Embed Size (px)
Citation preview

Analyzing and Predicting MT Utility and Post-Editing Productivity in Enterprise-scale
Translation Projects
Olga Beregovaya and David Clarke, Welocalize
Alon Lavie and Michael Denkowski, Safaba Translation Solutions

Challenges & Objectives
Status quo – “big picture” - unknowns at the launch of an enterprise MT-based program:
oIs the source content suitable for MT?
oIs the MT-driven program going to render productivity gains compared to human translation across all languages?
oAre all the segments in the job going to perform at the same level?
Solution: Segment-level Predictive Analysis
oReveal a correlations between productivity, expected MT PE quality and intrinsic properties of the text being translated
oPredict machine-translated segment utility and level of effort
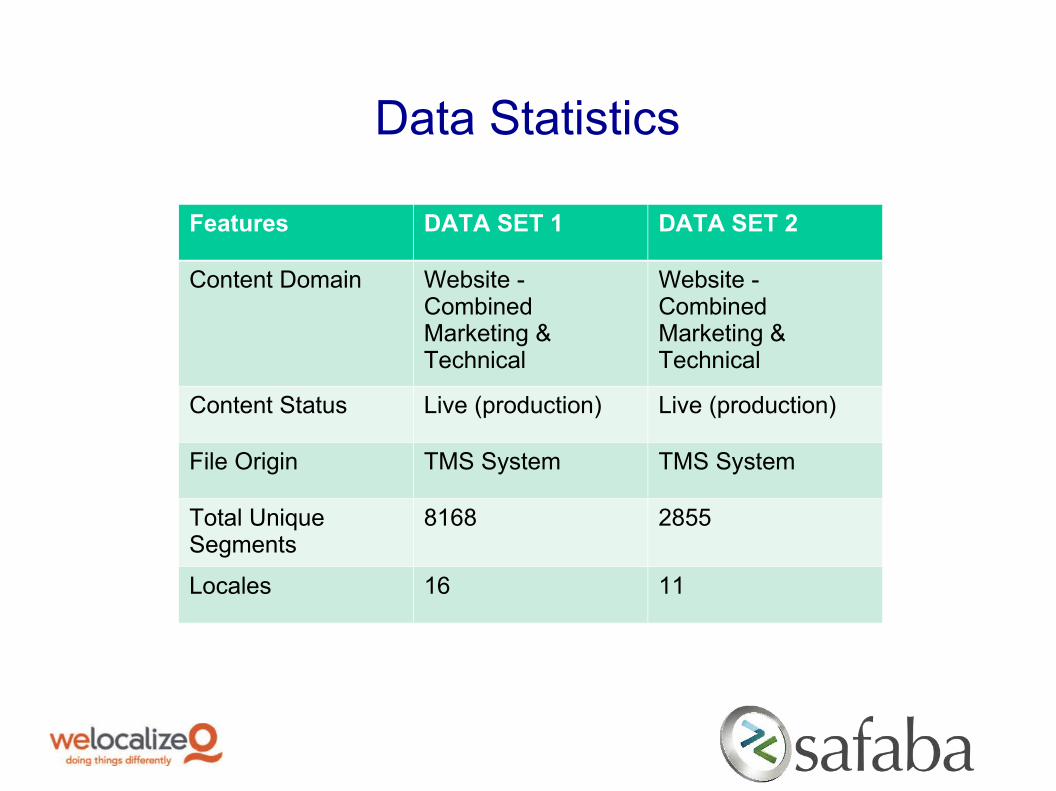
Data Statistics
Features DATA SET 1 DATA SET 2
Content Domain Website - Combined Marketing & Technical
Website - Combined Marketing & Technical
Content Status Live (production) Live (production)
File Origin TMS System TMS System
Total Unique Segments
8168 2855
Locales 16 11
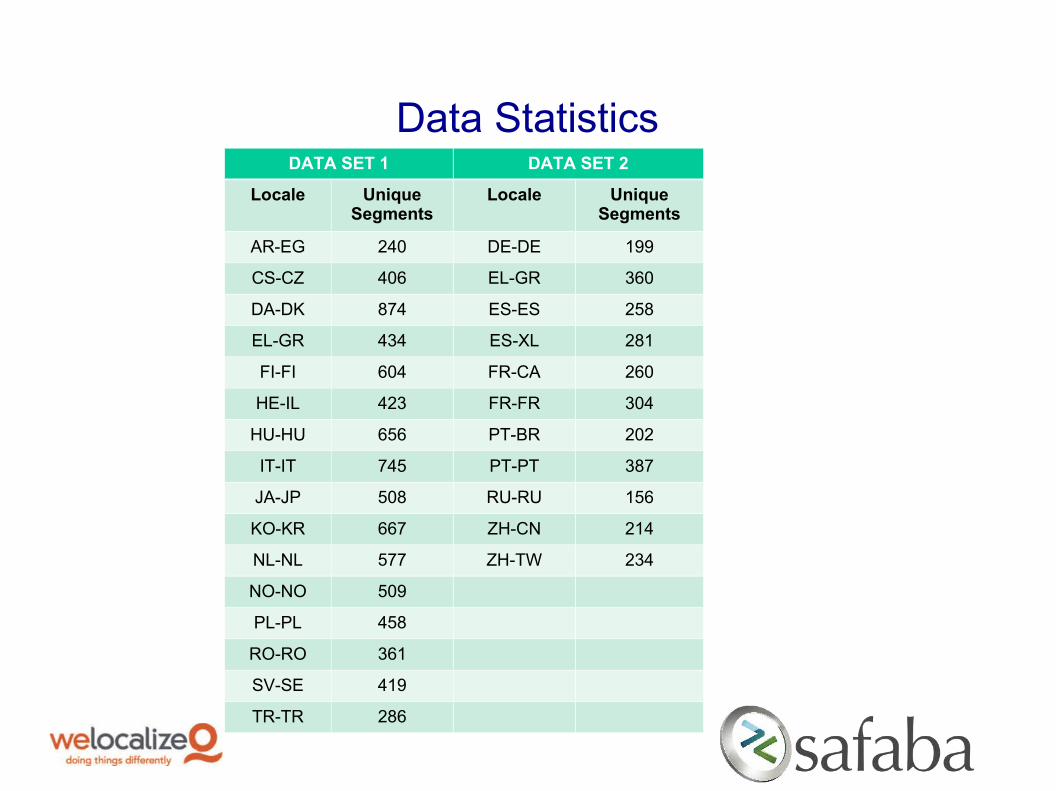
Data StatisticsDATA SET 1 DATA SET 2
Locale Unique Segments
Locale Unique Segments
AR-EG 240 DE-DE 199
CS-CZ 406 EL-GR 360
DA-DK 874 ES-ES 258
EL-GR 434 ES-XL 281
FI-FI 604 FR-CA 260
HE-IL 423 FR-FR 304
HU-HU 656 PT-BR 202
IT-IT 745 PT-PT 387
JA-JP 508 RU-RU 156
KO-KR 667 ZH-CN 214
NL-NL 577 ZH-TW 234
NO-NO 509
PL-PL 458
RO-RO 361
SV-SE 419
TR-TR 286

Methodology
o Analysis performed by Welocalize and Safaba on live, enterprise-scale MT Post Editing project environment
o Underlying data based on MT post-editing productivity information collected on a per-segment basis via an open-source CAT tool (iOmegaT)
o The analysis contrasts and correlates the collected productivity data with several MT quality evaluation metrics, human evaluation by trained post-editors and detailed characteristic properties of the source text
o The data is used to develop segment-level automated quality estimation scores, which is used to predict the expected utility of MT generated translation segments in future production projects.

Evaluation EnvironmentPre-processing middleware
oUsed for workflow/kitting
oiOmegaT
oA tool built on top of OmegaT, an open-source CAT tool adapted to measure various aspects of post-editing MT output
oDeveloped by John Moran (CNGL) in collaboration with Dave Clarke (Welocalize), it records:
Translation time
MT post-editing time
Fuzzy match editing time
+ an extended suite of industry-standard automated evaluation methodologies, human evaluation environment and translator surveys

Source Text Features
Source text features considered:
o Content type category (i.e. marketing/UI/UA)
o Length of the source segment
o Source segment morpho-syntactic complexity;
o Presence/absence of pre-defined glossary terms or multi-word glossary elements, UI elements, numeric variables, product lists, ‘do-not-translate’ and transliteration lists
o Metadata attributes and their representation in localization industry standard formats (“tags”).

Content Types
Source content types generally passed to the engine:
o Technical/IT/Training Exams
o Business/Management Comms/Training
o Corporate Image/Branding/Advertising
o Voiceover/Subtitles/Video
o Marketing/Transcreation/Copywriting/Blurbs
o Technical Documentation
o User Interface/website
o User Assistance/Consumer Documentation
*Content type explicitly set in the GMS within the project/TM attributes
Content used for this study: User Interface/Website

Analyzing Tag Projection Accuracy
• Commercial enterprise translation data is often in the form of files of structured formats converted for translation into XML-based schemas with heavily-tag-annotated segments of source text
• Example:
Source (EN): Click the <g0>Advanced</g0> tab, and click <g1>Change</g1>.
Reference (PT): Clique no separador <g0>Avançado</g0> e em <g1>Alterar</g1>.
• Correctly projecting and placing these segment-internal tags from the source language to the target language is a well-known difficult challenge for MT in general, and statistical MT engines in particular
• Safaba has focused significant effort over the past year to developing advanced high-accuracy algorithms for source-to-target tag projection within our EMTGlobal MT solution

Analyzing Tag Projection Accuracy
o Goal: Assess tag projection and placement accuracy of EMTGlobal version 1.1 versus 2.1, based on analysis of post-edited MT segments generated by Welocalize for Safaba’s Dell MarkCom MT engines in production
o Methodology: Estimate accuracy by aligning the target language raw MT output with the post-edited MT version and assess whether each tag is placed between the same target words on both sides
o Example:
Reference: Clique no separador <g0>Avançado</g0> e em <g1>Alterar</g1>.
EMTGlobal v1.1: <g0>Clique na guia Avançado e em</g0> <g1> Alterar.</g1>
EMTGlobal v2.1: Clique na guia <g0>Avançado</g0> e em <g1>Alterar</g1>.

Analyzing Tag Projection Accuracy
EMTGlobal version 1.1
Context MatchedTag Type Both Left Right Neither TotalBeginning 33.33% 19.44% 11.46% 35.76% 100.00%Ending 32.06% 10.10% 8.01% 49.83% 100.00%Stand-alone 56.91% 23.98% 18.29% 0.81% 100.00%Total 39.95% 17.54% 12.30% 30.21% 100.00%
EMTGlobal version 2.1
Contexts MatchedTag Type Both Left Right Neither TotalBeginning 66.67% 12.50% 9.38% 11.46% 100.00%Ending 63.41% 10.80% 11.50% 14.29% 100.00%Stand-alone 67.89% 18.29% 13.01% 0.81% 100.00%Total 65.90% 13.64% 11.21% 9.26% 100.00%
• Fraction of “Neither” likely incorrectly placed tags reduced from 30% to 9%• Fraction of “Both” confirmed correctly placed tags improved from 40% to 66%• Fraction of tags with partially-matched contexts reduced from 30% to 25%
• Data: Welocalize post-editing productivity data set• 26 target languages, one document per language, 4907 segments• For 15 languages (3211 segments), EMTGlobal v1.1 was post-edited• For 11 languages (1696 segments), EMTGlobal v2.1 was post-edited • Total of 830 tags in PE segments, 821 aligned with MT output (98.9%)

Tag Placement
Requirements:
oAll formatting elements have been retained and for the most part are in valid sequence order
oThe majority of translators’ work is fairly minor repositioning of tags
Source: <1><2>Thin design: </2></1><3>At a mere 0.9 inches (23 mm) and with up to 6 hours and 42 minutes</3><4><5>1</5></4><6> of battery life, XPS 14z is super-portable and ready to go anywhere.</6>
Target: <1><2> Schlankes Design <3>: Mit </3></2></1> einer Höhe von lediglich 23 mm (0,9 Zoll) und bis zu 6 Stunden und 42 Minuten <4><5><6> 1 Akkubetriebsdauer </6></5></4>, XPS 14z ist extrem mobil und einsatzbereit überall.
<1> correct; <2> correct, <3>, </3>, </2> and </1> slightly misplaced; <4> and <5> correct; <6>, </6>, </5> and </4> misplaced; </1> misplaced.
100% tags retained, 33% accurate tag placement (EMT Global V. 1.1) .

Tag Density Ratio
Goal: analyze the impact that the presence and ratio of the standard XLIFF tags have on the post-editing task duration and number of edit visits and factor this impact in the post-editing effort evaluation
New variable: Tag Density Ratio (tags per word) for the machine-translated segments
Tag Density Ratio components: string length (word count) ranges, tag quantification, tag density and visit frequency data
Hypothesis: segments with high tag density exhibit considerably higher than expected post-edit time as compared with low tag density segments of the same length since tag placement adjustment is necessary during post-editing.
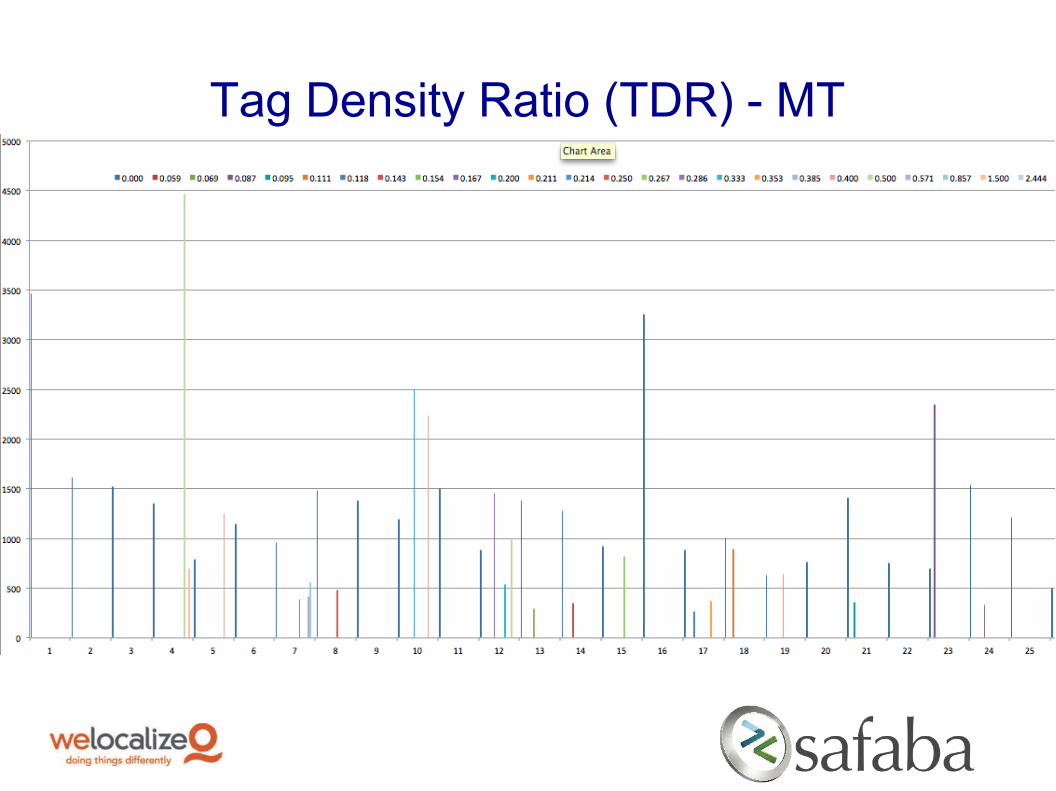
Tag Density Ratio (TDR) - MT
.

Tag Density Ratio (TDR) - HT

Tag Density Ratio (TDR) - Findings
o Human Translation vs. MT - no difference in TDR impact
o Higher TDR has no major impact on PE time across all sentence length groups
o The tags are handled intelligently/placed properly by the MT engine (Safaba EMTGlobal v. 2.1)

“Lower Effort” Elements
Goal: identify segments that contain:
o Glossary terms
o “DoNotTranslate” elements
o URL strings
o Other identifiable entities
Analyze their post-edit session duration in comparison with segments of similar length with no identified “easy-to-manipulate” or DNT elements
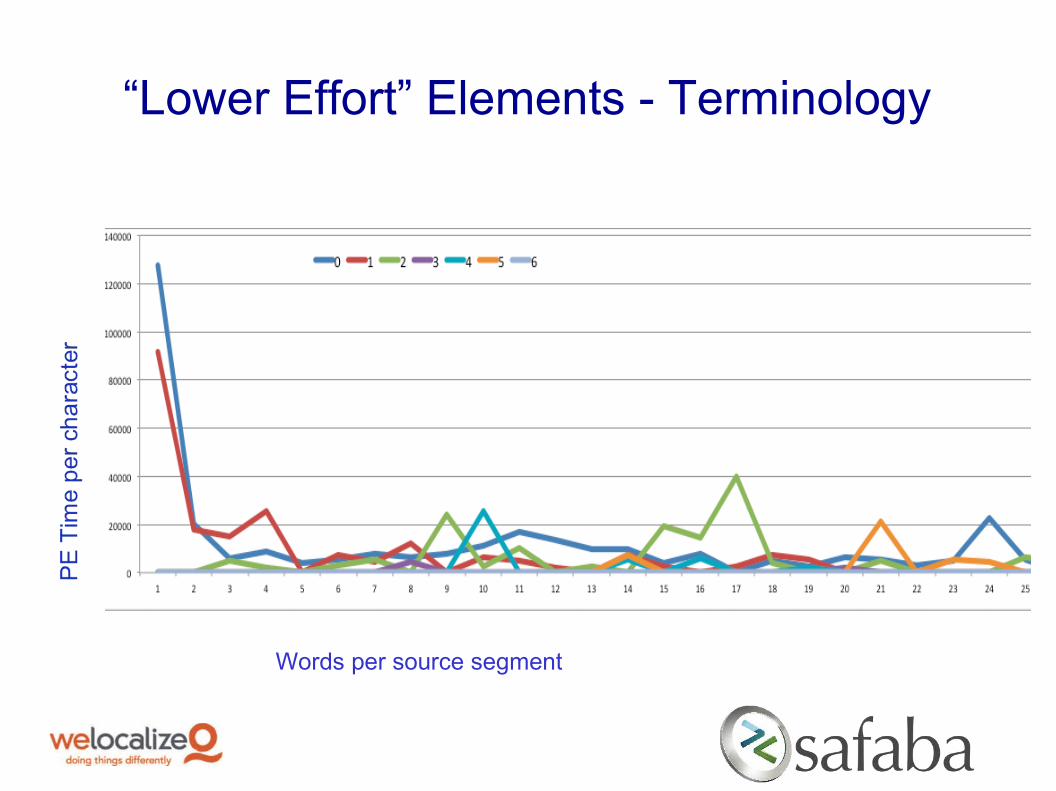
“Lower Effort” Elements - Terminology
Words per source segment

“Lower Effort” Elements - DNT
Words per source segment

“Lower Effort” Elements - Findings
o Presence of DNT elements and terminology hits has similar positive impact on the post-editing time
o DNT lists were created retroactively while the terminology is explicitly highlighted to the translator; creating DNT glossaries will render additional productivity gains
o Unlike the DNT elements, terminology entries may require edits (plural/singular, case), which demonstrates that the Safaba engine handles the morphological variants of terminology hits correctly
o Single isolated terminology hits slow down the translator – (standalone term with no context possibly requiring more validation?)
o Past the 20-25 words-per-segment range the impact of DNT and term hits is negligible

Source String Complexity
Goal: to perform a morpho-syntactic analysis of the input source sentences and cross-compare with the known “most difficult to handle” errors:

Source String Complexity - Findings
In each “segment length” group sentences falling under these categories or similar complexity categories required most post-editing time and effort even with the new improved version of Safaba Translation Engine (EMT Global 2.1) with post-editors’ feedback implemented
- Combining brains with brawn the Alienware® M17x is the most powerful 17” gaming notebook in the universe.
- With the swipe of a finger, the keyboard appears from under the display as the system is open.
- Through PartnerDirect, Registered and Certified Channel Partners can access software licensing from all of the major publishers including Microsoft, Symantec, VMware, Citrix, Oracle and many more
- Features a top-of-rack, 1U, multiprotocol design that supports Converged Enhanced Ethernet (CEE) and traditional Ethernet protocols, upgradable to support Fiber Channel and Fibre Channel over Ethernet (FCoE)
- The evolutionary design consumes less than 2.5 watts of power per port for exceptional power and cooling efficiency, and features consolidated power and fan assemblies to help improve environmental performance and reduce ownership costs.
Conclusion: source pre-edit rules still appear to be the most viable solution; patterns are traceable but more rules than what has been identified to-date will be needed (project WIP)

Relaxing PE Quality Requirements

Post-Editing Quality Requirements

Developing Quality Estimation Prediction Classifiers
• MT engines in production often vary significantly in their translation performance from segment to segment
• Goal: develop MT-engine-specific Quality Estimation components that generate for every MT-generated segment a predicted estimate of its expected quality
• Useful information for a variety of MT applications:
• For MT post-editing: provide indicators of predicted level of required post-editing effort
• For real-time raw MT applications: filter out MT-generated documents that are poorly translated

Safaba Quality Estimation Preliminary Study
• Goal: Develop and analyze the performance of basic QE components for Safaba’s EMTGlobal Dell MT engines using Welocalize post-editing productivity data
• English into 12 target languages
• Very small amounts of post-edited data for each language
• Binary classification: will post-editing be required for this segment?
Reliable quality estimation built for free
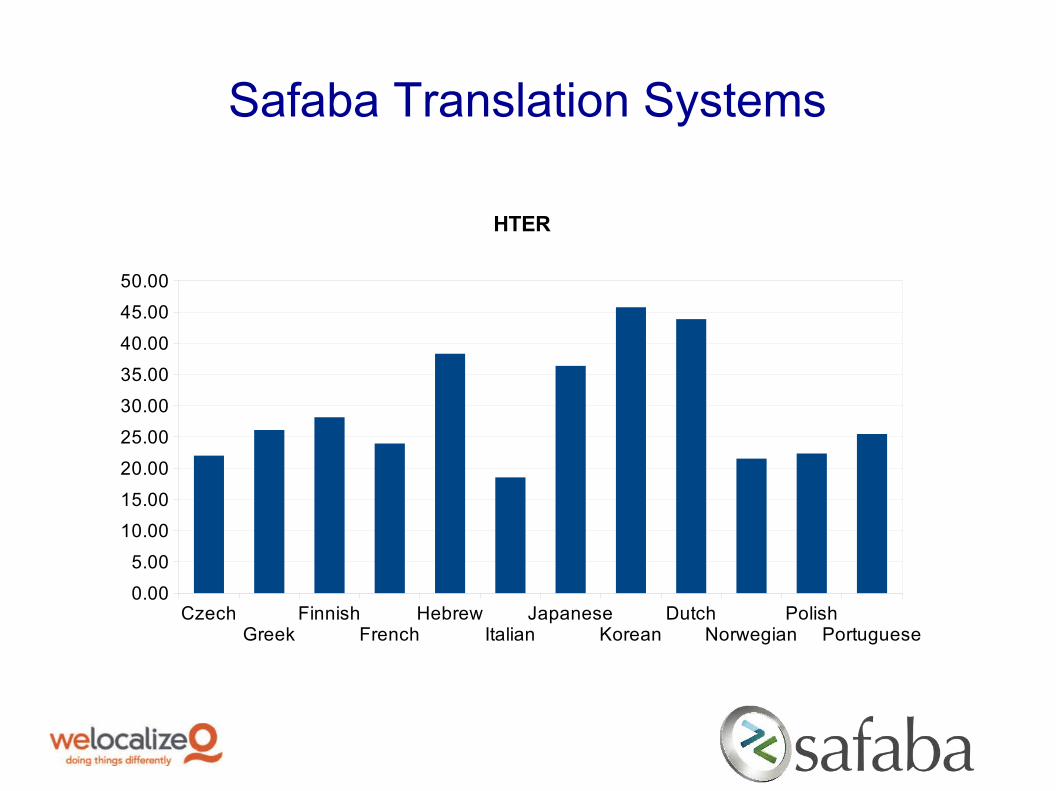
Safaba Translation Systems
CzechGreek
FinnishFrench
HebrewItalian
JapaneseKorean
DutchNorwegian
PolishPortuguese
0.00
5.00
10.00
15.00
20.00
25.00
30.00
35.00
40.00
45.00
50.00
HTER
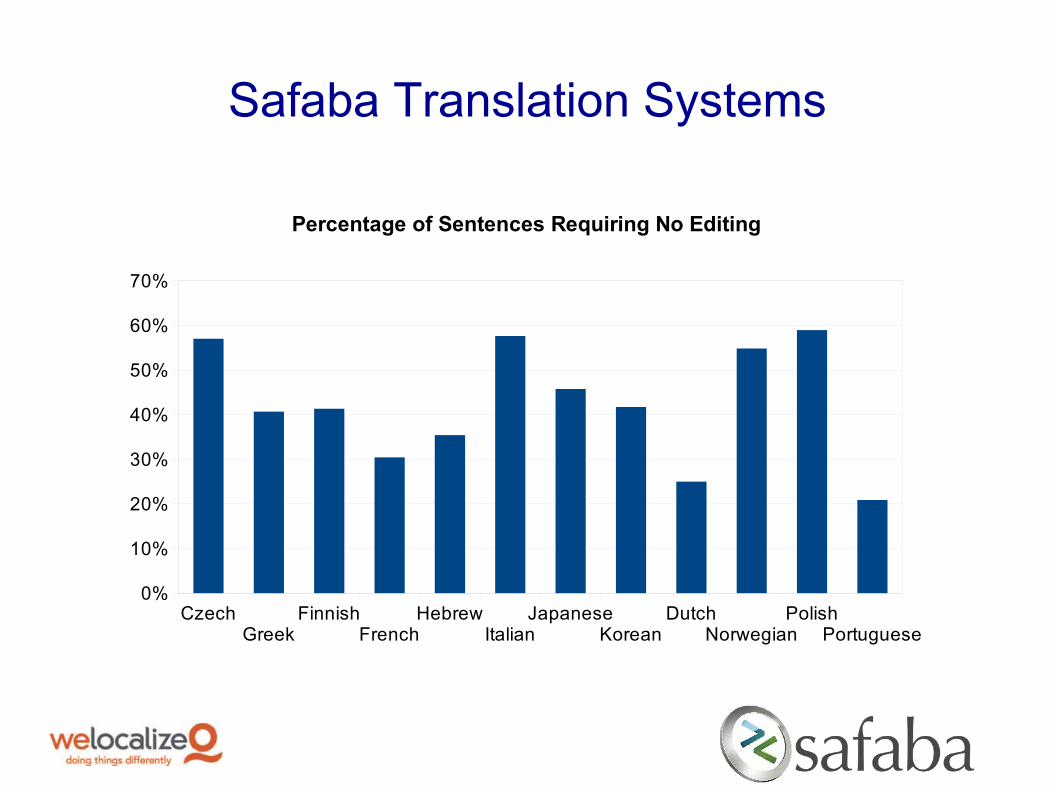
Safaba Translation Systems
CzechGreek
FinnishFrench
HebrewItalian
JapaneseKorean
DutchNorwegian
PolishPortuguese
0%
10%
20%
30%
40%
50%
60%
70%
Percentage of Sentences Requiring No Editing
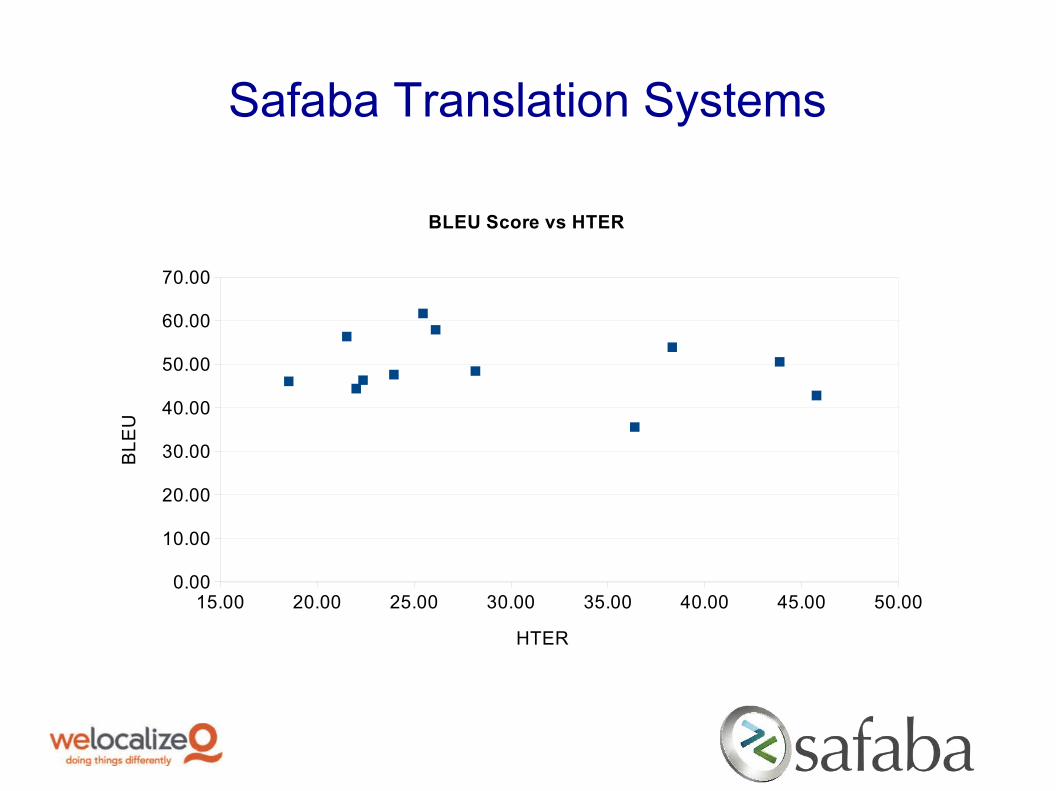
Safaba Translation Systems
15.00 20.00 25.00 30.00 35.00 40.00 45.00 50.000.00
10.00
20.00
30.00
40.00
50.00
60.00
70.00
BLEU Score vs HTER
HTER
BL
EU

Quality Estimation Systems
• Classifier: nu-support vector classifier(class of support vector machine)
• Features: 17 standard quality estimation features from ACL WMT shared tasks
• Training data: binary judgments on MT output post-edited by professional translators
All resources required for QE are available from the MT engine training process in a standard post-editing scenario

QE Feature Scoring
• Input: source sentence, MT-generated translation output
• Key features computed for classifier:− Source/target word count
− Source/target language model probability
− Average number of possible translations of each source word (by word-based translation model IBM-1)
− Counts of high and low frequency source/target unigrams/bigrams/trigrams
− Percentage of out-out-of-vocabulary source words

Models Required
• Source and target 4-gram language models• Source and target low and high frequency
n-gram tables• Source and target vocabularies
All built from existing MT system training data

Classifier Training
• Classify sentences into two groups:• Requires post-editing
• Does not require post-editing
• Training data:• Safaba EMTGlobal MT systems used in production for
post-editing
• In this study: triples of source, MT output, edited translation available from Welocalize productivity study
• Compare MT-generated output to final post-edited translation to determine if editing was required
No additional human annotation required

QE Prediction Preliminary Study
o Average of 250 sentences edited per languageo Classifiers trained and evaluated with 10-fold
cross-validation (found to perform comparably to leave-one-out validation)
o Outperforms random selection and majority class selection in 11 of 12 languages
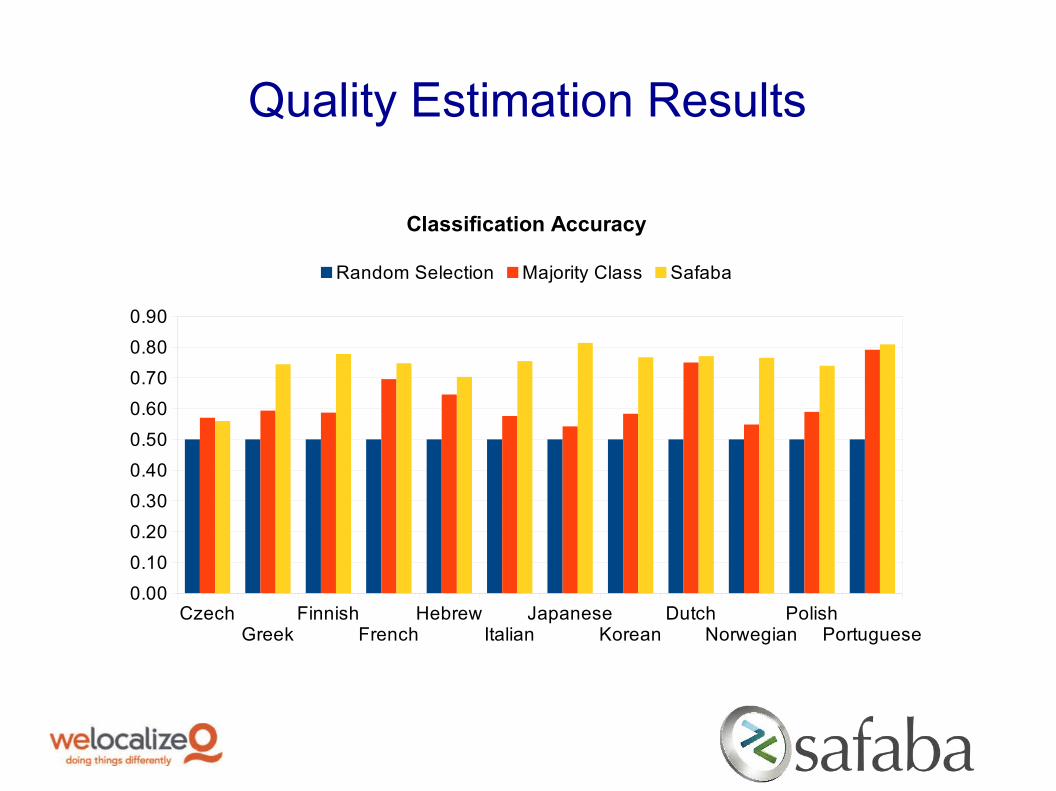
Quality Estimation Results
CzechGreek
FinnishFrench
HebrewItalian
JapaneseKorean
DutchNorwegian
PolishPortuguese
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
Classification Accuracy
Random Selection Majority Class Safaba

Quality Estimation Results
CzechGreek
FinnishFrench
HebrewItalian
JapaneseKorean
DutchNorwegian
PolishPortuguese
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
Classification Error
False + False -

Analysis of Results
o QE systems built entirely using small amounts of existing data
o 70-80% reliability in majority of languages
o Most errors are false negatives (good sentences marked as bad, less damaging case)
o Cases where QE performance is weaker:
o Small model training datao Skewed classifier training datao High statistical similarity between positive and negative
examples (Czech)

Future Work
o Build QE prediction components automatically for EMTGlobal production MT systems.
o Train QE classifiers automatically as client data is edited and fed back to Safaba
o Plug in additional sentence-level meta-data to predict other useful measures:
o Translation timeo HTER

![G0 - RF Safety G0 – ELECTRICAL AND RF SAFETY [2 Exam Questions - 2 groups] G0A - RF safety principles, rules and guidelines; routine station evaluation](https://img.pdfslide.us/doc/110x75/56649e2b5503460f94b1925a/g0-rf-safety-g0-electrical-and-rf-safety-2-exam-questions-2-groups.jpg)











![DM0I], ;LPV[RPALP8LPv _¼ XL8D[8, JS" V[g0 J[](https://img.pdfslide.us/doc/110x75/56649c915503460f9494ba0b/dm0i-lpvrpalp8lpv-xl8d8-js-vg0-j.jpg)















