Embed Size (px)
Citation preview

Automatic evaluation of Machine Translation (MT) BLEU its
shortcomings and other evaluation metrics
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
Part I Introduction and formulation of BLEU
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
Poetry is what gets Poetry is what gets lost in translationlost in translationrdquordquo
Robert FrostPoet (1874 ndash 1963)Wrote the famous poem lsquoStopping by woods on a snowy eveningrsquo better known as lsquoMiles to go before I sleeprsquo
Motivation
How do we judge a good translationCan a machine do this
Why should a machine do this Because humans take time
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEUbull Shortcomings in context of English-Hindi MT
Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an assessment Machine Translation Volume 8 pages 1ndash27 1993
K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
Part I
Part II
BLEU - IThe BLEU Score rises
EvaluationEvaluation [1][1]
Of NLP systemsOf MT systems
Evaluation in NLP PrecisionRecall
Precision How many results returned were correct
RecallWhat portion of correct results were returned
Adapting precisionrecall to NLP tasks
Evaluation in NLP PrecisionRecall
bull Document Retrieval
Precision = |Documents relevant and retrieved||Documents retrieved|
Recall=|Documents relevant and retrieved|| Documents relevant|
bull Classification
Precision = |True Positives||True Positives + False Positives|
Recall=|True Positives|| True Positives + False Negatives|
Evaluation in MT [1]
bull Operational evaluationndash ldquoIs MT system A operationally better than MT system B
Does MT system A cost lessrdquo
bull Typological evaluationndash ldquoHave you ensured which linguistic phenomena the MT
system coversrdquo
bull Declarative evaluationndash ldquoHow does quality of output of system A fare with respect
to that of Brdquo
Operational evaluation
bull Cost-benefit is the focusbull To establish cost-per-unit figures and use this
as a basis for comparisonbull Essentially lsquoblack boxrsquobull Realism requirement
Word-based SA
Sense-based SA
Cost of pre-processing (Stemming etc)Cost of learning a classifier
Cost of pre-processing (Stemming etc)Cost of learning a classifierCost of sense annotation
Typological evaluation
bull Use a test suite of examplesbull Ensure all relevant phenomena to be tested
are covered
bull Specific-to-language phenomenaFor example हर आख वाला लड़का म कराया
hari aankhon-wala ladka muskurayagreen eyes-with boy smiledThe boy with green eyes smiled
Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Part I Introduction and formulation of BLEU
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
Poetry is what gets Poetry is what gets lost in translationlost in translationrdquordquo
Robert FrostPoet (1874 ndash 1963)Wrote the famous poem lsquoStopping by woods on a snowy eveningrsquo better known as lsquoMiles to go before I sleeprsquo
Motivation
How do we judge a good translationCan a machine do this
Why should a machine do this Because humans take time
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEUbull Shortcomings in context of English-Hindi MT
Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an assessment Machine Translation Volume 8 pages 1ndash27 1993
K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
Part I
Part II
BLEU - IThe BLEU Score rises
EvaluationEvaluation [1][1]
Of NLP systemsOf MT systems
Evaluation in NLP PrecisionRecall
Precision How many results returned were correct
RecallWhat portion of correct results were returned
Adapting precisionrecall to NLP tasks
Evaluation in NLP PrecisionRecall
bull Document Retrieval
Precision = |Documents relevant and retrieved||Documents retrieved|
Recall=|Documents relevant and retrieved|| Documents relevant|
bull Classification
Precision = |True Positives||True Positives + False Positives|
Recall=|True Positives|| True Positives + False Negatives|
Evaluation in MT [1]
bull Operational evaluationndash ldquoIs MT system A operationally better than MT system B
Does MT system A cost lessrdquo
bull Typological evaluationndash ldquoHave you ensured which linguistic phenomena the MT
system coversrdquo
bull Declarative evaluationndash ldquoHow does quality of output of system A fare with respect
to that of Brdquo
Operational evaluation
bull Cost-benefit is the focusbull To establish cost-per-unit figures and use this
as a basis for comparisonbull Essentially lsquoblack boxrsquobull Realism requirement
Word-based SA
Sense-based SA
Cost of pre-processing (Stemming etc)Cost of learning a classifier
Cost of pre-processing (Stemming etc)Cost of learning a classifierCost of sense annotation
Typological evaluation
bull Use a test suite of examplesbull Ensure all relevant phenomena to be tested
are covered
bull Specific-to-language phenomenaFor example हर आख वाला लड़का म कराया
hari aankhon-wala ladka muskurayagreen eyes-with boy smiledThe boy with green eyes smiled
Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Poetry is what gets Poetry is what gets lost in translationlost in translationrdquordquo
Robert FrostPoet (1874 ndash 1963)Wrote the famous poem lsquoStopping by woods on a snowy eveningrsquo better known as lsquoMiles to go before I sleeprsquo
Motivation
How do we judge a good translationCan a machine do this
Why should a machine do this Because humans take time
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEUbull Shortcomings in context of English-Hindi MT
Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an assessment Machine Translation Volume 8 pages 1ndash27 1993
K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
Part I
Part II
BLEU - IThe BLEU Score rises
EvaluationEvaluation [1][1]
Of NLP systemsOf MT systems
Evaluation in NLP PrecisionRecall
Precision How many results returned were correct
RecallWhat portion of correct results were returned
Adapting precisionrecall to NLP tasks
Evaluation in NLP PrecisionRecall
bull Document Retrieval
Precision = |Documents relevant and retrieved||Documents retrieved|
Recall=|Documents relevant and retrieved|| Documents relevant|
bull Classification
Precision = |True Positives||True Positives + False Positives|
Recall=|True Positives|| True Positives + False Negatives|
Evaluation in MT [1]
bull Operational evaluationndash ldquoIs MT system A operationally better than MT system B
Does MT system A cost lessrdquo
bull Typological evaluationndash ldquoHave you ensured which linguistic phenomena the MT
system coversrdquo
bull Declarative evaluationndash ldquoHow does quality of output of system A fare with respect
to that of Brdquo
Operational evaluation
bull Cost-benefit is the focusbull To establish cost-per-unit figures and use this
as a basis for comparisonbull Essentially lsquoblack boxrsquobull Realism requirement
Word-based SA
Sense-based SA
Cost of pre-processing (Stemming etc)Cost of learning a classifier
Cost of pre-processing (Stemming etc)Cost of learning a classifierCost of sense annotation
Typological evaluation
bull Use a test suite of examplesbull Ensure all relevant phenomena to be tested
are covered
bull Specific-to-language phenomenaFor example हर आख वाला लड़का म कराया
hari aankhon-wala ladka muskurayagreen eyes-with boy smiledThe boy with green eyes smiled
Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
Motivation
How do we judge a good translationCan a machine do this
Why should a machine do this Because humans take time
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEUbull Shortcomings in context of English-Hindi MT
Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an assessment Machine Translation Volume 8 pages 1ndash27 1993
K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
Part I
Part II
BLEU - IThe BLEU Score rises
EvaluationEvaluation [1][1]
Of NLP systemsOf MT systems
Evaluation in NLP PrecisionRecall
Precision How many results returned were correct
RecallWhat portion of correct results were returned
Adapting precisionrecall to NLP tasks
Evaluation in NLP PrecisionRecall
bull Document Retrieval
Precision = |Documents relevant and retrieved||Documents retrieved|
Recall=|Documents relevant and retrieved|| Documents relevant|
bull Classification
Precision = |True Positives||True Positives + False Positives|
Recall=|True Positives|| True Positives + False Negatives|
Evaluation in MT [1]
bull Operational evaluationndash ldquoIs MT system A operationally better than MT system B
Does MT system A cost lessrdquo
bull Typological evaluationndash ldquoHave you ensured which linguistic phenomena the MT
system coversrdquo
bull Declarative evaluationndash ldquoHow does quality of output of system A fare with respect
to that of Brdquo
Operational evaluation
bull Cost-benefit is the focusbull To establish cost-per-unit figures and use this
as a basis for comparisonbull Essentially lsquoblack boxrsquobull Realism requirement
Word-based SA
Sense-based SA
Cost of pre-processing (Stemming etc)Cost of learning a classifier
Cost of pre-processing (Stemming etc)Cost of learning a classifierCost of sense annotation
Typological evaluation
bull Use a test suite of examplesbull Ensure all relevant phenomena to be tested
are covered
bull Specific-to-language phenomenaFor example हर आख वाला लड़का म कराया
hari aankhon-wala ladka muskurayagreen eyes-with boy smiledThe boy with green eyes smiled
Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEUbull Shortcomings in context of English-Hindi MT
Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an assessment Machine Translation Volume 8 pages 1ndash27 1993
K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
Part I
Part II
BLEU - IThe BLEU Score rises
EvaluationEvaluation [1][1]
Of NLP systemsOf MT systems
Evaluation in NLP PrecisionRecall
Precision How many results returned were correct
RecallWhat portion of correct results were returned
Adapting precisionrecall to NLP tasks
Evaluation in NLP PrecisionRecall
bull Document Retrieval
Precision = |Documents relevant and retrieved||Documents retrieved|
Recall=|Documents relevant and retrieved|| Documents relevant|
bull Classification
Precision = |True Positives||True Positives + False Positives|
Recall=|True Positives|| True Positives + False Negatives|
Evaluation in MT [1]
bull Operational evaluationndash ldquoIs MT system A operationally better than MT system B
Does MT system A cost lessrdquo
bull Typological evaluationndash ldquoHave you ensured which linguistic phenomena the MT
system coversrdquo
bull Declarative evaluationndash ldquoHow does quality of output of system A fare with respect
to that of Brdquo
Operational evaluation
bull Cost-benefit is the focusbull To establish cost-per-unit figures and use this
as a basis for comparisonbull Essentially lsquoblack boxrsquobull Realism requirement
Word-based SA
Sense-based SA
Cost of pre-processing (Stemming etc)Cost of learning a classifier
Cost of pre-processing (Stemming etc)Cost of learning a classifierCost of sense annotation
Typological evaluation
bull Use a test suite of examplesbull Ensure all relevant phenomena to be tested
are covered
bull Specific-to-language phenomenaFor example हर आख वाला लड़का म कराया
hari aankhon-wala ladka muskurayagreen eyes-with boy smiledThe boy with green eyes smiled
Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

BLEU - IThe BLEU Score rises
EvaluationEvaluation [1][1]
Of NLP systemsOf MT systems
Evaluation in NLP PrecisionRecall
Precision How many results returned were correct
RecallWhat portion of correct results were returned
Adapting precisionrecall to NLP tasks
Evaluation in NLP PrecisionRecall
bull Document Retrieval
Precision = |Documents relevant and retrieved||Documents retrieved|
Recall=|Documents relevant and retrieved|| Documents relevant|
bull Classification
Precision = |True Positives||True Positives + False Positives|
Recall=|True Positives|| True Positives + False Negatives|
Evaluation in MT [1]
bull Operational evaluationndash ldquoIs MT system A operationally better than MT system B
Does MT system A cost lessrdquo
bull Typological evaluationndash ldquoHave you ensured which linguistic phenomena the MT
system coversrdquo
bull Declarative evaluationndash ldquoHow does quality of output of system A fare with respect
to that of Brdquo
Operational evaluation
bull Cost-benefit is the focusbull To establish cost-per-unit figures and use this
as a basis for comparisonbull Essentially lsquoblack boxrsquobull Realism requirement
Word-based SA
Sense-based SA
Cost of pre-processing (Stemming etc)Cost of learning a classifier
Cost of pre-processing (Stemming etc)Cost of learning a classifierCost of sense annotation
Typological evaluation
bull Use a test suite of examplesbull Ensure all relevant phenomena to be tested
are covered
bull Specific-to-language phenomenaFor example हर आख वाला लड़का म कराया
hari aankhon-wala ladka muskurayagreen eyes-with boy smiledThe boy with green eyes smiled
Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

EvaluationEvaluation [1][1]
Of NLP systemsOf MT systems
Evaluation in NLP PrecisionRecall
Precision How many results returned were correct
RecallWhat portion of correct results were returned
Adapting precisionrecall to NLP tasks
Evaluation in NLP PrecisionRecall
bull Document Retrieval
Precision = |Documents relevant and retrieved||Documents retrieved|
Recall=|Documents relevant and retrieved|| Documents relevant|
bull Classification
Precision = |True Positives||True Positives + False Positives|
Recall=|True Positives|| True Positives + False Negatives|
Evaluation in MT [1]
bull Operational evaluationndash ldquoIs MT system A operationally better than MT system B
Does MT system A cost lessrdquo
bull Typological evaluationndash ldquoHave you ensured which linguistic phenomena the MT
system coversrdquo
bull Declarative evaluationndash ldquoHow does quality of output of system A fare with respect
to that of Brdquo
Operational evaluation
bull Cost-benefit is the focusbull To establish cost-per-unit figures and use this
as a basis for comparisonbull Essentially lsquoblack boxrsquobull Realism requirement
Word-based SA
Sense-based SA
Cost of pre-processing (Stemming etc)Cost of learning a classifier
Cost of pre-processing (Stemming etc)Cost of learning a classifierCost of sense annotation
Typological evaluation
bull Use a test suite of examplesbull Ensure all relevant phenomena to be tested
are covered
bull Specific-to-language phenomenaFor example हर आख वाला लड़का म कराया
hari aankhon-wala ladka muskurayagreen eyes-with boy smiledThe boy with green eyes smiled
Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Evaluation in NLP PrecisionRecall
Precision How many results returned were correct
RecallWhat portion of correct results were returned
Adapting precisionrecall to NLP tasks
Evaluation in NLP PrecisionRecall
bull Document Retrieval
Precision = |Documents relevant and retrieved||Documents retrieved|
Recall=|Documents relevant and retrieved|| Documents relevant|
bull Classification
Precision = |True Positives||True Positives + False Positives|
Recall=|True Positives|| True Positives + False Negatives|
Evaluation in MT [1]
bull Operational evaluationndash ldquoIs MT system A operationally better than MT system B
Does MT system A cost lessrdquo
bull Typological evaluationndash ldquoHave you ensured which linguistic phenomena the MT
system coversrdquo
bull Declarative evaluationndash ldquoHow does quality of output of system A fare with respect
to that of Brdquo
Operational evaluation
bull Cost-benefit is the focusbull To establish cost-per-unit figures and use this
as a basis for comparisonbull Essentially lsquoblack boxrsquobull Realism requirement
Word-based SA
Sense-based SA
Cost of pre-processing (Stemming etc)Cost of learning a classifier
Cost of pre-processing (Stemming etc)Cost of learning a classifierCost of sense annotation
Typological evaluation
bull Use a test suite of examplesbull Ensure all relevant phenomena to be tested
are covered
bull Specific-to-language phenomenaFor example हर आख वाला लड़का म कराया
hari aankhon-wala ladka muskurayagreen eyes-with boy smiledThe boy with green eyes smiled
Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Evaluation in NLP PrecisionRecall
bull Document Retrieval
Precision = |Documents relevant and retrieved||Documents retrieved|
Recall=|Documents relevant and retrieved|| Documents relevant|
bull Classification
Precision = |True Positives||True Positives + False Positives|
Recall=|True Positives|| True Positives + False Negatives|
Evaluation in MT [1]
bull Operational evaluationndash ldquoIs MT system A operationally better than MT system B
Does MT system A cost lessrdquo
bull Typological evaluationndash ldquoHave you ensured which linguistic phenomena the MT
system coversrdquo
bull Declarative evaluationndash ldquoHow does quality of output of system A fare with respect
to that of Brdquo
Operational evaluation
bull Cost-benefit is the focusbull To establish cost-per-unit figures and use this
as a basis for comparisonbull Essentially lsquoblack boxrsquobull Realism requirement
Word-based SA
Sense-based SA
Cost of pre-processing (Stemming etc)Cost of learning a classifier
Cost of pre-processing (Stemming etc)Cost of learning a classifierCost of sense annotation
Typological evaluation
bull Use a test suite of examplesbull Ensure all relevant phenomena to be tested
are covered
bull Specific-to-language phenomenaFor example हर आख वाला लड़का म कराया
hari aankhon-wala ladka muskurayagreen eyes-with boy smiledThe boy with green eyes smiled
Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Evaluation in MT [1]
bull Operational evaluationndash ldquoIs MT system A operationally better than MT system B
Does MT system A cost lessrdquo
bull Typological evaluationndash ldquoHave you ensured which linguistic phenomena the MT
system coversrdquo
bull Declarative evaluationndash ldquoHow does quality of output of system A fare with respect
to that of Brdquo
Operational evaluation
bull Cost-benefit is the focusbull To establish cost-per-unit figures and use this
as a basis for comparisonbull Essentially lsquoblack boxrsquobull Realism requirement
Word-based SA
Sense-based SA
Cost of pre-processing (Stemming etc)Cost of learning a classifier
Cost of pre-processing (Stemming etc)Cost of learning a classifierCost of sense annotation
Typological evaluation
bull Use a test suite of examplesbull Ensure all relevant phenomena to be tested
are covered
bull Specific-to-language phenomenaFor example हर आख वाला लड़का म कराया
hari aankhon-wala ladka muskurayagreen eyes-with boy smiledThe boy with green eyes smiled
Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Operational evaluation
bull Cost-benefit is the focusbull To establish cost-per-unit figures and use this
as a basis for comparisonbull Essentially lsquoblack boxrsquobull Realism requirement
Word-based SA
Sense-based SA
Cost of pre-processing (Stemming etc)Cost of learning a classifier
Cost of pre-processing (Stemming etc)Cost of learning a classifierCost of sense annotation
Typological evaluation
bull Use a test suite of examplesbull Ensure all relevant phenomena to be tested
are covered
bull Specific-to-language phenomenaFor example हर आख वाला लड़का म कराया
hari aankhon-wala ladka muskurayagreen eyes-with boy smiledThe boy with green eyes smiled
Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Typological evaluation
bull Use a test suite of examplesbull Ensure all relevant phenomena to be tested
are covered
bull Specific-to-language phenomenaFor example हर आख वाला लड़का म कराया
hari aankhon-wala ladka muskurayagreen eyes-with boy smiledThe boy with green eyes smiled
Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Declarative evaluation
bull Assign scores to specific qualities of outputndash Intelligibility How good the output is as a well-
formed target language entityndash Accuracy How good the output is in terms of
preserving content of the source text
For example I am attending a lectureम एक या यान बठा ह Main ek vyaakhyan baitha hoonI a lecture sit (Present-first person)I sit a lecture Accurate but not intelligibleम या यान ह Main vyakhyan hoonI lecture amI am lecture Intelligible but not accurate
Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Evaluation bottleneck
bull Typological evaluation is time-consumingbull Operational evaluation needs accurate
modeling of cost-benefit
bull Automatic MT evaluation DeclarativeBLEU Bilingual Evaluation Understudy
Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Deriving BLEU Deriving BLEU [2][2]
Incorporating PrecisionIncorporating Recall
How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

How is translation performance measured
The closer a machine translation is to a professional human translation the better it is
bull A corpus of good quality human reference translations
bull A numerical ldquotranslation closenessrdquo metric
Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Preliminaries
bull Candidate Translation(s) Translation returned by an MT system
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
Goal of BLEU To correlate with human judgment
Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Formulating BLEU (Step 1) PrecisionI had lunch now
Candidate 1 मन अब खाना खाया
maine ab khana khaya matching unigrams 3I now food ate matching bigrams 1I ate food now
Candidate 2 मन अभी लच एटmaine abhi lunch ate matching unigrams 2I now lunch ate
I ate lunch(OOV) now(OOV) matching bigrams 1Unigram precision Candidate 1 34 = 075 Candidate 2 24 = 05Similarly bigram precision Candidate 1 033 Candidate 2 = 033
Reference 1 मन अभी खाना खायाmaine abhi khana khayaI now food ateI ate food now
Reference 2 मन अभी भोजन कयाmaine abhi bhojan kiyaa
I now meal didI did meal now
Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Precision Not good enough
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 1 मर तरा स र छाया matching unigram 3
mere tera suroor chhaayamy your spell castYour spell cast my
Candidate 2 तरा तरा तरा स र matching unigrams 4tera tera tera surooryour your your spell
Unigram precision Candidate 1 34 = 075 Candidate 2 44 = 1
Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Formulating BLEU (Step 2) Modified Precision
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujh-par tera suroor chhaaya
me-on your spell castYour spell was cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spell
bull matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
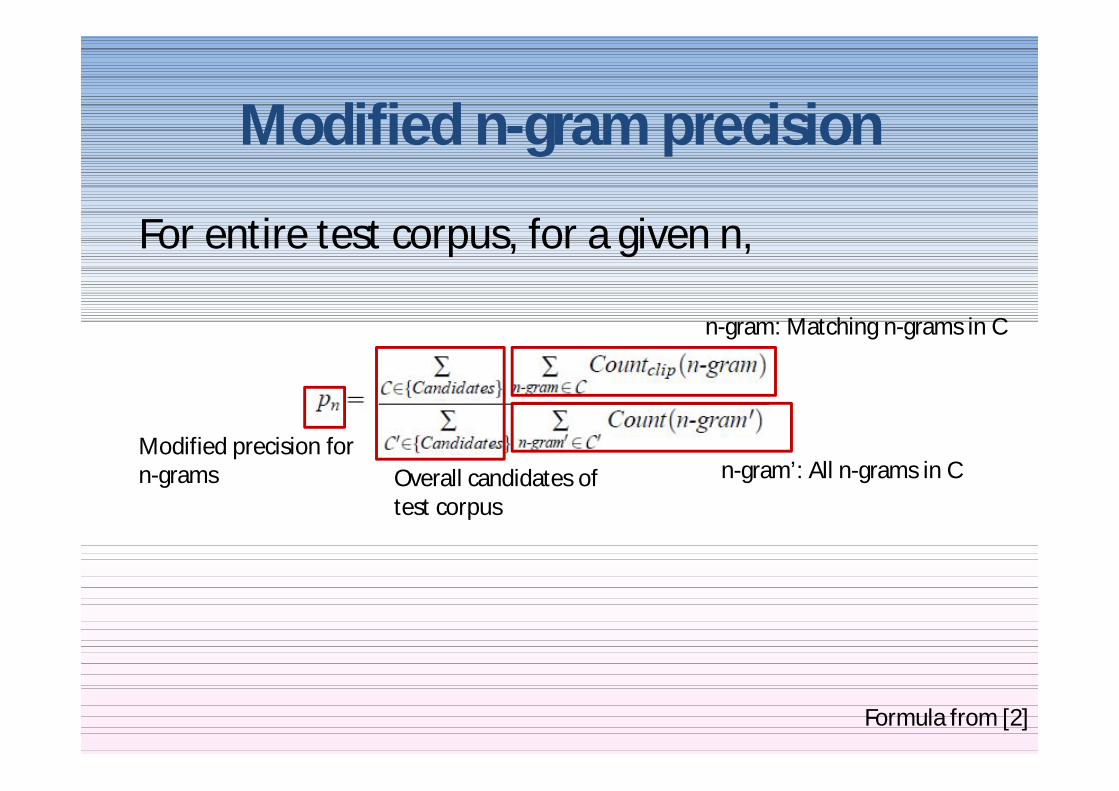
Modified n-gram precision
For entire test corpus for a given n
n-gram Matching n-grams in C
n-gramrsquo All n-grams in CModified precision for n-grams Overall candidates of
test corpus
Formula from [2]
Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Calculating modified n-gram precision (12)
bull 127 source sentences were translated by two human translators and three MT systems
bull Translated sentences evaluated against professional reference translations using modified n-gram precision
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
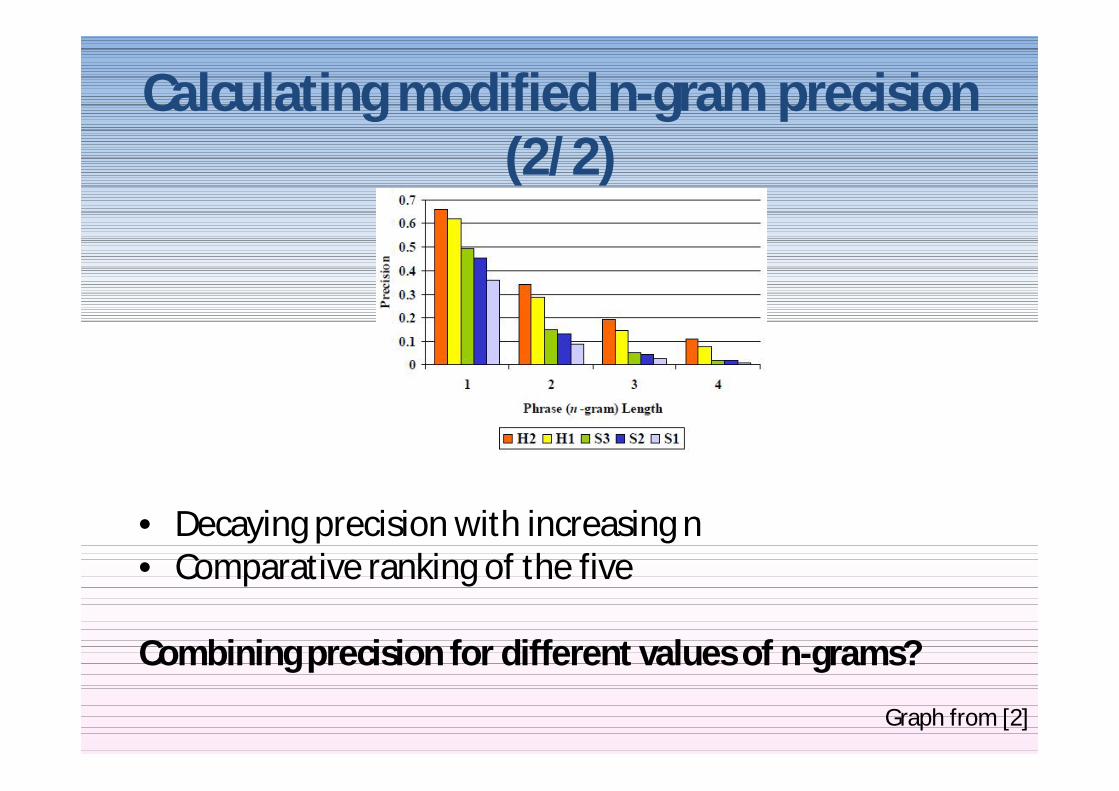
Calculating modified n-gram precision (22)
bull Decaying precision with increasing nbull Comparative ranking of the five
Combining precision for different values of n-grams
Graph from [2]
Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Formulation of BLEU Recap
bull Precision cannot be used as isbull Modified precision considers lsquoclipped word
countrsquo
Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Recall for MT (12)
bull Candidates shorter than referencesbull Reference या ल लब वा य क गणव ता को समझ
पाएगाkya blue lambe vaakya ki guNvatta ko samajh paaegawill blue long sentence-of quality (case-marker) understand able(III-person-male-singular)Will blue be able to understand quality of long sentence
Candidate लब वा य
lambe vaakyalong sentencelong sentence
modified unigram precision 22 = 1modified bigram precision 11 = 1
Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Recall for MT (22)
bull Candidates longer than referencesReference 2 मन भोजन कया
maine bhojan kiyaaI meal didI had meal
Candidate 1 मन खाना भोजन कया
maine khaana bhojan kiyaI food meal didI had food meal
Modified unigram precision 1
Reference 1 मन खाना खायाmaine khaana khaayaI food ateI ate food
Candidate 2 मन खाना खायाmaine khaana khaayaI food ateI ate food
Modified unigram precision 1
Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Formulating BLEU (Step 3) Incorporating recall
bull Sentence length indicates lsquobest matchrsquobull Brevity penalty (BP)
ndash Multiplicative factorndash Candidate translations that match reference
translations in length must be ranked higher
Candidate 1 लब वा य
Candidate 2 या ल लब वा य क गणव तासमझ पाएगा
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
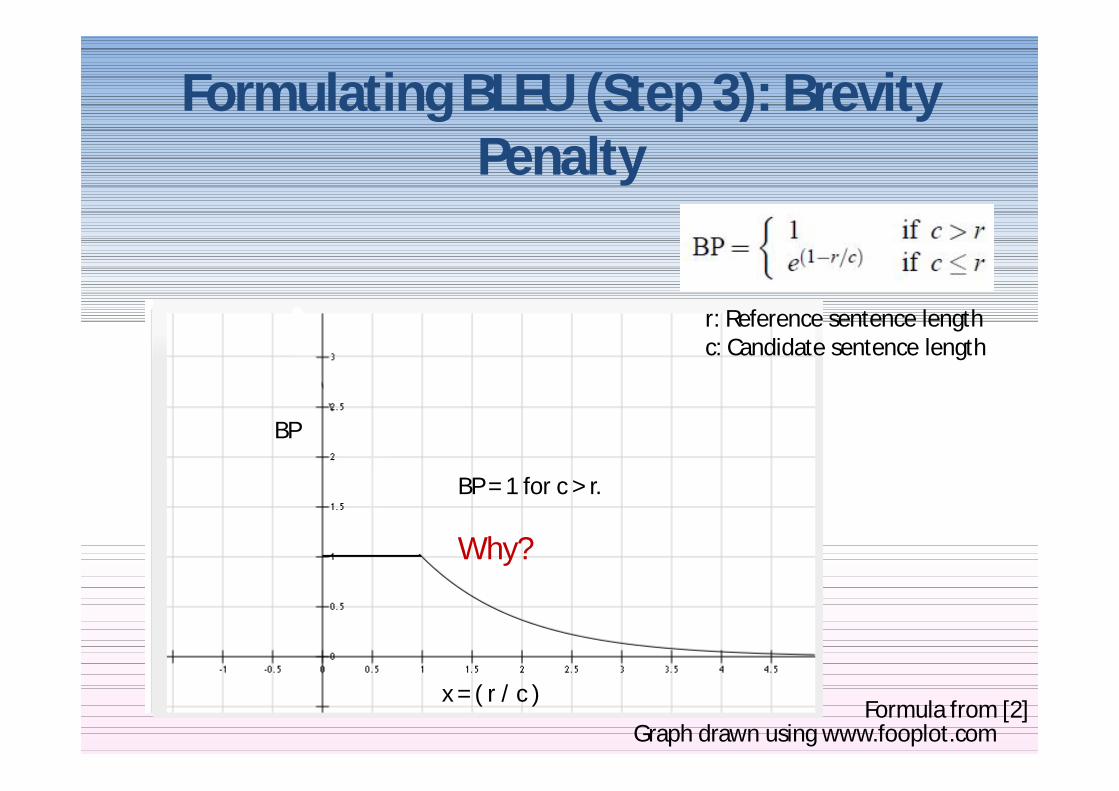
Formulating BLEU (Step 3) Brevity Penalty
e^(1-x)
Graph drawn using wwwfooplotcom
BP
BP = 1 for c gt r
Why
x = ( r c )Formula from [2]
r Reference sentence lengthc Candidate sentence length
BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

BP leaves out longer translations
WhyTranslations longer than reference are already
penalized by modified precision
Validating the claim
Formula from [2]
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
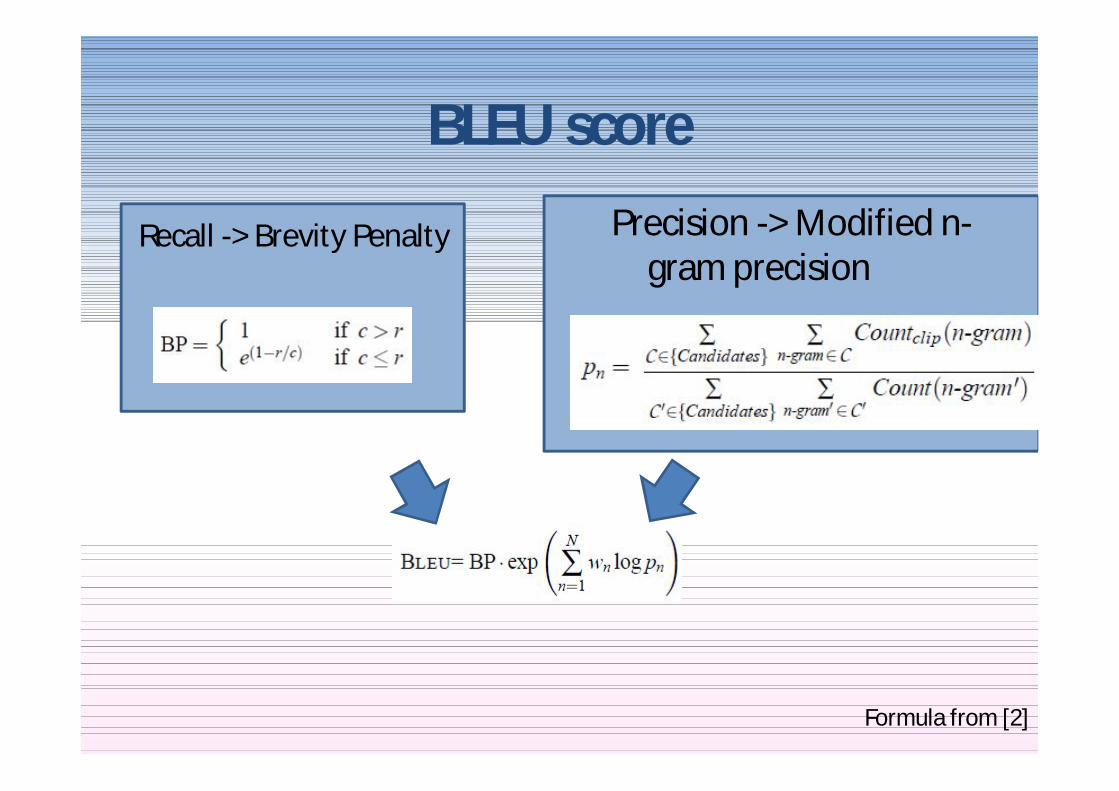
BLEU scorePrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Understanding BLEUUnderstanding BLEUDissecting the formulaUsing it news headline example
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
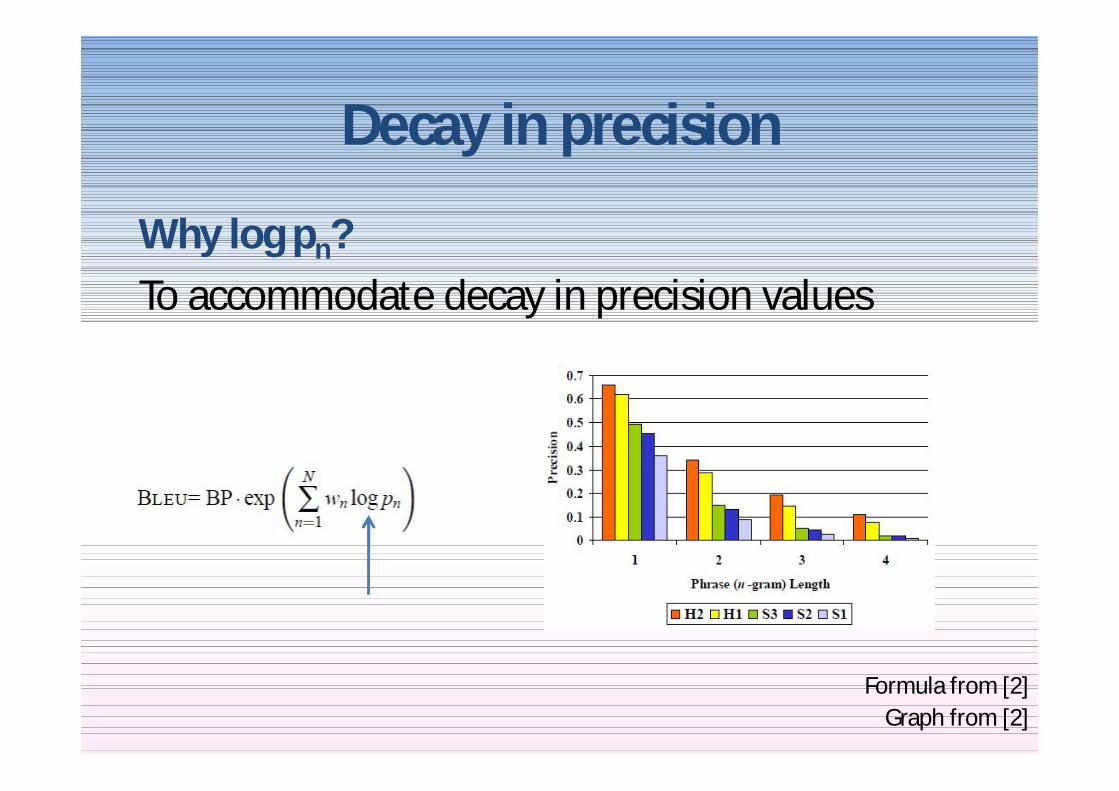
Decay in precision
Why log pnTo accommodate decay in precision values
Graph from [2]Formula from [2]
Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Dissecting the Formula
Claim BLEU should lie between 0 and 1Reason To intuitively satisfy ldquo1 implies perfect
translationrdquoUnderstanding constituents of the formula to
validate the claim
Brevity Penalty
Modified precision
Set to 1NFormula from [2]
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
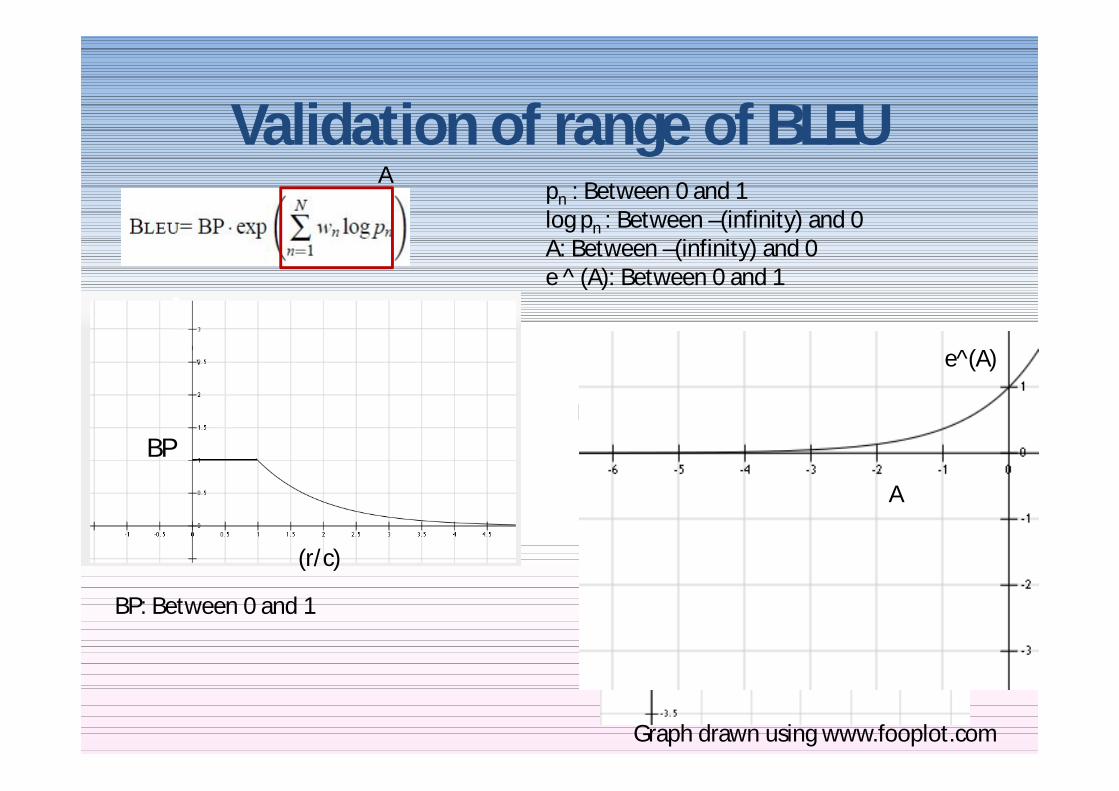
Validation of range of BLEU
BP
pn Between 0 and 1log pn Between ndash(infinity) and 0 A Between ndash(infinity) and 0 e ^ (A) Between 0 and 1
A
BP Between 0 and 1
Graph drawn using wwwfooplotcom
(rc)
pn
log pn
A
e^(A)
Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Calculating BLEU An actual example
Ref भावना मक एक करण लान क लए एक योहारbhaavanaatmak ekikaran laane ke liye ek tyohaaremotional unity bring-to a festivalA festival to bring emotional unity
C1 लान क लए एक योहार भावना मक एक करणlaane-ke-liye ek tyoaar bhaavanaatmak ekikaranbring-to a festival emotional unity (This is invalid Hindi ordering)
C2 को एक उ सव क बार म लाना भावना मक एक करणko ek utsav ke baare mein laana bhaavanaatmak ekikaran
for a festival-about to-bring emotional unity (This is invalid Hindi ordering)
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
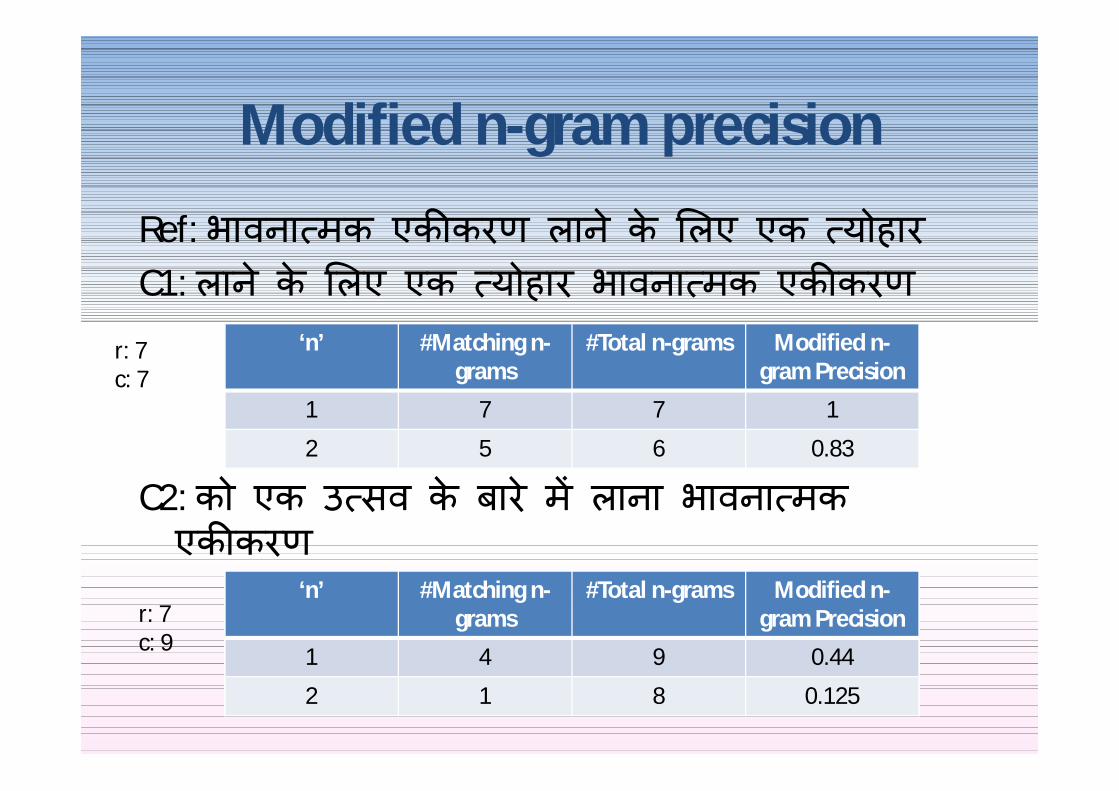
Modified n-gram precision
Ref भावना मक एक करण लान क लए एक योहारC1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 7 7 1
2 5 6 083
lsquonrsquo Matching n-grams
Total n-grams Modified n-gram Precision
1 4 9 044
2 1 8 0125
r 7c 7
r 7c 9
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
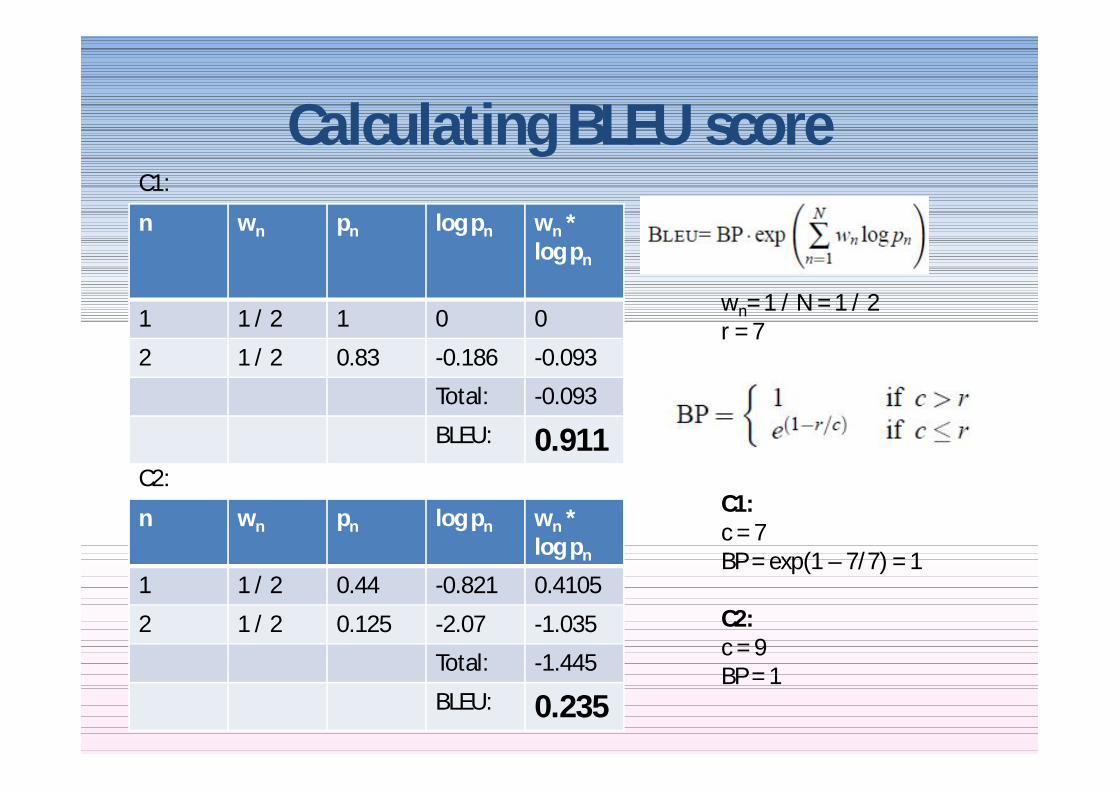
Calculating BLEU scoren wn pn log pn wn
log pn
1 1 2 1 0 0
2 1 2 083 -0186 -0093
Total -0093
BLEU 0911
wn= 1 N = 1 2r = 7
C1c = 7BP = exp(1 ndash 77) = 1
C2c = 9BP = 1
n wn pn log pn wn log pn
1 1 2 044 -0821 04105
2 1 2 0125 -207 -1035
Total -1445
BLEU 0235
C1
C2
Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Hence the BLEU scores
C1 लान क लए एक योहार भावना मक एक करण
C2 को एक उ सव क बार म लाना भावना मक एक करण
0911
0235
Ref भावना मक एक करण लान क लए एक योहार
BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

BLEU vs human BLEU vs human judgment judgment [2][2]
Target language EnglishSource language Chinese
Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Setup
BLEU scores obtained for each system
Five systems perform translation3 automatic MT systems2 human translators
Human judgment (on scale of 5) obtained for each system
bull Group 1 Ten Monolingual speakers of target language (English)
bull Group 2 Ten Bilingual speakers of Chinese and English
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
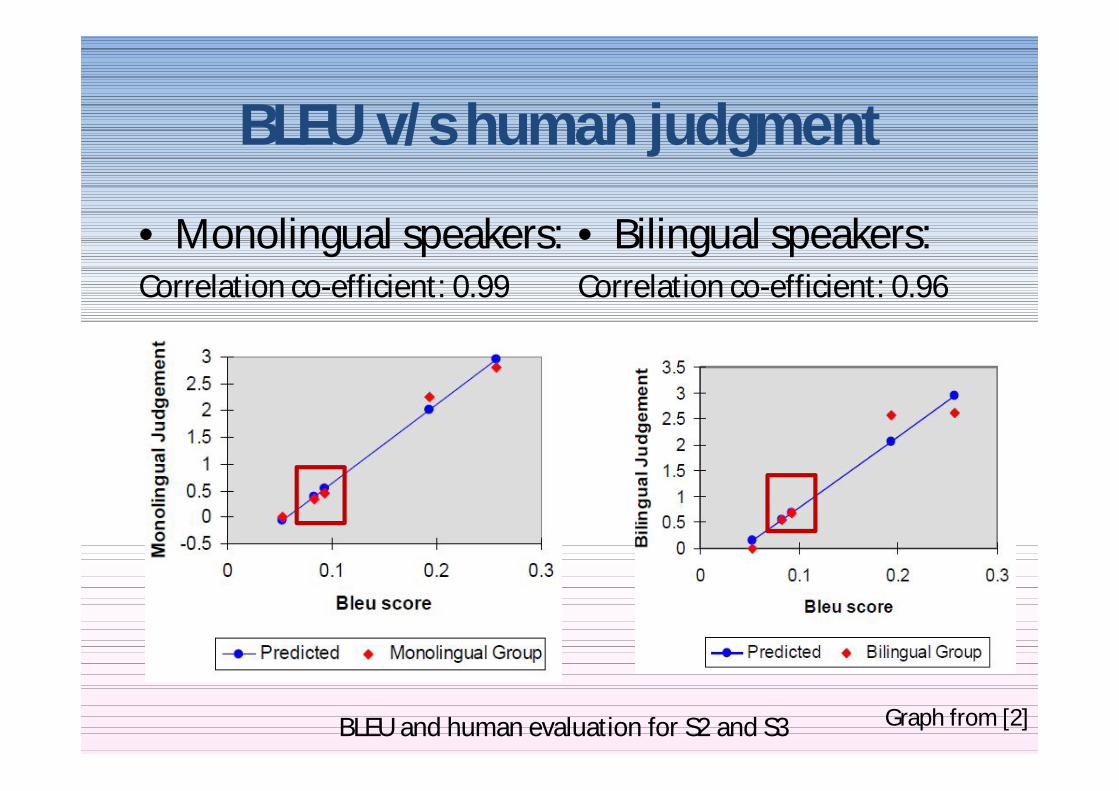
BLEU vs human judgment
bull Monolingual speakersCorrelation co-efficient 099
bull Bilingual speakersCorrelation co-efficient 096
BLEU and human evaluation for S2 and S3 Graph from [2]
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
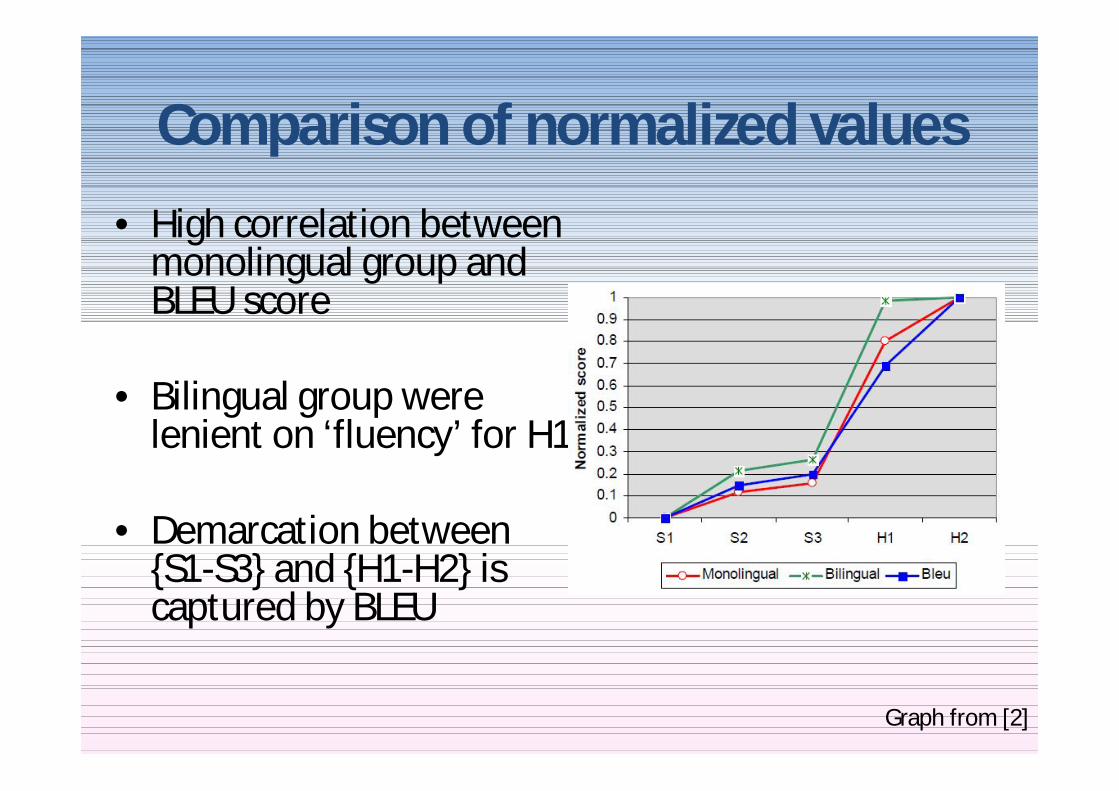
Comparison of normalized values
bull High correlation between monolingual group and BLEU score
bull Bilingual group were lenient on lsquofluencyrsquo for H1
bull Demarcation between S1-S3 and H1-H2 is captured by BLEU
Graph from [2]
Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Conclusion
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Part II Shortcomings of BLEU(continued from 7th March 2013)
Presented by(As a part of CS 712)
Aditya JoshiKashyap PopatShubham Gautam
IIT Bombay
GuideProf Pushpak Bhattacharyya
IIT Bombay
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
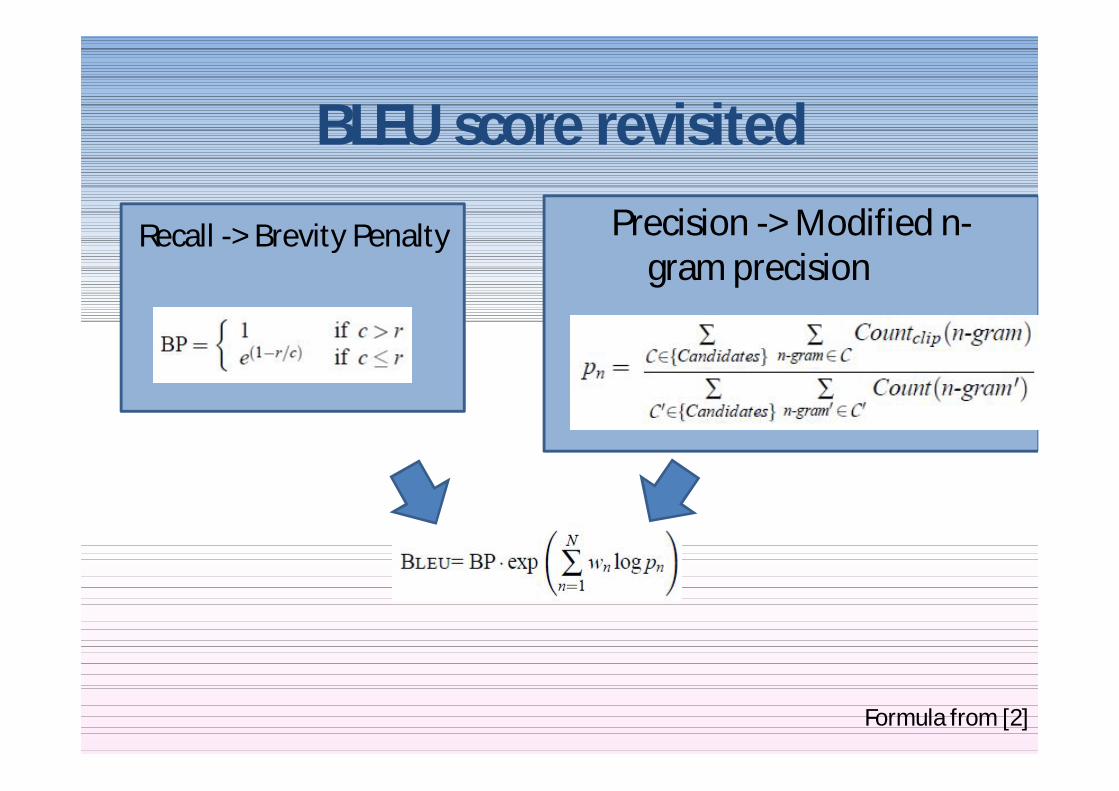
BLEU score revisitedPrecision -gt Modified n-
gram precisionRecall -gt Brevity Penalty
Formula from [2]
Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Outline
bull Evaluationbull Formulating BLEU Metricbull Understanding BLEU formulabull Shortcomings of BLEU in generalbull Shortcomings in context of English-Hindi MT
Part I
Part II
Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

[A domesticated bird wants to learn to fly]
I can do this I just have to work out the physics I have quadrated by vector angles I have adjusted for wind shear
This is it Lets fly Just keep it simple Thrust lift drag and wait Thrust lift drag wait[speeds up to get to the of the table]Thrust lift drag waiwaiwait [gets scared and tries to stop himself
but instead falls from the table]
Lines from Rio (2011)
- Blu the Macaw
ldquo
Image Source wwwfanpopcom
Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Use of BLEU metric [3]
bull Evaluating incremental system changesndash Neglecting actual examples
bull Systems ranked on basis of BLEU
bull Does minimizing error rate with respect to BLEU indeed guarantee translation improvements
Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Criticisms of BLEU [4]
bull Admits too much variation [3]
bull Admits too little variation [4] [3]
bull Poor correlation with human judgment [3]
Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Admits too much variation [3]
Permuting phrasesDrawing different items from reference set
Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Admits too much variation
bull BLEU relies on n-gram matching only
bull Puts very few constraints on how n-gram matches can be drawn from multiple reference translations
Brevity Penalty(Incorporating recall)
Modified precision
Set to 1N
Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Modified n-gram precision in BLEU [2]
bull Clip the total count of each candidate word with its maximum reference count
bull Countclip(n-gram) = min (count max_ref_count)
Reference मझपर तरा स र छायाmujhpar teraa suroor chhaayame-on your spell has-been-castYour spell has been cast on me
Candidate 2 तरा तरा तरा स रtera tera tera surooryour your your spellYour your your spell
matching unigrams (तरा min(3 1) = 1 ) (स र min (1 1) = 1)
Modified unigram precision 24 = 05
Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Permuting phrases [3]
bull Reordering of unmatched phrases does not affect precision
bull Bigram mismatch sites can be freely permuted
Possible to randomly produce other hypothesis translations that have the same BLEU score
B1 B2 B3 B4
B4 B2 B1 B3Bigram Bigrammismatch
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
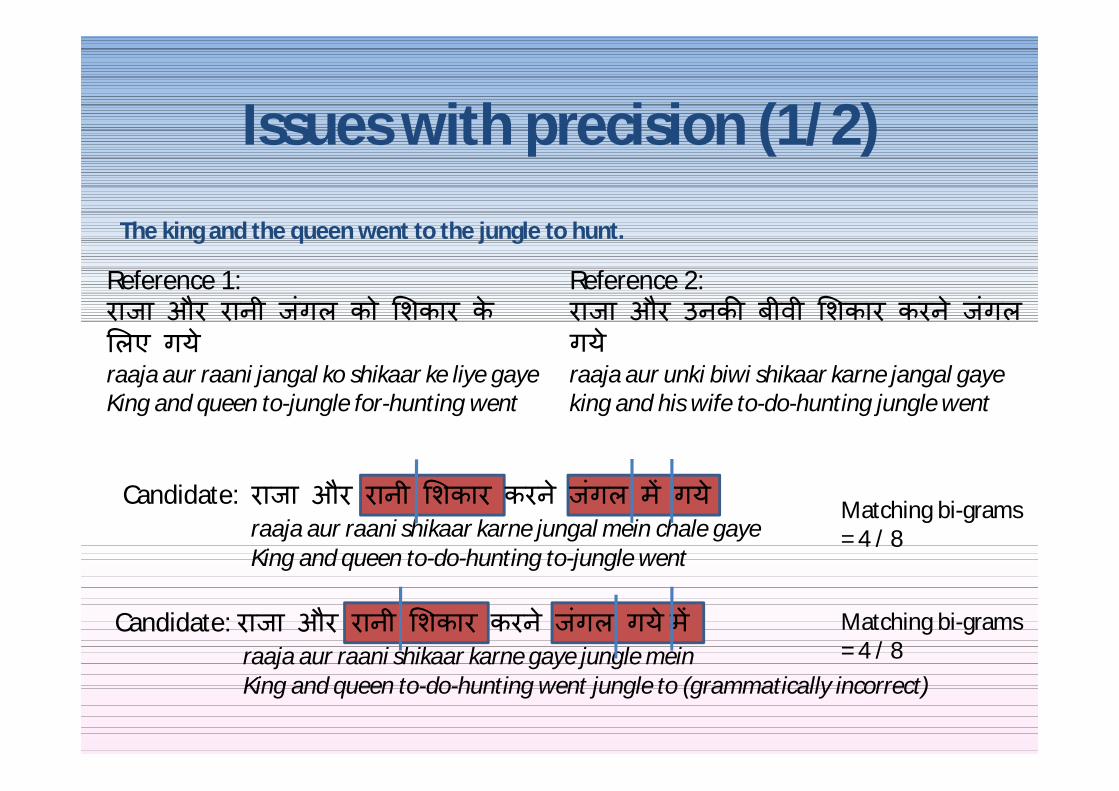
Issues with precision (12)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate राजा और रानी शकार करन जगल गय म raaja aur raani shikaar karne gaye jungle meinKing and queen to-do-hunting went jungle to (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
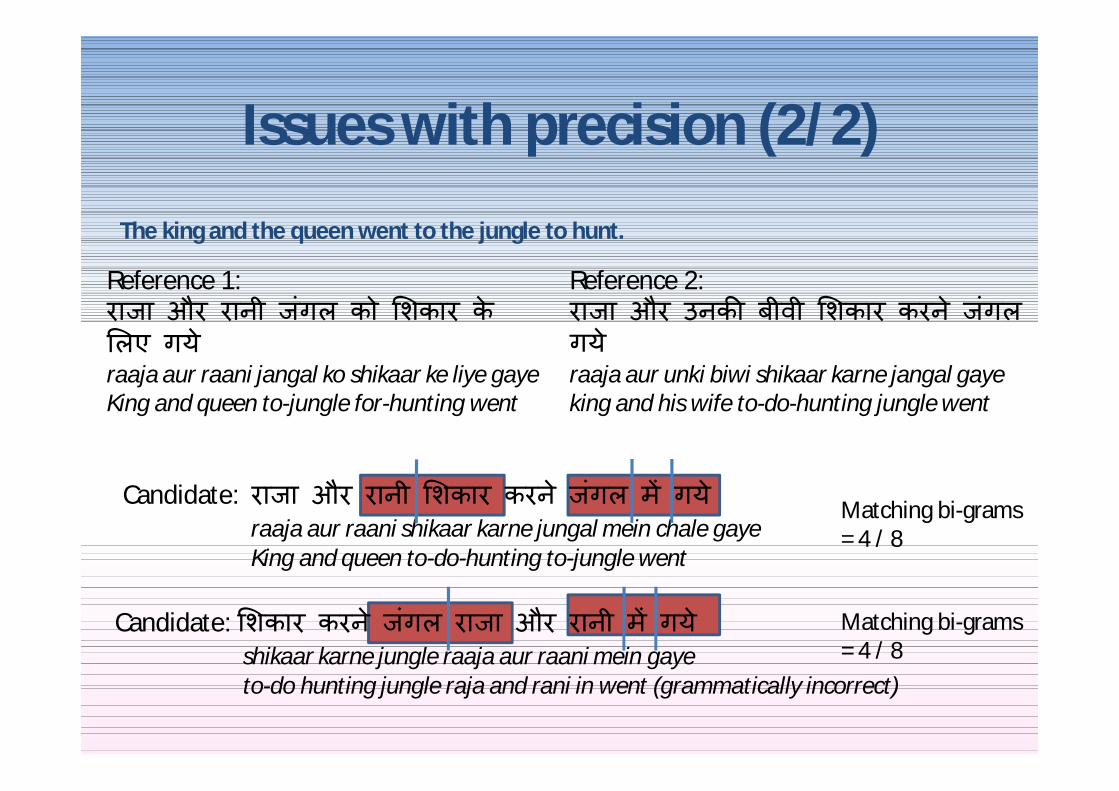
Issues with precision (22)
Candidate राजा और रानी शकार करन जगल म गय
raaja aur raani shikaar karne jungal mein chale gayeKing and queen to-do-hunting to-jungle went
Reference 1 राजा और रानी जगल को शकार क लए गय
raaja aur raani jangal ko shikaar ke liye gayeKing and queen to-jungle for-hunting went
Reference 2 राजा और उनक बीवी शकार करन जगल गय raaja aur unki biwi shikaar karne jangal gayeking and his wife to-do-hunting jungle went
Matching bi-grams = 4 8
Candidate शकार करन जगल राजा और रानी म गयshikaar karne jungle raaja aur raani mein gayeto-do hunting jungle raja and rani in went (grammatically incorrect)
The king and the queen went to the jungle to hunt
Matching bi-grams = 4 8
Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Permuting phrases in generalbull For lsquobrsquo bi-gram matches in a candidate translation of length
lsquokrsquo(k ndash b) possible ways to generate similarly score items using only the words
in this translation
In our example (8-4) = 24 candidate translations
In sentence of length ktotal bigrams = k ndash 1
matched bigrams = b
no of mismatched bigrams = k ndash 1 ndash bno of matched chunks = k ndash 1 ndash b + 1
= k ndash b
These (k-b) chunks can be reordered in (k ndash b) ways
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
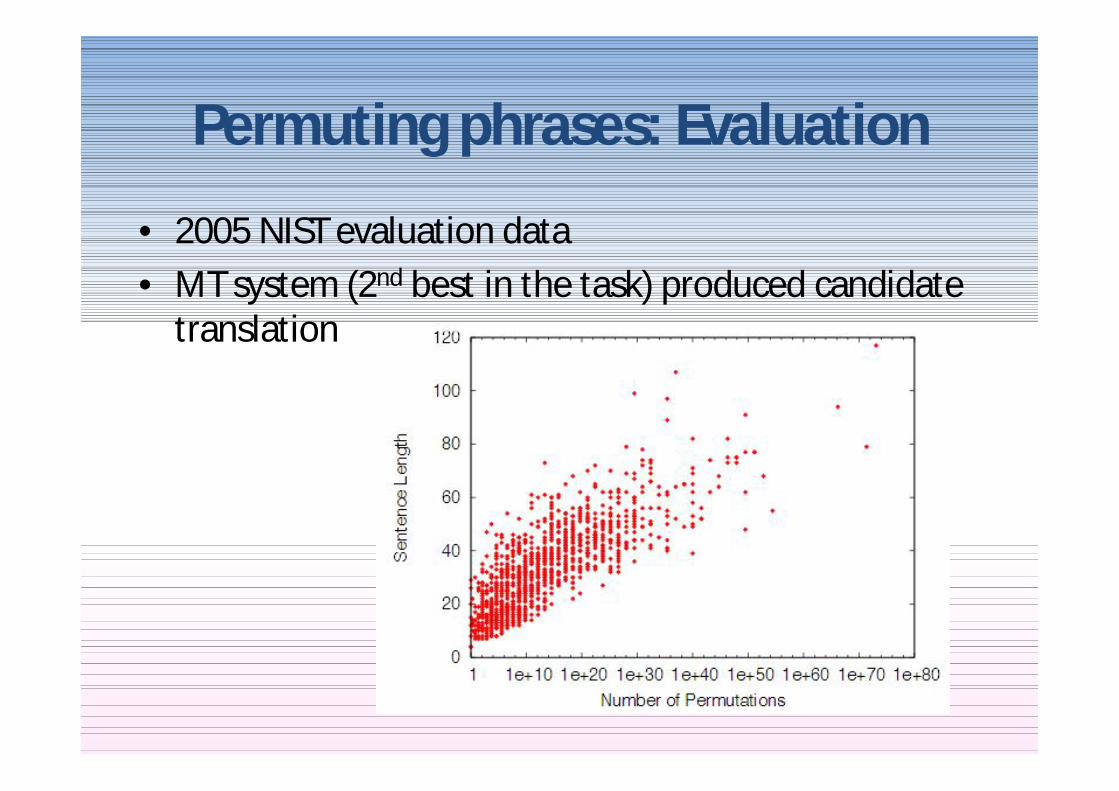
Permuting phrases Evaluation
bull 2005 NIST evaluation databull MT system (2nd best in the task) produced candidate
translation
Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Drawing different items from the reference set
bull If two systems lsquorecallrsquo x words each from a reference sentence
bull Precision may remain the samebull Brevity penalty remains the same
bull Translation quality need not remain the same
Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Drawing different items Example
You may omit lexical items altogether
Candidate 2 घर क मग दालGhar murgi daal hotiHouse chicken daal is
Unigram precision 1 1Bigram precision 2 3
Referenceघर क मग मतलब दाल होती ह Ghar ki murgi matlab daal jaisi hoti hai
House-of chicken means daal-like isChicken at home is like daal
Candidate 1मग मतलब होती ह Ki matlab jaisi haiOf means like is
Unigram precision 1 1Bigram precision 2 3
Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Drawing different items In general
bull If there are x unigram matches y bigram matches in candidate C1 and C2 bothndash BLEU score remains the same
ndash What words are actually matched is not accounted for
ndash Synonyms also indicate lsquomismatchrsquo
Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Failures in practice Evaluation 1 (12) [3]
bull NIST MT Evaluation exercisebull Failure to correlate with human judgment
ndash In 2005 exercise System ranked 1st in human judgment ranked 6th by BLEU score
bull Seven systems compared for adequacy and fluency
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
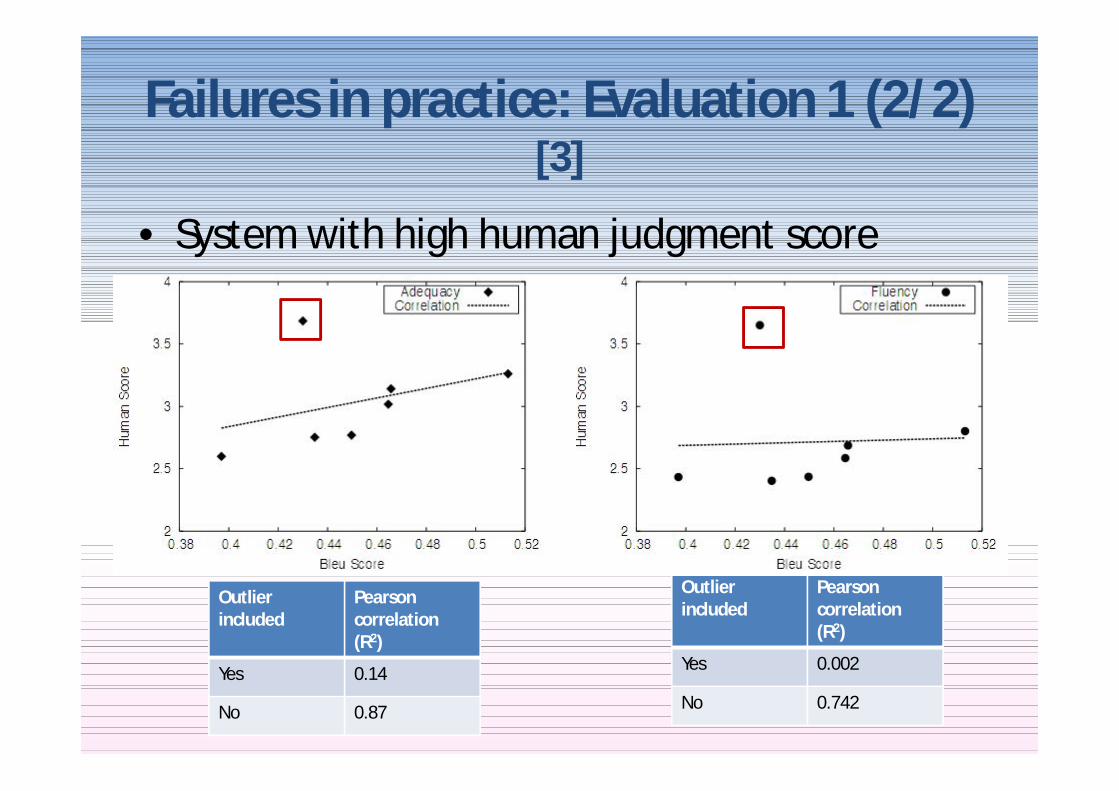
Failures in practice Evaluation 1 (22) [3]
bull System with high human judgment score
Graph
Outlierincluded
Pearson correlation (R2)
Yes 014
No 087
Outlierincluded
Pearson correlation (R2)
Yes 0002
No 0742
Graph
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
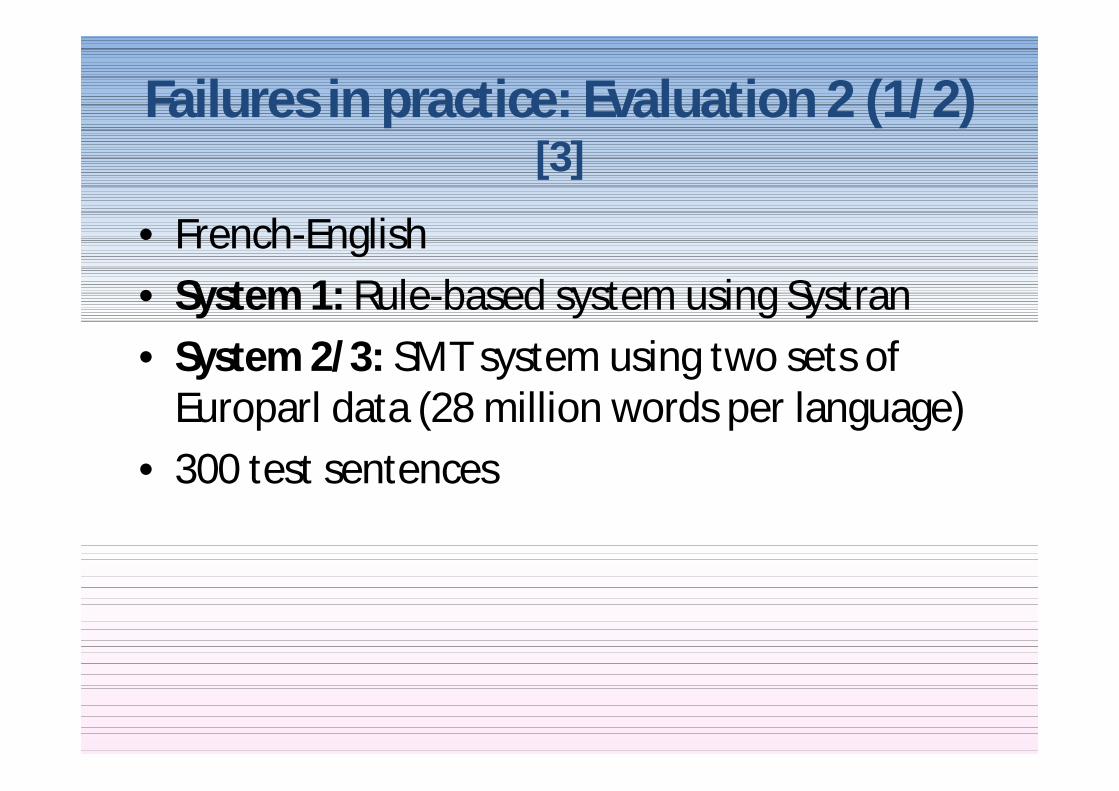
Failures in practice Evaluation 2 (12) [3]
bull French-Englishbull System 1 Rule-based system using Systranbull System 23 SMT system using two sets of
Europarl data (28 million words per language)bull 300 test sentences
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
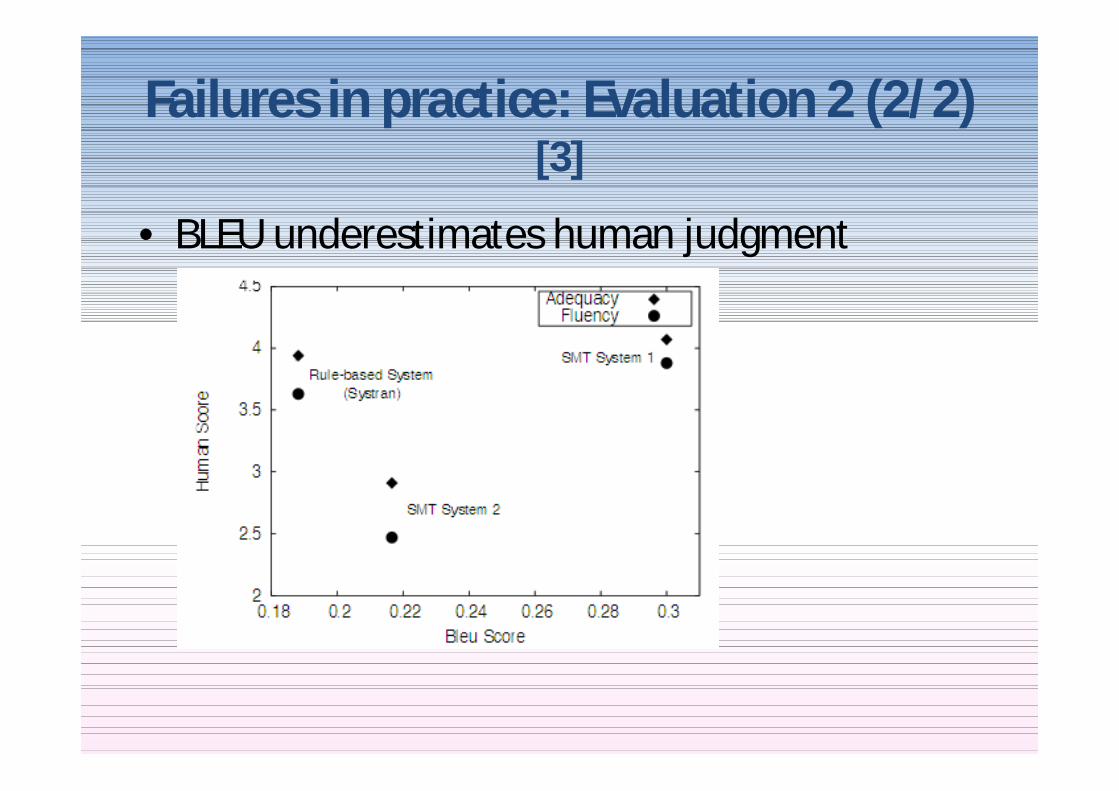
Failures in practice Evaluation 2 (22) [3]
bull BLEU underestimates human judgment
Graph
Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Admits too much and too Admits too much and too less variation less variation [[44]]
Indicative translationsLinguistic divergences amp evaluation
Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Indicative translation
bull Draft quality translationsbull For assimilation rather than dissemination
bull Virtually all general-purpose MT systems today produce indicative translations
Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Basic steps to obtain indicative translation English-Hindi
bull Structural transferndash S V O to S O V
bull Lexical transferndash Looking up corresponding wordndash Adding gender aspect tense etc information
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
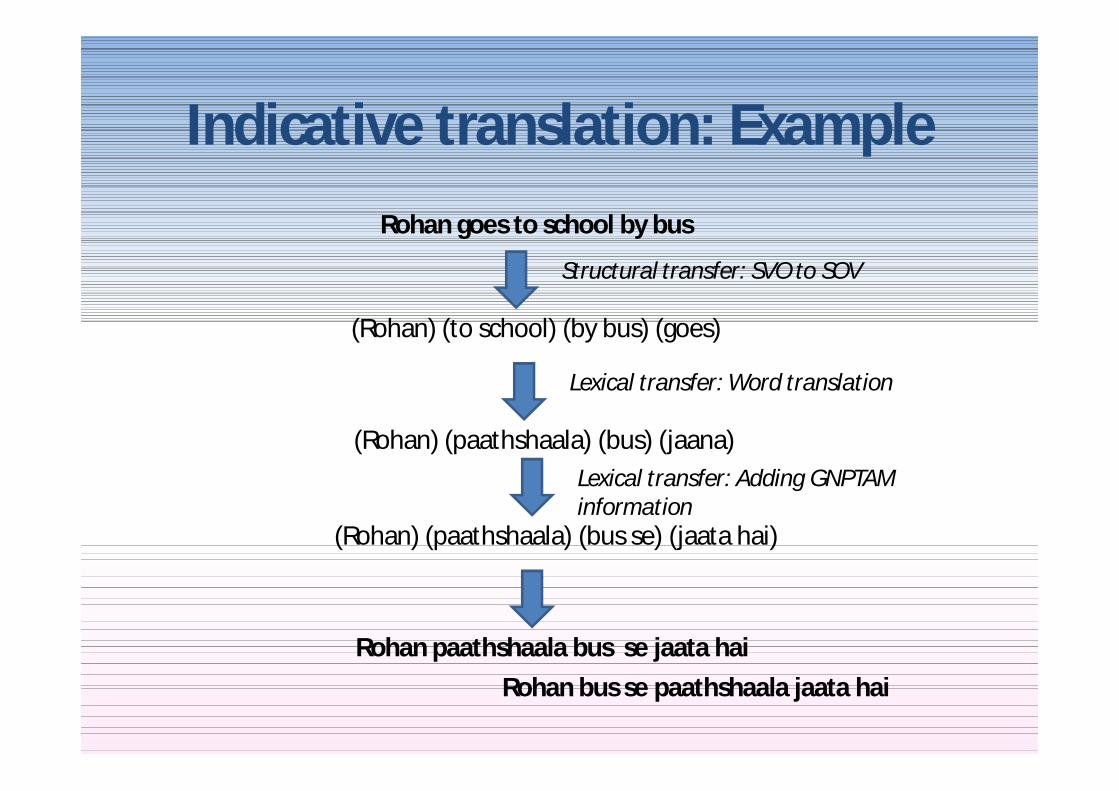
Indicative translation ExampleRohan goes to school by bus
Structural transfer SVO to SOV
(Rohan) (to school) (by bus) (goes)
Lexical transfer Word translation
(Rohan) (paathshaala) (bus) (jaana)Lexical transfer Adding GNPTAM information
(Rohan) (paathshaala) (bus se) (jaata hai)
Rohan paathshaala bus se jaata haiRohan bus se paathshaala jaata hai
Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Questions in context of indicative translations [4]
bull Can systems be compared with each other using human reference translations
bull Is it wise to track the progress of a system by comparing its output with human translations in case of indicative translations
Is ldquofailure of MTrdquo (defined using any measure) simply because of ldquofailure in relation to inappropriate goalsrdquo (translating like a human)
Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Linguistic Divergences
bull Categorical divergencebull Noun-noun compoundsbull Cultural differencesbull Pleonastic divergencebull Stylistic differencesbull WSD errors
Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Categorical divergence
bull Change in lexical category
Unigram precision 0Bigram precision 0BLEU score 0
E I am feeling hungry H मझ भख लग रह ह
mujhe bhookh lag rahi haito-me hunger feeling is
I म भखा महसस कर रहा ह main bhookha mehsoos kar raha hoon I hungry feel doing am
E I am sweating
H मझ पसीना आ रहा हMujhe paseena aa raha hai
To-me sweat coming is
Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Noun-noun compounds
The ten best Aamir Khan performances H
आ मर ख़ान क दस सव तम पफॉम सस Aamir khaan ki dus sarvottam performancesAamir khan-of ten best performances
I
दस सव तम आ मर ख़ान पफॉम ससDus sarvottam aamir khaan performancesTen best Aamir Khan performances
Unigrams precision 55Bi-grams precision 24
Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Cultural differences
Unigram precision 810Bigram precision 69bull lsquomaamaarsquorsquotaaursquo
E Food clothing and shelter are a mans basic needs H रोट कपड़ा और मकान एक मन य क ब नयाद ज़ रत ह
roti kapda aur makaan ek manushya ki buniyaadi zarooratein hain bread clothing and house a man of basic needs are
I खाना कपड़ा और आ य एक मन य क ब नयाद ज़ रत हkhaana kapdaa aur aashray ek manushya ki buniyaadi zarooratein hainfood clothing and shelter a man of basic needs are
Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Pleonastic divergence
bull Words with no semantic content in target language
Unigram precision 45Bigram precision 34
E It is raining H बा रश हो रह ह
baarish ho rahi hairain happening is
I यह बा रश हो रह ह yeh baarish ho rahi haiit rain happening is
E One should not trouble the weak
H दबल को परशान नह करना चा हए durbalon ko pareshaan nahi krana
chahiyeto-weak trouble not do shouldShould not trouble the weak
Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Stylistic differences
bull Typical styles in a language
Unigram precision 57Bigram precision 36
E The Lok Sabha has 545 membersH लोक सभा म 545 सद य ह
lok sabha mein 545 sadasya hainLok Sabha in 545 members are
I लोक सभा क पास 545 सद य हlok sabha ke paas 545 sadasya hainLok Sabha hasnear 545 members are
WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

WSD errors
bull Synonyms vs incorrect sensesE I purchased a batH मन एक ब ला खर दा (reference)
maine ek ballaa kharidaaI a cricket-bat boughtI bought a cricket bat
I मन एक चमगादड़ खर दाmaine ek chamgaadaD kharidaaI a bat (mammal) bought I bought a bat (mammal)
E The thieves were heldH चोर को गर तार कया
choron ko giraftaar kiyaathieves arrest doneThe thieves were arrested
I1 चोर को पकड़ाchoron ko pakdaathieves caughtThe thieves were caught
I2 चोर को आयोिजत कयाchoron ko aayojit kiyathieves organized doneThe thieves were organized
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
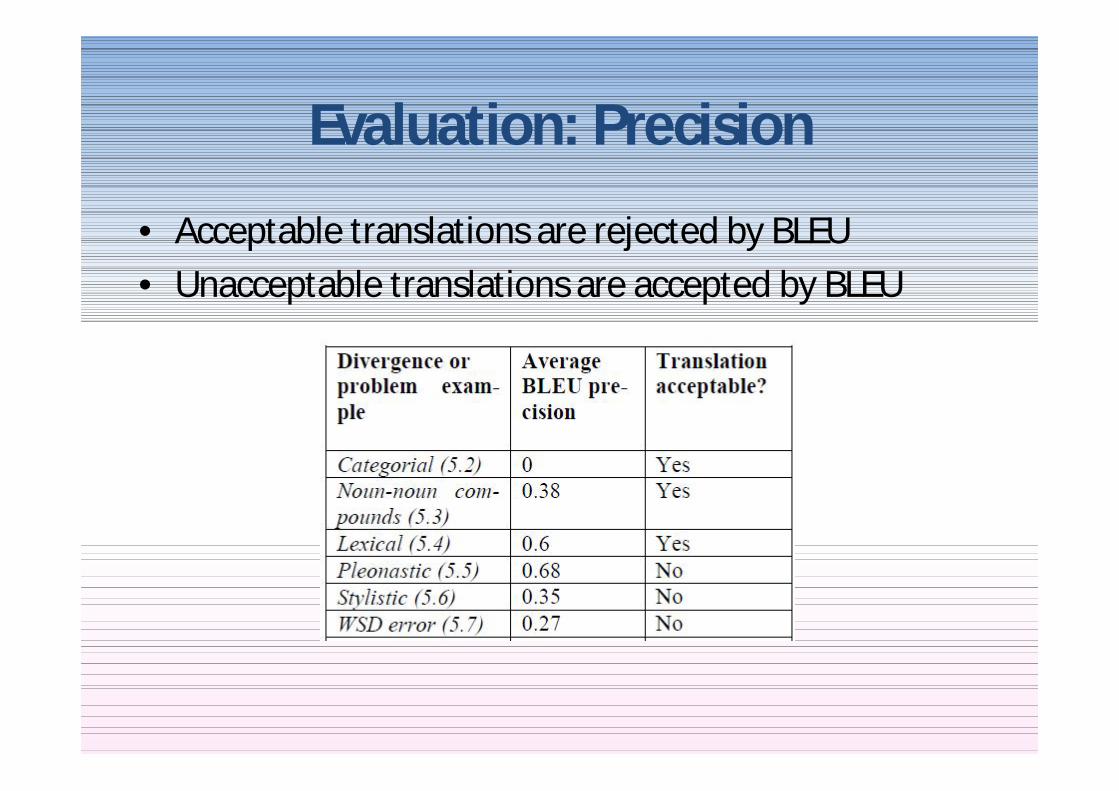
Evaluation Precision
bull Acceptable translations are rejected by BLEUbull Unacceptable translations are accepted by BLEU
Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Future of BLEU
bull Failed correlation with human judgment [3]
bull Suggested changes to BLEU score
bull Not be overly reliant on BLEU Use it only as an lsquoevaluation understudyrsquo
Re-defining a match [4]Allowing synonyms
Allowing root forms of wordsIncorporating specific language
divergences
Limiting use of BLEU [3] [4]Not use BLEU for radically
different systems
Evaluate on the basis of nature of indicative translation
Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Conclusion
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Part III Overview of MT Part III Overview of MT Evaluation MetricsEvaluation Metrics
Presented as a part of CS712 byAditya JoshiKashyap PopatShubham Gautam
21st March 2013
GuideProf Pushpak Bhattacharyya
IIT Bombay
Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Lord Ganesha and Lord Karthikeya set out on a race to go around the world
Source wwwjaishreeganeshacom
Lord Karthikeya ldquoI won I went around the earth the world oncerdquo
Lord Ganesha ldquoI won I went around my parents They are my worldrdquo
Who among them performed better Who won the race
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
OutlineOutline
Manual Evaluation
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Preliminaries
bull Candidate Translation(s) Translation returned by an MT systemndash Also called hypothesis translation
bull Reference Translation(s) lsquoPerfectrsquo translation by humans
bull Comparing metrics with BLEU
Handling incorrect words
Handling incorrect word order
Handling recall
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
OutlineOutline
Automatic Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Manual Evaluation
Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Manual evaluation [11]
Common techniques1 Assigning fluency and adequacy scores on
five (Absolute)
2 Ranking translated sentences relative to each other (Relative)
3 Ranking translations of syntactic constituents drawn from the source sentence (Relative)
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
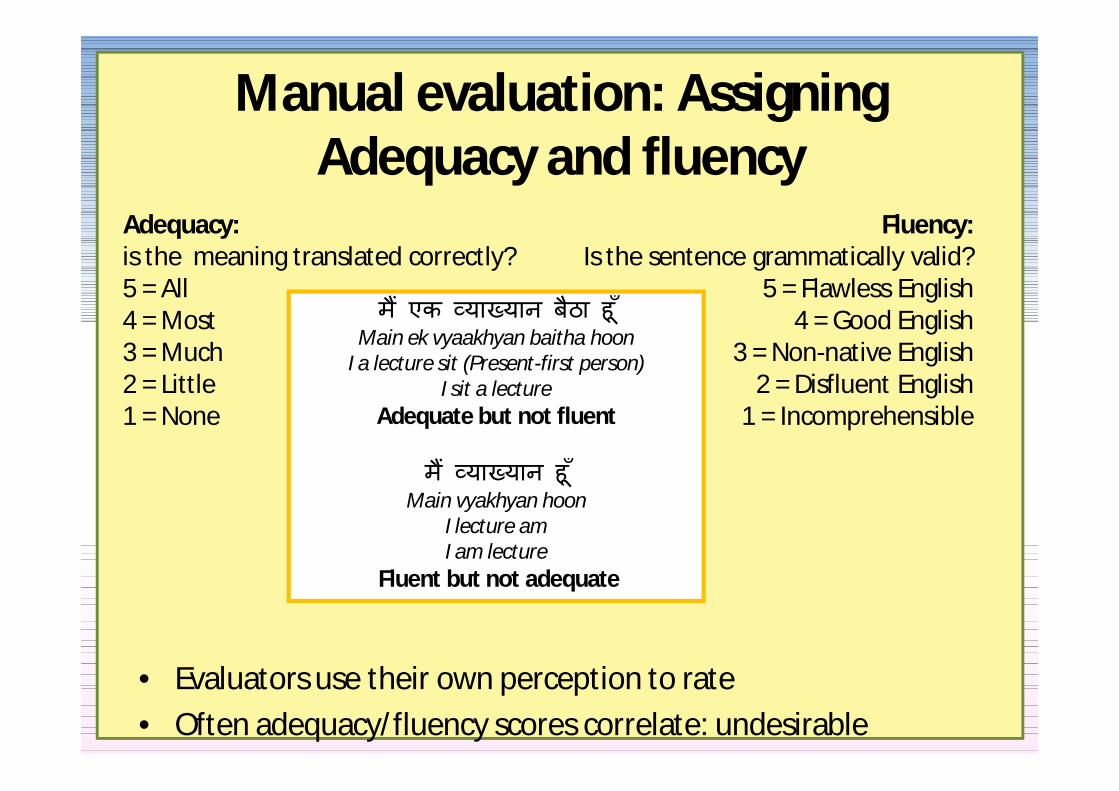
Manual evaluation Assigning Adequacy and fluency
bull Evaluators use their own perception to ratebull Often adequacyfluency scores correlate undesirable
Adequacyis the meaning translated correctly5 = All4 = Most3 = Much2 = Little1 = None
FluencyIs the sentence grammatically valid
5 = Flawless English4 = Good English
3 = Non-native English2 = Disfluent English
1 = Incomprehensible
म एक या यान बठा ह Main ek vyaakhyan baitha hoon
I a lecture sit (Present-first person)I sit a lecture
Adequate but not fluent
म या यान ह Main vyakhyan hoon
I lecture amI am lecture
Fluent but not adequate
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
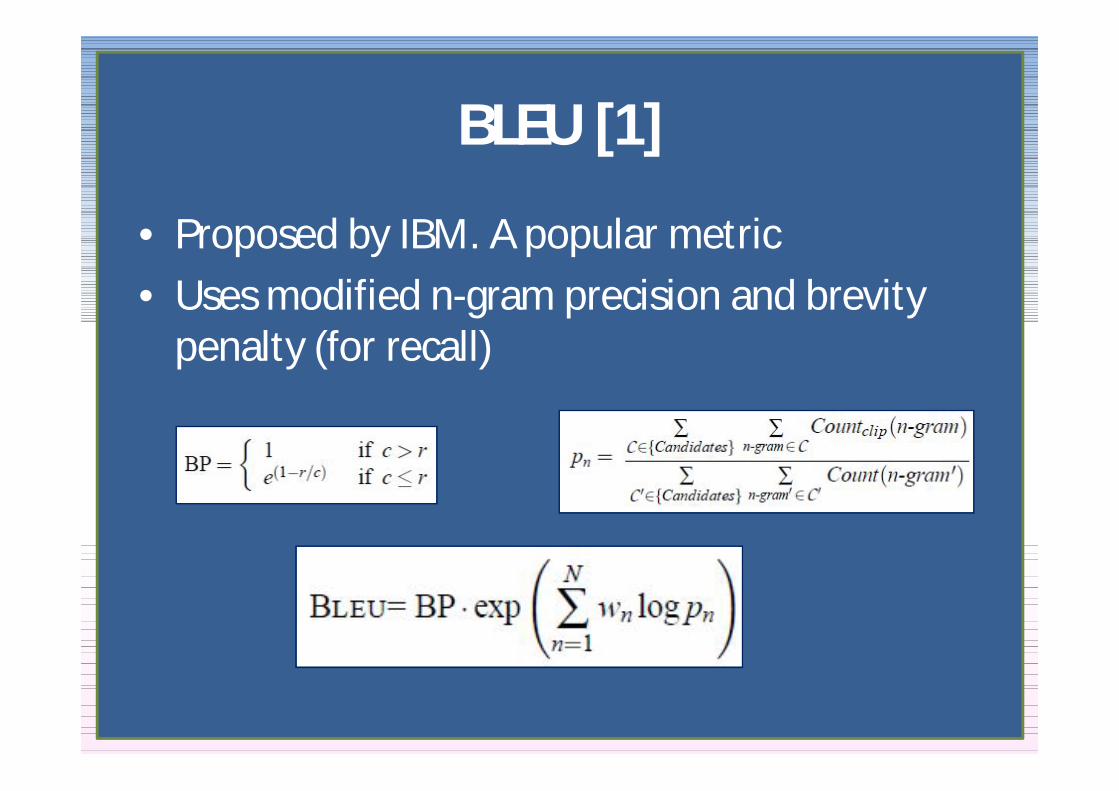
BLEU [1]
bull Proposed by IBM A popular metricbull Uses modified n-gram precision and brevity
penalty (for recall)
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Translation edit rate[5] (TER)
bull Introduced in GALE MT task
Central idea Edits required to change a hypothesis translation into a reference translation
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Shift Deletion Substitution Insertion
Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Prime Minister of India will address the nation today
Reference translationभारत क धान-म ी आज रा को सबो धत करग Bhaarat ke pradhaan-mantri aaj raashtra ko sambodhit karenge
Candidate translation धान-म ी भारत क आज को अ स करग आजPradhaan-mantri bhaarat ke aaj ko address karenge aaj
Formula for TER
TER = Edits Avg number of reference wordsbull Cost of shift lsquodistancersquo not incorporatedbull Mis-capitalization also considered an error
Shift Deletion Substitution Insertion
TER = 4 8
HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

HTER Human TER
bull Semi-supervised techniquebull Human annotators make new reference for
each translation based on system outputndash Must consider fluency and adequacy while
generating the closest target translation
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
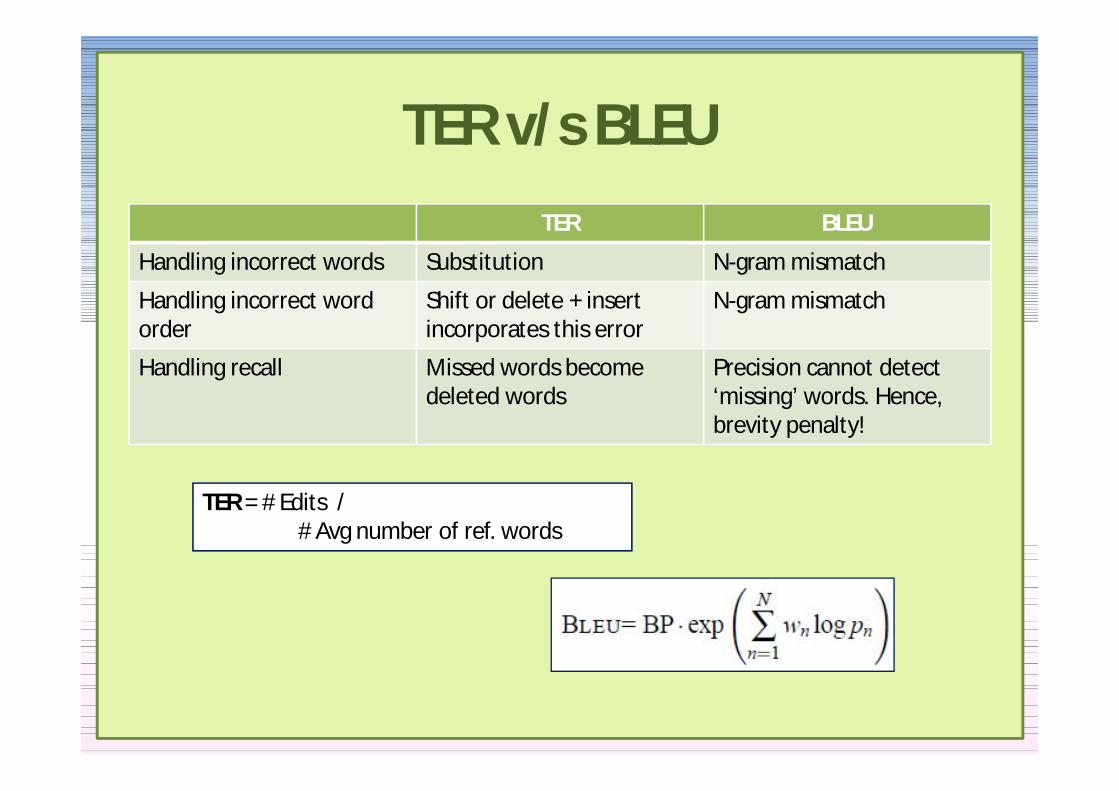
TER vs BLEUTER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Shift or delete + insertincorporates this error
N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Word Error Rate (WER) [9]
bull Based on the Levenshtein distance (Levenshtein 1966)
bull Minimum substitutions deletions and insertions that have to be performed to convert the generated text hyp into the reference text ref
bull Also position-independent word error rate (PER)
WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

WER Example
bull Order of words is importantbull Dynamic programming-based implementation
to find lsquominimumrsquo errors
Reference translationThis looks like the correct sentence
Candidate translation This seems the right sentence
errors 3
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
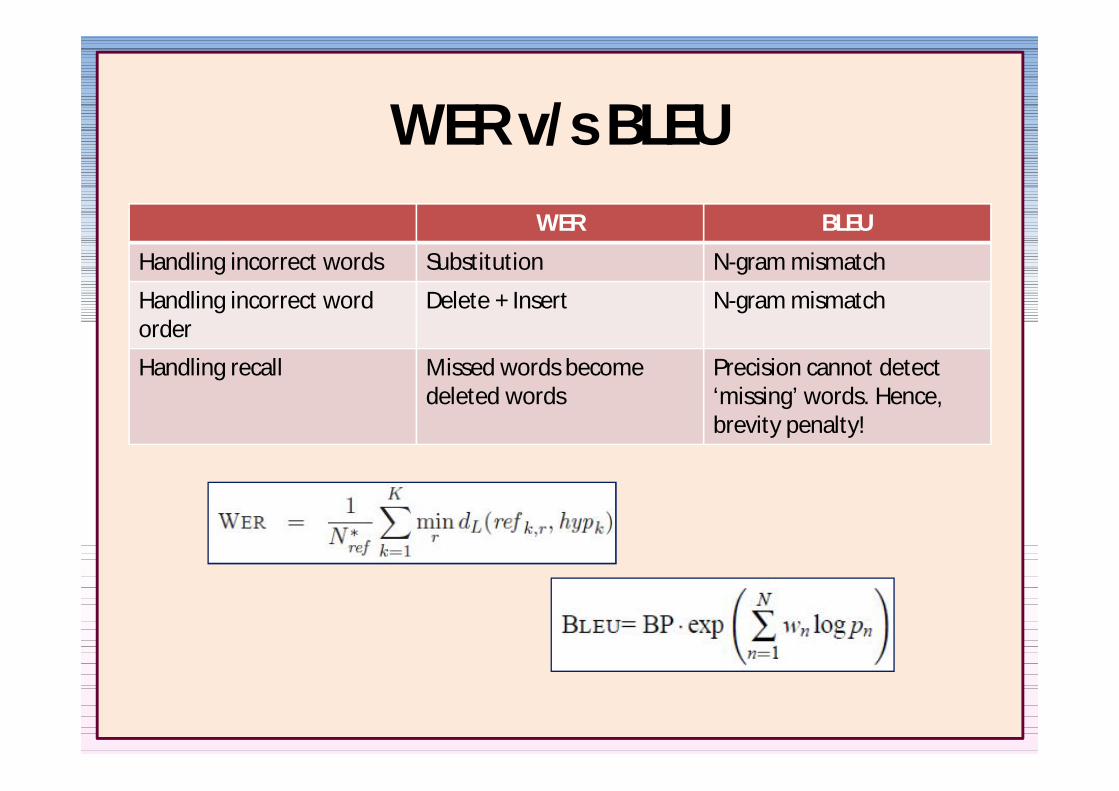
WER vs BLEUWER BLEU
Handling incorrect words Substitution N-gram mismatch
Handling incorrect word order
Delete + Insert N-gram mismatch
Handling recall Missed words becomedeleted words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
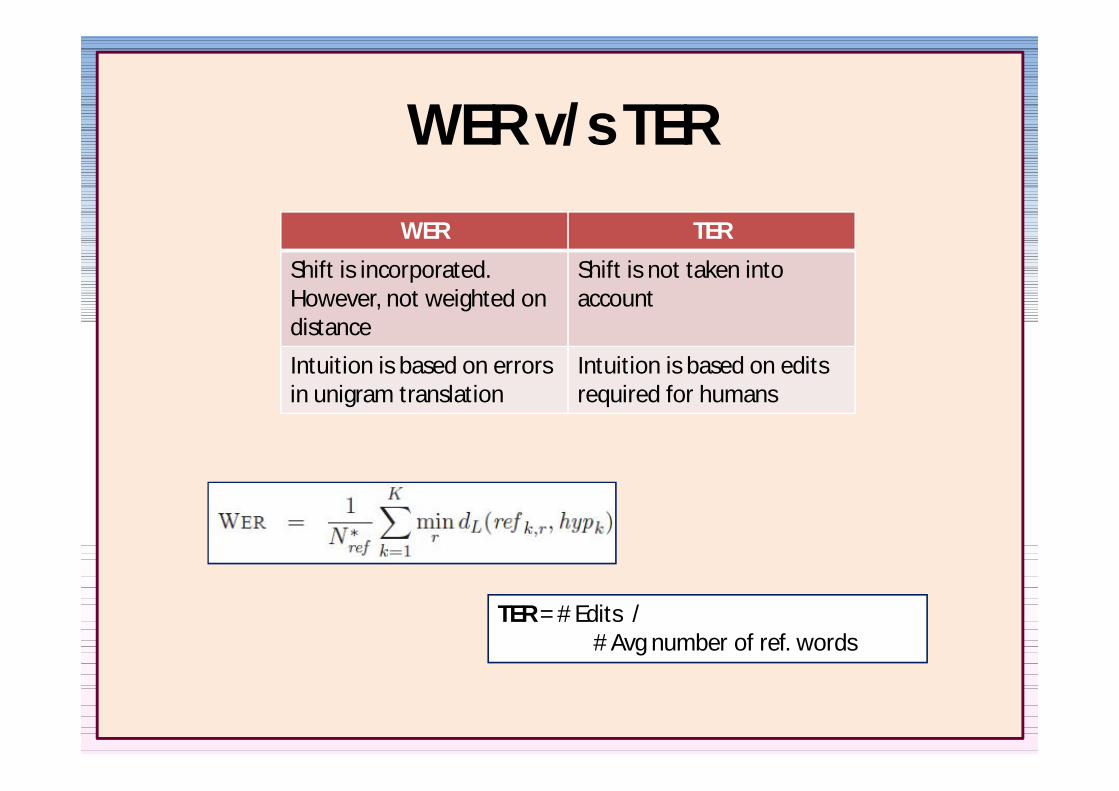
WER vs TER
WER TER
Shift is incorporatedHowever not weighted on distance
Shift is not taken into account
Intuition is based on errors in unigram translation
Intuition is based on editsrequired for humans
TER = Edits Avg number of ref words
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

ROUGE [6]
bull Recall-Oriented Understudy for Gisting Evaluation
bull ROUGE is a package of metrics ROUGE-N ROUGE-L ROUGE-W and ROUGE-S
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
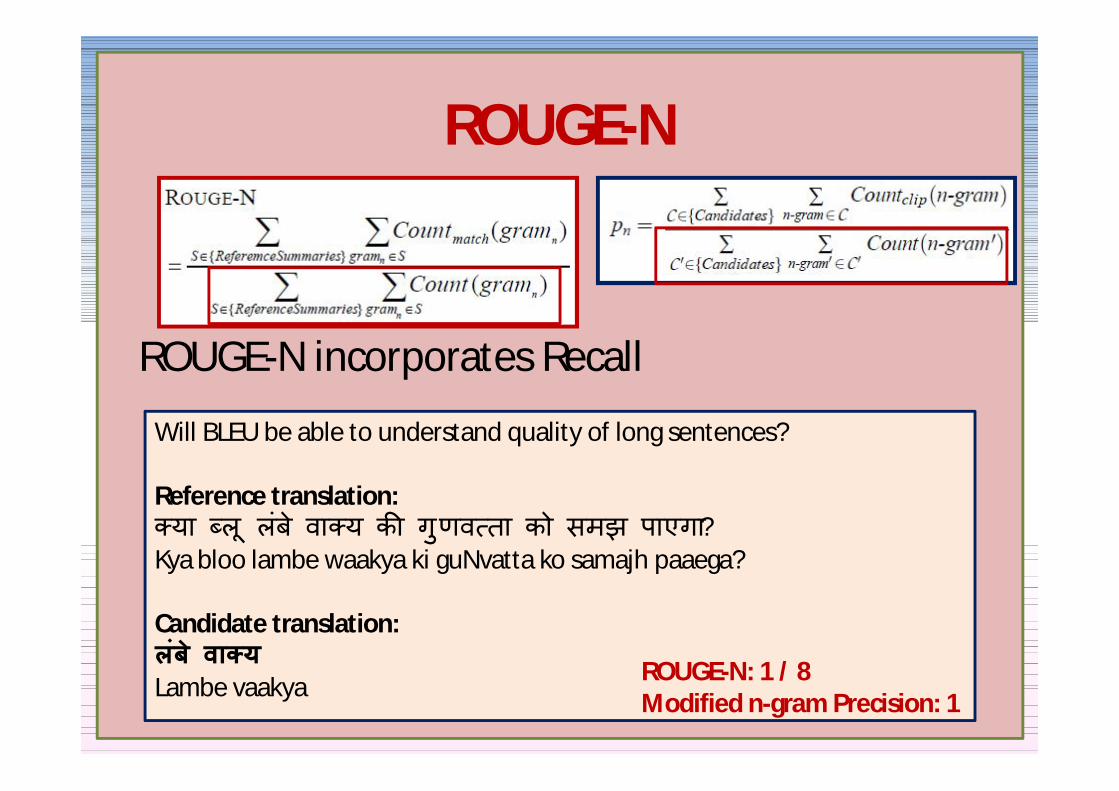
ROUGE-N
ROUGE-N incorporates Recall
Will BLEU be able to understand quality of long sentences
Reference translationया ल लब वा य क गणव ता को समझ पाएगा
Kya bloo lambe waakya ki guNvatta ko samajh paaega
Candidate translation लब वा यLambe vaakya ROUGE-N 1 8
Modified n-gram Precision 1
Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Other ROUGEs
bull ROUGE-Lndash Considers longest common subsequence
bull ROUGE-Wndash Weighted ROUGE-L All common subsequences
are considered with weight based on length
bull ROUGE-Sndash PrecisionRecall by matching skip bigrams
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
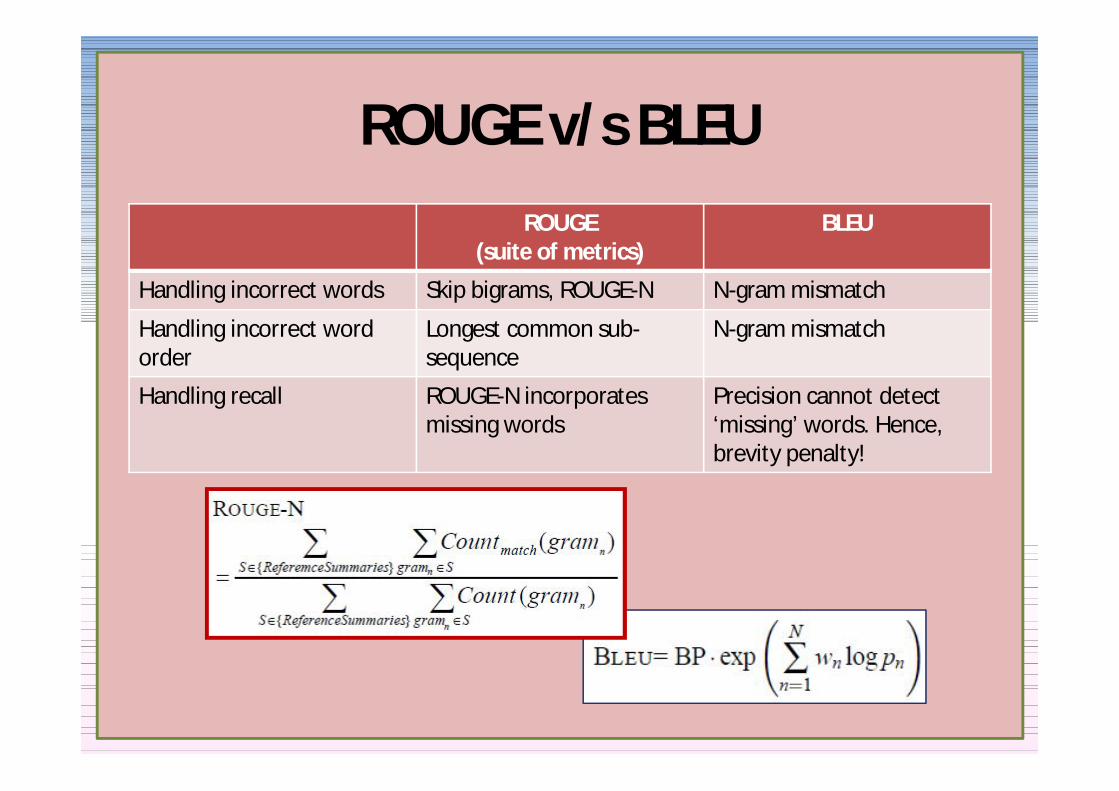
ROUGE vs BLEUROUGE
(suite of metrics)BLEU
Handling incorrect words Skip bigrams ROUGE-N N-gram mismatch
Handling incorrect word order
Longest common sub-sequence
N-gram mismatch
Handling recall ROUGE-N incorporates missing words
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
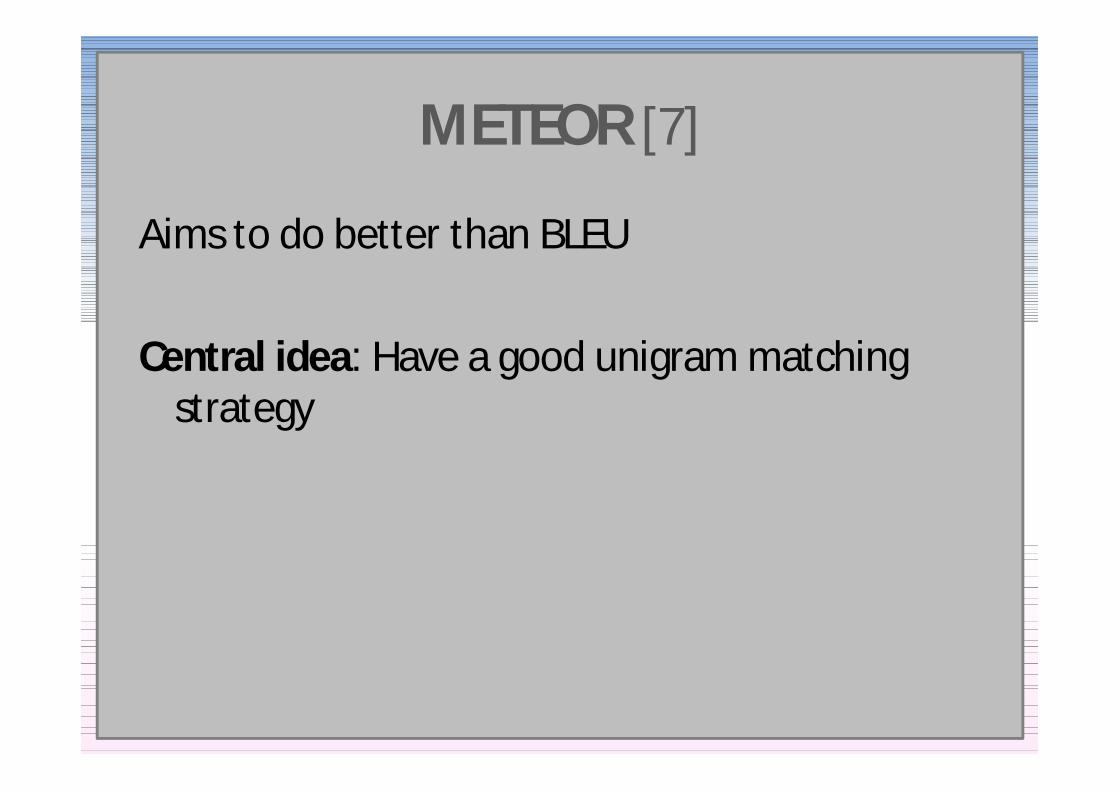
METEOR [7]
Aims to do better than BLEU
Central idea Have a good unigram matching strategy
METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

METEOR Criticisms of BLEU
bull Brevity penalty is punitivebull Higher order n-grams may not indicate
grammatical correctness of a sentencebull BLEU is often zero Should a score be zero
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
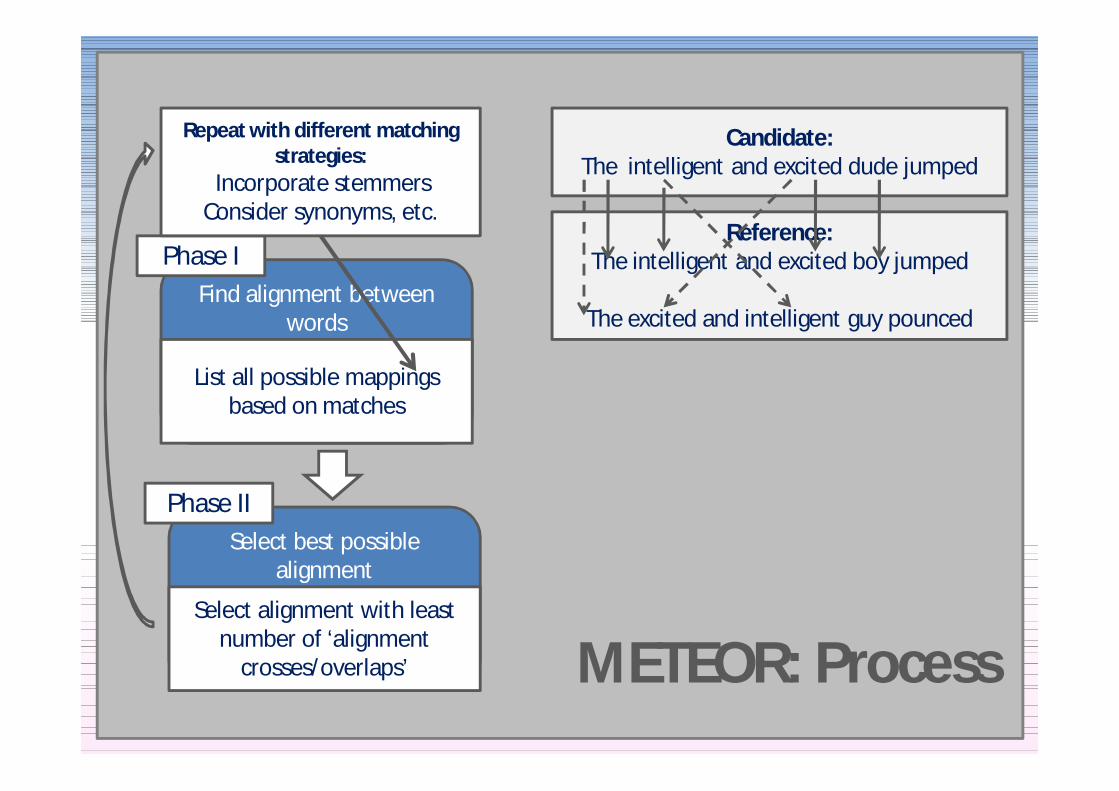
Find alignment between words
Phase I
List all possible mappings based on matches
Select best possible alignment
Phase II
Select alignment with least number of lsquoalignment
crossesoverlapsrsquo
Repeat with different matching strategies
Incorporate stemmersConsider synonyms etc
ReferenceThe intelligent and excited boy jumped
The excited and intelligent guy pounced
CandidateThe intelligent and excited dude jumped
METEOR Process
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
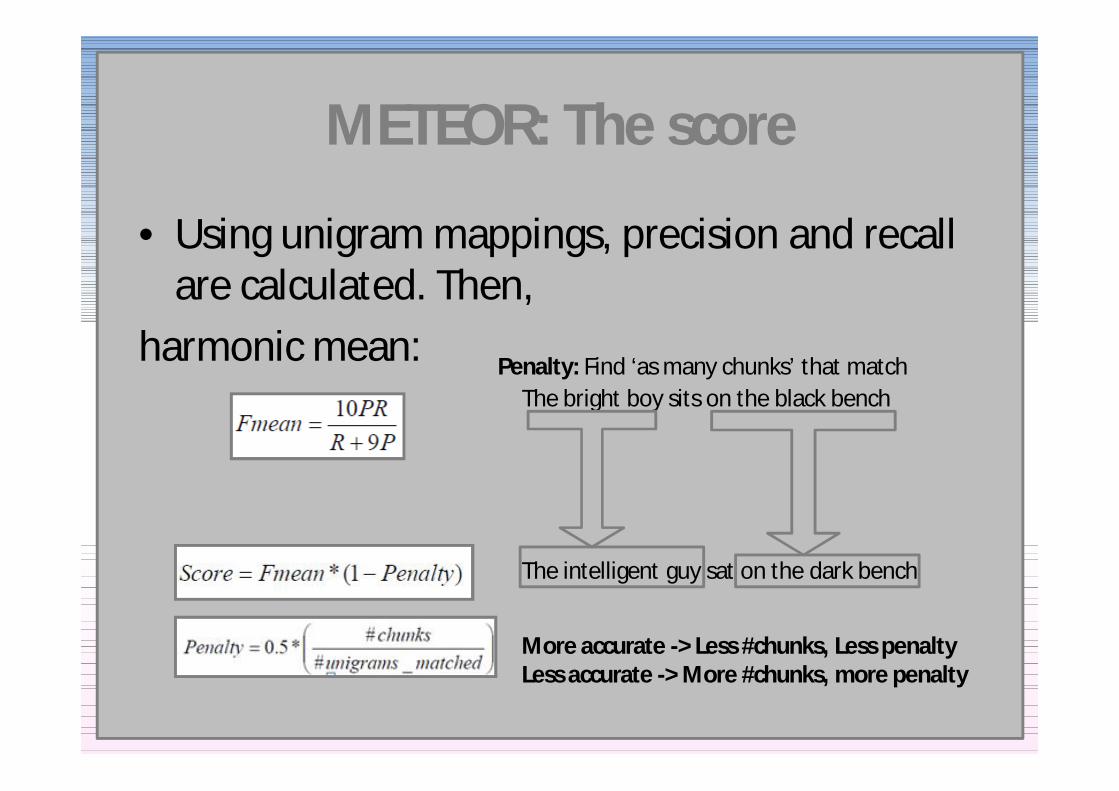
METEOR The score
bull Using unigram mappings precision and recall are calculated Then
harmonic mean Penalty Find lsquoas many chunksrsquo that matchThe bright boy sits on the black bench
The intelligent guy sat on the dark bench
More accurate -gt Less chunks Less penaltyLess accurate -gt More chunks more penalty
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
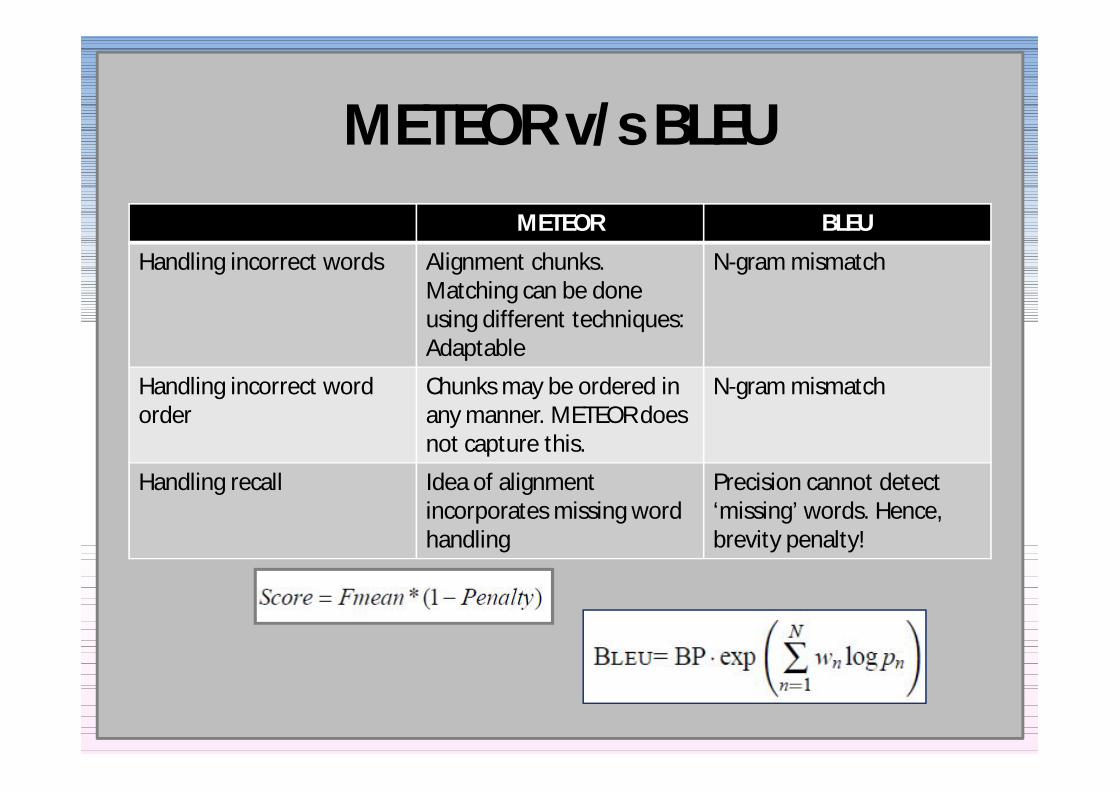
METEOR vs BLEUMETEOR BLEU
Handling incorrect words Alignment chunks Matching can be done using different techniques Adaptable
N-gram mismatch
Handling incorrect word order
Chunks may be ordered in any manner METEOR does not capture this
N-gram mismatch
Handling recall Idea of alignment incorporates missing word handling
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

NIST Metric Introduction [8]
bull MT Evaluation metric proposed by National Institute of Standards and Technology
bull Are all n-gram matches the samebull Weights more heavily those n-grams that are
more informative (ie rarer ones)bull Matching lsquoAmendment Actrsquo is better than lsquoof thersquo
bull When a correct n-gram is found the rarer that n-gram is the more weight it is given
NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

NIST Metric
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
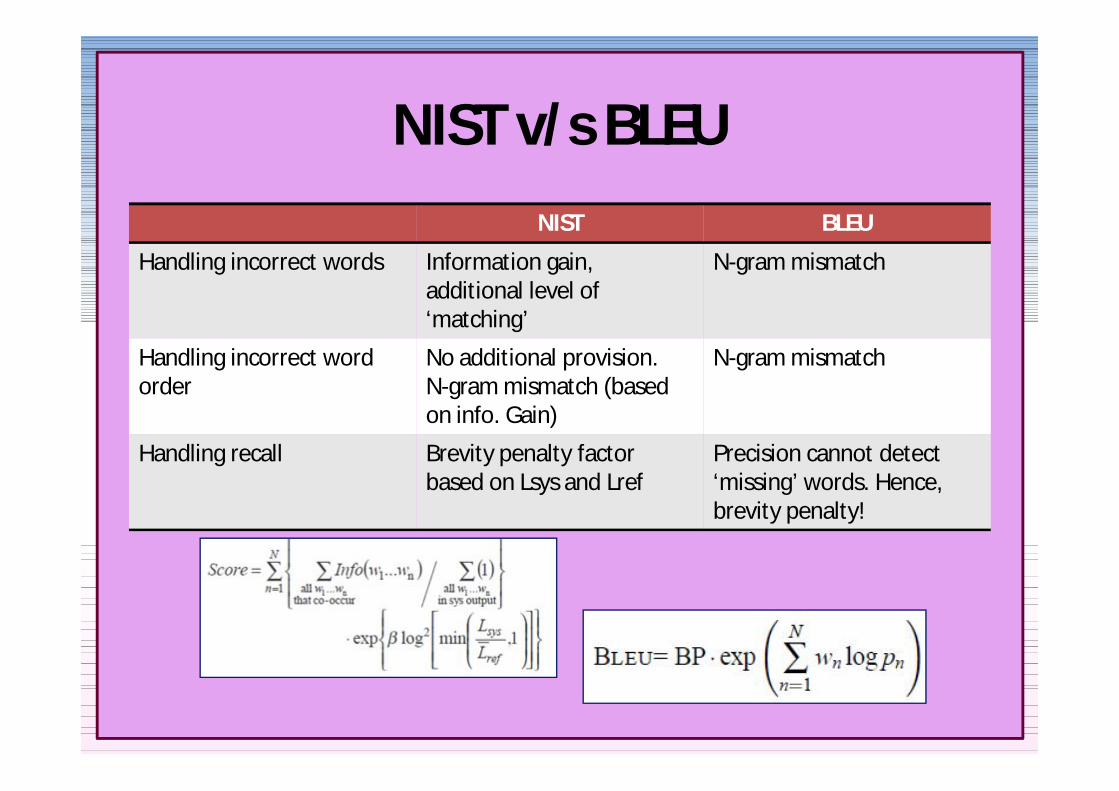
NIST vs BLEUNIST BLEU
Handling incorrect words Information gain additional level of lsquomatchingrsquo
N-gram mismatch
Handling incorrect word order
No additional provisionN-gram mismatch (based on info Gain)
N-gram mismatch
Handling recall Brevity penalty factor based on Lsys and Lref
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

GTM [10]
bull General Text Matcherbull F-score uses precision and recallbull Does not rely on lsquohuman judgmentrsquo
correlationndash What does BLEU score of 0006 mean
bull Comparison is easier
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
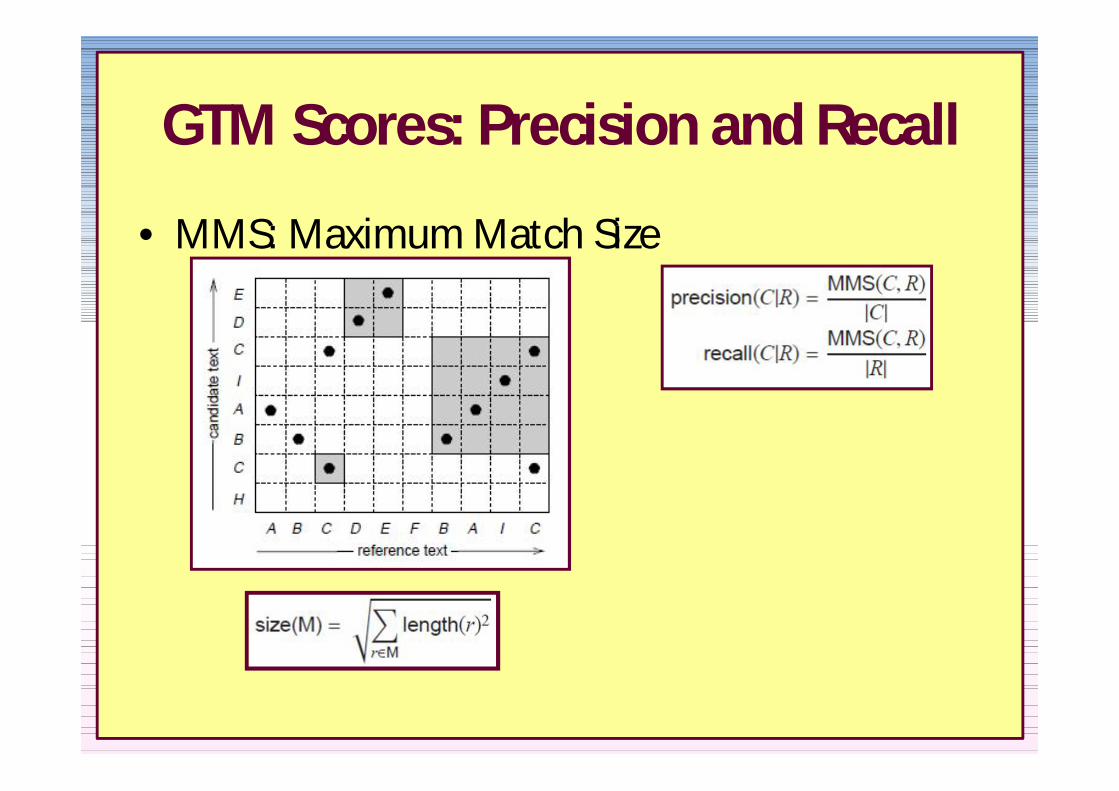
GTM Scores Precision and Recall
bull MMS Maximum Match Size
GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

GTM vs BLEUGTM BLEU
Handling incorrect words Precision based on maximum Match Size
N-gram mismatch
Handling incorrect word order
By considering maximum runs
N-gram mismatch
Handling recall Recall based on maximum match size
Precision cannot detect lsquomissingrsquo words Hence brevity penalty
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
OutlineOutline
Manual Evaluation
BLEUTERWERROUGEMETEORNISTGTMEntailment-based MT evaluation
Automatic Evaluation
Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Entailment-based evaluation [12]
Why entailment
E I am feeling hungry H(Ref) मझ भख लग रह ह
mujhe bhookh lag rahi haiCandidate म भखा महसस कर रहा ह
main bhookha mehsoos kar raha hoon BLEU Score 0Clearly candidate is entailed by reference
translation
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
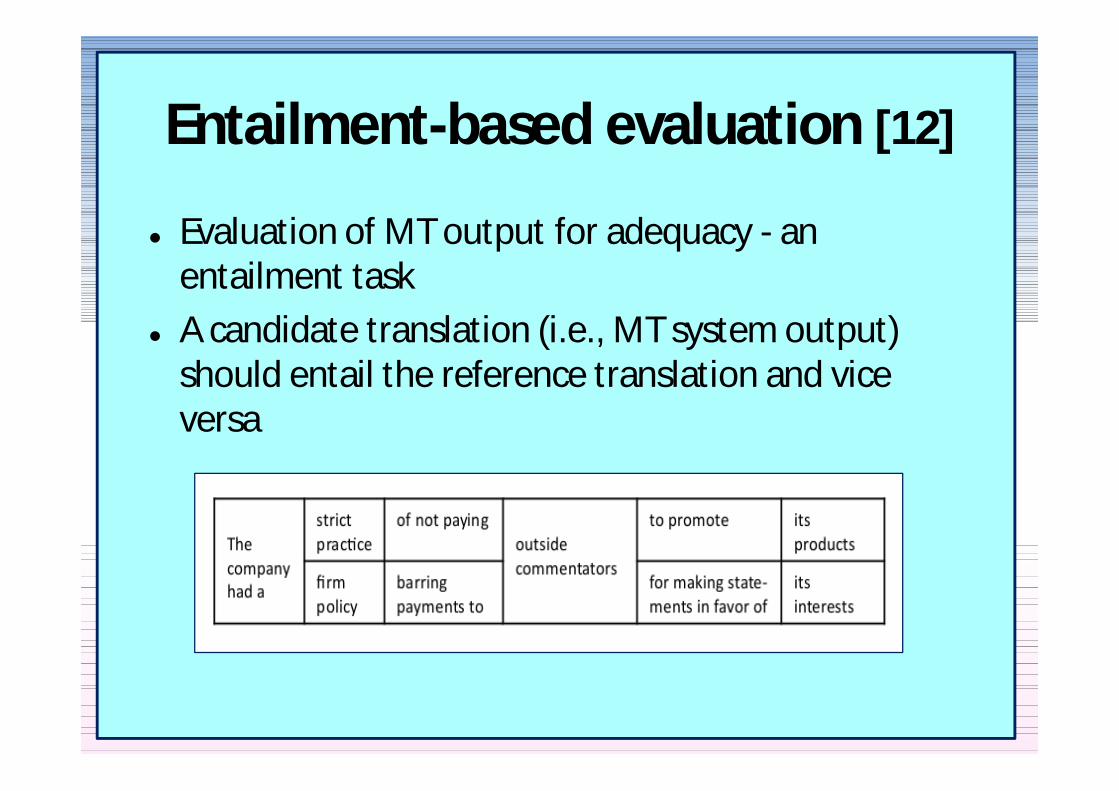
Entailment-based evaluation [12]
Evaluation of MT output for adequacy - an entailment task
A candidate translation (ie MT system output) should entail the reference translation and vice versa
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
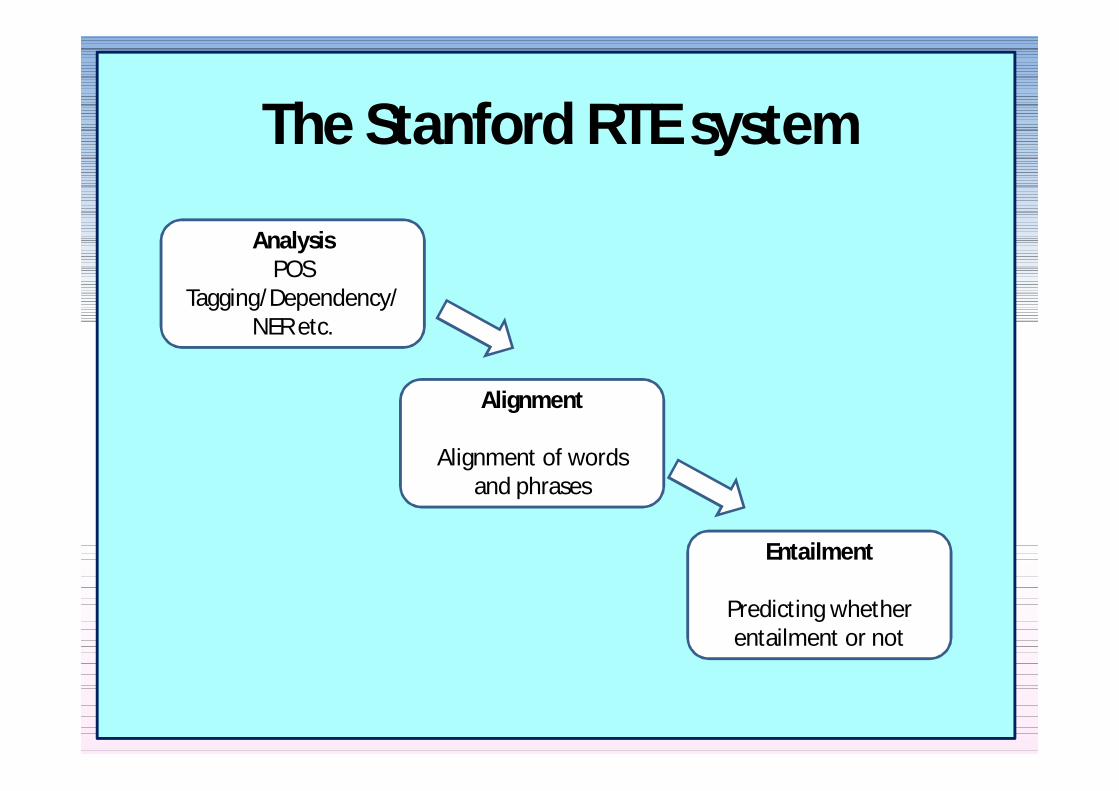
The Stanford RTE system
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
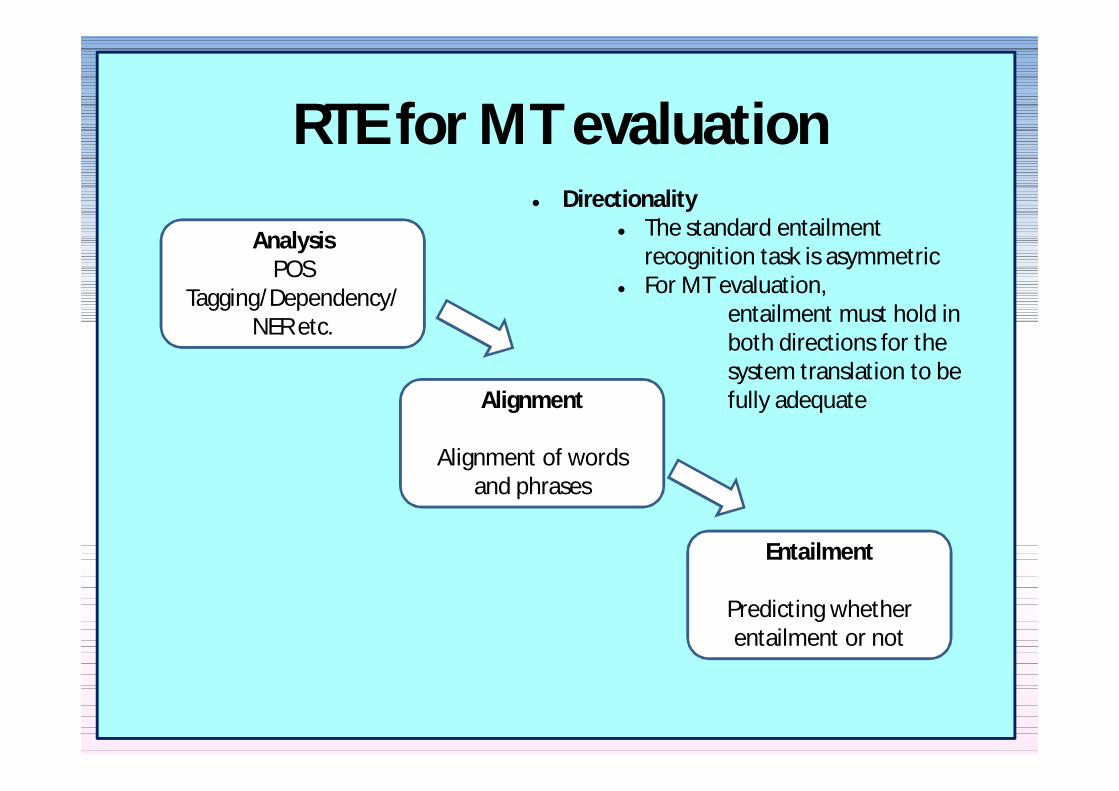
RTE for MT evaluation
AnalysisPOS
TaggingDependencyNER etc
Alignment
Alignment of words and phrases
Entailment
Predicting whether entailment or not
Directionality The standard entailment
recognition task is asymmetric For MT evaluation
entailment must hold in both directions for the system translation to be fully adequate
Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Experimental Setup Single reference translation Two MT datasets with English as target language
NIST MT dataset NIST06 The NIST MT-06 Arabic-to-English dataset NIST08A The NIST MT-08 Arabic-to-English dataset NIST08C The NIST MT-08 Chinese-to-English dataset NIST08U The NIST MT-08 Urdu-to-English dataset
ACL SMT dataset SMT06E The NAACL 2006 SMT workshop EUROPARL dataset SMT06C The NAACL 2006 SMT workshop Czech-English dataset SMT07E The ACL 2007 SMT workshop EUROPARL dataset SMT07C The ACL 2007 SMT workshop Czech-English dataset
Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Experimental Setup
4 systems are used BLEU-4 MT
RTE
RTE + MT
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
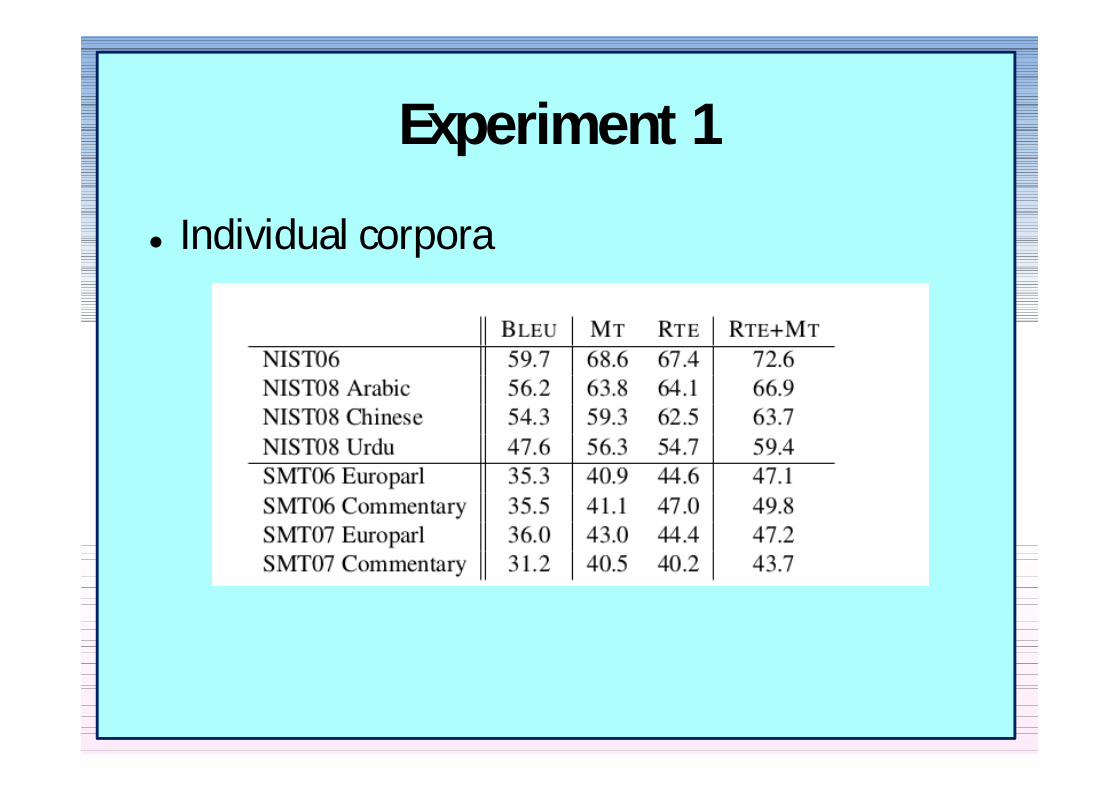
Experiment 1
Individual corpora
Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Experiment 2
Combined corpora
Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Conclusion Formulation of BLEU (13)
bull Introduced different evaluation methodsbull Formulated BLEU scorebull Analyzed the BLEU score by
ndash Considering constituents of formulandash Calculating BLEU for a dummy example
bull Compared BLEU with human judgment
Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

Conclusion Shortcomings of BLEU (23)
bull Permutation of phrases possible [3]
bull Different items may be drawn from reference sets [3]
bull Linguistic divergences in English-Hindi MT [4]
bull BLEUrsquos aim of correlating with human judgment does not go well with goals of indicative translation [4]
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008
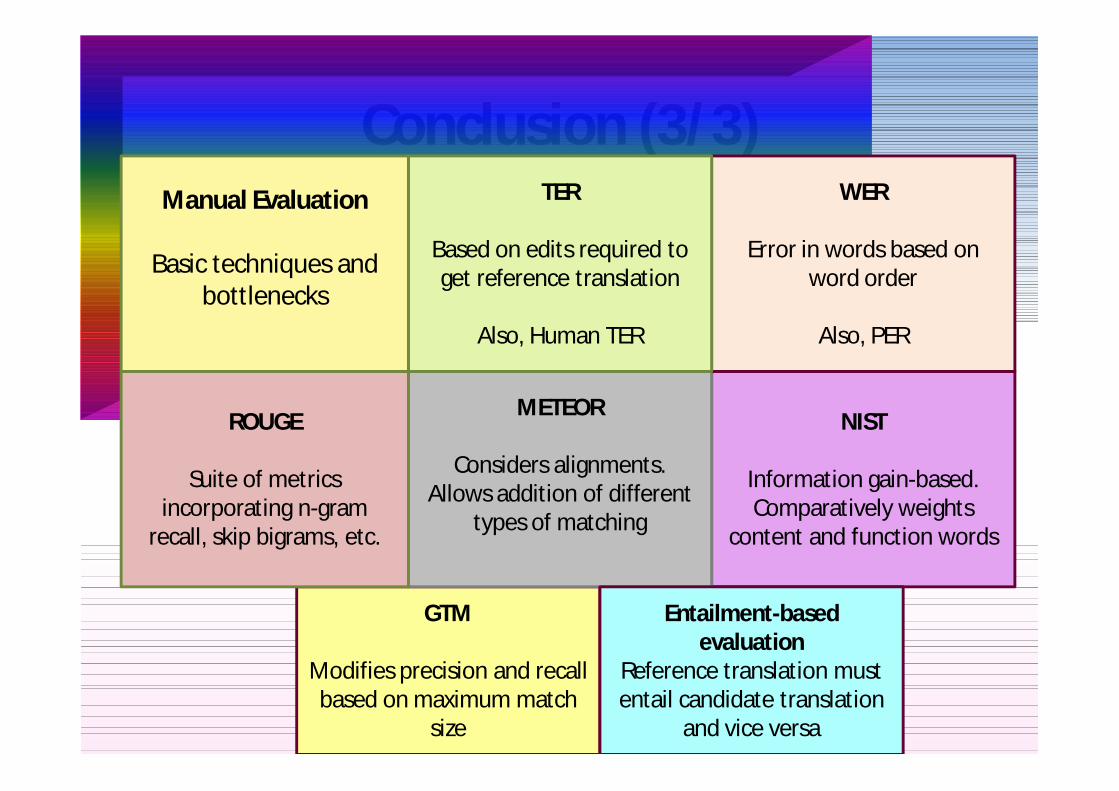
Conclusion (33)
GTM
Modifies precision and recall based on maximum match
size
NIST
Information gain-based Comparatively weights
content and function words
METEOR
Considers alignments Allows addition of different
types of matching
ROUGE
Suite of metrics incorporating n-gram
recall skip bigrams etc
WER
Error in words based on word order
Also PER
TER
Based on edits required to get reference translation
Also Human TER
Manual Evaluation
Basic techniques and bottlenecks
Entailment-based evaluation
Reference translation must entail candidate translation
and vice versa
References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

References[1] Doug Arnold Louisa Sadler and R Lee Humphreys Evaluation an
assessment Machine Translation Volume 8 pages 1ndash27 1993
[2] K Papineni S Roukos T Ward and W Zhu Bleu a method for automatic evaluation of machine translation IBM research report rc22176 (w0109-022) Technical report IBM Research Division Thomas J Watson Research Center 2001
[3] Chris Callison-Burch Miles Osborne Phillipp Koehn Re-evaluating the role of Bleu in Machine Translation Research European ACL (EACL) 2006 2006
[4] R Ananthakrishnan Pushpak Bhattacharyya M Sasikumar and Ritesh M Shah Some Issues in Automatic Evaluation of English-Hindi MT More Blues for BLEU ICON 2007 Hyderabad India Jan 2007
References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008

References[5] Matthew Snover and Bonnie Dorr and Richard Schwartz and Linnea Micciulla and John Makhoul A
study of translation edit rate with targeted human annotationIn Proceedings of Association for Machine Translation in the Americas2006
[6] Chin-yew Lin Rouge a package for automatic evaluation of summaries 2004 [7] Satanjeev Banerjee and Alon Lavie METEOR An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments Proceedings of the ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for MT andor Summarization 2005
[8] Doddington George Automatic evaluation of machine translation quality using n-gram co-occurrence statistics Proceedings of the second international conference on Human Language Technology Research HLT 2002
[9] Maja and Ney Hermann Word error rates decomposition over Pos classes and applications for error analysis Proceedings of the Second Workshop on Statistical Machine Translation StatMT2007
[10] Joseph Turian and Luke Shen and I Dan Melamed Evaluation of Machine Translation and its Evaluation In Proceedings of MT Summit IX pages 386-393 2003
[11] Chris Callison-Burch Cameron Fordyce Philipp Koehn Christof Monz and Josh Schroeder (Meta-) Evaluation of Machine Translation ACL Workshop on Statistical Machine Translation 2007
[12] Michel Galley Dan Jurafsky Chris Manning Evaluating MT output with entailment technology 2008





























