Embed Size (px)
Citation preview

APSIPAAsia-Pacific Signal and Information Processing AssociationAPSIPAAsia-Pacific Signal and Information Processing Association
Speaker Verification –The present and future of voiceprint based security
Prof. Eliathamby AmbikairajahHead of School of Electrical Engineering & Telecommunications,
University of New South Wales, Australia
30 June 2014

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
APSIPA Distinguished Lecturer Programs
APSIPA founded in 2009 APSIPA distinguished lecturer program (DLP) is an educational program that:• Serves its communities by organizing lectures given by distinguished experts.
• Promotes the research and development of signal and information processing in Asia Pacific region.
• APSIPA distinguished lecturer is an ambassador of APSIPA to promote APSIPA's image and reach out to new membership.
APSIPA Distinguished Lecturer Program ‐http://www.apsipa.org/edu.htm

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Outline
• Introduction• Speaker Verification Applications• Speaker Verification System• Performance measure• NIST Speaker Recognition Evaluation (SRE) • Discussion
3

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam 4
Introduction
What can you infer from speech?
What is being said What language is being
spoken Who is speaking Gender of the speaker Age of the speaker Emotion
Stress level Cognitive load level Depression level Is the person sleepy Is the person inebriated

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
“How are you?”Introduction
• Speech conveys several types of information– Linguistic: message and language information– Paralinguistic : emotional and physiological characteristics
Speech Recognition
Language Recognition
Speaker Recognition
Emotion Recognition
Cognitive load Estimation
“How are you?” English Hsing Ming Happy Low load
Linguistic Paralinguistic
5

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Introduction
Speech Recognition
Language Recognition
Speaker Recognition
Emotion Recognition
Cognitive load Estimation
“How are you?”
6
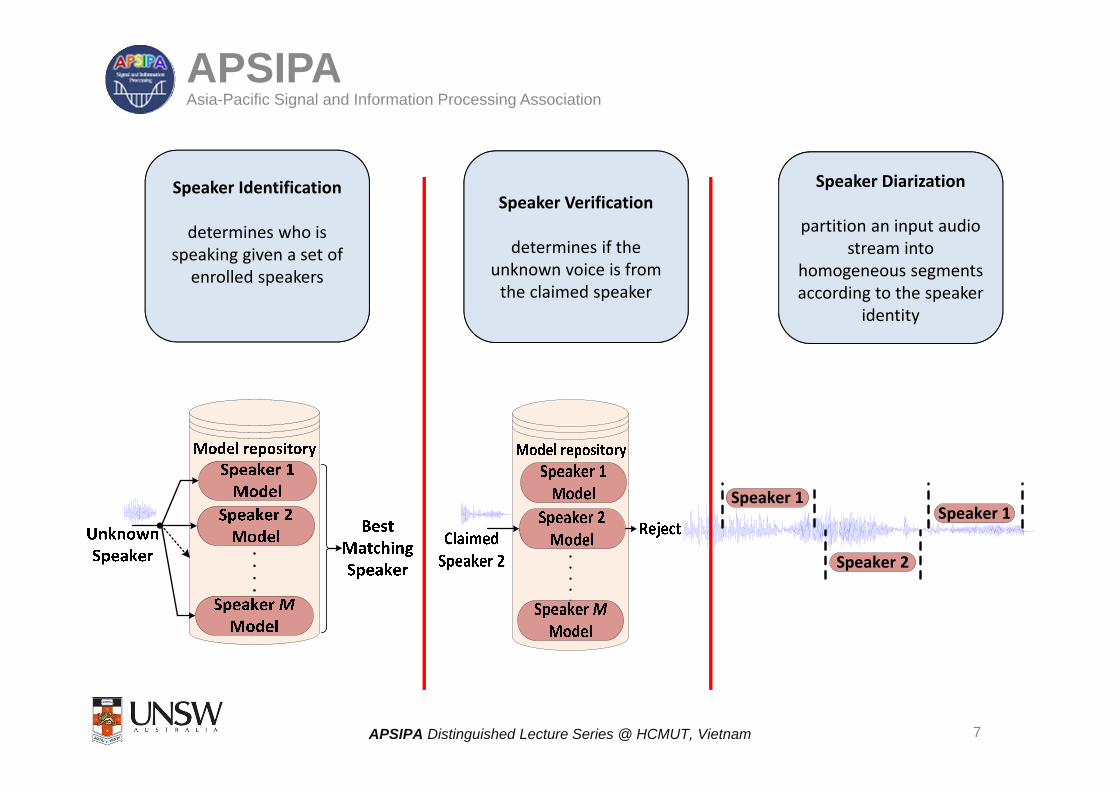
Speaker Identification
determines who is speaking given a set of
enrolled speakers
Speaker Verification
determines if the unknown voice is from the claimed speaker
Speaker Diarization
partition an input audio stream into
homogeneous segments according to the speaker
identity
APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam 7
Speaker Identification
determines who is speaking given a set of
enrolled speakers
Speaker Verification
determines if the unknown voice is from the claimed speaker
Speaker Diarization
partition an input audio stream into
homogeneous segments according to the speaker
identity
Speaker 1
Speaker 2
Speaker 1

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Speaker Verification Applications ‐ Biometrics
8
Physical facilities
Access control
Telephone credit card purchases
Transaction authentication
Reference: I2R @ Singapore Reference: Youtube

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Speaker Verification System – Basic Overview
• In automatic speaker verification, – The front‐end converts speech signal into a more convenient representation (typically a set of feature vectors)
– The back‐end compares this representation to a model of a speaker to determine how well they match
9
Feature Extraction ClassificationSpeech
Speaker Model
Decision Making Accept/Reject
Front‐end Back‐end

UBM: represent general, speaker independent model to be compared against a person‐specific model when making an accept or reject decision.
Speaker Verification SystemI am John
Determine level of Match
Determine level of Match
Likelihood of Generic Male
Likelihood of John
Likelihood Ratio Decision Making
NOT JOHN (i.e. reject)
Feature Extraction

Speaker Verification System – Speaker Enrolment
11

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Detailed Speaker Verification System
12

Front‐end: Feature Extraction
13
-5 0 5
-5 0 5
c0 c1 cnc2 c0 c1 cnc2 c0 c1 cnc2 c0 c1 cnc2
c0 c1 cnc2 c0 c1 cnc2 c0 c1 cnc2 c0 c1 cnc2
*n is usually 13 for speaker verification

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam 14
c0c1 cnc2 c0 c1 cnc2 c0 c1 cnc2
d0d1 dnd2 d0d1 dnd2 d0d1 dnd2
a0a1 ana2 a0a1 ana2 a0a1 ana2c0 c1 cnc2 d0d1 dnd2 a0a1 ana2

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Detailed Speaker Verification System
15

Speaker Modelling
-8 -6 -4 -2 0 2 4 6 8 100
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
16
4 4.5 5 5.5 6 6.5 7 7.5 8 8.5 93
4
5
6
7
8
9
45
67
89
3
4
5
6
7
8
9
0
0.2
0.4
Dim
ensi
on 1
(C0)
Example of 1 dimensional probability density function
Probability density function approximated by 3‐component Gaussian mixture models
Each Gaussian mixture consist of a mean ( ), covariance ( ) and weight ( )

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Database for creating UBM (example)
• Training set– 56 male speakers (each speaker consists of 2 minutes of active speech) for creating the UBM
• Target set– 20 male speakers (each speaker consists of 2 minutes of active speech) for speaker‐specific model
• Test set– 250 male utterances (each speaker has many test utterances) with the known identity
17

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Databases• The data involved in building an automatic speaker verification
system is split into three sets:
• huge dataset containing speech from many speakers from the expected target population
• used to train the UBM, subspace models and/or to draw impostor models for score normalization
Background set
• an evaluation database that is used for tuning system parameters to ensure classification performance is maximized for the expected conditions of audio acquisition
Development set
• second independent evaluation database that is used to evaluate the final system (that was optimized on the development set)
Evaluation set

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam 19
UBM
Target Speaker Data
TargetMode
Mean = 0.9
Covariance = 0.9
Mean = 0.8
Covariance = 0.5
Weight = 0.2
Weight = 0.3
Feature Dimension 1
Feat
ure
Dim
ensi
on 2
Feature Dimension 1
Feat
ure
Dim
ensi
on 2
Universal Background Model (UBM) consists of 1024 Gaussian
mixtures
Target speaker model consists of 1024 Gaussian mixtures
Gaussian mixture consists of a mean ( ), covariance ( ) and weight ( )
12
1024
998
1024
998

Representing GMMs
20
The UBM and each speaker model is a GMM
Each of them will be represented by a vector of weights, a matrix of means and a matrix of covariances
GMM for Speaker x1
Mixture 1 Mixture 2 Mixture 1024
1x1024 Weight vector
39x1024 Means matrix
39x1024 Covariances matrix
GMM REPRESENTATION

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Model Representation ‐ Supervectors
• Each GMM (speaker model) can be represented by a supervector.
• Supervector is formed by concatenating all individual mixture means, scaled by corresponding weights and covariances
• Speech of different durations can be represented by supervectors of fixed size.
• Model normalisation is typically carried out on supervectors

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Detailed Speaker Verification System
22

Decision Making
23
Speaker Models
Speaker 1 Model
John’s Model
Likelihood S came from speaker modelLikelihood S did not come from speaker model
Score, L = log
≶
Reject( )/Accept( )
Determine level of Match
Determine level of Match
Likelihood of Generic Male Likelihood of John
Feature Extraction

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Score Normalisation
Normalised scores (L) are comparable
24
Different Systems perform speaker
verification in parallel
May not fall in the same range. i.e., NOT directly comparable

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Fusion
25
Final score will be a weighted sum of score from each system
Speaker Verification System 1
Speaker Verification System 2
Speaker Verification System N
Speech
Score Normalisation
Score Normalisation
Score Normalisation
Normalised Score 1, s1
Normalised Score 2, s2
Normalised Score N, sN
Final Score = w1s1 + w2s2 +…+wNsN
Fusion
Performance measure
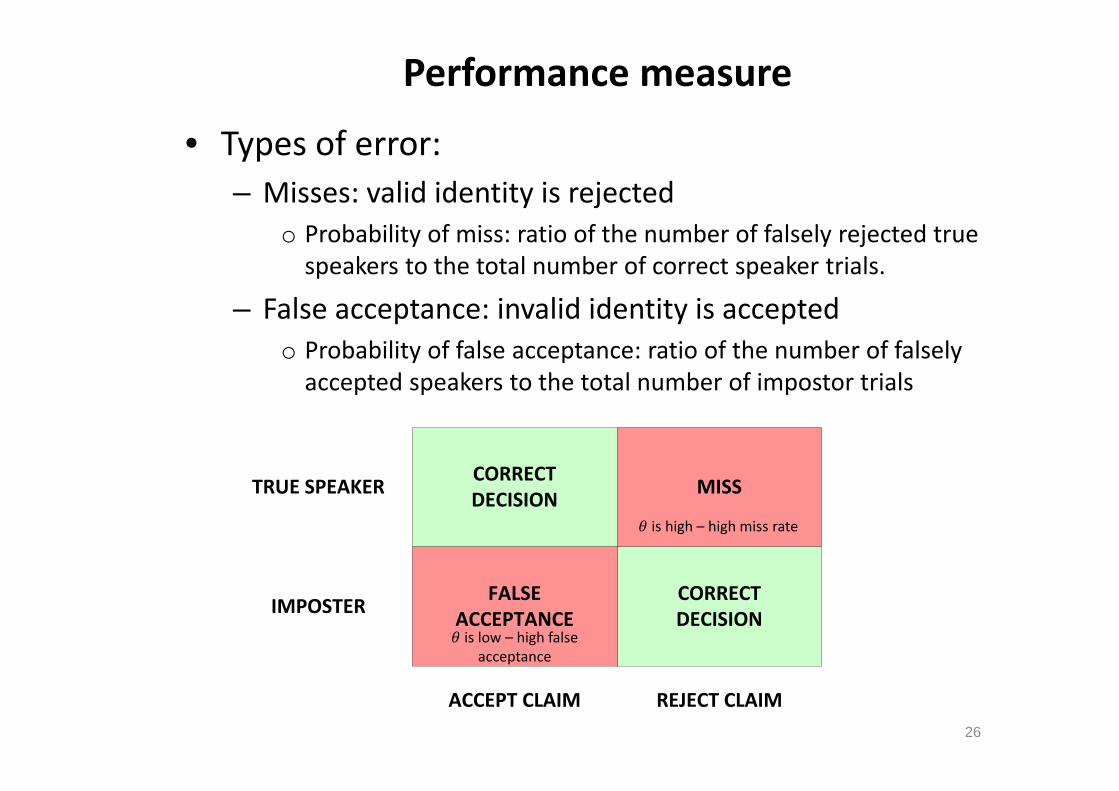
• Types of error:– Misses: valid identity is rejected
o Probability of miss: ratio of the number of falsely rejected true speakers to the total number of correct speaker trials.
– False acceptance: invalid identity is acceptedo Probability of false acceptance: ratio of the number of falsely accepted speakers to the total number of impostor trials
26
TRUE SPEAKER
IMPOSTER
ACCEPT CLAIM REJECT CLAIM
CORRECT DECISION
CORRECT DECISION
FALSE ACCEPTANCE
MISS
is low – high false acceptance
is high – high miss rate

Performance measure ‐ Detection error trade‐off (DET) curve
False Acceptance Rate (in %)
Miss R
ate (in
%)
Each point on the curve corresponds to a different threshold (
27

Performance measure ‐ Detection error trade‐off (DET) curve
Equal Error Rate (EER) = 1 %
Wire Transfer:
False acceptance is very costly
Users may tolerate rejections for security
Customization:
False rejections alienate customers
Any customization is beneficial
Application operating point depends on relative costs of the two error types
High Convenience
High Security
Balance
False Acceptance Rate (in %)
Miss R
ate (in
%)
28

NIST Speaker Recognition Evaluation (SRE)
• Ongoing text independent speaker recognition evaluations conducted by NIST (National Institute of Standards and Technology)
• (http://www.itl.nist.gov/iad/mig/tests/spk/)– driving force in advancing the state‐of‐the‐art– Conditions for different amounts of data
o 10 sec.o 3‐5 minuteso 8 minuteso Separate channel and summed channel conditions
– English‐speakers, non‐English speakers, multilingual speakers
29

NIST SRE Trends
• 1996 – First SRE in current series• 2000 – AHUMADA Spanish data, first non‐English speech
• 2001 – Cellular data, Automatic Speech Recognition (ASR) transcripts provided
• 2005 – Multiple languages with bilingual speakers, room mic recordings, cross‐channel trials
• 2008 – Interview data• 2010 – High and low vocal effort, aging, HASR (Human‐Assisted Speaker Recognition) Evaluation
• 2012 – Broad range of test conditions, with added noise and reverberation, target speakers defined beforehand 30

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Basic System
31
39xN
feat
ure
vect
ors
Nfra
mes
Spe
ech
Acc
ept /
Rej
ect

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Trends• In 2004’s: Classification
32
39xN
feat
ure
vect
ors
Nfra
mes
3993
6x1
supe
rvec
tor
(399
36 =
39x
1024
mix
ture
s)
Spee
ch
Acce
pt /
Rej
ect

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Trends• In 2005’s: Channel compensation ‐ NAP
33

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Trends• In 2007’s: Channel compensation ‐ JFA
34

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Trends• In 2009’s: Channel compensation – i‐vector
35
Factor analysis
i-vector extraction WCCN LDA
Cosine Distance Scoring
Total Variability
Matrix
Extract Supervectors
Feature Extraction
MAP adaptation
UBM
Represent supervectors as a combination of a small number of factors (speaker + channel)
Identity vector
Lower dimensional identity vector (w) used to represent speaker models
instead of supervectors
Linear Discriminant Analysis
Dimensionality reduced by retaining only the most discriminative
directions between speaker models
Comparing i‐vectors
Estimating similarity between speaker models based on angle between i‐
vectors

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam
Trends• In 2009’s: Channel compensation – PLDA
36
Spe
ech 39
xNfe
atur
e ve
ctor
s
Nfra
mes
3993
6x1
supe
rvec
tor
400x
1 i-v
ecto
r
Acce
pt /
Rej
ect

APSIPAAsia-Pacific Signal and Information Processing Association
APSIPA Distinguished Lecture Series @ HCMUT, Vietnam 37





























