Embed Size (px)
Citation preview

Date of publication xxxx 00, 0000, date of current version xxxx 00, 0000.
Digital Object Identifier 10.1109/ACCESS.xxxx.DOI
Automatic Speech Recognition usinglimited vocabulary: A surveyJEAN LOUIS K. E. FENDJI1, (Member, IEEE), DIANE M. TALA2, BLAISE O. YENKE1,(Member, IEEE), and MARCELLIN ATEMKENG31Department of Computer Engineering, University Institute of Technology, University of Ngaoundere, 455 Ngaoundere, Cameroon (e-mail: [email protected],[email protected])2Department Mathematics and Computer Science, Faculty of Science, University of Ngaoundere, 454 Ngaoundere, Cameroon (e-mail:[email protected])3Department of Mathematics, Rhodes University, Grahamstown 6140, South Africa (e-mail: [email protected])
Corresponding author: Jean Louis K.E. Fendji (e-mail: lfendji@ gmail.com), Marcellin Atemkeng (e-mail: [email protected]).
ABSTRACT Automatic Speech Recognition (ASR) is an active field of research due to its huge number ofapplications and the proliferation of interfaces or computing devices that can support speech processing. Butthe bulk of applications is based on well-resourced languages that overshadow under-resourced ones. YetASR represents an undeniable mean to promote such languages, especially when design human-to-humanor human-to-machine systems involving illiterate people. An approach to design an ASR system targetingunder-resourced languages is to start with a limited vocabulary. ASR using a limited vocabulary is a subsetof the speech recognition problem that focuses on the recognition of a small number of words or sentences.This paper aims to provide a comprehensive view of mechanisms behind ASR systems as well as techniques,tools, projects, recent contributions, and possibly future directions in ASR using a limited vocabulary. Thiswork consequently provides a way to go when designing ASR system using limited vocabulary. Althoughan emphasis is put on limited vocabulary, most of the tools and techniques reported in this survey applied toASR systems in general.
INDEX TERMS Deep learning, Dataset, Machine Learning, Limited Vocabulary, Speech Recognition.
I. INTRODUCTION
Automatic speech recognition (ASR) is the process and therelated technology applied to convert a speech signal intothe matching sequence of words or other linguistic entitiesusing algorithms implemented in computing devices [1].Automatic speech recognition has become an exciting fieldfor many researchers. Nowadays, users prefer to use devicessuch as computers, smartphones, or any other connected de-vice through speech. Automatic speech recognition can tech-nically be defined as graphical representations of frequenciesemitted as a function of time [2]. Current speech processingtechniques encompassing speech synthesis, speech process-ing, speaker identification or verification pave the way tocreate Human to Machine voice interfaces. Automatic speechrecognition can be applied in several applications includ-ing voice services [3], program control and data entry [3],avionics [3], disabled assistance [6], [7], etc. Although ASRcan be a plus to ease Human to Machine communication, insome cases, it is a must to help users with low literacy levelsto make use of important digital services, or to prevent the
extinction of under-resourced languages [8]. In fact, the highpenetration of communication tools such as smartphones inthe developing world [9] and their increasing presence inrural areas [10], [11] provides an unprecedent opportunity todevelop voice-based application that can help to mitigate thelow literacy level in those areas. Actually, smartphones offermany advantages over any PC-based interface, such as highmobility and portability, easy recharge of their batteries, andconventional embedded features such as microphones andspeakers.
A. MOTIVATIONIn regions with low literacy levels, people are used to speak-ing local languages that are most of the time considered asunder-resourced language because of the lack or insufficiencyof formal written grammar and vocabulary. Since people donot know how to read or to write well resourced languages(such as English or French), the development of automaticspeech recognition systems for under-resourced languagesappears as an appealing solution to overcome this limitation.
VOLUME 4, 2016 1
arX
iv:2
108.
1025
4v1
[cs
.AI]
23
Aug
202
1

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
Due to the complexity of the task, a good starting point is toconsider limited vocabulary.
This paper focuses on limited vocabulary in automaticspeech recognition to allow researchers who wish to workon under-resourced languages to have an overview on how todevelop a speech recognition system for limited vocabulary.In contrast to limited vocabulary systems, large vocabularycontinuous speech recognition (LVCSR) systems are usuallytrained on thousands of hours of speech and billions of wordsof text [12]. The development of large vocabulary systemsis complex since the larger the vocabulary, the harder themanipulation of learning algorithms with a need for a largernumber of rules to build the dataset. LVCSR systems can bevery efficient when they are applied on similar domains tothose on which they were trained [13]. However, they arenot robust enough to mismatched training and test conditionssince the context may not be well handled. In fact, most of theinput can be silence or contain background noise, that canbe mistaken for speech and increases the false positive rate[14]. LVCSR systems are not suitable for a transfer learningtargeting small or limited vocabulary.
B. POSITION WITH OTHER SURVEYSSeveral works have been done in speech recognition usinglimited vocabulary. Among the existing surveys, authors in[15] focused on Portuguese-based language and its varia-tions. They considered Portuguese as an understudied lan-guage compared to English, Arabic, and Asian languages.Among Asian languages, Indian languages received a par-ticular attention. Works on the development of ASR systemsdealing with Indian languages such as Hindi, Punjabi, Tamil,just to mention a few of them are presented in [16]. Anotherspecific language survey is provided in [17] where the au-thors focused on Russian language specificities, and appliedmodels for the development of Russian speech recognitionsystems in some organizations in Russia and abroad. Abroader survey inspecting more than 120 promising works onbiometric recognition (including voice) based on deep learn-ing models is provided in [18]. |ATMIn the latter, the authorspresented the strengths and potentials of deep learning indifferent applications. A narrowed survey is presented in [19]and highlights the major subjects and improvements made inASR. A conical survey focusing on various feature extractiontechniques in speech processing is provided in [20]. The workin [21] attempted to provide a comprehensive survey on noiseresistant features as well as similarity measurement, speechenhancement, and speech model compensation in noisy con-text. Due to the increasing penetration rate of mobile devices,the work in [22] investigated different approaches for pro-viding automatic speech recognition technology to mobileusers. Approaches used to design Chatbots and a comparisonbetween different design techniques from nine papers aregiven in [23]. To evaluate reliability of recognition resultsthe work in [24] summarizes most research works related toconfidence measures. One of the first comprehensive surveyon speech recognition system for under-resourced languages
is found in [8], notwithstanding the fact that many of theissues and approaches presented in the paper applied tospeech technology in general. In this survey, authors did notfocus on the limited vocabulary. Table 1 provides a summaryof the recent surveys on ASR.
C. CONTRIBUTIONSDespite the plethora of surveys, a survey on ASR usinglimited vocabularies is still missing. Yet ASR using limitedvocabulary is a tremendous opportunity as starting point forthe development of speech recognition systems for under-resourced languages. This survey helps to fill this gap bypresenting a summary of works done on ASR for limitedvocabulary. For a better understanding, ASR principle isdetailed along with the approach to build ASR systems, toconstruct datasets, and to evaluate the performance of suchsystems. Furthermore, close and open-source toolkits, andframeworks are also presented. Therefore, such a study canrapidly and easily enabling researchers who want to buildspeech recognition systems using limited vocabulary. Thecontributions of this paper are as follows:• A description of fundamental aspects of ASR.• A description of tools and process for creating ASR
systems.• A summary of important contributions in ASR with
limited vocabulary.• Orientations for future works.
The rest of the paper is organised around eleven sections asshown in Figure 1. Section 2 presents the methodology usedto conduct this survey. Section 3 provides an understandingof “limited vocabulary”. Section 4 describes the principleof speech recognition. Section 5 provides a description oftechniques used for automatic speech recognition. Section 6deals with the management of datasets. Section 7 presentsthe traditional performance metrics. Section 8 provides aninsight on the speech recognition frameworks. Section 9 sum-marizes works on speech recognition using limited vocabu-lary. Section 10 discusses possibly future directions, followedby a conclusion in section 11. The list of abbreviations usedthroughout this work is shown in Table 2.
II. METHODOLOGYThe research methodology is composed of three main steps:the collection of papers, filtering to keep only relevant paperswith significant findings, and analysis of the selected papers.The procedure used for the collection and filtering are de-tailed below.
A. COLLECTIONCollection of papers has been performed by a keyword-basedsearch on common repository , e.g., Scopus, IEEE Xplore,ACM, ScienceDirect, PubMed. In addition, the search hasbeen extended to web scientific indexing services namelyWeb of Science and Google Scholar. The aim was to col-lect as much as possible relevant papers on ASR. For that
2 VOLUME 4, 2016
Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
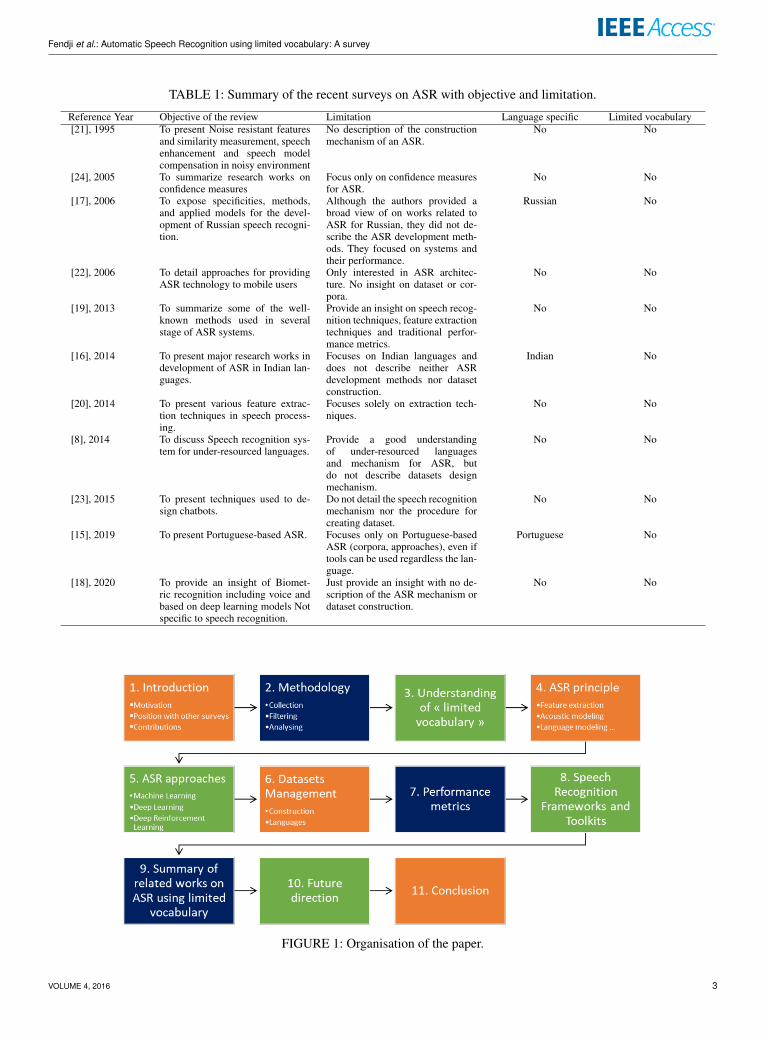
TABLE 1: Summary of the recent surveys on ASR with objective and limitation.
Reference Year Objective of the review Limitation Language specific Limited vocabulary[21], 1995 To present Noise resistant features
and similarity measurement, speechenhancement and speech modelcompensation in noisy environment
No description of the constructionmechanism of an ASR.
No No
[24], 2005 To summarize research works onconfidence measures
Focus only on confidence measuresfor ASR.
No No
[17], 2006 To expose specificities, methods,and applied models for the devel-opment of Russian speech recogni-tion.
Although the authors provided abroad view of on works related toASR for Russian, they did not de-scribe the ASR development meth-ods. They focused on systems andtheir performance.
Russian No
[22], 2006 To detail approaches for providingASR technology to mobile users
Only interested in ASR architec-ture. No insight on dataset or cor-pora.
No No
[19], 2013 To summarize some of the well-known methods used in severalstage of ASR systems.
Provide an insight on speech recog-nition techniques, feature extractiontechniques and traditional perfor-mance metrics.
No No
[16], 2014 To present major research works indevelopment of ASR in Indian lan-guages.
Focuses on Indian languages anddoes not describe neither ASRdevelopment methods nor datasetconstruction.
Indian No
[20], 2014 To present various feature extrac-tion techniques in speech process-ing.
Focuses solely on extraction tech-niques.
No No
[8], 2014 To discuss Speech recognition sys-tem for under-resourced languages.
Provide a good understandingof under-resourced languagesand mechanism for ASR, butdo not describe datasets designmechanism.
No No
[23], 2015 To present techniques used to de-sign chatbots.
Do not detail the speech recognitionmechanism nor the procedure forcreating dataset.
No No
[15], 2019 To present Portuguese-based ASR. Focuses only on Portuguese-basedASR (corpora, approaches), even iftools can be used regardless the lan-guage.
Portuguese No
[18], 2020 To provide an insight of Biomet-ric recognition including voice andbased on deep learning models Notspecific to speech recognition.
Just provide an insight with no de-scription of the ASR mechanism ordataset construction.
No No
FIGURE 1: Organisation of the paper.
VOLUME 4, 2016 3

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
TABLE 2: List of Abbreviations
Nomenclature Definition Nomenclature DefinitionACC: Accuracy AM: Acoustic ModelASR: Automatic Speech Recognition BD-4SK-ASR: Basic Dataset for Sorani Kurdish Automatic Speech
RecognitionCMU: Carnegie Mellon University CNN: Convolutional Neural NetworkCNTK: Microsoft CogNitive ToolKit CUED: Cambridge University Engineering DepartmentCSLU: Center for Spoken Language Understanding DCT: Discrete Cosine TransformationDL: Deep Learning DNN: Deep Neural NetworkDWT: Discrete Wavelet Transform FFT: Fast Fourier TransformationGMM: Gaussian Mixture Model HMM: Hidden Markov ModelHTK: Hidden Markov Model ToolKit LGB: Light Gradient Boosting MachineLM: Language Model LPC: Linear Predictive CodingLVCSR: Large Vocabulary Continuous Speech
RecognitionLVQ: Learning Vector Quantization Algorithm
MFCC: Mel-Frequency Cepstrum Coefficient PCM: Pulse-Code ModulationPLDA: Probabilistic Linear Discriminate Analysis RASTA: RelAtive SpecTralRNN: Recurrent Neural Network S2ST: Speech-to-Speech TranslationSAPI: Speech Application Programming Interface SDK: Software Development KitSMS: Short Message Service SVASR: Small Vocabulary Automatic Speech RecognitionWER: Word Error Rate
purpose, several keywords have been used such as: “SpeechRecognition”] AND [“limited vocabulary” OR “vocabulary”OR “commands”].
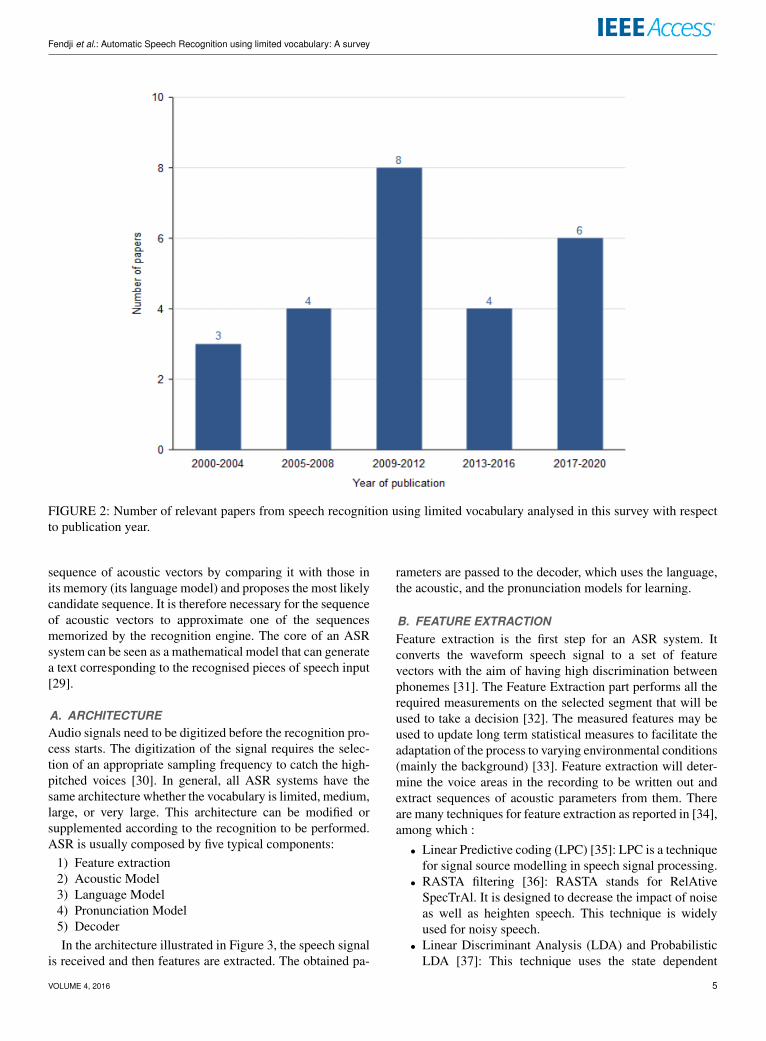
B. FILTERINGThis step consists of identifying relevant papers by read-ing the abstract and screwing the paper. Papers that arenot dealing directly with the topic or providing substantialcontribution have been removed. However, some of papersproviding relevant results have not been considered for thesynthesis because they did not provide most of the neededparameters such as the speech recognition language, the errorrate, the type of environment, the exact size of the vocabularyand the number of speakers. We have selected 25 papersfor data synthesis. Figure 2 presents the number of articlesselected that have been published between 2000 and 2020.
C. ANALYSINGEach paper has been analysed based on the following criteria:
• The language for which the recognition system wasdesigned;
• The toolkit used to design the models;• The size of the dataset;• The type of environment (noisy or not) for the recogni-
tion;• Number of speakers considered for the elaboration of
the dataset;• The accuracy or recognition rate.
III. UNDERSTANDING OF LIMITED VOCABULARYA vocabulary, in our context, is defined as a closed list oflexical units that can be recognized by an automatic speechrecognition system. The size of the vocabulary and the se-lection of lexical units in the vocabulary strongly influencethe performance of the automatic transcription system sincenot all words outside the vocabulary can be recognized bythe system. Speech recognition systems basically access a
dictionary of phonemes and words. Obviously, it is easierto seek the meaning of one out of ten words in a ten-worddictionary rather than one out of thousands of words in aWebster’s dictionary [25].
A phoneme is in essence the smallest unit of phoneticspeech that distinguishes one word from another [26]. Everyword can be decomposed into units (phonemes) of individualsounds that constitutes that word. The number of wordsor sentences an ASR system can recognise is an importantclassification criterion. As proposed in [27], an ASR systemcan be classified based on the size of the vocabulary asfollowing:
• Small Vocabulary: between 1 and 100 words or sen-tences;
• Medium Vocabulary: between 101 and 1000 words orsentences;
• Large Vocabulary: between 1001 and 10,000 words orsentences;
• Very-large vocabulary: more than 10,000 words or sen-tences.
A second classification is proposed by Whittaker andWoodland [28]. They also classified ASR systems into fourcategories: small vocabulary (up to thousand words), mediumvocabulary (up to 10,000 words), large vocabulary (up to100,000 words) and very/extra large vocabulary (>100,000words). In this second case, limited vocabulary can be con-sidered as a small vocabulary meaning up to thousand words.This size will be used in the rest of the paper as the maximalsize for limited vocabulary.
IV. AUTOMATIC SPEECH RECOGNITIONIn the basic principle of automatic speech recognition, theperson speaking emits pressure variations in his larynx. Thesounds produced are digitized by the microphone and trans-mitted through a medium or a network. Digitized soundsare transformed into acoustic units (or acoustic vectors) viaacoustic model. Then, the recognition engine analyzes this
4 VOLUME 4, 2016
Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
FIGURE 2: Number of relevant papers from speech recognition using limited vocabulary analysed in this survey with respectto publication year.
sequence of acoustic vectors by comparing it with those inits memory (its language model) and proposes the most likelycandidate sequence. It is therefore necessary for the sequenceof acoustic vectors to approximate one of the sequencesmemorized by the recognition engine. The core of an ASRsystem can be seen as a mathematical model that can generatea text corresponding to the recognised pieces of speech input[29].
A. ARCHITECTUREAudio signals need to be digitized before the recognition pro-cess starts. The digitization of the signal requires the selec-tion of an appropriate sampling frequency to catch the high-pitched voices [30]. In general, all ASR systems have thesame architecture whether the vocabulary is limited, medium,large, or very large. This architecture can be modified orsupplemented according to the recognition to be performed.ASR is usually composed by five typical components:
1) Feature extraction2) Acoustic Model3) Language Model4) Pronunciation Model5) DecoderIn the architecture illustrated in Figure 3, the speech signal
is received and then features are extracted. The obtained pa-
rameters are passed to the decoder, which uses the language,the acoustic, and the pronunciation models for learning.
B. FEATURE EXTRACTIONFeature extraction is the first step for an ASR system. Itconverts the waveform speech signal to a set of featurevectors with the aim of having high discrimination betweenphonemes [31]. The Feature Extraction part performs all therequired measurements on the selected segment that will beused to take a decision [32]. The measured features may beused to update long term statistical measures to facilitate theadaptation of the process to varying environmental conditions(mainly the background) [33]. Feature extraction will deter-mine the voice areas in the recording to be written out andextract sequences of acoustic parameters from them. Thereare many techniques for feature extraction as reported in [34],among which :• Linear Predictive coding (LPC) [35]: LPC is a technique
for signal source modelling in speech signal processing.• RASTA filtering [36]: RASTA stands for RelAtive
SpecTrAl. It is designed to decrease the impact of noiseas well as heighten speech. This technique is widelyused for noisy speech.
• Linear Discriminant Analysis (LDA) and ProbabilisticLDA [37]: This technique uses the state dependent
VOLUME 4, 2016 5

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
FIGURE 3: Architecture of an ASR.
variables of HMM based on i-vector extraction. The i-vector is a low dimensional vector with fixed length andcontaining relevant information.
• Mel-frequency cepstrum (MFCCs): It is the most com-monly used technique, with a frame shift and lengthusually between 20 and 32 ms, using 1024 frequencybins, 26 mel channels and between 10 and 40 cepstralcoefficients with cepstral mean normalization [44], [56],[57], [58]. This technique has a low complexity anda high accuracy of recognition. MFCC is the usualmethod for character extraction in most papers tacklingthe design of speech recognition systems for limited vo-cabulary [33], [40], [41]. The public sphinx base libraryprovides an implementation of this method that can bedirectly used as it is done in [42]. Figure 4 provides abrief description of the MFCC method encompassingsix steps.
1) Framing and windowing: For the acoustic parameters tobe stable, the speech signal must be examined over asufficiently short period. This step aims to cut windowsof 20 to 30 ms. The process is illustrated in Figure 5.
2) Hamming Window: The Hamming window is used toreduce the spectral distortion of the signal. In contrast toRectangular window that is simple but can cause prob-lem since it abruptly slices the signal at the boundaries,Hamming window reduces the signal values toward zeroat the boundaries. This help to avoid discontinuities.This is expressed mathematically as follows:
y(n) = x(n)× w(n), 0 ≤ n ≤ N − 1, (1)
where n is the number of windows, N is the number ofsamples in each frame, y(n) the output signal, x(n) theinput signal andw(n) the hamming windows defined as:
w(n) = 0.54− 0.46 cos
(2πn
N
). (2)
3) Fast Fourier Transformation (FFT) does the conversionof time domain windows into the frequency domain bydiscretising and interpolating the window onto a regulargrid before the Fourier transform is applied. The FFTdecreases the computation requirements compared tothe discrete Fourier transform. The latter is defined as:
S(k) =
N∑n=0
y(n)e−2πKnN , 0 ≤ k ≤ N, (3)
whereN is the number of windows, k is the index of thecoefficient and K is the number of coefficients.
4) Mel Filter Wrapping filter banks allow to reproduce theselectivity of the human auditory system by providing acoefficient that gives the energy of the signal:
X(m) =
N−1∑k=0
|S(k)|W (k,m), 1 ≤ m ≤M, M < N,
(4)where m is the index of the filter, M the number offilters and W is the weight function with inputs thekth energy spectrum bin contributing to the mth outputband.
5) Log allows to obtain the logarithmic spectrum of Meland to compress the sum X(m) using:
X ′(m) = ln(X(m)). (5)
6) Discrete Cosine Transform (DCT) reduces the influenceof low-energy components. MFCC coefficients are ob-tained by the discrete cosine transform given by:
c(k) =
N−1∑m=0
am cos
[π
M(m+
1
2)k
]X ′(m), 0 ≤ k ≤ K,
(6)where a0 = 1√
M, am =
√2M .
After this last step, the coefficients are return as outputs.
6 VOLUME 4, 2016

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
FIGURE 4: Block diagram of MFCC feature extraction
FIGURE 5: Illustration of Framing and Windowing process with a Frame Shift of 10ms, a Frame size of 25ms and tworepresentations: Hamming window and Rectangular window.
C. ACOUSTIC MODELING
Acoustic modeling (AM) of speech typically describes howstatistical representations of the feature vector sequencescomputed using the speech waveform are established. It aimsto predict the most likely phonemes in the audio that hasbeen given as input [2]. Challenging configurations mainlyinvolving noise may occur. Two cases can be identified: thenoise is isolated to a single band of frequencies, or the noiseis not isolated, meaning it is on several bands. In the firstcase, acoustic models are still reliable enough to properlytake the right decision. In the second case, models have nogood information and they are prone to mistakes [43]. TheBayesian process applied to automatic speech recognition
is as follows: Assuming that x is a sequence of unknownacoustic vectors and wi (i = 1, · · · ,K) is one of the Kpossible classes for an observation. The recognized class isgiven by:
w∗ = argimaxP (x|wi)P (wi)
P (x)(7)
= argimaxP (x|wi)P (wi). (8)
The recognized word w∗ will therefore be the one thatmaximizes this quantity, among all the candidate words wi.The probability P (x|wi) of observing a signal x knowing thesequence needed for the acoustic model estimation. The aprior P (wi) of the sequences is independent of the signal
VOLUME 4, 2016 7

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
and needs a language model for estimation. P (X) is theprobability to observe the sequence of acoustic vectors X .It is the same for each phoneme sequence (because P (X)does not depends on W ), so it can be ignored [44].
For automatic speech recognition using limited vocabu-lary, the most commonly used acoustic model to estimate theprobability P (X|W ) is the Hidden Markov Model (HMM)[40], [42], [45], [46]. An HMM is considered as a generatorof acoustic vectors. It is a finite state automaton in which thetransition from state qi to state qj has a probability of aij ateach time unit. This transition generates an acoustic vector xtwith a probability density bj(xt). The Markov model is thengiven by M = (πi, A,B), where πi represents the initialprobability distribution, A is the transition probability matrixaij , and B the set of observation densities B = {bj(xt)}.Several approaches for learning HMM models have beenproposed such as the Maximum likelihood estimation [47]and forward-backward estimation [48].
D. LANGUAGE MODEL
The language model in ASR is used to predict the most likelyword sequence for a given text. In limited vocabulary, thetraining text is divided in word classes during the trainingphase. Based on word classes, the class-based n-gram lan-guage model is elaborated. Then the standard bigram model,the class-based bigram model, and the interpolated model areobtained and used by the speech recognition system [49].
Language statistical model (for a sequence of wordsW = w1, w2, · · · , wN ) consists in calculating the probabil-ity P (W ):
P (w) =
N∏i=1
P (wi|w1, · · · , wi−1) (9)
=
N∏i=1
P (wi|hi), (10)
where hi = w1, ..., wi−1 is considered as the history of theword wi and P (wi|hi) is the probability of the word wi,knowing all the previous words.
In practice, as the sequence of words hi becomes richer,an estimation of the values of the conditional probabilitiesP (wi|hi) becomes more and more difficult because no cor-pus of learning text can observe all possible combinations ofhi = w1, ..., wi−1.
To reduce the complexity of the language model, andconsequently of its learning, the n-gram approach can beused. The principle is therefore the same and only the historyis limited to the previous n− 1 words. The probability P (w)is thus approximated as:
P (w) =
N∏i=1
P (wi|wi−n+1, · · · , wi−1). (11)
It is possible to find the probability of the occurrence of aword wi in the learning corpus:
P (wi) =C(wi)
C, (12)
where C(wi) is the number of times the word wi has beenobserved in the learning corpus and C the total number ofwords in the corpus. In practice, depending on the size of thelearning corpus, different sizes of the history can be chosen.We then speak of a unigram model if n = 1 (without history),a bigram if n = 2 or a trigram if n = 3.
E. PRONUNCIATION MODELThe pronunciation dictionary models describe how a wordis pronounced and represented. For small vocabulary, word-based models are used to define whole word as individualsound unit. The pronunciation dictionary is a part of pro-nunciation model. Translation of speech signal into text isachieved by classifying the speech signal into small soundunits. The pronunciation model determines how these smallunits can be combined to form valid words. For limitedvocabularies, pronunciation models can be constructed byhandwriting word pronunciations, deriving them with phono-logical rules, or finding frequent pronunciations in a hand-transcribed corpus [50]. Another way to design the pronun-ciation model for limited vocabularies is to develop inde-pendent statistical models for each word in the dataset. Theidea is to design a system in which each word has a numberof parts, and then a model is trained to recognize each partof the word [51]. Once the acoustic, the language, and thepronunciation models are developed, the decoder uses themto output the text corresponding to the received audio signal.
F. DECODER|ATMA decoder is seen as a graph search algorithm combinesacoustic and linguistic knowledge to automatically transcribethe input record [2]. The goal of decoding is to deducethe sequence of states that generated the given observations.From this sequence of states, it is easy to find the most likelysequence of phonemes that matches the observed parameters.For a limited vocabulary, the Viterbi search algorithm [52]uses the probabilities of the acoustic model and those of thelanguage model to accomplish the decoding task. The Viterbidecoder is good for short commands, meaning for small orlimited vocabulary [53], [54]. The Viterbi algorithm seeksthe most probable candidate among states in an HMM. Thissearch is done given the probability of observations obtainedfrom acoustic model, for each time step for each of the states(cepstral coefficient vector corresponding to the time step).
V. AUTOMATIC SPEECH RECOGNITION APPROACHESThree techniques in artificial intelligence are mainly used forASR in general, namely machine learning, deep learning, anddeep reinforcement learning.
8 VOLUME 4, 2016

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
A. MACHINE LEARNINGMachine learning (ML) is part of artificial intelligence tech-niques that refers to systems that can learn by themselves[55]. ML implies teaching a computer to recognize pattern incontrast to traditional approach that consists of programminga computer with specific rules. The teaching is done through atraining process that involves feeding large amounts of audiodata to the algorithm and allowing it to learn from data anddetect patterns that can later be used to achieve some tasks[56], [57]. ML techniques can be grouped into four categories[58]:
• Supervised Learning consists of inferring a classifica-tion or regression from labeled training data, to developpredictive models. Classification techniques predict dis-crete responses while regression techniques predict con-tinuous responses.
• Unsupervised Learning consists of drawing inferencesfrom datasets composed of unlabeled input data. Themost common technique in this category is the cluster-ing that is used for exploratory data analysis in order tofind hidden patterns or groupings in data.
• Semi-supervised Learning. The training of the systemin this learning technique makes use of both labeled andunlabeled data. This type of training is adequate when itis very expensive to obtain labeled data.
• Active Learning. This approach is used when there isa lot of unlabeled data, but labeling is expensive. Thealgorithm interactively queries the user to label data.
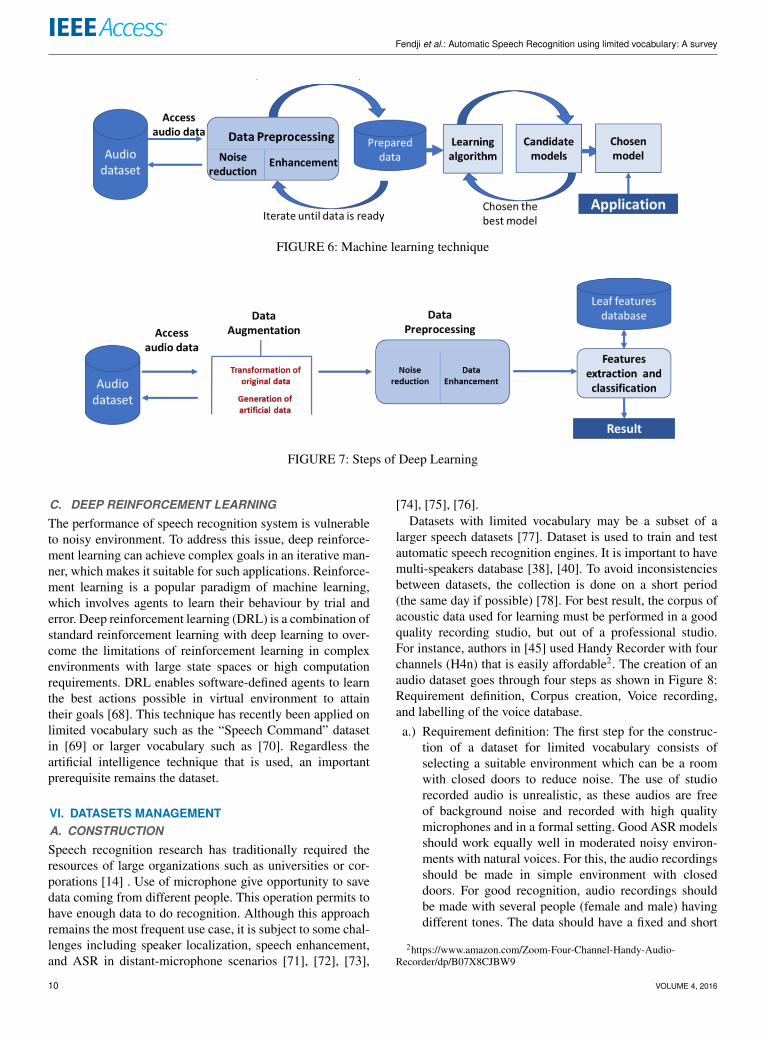
The different ML steps for speech recognition are providedin Figure 6 and are detailed as follows:
1) The first step is to select and prepare a training datasetcomposed of audios (from words or sentences) that havebeen acquired through microphones. This data will beused to feed the ML model during the learning processso that it can determine texts corresponding to audioinputs. Data must be meticulously prepared, organizedand cleaned with the aim to mitigate bias during thetraining process.
2) The second step is to perform a pre-processing on theinput data. This pre-processing includes the reductionof the noise in the audio and the enhancement of data.
3) The third step consists of choosing a parametric classwhere the model will be searched. This is a fine-tunedprocess that is ran on the training dataset. For speechrecognition using limited vocabulary, some algorithmslike Maximum Likelihood Linear Regression algorithm[42] can be used to train the acoustic model, and theViterbi algorithm [41], [42] for decoding. The type ofalgorithm to use depends on the type of problem to besolved.
4) The fourth step is the training of the algorithm. Thisis an iterative process. After running the algorithm, theresults are compared with expected ones. The weightsand bias are eventually tuned via the back propagationoptimization to increase the accuracy of the algorithm.
This process is repeated until a certain criterion is metand the resulting trained model is saved for furtheranalysis with the test data.
5) The fifth and final step is to use and improve the model.The model is then used on new data.
Different ML methods have been used for acoustic modelingin speech recognition systems [58]. The evaluation, decodingand training of HMMs are done by ML forward-backward[48], Viterbi [52] and Baum-Welch algorithms [47] respec-tively. In their work, Padmanabhan and collaborator [58]review these methods.
B. DEEP LEARNING
Deep Learning (DL) is a set of algorithms in Machine Learn-ing. It uses model architectures made up of multiple non-linear transformations (neural networks) to model high-levelabstractions in data [59]. Deep Neural Networks (DNNs)work well for ASR when compared with Gaussian MixtureModel based HMMs (GMM-HMM) systems, and they evenoutperform the latter in certain tasks [60]. Deep learning em-ploys Convolutional Neural Network (CNN) approach whichowns the ability to automatically learn the invariant featuresto distinguish and classify the audio [61]. By learning mul-tiple levels of data representations, DL can derive higher-level features from lower-level ones to form a hierarchy. Forinstance, in a speech classification task, the DL model cantake phonemes values in the input layer and assign labelsto the word in the sentence in the output layer. Betweenthese two layers there are a set of hidden layers that buildsuccessive higher-order features that are less sensitive toconditions such as noise in the user’s environment [62].
Deep Learning can be implemented using various tools.However, Tensor Flow seems to be one of the best applicationmethods currently available [63]. Figure 7 gives the stepsof DL in ASR. Data augmentation helps to improve theperformance of the model by generalizing better and therebyreducing overfitting [64], [65]. Data augmentation creates arich, diverse set of data from a small amount of data. Dataaugmentation can be applied as a pre-processing step beforetraining the model or later directly in real time. Differentaugmentation policies can be applied to audio data such asTime warping, Frequency masking, Time masking. Recently,a new augmentation method called SpecAugment has beenproposed by Park et al. in [66] for ASR system. They com-bined the warping of the features and the masking of blocksof frequency channels, as well as the blocks of time steps.To ease the augmentation process, a recent free MATLABToolbox called Audiogmenter1 have been proposed [67].
The feature extraction process aims to remove the non-dominant features and therefore reducing the training timewhile mitigating the complexity of the developed models.
1https://github.com/LorisNanni/Audiogmenter.
VOLUME 4, 2016 9
Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
FIGURE 6: Machine learning technique
FIGURE 7: Steps of Deep Learning
C. DEEP REINFORCEMENT LEARNING
The performance of speech recognition system is vulnerableto noisy environment. To address this issue, deep reinforce-ment learning can achieve complex goals in an iterative man-ner, which makes it suitable for such applications. Reinforce-ment learning is a popular paradigm of machine learning,which involves agents to learn their behaviour by trial anderror. Deep reinforcement learning (DRL) is a combination ofstandard reinforcement learning with deep learning to over-come the limitations of reinforcement learning in complexenvironments with large state spaces or high computationrequirements. DRL enables software-defined agents to learnthe best actions possible in virtual environment to attaintheir goals [68]. This technique has recently been applied onlimited vocabulary such as the “Speech Command” datasetin [69] or larger vocabulary such as [70]. Regardless theartificial intelligence technique that is used, an importantprerequisite remains the dataset.
VI. DATASETS MANAGEMENTA. CONSTRUCTION
Speech recognition research has traditionally required theresources of large organizations such as universities or cor-porations [14] . Use of microphone give opportunity to savedata coming from different people. This operation permits tohave enough data to do recognition. Although this approachremains the most frequent use case, it is subject to some chal-lenges including speaker localization, speech enhancement,and ASR in distant-microphone scenarios [71], [72], [73],
[74], [75], [76].Datasets with limited vocabulary may be a subset of a
larger speech datasets [77]. Dataset is used to train and testautomatic speech recognition engines. It is important to havemulti-speakers database [38], [40]. To avoid inconsistenciesbetween datasets, the collection is done on a short period(the same day if possible) [78]. For best result, the corpus ofacoustic data used for learning must be performed in a goodquality recording studio, but out of a professional studio.For instance, authors in [45] used Handy Recorder with fourchannels (H4n) that is easily affordable2. The creation of anaudio dataset goes through four steps as shown in Figure 8:Requirement definition, Corpus creation, Voice recording,and labelling of the voice database.a.) Requirement definition: The first step for the construc-
tion of a dataset for limited vocabulary consists ofselecting a suitable environment which can be a roomwith closed doors to reduce noise. The use of studiorecorded audio is unrealistic, as these audios are freeof background noise and recorded with high qualitymicrophones and in a formal setting. Good ASR modelsshould work equally well in moderated noisy environ-ments with natural voices. For this, the audio recordingsshould be made in simple environment with closeddoors. For good recognition, audio recordings shouldbe made with several people (female and male) havingdifferent tones. The data should have a fixed and short
2https://www.amazon.com/Zoom-Four-Channel-Handy-Audio-Recorder/dp/B07X8CJBW9
10 VOLUME 4, 2016

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
FIGURE 8: Construction of dataset for limited vocabulary
duration to facilitate the training of the learning modeland the evaluation process [14].
b.) Corpus creation: After requirement definition words orsentences of the limited vocabulary are chosen. Thechoice of words or sentences is made according to theneeds, and it is limited to the context in which speechrecognition will be performed. Only necessary datashould be selected. The maximum size of the corpusfor limited vocabulary is generally around a thousandof words.
c.) Voice recording: Sounds are recorded using a micro-phone that matches the desired conditions. It shouldminimize differences between training conditions andtest conditions. Speech recording are performed gen-erally in an anechoic room and usually digitized at 20kHz using 16 bits [79], [77] or at 8 kHz [45] or 16 kHz[14], [78]. The waveform audio file format container|ATMwith file extension .wav is generally used [14],[77]. The WAV formats encoded to PCM allow to obtainan uncompressed and high-fidelity digital sound. Sincethese formats are easy to process in the pre-processingphase of speech recognition and for further processing,it is necessary to convert the audio files obtained afterthe recording (for instance OGG, WMA, MID, etc.) intoWAV format.
d.) Labeling of the voice database: Most ML models aredone in a supervised approach. For supervised learningto work, a set of labeled data from which the model canlearn to make correct decisions is required. The labelingstep aims to identify raw data (text and audio files) andto add informative labels in order to specify the contextso that a ML model can learn from it. Each recordedfile is marked by sub word or phonemes. Labelingindicates which phonemes or words were spoken inthe audio recording. To label the data, humans makejudgments about some aspect of the unlabeled audiofile. For example, one might ask to label all audioscontaining a given word or phoneme. The ML modeluses the human-supplied labels to learn. The resultingtrained model is used to make predictions on new data.Some software such as Audio Labeler3 allows to definereference labels for audio datasets. Audio Labeler also
3https://www.mathworks.com/help/audio/ref/audiolabeler-app.html
allows to visualize these labels in an interactive way.A minimal structure of a dataset for a limited vocabularytakes into account elements such as the path to the audiofile, the text corresponding to the audio file, the gender ofthe speaker, the age and the language used if there are manylanguages in the dataset4. An excerpt of such a dataset forASR using limited vocabulary is given in Table 3.
If there are several speakers, then the speaker’s index willbe one key element in Table 3. Some researchers also takeinto account the emotion of the speaker, mentioning if he isneutral, happy, angry, surprised or sad [80].
B. LANGUAGES AND DATASETSIn the literature, several works have developed datasets suchas VoiceHome2 [81] that developed a French corpus fordistant microphone speech processing in domestic environ-ments. Still dealing with French, the work in [82] proposesa multi-source data selection for the training of LMs (Lan-guage Models) dedicated to the transcription of broadcastnews and TV shows. An important work focusing on the En-glish language is the reduced voice command database [83].It has been created from worldwide cloud speech databaseand in combination with training, testing and real time recog-nition algorithms based on artificial intelligence and deeplearning neural networks. Another important English datasetfor digits from 0 to 9, and 10 short phrases is the AV DigitsDatabase [84]. In a survey, 53 participants divided into 41males and 12 females were asked to read digits in English inrandom order five times. In the other hand, 33 agents wereasked to recorder sentences, each sentence was repeated fivetimes in 3 different modes: neutral, whisper and silent speech.A larger dataset is the Isolet dataset proposed in [85]. Thisdataset contains 150 voices divided into five groups of 30people. In this dataset, each speaker pronounces twice eachletter of the English alphabet, which provides a set of 52training examples for each speaker.
Apart from French and English, other languages such So-rani Kurdish has been tackled. BD-4SK-ASR (Basic Datasetfor Sorani Kurdish Automatic Speech Recognition) is anexperimental dataset which it used in the first attempt in de-veloping an automatic speech recognition for Sorani Kurdish[86].
4https://huggingface.co/datasets/timit_asr
VOLUME 4, 2016 11

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
TABLE 3: Structure of a multilingual dataset for limited vocabulary
Audio Wav file Text Age Sex Accent (Language)C:/dataset/audio1.wav One 23 M EnglishC:/dataset/audio2.wav Two 20 F English· · · · · · · · · · · · · · ·C:/dataset/audion.wav Dix 35 M French
A very large project run by Mozilla is the Common VoiceProject initiated with the aim of producing an open-sourcedatabase for automatic speech recognition [87]. MozillaCommon voice dataset created in 2017 is intended for devel-opers of language processing tools. In November 2020, morethan 60 languages were represented on the platform. Amongthese languages we can mention French, English, Chinese,Danish and Norwegian. Systems developed for speech recog-nition systems must be tested for efficiency, regardless thelanguage.
VII. PERFORMANCE METRICSThe quality of the output transcript of an ASR system istraditionally measured by the word error rate (WER) metric:
WER =S + I +D
N, (13)
where S is the number of incorrect words substituted, I isthe number of extra words inserted, D is the number ofwords deleted and N is the number of words in the correcttranscript. The WER metric is estimated in term of percent-age. But it is important to note that it is possible to havea WER value exceeding 100% and the WER threshold foracceptable performance depends on the applications. How-ever, Johnson et al. [88] have shown that it is still possibleto get a good retrieval performance with a WER value up to66%. However, the precision begins to fall off quickly whenWER gets above 30% [88]. Having an estimation of WERvalue and knowing the threshold for usable transcripts, theallocation of processing resources can be oriented only thosefiles predicted to yield usable results. If a spoken word is notincluded in the vocabulary, the corresponding transcript willbe considered as an error and the WER value will increase.
For detection of Keyword, authors in [89] proposed a newmethod to calculate the mean of accuracies of each keyword(acci). This is computed depending on the number of key-words correctly predicted (Ncp), the number of keywords notyet predicted (Nny) and the number of keywords incorrectlypredicted (Nip):
acci =Ncp −NipNcp +Nny
. (14)
The accuracy, ACC is computed from the above as:
ACC =1
N
N−1∑i=0
acci. (15)
The WER metric works well when the morphology of thelanguage is simple [8]. Otherwise more adequate metricsshould be applied such as the Letter or Character Error Rate
(LER or CER) [90], [91], the Syllable Error Rate (SylER)[92] or Speaker Attributed Word Error Rate (SA-WER) [93].
The language models can be evaluated separately fromthe acoustic model. The most commonly used measure isthe perplexity [94]. This measure is calculated on a text notseen during training (test-set perplexity). Another measureis based on Shannon’s game [95]. Existing frameworks areused to develop ASR systems. Having a look on them andthe previous works that used them can enable newcomers inthe field to develop ASR systems.
VIII. SPEECH RECOGNITION FRAMEWORKS ORTOOLKITSSeveral toolkits for ASR have been developed to traindatasets. Some toolkits are open-source code and other arenot. The presentation of close-source code and open-sourcecode system is the aim of this section.
A. CLOSE-SOURCE CODE SYSTEMSSeveral close-source system are available for ASR, namelyDragon Mobile SDK, Google Speech Recognition API,SiriKit, Yandex SpeechKit and Microsoft Speech API [96].
The Dragon Mobile SDK5 developed by Nuance since2011 provides speech services to enhance applications withspeech recognition and text-to-speech functionality. It con-sists of a set of sample projects, documentation, and aframework to ease the integration of speech services into anyapplication. It is a trialware that requires a paid subscriptionafter 90 days. Popular mobile platforms are supported: An-droid, iOS, and Windows phone. It has been used in someworks like [97] where a custom phonetic alphabet has beenoptimized to facilitate text entry on small displays.
The Yandex SpeechKit6 can be used to integrate speechrecognition, text-to-speech, music identification, and Yan-dex voice activation into Android mobile applications. Yan-dex SpeechKit supports the following languages for speechrecognition and text-to-speech: Russian, English, Ukrainian,Turkish. Yandex SpeechKit has been recently used in [98].
SiriKit7 is a toolkit that allows to integrate Siri into a third-party iOS or macOS application, to benefit from the ASRcapabilities. Siri is a speech recognition personal assistantunveiled by Apple in 2011 and working only on iOS andmacOS [99]. Even if potential dangers and ethical issues havebeen reported [100] [101], SiriKit is used in numerous worksincluding [102], [103].
5https://www.nuance.com/dragon/for-developers/dragon-software-developer-kit.html
6https://cloud.yandex.com/en/services/speechkit7https://developer.apple.com/documentation/sirikit
12 VOLUME 4, 2016

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
The Speech Application Programming Interface8 (short-ened SAPI) developed by Microsoft enables developers tointegrate speech recognition and speech synthesis withinWindows applications [104]. Several versions of the APIhave been released either as part of a Speech SDK or aspart of the Windows Operating System. SAPI is used inMicrosoft Office, Microsoft Agent and Microsoft SpeechServer. Several research works have also made use of thisAPI [105], [106].
Google Speech Recognition API9 is a C# toolkit based ona model trained with English and more than 120 languages.Google has improved its speech recognition by using a deepneural network in its applications, reaching 8% error rate in2015 compared to 23% in 2013 [107].
Table 4 provides a summary of selected close-source codespeech recognition toolkits.
As conventional close-source software, these toolkits arenot flexible and limited to the languages they have been de-signed for. Such limitations fostered the research communityto develop open-source frameworks and toolkits.
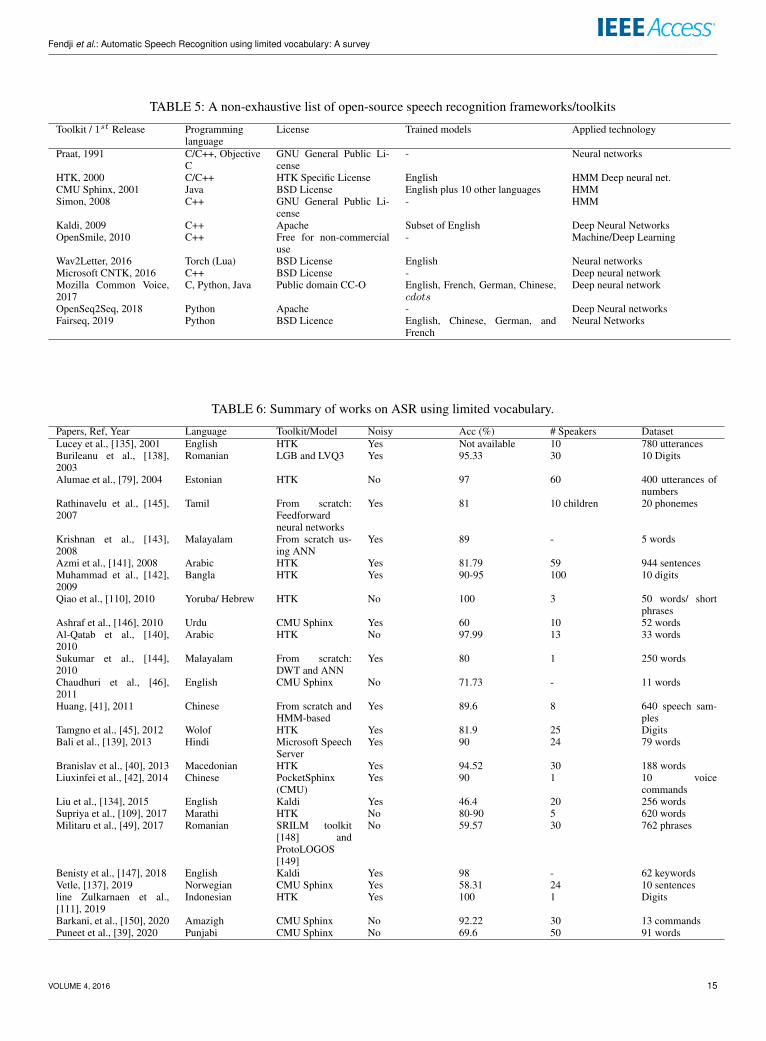
B. OPEN-SOURCE CODE SYSTEMS
A plethora of open-source frameworks, engine, or toolkits forASR systems are proposed in the literature. The following isa non-exhaustive list of main works or projects. Most of themcan easily handle small and large vocabulary. The HTK10
is one of the first speech recognition software developedsince the late 1980s. It is freely available for the researchcommunity since 2000 and maintained at the Speech Visionand Robotics Group11 of the Cambridge University Engi-neering Department (CUED) [108]. It provides recipes tobuild baseline systems with Hidden Markov Models (HMM).HTK is considered as a very simple and effective tool forresearch [109], [110]. It can build noise robust automaticspeech recognition system in a moderated noisy level en-vironment, especially for small vocabulary system. It is apractical solution to develop fast and accurate SVASR [111].Several works use this toolkit [112] [113] [114]. One of themost popular toolkits is the CMU Sphinx12, designed for bothmobile and server applications. CMU Sphinx is in fact a set oflibraries and tools that can be used to develop speech-enableapplications. It is developed at Carnegie Mellon Universitysince the late 1980s [115]. Several versions have been re-leased including Sphinx 1 to 4, and PocketSphinx for hand-held devices [116]. CMU Sphinx is currently attracting theattention of the research community. It offers the possibilityto build new language models using its language ModelingTool13.
8https://docs.microsoft.com/en-us/previous-versions/windows/desktop/ms720151(v=vs.85)
9https://cloud.google.com/speech-to-text?hl=en10https://htk.eng.cam.ac.uk/11http://mi.eng.cam.ac.uk12https://cmusphinx.github.io/13http://www.speech.cs.cmu.edu/tools/lmtool-new.html
A former toolkit that may no longer be available is theRapid Language Adaptation Toolkit (RLAT) introduced in[117] and used in [118], [119]. The website of the projectis unfortunately no longer available. Kaldi is an extendableand modular toolkit for ASR [120]. The large communitybehind the project is providing numerous third-party mod-ules that can be used for several tasks. It supports deepneural networks and offers an excellent documentation onits website14. Several works have been based on this toolkitincluding [121]–[123].
Microsoft also proposes an open-source CognitiveToolkit15 (CNTK). It is used to create DNNs that power manyMicrosoft services and products. It enables researchers anddata scientists to easily code such neural networks at the rightabstraction level, and to efficiently train and test them onproduction-scale data [124], [125]. Even if it is still used, itis a deprecated framework.
Julius16 is a software normally designed for LVCSR. It isbased on word N − gram and context-dependent HMM. Itis used in several works such as [126], [127].
Simon toolkit17 is a general public license speech recogni-tion framework developed in C++. It is designed to be flexibleas much as possible and it works with any language or dialect.Simon makes use of KDE libraries, CMU SPHINX or Juliustogether with HTK and it runs on Windows and Linux.
Praat18 is a framework that enables speech analysis, syn-thesis, and manipulation. In addition, it allows speech la-belling and segmentation. It has been used in [128], [129].Mozilla Common Voice19 is a free speech recognition soft-ware for developers that can be integrated into projects.It works with deep neural network technology and targetsseveral languages [87]. Besides Common Voice, Mozilla hasalso developed DeepSpeech20, an open-source Speech-To-Text engine. It makes use of a model trained by the machinelearning techniques proposed in [130].
Another larger project is the OpenSMILE (open-sourceSpeech and Music Interpretation by Large-space Extraction)project21 that is complete free of use for research purposes. Itreceived a lot of attention from the research community andclaims more than 150,000 downloads. A recent model calledJasper (Just Another Speech Recognizer) has been intro-duced in 2019 [131]. It can be used with the OpenSeq2Seq22
TensorFlow-based toolkit. OpenSeq2Seq enables among oth-ers speech recognition, speech commands, speech synthesis.It is used in recent works such as [132], [133].
Other recent engines for ASR have been released such as
14https://kaldi-asr.org/15https://docs.microsoft.com/en-us/cognitive-toolkit/16https://julius.osdn.jp/en_index.php17https://simon.kde.org/18https://www.fon.hum.uva.nl/praat/19https://commonvoice.mozilla.org/20https://github.com/mozilla/DeepSpeech21https://www.audeering.com/opensmile/22ttps://nvidia.github.io/OpenSeq2Seq/html/index.html
VOLUME 4, 2016 13

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
TABLE 4: A non-exhaustive list of close-source code speech recognition frameworks/toolkits
Toolkit/1st Release ProgrammingLanguage
Targeting language Applications Applied technology
Microsoft Speech API,1995
C# English, Chinese,Japanese Speech recognition, speech synthe-sis within windows applications
Context-dependent deep neural net-work hidden Markov model
SiriKit, 2011 Objective-C English, German, French Speech recognition Deep neural network and machinelearning
Dragon Mobile SDK,2011
C++ English, Spanish, French,German, Italian, Japanese
Speech recognition and text tospeech
Markov processes
Yandex Speechkit, 2014 C, Python Russian, English,Ukrainian, Turkish
Speech recognition, text to speech,music identification and voice acti-vation
Neural network
Google Speech Recogni-tion API, 2016
C# English, more than 120languages
Speech to text, speech recognition Deep learning neural network
Fairseq23 and Wav2Letter++24 both developed by Facebook,Athena25, ESPnet26, and Vosk27 which is an offline ASRtoolkit. Table 5 provides a summary of some open-sourcespeech recognition toolkits.
Several works have been done for limited vocabularies inautomatic speech recognition using the above toolkits, wemake a summary of these works in the following section.
IX. SUMMARY OF RELATED WORK ON ASR USINGLIMITED VOCABULARYA. SELECTED WORKS ON ASR USING LIMITEDVOCABULARYASR using limited vocabulary has attracted the attention ofresearchers. The literature proposed systems for Europeanlanguages such as English [134]–[136], Estonian [79], Nor-wegian [137], Romanian [138], [49], Macedonian [40], aswell as Asian languages including Chinese [42], [41], Hindi[139], Indonesian [111], Arabic [140], [141], Bangla [142],Malayalam [143], [144], Tamil [145], Marathi [109], Punjabi[39] and Urdu [146], [147]. Table 6 provides a list of selectedworks done on ASR using limited vocabulary base.
B. REMARKSEven though European and Asian languages are well repre-sented in the selected works, we noticed a particular focus onwell-resourced languages namely English, Chinese, Roma-nian. Only few works deal with African languages namelyWolof [45] and Yoruba [110]. The weak representation ofAfrican languages can be justified by the fact that most ofthem are under-resourced, in addition to the lack of localskills and awareness about the potential of ASR systemto prevent of the extinction of under-resourced languages.Although most of works did consider noisy environments,the severity was moderated and usually limited to natural en-vironmental noises. Due to the limited size of the vocabulary,such noise levels have been easily mitigated. This justifiedthe competitive accuracy in most works.
23https://github.com/pytorch/fairseq24https://github.com/facebookresearch/wav2letter25https://github.com/athena-team/athena26https://espnet.github.io/espnet/27https://alphacephei.com/vosk/
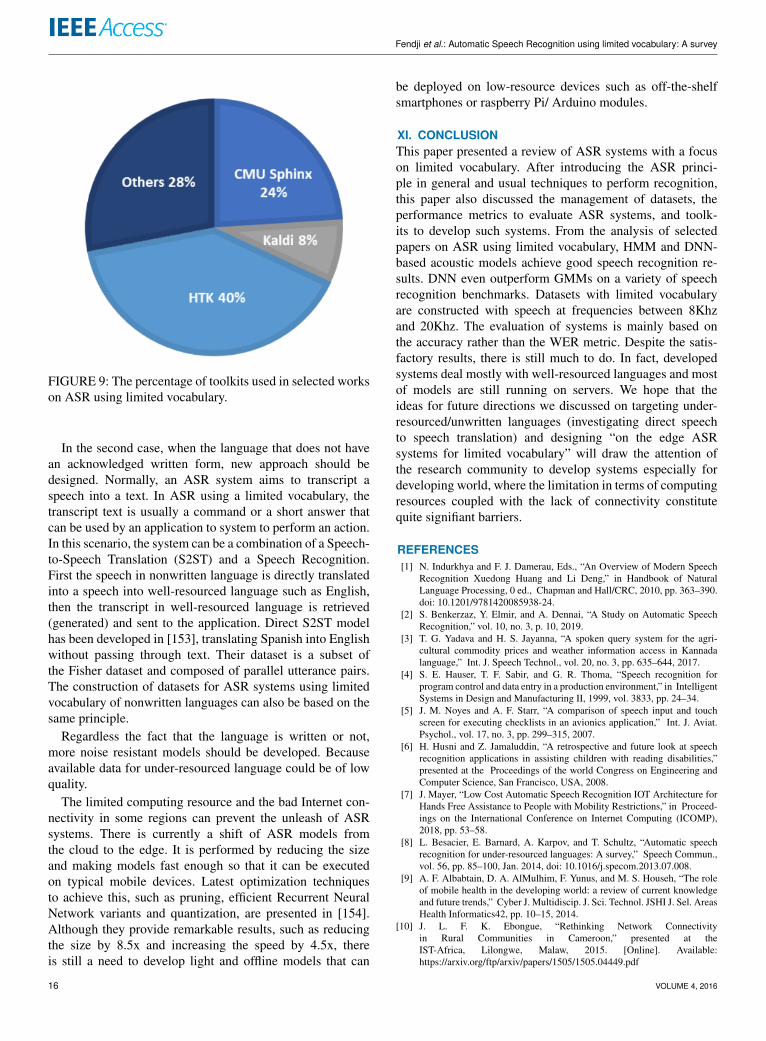
Figure 9 gives the percentage use of the different toolkits.We observe that HTK Toolkit is the most used for speechrecognition using limited vocabulary. Its success is explainedby the fact that it eases the manipulation of HMM parametersfor training and testing stage of the system development.
In general, the Bayesian equation allows to find the proba-bility that a word will be recognized in the speech recognitionprocess for limited vocabulary, and by ricochet the sequenceof words corresponding to a speech sequence. HMM andDNN are decent acoustic models that achieve good speechrecognition results. HMM is used to account for variability inspeech and DNN with many hidden layers have been shownto outperform GMMs on a variety of speech recognitionbenchmarks. The construction of dataset for ASR with lim-ited vocabulary is done with speech recorded and digitized atvarying frequencies between 8Khz and 20Khz in most cases.Finally, the accuracy of the system is calculated by using thenumber of words correctly predicted, the number of wordsnot yet predicted, and the number of words incorrectly pre-dicted. Accuracy of ASR for limited vocabulary for previousworks is between 46 and 100 percent.
X. FUTURE DIRECTIONSThe World counts more than 7000 languages according tothe Ethnologue website28, with the majority being under-resourced and even endangered. ASR systems offer an un-precedent opportunity to sustain such under-resourced lan-guages and to fight the extinction of endangered ones. Weshould differentiate two types of under-resourced languages:those with an acknowledged written form and those without.In the first case, new datasets should be created and requiresnew approaches for data recording and labeling, especiallywhen there are not enough native speakers during the creationprocess. This is really a challenge especially with tonal lan-guages. In fact, most languages in the developing world andespecially in Sub-Saharan Africa are tonal [151]. In a recentsurvey on ASR for tonal languages [152], only two Africanlanguages have been reported. In addition, some languages(especially dialects) are sharing some commons. So, ASRsystems with limited vocabulary targeting multiple similarlanguages can be designed.
28https://www.ethnologue.com
14 VOLUME 4, 2016
Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
TABLE 5: A non-exhaustive list of open-source speech recognition frameworks/toolkits
Toolkit / 1st Release Programminglanguage
License Trained models Applied technology
Praat, 1991 C/C++, ObjectiveC
GNU General Public Li-cense
- Neural networks
HTK, 2000 C/C++ HTK Specific License English HMM Deep neural net.CMU Sphinx, 2001 Java BSD License English plus 10 other languages HMMSimon, 2008 C++ GNU General Public Li-
cense- HMM
Kaldi, 2009 C++ Apache Subset of English Deep Neural NetworksOpenSmile, 2010 C++ Free for non-commercial
use- Machine/Deep Learning
Wav2Letter, 2016 Torch (Lua) BSD License English Neural networksMicrosoft CNTK, 2016 C++ BSD License - Deep neural networkMozilla Common Voice,2017
C, Python, Java Public domain CC-O English, French, German, Chinese,cdots
Deep neural network
OpenSeq2Seq, 2018 Python Apache - Deep Neural networksFairseq, 2019 Python BSD Licence English, Chinese, German, and
FrenchNeural Networks
TABLE 6: Summary of works on ASR using limited vocabulary.
Papers, Ref, Year Language Toolkit/Model Noisy Acc (%) # Speakers DatasetLucey et al., [135], 2001 English HTK Yes Not available 10 780 utterancesBurileanu et al., [138],2003
Romanian LGB and LVQ3 Yes 95.33 30 10 Digits
Alumae et al., [79], 2004 Estonian HTK No 97 60 400 utterances ofnumbers
Rathinavelu et al., [145],2007
Tamil From scratch:Feedforwardneural networks
Yes 81 10 children 20 phonemes
Krishnan et al., [143],2008
Malayalam From scratch us-ing ANN
Yes 89 - 5 words
Azmi et al., [141], 2008 Arabic HTK Yes 81.79 59 944 sentencesMuhammad et al., [142],2009
Bangla HTK Yes 90-95 100 10 digits
Qiao et al., [110], 2010 Yoruba/ Hebrew HTK No 100 3 50 words/ shortphrases
Ashraf et al., [146], 2010 Urdu CMU Sphinx Yes 60 10 52 wordsAl-Qatab et al., [140],2010
Arabic HTK No 97.99 13 33 words
Sukumar et al., [144],2010
Malayalam From scratch:DWT and ANN
Yes 80 1 250 words
Chaudhuri et al., [46],2011
English CMU Sphinx No 71.73 - 11 words
Huang, [41], 2011 Chinese From scratch andHMM-based
Yes 89.6 8 640 speech sam-ples
Tamgno et al., [45], 2012 Wolof HTK Yes 81.9 25 DigitsBali et al., [139], 2013 Hindi Microsoft Speech
ServerYes 90 24 79 words
Branislav et al., [40], 2013 Macedonian HTK Yes 94.52 30 188 wordsLiuxinfei et al., [42], 2014 Chinese PocketSphinx
(CMU)Yes 90 1 10 voice
commandsLiu et al., [134], 2015 English Kaldi Yes 46.4 20 256 wordsSupriya et al., [109], 2017 Marathi HTK No 80-90 5 620 wordsMilitaru et al., [49], 2017 Romanian SRILM toolkit
[148] andProtoLOGOS[149]
No 59.57 30 762 phrases
Benisty et al., [147], 2018 English Kaldi Yes 98 - 62 keywordsVetle, [137], 2019 Norwegian CMU Sphinx Yes 58.31 24 10 sentencesline Zulkarnaen et al.,[111], 2019
Indonesian HTK Yes 100 1 Digits
Barkani, et al., [150], 2020 Amazigh CMU Sphinx No 92.22 30 13 commandsPuneet et al., [39], 2020 Punjabi CMU Sphinx No 69.6 50 91 words
VOLUME 4, 2016 15
Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
FIGURE 9: The percentage of toolkits used in selected workson ASR using limited vocabulary.
In the second case, when the language that does not havean acknowledged written form, new approach should bedesigned. Normally, an ASR system aims to transcript aspeech into a text. In ASR using a limited vocabulary, thetranscript text is usually a command or a short answer thatcan be used by an application to system to perform an action.In this scenario, the system can be a combination of a Speech-to-Speech Translation (S2ST) and a Speech Recognition.First the speech in nonwritten language is directly translatedinto a speech into well-resourced language such as English,then the transcript in well-resourced language is retrieved(generated) and sent to the application. Direct S2ST modelhas been developed in [153], translating Spanish into Englishwithout passing through text. Their dataset is a subset ofthe Fisher dataset and composed of parallel utterance pairs.The construction of datasets for ASR systems using limitedvocabulary of nonwritten languages can also be based on thesame principle.
Regardless the fact that the language is written or not,more noise resistant models should be developed. Becauseavailable data for under-resourced language could be of lowquality.
The limited computing resource and the bad Internet con-nectivity in some regions can prevent the unleash of ASRsystems. There is currently a shift of ASR models fromthe cloud to the edge. It is performed by reducing the sizeand making models fast enough so that it can be executedon typical mobile devices. Latest optimization techniquesto achieve this, such as pruning, efficient Recurrent NeuralNetwork variants and quantization, are presented in [154].Although they provide remarkable results, such as reducingthe size by 8.5x and increasing the speed by 4.5x, thereis still a need to develop light and offline models that can
be deployed on low-resource devices such as off-the-shelfsmartphones or raspberry Pi/ Arduino modules.
XI. CONCLUSIONThis paper presented a review of ASR systems with a focuson limited vocabulary. After introducing the ASR princi-ple in general and usual techniques to perform recognition,this paper also discussed the management of datasets, theperformance metrics to evaluate ASR systems, and toolk-its to develop such systems. From the analysis of selectedpapers on ASR using limited vocabulary, HMM and DNN-based acoustic models achieve good speech recognition re-sults. DNN even outperform GMMs on a variety of speechrecognition benchmarks. Datasets with limited vocabularyare constructed with speech at frequencies between 8Khzand 20Khz. The evaluation of systems is mainly based onthe accuracy rather than the WER metric. Despite the satis-factory results, there is still much to do. In fact, developedsystems deal mostly with well-resourced languages and mostof models are still running on servers. We hope that theideas for future directions we discussed on targeting under-resourced/unwritten languages (investigating direct speechto speech translation) and designing “on the edge ASRsystems for limited vocabulary” will draw the attention ofthe research community to develop systems especially fordeveloping world, where the limitation in terms of computingresources coupled with the lack of connectivity constitutequite signifiant barriers.
REFERENCES[1] N. Indurkhya and F. J. Damerau, Eds., “An Overview of Modern Speech
Recognition Xuedong Huang and Li Deng,” in Handbook of NaturalLanguage Processing, 0 ed., Chapman and Hall/CRC, 2010, pp. 363–390.doi: 10.1201/9781420085938-24.
[2] S. Benkerzaz, Y. Elmir, and A. Dennai, “A Study on Automatic SpeechRecognition,” vol. 10, no. 3, p. 10, 2019.
[3] T. G. Yadava and H. S. Jayanna, “A spoken query system for the agri-cultural commodity prices and weather information access in Kannadalanguage,” Int. J. Speech Technol., vol. 20, no. 3, pp. 635–644, 2017.
[4] S. E. Hauser, T. F. Sabir, and G. R. Thoma, “Speech recognition forprogram control and data entry in a production environment,” in IntelligentSystems in Design and Manufacturing II, 1999, vol. 3833, pp. 24–34.
[5] J. M. Noyes and A. F. Starr, “A comparison of speech input and touchscreen for executing checklists in an avionics application,” Int. J. Aviat.Psychol., vol. 17, no. 3, pp. 299–315, 2007.
[6] H. Husni and Z. Jamaluddin, “A retrospective and future look at speechrecognition applications in assisting children with reading disabilities,”presented at the Proceedings of the world Congress on Engineering andComputer Science, San Francisco, USA, 2008.
[7] J. Mayer, “Low Cost Automatic Speech Recognition IOT Architecture forHands Free Assistance to People with Mobility Restrictions,” in Proceed-ings on the International Conference on Internet Computing (ICOMP),2018, pp. 53–58.
[8] L. Besacier, E. Barnard, A. Karpov, and T. Schultz, “Automatic speechrecognition for under-resourced languages: A survey,” Speech Commun.,vol. 56, pp. 85–100, Jan. 2014, doi: 10.1016/j.specom.2013.07.008.
[9] A. F. Albabtain, D. A. AlMulhim, F. Yunus, and M. S. Househ, “The roleof mobile health in the developing world: a review of current knowledgeand future trends,” Cyber J. Multidiscip. J. Sci. Technol. JSHI J. Sel. AreasHealth Informatics42, pp. 10–15, 2014.
[10] J. L. F. K. Ebongue, “Rethinking Network Connectivityin Rural Communities in Cameroon,” presented at theIST-Africa, Lilongwe, Malaw, 2015. [Online]. Available:https://arxiv.org/ftp/arxiv/papers/1505/1505.04449.pdf
16 VOLUME 4, 2016

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
[11] F. K. Ebongue and J. Louis, “Wireless Mesh Network: a rural communitycase,” Universitat Bremen, 2015. Accessed: Oct. 20, 2020. [Online].Available: http://oatd.org/oatd/record?record=oai%5C%3Aelib.suub.uni-bremen.de%5C%3ADISS%5C%2F00104709
[12] G. Saon and J.-T. Chien, “Large-vocabulary continuous speech recognitionsystems: A look at some recent advances,” IEEE Signal Process. Mag., vol.29, no. 6, pp. 18–33, 2012.
[13] L. Orosanu and D. Jouvet, “Adding New Words into a Language Modelusing Parameters of Known Words with Similar Behavior,” ProcediaComput. Sci., vol. 128, pp. 18–24, 2018, doi: 10.1016/j.procs.2018.03.003.
[14] P. Warden, “Speech Commands: A Dataset for Limited-Vocabulary SpeechRecognition,” ArXiv180403209 Cs, Apr. 2018, Accessed: Jan. 02, 2020.[Online]. Available: http://arxiv.org/abs/1804.03209
[15] T. Aguiar de Lima and M. Da Costa-Abreu, “A survey on auto-matic speech recognition systems for Portuguese language and its vari-ations,” Comput. Speech Lang., vol. 62, p. 101055, Jul. 2020, doi:10.1016/j.csl.2019.101055.
[16] C. Kurian, “A Survey on Speech Recogntion in Indian Languages,” vol. 5,p. 7, 2014.
[17] A. L. Ronzhin, R. M. Yusupov, I. V. Li, and A. B. Leontieva, “Survey ofRussian Speech Recognition Systems,” St Petersburg, p. 7, 2006.
[18] S. Minaee, A. Abdolrashidi, H. Su, M. Bennamoun, and D.Zhang, “Biometric Recognition Using Deep Learning: A Survey,”ArXiv191200271 Cs, Apr. 2020, Accessed: Apr. 12, 2020. [Online].Available: http://arxiv.org/abs/1912.00271
[19] N. Desai, K. Dhameliya, and V. Desai, “Feature Extraction and Classifica-tion Techniques for Speech Recognition: A Review,” vol. 3, no. 12, p. 5,2013.
[20] R. Hibare and A. Vibhute, “Feature Extraction Techniques in SpeechProcessing: A Survey,” Int. J. Comput. Appl., vol. 107, no. 5, pp. 1–8,Dec. 2014, doi: 10.5120/18744-9997.
[21] Y. Gong, “Speech recognition in noisy environments: A survey,” SpeechCommun., vol. 16, no. 3, pp. 261–291, Apr. 1995, doi: 10.1016/0167-6393(94)00059-J.
[22] D. Zaykovskiy, “Survey of the Speech Recognition Techniques for MobileDevices,” St Petersburg, p. 6, 2006.
[23] S. A. and Dr. John, “Survey on Chatbot Design Techniques in SpeechConversation Systems,” Int. J. Adv. Comput. Sci. Appl., vol. 6, no. 7, 2015,doi: 10.14569/IJACSA.2015.060712.
[24] H. Jiang, “Confidence measures for speech recognition: A survey,”Speech Commun., vol. 45, no. 4, pp. 455–470, Apr. 2005, doi:10.1016/j.specom.2004.12.004.
[25] M. Agnes and D. B. Guralnik, “Webster’s new world college dictionary,”1999.
[26] G. N. Clements, “The geometry of phonological features,” Phonology, vol.2, no. 1, pp. 225–252, 1985.
[27] S. Saksamudre, P. P. Shrishrimal, and R. Deshmukh, “A Review onDifferent Approaches for Speech Recognition System,” Int. J. Comput.Appl., vol. 115, pp. 23–28, Apr. 2015, doi: 10.5120/20284-2839.
[28] E. W. D. Whittaker and R. C. Woodland, “Efficient class-based lan-guage modelling for very large vocabularies,” in 2001 IEEE InternationalConference on Acoustics, Speech, and Signal Processing. Proceedings(Cat.No.01CH37221), Salt Lake City, UT, USA, 2001, vol. 1, pp. 545–548.doi: 10.1109/ICASSP.2001.940889.
[29] W. Ghai and N. Singh, “Literature Review on Automatic Speech Recog-nition,” Int. J. Comput. Appl., vol. 41, no. 8, pp. 42–50, Mar. 2012, doi:10.5120/5565-7646.
[30] R. Kraleva and V. Kralev, “On model architecture for a children’s speechrecognition interactive dialog system,” Nat. Sci., p. 6, 2009.
[31] “Feature Extraction for ASR: Intro | Formula Coding.”http://wantee.github.io/2015/03/14/feature-extraction-for-asr-intro/(accessed Jul. 01, 2021).
[32] N. Doukas, N. G. Bardis, and O. P. Markovskyi, "Task and Context AwareIsolated Word Recognition," in 2017 International Conference on Control,Artificial Intelligence, Robotics & Optimization (ICCAIRO), 2017, pp.330-334.
[33] N. Doukas and N. G. Bardis, “Current trends in small vocabulary speechrecognition for equipment control,” Cambridge, UK, 2017, p. 020029. doi:10.1063/1.4996686.
[34] S. Narang and D. Gupta, “Speech Feature Extraction Techniques: AReview,” p. 8, 2015.
[35] D. O’Shaughnessy, “Linear predictive coding,” IEEE Potentials, vol. 7, no.1, pp. 29–32, 1988.
[36] H. Hermansky and N. Morgan, “RASTA processing of speech,” IEEETrans. Speech Audio Process., vol. 2, no. 4, pp. 578–589, 1994.
[37] S. Ioffe, “Probabilistic linear discriminant analysis,” in European Confer-ence on Computer Vision, 2006, pp. 531–542.
[38] T. Bluche and T. Gisselbrecht, “Predicting detection filters for smallfootprint open-vocabulary keyword spotting,” ArXiv191207575Cs, Dec. 2019, Accessed: Jan. 02, 2020. [Online]. Available:http://arxiv.org/abs/1912.07575
[39] P. Mittal and N. Singh, “Subword analysis of small vocabulary and largevocabulary ASR for Punjabi language,” Int. J. Speech Technol., vol. 23,no. 1, pp. 71–78, Mar. 2020, doi: 10.1007/s10772-020-09673-3.
[40] B. Gerazov and Z. Ivanovski, “A Speaker Independent Small VocabularyAutomatic Speech Recognition System in Macedonian,” p. 5, 2013.
[41] F. L. Huang, “An Effective Approach for Chinese Speech Recognition onSmall size of Vocabulary,” Signal Image Process. Int. J., vol. 2, no. 2, pp.48–60, Jun. 2011, doi: 10.5121/sipij.2011.2205.
[42] X. F. Liu and H. Zhou, “A Chinese Small Vocabulary OfflineSpeech Recognition System Based on Pocketsphinx in Android Plat-form,” Appl. Mech. Mater., vol. 623, pp. 267–273, Aug. 2014, doi:10.4028/www.scientific.net/AMM.623.267.
[43] R. Fish, “Using Audio Quality to Predict Word Error Rate in an AutomaticSpeech Recognition System,” p. 4.
[44] S. Renals and G. Grefenstette, Eds., Text-and speech-triggered informationaccess: 8th ELSNET Summer School, Chios Island, Greece, July 15-30,2000: revised lectures. Berlin; New York: Springer, 2003.
[45] J. K. Tamgno, E. Barnard, C. Lishou, and M. Richomme, “Wolof SpeechRecognition Model of Digits and Limited-Vocabulary Based on HMMand ToolKit,” in 2012 UKSim 14th International Conference on ComputerModelling and Simulation, Cambridge, United Kingdom, Mar. 2012, pp.389–395. doi: 10.1109/UKSim.2012.118.
[46] S. Chaudhuri, B. Raj, and T. Ezzat, “A Paradigm for Limited VocabularySpeech Recognition Based on Redundant Spectro-Temporal Feature Sets,”2011.
[47] P. M. Baggenstoss, “A modified Baum-Welch algorithm for hiddenMarkov models with multiple observation spaces,” IEEE Trans. SpeechAudio Process., vol. 9, no. 4, pp. 411–416, 2001.
[48] S.-Z. Yu and H. Kobayashi, “An efficient forward-backward algorithm foran explicit-duration hidden Markov model,” IEEE Signal Process. Lett.,vol. 10, no. 1, pp. 11–14, 2003.
[49] D. Militaru and M. Lazar, “LIMITED-VOCABULARY SPEAKER INDE-PENDENT CONTINUOUS SPEECH RECOGNITION USING CLASS-BASED LANGUAGE MODEL,” vol. 58, no. 1, p. 6, 2017.
[50] J. E. Fosler-Lussier, “Dynamic Pronunciation Models for AutomaticSpeech Recognition,” p. 204.
[51] E. Fosler-Lussier, “A Tutorial on Pronunciation Modeling for Large Vo-cabulary Speech Recognition,” in Text- and Speech-Triggered InformationAccess, vol. 2705, S. Renals and G. Grefenstette, Eds. Berlin, Heidelberg:Springer Berlin Heidelberg, 2003, pp. 38–77. doi: 10.1007/978-3-540-45115-0_3.
[52] A. Viterbi, “Error bounds for convolutional codes and an asymptoticallyoptimum decoding algorithm,” IEEE Trans. Inf. Theory, vol. 13, no. 2, pp.260–269, 1967.
[53] J. Hui, “Speech Recognition — ASR Decoding,” Medium, Sep. 30,2019. https://jonathan-hui.medium.com/speech-recognition-asr-decoding-f152aebed779 (accessed Jun. 09, 2021).
[54] M. Novak, “Evolution of the ASR Decoder Design,” in Text, Speech andDialogue, vol. 6231, P. Sojka, A. Horak, I. Kopecek, and K. Pala, Eds.Berlin, Heidelberg: Springer Berlin Heidelberg, 2010, pp. 10–17. doi:10.1007/978-3-642-15760-8_3.
[55] “The Role of Artificial Intelligence and Machine Learning in SpeechRecognition,” Rev, Aug. 25, 2019. https://www.rev.com/blog/artificial-intelligence-machine-learning-speech-recognition (accessed Feb. 06,2020).
[56] M. G. S. Murshed, C. Murphy, D. Hou, N. Khan, G. Ananthanarayanan,and F. Hussain, “Machine Learning at the Network Edge: A Survey,”ArXiv190800080 Cs Stat, Jan. 2020, Accessed: Apr. 15, 2020. [Online].Available: http://arxiv.org/abs/1908.00080
[57] K. P. Murphy, Machine learning: a probabilistic perspective. Cambridge,MA: MIT Press, 2012.
[58] J. Padmanabhan and M. J. Johnson Premkumar, “Machine Learning inAutomatic Speech Recognition: A Survey,” IETE Tech. Rev., vol. 32, no.4, pp. 240–251, Jul. 2015, doi: 10.1080/02564602.2015.1010611.
VOLUME 4, 2016 17

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
[59] J. Li, L. Deng, R. Haeb-Umbach, and Y. Gong, “Introduction,” inRobust Automatic Speech Recognition, Elsevier, 2016, pp. 1–7. doi:10.1016/B978-0-12-802398-3.00001-5.
[60] G. Hinton et al., “Deep Neural Networks for Acoustic Modeling in SpeechRecognition,” p. 27, 2012.
[61] A. Dhankar, “Study of deep learning and CMU sphinx in automatic speechrecognition,” in 2017 International Conference on Advances in Comput-ing, Communications and Informatics (ICACCI), Udupi, Sep. 2017, pp.2296–2301. doi: 10.1109/ICACCI.2017.8126189.
[62] A. Hernández-Blanco, B. Herrera-Flores, D. Tomás, and B. Navarro-Colorado, “A Systematic Review of Deep Learning Approaches to Edu-cational Data Mining,” Complexity, vol. 2019, pp. 1–22, May 2019, doi:10.1155/2019/1306039.
[63] A. Dhankar, “Study of deep learning and CMU sphinx in automatic speechrecognition,” in 2017 International Conference on Advances in Comput-ing, Communications and Informatics (ICACCI), Udupi, Sep. 2017, pp.2296–2301. doi: 10.1109/ICACCI.2017.8126189.
[64] T. Ko, V. Peddinti, D. Povey, and S. Khudanpur, “Audio augmentation forspeech recognition,” 2015.
[65] J. Salamon and J. P. Bello, “Deep convolutional neural networks anddata augmentation for environmental sound classification,” IEEE SignalProcess. Lett., vol. 24, no. 3, pp. 279–283, 2017.
[66] D. S. Park et al., “Specaugment: A simple data augmentation method forautomatic speech recognition,” ArXiv Prepr. ArXiv190408779, 2019.
[67] G. Maguolo, M. Paci, L. Nanni, and L. Bonan, “Audiogmenter:A MATLAB toolbox for audio data augmentation,” ArXiv Prepr.ArXiv191205472, 2019.
[68] “deep reinforcement learning projects.”http://www.polodepensamento.com.br/blog/article.php?99f49d=deep-reinforcement-learning-projects (accessed Aug. 27, 2020).
[69] T. Rajapakshe, S. Latif, R. Rana, S. Khalifa, and B. W. Schuller, “DeepReinforcement Learning with Pre-training for Time-efficient Training ofAutomatic Speech Recognition,” ArXiv Prepr. ArXiv200511172, 2020.
[70] T. Kala and T. Shinozaki, “Reinforcement learning of speech recognitionsystem based on policy gradient and hypothesis selection,” in 2018 IEEEInternational Conference on Acoustics, Speech and Signal Processing(ICASSP), 2018, pp. 5759–5763.
[71] J. Baker et al., “Developments and directions in speech recognition andunderstanding, Part 1 [DSP Education],” IEEE Signal Process. Mag., vol.26, no. 3, pp. 75–80, May 2009, doi: 10.1109/MSP.2009.932166.
[72] J. McDonough and M. Wolfel, “Distant Speech Recognition: Bridg-ing the Gaps,” in 2008 Hands-Free Speech Communication andMicrophone Arrays, Trento, Italy, May 2008, pp. 108–114. doi:10.1109/HSCMA.2008.4538699.
[73] I. Cohen, J. Benesty, and S. Gannot, Eds., Speech processing in moderncommunication: challenges and perspectives. Berlin: Springer, 2010.
[74] T. Virtanen, R. Singh, and B. Raj, Eds., Techniques for Noise Robustnessin Automatic Speech Recognition: Virtanen/Techniques for Noise Robust-ness in Automatic Speech Recognition. Chichester, UK: John Wiley &Sons, Ltd, 2012. doi: 10.1002/9781118392683.
[75] J. Li, L. Deng, R. Haeb-Umbach, and Y. Gong, “Fundamentals of speechrecognition,” in Robust Automatic Speech Recognition, Elsevier, 2016, pp.9–40. doi: 10.1016/B978-0-12-802398-3.00002-7.
[76] E. Vincent, T. Virtanen, and S. Gannot, Eds., Audio source separation andspeech enhancement. Hoboken, NJ: John Wiley & Sons, 2018.
[77] A. Glasser, “Automatic Speech Recognition Services: Deaf and Hard-of-Hearing Usability,” Ext. Abstr. 2019 CHI Conf. Hum. Factors Comput.Syst., pp. 1–6, May 2019, doi: 10.1145/3290607.3308461.
[78] R. Hofe et al., “Small-vocabulary speech recognition using a silent speechinterface based on magnetic sensing,” Speech Commun., vol. 55, no. 1, pp.22–32, Jan. 2013, doi: 10.1016/j.specom.2012.02.001.
[79] T. Alumäe and L. Võhandu, “Limited-Vocabulary Estonian ContinuousSpeech Recognition System using Hidden Markov Models,” p. 12.
[80] K. Zhou, B. Sisman, R. Liu, and H. Li, “Emotional Voice Conversion:Theory, Databases and ESD,” ArXiv Prepr. ArXiv210514762, 2021.
[81] N. Bertin et al., “VoiceHome-2, an extended corpus for multichannelspeech processing in real homes,” Speech Commun., vol. 106, pp. 68–78,Jan. 2019, doi: 10.1016/j.specom.2018.11.002.
[82] F. Mezzoudj, D. Langlois, D. Jouvet, and A. Benyettou, “Textual DataSelection for Language Modelling in the Scope of Automatic SpeechRecognition,” Procedia Comput. Sci., vol. 128, pp. 55–64, 2018, doi:10.1016/j.procs.2018.03.008.
[83] S. Pleshkova, A. Bekyarski, and Z. Zahariev, “Reduced Database for VoiceCommands Recognition Using Cloud Technologies, Artificial Intelligence
and Deep Learning,” in 2019 16th Conference on Electrical Machines,Drives and Power Systems (ELMA), Varna, Bulgaria, Jun. 2019, pp. 1–4.doi: 10.1109/ELMA.2019.8771526.
[84] S. Petridis, J. Shen, D. Cetin, and M. Pantic, “Visual-only recognitionof normal, whispered and silent speech,” in 2018 IEEE InternationalConference on Acoustics, Speech and Signal Processing (ICASSP), 2018,pp. 6219–6223.
[85] A. Asuncion and D. Newman, “UCI machine learning repository.” Irvine,CA, USA, 2007.
[86] A. Qader and H. Hassani, “Kurdish (Sorani) Speech to Text: Presenting anExperimental Dataset,” ArXiv191113087 Cs Eess, Dec. 2019, Accessed:Mar. 26, 2020. [Online]. Available: http://arxiv.org/abs/1911.13087
[87] R. Ardila et al., “Common voice: A massively-multilingual speech cor-pus,” ArXiv Prepr. ArXiv191206670, 2019.
[88] S. E. Johnson, P. Jourlin, G. L. Moore, K. S. Jones, and P. C. Woodland,“The Cambridge University spoken document retrieval system,” in 1999IEEE International Conference on Acoustics, Speech, and Signal Process-ing. Proceedings. ICASSP99 (Cat. No.99CH36258), Phoenix, AZ, USA,1999, pp. 49–52 vol.1. doi: 10.1109/ICASSP.1999.758059.
[89] N. T. Anh and H. Thi, “KWA: A New Method of Calculation andRepresentation Accuracy for Speech Keyword Spotting in String Re-sults,” Int. J. Adv. Comput. Sci. Appl., vol. 11, no. 2, 2020, doi:10.14569/IJACSA.2020.0110283.
[90] M. Kurimo et al., “Unlimited vocabulary speech recognition for agglu-tinative languages,” in Proceedings of the Human Language TechnologyConference of the NAACL, Main Conference, 2006, pp. 487–494.
[91] M. Kurimo, M. Creutz, M. Varjokallio, E. Arsoy, and M. Saraclar, “Unsu-pervised segmentation of words into morphemes-Morpho challenge 2005Application to automatic speech recognition,” 2006.
[92] C. Huang, E. Chang, J. Zhou, and K.-F. Lee, “Accent modeling based onpronunciation dictionary adaptation for large vocabulary Mandarin speechrecognition,” 2000.
[93] O. Galibert, “Methodologies for the evaluation of speaker diarization andautomatic speech recognition in the presence of overlapping speech.,” inINTERSPEECH, 2013, pp. 1131–1134.
[94] F. Jelinek, R. L. Mercer, L. R. Bahl, and J. K. Baker, “Perplexity—ameasure of the difficulty of speech recognition tasks,” J. Acoust. Soc. Am.,vol. 62, no. S1, pp. S63–S63, Dec. 1977, doi: 10.1121/1.2016299.
[95] C. E. Shannon, “Prediction and entropy of printed English,” Bell Syst.Tech. J., vol. 30, no. 1, pp. 50–64, 1951.
[96] R. Matarneh, S. Maksymova, V. V. Lyashenko, and N. V. Belova, “SpeechRecognition Systems: A Comparative Review,” p. 9.
[97] K. Fujiwara, “Error correction of speech recognition by custom phoneticalphabet input for ultra-small devices,” in Proceedings of the 2016 CHIConference Extended Abstracts on Human Factors in Computing Systems,2016, pp. 104–109.
[98] D. Prozorov and A. Tatarinova, “Comparison Of Grapheme-to-PhonemeConversions For Spoken Document Retrieval,” in 2019 IEEE East-WestDesign & Test Symposium (EWDTS), 2019, pp. 1–4.
[99] S. Rawat, P. Gupta, and P. Kumar, “Digital life assistant using automatedspeech recognition,” in 2014 Innovative Applications of ComputationalIntelligence on Power, Energy and Controls with their impact on Hu-manity (CIPECH), Ghaziabad, UP, India, Nov. 2014, pp. 43–47. doi:10.1109/CIPECH.2014.7019075.
[100] T. G. Dietterich and E. J. Horvitz, “Rise of concerns about AI: reflectionsand directions,” Commun. ACM, vol. 58, no. 10, pp. 38–40, Sep. 2015,doi: 10.1145/2770869.
[101] D. Zeng, “AI Ethics: Science Fiction Meets Technological Reality,” IEEEIntell. Syst., vol. 30, no. 3, pp. 2–5, May 2015, doi: 10.1109/MIS.2015.53.
[102] D. Shibata, S. Wakamiya, K. Ito, M. Miyabe, A. Kinoshita, and E.Aramaki, “VocabChecker: measuring language abilities for detecting earlystage dementia,” in Proceedings of the 23rd International Conference onIntelligent User Interfaces Companion, 2018, pp. 1–2.
[103] D. Herbert and B. Kang, “Comparative analysis of intelligent personalagent performance,” in Pacific Rim Knowledge Acquisition Workshop,2019, pp. 127–141.
[104] C. Gaida, P. Lange, R. Petrick, P. Proba, A. Malatawy, and D.Suendermann-Oeft, “Comparing open-source speech recognition toolkits,”2014.
[105] A. Narayanaswami and C. Vassiliadis, “An online prototype speech-enabled information access tool using Java Speech Application Program-ming Interface,” in Proceedings of the 33rd Southeastern Symposium onSystem Theory (Cat. No. 01EX460), 2001, pp. 111–115.
18 VOLUME 4, 2016

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
[106] H. Shi and A. Maier, “Speech enabled shopping application using Mi-crosoft SAPI,” Int. J. Comput. Sci. Netw. Secur., vol. 6, no. 9, p. 33, 1996.
[107] V. Këpuska, “Comparing Speech Recognition Systems (Microsoft API,Google API And CMU Sphinx),” Int. J. Eng. Res. Appl., vol. 07, no. 03,pp. 20–24, Mar. 2017, doi: 10.9790/9622-0703022024.
[108] S. Young et al., “The HTK book,” Camb. Univ. Eng. Dep., vol. 3, no. 175,p. 12, 2002.
[109] S. Supriya and S. M. Handore, “Speech recognition using HTK toolkitfor Marathi language,” in 2017 IEEE International Conference on Power,Control, Signals and Instrumentation Engineering (ICPCSI), Chennai,Sep. 2017, pp. 1591–1597. doi: 10.1109/ICPCSI.2017.8391979.
[110] F. Qiao, J. Sherwani, and R. Rosenfeld, “Small-vocabulary speech recog-nition for resource-scarce languages,” in Proceedings of the First ACMSymposium on Computing for Development - ACM DEV ’10, London,United Kingdom, 2010, p. 1. doi: 10.1145/1926180.1926184.
[111] Z. Hatala, “Practical speech recognition with htk,” ArXiv Prepr.ArXiv190802119, 2019.
[112] A. Veiga, C. Lopes, L. Sá, and F. Perdigão, “Acoustic Similarity Scoresfor Keyword Spotting,” in Computational Processing of the PortugueseLanguage, vol. 8775, J. Baptista, N. Mamede, S. Candeias, I. Paraboni, T.A. S. Pardo, and M. das G. Volpe Nunes, Eds. Cham: Springer Interna-tional Publishing, 2014, pp. 48–58. doi: 10.1007/978-3-319-09761-9_5.
[113] J. C. Veras, T. de M. Prego, A. A. de Lima, T. N. Ferreira, and S. L. Netto,“Speech quality enhancement based on spectral subtraction,” 2014.
[114] H. Zen, Y. Agiomyrgiannakis, N. Egberts, F. Henderson, andP. Szczepaniak, “Fast, Compact, and High Quality LSTM-RNNBased Statistical Parametric Speech Synthesizers for Mobile Devices,”ArXiv160606061 Cs, Jun. 2016, Accessed: Apr. 14, 2020. [Online]. Avail-able: http://arxiv.org/abs/1606.06061
[115] K.-F. Lee, Automatic speech recognition: the development of theSPHINX system, vol. 62. Springer Science & Business Media, 1988.
[116] D. Huggins-Daines, M. Kumar, A. Chan, A. W. Black, M. Ravishankar,and A. I. Rudnicky, “Pocketsphinx: A free, real-time continuous speechrecognition system for hand-held devices,” in 2006 IEEE InternationalConference on Acoustics Speech and Signal Processing Proceedings,2006, vol. 1, p. I–I.
[117] T. Schultz, “Rapid language adaptation tools and technologies for multi-lingual speech processing systems,” 2008.
[118] T. Schlippe, M. Volovyk, K. Yurchenko, and T. Schultz, “Rapid boot-strapping of a ukrainian large vocabulary continuous speech recognitionsystem,” in 2013 IEEE International Conference on Acoustics, Speech andSignal Processing, 2013, pp. 7329–7333.
[119] N. T. Vu, T. Schlippe, F. Kraus, and T. Schultz, “Rapid bootstrappingof five eastern european languages using the rapid language adaptationtoolkit,” 2010.
[120] D. Povey et al., “The Kaldi speech recognition toolkit,” in IEEE 2011workshop on automatic speech recognition and understanding, 2011, no.CONF.
[121] P. Cosi, “A kaldi-dnn-based asr system for italian,” in 2015 internationaljoint conference on neural networks (IJCNN), 2015, pp. 1–5.
[122] J. Guglani and A. N. Mishra, “Continuous Punjabi speech recognitionmodel based on Kaldi ASR toolkit,” Int. J. Speech Technol., vol. 21, no. 2,pp. 211–216, 2018.
[123] P. Upadhyaya, O. Farooq, M. R. Abidi, and Y. V. Varshney, “ContinuousHindi speech recognition model based on Kaldi ASR toolkit,” in 2017International Conference on Wireless Communications, Signal Processingand Networking (WiSPNET), 2017, pp. 786–789.
[124] D. S. Banerjee, K. Hamidouche, and D. K. Panda, “Re-designing CNTKdeep learning framework on modern GPU enabled clusters,” in 2016IEEE international conference on cloud computing technology and science(CloudCom), 2016, pp. 144–151.
[125] F. Seide and A. Agarwal, “CNTK: Microsoft’s open-source deep-learningtoolkit,” in Proceedings of the 22nd ACM SIGKDD International Confer-ence on Knowledge Discovery and Data Mining, 2016, pp. 2135–2135.
[126] G. Paci, G. Sommavilla, F. Tesser, and P. Cosi, “Julius ASR for Italianchildren speech,” 2013.
[127] R. S. Sharma, S. H. Paladugu, K. J. Priya, and D. Gupta, “Speechrecognition in Kannada using HTK and julius: A comparative study,” in2019 International Conference on Communication and Signal Processing(ICCSP), 2019, pp. 0068–0072.
[128] M. Pleva, J. Juhár, and A. S. Thiessen, “Automatic Acoustic Speechsegmentation in Praat using cloud based ASR,” in 2015 25th Interna-tional Conference Radioelektronika (RADIOELEKTRONIKA), 2015, pp.172–175.
[129] N. Hateva, P. Mitankin, and S. Mihov, “BulPhonC: bulgarian speechcorpus for the development of ASR technology,” in Proceedings of theTenth International Conference on Language Resources and Evaluation(LREC’16), 2016, pp. 771–774.
[130] A. Hannun et al., “Deep speech: Scaling up end-to-end speech recogni-tion,” ArXiv Prepr. ArXiv14125567, 2014.
[131] J. Li et al., “Jasper: An end-to-end convolutional neural acoustic model,”ArXiv Prepr. ArXiv190403288, 2019.
[132] T. Afouras, J. S. Chung, and A. Zisserman, “ASR is all you need:Cross-modal distillation for lip reading,” in ICASSP 2020-2020 IEEEInternational Conference on Acoustics, Speech and Signal Processing(ICASSP), 2020, pp. 2143–2147.
[133] S. Liu, Y. Cao, N. Hu, D. Su, and H. Meng, “Fastsvc: Fast Cross-DomainSinging Voice Conversion With Feature-Wise Linear Modulation,” in 2021IEEE International Conference on Multimedia and Expo (ICME), 2021,pp. 1–6.
[134] Y. Liu, R. Iyer, K. Kirchhoff, and J. Bilmes, “SVitchboard II and FiSVerI: High-quality limited-complexity corpora of conversational Englishspeech,” 2015.
[135] S. Lucey, S. Sridharan, and V. Chandran, “Improving visual noise insen-sitivity in small vocabulary audio visual speech recognition applications,”in Proceedings of the Sixth International Symposium on Signal Processingand its Applications (Cat.No.01EX467), Kuala Lumpur, Malaysia, 2001,vol. 2, pp. 434–437. doi: 10.1109/ISSPA.2001.950173.
[136] S. Chaudhuri, B. Raj, and T. Ezzat, “A Paradigm for Limited VocabularySpeech Recognition Based on Redundant Spectro-Temporal Feature Sets,”p. 4.
[137] V. Haflan, “Noise Robustness in Small-Vocabulary Speech Recognition,”Master’s Thesis, NTNU, 2019.
[138] D. Burileanu, M. Sima, C. Negrescu, and V. Croitoru, “Robust recogni-tion of small-vocabulary telephone-quality speech,” 2003.
[139] K. Bali, S. Sitaram, S. Cuendet, and I. Medhi, “A Hindi speech recognizerfor an agricultural video search application,” in Proceedings of the 3rdACM Symposium on Computing for Development - ACM DEV ’13,Bangalore, India, 2013, p. 1. doi: 10.1145/2442882.2442889.
[140] B. A. Q. Al-Qatab and R. N. Ainon, “Arabic speech recognition usingHidden Markov Model Toolkit(HTK),” in 2010 International Symposiumon Information Technology, Kuala Lumpur, Malaysia, Jun. 2010, pp.557–562. doi: 10.1109/ITSIM.2010.5561391.
[141] M. M. Azmi and H. Tolba, “Syllable-based automatic Arabic speechrecognition in different conditions of noise,” in 2008 9th InternationalConference on Signal Processing, Beijing, China, Oct. 2008, pp. 601–604.doi: 10.1109/ICOSP.2008.4697204.
[142] G. Muhammad, Y. A. Alotaibi, and M. N. Huda, “Automatic speechrecognition for Bangla digits,” in 2009 12th International Conference onComputers and Information Technology, Dhaka, Bangladesh, Dec. 2009,pp. 379–383. doi: 10.1109/ICCIT.2009.5407267.
[143] V. R. V. Krishnan, A. Jayakumar, and A. P. Babu, “Speech Recognition ofIsolated Malayalam Words Using Wavelet Features and Artificial NeuralNetwork,” in 4th IEEE International Symposium on Electronic Design,Test and Applications (delta 2008), Hong Kong, Jan. 2008, pp. 240–243.doi: 10.1109/DELTA.2008.88.
[144] A. R. Sukumar, A. F. Shah, and P. B. Anto, “Isolated question wordsrecognition from speech queries by using Artificial Neural Networks,”in 2010 Second International conference on Computing, Communicationand Networking Technologies, Karur, India, Jul. 2010, pp. 1–4. doi:10.1109/ICCCNT.2010.5591733.
[145] A. Rathinavelu and G. Anupriya, “Speech Recognition Model for TamilStops,” p. 4, 2007.
[146] J. Ashraf, N. Iqbal, N. S. Khattak, and A. M. Zaidi, “Speaker IndependentUrdu Speech Recognition Using HMM,” in Natural Language Processingand Information Systems, vol. 6177, C. J. Hopfe, Y. Rezgui, E. Métais,A. Preece, and H. Li, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg,2010, pp. 140–148. doi: 10.1007/978-3-642-13881-2_14.
[147] H. Benisty, I. Katz, K. Crammer, and D. Malah, “Discriminative KeywordSpotting for limited-data applications,” Speech Commun., vol. 99, pp.1–11, May 2018, doi: 10.1016/j.specom.2018.02.003.
[148] A. Stolcke, “SRILM-an extensible language modeling tool,” 2002.[149] D. Militaru, I. Gavat, O. Dumitru, T. Zaharia, and S. Segarceanu, “Pro-
toLOGOS, system for Romanian language automatic speech recognitionand understanding (ASRU),” in 2009 Proceedings of the 5-th Conferenceon Speech Technology and Human-Computer Dialogue, 2009, pp. 1–9.
[150] F. Barkani, H. Satori, M. Hamidi, O. Zealouk, and N. Laaidi, “AmazighSpeech Recognition Embedded System,” in 2020 1st International Con-
VOLUME 4, 2016 19

Fendji et al.: Automatic Speech Recognition using limited vocabulary: A survey
ference on Innovative Research in Applied Science, Engineering andTechnology (IRASET), Meknes, Morocco, Apr. 2020, pp. 1–5. doi:10.1109/IRASET48871.2020.9092014.
[151] L. J. Downing and A. Rialland, Intonation in African tone languages, vol.24. Walter de Gruyter GmbH & Co KG, 2016.
[152] J. Kaur, A. Singh, and V. Kadyan, “Automatic Speech RecognitionSystem for Tonal Languages: State-of-the-Art Survey.,” Arch. Comput.Methods Eng., vol. 28, no. 3, 2021.
[153] Y. Jia et al., “Direct speech-to-speech translation with a sequence-to-sequence model,” ArXiv Prepr. ArXiv190406037, 2019.
[154] Y. Shangguan, J. Li, Q. Liang, R. Alvarez, and I. McGraw, “Optimizingspeech recognition for the edge,” ArXiv Prepr. ArXiv190912408, 2019.
JEAN LOUIS K. E. FENDJI (Mmember, IEEE)was born in Douala, Cameroon in 1986. Hereceived the B.S. and M.S. degrees in Com-puter Science from the University of Ngaoundere,Cameroon, in 2010 and the Ph.D. degree from theUniversity of Bremen, Germany, in 2015. From2011 to 2013, he was a Research Assistant with theBMBF Project between the University of Bremenand the Uiversity of Ngaoundere. Since 2015, hehas been a Senior Lecturer with the Computer
Engineering Department, University Technology Institute, At the Universityof Ngaoundere. He is the author of two book’s chapters and more than20 publications. He has been working for more than 10 years on Networkmodeling and optimization. His current research interests include MachineLearning, Deep Learning, NLP, Speech recognition, Optimization, AI inAgriculture and Education.
DIANE C. M. TALA was born in Bandjoun,Cameroun in 1987. She received her B.S. degreein fundamental Computer Science from Univer-sity of Dschang, Cameroon in 2011 and the M.S.degree in Systems and Software in DistributedEnvironments from the University of Ngaounderein 2015. She is currently pursuing a Ph.D. degreein Computer Sciences at the Faculty of Sciencesof the University of Ngaoundere in Cameroon.Since 2018, she is a Computer Science Teacher
for secondary school. Her research interests include Speech Recognition,Natural Language Processing, Network Cost Modeling, Simulation, andNeural Networks.
BLAISE O. YENKE (Member, IEEE) receivedthe Ph.D. degree in international joint supervisionfrom the University of Yaounde 1, Cameroon,and the University of Grenoble, France, in 2010.He is an Associate Professor and a Researcherin computer engineering. He is also the Head ofthe Department of Computer Engineering, Uni-versity Institute of Technology of Ngaoundéré,Cameroon. His current research interests includedistributed systems, high-performance computing,
fault tolerance, network modeling, simulation, sensor networks design, andsensor’s architecture.
PLACEPHOTOHERE
MARCELLIN ATEMKENG received the Ph.D.degree in the area of Applied Mathematics andScientific Computing from Rhodes University,Grahamstown, South Africa, in 2016. He was aSignal Analyst with VASTech; a telecommunica-tion industry and a former Postdoctoral researchfellows working with the Square Kilometre Arrayrelated projects. In 2019, he joined the Departmentof Mathematics at Rhodes University where he iscoordinating the Rhodes Artificial Intelligence Re-
search Group (RAIRG). He has published several articles in peer-reviewedjournals and was the 2019 recipient of the Kambule Doctoral Awardrecognising and encouraging excellence in research and writing by doctoralcandidates at African universities in any area of computational and statisticalsciences, and whose work demonstrates excellence through technical rigour,significance of contribution, and a strong role in strengthening Africanmachine learning. His research interests are in the areas of big data, signalprocessing, artificial intelligence and radio interferometric techniques andtechnologies.
20 VOLUME 4, 2016












![Continuous Bangla Speech Segmentation, Classification and ...ijcsi.org/papers/IJCSI-9-2-1-67-75.pdf · vocabulary speech recognition systems [2, 3], speaker recognition systems [4,](https://img.pdfslide.us/doc/110x75/5eb686045e13cc22f7661283/continuous-bangla-speech-segmentation-classification-and-ijcsiorgpapersijcsi-9-2-1-67-75pdf.jpg)
















