Embed Size (px)
Citation preview

Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
Algoritmi per IR
Prologo
References
Managing gigabytesA. Moffat, T. Bell e I. Witten, Kaufmann Publisher 1999.
A bunch of scientific papers available on the course site !!
Mining the Web: Discovering Knowledge from...S. Chakrabarti, Morgan-Kaufmann Publishers, 2003.
Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
About this course
It is a mix of algorithms for
data compression
data indexing
data streaming (and sketching)
data searching
data mining
Massive data !!
Paradigm shift...
Web 2.0 is about the many

Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
Big DATA Big PC ?
We have three types of algorithms:
T1(n) = n, T2(n) = n2, T3(n) = 2n
... and assume that 1 step = 1 time unit
How many input data n each algorithm may process within t time units?
n1 = t, n2 = √t, n3 = log2 t
What about a k-times faster processor?...or, what is n, when the time units are k*t ?
n1 = k * t, n2 = √k * √t, n3 = log2 (kt) = log2 k + log2 t
A new scenario
Data are more available than even before
n ∞... is more than a theoretical assumption
The RAM model is too simple
Step cost is Ω(1) time

Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
You should be “??-aware programmers”
Not just MIN #steps…
CPU RAM
1CPUregisters
L1 L2 RAM
Cache Few MbsSome nanosecsFew words fetched
Few GbsTens of nanosecsSome words fetched
HD net
Few Tbs
Many TbsEven secsPackets
Few millisecsB = 32K page
I/O-conscious Algorithms
Spatial locality vs Temporal locality
track
magnetic surface
read/write armread/write head
“The difference in speed between modern CPU and disk technologies is analogous to the difference in speed in sharpening a pencil using a sharpener on one’s desk or by taking an airplane to the other side of the world and using a sharpener on someone else’s desk.” (D. Comer)

Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
The space issue
M = memory size, N = problem size
T(n) = time complexity of an algorithm using linear space
p = fraction of memory accesses [0,3÷0,4 (Hennessy-Patterson)]
C = cost of an I/O [105 ÷ 106 (Hennessy-Patterson)]
If N=(1+f)M, then the ∆−avg cost per step is:
C * p * f/(1+f)
This is at least 104 * f/(1+f)
If we fetch B ≈ 4Kb in time C, and algo uses all of them:
(1/B) * (p * f/(1+f) * C) ≈ 30 * f/(1+f)
Space-conscious Algorithms
Compressed data structures
I/Os
search
access

Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
Streaming Algorithms
Data arrive continuously or we wish FEW scans
Streaming algorithms: Use few scans
Handle each element fast
Use small space
track
magnetic surface
read/write armread/write head
Cache-Oblivious Algorithms
Unknown and/or changing devices
Block access important on all levels of memory hierarchy
But memory hierarchies are very diverse
Cache-oblivious algorithms: Explicitly, algorithms do not assume any model parameters
Implicitly, algorithms use blocks efficiently on all memory levels
CPUregisters
L1 L2 RAM
Cache Few MbsSome nanosecsFew words fetched
Few GbsTens of nanosecsSome words fetched
HD net
Few Tbs
Many TbsEven secsPackets
Few millisecsB = 32K page
Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
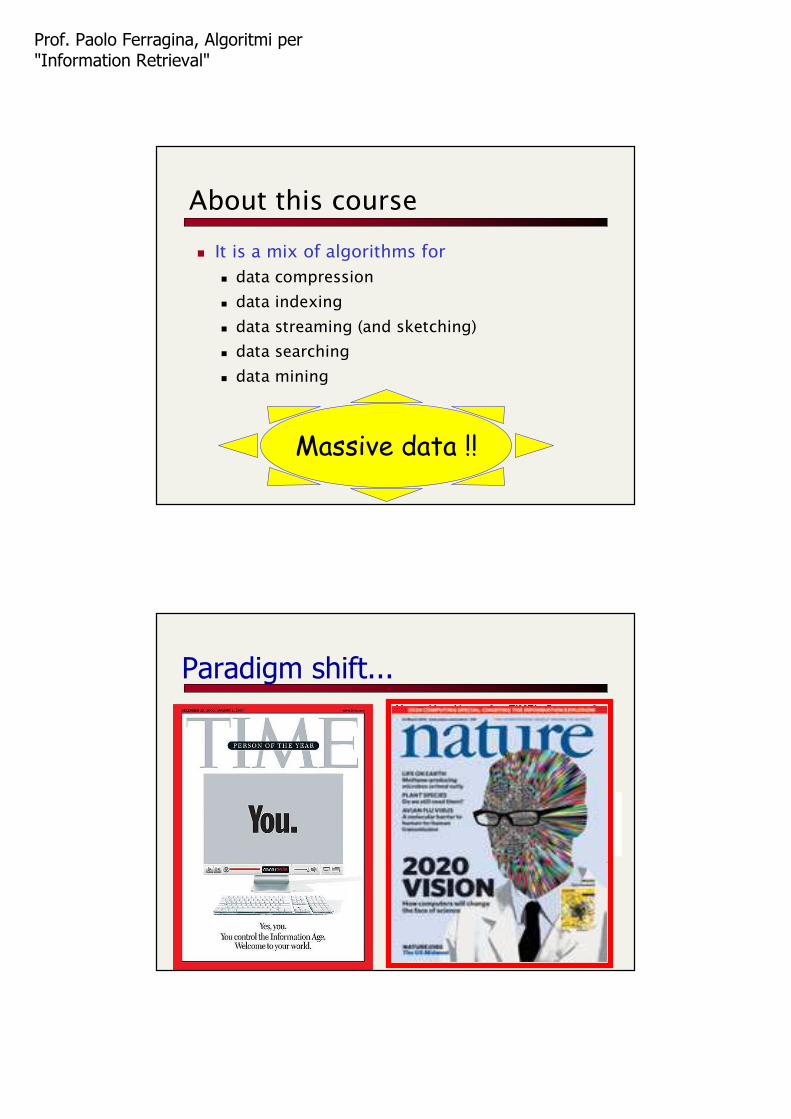
Toy problem #1: Max Subarray
A = 2 -5 6 1 -2 4 3 -13 9 -6 7
Goal: Given a stock, and its ∆-performance over the time, find the time window in which it achieved the best “market performance”.
Math Problem: Find the subarray of maximum sum.
106s
--
256K
7m
--
512K
26s
28h
128K
1s
3.5h
32K
--26m3m22sn3
28m000n2
1M16K8K4K
An optimal solution
Algorithm sum=0; max = -1;
For i=1,...,n do
If (sum + A[i] ≤ 0) sum=0;
else sum +=A[i]; MAXmax, sum;
A = 2 -5 6 1 -2 4 3 -13 9 -6 7
Note:•Sum < 0 when OPT starts;•Sum > 0 within OPT
A = Optimum<0 >0
We assume every subsum≠0

Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
Toy problem #2 : sorting
How to sort tuples (objects) on disk
Key observation:
Array A is an “array of pointers to objects”
For each object-to-object comparison A[i] vs A[j]:
2 random accesses to memory locations A[i] and A[j]
MergeSort Θ(n log n) random memory accesses (I/Os ??)
Memory containing the tuples
A
B-trees for sorting ?
Using a well-tuned B-tree library: Berkeley DB
n insertions Data get distributed arbitrarily !!!
Tuples
B-tree internal nodes
B-tree leaves(“tuple pointers")
What aboutlisting tuples in order ?
Possibly 109 random I/Os = 109 * 5ms ≅ 2 months

Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
Binary Merge-Sort
Merge-Sort(A,i,j)01 if (i < j) then02 m = (i+j)/2; 03 Merge-Sort(A,i,m);04 Merge-Sort(A,m+1,j);05 Merge(A,i,m,j)
Merge-Sort(A,i,j)01 if (i < j) then02 m = (i+j)/2; 03 Merge-Sort(A,i,m);04 Merge-Sort(A,m+1,j);05 Merge(A,i,m,j)
Divide
Conquer
Combine
Cost of Mergesort on large data
Take Wikipedia in Italian, compute word freq:
n=109 tuples few Gbs
Typical Disk (Seagate Cheetah 150Gb): seek time ~5ms
Analysis of mergesort on disk:
It is an indirect sort: Θ(n log2 n) random I/Os
[5ms] * n log2 n ≈ 1.5 years
In practice, it is faster because of caching...
Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
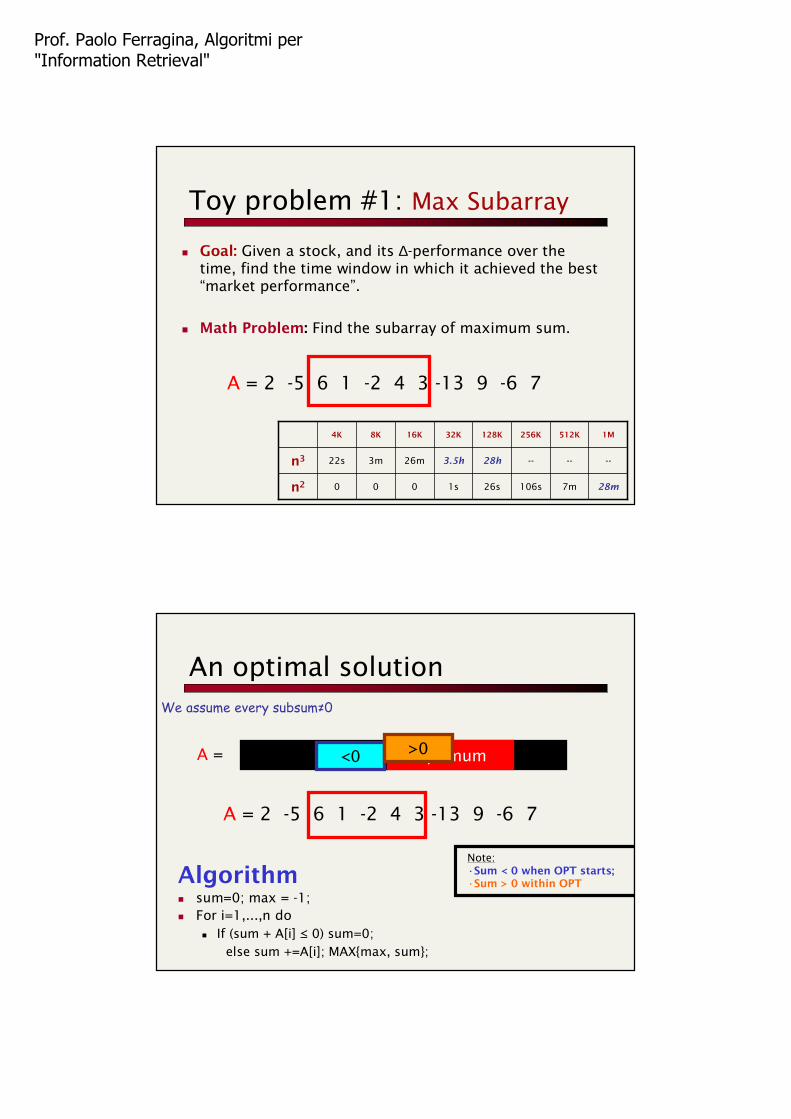
Merge-Sort Recursion Tree
10 2
2 10
5 1
1 5
13 19
13 19
9 7
7 9
15 4
4 15
8 3
3 8
12 17
12 17
6 11
6 11
1 2 5 10 7 9 13 19 3 4 8 15 6 11 12 17
1 2 5 7 9 10 13 19 3 4 6 8 11 12 15 17
1 2 3 4 5 6 7 8 9 10 11 12 13 15 17 19
log2 N
MN/M runs, each sorted in internal memory (no I/Os)
2 p
asses (R/W
)
— I/O-cost for merging is ≈ 2 (N/B) log2 (N/M)
If the run-size is larger than B (i.e. after first step!!),fetching all of it in memory for merging does not help
How do we deploythe disk/mem features ?
Multi-way Merge-Sort
The key is to balance run-size and #runs to merge
Sort N items with main-memory M and disk-pages B:
Pass 1: Produce (N/M) sorted runs.
Pass i: merge X ≅ M/B runs logM/B N/M passes
Main memory buffers of B items
INPUT 1
INPUT X
OUTPUT
DiskDisk
INPUT 2
. . . . . .. . .
Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
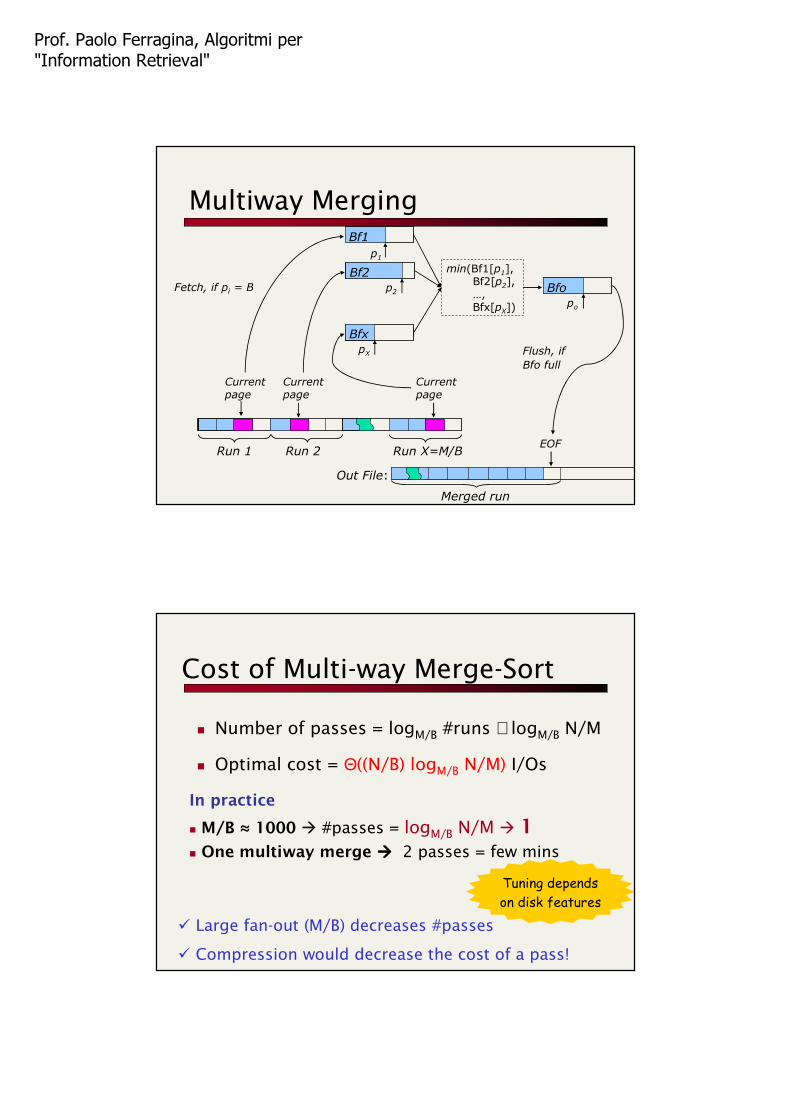
Multiway Merging
Out File:
Run 1 Run 2
Merged run
Current page
Current page
EOF
Bf1
p1
Bf2
p2 Bfo
po
min(Bf1[p1], Bf2[p2],…,Bfx[pX])
Fetch, if pi = B
Flush, if
Bfo full
Run X=M/B
Current page
Bfx
pX
Cost of Multi-way Merge-Sort
Number of passes = logM/B #runs ≅ logM/B N/M
Optimal cost = Θ((N/B) logM/B N/M) I/Os
Large fan-out (M/B) decreases #passes
In practice
M/B ≈ 1000 #passes = logM/B N/M 1 One multiway merge 2 passes = few mins
Tuning depends
on disk features
Compression would decrease the cost of a pass!
Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
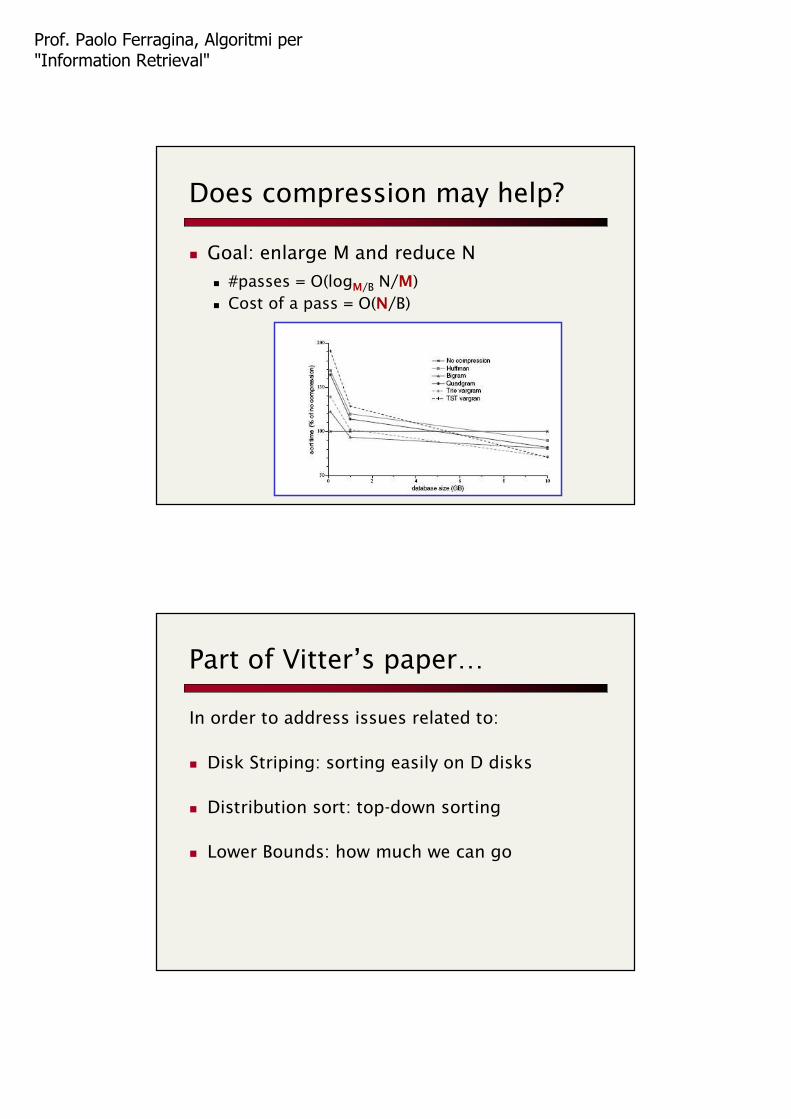
Does compression may help?
Goal: enlarge M and reduce N
#passes = O(logM/B N/M)
Cost of a pass = O(N/B)
Part of Vitter’s paper…
In order to address issues related to:
Disk Striping: sorting easily on D disks
Distribution sort: top-down sorting
Lower Bounds: how much we can go

Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
Toy problem #3: Top-freq elements
Algorithm Use a pair of variables <X,C>
For each item s of the stream,
if (X==s) then C++
else C--; if (C==0) X=s; C=1;
Return X;
Goal: Top queries over a stream of N items (Σ large).
Math Problem: Find the item y whose frequency is > N/2, using the smallest space. (i.e. If mode occurs > N/2)
ProofIf X≠y, then every one of y’soccurrences has a “negative” mate.
Hence these mates should be ≥#y.
As a result, 2 * #occ(y) > N...
A = b a c c c d c b a a a c c b c c c<b,1> <a,1><c,1><c,2><c,3> <c,2><c,3><c,2> <c,1> <a,1><a,2><a,1><c,1><b,1><c,1>.<c,2><c,3>
Problemsif ≤ N/2
Toy problem #4: Indexing
Consider the following TREC collection: N = 6 * 109 size = 6Gb
n = 106 documents
TotT= 109 (avg term length is 6 chars)
t = 5 * 105 distinct terms
What kind of data structure we build to support word-based searches ?
Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
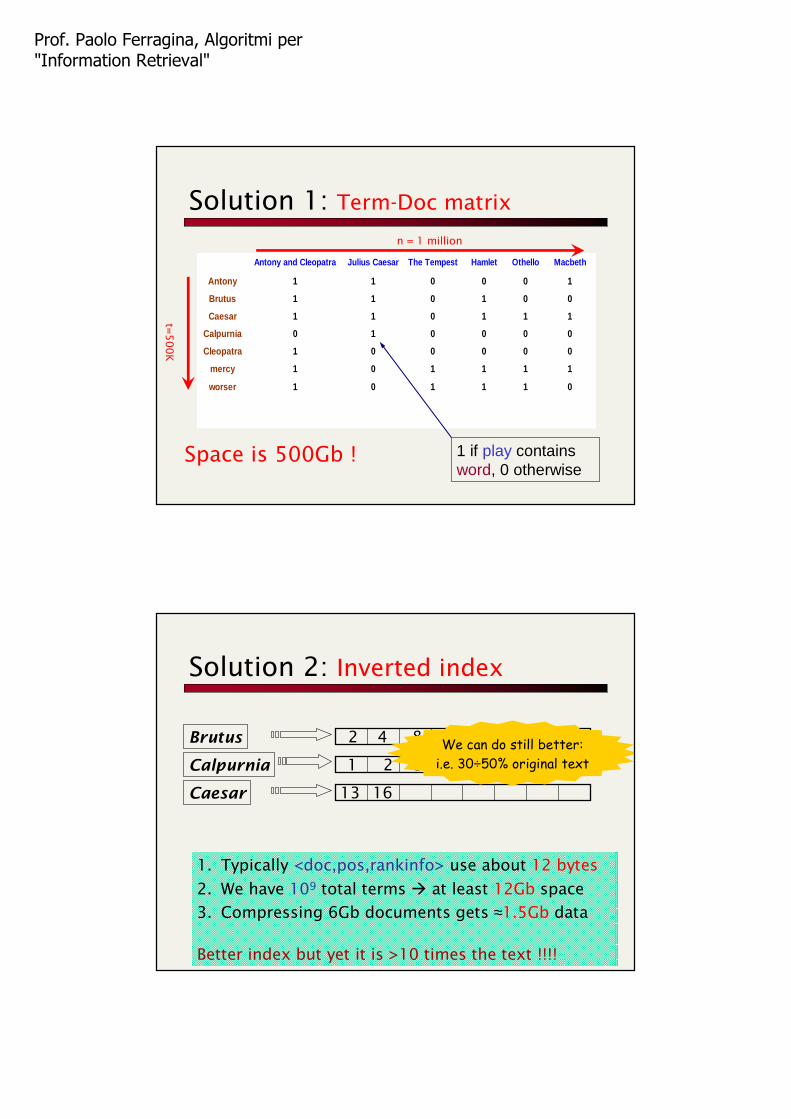
Solution 1: Term-Doc matrix
1 if play contains word, 0 otherwise
Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth
Antony 1 1 0 0 0 1
Brutus 1 1 0 1 0 0
Caesar 1 1 0 1 1 1
Calpurnia 0 1 0 0 0 0
Cleopatra 1 0 0 0 0 0
mercy 1 0 1 1 1 1
worser 1 0 1 1 1 0
t=500K
n = 1 million
Space is 500Gb !
Solution 2: Inverted index
Brutus
Calpurnia
Caesar
1 2 3 5 8 13 21 34
2 4 8 16 32 64128
13 16
1. Typically <doc,pos,rankinfo> use about 12 bytes
2. We have 109 total terms at least 12Gb space
3. Compressing 6Gb documents gets ≈1.5Gb data
Better index but yet it is >10 times the text !!!!
We can do still better:
i.e. 30÷50% original text
Prof. Paolo Ferragina, Algoritmi per "Information Retrieval"
Please !!Do not underestimate
the features of disks
in algorithmic design






![Algoritmi e Strutture Dati [24pt]Algoritmi probabilisticidisi.unitn.it/~montreso/asd/slides/17-prob.pdf8i;0 i](https://img.pdfslide.us/doc/110x75/60a8d6cc3dca5417a9000e3c/algoritmi-e-strutture-dati-24ptalgoritmi-montresoasdslides17-probpdf-8i0.jpg)