Embed Size (px)
Citation preview

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Aprendizaje de Reglas
Eduardo Morales, Hugo Jair Escalante
INAOE
(INAOE) 1 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Outline
1 IntroduccionSplitting vs. Covering
2 1R
3 PRISM
4 Otros sistemas de reglas
5 Valores desconocidos y numericos
(INAOE) 2 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Introduccion
Aprendizaje de Reglas
• El aprendizaje de reglas normalmente produceresultados mas faciles de entender.
• Las reglas son del tipo:
If Atri = valj ∨ Atrk = vall ∨ . . .Then Clase = valm
(INAOE) 3 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Introduccion Splitting vs. Covering
Splitting vs. Covering
• La estrategia basica de la construccion de arboles dedecision se basa en splitting:
• Divide el conjunto de datos en subconjuntosconsiderando un atributo seleccionado por unaheurıstica particular.
• Se consideran todas las clases dentro de la particion.• La idea basica es anadir atributos al arbol que se esta
construyendo buscando maximizar la separacion entrelas clases.
(INAOE) 4 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Introduccion Splitting vs. Covering
Splitting vs. Covering
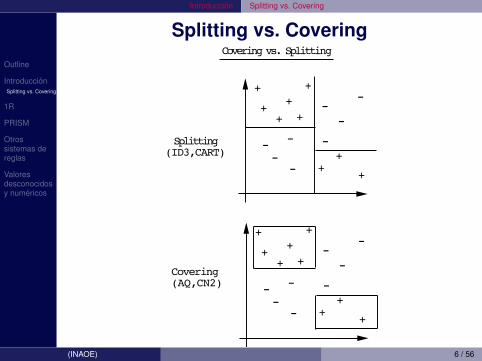
• La estrategia utilizada para aprender reglas, estabasada en covering:
• Encontrar condiciones de reglas (par atributo-valor) quecubra la mayor cantidad de ejemplos de una clase, y lamenor del resto de las clases.
• Se considera el cubrir una sola clase• La idea basica es anadir pruebas a cada regla que se
esta construyendo buscando maximizar coverturaminimizando errores (ver figura).
(INAOE) 5 / 56
Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Introduccion Splitting vs. Covering
Splitting vs. CoveringCovering vs. Splitting
+
-
+
+++
+
++
+
--
-
--
-
-
+
-
+
+++
+
++
+
--
-
--
-
-
Splitting(ID3,CART)
Covering(AQ,CN2)
(INAOE) 6 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Introduccion Splitting vs. Covering
Splitting vs. Covering
• Las reglas pueden expresar disjunciones de maneramas facil que los arboles.
• Por lo mismo, extaer reglas directamente de arbolestiende a producir reglas mas complejas de lo necesario.
• Los arboles tienen lo que se conoce como replicatedsubtree problem, ya que a veces repiten subarboles envarios lados.
• Por otro lado, si se quieren construir arboles a partir dereglas, no es trivial y tiende a dejar arboles incompletos.
• Las reglas muchas veces se prefieren con respecto alos arboles por representar “pedazos” de conocimientorelativamente independientes.
(INAOE) 7 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Introduccion Splitting vs. Covering
Listas de Decision
• Normalmente los sistemas generan lo que se llamanlistas de decision (decision lists)
• Son conjuntos de reglas que son evaluadas en orden.Esto facilita la evaluacion, pero disminuye sumodularidad.
• El tener reglas que pueden ser evaluadasindependientemente de su orden, permite que existanmas de una prediccion para un solo ejemplo y dificultael producir un solo resultado.
(INAOE) 8 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
1R
1R
• Vamos a ver primero un sistema muy simple (1R) quees el equivalente a un decision stump o arbol de unsolo nivel
• La idea es hacer reglas que prueban un solo atributo• Se prueban todos los pares atributo-valor de cada
atributo y se selecciona el atributo que ocasione elmenor numero de errores
(INAOE) 9 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
1R
Algoritmo 1R
Para cada atributoPara cada valor del atributo, crea una regla:
cuenta cuantas veces ocurre la claseencuentra la clase mas frecuenteasigna esa clase a la regla
Calcula el error de todas las reglasSelecciona las reglas del atributo con el error mas bajo
(INAOE) 10 / 56
Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
1R
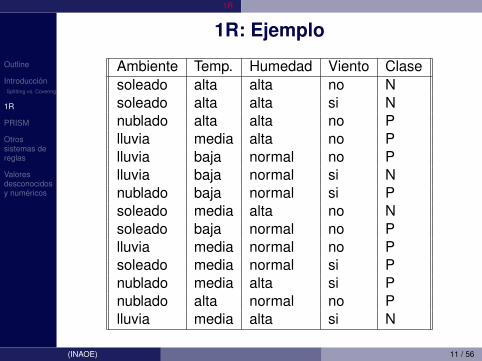
1R: Ejemplo
Ambiente Temp. Humedad Viento Clasesoleado alta alta no Nsoleado alta alta si Nnublado alta alta no Plluvia media alta no Plluvia baja normal no Plluvia baja normal si Nnublado baja normal si Psoleado media alta no Nsoleado baja normal no Plluvia media normal no Psoleado media normal si Pnublado media alta si Pnublado alta normal no Plluvia media alta si N
(INAOE) 11 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
1R
1R: Ejemplo
De la tabla:• Atributo Ambiente: 4 errores• Atributo Temperatura: 5 errores• Atributo Humedad: 4 errores• Atributo Viento: 5 errores
Los empates se rompen arbitrariamente
(INAOE) 12 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
1R
1R: Ejemplo
Resultado (para Ambiente):• If Atributo = soleado
Then clase = N (cubre 5 y tiene 2 errores)• If Atributo = nublado
Then clase = P (cubre 4 y tiene 0 errores)• If Atributo = lluvioso
Then clase = P (cubre 5 y tiene 2 errores)
(INAOE) 13 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
1R
1R: Valores faltantes y contınuos
• Los valores faltantes en 1R se tratan como un nuevovalor
• Para los atributos contınuos se hace una divisionsimple:
• Primero se ordenan los atributos con respecto a la clase(como lo vimos con arboles de decision).
• Se sugieren puntos de particion en cada lugar dondecambia la clase.
• Si existen dos clases diferentes con el mismo valor, semueve el punto de particion a un punto intermedio conel siguiente valor hacia arriba o abajo dependiendo dedonde esta la clase mayoritaria.
(INAOE) 14 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
1R
1R
• Un problema mas serio es que el algoritmo tenderıa afavorecer contruir reglas para cada una de lasparticiones, lo cual le da una clasificacion perfecta(pero muy poca prediccion futura).
• Lo que se hace es que se exige que cada particiontenga un numero mınimo de ejemplos de la clasemayoritaria.
• Cuando hay clases adyacentes con la misma clasemayoritaria, estas se juntan.
(INAOE) 15 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
1R
1R
Ejemplo:64 65 68 69 70 71 72 72 75 75 80 81 83 85P N P P P N N P P P N P P N
• Tomando los puntos intermedios serıa: 64.5, 66.5, 70.5, 72, 77.5,80.5 y 84.
P N P P P N N P P P N P P N
(INAOE) 16 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
1R
1R
P N P P P N N P P P N P P N
• Si tomamos al menos 3 elementos por particion (enresultados experimentales con varios dominios, estevalor se fijo a 6):
P N P P P N N P P P N P P N
• Si juntamos clases con la misma clase mayoritaria, nosqueda:
P N P P P N N P P P N P P N
(INAOE) 17 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
1R
1R
• Lo cual nos darıa una regla del tipo:
If Temperatura ≤ 77.5Then Clase = P (cubre 10 y tiene 3 errores)
If Temperatura > 77.5Then Clase = N (cubre 4 y tiene 2 errores)
• En la segunda regla se hizo una seleccion aleatoria, yaque se tenıa un empate.
(INAOE) 18 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
PRISM
PRISM
• Es un algoritmo basico de aprendizaje de reglas quesupone que no hay ruido en los datos
• Sea t el numero de ejemplos cubiertos por la regla y pel numero de ejemplos positivos cubiertos por la regla
• PRISM anade condiciones a reglas que maximicen larelacion p/t (relacion entre ejemplos positivos cubiertosy ejemplos cubiertos en total)
(INAOE) 19 / 56
Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
PRISM
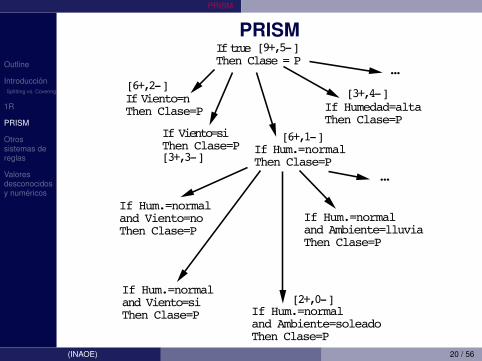
PRISMIf true Then Clase = P
If Viento=nThen Clase=P
If Viento=siThen Clase=P If Hum.=normal
Then Clase=P
If Humedad=altaThen Clase=P
If Hum.=normaland Viento=noThen Clase=P
If Hum.=normaland Viento=siThen Clase=P If Hum.=normal
and Ambiente=soleadoThen Clase=P
If Hum.=normaland Ambiente=lluviaThen Clase=P
...
...
[9+,5-]
[6+,2-]
[3+,3-]
[6+,1-]
[3+,4-]
[2+,0-]
(INAOE) 20 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
PRISM
Algoritmo de PRISM
Para cada clase CSea E = ejemplos de entrenamientoMientras E tenga ejemplos de clase C
Crea una regla R con LHS vacıo y clase CUntil R es perfecta do
Para cada atributo A no incluido en Ry cada valor v ,
Considera anadir la condicion “A = v ” a RSelecciona el par A = v que maximice p/t(en caso de empates, selecciona la que
tenga p mayor)Anade “A = v ” a R
Elimina de E los ejemplos cubiertos por R
(INAOE) 21 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
PRISM
Reglas Ordenadas vs. No Ordenadas
• Como PRISM va eliminando los ejemplos que vacubriendo cada regla, las reglas que se construyentienen que interpretarse en orden (las nuevas reglas sedisenan solo para cubrir los casos que faltan).
• Reglas que dependen del orden para su interpretacionse conocen como decision lists o listas de decision.
• Las reglas ordenadas son en general mas rapidas deproducir ya que van reduciendo el numero de ejemplosa considerar
• Reglas que no dependen del orden son masmodulares, pero pueden producir varias clasificacioneso no predecir nada.
• Con varias clasificaciones se puede seleccionar la reglaque cubra mas ejemplos, y cuando no se tiene unaclasificacion, escoger la clase mayoritaria.
(INAOE) 22 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
PRISM
Ejemplo
Consideremos la siguiente tabla:
A1 A2 A3 A4 Clase1 x 4 a P0 x © a N1 y 2 a P1 y 4 b P1 x 2 b N0 y © a P0 x 4 b N1 y © a P
(INAOE) 23 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
PRISM
Ejemplo
Si empezamos con la clase P construimos todas lasposibles combinaciones de atributo valor y evaluamos suprediccion sobre la clase P:If A1 = 1 If A1 = 0 If A2 = xThen Clase = P Then Clase = P Then Clase = P4/5 1/3 1/4
If A2 = y If A3 = 4 If A3 =©Then Clase = P Then Clase = P Then Clase = P4/4 2/3 2/3
If A3 = 2 If A4 = a If A4 = bThen Clase = P Then Clase = P Then Clase = P1/2 4/5 1/3
(INAOE) 24 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
PRISM
Ejemplo
En este caso una regla es perfecta: If A2 = y Then Clase =P, por lo que seleccionamos esa y eliminamos todos losejemplos que cubre:
A1 A2 A3 A4 Clase1 x 4 a P0 x © a N1 x 2 b N0 x 4 b N
Repetimos lo mismo con los ejemplos que quedan.
(INAOE) 25 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
PRISM
Ejemplo
If A1 = 1 If A1 = 0 If A2 = xThen Clase = P Then Clase = P Then Clase = P1/2 0/2 1/4
If A3 = 4 If A3 =© If A3 = 2
Then Clase = P Then Clase = P Then Clase = P1/2 0/1 0/1
If A4 = a If A4 = bThen Clase = P Then Clase = P1/2 0/2
En este caso, tenemos tres empates de 1/2 como valormaximo.
(INAOE) 26 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
PRISM
Ejemplo
Tomamos uno al azar y construimos todas las posiblesreglas anadiendole posibles pares atributo-valor:
If A1 = 1 If A1 = 1 If A1 = 1And A2 = x And A3 = 4 And A3 =©Then Clase = P Then Clase = P Then Clase = P1/2 1/1 0/0
If A1 = 1 If A1 = 1 If A1 = 1And A3 = 2 And A4 = a And A4 = bThen Clase = P Then Clase = P Then Clase = P0/1 1/1 0/1
De nuevo tenemos tres empates y tomamos unoaleatoriamente (el primero).
(INAOE) 27 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
PRISM
Ejemplo
• Las reglas entonces para la clase P son:
If A2 = y If A1 = 1 and A3 = 4Then Clase = P Then Clase = P
• Lo mismo hay que hacer para el resto de las clases• Para la clase N unas posibles reglas son:
If A2 = x and A1 = 0 If A2 = x and A3 = 2
Then Clase = N Then Clase = N
(INAOE) 28 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Otros sistemas de reglas
AQ
• AQ fue uno de los primeros sistemas de reglas• Desarrollado originalmente por Michalski (79), y
reimplementado y mejorado por otros autores (e.g.,AQ11, AQ15).
• Su salida es un conjunto de reglas de clasificacion deltipo “if...then...”
(INAOE) 29 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Otros sistemas de reglas
AQ: principios
• Selecciona aleatoriamente un ejemplo (semilla)• Identificar el ejemplo de otra clase que sea mas
cercano• Especializa la regla actual (anade condiciones
atributo-valor) para no cubrir ese ejemplo negativo• Trata de cubrir a la mayor cantidad de ejemplos
positivos.
(INAOE) 30 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Otros sistemas de reglas
AQ
Se exploran varias alternativas de reglas (beam-search).Heurısticas que se usaron para seleccionar la mejor regla:
• Sumar los ejemplos positivos cubiertos y los negativosexcluidos (en caso de empate, preferir la mas corta)
• Sumar el numero de ejemplos clasificadoscorrectamente dividido por el numero total de ejemploscubiertos
• Maximiza el numero de ejemplos positivos cubiertos
Una de sus principales desventajas de AQ es que essensible a ejemplos con ruido (i.e., si la semillaseleccionado tiene informacion erronea).
(INAOE) 31 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Otros sistemas de reglas
CN2
• CN2 (Clark and Niblett, 1988) se propuso para atacardatos con ruido y evitar el sobreajuste que seencontraba en sistemas como AQ
• Su contribucion principal es la de quitar la dependenciade un ejemplo especıfico durante su busqueda y formala base de muchos de los algoritmos de reglas actuales.
(INAOE) 32 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Otros sistemas de reglas
CN2
• En CN2 se pueden especificar valores don’t-care “∗” yvalores desconocidos “?”
• Sigue una busqueda tipo beam-search.• La heurıstica de busqueda original que sigue es basada
en entropıa:Entr = −
∑i
pi log2(pi)
donde pi es la distribucion de las clases que cubre cadaregla
• Se selecciona la regla de menor entropıa, esto es laregla que cubre muchos ejemplos de una clase y pocosde las demas
(INAOE) 33 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Otros sistemas de reglas
CN2
• En una version posterior usaron the Laplacian errorestimate:
AccuracyA(n,nc , k) = (n − nc + k − 1)/(n + k)
donde:n = numero total de ejemplos cubiertos por la reglanc = numero de ejemplos positivos cubiertos por lareglak = numero de clases en el problema.
(INAOE) 34 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Otros sistemas de reglas
CN2
• CN2 maneja tambien una medida de significancia paralas reglas
• El usuario proporciona un lımite para la medida designificancia, abajo del cual las reglas son rechazadas
• La medida esta basada en la razon de verosimilitud(likelihood ratio statistic) que mide una distancia entredos distribuciones, definida por:
2n∑
i=1
fi log(fiei)
(INAOE) 35 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Otros sistemas de reglas
CN2
Donde:• F = (f1, . . . , fn): Distribucion de frecuencias observada
de ejemplos dentro de las clases que satisfacen unaregla dada:
• Numero de ejemplos que satisfacen la regla entre elnumero total de ejemplos que satisface la regla
• E = (e1, . . . ,en): Frecuencia esperada en los mismosejemplos bajo la suposicion que la regla seleccionaejemplos aleatoriamente
• Numero de ejemplos cubiertos por la regla siguiendo ladistribucion de ejemplos del total de los ejemplos
• Entre mas baja es la medida es mas probable que laaparente regularidad expresada en la regla sea porcasualidad
(INAOE) 36 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Otros sistemas de reglas
Medidas Alternativas de Seleccion
• La mas simple (que ya vimos), es la frecuencia relativade ejemplos positivos cubiertos
m(R) =pt=
pp + n
t = numero total de ejemplos cubiertos por la regla =p + np = numero total de ejemplos positivos cubiertos por lareglaTiene problemas con muestras pequenas
• Estimador Laplaciano (CN2). Supone una distribucionuniforme de las k clases (k = 2)
m(R) =p + 1
p + n + k
(INAOE) 37 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Otros sistemas de reglas
Medidas Alternativas de Seleccion
• Estimador m: Considera que las distribuciones a prioride las clases (Pa(C)), son independientes del numerode clases y m es dependiente del dominio (entre masruido, se selecciona una m mayor).
m(R) =p + m · Pa(C)
p + n + m
• Ganancia de Informacion:
log2p
p + n− log2
PP + N
donde P y N son los ejemplos cubiertos antes de quese anadiera la nueva prueba
(INAOE) 38 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Otros sistemas de reglas
Medidas Alternativas de Seleccion
• Weighted Relative Accuracy:
wla =p + nP + N
(p
p + n− P
P + N)
(INAOE) 39 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Valores desconocidos y numericos
• Con valores desconocidos, en un algoritmo de coveringlo mejor es hacer como si no aparean ningunacondicion (ignorarlos).
• En este sentido, los algoritmos que aprenden decisionlists tienen cierta ventaja, ya que ejemplos que parecendifıciles al principio, se van quedando y al final sepueden resolver, en general, mas facilmente.
• Los atributos numericos se pueden tratar igual que conlos arboles.
(INAOE) 40 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Pruning
• Una forma de evaluar si una regla es buena esconsiderar la probabilidad de que una regla aleatorianos de resultados iguales o mejores que la regla aconsiderar, basados en la mejora en ejemplos positivoscubiertos
• Idea: Generar reglas que cubran puros ejemplospositivos.
• Esta regla es probable que este sobre-especializada.• Lo que se hace es que se elimina el ultimo termino que
se anadio y se verifica si esta regla es mejor a laanterior
• Este proceso se repite hasta que no existan mejoras
(INAOE) 41 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Algoritmo de podado de reglas
Inicializa E al conjunto de ejemplosUntil E sea vacıo do
Para cada clase CCrea una regla perfecta para la clase CCalcula la medida de probabilidad m(R) para la regla
y para la regla sin la ultima condicion m(R−)Mientras m(R−) < m(R), elimina la ultima condicion
de la regla y repite el procesoDe las reglas generadas, selecciona aquella
con m(R) menorElimina las instancias cubiertas por la regla
(INAOE) 42 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Algoritmo de podado de reglas
• Este algoritmo no garantiza encontrar las mejoresreglas por 3 razones principales:
1 El algoritmo para construir las reglas, nonecesariamente produce las mejores reglas para serreducidas
2 La reduccion de reglas empieza con la ultima condicion,y no necesariamente es el mejor orden
3 La reduccion de reglas termina cuando cambia laestimacion, lo cual no garantiza que el seguirrecortando pueda mejorar de nueva la estimacion
• Sin embargo, el procedimiento es bueno y rapido
(INAOE) 43 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Medida de Evaluacion para reduccion dereglas
• ¿Cual es la probabilidad que una regla seleccionadaaleatoriamente con la misma cantidad de ejemplos quecubre R tenga el mismo desempeno?
• Una regla que cubra t casos, de los cuales p sean de laclase C (sin reemplazo):
Pr(tC) =
(Pp
)(T − Pt − p
)(
Tt
)
(INAOE) 44 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Medida de Evaluacion para reduccion dereglas
Donde:• p es numero de instancias de la clase que la regla
selecciona• t es el numero total de instancias que cubre la regla• P es el numero total de instancias de la clase• T es el numero total de instancias
Si queremos ver la probabilidad de que cubra p casos omas, entonces:
m(R) =
min(t ,P)∑i=p
Pr(tC)
(INAOE) 45 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Medida de Evaluacion para reduccion dereglas
• Valores pequenos indican que la regla es buena, yaque es muy poco probable que la regla sea construidapor casualidad
• Como este es muy costoso de calcular, se puedenhacer aproximaciones
• Si el numero de ejemplos es grande, la probabilidad deque exactamente p ejemplos de los t sean de clase C(con reemplazo) es:
Pr(tC) =(
tp
)(PT)p(1− P
T)t−p
que corresponde a una distribucion binomial
(INAOE) 46 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Reduced Error Pruning
• La funcion acumulada se puede aproximar a unafuncion beta de la siguiente forma:
t∑i=p
(ti
)(PT)i(1− P
T)t−i = Iβ(p, t − p + 1)
• Todo esto (simplificacion de reglas) se puede hacer conun subconjunto del conjunto de ejemplos deentrenamiento (reduced error pruning)
(INAOE) 47 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Incremental REP• IREP (Incremental REP) simplifica reglas cada vez que
se construyen usando:
p + (N − n)P + N
• Sin embargo, le da la misma importancia a los ejemplosnegativos no cubiertos y los positivos cubiertos
• Por lo que si una regla cubre 2000 (p) de 3,000, estoes, que tiene 1,000 mal (n) es evaluada mejor que unaregla que cubre 1,000 (p) de 1,001 (n = 1)
• Otra medida popular es:
p − np + n
Pero sufre de problemas parecidos
(INAOE) 48 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
RIPPER
• Construye un conjunto de reglas usando covering• Reduce las reglas usando alguna heurıstica como las
de arriba con un conjunto de entrenamiento separado• Luego “optimiza” al mismo tiempo ese conjunto de
reglas
(INAOE) 49 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
RIPPER
RIPPER utiliza varias medidas e ideas al mismo tiempo:• Un conjunto de ejemplos separados para decidir podar
reglas• Ganancia de informacion para crecer las reglas• Medida de IREP para podar reglas• Medida basada en MDL como criterio de paro para el
conjunto global de reglas
(INAOE) 50 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
RIPPER
Una vez que construye un conjunto inicial de reglas:• Toma una regla Ri del conjunto total de reglas y la hace
crecer (revision)• Tambien hace crecer una nueva regla desde el principio• Al final se queda con la regla original o alguna de las
otras dos (la que hizo crecer o construyo desde cero)tomando en cuenta el error sobre el conjunto total delas reglas
(INAOE) 51 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Construir reglas usando arboles
• Es posible crear reglas directamente de un arbol dedecision, sin embargo, las reglas tienden a ser mascomplejas de lo necesario
• Se pueden utilizar los mecanismos planteados en laseccion anterior para ir podando las reglas
• Una alternativa es combinar una estrategia de coveringcon una de splitting
(INAOE) 52 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Construir reglas usando arboles
• Para construir una regla se construye un arbol podado(splitting) y la hoja con la mejor covertura se transformaen una regla
• Una vez construida una regla se eliminan todos losejemplos que cubre (covering) y se repite el proceso
• En lugar de construir un arbol completo, se construyenarboles parciales, expandiendo las hojas con mejoresmedidas de entropıa
• Este esquema tiende a producir conjuntos de reglassimples con muy buen desempeno
(INAOE) 53 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Ripple-down rules
• La idea es constuir primero las reglas que cubren lamayor cantidad de casos y luego irlas afinandomediante excepciones
• Primero se toma la clase mayoritaria de entrada• Todo lo que no se cumpla se toma como una excepcion
a esta• Se busca la mejor regla (la que cubra mas casos) de
otra clase y se anade como una excepcion• Esto divide de nuevo los datos en los que cumplen con
esa nueva condicion y los que no cumplen• Dentro de los que no cumplen de nuevo se busca la
mejor regla de otra clase y se anade como excepcion, yası sucesivamente hasta que se cubran todos los casos
(INAOE) 54 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Ejemplo de Ripple down rules
Default: repruebaexcepto
Si estudia=si AND memoriza=noEntonces pasaexcepto
Si copia=si AND descubren=siEntonces reprueba
ElseSi estudia=no AND copia=si AND descubren=noEntonces pasaexcepto
Si vecino-sabe=noEntonces reprueba
Una de las ventajas es que la mayorıa de los ejemplos secubren por las reglas de mas alto nivel, y las de bajo nivelrepresentan realmente las excepciones
(INAOE) 55 / 56

Outline
IntroduccionSplitting vs. Covering
1R
PRISM
Otrossistemas dereglas
Valoresdesconocidosy numericos
Valores desconocidos y numericos
Reglas que incluyen relaciones
• Hasta ahora todas las reglas consideran pruebas sobreatributos (proposicionales)
• En ocasiones es importante expresar relaciones entreatributos
• Por ejemplo, si vemos varias reglas del tipo:If ancho ≤ 3.5 and alto ≥ 4 Then paradoIf ancho ≥ 3.5 Then acostado
• Entonces generar reglas en donde lo importante no sonlos valores sino su relacionIf ancho < alto Then paradoIf ancho > alto Then acostado
• Estas reglas se llaman relacionales. En otro cursoveremos ILP y Aprendizaje en Grafos
(INAOE) 56 / 56





























