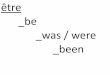Embed Size (px)
Citation preview

Apprentissage par Renforcement
Reinforcement Learning
Kenji [email protected]
ATR Human Information Science LaboratoriesCREST, Japan Science and Technology Corporation

Outline
Introduction to Reinforcement Learning (RL)Markov decision process (MDP)Current topics
RL in Continuous Space and TimeModel-free and model-based approaches
Learning to Stand UpDiscrete plans and continuous control
Modular DecompositionMultiple model-based RL (MMRL)

Learning to Walk (Doya & Nakano, 1985)
Action: cycle of 4 posturesReward: speed sensor output
Multiple solutions: creeping, jumping,…
QuickTime˛ Ç∆H.263 êLí£ÉvÉçÉOÉâÉÄ
ǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB

Markov Decision Process (MDP)
Environmentdynamics P(s’|s,a)reward P(r|s,a)
Agentpolicy P(a|s)
Goal: maximize cumulative future rewards E[ r(t+1) + r(t+2) + …]0≤≤1: discount factor
agent environment
reward r
action a
state s

Value Function and TD error
State value function V(s) = E[ r(t+1) + r(t+2) + …| s(t)=s, P(a|s)]
0≤≤1: discount factorConsistency condition
(t) = r(t) + V(s(t)) - V(s(t-1)) = 0 new estimate - old estimate
Dual role of temporal difference (TD) error (t)Reward prediction: (t) 0 in averageAction selection: (t)>0 better than average

QuickTime˛ Ç∆ÉrÉfÉI êLí£ÉvÉçÉOÉâÉÄ
ǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB
Example: Navigation
Reward field
24
6
2
4
6
-2
-1
0
1
2
Value function=0.9
24
6
2
4
6
-2
-1
0
1
2
=0.5

Actor-Critic Architecture
Critic: future reward predictionupdate value V(s(t-1)) (t)
Actor: action reinforcementincrease P(a(t-1)|s(t-1)) if (t) > 0
critic: V(s)
actor: P(a|s)
TD error reward r
environmentaction a
state s

Q Learning
Action value functionQ(s,a) = E[ r(t+1) + r(t+2) + …|
s(t)=s, a(t)=a, P(a|s)]= E[ r(t+1) + V(s(t+1))| s(t)=s,
a(t)=a]Action selection
a(t) = argmaxa Q(s(t),a) with prob. 1-
UpdateQ(s(t),a(t)) := r(t+1) + maxa[ Q(s(t+1),a)]
Q(s(t),a(t)) := r(t+1) + Q(s(t+1),a(t+1))

Dynamic Programming and RL
Dynamic Programminggiven models P(s’|s,a) and P(r|s,a)off-line solution of Bellman equation
V*(s) = maxa [ rrP(r|s,a) + s’V(s’)P(s’|s,a)]
Reinforcement Learningon-line learning with TD error
(t) = r(t) + V(s(t) - V(s(t-1))V(s(t-1)) = (t)Q(s(t-1),a(t-1)) = (t)

Model-free and Model-based RL
Model-free: e.g., learn action values Q(s,a) := r(s,a) + Q(s’,a’) a = argmaxa Q(s,a)
Model-based: forward model P(s’|s,a)action selection:
a = argmaxa E[ R(s,a) + s’ V(s’)P(s’|s,a)]
simulation: learn V(s) and/or Q(s,a) off-linedynamic programming: solve Bellman eq.
V(s) = maxa E[ R(s,a) + s’ V(s’)P(s’|s,a)]

Current Topics
Convergence proofswith function approximators
Learning with hidden states: POMDPestimate belief statesreactive, stochastic policyparameterized finite-state policies
Hierarchical architectureslearn to select fixed sub-modulestrain sub-modulesboth

Partially Observable Markov Decision Process (POMDP)
Update the belief stateobservation P(o|s): not identitybelief state b=(P(s1), P(s2),…): real valued
P(sk|o) P(o|sk) i P(sk|si,a) P(si)

Tiger Problem (Kaelbing et al., 1998)
state: a tiger is in {left,right}action: {left, right, listen}
observation with 15% error
policy tree finite state policy

Outline
Introduction to Reinforcement Learning (RL)Markov decision process (MDP)Current topics
RL in Continuous Space and TimeModel-free and model-based approaches
Learning to Stand UpDiscrete plans and continuous control
Modular DecompositionMultiple model-based RL (MMRL)

Why Continuous?
Analog control problemsdiscretization poor control performancehow to discretize?
Better theoretical propertiesdifferential algorithmsuse of local linear models

Continuous TD learning
Dynamics
Value function
TD error
Discount factor
Gradient Policy
€
˙ x =f (x,u)
V(x(t))= ew−tτ r(w)dw
t
∞∫
δ(t)=r(t)+ ˙ V (t)−1τ
V(t)
τ=Δt
1−γ, γ=1−
Δtτ
u(t) =g∂V∂x
∂f∂u
⎛
⎝ ⎜
⎞
⎠ ⎟
x(t)

On-line Learning of State Value
state x=(angle, angular vel.)
V(x)QuickTime˛ Ç∆
H.263 êLí£ÉvÉçÉOÉâÉÄǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB

Example: Cart-pole Swing up
Reward: height of the tipPunish: crash to wall
QuickTime˛ Ç∆H.263 êLí£ÉvÉçÉOÉâÉÄ
ǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB

Fast Learning by Internal Models
Pole balancing (Stefan Schaal, USC)
Forward modelof pole dynamics
Inverse modelof arm dynamics
QuickTime˛ Ç∆DV - NTSC êLí£ÉvÉçÉOÉâÉÄ
ǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB

Internal Models for Planning
Devil sticking (Chris Atkeson, CMU)
QuickTime˛ Ç∆ êLí£ÉvÉçÉOÉâÉÄ
ǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB

Outline
Introduction to Reinforcement Learning (RL)Markov decision process (MDP)Current topics
RL in Continuous Space and TimeModel-free and model-based approaches
Learning to Stand UpDiscrete plans and continuous control
Modular DecompositionMultiple model-based RL (MMRL)

Need for Hierarchical Architecture
Performance of controlMany high-precision sensors and actuatorProhibitively long time for learning
Speed of learningSearch in low-dimensional, low-resolution space

Learning to Stand up(Morimoto & Doya, 1998)
Reward: height of the headPunishment: tumbleState: pitch and joint angles, their derivatives
Simulation many thousands of trials to learn

Hierarchical Architecture
Upper leveldiscrete state/time
kinematicsaction: subgoalsreward: total task
Lower levelcontinuous state/time
dynamicsaction: motor torquereward:
achieving subgoals
Q(S,A)
V(s)
a=g(s)
sequence ofsubgoals

Learning in Simulation
early learning after ~700 trials
Upper levelsubgoals
Lower levelcontrol
QuickTime˛ Ç∆Animation êLí£ÉvÉçÉOÉâÉÄ
ǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB

Learning with Real Hardware(Morimoto & Doya, 2001)
after simulation
after ~100 physical trials
Adaptation by lower control modules
QuickTime˛ Ç∆ÉVÉlÉpÉbÉN êLí£ÉvÉçÉOÉâÉÄ
ǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB
QuickTime˛ Ç∆ÉVÉlÉpÉbÉN êLí£ÉvÉçÉOÉâÉÄ
ǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB

Outline
Introduction to Reinforcement Learning (RL)Markov decision process (MDP)Current topics
RL in Continuous Space and TimeModel-free and model-based approaches
Learning to Stand UpDiscrete plans and continuous control
Modular DecompositionMultiple model-based RL (MMRL)

Modularity in Motor Learning
Fast De-adaptation and Re-adaptationswitching rather than re-learning
Combination of Learned Modulesserial/parallel/sigmoidal mixture

‘Soft’ Switching of Adaptive Modules
‘Hard’ switching based on prediction errors(Narendra et al., 1995)
Can result in sub-optimal task decomposition with initially poor prediction models.
‘Soft’ switching by ‘softmax’ of prediction errors
(Wolpert and Kawato, 1998)
Can use ‘annealing’ for optimal decomposition.
(Pawelzik et al., 1996)

Responsibility by Competition
predict state change
responsibility
weight output/learning
€
u(t) = λi(t)i=1
n
∑ gi(x(t))
€
˙ ˆ x i(t)= fi(x(t),u(t))
€
λi(t) =exp− 1
2σ 2 ˙ ˆ x i(t)−˙ x (t)2⎛
⎝ ⎜
⎞ ⎠ ⎟
exp− 12σ 2 ˙ ˆ x j (t)−˙ x (t)
2⎛ ⎝ ⎜
⎞ ⎠ ⎟
j=1
n
∑
=softmax− ˙ ˆ x i(t)−˙ x (t)2
σ 2⎛ ⎝ ⎜
⎞ ⎠ ⎟
value Vi(x)
policy μi(x)
RL controller
statepredictor
responsibilitypredictor
Predictor
reward r(t)
actionu(t)
resp
onsib
ility
signal
λ i(t)
Environment
state x(t)
.x(t)
action u(t)
module 1
module n:
ui(t)
exp[-Ei (t)/ 2σ2]
λi(t)
.xi(t)
softm
ax
δi(t)
u(t)
x(t)

Multiple Linear Quadratic Controllers
Linear dynamic models
Quadratic reward models
Value functions
Action outputs
˙ ˆ x i(t)=Ai(x(t) −x i)+Biu(t)
u(t) =− λi(t)Kii=1
n
∑ (x(t)−x i); K i =R−1 ′ B iPi
ˆ r i (x(t),u(t))=r i −12 (x(t)−x i ′ ) Qi(x(t)−x i) −1
2 u(t ′ ) Riu(t)
Vi(x(t))= e−s−t
τt
∞∫ r(x(s),u(s))ds=−1
2(x(t) −x i ′ ) Pi(x(t)−x i)
0=−PiAi − ′ A iPi +PiBiR−1 ′ B iPi −Qi +
1τ
Pi

Swing-up control of a pendulum
Red: module 1 Green: module 2
-0.4 -0.2 0 0.2 0.4 0.6 0.8 1-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
1.2t=20.0
x1 [π]
x2 [π]
QuickTime˛ Ç∆Video êLí£ÉvÉçÉOÉâÉÄǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB

Non-linearity and Non-stationarity
Specialization by predictability in space and time
-20
-15
-10
-5
0
5
10
15
20
p 2p-p-2p 0-20
-15
-10
-5
0
5
10
15
20
p 2p-p-2p 0
0 20 40 60 80 100 120 140 160 180 200-10
-5
0
5
10
0 20 40 60 80 100 120 140 160 180 200-1
-0.5
0
0.5
1
(c) before learning (d) after 50 trials (e) after 200 trials[rad]q [rad]q[rad]q
Stationary non-Stationary
Trials
Stationary non-Stationary
Trials
(a) (b)
-20
-15
-10
-5
0
5
10
15
20
p 2p-p-2 p 0
module 3
module 4
module 1
module 2
1,2 3,4 1,2 3,4
1
2 3
44
3
{l=1.m=1}
{l=10.m=0.2}

Swing-up control of an ‘Acrobot’
Reward: height of the center of massLinearized around four fixed points

Swing-up motions
R=0.001 R=0.002
QuickTime˛ Ç∆Video êLí£ÉvÉçÉOÉâÉÄǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅBQuickTime˛ Ç∆Video êLí£ÉvÉçÉOÉâÉÄǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB

Module switching
trajectories x(t) R=0.001 R=0.002
responsibility i : symbol-like representation
1-2-1-2-1-3-4-1-3-4-3-4 1-2-1-2-1-2-1-3-4-1-3-4

t=0 10t=0t=0t=0t=0t=0t=0t=0
Stand Up by Multiple Modules
Seven locally linear models
0 0.5 1 1.5 2 2.5 3 3.5 4 4.51
2
3
4
5
6
7
RespTextEnd
QuickTime˛ Ç∆ÉrÉfÉI êLí£ÉvÉçÉOÉâÉÄ
ǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB
0 1 2 3 4 5 61
2
3
4
5
6
7
RespTextEnd
QuickTime˛ Ç∆ÉrÉfÉI êLí£ÉvÉçÉOÉâÉÄ
ǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB

Segmentation of Observed Trajectory
Predicted motor output
Predicted state change
Predicted responsibility
predictor 1
controller 1
predictor i
controller i
predictor n
controller n
.xo(t)
xo(t)demonstrator
xo(t) uoi(t)
oi( )t
.xo
i( )t^
softmax
i(t)
€
uio(t) =gi(x
o(t))
˙ ˆ x io =fi (x
o(t),uio(t))
λio(t) =
e− 1
2σ 2˙ ˆ x io (t)−˙ x o (t)
2
e− 1
2σ2˙ ˆ x jo(t)−˙ x o (t)
2
j=1
n
∑

Imitation of Acrobot Swing-up
1(0)=π/12 1(0)=π/6 1(0)=π/12 (imitation)
QuickTime˛ Ç∆Video êLí£ÉvÉçÉOÉâÉÄǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅBQuickTime˛ Ç∆Video êLí£ÉvÉçÉOÉâÉÄǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB
QuickTime˛ Ç∆Video êLí£ÉvÉçÉOÉâÉÄǙDZÇÃÉsÉNÉ`ÉÉÇ å©ÇÈÇ…ÇÕïKóvÇ≈Ç∑ÅB

Outline
Introduction to Reinforcement Learning (RL)Markov decision process (MDP)Current topics
RL in Continuous Space and TimeModel-free and model-based approaches
Learning to Stand UpDiscrete plans and continuous control
Modular DecompositionMultiple model-based RL (MMRL)

Future Directions
Autonomous learning agentsTuning of meta-parametersDesign of rewardsSelection of necessary/sufficient state coding
Neural mechanisms of RLDopamine neurons: encoding TD errorBasal ganglia: value-based action selectionCerebellum: internal modelsCerebral cortex: modular decomposition

What is Reward for a robot?
Should be grounded bySelf preservation: self rechargingSelf reproduction: copying control program
Cyber Rodent

The Cyber Rodent Project
Learning mechanisms under realistic constraints of self-preservation and self-reproduction
acquisition of task-oriented internal representationmetalearning algorithms
constraints of finite time and energymechanisms for collaborative behaviorsroles of communication
abstract/emotional, concrete/symbolicgene exchange rules for evolution

Input/Output
SensoryCCD camerarange sensorIR proximity x8acceleration/gylomicrophone x2
Motortwo wheelsjawR/G/B LEDspeaker

Computation/Communication
CPU: Hitachi SH-4 CPUFPGA image processorIO modules
CommunicationIR portwireless LAN
Softwarelearning/evolutiondynamic simulation