Embed Size (px)
Citation preview

Dept of Computer & Information Sciences!University of Delaware!
Auto-tuning a High-level Language!Targeted to GPU Codes!
Scott Grauer-Gray, Robert Searles, Lifan Xu, Sudhee Ayalasomayajula, John Cavazos!

Op#mizing GPU Code
• Constantly “tweaking” GPU code – Lots of low level details
• Resul#ng code is briBle – Op#miza#ons are applica#on (and inputs) and device specific!

High-‐level language for GPUs
• High-‐level languages – Good produc#vity, but low performance
High-‐level language Manual Code Performance ?

New Research Area: Autotuning
• Interes#ng new technique : – Search space of op#mized programs

Solu#on: Autotuning + HLL + GPUs
Goals of Project: High-Level Languages Low-Level Performance
HLL HLL
Best Optimized
GPU Program
Optimized GPU
Program

HMPP WORKBENCH
• High-‐Level Language for GPUs • Similar to OpenMP, but for GPUs
– Modify code through direc6ves
• Generates CUDA/OpenCL kernels

HMPP WORKBENCH (cont’d)
• Ini#a#ve to make an Open Standard – OpenHMPP (also OpenACC)
• Commercial product available here:
www.caps-‐entreprise.com/hmpp.html

HMPP WORKBENCH (cont’d)
• Direc6ves also drive GPU op#miza#ons – Permuta#on
– Tiling/unrolling – Fusion/fission
• But, there is no tool that helps programmer decide which op6miza6ons to use
Hard problem!

HMPP WORKBENCH
C or Fortran (sequential code) with
HMPP directives

HMPP WORKBENCH
HMPP source-to- source translator
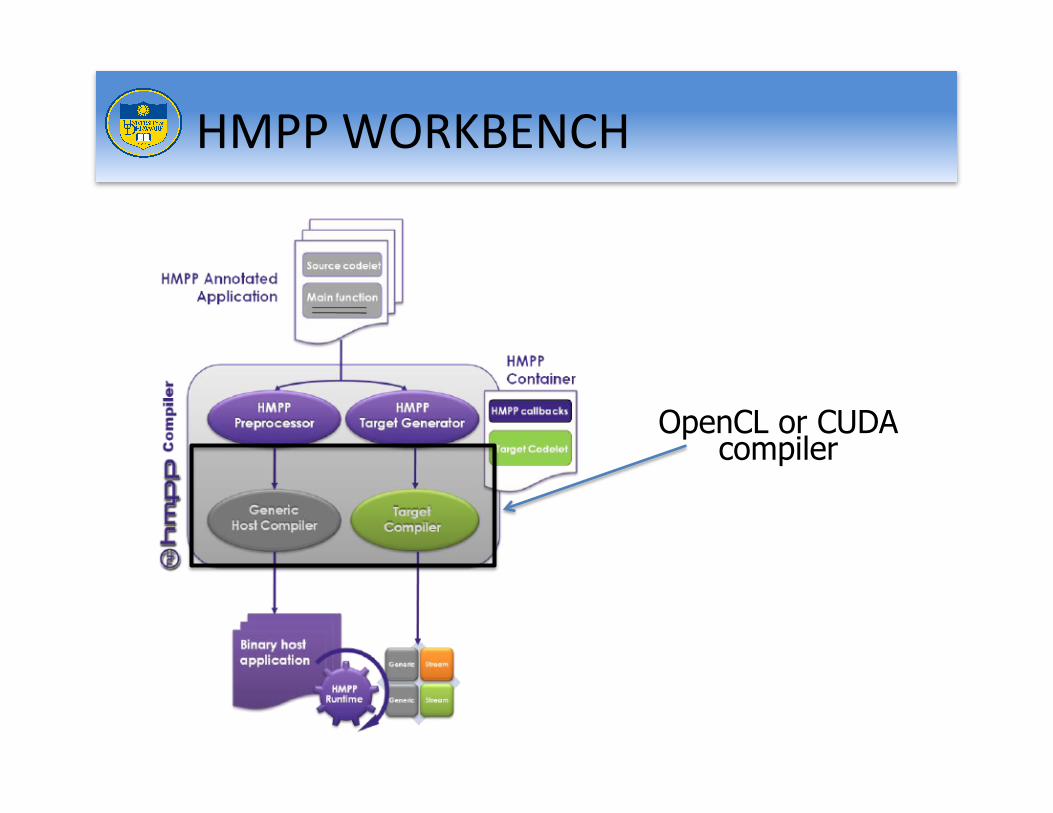
HMPP WORKBENCH
OpenCL or CUDA compiler

• Unroll makes copy of loop body – Pragma specifies “con#guous” unroll w/ factor 2
HMPP Unroll Pragma

• Resul#ng Code
.. B …
Thread 1
Thread 2
Thread N
HMPP Unroll Pragma

• Pragma specifies #ling w/ factor 2
HMPP Tiling Pragma

• Pragma specifies #ling w/ factor 2
New Inner loop for tiles
HMPP Unroll Pragma

• Collec6on of scien6fic kernels – Available at
http://www.cse.ohio-state.edu/~pouchet/software/polybench/
– Converted 14 of these kernels to CUDA, OpenCL, and HMPP
PolyBench

• Kernels coverted to CUDA/OpenCL – Linear algebra
• 2mm, 3mm, atax, bicg, gemm, gesummv, matmul, mvt, syr2k, syrk
– Linear algebra solvers • gramschmidt
– Datamining • correla#on, covariance
– Stencils • fdtd-‐2d
PolyBench

Pragma Descrip6on Parameter Values
Permute Re-‐orders loops in loop nest
Depends on kernel. Different ordering of loops
Unroll Unrolls loop at given factor
Unroll factors 1 through 8
Tile Tiles loop at given factor
Tiling factors 1 through 8
Blocksize Thread block dimensions
Kept fixed for these experiments
Op#miza#on Search Space

Case Study: Op#mizing GEMM
• Sequen#al code:

Pre-‐processed GEMM Code
• Permuta#on of “i” and “j” loops

Pre-‐processed GEMM Code
• Unrolling and #ling of “i”, “j” and “k” loops

Best Op#mized GEMM version
• Original permuta#on
• No unrolling/#ling on “i’ and “j” loops • Unrolling with “con#guous” op#on on innermost “k” loop

• Experiments performed on C2050 GPU (Fermi) – 448 CUDA cores
• Autotuned HMPP versions of PolyBench – Generated op#mized-‐version of CUDA and OpenCL
• Compared against hand-‐coded CUDA and OpenCL
PolyBench Experiments

Number of Op#mized Versions
Program Op6mized Versions
2mm 97
3mm 118
atax 67
bicg 161
correla6on 153
covariance 448
fdtd 141
Program Op6mized Versions
gemm 168
gesummv 631
matmul 337
gramschmidt 727
mvt 108
syr2k 97
syrk 281

0
0.5
1
1.5
2
2.5
Speedu
p over Defau
lt HMPP
CUDA
Opt HMPP CUDA
Manual CUDA
32.8 19.1 2.51 3.04
Autotuning HMPP / Manual CUDA

0
0.5
1
1.5
2
2.5
Speedu
p over Defau
lt HMPP
CUDA
Opt HMPP CUDA
Manual CUDA
32.8 19.1 2.51 3.04
Autotuning benefits 6 HMPP programs
Autotuning HMPP / Manual CUDA

0
0.5
1
1.5
2
2.5
Speedu
p over Defau
lt HMPP
CUDA
Opt HMPP CUDA
Manual CUDA
32.8 19.1 2.51 3.04
Manual better than Optimized HMPP
Autotuning HMPP / Manual CUDA

Autotuning HMPP / Manual CUDA
0
0.5
1
1.5
2
2.5
Speedu
p over Defau
lt HMPP
CUDA
Opt HMPP CUDA
Manual CUDA
32.8 19.1 2.51 3.04
Autotuning did not help some cases!

0
0.5
1
1.5
2
2.5
Speedu
p over Defau
lt HMPP
Ope
nCL
Opt HMPP OpenCL
Manual OpenCL
37.9 46.4
5.51 5.51 3.94 2.82 2.78
Autotuning benefits 4 HMPP programs targeted to OpenCL
Autotuning HMPP/Manual OpenCL

0
0.5
1
1.5
2
2.5
Speedu
p over Defau
lt HMPP
Ope
nCL
Opt HMPP OpenCL
Manual OpenCL
37.9 46.4
5.51 5.51 3.94 2.82 2.78
7 manual codes performed better than best-optimized HMPP
Autotuning HMPP/Manual OpenCL

0
0.5
1
1.5
2
2.5
Speedu
p over Defau
lt HMPP
Ope
nCL
Opt HMPP OpenCL
Manual OpenCL
37.9 46.4
5.51 5.51 3.94 2.82 2.78
6 manual OpenCL programs performed poorly.
Autotuning HMPP/Manual OpenCL

Summary Results
CUDA Geo-‐mean
Best HMPP 1.46
Manual .70
OpenCL Geo-‐ mean
Best HMPP 1.42
Manual 1.43
On average, best autotuned versions meet or exceed manual performance!

Best Op#miza#ons Found
Code Best Op6miza6ons Found
HMPP CUDA HMPP OpenCL
MVT Tile all four loops using factor 2 Tile first and third loops using factor 2
3MM Unroll 3rd, 6th, and 9th loops using “split” op#on with factor 3
Unroll 3rd, 6th, and 9th loops using “con#guous” op#on with factor 6
GEMM Unroll innermost loop using “con#guous” op#on with factor 64
Unroll innermost loop using “con#guous” op#on with factor 64
SYRK Unroll 3rd loop using “split” op#on with factor 2
Unroll 3rd loop using “split” op#on with factor 2

• Autotuning can be expensive • Model can predict best optimization to
apply Program
Characteriza#on Op#miza#on sequence
… …
Output: Predicted performance
Predic#ve Modeling

Op#mizing Belief Propaga#on
0 5 10 15 20
OpenCL Imp.
CUDA Imp.
Speedup over CPU
0 5 10 15 20
Manual CUDA
Op6mized HMPP
Default HMPP
..

Conclusions
• Achieve low-‐level performance using high-‐level language (HMPP)
– Autotuning HMPP comparable to hand-‐op#mized GPU Code
– Best op#miza#ons are different for CUDA and OpenCL

Extra Slides

Stereo Vision
• Two cameras take pictures – Separated by a distance
• Algorithm compares two images by shiming – Shifted amount is disparity

HMPP Belief Propaga#on
• Itera#ve algorithm
• Applied to stereo vision – Input: stereo set of two images – Output: disparity map between images
Image in Tsukuba stereo set Ground-truth disparity map

BP Message-‐Passing Func#on
• Disparity values computed for each pixel and passed to neighbors – Run#me dominated by this “message-‐passing” step
md
mu
mr ml
ml
ml mr
mu mu
md md
md
mu
mr ml
ml
mu mu
md md
mr ml ml mr
mr
ml mr
ml ml mr

HMPP Belief Propaga#on
• Input stereo set: – Tsukuba:
• Dimensions: 384 X 288
• 15 possible dispari#es
• Speedup over CPU implementa6on: – CUDA and OpenCl kernels generated by HMPP
– 250 message-‐passing itera#ons





























