmigriert
Wird teilweisemigriert
Wird nichtmigriert
Kommentare
MULTIPOINT X PostGISSpatial Data-Typ
MULTILINESTRING X PostGISSpatial Data-Typ
MULTIPOLYGON X PostGISSpatial Data-Typ
GEOMETRYCOLLECTION X PostGISSpatial Data-Typ
Note
Wenn der PostgreSQL-Datentyp NUMERIC(p,s) keine Genauigkeit und Skalierung angibt,verwendet AWS DMS standardmäßig eine Genauigkeit von 28 und eine Skalierung von 6,NUMERIC(28,6). Beispielsweise wird der Wert 0,611111104488373 von der Quelle in 0,611111auf dem PostgreSQL-Ziel konvertiert.
Migrieren räumlicher PostGIS-Datentypen
Räumliche Daten identifizieren die Geometrieinformationen eines Objekts oder einer Position im Raum.Objektrelationale PostgreSQL-Datenbanken unterstützen räumliche PostGIS-Datentypen.
Stellen Sie vor der Migration räumlicher Datenobjekte sicher, dass das PostGIS-Plugin auf globaler Ebeneaktiviert ist. Dadurch stellt AWS DMS sicher, dass die exakten Quelldatenspalten für die PostgreSQL-Zieldatenbank-Instance erstellt werden.
Bei homogenen Migrationen von PostgreSQL zu PostgreSQL unterstützt AWS DMS die Migration vongeometrischen und geographischen (geodätischen Koordinaten) PostGIS-Datenobjekttypen und -subtypenwie den folgenden:
• POINT• LINESTRING• POLYGON• MULTIPOINT• MULTILINESTRING• MULTIPOLYGON• GEOMETRYCOLLECTION
Voraussetzungen für die Verwendung einer PostgreSQL-Datenbank als Quelle für AWS DMSUm eine PostgreSQL-Datenbank als Quelle für AWS DMS zu verwenden, gehen Sie wie folgt vor:
• Verwenden Sie eine PostgreSQL-Datenbank der Version 9.4x oder höher.
API-Version API Version 2016-01-01169

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
• Erteilen Sie für Full-Load- plus Change Data Capture(CDC)-Aufgaben Superuser-Berechtigungen fürdas Benutzerkonto, das für die PostgreSQL-Quelldatenbank angegeben ist. Superuser-Berechtigungenwerden benötigt, um auf replikationsspezifische Funktionen in der Quelle zuzugreifen. Für Aufgaben mitvoller Last sind SELECT-Berechtigungen für Tabellen erforderlich, um sie zu migrieren.
• Fügen Sie der pg_hba.conf-Konfigurationsdatei die IP-Adresse des AWS DMS-Replikationsservershinzu, und aktivieren Sie Replikations- und Socketverbindungen. Zum Beispiel:
# Replication Instance host all all 12.3.4.56/00 md5 # Allow replication connections from localhost, by a user with the # replication privilege. host replication dms 12.3.4.56/00 md5
Die pg_hba.conf-Konfigurationsdatei von PostgreSQL steuert die Clientauthentifizierung. (HBAsteht für hostbasierte Authentifizierung) Die Datei wird üblicherweise im Datenverzeichnis desDatenbankclusters gespeichert.
• Legen Sie die folgenden Parameter und Werte in der Konfigurationsdatei postgresql.conf fest:• Legen Sie wal_level = logical fest.• Legen Sie für max_replication_slots einen Wert größer als 1 fest.
Der Wert max_replication_slots sollte gemäß der Anzahl der Aufgaben festgelegt werden, dieSie ausführen möchten. Wenn Sie beispielsweise fünf Aufgaben ausführen möchten, müssen Siemindestens fünf Slots festlegen. Slots werden automatisch geöffnet, sobald eine Aufgabe gestartetwird und bleiben geöffnet, selbst wenn die Aufgabe nicht mehr ausgeführt wird. Sie müssen geöffneteSlots manuell löschen.
• Legen Sie für max_wal_senders einen Wert größer als 1 fest.
Der Parameter max_wal_senders legt die Anzahl der Aufgaben fest, die gleichzeitig ausgeführtwerden können.
• Legen Sie wal_sender_timeout =0 fest.
Der Parameter wal_sender_timeout beendet Replikationsverbindungen, die länger als dieangegebene Anzahl von Millisekunden inaktiv sind. Obwohl der Standardwert "60 seconds" ist,empfehlen wir, diesen Parameter auf Null zu setzen, wodurch der Timeout Mechanismus deaktiviertwird.
Note
Einige Parameter können nur beim Serverstart festgelegt werden. Änderungen an ihrenEinträgen in der Konfigurationsdatei werden ignoriert, bis der Server neu gestartet wird. WeitereInformationen finden Sie in der PostgreSQL-Datenbankdokumentation.
• Der Parameter idle_in_transaction_session_timeout in PostgreSQL-Versionen 9.6 und höhergestattet Ihnen, für ungenutzte Transaktionen ein Timeout und ihr Fehlschlagen zu veranlassen. EinigeAWS DMS-Transaktionen sind für einige Zeit im Leerlauf, bevor die AWS DMS-Engine sie erneut nutzt.Beenden Sie Transaktionen im Leerlauf nicht, wenn Sie AWS DMS verwenden.
Sicherheitsanforderungen bei Verwendung einer PostgreSQL-Datenbank als Quelle für AWS DMSDie einzige Sicherheitsanforderung bei der Verwendung von PostgreSQL als Quelle ist, dass dasangegebene Benutzerkonto ein registrierter Benutzer in der PostgreSQL-Datenbank sein muss.
API-Version API Version 2016-01-01170

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
Einschränkungen bei der Verwendung einer PostgreSQL-Datenbank als Quelle für AWS DMSDie folgenden Einschränkungen gelten bei der Verwendung von PostgreSQL als Quelle für AWS DMS:
• AWS DMS funktioniert nicht mit Amazon RDS PostgreSQL 10.4 oder Amazon Aurora PostgreSQL 10.4als Quelle oder Ziel.
• Eine erfasste Tabelle muss über einen Primärschlüssel verfügen. Wenn eine Tabelle nicht über einenPrimärschlüssel verfügt, ignoriert AWS DMS DELETE- und UPDATE-Vorgänge für Datensätze in dieserTabelle.
• Zeitstempel mit Zeitzonentyp-Spalte wird nicht unterstützt.• AWS DMS ignoriert einen Versuch, ein Segment eines Primärschlüssels zu aktualisieren. In diesen
Fällen identifiziert die Zieldatenbank die Aktualisierung als eine, die keine Zeilen aktualisiert hat. Dadie Ergebnisse der Aktualisierung eines Primärschlüssels in PostgreSQL jedoch unvorhersehbar sind,werden keine Datensätze in die Ausnahmetabelle geschrieben.
• AWS DMS unterstützt die Ausführungsoption Start Process Changes from Timestamp(Prozessänderungen von Zeitstempel starten) nicht.
• AWS DMS unterstützt vollständiges Laden und Änderungsverarbeitung auf Amazon RDS fürPostgreSQL. Weitere Informationen zur Vorbereitung einer PostgreSQL-DB-Instance und zu ihrerEinrichtung für CDC finden Sie unter Einrichten einer Amazon RDS PostgreSQL-DB-Instance alsQuelle (p. 172).
• Replikation mehrerer Tabellen mit demselben Namen, wobei sich jedoch jeder Name in Groß/Kleinschreibung unterscheidet (z. B. tabelle1, TABELLE1 und Tabelle1), kann unvorhersehbaresVerhalten verursachen. Aufgrund dieses Problems unterstützt AWS DMS diese Art der Replikation nicht.
• In den meisten Fällen unterstützt AWS DMS Änderungsverarbeitung von CREATE-, ALTER- und DROPDDL-Anweisungen für Tabellen. AWS DMS unterstützt diese Änderungsverarbeitung nicht, wenn dieTabellen in einer inneren Funktion oder einem Procedure-Body-Block oder in anderen verschachteltenKonstrukten gehalten werden.
Die folgende Änderung wird z. B. nicht erfasst:
CREATE OR REPLACE FUNCTION attu.create_distributors1() RETURNS voidLANGUAGE plpgsqlAS $$BEGINcreate table attu.distributors1(did serial PRIMARY KEY,namevarchar(40) NOT NULL);END;$$;
• Derzeit werden boolean-Datentypen in einer PostgreSQL-Quelle als bit-Datentyp mit inkonsistentenWerten zu einem SQLServer-Ziel migriert. Als Problemumgehung erstellen Sie die Tabelle mit einemVARCHAR(1)-Datentyp für die Spalte (oder lassen Sie AWS DMS die Tabelle erstellen), und lassen Siedann die nachgeschaltete Verarbeitung ein „F“ als False und ein „T“ als True behandeln.
• AWS DMS unterstützt die Änderungsverarbeitung von TRUNCATE-Operationen nicht.• Der OID LOB-Datentyp wird nicht auf das Ziel migriert.• Wenn es sich bei Ihrer Quelle um eine lokale oder auf einer Amazon EC2-Instance ausgeführte
PostgreSQL-Datenbank handelt, stellen Sie sicher, dass das test_decoding-Ausgabe-Plug-in aufIhrem Quellendpunkt installiert ist. Sie finden dieses Plug-in im Postgres-Paket "contrib". WeitereInformationen zum Test-Decodier-Plugin finden Sie in der PostgreSQL-Dokumentation.
• AWS DMS unterstützt keine Änderungsverarbeitung zum Festlegen und Aufheben vonSpaltenstandardwerten (mit der Klausel ALTER COLUMN SET DEFAULT in ALTER TABLE-Anweisungen).
API-Version API Version 2016-01-01171

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
• AWS DMS unterstützt keine Änderungsverarbeitung zum Festlegen von NULL-Zulässigkeit der Spalte(mit der Klausel ALTER COLUMN [SET|DROP] NOT NULL in ALTER TABLE-Anweisungen).
• AWS DMS unterstützt die Replikation partitionierter Tabellen nicht. Wenn eine partitionierte Tabelleerkannt wird, geschieht Folgendes:• Der Endpunkt meldet eine Liste von über- und untergeordneten Tabellen.• AWS DMS erstellt die Tabelle auf der Zieldatenbank als eine reguläre Tabelle mit den gleichen
Eigenschaften wie die ausgewählten Tabellen.• Wenn die übergeordnete Tabelle in der Quelldatenbank denselben Primärschlüsselwert wie ihre
untergeordneten Tabellen hat, wird ein "Duplikatschlüssel" generiert.
Note
Um partitionierte Tabellen aus einer PostgreSQL-Quell- auf eine PostgreSQL-Zieldatenbank zureplizieren, müssen Sie zunächst die über- und untergeordneten Tabellen in der Zieldatenbankmanuell erstellen. Anschließend definieren Sie eine separate Aufgabe, um auf diese Tabellen zureplizieren. In solch einem Fall legen Sie die Aufgabenkonfiguration auf Truncate before loadingfest.Note
Der PostgreSQL-Datentyp NUMERIC verfügt über keine feste Größe. Wenn Sie Daten mitdem Datentyp NUMERIC, jedoch ohne Präzision und Skalierung übertagen, verwendet DMSstandardmäßig NUMERIC(28,6) (mit 28 als Genauigkeit und 6 als Skalierung). Beispielsweisewird der Wert 0,611111104488373 von der Quelle auf dem PostgreSQL-Ziel in 0,611111konvertiert.
Einrichten einer Amazon RDS PostgreSQL-DB-Instance alsQuelleSie können einen Amazon RDS für eine PostgreSQL DB-Instance oder Read Replica als Quelle für AWSDMS verwenden. Sie können eine DB-Instance sowohl für Volllastaufgaben als auch für die Change DataCapture (CDC) für die laufende Replikation verwenden. Sie können eine Read Replica nur für Aufgaben mitVolllast und nicht für CDC verwenden.
Sie können das AWS-Masterbenutzerkonto für die PostgreSQL-DB-Instance als das Benutzerkontofür den PostgreSQL-Quellendpunkt für AWS DMS verwenden. Das Masterbenutzerkonto hat dieerforderlichen Rollen für die CDC-Einrichtung. Wenn Sie ein anderes Konto als das Masterbenutzerkontoverwenden, muss das Konto über die Rolle rds_superuser und die Rolle rds_replication verfügen. Die Rollerds_replication erteilt Berechtigungen zur Verwaltung von logischen Slots und zum Streamen von Datenmithilfe von logischen Slots.
Wenn Sie das Masterbenutzerkonto für die DB-Instance nicht verwenden, müssen Sie von demMasterbenutzerkonto aus mehrere Objekte für das Konto erstellen, das Sie verwenden. WeitereInformationen zum Erstellen der benötigten Objekte finden Sie unter Migrieren eines Amazon RDS fürPostgreSQL-Datenbank ohne Verwendung des Masterbenutzerkontos (p. 174).
Verwenden von CDC mit einer RDS für PostgreSQL-DB-InstanceSie können die native Funktion zur logischen Replikation von PostgreSQL verwenden, um CDC währendeiner Datenbankmigration einer Amazon RDS für die PostgreSQL DB-Instance zu aktivieren. Dieser Ansatzreduziert Ausfallzeiten und stellt sicher, dass die Zieldatenbank mit der PostgreSQL-Quelldatenbanksynchronisiert ist. Amazon RDS unterstützt die logische Replikation für eine PostgreSQL-DB-Instance derVersion 9.4.9 und höher sowie 9.5.4 und höher.
Note
Sie können Amazon RDSnicht für PostgreSQL Read Replicas für CDC (laufende Replikation)verwenden.
API-Version API Version 2016-01-01172

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
So aktivieren Sie die logische Replikation für eine RDS PostgreSQL DB-Instance
1. Verwenden Sie das AWS-Masterbenutzerkonto für die PostgreSQL-DB-Instance als dasBenutzerkonto für den PostgreSQL-Quellendpunkt. Das Masterbenutzerkonto hat die erforderlichenRollen für die CDC-Einrichtung.
Wenn Sie ein anderes als das Masterbenutzerkonto verwenden, müssen Sie von demMasterbenutzerkonto aus mehrere Objekte für das Konto erstellen, das Sie verwenden. WeitereInformationen finden Sie unter Migrieren eines Amazon RDS für PostgreSQL-Datenbank ohneVerwendung des Masterbenutzerkontos (p. 174).
2. Legen Sie den Parameter rds.logical_replication in der DB-Parametergruppe auf 1fest. Für das Wirksamwerden dieses statischen Parameters ist ein Neustart der DB-Instanceerforderlich. Im Rahmen der Anwendung dieses Parameters legt AWS DMS die Parameterwal_level, max_wal_senders, max_replication_slots und max_connections fest.Diese Parameteränderungen können die WAL-Erzeugung (Write Ahead Log) erhöhen. Setzen Sierds.logical_replication also nur, wenn Sie logische Replikationsslots verwenden.
3. Bewährte Praxis ist es, den wal_sender_timeout-Parameter auf 0 zu setzen. Wenn dieserParameter auf 0 eingestellt wird, wird PostgreSQL dadurch daran gehindert, Replikationsverbindungenzu beenden, die länger als das angegebene Timeout inaktiv sind. Wenn AWS DMS Daten migriert,müssen Replikation-Verbindungen länger als das angegebene Timeout andauern können.
4. Aktivieren Sie native CDC-Startpunkte mit PostgreSQL als Quelle, indem Sie das zusätzlicheVerbindungsattribut slotName auf den Namen eines vorhandenen logischen Replikations-Slotssetzen, wenn Sie den Endpunkt erstellen. Dieser logische Replikations-Slot enthält laufendeÄnderungen ab dem Zeitpunkt der Erstellung des Endpunkts und unterstützt somit die Replikation abeinem früheren Zeitpunkt.
PostgreSQL schreibt die Datenbankänderungen in WAL-Dateien, die nur verworfen werden, nachdemein AWS DMS erfolgreich Änderungen aus dem logischen Replikations-Slot gelesen hat. Durch dieVerwendung von logischen Replikations-Slots können protokollierte Änderungen vor dem Löschengeschützt werden, bevor sie vom Replikationsmodul verwendet werden.
Je nach Änderungsrate und Verbrauch können Änderungen in einem logischen Replikations-Slot jedoch zu einer erhöhten Festplattennutzung führen. Es wird empfohlen, dass SieSpeicherplatznutzungsalarme in der PostgreSQL-Quellinstance festlegen, wenn logische Replikations-Slots verwendet werden. Weitere Informationen zur Einstellung des zusätzlichen VerbindungsattributsslotName finden Sie unter Zusätzliche Verbindungsattribute bei der Verwendung von PostgreSQL alsQuelle für AWS DMS (p. 178).
Note
Die Verwendung von nativen CDC-Startpunkten mit PostgreSQL als Quelle ist in AWS DMS-Versionen 3.1.0 und höher verfügbar.
Im folgenden Verfahren wird dieser Ansatz näher erläutert.
So verwenden Sie einen systemeigenen CDC-Startpunkt zum Einrichten einer CDC-Last einesPostgreSQL-Quellendpunkts:
1. Identifizieren Sie den logischen Replikations-Slot, der von einer früheren Replikationsaufgabe (einerübergeordneten Aufgabe) verwendet wird, die Sie als Startpunkt verwenden möchten. Fragen Sie danndie pg_replication_slots-Ansicht der Quelldatenbank ab, um sicherzustellen, dass dieser Slotüber keine aktiven Verbindungen verfügt. Wenn dies doch der Fall ist, lösen Sie sie auf und beendenSie sie, bevor Sie fortfahren.
Für die folgenden Schritte gehen Sie davon aus, dass Ihr logischer Replikations-Slotabc1d2efghijk_34567890_z0yx98w7_6v54_32ut_1srq_1a2b34c5d67ef ist.
API-Version API Version 2016-01-01173

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
2. Erstellen Sie einen neuen Quellendpunkt, der die folgenden zusätzlichenVerbindungsattributeinstellungen enthält.
slotName=abc1d2efghijk_34567890_z0yx98w7_6v54_32ut_1srq_1a2b34c5d67ef;
3. Erstellen Sie eine neue Nur-CDC-Aufgabe mithilfe der AWS DMS-API oder CLI. Mit der CLI könnenSie beispielsweise den folgenden create-replication-task-Befehl ausführen.
AWS DMS unterstützt derzeit nicht das Erstellen einer CDC-Aufgabe mit einem nativen Startpunktmithilfe der Konsole.
aws dms create-replication-task --replication-task-identifier postgresql-slot-name-test --source-endpoint-arn arn:aws:dms:us-west-2:012345678901:endpoint:ABCD1EFGHIJK2LMNOPQRST3UV4 --target-endpoint-arn arn:aws:dms:us-west-2:012345678901:endpoint:ZYX9WVUTSRQONM8LKJIHGF7ED6 --replication-instance-arn arn:aws:dms:us-west-2:012345678901:rep:AAAAAAAAAAA5BB4CCC3DDDD2EE --migration-type cdc --table-mappings "file://mappings.json" --cdc-start-position "4AF/B00000D0" --replication-task-settings "file://task-pg.json"
Im vorhergehenden Befehl werden die folgenden Optionen festgelegt:
• source-endpoint-arn ist auf den neuen Wert festgelegt, den Sie in Schritt 2 erstellt haben.• replication-instance-arn ist auf den gleichen Wert wie für die übergeordnete Aufgabe aus
Schritt 1 festgelegt.• table-mappings und replication-task-settings sind auf die gleichen Werte wie für die
übergeordnete Aufgabe aus Schritt 1 festgelegt.• cdc-start-position ist auf einen Startpositionswert festgelegt. Um diese Startposition zu finden,
fragen Sie entweder die pg_replication_slots-Ansicht Ihrer Quelldatenbank ab oder sehen Siesich die Konsolendetails für die übergeordnete Aufgabe in Schritt 1 an. Weitere Informationen findenSie unter Bestimmen eines nativen CDC-Startpunkts (p. 364).
Wenn diese CDC-Aufgabe ausgeführt wird, löst AWS DMS einen Fehler aus, wenn der angegebenelogische Replikations-Slot nicht vorhanden ist oder die Aufgabe nicht mit einer gültigen Einstellung fürcdc-start-position erstellt wurde.
Migrieren eines Amazon RDS für PostgreSQL-Datenbank ohne Verwendung desMasterbenutzerkontos
Unter Umständen können Sie das Masterbenutzerkonto für die Amazon RDS-PostgreSQL-DB-Instance, dieSie als Quelle verwenden, nicht nutzen. In diesen Fällen müssen Sie mehrere Objekte erstellen, um DDL-Ereignisse (Data Definition Language) zu erfassen. Sie erstellen diese Objekte in dem Konto, das nicht dasMasterkonto ist, und dann erstellen Sie einen Auslöser im Masterbenutzerkonto.
Note
Wenn Sie das zusätzliche Verbindungsattribut captureDDLs am Quellendpunkt auf N festlegen,müssen Sie folgende Tabelle und den folgenden Auslöser in der Quelldatenbank nicht erstellen.
Gehen Sie wie folgt vor, um diese Objekte zu erstellen. Das Benutzerkonto, das nicht das Masterkonto ist,wird in diesem Verfahren als NoPriv-Konto bezeichnet.
API-Version API Version 2016-01-01174

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
So erstellen Sie Objekte
1. Wählen Sie das Schema aus, in dem die Objekte erstellt werden sollen. Das Standardschema istpublic. Stellen Sie sicher, dass das Schema vorhanden ist und dass das NoPriv-Konto daraufzugreifen kann.
2. Melden Sie sich mit dem NoPriv-Konto bei der PostgreSQL-DB-Instance an.3. Erstellen Sie die Tabelle awsdms_ddl_audit, indem Sie den folgenden Befehl ausführen und dabei
objects_schema im folgenden Code durch den Namen des zu verwendenden Schemas ersetzen.
create table objects_schema.awsdms_ddl_audit( c_key bigserial primary key, c_time timestamp, -- Informational c_user varchar(64), -- Informational: current_user c_txn varchar(16), -- Informational: current transaction c_tag varchar(24), -- Either 'CREATE TABLE' or 'ALTER TABLE' or 'DROP TABLE' c_oid integer, -- For future use - TG_OBJECTID c_name varchar(64), -- For future use - TG_OBJECTNAME c_schema varchar(64), -- For future use - TG_SCHEMANAME. For now - holds current_schema c_ddlqry text -- The DDL query associated with the current DDL event)
4. Erstellen Sie die Funktion awsdms_intercept_ddl, indem Sie den folgenden Befehl ausführenund dabei objects_schema im folgenden Code durch den Namen des zu verwendenden Schemasersetzen.
CREATE OR REPLACE FUNCTION objects_schema.awsdms_intercept_ddl() RETURNS event_triggerLANGUAGE plpgsqlSECURITY DEFINER AS $$ declare _qry text;BEGIN if (tg_tag='CREATE TABLE' or tg_tag='ALTER TABLE' or tg_tag='DROP TABLE') then SELECT current_query() into _qry; insert into objects_schema.awsdms_ddl_audit values ( default,current_timestamp,current_user,cast(TXID_CURRENT()as varchar(16)),tg_tag,0,'',current_schema,_qry ); delete from objects_schema.awsdms_ddl_audit;end if;END;$$;
5. Melden Sie sich vom NoPriv-Konto ab und melden Sie sich mit einem Konto an, dem dierds_superuser-Rolle zugewiesen ist.
6. Erstellen Sie den Ereignisauslöser awsdms_intercept_ddl, indem Sie den folgenden Befehlausführen.
CREATE EVENT TRIGGER awsdms_intercept_ddl ON ddl_command_end EXECUTE PROCEDURE objects_schema.awsdms_intercept_ddl();
API-Version API Version 2016-01-01175

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
Wenn Sie das vorangegangene Verfahren ausgeführt haben, können Sie den AWS DMS-Quellendpunktmithilfe des NoPriv-Kontos erstellen.
Entfernen von AWS DMS-Artefakten aus einer PostgreSQL-QuelldatenbankUm DDL-Ereignisse zu erfassen, erstellt AWS DMS in der PostgreSQL-Datenbank verschiedene Artefakte,wenn eine Migrationsaufgabe gestartet wird. Wenn die Aufgabe abgeschlossen ist, können Sie dieseArtefakte entfernen. Entfernen Sie die Artefakte, indem Sie die folgenden Anweisungen ausgeben (in derReihenfolge, in der sie erscheinen), wobei {AmazonRDSMigration} das Schema ist, in dem die Artefakteerstellt wurden:
drop event trigger awsdms_intercept_ddl;
Der Ereignisauslöser gehört nicht zu einem bestimmten Schema.
drop function {AmazonRDSMigration}.awsdms_intercept_ddl()drop table {AmazonRDSMigration}.awsdms_ddl_auditdrop schema {AmazonRDSMigration}
Note
Ein Schema sollte nur mit extremer Vorsicht gelöscht werden, falls überhaupt. Löschen Sie nie einSchema, das in Betrieb ist, besonders kein öffentliches.
Zusätzliche Konfigurationseinstellungen bei der Verwendungeiner PostgreSQL-Datenbank als Quelle für AWS DMSSie können zusätzliche Konfigurationseinstellungen für die Migration von Daten aus einer PostgreSQL-Datenbank auf zwei Weisen hinzufügen:
• Sie können dem Attribut "Extra Connection" Werte hinzufügen, um DDL-Ereignisse zu erfassen undum das Schema anzugeben, in dem die betrieblichen DDL-Datenbankartefakte erstellt werden. WeitereInformationen finden Sie unter Zusätzliche Verbindungsattribute bei der Verwendung von PostgreSQL alsQuelle für AWS DMS (p. 178).
• Sie können Verbindungszeichenfolgenparameter außer Kraft setzen. Wählen Sie diese Option, wenn Sieeines der Folgenden tun müssen:• Interne AWS DMS-Parameter angeben. Solche Parameter sind selten erforderlich und werden daher
nicht auf der Benutzeroberfläche angezeigt.• Geben Sie Pass-Through-Werte (passthru) für den spezifischen Datenbank-Client an. AWS DMS fügt
Pass-Through-Parameter in die Verbindungszeichenfolge ein, die an den Datenbank-Client übergebenwird.
Verwenden von PostgreSQL-Version 10.x als Quelle für AWSDMSDie PostgreSQL-Datenbanken der Version 10.x und höher weisen im Vergleich zu früheren PostgreSQL-Versionen zahlreiche Änderungen bei Funktions- und Ordnernamen auf. Aufgrund dieser Änderungen sindeinige Migrationsaktionen bei Verwendung mit AWS DMS-Versionen vor 3.3.1 nicht abwärtskompatibel.
API-Version API Version 2016-01-01176

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
Note
Wenn Sie eine PostgreSQL 10.x-Datenbank als Quelle für AWS DMS 3.3.1 oder höherverwenden, führen Sie die nachfolgend beschriebenen Vorbereitungen nicht aus. Sie können diePostgreSQL-Quelle ohne zusätzliche Vorbereitung verwenden.
Da die meisten Namensänderungen nur oberflächlich sind, hat AWS DMS Wrapper-Funktionen erstellt, mitderen Hilfe AWS DMS die PostgreSQL-Versionen 10.x verwenden kann. Die Wrapper-Funktionen habeneine höhere Priorität als Funktionen in pg_catalog. Des Weiteren stellen wir sicher, dass die Schema-Sichtbarkeit vorhandener Schemata nicht geändert wird, damit wir keine anderen Systemkatalogfunktionen(wie z. B. benutzerdefinierte Funktionen) außer Kraft setzen.
Wenn Sie diese Wrapper-Funktionen verwenden möchten, bevor Sie Migrationsaufgaben ausführen,verwenden Sie dasselbe AWS DMS-Benutzerkonto (user_name), das Sie zum Erstellen desQuellendpunkts verwendet haben. Um diese Wrapper-Funktionen zu definieren und diesem Kontozuzuordnen, führen Sie den folgenden SQL-Code für die PostgreSQL-Quelldatenbank aus.
BEGIN;CREATE SCHEMA IF NOT EXISTS fnRenames;CREATE OR REPLACE FUNCTION fnRenames.pg_switch_xlog() RETURNS pg_lsn AS $$ SELECT pg_switch_wal(); $$ LANGUAGE SQL;CREATE OR REPLACE FUNCTION fnRenames.pg_xlog_replay_pause() RETURNS VOID AS $$ SELECT pg_wal_replay_pause(); $$ LANGUAGE SQL;CREATE OR REPLACE FUNCTION fnRenames.pg_xlog_replay_resume() RETURNS VOID AS $$ SELECT pg_wal_replay_resume(); $$ LANGUAGE SQL;CREATE OR REPLACE FUNCTION fnRenames.pg_current_xlog_location() RETURNS pg_lsn AS $$ SELECT pg_current_wal_lsn(); $$ LANGUAGE SQL;CREATE OR REPLACE FUNCTION fnRenames.pg_is_xlog_replay_paused() RETURNS boolean AS $$ SELECT pg_is_wal_replay_paused(); $$ LANGUAGE SQL;CREATE OR REPLACE FUNCTION fnRenames.pg_xlogfile_name(lsn pg_lsn) RETURNS TEXT AS $$ SELECT pg_walfile_name(lsn); $$ LANGUAGE SQL;CREATE OR REPLACE FUNCTION fnRenames.pg_last_xlog_replay_location() RETURNS pg_lsn AS $$ SELECT pg_last_wal_replay_lsn(); $$ LANGUAGE SQL;CREATE OR REPLACE FUNCTION fnRenames.pg_last_xlog_receive_location() RETURNS pg_lsn AS $$ SELECT pg_last_wal_receive_lsn(); $$ LANGUAGE SQL;CREATE OR REPLACE FUNCTION fnRenames.pg_current_xlog_flush_location() RETURNS pg_lsn AS $$ SELECT pg_current_wal_flush_lsn(); $$ LANGUAGE SQL;CREATE OR REPLACE FUNCTION fnRenames.pg_current_xlog_insert_location() RETURNS pg_lsn AS $$ SELECT pg_current_wal_insert_lsn(); $$ LANGUAGE SQL;CREATE OR REPLACE FUNCTION fnRenames.pg_xlog_location_diff(lsn1 pg_lsn, lsn2 pg_lsn) RETURNS NUMERIC AS $$ SELECT pg_wal_lsn_diff(lsn1, lsn2); $$ LANGUAGE SQL;CREATE OR REPLACE FUNCTION fnRenames.pg_xlogfile_name_offset(lsn pg_lsn, OUT TEXT, OUT INTEGER) AS $$ SELECT pg_walfile_name_offset(lsn); $$ LANGUAGE SQL;CREATE OR REPLACE FUNCTION fnRenames.pg_create_logical_replication_slot(slot_name name, plugin name, temporary BOOLEAN DEFAULT FALSE, OUT slot_name name, OUT xlog_position pg_lsn) RETURNS RECORD AS $$ SELECT slot_name::NAME, lsn::pg_lsn FROM pg_catalog.pg_create_logical_replication_slot(slot_name, plugin, temporary); $$ LANGUAGE SQL;ALTER USER user_name SET search_path = fnRenames, pg_catalog, "$user", public;
-- DROP SCHEMA fnRenames CASCADE;-- ALTER USER PG_User SET search_path TO DEFAULT;COMMIT;
API-Version API Version 2016-01-01177

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
Note
Wenn Sie in einer PostgreSQL 10.x-Datenbank diesen vorbereitenden Code für AWS DMS-Versionen vor 3.3.1 nicht ausführen, wird Ihnen eine Fehlermeldung wie die folgende angezeigt.
2018-10-29T02:57:50 [SOURCE_CAPTURE ]E: RetCode: SQL_ERROR SqlState: 42703 NativeError: 1 Message: ERROR: column "xlog_position" does not exist;, No query has been executed with that handle [1022502] (ar_odbc_stmt.c:3647)
Führen Sie die folgenden Schritte aus, nachdem Sie Ihre AWS DMS-Version auf 3.3.1 oder höheraktualisiert haben:
1. Entfernen Sie die fnRenames-Referenz von der ALTER USER-Anweisung, mit der Sie den PostgreSQL-Quell-10.x Konfigurationssuchpfad festlegen.
2. Löschen Sie das fnRenames-Schema aus Ihrer PostgreSQL-Datenbank.
Wenn Sie diese Schritte nach der Aktualisierung nicht befolgen, wird Ihnen beim Zugriff auf dasfnRenames-Schema die folgende Fehlermeldung im Protokoll angezeigt:
RetCode: SQL_ERROR SqlState: 42703 NativeError: 1 Message: ERROR: column "lsn" does not exist;
Wenn AWS DMS ein Nicht-Master-Benutzerkonto für die Datenbank verwendet, müssen Sie auchbestimmte Berechtigungen für den Zugriff auf diese Wrapper-Funktionen mit PostgreSQL 10.x-Quelldatenbanken festlegen. Um diese Berechtigungen festzulegen, führen Sie die folgendenZuwendungen aus.
GRANT USAGE ON SCHEMA fnRenames TO dms_superuser;GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA fnRenames TO dms_superuser;
Weitere Hinweise zur Verwendung von Nicht-Master-Benutzerkonten mit einer PostgreSQL 10.x-Quelldatenbank finden Sie unter Migrieren eines Amazon RDS für PostgreSQL-Datenbank ohneVerwendung des Masterbenutzerkontos (p. 174).
Zusätzliche Verbindungsattribute bei der Verwendung vonPostgreSQL als Quelle für AWS DMSSie können zusätzliche Verbindungsattribute verwenden, um Ihre PostgreSQL-Quelle zu konfigurieren.Sie geben diese Einstellungen beim Erstellen des Quellendpunkts an. Wenn Sie mehrereVerbindungsattributeinstellungen verwenden, trennen Sie diese durch Semikola und ohne zusätzlicheLeerräume voneinander (z. B. oneSetting;thenAnother).
Die folgende Tabelle zeigt die zusätzlichen Verbindungsattribute, die Sie verwenden können, umPostgreSQL als Quelle für AWS DMS zu konfigurieren.
Attributname Beschreibung
captureDDLs Um DDL-Ereignisse zu erfassen, erstellt AWS DMS in derPostgreSQL-Datenbank verschiedene Artefakte, wenndie Aufgabe gestartet wird. Sie können diese Artefaktezu einem späteren Zeitpunkt entfernen, wie im Abschnitt
API-Version API Version 2016-01-01178

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
Attributname BeschreibungEntfernen von AWS DMS-Artefakten aus einer PostgreSQL-Quelldatenbank (p. 176) beschrieben.
Wenn dieser Wert auf N gesetzt wird, müssen Sie für dieQuelldatenbank keine Tabellen/Auslöser erstellen. WeitereInformationen finden Sie unter Migrieren eines AmazonRDS für PostgreSQL-Datenbank ohne Verwendung desMasterbenutzerkontos (p. 174).
Gestreamte DDL-Ereignisse werden erfasst.
Standardwert: Y
Zulässige Werte: Y/N
Beispiel: captureDDLs=Y;
ddlArtifactsSchema Das Schema, in dem die operativen DDL-Datenbankartefakteerstellt werden.
Standardwert: öffentlich
Zulässige Werte: Zeichenfolge
Beispiel: ddlArtifactsSchema=xyzddlschema;
failTasksOnLobTruncation Mit der Einstellung true bewirkt dieser Wert, dass eineAufgabe fehlschlägt, wenn die tatsächliche Größe einer LOB-Spalte größer als der angegebene LobMaxSize-Wert ist.
Wenn die Aufgabe auf den eingeschränkten LOB-Modusfestgelegt ist und diese Option auf "true" festgelegt wurde,schlägt die Aufgabe fehl, anstatt LOB-Daten zu kürzen.
Standardwert: false
Zulässige Werte: Boolesch
Beispiel: failTasksOnLobTruncation=true;
executeTimeout Stellt die Zeitbeschränkung der Client-Anweisung für diePostgreSQL-Instance in Sekunden ein. Der Standardwert liegtbei 60 Sekunden.
Beispiel: executeTimeout=100;
API-Version API Version 2016-01-01179
AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
Attributname Beschreibung
slotName Legt den Namen eines zuvor erstellten logischenReplikations-Slots für eine CDC-Last der PostgreSQL-Quell-Instance fest.
Bei Verwendung mit dem AWS DMS-APICdcStartPosition-Anforderungsparameter ermöglichtdieses Attribut auch die Verwendung nativer CDC-Startpunkte. Das DMS überprüft, ob der angegebenelogische Replikations-Slot vorhanden ist, bevor dieAufgabe für das CDC-Laden gestartet wird. Es wird auchüberprüft, ob die Aufgabe mit einer gültigen Einstellungvon CdcStartPosition erstellt wurde. Wenn derangegebene Slot nicht existiert oder die Aufgabe keine gültigeCdcStartPosition-Einstellung besitzt, löst DMS einenFehler aus.
Weitere Informationen darüber, wie DMS logischeReplikations-Slots verwendet, um CDC-Ladevorgänge fürPostgreSQL zu starten, finden Sie unter Verwenden vonCDC mit einer RDS für PostgreSQL-DB-Instance (p. 172).Weitere Informationen zu den Einstellungen für denCdcStartPosition-Anforderungsparameter finden Sieunter Bestimmen eines nativen CDC-Startpunkts (p. 364).Weitere Informationen über das Verwenden derCdcStartPosition finden Sie in der Dokumentation für dieCreateReplicationTask-, StartReplicationTask-und die ModifyReplicationTask-API-Operationen in derAWS Database Migration Service API Reference.
Zulässige Werte: Zeichenfolge
Beispiel:slotName=abc1d2efghijk_34567890_z0yx98w7_6v54_32ut_1srq_1a2b34c5d67ef;
Quelldatentypen für PostgreSQLIn der folgenden Tabelle sind die PostgreSQL-Quelldatentypen, die bei Verwendung von AWS DMSunterstützt werden, sowie deren Standardzuweisung zu AWS DMS-Datentypen aufgeführt.
Weitere Informationen zum Anzeigen des Datentyps, der im Ziel zugewiesen ist, finden Sie im Abschnitt fürden Zielendpunkt, den Sie verwenden.
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
PostgreSQL-Datentyp AWS DMS-Datentypen
INTEGER INT4
SMALLINT INT2
BIGINT INT8
NUMERIC (p,s) Wenn die Präzision 0 bis 38 ist, verwenden SieNUMERIC.
API-Version API Version 2016-01-01180
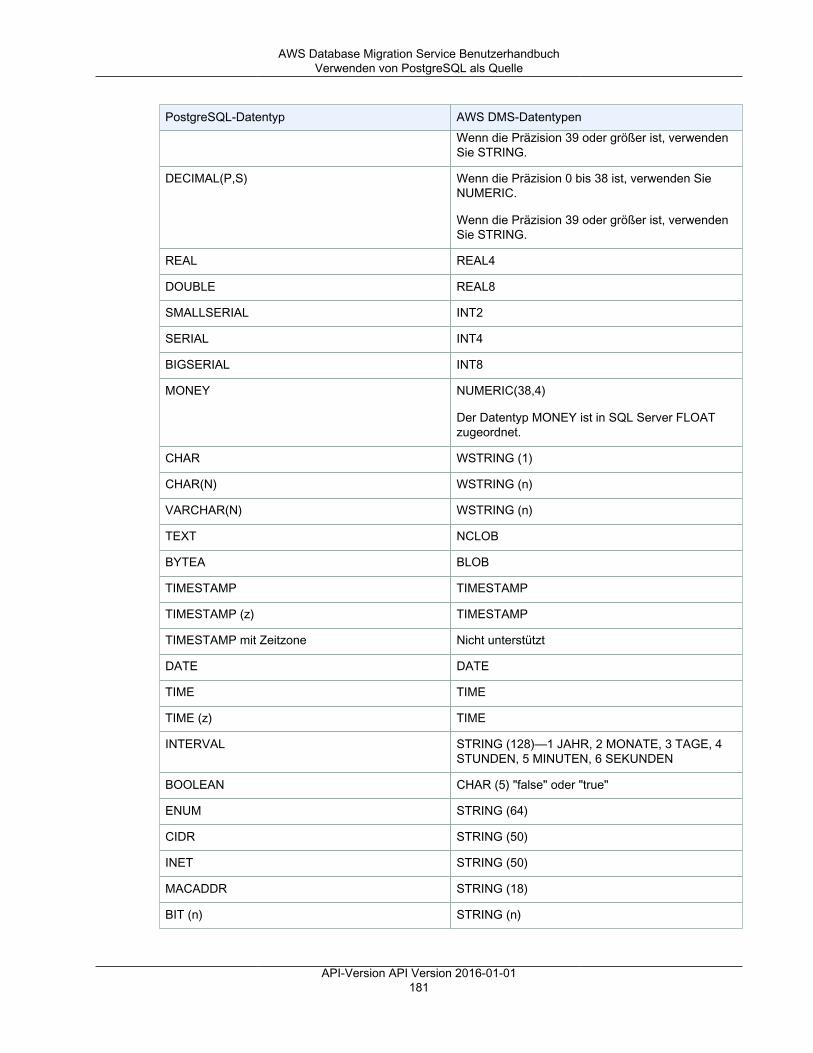
AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
PostgreSQL-Datentyp AWS DMS-DatentypenWenn die Präzision 39 oder größer ist, verwendenSie STRING.
DECIMAL(P,S) Wenn die Präzision 0 bis 38 ist, verwenden SieNUMERIC.
Wenn die Präzision 39 oder größer ist, verwendenSie STRING.
REAL REAL4
DOUBLE REAL8
SMALLSERIAL INT2
SERIAL INT4
BIGSERIAL INT8
MONEY NUMERIC(38,4)
Der Datentyp MONEY ist in SQL Server FLOATzugeordnet.
CHAR WSTRING (1)
CHAR(N) WSTRING (n)
VARCHAR(N) WSTRING (n)
TEXT NCLOB
BYTEA BLOB
TIMESTAMP TIMESTAMP
TIMESTAMP (z) TIMESTAMP
TIMESTAMP mit Zeitzone Nicht unterstützt
DATE DATE
TIME TIME
TIME (z) TIME
INTERVAL STRING (128)—1 JAHR, 2 MONATE, 3 TAGE, 4STUNDEN, 5 MINUTEN, 6 SEKUNDEN
BOOLEAN CHAR (5) "false" oder "true"
ENUM STRING (64)
CIDR STRING (50)
INET STRING (50)
MACADDR STRING (18)
BIT (n) STRING (n)
API-Version API Version 2016-01-01181
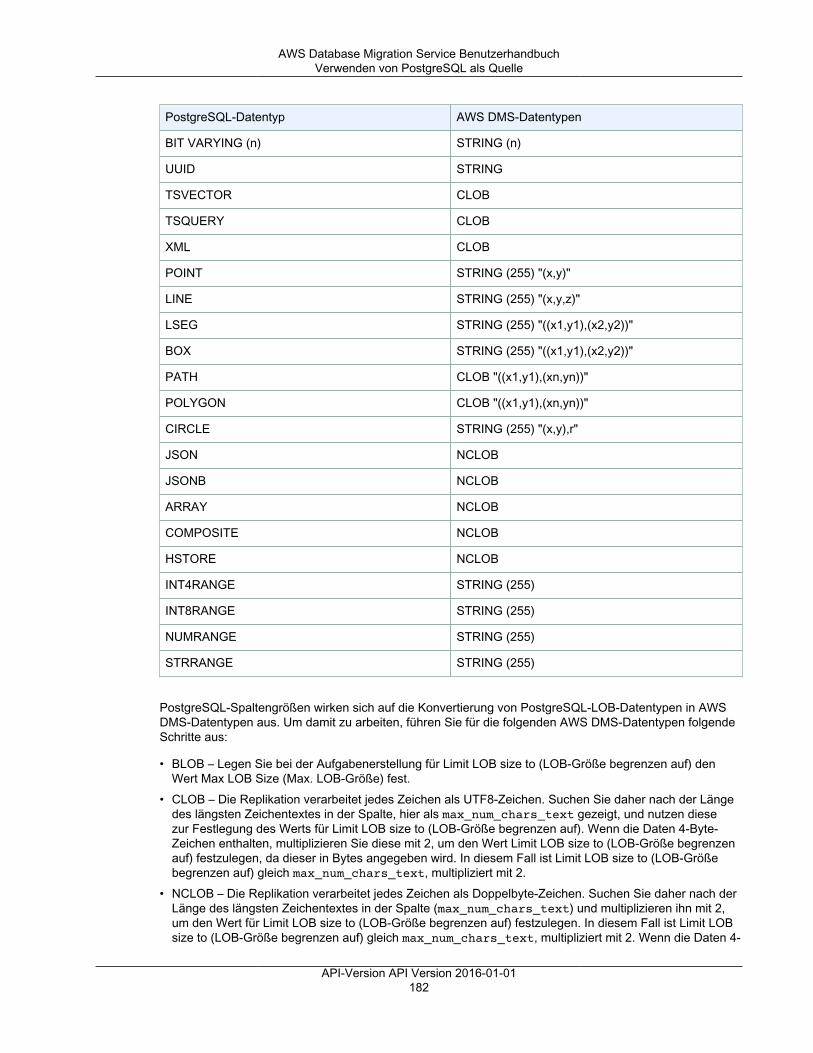
AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Quelle
PostgreSQL-Datentyp AWS DMS-Datentypen
BIT VARYING (n) STRING (n)
UUID STRING
TSVECTOR CLOB
TSQUERY CLOB
XML CLOB
POINT STRING (255) "(x,y)"
LINE STRING (255) "(x,y,z)"
LSEG STRING (255) "((x1,y1),(x2,y2))"
BOX STRING (255) "((x1,y1),(x2,y2))"
PATH CLOB "((x1,y1),(xn,yn))"
POLYGON CLOB "((x1,y1),(xn,yn))"
CIRCLE STRING (255) "(x,y),r"
JSON NCLOB
JSONB NCLOB
ARRAY NCLOB
COMPOSITE NCLOB
HSTORE NCLOB
INT4RANGE STRING (255)
INT8RANGE STRING (255)
NUMRANGE STRING (255)
STRRANGE STRING (255)
PostgreSQL-Spaltengrößen wirken sich auf die Konvertierung von PostgreSQL-LOB-Datentypen in AWSDMS-Datentypen aus. Um damit zu arbeiten, führen Sie für die folgenden AWS DMS-Datentypen folgendeSchritte aus:
• BLOB – Legen Sie bei der Aufgabenerstellung für Limit LOB size to (LOB-Größe begrenzen auf) denWert Max LOB Size (Max. LOB-Größe) fest.
• CLOB – Die Replikation verarbeitet jedes Zeichen als UTF8-Zeichen. Suchen Sie daher nach der Längedes längsten Zeichentextes in der Spalte, hier als max_num_chars_text gezeigt, und nutzen diesezur Festlegung des Werts für Limit LOB size to (LOB-Größe begrenzen auf). Wenn die Daten 4-Byte-Zeichen enthalten, multiplizieren Sie diese mit 2, um den Wert Limit LOB size to (LOB-Größe begrenzenauf) festzulegen, da dieser in Bytes angegeben wird. In diesem Fall ist Limit LOB size to (LOB-Größebegrenzen auf) gleich max_num_chars_text, multipliziert mit 2.
• NCLOB – Die Replikation verarbeitet jedes Zeichen als Doppelbyte-Zeichen. Suchen Sie daher nach derLänge des längsten Zeichentextes in der Spalte (max_num_chars_text) und multiplizieren ihn mit 2,um den Wert für Limit LOB size to (LOB-Größe begrenzen auf) festzulegen. In diesem Fall ist Limit LOBsize to (LOB-Größe begrenzen auf) gleich max_num_chars_text, multipliziert mit 2. Wenn die Daten 4-
API-Version API Version 2016-01-01182

AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Quelle
Byte-Zeichen enthalten, multiplizieren Sie diese erneut mit 2. In diesem Fall ist Limit LOB size to (LOB-Größe begrenzen auf) gleich max_num_chars_text, multipliziert mit 4.
Verwenden einer MySQL-kompatiblen Datenbank alsQuelle für AWS DMSSie können Daten aus jeder MySQL-kompatiblen Datenbank (MySQL, MariaDB oder Amazon AuroraMySQL) mit AWS Database Migration Service migrieren. MySQL-Versionen 5.5, 5.6 und 5.7. MariaDB-Versionen 10.0.24 bis 10.0.28, 10.1 und 10.2 sowie Amazon Aurora MySQL werden vor Ort unterstützt.
Sie können mit SSL Verbindungen zwischen Ihrem MySQL-kompatiblen Endpunkt und der Replikations-Instance verschlüsseln. Weitere Informationen zur Verwendung von SSL mit einem MySQL-kompatiblenEndpunkt finden Sie unter Verwenden von SSL mit AWS Database Migration Service (p. 82).
In den folgenden Abschnitten bezieht sich der Begriff "selbstverwaltet" auf jede Datenbank, die entwederlokal oder auf Amazon EC2 installiert ist. Der Begriff „von Amazon verwaltet“ gilt für jede Datenbank aufAmazon RDS, Amazon Aurora oder Amazon S3.
Weitere Informationen zum Arbeiten mit MySQL-kompatiblen Datenbanken und AWS DMS finden Sie inden folgenden Abschnitten.
Themen• Migrieren von MySQL auf MySQL mit AWS DMS (p. 183)• Verwenden einer beliebigen MySQL-kompatiblen Datenbank als Quelle für AWS DMS (p. 185)• Verwenden einer selbstverwalteten MySQL-kompatiblen Datenbank als Quelle für AWS DMS (p. 186)• Verwenden einer von Amazon verwalteten MySQL-kompatiblen Datenbank als Quelle für AWS
DMS (p. 187)• Einschränkungen bei der Verwendung einer MySQL-Datenbank als Quelle für AWS DMS (p. 187)• Zusätzliche Verbindungsattribute bei der Verwendung von MySQL als Quelle für AWS DMS (p. 188)• Quelldatentypen für MySQL (p. 189)
Migrieren von MySQL auf MySQL mit AWS DMSFür eine heterogene Migration, bei der Sie von einer anderen Datenbank-Engine als MySQL auf eineMySQL-Datenbank migrieren, eignet sich AWS DMS fast immer ideal als Migrationstool. Wenn Sie jedocheine homogene Migration durchführen möchten, bei der Sie aus einer MySQL-Datenbank auf eine MySQL-Datenbank migrieren, können native Tools effektiver sein.
Unter den folgenden Bedingungen empfehlen wir Ihnen die Verwendung von nativen MySQL-Datenbank-Migrationstools wie mysqldump:
• Sie möchten eine homogene Migration durchführen, bei der die MySQL-Ausgangsdatenbank auf eineMySQL-Zieldatenbank migriert werden soll.
• Sie möchten eine komplette Datenbank migrieren.• Die nativen Tools erlauben Ihnen, Ihre Daten mit einer minimalen Ausfallzeit zu migrieren.
Sie können Daten aus einer vorhandenen MySQL- oder MariaDB-Datenbank in eine Amazon RDS MySQL-oder MariaDB-DB-Instance importieren. Zu diesem Zweck kopieren Sie die Datenbank mit mysqldumpund importieren sie direkt in die Amazon RDS-MySQL- oder MariaDB-DB-Instance. Das Befehlszeilen-Hilfsprogramm mysqldump wird üblicherweise verwendet, um Backups zu erstellen und Daten aus einem
API-Version API Version 2016-01-01183
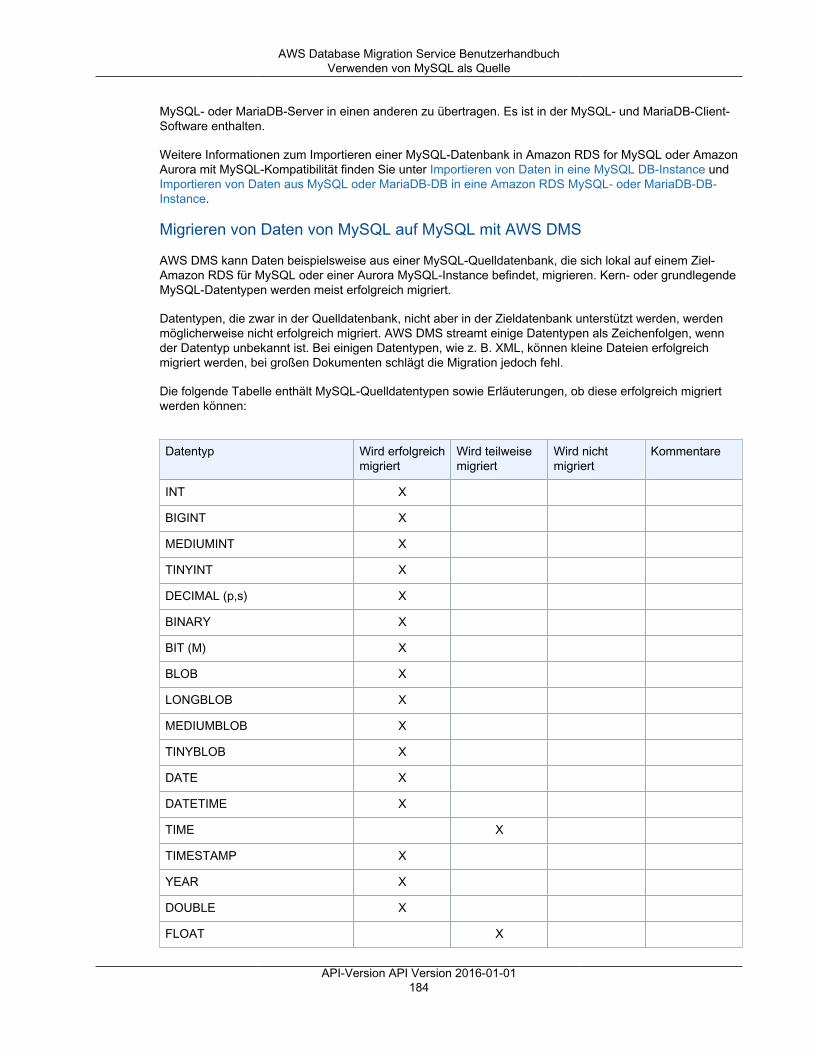
AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Quelle
MySQL- oder MariaDB-Server in einen anderen zu übertragen. Es ist in der MySQL- und MariaDB-Client-Software enthalten.
Weitere Informationen zum Importieren einer MySQL-Datenbank in Amazon RDS for MySQL oder AmazonAurora mit MySQL-Kompatibilität finden Sie unter Importieren von Daten in eine MySQL DB-Instance undImportieren von Daten aus MySQL oder MariaDB-DB in eine Amazon RDS MySQL- oder MariaDB-DB-Instance.
Migrieren von Daten von MySQL auf MySQL mit AWS DMS
AWS DMS kann Daten beispielsweise aus einer MySQL-Quelldatenbank, die sich lokal auf einem Ziel-Amazon RDS für MySQL oder einer Aurora MySQL-Instance befindet, migrieren. Kern- oder grundlegendeMySQL-Datentypen werden meist erfolgreich migriert.
Datentypen, die zwar in der Quelldatenbank, nicht aber in der Zieldatenbank unterstützt werden, werdenmöglicherweise nicht erfolgreich migriert. AWS DMS streamt einige Datentypen als Zeichenfolgen, wennder Datentyp unbekannt ist. Bei einigen Datentypen, wie z. B. XML, können kleine Dateien erfolgreichmigriert werden, bei großen Dokumenten schlägt die Migration jedoch fehl.
Die folgende Tabelle enthält MySQL-Quelldatentypen sowie Erläuterungen, ob diese erfolgreich migriertwerden können:
Datentyp Wird erfolgreichmigriert
Wird teilweisemigriert
Wird nichtmigriert
Kommentare
INT X
BIGINT X
MEDIUMINT X
TINYINT X
DECIMAL (p,s) X
BINARY X
BIT (M) X
BLOB X
LONGBLOB X
MEDIUMBLOB X
TINYBLOB X
DATE X
DATETIME X
TIME X
TIMESTAMP X
YEAR X
DOUBLE X
FLOAT X
API-Version API Version 2016-01-01184
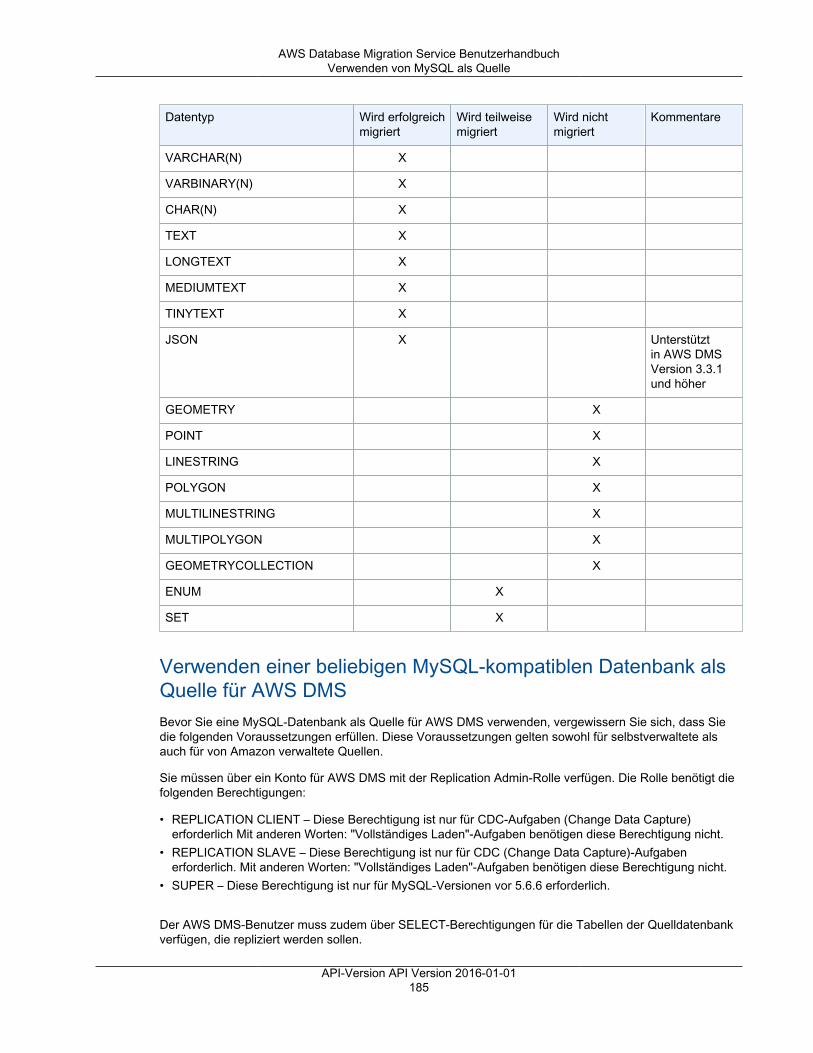
AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Quelle
Datentyp Wird erfolgreichmigriert
Wird teilweisemigriert
Wird nichtmigriert
Kommentare
VARCHAR(N) X
VARBINARY(N) X
CHAR(N) X
TEXT X
LONGTEXT X
MEDIUMTEXT X
TINYTEXT X
JSON X Unterstütztin AWS DMSVersion 3.3.1und höher
GEOMETRY X
POINT X
LINESTRING X
POLYGON X
MULTILINESTRING X
MULTIPOLYGON X
GEOMETRYCOLLECTION X
ENUM X
SET X
Verwenden einer beliebigen MySQL-kompatiblen Datenbank alsQuelle für AWS DMSBevor Sie eine MySQL-Datenbank als Quelle für AWS DMS verwenden, vergewissern Sie sich, dass Siedie folgenden Voraussetzungen erfüllen. Diese Voraussetzungen gelten sowohl für selbstverwaltete alsauch für von Amazon verwaltete Quellen.
Sie müssen über ein Konto für AWS DMS mit der Replication Admin-Rolle verfügen. Die Rolle benötigt diefolgenden Berechtigungen:
• REPLICATION CLIENT – Diese Berechtigung ist nur für CDC-Aufgaben (Change Data Capture)erforderlich Mit anderen Worten: "Vollständiges Laden"-Aufgaben benötigen diese Berechtigung nicht.
• REPLICATION SLAVE – Diese Berechtigung ist nur für CDC (Change Data Capture)-Aufgabenerforderlich. Mit anderen Worten: "Vollständiges Laden"-Aufgaben benötigen diese Berechtigung nicht.
• SUPER – Diese Berechtigung ist nur für MySQL-Versionen vor 5.6.6 erforderlich.
Der AWS DMS-Benutzer muss zudem über SELECT-Berechtigungen für die Tabellen der Quelldatenbankverfügen, die repliziert werden sollen.
API-Version API Version 2016-01-01185
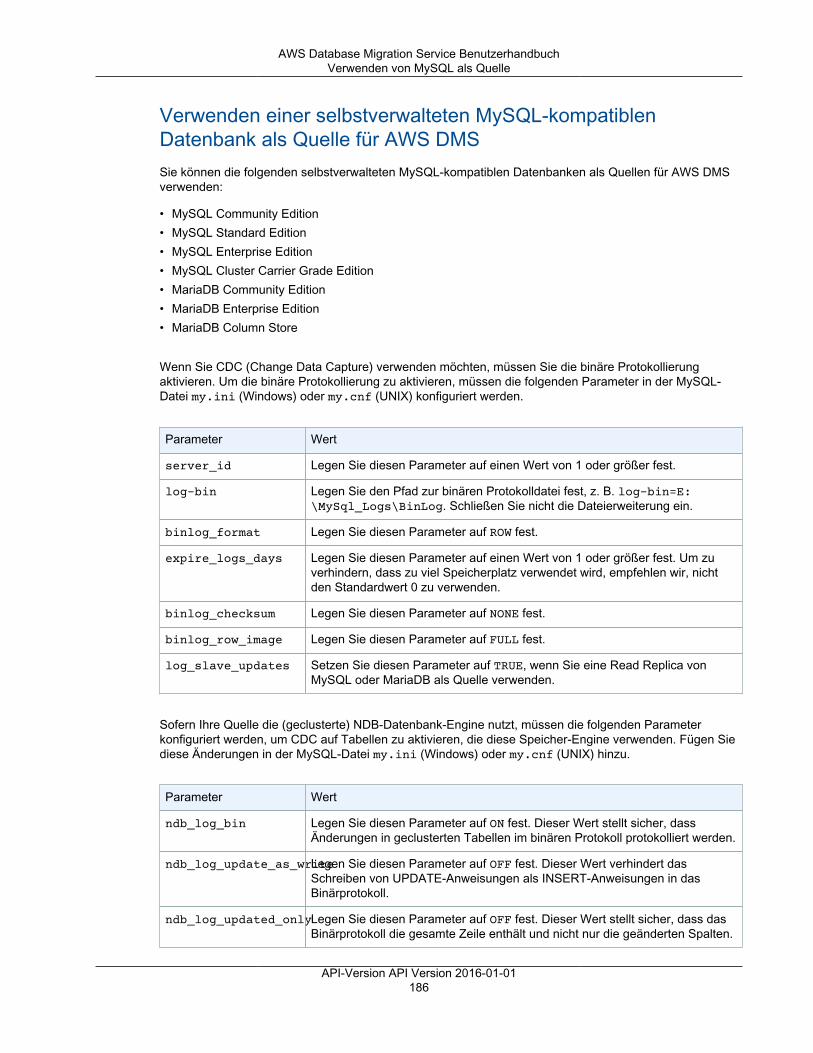
AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Quelle
Verwenden einer selbstverwalteten MySQL-kompatiblenDatenbank als Quelle für AWS DMSSie können die folgenden selbstverwalteten MySQL-kompatiblen Datenbanken als Quellen für AWS DMSverwenden:
• MySQL Community Edition• MySQL Standard Edition• MySQL Enterprise Edition• MySQL Cluster Carrier Grade Edition• MariaDB Community Edition• MariaDB Enterprise Edition• MariaDB Column Store
Wenn Sie CDC (Change Data Capture) verwenden möchten, müssen Sie die binäre Protokollierungaktivieren. Um die binäre Protokollierung zu aktivieren, müssen die folgenden Parameter in der MySQL-Datei my.ini (Windows) oder my.cnf (UNIX) konfiguriert werden.
Parameter Wert
server_id Legen Sie diesen Parameter auf einen Wert von 1 oder größer fest.
log-bin Legen Sie den Pfad zur binären Protokolldatei fest, z. B. log-bin=E:\MySql_Logs\BinLog. Schließen Sie nicht die Dateierweiterung ein.
binlog_format Legen Sie diesen Parameter auf ROW fest.
expire_logs_days Legen Sie diesen Parameter auf einen Wert von 1 oder größer fest. Um zuverhindern, dass zu viel Speicherplatz verwendet wird, empfehlen wir, nichtden Standardwert 0 zu verwenden.
binlog_checksum Legen Sie diesen Parameter auf NONE fest.
binlog_row_image Legen Sie diesen Parameter auf FULL fest.
log_slave_updates Setzen Sie diesen Parameter auf TRUE, wenn Sie eine Read Replica vonMySQL oder MariaDB als Quelle verwenden.
Sofern Ihre Quelle die (geclusterte) NDB-Datenbank-Engine nutzt, müssen die folgenden Parameterkonfiguriert werden, um CDC auf Tabellen zu aktivieren, die diese Speicher-Engine verwenden. Fügen Siediese Änderungen in der MySQL-Datei my.ini (Windows) oder my.cnf (UNIX) hinzu.
Parameter Wert
ndb_log_bin Legen Sie diesen Parameter auf ON fest. Dieser Wert stellt sicher, dassÄnderungen in geclusterten Tabellen im binären Protokoll protokolliert werden.
ndb_log_update_as_writeLegen Sie diesen Parameter auf OFF fest. Dieser Wert verhindert dasSchreiben von UPDATE-Anweisungen als INSERT-Anweisungen in dasBinärprotokoll.
ndb_log_updated_onlyLegen Sie diesen Parameter auf OFF fest. Dieser Wert stellt sicher, dass dasBinärprotokoll die gesamte Zeile enthält und nicht nur die geänderten Spalten.
API-Version API Version 2016-01-01186

AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Quelle
Verwenden einer von Amazon verwalteten MySQL-kompatiblenDatenbank als Quelle für AWS DMSSie können die folgenden von Amazon verwalteten MySQL-kompatiblen Datenbanken als Quellen für AWSDMS verwenden:
• MySQL Community Edition• MariaDB Community Edition• Amazon Aurora mit MySQL-Kompatibilität
Wenn Sie eine von Amazon verwaltete MySQL-kompatible Datenbank als Quelle für AWS DMSverwenden, vergewissern Sie sich, dass Sie die folgenden Voraussetzungen erfüllen:
• Aktivieren Sie automatische Sicherungen. Weitere Informationen zum Einrichten von automatischenSicherungen finden Sie unter Arbeiten mit automatischen Sicherungen im Amazon RDS-Benutzerhandbuch.
• Wenn Sie CDC (Change Data Capture) verwenden möchten, müssen Sie die binäre Protokollierungaktivieren. Weitere Informationen zum Einrichten der Binärprotokollierung für eine Amazon RDSMySQL-Datenbank finden Sie unter Arbeiten mit automatischen Sicherungen im Amazon RDS-Benutzerhandbuch.
• Stellen Sie sicher, dass die Binärprotokolle für AWS DMS verfügbar sind. Da die Binärprotokolleauf von Amazon verwalteten MySQL-kompatiblen Datenbanken möglichst schnell wieder gelöschtwerden, sollten Sie den Zeitraum verlängern, in dem diese Protokolle verfügbar bleiben. Um z. B. dieAufbewahrungszeit der Protokolle auf 24 Stunden zu verlängern, führen Sie den folgenden Befehl aus.
call mysql.rds_set_configuration('binlog retention hours', 24);
• Stellen Sie den Parameter binlog_format auf "ROW" ein.• Stellen Sie den Parameter binlog_checksum auf "NONE" ein. Weitere Informationen zum Festlegen
von Parametern in Amazon RDS MySQL finden Sie unter Arbeiten mit automatischen Sicherungen imAmazon RDS-Benutzerhandbuch.
• Wenn Sie eine Read Replica von Amazon RDS MySQL oder Amazon RDS MariaDB als Quelle nutzen,aktivieren Sie für die Read Replica Sicherungen.
Einschränkungen bei der Verwendung einer MySQL-Datenbankals Quelle für AWS DMSWenn Sie eine MySQL-Datenbank als Quelle verwenden, sollten Sie Folgendes beachten:
• CDC (Change Data Capture) wird nicht unterstützt für Amazon RDS MySQL 5.5 oder früher. Für AmazonRDS MySQL müssen Sie die Version 5.6 oder 5.7 verwenden, um CDC zu aktivieren. Beachten Sie,dass CDC für selbstverwaltete MySQL 5.5-Quellen unterstützt wird.
• Die DDL-Anweisungen (Data Definition Language) DROP TABLE und RENAME TABLE werden nichtunterstützt. Alle DDL-Anweisungen für partitionierte Tabellen werden ebenfalls nicht unterstützt.
• Wenn Sie für partitionierte Tabellen auf der Quelle Target table preparation mode (Vorbereitungsmodusfür Zieltabelle) die Option Drop tables on target (Tabellen auf dem Ziel verwerfen) auswählen, erstelltAWS DMS eine einfache Tabelle ohne Partitionen auf dem MySQL-Ziel. Wenn Sie partitionierte Tabellenin eine partitionierte Tabelle auf dem Ziel migrieren möchten, erstellen Sie zunächst die partitioniertenTabellen in der MySQL-Zieldatenbank.
API-Version API Version 2016-01-01187

AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Quelle
• Die Verwendung der Anweisung ALTER TABLEtable_name ADD COLUMN column_name zumHinzufügen von Spalten zum Anfang (FIRST) oder zur Mitte einer Tabelle (AFTER) wird nicht unterstützt.Spalten werden stets am Ende der Tabelle hinzugefügt.
• CDC wird nicht unterstützt, wenn ein Tabellenname Groß- und Kleinbuchstaben enthält und die Quell-Engine auf einem Betriebssystem mit Dateinamen ohne Berücksichtigung von Groß-/Kleinschreibunggehostet wird. Ein Beispiel dafür ist Windows oder OS X mit HFS+.
• Das Attribut AUTO_INCREMENT auf einer Spalte wird nicht zu einer Spalte in der Zieldatenbankmigriert.
• Das Erfassen von Änderungen, wenn die Binärprotokolle nicht auf Standardblockspeicher gespeichertsind, wird nicht unterstützt. Beispielsweise kann CDC nicht verwendet werden, falls die Binärprotokolleauf Amazon S3 gespeichert sind.
• Standardmäßig erstellt AWS DMS die Zieltabellen mit der Speicher-Engine InnoDB. Falls Sie eineandere Speicher-Engine als InnoDB benötigen, müssen Sie die Tabelle manuell erstellen und dann dieDaten mit dem „Do nothing“-Modus migrieren.
• Read Replicas von Aurora MySQL können nicht als Quelle für AWS DMS verwendet werden.• Im Falle, dass die MySQL-kompatible Quelle während des vollständigen Ladevorgangs gestoppt wird,
bricht die AWS DMS-Aufgabe nicht mit einem Fehler ab. Die Aufgabe wird erfolgreich abgeschlossen,aber das Ziel wurde möglicherweise nicht mit der Quelle synchronisiert. Wenn dies geschieht, starten Sieentweder die Aufgabe neu oder Sie laden die betroffenen Tabellen neu.
• Indizes, die auf einem Teil des Spaltenwerts erstellt wurden, werden nicht migriert. Beispielsweise wirdder Index CREATE INDEX first_ten_chars ON customer (name(10)) nicht auf dem Ziel erstellt.
• In einigen Fällen ist die Aufgabe so konfiguriert, dass LOBs nicht repliziert werden (in denAufgabeneinstellungen hat "SupportLobs" den Wert "false" oder in der Aufgabenkonsole ist "Don'tinclude LOB columns" (Keine LOB-Spalten) markiert). In diesen Fällen migriert AWS DMS keine Spaltendes Typs MEDIUMBLOB, LONGBLOB, MEDIUMTEXT und LONGTEXT zum Ziel.
Spalten des Typs BLOB, TINYBLOB, TEXT und TINYTEXT sind davon nicht betroffen und werden zumZiel migriert.
Zusätzliche Verbindungsattribute bei der Verwendung vonMySQL als Quelle für AWS DMSSie können zusätzliche Verbindungsattribute zum Konfigurieren einer MySQL-Quelle verwenden.Sie geben diese Einstellungen beim Erstellen des Quellendpunkts an. Wenn Sie mehrereVerbindungsattributeinstellungen verwenden, trennen Sie diese durch Semikola und ohne zusätzlicheLeerräume voneinander (z. B. oneSetting;thenAnother).
Die folgende Tabelle zeigt die zusätzlichen Verbindungsattribute, die verfügbar sind, wenn Sie AmazonRDS MySQL als Quelle für AWS DMS verwenden.
Name Beschreibung
eventsPollInterval Gibt an, wie oft das binäre Protokolle für neue Änderungen/Ereignisse überprüft wird, wenn die Datenbank inaktiv ist.
Standardwert: 5
Zulässige Werte: 1 – 60
Beispiel: eventsPollInterval=5;
Im Beispiel werden die Binärprotokolle alle fünf Sekunden vonAWS DMS auf Änderungen überprüft.
API-Version API Version 2016-01-01188
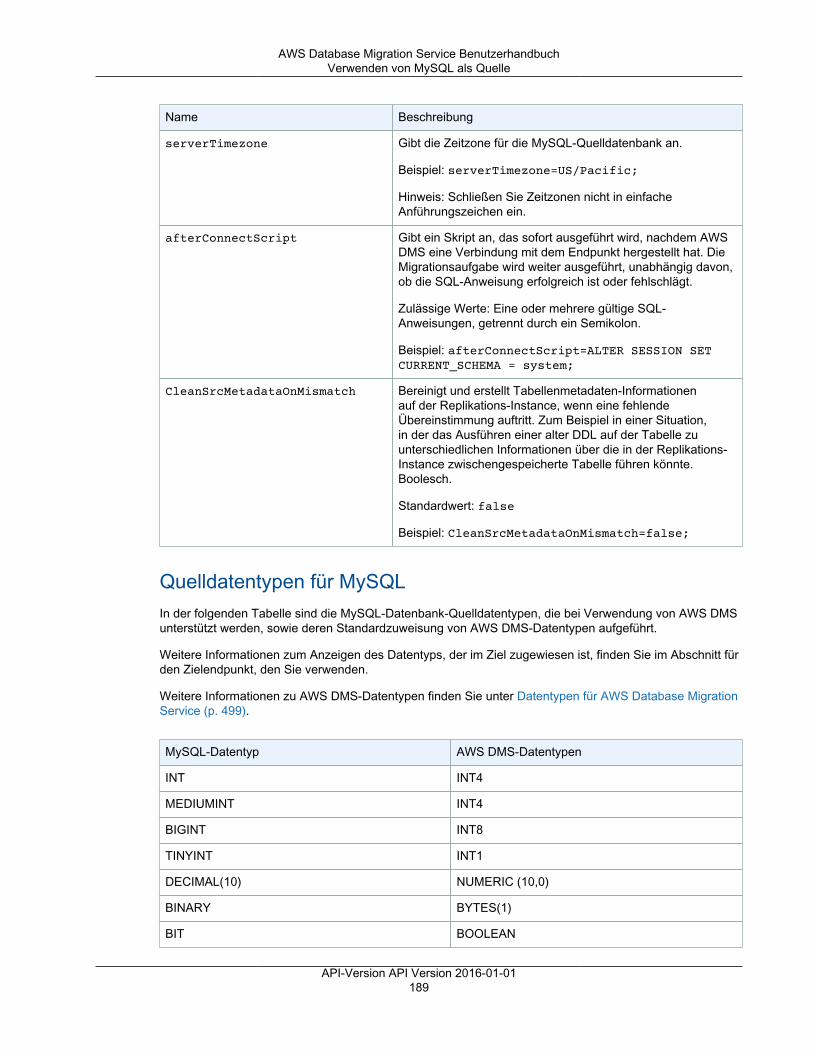
AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Quelle
Name Beschreibung
serverTimezone Gibt die Zeitzone für die MySQL-Quelldatenbank an.
Beispiel: serverTimezone=US/Pacific;
Hinweis: Schließen Sie Zeitzonen nicht in einfacheAnführungszeichen ein.
afterConnectScript Gibt ein Skript an, das sofort ausgeführt wird, nachdem AWSDMS eine Verbindung mit dem Endpunkt hergestellt hat. DieMigrationsaufgabe wird weiter ausgeführt, unabhängig davon,ob die SQL-Anweisung erfolgreich ist oder fehlschlägt.
Zulässige Werte: Eine oder mehrere gültige SQL-Anweisungen, getrennt durch ein Semikolon.
Beispiel: afterConnectScript=ALTER SESSION SETCURRENT_SCHEMA = system;
CleanSrcMetadataOnMismatch Bereinigt und erstellt Tabellenmetadaten-Informationenauf der Replikations-Instance, wenn eine fehlendeÜbereinstimmung auftritt. Zum Beispiel in einer Situation,in der das Ausführen einer alter DDL auf der Tabelle zuunterschiedlichen Informationen über die in der Replikations-Instance zwischengespeicherte Tabelle führen könnte.Boolesch.
Standardwert: false
Beispiel: CleanSrcMetadataOnMismatch=false;
Quelldatentypen für MySQLIn der folgenden Tabelle sind die MySQL-Datenbank-Quelldatentypen, die bei Verwendung von AWS DMSunterstützt werden, sowie deren Standardzuweisung von AWS DMS-Datentypen aufgeführt.
Weitere Informationen zum Anzeigen des Datentyps, der im Ziel zugewiesen ist, finden Sie im Abschnitt fürden Zielendpunkt, den Sie verwenden.
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
MySQL-Datentyp AWS DMS-Datentypen
INT INT4
MEDIUMINT INT4
BIGINT INT8
TINYINT INT1
DECIMAL(10) NUMERIC (10,0)
BINARY BYTES(1)
BIT BOOLEAN
API-Version API Version 2016-01-01189
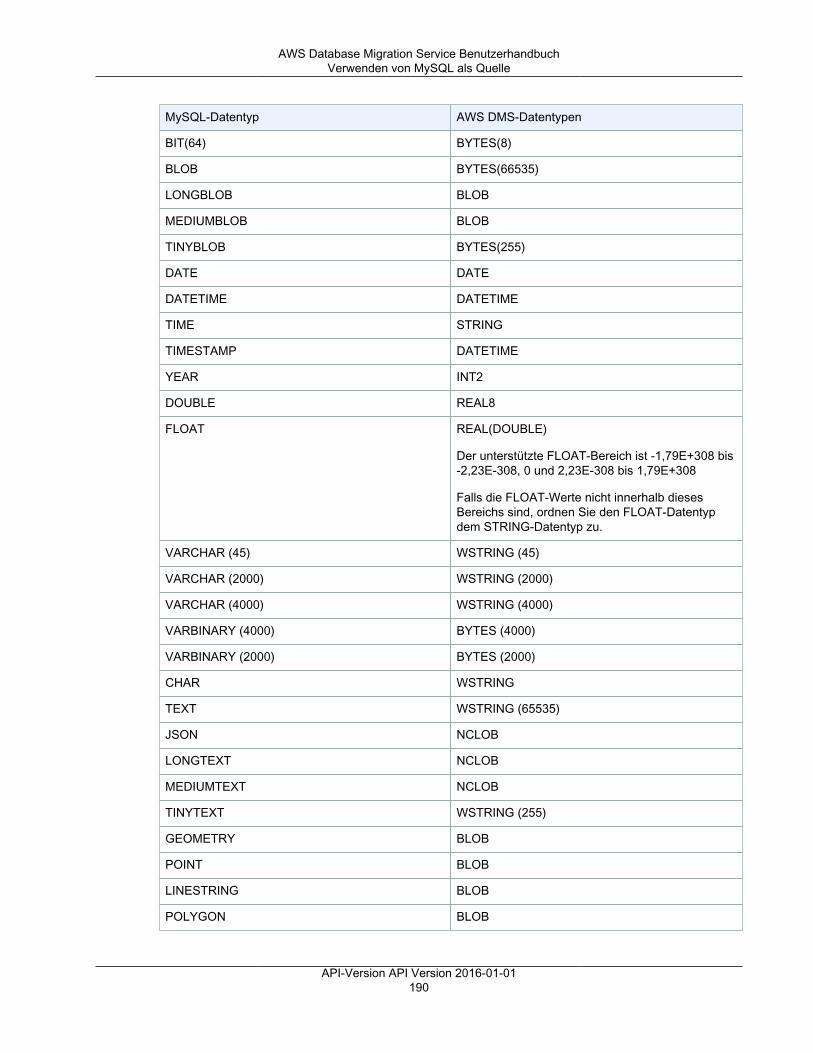
AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Quelle
MySQL-Datentyp AWS DMS-Datentypen
BIT(64) BYTES(8)
BLOB BYTES(66535)
LONGBLOB BLOB
MEDIUMBLOB BLOB
TINYBLOB BYTES(255)
DATE DATE
DATETIME DATETIME
TIME STRING
TIMESTAMP DATETIME
YEAR INT2
DOUBLE REAL8
FLOAT REAL(DOUBLE)
Der unterstützte FLOAT-Bereich ist -1,79E+308 bis-2,23E-308, 0 und 2,23E-308 bis 1,79E+308
Falls die FLOAT-Werte nicht innerhalb diesesBereichs sind, ordnen Sie den FLOAT-Datentypdem STRING-Datentyp zu.
VARCHAR (45) WSTRING (45)
VARCHAR (2000) WSTRING (2000)
VARCHAR (4000) WSTRING (4000)
VARBINARY (4000) BYTES (4000)
VARBINARY (2000) BYTES (2000)
CHAR WSTRING
TEXT WSTRING (65535)
JSON NCLOB
LONGTEXT NCLOB
MEDIUMTEXT NCLOB
TINYTEXT WSTRING (255)
GEOMETRY BLOB
POINT BLOB
LINESTRING BLOB
POLYGON BLOB
API-Version API Version 2016-01-01190

AWS Database Migration Service BenutzerhandbuchVerwenden von SAP ASE als Quelle
MySQL-Datentyp AWS DMS-Datentypen
MULTIPOINT BLOB
MULTILINESTRING BLOB
MULTIPOLYGON BLOB
GEOMETRYCOLLECTION BLOB
Note
• Wenn die Datentypen DATETIME und TIMESTAMP mit dem Wert "null" angegeben sind (d. h.0000-00-00), müssen Sie sicherstellen, dass die Zieldatenbank in der Replikationsaufgabe"null"-Werte für die Datentypen DATETIME und TIMESTAMP unterstützt. Andernfalls werdendiese Werte als "null" im Ziel erfasst.
• AWS DMS unterstützt den JSON-Datentyp in Version 3.3.1 und höher.
Die folgenden MySQL-Datentypen werden nur bei vollständigem Laden unterstützt.
MySQL-Datentyp AWS DMS-Datentypen
ENUM STRING
SET STRING
Verwenden einer SAP ASE-Datenbank als Quelle fürAWS DMSSie können Daten aus einer SAP ASE-Datenbank (Adaptive Server Enterprise)—ehemals Sybase—mithilfe von AWS DMS migrieren. Mit einer SAP ASE-Datenbank als Quelle können Sie Daten zu einerder anderen unterstützten AWS DMS-Zieldatenbanken migrieren. AWS DMS unterstützt die SAP ASE-Versionen 12.5.3 oder höher, 15, 15.5, 15.7, 16 und höher als Quellen.
Weitere Informationen zum Arbeiten mit SAP ASE-Datenbanken und AWS DMS finden Sie in denfolgenden Abschnitten.
Themen• Voraussetzungen für die Verwendung einer SAP ASE-Datenbank als Quelle für AWS DMS (p. 191)• Einschränkungen bei der Verwendung von SAP ASE als Quelle für AWS DMS (p. 193)• Erforderliche Berechtigungen für die Verwendung von SAP ASE als Quelle für AWS DMS (p. 194)• Entfernen des Kürzungspunkts (p. 194)• Quelldatentypen für SAP ASE (p. 195)
Voraussetzungen für die Verwendung einer SAP ASE-Datenbankals Quelle für AWS DMSUm eine SAP ASE-Datenbank als Quelle für AWS DMS zu verwenden, gehen Sie wie folgt vor:
API-Version API Version 2016-01-01191
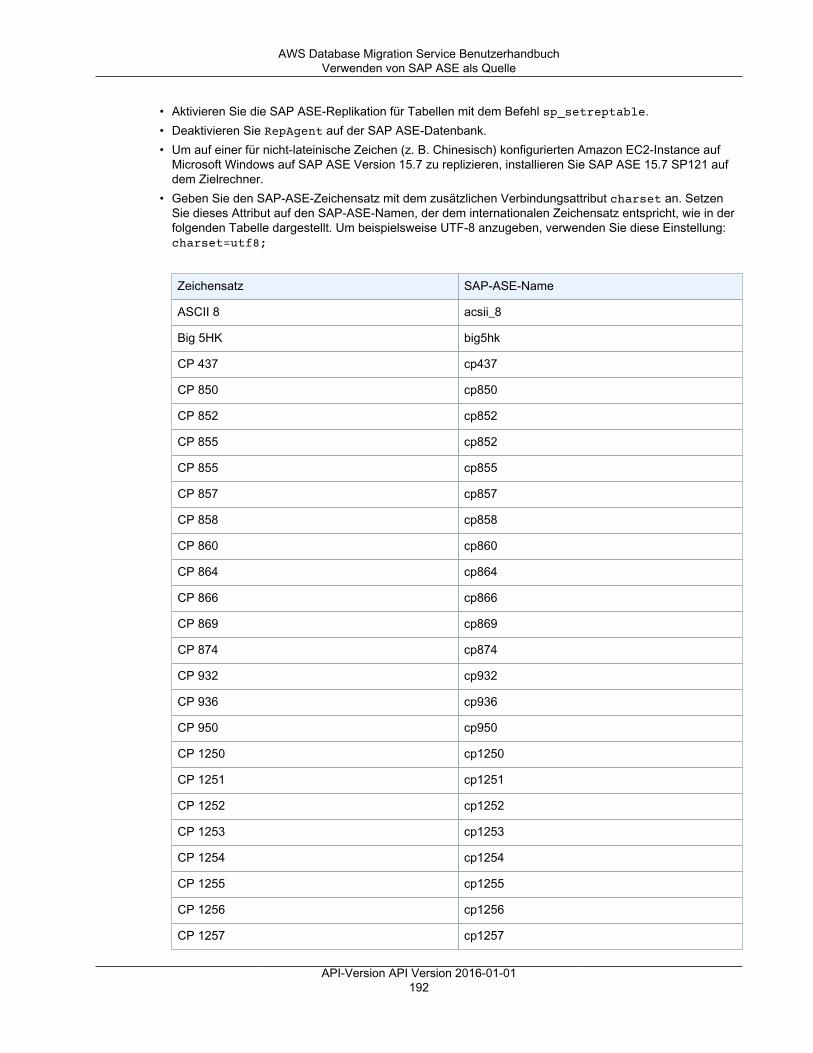
AWS Database Migration Service BenutzerhandbuchVerwenden von SAP ASE als Quelle
• Aktivieren Sie die SAP ASE-Replikation für Tabellen mit dem Befehl sp_setreptable.• Deaktivieren Sie RepAgent auf der SAP ASE-Datenbank.• Um auf einer für nicht-lateinische Zeichen (z. B. Chinesisch) konfigurierten Amazon EC2-Instance auf
Microsoft Windows auf SAP ASE Version 15.7 zu replizieren, installieren Sie SAP ASE 15.7 SP121 aufdem Zielrechner.
• Geben Sie den SAP-ASE-Zeichensatz mit dem zusätzlichen Verbindungsattribut charset an. SetzenSie dieses Attribut auf den SAP-ASE-Namen, der dem internationalen Zeichensatz entspricht, wie in derfolgenden Tabelle dargestellt. Um beispielsweise UTF-8 anzugeben, verwenden Sie diese Einstellung:charset=utf8;
Zeichensatz SAP-ASE-Name
ASCII 8 acsii_8
Big 5HK big5hk
CP 437 cp437
CP 850 cp850
CP 852 cp852
CP 855 cp852
CP 855 cp855
CP 857 cp857
CP 858 cp858
CP 860 cp860
CP 864 cp864
CP 866 cp866
CP 869 cp869
CP 874 cp874
CP 932 cp932
CP 936 cp936
CP 950 cp950
CP 1250 cp1250
CP 1251 cp1251
CP 1252 cp1252
CP 1253 cp1253
CP 1254 cp1254
CP 1255 cp1255
CP 1256 cp1256
CP 1257 cp1257
API-Version API Version 2016-01-01192
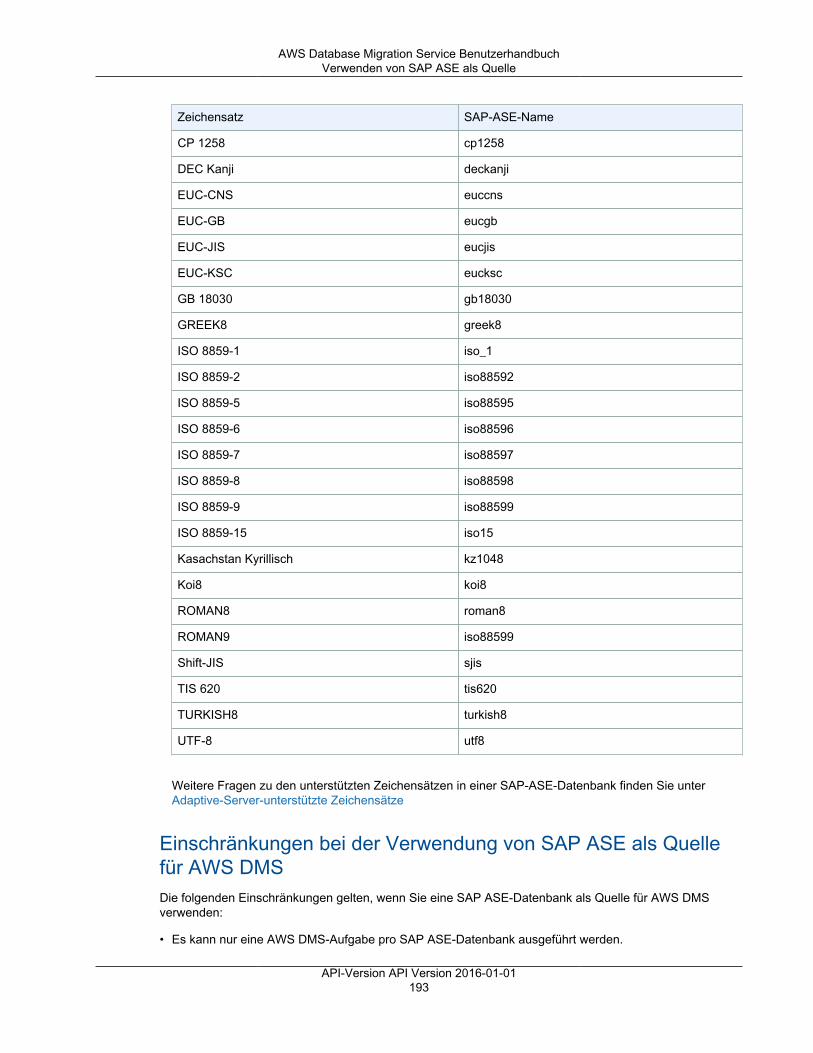
AWS Database Migration Service BenutzerhandbuchVerwenden von SAP ASE als Quelle
Zeichensatz SAP-ASE-Name
CP 1258 cp1258
DEC Kanji deckanji
EUC-CNS euccns
EUC-GB eucgb
EUC-JIS eucjis
EUC-KSC eucksc
GB 18030 gb18030
GREEK8 greek8
ISO 8859-1 iso_1
ISO 8859-2 iso88592
ISO 8859-5 iso88595
ISO 8859-6 iso88596
ISO 8859-7 iso88597
ISO 8859-8 iso88598
ISO 8859-9 iso88599
ISO 8859-15 iso15
Kasachstan Kyrillisch kz1048
Koi8 koi8
ROMAN8 roman8
ROMAN9 iso88599
Shift-JIS sjis
TIS 620 tis620
TURKISH8 turkish8
UTF-8 utf8
Weitere Fragen zu den unterstützten Zeichensätzen in einer SAP-ASE-Datenbank finden Sie unterAdaptive-Server-unterstützte Zeichensätze
Einschränkungen bei der Verwendung von SAP ASE als Quellefür AWS DMSDie folgenden Einschränkungen gelten, wenn Sie eine SAP ASE-Datenbank als Quelle für AWS DMSverwenden:
• Es kann nur eine AWS DMS-Aufgabe pro SAP ASE-Datenbank ausgeführt werden.
API-Version API Version 2016-01-01193
AWS Database Migration Service BenutzerhandbuchVerwenden von SAP ASE als Quelle
• Es ist nicht möglich, eine Tabelle umzubenennen. Der folgende Befehl beispielsweise schlägt fehl:
sp_rename 'Sales.SalesRegion', 'SalesReg;
• Es ist nicht möglich, eine Spalte umzubenennen. Der folgende Befehl beispielsweise schlägt fehl:
sp_rename 'Sales.Sales.Region', 'RegID', 'COLUMN';
• Nullwerte am Ende von Zeichenfolgen binären Datentyps werden gekürzt, wenn sie in der Zieldatenbankrepliziert werden. Beispielsweise wird 0x0000000000000000000000000100000100000000 in derQuelltabelle zu 0x00000000000000000000000001000001 in der Zieltabelle.
• Wenn die Datenbank standardmäßig keine NULL-Werte zulässt, erstellt AWS DMS die Zieltabelle mitSpalten, die keine NULL-Werte zulassen. Wenn also eine Aufgabe zum vollständigen Laden oder eineCDC-Replikationsaufgabe (Change Data Capture) leere Werte enthält, löst AWS DMS einen Fehleraus. Sie können diese Fehler verhindern, indem Sie mithilfe der folgenden Befehle NULL-Werte in derQuelldatenbank zulassen.
sp_dboption database_name, 'allow nulls by default', 'true'gouse database_nameCHECKPOINTgo
• Der Indexbefehl reorg rebuild wird nicht unterstützt.• Cluster werden nicht unterstützt.
Erforderliche Berechtigungen für die Verwendung von SAP ASEals Quelle für AWS DMSUm eine SAP ASE-Datenbank als Quelle in einer AWS DMS-Aufgabe zu verwenden, erteilen Sie dem inder AWS DMS-Datenbankdefinitionen angegebenen Benutzerkonto die folgenden Berechtigungen in derSAP ASE-Datenbank.
• sa_role• replication_role• sybase_ts_role• Wenn Sie beim Erstellen des SAP ASE-Quellendpunkts die Option Automatically enable Sybase
replication (Sybase-Replikation automatisch aktivieren) auf der Registerkarte Advanced (Erweitert)aktiviert haben, müssen Sie AWS DMS auch die Berechtigung zum Ausführen der gespeichertenProzedur sp_setreptable erteilen.
Entfernen des KürzungspunktsWenn eine Aufgabe gestartet wird, setzt AWS DMS einen $replication_truncation_point-Eintragin die syslogshold-Systemansicht. Damit wird angezeigt, dass ein Replikationsprozess läuft. WährendAWS DMS arbeitet, wird der Replikationskürzungspunkt in regelmäßigen Abständen weiter gesetzt,entsprechend der Menge der Daten, die bereits in das Ziel kopiert wurde.
Nachdem der Eintrag $replication_truncation_point eingerichtet wurde, muss die AWSDMS-Aufgabe ununterbrochen ausgeführt werden, um zu verhindern, dass das Datenbankprotokollübermäßig groß wird. Wenn Sie die AWS DMS-Aufgabe dauerhaft stoppen möchten, entfernen Sie denReplikationskürzungspunkt durch Ausgabe des folgenden Befehls:
API-Version API Version 2016-01-01194
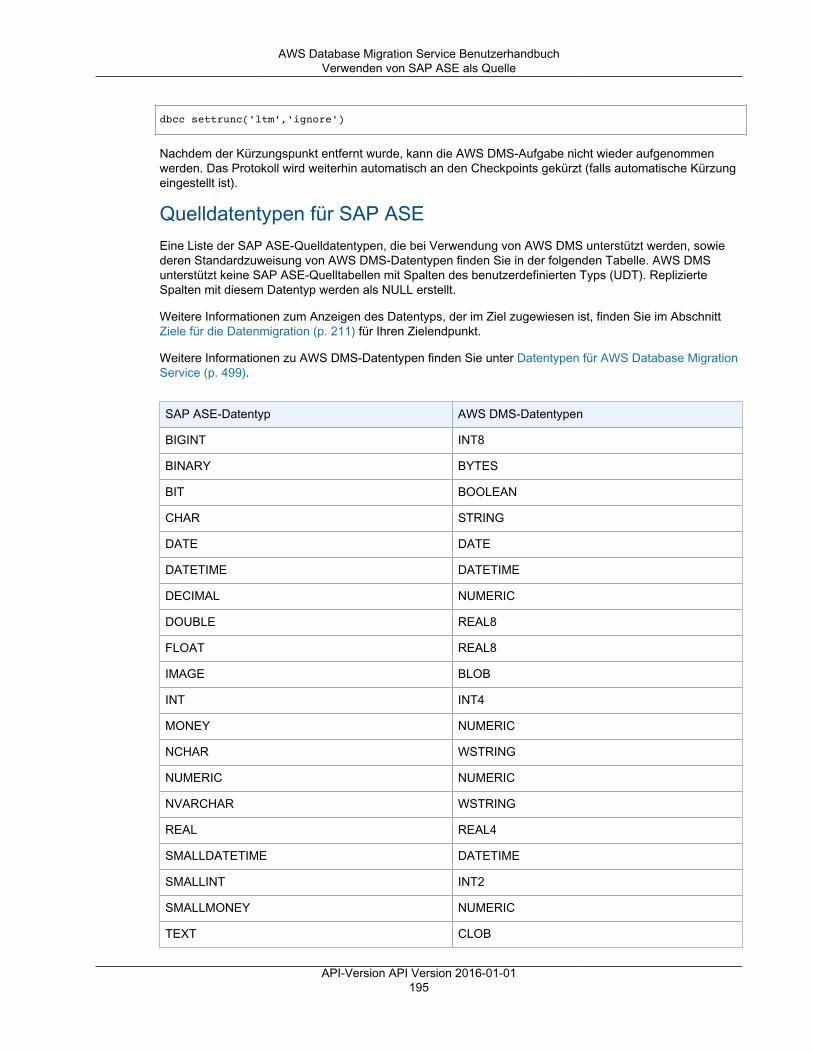
AWS Database Migration Service BenutzerhandbuchVerwenden von SAP ASE als Quelle
dbcc settrunc('ltm','ignore')
Nachdem der Kürzungspunkt entfernt wurde, kann die AWS DMS-Aufgabe nicht wieder aufgenommenwerden. Das Protokoll wird weiterhin automatisch an den Checkpoints gekürzt (falls automatische Kürzungeingestellt ist).
Quelldatentypen für SAP ASEEine Liste der SAP ASE-Quelldatentypen, die bei Verwendung von AWS DMS unterstützt werden, sowiederen Standardzuweisung von AWS DMS-Datentypen finden Sie in der folgenden Tabelle. AWS DMSunterstützt keine SAP ASE-Quelltabellen mit Spalten des benutzerdefinierten Typs (UDT). ReplizierteSpalten mit diesem Datentyp werden als NULL erstellt.
Weitere Informationen zum Anzeigen des Datentyps, der im Ziel zugewiesen ist, finden Sie im AbschnittZiele für die Datenmigration (p. 211) für Ihren Zielendpunkt.
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
SAP ASE-Datentyp AWS DMS-Datentypen
BIGINT INT8
BINARY BYTES
BIT BOOLEAN
CHAR STRING
DATE DATE
DATETIME DATETIME
DECIMAL NUMERIC
DOUBLE REAL8
FLOAT REAL8
IMAGE BLOB
INT INT4
MONEY NUMERIC
NCHAR WSTRING
NUMERIC NUMERIC
NVARCHAR WSTRING
REAL REAL4
SMALLDATETIME DATETIME
SMALLINT INT2
SMALLMONEY NUMERIC
TEXT CLOB
API-Version API Version 2016-01-01195

AWS Database Migration Service BenutzerhandbuchVerwenden von MongoDB als Quelle
SAP ASE-Datentyp AWS DMS-Datentypen
TIME TIME
TINYINT UINT1
UNICHAR UNICODE CHARACTER
UNITEXT NCLOB
UNIVARCHAR UNICODE
VARBINARY BYTES
VARCHAR STRING
Verwenden von MongoDB als Quelle für AWS DMSAWS DMS unterstützt MongoDB-Versionen 2.6.x und 3.x als Datenbankquelle.
Falls Sie noch keine Erfahrung mit MongoDB haben, beachten Sie die folgenden wichtigen MongoDB-Datenbankkonzepte:
• Ein Datensatz in MongoDB ist ein Dokument, bei dem es sich um eine Datenstruktur aus Feld-Wert-Paaren handelt. Der Wert eines Felds kann andere Dokumente, Arrays und Dokument-Arrays enthalten.Ein Dokument entspricht etwa einer Zeile in einer relationalen Datenbanktabelle.
• Eine Sammlung ist in MongoDB eine Gruppe von Dokumente und entspricht in etwa einer Tabelle ineiner relationalen Datenbank.
• Intern wird ein MongoDB-Dokument als binäre JSON-Datei (BSON) in einem komprimierten Formatgespeichert, das einen Typ für jedes Feld im Dokument enthält. Jedes Dokument hat eine eindeutige ID.
AWS DMS unterstützt zwei Migrationsmodi bei der Verwendung von MongoDB als Quelle. Sie könnenden Migrationsmodus mit dem Parameter Metadata mode (Metadatenmodus) mithilfe der AWS-Managementkonsole oder mit dem zusätzlichen Verbindungsattribut nestingLevel angeben, wenn Sieden MongoDB-Endpunkt erstellen. Die Wahl des Migrationsmodus wirkt sich wie nachstehend erläutert aufdas resultierende Format der Zieldaten aus.
Dokumentmodus
Im Dokumentmodus wird das MongoDB-Dokument unverändert migriert. Dies bedeutet, dass dieDokumentdaten in einer einzelnen Spalte mit dem Namen _doc in einer Zieltabelle zusammengefasstwerden. Der Dokumentmodus ist die Standardeinstellung, wenn Sie MongoDB als Quellendpunktverwenden.
Nehmen wir als Beispiel die folgenden Dokumente in einer MongoDB-Sammlung mit dem Namen"myCollection".
> db.myCollection.find(){ "_id" : ObjectId("5a94815f40bd44d1b02bdfe0"), "a" : 1, "b" : 2, "c" : 3 }{ "_id" : ObjectId("5a94815f40bd44d1b02bdfe1"), "a" : 4, "b" : 5, "c" : 6 }
Nach der Migration der Daten in eine relationale Datenbanktabelle mit Dokumentmodus sind dieDaten folgendermaßen strukturiert. Die Datenfelder im MongoDB-Dokument sind in der Spalte _doczusammengefasst.
oid_id _doc
API-Version API Version 2016-01-01196

AWS Database Migration Service BenutzerhandbuchVerwenden von MongoDB als Quelle
5a94815f40bd44d1b02bdfe0 { "a" : 1, "b" : 2, "c" : 3 }
5a94815f40bd44d1b02bdfe1 { "a" : 4, "b" : 5, "c" : 6 }
Sie können optional den extractDocID des zusätzlichen Verbindungsattributs auf true einstellen,um eine zweite Spalte mit dem Namen "_id" zu erstellen, die als Primärschlüssel fungiert. Wenn SieChange Data Capture (CDC) verwenden möchten, setzen Sie diesen Parameter auf true, außer wennSie Amazon DocumentDB als Ziel verwenden.
Nachfolgend ist dargestellt, wie AWS DMS die Erstellung und Umbenennung von Sammlungen imDokumentmodus verwaltet:• Wenn Sie eine neue Sammlung zur Quelldatenbank hinzufügen, erstellt AWS DMS eine neue
Zieltabelle für die Sammlung und repliziert alle Dokumente.• Wenn Sie eine vorhandene Sammlung in der Quelldatenbank umbenennen, benennt AWS DMS die
Zieltabelle nicht um.Tabellenmodus
Im Tabellenmodus wandelt AWS DMS jedes Top-Level-Feld in einem MongoDB-Dokument in eineSpalte in der Zieltabelle um. Wenn ein Feld verschachtelt ist, reduziert AWS DMS die verschachteltenWerte auf eine einzelne Spalte. AWS DMS fügt der Spaltengruppe in der Zieltabelle dann einSchlüsselfeld und Datentypen hinzu.
Für jedes MongoDB-Dokument fügt AWS DMS jeden Schlüssel und Typ der Spaltengruppe in derTabelle der Zieldatenbank hinzu. Im Tabellenmodus migriert AWS DMS beispielsweise das vorherigeBeispiel in die folgende Tabelle.
oid_id a b c
5a94815f40bd44d1b02bdfe01 2 3
5a94815f40bd44d1b02bdfe14 5 6
Verschachtelte Werte werden in einer Spalte mit durch Punkte getrennte Schlüsselnamen auf eineEbene gebracht. Die Spalte erhält als Name die Namensverkettung der reduzierten Felder, die durchPunkte voneinander getrennt sind. Beispiel: AWS DMS migriert ein JSON-Dokument mit einem Feldverschachtelter Werte wie beispielsweise {"a" : {"b" : {"c": 1}}} in eine Spalte mit demNamen a.b.c..
Zum Erstellen der Zielspalten scannt AWS DMS eine angegebene Anzahl von MongoDB-Dokumentenund erstellt eine Gruppe aller Felder und deren Typen. AWS DMS verwendet diese Gruppe dann,um die Spalten der Zieltabelle zu erstellen. Wenn Sie Ihren MongoDB-Quellendpunkt mithilfe derKonsole erstellen oder ändern, können Sie die Anzahl der zu scannenden Dokumente angeben. DerStandardwert ist 1000 Dokumente. Wenn Sie die AWS CLI verwenden, können Sie das zusätzlicheVerbindungsattribut docsToInvestigate verwenden.
Hier sehen Sie, wie AWS DMS Dokumente und Sammlungen im Tabellenmodus verwaltet:• Wenn Sie ein Dokument zu einer vorhandenen Sammlung hinzufügen, wird das Dokument repliziert.
Wenn es Felder gibt, die am Ziel nicht vorhanden sind, werden diese Felder nicht repliziert.• Wenn Sie ein Dokument aktualisieren, wird das aktualisierte Dokument repliziert. Wenn es Felder
gibt, die am Ziel nicht vorhanden sind, werden diese Felder nicht repliziert.• Das Löschen eines Dokuments wird vollständig unterstützt.• Das Hinzufügen einer neuen Sammlung führt nicht zu einer neuen Tabelle in der Zieldatenbank,
wenn der Vorgang zeitgleich mit einer CDC-Aufgabe erfolgt.• Das Umbenennen einer Sammlung wird nicht unterstützt.
API-Version API Version 2016-01-01197
AWS Database Migration Service BenutzerhandbuchVerwenden von MongoDB als Quelle
Erforderliche Berechtigungen für die Verwendung von MongoDBals Quelle für AWS DMSBei einer AWS DMS-Migration mit einer MongoDB-Quelle können Sie entweder ein Benutzerkonto mitStammverzeichnisberechtigungen oder einen Benutzer nur mit Berechtigungen für die zu migrierendeDatenbank erstellen.
Der folgende Code erstellt einen Benutzer als Stammkonto.
use admindb.createUser( { user: "root", pwd: "password", roles: [ { role: "root", db: "admin" } ] })
Der folgende Code erstellt einen Benutzer mit minimalen Berechtigungen für die zu migrierendeDatenbank.
use database_to_migratedb.createUser( { user: "dms-user", pwd: "password", roles: [ { role: "read", db: "local" }, "read"] })
Konfigurieren eines MongoDB-Replikatsatzes für Change DataCapture (CDC)Zur Verwendung der fortlaufenden Replikation oder von Change Data Capture (CDC) mit MongoDBbenötigt AWS DMS Zugriff auf das Protokoll der MongoDB-Operationen (oplog). Zum Erstellen desProtokolls "oplog" müssen Sie einen Replikatsatz bereitstellen, sofern keiner vorhanden ist. WeitereInformationen finden Sie in der MongoDB-Dokumentation.
Sie können CDC mit dem primären oder sekundären Knoten eines MongoDB-Replikatsatzes alsQuellendpunkt verwenden.
So wandeln Sie eine eigenständige Instance in einen Replikatsatz um
1. Stellen Sie über die Befehlszeile eine Verbindung mit mongo her.
mongo localhost
2. Stoppen Sie den Service mongod.
service mongod stop
3. Starten Sie mongod mit dem folgenden Befehl neu:
mongod --replSet "rs0" --auth -port port_number
4. Testen Sie die Verbindung zum Replikatsatz mithilfe der folgenden Befehle:
API-Version API Version 2016-01-01198

AWS Database Migration Service BenutzerhandbuchVerwenden von MongoDB als Quelle
mongo -u root -p password --host rs0/localhost:port_number --authenticationDatabase "admin"
Wenn Sie eine Migration im Dokumentmodus durchführen möchten, wählen Sie beim Erstellen desMongoDB-Endpunkts die Option _id as a separate column aus. Bei Auswahl dieser Option wird einezweite Spalte namens _id erstellt, die als Primärschlüssel fungiert. Diese zweite Spalte wird von AWSDMS zur Unterstützung von DML-Operationen (Data Manipulation Language) benötigt.
Sicherheitsanforderungen für die Verwendung von MongoDB alsQuelle für AWS DMSAWS DMS unterstützt zwei Authentifizierungsmethoden für MongoDB. Die beidenAuthentifizierungsmethoden werden verwendet, um das Passwort zu verschlüsseln, daher werden sie nurverwendet, wenn der Parameter authType auf PASSWORD festgelegt ist.
Die MongoDB-Authentifizierungsmethoden sind:
• MONGODB-CR – die Standardeinstellung bei der Verwendung von MongoDB 2.x-Authentifizierung.• SCRAM-SHA-1 – die Standardeinstellung bei der Verwendung von MongoDB-Version 3.x-
Authentifizierung
Wenn keine Authentifizierungsmethode angegeben ist, verwendet AWS DMS die Standardmethode für dieVersion der MongoDB-Quelle.
Einschränkungen bei der Verwendung von MongoDB als Quellefür AWS DMSDie folgenden Einschränkungen gelten bei der Verwendung von MongoDB als Quelle für AWS DMS:
• Wenn die Option _id als separate Spalte gesetzt ist, darf der ID-String 200 Zeichen nicht überschreiten.• Objekt-ID und Array-Schlüssel werden in Spalten konvertiert, die mit dem Präfix oid und array im
Tabellenmodus versehen sind.
Intern wird auf diese Spalten mit den mit Präfix versehenen Namen verwiesen. Wenn Sie inAWS DMS Transformationsregeln verwenden, die auf diese Spalten verweisen, müssen Sie denmit Präfix versehenen Spaltenamen angeben. Sie geben z. B. ${oid__id} statt ${_id} oder${array__addresses} und nicht ${_addresses} an.
• Namen für Sammlungen dürfen das Dollarzeichen ($) nicht enthalten.• Der Tabellenmodus und der Dokumentmodus haben die oben genannten Einschränkungen.
Zusätzliche Verbindungsattribute bei der Verwendung vonMongoDB als Quelle für AWS DMSWenn Sie Ihren MongoDB-Quellendpunkt festlegen, können Sie zusätzliche Verbindungsattributeangeben. Extra connection attributes werden als Schlüssel-Wert-Paare angegeben. Wenn Sie mehrereVerbindungsattributeinstellungen verwenden, trennen Sie diese durch Semikola und ohne zusätzlicheLeerräume voneinander (z. B. oneSetting;thenAnother).
Die folgende Tabelle beschreibt die zusätzlichen Verbindungsattribute, die bei der Verwendung vonMongoDB-Datenbanken als AWS DMS-Quelle verfügbar sind.
API-Version API Version 2016-01-01199
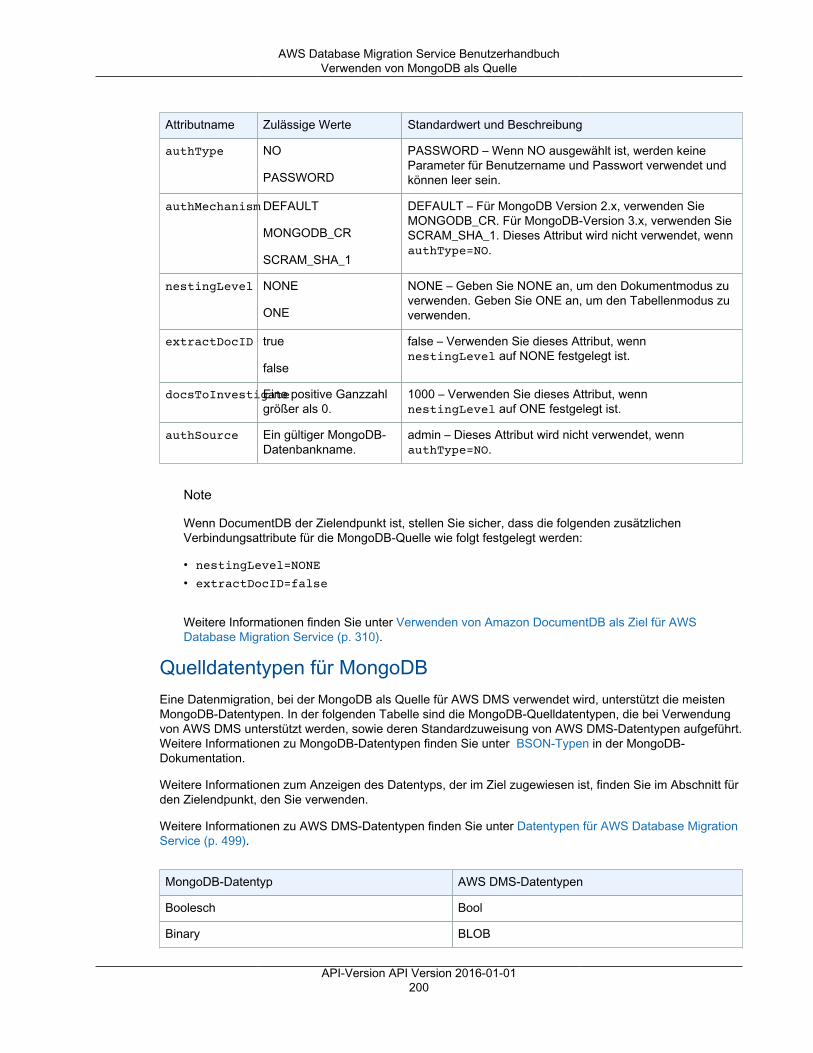
AWS Database Migration Service BenutzerhandbuchVerwenden von MongoDB als Quelle
Attributname Zulässige Werte Standardwert und Beschreibung
authType NO
PASSWORD
PASSWORD – Wenn NO ausgewählt ist, werden keineParameter für Benutzername und Passwort verwendet undkönnen leer sein.
authMechanismDEFAULT
MONGODB_CR
SCRAM_SHA_1
DEFAULT – Für MongoDB Version 2.x, verwenden SieMONGODB_CR. Für MongoDB-Version 3.x, verwenden SieSCRAM_SHA_1. Dieses Attribut wird nicht verwendet, wennauthType=NO.
nestingLevel NONE
ONE
NONE – Geben Sie NONE an, um den Dokumentmodus zuverwenden. Geben Sie ONE an, um den Tabellenmodus zuverwenden.
extractDocID true
false
false – Verwenden Sie dieses Attribut, wennnestingLevel auf NONE festgelegt ist.
docsToInvestigateEine positive Ganzzahlgrößer als 0.
1000 – Verwenden Sie dieses Attribut, wennnestingLevel auf ONE festgelegt ist.
authSource Ein gültiger MongoDB-Datenbankname.
admin – Dieses Attribut wird nicht verwendet, wennauthType=NO.
Note
Wenn DocumentDB der Zielendpunkt ist, stellen Sie sicher, dass die folgenden zusätzlichenVerbindungsattribute für die MongoDB-Quelle wie folgt festgelegt werden:
• nestingLevel=NONE
• extractDocID=false
Weitere Informationen finden Sie unter Verwenden von Amazon DocumentDB als Ziel für AWSDatabase Migration Service (p. 310).
Quelldatentypen für MongoDBEine Datenmigration, bei der MongoDB als Quelle für AWS DMS verwendet wird, unterstützt die meistenMongoDB-Datentypen. In der folgenden Tabelle sind die MongoDB-Quelldatentypen, die bei Verwendungvon AWS DMS unterstützt werden, sowie deren Standardzuweisung von AWS DMS-Datentypen aufgeführt.Weitere Informationen zu MongoDB-Datentypen finden Sie unter BSON-Typen in der MongoDB-Dokumentation.
Weitere Informationen zum Anzeigen des Datentyps, der im Ziel zugewiesen ist, finden Sie im Abschnitt fürden Zielendpunkt, den Sie verwenden.
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
MongoDB-Datentyp AWS DMS-Datentypen
Boolesch Bool
Binary BLOB
API-Version API Version 2016-01-01200

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Quelle
MongoDB-Datentyp AWS DMS-Datentypen
Datum Datum
Zeitstempel Datum
Int INT4
Long INT8
Double REAL8
String (UTF-8) CLOB
Array CLOB
OID Zeichenfolge
REGEX CLOB
CODE CLOB
Verwenden von Amazon S3 als Quelle für AWS DMSSie können Daten aus einem Amazon S3-Bucket mithilfe von AWS DMS migrieren. Erteilen Sie dazuZugriff auf einen Amazon S3-Bucket mit einer oder mehreren Datendateien. Fügen Sie diesem S3-Bucketeine JSON-Datei hinzu, die die Zuweisung zwischen den Daten und den Datenbanktabellen der Daten indiesen Dateien beschreibt.
Die Quelldatendateien müssen im Amazon S3-Bucket enthalten sein, bevor das vollständige Ladenbeginnt. Geben Sie den Bucket-Namen mit dem bucketName-Parameter an.
Die Quelldatendateien müssen im CSV-Format vorliegen. Geben Sie Ihnen einen Namen und verwendenSie dazu die folgende Namenskonvention. In dieser Konvention ist schemaName das Quellschema undtableName ist der Name einer Tabelle in diesem Schema.
/schemaName/tableName/LOAD001.csv/schemaName/tableName/LOAD002.csv/schemaName/tableName/LOAD003.csv...
Angenommen, Ihre Datendateien befinden sich in mybucket im folgenden Amazon S3-Pfad.
s3://mybucket/hr/employee
Zur Ladezeit nimmt AWS DMS an, dass der Name des Quellschemas hr und der Name der Quelltabelleemployee ist.
Zusätzlich zu bucketName (erforderlich) können Sie optional einen bucketFolder-Parameterbereitstellen, um anzugeben, wo AWS DMS nach Datendateien im Amazon S3-Bucket suchen soll. WennSie im vorherigen Beispiel bucketFolder auf sourcedata festlegen, liest AWS DMS die Datendateien imfolgenden Pfad.
s3://mybucket/sourcedata/hr/employee
Sie können mithilfe der zusätzlichen Verbindungsattribute die Trennzeichen für die Spalte und die Zeilesowie den Nullwertindikator und andere Parameter festlegen. Weitere Informationen finden Sie unterZusätzliche Verbindungsattribute für Amazon S3 als Quelle für AWS DMS (p. 205).
API-Version API Version 2016-01-01201

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Quelle
Definieren von externen Tabellen für Amazon S3 als Quelle fürAWS DMSZusätzlich zu den Datendateien müssen Sie auch eine externe Tabellendefinition bereitstellen. Eineexterne Tabellendefinition ist ein JSON-Dokument, in dem beschrieben wird, wie AWS DMS die Datenaus Amazon S3 interpretieren soll. Die maximale Größe dieses Dokuments ist 2 MB. Wenn Sie einenQuellendpunkt mithilfe der AWS DMS-Managementkonsole erstellen, können Sie JSON direkt in dasTabellenzuweisungsfeld eingeben. Wenn Sie die AWS Command Line Interface (AWS CLI) oder AWSDMS-API zum Durchführen von Migrationen verwenden, können Sie eine JSON-Datei zur Angabe derexternen Tabellendefinition erstellen.
Angenommen, Sie haben eine Datei mit den folgenden Daten.
101,Smith,Bob,2014-06-04,New York102,Smith,Bob,2015-10-08,Los Angeles103,Smith,Bob,2017-03-13,Dallas104,Smith,Bob,2017-03-13,Dallas
Im Folgenden sehen Sie ein Beispiel für eine externe Tabellendefinition für diese Daten.
{ "TableCount": "1", "Tables": [ { "TableName": "employee", "TablePath": "hr/employee/", "TableOwner": "hr", "TableColumns": [ { "ColumnName": "Id", "ColumnType": "INT8", "ColumnNullable": "false", "ColumnIsPk": "true" }, { "ColumnName": "LastName", "ColumnType": "STRING", "ColumnLength": "20" }, { "ColumnName": "FirstName", "ColumnType": "STRING", "ColumnLength": "30" }, { "ColumnName": "HireDate", "ColumnType": "DATETIME" }, { "ColumnName": "OfficeLocation", "ColumnType": "STRING", "ColumnLength": "20" } ], "TableColumnsTotal": "5" } ]}
In diesem JSON-Dokument sind folgende Elemente enthalten:
API-Version API Version 2016-01-01202

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Quelle
TableCount – die Anzahl der Quelltabellen. In diesem Beispiel es nur eine Tabelle.
Tables – ein Array bestehend aus einer JSON-Zuweisung je Quelltabelle. In diesem Beispiel es nur eineZuweisung. Jede Zuweisung umfasst die folgenden Schlüsselelemente:
• TableName – der Name der Quelltabelle.• TablePath – der Pfad in Ihrem Amazon S3-Bucket, in dem AWS DMS die Datei mit den Daten zum
vollständigen Laden finden kann. Wenn ein bucketFolder-Wert angegeben ist, wird dieser Wert demPfad vorangestellt.
• TableOwner – der Name des Schemas für diese Tabelle.• TableColumns – ein Array einer oder mehrerer Zuweisungen, die jeweils eine Spalte in der Quelltabelle
beschreiben:• ColumnName – der Name einer Spalte in der Quelltabelle.• ColumnType – der Datentyp für die Spalte. Die zulässigen Datentypen finden Sie unter
Quelldatentypen für Amazon S3 (p. 207).• ColumnLength – die Anzahl an Bytes in dieser Spalte. Die maximale Spaltenlänge ist auf
2.147.483.647 Bytes (2.047 MegaBytes) begrenzt, da eine S3-Quelle den FULL LOB-Modus nichtunterstützt.
• ColumnNullable – (optional) ein boolescher Wert, der true lautet, wenn diese Spalte NULL-Werteenthalten darf.
• ColumnIsPk – (optional) ein boolescher Wert, der true lautet, wenn diese Spalte Teil desPrimärschlüssels ist.
• TableColumnsTotal – die Gesamtanzahl der Spalten. Diese Anzahl muss der Anzahl der Elemente imTableColumns-Array entsprechen.
ColumnLength gilt für die folgenden Datentypen:
• BYTE• STRING
Wenn Sie nichts anderes angeben, geht AWS DMS davon aus, dass ColumnLength Null ist.Note
In DMS Versionen 3.1.4 und höher können die S3-Quelldaten auch eine optionaleOperationsspalte als erste Spalte enthalten, die sich vor dem TableName-Spaltenwert befindet.Diese Operationsspalte identifiziert die Operation (INSERT), die verwendet wird, um die Datenwährend eines vollständigen Ladevorgangs zu einem S3-Zielendpunkt zu migrieren.Falls vorhanden, ist der Wert dieser Spalte das erste Zeichen des INSERT-Schlüsselworts derOperation (I). Sofern vorhanden, gibt diese Spalte in der Regel an, dass die S3-Quelle währendeiner früheren Migration durch DMS als S3-Ziel erstellt wurde.In früheren DMS-Versionen war diese Spalte in den S3-Quelldaten, die aus einem früherenvollständigen DMS-Ladevorgang erstellt wurden, nicht vorhanden. Durch das Hinzufügen dieserSpalte zu den S3-Zieldaten werden alle Zeilen in einem konsistenten Format zum S3-Zielgeschrieben. Dies geschieht unabhängig davon, ob die Daten während eines vollständigen oderwährend eines CDC-Ladevorgangs geschrieben werden. Weitere Informationen zu den Optionenzum Formatieren von S3-Zieldaten finden Sie unter Angabe von Quelldatenbankoperationen inmigrierten S3-Daten (p. 269).
Für eine Spalte des Typs NUMERIC müssen Sie die Genauigkeit und Skalierung festlegen. Genauigkeit istdie Gesamtanzahl der Stellen in einer Zahl und Skalierung die Anzahl der Dezimalstellen. Dafür verwendenSie die Elemente ColumnPrecision und ColumnScale, wie im Folgenden dargestellt.
... {
API-Version API Version 2016-01-01203

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Quelle
"ColumnName": "HourlyRate", "ColumnType": "NUMERIC", "ColumnPrecision": "5" "ColumnScale": "2" }...
Verwenden von CDC mit Amazon S3 als Quelle für AWS DMSNachdem AWS DMS einen vollständigen Datenladevorgang ausgeführt hat, können optionalDatenänderungen für den Zielendpunkt repliziert werden. Zu diesem Zweck laden Sie Change DataCapture-Dateien (CDC-Dateien) in Ihren Amazon S3-Bucket hoch. AWS DMS liest diese CDC-Dateien,wenn Sie sie hochladen. Anschließend werden die Änderungen für den Zielendpunkt übernommen.
Die CDC-Dateien werden wie folgt benannt:
CDC00001.csvCDC00002.csvCDC00003.csv...
Note
Um CDC-Dateien im Änderungsdatenordner zu replizieren, laden Sie sie erfolgreich inlexikalischer (sequenzieller) Reihenfolge hoch. Laden Sie z. B. die Datei „CDC00002.csv“ vorder Datei „CDC00003.csv“ hoch. Andernfalls wird die Datei „CDC00002.csv“ übersprungen undnicht repliziert, wenn Sie sie zeitlich nach „CDC00003.csv“ laden. Die Datei „CDC00004.csv“ wirdjedoch erfolgreich repliziert, wenn sie nach der Datei „CDC00003.csv“ geladen wird.
Um anzugeben, wo AWS DMS die Dateien finden kann, müssen Sie den Parameter cdcPath festlegen.Wenn Sie im vorherigen Beispiel cdcPath auf changedata setzen, liest AWS DMS die CDC-Dateien imfolgenden Pfad.
s3://mybucket/changedata
Die Datensätze in einer CDC-Datei werden wie folgt formatiert:
• Operation – die Änderungsoperation, die ausgeführt werden soll: INSERT oder I, UPDATE oderU, DELETE oder D. Diese Schlüsselwort- und Zeichenwerte unterscheiden zwischen Groß- undKleinschreibung.
Note
In den AWS DMS-Versionen 3.1.4 und höher kann DMS die Operation, die für die einzelnenDatensätze ausgeführt werden soll, auf zwei Arten erkennen. DMS leitet dies anhand desSchlüsselwortwerts des Datensatzes (z. B. INSERT) oder anhand des Anfangszeichens desSchlüsselworts (z. B. I) ab. In früheren Versionen konnte DMS die Ladeoperation nur amvollständigen Wert des Schlüsselworts erkennen.In früheren Versionen von DMS wurde der vollständige Wert des Schlüsselworts geschrieben,um die CDC-Daten zu protokollieren. Vorherige Versionen schrieben den Operationswert nurmithilfe des Anfangszeichens des Schlüsselworts in die einzelnen S3-Ziele.Dadurch, dass nun beide Formate erkannt werden, kann DMS die Operation bearbeiten,unabhängig davon, wie die Operationsspalte zum Erstellen der S3-Quelldaten geschriebenwurde. Dieser Ansatz unterstützt die Verwendung von S3-Zieldaten als Quelle für eine spätereMigration. Dank dieses Ansatzes müssen Sie nicht länger das Format des Anfangszeichenseines Schlüsselworts ändern, das in der Operationsspalte der späteren S3-Quelle erscheint
• Tabellenname – der Name der Quelltabelle.• Schemaname – der Name des Quellschemas.
API-Version API Version 2016-01-01204

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Quelle
• Daten – eine oder mehrere Spalten, die die zu ändernden Daten darstellen.
Im Folgenden sehen Sie ein Beispiel einer CDC-Datei für eine Tabelle mit dem Namen employee.
INSERT,employee,hr,101,Smith,Bob,2014-06-04,New YorkUPDATE,employee,hr,101,Smith,Bob,2015-10-08,Los AngelesUPDATE,employee,hr,101,Smith,Bob,2017-03-13,DallasDELETE,employee,hr,101,Smith,Bob,2017-03-13,Dallas
Voraussetzungen für die Verwendung von Amazon S3 als Quellefür AWS DMSWenn Sie Amazon S3 als Quelle für AWS DMS verwenden, muss sich der S3-Quell-Bucket in derselbenAWS-Region befinden wie die DMS-Replikations-Instance, mit der Sie Ihre Daten migrieren. Darüberhinaus muss das AWS-Konto, das Sie für die Migration verwenden, über Lesezugriff zum Quell-Bucketverfügen.
Die dem Benutzerkonto zugewiesene AWS Identity and Access Management (IAM)-Rolle, mit der dieMigrationsaufgabe erstellt wird, muss den folgenden Satz von Berechtigungen aufweisen.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject" ], "Resource": [ "arn:aws:s3:::mybucket*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::mybucket*" ] } ]}
Zusätzliche Verbindungsattribute für Amazon S3 als Quelle fürAWS DMSSie können die folgenden Optionen als zusätzliche Verbindungsattribute festlegen.
Option Description (Beschreibung)
bucketFolder (Optional) Ein Ordnername im S3-Bucket. Wenn dieses Attributangegeben ist, werden die Source-Dateien und CDC-Dateien im PfadbucketFolder/schemaName/tableName/ gelesen. Wenn dieses Attributnicht angegeben ist, wird der Pfad schemaName/tableName/ verwendet.Ein Beispiel folgt.
API-Version API Version 2016-01-01205
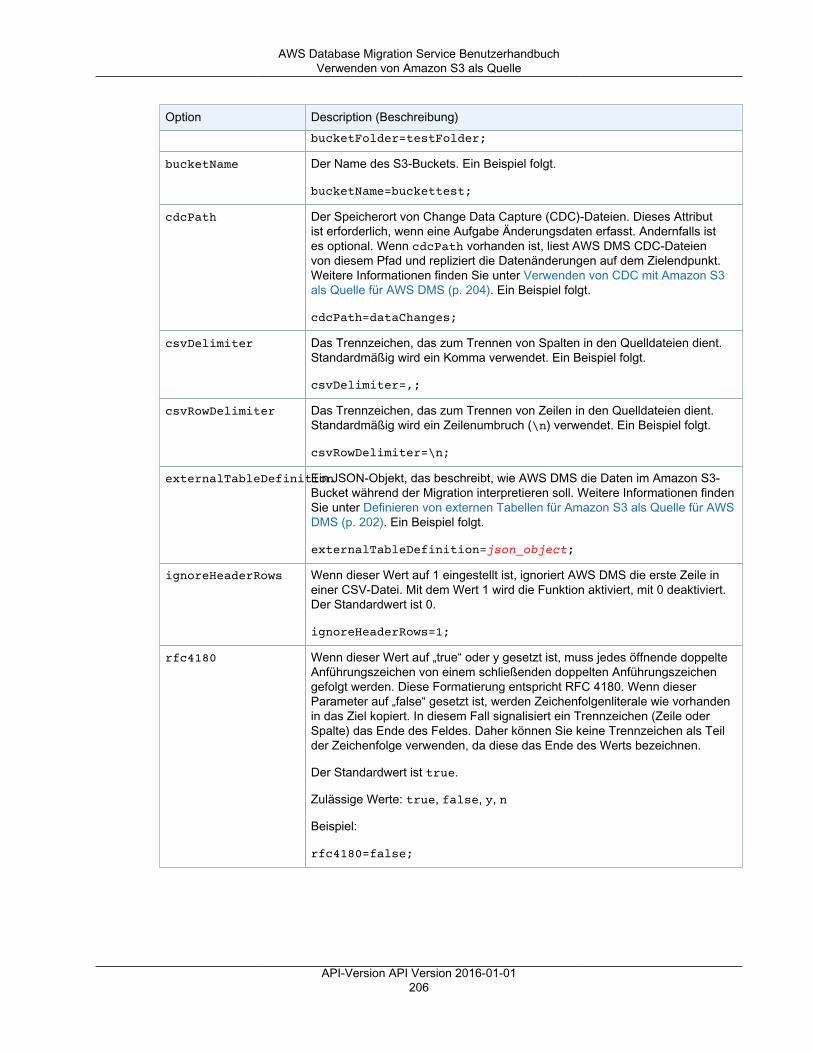
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Quelle
Option Description (Beschreibung)bucketFolder=testFolder;
bucketName Der Name des S3-Buckets. Ein Beispiel folgt.
bucketName=buckettest;
cdcPath Der Speicherort von Change Data Capture (CDC)-Dateien. Dieses Attributist erforderlich, wenn eine Aufgabe Änderungsdaten erfasst. Andernfalls istes optional. Wenn cdcPath vorhanden ist, liest AWS DMS CDC-Dateienvon diesem Pfad und repliziert die Datenänderungen auf dem Zielendpunkt.Weitere Informationen finden Sie unter Verwenden von CDC mit Amazon S3als Quelle für AWS DMS (p. 204). Ein Beispiel folgt.
cdcPath=dataChanges;
csvDelimiter Das Trennzeichen, das zum Trennen von Spalten in den Quelldateien dient.Standardmäßig wird ein Komma verwendet. Ein Beispiel folgt.
csvDelimiter=,;
csvRowDelimiter Das Trennzeichen, das zum Trennen von Zeilen in den Quelldateien dient.Standardmäßig wird ein Zeilenumbruch (\n) verwendet. Ein Beispiel folgt.
csvRowDelimiter=\n;
externalTableDefinitionEin JSON-Objekt, das beschreibt, wie AWS DMS die Daten im Amazon S3-Bucket während der Migration interpretieren soll. Weitere Informationen findenSie unter Definieren von externen Tabellen für Amazon S3 als Quelle für AWSDMS (p. 202). Ein Beispiel folgt.
externalTableDefinition=json_object;
ignoreHeaderRows Wenn dieser Wert auf 1 eingestellt ist, ignoriert AWS DMS die erste Zeile ineiner CSV-Datei. Mit dem Wert 1 wird die Funktion aktiviert, mit 0 deaktiviert.Der Standardwert ist 0.
ignoreHeaderRows=1;
rfc4180 Wenn dieser Wert auf „true“ oder y gesetzt ist, muss jedes öffnende doppelteAnführungszeichen von einem schließenden doppelten Anführungszeichengefolgt werden. Diese Formatierung entspricht RFC 4180. Wenn dieserParameter auf „false“ gesetzt ist, werden Zeichenfolgenliterale wie vorhandenin das Ziel kopiert. In diesem Fall signalisiert ein Trennzeichen (Zeile oderSpalte) das Ende des Feldes. Daher können Sie keine Trennzeichen als Teilder Zeichenfolge verwenden, da diese das Ende des Werts bezeichnen.
Der Standardwert ist true.
Zulässige Werte: true, false, y, n
Beispiel:
rfc4180=false;
API-Version API Version 2016-01-01206

AWS Database Migration Service BenutzerhandbuchVerwenden von IBM Db2 LUW als Quelle
Quelldatentypen für Amazon S3Eine Datenmigration, die Amazon S3 als Quelle für AWS DMS verwendet, muss die Daten aus AmazonS3 den AWS DMS-Datentypen zuordnen. Weitere Informationen finden Sie unter Definieren von externenTabellen für Amazon S3 als Quelle für AWS DMS (p. 202).
Weitere Informationen zum Anzeigen des Datentyps, der im Ziel zugewiesen ist, finden Sie im Abschnitt fürden Zielendpunkt, den Sie verwenden.
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
Die folgenden AWS DMS-Datentypen werden mit Amazon S3 als Quelle verwendet:
• BYTE – Erfordert ColumnLength. Weitere Informationen finden Sie unter Definieren von externenTabellen für Amazon S3 als Quelle für AWS DMS (p. 202).
• DATE• TIME• DATETIME• TIMESTAMP• INT1• INT2• INT4• INT8• NUMERIC – Erfordert ColumnPrecision und ColumnScale. Weitere Informationen finden Sie unter
Definieren von externen Tabellen für Amazon S3 als Quelle für AWS DMS (p. 202).• REAL4• REAL8• STRING – erfordert ColumnLength. Weitere Informationen finden Sie unter Definieren von externen
Tabellen für Amazon S3 als Quelle für AWS DMS (p. 202).• UINT1• UINT2• UINT4• UINT8• BLOB• CLOB• BOOLEAN
Verwenden von IBM Db2 für Linux, Unix undWindows-Datenbank (Db2 LUW) als Quelle für AWSDMSSie können Daten aus einer IBM Db2 für Linux, Unix und Windows-Datenbank (Db2 LUW) mithilfe vonAWS Database Migration Service (AWS DMS) zu einer beliebigen unterstützten Zieldatenbank migrieren.AWS DMS unterstützt die folgenden Db2 LUW-Versionen als Quelle für die Migration:
• Version 9.7, alle Fix Packs werden unterstützt.• Version 10.1, alle Fix Packs werden unterstützt.• Version 10.5, alle Fix Packs außer Fix Pack 5 werden unterstützt.
API-Version API Version 2016-01-01207

AWS Database Migration Service BenutzerhandbuchVerwenden von IBM Db2 LUW als Quelle
• Version 11.1, alle Fix Packs werden unterstützt.
Sie können Secure Sockets Layer (SSL) verwenden, um Verbindungen zwischen Ihrem Db2 LUW-Endpunkt und der Replikations-Instance zu verschlüsseln. Nutzen Sie bei Verwendung von SSL AWSDMS-Engine-Version 2.4.2 oder höher. Weitere Informationen zur Verwendung von SSL mit einem Db2LUW-Endpunkt finden Sie unter Verwenden von SSL mit AWS Database Migration Service (p. 82).
Voraussetzungen für die Verwendung von Db2 LUW als Quellefür AWS DMSDie folgenden Voraussetzungen müssen erfüllt sein, damit Sie eine Db2 LUW-Datenbank als Quelleverwenden können.
Zum Aktivieren einer fortlaufenden Replikation, auch als Change Data Capture (CDC) bezeichnet, gehenSie wie folgt vor:
• Konfigurieren Sie die Datenbank als wiederherstellbar, damit AWS DMS Änderungen erfassen kann.Eine Datenbank ist wiederherstellbar, wenn einer oder beide der Datenbank-KonfigurationsparameterLOGARCHMETH1 und LOGARCHMETH2 auf ON eingestellt sind.
• Erteilen Sie dem Benutzerkonto die folgenden Berechtigungen:
SYSADM oder DBADM
DATAACCESS
Einschränkungen bei der Verwendung von Db2 LUW als Quellefür AWS DMSAWS DMS unterstützt keine Datenbanken in Clustern. Sie können jedoch für jeden der Endpunkteeines Clusters eine separate Db2 LUW definieren. Weitere Informationen finden Sie in der Db2 LUW-Dokumentation.
Bei der Verwendung der fortlaufenden Replikation (CDC) gelten die folgenden Einschränkungen:
• Wenn eine Tabelle mit mehreren Partitionen verkürzt wird, entspricht die Anzahl der in der AWS DMS-Konsole angezeigten DDL-Ereignisse der Anzahl der Partitionen. Der Grund hierfür ist, dass Db2 LUWeine separate DDL für jede Partition aufzeichnet.
• Die folgenden DDL-Aktionen werden für partitionierte Tabellen nicht unterstützt:• ALTER TABLE ADD PARTITION• ALTER TABLE DETACH PARTITION• ALTER TABLE ATTACH PARTITION
• Der Datentyp DECFLOAT wird nicht unterstützt. Folglich werden Änderungen an DECFLOAT-Spaltenwährend der fortlaufenden Replikation ignoriert.
• Die Anweisung RENAME COLUMN wird nicht unterstützt.• Beim Ausführen von Aktualisierungen für MDC-Tabellen (Multi-Dimensional Clustering) wird jede
Aktualisierung in der AWS DMS-Konsole als INSERT + DELETE angezeigt.• Wenn die Aufgabeneinstellung Include LOB columns in replication (LOB-Spalten in Replikation
einschließen) nicht aktiviert ist, werden alle Tabellen mit LOB-Spalten während der fortlaufendenReplikation gesperrt.
• Wenn die Option „Audit table“ (Prüfungstabelle) aktiviert ist, wird in der Prüfungstabelle als ersterZeitstempel NULL aufgezeichnet.
• Wenn die Option "Change table" (Änderungstabelle) aktiviert ist, wird als erster Zeitstempel in derTabelle null aufgezeichnet (z. B. 1970-01-01 00:00:00.000000).
API-Version API Version 2016-01-01208

AWS Database Migration Service BenutzerhandbuchVerwenden von IBM Db2 LUW als Quelle
• Für Db2 LUW-Versionen 10.5 und höher werden Zeichenfolgen-Spalten variabler Länge mit Daten, dieaußerhalb der Zeile gespeichert werden, ignoriert. Diese Einschränkung gilt nur für Tabellen, die miterweiterter Zeilengröße erstellt wurden.
Zusätzliche Verbindungsattribute bei der Verwendung von Db2LUW als Quelle für AWS DMSSie können zusätzliche Verbindungsattribute verwenden, um Ihre Db2 LUW-Quelle zu konfigurieren.Sie geben diese Einstellungen beim Erstellen des Quellendpunkts an. Wenn Sie mehrereVerbindungsattributeinstellungen verwenden, trennen Sie diese durch Semikola und ohne zusätzlicheLeerräume voneinander (z. B. oneSetting;thenAnother).
Die folgende Tabelle zeigt die zusätzlichen Verbindungsattribute, die Sie verwenden können, wennDb2 LUW die Quelle ist.
Name Beschreibung
CurrentLSN Verwenden Sie für die laufende Replikation (CDC)CurrentLSN, um eine Protokoll-Sequenznummer (LogSequence Number, LSN) anzugeben, ab der die Replikationbeginnen soll.
MaxKBytesPerRead Maximale Anzahl von Bytes pro Lesezugriff als NUMBER-Wert. Der Standardwert ist 64 KB.
SetDataCaptureChanges Aktiviert die fortlaufende Replikation (CDC) als BOOLEAN-Wert. Der Standardwert ist "true".
Quelldatentypen für IBM Db2 LUWEine Datenmigration, bei der Db2 LUW als Quelle für AWS DMS verwendet wird, unterstützt die meistenDb2 LUW-Datentypen. In der folgenden Tabelle sind die Db2 LUW Server-Quelldatentypen, die beiVerwendung von AWS DMS unterstützt werden, sowie deren Standardzuweisung von AWS DMS-Datentypen aufgeführt. Weitere Informationen über die Db2 LUW-Datentypen finden Sie in der Db2 LUW-Dokumentation.
Weitere Informationen zum Anzeigen des Datentyps, der im Ziel zugewiesen ist, finden Sie im Abschnitt fürden Zielendpunkt, den Sie verwenden.
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
Db2 LUW-Datentypen AWS DMS-Datentypen
INTEGER INT4
SMALLINT INT2
BIGINT INT8
DECIMAL (p,s) NUMERIC (p,s)
FLOAT REAL8
DOUBLE REAL8
API-Version API Version 2016-01-01209
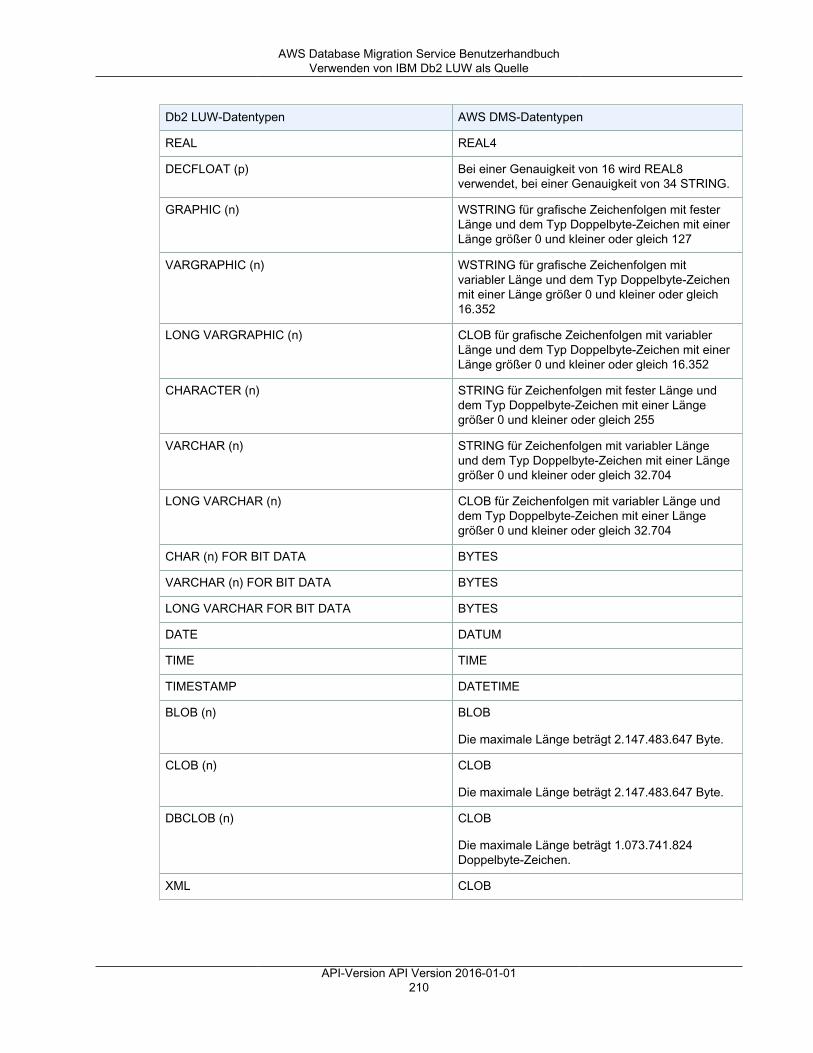
AWS Database Migration Service BenutzerhandbuchVerwenden von IBM Db2 LUW als Quelle
Db2 LUW-Datentypen AWS DMS-Datentypen
REAL REAL4
DECFLOAT (p) Bei einer Genauigkeit von 16 wird REAL8verwendet, bei einer Genauigkeit von 34 STRING.
GRAPHIC (n) WSTRING für grafische Zeichenfolgen mit festerLänge und dem Typ Doppelbyte-Zeichen mit einerLänge größer 0 und kleiner oder gleich 127
VARGRAPHIC (n) WSTRING für grafische Zeichenfolgen mitvariabler Länge und dem Typ Doppelbyte-Zeichenmit einer Länge größer 0 und kleiner oder gleich16.352
LONG VARGRAPHIC (n) CLOB für grafische Zeichenfolgen mit variablerLänge und dem Typ Doppelbyte-Zeichen mit einerLänge größer 0 und kleiner oder gleich 16.352
CHARACTER (n) STRING für Zeichenfolgen mit fester Länge unddem Typ Doppelbyte-Zeichen mit einer Längegrößer 0 und kleiner oder gleich 255
VARCHAR (n) STRING für Zeichenfolgen mit variabler Längeund dem Typ Doppelbyte-Zeichen mit einer Längegrößer 0 und kleiner oder gleich 32.704
LONG VARCHAR (n) CLOB für Zeichenfolgen mit variabler Länge unddem Typ Doppelbyte-Zeichen mit einer Längegrößer 0 und kleiner oder gleich 32.704
CHAR (n) FOR BIT DATA BYTES
VARCHAR (n) FOR BIT DATA BYTES
LONG VARCHAR FOR BIT DATA BYTES
DATE DATUM
TIME TIME
TIMESTAMP DATETIME
BLOB (n) BLOB
Die maximale Länge beträgt 2.147.483.647 Byte.
CLOB (n) CLOB
Die maximale Länge beträgt 2.147.483.647 Byte.
DBCLOB (n) CLOB
Die maximale Länge beträgt 1.073.741.824Doppelbyte-Zeichen.
XML CLOB
API-Version API Version 2016-01-01210

AWS Database Migration Service BenutzerhandbuchZiele für die Datenmigration
Ziele für die DatenmigrationAWS Database Migration Service (AWS DMS) kann viele der beliebtesten Datenbanken als Ziel für dieDatenreplikation verwenden. Das Ziel kann sich auf einer Amazon Elastic Compute Cloud(Amazon EC2)-Instance, einer Amazon Relational Database Service(Amazon RDS)-Instance oder einer lokalen Datenbankbefinden.
Die Datenbanken umfassen Folgendes:
Lokale und Amazon EC2-Instance-Datenbanken
• Oracle Versionen 10g, 11g, 12c, 18c und 19c für die Editionen Enterprise, Standard, Standard One undStandard Two.
Note
• Unterstützung für Oracle-Version 19c als Ziel ist in den AWS DMS-Versionen 3.3.2 und höherverfügbar.
• Unterstützung für Oracle-Version 18c als Ziel ist in den AWS DMS-Versionen 3.3.1 und höherverfügbar.
• Microsoft SQL Server-Versionen 2005, 2008, 2008R2, 2012, 2014, 2016, 2017 und 2019. Die EditionenEnterprise, Standard, Workgroup und Developer werden unterstützt. Die Web und Express Editionwerden von AWS DMS nicht unterstützt.
Note
Unterstützung für Microsoft SQL Server Version 2019 als Ziel ist in den AWS DMS-Versionen3.3.2 und höher verfügbar.
• MySQL-Versionen 5.5, 5.6, 5.7 und 8.0.
Note
Unterstützung für MySQL 8.0 ist in den AWS DMS-Versionen 3.3.1 und höher verfügbar.• MariaDB (unterstützt als MySQL-kompatibles Datenziel), Versionen 10.0.24 bis 10.0.28, 10.1, 10.2 und
10.3.
Note
Unterstützung für MariaDB als Ziel ist in allen AWS DMS-Versionen verfügbar, in denen MySQLunterstützt wird.
• PostgreSQL-Version 9.4 und höher (für Versionen 9.x), 10.x und 11.x.
Note
Die PostgreSQL-Versionen 11.x werden nur in den AWS DMS-Versionen 3.3.1 und höher alsZiel unterstützt. Sie können die PostgreSQL-Versionen 9.4 und höher (für Versionen 9.x) und10.x als Ziel in jeder beliebigen DMS-Version verwenden.
• SAP Adaptive Server Enterprise (ASE)-Versionen 15, 15.5, 15.7, 16 und höher.
Amazon RDS-Instance-Datenbanken, Amazon Redshift, Amazon S3, Amazon DynamoDB,Amazon Elasticsearch Service, Amazon Kinesis Data Streams und Amazon DocumentDB
• Amazon RDS für die Oracle-Versionen 11g (Versionen 11.2.0.3.v1 und höher), 12c, 18c und 19c für dieEditionen Enterprise, Standard, Standard One und Standard Two.
API-Version API Version 2016-01-01211

AWS Database Migration Service BenutzerhandbuchZiele für die Datenmigration
Note
• Unterstützung für Oracle-Version 19c als Ziel ist in den AWS DMS-Versionen 3.3.2 und höherverfügbar.
• Unterstützung für Oracle-Version 18c als Ziel ist in den AWS DMS-Versionen 3.3.1 und höherverfügbar.
• Amazon RDS für Microsoft SQL Server-Versionen 2008R2, 2012, 2014, 2016, 2017 und 2019. DieEditionen Enterprise, Standard, Workgroup und Developer werden unterstützt. Die Web und ExpressEdition werden von AWS DMS nicht unterstützt.
Note
Unterstützung für Microsoft SQL Server Version 2019 als Ziel ist in den AWS DMS-Versionen3.3.2 und höher verfügbar.
• Amazon RDS für MySQL-Versionen 5.5, 5.6, 5.7 und 8.0.
Note
Unterstützung für MySQL 8.0 ist in den AWS DMS-Versionen 3.3.1 und höher verfügbar.• MariaDB (unterstützt als MySQL-kompatibles Datenziel), Versionen 10.0.24 bis 10.0.28, 10.1, 10.2 und
10.3.
Note
Unterstützung für MariaDB als Ziel ist in allen AWS DMS-Versionen verfügbar, in denen MySQLunterstützt wird.
• PostgreSQL-Version 9.4 und höher (für Versionen 9.x), 10.x und 11.x.
Note
Die PostgreSQL-Versionen 11.x werden nur in den AWS DMS-Versionen 3.3.1 und höher alsZiel unterstützt. Sie können die PostgreSQL-Versionen 9.4 und höher (für Versionen 9.x) und10.x als Ziel in jeder beliebigen DMS-Version verwenden.
• Amazon Aurora mit MySQL-Kompatibilität aus.• Amazon Aurora mit PostgreSQL-Kompatibilität aus.• Amazon Redshift aus.• Amazon S3 aus.• Amazon DynamoDB aus.• Amazon Elasticsearch Service aus.• Amazon Kinesis Data Streams aus.• Apache Kafka – Amazon Managed Streaming for Apache Kafka (Amazon MSK) und selbstverwaltetes
Apache Kafka.• Amazon DocumentDB (mit MongoDB-Kompatibilität) aus.
Note
AWS DMS unterstützt keine regionsübergreifende Migration für die folgenden Ziel-Endpunkttypen:
• Amazon DynamoDB• Amazon Elasticsearch Service• Amazon Kinesis Data Streams
ThemenAPI-Version API Version 2016-01-01
212

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Ziel
• Verwenden einer Oracle-Datenbank als Ziel für AWS Database Migration Service (p. 213)• Verwenden einer Microsoft SQL Server-Datenbank als Ziel für AWS Database Migration
Service (p. 219)• Verwenden einer PostgreSQL-Datenbank als Ziel für AWS Database Migration Service (p. 222)• Verwenden einer MySQL-kompatiblen Datenbank als Ziel für AWS Database Migration
Service (p. 226)• Verwenden einer Amazon Redshift-Datenbank als Ziel für AWS Database Migration Service (p. 231)• Verwenden einer SAP ASE-Datenbank als Ziel für AWS Database Migration Service (p. 243)• Verwenden von Amazon S3 als Ziel für AWS Database Migration Service (p. 245)• Verwenden einer Amazon DynamoDB-Datenbank als Ziel für AWS Database Migration
Service (p. 271)• Verwenden von Amazon Kinesis Data Streams als Ziel für AWS Database Migration Service (p. 285)• Verwendung von Apache Kafka als Ziel für AWS Database Migration Service (p. 296)• Verwenden eines Amazon Elasticsearch Service-Clusters als Ziel für AWS Database Migration
Service (p. 306)• Verwenden von Amazon DocumentDB als Ziel für AWS Database Migration Service (p. 310)
Verwenden einer Oracle-Datenbank als Ziel für AWSDatabase Migration ServiceSie können Daten mithilfe von AWS DMS entweder aus einer anderen Oracle-Datenbank oder einer deranderen unterstützten Datenbanken in Oracle-Zieldatenbanken migrieren. Sie können Secure SocketsLayer (SSL) verwenden, um Verbindungen zwischen Ihrem Oracle-Endpunkt und der Replikations-Instancezu verschlüsseln. Weitere Informationen zur Verwendung von SSL mit einem Oracle-Endpunkt finden Sieunter Verwenden von SSL mit AWS Database Migration Service (p. 82). AWS DMS unterstützt auch dieVerwendung von Oracle Transparent Data Encryption (TDE) zum Verschlüsseln von Daten in Ruhe, diesich in der Zieldatenbank befinden, da Oracle TDE keinen Verschlüsselungsschlüssel und kein Passwortbenötigt, um in die Datenbank zu schreiben.
AWS DMS unterstützt die Oracle-Versionen 10g, 11g, 12c, 18c und 19c für On-Premise- und EC2-Instances für die Editionen Enterprise, Standard, Standard One und Standard Two als Ziele. AWS DMSunterstützt die Oracle-Versionen 11g (Version 11.2.0.3.v1 und höher), 12c, 18c und 19c für Amazon RDS-Instance-Datenbanken für die Editionen Enterprise, Standard, Standard One und Standard Two.
Note
• Unterstützung für Oracle-Version 19c als Ziel ist in den AWS DMS-Versionen 3.3.2 und höherverfügbar.
• Unterstützung für Oracle-Version 18c als Ziel ist in den AWS DMS-Versionen 3.3.1 und höherverfügbar.
Wenn Sie Oracle als Ziel verwenden, gehen wir davon aus, dass die Daten in das Schema oder denBenutzer migriert werden sollen, das bzw. der für die Zielverbindung verwendet wird. Wenn Sie Daten inein anderes Schema migrieren möchten, verwenden Sie dazu eine Schematransformation. Nehmen wir an,Ihr Zielendpunkt stellt eine Verbindung mit dem Benutzer RDSMASTER her und Sie möchten vom BenutzerPERFDATA zu PERFDATA migrieren. Erstellen Sie in diesem Fall eine Transformation, die dem folgendenBeispiel ähnelt.
{ "rule-type": "transformation",
API-Version API Version 2016-01-01213

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Ziel
"rule-id": "2", "rule-name": "2", "rule-action": "rename", "rule-target": "schema", "object-locator": { "schema-name": "PERFDATA"},"value": "PERFDATA"}
Wir gehen darüber hinaus davon aus, dass alle vorhandenen Tabellen- oder Index-Tabellenraumzuweisungen beibehalten werden, wenn es sich bei dem Quellendpunkt auch um Oraclehandelt. Ist der Quellendpunkt nicht Oracle, verwenden wir die standardmäßigen Tabellen- und Index-Tabellenräume in der Zieldatenbank. Wenn Sie Tabellen und Indizes auf verschiedene Tabellen- undIndizes-Namespaces migrieren möchten, verwenden Sie eine Tablespace-Transformation. Angenommen,Sie verfügen über eine Reihe von Tabellen im INVENTORY-Schema, die einigen Tablespaces in derOracle-Quelldatenbank zugeordnet sind. Für die Migration möchten Sie all diese Tabellen zu einemeinzelnen INVENTORYSPACE-Tabellenraum in der Zieldatenbank zuweisen. Erstellen Sie in diesem Falleine Transformation, die dem folgenden Beispiel ähnelt.
{ "rule-type": "transformation", "rule-id": "3", "rule-name": "3", "rule-action": "rename", "rule-target": "table-tablespace", "object-locator": { "schema-name": "INVENTORY", "table-name": "%", "table-tablespace-name": "%" }, "value": "INVENTORYSPACE"}
Weitere Informationen zu Umwandlungen finden Sie unter Festlegen der Tabellenauswahl undTransformationen durch Tabellenzuweisungen mit JSON (p. 377).
Weitere Informationen zum Arbeiten mit Oracle-Datenbanken als Ziel für AWS DMS finden Sie in denfolgenden Abschnitten:
Themen• Einschränkungen bei Oracle als Ziel für AWS Database Migration Service (p. 214)• Benutzerkontoberechtigungen, die bei der Verwendung von Oracle als Ziel erforderlich sind (p. 215)• Konfigurieren einer Oracle-Datenbank als Ziel für AWS Database Migration Service (p. 216)• Zusätzliche Verbindungsattribute bei der Verwendung von Oracle als Ziel für AWS DMS (p. 216)• Zieldatentypen für Oracle (p. 217)
Einschränkungen bei Oracle als Ziel für AWS Database MigrationServiceBei der Verwendung von Oracle als Ziel für die Datenmigration gelten folgende Einschränkungen:
• AWS DMS erstellt kein Schema in der Oracle-Zieldatenbank. Sie müssen gewünschte Schemata selbstin der Oracle-Zieldatenbank erstellen. Der Schemaname muss für das Oracle-Ziel bereits vorhandensein. Tabellen des Quellschemas werden in die Benutzer- oder Schematabelle importiert, die AWS DMS
API-Version API Version 2016-01-01214

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Ziel
zur Herstellung der Verbindung mit der Ziel-Instance verwendet. Um mehrere Schemata zu migrieren,erstellen Sie mehrere Replikationsaufgaben.
• AWS DMS unterstützt die Option Use direct path full load nicht für Tabellen mit INDEXTYPECONTEXT. Um dieses Problem zu umgehen, können Sie den Array-Ladevorgang ausführen.
• Mit der Batch-optimierten Option „Apply (Anwenden)“ wird beim Laden in die Nettoänderungstabelle eindirekter Pfad verwendet, der den XML-Typ nicht unterstützt. Um dieses Problem zu umgehen, könnenSie den transaktionalen Modus „Apply (Anwenden)“ verwenden.
• Leere Zeichenfolgen, die aus Quelldatenbanken migriert werden, können vom Oracle-Ziel unterschiedlichbehandelt (z. B. in eine Leerzeichenfolge konvertiert) werden. Dies kann dazu führen, dass die AWSDMS-Validierung eine Nichtübereinstimmung meldet.
Benutzerkontoberechtigungen, die bei der Verwendung vonOracle als Ziel erforderlich sindUm ein Oracle-Ziel in einer AWS Database Migration Service-Aufgabe zu verwenden, müssen Sie diefolgenden Berechtigungen in der Oracle-Datenbank gewähren. Sie erteilen diese Berechtigungen demBenutzerkonto, das in den Oracle-Datenbankdefinitionen für AWS DMS angegeben wurde.
• SELECT ANY TRANSACTION• SELECT on V$NLS_PARAMETERS• SELECT on V$TIMEZONE_NAMES• SELECT on ALL_INDEXES• SELECT on ALL_OBJECTS• SELECT on DBA_OBJECTS• SELECT on ALL_TABLES• SELECT on ALL_USERS• SELECT on ALL_CATALOG• SELECT on ALL_CONSTRAINTS• SELECT on ALL_CONS_COLUMNS• SELECT on ALL_TAB_COLS• SELECT on ALL_IND_COLUMNS• DROP ANY TABLE• SELECT ANY TABLE• INSERT ANY TABLE• UPDATE ANY TABLE• CREATE ANY VIEW• DROP ANY VIEW• CREATE ANY PROCEDURE• ALTER ANY PROCEDURE• DROP ANY PROCEDURE• CREATE ANY SEQUENCE• ALTER ANY SEQUENCE• DROP ANY SEQUENCE
Erteilen Sie für die im Folgenden angegebenen Anforderungen die genannten zusätzlichenBerechtigungen:
API-Version API Version 2016-01-01215

AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Ziel
• Um eine bestimmte Tabellenliste zu verwenden, weisen Sie den replizierten Tabellen die BerechtigungenSELECT und auch ALTER zu.
• Damit ein Benutzer in einem Standardtabellenbereich eine Tabelle erstellen kann, erteilen Sie dieBerechtigung GRANT UNLIMITED TABLESPACE.
• Für die Anmeldung gewähren Sie die Berechtigung CREATE SESSION.• Bei Verwendung eines direkten Pfads erteilen Sie die Berechtigung LOCK ANY TABLE.• Wenn die Option "DROP and CREATE table" oder "TRUNCATE before loading" in den Einstellungen
des vollständigen Ladevorgangs ausgewählt wird und sich das Schema der Zieltabelle vom Schema desAWS DMS-Benutzers unterscheidet, erteilen Sie die Berechtigung DROP ANY TABLE.
• Um Änderungen in Änderungstabellen oder einer Prüfungstabelle zu speichern, wenn sich das Schemader Zieltabelle von dem des AWS DMS-Benutzers unterscheidet, gewähren Sie die BerechtigungenCREATE ANY TABLE und CREATE ANY INDEX.
Erforderliche Leseberechtigungen für AWS Database Migration Service in derZieldatenbank
Dem AWS DMS-Benutzerkonto müssen Leseberechtigungen für die folgenden DBA-Tabellen erteiltwerden:
• SELECT on DBA_USERS• SELECT on DBA_TAB_PRIVS• SELECT on DBA_OBJECTS• SELECT on DBA_SYNONYMS• SELECT on DBA_SEQUENCES• SELECT on DBA_TYPES• SELECT on DBA_INDEXES• SELECT on DBA_TABLES• SELECT on DBA_TRIGGERS
Wenn eine der erforderlichen Berechtigungen V$xxx nicht erteilt werden kann, erteilen Sie sie V_$xxx.
Konfigurieren einer Oracle-Datenbank als Ziel für AWS DatabaseMigration ServiceDamit Sie eine Oracle-Datenbank als Datenmigrationsziel verwenden können, müssen Sie für AWS DMSein Oracle-Benutzerkonto festlegen. Das Benutzerkonto muss über Lese-/Schreibberechtigungen für dieOracle-Datenbank verfügen, wie angegeben unter Benutzerkontoberechtigungen, die bei der Verwendungvon Oracle als Ziel erforderlich sind (p. 215).
Zusätzliche Verbindungsattribute bei der Verwendung von Oracleals Ziel für AWS DMSSie können zusätzliche Verbindungsattribute verwenden, um Ihr Oracle-Ziel zu konfigurieren. Sie gebendiese Einstellungen beim Erstellen des Zielendpunkts an. Wenn Sie mehrere Attributeinstellungenverwenden, müssen diese durch Semikolons und ohne zusätzlichen Leerraum voneinander getrenntwerden.
Die folgende Tabelle zeigt die zusätzlichen Verbindungsattribute, die bei der Verwendung von Oracle alsZiel verfügbar sind.
API-Version API Version 2016-01-01216
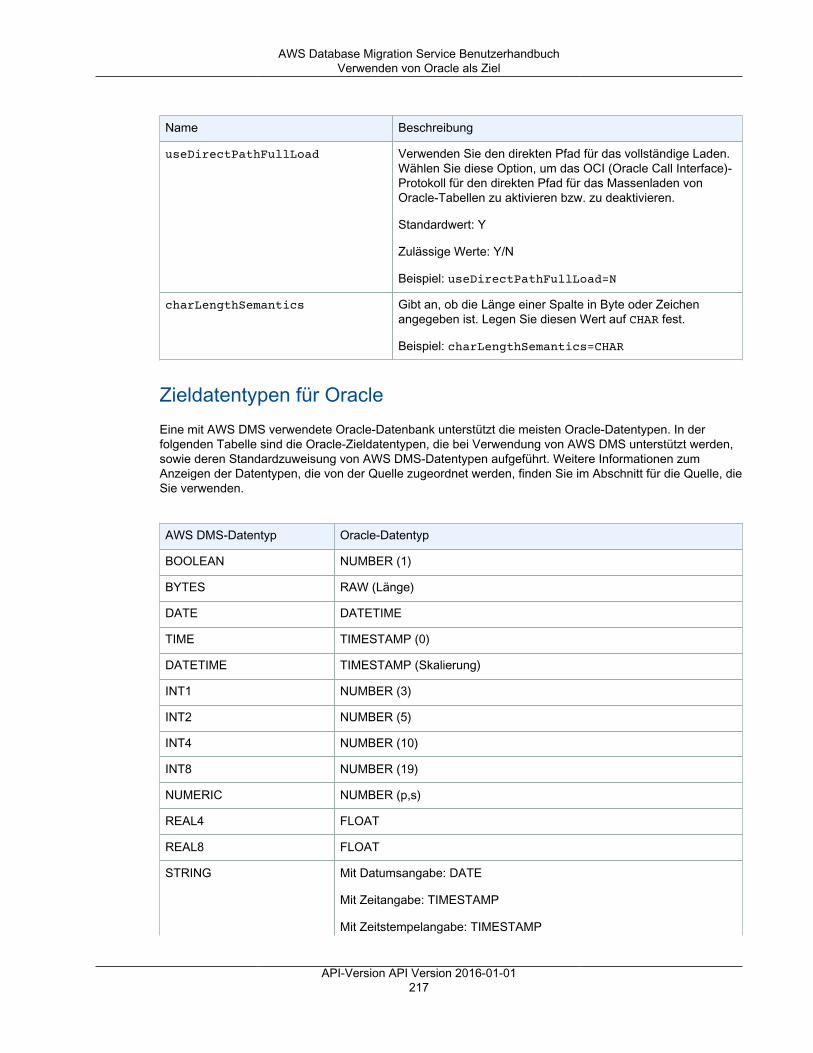
AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Ziel
Name Beschreibung
useDirectPathFullLoad Verwenden Sie den direkten Pfad für das vollständige Laden.Wählen Sie diese Option, um das OCI (Oracle Call Interface)-Protokoll für den direkten Pfad für das Massenladen vonOracle-Tabellen zu aktivieren bzw. zu deaktivieren.
Standardwert: Y
Zulässige Werte: Y/N
Beispiel: useDirectPathFullLoad=N
charLengthSemantics Gibt an, ob die Länge einer Spalte in Byte oder Zeichenangegeben ist. Legen Sie diesen Wert auf CHAR fest.
Beispiel: charLengthSemantics=CHAR
Zieldatentypen für OracleEine mit AWS DMS verwendete Oracle-Datenbank unterstützt die meisten Oracle-Datentypen. In derfolgenden Tabelle sind die Oracle-Zieldatentypen, die bei Verwendung von AWS DMS unterstützt werden,sowie deren Standardzuweisung von AWS DMS-Datentypen aufgeführt. Weitere Informationen zumAnzeigen der Datentypen, die von der Quelle zugeordnet werden, finden Sie im Abschnitt für die Quelle, dieSie verwenden.
AWS DMS-Datentyp Oracle-Datentyp
BOOLEAN NUMBER (1)
BYTES RAW (Länge)
DATE DATETIME
TIME TIMESTAMP (0)
DATETIME TIMESTAMP (Skalierung)
INT1 NUMBER (3)
INT2 NUMBER (5)
INT4 NUMBER (10)
INT8 NUMBER (19)
NUMERIC NUMBER (p,s)
REAL4 FLOAT
REAL8 FLOAT
STRING Mit Datumsangabe: DATE
Mit Zeitangabe: TIMESTAMP
Mit Zeitstempelangabe: TIMESTAMP
API-Version API Version 2016-01-01217
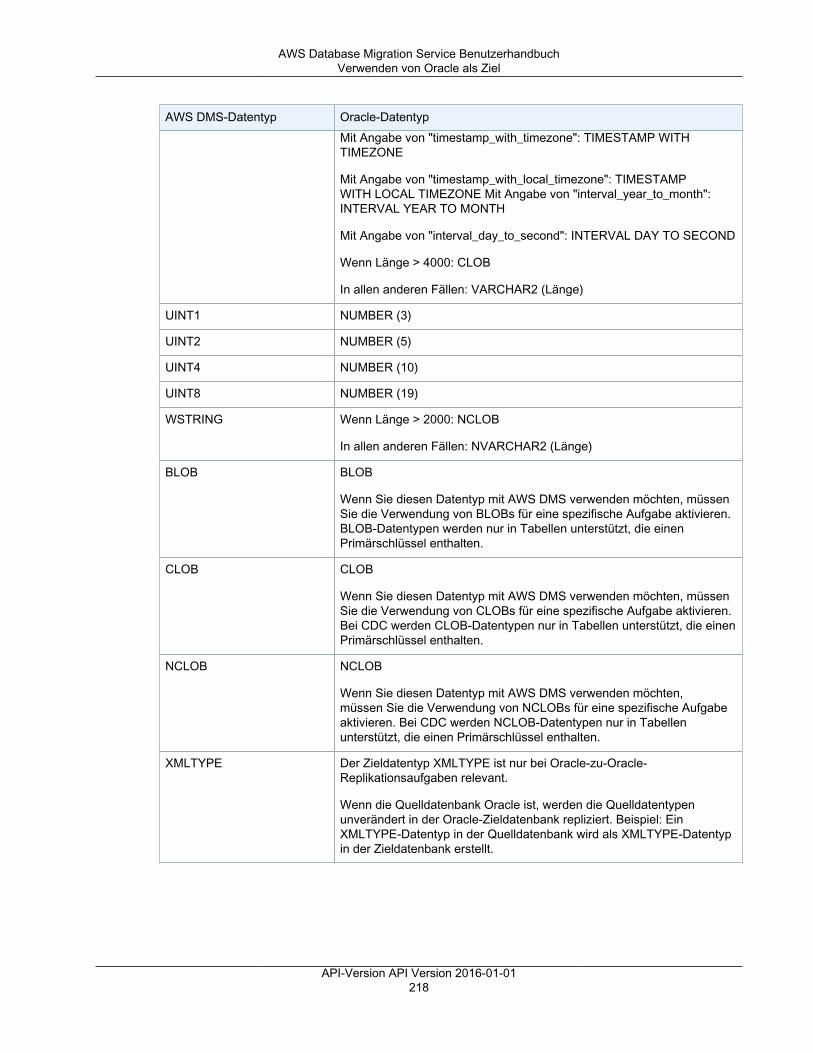
AWS Database Migration Service BenutzerhandbuchVerwenden von Oracle als Ziel
AWS DMS-Datentyp Oracle-DatentypMit Angabe von "timestamp_with_timezone": TIMESTAMP WITHTIMEZONE
Mit Angabe von "timestamp_with_local_timezone": TIMESTAMPWITH LOCAL TIMEZONE Mit Angabe von "interval_year_to_month":INTERVAL YEAR TO MONTH
Mit Angabe von "interval_day_to_second": INTERVAL DAY TO SECOND
Wenn Länge > 4000: CLOB
In allen anderen Fällen: VARCHAR2 (Länge)
UINT1 NUMBER (3)
UINT2 NUMBER (5)
UINT4 NUMBER (10)
UINT8 NUMBER (19)
WSTRING Wenn Länge > 2000: NCLOB
In allen anderen Fällen: NVARCHAR2 (Länge)
BLOB BLOB
Wenn Sie diesen Datentyp mit AWS DMS verwenden möchten, müssenSie die Verwendung von BLOBs für eine spezifische Aufgabe aktivieren.BLOB-Datentypen werden nur in Tabellen unterstützt, die einenPrimärschlüssel enthalten.
CLOB CLOB
Wenn Sie diesen Datentyp mit AWS DMS verwenden möchten, müssenSie die Verwendung von CLOBs für eine spezifische Aufgabe aktivieren.Bei CDC werden CLOB-Datentypen nur in Tabellen unterstützt, die einenPrimärschlüssel enthalten.
NCLOB NCLOB
Wenn Sie diesen Datentyp mit AWS DMS verwenden möchten,müssen Sie die Verwendung von NCLOBs für eine spezifische Aufgabeaktivieren. Bei CDC werden NCLOB-Datentypen nur in Tabellenunterstützt, die einen Primärschlüssel enthalten.
XMLTYPE Der Zieldatentyp XMLTYPE ist nur bei Oracle-zu-Oracle-Replikationsaufgaben relevant.
Wenn die Quelldatenbank Oracle ist, werden die Quelldatentypenunverändert in der Oracle-Zieldatenbank repliziert. Beispiel: EinXMLTYPE-Datentyp in der Quelldatenbank wird als XMLTYPE-Datentypin der Zieldatenbank erstellt.
API-Version API Version 2016-01-01218

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Ziel
Verwenden einer Microsoft SQL Server-Datenbank alsZiel für AWS Database Migration ServiceSie können Daten mithilfe von AWS DMS in Microsoft SQL Server-Datenbanken migrieren. Mit einer SQLServer-Datenbank als Ziel können Sie Daten aus einer anderen SQL Server-Datenbank oder einer deranderen unterstützten Datenbanken migrieren.
Für lokale und Amazon EC2-Instance-Datenbanken unterstützt AWS DMS als Ziel die SQL Server-Versionen 2005, 2008, 2008R2, 2012, 2014, 2016, 2017 und 2019. Die Editionen Enterprise, Standard,Workgroup, Developer und Web werden von AWS DMS unterstützt.
Für Amazon RDS-Instance-Datenbanken unterstützt AWS DMS als Ziel-SQL Server-Versionen 2008R2,2012, 2014, 2016, 2017 und 2019. Die Editionen Enterprise, Standard, Workgroup, Developer und Webwerden von AWS DMS unterstützt.
Note
Unterstützung für Microsoft SQL Server Version 2019 als Ziel ist in den AWS DMS-Versionen3.3.2 und höher verfügbar.
Weitere Informationen zur Arbeit mit AWS DMS und SQL Server-Zieldatenbanken finden Sie in denfolgenden Themen.
Einschränkungen bei der Verwendung von SQL Server als Zielfür AWS Database Migration ServiceDie folgenden Einschränkungen gelten, wenn Sie eine SQL Server-Datenbank als Ziel für AWS DMSverwenden:
• Wenn Sie eine SQL Server-Zieltabelle mit einer berechneten Spalte manuell erstellen, wird dieVolllastreplikation bei Verwendung des BCP-Dienstprogramms zum Kopieren großer Datenmengen nichtunterstützt. Um die Volllastreplikation zu nutzen, deaktivieren Sie die Option Verwenden von BCP für dasLaden von Tabellen in der Registerkarte Advanced (Erweitert) der Konsole. Weitere Informationen zumArbeiten mit BCP finden Sie in der Microsoft SQL Server-Dokumentation.
• Bei der Replikation von Tabellen mit den räumlichen Datentypen von SQL Server (GEOMETRY undGEOGRAPHY) ersetzt AWS DMS alle räumlichen Referenzkennungen (Spatial Reference Identifier,SRID), die Sie möglicherweise mit der Standard-SRID eingefügt haben. Die Standard-SRID fürGEOMETRY ist 0 und für GEOGRAPHY 4326.
• Temporäre Tabellen werden nicht unterstützt. Die Migration von temporären Tabellen ist mit einer reinenReplikationsaufgabe im transaktionalen Anwendungsmodus möglich, wenn diese Tabellen manuell aufdem Ziel erstellt werden.
• Derzeit werden boolean-Datentypen in einer PostgreSQL-Quelle als bit-Datentyp mit inkonsistentenWerten zu einem SQLServer-Ziel migriert. Als Problemumgehung erstellen Sie die Tabelle mit einemVARCHAR(1)-Datentyp für die Spalte (oder lassen Sie AWS DMS die Tabelle erstellen), und lassen Siedann die nachgeschaltete Verarbeitung ein „F“ als False und ein „T“ als True behandeln.
Sicherheitsanforderungen bei der Verwendung von SQL Serverals Ziel für AWS Database Migration ServiceIm folgenden Abschnitt werden die Sicherheitsanforderungen bei der Verwendung von AWS DMS miteinem Microsoft SQL Server-Ziel beschrieben:
• Das AWS DMS-Benutzerkonto muss mindestens über die db_owner-Benutzerrolle für die Microsoft SQLServer-Datenbank verfügen, mit der Sie eine Verbindung herstellen.
API-Version API Version 2016-01-01219

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Ziel
• Ein SQL Server-Systemadministrator muss diese Berechtigung allen AWS DMS-Benutzerkonten erteilen.
Zusätzliche Verbindungsattribute bei der Verwendung von SQLServer als Ziel für AWS DMSSie können zusätzliche Verbindungsattribute verwenden, um Ihr SQL Server-Ziel zu konfigurieren. Siegeben diese Einstellungen beim Erstellen des Zielendpunkts an. Wenn Sie mehrere Attributeinstellungenverwenden, müssen diese durch Semikolons und ohne zusätzlichen Leerraum voneinander getrenntwerden.
Die folgende Tabelle zeigt die zusätzlichen Verbindungsattribute, die Sie verwenden können, wenn SQLServer das Ziel ist.
Name Beschreibung
useBCPFullLoad Verwenden Sie dieses Attribut zum Übertragen von Datenfür vollständige Ladevorgänge mithilfe von BCP. Wenn dieZieltabelle eine Identitätsspalte enthält, die in der Quelltabellenicht vorhanden ist, müssen Sie die Option use BCP forloading table (BCP zum Laden der Tabelle verwenden)deaktivieren.
Standardwert: Y
Zulässige Werte: Y/N
Beispiel: useBCPFullLoad=Y
BCPPacketSize Die maximale Größe der Pakete (in Byte) zum Übertragen vonDaten mithilfe von BCP.
Standardwert: 16384
Zulässige Werte: 1 – 100000
Beispiel : BCPPacketSize=16384
controlTablesFileGroup Geben Sie eine Dateigruppe für die internen AWSDMS-Tabellen an. Wenn die Replikationsaufgabegestartet wird, werden alle internen AWS DMS-Steuerungstabellen (awsdms_ apply_exception,awsdms_apply, awsdms_changes) in der angegebenenDateigruppe erstellt.
Standardwert: –
Zulässige Werte: Zeichenfolge
Beispiel: controlTablesFileGroup=filegroup1
Es folgt ein Beispiel für einen Befehl zum Erstellen einerDateigruppe.
ALTER DATABASE replicate ADD FILEGROUP Test1FG1; GO ALTER DATABASE replicate ADD FILE ( NAME = test1dat5,
API-Version API Version 2016-01-01220

AWS Database Migration Service BenutzerhandbuchVerwenden von SQL Server als Ziel
Name Beschreibung FILENAME = 'C:\temp\DATA\t1dat5.ndf', SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 5MB ) TO FILEGROUP Test1FG1; GO
Zieldatentypen für Microsoft SQL ServerIn der folgenden Tabelle sind die Microsoft SQL Server-Zieldatentypen aufgeführt, die bei Verwendungvon AWS DMS unterstützt werden, sowie deren Standardzuweisung von AWS DMS-Datentypen. WeitereInformationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
AWS DMS-Datentyp SQL Server-Datentyp
BOOLEAN TINYINT
BYTES VARBINARY (Länge)
DATE Verwenden Sie für SQL Server 2008 und höher DATE.
Verwenden Sie für frühere Versionen, wenn die Skalierung 3 oderweniger ist, DATETIME. Verwenden Sie in allen anderen FällenVARCHAR (37).
TIME Verwenden Sie für SQL Server 2008 und höher DATETIME2 (%d).
Verwenden Sie für frühere Versionen, wenn die Skalierung 3 oderweniger ist, DATETIME. Verwenden Sie in allen anderen FällenVARCHAR (37).
DATETIME Verwenden Sie für SQL Server 2008 und höher DATETIME2(Skalierung).
Verwenden Sie für frühere Versionen, wenn die Skalierung 3 oderweniger ist, DATETIME. Verwenden Sie in allen anderen FällenVARCHAR (37).
INT1 SMALLINT
INT2 SMALLINT
INT4 INT
INT8 BIGINT
NUMERIC NUMERIC (p,s)
REAL4 REAL
REAL8 FLOAT
STRING Wenn die Spalte eine Datums- oder Zeitspalte ist, gehen Sie wie folgtvor:
API-Version API Version 2016-01-01221
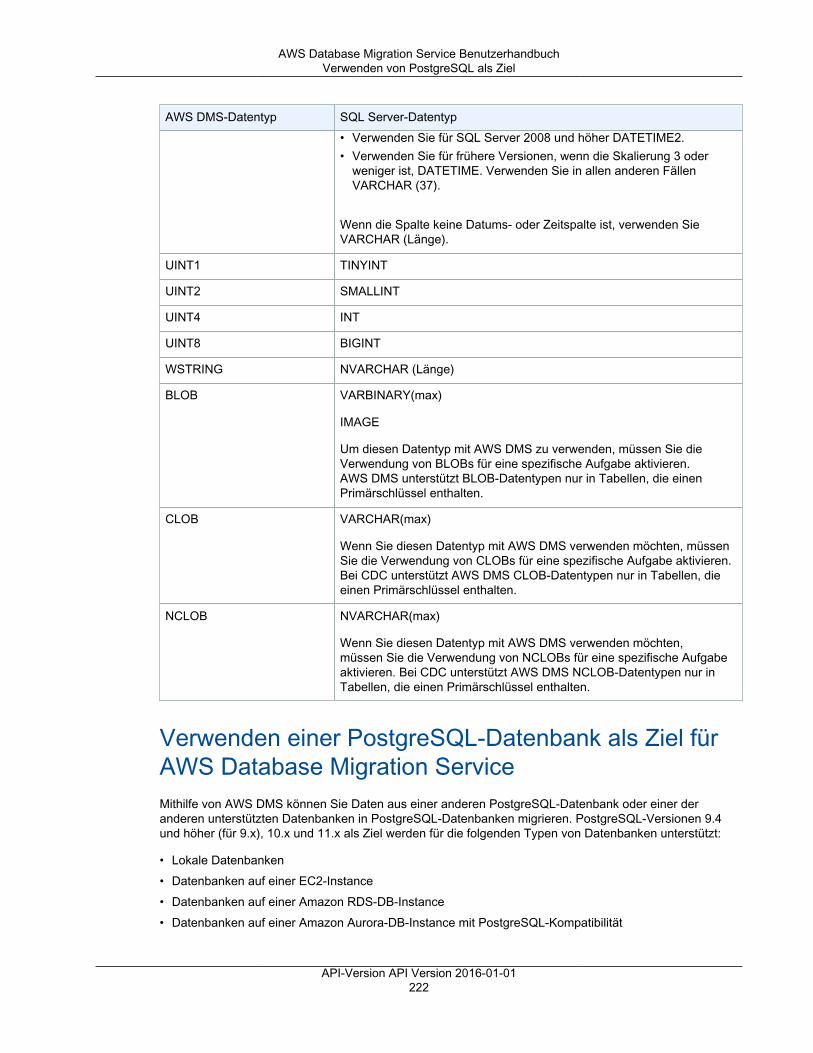
AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Ziel
AWS DMS-Datentyp SQL Server-Datentyp• Verwenden Sie für SQL Server 2008 und höher DATETIME2.• Verwenden Sie für frühere Versionen, wenn die Skalierung 3 oder
weniger ist, DATETIME. Verwenden Sie in allen anderen FällenVARCHAR (37).
Wenn die Spalte keine Datums- oder Zeitspalte ist, verwenden SieVARCHAR (Länge).
UINT1 TINYINT
UINT2 SMALLINT
UINT4 INT
UINT8 BIGINT
WSTRING NVARCHAR (Länge)
BLOB VARBINARY(max)
IMAGE
Um diesen Datentyp mit AWS DMS zu verwenden, müssen Sie dieVerwendung von BLOBs für eine spezifische Aufgabe aktivieren.AWS DMS unterstützt BLOB-Datentypen nur in Tabellen, die einenPrimärschlüssel enthalten.
CLOB VARCHAR(max)
Wenn Sie diesen Datentyp mit AWS DMS verwenden möchten, müssenSie die Verwendung von CLOBs für eine spezifische Aufgabe aktivieren.Bei CDC unterstützt AWS DMS CLOB-Datentypen nur in Tabellen, dieeinen Primärschlüssel enthalten.
NCLOB NVARCHAR(max)
Wenn Sie diesen Datentyp mit AWS DMS verwenden möchten,müssen Sie die Verwendung von NCLOBs für eine spezifische Aufgabeaktivieren. Bei CDC unterstützt AWS DMS NCLOB-Datentypen nur inTabellen, die einen Primärschlüssel enthalten.
Verwenden einer PostgreSQL-Datenbank als Ziel fürAWS Database Migration ServiceMithilfe von AWS DMS können Sie Daten aus einer anderen PostgreSQL-Datenbank oder einer deranderen unterstützten Datenbanken in PostgreSQL-Datenbanken migrieren. PostgreSQL-Versionen 9.4und höher (für 9.x), 10.x und 11.x als Ziel werden für die folgenden Typen von Datenbanken unterstützt:
• Lokale Datenbanken• Datenbanken auf einer EC2-Instance• Datenbanken auf einer Amazon RDS-DB-Instance• Datenbanken auf einer Amazon Aurora-DB-Instance mit PostgreSQL-Kompatibilität
API-Version API Version 2016-01-01222

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Ziel
Note
Die PostgreSQL-Versionen 11.x werden nur in den AWS DMS-Versionen 3.3.1 und höher als Zielunterstützt. Sie können die PostgreSQL-Versionen 9.4 und höher (für Versionen 9.x) und 10.x alsZiel in jeder beliebigen DMS-Version verwenden.
AWS DMS verfolgt bei der Migration von Daten von der Quelle ins Ziel in der Volllastphase einen Tabelle-zu-Tabelle-Ansatz. Die Tabellenreihenfolge kann während der Volllastphase nicht garantiert werden.Die Tabellen sind während der Vollastphase und während des Anwendens der zwischengespeichertenTransaktionen für einzelne Tabellen nicht synchron. Dies hat zur Folge, dass aktive referentielleIntegritätseinschränkungen während der Volllastphase zu Aufgabenfehlern führen können.
In PostgreSQL werden Fremdschlüssel (referentielle Integritätseinschränkungen) mithilfe von Auslösernimplementiert. Während der Volllastphase lädt AWS DMS nacheinander alle Tabellen. Es wird ausdrücklichempfohlen, dass Sie Fremdschlüsseleinschränkungen während eines vollständigen Ladevorgangs mit einerder folgenden Methoden deaktivieren:
• Deaktivieren Sie vorübergehend alle Auslöser aus der Instance und beenden Sie den vollständigenLadevorgang.
• Verwenden Sie den session_replication_role-Parameter in PostgreSQL.
Ein Auslöser kann sich zu jedem beliebigen Zeitpunkt in einem der folgenden Zustände befinden: origin,replica, always und disabled. Wenn der session_replication_role-Parameter auf replicagesetzt ist, sind nur Auslöser aktiv, die sich im Status replica befinden, und sie werden ausgelöst, wennsie aufgerufen werden. Andernfalls bleiben die Auslöser inaktiv.
PostgreSQL verfügt über einen ausfallsicheren Mechanismus, um zu verhindern, dass eine Tabelle gekürztwird, auch dann, wenn session_replication_role festgelegt ist. Sie können diesen als Alternativezur Deaktivierung von Auslösern verwenden, um den vollständigen Ladevorgang abzuschließen. Legen Siehierfür den Vorbereitungsmodus der Zieltabelle auf DO_NOTHING fest. Andernfalls schlagen DROP- undTRUNCATE-Operationen fehl, wenn Fremdschlüsseleinschränkungen bestehen.
In Amazon RDS können Sie diesen Parameter mithilfe einer Parametergruppe steuern/festlegen. Für einePostgreSQL-Instance, die auf Amazon EC2 ausgeführt wird, können Sie den Parameter direkt festlegen.
Weitere Informationen zum Arbeiten mit einer PostgreSQL-Datenbank als Ziel für AWS DMS finden Sie inden folgenden Abschnitten:
Themen• Einschränkungen bei der Verwendung von PostgreSQL als Ziel für AWS Database Migration Service
(p. 223)• Sicherheitsanforderungen bei Verwendung einer PostgreSQL-Datenbank als Ziel für AWS Database
Migration Service (p. 224)• Zusätzliche Verbindungsattribute bei der Verwendung von PostgreSQL als Ziel für AWS
DMS (p. 224)• Zieldatentypen für PostgreSQL (p. 224)
Einschränkungen bei der Verwendung von PostgreSQL als Zielfür AWS Database Migration ServiceBei der Verwendung einer PostgreSQL-Datenbank als Ziel für AWS DMS gelten die folgendenEinschränkungen:
• Der JSON-Datentyp wird in den systemeigenen CLOB-Datentyp umgewandelt.
API-Version API Version 2016-01-01223

AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Ziel
• Wenn bei der Migration von Oracle zu PostgreSQL eine Spalte in Oracle ein NULL-Zeichen(Hexadezimalwert U+0000) enthält, konvertiert AWS DMS das NULL-Zeichen zu einer Leerstelle(Hexadezimalwert U+0020). Der Grund hierfür ist eine PostgreSQL-Einschränkung.
Sicherheitsanforderungen bei Verwendung einer PostgreSQL-Datenbank als Ziel für AWS Database Migration ServiceAus Sicherheitsgründen muss das für die Datenmigration verwendete Benutzerkonto ein registrierterBenutzer in einer PostgreSQL-Zieldatenbank sein.
Zusätzliche Verbindungsattribute bei der Verwendung vonPostgreSQL als Ziel für AWS DMSSie können zusätzliche Verbindungsattribute verwenden, um Ihr PostgreSQL-Ziel zu konfigurieren. Siegeben diese Einstellungen beim Erstellen des Zielendpunkts an. Wenn Sie mehrere Attributeinstellungenverwenden, müssen diese durch Semikolons und ohne zusätzlichen Leerraum voneinander getrenntwerden.
Die folgende Tabelle zeigt die zusätzlichen Verbindungsattribute, die Sie verwenden können, umPostgreSQL als Ziel für AWS DMS zu konfigurieren.
Name Beschreibung
maxFileSize Gibt die maximale Größe (in KB) der CSV-Datei zumÜbertragen von Daten nach PostgreSQL an.
Standardwert: 32768 KB (32 MB)
Zulässige Werte: 1 – 1048576
Beispiel: maxFileSize=512
executeTimeout Stellt die Zeitbeschränkung der Client-Anweisung für diePostgreSQL-Instance in Sekunden ein. Der Standardwert liegtbei 60 Sekunden.
Beispiel: executeTimeout=100
afterConnectScript=SETsession_replication_role='replica'
Nur für die Verwendung mit Change Data Capture (CDC)lässt dieses Attribut AWS DMS Fremdschlüssel undBenutzerauslöser umgehen, um die Zeit zu reduzieren, diezum Massenladen von Daten benötigt wird.
Note
Dieses Attribut ist nur im Change Data Capture-Modus wirksam.
Zieldatentypen für PostgreSQLDer PostgreSQL-Datenbankendpunkt für AWS DMS unterstützt die meisten PostgreSQL-Datenbank-Datentypen. In der folgenden Tabelle sind die PostgreSQL-Datenbank-Zieldatentypen aufgeführt, diebei Verwendung von AWS DMS unterstützt werden, sowie deren Standardzuweisung von AWS DMS-Datentypen. Nicht unterstützte Datentypen sind im Anschluss an die Tabelle aufgeführt.
API-Version API Version 2016-01-01224
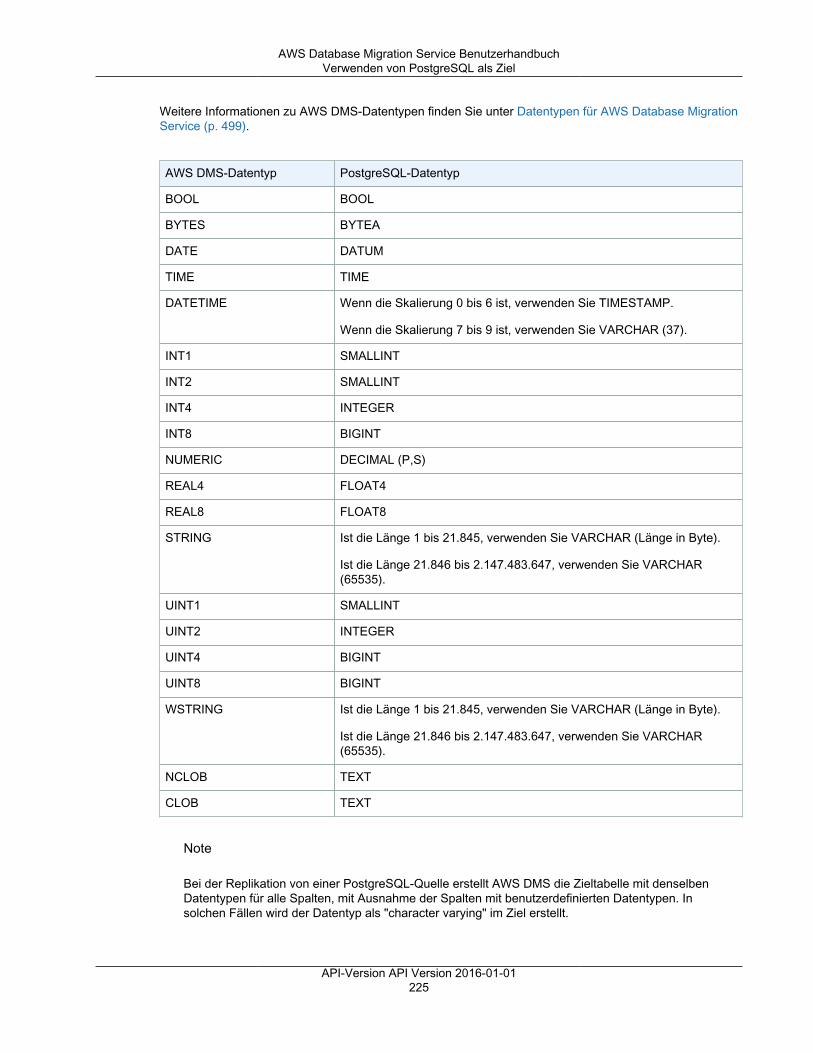
AWS Database Migration Service BenutzerhandbuchVerwenden von PostgreSQL als Ziel
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
AWS DMS-Datentyp PostgreSQL-Datentyp
BOOL BOOL
BYTES BYTEA
DATE DATUM
TIME TIME
DATETIME Wenn die Skalierung 0 bis 6 ist, verwenden Sie TIMESTAMP.
Wenn die Skalierung 7 bis 9 ist, verwenden Sie VARCHAR (37).
INT1 SMALLINT
INT2 SMALLINT
INT4 INTEGER
INT8 BIGINT
NUMERIC DECIMAL (P,S)
REAL4 FLOAT4
REAL8 FLOAT8
STRING Ist die Länge 1 bis 21.845, verwenden Sie VARCHAR (Länge in Byte).
Ist die Länge 21.846 bis 2.147.483.647, verwenden Sie VARCHAR(65535).
UINT1 SMALLINT
UINT2 INTEGER
UINT4 BIGINT
UINT8 BIGINT
WSTRING Ist die Länge 1 bis 21.845, verwenden Sie VARCHAR (Länge in Byte).
Ist die Länge 21.846 bis 2.147.483.647, verwenden Sie VARCHAR(65535).
NCLOB TEXT
CLOB TEXT
Note
Bei der Replikation von einer PostgreSQL-Quelle erstellt AWS DMS die Zieltabelle mit denselbenDatentypen für alle Spalten, mit Ausnahme der Spalten mit benutzerdefinierten Datentypen. Insolchen Fällen wird der Datentyp als "character varying" im Ziel erstellt.
API-Version API Version 2016-01-01225

AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Ziel
Verwenden einer MySQL-kompatiblen Datenbank alsZiel für AWS Database Migration ServiceSie können mithilfe von AWS DMS Daten aus jeder von AWS DMS unterstützten Quelldaten-Engine zujeder MySQL-kompatiblen Datenbank migrieren. Wenn Sie in eine lokale MySQL-kompatible Datenbankmigrieren, erfordert AWS DMS, dass sich Ihre Quell-Engine innerhalb des AWS-Ökosystems befindet. DieEngine kann sich in einem von Amazon verwalteten Service befinden, wie beispielsweise Amazon RDS,Amazon Aurora oder Amazon S3. Alternativ kann sich die Engine in einer selbstverwalteten Datenbank aufAmazon EC2 befinden.
Sie können mit SSL Verbindungen zwischen Ihrem MySQL-kompatiblen Endpunkt und der Replikations-Instance verschlüsseln. Weitere Informationen zur Verwendung von SSL mit einem MySQL-kompatiblenEndpunkt finden Sie unter Verwenden von SSL mit AWS Database Migration Service (p. 82).
AWS DMS unterstützt die Versionen 5.5, 5.6, 5.7 und 8.0 von MySQL- sowie Aurora MySQL. Darüberhinaus unterstützt AWS DMS die MariaDB-Versionen 10.0.24 bis 10.0.28, 10.1, 10.2 und 10.3.
Note
Unterstützung für MySQL 8.0 ist in den AWS DMS-Versionen 3.3.1 und höher verfügbar.
Sie können die folgenden MySQL-kompatiblen Datenbanken als Ziele für AWS DMS verwenden:
• MySQL Community Edition• MySQL Standard Edition• MySQL Enterprise Edition• MySQL Cluster Carrier Grade Edition• MariaDB Community Edition• MariaDB Enterprise Edition• MariaDB Column Store• Amazon Aurora MySQL
Note
Unabhängig von der Quell-Speicher-Engine (MyISAM, MEMORY usw.) erstellt AWS DMSeine MySQL-kompatible Zieltabelle standardmäßig als InnoDB-Tabelle. Wenn Sie eine Tabellebenötigen, die eine andere Speicher-Engine als InnoDB verwendet, können Sie die Tabelle inder MySQL-kompatiblen Zieldatenbank manuell erstellen und die Tabelle mithilfe des Modus "DoNothing" migrieren. Weitere Informationen zum Modus "Do Nothing" finden Sie unter Full-Load-Aufgabeneinstellungen (p. 344).
Weitere Details zum Arbeiten mit einer MySQL-kompatiblen Datenbank als Ziel für AWS DMS finden Sie inden folgenden Abschnitten.
Themen• Verwenden einer beliebigen MySQL-kompatiblen Datenbank als Ziel für AWS Database Migration
Service (p. 227)• Einschränkungen bei der Verwendung einer MySQL-kompatiblen Datenbank als Ziel für AWS
Database Migration Service (p. 227)• Zusätzliche Verbindungsattribute bei der Verwendung einer MySQL-kompatiblen Datenbank als Ziel für
AWS DMS (p. 228)
API-Version API Version 2016-01-01226

AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Ziel
• Zieldatentypen für MySQL (p. 229)
Verwenden einer beliebigen MySQL-kompatiblen Datenbank alsZiel für AWS Database Migration ServiceBevor Sie mit einer MySQL-kompatiblen Datenbank als Ziel für AWS DMS arbeiten, stellen Sie sicher, dassSie die folgenden Voraussetzungen erfüllt haben:
• Stellen Sie ein Benutzerkonto für AWS DMS bereit, das über Lese-/Schreibberechtigungen für dieMySQL-kompatible Datenbank verfügt. Führen Sie die folgenden Befehle aus, um die erforderlichenBerechtigungen zu erstellen.
CREATE USER '<user acct>'@'%' IDENTIFIED BY '<user password>';GRANT ALTER, CREATE, DROP, INDEX, INSERT, UPDATE, DELETE, SELECT ON <schema>.* TO '<user acct>'@'%';GRANT ALL PRIVILEGES ON awsdms_control.* TO '<user acct>'@'%';
• Während der Volllast-Migrationsphase müssen Sie Fremdschlüssel in Ihren Zieltabellen deaktivieren.Um während eines vollständigen Ladevorgangs Fremdschlüsselprüfungen in einer MySQL-kompatiblenDatenbank zu deaktivieren, können Sie den folgenden Befehl zu Extra Connection Attributes (ZusätzlicheVerbindungsattribute) im Bereich Advanced (Erweitert) des Zielendpunkts hinzufügen:
initstmt=SET FOREIGN_KEY_CHECKS=0
• Legen Sie den Datenbankparameter local_infile = 1 fest, um AWS DMS das Laden von Daten indie Zieldatenbank zu ermöglichen.
Einschränkungen bei der Verwendung einer MySQL-kompatiblenDatenbank als Ziel für AWS Database Migration ServiceBei der Verwendung einer MySQL-Datenbank als Ziel unterstützt AWS DMS Folgendes nicht:
• Die DDL-Anweisungen (Data Definition Language) TRUNCATE PARTITION, DROP TABLE undRENAME TABLE.
• Verwenden einer ALTER TABLE <table_name> ADD COLUMN <column_name>-Anweisung zumHinzufügen von Spalten an den Anfang oder in die Mitte einer Tabelle
• Wenn nur die LOB-Spalte in einer Quelltabelle aktualisiert wird, aktualisiert AWS DMS die entsprechendeZielspalte nicht. Das Ziel-LOB wird nur aktualisiert, wenn mindestens eine andere Spalte in derselbenTransaktion aktualisiert wird.
• Beim Laden von Daten in ein MySQL-kompatibles Ziel in einem vollständigen Ladevorgang meldet AWSDMS keine Fehler durch Duplikatschlüssel im Aufgabenprotokoll.
• Wenn Sie den Wert einer Spalte auf den vorhandenen Wert aktualisieren, geben MySQL-kompatibleDatenbanken die Warnung 0 rows affected zurück. Obwohl dieses Verhalten technisch gesehenkein Fehler ist, unterscheidet es sich von der Art und Weise, wie andere Datenbank-Engines mitsolchen Fällen umgehen. Oracle führt beispielsweise eine Aktualisierung einer Zeile durch. FürMySQL-kompatible Datenbanken generiert AWS DMS einen Eintrag in der Steuerungstabelleawsdms_apply_exceptions und protokolliert folgende Warnung.
Some changes from the source database had no impact when applied to
API-Version API Version 2016-01-01227

AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Ziel
the target database. See awsdms_apply_exceptions table for details.
Zusätzliche Verbindungsattribute bei der Verwendung einerMySQL-kompatiblen Datenbank als Ziel für AWS DMSSie können zusätzliche Verbindungsattribute verwenden, um Ihr MySQL-kompatibles Ziel zukonfigurieren. Sie geben diese Einstellungen beim Erstellen des Zielendpunkts an. Wenn Sie mehrereAttributeinstellungen verwenden, müssen diese durch Semikolons und ohne zusätzlichen Leerraumvoneinander getrennt werden.
Die folgende Tabelle zeigt zusätzliche Konfigurationseinstellungen, die Sie bei der Erstellung eines MySQL-kompatiblen Ziels für AWS DMS verwenden können.
Name Beschreibung
targetDbType Gibt an, wo die Quelltabellen in der Zieldatenbank migriertwerden, entweder in einer einzelnen Datenbank odermehreren Datenbanken.
Standardwert: MULTIPLE_DATABASES
Zulässige Werte: {SPECIFIC_DATABASE,MULTIPLE_DATABASES}
Beispiel: targetDbType=MULTIPLE_DATABASES
parallelLoadThreads Verbessert die Leistung beim Laden von Daten in die MySQL-kompatible Zieldatenbank. Gibt an, wie viele Threads zumLaden der Daten in die MySQL-kompatible Zieldatenbankverwendet werden sollen. Das Festlegen einer großen Anzahlvon Threads kann die Datenbankleistung beeinträchtigen, dafür jeden Thread eine separate Verbindung erforderlich ist.
Standardwert: 1
Zulässige Werte: 1 – 5
Beispiel: parallelLoadThreads=1
initstmt=SETFOREIGN_KEY_CHECKS=0
Deaktiviert die Fremdschlüsselprüfungen.
initstmt=SET time_zone Gibt die Zeitzone für die MySQL-kompatible Zieldatenbank an.
Standardwert: UTC
Zulässige Werte: Eine Abkürzung aus drei oder vier Zeichenfür die Zeitzone, die Sie verwenden möchten. Die zulässigenWerte entsprechen den Standardabkürzungen für Zeitzonenfür das Betriebssystem, auf der die MySQL-kompatibleDatenbank gehostet wird.
Beispiel: initstmt=SET time_zone=UTC
afterConnectScript=SETcharacter_set_connection='latin1'
Gibt an, dass das MySQL-kompatible Ziel empfangeneAnweisungen in den Latin1-Zeichensatz übersetzen soll. Dies
API-Version API Version 2016-01-01228
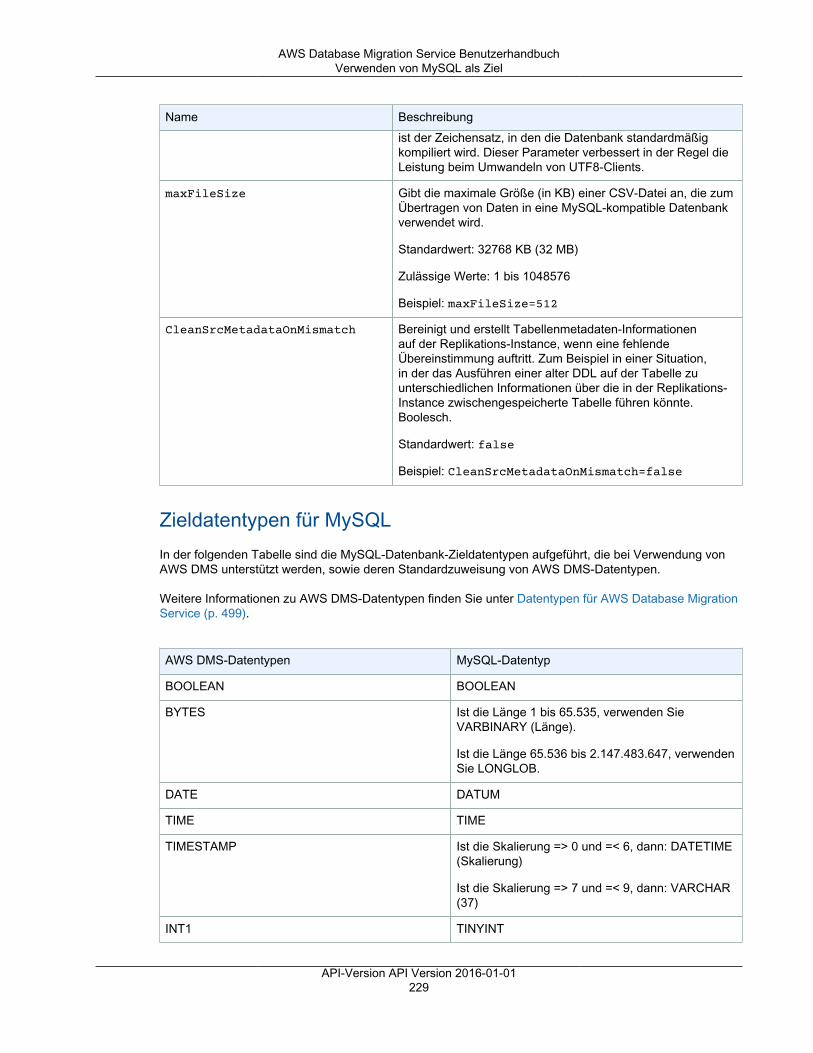
AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Ziel
Name Beschreibungist der Zeichensatz, in den die Datenbank standardmäßigkompiliert wird. Dieser Parameter verbessert in der Regel dieLeistung beim Umwandeln von UTF8-Clients.
maxFileSize Gibt die maximale Größe (in KB) einer CSV-Datei an, die zumÜbertragen von Daten in eine MySQL-kompatible Datenbankverwendet wird.
Standardwert: 32768 KB (32 MB)
Zulässige Werte: 1 bis 1048576
Beispiel: maxFileSize=512
CleanSrcMetadataOnMismatch Bereinigt und erstellt Tabellenmetadaten-Informationenauf der Replikations-Instance, wenn eine fehlendeÜbereinstimmung auftritt. Zum Beispiel in einer Situation,in der das Ausführen einer alter DDL auf der Tabelle zuunterschiedlichen Informationen über die in der Replikations-Instance zwischengespeicherte Tabelle führen könnte.Boolesch.
Standardwert: false
Beispiel: CleanSrcMetadataOnMismatch=false
Zieldatentypen für MySQLIn der folgenden Tabelle sind die MySQL-Datenbank-Zieldatentypen aufgeführt, die bei Verwendung vonAWS DMS unterstützt werden, sowie deren Standardzuweisung von AWS DMS-Datentypen.
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
AWS DMS-Datentypen MySQL-Datentyp
BOOLEAN BOOLEAN
BYTES Ist die Länge 1 bis 65.535, verwenden SieVARBINARY (Länge).
Ist die Länge 65.536 bis 2.147.483.647, verwendenSie LONGLOB.
DATE DATUM
TIME TIME
TIMESTAMP Ist die Skalierung => 0 und =< 6, dann: DATETIME(Skalierung)
Ist die Skalierung => 7 und =< 9, dann: VARCHAR(37)
INT1 TINYINT
API-Version API Version 2016-01-01229
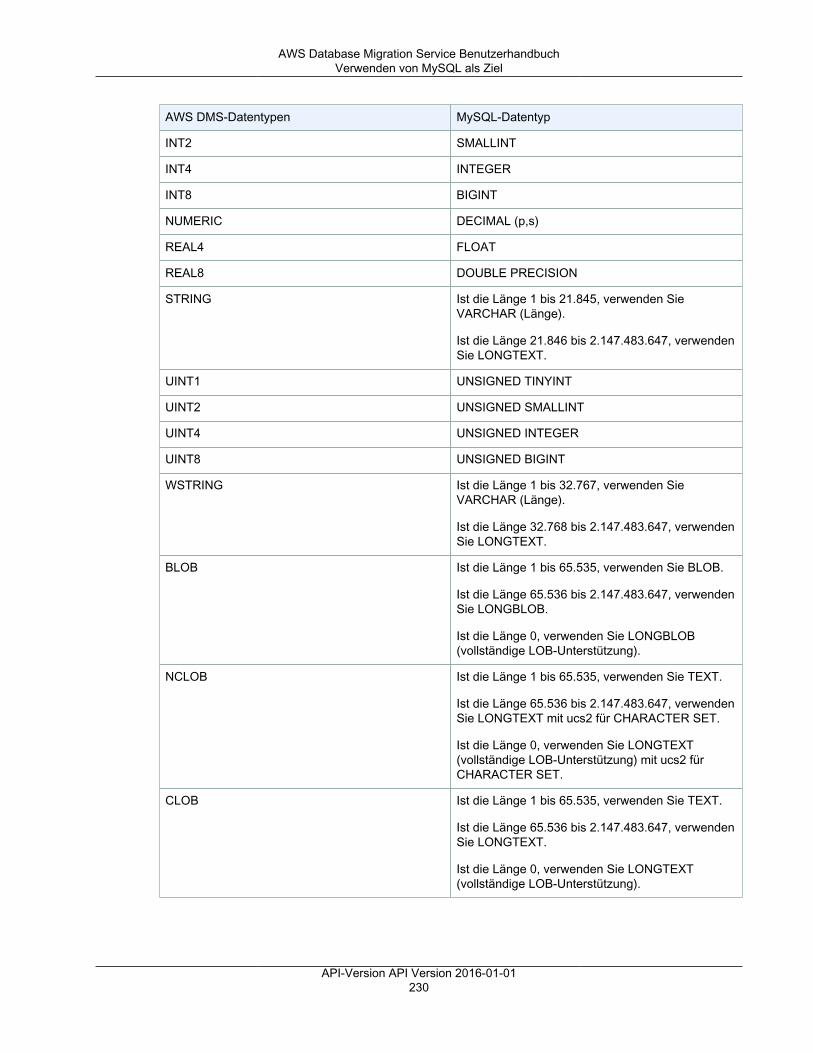
AWS Database Migration Service BenutzerhandbuchVerwenden von MySQL als Ziel
AWS DMS-Datentypen MySQL-Datentyp
INT2 SMALLINT
INT4 INTEGER
INT8 BIGINT
NUMERIC DECIMAL (p,s)
REAL4 FLOAT
REAL8 DOUBLE PRECISION
STRING Ist die Länge 1 bis 21.845, verwenden SieVARCHAR (Länge).
Ist die Länge 21.846 bis 2.147.483.647, verwendenSie LONGTEXT.
UINT1 UNSIGNED TINYINT
UINT2 UNSIGNED SMALLINT
UINT4 UNSIGNED INTEGER
UINT8 UNSIGNED BIGINT
WSTRING Ist die Länge 1 bis 32.767, verwenden SieVARCHAR (Länge).
Ist die Länge 32.768 bis 2.147.483.647, verwendenSie LONGTEXT.
BLOB Ist die Länge 1 bis 65.535, verwenden Sie BLOB.
Ist die Länge 65.536 bis 2.147.483.647, verwendenSie LONGBLOB.
Ist die Länge 0, verwenden Sie LONGBLOB(vollständige LOB-Unterstützung).
NCLOB Ist die Länge 1 bis 65.535, verwenden Sie TEXT.
Ist die Länge 65.536 bis 2.147.483.647, verwendenSie LONGTEXT mit ucs2 für CHARACTER SET.
Ist die Länge 0, verwenden Sie LONGTEXT(vollständige LOB-Unterstützung) mit ucs2 fürCHARACTER SET.
CLOB Ist die Länge 1 bis 65.535, verwenden Sie TEXT.
Ist die Länge 65.536 bis 2.147.483.647, verwendenSie LONGTEXT.
Ist die Länge 0, verwenden Sie LONGTEXT(vollständige LOB-Unterstützung).
API-Version API Version 2016-01-01230

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Redshift als Ziel
Verwenden einer Amazon Redshift-Datenbank als Zielfür AWS Database Migration ServiceSie können mithilfe von AWS Database Migration Service Daten in Amazon Redshift-Datenbankenmigrieren. Amazon Redshift ist ein vollständig verwalteter Data-Warehouse-Service in Petabytegröße in derCloud. Mit einer Amazon Redshift-Datenbank als Ziel können Sie Daten aus allen anderen unterstütztenQuelldatenbanken migrieren.
Der Amazon Redshift-Cluster muss sich in demselben AWS-Konto und derselben AWS-Region wie dieReplikations-Instance befinden.
Während einer Datenbankmigration in Amazon Redshift verschiebt AWS DMS Daten zuerst in einenAmazon S3-Bucket. Wenn sich die Dateien in einem Amazon S3-Bucket befinden, übertragt AWS DMS siean die entsprechenden Tabellen im Amazon Redshift Data Warehouse. AWS DMS erstellt den S3-Bucketin derselben AWS-Region, in der sich auch die Amazon Redshift-Datenbank befindet. Die AWS DMS-Replikations-Instance muss sich in derselben Region befinden.
Wenn Sie mithilfe der AWS Command Line Interface (AWS CLI) oder der DMS-API Daten nach AmazonRedshift migrieren, müssen Sie eine AWS Identity and Access Management (IAM)-Rolle einrichten, dieden S3-Zugriff zulässt. Weitere Informationen zum Erstellen dieser IAM-Rolle finden Sie unter Erstellen derIAM-Rollen für die Verwendung mit der AWS CLI- und AWS DMS-API (p. 68).
Der Amazon Redshift-Endpunkt bietet eine vollständige Automatisierung für die folgenden Aufgaben:
• Schemagenerierung und Datentypzuweisung• Vollständiges Laden von Quelldatenbanktabellen• Inkrementelles Laden der an Quelltabellen vorgenommenen Änderungen• Anwendung von Schemaänderungen in DDL (Data Definition Language), die an Quelltabellen
vorgenommen wurden• Synchronisierung zwischen vollständigen Ladevorgängen und CDC-Prozessen (Change Data Capture,
Erfassung von Änderungsdaten)
AWS Database Migration Service unterstützt sowohl vollständige Ladevorgänge als auch Vorgängezur Verarbeitung von Änderungen. AWS DMS liest die Daten aus der Quelldatenbank und erstellt eineReihe von CSV-Dateien (Comma-Separated Value, durch Trennzeichen getrennt). Bei vollständigenLadevorgängen erstellt AWS DMS Dateien für jede Tabelle. AWS DMS kopiert dann die Tabellendateienfür jede Tabelle in einen separaten Ordner in Amazon S3. Wenn Dateien auf Amazon S3 hochgeladenwerden, sendet AWS DMS einen Kopierbefehl und die in den Dateien enthaltenen Daten werden nachAmazon Redshift kopiert. Bei Vorgängen zur Verarbeitung von Änderungen kopiert AWS DMS die reinenÄnderungen in die CSV-Dateien. Anschließend lädt AWS DMS die Dateien mit reinen Änderungen inAmazon S3 hoch und kopiert die Daten nach Amazon Redshift.
Weitere Informationen zum Arbeiten mit Amazon Redshift als Ziel für AWS DMS finden Sie in denfolgenden Abschnitten:
Themen• Voraussetzungen für die Verwendung einer Amazon Redshift-Datenbank als Ziel für AWS Database
Migration Service (p. 232)• Einschränkungen bei der Verwendung von Amazon Redshift als Ziel für AWS Database Migration
Service (p. 232)• Konfigurieren einer Amazon Redshift-Datenbank als Ziel für AWS Database Migration
Service (p. 233)• Verwenden von Enhanced VPC Routing mit einer Amazon Redshift-Datenbank als Ziel für AWS
Database Migration Service (p. 233)
API-Version API Version 2016-01-01231

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Redshift als Ziel
• Erstellen und Verwenden von AWS KMS-Schlüsseln für die Verschlüsselung von Amazon Redshift-Zieldaten (p. 234)
• Endpunkteinstellungen bei der Verwendung von Amazon Redshift als Ziel für AWS DMS (p. 237)• Zusätzliche Verbindungsattribute bei der Verwendung von Amazon Redshift als Ziel für AWS
DMS (p. 239)• Zieldatentypen für Amazon Redshift (p. 242)
Voraussetzungen für die Verwendung einer Amazon Redshift-Datenbank als Ziel für AWS Database Migration ServiceIn der folgenden Liste werden die erforderlichen Voraussetzungen für die Arbeit mit Amazon Redshift alsZiel für die Datenmigration beschrieben:
• Starten Sie einen Amazon Redshift-Cluster über die AWS-Managementkonsole. Notieren Sie sich diegrundlegenden Angaben zu Ihrem AWS-Konto und Amazon Redshift-Cluster, wie beispielsweise IhrPasswort, Ihren Benutzernamen und den Datenbanknamen. Sie benötigen diese Werte beim Erstellendes Amazon Redshift-Zielendpunkts.
• Der Amazon Redshift-Cluster muss sich in demselben AWS-Konto und derselben AWS-Region wie dieReplikations-Instance befinden.
• Die AWS DMS-Replikations-Instance benötigt Netzwerkkonnektivität mit dem Amazon Redshift-Endpunkt(Hostname und Port), den Ihr Cluster verwendet.
• AWS DMS verwendet einen Amazon S3-Bucket zum Übertragen von Daten zu der Amazon Redshift-Datenbank. Damit AWS DMS den Bucket erstellen kann, verwendet die DMS-Konsole eine IAM-Rolle, dms-access-for-endpoint. Wenn Sie die AWS CLI- oder DMS-API zum Erstellen einerDatenbankmigration mit Amazon Redshift als Zieldatenbank verwenden, müssen Sie diese IAM-Rolleerstellen. Weitere Informationen zum Erstellen dieser Rolle finden Sie unter Erstellen der IAM-Rollen fürdie Verwendung mit der AWS CLI- und AWS DMS-API (p. 68).
• AWS DMS konvertiert BLOBs, CLOBs und NCLOBs in einen VARCHAR-Datentyp auf der AmazonRedshift-Ziel-Instance. Amazon Redshift unterstützt keine VARCHAR-Datentypen, die größer als 64 KBsind. Daher können Sie keine traditionellen LOBs in Amazon Redshift speichern.
• Legen Sie die Ziel-Metadatenaufgabe BatchApplyEnabled (p. 350) auf true für AWS DMS fest, umÄnderungen an Amazon Redshift-Zieltabellen während CDC zu verarbeiten. Ein Primärschlüssel fürdie Quell- und Zieltabelle ist erforderlich. Ohne Primärschlüssel werden Änderungen Anweisung fürAnweisung angewendet. Dies kann sich negativ auf die Aufgabenleistung während der CDC auswirken,indem Ziellatenz verursacht wird und sich auf die Cluster-Commit-Warteschlange auswirkt.
Einschränkungen bei der Verwendung von Amazon Redshift alsZiel für AWS Database Migration ServiceBei der Verwendung einer Amazon Redshift-Datenbank als Ziel unterstützt AWS DMS Folgendes nicht:
• Die folgende DDL wird nicht unterstützt:
ALTER TABLE <table name> MODIFY COLUMN <column name> <data type>;
• AWS DMS kann keine Änderungen in ein Schema mit einem Namen migrieren oder replizieren, dermit einem Unterstrich (_) beginnt. Verwenden Sie für Schemata, deren Namen mit einem Unterstrichbeginnen, Zuweisungstransformationen, um das Schema im Ziel umzubenennen.
• Amazon Redshift unterstützt keine VARCHARs über 64 KB. Daher können LOBs aus traditionellenDatenbanken nicht in Amazon Redshift gespeichert werden.
API-Version API Version 2016-01-01232

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Redshift als Ziel
• Das Anwenden einer DELETE-Anweisung auf eine Tabelle mit einem mehrspaltigen Primärschlüsselwird nicht unterstützt, wenn einer der Primärschlüsselspaltennamen ein reserviertes Wort verwendet.Wechseln Sie hierher, um eine Liste der für Amazon Redshift reservierten Wörter anzuzeigen.
Konfigurieren einer Amazon Redshift-Datenbank als Ziel für AWSDatabase Migration ServiceDer AWS Database Migration Service muss so konfiguriert werden, dass er mit der Amazon Redshift-Instance funktioniert. Die folgende Tabelle beschreibt die verfügbaren Konfigurationseigenschaften für denAmazon Redshift-Endpunkt.
Eigenschaft Beschreibung
server Der Name des verwendeten Amazon Redshift-Clusters.
port Die Portnummer für Amazon Redshift. Der Standardwert lautet 5439.
username Ein Amazon Redshift-Benutzername eines registrierten Benutzers.
password Das Passwort für den Benutzer, der in der Eigenschaft "Benutzername"angegeben ist.
database Der Name des Amazon Redshift Data Warehouse (Service), mit dem Siearbeiten.
Wenn Sie zusätzliche Attribute für Verbindungszeichenfolgen zu Ihrem Amazon Redshift-Endpunkthinzufügen möchten, können Sie die Attribute maxFileSize und fileTransferUploadStreamsfestlegen. Weitere Informationen zu diesen Attributen finden Sie unter Zusätzliche Verbindungsattribute beider Verwendung von Amazon Redshift als Ziel für AWS DMS (p. 239).
Verwenden von Enhanced VPC Routing mit einer AmazonRedshift-Datenbank als Ziel für AWS Database Migration ServiceWenn Sie Enhanced VPC Routing mit Ihrem Amazon Redshift-Ziel verwenden, wird der gesamte COPY-Datenverkehr zwischen Ihrem Amazon Redshift-Cluster und Ihren Datenrepositorys über Ihre VPC geleitet.Da sich Enhanced VPC Routing (Erweitertes VPC-Routing) auf die Art und Weise auswirkt, wie AmazonRedshift auf andere Ressourcen zugreift, schlagen COPY-Befehle möglicherweise fehl, wenn die VPC nichtordnungsgemäß konfiguriert wurde.
AWS DMS kann durch dieses Verhalten beeinflusst werden, da es mit dem COPY-Befehl Daten von S3 ineinen Amazon Redshift-Cluster verschiebt.
Im Folgenden sind die von AWS DMS ausgeführten Schritte zum Laden von Daten in ein Amazon Redshift-Ziel aufgeführt:
1. AWS DMS kopiert Daten von der Quelle in CSV-Dateien auf dem Replikationsserver.2. AWS DMS kopiert die CSV-Dateien mithilfe des AWS SDK in einen S3-Bucket auf Ihrem Konto.3. Anschließend verwendet AWS DMS den COPY-Befehl in Amazon Redshift zum Kopieren von Daten aus
den CSV-Dateien in S3 in eine entsprechende Tabelle in Amazon Redshift.
Wenn die Funktion Enhanced VPC Routing nicht aktiviert ist, leitet Amazon Redshift den Datenverkehr überdas Internet weiter, einschließlich Datenverkehr an andere Services im AWS-Netzwerk. Bei deaktivierterFunktion müssen Sie den Netzwerkpfad nicht konfigurieren. Wenn die Funktion aktiviert ist, müssen Siespeziell einen Netzwerkpfad zwischen Ihrem VPC-Cluster und Ihren Datenressourcen erstellen. Weitere
API-Version API Version 2016-01-01233

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Redshift als Ziel
Informationen zu der erforderlichen Konfiguration finden Sie unter Enhanced VPC Routing in der AmazonRedshift-Dokumentation.
Erstellen und Verwenden von AWS KMS-Schlüsseln für dieVerschlüsselung von Amazon Redshift-ZieldatenSie können Ihre an Amazon S3 zu übertragenen Zieldaten verschlüsseln, bevor Sie sie nach AmazonRedshift kopieren. Um dies zu tun, können Sie benutzerdefinierte AWS KMS-Schlüssel erstellen undverwenden. Sie können den Schlüssel verwenden, den Sie zur Verschlüsselung Ihrer Zieldaten erstellthaben. Verwenden Sie dazu beim Erstellen des Amazon Redshift-Zielendpunkts, einen der folgendenMechanismen:
• Verwenden Sie die folgende Option beim Ausführen des create-endpoint-Befehls mithilfe der AWSCLI.
--redshift-settings '{"EncryptionMode": "SSE_KMS", "ServerSideEncryptionKmsKeyId": "your-kms-key-ARN"}'
Hier handelt es sich bei your-kms-key-ARN um den Amazon-Ressourcennamen (ARN) für IhrenKMS-Schlüssel. Weitere Informationen finden Sie unter Endpunkteinstellungen bei der Verwendung vonAmazon Redshift als Ziel für AWS DMS (p. 237).
• Richten Sie für das zusätzliche Verbindungsattribut encryptionMode den Wert SSE_KMS und für daszusätzliche Verbindungsattribut serverSideEncryptionKmsKeyId den ARN für Ihren KMS-Schlüsselein. Weitere Informationen finden Sie unter Zusätzliche Verbindungsattribute bei der Verwendung vonAmazon Redshift als Ziel für AWS DMS (p. 239).
Um Amazon Redshift-Zieldaten mithilfe eines KMS-Schlüssels zu verschlüsseln, benötigen Sie eine AWSIdentity and Access Management (IAM)-Rolle mit Berechtigungen für den Zugriff auf Amazon Redshift-Daten. Auf diese IAM-Rolle wird dann in einer Richtlinie (einer Schlüsselrichtlinie) zugegriffen, die dem vonIhnen erstellten Verschlüsselungsschlüssel zugewiesen ist. Durch die Erstellung der folgenden Elemente,können Sie diesen Vorgang in Ihrer IAM-Konsole ausführen:
• Eine IAM-Rolle mit einer von Amazon verwalteten Richtlinie.• Ein KMS-Verschlüsselungsschlüssel mit einer Schlüsselrichtlinie, die sich auf diese Rolle bezieht.
Die entsprechende Vorgehensweise wird nachfolgend beschrieben.
So erstellen Sie eine IAM-Rolle mit der erforderlichen von Amazon verwalteten Richtlinie
1. Öffnen Sie die IAM-Konsole unter https://console.aws.amazon.com/iam/.2. Wählen Sie im Navigationsbereich Roles aus. Die Seite Roles (Rollen) wird geöffnet.3. Wählen Sie Create role aus. Die Seite Create role (Rolle erstellen) wird geöffnet.4. Wählen Sie AWS-Service als vertrauenswürdige Entität und anschließend DMS als den Service aus,
der die Rolle verwendet.5. Wählen Sie Next: Permissions (Weiter: Berechtigungen) aus. Die Seite Attach permissions policies
(Berechtigungsrichtlinien anfügen) wird angezeigt.6. Suchen und wählen Sie die AmazonDMSRedshiftS3Role-Richtlinie aus.7. Wählen Sie Next: Tags (Weiter: Tags) aus. Die Seite Add tags (Tags hinzufügen) wird angezeigt. Hier
können Sie alle gewünschten Tags hinzufügen.8. Wählen Sie Next: Review (Weiter: Prüfen) aus und überprüfen Sie Ihre Ergebnisse.9. Wenn die Einstellungen Ihren Vorstellungen entsprechen, geben Sie einen Namen für die Rolle (z. B.
DMS-Redshift-endpoint-access-role) sowie eine zusätzliche Beschreibung ein und wählen Sie
API-Version API Version 2016-01-01234

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Redshift als Ziel
anschließend Create role (Rolle erstellen) aus. Die Seite Roles (Rollen) wird geöffnet und zeigt eineMitteilung an, die darauf hinweist, dass Ihre Rolle erstellt wurde.
Sie haben jetzt die neue Rolle erstellt, über die Sie auf Amazon Redshift-Ressourcen zugreifen können,um diese mit einem angegebenen Namen, z. B. DMS-Redshift-endpoint-access-role, zuverschlüsseln.
So erstellen Sie einen AWS KMS-Verschlüsselungsschlüssel mit einer Schlüsselrichtlinie, die sichauf Ihre IAM-Rolle bezieht:
Note
Weitere Hinweise zur Funktionsweise von AWS DMS mit AWS KMS-Verschlüsselungsschlüsselnfinden Sie unter Einrichten eines Verschlüsselungsschlüssels und Angeben von AWS KMS-Berechtigungen (p. 79).
1. Melden Sie sich bei der AWS Management Console an und öffnen Sie die AWS Key ManagementService(AWS KMS)-Konsole unter https://console.aws.amazon.com/kms.
2. Um die AWS-Region zu ändern, verwenden Sie die Regionenauswahl in der oberen rechten Ecke derSeite.
3. Klicken Sie im Navigationsbereich auf Customer managed keys (Vom Kunden verwaltete Schlüssel).4. Klicken Sie auf Create key. Die Seite Configure key (Schlüssel konfigurieren) wird geöffnet.5. Wählen Sie für Key type (Schlüsseltyp) Symmetric (Symmetrisch).
Note
Wenn Sie diesen Schlüssel erstellen, können Sie nur einen symmetrischen Schlüsselerstellen, da alle AWS-Services, wie z. B. Amazon Redshift, nur mit symmetrischenVerschlüsselungsschlüsseln arbeiten.
6. Wählen Sie Erweiterte Optionen aus. Stellen Sie für Key material origin (Schlüsselmaterialherkunft)sicher, dass KMS ausgewählt ist, und wählen Sie dann Next (Weiter). Die Seite Add Labels (Etikettenhinzufügen) wird geöffnet.
7. Geben Sie unter Create alias and description (Alias und Beschreibung erstellen) einen Alias fürden Schlüssel (z. B. DMS-Redshift-endpoint-encryption-key) und eventuell eine weitereBeschreibung ein.
8. Fügen Sie unter Tags alle Tags hinzu, die Sie verwenden möchten, um den Schlüssel zu identifizierenund seine Nutzung zu verfolgen, und wählen Sie anschließend Next Step (Nächster Schritt) aus. DieSeite Define key administrative permissions (Schlüsselverwaltungsberechtigungen definieren) wirdgeöffnet und zeigt eine Liste der Benutzer und Rollen an, aus denen Sie auswählen können.
9. Fügen Sie die Benutzer und Rollen hinzu, die den Schlüssel verwalten sollen. Stellen Sie sicher, dassdiese Benutzer und Rollen über die erforderlichen Berechtigungen verfügen, um den Schlüssel zuverwalten.
10. Wählen Sie unter Key deletion (Schlüssellöschung) aus, ob die Schlüsseladministratoren denSchlüssel löschen können, und klicken Sie anschließend auf Next Step (Nächster Schritt). Die SeiteDefine Key usage permissions (Schlüsselnutzungsberechtigungen definieren) wird geöffnet und zeigteine weitere Liste mit Benutzern und Rollen an, aus denen Sie auswählen können.
11. Wählen Sie unter This account (Dieses Konto) die verfügbaren Benutzer aus, die kryptografischeOperationen für Amazon Redshift-Ziele ausführen können sollen. Wählen Sie zudem die Rolle aus, dieSie zuvor unter Roles (Rollen) erstellt haben, um den Zugriff auf Amazon Redshift-Zielobjekte für dieVerschlüsselung zu aktivieren, z. B. DMS-Redshift-endpoint-access-role.
12. Wenn Sie weitere Konten hinzufügen möchten, die nicht für denselben Zugriff aufgeführt sind, wählenSie unter Other AWS accounts (Andere Konten) die Option Add another AWS account (AnderesKonto hinzufügen) und dann Next (Weiter). Die Seite Review and edit key policy (Schlüsselrichtlinieprüfen und bearbeiten) wird geöffnet. Hier wird das JSON für die Schlüsselrichtlinie angezeigt, dieSie überprüfen und bearbeiten können, indem Sie in den vorhandenen JSON-Inhalt schreiben.
API-Version API Version 2016-01-01235

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Redshift als Ziel
Hier können Sie sehen, wo die Schlüsselrichtlinie auf die Rolle und die Benutzer (z. B. Admin undUser1) verweist, die Sie im vorherigen Schritt ausgewählt haben. Sie können auch die verschiedenenSchlüsselaktionen sehen, die für die verschiedenen Prinzipale (Benutzer und Rollen) zulässig sind, wieim folgenden Beispiel gezeigt.
{ "Id": "key-consolepolicy-3", "Version": "2012-10-17", "Statement": [ { "Sid": "Enable IAM User Permissions", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::944454115380:root" ] }, "Action": "kms:*", "Resource": "*" }, { "Sid": "Allow access for Key Administrators", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::944454115380:role/Admin" ] }, "Action": [ "kms:Create*", "kms:Describe*", "kms:Enable*", "kms:List*", "kms:Put*", "kms:Update*", "kms:Revoke*", "kms:Disable*", "kms:Get*", "kms:Delete*", "kms:TagResource", "kms:UntagResource", "kms:ScheduleKeyDeletion", "kms:CancelKeyDeletion" ], "Resource": "*" }, { "Sid": "Allow use of the key", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::944454115380:role/DMS-Redshift-endpoint-access-role", "arn:aws:iam::944454115380:role/Admin", "arn:aws:iam::944454115380:role/User1" ] }, "Action": [ "kms:Encrypt", "kms:Decrypt", "kms:ReEncrypt*", "kms:GenerateDataKey*", "kms:DescribeKey" ], "Resource": "*"
API-Version API Version 2016-01-01236

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Redshift als Ziel
}, { "Sid": "Allow attachment of persistent resources", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::944454115380:role/DMS-Redshift-endpoint-access-role", "arn:aws:iam::944454115380:role/Admin", "arn:aws:iam::944454115380:role/User1" ] }, "Action": [ "kms:CreateGrant", "kms:ListGrants", "kms:RevokeGrant" ], "Resource": "*", "Condition": { "Bool": { "kms:GrantIsForAWSResource": true } } } ]
13. Klicken Sie auf Finish. Die Seite Encryption keys (Verschlüsselungsschlüssel) wird geöffnet und zeigteine Mitteilung an, die darauf hinweist, dass Ihr Master-Verschlüsselungsschlüssel erstellt wurde.
Damit haben Sie einen neuen KMS-Schlüssel mit einem angegebenen Alias (z. B. DMS-Redshift-endpoint-encryption-key) erstellt. Dieser Schlüssel ermöglicht es AWS DMS, Amazon Redshift-Zieldaten zu verschlüsseln.
Endpunkteinstellungen bei der Verwendung von Amazon Redshiftals Ziel für AWS DMSSie können Endpunkteinstellungen, ähnlich wie zusätzliche Verbindungsattribute, zum Konfigurieren IhresAmazon Redshift-Ziels verwenden. Sie können diese Einstellungen beim Erstellen des Zielendpunktsmithilfe des create-endpoint-Befehls in der AWS CLI angeben. Verwenden Sie dazu die --redshift-settings "json-settings"-Option. Hier handelt es sich bei json-settings umein JSON-Objekt mit Parametern zum Angeben der Einstellungen. Sie können auch eine JSON-Dateifestlegen, die das gleiche json-settings-Objekt umfasst, wie im folgenden Beispiel dargestellt:--redshift-settings file:///your-file-path/my_redshift_settings.json. Hier istmy_redshift_settings.json der Name der JSON-Datei, die das gleiche json-settings objectenthält.
Die Parameternamen für die Endpunkteinstellungen sind mit den Namen der entsprechenden zusätzlichenVerbindungsattribute identisch. Der einzige Unterschied besteht darin, dass die Parameternamen fürdie Endpunkteinstellungen mit Großbuchstaben beginnen. Beachten Sie auch, dass nicht alle AmazonRedshift-Zielendpunkteinstellungen, die zusätzliche Verbindungsattribute mithilfe der --redshift-settings-Option des create-endpoint-Befehls verwenden, verfügbar sind. Weitere Informationen überdie verfügbaren Einstellungen in einem AWS CLI-Aufruf von create-endpoint finden Sie unter create-endpoint in der AWS CLI Command Reference AWS DMS. Weitere Informationen über diese Einstellungenfinden Sie im Abschnitt zu den entsprechenden zusätzlichen Verbindungsattributen unter ZusätzlicheVerbindungsattribute bei der Verwendung von Amazon Redshift als Ziel für AWS DMS (p. 239).
Sie können die Einstellungen für den Amazon Redshift-Zielendpunkt verwenden, um Folgendes zukonfigurieren:
API-Version API Version 2016-01-01237

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Redshift als Ziel
• Ein benutzerdefinierter AWS KMS-Datenverschlüsselungsschlüssel. Sie können diesen Schlüsselverwenden, um Ihre an Amazon S3 übertragenen Daten zu verschlüsseln, bevor Sie sie nach AmazonRedshift kopieren.
• Ein benutzerdefinierter S3-Bucket als Zwischenspeicher für die zu Amazon Redshift migrierten Daten.
KMS-Schlüsseleinrichtungen für die Datenverschlüsselung
Die folgenden Beispiele veranschaulichen die Konfiguration eines benutzerdefinierten KMS-Schlüssels, umIhre per Push an S3 übertragenen Daten zu verschlüsseln. Um zu beginnen, können Sie den folgendencreate-endpoint-Aufruf in der AWS CLI ausführen.
aws dms create-endpoint --endpoint-identifier redshift-target-endpoint --endpoint-type target --engine-name redshift --username your-username --password your-password --server-name your-server-name --port 5439 --database-name your-db-name --redshift-settings '{"EncryptionMode": "SSE_KMS", "ServerSideEncryptionKmsKeyId": "arn:aws:kms:us-east-1:944454115380:key/24c3c5a1-f34a-4519-a85b-2debbef226d1"}'
Das durch die --redshift-settings-Option angegebene JSON-Objekt definiert zweiParameter. Der eine ist ein EncryptionMode-Parameter mit dem Wert SSE_KMS. Der andereist ein ServerSideEncryptionKmsKeyId-Parameter mit dem Wert arn:aws:kms:us-east-1:944454115380:key/24c3c5a1-f34a-4519-a85b-2debbef226d1. Bei diesem Wert handeltes sich um einen Amazon-Ressourcenname (ARN) für Ihren benutzerdefinierten KMS-Schlüssel.
Standardmäßig erfolgt S3-Datenverschlüsselung mithilfe von serverseitiger S3-Verschlüsselung.Für das Amazon Redshift-Ziel des vorherigen Beispiels ist dies gleichbedeutend mit der Angabe derEndpunkteinstellungen, wie im folgenden Beispiel dargestellt.
aws dms create-endpoint --endpoint-identifier redshift-target-endpoint --endpoint-type target --engine-name redshift --username your-username --password your-password --server-name your-server-name --port 5439 --database-name your-db-name --redshift-settings '{"EncryptionMode": "SSE_S3"}'
Weitere Informationen über das Arbeiten mit serverseitiger S3-Verschlüsselung finden Sie unter Schützenvon Daten mithilfe serverseitiger Verschlüsselung.
Amazon S3-Bucket-Einstellungen
Wenn Sie Daten in einen Amazon Redshift-Zielendpunkt migrieren, verwendet AWS DMS einen Standard-Amazon S3-Bucket als Zwischenspeicher für Aufgaben, bevor die Daten in Amazon Redshift kopiertwerden. Beispielsweise wird in den dargelegten Beispielen für das Erstellen eines Amazon Redshift-Zielendpunkts mit einem KMS-Datenverschlüsselungsschlüssel dieser Standard-S3-Bucket verwendet(siehe KMS-Schlüsseleinrichtungen für die Datenverschlüsselung (p. 238)).
Sie können stattdessen einen benutzerdefinierten S3-Bucket für diese Zwischenspeicherung angeben,indem Sie die folgenden Parameter in den Wert Ihrer --redshift-settings-Option des AWS CLI-Befehls „create-endpoint“ einschließen:
• BucketName – Eine Zeichenfolge, die Sie als Namen des S3-Bucketspeichers angeben.• BucketFolder – (Optional) Eine Zeichenfolge die Sie als Namen des Speicherordners im angegebenen
S3-Bucket angeben können.• ServiceAccessRoleArn – Der ARN einer IAM-Rolle, die administrativen Zugriff auf den S3-Bucket
erlaubt. In der Regel erstellen Sie diese Rolle auf Grundlage der AmazonDMSRedshiftS3Role-Richtlinie. Ein Beispiel finden Sie unter dem Vorgehen zum Erstellen einer IAM-Rolle mit der
API-Version API Version 2016-01-01238

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Redshift als Ziel
erforderlichen Amazon-verwalteten Richtlinie in Erstellen und Verwenden von AWS KMS-Schlüsseln fürdie Verschlüsselung von Amazon Redshift-Zieldaten (p. ).
Note
Wenn Sie mithilfe der --service-access-role-arn Option des create-endpoint-Befehls den ARN einer anderen IAM-Rolle angeben, hat diese IAM-Rollenoption Priorität.
Im folgenden Beispiel wird gezeigt, wie Sie diese Parameter verwenden, um über die AWS CLI mitfolgendem create-endpoint-Aufruf einen benutzerdefinierten Amazon S3-Bucket anzugeben.
aws dms create-endpoint --endpoint-identifier redshift-target-endpoint --endpoint-type target --engine-name redshift --username your-username --password your-password --server-name your-server-name --port 5439 --database-name your-db-name --redshift-settings '{"ServiceAccessRoleArn": "your-service-access-ARN", "BucketName": "your-bucket-name", "BucketFolder": "your-bucket-folder-name"}'
Zusätzliche Verbindungsattribute bei der Verwendung vonAmazon Redshift als Ziel für AWS DMSSie können zusätzliche Verbindungsattribute verwenden, um Ihr Amazon Redshift-Ziel zu konfigurieren. Siegeben diese Einstellungen beim Erstellen des Zielendpunkts an. Wenn Sie mehrere Attributeinstellungenverwenden, müssen diese durch Semikolons und ohne zusätzlichen Leerraum voneinander getrenntwerden.
Die folgende Tabelle zeigt die zusätzlichen Verbindungsattribute, die verfügbar sind, wenn AmazonRedshift das Ziel ist.
Name Beschreibung
maxFileSize Gibt die maximale Größe (in KB) der CSV-Datei zumÜbertragen von Daten nach Amazon Redshift an.
Standardwert: 32768 KB (32 MB)
Zulässige Werte: 1– 1048576
Beispiel: maxFileSize=512
fileTransferUploadStreams Gibt die Anzahl von Threads an, die verwendet werden, umeine Datei hochzuladen.
Standardwert: 10
Zulässige Werte: 1–64
Beispiel: fileTransferUploadStreams=20
acceptanydate Gibt an, ob ein beliebiges Datumsformat akzeptiert wird,einschließlich ungültiger Datumsformate wie 0000-00-00-00.Boolescher Wert:
Standardwert: false
Zulässige Werte: true | false
Beispiel: acceptanydate=true
API-Version API Version 2016-01-01239
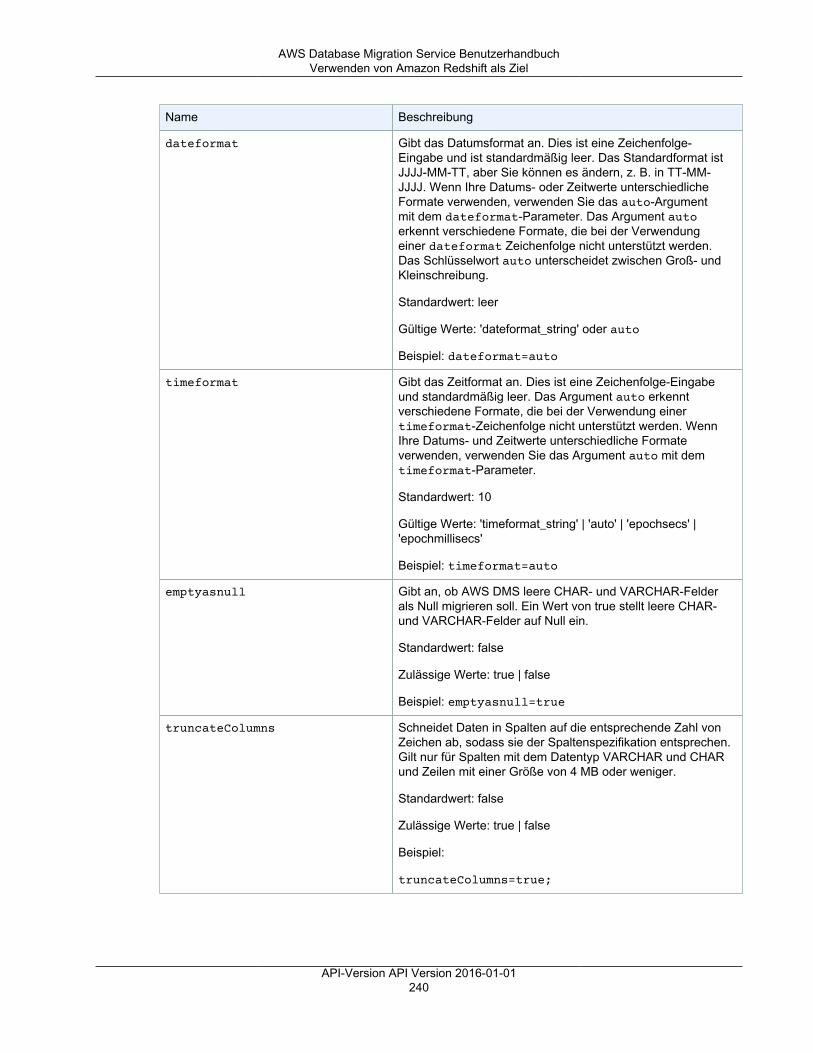
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Redshift als Ziel
Name Beschreibung
dateformat Gibt das Datumsformat an. Dies ist eine Zeichenfolge-Eingabe und ist standardmäßig leer. Das Standardformat istJJJJ-MM-TT, aber Sie können es ändern, z. B. in TT-MM-JJJJ. Wenn Ihre Datums- oder Zeitwerte unterschiedlicheFormate verwenden, verwenden Sie das auto-Argumentmit dem dateformat-Parameter. Das Argument autoerkennt verschiedene Formate, die bei der Verwendungeiner dateformat Zeichenfolge nicht unterstützt werden.Das Schlüsselwort auto unterscheidet zwischen Groß- undKleinschreibung.
Standardwert: leer
Gültige Werte: 'dateformat_string' oder auto
Beispiel: dateformat=auto
timeformat Gibt das Zeitformat an. Dies ist eine Zeichenfolge-Eingabeund standardmäßig leer. Das Argument auto erkenntverschiedene Formate, die bei der Verwendung einertimeformat-Zeichenfolge nicht unterstützt werden. WennIhre Datums- und Zeitwerte unterschiedliche Formateverwenden, verwenden Sie das Argument auto mit demtimeformat-Parameter.
Standardwert: 10
Gültige Werte: 'timeformat_string' | 'auto' | 'epochsecs' |'epochmillisecs'
Beispiel: timeformat=auto
emptyasnull Gibt an, ob AWS DMS leere CHAR- und VARCHAR-Felderals Null migrieren soll. Ein Wert von true stellt leere CHAR-und VARCHAR-Felder auf Null ein.
Standardwert: false
Zulässige Werte: true | false
Beispiel: emptyasnull=true
truncateColumns Schneidet Daten in Spalten auf die entsprechende Zahl vonZeichen ab, sodass sie der Spaltenspezifikation entsprechen.Gilt nur für Spalten mit dem Datentyp VARCHAR und CHARund Zeilen mit einer Größe von 4 MB oder weniger.
Standardwert: false
Zulässige Werte: true | false
Beispiel:
truncateColumns=true;
API-Version API Version 2016-01-01240
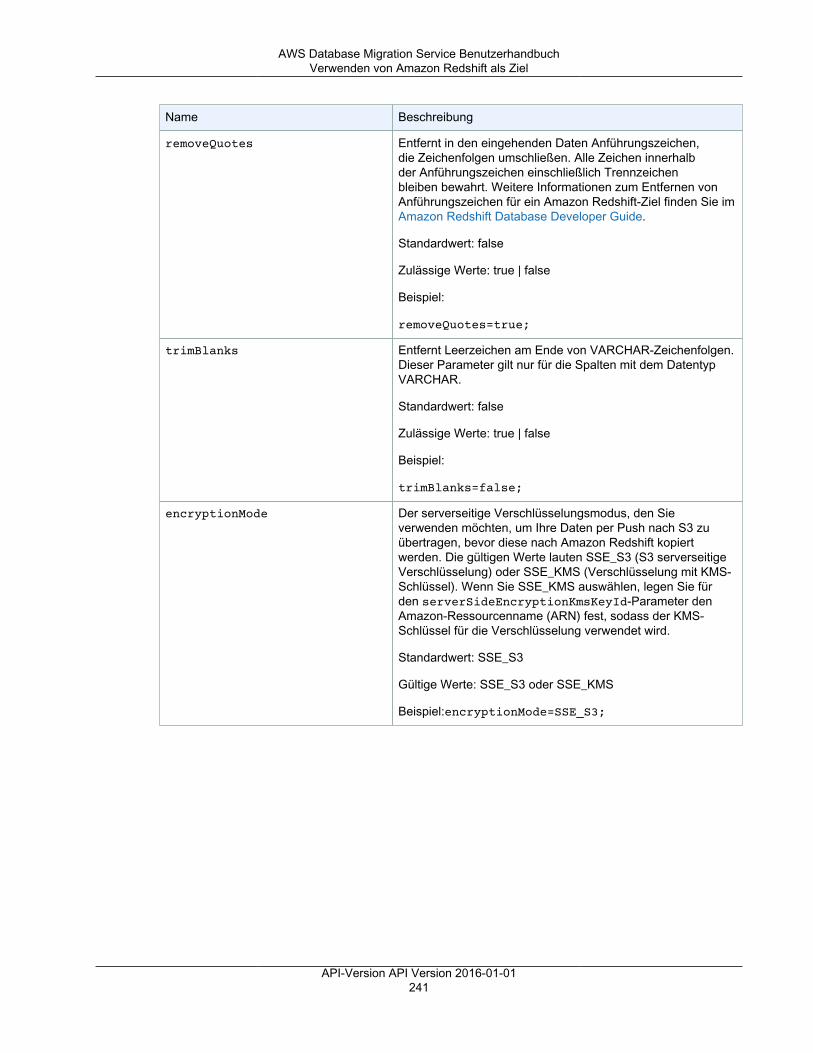
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Redshift als Ziel
Name Beschreibung
removeQuotes Entfernt in den eingehenden Daten Anführungszeichen,die Zeichenfolgen umschließen. Alle Zeichen innerhalbder Anführungszeichen einschließlich Trennzeichenbleiben bewahrt. Weitere Informationen zum Entfernen vonAnführungszeichen für ein Amazon Redshift-Ziel finden Sie imAmazon Redshift Database Developer Guide.
Standardwert: false
Zulässige Werte: true | false
Beispiel:
removeQuotes=true;
trimBlanks Entfernt Leerzeichen am Ende von VARCHAR-Zeichenfolgen.Dieser Parameter gilt nur für die Spalten mit dem DatentypVARCHAR.
Standardwert: false
Zulässige Werte: true | false
Beispiel:
trimBlanks=false;
encryptionMode Der serverseitige Verschlüsselungsmodus, den Sieverwenden möchten, um Ihre Daten per Push nach S3 zuübertragen, bevor diese nach Amazon Redshift kopiertwerden. Die gültigen Werte lauten SSE_S3 (S3 serverseitigeVerschlüsselung) oder SSE_KMS (Verschlüsselung mit KMS-Schlüssel). Wenn Sie SSE_KMS auswählen, legen Sie fürden serverSideEncryptionKmsKeyId-Parameter denAmazon-Ressourcenname (ARN) fest, sodass der KMS-Schlüssel für die Verschlüsselung verwendet wird.
Standardwert: SSE_S3
Gültige Werte: SSE_S3 oder SSE_KMS
Beispiel:encryptionMode=SSE_S3;
API-Version API Version 2016-01-01241
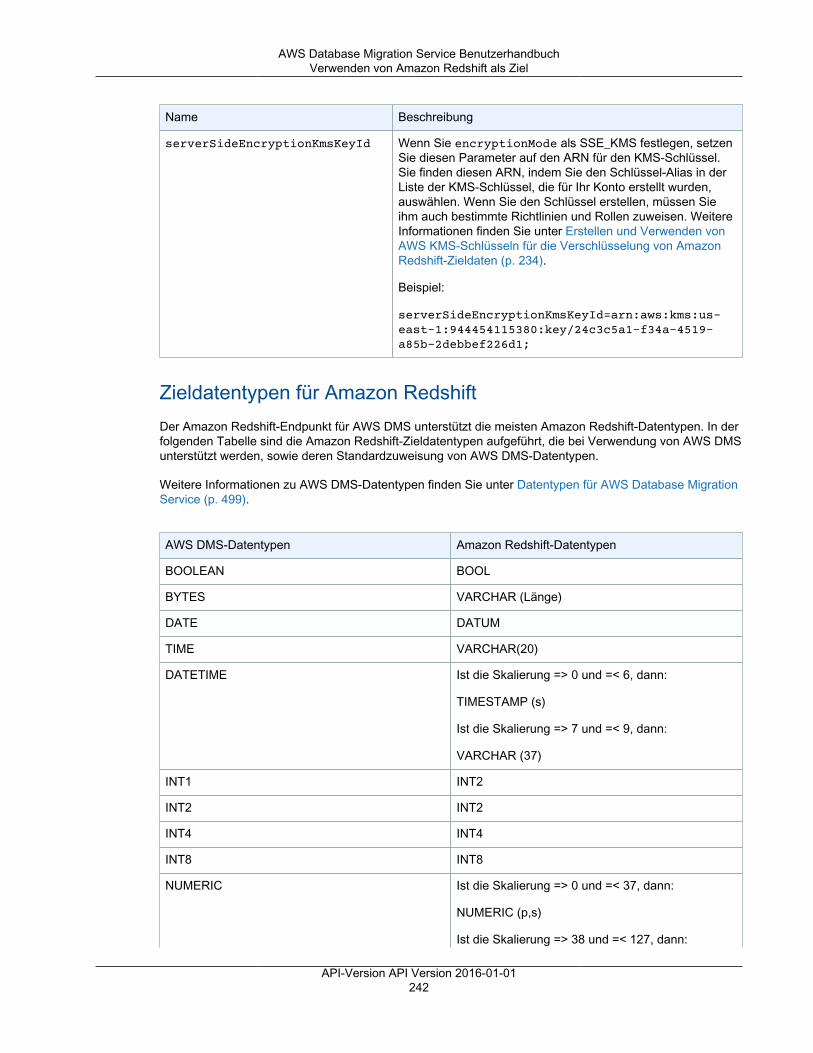
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Redshift als Ziel
Name Beschreibung
serverSideEncryptionKmsKeyId Wenn Sie encryptionMode als SSE_KMS festlegen, setzenSie diesen Parameter auf den ARN für den KMS-Schlüssel.Sie finden diesen ARN, indem Sie den Schlüssel-Alias in derListe der KMS-Schlüssel, die für Ihr Konto erstellt wurden,auswählen. Wenn Sie den Schlüssel erstellen, müssen Sieihm auch bestimmte Richtlinien und Rollen zuweisen. WeitereInformationen finden Sie unter Erstellen und Verwenden vonAWS KMS-Schlüsseln für die Verschlüsselung von AmazonRedshift-Zieldaten (p. 234).
Beispiel:
serverSideEncryptionKmsKeyId=arn:aws:kms:us-east-1:944454115380:key/24c3c5a1-f34a-4519-a85b-2debbef226d1;
Zieldatentypen für Amazon RedshiftDer Amazon Redshift-Endpunkt für AWS DMS unterstützt die meisten Amazon Redshift-Datentypen. In derfolgenden Tabelle sind die Amazon Redshift-Zieldatentypen aufgeführt, die bei Verwendung von AWS DMSunterstützt werden, sowie deren Standardzuweisung von AWS DMS-Datentypen.
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
AWS DMS-Datentypen Amazon Redshift-Datentypen
BOOLEAN BOOL
BYTES VARCHAR (Länge)
DATE DATUM
TIME VARCHAR(20)
DATETIME Ist die Skalierung => 0 und =< 6, dann:
TIMESTAMP (s)
Ist die Skalierung => 7 und =< 9, dann:
VARCHAR (37)
INT1 INT2
INT2 INT2
INT4 INT4
INT8 INT8
NUMERIC Ist die Skalierung => 0 und =< 37, dann:
NUMERIC (p,s)
Ist die Skalierung => 38 und =< 127, dann:
API-Version API Version 2016-01-01242
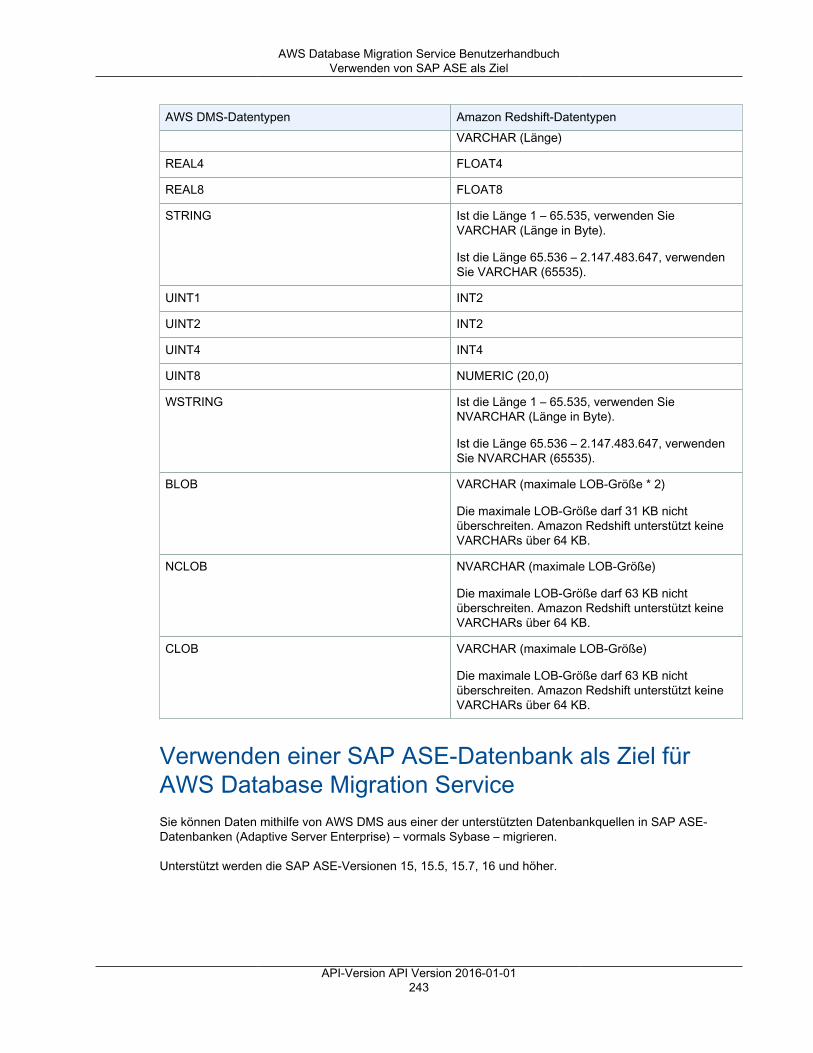
AWS Database Migration Service BenutzerhandbuchVerwenden von SAP ASE als Ziel
AWS DMS-Datentypen Amazon Redshift-DatentypenVARCHAR (Länge)
REAL4 FLOAT4
REAL8 FLOAT8
STRING Ist die Länge 1 – 65.535, verwenden SieVARCHAR (Länge in Byte).
Ist die Länge 65.536 – 2.147.483.647, verwendenSie VARCHAR (65535).
UINT1 INT2
UINT2 INT2
UINT4 INT4
UINT8 NUMERIC (20,0)
WSTRING Ist die Länge 1 – 65.535, verwenden SieNVARCHAR (Länge in Byte).
Ist die Länge 65.536 – 2.147.483.647, verwendenSie NVARCHAR (65535).
BLOB VARCHAR (maximale LOB-Größe * 2)
Die maximale LOB-Größe darf 31 KB nichtüberschreiten. Amazon Redshift unterstützt keineVARCHARs über 64 KB.
NCLOB NVARCHAR (maximale LOB-Größe)
Die maximale LOB-Größe darf 63 KB nichtüberschreiten. Amazon Redshift unterstützt keineVARCHARs über 64 KB.
CLOB VARCHAR (maximale LOB-Größe)
Die maximale LOB-Größe darf 63 KB nichtüberschreiten. Amazon Redshift unterstützt keineVARCHARs über 64 KB.
Verwenden einer SAP ASE-Datenbank als Ziel fürAWS Database Migration ServiceSie können Daten mithilfe von AWS DMS aus einer der unterstützten Datenbankquellen in SAP ASE-Datenbanken (Adaptive Server Enterprise) – vormals Sybase – migrieren.
Unterstützt werden die SAP ASE-Versionen 15, 15.5, 15.7, 16 und höher.
API-Version API Version 2016-01-01243

AWS Database Migration Service BenutzerhandbuchVerwenden von SAP ASE als Ziel
Voraussetzungen für die Verwendung einer SAP ASE-Datenbankals Ziel für AWS Database Migration ServiceBevor Sie eine SAP ASE-Datenbank als Ziel für AWS DMS verwenden, vergewissern Sie sich, dass Sie diefolgenden Voraussetzungen erfüllen:
• Sie müssen dem AWS DMS-Benutzer Zugriff auf das SAP ASE-Konto erteilen. Dieser Benutzer mussüber Lese-/Schreibberechtigung für die SAP ASE-Datenbank verfügen.
• Wenn die Replikation zu SAP ASE Version 15.7 erfolgt, die auf einer Windows EC2-Instance installiertund mit nicht-lateinischen Zeichen (z. B. Chinesisch) konfiguriert ist, erfordert AWS DMS, dass SAP ASE15.7 SP121 auf der SAP ASE-Zielmaschine installiert ist.
Zusätzliche Verbindungsattribute bei der Verwendung von SAPASE als Ziel für AWS DMSSie können zusätzliche Verbindungsattribute verwenden, um Ihr SAP ASE-Ziel zu konfigurieren. Siegeben diese Einstellungen beim Erstellen des Zielendpunkts an. Wenn Sie mehrere Attributeinstellungenverwenden, müssen diese durch Semikolons und ohne zusätzlichen Leerraum voneinander getrenntwerden.
Die folgende Tabelle zeigt die zusätzlichen Verbindungsattribute, die verfügbar sind, wenn SAP ASE alsZiel verwendet wird:
Name Beschreibung
enableReplication Legen Sie diese Option auf Y fest, um die SAP ASE-Replikation automatisch zu aktivieren. Dies ist nur erforderlich,wenn die SAP ASE-Replikation nicht bereits aktiviert ist.
additionalConnectionProperties Alle zusätzlichen ODBC-Verbindungsparameter, die Sieangeben möchten.
Note
Wenn der Benutzername oder das Passwort in der Verbindungszeichenfolge nicht-lateinischeZeichen (z. B. Chinesisch) enthält, ist die folgende Eigenschaft erforderlich: charset=gb18030
Zieldatentypen für SAP ASEIn der folgenden Tabelle sind die SAP ASE-Datenbank-Zieldatentypen aufgeführt, die bei Verwendung vonAWS DMS unterstützt werden, sowie deren Standardzuweisung von AWS DMS-Datentypen.
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
AWS DMS-Datentypen SAP ASE-Datentyp
BOOLEAN BIT
BYTES VARBINARY (Länge)
DATE DATE
TIME TIME
API-Version API Version 2016-01-01244

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
AWS DMS-Datentypen SAP ASE-Datentyp
TIMESTAMP Ist die Skalierung => 0 und =< 6, dann:BIGDATETIME
Ist die Skalierung => 7 und =< 9, dann: VARCHAR(37)
INT1 TINYINT
INT2 SMALLINT
INT4 INTEGER
INT8 BIGINT
NUMERIC NUMERIC (p,s)
REAL4 REAL
REAL8 DOUBLE PRECISION
STRING VARCHAR (Länge)
UINT1 TINYINT
UINT2 UNSIGNED SMALLINT
UINT4 UNSIGNED INTEGER
UINT8 UNSIGNED BIGINT
WSTRING VARCHAR (Länge)
BLOB IMAGE
CLOB UNITEXT
NCLOB TEXT
AWS DMS unterstützt keine Tabellen, die Felder mit den folgenden Datentypen enthalten. ReplizierteSpalten mit diesen Datentypen werden als Null angezeigt.
• Benutzerdefinierter Typ (UDT)
Verwenden von Amazon S3 als Ziel für AWSDatabase Migration ServiceSie können Daten mithilfe von AWS DMS aus einer der unterstützten Datenbankquellen in Amazon S3migrieren. Bei der Verwendung von Amazon S3 als Ziel in einer AWS DMS-Aufgabe werden Daten desvollständigen Ladevorgangs sowie CDC-Daten (Change Data Capture, Erfassung von Änderungsdaten)standardmäßig in CSV-Dateien (Comma-Separated Value, durch Trennzeichen getrennte Werte)geschrieben. Für kompaktere Speicher- und schnellere Abfrageoptionen haben Sie zudem die Möglichkeit,die Daten im Apache Parquet-Format (.parquet) zu schreiben.
AWS DMS verwendet zum Benennen der während eines vollständigen Ladevorgangs erstellten Dateieneinen inkrementellen hexadezimalen Zähler – z. B. LOAD00001.csv, LOAD00002..., LOAD00009,LOAD0000A usw. für CSV-Dateien. Zum Benennen von CDC-Dateien verwendet AWS DMS Zeitstempel,
API-Version API Version 2016-01-01245

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
z. B. 20141029-1134010000.csv. Für jede Quelltabelle erstellt AWS DMS einen Ordner unter demangegebenen Zielordner. AWS DMS schreibt alle Dateien des vollständigen Ladevorgangs und CDC-Dateien an den angegebenen Amazon S3-Bucket.
Der Parameter bucketFolder enthält den Speicherort, an dem die CSV- oder Parquet-Dateien vor demHochladen in den S3-Bucket gespeichert werden. Die Tabellendaten für CSV-Dateien werden im S3-Bucket im folgenden Format gespeichert.
<schema_name>/<table_name>/LOAD00000001.csv<schema_name>/<table_name>/LOAD00000002.csv...<schema_name>/<table_name>/LOAD00000009.csv<schema_name>/<table_name>/LOAD0000000A.csv<schema_name>/<table_name>/LOAD0000000B.csv...<schema_name>/<table_name>/LOAD0000000F.csv<schema_name>/<table_name>/LOAD00000010.csv...
Sie können mithilfe der zusätzlichen Verbindungsattribute die Trennzeichen für die Spalte und die Zeilesowie andere Parameter festlegen. Weitere Informationen zu den zusätzlichen Verbindungsattributenfinden Sie unter Zusätzliche Verbindungsattribute bei der Verwendung von Amazon S3 als Ziel für AWSDMS (p. 260) am Ende dieses Abschnitts.
Wenn Sie AWS DMS verwenden, um Datenänderungen zu replizieren, gibt die erste Spalte der CSV-oder Parquet-Ausgabedatei an, wie die Daten geändert wurden. Dies wird in der folgenden CSV-Dateidargestellt.
I,101,Smith,Bob,4-Jun-14,New YorkU,101,Smith,Bob,8-Oct-15,Los AngelesU,101,Smith,Bob,13-Mar-17,DallasD,101,Smith,Bob,13-Mar-17,Dallas
Für dieses Beispiel nehmen wir an, dass es eine EMPLOYEE-Tabelle in der Quelldatenbank gibt. AWS DMSschreibt Daten in die CSV- oder Parquet-Datei als Reaktion auf die folgenden Ereignisse:
• Ein neuer Mitarbeiter (Bob Smith, Mitarbeiter-ID 101) wird am 04. Juni 2014 in der Niederlassung in NewYork eingestellt. In der CSV- oder Parquet-Datei gibt das I in der ersten Spalte an, dass eine neue Zeilein die MITARBEITER-Tabelle in der Quelldatenbank INSERTed (eingefügt) wurde.
• Am 08. Oktober 2015 wechselt Bob zur Niederlassung in Los Angeles. In der CSV- oder Parquet-Datei gibt das U an, dass die entsprechende Zeile in der MITARBEITER-Tabelle UPDATEd (aktualisiert)wurde, um Bobs neuen Firmenstandort widerzuspiegeln. Der Rest der Linie spiegelt die Zeile in derMITARBEITER-Tabelle wider, wie sie nach dem UPDATE angezeigt wird.
• Am 13. März 2017 wechselt Bob erneut zur Niederlassung in Dallas. In der CSV- oder Parquet-Datei gibtdas U an, dass diese Zeile erneut UPDATEd (aktualisiert) wurde. Der Rest der Linie spiegelt die Zeile inder MITARBEITER-Tabelle wider, wie sie nach dem UPDATE angezeigt wird.
• Nach einiger Zeit der Arbeit in Dallas verlässt Bob die Firma. In der CSV- oder Parquet-Datei gibt das Dan, dass die Zeile in der Quelltabelle DELETEd (gelöscht) wurde. Der Rest der Linie spiegelt wider, wiedie Zeile in der MITARBEITER-Tabelle vor der Löschung angezeigt wurde.
Voraussetzungen für die Verwendung von Amazon S3 als ZielBevor Sie Amazon S3 als Ziel verwenden, müssen Sie überprüfen, ob folgende Bedingungen erfülltwerden:
API-Version API Version 2016-01-01246

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
• Der S3-Bucket, den Sie als Ziel verwenden, befindet sich in derselben Region wie die DMS-Replikations-Instance, die Sie für die Migration der Daten verwenden.
• Das AWS-Konto, das Sie für die Migration verwenden, besitzt eine IAM-Rolle mit Schreib- undLöschzugriff auf den S3-Bucket, den Sie als Ziel verwenden.
• Diese Rolle besitzt Tagging-Zugriff, sodass Sie alle S3-Objekte, die in den Ziel-Bucket geschriebenwerden, markieren können.
Um diesen Kontozugriff einzurichten, vergewissern Sie sich, dass die dem Benutzerkonto zugewieseneRolle, mit der die Migrationsaufgabe erstellt wird, den folgenden Satz von Berechtigungen aufweist.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:DeleteObject", "s3:PutObjectTagging" ], "Resource": [ "arn:aws:s3:::buckettest2/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::buckettest2" ] } ]}
Einschränkungen bei der Verwendung von Amazon S3 als ZielFür eine Datei in Amazon S3, die Sie als Ziel verwenden, gelten die folgenden Einschränkungen:
• Es werden nur die folgenden DDL-Befehle (Data Definition Language) unterstützt: TRUNCATE TABLE,DROP TABLE und CREATE TABLE.
• Der vollständige LOB-Modus wird nicht unterstützt.• Änderungen an der Quelltabellenstruktur während des vollständigen Ladevorgangs werden nicht
unterstützt. Änderungen an den Daten werden während des vollständigen Ladevorgangs unterstützt.• Mehrere Aufgaben, die Daten aus derselben Quelltabelle in denselben S3-Ziel-Endpunkt-Bucket
replizieren, führen dazu, dass diese Aufgaben in dieselbe Datei schreiben. Wir empfehlen,unterschiedliche Zielendpunkte (Buckets) anzugeben, wenn die Datenquelle aus derselben Tabellestammt.
SicherheitUm Amazon S3 als Ziel zu nutzen, muss das für die Migration eingesetzte Konto über Zugriff zumSchreiben und Löschen für den Amazon S3-Bucket verfügen, den Sie als Ziel verwenden. Sie müssen denAmazon-Ressourcennamen (ARN) einer IAM-Rolle angeben, die über die für den Zugriff auf Amazon S3erforderlichen Berechtigungen verfügt.
API-Version API Version 2016-01-01247

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
AWS DMS unterstützt eine Reihe vordefinierter Rechte für Amazon S3, auch als vordefinierteZugriffskontrolllisten (Access Control Lists, ACLs) bezeichnet. Jede vordefinierte ACL verfügt über eineReihe von Empfänger und Berechtigungen, die Sie verwenden können, um Berechtigungen für denAmazon S3-Bucket festzulegen. Sie können eine vordefinierte ACL mit dem cannedAclForObjectsin dem Attribut der Verbindungszeichenfolge für Ihren S3-Zielendpunkt festlegen. Weitere Informationenzur Verwendung des zusätzlichen Oracle-Verbindungsattributs cannedAclForObjects finden Sie unterZusätzliche Verbindungsattribute bei der Verwendung von Amazon S3 als Ziel für AWS DMS (p. 260).Weitere Informationen zu vordefinierten ACLs von Amazon S3 finden Sie unter Vordefinierte ACL.
Die IAM-Rolle, die Sie für die Migration verwenden, muss in der Lage sein, die API-Operations3:PutObjectAcl durchzuführen.
Speichern von Amazon S3 Objekten mithilfe von Apache ParquetDas CSV-Format ist das Standardspeicherformat für Amazon S3 Ziel-Objekte. Das Apache Parquet-Speicherformat (.parquet) bietet indessen kompaktere Speicheroptionen und schnellere Abfragen.
Apache Parquet ist ein Open-Source-Dateispeicherformat, das ursprünglich für Hadoop entwickelt wurde.Weitere Informationen über Apache Parquet finden Sie unter https://parquet.apache.org/.
Um .parquet als das Speicherformat für Ihre migrierten S3-Zielobjekte festzulegen, können Sie diefolgenden Mechanismen verwenden:
• Endpunkteinstellungen, die Sie bei der Erstellung des Endpunkts mithilfe der AWS CLI oder der APIfür AWS DMS als Parameter für ein JSON-Objekt angeben. Weitere Informationen finden Sie unterEndpunkteinstellungen bei der Verwendung von Amazon S3 als Ziel für AWS DMS (p. 258).
• Zusätzliche Verbindungsattribute, die Sie bei der Erstellung des Endpunkts als eine durch Semikolonsgetrennte Liste bereitstellen. Weitere Informationen finden Sie unter Zusätzliche Verbindungsattribute beider Verwendung von Amazon S3 als Ziel für AWS DMS (p. 260).
Markieren von Amazon S3-ObjektenSie können von einer Replikations-Instance erstellte Amazon S3-Objekte markieren, indem Sieentsprechende JSON-Objekte als Teil der Zuweisungsregeln von Aufgabentabellen angeben. WeitereInformationen über die Anforderungen und Optionen für das Markieren von S3-Objekten, einschließlichgültiger Tag-Namen, finden Sie unter Markieren von Objekten im Entwicklerhandbuch für Amazon SimpleStorage Service. Weitere Informationen über Tabellenzuweisungen mithilfe von JSON finden Sie unter Festlegen der Tabellenauswahl und Transformationen durch Tabellenzuweisungen mit JSON (p. 377).
Sie markieren S3-Objekte, die für bestimmte Tabellen und Schemata erstellt wurden, mithilfe eines odermehrerer JSON-Objekte des selection-Regeltyps. Nach Ausführung dieses selection-Objekts (oderdieser Objekte) können Sie ein oder mehrere JSON-Objekte des post-processing-Regeltyps mithilfeder add-tag-Aktion hinzufügen. Diese Nachbearbeitungsregeln identifizieren die zu markierenden S3-Objekte und geben die Namen und Werte der Tags an, die Sie diesen S3-Objekten hinzufügen möchten.
Sie finden die Parameter zur Angabe in den JSON-Objekten des post-processing-Regeltyps in derfolgenden Tabelle.
Parameter Mögliche Werte Beschreibung
rule-type post-processing Ein Wert, der die Aktionen zurNachbereitung auf die generiertenZielobjekte anwendet. Sie können eineoder mehrere Nachbereitungsregelnfestlegen, um ausgewählte S3-Objektezu markieren.
API-Version API Version 2016-01-01248
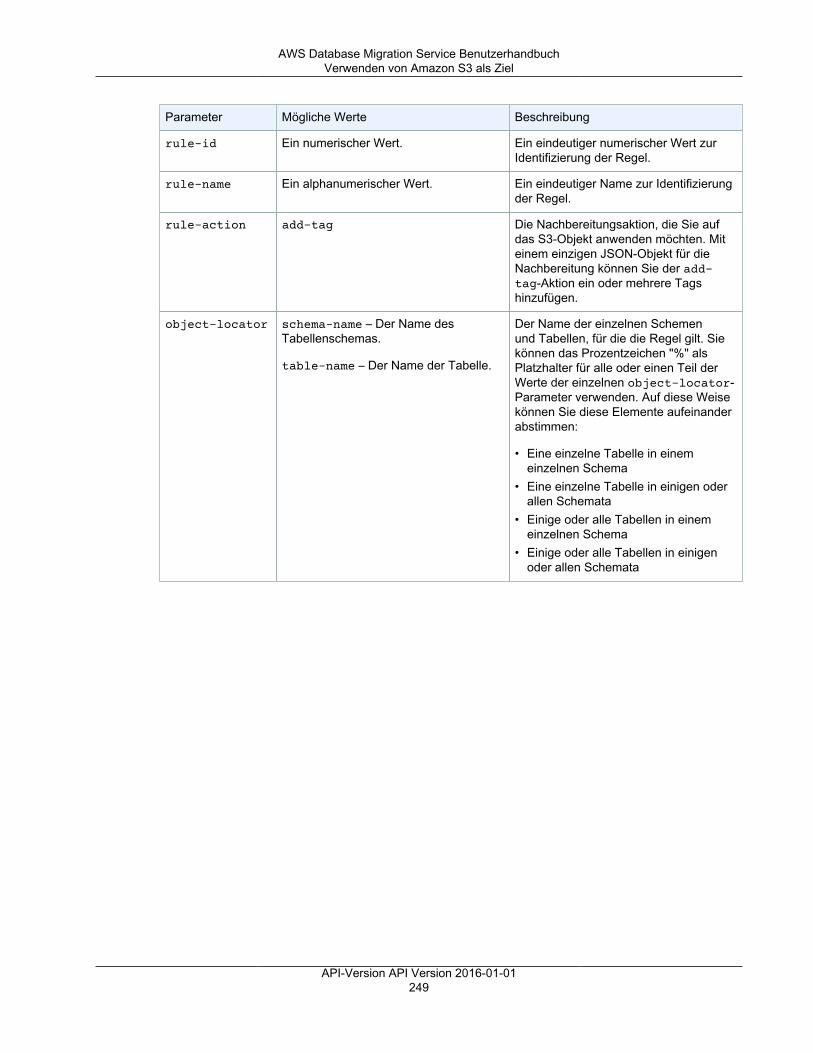
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Parameter Mögliche Werte Beschreibung
rule-id Ein numerischer Wert. Ein eindeutiger numerischer Wert zurIdentifizierung der Regel.
rule-name Ein alphanumerischer Wert. Ein eindeutiger Name zur Identifizierungder Regel.
rule-action add-tag Die Nachbereitungsaktion, die Sie aufdas S3-Objekt anwenden möchten. Miteinem einzigen JSON-Objekt für dieNachbereitung können Sie der add-tag-Aktion ein oder mehrere Tagshinzufügen.
object-locator schema-name – Der Name desTabellenschemas.
table-name – Der Name der Tabelle.
Der Name der einzelnen Schemenund Tabellen, für die die Regel gilt. Siekönnen das Prozentzeichen "%" alsPlatzhalter für alle oder einen Teil derWerte der einzelnen object-locator-Parameter verwenden. Auf diese Weisekönnen Sie diese Elemente aufeinanderabstimmen:
• Eine einzelne Tabelle in einemeinzelnen Schema
• Eine einzelne Tabelle in einigen oderallen Schemata
• Einige oder alle Tabellen in einemeinzelnen Schema
• Einige oder alle Tabellen in einigenoder allen Schemata
API-Version API Version 2016-01-01249
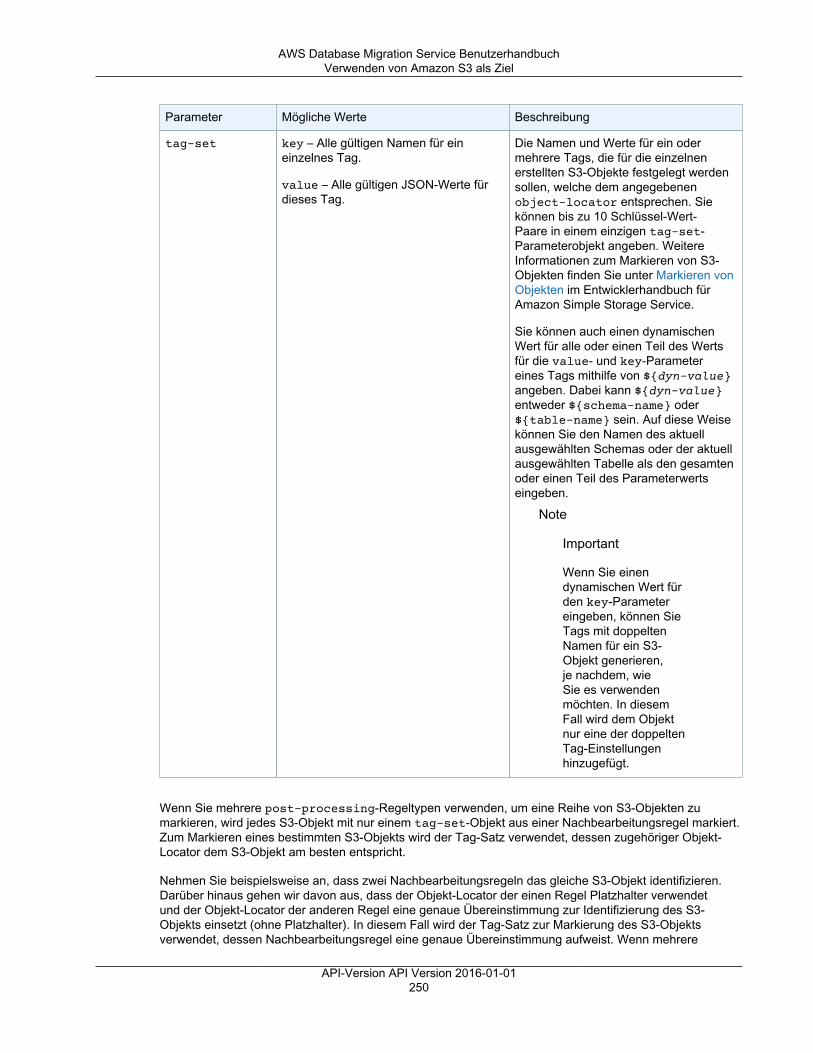
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Parameter Mögliche Werte Beschreibung
tag-set key – Alle gültigen Namen für eineinzelnes Tag.
value – Alle gültigen JSON-Werte fürdieses Tag.
Die Namen und Werte für ein odermehrere Tags, die für die einzelnenerstellten S3-Objekte festgelegt werdensollen, welche dem angegebenenobject-locator entsprechen. Siekönnen bis zu 10 Schlüssel-Wert-Paare in einem einzigen tag-set-Parameterobjekt angeben. WeitereInformationen zum Markieren von S3-Objekten finden Sie unter Markieren vonObjekten im Entwicklerhandbuch fürAmazon Simple Storage Service.
Sie können auch einen dynamischenWert für alle oder einen Teil des Wertsfür die value- und key-Parametereines Tags mithilfe von ${dyn-value}angeben. Dabei kann ${dyn-value}entweder ${schema-name} oder${table-name} sein. Auf diese Weisekönnen Sie den Namen des aktuellausgewählten Schemas oder der aktuellausgewählten Tabelle als den gesamtenoder einen Teil des Parameterwertseingeben.
Note
Important
Wenn Sie einendynamischen Wert fürden key-Parametereingeben, können SieTags mit doppeltenNamen für ein S3-Objekt generieren,je nachdem, wieSie es verwendenmöchten. In diesemFall wird dem Objektnur eine der doppeltenTag-Einstellungenhinzugefügt.
Wenn Sie mehrere post-processing-Regeltypen verwenden, um eine Reihe von S3-Objekten zumarkieren, wird jedes S3-Objekt mit nur einem tag-set-Objekt aus einer Nachbearbeitungsregel markiert.Zum Markieren eines bestimmten S3-Objekts wird der Tag-Satz verwendet, dessen zugehöriger Objekt-Locator dem S3-Objekt am besten entspricht.
Nehmen Sie beispielsweise an, dass zwei Nachbearbeitungsregeln das gleiche S3-Objekt identifizieren.Darüber hinaus gehen wir davon aus, dass der Objekt-Locator der einen Regel Platzhalter verwendetund der Objekt-Locator der anderen Regel eine genaue Übereinstimmung zur Identifizierung des S3-Objekts einsetzt (ohne Platzhalter). In diesem Fall wird der Tag-Satz zur Markierung des S3-Objektsverwendet, dessen Nachbearbeitungsregel eine genaue Übereinstimmung aufweist. Wenn mehrere
API-Version API Version 2016-01-01250

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Nachbearbeitungsregeln einem bestimmten S3-Objekt gleich gut entsprechen, wird der Tag-Satz zurMarkierung des Objekts verwendet, der der ersten dieser Nachbearbeitungsregeln zugewiesen ist.
Example Hinzufügen von statischen Tags zu einem S3-Objekt, das für ein einzelnes Schema undeine einzelne Tabelle erstellt wurde
Die folgenden Auswahl- und Nachbearbeitungsregeln fügen einem erstellten S3-Objekt drei Tags (tag_1,tag_2 und tag_3 mit den entsprechenden statischen Werten value_1, value_2 und value_3) hinzu.Dieses S3-Objekt entspricht einer einzelnen Tabelle in der Quelle mit dem Namen STOCK mit einemSchema mit dem Namen aat2.
{ "rules": [ { "rule-type": "selection", "rule-id": "5", "rule-name": "5", "object-locator": { "schema-name": "aat2", "table-name": "STOCK" }, "rule-action": "include" }, { "rule-type": "post-processing", "rule-id": "41", "rule-name": "41", "rule-action": "add-tag", "object-locator": { "schema-name": "aat2", "table-name": "STOCK", }, "tag-set": [ { "key": "tag_1", "value": "value_1" }, { "key": "tag_2", "value": "value_2" }, { "key": "tag_3", "value": "value_3" } ] } ]}
Example Hinzufügen von statischen und dynamischen Tags zu S3-Objekten, die für mehrereTabellen und Schemata erstellt wurden
Das folgende Beispiel zeigt eine Auswahlregel und zwei Nachbearbeitungsregeln, wobei die Eingabe ausder Quelle alle Tabellen und deren zugehörigen Schemata umfasst.
{ "rules": [ { "rule-type": "selection", "rule-id": "1",
API-Version API Version 2016-01-01251

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
"rule-name": "1", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "post-processing", "rule-id": "21", "rule-name": "21", "rule-action": "add-tag", "object-locator": { "schema-name": "%", "table-name": "%", }, "tag-set": [ { "key": "dw-schema-name", "value":"${schema-name}" }, { "key": "dw-schema-table", "value": "my_prefix_${table-name}" } ] }, { "rule-type": "post-processing", "rule-id": "41", "rule-name": "41", "rule-action": "add-tag", "object-locator": { "schema-name": "aat", "table-name": "ITEM", }, "tag-set": [ { "key": "tag_1", "value": "value_1" }, { "key": "tag_2", "value": "value_2" } ] } ]}
Die erste Nachbearbeitungsregel fügt die beiden Tags (dw-schema-name und dw-schema-table) sowiedie dazugehörigen dynamischen Werte (${schema-name} und my_prefix_${table-name}) fast allenS3-Objekten hinzu, die in der Zieldatenbank erstellt wurden. Eine Ausnahme bildet das S3-Objekt, dasüber die zweite Nachbearbeitungsregel identifiziert und markiert wird. Daher wird jedes S3-Zielobjekt, dasdurch den Platzhalter-Objekt-Locator identifiziert wurde, mit Tags erstellt, die das Schema und die Tabelleerkennen lassen, dem es in der Quelle zugewiesen ist.
Die zweite Nachbearbeitungsregel fügt tag_1 und tag_2 mit den entsprechenden statischen Wertenvalue_1 und value_2 einem erstellten S3-Objekt hinzu, welches von einem Objekt-Locator alseine genaue Übereinstimmung identifiziert wurde. Dieses erstellte S3-Objekt entspricht daher dereinzigen Tabelle in der Quelle mit dem Namen ITEM mit einem Schema mit dem Namen aat. Aufgrundder genauen Entsprechung ersetzen diese Tags alle Tags für dieses Objekt, die von der erstenNachbearbeitungsregel hinzugefügt wurden, da diese den S3-Objekten nur aufgrund der Platzhalterentsprechen.
API-Version API Version 2016-01-01252

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Example Hinzufügen von dynamischen Tag-Namen und -Werten zu S3-Objekten
Das folgende Beispiel umfasst zwei Auswahlregeln und eine Nachbearbeitungsregel. Die Eingabe aus derQuelle schließt nur die ITEM-Tabelle entweder im retail- oder wholesale-Schema ein.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "retail", "table-name": "ITEM" }, "rule-action": "include" }, { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "wholesale", "table-name": "ITEM" }, "rule-action": "include" }, { "rule-type": "post-processing", "rule-id": "21", "rule-name": "21", "rule-action": "add-tag", "object-locator": { "schema-name": "%", "table-name": "ITEM", }, "tag-set": [ { "key": "dw-schema-name", "value":"${schema-name}" }, { "key": "dw-schema-table", "value": "my_prefix_ITEM" }, { "key": "${schema-name}_ITEM_tag_1", "value": "value_1" }, { "key": "${schema-name}_ITEM_tag_2", "value": "value_2" } ] ]}
Der Tag-Satz für die Nachbereitungsregel fügt allen S3-Objekten, die für die ITEM-Tabelle in derZieldatenbank erstellt wurden, zwei Tags (dw-schema-name und dw-schema-table) hinzu. Daserste Tag hat den dynamischen Wert "${schema-name}" und das zweite Tag den statischen Wert"my_prefix_ITEM". Daher wird jedes S3-Zielobjekt mit Tags erstellt, die das Schema und die Tabelleerkennen lassen, dem es in der Quelle zugewiesen ist.
API-Version API Version 2016-01-01253

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Darüber hinaus fügt das Tag-Set zwei zusätzliche Tags mit dynamischen Namen hinzu (${schema-name}_ITEM_tag_1 und "${schema-name}_ITEM_tag_2"). Diese haben die entsprechendenstatischen Werte value_1 und value_2. Aus diesem Grund werden diese Tags nach dem aktuellenSchema benannt, retail oder wholesale. In diesem Objekt ist es nicht möglich, einen doppeltendynamischen Tag-Namen zu verleihen, da jedes Objekt für einen einzelnen eindeutigen Schemanamenerstellt wurde. Der Schemaname wird dazu verwendet, einen anderweitig eindeutigen Tag-Namen zuerstellen.
Erstellen von AWS KMS-Schlüsseln zum Verschlüsseln vonAmazon S3-ZielobjektenSie können benutzerdefinierte AWS KMS-Schlüssel erstellen und verwenden und mit ihnen Ihre AmazonS3 Zielobjekte verschlüsseln. Nachdem Sie einen entsprechenden AWS KMS-Schlüssel erstellt haben,können Sie diesen Schlüssel beim Erstellen des S3-Zielendpunkts dazu verwenden, die Objekte anhandder folgenden Mechanismen zu verschlüsseln:
• Verwenden Sie die folgenden Optionen für die S3-Zielobjekte (im standardmäßigen CSV-Dateispeicherformat), wenn Sie den create-endpoint-Befehl mithilfe der AWS CLI ausführen.
--s3-settings '{"ServiceAccessRoleArn": "your-service-access-ARN", "CsvRowDelimiter": "\n", "CsvDelimiter": ",", "BucketFolder": "your-bucket-folder", "BucketName": "your-bucket-name", "EncryptionMode": "SSE_KMS", "ServerSideEncryptionKmsKeyId": "your-KMS-key-ARN"}'
Hier handelt es sich bei your-KMS-key-ARN um den Amazon-Ressourcennamen (ARN) für Ihren AWSKMS-Schlüssel. Weitere Informationen finden Sie unter Endpunkteinstellungen bei der Verwendung vonAmazon S3 als Ziel für AWS DMS (p. 258).
• Setzen Sie das zusätzliche Verbindungsattribut encryptionMode auf den Wert SSE_KMS und daszusätzliche Verbindungsattribut serverSideEncryptionKmsKeyId auf den ARN für Ihren AWS KMS-Schlüssel. Weitere Informationen finden Sie unter Zusätzliche Verbindungsattribute bei der Verwendungvon Amazon S3 als Ziel für AWS DMS (p. 260).
Um Amazon S3-Zielobjekte mithilfe eines AWS KMS-Schlüssels zu verschlüsseln, benötigen Sieeine IAM-Rolle mit Berechtigungen für den Zugriff auf den Amazon S3-Bucket. Auf diese IAM-Rollewird dann in einer Richtlinie (einer Schlüsselrichtlinie) zugegriffen, die dem von Ihnen erstelltenVerschlüsselungsschlüssel zugewiesen ist. Durch die Erstellung der folgenden Elemente, können Siediesen Vorgang in Ihrer IAM-Konsole ausführen:
• Eine Richtlinie mit Berechtigungen für den Zugriff auf den Amazon S3-Bucket.• Eine IAM-Richtlinie mit dieser Richtlinie.• Ein AWS KMS-Verschlüsselungsschlüssel mit einer Schlüsselrichtlinie, die sich auf diese Rolle bezieht.
Die entsprechende Vorgehensweise wird nachfolgend beschrieben.
So erstellen Sie eine IAM-Richtlinie mit Berechtigungen für den Zugriff auf den Amazon S3-Bucket
1. Öffnen Sie die IAM-Konsole unter https://console.aws.amazon.com/iam/.2. Wählen Sie im Navigationsbereich die Option Policies (Richtlinien) aus. Die Seite Policies (Richtlinien)
wird geöffnet.3. Klicken Sie auf Create Policy (Richtlinie erstellen). Die Seite Create policy (Richtlinie erstellen) wird
geöffnet.4. Wählen Sie Service und anschließend die Option S3 aus. Es wird eine Liste mit den
Aktionsberechtigungen angezeigt.
API-Version API Version 2016-01-01254

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
5. Wählen Sie Expand all (Alle maximieren) aus, um die Liste zu erweitern, und aktivieren Sie zumindestdie folgenden Berechtigungen:
• ListBucket• PutObject• DeleteObject
Wählen Sie alle anderen Berechtigungen aus, die Sie benötigen, und klicken Sie anschließend aufCollapse all (Alle minimieren), um die Liste zu reduzieren.
6. Wählen Sie Resources (Ressourcen) aus, um die Ressourcen festzulegen, auf die Sie Zugriff erlangenmöchten. Wählen Sie zumindest All resources (Alle Ressourcen) aus, um den allgemeinen Zugriff aufdie Amazon S3-Ressourcen zu gewähren.
7. Fügen Sie alle anderen Bedingungen oder Berechtigungen hinzu, die Sie benötigen, und wählen Siedann Review policy (Richtlinie überprüfen) aus. Überprüfen Sie die Ergebnisse auf der Seite Reviewpolicy (Richtlinie prüfen).
8. Wenn die Einstellungen Ihren Vorstellungen entsprechen, geben Sie einen Namen für die Richtlinie(z. B. DMS-S3-endpoint-access) sowie eine Beschreibung ein und wählen Sie anschließendCreate policy (Richtlinie erstellen) aus. Die Seite Policies (Richtlinien) wird geöffnet und zeigt eineMitteilung an, die darauf hinweist, dass Ihre Richtlinie erstellt wurde.
9. Wählen Sie den Richtliniennamen aus der Liste mit den Policies (Richtlinien) aus. Die Seite Summary(Übersicht) wird geöffnet und zeigt den JSON-Code für die Richtlinie an, der dem folgenden Beispielähnelt.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:ListBucket", "s3:DeleteObject" ], "Resource": "*" } ]}
Sie haben jetzt die neue Richtlinie für den Zugriff auf Amazon S3-Ressourcen erstellt, um sie einemangegebenen Namen, z. B. DMS-S3-endpoint-access, zu verschlüsseln.
So erstellen Sie eine IAM-Rolle mit dieser Richtlinie
1. Wählen Sie im Navigationsbereich Ihrer IAM-Konsole Roles (Rollen) aus. Die Detailseite Roles(Rollen) wird geöffnet.
2. Wählen Sie Create role aus. Die Seite Create role (Rolle erstellen) wird geöffnet.3. Wählen Sie AWS-Service als vertrauenswürdige Entität und anschließend DMS als den Service aus,
der die Rolle verwenden wird.4. Wählen Sie Next: Permissions (Weiter: Berechtigungen) aus. Die Ansicht Attach permissions policies
(Berechtigungsrichtlinien hinzufügen) wird auf der Seite Create role (Rolle erstellen) angezeigt.5. Wählen Sie die Rollenrichtlinie aus, die Sie im vorherigen Vorgang (DMS-S3-endpoint-access)
erstellt haben.
API-Version API Version 2016-01-01255

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
6. Wählen Sie Next: Tags (Weiter: Tags) aus. Die Ansicht Add tags (Tags hinzufügen) wird auf der SeiteCreate role (Rolle erstellen) angezeigt. Hier können Sie alle gewünschten Tags hinzufügen.
7. Klicken Sie auf Next: Review (Weiter: Prüfen). Die Ansicht Review (Überprüfen) wird auf der SeiteCreate role (Rolle erstellen) angezeigt. Hier können Sie die Ergebnisse überprüfen.
8. Wenn die Einstellungen Ihren Vorstellungen entsprechen, geben Sie einen Namen für die Rolle(Pflichtangabe, z. B. DMS-S3-endpoint-access-role) sowie eine zusätzliche Beschreibung ein,und wählen Sie anschließend Create role (Rolle erstellen) aus. Die Detailseite Roles (Rollen) wirdgeöffnet und zeigt eine Mitteilung an, die darauf hinweist, dass Ihre Rolle erstellt wurde.
Sie haben jetzt die neue Rolle für den Zugriff auf Amazon S3-Ressourcen zur Verschlüsselung mit einemangegebenen Namen, z. B. DMS-S3-endpoint-access-role, erstellt.
So erstellen Sie einen AWS KMS-Verschlüsselungsschlüssel mit einer Schlüsselrichtlinie, die sichauf Ihre IAM-Rolle bezieht:
Note
Weitere Hinweise zur Funktionsweise von AWS DMS mit AWS KMS-Verschlüsselungsschlüsselnfinden Sie unter Einrichten eines Verschlüsselungsschlüssels und Angeben von AWS KMS-Berechtigungen (p. 79).
1. Melden Sie sich bei der AWS Management Console an und öffnen Sie die AWS Key ManagementService(AWS KMS)-Konsole unter https://console.aws.amazon.com/kms.
2. Um die AWS-Region zu ändern, verwenden Sie die Regionenauswahl in der oberen rechten Ecke derSeite.
3. Klicken Sie im Navigationsbereich auf Customer managed keys (Vom Kunden verwaltete Schlüssel).4. Klicken Sie auf Create key. Die Seite Configure key (Schlüssel konfigurieren) wird geöffnet.5. Wählen Sie für Key type (Schlüsseltyp) Symmetric (Symmetrisch).
Note
Wenn Sie diesen Schlüssel erstellen, können Sie nur einen symmetrischen Schlüsselerstellen, da alle AWS-Services, wie z. B. Amazon S3, nur mit symmetrischenVerschlüsselungsschlüsseln arbeiten.
6. Wählen Sie Erweiterte Optionen aus. Stellen Sie für Key material origin (Schlüsselmaterialherkunft)sicher, dass KMS ausgewählt ist, und wählen Sie dann Next (Weiter). Die Seite Add Labels (Etikettenhinzufügen) wird geöffnet.
7. Geben Sie unter Create alias and description (Alias und Beschreibung erstellen) einen Alias für denSchlüssel (z. B. DMS-S3-endpoint-encryption-key) und eventuell eine weitere Beschreibungein.
8. Fügen Sie unter Tags alle Tags hinzu, die Sie verwenden möchten, um den Schlüssel zu identifizierenund seine Nutzung zu verfolgen, und wählen Sie anschließend Next Step (Nächster Schritt) aus. DieSeite Define key administrative permissions (Schlüsselverwaltungsberechtigungen definieren) wirdgeöffnet und zeigt eine Liste der Benutzer und Rollen an, aus denen Sie auswählen können.
9. Fügen Sie die Benutzer und Rollen hinzu, die den Schlüssel verwalten sollen. Stellen Sie sicher, dassdiese Benutzer und Rollen über die erforderlichen Berechtigungen verfügen, um den Schlüssel zuverwalten.
10. Wählen Sie unter Key deletion (Schlüssellöschung) aus, ob die Schlüsseladministratoren denSchlüssel löschen können, und klicken Sie anschließend auf Next Step (Nächster Schritt). Die SeiteDefine Key usage permissions (Schlüsselnutzungsberechtigungen definieren) wird geöffnet und zeigteine weitere Liste mit Benutzern und Rollen an, aus denen Sie auswählen können.
11. Wählen Sie unter This account (Dieses Konto) die verfügbaren Benutzer aus, die kryptografischeOperationen für Amazon S3-Ziele ausführen können sollen. Wählen Sie zudem die Rolle aus, die
API-Version API Version 2016-01-01256

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Sie zuvor unter Roles (Rollen) erstellt haben, um den Zugriff auf Amazon S3-Zielobjekte für dieVerschlüsselung zu aktivieren, z. B. DMS-S3-endpoint-access-role.
12. Wenn Sie weitere Konten hinzufügen möchten, die nicht für denselben Zugriff aufgeführt sind, wählenSie unter Other AWS accounts (Andere Konten) die Option Add another AWS account (AnderesKonto hinzufügen) und dann Next (Weiter). Die Seite Review and edit key policy (Schlüsselrichtlinieprüfen und bearbeiten) wird geöffnet. Hier wird das JSON für die Schlüsselrichtlinie angezeigt, dieSie überprüfen und bearbeiten können, indem Sie in den vorhandenen JSON-Inhalt schreiben.Hier können Sie sehen, wo die Schlüsselrichtlinie auf die Rolle und die Benutzer (z. B. Admin undUser1) verweist, die Sie im vorherigen Schritt ausgewählt haben. Sie können auch die verschiedenenSchlüsselaktionen sehen, die für die verschiedenen Prinzipale (Benutzer und Rollen) zulässig sind, wieim folgenden Beispiel gezeigt.
{ "Id": "key-consolepolicy-3", "Version": "2012-10-17", "Statement": [ { "Sid": "Enable IAM User Permissions", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::944454115380:root" ] }, "Action": "kms:*", "Resource": "*" }, { "Sid": "Allow access for Key Administrators", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::944454115380:role/Admin" ] }, "Action": [ "kms:Create*", "kms:Describe*", "kms:Enable*", "kms:List*", "kms:Put*", "kms:Update*", "kms:Revoke*", "kms:Disable*", "kms:Get*", "kms:Delete*", "kms:TagResource", "kms:UntagResource", "kms:ScheduleKeyDeletion", "kms:CancelKeyDeletion" ], "Resource": "*" }, { "Sid": "Allow use of the key", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::944454115380:role/DMS-S3-endpoint-access-role", "arn:aws:iam::944454115380:role/Admin", "arn:aws:iam::944454115380:role/User1" ] },
API-Version API Version 2016-01-01257

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
"Action": [ "kms:Encrypt", "kms:Decrypt", "kms:ReEncrypt*", "kms:GenerateDataKey*", "kms:DescribeKey" ], "Resource": "*" }, { "Sid": "Allow attachment of persistent resources", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::944454115380:role/DMS-S3-endpoint-access-role", "arn:aws:iam::944454115380:role/Admin", "arn:aws:iam::944454115380:role/User1" ] }, "Action": [ "kms:CreateGrant", "kms:ListGrants", "kms:RevokeGrant" ], "Resource": "*", "Condition": { "Bool": { "kms:GrantIsForAWSResource": true } } } ]
13. Klicken Sie auf Finish. Die Seite Encryption keys (Verschlüsselungsschlüssel) wird geöffnet und zeigteine Mitteilung an, die darauf hinweist, dass Ihr Master-Verschlüsselungsschlüssel erstellt wurde.
Damit haben Sie einen neuen AWS KMS-Schlüssel mit einem angegebenen Alias (z. B. DMS-S3-endpoint-encryption-key) erstellt. Dieser Schlüssel ermöglicht es AWS DMS, Amazon S3-Zielobjektezu verschlüsseln.
Endpunkteinstellungen bei der Verwendung von Amazon S3 alsZiel für AWS DMSSie können Endpunkteinstellungen, ähnlich wie zusätzliche Verbindungsattribute, zum KonfigurierenIhres Amazon S3-Ziels verwenden. Sie können diese Einstellungen beim Erstellen des Zielendpunktsmithilfe des create-endpoint-Befehls in der AWS CLI angeben. Verwenden Sie dazu die --s3-settings 'json-settings'-Option. Hier handelt es sich bei json-settings um ein JSON-Objektmit Parametern zum Angeben der Einstellungen. Sie können auch eine JSON-Datei festlegen, die dasgleiche json-settings-Objekt umfasst, wie im folgenden Beispiel dargestellt: --s3-settingsfile:///your-file-path/my_s3_settings.json. Hier ist my_s3_settings.json der Name derJSON-Datei, die das gleiche json-settings object enthält.
Beachten Sie, dass die Parameternamen für die Endpunkteinstellungen mit den Namen derentsprechenden zusätzlichen Verbindungsattribute identisch sind. Der einzige Unterschied besteht darin,dass die Parameternamen für die Endpunkteinstellungen mit Großbuchstaben beginnen. Beachten Sieauch, dass nicht alle S3-Zielendpunkteinstellungen, die zusätzliche Verbindungsattributen mithilfe der --s3-settings-Option des create-endpoint-Befehls verwenden, verfügbar sind. Weitere Informationenüber die verfügbaren Einstellungen in einem AWS CLI-Aufruf von create-endpoint finden Sie untercreate-endpoint in der AWS CLI Command Reference AWS DMS. Weitere Informationen über diese
API-Version API Version 2016-01-01258

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Einstellungen finden Sie im Abschnitt zu den entsprechenden zusätzlichen Verbindungsattributen unterZusätzliche Verbindungsattribute bei der Verwendung von Amazon S3 als Ziel für AWS DMS (p. 260).
Sie können die Einstellungen für den S3-Zielendpunkt verwenden, um Folgendes zu konfigurieren:
• Einen benutzerdefinierten AWS KMS-Schlüssel für die Verschlüsselung Ihrer S3-Zielobjekte• Parquet-Dateien als Speicherformat für S3-Zielobjekte
AWS KMS-Schlüsseleinstellungen für die Datenverschlüsselung
Die folgenden Beispiele veranschaulichen die Konfiguration eines benutzerdefinierten AWS KMS-Schlüssels für die Verschlüsselung Ihrer S3-Zielobjekte. Um zu beginnen, können Sie den folgendencreate-endpoint-Aufruf in der AWS CLI ausführen.
aws dms create-endpoint --endpoint-identifier s3-target-endpoint --engine-name s3 --endpoint-type target --s3-settings '{"ServiceAccessRoleArn": "your-service-access-ARN", "CsvRowDelimiter": "\n", "CsvDelimiter": ",", "BucketFolder": "your-bucket-folder", "BucketName": "your-bucket-name", "EncryptionMode": "SSE_KMS", "ServerSideEncryptionKmsKeyId": "arn:aws:kms:us-east-1:944454115380:key/72abb6fb-1e49-4ac1-9aed-c803dfcc0480"}'
Das durch die --s3-settings-Option angegebene JSON-Objekt definiert zwei Parameter.Der eine ist ein EncryptionMode-Parameter mit dem Wert SSE_KMS. Der andere istein ServerSideEncryptionKmsKeyId-Parameter mit dem Wert arn:aws:kms:us-east-1:944454115380:key/72abb6fb-1e49-4ac1-9aed-c803dfcc0480. Bei diesem Wert handeltes sich um einen Amazon-Ressourcennamen (ARN) für Ihren benutzerdefinierten AWS KMS-Schlüssel.Bei einem S3-Ziel legen Sie auch zusätzliche Einstellungen fest. Diese identifizieren die Zugriffsrolle desServers, legen die Trennzeichen für das CSV-Objektspeicherformat fest und geben den Speicherort sowieden Namen des Buckets zum Speichern von S3-Zielobjekten an.
Standardmäßig erfolgt S3-Datenverschlüsselung mithilfe von serverseitiger S3-Verschlüsselung. Für dasS3-Ziel des vorherigen Beispiels ist dies gleichbedeutend mit der Angabe der Endpunkteinstellungen, wieim folgenden Beispiel dargestellt.
aws dms create-endpoint --endpoint-identifier s3-target-endpoint --engine-name s3 --endpoint-type target--s3-settings '{"ServiceAccessRoleArn": "your-service-access-ARN", "CsvRowDelimiter": "\n", "CsvDelimiter": ",", "BucketFolder": "your-bucket-folder", "BucketName": "your-bucket-name", "EncryptionMode": "SSE_S3"}'
Weitere Informationen über das Arbeiten mit serverseitiger S3-Verschlüsselung finden Sie unter Schützenvon Daten mithilfe serverseitiger Verschlüsselung.
Einstellungen für das Speichern von S3-Zielobjekten mithilfe von Parquet-Dateien
Das Standardformat für die Erstellung von S3-Zielobjekten ist CSV-Dateien. Die folgenden Beispiele zeigeneinige Endpunkteinstellungen, um Parquet-Dateien als Format für die Erstellung von S3-Zielobjektenfestzulegen. Sie können das Parquet-Dateiformat mit allen Standardeinstellungen angeben, wie imfolgenden Beispiel gezeigt.
aws dms create-endpoint --endpoint-identifier s3-target-endpoint --engine-name s3 --endpoint-type target
API-Version API Version 2016-01-01259

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
--s3-settings '{"ServiceAccessRoleArn": "your-service-access-ARN", "DataFormat": "parquet"}'
Hier wird der DataFormat-Parameter als parquet festgelegt, um das Format mit allen S3-Standardszu ermöglichen. Diese Standardwerte umfassen eine Verzeichniskodierung ("EncodingType: "rle-dictionary"), die eine Kombination aus Bit-Packing und Run-Length-Kodierung verwendet, um sichwiederholende Werte effizienter zu speichern.
Sie können zusätzliche Einstellungen für Optionen festlegen, die nicht zu den Standardeinstellungengehören, wie im folgenden Beispiel gezeigt.
aws dms create-endpoint --endpoint-identifier s3-target-endpoint --engine-name s3 --endpoint-type target--s3-settings '{"ServiceAccessRoleArn": "your-service-access-ARN", "BucketFolder": "your-bucket-folder","BucketName": "your-bucket-name", "CompressionType": "GZIP", "DataFormat": "parquet", "EncodingType: "plain-dictionary", "dictPageSizeLimit": 3,072,000,"EnableStatistics": false }'
Hier werden zusätzlich zu den Parametern für mehrere S3-Bucket-Standardoptionen und demDataFormat-Parameter die folgenden zusätzlichen Parquet-Dateiparameter festgelegt:
• EncodingType – Als Verzeichniskodierung (plain-dictionary) festgelegt, die die in den einzelnenSpalten auftretenden Werte in einem Block auf der Verzeichnisseite speichert, der auch nach Spaltenorganisiert ist.
• dictPageSizeLimit – Für eine maximale Verzeichnisseitengröße von 3 MB festgelegt.• EnableStatistics – Deaktiviert den Standard, der die Sammlung von Statistiken über Parquet-
Dateiseiten und -Zeilengruppen ermöglicht.
Zusätzliche Verbindungsattribute bei der Verwendung vonAmazon S3 als Ziel für AWS DMSSie können die folgenden Optionen als zusätzliche Verbindungsattribute festlegen. Wenn Sie mehrereAttributeinstellungen verwenden, müssen diese durch Semikolons und ohne zusätzlichen Leerraumvoneinander getrennt werden.
Option Description (Beschreibung)
addColumnName Ein optionaler Parameter, den sie, sofern er auf true oder y festgelegtist, verwenden können, um der CSV-Ausgabedatei Informationen zuSpaltennamen hinzuzufügen.
Standardwert: false
Zulässige Werte: true, false, y, n
Beispiel:
addColumnName=true;
bucketFolder Ein optionaler Parameter zum Festlegen eines Ordnernamens im S3-Bucket.Wenn angegeben, werden Zielobjekte als CSV- oder Parquet-Dateien imPfad bucketFolder/schema_name/table_name/ erstellt. Wenn dieserParameter nicht angegeben ist, wird der Pfad schema_name/table_name/verwendet.
API-Version API Version 2016-01-01260
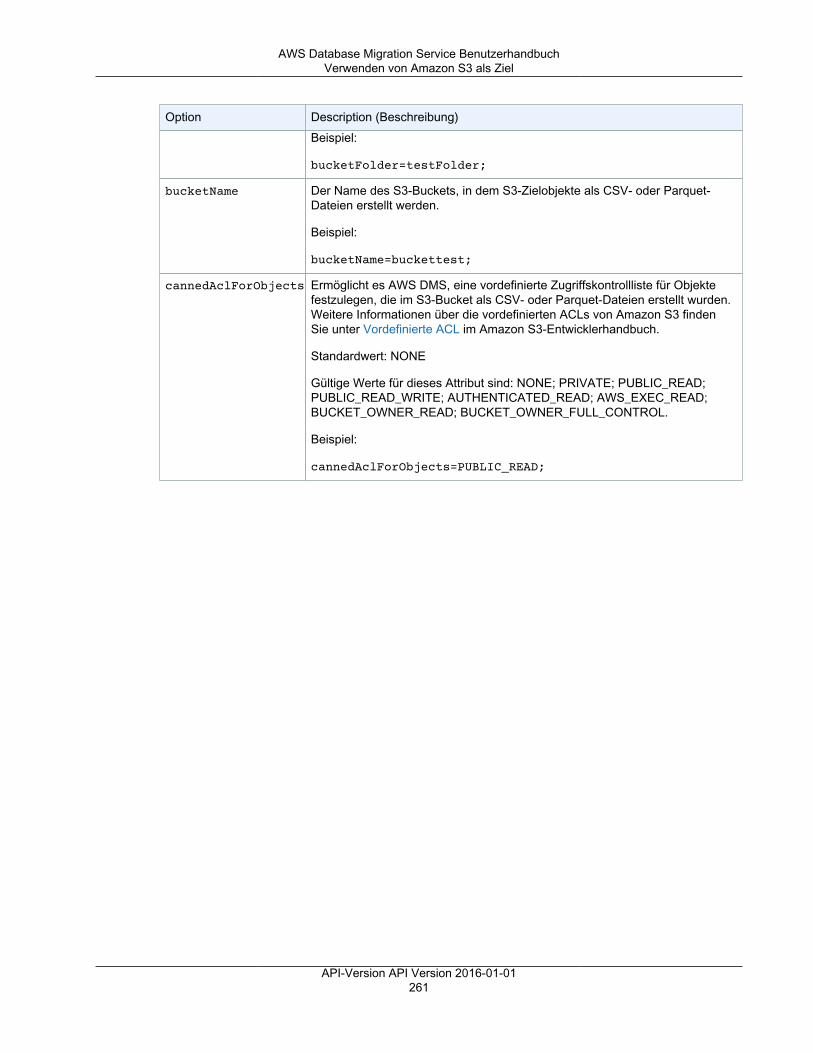
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Option Description (Beschreibung)Beispiel:
bucketFolder=testFolder;
bucketName Der Name des S3-Buckets, in dem S3-Zielobjekte als CSV- oder Parquet-Dateien erstellt werden.
Beispiel:
bucketName=buckettest;
cannedAclForObjects Ermöglicht es AWS DMS, eine vordefinierte Zugriffskontrollliste für Objektefestzulegen, die im S3-Bucket als CSV- oder Parquet-Dateien erstellt wurden.Weitere Informationen über die vordefinierten ACLs von Amazon S3 findenSie unter Vordefinierte ACL im Amazon S3-Entwicklerhandbuch.
Standardwert: NONE
Gültige Werte für dieses Attribut sind: NONE; PRIVATE; PUBLIC_READ;PUBLIC_READ_WRITE; AUTHENTICATED_READ; AWS_EXEC_READ;BUCKET_OWNER_READ; BUCKET_OWNER_FULL_CONTROL.
Beispiel:
cannedAclForObjects=PUBLIC_READ;
API-Version API Version 2016-01-01261
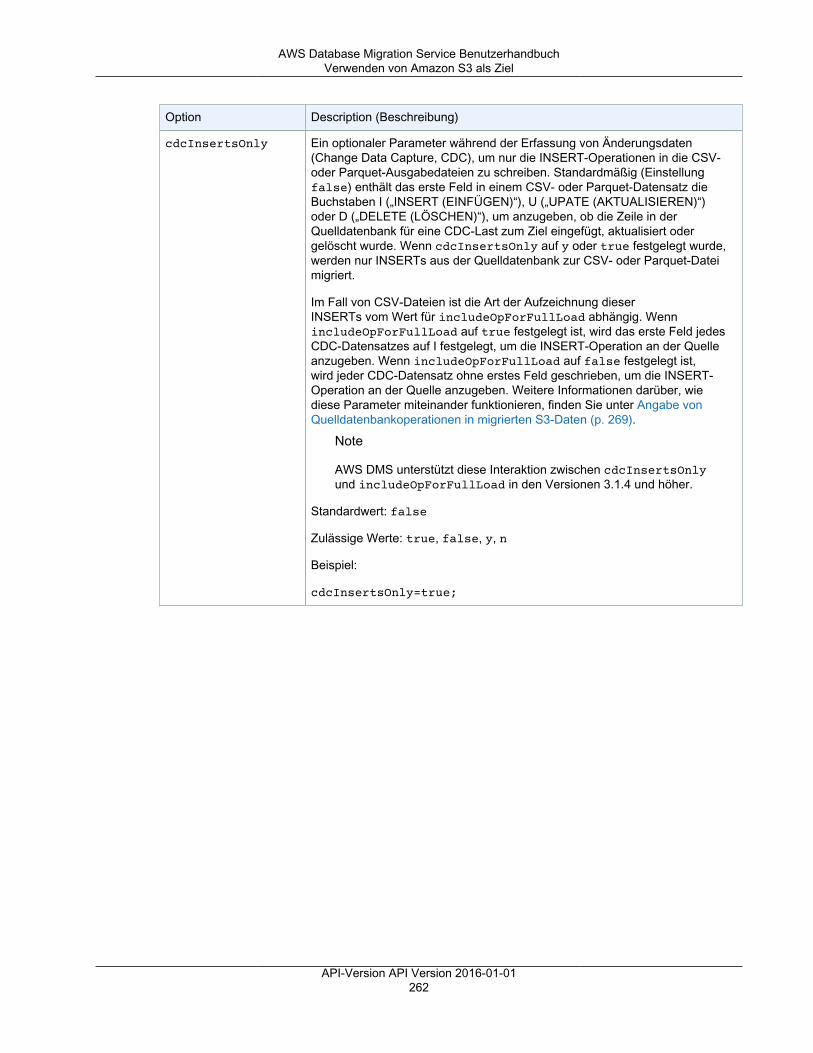
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Option Description (Beschreibung)
cdcInsertsOnly Ein optionaler Parameter während der Erfassung von Änderungsdaten(Change Data Capture, CDC), um nur die INSERT-Operationen in die CSV-oder Parquet-Ausgabedateien zu schreiben. Standardmäßig (Einstellungfalse) enthält das erste Feld in einem CSV- oder Parquet-Datensatz dieBuchstaben I („INSERT (EINFÜGEN)“), U („UPATE (AKTUALISIEREN)“)oder D („DELETE (LÖSCHEN)“), um anzugeben, ob die Zeile in derQuelldatenbank für eine CDC-Last zum Ziel eingefügt, aktualisiert odergelöscht wurde. Wenn cdcInsertsOnly auf y oder true festgelegt wurde,werden nur INSERTs aus der Quelldatenbank zur CSV- oder Parquet-Dateimigriert.
Im Fall von CSV-Dateien ist die Art der Aufzeichnung dieserINSERTs vom Wert für includeOpForFullLoad abhängig. WennincludeOpForFullLoad auf true festgelegt ist, wird das erste Feld jedesCDC-Datensatzes auf I festgelegt, um die INSERT-Operation an der Quelleanzugeben. Wenn includeOpForFullLoad auf false festgelegt ist,wird jeder CDC-Datensatz ohne erstes Feld geschrieben, um die INSERT-Operation an der Quelle anzugeben. Weitere Informationen darüber, wiediese Parameter miteinander funktionieren, finden Sie unter Angabe vonQuelldatenbankoperationen in migrierten S3-Daten (p. 269).
Note
AWS DMS unterstützt diese Interaktion zwischen cdcInsertsOnlyund includeOpForFullLoad in den Versionen 3.1.4 und höher.
Standardwert: false
Zulässige Werte: true, false, y, n
Beispiel:
cdcInsertsOnly=true;
API-Version API Version 2016-01-01262
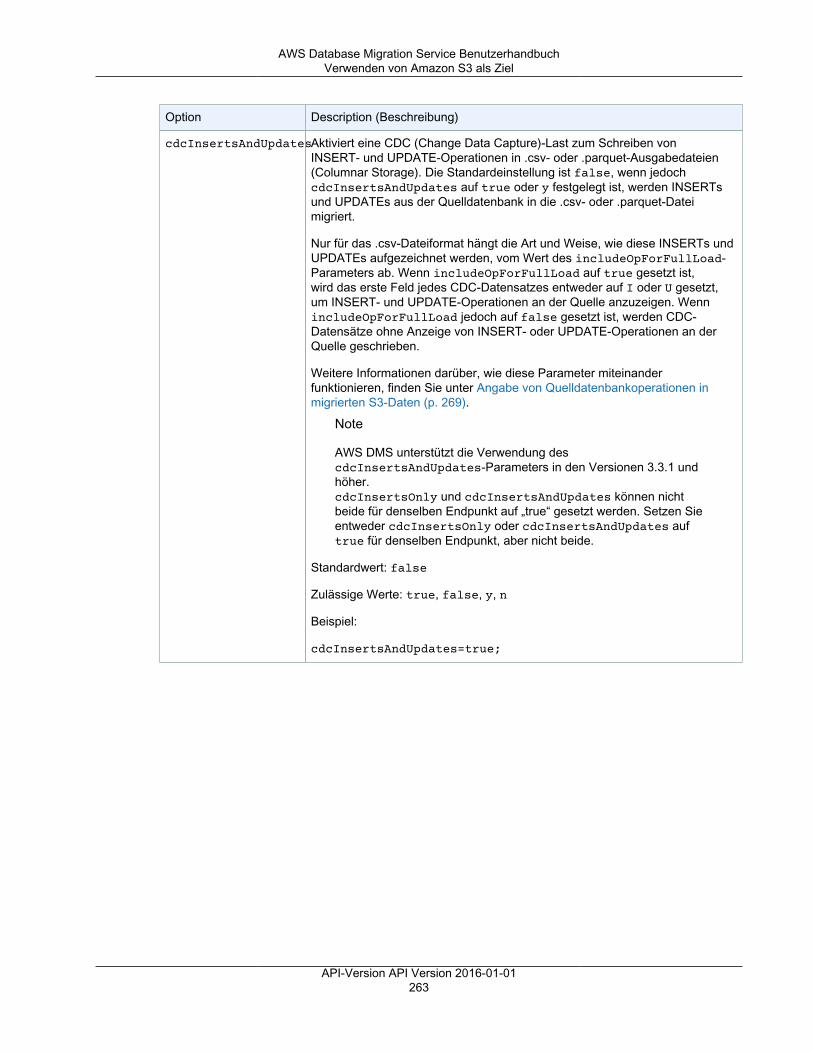
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Option Description (Beschreibung)
cdcInsertsAndUpdatesAktiviert eine CDC (Change Data Capture)-Last zum Schreiben vonINSERT- und UPDATE-Operationen in .csv- oder .parquet-Ausgabedateien(Columnar Storage). Die Standardeinstellung ist false, wenn jedochcdcInsertsAndUpdates auf true oder y festgelegt ist, werden INSERTsund UPDATEs aus der Quelldatenbank in die .csv- oder .parquet-Dateimigriert.
Nur für das .csv-Dateiformat hängt die Art und Weise, wie diese INSERTs undUPDATEs aufgezeichnet werden, vom Wert des includeOpForFullLoad-Parameters ab. Wenn includeOpForFullLoad auf true gesetzt ist,wird das erste Feld jedes CDC-Datensatzes entweder auf I oder U gesetzt,um INSERT- und UPDATE-Operationen an der Quelle anzuzeigen. WennincludeOpForFullLoad jedoch auf false gesetzt ist, werden CDC-Datensätze ohne Anzeige von INSERT- oder UPDATE-Operationen an derQuelle geschrieben.
Weitere Informationen darüber, wie diese Parameter miteinanderfunktionieren, finden Sie unter Angabe von Quelldatenbankoperationen inmigrierten S3-Daten (p. 269).
Note
AWS DMS unterstützt die Verwendung descdcInsertsAndUpdates-Parameters in den Versionen 3.3.1 undhöher.cdcInsertsOnly und cdcInsertsAndUpdates können nichtbeide für denselben Endpunkt auf „true“ gesetzt werden. Setzen Sieentweder cdcInsertsOnly oder cdcInsertsAndUpdates auftrue für denselben Endpunkt, aber nicht beide.
Standardwert: false
Zulässige Werte: true, false, y, n
Beispiel:
cdcInsertsAndUpdates=true;
API-Version API Version 2016-01-01263
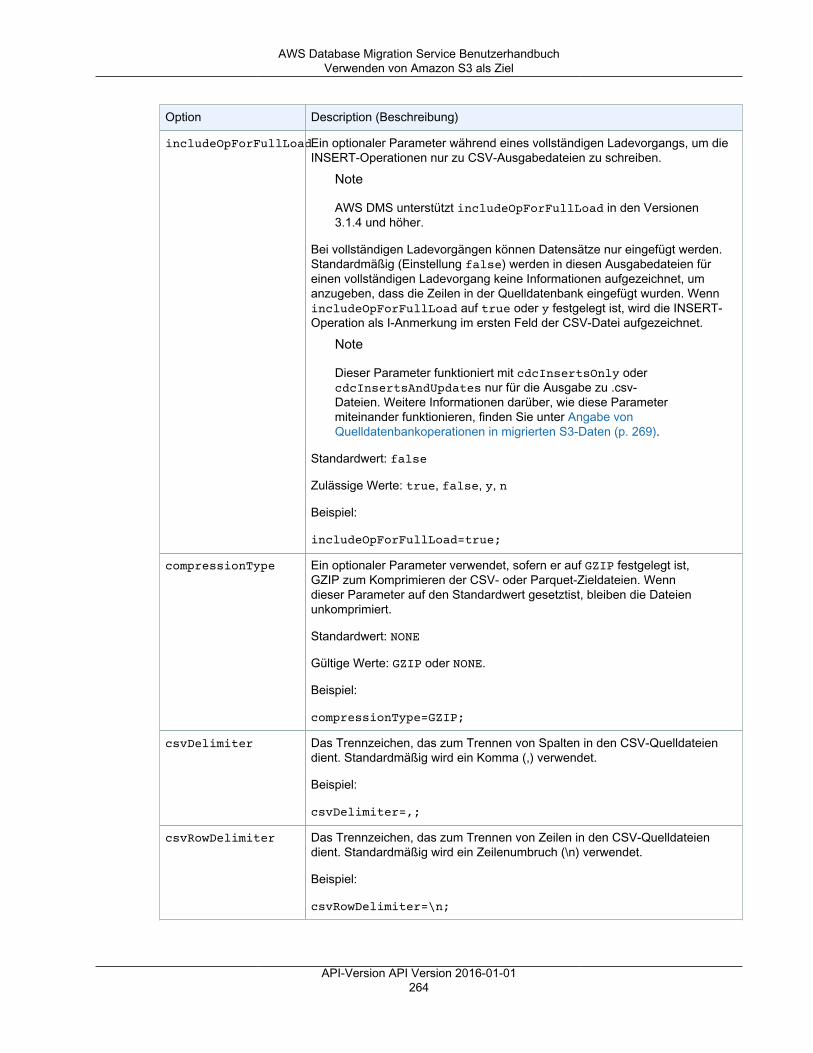
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Option Description (Beschreibung)
includeOpForFullLoadEin optionaler Parameter während eines vollständigen Ladevorgangs, um dieINSERT-Operationen nur zu CSV-Ausgabedateien zu schreiben.
Note
AWS DMS unterstützt includeOpForFullLoad in den Versionen3.1.4 und höher.
Bei vollständigen Ladevorgängen können Datensätze nur eingefügt werden.Standardmäßig (Einstellung false) werden in diesen Ausgabedateien füreinen vollständigen Ladevorgang keine Informationen aufgezeichnet, umanzugeben, dass die Zeilen in der Quelldatenbank eingefügt wurden. WennincludeOpForFullLoad auf true oder y festgelegt ist, wird die INSERT-Operation als I-Anmerkung im ersten Feld der CSV-Datei aufgezeichnet.
Note
Dieser Parameter funktioniert mit cdcInsertsOnly odercdcInsertsAndUpdates nur für die Ausgabe zu .csv-Dateien. Weitere Informationen darüber, wie diese Parametermiteinander funktionieren, finden Sie unter Angabe vonQuelldatenbankoperationen in migrierten S3-Daten (p. 269).
Standardwert: false
Zulässige Werte: true, false, y, n
Beispiel:
includeOpForFullLoad=true;
compressionType Ein optionaler Parameter verwendet, sofern er auf GZIP festgelegt ist,GZIP zum Komprimieren der CSV- oder Parquet-Zieldateien. Wenndieser Parameter auf den Standardwert gesetztist, bleiben die Dateienunkomprimiert.
Standardwert: NONE
Gültige Werte: GZIP oder NONE.
Beispiel:
compressionType=GZIP;
csvDelimiter Das Trennzeichen, das zum Trennen von Spalten in den CSV-Quelldateiendient. Standardmäßig wird ein Komma (,) verwendet.
Beispiel:
csvDelimiter=,;
csvRowDelimiter Das Trennzeichen, das zum Trennen von Zeilen in den CSV-Quelldateiendient. Standardmäßig wird ein Zeilenumbruch (\n) verwendet.
Beispiel:
csvRowDelimiter=\n;
API-Version API Version 2016-01-01264

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Option Description (Beschreibung)
maxFileSize Ein Wert, der die maximale Größe (in KB) der CSV-Datei angibt, die erstelltwerden soll, während die Migration zum S3-Ziel in der Volllastphaseausgeführt wird.
Standardwert: 1048576 KB (1 GB)
Zulässige Werte: 1– 1048576
Beispiel:
maxFileSize=512
rfc4180 Ein optionaler Parameter , der verwendet wird, um das Verhalten soeinzustellen, dass es RFC für Daten entspricht, die nur im CSV-Format zuAmazon S3 migriert werden. Wenn dieser Wert auf true oder y eingestelltist, umschließt AWS DMS bei Verwendung von Amazon S3 als ein Zieldie gesamte Spalte mit einem zusätzlichen Anführungszeichen (“), soferndie Daten Anführungszeichen oder Umbruchzeichen enthalten. JedesAnführungszeichen innerhalb der Daten wird zweimal wiederholt. DieseFormatierung entspricht RFC 4180.
Standardwert: true
Zulässige Werte: true, false, y, n
Beispiel:
rfc4180=false;
encryptionMode Der serverseitige Verschlüsselungsmodus, mit dem Sie Ihre CSV- oderParquet-Objektdateien, die Sie nach S3 kopiert haben, verschlüsselnmöchten, Die gültigen Werte sind SSE_S3 (S3-serverseitige Verschlüsselung)oder SSE_KMS (AWS KMS-Verschlüsselung). Wenn Sie SSE_KMS auswählen,setzen Sie den serverSideEncryptionKmsKeyId-Parameter auf denAmazon-Ressourcennamen (ARN), so dass der AWS KMS-Schlüssel für dieVerschlüsselung verwendet wird.
Standardwert: SSE_S3
Gültige Werte: SSE_S3 oder SSE_KMS.
Beispiel:
encryptionMode=SSE_S3;
API-Version API Version 2016-01-01265
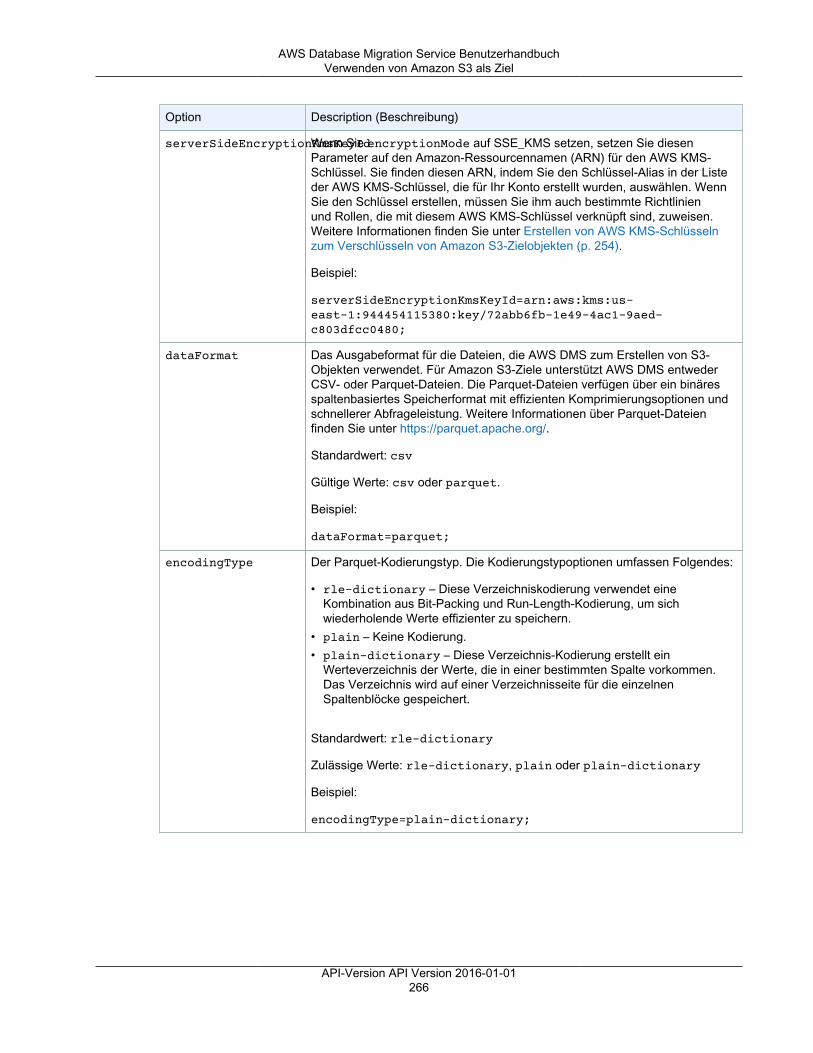
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Option Description (Beschreibung)
serverSideEncryptionKmsKeyIdWenn Sie encryptionMode auf SSE_KMS setzen, setzen Sie diesenParameter auf den Amazon-Ressourcennamen (ARN) für den AWS KMS-Schlüssel. Sie finden diesen ARN, indem Sie den Schlüssel-Alias in der Listeder AWS KMS-Schlüssel, die für Ihr Konto erstellt wurden, auswählen. WennSie den Schlüssel erstellen, müssen Sie ihm auch bestimmte Richtlinienund Rollen, die mit diesem AWS KMS-Schlüssel verknüpft sind, zuweisen.Weitere Informationen finden Sie unter Erstellen von AWS KMS-Schlüsselnzum Verschlüsseln von Amazon S3-Zielobjekten (p. 254).
Beispiel:
serverSideEncryptionKmsKeyId=arn:aws:kms:us-east-1:944454115380:key/72abb6fb-1e49-4ac1-9aed-c803dfcc0480;
dataFormat Das Ausgabeformat für die Dateien, die AWS DMS zum Erstellen von S3-Objekten verwendet. Für Amazon S3-Ziele unterstützt AWS DMS entwederCSV- oder Parquet-Dateien. Die Parquet-Dateien verfügen über ein binäresspaltenbasiertes Speicherformat mit effizienten Komprimierungsoptionen undschnellerer Abfrageleistung. Weitere Informationen über Parquet-Dateienfinden Sie unter https://parquet.apache.org/.
Standardwert: csv
Gültige Werte: csv oder parquet.
Beispiel:
dataFormat=parquet;
encodingType Der Parquet-Kodierungstyp. Die Kodierungstypoptionen umfassen Folgendes:
• rle-dictionary – Diese Verzeichniskodierung verwendet eineKombination aus Bit-Packing und Run-Length-Kodierung, um sichwiederholende Werte effizienter zu speichern.
• plain – Keine Kodierung.• plain-dictionary – Diese Verzeichnis-Kodierung erstellt ein
Werteverzeichnis der Werte, die in einer bestimmten Spalte vorkommen.Das Verzeichnis wird auf einer Verzeichnisseite für die einzelnenSpaltenblöcke gespeichert.
Standardwert: rle-dictionary
Zulässige Werte: rle-dictionary, plain oder plain-dictionary
Beispiel:
encodingType=plain-dictionary;
API-Version API Version 2016-01-01266
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Option Description (Beschreibung)
dictPageSizeLimit Die zulässige Maximalgröße (in Bytes) für eine Verzeichnisseite in einerParquet-Datei. Wenn eine Verzeichnisseite diesen Wert überschreitet,verwendet die Seite die einfache Kodierung.
Standardwert: 1.024.000 (1 MB)
Zulässige Werte: Jede gültige Ganzzahl
Beispiel:
dictPageSizeLimit=2,048,000;
rowGroupLength Die Anzahl der Zeilen einer Zeilengruppe in einer Parquet-Datei.
Standardwert: 10.024 (10 KB)
Zulässige Werte: Jede gültige Ganzzahl
Beispiel:
rowGroupLength=20,048;
dataPageSize Die zulässige Maximalgröße (in Bytes) für eine Datenseite in einer Parquet-Datei.
Standardwert: 1.024.000 (1 MB)
Zulässige Werte: Jede gültige Ganzzahl
Beispiel:
dataPageSize=2,048,000;
parquetVersion Die Version des Parquet-Dateiformats.
Standardwert: PARQUET_1_0
Gültige Werte: PARQUET_1_0 oder PARQUET_2_0.
Beispiel:
parquetVersion=PARQUET_2_0;
enableStatistics Legen Sie true oder y fest, um Statistiken über Parquet-Dateiseiten undZeilengruppen zu aktivieren.
Standardwert: true
Zulässige Werte: true, false, y, n
Beispiel:
enableStatistics=false;
API-Version API Version 2016-01-01267

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Option Description (Beschreibung)
timestampColumnName Ein optionaler Parameter, um eine Zeitstempelspalte in die S3-Zielendpunktdaten einzufügen.
Note
AWS DMS unterstützt timestampColumnName in den Versionen3.1.4 und höher.
AWS DMS enthält eine zusätzliche STRING-Spalte in den .csv- oder.parquet-Objektdateien der migrierten Daten, wenn Sie timestampColumnName aufeinen nicht leeren Wert festlegen.
Bei einem vollständigen Ladevorgang enthält jede Zeile der Zeitstempelspalteeinen Zeitstempel für den Zeitpunkt, an dem die Daten von DMS von derQuelle zum Ziel übertragen wurden.
Bei einem CDC-Ladevorgang enthält jede Zeile der Zeitstempelspalte denZeitstempel für den Commit dieser Zeile in der Quelldatenbank.
Das Zeichenfolgeformat für den Wert dieser Zeitstempelspalte ist yyyy-MM-dd HH:mm:ss.SSSSSS. Standardmäßig wird die Genauigkeit für diesenWert in Mikrosekunden angegeben. Für einen CDC-Ladevorgang hängt dieRundung für die Genauigkeit vom Commit-Zeitstempel ab, der von DMS fürdie Quell-Datenbank unterstützt wird.
Wenn der addColumnName-Parameter auf true festgelegt ist, enthält DMSauch den Namen für die Zeitstempelspalte, den Sie als den nicht leeren Wertvon timestampColumnName festlegen.
Beispiel:
timestampColumnName=TIMESTAMP;
API-Version API Version 2016-01-01268

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Option Description (Beschreibung)
parquetTimestampInMillisecondEin optionaler Parameter, der die Genauigkeit der TIMESTAMP-Spaltenwerteangibt, die in eine S3-Objektdatei im .parquet-Format geschrieben werden.
Note
AWS DMS unterstützt parquetTimestampInMillisecond in denVersionen 3.1.4 und höher.
Wenn dieses Attribut auf true oder y festgelegt ist, schreibt AWS DMS alleTIMESTAMP-Spalten in eine .parquet-formatierte Datei mit einer Genauigkeitvon Millisekunden. Andernfalls schreibt DMS sie mit einer Genauigkeit inMikrosekunden.
Derzeit können Amazon Athena und AWS Glue nur Millisekunden-Genauigkeitfür TIMESTAMP-Werte verarbeiten. Setzen Sie dieses Attribut für .parquet-formatierte S3-Endpunkt-Objektdateien nur dann auf „true“, wenn Sievorhaben, die Daten mithilfe von Athena oder AWS Glue abzufragen oder zuverarbeiten.
Note
• AWS DMS verwendet für alle TIMESTAMP-Spaltenwerte, diein eine S3-Datei im .csv-Format geschrieben werden, eineGenauigkeit in Mikrosekunden.
• Die Einstellung dieses Attributs hat keine Auswirkung auf dasZeichenfolgeformat des Zeitstempelspaltenwerts; der durchFestlegen des timestampColumnName-Attributs eingefügt wird.
Standardwert: false
Zulässige Werte: true, false, y, n
Beispiel:
parquetTimestampInMillisecond=true;
Angabe von Quelldatenbankoperationen in migrierten S3-Daten
Wenn AWS DMS Datensätze zu einem S3-Ziel migriert, kann es in jedem migrierten Datensatz einzusätzliches Feld erstellen. Dieses zusätzliche Feld gibt die Operation an, die auf den Datensatz in derQuelldatenbank angewendet wird.
Wenn im Fall eines vollständigen Ladevorgangs includeOpForFullLoad true ist, und dasAusgabeformat ist CSV, erstellt DMS in jedem CSV-Datensatz stets ein zusätzliches erstes Feld.Dieses Feld enthält den Buchstaben I (INSERT), um anzugeben, dass die Zeile in der Quelldatenbankeingefügt wurde. Wenn im Fall eines CDC-Ladevorgangs cdcInsertsOnly false ist (Standard), erstelltDMS ebenfalls in jedem CSV- oder Parquet-Datensatz stets ein zusätzliches erstes Feld. Dieses Feldenthält die Buchstaben I (INSERT), U (UPDATE) oder D (DELETE), um anzugeben, ob die Zeile in derQuelldatenbank eingefügt, aktualisiert oder gelöscht wurde.
Wenn das Ausgabeformat nur .csv ist, hängt es von den Einstellungen für includeOpForFullLoad undcdcInsertsOnly oder cdcInsertsAndUpdates ab, ob und wie DMS dieses erste Feld erstellt undfestlegt.
API-Version API Version 2016-01-01269
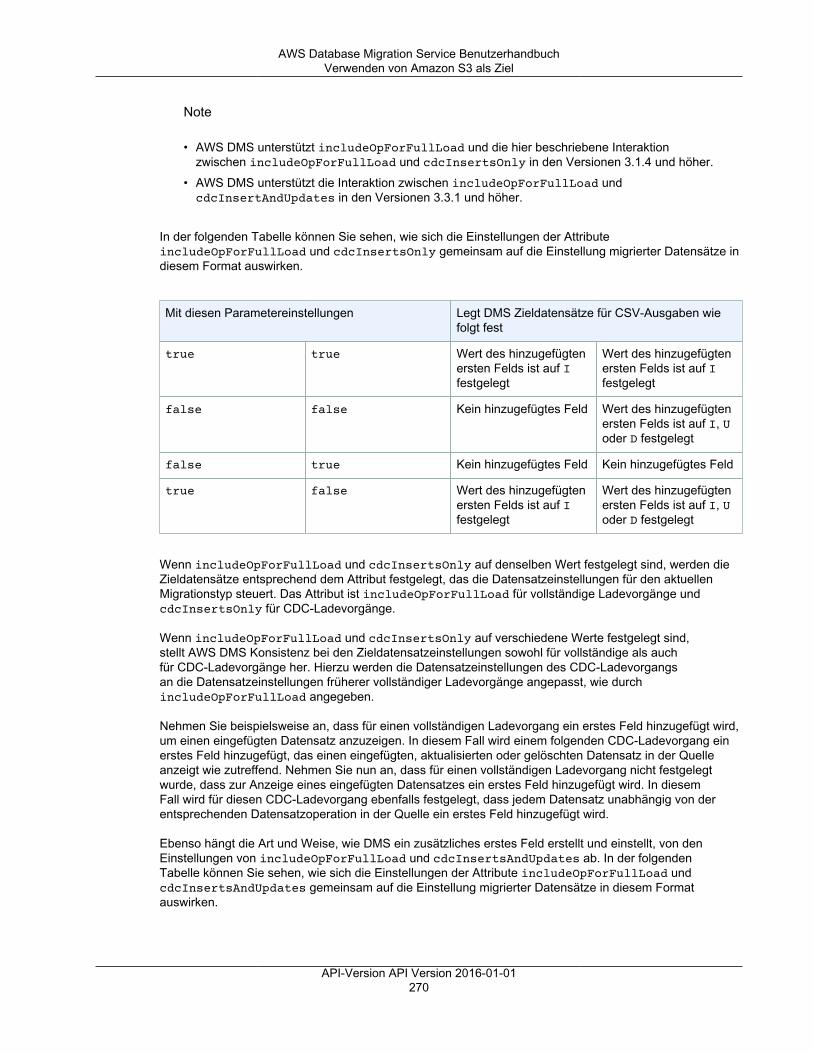
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon S3 als Ziel
Note
• AWS DMS unterstützt includeOpForFullLoad und die hier beschriebene Interaktionzwischen includeOpForFullLoad und cdcInsertsOnly in den Versionen 3.1.4 und höher.
• AWS DMS unterstützt die Interaktion zwischen includeOpForFullLoad undcdcInsertAndUpdates in den Versionen 3.3.1 und höher.
In der folgenden Tabelle können Sie sehen, wie sich die Einstellungen der AttributeincludeOpForFullLoad und cdcInsertsOnly gemeinsam auf die Einstellung migrierter Datensätze indiesem Format auswirken.
Mit diesen Parametereinstellungen Legt DMS Zieldatensätze für CSV-Ausgaben wiefolgt fest
true true Wert des hinzugefügtenersten Felds ist auf Ifestgelegt
Wert des hinzugefügtenersten Felds ist auf Ifestgelegt
false false Kein hinzugefügtes Feld Wert des hinzugefügtenersten Felds ist auf I, Uoder D festgelegt
false true Kein hinzugefügtes Feld Kein hinzugefügtes Feld
true false Wert des hinzugefügtenersten Felds ist auf Ifestgelegt
Wert des hinzugefügtenersten Felds ist auf I, Uoder D festgelegt
Wenn includeOpForFullLoad und cdcInsertsOnly auf denselben Wert festgelegt sind, werden dieZieldatensätze entsprechend dem Attribut festgelegt, das die Datensatzeinstellungen für den aktuellenMigrationstyp steuert. Das Attribut ist includeOpForFullLoad für vollständige Ladevorgänge undcdcInsertsOnly für CDC-Ladevorgänge.
Wenn includeOpForFullLoad und cdcInsertsOnly auf verschiedene Werte festgelegt sind,stellt AWS DMS Konsistenz bei den Zieldatensatzeinstellungen sowohl für vollständige als auchfür CDC-Ladevorgänge her. Hierzu werden die Datensatzeinstellungen des CDC-Ladevorgangsan die Datensatzeinstellungen früherer vollständiger Ladevorgänge angepasst, wie durchincludeOpForFullLoad angegeben.
Nehmen Sie beispielsweise an, dass für einen vollständigen Ladevorgang ein erstes Feld hinzugefügt wird,um einen eingefügten Datensatz anzuzeigen. In diesem Fall wird einem folgenden CDC-Ladevorgang einerstes Feld hinzugefügt, das einen eingefügten, aktualisierten oder gelöschten Datensatz in der Quelleanzeigt wie zutreffend. Nehmen Sie nun an, dass für einen vollständigen Ladevorgang nicht festgelegtwurde, dass zur Anzeige eines eingefügten Datensatzes ein erstes Feld hinzugefügt wird. In diesemFall wird für diesen CDC-Ladevorgang ebenfalls festgelegt, dass jedem Datensatz unabhängig von derentsprechenden Datensatzoperation in der Quelle ein erstes Feld hinzugefügt wird.
Ebenso hängt die Art und Weise, wie DMS ein zusätzliches erstes Feld erstellt und einstellt, von denEinstellungen von includeOpForFullLoad und cdcInsertsAndUpdates ab. In der folgendenTabelle können Sie sehen, wie sich die Einstellungen der Attribute includeOpForFullLoad undcdcInsertsAndUpdates gemeinsam auf die Einstellung migrierter Datensätze in diesem Formatauswirken.
API-Version API Version 2016-01-01270
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
Mit diesen Parametereinstellungen Legt DMS Zieldatensätze für CSV-Ausgaben wiefolgt fest
true true Wert des hinzugefügtenersten Felds ist auf Ifestgelegt
Wert des hinzugefügtenersten Felds ist auf Ioder U gesetzt
false false Kein hinzugefügtes Feld Kein hinzugefügtes Feld
false true Kein hinzugefügtes Feld Kein hinzugefügtes Feld
true false Wert des hinzugefügtenersten Felds ist auf Ifestgelegt
Wert des hinzugefügtenersten Felds ist auf I, Uoder D festgelegt
Verwenden einer Amazon DynamoDB-Datenbank alsZiel für AWS Database Migration ServiceSie können AWS DMS verwenden, um Daten in eine Amazon DynamoDB-Tabelle zu migrieren. AmazonDynamoDB ist ein vollständig verwalteter NoSQL-Datenbankservice, der schnelle und berechenbareLeistung mit nahtloser Skalierbarkeit bietet. AWS DMS unterstützt die Verwendung einer relationalenDatenbank oder von MongoDB als Quelle.
In DynamoDB sind Tabellen, Elemente und Attribute die Kernkomponenten, mit denen Sie arbeiten. EineTabelle ist eine Sammlung von Elementen. Jedes Element ist eine Sammlung von Attributen. DynamoDBverwendet Primärschlüssel, sogenannte Partitionsschlüssel, um jedes Element in einer Tabelle eindeutigzu identifizieren. Sie können auch Schlüssel und sekundäre Indizes verwenden, um die Abfrage flexibler zugestalten.
Verwenden Sie Objektzuweisungen zum Migrieren Ihrer Daten aus einer Quelldatenbank in eineDynamoDB-Zieltabelle. Anhand von Objektzuweisungen können Sie bestimmen, wo sich die Quelldaten inder Zieltabelle befinden.
Wenn AWS DMS Tabellen in einem DynamoDB-Zielendpunkt erstellt, werden so viele Tabellen wieim Quelldatenbankendpunkt erstellt. AWS DMS legt zudem mehrere DynamoDB-Parameterwerte fest.Die Kosten für die Erstellung der Tabelle sind abhängig von der Datenmenge und der Anzahl der zumigrierenden Tabellen.
Um die Übertragunggeschwindigkeit zu erhöhen, unterstützt AWS DMS vollständige Multithread-Ladevorgänge in eine DynamoDB-Ziel-Instance. DMS unterstützt Multithreading u. a. mithilfe der folgendenAufgabeneinstellungen:
• MaxFullLoadSubTasks – Geben Sie diese Option an, um die maximale Anzahl von Quelltabellenfestzulegen, die parallel geladen werden sollen. DMS lädt jede Tabelle in die entsprechende DynamoDB-Zieltabelle mithilfe einer dedizierten Unteraufgabe. Der Standardwert beträgt 8; der Maximalwert beträgt49.
• ParallelLoadThreads – Verwenden Sie diese Option, um die Anzahl der Threads anzugeben, dieAWS DMS zum Laden der einzelnen Tabellen in ihre DynamoDB-Zieltabellen verwendet. Der maximaleWert für ein DynamoDB-Ziel ist 32. Sie können eine Erhöhung dieses Höchstwerts anfordern.
• ParallelLoadBufferSize – Verwenden Sie diese Option, um die maximale Anzahl der Datensätzeanzugeben, die in dem Puffer geladen werden können, der von den parallelen Lade-Threads zum Ladenvon Daten in das DynamoDB-Ziel verwendet wird. Der Standardwert lautet 50. Die maximale Wert ist1.000. Verwenden Sie diese Einstellung mit ParallelLoadThreads; ParallelLoadBufferSize istnur gültig, wenn es mehr als einen Thread gibt.
API-Version API Version 2016-01-01271

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
• Table-Mapping-Einstellungen für einzelne Tabellen – Verwenden Sie table-settings-Regeln, umeinzelne Tabellen von der Quelle zu unterscheiden, die Sie parallel laden möchten. Verwenden Siediese Regeln darüber hinaus, um festzulegen, wie die Zeilen jeder Tabelle für das Multithread-Ladenaufgegliedert werden sollen. Weitere Informationen finden Sie unter Tabelleneinstellungen für Regelnund Operationen (p. 397).
Note
DMS weist jedem Segment einer Tabelle einen eigenen Thread zum Laden zu. Geben Sie ausdiesem Grund für ParallelLoadThreads die maximale Anzahl der Segmente an, die Sie füreine Tabelle in der Quelle verwenden werden.
Wenn AWS DMS DynamoDB-Parameterwerte für eine Migrationsaufgabe festlegt, ist der standardmäßigeParameterwert für Lesekapazitätseinheiten (Read Capacity Units, RCU) auf 200 festgelegt.
Der Schreibkapazitätseinheiten (WCU)-Parameterwert ist auch festgelegt, aber sein Wert hängt vonmehreren anderen Einstellungen ab:
• Der Standardwert für den WCU-Parameter lautet 200.• Wenn die Einstellung für die ParallelLoadThreads-Aufgabe größer als 1 ist (der Standard ist 0),
dann wird der WCU-Parameter auf das 200-fache des ParallelLoadThreads-Werts festgelegt.• In der Region USA Ost (Nord-Virginia) (us-east-1) ist der höchstmögliche WCU-Parameterwert 40.000.
Wenn die AWS-Region "us-east-1" ist und der WCU-Parameterwert größer als 40,000 ist, wird der WCU-Parameterwert auf 40.000 festgelegt.
• In anderen AWS-Regionen, abgesehen von us-east-1, lautet der höchstmögliche WCU-Parameterwert10.000. Für alle AWS-Regionen außer "us-east-1" gilt: Wenn der WCU-Parameterwert größer als 10.000festgelegt wird, wird der WCU-Parameterwert auf 10.000 festgelegt.
Migration aus einer relationalen Datenbank in eine DynamoDB-TabelleAWS DMS unterstützt die Migration von Daten in skalare DynamoDB-Datentypen. Bei der Migration vonDaten aus einer relationalen Datenbank wie Oracle oder MySQL zu DynamoDB sollten Sie die Art undWeise, wie Sie diese Daten speichern, umstrukturieren.
Derzeit unterstützt AWS DMS die Umstrukturierung einzelner Tabellen in die skalaren DynamoDB-Datentypattribute. Wenn Sie Daten aus einer relationalen Datenbanktabelle zu DynamoDB migrieren,formatieren Sie die Daten aus einer Tabelle in die skalaren DynamoDB-Datentypattribute um. DieseAttribute können Daten aus mehreren Spalten aufnehmen und Sie können eine Spalte direkt einem Attributzuweisen.
AWS DMS unterstützt die folgenden skalaren DynamoDB-Datentypen:
• Zeichenfolge• Zahl• Boolesch
Note
NULL-Daten aus der Quelle werden auf dem Ziel ignoriert.
API-Version API Version 2016-01-01272

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
Voraussetzungen für die Verwendung von DynamoDB als Ziel fürAWS Database Migration ServiceBevor Sie eine DynamoDB-Datenbank als Ziel für AWS DMS einsetzen können, stellen Sie sicher, dass Sieeine IAM-Rolle erstellt haben. Diese IAM-Rolle sollte AWS DMS zum Zugriff und Gewähren von Zugriff aufdie DynamoDB-Tabellen berechtigen, in die migriert wird. Im folgenden Beispiel für Rollenrichtlinien sinddie Mindestzugriffsberechtigungen dargestellt.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "dms.amazonaws.com" }, "Action": "sts:AssumeRole" }]}
Die Rolle, die Sie für die Migration zu DynamoDB verwenden, muss die folgenden Berechtigungenaufweisen.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "dynamodb:PutItem", "dynamodb:CreateTable", "dynamodb:DescribeTable", "dynamodb:DeleteTable", "dynamodb:DeleteItem", "dynamodb:UpdateItem" ], "Resource": [ "arn:aws:dynamodb:us-west-2:account-id:table/name1", "arn:aws:dynamodb:us-west-2:account-id:table/OtherName*", "arn:aws:dynamodb:us-west-2:account-id:table/awsdms_apply_exceptions", "arn:aws:dynamodb:us-west-2:account-id:table/awsdms_full_load_exceptions" ] }, { "Effect": "Allow", "Action": [ "dynamodb:ListTables" ], "Resource": "*" } ]}
API-Version API Version 2016-01-01273

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
Einschränkungen bei der Verwendung von DynamoDB als Ziel fürAWS Database Migration ServiceBei der Verwendung von DynamoDB als Ziel gelten die folgenden Einschränkungen:
• DynamoDB begrenzt die Genauigkeit des Number-Datentyps auf 38 Stellen. Speichern Sie alleDatentypen mit einer höheren Genauigkeit als Zeichenfolge. Sie müssen dies explizit mithilfe derObjektzuweisungsfunktion festlegen.
• Da DynamoDB keinen Datumsdatentyp aufweist, werden die Daten, die diesen Datentyp verwenden, inZeichenfolgen umgewandelt.
• DynamoDB lässt keine Updates für die primären Schlüsselattribute zu. Diese Einschränkung ist wichtig,wenn Sie die laufende Replikation mit Change Data Capture (CDC) verwenden, da sie zu unerwünschtenDaten im Ziel führen kann. Je nachdem, wie Sie das Objekt zuweisen, kann eine CDC-Operation, die denPrimärschlüssel aktualisiert, Folgendes tun. Es kann entweder fehlschlagen oder ein neues Element mitdem aktualisierten Primärschlüssel und unvollständigen Daten einfügen.
• AWS DMS unterstützt nur die Replikation von Tabellen mit nicht zusammengesetzten Primärschlüsseln.Die Ausnahme ist, wenn Sie eine Objektzuweisung für die Zieltabelle mit einem benutzerdefiniertenPartitionsschlüssel oder Sortierschlüssel (oder beiden) festlegen.
• AWS DMS unterstützt keine LOB-Daten, es sei denn, es handelt sich um CLOB-Daten. Beim Migrierender Daten wandelt AWS DMS CLOB-Daten in eine DynamoDB-Zeichenfolge um.
• Bei der Verwendung von DynamoDB als Ziel wird nur die Steuerungstabelle „Apply Exceptions(Ausnahmen anwenden)“ (dmslogs.awsdms_apply_exceptions) unterstützt. Weitere Informationenzu Steuerungstabellen finden Sie unter Einstellungen der Kontrolltabelle für Aufgaben (p. 346).
Verwenden der Objektzuweisung zum Migrieren von Daten zuDynamoDBAWS DMS nutzt Tabellenzuweisungsregeln zum Zuweisen von Daten von der Quelle zurDynamoDB-Zieltabelle. Um Daten einem DynamoDB-Ziel zuzuweisen, verwenden Sie eine Art vonTabellenzuweisungsregel, die als object-mapping bezeichnet wird. Mit Objektzuweisungen könnenSie Attributnamen und die zu ihnen zu migrierenden Daten definieren. Bei der Verwendung derObjektzuweisung müssen Sie über Auswahlregeln verfügen.
DynamoDB hat keine voreingestellte Struktur, mit Ausnahme eines Partitionsschlüssels und einesoptionalen Sortierschlüssels. Wenn Sie über einen nicht zusammengesetzten Primärschlüssel verfügen,wird dieser von AWS DMS verwendet. Wenn Sie über einen zusammengesetzten Primärschlüssel verfügenoder einen Sortierschlüssel verwenden möchten, müssen Sie diese Schlüssel und die anderen Attribute inIhrer DynamoDB-Zieltabelle definieren.
Zum Erstellen einer Objektzuweisungsregel legen Sie rule-type als object-mapping fest. Diese Regelgibt an, welchen Objektzuweisungstyp Sie verwenden möchten.
Die Struktur für die Regel lautet wie folgt:
{ "rules": [ { "rule-type": "object-mapping", "rule-id": "<id>", "rule-name": "<name>", "rule-action": "<valid object-mapping rule action>", "object-locator": { "schema-name": "<case-sensitive schema name>", "table-name": "" },
API-Version API Version 2016-01-01274

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
"target-table-name": "<table_name>" } } ]}
AWS DMS unterstützt derzeit map-record-to-record und map-record-to-document als einzigegültige Werte für den rule-action-Parameter. Diese Werte geben an, wie AWS DMS standardmäßigDatensätze handhabt, die als Teil der exclude-columns-Attributliste nicht ausgeschlossen sind. DieseWerte wirken sich in keiner Weise auf die Attributzuweisungen aus.
• Sie können map-record-to-record beim Migrieren aus einer relationalen Datenbank zu DynamoDBverwenden. Es wird der Primärschlüssel aus der relationalen Datenbank als Partitionsschlüssel inDynamoDB verwendet und ein Attribut für jede Spalte in der Quelldatenbank erstellt. Wenn Sie map-record-to-record für eine Spalte in der Quelltabelle verwenden, die nicht in der exclude-columns-Attributliste aufgeführt ist, erstellt AWS DMS ein entsprechendes Attribut auf der DynamoDB Ziel-Instance. Dies geschieht unabhängig davon, ob diese Quellspalte in einer Attributzuweisung verwendetwird oder nicht.
• Verwenden Sie map-record-to-document, um Quellspalten mithilfe des Attributnamens "_doc" ineiner einzelnen, flachen DynamoDB-Zuweisung auf dem Ziel zu platzieren. Wenn Sie map-record-to-document verwenden, werden die Daten von AWS DMS in einem einzigen, flachen DynamoDB-Zuweisungsattribut in der Quelle platziert. Dieses Attribut hat den Namen "_doc". Diese Platzierung giltfür jede Spalte der Quelltabelle, die nicht in der exclude-columns-Attributliste aufgeführt ist.
Der Unterschied zwischen den rule-action-Parametern map-record-to-record und map-record-to-document lässt sich am besten verstehen, wenn Sie die beiden Parameter in Aktion erleben. Indiesem Beispiel wird davon ausgegangen, dass Sie mit einer Tabellenzeile einer relationalen Datenbankbeginnen, die die folgende Struktur aufweist und die folgenden Daten enthält:
Um diese Informationen zu DynamoDB zu migrieren, erstellen Sie Regeln zum Zuweisen der Daten inein DynamoDB-Tabellenelement. Beachten Sie die für den exclude-columns-Parameter aufgeführtenSpalten. Diese Spalten werden nicht direkt dem Ziel zugewiesen. Stattdessen werden die Daten mithilfe derAttributzuweisung in neue Elemente kombiniert, z. B. werden FirstName und LastName im DynamoDB-Zielin CustomerName gruppiert. NickName und income sind nicht ausgeschlossen.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "1", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer"
API-Version API Version 2016-01-01275

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
}, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "dynamodb-map", "value": { "M": { "Home": { "M": { "Address": { "S": "${HomeAddress}" }, "Phone": { "S": "${HomePhone}" } } }, "Work": { "M": { "Address": { "S": "${WorkAddress}" }, "Phone": { "S": "${WorkPhone}" } } } } } } ] } } ]}
Bei Verwendung des rule-action-Parameters map-record-to-record werden die Daten für NickNameund income zu den Elementen mit demselben Namen im DynamoDB-Ziel zugewiesen.
API-Version API Version 2016-01-01276

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
Angenommen, Sie verwenden die gleichen Regeln, ändern aber den rule-action-Parameter in map-record-to-document. In diesem Fall werden die Spalten NickName und income, die nicht im exclude-columns-Parameter aufgeführt sind, einem _doc-Element zugeordnet.
Verwenden von benutzerdefinierten Bedingungsausdrücken mit ObjektzweisungSie können die DynamoDB-Funktion für bedingte Ausdrücke verwenden, um Daten zu bearbeiten, diein eine DynamoDB-Tabelle geschrieben werden. Weitere Informationen zu Bedingungsausdrücken inDynamoDB finden Sie unter Bedingungsausdrücke.
Ein Bedingungsausdruckselement besteht aus:
• einem Ausdruck (erforderlich)• Ausdrucksattributwerten (optional). Gibt eine DynamoDB-JSON-Struktur des Attributwerts an.• Ausdrucksattributnamen (optional)• Optionen für die Verwendung des Bedingungsausdrucks (optional). Der Standardwert lautet "apply-
during-cdc = false and apply-during-full-load = true".
API-Version API Version 2016-01-01277
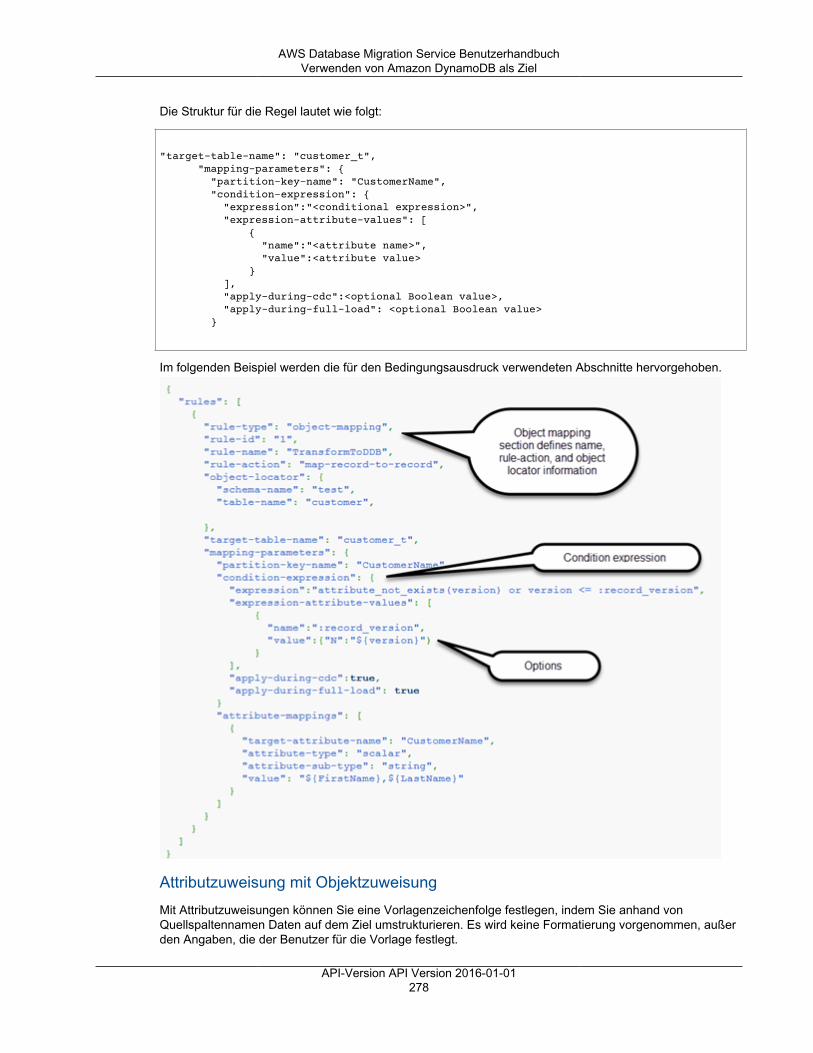
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
Die Struktur für die Regel lautet wie folgt:
"target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "condition-expression": { "expression":"<conditional expression>", "expression-attribute-values": [ { "name":"<attribute name>", "value":<attribute value> } ], "apply-during-cdc":<optional Boolean value>, "apply-during-full-load": <optional Boolean value> }
Im folgenden Beispiel werden die für den Bedingungsausdruck verwendeten Abschnitte hervorgehoben.
Attributzuweisung mit ObjektzuweisungMit Attributzuweisungen können Sie eine Vorlagenzeichenfolge festlegen, indem Sie anhand vonQuellspaltennamen Daten auf dem Ziel umstrukturieren. Es wird keine Formatierung vorgenommen, außerden Angaben, die der Benutzer für die Vorlage festlegt.
API-Version API Version 2016-01-01278

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
Das folgende Beispiel zeigt die Struktur der Quelldatenbank und die gewünschte Struktur des DynamoDB-Ziels. Zuerst wird die Struktur der Quelle dargestellt, in diesem Fall eine Oracle-Datenbank, und dann diegewünschte Struktur der Daten in DynamoDB. Am Ende des Beispiels ist das JSON-Format dargestellt, mitdem die gewünschte Zielstruktur erstellt wird.
Die Struktur der Oracle-Daten ist im Folgenden angegeben:
FirstNameLastNameStoreIdHomeAddressHomePhoneWorkAddressWorkPhoneDateOfBirth
Primärschlüssel –
RandyMarsh5 221BBakerStreet
123456789031SpoonerStreet,Quahog
987654321002/29/1988
Die Struktur der DynamoDB-Daten ist wie folgt:
CustomerNameStoreId ContactDetails DateOfBirth
PartitionsschlüsselSortierschlüssel –
Randy,Marsh5 { "Name": "Randy", "Home": { "Address": "221B Baker Street", "Phone": 1234567890 }, "Work": { "Address": "31 Spooner Street, Quahog", "Phone": 9876541230 }}
02/29/1988
Im folgenden JSON-Beispiel sind die Objekt- und Spaltenzuweisungen dargestellt, mit denen dieDynamoDB-Struktur erzielt wird:
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": {
API-Version API Version 2016-01-01279

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
"schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "sort-key-name": "StoreId", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "StoreId", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${StoreId}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "{\"Name\":\"${FirstName}\",\"Home\":{\"Address\":\"${HomeAddress}\",\"Phone\":\"${HomePhone}\"}, \"Work\":{\"Address\":\"${WorkAddress}\",\"Phone\":\"${WorkPhone}\"}}" } ] } } ]}
Alternativ kann bei der Spaltenzuweisung das DynamoDB-Format als Dokumenttyp verwendet werden.Im folgenden Codebeispiel wird dynamodb-map als attribute-sub-type für die Attributzuweisungverwendet.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB",
API-Version API Version 2016-01-01280

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
"rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "sort-key-name": "StoreId", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "StoreId", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${StoreId}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "dynamodb-map", "value": { "M": { "Name": { "S": "${FirstName}" }, "Home": { "M": { "Address": { "S": "${HomeAddress}" }, "Phone": { "S": "${HomePhone}" } } }, "Work": { "M": { "Address": { "S": "${WorkAddress}" }, "Phone": { "S": "${WorkPhone}" } } } } } } ] } } ]
API-Version API Version 2016-01-01281
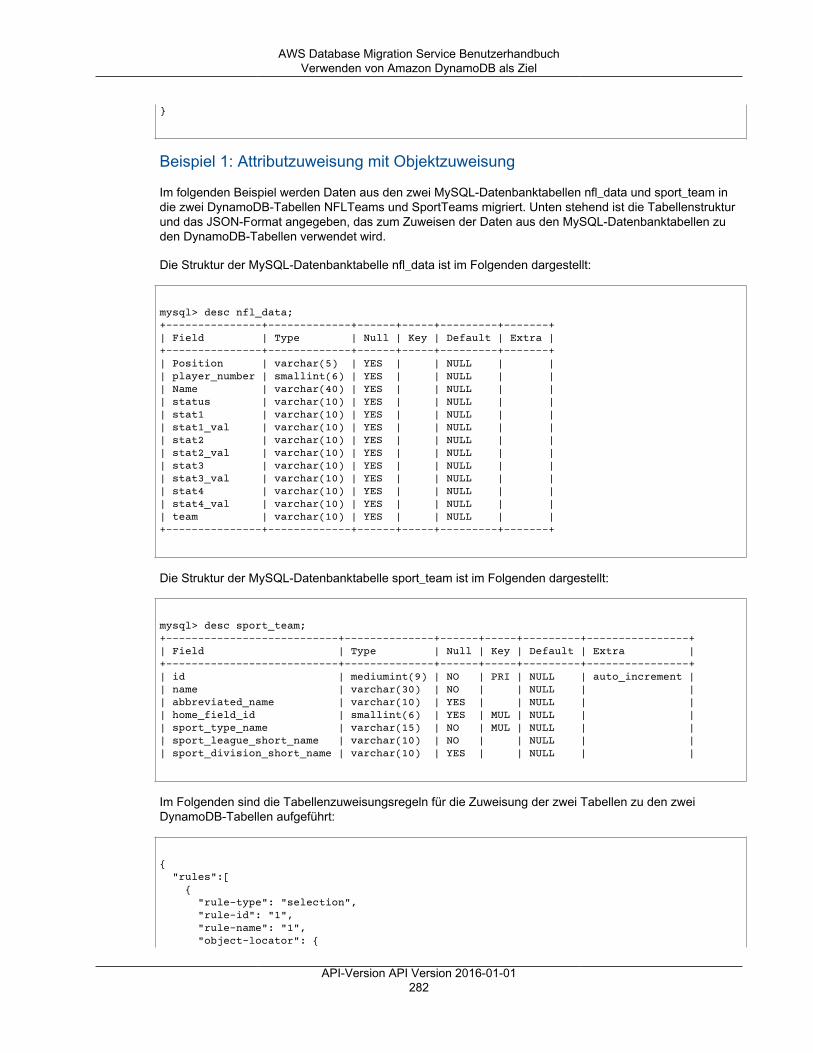
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
}
Beispiel 1: Attributzuweisung mit Objektzuweisung
Im folgenden Beispiel werden Daten aus den zwei MySQL-Datenbanktabellen nfl_data und sport_team indie zwei DynamoDB-Tabellen NFLTeams und SportTeams migriert. Unten stehend ist die Tabellenstrukturund das JSON-Format angegeben, das zum Zuweisen der Daten aus den MySQL-Datenbanktabellen zuden DynamoDB-Tabellen verwendet wird.
Die Struktur der MySQL-Datenbanktabelle nfl_data ist im Folgenden dargestellt:
mysql> desc nfl_data;+---------------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+---------------+-------------+------+-----+---------+-------+| Position | varchar(5) | YES | | NULL | || player_number | smallint(6) | YES | | NULL | || Name | varchar(40) | YES | | NULL | || status | varchar(10) | YES | | NULL | || stat1 | varchar(10) | YES | | NULL | || stat1_val | varchar(10) | YES | | NULL | || stat2 | varchar(10) | YES | | NULL | || stat2_val | varchar(10) | YES | | NULL | || stat3 | varchar(10) | YES | | NULL | || stat3_val | varchar(10) | YES | | NULL | || stat4 | varchar(10) | YES | | NULL | || stat4_val | varchar(10) | YES | | NULL | || team | varchar(10) | YES | | NULL | |+---------------+-------------+------+-----+---------+-------+
Die Struktur der MySQL-Datenbanktabelle sport_team ist im Folgenden dargestellt:
mysql> desc sport_team;+---------------------------+--------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+---------------------------+--------------+------+-----+---------+----------------+| id | mediumint(9) | NO | PRI | NULL | auto_increment || name | varchar(30) | NO | | NULL | || abbreviated_name | varchar(10) | YES | | NULL | || home_field_id | smallint(6) | YES | MUL | NULL | || sport_type_name | varchar(15) | NO | MUL | NULL | || sport_league_short_name | varchar(10) | NO | | NULL | || sport_division_short_name | varchar(10) | YES | | NULL | |
Im Folgenden sind die Tabellenzuweisungsregeln für die Zuweisung der zwei Tabellen zu den zweiDynamoDB-Tabellen aufgeführt:
{ "rules":[ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": {
API-Version API Version 2016-01-01282

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
"schema-name": "dms_sample", "table-name": "nfl_data" }, "rule-action": "include" }, { "rule-type": "selection", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "dms_sample", "table-name": "sport_team" }, "rule-action": "include" }, { "rule-type":"object-mapping", "rule-id":"3", "rule-name":"MapNFLData", "rule-action":"map-record-to-record", "object-locator":{ "schema-name":"dms_sample", "table-name":"nfl_data" }, "target-table-name":"NFLTeams", "mapping-parameters":{ "partition-key-name":"Team", "sort-key-name":"PlayerName", "exclude-columns": [ "player_number", "team", "Name" ], "attribute-mappings":[ { "target-attribute-name":"Team", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${team}" }, { "target-attribute-name":"PlayerName", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${Name}" }, { "target-attribute-name":"PlayerInfo", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"{\"Number\": \"${player_number}\",\"Position\": \"${Position}\",\"Status\": \"${status}\",\"Stats\": {\"Stat1\": \"${stat1}:${stat1_val}\",\"Stat2\": \"${stat2}:${stat2_val}\",\"Stat3\": \"${stat3}:${stat3_val}\",\"Stat4\": \"${stat4}:${stat4_val}\"}" } ] } }, { "rule-type":"object-mapping", "rule-id":"4", "rule-name":"MapSportTeam", "rule-action":"map-record-to-record", "object-locator":{ "schema-name":"dms_sample", "table-name":"sport_team" }, "target-table-name":"SportTeams",
API-Version API Version 2016-01-01283

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DynamoDB als Ziel
"mapping-parameters":{ "partition-key-name":"TeamName", "exclude-columns": [ "name", "id" ], "attribute-mappings":[ { "target-attribute-name":"TeamName", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${name}" }, { "target-attribute-name":"TeamInfo", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"{\"League\": \"${sport_league_short_name}\",\"Division\": \"${sport_division_short_name}\"}" } ] } } ]}
Die Beispielausgabe für die DynamoDB-Tabelle NFLTeams ist im Folgenden dargestellt:
"PlayerInfo": "{\"Number\": \"6\",\"Position\": \"P\",\"Status\": \"ACT\",\"Stats\": {\"Stat1\": \"PUNTS:73\",\"Stat2\": \"AVG:46\",\"Stat3\": \"LNG:67\",\"Stat4\": \"IN 20:31\"}", "PlayerName": "Allen, Ryan", "Position": "P", "stat1": "PUNTS", "stat1_val": "73", "stat2": "AVG", "stat2_val": "46", "stat3": "LNG", "stat3_val": "67", "stat4": "IN 20", "stat4_val": "31", "status": "ACT", "Team": "NE"}
Die Beispielausgabe für die DynamoDB-Tabelle SportsTeams ist im Folgenden dargestellt:
{ "abbreviated_name": "IND", "home_field_id": 53, "sport_division_short_name": "AFC South", "sport_league_short_name": "NFL", "sport_type_name": "football", "TeamInfo": "{\"League\": \"NFL\",\"Division\": \"AFC South\"}", "TeamName": "Indianapolis Colts"}
API-Version API Version 2016-01-01284
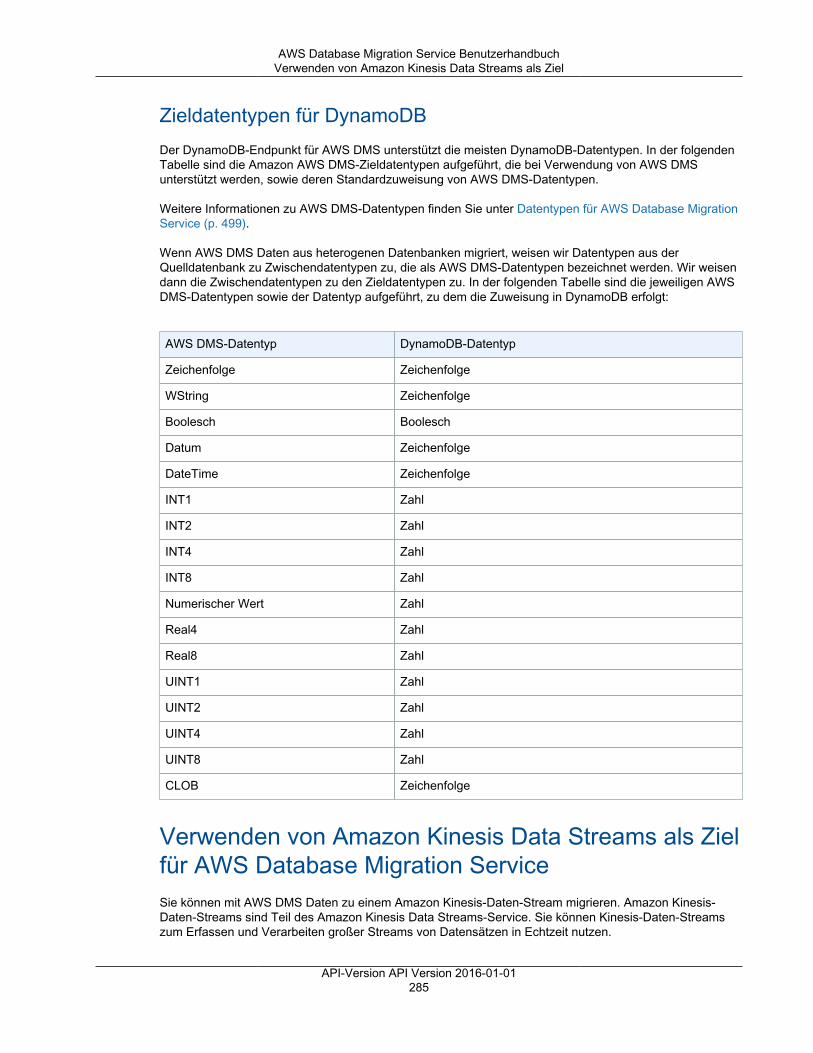
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Kinesis Data Streams als Ziel
Zieldatentypen für DynamoDBDer DynamoDB-Endpunkt für AWS DMS unterstützt die meisten DynamoDB-Datentypen. In der folgendenTabelle sind die Amazon AWS DMS-Zieldatentypen aufgeführt, die bei Verwendung von AWS DMSunterstützt werden, sowie deren Standardzuweisung von AWS DMS-Datentypen.
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
Wenn AWS DMS Daten aus heterogenen Datenbanken migriert, weisen wir Datentypen aus derQuelldatenbank zu Zwischendatentypen zu, die als AWS DMS-Datentypen bezeichnet werden. Wir weisendann die Zwischendatentypen zu den Zieldatentypen zu. In der folgenden Tabelle sind die jeweiligen AWSDMS-Datentypen sowie der Datentyp aufgeführt, zu dem die Zuweisung in DynamoDB erfolgt:
AWS DMS-Datentyp DynamoDB-Datentyp
Zeichenfolge Zeichenfolge
WString Zeichenfolge
Boolesch Boolesch
Datum Zeichenfolge
DateTime Zeichenfolge
INT1 Zahl
INT2 Zahl
INT4 Zahl
INT8 Zahl
Numerischer Wert Zahl
Real4 Zahl
Real8 Zahl
UINT1 Zahl
UINT2 Zahl
UINT4 Zahl
UINT8 Zahl
CLOB Zeichenfolge
Verwenden von Amazon Kinesis Data Streams als Zielfür AWS Database Migration ServiceSie können mit AWS DMS Daten zu einem Amazon Kinesis-Daten-Stream migrieren. Amazon Kinesis-Daten-Streams sind Teil des Amazon Kinesis Data Streams-Service. Sie können Kinesis-Daten-Streamszum Erfassen und Verarbeiten großer Streams von Datensätzen in Echtzeit nutzen.
API-Version API Version 2016-01-01285

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Kinesis Data Streams als Ziel
Note
Support für Amazon Kinesis Data Streams als Ziel ist in den AWS DMS-Versionen 3.1.2 und höherverfügbar.
Ein Kinesis-Daten-Stream besteht aus Shards. Shards sind eindeutig identifizierbare Sequenzen vonDatensätzen in einem Stream. Weitere Informationen zu Shards in Amazon Kinesis Data Streams findenSie unter Shards im Amazon Kinesis Data Streams-Entwicklerhandbuch.
AWS Database Migration Service veröffentlicht Datensätze an einen Kinesis-Daten-Stream mithilfe vonJSON. Während der Konvertierung serialisiert AWS DMS jeden Datensatz aus der Quelldatenbankin ein Attributwertpaar im JSON-Format oder in ein JSON_UNFORMATTED-Nachrichtenformat.Ein JSON_UNFORMATTED-Nachrichtenformat ist eine einzeilige JSON-Zeichenfolge mit neuemZeilenbegrenzer. Damit kann Amazon Kinesis Data Firehose Kinesis-Daten an ein Amazon S3-Ziel liefernund diese dann mit verschiedenen Abfrage-Engines, einschließlich Amazon Athena, abfragen.
Note
Die Unterstützung für das Kinesis-Nachrichtenformat JSON_UNFORMATTED ist in den AWSDMS-Versionen 3.3.1 und höher verfügbar.
Sie verwenden die Objektzuweisung zum Migrieren Ihrer Daten von einer unterstützten Datenquelle zueinem Ziel-Stream. Mit der Objektzuweisung bestimmen Sie, wie die Datensätze im Stream zu strukturierensind. Außerdem definieren Sie einen Partitionsschlüssel für jede Tabelle, die Kinesis Data Streams zumGruppieren der Daten in Shards verwendet.
Wenn AWS DMS Tabellen in einem Amazon Kinesis Data Streams-Zielendpunkt erstellt, erstellt es soviele Tabellen wie in dem Quelldatenbankendpunkt. AWS DMS legt auch mehrere Kinesis Data Streams-Parameterwerte fest. Die Kosten für die Erstellung der Tabelle sind abhängig von der Datenmenge und derAnzahl der zu migrierenden Tabellen.
Kinesis Data Streams Endpunkt-Einstellungen
Sie können Transaktions- und Steuerungsdetailinformationen über die Verwendung von Amazon KinesisData Streams-Zielendpunkten mithilfe der Endpunkteinstellungen in der AWS DMS-Konsole oder derKinesisSettings-Option der AWS DMS-API abrufen. Verwenden Sie in der AWS DMS-CLI dieAnforderungsparameter der folgenden --kinesis-settings-Option:
Note
Unterstützung für die Verwendung der folgenden Endpunkteinstellungen für Amazon Kinesis DataStreams-Zielendpunkte ist in AWS DMS-Version 3.3.1 und höher verfügbar.
• IncludeControlDetails – Zeigt detaillierte Kontrollinformationen für Tabellendefinition,Spaltendefinition und Tabellen- und Spaltenänderungen in der Kinesis-Nachrichtenausgabe an. DerStandardwert ist false.
• IncludePartitionValue – Zeigt den Partitionswert innerhalb der Kinesis-Nachrichtenausgabe an, essei denn, der Partitionstyp ist schema-table-type. Der Standardwert ist false.
• IncludeTableAlterOperations – Enthält alle DDL (Data Definition Language)-Operationen, diedie Tabelle in den Steuerelementdaten ändern, wie etwa rename-table, drop-table, add-column,drop-column und rename-column Der Standardwert ist false.
• IncludeTransactionDetails – Stellt detaillierte Transaktionsinformationen aus der Quelldatenbankbereit. Diese Informationen beinhalten einen Durchführungszeitstempel, eine Protokollposition sowieWerte für transaction_id, previous_transaction_id und transaction_record_id (denDatensatzoffset innerhalb einer Transaktion). Der Standardwert ist false.
• PartitionIncludeSchemaTable – Fügt Schema- und Tabellennamen zu Partitionswerten als Präfixhinzu, wenn der Partitionstyp primary-key-type ist. Dadurch wird die Datenverteilung zwischenKinesis-Shards erhöht. Angenommen, ein SysBench-Schema hat Tausende von Tabellen und jededavon hat nur einen begrenzten Bereich für einen Primärschlüssel. In diesem Fall wird derselbe
API-Version API Version 2016-01-01286

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Kinesis Data Streams als Ziel
Primärschlüssel von Tausenden von Tabellen an denselben Shard gesendet, was zu einer Drosselungführt. Der Standardwert ist false.
Aufgabeneinstellungen für Multithread-Volllast
Um die Übertragungsgeschwindigkeit zu erhöhen, unterstützt AWS DMS vollständige Multithread-Ladevorgänge in eine Kinesis Data Streams-Ziel-Instance. DMS unterstützt Multithreading u. a. mithilfe derfolgenden Aufgabeneinstellungen:
Note
Support für vollständige Multithread-Ladevorgänge in Amazon Kinesis Data Streams-Ziele ist inden AWS DMS-Versionen 3.1.4 und höher verfügbar.
• MaxFullLoadSubTasks – Geben Sie diese Option an, um die maximale Anzahl von Quelltabellenfestzulegen, die parallel geladen werden sollen. DMS lädt jede Tabelle in die entsprechende Kinesis-Zieltabelle mithilfe einer dedizierten Unteraufgabe. Der Standardwert beträgt 8; der Maximalwert beträgt49.
• ParallelLoadThreads – Verwenden Sie diese Option, um die Anzahl der Threads anzugeben, dieAWS DMS zum Laden der einzelnen Tabellen in ihre Kinesis-Zieltabellen verwendet. Der maximale Wertfür ein Kinesis Data Streams-Ziel ist 32. Sie können eine Erhöhung dieses Höchstwerts anfordern.
• ParallelLoadBufferSize – Verwenden Sie diese Option, um die maximale Anzahl der Datensätzeanzugeben, die in dem Puffer geladen werden können, der von den parallelen Lade-Threads zum Ladenvon Daten in das Kinesis-Ziel verwendet wird. Der Standardwert lautet 50. Die maximale Wert ist 1.000.Verwenden Sie diese Einstellung mit ParallelLoadThreads; ParallelLoadBufferSize ist nurgültig, wenn es mehr als einen Thread gibt.
• ParallelLoadQueuesPerThread – Verwenden Sie diese Option, um die Anzahl der Warteschlangenanzugeben, auf die jeder gleichzeitige Thread zugreift, um Datensätze aus Warteschlangen zuentfernen und eine Stapellast für das Ziel zu generieren. Der Standardwert ist 1. Für Kinesis-Ziele mitverschiedenen Nutzlastgrößen beträgt der gültige Bereich jedoch 5–512 Warteschlangen pro Thread.
• Table-Mapping-Einstellungen für einzelne Tabellen – Verwenden Sie table-settings-Regeln, umeinzelne Tabellen von der Quelle zu unterscheiden, die Sie parallel laden möchten. Verwenden Siediese Regeln darüber hinaus, um festzulegen, wie die Zeilen jeder Tabelle für das Multithread-Ladenaufgegliedert werden sollen. Weitere Informationen finden Sie unter Tabelleneinstellungen für Regelnund Operationen (p. 397).
Note
DMS weist jedem Segment einer Tabelle einen eigenen Thread zum Laden zu. Geben Sie ausdiesem Grund für ParallelLoadThreads die maximale Anzahl der Segmente an, die Sie füreine Tabelle in der Quelle verwenden werden.
Aufgabeneinstellungen für Multithreaded CDC-Last
Sie können die Leistung der Änderungsdatenerfassung (CDC) für Echtzeitdaten-Streaming-Zielendpunkteverbessern, z. B. die Verwendung von Aufgabeneinstellungen durch Kinesis, um das Verhaltendes PutRecords-API-Aufrufs zu ändern. Dazu können Sie die Anzahl der gleichzeitigen Threads,der Warteschlangen pro Thread und die Anzahl der Datensätze angeben, die in einem Puffer unterVerwendung von ParallelApply*-Aufgabeneinstellungen gespeichert werden sollen. Beispiel: Siemöchten eine CDC-Last durchführen und 128 Threads parallel anwenden. Außerdem möchten Sie auf 64Warteschlangen pro Thread zugreifen, wobei 50 Datensätze pro Puffer gespeichert sind.
Note
Unterstützung für die Verwendung von ParallelApply*-Aufgabeneinstellungen beim CDC-Vorgang zu Amazon Kinesis Data Streams-Zielendpunkten ist in den AWS DMS-Versions 3.3.1und höher verfügbar.
API-Version API Version 2016-01-01287

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Kinesis Data Streams als Ziel
Zur Steigerung der CDC-Leistung werden folgende Aufgabeneinstellungen von AWS DMS unterstützt:
• ParallelApplyThreads – Gibt die Anzahl der gleichzeitigen Threads an, die AWS DMS währendeiner CDC-Last verwendet, um Datensätze an einen Kinesis-Zielendpunkt zu übertragen. DerStandardwert ist Null (0) und der maximale Wert ist 32.
• ParallelApplyBufferSize – Gibt die maximale Anzahl von Datensätzen an, die in jederPufferwarteschlange für gleichzeitige Threads gespeichert werden sollen, die während einer CDC-Lastan einen Kinesis-Zielendpunkt übertragen werden sollen. Der Standardwert ist 50 und der maximale Wert1.000. Verwenden Sie diese Option, wenn ParallelApplyThreads mehrere Threads angibt.
• ParallelApplyQueuesPerThread – Gibt die Anzahl der Warteschlangen an, auf die jeder Threadzugreift, um Datensätze aus Warteschlangen zu entfernen und während des CDC eine Stapellast füreinen Kinesis-Endpunkt zu generieren.
Wenn Sie ParallelApply*-Aufgabeneinstellungen verwenden, ist der primary-key der Tabelle derpartition-key-type-Standardwert, nicht schema-name.table-name.
Verwenden eines Vorher-Abbilds zum Anzeigen vonOriginalwerten von CDC-Zeilen für einen Kinesis-Datenstrom alsZielWenn Sie CDC-Aktualisierungen in ein Data-Streaming-Ziel wie Kinesis schreiben, können Sie dieursprünglichen Werte einer Quelldatenbankzeile vor der Änderung durch eine Aktualisierung anzeigen.Um dies zu ermöglichen, zeigt AWS DMS ein Vorher-Abbild von Aktualisierungsereignissen basierend aufDaten, die von der Quelldatenbank-Engine bereitgestellt werden.
Note
Unterstützung für die Verwendung von Vorher-Abbild-Aufgabeneinstellungen beim CDC-Vorgangzu Amazon Kinesis Data Streams-Zielendpunkten ist in den AWS DMS-Versionen 3.3.1 und höherverfügbar.
Verschiedene Quelldatenbank-Engines liefern unterschiedliche Mengen an Informationen für ein Vorher-Abbild:
• Oracle stellt für Spalten nur dann Aktualisierungen bereit, wenn sie sich ändern.• PostgreSQL stellt nur Daten für Spalten bereit, die Teil des Primärschlüssels sind (geändert oder nicht).• MySQL stellt generell Daten für alle Spalten (geändert oder nicht) bereit.
Verwenden Sie entweder die BeforeImageSettings-Aufgabeneinstellung oder den add-before-image-columns-Parameter, um die Erstellung von Vorher-Abbildern zum Hinzufügen von Originalwertenaus der Quelldatenbank zur AWS DMS-Ausgabe zu aktivieren. Dieser Parameter wendet eine Spalten-Transformationsregel an.
BeforeImageSettings fügt jeder Aktualisierungsoperation ein neues JSON-Attribut mit Werten hinzu,die aus dem Quelldatenbanksystem erfasst werden, wie nachfolgend gezeigt.
"BeforeImageSettings": { "EnableBeforeImage": boolean, "FieldName": string, "ColumnFilter": pk-only (default) / non-lob / all (but only one)}
API-Version API Version 2016-01-01288

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Kinesis Data Streams als Ziel
Note
Wenden Sie BeforeImageSettings auf Volllast plus CDC-Aufgaben (die vorhandeneDaten migrieren und laufende Änderungen replizieren) oder nur auf CDC-Aufgaben (die nurDatenänderungen replizieren) an. Wenden Sie BeforeImageSettings nicht auf Nur-Volllast-Aufgaben an.
Für BeforeImageSettings-Optionen gilt Folgendes:
• Legen Sie die EnableBeforeImage-Option vor dem Imaging auf true fest. Der Standardwert istfalse.
• Verwenden Sie die FieldName-Option, um dem neuen JSON-Attribut einen Namen zuzuweisen. WannEnableBeforeImage true ist, ist FieldName erforderlich und darf nicht leer sein.
• Die ColumnFilter-Option gibt eine Spalte an, die vor dem Imaging hinzugefügt werden soll. WennSie nur Spalten hinzufügen möchten, die Teil der Primärschlüssel der Tabelle sind, verwenden Sieden Standardwert pk-only. Wenn Sie nur Spalten hinzufügen möchten, die nicht vom LOB-Typ sind,verwenden Sie non-lob. Wenn Sie eine Spalte hinzufügen möchten, die einen Vorher-Abbild-Wert hat,verwenden Sie all.
"BeforeImageSettings": { "EnableBeforeImage": true, "FieldName": "before-image", "ColumnFilter": "pk-only" }
Note
Amazon S3-Ziele unterstützen BeforeImageSettings nicht. Verwenden Sie für S3-Ziele nur dieadd-before-image-columns-Transformationsregel, die vor de- Imaging während des CDC-Vorgangs ausgeführt werden soll.
Verwenden einer Vorher-Abbild-Transformationsregel
Alternativ zu den Aufgabeneinstellungen können Sie den add-before-image-columns-Parameterverwenden, der eine Spalten-Transformationsregel anwendet. Mit diesem Parameter können Sie dasVorher-Imaging während des CDC-Vorgangs auf Data-Streaming-Zielen wie Kinesis aktivieren.
Wenn Sie add-before-image-columns in einer Transformationsregel verwenden, können Sie einefeinere Steuerung der Ergebnisse für das Vorher-Abbild anwenden. Mit Transformationsregeln können Sieeinen Objekt-Locator verwenden, der Ihnen die Kontrolle über die für die Regel ausgewählten Tabellengibt. Außerdem können Sie Transformationsregeln miteinander verketten, wodurch verschiedene Regelnauf verschiedene Tabellen angewendet werden können. Anschließend können Sie die erzeugten Spaltenmithilfe anderer Regeln bearbeiten.
Note
Verwenden Sie den add-before-image-columns-Parameter nicht zusammen mit derBeforeImageSettings-Aufgabeneinstellung innerhalb derselben Aufgabe. Verwenden Siestattdessen entweder den Parameter oder die Einstellung, aber nicht beide, für eine einzelneAufgabe.
Ein transformation-Regeltyp mit dem add-before-image-columns-Parameter für eine Spalte musseinen before-image-def-Abschnitt bereitstellen. Es folgt ein Beispiel.
{
API-Version API Version 2016-01-01289

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Kinesis Data Streams als Ziel
"rule-type": "transformation", … "rule-target": "column", "rule-action": "add-before-image-columns", "before-image-def":{ "column-filter": one-of (pk-only / non-lob / all), "column-prefix": string, "column-suffix": string, } }
Der Wert von column-prefix wird einem Spaltennamen vorangestellt, und der Standardwert voncolumn-prefix ist BI_. Der Wert von column-suffix wird an den Spaltennamen angehängt, undder Standardwert ist leer. Setzen Sie nicht sowohl column-prefix, als auch column-suffix auf leereZeichenfolgen.
Wählen Sie einen Wert für column-filter. Wenn Sie nur Spalten hinzufügen möchten, die Teilder Primärschlüssel der Tabelle sind, wählen Sie pk-only . Wählen Sie non-lob, um nur Spaltenhinzuzufügen, die nicht vom LOB-Typ sind. Oder lassenall Sie eine Spalte hinzufügen, die einen Vorher-Abbild-Wert hat.
Beispiel für eine Vorher-Abbild-Transformationsregel
Die Transformationsregel im folgenden Beispiel fügt eine neue Spalte mit dem Namen BI_emp_no aufdem Ziel hinzu. Eine Anweisung wie UPDATE employees SET emp_no = 3 WHERE emp_no = 1;füllt daher das BI_emp_no Feld mit 1. Wenn Sie CDC-Aktualisierungen für Amazon S3-Ziele schreiben,ermöglicht die BI_emp_no-Spalte, zu erkennen, welche ursprüngliche Zeile aktualisiert wurde.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-target": "column", "object-locator": { "schema-name": "%", "table-name": "employees" }, "rule-action": "add-before-image-columns", "before-image-def": { "column-prefix": "BI_", "column-suffix": "", "column-filter": "pk-only" } } ]}
Weitere Informationen zur Verwendung der add-before-image-columns-Regelaktion finden Sie unter Transformationsregeln und Aktionen (p. 382).
API-Version API Version 2016-01-01290

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Kinesis Data Streams als Ziel
Voraussetzungen für die Verwendung eines Kinesis-Daten-Streams als Ziel für AWS Database Migration ServiceBevor Sie einen Kinesis-Daten-Stream als Ziel für AWS DMS einrichten, stellen Sie sicher, dass Sie eineIAM-Rolle erstellt haben. Diese Rolle muss AWS DMS zum Zugriff und Gewähren von Zugriff auf dieKinesis-Daten-Streams berechtigen, in die migriert wird. In der folgenden Beispiel-Rollenrichtlinie wird derMindestsatz von Zugriffsberechtigungen dargestellt.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "1", "Effect": "Allow", "Principal": { "Service": "dms.amazonaws.com" }, "Action": "sts:AssumeRole" }]}
Die Rolle, die Sie für die Migration zu einem Kinesis-Daten-Stream verwenden, muss über die folgendenBerechtigungen verfügen.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "kinesis:DescribeStream", "kinesis:PutRecord", "kinesis:PutRecords" ], "Resource": "arn:aws:kinesis:region:accountID:stream/streamName" } ]}
Einschränkungen bei der Verwendung von Kinesis Data Streamsals Ziel für AWS Database Migration ServiceBei der Verwendung von Kinesis Data Streams als Ziel gelten die folgenden Einschränkungen:
• AWS DMS unterstützt eine maximale Nachrichtengröße von 1 MiB für ein Kinesis Data Streams-Ziel.• AWS DMS veröffentlicht jedes Update zu einem einzelnen Datensatz in der Quelldatenbank als
einen Datensatz in einem bestimmten Kinesis-Daten-Stream, unabhängig von Transaktionen. Siekönnen jedoch Transaktionsdetails für jeden Datensatz hinzufügen, indem Sie relevante Parameter derKinesisSettings-API verwenden.
• Kinesis Data Streams unterstützen keine Deduplizierung. Anwendungen, die Daten aus einem Streamaufnehmen, müssen doppelte Datensätze verarbeiten können. Weitere Informationen finden Sie unterUmgang mit doppelten Datensätzen im Amazon Kinesis Data Streams-Entwicklerhandbuch.
API-Version API Version 2016-01-01291

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Kinesis Data Streams als Ziel
• AWS DMS unterstützt die folgenden zwei Formen für Partitionsschlüssel:• SchemaName.TableName: Eine Kombination des Schema- und Tabellennamens.• ${AttributeName}: Der Wert in einem der Felder in der JSON-Datei oder der Primärschlüssel der
Tabelle in der Quelldatenbank.• Weitere Informationen zum Verschlüsseln Ihrer Daten in Ruhe in Kinesis Data Streams finden Sie unter
Datenschutz in Kinesis Data Streams im AWS Key Management Service-Entwicklerhandbuch.
Verwenden der Objektzuweisung zum Migrieren von Daten zueinem Kinesis-Daten-StreamAWS DMS nutzt Tabellenzuweisungsregeln zum Zuweisen von Daten von der Quelle zum Kinesis-Daten-Stream. Um Daten einem Ziel-Stream zuzuweisen , verwenden Sie eine Art von Tabellenzuweisungsregel,die als Objektzuweisung bezeichnet wird. Legen Sie durch Objektzuweisung fest, wie Datensätze in derQuelle den im Kinesis-Daten-Stream veröffentlichten Datensätzen zugewiesen werden.
Kinesis-Daten-Streams verfügen bis auf einen Partitionsschlüssel über keine voreingestellte Struktur. Ineiner Objektzuweisungsregel sind die möglichen Werte eines partition-key-type für Datensätzeschema-table, transaction-id, primary-key, constant und attribute-name.
Um eine Objektzuweisungsregel zu erstellen, legen Sie rule-type als object-mapping fest. DieseRegel gibt an, welchen Objektzuweisungstyp Sie verwenden möchten.
Die Struktur für die Regel lautet wie folgt.
{ "rules": [ { "rule-type": "object-mapping", "rule-id": "id", "rule-name": "name", "rule-action": "valid object-mapping rule action", "object-locator": { "schema-name": "case-sensitive schema name", "table-name": "" } } ]}
AWS DMS unterstützt derzeit map-record-to-record und map-record-to-document als einzigegültige Werte für den rule-action-Parameter. Die Werte map-record-to-record und map-record-to-document geben an, wie AWS DMS standardmäßig Datensätze handhabt, die nicht als Teil derexclude-columns-Attributliste nicht ausgeschlossen werden. Diese Werte wirken sich in keiner Weiseauf die Attributzuweisungen aus.
Verwenden Sie map-record-to-record beim Migrieren aus einer relationalen Datenbank zu einemKinesis-Daten-Stream. Dieser Regeltyp verwendet den taskResourceId.schemaName.tableName-Wert aus der relationalen Datenbank als Partitionsschlüssel im Kinesis-Daten-Stream und erstellt einAttribut für jede Spalte in der Quelldatenbank. Wenn Sie map-record-to-record für eine Spalte in derQuelltabelle verwenden, die nicht in der exclude-columns-Attributliste aufgeführt ist, erstellt AWS DMSein entsprechendes Attribut im Ziel-Stream. Dieses entsprechende Attribut wird unabhängig davon erstellt,ob diese Quellspalte in einer Attributzuweisung verwendet wird oder nicht.
Eine Möglichkeit, map-record-to-record zu verstehen, besteht darin, sich die praktische Anwendungzu veranschaulichen. In diesem Beispiel wird davon ausgegangen, dass Sie mit einer Tabellenzeile einerrelationalen Datenbank beginnen, die die folgende Struktur aufweist und die folgenden Daten enthält.
API-Version API Version 2016-01-01292

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Kinesis Data Streams als Ziel
FirstName LastName StoreId HomeAddressHomePhone WorkAddressWorkPhone DateofBirth
Randy Marsh 5 221BBakerStreet
1234567890 31SpoonerStreet,Quahog
9876543210 02/29/1988
Um diese Informationen von einem Schema mit dem Namen Test zu einem Kinesis-Daten-Streamzu migrieren, erstellen Sie Regeln zur Zuordnung der Daten zu dem Ziel-Stream. Die folgende Regelveranschaulicht die Zuweisung.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "rule-action": "include", "object-locator": { "schema-name": "Test", "table-name": "%" } }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "DefaultMapToKinesis", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "Test", "table-name": "Customers" } } ]}
Im Folgenden wird das resultierende Datensatzformat im Kinesis-Daten-Stream illustriert.
• StreamName: XXX• PartitionKey: Test.Customers //schmaName.tableName• Data: //Die folgende JSON-Meldung
{ "FirstName": "Randy", "LastName": "Marsh", "StoreId": "5", "HomeAddress": "221B Baker Street", "HomePhone": "1234567890", "WorkAddress": "31 Spooner Street, Quahog", "WorkPhone": "9876543210", "DateOfBirth": "02/29/1988" }
API-Version API Version 2016-01-01293

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Kinesis Data Streams als Ziel
Umstrukturieren von Daten mit Attributzuweisung
Sie können die Daten umstrukturieren, während Sie sie mittels einer Attributzuordnung zu einemKinesis-Daten-Stream migrieren. So möchten Sie zum Beispiel vielleicht mehrere Felder in der Quelle ineinem einzigen Feld im Ziel vereinen. Die folgenden Attributzuordnung veranschaulicht, wie die Datenumstrukturiert werden.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "rule-action": "include", "object-locator": { "schema-name": "Test", "table-name": "%" } }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToKinesis", "rule-action": "map-record-to-record", "target-table-name": "CustomerData", "object-locator": { "schema-name": "Test", "table-name": "Customers" }, "mapping-parameters": { "partition-key-type": "attribute-name", "partition-key-name": "CustomerName", "exclude-columns": [ "firstname", "lastname", "homeaddress", "homephone", "workaddress", "workphone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${lastname}, ${firstname}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "json", "value": { "Home": { "Address": "${homeaddress}", "Phone": "${homephone}" }, "Work": { "Address": "${workaddress}", "Phone": "${workphone}" } } } ] }
API-Version API Version 2016-01-01294

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Kinesis Data Streams als Ziel
} ]}
Um einen konstanten Wert für partition-key festzulegen, geben Sie einen partition-key-Wertan. So könnten Sie auf diese Weise beispielsweise erzwingen, dass alle Daten in einem einzigen Shardgespeichert werden. Die folgende Darstellung veranschaulicht dieses Konzept.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "Test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "1", "rule-name": "TransformToKinesis", "rule-action": "map-record-to-document", "object-locator": { "schema-name": "Test", "table-name": "Customer" }, "mapping-parameters": { "partition-key": { "value": "ConstantPartitionKey" }, "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "attribute-name": "CustomerName", "value": "${FirstName},${LastName}" }, { "attribute-name": "ContactDetails", "value": { "Home": { "Address": "${HomeAddress}", "Phone": "${HomePhone}" }, "Work": { "Address": "${WorkAddress}", "Phone": "${WorkPhone}" } } }, { "attribute-name": "DateOfBirth", "value": "${DateOfBirth}" } ]
API-Version API Version 2016-01-01295

AWS Database Migration Service BenutzerhandbuchVerwendung von Apache Kafka als Ziel
} } ]}
Note
Der partition-key-Wert für einen Steuerungsdatensatz, der für eine spezifische Tabellebestimmt ist, lautet TaskId.SchemaName.TableName. Der partition-key-Wert füreinen Steuerungsdatensatz, der für eine spezifische Aufgabe bestimmt ist, ist die TaskId desbetreffenden Datensatzes. Wenn Sie einen partition-key-Wert in der Objektzuweisungangeben, hat dies keine Auswirkungen auf den partition-key für einen Steuerungsdatensatz.
Nachrichtformat für Kinesis Data StreamsDie JSON-Ausgabe ist einfach eine Liste von Schlüssel-Wert-Paaren. Ein JSON_UNFORMATTED-Nachrichtenformat ist eine einzeilige JSON-Zeichenfolge mit neuem Zeilenbegrenzer.
Note
Unterstützung für das Nachrichtenformat JSON_UNFORMATTED Kinesis ist in den AWS DMS-Versionen 3.3.1 und höher verfügbar.
AWS DMS stellt die folgenden reservierten Felder bereit, um die Verwendung der Daten aus dem KinesisData Streams zu erleichtern:
RecordType
Der Datensatztyp kann entweder für Daten oder zur Steuerung bestimmt sein. Datensätze fürDatenrepräsentieren die tatsächlichen Zeilen in der Quelle. Steuerungsdatensätze sind für wichtigeEreignisse im Stream bestimmt, z. B. einen Neustart der Aufgabe.
Operation
Mögliche Operationen für Datensätze für Daten sind create, read, update oder delete.
Mögliche Operationen für Steuerungsdatensätze sind TruncateTable oder DropTable.SchemaName
Das Quellschema für den Datensatz. Dieses Feld kann für einen Steuerungsdatensatz leer sein.TableName
Die Quelltabelle für den Datensatz. Dieses Feld kann für einen Steuerungsdatensatz leer sein.Zeitstempel
Der Zeitstempel für den Zeitpunkt, an dem die JSON-Nachricht erstellt wurde. Das Feld ist mit demISO-8601-Format formatiert.
Verwendung von Apache Kafka als Ziel für AWSDatabase Migration ServiceSie können mit AWS DMS Daten zu einem Apache Kafka-Cluster migrieren. Apache Kafka-Cluster sindTeil des Apache Kafka-Services. Sie können Kafka-Clusters zum Erfassen und Verarbeiten großer Streamsvon Datensätzen in Echtzeit nutzen.
Note
Unterstützung für Apache Kafka als Ziel ist in den AWS DMS-Versionen 3.3.1 und höherverfügbar.
API-Version API Version 2016-01-01296

AWS Database Migration Service BenutzerhandbuchVerwendung von Apache Kafka als Ziel
AWS ermöglicht auch die Verwendung von Amazon Managed Streaming for Apache Kafka (Amazon MSK)als AWS DMS-Ziel. Amazon MSK ist ein vollständig verwalteter Apache Kafka Streaming-Service, derdie Implementierung und Verwaltung von Apache Kafka-Instances vereinfacht. Er funktioniert mit Open-Source-Apache Kafka-Versionen, und Sie greifen auf Amazon MSK-Instances als AWS DMS- Ziele genauwie auf jede Apache-Kafka-Instance zu. Weitere Informationen finden Sie unter Was ist Amazon MSK? imAmazon Managed Streaming for Apache Kafka Entwicklerhandbuch.
Ein Kafka-Cluster verwaltet Multi-Subscriber-Themen, die in Partitionen unterteilt sind. Partitionen sindeindeutig identifizierte Sequenzen von Datensätzen (Nachrichten) in einem Stream. Partitionen könnenüber mehrere Broker in einem Cluster verteilt werden, um die parallele Verarbeitung des Streams zuermöglichen. Weitere Informationen zu Themen und Partitionen und ihrer Verteilung in Apache Kafkafinden Sie unter Themen und Protokolle und Verteilung.
AWS Database Migration Service veröffentlicht Datensätze in einem Kafka-Cluster unter Verwendung vonJSON. Während der Konvertierung serialisiert AWS DMS jeden Datensatz aus der Quelldatenbank in einAttribut/Wert-Paar im JSON-Format.
Sie verwenden die Objektzuweisung zum Migrieren Ihrer Daten von einer unterstützten Datenquellezu einem Ziel-Stream. Mit der Objektzuweisung bestimmen Sie, wie die Datensätze im Stream zustrukturieren sind. Außerdem definieren Sie einen Partitionsschlüssel für jede Tabelle, die Apache Kafkazum Gruppieren der Daten in seine Partitionen verwendet.
Wenn AWS DMS Tabellen auf einem Apache Kafka-Zielendpunkt erstellt, erstellt es so viele Tabellenwie in dem Quelldatenbankendpunkt. AWS DMS legt dazu auch mehrere Apache Kafka-Parameterwertefest. Die Kosten für die Erstellung der Tabelle sind abhängig von der Datenmenge und der Anzahl der zumigrierenden Tabellen.
Apache Kafka-Endpunkteinstellungen
Sie können Verbindungsdetails über Endpunkteinstellungen in der AWS DMS-Konsole oder über die--kafka-settings-Option in der AWS DMS-CLI angeben. Es folgen die Anforderungen für jedeEinstellung:
• Broker – Geben Sie den Broker-Standort im Formular broker-hostname:port an. Beispiel,"ec2-12-345-678-901.compute-1.amazonaws.com:2345". Dies kann der Speicherort einesbeliebigen Brokers in dem Cluster sein. Die Cluster-Broker kommunizieren miteinander, um diePartitionierung von Datensätzen zu verarbeiten, die zu dem Thema migriert wurden.
• Topic – (Optional) Geben Sie den Themennamen mit einer maximalen Länge von 255 Buchstaben undSymbolen an. Sie können Punkt (.), Unterstrich (_) und Minuszeichen (-) verwenden. Themennamen miteinem Punkt (.) oder einem Unterstrich (_) können in internen Datenstrukturen kollidieren. VerwendenSie entweder eines, aber nicht beide dieser Symbole im Namen des Themas. Wenn Sie keinenThemennamen angeben, verwendet AWS DMS "kafka-default-topic" als Migrationsthema.
Note
Damit AWS DMS entweder ein von ihnen angegebenes Migrationsthema oder dasStandardthema verwendet, stellen Sie auto.create.topics.enable = true als Teil IhrerKafka-Cluster-Konfiguration ein. Weitere Informationen finden Sie unter Einschränkungen beider Verwendung von Apache Kafka als Ziel für AWS Database Migration Service (p. 301)
Aufgabeneinstellungen für Multithread-Volllast
Sie können Einstellungen verwenden, um die Übertragungsgeschwindigkeit zu erhöhen. Dazu unterstütztAWS DMS eine Multithread-Volllast zu einer Apache Kafka-Ziel-Instance. AWS DMS unterstützt diesesMultithreading mit Aufgabeneinstellungen, die Folgendes beinhalten:
• MaxFullLoadSubTasks – Verwenden Sie diese Option, um die maximale Anzahl der parallel zuladenden Quelltabellen anzugeben. AWS DMS lädt jede Tabelle mit einer dedizierten Teilaufgabe in dieentsprechende Kafka-Zieltabelle. Der Standardwert beträgt 8; der Maximalwert beträgt 49.
API-Version API Version 2016-01-01297

AWS Database Migration Service BenutzerhandbuchVerwendung von Apache Kafka als Ziel
• ParallelLoadThreads – Verwenden Sie diese Option, um die Anzahl der Threads anzugeben, dieAWS DMS zum Laden der einzelnen Tabellen in die Kafka-Zieltabelle verwendet. Der maximale Wert fürein Apache Kafka-Ziel ist 32. Sie können eine Erhöhung dieses Höchstwerts anfordern.
• ParallelLoadBufferSize – Verwenden Sie diese Option, um die maximale Anzahl der Datensätzeanzugeben, die in dem Puffer gespeichert werden können, der von den parallelen Lade-Threads zumLaden von Daten zum Kafka-Ziel verwendet wird. Der Standardwert lautet 50. Die maximale Wert ist1.000. Verwenden Sie diese Einstellung mit ParallelLoadThreads; ParallelLoadBufferSize istnur gültig, wenn es mehr als einen Thread gibt.
• ParallelLoadQueuesPerThread – Verwenden Sie diese Option, um die Anzahl der Warteschlangenanzugeben, auf die jeder gleichzeitige Thread zugreift, um Datensätze aus Warteschlangen zu entfernenund eine Stapellast für das Ziel zu generieren. Der Standardwert ist 1. Für Kafka-Ziele mit verschiedenenNutzlastgrößen beträgt der gültige Bereich jedoch 5–512 Warteschlangen pro Thread.
• Table-Mapping-Einstellungen für einzelne Tabellen – Verwenden Sie table-settings-Regeln, umeinzelne Tabellen von der Quelle zu unterscheiden, die Sie parallel laden möchten. Verwenden Siediese Regeln darüber hinaus, um festzulegen, wie die Zeilen jeder Tabelle für das Multithread-Ladenaufgegliedert werden sollen. Weitere Informationen finden Sie unter Tabelleneinstellungen für Regelnund Operationen (p. 397).
Note
DMS weist jedem Segment einer Tabelle einen eigenen Thread zum Laden zu. Geben Sie ausdiesem Grund für ParallelLoadThreads die maximale Anzahl der Segmente an, die Sie füreine Tabelle in der Quelle verwenden werden.
Aufgabeneinstellungen für Multithreaded CDC-Last
Sie können die Leistung der Änderungsdatenerfassung (Change data Capture, CDC) für Echtzeitdaten-Streaming-Zielendpunkte wie Kafka mithilfe von Aufgabeneinstellungen verbessern, die das Verhaltendes PutRecords-API-Aufrufs ändern. Dazu können Sie die Anzahl der gleichzeitigen Threads,der Warteschlangen pro Thread und die Anzahl der Datensätze angeben, die in einem Puffer unterVerwendung von ParallelApply*-Aufgabeneinstellungen gespeichert werden sollen. Beispiel: Siemöchten eine CDC-Last durchführen und 128 Threads parallel anwenden. Außerdem möchten Sie auf 64Warteschlangen pro Thread zugreifen, wobei 50 Datensätze pro Puffer gespeichert sind.
Zur Steigerung der CDC-Leistung werden folgende Aufgabeneinstellungen von AWS DMS unterstützt:
• ParallelApplyThreads – Gibt die Anzahl der gleichzeitigen Threads an, die AWS DMS währendeiner CDC-Last verwendet, um Datensätze an einen Kafka-Zielendpunkt zu übertragen. DerStandardwert ist Null (0) und der maximale Wert ist 32.
• ParallelApplyBufferSize – Gibt die maximale Anzahl von Datensätzen an, die in jederPufferwarteschlange für gleichzeitige Threads gespeichert werden sollen, die während einer CDC-Lastan einen Kafka-Zielendpunkt übertragen werden sollen. Der Standardwert ist 50 und der maximale Wert1.000. Verwenden Sie diese Option, wenn ParallelApplyThreads mehrere Threads angibt.
• ParallelApplyQueuesPerThread – Gibt die Anzahl der Warteschlangen an, auf die jeder Threadzugreift, um Datensätze aus Warteschlangen zu entfernen und während des CDC eine Stapellast füreinen Kafka-Endpunkt zu generieren.
Wenn Sie ParallelApply*-Aufgabeneinstellungen verwenden, ist der primary-key der Tabelle derpartition-key-type-Standardwert, nicht schema-name.table-name.
Verwenden eines Vorher-Abbilds zum Anzeigen vonOriginalwerten von CDC-Zeilen für Apache Kafka als ZielBeim Schreiben von CDC-Aktualisierungen auf ein Data-Streaming-Ziel wie Kafka können Sie dieursprünglichen Werte einer Quelldatenbankzeile anzeigen, bevor sie durch eine Aktualisierung geändert
API-Version API Version 2016-01-01298

AWS Database Migration Service BenutzerhandbuchVerwendung von Apache Kafka als Ziel
werden. Um dies zu ermöglichen, zeigt AWS DMS ein Vorher-Abbild von Aktualisierungsereignissenbasierend auf Daten, die von der Quelldatenbank-Engine bereitgestellt werden.
Verschiedene Quelldatenbank-Engines liefern unterschiedliche Mengen an Informationen für ein Vorher-Abbild:
• Oracle stellt für Spalten nur dann Aktualisierungen bereit, wenn sie sich ändern.• PostgreSQL stellt nur Daten für Spalten bereit, die Teil des Primärschlüssels sind (geändert oder nicht).• MySQL stellt generell Daten für alle Spalten (geändert oder nicht) bereit.
Verwenden Sie entweder die BeforeImageSettings-Aufgabeneinstellung oder den add-before-image-columns-Parameter, um die Erstellung von Vorher-Abbildern zum Hinzufügen von Originalwertenaus der Quelldatenbank zur AWS DMS-Ausgabe zu aktivieren. Dieser Parameter wendet eine Spalten-Transformationsregel an.
BeforeImageSettings fügt jeder Aktualisierungsoperation ein neues JSON-Attribut mit Werten hinzu,die aus dem Quelldatenbanksystem erfasst werden, wie nachfolgend gezeigt.
"BeforeImageSettings": { "EnableBeforeImage": boolean, "FieldName": string, "ColumnFilter": pk-only (default) / non-lob / all (but only one)}
Note
Wenden Sie BeforeImageSettings auf Volllast plus CDC-Aufgaben (die vorhandeneDaten migrieren und laufende Änderungen replizieren) oder nur auf CDC-Aufgaben (die nurDatenänderungen replizieren) an. Wenden Sie BeforeImageSettings nicht auf Nur-Volllast-Aufgaben an.
Für BeforeImageSettings-Optionen gilt Folgendes:
• Legen Sie die EnableBeforeImage-Option vor dem Imaging auf true fest. Der Standardwert istfalse.
• Verwenden Sie die FieldName-Option, um dem neuen JSON-Attribut einen Namen zuzuweisen. WannEnableBeforeImage true ist, ist FieldName erforderlich und darf nicht leer sein.
• Die ColumnFilter-Option gibt eine Spalte an, die vor dem Imaging hinzugefügt werden soll. WennSie nur Spalten hinzufügen möchten, die Teil der Primärschlüssel der Tabelle sind, verwenden Sieden Standardwert pk-only. Wenn Sie nur Spalten hinzufügen möchten, die nicht vom LOB-Typ sind,verwenden Sie non-lob. Wenn Sie eine Spalte hinzufügen möchten, die einen Vorher-Abbild-Wert hat,verwenden Sie all.
"BeforeImageSettings": { "EnableBeforeImage": true, "FieldName": "before-image", "ColumnFilter": "pk-only" }
Note
Amazon S3-Ziele unterstützen BeforeImageSettings nicht. Verwenden Sie für S3-Ziele nur dieadd-before-image-columns-Transformationsregel, die vor de- Imaging während des CDC-Vorgangs ausgeführt werden soll.
API-Version API Version 2016-01-01299

AWS Database Migration Service BenutzerhandbuchVerwendung von Apache Kafka als Ziel
Verwenden einer Vorher-Abbild-TransformationsregelAlternativ zu den Aufgabeneinstellungen können Sie den add-before-image-columns-Parameterverwenden, der eine Spalten-Transformationsregel anwendet. Mit diesem Parameter können Sie dasVorher-Imaging während des CDC-Vorgangs auf Data-Streaming-Zielen wie Kafka aktivieren.
Wenn Sie add-before-image-columns in einer Transformationsregel verwenden, können Sie einefeinere Steuerung der Ergebnisse für das Vorher-Abbild anwenden. Mit Transformationsregeln können Sieeinen Objekt-Locator verwenden, der Ihnen die Kontrolle über die für die Regel ausgewählten Tabellengibt. Außerdem können Sie Transformationsregeln miteinander verketten, wodurch verschiedene Regelnauf verschiedene Tabellen angewendet werden können. Anschließend können Sie die erzeugten Spaltenmithilfe anderer Regeln bearbeiten.
Note
Verwenden Sie den add-before-image-columns-Parameter nicht zusammen mit derBeforeImageSettings-Aufgabeneinstellung innerhalb derselben Aufgabe. Verwenden Siestattdessen entweder den Parameter oder die Einstellung, aber nicht beide, für eine einzelneAufgabe.
Ein transformation-Regeltyp mit dem add-before-image-columns-Parameter für eine Spalte musseinen before-image-def-Abschnitt bereitstellen. Es folgt ein Beispiel.
{ "rule-type": "transformation", … "rule-target": "column", "rule-action": "add-before-image-columns", "before-image-def":{ "column-filter": one-of (pk-only / non-lob / all), "column-prefix": string, "column-suffix": string, } }
Der Wert von column-prefix wird einem Spaltennamen vorangestellt, und der Standardwert voncolumn-prefix ist BI_. Der Wert von column-suffix wird an den Spaltennamen angehängt, undder Standardwert ist leer. Setzen Sie nicht sowohl column-prefix, als auch column-suffix auf leereZeichenfolgen.
Wählen Sie einen Wert für column-filter. Wenn Sie nur Spalten hinzufügen möchten, die Teilder Primärschlüssel der Tabelle sind, wählen Sie pk-only . Wählen Sie non-lob, um nur Spaltenhinzuzufügen, die nicht vom LOB-Typ sind. Oder lassenall Sie eine Spalte hinzufügen, die einen Vorher-Abbild-Wert hat.
Beispiel für eine Vorher-Abbild-TransformationsregelDie Transformationsregel im folgenden Beispiel fügt eine neue Spalte mit dem Namen BI_emp_no aufdem Ziel hinzu. Eine Anweisung wie UPDATE employees SET emp_no = 3 WHERE emp_no = 1;füllt daher das BI_emp_no Feld mit 1. Wenn Sie CDC-Aktualisierungen für Amazon S3-Ziele schreiben,ermöglicht die BI_emp_no-Spalte, zu erkennen, welche ursprüngliche Zeile aktualisiert wurde.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%",
API-Version API Version 2016-01-01300

AWS Database Migration Service BenutzerhandbuchVerwendung von Apache Kafka als Ziel
"table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-target": "column", "object-locator": { "schema-name": "%", "table-name": "employees" }, "rule-action": "add-before-image-columns", "before-image-def": { "column-prefix": "BI_", "column-suffix": "", "column-filter": "pk-only" } } ]}
Weitere Informationen zur Verwendung der add-before-image-columns-Regelaktion finden Sie unter Transformationsregeln und Aktionen (p. 382).
Einschränkungen bei der Verwendung von Apache Kafka als Zielfür AWS Database Migration ServiceBei der Verwendung von Apache Kafka als Ziel gelten die folgenden Einschränkungen:
• AWS DMS unterstützt eine maximale Nachrichtengröße von 1 MiB für ein Kafka-Ziel.• Konfigurieren Sie sowohl Ihre AWS DMS-Replikations-Instance als auch Ihren Kafka-Cluster in derselben
Amazon Virtual Private Cloud (Amazon VPC) und derselben Sicherheitsgruppe. Der Kafka-Clusterkann entweder eine Amazon MSK-Instance oder Ihre eigene Kafka-Instance sein, die auf Amazon EC2ausgeführt wird. Weitere Informationen finden Sie unter Einrichten eines Netzwerks für eine Replikations-Instance (p. 103).
Note
Um eine Sicherheitsgruppe für Amazon MSK anzugeben, wählen Sie auf der Seite Createcluster (Cluster erstellen) Advanced Settings (Erweiterte Einstellungen), Customize settings(Einstellungen anpassen) und dann die Sicherheitsgruppe aus oder übernehmen Sie dieStandardeinstellung, wenn sie mit der für die Replikations-Instance identisch ist.
• Geben Sie eine Kafka-Konfigurationsdatei für Ihren Cluster mit Eigenschaften an, die AWSDMS das automatische Erstellen neuer Themen ermöglichen. Schließen Sie die Einstellungauto.create.topics.enable = true ein. Wenn Sie Amazon MSK verwenden, könnenSie beim Erstellen Ihres Kafka-Clusters die Standardkonfiguration angeben und dann dieauto.create.topics.enable-Einstellung zu true ändern. Weitere Informationen zu denStandardkonfigurationseinstellungen finden Sie unter Die standardmäßige Amazon MSK-Konfigurationim Amazon Managed Streaming for Apache Kafka Entwicklerhandbuch. Wenn Sie einen vorhandenenKafka-Cluster ändern müssen, der mit Amazon MSK erstellt wurde, führen Sie den AWS-CLI-Befehl awskafka create-configuration aus, um Ihre Kafka-Konfiguration zu aktualisieren, wie im folgendenBeispiel gezeigt:
14:38:41 $ aws kafka create-configuration --name "kafka-configuration" --kafka-versions "2.2.1" --server-properties file://~/kafka_configuration{ "LatestRevision": {
API-Version API Version 2016-01-01301

AWS Database Migration Service BenutzerhandbuchVerwendung von Apache Kafka als Ziel
"Revision": 1, "CreationTime": "2019-09-06T14:39:37.708Z" }, "CreationTime": "2019-09-06T14:39:37.708Z", "Name": "kafka-configuration", "Arn": "arn:aws:kafka:us-east-1:111122223333:configuration/kafka-configuration/7e008070-6a08-445f-9fe5-36ccf630ecfd-3"}
Hier ist //~/kafka_configuration die Konfigurationsdatei, die Sie mit den erforderlichenEigenschaftseinstellungen erstellt haben.
Wenn Sie Ihre eigene Kafka-Instance verwenden, die auf Amazon EC2 installiert ist, ändernSie die Kafka-Cluster-Konfiguration mit ähnlichen Eigenschaftseinstellungen, einschließlichauto.create.topics.enable = true, unter Verwendung der mit Ihrer Instance bereitgestelltenOptionen.
• AWS DMS veröffentlicht jede Aktualisierung in einem einzelnen Datensatz in der Quelldatenbank alseinen Datensatz in einem bestimmten Kafka-Thema, unabhängig von Transaktionen.
• AWS DMS unterstützt die folgenden zwei Formen für Partitionsschlüssel:• SchemaName.TableName: Eine Kombination des Schema- und Tabellennamens.• ${AttributeName}: Der Wert in einem der Felder in der JSON-Datei oder der Primärschlüssel der
Tabelle in der Quelldatenbank.
Verwenden der Objektzuweisung zum Migrieren von Daten zueinem Kafka-Daten-StreamAWS DMS verwendet Tabellenzuweisungsregeln zum Zuweisen von Daten von der Quelle zumKafka-Cluster. Um Daten einem Ziel-Kafka-Cluster zuzuweisen, verwenden Sie eine Art vonTabellenzuweisungsregel, die als Objektzuweisung bezeichnet wird. Mit der Objektzuweisung legen Siefest, wie Datensätze in der Quelle den in einem Kafka-Thema veröffentlichten Datensätzen zugewiesenwerden.
Kafka-Themen verfügen bis auf einen Partitionsschlüssel über keine voreingestellte Struktur.
Um eine Objektzuweisungsregel zu erstellen, legen Sie rule-type als object-mapping fest. DieseRegel gibt an, welchen Objektzuweisungstyp Sie verwenden möchten.
Die Struktur für die Regel lautet wie folgt.
{ "rules": [ { "rule-type": "object-mapping", "rule-id": "id", "rule-name": "name", "rule-action": "valid object-mapping rule action", "object-locator": { "schema-name": "case-sensitive schema name", "table-name": "" } } ]}
AWS DMS unterstützt derzeit map-record-to-record und map-record-to-document als einzigegültige Werte für den rule-action-Parameter. Die Werte map-record-to-record und map-record-to-document geben an, wie AWS DMS standardmäßig Datensätze handhabt, die nicht als Teil der
API-Version API Version 2016-01-01302

AWS Database Migration Service BenutzerhandbuchVerwendung von Apache Kafka als Ziel
exclude-columns-Attributliste nicht ausgeschlossen werden. Diese Werte wirken sich in keiner Weiseauf die Attributzuweisungen aus.
Verwenden Sie map-record-to-record beim Migrieren aus einer relationalen Datenbank zu einemKafka-Thema. Dieser Regeltyp verwendet den taskResourceId.schemaName.tableName-Wertaus der relationalen Datenbank als Partitionsschlüssel in dem Kafka-Thema und erstellt ein Attributfür jede Spalte in der Quelldatenbank. Wenn Sie map-record-to-record für eine Spalte in derQuelltabelle verwenden, die nicht in der exclude-columns-Attributliste aufgeführt ist, erstellt AWS DMSein entsprechendes Attribut im Ziel-Stream. Dieses entsprechende Attribut wird unabhängig davon erstellt,ob diese Quellspalte in einer Attributzuweisung verwendet wird oder nicht.
Eine Möglichkeit, map-record-to-record zu verstehen, besteht darin, sich die praktische Anwendungzu veranschaulichen. In diesem Beispiel wird davon ausgegangen, dass Sie mit einer Tabellenzeile einerrelationalen Datenbank beginnen, die die folgende Struktur aufweist und die folgenden Daten enthält.
FirstName LastName StoreId HomeAddressHomePhone WorkAddressWorkPhone DateofBirth
Randy Marsh 5 221BBakerStreet
1234567890 31SpoonerStreet,Quahog
9876543210 02/29/1988
Um diese Informationen von einem Schema mit dem Namen Test zu einem Kafka-Thema zu migrieren,erstellen Sie Regeln, um die Daten dem Zielthema zuzuweisen. Die folgende Regel veranschaulicht dieZuweisung.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "rule-action": "include", "object-locator": { "schema-name": "Test", "table-name": "%" } }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "DefaultMapToKafka", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "Test", "table-name": "Customers" } } ]}
Nachfolgend wird das resultierende Datensatzformat bei Verwendung unserer Beispieldaten indem Kafka-Thema für einen bestimmten Stream-Namen und Partitionsschlüssel (in diesem FalltaskResourceId.schemaName.tableName) illustriert.
{ "FirstName": "Randy", "LastName": "Marsh",
API-Version API Version 2016-01-01303

AWS Database Migration Service BenutzerhandbuchVerwendung von Apache Kafka als Ziel
"StoreId": "5", "HomeAddress": "221B Baker Street", "HomePhone": "1234567890", "WorkAddress": "31 Spooner Street, Quahog", "WorkPhone": "9876543210", "DateOfBirth": "02/29/1988" }
Umstrukturieren von Daten mit AttributzuweisungSie können die Daten umstrukturieren, während Sie sie mittels einer Attributzuweisung zu einem Kafka-Thema migrieren. So möchten Sie zum Beispiel vielleicht mehrere Felder in der Quelle in einem einzigenFeld im Ziel vereinen. Die folgenden Attributzuordnung veranschaulicht, wie die Daten umstrukturiertwerden.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "rule-action": "include", "object-locator": { "schema-name": "Test", "table-name": "%" } }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToKafka", "rule-action": "map-record-to-record", "target-table-name": "CustomerData", "object-locator": { "schema-name": "Test", "table-name": "Customers" }, "mapping-parameters": { "partition-key-type": "attribute-name", "partition-key-name": "CustomerName", "exclude-columns": [ "firstname", "lastname", "homeaddress", "homephone", "workaddress", "workphone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${lastname}, ${firstname}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "json", "value": { "Home": { "Address": "${homeaddress}", "Phone": "${homephone}" },
API-Version API Version 2016-01-01304

AWS Database Migration Service BenutzerhandbuchVerwendung von Apache Kafka als Ziel
"Work": { "Address": "${workaddress}", "Phone": "${workphone}" } } } ] } } ]}
Um einen konstanten Wert für partition-key festzulegen, geben Sie einen partition-key-Wertan. So könnten Sie auf diese Weise beispielsweise erzwingen, dass alle Daten in einer einzigen Partitiongespeichert werden. Die folgende Darstellung veranschaulicht dieses Konzept.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "Test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "1", "rule-name": "TransformToKafka", "rule-action": "map-record-to-document", "object-locator": { "schema-name": "Test", "table-name": "Customer" }, "mapping-parameters": { "partition-key": { "value": "ConstantPartitionKey" }, "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "attribute-name": "CustomerName", "value": "${FirstName},${LastName}" }, { "attribute-name": "ContactDetails", "value": { "Home": { "Address": "${HomeAddress}", "Phone": "${HomePhone}" }, "Work": { "Address": "${WorkAddress}", "Phone": "${WorkPhone}"
API-Version API Version 2016-01-01305

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Elasticsearch Service als Ziel
} } }, { "attribute-name": "DateOfBirth", "value": "${DateOfBirth}" } ] } } ]}
Note
Der partition-key-Wert für einen Steuerungsdatensatz, der für eine spezifische Tabellebestimmt ist, lautet TaskId.SchemaName.TableName. Der partition-key-Wert füreinen Steuerungsdatensatz, der für eine spezifische Aufgabe bestimmt ist, ist die TaskId desbetreffenden Datensatzes. Wenn Sie einen partition-key-Wert in der Objektzuweisungangeben, hat dies keine Auswirkungen auf den partition-key für einen Steuerungsdatensatz.
Nachrichtenformat für Apache Kafka
Die JSON-Ausgabe ist einfach eine Liste von Schlüssel-Wert-Paaren.
RecordType
Der Datensatztyp kann entweder für Daten oder zur Steuerung bestimmt sein. Datensätze fürDatenrepräsentieren die tatsächlichen Zeilen in der Quelle. Steuerungsdatensätze sind für wichtigeEreignisse im Stream bestimmt, z. B. einen Neustart der Aufgabe.
Operation
Mögliche Operationen für Datensätze sind create, read, update oder delete.
Mögliche Operationen für Steuerungsdatensätze sind TruncateTable oder DropTable.SchemaName
Das Quellschema für den Datensatz. Dieses Feld kann für einen Steuerungsdatensatz leer sein.TableName
Die Quelltabelle für den Datensatz. Dieses Feld kann für einen Steuerungsdatensatz leer sein.Zeitstempel
Der Zeitstempel für den Zeitpunkt, an dem die JSON-Nachricht erstellt wurde. Das Feld ist mit demISO-8601-Format formatiert.
Verwenden eines Amazon Elasticsearch Service-Clusters als Ziel für AWS Database Migration ServiceSie können AWS DMS zum Migrieren von Daten zu Amazon Elasticsearch Service (Amazon ES)verwenden. Amazon ES ist ein verwalteter Service für das einfache Bereitstellen, Betreiben und Skaliereneines Elasticsearch-Clusters.
Note
Support für Amazon Elasticsearch Service als Ziel ist in den AWS DMS-Versionen 3.1.2 und höherverfügbar.
API-Version API Version 2016-01-01306

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Elasticsearch Service als Ziel
In Elasticsearch arbeiten Sie mit Indizes und Dokumenten. Ein Index ist eine Sammlung von Dokumenten,und ein Dokument ist ein JSON-Objekt mit skalaren Werten, Arrays und anderen Objekten. Elasticsearchbietet eine JSON-basierte Abfragesprache, sodass Sie Daten in einem Index abfragen und dieentsprechenden Dokumente abrufen können.
Wenn AWS DMS Indizes für einen Zielendpunkt für Amazon ES anlegt, erstellt es einen Index für jedeTabelle vom Quellendpunkt. Die Kosten für das Erstellen eines Elasticsearch-Indexes hängt von mehrerenFaktoren ab. Dazu gehören die Anzahl der erstellten Indizes, die Gesamtmenge von Daten in diesenIndizes und die geringe Menge von Metadaten, die Elasticsearch für jedes Dokument speichert.
Um die Übertragunggeschwindigkeit zu erhöhen, unterstützt AWS DMS vollständige Multithread-Ladevorgänge in einen Amazon ES-Ziel-Cluster. DMS unterstützt Multithreading u. a. mithilfe der folgendenAufgabeneinstellungen:
• MaxFullLoadSubTasks – Geben Sie diese Option an, um die maximale Anzahl von Quelltabellenfestzulegen, die parallel geladen werden sollen. DMS lädt jede Tabelle in den entsprechendenElasticsearch-Ziel-Index mithilfe einer dedizierten Unteraufgabe. Der Standardwert beträgt 8; derMaximalwert beträgt 49.
• ParallelLoadThreads – Verwenden Sie diese Option, um die Anzahl der Threads anzugeben, dieAWS DMS zum Laden der einzelnen Tabellen in den Elasticsearch-Ziel-Index verwendet. Der maximaleWert für ein Amazon ES-Ziel ist 32. Sie können eine Erhöhung dieses Höchstwerts anfordern.
Note
Wenn Sie am Standardwert für ParallelLoadThreads (0) keine Änderung vornehmen,überträgt AWS DMS jeweils immer nur einen Datensatz. Durch diesen Ansatz wird derElasticsearch-Cluster unnötig belastet. Überprüfen Sie, dass für diese Option ein Wert 1 odermehr angegeben wurde.
• ParallelLoadBufferSize – Verwenden Sie diese Option, um die maximale Anzahl der Datensätzeanzugeben, die in dem Puffer geladen werden können, der von den parallelen Lade-Threads zum Ladenvon Daten in das Elasticsearch-Ziel verwendet wird. Der Standardwert lautet 50. Die maximale Wert ist1.000. Verwenden Sie diese Einstellung mit ParallelLoadThreads; ParallelLoadBufferSize istnur gültig, wenn es mehr als einen Thread gibt.
• Table-Mapping-Einstellungen für einzelne Tabellen – Verwenden Sie table-settings-Regeln, umeinzelne Tabellen von der Quelle zu unterscheiden, die Sie parallel laden möchten. Verwenden Siediese Regeln darüber hinaus, um festzulegen, wie die Zeilen jeder Tabelle für das Multithread-Ladenaufgegliedert werden sollen. Weitere Informationen finden Sie unter Tabelleneinstellungen für Regelnund Operationen (p. 397).
Note
DMS weist jedem Segment einer Tabelle einen eigenen Thread zum Laden zu. Geben Sie ausdiesem Grund für ParallelLoadThreads die maximale Anzahl der Segmente an, die Sie füreine Tabelle in der Quelle verwenden werden.
Weitere Informationen dazu, wie DMS einen Elasticsearch-Cluster mithilfe des Multithreadinglädt, findenSie im AWS-Blogbeitrag Scale Amazon Elasticsearch Service for AWS Database Migration Servicemigrations.
Konfigurieren Sie Ihren Elasticsearch-Cluster mit Rechen- und Speicherressourcen, die für den UmfangIhrer Migration angemessen sind. Wir empfehlen, dass Sie abhängig von der Replikationsaufgabe, die Sieverwenden möchten, die folgenden Faktoren berücksichtigen:
• Erwägen Sie für einen vollständigen Datenladevorgang die Gesamtmenge der Daten, die Sie migrierenmöchten, sowie auch die Übertragungsgeschwindigkeit.
• Berücksichtigen Sie für die Replikation fortlaufender Änderungen die Häufigkeit der Aktualisierungen undIhre Anforderungen für eine End-to-End-Latenz.
API-Version API Version 2016-01-01307
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Elasticsearch Service als Ziel
Konfigurieren Sie die Index-Einstellungen zudem auf Ihrem Elasticsearch-Cluster, und achten Sie dabeigenau auf die Dokumentenanzahl.
Migration aus einer relationalen Datenbanktabelle zu einemAmazon ES-IndexAWS DMS unterstützt die Migration von Daten in die skalaren Elasticsearch-Datentypen. Bei der Migrationvon Daten aus einer relationalen Datenbank wie Oracle oder MySQL zu Elasticsearch möchten Siemöglicherweise umstrukturieren, wie diese Daten gespeichert werden.
AWS DMS unterstützt die folgenden skalaren Elasticsearch-Datentypen:
• Boolesch• Datum• Gleitkommazahl• Int• Zeichenfolge
AWS DMS wandelt Daten vom Type "Datum" in den Typ "Zeichenfolge" um. Sie können zum Auslegendieser Datumsangaben eine benutzerdefinierte Zuweisung angeben.
AWS DMS unterstützt keine Migration von LOB-Datentypen.
Voraussetzungen für die Verwendung von Amazon ElasticsearchService als Ziel für AWS Database Migration ServiceBevor Sie eine Elasticsearch-Datenbank als Ziel für AWS DMS einsetzen können, stellen Sie sicher,dass Sie eine AWS Identity and Access Management (IAM)-Rolle erstellt haben. Diese Rolle sollte AWSDMS den Zugriff auf die Elasticsearch-Indizes am Zielendpunkt gewähren. Im folgenden Beispiel fürRollenrichtlinien sind die Mindestzugriffsberechtigungen dargestellt.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "1", "Effect": "Allow", "Principal": { "Service": "dms.amazonaws.com" }, "Action": "sts:AssumeRole" } ]}
Die Rolle, die Sie für die Migration zu Elasticsearch verwenden, muss über die folgenden Berechtigungenverfügen.
{ "Version": "2012-10-17", "Statement": [ {
API-Version API Version 2016-01-01308

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon Elasticsearch Service als Ziel
"Effect": "Allow", "Action": [ "es:ESHttpDelete", "es:ESHttpGet", "es:ESHttpHead", "es:ESHttpPost", "es:ESHttpPut" ], "Resource": "arn:aws:es:region:account-id:domain/domain-name/*" } ]}
Ersetzen Sie im vorherigen Beispiel region durch die AWS-Region-ID, account-id durch Ihre AWS-Konto-ID und domain-name durch den Namen Ihrer Amazon Elasticsearch Service-Domäne. Ein Beispielist arn:aws:es:us-west-2:123456789012:domain/my-es-domain.
Zusätzliche Verbindungsattribute bei der Verwendung vonElasticsearch als Ziel für AWS DMSWenn Sie Ihren Elasticsearch-Zielendpunkt festlegen, können Sie zusätzliche Verbindungsattributeangeben. Zusätzliche Verbindungsattribute werden als Schlüssel-Wert-Paare angegeben und durchSemikolon getrennt.
Die folgende Tabelle beschreibt die zusätzlichen Verbindungsattribute, die bei der Verwendung einerElasticsearch-Instance als AWS DMS-Quelle verfügbar sind.
Attributname Zulässige Werte Standardwert und Beschreibung
fullLoadErrorPercentageEine positive Ganzzahlgrößer als 0, aber nichtgrößer als 100.
10 – Bei einem vollständigen Ladevorgang bestimmt diesesAttribut den Schwellenwert von Fehlern, die zulässig sind,bevor die Aufgabe fehlschlägt. Nehmen wir beispielsweisean, dass 1.500 Zeilen am Quellendpunkt vorhanden sindund dieser Parameter auf 10 eingestellt ist. Die Aufgabeschlägt dann fehl, wenn AWS DMS mehr als 150 Fehler(10 Prozent der Zeilenanzahl) beim Schreiben zumZielendpunkt antrifft.
errorRetryDurationEine positive Ganzzahlgrößer als 0.
300 – Wenn am Zielendpunkt ein Fehler auftritt, wiederholtAWS DMS den Vorgang für die angegebene Anzahl vonSekunden. Andernfalls schlägt die Aufgabe fehl.
Einschränkungen bei der Verwendung von Amazon ElasticsearchService als Ziel für AWS Database Migration ServiceBei der Verwendung von Amazon Elasticsearch Service als Ziel gelten die folgenden Einschränkungen:
• AWS DMS unterstützt nur die Replikation von Tabellen mit nicht zusammengesetzten Primärschlüsseln.Der Primärschlüssel der Quelltabelle muss aus einer einzelnen Spalte bestehen.
• Elasticsearch bestimmt anhand der dynamischen Zuweisung (eines automatischen Schätzwertes) die fürmigrierte Daten zu verwendenden Datentypen.
• Elasticsearch speichert jedes Dokument mit einer eindeutigen ID. Es folgt ein Beispiel für eine solche ID.
"_id": "D359F8B537F1888BC71FE20B3D79EAE6674BE7ACA9B645B0279C7015F6FF19FD"
API-Version API Version 2016-01-01309

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
Jede Dokument-ID ist 64 Bytes lang. Dies kann daher als Speicheranforderung vorausgesetzt werden.Wenn Sie zum Beispiel 100.000 Zeilen von einer AWS DMS-Quelle migrieren, erfordert der resultierendeElasticsearch-Index Speicher für zusätzliche 6.400.000 Bytes.
• Amazon ES lässt keine Updates für die Primärschlüsselattribute zu. Diese Einschränkung ist wichtig,wenn Sie die laufende Replikation mit Change Data Capture (CDC) verwenden, da sie zu unerwünschtenDaten im Ziel führen kann. In CDC-Modus werden Primärschlüssel SHA256-Werten zugeordnet, die 32Bytes lang sind. Diese werden in visuell lesbare 64-Byte-Zeichenfolgen konvertiert und als Elasticsearch-Dokument-IDs verwendet.
• Wenn AWS DMS auf Elemente trifft, die nicht migriert werden können, wird eine Fehlermeldungen inAmazon CloudWatch Logs geschrieben. Dieses Verhalten unterscheidet sich von anderen AWS DMS-Ziel-Endpunkte, bei denen Fehler in eine Ausnahmetabelle geschrieben werden.
Zieldatentypen für Amazon Elasticsearch ServiceWenn AWS DMS Daten aus heterogenen Datenbanken migriert, ordnet der Service Datentypen aus derQuelldatenbank Zwischendatentypen zu, die als AWS DMS-Datentypen bezeichnet werden. Der Serviceordnet dann die Zwischendatentypen den Zieldatentypen zu. In der folgenden Tabelle sind die jeweiligenAWS DMS-Datentypen sowie der Datentyp aufgeführt, zu dem die Zuordnung in Elasticsearch erfolgt.
AWS DMS-Datentyp Elasticsearch-Datentyp
Boolesch Boolean
Datum string
Zeit date
Zeitstempel date
INT4 integer
Real4 float
UINT4 integer
Weitere Informationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
Verwenden von Amazon DocumentDB als Ziel fürAWS Database Migration ServiceSie können mithilfe von AWS DMS Daten zu Amazon DocumentDB (mit MongoDB-Kompatibilität)migrieren – und zwar von jeder der Quelldaten-Engines, die AWS DMS unterstützt. Die Quell-Enginekann sich in einem von Amazon verwalteten Service befinden, wie beispielsweise Amazon RDS, Aurora,oder Amazon S3. Alternativ kann sich die Engine in einer selbstverwalteten Datenbank befinden, wiebeispielsweise MongoDB, das auf Amazon EC2 oder vor Ort ausgeführt wird.
Note
Support für Amazon DocumentDB (mit MongoDB-Kompatibilität) als Ziel ist in den AWS DMS-Versionen 3.1.3 und höher verfügbar.
Sie können AWS DMS verwenden, um Quelldaten zu Amazon DocumentDB-Datenbanken, -Sammlungenoder -Dokumenten zu replizieren.
API-Version API Version 2016-01-01310

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
Wenn der Quellendpunkt MongoDB ist, stellen Sie sicher, dass Sie die folgenden zusätzlichenVerbindungsattribute aktivieren:
• nestingLevel=NONE
• extractDocID=false
Weitere Informationen finden Sie unter Zusätzliche Verbindungsattribute bei der Verwendung vonMongoDB als Quelle für AWS DMS (p. 199).
MongoDB speichert Daten in einem binären JSON-Format (BSON). AWS DMS unterstützt alle BSON-Datentypen, die von Amazon DocumentDB unterstützt werden. Eine Liste dieser Datentypen findenSie unter Unterstützte MongoDB-APIs, -Operationen und -Datentypen im Amazon DocumentDB-Entwicklerhandbuch.
Wenn es sich beim Quellendpunkt um eine relationale Datenbank handelt, ordnet AWS DMSDatenbankobjekte wie folgt Amazon DocumentDB zu:
• Eine relationale Datenbank oder ein Datenbankschema entspricht einer AmazonDocumentDB-Datenbank.
• Tabellen innerhalb einer relationalen Datenbank entsprechen Sammlungen in Amazon DocumentDB.• Datensätze in einer relationalen Tabelle entsprechen Dokumenten in Amazon DocumentDB. Jedes
Dokument wird aus den Daten des Quelldatensatzes erstellt.
Wenn der Quellendpunkt Amazon S3 ist, dann entsprechen die resultierenden Amazon DocumentDB-Objekte den AWS DMS-Zuweisungsregeln für Amazon S3. Betrachten Sie beispielsweise die folgende URI:
s3://mybucket/hr/employee
In diesem Fall ordnet AWS DMS die Objekte in mybucket wie folgt Amazon DocumentDB zu:
• Der Top-Level-URI-Teil (hr) entspricht einer Amazon DocumentDB-Datenbank.• Der nächste URI-Teil (employee) entspricht einer Amazon DocumentDB-Sammlung.• Jedes Objekt in employee entspricht einem Dokument in Amazon DocumentDB.
Weitere Informationen zu den Zuweisungsregeln für Amazon S3 finden Sie unter Verwenden von AmazonS3 als Quelle für AWS DMS (p. 201).
Um die Übertragunggeschwindigkeit zu erhöhen, unterstützt AWS DMS vollständige Multithread-Ladevorgänge in eine Amazon DocumentDB-Ziel-Instance. DMS unterstützt Multithreading u. a. mithilfe derfolgenden Aufgabeneinstellungen:
• MaxFullLoadSubTasks – Geben Sie diese Option an, um die maximale Anzahl von Quelltabellenfestzulegen, die parallel geladen werden sollen. DMS lädt jede Tabelle in die entsprechende AmazonDocumentDB-Zieltabelle mithilfe einer dedizierten Unteraufgabe. Der Standardwert beträgt 8; derMaximalwert beträgt 49.
• Table-Mapping-Einstellungen für einzelne Tabellen – Verwenden Sie table-settings-Regeln, umeinzelne Tabellen von der Quelle zu unterscheiden, die Sie parallel laden möchten. Verwenden Siediese Regeln darüber hinaus, um festzulegen, wie die Zeilen jeder Tabelle für das Multithread-Ladenaufgegliedert werden sollen. Weitere Informationen finden Sie unter Tabelleneinstellungen für Regelnund Operationen (p. 397).
API-Version API Version 2016-01-01311

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
Note
DMS weist jedem Segment einer Tabelle einen eigenen Thread zum Laden zu. Geben Sie ausdiesem Grund für ParallelLoadThreads die maximale Anzahl der Segmente an, die Sie füreine Tabelle in der Quelle verwenden werden.
Weitere Details zur Arbeit mit Amazon DocumentDB als Ziel für AWS DMS, einschließlich einerschrittweisen Anleitung für den Migrationsprozess, finden Sie in den folgenden Abschnitten.
Themen• Zuweisung von Daten von einer Quelle auf ein Amazon DocumentDB-Ziel (p. 312)• Fortlaufende Replikation mit Amazon DocumentDB als Ziel (p. 315)• Einschränkungen bei der Verwendung von Amazon DocumentDB als Ziel (p. 316)• Zieldatentypen für Amazon DocumentDB (p. 317)• Anleitung: Migration von MongoDB nach Amazon DocumentDB (p. 318)
Zuweisung von Daten von einer Quelle auf ein AmazonDocumentDB-ZielAWS DMS liest Datensätze aus dem Quellendpunkt und erstellt JSON-Dokumente basierend auf dengelesenen Daten. Für jedes JSON-Dokument muss AWS DMS ein _id-Feld bestimmen, das als eindeutigeKennung fungiert. Anschließend schreibt es das JSON-Dokument in eine Amazon DocumentDB-Sammlungund verwendet dabei das _id-Feld als Primärschlüssel.
Quelldaten, die eine einzelne Spalte darstellen
Wenn die Quelldaten aus einer einzelnen Spalte bestehen, müssen die Daten vom Typ Zeichenfolge sein.(Abhängig von der Quell-Engine kann der tatsächliche Datentyp VARCHAR, NVARCHAR, TEXT, LOB,CLOB oder Ähnliches sein.) AWS DMS geht davon aus, dass es sich bei den Daten um ein gültiges JSON-Dokument handelt, und repliziert die Daten unverändert nach Amazon DocumentDB.
Wenn das resultierende JSON-Dokument ein Feld mit dem Namen _id enthält, wird dieses Feld alseindeutige _id in Amazon DocumentDB verwendet.
Wenn das JSON-Dokument kein _id-Feld enthält, generiert Amazon DocumentDB automatisch einen _id-Wert.
Quelldaten, die mehrere Spalten darstellen
Wenn die Quelldaten aus mehreren Spalten bestehen, erstellt AWS DMS aus all diesen Spalten ein JSON-Dokument. Um das _id-Feld für das Dokument zu bestimmen, geht AWS DMS wie folgt vor:
• Wenn der Name einer der Spalten _id lautet, dann werden die Daten in dieser Spalte als Ziel-_idverwendet.
• Wenn keine _id-Spalte vorhanden ist, aber die Quelldaten über einen Primärschlüssel oder eineneindeutigen Index verfügen, dann verwendet AWS DMS diesen Schlüssel oder Indexwert als _id-Wert.Die Daten aus dem Primärschlüssel oder eindeutigen Index erscheinen auch als explizite Felder imJSON-Dokument.
• Wenn keine _id-Spalte vorhanden ist und es keinen Primärschlüssel oder einen eindeutigen Index gibt,dann generiert Amazon DocumentDB automatisch einen _id-Wert.
API-Version API Version 2016-01-01312

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
Zwingen eines Datentyps an den ZielendpunktAWS DMS kann Datenstrukturen ändern, wenn es in einen Amazon DocumentDB-Zielendpunkt schreibt.Sie können diese Änderungen anfordern, indem Sie Spalten und Tabellen am Quellendpunkt umbenennenoder Transformationsregeln bereitstellen, die bei der Ausführung einer Aufgabe angewendet werden.
Verwenden eines verschachtelten JSON-Dokuments (json_-Präfix)
Um einen Datentyp zu erzwingen, können Sie dem Namen der Quellspalte das Präfix json_ (d. h.json_columnName) entweder manuell oder mittels einer Transformation voranstellen. In diesem Fallwird die Spalte nicht als Zeichenfolgenfeld, sondern als verschachteltes JSON-Dokument innerhalb desZieldokuments erstellt.
Angenommen, Sie möchten beispielsweise das folgende Dokument von einem MongoDB-Quellenendpunktmigrieren.
{ "_id": "1", "FirstName": "John", "LastName": "Doe", "ContactDetails": "{"Home": {"Address": "Boston","Phone": "1111111"},"Work": { "Address": "Boston", "Phone": "2222222222"}}"}
Wenn Sie keinen der Quelldatentypen erzwingen, wird das eingebettete ContactDetails-Dokument alsZeichenfolge migriert.
{ "_id": "1", "FirstName": "John", "LastName": "Doe", "ContactDetails": "{\"Home\": {\"Address\": \"Boston\",\"Phone\": \"1111111\"},\"Work\": { \"Address\": \"Boston\", \"Phone\": \"2222222222\"}}"}
Sie können jedoch eine Transformationsregel hinzufügen, um ContactDetails zu einem JSON-Objektumzuwandeln. Angenommen, der ursprüngliche Name der Quellspalte ist ContactDetails. Nehmen wirzudem an, dass die umbenannte Quellspalte json_ContactDetails sein soll. AWS DMS repliziert dasContactDetails-Feld wie folgt als verschachteltes JSON-Dokument.
{ "_id": "1", "FirstName": "John", "LastName": "Doe", "ContactDetails": { "Home": { "Address": "Boston", "Phone": "1111111111" }, "Work": { "Address": "Boston", "Phone": "2222222222" } }}
Verwenden eines JSON-Arrays (array_-Präfix)
Um einen Datentyp zu erzwingen, können Sie einem Spaltennamen das Präfix array_ (d. h.array_columnName) entweder manuell oder mittels einer Transformation voranstellen. In diesem Fallbetrachtet AWS DMS die Spalte als JSON-Array und erstellt sie als solches im Zieldokument.
API-Version API Version 2016-01-01313
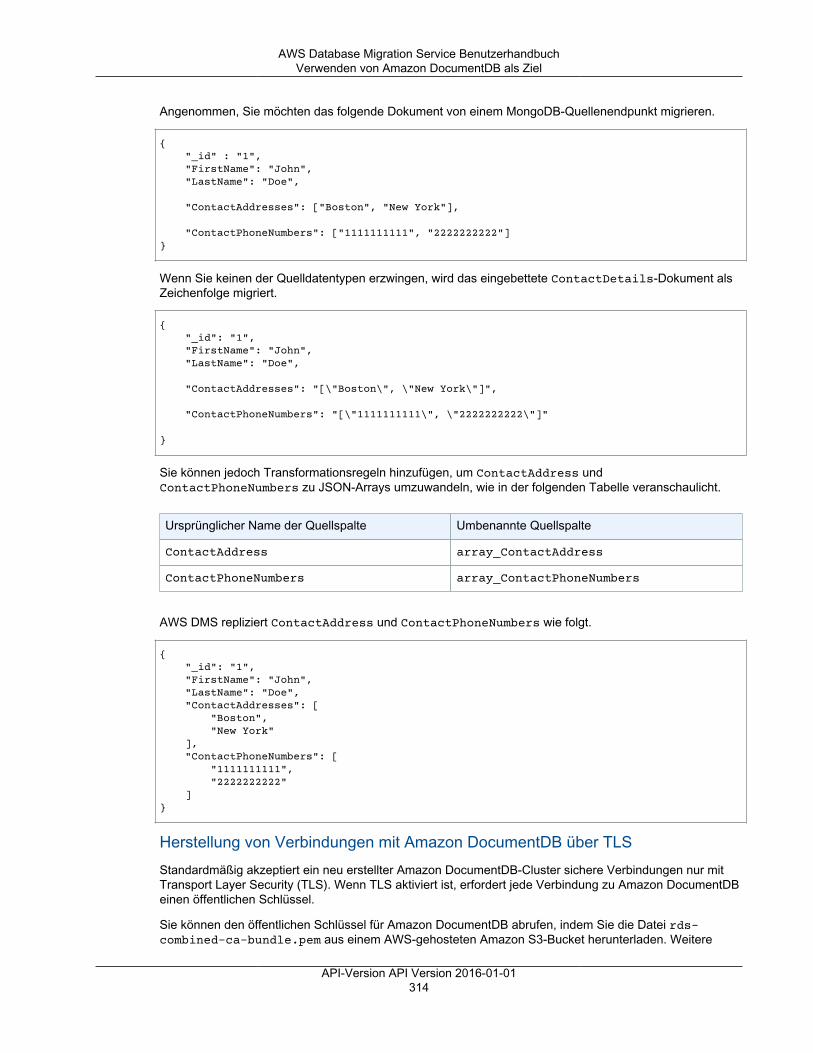
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
Angenommen, Sie möchten das folgende Dokument von einem MongoDB-Quellenendpunkt migrieren.
{ "_id" : "1", "FirstName": "John", "LastName": "Doe",
"ContactAddresses": ["Boston", "New York"], "ContactPhoneNumbers": ["1111111111", "2222222222"]}
Wenn Sie keinen der Quelldatentypen erzwingen, wird das eingebettete ContactDetails-Dokument alsZeichenfolge migriert.
{ "_id": "1", "FirstName": "John", "LastName": "Doe",
"ContactAddresses": "[\"Boston\", \"New York\"]", "ContactPhoneNumbers": "[\"1111111111\", \"2222222222\"]"
}
Sie können jedoch Transformationsregeln hinzufügen, um ContactAddress undContactPhoneNumbers zu JSON-Arrays umzuwandeln, wie in der folgenden Tabelle veranschaulicht.
Ursprünglicher Name der Quellspalte Umbenannte Quellspalte
ContactAddress array_ContactAddress
ContactPhoneNumbers array_ContactPhoneNumbers
AWS DMS repliziert ContactAddress und ContactPhoneNumbers wie folgt.
{ "_id": "1", "FirstName": "John", "LastName": "Doe", "ContactAddresses": [ "Boston", "New York" ], "ContactPhoneNumbers": [ "1111111111", "2222222222" ]}
Herstellung von Verbindungen mit Amazon DocumentDB über TLSStandardmäßig akzeptiert ein neu erstellter Amazon DocumentDB-Cluster sichere Verbindungen nur mitTransport Layer Security (TLS). Wenn TLS aktiviert ist, erfordert jede Verbindung zu Amazon DocumentDBeinen öffentlichen Schlüssel.
Sie können den öffentlichen Schlüssel für Amazon DocumentDB abrufen, indem Sie die Datei rds-combined-ca-bundle.pem aus einem AWS-gehosteten Amazon S3-Bucket herunterladen. Weitere
API-Version API Version 2016-01-01314

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
Informationen zum Herunterladen dieser Datei finden Sie unter Verschlüsseln von Verbindungen mit TLSim Amazon DocumentDB-Entwicklerhandbuch.
Nachdem Sie diese PEM-Datei heruntergeladen haben, können Sie den darin enthaltenen öffentlichenSchlüssel wie im Folgenden beschrieben in AWS DMS importieren.
AWS Management Console
So importieren Sie die Datei mit dem öffentlichen Schlüssel (.pem)
1. Öffnen Sie die AWS DMS-Konsole unter https://console.aws.amazon.com/dms.2. Wählen Sie im Navigationsbereich Certificates aus.3. Wählen Sie Import certificate (Zertifikat importieren) aus und gehen Sie folgendermaßen vor:
• Geben Sie für Certificate Identifier (Zertifikat-ID) einen eindeutigen Namen für das Zertifikat ein, z. B.docdb-cert.
• Für Import file (Datei importieren) navigieren Sie zum Speicherort der .pem-Datei.
Wenn Sie die gewünschten Einstellungen vorgenommen haben, wählen Sie Add new CA certificate(Neues CA-Zertifikat hinzufügen) aus.
AWS CLI
Verwenden Sie den Befehl aws dms import-certificate, wie im folgenden Beispiel gezeigt.
aws dms import-certificate \ --certificate-identifier docdb-cert \ --certificate-pem file://./rds-combined-ca-bundle.pem
Wenn Sie einen AWS DMS-Zielendpunkt erstellen, stellen Sie die Zertifikat-ID bereit (z. B. docdb-cert).Legen Sie außerdem den SSL-Modus-Parameter auf verify-full fest.
Fortlaufende Replikation mit Amazon DocumentDB als ZielWenn die fortlaufende Replikation aktiviert ist, stellt AWS DMS sicher, dass Dokumente in AmazonDocumentDB mit der Quelle synchron bleiben. Wenn ein Quelldatensatz erstellt oder aktualisiert wird, mussAWS DMS zunächst bestimmen, welcher Amazon DocumentDB-Datensatz betroffen ist, indem wie folgtvorgegangen wird:
• Wenn der Quelldatensatz über eine Spalte mit dem Namen _id verfügt, bestimmt der Wert dieser Spalteden entsprechenden _id in der Amazon DocumentDB-Sammlung.
• Wenn keine _id-Spalte vorhanden ist, aber die Quelldaten über einen Primärschlüssel oder eineneindeutigen Index verfügen, verwendet AWS DMS diesen Schlüssel oder Indexwert als _id für dieAmazon DocumentDB-Sammlung.
• Wenn der Quelldatensatz keine _id-Spalte, keinen Primärschlüssel oder keinen eindeutigen Index hat,dann ordnet AWS DMS alle Quellspalten den entsprechenden Feldern in der Amazon DocumentDB-Sammlung zu.
Wenn ein neuer Quelldatensatz erstellt wird, schreibt AWS DMS ein entsprechendes Dokument inAmazon DocumentDB. Wenn ein vorhandener Quelldatensatz aktualisiert wird, aktualisiert AWS DMS dieentsprechenden Felder im Zieldokument in Amazon DocumentDB. Alle Felder, die zwar im Zieldokument,aber nicht im Quelldatensatz vorhanden sind, bleiben unberührt.
Wenn ein Quelldatensatz gelöscht wird, löscht AWS DMS das entsprechende Dokument aus AmazonDocumentDB.
API-Version API Version 2016-01-01315
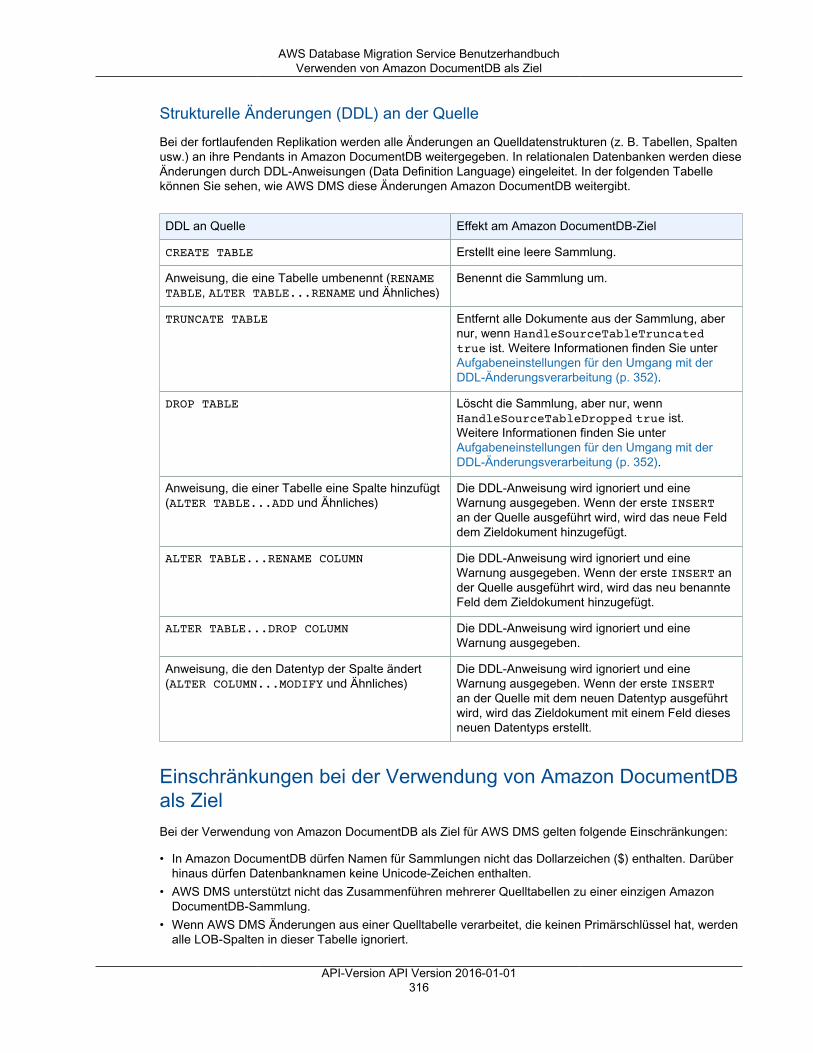
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
Strukturelle Änderungen (DDL) an der QuelleBei der fortlaufenden Replikation werden alle Änderungen an Quelldatenstrukturen (z. B. Tabellen, Spaltenusw.) an ihre Pendants in Amazon DocumentDB weitergegeben. In relationalen Datenbanken werden dieseÄnderungen durch DDL-Anweisungen (Data Definition Language) eingeleitet. In der folgenden Tabellekönnen Sie sehen, wie AWS DMS diese Änderungen Amazon DocumentDB weitergibt.
DDL an Quelle Effekt am Amazon DocumentDB-Ziel
CREATE TABLE Erstellt eine leere Sammlung.
Anweisung, die eine Tabelle umbenennt (RENAMETABLE, ALTER TABLE...RENAME und Ähnliches)
Benennt die Sammlung um.
TRUNCATE TABLE Entfernt alle Dokumente aus der Sammlung, abernur, wenn HandleSourceTableTruncatedtrue ist. Weitere Informationen finden Sie unterAufgabeneinstellungen für den Umgang mit derDDL-Änderungsverarbeitung (p. 352).
DROP TABLE Löscht die Sammlung, aber nur, wennHandleSourceTableDropped true ist.Weitere Informationen finden Sie unterAufgabeneinstellungen für den Umgang mit derDDL-Änderungsverarbeitung (p. 352).
Anweisung, die einer Tabelle eine Spalte hinzufügt(ALTER TABLE...ADD und Ähnliches)
Die DDL-Anweisung wird ignoriert und eineWarnung ausgegeben. Wenn der erste INSERTan der Quelle ausgeführt wird, wird das neue Felddem Zieldokument hinzugefügt.
ALTER TABLE...RENAME COLUMN Die DDL-Anweisung wird ignoriert und eineWarnung ausgegeben. Wenn der erste INSERT ander Quelle ausgeführt wird, wird das neu benannteFeld dem Zieldokument hinzugefügt.
ALTER TABLE...DROP COLUMN Die DDL-Anweisung wird ignoriert und eineWarnung ausgegeben.
Anweisung, die den Datentyp der Spalte ändert(ALTER COLUMN...MODIFY und Ähnliches)
Die DDL-Anweisung wird ignoriert und eineWarnung ausgegeben. Wenn der erste INSERTan der Quelle mit dem neuen Datentyp ausgeführtwird, wird das Zieldokument mit einem Feld diesesneuen Datentyps erstellt.
Einschränkungen bei der Verwendung von Amazon DocumentDBals ZielBei der Verwendung von Amazon DocumentDB als Ziel für AWS DMS gelten folgende Einschränkungen:
• In Amazon DocumentDB dürfen Namen für Sammlungen nicht das Dollarzeichen ($) enthalten. Darüberhinaus dürfen Datenbanknamen keine Unicode-Zeichen enthalten.
• AWS DMS unterstützt nicht das Zusammenführen mehrerer Quelltabellen zu einer einzigen AmazonDocumentDB-Sammlung.
• Wenn AWS DMS Änderungen aus einer Quelltabelle verarbeitet, die keinen Primärschlüssel hat, werdenalle LOB-Spalten in dieser Tabelle ignoriert.
API-Version API Version 2016-01-01316
AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
• Wenn die Option Change table (Änderungstabelle) aktiviert ist und AWS DMS auf eine Quellspalte mitdem Namen "_id" trifft, dann erscheint diese Spalte als "__id" (zwei Unterstriche) in der Änderungstabelle.
• Wenn Sie Oracle als Quellendpunkt wählen, muss für die Oracle-Quelle die vollständige ergänzendeProtokollierung aktiviert sein. Andernfalls, wenn es Spalten an der Quelle gibt, die nicht geändert wurden,werden die Daten als Nullwerte in Amazon DocumentDB geladen.
Zieldatentypen für Amazon DocumentDBIn der folgenden Tabelle finden Sie die Zieldatentypen Amazon DocumentDB, die bei Verwendung vonAWS DMS unterstützt werden, sowie deren Standardzuweisung von AWS DMS-Datentypen. WeitereInformationen zu AWS DMS-Datentypen finden Sie unter Datentypen für AWS Database MigrationService (p. 499).
AWS DMS-Datentyp Amazon DocumentDB-Datentyp
BOOLEAN Boolesch
BYTES Binäre Daten
DATUM Datum
TIME String (UTF8)
DATETIME Datum
INT1 32-Bit-Ganzzahl
INT2 32-Bit-Ganzzahl
INT4 32-Bit-Ganzzahl
INT8 64-Bit-Ganzzahl
NUMERIC String (UTF8)
REAL4 Double
REAL8 Double
STRING Wenn die Daten als JSON erkannt werden, migriert AWS DMS sie alsDokument nach Amazon DocumentDB. Andernfalls werden die Datendem String (UTF8) zugewiesen.
UINT1 32-Bit-Ganzzahl
UINT2 32-Bit-Ganzzahl
UINT4 64-Bit-Ganzzahl
UINT8 String (UTF8)
WSTRING Wenn die Daten als JSON erkannt werden, migriert AWS DMS sie alsDokument nach Amazon DocumentDB. Andernfalls werden die Datendem String (UTF8) zugewiesen.
BLOB Binary
API-Version API Version 2016-01-01317

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
AWS DMS-Datentyp Amazon DocumentDB-Datentyp
CLOB Wenn die Daten als JSON erkannt werden, migriert AWS DMS sie alsDokument nach Amazon DocumentDB. Andernfalls werden die Datendem String (UTF8) zugewiesen.
NCLOB Wenn die Daten als JSON erkannt werden, migriert AWS DMS sie alsDokument nach Amazon DocumentDB. Andernfalls werden die Datendem String (UTF8) zugewiesen.
Anleitung: Migration von MongoDB nach Amazon DocumentDBVerwenden Sie die folgende Anleitung, die Sie durch den Prozess der Migration von MongoDB nachAmazon DocumentDB (mit MongoDB-Kompatibilität) leiten wird. In dieser schrittweisen Anleitung gehenSie wie folgt vor:
• Installieren Sie MongoDB auf einer Amazon EC2-Instance.• Füllen Sie MongoDB mit Beispieldaten.• Erstellen Sie eine AWS DMS Replikations-Instance, einen Quellendpunkt (für MongoDB) und einen
Zielendpunkt (für Amazon DocumentDB).• Führen Sie eine AWS DMS-Aufgabe zur Migration der Daten vom Quellendpunkt zum Zielendpunkt aus.
Important
Bevor Sie beginnen, stellen Sie sicher, dass Sie einen Amazon DocumentDB-Cluster in IhrerStandard-VPC (Virtual Private Cloud) starten. Weitere Informationen finden Sie unter ErsteSchritte im Amazon DocumentDB-Entwicklerhandbuch.
Themen• Schritt 1: Starten einer Amazon EC2-Instance (p. 318)• Schritt 2: Installieren und Konfigurieren der MongoDB Community Edition (p. 319)• Schritt 3: Erstellen einer AWS DMS-Replikations-Instance (p. 321)• Schritt 4: Erstellen von Quell- und Zielendpunkten (p. 321)• Schritt 5: Erstellen und Ausführen einer Migrationsaufgabe (p. 324)
Schritt 1: Starten einer Amazon EC2-InstanceBei dieser schrittweisen Anleitung starten Sie eine Amazon EC2-Instance in Ihrer Standard-VPC.
Starten Sie eine Amazon EC2-Instance wie folgt:
1. Öffnen Sie die Amazon EC2-Konsole unter https://console.aws.amazon.com/ec2/.2. Wählen Sie Launch Instance (Instance starten) aus und gehen Sie folgendermaßen vor:
a. Auf der Seite Choose an Amazon Machine Image (AMI) (Amazon-Systemabbild (AMI) wählen),ganz oben in der Liste der AMIs, gehen Sie zu Amazon Linux AMI und wählen Sie Select(Auswählen) aus.
b. Auf der Seite Choose an Instance Type (Wählen eines Instance-Typs), oben in der Liste derInstance-Typen, wählen Sie t2.micro aus. Wählen Sie dann die Option Next: Configure InstanceDetails (Instance-Details konfigurieren) aus.
c. Wählen Sie auf der Seite Configure Instance Details (Instance-Details konfigurieren) IhreStandard-VPC unter Network (Netzwerk) aus. Wählen Sie dann Next: Add Storage (Weiter:Speicher hinzufügen) aus.
API-Version API Version 2016-01-01318

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
d. Überspringen Sie auf der Seite Add Storage (Speicher hinzufügen) diesen Schritt, indem Sie Next:Add Tags (Weiter: Tags hinzufügen) auswählen.
e. Überspringen Sie auf der Seite Add Tags (Tags hinzufügen) diesen Schritt, indem Sie Next:Configure Security Group (Weiter: Konfigurieren der Sicherheitsgruppe) auswählen.
f. Führen Sie auf der Seite Configure Security Group (Sicherheitsgruppe konfigurieren) diefolgenden Schritte aus:
1. Wählen Sie Select an existing security group aus.2. Wählen Sie in der Liste der Sicherheitsgruppen default aus. Dadurch wird die
Standardsicherheitsgruppe für Ihre VPC ausgewählt. Standardmäßig akzeptiert dieSicherheitsgruppe eingehende SSH-Verbindungen (Secure Shell) auf TPC-Port 22. Wenn diesbei Ihrem VPC nicht der Fall ist, fügen Sie diese Regel hinzu. Weitere Informationen finden Sieunter Was ist Amazon VPC? im Amazon VPC Benutzerhandbuch.
3. Wählen Sie Next: Review and Launch aus.g. Prüfen Sie die Informationen und wählen Sie Launch (Starten) aus.
3. Führen Sie im Fenster Select an existing key pair or create a new key pair einen der folgenden Schritteaus:
• Wenn Sie nicht über ein Amazon EC2-Schlüsselpaar verfügen, wählen Sie Create a new keypair (Neues Schlüsselpaar erstellen) aus und befolgen Sie die Anweisungen. Sie werden dazuaufgefordert, eine private Schlüsseldatei (.pem-Datei) herunterzuladen. Sie benötigen diese Dateispäter, wenn Sie sich bei Ihrer Amazon EC2-Instance anmelden.
• Wenn Sie bereits über ein Amazon EC2-Schlüsselpaar verfügen, wählen Sie für Select a key pair(Ein Schlüsselpaar auswählen) Ihr Schlüsselpaar aus der Liste aus. Beachten Sie, dass Sie bereitsüber die private Schlüsseldatei (.pem-Datei) verfügen müssen, um sich bei Ihrer Amazon EC2-Instance anmelden zu können.
4. Nachdem Sie Ihr Schlüsselpaar konfiguriert haben, wählen Sie Launch Instances (Instances starten)aus.
Wählen Sie im Navigationsbereich der Konsole zuerst EC2 Dashboard und anschließend diegestartete Instance aus. Suchen Sie im unteren Bereich der Registerkarte Description (Beschreibung)den Ort Public DNS (Öffentliches DNS) für Ihre Instance, beispielsweise: ec2-11-22-33-44.us-west-2.compute.amazonaws.com.
Es dauert einige Minuten, bis Ihre Amazon EC2-Instance verfügbar ist.5. Verwenden Sie, wie im folgenden Beispiel, den Befehl ssh, um sich bei der Amazon EC2-Instance
anzumelden.
chmod 400 my-keypair.pemssh -i my-keypair.pem ec2-user@public-dns-name
Geben Sie Ihre private Schlüsseldatei (.pem-Datei) und den öffentlichen DNS-Namen Ihrer EC2-Instance an. Die Anmelde-ID lautet ec2-user. Es ist kein Passwort erforderlich.
Weitere Informationen zum Herstellen einer Verbindung mit Ihrer EC2-Instance finden Sie unterHerstellen einer Verbindung mit Ihrer Linux-Instance per SSH im Amazon EC2-Benutzerhandbuch fürLinux-Instances.
Schritt 2: Installieren und Konfigurieren der MongoDB Community Edition
Führen Sie diese Schritte auf der Amazon EC2-Instance aus, die Sie in Schritt 1: Starten einer AmazonEC2-Instance (p. 318) gestartet haben.
API-Version API Version 2016-01-01319

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
So installieren und konfigurieren Sie MongoDB Community Edition auf Ihrer EC2-Instance
1. Gehen Sie zu Install MongoDB Community Edition on Amazon Linux (MongoDB Community Editionon Amazon Linux installieren) in der MongoDB-Dokumentation und befolgen Sie die dortigenAnweisungen.
2. Standardmäßig erlaubt der MongoDB-Server (mongod) nur Loopback-Verbindungen von der IP-Adresse 127.0.0.1 ("localhost"). Um Verbindungen an anderer Stelle in Ihrer Amazon VPC zuerlauben, gehen Sie wie folgt vor:
a. Bearbeiten Sie die Datei /etc/mongod.conf und suchen Sie nach den folgenden Zeilen.
# network interfacesnet: port: 27017 bindIp: 127.0.0.1 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
b. Ändern Sie die Zeile bindIp, sodass sie wie folgt aussieht.
bindIp: public-dns-name
c. Ersetzen Sie public-dns-name durch den tatsächlichen öffentlichen DNS-Namen für IhreInstance, zum Beispiel ec2-11-22-33-44.us-west-2.compute.amazonaws.com.
d. Speichern Sie die /etc/mongod.conf-Datei und starten Sie mongod neu.
sudo service mongod restart
3. Füllen Sie Ihre MongoDB-Instance mit Daten, indem Sie die folgenden Schritte ausführen:
a. Verwenden Sie den wget-Befehl, um eine JSON-Datei mit Beispieldaten herunterzuladen.
wget http://media.mongodb.org/zips.json
b. Verwenden Sie den mongoimport-Befehl, um die Daten in eine neue Datenbank zu importieren(zips-db).
mongoimport --host public-dns-name:27017 --db zips-db --file zips.json
c. Nachdem der Import abgeschlossen ist, verwenden Sie die mongo-Shell, um eine Verbindung zuMongoDB herzustellen und zu überprüfen, ob die Daten erfolgreich geladen wurden.
mongo --host public-dns-name:27017
d. Ersetzen Sie public-dns-name durch den tatsächlichen öffentlichen DNS-Namen für IhreInstance.
e. Geben Sie bei der mongo-Shell-Eingabeaufforderung die folgenden Befehle ein.
use zips-db db.zips.count()
db.zips.aggregate( [ { $group: { _id: { state: "$state", city: "$city" }, pop: { $sum: "$pop" } } }, { $group: { _id: "$_id.state", avgCityPop: { $avg: "$pop" } } }] )
API-Version API Version 2016-01-01320

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
Die Ausgabe sollte Folgendes anzeigen:
• Name der Datenbank (zips-db)• Anzahl der Dokumente in der zips-Sammlung (29353)• Die durchschnittliche Einwohnerzahl der Städte in jedem Staat
f. Beenden Sie die mongo-Shell und kehren Sie mit dem folgenden Befehl zurück zurEingabeaufforderung.
exit
Schritt 3: Erstellen einer AWS DMS-Replikations-InstanceUm die Replikation in AWS DMS durchzuführen, benötigen Sie eine Replikations-Instance.
So erstellen Sie eine AWS DMS-Replikations-Instance
1. Öffnen Sie die AWS DMS-Konsole unter https://console.aws.amazon.com/dms/.2. Wählen Sie im Navigationsbereich Replication instances aus.3. Wählen Sie Create replication instance (Replikations-Instance erstellen) aus und geben Sie die
folgenden Informationen ein:
• Geben Sie unter Name mongodb2docdb ein.• Geben Sie für Description (Beschreibung) den Text MongoDB to Amazon DocumentDBreplication instance ein.
• Für Instance class (Instance-Klasse) behalten Sie den Standardwert bei.• Für Engine version (Engine-Version) behalten Sie den Standardwert bei.• Wählen Sie bei VPC Ihre Standard-VPC aus.• Für Multi-AZ wählen Sie No (Nein) aus.• Für Publicly accessible (Öffentlich zugänglich) aktivieren Sie diese Option.
Wenn die Einstellungen Ihren Wünschen entsprechen, wählen Sie Create replication instance(Replikations-Instance erstellen) aus.
Note
Sie können Ihre Replikations-Instance verwenden, wenn sich der Status in available (verfügbar)ändert. Dies kann mehrere Minuten dauern.
Schritt 4: Erstellen von Quell- und ZielendpunktenDer Quellendpunkt ist der Endpunkt für Ihre MongoDB-Installation, die auf Ihrer Amazon EC2-Instanceausgeführt wird.
So erstellen Sie einen Quellendpunkt
1. Öffnen Sie die AWS DMS-Konsole unter https://console.aws.amazon.com/dms/.2. Klicken Sie im Navigationsbereich auf Endpoints.3. Wählen Sie Create endpoint (Endpunkt erstellen) und geben Sie die folgenden Informationen ein:
• Für Endpoint type (Endpunkttyp) wählen Sie Source (Quelle) aus.• Für Endpoint Identifier (Endpunkt-ID) geben Sie einen Namen ein, der leicht zu merken ist, zum
Beispiel mongodb-source.
API-Version API Version 2016-01-01321

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
• Für Source engine (Quell-Engine) wählen Sie mongodb aus.• Für Server name (Servername) geben Sie den öffentlichen DNS-Namen Ihrer Amazon EC2-Instance
ein, zum Beispiel ec2-11-22-33-44.us-west-2.compute.amazonaws.com.• Geben Sie im Feld Port den Wert 27017 ein.• Für SSL mode (SSL-Modus) wählen Sie none (keine) aus.• Für Authentication mode (Authentifizierungsmodus) wählen Sie none (keine) aus.• Für Database name (Datenbankname) geben Sie zips-db ein.• Für Authentication mechanism (Authentifizierungsmechanismus) wählen Sie default (Standard) aus.• Für Metadata mode (Metadatenmodus) wählen Sie document (Dokument) aus.
Wenn Sie alle gewünschten Einstellungen vorgenommen haben, wählen Sie Create endpoint(Endpunkt erstellen) aus.
Als Nächstes erstellen Sie einen Zielendpunkt. Dieser Endpunkt ist für Ihren Amazon DocumentDB-Cluster,der bereits ausgeführt werden sollte. Weitere Informationen zum Starten Ihres Amazon DocumentDB-Clusters finden Sie unter Erste Schritte im Amazon DocumentDB-Entwicklerhandbuch.
Important
Bevor Sie fortfahren, gehen Sie wie folgt vor:
• Halten Sie den Hauptbenutzernamen und das Passwort für Ihren Amazon DocumentDB-Clusterbereit.
• Halten Sie den DNS-Namen und die Portnummer Ihres Amazon DocumentDB-Clusters bereit,damit sich AWS DMS mit ihm verbinden kann. Um diese Informationen zu ermitteln, verwendenSie den folgenden AWS CLI-Befehl. Ersetzen Sie dabei cluster-id durch den Namen IhresAmazon DocumentDB-Clusters.
aws docdb describe-db-clusters \ --db-cluster-identifier cluster-id \ --query "DBClusters[*].[Endpoint,Port]"
• Laden Sie ein Zertifikat-Bundle herunter, mit dem Amazon DocumentDB SSL-Verbindungenüberprüfen kann. Geben Sie dazu den folgenden Befehl ein. Hier vervollständigt aws-api-domain die Amazon S3-Domäne in Ihrer Region, die für den Zugriff auf den angegebenen S3-Bucket und die bereitgestellten rds-combined-ca-bundle.pem-Datei erforderlich ist.
wget https://s3.aws-api-domain/rds-downloads/rds-combined-ca-bundle.pem
So erstellen Sie einen Zielendpunkt
1. Klicken Sie im Navigationsbereich auf Endpoints.2. Wählen Sie Create endpoint (Endpunkt erstellen) und geben Sie die folgenden Informationen ein:
• Für Endpoint type (Endpunkttyp) wählen Sie Target (Ziel) aus.• Für Endpoint Identifier (Endpunkt-ID) geben Sie einen Namen ein, der leicht zu merken ist, zum
Beispiel docdb-target.• Für Target engine (Ziel-Engine) wählen Sie docdb aus.• Geben Sie für Server name (Servername) den DNS-Namen Ihres Amazon DocumentDB-Clusters
ein.• Geben Sie für Port die Portnummer Ihres Amazon DocumentDB-Clusters ein.
API-Version API Version 2016-01-01322

AWS Database Migration Service BenutzerhandbuchVerwenden von Amazon DocumentDB als Ziel
• Für SSL mode (SSL-Modus) wählen Sie verify-full aus.• Bei CA-Zertifikaten führen Sie einen der folgenden Schritte aus, um das SSL-Zertifikat Ihrem
Endpunkt anzufügen:• Falls verfügbar, wählen Sie das vorhandene rds-combined-ca-bundle-Zertifikat aus der Dropdown-
Liste unter Choose a certificate (Wählen Sie ein Zertifikat aus) aus.• Klicken Sie auf Add new CA certificate (Neues CA-Zertifikat hinzufügen). Geben Sie dann
für Certificate identifier (Zertifikats-ID) rds-combined-ca-bundle ein. Wählen Sie unterImport certificate file (Zertifikatsdatei importieren) die Option Choose file (Datei auswählen) undnavigieren Sie zu der rds-combined-ca-bundle.pem-Datei, die Sie zuvor heruntergeladenhaben. Wählen Sie die Datei aus und öffnen Sie sie. Wählen Sie Import certificate (Zertifikatimportieren) aus, klicken Sie dann auf rds-combined-ca-bundle aus der Dropdown-Liste unterChoose a certificate (Zertifikat auswählen).
• Geben Sie für User name (Benutzername) den Hauptbenutzernamen Ihres Amazon DocumentDB-Clusters ein.
• Geben Sie für Password (Passwort) das Hauptpasswort Ihres Amazon DocumentDB-Clusters ein.• Für Database name (Datenbankname) geben Sie zips-db ein.
Wenn Sie alle gewünschten Einstellungen vorgenommen haben, wählen Sie Create endpoint(Endpunkt erstellen) aus.
Nachdem Sie nun den Quell- und den Ziel-Endpunkt erstellt haben, testen Sie diese, um sicherzustellen,dass sie ordnungsgemäß funktionieren. Um darüber hinaus sicherzustellen, dass AWS DMS an jedemEndpunkt auf die Datenbankobjekte zugreifen kann, aktualisieren Sie die Schemata der Endpunkte.
So testen Sie einen Endpunkt
1. Klicken Sie im Navigationsbereich auf Endpoints.2. Wählen Sie den Quellendpunkt (mongodb-source) und wählen Sie dann Test connection
(Verbindung testen).3. Wählen Sie Ihre Replikations-Instance (mongodb2docdb) und dann Run test (Test ausführen). Es
dauert einige Minuten, bis der Test abgeschlossen ist und sich der Status in successful (erfolgreich)ändert.
Wenn sich der Status stattdessen in failed (fehlgeschlagen) ändert, überprüfen Sie die Fehlermeldung.Korrigieren Sie eventuell vorhandene Fehler und testen Sie den Endpunkt erneut.
Note
Wiederholen Sie dieses Verfahren für den Zielendpunkt (docdb-target).
So aktualisieren Sie Schemata
1. Klicken Sie im Navigationsbereich auf Endpoints.2. Wählen Sie den Quellendpunkt (mongodb-source) und wählen Sie dann Refresh schemas
(Schemata aktualisieren).3. Wählen Sie Ihre Replikations-Instance (mongodb2docdb) und wählen Sie dann Refresh schemas
(Schemata aktualisieren).
Note
Wiederholen Sie dieses Verfahren für den Zielendpunkt (docdb-target).
API-Version API Version 2016-01-01323

AWS Database Migration Service BenutzerhandbuchErstellen der Quell- und Zielendpunkte
Schritt 5: Erstellen und Ausführen einer MigrationsaufgabeSie sind nun bereit zum Starten einer AWS DMS-Migrationsaufgabe, um die zips-Daten von MongoDBnach Amazon DocumentDB zu migrieren.
1. Öffnen Sie die AWS DMS-Konsole unter https://console.aws.amazon.com/dms/.2. Wählen Sie im Navigationsbereich Tasks aus.3. Wählen Sie Create task (Aufgabe erstellen) und geben Sie die folgenden Informationen ein:
• Für Task name (Aufgabenname) geben Sie einen Namen ein, der leicht zu merken ist, zum Beispielmy-dms-task.
• Für Replication instance (Replikations-Instance) wählen Sie die Replikations-Instance aus, die Sie inSchritt 3: Erstellen einer AWS DMS-Replikations-Instance (p. 321) erstellt haben.
• Wählen Sie für Source endpoint (Quellendpunkt) den Quellendpunkt aus, den Sie in Schritt 4:Erstellen von Quell- und Zielendpunkten (p. 321) erstellt haben.
• Wählen Sie für Target endpoint (Zielendpunkt) den Zielendpunkt aus, den Sie in Schritt 4: Erstellenvon Quell- und Zielendpunkten (p. 321) erstellt haben.
• Wählen Sie für Migration type (Migrationstyp) die Option Migrate existing data (Vorhandene Datenmigrieren) aus.
• Für Start task on create (Aufgabe nach Erstellung beginnen) aktivieren Sie diese Option.
Behalten Sie im Abschnitt Task Settings (Aufgabeneinstellungen) alle Standardwerte für die Optionenbei.
Wählen Sie im Abschnitt Table mappings (Tabellenzuweisungen) die Registerkarte Guided (Angeleitet)aus. Geben Sie anschließend die folgenden Informationen ein:
• Für Schema name is (Schemaname ist) wählen Sie Enter a schema (Ein Schema eingeben) aus.• Behalten Sie für Schema name is like (Schemaname ist wie) die Standardeinstellung (%) bei.• Behalten Sie für Table name is like (Tabellenname ist wie) die Standardeinstellung (%) bei.
Wählen Sie Add selection rule (Auswahlregel hinzufügen) um zu bestätigen, dass die Informationenrichtig sind.
Wenn Sie die gewünschten Einstellungen vorgenommen haben, wählen Sie Create task (Aufgabeerstellen) aus.
AWS DMS beginnt nun mit der Migration von Daten aus MongoDB nach Amazon DocumentDB. DerAufgabenstatus ändert sich von Starting (Wird gestartet) in Running (Wird ausgeführt). Sie können denFortschritt überwachen, indem Sie Tasks (Aufgaben) in der AWS DMS-Konsole auswählen. Nach einigenMinuten ändert sich der Status in Load complete (Laden abgeschlossen).
Note
Nachdem die Migration abgeschlossen ist, können Sie die Mongo-Shell verwenden, um sich mitIhrem Amazon DocumentDB-Cluster zu verbinden und die zips-Daten anzuzeigen. WeitereInformationen finden Sie unter Zugriff auf Ihren Amazon DocumentDB-Cluster mithilfe der mongo-Shell im Amazon DocumentDB-Entwicklerhandbuch.
Erstellen der Quell- und ZielendpunkteSie können Quell- und Zielendpunkte beim Anlegen Ihrer Replikations-Instance oder nach dem AnlegenIhrer Replikations-Instance erstellen. Die Quell- und Zieldatenspeicher können sich auf einer Amazon EC2-
API-Version API Version 2016-01-01324
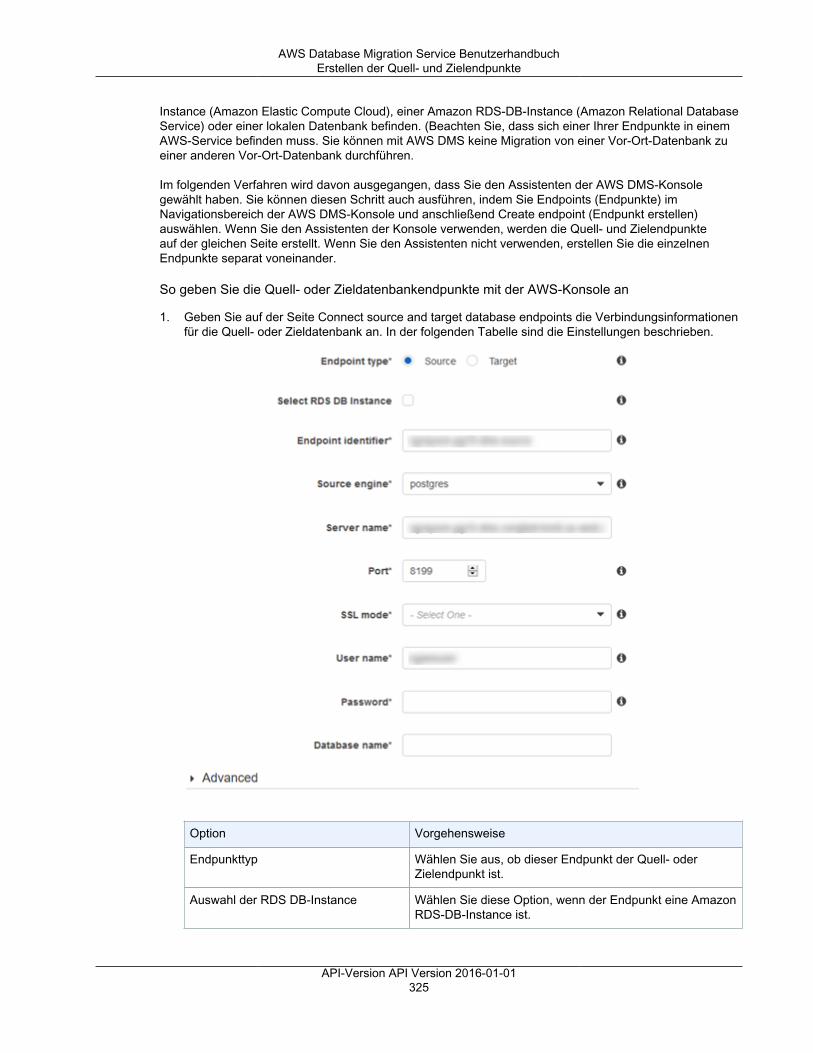
AWS Database Migration Service BenutzerhandbuchErstellen der Quell- und Zielendpunkte
Instance (Amazon Elastic Compute Cloud), einer Amazon RDS-DB-Instance (Amazon Relational DatabaseService) oder einer lokalen Datenbank befinden. (Beachten Sie, dass sich einer Ihrer Endpunkte in einemAWS-Service befinden muss. Sie können mit AWS DMS keine Migration von einer Vor-Ort-Datenbank zueiner anderen Vor-Ort-Datenbank durchführen.
Im folgenden Verfahren wird davon ausgegangen, dass Sie den Assistenten der AWS DMS-Konsolegewählt haben. Sie können diesen Schritt auch ausführen, indem Sie Endpoints (Endpunkte) imNavigationsbereich der AWS DMS-Konsole und anschließend Create endpoint (Endpunkt erstellen)auswählen. Wenn Sie den Assistenten der Konsole verwenden, werden die Quell- und Zielendpunkteauf der gleichen Seite erstellt. Wenn Sie den Assistenten nicht verwenden, erstellen Sie die einzelnenEndpunkte separat voneinander.
So geben Sie die Quell- oder Zieldatenbankendpunkte mit der AWS-Konsole an
1. Geben Sie auf der Seite Connect source and target database endpoints die Verbindungsinformationenfür die Quell- oder Zieldatenbank an. In der folgenden Tabelle sind die Einstellungen beschrieben.
Option Vorgehensweise
Endpunkttyp Wählen Sie aus, ob dieser Endpunkt der Quell- oderZielendpunkt ist.
Auswahl der RDS DB-Instance Wählen Sie diese Option, wenn der Endpunkt eine AmazonRDS-DB-Instance ist.
API-Version API Version 2016-01-01325
AWS Database Migration Service BenutzerhandbuchErstellen der Quell- und Zielendpunkte
Option Vorgehensweise
Endpoint identifier Geben Sie den Namen des Endpunkts an. Sie könnenzum Namen den Endpunkttyp hinzufügen, z. B. oracle-source oder PostgreSQL-target. Der Name muss füralle Replikations-Instances eindeutig sein.
Source engine und Target engine Wählen Sie den Typ der Datenbank-Engine aus, die denEndpunkt darstellt.
Server name Geben Sie den Servernamen ein. Für eine lokaleDatenbank kann dies die IP-Adresse oder deröffentliche Hostname sein. Für eine AmazonRDS-DB-Instance kann dies der Endpunkt (auchals DNS-Name bezeichnet) für die DB-Instancesein, z. B. mysqlsrvinst.abcd12345678.us-west-2.rds.amazonaws.com.
Port Geben Sie den Port an, der von der Datenbank verwendetwird.
SSL mode Wählen Sie einen SSL-Modus aus, wenn Sie dieVerbindungsverschlüsselung für diesen Endpunktaktivieren möchten. Je nach ausgewähltemModus müssen Sie möglicherweise Zertifikat- undServerzertifikatinformationen angeben.
Benutzername Geben Sie den Benutzernamen mit den für dieDatenmigration erforderlichen Berechtigungen ein. WeitereInformationen zu den erforderlichen Berechtigungenfinden Sie im Abschnitt zur Sicherheit für die Quell- oderZieldatenbank-Engine in diesem Benutzerhandbuch.
Passwort Geben Sie das Passwort für das Konto mit denerforderlichen Berechtigungen ein.
Datenbankname Der Name der Datenbank, die Sie als Endpunkt verwendenmöchten.
2. Wählen Sie die Registerkarte Advanced (siehe unten), um ggf. Werte für die Verbindungszeichenfolgeund den Verschlüsselungsschlüssel einzugeben. Sie können die Endpunktverbindung testen, indemSie Run test wählen.
API-Version API Version 2016-01-01326
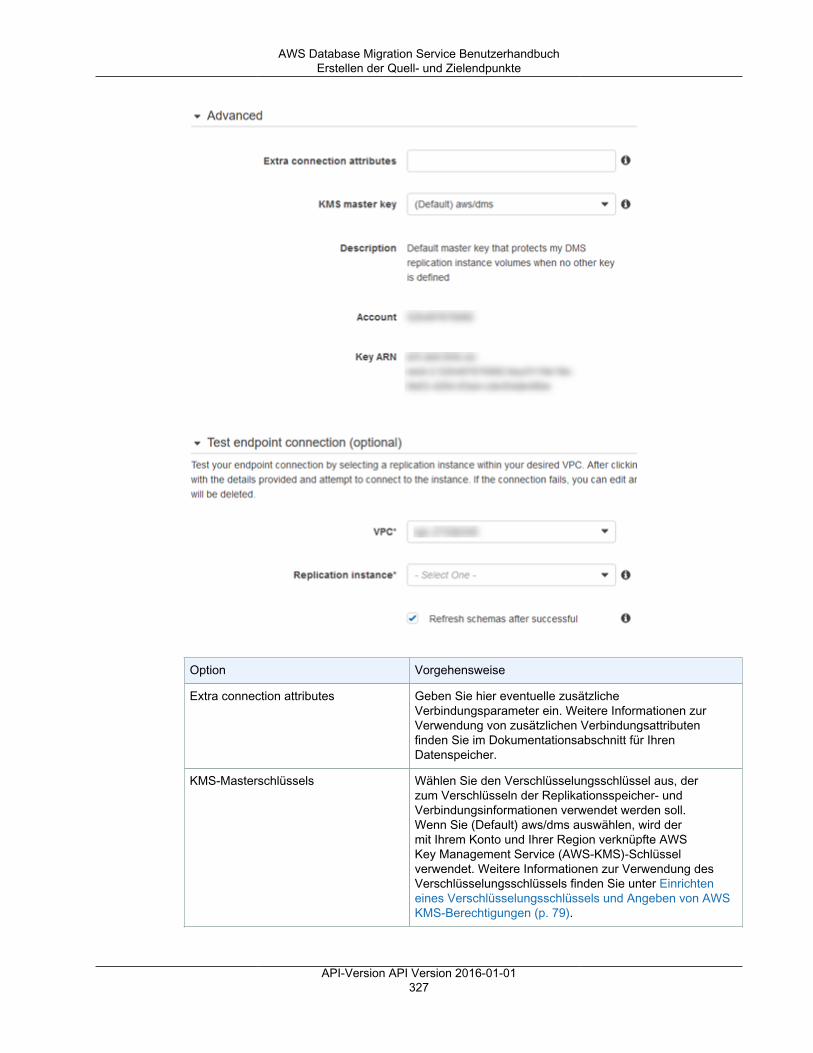
AWS Database Migration Service BenutzerhandbuchErstellen der Quell- und Zielendpunkte
Option Vorgehensweise
Extra connection attributes Geben Sie hier eventuelle zusätzlicheVerbindungsparameter ein. Weitere Informationen zurVerwendung von zusätzlichen Verbindungsattributenfinden Sie im Dokumentationsabschnitt für IhrenDatenspeicher.
KMS-Masterschlüssels Wählen Sie den Verschlüsselungsschlüssel aus, derzum Verschlüsseln der Replikationsspeicher- undVerbindungsinformationen verwendet werden soll.Wenn Sie (Default) aws/dms auswählen, wird dermit Ihrem Konto und Ihrer Region verknüpfte AWSKey Management Service (AWS-KMS)-Schlüsselverwendet. Weitere Informationen zur Verwendung desVerschlüsselungsschlüssels finden Sie unter Einrichteneines Verschlüsselungsschlüssels und Angeben von AWSKMS-Berechtigungen (p. 79).
API-Version API Version 2016-01-01327

AWS Database Migration Service BenutzerhandbuchErstellen der Quell- und Zielendpunkte
Option Vorgehensweise
Testen der Endpunktverbindung(optional)
Hinzufügen der VPC und des Replikations-Instance-Namens. Wählen Sie zum Testen der Verbindung Run test(Test ausführen) aus.
API-Version API Version 2016-01-01328

AWS Database Migration Service Benutzerhandbuch
Arbeiten mit AWS DMS-AufgabenÜber eine AWS Database Migration Service(AWS DMS)-Aufgabe wird die gesamte Arbeit abgewickelt.Sie geben an, welche Tabellen (oder Ansichten) und Schemas für die Migration verwendet werden sollen.Zudem legen Sie eine spezielle Verarbeitung, z. B. die Protokollierung von Anforderungen, die Steuerungvon Tabellendaten und die Fehlerbehandlung, fest.
Bei der Erstellung einer Migrationsaufgabe müssen Sie mehrere Dinge beachten:
• Bevor Sie eine Aufgabe erstellen können, müssen Sie einen Quellendpunkt, einen Zielendpunkt und eineReplikations-Instance erstellen.
• Sie können viele Aufgabeneinstellungen festlegen, um Ihre Migrationsaufgabe anzupassen. DieseEinstellungen können Sie über die AWS Management Console, die AWS Command Line Interface(AWS CLI) oder die AWS DMS-API vornehmen. Dazu gehören Einstellungen, die die Behandlung vonMigrationsfehlern, die Fehlerprotokollierung und Informationen zu Steuerungstabellen betreffen.
• Nachdem Sie eine Aufgabe erstellt haben, können Sie sie sofort ausführen. Die Zieltabellen mit denerforderlichen Metadatendefinitionen werden automatisch erstellt und geladen, und Sie können dielaufende Replikation angeben.
• Standardmäßig startet AWS DMS Ihre Aufgabe, sobald Sie sie erstellen. In manchen Situationenmöchten Sie den Beginn einer Aufgabe jedoch möglicherweise verschieben. Wenn Sie zum Beispiel dieAWS CLI verwenden, gibt es ggf. einen Prozess, der eine Aufgabe erstellt, und einen anderen Prozess,der die Aufgabe basierend auf einem auslösenden Ereignis startet. Bei Bedarf können Sie den BeginnIhrer Aufgabe verschieben.
• Sie können Aufgaben über die AWS DMS-Konsole, die AWS CLI oder die AWS DMS-API überwachen,stoppen oder neu starten.
Die folgenden Aktionen können Sie bei der Durchführung einer AWS DMS-Aufgabe ausführen.
Aufgabe Relevante Dokumentation
Erstellen einesAufgabenbewertungsberichts
Sie können einenAufgabenbewertungsbericht erstellen,der alle nicht unterstützten Datentypenaufzeigt, die während der Migration zuProblemen führen könnten. Sie könnendiesen Bericht vor der Ausführung IhrerAufgabe ausführen, um potenzielleProbleme aufzuzeigen.
Erstellen eines Aufgabenbewertungsberichts (p. 331)
Erstellen einer Aufgabe
Wenn Sie eine Aufgabe erstellen,geben Sie die Quelle, das Ziel und dieReplikations-Instance zusammen mitden Migrationseinstellungen an.
Erstellen einer Aufgabe (p. 333)
Erstellen einer laufendenReplikationsaufgabe
Erstellen von Aufgaben für die laufende Replikation mit AWSDMS (p. 363)
API-Version API Version 2016-01-01329
AWS Database Migration Service Benutzerhandbuch
Aufgabe Relevante DokumentationSie können eine Aufgabe einrichten, umdie fortlaufende Replikation zwischenQuelle und Ziel bereitzustellen.
Anwenden der Aufgabeneinstellungen
Jede Aufgabe hat Einstellungen, dieentsprechend den AnforderungenIhrer Datenbankmigration konfiguriertwerden können. Sie erstellen dieseEinstellungen in einer JSON-Datei oderSie können einige Einstellungen mithilfeder AWS DMS-Konsole angeben.
Angeben von Aufgabeneinstellungen für AWS DatabaseMigration Service-Aufgaben (p. 340)
Datenvalidierung
Bei der Datenvalidierung handelt essich um eine Aufgabeneinstellung,bei der AWS DMS die Daten in IhremZieldatenspeicher mit den Daten inIhrem Quelldatenspeicher vergleicht.
Validieren von AWS DMS-Aufgaben (p. 434)
Ändern einer Aufgabe
Wenn eine Aufgabe angehalten wird,können Sie die Einstellungen für dieAufgabe ändern.
Ändern einer Aufgabe (p. 369)
Erneutes Laden von Tabellen währendeiner Aufgabe
Sie können eine Tabelle während einerAufgabe neu laden, wenn während einerAufgabe ein Fehler auftritt.
Erneutes Laden von Tabellen während einerAufgabe (p. 370)
Using Table Mapping (Verwenden derTabellenzuweisung)
Die Zuweisung von Tabellen verwendetmehrere Arten von Regeln fürdie Angabe der Datenquelle, desQuellschemas, der Daten und allerTransformationen, die während derAufgabe auftreten sollten.
AuswahlregelnAuswahlregeln und Aktionen (p. 378)
TransformationsregelnTransformationsregeln und Aktionen (p. 382)
Anwenden von Filtern
Sie können Quellfilter verwenden,um Anzahl und Art der Datensätze zubeschränken, die von Ihrer Quelle auf IhrZiel übertragen werden. So können Siebeispielsweise festlegen, dass nur dieam Hauptsitz ansässigen Angestelltenin die Zieldatenbank übertragen werden.Sie wenden Filter auf eine Datenspaltean.
Verwenden von Quellfiltern (p. 416)
API-Version API Version 2016-01-01330

AWS Database Migration Service BenutzerhandbuchErstellen eines Aufgabenbewertungsberichts
Aufgabe Relevante Dokumentation
Überwachen einer Aufgabe
Es gibt mehrere Möglichkeiten, umInformationen über die Durchführungeiner Aufgabe und die von der Aufgabeverwendeten Tabellen zu erhalten.
Überwachen von AWS DMS-Aufgaben (p. 421)
Verwalten von Aufgabenprotokollen
Sie können Aufgabenprotokolle überdie AWS DMS-API oder die AWS CLIansehen und löschen.
Verwalten von AWS DMS-Aufgabenprotokollen (p. 429)
Themen• Erstellen eines Aufgabenbewertungsberichts (p. 331)• Erstellen einer Aufgabe (p. 333)• Erstellen von Aufgaben für die laufende Replikation mit AWS DMS (p. 363)• Ändern einer Aufgabe (p. 369)• Erneutes Laden von Tabellen während einer Aufgabe (p. 370)• Verwenden der Tabellenzuweisung zum Angeben von Aufgabeneinstellungen (p. 372)
Erstellen eines AufgabenbewertungsberichtsDie Aufgabenbewertungsfunktion identifiziert Datentypen, die möglicherweise nicht korrekt migriert werden.Während einer Aufgabenbewertung liest AWS DMS das Quelldatenbankschema und erstellt eine Liste derDatentypen. Anschließend vergleicht es diese Liste mit einer vordefinierten Liste der Datentypen, die vonAWS DMS unterstützt werden. AWS DMS erstellt einen Bericht, anhand dem Sie überprüfen können, obIhre Migrationsaufgabe über Datentypen verfügt, die nicht unterstützt werden.
Der Aufgabenbewertungsbericht enthält eine Zusammenfassung, die die nicht unterstützten Datentypensowie deren jeweilige Spaltenanzahl anzeigt. Er enthält für jeden nicht unterstützten Datentyp eine Liste derDatenstrukturen in JSON. Sie können den Bericht dazu verwenden, die Quelldatentypen zu ändern und dieChancen für eine erfolgreiche Migration zu verbessern.
Es gibt zwei Ebenen von nicht unterstützten Datentypen. Datentypen, die in dem Bericht als "nichtunterstützt" angezeigt werden, können nicht migriert werden. Datentypen, die in dem Bericht als "teilweiseunterstützt" angezeigt werden, können eventuell in einen anderen Datentyp konvertiert werden, migrierenaber möglicherweise auf unerwartete Art und Weise.
Nachfolgend finden Sie das Beispiel eines Aufgabenbewertungsberichts.
{ "summary":{ "task-name":"test15", "not-supported":{ "data-type": [ "sql-variant" ], "column-count":3 }, "partially-supported":{
API-Version API Version 2016-01-01331

AWS Database Migration Service BenutzerhandbuchErstellen eines Aufgabenbewertungsberichts
"data-type":[ "float8", "jsonb" ], "column-count":2 } }, "types":[ { "data-type":"float8", "support-level":"partially-supported", "schemas":[ { "schema-name":"schema1", "tables":[ { "table-name":"table1", "columns":[ "column1", "column2" ] }, { "table-name":"table2", "columns":[ "column3", "column4" ] } ] }, { "schema-name":"schema2", "tables":[ { "table-name":"table3", "columns":[ "column5", "column6" ] }, { "table-name":"table4", "columns":[ "column7", "column8" ] } ] } ] }, { "datatype":"int8", "support-level":"partially-supported", "schemas":[ { "schema-name":"schema1", "tables":[ { "table-name":"table1", "columns":[ "column9", "column10" ] },
API-Version API Version 2016-01-01332

AWS Database Migration Service BenutzerhandbuchErstellen einer Aufgabe
{ "table-name":"table2", "columns":[ "column11", "column12" ] } ] } ] } ]}
Den neuesten Aufgabenbewertungsbericht finden Sie auf der Registerkarte Assessment(Bewertung) auf der Seite Tasks (Aufgaben) in der AWS-Konsole. AWS DMS speichert frühereAufgabenbewertungsberichte in einem Amazon S3-Bucket. Der Amazon S3-Bucket-Name hat das folgendeFormat.
dms-<customerId>-<customerDNS>
Der Bericht wird im Bucket in einem Ordner mit dem Namen der Aufgabe gespeichert. Der Dateinamedes Berichts hat das Datum der Bewertung im Format JJJJ-MM-TT-hh-mm. Sie können frühereAufgabenbewertungsberichte in der Amazon S3-Konsole anzeigen und vergleichen.
AWS DMS erstellt außerdem eine AWS Identity and Access Management (IAM)-Rolle, um Zugriff auf denS3-Bucket zu gewähren, der Rollennamen lautet dms-access-for-tasks. Die Rolle verwendet die RichtlinieAmazonDMSRedshiftS3Role.
Sie können die Aufgabenbewertungsfunktion mit der AWS-Konsole, der AWS CLI oder der DMS-APIaktivieren:
• Wählen Sie auf der Konsole Task Assessment aus, wenn Sie eine Aufgabe erstellen oder ändernmöchten. Zum Anzeigen des Aufgabenbewertungsberichts in der Konsole wählen Sie die Aufgabe aufder Seite Tasks aus und klicken Sie anschließend im Detailbereich auf die Registerkarte Assessmentresults.
• Der CLI-Befehl zum Starten einer Aufgabenbewertung lautet start-replication-task-assessment und der Befehl, um den Aufgabenbewertungsbericht im JSON-Format zu erhalten, lautetdescribe-replication-task-assessment-results.
• Die AWS DMS-API verwendet die Aktion StartReplicationTaskAssessment, um eineAufgabenbewertung zu beginnen, und die Aktion DescribeReplicationTaskAssessment, um denAufgabenbewertungsbericht im JSON-Format zu erhalten.
Erstellen einer AufgabeUm eine AWS DMS-Migrationsaufgabe zu erstellen, müssen Sie verschiedene Schritte erledigen:
• Erstellen Sie einen Quellendpunkt, einen Zielendpunkt und eine Replikations-Instance, bevor Sie eineMigrationsaufgabe erstellen.
• Wählen Sie eine Migrationsmethode aus:• Migrieren von Daten in die Zieldatenbank – Dieser Prozess erstellt Dateien oder Tabellen in der
Zieldatenbank und definiert automatisch die Metadaten, die am Ziel erforderlich sind. Außerdem füllt erdie Tabellen mit Daten aus der Quelle aus. Für eine bessere Effizienz werden die Daten parallel aus
API-Version API Version 2016-01-01333

AWS Database Migration Service BenutzerhandbuchErstellen einer Aufgabe
den Tabellen geladen. Bei diesem Prozess handelt es sich in der AWS-Konsole um die Option Migrateexisting data und in der API um Full Load.
• Aufzeichnen von Änderungen während der Migration – Dieser Prozess erfasst Änderungen an derQuelldatenbank, die während der Migration der Daten von der Quelle bis zum Ziel auftreten. Wenndie Migration der ursprünglich angefragten Daten abgeschlossen ist, wendet der CDC (ChangeData Capture)-Prozess die erfassten Änderungen auf die Zieldatenbank an. Änderungen werdenerfasst und als Einheiten einzelner durchgeführter Transaktionen angewendet. Sie können mehrereverschiedene Tabellen als Commit einer einzelnen Quelle aktualisieren. Dieser Ansatz garantiertTransaktionsintegrität in der Zieldatenbank. Bei diesem Prozess handelt es sich in der AWS-Konsoleum die Option Migrate existing data and replicate ongoing changes und in der API um full-load-and-cdc.
• Nur Replizieren von Datenänderungen in der Quelldatenbank – Dieser Vorgang liest dasWiederherstellungsprotokoll des Quell-DBMS (Datenbankmanagementsystem) und gruppiert dieEinträge für jede Transaktion zusammen. In einigen Fällen kann AWS DMS Änderungen nichtinnerhalb eines angemessenen Zeitraums auf das Ziel anwenden (z. B. wenn der Zugriff auf dasZiel nicht möglich ist). In diesen Fällen puffert AWS DMS die Änderungen so lange wie nötig aufdem Replikationsserver. Er liest die Quell-DBMS-Protokolle nicht erneut, was viel Zeit in Anspruchnehmen kann. Dieser Prozess wird in der AWS DMS-Konsole Replicate data changes only (NurDatenänderungen replizieren) genannt.
• Bestimmen, wie die Aufgabe große Binärobjekte (LOBs) auf der Quelldatenbank verarbeiten soll. WeitereInformationen finden Sie unter Festlegen von LOB-Support für Quelldatenbanken in einer AWS DMS-Aufgabe (p. 361).
• Geben Sie die Migrationsaufgabeneinstellungen an. Dazu gehören die Einrichtung der Protokollierung,Angaben dazu, welche Daten in die Migrationssteuertabelle geschrieben werden, wie Fehler behandeltwerden sowie andere Einstellungen. Weitere Informationen zu den Aufgabeneinstellungen finden Sieunter Angeben von Aufgabeneinstellungen für AWS Database Migration Service-Aufgaben (p. 340).
• Einrichten der Tabellenzuweisung, um Regeln zu definieren, anhand derer die zu migrierenden Datenausgewählt und gefiltert werden. Weitere Informationen zur Tabellenzuweisung finden Sie unterVerwenden der Tabellenzuweisung zum Angeben von Aufgabeneinstellungen (p. 372). Bevor Sie IhreZuweisung angeben, sollten Sie den Abschnitt in der Dokumentation zur Zuweisung der Datentypen fürIhre Quell- und Zieldatenbank lesen.
Sie können festlegen, dass eine Aufgabe gestartet wird, sobald Sie die Informationen zu dieser Aufgabeauf der Seite Create task (Aufgabe erstellen) angegeben haben. Alternativ können Sie die Aufgabe über dieDashboard-Seite starten, nachdem Sie alle Angaben für die Aufgabe gemacht haben.
Im folgenden Verfahren wird davon ausgegangen, dass Sie den Assistenten der AWS DMS-Konsolegewählt und die Informationen zur Replikations-Instance und zu den Endpunkten über den Assistentenangegeben haben. Sie können diesen Schritt auch ausführen, indem Sie Tasks (Aufgaben) imNavigationsbereich der AWS DMS-Konsole und dann Create task (Aufgabe erstellen) auswählen.
So erstellen Sie eine Migrationsaufgabe
1. Legen Sie auf der Seite Create Task die Aufgabenoptionen fest. In der folgenden Tabelle sind dieEinstellungen beschrieben.
API-Version API Version 2016-01-01334
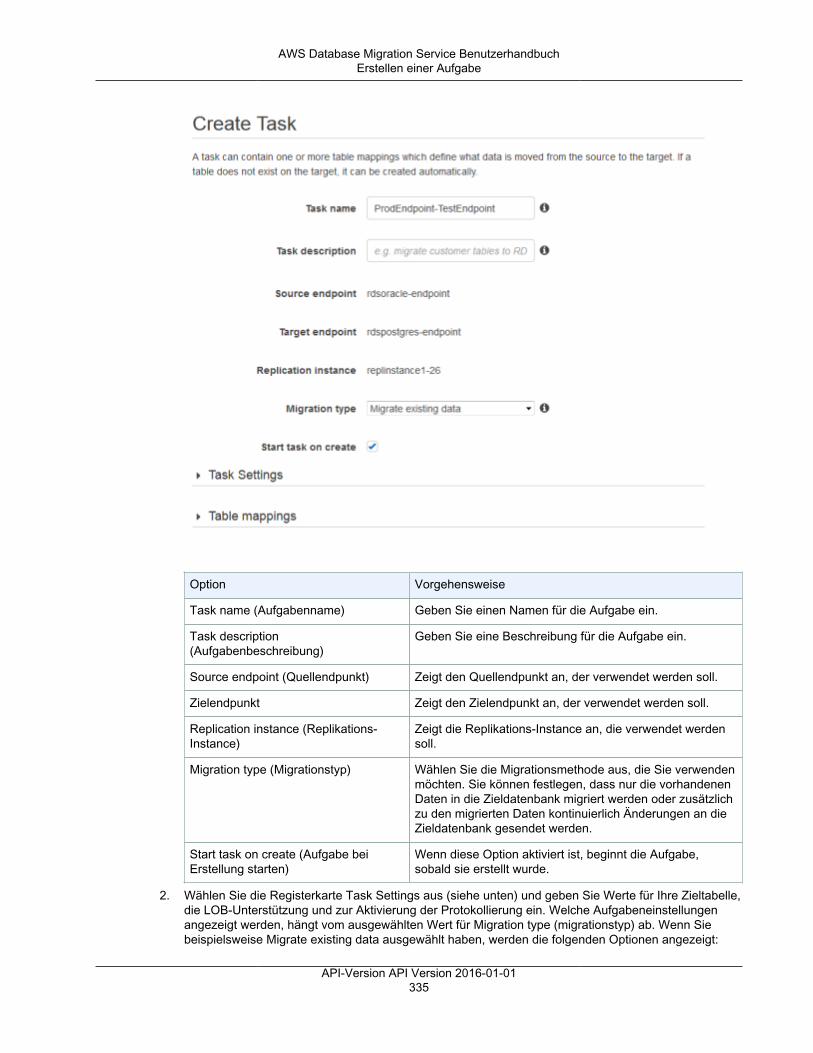
AWS Database Migration Service BenutzerhandbuchErstellen einer Aufgabe
Option Vorgehensweise
Task name (Aufgabenname) Geben Sie einen Namen für die Aufgabe ein.
Task description(Aufgabenbeschreibung)
Geben Sie eine Beschreibung für die Aufgabe ein.
Source endpoint (Quellendpunkt) Zeigt den Quellendpunkt an, der verwendet werden soll.
Zielendpunkt Zeigt den Zielendpunkt an, der verwendet werden soll.
Replication instance (Replikations-Instance)
Zeigt die Replikations-Instance an, die verwendet werdensoll.
Migration type (Migrationstyp) Wählen Sie die Migrationsmethode aus, die Sie verwendenmöchten. Sie können festlegen, dass nur die vorhandenenDaten in die Zieldatenbank migriert werden oder zusätzlichzu den migrierten Daten kontinuierlich Änderungen an dieZieldatenbank gesendet werden.
Start task on create (Aufgabe beiErstellung starten)
Wenn diese Option aktiviert ist, beginnt die Aufgabe,sobald sie erstellt wurde.
2. Wählen Sie die Registerkarte Task Settings aus (siehe unten) und geben Sie Werte für Ihre Zieltabelle,die LOB-Unterstützung und zur Aktivierung der Protokollierung ein. Welche Aufgabeneinstellungenangezeigt werden, hängt vom ausgewählten Wert für Migration type (migrationstyp) ab. Wenn Siebeispielsweise Migrate existing data ausgewählt haben, werden die folgenden Optionen angezeigt:
API-Version API Version 2016-01-01335
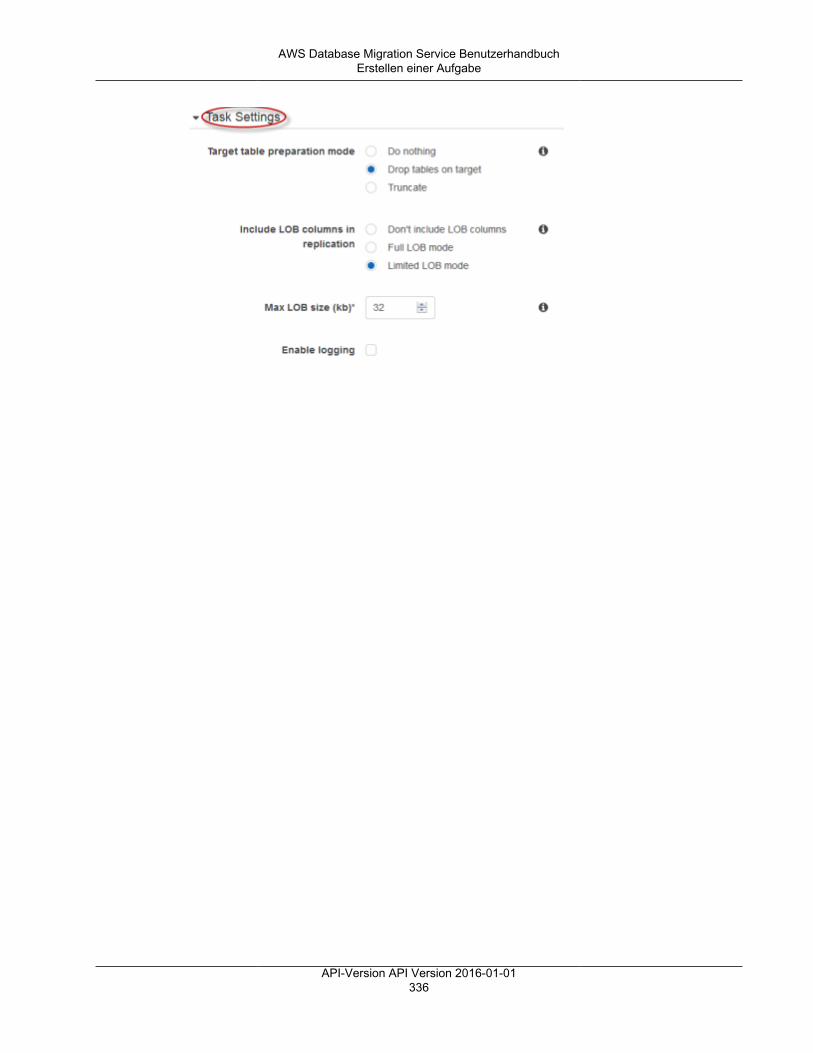
AWS Database Migration Service BenutzerhandbuchErstellen einer Aufgabe
API-Version API Version 2016-01-01336
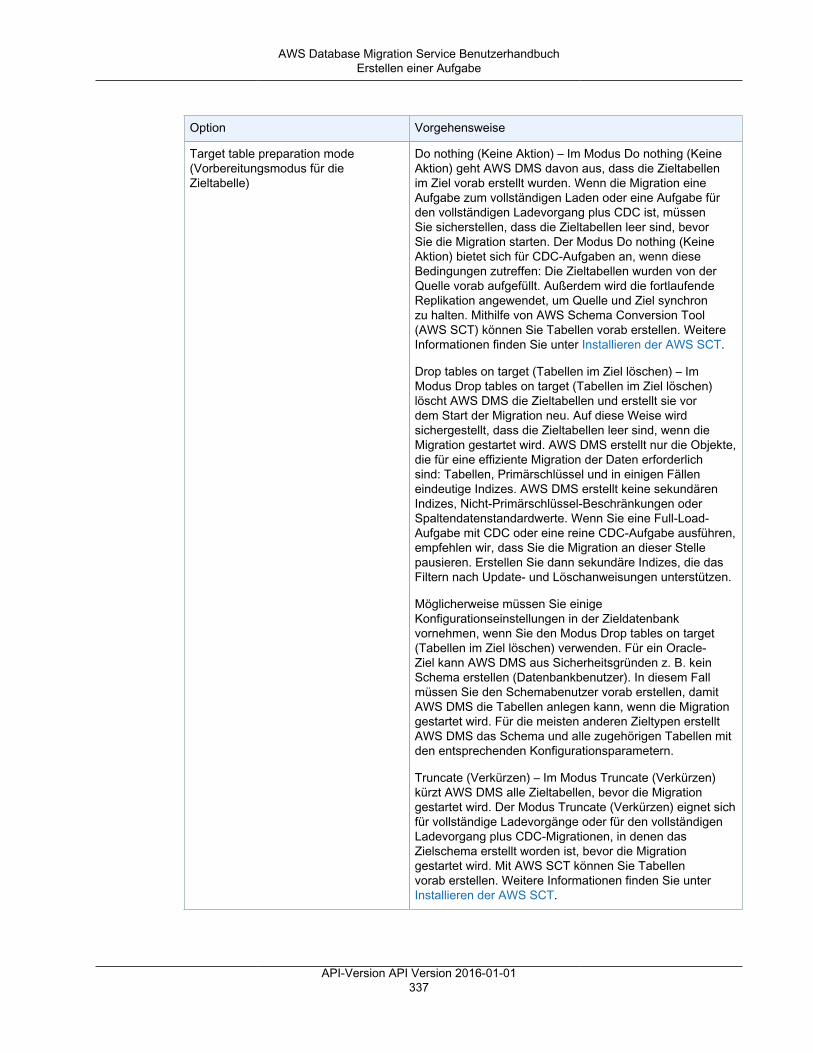
AWS Database Migration Service BenutzerhandbuchErstellen einer Aufgabe
Option Vorgehensweise
Target table preparation mode(Vorbereitungsmodus für dieZieltabelle)
Do nothing (Keine Aktion) – Im Modus Do nothing (KeineAktion) geht AWS DMS davon aus, dass die Zieltabellenim Ziel vorab erstellt wurden. Wenn die Migration eineAufgabe zum vollständigen Laden oder eine Aufgabe fürden vollständigen Ladevorgang plus CDC ist, müssenSie sicherstellen, dass die Zieltabellen leer sind, bevorSie die Migration starten. Der Modus Do nothing (KeineAktion) bietet sich für CDC-Aufgaben an, wenn dieseBedingungen zutreffen: Die Zieltabellen wurden von derQuelle vorab aufgefüllt. Außerdem wird die fortlaufendeReplikation angewendet, um Quelle und Ziel synchronzu halten. Mithilfe von AWS Schema Conversion Tool(AWS SCT) können Sie Tabellen vorab erstellen. WeitereInformationen finden Sie unter Installieren der AWS SCT.
Drop tables on target (Tabellen im Ziel löschen) – ImModus Drop tables on target (Tabellen im Ziel löschen)löscht AWS DMS die Zieltabellen und erstellt sie vordem Start der Migration neu. Auf diese Weise wirdsichergestellt, dass die Zieltabellen leer sind, wenn dieMigration gestartet wird. AWS DMS erstellt nur die Objekte,die für eine effiziente Migration der Daten erforderlichsind: Tabellen, Primärschlüssel und in einigen Fälleneindeutige Indizes. AWS DMS erstellt keine sekundärenIndizes, Nicht-Primärschlüssel-Beschränkungen oderSpaltendatenstandardwerte. Wenn Sie eine Full-Load-Aufgabe mit CDC oder eine reine CDC-Aufgabe ausführen,empfehlen wir, dass Sie die Migration an dieser Stellepausieren. Erstellen Sie dann sekundäre Indizes, die dasFiltern nach Update- und Löschanweisungen unterstützen.
Möglicherweise müssen Sie einigeKonfigurationseinstellungen in der Zieldatenbankvornehmen, wenn Sie den Modus Drop tables on target(Tabellen im Ziel löschen) verwenden. Für ein Oracle-Ziel kann AWS DMS aus Sicherheitsgründen z. B. keinSchema erstellen (Datenbankbenutzer). In diesem Fallmüssen Sie den Schemabenutzer vorab erstellen, damitAWS DMS die Tabellen anlegen kann, wenn die Migrationgestartet wird. Für die meisten anderen Zieltypen erstelltAWS DMS das Schema und alle zugehörigen Tabellen mitden entsprechenden Konfigurationsparametern.
Truncate (Verkürzen) – Im Modus Truncate (Verkürzen)kürzt AWS DMS alle Zieltabellen, bevor die Migrationgestartet wird. Der Modus Truncate (Verkürzen) eignet sichfür vollständige Ladevorgänge oder für den vollständigenLadevorgang plus CDC-Migrationen, in denen dasZielschema erstellt worden ist, bevor die Migrationgestartet wird. Mit AWS SCT können Sie Tabellenvorab erstellen. Weitere Informationen finden Sie unterInstallieren der AWS SCT.
API-Version API Version 2016-01-01337
AWS Database Migration Service BenutzerhandbuchErstellen einer Aufgabe
Option Vorgehensweise
Include LOB columns in replicationLOB-Spalten in Replikationeinschließen)
Don't include LOB columns (Keine LOB-Spalteneinschließen) – Die LOB-Spalten sind von der Migrationausgeschlossen.
Full LOB mode (Vollständiger LOB-Modus) – Die LOBswerden vollständig migriert, unabhängig von ihrer Größe.AWS DMS migriert LOBs stückweise in Blöcken, dievom Parameter Max LOB size (Maximale LOB-Größe)gesteuert werden. Dieser Modus ist langsamer als derModus "Limited LOB".
Limited LOB mode (Eingeschränkter LOB-Modus) – DieLOBs werden auf den Wert des Parameters Max LOB size(Maximale LOB-Größe) gekürzt. Dieser Modus ist schnellerals der Modus "Full LOB".
Max LOB size (kb) (Max LOB-Größe(kb))
Im Limited LOB Mode (Eingeschränkter LOB-Modus)werden LOB-Spalten, die den Wert unter Max LOB Size(Maximale LOB-Größe) überschreiten, auf die angegebeneMax LOB Size (Maximale LOB-Größe) gekürzt.
Enable validation (Validierungaktivieren)
Aktiviert die Datenvalidierung, um sicherzustellen, dassdie Daten korrekt von der Quelle ans Ziel migriert werden.Weitere Informationen finden Sie unter Validieren von AWSDMS-Aufgaben (p. 434).
Enable logging (Protokollierungaktivieren)
Aktiviert die Protokollierung nach Amazon CloudWatch.
Wenn Sie beispielsweise Migrate existing data and replicate (Vorhandene Daten migrieren undreplizieren) für Migration type (Migrationstyp) ausgewählt haben, werden die folgenden Optionenangezeigt:
API-Version API Version 2016-01-01338
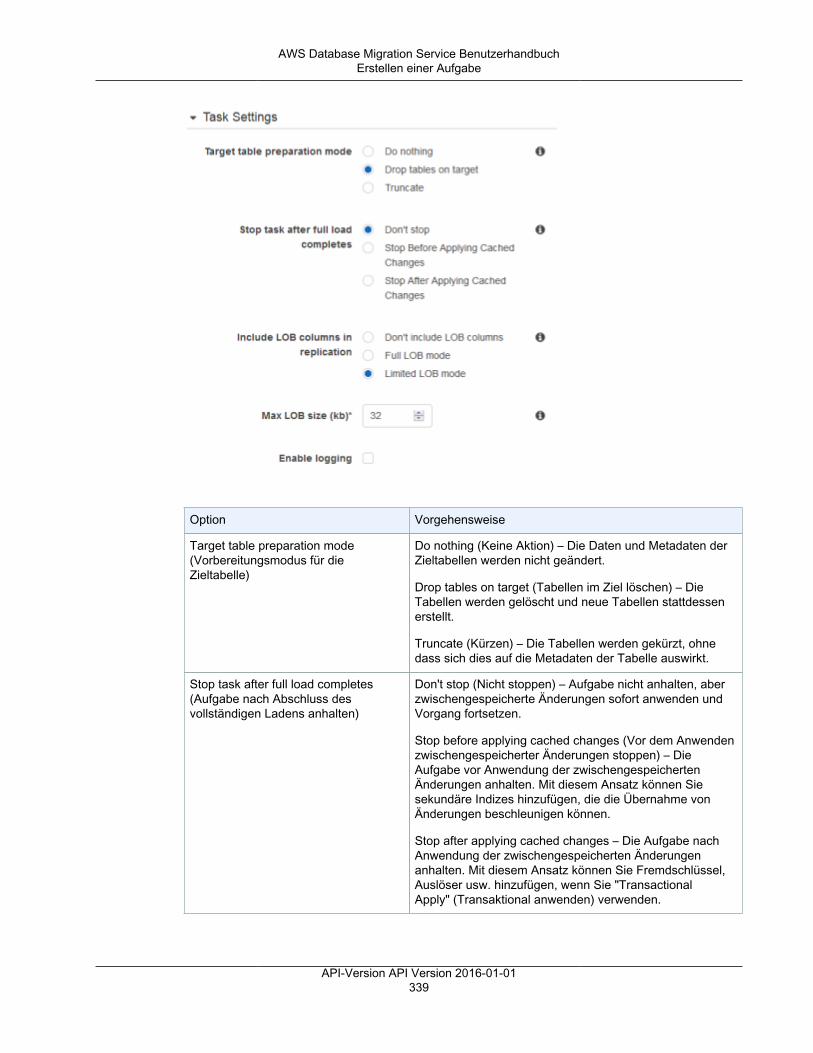
AWS Database Migration Service BenutzerhandbuchErstellen einer Aufgabe
Option Vorgehensweise
Target table preparation mode(Vorbereitungsmodus für dieZieltabelle)
Do nothing (Keine Aktion) – Die Daten und Metadaten derZieltabellen werden nicht geändert.
Drop tables on target (Tabellen im Ziel löschen) – DieTabellen werden gelöscht und neue Tabellen stattdessenerstellt.
Truncate (Kürzen) – Die Tabellen werden gekürzt, ohnedass sich dies auf die Metadaten der Tabelle auswirkt.
Stop task after full load completes(Aufgabe nach Abschluss desvollständigen Ladens anhalten)
Don't stop (Nicht stoppen) – Aufgabe nicht anhalten, aberzwischengespeicherte Änderungen sofort anwenden undVorgang fortsetzen.
Stop before applying cached changes (Vor dem Anwendenzwischengespeicherter Änderungen stoppen) – DieAufgabe vor Anwendung der zwischengespeichertenÄnderungen anhalten. Mit diesem Ansatz können Siesekundäre Indizes hinzufügen, die die Übernahme vonÄnderungen beschleunigen können.
Stop after applying cached changes – Die Aufgabe nachAnwendung der zwischengespeicherten Änderungenanhalten. Mit diesem Ansatz können Sie Fremdschlüssel,Auslöser usw. hinzufügen, wenn Sie "TransactionalApply" (Transaktional anwenden) verwenden.
API-Version API Version 2016-01-01339
AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
Option Vorgehensweise
Include LOB columns in replicationLOB-Spalten in Replikationeinschließen)
Don't include LOB columns (Keine LOB-Spalteneinschließen) – Die LOB-Spalten sind von der Migrationausgeschlossen.
Full LOB mode (Vollständiger LOB-Modus) – Die LOBswerden vollständig migriert, unabhängig von ihrer Größe.LOBs werden stückweise in Blöcken migriert, je nach LOB-Blockgröße. Diese Methode ist langsamer als der Modus"Limited LOB Mode".
Limited LOB mode (Eingeschränkter LOB-Modus) – DieLOBs werden auf die maximale LOB-Größe gekürzt. DieseMethode ist schneller als der Modus "Full LOB Mode(Vollständiger LOB-Modus)".
Max LOB size (KB) (Maximale LOB-Größe (KB))
Im Limited LOB Mode (Eingeschränkter LOB-Modus)werden LOB-Spalten, die den Wert unter Max LOB Size(Maximale LOB-Größe) überschreiten, auf die angegebene"Max LOB Size (Maximale LOB-Größe)" gekürzt.
Enable validation (Validierungaktivieren)
Aktiviert die Datenvalidierung, um sicherzustellen, dassdie Daten korrekt von der Quelle ans Ziel migriert werden.Weitere Informationen finden Sie unter Validieren von AWSDMS-Aufgaben (p. 434).
Enable logging (Protokollierungaktivieren)
Aktiviert die Protokollierung nach CloudWatch.
3. Wählen Sie die Registerkarte Table mappings (Tabellenzuweisungen) (siehe unten), um Werte für dieSchemazuweisung und Zuweisungsmethode festzulegen. Wenn Sie Custom wählen, können Sie dasZielschema und die Tabellenwerte angeben. Weitere Informationen zur Tabellenzuweisung finden Sieunter Verwenden der Tabellenzuweisung zum Angeben von Aufgabeneinstellungen (p. 372).
4. Wenn Sie mit den Aufgabeneinstellungen fertig sind, wählen Sie Create task (Aufgabe erstellen) aus.
Angeben von Aufgabeneinstellungen für AWSDatabase Migration Service-AufgabenJede Aufgabe hat Einstellungen, die entsprechend den Anforderungen Ihrer Datenbankmigrationkonfiguriert werden können. Sie erstellen diese Einstellungen in einer JSON-Datei oder Sie können einigeEinstellungen mithilfe der AWS DMS-Konsole angeben.
API-Version API Version 2016-01-01340

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
Es gibt mehrere Hauptarten von Aufgabeneinstellungen, wie nachfolgend aufgelistet:
Themen• Ziel-Metadaten-Aufgabeneinstellungen (p. 343)• Full-Load-Aufgabeneinstellungen (p. 344)• Einstellungen für das Protokollieren von Aufgaben (p. 345)• Einstellungen der Kontrolltabelle für Aufgaben (p. 346)• Aufgabeneinstellungen für Stream-Puffer (p. 349)• Einstellungen für die Optimierung der Verarbeitung von Änderungen (p. 350)• Aufgabeneinstellungen zur Datenvalidierung (p. 351)• Aufgabeneinstellungen für den Umgang mit der DDL-Änderungsverarbeitung (p. 352)• Einstellungen der Zeichenersetzungsaufgabe (p. 352)• Vorher-Abbild-Aufgabeneinstellungen (p. 357)• Aufgabeneinstellungen zur Fehlerbehandlung (p. 358)• Speichern der Aufgabeneinstellungen (p. 360)
Eine JSON-Datei für Aufgabeneinstellungen kann folgendermaßen aussehen.
{ "TargetMetadata": { "TargetSchema": "", "SupportLobs": true, "FullLobMode": false, "LobChunkSize": 64, "LimitedSizeLobMode": true, "LobMaxSize": 32, "InlineLobMaxSize": 0, "LoadMaxFileSize": 0, "ParallelLoadThreads": 0, "ParallelLoadBufferSize":0, "ParallelLoadQueuesPerThread": 1, "ParallelApplyThreads": 0, "ParallelApplyBufferSize": 50, "ParallelApplyQueuesPerThread": 1, "BatchApplyEnabled": false, "TaskRecoveryTableEnabled": false }, "FullLoadSettings": { "TargetTablePrepMode": "DO_NOTHING", "CreatePkAfterFullLoad": false, "StopTaskCachedChangesApplied": false, "StopTaskCachedChangesNotApplied": false, "MaxFullLoadSubTasks": 8, "TransactionConsistencyTimeout": 600, "CommitRate": 10000 }, "Logging": { "EnableLogging": false }, "ControlTablesSettings": { "ControlSchema":"", "HistoryTimeslotInMinutes":5, "HistoryTableEnabled": false, "SuspendedTablesTableEnabled": false, "StatusTableEnabled": false }, "StreamBufferSettings": {
API-Version API Version 2016-01-01341

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
"StreamBufferCount": 3, "StreamBufferSizeInMB": 8 }, "ChangeProcessingTuning": { "BatchApplyPreserveTransaction": true, "BatchApplyTimeoutMin": 1, "BatchApplyTimeoutMax": 30, "BatchApplyMemoryLimit": 500, "BatchSplitSize": 0, "MinTransactionSize": 1000, "CommitTimeout": 1, "MemoryLimitTotal": 1024, "MemoryKeepTime": 60, "StatementCacheSize": 50 }, "ChangeProcessingDdlHandlingPolicy": { "HandleSourceTableDropped": true, "HandleSourceTableTruncated": true, "HandleSourceTableAltered": true }, "LoopbackPreventionSettings": { "EnableLoopbackPrevention": true, "SourceSchema": "LOOP-DATA", "TargetSchema": "loop-data" }, "ValidationSettings": { "EnableValidation": true, "ThreadCount": 5 }, "CharacterSetSettings": { "CharacterReplacements": [ { "SourceCharacterCodePoint": 35, "TargetCharacterCodePoint": 52 }, { "SourceCharacterCodePoint": 37, "TargetCharacterCodePoint": 103 } ], "CharacterSetSupport": { "CharacterSet": "UTF16_PlatformEndian", "ReplaceWithCharacterCodePoint": 0 } }, "BeforeImageSettings": { "EnableBeforeImage": false, "FieldName": "", "ColumnFilter": pk-only }, "ErrorBehavior": { "DataErrorPolicy": "LOG_ERROR", "DataTruncationErrorPolicy":"LOG_ERROR", "DataErrorEscalationPolicy":"SUSPEND_TABLE", "DataErrorEscalationCount": 50, "TableErrorPolicy":"SUSPEND_TABLE", "TableErrorEscalationPolicy":"STOP_TASK", "TableErrorEscalationCount": 50, "RecoverableErrorCount": 0, "RecoverableErrorInterval": 5, "RecoverableErrorThrottling": true, "RecoverableErrorThrottlingMax": 1800, "ApplyErrorDeletePolicy":"IGNORE_RECORD", "ApplyErrorInsertPolicy":"LOG_ERROR", "ApplyErrorUpdatePolicy":"LOG_ERROR", "ApplyErrorEscalationPolicy":"LOG_ERROR", "ApplyErrorEscalationCount": 0, "FullLoadIgnoreConflicts": true
API-Version API Version 2016-01-01342

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
}}
Ziel-Metadaten-AufgabeneinstellungenZu den Ziel-Metadateneinstellungen gehören die Folgenden:
• TargetSchema – Der Name des Zieltabellenschemas. Wenn diese Metadatenoption leer ist, wird dasSchema der Quelltabelle verwendet. AWS DMS fügt allen Tabellen automatisch das Eigentümerpräfix fürdie Zieldatenbank hinzu, wenn kein Quellschema definiert ist. Diese Option sollte für Ziel-Endpunkte vomTyp MySQL leer gelassen werden.
• LOB-Einstellungen – Einstellungen, die bestimmen, wie große Objekte (LOBs) verwaltet werden. WennSie SupportLobs=true festlegen, müssen Sie eines der Folgenden auf true setzen:• FullLobMode – Wenn Sie diese Option auf true setzen, müssen Sie einen Wert für die OptionLobChunkSize eingeben. Geben Sie die zu verwendende Größe der LOB-Blöcke (in Kilobyte) ein,wenn die Daten in der Zieldatenbank repliziert werden. Die Option FullLobMode funktioniert ambesten bei sehr großen LOB-Größen, verlangsamt jedoch den Ladevorgang.
• InlineLobMaxSize – Dieser Wert bestimmt, welche LOBs AWS Database Migration Service beieinem vollständigen Ladevorgang inline übertragt. Es ist effizienter, kleine LOBs zu übertragen alssie in einer Quelltabelle nachzuschlagen. Bei einem vollständigen Ladevorgang überprüft AWSDatabase Migration Service alle LOBs und führt eine Inline-Übertragung der LOBs aus, die kleinerals InlineLobMaxSize sind. AWS Database Migration Service überträgt alle LOBs, die größer alsInlineLobMaxSize sind, im FullLobMode. Der Standardwert für InlineLobMaxSize ist 0. DerBereich liegt zwischen 1 Kilobyte und 2 Gigabyte. Legen Sie einen Wert für InlineLobMaxSizenur fest, wenn Sie wissen, dass die meisten LOBs kleiner sind als der unter InlineLobMaxSizefestgelegte Wert.
• LimitedSizeLobMode – Wenn Sie diese Option auf true setzen, müssen Sie einen Wert für dieOption LobMaxSize eingeben. Geben Sie die maximale Größe in Kilobyte für ein einzelnes LOB ein.
Weitere Informationen zu den Kriterien für die Verwendung dieser Aufgaben-LOB-Einstellungen findenSie unter Festlegen von LOB-Support für Quelldatenbanken in einer AWS DMS-Aufgabe (p. 361). Siekönnen auch die Verwaltung von LOBs für einzelne Tabellen steuern. Weitere Informationen finden Sieunter Tabelleneinstellungen für Regeln und Operationen (p. 397).
• LoadMaxFileSize – Eine Option für MySQL-Zielendpunkte, die die maximale Größe von auf derFestplatte gespeicherten, nicht geladenen Daten, wie z. B. .csv-Dateien definiert. Diese Option setzt dasVerbindungsattribut außer Kraft. Sie können Werte von 0 bis 100.000 KB angeben, wobei "0" anzeigt,dass diese Option das Verbindungsattribut nicht außer Kraft setzt.
• BatchApplyEnabled – Legt fest, ob jede Transaktion einzeln angewendet wird oder ob Änderungen inStapeln übernommen werden. Der Standardwert ist false.
Der Parameter BatchApplyEnabled wird in Verbindung mit dem ParameterBatchApplyPreserveTransaction verwendet. Wenn BatchApplyEnabled auf true festgelegt ist,bestimmt der Parameter BatchApplyPreserveTransaction die Integrität der Transaktionen.
Wenn BatchApplyPreserveTransaction auf true festgelegt ist, wird die Transaktionsintegritätbewahrt und ein Stapel enthält garantiert alle Änderungen innerhalb einer Transaktion von der Quelle.
Wenn BatchApplyPreserveTransaction auf false festgelegt ist, kann es zu temporären Ausfällenbei der Transaktionsintegrität kommen, um die Leistung zu verbessern.
Der Parameter BatchApplyPreserveTransaction gilt ausschließlich für Oracle-Zielendpunkte undist nur relevant, wenn der Parameter BatchApplyEnabled auf true festgelegt ist.
Wenn die Replikation LOB-Spalten enthält, können Sie BatchApplyEnabled nur im Limited LOB-Modus verwenden.
API-Version API Version 2016-01-01343

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
Weitere Informationen zur Verwendung dieser Einstellungen zum Laden von CDC (Change DataCapture) finden Sie unter Einstellungen für die Optimierung der Verarbeitung von Änderungen (p. 350).
• ParallelLoadThreads – Gibt die Anzahl der Threads an, die AWS DMS verwendet, um jede Tabellein die Zieldatenbank zu laden. Der maximale Wert für ein MySQL-Ziel ist 16. Der maximale Wert fürein Amazon DynamoDB-, Amazon Kinesis Data Streams-, Apache Kafka- oder Amazon ElasticsearchService-Ziel ist 32. Sie können eine Erhöhung dieses Höchstwerts anfordern. Weitere Informationenzu den Einstellungen, mit denen das parallele Laden einzelner Tabellen aktiviert wird, finden Sie unterTabelleneinstellungen für Regeln und Operationen (p. 397).
• ParallelLoadBufferSize – Gibt die maximale Anzahl der Datensätze an, die in dem Puffer geladenwerden können, der von den parallelen Lade-Threads zum Laden von Daten in das Ziel verwendet wird.Der Standardwert lautet 50. Die maximale Wert ist 1.000. Diese Einstellung ist derzeit nur gültig, wennDynamoDB, Kinesis, Apache Kafka oder Elasticsearch das Ziel ist. Verwenden Sie diesen Parametersmit ParallelLoadThreads. ParallelLoadBufferSize ist nur gültig, wenn mehr als ein Threadvorhanden ist. Weitere Informationen zu den Einstellungen, mit denen das parallele Laden einzelnerTabellen aktiviert wird, finden Sie unter Tabelleneinstellungen für Regeln und Operationen (p. 397).
Note
Support für die Parameter ParallelLoadThreads und ParallelLoadBufferSize mit KinesisData Streams als Ziel ist in den AWS DMS-Versionen 3.1.4 und höher verfügbar.
• ParallelLoadQueuesPerThread – Gibt die Anzahl der Warteschlangen an, auf die jeder gleichzeitigeThread zugreift, um Datensätze aus Warteschlangen zu entfernen und eine Stapellast für das Ziel zugenerieren. Der Standardwert ist 1.
• ParallelApplyThreads – Gibt die Anzahl der gleichzeitigen Threads an, die AWS DMS währendeiner CDC-Last verwendet, um Datensätze an einen Kinesis- oder Kafka-Zielendpunkt zu übertragen.
• ParallelApplyBufferSize – Gibt die maximale Anzahl von Datensätzen an, die in jederPufferwarteschlange für gleichzeitige Threads gespeichert werden sollen, die während einer CDC-Lastan einen Kinesis- oder Kafka-Zielendpunkt übertragen werden sollen. Verwenden Sie diese Option, wennParallelApplyThreads mehrere Threads angibt.
• ParallelApplyQueuesPerThread – Gibt die Anzahl der Warteschlangen an, auf die jeder Threadzugreift, um Datensätze aus Warteschlangen zu entfernen und während des CDC eine Stapellast füreinen Kinesis- und Kafka-Endpunkt zu generieren.
Note
Unterstützung für die Parameter ParallelLoadQueuesPerThread, ParallelApplyThreads,ParallelApplyBufferSize und ParallelApplyQueuesPerThread als Ziel ist in den AWSDMS-Versionen 3.3.1 und höher verfügbar.
Full-Load-AufgabeneinstellungenZu den Full-Load-Einstellungen zählen die Folgenden:
• Um anzuzeigen, wie das Laden der Zieldatenbank beim Start von Full Load zu behandeln ist, bestimmenSie einen der folgenden Werte für die Option TargetTablePrepMode:• DO_NOTHING – Daten und Metadaten der vorhandenen Zieltabelle sind nicht betroffen.• DROP_AND_CREATE – Die vorhandene Tabelle wird gelöscht und eine neue Tabelle wird stattdessen
erstellt.• TRUNCATE_BEFORE_LOAD – Daten werden abgeschnitten, ohne dass sich dies auf die Metadaten der
Tabelle auswirkt.• Um das Erstellen des Primärschlüssels oder des eindeutigen Indexes bis nach Abschluss des
vollständigen Ladens zu verzögern, legen Sie die Option CreatePkAfterFullLoad fest.
API-Version API Version 2016-01-01344

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
Wenn diese Option aktiviert ist, können Sie nicht abgeschlossene Full-Load-Aufgaben nichtwiederaufnehmen.
• Für Aufgaben, bei denen Full-Load und CDC aktiviert sind, können Sie die folgenden Optionen für Stoptask after full load completes festlegen:• StopTaskCachedChangesApplied – Legen Sie diese Option auf true fest, um eine Aufgabe zu
beenden, nachdem das vollständige Laden abgeschlossen und zwischengespeicherte Änderungenangewendet wurden.
• StopTaskCachedChangesNotApplied – Legen Sie diese Option auf true fest, um eine Aufgabezu beenden, bevor zwischengespeicherte Änderungen angewendet werden.
• Um die maximale Anzahl von Tabellen anzugeben, die parallel geladen werden, legen Sie die OptionMaxFullLoadSubTasks fest. Der Standardwert beträgt 8; der Maximalwert beträgt 49.
• Sie können die Anzahl der Sekunden festlegen, die AWS DMS wartet, bis Transaktionen geschlossenwerden, bevor eine Full-Load-Operation beginnt. Wenn Transaktionen beim Start der Aufgabe geöffnetsind, legen Sie dazu die Option TransactionConsistencyTimeout fest. Der Standardwert ist 600(10 Minuten). AWS DMS beginnt das vollständige Laden, nachdem der Timeout-Wert erreicht ist, auchwenn noch Transaktionen offen sind. Eine Aufgabe nur für den vollständigen Ladevorgang wartet keine10 Minuten, sondern startet sofort.
• Um die maximale Anzahl von Ereignissen anzugeben, die zusammen übertragen werden können, legenSie die Option CommitRate fest.
Einstellungen für das Protokollieren von AufgabenDie Protokollfunktion verwendet Amazon CloudWatch zum Protokollieren von Informationen währendder Migration. Mit den Einstellungen der Protokollierungsaufgabe können Sie angeben, welcheKomponentenaktivitäten protokolliert und welche Menge an Informationen in das Protokoll geschriebenwird. Einstellungen für die Protokollierung werden in eine JSON-Datei geschrieben.
Sie können die CloudWatch-Protokollierung auf verschiedene Arten aktivieren. Sie können die OptionEnableLogging in der AWS Management Console auswählen, wenn Sie eine Migrationsaufgabeerstellen. Alternativ können Sie die Option EnableLogging auf true setzen, wenn Sie eine Aufgabemithilfe der AWS DMS-API erstellen. Sie können auch "EnableLogging": true in JSON im AbschnittProtokollierung der Aufgabeneinstellungen angeben.
Note
Amazon CloudWatch ist integriert in AWS Identity and Access Management (IAM), sodass Sieangeben können, welche CloudWatch-Aktionen ein Benutzer in Ihrem AWS-Konto ausführenkann. Weitere Informationen finden Sie in diesen Seiten der Amazon CloudWatch-Dokumentation.Amazon CloudWatch – Häufig gestellte FragenIdentity and Access Management für Amazon CloudWatchProtokollieren von Amazon CloudWatch-API-Aufrufen
Um die Aufgabenprotokolle zu löschen, können Sie "DeleteTaskLogs": true in JSON im AbschnittProtokollierung der Aufgabeneinstellungen angeben.
Sie können Protokollierung für die folgenden Komponentenaktivitäten angeben:
• SOURCE_UNLOAD – Die Daten werden von der Quelldatenbank entladen.• SOURCE_CAPTURE – Die Daten werden von der Quelldatenbank erfasst.• TARGET_LOAD – Die Daten werden in die Zieldatenbank geladen.• TARGET_APPLY – Daten und Data Definition Language (DDL)-Anweisungen werden auf die
Zieldatenbank angewendet.• TASK_MANAGER – Der Aufgabenmanager löst ein Ereignis aus.
API-Version API Version 2016-01-01345

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
Nachdem Sie eine Komponentenaktivität angegeben haben, können Sie festlegen, wie viele Informationenprotokolliert werden. Die folgende Liste ist von der niedrigsten Informationsstufe bis zur höchstenInformationsstufe geordnet. Die höheren Stufen enthalten immer Informationen von den niedrigeren Stufen.Diese Schweregradwerte umfassen:
• LOGGER_SEVERITY_ERROR – Fehlermeldungen werden in das Protokoll geschrieben.• LOGGER_SEVERITY_WARNING – Warnungen und Fehlermeldungen werden in das Protokoll
geschrieben.• LOGGER_SEVERITY_INFO – Informationsmeldungen, Warnungen und Fehlermeldungen werden in das
Protokoll geschrieben.• LOGGER_SEVERITY_DEFAULT – Informationsmeldungen, Warnungen und Fehlermeldungen werden in
das Protokoll geschrieben.• LOGGER_SEVERITY_DEBUG – Debug-Nachrichten, Informationsmeldungen, Warnungen und
Fehlermeldungen werden in das Protokoll geschrieben.• LOGGER_SEVERITY_DETAILED_DEBUG – Alle Informationen werden in das Protokoll geschrieben.
Beispielsweise enthält der folgende JSON-Abschnitt Aufgabeneinstellungen für die Protokollierung für alleKomponentenaktivitäten.
… "Logging": { "EnableLogging": true, "LogComponents": [{ "Id": "SOURCE_UNLOAD", "Severity": "LOGGER_SEVERITY_DEFAULT" },{ "Id": "SOURCE_CAPTURE", "Severity": "LOGGER_SEVERITY_DEFAULT" },{ "Id": "TARGET_LOAD", "Severity": "LOGGER_SEVERITY_DEFAULT" },{ "Id": "TARGET_APPLY", "Severity": "LOGGER_SEVERITY_INFO" },{ "Id": "TASK_MANAGER", "Severity": "LOGGER_SEVERITY_DEBUG" }] }, …
Einstellungen der Kontrolltabelle für AufgabenSteuerungstabellen bieten Informationen zu einer AWS DMS-Aufgabe. Sie bieten auch nützlicheStatistiken, mit denen Sie sowohl die aktuelle Migrationsaufgabe als auch zukünftige Aufgaben planenund verwalten können. Sie können diese Aufgabeneinstellungen in einer JSON-Datei anwendenoder durch Auswahl von Advanced Settings (Erweiterte Einstellungen) auf der Seite Create task(Aufgabe erstellen) in der AWS DMS-Konsole verwenden. Die Tabelle "Apply Exceptions (Ausnahmenanwenden)" (dmslogs.awsdms_apply_exceptions) wird immer erstellt. Sie können auch zusätzlicheTabellen erstellen, einschließlich der folgenden:
• Replication Status (dmslogs.awsdms_status) (Replikationsstatus) – Diese Tabelle gibt Details zuraktuellen Aufgabe an. Dazu gehören der Aufgabenstatus, die Größe des von der Aufgabe genutztenSpeichers und die Anzahl an Änderungen, die noch nicht auf das Ziel angewendet wurden. Diese Tabellegibt auch die Position in der Quelldatenbank an, an der AWS DMS derzeit liest. Außerdem erfahren Sie,ob es sich um eine Full-Load- oder um eine CDC (Change Data Capture)-Aufgabe handelt.
API-Version API Version 2016-01-01346
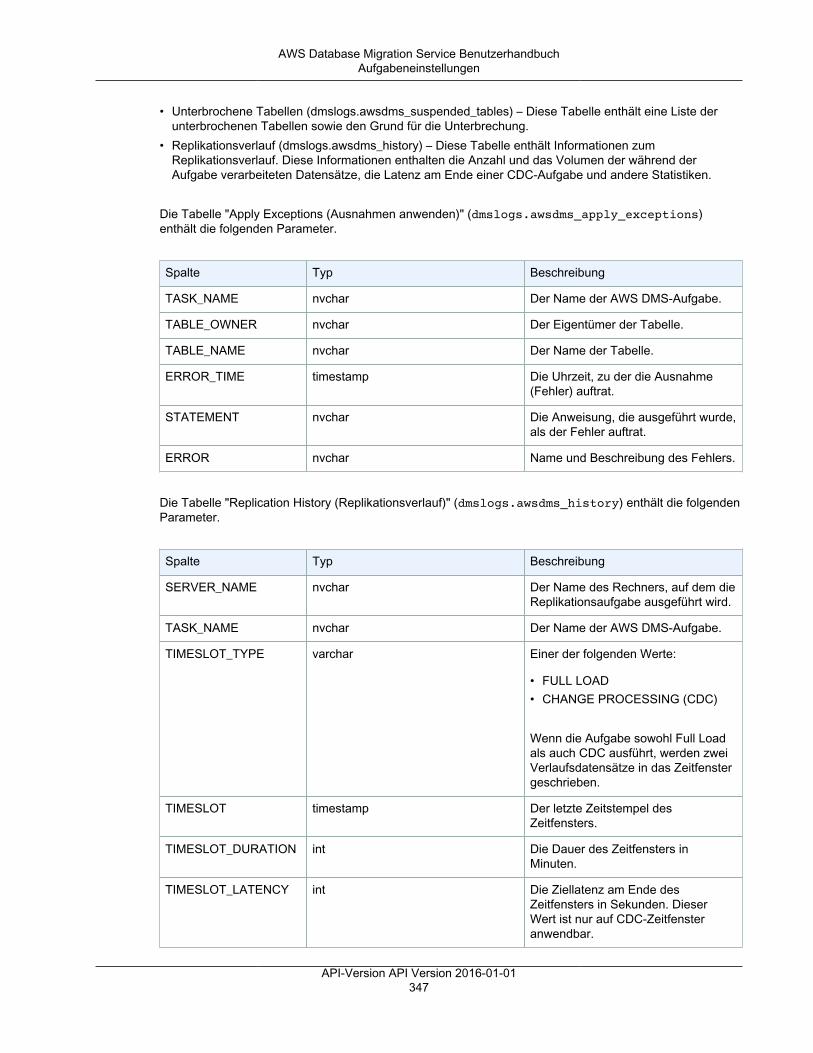
AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
• Unterbrochene Tabellen (dmslogs.awsdms_suspended_tables) – Diese Tabelle enthält eine Liste derunterbrochenen Tabellen sowie den Grund für die Unterbrechung.
• Replikationsverlauf (dmslogs.awsdms_history) – Diese Tabelle enthält Informationen zumReplikationsverlauf. Diese Informationen enthalten die Anzahl und das Volumen der während derAufgabe verarbeiteten Datensätze, die Latenz am Ende einer CDC-Aufgabe und andere Statistiken.
Die Tabelle "Apply Exceptions (Ausnahmen anwenden)" (dmslogs.awsdms_apply_exceptions)enthält die folgenden Parameter.
Spalte Typ Beschreibung
TASK_NAME nvchar Der Name der AWS DMS-Aufgabe.
TABLE_OWNER nvchar Der Eigentümer der Tabelle.
TABLE_NAME nvchar Der Name der Tabelle.
ERROR_TIME timestamp Die Uhrzeit, zu der die Ausnahme(Fehler) auftrat.
STATEMENT nvchar Die Anweisung, die ausgeführt wurde,als der Fehler auftrat.
ERROR nvchar Name und Beschreibung des Fehlers.
Die Tabelle "Replication History (Replikationsverlauf)" (dmslogs.awsdms_history) enthält die folgendenParameter.
Spalte Typ Beschreibung
SERVER_NAME nvchar Der Name des Rechners, auf dem dieReplikationsaufgabe ausgeführt wird.
TASK_NAME nvchar Der Name der AWS DMS-Aufgabe.
TIMESLOT_TYPE varchar Einer der folgenden Werte:
• FULL LOAD• CHANGE PROCESSING (CDC)
Wenn die Aufgabe sowohl Full Loadals auch CDC ausführt, werden zweiVerlaufsdatensätze in das Zeitfenstergeschrieben.
TIMESLOT timestamp Der letzte Zeitstempel desZeitfensters.
TIMESLOT_DURATION int Die Dauer des Zeitfensters inMinuten.
TIMESLOT_LATENCY int Die Ziellatenz am Ende desZeitfensters in Sekunden. DieserWert ist nur auf CDC-Zeitfensteranwendbar.
API-Version API Version 2016-01-01347
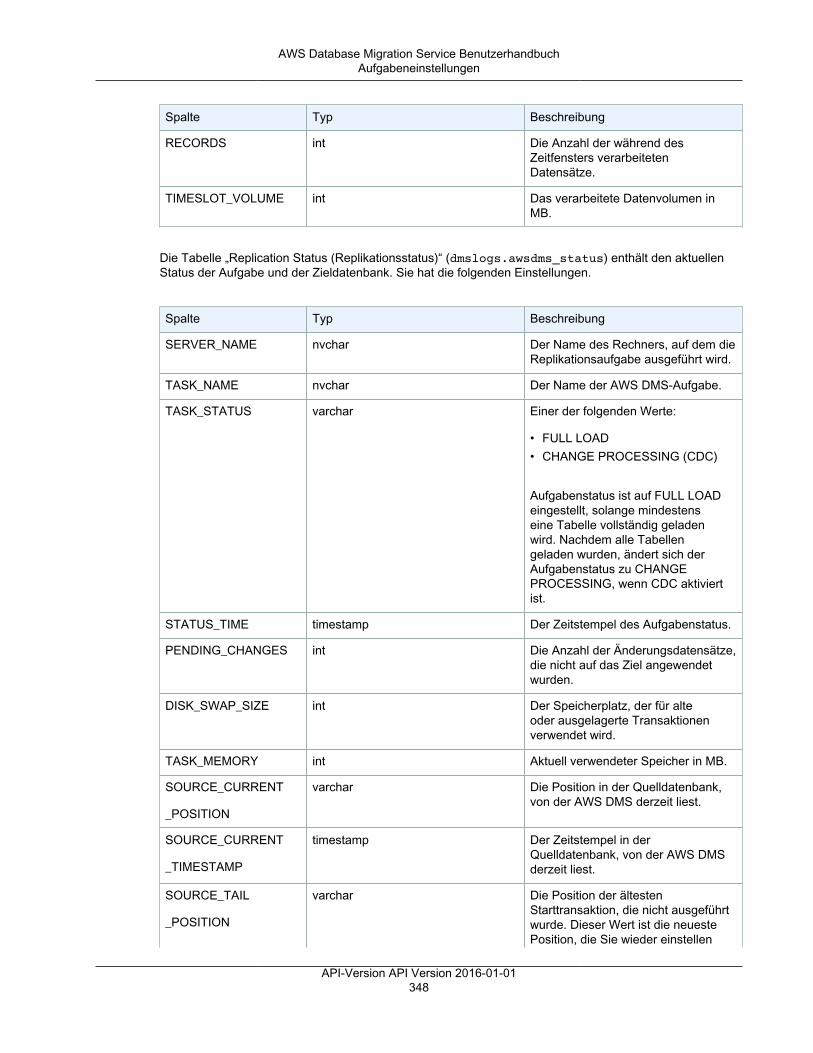
AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
Spalte Typ Beschreibung
RECORDS int Die Anzahl der während desZeitfensters verarbeitetenDatensätze.
TIMESLOT_VOLUME int Das verarbeitete Datenvolumen inMB.
Die Tabelle „Replication Status (Replikationsstatus)“ (dmslogs.awsdms_status) enthält den aktuellenStatus der Aufgabe und der Zieldatenbank. Sie hat die folgenden Einstellungen.
Spalte Typ Beschreibung
SERVER_NAME nvchar Der Name des Rechners, auf dem dieReplikationsaufgabe ausgeführt wird.
TASK_NAME nvchar Der Name der AWS DMS-Aufgabe.
TASK_STATUS varchar Einer der folgenden Werte:
• FULL LOAD• CHANGE PROCESSING (CDC)
Aufgabenstatus ist auf FULL LOADeingestellt, solange mindestenseine Tabelle vollständig geladenwird. Nachdem alle Tabellengeladen wurden, ändert sich derAufgabenstatus zu CHANGEPROCESSING, wenn CDC aktiviertist.
STATUS_TIME timestamp Der Zeitstempel des Aufgabenstatus.
PENDING_CHANGES int Die Anzahl der Änderungsdatensätze,die nicht auf das Ziel angewendetwurden.
DISK_SWAP_SIZE int Der Speicherplatz, der für alteoder ausgelagerte Transaktionenverwendet wird.
TASK_MEMORY int Aktuell verwendeter Speicher in MB.
SOURCE_CURRENT
_POSITION
varchar Die Position in der Quelldatenbank,von der AWS DMS derzeit liest.
SOURCE_CURRENT
_TIMESTAMP
timestamp Der Zeitstempel in derQuelldatenbank, von der AWS DMSderzeit liest.
SOURCE_TAIL
_POSITION
varchar Die Position der ältestenStarttransaktion, die nicht ausgeführtwurde. Dieser Wert ist die neuestePosition, die Sie wieder einstellen
API-Version API Version 2016-01-01348
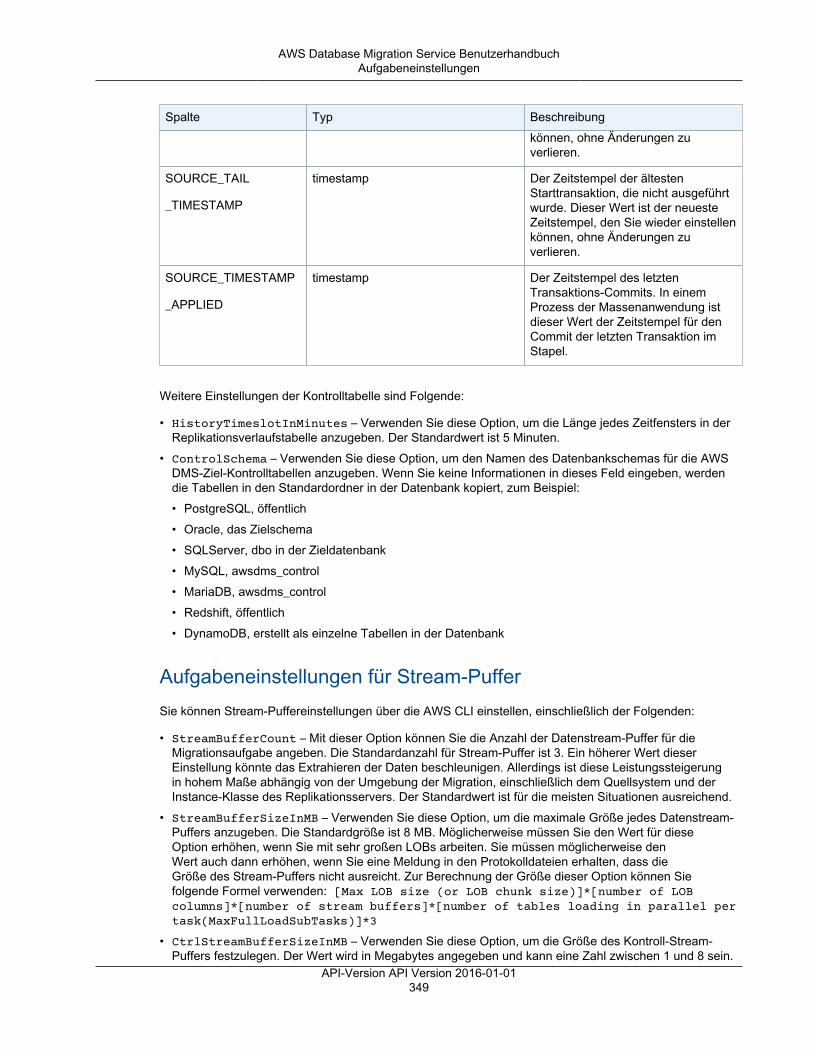
AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
Spalte Typ Beschreibungkönnen, ohne Änderungen zuverlieren.
SOURCE_TAIL
_TIMESTAMP
timestamp Der Zeitstempel der ältestenStarttransaktion, die nicht ausgeführtwurde. Dieser Wert ist der neuesteZeitstempel, den Sie wieder einstellenkönnen, ohne Änderungen zuverlieren.
SOURCE_TIMESTAMP
_APPLIED
timestamp Der Zeitstempel des letztenTransaktions-Commits. In einemProzess der Massenanwendung istdieser Wert der Zeitstempel für denCommit der letzten Transaktion imStapel.
Weitere Einstellungen der Kontrolltabelle sind Folgende:
• HistoryTimeslotInMinutes – Verwenden Sie diese Option, um die Länge jedes Zeitfensters in derReplikationsverlaufstabelle anzugeben. Der Standardwert ist 5 Minuten.
• ControlSchema – Verwenden Sie diese Option, um den Namen des Datenbankschemas für die AWSDMS-Ziel-Kontrolltabellen anzugeben. Wenn Sie keine Informationen in dieses Feld eingeben, werdendie Tabellen in den Standardordner in der Datenbank kopiert, zum Beispiel:• PostgreSQL, öffentlich• Oracle, das Zielschema• SQLServer, dbo in der Zieldatenbank• MySQL, awsdms_control• MariaDB, awsdms_control• Redshift, öffentlich• DynamoDB, erstellt als einzelne Tabellen in der Datenbank
Aufgabeneinstellungen für Stream-PufferSie können Stream-Puffereinstellungen über die AWS CLI einstellen, einschließlich der Folgenden:
• StreamBufferCount – Mit dieser Option können Sie die Anzahl der Datenstream-Puffer für dieMigrationsaufgabe angeben. Die Standardanzahl für Stream-Puffer ist 3. Ein höherer Wert dieserEinstellung könnte das Extrahieren der Daten beschleunigen. Allerdings ist diese Leistungssteigerungin hohem Maße abhängig von der Umgebung der Migration, einschließlich dem Quellsystem und derInstance-Klasse des Replikationsservers. Der Standardwert ist für die meisten Situationen ausreichend.
• StreamBufferSizeInMB – Verwenden Sie diese Option, um die maximale Größe jedes Datenstream-Puffers anzugeben. Die Standardgröße ist 8 MB. Möglicherweise müssen Sie den Wert für dieseOption erhöhen, wenn Sie mit sehr großen LOBs arbeiten. Sie müssen möglicherweise denWert auch dann erhöhen, wenn Sie eine Meldung in den Protokolldateien erhalten, dass dieGröße des Stream-Puffers nicht ausreicht. Zur Berechnung der Größe dieser Option können Siefolgende Formel verwenden: [Max LOB size (or LOB chunk size)]*[number of LOBcolumns]*[number of stream buffers]*[number of tables loading in parallel pertask(MaxFullLoadSubTasks)]*3
• CtrlStreamBufferSizeInMB – Verwenden Sie diese Option, um die Größe des Kontroll-Stream-Puffers festzulegen. Der Wert wird in Megabytes angegeben und kann eine Zahl zwischen 1 und 8 sein.
API-Version API Version 2016-01-01349

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
Der Standardwert ist 5. Möglicherweise müssen Sie den Wert für diese Option erhöhen, wenn Sie miteiner sehr großen Anzahl Tabellen arbeiten, etwa Zehntausende von Tabellen.
Einstellungen für die Optimierung der Verarbeitung vonÄnderungenDie folgenden Einstellungen bestimmen, wie AWS DMS Änderungen für Zieltabellen währendCDC (Change Data Capture) verarbeitet. Mehrere dieser Einstellungen sind abhängig vom Wertdes Ziel-Metadatenparameters BatchApplyEnabled. Weitere Informationen zum ParameterBatchApplyEnabled erhalten Sie unter Ziel-Metadaten-Aufgabeneinstellungen (p. 343).
Zu den Einstellungen für die Optimierung der Verarbeitung von Änderungen zählen die Folgenden:
Die folgenden Einstellungen gelten nur, wenn der Ziel-Metadatenparameter BatchApplyEnabled auftrue festgelegt ist.
• BatchApplyPreserveTransaction – Wenn auf true festgelegt, wird die Transaktionsintegritätbewahrt und ein Stapel enthält garantiert alle Änderungen innerhalb einer Transaktion von der Quelle.Der Standardwert ist true. Diese Einstellung gilt nur für Oracle-Zielendpunkte.
Wenn auf false festgelegt, kann es zu temporären Ausfällen bei der Transaktionsintegrität kommen, umdie Leistung zu verbessern. Es gibt keine Garantie, dass alle Änderungen innerhalb einer Transaktionvon der Quelle in einem einzigen Stapel auf das Ziel angewendet werden.
• BatchApplyTimeoutMin – Legt die minimale Zeit in Sekunden fest, die AWS DMS zwischen jederstapelweisen Anwendung von Änderungen wartet. Der Standardwert lautet 1.
• BatchApplyTimeoutMax – Legt die maximale Zeit in Sekunden fest, die AWS DMS zwischen jederstapelweisen Anwendung von Änderungen bis zum Timeout wartet. Der Standardwert lautet 30.
• BatchApplyMemoryLimit – Legt den maximalen Speicher (in MB) für die Vorverarbeitung in Batchoptimized apply mode (Modus "stapeloptimierte Anwendung") fest. Der Standardwert lautet 500.
• BatchSplitSize – Legt die maximale Anzahl der Änderungen fest, die in einem einzigen Stapelangewendet werden. Der Standardwert 0 bedeutet, dass kein Grenzwert angewendet wird.
Die folgenden Einstellungen gelten nur, wenn der Ziel-Metadatenparameter BatchApplyEnabled auffalse festgelegt ist.
• MinTransactionSize – Legt die minimale Anzahl der in jeder Transaktion enthaltenen Änderungenfest. Der Standardwert lautet 1000.
• CommitTimeout – Legt die maximale Zeit in Sekunden fest, in der AWS DMS Transaktionen in Stapelnsammelt, bevor ein Timeout erklärt wird. Der Standardwert lautet 1.
Die folgende Einstellung gilt, wenn der Zielmetadatenparameter BatchApplyEnabled auf true oderfalse festgelegt ist.
• HandleSourceTableAltered – Legen Sie diese Option auf true fest, um die Zieltabelle zu ändern,wenn sich die Quelltabelle ändert.
Die folgenden Einstellungen gelten nur, wenn BatchApplyEnabled auf false festgelegt ist.
• LoopbackPreventionSettings – Diese Einstellungen bieten für jede laufende Replikationsaufgabebei jedem Aufgabenpaar, das an einer bidirektionalen Replikation beteiligt ist, die Verhinderungvon Loopbacks. Mit der Loopback-Verhinderung wird unterbunden, dass identische Änderungen inbeiden Richtungen der bidirektionalen Replikation angewendet werden, wodurch Daten fehlerhaftwerden können. Weitere Hinweise zur bidirektionalen Replikation finden Sie unter Durchführen derbidirektionalen Replikation (p. 367).
API-Version API Version 2016-01-01350

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
AWS DMS versucht, Transaktionsdaten im Arbeitsspeicher zu halten, bis die Transaktion vollständig aufder Quelle, auf dem Ziel oder auf beidem gespeichert ist. Allerdings werden Transaktionen, die größer sindals der zugewiesene Speicher oder die innerhalb des festgelegten Zeitraums nicht gespeichert wurden, aufdie Festplatte geschrieben.
Die folgenden Einstellungen gelten für die Optimierung der Verarbeitung von Änderungen unabhängig vondem Modus der Änderungsverarbeitung.
• MemoryLimitTotal – Legt die maximale Größe (in MB) fest, die alle Transaktionen im Arbeitsspeicherbelegen können, bevor sie auf die Festplatte geschrieben werden. Der Standardwert lautet 1024.
• MemoryKeepTime – Legt die maximale Zeit in Sekunden fest, die jede Transaktion im Arbeitsspeicherbleiben kann, bevor sie auf den Datenträger geschrieben wird. Die Dauer wird ab dem Zeitpunktberechnet, zu dem AWS DMS die Erfassung der Transaktion gestartet hat. Der Standardwert lautet 60.
• StatementCacheSize – Legt die maximale Anzahl der vorbereiteten Anweisungen fest, die auf demServer für die spätere Ausführung gespeichert werden, wenn Änderungen auf das Ziel angewendetwerden. Der Standardwert lautet 50. Der maximale Wert beträgt 200.
Aufgabeneinstellungen zur DatenvalidierungSie können sicherstellen, dass Ihre Daten korrekt von der Quelle zum Ziel migriert wurden. Wenn Sie dieValidierung für eine Aufgabe aktivieren, vergleicht AWS DMS die Quell- und Zieldaten sofort, nachdemeine Tabelle vollständig geladen wurde. Weitere Informationen zur Aufgabendatenvalidierung, derenAnforderungen, den Umfang des Datenbank-Supports und die gemeldeten Metriken finden Sie unterValidieren von AWS DMS-Aufgaben (p. 434).
Zu den Datenvalidierungseinstellungen und deren Werten gehören:
• EnableValidation – Aktiviert die Datenvalidierung, wenn die Einstellung auf "true" gesetzt wurde.Andernfalls wird die Validierung für die Aufgabe deaktiviert. Der Standardwert von "false".
• FailureMaxCount – Gibt die maximale Anzahl der Datensätze an, bei denen die Validierungfehlschlagen kann, bevor sie für die Aufgabe gesperrt wird. Der Standardwert lautet 10.000. Wenn Siemöchten, dass die Validierung unabhängig von der Anzahl der Datensätze, bei denen die Validierungfehlgeschlagen ist, fortgesetzt wird, setzen Sie diesen Wert höher als die Anzahl der Datensätze in derQuelle.
• HandleCollationDiff – Wenn diese Option auf "true" gesetzt ist, kommt die Validierung fürUnterschiede bei der Spaltensortierung in PostgreSQL-Endpunkten auf, wenn zu vergleichendeQuellen- und Zieldatensätze identifiziert werden. Andernfalls werden jegliche Unterschiede bei derSpaltensortierung für die Validierung ignoriert. Bei PostgreSQL-Endpunkten können Spaltensortierungendie Reihenfolge der Zeilen bestimmen, was für die Datenvalidierung wichtig ist. Das Festlegen vonHandleCollationDiff auf "true" behebt diese Sortierungsunterschiede automatisch und verhindertFehlalarme bei der Datenvalidierung. Der Standardwert von "false".
• RecordFailureDelayLimitInMinutes – Gibt die Verzögerung an, bevor Details überdas Fehlschlagen der Validierung gemeldet werden. Normalerweise verwendet AWS DMS dieAufgabenlatenz, um die tatsächliche Verzögerung von Änderungen, die am Ziel durchgeführt werden,zu erkennen und Fehlalarme zu verhindern. Diese Einstellung überschreibt den tatsächlichenVerzögerungswert und Sie können eine größere Verzögerung festlegen, bevor Validierungsmetrikengemeldet werden. Der Standardwert lautet 0.
• TableFailureMaxCount – Gibt die maximale Anzahl der Tabellen an, bei denen die Validierungfehlschlagen kann, bevor sie für die Aufgabe gesperrt wird. Der Standardwert lautet 1.000. Wenn Siemöchten, dass die Validierung unabhängig von der Anzahl der Tabellen, bei denen die Validierungfehlgeschlagen ist, fortgesetzt wird, setzen Sie diesen Wert höher als die Anzahl der Datensätze in derQuelle.
• ThreadCount – Gibt die Anzahl der Ausführungs-Threads an, die AWS DMS während der Validierungnutzt. Jeder Thread wählt noch nicht validierte Daten aus der Quelle und dem Ziel aus, um diese zuvergleichen und zu validieren. Der Standardwert lautet 5. Wenn Sie ThreadCount auf eine höhere Zahl
API-Version API Version 2016-01-01351

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
festlegen, kann AWS DMS die Validierung schneller abschließen. Allerdings führt AWS DMS dann auchmehr simultane Abfragen aus, sodass bei Quelle und Ziel mehr Ressourcen verbraucht werden.
• ValidationOnly – Wenn diese Option auf „true“ gesetzt ist, lädt die Aufgabe eine Vorversion derDatenvalidierung, ohne eine Migration oder Replikation von Daten durchzuführen.
Zum Festlegen dieser Option legen Sie in der AWS DMS-Konsole die Aufgabe Migration type(Migrationstyp) auf Replicate data changes only (Nur Datenänderungen replizieren) fest. Alternativ legenSie in der AWS DMS-API den Migrationstyp auf cdc fest:
Mit diesem Ansatz können Sie die Validierungsergebnisse anzeigen und alle Fehler lösen, bevor Sie dieDaten tatsächlich verschieben. Diese Option ist möglicherweise effizienter als mit dem Lösen der Fehlerzu warten bis alle Quelldaten zum Ziel migriert wurden. Der Standardwert von "false".
Beispielsweise kann mit der folgenden JSON die Datenvalidierung mit der doppelten Standard-Anzahl an Threads ausgeführt werden. Außerdem kommt dies für die Unterschiede in der Reihenfolgevon Datensätzen auf, die durch Unterschiede bei der Spaltensortierung in PostgreSQL-Endpunktenbedingt wurden. Auch wird eine Validierungs-Berichtverzögerung bereitgestellt, um für zusätzliche Zeitaufzukommen, die benötigt wird, um Validierungsfehler zu verarbeiten.
"ValidationSettings": { "EnableValidation": true, "ThreadCount": 10, "HandleCollationDiff": true, "RecordFailureDelayLimitInMinutes": 30 }
Note
Bei einem Oracle-Endpunkt nutzt AWS DMS DBMS_CRYPTO zur BLOB-Validierung. Wenn IhrOracle-Endpunkt BLOBs verwendet, erteilen Sie dem Benutzerkonto die Ausführungsberechtigungfür DBMS_CRYPTO, über das auf den Oracle-Endpunkt zugegriffen wird. Führen Sie dazu diefolgende Anweisung aus.
grant execute on sys.dbms_crypto to <dms_endpoint_user>;
Aufgabeneinstellungen für den Umgang mit der DDL-ÄnderungsverarbeitungDie folgenden Einstellungen bestimmen, wie AWS DMS Data Definition Language (DDL)-Änderungen fürZieltabellen während CDC (Change Data Capture) verarbeitet. Die Aufgabeneinstellungen für den Umgangmit der DDL-Änderungsverarbeitung umfassen die Folgenden:
• HandleSourceTableDropped – Legen Sie diese Option auf true fest, um die Zieltabelle zu löschen,wenn die Quelltabelle gelöscht wird.
• HandleSourceTableTruncated – Legen Sie diese Option auf true fest, um die Zieltabelle zu kürzen,wenn die Quelltabelle gekürzt wird.
• HandleSourceTableAltered – Legen Sie diese Option auf true fest, um die Zieltabelle zu ändern,wenn sich die Quelltabelle ändert.
Einstellungen der ZeichenersetzungsaufgabeSie können angeben, dass Ihre Replikationsaufgabe Zeichenersetzungen in der Zieldatenbank für alleQuelldatenbankspalten mit dem AWS DMS-Datentyp STRING oder WSTRING durchführt. Sie können
API-Version API Version 2016-01-01352

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
die Zeichenersetzung für jede Aufgabe mit Endpunkten aus den folgenden Quell- und Zieldatenbankenkonfigurieren:
• Quelldatenbanken:• Oracle• Microsoft SQL Server• MySQL• PostgreSQL• SAP Adaptive Server Enterprise (ASE)• IBM Db2 (LUW)
• Zieldatenbanken:• Oracle• Microsoft SQL Server• MySQL• PostgreSQL• SAP Adaptive Server Enterprise (ASE)• Amazon Redshift
Note
AWS DMS unterstützt die Zeichenersetzung ab Version 3.1.3.
Sie können Zeichenersetzungen mithilfe des Parameters CharacterSetSettings in IhrenAufgabeneinstellungen angeben. Diese Zeichenersetzungen erfolgen für Zeichen, die mit dem Unicode-Codepunktwert in Hexadezimalnotation angegeben werden. Sie können die Ersetzungen in zwei Phasen inder folgenden Reihenfolge implementieren, wenn beide angegeben sind:
1. Einzelne Zeichenersetzung – AWS DMS kann die Werte der ausgewählten Zeichen in der Quelle durchdie angegebenen Ersatzwerte der entsprechenden Zeichen auf dem Ziel ersetzen. Verwenden Sie dasCharacterReplacements-Array in CharacterSetSettings, um alle Quellzeichen mit den vonIhnen angegebenen Unicode-Codepunkten auszuwählen. Verwenden Sie dieses Array auch, um dieErsatz-Codepunkte für die entsprechenden Zeichen auf dem Ziel anzugeben.
Um alle Zeichen in der Quelle auszuwählen, die einen bestimmten Codepunkt haben, legen Sieeine Instance von SourceCharacterCodePoint im CharacterReplacements-Array auf diesenCodepunkt fest. Geben Sie dann den Ersatz-Codepunkt für alle gleichwertigen Zielzeichen an, indemSie die entsprechende Instance von TargetCharacterCodePoint in diesem Array festlegen.Um Zielzeichen zu löschen, anstatt sie zu ersetzen, setzen Sie die entsprechenden Instances vonTargetCharacterCodePoint auf Null (0). Sie können beliebig viele verschiedene Werte vonZielzeichen ersetzen oder löschen, indem Sie zusätzliche Paare von SourceCharacterCodePoint-und TargetCharacterCodePoint-Einstellungen im CharacterReplacements-Array angeben.Wenn Sie denselben Wert für mehrere Instances von SourceCharacterCodePoint angeben, gilt derWert der letzten entsprechenden Einstellung von TargetCharacterCodePoint für das Ziel.
Angenommen, Sie geben z. B. die folgenden Werte für CharacterReplacements an.
"CharacterSetSettings": { "CharacterReplacements": [ { "SourceCharacterCodePoint": 62, "TargetCharacterCodePoint": 61 }, { "SourceCharacterCodePoint": 42, "TargetCharacterCodePoint": 41 } ]
API-Version API Version 2016-01-01353

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
}
In diesem Beispiel ersetzt AWS DMS alle Zeichen mit dem Quellcodepunkt-Hexadezimalwert 62 aufdem Ziel durch Zeichen mit dem Codepunkt-Wert 61. Außerdem ersetzt AWS DMS alle Zeichen mit demQuellcodepunkt 42 auf dem Ziel durch Zeichen mit dem Codepunkt-Wert 41. Anders gesagt, ersetztAWS DMS alle Instances des Buchstaben 'b'auf dem Ziel durch den Buchstaben 'a'. EntsprechendAWS DMS ersetzt alle Instances des Buchstaben 'B' auf dem Ziel durch den Buchstaben 'A'.
2. Zeichensatzvalidierung und -ersetzung – Nachdem der Austausch einzelner Zeichen abgeschlossenist, kann AWS DMS überprüfen und sicherstellen, dass alle Zielzeichen in dem von Ihnenangegebenen einzelnen Zeichensatz über gültige Unicode-Codepunkte verfügen. Sie verwendenCharacterSetSupport in CharacterSetSettings, um diese Verifizierung und Modifizierung vonZielzeichen zu konfigurieren. Um den Verifizierungszeichensatz anzugeben, legen Sie CharacterSetin CharacterSetSupport auf den Zeichenfolgenwert des Zeichensatzes fest. (Nachstehend findenSie die möglichen Werte für CharacterSet.) Sie können die ungültigen Zielzeichen mit AWS DMS aufeine der folgenden Arten ändern:• Geben Sie einen einzigen Ersatz-Unicode-Codepunkt für alle ungültigen Zielzeichen an, unabhängig
von ihrem aktuellen Codepunkt. Um diesen Ersatz-Codepunkt zu konfigurieren, setzen SieReplaceWithCharacterCodePoint in CharacterSetSupport auf den angegebenen Wert.
• Konfigurieren Sie das Löschen aller ungültigen Zielzeichen, indem SieReplaceWithCharacterCodePoint auf Null (0) setzen.
Angenommen, Sie geben z. B. die folgenden Werte für CharacterSetSupport an.
"CharacterSetSettings": { "CharacterSetSupport": { "CharacterSet": "UTF16_PlatformEndian", "ReplaceWithCharacterCodePoint": 0 }}
In diesem Beispiel löscht AWS DMS alle Zeichen, die im Ziel gefunden wurden und die im Zeichensatz"UTF16_PlatformEndian" ungültig sind. Daher werden alle mit dem Hexadezimalwert 2FB6angegebenen Zeichen gelöscht. Dieser Wert ist ungültig, da es sich um einen 4-Byte-Unicode-Codepunkt handelt und UTF16-Zeichensätze nur Zeichen mit 2-Byte-Codepunkten akzeptieren.
Note
Die Replikationsaufgabe schließt alle angegebenen Zeichenersetzungen ab, bevor globaleTransformationen oder Transformationen auf Tabellenebene gestartet werden, die Sie über dieTabellenzuordnung angeben. Weitere Informationen zur Tabellenzuweisung finden Sie unterVerwenden der Tabellenzuweisung zum Angeben von Aufgabeneinstellungen (p. 372).
Die Werte, die AWS DMS für CharacterSet unterstützt, werden in der folgenden Tabelle angezeigt.
UTF-8 ibm-860_P100-1995 ibm-280_P100-1995
UTF-16 ibm-861_P100-1995 ibm-284_P100-1995
UTF-16BE ibm-862_P100-1995 ibm-285_P100-1995
UTF-16LE ibm-863_P100-1995 ibm-290_P100-1995
UTF-32 ibm-864_X110-1999 ibm-297_P100-1995
UTF-32BE ibm-865_P100-1995 ibm-420_X120-1999
API-Version API Version 2016-01-01354
AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
UTF-32LE ibm-866_P100-1995 ibm-424_P100-1995
UTF16_PlatformEndian ibm-867_P100-1998 ibm-500_P100-1995
UTF16_OppositeEndian ibm-868_P100-1995 ibm-803_P100-1999
UTF32_PlatformEndian ibm-869_P100-1995 ibm-838_P100-1995
UTF32_OppositeEndian ibm-878_P100-1996 ibm-870_P100-1995
UTF-16BE,version=1 ibm-901_P100-1999 ibm-871_P100-1995
UTF-16LE,version=1 ibm-902_P100-1999 ibm-875_P100-1995
UTF-16,version=1 ibm-922_P100-1999 ibm-918_P100-1995
UTF-16,version=2 ibm-1168_P100-2002 ibm-930_P120-1999
UTF-7 ibm-4909_P100-1999 ibm-933_P110-1995
IMAP-mailbox-name ibm-5346_P100-1998 ibm-935_P110-1999
SCSU ibm-5347_P100-1998 ibm-937_P110-1999
BOCU-1 ibm-5348_P100-1997 ibm-939_P120-1999
CESU-8 ibm-5349_P100-1998 ibm-1025_P100-1995
ISO-8859-1 ibm-5350_P100-1998 ibm-1026_P100-1995
US-ASCII ibm-9447_P100-2002 ibm-1047_P100-1995
gb18030 ibm-9448_X100-2005 ibm-1097_P100-1995
ibm-912_P100-1995 ibm-9449_P100-2002 ibm-1112_P100-1995
ibm-913_P100-2000 ibm-5354_P100-1998 ibm-1122_P100-1999
ibm-914_P100-1995 ibm-1250_P100-1995 ibm-1123_P100-1995
ibm-915_P100-1995 ibm-1251_P100-1995 ibm-1130_P100-1997
ibm-1089_P100-1995 ibm-1252_P100-2000 ibm-1132_P100-1998
ibm-9005_X110-2007 ibm-1253_P100-1995 ibm-1137_P100-1999
ibm-813_P100-1995 ibm-1254_P100-1995 ibm-4517_P100-2005
ibm-5012_P100-1999 ibm-1255_P100-1995 ibm-1140_P100-1997
ibm-916_P100-1995 ibm-5351_P100-1998 ibm-1141_P100-1997
ibm-920_P100-1995 ibm-1256_P110-1997 ibm-1142_P100-1997
iso-8859_10-1998 ibm-5352_P100-1998 ibm-1143_P100-1997
iso-8859_11-2001 ibm-1257_P100-1995 ibm-1144_P100-1997
ibm-921_P100-1995 ibm-5353_P100-1998 ibm-1145_P100-1997
iso-8859_14-1998 ibm-1258_P100-1997 ibm-1146_P100-1997
ibm-923_P100-1998 macos-0_2-10.2 ibm-1147_P100-1997
API-Version API Version 2016-01-01355
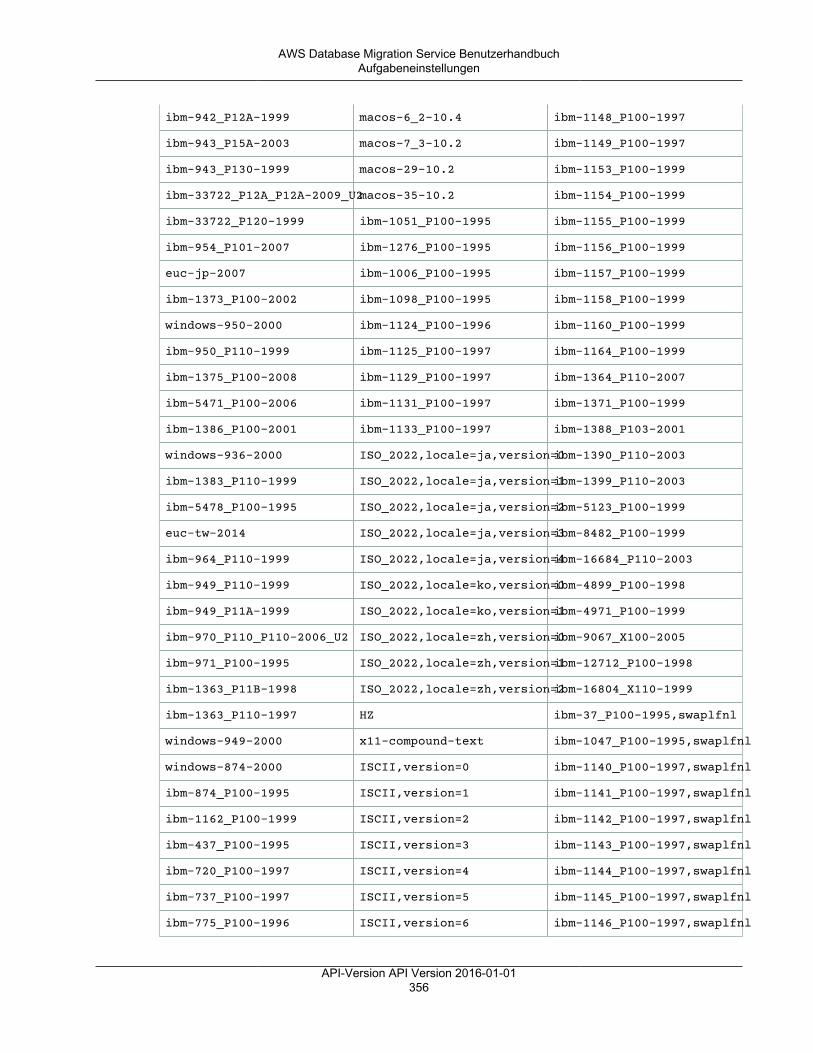
AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
ibm-942_P12A-1999 macos-6_2-10.4 ibm-1148_P100-1997
ibm-943_P15A-2003 macos-7_3-10.2 ibm-1149_P100-1997
ibm-943_P130-1999 macos-29-10.2 ibm-1153_P100-1999
ibm-33722_P12A_P12A-2009_U2macos-35-10.2 ibm-1154_P100-1999
ibm-33722_P120-1999 ibm-1051_P100-1995 ibm-1155_P100-1999
ibm-954_P101-2007 ibm-1276_P100-1995 ibm-1156_P100-1999
euc-jp-2007 ibm-1006_P100-1995 ibm-1157_P100-1999
ibm-1373_P100-2002 ibm-1098_P100-1995 ibm-1158_P100-1999
windows-950-2000 ibm-1124_P100-1996 ibm-1160_P100-1999
ibm-950_P110-1999 ibm-1125_P100-1997 ibm-1164_P100-1999
ibm-1375_P100-2008 ibm-1129_P100-1997 ibm-1364_P110-2007
ibm-5471_P100-2006 ibm-1131_P100-1997 ibm-1371_P100-1999
ibm-1386_P100-2001 ibm-1133_P100-1997 ibm-1388_P103-2001
windows-936-2000 ISO_2022,locale=ja,version=0ibm-1390_P110-2003
ibm-1383_P110-1999 ISO_2022,locale=ja,version=1ibm-1399_P110-2003
ibm-5478_P100-1995 ISO_2022,locale=ja,version=2ibm-5123_P100-1999
euc-tw-2014 ISO_2022,locale=ja,version=3ibm-8482_P100-1999
ibm-964_P110-1999 ISO_2022,locale=ja,version=4ibm-16684_P110-2003
ibm-949_P110-1999 ISO_2022,locale=ko,version=0ibm-4899_P100-1998
ibm-949_P11A-1999 ISO_2022,locale=ko,version=1ibm-4971_P100-1999
ibm-970_P110_P110-2006_U2 ISO_2022,locale=zh,version=0ibm-9067_X100-2005
ibm-971_P100-1995 ISO_2022,locale=zh,version=1ibm-12712_P100-1998
ibm-1363_P11B-1998 ISO_2022,locale=zh,version=2ibm-16804_X110-1999
ibm-1363_P110-1997 HZ ibm-37_P100-1995,swaplfnl
windows-949-2000 x11-compound-text ibm-1047_P100-1995,swaplfnl
windows-874-2000 ISCII,version=0 ibm-1140_P100-1997,swaplfnl
ibm-874_P100-1995 ISCII,version=1 ibm-1141_P100-1997,swaplfnl
ibm-1162_P100-1999 ISCII,version=2 ibm-1142_P100-1997,swaplfnl
ibm-437_P100-1995 ISCII,version=3 ibm-1143_P100-1997,swaplfnl
ibm-720_P100-1997 ISCII,version=4 ibm-1144_P100-1997,swaplfnl
ibm-737_P100-1997 ISCII,version=5 ibm-1145_P100-1997,swaplfnl
ibm-775_P100-1996 ISCII,version=6 ibm-1146_P100-1997,swaplfnl
API-Version API Version 2016-01-01356

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
ibm-850_P100-1995 ISCII,version=7 ibm-1147_P100-1997,swaplfnl
ibm-851_P100-1995 ISCII,version=8 ibm-1148_P100-1997,swaplfnl
ibm-852_P100-1995 LMBCS-1 ibm-1149_P100-1997,swaplfnl
ibm-855_P100-1995 ibm-37_P100-1995 ibm-1153_P100-1999,swaplfnl
ibm-856_P100-1995 ibm-273_P100-1995 ibm-12712_P100-1998,swaplfnl
ibm-857_P100-1995 ibm-277_P100-1995 ibm-16804_X110-1999,swaplfnl
ibm-858_P100-1997 ibm-278_P100-1995 ebcdic-xml-us
Vorher-Abbild-AufgabeneinstellungenWenn Sie CDC-Aktualisierungen auf ein Data-Streaming-Ziel wie Kinesis oder Kafka schreiben, könnenSie die ursprünglichen Werte einer Quelldatenbank anzeigen, bevor Sie durch eine Aktualisierung geändertwerden. Um dies zu ermöglichen, zeigt AWS DMS ein Vorher-Abbild von Aktualisierungsereignissenbasierend auf Daten, die von der Quelldatenbank-Engine bereitgestellt werden.
BeforeImageSettings – Fügt jeder Aktualisierungsoperation ein neues JSON-Attribut hinzu, wobeiWerte aus dem Quelldatenbanksystem gesammelt werden.
Note
Wenden Sie BeforeImageSettings auf Volllast plus CDC-Aufgaben (die vorhandeneDaten migrieren und laufende Änderungen replizieren) oder nur auf CDC-Aufgaben (die nurDatenänderungen replizieren) an. Wenden Sie BeforeImageSettings nicht auf Nur-Volllast-Aufgaben an.
• EnableBeforeImage – Wird vor dem Imaging aktiviert, wenn diese Einstellung auf true festgelegt ist.Der Standardwert ist false.
• FieldName – Weist dem neuen JSON-Attribut einen Namen zu. Wann EnableBeforeImage true ist,ist FieldName erforderlich und darf nicht leer sein.
• ColumnFilter – Gibt eine Spalte an, die mithilfe des Vorher-Imagings hinzugefügt werden soll. WennSie nur Spalten hinzufügen möchten, die Teil der Primärschlüssel der Tabelle sind, verwenden Sieden Standardwert pk-only. Wenn Sie nur Spalten hinzufügen möchten, die nicht vom LOB-Typ sind,verwenden Sie non-lob. Wenn Sie eine Spalte hinzufügen möchten, die einen Vorher-Abbild-Wert hat,verwenden Sie all.
Zum Beispiel:
"BeforeImageSettings": { "EnableBeforeImage": true, "FieldName": "before-image", "ColumnFilter": "pk-only" }
Weitere Informationen zu den Vorher-Abbild-Einstellungen für Kinesis, einschließlich zusätzlicherTabellenzuordnungseinstellungen, finden Sie unter Verwenden eines Vorher-Abbilds zum Anzeigen vonOriginalwerten von CDC-Zeilen für einen Kinesis-Datenstrom als Ziel (p. 288).
Weitere Informationen zu den Vorher-Abbild-Einstellungen für Kafka, einschließlich zusätzlicherTabellenzuordnungseinstellungen, finden Sie unter Verwenden eines Vorher-Abbilds zum Anzeigen vonOriginalwerten von CDC-Zeilen für Apache Kafka als Ziel (p. 298).
API-Version API Version 2016-01-01357

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
Aufgabeneinstellungen zur FehlerbehandlungSie können das Fehlerbehandlungsverhalten der Replikationsaufgabe während der Erfassung vonÄnderungsdaten (Change Data Capture, CDC) mit den folgenden Einstellungen festlegen:
• DataErrorPolicy – Legt die Aktion fest, die AWS DMS ausführt, wenn ein Fehler im Zusammenhangmit der Datenverarbeitung auf Datensatzebene vorliegt. Einige Beispiele für Fehler bei derDatenverarbeitung sind Konvertierungsfehler, Fehler bei der Transformation und ungültige Daten. DerStandardwert ist LOG_ERROR.• IGNORE_RECORD – Die Aufgabe wird fortgesetzt und die Daten für diesen Datensatz werden ignoriert.
Der Fehlerzähler für die Eigenschaft DataErrorEscalationCount wird erhöht. Wenn Sie also einLimit für Fehler für eine Tabelle festlegen, wird dieser Fehler auf dieses Limit angerechnet.
• LOG_ERROR – Die Aufgabe wird fortgesetzt und der Fehler wird in das Aufgabenprotokoll geschrieben.• SUSPEND_TABLE – Die Aufgabe wird fortgesetzt, Daten aus der Tabelle mit dem fehlerhaften
Datensatz werden jedoch in einen Fehlerstatus verschoben und die Daten werden nicht repliziert.• STOP_TASK – Die Aufgabe wird angehalten und manuelles Eingreifen ist erforderlich.
• DataTruncationErrorPolicy – Legt die Aktion fest, die AWS DMS ausführt, wenn Daten gekürztwerden. Der Standardwert ist LOG_ERROR.• IGNORE_RECORD – Die Aufgabe wird fortgesetzt und die Daten für diesen Datensatz werden ignoriert.
Der Fehlerzähler für die Eigenschaft DataErrorEscalationCount wird erhöht. Wenn Sie also einLimit für Fehler für eine Tabelle festlegen, wird dieser Fehler auf dieses Limit angerechnet.
• LOG_ERROR – Die Aufgabe wird fortgesetzt und der Fehler wird in das Aufgabenprotokoll geschrieben.• SUSPEND_TABLE – Die Aufgabe wird fortgesetzt, Daten aus der Tabelle mit dem fehlerhaften
Datensatz werden jedoch in einen Fehlerstatus verschoben und die Daten werden nicht repliziert.• STOP_TASK – Die Aufgabe wird angehalten und manuelles Eingreifen ist erforderlich.
• DataErrorEscalationPolicy – Legt die Aktion fest, die AWS DMS ausführt, wenn die maximaleAnzahl an Fehlern (im Parameter DataErrorsEscalationCount festgelegt) erreicht ist. DerStandardwert ist SUSPEND_TABLE.• SUSPEND_TABLE – Die Aufgabe wird fortgesetzt, Daten aus der Tabelle mit dem fehlerhaften
Datensatz werden jedoch in einen Fehlerstatus verschoben und die Daten werden nicht repliziert.• STOP_TASK – Die Aufgabe wird angehalten und manuelles Eingreifen ist erforderlich.
• DataErrorEscalationCount – Legt die maximale Anzahl an Fehlern fest, die für einen bestimmtenDatensatz auftreten können. Wenn diese Anzahl erreicht ist, werden die Daten für die Tabelle, die denfehlerhaften Datensatz enthält, gemäß der Richtlinie behandelt, die in DataErrorEscalationPolicyfestgelegt ist. Der Standardwert ist 0.
• TableErrorPolicy – Legt die Aktion fest, die AWS DMS ausführt, wenn bei der Verarbeitung vonDaten oder Metadaten für eine bestimmte Tabelle ein Fehler auftritt. Dieser Fehler gilt nur für allgemeineTabellendaten und ist kein Fehler, die sich auf einen bestimmten Datensatz bezieht. Der Standardwert istSUSPEND_TABLE.• SUSPEND_TABLE – Die Aufgabe wird fortgesetzt, Daten aus der Tabelle mit dem fehlerhaften
Datensatz werden jedoch in einen Fehlerstatus verschoben und die Daten werden nicht repliziert.• STOP_TASK – Die Aufgabe wird angehalten und manuelles Eingreifen ist erforderlich.
• TableErrorEscalationPolicy – Legt die Aktion fest, die AWS DMS ausführt, wenn die maximaleAnzahl an Fehlern (über den Parameter TableErrorEscalationCount festzulegen) erreicht ist.Die Standard- und einzige Benutzereinstellung ist STOP_TASK: Die Aufgabe wird angehalten und einmanueller Eingriff ist erforderlich.
• TableErrorEscalationCount – Die maximale Anzahl an Fehlern, die bei allgemeinen Datenoder Metadaten für eine bestimmte Tabelle auftreten können. Wenn diese Anzahl erreicht ist, werdendie Daten für die Tabelle gemäß der Richtlinie behandelt, die in TableErrorEscalationPolicyfestgelegt wurde. Der Standardwert ist 0.
• RecoverableErrorCount – Die maximale Anzahl an Versuchen zum Neustart einer Aufgabe, wennein Umgebungsfehler auftritt. Nachdem das System so oft wie angegeben versucht hat, die Aufgabe neu
API-Version API Version 2016-01-01358

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
zu starten, wird die Aufgabe angehalten und ein manueller Eingriff ist erforderlich. Der Standardwert ist-1. Hiermit wird AWS DMS angewiesen, die Aufgabe unbegrenzt neu zu starten. Legen Sie diesen Wertauf 0 fest, um nie zu versuchen, eine Aufgabe neu zu starten. Wenn ein schwerwiegender Fehler auftritt,hört AWS DMS nach sechs Versuchen auf, die Aufgabe neu zu starten.
• RecoverableErrorInterval – Die Anzahl an Sekunden, die AWS DMS zwischen Versuchen zumNeustart einer Aufgabe wartet. Der Standardwert ist 5.
• RecoverableErrorThrottling – Wenn diese Option aktiviert ist, wird das Intervall zwischenversuchten Neustarts einer Aufgabe jedes Mal erhöht, wenn ein Neustart versucht wird. DerStandardwert ist true.
• RecoverableErrorThrottlingMax – Die maximale Anzahl an Sekunden, die AWS DMS zwischenversuchten Neustarts einer Aufgabe wartet, wenn RecoverableErrorThrottling aktiviert ist. DerStandardwert ist 1800.
• ApplyErrorDeletePolicy – Legt fest, welche Aktion AWS DMS ausführt, wenn es zu einem Konfliktmit einem DELETE-Vorgang kommt. Der Standardwert ist IGNORE_RECORD.• IGNORE_RECORD – Die Aufgabe wird fortgesetzt und die Daten für diesen Datensatz werden ignoriert.
Der Fehlerzähler für die Eigenschaft ApplyErrorEscalationCount wird erhöht. Wenn Sie also einLimit für Fehler für eine Tabelle festlegen, wird dieser Fehler auf dieses Limit angerechnet.
• LOG_ERROR – Die Aufgabe wird fortgesetzt und der Fehler wird in das Aufgabenprotokoll geschrieben.• SUSPEND_TABLE – Die Aufgabe wird fortgesetzt, Daten aus der Tabelle mit dem fehlerhaften
Datensatz werden jedoch in einen Fehlerstatus verschoben und die Daten werden nicht repliziert.• STOP_TASK – Die Aufgabe wird angehalten und manuelles Eingreifen ist erforderlich.
• ApplyErrorInsertPolicy – Legt fest, welche Aktion AWS DMS ausführt, wenn es zu einem Konfliktmit einem INSERT-Vorgang kommt. Der Standardwert ist LOG_ERROR.• IGNORE_RECORD – Die Aufgabe wird fortgesetzt und die Daten für diesen Datensatz werden ignoriert.
Der Fehlerzähler für die Eigenschaft ApplyErrorEscalationCount wird erhöht. Wenn Sie also einLimit für Fehler für eine Tabelle festlegen, wird dieser Fehler auf dieses Limit angerechnet.
• LOG_ERROR – Die Aufgabe wird fortgesetzt und der Fehler wird in das Aufgabenprotokoll geschrieben.• SUSPEND_TABLE – Die Aufgabe wird fortgesetzt, Daten aus der Tabelle mit dem fehlerhaften
Datensatz werden jedoch in einen Fehlerstatus verschoben und die Daten werden nicht repliziert.• STOP_TASK – Die Aufgabe wird angehalten und manuelles Eingreifen ist erforderlich.• INSERT_RECORD – Wenn ein bereits bestehender Zieldatensatz denselben Primärschlüssel wie der
eingefügte Quelldatensatz hat, wird der Zieldatensatz aktualisiert.• ApplyErrorUpdatePolicy – Legt fest, welche Aktion AWS DMS ausführt, wenn es zu einem Konflikt
mit einem UPDATE-Vorgang kommt. Der Standardwert ist LOG_ERROR.• IGNORE_RECORD – Die Aufgabe wird fortgesetzt und die Daten für diesen Datensatz werden ignoriert.
Der Fehlerzähler für die Eigenschaft ApplyErrorEscalationCount wird erhöht. Wenn Sie also einLimit für Fehler für eine Tabelle festlegen, wird dieser Fehler auf dieses Limit angerechnet.
• LOG_ERROR – Die Aufgabe wird fortgesetzt und der Fehler wird in das Aufgabenprotokoll geschrieben.• SUSPEND_TABLE – Die Aufgabe wird fortgesetzt, Daten aus der Tabelle mit dem fehlerhaften
Datensatz werden jedoch in einen Fehlerstatus verschoben und die Daten werden nicht repliziert.• STOP_TASK – Die Aufgabe wird angehalten und manuelles Eingreifen ist erforderlich.• UPDATE_RECORD – Wenn der Zieldatensatz fehlt, wird der fehlende Zieldatensatz in die Zieltabelle
eingefügt. Wenn diese Option ausgewählt wird, muss die vollständige ergänzende Protokollierung füralle Quelltabellenspalten aktiviert werden, wenn Oracle die Quelldatenbank ist.
• ApplyErrorEscalationPolicy – Legt die Aktion fest, die AWS DMS ausführt, wenn die maximaleAnzahl an Fehlern (über den Parameter ApplyErrorsEscalationCount festzulegen) erreicht ist.• LOG_ERROR – Die Aufgabe wird fortgesetzt und der Fehler wird in das Aufgabenprotokoll geschrieben.• SUSPEND_TABLE – Die Aufgabe wird fortgesetzt, Daten aus der Tabelle mit dem fehlerhaften
Datensatz werden jedoch in einen Fehlerstatus verschoben und die Daten werden nicht repliziert.• STOP_TASK – Die Aufgabe wird angehalten und manuelles Eingreifen ist erforderlich.API-Version API Version 2016-01-01
359

AWS Database Migration Service BenutzerhandbuchAufgabeneinstellungen
• ApplyErrorEscalationCount – Legt die maximale Anzahl der APPLY-Konflikte fest, diewährend einer Prozessänderung für eine bestimmte Tabelle auftreten können. Wenn diese Anzahlerreicht ist, werden die Daten für die Tabelle gemäß der Richtlinie behandelt, die im ParameterApplyErrorEscalationPolicy festgelegt wurde. Der Standardwert ist 0.
• ApplyErrorFailOnTruncationDdl – Setzen Sie dies auf true, damit die Aufgabe fehlschlägt, wennan einer der nachverfolgten Tabellen während der CDC eine Kürzung vorgenommen wird. Dafür wird dieFehlermeldung lauten: "Truncation DDL detected." Der Standardwert ist false.
Dieser Ansatz funktioniert nicht mit PostgreSQL oder einem anderen Quellendpunkt, der die DDL-Tabellenkürzung nicht repliziert.
• FailOnNoTablesCaptured – Setzen Sie dies auf true, damit die Aufgabe fehlschlägt, wenn die füreine Aufgabe definierten Transformierungsregeln beim Start der Aufgabe keine Tabellen finden. DerStandardwert ist false.
• FailOnTransactionConsistencyBreached – Diese Option trifft auf Aufgaben zu, die für CDCOracle als Quelle verwenden. Geben Sie dies mit true an, damit eine Aufgabe fehlschlägt, wenn eineTransaktion länger als der angegebene Timeoutwert geöffnet ist und verworfen werden könnte.
Wenn eine CDC-Aufgabe mit Oracle gestartet wird, wartet AWS DMS einen begrenzten Zeitraum,damit die älteste offene Transaktion geschlossen wird, bevor CDC beginnt. Wenn die älteste offeneTransaktion vor Ablauf des Timeouts nicht geschlossen wird, startet CDC normalerweise trotzdem unddie Transaktion wird ignoriert. Wenn diese Einstellung mit true angegeben ist, schlägt die Aufgabe fehl.
• FullLoadIgnoreConflicts – Setzen Sie dies auf true, damit AWS DMS die Fehler „zero rowsaffected (null Zeilen betroffen)“ und „duplicates (Duplikate)“ ignoriert, wenn zwischengespeicherteEreignisse angewendet werden. Bei Einstellung auf false meldet AWS DMS alle Fehler, anstatt sie zuignorieren. Der Standardwert ist true.
Speichern der AufgabeneinstellungenSie können die Einstellungen für eine Aufgabe als JSON-Datei speichern, falls Sie die Einstellungen füreine andere Aufgabe wiederverwenden möchten.
Zum Beispiel enthält die folgende JSON-Datei gespeicherte Einstellungen für eine Aufgabe.
{ "TargetMetadata": { "TargetSchema": "", "SupportLobs": true, "FullLobMode": false, "LobChunkSize": 64, "LimitedSizeLobMode": true, "LobMaxSize": 32, "BatchApplyEnabled": true }, "FullLoadSettings": { "TargetTablePrepMode": "DO_NOTHING", "CreatePkAfterFullLoad": false, "StopTaskCachedChangesApplied": false, "StopTaskCachedChangesNotApplied": false, "MaxFullLoadSubTasks": 8, "TransactionConsistencyTimeout": 600, "CommitRate": 10000 }, "Logging": { "EnableLogging": false }, "ControlTablesSettings": { "ControlSchema":"", "HistoryTimeslotInMinutes":5,
API-Version API Version 2016-01-01360

AWS Database Migration Service BenutzerhandbuchEinrichten der LOB-Unterstützung
"HistoryTableEnabled": false, "SuspendedTablesTableEnabled": false, "StatusTableEnabled": false }, "StreamBufferSettings": { "StreamBufferCount": 3, "StreamBufferSizeInMB": 8 }, "ChangeProcessingTuning": { "BatchApplyPreserveTransaction": true, "BatchApplyTimeoutMin": 1, "BatchApplyTimeoutMax": 30, "BatchApplyMemoryLimit": 500, "BatchSplitSize": 0, "MinTransactionSize": 1000, "CommitTimeout": 1, "MemoryLimitTotal": 1024, "MemoryKeepTime": 60, "StatementCacheSize": 50 }, "ChangeProcessingDdlHandlingPolicy": { "HandleSourceTableDropped": true, "HandleSourceTableTruncated": true, "HandleSourceTableAltered": true }, "ErrorBehavior": { "DataErrorPolicy": "LOG_ERROR", "DataTruncationErrorPolicy":"LOG_ERROR", "DataErrorEscalationPolicy":"SUSPEND_TABLE", "DataErrorEscalationCount": 50, "TableErrorPolicy":"SUSPEND_TABLE", "TableErrorEscalationPolicy":"STOP_TASK", "TableErrorEscalationCount": 50, "RecoverableErrorCount": 0, "RecoverableErrorInterval": 5, "RecoverableErrorThrottling": true, "RecoverableErrorThrottlingMax": 1800, "ApplyErrorDeletePolicy":"IGNORE_RECORD", "ApplyErrorInsertPolicy":"LOG_ERROR", "ApplyErrorUpdatePolicy":"LOG_ERROR", "ApplyErrorEscalationPolicy":"LOG_ERROR", "ApplyErrorEscalationCount": 0, "FullLoadIgnoreConflicts": true }}
Festlegen von LOB-Support für Quelldatenbanken ineiner AWS DMS-AufgabeGroße binäre Objekte (LOBs) lassen sich manchmal nur schwierig zwischen Systemen migrieren.AWS DMS bietet eine Reihe von Optionen, die Ihnen bei der Optimierung von LOB-Spalten helfen.Informationen dazu, wann welche Datentypen von AWS DMS als LOBs betrachtet werden, finden Sie in derDokumentation zu AWS DMS.
Beim Migrieren von Daten von einer Datenbank in eine andere, sollten Sie überdenken, wie Ihre LOBsgespeichert werden. Dies gilt insbesondere für heterogene Migrationen. Wenn Sie dies möchten, müssenSie die LOB-Daten nicht migrieren.
Wenn Sie sich für LOBs entschieden haben, können Sie die anderen LOB-Einstellungen festlegen:
• Der LOB-Modus bestimmt, wie LOBs verarbeitet werden:
API-Version API Version 2016-01-01361

AWS Database Migration Service BenutzerhandbuchErstellen mehrerer Aufgaben
• Full LOB mode (Vollständiger LOB-Modus) – Im vollständigen LOB-Modus migriert AWS DMS alleLOBs unabhängig von der Größe von der Quell- in die Zieldatenbank. Bei dieser Konfiguration verfügtAWS DMS über keine Informationen zur maximalen Größe der zu erwartenden LOBs. Folglich werdendie LOBs einzeln migriert. Der vollständige LOB-Modus kann recht langsam sein.
• Limited LOB mode (Eingeschränkter LOB-Modus) – Im eingeschränkten LOB-Modus können Sie einemaximale LOB-Größe festlegen, die von AWS DMS akzeptiert werden sollte. Auf diese Weise kannAWS DMS vorab Speicher zuweisen und die LOB-Daten massenweise laden. LOBs, die die maximaleLOB-Größe überschreiten, werden abgeschnitten und in der Protokolldatei wird eine entsprechendeWarnung ausgegeben. Im eingeschränkten LOB-Modus kann gegenüber dem vollständigen LOB-Modus eine erhebliche Steigerung der Performance erzielt werden. Wir empfehlen Ihnen, nachMöglichkeit den eingeschränkten LOB-Modus zu verwenden.
Note
Bei Oracle werden LOBs als VARCHAR-Datentypen behandelt, wann immer dies möglichist. Dieser Ansatz bedeutet konkret, dass AWS DMS diese Objekte massenweise von derDatenbank abruft. Dies ist deutlich schneller als die anderen Methoden. Die maximale Größeeines VARCHAR in Oracle ist 64 K. Wenn Oracle Ihre Quelldatenbank ist, ist eine auf wenigerals 64 K beschränkte LOB-Größe daher optimal.
• Wenn eine Aufgabe zur Ausführung im eingeschränkten LOB-Modus konfiguriert wurde, wird mit derOption Max LOB size (K) (Maximale LOB-Größe (K)) die maximale LOB-Größe festgelegt, die von AWSDMS akzeptiert wird. Alle LOBs, die diesen Wert überschreiten, werden auf diesen Wert gekürzt.
• Wenn eine Aufgabe zur Verwendung des vollständigen LOB-Modus konfiguriert wurde, ruft AWS DMSLOBs stückweise ab. Die Option LOB chunk size (K) (LOB-Teilegröße) bestimmt die Größe der einzelnenTeile. Wenn Sie diese Option festlegen, achten Sie besonders auf die maximale Paketgröße, die gemäßIhrer Netzwerkkonfiguration zulässig ist. Wenn die LOB-Blockgröße die maximal zulässige Paketgrößeüberschreitet, erhalten Sie möglicherweise Trennungsfehler.
Weitere Informationen zu den Aufgabeneinstellungen zum Angeben dieser Optionen finden Sie unter Ziel-Metadaten-Aufgabeneinstellungen (p. 343)
Erstellen mehrerer AufgabenIn einigen Migrationsszenarien müssen Sie möglicherweise mehrere Migrationsaufgaben erstellen.Aufgaben funktionieren unabhängig voneinander und können gleichzeitig ausgeführt werden. Jede Aufgabehat ihren eigenen Prozess für das anfängliche Laden, CDC und das Lesen von Protokollen. Tabellen,die über DML (Datenmanipulationssprache) miteinander in Beziehung stehen, müssen Teil der gleichenAufgabe sein.
Einige Gründe für das Erstellen mehrerer Aufgaben für eine Migration sind Folgende:
• Die Zieltabellen für die Aufgaben liegen auf verschiedenen Datenbanken, z. B., wenn Sie ein Systemerweitern oder in mehrere Systeme unterteilen.
• Sie möchten die Migration einer großen Tabelle mithilfe von Filtern in mehrere Aufgaben unterteilen.
Note
Da jede Aufgabe ihren eigenen Prozess für das Erfassen von Änderungen und das Lesen vonProtokollen hat, werden Änderungen nicht über Aufgaben hinweg koordiniert. Vergewissern Siesich daher, wenn Sie mehrere Aufgaben für die Durchführung einer Migration verwenden, dassQuelltransaktionen vollständig innerhalb einer einzigen Aufgabe enthalten sind.
API-Version API Version 2016-01-01362

AWS Database Migration Service BenutzerhandbuchFortlaufende Replikationsaufgaben
Erstellen von Aufgaben für die laufende Replikationmit AWS DMS
Sie können eine AWS DMS-Aufgabe erstellen, die fortlaufenden Änderungen am Quell-Datenspeichererfasst. Diese Erfassung kann erfolgen, während Sie Ihre Daten migrieren. Sie können auch eine Aufgabeerstellen, die laufende Änderungen erfasst, nachdem Sie Ihre erste (Full-Load) Migration auf einenunterstützten Zieldatenspeicher abgeschlossen haben. Dieser Prozess wird als fortlaufende Replikationoder Change Data Capture (CDC) bezeichnet. AWS DMS verwendet diesen Prozess beim Replizieren vonlaufenden Änderungen aus einem Quelldatenspeicher. Bei diesem Prozess werden Änderungen an denDatenbankprotokollen mithilfe der Datenbank-Engine der nativen API erfasst.
Note
Sie können Ansichten nur mithilfe von Full-Load-Aufgaben migrieren. Wenn es sich bei IhrerAufgabe entweder um eine reine CDC-Aufgabe oder eine Full-Load-Aufgabe handelt, dieCDC nach ihrem Abschluss startet, enthält die Migration nur Tabellen aus der Quelle. Miteiner Full-Load-Aufgabe können Sie Ansichten oder eine Kombination aus Tabellen undAnsichten migrieren. Weitere Informationen finden Sie unter Festlegen der Tabellenauswahl undTransformationen durch Tabellenzuweisungen mit JSON (p. 377).
Jede Quell-Engine verfügt über spezifische Konfigurationsanforderungen für die Bereitstellung diesesÄnderungsstroms für ein bestimmtes Benutzerkonto. Die meisten Engines erfordern eine zusätzlicheKonfiguration, damit der Erfassungsprozess die Änderungsdaten sinnvoll und ohne Datenverlustverwerten kann. Zum Beispiel erfordert Oracle eine zusätzliche Protokollierung und MySQL eine binäreProtokollierung auf Zeilenebene.
Um fortlaufende Änderungen aus der Quelldatenbank zu lesen, verwendet AWS DMS zum Lesen vonÄnderungen aus den Transaktionsprotokollen der Quell-Engine jeweils für eine Engine spezifische API-Aktionen. Nachfolgend finden Sie einige Beispiele dafür, wie AWS DMS dabei vorgeht:
• Für Oracle nutzt AWS DMS entweder die Oracle LogMiner-API oder die binäre Leser-API (bfile-API),um fortlaufende Änderungen zu lesen. AWS DMS liest fortlaufende Änderungen aus den Online- oderArchiv-Redo-Protokollen basierend auf der Systemänderungsnummer (SCN).
• Für Microsoft SQL Server verwendet AWS DMS MS Replication oder MS-CDC, um Informationen in dasSQL Server-Transaktionsprotokoll zu schreiben. Anschließend wird die Funktion fn_dblog() oder fn_dump_dblog() in SQL Server zum Lesen der Änderungen im Transaktionsprotokoll basierend aufder Log-Sequenznummer (LSN) verwendet.
• Für MySQL liest AWS DMS Änderungen aus den zeilenbasierten Binärprotokollen und migriert dieseÄnderungen in die Zieldatenbank.
• Für PostgreSQL richtet AWS DMS logische Replikations-Slots ein und verwendet das test_decoding-Plugin, um Änderungen aus der Quelldatenbank zu lesen und in die Zieldatenbank zu migrieren.
• Für Amazon RDS als Quelle sollten Sie sicherstellen, dass zur Einrichtung von CDC Sicherungenaktiviert sind. Wir empfehlen außerdem, sicherzustellen, dass die Quelldatenbank so konfiguriert ist,dass Änderungsprotokolle für einen ausreichenden Zeitraum aufbewahrt werden — in der Regel sind24 Stunden ausreichend.
Es gibt zwei Arten von fortlaufenden Replikationsaufgaben:
• Der vollständige Ladevorgang plus CDC – Die Aufgabe migriert vorhandene Daten und aktualisiert danndie Zieldatenbank basierend auf den Änderungen an der Quelldatenbank.
• Nur CDC – Die Aufgabe migriert laufende Änderungen, nachdem Sie Daten in Ihrer Zieldatenbankvorliegen haben.
API-Version API Version 2016-01-01363

AWS Database Migration Service BenutzerhandbuchStarten der Replikation von einem CDC-Startpunkt aus
Durchführen der Replikation von einem CDC-Startpunkt ausSie können eine fortlaufende AWS DMS-Replikationsaufgabe (reine Change Data Capture-Aufgabe) vonmehreren Punkten aus starten. Diese umfassen u. a. folgende:
• Ab einer benutzerdefinierten CDC-Startzeit – Sie können mithilfe der AWS Management Console oderder AWS CLI einen Zeitstempel des Zeitpunkts für AWS DMS bereitstellen, an dem die Replikationbeginnen soll. AWS DMS startet eine fortlaufende Replikationsaufgabe ab dieser benutzerdefiniertenCDC-Startzeit. AWS DMS wandelt den angegebenen Zeitstempel (in UTC) in einen nativen Startpunktum, wie z. B. eine LSN für SQL Server oder eine SCN für Oracle. AWS DMS verwendet Engine-spezifische Methoden, um zu ermitteln, wo genau die Migrationsaufgabe basierend auf demÄnderungsstream der Quell-Engine gestartet werden soll.
Note
PostgreSQL als Quelle unterstützt die benutzerdefinierte CDC-Startzeit nicht. Der Grund hierfürist, dass die PostgreSQL-Datenbank-Engine keine Möglichkeit hat, einen Zeitstempel zu einemLSN oder SCN zuzuordnen, wie es Oracle und SQL Server tun.
• Ab einem nativen CDC-Startpunkt – Sie können auch einen nativen Punkt im Transaktionsprotokoll derQuell-Engine als Startpunkt verwenden. In manchen Fällen kann dieser Ansatz besser geeignet sein, daein Zeitstempel mehrere native Punkte im Transaktionsprotokoll angeben kann. AWS DMS unterstütztdiese Funktion für die folgenden Quellendpunkte:• SQL Server• PostgreSQL• Oracle• MySQL
Bestimmen eines nativen CDC-StartpunktsEin nativer CDC-Startpunkt ist ein Punkt im Datenbank-Engine-Protokoll, der einen Zeitpunkt festlegt, abdem Sie mit der CDC beginnen können. Nehmen wir als Beispiel an, dass ein Massendaten-Dump abeinem Zeitpunkt auf das Ziel angewendet wurde. In diesem Fall können Sie die nativen Startpunkt für diefortlaufende reine Replikationsaufgabe ab einem Punkt suchen, der vor der Dump-Erstellung liegt.
Nachstehend finden Sie Beispiele dafür, wie Sie den nativen CDC-Startpunkt über unterstützte Quell-Engines finden:
SQL Server
Bei SQL Server besteht eine Log-Sequenznummer (LSN) aus drei Teilen:• Virtual Log File (VLF)-Sequenznummer• Anfangsversatz eines Protokollblocks• Slot-Nummer
Die LSN lautet z. B.: 00000014:00000061:0001
Mit der Funktion fn_dblog() oder fn_dump_dblog() in SQL Server können Sie denStartpunkt einer SQL Server-Migrationsaufgabe basierend auf den Sicherungseinstellungen IhresTransaktionsprotokolls anfordern.
Um den nativen CDC-Startpunkt mit SQL Server zu verwenden, erstellen Sie eine Veröffentlichungfür jede Tabelle, die an der laufenden Replikation beteiligt ist. Weitere Informationen zum Erstelleneiner Veröffentlichung finden Sie unter Erstellen einer SQL Server-Veröffentlichung für die laufende
API-Version API Version 2016-01-01364

AWS Database Migration Service BenutzerhandbuchStarten der Replikation von einem CDC-Startpunkt aus
Replikation (p. 156). AWS DMS erstellt die Veröffentlichung automatisch, wenn Sie CDC ohne nativenCDC Startpunkt verwenden.
PostgreSQL
Sie können einen CDC-Wiederherstellungsprüfpunkt für Ihre PostgreSQL-Quelldatenbankverwenden. Dieser Prüfpunktwert wird an verschiedenen Punkten generiert, während eine laufendeReplikationsaufgabe für Ihre Quelldatenbank (die übergeordnete Aufgabe) ausgeführt wird. WeitereInformationen zu Prüfpunkten im Allgemeinen finden Sie unter Verwendung eines Kontrollpunkts alsCDC-Startpunkt (p. 366).
Um den Prüfpunkt zu identifizieren, der als Ihr nativer Startpunkt verwendet werden soll,verwenden Sie Ihre Datenbank-pg_replication_slots-Ansicht oder die Übersichtsdetails Ihrerübergeordneten Aufgabe aus der AWS Management Console.
So finden Sie die Übersichtsdetails für Ihre übergeordnete Aufgabe auf der Konsole
1. Melden Sie sich bei der AWS Management Console an und öffnen Sie die AWS DMS-Konsoleunter https://console.aws.amazon.com/dms/v2/.
2. Wählen Sie im Navigationsbereich die Option Database migration tasks(Datenbankmigrationsaufgaben) aus.
3. Wählen Sie Ihre übergeordnete Aufgabe aus der Liste auf der Seite Database migration tasks(Datenbankmigrationsaufgaben) aus. Dadurch wird die Seite der übergeordneten Aufgabengeöffnet, auf der die Übersichtsdetails angezeigt werden.
4. Suchen Sie unter Change Data Capture (CDC), Change Data Capture (CDC) start position(CDC-Startposition) und Change Data Capture (CDC) Recovery Checkpoint (CDC-Wiederherstellungsprüfpunkt) nach dem Prüfpunktwert.
Der Wert ähnelt dem folgenden:
checkpoint:V1#1#000004AF/B00000D0#0#0#*#0#0
Hier ist es die Komponente 4AF/B00000D0, die Sie benötigen, um diesen nativen CDC-Startpunkt anzugeben. Setzen Sie beim Erstellen der CDC-Aufgabe den DMS-API-ParameterCdcStartPosition auf diesen Wert, um die Replikation an diesem Startpunkt für IhrePostgreSQL-Quelle zu beginnen. Weitere Informationen zum Verwenden der AWS CLIzum Erstellen dieser CDC-Aufgabe finden Sie unter Verwenden von CDC mit einer RDS fürPostgreSQL-DB-Instance (p. 172).
Oracle
Eine Systemänderungsnummer (SCN) ist ein logischer, interner Zeitstempel von Oracle-Datenbanken.SCNs dienen zur Anordnung von Ereignissen, die innerhalb der Datenbank auftreten. Dies isterforderlich, um die ACID-Eigenschaften einer Transaktion zu erfüllen. Oracle-Datenbankenverwenden SCNs, um den Speicherort zu markieren, an dem alle Änderungen auf die Festplattegeschrieben wurden, sodass eine Wiederherstellungsaktion keine bereits geschriebenen Änderungenübernimmt. Oracle verwendet SCNs zudem zur Markierung des Punkts, an dem für einen Satz vonDaten kein Redo vorhanden ist, sodass die Wiederherstellung enden kann. Weitere Informationen zuOracle SCNs finden Sie in der Oracle-Dokumentation.
Führen Sie den folgenden Befehl aus, um die aktuelle SCN in einer Oracle-Datenbank zu erhalten:
SELECT current_scn FROM V$DATABASE
MySQL
Vor der Veröffentlichung von MySQL Version 5.6.3 bestand die Log-Sequenznummer (LSN) fürMySQL aus einer 4-Byte-Ganzzahl ohne Vorzeichen. In MySQL Version 5.6.3 wurde die LSN mit
API-Version API Version 2016-01-01365

AWS Database Migration Service BenutzerhandbuchStarten der Replikation von einem CDC-Startpunkt aus
der Erhöhung des Redo-Log-Dateigrößenlimits von 4 GB auf 512 GB zu einer 8-Byte-Ganzzahlohne Vorzeichen. Die Erhöhung berücksichtigt, dass weitere Byte zum Speichern zusätzlicherGrößeninformationen erforderlich waren. Anwendungen, die auf MySQL 5.6.3 oder höher basierenund LSN-Werte nutzen, sollten zum Speichern und Vergleichen von LSN-Werten 64-Bit- anstellevon 32-Bit-Variablen verwenden. Weitere Informationen zu MySQL LSNs finden Sie in der MySQL-Dokumentation.
Führen Sie den folgenden Befehl aus, um die aktuelle LSN in einer MySQL-Datenbank zu erhalten:
mysql> show master status;
Die Abfrage gibt einen Binärprotokoll-Dateinamen, die Position und einige andere Werte zurück.Der native CDC-Startpunkt ist eine Kombination aus dem Namen der Binärprotokolldatei undder Position, z. B. mysql-bin-changelog.000024:373. In diesem Beispiel ist mysql-bin-changelog.000024 der Binärprotokoll-Dateiname und 373 die Position, an der AWS DMS dieErfassung der Änderungen beginnen muss.
Verwendung eines Kontrollpunkts als CDC-StartpunktEine fortlaufende Replikationsaufgabe migriert Änderungen und AWS DMS legt von Zeit zu Zeit AWS DMS-spezifische Prüfpunktangaben im Zwischenspeicher ab. Der Prüfpunkt, den AWS DMS erstellt, enthältInformationen, sodass die Replikations-Engine den Wiederherstellungspunkt für den Änderungsstreamkennt. Sie können den Prüfpunkt verwenden, um in der Zeitleiste der Änderungen zurückzugehen und einefehlgeschlagene Migrationsaufgabe wiederherzustellen. Mit einem Prüfpunkt können Sie auch eine weiterelaufende Replikationsaufgabe für ein anderes Ziel zu einem bestimmten Zeitpunkt starten.
Zum Abrufen der Prüfpunktinformationen gibt es zwei Möglichkeiten:
• Führen Sie den API-Befehl DescribeReplicationTasks aus und sehen Sie sich die Ergebnisse an.Sie können die Informationen nach Aufgabe filtern und nach dem Prüfpunkt suchen. Sie können denletzten Kontrollpunkt abrufen, wenn sich die Aufgabe im angehaltenen oder fehlgeschlagenen Zustandbefindet.
• Zeigen Sie die Metadatentabelle mit dem Namen awsdms_txn_state auf der Ziel-Instance an. Siekönnen die Tabelle abfragen, um Prüfpunktinformationen abzurufen. Zum Erstellen der Metadatentabellelegen Sie den TaskRecoveryTableEnabled-Parameter auf Yes fest, wenn Sie eine Aufgabe erstellen.Mit dieser Einstellung schreibt AWS DMS kontinuierlich Kontrollpunktangaben in die Ziel-Metadaten-Tabelle. Diese Informationen gehen verloren, wenn eine Aufgabe gelöscht wird.
Das folgende Beispiel zeigt einen Prüfpunkt in der Metadaten-Tabelle:checkpoint:V1#34#00000132/0F000E48#0#0#*#0#121
Anhalten einer Aufgabe an einem Commit- oder Server-ZeitpunktMit der Einführung nativer CDC-Startpunkte hat AWS DMS auch die Möglichkeit, eine Aufgabe zu denfolgenden Zeitpunkten anzuhalten:
• Commit-Zeitpunkt in der Quelle• Server-Zeitpunkt auf der Replikations-Instance
Sie können eine Aufgabe ändern und eine Uhrzeit zum Anhalten in koordinierter Weltzeit (UTC) wieerforderlich festlegen. Die Aufgabe wird basierend auf dem Commit- oder Server-Zeitpunkt, den Siefestgelegt haben, automatisch gestoppt. Wenn Sie zum Zeitpunkt der Aufgabenerstellung wissen, wann dieMigrationsaufgabe enden soll, können Sie im Rahmen der Erstellung auch den betreffenden Zeitpunkt zumStoppen festlegen.
API-Version API Version 2016-01-01366

AWS Database Migration Service BenutzerhandbuchDurchführen der bidirektionalen Replikation
Durchführen der bidirektionalen ReplikationSie können AWS DMS-Aufgaben verwenden, um eine bidirektionale Replikation zwischen zwei Systemendurchzuführen. Bei der bidirektionalen Replikation replizieren Sie Daten aus derselben Tabelle (oder einemSatz von Tabellen) zwischen zwei Systemen in beide Richtungen.
Beispielsweise können Sie eine Tabelle MITARBEITER von Datenbank A nach Datenbank B kopierenund Änderungen an der Tabelle von Datenbank A nach Datenbank B replizieren. Sie können auchÄnderungen an der Tabelle MITARBEITER von Datenbank B zurück nach A replizieren. Sie führen alsoeine bidirektionale Replikation durch.
Note
Die bidirektionale AWS DMS-Replikation ist nicht als vollständige Multi-Master-Lösung mit einemPrimärknoten, Konfliktlösung usw. gedacht.
Verwenden Sie die bidirektionale Replikation für Situationen, in denen Daten auf verschiedenen Knotenoperativ getrennt sind. Anders ausgedrückt: Angenommen, Sie lassen ein Datenelement von einerAnwendung ändern, die auf Knoten A ausgeführt wird, und Knoten A führt eine bidirektionale Replikationmit Knoten B durch. Dieses Datenelement auf Knoten A wird niemals von einer Anwendung geändert, dieauf Knoten B ausgeführt wird.
Die AWS DMS-Versionen 3.3.1 und höher unterstützen die bidirektionale Replikation auf diesenDatenbank-Engines:
• Oracle• SQL Server• MySQL• PostgreSQL• Amazon Aurora mit MySQL-Kompatibilität• Aurora mit PostgreSQL-Kompatibilität
Erstellen von bidirektionalen ReplikationsaufgabenUm eine bidirektionale AWS DMS-Replikation zu ermöglichen, konfigurieren Sie Quell- und Ziel-Endpunktefür beide Datenbanken (A und B). Konfigurieren Sie z. B. einen Quell-Endpunkt für Datenbank A, einenQuell-Endpunkt für Datenbank B, einen Ziel-Endpunkt für Datenbank A und einen Ziel-Endpunkt fürDatenbank B.
Erstellen Sie dann zwei Aufgaben: eine Aufgabe für Quelle A zum Verschieben von Daten nach Ziel B undeine weitere Aufgabe für Quelle B zum Verschieben von Daten nach Ziel A. Stellen Sie außerdem sicher,dass jede Aufgabe mit einer Loopback-Verhinderung konfiguriert ist. Auf diese Weise wird verhindert,dass identische Änderungen an den Zielen beider Aufgaben vorgenommen werden und somit die Datenfür mindestens eine der beiden Aufgaben fehlerhaft werden. Weitere Informationen finden Sie unterVerhindern eines Loopbacks (p. 368).
Die einfachste Methode ist, mit identischen Datensätzen sowohl in Datenbank A als auch in Datenbank Bzu beginnen. Erstellen Sie dann zwei Nur-CDC-Aufgaben, eine Aufgabe, um Daten von A nach B zureplizieren, und eine weitere Aufgabe, um Daten von B nach A zu replizieren.
Um AWS DMS zur Instanziierung eines neuen Datensatzes (Datenbank) auf Knoten B von Knoten A zuverwenden, gehen Sie wie folgt vor:
1. Verwenden Sie eine Aufgabe zum vollständigen Laden und eine CDC-Aufgabe, um Daten vonDatenbank A nach B zu verschieben. Stellen Sie sicher, dass während dieser Zeit keine AnwendungenDaten in Datenbank B ändern.
API-Version API Version 2016-01-01367

AWS Database Migration Service BenutzerhandbuchDurchführen der bidirektionalen Replikation
2. Wenn das vollständige Laden abgeschlossen ist und bevor Anwendungen Daten in Datenbank B änderndürfen, notieren Sie die Uhrzeit oder die CDC-Startposition von Datenbank B. Anweisungen finden Sieunter Durchführen der Replikation von einem CDC-Startpunkt aus (p. 364).
3. Erstellen Sie eine Nur-CDC-Aufgabe, bei der die Daten von Datenbank B zurück nach A unterVerwendung dieser Startzeit oder CDC-Startposition verschoben werden.
Note
Nur eine Aufgabe in einem bidirektionalen Paar kann eine Aufgabe für vollständiges Laden undCDC sein.
Verhindern eines LoopbacksUm das Verhindern eines Loopbacks anzuzeigen, nehmen wir an, dass AWS DMS in einer AufgabeT1 Änderungsprotokolle aus der Quelldatenbank A liest und die Änderungen auf die Zieldatenbank Banwendet.
Als nächstes werden über zweite Aufgabe, T2, Änderungsprotokolle aus der Quelldatenbank B gelesenund zurück auf die Zieldatenbank A angewendet. Bevor T2 dies tut, muss das DMS sicherstellen, dassdieselben Änderungen, die von der Quelldatenbank A in der Zieldatenbank B vorgenommen wurden, nichtauch in der Quelldatenbank B vorgenommen werden. Anders ausgedrückt: Das DMS muss sicherstellen,dass diese Änderungen nicht auf die Zieldatenbank A zurückreflektiert (zurückgeschleift) werden.
Um ein Loopback (eine Schleifenschaltung) von Änderungen zu verhindern, fügen Sie die folgendenAufgabeneinstellungen zu jeder bidirektionalen Replikationsaufgabe hinzu. Dadurch wird sichergestellt,dass eine Loopback-Datenbeschädigung nicht in beide Richtungen auftritt.
{. . .
"LoopbackPreventionSettings": { "EnableLoopbackPrevention": Boolean, "SourceSchema": String, "TargetSchema": String },
. . .}
Über die Aufgabeneinstellungen von LoopbackPreventionSettings wird festgestellt, ob eineTransaktion neu ist oder ein Echo von der Aufgabe für die entgegengesetzte Replikation. Wenn dasAWS DMS eine Transaktion auf eine Zieldatenbank anwendet, aktualisiert es eine DMS-Tabelle(awsdms_loopback_prevention) mit einem Hinweis auf die Änderung. Bevor jede Transaktionauf ein Ziel angewendet wird, ignoriert das DMS jede Transaktion, die einen Verweis auf dieseawsdms_loopback_prevention-Tabelle enthält. Daher wendet es die Änderung nicht an.
Nehmen Sie diese Aufgabeneinstellungen bei jeder Replikationsaufgabe in ein bidirektionales Paarauf. Diese Einstellungen aktivieren die Loopback-Verhinderung. Sie geben auch das Schema für jedeQuell- und Zieldatenbank in der Aufgabe an, die die awsdms_loopback_prevention-Tabelle für jedenEndpunkt enthält.
Damit jede Aufgabe ein solches Echo identifizieren und ausschalten kann, setzen SieEnableLoopbackPrevention auf true. Um an der Quelle ein Schema anzugeben, dasawsdms_loopback_prevention enthält, setzen Sie SourceSchema auf den Namen für dieses Schemain der Quelldatenbank. Um am Ziel ein Schema anzugeben, das dieselbe Tabelle enthält, setzen SieTargetSchema auf den Namen für dieses Schema in der Zieldatenbank.
API-Version API Version 2016-01-01368

AWS Database Migration Service BenutzerhandbuchÄndern einer Aufgabe
Im folgenden Beispiel werden die SourceSchema- und TargetSchema-Einstellungen für eineReplikationsaufgabe T1 und ihre Aufgabe T2 für die entgegengesetzte Replikation mit entgegengesetztenEinstellungen angegeben.
Die Einstellungen für die Aufgabe T1 sind wie folgt.
{. . .
"LoopbackPreventionSettings": { "EnableLoopbackPrevention": true, "SourceSchema": "LOOP-DATA", "TargetSchema": "loop-data" },
. . .}
Die Einstellungen für die Aufgabe T2 für die entgegengesetzte Replikation sind wie folgt.
{. . .
"LoopbackPreventionSettings": { "EnableLoopbackPrevention": true, "SourceSchema": "loop-data", "TargetSchema": "LOOP-DATA" },
. . .}
Note
Wenn Sie die AWS CLI verwenden, verwenden Sie nur die Befehle create-replication-task oder modify-replication-task, um die LoopbackPreventionSettings in IhrenAufgaben für die bidirektionale Replikation zu konfigurieren.
Einschränkungen der bidirektionalen ReplikationDie bidirektionale Replikation für AWS DMS weist folgende Einschränkungen auf:
• Die Loopback-Verhinderung verfolgt nur DML-Anweisungen (Data Manipulation Language). AWS DMSunterstützt die Verhinderung des DDL-Loopback (Data Definition Language) nicht. Konfigurieren Siedazu eine der Aufgaben in einem bidirektionalen Paar, um DDL-Anweisungen herauszufiltern.
• Aufgaben, bei denen die Loopback-Verhinderung verwendet wird, unterstützen nicht die Übergabe vonÄnderungen in Stapeln. Um eine Aufgabe mit Loopback-Verhinderung zu konfigurieren, stellen Siesicher, dass BatchApplyEnabled auf false gesetzt ist.
• Die bidirektionale DMS-Replikation umfasst keine Konflikterkennung oder -lösung. UmDateninkonsistenzen zu erkennen, verwenden Sie die Datenvalidierung für beide Aufgaben.
Ändern einer AufgabeSie können eine Aufgabe ändern, wenn Sie die Aufgabeneinstellungen, Tabellenzuweisung oder andereEinstellungen ändern müssen. Sie ändern eine Aufgabe in der DMS-Konsole, indem Sie die Aufgabe
API-Version API Version 2016-01-01369

AWS Database Migration Service BenutzerhandbuchErneutes Laden von Tabellen während einer Aufgabe
auswählen und anschließend auf Modify klicken. Sie können auch die AWS CLI oder den AWS DMS-API-Befehl ModifyReplicationTask verwenden.
Es gibt einige Einschränkungen für das Ändern einer Aufgabe. Dazu zählen:
• Sie können den Quell- oder Zielendpunkt einer Aufgabe nicht ändern.• Sie können den Migrationstyp einer Aufgabe nicht ändern.• Aufgaben, die ausgeführt wurden, müssen den Status Stopped (Angehalten) oder Failed
(Fehlgeschlagen) aufweisen, um geändert werden zu können.
Erneutes Laden von Tabellen während einerAufgabe
Während eine Aufgabe ausgeführt wird, können Sie eine Zieldatenbanktabelle mit Daten aus der Quelleerneut laden. Möglicherweise möchten Sie eine Tabelle neu laden, wenn während der Aufgabe ein Fehlerauftritt oder Daten sich aufgrund von Partitions-Operationen ändern (z. B. bei der Verwendung von Oracle).Sie können bis zu 10 Tabellen von einer Aufgabe erneut laden.
Um eine Tabelle erneut zu laden, müssen die folgenden Bedingungen erfüllt sein:
• Die Aufgabe muss ausgeführt werden.• Die Migrationsmethode für die Aufgabe muss entweder "Full Load" oder "Full Load with CDC" sein.• Doppelte Tabellen sind nicht zulässig.• AWS DMS behält die vorherige Tabellendefinition bei und erstellt sie während des erneuten Ladens nicht
neu. Alle DDL-Anweisungen wie ALTER TABLE ADD COLUMN, DROP COLUMN, die auf die Tabelleangewendet werden, bevor diese neu geladen wird, können bewirken, dass das Neuladen fehlschlägt.
AWS Management ConsoleSo laden Sie eine Tabelle mithilfe der AWS DMS-Konsole erneut
1. Melden Sie sich bei der AWS Management Console an und wählen Sie AWS DMS aus. Wenn Sie alsBenutzer von AWS Identity and Access Management (IAM) angemeldet sind, müssen Sie über dieentsprechenden Berechtigungen für den Zugriff auf AWS DMS verfügen. Weitere Informationen zu denerforderlichen Berechtigungen finden Sie unter Erforderliche IAM-Berechtigungen zur Verwendung vonAWS DMS (p. 65).
2. Wählen Sie im Navigationsbereich Tasks aus.3. Wählen Sie die ausgeführte Aufgabe mit der Tabelle, die Sie erneut laden möchten.4. Wählen Sie die Registerkarte Table Statistics (Tabellenstatistiken).
API-Version API Version 2016-01-01370
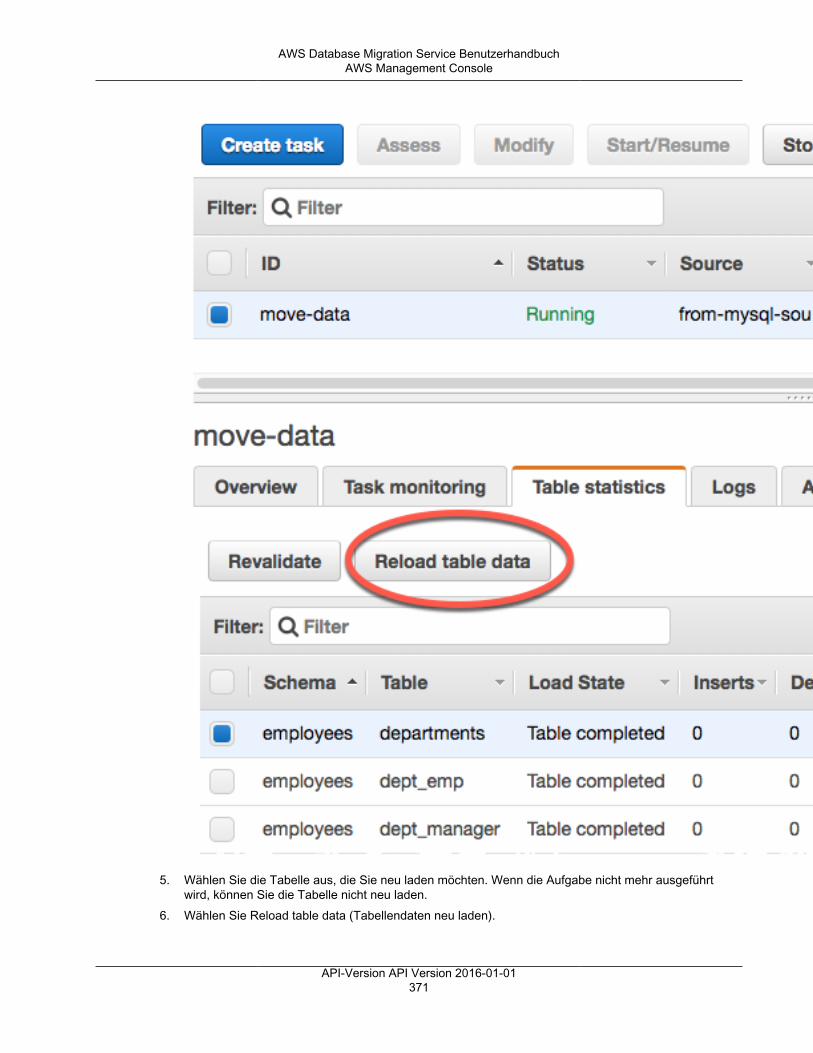
AWS Database Migration Service BenutzerhandbuchAWS Management Console
5. Wählen Sie die Tabelle aus, die Sie neu laden möchten. Wenn die Aufgabe nicht mehr ausgeführtwird, können Sie die Tabelle nicht neu laden.
6. Wählen Sie Reload table data (Tabellendaten neu laden).
API-Version API Version 2016-01-01371

AWS Database Migration Service BenutzerhandbuchTabellenzuweisung
Wenn AWS DMS das erneute Laden einer Tabelle vorbereitet, ändert die Konsole den Tabellenstatus inTable is being reloaded (Tabelle wird erneut geladen).
Verwenden der Tabellenzuweisung zum Angebenvon Aufgabeneinstellungen
Die Zuweisung von Tabellen verwendet mehrere Arten von Regeln für die Angabe der Datenquelle, desQuellschemas, der Daten und aller Transformationen, die während der Aufgabe auftreten sollten. Siekönnen mithilfe von Tabellenzuweisung einzelne zu migrierende Tabellen in einer Datenbank und das fürdie Migration zu verwendende Schema bestimmen. Auch können Sie mit Filtern festlegen, welche Datenaus einer bestimmten Tabellenspalte repliziert werden sollen. Außerdem können Sie Transformationenverwenden, um ausgewählte Schemata, Tabellen oder Ansichten zu ändern, bevor sie in die Zieldatenbankgeschrieben werden.
Festlegen der Tabellenauswahl und Transformationendurch Tabellenzuweisungen über die KonsoleSie können mithilfe der AWS Management Console die Tabellenzuweisung durchführen, einschließlich derAngabe von Auswahl und Transformation von Tabellen. In der Konsole können Sie im Bereich Where (Wo)Schema, Tabelle und Aktion (Einschließen oder Ausschließen) angeben. Im Bereich Filter können Sie denSpaltennamen in einer Tabelle sowie die Bedingungen angeben, die für eine Replikationsaufgabe geltensollen. Zusammen erstellen diese beiden Aktionen eine Auswahlregel.
Sie können Transformationen in einer Tabellenzuweisung einschließen, nachdem Sie mindestens eineAuswahlregel angegeben haben. Sie können Transformationen dazu verwenden, ein Schema oder eineTabelle umzubenennen, einem Schema oder einer Tabelle ein Präfix oder Suffix anzufügen oder eineTabellenspalte zu entfernen.
Das folgende Beispiel zeigt, wie Sie Auswahlregeln für eine Tabelle namens Customers in einem Schemanamens EntertainmentAgencySample einrichten. Sie erstellen Auswahlregeln und Transformationenauf der Registerkarte Guided (Angeleitet) tab. Diese Registerkarte wird nur angezeigt, wenn einQuellendpunkt mit Schema- und Tabelleninformationen vorhanden ist.
So geben Sie eine Tabellenauswahl, Filterkriterien und Transformationen mithilfe der AWS-Konsole an
1. Melden Sie sich bei der AWS Management Console an und wählen Sie AWS DMS aus. Wenn Sie alsBenutzer von AWS Identity and Access Management (IAM) angemeldet sind, müssen Sie über dieentsprechenden Berechtigungen für den Zugriff auf AWS DMS verfügen. Weitere Informationen zu denerforderlichen Berechtigungen finden Sie unter Erforderliche IAM-Berechtigungen zur Verwendung vonAWS DMS (p. 65).
2. Wählen Sie auf der Seite Dashboard Tasks aus.3. Wählen Sie Create Task aus.4. Geben Sie die Aufgabeninformationen ein, einschließlich Task name (Aufgabenname),
Replication instance (Replikations-Instance, Source endpoint (Quellendpunkt), Target endpoint(Zielendpunkt) und Migration type. Wählen Sie Guided (Angeleitet) aus dem Bereich Table mappings(Tabellenzuweisungen) aus.
API-Version API Version 2016-01-01372

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen über die Konsole
5. Wählen Sie im Bereich Table mapping (Tabellenzuweisung) den Schemanamen und denTabellennamen aus. Sie können "%" bei der Angabe des Tabellennamens als Platzhalterzeichenverwenden. Geben Sie die auszuführende Aktion an, um vom Filter definierte Daten ein- oderauszuschließen.
API-Version API Version 2016-01-01373
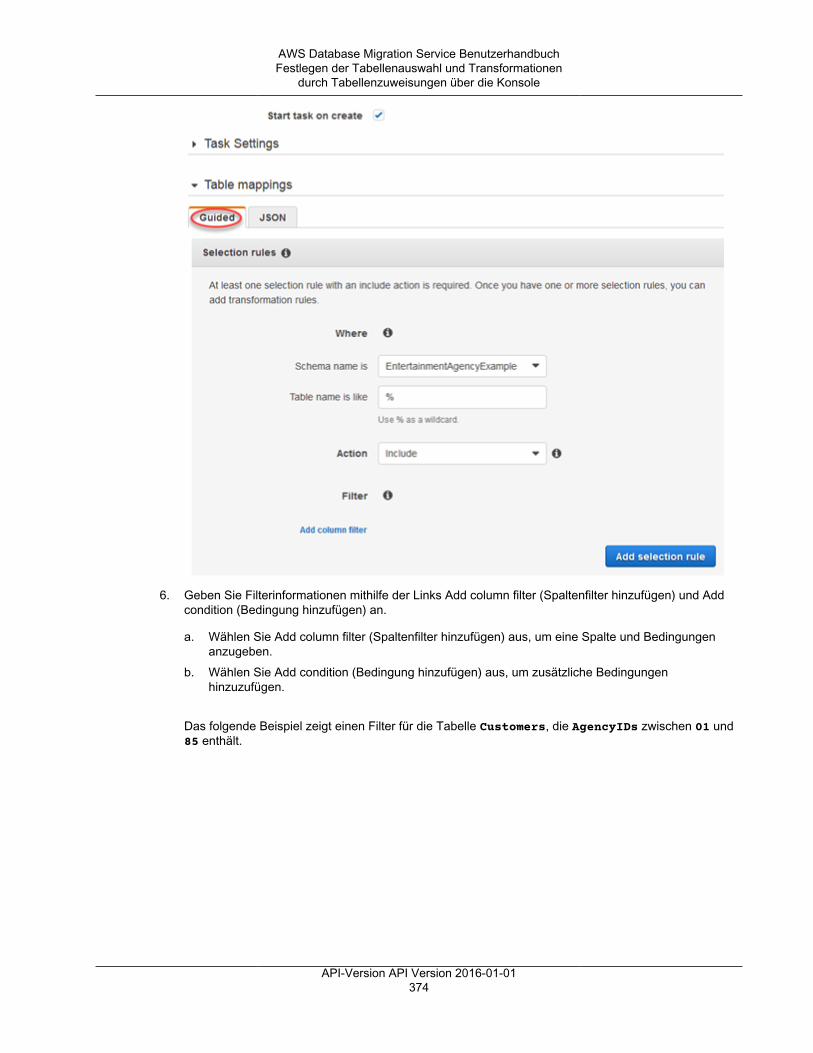
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen über die Konsole
6. Geben Sie Filterinformationen mithilfe der Links Add column filter (Spaltenfilter hinzufügen) und Addcondition (Bedingung hinzufügen) an.
a. Wählen Sie Add column filter (Spaltenfilter hinzufügen) aus, um eine Spalte und Bedingungenanzugeben.
b. Wählen Sie Add condition (Bedingung hinzufügen) aus, um zusätzliche Bedingungenhinzuzufügen.
Das folgende Beispiel zeigt einen Filter für die Tabelle Customers, die AgencyIDs zwischen 01 und85 enthält.
API-Version API Version 2016-01-01374
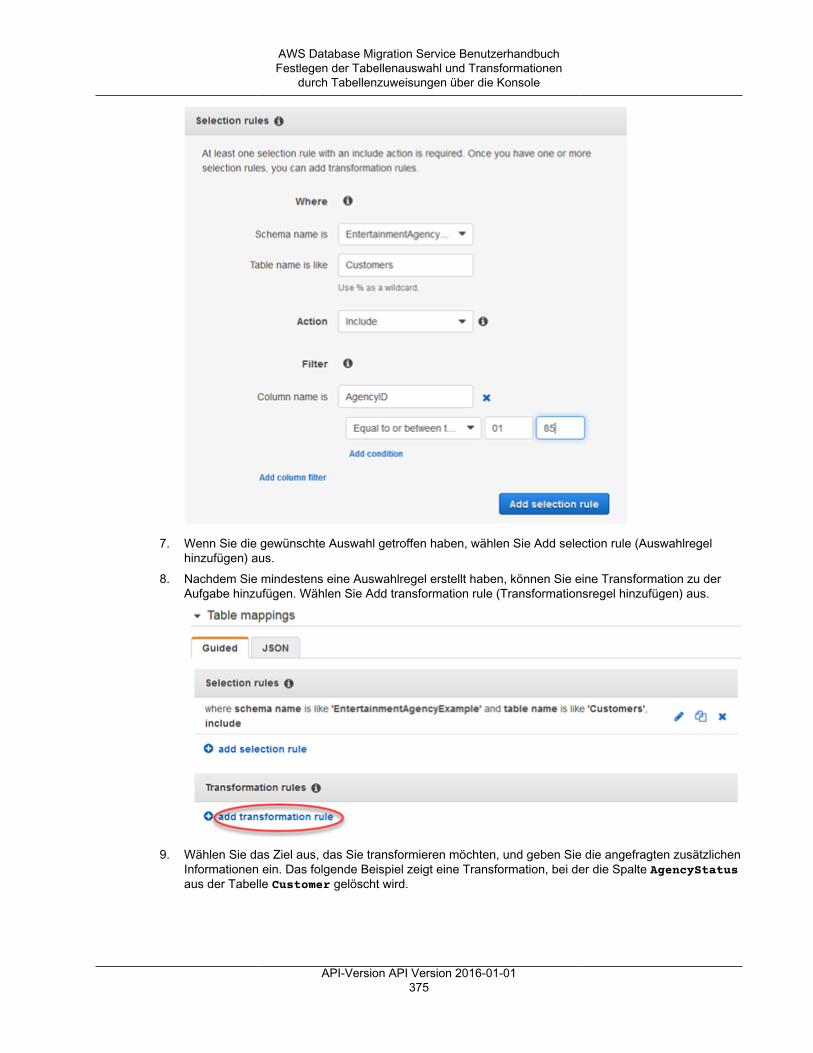
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen über die Konsole
7. Wenn Sie die gewünschte Auswahl getroffen haben, wählen Sie Add selection rule (Auswahlregelhinzufügen) aus.
8. Nachdem Sie mindestens eine Auswahlregel erstellt haben, können Sie eine Transformation zu derAufgabe hinzufügen. Wählen Sie Add transformation rule (Transformationsregel hinzufügen) aus.
9. Wählen Sie das Ziel aus, das Sie transformieren möchten, und geben Sie die angefragten zusätzlichenInformationen ein. Das folgende Beispiel zeigt eine Transformation, bei der die Spalte AgencyStatusaus der Tabelle Customer gelöscht wird.
API-Version API Version 2016-01-01375
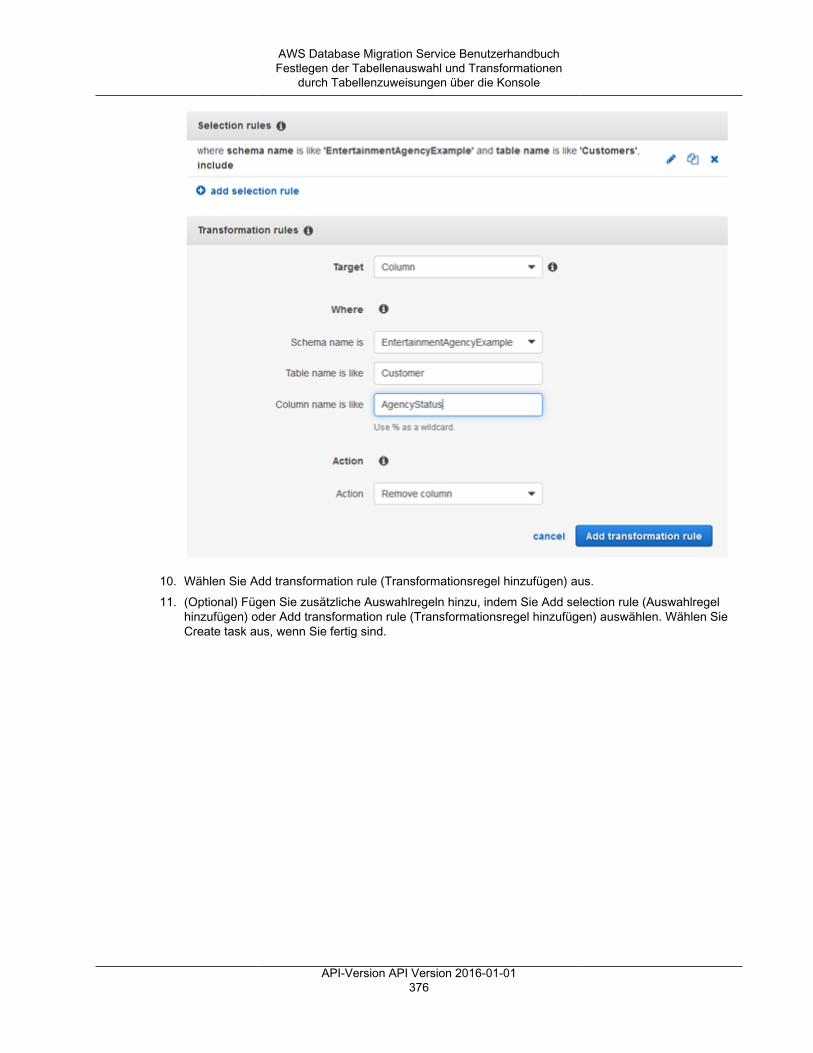
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen über die Konsole
10. Wählen Sie Add transformation rule (Transformationsregel hinzufügen) aus.11. (Optional) Fügen Sie zusätzliche Auswahlregeln hinzu, indem Sie Add selection rule (Auswahlregel
hinzufügen) oder Add transformation rule (Transformationsregel hinzufügen) auswählen. Wählen SieCreate task aus, wenn Sie fertig sind.
API-Version API Version 2016-01-01376
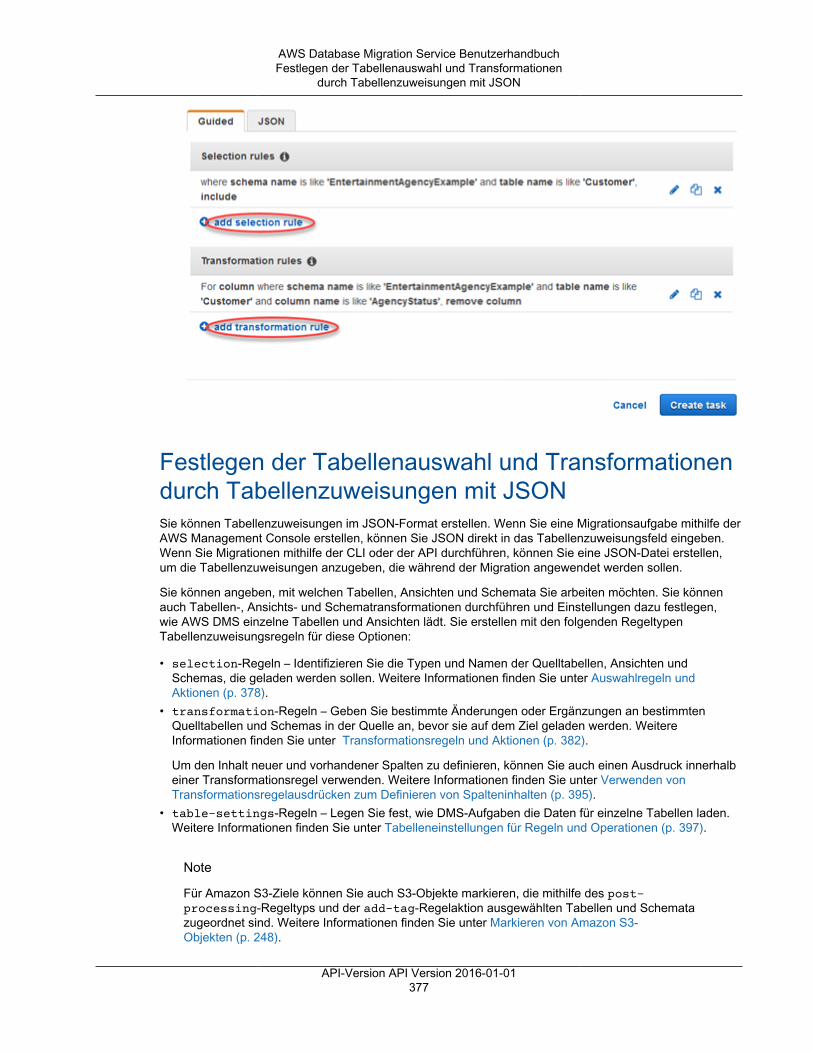
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Festlegen der Tabellenauswahl und Transformationendurch Tabellenzuweisungen mit JSONSie können Tabellenzuweisungen im JSON-Format erstellen. Wenn Sie eine Migrationsaufgabe mithilfe derAWS Management Console erstellen, können Sie JSON direkt in das Tabellenzuweisungsfeld eingeben.Wenn Sie Migrationen mithilfe der CLI oder der API durchführen, können Sie eine JSON-Datei erstellen,um die Tabellenzuweisungen anzugeben, die während der Migration angewendet werden sollen.
Sie können angeben, mit welchen Tabellen, Ansichten und Schemata Sie arbeiten möchten. Sie könnenauch Tabellen-, Ansichts- und Schematransformationen durchführen und Einstellungen dazu festlegen,wie AWS DMS einzelne Tabellen und Ansichten lädt. Sie erstellen mit den folgenden RegeltypenTabellenzuweisungsregeln für diese Optionen:
• selection-Regeln – Identifizieren Sie die Typen und Namen der Quelltabellen, Ansichten undSchemas, die geladen werden sollen. Weitere Informationen finden Sie unter Auswahlregeln undAktionen (p. 378).
• transformation-Regeln – Geben Sie bestimmte Änderungen oder Ergänzungen an bestimmtenQuelltabellen und Schemas in der Quelle an, bevor sie auf dem Ziel geladen werden. WeitereInformationen finden Sie unter Transformationsregeln und Aktionen (p. 382).
Um den Inhalt neuer und vorhandener Spalten zu definieren, können Sie auch einen Ausdruck innerhalbeiner Transformationsregel verwenden. Weitere Informationen finden Sie unter Verwenden vonTransformationsregelausdrücken zum Definieren von Spalteninhalten (p. 395).
• table-settings-Regeln – Legen Sie fest, wie DMS-Aufgaben die Daten für einzelne Tabellen laden.Weitere Informationen finden Sie unter Tabelleneinstellungen für Regeln und Operationen (p. 397).
Note
Für Amazon S3-Ziele können Sie auch S3-Objekte markieren, die mithilfe des post-processing-Regeltyps und der add-tag-Regelaktion ausgewählten Tabellen und Schematazugeordnet sind. Weitere Informationen finden Sie unter Markieren von Amazon S3-Objekten (p. 248).
API-Version API Version 2016-01-01377
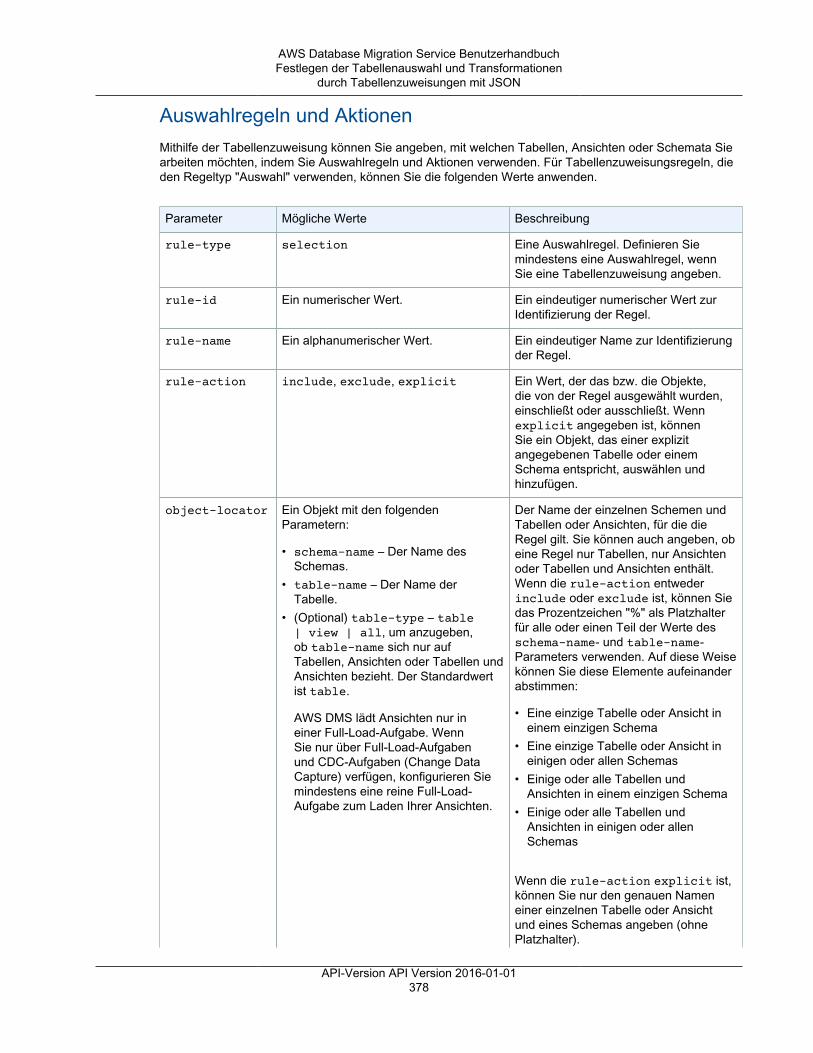
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Auswahlregeln und AktionenMithilfe der Tabellenzuweisung können Sie angeben, mit welchen Tabellen, Ansichten oder Schemata Siearbeiten möchten, indem Sie Auswahlregeln und Aktionen verwenden. Für Tabellenzuweisungsregeln, dieden Regeltyp "Auswahl" verwenden, können Sie die folgenden Werte anwenden.
Parameter Mögliche Werte Beschreibung
rule-type selection Eine Auswahlregel. Definieren Siemindestens eine Auswahlregel, wennSie eine Tabellenzuweisung angeben.
rule-id Ein numerischer Wert. Ein eindeutiger numerischer Wert zurIdentifizierung der Regel.
rule-name Ein alphanumerischer Wert. Ein eindeutiger Name zur Identifizierungder Regel.
rule-action include, exclude, explicit Ein Wert, der das bzw. die Objekte,die von der Regel ausgewählt wurden,einschließt oder ausschließt. Wennexplicit angegeben ist, könnenSie ein Objekt, das einer explizitangegebenen Tabelle oder einemSchema entspricht, auswählen undhinzufügen.
object-locator Ein Objekt mit den folgendenParametern:
• schema-name – Der Name desSchemas.
• table-name – Der Name derTabelle.
• (Optional) table-type – table| view | all, um anzugeben,ob table-name sich nur aufTabellen, Ansichten oder Tabellen undAnsichten bezieht. Der Standardwertist table.
AWS DMS lädt Ansichten nur ineiner Full-Load-Aufgabe. WennSie nur über Full-Load-Aufgabenund CDC-Aufgaben (Change DataCapture) verfügen, konfigurieren Siemindestens eine reine Full-Load-Aufgabe zum Laden Ihrer Ansichten.
Der Name der einzelnen Schemen undTabellen oder Ansichten, für die dieRegel gilt. Sie können auch angeben, obeine Regel nur Tabellen, nur Ansichtenoder Tabellen und Ansichten enthält.Wenn die rule-action entwederinclude oder exclude ist, können Siedas Prozentzeichen "%" als Platzhalterfür alle oder einen Teil der Werte desschema-name- und table-name-Parameters verwenden. Auf diese Weisekönnen Sie diese Elemente aufeinanderabstimmen:
• Eine einzige Tabelle oder Ansicht ineinem einzigen Schema
• Eine einzige Tabelle oder Ansicht ineinigen oder allen Schemas
• Einige oder alle Tabellen undAnsichten in einem einzigen Schema
• Einige oder alle Tabellen undAnsichten in einigen oder allenSchemas
Wenn die rule-action explicit ist,können Sie nur den genauen Nameneiner einzelnen Tabelle oder Ansichtund eines Schemas angeben (ohnePlatzhalter).
API-Version API Version 2016-01-01378

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Mögliche Werte BeschreibungZu den unterstützten Quellen fürAnsichten gehören:
• Oracle• Microsoft SQL Server• MySQL• PostgreSQL• IBM Db2 (LUW)• SAP Adaptive Server Enterprise
(ASE)
Note
AWS DMS lädt nie eineQuellansicht in eine Zielansicht.Eine Quellansicht wird in einegleichwertige Tabelle auf demZiel mit demselben Namenwie die Ansicht auf der Quellegeladen.
load-order Eine positive Ganzzahl. Der maximaleWert beträgt 2.147.483.647.
Die Priorität für das Laden von Tabellenund Ansichten. Tabellen und Ansichtenmit höheren Werten werden zuerstgeladen.
filters Ein Array von Objekten. Ein oder mehrere Objekte zum Filternder Quelle. Sie geben Objektparameterzum Filtern auf einer einzelnen Spalte inder Quelle an. Sie geben einige Objektezum Filtern auf mehreren Spalten an.Weitere Informationen finden Sie unterVerwenden von Quellfiltern (p. 416).
Example Migration aller Tabellen in einem Schema
Im folgenden Beispiel werden alle Tabellen aus einem Schema mit dem Namen Test in Ihrer Quelle zuIhrem Zielendpunkt migriert.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "Test", "table-name": "%" }, "rule-action": "include" } ]}
API-Version API Version 2016-01-01379

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Example Migrieren einiger Tabellen in einem Schema
Im folgenden Beispiel werden alle Tabellen außer denjenigen, die mit DMS beginnen, aus einem Schemamit dem Namen Test in Ihrer Quelle zu Ihrem Zielendpunkt migriert.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "Test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "selection", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "Test", "table-name": "DMS%" }, "rule-action": "exclude" } ]}
Example Migrieren eines Specified Single Table im Single Schema
Im folgenden Beispiel wird die Customer-Tabelle aus dem NewCust-Schema in Ihrer Quelle zu IhremZielendpunkt migriert.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "NewCust", "table-name": "Customer" }, "rule-action": "explicit" } ]}
Note
Sie können explizit auf mehreren Tabellen und Schemata auswählen, indem Sie mehrereAuswahlregeln angeben.
Example Migrieren Sie Tabellen in einer festgelegten Reihenfolge
Beim folgenden Beispiel werden zwei Tabellen migriert. Die Table loadfirst (mit Priorität 2) wird vor derTabelle loadsecond migriert.
{"rules": [
API-Version API Version 2016-01-01380

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "Test", "table-name": "loadfirst" }, "rule-action": "include", "load-order": "2" }, { "rule-type": "selection", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "Test", "table-name": "loadsecond" }, "rule-action": "include", "load-order": "1" } ] }
Example Migrieren einiger Ansichten in einem Schema
Im folgenden Beispiel werden einige Ansichten aus einem Schema mit dem Namen Test in Ihrer Quelle ingleichwertige Tabellen in Ihrem Ziel migriert.
{ "rules": [ { "rule-type": "selection", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "Test", "table-name": "view_DMS%", "table-type": "view" }, "rule-action": "include" } ]}
Example Migrieren aller Tabellen und Ansichten in einem Schema
Im folgenden Beispiel werden alle Tabellen und Ansichten aus einem Schema mit dem Namen report inIhrer Quelle in gleichwertige Tabellen in Ihrem Ziel migriert.
{ "rules": [ { "rule-type": "selection", "rule-id": "3", "rule-name": "3", "object-locator": { "schema-name": "report", "table-name": "%", "table-type": "all" }, "rule-action": "include"
API-Version API Version 2016-01-01381
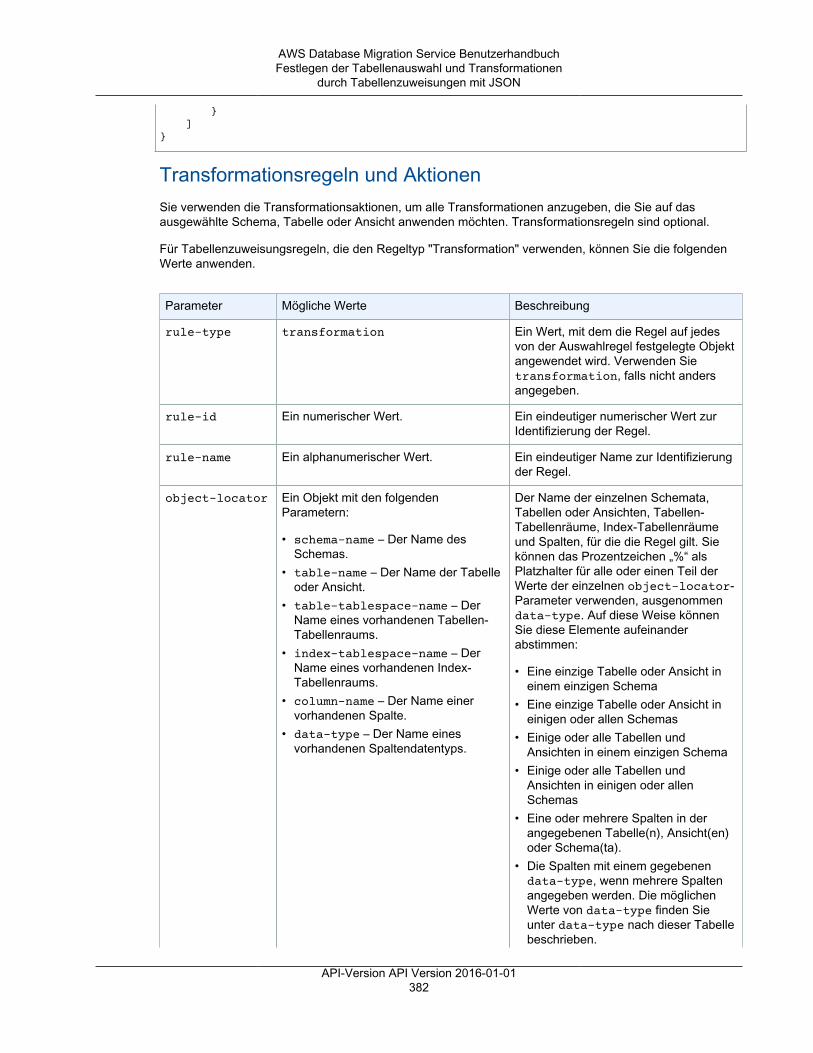
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
} ]}
Transformationsregeln und AktionenSie verwenden die Transformationsaktionen, um alle Transformationen anzugeben, die Sie auf dasausgewählte Schema, Tabelle oder Ansicht anwenden möchten. Transformationsregeln sind optional.
Für Tabellenzuweisungsregeln, die den Regeltyp "Transformation" verwenden, können Sie die folgendenWerte anwenden.
Parameter Mögliche Werte Beschreibung
rule-type transformation Ein Wert, mit dem die Regel auf jedesvon der Auswahlregel festgelegte Objektangewendet wird. Verwenden Sietransformation, falls nicht andersangegeben.
rule-id Ein numerischer Wert. Ein eindeutiger numerischer Wert zurIdentifizierung der Regel.
rule-name Ein alphanumerischer Wert. Ein eindeutiger Name zur Identifizierungder Regel.
object-locator Ein Objekt mit den folgendenParametern:
• schema-name – Der Name desSchemas.
• table-name – Der Name der Tabelleoder Ansicht.
• table-tablespace-name – DerName eines vorhandenen Tabellen-Tabellenraums.
• index-tablespace-name – DerName eines vorhandenen Index-Tabellenraums.
• column-name – Der Name einervorhandenen Spalte.
• data-type – Der Name einesvorhandenen Spaltendatentyps.
Der Name der einzelnen Schemata,Tabellen oder Ansichten, Tabellen-Tabellenräume, Index-Tabellenräumeund Spalten, für die die Regel gilt. Siekönnen das Prozentzeichen „%“ alsPlatzhalter für alle oder einen Teil derWerte der einzelnen object-locator-Parameter verwenden, ausgenommendata-type. Auf diese Weise könnenSie diese Elemente aufeinanderabstimmen:
• Eine einzige Tabelle oder Ansicht ineinem einzigen Schema
• Eine einzige Tabelle oder Ansicht ineinigen oder allen Schemas
• Einige oder alle Tabellen undAnsichten in einem einzigen Schema
• Einige oder alle Tabellen undAnsichten in einigen oder allenSchemas
• Eine oder mehrere Spalten in derangegebenen Tabelle(n), Ansicht(en)oder Schema(ta).
• Die Spalten mit einem gegebenendata-type, wenn mehrere Spaltenangegeben werden. Die möglichenWerte von data-type finden Sieunter data-type nach dieser Tabellebeschrieben.
API-Version API Version 2016-01-01382
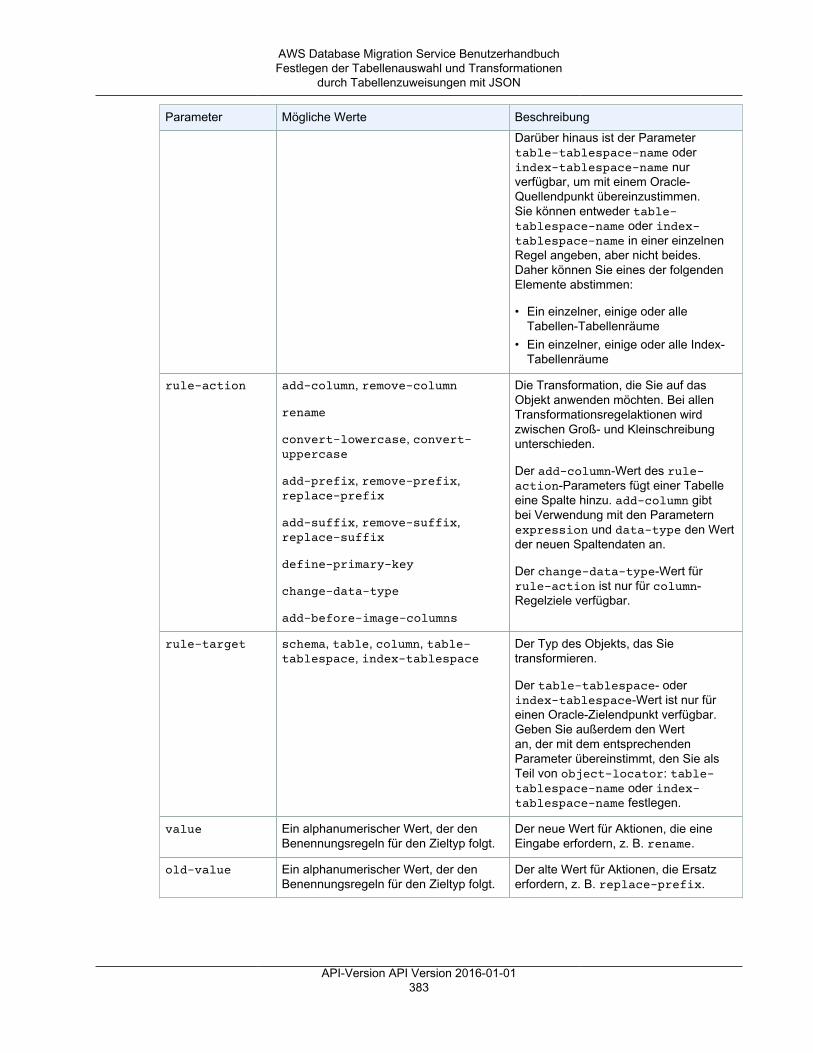
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Mögliche Werte BeschreibungDarüber hinaus ist der Parametertable-tablespace-name oderindex-tablespace-name nurverfügbar, um mit einem Oracle-Quellendpunkt übereinzustimmen.Sie können entweder table-tablespace-name oder index-tablespace-name in einer einzelnenRegel angeben, aber nicht beides.Daher können Sie eines der folgendenElemente abstimmen:
• Ein einzelner, einige oder alleTabellen-Tabellenräume
• Ein einzelner, einige oder alle Index-Tabellenräume
rule-action add-column, remove-column
rename
convert-lowercase, convert-uppercase
add-prefix, remove-prefix,replace-prefix
add-suffix, remove-suffix,replace-suffix
define-primary-key
change-data-type
add-before-image-columns
Die Transformation, die Sie auf dasObjekt anwenden möchten. Bei allenTransformationsregelaktionen wirdzwischen Groß- und Kleinschreibungunterschieden.
Der add-column-Wert des rule-action-Parameters fügt einer Tabelleeine Spalte hinzu. add-column gibtbei Verwendung mit den Parameternexpression und data-type den Wertder neuen Spaltendaten an.
Der change-data-type-Wert fürrule-action ist nur für column-Regelziele verfügbar.
rule-target schema, table, column, table-tablespace, index-tablespace
Der Typ des Objekts, das Sietransformieren.
Der table-tablespace- oderindex-tablespace-Wert ist nur füreinen Oracle-Zielendpunkt verfügbar.Geben Sie außerdem den Wertan, der mit dem entsprechendenParameter übereinstimmt, den Sie alsTeil von object-locator: table-tablespace-name oder index-tablespace-name festlegen.
value Ein alphanumerischer Wert, der denBenennungsregeln für den Zieltyp folgt.
Der neue Wert für Aktionen, die eineEingabe erfordern, z. B. rename.
old-value Ein alphanumerischer Wert, der denBenennungsregeln für den Zieltyp folgt.
Der alte Wert für Aktionen, die Ersatzerfordern, z. B. replace-prefix.
API-Version API Version 2016-01-01383
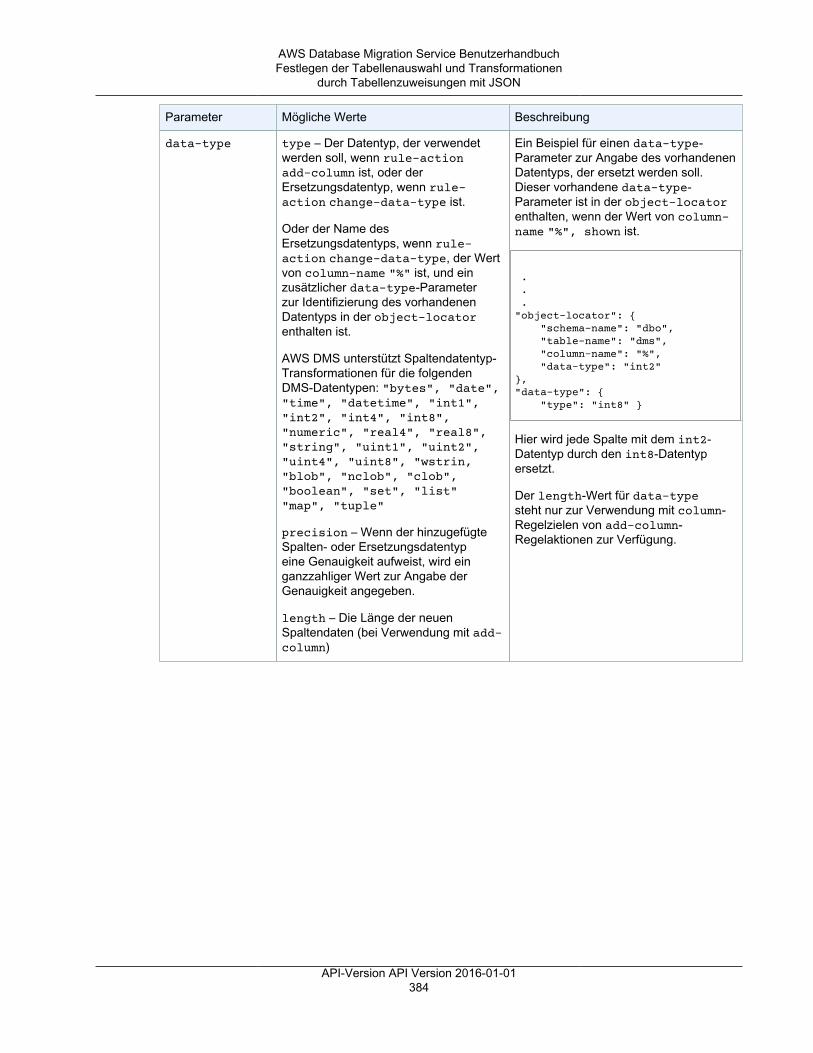
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Mögliche Werte Beschreibung
data-type type – Der Datentyp, der verwendetwerden soll, wenn rule-actionadd-column ist, oder derErsetzungsdatentyp, wenn rule-action change-data-type ist.
Oder der Name desErsetzungsdatentyps, wenn rule-action change-data-type, der Wertvon column-name "%" ist, und einzusätzlicher data-type-Parameterzur Identifizierung des vorhandenenDatentyps in der object-locatorenthalten ist.
AWS DMS unterstützt Spaltendatentyp-Transformationen für die folgendenDMS-Datentypen: "bytes", "date","time", "datetime", "int1","int2", "int4", "int8","numeric", "real4", "real8","string", "uint1", "uint2","uint4", "uint8", "wstrin,"blob", "nclob", "clob","boolean", "set", "list""map", "tuple"
precision – Wenn der hinzugefügteSpalten- oder Ersetzungsdatentypeine Genauigkeit aufweist, wird einganzzahliger Wert zur Angabe derGenauigkeit angegeben.
length – Die Länge der neuenSpaltendaten (bei Verwendung mit add-column)
Ein Beispiel für einen data-type-Parameter zur Angabe des vorhandenenDatentyps, der ersetzt werden soll.Dieser vorhandene data-type-Parameter ist in der object-locatorenthalten, wenn der Wert von column-name "%", shown ist.
. . ."object-locator": { "schema-name": "dbo", "table-name": "dms", "column-name": "%", "data-type": "int2"},"data-type": { "type": "int8" }
Hier wird jede Spalte mit dem int2-Datentyp durch den int8-Datentypersetzt.
Der length-Wert für data-typesteht nur zur Verwendung mit column-Regelzielen von add-column-Regelaktionen zur Verfügung.
API-Version API Version 2016-01-01384
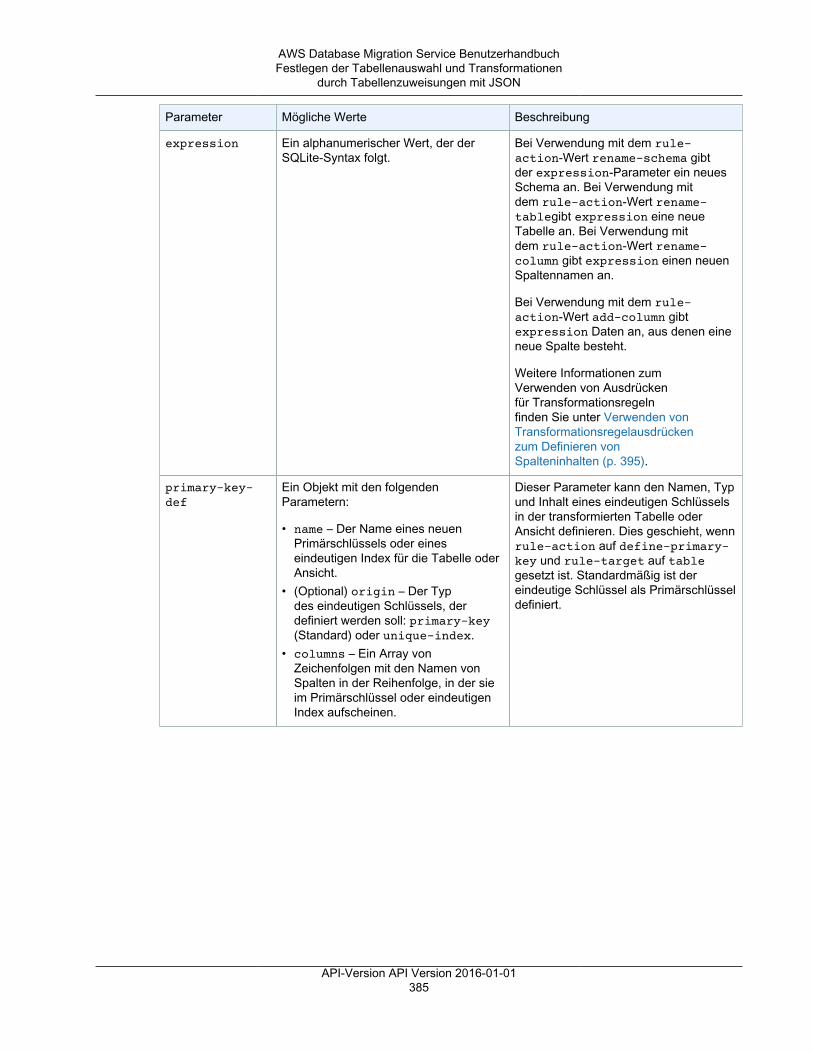
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Mögliche Werte Beschreibung
expression Ein alphanumerischer Wert, der derSQLite-Syntax folgt.
Bei Verwendung mit dem rule-action-Wert rename-schema gibtder expression-Parameter ein neuesSchema an. Bei Verwendung mitdem rule-action-Wert rename-tablegibt expression eine neueTabelle an. Bei Verwendung mitdem rule-action-Wert rename-column gibt expression einen neuenSpaltennamen an.
Bei Verwendung mit dem rule-action-Wert add-column gibtexpression Daten an, aus denen eineneue Spalte besteht.
Weitere Informationen zumVerwenden von Ausdrückenfür Transformationsregelnfinden Sie unter Verwenden vonTransformationsregelausdrückenzum Definieren vonSpalteninhalten (p. 395).
primary-key-def
Ein Objekt mit den folgendenParametern:
• name – Der Name eines neuenPrimärschlüssels oder eineseindeutigen Index für die Tabelle oderAnsicht.
• (Optional) origin – Der Typdes eindeutigen Schlüssels, derdefiniert werden soll: primary-key(Standard) oder unique-index.
• columns – Ein Array vonZeichenfolgen mit den Namen vonSpalten in der Reihenfolge, in der sieim Primärschlüssel oder eindeutigenIndex aufscheinen.
Dieser Parameter kann den Namen, Typund Inhalt eines eindeutigen Schlüsselsin der transformierten Tabelle oderAnsicht definieren. Dies geschieht, wennrule-action auf define-primary-key und rule-target auf tablegesetzt ist. Standardmäßig ist dereindeutige Schlüssel als Primärschlüsseldefiniert.
API-Version API Version 2016-01-01385

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Mögliche Werte Beschreibung
before-image-def
Ein Objekt mit den folgendenParametern:
• column-prefix – Ein Wert, dereinem Spaltennamen vorangestelltwird. Der Standardwert ist BI_.
• column-suffix – Ein Wert, der anden Spaltennamen angehängt wird.Der Standardwert ist leer.
• column-filter – Erfordert einender folgenden Werte: pk-only(Standard), non-lob (optional) undall (optional).
Dieser Parameter definiert eineBenennungskonvention zumIdentifizieren der Vorher-Abbild-Spalten und gibt einen Filter an, um zuidentifizieren, für welche QuellspaltenVorher-Abbild-Spalten auf dem Zielerstellt werden können. Sie könnendiesen Parameter angeben, wennrule-action auf add-before-image-columns und rule-targetauf column gesetzt ist.
Setzen Sie nicht column-prefixund column-suffix auf leereZeichenfolgen.
Wählen Sie bei column-filterfolgende Optionen:
• pk-only – Zum Hinzufügen nur vonSpalten, die Teil der Primärschlüsselder Tabelle sind.
• non-lob – Zum Hinzufügen nur vonSpalten, die nicht vom LOB-Typ sind.
• all – Zum Hinzufügen einer Spalte,die einen Vorher-Abbild-Wert hat.
Weitere Informationen zur Unterstützungvon Vorher-Abbildern für AWS DMS-Zielendpunkte finden Sie unter:
• Verwenden eines Vorher-Abbildszum Anzeigen von Originalwertenvon CDC-Zeilen für einen Kinesis-Datenstrom als Ziel (p. 288)
• Verwenden eines Vorher-Abbildszum Anzeigen von Originalwertenvon CDC-Zeilen für Apache Kafka alsZiel (p. 298)
Example Umbenennen eines Schemas
Im folgenden Beispiel wird ein Schema von Test in Ihrer Quelle auf Test1 in Ihrem Ziel umbenannt.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "Test", "table-name": "%" },
API-Version API Version 2016-01-01386

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
"rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "rename", "rule-target": "schema", "object-locator": { "schema-name": "Test" }, "value": "Test1" } ]}
Example Umbenennen einer Tabelle
Im folgenden Beispiel wird eine Tabelle von Actor in Ihrer Quelle auf Actor1 in Ihrem Ziel umbenannt.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "Test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "rename", "rule-target": "table", "object-locator": { "schema-name": "Test", "table-name": "Actor" }, "value": "Actor1" } ]}
Example Umbenennen einer Spalte
Im folgenden Beispiel wird eine Spalte in Tabelle Actor von first_name in Ihrer Quelle auf fname inIhrem Zielendpunkt umbenannt.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include"
API-Version API Version 2016-01-01387

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
}, { "rule-type": "transformation", "rule-id": "4", "rule-name": "4", "rule-action": "rename", "rule-target": "column", "object-locator": { "schema-name": "test", "table-name": "Actor", "column-name" : "first_name" }, "value": "fname" } ]}
Example Umbenennen eines Oracle Tabellen-Tabellenraums
Im folgenden Beispiel wird der Tabellen-Tabellenraum mit dem Namen SetSpace für eine Tabelle mit demNamen Actor in Ihrer Oracle-Quelle auf SceneTblSpace in Ihrem Oracle-Zielendpunkt umbenannt.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "Play", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "rename", "rule-target": "table-tablespace", "object-locator": { "schema-name": "Play", "table-name": "Actor", "table-tablespace-name: "SetSpace" }, "value": "SceneTblSpace" } ]}
Example Umbenennen eines Oracle Index-Tabellenraums
Im folgenden Beispiel wird der Index-Tabellenraum mit dem Namen SetISpace für eine Tabelle mit demNamen Actor in Ihrer Oracle-Quelle auf SceneIdxSpace in Ihrem Oracle-Zielendpunkt umbenannt.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": {
API-Version API Version 2016-01-01388

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
"schema-name": "Play", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "rename", "rule-target": "table-tablespace", "object-locator": { "schema-name": "Play", "table-name": "Actor", "table-tablespace-name: "SetISpace" }, "value": "SceneIdxSpace" } ]}
Example Hinzufügen einer Spalte
Im folgenden Beispiel wird der Tabelle Actor im Schema test eine datetime- Spalte hinzugefügt.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "add-column", "rule-target": "table", "object-locator": { "schema-name": "test", "table-name": "actor" }, "value": "last_updated", "data-type": { "type": "datetime", "precision": 6 } } ]}
Example Entfernen einer Spalte
Im folgenden Beispiel wird die Tabelle mit dem Namen Actor in Ihrer Quelle so transformiert, dass alleSpalten, die mit den Zeichen col beginnen, in Ihrem Ziel daraus entfernt werden.
{ "rules": [{
API-Version API Version 2016-01-01389

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
"rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "remove-column", "rule-target": "column", "object-locator": { "schema-name": "test", "table-name": "Actor", "column-name": "col%" } }] }
Example Umwandeln in Kleinschreibung
Im folgenden Beispiel wird ein Tabellenname von ACTOR in Ihrer Quelle auf actor in Ihrem Zielumgewandelt.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "convert-lowercase", "rule-target": "table", "object-locator": { "schema-name": "test", "table-name": "ACTOR" } }]}
Example Umwandeln in Großschreibung
Im folgenden Beispiel werden alle Spalten in allen Tabellen und allen Schemata von Kleinschreibung anIhrer Quelle in Großschreibung an Ihrem Ziel umgewandelt.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test",
API-Version API Version 2016-01-01390

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
"table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "convert-uppercase", "rule-target": "column", "object-locator": { "schema-name": "%", "table-name": "%", "column-name": "%" } } ]}
Example Hinzufügen eines Präfix
Im folgenden Beispiel werden alle Tabellen in Ihrer Quelle so transformiert, dass ihnen das Präfix DMS_ inIhrem Ziel hinzugefügt wird.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "add-prefix", "rule-target": "table", "object-locator": { "schema-name": "test", "table-name": "%" }, "value": "DMS_" }] }
Example Ersetzen eines Präfix
Im folgenden Beispiel werden alle Spalten, die das Präfix Pre_ in Ihrer Quelle enthalten, so transformiert,dass das Präfix durch NewPre_ in Ihrem Ziel ersetzt wird.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%"
API-Version API Version 2016-01-01391

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
}, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "replace-prefix", "rule-target": "column", "object-locator": { "schema-name": "%", "table-name": "%", "column-name": "%" }, "value": "NewPre_", "old-value": "Pre_" } ]}
Example Entfernen eines Suffix
Im folgenden Beispiel werden alle Tabellen in Ihrer Quelle so transformiert, dass aus ihnen das Suffix _DMSin Ihrem Ziel entfernt wird.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "remove-suffix", "rule-target": "table", "object-locator": { "schema-name": "test", "table-name": "%" }, "value": "_DMS" }]}
Example Definieren eines Primärschlüssels
Das folgende Beispiel definiert einen Primärschlüssel mit dem Namen ITEM-primary-key auf dreiSpalten der ITEM-Tabelle, die zu Ihrem Zielendpunkt migriert wurde.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "inventory", "table-name": "%" },
API-Version API Version 2016-01-01392

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
"rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "define-primary-key", "rule-target": "table", "object-locator": { "schema-name": "inventory", "table-name": "ITEM" }, "primary-key-def": { "name": ITEM-primary-key, "columns": [ "ITEM-NAME", "BOM-MODEL-NUM", "BOM-PART-NUM" ] } }]}
Example Definieren eines eindeutigen Index
Das folgende Beispiel definiert einen eindeutigen Index mit dem Namen ITEM-unique-idx auf dreiSpalten der ITEM-Tabelle, die zu Ihrem Zielendpunkt migriert wurde.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "inventory", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "define-primary-key", "rule-target": "table", "object-locator": { "schema-name": "inventory", "table-name": "ITEM" }, "primary-key-def": { "name": ITEM-unique-idx, "origin": unique-index, "columns": [ "ITEM-NAME", "BOM-MODEL-NUM", "BOM-PART-NUM" ] } }]}
Example Datentyp der Zielspalte ändern
Im folgenden Beispiel wird der Datentyp einer Zielspalte namens SALE_AMOUNT von einem vorhandenenDatentyp in int8 geändert.
API-Version API Version 2016-01-01393

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
{ "rule-type": "transformation", "rule-id": "1", "rule-name": "RuleName 1", "rule-action": "change-data-type", "rule-target": "column", "object-locator": { "schema-name": "dbo", "table-name": "dms", "column-name": "SALE_AMOUNT" }, "data-type": { "type": "int8" }}
Example Hinzufügen einer Vorher-Abbild-Spalte
Für eine Quellspalte mit dem Namen emp_no fügt die Transformationsregel im folgenden Beispiel eineneue Spalte mit dem Namen BI_emp_no auf dem Ziel hinzu.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-target": "column", "object-locator": { "schema-name": "%", "table-name": "employees" }, "rule-action": "add-before-image-columns", "before-image-def": { "column-prefix": "BI_", "column-suffix": "", "column-filter": "pk-only" } } ]}
Hier füllt die folgende Anweisung eine BI_emp_no-Spalte in der entsprechenden Zeile mit 1.
UPDATE employees SET emp_no = 3 WHERE emp_no = 1;
Beim Schreiben von CDC-Aktualisierungen auf unterstützte AWS DMS-Ziele ermöglicht die BI_emp_no-Spalte, zu sehen, welche Zeilen aktualisierte Werte in der emp_no-Spalte aufweisen.
API-Version API Version 2016-01-01394

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Verwenden von Transformationsregelausdrücken zum Definierenvon SpalteninhaltenUm Inhalte für neue und vorhandene Spalten zu definieren, können Sie einen Ausdruck innerhalb einerTransformationsregel verwenden. Beispielsweise können Sie mithilfe von Ausdrücken eine Spaltehinzufügen oder Quelltabellenüberschriften zu einem Ziel replizieren. Sie können Ausdrücke auchverwenden, um Datensätze in Zieltabellen als eingefügt, aktualisiert oder an der Quelle gelöscht zukennzeichnen.
Hinzufügen einer Spalte mithilfe eines Ausdrucks
Verwenden Sie eine add-column-Regelaktion und ein column-Regelziel, um Tabellen mithilfe einesAusdrucks in einer Transformationsregel Spalten hinzuzufügen.
Im folgenden Beispiel wird der ITEM-Tabelle eine neue Spalte hinzugefügt. Der Name der neuen Spalte istFULL_NAME, der Datentyp string, und die Länge ist 50 Zeichen. Der Ausdruck verkettet die Werte zweiervorhandener Spalten, FIRST_NAME und LAST_NAME, so dass sie zu FULL_NAME ausgewertet werden.
{ "rules": [ { "rule-type": "selection",can "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "Test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "add-column", "rule-target": "column", "object-locator": { "schema-name": "Test", "table-name": "ITEM" }, "value": "FULL_NAME", "expression": "$FIRST_NAME||'_'||$LAST_NAME”, "data-type": { "type": "string", "length": 50 } } ]}
Markieren von Zieldatensätzen mithilfe eines Ausdrucks
Um Datensätze in Zieltabellen als eingefügt, aktualisiert oder gelöscht in der Quelltabelle zu kennzeichnen,verwenden Sie einen Ausdruck in einer Transformationsregel. Der Ausdruck verwendet eineoperation_indicator-Funktion, um Datensätze zu kennzeichnen. Datensätze, die aus der Quellegelöscht werden, werden nicht aus dem Ziel gelöscht. Stattdessen wird der Zieldatensatz mit einem vomBenutzer angegebenen Wert markiert, um anzuzeigen, dass er aus der Quelle gelöscht wurde.
API-Version API Version 2016-01-01395

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Note
Die operation_indicator-Funktion funktioniert nur für Tabellen, die einen Primärschlüsselhaben.
Beispielsweise fügt die folgende Transformationsregel einer Zieltabelle zuerst eine neue Operation-Spalte hinzu. Anschließend wird die Spalte mit dem Wert D aktualisiert, wenn ein Datensatz aus einerQuelltabelle gelöscht wird.
{ "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-target": "column", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "add-column", "value": "Operation", "expression": "operation_indicator('D', 'U', 'I')", "data-type": { "type": "string", "length": 50 }
Replizieren von Quelltabellenheadern mithilfe von Ausdrücken
Standardmäßig werden Header für Quelltabellen nicht auf das Ziel repliziert. Um anzugeben, welcheHeader repliziert werden sollen, verwenden Sie eine Transformationsregel mit einem Ausdruck, der denSpaltenheader der Tabelle enthält.
Sie können die folgenden Spaltenheader in Ausdrücken verwenden.
Header Wert bei fortlaufenderReplikation
Wert bei Volllast Datentyp
AR_H_ STREAM_POSITION
Der Wert der Stream-Position aus der Quelle.Dieser Wert kann jenach Quellendpunkt dieSystemänderungsnummer(SCN) oder dieProtokollsequenznummer(LSN) sein.
Eine leere Zeichenfolge. STRING
AR_H_ TIMESTAMP Ein Zeitstempel, der denZeitpunkt der Änderungangibt.
Ein Zeitstempel, der dieaktuelle Uhrzeit angibt.
DATETIME
AR_H_ COMMIT_TIMESTAMP
Ein Zeitstempel, der denZeitpunkt des Commitsangibt.
Ein Zeitstempel, der dieaktuelle Uhrzeit angibt.
DATETIME
AR_H_ OPERATION INSERT, UPDATE oderDELETE
INSERT STRING
AR_H_ USER Der Benutzername,die ID oder andere
Die Transformation,die Sie auf das
STRING
API-Version API Version 2016-01-01396
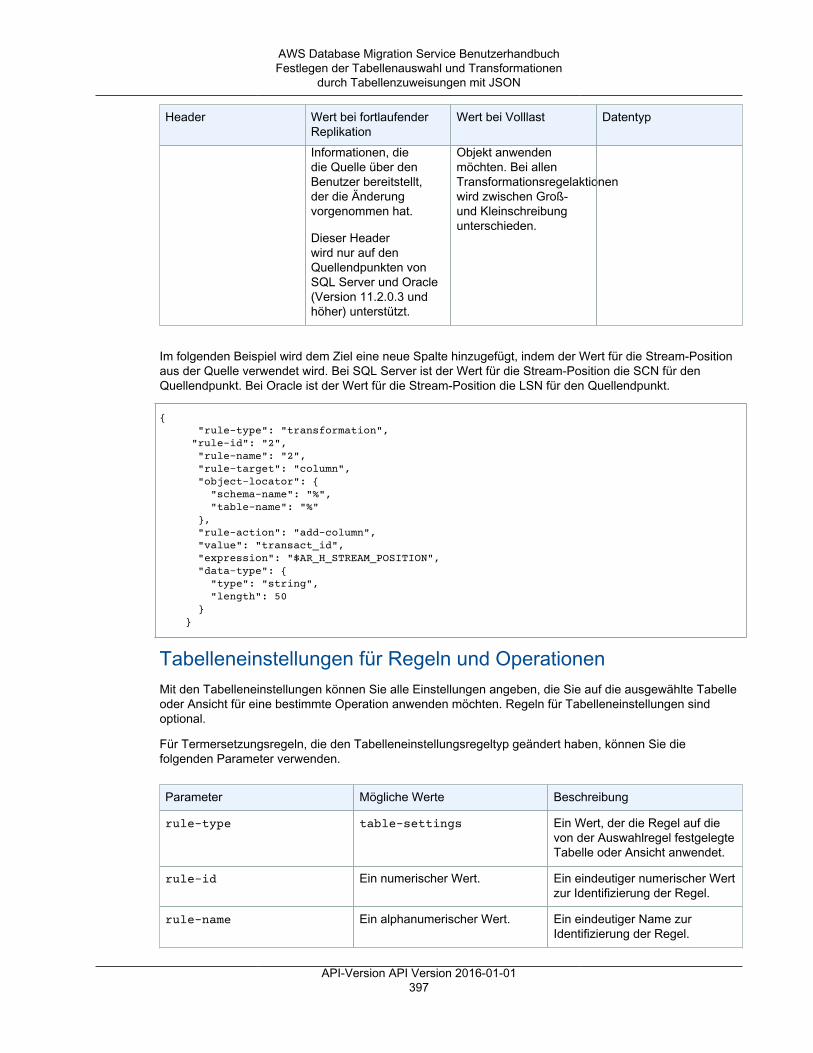
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Header Wert bei fortlaufenderReplikation
Wert bei Volllast Datentyp
Informationen, diedie Quelle über denBenutzer bereitstellt,der die Änderungvorgenommen hat.
Dieser Headerwird nur auf denQuellendpunkten vonSQL Server und Oracle(Version 11.2.0.3 undhöher) unterstützt.
Objekt anwendenmöchten. Bei allenTransformationsregelaktionenwird zwischen Groß-und Kleinschreibungunterschieden.
Im folgenden Beispiel wird dem Ziel eine neue Spalte hinzugefügt, indem der Wert für die Stream-Positionaus der Quelle verwendet wird. Bei SQL Server ist der Wert für die Stream-Position die SCN für denQuellendpunkt. Bei Oracle ist der Wert für die Stream-Position die LSN für den Quellendpunkt.
{ "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-target": "column", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "add-column", "value": "transact_id", "expression": "$AR_H_STREAM_POSITION", "data-type": { "type": "string", "length": 50 } }
Tabelleneinstellungen für Regeln und OperationenMit den Tabelleneinstellungen können Sie alle Einstellungen angeben, die Sie auf die ausgewählte Tabelleoder Ansicht für eine bestimmte Operation anwenden möchten. Regeln für Tabelleneinstellungen sindoptional.
Für Termersetzungsregeln, die den Tabelleneinstellungsregeltyp geändert haben, können Sie diefolgenden Parameter verwenden.
Parameter Mögliche Werte Beschreibung
rule-type table-settings Ein Wert, der die Regel auf dievon der Auswahlregel festgelegteTabelle oder Ansicht anwendet.
rule-id Ein numerischer Wert. Ein eindeutiger numerischer Wertzur Identifizierung der Regel.
rule-name Ein alphanumerischer Wert. Ein eindeutiger Name zurIdentifizierung der Regel.
API-Version API Version 2016-01-01397

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Mögliche Werte Beschreibung
object-locator Ein Objekt mit den folgendenParametern:
• schema-name – Der Namedes Schemas.
• table-name – Der Name derTabelle oder Ansicht.
Der Name eines bestimmtenSchemas und einer Tabelleoder Ansicht (keine Platzhalterzulässig).
API-Version API Version 2016-01-01398
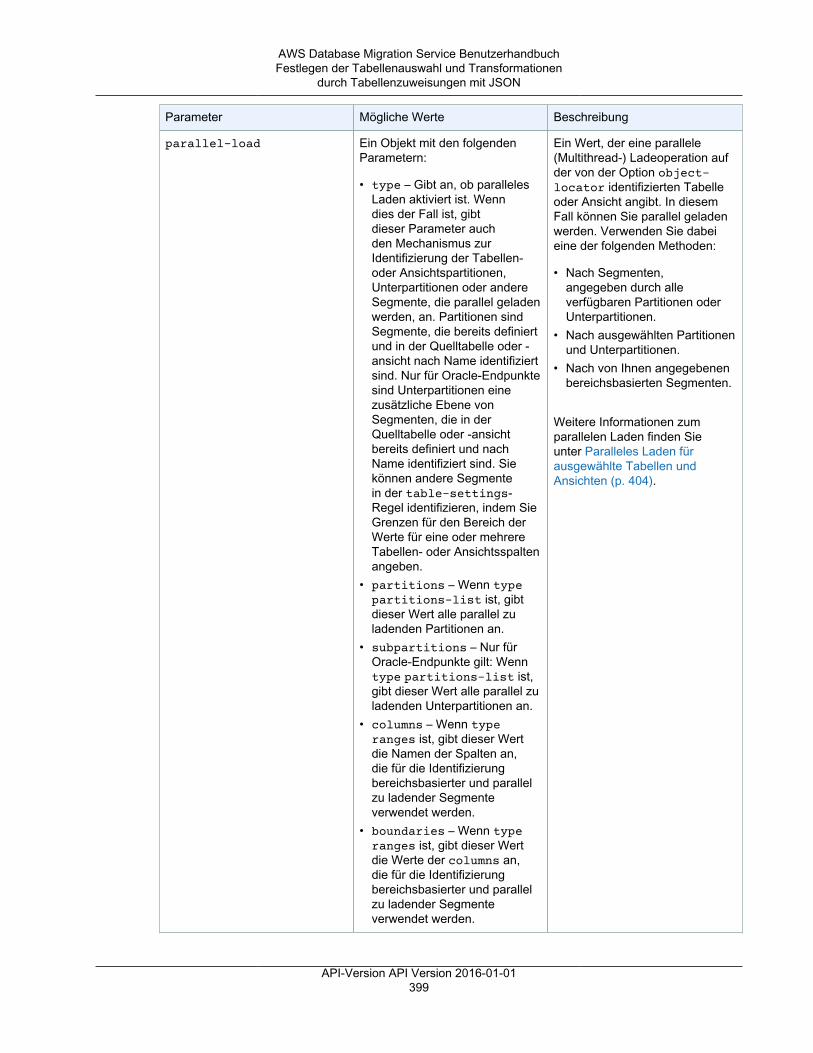
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Mögliche Werte Beschreibung
parallel-load Ein Objekt mit den folgendenParametern:
• type – Gibt an, ob parallelesLaden aktiviert ist. Wenndies der Fall ist, gibtdieser Parameter auchden Mechanismus zurIdentifizierung der Tabellen-oder Ansichtspartitionen,Unterpartitionen oder andereSegmente, die parallel geladenwerden, an. Partitionen sindSegmente, die bereits definiertund in der Quelltabelle oder -ansicht nach Name identifiziertsind. Nur für Oracle-Endpunktesind Unterpartitionen einezusätzliche Ebene vonSegmenten, die in derQuelltabelle oder -ansichtbereits definiert und nachName identifiziert sind. Siekönnen andere Segmentein der table-settings-Regel identifizieren, indem SieGrenzen für den Bereich derWerte für eine oder mehrereTabellen- oder Ansichtsspaltenangeben.
• partitions – Wenn typepartitions-list ist, gibtdieser Wert alle parallel zuladenden Partitionen an.
• subpartitions – Nur fürOracle-Endpunkte gilt: Wenntype partitions-list ist,gibt dieser Wert alle parallel zuladenden Unterpartitionen an.
• columns – Wenn typeranges ist, gibt dieser Wertdie Namen der Spalten an,die für die Identifizierungbereichsbasierter und parallelzu ladender Segmenteverwendet werden.
• boundaries – Wenn typeranges ist, gibt dieser Wertdie Werte der columns an,die für die Identifizierungbereichsbasierter und parallelzu ladender Segmenteverwendet werden.
Ein Wert, der eine parallele(Multithread-) Ladeoperation aufder von der Option object-locator identifizierten Tabelleoder Ansicht angibt. In diesemFall können Sie parallel geladenwerden. Verwenden Sie dabeieine der folgenden Methoden:
• Nach Segmenten,angegeben durch alleverfügbaren Partitionen oderUnterpartitionen.
• Nach ausgewählten Partitionenund Unterpartitionen.
• Nach von Ihnen angegebenenbereichsbasierten Segmenten.
Weitere Informationen zumparallelen Laden finden Sieunter Paralleles Laden fürausgewählte Tabellen undAnsichten (p. 404).
API-Version API Version 2016-01-01399
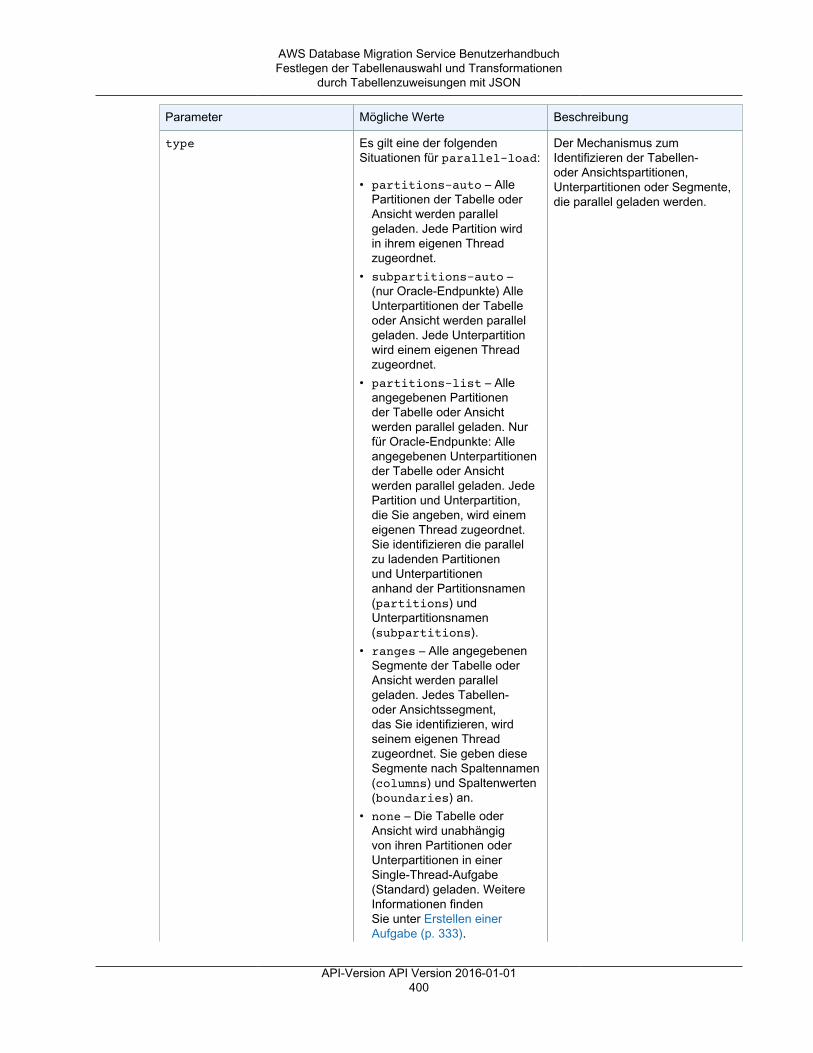
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Mögliche Werte Beschreibung
type Es gilt eine der folgendenSituationen für parallel-load:
• partitions-auto – AllePartitionen der Tabelle oderAnsicht werden parallelgeladen. Jede Partition wirdin ihrem eigenen Threadzugeordnet.
• subpartitions-auto –(nur Oracle-Endpunkte) AlleUnterpartitionen der Tabelleoder Ansicht werden parallelgeladen. Jede Unterpartitionwird einem eigenen Threadzugeordnet.
• partitions-list – Alleangegebenen Partitionender Tabelle oder Ansichtwerden parallel geladen. Nurfür Oracle-Endpunkte: Alleangegebenen Unterpartitionender Tabelle oder Ansichtwerden parallel geladen. JedePartition und Unterpartition,die Sie angeben, wird einemeigenen Thread zugeordnet.Sie identifizieren die parallelzu ladenden Partitionenund Unterpartitionenanhand der Partitionsnamen(partitions) undUnterpartitionsnamen(subpartitions).
• ranges – Alle angegebenenSegmente der Tabelle oderAnsicht werden parallelgeladen. Jedes Tabellen-oder Ansichtssegment,das Sie identifizieren, wirdseinem eigenen Threadzugeordnet. Sie geben dieseSegmente nach Spaltennamen(columns) und Spaltenwerten(boundaries) an.
• none – Die Tabelle oderAnsicht wird unabhängigvon ihren Partitionen oderUnterpartitionen in einerSingle-Thread-Aufgabe(Standard) geladen. WeitereInformationen findenSie unter Erstellen einerAufgabe (p. 333).
Der Mechanismus zumIdentifizieren der Tabellen-oder Ansichtspartitionen,Unterpartitionen oder Segmente,die parallel geladen werden.
API-Version API Version 2016-01-01400
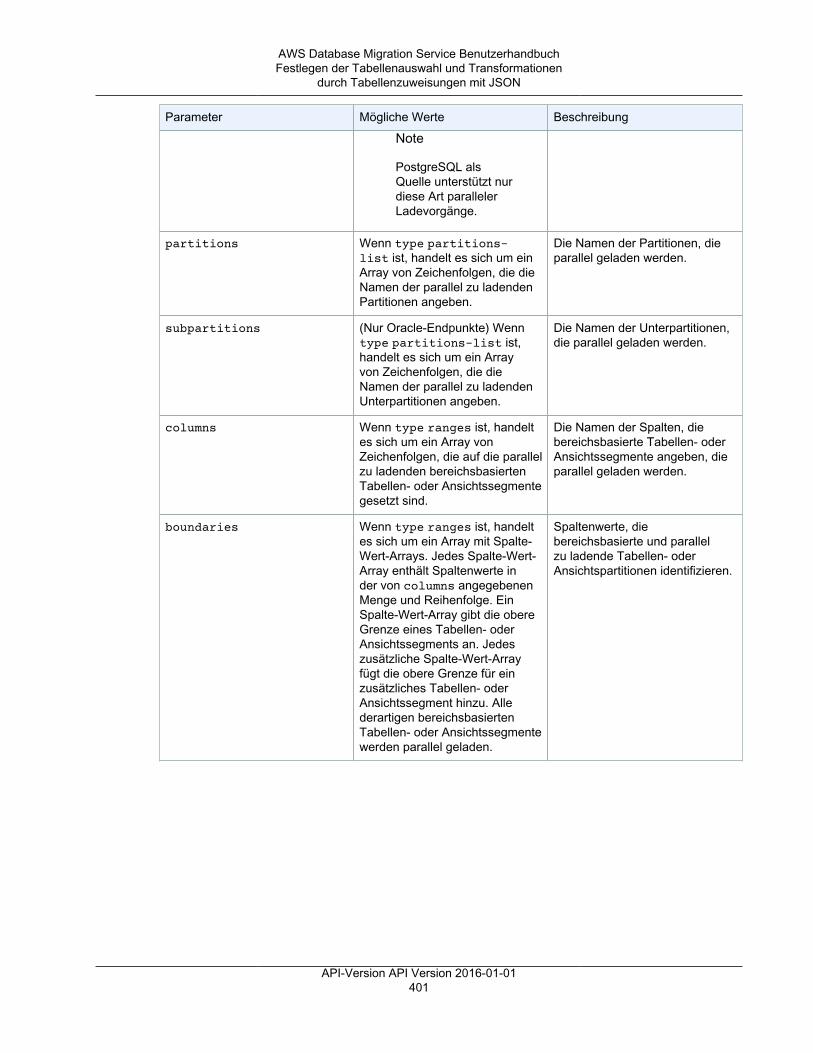
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Mögliche Werte Beschreibung
Note
PostgreSQL alsQuelle unterstützt nurdiese Art parallelerLadevorgänge.
partitions Wenn type partitions-list ist, handelt es sich um einArray von Zeichenfolgen, die dieNamen der parallel zu ladendenPartitionen angeben.
Die Namen der Partitionen, dieparallel geladen werden.
subpartitions (Nur Oracle-Endpunkte) Wenntype partitions-list ist,handelt es sich um ein Arrayvon Zeichenfolgen, die dieNamen der parallel zu ladendenUnterpartitionen angeben.
Die Namen der Unterpartitionen,die parallel geladen werden.
columns Wenn type ranges ist, handeltes sich um ein Array vonZeichenfolgen, die auf die parallelzu ladenden bereichsbasiertenTabellen- oder Ansichtssegmentegesetzt sind.
Die Namen der Spalten, diebereichsbasierte Tabellen- oderAnsichtssegmente angeben, dieparallel geladen werden.
boundaries Wenn type ranges ist, handeltes sich um ein Array mit Spalte-Wert-Arrays. Jedes Spalte-Wert-Array enthält Spaltenwerte inder von columns angegebenenMenge und Reihenfolge. EinSpalte-Wert-Array gibt die obereGrenze eines Tabellen- oderAnsichtssegments an. Jedeszusätzliche Spalte-Wert-Arrayfügt die obere Grenze für einzusätzliches Tabellen- oderAnsichtssegment hinzu. Allederartigen bereichsbasiertenTabellen- oder Ansichtssegmentewerden parallel geladen.
Spaltenwerte, diebereichsbasierte und parallelzu ladende Tabellen- oderAnsichtspartitionen identifizieren.
API-Version API Version 2016-01-01401

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Mögliche Werte Beschreibung
lob-settings Ein Objekt mit den folgendenParametern:
• mode – Gibt denMigrationsbearbeitungs-Modusfür LOBs an.
• bulk-max-size – Gibt diemaximale Größe der LOBsabhängig von der mode-Einstellung an.
Ein Wert, der die LOB-Verarbeitung für die von derOption object-locatoridentifizierte Tabelle oder Ansichtangibt. Die angegebene LOB-Verarbeitung überschreibt alleAufgaben-LOB-Einstellungennur für diese Tabelle oderAnsicht. Weitere Informationenzum Verwendung der LOB-Einstellungsparameter findenSie unter LOB-Einstellungen füreine ausgewählte Tabelle oderAnsicht (p. 408).
API-Version API Version 2016-01-01402

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Mögliche Werte Beschreibung
mode Gibt die Migrationsverarbeitungfür LOBs in der angegebenenTabelle oder Ansicht unterVerwendung der folgenden Wertean:
• limited – (Standard) DieserWert legt die Migration aufden eingeschränkten LOB-Modus fest, wobei alle LOBsgemeinsam mit allen anderenSpaltendatentypen in derTabelle oder Ansicht migriertwerden. Verwenden Siediesen Wert, wenn Sie zumeistkleine LOBs (100 MB oderweniger) replizieren. GebenSie außerdem einen bulk-max-size-Wert an (Nullist ungültig). Alle migriertenLOBs über bulk-max-sizeabgeschnitten, um der vonIhnen eingestellten Größe zuentsprechen.
• unlimited – Dieser Wertlegt die Migration auf denvollständigen LOB-Modus fest.Verwenden Sie diesen Wert,wenn alle oder die meistenLOBs, die Sie replizierenmöchten, größer als 1 GBsind. Wenn Sie den bulk-max-size-Wert Null angeben,werden alle LOBs im Standard-LOB-Modus (vollständig)migriert. In dieser Form desunlimited-Modus werdenalle LOBs getrennt vonanderen Spaltendatentypenmithilfe einer Suche aus derQuelltabelle oder -ansichtmigriert. Wenn Sie einenbulk-max-size-Wert größerals Null festlegen, werdenalle LOBs im Kombinations-LOB-Modus (vollständig)migriert. In dieser Form desunlimited-Modus werdenLOBs über bulk-max-size unter Verwendungeiner Quelltabellen- oderQuellansichtssuche migriert,ähnlich wie im Standard-LOB-Modus (vollständig).Andernfalls werden LOBs bis
Der Mechanismus zum Migrierenvon LOBs.
API-Version API Version 2016-01-01403
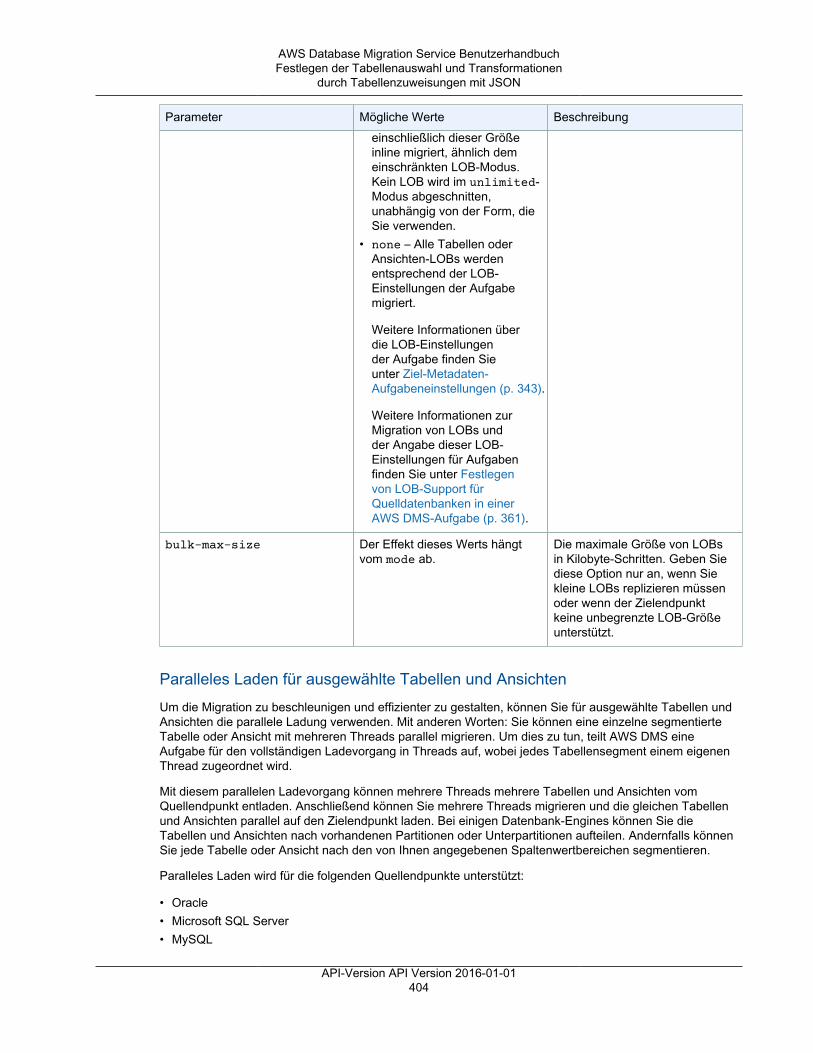
AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Mögliche Werte Beschreibungeinschließlich dieser Größeinline migriert, ähnlich demeinschränkten LOB-Modus.Kein LOB wird im unlimited-Modus abgeschnitten,unabhängig von der Form, dieSie verwenden.
• none – Alle Tabellen oderAnsichten-LOBs werdenentsprechend der LOB-Einstellungen der Aufgabemigriert.
Weitere Informationen überdie LOB-Einstellungender Aufgabe finden Sieunter Ziel-Metadaten-Aufgabeneinstellungen (p. 343).
Weitere Informationen zurMigration von LOBs undder Angabe dieser LOB-Einstellungen für Aufgabenfinden Sie unter Festlegenvon LOB-Support fürQuelldatenbanken in einerAWS DMS-Aufgabe (p. 361).
bulk-max-size Der Effekt dieses Werts hängtvom mode ab.
Die maximale Größe von LOBsin Kilobyte-Schritten. Geben Siediese Option nur an, wenn Siekleine LOBs replizieren müssenoder wenn der Zielendpunktkeine unbegrenzte LOB-Größeunterstützt.
Paralleles Laden für ausgewählte Tabellen und AnsichtenUm die Migration zu beschleunigen und effizienter zu gestalten, können Sie für ausgewählte Tabellen undAnsichten die parallele Ladung verwenden. Mit anderen Worten: Sie können eine einzelne segmentierteTabelle oder Ansicht mit mehreren Threads parallel migrieren. Um dies zu tun, teilt AWS DMS eineAufgabe für den vollständigen Ladevorgang in Threads auf, wobei jedes Tabellensegment einem eigenenThread zugeordnet wird.
Mit diesem parallelen Ladevorgang können mehrere Threads mehrere Tabellen und Ansichten vomQuellendpunkt entladen. Anschließend können Sie mehrere Threads migrieren und die gleichen Tabellenund Ansichten parallel auf den Zielendpunkt laden. Bei einigen Datenbank-Engines können Sie dieTabellen und Ansichten nach vorhandenen Partitionen oder Unterpartitionen aufteilen. Andernfalls könnenSie jede Tabelle oder Ansicht nach den von Ihnen angegebenen Spaltenwertbereichen segmentieren.
Paralleles Laden wird für die folgenden Quellendpunkte unterstützt:
• Oracle• Microsoft SQL Server• MySQL
API-Version API Version 2016-01-01404

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
• PostgreSQL• IBM Db2• SAP Adaptive Server Enterprise (ASE)
Das parallele Laden zur Verwendung mit Tabelleneinstellungsregeln wird für die folgenden Zielendpunkteunterstützt:
• Oracle• Microsoft SQL Server• MySQL• PostgreSQL• Amazon Redshift• SAP Adaptive Server Enterprise (ASE)
Verwenden Sie die MaxFullLoadSubTasks-Aufgabeneinstellung, um die maximale Anzahl an Tabellenund Ansichten anzugeben, die parallel geladen werden. Verwenden Sie die ParallelLoadThreads-Aufgabeneinstellung, um die maximale Anzahl an Threads pro Tabelle oder Ansicht anzugeben, die füreine Aufgabe zum parallelen Laden verwendet wird. Sie geben die Puffergröße für eine Aufgabe zumparallelen Laden mithilfe der ParallelLoadBufferSize-Aufgabeneinstellung an. Die Verfügbarkeit vonParallelLoadThreadsund ParallelLoadBufferSize sowie deren Einstellungen hängen vom Ziel-Endpunkt ab.
Weitere Informationen zu den Einstellungen ParallelLoadThreads und ParallelLoadBufferSizefinden Sie unter Ziel-Metadaten-Aufgabeneinstellungen (p. 343). Weitere Informationen zurMaxFullLoadSubTasks-Einstellung finden Sie unter Full-Load-Aufgabeneinstellungen (p. 344). WeitereInformationen zu den Zielendpunkten finden Sie unter den entsprechenden Themen.
Wenn Sie paralleles Laden verwenden möchten, können Sie mit der parallel-load-Option eineTabellenzuweisungsregel des Typs table-settings angeben. In der table-settings-Regel könnenSie die Segmentierungskriterien für eine einzelne Tabelle oder Ansicht, die parallel geladen werden soll,angeben. Um dies zu tun, setzen Sie den type-Parameter der parallel-load-Option auf eine derverschiedenen Optionen. Wie Sie es machen, hängt davon ab, wie Sie die Tabelle oder Ansicht für dasparallele Laden segmentieren möchten:
• Nach Partitionen – Alle vorhandenen Tabellen- oder Ansichtspartitionen werden mithilfe despartitions-auto-Typs geladen. Oder Laden nur ausgewählter Partitionen mithilfe des partitions-list-Typs mit einem partitions-Array.
• (Nur Oracle-Endpunkte) Nach Unterpartitionen – Laden alle vorhandenen Tabellen- oderAnsichtsunterpartitionen mithilfe des subpartitions-auto-Typs. Oder Laden nur ausgewählterUnterpartitionen mithilfe des partitions-list-Typs mit einem subpartitions-Array.
• Nach Segmente, die Sie definieren – Laden von Ihnen definierter Tabellen- oder Ansichtssegmentemithilfe von Spalte-Wert-Grenzen. Um dies zu tun, verwenden Sie den ranges-Typ mit angegebenencolumns- und boundaries-Arrays.
Note
PostgreSQL als Quelle unterstützt nur diese Art paralleler Ladevorgänge.
Um weitere Tabellen oder Ansichten zum parallelen Laden zu identifizieren, geben Sie zusätzliche table-settings-Objekte mit parallel-load-Optionen an.
Die folgenden Verfahren beschreiben das Codieren von JSON für jeden parallelen Ladetyp, vomeinfachsten zum kompliziertesten.
API-Version API Version 2016-01-01405

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
So geben Sie alle Tabellen- oder Ansichtspartitionen oder alle Tabellen- oder Unterpartitionen an
• Geben Sie parallel-load entweder mit dem partitions-auto-Typ oder dem subpartitions-auto-Typ an (aber nicht mit beiden).
Jede Tabellen- oder Ansichtspartition oder -unterpartition wird dann automatisch einem eigenenThread zugeordnet.
Note
Paralleles Laden enthält Partitionen oder Unterpartitionen nur, wenn sie bereits für die Tabelleoder Ansicht definiert sind.
So geben Sie ausgewählte Tabellen- oder Ansichtspartitionen, -unterpartitionen oder beides an:
1. Geben Sie parallel-load mit dem partitions-list-Typ an.2. (Optional) Fügen Sie Partitionen ein, indem Sie ein Array von Partitionsnamen als den Wert für
partitions angeben.
Jede angegebene Partition wird dann einem eigenen Thread zugeordnet.3. (Optional, nur für Oracle Endpunkte) Fügen Sie Unterpartitionen ein, indem Sie ein Array von
Unterpartitionsnamen als den Wert für subpartitions angeben.
Jede angegebene Unterpartition wird dann einem eigenen Thread zugeordnet.
Note
Paralleles Laden enthält Partitionen oder Unterpartitionen nur, wenn sie bereits für die Tabelleoder Ansicht definiert sind.
Sie können Tabellen- oder Ansichtssegmente als Bereiche von Spaltenwerten angeben. Wenn Sie dies tun,achten Sie auf diese Spalteneigenschaften:
• Die Angabe indizierter Spalten verbessert die Leistung erheblich.• Sie können bis zu 10 Spalten angeben.• Sie können keine Spalten zur Definition von Segmentgrenzen mit den folgenden AWS DMS-Datentypen
verwenden: DOUBLE, FLOAT, BLOB, CLOB und NCLOB• Datensätze mit Nullwerten werden nicht repliziert.
So geben Sie Tabellen- oder Ansichtssegmente als Bereiche von Spaltenwerten an
1. Geben Sie parallel-load mit dem ranges-Typ an.2. Definieren Sie eine Begrenzung zwischen Tabellen- oder Ansichtssegmenten, indem Sie ein Array von
Tabellenspaltennamen als den Wert für columns angeben. Wiederholen Sie diese Schritte für jedeSpalte, für die Sie eine Begrenzung zwischen Tabellen- oder Ansichtssegmenten definieren möchten.
Beachten Sie, dass die Reihenfolge der Spalten von Bedeutung ist. Dabei ist die erste Spalte bei derDefinition jeder Begrenzung am wichtigsten und die letzte Spalte ist am unwichtigsten. Einzelheitendazu finden Sie in den folgenden Schritten und Abschnitten.
3. Definieren Sie die Datenbereiche für alle Tabellen- oder Ansichtssegmente durch Angabe einesBegrenzungsarrays als Wert für boundaries. Bei einem Begrenzungsarray handelt es sich um einArray mit Spalte-Wert-Arrays. Führen Sie dazu die folgenden Schritte aus:
a. Geben Sie jedes Element eines Spalte-Wert-Arrays als Wert an, der jeder Spalte entspricht. Dabeistellt jedes Spalte-Wert-Array die obere Grenze für jedes Tabellen- oder Ansichtssegment dar, dasAPI-Version API Version 2016-01-01
406

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Sie definieren möchten: Geben Sie jede Spalte in der gleichen Reihenfolge an, in der Sie dieseSpalte in dem columns-Array angegeben haben.
Note
Geben Sie Werte für DATE-Spalten in dem von der Quelle unterstützten Format an.b. Geben Sie jedes Spalte-Wert-Array als obere Grenze in Reihenfolge jedes Segments an, vom
untersten zum nächst höheren Segment der Tabelle oder Ansicht. Wenn Zeilen oberhalb der vonIhnen angegebenen oberen Grenze vorhanden sind, stellend diese Zeilen die oberen Segmentder Tabelle oder Ansicht dar. Damit ist die Anzahl der bereichsbasierten Segmente potentielleins höher, als die Anzahl der Segmentgrenzen im Grenz-Array. Jedes dieser bereichsbasiertenSegmente wird einem eigenen Thread zugeordnet.
Note
Alle Tabellendaten, die nicht Null sind, werden repliziert. Dies gilt auch, wenn Sie nicht füralle Spalten in der Tabelle oder Ansicht Datenbereiche definieren.
Beispiel: Sie definieren drei Spalte-Wert-Arrays für die Spalten, COL2 und COL3 COL1 wie folgt.
COL1 COL2 COL3
10 30 105
20 20 120
100 12 99
Sie haben drei Segmentgrenzen für einen möglichen Gesamtwert von vier Segmenten definiert.
Um die Bereiche der für jedes Segment zu replizierenden Zeilen zu identifizieren, wendet dieReplikations-Instance einen Suchalgorithmus auf diese drei Spalten für jedes der vier Segmente an.Die Suche sieht wie folgt aus:
Segment 1
Replizieren Sie alle Zeilen, in denen Folgendes zutrifft: Die ersten Werte mit zwei Spalten sindkleiner oder gleich den entsprechenden Werten für die Obergrenze für Segment 1. Außerdem sinddie Werte der dritten Spalte kleiner als der Wert der Obergrenze für Segment 1 .
Segment 2
Replizieren Sie alle Zeilen (außer Segment 1-Zeilen), wobei Folgendes zutrifft: Die ersten Wertemit zwei Spalten sind kleiner oder gleich den entsprechenden Werten für die Obergrenze fürSegment 2. Außerdem sind die Werte der dritten Spalte kleiner als der Wert der Obergrenze fürSegment 2 .
Segment 3
Replizieren Sie alle Zeilen (außer Segment 2-Zeilen), wobei Folgendes zutrifft: Die ersten Wertemit zwei Spalten sind kleiner oder gleich den entsprechenden Werten für die Obergrenze fürSegment 3. Außerdem sind die Werte der dritten Spalte kleiner als der Wert für den oberenGrenzwert für Segment 3 .
Segment 4
Replizieren Sie alle verbleibenden Zeilen (außer den Zeilen Segment 1, 2 und 3).
API-Version API Version 2016-01-01407

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
In diesem Fall erstellt die Replikations-Instance wie folgt eine WHERE-Klausel zum Laden jedesSegment:
Segment 1
((COL1 < 10) OR ((COL1 = 10) AND (COL2 < 30)) OR ((COL1 = 10) AND (COL2= 30) AND (COL3 < 105)))
Segment 2
NOT ((COL1 < 10) OR ((COL1 = 10) AND (COL2 < 30)) OR ((COL1 = 10) AND(COL2 = 30) AND (COL3 < 105))) AND ((COL1 < 20) OR ((COL1 = 20) AND(COL2 < 20)) OR ((COL1 = 20) AND (COL2 = 20) AND (COL3 < 120)))
Segment 3
NOT ((COL1 < 20) OR ((COL1 = 20) AND (COL2 < 20)) OR ((COL1 = 20) AND(COL2 = 20) AND (COL3 < 120))) AND ((COL1 < 100) OR ((COL1 = 100) AND(COL2 < 12)) OR ((COL1 = 100) AND (COL2 = 12) AND (COL3 < 99)))
Segment 4
NOT ((COL1 < 100) OR ((COL1 = 100) AND (COL2 < 12)) OR ((COL1 = 100) AND(COL2 = 12) AND (COL3 < 99)))
LOB-Einstellungen für eine ausgewählte Tabelle oder AnsichtSie können die LOB-Aufgabeneinstellungen für eine oder mehrere Tabellen einrichten, indem Sie eineTabellenzuordnungsregel des Typs table-settings mit der lob-settings-Option für ein odermehrere table-settings-Objekte erstellen.
Das Angeben von LOB-Einstellungen für ausgewählte Tabellen oder Ansichten wird für die folgendenQuell-Endpunkte unterstützt:
• Oracle• Microsoft SQL Server• MySQL• PostgreSQL• IBM Db2, abhängig von den mode- und bulk-max-size-Einstellungen, wie im Folgenden beschrieben• SAP Adaptive Server Enterprise (ASE), abhängig von den mode-und bulk-max-size-Einstellungen,
wie im Folgenden beschrieben
Das Angeben von LOB-Einstellungen für ausgewählte Tabellen oder Ansichten wird für die folgendenZielendpunkte unterstützt:
• Oracle• Microsoft SQL Server• MySQL• PostgreSQL• SAP ASE, je nach den mode- und bulk-max-size-Einstellungen, wie im Folgenden beschrieben
Note
Sie können LOB-Datentypen nur mit Tabellen und Ansichten verwenden, die einenPrimärschlüssel enthalten.
API-Version API Version 2016-01-01408

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Wenn Sie LOB-Einstellungen für eine ausgewählte Tabelle oder Ansicht verwenden möchten, erstellenSie eine Tabellenzuweisungsregel des Typs table-settings mit der lob-settings-Option. Damitwird die LOB-Behandlung für die Tabelle oder Ansicht angegeben, die von der object-locator-Optionidentifiziert wird. In der table-settings-Regel können Sie mit den folgenden Parametern ein lob-settings-Objekt angeben:
• mode – Gibt den Mechanismus für die Behandlung der LOB-Migration für die ausgewählte Tabelle oderAnsicht wie folgt an:• limited – Dieser eingeschränkte LOB-Standardmodus ist der schnellste und effizienteste Modus.
Verwenden Sie diesen Modus nur dann, wenn alle Ihre LOBs klein (unter 100 MB) sind oder der Ziel-Endpunkt keine unbegrenzte LOB-Größe unterstützt. Weiterhin gilt: Wenn Sie limited verwenden,müssen alle LOBs in dem Größenbereich liegen, den Sie für bulk-max-size eingerichtet haben.
In diesem Modus für eine vollständige Ladungsaufgabe migriert die Replikations-Instance alle LOBsinline zusammen mit anderen Spaltendatentypen als Teil des Haupttabellen-oder -ansichtsspeichers.Die Instance kürzt allerdings jedes LOB, das größer als Ihr bulk-max-size-Wert ist, auf dieangegebene Größe. Für eine Change Data Capture (CDC)-Ladeaufgabe migriert die Instance alleLOBs mithilfe einer Quelltabellensuche unabhängig von der LOB-Größe als vollständigen LOB-Standardmodus (siehe unten). Dies geschieht unabhängig von der LOB-Größe.
Note
Sie können Ansichten nur für Full-Load-Aufgaben migrieren.• unlimited – Der Migrationsmechanismus für den vollständigen LOB-Modus hängt von dem Wert ab,
den Sie wie folgt für bulk-max-size festgelegt haben:• Vollständiger LOB-Standardmodus – Wenn Sie bulk-max-size auf Null festlegen, migriert die
Replikations-Instance alle LOBs mithilfe des vollständigen LOB-Standardmodus. Dieser Moduserfordert eine Suche in der Quelltabelle oder -ansicht, um jedes LOB unabhängig von seinerGröße zu migrieren. Dies führt in der Regel zu einer sehr viel langsameren Migration als imeingeschränkten LOB-Modus. Verwenden Sie diesen Modus nur, wenn alle oder die meisten IhrerLOBs groß sind (1 GB oder größer).
• Vollständiger LOB-Kombinationsmodus – Wenn Sie bulk-max-size auf einen Wert ungleichNull festlegen, verwendet dieser vollständige LOB-Modus eine Kombination aus eingeschränktemLOB-Modus und vollständigem LOB-Standardmodus. Das heißt, wenn eine LOB-Größe innerhalbIhres bulk-max-size-Werts liegt, migriert die Instance das LOB inline wie im eingeschränktenLOB-Modus. Wenn die LOB-Größe diesen Wert übersteigt, migriert die Instance das LOB mithilfeeiner Quelltabellen- oder Quellansichtssuche wie im vollständigen LOB-Standardmodus. Füreine Change Data Capture (CDC)-Ladeaufgabe migriert die Instance alle LOBs mithilfe einerQuelltabellensuche unabhängig von der LOB-Größe als vollständigen LOB-Standardmodus (sieheunten). Dies geschieht unabhängig von der LOB-Größe.
Note
Sie können Ansichten nur für Full-Load-Aufgaben migrieren.
Dieser Modus resultiert in einem Kompromiss bei der Migrationsgeschwindigkeit. Sie liegtzwischen dem schnelleren eingeschränkten LOB-Modus und dem langsameren vollständigen LOB-Standardmodus. Verwenden Sie diesen Modus nur bei einer Mischung aus kleinen und großenLOBs, wobei die meisten LOBs klein sind.
Dieser kombinierte vollständige LOB-Modus ist nur verfügbar für die folgenden Endpunkte:• IBM Db2 als Quelle• SAP ASE als Quelle oder Ziel
Unabhängig davon, welchen Mechanismus Sie für den unlimited-Modus angeben, migriert dieInstance alle LOBs vollständig und ohne Kürzung.
API-Version API Version 2016-01-01409

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
• none – Die Replikations-Instance migriert LOBs in der ausgewählten Tabelle oder Ansicht anhandIhrer LOB-Einstellungen für Aufgaben. Sie können diese Option verwenden, um Migrationsergebnissemit und ohne LOB-Einstellungen besonders für die ausgewählte Tabelle oder Ansicht zu vergleichen.
Wenn die angegebene Tabelle oder Ansicht LOBs in die Replikation einschließt, können Sie dieBatchApplyEnabled-Aufgabeneinstellung nur bei Verwendung des limited-LOB-Modus auf truesetzen.
In einigen Fällen könnten Sie BatchApplyEnabled auf true undBatchApplyPreserveTransaction auf false setzen. In diesen Fällen setzt die InstanceBatchApplyPreserveTransaction auf true, wenn die Tabelle oder Ansicht LOBs besitzt und dieQuell- und Ziel-Endpunkte Oracle sind.
• bulk-max-size – Legen Sie diesen Wert in Kilobyte auf Null oder ungleich Null fest. Dies ist, wiebereits für vorherige Elemente beschrieben, vom mode abhängig. Im limited-Modus müssen Sie fürdiesen Parameter einen Wert ungleich Null setzen.
Die Instance konvertiert LOBs in das Binärformat. Aus diesem Grund multiplizieren Sie die Größe dergrößten LOBs, die Sie replizieren müssen, mit drei. Beispiel: Wenn Ihr größtes LOB 2 MB groß ist, legenSie bulk-max-size auf 6.000 (6 MB) fest.
Beispiele für Tabelleneinstellungen
Im Folgenden finden Sie einige Beispiele, die die Verwendung der Tabelleneinstellungen illustrieren.
Example Laden einer nach Partitionen segmentierten Tabelle
Im folgenden Beispiel wird eine SALES-Tabelle effizienter in Ihre Quelle geladen, indem basierend auf allenPartitionen sie parallel geladen wird.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "table-settings", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "HR", "table-name": "SALES" }, "parallel-load": { "type": "partitions-auto" } } ]}
Example Laden einer nach Unterpartitionen segmentierten Tabelle
Im folgenden Beispiel wird eine SALES-Tabelle effizienter in Ihre Oracle-Quelle geladen, indem sie auf allenUnterpartitionen parallel geladen wird.
API-Version API Version 2016-01-01410

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "table-settings", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "HR", "table-name": "SALES" }, "parallel-load": { "type": "subpartitions-auto" } } ]}
Example Laden einer segmentierten Tabelle entsprechend einer Partitionsliste
Im folgenden Beispiel wird eine SALES-Tabelle in Ihre Quelle geladen, indem sie entsprechend einerbestimmten Partitionsliste parallel geladen wird. Hier werden die angegebenen Partitionen nach Wertenbenannt, beginnend mit Teilen des englischen Alphabets, z. B. ABCD, EFGH usw.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "table-settings", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "HR", "table-name": "SALES" }, "parallel-load": { "type": "partitions-list", "partitions": [ "ABCD", "EFGH", "IJKL", "MNOP", "QRST", "UVWXYZ" ] } }
API-Version API Version 2016-01-01411

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
]}
Example Laden einer segmentierten Oracle-Tabelle entsprechend einer ausgewählten Liste mitPartitionen und Unterpartitionen
Im folgenden Beispiel wird eine SALES-Tabelle in Ihre Oracle-Quelle geladen, indem sie entsprechendeiner ausgewählten Liste mit Partitionen und Unterpartitionen parallel geladen wird. Hier werden dieangegebenen Partitionen nach Werten benannt, beginnend mit Teilen des englischen Alphabets, z. B.ABCD, EFGH usw. Die angegebenen Unterpartitionen sind nach mit Zahlen beginnenden Werten benannt,z. B. 01234 und 56789.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "table-settings", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "HR", "table-name": "SALES" }, "parallel-load": { "type": "partitions-list", "partitions": [ "ABCD", "EFGH", "IJKL", "MNOP", "QRST", "UVWXYZ" ], "subpartitions": [ "01234", "56789" ] } } ]}
Example Laden einer durch Spaltenwertbereiche segmentierten Tabelle
Im folgenden Beispiel wird eine SALES-Tabelle in Ihre Quelle geladen, indem sie nach den durch Bereichder SALES_NO- und REGION-Spaltenwerte angegebenen Segmente parallel geladen wird.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%",
API-Version API Version 2016-01-01412

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
"table-name": "%" }, "rule-action": "include" }, { "rule-type": "table-settings", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "HR", "table-name": "SALES" }, "parallel-load": { "type": "ranges", "columns": [ "SALES_NO", "REGION" ], "boundaries": [ [ "1000", "NORTH" ], [ "3000", "WEST" ] ] } } ]}
Hier werden zwei Spalten für die Segmentbereiche mit den Namen SALES_NO und REGION angegeben. Eswerden zwei Grenzen mit den beiden Spaltenwertsätzen ["1000","NORTH"] und ["3000","WEST"]angegeben.
Diese beiden Grenzen identifizieren somit die folgenden drei Tabellensegmente, die parallel geladenwerden:
Segment 1
Zeilen mit SALES_NO kleiner oder gleich 1.000 und mit REGION kleiner als "NORTH" sind. Mit anderenWorten: Verkaufszahlen bis zu 1.000 in der EAST-Region.
Segment 2
Andere Zeilen als Segment 1 mit SALES_NO kleiner oder gleich 3.000 und REGION kleiner als "WEST".Mit anderen Worten: Verkaufszahlen zwischen 1.000 und 3.000 in den Regionen „NORTH“ und„SOUTH“.
Segment 3
Alle verbleibenden Zeilen außer Segment 1 und Segment 2. Mit anderen Worten: Verkaufszahlen über3.000 in der WEST-Region.
Example Laden von zwei Tabellen: Eine nach Bereichen, die andere nach Partitionen segmentiert
Das folgende Beispiel lädt eine SALES-Tabelle parallel nach Segmentgrenzen, die Sie identifizieren. Es lädtaußerdem eine ORDERS-Tabelle parallel nach allen ihren Partitionen, wie in früheren Beispielen.
{ "rules": [{ "rule-type": "selection",
API-Version API Version 2016-01-01413

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
"rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "table-settings", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "HR", "table-name": "SALES" }, "parallel-load": { "type": "ranges", "columns": [ "SALES_NO", "REGION" ], "boundaries": [ [ "1000", "NORTH" ], [ "3000", "WEST" ] ] } }, { "rule-type": "table-settings", "rule-id": "3", "rule-name": "3", "object-locator": { "schema-name": "HR", "table-name": "ORDERS" }, "parallel-load": { "type": "partitions-auto" } } ]}
Example Laden einer Tabelle mit LOBs mithilfe des eingeschränkten LOB-Modus
Im folgenden Beispiel wird eine ITEMS-Tabelle, einschließlich LOBs in Ihre Quelle mithilfe deseingeschränkten LOB-Modus (Standard) mit einer maximalen nicht gekürzten Größe von 100 MB geladen.Alle LOBs, die größer als dieser Wert sind, werden auf 100 MB gekürzt. Alle LOBs werden inline mit allenanderen Spaltendatentypen geladenen.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%", "table-name": "%"
API-Version API Version 2016-01-01414

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
}, "rule-action": "include" }, { "rule-type": "table-settings", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "INV", "table-name": "ITEMS" }, "lob-settings": { "bulk-max-size": "100000" } } ]}
Example Laden einer Tabelle mit LOBs mithilfe des vollständigen LOB-Standardmodus
Im folgenden Beispiel wird eine ITEMS-Tabelle einschließlich aller ihrer LOBs ohne Kürzung in Ihre Quellegeladen. Dies erfolgt über den vollständigen LOB-Standardmodus. Es werden alle LOBs unabhängigihrer Größe getrennt von anderen Datentypen geladen, die eine Suche für jedes LOB in der Quelltabelleverwenden.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "table-settings", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "INV", "table-name": "ITEMS" }, "lob-settings": { "mode": "unlimited" "bulk-max-size": "0" } } ]}
Example Laden einer Tabelle mit LOBs mithilfe des vollständigen LOB-Kombinationsmodus
Im folgenden Beispiel wird eine ITEMS-Tabelle einschließlich aller ihrer LOBs ohne Kürzung in Ihrer Quellegeladen. Dies erfolgt über de vollständigen LOB-Kombinationsmodus. Alle LOBs mit einer Maximalgrößevon 100 MB werden-zusammen mit anderen Datentypen inline geladen, wie im eingeschränkten LOB-Modus. Alle LOBs mit einer Größe von über 100 MB werden getrennt von anderen Datentypen geladen.Dieser separate Ladevorgang verwendet eine Suche für jedes dieser LOB in der Quelltabelle, wie imstandardmäßigen vollständigen LOB-Modus.
{
API-Version API Version 2016-01-01415

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
"rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "table-settings", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "INV", "table-name": "ITEMS" }, "lob-settings": { "mode": "unlimited" "bulk-max-size": "100000" } } ]}
Example Laden einer Tabelle mit LOBs über die LOB-Einstellungen für Aufgaben
Im folgenden Beispiel wird eine ITEMS-Tabelle mithilfe der LOB-Einstellungen für Aufgaben einschließlichaller LOBs in Ihre Quelle geladen. Die bulk-max-size-Einstellung von 100 MB wird ignoriert und nur fürein schnelles Zurücksetzen auf den limited- oder unlimited-Modus beibehalten.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "%", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "table-settings", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "INV", "table-name": "ITEMS" }, "lob-settings": { "mode": "none" "bulk-max-size": "100000" } } ]}
Verwenden von QuellfilternSie können Quellfilter verwenden, um Anzahl und Art der Datensätze zu beschränken, die von IhrerQuelle auf Ihr Ziel übertragen werden. So können Sie beispielsweise festlegen, dass nur die am Hauptsitz
API-Version API Version 2016-01-01416

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
ansässigen Angestellten in die Zieldatenbank übertragen werden. Filter sind Teil einer Auswahlregel. Siewenden Filter auf eine Datenspalte an.
Quellfilter müssen diese Einschränkungen befolgen:
• Eine Auswahlregel kann keine Filter oder einen oder mehrere Filter haben.• Jeder Filter kann eine oder mehrere Filterbedingungen haben.• Wenn mehr als ein Filter verwendet wird, wird die Liste der Filter kombiniert, als ob die Filter mit einem
UND-Operator verbunden wären.• Wenn mehr als eine Filterbedingung in einem einzigen Filter verwendet wird, wird die Liste der
Filterbedingungen so kombiniert, als ob die Filterbedingungen mit einem ODER-Operator verbundenwären.
• Filter werden nur angewendet, wenn rule-action = 'include'.• Filter erfordern einen Spaltennamen und eine Liste von Filterbedingungen. Filterbedingungen müssen
einen Filteroperator und einen Wert haben.• Bei Spaltennamen, Tabellennamen, Ansichtsnamen und Schemanamen wird zwischen Groß- und
Kleinschreibung unterschieden.
Die folgenden Einschränkungen gelten für die Verwendung von Quellfiltern:
• Filter berechnen keine Spalten von Rechts-nach-links-Sprachen.• Wenden Sie keine Filter auf LOB-Spalten an.• Wenden Sie Filter nur auf unveränderliche Spalten an. Wenn Quellfilter auf veränderbare Spalten
angewendet werden, kann dies zu einem negativen Verhalten führen. zum Beispiel:
Ein Filter zum Ausschließen oder Einschließen bestimmter Zeilen in einer Spalte schließt dieangegebenen Zeilen immer aus bzw. ein, selbst wenn die Zeilen später geändert werden. Wenn Sie z. B.die Zeilen 1 bis 10 in Spalte A ausschließen oder einschließen und sie später zu den Zeilen 11 bis 20werden, werden sie weiterhin ausgeschlossen bzw. eingeschlossen, selbst wenn die Daten nicht mehrdie gleichen sind.
Und wenn eine Zeile, die sich außerhalb des Filterbereichs befindet, später aktualisiert wird (oderaktualisiert und gelöscht wird) und dann wie vom Filter definiert ausgeschlossen oder eingeschlossenwird, wird sie am Ziel nicht repliziert.
Erstellen von Quellfilterregeln in JSON
Sie können Quellfilter erstellen, indem Sie den JSON-Parameter filters einer Auswahlregel verwenden.Der filters-Parameter gibt ein Array von einem oder mehreren JSON-Objekten an. Jedes Objektverfügt über Parameter, die den Quell-Filtertyp, Spaltennamen und die Filterbedingungen festlegen. DieseFilterbedingungen umfassen einen oder mehrere Filteroperatoren und Filterwerte.
Die folgende Tabelle zeigt die Parameter, die Quellfilterung in einem filters-Objekt festlegen.
Parameter Wert
filter-type source
column-name Der Name der Quellspalte, auf die der Filter angewendet werden soll.Der Name berücksichtigt Groß- und Kleinschreibung.
filter-conditions Ein Array von einem oder mehreren Objekten, die einen filter-operator-Parameter und einen entsprechenden Wertparameterenthalten, entsprechend dem filter-operator-Wert.
API-Version API Version 2016-01-01417

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Parameter Wert
filter-operator Folgende Parameterwerte sind möglich:
• ste – kleiner als oder gleich• gte – größer als oder gleich• eq – gleich• between – gleich oder zwischen zwei Werten
value oder
start-value
end-value
Der Wert des filter-operator-Parameters. Wenn der filter-operator einen anderen Wert als between hat, verwenden Sie value.Wenn der filter-operator auf between gesetzt ist, geben Sie zweiWerte an, einen für start-value und einen für end-value.
Die folgenden Beispiele zeigen einige gängige Möglichkeiten zur Nutzung von Quellfiltern.
Example Einzelne Filter
Der folgende Filter repliziert alle Angestellten mit dem Wert empid >= 100 in die Zieldatenbank.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "employee" }, "rule-action": "include", "filters": [{ "filter-type": "source", "column-name": "empid", "filter-conditions": [{ "filter-operator": "gte", "value": "100" }] }] }]}
Example Mehrere Filteroperatoren
Die folgenden Filter wenden mehrere Filteroperatoren auf eine einzelne Datenspalte an. Der folgende Filterrepliziert alle Angestellten mit dem Wert (empid <=10) ODER (empid is between 50 and 75)ODER (empid >= 100) in die Zieldatenbank.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "employee" },
API-Version API Version 2016-01-01418

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
"rule-action": "include", "filters": [{ "filter-type": "source", "column-name": "empid", "filter-conditions": [{ "filter-operator": "ste", "value": "10" }, { "filter-operator": "between", "start-value": "50", "end-value": "75" }, { "filter-operator": "gte", "value": "100" }] }] }] }
Example Mehrere Filter
Der folgende Filter wendet mehrere Filter auf zwei Spalten in einer Tabelle an. Der Filter repliziert alleAngestellten mit dem Wert (empid <= 100) UND (dept= tech) in die Zieldatenbank.
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "employee" }, "rule-action": "include", "filters": [{ "filter-type": "source", "column-name": "empid", "filter-conditions": [{ "filter-operator": "ste", "value": "100" }] }, { "filter-type": "source", "column-name": "dept", "filter-conditions": [{ "filter-operator": "eq", "value": "tech" }] }] }]}
Filtern nach Zeit und Datum
Wenn Sie Daten zum Importieren auswählen, können Sie ein Datum oder eine Uhrzeit als Teil IhrerFilterkriterien bestimmen. AWS DMS verwendet das Datumsformat JJJJ-MM-TT und das UhrzeitformatJJJJ-MM-TT HH:MM:SS zum Filtern. Die AWS DMS-Vergleichsfunktionen befolgen die SQLite-Konventionen. Weitere Informationen zu SQLite-Datentypen und -Datenvergleichen finden Sie unterDatatypes In SQLite Version 3 in der SQLite-Dokumentation.
API-Version API Version 2016-01-01419

AWS Database Migration Service BenutzerhandbuchFestlegen der Tabellenauswahl und Transformationen
durch Tabellenzuweisungen mit JSON
Im folgenden Beispiel wird gezeigt, wie Sie nach einem Datum filtern. Er repliziert alle Angestellten mit demWert empstartdate >= January 1, 2002 in die Zieldatenbank.
Example Einzelner Datumsfilter
{ "rules": [{ "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "employee" }, "rule-action": "include", "filters": [{ "filter-type": "source", "column-name": "empstartdate", "filter-conditions": [{ "filter-operator": "gte", "value": "2002-01-01" }] }] }]}
API-Version API Version 2016-01-01420

AWS Database Migration Service BenutzerhandbuchAufgabenstatus
Überwachen von AWS DMS-Aufgaben
Sie können den Fortschritt einer Aufgabe überwachen, indem Sie den Aufgabenstatus überprüfen und dieSteuerungstabelle der Aufgabe überwachen. Weitere Informationen zu Steuerungstabellen finden Sie unterEinstellungen der Kontrolltabelle für Aufgaben (p. 346).
Sie können den Fortschritt Ihrer Aufgaben auch mithilfe von Amazon CloudWatch überwachen. WennSie die AWS-Managementkonsole, die AWS-Befehlszeilenschnittstelle (CLI) oder die AWS DMS-API verwenden, können Sie den Fortschritt der Aufgabe sowie die Ressourcen und verwendeteNetzwerkverbindung überwachen.
Schließlich können Sie auch den Status der Quelltabellen in einer Aufgabe überwachen, indem Sie sichden Tabellenstatus anschauen.
Beachten Sie, dass die Spalte für "Letzte Aktualisierung" der DMS-Konsole nur den Zeitpunkt anzeigt, andem AWS DMS zuletzt den Tabellenstatistikdatensatz für eine Tabelle aktualisiert hat. Es wird nicht derZeitpunkt der letzten Tabellenaktualisierung angegeben.
Weitere Informationen finden Sie unter den folgenden Themen.
Themen• Aufgabenstatus (p. 421)• Tabellenstatus während der Aufgaben (p. 422)• Überwachen von Replikationsaufgaben mit Amazon CloudWatch (p. 423)• Metriken von Data Migration Service (p. 425)• Verwalten von AWS DMS-Aufgabenprotokollen (p. 429)• Protokollieren von AWS DMS-API-Aufrufen mit AWS CloudTrail (p. 430)
AufgabenstatusDer Aufgabenstatus zeigt die Bedingung der Aufgabe an. Die folgende Tabelle zeigt die möglichen Statuseiner Aufgabe:
Aufgabenstatus Beschreibung
Erstellen AWS DMS erstellt die Aufgabe.
In Ausführung Die Aufgabe führt die angegebenen Migrationsvorgänge aus.
Angehaltene Die Aufgabe wird angehalten.
Stopping Die Aufgabe wird angehalten. Dies ist in der Regel einHinweis auf ein Eingreifen in die Aufgabe durch denBenutzer.
Deleting Die Aufgabe wird gelöscht, in der Regel von einerAnforderung für einen Benutzereingriff.
Fehlgeschlagen Die Aufgabe ist fehlgeschlagen. Weitere Informationen findenSie in den Aufgabenprotokolldateien.
API-Version API Version 2016-01-01421
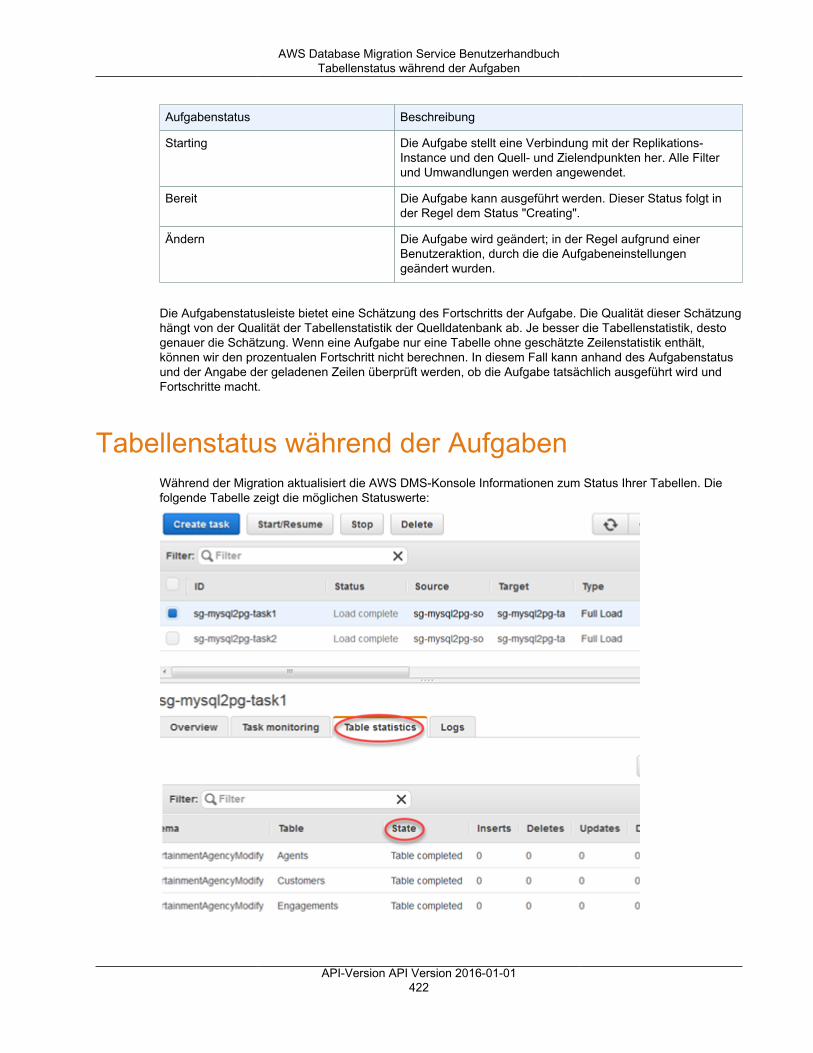
AWS Database Migration Service BenutzerhandbuchTabellenstatus während der Aufgaben
Aufgabenstatus Beschreibung
Starting Die Aufgabe stellt eine Verbindung mit der Replikations-Instance und den Quell- und Zielendpunkten her. Alle Filterund Umwandlungen werden angewendet.
Bereit Die Aufgabe kann ausgeführt werden. Dieser Status folgt inder Regel dem Status "Creating".
Ändern Die Aufgabe wird geändert; in der Regel aufgrund einerBenutzeraktion, durch die die Aufgabeneinstellungengeändert wurden.
Die Aufgabenstatusleiste bietet eine Schätzung des Fortschritts der Aufgabe. Die Qualität dieser Schätzunghängt von der Qualität der Tabellenstatistik der Quelldatenbank ab. Je besser die Tabellenstatistik, destogenauer die Schätzung. Wenn eine Aufgabe nur eine Tabelle ohne geschätzte Zeilenstatistik enthält,können wir den prozentualen Fortschritt nicht berechnen. In diesem Fall kann anhand des Aufgabenstatusund der Angabe der geladenen Zeilen überprüft werden, ob die Aufgabe tatsächlich ausgeführt wird undFortschritte macht.
Tabellenstatus während der AufgabenWährend der Migration aktualisiert die AWS DMS-Konsole Informationen zum Status Ihrer Tabellen. Diefolgende Tabelle zeigt die möglichen Statuswerte:
API-Version API Version 2016-01-01422

AWS Database Migration Service BenutzerhandbuchÜberwachen von Replikationsaufgaben
mit Amazon CloudWatch
Status Beschreibung
Table does not exist (Tabelle nichtvorhanden)
AWS DMS kann die Tabelle auf dem Quellendpunkt nichtfinden.
Before load (Vor dem Laden) Der vollständige Ladevorgang wurde aktiviert, hat aber nochnicht begonnen.
Full load Der vollständige Ladevorgang wird ausgeführt.
Table completed Der vollständige Ladevorgang ist abgeschlossen.
Table cancelled Das Laden der Tabelle wurde abgebrochen.
Table error Beim Laden der Tabelle ist ein Fehler aufgetreten.
Überwachen von Replikationsaufgaben mit AmazonCloudWatch
Sie können Amazon CloudWatch-Alarme oder -Ereignisse verwenden, um Ihre Migration noch genauerzu überwachen. Weitere Informationen zu Amazon CloudWatch finden Sie unter Was sind AmazonCloudWatch, Amazon CloudWatch Events und Amazon CloudWatch Logs? im Amazon CloudWatch-Benutzerhandbuch. Beachten Sie, dass für die Nutzung von Amazon CloudWatch Gebühren anfallen.
Die AWS DMS-Konsole zeigt einfache CloudWatch-Statistiken für jede Aufgabe an, darunterAufgabenstatus, abgeschlossener Prozentsatz, verstrichene Zeit und Tabellenstatistiken, wie im Folgendendargestellt. Wählen Sie die Replikationsaufgabe und dann die Registerkarte Task monitoring aus.
API-Version API Version 2016-01-01423
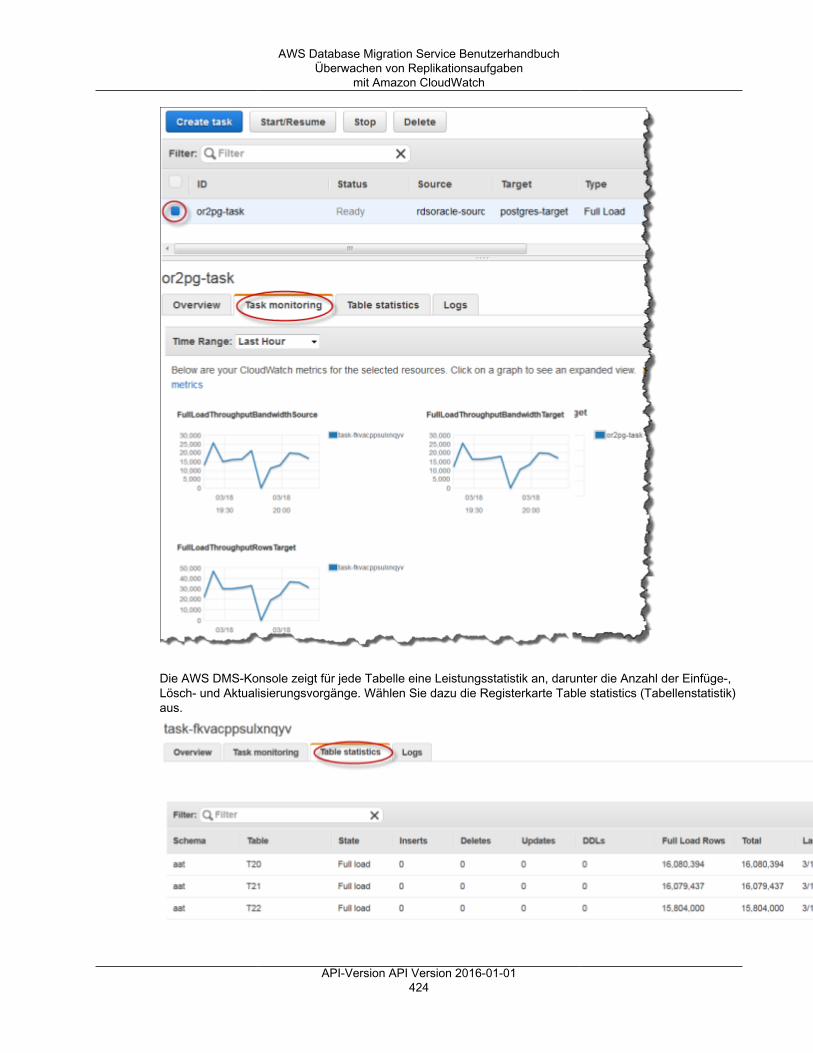
AWS Database Migration Service BenutzerhandbuchÜberwachen von Replikationsaufgaben
mit Amazon CloudWatch
Die AWS DMS-Konsole zeigt für jede Tabelle eine Leistungsstatistik an, darunter die Anzahl der Einfüge-,Lösch- und Aktualisierungsvorgänge. Wählen Sie dazu die Registerkarte Table statistics (Tabellenstatistik)aus.
API-Version API Version 2016-01-01424
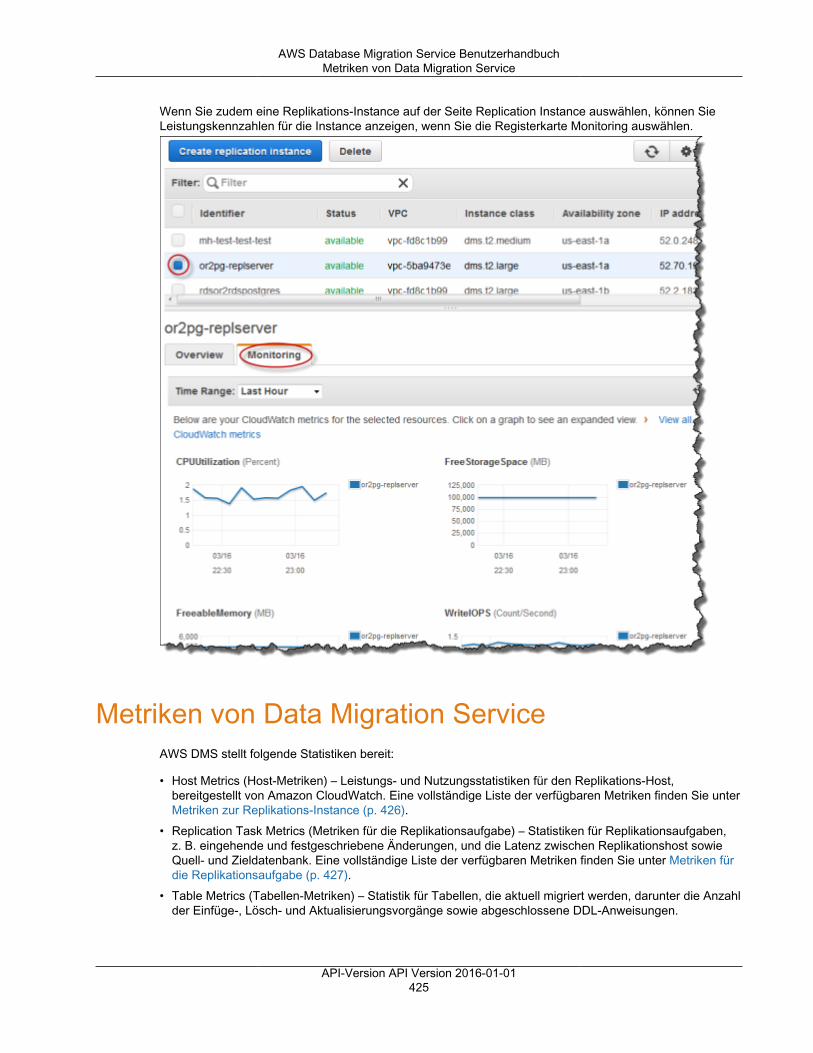
AWS Database Migration Service BenutzerhandbuchMetriken von Data Migration Service
Wenn Sie zudem eine Replikations-Instance auf der Seite Replication Instance auswählen, können SieLeistungskennzahlen für die Instance anzeigen, wenn Sie die Registerkarte Monitoring auswählen.
Metriken von Data Migration ServiceAWS DMS stellt folgende Statistiken bereit:
• Host Metrics (Host-Metriken) – Leistungs- und Nutzungsstatistiken für den Replikations-Host,bereitgestellt von Amazon CloudWatch. Eine vollständige Liste der verfügbaren Metriken finden Sie unterMetriken zur Replikations-Instance (p. 426).
• Replication Task Metrics (Metriken für die Replikationsaufgabe) – Statistiken für Replikationsaufgaben,z. B. eingehende und festgeschriebene Änderungen, und die Latenz zwischen Replikationshost sowieQuell- und Zieldatenbank. Eine vollständige Liste der verfügbaren Metriken finden Sie unter Metriken fürdie Replikationsaufgabe (p. 427).
• Table Metrics (Tabellen-Metriken) – Statistik für Tabellen, die aktuell migriert werden, darunter die Anzahlder Einfüge-, Lösch- und Aktualisierungsvorgänge sowie abgeschlossene DDL-Anweisungen.
API-Version API Version 2016-01-01425

AWS Database Migration Service BenutzerhandbuchMetriken zur Replikations-Instance
Die Aufgabenmetriken werden in Statistiken zwischen Replikationshost und Quellendpunkt und zwischenReplikationshost und Zielendpunkt untergliedert. Sie können die Gesamtstatistik für eine Aufgabeanzeigen, indem Sie zwei verwandte Statistiken zusammen hinzufügen. Sie können beispielsweise dieGesamtlatzenzzeit oder die Replikatverzögerung für eine Aufgabe bestimmen, indem Sie die WerteCDCLatencySource und CDCLatencyTarget kombinieren.
Die Metrikwerte für Aufgaben können durch aktuelle Aktivitäten in Ihrer Quelldatenbank beeinflusst werden.Wenn z. B. eine Transaktion begonnen hat, aber noch nicht festgeschrieben wurde, erhöht sich die MetrikCDCLatencySource, bis die Transaktion festgeschrieben ist.
Bei der Replikations-Instance erfordert die Metrik FreeableMemory eine Klärung. Der freisetzbareArbeitsspeicher gibt keinen Hinweis auf den tatsächlich verfügbaren Speicher. Es handelt sich dabei umder derzeit verwendeten Arbeitsspeicher, der freigegeben und für andere Zwecke eingesetzt werden. Esist eine Kombination aus aktuell verwendeten Puffern und dem Zwischenspeicher auf der Replikations-Instance.
Während die FreeableMemory-Metrik nicht den tatsächlich verfügbaren Arbeitsspeicher wiedergibt, gibt dieKombination der Metriken FreeableMemory und SwapUsage an, ob die Replikations-Instance überlastet ist.
Überwachen Sie die beiden Metriken auf die folgenden Bedingungen.
• Die Metrik FreeableMemory nähert sich Null.
• Die Metrik SwapUsage steigt oder schwankt.
Ist eine dieser Bedingungen erfüllt, ist dies ein Hinweis darauf, dass Sie eine größere Replikations-Instanceverwenden sollten. Sie sollten auch die Reduzierung der Anzahl und Art der Aufgaben in Betracht ziehen,die auf der Replikations-Instance ausgeführt werden. Full Load-Aufgaben benötigen mehr Speicher alsAufgaben, die nur Änderungen replizieren.
Metriken zur Replikations-InstanceDie Überwachung der Replikations-Instance umfasst Amazon CloudWatch-Metriken für die folgendenStatistiken:
CPUUtilization
Die Menge genutzter CPU
Einheiten: ProzentFreeStorageSpace
Verfügbarer Speicherplatz
Einheiten: ByteFreeableMemory
Verfügbarer Arbeitsspeicher.
Einheiten: ByteWriteIOPS
Durchschnittliche Anzahl von Festplatten-E/A-Schreibvorgänge pro Sekunde.
Einheiten: Anzahl/SekundeReadIOPS
Durchschnittliche Anzahl der Festplatten-E/A-Lesevorgänge pro Sekunde.
API-Version API Version 2016-01-01426

AWS Database Migration Service BenutzerhandbuchMetriken für die Replikationsaufgabe
Einheiten: Anzahl/SekundeWriteThroughput
Die durchschnittliche Anzahl Byte, die pro Sekunde auf Festplatte geschrieben werden.
Einheiten: Byte/SekundeReadThroughput
Die durchschnittliche Anzahl Byte, die pro Sekunde vom Datenträger gelesen werden
Einheiten: Byte/SekundeWriteLatency
Die durchschnittliche Dauer für einen Festplatten-E/A(Ausgabe)-Vorgang.
Einheiten: MillisekundenReadLatency
Die durchschnittliche Dauer für einen Festplatten-E/A(Eingabe)-Vorgang.
Einheiten: MillisekundenSwapUsage
Die Menge des für die Replikations-Instance verwendeten Auslagerungsbereichs
Einheiten: ByteNetworkTransmitThroughput
Der ausgehende Netzwerkverkehr (Transmit) auf der Replikations-Instance, einschließlichKundendatenbankverkehr und AWS DMS-Datenverkehr, der für Überwachung und Replikationverwendet wird
Einheiten: Byte/SekundeNetworkReceiveThroughput
Der eingehenden Netzwerkverkehr (Receive) auf der Replikations-Instance, einschließlichKundendatenbankverkehr und AWS DMS-Datenverkehr, der für Überwachung und Replikationverwendet wird
Einheiten: Byte/Sekunde
Metriken für die ReplikationsaufgabeDie Überwachung von Replikationsaufgaben umfasst Metriken für die folgenden Statistiken:
FullLoadThroughputBandwidthSource
Eingehende Netzwerkbandbreite von einem vollständigen Ladevorgang von der Quelle in Kilobyte (KB)pro Sekunde
FullLoadThroughputBandwidthTarget
Ausgehende Netzwerkbandbreite von einem vollständigen Ladevorgang für das Ziel in KB proSekunde
FullLoadThroughputRowsSource
Eingehende Änderungen von einem vollständigen Ladevorgang von der Quelle in Zeilen pro Sekunde
API-Version API Version 2016-01-01427

AWS Database Migration Service BenutzerhandbuchMetriken für die Replikationsaufgabe
FullLoadThroughputRowsTarget
Ausgehende Änderungen von einem vollständigen Ladevorgang für das Ziel in Zeilen pro SekundeCDCIncomingChanges
Die Gesamtanzahl der Änderungsereignisse zu einem Zeitpunkt, die darauf warten, auf dasZiel angewendet zu werden. Beachten Sie, dass dies nicht dasselbe ist wie eine Messung derTransaktionsänderungsrate am Quellendpunkt. Eine hohe Zahl bei dieser Metrik weist in der Regeldarauf hin, dass AWS DMS nicht in der Lage ist, erfasste Änderungen zeitgerecht anzuwenden, waszu einer hohen Ziellatenz führt.
CDCChangesMemorySource
Anzahl der Zeilen, die sich in einem Arbeitsspeicher angesammelt haben und auf Festschreibung vonder Quelle warten
CDCChangesMemoryTarget
Anzahl der Zeilen, die sich in einem Arbeitsspeicher angesammelt haben und auf Festschreibung imZiel warten
CDCChangesDiskSource
Anzahl der Zeilen, die sich auf einem Datenträger angesammelt haben und auf Festschreibung von derQuelle warten
CDCChangesDiskTarget
Anzahl der Zeilen, die sich auf einem Datenträger angesammelt haben und auf Festschreibung im Zielwarten
CDCThroughputBandwidthSource
Netzwerkbandbreite für die Quelle in KB pro Sekunde. CDCThroughputBandwidth erfasst dieBandbreite an bestimmten Punkten. Wenn kein Netzwerkverkehr gefunden wird, ist der Wertnull. Da CDC keine Langläufer-Transaktionen ausgibt, wird der Netzwerkdatenverkehr u. U. nichtaufgezeichnet.
CDCThroughputBandwidthTarget
Netzwerkbandbreite für das Ziel in KB pro Sekunde. CDCThroughputBandwidth erfasst die Bandbreitean bestimmten Punkten. Wenn kein Netzwerkverkehr gefunden wird, ist der Wert null. Da CDC keineLangläufer-Transaktionen ausgibt, wird der Netzwerkdatenverkehr u. U. nicht aufgezeichnet.
CDCThroughputRowsSource
Eingehende Aufgabenänderungen von der Quelle in Zeilen pro SekundeCDCThroughputRowsTarget
Ausgehende Aufgabenänderungen für das Ziel in Zeilen pro SekundeCDCLatencySource
Die Anzahl der Sekunden zwischen dem zuletzt erfassten Ereignis vom Quellendpunkt und demaktuellen Systemzeitstempel der AWS DMS-Instance. Wenn aufgrund des Aufgabenumfangs keineÄnderungen von der Quelle erfasst wurden, legt AWS DMS diesen Wert auf Null fest.
CDCLatencyTarget
Die Anzahl der Sekunden zwischen dem ersten Ereigniszeitstempel, für den auf dem Ziel ein Commitausgeführt werden soll, und dem aktuellen Zeitstempel der AWS DMS-Instance. Dieser Wert trittauf, wenn Transaktionen vorhanden sind, die nicht vom Ziel verarbeitet werden. Andernfalls ist dieZiellatenz identisch mit der Quelllatenz, wenn alle Transaktionen angewendet werden. Die Ziellatenzsollte nie kleiner sein als die Quelllatenz.
API-Version API Version 2016-01-01428

AWS Database Migration Service BenutzerhandbuchVerwalten von AWS DMS-Protokollen
Verwalten von AWS DMS-AufgabenprotokollenAWS DMS verwendet Amazon CloudWatch, um Aufgabeninformationen während des Migrationsprozesseszu protokollieren. Sie können die AWS-CLI oder die AWS DMS-API verwenden, um sichInformationen zu den Aufgabenprotokollen anzeigen zu lassen. Verwenden Sie dazu den BefehlAWS CLI describe-replication-instance-task-logs oder die AWS DMS-API-AktionDescribeReplicationInstanceTaskLogs.
Der folgende AWS CLI-Befehl zeigt beispielsweise die Metadaten des Aufgabenprotokolls im JSON-Formatan.
$ aws dms describe-replication-instance-task-logs \ --replication-instance-arn arn:aws:dms:us-east-1:237565436:rep:CDSFSFSFFFSSUFCAY
Eine Beispielantwort des Befehls lautet wie folgt.
{ "ReplicationInstanceTaskLogs": [ { "ReplicationTaskArn": "arn:aws:dms:us-east-1:237565436:task:MY34U6Z4MSY52GRTIX3O4AY", "ReplicationTaskName": "mysql-to-ddb", "ReplicationInstanceTaskLogSize": 3726134 } ], "ReplicationInstanceArn": "arn:aws:dms:us-east-1:237565436:rep:CDSFSFSFFFSSUFCAY"}
In dieser Antwort gibt es ein einzelnes Aufgabenprotokoll (mysql-to-ddb), das mit der Replikations-Instance verknüpft ist. Die Größe dieser Protokolldatei beträgt 3.726.124 Bytes.
Sie können die von describe-replication-instance-task-logs zurückgegebenen Informationenverwenden, um Probleme mit Aufgabenprotokollen zu diagnostizieren und zu beheben. Wenn Sie z. B. diedetaillierte Debug-Protokollierung für eine Aufgabe aktivieren, wird die Größe der Aufgabenprotokolldateischnell zunehmen — möglicherweise wird der gesamte verfügbare Speicherplatz auf der Replikations-Instance benötigt und der Status der Instance ändert sich in storage-full. Durch Beschreiben derAufgabenprotokolle können Sie feststellen, welche nicht mehr benötigt werden. Diese können Sie dannlöschen und so Speicherplatz freigeben.
Note
Stoppen Sie die Ausführung der zugeordneten Aufgabe, bevor Sie ein Protokoll löschen. EinProtokoll kann nicht mit der AWS CLI oder der AWS DMS-Konsole gelöscht werden, während diezugehörige Aufgabe weiterhin ausgeführt wird.
Um die Aufgabenprotokolle einer Aufgabe zu löschen, setzen Sie die AufgabeneinstellungDeleteTaskLogs auf "true". Beispielsweise löscht der folgende JSON die Aufgabenprotokolle, wenn ereine Aufgabe mit dem Befehl AWS CLI modify-replication-task oder der AWS DMS API-AktionModifyReplicationTask modifiziert.
{ "Logging": { "DeleteTaskLogs":true
API-Version API Version 2016-01-01429

AWS Database Migration Service BenutzerhandbuchProtokollieren von AWS DMS-
API-Aufrufen mit AWS CloudTrail
}}
Protokollieren von AWS DMS-API-Aufrufen mitAWS CloudTrail
AWS DMS ist in AWS CloudTrail integriert. Dies ist ein Service, der die Aktionen eines Benutzers, einerRolle oder eines AWS-Services in AWS DMS aufzeichnet. CloudTrail erfasst alle API-Aufrufe für AWS DMSals Ereignisse, einschließlich Aufrufen von der AWS DMS-Konsole und von Code-Aufrufen an die AWSDMS-APIs. Wenn Sie einen Trail erstellen, können Sie die kontinuierliche Bereitstellung von CloudTrail-Ereignissen an einen Amazon S3-Bucket, einschließlich Ereignissen für AWS DMS, aktivieren. Auch wennSie keinen Trail konfigurieren, können Sie die neuesten Ereignisse in der CloudTrail-Konsole in Eventhistory (Ereignisverlauf) anzeigen. Mit den von CloudTrail gesammelten Informationen können Sie die anAWS DMS gestellte Anfrage, die IP-Adresse, von der die Anfrage gestellt wurde, den Initiator der Anfrage,den Zeitpunkt der Anfrage und weitere Angaben bestimmen.
Weitere Informationen zu CloudTrail finden Sie im AWS CloudTrail User Guide.
AWS DMS-Informationen in CloudTrailCloudTrail wird beim Erstellen Ihres AWS-Kontos für Sie aktiviert. Die in AWS DMS auftretenden Aktivitätenwerden als CloudTrail-Ereignis zusammen mit anderen AWS-Serviceereignissen in Event history(Ereignisverlauf) aufgezeichnet. Sie können die neusten Ereignisse in Ihrem AWS-Konto anzeigen, suchenund herunterladen. Weitere Informationen finden Sie unter Anzeigen von Ereignissen mit dem CloudTrail-API-Ereignisverlauf.
Erstellen Sie für eine fortlaufende Aufzeichnung der Ereignisse in Ihrem AWS-Konto, einschließlichEreignissen für AWS DMS, einen Trail. Ein Trail ermöglicht CloudTrail die Übermittlung vonProtokolldateien an einen Amazon S3-Bucket. Wenn Sie einen Pfad in der Konsole anlegen, gilt dieserstandardmäßig für alle Regionen. Der Trail protokolliert Ereignisse aus allen Regionen in der AWS-Partition und übermittelt die Protokolldateien an den von Ihnen angegebenen Amazon S3-Bucket. Darüberhinaus können Sie andere AWS-Services konfigurieren, um die in den CloudTrail-Protokollen erfasstenEreignisdaten weiter zu analysieren und entsprechend zu agieren. Weitere Informationen finden Sie unter:
• Übersicht zum Erstellen eines Pfads• In CloudTrail unterstützte Services und Integrationen• Konfigurieren von Amazon SNS-Benachrichtigungen für CloudTrail• Empfangen von CloudTrail-Protokolldateien aus mehreren Regionen und EmpfangenCloudTrail von
Protokolldateien aus mehreren Konten
Alle AWS DMS-Aktionen werden von CloudTrail protokolliert und in der AWS Database Migration ServiceAPI Reference dokumentiert. Zum Beispiel werden durch Aufrufe der CreateReplicationInstance-,TestConnection- und StartReplicationTask-Aktionen Einträge in den CloudTrail-Protokolldateiengeneriert.
Jedes Event oder jeder Protokolleintrag enthält Informationen über den Ersteller der Anfrage. Anhand derIdentitätsinformationen zur Benutzeridentität können Sie Folgendes bestimmen:
• Ob die Anforderung mit Root- oder IAM-Benutzeranmeldeinformationen ausgeführt wurde.• Ob die Anforderung mit temporären Sicherheitsanmeldeinformationen für eine Rolle oder einen
föderierten Benutzer ausgeführt wurde.
API-Version API Version 2016-01-01430

AWS Database Migration Service BenutzerhandbuchGrundlagen zu AWS DMS-Protokolldateieinträgen
• Ob die Anforderung von einem anderen AWS-Service getätigt wurde.
Weitere Informationen finden Sie unter CloudTrail-Element "userIdentity".
Grundlagen zu AWS DMS-ProtokolldateieinträgenEin Trail ist eine Konfiguration, durch die Ereignisse an den von Ihnen angegebenen Amazon S3-Bucket übermittelt werden. CloudTrail-Protokolldateien können einen oder mehrere Einträge enthalten.Ein Ereignis stellt eine einzelne Anfrage aus einer beliebigen Quelle dar und enthält unter anderemInformationen über die angeforderte Aktion, das Datum und die Uhrzeit der Aktion sowie über dieAnfrageparameter. CloudTrail-Protokolldateien sind kein geordnetes Stacktrace der öffentlichen API-Aufrufe und erscheinen daher nicht in einer bestimmten Reihenfolge.
Das folgende Beispiel zeigt einen CloudTrail-Protokolleintrag, der die AktionRebootReplicationInstance demonstriert.
{ "eventVersion": "1.05", "userIdentity": { "type": "AssumedRole", "principalId": "AKIAIOSFODNN7EXAMPLE:johndoe", "arn": "arn:aws:sts::123456789012:assumed-role/admin/johndoe", "accountId": "123456789012", "accessKeyId": "ASIAYFI33SINADOJJEZW", "sessionContext": { "attributes": { "mfaAuthenticated": "false", "creationDate": "2018-08-01T16:42:09Z" }, "sessionIssuer": { "type": "Role", "principalId": "AKIAIOSFODNN7EXAMPLE", "arn": "arn:aws:iam::123456789012:role/admin", "accountId": "123456789012", "userName": "admin" } } }, "eventTime": "2018-08-02T00:11:44Z", "eventSource": "dms.amazonaws.com", "eventName": "RebootReplicationInstance", "awsRegion": "us-east-1", "sourceIPAddress": "72.21.198.64", "userAgent": "console.amazonaws.com", "requestParameters": { "forceFailover": false, "replicationInstanceArn": "arn:aws:dms:us-east-1:123456789012:rep:EX4MBJ2NMRDL3BMAYJOXUGYPUE" }, "responseElements": { "replicationInstance": { "replicationInstanceIdentifier": "replication-instance-1", "replicationInstanceStatus": "rebooting", "allocatedStorage": 50, "replicationInstancePrivateIpAddresses": [ "172.31.20.204" ], "instanceCreateTime": "Aug 1, 2018 11:56:21 PM", "autoMinorVersionUpgrade": true, "engineVersion": "2.4.3", "publiclyAccessible": true,
API-Version API Version 2016-01-01431

AWS Database Migration Service BenutzerhandbuchGrundlagen zu AWS DMS-Protokolldateieinträgen
"replicationInstanceClass": "dms.t2.medium", "availabilityZone": "us-east-1b", "kmsKeyId": "arn:aws:kms:us-east-1:123456789012:key/f7bc0f8e-1a3a-4ace-9faa-e8494fa3921a", "replicationSubnetGroup": { "vpcId": "vpc-1f6a9c6a", "subnetGroupStatus": "Complete", "replicationSubnetGroupArn": "arn:aws:dms:us-east-1:123456789012:subgrp:EDHRVRBAAAPONQAIYWP4NUW22M", "subnets": [ { "subnetIdentifier": "subnet-cbfff283", "subnetAvailabilityZone": { "name": "us-east-1b" }, "subnetStatus": "Active" }, { "subnetIdentifier": "subnet-d7c825e8", "subnetAvailabilityZone": { "name": "us-east-1e" }, "subnetStatus": "Active" }, { "subnetIdentifier": "subnet-6746046b", "subnetAvailabilityZone": { "name": "us-east-1f" }, "subnetStatus": "Active" }, { "subnetIdentifier": "subnet-bac383e0", "subnetAvailabilityZone": { "name": "us-east-1c" }, "subnetStatus": "Active" }, { "subnetIdentifier": "subnet-42599426", "subnetAvailabilityZone": { "name": "us-east-1d" }, "subnetStatus": "Active" }, { "subnetIdentifier": "subnet-da327bf6", "subnetAvailabilityZone": { "name": "us-east-1a" }, "subnetStatus": "Active" } ], "replicationSubnetGroupIdentifier": "default-vpc-1f6a9c6a", "replicationSubnetGroupDescription": "default group created by console for vpc id vpc-1f6a9c6a" }, "replicationInstanceEniId": "eni-0d6db8c7137cb9844", "vpcSecurityGroups": [ { "vpcSecurityGroupId": "sg-f839b688", "status": "active" } ], "pendingModifiedValues": {}, "replicationInstancePublicIpAddresses": [
API-Version API Version 2016-01-01432

AWS Database Migration Service BenutzerhandbuchGrundlagen zu AWS DMS-Protokolldateieinträgen
"18.211.48.119" ], "replicationInstancePublicIpAddress": "18.211.48.119", "preferredMaintenanceWindow": "fri:22:44-fri:23:14", "replicationInstanceArn": "arn:aws:dms:us-east-1:123456789012:rep:EX4MBJ2NMRDL3BMAYJOXUGYPUE", "replicationInstanceEniIds": [ "eni-0d6db8c7137cb9844" ], "multiAZ": false, "replicationInstancePrivateIpAddress": "172.31.20.204", "patchingPrecedence": 0 } }, "requestID": "a3c83c11-95e8-11e8-9d08-4b8f2b45bfd5", "eventID": "b3c4adb1-e34b-4744-bdeb-35528062a541", "eventType": "AwsApiCall", "recipientAccountId": "123456789012"}
API-Version API Version 2016-01-01433

AWS Database Migration Service Benutzerhandbuch
Validieren von AWS DMS-AufgabenThemen
• Replikationsaufgaben-Statistiken (p. 435)• Erneutes Validieren von Tabellen während einer Aufgabe (p. 437)• Fehlersuche (p. 437)• Einschränkungen (p. 438)
AWS DMS unterstützt eine Datenvalidierung, um sicherzustellen, dass Ihre Daten korrekt von der Quellezum Ziel migriert wurden. Wenn Sie die Validierung für eine Aufgabe aktivieren, vergleicht AWS DMS dieQuell- und Zieldaten sofort, nachdem eine Tabelle vollständig geladen wurde.
Die Datenvalidierung ist optional. AWS DMS vergleicht die Quell- und Zieldatensätze und meldet fehlendeÜbereinstimmungen. Darüber hinaus vergleicht AWS DMS bei einer Aufgabe, bei der CDC aktiviert ist, dieinkrementellen Änderungen und meldet alle Abweichungen.
Während der Datenvalidierung vergleicht AWS DMS jede Zeile in der Quelle mit der entsprechenden Zeileim Ziel und stellt sicher, dass die Zeilen die gleichen Daten enthalten. Zu diesem Zweck führt AWS DMSentsprechende Abfragen durch, um die Daten abzurufen. Beachten Sie, dass diese Abfragen zusätzlicheRessourcen bei den Quell- und Zieldatenbanken verbrauchen und zudem mehr Netzwerkressourcen inAnspruch genommen werden.
Die Datenvalidierung funktioniert mit den folgenden Datenbanken dort, wo AWS DMS sie als Quell- undZiel-Endpunkte unterstützt:
• Oracle• PostgreSQL• MySQL• MariaDB• Microsoft SQL Server• Amazon Aurora (MySQL)• Amazon Aurora (PostgreSQL)• IBM Db2 (LUW)
Weitere Informationen zu den unterstützten Endpunkten finden Sie unter Arbeiten mit AWS DMS-Endpunkten (p. 122).
Die Datenvalidierung erfordert zusätzliche Zeit, die über die Dauer hinausgeht, die für die Migration selbsterforderlich ist. Die zusätzlich benötigte Zeit hängt davon ab, wie viele Daten migriert wurden.
Zu den Datenvalidierungseinstellungen gehören:
• EnableValidation – Aktiviert oder deaktiviert die Datenvalidierung.• FailureMaxCount – Gibt die maximale Anzahl der Datensätze an, bei denen die Validierung
fehlschlagen kann, bevor sie für die Aufgabe gesperrt wird.• HandleCollationDiff – Behandelt Spaltensortierungsunterschiede in PostgreSQL-Endpunkten,
wenn zu vergleichende Quell- und Zieldatensätze ermittelt werden.• RecordFailureDelayLimitInMinutes – Gibt die Verzögerung an, bevor Details über das
Fehlschlagen der Validierung gemeldet werden.• TableFailureMaxCount – Gibt die maximale Anzahl der Tabellen an, bei denen die Validierung
fehlschlagen kann, bevor sie für die Aufgabe gesperrt wird.
API-Version API Version 2016-01-01434

AWS Database Migration Service BenutzerhandbuchReplikationsaufgaben-Statistiken
• ThreadCount – Passt die Anzahl der Ausführungs-Threads an, die AWS DMS während der Validierungnutzt.
• ValidationOnly – Zeigt eine Vorschau der Validierung für die Aufgabe an, ohne eine Migrationoder Replikation von Daten durchzuführen. Um diese Option zu verwenden, legen Sie den Typ derAufgabenmigration in der AWS DMS-Konsole auf Nur Datenänderungen replizieren fest oder legen Sieden Migrationstyp in der AWS DMS-API auf cdc fest. Legen Sie außerdem die Aufgabeneinstellung fürdie Zieltabelle, TargetTablePrepMode, auf DO_NOTHING fest.
Das folgende JSON-Beispiel aktiviert die Validierung, erhöht die Anzahl der Threads auf acht undunterbricht die Validierung, wenn bei einer Tabelle ein Validierungsfehler auftritt.
ValidationSettings": { "EnableValidation":true, "ThreadCount":8, "TableFailureMaxCount":1}
Weitere Informationen zu diesen Einstellungen finden Sie unter Aufgabeneinstellungen zurDatenvalidierung (p. 351).
Replikationsaufgaben-StatistikenWenn die Datenvalidierung aktiviert ist, stellt AWS DMS die folgenden Statistiken auf Tabellenebene bereit:
• ValidationState — Der Validierungsstatus der Tabelle. Folgende Parameterwerte sind möglich:• Not enabled (Nicht aktiviert) — Für die Tabelle in der Migrationsaufgabe ist keine Validierung aktiviert.• Pending records (Ausstehende Datensätze) — Einige Datensätze in der Tabelle müssen noch validiert
werden.• Mismatched records (Nicht übereinstimmende Datensätze) —Bei einigen Datensätzen in der Tabelle
gibt es eine Abweichung zwischen Quelle und Ziel. Ein Konflikt kann aus unterschiedlichen Gründenauftreten. Weitere Informationen finden Sie in der Tabelle awsdms_validation_failures_v1 aufdem Ziel-Endpunkt.
• Suspended records (Ausgesetzte Datensätze) — Einige Datensätze in der Tabelle können nichtvalidiert werden.
• No primary key (Kein Primärschlüssel) —Die Tabelle kann aufgrund eines fehlenden Primärschlüsselsnicht validiert werden.
• Table error (Tabellenfehler) — Die Tabelle wurde aufgrund ihres Fehlerstatus nicht validiert und einigeDaten wurden nicht migriert.
• Validated (Validiert) — Alle Zeilen der Tabelle wurden validiert. Wenn die Tabelle aktualisiert wurde,ändert sich der Status möglicherweise in "Validated".
• Error (Fehler) — Die Tabelle kann aufgrund eines unerwarteten Fehlers nicht validiert werden.• ValidationPending — Die Anzahl der Datensätze, die in die Zieldatenbank migriert, jedoch noch nicht
validiert wurden.
ValidationSuspended — Die Anzahl der Datensätze, die AWS DMS nicht vergleichen kann. Wennbeispielsweise ein Datensatz an der Quelle ständig aktualisiert wird, kann AWS DMS Quelleund Ziel nicht vergleichen. Weitere Informationen finden Sie unter Aufgabeneinstellungen zurFehlerbehandlung (p. 358)
• ValidationFailed — Die Anzahl der Datensätze, die die Validierungsphase nicht bestanden haben.Weitere Informationen finden Sie unter Aufgabeneinstellungen zur Fehlerbehandlung (p. 358).
API-Version API Version 2016-01-01435

AWS Database Migration Service BenutzerhandbuchReplikationsaufgaben-Statistiken
• ValidationSucceededRecordCount — Anzahl der Zeilen, die von AWS DMS pro Minute validiert wurden.• ValidationAttemptedRecordCount — Anzahl der Zeilen, für die pro Minute eine Validierung versucht
wurde.• ValidationFailedOverallCount — Anzahl der Zeilen, bei denen die Validierung fehlschlug.• ValidationSuspendedOverallCount — Anzahl der Zeilen, bei denen die Validierung ausgesetzt wurde.• ValidationPendingOverallCount — Anzahl der Zeilen, bei denen eine Validierung noch ansteht.• ValidationBulkQuerySourceLatency— AWS DMS kann die Datenvalidierung gebündelt durchführen. Dies
ist insbesondere bei bestimmten Szenarien während des vollständigen Ladens oder der fortlaufendenReplikation relevant, wenn viele Änderungen vorliegen. Diese Metrik gibt die Latenz an, die zum Leseneines Massendatensatzes aus dem Quellendpunkt erforderlich ist.
• ValidationBulkQueryTargetLatency— AWS DMS kann die Datenvalidierung gebündelt durchführen. Diesist insbesondere bei bestimmten Szenarien während des vollständigen Ladens oder der fortlaufendenReplikation relevant, wenn viele Änderungen vorliegen. Diese Metrik gibt die Latenz an, die zum Leseneines Massendatensatzes am Zielendpunkt erforderlich ist.
• ValidationItemQuerySourceLatency— Während der fortlaufenden Replikation können mit derDatenvalidierung fortlaufende Änderungen identifiziert und validiert werden. Diese Metrik gibt die Latenzan, die zum Lesen solcher Änderungen aus der Quelle erforderlich ist. Die Validierung kann mehrAbfragen als basierend auf der Anzahl von Änderungen erforderlich ausführen, wenn während derValidierung Fehler aufgetreten sind.
• ValidationItemQueryTargetLatency— Während der fortlaufenden Replikation können mit derDatenvalidierung fortlaufende Änderungen identifiziert und zeilenweise validiert werden. Diese Metrikgibt die Latenz zum Lesen solcher Änderungen am Ziel an. Die Validierung kann mehr Abfragen alsbasierend auf der Anzahl von Änderungen erforderlich ausführen, wenn während der Validierung Fehleraufgetreten sind.
Sie können die Informationen zur Datenvalidierung mit der AWS-Konsole, der CLI oder der AWS DMS-APIanzeigen.
• Sie können in der Konsole eine Aufgabe zur Validierung auswählen, wenn Sie die Aufgabe erstellen oderändern. Zum Anzeigen des Validierungsberichts in der Konsole wählen Sie die Aufgabe auf der SeiteTasks aus und klicken dann im Detailbereich auf Table statistics.
• Wenn Sie die CLI verwenden, setzen Sie den EnableValidation-Parameter auf true, wenn Sie eineAufgabe erstellen oder ändern, um mit der Datenvalidierung zu beginnen. Im folgenden Beispiel wird eineAufgabe erstellt und die Datenvalidierung aktiviert.
create-replication-task --replication-task-settings '{"ValidationSettings":{"EnableValidation":true}}' --replication-instance-arn arn:aws:dms:us-east-1:5731014: rep:36KWVMB7Q --source-endpoint-arn arn:aws:dms:us-east-1:5731014: endpoint:CSZAEFQURFYMM --target-endpoint-arn arn:aws:dms:us-east-1:5731014: endpoint:CGPP7MF6WT4JQ --migration-type full-load-and-cdc --table-mappings '{"rules": [{"rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": {"schema-name": "data_types", "table-name": "%"}, "rule-action": "include"}]}'
Verwenden Sie den Befehl describe-table-statistics, um den Datenvalidierungsbericht imJSON-Format zu erhalten. Mit dem folgenden Befehl wird der Datenvalidierungsbericht angezeigt.
aws dms describe-table-statistics --replication-task-arn arn:aws:dms:us-east-1:5731014:rep:36KWVMB7Q
API-Version API Version 2016-01-01436

AWS Database Migration Service BenutzerhandbuchErneutes Validieren von Tabellen während einer Aufgabe
Der Bericht sieht in etwa wie folgt aus.
{ "ReplicationTaskArn": "arn:aws:dms:us-west-2:5731014:task:VFPFTYKK2RYSI", "TableStatistics": [ { "ValidationPendingRecords": 2, "Inserts": 25, "ValidationState": "Pending records", "ValidationSuspendedRecords": 0, "LastUpdateTime": 1510181065.349, "FullLoadErrorRows": 0, "FullLoadCondtnlChkFailedRows": 0, "Ddls": 0, "TableName": "t_binary", "ValidationFailedRecords": 0, "Updates": 0, "FullLoadRows": 10, "TableState": "Table completed", "SchemaName": "d_types_s_sqlserver", "Deletes": 0 }}
• Wenn Sie die AWS DMS-API verwenden, erstellen Sie eine Aufgabe mithilfe der CreateReplicationTask-Aktion und setzen den EnableValidation-Parameter auf true, um die über die Aufgabe migriertenDaten zu validieren. Nutzen Sie die DescribeTableStatistics-Aktion, um den Datenvalidierungsbericht imJSON-Format zu erhalten.
Erneutes Validieren von Tabellen während einerAufgabe
Während eine Aufgabe ausgeführt wird, können Sie von AWS DMS eine Datenvalidierung anfordern.
AWS Management Console1. Melden Sie sich bei der AWS Management Console an und wählen Sie AWS DMS aus. Wenn Sie als
Benutzer von AWS Identity and Access Management (IAM) angemeldet sind, müssen Sie über dieentsprechenden Berechtigungen für den Zugriff auf AWS DMS verfügen. Weitere Informationen zu denerforderlichen Berechtigungen finden Sie unter Erforderliche IAM-Berechtigungen zur Verwendung vonAWS DMS (p. 65).
2. Wählen Sie im Navigationsbereich Tasks aus.3. Wählen Sie die laufende Aufgabe mit der Tabelle aus, die sie erneut validieren möchten.4. Wählen Sie die Registerkarte Table Statistics (Tabellenstatistiken).5. Wählen Sie die Tabelle aus, die Sie erneut validieren möchten (Sie können bis zu 10 Tabellen
gleichzeitig auswählen). Für Aufgaben, die derzeit nicht mehr ausgeführt werden, kann die Tabellebzw. können die Tabellen nicht erneut validiert werden.
6. Wählen Sie Revalidate (Erneut validieren).
FehlersucheWährend der Validierung erstellt AWS DMS eine neue Tabelle am Zielendpunkt:awsdms_validation_failures_v1. Wenn ein Datensatz in den Status ValidationSuspended oder
API-Version API Version 2016-01-01437

AWS Database Migration Service BenutzerhandbuchEinschränkungen
ValidationFailed wechselt, schreibt AWS DMS Diagnosedaten in awsdms_validation_failures_v1.Sie können diese Tabelle zur Behebung von Validierungsfehlern abfragen.
Im Folgenden finden Sie eine Beschreibung der Tabelle awsdms_validation_failures_v1:
Spaltenname Datentyp Beschreibung
TASK_NAME VARCHAR(128)NOT NULL
AWS DMS-Aufgaben-ID.
TABLE_OWNERVARCHAR(128)NOT NULL
Der Name des Schemabesitzers.
TABLE_NAMEVARCHAR(128)NOT NULL
Tabellenname.
FAILURE_TIMEDATETIME(3)NOT NULL
Zeitpunkt, zu dem der Fehler aufgetreten ist.
KEY TEXT NOT NULL Dies ist der Primärschlüssel für den Zeilendatensatztyp.
FAILURE_TYPEVARCHAR(128)NOT NULL
Schweregrad des Validierungsfehlers. Kann Failed oderSuspended sein.
Die folgende Abfrage zeigt Ihnen alle Fehler einer Aufgabe an, indem die Tabelleawsdms_validation_failures_v1 abgefragt wird. Der Aufgabenname sollte die externe Ressourcen-ID der Aufgabe sein. Die externe Ressourcen-ID der Aufgabe ist der letzte Wert des Aufgaben-ARNs. Beieiner Aufgabe mit einem ARN-Wert von arn:aws:dms:us-west-2:5599:task: VFPFKH4FJR3FTYKK2RYSIwäre die externe Ressourcen-ID beispielsweise VFPFKH4FJR3FTYKK2RYSI.
select * from awsdms_validation_failures_v1 where TASK_NAME = 'VFPFKH4FJR3FTYKK2RYSI'
Sobald Sie den Primärschlüssel des fehlgeschlagenen Datensatzes haben, können Sie die Quell- undZielendpunkte abfragen, um zu sehen, welcher Teil des Datensatzes nicht übereinstimmt.
Einschränkungen• Die Validierung erfordert, dass die Tabelle über einen Primärschlüssel oder eindeutigen Index verfügt.
• Primärschlüsselspalten dürfen nicht vom Typ CLOB, BLOB oder BYTE sein.• Bei Primärschlüsselspalten vom Typ VARCHAR oder CHAR muss die Länge kleiner sein als 1024.
• Wenn die Kollation der Primärschlüsselspalte in der Ziel-PostgreSQL-Instance nicht auf "C" gesetzt ist,weicht die Sortierreihenfolge des Primärschlüssels von der Sortierreihenfolge in Oracle ab. Wenn sich dieSortierreihenfolgen in PostgreSQL und Oracle unterscheiden, kann die Datenvalidierung die Datensätzenicht validieren.
• Die Validierung generiert zusätzliche Abfragen für die Quell- und Zieldatenbanken. Sie müssen dafürsorgen, dass beide Datenbanken über ausreichend Ressourcen für diese zusätzliche Auslastungverfügen.
• Die Datenvalidierung wird nicht unterstützt, wenn bei einer Migration eine benutzerdefinierte Filterungangewendet wird oder mehrere Datenbanken zu einer zusammengeführt werden.
• AWS DMS unterstützt die teilweise Validierung von LOBs für MySQL-, Oracle- und PostgreSQL-Endpunkte.
API-Version API Version 2016-01-01438

AWS Database Migration Service BenutzerhandbuchEinschränkungen
• Bei einem Quell- oder Ziel-Oracle-Endpunkt nutzt AWS DMS DBMS_CRYPTO zur Validierung von LOBs.Wenn Ihr Oracle-Endpunkt LOBs verwendet, müssen Sie dem Benutzerkonto, das für den Zugriff auf denOracle-Endpunkt verwendet wird, die Ausführungserlaubnis auf dbms_crypto erteilen. Sie können dazudie folgende Anweisung ausführen:
grant execute on sys.dbms_crypto to <dms_endpoint_user>;
• Wenn die Zieldatenbank während der Validierung außerhalb von AWS DMS geändert wird, werdenAbweichungen möglicherweise nicht korrekt wiedergegeben. Dies kann der Fall sein, wenn eine IhrerAnwendungen Daten in die Zieltabelle schreibt, während AWS DMS diese Tabelle validiert.
• Wenn eine oder mehrere Zeilen während der Validierung kontinuierlich geändert werden, kann AWSDMS diese Zeilen nicht validieren. Nach Abschluss der Aufgabe können Sie diese Zeilen aber manuellvalidieren.
• Wenn AWS DMS feststellt, dass mehr als 10 000 Datensätze fehlschlugen oder ausgesetzt wurden, wirddie Validierung gestoppt. Bevor Sie fortfahren, müssen Sie sämtliche zugrundeliegenden Datenproblemelösen.
API-Version API Version 2016-01-01439

AWS Database Migration Service Benutzerhandbuch
Taggen von Ressourcen in AWSDatabase Migration Service
Mithilfe von Tags können Sie in AWS Database Migration Service (AWS DMS) Metadaten zu IhrenRessourcen hinzufügen. Darüber hinaus können Sie diese Tags mit AWS Identity and AccessManagement(IAM)-Richtlinien verwenden, um den Zugriff auf AWS DMS-Ressourcen zu verwalten und zusteuern, welche Aktionen auf die AWS DMS-Ressourcen angewendet werden können. Außerdem könnenSie mit diesen Tags auch Kosten verfolgen, indem Ausgaben für ähnlich getaggte Ressourcen gruppiertwerden.
Alle AWS DMS-Ressourcen können getaggt werden:
• Zertifikate• Endpunkte• Ereignisabonnements• Replikations-Instances• Replikations-Subnetzgruppen (Sicherheit)• Replikationsaufgaben
Ein AWS DMS-Tag ist ein Name-Wert-Paar, das Sie definieren und mit einer AWS DMS-Ressourceverknüpfen. Der Name wird als Schlüssel bezeichnet. Die Angabe eines Wertes für den Schlüsselist optional. Sie können Tags verwenden, um einer AWS DMS-Ressource beliebige Informationenzuzuweisen. Ein Tag-Schlüssel könnte z. B. verwendet werden, um eine Kategorie zu definieren, undein Tag-Wert könnte ein Element in dieser Kategorie sein. Sie können beispielsweise den Tag-Schlüssel"Projekt" und den Tag-Wert "Salix" definieren. Dies bedeutet, dass die AWS DMS-Ressource dem Projekt"Salix" zugewiesen ist. Sie können mit Tags auch AWS DMS-Ressourcen kennzeichnen, die zu Test-oder Produktionszwecken verwendet werden, indem Sie einen Schlüssel wie z. B. Umgebung = Test oderUmgebung = Produktion verwenden. Wir empfehlen, einheitliche Tag-Schlüssel zu verwenden, um die mitAWS DMS-Ressourcen verknüpften Metadaten einfacher verfolgen zu können.
Verwenden Sie Tags zum Organisieren Ihrer AWS-Kontorechnung, um Ihre eigene Kostenstrukturdarzustellen. Dazu müssen Sie sich registrieren, um Ihre AWS-Kontorechnung mit Tag-Schlüsselwertenzu erhalten. Um dann die Kosten kombinierter Ressourcen anzuzeigen, organisieren Sie IhreFakturierungsinformationen nach Ressourcen mit gleichen Tag-Schlüsselwerten. Beispielsweisekönnen Sie mehrere Ressourcen mit einem bestimmten Anwendungsnamen markieren und dann IhreFakturierungsinformationen so organisieren, dass Sie die Gesamtkosten dieser Anwendung über mehrereServices hinweg sehen können. Weitere Informationen finden Sie unter Cost Allocation and Tagging inAbout AWS Billing and Cost Management.
Jede AWS DMS-Ressource verfügt über einen Tag-Satz, der alle Tags enthält, die dieser AWS DMS-Ressource zugewiesen sind. Ein Tag-Satz kann bis zu zehn Tags enthalten oder leer sein. Wenn Sie einerAWS DMS-Ressource ein Tag hinzufügen, das denselben Schlüssel hat wie ein bereits vorhandenes Tagder Ressource, überschreibt der neue Wert den alten.
In AWS haben Tags keine semantische Bedeutung, sondern werden als reine Zeichenfolgen interpretiert.AWS DMS kann Tags in einer AWS DMS-Ressource setzen. Dies hängt von den Einstellungen ab, die Siebeim Erstellen der Ressource verwenden.
In der folgenden Liste werden die Merkmale eines AWS DMS-Tags beschrieben.
• Der Tag-Schlüssel ist der erforderliche Name des Tags. Der Zeichenfolgenwert kann aus 1 bis 128Unicode-Zeichen bestehen. Ihm darf kein "aws:" oder "dms:" vorangestellt werden. Die Zeichenfolge darf
API-Version API Version 2016-01-01440

AWS Database Migration Service BenutzerhandbuchAPI
nur Unicode-Zeichen, Ziffern, Leerzeichen sowie '_', '.', '/', '=', '+', '-' enthalten (Java-Regex: "^([\\p{L}\\p{Z}\\p{N}_.:/=+\\-]*)$").
• Der Tag-Wert ist ein optionaler Zeichenfolgenwert des Tags. Der Zeichenfolgenwert kann aus 1 bis 256Unicode-Zeichen bestehen. Ihm darf kein "aws:" oder "dms:" vorangestellt werden. Die Zeichenfolge darfnur Unicode-Zeichen, Ziffern, Leerzeichen sowie '_', '.', '/', '=', '+', '-' enthalten (Java-Regex: "^([\\p{L}\\p{Z}\\p{N}_.:/=+\\-]*)$").
Die Werte innerhalb eines Tag-Satzes müssen nicht eindeutig und können null sein. Sie könnenbeispielsweise über ein Schlüssel-Wert-Paar in einem Tag-Satz "Projekt/Trinity" und "Kostenstelle/Trinity" verfügen.
Sie können die AWS-Befehlszeilenschnittstelle oder die AWS DMS-API verwenden, um Tags für AWSDMS-Ressourcen hinzuzufügen, aufzulisten oder zu löschen. Wenn Sie die AWS-Befehlszeilenschnittstelleoder die AWS DMS-API verwenden, müssen Sie den Amazon-Ressourcennamen (ARN) für die AWS DMSRessource angeben, mit der Sie arbeiten möchten. Weitere Informationen zum Erstellen eines ARN findenSie unter Erstellen eines Amazon-Ressourcennamens (ARN) für AWS DMS (p. 15).
Beachten Sie, dass Tags für Autorisierungszwecke zwischengespeichert werden. Daher könnenErgänzungen und Aktualisierungen für Tags von AWS DMS-Ressourcen einige Minuten in Anspruchnehmen, bevor sie verfügbar sind.
APIMithilfe der AWS DMS-API können Sie Tags für eine AWS DMS-Ressource hinzufügen, auflisten oderentfernen.
• Verwenden Sie die API-Operation AddTagsToResource, um ein Tag zu einer AWS DMS-Ressourcehinzuzufügen.
• Verwenden Sie die Operation ListTagsForResource, um die Tags für eine AWS DMS-Ressourceaufzulisten.
• Verwenden Sie die API-Operation RemoveTagsFromResource, um Tags aus einer AWS DMS-Ressource zu entfernen.
Weitere Informationen zum Erstellen des erforderlichen ARN finden Sie unter Erstellen eines Amazon-Ressourcennamens (ARN) für AWS DMS (p. 15).
Wenn Sie in der AWS DMS-API mit XML arbeiten, nutzen Sie das folgende Schema:
<Tagging> <TagSet> <Tag> <Key>Project</Key> <Value>Trinity</Value> </Tag> <Tag> <Key>User</Key> <Value>Jones</Value> </Tag> </TagSet></Tagging>
Die folgende Tabelle enthält eine Liste der zulässigen XML-Tags und deren Eigenschaften. Beachten Sie,dass für die Werte für Schlüssel und Wert zwischen Klein- und Großbuchstaben unterschieden wird. ZumBeispiel sind "project = Trinity" und "PROJECT = Trinity" zwei verschiedene Tags.
API-Version API Version 2016-01-01441
AWS Database Migration Service BenutzerhandbuchAPI
Markieren vonElementen
Beschreibung
Tag-Satz Ein Tag-Satz ist ein Container für alle Tags, die einer Amazon RDS-Ressource zugewiesen sind. Es ist nur ein Tag-Satz pro Ressource zulässig.Die Bearbeitung von Tag-Sätzen ist ausschließlich über die AWS DMS-APImöglich.
Tag Ein Tag ist ein benutzerdefiniertes Schlüssel-Wert-Paar. Ein Tag-Satz kann 1bis 10 Tags enthalten.
Schlüssel Ein Schlüssel ist der erforderliche Name des Tags. Der Zeichenfolgenwertkann aus 1 bis 128 Unicode-Zeichen bestehen. Ihm darf kein "aws:" oder"dms:" vorangestellt werden. Die Zeichenfolge darf nur Unicode-Zeichen,Ziffern, Leerzeichen sowie '_', '.', '/', '=', '+', '-' enthalten (Java-Regex: "^([\\p{L}\\p{Z}\\p{N}_.:/=+\\-]*)$").
Schlüssel müssen in einem Tag-Satz eindeutig sein. Sie können z. B. in einemTag-Satz kein Schlüsselpaar mit gleichem Schlüssel, aber unterschiedlichenWerten verwenden, wie "Projekt/Trinity" und "Projekt/Xanadu".
Value Ein Wert ist der optionale Wert des Tags. Der Zeichenfolgenwert kann aus1 bis 256 Unicode-Zeichen bestehen. Ihm darf kein "aws:" oder "dms:"vorangestellt werden. Die Zeichenfolge darf nur Unicode-Zeichen, Ziffern,Leerzeichen sowie '_', '.', '/', '=', '+', '-' enthalten (Java-Regex: "^([\\p{L}\\p{Z}\\p{N}_.:/=+\\-]*)$").
Die Werte innerhalb eines Tag-Satzes müssen nicht eindeutig und können nullsein. Sie können beispielsweise über ein Schlüssel-Wert-Paar in einem Tag-Satz "Projekt/Trinity" und "Kostenstelle/Trinity" verfügen.
API-Version API Version 2016-01-01442

AWS Database Migration Service Benutzerhandbuch
Arbeiten mit Ereignissen undBenachrichtigungen in AWSDatabase Migration Service
AWS Database Migration Service (AWS DMS) verwendet Amazon Simple Notification Service (AmazonSNS) zum Bereitstellen von Benachrichtigungen, wenn ein AWS DMS-Ereignis auftritt, z. B beim Erstellenoder Löschen einer Replikations-Instance. Sie können mit diesen Benachrichtigungen in einem beliebigenFormat arbeiten, das von Amazon SNS für eine AWS-Region unterstützt wird, z. B. eine E-Mail-Nachricht,eine Textnachricht oder ein Anruf an einen HTTP-Endpunkt.
AWS DMS stuft Ereignisse in Kategorien ein, die Sie abonnieren können. Dadurch werden Siebenachrichtigt, wenn ein Ereignis in dieser Kategorie auftritt. Wenn Sie beispielsweise die Kategorie"Erstellung" für eine bestimmte Replikations-Instance abonnieren, werden Sie benachrichtigt, sobaldein erstellungsbezogenes Ereignis auftritt, das sich auf Ihre Replikations-Instance auswirkt. WennSie eine Konfigurationsänderungs-Kategorie für eine Replikations-Instance abonnieren, werden Siebenachrichtigt, wenn die Konfiguration der Replikations-Instance geändert wird. Außerdem erhalten Sieeine Benachrichtigung, wenn ein Abonnement für Ereignisbenachrichtigungen geändert wird. Eine Liste dervon AWS DMS bereitgestellten Ereigniskategorien finden Sie im Folgenden unter Ereigniskategorien undEreignismeldungen in AWS DMS (p. 444).
AWS DMS sendet Ereignisbenachrichtigungen an die Adressen, die Sie beim Erstellen einesEreignisabonnements angeben. Sie sollten mehrere verschiedene Abonnements erstellen, beispielsweiseein Abonnement, das alle Ereignisbenachrichtigungen empfängt, und ein anderes Abonnement, dasnur kritische Ereignisse für Ihre DMS-Produktionsressourcen enthält. Sie können Benachrichtigungeneinfach deaktivieren, ohne ein Abonnement zu löschen. Stelhttps://docs.aws.amazon.com/sns/latest/dg/len Sie dafür die Option Enabled (Aktiviert) in der AWS DMS-Konsole auf No (Nein) oder den Parameter„Enabled“ mithilfe der AWS DMS-API auf false (falsch) ein.
Note
AWS DMS-Ereignisbenachrichtigungen mithilfe von SMS-Nachrichten sind derzeit nur für AWSDMS-Ressourcen in allen Regionen verfügbar, in denen AWS DMS unterstützt wird. WeitereInformationen zum Verwenden von SMS-Nachrichten mit SNS finden Sie unter Senden undEmpfangen von SMS-Benachrichtigungen mit Amazon SNS.
AWS DMS verwendet eine Abonnement-ID zum Identifizieren des jeweiligen Abonnements. Sie könnenmehrere AWS DMS-Ereignisabonnements in demselben Amazon SNS-Thema veröffentlichen. Wenn SieEreignisbenachrichtigungen nutzen, fallen Amazon SNS-Gebühren an. Weitere Informationen zu AmazonSNS-Abrechnungen finden Sie unter Amazon SNS – Preise.
Zum Abonnieren von AWS DMS-Ereignissen führen Sie das folgende Verfahren aus:
1. Erstellen Sie ein Amazon SNS-Thema. Im Thema geben Sie an, welche Art von Benachrichtigung Sieempfangen möchten und an welche Adresse oder Nummer die Benachrichtigung gesendet werden soll.
2. Erstellen Sie mit der AWS Management Console, der AWS CLI oder der AWS DMS-API einAbonnement für AWS DMS-Ereignisbenachrichtigungen.
3. AWS DMS sendet eine Bestätigungs-E-Mail oder SMS-Nachricht an die Adressen, die Sie mit IhremAbonnement übermittelt haben. Um Ihr Abonnement zu bestätigen, klicken Sie in der Bestätigungs-E-Mail oder SMS-Nachricht auf den Link.
4. Wenn Sie das Abonnement bestätigt haben, wird der Status Ihres Abonnements im Abschnitt EventSubscriptions (Ereignisabonnements) in der AWS DMS-Konsole aktualisiert.
5. Sie erhalten dann Ereignisbenachrichtigungen.
API-Version API Version 2016-01-01443

AWS Database Migration Service BenutzerhandbuchEreigniskategorien und Ereignismeldungen in AWS DMS
Die Liste der Kategorien und Ereignisse, über die Sie benachrichtigt werden können, finden Sieim folgenden Abschnitt. Weitere Informationen zum Abonnieren von und Arbeiten mit AWS DMS-Ereignisabonnements finden Sie unter Abonnieren von AWS DMS-Ereignisbenachrichtigungen (p. 446).
Ereigniskategorien und Ereignismeldungen in AWSDMS
AWS DMS generiert eine beträchtliche Anzahl von Ereignissen in Kategorien, die Sie mithilfe der AWSDMS-Konsole oder der AWS DMS-API abonnieren können. Jede Kategorie gilt für einen Quelltyp. Derzeitunterstützt AWS DMS die Quelltypen "Replikations-Instance" und "Replikationsaufgabe".
In der folgenden Tabelle sind die möglichen Kategorien und Ereignisse für den Quelltyp "Replikations-Instance" angegeben.
Kategorie DMS-Ereignis-ID Beschreibung
KonfigurationsänderungDMS-EVENT-0012 REP_INSTANCE_CLASS_CHANGING – DieReplikations-Instance-Klasse für diese Replikations-Instance wird geändert.
KonfigurationsänderungDMS-EVENT-0014 REP_INSTANCE_CLASS_CHANGE_COMPLETE– Die Replikations-Instance-Klasse für dieseReplikations-Instance wurde geändert.
KonfigurationsänderungDMS-EVENT-0018 BEGIN_SCALE_STORAGE – Der Speicher für dieReplikations-Instance wird erweitert.
KonfigurationsänderungDMS-EVENT-0017 FINISH_SCALE_STORAGE – Der Speicher für dieReplikations-Instance wurde erweitert.
KonfigurationsänderungDMS-EVENT-0024 BEGIN_CONVERSION_TO_HIGH_AVAILABILITY– Die Replikations-Instance wird in eine Multi-AZ-Konfiguration umgewandelt.
KonfigurationsänderungDMS-EVENT-0025 FINISH_CONVERSION_TO_HIGH_AVAILABILITY– Die Replikations-Instance wurde in eine Multi-AZ-Konfiguration umgewandelt.
KonfigurationsänderungDMS-EVENT-0030 BEGIN_CONVERSION_TO_NON_HIGH_AVAILABILITY– Die Replikations-Instance wird in eine Einzel-AZ-Konfiguration umgewandelt.
KonfigurationsänderungDMS-EVENT-0029 FINISH_CONVERSION_TO_NON_HIGH_AVAILABILITY– Die Replikations-Instance wurde in eine Einzel-AZ-Konfiguration umgewandelt.
Erstellung DMS-EVENT-0067 CREATING_REPLICATION_INSTANCE – EineReplikations-Instance wird erstellt.
Erstellung DMS-EVENT-0005 CREATED_REPLICATION_INSTANCE – EineReplikations-Instance wurde erstellt.
Löschung DMS-EVENT-0066 DELETING_REPLICATION_INSTANCE – DieReplikations-Instance wird gelöscht.
API-Version API Version 2016-01-01444
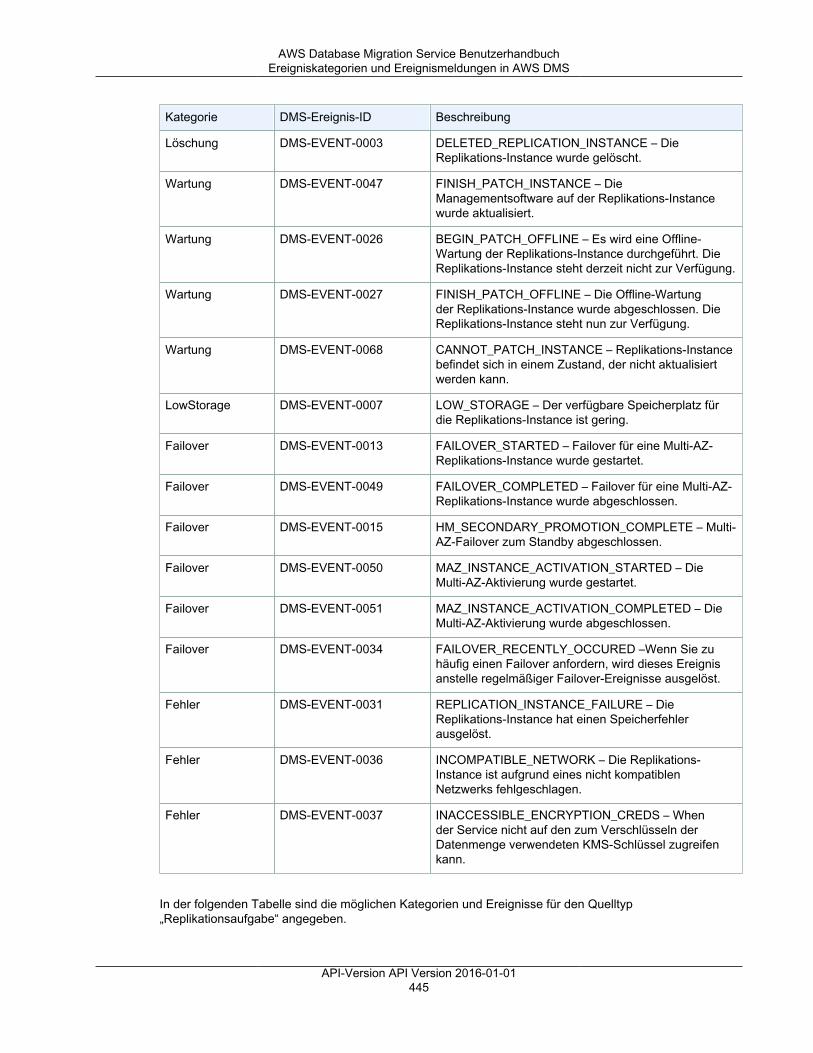
AWS Database Migration Service BenutzerhandbuchEreigniskategorien und Ereignismeldungen in AWS DMS
Kategorie DMS-Ereignis-ID Beschreibung
Löschung DMS-EVENT-0003 DELETED_REPLICATION_INSTANCE – DieReplikations-Instance wurde gelöscht.
Wartung DMS-EVENT-0047 FINISH_PATCH_INSTANCE – DieManagementsoftware auf der Replikations-Instancewurde aktualisiert.
Wartung DMS-EVENT-0026 BEGIN_PATCH_OFFLINE – Es wird eine Offline-Wartung der Replikations-Instance durchgeführt. DieReplikations-Instance steht derzeit nicht zur Verfügung.
Wartung DMS-EVENT-0027 FINISH_PATCH_OFFLINE – Die Offline-Wartungder Replikations-Instance wurde abgeschlossen. DieReplikations-Instance steht nun zur Verfügung.
Wartung DMS-EVENT-0068 CANNOT_PATCH_INSTANCE – Replikations-Instancebefindet sich in einem Zustand, der nicht aktualisiertwerden kann.
LowStorage DMS-EVENT-0007 LOW_STORAGE – Der verfügbare Speicherplatz fürdie Replikations-Instance ist gering.
Failover DMS-EVENT-0013 FAILOVER_STARTED – Failover für eine Multi-AZ-Replikations-Instance wurde gestartet.
Failover DMS-EVENT-0049 FAILOVER_COMPLETED – Failover für eine Multi-AZ-Replikations-Instance wurde abgeschlossen.
Failover DMS-EVENT-0015 HM_SECONDARY_PROMOTION_COMPLETE – Multi-AZ-Failover zum Standby abgeschlossen.
Failover DMS-EVENT-0050 MAZ_INSTANCE_ACTIVATION_STARTED – DieMulti-AZ-Aktivierung wurde gestartet.
Failover DMS-EVENT-0051 MAZ_INSTANCE_ACTIVATION_COMPLETED – DieMulti-AZ-Aktivierung wurde abgeschlossen.
Failover DMS-EVENT-0034 FAILOVER_RECENTLY_OCCURED –Wenn Sie zuhäufig einen Failover anfordern, wird dieses Ereignisanstelle regelmäßiger Failover-Ereignisse ausgelöst.
Fehler DMS-EVENT-0031 REPLICATION_INSTANCE_FAILURE – DieReplikations-Instance hat einen Speicherfehlerausgelöst.
Fehler DMS-EVENT-0036 INCOMPATIBLE_NETWORK – Die Replikations-Instance ist aufgrund eines nicht kompatiblenNetzwerks fehlgeschlagen.
Fehler DMS-EVENT-0037 INACCESSIBLE_ENCRYPTION_CREDS – Whender Service nicht auf den zum Verschlüsseln derDatenmenge verwendeten KMS-Schlüssel zugreifenkann.
In der folgenden Tabelle sind die möglichen Kategorien und Ereignisse für den Quelltyp„Replikationsaufgabe“ angegeben.
API-Version API Version 2016-01-01445
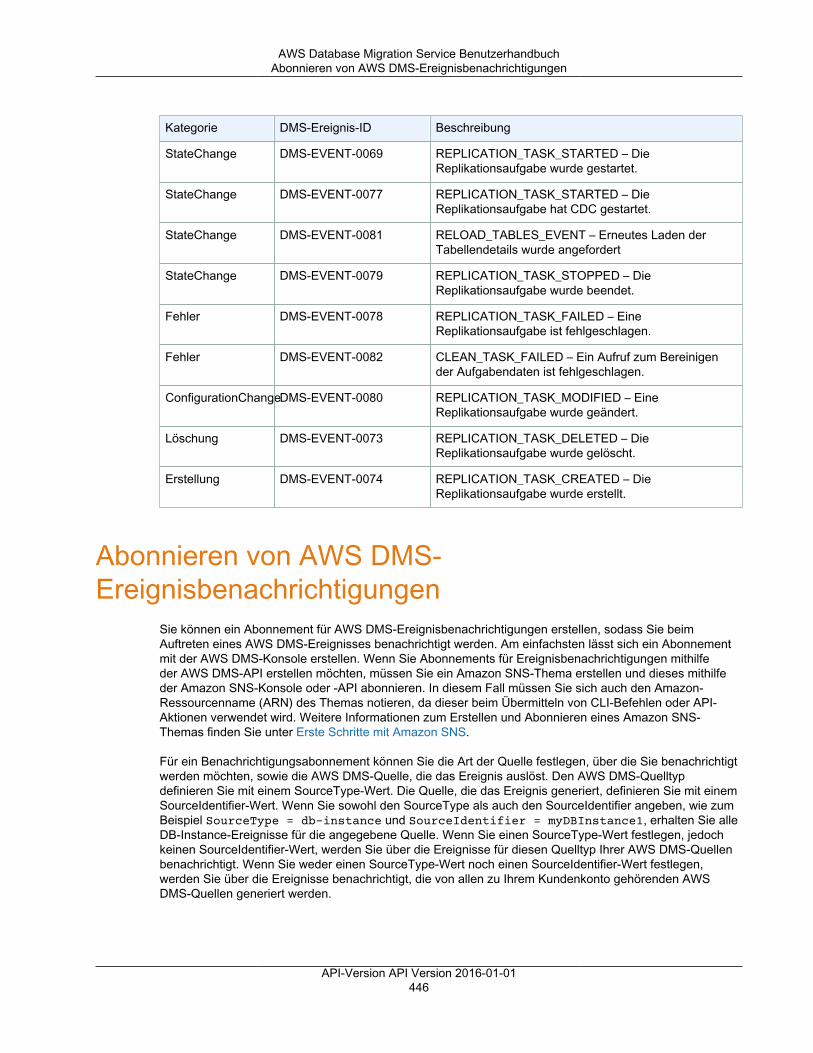
AWS Database Migration Service BenutzerhandbuchAbonnieren von AWS DMS-Ereignisbenachrichtigungen
Kategorie DMS-Ereignis-ID Beschreibung
StateChange DMS-EVENT-0069 REPLICATION_TASK_STARTED – DieReplikationsaufgabe wurde gestartet.
StateChange DMS-EVENT-0077 REPLICATION_TASK_STARTED – DieReplikationsaufgabe hat CDC gestartet.
StateChange DMS-EVENT-0081 RELOAD_TABLES_EVENT – Erneutes Laden derTabellendetails wurde angefordert
StateChange DMS-EVENT-0079 REPLICATION_TASK_STOPPED – DieReplikationsaufgabe wurde beendet.
Fehler DMS-EVENT-0078 REPLICATION_TASK_FAILED – EineReplikationsaufgabe ist fehlgeschlagen.
Fehler DMS-EVENT-0082 CLEAN_TASK_FAILED – Ein Aufruf zum Bereinigender Aufgabendaten ist fehlgeschlagen.
ConfigurationChangeDMS-EVENT-0080 REPLICATION_TASK_MODIFIED – EineReplikationsaufgabe wurde geändert.
Löschung DMS-EVENT-0073 REPLICATION_TASK_DELETED – DieReplikationsaufgabe wurde gelöscht.
Erstellung DMS-EVENT-0074 REPLICATION_TASK_CREATED – DieReplikationsaufgabe wurde erstellt.
Abonnieren von AWS DMS-Ereignisbenachrichtigungen
Sie können ein Abonnement für AWS DMS-Ereignisbenachrichtigungen erstellen, sodass Sie beimAuftreten eines AWS DMS-Ereignisses benachrichtigt werden. Am einfachsten lässt sich ein Abonnementmit der AWS DMS-Konsole erstellen. Wenn Sie Abonnements für Ereignisbenachrichtigungen mithilfeder AWS DMS-API erstellen möchten, müssen Sie ein Amazon SNS-Thema erstellen und dieses mithilfeder Amazon SNS-Konsole oder -API abonnieren. In diesem Fall müssen Sie sich auch den Amazon-Ressourcenname (ARN) des Themas notieren, da dieser beim Übermitteln von CLI-Befehlen oder API-Aktionen verwendet wird. Weitere Informationen zum Erstellen und Abonnieren eines Amazon SNS-Themas finden Sie unter Erste Schritte mit Amazon SNS.
Für ein Benachrichtigungsabonnement können Sie die Art der Quelle festlegen, über die Sie benachrichtigtwerden möchten, sowie die AWS DMS-Quelle, die das Ereignis auslöst. Den AWS DMS-Quelltypdefinieren Sie mit einem SourceType-Wert. Die Quelle, die das Ereignis generiert, definieren Sie mit einemSourceIdentifier-Wert. Wenn Sie sowohl den SourceType als auch den SourceIdentifier angeben, wie zumBeispiel SourceType = db-instance und SourceIdentifier = myDBInstance1, erhalten Sie alleDB-Instance-Ereignisse für die angegebene Quelle. Wenn Sie einen SourceType-Wert festlegen, jedochkeinen SourceIdentifier-Wert, werden Sie über die Ereignisse für diesen Quelltyp Ihrer AWS DMS-Quellenbenachrichtigt. Wenn Sie weder einen SourceType-Wert noch einen SourceIdentifier-Wert festlegen,werden Sie über die Ereignisse benachrichtigt, die von allen zu Ihrem Kundenkonto gehörenden AWSDMS-Quellen generiert werden.
API-Version API Version 2016-01-01446

AWS Database Migration Service BenutzerhandbuchAWS Management Console
AWS Management ConsoleSo abonnieren Sie AWS DMS-Ereignisbenachrichtigungen mithilfe der Konsole
1. Melden Sie sich bei der AWS-Managementkonsole an und wählen Sie AWS DMS aus. Beachten SieFolgendes: Wenn Sie als AWS Identity and Access Management(IAM)-Benutzer angemeldet sind,müssen Sie über die entsprechenden Berechtigungen für den Zugriff auf AWS DMS verfügen.
2. Wählen Sie im Navigationsbereich Event Subscriptions aus.3. Wählen Sie auf der Seite Event Subscriptions Create Event Subscription aus.4. Führen Sie auf der Seite Create Event Subscription die folgenden Schritte aus:
a. Geben Sie unter Name einen Namen für das Abonnement für Ereignisbenachrichtigungen ein.b. Wählen Sie entweder ein vorhandenes Amazon SNS-Thema für Send notifications to
(Benachrichtigungen senden an) oder create topic (Thema erstellen) aus. Entweder müssen Sieein vorhandenes Amazon SNS-Thema haben, an das Sie Benachrichtigungen senden möchten,oder Sie müssen das Thema selbst erstellen. Wenn Sie create topic auswählen, können Sie eineE-Mail-Adresse eingeben, an die die Benachrichtigungen gesendet werden sollen.
c. Wählen Sie unter Source Type einen Quellen-Typen aus. Die einzige Option ist replicationinstance (Replikations-Instance).
d. Wählen Sie Yes aus, um das Abonnement zu aktivieren. Wenn Sie das Abonnement erstellenmöchten, jedoch noch keine Benachrichtigungen gesendet haben, wählen Sie No aus.
e. Je nach ausgewähltem Quelltyp wählen Sie die Ereigniskategorien und Quellen aus, für die SieEreignisbenachrichtigungen erhalten möchten.
f. Wählen Sie Create aus.
In der AWS DMS-Konsole wird die Erstellung des Abonnements angezeigt.
AWS DMS-APISo abonnieren Sie AWS DMS-Ereignisbenachrichtigungen mithilfe der AWS DMS-API
• Rufen Sie CreateEventSubscription an.
API-Version API Version 2016-01-01447

AWS Database Migration Service Benutzerhandbuch
Migrieren von großen Datenspeichernmit AWS Database Migration Serviceund AWS Snowball Edge
Größere Datenmigrationen können viele Terabytes an Daten umfassen. Dieser Prozess kann aufgrund vonEinschränkungen der Netzwerkbandbreite oder allein aufgrund der schieren Datenmenge mühsam sein.AWS Database Migration Service (AWS DMS) kann AWS Snowball Edge und Amazon S3 verwenden, umgroße Datenbanken schneller als mit anderen Methoden zu migrieren.
AWS Snowball Edge ist ein AWS-Service, der ein Edge-Device bereitstellt, mit dem Sie Daten in dieCloud übertragen können. Dies geschieht mit Geschwindigkeiten, die die Netzwerkgeschwindigkeit beiweitem überbieten. Bei einem Edge-Gerät handelt es sich um eine AWS-eigene Appliance mit großeminternen Speicher. Es verwendet eine 256-Bit-Verschlüsselung und ein branchenübliches TPM (TrustedPlatform Module), das sowohl die Sicherheit als auch eine umfassende Überwachungskette für Ihre Datengewährleistet. AWS Snowball Edge bietet viele zusätzliche Funktionen. Weitere Informationen finden Sieunter Was ist eine AWS Snowball Edge-Appliance? im AWS Snowball Edge-Entwicklerhandbuch.
Amazon S3 ist ein AWS-Speicher- und Abrufservice. Um Objekte in Amazon S3 zu speichern, laden Siedie Datei hoch, die Sie in einem Bucket speichern möchten. Beim Hochladen einer Datei können SieBerechtigungen für das Objekt sowie für beliebige Metadaten festlegen. Weitere Informationen finden Sie inder S3-Dokumentation.
Wenn Sie ein Edge-Gerät verwenden, weist die Datenmigration die folgenden Phasen auf:
1. Sie verwenden das AWS Schema Conversion Tool (AWS SCT) zum lokalen Extrahieren der Daten undVerschieben auf ein Edge-Gerät.
2. Sie senden das Edge-Gerät oder die Edge-Geräte zurück an AWS.3. Nachdem AWS Ihre Sendung erhalten hat, lädt das Edge-Gerät automatisch seine Daten in einen
Amazon S3-Bucket.4. AWS DMS migriert die Dateien in den Zieldatenspeicher. Wenn Sie Change Data Capture (CDC)
verwenden, werden diese Aktualisierungen in den Amazon S3-Bucket geschrieben und dann auf denZieldatenspeicher angewendet.
In den folgenden Abschnitten erfahren Sie mehr über die Verwendung eines Edge-Geräts zum Migrierenvon relationalen Datenbanken mit AWS SCT und AWS DMS. Sie können auch ein Edge-Gerät und AWSSCT für die Migration von lokalen Data Warehouses in die AWS Cloud verwenden. Weitere Informationenzu Data Warehouse-Migrationen finden Sie unter Migration von Daten aus einem lokalen Data Warehousezu Amazon Redshift im AWS Schema Conversion Tool – Benutzerhandbuch.
Themen• Übersicht über das Migrieren von großen Datenspeichern mit DMS und Snowball Edge (p. 449)• Voraussetzungen für das Migrieren von großen Datenspeichern mit DMS und Snowball Edge (p. 450)• Checkliste für die Migration (p. 450)• Schrittweise Anleitungen für das Migrieren von Daten mithilfe von AWS DMS mit Snowball
Edge (p. 452)
API-Version API Version 2016-01-01448

AWS Database Migration Service BenutzerhandbuchProzessübersicht
• Einschränkungen beim Arbeiten mit Snowball Edge und AWS DMS (p. 469)
Übersicht über das Migrieren von großenDatenspeichern mit DMS und Snowball Edge
Das Verwenden von AWS DMS und AWS Snowball Edge umfasst sowohl lokale Anwendungen als auchvon Amazon verwaltete Services. Wir verwenden die Begriffe lokal und remote, um diese Komponenten zuunterscheiden.
Lokale Komponenten beinhalten Folgendes:
• AWS SCT• AWS DMS-Agent (eine lokale Version von AWS DMS, arbeitet lokal)• Snowball Edge-Geräte
Remote-Komponenten beinhalten Folgendes:
• Amazon S3• AWS DMS
In den folgenden Abschnitten finden Sie eine schrittweise Anleitung für die Konfiguration, Installation undVerwaltung einer AWS DMS-Migration mit einem Edge-Gerät oder Edge-Geräten.
Die folgende Abbildung zeigt eine Übersicht über den Migrationsvorgang.
Die Migration umfasst eine lokale Aufgabe, bei der Sie Daten mithilfe des DMS-Agenten zu einem Edge-Gerät verschieben. Nachdem ein Edge-Gerät geladen ist, senden Sie es an AWS zurück. Wenn Siemehrere Edge-Geräte haben, können Sie sie gleichzeitig oder einzeln nacheinander zurückgeben.Wenn AWS ein Edge-Gerät erhält, lädt eine Remote-Aufgabe mithilfe von AWS DMS die Daten in denZieldatenspeicher in AWS.
Zum Migrieren aus einem lokalen Datenspeicher in einen AWS-Datenspeicher führen Sie die folgendenSchritte aus:
1. Verwenden Sie die AWS Snowball Management Console zum Erstellen eines neuen Auftrags für dasImportieren von Daten in S3 mit einem Snowball Edge Storage Optimized-Gerät. Der Auftrag umfasstdie Anforderung, dass das Gerät an Ihre Adresse gesendet wird.
2. Richten Sie AWS SCT auf einem lokalen Computer ein, der auf AWS zugreifen kann. Installieren Sie dasSnowball Edge-Client-Tool auf einem anderen lokalen Computer.
API-Version API Version 2016-01-01449

AWS Database Migration Service BenutzerhandbuchVoraussetzungen
3. Wenn das Edge-Gerät eintrifft, schalten Sie es ein, stellen Sie die Verbindung dazu her und heben Siedann die Sperrung mit dem Client-Tool auf. Informationen mit einzelnen Schritten finden Sie unter ErsteSchritte mit AWS Snowball Edge: Der erste Auftrag im AWS Snowball Edge-Entwicklerhandbuch.
4. Installieren Sie die Open Database Connectivity (ODBC)-Treiber für Ihre Datenquellen. Speichern Siediese auf dem Computer mit dem Edge-Client-Tool.
5. Installieren und konfigurieren Sie den AWS DMS-Agent-Host auf dem Computer mit dem Edge-Client-Tool.
Der DMS-Agent muss eine Anbindung an die Quelldatenbank, AWS SCT, AWS und Snowball Edgehaben. Der DMS-Agent wird nur auf den folgenden Linux-Plattformen unterstützt:• Red Hat Enterprise Linux-Versionen 6.2 bis 6.8, 7.0 und 7.1 (64-Bit)• SUSE Linux-Version 12 (64-Bit)
Obwohl der DMS-Agent im AWS SCT-Installationspaket enthalten ist, befinden sie sich besser nichtan der gleichen Stelle. Wir empfehlen Ihnen, den DMS-Agenten auf einem anderen Computer zuinstallieren – nicht auf dem Computer, auf dem Sie AWS SCT installiert haben.
6. Erstellen Sie ein neues Projekt in AWS SCT.7. Konfigurieren Sie AWS SCT für die Verwendung des Snowball Edge-Geräts.8. Registrieren Sie den DMS-Agenten bei AWS SCT.9. Erstellen Sie eine lokale Aufgabe und eine DMS-Aufgabe in SCT.10.Führen Sie die Aufgabe in SCT aus und überwachen Sie sie.
Voraussetzungen für das Migrieren von großenDatenspeichern mit DMS und Snowball Edge
Bevor Sie den Migrationsprozess starten, müssen folgende Voraussetzungen erfüllt sein:
• Sie sind mit dem grundsätzlichen Betrieb von AWS SCT vertraut.• Sie haben den S3-Bucket oder die S3-Buckets für die Verwendung für die Migration erstellt oder können
dies tun.• Sie haben eine AWS DMS-Replikations-Instance in derselben Region wie der S3-Bucket.• Sie sind mit der Verwendung der AWS Command Line Interface (AWS CLI) vertraut.• Sie sind mit dem Snowball Edge-Entwicklerhandbuch vertraut.
Checkliste für die MigrationUm den Ablauf während der Migration zu erleichtern, können Sie die folgende Checkliste verwenden, umeine Liste der Elemente zu erstellen, die Sie während der Migration benötigen.
----------------------------------------------------------------DMS Migration Checklist----------------------------------------------------------------
This checklist is for my schemas named:
The database engine that my schemas reside on is:
----------------------------------------------------------------
AWS Region for the migration:
API-Version API Version 2016-01-01450

AWS Database Migration Service BenutzerhandbuchCheckliste für die Migration
Name of migration job that you created in the AWS Snowball Management Console:
S3 bucket (and folder) for this job:
IAM role that has access to the S3 Bucket and the target database on AWS:
----------------------------------------------------------------
Path to the installation directory of AWS SCT (needed for a future step):
Name/IP of Machine #1 (SCT):
Name/IP of Machine #2 (Connectivity):
----------------------------------------------------------------
IP address of your Snowball Edge:
Port for the Snowball Edge:
Unlock code for the Snowball Edge device:
Path to the manifest file:
Output of the command snowballEdge get-secret-access-key: AWS access key ID: AWS secret access Key:
----------------------------------------------------------------
Confirm ODBC drivers is installed on Machine #2 (Connectivity):
----------------------------------------------------------------
Confirm DMS Agent is installed on Machine #2 (Connectivity):
Confirm DMS Agent is running two processes:
DMS Agent password:
DMS Agent port number:
Confirm that your firewall allows connectivity:
----------------------------------------------------------------
Name of SCT project:
----------------------------------------------------------------
Confirm that DMS Agent is registered with SCT:
New agent or service profile name that you provided:
----------------------------------------------------------------
Confirm local and DMS task exists:
Task name that you provided:
----------------------------------------------------------------
Confirm:
DMS Agent connects to the following:
API-Version API Version 2016-01-01451

AWS Database Migration Service BenutzerhandbuchSchrittweise Anleitungen
__ The source database __ The staging S3 bucket __ The Edge device
DMS task connects to the following: __ The staging S3 bucket __ The target database on AWS
----------------------------------------------------------------
Confirm the following: __ Stopped Edge client __ Powered off Edge device __ Returned Edge device to AWS
Schrittweise Anleitungen für das Migrieren vonDaten mithilfe von AWS DMS mit Snowball Edge
In den folgenden Abschnitten finden Sie ausführliche Informationen über die einzelnen Migrationsschritte.
Schritt 1: Erstellen eines Snowball Edge-AuftragsBefolgen Sie die Schritte im Abschnitt Erste Schritte mit einem Snowball Edge-Gerät im AWSSnowball Edge-Entwicklerhandbuch. Öffnen Sie die AWS Snowball Management Console und erstellen Sieeinen neuen Auftrag für Import into Amazon S3 (In Amazon S3 importieren).
Fordern Sie unbedingt ein Snowball Edge-Gerät (Snowball Edge Storage Optimized (SpeicheroptimiertesSnowball Edge)) an, da reguläre Snowball-Geräte nicht für AWS DMS unterstützt werden. Folgen Sie denAnweisungen auf dem Bildschirm für die verbleibenden Einstellungen. Sie haben die Möglichkeit, IhreEinstellungen zu überprüfen, bevor Sie den Auftrag erstellen.
Schritt 2: Herunterladen und Installieren von AWSSchema Conversion Tool (AWS SCT)Sie benötigen, zusätzlich zu dem Edge-Gerät, zwei lokale Computer zur Ausführung dieses Prozesses.
Laden Sie die AWS Schema Conversion Tool-App herunter und installieren Sie sie auf einem lokalenComputer mit Zugriff auf AWS. Anweisungen, die Informationen über kompatible Betriebssystemeumfassen, finden Sie im Artikel zum Installieren und Aktualisieren des AWS Schema Conversion Tool.
Laden Sie auf einem anderen Computer, auf dem Sie den DMS-Agenten installieren möchten, denSnowball Edge-Client aus AWS Snowball Edge-Ressourcen herunter und installieren Sie ihn.
Nachdem Sie diesen Schritt abgeschlossen haben, sollten Sie zwei Computer haben:
• Computer Nr. 1 (SCT), mit installiertem AWS SCT• Computer Nr. 2 (Anbindung), mit dem Edge-Client, auf dem Sie den DMS-Agenten und die ODBC-
Treiber für die Datenbanken installieren möchten, die Sie migrieren
Schritt 3: Entsperren des Snowball Edge-GerätsWenn das Edge-Gerät eintrifft, bereiten Sie es für die Verwendung vor.
API-Version API Version 2016-01-01452
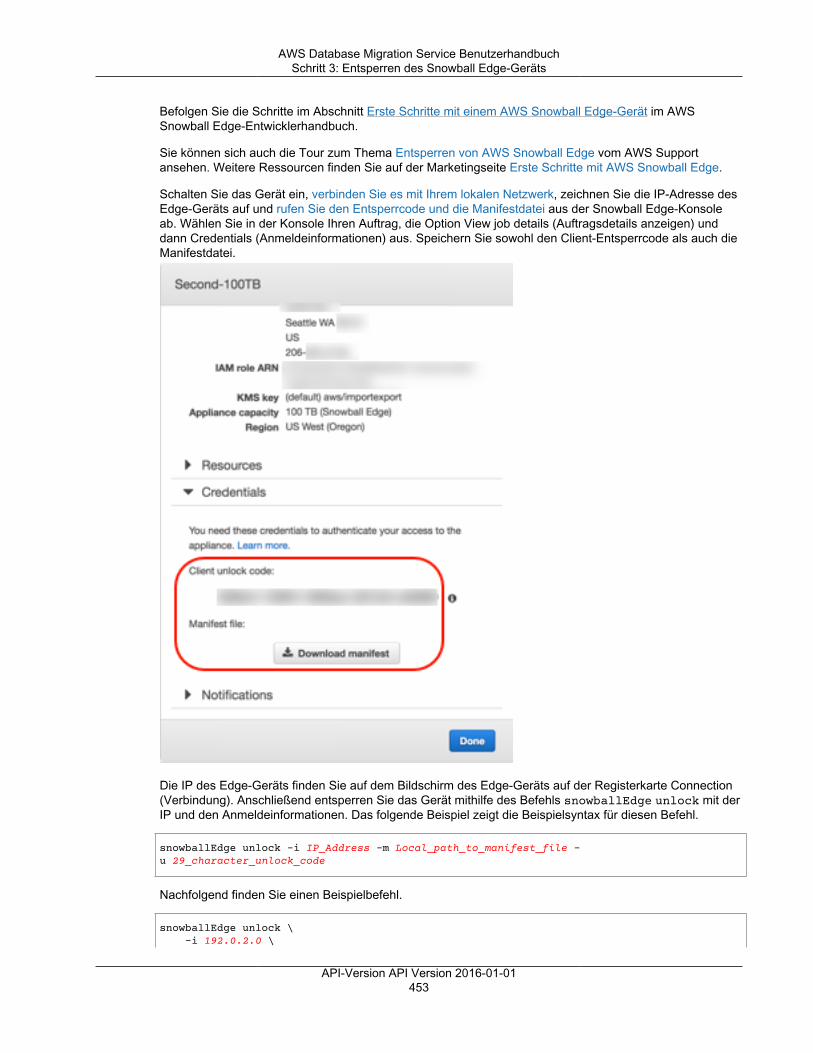
AWS Database Migration Service BenutzerhandbuchSchritt 3: Entsperren des Snowball Edge-Geräts
Befolgen Sie die Schritte im Abschnitt Erste Schritte mit einem AWS Snowball Edge-Gerät im AWSSnowball Edge-Entwicklerhandbuch.
Sie können sich auch die Tour zum Thema Entsperren von AWS Snowball Edge vom AWS Supportansehen. Weitere Ressourcen finden Sie auf der Marketingseite Erste Schritte mit AWS Snowball Edge.
Schalten Sie das Gerät ein, verbinden Sie es mit Ihrem lokalen Netzwerk, zeichnen Sie die IP-Adresse desEdge-Geräts auf und rufen Sie den Entsperrcode und die Manifestdatei aus der Snowball Edge-Konsoleab. Wählen Sie in der Konsole Ihren Auftrag, die Option View job details (Auftragsdetails anzeigen) unddann Credentials (Anmeldeinformationen) aus. Speichern Sie sowohl den Client-Entsperrcode als auch dieManifestdatei.
Die IP des Edge-Geräts finden Sie auf dem Bildschirm des Edge-Geräts auf der Registerkarte Connection(Verbindung). Anschließend entsperren Sie das Gerät mithilfe des Befehls snowballEdge unlock mit derIP und den Anmeldeinformationen. Das folgende Beispiel zeigt die Beispielsyntax für diesen Befehl.
snowballEdge unlock -i IP_Address -m Local_path_to_manifest_file -u 29_character_unlock_code
Nachfolgend finden Sie einen Beispielbefehl.
snowballEdge unlock \ -i 192.0.2.0 \
API-Version API Version 2016-01-01453

AWS Database Migration Service BenutzerhandbuchSchritt 4: Konfigurieren des DMS-Agent-Hosts mit ODBC-Treibern
-m /Downloads/JID2EXAMPLE-0c40-49a7-9f53-916aEXAMPLE81-manifest.bin \ -u 12345-abcde-12345-ABCDE-12345
Abschließend rufen Sie den Snowball Edge-Zugriffsschlüssel und den geheimen Schlüssel aus dem Gerätmithilfe des Edge-Clients ab. Nachfolgend sehen Sie eine Beispieleingabe und -ausgabe für den Befehlzum Abrufen des Zugriffsschlüssels.
Beispieleingabe
snowballEdge list-access-keys \ --endpoint https://192.0.2.0 \ --manifest-file Path_to_manifest_file \ --unlock-code 12345-abcde-12345-ABCDE-12345
Beispielausgabe
{ "AccessKeyIds" : [ "AKIAIOSFODNN7EXAMPLE" ]}
Nachfolgend sehen Sie eine Beispieleingabe und -ausgabe für den Befehl zum Abrufen des geheimenSchlüssels.
Beispieleingabe
snowballEdge get-secret-access-key \ --access-key-id AKIAIOSFODNN7EXAMPLE \ --endpoint https://192.0.2.0 \ --manifest-file /Downloads/JID2EXAMPLE-0c40-49a7-9f53-916aEXAMPLE81-manifest.bin \ --unlock-code 12345-abcde-12345-ABCDE-12345
Beispielausgabe
[snowballEdge]aws_access_key_id = AKIAIOSFODNN7EXAMPLEaws_secret_access_key = wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Wenn die Snowball Edge-Appliance zur Verwendung bereit ist, können Sie mithilfe der AWS CLI oder desS3 SDK-Adapters für Snowball direkt mit ihr interagieren. Dieser Adapter funktioniert auch mit dem Edge-Gerät.
Schritt 4: Konfigurieren des DMS-Agent-Hosts mitODBC-TreibernVerwenden Sie Computer Nr. 2 (Anbindung) aus Schritt 2, auf dem der Edge-Client bereits installiert ist,und installieren Sie die erforderlichen ODBC-Treiber. Diese Treiber sind notwendig, um eine Verbindungzu Ihrer Quelldatenbank herzustellen. Der erforderliche Treiber hängt von der jeweiligen Datenbank-Engineab. In den folgenden Abschnitten finden Sie Informationen zu den einzelnen Datenbank-Engines.
Themen• Oracle (p. 455)• Microsoft SQL Server (p. 455)• ASE SAP Sybase (p. 455)• MySQL (p. 455)• PostgreSQL (p. 456)
API-Version API Version 2016-01-01454

AWS Database Migration Service BenutzerhandbuchSchritt 4: Konfigurieren des DMS-Agent-Hosts mit ODBC-Treibern
OracleInstallieren Sie den Oracle Instant Client für die Linux (x86-64)-Version 11.2.0.3.0 oder höher.
Ist dies noch nicht erfolgt, müssen Sie zusätzlich im Verzeichnis $ORACLE_HOME\lib directoryeinen symbolischen Link erstellen. Dieser Link sollte als libclntsh.so bezeichnet werden und auf einebestimmte Version dieser Datei verweisen. So verwenden Sie beispielsweise auf einem Oracle 12c-Clientfolgenden Code.
lrwxrwxrwx 1 oracle oracle 63 Oct 2 14:16 libclntsh.so ->/u01/app/oracle/home/lib/libclntsh.so.12.1
Darüber hinaus sollte die Umgebungsvariable LD_LIBRARY_PATH dem Verzeichnis "Oracle lib" angehängtund dem Skript site_arep_login.sh im Ordner "lib" der Installation hinzugefügt werden. Fügen Siedieses Skript hinzu, wenn es noch nicht vorhanden ist.
vi /opt/amazon/aws-schema-conversion-tool-dms-agent/bin/site_arep_login.sh
export ORACLE_HOME=/usr/lib/oracle/12.2/client64; export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$ORACLE_HOME/lib
Microsoft SQL ServerInstallieren Sie den Microsoft ODBC-Treiber.
Aktualisieren Sie das Skript site_arep_login.sh mit folgendem Code.
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/microsoft/msodbcsql/lib64/
ASE SAP SybaseDer SAP Sybase ASE ODBC-64-Bit-Client sollte installiert sein.
Wenn das Installationsverzeichnis /opt/sap ist, aktualisieren Sie das site_arep_login.sh-Skript mitdem folgenden Code.
export SYBASE_HOME=/opt/sapexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$SYBASE_HOME/DataAccess64/ODBC/lib:$SYBASE_HOME/DataAccess/ODBC/lib:$SYBASE_HOME/OCS-16_0/lib:$SYBASE_HOME/OCS-16_0/lib3p64:$SYBASE_HOME/OCS-16_0/lib3p
Die Datei /etc/odbcinst.ini sollte folgende Einträge enthalten.
[Sybase]Driver=/opt/sap/DataAccess64/ODBC/lib/libsybdrvodb.soDescription=Sybase ODBC driver
MySQLInstallieren Sie MySQL Connector/ODBC für Linux, Version 5.2.6 oder höher.
Stellen Sie sicher, dass die Datei /etc/odbcinst.ini einen Eintrag für MySQL enthält, wie imfolgenden Beispiel gezeigt.
API-Version API Version 2016-01-01455
AWS Database Migration Service BenutzerhandbuchSchritt 5: Installieren des DMS-Agenten
[MySQL ODBC 5.2.6 Unicode Driver]Driver = /usr/lib64/libmyodbc5w.so UsageCount = 1
PostgreSQLInstallieren Sie postgresql94-9.4.4-1PGDG.<OS Version>.x86_64.rpm. Dieses Paket enthältdie ausführbare Datei "psql". Zum Beispiel ist postgresql94-9.4.4-1PGDG.rhel7.x86_64.rpm dasPaket, das für Red Hat 7 erforderlich ist.
Installieren Sie den ODBC-Treiber postgresql94-odbc-09.03.0400-1PGDG.<OSversion>.x86_64 oder höher für Linux, wobei <OS version> dem Betriebssystem desAgentencomputers entspricht. So ist postgresql94-odbc-09.03.0400-1PGDG.rhel7.x86_64beispielsweise der Client, der für Red Hat 7 erforderlich ist.
Stellen Sie sicher, dass die Datei /etc/odbcinst.ini einen Eintrag für PostgreSQL enthält, wie imfolgenden Beispiel gezeigt.
[PostgreSQL]Description = PostgreSQL ODBC driverDriver = /usr/pgsql-9.4/lib/psqlodbc.so Setup = /usr/pgsql-9.4/lib/psqlodbcw.so Debug = 0 CommLog = 1 UsageCount = 2
Schritt 5: Installieren des DMS-AgentenVerwenden Sie Computer Nr. 2 (Anbindung) aus Schritt 2, auf dem der Edge-Client und die ODBC-Treiber bereits installiert sind, und installieren und konfigurieren Sie den DMS-Agenten. Der DMS-Agentwird als Teil des AWS SCT-Installationspakets bereitgestellt, wie im AWS Schema Conversion Tool –Benutzerhandbuch beschrieben.
Nachdem Sie diesen Schritt abgeschlossen haben, sollten Sie zwei lokale Computer vorbereitet haben:
• Computer Nr. 1 (SCT), mit installiertem AWS SCT• Computer Nr. 2 (Anbindung) mit installiertem Edge-Client, ODBC-Treibern und DMS-Agenten
So installieren Sie den DMS-Agenten
1. Suchen Sie im AWS SCT-Installationsverzeichnis die RPM-Datei mit dem Namen aws-schema-conversion-tool-dms-agent-2.4.1-R1.x86_64.rpm.
Kopieren Sie sie auf den Computer Nr. 2 (Anbindung), den DMS-Agentencomputer. SCT und derDMS-Agent sollten auf separaten Computern installiert sein. Der DMS-Agent sollte sich auf demselbenComputer befinden wie der Edge-Client und die ODBC-Treiber.
2. Führen Sie auf Computer Nr. 2 (Anbindung) den folgenden Befehl aus, um den DMS-Agenten zuinstallieren. Um Berechtigungen zu vereinfachen, führen Sie diesen Befehl als root-Benutzer aus.
sudo rpm -i aws-schema-conversion-tool-dms-agent-2.4.0-R2.x86_64.rpm
Dieser Befehl verwendet das standardmäßige Installationsverzeichnis /opt/amazon/aws-schema-conversion-tool-dms-agent. Um den DMS-Agenten an einem anderen Speicherort zuinstallieren, verwenden Sie die folgende Option.
API-Version API Version 2016-01-01456

AWS Database Migration Service BenutzerhandbuchSchritt 5: Installieren des DMS-Agenten
sudo rpm --prefix <installation_directory> -i aws-schema-conversion-tool-dms-agent-2.4.0-R2.x86_64.rpm
3. Verwenden Sie den folgenden Befehl, um zu bestätigen, dass der DMS-Agent ausgeführt wird.
ps -ef | grep repctl
Die Ausgabe dieses Befehls sollte die Ausführung zweier Prozesse anzeigen.
Um den DMS-Agenten konfigurieren zu können, müssen Sie ein Passwort und eine Portnummerangeben. Sie verwenden das Passwort später, um den DMS-Agenten bei AWS SCT zu registrieren,halten Sie es daher bereit. Wählen Sie eine ungenutzte Portnummer für den DMS-Agenten, um AWSSCT-Verbindungen zu überwachen. Möglicherweise müssen Sie Ihre Firewall konfigurieren, um dieKonnektivität zuzulassen.
Jetzt konfigurieren Sie den DMS-Agenten mit dem configure.sh-Skript.
sudo /opt/amazon/aws-schema-conversion-tool-dms-agent/bin/configure.sh
Die folgende Eingabeaufforderung wird angezeigt. Geben Sie das Passwort ein. Wenn Sie dazuaufgefordert werden, geben Sie das Passwort erneut ein, um es zu bestätigen.
Configure the AWS Schema Conversion Tool DMS Agent serverNote: you will use these parameters when configuring agent in AWS Schema Conversion Tool
Please provide password for the serverUse minimum 8 and up to 20 alphanumeric characters with at least one digit and one capital case character
Password:
Die Ausgabe sieht wie folgt aus. Geben Sie eine Portnummer ein.
chown: missing operand after 'amazon:amazon'Try 'chown --help' for more information./opt/amazon/aws-schema-conversion-tool-dms-agent/bin/repctl: /opt/amazon/aws-schema-conversion-tool-dms-agent/lib/libcom_err.so.3: no version information available (required by /opt/amazon/aws-schema-conversion-tool-dms-agent/lib/libgssapi_krb5.so.2)/opt/amazon/aws-schema-conversion-tool-dms-agent/bin/repctl: /opt/amazon/aws-schema-conversion-tool-dms-agent/lib/libcom_err.so.3: no version information available (required by /opt/amazon/aws-schema-conversion-tool-dms-agent/lib/libkrb5.so.3)[setserverpassword command] Succeeded
Please provide port number the server will listen on (default is 3554)Note: you will have to configure your firewall rules accordinglyPort:
Die Ausgabe sieht wie folgt aus und bestätigt, dass der Service gestartet wurde.
Starting service.../opt/amazon/aws-schema-conversion-tool-dms-agent/bin/repctl: /opt/amazon/aws-schema-conversion-tool-dms-agent/lib/libcom_err.so.3: no version information available (required by
API-Version API Version 2016-01-01457

AWS Database Migration Service BenutzerhandbuchSchritt 6: Erstellen eines neuen AWS SCT-Projekts
/opt/amazon/aws-schema-conversion-tool-dms-agent/lib/libgssapi_krb5.so.2)/opt/amazon/aws-schema-conversion-tool-dms-agent/bin/repctl: /opt/amazon/aws-schema-conversion-tool-dms-agent/lib/libcom_err.so.3: no version information available (required by /opt/amazon/aws-schema-conversion-tool-dms-agent/lib/libkrb5.so.3)AWS Schema Conversion Tool DMS Agent was sent a stop signalAWS Schema Conversion Tool DMS Agent is no longer running[service command] Succeeded/opt/amazon/aws-schema-conversion-tool-dms-agent/bin/repctl: /opt/amazon/aws-schema-conversion-tool-dms-agent/lib/libcom_err.so.3: no version information available (required by /opt/amazon/aws-schema-conversion-tool-dms-agent/lib/libgssapi_krb5.so.2)/opt/amazon/aws-schema-conversion-tool-dms-agent/bin/repctl: /opt/amazon/aws-schema-conversion-tool-dms-agent/lib/libcom_err.so.3: no version information available (required by /opt/amazon/aws-schema-conversion-tool-dms-agent/lib/libkrb5.so.3)AWS Schema Conversion Tool DMS Agent was started as PID 1608
Wir empfehlen Ihnen, die AWS Command Line Interface (AWS CLI) zu installieren. Mit der AWSCLI können Sie die Snowball Edge-Appliance abfragen, um die Datendateien zu sehen, die aufdas Gerät geschrieben wurden. Verwenden Sie die von der Edge-Appliance abgerufenen AWS-Anmeldeinformationen für den Zugriff auf das Edge-Gerät. Sie könnten beispielsweise folgenden Befehlausführen.
aws s3 ls --profile SnowballEdge --endpoint https://192.0.2.0 :8080 bucket-name --recursive
Die Ausgabe dieses Befehls sieht wie folgt aus.
2018-08-20 10:55:31 53074692 streams/load00000001000573E166ACF4C0/00000001.fcd.gz2018-08-20 11:14:37 53059667 streams/load00000001000573E166ACF4C0/00000002.fcd.gz2018-08-20 11:31:42 53079181 streams/load00000001000573E166ACF4C0/00000003.fcd.gz
Um den DMS-Agenten zu beenden, führen Sie folgenden Befehl im Verzeichnis /opt/amazon/aws-schema-conversion-tool-dms-agent/bin aus.
./aws-schema-conversion-tool-dms-agent stop
Um den DMS-Agenten zu starten, führen Sie folgenden Befehl im Verzeichnis /opt/amazon/aws-schema-conversion-tool-dms-agent/bin aus.
./aws-schema-conversion-tool-dms-agent start
Schritt 6: Erstellen eines neuen AWS SCT-ProjektsAls Nächstes erstellen Sie ein neues AWS SCT-Projekt, das die Quell- und Zieldatenbanken angibt.Weitere Informationen finden Sie unter Erstellen eines AWS Schema Conversion Tool-Projekts im AWSSchema Conversion Tool – Benutzerhandbuch.
So erstellen Sie ein neues Projekt in AWS SCT
1. Starten Sie AWS SCT und wählen Sie File (Datei) und dann New Project (Neues Projekt) aus. DasDialogfeld New Project (Neues Projekt) wird angezeigt.
2. Fügen Sie die folgenden Projektinformationen hinzu.
API-Version API Version 2016-01-01458

AWS Database Migration Service BenutzerhandbuchSchritt 7: Konfigurieren von AWS SCT zurVerwendung der Snowball Edge-Appliance
Für diesen Parameter Vorgehensweise
Project Name (Projektname) Geben Sie einen Namen für Ihr Projekt ein, das lokal aufIhrem Computer gespeichert wird.
Location (Ort) Geben Sie den Speicherort für Ihre lokale Projektdatei an.
OLTP Wählen Sie Transactional Database (OLTP)(Transaktionsdatenbank (OLTP)) aus.
Source DB Engine (Quell-DB-Engine) Wählen Sie Ihren Quelldatenspeicher aus.
Target DB Engine (Ziel-DB-Engine) Wählen Sie Ihren Zieldatenspeicher aus.
3. Wählen Sie OK aus, um Ihr AWS SCT-Projekt zu erstellen.4. Stellen Sie eine Verbindung mit Ihren Quell- und Zieldatenbanken her.
Schritt 7: Konfigurieren von AWS SCT zurVerwendung der Snowball Edge-ApplianceIhr AWS SCT-Serviceprofil muss aktualisiert werden, um den DMS-Agenten verwenden zu können. Dabeihandelt es sich um lokales, vor Ort arbeitendes AWS DMS.
So aktualisieren Sie das AWS SCT-Profil für das Arbeiten mit dem DMS-Agenten
1. Starten AWS SCT.2. Wählen Sie Settings (Einstellungen), Global Settings (Globale Einstellungen), AWS Service Profiles
(AWS-Serviceprofile) aus.3. Wählen Sie Add new AWS Service Profile (Neues AWS-Serviceprofil hinzufügen) aus.
API-Version API Version 2016-01-01459
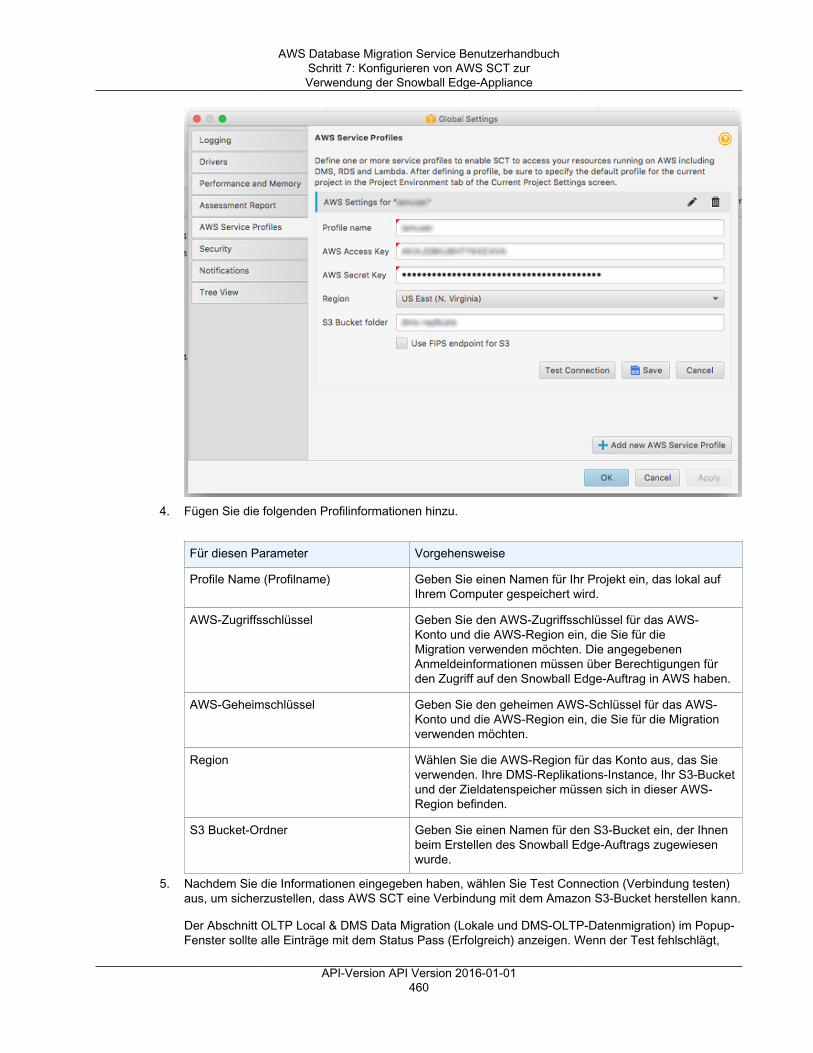
AWS Database Migration Service BenutzerhandbuchSchritt 7: Konfigurieren von AWS SCT zurVerwendung der Snowball Edge-Appliance
4. Fügen Sie die folgenden Profilinformationen hinzu.
Für diesen Parameter Vorgehensweise
Profile Name (Profilname) Geben Sie einen Namen für Ihr Projekt ein, das lokal aufIhrem Computer gespeichert wird.
AWS-Zugriffsschlüssel Geben Sie den AWS-Zugriffsschlüssel für das AWS-Konto und die AWS-Region ein, die Sie für dieMigration verwenden möchten. Die angegebenenAnmeldeinformationen müssen über Berechtigungen fürden Zugriff auf den Snowball Edge-Auftrag in AWS haben.
AWS-Geheimschlüssel Geben Sie den geheimen AWS-Schlüssel für das AWS-Konto und die AWS-Region ein, die Sie für die Migrationverwenden möchten.
Region Wählen Sie die AWS-Region für das Konto aus, das Sieverwenden. Ihre DMS-Replikations-Instance, Ihr S3-Bucketund der Zieldatenspeicher müssen sich in dieser AWS-Region befinden.
S3 Bucket-Ordner Geben Sie einen Namen für den S3-Bucket ein, der Ihnenbeim Erstellen des Snowball Edge-Auftrags zugewiesenwurde.
5. Nachdem Sie die Informationen eingegeben haben, wählen Sie Test Connection (Verbindung testen)aus, um sicherzustellen, dass AWS SCT eine Verbindung mit dem Amazon S3-Bucket herstellen kann.
Der Abschnitt OLTP Local & DMS Data Migration (Lokale und DMS-OLTP-Datenmigration) im Popup-Fenster sollte alle Einträge mit dem Status Pass (Erfolgreich) anzeigen. Wenn der Test fehlschlägt,
API-Version API Version 2016-01-01460
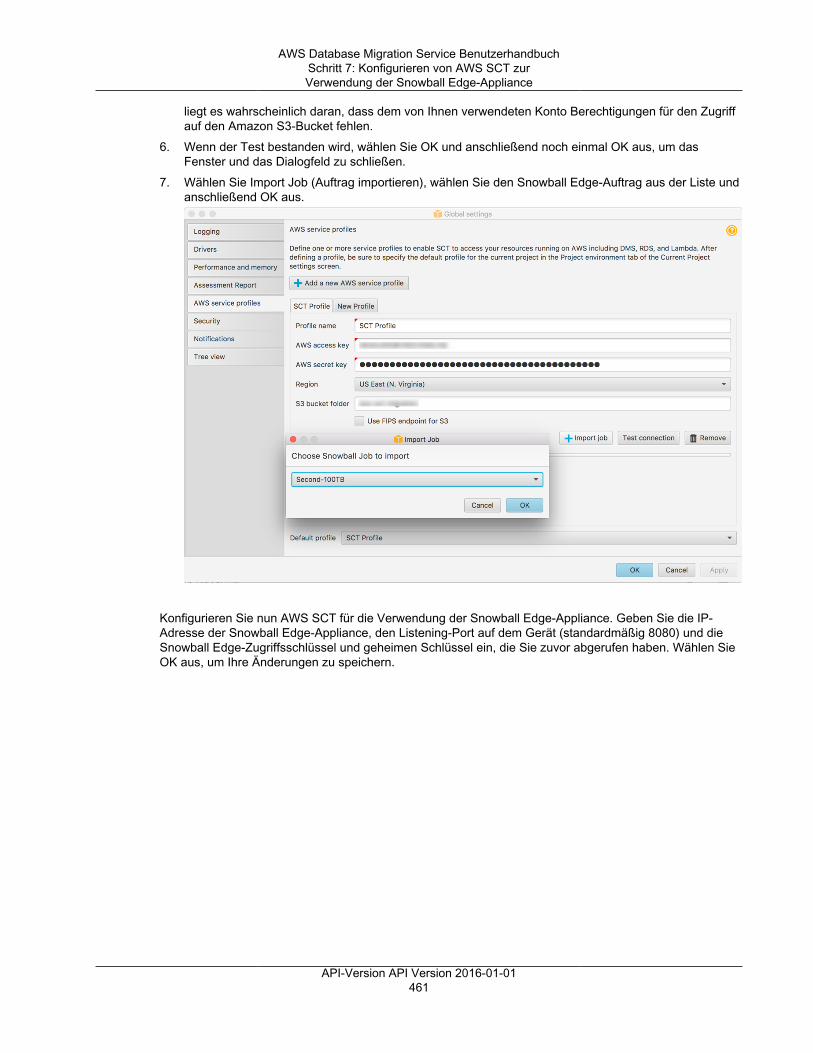
AWS Database Migration Service BenutzerhandbuchSchritt 7: Konfigurieren von AWS SCT zurVerwendung der Snowball Edge-Appliance
liegt es wahrscheinlich daran, dass dem von Ihnen verwendeten Konto Berechtigungen für den Zugriffauf den Amazon S3-Bucket fehlen.
6. Wenn der Test bestanden wird, wählen Sie OK und anschließend noch einmal OK aus, um dasFenster und das Dialogfeld zu schließen.
7. Wählen Sie Import Job (Auftrag importieren), wählen Sie den Snowball Edge-Auftrag aus der Liste undanschließend OK aus.
Konfigurieren Sie nun AWS SCT für die Verwendung der Snowball Edge-Appliance. Geben Sie die IP-Adresse der Snowball Edge-Appliance, den Listening-Port auf dem Gerät (standardmäßig 8080) und dieSnowball Edge-Zugriffsschlüssel und geheimen Schlüssel ein, die Sie zuvor abgerufen haben. Wählen SieOK aus, um Ihre Änderungen zu speichern.
API-Version API Version 2016-01-01461
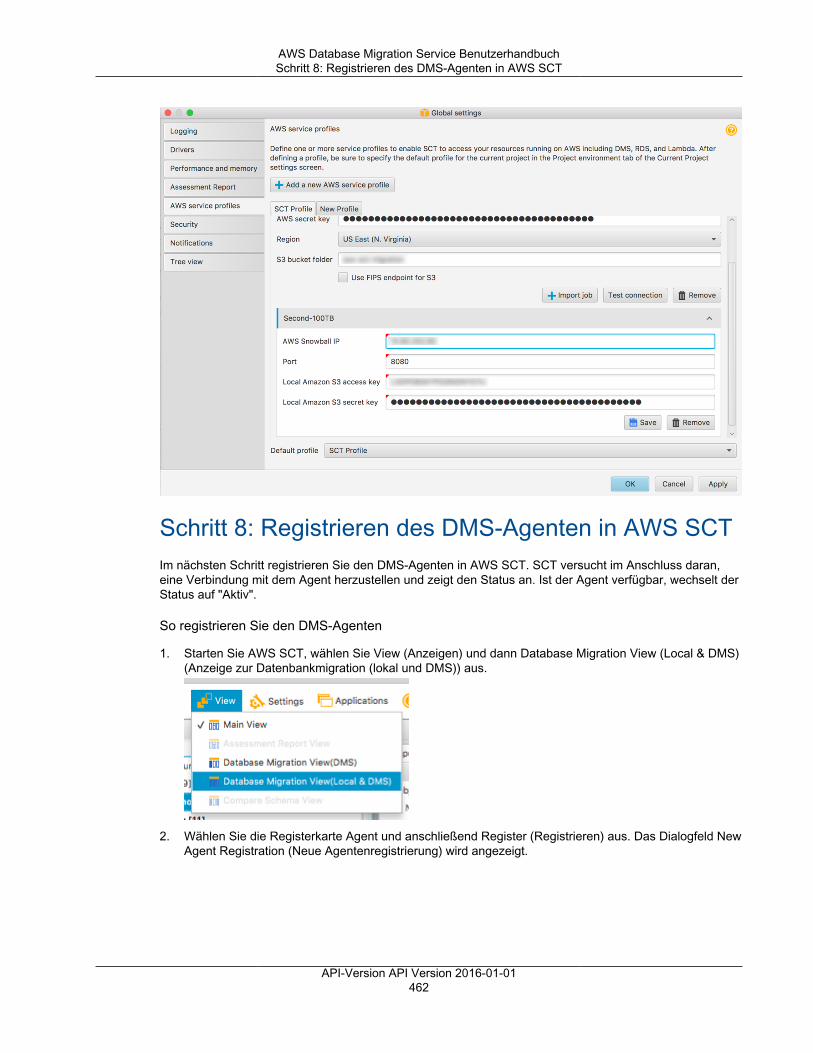
AWS Database Migration Service BenutzerhandbuchSchritt 8: Registrieren des DMS-Agenten in AWS SCT
Schritt 8: Registrieren des DMS-Agenten in AWS SCTIm nächsten Schritt registrieren Sie den DMS-Agenten in AWS SCT. SCT versucht im Anschluss daran,eine Verbindung mit dem Agent herzustellen und zeigt den Status an. Ist der Agent verfügbar, wechselt derStatus auf "Aktiv".
So registrieren Sie den DMS-Agenten
1. Starten Sie AWS SCT, wählen Sie View (Anzeigen) und dann Database Migration View (Local & DMS)(Anzeige zur Datenbankmigration (lokal und DMS)) aus.
2. Wählen Sie die Registerkarte Agent und anschließend Register (Registrieren) aus. Das Dialogfeld NewAgent Registration (Neue Agentenregistrierung) wird angezeigt.
API-Version API Version 2016-01-01462
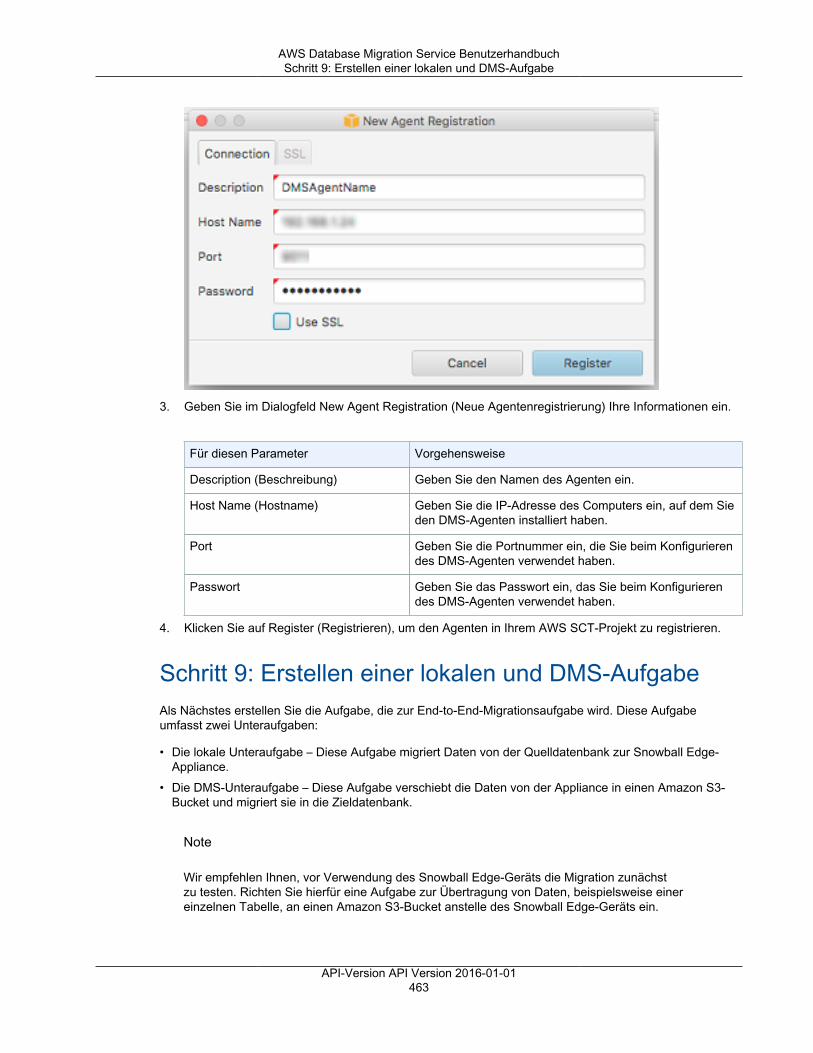
AWS Database Migration Service BenutzerhandbuchSchritt 9: Erstellen einer lokalen und DMS-Aufgabe
3. Geben Sie im Dialogfeld New Agent Registration (Neue Agentenregistrierung) Ihre Informationen ein.
Für diesen Parameter Vorgehensweise
Description (Beschreibung) Geben Sie den Namen des Agenten ein.
Host Name (Hostname) Geben Sie die IP-Adresse des Computers ein, auf dem Sieden DMS-Agenten installiert haben.
Port Geben Sie die Portnummer ein, die Sie beim Konfigurierendes DMS-Agenten verwendet haben.
Passwort Geben Sie das Passwort ein, das Sie beim Konfigurierendes DMS-Agenten verwendet haben.
4. Klicken Sie auf Register (Registrieren), um den Agenten in Ihrem AWS SCT-Projekt zu registrieren.
Schritt 9: Erstellen einer lokalen und DMS-AufgabeAls Nächstes erstellen Sie die Aufgabe, die zur End-to-End-Migrationsaufgabe wird. Diese Aufgabeumfasst zwei Unteraufgaben:
• Die lokale Unteraufgabe – Diese Aufgabe migriert Daten von der Quelldatenbank zur Snowball Edge-Appliance.
• Die DMS-Unteraufgabe – Diese Aufgabe verschiebt die Daten von der Appliance in einen Amazon S3-Bucket und migriert sie in die Zieldatenbank.
Note
Wir empfehlen Ihnen, vor Verwendung des Snowball Edge-Geräts die Migration zunächstzu testen. Richten Sie hierfür eine Aufgabe zur Übertragung von Daten, beispielsweise einereinzelnen Tabelle, an einen Amazon S3-Bucket anstelle des Snowball Edge-Geräts ein.
API-Version API Version 2016-01-01463
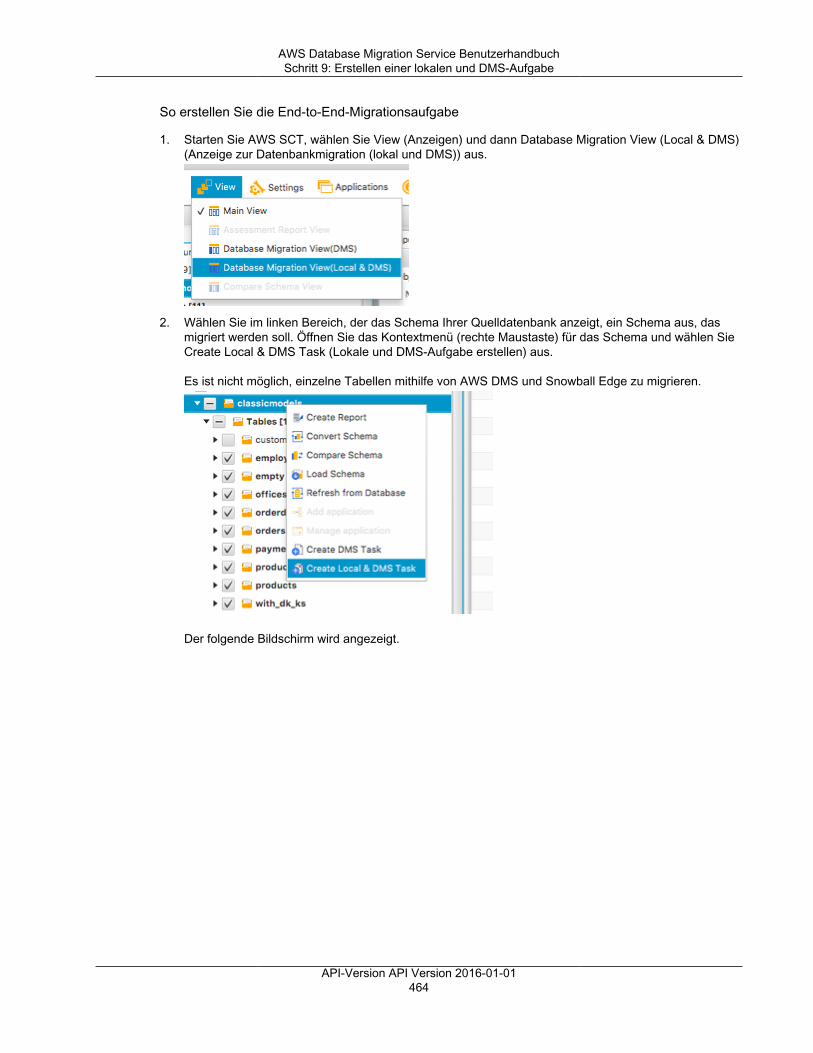
AWS Database Migration Service BenutzerhandbuchSchritt 9: Erstellen einer lokalen und DMS-Aufgabe
So erstellen Sie die End-to-End-Migrationsaufgabe
1. Starten Sie AWS SCT, wählen Sie View (Anzeigen) und dann Database Migration View (Local & DMS)(Anzeige zur Datenbankmigration (lokal und DMS)) aus.
2. Wählen Sie im linken Bereich, der das Schema Ihrer Quelldatenbank anzeigt, ein Schema aus, dasmigriert werden soll. Öffnen Sie das Kontextmenü (rechte Maustaste) für das Schema und wählen SieCreate Local & DMS Task (Lokale und DMS-Aufgabe erstellen) aus.
Es ist nicht möglich, einzelne Tabellen mithilfe von AWS DMS und Snowball Edge zu migrieren.
Der folgende Bildschirm wird angezeigt.
API-Version API Version 2016-01-01464
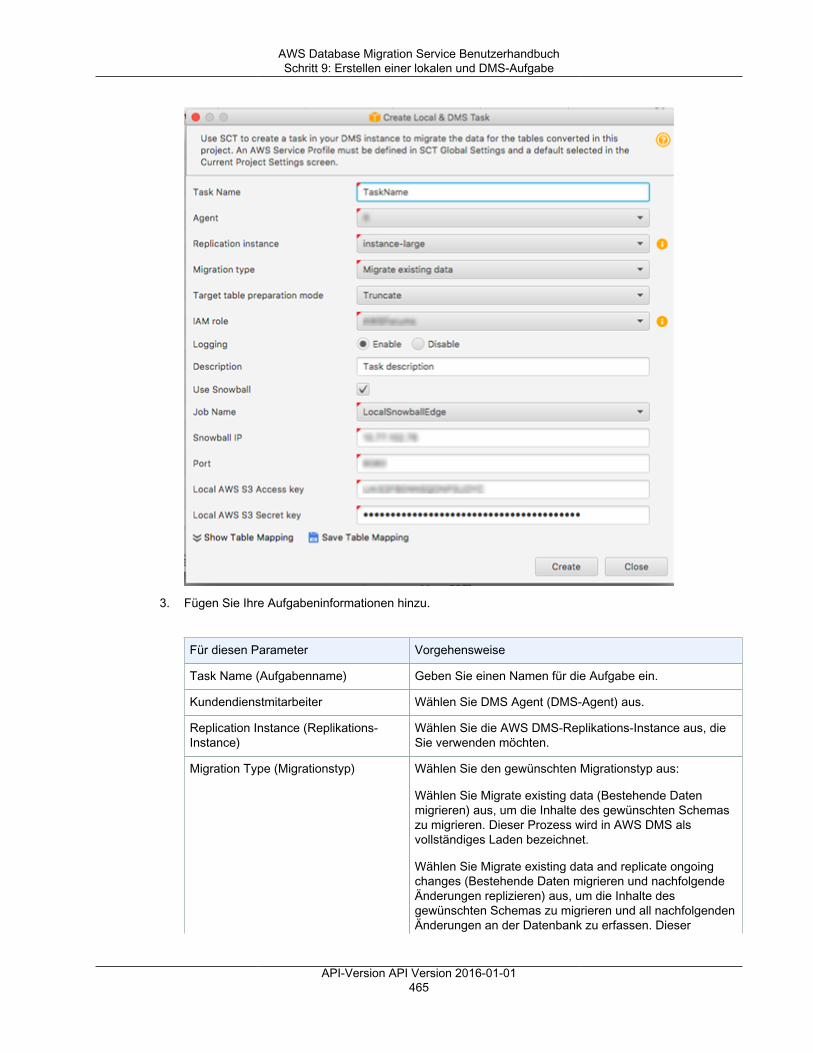
AWS Database Migration Service BenutzerhandbuchSchritt 9: Erstellen einer lokalen und DMS-Aufgabe
3. Fügen Sie Ihre Aufgabeninformationen hinzu.
Für diesen Parameter Vorgehensweise
Task Name (Aufgabenname) Geben Sie einen Namen für die Aufgabe ein.
Kundendienstmitarbeiter Wählen Sie DMS Agent (DMS-Agent) aus.
Replication Instance (Replikations-Instance)
Wählen Sie die AWS DMS-Replikations-Instance aus, dieSie verwenden möchten.
Migration Type (Migrationstyp) Wählen Sie den gewünschten Migrationstyp aus:
Wählen Sie Migrate existing data (Bestehende Datenmigrieren) aus, um die Inhalte des gewünschten Schemaszu migrieren. Dieser Prozess wird in AWS DMS alsvollständiges Laden bezeichnet.
Wählen Sie Migrate existing data and replicate ongoingchanges (Bestehende Daten migrieren und nachfolgendeÄnderungen replizieren) aus, um die Inhalte desgewünschten Schemas zu migrieren und all nachfolgendenÄnderungen an der Datenbank zu erfassen. Dieser
API-Version API Version 2016-01-01465
AWS Database Migration Service BenutzerhandbuchSchritt 9: Erstellen einer lokalen und DMS-Aufgabe
Für diesen Parameter VorgehensweiseProzess wird in AWS DMS als vollständiges Laden undCDC bezeichnet.
Target table preparation mode(Vorbereitungsmodus für dieZieltabelle)
Wählen Sie den Vorbereitungsmodus aus, den Sieverwenden möchten:
Truncate (Kürzen) – Die Tabellen werden gekürzt, ohnedass sich dies auf die Metadaten der Tabelle auswirkt.
Drop tables on target (Tabelle im Ziel verwerfen) – DieTabellen werden gelöscht und stattdessen neue Tabellenerstellt.
Do nothing (Nichts tun) – Die Daten und Metadaten derZieltabellen werden nicht geändert.
IAM-Rolle Wählen Sie die vordefinierte IAM-Rolle aus, die für denZugriff auf den Amazon S3-Bucket und die Zieldatenbankberechtigt ist. Weitere Informationen über die für denZugriff auf einen Amazon S3-Bucket erforderlichenBerechtigungen finden Sie unter Voraussetzungen für dieVerwendung von Amazon S3 als Quelle für AWS DMS.
Compression format(Komprimierungsformat)
Legen Sie fest, ob komprimierte Dateien hochgeladenwerden sollen oder nicht:
GZIP – Dateien werden vor dem Laden komprimiert. Diesist die Standardeinstellung.
No Compression (Keine Komprimierung) – Extrahiertschneller, nimmt aber mehr Speicherplatz in Anspruch.
Logging (Protokollierung) Wählen Sie Enable (Aktivieren) aus, damit AmazonCloudWatch Protokolle für die Migration erstellt. Für diesenService fallen Gebühren an. Weitere Informationen überCloudWatch finden Sie unter Funktionsweise von AmazonCloudWatch.
Description (Beschreibung) Geben Sie eine Beschreibung der Aufgabe ein.
S3 Bucket (S3-Bucket) Geben Sie den Namen eines S3-Buckets ein, der fürdiesen Snowball Edge-Auftrag in der Snowball Edge-Konsole konfiguriert ist.
Use Snowball Edge (Snowball Edgeverwenden)
Aktivieren Sie dieses Kontrollkästchen, um SnowballEdge zu verwenden. Wenn dieses Kontrollkästchen nichtaktiviert ist, werden die Daten direkt in den S3-Buckethochgeladen.
Auftragsname Wählen Sie den Namen des Snowball Edge-Auftrags aus,den Sie erstellt haben.
Snowball Edge IP (Snowball Edge-IP) Geben Sie die IP-Adresse der Snowball Edge-Applianceein.
Port Geben Sie den Port-Wert für die Snowball Edge-Applianceein.
API-Version API Version 2016-01-01466
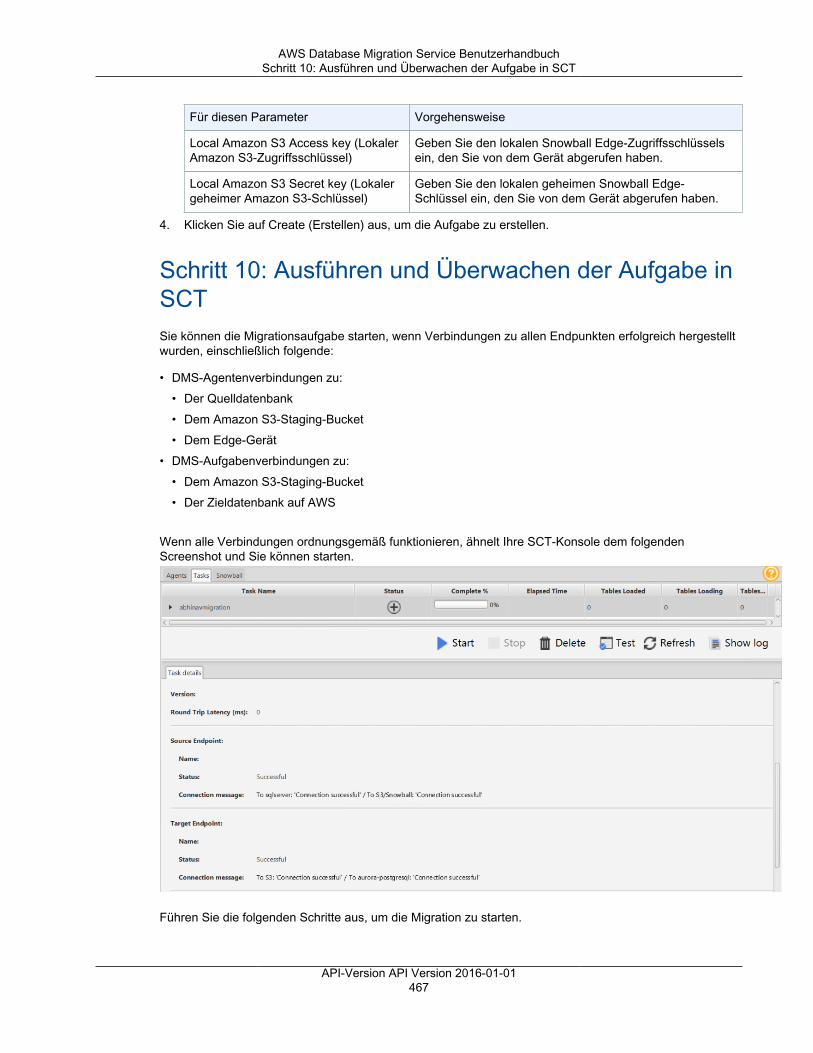
AWS Database Migration Service BenutzerhandbuchSchritt 10: Ausführen und Überwachen der Aufgabe in SCT
Für diesen Parameter Vorgehensweise
Local Amazon S3 Access key (LokalerAmazon S3-Zugriffsschlüssel)
Geben Sie den lokalen Snowball Edge-Zugriffsschlüsselsein, den Sie von dem Gerät abgerufen haben.
Local Amazon S3 Secret key (Lokalergeheimer Amazon S3-Schlüssel)
Geben Sie den lokalen geheimen Snowball Edge-Schlüssel ein, den Sie von dem Gerät abgerufen haben.
4. Klicken Sie auf Create (Erstellen) aus, um die Aufgabe zu erstellen.
Schritt 10: Ausführen und Überwachen der Aufgabe inSCTSie können die Migrationsaufgabe starten, wenn Verbindungen zu allen Endpunkten erfolgreich hergestelltwurden, einschließlich folgende:
• DMS-Agentenverbindungen zu:• Der Quelldatenbank• Dem Amazon S3-Staging-Bucket• Dem Edge-Gerät
• DMS-Aufgabenverbindungen zu:• Dem Amazon S3-Staging-Bucket• Der Zieldatenbank auf AWS
Wenn alle Verbindungen ordnungsgemäß funktionieren, ähnelt Ihre SCT-Konsole dem folgendenScreenshot und Sie können starten.
Führen Sie die folgenden Schritte aus, um die Migration zu starten.
API-Version API Version 2016-01-01467
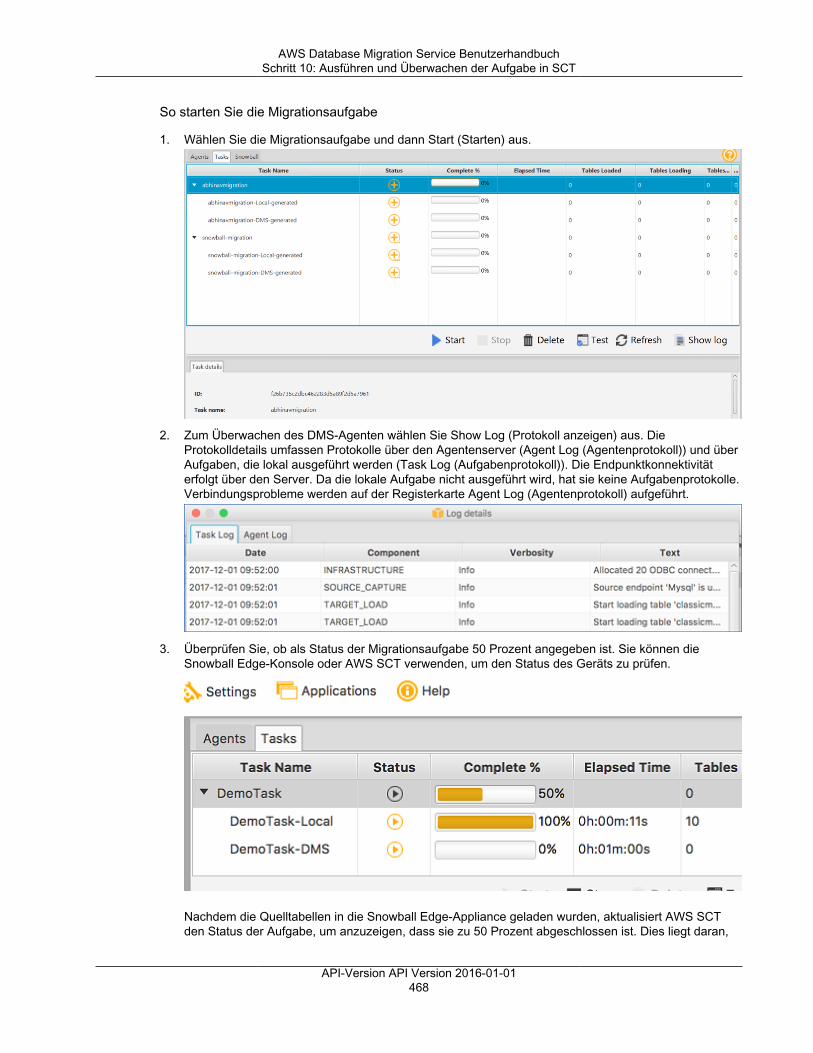
AWS Database Migration Service BenutzerhandbuchSchritt 10: Ausführen und Überwachen der Aufgabe in SCT
So starten Sie die Migrationsaufgabe
1. Wählen Sie die Migrationsaufgabe und dann Start (Starten) aus.
2. Zum Überwachen des DMS-Agenten wählen Sie Show Log (Protokoll anzeigen) aus. DieProtokolldetails umfassen Protokolle über den Agentenserver (Agent Log (Agentenprotokoll)) und überAufgaben, die lokal ausgeführt werden (Task Log (Aufgabenprotokoll)). Die Endpunktkonnektivitäterfolgt über den Server. Da die lokale Aufgabe nicht ausgeführt wird, hat sie keine Aufgabenprotokolle.Verbindungsprobleme werden auf der Registerkarte Agent Log (Agentenprotokoll) aufgeführt.
3. Überprüfen Sie, ob als Status der Migrationsaufgabe 50 Prozent angegeben ist. Sie können dieSnowball Edge-Konsole oder AWS SCT verwenden, um den Status des Geräts zu prüfen.
Nachdem die Quelltabellen in die Snowball Edge-Appliance geladen wurden, aktualisiert AWS SCTden Status der Aufgabe, um anzuzeigen, dass sie zu 50 Prozent abgeschlossen ist. Dies liegt daran,
API-Version API Version 2016-01-01468

AWS Database Migration Service BenutzerhandbuchEinschränkungen
dass die andere Hälfte der Aufgabe daraus besteht, dass AWS DMS die Daten von Amazon S3 zumZieldatenbankspeicher verschiebt.
4. Folgen Sie den Schritten in der Snowball Edge-Dokumentation, beginnend mit dem Abschnitt mit demNamen Stoppen des Snowball-Clients und Ausschalten der Snowball Edge-Appliance. Diese Schritteumfassen Folgendes:
• Anhalten des Snowball Edge-Clients• Abschalten des Edge-Geräts• Zurückgeben des Edge-Geräts an AWS
5. Das Beenden der Migration, nachdem das Gerät an AWS zurückgegeben wurde, umfasst Wartezeiten,bis die Remote-Aufgabe abgeschlossen ist.
Wenn die Snowball Edge-Appliance bei AWS eintrifft, wird die Ausführung der Remote-Aufgabe(DMS) gestartet. Wenn für den Migrationstyp der Aufgabe Migrate existing data (Bestehende Datenmigrieren) ausgewählt wurde, wird der Status der DMS-Aufgabe mit als zu 100 Prozent abgeschlossenangegeben, nachdem die Daten von Amazon S3 auf den Zieldatenspeicher übertragen wurden.
Wenn der Aufgabenmodus auch die laufenden Replikationen einschließen soll, dann wird die Aufgabenach dem vollständigen Laden weiterhin ausgeführt, während AWS DMS immer noch Änderungenvornimmt.
Einschränkungen beim Arbeiten mit Snowball Edgeund AWS DMS
Bei der Verwendung von AWS Snowball Edge sollten Sie einige Einschränkungen beachten:
• Jede AWS SCT-Aufgabe erstellt zwei Endpunktverbindungen in AWS DMS. Wenn Sie mehrereAufgaben erstellen, können Sie eine Ressourcenbegrenzung für die Anzahl der Endpunkte, die Sieerstellen können, erreichen.
• Ein Schema ist der minimale Aufgabenumfang bei der Verwendung von Snowball Edge. Es ist nichtmöglich, einzelne Tabellen oder Teilmengen von Tabellen mit Snowball Edge zu migrieren.
• Der DMS-Agent unterstützt keine HTTP/HTTPS- oder SOCKS-Proxy-Konfigurationen. Verbindungen zuQuelle und Ziel können fehlschlagen, wenn der DMS-Agent-Host Proxys verwendet.
• Die LOB-Modus beschränkt die LOB-Dateigröße auf 32 K. LOBs, die größer sind als 32 K, werden nichtmigriert.
• In einigen Fällen kann beim Laden aus der lokalen Datenbank in das Edge-Gerät oder beim Ladenvon Daten aus Amazon S3 in die Zieldatenbank ein Fehler auftreten. In einigen Fällen ist der Fehlerumkehrbar und die Aufgabe kann neu starten. Wenn der Fehler in AWS DMS nicht behoben werdenkann, wird die Migration angehalten. Sollte das zutreffen, wenden Sie sich bitte an den AWS Support.
API-Version API Version 2016-01-01469

AWS Database Migration Service BenutzerhandbuchLangsame Ausführung von Migrationsaufgaben
Fehlerbehebung fürMigrationsaufgaben in AWSDatabase Migration Service
In den folgenden Abschnitten erhalten Sie Informationen zum Beheben von Problemen mit AWS DatabaseMigration Service (AWS DMS).
Themen• Langsame Ausführung von Migrationsaufgaben (p. 470)• Aufgabenstatusleiste bewegt sich nicht (p. 471)• Fehlende Fremdschlüssel und sekundäre Indizes (p. 471)• Probleme mit Amazon RDS-Verbindungen (p. 471)• Netzwerkprobleme (p. 472)• CDC nach vollständigem Ladevorgang hängen geblieben (p. 472)• Fehler durch Primärschlüsselverletzung beim Neustarten einer Aufgabe (p. 473)• Erstes Laden des Schemas fehlgeschlagen (p. 473)• Aufgaben mit unbekanntem Fehler fehlgeschlagen (p. 473)• Bei erneutem Laden der Aufgabe werden Tabellen von Beginn an geladen (p. 473)• Anzahl der Tabellen pro Aufgabe (p. 473)• Aufgaben schlagen fehl, wenn der Primärschlüssel in der LOB-Spalte erstellt wird (p. 474)• Doppelte Datensätzen in der Zieltabelle ohne Primärschlüssel (p. 474)• Quellendpunkte im reservierten IP-Bereich (p. 474)• Behebung von Oracle-spezifischen Problemen (p. 474)• Behebung von MySQL-spezifischen Problemen (p. 477)• Behebung von PostgreSQL-spezifischen Problemen (p. 481)• Behebung von Problemen im Zusammenhang mit Microsoft SQL Server (p. 483)• Behebung von Amazon Redshift-spezifischen Problemen (p. 485)• Behebung von Amazon Aurora MySQL-spezifischen Problemen (p. 487)
Langsame Ausführung von MigrationsaufgabenVerschiedene Probleme können dazu führen, dass eine Migrationsaufgabe langsam ausgeführt wirdoder dass nachfolgende Aufgaben langsamer ausgeführt werden als die erste Aufgabe. Der häufigsteGrund dafür, dass eine Migrationsaufgabe langsam ausgeführt wird, ist, dass der AWS DMS-Replikations-Instance unzureichende Ressourcen zugewiesen sind. Überprüfen Sie Ihre Replikations-Instance aufdie Nutzung von CPU, Arbeitsspeicher, Swap-Dateien und IOPS, um sicherzustellen, dass Ihre Instanceüber ausreichend Ressourcen für die Aufgaben verfügt, die Sie damit ausführen. So ist beispielsweise dieAusführung mehrerer Aufgaben mit Amazon Redshift als Endpunkt recht E/A-intensiv. Sie können die IOPS
API-Version API Version 2016-01-01470

AWS Database Migration Service BenutzerhandbuchAufgabenstatusleiste bewegt sich nicht
für Ihre Replikations-Instance erhöhen oder Ihre Aufgaben über mehrere Replikations-Instances verteilen,um die Migration effizienter zu gestalten.
Weitere Informationen zur Bestimmung der Größe Ihrer Replikations-Instance finden Sie unter Wählen deroptimalen Größe einer Replikations-Instance (p. 490).
Sie können die Geschwindigkeit eines ersten Ladevorgangs bei einer Migration wie folgt erhöhen:
• Wenn Ihr Ziel eine Amazon RDS-DB-Instance ist, stellen Sie sicher, dass für die DB-Ziel-Instance keinMulti-AZ aktiviert ist.
• Deaktivieren Sie alle automatischen Sicherungen oder Protokollierungen für die Zieldatenbank währenddes Ladevorgangs und aktivieren Sie sie wieder nach Abschluss der Migration.
• Sofern auf dem Ziel verfügbar, verwenden Sie die Funktion für bereitgestellte IOPS.• Wenn Ihre Migrationsdaten große Objekte (LOBs) enthalten, stellen Sie sicher, dass die Aufgabe für
eine LOB-Migration optimiert ist. Weitere Informationen zur Optimierung für LOBs finden Sie unter Ziel-Metadaten-Aufgabeneinstellungen (p. 343).
Aufgabenstatusleiste bewegt sich nichtDie Aufgabenstatusleiste bietet eine Schätzung des Fortschritts der Aufgabe. Die Qualität dieser Schätzunghängt von der Qualität der Tabellenstatistik der Quelldatenbank ab. Je besser die Tabellenstatistik, destogenauer die Schätzung. Wenn eine Aufgabe nur eine Tabelle ohne geschätzte Zeilenstatistik enthält,können wir den prozentualen Fortschritt nicht berechnen. In diesem Fall kann anhand des Aufgabenstatusund der Angabe der geladenen Zeilen überprüft werden, ob die Aufgabe tatsächlich ausgeführt wird undFortschritte macht.
Fehlende Fremdschlüssel und sekundäre IndizesAWS DMS erstellt Tabellen, Primärschlüssel und in einigen Fällen eindeutige Indizes, der Service erstelltjedoch keine anderen Objekte, die für eine effiziente Migration der Daten von der Quelle nicht erforderlichsind. So erstellt DMS z. B. keine sekundären Indizes, Nicht-Primärschlüssel-Beschränkungen oderDatenstandardwerte.
Um sekundäre Objekte von der Datenbank zu migrieren, verwenden Sie die nativen Tools der Datenbank,wenn Sie die Migration auf derselben Datenbank-Engine wie Ihre Quelldatenbank durchführen. VerwendenSie das Schema Conversion Tool, wenn Sie die Migration auf eine andere Datenbank-Engine durchführenals die, die von Ihrer Quelldatenbank für die Migration sekundärer Objekte verwendet wird.
Probleme mit Amazon RDS-VerbindungenEs kann mehrere Gründe geben, warum Sie nicht in der Lage sind, sich mit einer Amazon RDS-DB-Instance zu verbinden, die Sie als Endpunkt festgelegt haben. Dazu zählen:
• Die Kombination aus Benutzername und Passwort ist falsch.• Stellen Sie sicher, dass der Endpunktwert, der in der Amazon RDS-Konsole für die Instance angezeigt
wird, mit der Endpunktkennung identisch ist, die Sie zum Erstellen des AWS DMS-Endpunkts verwendethaben.
• Stellen Sie sicher, dass der in der Amazon RDS-Konsole für die Instance angezeigte Port-Wert mit demPort übereinstimmt, der dem AWS DMS-Endpunkt zugewiesen ist.
API-Version API Version 2016-01-01471

AWS Database Migration Service BenutzerhandbuchFehlermeldung: Incorrect thread
connection string: incorrect thread value 0
• Stellen Sie sicher, dass die der Amazon RDS-DB-Instance zugewiesene SicherheitsgruppeVerbindungen von der AWS DMS-Replikations-Instance zulässt.
• Wenn sich die AWS DMS-Replikations-Instance und die Amazon RDS-DB-Instance nicht in derselbenVPC befinden, vergewissern Sie sich, dass die DB-Instance öffentlich zugänglich ist.
Fehlermeldung: Incorrect thread connection string:incorrect thread value 0Dieser Fehler kann häufig auftreten, wenn Sie die Verbindung zu einem Endpunkt testen. Der Fehler gibtan, dass die Verbindungszeichenfolge fehlerhaft ist, z. B. ein Leerzeichen nach der Host-IP-Adresse enthältoder ein fehlerhaftes Zeichen in die Verbindungszeichenfolge kopiert wurde.
NetzwerkproblemeDas häufigste Netzwerkproblem betrifft die VPC-Sicherheitsgruppe, die von der AWS DMS-Replikations-Instance verwendet wird. Standardmäßig verfügt diese Sicherheitsgruppe über Regeln, die ausgehendenDatenverkehr zu 0.0.0.0/0 auf allen Ports zulassen. Wenn Sie diese Sicherheitsgruppe ändern oderIhre eigene Sicherheitsgruppe Egress verwenden, muss der Ausgang mindestens zu den Quell- undZielendpunkten auf den jeweiligen Datenbankports zugelassen werden.
Weitere Probleme im Zusammenhang mit der Konfiguration sind u. a.:
• Replication-Instance sowie Quell- und Zielendpunkt in derselben VPC — Die von den Endpunktenverwendete Sicherheitsgruppe muss eingehenden Datenverkehr am Datenbankport von derReplikations-Instance zulassen. Stellen Sie sicher, dass die von der Replikations-Instance verwendeteSicherheitsgruppe Eingang zu den Endpunkten hat, oder Sie können eine Regel in der von denEndpunkten verwendeten Sicherheitsgruppe erstellen, die der privaten IP-Adresse der Replikations-Instance den Zugriff erlaubt.
• Der Quellendpunkt befindet sich außerhalb der von der Replikations-Instance verwendeten VPC (überInternet-Gateway) — Die VPC-Sicherheitsgruppe muss über Routing-Regeln verfügen, die Datenverkehr,der nicht für die VPC bestimmt ist, an das Internet-Gateway senden. In dieser Konfiguration scheintes, dass die Verbindung zum Endpunkt von der öffentlichen IP-Adresse auf der Replikations-Instancekommt.
• Der Quellendpunkt befindet sich außerhalb der von der Replikations-Instance verwendeten VPC (überNAT-Gateway) — Sie können ein NAT-Gateway (Network Address Translation) mit einer einzelnenElastic IP-Adresse konfigurieren, die an eine einzelne Elastic Network-Schnittstelle gebunden ist, diedann eine NAT-Kennung (nat-#####) empfängt. Wenn die VPC eine Standardroute zu diesem NAT-Gateway anstatt zu dem Internet-Gateway enthält, wird es stattdessen scheinen, dass die Replikations-Instance den Datenbankendpunkt mit der öffentlichen IP-Adresse des Internet-Gateway kontaktiert. Indiesem Fall muss der Eingang zum Datenbankendpunkt außerhalb der VPC den Eingang von der NAT-Adresse anstatt von der öffentlichen IP-Adresse der Replikations-Instance erlauben.
CDC nach vollständigem Ladevorgang hängengeblieben
Langsame oder hängen gebliebene Replikationsänderungen können nach einem vollständigenMigrationsladevorgang auftreten, wenn mehrere AWS DMS-Einstellungen miteinander in Konflikt stehen.Beispiel: Wenn der Parameter Target table preparation mode (Vorbereitungsmodus der Zieltabelle)auf Do nothing (Nichts unternehmen) oder Truncate (Verkürzen) festgelegt ist, haben Sie AWS DMS
API-Version API Version 2016-01-01472

AWS Database Migration Service BenutzerhandbuchFehler durch Primärschlüsselverletzung
beim Neustarten einer Aufgabe
angewiesen, kein Setup für die Zieltabellen auszuführen. Dies umfasst auch primäre und eindeutigeIndizes. Wenn Sie keine primären oder eindeutigen Schlüssel für die Zieltabellen erstellt haben, muss AWSDMS eine vollständige Tabellenprüfung für jede Aktualisierung durchführen, was die Leistung erheblichbeeinträchtigen kann.
Fehler durch Primärschlüsselverletzung beimNeustarten einer Aufgabe
Dieser Fehler kann auftreten, wenn Daten von einer vorherigen Migrationsaufgabe in der Zieldatenbankverbleiben. Wenn der Parameter Target table preparation mode (Vorbereitungsmodus der Zieltabelle)auf Do nothing (Nichts unternehmen) festgelegt ist, führt AWS DMS keine Vorbereitung für die Zieltabelledurch. Dies umfasst auch die Bereinigung von Daten aus einer vorherigen Aufgabe. Um Ihre Aufgabeerneut zu starten und diese Fehler zu vermeiden, müssen Sie die in die Zieltabellen von einer vorherigenAufgabe eingefügten Zeilen entfernen.
Erstes Laden des Schemas fehlgeschlagenWenn der erste Ladevorgang Ihres Schemas mit dem FehlerOperation:getSchemaListDetails:errType=, status=0, errMessage=, errDetails=fehlschlägt, verfügt das Benutzerkonto, das von AWS DMS zum Herstellen einer Verbindung zumQuellendpunkt verwendet wird, nicht über die erforderlichen Berechtigungen.
Aufgaben mit unbekanntem Fehler fehlgeschlagenDie Ursache für diese Art von Fehler kann sehr unterschiedlich sein. Oftmals lässt sich das Problemjedoch darauf zurückführen, dass der Replikations-Instance von AWS DMS unzureichende Ressourcenzugewiesen sind. Überprüfen Sie die Nutzung von CPU, Arbeitsspeicher, Swap-Dateien und IOPS derReplikations-Instance, um sicherzustellen, dass Ihre Instance über ausreichende Ressourcen für dieMigration verfügt. Weitere Informationen zur Überwachung finden Sie unter Metriken von Data MigrationService (p. 425).
Bei erneutem Laden der Aufgabe werden Tabellenvon Beginn an geladen
AWS DMS startet den Ladevorgang der Tabellen neu von vorne, wenn der erste Ladevorgang einerTabelle noch nicht abgeschlossen ist. Beim erneuten Starten einer Aufgabe lädt AWS DMS keine Tabellenneu, für die der erste Ladevorgang abgeschlossen ist. Es werden jedoch diejenigen Tabellen neu vonvorne geladen, deren erster Ladevorgang nicht abgeschlossen wurde.
Anzahl der Tabellen pro AufgabeFür die Anzahl der Tabellen pro Replikationsaufgabe gibt es zwar keine Begrenzung, wir haben jedochfestgestellt, dass die Begrenzung der Anzahl der Tabellen in einer Aufgabe auf unter 60.000 ist eine gute
API-Version API Version 2016-01-01473

AWS Database Migration Service BenutzerhandbuchAufgaben schlagen fehl, wenn der
Primärschlüssel in der LOB-Spalte erstellt wird
Regel ist. Die Ressourcennutzung wird oft zum Engpass, wenn eine einzige Aufgabe mehr als 60.000Tabellen verwendet.
Aufgaben schlagen fehl, wenn der Primärschlüsselin der LOB-Spalte erstellt wird
Im FULL LOB- oder LIMITED LOB-Modus unterstützt AWS DMS keine Replikation von Primärschlüsselndes Datentyps LOB. DMS migriert zunächst eine Zeile mit einer LOB-Spalte als Null und aktualisiert späterdie LOB-Spalte. Wenn der Primärschlüssel in einer LOB-Spalte erstellt wird, schlägt daher die anfänglicheEinfügung fehl, da der Primärschlüssel nicht null sein darf. Fügen Sie zur Umgehung des Problems eineweitere Spalte als Primärschlüssel hinzu und entfernen Sie den Primärschlüssel aus der LOB-Spalte.
Doppelte Datensätzen in der Zieltabelle ohnePrimärschlüssel
Das Ausführen einer Volllast-und-CDC-Aufgabe kann zu doppelten Datensätzen in Zieltabellen führen,die keinen Primärschlüssel oder eindeutigen Index haben. Um das Duplizieren von Datensätzen inZieltabellen bei Volllast- und-CDC-Aufgaben zu vermeiden, stellen Sie sicher, dass die Zieltabellen übereinen Primärschlüssel oder einen eindeutigen Index verfügen.
Quellendpunkte im reservierten IP-BereichWenn eine AWS DMS-Quelldatenbank eine IP-Adresse im reservierten IP-Bereich von 192.168.0.0/24verwendet, schlägt der Test der Quellendpunktverbindung fehl. Die folgenden Schritte illustrieren einemögliche Umgehung des Problems:
1. Suchen Sie eine EC2-Instance, die sich nicht im reservierten Bereich befindet und unter192.168.0.0/24 mit der Quelldatenbank kommunizieren kann.
2. Installieren Sie einen Socat-Proxy und führen Sie ihn aus. Zum Beispiel:
yum install socat socat -d -d -lmlocal2 tcp4-listen:database port,bind=0.0.0.0,reuseaddr,fork tcp4:source_database_ip_address:database_port&
Verwenden Sie die IP-Adresse der EC2-Instance und den oben angegebenen Datenbankport für den AWSDMS-Endpunkt. Stellen Sie sicher, dass der Endpunkt über die Sicherheitsgruppe verfügt, mit der AWSDMS am Datenbankport mit ihm kommunizieren kann.
Behebung von Oracle-spezifischen ProblemenDie folgenden Probleme gelten speziell für den Einsatz von AWS DMS mit Oracle-Datenbanken.
Themen• Abrufen von Daten aus Ansichten (p. 475)
API-Version API Version 2016-01-01474

AWS Database Migration Service BenutzerhandbuchAbrufen von Daten aus Ansichten
• Migrieren von LOBs aus Oracle 12c (p. 475)• Wechseln zwischen Oracle LogMiner und Binary Reader (p. 475)• Fehler: Oracle CDC angehalten 122301 Oracle CDC maximale Wiederholversuche
überschritten (p. 476)• Automatisches Hinzufügen der zusätzlichen Protokollierung zu einem Oracle-Quellendpunkt (p. 476)• Nicht erfasste LOB-Änderungen (p. 476)• Fehler: ORA-12899: Wert zu groß für Spalte <Spaltenname> (p. 477)• Datentyp NUMBER wird nicht richtig interpretiert (p. 477)
Abrufen von Daten aus AnsichtenSie können Daten aus einer Ansicht einmal abrufen; Sie können sie nicht für die laufende Replikationverwenden. Um Daten aus Ansichten extrahieren zu können, müssen Sie den folgenden Code zu Extraconnection attributes im Abschnitt Advanced des Oracle-Quellendpunkts hinzufügen. Beachten Sie, dassbeim Extrahieren von Daten aus einer Ansicht, diese im Zielschema als Tabelle angezeigt wird.
exposeViews=true
Migrieren von LOBs aus Oracle 12cAWS DMS kann für die Erfassung von Änderungen an einer Oracle-Datenbank zwei Methoden verwenden:Binary Reader und Oracle LogMiner. Standardmäßig verwendet AWS DMS Oracle LogMiner, umÄnderungen zu erfassen. Unter Oracle 12c unterstützt Oracle LogMiner allerdings keine LOB-Spalten. UmÄnderungen an LOB-Spalten unter Oracle 12c zu erfassen, verwenden Sie Binary Reader.
Wechseln zwischen Oracle LogMiner und BinaryReaderAWS DMS kann für die Erfassung von Änderungen an einer Oracle-Quelldatenbank zwei Methodenverwenden: Binary Reader und Oracle LogMiner. Oracle LogMiner ist die Standardeinstellung. Um BinaryReader zur Erfassung von Änderungen verwenden, führen Sie die folgenden Schritte aus:
So verwenden Sie Binary Reader für die Erfassung von Änderungen
1. Melden Sie sich bei der AWS-Managementkonsole an und wählen Sie DMS aus.2. Wählen Sie Endpoints aus.3. Wählen Sie den Oracle-Quellendpunkt, für den Sie Binary Reader verwenden möchten.4. Wählen Sie Modify aus.5. Wählen Sie "Advanced" aus und fügen Sie dann den folgenden Code im Textfeld "Extra connection
attributes" hinzu:
useLogminerReader=N
6. Verwenden Sie ein Oracle-Entwickler-Tool wie z. B. SQL-Plus, um dem AWS DMS-Benutzerkonto,über das die Verbindung zum Oracle-Endpunkt hergestellt wird, die folgenden zusätzlichenBerechtigungen zu erteilen:
SELECT ON V_$TRANSPORTABLE_PLATFORM
API-Version API Version 2016-01-01475

AWS Database Migration Service BenutzerhandbuchFehler: Oracle CDC angehalten 122301 Oracle
CDC maximale Wiederholversuche überschritten
Fehler: Oracle CDC angehalten 122301 Oracle CDCmaximale Wiederholversuche überschrittenDieser Fehler tritt auf, wenn die erforderlichen Oracle-Archivprotokolle von Ihrem Server entfernt wurden,bevor AWS DMS anhand dieser Protokolle Änderungen erfassen konnte. Erhöhen Sie die Richtlinien für dieAufbewahrung von Protokollen auf Ihrem Datenbankserver. Führen Sie für eine Amazon RDS-Datenbankdie folgenden Schritte aus, um die Aufbewahrungsfrist für Protokolle zu erhöhen. Im folgenden Beispielwird durch den Code die Aufbewahrung für Protokolle für eine Amazon RDS-DB-Instance auf 24 Stundenerhöht.
exec rdsadmin.rdsadmin_util.set_configuration('archivelog retention hours',24);
Automatisches Hinzufügen der zusätzlichenProtokollierung zu einem Oracle-QuellendpunktStandardmäßig ist in AWS DMS die zusätzliche Protokollierung deaktiviert. Um die zusätzlicheProtokollierung für einen Oracle-Quellendpunkt automatisch zu aktivieren, führen Sie die folgenden Schritteaus:
So fügen Sie einem Oracle-Quellendpunkt die zusätzliche Protokollierung hinzu
1. Melden Sie sich bei der AWS-Managementkonsole an und wählen Sie DMS aus.2. Wählen Sie Endpoints aus.3. Wählen Sie den Oracle-Quellendpunkt, dem Sie die zusätzliche Protokollierung hinzufügen möchten.4. Wählen Sie Modify aus.5. Wählen Sie Advanced aus und fügen Sie dann den folgenden Code im Textfeld Extra connection
attributes hinzu:
addSupplementalLogging=Y
6. Wählen Sie Modify aus.
Nicht erfasste LOB-ÄnderungenDerzeit muss eine Tabelle über einen Primärschlüssel für AWS DMS verfügen, um LOB-Änderungenerfassen zu können. Wenn eine Tabelle mit LOBs über keinen Primärschlüssel verfügt, können Siemehrere Aktionen zur Erfassung von LOB-Änderungen durchführen:
• Fügen Sie der Tabelle einen Primärschlüssel hinzu. Dazu fügen Sie einfach eine ID-Spalte hinzu undfüllen diese mit einer Sequenz unter Verwendung eines Auslösers.
• Erstellen Sie eine materialisierte Ansicht der Tabelle, die eine vom System generierte ID alsPrimärschlüssel enthält, und migrieren Sie dann die materialisierte Ansicht und nicht die Tabelle.
• Erstellen Sie einen logische Standby, fügen Sie der Tabelle einen Primärschlüssel hinzu, und migrierenSie vom logischen Standby.
API-Version API Version 2016-01-01476

AWS Database Migration Service BenutzerhandbuchFehler: ORA-12899: Wert zu groß für Spalte <Spaltenname>
Fehler: ORA-12899: Wert zu groß für Spalte<Spaltenname>Die Fehlermeldung "ORA-12899: Wert zu groß für Spalte <Spaltenname>" wird häufig durch einenKonflikt der Zeichensätze von der Quell- und Zieldatenbank hervorgerufen, oder wenn sich die NLS-Einstellungen zwischen den beiden Datenbanken unterscheiden. Ein häufiger Grund für diesenFehler ist, wenn der NLS_LENGTH_SEMANTICS-Parameter der Quelldatenbank auf CHAR und derNLS_LENGTH_SEMANTICS-Parameter der Zieldatenbank auf BYTE festgelegt sind.
Datentyp NUMBER wird nicht richtig interpretiertDer Oracle-Datentyp NUMBER wird in verschiedene AWS DMS-Datentypen konvertiert, je nachGenauigkeit und Skalierung von NUMBER. Diese Konvertierungen sind hier dokumentiert: Quelldatentypenfür Oracle (p. 148). Die Art und Weise, wie der Datentyp NUMBER konvertiert wird, kann auch von derVerwendung der zusätzlichen Verbindungsattribute für den Oracle-Quellendpunkt abhängen. Diesezusätzlichen Verbindungsattribute sind unter Zusätzliche Verbindungsattribute bei der Verwendung vonOracle als Quelle für AWS DMS (p. 142) dokumentiert.
Behebung von MySQL-spezifischen ProblemenDie folgenden Probleme gelten speziell für den Einsatz von AWS DMS mit MySQL-Datenbanken.
Themen• CDC-Aufgabe schlägt für Amazon RDS-DB-Instance-Endpunkt aufgrund deaktivierter binärer
Protokollierung fehl (p. 477)• Verbindungen mit einer MySQL-Ziel-Instance werden während einer Aufgabe getrennt (p. 478)• Hinzufügen von Autocommit zu einem MySQL-kompatiblen Endpunkt (p. 478)• Deaktivieren von Fremdschlüsseln auf einem MySQL-kompatiblen Zielendpunkt (p. 479)• Zeichen ersetzt durch Fragezeichen (p. 479)• "Bad event"-Protokolleinträge (p. 479)• Change Data Capture (CDC) mit MySQL 5.5 (p. 479)• Erhöhen der Aufbewahrungszeit für binäre Protokolle für Amazon RDS-DB-Instances (p. 479)• Protokollmeldung: Einige Änderungen von der Quelldatenbank hatten bei Anwendung auf die
Zieldatenbank keine Auswirkungen. (p. 480)• Fehler: Bezeichner zu lang (p. 480)• Fehler: Felddatenumwandlung schlägt aufgrund nicht unterstützten Zeichensatzes fehl (p. 480)• Fehler: Codeseite 1252 zu UTF8 [120112] Eine Felddatenkonvertierung ist fehlgeschlagen (p. 481)
CDC-Aufgabe schlägt für Amazon RDS-DB-Instance-Endpunkt aufgrund deaktivierter binärerProtokollierung fehlDieses Problem tritt bei Amazon RDS-DB-Instances auf, wenn automatische Sicherungen deaktiviert sind.Aktivieren Sie automatische Sicherungen, indem Sie den Aufbewahrungszeitraum für Backups auf einenWert größer als null festlegen.
API-Version API Version 2016-01-01477

AWS Database Migration Service BenutzerhandbuchVerbindungen mit einer MySQL-Ziel-Instance
werden während einer Aufgabe getrennt
Verbindungen mit einer MySQL-Ziel-Instance werdenwährend einer Aufgabe getrenntWenn eine Aufgabe mit LOBs von einem MySQL-Ziel mit den folgenden Arten von Fehlern imAufgabenprotokoll getrennt wird, müssen Sie möglicherweise einige Ihrer Aufgabeneinstellungenanpassen.
[TARGET_LOAD ]E: RetCode: SQL_ERROR SqlState: 08S01 NativeError: 2013 Message: [MySQL][ODBC 5.3(w) Driver][mysqld-5.7.16-log]Lost connection to MySQL server during query [122502] ODBC general error.
[TARGET_LOAD ]E: RetCode: SQL_ERROR SqlState: HY000 NativeError: 2006 Message: [MySQL][ODBC 5.3(w) Driver]MySQL server has gone away [122502] ODBC general error.
Um das Problem einer Aufgabe zu lösen, die von einem MySQL-Ziel getrennt wird, führen Sie diefolgenden Schritte aus:
• Stellen Sie sicher, dass Ihre Datenbankvariable max_allowed_packet auf einen ausreichend großenWert festgelegt ist, um Ihre größten LOBs zu speichern.
• Stellen Sie sicher, dass die folgenden Variablen auf einen hohen Zeitüberschreitungswert festgelegt sind.Wir empfehlen, einen Wert von mindestens 5 Minuten für jede dieser Variablen zu verwenden.• net_read_timeout
• net_write_timeout
• wait_timeout
• interactive_timeout
Hinzufügen von Autocommit zu einem MySQL-kompatiblen EndpunktSo fügen Sie Autocommit zu einem MySQL-kompatiblen Zielendpunkt hinzu
1. Melden Sie sich bei der AWS-Managementkonsole an und wählen Sie DMS aus.2. Wählen Sie Endpoints aus.3. Wählen Sie den MySQL-kompatiblen Zielendpunkt aus, dem Sie Autocommit hinzufügen möchten.4. Wählen Sie Modify aus.5. Wählen Sie Advanced aus und fügen Sie dann den folgenden Code im Textfeld Extra connection
attributes hinzu:
Initstmt= SET AUTOCOMMIT=1
6. Wählen Sie Modify aus.
API-Version API Version 2016-01-01478

AWS Database Migration Service BenutzerhandbuchDeaktivieren von Fremdschlüsseln auf
einem MySQL-kompatiblen Zielendpunkt
Deaktivieren von Fremdschlüsseln auf einem MySQL-kompatiblen ZielendpunktSie können Fremdschlüsselprüfungen für MySQL deaktivieren, indem Sie Folgendes zu Extra ConnectionAttributes (Zusätzliche Verbindungsattribute) im Abschnitt Advanced (Erweitert) des MySQL-, AmazonAurora mit MySQL-Kompatibilität- oder MariaDB-Zielendpunkts hinzufügen.
So deaktivieren Sie Fremdschlüssel auf einem MySQL-kompatiblen Zielendpunkt
1. Melden Sie sich bei der AWS-Managementkonsole an und wählen Sie DMS aus.2. Wählen Sie Endpoints aus.3. Wählen Sie den MySQL-, Aurora MySQL- oder MariaDB-Zielendpunkt aus, für den Sie Fremdschlüssel
deaktivieren möchten.4. Wählen Sie Modify aus.5. Wählen Sie Advanced aus und fügen Sie dann den folgenden Code im Textfeld Extra connection
attributes hinzu:
Initstmt=SET FOREIGN_KEY_CHECKS=0
6. Wählen Sie Modify aus.
Zeichen ersetzt durch FragezeichenDieses Problem tritt am häufigsten auf, wenn die Zeichen des Quellendpunkts von einem Zeichensatzkodiert wurden, der nicht von AWS DMS unterstützt wird. Beispielsweise bieten AWS DMS-Engine-Versionen vor Version 3.1.1 keine Unterstützung für den Zeichensatz UTF8MB4.
"Bad event"-Protokolleinträge"Bad event"-Protokolleinträge in den Migrationsprotokollen weisen in der Regel darauf hin, dass auf demEndpunkt der Quelldatenbank ein nicht unterstützter DDL-Vorgang versucht wurde. Nicht unterstützteDDL-Vorgänge führen zu einem Ereignis, das die Replikations-Instance nicht überspringen kann, sodassein fehlerhaftes Ereignis ("Bad event") protokolliert wird. Um dieses Problem zu beheben, starten Sie dieAufgabe von Anfang an neu. Dadurch werden die Tabellen neu geladen und die Erfassung der Änderungenbeginnt an einem Punkt, nachdem der nicht unterstützte DDL-Vorgang ausgegeben wurde.
Change Data Capture (CDC) mit MySQL 5.5Change Data Capture (CDC) von AWS DMS für MySQL-kompatible Amazon RDS-Datenbanken erforderteine zeilenbasierte binäre Protokollierung mit vollständigem Abbild. Dies wird in MySQL Version 5.5 oderfrüher nicht unterstützt. Um CDC von AWS DMS zu verwenden, müssen Sie Ihre Amazon RDS-DB-Instance auf MySQL-Version 5.6 aktualisieren.
Erhöhen der Aufbewahrungszeit für binäre Protokollefür Amazon RDS-DB-InstancesAWS DMS erfordert die Aufbewahrung von binären Protokolldateien für die Erfassung geänderter Daten.Um die Aufbewahrungsfrist für Protokolle für eine Amazon RDS-DB-Instance zu erhöhen, gehen Sie wiefolgt vor. Beim folgenden Beispiel wird die Aufbewahrungszeit für binäre Protokolle auf 24 Stunden erhöht.
API-Version API Version 2016-01-01479

AWS Database Migration Service BenutzerhandbuchProtokollmeldung: Einige Änderungen vonder Quelldatenbank hatten bei Anwendungauf die Zieldatenbank keine Auswirkungen.
call mysql.rds_set_configuration('binlog retention hours', 24);
Protokollmeldung: Einige Änderungen von derQuelldatenbank hatten bei Anwendung auf dieZieldatenbank keine Auswirkungen.Wenn AWS DMS den Wert einer MySQL-Datenbankspalte auf seinen vorhandenen Wert aktualisiert, wirdvon MySQL die Meldung zero rows affectedzurückgegeben. Dieses Verhalten ist nicht identisch mitdem von anderen Datenbank-Engines wie Oracle und SQL Server, die eine Zeile aktualisieren, auch wennder ersetzende Wert nicht der gleiche wie der aktuelle Wert ist.
Fehler: Bezeichner zu langDer folgende Fehler tritt auf, wenn ein Bezeichner zu lang ist:
TARGET_LOAD E: RetCode: SQL_ERROR SqlState: HY000 NativeError: 1059 Message: MySQLhttp://ODBC 5.3(w) Driverhttp://mysqld-5.6.10Identifier name '<name>' is too long 122502 ODBC general error. (ar_odbc_stmt.c:4054)
Wenn AWS DMS so konfiguriert ist, dass die Tabellen und Primärschlüssel in der Zieldatenbank erstelltwerden, verwendet es derzeit nicht dieselben Namen für die Primärschlüssel, die in der Quelldatenbankverwendet wurden. Stattdessen erstellt AWS DMS die Primärschlüsselnamen basierend auf denTabellennamen. Wenn der Tabellenname zu lang ist, kann es vorkommen, dass der automatisch generierteBezeichner länger ist als die von MySQL zulässigen Grenzwerte. Derzeit lässt sich das Problem lösen,indem Sie die Tabellen und Primärschlüssel vorab in der Zieldatenbank erstellen und eine Aufgabeverwenden, für die die Einstellung Target table preparation mode auf Do nothing oder Truncate festgelegtist, um die Zieltabellen zu füllen.
Fehler: Felddatenumwandlung schlägt aufgrund nichtunterstützten Zeichensatzes fehlDer folgende Fehler tritt auf, wenn ein nicht unterstützter Zeichensatz dazu führt, dass eineFelddatenumwandlung fehlschlägt:
"[SOURCE_CAPTURE ]E: Column '<column name>' uses an unsupported character set [120112] A field data conversion failed. (mysql_endpoint_capture.c:2154)
Dieser Fehler tritt oft bei Tabellen oder Datenbanken mit UTF8MB4-Codierung auf. AWS DMS-Engine-Versionen vor 3.1.1. unterstützen den Zeichensatz UTF8MB4 nicht. Überprüfen Sie außerdem dieParameter Ihrer Datenbank bezüglich Verbindungen. Mit dem folgenden Befehl können Sie dieseParameter anzeigen:
SHOW VARIABLES LIKE '%char%';
API-Version API Version 2016-01-01480

AWS Database Migration Service BenutzerhandbuchFehler: Codeseite 1252 zu UTF8 [120112] Eine
Felddatenkonvertierung ist fehlgeschlagen
Fehler: Codeseite 1252 zu UTF8 [120112] EineFelddatenkonvertierung ist fehlgeschlagenDie folgenden Fehler kann während einer Migration auftreten, wenn Sie andere als Codepage-1252-Zeichen in der MySQL-Quelldatenbank haben.
[SOURCE_CAPTURE ]E: Error converting column 'column_xyz' in table'table_xyz with codepage 1252 to UTF8 [120112] A field data conversion failed. (mysql_endpoint_capture.c:2248)
Als Abhilfe können Sie das zusätzliche Verbindungsattribut CharsetMapping mit Ihrem MySQL-Quellendpunkt verwenden, um die Zeichensatzzuordnung festzulegen. Möglicherweise müssen Sie dieAWS DMS-Migrationsaufgabe von Beginn an neu starten, wenn Sie dieses zusätzliche Verbindungsattributhinzufügen.
Beispielsweise könnte das folgende zusätzliche Verbindungsattribut für einen MySQL-Quellendpunktverwendet werden, wo der Quell-Zeichensatz auf utf8 oder latin1 gesetzt ist. 65001 ist die UTF8-Codepage-ID.
CharsetMapping=utf8,65001CharsetMapping=latin1,65001
Behebung von PostgreSQL-spezifischen ProblemenDie folgenden Probleme gelten speziell für den Einsatz von AWS DMS mit PostgreSQL-Datenbanken.
Themen• Verkürzte JSON-Datentypen (p. 481)• Spalten eines benutzerdefinierten Datentyps werden nicht korrekt migriert (p. 482)• Fehler: Kein Schema zum Erstellen ausgewählt (p. 482)• Lösch- und Aktualisierungsvorgänge für eine Tabelle werden nicht mit CDC repliziert (p. 482)• Truncate-Anweisungen werden nicht ordnungsgemäß verteilt (p. 482)• Verhindern, dass PostgreSQL DDL erfasst (p. 483)• Auswahl des Schemas, in dem Datenbankobjekte für die DDL-Erfassung erstellt werden (p. 483)• Oracle-Tabellen fehlen nach Migration zu PostgreSQL (p. 483)• Für Aufgabe, die Ansicht als Quelle verwendet, wurden keine Zeilen kopiert (p. 483)
Verkürzte JSON-DatentypenAWS DMS verarbeitet den JSON-Datentyp in PostgreSQL als LOB-Datentypspalte. Das bedeutet, dassdie LOB-Größenbeschränkung für JSON-Daten gilt, wenn Sie den beschränkten LOB-Modus verwenden.Wenn beispielsweise der beschränkte LOB-Modus auf 4096 KB festgelegt ist, werden alle JSON-Daten,
API-Version API Version 2016-01-01481
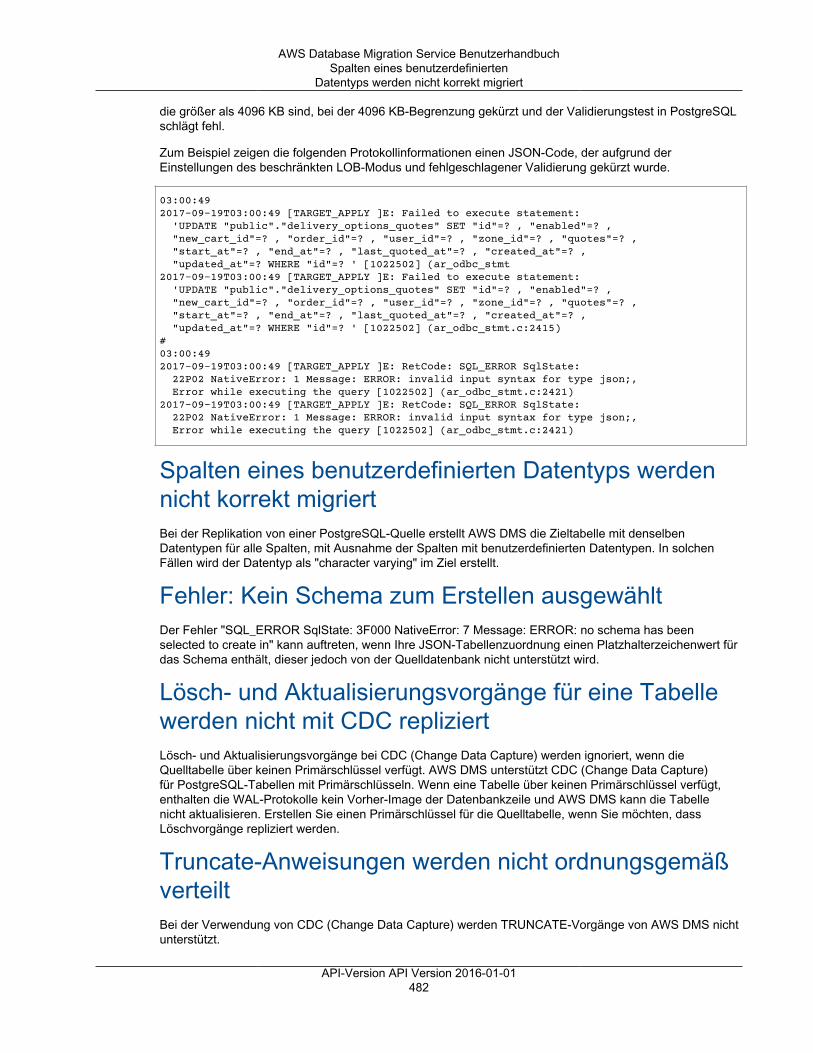
AWS Database Migration Service BenutzerhandbuchSpalten eines benutzerdefinierten
Datentyps werden nicht korrekt migriert
die größer als 4096 KB sind, bei der 4096 KB-Begrenzung gekürzt und der Validierungstest in PostgreSQLschlägt fehl.
Zum Beispiel zeigen die folgenden Protokollinformationen einen JSON-Code, der aufgrund derEinstellungen des beschränkten LOB-Modus und fehlgeschlagener Validierung gekürzt wurde.
03:00:492017-09-19T03:00:49 [TARGET_APPLY ]E: Failed to execute statement: 'UPDATE "public"."delivery_options_quotes" SET "id"=? , "enabled"=? , "new_cart_id"=? , "order_id"=? , "user_id"=? , "zone_id"=? , "quotes"=? , "start_at"=? , "end_at"=? , "last_quoted_at"=? , "created_at"=? , "updated_at"=? WHERE "id"=? ' [1022502] (ar_odbc_stmt2017-09-19T03:00:49 [TARGET_APPLY ]E: Failed to execute statement: 'UPDATE "public"."delivery_options_quotes" SET "id"=? , "enabled"=? , "new_cart_id"=? , "order_id"=? , "user_id"=? , "zone_id"=? , "quotes"=? , "start_at"=? , "end_at"=? , "last_quoted_at"=? , "created_at"=? , "updated_at"=? WHERE "id"=? ' [1022502] (ar_odbc_stmt.c:2415)#03:00:492017-09-19T03:00:49 [TARGET_APPLY ]E: RetCode: SQL_ERROR SqlState: 22P02 NativeError: 1 Message: ERROR: invalid input syntax for type json;, Error while executing the query [1022502] (ar_odbc_stmt.c:2421)2017-09-19T03:00:49 [TARGET_APPLY ]E: RetCode: SQL_ERROR SqlState: 22P02 NativeError: 1 Message: ERROR: invalid input syntax for type json;, Error while executing the query [1022502] (ar_odbc_stmt.c:2421)
Spalten eines benutzerdefinierten Datentyps werdennicht korrekt migriertBei der Replikation von einer PostgreSQL-Quelle erstellt AWS DMS die Zieltabelle mit denselbenDatentypen für alle Spalten, mit Ausnahme der Spalten mit benutzerdefinierten Datentypen. In solchenFällen wird der Datentyp als "character varying" im Ziel erstellt.
Fehler: Kein Schema zum Erstellen ausgewähltDer Fehler "SQL_ERROR SqlState: 3F000 NativeError: 7 Message: ERROR: no schema has beenselected to create in" kann auftreten, wenn Ihre JSON-Tabellenzuordnung einen Platzhalterzeichenwert fürdas Schema enthält, dieser jedoch von der Quelldatenbank nicht unterstützt wird.
Lösch- und Aktualisierungsvorgänge für eine Tabellewerden nicht mit CDC repliziertLösch- und Aktualisierungsvorgänge bei CDC (Change Data Capture) werden ignoriert, wenn dieQuelltabelle über keinen Primärschlüssel verfügt. AWS DMS unterstützt CDC (Change Data Capture)für PostgreSQL-Tabellen mit Primärschlüsseln. Wenn eine Tabelle über keinen Primärschlüssel verfügt,enthalten die WAL-Protokolle kein Vorher-Image der Datenbankzeile und AWS DMS kann die Tabellenicht aktualisieren. Erstellen Sie einen Primärschlüssel für die Quelltabelle, wenn Sie möchten, dassLöschvorgänge repliziert werden.
Truncate-Anweisungen werden nicht ordnungsgemäßverteiltBei der Verwendung von CDC (Change Data Capture) werden TRUNCATE-Vorgänge von AWS DMS nichtunterstützt.
API-Version API Version 2016-01-01482

AWS Database Migration Service BenutzerhandbuchVerhindern, dass PostgreSQL DDL erfasst
Verhindern, dass PostgreSQL DDL erfasstSie können verhindern, dass ein PostgreSQL-Zielendpunkt DDL-Anweisungen erfasst, indem Sie diefolgende Extra Connection Attribute-Anweisung hinzufügen. Den Extra Connection Attribut-Parameterfinden Sie in der Registerkarte Advanced des Quellendpunkts.
captureDDLs=N
Auswahl des Schemas, in dem Datenbankobjekte fürdie DDL-Erfassung erstellt werdenSie können steuern, in welchem Schema die Datenbankobjekte im Zusammenhang mit der Erfassungvon DDL erstellt werden. Fügen Sie die folgende Extra Connection Attribute-Anweisung hinzu. Den ExtraConnection Attribut-Parameter finden Sie in der Registerkarte Advanced des Zielendpunkts.
ddlArtifactsSchema=xyzddlschema
Oracle-Tabellen fehlen nach Migration zu PostgreSQLBei Oracle werden Tabellennamen standardmäßig in Großbuchstaben und bei PostgreSQL standardmäßigin Kleinbuchstaben geschrieben. Wenn Sie eine Migration von Oracle zu PostgreSQL durchführen, müssenSie in der Regel Transformationsregeln unter dem Abschnitt für die Tabellenzuordnung Ihrer Aufgabeangeben, um die Groß-/Kleinbuchstaben Ihrer Tabellennamen umzuwandeln.
Auf Ihre Tabellen und Daten kann weiterhin zugegriffen werden. Wenn Sie Ihre Tabellen ohneTransformationsregeln für die Umwandlung der Groß-/Kleinschreibung der Tabellennamen migriert haben,müssen Sie die Tabellennamen in Anführungszeichen setzen, wenn Sie darauf verweisen.
Für Aufgabe, die Ansicht als Quelle verwendet,wurden keine Zeilen kopiertEine Ansicht als PostgreSQL-Quellendpunkt wird von AWS DMS nicht unterstützt.
Behebung von Problemen im Zusammenhang mitMicrosoft SQL Server
Die folgenden Probleme betreffen speziell den Einsatz von AWS DMS mit Microsoft SQL Server-Datenbanken.
Themen• Spezielle Berechtigungen für AWS DMS-Benutzerkonto für die Verwendung von CDC (p. 484)• Fehler bei Erfassung von Änderungen für SQL Server-Datenbank (p. 484)
API-Version API Version 2016-01-01483

AWS Database Migration Service BenutzerhandbuchSpezielle Berechtigungen für AWS DMS-
Benutzerkonto für die Verwendung von CDC
• Fehlende Identitätsspalten (p. 484)• Fehler: SQL Server unterstützt keine Publikationen (p. 484)• Änderungen werden im Ziel nicht angezeigt (p. 484)• Uneinheitliche Tabelle, die über Partitionen hinweg zugeordnet ist (p. 485)
Spezielle Berechtigungen für AWS DMS-Benutzerkonto für die Verwendung von CDCDas mit AWS DMS verwendete Benutzerkonto erfordert die Rolle "SQL Server SysAdmin", damit es beiVerwendung von Change Data Capture (CDC) ordnungsgemäß funktioniert.
Fehler bei Erfassung von Änderungen für SQL Server-DatenbankFehler während Change Data Capture (CDC) weisen häufig darauf hin, dass eine der Voraussetzungennicht erfüllt sind. Zum Beispiel ist eine der am häufigsten übersehenen Voraussetzungen eine vollständigeDatenbanksicherung. Das Aufgabenprotokoll gibt dieses Versäumnis mit dem folgenden Fehler an:
SOURCE_CAPTURE E: No FULL database backup found (under the 'FULL' recovery model). To enable all changes to be captured, you must perform a full database backup. 120438 Changes may be missed. (sqlserver_log_queries.c:2623)
Überprüfen Sie die Voraussetzungen für die Verwendung von SQL Server als Quelle unter Verwendeneiner Microsoft SQL Server-Datenbank als Quelle für AWS DMS (p. 151).
Fehlende IdentitätsspaltenAWS DMS unterstützt bei der Erstellung eines Zielschemas keine Identitätsspalten. Sie müssen siehinzufügen, nachdem der erste Ladevorgang abgeschlossen ist.
Fehler: SQL Server unterstützt keine PublikationenDie folgende Fehlermeldung wird angezeigt, wenn Sie SQL Server Express als Quellendpunkt verwenden:
RetCode: SQL_ERROR SqlState: HY000 NativeError: 21106 Message: This edition of SQL Server does not support publications.
AWS DMS unterstützt derzeit nicht SQL Server Express als Quelle oder Ziel.
Änderungen werden im Ziel nicht angezeigtAWS DMS erfordert, dass eine SQL Server-Quelldatenbank entweder im Datenwiederherstellungsmodell"FULL" oder "BULK LOGGED" operiert, um Änderungen konsistent erfassen zu können. Das Modell"SIMPLE" wird nicht unterstützt.
API-Version API Version 2016-01-01484

AWS Database Migration Service BenutzerhandbuchUneinheitliche Tabelle, die über
Partitionen hinweg zugeordnet ist
Beim Wiederherstellungsmodell SIMPLE werden minimale Informationen protokolliert, die erforderlichsind, damit Benutzer ihre Datenbank wiederherstellen können. Alle inaktiven Protokolleinträge werdenautomatisch abgeschnitten, wenn ein Prüfpunkt eintritt. Alle Vorgänge werden zwar weiterhin protokolliert,sobald jedoch ein Prüfpunkt eintritt, wird das Protokoll automatisch abgeschnitten. Dies bedeutet, dasses zur Wiederverwendung verfügbar ist und ältere Protokolleinträge überschrieben werden können.Wenn Protokolleinträge überschrieben werden, können keine Änderungen erfasst werden. Deshalbwird das Wiederherstellungsmodell SIMPLE von AWS DMS nicht unterstützt. Informationen zu weiterenerforderlichen Voraussetzungen für die Verwendung von SQL Server als Quelle finden Sie unterVerwenden einer Microsoft SQL Server-Datenbank als Quelle für AWS DMS (p. 151).
Uneinheitliche Tabelle, die über Partitionen hinwegzugeordnet istWährend der Change Data Capture (CDC) wird die Migration einer Tabelle mit einer spezialisierten Strukturunterbrochen, wenn AWS DMS CDC nicht ordnungsgemäß für die Tabelle ausführen kann. Nachrichtenwie diese werden ausgegeben:
[SOURCE_CAPTURE ]W: Table is not uniformly mapped across partitions. Therefore - it is excluded from CDC (sqlserver_log_metadata.c:1415)[SOURCE_CAPTURE ]I: Table has been mapped and registered for CDC. (sqlserver_log_metadata.c:835)
Beim Ausführen von CDC in SQL Server-Tabellen werden die SQL Server-Tlogs von AWS DMS analysiert.AWS DMS analysiert auf jedem Tlog-Datensatz hexadezimale Werte, die Daten für Spalten enthalten, diewährend einer Änderung eingefügt, aktualisiert oder gelöscht wurden.
Um den Hexadezimaldatensatz zu analysieren, liest AWS DMS die Tabellenmetadaten aus den SQLServer-Systemtabellen. Diese Systemtabellen identifizieren, was die speziell strukturierten Tabellenspaltensind und zeigen einige ihrer internen Eigenschaften, wie „xoffset“ und „null bit position“.
AWS DMS erwartet, dass Metadaten für alle unformatierten Partitionen der Tabelle identisch sind. Wennjedoch speziell strukturierte Tabellen nicht über die gleichen Metadaten auf allen Partitionen verfügen,kann AWS DMS CDC in dieser Tabelle unterbrechen, um zu vermeiden, dass Änderungen falsch analysiertwerden und dem Ziel falsche Daten bereitgestellt werden. Zu den Problemumgehungen gehören:
• Wenn die Tabelle über einen gruppierten Index verfügt, führen Sie einen Indexneuaufbau durch.• Wenn die Tabelle keinen gruppierten Index hat, fügen Sie der Tabelle einen gruppierten Index hinzu (Sie
können ihn später löschen, wenn Sie möchten).
Behebung von Amazon Redshift-spezifischenProblemen
Die folgenden Probleme gelten speziell für den Einsatz von AWS DMS mit Amazon Redshift-Datenbanken.
Themen• Laden in einen Amazon Redshift-Cluster in einer anderen Region als die AWS DMS-Replikations-
Instance (p. 486)• Fehler: Beziehung "attrep_apply_exceptions" bereits vorhanden (p. 486)• Fehler mit Tabellen, deren Name mit "awsdms_changes" beginnt (p. 486)
API-Version API Version 2016-01-01485

AWS Database Migration Service BenutzerhandbuchLaden in einen Amazon Redshift-Cluster in einer
anderen Region als die AWS DMS-Replikations-Instance
• Anzeigen von Tabellen in Clustern mit Namen wie "dms.awsdms_changes000000000XXXX" (p. 486)• Berechtigungen für die Verwendung mit Amazon Redshift erforderlich (p. 486)
Laden in einen Amazon Redshift-Cluster in eineranderen Region als die AWS DMS-Replikations-InstanceDieser Vorgang kann nicht durchgeführt werden. AWS DMS setzt voraus, dass sich die AWS DMS-Replikations-Instance und der Redshift-Cluster in derselben Region befinden.
Fehler: Beziehung "attrep_apply_exceptions" bereitsvorhandenDer Fehler "Relation "awsdms_apply_exceptions" already exists" tritt häufig aus, wenn ein Redshift-Endpunkt als PostgreSQL-Endpunkt angegeben wird. Um dieses Problem zu beheben, ändern Sie denEndpunkt und ändern Sie die Target engine in "redshift".
Fehler mit Tabellen, deren Name mit"awsdms_changes" beginntFehlermeldungen zu Tabellen mit Namen, die mit "awsdms_changes" beginnen, treten häufig auf, wennzwei Aufgaben, die versuchen, Daten in den gleichen Amazon Redshift-Cluster zu laden, gleichzeitigausgeführt werden. Aufgrund der Art und Weise, wie temporäre Tabellen benannt sind, könnengleichzeitige Aufgaben in Konflikt geraten, wenn die gleiche Tabelle aktualisiert wird.
Anzeigen von Tabellen in Clustern mit Namen wie"dms.awsdms_changes000000000XXXX"AWS DMS erstellt temporäre Tabellen, wenn Daten von in S3 gespeicherten Dateien geladen werden.Dem Namen dieser temporären Tabellen ist "dms.awsdms_changes" vorangestellt. Diese Tabellen sinderforderlich, damit AWS DMS Daten speichern kann, wenn sie zum ersten Mal geladen und bevor sie in derendgültigen Zieltabelle abgelegt werden.
Berechtigungen für die Verwendung mit AmazonRedshift erforderlichUm AWS DMS mit Amazon Redshift verwenden zu können, muss das Benutzerkonto, mit dem Sie aufAmazon Redshift zugreifen, über die folgenden Berechtigungen verfügen:
• Auswählen, Einfügen, Aktualisieren, Löschen (CRUD)• Massenladevorgang• Erstellen, Ändern, Löschen (falls gemäß Aufgabendefinition erforderlich)
Sie finden alle Voraussetzungen für die Verwendung von Amazon Redshift als Ziel unter Verwenden einerAmazon Redshift-Datenbank als Ziel für AWS Database Migration Service (p. 231).
API-Version API Version 2016-01-01486

AWS Database Migration Service BenutzerhandbuchBehebung von Amazon Aurora
MySQL-spezifischen Problemen
Behebung von Amazon Aurora MySQL-spezifischenProblemen
Die folgenden Probleme gelten speziell für den Einsatz von AWS DMS mit Amazon Aurora MySQL-Datenbanken.
Themen• Fehler: CHARACTER SET UTF8-Felder beendet durch ',' umschlossen von '"' Zeilen beendet durch
'\n' (p. 487)
Fehler: CHARACTER SET UTF8-Felder beendetdurch ',' umschlossen von '"' Zeilen beendet durch '\n'Wenn Sie Amazon Aurora MySQL als Ziel verwenden und einen Fehler wie den folgenden in denProtokollen feststellen, weist dies in der Regel darauf hin, dass Sie ANSI_QUOTES im ParameterSQL_MODE verwenden. Die Verwendung von ANSI_QUOTES im SQL_MODE-Parameter sorgt dafür,dass doppelte Anführungszeichen wie einfache Anführungszeichen verwendet werden, was bei Ausführungeiner Aufgabe zu Problemen führen kann. Um diesen Fehler zu beheben, entfernen Sie ANSI_QUOTESaus dem SQL_MODE-Parameter.
2016-11-02T14:23:48 [TARGET_LOAD ]E: Load data sql statement. load data local infile "/rdsdbdata/data/tasks/7XO4FJHCVON7TYTLQ6RX3CQHDU/data_files/4/LOAD000001DF.csv" into table `VOSPUSER`.`SANDBOX_SRC_FILE` CHARACTER SET UTF8 fields terminated by ',' enclosed by '"' lines terminated by '\n'( `SANDBOX_SRC_FILE_ID`,`SANDBOX_ID`,`FILENAME`,`LOCAL_PATH`,`LINES_OF_CODE`,`INSERT_TS`,`MODIFIED_TS`,`MODIFIED_BY`,`RECORD_VER`,`REF_GUID`,`PLATFORM_GENERATED`,`ANALYSIS_TYPE`,`SANITIZED`,`DYN_TYPE`,`CRAWL_STATUS`,`ORIG_EXEC_UNIT_VER_ID` ) ; (provider_syntax_manager.c:2561)
API-Version API Version 2016-01-01487

AWS Database Migration Service BenutzerhandbuchVerbessern der Leistung
Bewährte Methoden für AWSDatabase Migration Service
Um AWS Database Migration Service (AWS DMS) möglichst effektiv zu nutzen, schauen Sie sich dieEmpfehlungen in diesem Abschnitt zu den effizientesten Datenmigrationsmethoden an.
Themen• Verbessern der Leistung einer AWS DMS-Migration (p. 488)• Wählen der optimalen Größe einer Replikations-Instance (p. 490)• Reduzieren der Last Ihrer Quelldatenbank (p. 491)• Verwenden des Aufgabenprotokolls für die Behebung von Migrationsproblemen (p. 491)• Konvertieren des Schemas (p. 492)• Migrieren von Binary Large Objects (LOBs) (p. 492)• Fortlaufende Replikation (p. 493)• Ändern des Benutzers und des Schemas für ein Oracle-Ziel (p. 493)• Ändern von Tabellen- und Index-Tabellenräumen für ein Oracle-Ziel (p. 494)• Verbessern der Leistung beim Migrieren umfangreicher Tabellen (p. 495)• Verwenden Ihres eigenen On-Premise-Nameservers (p. 495)
Verbessern der Leistung einer AWS DMS-MigrationDie Leistung Ihrer AWS DMS-Migration wird von verschiedenen Faktoren beeinflusst:
• Ressourcenverfügbarkeit in der Quelle• Verfügbarer Netzwerkdurchsatz• Ressourcenkapazität des Replikationsservers• Fähigkeit des Ziels, Änderungen aufzunehmen• Art und Verteilung der Quelldaten• Anzahl der zu migrierenden Objekte
Bei unseren Tests haben wir ein Terabyte Daten unter idealen Bedingungen in etwa 12 bis 13 Stundenmittels einer einzelnen AWS DMS-Aufgabe migriert. Zu diesen idealen Bedingungen gehört dieVerwendung von Quelldatenbanken auf Amazon EC2 und in Amazon RDS mit Zieldatenbanken in AmazonRDS, die sich alle in derselben Availability Zone befinden. Unsere Quelldatenbanken enthielten einerepräsentative Menge relativ gleichmäßig verteilter Daten mit ein paar großen Tabellen mit bis zu 250 GBDaten. Die Quelldaten enthielten keine komplexen Datentypen wie BLOB-Daten.
Es ist möglich, durch Beachtung einiger oder aller der nachstehend erwähnten bewährten Methoden dieLeistung zu verbessern. Ob Sie eine dieser Methoden anwenden können oder nicht, hängt zu einemgroßen Teil von Ihrem speziellen Anwendungsfall ab. Wir erwähnen ggf. zutreffende Einschränkungen.
Paralleles Laden mehrerer Tabellen
Standardmäßig lädt AWS DMS immer acht Tabellen gleichzeitig. Möglicherweise lässt sich eineLeistungsverbesserung erzielen, wenn Sie diese Menge etwas erhöhen, sofern Sie einen sehr großenReplikationsserver verwenden wie einen dms.c4.xlarge oder eine größere Instance. Es kann jedoch
API-Version API Version 2016-01-01488

AWS Database Migration Service BenutzerhandbuchVerbessern der Leistung
auch vorkommen, dass die Leistung durch Erhöhen der parallelen Ausführung an einem bestimmtenPunkt abfällt. Wenn Ihr Replikationsserver relativ klein ist, z. B. ein dms.t2.medium, sollten Sie dieAnzahl der parallel geladenen Tabellen reduzieren.
Um diese Zahl in der AWS Management Console zu ändern, öffnen Sie die Konsole, wählen Tasks(Aufgaben), wählen aus, ob Sie eine Aufgabe erstellen oder ändern möchten, und klicken Sie dannauf Advanced Settings (Erweiterte Einstellungen). Ändern Sie unter Tuning Settings (Optimierung derEinstellungen) die Option Maximum number of tables to load in parallel (Maximale Anzahl parallel zuladender Tabellen).
Um diese Zahl mit der AWS CLI zu ändern, ändern Sie den MaxFullLoadSubTasks-Parameter unterTaskSettings.
Die Arbeit mit Indizes, Auslösern und Einschränkungen bezüglich der referenziellen Integrität
Indizes, Auslöser und Einschränkungen bezüglich der referenziellen Integrität können sich auf IhreMigrationsleistung auswirken kann dazu führen, dass Ihre Migration fehlschlägt. Wie sich diese aufdie Migration auswirken, hängt davon ab, ob Ihre Replikationsaufgabe eine Volllastaufgabe oder einelaufende Replikationsaufgabe (CDC) ist.
Für eine Volllastaufgabe empfehlen wir, Primärschlüsselindizes, Sekundärindizes, referentielleIntegritätsbeschränkungen und DML-Trigger (Data Manipulation Language) zu löschen. Alternativkönnen Sie ihre Erstellung bis zum Abschluss der Volllastaufgaben verzögern. Während einer Aufgabezum vollständigen Laden sind keine Indizes erforderlich und entstehen Fixkosten für die Wartung,wenn sie vorhanden sind. Da die Aufgabe zum vollständigen Laden Tabellen gruppenweise lädt, wirdgegen Einschränkungen bezüglich der referenziellen Integrität verstoßen. Gleichermaßen kann dasEinfügen, Aktualisieren und Löschen von Auslösern Fehler verursachen, wenn z. B. für eine zuvormassenweise geladene Tabelle das Einfügen einer Zeile ausgelöst wird. Andere Arten von Auslöserbeeinträchtigen aufgrund der zusätzlichen Verarbeitung ebenfalls die Leistung.
Sie können Primärschlüssel und sekundäre Indizes vor einer Aufgabe zum vollständigen Ladenerstellen, wenn Ihre Daten-Volumes relativ klein sind und die zusätzliche Migrationszeit nicht vonBedeutung ist. Einschränkungen bezüglich der referenziellen Integrität und Auslöser sollten immerdeaktiviert werden.
Für einen vollständigen Ladevorgang + CDC-Aufgabe empfehlen wir, dass Sie vor der CDC-Aufgabesekundäre Indizes hinzufügen. Da AWS DMS eine logische Replikation verwendet, sollten sekundäreIndizes, die DML-Operationen unterstützen, vorhanden sein, um vollständige Tabellen-Scans zuverhindern. Sie können die Replikationsaufgabe vor der CDC-Phase anhalten, um Indizes, Auslöserund referenzielle Integritätsbeschränkungen zu erstellen, bevor Sie die Aufgabe neu starten.
Deaktivieren von Sicherungen und der Transaktionsprotokollierung
Bei der Migration zu einer Amazon RDS-Datenbank wird empfohlen, Sicherungen und Multi-AZfür ein Ziel zu deaktivieren, bis Sie zum Produktivstart bereit sind. Auch wenn die Migration zuSystemen erfolgt, die keine Amazon RDS-Systeme sind, sollten Sie bis zum Produktivstart jeglicheProtokollierung am Ziel deaktivieren.
Verwenden mehrerer Aufgaben
Manchmal lässt sich durch die Verwendung mehrerer Aufgaben für eine einzelne Migrationdie Leistung verbessern. Wenn einige Ihrer Tabellen nicht an gemeinsamen Transaktionenteilnehmen, können Sie Ihre Migration ggf. in mehrere Aufgaben aufteilen. Innerhalb einer Aufgabeist transaktionale Konsistenz gewährleistet. Deshalb ist es wichtig, dass Tabellen in separatenAufgaben nicht an gemeinsamen Transaktionen teilnehmen. Außerdem lesen alle Aufgaben denTransaktionsstrom unabhängig voneinander. Achten Sie also darauf, die Quelldatenbank nicht zu sehrzu belasten.
Sie können mit mehreren Aufgaben separate Replikationsströme erstellen, damit Lesevorgänge inder Quelldatenbank, Prozesse auf der Replikations-Instance und Schreibvorgänge zur Zieldatenbankparallel ausgeführt werden.
API-Version API Version 2016-01-01489

AWS Database Migration Service BenutzerhandbuchBestimmen der Größe einer Replikations-Instance
Optimieren der Verarbeitung von Änderungen
Standardmäßig verarbeitet AWS DMS Änderungen in einem transaktionalen Modus, beidem die Integrität der Transaktionen gewahrt wird. Wenn Sie sich temporäre Ausfälle bei derTransaktionsintegrität leisten können, können Sie stattdessen die Option batch optimized applyverwenden. Bei dieser Option werden Transaktionen auf effiziente Weise gruppiert und in Stapelnangewendet, um die Effizienz zu erhöhen. Die Verwendung der Option der stapeloptimiertenAnwendung höchstwahrscheinlich gegen Einschränkungen bezüglich der referenziellen Integritätverstößt. Deshalb sollten Sie diese während des Migrationsprozesses deaktivieren und beimProduktivstart erneut aktivieren.
Wählen der optimalen Größe einer Replikations-Instance
Die Wahl der geeigneten Replikations-Instance hängt von mehreren Faktoren ab, die sich auf IhrenAnwendungsfall beziehen. Um zu verstehen, wie die Replikations-Instance-Ressourcen verwendet werden,lesen Sie die folgende Diskussion. Sie deckt das übliche Szenario einer Volllast + CDC-Aufgabe ab.
Während einer Aufgabe zum vollständigen Laden, lädt AWS DMS Tabellen gleichzeitig. Standardmäßigwerden acht Tabellen gleichzeitig geladen. AWS DMS erfasst laufende Änderungen an der Quelle währendeiner Aufgabe zum vollständigen Laden, sodass die Änderungen später auf dem Zielendpunkt angewendetwerden können. Die Änderungen werden zwischengespeichert. Wenn der verfügbare Arbeitsspeichererschöpft ist, werden die Änderungen auf der Festplatte zwischengespeichert. Wenn eine Aufgabe zumvollständigen Laden für eine Tabelle abgeschlossen wurde, wendet AWS DMS die zwischengespeichertenÄnderungen umgehend auf die Zieltabelle an.
Nachdem alle ausstehenden zwischengespeicherten Änderungen für eine Tabelle übernommen wurden,befindet sich der Ziel-Endpunkt in einem transaktionskonsistenten Status. An diesem Punkt ist das Zielmit dem Quellenendpunkt hinsichtlich der zuletzt zwischengespeicherten Änderungen synchronisiert.Anschließend beginnt AWS DMS die fortlaufende Replikation zwischen Quelle und Ziel. Dazu verwendetAWS DMS Änderungsoperationen aus den Quell-Transaktionsprotokollen und wendet sie auf einetransaktionell konsistente Weise (sofern stapeloptimiertes Anwenden nicht aktiviert ist) auf das Ziel an.AWS DMS streamt fortlaufende Änderungen nach Möglichkeit durch den Speicher auf der Replikations-Instance. Wenn dies nicht möglich ist, schreibt AWS DMS Änderungen auf die Festplatte der Replikations-Instance, bis sie auf das Ziel angewendet werden können.
Sie haben eine gewisse Kontrolle darüber, wie die Replikations-Instance die Änderungsverarbeitunghandhabt und wie der Arbeitsspeicher bei diesem Prozess verwendet wird. Weitere Informationenzur Optimierung der Änderungsverarbeitung finden Sie unter Einstellungen für die Optimierung derVerarbeitung von Änderungen (p. 350).
Aus der voranstehenden Erklärung geht hervor, dass der insgesamt verfügbare Arbeitsspeicher einwichtiger Aspekt ist. Wenn die Replikations-Instance über ausreichend Arbeitsspeicher verfügt, sodassAWS DMS zwischengespeicherte und fortlaufende Änderungen streamen kann, ohne sie auf die Festplattezu schreiben, steigt die Migrationsleistung erheblich. Ebenso erhöht die Konfiguration der Replikations-Instance mit ausreichend Speicherplatz für das Änderungs-Caching und die Protokollspeicherung dieLeistung. Die maximal möglichen IOPS hängen von der gewählten Festplattengröße ab.
Berücksichtigen Sie bei der Auswahl einer Replikations-Instance-Klasse und des verfügbaremSpeicherplatzes die folgenden Faktoren:
• Tabellengröße – Das Laden großer Tabellen dauert länger; folglich müssen die Transaktionen für dieseTabellen zwischengespeichert werden, bis die Tabelle geladen ist. Nachdem eine Tabelle geladenwurde, werden diese zwischengespeicherten Transaktionen angewendet und von der Festplatte entfernt.
• DML-Aktivität (Data Manipulation Language) – Eine ausgelastete Datenbank generiert mehrTransaktionen. Diese Transaktionen müssen zwischengespeichert werden, bis die Tabelle geladen ist.
API-Version API Version 2016-01-01490

AWS Database Migration Service BenutzerhandbuchReduzieren des Workloads Ihrer Quelldatenbank
Transaktionen für eine einzelne Tabelle werden so bald wie möglich nach Laden der Tabelle angewendet– bis alle Tabellen geladen sind.
• Transaktionsgröße – Lang andauernde Transaktionen können viele Änderungen generieren. WennAWS DMS im Transaktionsmodus Änderungen übernimmt, muss für eine optimale Leistung ausreichendArbeitsspeicher zum Streamen aller Änderungen in der Transaktion verfügbar sein.
• Gesamtgröße der Migration – Umfangreiche Migrationen dauern länger und generieren eineverhältnismäßig große Anzahl von Protokolldateien.
• Anzahl der Aufgaben – Je mehr Aufgaben vorhanden sind, desto mehr Zwischenspeicherung istwahrscheinlich erforderlich und desto mehr Protokolldateien werden erstellt.
• Große Objekte – Das Laden von Tabellen mit LOBs dauert länger.
Die Erfahrung zeigt, dass Protokolldateien den Großteil des für AWS DMS erforderlichen Speicherplatzesbelegen. Die Standardspeicherkonfigurationen sind in der Regel ausreichend.
Replikations-Instances, die verschiedene Aufgaben ausführen, erfordern jedoch möglicherweise mehrSpeicherplatz. Wenn Ihre Datenbank große und aktive Tabellen umfasst, müssen Sie zudem denSpeicherplatz für Transaktionen erhöhen, die während einer Aufgabe zum vollständigen Laden auf derFestplatte zwischengespeichert werden. Wenn Ihr Ladevorgang z. B. 24 Stunden dauert und Sie 2 GBTransaktionen pro Stunde erzeugen, sollten Sie sicherstellen, dass Sie über 48 GB Speicherplatz fürzwischengespeicherte Transaktionen verfügen. Desto mehr Speicherplatz Sie der Replikations-Instancezuordnen, desto höher sind auch die resultierenden E/A-Vorgänge pro Sekunde.
Die vorangegangenen Richtlinien decken nicht alle möglichen Szenarien ab. Es ist äußerst wichtig,die Besonderheiten Ihres speziellen Anwendungsfalles zu berücksichtigen, wenn Sie die Größe IhrerReplikations-Instance bestimmen. Nachdem die Migration ausgeführt wird, überwachen Sie die Werte fürCPU, freigebbaren Arbeitsspeicher, freier Speicherplatz und E/A-Leistung pro Sekunde Ihrer Replikations-Instance. Basierend auf den Daten, die Sie erfassen, können Sie Ihre Replikations-Instance nach Bedarfvergrößern oder verkleinern.
Reduzieren der Last Ihrer QuelldatenbankAWS DMS nutzt einige Ressourcen in Ihrer Quelldatenbank. Während einer Aufgabe zum vollständigenLaden führt AWS DMS eine vollständige Tabellenprüfung der Quelltabelle parallel für jede verarbeiteteTabelle aus. Zudem fragt jede Aufgabe, die Sie als Teil einer Migration erstellen, die Quelldatenbank imRahmen des CDC-Prozesses nach Änderungen ab. Bei einigen Quelldatenbanken, wie Oracle, müssenSie möglicherweise die in das Änderungsprotokoll Ihrer Datenbanken geschriebene Datenmenge erhöhen,damit AWS DMS den CDC-Vorgang durchführen kann.
Wenn Sie feststellen, dass Ihre Quelldatenbank überlastet wird, können Sie die Anzahl der Aufgabenund/oder Tabellen pro Aufgabe für die Migration reduzieren. Da die einzelnen Aufgaben unabhängigvoneinander Änderungen erhalten, kann die Änderungserfassungslast durch die Konsolidierung derAufgaben verringert werden.
Verwenden des Aufgabenprotokolls für dieBehebung von Migrationsproblemen
In einigen Fällen kann AWS DMS auf Probleme stoßen, bei denen Warnungen oder Fehlermeldungen nurim Aufgabenprotokoll erscheinen. Insbesondere Probleme mit der Kürzung von Daten oder Ablehnungvon Zeilen aufgrund von Fremdschlüsselverstößen werden nur in das Aufgabenprotokoll geschrieben.Daher ist es wichtig, das Aufgabenprotokoll bei einer Datenbankmigration zu überprüfen. Um die
API-Version API Version 2016-01-01491

AWS Database Migration Service BenutzerhandbuchSchemakonvertierung
Anzeige des Aufgabenprotokolls zu ermöglichen, konfigurieren Sie Amazon CloudWatch als Teil derAufgabenerstellung.
Konvertieren des SchemasAWS DMS führt keine Schema- oder Codekonvertierung durch. Wenn Sie ein vorhandenes Schema in eineandere Datenbank-Engine konvertieren möchten, können Sie das AWS Schema Conversion Tool (AWSSCT) verwenden. AWS SCT konvertiert Quell-Objekte, Tabellen, Indizes, Ansichten, Auslöser und andereSystemobjekte in das Ziel-DDL-Format (Data Definition Language). Sie können mithilfe von AWS SCT aucheine Großteil des Anwendungscodes, wie PL/SQL oder TSQL, in die gleichwertige Zielsprache umwandeln.
Sie erhalten AWS SCT als kostenloser Download von AWS. Weitere Informationen zum AWS SCT findenSie unter AWS Schema Conversion Tool-Benutzerhandbuch.
Sie können Tools wie Oracle SQL Developer, MySQL Workbench oder PgAdmin4 verwenden, um IhrSchema zu verschieben, sofern Quell- und Zielendpunkte auf der gleichen Datenbank-Engine liegen.
Migrieren von Binary Large Objects (LOBs)Im Allgemeinen migriert AWS DMS LOB-Daten in zwei Phasen.
1. AWS DMS erstellt eine neue Zeile in der Zieltabelle und füllt die Zeile mit allen Daten mit Ausnahme deszugehörigen LOB-Werts.
2. AWS DMS aktualisiert die Zeile in der Zieltabelle mit den LOB-Daten.
Dieser Migrationsvorgang für LOBs erfordert, dass alle LOB-Spalten in der Zieltabelle während derMigration nullwertfähig sein müssen. Dies gilt auch dann, wenn die LOB-Spalten in der Quelltabellenicht nullwertfähig sind. Wenn AWS DMS die Zieltabellen erstellt, werden LOB-Spalten standardmäßigals löschbar festgelegt. Wenn Sie die Zieltabellen mit einer anderen Methode, wie z. B. Import/Export, erstellen, müssen Sie sicherstellen, dass alle LOB-Spalten nullwertfähig sind, bevor Sie dieMigrationsaufgabe starten.
Für diese Anforderung gibt es eine Ausnahme. Angenommen, Sie führen eine homogene Migration voneiner Oracle-Quelle zu einem Oracle-Ziel durch und wählen Limited Lob-Modus. In diesem Fall wird diegesamte Zeile auf einmal gefüllt, einschließlich aller LOB-Werte. In einem solchen Fall kann AWS DMS dieLOB-Spalten der Zieltabelle bei Bedarf mit nicht löschbaren Einschränkungen erstellen.
Verwenden des begrenzten LOB-ModusAWS DMS nutzt zwei Methoden, um Leistung und Benutzerfreundlichkeit gegeneinander abzuwägen, wennIhre Migration LOB-Werte enthält.
• Mit Limited LOB-Modus (Begrenzter LOB-Modus) werden alle LOB-Werte bis zu einer vom Benutzerangegebenen Größe (Standard: 32 KB) migriert. LOB-Werte, die größer als das Größenlimit sind,müssen manuell migriert werden. Limited LOB mode (Begrenzter LOB-Modus), der Standard für alleMigrationsaufgaben, bietet in der Regel die beste Leistung. Sie müssen jedoch sicherstellen, dass dieEinstellung des Parameters Max LOB size (Max. LOB-Größe) korrekt ist. Dieser Parameter sollte auf diemaximale LOB-Größe für alle Ihre Tabellen eingestellt sein.
• Full LOB mode (Vollständiger LOB-Modus) migriert alle LOB-Daten in Ihren Tabellen unabhängig vonder Größe. Full LOB mode (Vollständiger LOB-Modus) bietet die Möglichkeit, alle LOB-Daten in IhrenTabellen zu verschieben, aber der Prozess kann die Leistung signifikant beeinträchtigen.
API-Version API Version 2016-01-01492

AWS Database Migration Service BenutzerhandbuchFortlaufende Replikation
Bei einigen Datenbank-Engines, z. B. PostgreSQL, behandelt AWS DMS JSON-Datentypen wie LOBs.Stellen Sie sicher, dass wenn Sie Limited LOB mode (Begrenzter LOB-Modus) verwenden, die OptionMax LOB size (Max. LOB-Größe) auf einen Wert festgelegt ist, der nicht dazu führt, dass die JSON-Datengekürzt werden.
AWS DMS bietet vollen Support für die Verwendung großer Objektdatentypen (BLOBs, CLOBs undNCLOBs). Für die folgenden Quellendpunkte werden LOBs uneingeschränkt unterstützt:
• Oracle• Microsoft SQL Server• ODBC
Für die folgenden Zielendpunkte werden LOBs uneingeschränkt unterstützt:
• Oracle• Microsoft SQL Server
Der folgende Zielendpunkt verwendet eine eingeschränkte LOB-Unterstützung. Sie können keineunbegrenzte LOB-Größe für diesen Zielendpunkt verwenden.
• Amazon Redshift
Für Endpunkte mit uneingeschränkter LOB-Unterstützung können Sie auch eine Obergrenze für LOB-Datentypen festlegen.
Fortlaufende ReplikationAWS DMS bietet eine fortlaufende Replikation von Daten, um die Synchronität der Quell- undZieldatenbank aufrechtzuhalten. Es wird allerdings nur eine begrenzte Menge an DDL-Daten(Data Definition Language) repliziert. AWS DMS verbreitet keine Elemente wie Indizes, Benutzer,Berechtigungen, gespeicherte Prozeduren und andere Datenbankänderungen, die sich nicht direkt auf dieTabellendaten beziehen.
Wenn Sie die fortlaufende Replikation verwenden möchten, sollten Sie die Option Multi-AZ bei derErstellung Ihrer Replikations-Instance aktivieren. Die Option Multi-AZ bietet für die Replikations-Instancehohe Verfügbarkeit und Failover-Unterstützung. Diese Option kann sich jedoch auf die Leistung auswirken.
Ändern des Benutzers und des Schemas für einOracle-Ziel
Wenn Sie Oracle als Ziel verwenden, migriert AWS DMS die Daten zu dem Schema, das im Besitz desZielendpunkt-Benutzers ist.
Nehmen Sie zum Beispiel an, dass Sie ein Schema mit dem Namen PERFDATA zu einem Oracle-Zielendpunkt migrieren und der Benutzername des Zielendpunktes MASTER ist. AWS DMS stellt eineVerbindung mit dem Oracle-Ziel als MASTER her und füllt das MASTER-Schema mit Datenbankobjekten ausPERFDATA.
Um dieses Verhalten zu überschreiben, müssen Sie eine Schematransformation bereitstellen. Wenn Siebeispielsweise die PERFDATA-Schemaobjekte zu einem PERFDATA-Schema am Zielendpunkt migrierenmöchten, können Sie die folgende Transformation verwenden:
API-Version API Version 2016-01-01493

AWS Database Migration Service BenutzerhandbuchÄndern von Tabellen- und Index-Tabellenräumen für ein Oracle-Ziel
{ "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "PERFDATA" }, "rule-target": "schema", "rule-action": "rename", "value": "PERFDATA"}
Weitere Informationen zu Umwandlungen finden Sie unter Festlegen der Tabellenauswahl undTransformationen durch Tabellenzuweisungen mit JSON (p. 377).
Ändern von Tabellen- und Index-Tabellenräumenfür ein Oracle-Ziel
Wenn Sie Oracle als Ziel verwenden, migriert AWS DMS die Tabellenräume, wie in der Quelle angegeben,wenn die Quelle ebenfalls Oracle ist. Wenn die Quelle jedoch nicht Oracle ist, migriert AWS DMS alleTabellen und Indizes zur Standard-Tabelle und Index-Tabellenräumen im Ziel.
Nehmen Sie beispielsweise an, dass Ihre Quelle eine andere Datenbank-Engine als Oracle ist. AlleZieltabellen und Indizes werden zu denselben Standard-Tabellenräumen migriert.
Um dieses Verhalten zu überschreiben, müssen Sie entsprechende Transformationen von Tabellenräumenbereitstellen. Nehmen Sie beispielsweise an, dass Sie Tabellen und Indizes zu Tabellen- und Index-Tabellenräumen im Oracle-Ziel migrieren möchten, die nach dem Schema in der Quelle benannt sind. Indiesem Fall können Sie Transformationen verwenden, die den folgenden ähnlich sind. Hier hat das Schemain der Quelle den Namen INVENTORY und die entsprechenden Tabellen- und Index-Tabellenräume im Zielhaben den Namen INVENTORYTBL bzw. INVENTORYIDX.
{ "rule-type": "transformation", "rule-id": "3", "rule-name": "3", "rule-action": "rename", "rule-target": "table-tablespace", "object-locator": { "schema-name": "INVENTORY", "table-name": "%", "table-tablespace-name": "%" }, "value": "INVENTORYTBL"},{ "rule-type": "transformation", "rule-id": "4", "rule-name": "4", "rule-action": "rename", "rule-target": "index-tablespace", "object-locator": { "schema-name": "INVENTORY", "table-name": "%", "index-tablespace-name": "%" }, "value": "INVENTORYIDX"
API-Version API Version 2016-01-01494

AWS Database Migration Service BenutzerhandbuchVerbessern der Leistung beim
Migrieren umfangreicher Tabellen
}
Weitere Informationen zu Umwandlungen finden Sie unter Festlegen der Tabellenauswahl undTransformationen durch Tabellenzuweisungen mit JSON (p. 377).
Verbessern der Leistung beim Migrierenumfangreicher Tabellen
Wenn Sie die Leistung beim Migrieren großer Tabellen verbessern möchten, können Sie die Migrationin mehr als eine Aufgabe unterteilen. Sie können einen Schlüssel oder einen Partitionsschlüsselverwenden, um die Migration mittels Zeilenfilterung in mehrere Aufgaben aufzuteilen. Mit einer Ganzzahl-Primärschlüssel-ID von 1 bis 8.000.000 können Sie mittels Zeilenfilterung acht Aufgaben erstellen, umjeweils eine Million Datensätze zu migrieren.
Um die Zeilenfilterung in der AWS Management Console anzuwenden, öffnen Sie die Konsole,wählen Tasks (Aufgaben) und erstellen eine neue Aufgabe. Fügen Sie im Abschnitt Table mappings(Tabellenzuordnungen) einen Wert für Selection Rule (Auswahlregel) hinzu. Sie können danneinen Spaltenfilter mit der Bedingung "kleiner oder gleich", "größer oder gleich", "gleich" oder einerBereichsbedingung (zwischen zwei Werten) hinzufügen. Weitere Informationen zur Spaltenfilterung findenSie unter Festlegen der Tabellenauswahl und Transformationen durch Tabellenzuweisungen über dieKonsole (p. 372).
Alternativ können Sie bei einer großen Tabelle, die nach Datum partitioniert ist, Daten basierend auf demDatum migrieren. Angenommen, Sie haben eine Tabelle nach Monaten partitioniert und nur die Daten desaktuellen Monats werden aktualisiert. In diesem Fall können Sie für jede statische Monatspartition eineVolllastaufgabe und für die aktuell aktualisierte Partition eine Volllast- + CDC-Aufgabe erstellen.
Verwenden Ihres eigenen On-Premise-Nameservers
Normalerweise verwendet eine AWS DMS-Replikations-Instance den DNS-Resolver in einer EC2-Instance,um Domänenendpunkte aufzulösen. Sie können jedoch Ihren eigenen lokalen Nameserver verwenden,um bestimmte Endpunkte aufzulösen, wenn Sie den AWS Route 53 DNS-Resolver verwenden. Es handeltsich dabei um eine Reihe von Funktionen, die eine bidirektionale Abfrage zwischen On-Premises undAWS über private Verbindungen ermöglichen. Sie verwenden eingehende und ausgehende Endpunkte,Weiterleitungsregeln und eine private Verbindung über DirectConnect (DX) oder Virtual Private Network(VPN), um den AWS Route 53 DNS-Resolver zu aktivieren.
Die Funktion für eingehende Abfragen wird von Endpunkten bereitgestellt, die DNS-Abfragen lokalenUrsprungs ermöglichen, von AWS gehostete Domänen aufzulösen. Die Endpunkte werden durchZuweisung der IP-Adresse in jedem Subnetz konfiguriert, für das Sie einen Resolver bereitstellen möchten.Die Verbindung zwischen Ihrer lokalen DNS-Infrastruktur und AWS muss über ein Direct Connect- (DX)oder ein Virtual Private Network (VPN) hergestellt werden.
Ausgehende Endpunkte stellen eine Verbindung zu Ihrem lokalen Nameserver her. Die Sicherheitsgruppedes ausgehenden Endpunkts muss mit der Sicherheitsgruppe der Replikations-Instance übereinstimmen.Dazu müssen die IP-Adressen, die in dem ausgehenden Endpunkt festgelegt sind, in dem Nameserver aufdie Whitelist gesetzt werden (Zugriff gewährt). Die IP-Adresse Ihres Nameservers ist die Ziel-IP-Adresse.
Weiterleitungsregeln werden verwendet, um Domänen auszuwählen, die an den Nameserver weitergeleitetwerden sollen. Für einen ausgehenden Endpunkt können mehrere Weiterleitungsregeln vorhandensein. Der Geltungsbereich der Weiterleitungsregel ist die Virtual Private Cloud (VPC). Mit einer
API-Version API Version 2016-01-01495
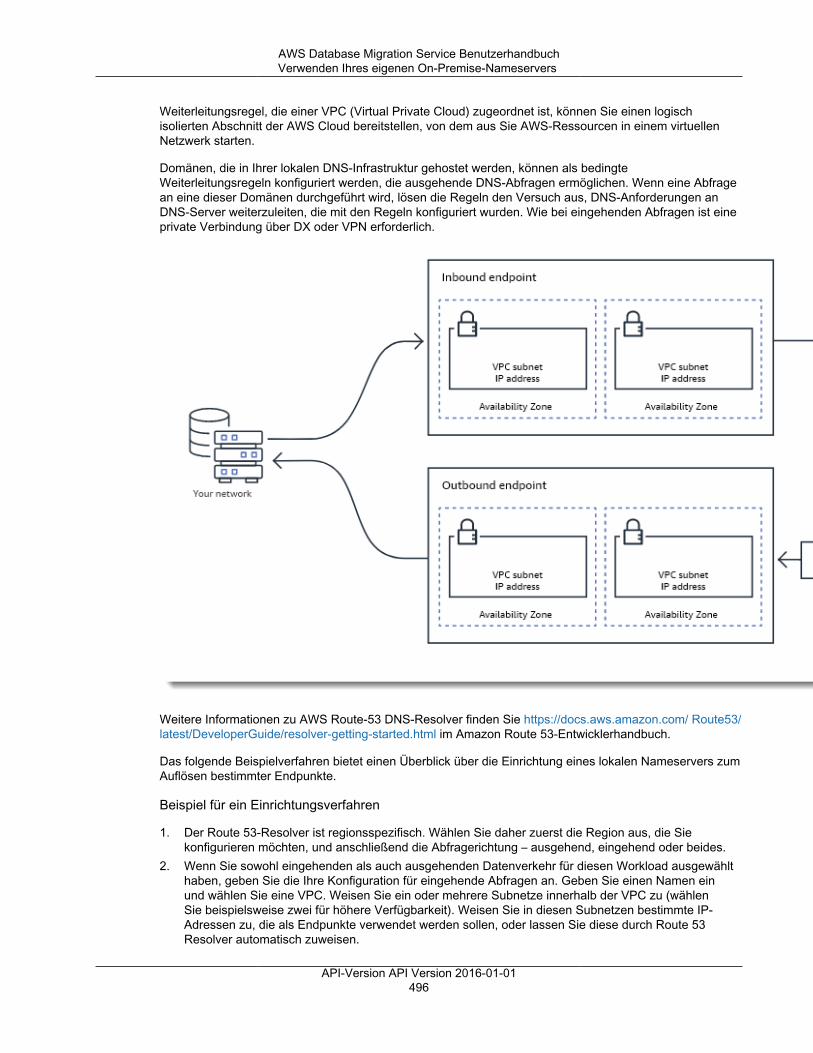
AWS Database Migration Service BenutzerhandbuchVerwenden Ihres eigenen On-Premise-Nameservers
Weiterleitungsregel, die einer VPC (Virtual Private Cloud) zugeordnet ist, können Sie einen logischisolierten Abschnitt der AWS Cloud bereitstellen, von dem aus Sie AWS-Ressourcen in einem virtuellenNetzwerk starten.
Domänen, die in Ihrer lokalen DNS-Infrastruktur gehostet werden, können als bedingteWeiterleitungsregeln konfiguriert werden, die ausgehende DNS-Abfragen ermöglichen. Wenn eine Abfragean eine dieser Domänen durchgeführt wird, lösen die Regeln den Versuch aus, DNS-Anforderungen anDNS-Server weiterzuleiten, die mit den Regeln konfiguriert wurden. Wie bei eingehenden Abfragen ist eineprivate Verbindung über DX oder VPN erforderlich.
Weitere Informationen zu AWS Route-53 DNS-Resolver finden Sie https://docs.aws.amazon.com/ Route53/latest/DeveloperGuide/resolver-getting-started.html im Amazon Route 53-Entwicklerhandbuch.
Das folgende Beispielverfahren bietet einen Überblick über die Einrichtung eines lokalen Nameservers zumAuflösen bestimmter Endpunkte.
Beispiel für ein Einrichtungsverfahren
1. Der Route 53-Resolver ist regionsspezifisch. Wählen Sie daher zuerst die Region aus, die Siekonfigurieren möchten, und anschließend die Abfragerichtung – ausgehend, eingehend oder beides.
2. Wenn Sie sowohl eingehenden als auch ausgehenden Datenverkehr für diesen Workload ausgewählthaben, geben Sie die Ihre Konfiguration für eingehende Abfragen an. Geben Sie einen Namen einund wählen Sie eine VPC. Weisen Sie ein oder mehrere Subnetze innerhalb der VPC zu (wählenSie beispielsweise zwei für höhere Verfügbarkeit). Weisen Sie in diesen Subnetzen bestimmte IP-Adressen zu, die als Endpunkte verwendet werden sollen, oder lassen Sie diese durch Route 53Resolver automatisch zuweisen.
API-Version API Version 2016-01-01496
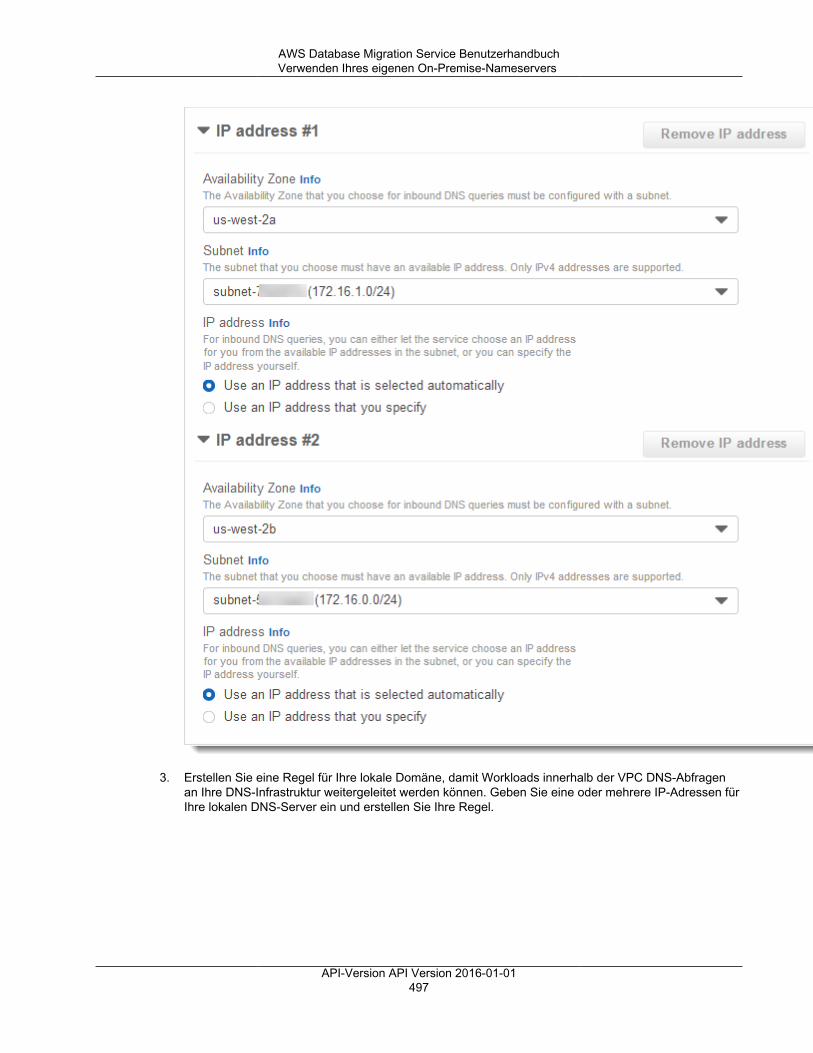
AWS Database Migration Service BenutzerhandbuchVerwenden Ihres eigenen On-Premise-Nameservers
3. Erstellen Sie eine Regel für Ihre lokale Domäne, damit Workloads innerhalb der VPC DNS-Abfragenan Ihre DNS-Infrastruktur weitergeleitet werden können. Geben Sie eine oder mehrere IP-Adressen fürIhre lokalen DNS-Server ein und erstellen Sie Ihre Regel.
API-Version API Version 2016-01-01497
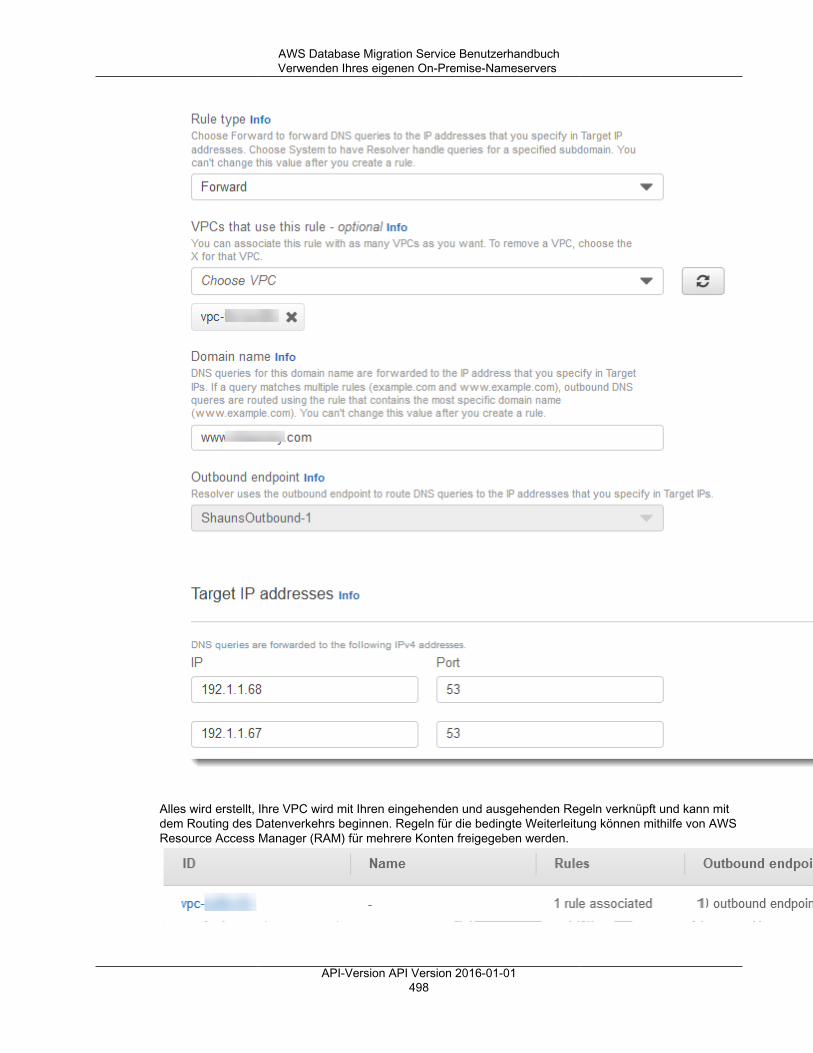
AWS Database Migration Service BenutzerhandbuchVerwenden Ihres eigenen On-Premise-Nameservers
Alles wird erstellt, Ihre VPC wird mit Ihren eingehenden und ausgehenden Regeln verknüpft und kann mitdem Routing des Datenverkehrs beginnen. Regeln für die bedingte Weiterleitung können mithilfe von AWSResource Access Manager (RAM) für mehrere Konten freigegeben werden.
API-Version API Version 2016-01-01498

AWS Database Migration Service BenutzerhandbuchAWS DMS-Datentypen
AWS DMS-ReferenzIn diesem Referenzabschnitt finden Sie zusätzliche Informationen, die Sie bei der Verwendung von AWSDatabase Migration Service (AWS DMS) möglicherweise benötigen, einschließlich Informationen zurDatentypkonvertierung.
AWS DMS verwaltet Datentypen, wenn Sie eine homogene Datenbankmigration durchführen, bei derQuelle und Ziel denselben Engine-Typ verwenden. Wenn Sie eine heterogene Migration durchführen,bei der von einem Datenbank-Engine-Typ zu einem andersartigen Datenbank-Engine-Typ migriertwird, werden die Datentypen in einen vorübergehenden Datentyp konvertiert. Um festzustellen, wie dieDatentypen in der Zieldatenbank angezeigt werden, sehen Sie sich die Datentyptabellen für die Quell- undZiel-Datenbank-Engines an.
Es gibt einige wichtige Aspekte, die Sie hinsichtlich der Datentypen bei der Datenbankmigrationberücksichtigen sollten:
• Der FLOAT-Datentyp ist ein Näherungswert. Wenn Sie einen bestimmten Wert von FLOAT einfügen,wird er in der Datenbank möglicherweise anders dargestellt. Dieser Unterschied entsteht, weil FLOATkein präziser Datentyp ist, wie beispielsweise ein Dezimaldatentyp wie NUMBER oder NUMBER(p, s).Dies hat zur Folge, dass sich der interne Wert des in der Datenbank gespeicherten FLOAT von dem vonIhnen eingefügten Wert unterscheidet. Daher stimmt der migrierte Wert eines FLOAT möglicherweisenicht genau mit dem Wert in der Quelldatenbank überein.
Weitere Informationen zu diesem Problem finden Sie in den folgenden Artikeln:• IEEE-Gleitkommawerte in Wikipedia• Darstellung von IEEE-Gleitkommawerten auf MSDN• Warum Gleitkommazahlen ihre Genauigkeit verlieren können auf MSDN
Themen• Datentypen für AWS Database Migration Service (p. 499)
Datentypen für AWS Database Migration ServiceAWS Database Migration Service verwendet integrierte Datentypen für die Migration von Daten einesDatenbank-Engine-Typs zu einem anderen Datenbank-Engine-Typ. In der folgenden Tabelle sind dieintegrierten Datentypen mit ihren Beschreibungen aufgeführt.
AWS DMS-Datentypen Beschreibung
STRING Eine Zeichenfolge
WSTRING Eine Doppelbyte-Zeichenfolge
BOOLEAN Ein Boolescher Wert
BYTES Ein binärer Datenwert
DATUM Ein Datumswert: Jahr, Monat, Tag
TIME Ein Zeitwert: Stunden, Minuten, Sekunden
API-Version API Version 2016-01-01499
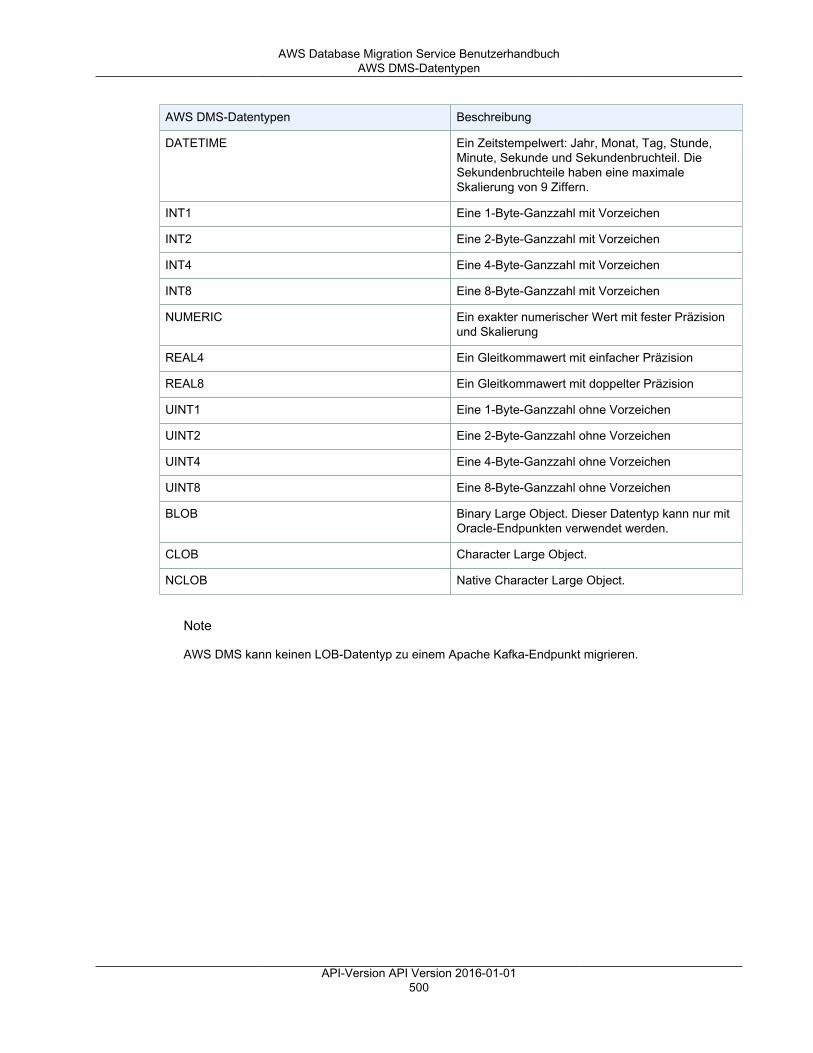
AWS Database Migration Service BenutzerhandbuchAWS DMS-Datentypen
AWS DMS-Datentypen Beschreibung
DATETIME Ein Zeitstempelwert: Jahr, Monat, Tag, Stunde,Minute, Sekunde und Sekundenbruchteil. DieSekundenbruchteile haben eine maximaleSkalierung von 9 Ziffern.
INT1 Eine 1-Byte-Ganzzahl mit Vorzeichen
INT2 Eine 2-Byte-Ganzzahl mit Vorzeichen
INT4 Eine 4-Byte-Ganzzahl mit Vorzeichen
INT8 Eine 8-Byte-Ganzzahl mit Vorzeichen
NUMERIC Ein exakter numerischer Wert mit fester Präzisionund Skalierung
REAL4 Ein Gleitkommawert mit einfacher Präzision
REAL8 Ein Gleitkommawert mit doppelter Präzision
UINT1 Eine 1-Byte-Ganzzahl ohne Vorzeichen
UINT2 Eine 2-Byte-Ganzzahl ohne Vorzeichen
UINT4 Eine 4-Byte-Ganzzahl ohne Vorzeichen
UINT8 Eine 8-Byte-Ganzzahl ohne Vorzeichen
BLOB Binary Large Object. Dieser Datentyp kann nur mitOracle-Endpunkten verwendet werden.
CLOB Character Large Object.
NCLOB Native Character Large Object.
Note
AWS DMS kann keinen LOB-Datentyp zu einem Apache Kafka-Endpunkt migrieren.
API-Version API Version 2016-01-01500

AWS Database Migration Service BenutzerhandbuchVersionshinweise zu AWS DMS 3.3.2
AWS DMS-VersionshinweiseIm Folgenden finden Sie Versionshinweise für Versionen von AWS Database Migration Service (AWSDMS).
Note
• AWS DMS-Version 3.3.0 ist jetzt veraltet. Sie können Ihre Version 3.3.0 direkt auf Version 3.3.2aktualisieren.
• AWS DMS-Version 3.1.3 ist jetzt eingestellt. Sie können Ihre Version 3.1.3 direkt auf Version3.3.2 aktualisieren.
Die folgende Tabelle zeigt die derzeit unterstützten Upgrade-Pfade von einer beliebigen AWS DMS-Versionzu einer späteren Version.
Upgrade von dieser Version... Zu dieser Version...
2.4.4 3.3.2
2.4.5 3.3.2
3.1.2 3.3.2
3.1.3 3.3.2
3.1.4 3.3.2
3.3.0 3.3.2
3.3.1 3.3.2
Versionshinweise zu AWS Database MigrationService (AWS DMS) 3.3.2
Die folgende Tabelle zeigt die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 3.3.2.
Neue Funktion oderVerbesserung
Beschreibung
Datentransformationen Fügt Unterstützung zur Tabellenzuordnung für die Verwendungvon Ausdrücken mit ausgewählten Regelaktionen desTransformationsregeltyps hinzu. Weitere Informationen finden Sie unterVerwenden von Transformationsregelausdrücken zum Definieren vonSpalteninhalten (p. 395). Dies beinhaltet auch Unterstützung für dasHinzufügen des Vorher-Abbilds aktualisierter oder gelöschter Spaltenim JSON, die entweder in Kinesis Data Streams oder Apache Kafka alsZiel geschrieben wurden. Dies beinhaltet eine Auswahl aller Spalten ausder Quelle, der Primärschlüsselspalte oder aus Spalten ohne LOBs alsseparates Feld. Weitere Informationen finden Sie unter Vorher-Abbild-Aufgabeneinstellungen (p. 357).
API-Version API Version 2016-01-01501

AWS Database Migration Service BenutzerhandbuchVersionshinweise zu AWS DMS 3.3.1
Neue Funktion oderVerbesserung
Beschreibung
Neue Oracle-Version Oracle Version 19c wird jetzt als Quelle und Ziel unterstützt. BeachtenSie, dass diese Unterstützung derzeit nicht die Verwendung von OracleTransparent Data Encryption (TDE) mit Oracle Version 19c als Quellebeinhaltet.
Neue SQL Server-Version SQL Server 2019 wird jetzt als Quelle und Ziel unterstützt.
Unterstützung für LOBs inKafka als Ziel
Das Replizieren von LOB-Daten auf ein Kafka-Ziel wird jetzt unterstützt.
Unterstützung für dieteilweise Validierung vonLOBs
Unterstützung für die teilweise Validierung von LOBs für MySQL-,Oracle- und PostgreSQL-Endpunkte hinzugefügt.
Die Probleme werden wie folgt behoben.
• Mehrere auf die Datenvalidierung bezogene Fehlerbehebungen:• Validierung für lange Oracle-Typen deaktiviert.• Verbesserte Wiederholungsmechanismen basierend auf Treiberfehlercodes.• Behebung eines Problems, bei dem die Validierung beim Abrufen von Daten aus Quelle und Ziel
unbegrenzt hing.• Behebung eines Problems mit der PostgreSQL UUID-Typvalidierung.• Behebung mehrerer Probleme mit angehaltenen Validierungen.
• Behebung eines Problems, bei dem Datenverlust mit S3 als Ziel aufgetreten ist, wenn derReplikationsaufgabenprozess auf der Replikations-Instance abstürzte.
• Behebung eines Problems, bei dem Spalten mit Zeitstempeldatentypen nicht migriert wurden, wennAttributzuordnungen in Kinesis und Kafka verwendet wurden.
• Behebung eines Problems, bei dem Replikationsaufgaben mit Oracle oder PostgreSQL als Quelle in denStatus „fehlgeschlagen“ wechselten, wenn versucht wurde, sie anzuhalten.
• Behebung eines Problems, bei dem Batch-Anwendungen für Replizierungen zu Redshift bei Verwendungvon zusammengesetzten Primärschlüsseln nicht wie erwartet funktionierten.
• Behebung eines Speicherproblems in der Replikations-Instance bei der Verwendung von MariaDB alsQuelle.
• Behebung eines Problems, bei dem AWS DMS anstelle der erwarteten Nullwerte Zufallswerte in ein S3-Ziel einfügte.
Versionshinweise zu AWS Database MigrationService (AWS DMS) 3.3.1
Die folgende Tabelle zeigt die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 3.3.1.
Neue Funktion oderVerbesserung
Beschreibung
Unterstützung fürbidirektionale Replikation
Fügt Unterstützung für die Replikation von Änderungen zwischen zweiverschiedenen Datenbanken unter Verwendung von zwei gleichzeitigen
API-Version API Version 2016-01-01502
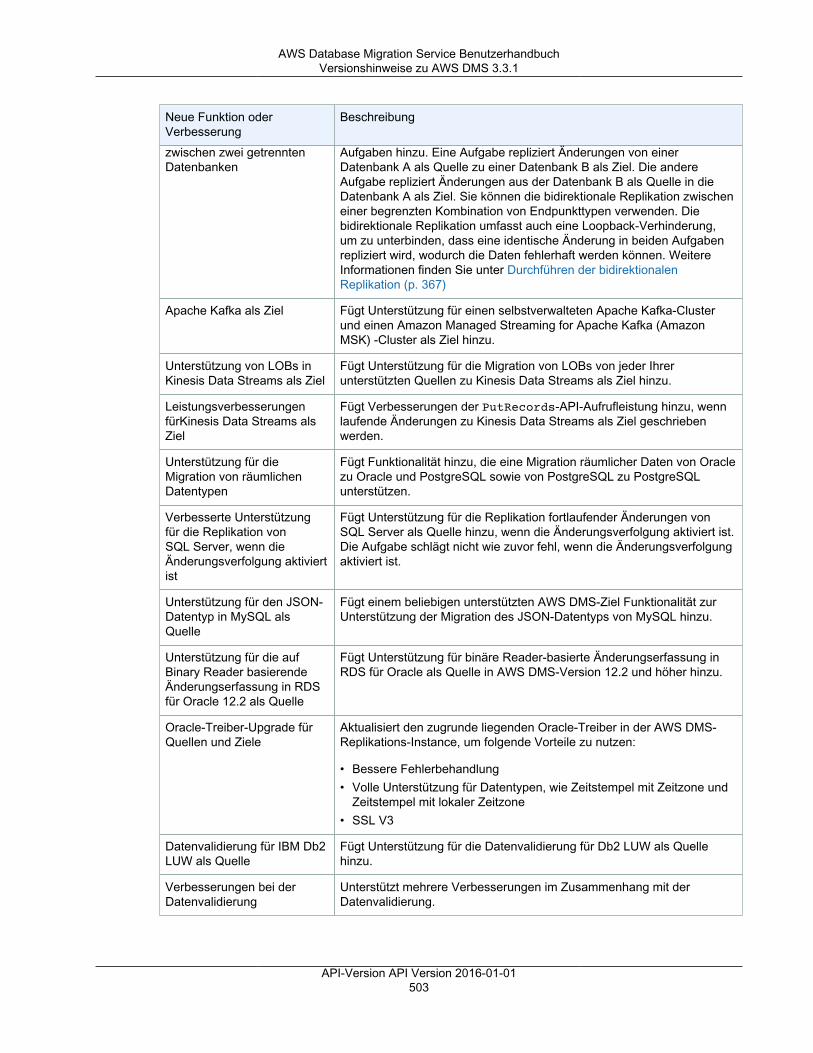
AWS Database Migration Service BenutzerhandbuchVersionshinweise zu AWS DMS 3.3.1
Neue Funktion oderVerbesserung
Beschreibung
zwischen zwei getrenntenDatenbanken
Aufgaben hinzu. Eine Aufgabe repliziert Änderungen von einerDatenbank A als Quelle zu einer Datenbank B als Ziel. Die andereAufgabe repliziert Änderungen aus der Datenbank B als Quelle in dieDatenbank A als Ziel. Sie können die bidirektionale Replikation zwischeneiner begrenzten Kombination von Endpunkttypen verwenden. Diebidirektionale Replikation umfasst auch eine Loopback-Verhinderung,um zu unterbinden, dass eine identische Änderung in beiden Aufgabenrepliziert wird, wodurch die Daten fehlerhaft werden können. WeitereInformationen finden Sie unter Durchführen der bidirektionalenReplikation (p. 367)
Apache Kafka als Ziel Fügt Unterstützung für einen selbstverwalteten Apache Kafka-Clusterund einen Amazon Managed Streaming for Apache Kafka (AmazonMSK) -Cluster als Ziel hinzu.
Unterstützung von LOBs inKinesis Data Streams als Ziel
Fügt Unterstützung für die Migration von LOBs von jeder Ihrerunterstützten Quellen zu Kinesis Data Streams als Ziel hinzu.
LeistungsverbesserungenfürKinesis Data Streams alsZiel
Fügt Verbesserungen der PutRecords-API-Aufrufleistung hinzu, wennlaufende Änderungen zu Kinesis Data Streams als Ziel geschriebenwerden.
Unterstützung für dieMigration von räumlichenDatentypen
Fügt Funktionalität hinzu, die eine Migration räumlicher Daten von Oraclezu Oracle und PostgreSQL sowie von PostgreSQL zu PostgreSQLunterstützen.
Verbesserte Unterstützungfür die Replikation vonSQL Server, wenn dieÄnderungsverfolgung aktiviertist
Fügt Unterstützung für die Replikation fortlaufender Änderungen vonSQL Server als Quelle hinzu, wenn die Änderungsverfolgung aktiviert ist.Die Aufgabe schlägt nicht wie zuvor fehl, wenn die Änderungsverfolgungaktiviert ist.
Unterstützung für den JSON-Datentyp in MySQL alsQuelle
Fügt einem beliebigen unterstützten AWS DMS-Ziel Funktionalität zurUnterstützung der Migration des JSON-Datentyps von MySQL hinzu.
Unterstützung für die aufBinary Reader basierendeÄnderungserfassung in RDSfür Oracle 12.2 als Quelle
Fügt Unterstützung für binäre Reader-basierte Änderungserfassung inRDS für Oracle als Quelle in AWS DMS-Version 12.2 und höher hinzu.
Oracle-Treiber-Upgrade fürQuellen und Ziele
Aktualisiert den zugrunde liegenden Oracle-Treiber in der AWS DMS-Replikations-Instance, um folgende Vorteile zu nutzen:
• Bessere Fehlerbehandlung• Volle Unterstützung für Datentypen, wie Zeitstempel mit Zeitzone und
Zeitstempel mit lokaler Zeitzone• SSL V3
Datenvalidierung für IBM Db2LUW als Quelle
Fügt Unterstützung für die Datenvalidierung für Db2 LUW als Quellehinzu.
Verbesserungen bei derDatenvalidierung
Unterstützt mehrere Verbesserungen im Zusammenhang mit derDatenvalidierung.
API-Version API Version 2016-01-01503

AWS Database Migration Service BenutzerhandbuchVersionshinweise zu AWS DMS 3.3.1
Neue Funktion oderVerbesserung
Beschreibung
Verbesserungen bei S3 alsZiel (Data Lake)
Fügt Funktionalität hinzu, um Einfügungen und Aktualisierungen nur fürAmazon S3 als Ziel zu erfassen und zu replizieren.
Verbesserungen beiDynamoDB als Ziel
Fügt Unterstützung für die Migration des CLOB-Datentyps zu AmazonDynamoDB als Ziel hinzu.
Die Probleme werden wie folgt behoben.
• Es wurde ein Problem behoben, bei dem die fortlaufende Replikation auf PostgreSQL 11+ als Quelle mitAWS DMS 3.3.0 Beta fehlschlägt.
• Die folgenden Probleme im Zusammenhang mit der Replikation laufender Änderungen im Parquet/CSV-Format in Amazon S3 wurden behoben:• Es wurde ein Problem mit fehlenden Daten in CSV/Parquet-Dateien beim Anhalten und Fortsetzen der
Aufgabe behoben.• Fehler bei der Replikation von Nulldaten im Parquet-Format behoben.• Die Verarbeitung von INT-Typen beim Replizieren von Daten im Parquet-Format wurde korrigiert.• Es wurde ein Problem behoben, durch das eine fortlaufende Replikationsaufgabe mit S3 als Ziel von
einer Race-Bedingung im Replikationsmodul fehlschlägt.• Es wurde ein Segmentierungsfehler behoben, der auftrat, wenn laufende Änderungen im Parquet-
Format in S3 als Ziel geschrieben wurden.• Es wurde ein Problem in Kinesis Data Streams als Ziel behoben, das auftrat, wenn partition-key-type in der Objektzuweisung nicht auf primary-key eingestellt war.
• Es wurde ein Problem bei der Datenvalidierung behoben, bei dem ein Massenabruf während derlaufenden Replikation eine hohe Latenz aufwies. Dies verursacht Probleme mit Validierungsmetriken.
• Es wurde ein Speicherverlust in der AWS DMS-Replikations-Instance in Version 3.3 behoben, durch denReplikationsaufgaben beendet wurden.
• Es wurde ein Problem mit einem parallelen partitionsbasierten Entladen von Oracle als Quelle behoben,bei dem Metadatenabfragen, die zum Erstellen von Lesevorgängen von jeder Partition verwendetwerden, langsam waren und gelegentlich hingen.
• Es wurde ein Problem behoben, durch das der datetime-Datentyp in Oracle nicht wie erwartet auf dieZiele RDS für PostgreSQL und Aurora PostgreSQL migriert wurde.
• Ein Problem mit fehlenden Daten wurde behoben, das auftrat, wenn laufende Änderungen von Oracle alsQuelle zu Amazon Redshift repliziert wurden.
• Mehrere Protokollierungsprobleme für Ziele wie Amazon S3 und Amazon Redshift wurden behoben.• Es wurde ein Problem behoben, durch das DMS auf die Verwendung von Speicherpunkten für
PostgreSQL als Ziel wechselt, in einer Schleife stecken bleibt und nicht mehr von der Speicherpunkt-Verwendung zurückwechselt und dadurch Speicherdruck verursacht.
• Es wurde ein Problem behoben, bei dem das auf automatisches partitionieren basierte Entladen nicht wieerwartet mit Db2 LUW als Quelle funktioniert.
• Es wurde ein Problem behoben, bei dem AWS DMS die Trennung vom Oplog für die MongoDB-Quellenicht reibungslos behandelt und weiterhin funktioniert, ohne Probleme beim Trennen zu melden.
• Es wurde ein Problem behoben, bei dem Nulldaten nicht wie erwartet behandelt werden, wenn sie zuPostgreSQL und Redshift als Ziel migriert wurden.
• Es wurde ein timestamp-Formatierungsproblem in Kinesis Data Streams, DynamoDB und Elasticsearchals Ziel behoben. Wenn die Genauigkeit für Sekunden einstellig ist, enthält sie keine zusätzliche 0-Polsterung.
API-Version API Version 2016-01-01504

AWS Database Migration Service BenutzerhandbuchAWS DMS 3.3.0 – Versionshinweise
• Es wurde ein Problem mit allen relationalen Zielen behoben, bei denen eine Anweisung zurTabellenänderung fälschlicherweise einen NULL-Parameter enthält. Dies führt zu einer unerwartetenÄnderung der Nullbarkeit der Zielspalte.
AWS Database Migration Service (AWS DMS) 3.3.0Beta – Versionshinweise
Die folgenden Tabellen zeigen die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 3.3.0 Beta.
Note
Version 3.3.0 ist jetzt veraltet. Sie können Ihre Version 3.3.0 direkt auf Version 3.3.2 aktualisieren.
Neue Funktion oderVerbesserung
Beschreibung
Neue Oracle-Versionen Oracle 18c wird jetzt als Quell- und Ziel-Endpunkt unterstützt.
Neue PostgreSQL-Versionen PostgreSQL-Version 10.x und 11.x werden jetzt als Quell- und Ziel-Endpunkt unterstützt.
Erweiterungen für Oracle alsQuellendpunkt
Unterstützung für Folgendes wurde hinzugefügt:
• Verschachtelte Tabellen.• Der Befehl RESETLOGS.• Steuert die Anzahl der parallel gelesenen Threads und der Read-
Ahead-Puffer für Oracle Automatic Storage Management (ASM),wenn Änderungen für eine Change Data Capture (CDC)-Last erfasstwerden. Weitere Informationen zu diesen Erweiterungen für dieVerwendung mit Oracle ASM finden Sie unter Konfiguration für CDC(Change Data Capture) auf einer Oracle-Quelldatenbank (p. 127).
Erweiterungen fürMicrosoft SQL Server alsQuellendpunkt
Erweiterter AlwaysOn-Support hinzugefügt. Sie können jetzt Änderungenaus einem AlwaysOn-Replikat migrieren.
Support für großeAktualisierungen für AmazonDynamoDB
Zusätzlicher Support, um große Aktualisierungen in mehrere Blöckemit weniger als 4 KB pro Element aufzuteilen, die anschließend aufDynamoDB angewendet werden. So können mögliche Einschränkungenbei den Aktualisierungen umgangen werden. Eine Warnmeldung weistdarauf hin, wenn dies geschieht.
Die Probleme werden wie folgt behoben.
• Es wurde ein Problem behoben, bei dem DMS keine Verbindung zu einer Azure SQL Server-Quelleherstellen konnte.
• Es wurde ein Problem behoben, bei dem JSON-LOB-Spalten in PostgreSQL nicht korrekt migriertwurden.
• Es wurde ein Problem behoben, bei dem 0000-00-00 Datumsangaben in einer MySQL-auf-MySQL-Migration als 0101-01-01 migriert wurden.
• Es wurde ein Problem behoben, bei dem DMS nicht in der Lage war, eine Tabelle mit einer numerischenArray-Spalte während der fortlaufenden Replikation nach PostgreSQL zu erstellen.
API-Version API Version 2016-01-01505

AWS Database Migration Service BenutzerhandbuchAWS DMS 3.1.4 – Versionshinweise
• Es wurde ein Problem behoben, bei dem Aktualisierungen nicht auf die Ziel-Amazon Redshift-Instanceangewendet wurden, wenn die Tabelle nicht über einen PS verfügt.
• Es wurde ein Problem behoben, bei dem DMS keine Tabellen aus Schema auswählen konnte, derenNamen in PostgreSQL-Quellen mit "pg%" beginnen.
• Es wurde ein Problem behoben, bei dem eine Aufgabe fehlschlug, wenn ein boolescher Wert bei derMigration von Aurora PostgreSQL nach Amazon Redshift migriert wurde.
• Es wurde ein Problem behoben, bei dem Sonderzeichen mit EUC_JP-Kodierung nicht korrekt vonPostgreSQL nach PostgreSQL migriert wurden.
• Es wurde ein Problem behoben, bei dem eine DMS-Aufgabe fehlschlug, da sie die aws_dms_apply_exceptions-Steuerungstabelle nicht erstellen konnte.
• Es wurde ein Problem behoben, bei dem der SQL Server und Oracle als Quelle bei der fortlaufendenReplikation zu einem bestimmten Zeitpunkt mit dem Fehler „"Not a valid time value supplied“ (Keingültiger Zeitwert angegeben) fehlschlugen.
• Es wurde ein Problem behoben, bei dem die fortlaufende Replikation unterbrochen wird, wenn eineTabelle über einen Primärschlüssel und eine eindeutige Einschränkung verfügt sowie laufendeÄnderungen an der eindeutigen Einschränkungs-Spalte vorgenommen werden.
• Es wurde ein Problem behoben, bei dem die Migration der MySQL-TIMESTAMP(0)-Spalte dazu führte,dass das Replizieren der Änderungen eingestellt wurde.
AWS Database Migration Service (AWS DMS)3.1.4 – Versionshinweise
Die folgende Tabelle zeigt die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 3.1.4.
Neue Funktion oderVerbesserung
Beschreibung
Hinzufügen einer Quell-Commit-Zeitstempelspalte zuden Amazon S3 Zieldateien
Sie können jetzt einen Zielendpunkt festlegen, um die Quell-Commit-Zeitstempel bei der Migration nach S3 in .csv- oder .parquet-Dateien ineine zusätzliche Spalte einzugeben. Sie können auch den Namen derzusätzlichen Spalte angeben. Weitere Informationen finden Sie untertimestampColumnName.
Einbeziehen derOperationsspalte fürvollständige Ladevorgänge inAmazon S3-Zieldateien
Um S3-Zieldateien sowohl für vollständige Ladevorgänge als auchfür die fortlaufende Replikation konsistent zu halten, können Sie jetzteinen Zielendpunkt festlegen, über den während eines vollständigenLadevorgangs eine Operationsspalte hinzugefügt wird (nur .csv-Format).Weitere Informationen finden Sie unter includeOpForFullLoad.
Konsistende Gestaltung derFormate für die Amazon S3-Quell- und Amazon S3-Ziel-Dateien
Verbesserungen hinzugefügt, um das S3 Quelldateiformat mit demS3-Ziel-Dateiformat konsistent zu gestalten. Weitere Informationendarüber, wie die Werte der Operationsspalten in S3-Dateien codiertwerden, finden Sie in den Hinweisen unter Verwenden von AmazonS3 als Quelle für AWS DMS (p. 201). Weitere Informationen zuden Kodierungsoptionen dieser Werte finden Sie unter Angabe vonQuelldatenbankoperationen in migrierten S3-Daten (p. 269).
Genauigkeitsangaben fürTIMESTAMP-Spalten inAmazon S3-Zieldateienim .parquet-Dateiformat
Nur bei S3-Zieldateien im .parquet-Format können Sie angeben, obdie Genauigkeit der TIMESTAMP-Spalten entweder in Mikrosekundenoder Millisekunden angebeben wird. Aufgrund der Angabe inMillisekunde können die Daten mithilfe von Amazon Athena und AWS
API-Version API Version 2016-01-01506

AWS Database Migration Service BenutzerhandbuchAWS DMS 3.1.4 – Versionshinweise
Neue Funktion oderVerbesserung
Beschreibung
Glue verarbeitet werden. Weitere Informationen finden Sie unterparquetTimestampInMillisecond.
Multithread-Ladevorgängein Amazon Kinesis DataStreams
Diese Version von DMS ermöglicht aufgrund der Verwendung mehrererThreads schnellere Ladevorgänge in Kinesis Data Streams.
Support für großeAktualisierungen für AmazonDynamoDB
Zusätzlicher Support, um große Aktualisierungen in mehrere Blöckemit weniger als 4 KB pro Element aufzuteilen, die anschließend aufDynamoDB angewendet werden. So können mögliche Einschränkungenbei den Aktualisierungen umgangen werden. Eine Warnmeldung weistdarauf hin, wenn dies geschieht.
VerschiedeneLeistungsverbesserungen beider Datenvalidierung
Verschiedene Leistungsverbesserungen bei der Datenvalidierungwurden hinzugefügt, einschließlich der Fähigkeit zur Verarbeitungnullwertfähiger eindeutiger Schlüssel.
Verbesserungen bei derProtokollierung
Verschiedene Verbesserungen bei der Protokollierung hinzugefügt.
Die Probleme werden wie folgt behoben.
• Es wurde ein Problem behoben, bei dem DMS die Änderungen einer Oracle-Quelle nicht erfassenkonnte, wenn ASM konfiguriert war und parallele Lesevorgänge ausgeführt wurden.
• Es wurde ein Problem behoben, bei dem DMS die Änderungen an einer nvarchar-Spalteder Microsoft SQL Serverquellen nicht erfassen konnte, während die Änderungen derTransaktionsprotokollsicherungen gelesen wurden.
• Es wurde ein Problem behoben, bei dem eine DMS-Aufgabe abstürzte, da der Replikationsprozesskeine Details über eine Spalte in einer Tabelle finden konnte, für die die zusätzliche Protokollierung vonTabellenmetadaten in Oracle aktiviert war.
• Es wurde ein Problem behoben, bei dem DMS ungültige Parameter weiterleitete, wenn das Erfassen vonÄnderungen dort fortgesetzt werden sollte, wo es unterbrochen wurde. Stattdessen wurde nach älterenÄnderungen gesucht, die bereits gelöscht wurden.
• Geänderte Stream-Puffer-Nachrichten in werden in den DMS-Aufgabenprotokollen nur einmal und nichtmehrere Male protokolliert. Das mehrfache Protokollieren dieser Nachrichten führte dazu, dass sich derzugrunde liegende Speicher füllte, darüber hinaus traten auch andere Leistungsprobleme auf.
• Es wurde ein Fehler behoben, bei dem der Status einer Aufgabe beim Versuch eines Benutzers, dieAufgabe anzuhalten, als „Fehlgeschlagen“ und nicht als „Angehalten“ angegeben wurde.
• Es wurde ein Fehler mit der Segmentierung bei IBM Db2 für Linux, UNIX und Windows (Db2 LUW) alsQuelle behoben, wenn zusätzliche Verbindungsattribute mit Db2 als Quelle verwendet wurden.
• Es wurden mehrere Fehler bei der Kürzung und LOB-Kürzung behoben, wenn PostgreSQL als Quelleverwendet wurde.
• Es wurde ein Problem behoben, bei dem die Aufgabe auch beim Fehlen eines S3-Quell-Buckets nichtfehlschlug. Die Aufgabe schlägt jetzt fehlt und zeigt eine entsprechende Fehlermeldung an.
• Bei der Migration von S3-Daten in das Parquet-Dateiformat durch DMS wurde ein Speicherverlustbehoben.
• Dies schließt auch verschiedene Probleme bei der Datenvalidierung ein.• Es wurde ein Problem behoben, bei dem ein Befehl der Drop-Sammlung in MongoDB einen Fehler
verursachte, wenn die zu verwerfende Sammlung nicht im Aufgabenumfang enthalten war.• Es wurde ein Problem behoben, bei dem Aufgaben mit einem S3-Ziel-Endpunkt aufgrund von NULL-
Werten in den Daten abstürzten.
API-Version API Version 2016-01-01507

AWS Database Migration Service BenutzerhandbuchAWS DMS 3.1.3 – Versionshinweise
• Es wurde ein Problem behoben, bei dem Massenladevorgänge nach S3 langsam ausgeführt wurden,da neue Speicherpools erstellt wurden. Vollständige Ladevorgänge nach S3 erfolgen nun in DMS 3.1.420 Prozent schneller.
AWS Database Migration Service (AWS DMS) 3.1.3– Versionshinweise
Die folgende Tabellen zeigen die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 3.1.3.
Note
Version 3.1.3 ist jetzt eingestellt. Sie können Ihre Version 3.1.3 direkt auf Version 3.3.2aktualisieren.
Neue Funktion oderVerbesserung
Beschreibung
Support für AmazonDocumentDB (mit MongoDB-Kompatibilität) als Ziel
Sie können jetzt Amazon DocumentDB als Ziel verwenden und so einenschnellen, zuverlässigen und vollständig verwalteten Datenbank-Servicebereitstellen, der Ihnen das Einrichten, Betreiben und Skalieren vonMongoDB-kompatiblen Datenbanken erleichtert.
Apache Parquet-Speicherformat,Unterstützung für AmazonS3-Ziele
Sie können jetzt .parquet-Dateien als Speicherformat für S3-Zielobjekteauswählen und konfigurieren.
AWS Key ManagementService (AWS KMS)-Schlüsselverschlüsselungfür Amazon Redshift- undAmazon S3-Zieldaten
Sie können jetzt KMS-Schlüssel für die serverseitige Verschlüsselungvon Daten für Amazon Redshift- und S3-Ziele verwenden.
Erweiterte Auswahl undDatentransformation mitTabellenzuweisung
Sie können jetzt explizit eine Tabelle und deren Schema auswählen.Sie können auch Tabellen- und Index-Tabellenräume für ein Oracle-Ziel umwandeln und den primären Schlüssel für eine Tabelle auf einembeliebigen Ziel aktualisieren.
Markierungs-Support fürAmazon S3-Zielobjekte
Sie können jetzt beliebigen, in einem S3-Ziel-Bucket gespeichertenObjekten Tags zuordnen.
Von Microsoft SQL Server aufausgewählte Ziele migrierteTIMESTAMP-Datentypen
Von Microsoft SQL Server auf Amazon Elasticsearch Service- oderAmazon Kinesis-Ziele migrierte TIMESTAMP-Datentypen werden jetztvon binär auf hexadezimalverschlüsselte Zeichenfolgen (z. B. 0x654738)konvertiert. Bisher gingen diese TIMESTAMP-Werte bei der Zuordnungals Binärdaten verloren.
Übergänge zuProtokollierungsebeneDEFAULT oder INFO
AWS DMS protokolliert jetzt auch, wenn die Protokollebene zurück zuDEFAULT oder INFO geändert wird. Bisher wurden Übergänge aufdiesen Protokollebenen nicht protokolliert.
Datenvalidierung undFiltereinstellungen
Bei der Datenvalidierung werden jetzt die Zeilenfiltereinstellungenberücksichtigt, wenn Daten zwischen Quelle und Ziel validiert werden.
API-Version API Version 2016-01-01508
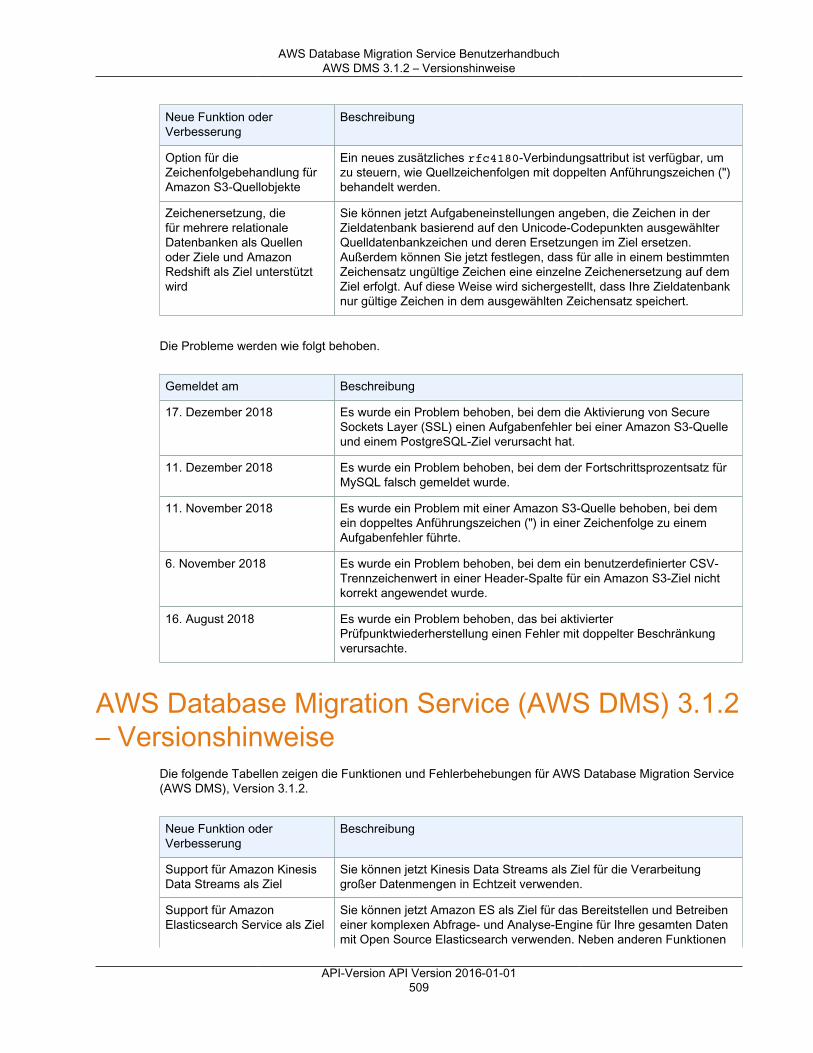
AWS Database Migration Service BenutzerhandbuchAWS DMS 3.1.2 – Versionshinweise
Neue Funktion oderVerbesserung
Beschreibung
Option für dieZeichenfolgebehandlung fürAmazon S3-Quellobjekte
Ein neues zusätzliches rfc4180-Verbindungsattribut ist verfügbar, umzu steuern, wie Quellzeichenfolgen mit doppelten Anführungszeichen (")behandelt werden.
Zeichenersetzung, diefür mehrere relationaleDatenbanken als Quellenoder Ziele und AmazonRedshift als Ziel unterstütztwird
Sie können jetzt Aufgabeneinstellungen angeben, die Zeichen in derZieldatenbank basierend auf den Unicode-Codepunkten ausgewählterQuelldatenbankzeichen und deren Ersetzungen im Ziel ersetzen.Außerdem können Sie jetzt festlegen, dass für alle in einem bestimmtenZeichensatz ungültige Zeichen eine einzelne Zeichenersetzung auf demZiel erfolgt. Auf diese Weise wird sichergestellt, dass Ihre Zieldatenbanknur gültige Zeichen in dem ausgewählten Zeichensatz speichert.
Die Probleme werden wie folgt behoben.
Gemeldet am Beschreibung
17. Dezember 2018 Es wurde ein Problem behoben, bei dem die Aktivierung von SecureSockets Layer (SSL) einen Aufgabenfehler bei einer Amazon S3-Quelleund einem PostgreSQL-Ziel verursacht hat.
11. Dezember 2018 Es wurde ein Problem behoben, bei dem der Fortschrittsprozentsatz fürMySQL falsch gemeldet wurde.
11. November 2018 Es wurde ein Problem mit einer Amazon S3-Quelle behoben, bei demein doppeltes Anführungszeichen (") in einer Zeichenfolge zu einemAufgabenfehler führte.
6. November 2018 Es wurde ein Problem behoben, bei dem ein benutzerdefinierter CSV-Trennzeichenwert in einer Header-Spalte für ein Amazon S3-Ziel nichtkorrekt angewendet wurde.
16. August 2018 Es wurde ein Problem behoben, das bei aktivierterPrüfpunktwiederherstellung einen Fehler mit doppelter Beschränkungverursachte.
AWS Database Migration Service (AWS DMS) 3.1.2– Versionshinweise
Die folgende Tabellen zeigen die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 3.1.2.
Neue Funktion oderVerbesserung
Beschreibung
Support für Amazon KinesisData Streams als Ziel
Sie können jetzt Kinesis Data Streams als Ziel für die Verarbeitunggroßer Datenmengen in Echtzeit verwenden.
Support für AmazonElasticsearch Service als Ziel
Sie können jetzt Amazon ES als Ziel für das Bereitstellen und Betreibeneiner komplexen Abfrage- und Analyse-Engine für Ihre gesamten Datenmit Open Source Elasticsearch verwenden. Neben anderen Funktionen
API-Version API Version 2016-01-01509
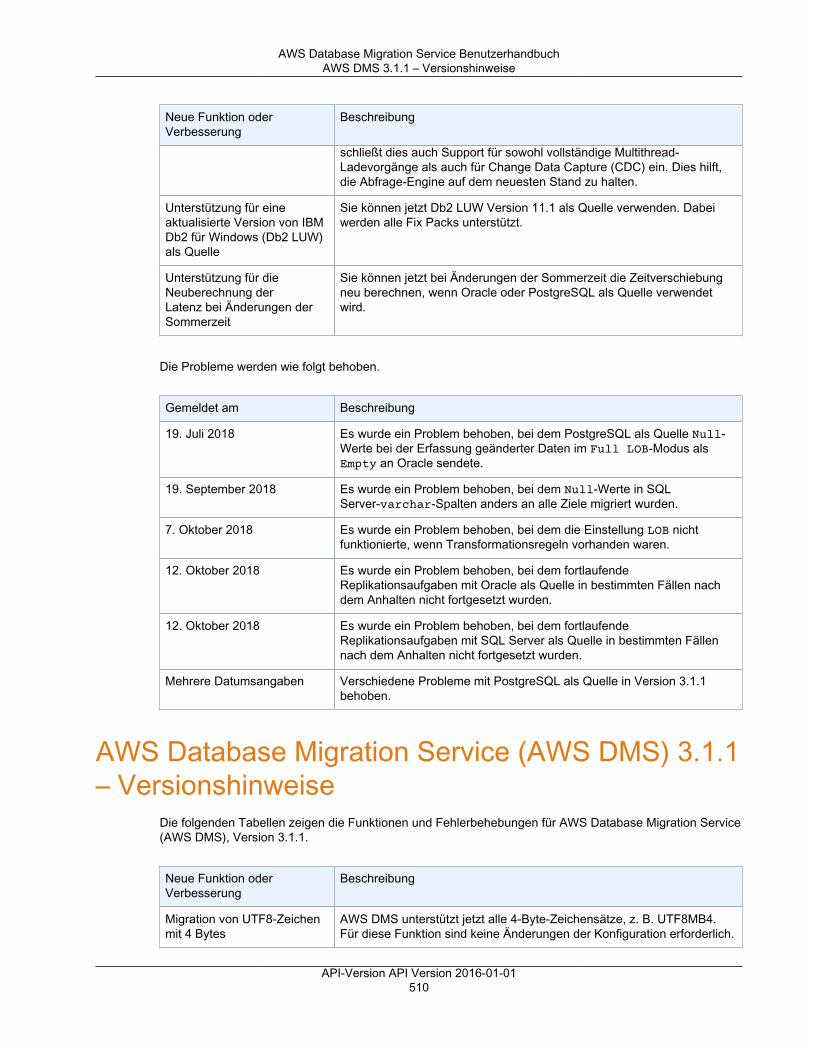
AWS Database Migration Service BenutzerhandbuchAWS DMS 3.1.1 – Versionshinweise
Neue Funktion oderVerbesserung
Beschreibung
schließt dies auch Support für sowohl vollständige Multithread-Ladevorgänge als auch für Change Data Capture (CDC) ein. Dies hilft,die Abfrage-Engine auf dem neuesten Stand zu halten.
Unterstützung für eineaktualisierte Version von IBMDb2 für Windows (Db2 LUW)als Quelle
Sie können jetzt Db2 LUW Version 11.1 als Quelle verwenden. Dabeiwerden alle Fix Packs unterstützt.
Unterstützung für dieNeuberechnung derLatenz bei Änderungen derSommerzeit
Sie können jetzt bei Änderungen der Sommerzeit die Zeitverschiebungneu berechnen, wenn Oracle oder PostgreSQL als Quelle verwendetwird.
Die Probleme werden wie folgt behoben.
Gemeldet am Beschreibung
19. Juli 2018 Es wurde ein Problem behoben, bei dem PostgreSQL als Quelle Null-Werte bei der Erfassung geänderter Daten im Full LOB-Modus alsEmpty an Oracle sendete.
19. September 2018 Es wurde ein Problem behoben, bei dem Null-Werte in SQLServer-varchar-Spalten anders an alle Ziele migriert wurden.
7. Oktober 2018 Es wurde ein Problem behoben, bei dem die Einstellung LOB nichtfunktionierte, wenn Transformationsregeln vorhanden waren.
12. Oktober 2018 Es wurde ein Problem behoben, bei dem fortlaufendeReplikationsaufgaben mit Oracle als Quelle in bestimmten Fällen nachdem Anhalten nicht fortgesetzt wurden.
12. Oktober 2018 Es wurde ein Problem behoben, bei dem fortlaufendeReplikationsaufgaben mit SQL Server als Quelle in bestimmten Fällennach dem Anhalten nicht fortgesetzt wurden.
Mehrere Datumsangaben Verschiedene Probleme mit PostgreSQL als Quelle in Version 3.1.1behoben.
AWS Database Migration Service (AWS DMS) 3.1.1– Versionshinweise
Die folgenden Tabellen zeigen die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 3.1.1.
Neue Funktion oderVerbesserung
Beschreibung
Migration von UTF8-Zeichenmit 4 Bytes
AWS DMS unterstützt jetzt alle 4-Byte-Zeichensätze, z. B. UTF8MB4.Für diese Funktion sind keine Änderungen der Konfiguration erforderlich.
API-Version API Version 2016-01-01510
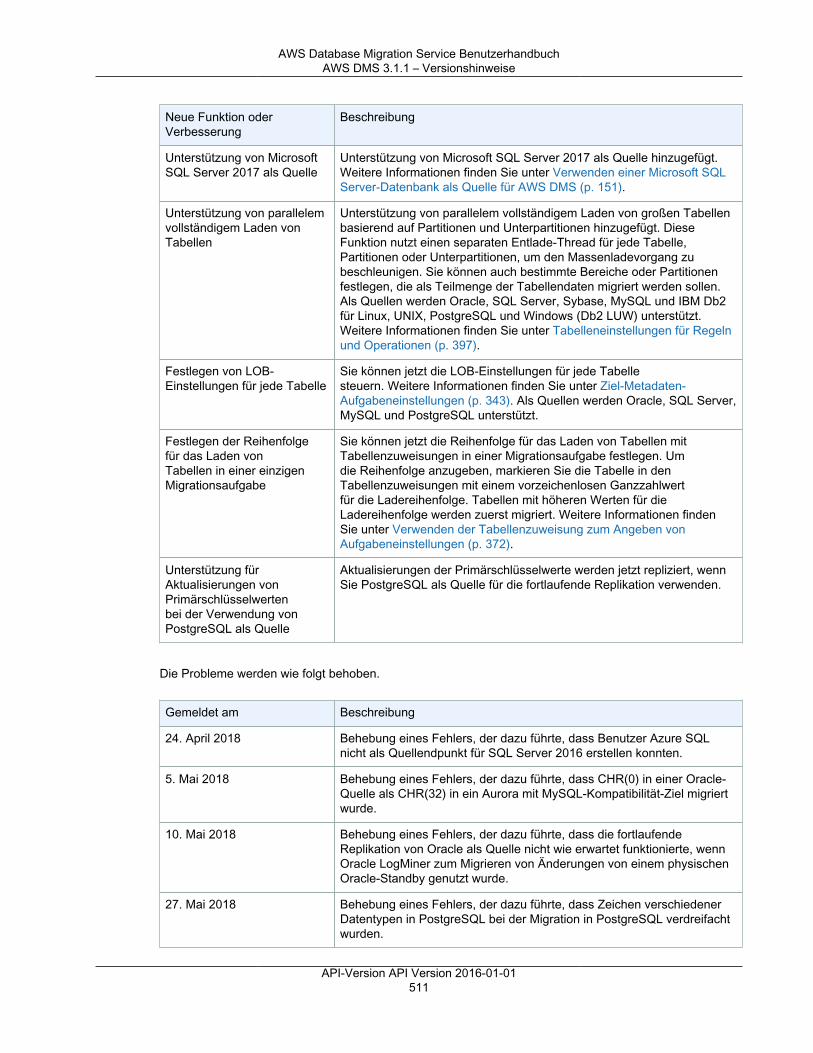
AWS Database Migration Service BenutzerhandbuchAWS DMS 3.1.1 – Versionshinweise
Neue Funktion oderVerbesserung
Beschreibung
Unterstützung von MicrosoftSQL Server 2017 als Quelle
Unterstützung von Microsoft SQL Server 2017 als Quelle hinzugefügt.Weitere Informationen finden Sie unter Verwenden einer Microsoft SQLServer-Datenbank als Quelle für AWS DMS (p. 151).
Unterstützung von parallelemvollständigem Laden vonTabellen
Unterstützung von parallelem vollständigem Laden von großen Tabellenbasierend auf Partitionen und Unterpartitionen hinzugefügt. DieseFunktion nutzt einen separaten Entlade-Thread für jede Tabelle,Partitionen oder Unterpartitionen, um den Massenladevorgang zubeschleunigen. Sie können auch bestimmte Bereiche oder Partitionenfestlegen, die als Teilmenge der Tabellendaten migriert werden sollen.Als Quellen werden Oracle, SQL Server, Sybase, MySQL und IBM Db2für Linux, UNIX, PostgreSQL und Windows (Db2 LUW) unterstützt.Weitere Informationen finden Sie unter Tabelleneinstellungen für Regelnund Operationen (p. 397).
Festlegen von LOB-Einstellungen für jede Tabelle
Sie können jetzt die LOB-Einstellungen für jede Tabellesteuern. Weitere Informationen finden Sie unter Ziel-Metadaten-Aufgabeneinstellungen (p. 343). Als Quellen werden Oracle, SQL Server,MySQL und PostgreSQL unterstützt.
Festlegen der Reihenfolgefür das Laden vonTabellen in einer einzigenMigrationsaufgabe
Sie können jetzt die Reihenfolge für das Laden von Tabellen mitTabellenzuweisungen in einer Migrationsaufgabe festlegen. Umdie Reihenfolge anzugeben, markieren Sie die Tabelle in denTabellenzuweisungen mit einem vorzeichenlosen Ganzzahlwertfür die Ladereihenfolge. Tabellen mit höheren Werten für dieLadereihenfolge werden zuerst migriert. Weitere Informationen findenSie unter Verwenden der Tabellenzuweisung zum Angeben vonAufgabeneinstellungen (p. 372).
Unterstützung fürAktualisierungen vonPrimärschlüsselwertenbei der Verwendung vonPostgreSQL als Quelle
Aktualisierungen der Primärschlüsselwerte werden jetzt repliziert, wennSie PostgreSQL als Quelle für die fortlaufende Replikation verwenden.
Die Probleme werden wie folgt behoben.
Gemeldet am Beschreibung
24. April 2018 Behebung eines Fehlers, der dazu führte, dass Benutzer Azure SQLnicht als Quellendpunkt für SQL Server 2016 erstellen konnten.
5. Mai 2018 Behebung eines Fehlers, der dazu führte, dass CHR(0) in einer Oracle-Quelle als CHR(32) in ein Aurora mit MySQL-Kompatibilität-Ziel migriertwurde.
10. Mai 2018 Behebung eines Fehlers, der dazu führte, dass die fortlaufendeReplikation von Oracle als Quelle nicht wie erwartet funktionierte, wennOracle LogMiner zum Migrieren von Änderungen von einem physischenOracle-Standby genutzt wurde.
27. Mai 2018 Behebung eines Fehlers, der dazu führte, dass Zeichen verschiedenerDatentypen in PostgreSQL bei der Migration in PostgreSQL verdreifachtwurden.
API-Version API Version 2016-01-01511

AWS Database Migration Service BenutzerhandbuchAWS DMS 2.4.5 – Versionshinweise
Gemeldet am Beschreibung
12. Juni 2018 Behebung eines Fehlers, der dazu geführt hat, dass bei einerMigration von TEXT zu NCLOB (PostgreSQL zu Oracle) wegen derunterschiedlichen Behandlung von Nullen in einer Zeichenfolge durchdiese Engines Daten geändert wurden.
17. Juni 2018 Behebung eines Fehlers, der dazu geführt hat, dass dieReplikationsaufgabe bei der Migration aus einer MySQL-5.5-Quell-Instance keine Primärschlüssel in der MySQL-5.5-Ziel-Instance erstellenkonnte.
23. Juni 2018 Behebung eines Fehlers, der dazu geführt hat, dass bei der Migrationvon einer PostgreSQL-Instance zu Aurora mit PostgreSQL-KompatibilitätJSON-Spalten im vollständigen LOB-Modus verkürzt wurden.
27. Juni 2018 Behebung eines Fehlers, der dazu geführt hat, dass Stapelanwendungenvon Änderungen auf PostgreSQL als Ziel fehlschlugen, da ein Problembeim Erstellen der Tabelle mit zwischenzeitlichen reinen Änderungen aufdem Ziel auftrat.
30. Juni 2018 Behebung eines Fehlers, der dazu geführt hat, dass der MySQL-Zeitstempel '0000-00-00 00:00:00' beim vollständigen Laden nichtwie erwartet migriert wurde.
2. Juli 2018 Behebung eines Fehlers, der dazu geführt hat, dass eine DMS-Replikationsaufgabe nach einem Failover des Quell-Aurora MySQL nichtwie erwartet fortgesetzt wurde.
9. Juli 2018 Behebung eines Fehlers, der dazu geführt hat, dass bei einer Migrationvon MySQL auf Amazon Redshift die Aufgabe mit einem unbekanntenSpalten- und Datentypfehler fehlgeschlagen ist.
21. Juli 2018 Behebung eines Fehlers, der dazu geführt hat, dass Null-Zeichen ineiner Zeichenfolge im eingeschränkten LOB-Modus und im vollständigenLOB-Modus unterschiedlich von SQL Server zu PostgreSQL migriertwurden.
23. Juli 2018 Behebung eines Fehlers, der dazu geführt hat, dass dieSicherheitstransaktionen in SQL Server als Quelle imTransaktionsprotokoll von SQL Server enthalten waren.
26. Juli 2018 Behebung eines Fehlers, der dazu geführt hat, dass Nullwerte bei einerRoll-Forward-Migration von PostgreSQL zu Oracle als leere Wertemigriert wurden.
Mehrere Datumsangaben Behebung diverser Protokollierungsfehler, damit Benutzer durch AmazonCloudWatch-Protokolle besser über die Migration informiert werden.
Mehrere Datumsangaben Verschiedene Datenvalidierungsprobleme wurden behoben.
AWS Database Migration Service (AWS DMS) 2.4.5– Versionshinweise
Die folgende Tabellen zeigen die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 2.4.5.
API-Version API Version 2016-01-01512
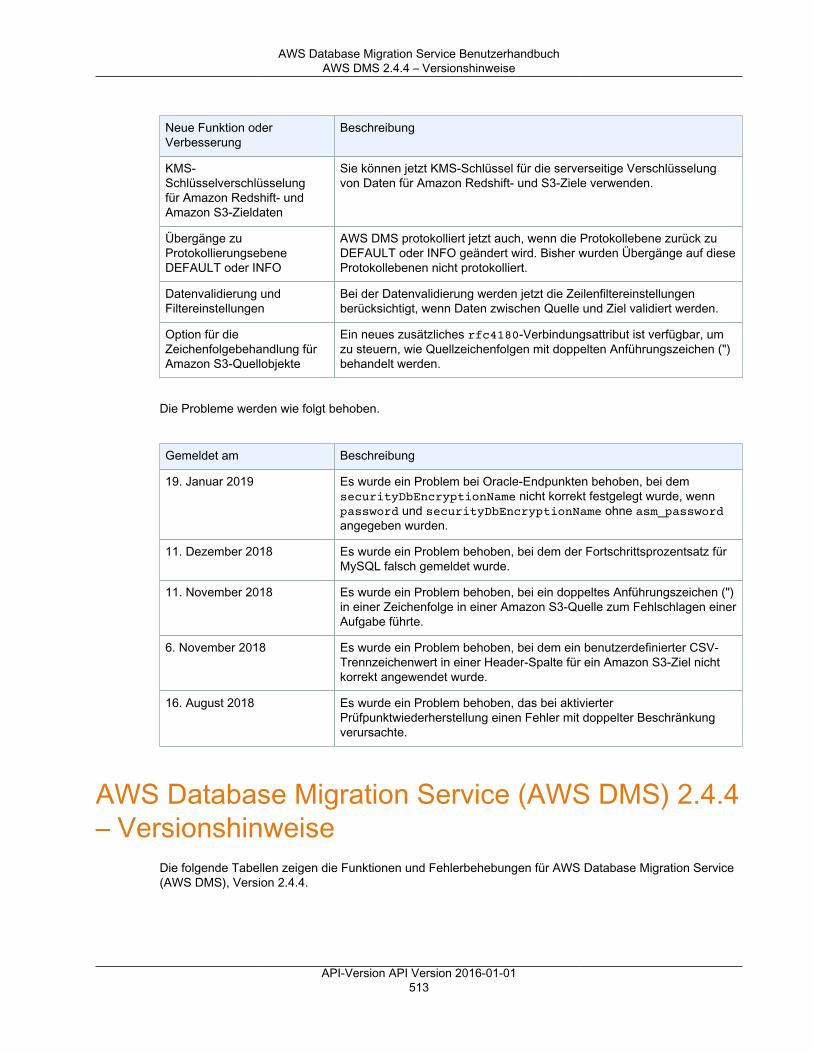
AWS Database Migration Service BenutzerhandbuchAWS DMS 2.4.4 – Versionshinweise
Neue Funktion oderVerbesserung
Beschreibung
KMS-Schlüsselverschlüsselungfür Amazon Redshift- undAmazon S3-Zieldaten
Sie können jetzt KMS-Schlüssel für die serverseitige Verschlüsselungvon Daten für Amazon Redshift- und S3-Ziele verwenden.
Übergänge zuProtokollierungsebeneDEFAULT oder INFO
AWS DMS protokolliert jetzt auch, wenn die Protokollebene zurück zuDEFAULT oder INFO geändert wird. Bisher wurden Übergänge auf dieseProtokollebenen nicht protokolliert.
Datenvalidierung undFiltereinstellungen
Bei der Datenvalidierung werden jetzt die Zeilenfiltereinstellungenberücksichtigt, wenn Daten zwischen Quelle und Ziel validiert werden.
Option für dieZeichenfolgebehandlung fürAmazon S3-Quellobjekte
Ein neues zusätzliches rfc4180-Verbindungsattribut ist verfügbar, umzu steuern, wie Quellzeichenfolgen mit doppelten Anführungszeichen (")behandelt werden.
Die Probleme werden wie folgt behoben.
Gemeldet am Beschreibung
19. Januar 2019 Es wurde ein Problem bei Oracle-Endpunkten behoben, bei demsecurityDbEncryptionName nicht korrekt festgelegt wurde, wennpassword und securityDbEncryptionName ohne asm_passwordangegeben wurden.
11. Dezember 2018 Es wurde ein Problem behoben, bei dem der Fortschrittsprozentsatz fürMySQL falsch gemeldet wurde.
11. November 2018 Es wurde ein Problem behoben, bei ein doppeltes Anführungszeichen (")in einer Zeichenfolge in einer Amazon S3-Quelle zum Fehlschlagen einerAufgabe führte.
6. November 2018 Es wurde ein Problem behoben, bei dem ein benutzerdefinierter CSV-Trennzeichenwert in einer Header-Spalte für ein Amazon S3-Ziel nichtkorrekt angewendet wurde.
16. August 2018 Es wurde ein Problem behoben, das bei aktivierterPrüfpunktwiederherstellung einen Fehler mit doppelter Beschränkungverursachte.
AWS Database Migration Service (AWS DMS) 2.4.4– Versionshinweise
Die folgende Tabellen zeigen die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 2.4.4.
API-Version API Version 2016-01-01513
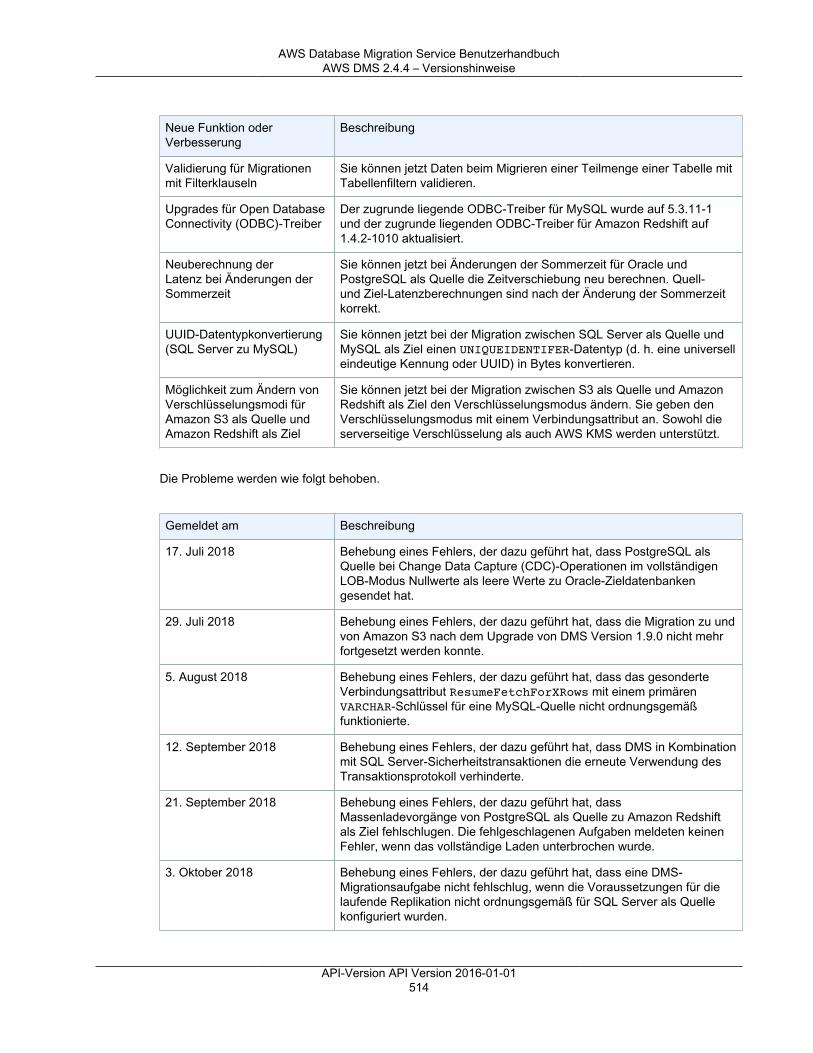
AWS Database Migration Service BenutzerhandbuchAWS DMS 2.4.4 – Versionshinweise
Neue Funktion oderVerbesserung
Beschreibung
Validierung für Migrationenmit Filterklauseln
Sie können jetzt Daten beim Migrieren einer Teilmenge einer Tabelle mitTabellenfiltern validieren.
Upgrades für Open DatabaseConnectivity (ODBC)-Treiber
Der zugrunde liegende ODBC-Treiber für MySQL wurde auf 5.3.11-1und der zugrunde liegenden ODBC-Treiber für Amazon Redshift auf1.4.2-1010 aktualisiert.
Neuberechnung derLatenz bei Änderungen derSommerzeit
Sie können jetzt bei Änderungen der Sommerzeit für Oracle undPostgreSQL als Quelle die Zeitverschiebung neu berechnen. Quell-und Ziel-Latenzberechnungen sind nach der Änderung der Sommerzeitkorrekt.
UUID-Datentypkonvertierung(SQL Server zu MySQL)
Sie können jetzt bei der Migration zwischen SQL Server als Quelle undMySQL als Ziel einen UNIQUEIDENTIFER-Datentyp (d. h. eine universelleindeutige Kennung oder UUID) in Bytes konvertieren.
Möglichkeit zum Ändern vonVerschlüsselungsmodi fürAmazon S3 als Quelle undAmazon Redshift als Ziel
Sie können jetzt bei der Migration zwischen S3 als Quelle und AmazonRedshift als Ziel den Verschlüsselungsmodus ändern. Sie geben denVerschlüsselungsmodus mit einem Verbindungsattribut an. Sowohl dieserverseitige Verschlüsselung als auch AWS KMS werden unterstützt.
Die Probleme werden wie folgt behoben.
Gemeldet am Beschreibung
17. Juli 2018 Behebung eines Fehlers, der dazu geführt hat, dass PostgreSQL alsQuelle bei Change Data Capture (CDC)-Operationen im vollständigenLOB-Modus Nullwerte als leere Werte zu Oracle-Zieldatenbankengesendet hat.
29. Juli 2018 Behebung eines Fehlers, der dazu geführt hat, dass die Migration zu undvon Amazon S3 nach dem Upgrade von DMS Version 1.9.0 nicht mehrfortgesetzt werden konnte.
5. August 2018 Behebung eines Fehlers, der dazu geführt hat, dass das gesonderteVerbindungsattribut ResumeFetchForXRows mit einem primärenVARCHAR-Schlüssel für eine MySQL-Quelle nicht ordnungsgemäßfunktionierte.
12. September 2018 Behebung eines Fehlers, der dazu geführt hat, dass DMS in Kombinationmit SQL Server-Sicherheitstransaktionen die erneute Verwendung desTransaktionsprotokoll verhinderte.
21. September 2018 Behebung eines Fehlers, der dazu geführt hat, dassMassenladevorgänge von PostgreSQL als Quelle zu Amazon Redshiftals Ziel fehlschlugen. Die fehlgeschlagenen Aufgaben meldeten keinenFehler, wenn das vollständige Laden unterbrochen wurde.
3. Oktober 2018 Behebung eines Fehlers, der dazu geführt hat, dass eine DMS-Migrationsaufgabe nicht fehlschlug, wenn die Voraussetzungen für dielaufende Replikation nicht ordnungsgemäß für SQL Server als Quellekonfiguriert wurden.
API-Version API Version 2016-01-01514

AWS Database Migration Service BenutzerhandbuchAWS DMS 2.4.3 – Versionshinweise
Gemeldet am Beschreibung
Mehrere Datumsangaben Behebung mehrerer Fehler im Zusammenhang mit der Datenvalidierungund erweiterte Unterstützung von UTF-8-Zeichen mit mehreren Bytes.
AWS Database Migration Service (AWS DMS) 2.4.3– Versionshinweise
Die folgende Tabellen zeigen die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 2.4.3.
Neue Funktion oderVerbesserung
Beschreibung
Neuerstellung vonTabellenmetadaten beifehlender Übereinstimmung
Ein neues zusätzliches Verbindungsattribut für MySQL-Endpunkte wurdehinzugefügt: CleanSrcMetadataOnMismatch
Dabei handelt es sich um ein Boolesches Attribut, dasTabellenmetadaten-Informationen auf der Replikations-Instancebereinigt und erstellt, wenn eine fehlende Übereinstimmung auftritt.Ein Beispiel ist eine Situation, in der das Ausführen einer verändertenAnweisung in Data Definition Language (DDL) auf einer Tabelle zuunterschiedlichen Informationen über die in der Replikations-Instancezwischengespeicherte Tabelle führen könnte. Standardmäßig ist diesesAttribut auf "false" gesetzt.
Leistungsverbesserungen fürdie Datenvalidierung
Es wurden u. a. folgende Verbesserungen vorgenommen:
• Die Datenvalidierung partitioniert nun die Daten, bevor sie beginnt,sodass sie sie wie Partitionen vergleichen und validieren kann.Diese Version enthält Verbesserungen an den Änderungen, die diePartitionierung beschleunigen und die Datenvalidierung schnellermachen.
• Verbesserungen bei der automatischen Behandlung vonSortierdifferenzen basierend auf den Aufgabeneinstellungen.
• Verbesserungen bei der Erkennung von Fehleinstufungen währendder Validierung, wodurch auch Fehleinstufungen während der Phasezwischengespeicherter Änderungen reduziert werden.
• Allgemeine Verbesserungen bei der Protokollierung derDatenvalidierung.
• Verbesserungen an Abfragen, die von der Datenvalidierung verwendetwerden, wenn Tabellen zusammengesetzte primäre Schlüssel haben.
Die Probleme werden wie folgt behoben.
Gemeldet am Beschreibung
12. Februar 2018 Es wurde ein Problem bei der laufenden Replikation mitStapelanwendung behoben, bei dem AWS DMS einige Eingaben fehlte,da eine eindeutige Einschränkung in der Tabelle aktualisiert wurde.
API-Version API Version 2016-01-01515

AWS Database Migration Service BenutzerhandbuchAWS DMS 2.4.2 – Versionshinweise
Gemeldet am Beschreibung
16. März 2018 Es wurde ein Problem behoben, bei dem eine Oracle-PostgreSQL-Migrationsaufgabe während der laufenden Replikationsphase aufgrundvon Multi-AZ-Failover auf der Oracle-Amazon RDS-Quell-Instanceabstürzte.
AWS Database Migration Service (AWS DMS) 2.4.2– Versionshinweise
Die folgende Tabellen zeigen die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 2.4.2.
Neue Funktion oderVerbesserung
Beschreibung
Binary Reader-Unterstützungfür Amazon RDS for Oraclewährend Change DataCapture
Es wurde Unterstützung für die Nutzung von Binary Reader in ChangeData Capture (CDC)-Szenarien aus einer Amazon RDS für die Oracle-Quelle während der fortlaufenden Replikation hinzugefügt.
Zusätzliche COPY-Befehlsparameter für AmazonRedshift als Ziel
Über die zusätzlichen Verbindungsattribute eingeführte Unterstützung fürdie folgenden zusätzlichen Amazon Redshift-Kopierparameter. WeitereInformationen finden Sie unter Zusätzliche Verbindungsattribute bei derVerwendung von Amazon Redshift als Ziel für AWS DMS (p. 239).
• TRUNCATECOLUMNS
• REMOVEQUOTES
• TRIMBLANKS
Option zum Fehlschlageneiner Migrationsaufgabe,wenn eine Tabelle in einerPostgreSQL-Quelle gekürztist
Unterstützung für das Fehlschlagen einer Aufgabe eingeführt, wenn beider Verwendung einer neuen Aufgabeneinstellung in einer PostgreSQL-Quelle eine Kürzung festgestellt wird. Weitere Informationen finden Sieunter ApplyErrorFailOnTruncationDdl-Einstellung im AbschnittAufgabeneinstellungen zur Fehlerbehandlung (p. 358).
Unterstützung der Validierungfür JSON/JSONB/HSTORE inPostgreSQL-Endpunkten
Es wurde Unterstützung der Datenvalidierung für JSON-, JSONB- undHSTORE-Spalten für PostgreSQL als Quelle und Ziel eingeführt.
Verbesserte Protokollierungfür MySQL-Quellen
Die Übersichtlichkeit des Protokolls wurde für Probleme beim Lesenvon MySQL-Binärprotokollen während Change Data Capture (CDC)verbessert. Protokolle zeigen nun deutlich einen Fehler/eine Warnung,wenn Probleme beim Zugriff auf MySQL-Quell-Binärprotokolle währendCDC auftreten.
ZusätzlicheDatenvalidierungs-Statistiken
Es wurden weitere Replikationstabellen-Statistiken hinzugefügt. WeitereInformationen finden Sie unter Replikationsaufgaben-Statistiken (p. 435).
Die Probleme werden wie folgt behoben.
API-Version API Version 2016-01-01516
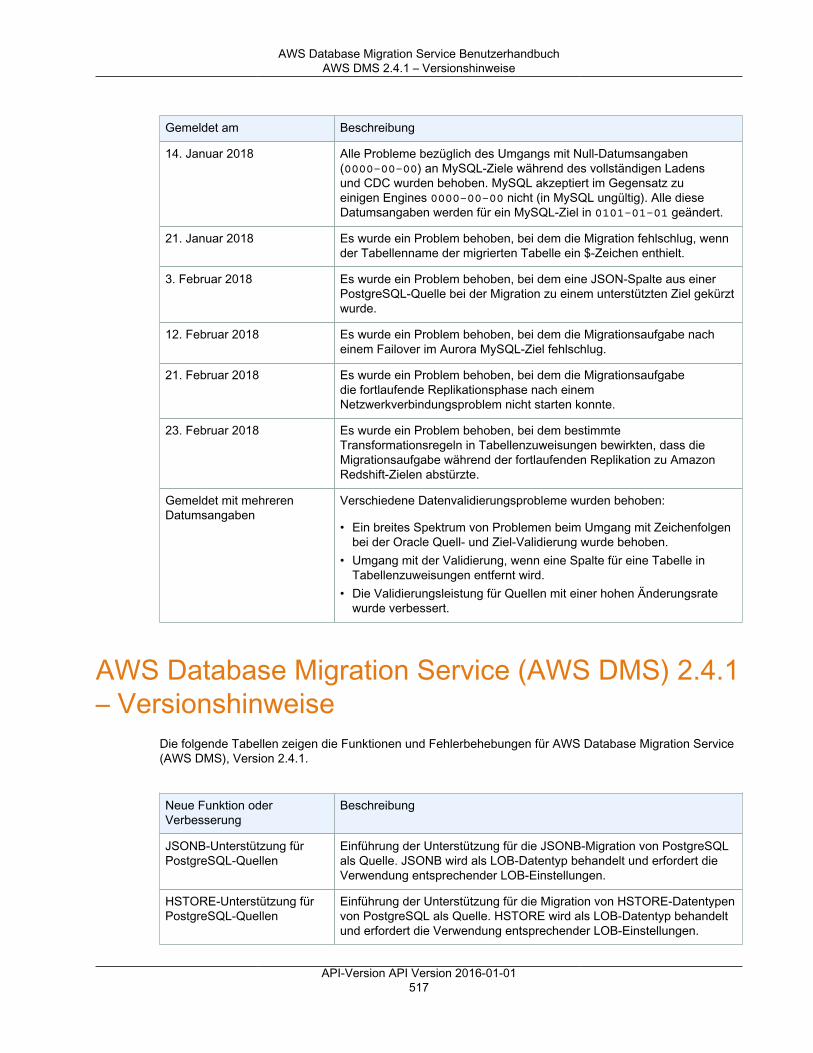
AWS Database Migration Service BenutzerhandbuchAWS DMS 2.4.1 – Versionshinweise
Gemeldet am Beschreibung
14. Januar 2018 Alle Probleme bezüglich des Umgangs mit Null-Datumsangaben(0000-00-00) an MySQL-Ziele während des vollständigen Ladensund CDC wurden behoben. MySQL akzeptiert im Gegensatz zueinigen Engines 0000-00-00 nicht (in MySQL ungültig). Alle dieseDatumsangaben werden für ein MySQL-Ziel in 0101-01-01 geändert.
21. Januar 2018 Es wurde ein Problem behoben, bei dem die Migration fehlschlug, wennder Tabellenname der migrierten Tabelle ein $-Zeichen enthielt.
3. Februar 2018 Es wurde ein Problem behoben, bei dem eine JSON-Spalte aus einerPostgreSQL-Quelle bei der Migration zu einem unterstützten Ziel gekürztwurde.
12. Februar 2018 Es wurde ein Problem behoben, bei dem die Migrationsaufgabe nacheinem Failover im Aurora MySQL-Ziel fehlschlug.
21. Februar 2018 Es wurde ein Problem behoben, bei dem die Migrationsaufgabedie fortlaufende Replikationsphase nach einemNetzwerkverbindungsproblem nicht starten konnte.
23. Februar 2018 Es wurde ein Problem behoben, bei dem bestimmteTransformationsregeln in Tabellenzuweisungen bewirkten, dass dieMigrationsaufgabe während der fortlaufenden Replikation zu AmazonRedshift-Zielen abstürzte.
Gemeldet mit mehrerenDatumsangaben
Verschiedene Datenvalidierungsprobleme wurden behoben:
• Ein breites Spektrum von Problemen beim Umgang mit Zeichenfolgenbei der Oracle Quell- und Ziel-Validierung wurde behoben.
• Umgang mit der Validierung, wenn eine Spalte für eine Tabelle inTabellenzuweisungen entfernt wird.
• Die Validierungsleistung für Quellen mit einer hohen Änderungsratewurde verbessert.
AWS Database Migration Service (AWS DMS) 2.4.1– Versionshinweise
Die folgende Tabellen zeigen die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 2.4.1.
Neue Funktion oderVerbesserung
Beschreibung
JSONB-Unterstützung fürPostgreSQL-Quellen
Einführung der Unterstützung für die JSONB-Migration von PostgreSQLals Quelle. JSONB wird als LOB-Datentyp behandelt und erfordert dieVerwendung entsprechender LOB-Einstellungen.
HSTORE-Unterstützung fürPostgreSQL-Quellen
Einführung der Unterstützung für die Migration von HSTORE-Datentypenvon PostgreSQL als Quelle. HSTORE wird als LOB-Datentyp behandeltund erfordert die Verwendung entsprechender LOB-Einstellungen.
API-Version API Version 2016-01-01517
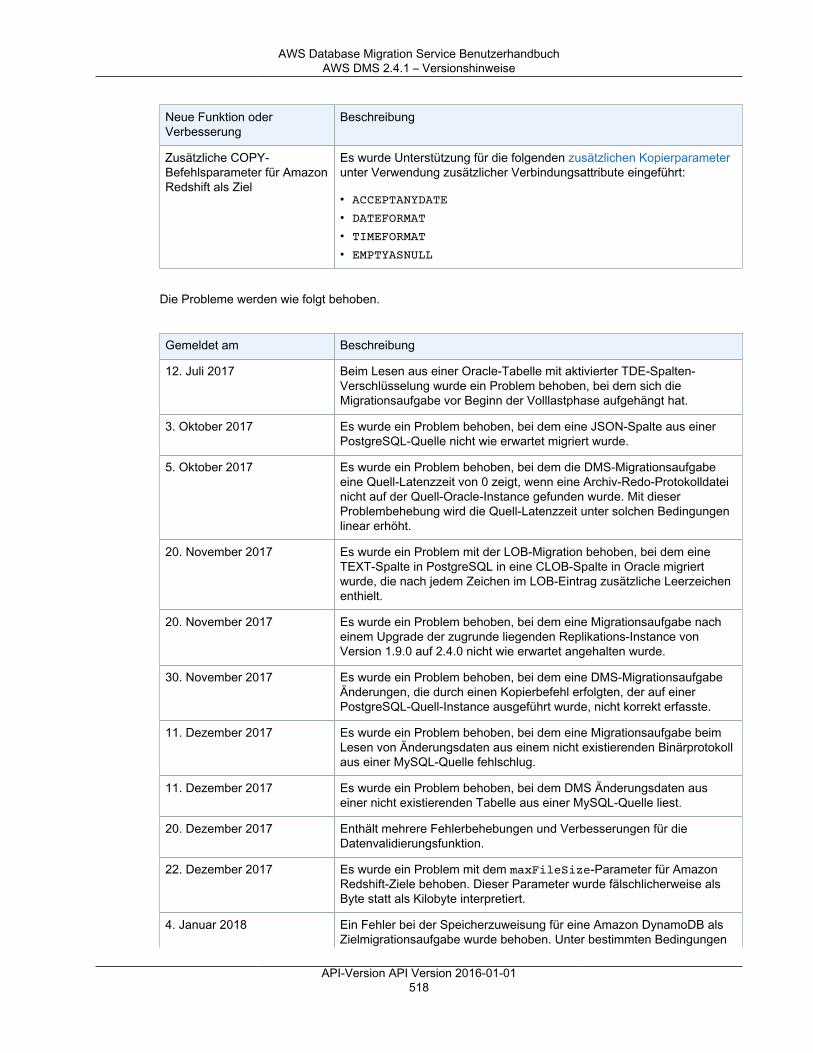
AWS Database Migration Service BenutzerhandbuchAWS DMS 2.4.1 – Versionshinweise
Neue Funktion oderVerbesserung
Beschreibung
Zusätzliche COPY-Befehlsparameter für AmazonRedshift als Ziel
Es wurde Unterstützung für die folgenden zusätzlichen Kopierparameterunter Verwendung zusätzlicher Verbindungsattribute eingeführt:
• ACCEPTANYDATE
• DATEFORMAT
• TIMEFORMAT
• EMPTYASNULL
Die Probleme werden wie folgt behoben.
Gemeldet am Beschreibung
12. Juli 2017 Beim Lesen aus einer Oracle-Tabelle mit aktivierter TDE-Spalten-Verschlüsselung wurde ein Problem behoben, bei dem sich dieMigrationsaufgabe vor Beginn der Volllastphase aufgehängt hat.
3. Oktober 2017 Es wurde ein Problem behoben, bei dem eine JSON-Spalte aus einerPostgreSQL-Quelle nicht wie erwartet migriert wurde.
5. Oktober 2017 Es wurde ein Problem behoben, bei dem die DMS-Migrationsaufgabeeine Quell-Latenzzeit von 0 zeigt, wenn eine Archiv-Redo-Protokolldateinicht auf der Quell-Oracle-Instance gefunden wurde. Mit dieserProblembehebung wird die Quell-Latenzzeit unter solchen Bedingungenlinear erhöht.
20. November 2017 Es wurde ein Problem mit der LOB-Migration behoben, bei dem eineTEXT-Spalte in PostgreSQL in eine CLOB-Spalte in Oracle migriertwurde, die nach jedem Zeichen im LOB-Eintrag zusätzliche Leerzeichenenthielt.
20. November 2017 Es wurde ein Problem behoben, bei dem eine Migrationsaufgabe nacheinem Upgrade der zugrunde liegenden Replikations-Instance vonVersion 1.9.0 auf 2.4.0 nicht wie erwartet angehalten wurde.
30. November 2017 Es wurde ein Problem behoben, bei dem eine DMS-MigrationsaufgabeÄnderungen, die durch einen Kopierbefehl erfolgten, der auf einerPostgreSQL-Quell-Instance ausgeführt wurde, nicht korrekt erfasste.
11. Dezember 2017 Es wurde ein Problem behoben, bei dem eine Migrationsaufgabe beimLesen von Änderungsdaten aus einem nicht existierenden Binärprotokollaus einer MySQL-Quelle fehlschlug.
11. Dezember 2017 Es wurde ein Problem behoben, bei dem DMS Änderungsdaten auseiner nicht existierenden Tabelle aus einer MySQL-Quelle liest.
20. Dezember 2017 Enthält mehrere Fehlerbehebungen und Verbesserungen für dieDatenvalidierungsfunktion.
22. Dezember 2017 Es wurde ein Problem mit dem maxFileSize-Parameter für AmazonRedshift-Ziele behoben. Dieser Parameter wurde fälschlicherweise alsByte statt als Kilobyte interpretiert.
4. Januar 2018 Ein Fehler bei der Speicherzuweisung für eine Amazon DynamoDB alsZielmigrationsaufgabe wurde behoben. Unter bestimmten Bedingungen
API-Version API Version 2016-01-01518

AWS Database Migration Service BenutzerhandbuchAWS DMS 2.4.0 – Versionshinweise
Gemeldet am Beschreibunghat AWS DMS nicht genügend Speicher zugewiesen, wenn dieverwendete Objektzuweisung einen Sortierschlüssel enthielt.
10. Januar 2018 Es wurde ein Problem mit Oracle 12.2 als Quelle behoben, bei dem DataManipulation Language (DML)-Anweisungen nicht wie erwartet erfasstwurden, wenn ROWDEPENDENCIES verwendet wurden.
AWS Database Migration Service (AWS DMS) 2.4.0– Versionshinweise
Die folgende Tabellen zeigen die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 2.4.0.
Neue Funktion oderVerbesserung
Beschreibung
Replizieren von Oracle-Index-Tabellenräumen
Fügt Funktionen zur Unterstützung der Replikation von Oracle IndexTablespaces hinzu. Weitere Informationen zu Index-Tabellenräumenfinden Sie hier.
Unterstützung deskontoübergreifenden AmazonS3-Zugriffs
Fügt Funktionen zur Unterstützung vorgefertigter ACLs (vordefinierteRechte) zur Realisierung eines kontoübergreifenden Zugriffs mit S3-Endpunkten hinzu. Weitere Informationen zu vordefinierten ACLs findenSie unter Vordefinierte ACL im Entwicklerhandbuch für Amazon SimpleStorage Service.
Verwendung: Festlegen eines zusätzlichen Attributs im S3-Endpunkt –CannedAclForObjects=value Mögliche Werte können sein wie folgt:
• NONE
• PRIVATE
• PUBLIC_READ
• PUBLIC_READ_WRITE
• AUTHENTICATED_READ
• AWS_EXEC_READ
• BUCKET_OWNER_READ
• BUCKET_OWNER_FULL_CONTROL
Die Probleme werden wie folgt behoben.
Gemeldet am Beschreibung
19. Juli 2017 Es wurde ein Problem behoben, bei dem Replikationsaufgabenfortlaufend in einer Retry-Schleife ausgeführt wurden, wenn einerPostgreSQL-Quell-Instance keine Replikations-Slots mehr zur Verfügungstanden. Durch die Fehlerbehebung schlägt die Aufgabe fehl undgibt eine Fehlermeldung aus, die besagt, dass DMS keinen logischenReplikations-Slot erstellen kann.
API-Version API Version 2016-01-01519

AWS Database Migration Service BenutzerhandbuchAWS DMS 2.3.0 – Versionshinweise
Gemeldet am Beschreibung
27. Juli 2017 Es wurde ein Problem mit der Replikations-Engine behoben, bei demder MySQL-Datentyp "enum" bei der Aufgabenausführung einenSpeicherzuweisungsfehler verursachte.
7. August 2017 Es wurde ein Problem behoben, bei dem bei Migrationsaufgaben mitOracle als Quelle ein unerwartetes Verhalten auftrat, wenn die Quelle fürmehr als 5 Minuten nicht verfügbar war. Das Problem führte dazu, dassdie fortlaufende Replikationsphase auch dann hängenblieb, wenn dieQuelle wieder verfügbar war.
24. August 2017 Es wurde ein Problem mit dem PostgreSQL-Ziel behoben, bei dem derBruchteil im Datentyp TIME falsch verarbeitet wurde.
14. September 2017 Es wurde ein Problem behoben, bei dem während der Updates in derCDC-Phase falsche Werte in TOAST-Felder in PostgreSQL-basierteZiele geschrieben wurden.
8. Oktober 2017 Es wurde ein Problem in Version 2.3.0 behoben, bei dem diekontinuierliche Replikation mit MySQL 5.5-Quellen nicht wie erwartetfunktionierte.
12. Oktober 2017 Es wurde ein Problem mit dem Lesen von Änderungen voneiner SQL Server 2016-Quelle behoben, das während derkontinuierlichen Replikationsphase auftrat. Diese Lösungmuss in Verbindung mit dem folgenden zusätzlichenVerbindungsattribut im SQL Server-Quellendpunkt verwendet werden:IgnoreTxnCtxValidityCheck=true
AWS Database Migration Service (AWS DMS) 2.3.0– Versionshinweise
Die folgende Tabellen zeigen die Funktionen und Fehlerbehebungen für AWS Database Migration Service(AWS DMS), Version 2.3.0.
Neue Funktion oderVerbesserung
Beschreibung
S3 als Quelle Verwenden von Amazon S3 als Quelle für AWS DMS (p. 201)
SQL Azure als Quelle Verwenden einer Microsoft Azure SQL-Datenbank als Quelle für AWSDMS (p. 164)
Plattform – AWS SDK-Update Aktualisierung des AWS-SDKs in der Replikations-Instance auf 1.0.113.Das AWS-SDK wird für bestimmte Endpunkte (wie Amazon Redshiftund S3) zum Hochladen von Daten im Namen des Kunden in dieseEndpunkte verwendet. Die Verwendung ist nicht eingeschränkt.
Oracle-Quelle: Unterstützungder Replikation vonTabellenräumen in Oracle
Die Möglichkeit zur Migration von Tabellenräumen von einer Oracle-Quelle, sodass vor der Migration keine Tabellenräume im Ziel generiertwerden müssen.
Verwendung: Verwenden Sie die ReadTableSpaceName-Einstellungin den zusätzlichen Verbindungsattributen im Oracle-Quellendpunkt und
API-Version API Version 2016-01-01520
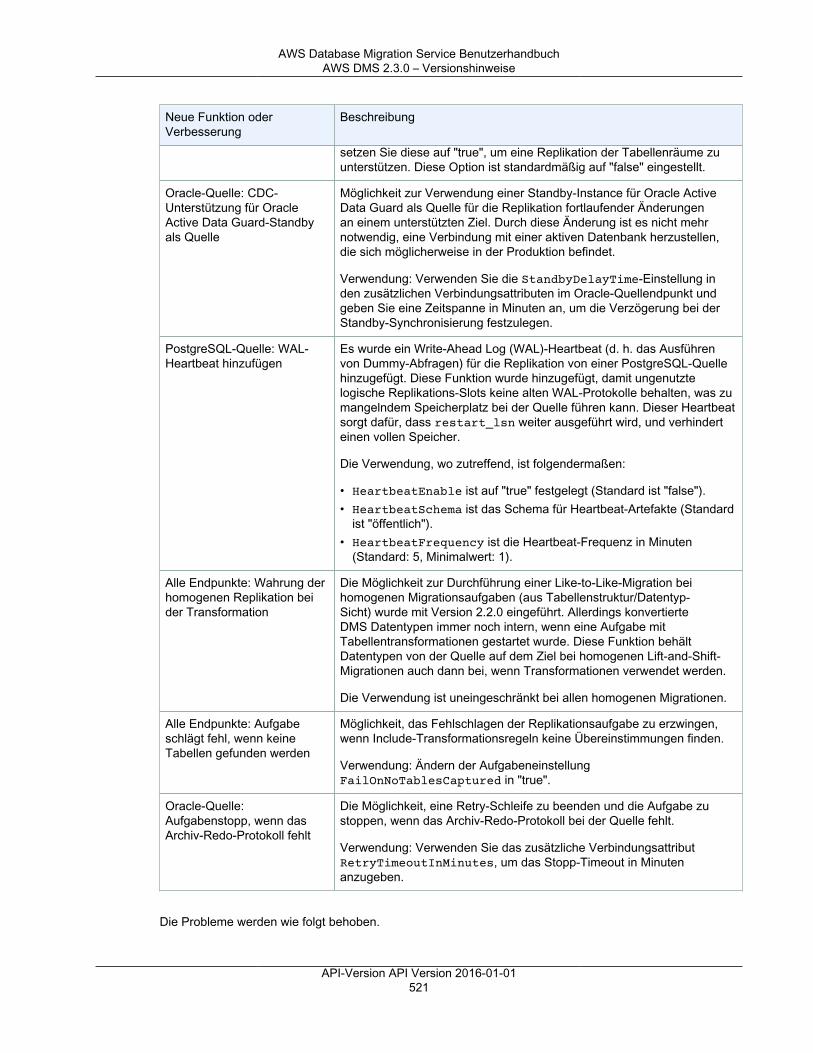
AWS Database Migration Service BenutzerhandbuchAWS DMS 2.3.0 – Versionshinweise
Neue Funktion oderVerbesserung
Beschreibung
setzen Sie diese auf "true", um eine Replikation der Tabellenräume zuunterstützen. Diese Option ist standardmäßig auf "false" eingestellt.
Oracle-Quelle: CDC-Unterstützung für OracleActive Data Guard-Standbyals Quelle
Möglichkeit zur Verwendung einer Standby-Instance für Oracle ActiveData Guard als Quelle für die Replikation fortlaufender Änderungenan einem unterstützten Ziel. Durch diese Änderung ist es nicht mehrnotwendig, eine Verbindung mit einer aktiven Datenbank herzustellen,die sich möglicherweise in der Produktion befindet.
Verwendung: Verwenden Sie die StandbyDelayTime-Einstellung inden zusätzlichen Verbindungsattributen im Oracle-Quellendpunkt undgeben Sie eine Zeitspanne in Minuten an, um die Verzögerung bei derStandby-Synchronisierung festzulegen.
PostgreSQL-Quelle: WAL-Heartbeat hinzufügen
Es wurde ein Write-Ahead Log (WAL)-Heartbeat (d. h. das Ausführenvon Dummy-Abfragen) für die Replikation von einer PostgreSQL-Quellehinzugefügt. Diese Funktion wurde hinzugefügt, damit ungenutztelogische Replikations-Slots keine alten WAL-Protokolle behalten, was zumangelndem Speicherplatz bei der Quelle führen kann. Dieser Heartbeatsorgt dafür, dass restart_lsn weiter ausgeführt wird, und verhinderteinen vollen Speicher.
Die Verwendung, wo zutreffend, ist folgendermaßen:
• HeartbeatEnable ist auf "true" festgelegt (Standard ist "false").• HeartbeatSchema ist das Schema für Heartbeat-Artefakte (Standard
ist "öffentlich").• HeartbeatFrequency ist die Heartbeat-Frequenz in Minuten
(Standard: 5, Minimalwert: 1).
Alle Endpunkte: Wahrung derhomogenen Replikation beider Transformation
Die Möglichkeit zur Durchführung einer Like-to-Like-Migration beihomogenen Migrationsaufgaben (aus Tabellenstruktur/Datentyp-Sicht) wurde mit Version 2.2.0 eingeführt. Allerdings konvertierteDMS Datentypen immer noch intern, wenn eine Aufgabe mitTabellentransformationen gestartet wurde. Diese Funktion behältDatentypen von der Quelle auf dem Ziel bei homogenen Lift-and-Shift-Migrationen auch dann bei, wenn Transformationen verwendet werden.
Die Verwendung ist uneingeschränkt bei allen homogenen Migrationen.
Alle Endpunkte: Aufgabeschlägt fehl, wenn keineTabellen gefunden werden
Möglichkeit, das Fehlschlagen der Replikationsaufgabe zu erzwingen,wenn Include-Transformationsregeln keine Übereinstimmungen finden.
Verwendung: Ändern der AufgabeneinstellungFailOnNoTablesCaptured in "true".
Oracle-Quelle:Aufgabenstopp, wenn dasArchiv-Redo-Protokoll fehlt
Die Möglichkeit, eine Retry-Schleife zu beenden und die Aufgabe zustoppen, wenn das Archiv-Redo-Protokoll bei der Quelle fehlt.
Verwendung: Verwenden Sie das zusätzliche VerbindungsattributRetryTimeoutInMinutes, um das Stopp-Timeout in Minutenanzugeben.
Die Probleme werden wie folgt behoben.
API-Version API Version 2016-01-01521
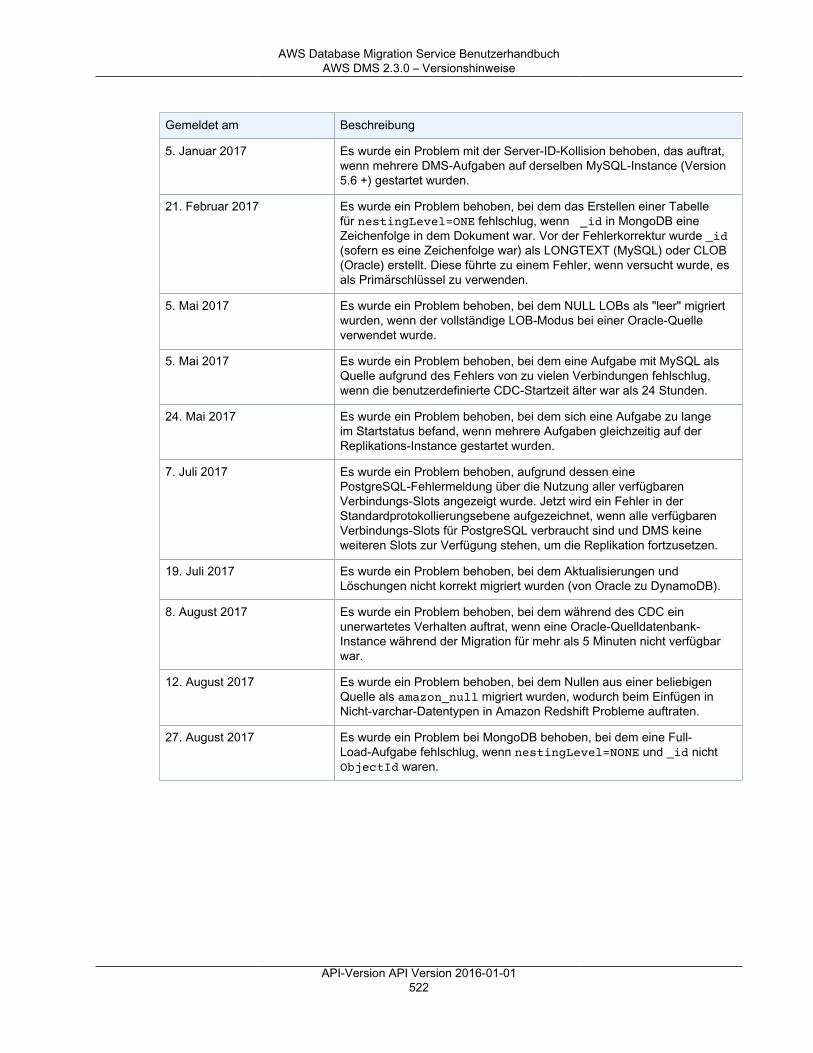
AWS Database Migration Service BenutzerhandbuchAWS DMS 2.3.0 – Versionshinweise
Gemeldet am Beschreibung
5. Januar 2017 Es wurde ein Problem mit der Server-ID-Kollision behoben, das auftrat,wenn mehrere DMS-Aufgaben auf derselben MySQL-Instance (Version5.6 +) gestartet wurden.
21. Februar 2017 Es wurde ein Problem behoben, bei dem das Erstellen einer Tabellefür nestingLevel=ONE fehlschlug, wenn _id in MongoDB eineZeichenfolge in dem Dokument war. Vor der Fehlerkorrektur wurde _id(sofern es eine Zeichenfolge war) als LONGTEXT (MySQL) oder CLOB(Oracle) erstellt. Diese führte zu einem Fehler, wenn versucht wurde, esals Primärschlüssel zu verwenden.
5. Mai 2017 Es wurde ein Problem behoben, bei dem NULL LOBs als "leer" migriertwurden, wenn der vollständige LOB-Modus bei einer Oracle-Quelleverwendet wurde.
5. Mai 2017 Es wurde ein Problem behoben, bei dem eine Aufgabe mit MySQL alsQuelle aufgrund des Fehlers von zu vielen Verbindungen fehlschlug,wenn die benutzerdefinierte CDC-Startzeit älter war als 24 Stunden.
24. Mai 2017 Es wurde ein Problem behoben, bei dem sich eine Aufgabe zu langeim Startstatus befand, wenn mehrere Aufgaben gleichzeitig auf derReplikations-Instance gestartet wurden.
7. Juli 2017 Es wurde ein Problem behoben, aufgrund dessen einePostgreSQL-Fehlermeldung über die Nutzung aller verfügbarenVerbindungs-Slots angezeigt wurde. Jetzt wird ein Fehler in derStandardprotokollierungsebene aufgezeichnet, wenn alle verfügbarenVerbindungs-Slots für PostgreSQL verbraucht sind und DMS keineweiteren Slots zur Verfügung stehen, um die Replikation fortzusetzen.
19. Juli 2017 Es wurde ein Problem behoben, bei dem Aktualisierungen undLöschungen nicht korrekt migriert wurden (von Oracle zu DynamoDB).
8. August 2017 Es wurde ein Problem behoben, bei dem während des CDC einunerwartetes Verhalten auftrat, wenn eine Oracle-Quelldatenbank-Instance während der Migration für mehr als 5 Minuten nicht verfügbarwar.
12. August 2017 Es wurde ein Problem behoben, bei dem Nullen aus einer beliebigenQuelle als amazon_null migriert wurden, wodurch beim Einfügen inNicht-varchar-Datentypen in Amazon Redshift Probleme auftraten.
27. August 2017 Es wurde ein Problem bei MongoDB behoben, bei dem eine Full-Load-Aufgabe fehlschlug, wenn nestingLevel=NONE und _id nichtObjectId waren.
API-Version API Version 2016-01-01522

AWS Database Migration Service BenutzerhandbuchFrühere Aktualisierungen
DokumentverlaufIn der folgenden Tabelle werden wichtige Änderungen der Dokumentation seit Januar 2018 des AWSDatabase Migration Service-Benutzerhandbuchs beschrieben.
Sie können einen RSS-Feed abonnieren, um Benachrichtigungen über Aktualisierungen dieserDokumentation zu erhalten.
update-history-change update-history-description update-history-date
Migrieren mit AWS SnowballEdge
Aktualisierte Dokumentationfür die Verwendung von AWSSnowball Edge für die Migrationgroßer Datenbanken.
January 24, 2019
Unterstützung für AmazonElasticsearch Service undAmazon Kinesis Data Streamsals Ziele
Zusätzliche Unterstützungfür Amazon ES und KinesisData Streams als Ziele fürDatenmigration.
November 15, 2018
Support für native CDC-Startpunkte
Native Startpunkte bei derVerwendung von Change DataCapture (CDC) werden nununterstützt.
June 28, 2018
R4-Support Unterstützung für R4Replikations-Instance-Klassenhinzugefügt.
May 10, 2018
Db2 LUW-Support IBM Db2 LUW als Quelleder Datenmigration wird nununterstützt.
April 26, 2018
Support für dasAufgabenprotokoll
Es wurde Unterstützung für dieAnzeige der Aufgabenprotokoll-Nutzung und für das Löschen vonAufgabenprotokollen hinzugefügt.
February 8, 2018
Support für SQL Server als Ziel Es wurde Unterstützung fürAmazon RDS for Microsoft SQLServer als Quelle hinzugefügt.
February 6, 2018
Frühere AktualisierungenIn der folgenden Tabelle werden wichtige Änderungen der Dokumentation vor Januar 2018 des AWSDatabase Migration Service-Benutzerhandbuchs beschrieben.
Änderung Beschreibung Datum geändert
Neue Funktion Zusätzliche Unterstützung für die Verwendung von AWSDMS mit AWS Snowball, um große Datenbanken zumigrieren. Weitere Informationen finden Sie unter Migrierenvon großen Datenspeichern mit AWS Database MigrationService und AWS Snowball Edge (p. 448).
17. November 2017
API-Version API Version 2016-01-01523
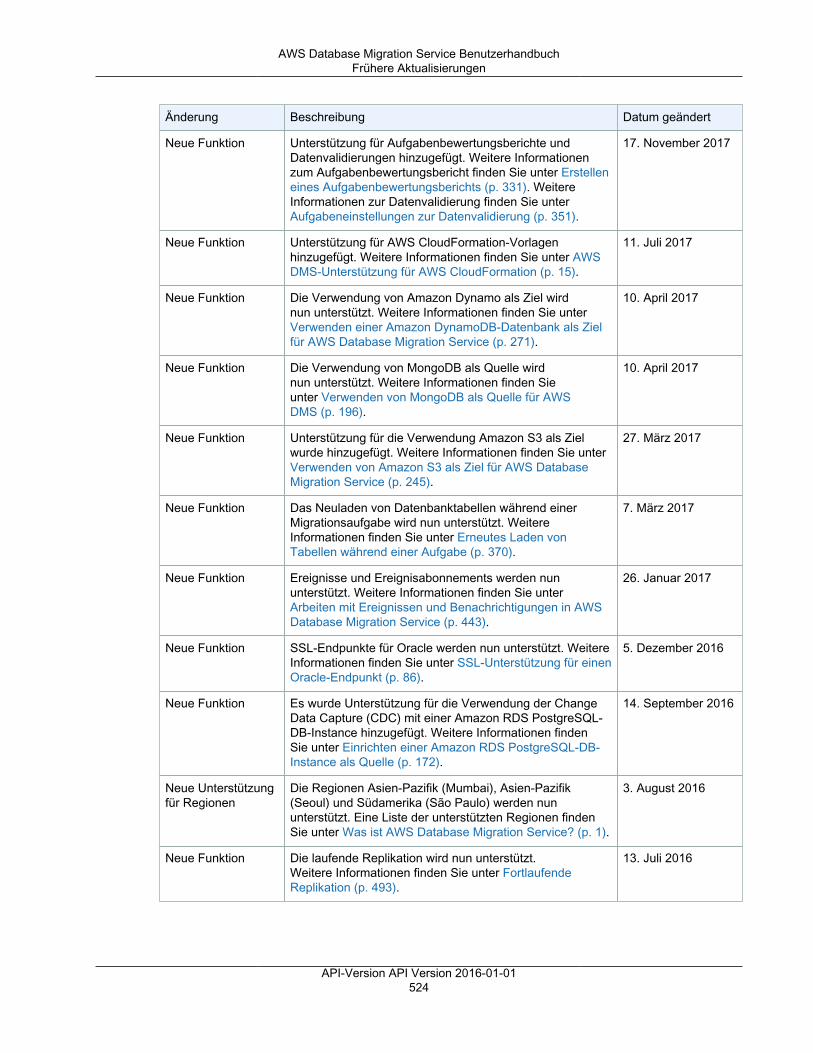
AWS Database Migration Service BenutzerhandbuchFrühere Aktualisierungen
Änderung Beschreibung Datum geändert
Neue Funktion Unterstützung für Aufgabenbewertungsberichte undDatenvalidierungen hinzugefügt. Weitere Informationenzum Aufgabenbewertungsbericht finden Sie unter Erstelleneines Aufgabenbewertungsberichts (p. 331). WeitereInformationen zur Datenvalidierung finden Sie unter Aufgabeneinstellungen zur Datenvalidierung (p. 351).
17. November 2017
Neue Funktion Unterstützung für AWS CloudFormation-Vorlagenhinzugefügt. Weitere Informationen finden Sie unter AWSDMS-Unterstützung für AWS CloudFormation (p. 15).
11. Juli 2017
Neue Funktion Die Verwendung von Amazon Dynamo als Ziel wirdnun unterstützt. Weitere Informationen finden Sie unterVerwenden einer Amazon DynamoDB-Datenbank als Zielfür AWS Database Migration Service (p. 271).
10. April 2017
Neue Funktion Die Verwendung von MongoDB als Quelle wirdnun unterstützt. Weitere Informationen finden Sieunter Verwenden von MongoDB als Quelle für AWSDMS (p. 196).
10. April 2017
Neue Funktion Unterstützung für die Verwendung Amazon S3 als Zielwurde hinzugefügt. Weitere Informationen finden Sie unterVerwenden von Amazon S3 als Ziel für AWS DatabaseMigration Service (p. 245).
27. März 2017
Neue Funktion Das Neuladen von Datenbanktabellen während einerMigrationsaufgabe wird nun unterstützt. WeitereInformationen finden Sie unter Erneutes Laden vonTabellen während einer Aufgabe (p. 370).
7. März 2017
Neue Funktion Ereignisse und Ereignisabonnements werden nununterstützt. Weitere Informationen finden Sie unterArbeiten mit Ereignissen und Benachrichtigungen in AWSDatabase Migration Service (p. 443).
26. Januar 2017
Neue Funktion SSL-Endpunkte für Oracle werden nun unterstützt. WeitereInformationen finden Sie unter SSL-Unterstützung für einenOracle-Endpunkt (p. 86).
5. Dezember 2016
Neue Funktion Es wurde Unterstützung für die Verwendung der ChangeData Capture (CDC) mit einer Amazon RDS PostgreSQL-DB-Instance hinzugefügt. Weitere Informationen findenSie unter Einrichten einer Amazon RDS PostgreSQL-DB-Instance als Quelle (p. 172).
14. September 2016
Neue Unterstützungfür Regionen
Die Regionen Asien-Pazifik (Mumbai), Asien-Pazifik(Seoul) und Südamerika (São Paulo) werden nununterstützt. Eine Liste der unterstützten Regionen findenSie unter Was ist AWS Database Migration Service? (p. 1).
3. August 2016
Neue Funktion Die laufende Replikation wird nun unterstützt.Weitere Informationen finden Sie unter FortlaufendeReplikation (p. 493).
13. Juli 2016
API-Version API Version 2016-01-01524
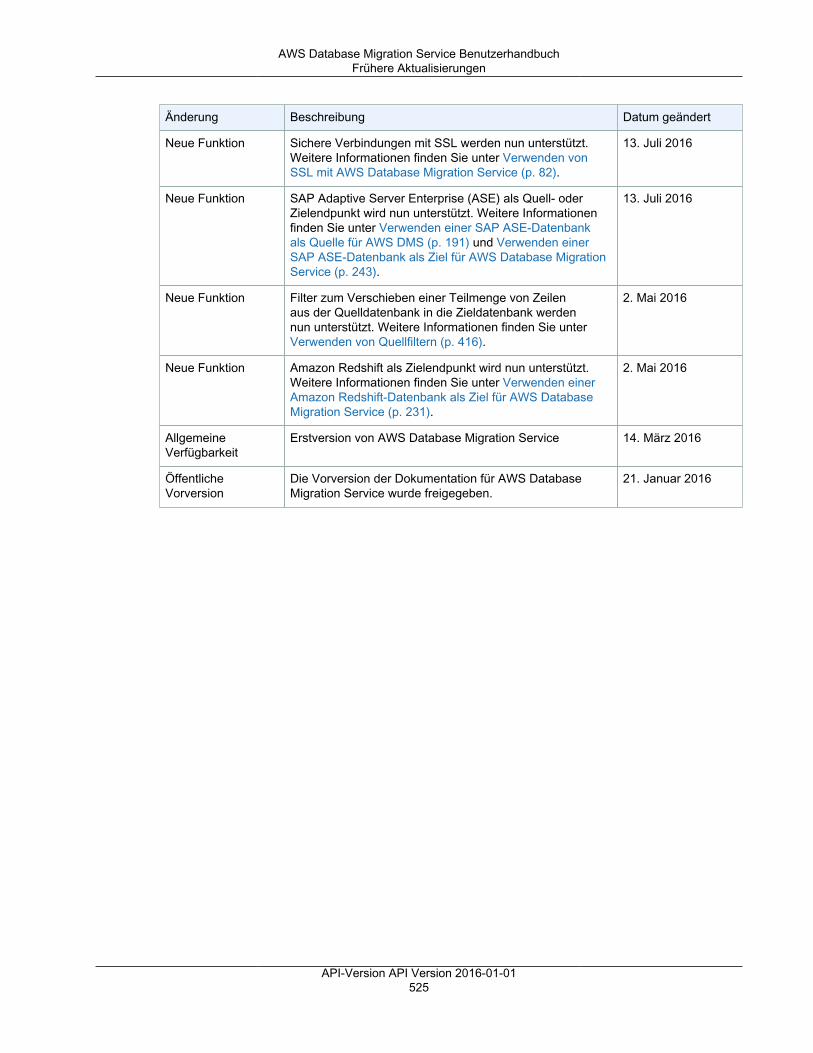
AWS Database Migration Service BenutzerhandbuchFrühere Aktualisierungen
Änderung Beschreibung Datum geändert
Neue Funktion Sichere Verbindungen mit SSL werden nun unterstützt.Weitere Informationen finden Sie unter Verwenden vonSSL mit AWS Database Migration Service (p. 82).
13. Juli 2016
Neue Funktion SAP Adaptive Server Enterprise (ASE) als Quell- oderZielendpunkt wird nun unterstützt. Weitere Informationenfinden Sie unter Verwenden einer SAP ASE-Datenbankals Quelle für AWS DMS (p. 191) und Verwenden einerSAP ASE-Datenbank als Ziel für AWS Database MigrationService (p. 243).
13. Juli 2016
Neue Funktion Filter zum Verschieben einer Teilmenge von Zeilenaus der Quelldatenbank in die Zieldatenbank werdennun unterstützt. Weitere Informationen finden Sie unterVerwenden von Quellfiltern (p. 416).
2. Mai 2016
Neue Funktion Amazon Redshift als Zielendpunkt wird nun unterstützt.Weitere Informationen finden Sie unter Verwenden einerAmazon Redshift-Datenbank als Ziel für AWS DatabaseMigration Service (p. 231).
2. Mai 2016
AllgemeineVerfügbarkeit
Erstversion von AWS Database Migration Service 14. März 2016
ÖffentlicheVorversion
Die Vorversion der Dokumentation für AWS DatabaseMigration Service wurde freigegeben.
21. Januar 2016
API-Version API Version 2016-01-01525

AWS Database Migration Service Benutzerhandbuch
AWS-GlossarDie aktuelle AWS-Terminologie finden Sie im AWS-Glossar im AWS General Reference.
API-Version API Version 2016-01-01526