Embed Size (px)
Citation preview

Advancing Trace Recovery Evaluation
– Applied Information Retrieval in a
Software Engineering Context
Markus Borg
Licentiate Thesis, 2012
Department of Computer Science
Lund University

ii
Licentiate Thesis 13, 2012ISSN 1652-4691Department of Computer ScienceLund UniversityBox 118SE-221 00 LundSweden
Email: [email protected]: http://cs.lth.se/markus_borg
Cover art: “Exodus from the cave” by Hannah OredssonTypeset using LATEXPrinted in Sweden by Tryckeriet i E-huset, Lund, 2012
c© 2012 Markus Borg

ABSTRACT
Successful development of software systems involves the efficient navigation ofsoftware artifacts. However, as artifacts are continuously produced and modified,engineers are typically plagued by challenging information landscapes. One state-of-practice approach to structure information is to establish trace links betweenartifacts; a practice that is also enforced by several development standards. Un-fortunately, manually maintaining trace links in an evolving system is a tedioustask. To tackle this issue, several researchers have proposed treating the captureand recovery of trace links as an Information Retrieval (IR) problem. The goalof this thesis is to contribute to the evaluation of IR-based trace recovery, both bypresenting new empirical results and by suggesting how to increase the strength ofevidence in future evaluative studies.
This thesis is based on empirical software engineering research. In a System-atic Literature Review (SLR) we show that a majority of previous evaluations ofIR-based trace recovery have been technology-oriented, conducted in “the cave ofIR evaluation”, using small datasets as experimental input. Also, software artifactsoriginating from student projects have frequently been used in evaluations. Weconducted a survey among traceability researchers and found that while a majorityconsider student artifacts to be only partly representative of industrial counterparts,such artifacts were typically not validated for industrial representativeness. Ourfindings call for additional case studies to evaluate IR-based trace recovery withinthe full complexity of an industrial setting. Thus, we outline future research onIR-based trace recovery in an industrial study on safety-critical impact analysis.
Also, this thesis contributes to the body of empirical evidence of IR-based tracerecovery in two experiments with industrial software artifacts. The technology-oriented experiment highlights the clear dependence between datasets and the ac-curacy of IR-based trace recovery, in line with findings from the SLR. The human-oriented experiment investigates how different quality levels of tool output affectthe tracing accuracy of engineers. While the results are not conclusive, there areindications that it is worthwhile further investigating into the actual value of im-proving tool support for IR-based trace recovery. Finally, we present how tools andmethods are evaluated in the general field of IR research, and propose a taxonomyof evaluation contexts tailored for IR-based trace recovery in software engineering.


ACKNOWLEDGEMENTS
This work was funded by the Industrial Excellence Center EASE – EmbeddedApplications Software Engineering.
First and foremost, I would like to express my deepest gratitude to my supervisor,Prof. Dr. Per Runeson, for all his support and for showing me another continent.I will never forget the hospitality his family extended to me during my winter inNorth Carolina.
Secondly, thanks go to my assistant supervisor, Prof. Dr. Björn Regnell, forstimulating discussions in the EASE Theme D project. I am also very grateful toDr. Dietmar Pfahl. Thank you for giving your time to explain all those thingsI should have known already. I want to thank my co-authors Krzysztof Wnuk,Dr. Anders Ardö, and Dr. Saïd Assar. All of you have shown me how researchcan be discussed outside the office sphere. Furthermore, I would like to clearlyacknowledge my other colleagues at the Department of Computer Science andthe Software Engineering Research Group, as well as my colleagues in the EASETheme D project and in the SWELL research school.
Moreover, as a software engineer on study leave, I would like to recognize mycolleagues at ABB in Malmö. In particular, I want to thank my former managerHenrik Holmqvist for suggesting the position as a PhD student. Also, thanks goto both my current manager Christer Gerding for continual support, and to JohanGren for being my main entry point regarding communication with the real world.
Finally, I want to thank all my family and friends, and to express my honestgratitude to my parents for always helping me with my homework, and withoutwhose support I wouldn’t have begun this journey. And I am indebted to Hannahfor the cover art and to Ulla and Ronny for wining and dining me while I wrappedup this thesis. And most importantly, thank you to Marie for all the love and beingthe most stubborn of reviewers. Of course, you have mattered the most!
Markus BorgMalmö, August 2012
Pursuing that doctoral degree(V) (;„;) (V)


LIST OF PUBLICATIONS
Publications included in the thesis
I Recovering from a decade: A systematic literature review of informa-tion retrieval approaches to software traceabilityMarkus Borg, Per Runeson, and Anders ArdöSubmitted to a journal, 2012.
II Industrial comparability of student artifacts in traceability recovery re-search - An exploratory surveyMarkus Borg, Krzysztof Wnuk, and Dietmar PfahlIn Proceedings of the 16th European Conference on Software Maintenanceand Reengineering (CSMR’12), Szeged, Hungary, pp. 181–190, 2012.
III Evaluation of traceability recovery in context: A taxonomy for infor-mation retrieval toolsMarkus Borg, Per Runeson, and Lina BrodénIn Proceedings of the 16th International Conference on Evaluation & As-sessment in Software Engineering (EASE’12), Ciudad Real, Spain, pp. 111–120, 2012.
IV Do better IR tools improve software engineers’ traceability recovery?Markus Borg, and Dietmar PfahlIn Proceedings of the International Workshop on Machine Learning Tech-nologies in Software Engineering (MALETS’11), Lawrence, KS, USA, pp.27–34, 2011.
The following papers are related, but not included in this thesis. The researchagenda presented in Section 8 is partly based on Paper V, which was published asa position paper. Paper VI contains a high-level discussion on information man-agement in a large-scale software engineering context.

viii
Related publicationsV Findability through traceability - A realistic application of candidate
trace links?Markus BorgIn Proceedings of 7th International Conference on Evaluation of Novel Ap-proaches to Software Engineering (ENASE’12), Wrocław, Poland, pp. 173–181, 2012.
VI Towards scalable information modeling of requirements architecturesKrzysztof Wnuk, Markus Borg, and Saïd AssarTo appear in the Proceedings of the 1st International Workshop on Mod-elling for Data-Intensive Computing, (MoDIC’12), Florence, Italy, 2012.
Contribution statementMarkus Borg is the first author of all included papers. He was the main inventorand designer of the studies, and was responsible for running the research processes.Also, he conducted most of the writing.
The SLR reported in Paper I was a prolonged study, which was conducted inparallel to the rest of the work included in this licentiate thesis. The study wasco-designed with Prof. Per Runeson, but Markus Borg wrote a clear majority ofthe paper. Furthermore, Mats Skogholm, a librarian at the Lund University librarycontributed to the development of search strings, and Dr. Anders Ardö validatedthe data extraction process and reviewed technical contents of the final report.
The survey in Paper II was conducted by Markus Borg and Krzysztof Wnuk.They co-designed the study and distributed the questionnaire in parallel, howeverMarkus Borg was responsible for the collection and analysis of the data. MarkusBorg wrote a majority of the report, however with committed assistance from Dr.Dietmar Pfahl and Krzysztof Wnuk.
The experimental parts of Paper III started as a master thesis project by LinaBrodén. Markus Borg was the main supervisor, responsible for research designand collection of data from industry. Prof. Per Runeson had the role as examiner,and also gave initial input to the study design. The outcome of the master thesisproject was then used by Markus Borg as input to Paper III, who extended it witha discussion on evaluation contexts.
The experimental setup in Paper IV was originally designed by Markus Borg,and then further improved together with Dr. Dietmar Pfahl. Markus Borg executedthe experiment, analyzed the data, and conducted most of the writing. Dr. DietmarPfahl also contributed as an active reviewer and initiated rewarding discussions.

CONTENTS
Introduction 11 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 Background and Related Work . . . . . . . . . . . . . . . . . . . 23 Research Focus . . . . . . . . . . . . . . . . . . . . . . . . . . . 94 Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136 Synthesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157 Threats to Validity . . . . . . . . . . . . . . . . . . . . . . . . . . 188 Agenda for Future Research . . . . . . . . . . . . . . . . . . . . 209 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24Bibliography . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
I Recovering from a Decade: A Systematic Review of Information Re-trieval Approaches to Software Traceability 371 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . . 444 Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 525 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 616 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 727 Summary and Future Work . . . . . . . . . . . . . . . . . . . . . 81Bibliography . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
II Industrial comparability of student artifacts in traceability recoveryresearch - An exploratory survey 1111 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1122 Background and Related Work . . . . . . . . . . . . . . . . . . . 1133 Research Design . . . . . . . . . . . . . . . . . . . . . . . . . . 1154 Results and Analysis . . . . . . . . . . . . . . . . . . . . . . . . 1195 Threats to Validity . . . . . . . . . . . . . . . . . . . . . . . . . . 1266 Discussion and Concluding Remarks . . . . . . . . . . . . . . . . 127

x CONTENTS
Bibliography . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
III Evaluation of Traceability Recovery in Context: A Taxonomy for In-formation Retrieval Tools 1331 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1342 Background and Related work . . . . . . . . . . . . . . . . . . . 1353 Derivation of Context Taxonomy . . . . . . . . . . . . . . . . . . 1374 Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1385 Results and Interpretation . . . . . . . . . . . . . . . . . . . . . . 1446 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1457 Conclusions and Future Work . . . . . . . . . . . . . . . . . . . . 150Bibliography . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
IV Do Better IR Tools Improve the Accuracy of Engineers’ TraceabilityRecovery? 1571 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1582 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1593 Experimental Setup . . . . . . . . . . . . . . . . . . . . . . . . . 1604 Results and Data Analysis . . . . . . . . . . . . . . . . . . . . . 1655 Threats to Validity . . . . . . . . . . . . . . . . . . . . . . . . . . 1686 Discussion and Future Work . . . . . . . . . . . . . . . . . . . . 171Bibliography . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173

1 Introduction 1
1 Introduction
Modern society depends on software-intensive systems. Software operates invis-ibly in everything from kitchen appliances to critical infrastructure, and livinga life without daily relying on systems running software requires a determineddownshifting from life as most people enjoy it. As the significance of softwarecontinuously grows, so does the importance of being able to create it efficiently.
Software development is an inclusive expression used to describe any approachto produce source code and its related documentation. During the software crisis ofthe 1960s, it became clear that software complexity quickly rises when scaled up tolarger systems. The development methods that were applied at the time did not re-sult in required software in a predictable manner. Software engineering was coinedto denote software developed according to a systematic and organized approach,aiming to effectively produce high-quality software with reduced uncertainty [72].By applying the engineering paradigm to software development, activities such asanalysis, specification, design, implementation, verification, and evolution turnedinto well-defined practices. On the other hand, additional knowledge-intensiveactivities tend to increase the number of documents maintained in a project [97].
Large projects risk being characterized by information overload, a state whereindividuals do not have time or capacity to process all available information [33].Knowledge workers frequently report the stressing feeling of having to deal withtoo much information [32], and in general spend a substantial effort on locatingrelevant information [59, 65]. Also, in software engineering the challenge of deal-ing with a plentitude of software artifacts has been highlighted [37, 74]. Thus,an important characteristic of a software engineering organization is the findabil-ity it provides, herein defined as “the degree to which a system or environmentsupports navigation and retrieval” [71], particularly in globally distributed devel-opment [28].
One state-of-practice way to support findability in software engineering is tomaintain trace links between artifacts. Traceability is widely recognized as an im-portant factor for efficient software engineering [5, 18, 29]. Traceability supportsengineering activities related to software evolution, e.g., change management, im-pact analyses, and regression testing [5, 16]. Also, traceability assists engineers inless concrete tasks such as system comprehension, knowledge transfer, and processalignment [23, 80, 85]. On the other hand, maintaining trace links in an evolvingsystem is known to be a tedious task [29,34,48]. Thus, to support trace link main-tenance, several researchers have proposed tool support for trace recovery, i.e.,proposing candidate trace links among existing artifacts, based on InformationRetrieval (IR) approaches [5, 23, 48, 68, 70]. The rationale is that IR refers to a setof techniques for finding relevant documents from within large collections [6, 69],and that the search for trace links can be interpreted as an attempt to satisfy aninformation need.
This thesis includes an aggregation of empirical evidence of IR-based trace

2 INTRODUCTION
recovery, and contributes to the body of knowledge on conducting evaluative stud-ies on IR-based trace recovery tools. As applied researchers, our main interestlies in understanding how feasible trace recovery tools would be for engineers inindustrial settings. Paper I contains a comprehensive literature review of previousresearch on the topic. Based on questions that arose during the literature review,other studies were designed and conducted in parallel. Paper II provides an in-creased understanding of the validity of using artifacts originating from studentprojects as experimental input. Paper III reports from an experiment with trace re-covery tools on artifacts collected from industry, and also proposes a taxonomy ofevaluation contexts tailored for IR-based trace recovery. Finally, Paper IV presentsa novel experiment design, addressing the value of slight tool improvements.
This introduction chapter provides a background for the papers and describesrelationships between studies. The remainder of this chapter is organized as fol-lows. Section 2 presents a brief background of traceability research and introducesfundamentals of IR. Also, it presents how IR can be applied to address trace recov-ery. Section 3 expresses the overall aim of this thesis as research questions, andproposes three viewpoints from which the results can be interpreted. Also, Sec-tion 4 presents the research methodologies used to answer the research questions.The results of each individual paper are presented in Section 5, while Section 6draws together the results to provide answers to the research questions. Section 7highlights some threats to validity in the presented research. In Section 8, wepresent how we plan to continue our work in future studies. Finally, Section 9concludes the introduction of this thesis.
2 Background and Related Work
This section presents a background of traceability and IR, the two main researchareas on which this thesis rests. Also, we present how IR has been applied tosupport trace link maintenance. Finally, we present related work on advancingIR-based trace recovery evaluation.
2.1 Traceability - A Fundamental Software EngineeringChallenge
The concept of traceability has been discussed in software engineering since thevery beginning. Already at the pioneering NATO Working Conference on Soft-ware Engineering in 1968, a paper by Randall recognized the need for a devel-oped software system to “contain explicit traces of the design process” [81]. Inan early survey of software engineering state-of-the-art in the 1970s by Boehm,“traceability” was mentioned six times, both in relation to engineering challengesat the time, and when predicting future trends [12]. In the software industry, trace-ability became acknowledged as an important aspect in high quality development.

2 Background and Related Work 3
Consequently, by the 1980s several development standards specified process re-quirements on the maintenance of traceability information [30]. At the time, theIEEE definition of traceability was “the degree to which a relationship can be es-tablished between two or more products of the development process, especiallyproducts having a predecessor-successor or master-subordinate relationship to oneanother; for example, the degree to which the requirements and design of a givensoftware component match” [50].
In the 1990s, the requirements engineering community emerged and estab-lished dedicated publication fora. As traceability was in scope, published researchon the topic increased and its relation to requirements engineering was further em-phasized. A paper by Gotel and Finkelstein in 1994 identified the lack of a com-mon definition of requirements traceability and suggested: “Requirements trace-ability refers to the ability to describe and follow the life of a requirement, in botha forwards and backwards direction (i.e., from its origins, through its developmentand specification, to its subsequent deployment and use, and through all periodsof on-going refinement and iteration in any of these phases)” [40]. According to arecent systematic literature review by Torkar et al., this definition of requirementstraceability is the most commonly cited in research publications [91].
While traceability has been questioned by some of the lean-thinkers of theagile movement in the 2000s to be too costly in relation to its benefits [79], trace-ability continues to be a fundamental aspect in many development contexts. Sincetraceability is important to software verification, general safety standards such asIEC 61508 [53], and industry-specific variants (e.g., ISO 26262 in the automo-tive industry [54] and IEC 61511 in the process industry [52]) mandate mainte-nance of traceability information. Furthermore, as traceability has a connectionto quality, it is also required by organizations aiming at process improvement asdefined by CMMI (Capability Maturity Model Integration) [14]. Thus, traceabilityis neither negotiable in safety certifications nor in CMMI appraisals. In 2006, theinternational organization CoEST, the Center of Excellence for Software Trace-ability1, was founded to gather academics and practitioners to advance traceabilityresearch.
In the beginning of 2012, an extensive publication edited by Cleland-Huang etal. was published [18], containing contributions from several leading researchersin the traceability community. Apart from summarizing various research topics ontraceability, the work presents a number of fundamental definitions. We follow theproposed terminology in the introduction chapter of this thesis. However, whenthe included Papers II-IV were written, the terminology was not yet aligned in thecommunity. Cleland-Huang et al. define traceability as: “the potential for traces tobe established and used” [39], i.e., the trace ability is stressed. On the other hand,they also present the more specific definition of requirements traceability by Goteland Finkelstein in its original form.
1www.coest.org

4 INTRODUCTION
A number of other terms relevant for this thesis are also defined in the book.A trace artifact denotes a traceable unit of data. A trace link is an associationforged between two trace artifacts, representing relations such as overlap, depen-dency, contribution, evolution, refinement, or conflict [80]. The main subject inthis thesis, trace recovery, denotes an approach to create trace links among ex-isting software artifacts. This is equivalent to what we consistently referred to astraceability recovery in the Papers II-IV.
2.2 Information Retrieval - Satisfying an Information Need
A central concept in this thesis is information seeking, the “conscious effort toacquire information in response to a gap in knowledge” [15]. Particularly, we areinterested in finding pieces of information that enable trace links to be recovered,i.e. trace link seeking. One approach to seek information is information retrieval,meaning “finding material (usually documents) of an unstructured nature (usuallytext) that satisfies an information need from within large collections (usually storedon computers)” [69]. This section briefly presents the two main categories of IRmodels. A longer presentation is available in Paper I.
Typically, IR models apply the bag-of-words model, a simplifying assumptionthat represents a document as an unordered collection of words, disregarding wordorder [69]. Most IR models can be classified as either algebraic or probabilistic,depending on how relevance between queries and documents is measured. Alge-braic IR models assume that relevance is correlated with similarity, while prob-abilistic retrieval is based on models estimating the likelihood of queries beingrelated to documents.
The Vector Space Model (VSM), developed in the 1960s, is the most com-monly applied algebraic IR model [86]. VSM represents both documents andqueries as vectors in a high-dimensional space and similarities are calculated be-tween vectors using distance functions. In principle, every term constitutes a di-mension. Usually, terms are weighted using some variant of Term Frequency-Inverse Document Frequency (TF-IDF). TF-IDF is used to weight a term basedon the length of the document and the frequency of the term, both in the docu-ment and in the entire document collection. Latent Semantic Indexing (LSI) isan approach to reduce the dimension space, sometimes successful in reducing theeffects of synonymy and polysemy [25]. LSI uses singular value decompositionto transform the dimensions from individual terms to combinations of terms, i.e.,concepts constitute the dimensions rather than individual terms.
In probabilistic models, documents are ranked according to their probabilityof being relevant to the query. Two common models are the Binary Independenceretrieval Model (BIM) [25] [82] and Probabilistic Inference Networks [92]. A sub-set of probabilistic retrieval estimate Language Models (LM) for each document.Documents are then ranked based on the probability that a document would gen-erate the terms of a query [78]. A later refinement of simple LMs, topic models,

2 Background and Related Work 5
describes documents as a mixture over topics, where each topic is characterized byan LM. Examples include probabilistic latent semantic indexing [45] and LatentDirichlet Allocation (LDA) [11].
2.3 Information Retrieval Evaluation
IR is a highly experimental discipline, and empirical evaluations are the main re-search tool to scientifically compare IR algorithms. The state-of-the-art has ad-vanced through careful examination and interpretation of experimental results.Traditional IR evaluation, as it was developed by Cleverdon in the Cranfield projectin the late 1950s [20], consists of three main elements: a document collection, a setof information needs (typically formulated as queries), and relevance judgmentstelling what documents are relevant to these information needs, i.e., a gold stan-dard. Thus, as the experimental units are central in IR evaluation it is important toaddress threats to content validity, i.e., the extent to which the experimental unitsreflect and represent the elements of the domain under study [93]. A selection ofexperimental units that match the real-world setting should carefully be selected,and the sample should be sufficiently large to be representative to the domain.
The most common way to evaluate the effectiveness of an IR system is tomeasure precision and recall. As displayed in Figure 1, precision is the fractionof retrieved documents that are relevant, while recall is the fraction of relevantdocuments that are retrieved. The outcome is often visualized as a Precision-Recall(P-R) curve where the average precision is plotted at fixed recall values, presentedas PR@Fix in Figure 1. However, this set-based approach has been criticizedfor being opaque, as the resulting curve obscure the actual numbers of retrieveddocuments needed to get beyond low recall [90]. Alternatively, the ranking ofretrieval results can be taken into account. The most straightforward approachis to plot the P-R curve for the top k retrieved documents instead [69], shownas PR@k in Figure 1. In such curves, one can see the average accuracy of thefirst search result, the first ten search results etc. The Text Retrieval Conference(TREC), hosting the most distinguished evaluation series for IR, reports resultsusing both precision at 11 fixed recall values (0.0, 0.1 ... 1.0) and precision at thetop 5, 10, 15, 30, 100 and 200 retrieved documents [90]. A discussion on IR-basedtrace recovery evaluation styles is available in Paper I.
There are several other measures available for IR evaluations, including F-measure, ROC curve, R-precision and the break-even point [69], but none of themare as established as P-R curves. On the other hand, two measures offering sin-gle figure effectiveness have gained increased attention. Mean Average Precision(MAP), roughly the area under the P-R curve for a set of queries, is establishedin the TREC community. Normalized Discounted Cumulative Gain [56], similarto precision at top k retrieved documents but especially designed for non-binaryrelevance judgments, is popular especially among researchers employing machinelearning techniques to rank search results.

6 INTRODUCTION
Figure 1: Traditional IR evaluation using P-R curves showing PR@Fix andPR@k. In the center part of the figure, displaying a document space, the rele-vant items are to the right of the straight line while the retrieved items are withinthe oval.
The experimental setups of IR evaluations rarely fulfil assumptions requiredfor significance testing, e.g., independence between retrieval results, randomlysampled document collections, and normal distributions. Thus, traditional statis-tics has not had a large impact on IR evaluation [41]. However, it has been pro-posed both to use hypergeometric distributions to compute retrieval accuracy to beexpected by chance [87], and to apply the Monte Carlo method [13].
Although IR evaluation has been dominated by technology-oriented experi-ments, it has also been challenged for its unrealistic lack of user involvement [61].Ingwersen and Järvelin argued that IR is always evaluated in a context and pro-posed an evaluation framework, where the most simplistic evaluation context isreferred to as “the cave of IR evaluation” [51]. In Paper III, we present theirframework and an adapted version tailored for IR-based trace recovery.
2.4 Trace Recovery - An Information Retrieval Problem
Tool support for linking artifacts containing Natural Language (NL) has been ex-plored by researchers since at least the early 1990s. Whilst a longer history of IR-based trace recovery is available in Paper I, this section introduces the approachand highlights some key publications.
The underlying assumption of using IR for trace recovery is that artifacts withhighly similar textual content are good candidates to be linked. Figure 2 shows thekey steps involved in IR-based trace recovery, organized in a pipeline architectureas suggested by De Lucia et al. [24]. First, input documents are parsed and prepro-cessed, typically using stop word removal and stemming. In the second step, the

2 Background and Related Work 7
Figure 2: Key steps in IR-based trace recovery, adapted from De Lucia et al. [24].
documents are indexed using the IR model. Then, candidate trace links are gen-erated, ranked according to the IR model, and the result is visualized. Finally, theresult is presented to the engineer, as emphasized in Figure 2, who gets to assessthe output. The rationale is that it is faster for an engineer to assess a ranked listof candidate trace links, despite both missed links and false positives, than seekingtrace links from scratch.
In 1998, a pioneering study by Fiutem and Antoniol proposed a trace recov-ery process to bridge the gap between design and code, based on edit distancesbetween NL content of artifacts [36]. They coined the term “traceability recov-ery”, and published several papers on the topic. Also, they were the first to expressidentification of trace links as an IR problem [4]. Their well-cited work from 2002compared the accuracy of candidate trace links from two IR models, BIM andVSM [5]. Marcus and Maletic were the first to apply LSI to recover trace linksbetween source code and NL documentation [70]. Huffman Hayes et al. enhancedtrace recovery based on VSM with relevance feedback. They had from early on ahuman-oriented perspective, aiming at supporting V&V activities at NASA usingtheir tool RETRO [49]. De Lucia et al. have conducted work focused on empir-ically evaluating LSI-based traceability recovery in their document managementsystem ADAMS [22]. They have advanced the empirical foundation by conductinga series of controlled experiments and case studies with student subjects. Cleland-Huang and colleagues have published several studies using probabilistic IR modelsfor trace recovery, implemented in their tool Poirot [66]. Much of their work hasfocused on improving the accuracy of their tool by various enhancements.
Lately, a number of publications suggest that the P-R differences for tracerecovery between different IR models are minor. Oliveto et al. compared VSM,LSI, LM and LDA on artifacts originating from two student projects, and foundno significant differences [73]. Also a review by Binkley and Lawrie reportedthe same phenomenon [10]. Falessi et al. proposed a taxonomy of algebraic IRmodels and experimentally studied how differently configured algebraic IR modelsperformed in detecting duplicated requirements [34]. They concluded that simpleIR solutions tend to produce more accurate output.
We have identified some progress related to IR-based trace recovery in non-academic environments. In May 2012, a US patent with the title “System andmethod for maintaining requirements traceability” was granted [9]. The patent ap-

8 INTRODUCTION
plication, filed in 2007, describes an application used to synchronize artifacts in arequirements repository and a testing repository. Though the actual linking processis described in general terms, a research publication implementing trace recoverybased on LSI is cited. Also indicating industrial interest in IR-based trace recoveryis that HP Quality Center, a component of HP Application Lifecycle Management,provides a feature to link artifacts based on textual similarity analysis [44]. Whileit is implemented to detect duplicate defect reports, the same technique could beapplied for trace recovery.
2.5 Previous Work on Advancing IR-based Trace Recov-ery Evaluation
While there are several general guidelines on software engineering research (e.g.,experiments [95], case studies [84], reporting [57], replications [88], literaturereviews [62]), only few publications have specifically addressed research on IR-based trace recovery. The closest related work is described in this section.
Huffman Hayes and Dekhtyar proposed a framework for comparing experi-ments on requirements tracing [47]. Their framework describes the four exper-imental phases: definition, planning, realization and interpretation. We evalu-ated the framework in Paper III, and concluded that it provides valuable structurefor conducting technology-oriented experiments. However, concerning human-oriented experiments, there is room for enhancements. Huffman Hayes et al. alsosuggested categorizing trace recovery research as either studies of methods (arethe tools capable of providing accurate results fast?) or studies of human analysts(how do humans use the tool output?) [48]. Furthermore, in the same publica-tion, they suggested assessing the accuracy of tool output according to the qualityintervals “Acceptable/Good/Excellent”, with specified P-R levels. In Paper I, wecatalog the primary publications according to their suggestions, but we also catalogthe primary publications according to the context taxonomy we propose in PaperIII. A recent publication by Falessi et al. proposed seven “empirical principles”for technology-oriented evaluation of IR tools in software engineering, explicitlymentioning trace recovery as one application [35]. Despite the absence of statisti-cal analysis in traditional IR evaluation [41], they argued for both increased differ-ence and equivalence testing. In Paper IV, we also propose equivalence testing ofIR-based trace recovery, however in the context of human-oriented experiments.
A number of researchers connected to CoEST have repeatedly argued that arepository of benchmarks for trace recovery research should be established, in linewith what has driven large scale IR evaluations at TREC [17,26,27]. Furthermore,Ben Charrada et al. have presented a possible benchmark for traceability studies,originating from an example in a textbook on software design [8]. We support theattempt to develop large public datasets, but there are also risks involved in bench-marks. As mentioned in Section 2.3, the results of IR evaluations depend on theexperimental input. Thus, there is a risk of over-engineering tools on datasets that

3 Research Focus 9
Tool developer Which IR model should we implement in our(Paper I, Paper IV) new trace recovery tool?RQ1 Which IR model has most frequently been imple-
mented in research tools?RQ2 Which IR model has displayed the most promising
results?Development manager Should we deploy an IR-based trace recovery(Paper I, II) tool in our organization?RQ3 What evidence is there that IR-based trace recovery
is feasible in an industrial setting?Traceability researcher How can we strengthen the base of empirical(Paper I, III) evidence of IR-based trace recovery?RQ4 How can we advance technology-oriented studies
on IR-based trace recovery?RQ5 How can we advance human-oriented studies
on IR-based trace recovery?
Table 1: Viewpoints further broken down into RQs. The scope of trace recoveryis implicit in RQ1-2, while explicit in RQ3-5.
do not have acceptable content validity. Benchmarking in IR-based trace recoveryis further discussed in Paper III.
Another project, also promoted by CoEST, is the TraceLab project [17, 60].TraceLab is a visual experimental workbench, highly customized for traceabil-ity research. It is currently under Alpha release to project collaborators. CoESTclaims that it can be used for designing, constructing, and executing trace recoveryexperiments, and facilitating evaluation of different techniques. TraceLab is saidto be similar to existing data mining tools such as Weka and RapidMiner, and aimsat providing analogous infrastructure to simplify experimentation on traceability.However, to what extent traceability researchers are interested in a common ex-perimental workbench remains an open question.
3 Research Focus
This section describes how this thesis contributes to the body of knowledge onIR-based trace recovery in general, and evaluations of IR-based trace recoveryin particular. We base the discussion on the viewpoints from the perspectives ofthree stakeholders, each with his own pictured consideration: (1) a CASE tooldeveloper responsible for a new trace recovery tool, (2) a manager responsible fora large software development organization, and (3) an academic researcher tryingto advance the trace recovery research frontier. We further divide each viewpointinto more specific Research Questions (RQ), as presented in Table 1.

10 INTRODUCTION
As the included papers are closely related, all papers to some extent contributeto the three viewpoints. Paper I is the most recent publication included in thisthesis, and by far the most comprehensive. As such, it contributes to all individ-ual RQs presented in Table 1. Papers II, III, and IV primarily address the RQsfrom the perspective of a development manager, an academic researcher, and atool developer respectively. Figure 3 positions this thesis in relation to existing re-search on IR and its application on traceability. The rows in the figure show threedifferent research foci: development and application of retrieval models, improv-ing technology-oriented IR evaluations, and improving human-oriented IR evalu-ations. The arrows A-C indicate how approaches from the IR domain have beenapplied in traceability research.
• The A arrow represents pioneering work on applying IR models to trace re-covery, such as presented by Antoniol et al. [5] and Marcus and Maletic [70].
• The B arrow denotes contributions to technology-oriented evaluations of IR-based trace recovery, inspired by methods used in the general IR domain.Examples include the experimental framework proposed by Huffman Hayesand Dekhtyar [47] and CoEST’s ambition to create benchmarks [17].
• The context taxonomy we propose in Paper III is an example of work alongarrow C, where we apply results from human-oriented IR evaluations totraceability research.
To the right in Figure 3, the internal relations among the included papers arepresented. The study in Paper II on industrial comparability of student artifactswas initiated to further explore early results from the work in Paper I. The exper-iment on human subjects in Paper IV was designed to further analyze the differ-ences between the technology-oriented experimental results in Paper III. Finally,the evaluation taxonomy proposed in paper IV was used in Paper I to structureparts of the literature review.
The right box in Figure 3 also shows to which research focus the includedpapers mainly contribute. Paper I contributes to all foci. Paper II mainly con-tributes to improving technology-oriented IR evaluations, as it addresses the con-tent validity of experimental input originating from student projects. Paper IIIproposes a taxonomy of evaluation contexts, and thus contributes to improvinghuman-oriented IR evaluations. Finally, while Paper IV questions the implicationsof minor differences of tool output in previous technology-oriented experiments,we consider it to mainly contribute by providing empirical results on the applica-tion of IR models on a realistic work task involving trace recovery.
4 MethodThe research in this thesis is mainly based on empirical research, a way to obtainknowledge through observing and measuring phenomena. Empirical studies result

4 Method 11
Figure 3: Contributions of this thesis, presented in relation to research on IRand traceability. Arrows A-C denote examples of knowledge transfer between thedomains. The right side of the figure positions the individual papers of this thesis,and shows their internal relationships.
in evidence, pieces of information that support conclusions. Since evidence isneeded to build and verify theories [63], empirical studies should be conducted toimprove the body of software engineering knowledge [31, 84, 89]. However, asengineers, we also have an ambition to create innovations that advance the fieldof software engineering. One research paradigm that seeks to create innovativeartifacts to improve the state-of-practice is design science [43]. Design scienceoriginates from engineering and is fundamentally a problem solving paradigm. Aspresented in Figure 4, the build-evaluate loop is central in design science (in somedisciplines referred to as action research [83]). Based on empirical understandingof a context, innovations in the form of tools and practices are developed. Theinnovations are then evaluated empirically in the target context. These steps mightthen be iterated until satisfactory results have been reached.
This thesis mainly contains exploratory and evaluative empirical research,based on studies using experiments, surveys, and systematic literature reviews asresearch methodology. However, also case studies are relevant for this thesis, assuch studies are discussed as possible future work in Section 8. Future work alsoinvolves design tasks to improve industry practice, after proper assessment.
Exploratory research is typically conducted in early stages of research projects,and attempts to bring initial understanding to a phenomenon, preferably from richqualitative data [31]. An exploratory study is seldom used to draw definitive con-clusions, but is rather used to guide further work. Decisions on future study design,data collection methods, and sample selections can be supported by preceding ex-ploratory research. Paper I and Paper II explored both tool support for IR-based

12 INTRODUCTION
Figure 4: Design science and the build-evaluate loop. Adapted from Hevner etal. [43]
trace recovery in general, and evaluation of such tools in particular.Evaluative research can be conducted to assess the effects and effectiveness of
innovations, interventions, practices etc. [83]. An evaluative study involves a sys-tematic collection of data, which can be of both qualitative and quantitative nature.Paper III contains a quantitative evaluation of two IR-based trace recovery toolscompared to a naïve benchmark. Paper IV reports from an evaluation comparinghow human subjects solve a realistic work task when supported by IR-based tracerecovery. Both papers use industrial artifacts as input to the evaluative studies.
4.1 Research Methods
Experiments (or controlled experiments) are commonly used in software engineer-ing to investigate the cause-effect relationships of introducing new methods, tech-niques or tools. Different treatments are applied to or by different subjects, whileother variables are kept constant, and the effects on outcome variables are mea-sured [95]. Experiments are categorized as either technology-oriented or human-oriented, depending on whether objects or human subjects are given various treat-ments. Involving human subjects is expensive, consequently university studentsare commonly used and not engineers working in industry [46]. Paper III presentsa technology-oriented experiment, while Paper IV describes an experimental setupof a human-oriented experiment, and results from a pilot run using both studentsand senior researchers as subjects.
A case study in software engineering is conducted to study a phenomenonwithin its real-life context. Such a study draws on multiple sources of evidenceto investigate one or more instances of the phenomenon, and is especially appli-cable when the boundary between phenomenon and its context cannot be clearlyspecified [84]. While this thesis does not include any case studies, such studies areplanned as future work, and are further discussed in Section 8.

5 Results 13
Works Type of research Research methodPaper I Exploratory Systematic literature reviewPaper II Exploratory Questionnaire-based surveyPaper III Evaluative Technology-oriented experimentPaper IV Evaluative Human-oriented experiment
Table 2: Type and method of research in the included papers.
A Systematic Literature Review (SLR) is a secondary study aimed at aggregat-ing a base of empirical evidence. It is an increasingly popular method in softwareengineering research, relying on a rigid search and analysis strategy to ensure acomprehensive collection of publications [62]. A variant of an SLR is a Sys-tematic Mapping (SM) study, a less granular literature study, designed to identifyresearch gaps and direct future research [62, 76]. The primary contribution of thisthesis comes from the SLR presented in Paper I.
Survey research is used to describe what exists, and to what extent, in a givenpopulation [55]. Three distinctive characteristics of survey research can be identi-fied [77]. First, it is used to quantitatively (sometimes also qualitatively) describeaspects of a given population. Second, the collected data is collected from peopleand thus subjective. Third, survey research uses findings from a portion of a popu-lation to generalize back to the entire population. Surveys can be divided into twocategories based on how they are executed: written surveys (i.e., questionnaires)and verbal surveys (i.e., telephone or face-to-face interviews). Paper II reports howvalid traceability researchers consider studies on student artifacts to be, based onempirical data collected using a questionnaire-based survey.
Table 2 summarizes the type of research, and the selected research method, inthe included papers.
5 Results
This section presents the main results from each of the included papers.
Paper I: A Systematic Literature Review of IR-based TraceRecovery
The objective of the study was to conduct a comprehensive review of IR-basedtrace recovery. Particularly focusing on previous evaluations, we explored col-lected evidence of the feasibility of deploying an IR-based trace recovery tool inan industrial setting. Using a rigorous methodology, we aggregated empirical datafrom 132 studies reported in 79 publications. We found that a majority of thepublications implemented algebraic IR models, most often the classic VSM. Also,

14 INTRODUCTION
we found that no IR model regularly outperforms VSM. Most studies do not an-alyze the usefulness of the IR-based trace recovery further than tool output, i.e.,evaluations conducted “in the cave”, entirely based on P-R curves dominate. Thestrongest evidence of the benefits of IR-based trace recovery comes from a num-ber of controlled experiments. Several experiments report that subjects performcertain software engineering work tasks faster (and/or with higher quality) whensupported by IR-based trace recovery tools. However, the experimental settingshave been artificial using mainly student subjects and small sets of software arti-facts. In technology-oriented evaluations, we found a clear dependence betweendatasets used in evaluations and the experimental results. Also, we found that fewcase studies have been conducted, and only one in an industrial context. Finally,we conclude that the overall quality of reporting should be improved regardingboth context and tool details, measures reported, and use of IR terminology.
Paper II: Researchers’ Perspectives on the Validity of Stu-dent Artifacts
While conducting the SLR in Paper I, we found that in roughly half of the evalu-ative studies on IR-based trace recovery, output from student projects was used asexperimental input. Paper II explores to what extent student artifacts differ fromindustrial counterparts when used in evaluations of IR-based trace recovery. In asurvey among authors identified in the SLR in Paper I, including both academicsand practitioners, we found that a majority of the respondents consider softwareartifacts originating from student projects to be only partly comparable to indus-trial artifacts. Moreover, only few respondents reported that they validated studentartifacts for industrial representativeness before using them as experimental input.Also, our respondents made suggestions for improving the description of artifactsets used in IR-based trace recovery studies.
Paper III: A Taxonomy of Evaluation Contexts and a CaveStudy
Paper III contains a technology-oriented experiment, an evaluation “in the cave”,of two publicly available IR-based trace recovery tools. We use both a de-factotraceability benchmark originating from a NASA project, and artifacts collectedfrom a company in the domain of process automation. Our study shows that eventhough both artifact sets contain software artifacts from embedded development,their characteristics differ considerably, and consequently the accuracy of the re-covered trace links. Furthermore, Paper III proposes a context taxonomy for eval-uations of IR-based trace recovery, covering evaluation contexts from “the cave”to in-vivo evaluations in industrial projects. This taxonomy was then used to struc-ture parts of the SLR in Paper I.

6 Synthesis 15
Paper IV: Towards Understanding Minor Tool Improvements
Since a majority of previous studies evaluated IR-based trace recovery only basedon P-R curves, one might wonder to what extent minor improvements of tool out-put actually influence engineers working with the tools. Is it worthwhile to keephunting slight improvements in precision and recall? To tackle this question, weconducted a pilot experiment with eight subjects, supported by tool output fromthe two tools evaluated in Paper IV. As such, the subjects were supported by tooloutput matching two different P-R curves. Inspired by research in medicine, morespecifically a study on vaccination coverage [7], we then analyzed the data usingstatistical testing of equivalence [94]. The low number of subjects did not resultin any statistically significant results, but we found that the effect size of beingsupported by the slightly more accurate tool output was of practical significance.While our results are not conclusive, the pilot experiment indicates that it is worth-while to investigate further into the actual value of improving tool support for tracerecovery, in a replication with more subjects.
6 Synthesis
This section presents a synthesis of the results from the included papers to provideanswers to the research questions asked in this thesis.
RQ1: Which IR model has most frequently been imple-mented in research tools?
Paper I concludes that algebraic IR models have been implemented more oftenthan probabilistic IR models. Although there has been an increasing trend of tracerecovery based on probabilistic LMs the last five years, a majority of publicationsreport IR-based trace recovery using vector space retrieval. In roughly half of thepapers applying VSM, the number of dimensions of the vector space is reducedusing LSI. However, it is important to note that one reason for the many studies onvector space retrieval is that it is frequently used as a benchmark when comparingthe output from more advanced IR models.
RQ2: Which IR model has displayed the most promisingresults?
As presented in Paper I, no IR model has been reported to repeatedly outperformthe classic VSM developed in the 60s. This confirms previous work by Oliveto etal. [73], Binkley and Lawrie [10], and Falessi et al. [34]. Instead, our work showsthat the input software artifacts have a much larger impact on the outcome of tracerecovery experiments than the choice of IR model. While this is well known in

16 INTRODUCTION
IR research [69], and has been mentioned by Ali et al. in the traceability commu-nity [2], it has not been highlighted as clearly before in traceability research.
RQ3: What evidence is there that IR-based trace recoveryis feasible in an industrial setting?
The software engineering literature identified in Paper I does not contain any sub-stantial success stories from in-vivo evaluations. Only one industrial case study,conducted in a short 5-people project, has reported that IR-based trace recoverywas beneficial. Apart from this study, the strongest empirical evidence comes fromcontrolled experiments with student subjects (similar to our contribution in PaperIV) and case studies in student projects. While these studies suggest that certaintraceability-centric work tasks can be supported by IR-based trace recovery tools,the majority of studies do not go further than reporting P-R curves “in the caveof IR evaluation” (similar to our contribution in Paper III). However, some identi-fied non-academic activity indicates a usefulness of the approach. In May 2012, apatent was granted protecting a “System and method for maintaining requirementstraceability” [9]. Furthermore, the CASE tool HP Quality Center describes an IRfeature in its marketing of the product [44].
RQ4: How can we advance technology-oriented studieson IR-based trace recovery?
As the results of IR-based trace recovery are so dependent on the input softwareartifacts, there is little value in additional evaluations based on a small numberof artifacts. It is critical to conduct experiments on large, preferably publiclyavailable, datasets. While this has been proposed by members of COEST be-fore [8, 17, 26, 27], Paper I underlines how few previous evaluations have beenconducted using datasets of reasonable size. Moreover, in Paper II we argue that ifstudent artifacts are to be used as experimental input, they should first be properlyvalidated for industrial representability. In the IR sub-domain of enterprise search,it has been proposed to extract documents from companies that no longer exist [42](e.g., Enron), an option that could be explored also in software engineering. In Pa-per I we argue that the reporting of technical details of IR implementations shouldbe improved, while Paper II stresses the importance to clearly describe the inputartifacts in technology-oriented experiments. Describing the artifacts is especiallyimportant in studies where the artifacts cannot be disclosed, e.g., for confidential-ity reasons, as it obstructs secondary studies.
6 Synthesis 17
Viewpoint Consideration Recommendation
Tool devel-oper
Which IR model shouldwe implement in our newtrace recovery tool?
The classic VSM, since sev-eral efficient implementationsare available as open source.There is no empirical evidencethat more advanced IR mod-els produce more accurate tracelinks.
Developmentmanager
Should we deploy an IR-based trace recovery toolin our organization?
Await empirical evidence fromfuture in-vivo studies. In themeantime, assure that your gen-eral search solutions make traceartifacts findable.
Traceabilityresearcher
How can we strengthenthe base of empirical ev-idence of IR-based tracerecovery?
Case studies in industrial set-tings are required. Furthermore,larger datasets containing indus-trial artifacts should be used asexperimental input. Also, thereporting of evaluation contexts,input artifacts, and IR solutionsshould be improved.
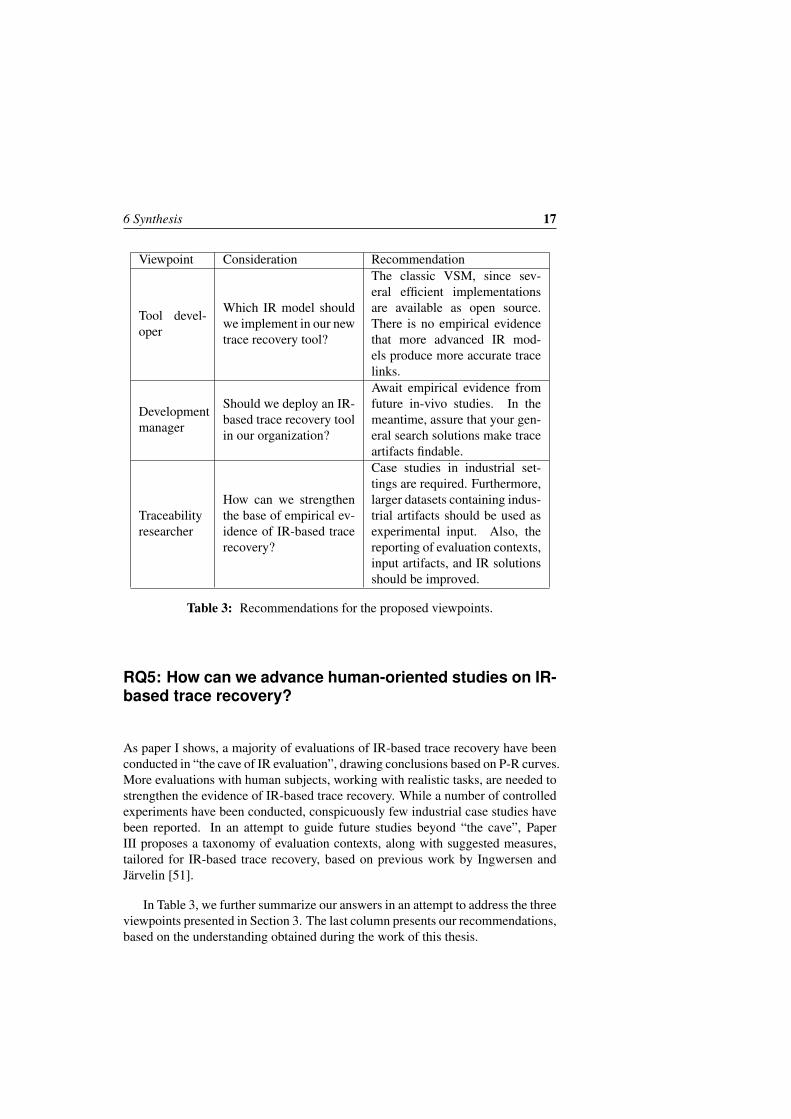
Table 3: Recommendations for the proposed viewpoints.
RQ5: How can we advance human-oriented studies on IR-based trace recovery?
As paper I shows, a majority of evaluations of IR-based trace recovery have beenconducted in “the cave of IR evaluation”, drawing conclusions based on P-R curves.More evaluations with human subjects, working with realistic tasks, are needed tostrengthen the evidence of IR-based trace recovery. While a number of controlledexperiments have been conducted, conspicuously few industrial case studies havebeen reported. In an attempt to guide future studies beyond “the cave”, PaperIII proposes a taxonomy of evaluation contexts, along with suggested measures,tailored for IR-based trace recovery, based on previous work by Ingwersen andJärvelin [51].
In Table 3, we further summarize our answers in an attempt to address the threeviewpoints presented in Section 3. The last column presents our recommendations,based on the understanding obtained during the work of this thesis.

18 INTRODUCTION
7 Threats to Validity
The results of any research effort should be questioned, even though proper re-search methodologies were applied. The validity of the research is the foundationon which the trustworthiness of the results is established. In this thesis, threats tovalidity, and actions taken to reduce the threats, are discussed based on the clas-sification proposed by Wohlin et al. [95]. Further details on validity threats areavailable in the individual papers.
Construct validity is concerned with the relation between theories behind theresearch and the observations. Consequently, it covers the choice and collection ofmeasures for the studied concepts. For example, the questions of a questionnairemust not be misunderstood or misinterpreted by the respondents. One strategy toincrease construct validity is to use multiple sources of evidence, and to establishchains of evidence [96].
In Paper I, we partly aggregate evidence from previous evaluations based ondata in tables or directly from P-R curves. Thus, we were limited by the levelsof detail included in the reviewed publications. A possible way to obtain richerdata would have been to contact the corresponding authors and ask for access toall measurements from the studies. As 79 publications from the last decade wereincluded, it would have required a large effort. On the other hand, as we extracteddata from P-R values from 48 publications and, whenever possible, followed theTREC convention of reporting both precision at fixed recall levels as well as pre-cision and recall at certain cut off levels, we limit this threat. Regarding the surveyin Paper II, the questionnaire was reviewed by a native English speaker, and a pilotstudy was conducted on five senior software engineering researchers.
Internal validity is related to issues that may affect the causal relationship be-tween treatment and outcome. In experiments, used in both Paper III and IV, theinternal validity questions whether the effect is caused by the independent vari-ables or other factors. Internal validity is typically not a threat to descriptive orexploratory studies, as casual claims rarely are made [96].
The SLR in Paper I is subject to a number of threats to internal validity. Asmost evaluations of IR-based trace recovery have been conducted in controlledsettings, e.g., in university classrooms, we have not considered different domainsin the analysis of the results. Further research is required to study whether theapproach is more feasible in certain contexts such as safety-critical development.Also, as the use of terminology in the publications was not aligned, our choice ofsearch string might have influenced the resulting evidence base. These threats wereaddressed by combining database searches with snowball sampling, and by incre-mentally developing the search string based on a gold standard of publications.Another threat to the SLR is publication bias, e.g., authors might be less likely topublish negative results, or IR-based trace recovery might be successfully used inindustry even though it is not reported in research publications. As the results inPaper I are related to all RQs, so are the threats to internal validity. Furthermore,

7 Threats to Validity 19
regarding the experiments included in this thesis, our understanding of the studiedIR-based trace recovery tools (Paper III), and the subjects’ understanding of thework task (Paper IV), are confounding factors. In both experiments we addressedthreats to internal validity by running pilot experiments.
External validity concerns the ability to generalize the findings outside theactual scope of the study. Results obtained in a specific context may not be validin other contexts. Strategies to address threats to external validity include studyingmultiple cases and replicating experiments [96].
In Paper II, we surveyed published researchers in the traceability community.However, as the number of respondents was low, we do not have a strong basis forgeneralizing our results to the entire population of traceability researchers. On theother hand, considering the exploratory nature of our study, the external validityof the survey is acceptable. Another threat to external validity is that all softwareartifacts used as experimental input in Paper III and IV originate from embed-ded development contexts, either from the space domain or process automation.Furthermore, as emphasized in Paper I, the limited number of artifacts makes gen-eralizations to larger document spaces uncertain.
Conclusion validity results from the ability to draw correct conclusions aboutthe relation between the treatment and the outcome. This type of validity is relatedto the repeatability of a study. Threats to conclusion validity in quantitative studiesare often related to statistics [95]. In qualitative studies on the other hand, it canbe used to discuss to which extent the data and the analysis are dependent on thespecific researchers, then sometimes also referred to as reliability [84, 96].
In Paper III, the technology-oriented experimental results were not analyzedusing significance testing since assumptions underlying statistical treatment suchas independence, random sampling and normality were not met. Instead, the out-put differences were analyzed in a human-oriented experiment in Paper IV. Whilethese results were analyzed using statistical testing, the low number of subjects didnot result in any statistically significant results. On the other hand, we consider theeffect sizes reported in Paper IV to be of practical significance.
In Paper I, we assess the strength of evidence of the industrial feasibility ofIR-based trace recovery. This assessment involves interpretation. While we do notconsider P-R curves from small evaluations “in the cave” to be particularly strongpieces of evidence, other researchers might value them differently. For example,the foreword by Finkelstein in the recently published textbook on software and sys-tems traceability discusses IR-based trace recovery in a less critical manner [18].However, in line with practices in reflexive methodology, there is a demand forreflection in research in conjunction with interpretation [3]. As such, a researchershould be aware of, and critically confront, favored lines of interpretation. Natu-rally, there is a risk of bias in the foreword of a textbook, written by a notable partof the traceability research community. In such a foreword, there are few incen-tives to present sceptical views on the research. On the other hand, there is also arisk that the work in this licentiate thesis, written by a junior PhD student fostered

20 INTRODUCTION
in a strictly empirical research tradition, is overly critical to the mainly technology-oriented research strategy. Our conclusion, that there is a need for evaluations thatgo beyond “the cave”, might be in the interest of the individual researcher, as anattempt to pave the way for future empirical studies. To conclude, the conclusionvalidity is a threat to RQ5 and RQ6, as other researchers might suggest differentways to advance evaluation of IR-based trace recovery.
8 Agenda for Future Research
This section presents a speculative research agenda for future work, partly basedon Paper V. We intend to continue our research with a focus on trace links, howeverin a more solution-oriented manner. Our ambition is to study a specific work taskthat requires an engineer to explicitly specify trace links among artifacts, namelychange impact analysis in a safety-critical context. As we suspect that softwareengineers are more comfortable navigating the source code than its related doc-umentation, we intend to focus specifically on trace links between non-code ar-tifacts. A summary of the planned work in this section is presented as Futureresearch Questions (FQ) and planned Design science Tasks (DT) in Table 5.
8.1 Description of the Context
The targeted impact analysis process is applied by a large multinational companyactive in the power and automation sector. The development context is safety-critical embedded development in the domain of industrial control systems, gov-erned by IEC 61511 [52]. The number of developers is in the magnitude of hun-dreds; a project has typically a length of 12-18 months and follows an iterativestage-gate project management model. Also, the software is certified to a SafetyIntegrity Level (SIL) of 2 as defined by IEC 61508 [53], corresponding to a riskreduction factor of 1.000.000-10.000.000 for continuous operation. Process re-quirements mandate maintenance of traceability information, especially betweenrequirements and test cases. Both requirements and test case descriptions are pre-dominantly specified in English NL text.
As specified in IEC 61511 [52], impact of proposed software changes, e.g.,for error corrections, should be analyzed before implementation. In the initiallystudied case, as presented in Paper V, this process is integrated in the issue track-ing system. As part of the analysis, engineers are required to investigate impact,and report their results according to a project specific template, validated by anexternal certifying agency. A slightly modified version of this template, recentlydescribed as part of a master thesis project [64], is presented in Table 4. As seenin Table 4, several questions explicitly ask for trace links (6 out of 13 questions).The engineer is required to specify source code that will be modified (with a file-level granularity), and also which related software artifacts need to be updated to

8 Agenda for Future Research 21
Impact Analysis Questions for Error Corrections1) Is the reported problem safety critical?2) In which versions/revisions does this problem exist?3) How are general system functions and properties affected by the
change?4) List modified code files/modules and their SIL classifications,
and/or affected safety safety related hardware modules.5) How are general system functions and properties affected by the
change?6) Which library items are affected by the change? (e.g., library types,
firmware functions, HW types, HW libraries)7) Which documents need to be modified? (e.g., product requirements
specifications, architecture, functional requirements specifications,design descriptions, schematics, functional test descriptions, designtest descriptions)
8) Which test cases need to be executed? (e.g., design tests, functionaltests, sequence tests, environmental/EMC tests, FPGA simulations)
9) Which user documents, including online help, need to be modified?10) How long will it take to correct the problem, and verify the correction?11) What is the root cause of this problem?12) How could this problem been avoided?13) Which requirements and functions need to be retested by product
test/system test organization?
Table 4: Impact analysis template. Questions in bold fonts require explicit tracelinks to other artifacts. Based on a description by Klevin [64].
reflect the changes, e.g., requirement specifications, design documentation, testcase descriptions, test scripts and user manuals. Furthermore, the impact analysisshould specify which high-level system requirements cover the involved features,and which test cases should be executed to verify that the changes are correct onceimplemented in the system. Consequently, the impact analysis reports explicitlyconnect requirements and test artifacts. As this has been reported as a specificchallenge in requirements and verification alignment [85], we also intend to ex-plore how the knowledge embedded in the impact analysis reports can be used tosupport this aspect of large-scale software development.
8.2 Solution idea
While an important part of the impact analysis work task involves specifying tracelinks to related software artifacts, there are rarely any traceability matrices to con-sult. Consequently, if engineers do not already know which artifacts are impacted,

22 INTRODUCTION
a substantial part of the impact analysis work task turns into an information seek-ing activity. In Figure 5, we present an initial model of the trace link seekingactivity involved in the impact analysis. At first, depicted in the left of the fig-ure, the engineer starts the work task with six questions that require explicit tracelinks. The engineer then enters the process of trace link seeking, presented as thesecond step in Figure 5. Typically, this is an iterative process where the engineerseeks information suggesting trace links in different ways. Knowledge embeddedin previous impact analysis reports can be reused, project documentation can bestudied, and colleagues can be asked. As reported by Dagenais et al., especiallyjunior engineers and newcomers rely on communication with more experiencedcolleagues, in particular when project findability is low due to poor search solu-tions [21]. Finally, as presented to the right in Figure 5, enough information hasbeen found to specify required trace links in the impact analysis template. Aspresented in Table 5, we intend to improve the trace link seeking model (DT1)based on observational studies with protocol analysis. This work could comple-ment Freund et al.’s more general work on modeling the information behavior ofsoftware engineer [37] by exploring a specific work task. Moreover, we plan toassess whether the trace link seeking model is applicable to other contexts withstrict process requirements on maintenance of traceability information (FQ1).
Currently, as presented in Paper V, engineers conduct the trace link seekingsupported by a low level of automation [75]. Our plan is to increase the levelof automation in two areas of the trace link seeking process, as indicated by thecogwheels in Figure 5. In the present work flow, engineers use the search features(primarily keyword-based) of the issue tracking system and the document manage-ment system to gather enough information to specify trace links. Our hypothesisis that these steps could be supported by a recommendation system based on tex-tual similarity analysis. As discussed in Paper V, our goal is to support trace linkseeking by deploying a plug-in to the issue tracking system (presented as DT2 inTable 5). Developing plug-ins to tools already deployed in industry enables in-vivostudies without introducing additional external tools.
Another direction we want to explore is to consider artifact meta-informationto improve the trace recovery, presented as FQ2 in Table 5. One possibility, thatwe initially have explored, is to exploit the already existing link structures amongsoftware artifacts. Using link mining, we have explored clusters of issue reportsfrom the public Android issue tracking system. Figure 6 visualizes link structuresamong Android issue reports, extracted from hyperlinks manually established bydevelopers. We expect to find patterns of linked artifacts also in the targeted safety-critical case, however also between different types of artifacts, when conductinglink mining in the impact analysis reports in the issue tracking system. As hyper-links have proven useful in tasks such as object ranking, link prediction, and sub-graph discovery [38], we hope it can also be used to advance trace recovery. A linkmining approach might move our research closer to work on semantic networks ofsoftware artifacts, which previously has been used to significantly improve search-

8 Agenda for Future Research 23
Figure 5: Trace link seeking in the impact analysis work task. Adapted from Pa-per V. Cogwheels indicate an information seeking activity that could be supportedby IR-based trace recovery.
ing based on textual similarity in the software engineering context [58]. Further-more, work on trace link structures would enable us to explore the use of visual-ization techniques to support engineers’ trace links seeking, as has previously beenproposed by Cleland-Huang and Habrat [19].
We also suspect that other pieces of artifact meta-information could be usefulin trace recovery. Web search engines consider hundreds of features to assess therelevance of web pages for ranking purposes [1]. Learning-to-rank methods arethen used on training data to learn the optimal combination of feature weights, re-sulting in the best ranking of search results [67]. In the context of trace recovery,we envision that both nominal software artifact features (e.g., responsible team,subsystem), ordinal features (e.g., safety level, severity), and features measurableon a ratio scale (e.g, resolution time, link structure) can be used to improve rank-ing of candidate trace links, in particular when combined with information aboutthe user of the tool. Engineers conducting trace recovery might not consider therelevance of candidate trace links to be binary, but rather of a multi-dimensionalnature [61], i.e., dynamic and situational. For example, the relevance of a tracelink might depend on the role of the tracing engineer (tester, developer, manager,etc.), the current phase of the development project (pre-study, implementation, ver-ification, etc.), and which other trace links have already been identified (as theremight be dependencies). Using meta-information and user information, IR-basedtrace recovery could assumably be advanced beyond what is possible using merelytextual similarity analysis.

24 INTRODUCTION
Figure 6: Linked structures of issue reports in the public Android issue trackingsystem.
We anticipate certain challenges as we continue our work. First, in many en-terprises, information access is hindered by information being widely dispersedin information management systems with poor interoperability [69], resulting inwhat is referred to as information silos. It is uncertain which artifacts could beaccessed without major engineering efforts and without breaking information ac-cess policies. Second, as identified by Klevin [64], the impact analysis reports inthe targeted case, i.e., the answers to the template presented in Table 4, are storedin the issue tracking system as unstructured text. Clearly, this will complicate in-formation extraction and data mining from the reports. Third, while the numberof software artifacts in large projects can be challenging, it is several orders ofmagnitude smaller than the number of web pages indexed by modern web searchengines. There is a risk that we will not be able to gather enough data for machinelearning methods to do themselves justice.
9 Conclusion
The challenge of maintaining trace links in large-scale software engineering hasbeen addressed by IR approaches in roughly a hundred previous publications. Inan SLR, we identified 79 publications reporting empirical evaluations of IR-basedtrace recovery. We found that most often algebraic IR models have been applied

9 Conclusion 25
Futurework
Description Researchmethod
Type of re-search
DT1 How can we further improve thetrace link seeking model?
Design science Modeling
FQ1 Is the trace link seeking model ap-plicable in other development con-texts with process requirements ontraceability?
Multi-casestudy
Exploratory
DT2 How can textual similarity analysisbe applied to support trace recoveryin the impact analysis?
Design science Tool devel-opment
FQ2 Can the accuracy of the tool outputbe improved by considering artifactmeta-information?
Technology-orientedexperiment
Evaluative
FQ3 Does the tool support the impactanalysis work task?
Case study Evaluative
Table 5: Future research questions and planned design science tasks.
(RQ1), and confirm the previous claim that no IR model regularly outperformstrace recovery based on VSM (RQ2).
A majority of previous evaluations of IR-based trace recovery have been techno-logy-oriented, conducted in what Ingwersen and Järvelin refer to as “the cave of IRevaluation”. Also, we show that evaluations of IR-based trace recovery primarilyhave been conducted using simplified datasets, both in relation to size (most oftenless than 500 artifacts) and origin (frequently former student projects, typically notvalidated for industrial representability). As such, the validity of concluding thatIR-based trace recovery is feasible in an industrial setting, based on P-R curves “inthe cave”, can be questioned (RQ3).
On the other hand, a set of previous evaluations conducted with human subjectssuggest that engineers would benefit from IR-based trace recovery tools when per-forming certain work tasks (RQ3). To further strengthen the evidence of IR-basedtrace recovery, more studies involving humans are needed, particularly industrialcase studies (RQ5). Moreover, evaluative studies should be conducted on diversedatasets containing a higher number of artifacts (RQ4). Consequently, our findingsintensify the call for additional empirical research by CoEST.
This thesis also includes two experiments on IR-based trace recovery. Thetechnology-oriented experiment highlights the clear dependence between datasetsand the accuracy of IR-based trace recovery, which was also confirmed by the SLR.Thus, to enable replications and secondary studies, we argue that datasets shouldbe thoroughly characterized in future studies on trace recovery, especially whenthey cannot be disclosed (RQ4). The human-oriented experiment suggests that it

26 INTRODUCTION
is worthwhile investigating further into the actual value of improved P-R curves.The pilot experiment showed that the effect size of using a slightly better toolis of practical significance regarding precision and F-measure. Finally, based onresearch on general IR evaluation, we propose a taxonomy of evaluation contextstailored for IR-based trace recovery (RQ5).
As future work, we intend to target an industrial case of impact analysis ina safety-critical development context. In the case, engineers perform trace linkseeking among textual artifacts, and explicitly specify the trace links according toa template. Consequently, the case appears to be suitable for evaluating IR-basedtrace recovery in an in-vivo setting.

BIBLIOGRAPHY
[1] E. Agichtein, E. Brill, and S. Dumais. Improving Web search ranking byincorporating user behavior information. In Proceedings of the 29th annualinternational ACM SIGIR conference on Research and development in infor-mation retrieval, pages 19–26, 2006.
[2] N. Ali, Y-G. Guéhéneuc, and G. Antoniol. Factors impacting the inputs oftraceability recovery approaches. In J. Cleland-Huang, O. Gotel, and A. Zis-man, editors, Software and Systems Traceability. Springer, 2012.
[3] M. Alvesson and K. Sköldberg. Reflexive methodology: New vistas for qual-itative research. Sage Publications, 2000.
[4] G. Antoniol, G. Canfora, G. Casazza, and A. De Lucia. Information retrievalmodels for recovering traceability links between code and documentation. InConference on Software Maintenance, pages 40–49, 2000.
[5] G. Antoniol, G. Canfora, G. Casazza, A. De Lucia, and E. Merlo. Recover-ing traceability links between code and documentation. In Transactions onSoftware Engineering, volume 28, pages 970–983, 2002.
[6] R. Baeza-Yates and B. Ribeiro-Neto. Modern information retrieval: Theconcepts and technology behind search. Addison-Wesley, 2nd edition, 2011.
[7] L. Barker, E. Luman, M. McCauley, and S. Chu. Assessing equivalence: Analternative to the use of difference tests for measuring disparities in vacci-nation coverage. American Journal of Epidemiology, 156(11):1056–1061,2002.
[8] E. Ben Charrada, D. Caspar, C. Jeanneret, and M. Glinz. Towards a bench-mark for traceability. In Proceedings of the 12th International Workshop onPrinciples on Software Evolution, pages 21–30, 2011.
[9] J. Berlik, S. Dharmadhikari, M. Harding, and N. Singh. System and methodfor maintaining requirements traceability, United States Patent 8191044,2012.

28 INTRODUCTION
[10] D. Binkley and D. Lawrie. Information retrieval applications in softwaremaintenance and evolution. In J. Marciniak, editor, Encyclopedia of softwareengineering. Taylor & Francis, 2nd edition, 2010.
[11] D. Blei, A. Ng, and M. Jordan. Latent dirichlet allocation. The Journal ofMachine Learning Research, 3(4-5):993–1022, 2003.
[12] B. Boehm. Software engineering. 25(12):1226–1241, 1976.
[13] R. Burgin. The Monte Carlo method and the evaluation of retrieval sys-tem performance. Journal of the American Society for Information Science,50(2):181–191, 1999.
[14] Carnegie Mellon Software Engineering Institute. CMMI for development,Version 1.3, 2010.
[15] D. Case. Looking for information: A survey of research on information seek-ing, needs and behavior. Academic Press, 2nd edition, 2007.
[16] J. Cleland-Huang, C. K Chang, and M. Christensen. Event-based traceabilityfor managing evolutionary change. Transactions on Software Engineering,29(9):796– 810, 2003.
[17] J. Cleland-Huang, A. Czauderna, A. Dekhtyar, O. Gotel, J. Huffman Hayes,E. Keenan, J. Maletic, D. Poshyvanyk, Y. Shin, A. Zisman, G. Antoniol,B. Berenbach, A. Egyed, and P. Mäder. Grand challenges, benchmarks, andTraceLab: Developing infrastructure for the software traceability researchcommunity. In Proceedings of the 6th International Workshop on Traceabil-ity in Emerging Forms of Software Engineering, 2011.
[18] J. Cleland-Huang, O. Gotel, and A. Zisman, editors. Software and systemstraceability. Springer, 2012.
[19] J. Cleland-Huang and R. Habrat. Visualization and analysis in automatedtrace retrieval. In Proceedings of the 2nd International Workshop on Re-quirements Engineering Visualization, 2007.
[20] C. Cleverdon. The significance of the Cranfield tests on index languages. InProceedings of the 14th Annual International SIGIR Conference on Researchand Development in Information Retrieval, pages 3–12, 1991.
[21] B. Dagenais, H. Ossher, R. Bellamy, M. Robillard, and J. de Vries. Movinginto a new software project landscape. In Proceedings of the 32nd Interna-tional Conference on Software Engineering, pages 275–284, 2010.
[22] A. De Lucia, F. Fasano, R. Oliveto, and G. Tortora. ADAMS re-trace: Atraceability recovery tool. In Proceedings of the 9th European Conferenceon Software Maintenance and Reengineering, pages 32–41, 2005.

BIBLIOGRAPHY 29
[23] A. De Lucia, F. Fasano, R. Oliveto, and G. Tortora. Recovering traceabilitylinks in software artifact management systems using information retrievalmethods. Transactions on Software Engineering and Methodology, 16(4),2007.
[24] A. De Lucia, A. Marcus, R. Oliveto, and D. Poshyvanyk. Informa-tion retrieval methods for automated traceability recovery. In J. Cleland-Huang, O. Gotel, and A. Zisman, editors, Software and Systems Traceability.Springer, 2012.
[25] S. Deerwester, S. Dumais, G. Furnas, T. Landauer, and R. Harshman. Index-ing by latent semantic analysis. Journal of the American Society for Infor-mation Science, 41(6):391–407, 1990.
[26] A. Dekhtyar and J. Huffman Hayes. Good benchmarks are hard to find:Toward the benchmark for information retrieval applications in software en-gineering. Proceedings of the International Conference on Software Mainte-nance, 2006.
[27] A. Dekhtyar, J. Huffman Hayes, and G. Antoniol. Benchmarks for traceabil-ity? In Proceedings of the International Symposium on Grand Challenges inTraceability, 2007.
[28] K. Desouza, Y. Awazu, and P. Baloh. Managing knowledge in global soft-ware development efforts: Issues and practices. Software, IEEE, 23(5):30–37, 2006.
[29] R. Dömges and K. Pohl. Adapting traceability environments to project-specific needs. Communications of the ACM, 41(12):54–62, 1998.
[30] M. Dorfman. Standards, guidelines, and examples on system and softwarerequirements engineering. IEEE Computer Society Press, 1994.
[31] S. Easterbrook, J. Singer, M. Storey, and D. Damian. Selecting empiri-cal methods for software engineering research. In F. Shull, J. Singer, andD. Sjöberg, editors, Guide to Advanced Empirical Software Engineering,pages 285–311. Springer, 2008.
[32] A. Edmunds and A. Morris. The problem of information overload in businessorganisations: A review of the literature. International Journal of Informa-tion Management, 20(1):17–28, 2000.
[33] M. Eppler and J. Mengis. The concept of information overload: A review ofliterature from organization science, accounting, marketing, MIS, and relateddisciplines. The Information Society, 20(5):325–344, 2004.

30 INTRODUCTION
[34] D. Falessi, G. Cantone, and G. Canfora. A comprehensive characterization ofNLP techniques for identifying equivalent requirements. In Proceedings ofthe International Symposium on Empirical Software Engineering and Mea-surement, 2010.
[35] D. Falessi, G. Cantone, and G. Canfora. Empirical principles and an indus-trial case study in retrieving equivalent requirements via natural languageprocessing techniques. Transactions on Software Engineering, 2011.
[36] R. Fiutem and G. Antoniol. Identifying design-code inconsistencies inobject-oriented software: A case study. In Proceedings of the InternationalConference on Software Maintenance, pages 94–102, 1998.
[37] L. Freund, E. Toms, and J. Waterhouse. Modeling the information behaviourof software engineers using a work - task framework. Proceedings of theAmerican Society for Information Science and Technology, 42(1), 2005.
[38] L. Getoor and C. Diehl. Link mining: A survey. SIGKDD ExplorationsNewsletter, 7(2):3–12, 2005.
[39] O. Gotel, J. Cleland-Huang, J. Huffman Hayes, A. Zisman, A. Egyed,P. Grünbacher, A. Dekhtyar, G. Antoniol, J. Maletic, and P. Mäder. Trace-ability fundamentals. In J. Cleland-Huang, O. Gotel, and A. Zisman, editors,Software and Systems Traceability, pages 3–22. Springer, 2012.
[40] O. Gotel and C. Finkelstein. An analysis of the requirements traceabilityproblem. In Proceedings of the First International Conference on Require-ments Engineering, pages 94–101, 1994.
[41] S. Harter and C. Hert. Evaluation of information retrieval systems: Ap-proaches, issues, and methods. Annual Review of Information Science andTechnology, 32:3–94, 1997.
[42] D. Hawking. Challenges in enterprise search. In Proceedings of the 15thAustralasian database conference, pages 15–24, 2004.
[43] A. Hevner, S. March, J. Park, and S. Ram. Design science in informationsystems research. MIS Quarterly, 28(1):75–105, 2004.
[44] Hewlett Packard Development Company. HP quality center software (for-merly HP TestDirector for quality center software) Data sheet, 4AA0-9587ENW rev. 3, 2009.
[45] T. Hofman. Unsupervised learning by probabilistic latent semantic analysis.Machine Learning, 42(1-2):177–196, 2001.

BIBLIOGRAPHY 31
[46] M Höst, B. Regnell, and C. Wohlin. Using students as subjects: A com-parative study of students and professionals in lead-time impact assessment.Empirical Software Engineering, 5(3):201–214, 2000.
[47] J. Huffman Hayes and A. Dekhtyar. A framework for comparing require-ments tracing experiments. Interational Journal of Software Engineeringand Knowledge Engineering, 15(5):751–781, 2005.
[48] J. Huffman Hayes, A. Dekhtyar, and S. Sundaram. Advancing candidate linkgeneration for requirements tracing: The study of methods. Transactions onSoftware Engineering, 32(1):4–19, 2006.
[49] J. Huffman Hayes, A. Dekhtyar, S. Sundaram, A. Holbrook, S. Vadlamudi,and A. April. REquirements TRacing on target (RETRO): improving soft-ware maintenance through traceability recovery. Innovations in Systems andSoftware Engineering, 3(3):193–202, 2007.
[50] IEEE Computer Society. 610.12-1990 IEEE Standard glossary of softwareengineering terminology. Technical report, 1990.
[51] P. Ingwersen and K. Järvelin. The turn: Integration of information seekingand retrieval in context. Springer, 2005.
[52] International Electrotechnical Commission. IEC 61511-1 ed 1.0, Safety in-strumented systems for the process industry sector, 2003.
[53] International Electrotechnical Commission. IEC 61508 ed 2.0, Electrical/-Electronic/Programmable electronic safety-related systems, 2010.
[54] International Organization for Standardization. ISO 26262-1:2011 Road ve-hicles –Functional safety –, 2011.
[55] S. Isaac and W. Michael. Handbook in research and evaluation: A collectionof principles, methods, and strategies useful in the planning, design, andevaluation of studies in education and the behavioral sciences. Edits Pub,3rd edition, 1995.
[56] K. Järvelin and J. Kekäläinen. IR evaluation methods for retrieving highlyrelevant documents. In Proceedings of the 23rd Annual International ACMSIGIR Conference on Research and Development in Information Retrieval,pages 41–48, 2000.
[57] A. Jedlitschka, M. Ciolkowski, and D. Pfahl. Reporting experiments in soft-ware engineering. In F. Shull, J. Singer, and D. Sjöberg, editors, Guide toAdvanced Empirical Software Engineering, pages 201–228. Springer, Lon-don, 2008.

32 INTRODUCTION
[58] G. Karabatis, Z. Chen, V. Janeja, T. Lobo, M. Advani, M. Lindvall, andR. Feldmann. Using semantic networks and context in search for relevantsoftware engineering artifacts. In S. Spaccapietra and L. Delcambre, editors,Journal on Data Semantics XIV, pages 74–104. Springer, Berlin, 2009.
[59] P. Karr-Wisniewski and Y. Lu. When more is too much: Operationalizingtechnology overload and exploring its impact on knowledge worker produc-tivity. Computers in Human Behavior, 26(5):1061–1072, 2010.
[60] E. Keenan, A. Czauderna, G. Leach, J. Cleland-Huang, Y. Shin, E. Mor-litz, M. Gethers, D. Poshyvanyk, J. Maletic, J. Huffman Hayes, A. Dekhtyar,A. Manukian, S. Hussein, and D. Hearn. TraceLab: an experimental work-bench for equipping researchers to innovate, synthesize, and comparativelyevaluate traceability solutions. In Proceedings of the 34th International Con-ference on Software Engineering, 2012.
[61] J. Kekäläinen and K. Järvelin. Evaluating information retrieval systems un-der the challenges of interaction and multidimensional dynamic relevance.Proceedings of the COLIS 4 Conference, pages 253—270, 2002.
[62] B. Kitchenham and S. Charters. Guidelines for performing systematic litera-ture reviews in software engineering. EBSE Technical Report, 2007.
[63] B. Kitchenham, T. Dybå, and M. Jörgensen. Evidence-based software engi-neering. In Proceedings of the 26th International Conference on SoftwareEngineering, volume 2004, pages 273–281, 2004.
[64] A. Klevin. People, process and tools: A study of impact analysis ina change process. Master thesis, Lund University, ISSN 1650-2884,http://sam.cs.lth.se/ExjobGetFile?id=434, 2012.
[65] G. Leckie, K. Pettigrew, and C. Sylvain. Modeling the information seekingof professionals: A general model derived from research on engineers, healthcare professionals, and lawyers. Library Quarterly, 66(2):161–93, 1996.
[66] J. Lin, L. Chan, J. Cleland-Huang, R. Settimi, J. Amaya, G. Bedford,B. Berenbach, O. B Khadra, D. Chuan, and X. Zou. Poirot: A distributedtool supporting enterprise-wide automated traceability. In Proceedings ofthe 14th International Conference on Requirements Engineering, pages 363–364, 2006.
[67] T-Y Liu. Learning to rank for information retrieval. Springer, 2011.
[68] M. Lormans and A. van Deursen. Can LSI help reconstructing requirementstraceability in design and test? In Proceedings of the 10th European Confer-ence on Software Maintenance and Reengineering, pages 45–54, 2006.

BIBLIOGRAPHY 33
[69] C. Manning, P. Raghavan, and H. Schütze. Introduction to information re-trieval. Cambridge University Press, 2008.
[70] A. Marcus and J. Maletic. Recovering documentation-to-source-code trace-ability links using latent semantic indexing. In Proceedings of the Interna-tional Conference on Software Engineering, pages 125–135, 2003.
[71] P. Morville. Ambient findability: What we find changes who we become.O’Reilly Media, 2005.
[72] P. Naur and B. Randell, editors. Software Engineering: Report of a confer-ence sponsored by the NATO Science Committee. 1969.
[73] R. Oliveto, M. Gethers, D. Poshyvanyk, and A. De Lucia. On the equivalenceof information retrieval methods for automated traceability link recovery. InInternational Conference on Program Comprehension, pages 68–71, 2010.
[74] T. Olsson. Software information management in requirements and test docu-mentation. Licentiate thesis, Lund University, 2002.
[75] R. Parasuraman, T. Sheridan, and C. Wickens. A model for types and levelsof human interaction with automation. Transactions on Systems, Man andCybernetics, 30(3):286–297, 2000.
[76] K. Petersen, R. Feldt, S. Mujtaba, and M. Mattsson. Systematic mappingstudies in software engineering. In Proceedings of the 12th InternationalConference on Evaluation and Assessment in Software Engineering, pages71–80, 2008.
[77] A. Pinsonneault and K. Kraemer. Survey research methodology in manage-ment information systems: An assessment. Journal of Management Infor-mation Systems, 10(2):75–105, 1993.
[78] J. Ponte and B. Croft. A language modeling approach to information re-trieval. In Proceedings of the 21st Annual International SIGIR Conference onResearch and Development in Information Retrieval, pages 275–281, 1998.
[79] M. Poppendieck and T. Poppendieck. Lean software development: An agiletoolkit. Addison-Wesley Professional, 2003.
[80] B. Ramesh. Process knowledge management with traceability. IEEE Soft-ware, 19(3):50–52, 2002.
[81] B. Randall. Towards a methodology of computing system design. In P. Naurand B. Randall, editors, NATO Working Conference on Software Engineering1968, Report on a Conference Sponsored by NATO Scientific Committee,pages 204–208. 1969.

34 INTRODUCTION
[82] S. E. Robertson and S. Jones. Relevance weighting of search terms. Journalof the American Society for Information Science, 27(3):129–146, 1976.
[83] B. Robson. Real world research. Blackwell, 2nd edition, 2002.
[84] P. Runeson, M. Höst, A. Rainer, and B. Regnell. Case study research insoftware engineering: Guidelines and examples. Wiley, 2012.
[85] G. Sabaliauskaite, A. Loconsole, E. Engström, M. Unterkalmsteiner, B. Reg-nell, P. Runeson, T. Gorschek, and R. Feldt. Challenges in aligning require-ments engineering and verification in a large-scale industrial context. In Re-quirements Engineering: Foundation for Software Quality, pages 128–142,2010.
[86] G. Salton, A. Wong, and C. Yang. A vector space model for automatic in-dexing. Commununications of the ACM, 18(11):613–620, 1975.
[87] W. Shaw Jr, R. Burgin, and P. Howell. Performance standards and evaluationsin IR test collections: Vector-space and other retrieval models. InformationProcessing & Management, 33(1):15–36, 1997.
[88] F. Shull, J. Carver, S. Vegas, and N. Juristo. The role of replications inempirical software engineering. Empirical Software Engineering, 13(2):211–218, 2008.
[89] F. Shull, J. Singer, and D. Sjöberg. Guide to advanced empirical softwareengineering. Springer, 1st edition, 2010.
[90] K. Spärck Jones, S. Walker, and S. E. Robertson. A probabilistic model of in-formation retrieval: Development and comparative experiments. InformationProcessing and Management, 36(6):779–808, 2000.
[91] R. Torkar, T. Gorschek, R. Feldt, M. Svahnberg, U. Raja, and K. Kamran.Requirements traceability: A systematic review and industry case study. In-ternational Journal of Software Engineering and Knowledge Engineering,22(3):1–49, 2012.
[92] H. Turtle and B. Croft. Evaluation of an inference network-based retrievalmodel. Transactions on Information Systems, 9(3):187–222, 1991.
[93] J. Urbano. Information retrieval meta-evaluation: Challenges and opportu-nities in the music domain. In International Society for Music InformationRetrieval Conference, pages 597–602, 2011.
[94] S. Wellek. Testing statistical hypotheses of equivalence. Chapman and Hall,2003.

BIBLIOGRAPHY 35
[95] C. Wohlin, P. Runeson, M. Höst, M. Ohlsson, B. Regnell, and A. Wesslén.Experimentation in software engineering: A practical guide. Springer, 2012.
[96] R. Yin. Case study research: Design and methods. Sage Publications, 3rdedition, 2003.
[97] H. Zantout and F. Marir. Document management systems from current capa-bilities towards intelligent information retrieval: An overview. InternationalJournal of Information Management, 19(6):471–484, 1999.


PAPER I
RECOVERING FROM ADECADE: A SYSTEMATICREVIEW OF INFORMATION
RETRIEVAL APPROACHES TOSOFTWARE TRACEABILITY
Abstract
Context: Engineers in large-scale software development have to manage largeamounts of information, spread across many artifacts. Several researchers haveproposed expressing retrieval of trace links among artifacts, i.e., trace recovery,as an Information Retrieval (IR) problem. Objective: The objective of this studyis to review work on IR-based trace recovery, with a particular focus on previousevaluations and strength of evidence. Method: We conducted a systematic litera-ture review of IR-based trace recovery. Results: Of the 79 publications classified,a majority applied algebraic IR models. We found no IR model to regularly out-perform the classic vector space model. While a set of studies on students indicatethat IR-based trace recovery tools support certain work tasks, most previous stud-ies do not go beyond reporting precision and recall of candidate trace links fromevaluations using datasets containing less than 500 artifacts. Conclusions: Wefound a clear dependence between datasets and the accuracy of IR-based trace re-covery. Also, our review identified a need of industrial case studies. Furthermore,we conclude that the overall quality of reporting should be improved regardingboth context and tool details, measures reported, and use of IR terminology. Fi-nally, based on our empirical findings, we present suggestions on how to advanceresearch on IR-based trace recovery.
Markus Borg, Per Runeson, and Anders Ardö, Submitted to a journal, 2012

38 Recovering from a Decade: A Systematic Review of Information . . .
1 Introduction
The successful evolution of software systems involves concise and quick access toinformation. However, information overload plagues software engineers, as largeamounts of formal and informal information is continuously produced and mod-ified [36, 133]. Inevitably, especially in large-scale projects, this leads to a chal-lenging information landscape, that includes, apart from the source code itself,requirements specifications of various abstraction levels, test case descriptions,defect reports, manuals, and the like. The state-of-practice approach to structuresuch information is to organize artifacts in databases, e.g., document managementsystems, requirements databases, and code repositories, and to manually main-tain trace links [80, 88]. With access to trace information, engineers can moreefficiently perform work tasks such as impact analysis, identification of reusableartifacts, and requirements validation [7, 169]. Furthermore, research has identi-fied lack of traceability to be a major contributing factor in project overruns andfailures [36, 69, 80]. Moreover, as traceability plays a role in software verifica-tion, safety standards such as ISO 26262 [94] for the automotive industry, and IEC61511 [93] for the process industry, mandate maintenance of traceability informa-tion [99], as does the CMMI process improvement model [31]. However, manuallymaintaining trace links is an approach that does not scale [81]. In addition, the dy-namics of software development makes it tedious and error-prone [69, 73, 88].
As a consequence, engineers would benefit from additional means of dealingwith information seeking and retrieval, to navigate effectively the heterogeneousinformation landscape of software development projects. Several researchers haveclaimed it feasible to treat traceability as an information retrieval (IR) problem [7,51, 88, 115, 120]. Also, other studies have reported that the use of semi-automatedtrace recovery reduces human effort when performing requirements tracing [49,54,58,88,130]. The IR approach builds upon the assumption that if engineers refer tothe same aspects of the system, similar language is used across different softwareartifacts. Thus, tools suggest trace links based on Natural Language (NL) con-tent. During the first decade of the millennium, substantial research effort has beenspent on tailoring, applying, and evaluating IR techniques to software engineering,but we found that a comprehensive overview of the field is missing. Such a sec-ondary analysis would provide an evidence based foundation for future research,and advise industry practice [103]. As such, the gathered empirical evidence couldbe used to validate, and possibly intensify, the recent calls for future research bythe traceability research community [79], organized by the Center of Excellencefor Software Traceability (CoEST)1. Furthermore, it could assess the recent claimsthat applying more advanced IR models does not improve results [73, 132].
We have conducted a Systematic Mapping (SM) study [102, 136] that clusterspublications on IR-based trace recovery. Then, as suggested by Kitchenham andCharters [103], we used the resulting map as a starting point for a Systematic Lit-
1www.coest.org

2 Background 39
erature Review (SLR). SMs and SLRs are primarily distinguished by their drivingResearch Questions (RQ) [102], i.e., an SM identifies research gaps and clustersevidence to direct future research, while an SLR synthesizes empirical evidence ona specific RQ. The rigor of the methodologies is a key asset in ensuring a compre-hensive collection of published evidence. We define our overall goals of this studyin four RQs (RQ1 and RQ2 guided the SM, while RQ3 and RQ4 were subsequentstarting points for the SLR):
RQ1 Which IR models and enhancement strategies have been most frequentlyapplied to perform trace recovery among NL software artifacts?
RQ2 Which types of NL software artifacts have been most frequently linked inIR-based trace recovery studies?
RQ3 How strong is the evidence, wrt. degree of realism in the evaluations, ofIR-based trace recovery?
RQ4 Which IR model has been the most effective, wrt. precision and recall, inrecovering trace links?
This paper is organized as follows. Section 2 contains a thorough definition ofthe IR terminology we refer to throughout this paper, and a description of how IRtools can be used in a trace recovery process. Section 3 presents related work, i.e.,the history of IR-based trace recovery, and related secondary and methodologicalstudies. Section 4 describes how the SLR was conducted, including the collectionof studies and the subsequent synthesis of empirical results. Section 4 shows theresults from the study. Section 6 discusses our research questions based on theresults. Finally, Section 7 presents a summary of our contributions and suggestsdirections for future research.
2 BackgroundThis section presents fundamentals of IR, and how tools implementing IR modelscan be used in a trace recovery process.
2.1 IR background and terminology
As the study identified variations in use of terminology, this section defines theterminology used in this study (summarized in Table 1), which is aligned withrecently redefined terms [39]. We use the following IR definition: “informationretrieval is finding material (usually documents) of an unstructured nature (usu-ally text) that satisfies an information need from within large collections (usuallystored on computers)” [119]. If a retrieved document satisfies such a need, weconsider it relevant. We solely consider text retrieval in the study, yet we follow

40 Recovering from a Decade: A Systematic Review of Information . . .
convention and refer to it as IR. In our interpretation, the starting point is that anyapproach that retrieves documents relevant to a query qualifies as IR. The termsNatural Language Processing (NLP) and Linguistic Engineering (LE) are used ina subset of the mapped publications of this study, even if they refer to the sameIR techniques. We consider NLP and LE to be equivalent and borrow two defini-tions from Liddy [111]: “NL text is text written in a language used by humans tocommunicate to one another”, and “NLP is a range of computational techniquesfor analyzing and representing NL text”. As a result, IR (referring to a processsolving a problem) and NLP (referring to a set of techniques) are overlapping. Incontrast to the decision by Falessi et al. [73] to consistently apply the term NLP,we choose to use IR in this study, as we prefer to focus on the process rather thanthe techniques. While trace recovery truly deals with solutions targeting NL text,we prefer to primarily consider it as a problem of satisfying an information need.
Furthermore, a “software artifact is any piece of information, a final or inter-mediate work product, which is produced and maintained during software devel-opment” [106], e.g., requirements, design documents, source code, test specifica-tions, manuals, and defect reports. To improve readability, we refer to such piecesof information only as ‘artifacts’. Regarding traceability, we use two recent def-initions: “traceability is the potential for traces to be established and used” and“trace recovery is an approach to create trace links after the artifacts that theyassociate have been generated or manipulated” [39]. In the literature, the tracerecovery process is referred to in heterogeneous ways including traceability linkrecovery, inter-document correlation, document dependency/similarity detection,and document consolidation. We refer to all such approaches as trace recovery,and also use the term links without differentiating between dependencies, relationsand similarities between artifacts.
In line with previous research, we use the term dataset to refer to the set of arti-facts that is used as input in evaluations and preprocessing to refer to all processingof NL text before the IR models (discussed next) are applied [14], e.g., stop wordremoval, stemming and identifier (ID) splitting names expressed in CamelCase(i.e., identifiers named according to the coding convention to capitalize the firstcharacter in every word) or identifiers named according to the under_score con-vention. Feature selection is the process of selecting a subset of terms to representa document, in an attempt to decrease the size of the effective vocabulary and toremove noise [119].
To support trace recovery, several IR models have been applied. Since weidentified contradicting interpretations of what is considered a model, weight-ing scheme, and similarity measure, we briefly present our understanding of theIR field. IR models often apply the bag-of-words model, a simplifying assump-tion that represents a document as an unordered collection of words, disregardingword order [119]. Most existing IR models can be classified as either algebraicor probabilistic, depending on how relevance between queries and documents ismeasured. In algebraic IR models, relevance is assumed to be correlated with

2 Background 41
similarity [173]. The most well-known algebraic model is the commonly appliedVector Space Model (VSM) [150], which due to its many variation points acts asa framework for retrieval. Common to all variations of VSM is that both docu-ments and queries are represented as vectors in a high-dimensional space (everyterm, after preprocessing, in the document collection constitutes a dimension) andthat similarities are calculated between vectors using some distance function. In-dividual terms are not equally meaningful in characterizing documents, thus theyare weighted accordingly. Term weights can be both binary (i.e., existing or non-existing) and raw (i.e., based on term frequency) but usually some variant of TermFrequency-Inverse Document Frequency (TF-IDF) weighting is applied. TF-IDFis used to weight a term based on the length of the document and the frequency ofthe term, both in the document and in the entire document collection [154]. Re-garding similarity measures, the cosine similarity (calculated as the cosine of theangle between vectors) is dominating in IR-based trace recovery using algebraicmodels, but also Dice’s coefficient and the Jaccard index [119] have been applied.In an attempt to reduce the noise of NL (such as synonymy and polysemy), La-tent Semantic Indexing (LSI) was introduced [60]. LSI reduces the dimensionsof the vector space, finding semi-dimensions using singular value decomposition.The new dimensions are no longer individual terms, but concepts represented ascombinations of terms. In the VSM, relevance feedback (i.e., improving the querybased on human judgement of partial search results, followed by re-executing animproved search query) is typically achieved by updating the query vector [173].In IR-based trace recovery, this is commonly implemented using the Standard Roc-chio method [145]. The method adjusts the query vector toward the centroid vectorof the relevant documents, and away from the centroid vector of the non-relevantdocuments.
In probabilistic retrieval, relevance between a query and a document is es-timated by probabilistic models. The IR is expressed as a classification problem,documents being either relevant or non-relevant [154]. Documents are then rankedaccording to their probability of being relevant [124], referred to as the probabilis-tic ranking principle [141]. In trace recovery, the Binary Independence Retrievalmodel (BIM) [144] was first applied to establish links. BIM naïvely assumes thatterms are independently distributed, and essentially applies the Naïve Bayes classi-fier for document ranking [109]. Different weighting schemes have been exploredto improve results, and currently the BM25 weighting used in the non-binary Okapisystem [143] constitutes state-of-the-art.
Another category of probabilistic retrieval is based on the model of an infer-ence process in a Probabilistic Inference Network (PIN) [164]. In an inference net-work, relevance is modeled by the uncertainty associated with inferring the queryfrom the document [173]. Inference networks can embed most other IR models,which simplifies the combining of approaches. In its simplest implementation, adocument instantiates every term with a certain strength and multiple terms accu-mulate to a numerical score for a document given each specific query. Relevance

42 Recovering from a Decade: A Systematic Review of Information . . .
feedback is possible also for BIM and PIN retrieval [173], but we have not identi-fied any such attempts within the trace recovery research.
In the last years, another subset of probabilistic IR models has been appliedto trace recovery. Statistical Language Models (LM) estimate an LM for eachdocument, then documents are ranked based on the probability that the LM of adocument would generate the terms of the query [138]. A refinement of simpleLMs, topic models, describes documents as a mixture over topics. Each individualtopic is then characterized by an LM [174]. In trace recovery research, studies ap-plying the four topic models Probabilistic Latent Semantic Indexing (PLSI) [82],Latent Dirichlet Allocation (LDA) [20], Correlated Topic Model (CTM) [19] andRelational Topic Model (RTM) [33] have been conducted. To measure the dis-tance between LMs, where documents and queries are represented as stochasticvariables, several different measures of distributional similarity exist, such as theJensen-Shannon divergence (JS). To the best of our knowledge, the only imple-mentation of relevance feedback in LM-based trace recovery was based on theMixture Model method [175].
Finally, a number of measures used to evaluate IR tools need to be defined. Ac-curacy of a set of search results is primarily measured by the standard IR-measuresprecision (the fraction of retrieved instances that are relevant), recall (the fractionof relevant instances that are retrieved) and F-measure (harmonic mean of pre-cision and recall, possibly weighted to favour one over another) [14]. Precisionand recall values (P-R values) are typically reported pairwise or as precision andrecall curves (P-R curves). Two other set-based measures, originating from thetraceability community, are Recovery Effort Index (REI) [7] and Selectivity [162].Secondary measures aim to go further than comparing sets of search results, andalso consider their internal ranking. Two standard IR measures are Mean AveragePrecision (MAP) of precision scores for a query [119], and Discounted CumulativeGain (DCG) [95] (a graded relevance scale based on the position of a documentamong search results). To address this matter in the specific application of tracerecovery, Sundaram et al. [162] proposed DiffAR, DiffMR, and Lag to assess thequality of retrieved candidate links.
2.2 IR-based support in a trace recovery processAs the candidate trace links generated by state-of-the-art IR-based trace recoverytypically are too inaccurate, the current tools are proposed to be used in a semi-automatic process. De Lucia et al. describe this process as a sequence of four keysteps, where the fourth step requires human judgement [55]. Although steps 2 and3 mainly apply to algebraic IR models, also other IR models can be described bya similar sequential process flow. The four steps are:
1. document parsing, extraction, and pre-processing
2. corpus indexing with an IR method

2 Background 43
Retrieval Models Misc.Algebraic Probabilistic Statistical Weighting Similarity Relevance
models models language schemes measures / feedbackmodels distance models
functionsVector Binary Language Binary Cosine StandardSpace Independence Model similarity RochioModel Model (LM)(VSM) (BIM)Latent Probabilistic Probabilistic Raw Dice’s Mixture
Semantic Inference Latent coefficient ModelIndexing Network Semantic
(LSI) (PIN) Indexing(PLSI)
Best Match 25 Latent Term Frequency Jaccard(BM25)a Dirichlet Inverse Document index
Allocation Frequency(LDA) (TFIDF)
Correlated Best Match 25 Jensen-Topics (BM25)a ShannonModel divergence(CTM) (JS)
RelationalTopicsModel(RTM)
a Okapi BM25 is used to refer both to a non-binary probabilistic model, and its weighting scheme.
Table 1: A summary of fundamental IR terms applied in trace recovery. Note thatonly the vertical organization carries a meaning.

44 Recovering from a Decade: A Systematic Review of Information . . .
3. ranked list generation
4. analysis of candidate links
In the first step, the artifacts in the targeted information space are processedand represented as a set of documents at a given granularity level, e.g., sections,class files or individual requirements. In the second step, for algebraic IR models,features from the set of documents are extracted and weighted to create an index.When also the query has been indexed in the same way, the output from step 2 isused to calculate similarities between artifacts to rank candidate trace links accord-ingly. In the final step, these candidate trace links are provided to an engineer forexamination. Typically, the engineer then reviews the candidate source and targetartifacts of every candidate trace link, and determines whether the link should beconfirmed or not. Consequently, the final outcome of the process of IR-based tracerecovery is based on human judgment.
A number of publications propose advice for engineers working with candi-date trace links. De Lucia et al. have suggested that an engineer should iterativelydecrease the similarity threshold, and stop considering candidate trace links whenthe fraction of incorrect links get too high [56, 57]. Based on an experiment withstudent subjects, they concluded that an incremental approach in general both im-proves the accuracy and reduces the effort involved in a tracing task supportedby IR-based trace recovery. Furthermore, they report that the subjects preferredworking in an incremental manner. Working incrementally with candidate tracelinks can to some subjects also be an intuitive approach. In a previous experimentby Borg and Pfahl, several subjects described such an approach to deal with tooloutput, even without explicit instructions [22]. Coverage analysis is another strat-egy proposed by De Lucia et al., intended to follow up on the step of iterativelydecreasing the similarity threshold [59]. By analyzing the confirmed candidatetrace links, i.e., conducting a coverage analysis, De Lucia et al. suggest that en-gineers should focus on tracing artifacts that have few trace links. Also, in anexperiment with students, they demonstrated that an engineer working accordingto this strategy recovers more correct trace links.
3 Related work
This section presents a chronological overview of IR-based trace recovery, previ-ous overviews of the field, and related work on advancing empirical evaluations ofIR-based trace recovery.
3.1 A brief history of IR-based trace recovery
Tool support for the linking process of NL artifacts has been explored by re-searchers since at least the early 1990s. Pioneering work was done in the LESD

3 Related work 45
project (Linguistic Engineering for Software Design) by Borillo et al., in which atool suite analyzing NL requirements was developed [25]. The tool suite parsedNL requirements to build semantic representations, and used artificial intelligenceapproaches to help engineers establish trace links between individual require-ments [26]. Apart from analyzing relations between artifacts, the tools evaluatedconsistency, completeness, verifiability and modifiability [32]. In 1998, a studyby Fiutem and Antoniol presented a recovery process to bridge the gap betweendesign and code, based on edit distances between artifacts [75]. They coined theterm “traceability recovery”, and Antoniol et al. published several papers on thetopic. Also, they were the first to clearly express identification of trace links asan IR problem [5]. Their milestone work from 2002 compared two standard IRmodels, probabilistic retrieval using the BIM and the VSM [7]. Simultaneously,in the late 1990s, Park et al. worked on tracing dependencies between artifacts us-ing a sliding window combined with syntactic parsing [134]. Similarities betweensentences were calculated using cosine similarities.
During the first decade of the new millennium, several research groups ad-vanced IR-based trace recovery. Natt och Dag et al. did research on requirementdependencies in the dynamic environment of market-driven requirements engi-neering [129]. They developed the tool ReqSimile, implementing trace recoverybased on the VSM, and later evaluated it in a controlled experiment [130]. Apublication by Marcus and Maletic, the second most cited article in the field, con-stitutes a technical milestone in IR-based trace recovery [120]. They introducedLatent Semantic Indexing (LSI) to recover trace links between source code andNL documentation, a technique that has been used by multiple researchers since.Huffman Hayes and Dekhtyar enhanced VSM retrieval with relevance feedbackand introduced secondary performance metrics [90]. From early on, their researchhad a human-oriented perspective, aimed at supporting V&V activities at NASAusing their tool RETRO [89].
De Lucia et al. have conducted work focused on empirically evaluating LSI-based trace recovery in their document management system ADAMS [52]. Theyhave advanced the empirical foundation by conducting a series of controlled ex-periments and case studies with student subjects [53, 54, 58]. Cleland-Huang andcolleagues have published several studies on IR-based trace recovery. They intro-duced probabilistic trace recovery using a PIN-based retrieval model, implementedin their tool Poirot [112]. Much of their work has focused on improving the ac-curacy of their tool by enhancements such as: applying a thesaurus to deal withsynonymy [152], extraction of key phrases [180], and using a project glossary toweight the most important terms higher [180].
Recent work on IR-based trace recovery has, with various results, gone be-yond the traditional models for information retrieval. In particular, trace recoverysupported by probabilistic topic models has been explored by several researchers.Dekhtyar et al. combined several IR models using a voting scheme, including theprobabilistic topic model Latent Dirachlet Allocation (LDA) [65]. Parvathy et al.

46 Recovering from a Decade: A Systematic Review of Information . . .
proposed using the Correlated Topic Model (CTM) [135], and Gethers et al. sug-gested using Relational Topic Model (RTM) [77]. Abadi et al. proposed usingProbabilistic Latent Semantic Indexing (PLSI) and utilizing two concepts basedon information theory, Sufficient Dimensionality Reduction (SDR) and Jensen-Shannon Divergence (JS) [1]. Capobianco et al. proposed representing NL ar-tifacts as B-splines and calculating similarities as distances between them on theCartesian plane [30]. Sultanov and Huffman Hayes implemented trace recoveryusing a swarm technique [160], an approach in which a non-centralized group ofnon-intelligent self-organized agents perform work that, when combined, enablesconclusions to be drawn.
3.2 Previous overviews on IR-based trace recovery
Basically every publication on IR-based trace recovery contains some informationon previous research in the field. In our opinion, the previously most compre-hensive summary of the field was provided by De Lucia et al. [58]. Even thoughthe summary was not the primary contribution of the publication, they chrono-logically described the development, presented 15 trace recovery methods and 5tool implementations. They compared underlying IR models, enhancing strate-gies, evaluation methodologies and types of recovered links. However, regardingboth methodological rigor and depth of the analysis, it is not a complete SLR. DeLucia et al. have also surveyed proposed approaches to traceability managementfor impact analysis [50]. They discussed previous work based on a conceptualframework by Bianchi et al. [17], consisting of the three traceability dimensions:type of links, source of information to derive links, and their internal representa-tion. Apart from IR-based methods, the survey by De Lucia et al. contains bothrule-based and data mining-based trace recovery. Also Binkley and Lawrie havepresented a survey of IR-based trace recovery as part of an overview of applica-tions of IR in software engineering [18]. They concluded that the main focus ofthe research has been to improve the accuracy of candidate links wrt. P-R values,and that LSI has been the most popular IR model. However, they also report thatno IR model has been reported as superior for trace recovery. While our work issimilar to previous work, our review is more structured and goes deeper with amore narrow scope.
Another set of publications has presented taxonomies on IR techniques in soft-ware engineering. In an attempt to harmonize the terminology of the IR appli-cations, Canfora and Cerulo presented a taxonomy of IR models [28]. However,their surveyed IR applications are not explicitly focusing on software engineering.Furthermore, their proposed taxonomy does not cover recent IR models identi-fied in our study, and the subdivision into ‘representation’ and ‘reasoning’ poorlyserves our intentions. Falessi et al. recently published a comprehensive taxonomyof IR techniques available to identify equivalent requirements [73]. They adoptedthe term variation point from Software Product Line Engineering [137], to stress

3 Related work 47
the fact that an IR solution is a combination of different, often orthogonal, designchoices. They consider an IR solution to consist of a combination of algebraicmodel, term extraction, weighting scheme and similarity metric. Finally, theyconducted an empirical study of various combinations and concluded that sim-ple approaches yielded the most accurate results on their dataset. We share theirview on variation points, but fail to apply it since our literature review is limited bywhat previous publications report on IR-based trace recovery. Also, their proposedtaxonomy only covers algebraic IR models, excluding other models (most impor-tantly, the entire family of probabilistic retrieval). The main difference betweenour study and the work by Falessi et al. is that they identified variation points ofIR approaches and found the best combination by experimentation. Our study onthe other hand systematically extracts empirical evidence from previous research,using the systematic literature approach, and aggregates results in a secondaryanalysis. However, since our IR taxonomies partly overlap, empirical results fromthe two studies can be compared.
Concept location (a.k.a. feature location) is a research topic that overlaps tracerecovery. It can be seen as the first step of a change impact analysis process [122].Given a concept (or feature) that is to be modified, the initial information need ofa developer is to locate the part of the source code where it is embedded. Clearly,this information need could be fulfilled by utilizing IR. However, we distinguishthe topics by considering concept location to be more query-oriented [76]. Fur-thermore, whereas trace recovery typically is evaluated by linking n artifacts to mother artifacts, evaluations of concept location tend to focus on n queries targetinga document set of m source code artifacts (where n << m), as for example inthe study by Torchiano and Ricca [163]. Also, while it is often argued that tracerecovery should retrieve trace links with a high recall, the goal of concept locationis mainly to retrieve one single location in the code with high precision. Dit et al.recently published a literature review on feature location [68].
3.3 Related contributions to the empirical study of IR-based trace recovery
A number of previous publications have aimed at structuring or advancing the re-search on IR-based trace recovery, and are thus closely related to our study. Anearly attempt to advance reporting and conducting of empirical experiments waspublished by Huffman Hayes and Dekhtyar [84]. Their experimental frameworkdescribes the four phases: definition, planning, realization and interpretation. Inaddition, they used their framework to characterize previous publications. Un-fortunately, the framework has not been applied frequently and the quality of thereporting of empirical evaluations varies greatly [24]. Huffman Hayes et al. alsopresented the distinction between studies of methods (are the tools capable of pro-viding accurate results fast?) and studies of human analysts (how do humans usethe tool output?) [88]. Furthermore, they proposed assessing the accuracy of tool

48 Recovering from a Decade: A Systematic Review of Information . . .
Figure 1: The Integrated Cognitive Research Framework by Ingwersen andJärvelin [92], a framework for IR evaluations in context.
output according to quality intervals named ‘acceptable’, ‘good’, and ‘excellent’,based on Huffman Hayes’ industrial experience of working with traceability ma-trices of various qualities. Huffman Hayes et al.’s quality levels were defined torepresent the effort that would be required by an engineer to vet an entire candidatetraceability matrix. In our study, we use both classification schemes proposed byHuffman Hayes et al. to map the identified primary publications.
Considering empirical evaluations, we extend the classifications proposed byHuffman Hayes et al. [88] by an adapted version of the Integrated Cognitive Re-search Framework by Ingwersen and Järvelin [92]. Their work aimed at extendingthe de-facto standard of IR evaluation, the Laboratory Model of IR Evaluation, de-veloped in the Cranfield tests in the 60s [44], challenged for its unrealistic lack ofuser involvement [101]. Ingwersen and Järvelin argued that IR is always evaluatedin a context, referred to the innermost context as “the cave of IR evaluation”, andproposed a framework consisting of four integrated contexts (see Figure 1). Wehave adapted their framework to a four-level context taxonomy, tailored for IR-based trace recovery, to classify in which contexts previous evaluations have beenconducted, see Table 2. Also, we add a dimension of study environments (uni-versity, proprietary, and open source environment), as presented in Figure 12 inSection 4. For more information on the context taxonomy, we refer to our originalpublication [23].
In the field of IR-based trace recovery, the empirical evaluations are termedvery differently by different authors. Some call them ‘experiments’, others ‘casestudies’, and yet others only ‘studies’. We use the following definitions, which areestablished in the field of software engineering.
Case study in software engineering is an empirical enquiry that draws on mul-tiple sources of evidence to investigate one instance (or a small number ofinstances) of a contemporary software engineering phenomenon within itsreal-life context, especially when the boundary between phenomenon andcontext cannot be clearly specified. [147]
Experiment (or controlled experiment) in software engineering is an empiricalenquiry that manipulates one factor or variable of the studied setting. Based

3 Related work 49
in randomization, different treatments are applied to or by different sub-jects, while keeping other variables constant, and measuring the effects onoutcome variables. In human-oriented experiments, humans apply differenttreatments to objects, while in technology-oriented experiments, differenttechnical treatments are applied to different objects. [170]
Empirical evaluations of IR-based trace recovery may be classified as casestudies, if they evaluate the use of, e.g., IR-based trace recovery tools in a com-plex software engineering environment, where it is not clear whether the tool isthe main factor or other factors are at play. These are typically level 4 studies inour taxonomy, see Table 2. Human-oriented controlled experiments may evaluatehuman performance when using two different IR-tools in an artificial (in vitro) orwell-controlled real (in vivo) environment, typically at level 3 of the taxonomy.The stochastical variation is here primarily assumed to be in the human behav-ior, although there of course are interactions between the human behavior, theartifacts and the tools. Technology-oriented controlled experiments evaluate toolperformance on different artifacts, without human intervention, corresponding tolevels 1 and 2 in our taxonomy. The variation factor is here the artifacts, and hencethe technology-oriented experiment may be seen as benchmarking studies, whereone technique is compared to another technique, using the same artifacts, or theperformance of one technique is compared for multiple different artifacts.
The validity of the datasets used as input in evaluations in IR-based trace re-covery is frequently discussed in the literature. Also, two recent publications pri-marily address this issue. Ali et al. present a literature review on characteristicsof artifacts reported to impact trace recovery evaluations [4], e.g., ambiguous andvague requirements, and the quality of source code identifiers. Ali et al. extractedP-R values from eight previous trace recovery evaluations, not limited to IR-basedtrace recovery, and show that the same techniques generate candidate trace linksof very different accuracy across datasets. They conclude that research targetingonly recovery methods in isolation is not expected to lead to any major break-throughs, instead they suggest that factors impacting the input artifacts should bebetter controlled. Borg et al. recently highlighted that a majority of previous eval-uations of IR-based trace recovery have been conducted using artifacts developedby students [24]. The authors explored this potential validity threat in a surveyof the traceability community. Their results indicate that while most authors con-sider artifacts originating from student projects to be only partly representative toindustrial artifacts, few respondents explicitly validated them before using them asexperimental input.
3.4 Precision and recall evaluation styles for technology-oriented trace recovery
In the primary publications, two principally different styles to report output fromtechnology-oriented experiments have been used, i.e., presentation of P-R val-

50 Recovering from a Decade: A Systematic Review of Information . . .
Level 1: The most simplified context, referred to Precision, recall, Experiments onRetrieval as “the cave of IR evaluation”. F-measure benchmarks,context A strict retrieval context, performance possibly with
is evaluated wrt. the accuracy of a set simulatedof search results. Quantitative studies feedbackdominate.
Level 2: A first step towards realistic applications Secondary measures. Experiments onSeeking of the tool, “drifting outside the cave’. General IR: benchmarks,context A seeking context with a focus on how MAP, DCG. possibly with
the human finds relevant information Traceability specific: simulatedin what was retrieved by the system. Lag, DiffAR, DiffMR. feedbackQuantitative studies dominate.
Level 3: Humans complete real tasks, but in an Time spent on ControlledWork task in-vitro setting. Goal of evaluation is task and quality experiments
context to assess the casual effect of an IR tool of work. with humanwhen completing a task. A mix of subjects.quantitative and qualitative studies.
Level 4: Evaluations in a social-organizational User satisfaction, Case studiesProject context. The IR tool is studied when tool usagecontext used by engineers within the full
complexity of an in-vivo setting.Qualitative studies dominate.
Table 2: A context taxonomy of IR-based trace recovery evaluations. Level 1 istechnology-oriented, and level 3 and 4 are human-oriented. Level 2 typically hasa mixed focus.
ues from evaluations in the retrieval and seeking contexts. A number of publica-tions, including the pioneering work by Antoniol et al. [7], used the traditionalstyle from the ad hoc retrieval task organized by the Text REtrieval Conference(TREC) [166], driving large-scale evaluations of IR. In this style, a number ofqueries are executed on a document set, and each query results in a ranked list ofsearch results (cf. (a) in Figure 2). The accuracy of the IR system is then calcu-lated as an average of the precision and recall over the queries. For example, inAntoniol et al.’s evaluation, source code files were used as queries and the doc-ument set consisted of individual manual pages. We refer to this reporting styleas query-based evaluation. This setup evaluates the IR problem: “given this traceartifact, to which other trace artifacts should trace links be established?” The IRproblem is reformulated for each trace artifact used as a query, and the results canbe presented as a P-R curve displaying the average accuracy of candidate tracelinks over n queries. This reporting style shows how accurately an IR-based tracerecovery tool supports a work task that requires single on-demand tracing efforts(a.k.a. reactive tracing or just-in-time tracing), e.g., establishing traces as part ofan impact analysis work task [7, 22, 110].
In the other type of reporting style used in the primary publications, documentsof different types are compared to each other, and the result from the similarity-or probability-based retrieval is reported as one single ranked list of candidate
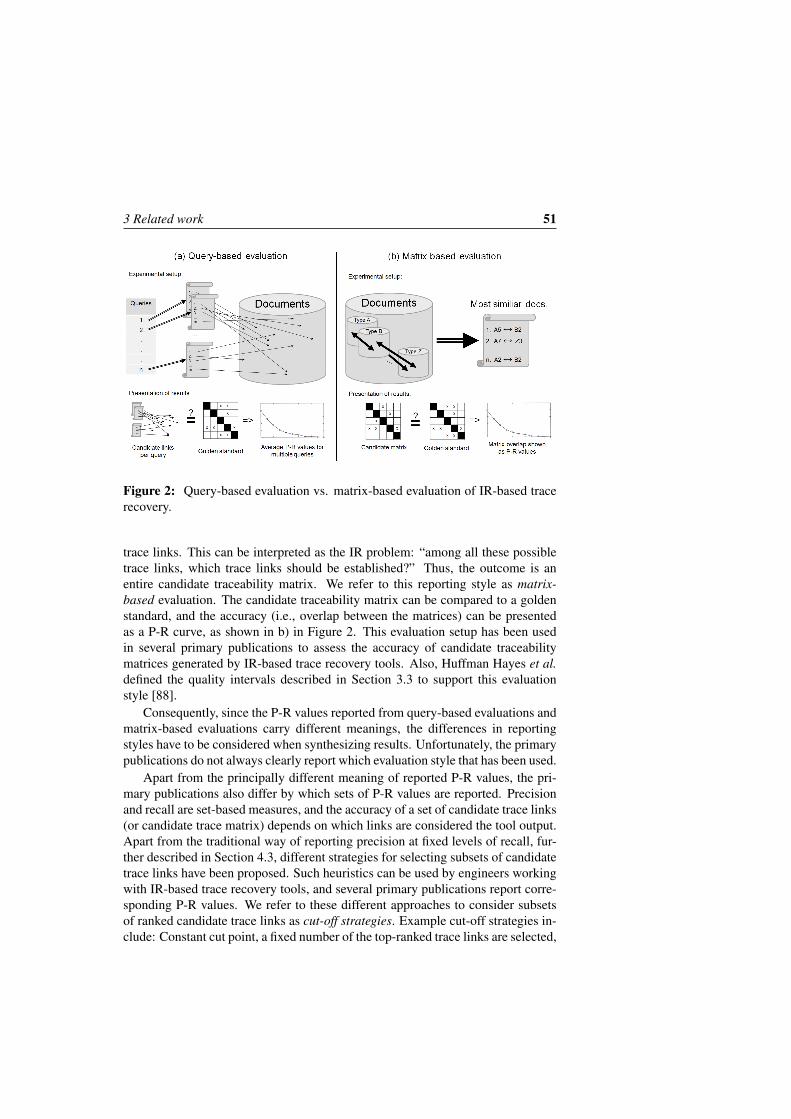
3 Related work 51
Figure 2: Query-based evaluation vs. matrix-based evaluation of IR-based tracerecovery.
trace links. This can be interpreted as the IR problem: “among all these possibletrace links, which trace links should be established?” Thus, the outcome is anentire candidate traceability matrix. We refer to this reporting style as matrix-based evaluation. The candidate traceability matrix can be compared to a goldenstandard, and the accuracy (i.e., overlap between the matrices) can be presentedas a P-R curve, as shown in b) in Figure 2. This evaluation setup has been usedin several primary publications to assess the accuracy of candidate traceabilitymatrices generated by IR-based trace recovery tools. Also, Huffman Hayes et al.defined the quality intervals described in Section 3.3 to support this evaluationstyle [88].
Consequently, since the P-R values reported from query-based evaluations andmatrix-based evaluations carry different meanings, the differences in reportingstyles have to be considered when synthesizing results. Unfortunately, the primarypublications do not always clearly report which evaluation style that has been used.
Apart from the principally different meaning of reported P-R values, the pri-mary publications also differ by which sets of P-R values are reported. Precisionand recall are set-based measures, and the accuracy of a set of candidate trace links(or candidate trace matrix) depends on which links are considered the tool output.Apart from the traditional way of reporting precision at fixed levels of recall, fur-ther described in Section 4.3, different strategies for selecting subsets of candidatetrace links have been proposed. Such heuristics can be used by engineers workingwith IR-based trace recovery tools, and several primary publications report corre-sponding P-R values. We refer to these different approaches to consider subsetsof ranked candidate trace links as cut-off strategies. Example cut-off strategies in-clude: Constant cut point, a fixed number of the top-ranked trace links are selected,

52 Recovering from a Decade: A Systematic Review of Information . . .
e.g. 5, 10, or 50. Variable cut point, a fixed percentage of the total number of can-didate trace links is selected, e.g. 5% or 10%. Constant threshold, all candidatetrace links representing similarities (or probabilities) above a specified thresholdis selected, e.g. above a cosine similarity of 0.7.
The choice of what subset of candidate trace links to represent by P-R valuesreflects the cut-off strategy an imagined engineer could use when working with thetool output. However, which strategy results in the most accurate subset of tracelinks depends on the specific case evaluated. Moreover, in reality it is possible thatengineers would not be consistent in how they work with candidate trace links.As a consequence of the many possibly ways to report P-R values, the primarypublications view output from IR-based trace recovery tools from rather differentperspectives. For work tasks supported by a separate list of candidate trace linksper source artifact, there are indications that human subjects seldom consider morethan 10 candidate trace links [22], in line with what is commonplace to present asa ‘pages-worth’ output of major search engines such as Google, Bing and Yahoo.On the other hand, when an IR-based trace recovery tool is used to generate acandidate traceability matrix over an entire information space, considering onlythe first 10 candidate links would obviously be insufficient, as there would likelybe thousands of correct trace links to recover. However, regardless of reportingstyle, the number of candidate trace links a P-R value represents is important inany evaluation of IR-based trace recovery tools, since a human is intended to vetthe output.
4 MethodThe overall goal of this study was to form a comprehensive overview of the ex-isting research on IR-based trace recovery. To achieve this objective, we system-atically collected empirical evidence to answer research questions characteristicboth for an SM and an SLR [103, 136]. The study was conducted in the followingdistinct steps, (i) development of the review protocol, (ii) selection of publications,(iii) data extraction and mapping of publications, which were partly iterated andeach of them was validated.
4.1 Protocol developmentFollowing the established review guidelines for SLRs in software engineering [103],we iteratively developed a review protocol in consensus meetings between the au-thors. The protocol defined the research questions (stated in Section 1), the searchstrategy (described in Section 4.2), the inclusion/exclusion criteria (presented inTable 3), and the classification scheme used for the data extraction (described inSection 4.3). Also, the protocol specified use of qualitative cross-case analysis tosynthesize data extracted from the primary studies [126], sometimes however ex-tended by pieces of quantitative information. The extracted data were organized

4 Method 53
in a tabular format to support comparison across studies. Evidence was summa-rized per category, and commonalities and differences between studies were in-vestigated. Also, the review protocol specified the use of Zotero2 as the referencemanagement system, to simplify general tasks such as sorting, searching and re-moval of duplicates. An important deviation from the terminology used in the SLRguidelines is that we distinguish between primary publications (i.e., included unitsof publication) and primary studies (i.e., included pieces of empirical evidence),since a number of publications report multiple studies.
Table 3 states our inclusion/exclusion criteria, along with rationales and exam-ples. A number of general decisions accompanied the criteria:
• Empirical results presented in several articles, we only included from themost extensive publication. Examples of excluded publications include pi-oneering work later extended to journal publications, the most notable be-ing work by Antoniol et al. [5] and Marcus and Maletic [120]. However,we included publications describing all independent replications (deliberatevariations of one or more major aspects), and dependant replications (sameor very similar experimental setups) by other researchers [153].
• Our study included publications that apply techniques in E2a-d in Table 3,but use an IR model as benchmark. In such cases, we included the IR bench-mark, and noted possible complementary approaches as enhancements. Anexample is work using probabilistic retrieval enhanced by machine learningfrom existing trace links [66].
• We included approaches that use structured NL as input, i.e., source code ortabular data, but treat the information as unstructured. Instead, we consid-ered any attempts to utilize document structure as enhancements.
• Our study only included linking between software artifacts, i.e., artifacts thatare produced and maintained during development [106]. Thus, we excludedlinking approaches to entities such as e-mails [13] and tacit knowledge [83,159].
• We excluded studies evaluating trace recovery in which neither the sourcenor the target artifacts dominantly represent information as NL text. Ex-cluded publications comprise linking source code to test code [165], andwork linking source code to text expressed in specific modelling notation [9,41].
4.2 Selection of publicationsThe systematic identification of publications consisted of two main phases: (i) de-velopment of a golden standard of primary publications, and (ii) a search string that
2www.zotero.org

54 Recovering from a Decade: A Systematic Review of Information . . .
Inclusion criteria Rationale/commentsI1 Publication available in English in
full textWe assumed that all relevant publications would beavailable in English.
I2 Publication is a peer-reviewed pieceof software engineering work
As a quality assurance, we did not include technicalreports, master theses etc.
I3 Publication contains empirical re-sults (case study, experiment, sur-vey etc.) of IR-based trace recoverywhere natural language artifacts areeither source or target
Defined our main scope based on our RQs. Publi-cation should clearly link artifacts, thus we excludedtools supporting a broader sense of program under-standing such as COCONUT [48]. Also, the ap-proach should treat the linking as an IR problem.However, we excluded solutions exclusively extract-ing specific character sequences in NL text, such aswork on Mozilla defect reports [12].
Exclusion criteria Rationale/commentsE1 Answer is no to I1, I2 or I3E2 Publication proposes one of the fol-
lowing approaches to recover tracelinks, rather than IR:
We included only publications that are deployable inan industrial setting with limited effort. Thus, welimited our study to techniques that require nothingbut unstructured NL text as input. Other approachescould arguably be applied to perform IR, but are toodifferent to fit our scope. Excluded approaches in-clude: rules [71,157], ontologies [10], supervised ma-chine learning [156], semantic networks [113], anddynamic analysis [72].
a) rule-based extractionb) ontology-based extractionc) machine learning approachesthat require supervised learningd) dynamic/execution analysis
E3 Article explicitly targets one of thefollowing topics, instead of trace re-covery:
We excluded both concept location and duplicate de-tection since it deals with different problems, evenif some studies apply IR models. Excluded publica-tions include: duplicate detection of defects [146], de-tection of equivalent requirements [73], and conceptlocation [122]. We explicitly added the topics codeclustering, class cohesion, and cross cutting concernsto clarify our scope.
a) concept/feature locationb) duplicate/clone detectionc) code clusteringd) class cohesione) cross cutting concerns/aspectmining
Table 3: Inclusion/exclusion criteria applied in our study. The rightmost columnmotivates our decisions.

4 Method 55
Figure 3: Overview of the publication selection phase. Smileys show the numberof people involved in a step, while double frames represent a validation. Numbersrefer to number of publications.
retrieves them, and a systematic search for publications, as shown in Figure 1. Inthe first phase, a set of publications was identified through exploratory searching,mainly by snowball sampling from a subset of an informal literature review. Themost frequently recurring publication fora were then scanned for additional pub-lications. This activity resulted in 59 publications, which was deemed our goldenstandard3. The first phase led to an understanding of the terminology used in thefield, and made it possible to develop valid search terms.
The second step of the first phase consisted of iterative development of thesearch string. Together with a librarian at the department, we repeatedly evaluatedour search string using combined searches in the Inspec/Compendex databases.Fifty-five papers in the golden standard were available in those databases. Weconsidered the search string good enough when it resulted in 224 unique hits with80% recall and 20% precision when searching for the golden standard, i.e., 44 ofthe 55 primary publications plus 176 additional publications were retrieved.
The final search string was composed of four parts connected with ANDs,specifying the activity, objects, domain, and approach respectively.
3The golden standard was not considered the end goal of our study, but was the target during theiterative development of the search string described next.

56 Recovering from a Decade: A Systematic Review of Information . . .
Primary Databases Search options #Search resultsInspec Title+abstract, no auto-stem 194Compendex Title+abstract, no auto-stem 143IEEE Explore All fields 136Web of Science Title+abstract+keywords 108Secondary Databases Search options #Search resultsACM Digital Library All fields, auto-stem 1038SciVerse Hub Beta Science Direct+SCOPUS 203
Table 4: Search options used in databases, and the number of search results.
(traceability OR "requirements tracing" OR "requirements trace" OR"trace retrieval")
AND(requirement* OR specification* OR document OR documents ORdesign OR code OR test OR tests OR defect* OR artefact* ORartifact* OR link OR links)
AND(software OR program OR source OR analyst)AND("information retrieval" OR IR OR linguistic OR lexical ORsemantic OR NLP OR recovery OR retrieval)
The search string was first applied to the four databases supporting export ofsearch results to BibTeX format, as presented in Table 4. The resulting 581 paperswere merged in Zotero. After manual removal of duplicates, 281 unique publica-tions remained. This result equals 91% recall and 18% precision compared to thegolden standard. The publications were filtered by our inclusion/exclusion crite-ria, as shown in Figure 1, and specified in Section 4.1. Borderline articles werediscussed in a joint session of the first two authors. Our inclusion/exclusion crite-ria were validated by having the last two authors compare 10% of the 581 papersretrieved from the primary databases. The comparison resulted in a free-marginalmulti-rater kappa of 0.85 [140], which constitutes a substantial inter-rater agree-ment.
As the next step, we applied the search string to two databases without Bib-TeX export support. One of them, ACM Digital Library, automatically stemmedthe search terms, resulting in more than 1000 search results. The inclusion/exclu-sion criteria were then applied to the total 1241 publications. This step extendedour primary studies by 13 publications, after duplicate removal, and applicationof inclusion/exclusion criteria, 10 identified in ACM Digital Library and 3 fromSciVerse.
As the last step of our publication selection phase, we again conducted ex-ploratory searching. Based on our new understanding of the domain, we scannedthe top publication fora and the most published scholars for missed publications.As a last complement, we searched for publications using Google Scholar. In total,

4 Method 57
this last phase identified 8 additional publications. Thus, the systematic databasesearch generated 89% of the total number of primary publications, which is inaccordance with expectations from the validation of the search string.
As a final validation step, we visualized the selection of the 70 primary pub-lications using REVIS, a tool developed to support SLRs based on visual textmining [74]. REVIS takes a set of primary publications in an extended BibTeXformat and, as presented in Figure 4, visualizes the set as a document map (a), edgebundles (b), and a citation network for the document set (c). While REVIS wasdeveloped to support the entire SLR process, we solely used the tool as a means tovisually validate our selection of publications.
In Figure 4, every node represents a publication, and a black outline distin-guishes primary publications (in c), not only primary publications are visualized).In a), the document map, similarity of the language used in title and abstract ispresented, calculated using the VSM and cosine similarities. In the clustering,only absolute distances between publications carry a meaning. The arrows pointout Antoniol et al.’s publication from 2002 [7], the most cited publication on IR-based trace recovery. The closest publications in a) are also authored by Antoniolet al. [6, 8]. An analysis of a) showed that publications sharing many co-authorstend to congregate. As an example, all primary publications authored by De Lu-cia et al. [51–54, 56–59], Capobianco et al. [29, 30], and Oliveto et al. [132] arefound within the rectangle. No single outlier stands out, indicating that none ofthe primary publications uses a very different language.
In b), the internal reference structure of the primary studies is shown, displayedby edges connecting primary publications in the outer circle. Analyzing the cita-tions between the primary publications shows one outlier, just below the arrow.The publication by Park et al. [134], describing work conducted concurrently withAntoniol et al. [7], has not been cited by any primary publications. This questionedthe inclusion of the work by Park et al., but as it meets our inclusion/exclusion cri-teria described in Section 4.1, we decided to keep it.
Finally, in c), the total citation network of the primary studies is presented.Regarding common citations in total, again Park et al. [134] is an outlier, shownas I in c). The two other salient data points, II and III, are both authored by Nattoch Dag et al. [128, 130]. However, according to our inclusion/exclusion criteria,there is no doubt that they should be among the primary publications. Thus, inDecember 2011, we concluded the set of 70 primary publications.
However, as IR-based trace recovery is an active research field, several newstudies were published while this publication was in submission. To catch upwith the latest research, we re-executed the search string in the databases listed inTable 4 in June 2012, to catch up with publications from the second half of 2011.This step resulted in 9 additional publications, increasing the number of primarypublications to 79. In the rest of this paper, we refer to the original 70 publicationsas the “core primary publications”, and the 79 publications as just the “primarypublications”.

58 Recovering from a Decade: A Systematic Review of Information . . .
Figure 4: Visualization of core primary publications. a) document map, showssimilarities in language among the core primary publications. b) edge bundle,displays citations among the core primary publications. c) citation network, showsshared citations among the core primary publications.

4 Method 59
4.3 Data extraction and mapping
During the stage of the study, data was extracted from the primary publicationsaccording to the pre-defined extraction form of the review protocol. We extractedgeneral information (title, authors, affiliation, publication forum, citations), de-tails about the applied IR approach (IR model applied, selection and weighting offeatures, enhancements) and information about the empirical evaluation (types ofartifacts linked, size and origin of dataset, research methodology, context of IRevaluation, results of evaluation).
The extraction process was validated by the second and third authors, work-ing on a 30% sample of the core primary publications. Half the sample, 15% ofthe core primary publications, was used to validate extraction of IR details. Theother half was used by the other author to validate empirical details. As expected,the validation process showed that the data extraction activity, and the qualitativeanalysis inherent in that work, inevitably leads to some deviating interpretations.Classifying according to the four levels of IR contexts, which was validated forthe entire 30% sample, showed the least consensus. This divergence, and otherminor discrepancies detected, were discussed until an agreement was found andfollowed for the rest of the primary publications. Regarding the IR contexts inparticular, we adopted an inclusive strategy, typically selecting the higher levelsfor borderline publications.
Regarding results from studies dominated by evaluations in the retrieval andseeking contexts, as described in Section 3.3, we extracted information in twoseparate ways. For publications comparing multiple underlying IR models, weextracted the conclusions of the original authors, a process that in some casesrequired qualitative analysis. Also, while the authors of the primary publicationsbased their conclusions on different types of evidence, we treated all conclusionsas equally strong.
Also, we extracted P-R values from the primary publications based on ourdiscussions in Section 3.4. However, as highlighted by Banko and Brill in the em-pirical NLP community [15], the effect of large number of evaluations conductedon small datasets is an open question. One has to wonder what conclusions drawnon small datasets may carry over to datasets of industrial size. In trace recov-ery research, this is particularly notable regarding context-dependent enhancementstrategies, as they risk leading to overtrained or over-engineered solutions that arenot generalizable. To mitigate this possible bias, in line with our interest in generalsolutions that are easily deployable, we extracted P-R values from basic trace re-covery methods rather than enhancements. Instead, the various enhancements arereported in Section 5.1.
We agree with the opinion of Spärck Jones et al., pioneers of standardized testcollections for IR evaluations, that the widely reported precision at standard recalllevels is opaque [158]. The figures obscure the actual numbers of retrieved docu-ments needed to get beyond low recall. Still, we follow the convention established

60 Recovering from a Decade: A Systematic Review of Information . . .
at TREC and report both precision at fixed levels of recall as well as precisionat specific cut-off levels. In line with what was reported for the ad hoc retrievaltask at TREC, we report precision at ten recall levels from 0.1 to 1 (referred toas PR@Fix). However, while TREC established the cut-off levels 5, 10, 15, 20,30 and 100 [98], evaluations on IR-based trace recovery have typically not beenreported at such a level of detail. As a consequence, we report P-R values fromonly the cut-off levels 5, 10 and 100 (referred to as PR@N), as they are the mostfrequently reported in the primary publications.
Furthermore, as discussed in Section 3.4, neither PR@Fix nor PR@N coverall P-R reporting styles in the primary publications. Thus, we also extracted P-Rvalues beyond standard TREC practice. We extracted P-R values correspondingto a set of candidate trace links with a cosine similarity ≥ 0.7 (referred to [email protected]). Finally, to ensure that all primary publications reporting P-R val-ues contributed to our synthesis, we also report from an inclusive aggregation ofmiscellaneous P-R values (referred to as PR@Tot).
While we extracted P-R values from tables whenever possible, a majority wereextracted from figures presenting P-R curves. As both the information density andresolution of such figures vary, so did the errors involved in the manual measuringprocess. Consequently, the extracted data should be interpreted as a general trendrather than exact results.
4.4 Threats to validity
Threats to the validity of the mapping study are analyzed with respect to constructvalidity, reliability, internal validity and external validity [172]. Particularly, wereport deviations from the SLR guidelines [103].
Construct validity concerns the relation between measures used in the studyand the theories in which the research questions are grounded. In this study, thisconcerns the identification of papers, which is inherently qualitative and dependenton the coherence of the terminology in the field. To mitigate this threat, we tookthe following actions. The search string we used was validated using a golden setof publications, and we executed it in six different publication databases. Further-more, our subsequent exploratory search further improved our publication cover-age. A single researcher applied the inclusion/exclusion criteria, although, as avalidation proposed by Kitchenham and Charters [103], another researcher justi-fied 10% of the search results from the primary databases. There is a risk thatthe specific terms of the search string related to ‘activity’ (e.g., “requirementstracing”) and ‘objects’ cause a bias toward both requirements research and pub-lications with technical focus. However, the golden set of publications was es-tablished by a broad scanning of related work, using both searching and browsing,and was not restricted to specific search terms. Finally, as this work was conductedboth as an SM and an SLR, the quality assessment was expressed as a RQ in itsown (RQ3). As such, quality was assessed further than by the inclusion/exclusion

5 Results 61
criteria. Furthermore, applicable to RQ4, quality differences were accounted forby considering single publications reporting multiple studies as multiple units ofempirical evidence.
An important threat to reliability concerns whether other researchers wouldcome to the same conclusions based on the publications we selected. The ma-jor threat is the extraction of data, as mainly qualitative synthesis was applied, amethod that involves interpretation. A single researcher extracted data from theprimary publications, and the other two researchers reviewed the process, as sug-gested by Brereton et al. [27]. As a validation, both the reviewers individuallyrepeated the data extraction on a 15% sample of the core primary publications.Another reliability threat is that we present qualitative results with quantitativefigures. Thus, the conclusions we draw might depend on the data we decidedto visualize; however, the primary studies are publicly available, allowing oth-ers to validate our conclusions. Furthermore, as our study contains no formalmeta-analysis, no sensitivity analysis was conducted, neither was publication biasexplored explicitly.
Internal validity concerns confounding factors that can affect the causal rela-tionship between the treatment and the outcome, especially relevant to RQ4. Thereis a threat that the reporting style in the primary publications has a bigger impacton our conclusions than the actual output from tools. Consequently, there is a riskthat we failed to include results due to differences in both experimental setups andlevel of detail in reports. Also regarding RQ4, we aggregate evidence from pre-vious comparisons made in different ways, some report statistical analysis whileothers discuss results in more general terms. We do not weight the contributions ofthe individual studies based on this. Moreover, while we attempted to distinguishbetween query-based and matrix-based evaluations in the synthesis, different con-texts (e.g., domain, work task, artifact types, language of the artifacts) were allincluded in the synthesis of P-R values.
External validity refers to generalization from this study. As we do not claimthat our results apply to other applications of IR in software engineering, this isa minor threat. On the other hand, due to the comprehensive nature of our study,we extrapolate our conclusions on RQ4 to all studies on IR-based trace recoverypublished until December 2011, including studies that did not report a sufficientamount of details.
5 Results
Following the method defined in Section 4.2, we identified 79 primary publica-tions. Most of the publications were published in conferences or workshops (67of 79, 85%), while twelve (15%) were published in scientific journals. Table 5presents the top publication channels for IR-based trace recovery, showing that itspans several research topics. Figure 5 depicts the number of primary publications

62 Recovering from a Decade: A Systematic Review of Information . . .
Publication forum #PublicationsInternational Requirements Engineering 9ConferenceInternational Conference on Automated 7Software EngineeringInternational Conference on Program 6ComprehensionInternational Workshop on Traceability in 6Emerging Forms of Software EngineeringWorking Conference on Reverse 5EngineeringEmpirical Software Engineering 4
International Conference on Software 4EngineeringInternational Conference on Software 4Maintenance
Other publication fora 34(two or fewer publications)
Table 5: Top publication channels for IR-based trace recovery.
per year, starting from Antoniol et al.’s pioneering work from 1999. Almost 150authors have contributed to the 79 primary publications, on average writing 2.2of the articles. The top five authors have on average authored 14 of the primarypublications, and are in total included as authors in 53% of the articles. Thus,a wide variety of researchers have been involved in IR-based trace recovery, butthere is a group of a few well-published authors. More details and statistics aboutthe primary publications are available in Appendix 6.
Several publications report empirical results from multiple evaluations. Con-sequently, our mapping includes 132 unique empirical contributions, i.e., the map-ping comprises results from 132 unique combinations of an applied IR model andits corresponding evaluation on a dataset. As described in Section 4.1, we denote
Figure 5: IR-based trace recovery publication trend. The curve shows the numberof publications, while the bars display empirical studies in these publications.

5 Results 63
Figure 6: Taxonomy of IR models in trace recovery. The numbers show in howmany of the primary publications a specific model has been applied, the numbersin parentheses show IR models applied since 2008.
such a unit of empirical evidence a ‘study’, to distinguish from ‘publications’.
5.1 IR models applied to trace recovery (RQ1)
In Figure 6, reported studies in the primary publications are mapped accordingto the (one or several) IR models applied, as defined in Section 2. The most fre-quently reported IR models are the algebraic models, VSM and LSI. Various prob-abilistic models have been applied in 29 of the 113 evaluations, including 14 appli-cations of statistical LMs. Five of the applied approaches identified do not fit in thetaxonomy; examples include utilizing swarm techniques [160] and B-splines [30].As shown in Figure 6, VSM has been the most applied model 2008-2011, howeverrepeatedly as a benchmark to compare new IR models against. An apparent trendis that trace recovery based on LMs has received an increasing research interestduring the last years.
Only 46 (71%) of the 65 primary publications with technical foci report whichpreprocessing operations were applied to NL text. Also, in several publicationsone might suspect that the complete preprocessing was not reported. As a result,a reliable report of feature selection for IR-based trace recovery is not possible.Furthermore, several papers do not report any differences regarding preprocess-ing of NL text and source code. Among the publications reporting preprocessing,29 report conducting stop word removal and stemming, making it the most com-mon combination. The remaining publications report other combinations of stopword removal, stemming and ID splitting. Also, two publications report applying

64 Recovering from a Decade: A Systematic Review of Information . . .
Figure 7: Preprocessing operations used in IR-based trace recovery. The figureshows the number of times a specific operation has been reported in the primarypublications. Black bars refer to preprocessing of NL text, gray bars show prepro-cessing of text extracted from source code.
Google Translate as a preprocessing step to translate NL text to English [91, 110].Figure 7 presents in how many primary publications different preprocessing stepsare explicitly mentioned, both for NL text and source code.
Regarding NL text, most primary publications select all terms that remain af-ter preprocessing as features. However, two publications select only nouns andverbs [176, 177], and one selects only nouns [30]. Also, Capobianco et al. haveexplicitly explored the semantic role of nouns [29]. For the purposes of the map-ping of primary publications dealing with source code, a majority unfortunatelydoes not clearly report about the feature selection (i.e., selecting which subset ofterms to extract to represent the artifact). Seven publications report that only IDswere selected, while four publications selected both IDs and comments. Threeother publications report more advanced feature selection, including function ar-guments, return types and commit comments [1, 3, 28].
Among the primary publications, the weighting scheme applied to selectedfeatures is reported in 58 articles. Although arguably more tangible for alge-braic retrieval models, feature weighting is also important in probabilistic retrieval.Moreover, most weighing schemes are actually families of configuration vari-ants [149], but since this level of detail often is omitted in publications on IR-basedtrace recovery [131], we were not able to investigate this further. Figure 8 showshow many times, in the primary publications, various types of feature weightingschemes have been applied. Furthermore, one publication reports upweighting ofverbs in the TFIDF weighting scheme, motivated by verbs’ nature of describingthe functionality of software [117].
Several strategies to improve the performance of IR-based trace recovery toolsare proposed, as presented in Figure 9. The figure shows how many times differentenhancement strategies have been applied in the primary publications. Most en-hancements aim at improving the precision and recall of the tool output, howeveralso a (computation) performance enhancement is reported [97]. The most fre-

5 Results 65
Figure 8: Feature weighting schemes in IR-based trace recovery. Bars depict howmany times a specific weighting scheme has been reported in the primary publi-cations. Black color shows reported weighting in publications applying algrebraicIR models.
quently applied enhancement strategy is relevance feedback, giving the human achance to judge partial search results, followed by re-executing an improved searchquery. The following most frequently applied strategies are applying a thesaurusto deal with synonyms, clustering (organizing/ranking results depending on forinstance document structure), phrasing (going beyond the bag of word model byconsidering sequences of words). Other enhancement strategies repeatedly appliedinclude: up-weighting terms considered important by applying a project glossary,machine learning approaches to improve results based on for example the existingtrace link structure, and combining the results from different retrieval models invoting systems. Yet another set of enhancements have only been proposed in sin-gle primary publications, such as query expansion, analyses of call graphs, regularexpressions, and smoothing filters.
5.2 Types of software artifacts linked (RQ2)
Figure 10 maps onto the classical software development V-model the various soft-ware artifact types that have been used in IR-based trace recovery evaluations. Re-quirements, the left part of the model, include all artifacts that specify expectationson a system, e.g., market requirements, system requirements, functional require-ments, use cases, and design specifications. The distinction between these are notalways possible to derive from the publications, and hence we have grouped themtogether under the broad label ‘requirements’. The right part of the model repre-sents all artifacts related to verification activities, e.g., test case descriptions andtest scripts. Source code artifacts constitute the bottom part of the model. Notehowever, that our inclusion/exclusion criteria, excluding duplication analyses andstudies where not either source or target artifacts are dominated by NL text, resultsin fewer links between requirements-requirements, code-code, code-test, test-test

66 Recovering from a Decade: A Systematic Review of Information . . .
Figure 9: Enhancement strategies in IR-based trace recovery. Bars depict howmany times a specific strategy has been reported in the primary publications. Blackcolor represents enhancements reported in publications using algebraic IR models.
and defect-defect than would have been the case if we had studied the entire fieldof IR applications within software engineering.
The most common type of links that has been studied was found to be betweenrequirements (37 evaluations), either of the same type or of different levels of ab-straction. The second most commonly studied artifact linking is between require-ments and source code (32 evaluations). Then, in decreasing order, mixed links inan information space of requirements, source code and tests (10 evaluations), linksbetween requirements and tests (9 evaluations) and links between source code andmanuals (6 evaluations). Less frequently studied trace links include links betweensource code and defects/change requests and links between tests. In three primarypublications, the types of artifacts traced are unclear, either not specified at all ormerely described as ‘documents’.
5.3 Strength of evidence (RQ3)
An overview of the datasets used for evaluations in the primary publications isshown in Figure 1. In total we identified 132 evaluations; in 42 (32%) cases propri-etary artifacts, either originating from development projects in private companiesor the US agency NASA, were studied. Nineteen (14%) evaluations using artifactscollected from open source projects have been published and 65 (49%) employ-ing artifacts originating from a university environment. Among the datasets fromuniversity environments, 34 consist of artifacts developed by students. In six pri-mary publications, the origin of the artifacts is mixed or unclear. Figure 1 alsodepicts the sizes of the datasets used in the evaluations, wrt. the number of arti-

5 Results 67
Figure 10: Types of links recovered in IR-based trace recovery. The table showsthe number of times a specific type of link is the recovery target in the primarypublications, also represented by the weight of the edges in the figure.
facts. The majority of the evaluations in the primary publications were conductedusing an information space of less than 500 artifacts. In 38 of the evaluations, lessthan 100 artifacts were used as input. The primary publications with the by farhighest number of artifacts, evaluated links between 3.779 business requirementsand 8.334 market requirements at Baan [128] (now owned by Infor Global Solu-tions), and trace links between 9 defect reports and 13380 test cases at Researchin Motion [100].
Table 6 presents the six datasets that have been most frequently used in evalua-tions of IR-based trace recovery, sorted by the number of primary studies in whichthey were used. CM-1, MODIS, and EasyClinic are publicly available from theCoEST web page4. Note that most publicly available datasets except EasyClinicare bipartite, i.e., the dataset contains only links between two disjunct subsets ofartifacts.
All primary publications report some form of empirical evaluations, a majority(80%) conducting “studies of methods” [88]. Fourteen publications (18%) reportresults regarding the human analyst, two primary publications study both methodsand human analysts. Figure 12 shows the primary publications mapped to thefour levels of the context taxonomy described in Section 3.3. Note that a numberof publications cover more than one environment, due to either mixed artifactsor multiple studies. Also, two publications did not report the environment, andcould not be mapped. A majority of the publications (50), exclusively conductedevaluations taking place in the innermost retrieval context, the so-called “cave ofIR evaluation” [92]. As mentioned in Section 2, evaluations in the cave display an
4coest.org

68 Recovering from a Decade: A Systematic Review of Information . . .
# Dataset Artifacts Links Origin Developmentcharacteristics
Sizea
17 CM-1 Requirementsspecifyingsystem re-quirementsand detaileddesign
Bipartitedataset,many-to-manylinks
NASA Embeddedsoftware de-velopment ingovernmentalagency
455
16 EasyClinic Use cases,sequence dia-grams, sourcecode, test casedescriptions.Language:Italian.
Many-to-manylinks
Univ. of San-nio
Student project 150
8 MODIS Requirementsspecifyingsystem re-quirementsand detaileddesign
Bipartitedataset,many-to-manylinks.
NASA Embeddedsoftware de-velopment ingovernmentalagency
68
7 Ice-BreakerSystem(IBS)
Functionalrequirementsand sourcecode
Not publiclyavailable infull detail
[142] Textbook on re-quirements engi-neering
185
6 LEDA Source codeand user doc-umentation
Bipartitedataset,many-to-one links
Max PlanckInst. forInformaticsSaarbrücken
Scientific com-puting
296
5 Event-BasedTrace-ability(EBT)
Functionalrequirementsand sourcecode
Not publiclyavailable
DePaul Univ. Tool from re-search project
138
a Size is presented as the total number of artifacts.
Table 6: Summary of the datasets most frequently used for evaluations.

5 Results 69
Figure 11: Datasets used in studies on IR-based trace recovery. Bars show num-ber and origin of artifacts.
inconsistent use of terminology. Nineteen (38%) of the primary publications referto their evaluations in the retrieval context as experiments, 22 (44%) call them casestudies, and in nine (18%) publications they are merely referred to as studies.
Since secondary measures were applied, fourteen publications (18%) are con-sidered to have been conducted in the seeking context. Eleven primary publica-tions conducted evaluations in the work context, mostly through controlled exper-iments with student subjects. Only three evaluations are reported in the outermostcontext of IR evaluation, the project context, i.e., evaluating the usefulness of tracerecovery in an actual end user environment. Among these, only a single publica-tion reports an evaluation from a non-student development project [110].
5.4 Patterns regarding output accuracy (RQ4)
Meta-analysis was not possible due to inhomogeneous experimental setups andpresentation. Therefore, we applied vote counting analysis. Among the primarypublications, 25 compare the output accuracy of trace recovery when applying dif-ferent IR models. Figure 13 depicts the outcomes of the comparisons, based onthe original authors’ conclusions. An edge represents a comparison of two im-plemented IR models on a dataset, thus a single publication can introduce severalarrows. The direction of an edge points at the IR model that produced the most ac-curate output, i.e., an arrow points at the better model. Accordingly, an undirectededge (dotted) shows inconclusive comparisons. Finally, an increased edge weightdepicts multiple comparisons between the IR models, also presented as a label onthe edge.
VSM and LSI are the two IR models that have been most frequently evaluatedin comparing studies. Among those, and among comparing studies in general,

70 Recovering from a Decade: A Systematic Review of Information . . .
Figure 12: Contexts of evaluations of IR-based trace recovery, along with studyenvironments. Numbers show the number of primary publications that target eachcombination.
VSM has presented the best results. On the other hand, implementing LMs andmeasuring similarities using JS divergence has been concluded as a better tech-nique in four studies and has never underperformed any other models. As it hasbeen compared to VSM in three publications, it appears to perform trace recoverywith a similar accuracy [1, 30, 132]. Also conducting retrieval based on B-splinesand swarm techniques has not been reported to perform worse than other mod-els, but has only been explored in two primary publications [30, 160]. Notably,one of the commonly applied IR models, PIN, has not been explicitly studied incomparison to other IR models within the context of trace recovery.
We also present P-R values extracted from the primary publications as shownin Figures 14 and 15. In the upper right corners of figures, constituting the idealoutput accuracy of an IR-based trace recovery tool, we show intervals representing‘Excellent’, ‘Good’, and ‘Acceptable’ as proposed by Huffman Hayes et al. [88].As discussed in Section 3.4, it is unclear in several primary publications whethera query-based or matrix-based evaluation style has been used. However, it is ap-parent that a majority of the P-R values in PR@5/10/100 originate from query-based evaluations, and that the P-R values in [email protected]/Fix/Tot are dominatedby matrix-based evaluations.
Figure 14 show P-R footprints from trace recovery evaluations with constantcutpoints at 5, 10, and 100 candidate trace links respectively. Evaluations on fivedatasets (Leda, CM-1, Gedit, Firefox, and ArgoUML) are marked with separatesymbols, as shown in the legend. Especially for PR@5 and PR@10, the pri-mary publications contain several empirical results from trace recovery on these

5 Results 71
Figure 13: Empirical comparisons of IR models in trace recovery. Squares showalgebraic models, circles represent probabilistic models, diamonds show othermodels.
datasets. The P-R values in PR@5, PR@10 and PR@100 represent evaluationsusing: LDA (24 results), LSI (19 results), BM25 (18 results), VSM (14 results),LM (12 results), BIM (7 results), PLSI (6 results), and SDR (6 results).
No clear pattern related to the IR models can be observed in Figure 14. Instead,different implementations performed similarly when applied to the same datasets.This is particularly evident for evaluations on LEDA, for which we could extractseveral P-R values (shown as squares in Figure 14). In the footprint PR@5, nineP-R values from four different research groups implementing VSM [7], BIM [7],and LSI [97,121,167] cluster in the lower right corner. Also, the footprint PR@10shows five results from evaluations on LEDA, clustered in the very right corner,corresponding to P-R values from three different research groups implementingVSM [7], BIM [7], and LSI [97, 121]. No results on LEDA have been reported atthe constant cut-off 100. In line with the results on LEDA, PR@5/10/100 showclustered P-R values from trace recovery using different configurations of BM25on the Firefox dataset (diamonds) and Gedit (triangles). Similar results can beseen regarding evaluations on CM-1 (circles) in PR@5 and ArgoUML (pluses) inPR@100. However, results on CM-1 in PR@10/100 and ArgoUML in PR@5/10are less clear as they display lower degrees of clustering.
Few P-R values originating from query-based evaluations are within the threegoodness zones. Seven P-R values, corresponding to evaluations on LEDA (4results), Firefox (2 results), and MODIS (1 result) are within the ‘acceptable’ zonein PR@5. On the other hand, no P-R values within any goodness zones havebeen reported in the primary publications neither in PR@10 nor PR@100. Ingeneral, this is due to unacceptable precision values. In Figure 14, a number of P-

72 Recovering from a Decade: A Systematic Review of Information . . .
R values display precision values above 0.4, however they represent matrix-basedevaluation of trace recovery in the EasyClinic and eTour datasets.
In studies where constant cut-points have not been used, P-R values in all good-ness zones have been reported. In the footprint [email protected] in Figure 15, show-ing P-R values corresponding to candidate trace links with a cosine similarity of≥ 0.7, P-R values are located in the entire P-R space. Four ‘good’ values are re-ported from a publication recovering trace links in the EasyClinic dataset [53]. InPR@Fix, the expected precision-recall tradeoff is evident as shown by the trend-line. Several primary publications report both ‘acceptable’ and ‘good’ P-R values.Six P-R values are even reported within the ‘excellent’ zone, all originating fromevaluations of trace recovery based on LSI. However, all six evaluations were con-ducted on datasets containing around 150 artifacts, CoffeeMaker (5 results) andEasyClinic (1 result). In PR@Tot, showing 1.076 P-R values, 19 (1.8%) are in the‘excellent’ zone. Apart from the six P-R values that are also present in PR@Fix,additional ‘excellent’ results have been reported on EasyClinic based on LSI (6results) and VSM (1 result). Also, P-R values in the ‘excellent’ zone have been re-ported from evaluations of VSM-based recovery of trace links between documen-tation and source code on JDK1.5 (2 results) [34], trace recovery in the MODISdataset (1 result) [162] and, also implementing VSM, from recovered trace linksin an undisclosed dataset (2 results) [135].
In total, we extracted 270 P-R values (25.2%) within the ‘acceptable’ zone, 129P-R values (12.0%) in the ‘good’ zone, and 19 P-R values (1.8%) in the ‘excellent’zone. The average (balanced) F-measure for the P-R values in PR@Tot is 0.31with a standard deviation of 0.07. The F-measure of the lowest acceptable P-Rvalue is lower, 0.24 (corresponding to recall=0.6, precision=0.2), which reflectsthe difficulty in achieving reasonably balanced precision and recall in IR-basedtrace recovery. Among the 100 P-R values with the highest F-measure in PR@Tot,69 have been reported when evaluating trace recovery on the EasyClinic dataset,extracted from 9 different publications. However, the other 31 P-R values comefrom evaluations on 9 other datasets originating from either industrial, open sourceor academic contexts.
6 Discussion
Our set of 79 primary publications shows that there are more publications on IR-based trace recovery than has previously been acknowledged. Based on our com-prehensive study, the rest of this section discusses our research questions. Alongwith the discussions, we conclude every question with concrete suggestions onhow to advance research on IR-based trace recovery. Finally, in Section 6.5,we map our recommendations to the traceability challenges articulated by Co-EST [79].

6 Discussion 73
Figure 14: P-R footprints for trace recovery tools. The figures show P-R valuesat the constant cut-offs PR@5, PR@10 and PR@100.

74 Recovering from a Decade: A Systematic Review of Information . . .
Figure 15: P-R footprints for trace recovery tools. The figures show P-R valuesrepresenting a cut-off at the cosine similarity 0.7 ([email protected]), precision at fixedrecall levels (PR@Fix), and an aggregation of all collected P-R values (PR@Tot).The figures PR@Fix and PR@Tot also present a P-R curve calculated as an expo-nential trendline.

6 Discussion 75
6.1 IR models applied to trace recovery (RQ1)
During the last decade, a wide variety of IR models have been applied to recovertrace links between artifacts. Our study shows that the most frequently appliedmodels have been algebraic, i.e., Salton’s classic VSM from the 60s [150] andLSI, the enhancement developed by Deerswester in the 90s [60]. Also, we showthat VSM has been implemented more frequently than LSI, in contrast to what wasreported by Binkley and Lawrie [18]. The interest in algebraic models might havebeen caused by the straightforwardness of the techniques; they have concrete geo-metrical interpretations, and are rather easy to understand also for non-IR experts.Moreover, several open source implementations are available. Consequently, thealgebraic models are highly applicable to trace recovery studies, and they consti-tute feasible benchmarks when developing new methods. However, in line withthe development in the general IR field [173], LMs [138] have been getting moreattention in the last years.
While implementing an IR model, the developers inevitably have to make avariety of design decisions. Consequently, this applies also to IR-based trace re-covery tools. As a result, tools implementing the same IR model can producerather different output [23]. Thus, omitting details in the reporting obstructs thepossibility to advance the field of trace recovery through secondary studies andevidence-based software engineering techniques [96]. Unfortunately, even funda-mental information about the implementation of IR is commonly left out in tracerecovery publications. Concrete examples include feature selection and weight-ing (particularly neglected for publications indexing source code) and the num-ber of dimensions of the LSI subspace. Furthermore, the heterogeneous use ofterminology is an unnecessary difficulty in IR-based trace recovery publications.Concerning general traceability terminology, improvements can be expected asCleland-Huang et al. dedicated an entire chapter of their recent book to this is-sue [39]. However, we hope that Section 1 of this paper is a step toward aligningalso the IR terminology in the community.
To support future replications and secondary studies on IR-based trace recovery,we suggest that:
• Studies on IR-based trace recovery should use IR terminology consistently,e.g., as presented in Table 1 and Figure 6, and use general traceability ter-minology as proposed by Cleland Huang et al. [39].
• Authors of articles on IR-based trace recovery should carefully report theirimplemented IR model, to enable aggregating empirical evidence.
• Technology-oriented experiments on IR-based trace recovery should adhereto rigorous methodologies such as the framework by Huffman Hayes andDekhtyar [84].

76 Recovering from a Decade: A Systematic Review of Information . . .
6.2 Types of software artifacts linked (RQ2)
Most published evaluations on IR-based trace recovery aim at establishing tracelinks between requirements of different kinds, or between requirements and sourcecode. Apparently, the artifacts of the V&V side of the V-model are not as fre-quently in focus of researchers working on IR-based trace recovery. One can thinkof several reasons for this unbalance. First, researchers might consider that thestructure of the document subspace of the requirement side of the V-model is moreimportant to study. Second, the early public availability of a few datasets contain-ing requirements of various kinds, might have paved the way for a series of studiesby various researchers. Third, publicly available artifacts from the open sourcecommunity might contain more requirements artifacts than V&V artifacts. Never-theless, research on trace recovery would benefit from studies on a more diversemix of artifacts. For instance, the gap between requirements artifacts and V&Vartifacts is an important industrial challenge [148]. Hence, exploring whether IR-based trace recovery could be a way to align “the two ends of software develop-ment” is worth an effort.
Apart from the finding that requirement-centric studies on IR-based trace re-covery are over-represented, we found that too few studies go beyond trace re-covery in bipartite traceability graphs. Such simplified datasets hardly representthe diverse information landscapes of large-scale software development projects.Exceptions include studies by De Lucia et al., who repeatedly have evaluated IR-based trace recovery among use cases, functional requirements, source code andtest cases [47,51,53,56–59], however originating from student projects, which re-duces the industrial relevance.
To further advance the research of IR-based trace recovery, we suggest that:
• Studies should be conducted on diverse datasets containing a higher numberof artifacts.
• Studies should go beyond bipartite datasets to better represent the heteroge-neous information landscape of software engineering.
6.3 Strength of evidence (RQ3)
Most evaluations on IR-based trace recovery were conducted on bipartite datasetscontaining fewer than 500 artifacts. Obviously, as pointed out by several re-searchers, any software development project involves much larger informationlandscapes, that also consist of heterogeneous artifacts. A majority of the eval-uations of datasets containing more than 1,000 artifacts were conducted usingopen source artifacts, an environment in which fewer types of artifacts are typi-cally maintained [28, 151], thus links to or from source code are more likely tobe studied. Even though small datasets might be reasonable to study, only two

6 Discussion 77
primary publications report from evaluations containing more than 10,000 arti-facts [100, 128]. As a result, the question of whether the state-of-the-art IR-basedtrace recovery scales to larger document spaces or not, commonly mentioned asfuture work [54, 78, 90, 107, 118, 167] remains unanswered, is a major threat toexternal validity.
Regarding the validity of datasets used in evaluations, a majority used artifactsoriginating from university environments as input. Furthermore, most studies onproprietary artifacts used only the CM-1 or MODIS datasets collected from NASAprojects, resulting in their roles as de-facto benchmarks from an industrial context.Clearly, again the external validity of state-of-the-art trace recovery must be ques-tioned. On one hand, benchmarking can be a way to advance IR tool development,as TREC have demonstrated in the general IR research [155], but on the otherhand it can also lead the research community to over-engineering tools on specificdatasets [23]. The benchmark discussion has been very active in the traceabilitycommunity the last years [16, 37, 62, 63, 79].
A related problem, in particular for proprietary datasets that cannot be dis-closed, is that datasets often are poorly described [24]. In some particular publica-tions, NL artifacts in datasets are only described as ‘documents’. Thus, as alreadydiscussed related to RQ1 in Section 6.1, inadequate reporting obstructs replica-tions and secondary studies. Moreover, as Figure 14 shows, the choice of datasetsin evaluations of IR-based trace recovery can impact the tool output far more thanthe choice of IR model, in line with results by Ali et al. [4].
Most empirical evaluations of IR-based trace recovery were conducted in theinnermost of IR contexts, i.e., a clear majority of the research was conducted “inthe cave” or just outside [92]. For some datasets, the output accuracy of IR mod-els has been well-studied during the last decade. However, more studies on howhumans interact with the tools are required; similar to what has been explored byHuffman Hayes et al. [45, 64, 85, 90] and De Lucia et al. [56–58]. Thus, moreevaluations in a work task context or a project context are needed. Regardingthe outermost IR context, only one industrial in-vivo evaluation [110] and threeevaluations in student projects [52–54] have been reported. Finally, regarding theinnermost IR contexts, the discrepancy of methodological terminology should beharmonized in future studies.
To further advance evaluations of IR-based trace recovery, we suggest that:
• The community should continue its struggle to acquire a set of more repre-sentative benchmarks.
• Researchers should better characterize the datasets used in evaluations, inparticular when they cannot be disclosed for confidentiality reasons.
• An industrial case study, even a small but well-conducted study, should behighly encouraged as an important empirical contribution.

78 Recovering from a Decade: A Systematic Review of Information . . .
6.4 Patterns regarding output accuracy (RQ4)
We synthesized P-R values from 48 primary publications and concluded that thereis no empirical evidence that the extensive research on new IR models for tracerecovery has improved the accuracy of the candidate trace links. Hence, our resultsconfirm previous findings by Oliveto et al. [132] and Binkley and Lawrie [18], thatno IR model is consequently outperforming others. Instead, our results suggestthat the classic VSM, developed by Salton et al. in the 60s [150], performs betteror as good as other models. Our findings are also in line with the claim by Falessiet al., that simple IR techniques are typically the most useful [73]. Thus, as alsopointed out by Ali et al. [4], we see little value for the traceability community tocontinue publishing studies that solely hunt improved P-R values “in the cave”,without considering other factors that impact trace recovery, e.g., the validity ofthe dataset and the specific work task the tools are intended to support.
Furthermore, as Cuddeback et al. rather controversially highlighted, humansubjects vetting entire candidate traceability matrices do not necessarily benefitfrom more accurate candidate trace links [45]. Instead, Cuddeback et al. showedthat humans tend to vet the candidate traceability matrix in a way that balancesprecision and recall. Furthermore, while humans provided with low accuracy can-didate traceability matrices improved them significantly, humans vetting highlyaccurate candidate traceability matrices often decreased their accuracy. Thesefindings have also been statistically confirmed by Dekhtyar et al. [61], in a studywith 84 subjects. While these findings concern matrix-based evaluations, Borg andPfahl explored this phenomenon preliminary in a query-based evaluation environ-ment [22]. In a pilot experiment on impact analysis, subjects were provided withlists of candidate trace links, i.e., one ranked search list per artifact to trace, repre-senting different accuracy levels. While the results were inconclusive, there wereindications that subjects benefited from more accurate tool output. However, alsoin this experiment, humans tended to complete the task in a way that balanced theprecision and recall of the final set of trace links. More human-oriented researchis needed, including visualization of trace links as has been initially compassed byMarcus et al. [123] and Chen [34].
Regarding matrix-based evaluations of IR-based trace recovery, the aggrega-tion of precision at fixed levels clearly displays the expected trade-off betweenthe two measures. Also, when comparing to the quality levels defined by HuffmanHayes et al. [88], the challenge of reaching ‘acceptable’ precision and ‘acceptable’recall is evident, as it is only achieved in about a quarter of the reported P-R val-ues. While the appropriateness of the proposed quality levels (originally presentedby Huffman Hayes et al. as an attempt to “draw a line in the sand”), cannot bevalidated without user studies, they constitute a starting point for the synthesis ofempirical results. Some published results are ‘acceptable’, a few are even ‘good’or ‘excellent’, while a majority of the results are ‘unacceptable’. However, morework similar to what Cuddeback et al. [45] and Dekhtyar et al. [61] have presented

6 Discussion 79
is required to validate the quality levels.
Our findings also confirm the difficulty to determine which set of candidatetrace links to present to the user of an IR-based trace recovery tool, i.e, decidingwhich cut-off strategy is the most feasible for the specific context. The accuracyof a set of trace links is unknown at recovery time of the IR tool, at least unless itcan be compared to a set of pre-established trace links. Thus, as only a quarter ofthe reported P-R values are ‘acceptable’, this supports the suggestion by De Luciaet al., that an engineer should work incrementally with output from IR-based tracerecovery tools [57]. As described by De Lucia et al., the engineer can then itera-tively balance on the P-R trade-off, in a manner that is suitable for the work taskat hand. However, while we argue that the fact that a user can achieve more effi-cient results with specific ways of using a tool, it does not mean that studies shouldreport non-conventional P-R values in place of PR@Fix and PR@N. This is espe-cially true regarding PR@N, as publications on IR-based trace recovery often hidethe number of candidate trace links required to reach a certain level of recall, i.e.,only PR@Fix is reported. Thus, as argued by Spärck Jones et al. [158], researchersshould make an effort to also report PR@N to display the amount of information auser would have to process. Obviously, in the case of a matrix-based evaluation ina large document space a very high N might be required to recover enough tracelinks, but still it is meaningful to report this piece of information. Concerningquery-based evaluations of IR-based trace recovery, the proposed quality levels donot seem to be appropriate, thus PR@Fix and PR@N should instead be evaluatedusing secondary measures such as MAP and DCG.
As discussed in Section 6.3, several studies have reported that IR-based tracerecovery tools support humans when performing tasks involving tracing. Thus, asa majority of the P-R values reported by state-of-the-art IR-based trace recoverytools does not reach ‘acceptable’ accuracy levels, this suggests that even support-ing an engineer with rather inaccurate tool support is better than working manuallywith tracing tasks. This seems reasonable also in the light of work by Cuddeback etal. [45] and Dekhtyar et al. [61], in which they show that human subjects providedpoor starting points for tracing improve them significantly. Consequently, as muchstate-of-the-practice tracing work is done in environments with rather limited toolsupport [21, 88], providing an engineer with state-of-the-art candidate trace linkshas a potential to increase the traceability in an industrial project, as well as the re-lated concept findability, defined as “the degree to which a system or environmentsupports navigation and retrieval” [127].
To strengthen the validity of evaluations of IR-based trace recovery, we suggestthat:
• Results should be carefully reported using PR@Fix and PR@N, comple-mented by secondary measures.

80 Recovering from a Decade: A Systematic Review of Information . . .
Research theme Goal to reach by 2035Purposed traceability to define and instrument prototypical traceability profiles
and patternsCost-effective traceability to perform systematic quality assessment and assurance of
the traceabilityConfigurable traceability to provide for levels of abstraction and granularity in
traceability techniques, methods and tools, facilitatedby improved trace visualisations, to handle very largedatasets and the longevity of these data
Trusted traceability to develop cost-benefit models for analysing stakeholderrequirements for traceability and associated solutionoptions at a fine-grained level of detail
Scalable traceability to use dynamic, heterogeneous and semantically richtraceability information models to guide the definitionand provision of traceability
Portable traceability to agree upon universal policies, standards, and a unifiedrepresentation or language for expressing traceabilityconcepts
Valued traceability to raise awareness of the value of traceability, to gainbuy-in to education and training, and to get commitmentto implementation
Ubiquitous traceability to provide automation such that traceability isencompassed within broader software and systemsengineering processes, and is integral to all tool support
Table 7: Traceability research themes defined by CoEST [79]. Ubiquitous trace-ability is referred to as “the grand challenge of traceability”, since it requires sig-nificant progress in the other research themes.
• It should be made clear whether a query-based or matrix-based evaluationstyle has been used, especially when reporting P-R values.
• Focus on tool enhancements “in the cave” should be shifted towards evalu-ations in the work task or project context.
6.5 In the light of the CoEST research agendaGotel et al. recently published a framework of challenges in traceability research [79],a CoEST community effort based on a draft from 2006 [40]. The intention of theframework is to provide a structure to direct future research on traceability. Co-EST defines eight research themes, addressing challenges that are envisioned assolved in 2035, as presented in Table 7. Our work mainly contributes to threeof the research themes, purposed traceability, trusted traceability, and scalabletraceability. Below, we discuss the three research themes in relation to IR-basedtrace recovery, based on our empirical findings.
The research theme purposed traceability charts the development of a classifi-cation scheme for traceability contexts, and a collection of possible stakeholder re-quirements on traceability. Also, a “Traceability Book of Knowledge” is planned,

7 Summary and Future Work 81
including e.g., terminology, methods, and practices. Furthermore, the researchagenda calls for additional empirical studies. Our contribution intensifies CoEST’scall for additional industrial case studies, by showing that a majority of IR-basedtrace recovery studies have been conducted in the “cave of IR evalution”. To guidefuture empirical studies, we propose an adapted version of the model of IR evalua-tion contexts by Ingwersen and Järvelin [92], tailored for IR-based trace recovery.Also, we confirm the need for a “Traceability Book of Knowledge” and an alignedterminology in the traceability community, as our secondary study was obstructedbe language discrepancies.
Trusted traceability comprises research to gain improvements in the qualityof creation and maintenance of automatic trace links. Also, the research themecalls for empirical evidence as to the quality of traceability methods and tools withrespect to the quality of the trace links. Our work, founded in evidence-basedsoftware engineering approaches, aggregated the empirical evidence of IR-basedtrace recovery until December 2011. Based on this, we provide several advice onhow to advance future evaluations.
Finally, the research theme scalable traceability calls for the traceability com-munity to obtain and publish large industrial datasets from various domains toenable researchers to investigate scalability of traceability methods. Also this callfor research is intensified by our work, as we empirically show that alarmingly fewevaluations of IR-based trace recovery have been conducted on industrial datasetsof representative sizes.
7 Summary and Future Work
Our review of IR-based trace recovery compares 79 publications containing 132empirical studies, systematically derived according to established procedures [103].Our study constitutes the most extensive summary of publications of IR-basedtrace recovery yet published, enabling an overview of the topic based on empiricalresults.
More than 10 IR models have been applied to trace recovery (RQ1). Morestudies have evaluated algebraic IR models (i.e., VSM and LSI), than probabilisticmodels (e.g., BIM, PIN, LM, LDA). A visible trend is, in line with development inthe general field of IR, that the probabilistic subset of statistical language modelshave received increased attention in recent years. While extracting data from theprimary publications, it became clear that the inconsistent use of IR terminologyis an issue in the field. In an attempt to homogenize the language, we presentstructure in the form of a hierarchy of IR models (Figure 6) and a collection of IRterminology (Table 1).
In the 132 mapped empirical studies, artifacts from the entire developmentprocess have been linked (RQ2). The dominant artifact type is requirements atvarious level of abstraction, followed by source code. Substantially fewer studies

82 Recovering from a Decade: A Systematic Review of Information . . .
have been conducted on test artifacts, and only single publications have targeteduser manuals and defect reports. Furthermore, a majority of the evaluations ofIR-based trace recovery have been made on bipartite datasets, i.e., only trace linksbetween two disjoint sets of artifacts were recovered.
Among the 79 primary publications mapped in our study, we conclude that theheterogeneity of reporting detail obstructs the aggregation of empirical evidence(RQ3). Also, most evaluations have been conducted on small bipartite datasetscontaining fewer than 500 artifacts, which is a severe threat to external validity.Furthermore, a majority of evaluations have been using artifacts originating froma university environment, or a dataset of proprietary artifacts from NASA. As aresult, the two small datasets EasyClinic and CM-1 constitute the de-facto bench-mark in IR-based trace recovery. Another validity threat to the applicability ofIR-based trace recovery is that a clear majority of the evaluations have been con-ducted in “the cave of IR evaluation” as described in Table 2, and reported inFigure 12. Thus, we argue that in-vivo evaluations, in which IR-based trace re-covery should be studied within the full complexity of an industrial setting, areneeded to motivate the feasibility of the approach and further studies on the topic.As such, our empirical findings intensify the recent call for additional empiricalstudies by CoEST [79].
Based on our synthesized results from IR-based trace recovery tools, we foundno empirical evidence that the technologically-oriented research on tools has re-sulted in more accurate trace recovery (RQ4). No IR model regularly outperformsthe classic VSM with TFIDF feature weighting on text preprocessed by stop wordremoval and stemming, as presented in Figure 13. As long as trace recovery isbased on nothing but the limited NL content of artifacts, there appears to be littlevalue in solely hunting improved P-R values in small datasets, in line with sugges-tions by Ali et al. [4]. Instead, our recommendation is to focus on the evaluationsrather than the technical details of the tools. Simply evaluating VSM for trace re-covery, the classical IR model with several available open source implementations,in an industrial context has a large potential to contribute to the field.
The strongest empirical evidence in favor of IR-based trace recovery toolscomes from a set of controlled experiments on student subjects, reporting thattool-supported subjects outperform manual control groups. However, our resultsshow that only a quarter of the reported P-R values in the primary publicationsreach ‘acceptable’ level as defined by Huffman Hayes et al. [88]. This suggeststhat more research is required on how accurate candidate trace links need to befor an engineer to benefit from them, as has been investigated by Cuddeback etal. [45], Dekhtyar et al. [61], and Borg and Pfahl [22].
In several primary publications it is not made clear whether a query-based ormatrix-based evaluation style has been used. Also, the different reporting styles ofP-R values make aggregation of candidate trace link accuracies challenging. Weargue that the standard measures precision at fixed recall levels and P-R at specificdocument cut-offs should be reported, complemented by secondary measures such

7 Summary and Future Work 83
as MAP and DCG. Moreover, based on P-R values extracted from the query-basedevaluations in the primary publications, we show that IR-based trace recovery isconsiderably more sensitive to the choice of input dataset than to the applied IRmodel.
As a continuation of this literature study, we intend to publish the extracteddata to allow for collaborative editing, and for interested readers to review the de-tails. A possible future study would be to conduct a deeper analysis of the enhance-ment strategies that have been reported as successful in the primary publications,to investigate patterns concerning in which contexts they have been successfullyapplied. Also, future work could include categorizing the primary publicationsaccording to other frameworks, such as positioning them related to the CoESTresearch themes.
AcknowledgementThis work was funded by the Industrial Excellence Center EASE – EmbeddedApplications Software Engineering5. Thanks go to our librarian Mats Berglundfor working on the search strings, and Lorand Dali for excellent comments on IRdetails.
5http://ease.cs.lth.se

84 Recovering from a Decade: A Systematic Review of Information . . .
AppendixTables 8-15 present our classification of the primary publications, sorted by num-ber of citations according to Google Scholar (July 1, 2012). Note that the well-cited works by Marcus and Maletic [120] (354 citations) and Antoniol et al. [5](85 citations) are not listed.
Datasets are classified according to origin: proprietary (Ind), open source (OS),university (Univ), student (Stud), not clearly reported (Unclear), and mixed ori-gin (Mixed). Numbers in parentheses show the number of artifacts studied, a ‘?’is used when it is not reported. Unless the full dataset name is presented, thefollowing abbreviations are used: IBS (Ice Breaker System), EBT (Event-BasedTraceability), LC (Light Control system), TM (Transient Meter). Evaluation, therightmost column, maps primary publications to the context taxonomy describedin Section 3 (Level 1-4 = retrieval context, seeking context, work task context,project context). Finally, Tables 16 show the distinctly most productive authorsand affiliations, based upon our primary publications.

7 Summary and Future Work 85
Cit. Title Authors IR mod. Dataset Evaluation486 Recovering traceabil-
ity links between codeand documentation
Antoniol,Canfora, DeLucia, Merlo
BIM,VSM
Univ: LEDA(296), Stud:Albergate (116)
Level 1,Level 3 (8subj.)
205 Advancing candidatelink tracing Genera-tion for requirements:The study of methods
HuffmanHayes,Dekhtyar,Sundaram
VSM,LSI
Ind: MODIS(68), CM-1 (455)
Level 2
169 Improving require-ments tracing viainformation retrieval
HuffmanHayes,Dekhtyar,Osborne
VSM Ind: MODIS (68) Level 1
140 Recovering traceabil-ity links in systemsusing information re-trieval methods
De Lucia,Fasano,Oliveto,Tortora
LSI Stud: (Multipleprojects)
Level 4 (150subj.)
99 Utilizing supportingevidence to improvedynamic requirementstraceability
Cleland-Huang,Settimi,Duan, Zou
PIN Univ: IBS (252),EBT (114), LC(61)
Level 1
79 Best practices for au-tomated traceability
Cleland-Huang,Beren-bach, Clark,Settimi,Romanova
PIN Ind: SiemensLogistics andAutomation (?),Univ: IBT (255),EBT (114)
Level 1
74 Helping analysts tracerequirements: An ob-jective look
HuffmanHayes,Dekhtyar,Sundaram,Howard
VSM Ind: MODIS (68) Level 2
70 Can LSI help recon-structing require-ments traceability indesign and test?
Lormans,van Deursen
LSI Ind: Philips(359), Stud:PacMan (46),Callisto (?)
Level 1
68 Supporting softwareevolution throughdynamically retriev-ing traces to UMLartifacts
Settimi,Cleland-Huang,Khadra,Mody,Lukasik,DePalma
VSM Univ: EBT (138) Level 1
64 Enhancing an artefactmanagement systemwith traceabilityrecovery Features
De Lucia,Fasano,Oliveto,Tortora
LSI Stud: EasyClinic(150)
Level 1
Table 8: Classification of primary publications, part I.

86 Recovering from a Decade: A Systematic Review of Information . . .
Cit. Title Authors IR mod. Dataset Evaluation58 Recovery of trace-
ability links betweensoftware documen-tation and sourcecode
Marcus,Maletic,Sergeyev
LSI Univ: LEDA(228-803), Stud:Albergate (73)
Level 1
44 Recovering code todocumentation linksin OO systems
Antoniol,Canfora, DeLucia, Marlo
BIM Univ: LEDA(296)
Level 1
40 Fine grained indexingof software reposito-ries to support impactanalysis
Canfora,Cerulo
BM25 OS: Gedit (233),ArgoUML(2208), Firefox(680)
Level 1
38 ADAMS Re-Trace: Atraceability recoverytool
De Lucia,Fasano,Oliveto,Tortora
LSI Stud: (48, 50, 54,55, 73, 74, 111)
Level 4 (7proj.)
36 On the equivalenceof information re-trieval methods forautomated traceabilitylink recovery
Oliveto,Gethers,Poshyvanyk,De Lucia
VSM,LSI,LM,LDA
Stud: EasyClinic(77), eTour (174)
Level 1
33 Incremental approachand user feedbacks: Asilver bullet for trace-ability recovery
De Lucia,Oliveto,Sgueglia
VSM,LSI
Ind: MODIS(68), Stud:EasyClinic (150)
Level 1
30 A machine learningapproach for tracingregulatory codes toproduct specific re-quirements
Cleland-Huang,Czauderna,Gibiec,Emenecker
PIN Mixed: (254) Level 2
30 Assessing IR-basedtraceability recoverytools through con-trolled experiments
De Lucia,Oliveto,Tortora
LSI Stud: EasyClinic(150)
Level 3 (20,12 subj.)
29 A traceability tech-nique for specifica-tions
Abadi,Nisenson,Simionovici
VSM,LSI,PLSI,SDR,LM
OS: SCA (1311),CORBA (3340)
Level 2
29 Can informationretrieval techniqueseffectively supporttraceability linkrecovery?
De Lucia,Fasano,Oliveto,Tortora
LSI Stud: EasyClinic(150), Univ:ADAMS (309),LEDA (803)
Level 1,Level 4 (150subj.)
Table 9: Classification of primary publications, part II.

7 Summary and Future Work 87
Cit. Title Authors IR mod. Dataset Evaluation29 Software traceability
with topic modelingAsuncion,Asuncion,Taylor
LSI,LDA
Univ: ArchStu-dio (?), Stud:EasyClinic (160)
Level 1
29 Speeding up require-ments to managementin a product softwarecompany: Linkingcustomer wishes toproduct requirementsthrough linguisticengineering
Natt ochDag,Gervasi,Brinkkem-per, Regnell
VSM Ind: Baan(12083)
Level 2
29 Tracing object-oriented code intofunctional require-ments
Antoniol,Canfora,De Lucia,Casazza,Merlo
BIM Stud: Albergate(76)
Level 1
28 Clustering support forautomated tracing
Duan,Cleland-Huang
PIN Univ: IBS (185) Level 1
27 Text mining for soft-ware engineering:how analyst feedbackimpacts final results
HuffmanHayes,Dekhtyar,Sundaram
N/A Ind: MODIS (68) Level 3 (3subj.)
26 A feasibility studyof automated naturallanguage require-ments analysis inmarket-driven devel-opment
Natt ochDag, Reg-nell, Carl-shamre,Andersson,Karlsson
VSM Ind: Telelogic(1891, 1089)
Level 1
26 Implementation of anefficient requirementsanalysis support-ing system usingsimilarity measuretechniques
Park, Kim,Ko, Seo
Slidingwindow,syntacticparser
Ind: Unclear (33) Level 1
25 Traceability recoveryin RAD software sys-tems
Di Penta,Gradara,Antoniol
BIM Univ: TM (49) Level 1
23 REquirementsTRacing On target(RETRO): Improvingsoftware maintenancethrough traceabilityrecovery
HuffmanHayes,Dekhtyar,Holbrook,Sundaram,Vadlamudi,April
VSM Ind: CM-1 (74) Level 3 (30subj.)
22 Phrasing in dynamicrequirements trace re-trieval
Zou, Settimi,Cleland-Huang
PIN Univ: IBS (235),LC (59), EBT(93)
Level 1
Table 10: Classification of primary publications, part III.

88 Recovering from a Decade: A Systematic Review of Information . . .
Cit. Title Authors IR mod. Dataset Evaluation21 Combining textual
and structural analysisof software artifactsfor traceability linkrecovery
McMillan,Poshyvanyk,Revelle
LSI Univ: Cof-feeMaker (143)
Level 1
20 Tracing requirementsto defect reports: Anapplication of infor-mation retrieval tech-niques
Yadla, Huff-man Hayes,Dekhtyar
VSM Ind: CM-1(68,118)
Level 2
18 Automated require-ments traceability:The study of humananalysts
Cuddeback,Dekhtyar,HuffmanHayes
VSM OS: BlueJ Plugin(49)
Level 3 (26subj.)
18 Incremental latent se-mantic indexing forautomatic traceabilitylink evolution man-agement
Jiang,Nguyen,Chen, Jay-garl, Chang
LSI Univ: LEDA(634)
Level 1
18 Understanding howthe requirementsare implemented insource code
Zhao, Zhang,Liu, Juo, Sun
VSM OS: Desktop Cal-culator (123)
Level 1
17 Improving automatedrequirements trace re-trieval: A study ofterm-based enhance-ment methods
Zou, Settimi,Cleland-Huang
PIN Ind: CM-1(455), Univ: IBS(235), EBT (93),LC (89), Stud:SE450 (521)
Level 2
17 IR-based traceabilityrecovery processes:An empirical compar-ison of "one-shot" andincremental processes
De Lucia,Oliveto,Tortora
LSI Stud: EasyClinic(150)
Level 3 (30subj.)
17 Make the most of yourtime: how shouldthe analyst work withautomated traceabilitytools?
Dekhtyar,HuffmanHayes,Larsen
VSM Ind: CM-1 (455) Level 2
16 Baselines in require-ments tracing
Sundaram,HuffmanHayes,Dekhtyar
VSM,LSI
Ind: CM-1 (455),MODIS (68)
Level 2
11 Challenges for semi-automatic trace recov-ery in the automotivedomain
Leuser VSM,LSI
Ind: Daimler AG(1500)
Level 1
Table 11: Classification of primary publications, part IV.

7 Summary and Future Work 89
Cit. Title Authors IR mod. Dataset Evaluation11 Monitoring require-
ments coverage usingreconstructed views:an industrial casestudy
Lormans,Gross, vanDeursen,Stehouwer,van Solingen
LSI Ind: LogicaCMG(219)
Level 1
11 On the role of thenouns in IR-basedtraceability recovery
Capobianco,De Lucia,Oliveto,Panichella,Panichella
LSI, LM Stud: EasyClinic(150)
Level 1
10 An experiment onlinguistic tool supportfor consolidation ofrequirements frommultiple sources inmarket-driven productdevelopment
Natt ochDag, Thelin,Regnell
VSM Stud: PUSS(299)
Level 3 (23subj.)
9 An industrial casestudy in reconstruct-ing requirementsviews
Lormans,van Deursen,Gross
LSI Ind: LogicaCMG(293)
Level 1
9 Towards mining re-placement queries forhard-to-retrieve traces
Gibiec,Czauderna,Cleland-Huang
VSM Mixed: (254) Level 2
8 Recovering rela-tionships betweendocumentation andsource code based onthe characteristics ofsoftware engineering
Wang, Lai,Liu
LSI,BIM
Univ: LEDA(597), IBS (270)
Level 1
8 Trace retrieval forevolving artifacts
Winkler LSI Ind: RobertBosch GmbH(500), MODIS(68)
Level 1
8 Traceability recoveryusing numerical anal-ysis
Capobianco,De Lucia,Oliveto,Panichella,Panichella
VSM,LSI,LM, B-splines
Stud: EasyClinic(150)
Level 1
7 Assessing traceabilityof software engineer-ing artifacts
Sundaram,HuffmanHayes,Dekhtyar,Holbrook
VSM,LSI
Ind: MODIS(68), CM-1(455), Stud: 22*Waterloo (65)
Level 2
7 Requirement-centrictraceability for changeimpact analysis: Acase study
Li, Li, Yang,Li
VSM Unclear: Re-quirementsManagementSystem (501)
Level 4 (5subj.)
Table 12: Classification of primary publications, part V.
90 Recovering from a Decade: A Systematic Review of Information . . .
Cit. Title Authors IR mod. Dataset Evaluation6 How do we trace re-
quirements: An initialstudy of analyst be-havior in trace valida-tion tasks
Kong, Huff-man Hayes,Dekhtyar,Holden
N/A OS: BlueJ plugin(49)
Level 3 (13subj.)
6 Technique integrationfor requirements ass-esment
Dekhtyar,HuffmanHayes,Sundaram,Holbrook,Dekhtyar
VSM,LSI,BIM,LDA,Chi2key extr.
Ind: CM-1 (455) Level 1
4 Application of swarmtechniques for re-quirements engineer-ing: Requirementstracing
Sultanov,HuffmanHayes
VSM,Swarm
Ind: CM-1 (455),Univ: PINE (182)
Level 1
4 On integrating orthog-onal information re-trieval methods to im-prove traceability re-covery
Gethers,Oliveto,Posyvanyk,De Lucia
VSM,LM,RTM
Stud: eAnsi(194), eAnsi (67),EasyClinic (57),EasyClinic (100),eTour (232),SMOS (167)
Level 1
3 A clustering-basedapproach for tracingobject-oriented designto requirement
Zhou, Yu VSM Univ: ResourceManagementSoftware (33)
Level 1
3 Evaluating the use ofproject glossaries inautomated trace re-trieval
Zou, Settimi,Cleland-Huang
PIN Ind: CM-1 (455),Univ: IBS (235),Stud: SE450 (61)
Level 1
3 On human analystperformance in as-sisted requirementstracing: Statisticalanalysis
Dekhtyar,Dekhtyar,Holden,HuffmanHayes, Cud-deback,Kong
VSM OS: BlueJ (49) Level 3 (84subj.)
3 Tackling semi-automatic tracerecovery for largespecifications
Leuser, Ott VSM Ind: Daimler(2095, 944)
Level 1
2 Extraction and visual-ization of traceabilityrelationships betweendocuments and sourcecode
Chen Unclear OS: JDK1.5 (?),uDig 1.1.1 (?)
Level 1
2 Source code indexingfor automated tracing
Mahmoud,Niu
VSM Stud: eTour(174), iTrust(264)
Level 1
Table 13: Classification of primary publications, part VI.

7 Summary and Future Work 91
Cit. Title Authors IR mod. Dataset Evaluation2 Traceability challenge
2011: Using Tracelabto evaluate the impactof local versus globalIDF on trace retrieval
Czauderna,Gibiec,Leach,Li, Shin,Keenan,Cleland-Huang
VSM Ind: CM-1 (75),WV-CCHIT(1180)
Level 2
2 Trust-based require-ments traceability
Ali, Gue-heneuc,Antoniol
VSM OS: Pooka (388),SIP (1853)
Level 1
1 An adaptive approachto impact analysisfrom change requeststo source code
Gethers,Kagdi, Dit,Poshyvanyk
LSI OS: ArgoUML(qualitativeanalysis)
Level 2
1 Do better IR tools im-prove the accuracy ofengineers’ traceabilityrecovery?
Borg, Pfahl VSM Ind: CM-1 (455) Level 3 (8subj.)
1 Experiences with textmining large collec-tions of unstructuredsystems developmentartifacts at JPL
Port, Nikora,Hihn, Huang
LSI Unclear Level 3
1 Improving automateddocumentation tocode traceability bycombining retrievaltechniques
Chen,Grundy
VSM OS: JDK (431) Level 1
1 Improving IR-basedtraceability recoveryusing smoothingfilters
De Lucia,Di Penta,Oliveto,Panichella,Panichella
VSM,LSI
Univ: PINE(131), Stud:EasyClinic (150)
Level 1
1 Using semantics-enabled informationretrieval in require-ments tracing: Anongoing experimentalinvestigation
Mahmoud,Niu
VSM Ind: CM-1 (455) Level 1
1 Traceclipse: Aneclipse plug-in fortraceability linkrecovery and manage-ment
Klock, Geth-ers, Dit,Poshyvanyk
Unclear Ind: CM-1 (455),Stud: EasyClinic(150)
Level 1
0 A combination ap-proach for enhancingautomated traceability(NIER track)
Chen, Hosk-ing, Grundy
VSM OS: JDK 1.5 (?) Level 1
Table 14: Classification of primary publications, part VII.

92 Recovering from a Decade: A Systematic Review of Information . . .
Cit. Title Authors IR mod. Dataset Evaluation0 A comparative study
of document corre-lation techniques fortraceability analysis
Parvathy,Vasudevan,Balakrishnan
VSM,LSI,LDA,CTM
Unclear: (43),(261)
Level 1
0 A requirement trace-ability refinementmethod based onrelevance feedback
Kong, Li, Li,Yang, Wang
VSM,LM
Ind: Web app(511)
Level 1
0 An improving ap-proach for recoveringrequirements-to-design traceabilitylinks
Di, Zhang BIM Ind: CM-1 (455),MODIS (68)
Level 1
0 Proximity-basedtraceability: Anempirical validationusing ranked re-trieval and set-basedmeasures
Kong, Huff-man Hayes
VSM Ind: CM-1(75), OS: Pine(182), Univ:StyleChecker(49), Stud:EasyClinic (77)
Level 2
0 Reconstructing trace-ability between bugsand test cases: An ex-perimental study
Kaushik,Tahvildari,Moore
LSI Ind: RIM(13389)
Level 1
0 Requirements trace-ability for objectoriented systems bypartitioning sourcecode
Ali, Gue-henuec,Antoniol
VSM OS: Pooka (388),SIP (1853), Univ:iTrust (526)
Level 1
0 Software verifica-tion and validationresearch laboratory(SVVRL) of the Uni-versity of Kentucky:Traceability challenge2011: Languagetranslation
HuffmanHayes, Sul-tanov, Kong,Li
VSM Stud: EasyClinic(150), eTour(174)
Level 2
0 The role of the cov-erage analysis duringIR-based traceabil-ity recovery: Acontrolled experiment
De Lucia,Oliveto,Tortora
LSI Stud: EasyClinic(150)
Level 3 (30subj.)
0 Towards a benchmarkfor traceability
Ben Char-rada, Casper,Jeanneret,Glinz
VSM Univ: AquaLush(793)
Level 1
Table 15: Classification of primary publications, part VIII.

7 Summary and Future Work 93
Author PublicationsAndrea De Lucia 16 (9)Jane Huffman Hayes 16 (6)Alexander Dekhtyar 15 (3)Rocco Oliveto 13 (1)Jane Cleland-Huang 10 (3)Affiliation PublicationsUniversity of Kentucky, United States 13University of Salerno, Italy 11DePaul University, United States 10University of Sannio, Italy 5
Table 16: Most productive authors and affiliations. For authors, the first numberis the total number of primary publications, while the number in parenthesis isfirst-authored primary publications. For affiliations, the numbers show the numberof primary publications first-authored by an affiliated researcher.

94 Recovering from a Decade: A Systematic Review of Information . . .
Bibliography
[1] A. Abadi, M. Nisenson, and Y. Simionovici. A traceability technique forspecifications. In Proceedings of the 16th International Conference on Pro-gram Comprehension, pages 103–112, 2008.
[2] N. Ali, Y-G. Guéhéneuc, and G. Antoniol. Requirements traceability forobject oriented systems by partitioning source code. In Proceedings of the18th Working Conference on Reverse Engineering, pages 45–54, 2011.
[3] N. Ali, Y-G. Guéhéneuc, and G. Antoniol. Trust-based requirements trace-ability. In Proceedings of the 19th International Conference on ProgramComprehension, pages 111–120, 2011.
[4] N. Ali, Y-G. Guéhéneuc, and G. Antoniol. Factors impacting the inputsof traceability recovery approaches. In J. Cleland-Huang, O. Gotel, andA. Zisman, editors, Software and Systems Traceability. Springer, 2012.
[5] G. Antoniol, G. Canfora, G. Casazza, and A. De Lucia. Information re-trieval models for recovering traceability links between code and documen-tation. In Conference on Software Maintenance, pages 40–49, 2000.
[6] G. Antoniol, G. Canfora, G. Casazza, A. De Lucia, and E. Merlo. Tracingobject-oriented code into functional requirements. In Proceedings of the 8thInternational Workshop on Program Comprehension, pages 79–86, 2000.
[7] G. Antoniol, G. Canfora, G. Casazza, A. De Lucia, and E. Merlo. Recover-ing traceability links between code and documentation. In Transactions onSoftware Engineering, volume 28, pages 970–983, 2002.
[8] G. Antoniol, G. Canfora, A. De Lucia, and E. Merlo. Recovering code todocumentation links in OO systems. In Proceedings of the 6th WorkingConference on Reverse Engineering, pages 136–144, 1999.
[9] G. Antoniol, A. Potrich, P. Tonella, and R. Fiutem. Evolving object orienteddesign to improve code traceability. In Proceedings of the 7th InternationalWorkshop on Program Comprehension, pages 151–160, 1999.
[10] N. Assawamekin, T. Sunetnanta, and C. Pluempitiwiriyawej. Ontology-based multiperspective requirements traceability framework. Knowledgeand Information Systems, 25(3):493–522, 2010.
[11] H. Asuncion, A. Asuncion, and R. Taylor. Software traceability with topicmodeling. In Proceedings of the International Conference on Software En-gineering, pages 95–104, 2010.

Bibliography 95
[12] K. Ayari, P. Meshkinfam, G. Antoniol, and M. Di Penta. Threats on build-ing models from CVS and Bugzilla repositories: The Mozilla case study.In Proceedings of the Conference of the Center for Advanced Studies onCollaborative Research, pages 215–228, 2007.
[13] A. Bacchelli, M. Lanza, and R. Robbes. Linking e-mails and source codeartifacts. In Proceedings of the 32nd International Conference on SoftwareEngineering, pages 375–384, 2010.
[14] R. Baeza-Yates and B. Ribeiro-Neto. Modern information retrieval: Theconcepts and technology behind search. Addison-Wesley, 2nd edition,2011.
[15] M. Banko and E. Brill. Scaling to very very large corpora for natural lan-guage disambiguation. In Proceedings of the 39th Annual Meeting on As-sociation for Computational Linguistics, pages 26–33, 2001.
[16] E. Ben Charrada, D. Caspar, C. Jeanneret, and M. Glinz. Towards a bench-mark for traceability. In Proceedings of the 12th International Workshop onPrinciples on Software Evolution, pages 21–30, 2011.
[17] A. Bianchi, A. Fasolino, and G. Visaggio. An exploratory case study ofthe maintenance effectiveness of traceability models. In Proceedings of the8th International Workshop on Program Comprehension, pages 149–158,2000.
[18] D. Binkley and D. Lawrie. Information retrieval applications in softwaremaintenance and evolution. In J. Marciniak, editor, Encyclopedia of soft-ware engineering. Taylor & Francis, 2nd edition, 2010.
[19] D. Blei and J. Lafferty. A correlated topic model of science. Annals ofApplied Statistics, 1(1):17–35, 2007.
[20] D. Blei, A. Ng, and M. Jordan. Latent dirichlet allocation. The Journal ofMachine Learning Research, 3(4-5):993–1022, 2003.
[21] M. Borg. Findability through traceability: A realistic application of can-didate trace links? In Proceedings of the 7th International Conferenceon Evaluating Novel Approaches to Software Engineering, pages 173–181,2012.
[22] M. Borg and D. Pfahl. Do better IR tools improve the accuracy of engi-neers’ traceability recovery? In Proceedings of the International Workshopon Machine Learning Technologies in Software Engineering, pages 27–34,2011.

96 Recovering from a Decade: A Systematic Review of Information . . .
[23] M. Borg, P. Runeson, and L. Brodén. Evaluation of traceability recoveryin context: A taxonomy for information retrieval tools. In Proceedings ofthe 16th International Conference on Evaluation & Assessment in SoftwareEngineering, pages 111–120, 2012.
[24] M. Borg, K. Wnuk, and D. Pfahl. Industrial comparability of student ar-tifacts in traceability recovery research - an exploratory survey. In Pro-ceedings of the 16th European Conference on Software Maintenance andReengineering, pages 181–190, 2012.
[25] M. Borillo, A. Borillo, N. Castell, D. Latour, Y. Toussaint, and M. Fe-lisa Verdejo. Applying linguistic engineering to spatial software engineer-ing: The traceability problem. In Proceedings of the 10th European Con-ference on Artificial Intelligence, pages 593–595, 1992.
[26] M. Bras and Y. Toussaint. Artificial intelligence tools for software engineer-ing: Processing natural language requirements. In Applications of ArtificialIntelligence in Engineering, pages 275–290, 1993.
[27] P. Brereton, B. Kitchenham, D. Budgen, M. Turner, and M. Khalil. Lessonsfrom applying the systematic literature review process within the softwareengineering domain. Journal of Systems and Software, 80(4):571–583,2007.
[28] G. Canfora and L. Cerulo. Fine grained indexing of software repositories tosupport impact analysis. In Proceedings of the International Workshop onMining software repositories, pages 105–111, 2006.
[29] G. Capobianco, A. De Lucia, R. Oliveto, A. Panichella, and S. Panichella.On the role of the nouns in IR-based traceability recovery. In Proceedingsof the 17th International Conference on Program Comprehension, pages148–157, 2009.
[30] G. Capobianco, A. De Lucia, R. Oliveto, A. Panichella, and S. Panichella.Traceability recovery using numerical analysis. In Proceedings of the 16thWorking Conference on Reverse Engineering, pages 195–204, 2009.
[31] Carnegie Mellon Software Engineering Institute. CMMI for development,Version 1.3, 2010.
[32] N. Castell, O. Slavkova, Y. Toussaint, and A. Tuells. Quality control ofsoftware specifications written in natural language. In Proceedings of the7th International Conference on Industrial and Engineering Applications ofArtificial Intelligence and Expert Systems, pages 37–44, 1994.
[33] J. Chang and D. Blei. Hierarchical relational models for document net-works. The Annals of Applied Statistics, 4(1):124–150, 2010.

Bibliography 97
[34] X. Chen. Extraction and visualization of traceability relationships betweendocuments and source code. In Proceedings of the International Conferenceon Automated Software Engineering, pages 505–509, 2010.
[35] X. Chen, J. Hosking, and J. Grundy. A combination approach for enhancingautomated traceability. In Proceeding of the 33rd International Conferenceon Software Engineering, (NIER track), pages 912–915, 2011.
[36] J. Cleland-Huang, C. K Chang, and M. Christensen. Event-based traceabil-ity for managing evolutionary change. Transactions on Software Engineer-ing, 29(9):796– 810, 2003.
[37] J. Cleland-Huang, A. Czauderna, A. Dekhtyar, O. Gotel, J. Huffman Hayes,E. Keenan, J. Maletic, D. Poshyvanyk, Y. Shin, A. Zisman, G. Antoniol,B. Berenbach, A. Egyed, and P. Mäder. Grand challenges, benchmarks, andTraceLab: Developing infrastructure for the software traceability researchcommunity. In Proceedings of the 6th International Workshop on Trace-ability in Emerging Forms of Software Engineering, 2011.
[38] J. Cleland-Huang, A. Czauderna, M. Gibiec, and J. Emenecker. A machinelearning approach for tracing regulatory codes to product specific require-ments. In Proceedings International Conference on Software Engineering,pages 155–164, 2010.
[39] J. Cleland-Huang, O. Gotel, and A. Zisman, editors. Software and systemstraceability. Springer, 2012.
[40] J. Cleland-Huang, J. Huffman Hayes, and A. Dekhtyar. Center of excel-lence for traceability: Problem statement and grand challenges in traceabil-ity (v0.1). Technical Report COET-GCT-06-01-0.9, 2006.
[41] J. Cleland-Huang, W. Marrero, and B. Berenbach. Goal-centric traceability:Using virtual plumblines to maintain critical systemic qualities. Transac-tions on Software Engineering, 34(5):685–699, 2008.
[42] J. Cleland-Huang, R. Settimi, C. Duan, and X. C. Zou. Utilizing support-ing evidence to improve dynamic requirements traceability. In Proceedingsof the 13th International Conference on Requirements Engineering, pages135–144, 2005.
[43] J. Cleland-Huang, R. Settimi, E. Romanova, B. Berenbach, and S. Clark.Best practices for automated traceability. Computer, 40(6):27–35, 2007.
[44] C. Cleverdon. The significance of the Cranfield tests on index languages.In Proceedings of the 14th Annual International SIGIR Conference on Re-search and Development in Information Retrieval, pages 3–12, 1991.

98 Recovering from a Decade: A Systematic Review of Information . . .
[45] D. Cuddeback, A. Dekhtyar, and J. Huffman Hayes. Automated require-ments traceability: The study of human analysts. In Proceedings of the18th International Requirements Engineering Conference, pages 231–240,2010.
[46] A. Czauderna, M. Gibiec, G. Leach, Y. Li, Y. Shin, E. Keenan, andJ. Cleland-Huang. Traceability challenge 2011: Using Tracelab to evalu-ate the impact of local versus global IDF on trace retrieval. In Proceedingof the 6th International Workshop on Traceability in Emerging Forms ofSoftware Engineering, pages 75–78, 2011.
[47] A. De Lucia, M. Di Penta, R. Oliveto, A. Panichella, and S. Panichella.Improving IR-based traceability recovery using smoothing filters. In Pro-ceedings of the 19th International Conference on Program Comprehension,pages 21–30, 2011.
[48] A. De Lucia, M. Di Penta, R. Oliveto, and F. Zurolo. COCONUT: COdeCOmprehension nurturant using traceability. In Proceedings of the 22ndInternational Conference on Software Maintenance, pages 274–275, 2006.
[49] A. De Lucia, M. Di Penta, R. Oliveto, and F. Zurolo. Improving compre-hensibility of source code via traceability information: A controlled exper-iment. In Proceedings of the International Conference on Program Com-prehension, pages 317–326, 2006.
[50] A. De Lucia, F. Fasano, and R. Oliveto. Traceability management for impactanalysis. In Frontiers of Software Maintenance, pages 21–30, 2008.
[51] A. De Lucia, F. Fasano, R. Oliveto, and G. Tortora. Enhancing an artefactmanagement system with traceability recovery features. In Proceedings ofthe 20th International Conference on Software Maintenance, pages 306–315, 2004.
[52] A. De Lucia, F. Fasano, R. Oliveto, and G. Tortora. ADAMS re-trace: Atraceability recovery tool. In Proceedings of the 9th European Conferenceon Software Maintenance and Reengineering, pages 32–41, 2005.
[53] A. De Lucia, F. Fasano, R. Oliveto, and G. Tortora. Can information re-trieval techniques effectively support traceability link recovery? In Pro-ceedings of the 14th International Conference on Program Comprehension,pages 307–316, 2006.
[54] A. De Lucia, F. Fasano, R. Oliveto, and G. Tortora. Recovering traceabilitylinks in software artifact management systems using information retrievalmethods. Transactions on Software Engineering and Methodology, 16(4),2007.

Bibliography 99
[55] A. De Lucia, A. Marcus, R. Oliveto, and D. Poshyvanyk. Information re-trieval methods for automated traceability recovery. In J. Cleland-Huang,O. Gotel, and A. Zisman, editors, Software and Systems Traceability.Springer, 2012.
[56] A. De Lucia, R. Oliveto, and P. Sgueglia. Incremental approach and userfeedbacks: A silver bullet for traceability recovery? In Proceedings of theInternational Conference on Software Maintenance, pages 299–308, 2006.
[57] A. De Lucia, R. Oliveto, and G. Tortora. IR-based traceability recoveryprocesses: An empirical comparison of "one-shot" and incremental pro-cesses. In Proceedings of the 23rd International Conference on AutomatedSoftware Engineering, pages 39–48, 2008.
[58] A. De Lucia, R. Oliveto, and G. Tortora. Assessing IR-based traceabilityrecovery tools through controlled experiments. Empirical Software Engi-neering, 14(1):57–92, 2009.
[59] A. De Lucia, R. Oliveto, and G. Tortora. The role of the coverage analysisduring IR-based traceability recovery: A controlled experiment. In Pro-ceedings of the International Conference on Software Maintenance, pages371–380, 2009.
[60] S. Deerwester, S. Dumais, G. Furnas, T. Landauer, and R. Harshman. In-dexing by latent semantic analysis. Journal of the American Society forInformation Science, 41(6):391–407, 1990.
[61] A. Dekhtyar, O. Dekhtyar, J. Holden, J. Huffman Hayes, D. Cuddeback, andW. Kong. On human analyst performance in assisted requirements tracing:Statistical analysis. In Proceedings of the 19th International RequirementsEngineering Conference, pages 111–120, 2011.
[62] A. Dekhtyar and J. Huffman Hayes. Good benchmarks are hard to find: To-ward the benchmark for information retrieval applications in software engi-neering. Proceedings of the International Conference on Software Mainte-nance, 2006.
[63] A. Dekhtyar, J. Huffman Hayes, and G. Antoniol. Benchmarks for traceabil-ity? In Proceedings of the International Symposium on Grand Challengesin Traceability, 2007.
[64] A. Dekhtyar, J. Huffman Hayes, and J. Larsen. Make the most of yourtime: How should the analyst work with automated traceability tools? InProceedings of the 3rd International Workshop on Predictor Models in Soft-ware Engineering, 2007.

100 Recovering from a Decade: A Systematic Review of Information . . .
[65] A. Dekhtyar, J. Huffman Hayes, S. Sundaram, A. Holbrook, and O. Dekht-yar. Technique integration for requirements assessment. In Proceedings ofthe 15th International Requirements Engineering Conference, pages 141–152, 2007.
[66] F. Di and M. Zhang. An improving approach for recovering requirements-to-design traceability links. In Proceedings of the International Conferenceon Computational Intelligence and Software Engineering, pages 1–6, 2009.
[67] M. Di Penta, S. Gradara, and G. Antoniol. Traceability recovery in RADsoftware systems. In Proceedings of the 10th International Workshop onProgram Comprehension, pages 207–216, 2002.
[68] B. Dit, M. Revelle, M. Gethers, and D. Poshyvanyk. Feature location insource code: A taxonomy and survey. Journal of Software Maintenanceand Evolution: Research and Practice, 2011.
[69] R. Dömges and K. Pohl. Adapting traceability environments to project-specific needs. Communications of the ACM, 41(12):54–62, 1998.
[70] C. Duan and J. Cleland-Huang. Clustering support for automated tracing.In Proceedings of the International Conference on Automated Software En-gineering, pages 244–253, 2007.
[71] A. Egyed and P. Grünbacher. Automating requirements traceability: Be-yond the record replay paradigm. In Proceedings of the 17th InternationalConference on Automated Software Engineering, pages 163–171, 2002.
[72] T. Eisenbarth, R. Koschke, and D. Simon. Locating features in source code.Transactions on Software Engineering, 29(3):210– 224, 2003.
[73] D. Falessi, G. Cantone, and G. Canfora. A comprehensive characterizationof NLP techniques for identifying equivalent requirements. In Proceed-ings of the International Symposium on Empirical Software Engineeringand Measurement, 2010.
[74] K. R Felizardo, N. Salleh, R. M Martins, E. Mendes, S. G MacDonell, andJ. C Maldonado. Using visual text mining to support the study selectionactivity in systematic literature reviews. In Proceedings of the InternationalSymposium on Empirical Software Engineering and Measurement, pages77–86, 2011.
[75] R. Fiutem and G. Antoniol. Identifying design-code inconsistencies inobject-oriented software: A case study. In Proceedings of the InternationalConference on Software Maintenance, pages 94–102, 1998.

Bibliography 101
[76] G. Gay, S. Haiduc, A. Marcus, and T. Menzies. On the use of relevancefeedback in IR-based concept location. In Proceedings of the 25th Interna-tional Conference on Software Maintenance, pages 351–360, 2009.
[77] M. Gethers, R. Oliveto, D. Poshyvanyk, and A. De Lucia. On integratingorthogonal information retrieval methods to improve traceability recovery.In Proceedings of the International Conference on Software Maintenance,pages 133–142, 2011.
[78] M. Gibiec, A. Czauderna, and J. Cleland-Huang. Towards mining replace-ment queries for hard-to-retrieve traces. In Proceedings of the InternationalConference on Automated Software Engineering, pages 245–254, 2010.
[79] O. Gotel, J. Cleland-Huang, J. Huffman Hayes, A. Zisman, A. Egyed,P. Grünbacher, A. Dekhtyar, G. Antoniol, and J. Maletic. The grand chal-lenge of traceability (v1.0). In J. Cleland-Huang, O. Gotel, and A. Zisman,editors, Software and Systems Traceability. Springer, 2012.
[80] O. Gotel and C. Finkelstein. An analysis of the requirements traceabilityproblem. In Proceedings of the First International Conference on Require-ments Engineering, pages 94–101, 1994.
[81] M. Heindl and S. Biffl. A case study on value-based requirements tracing.In Proceedings of the 10th European Software Engineering Conference heldjointly with the 13th SIGSOFT International Symposium on Foundations ofSoftware Engineering, pages 60–69, 2005.
[82] T. Hofman. Unsupervised learning by probabilistic latent semantic analysis.Machine Learning, 42(1-2):177–196, 2001.
[83] J. Huffman Hayes, G. Antoniol, and Y-G. Guéhéneuc. PREREQIR: re-covering pre-requirements via cluster analysis. In Proceedings of the 15thWorking Conference on Reverse Engineering, pages 165–174, 2008.
[84] J. Huffman Hayes and A. Dekhtyar. A framework for comparing require-ments tracing experiments. Interational Journal of Software Engineeringand Knowledge Engineering, 15(5):751–781, 2005.
[85] J. Huffman Hayes and A. Dekhtyar. Humans in the traceability loop: Can’tlive with ’em, can’t live without ’em. In Proceedings of the 3rd Interna-tional Workshop on Traceability in Emerging Forms of Software Engineer-ing, pages 20–23, 2005.
[86] J. Huffman Hayes, A. Dekhtyar, and J. Osborne. Improving requirementstracing via information retrieval. In Proceedings of the 11th InternationlRequirements Engineering Conference, pages 138–147, 2003.

102 Recovering from a Decade: A Systematic Review of Information . . .
[87] J. Huffman Hayes, A. Dekhtyar, and S. Sundaram. Text mining for softwareengineering: How analyst feedback impacts final results. In Proceedings ofthe International Workshop on Mining Software Repositories, pages 1–5,2005.
[88] J. Huffman Hayes, A. Dekhtyar, and S. Sundaram. Advancing candidatelink generation for requirements tracing: The study of methods. Transac-tions on Software Engineering, 32(1):4–19, 2006.
[89] J. Huffman Hayes, A. Dekhtyar, S. Sundaram, A. Holbrook, S. Vadlamudi,and A. April. REquirements TRacing on target (RETRO): improving soft-ware maintenance through traceability recovery. Innovations in Systems andSoftware Engineering, 3(3):193–202, 2007.
[90] J. Huffman Hayes, A. Dekhtyar, S. Sundaram, and S. Howard. Helpinganalysts trace requirements: An objective look. In Proceedings of the Inter-national Conference on Requirements Engineering, pages 249–259, 2004.
[91] J. Huffman Hayes, H. Sultanov, W. Kong, and W. Li. Software verificationand validation research laboratory (SVVRL) of the University of Kentucky:Traceability challenge 2011: Language translation. In Proceeding of the6th international workshop on Traceability in emerging forms of softwareengineering, pages 50–53. ACM, 2011.
[92] P. Ingwersen and K. Järvelin. The turn: Integration of information seekingand retrieval in context. Springer, 2005.
[93] International Electrotechnical Commission. IEC 61511-1 ed 1.0, Safetyinstrumented systems for the process industry sector, 2003.
[94] International Organization for Standardization. ISO 26262-1:2011 Roadvehicles –Functional safety –, 2011.
[95] K. Järvelin and J. Kekäläinen. IR evaluation methods for retrieving highlyrelevant documents. In Proceedings of the 23rd Annual International ACMSIGIR Conference on Research and Development in Information Retrieval,pages 41–48, 2000.
[96] A. Jedlitschka, M. Ciolkowski, and D. Pfahl. Reporting experiments in soft-ware engineering. In F. Shull, J. Singer, and D. Sjöberg, editors, Guide toAdvanced Empirical Software Engineering, pages 201–228. Springer, Lon-don, 2008.
[97] H. Jiang, T. Nguyen, I. Chen, H. Jaygarl, and C. Chang. Incremental latentsemantic indexing for automatic traceability link evolution management. InProceedings of the 23rd International Conference on Automated SoftwareEngineering, pages 59–68, 2008.

Bibliography 103
[98] N. Kando. NTCIR workshop : Japanese- and Chinese-English cross-lingual information retrieval and multi-grade relevance judgments. InCross-Language Information Retrieval and Evaluation, volume 2069, pages24–35. 2001.
[99] V. Katta and T. Stålhane. A conceptual model of traceability for safetysystems. In Proceedings of the Complex Systems Design & ManagementConference, 2011.
[100] N. Kaushik, L. Tahvildari, and M. Moore. Reconstructing traceability be-tween bugs and test cases: An experimental study. In Proceedings of theWorking Conference on Reverse Engineering, pages 411–414, 2011.
[101] J. Kekäläinen and K. Järvelin. Evaluating information retrieval systems un-der the challenges of interaction and multidimensional dynamic relevance.Proceedings of the COLIS 4 Conference, pages 253—270, 2002.
[102] B. Kitchenham, D. Budgen, and P. Brereton. Using mapping studies as thebasis for further research - A participant-observer case study. Informationand Software Technology, 53(6):638–651, 2011.
[103] B. Kitchenham and S. Charters. Guidelines for performing systematic liter-ature reviews in software engineering. EBSE Technical Report, 2007.
[104] S. Klock, M. Gethers, B. Dit, and D. Poshyvanyk. Traceclipse: An eclipseplug-in for traceability link recovery and management. In Proceeding of the6th International Workshop on Traceability in Emerging Forms of SoftwareEengineering, pages 24–30, 2011.
[105] L. Kong, J. Li, Y. Li, Y. Yang, and Q. Wang. A requirement traceabilityrefinement method based on relevance feedback. In Proceedings of the 21stInternational Conference on Software Engineering and Knowledge Engi-neering, 2009.
[106] P. Kruchten. The Rational Unified Process: An introduction. Addison-Wesley Professional, 2004.
[107] J. Leuser. Challenges for semi-automatic trace recovery in the automotivedomain. In Proceedings of the International Workshop on Traceability inEmerging Forms of Software Engineering, pages 31–35, 2009.
[108] J. Leuser and D. Ott. Tackling semi-automatic trace recovery for large spec-ifications. In Requirements Engineering: Foundation for Software Quality,pages 203–217, 2010.
[109] D. Lewis. Naive (Bayes) at forty: The independence assumption in infor-mation retrieval. In Machine Learning: ECML-98, volume 1398, pages4–15. Springer, 1998.

104 Recovering from a Decade: A Systematic Review of Information . . .
[110] Y. Li, J. Li, Y. Yang, and M. Li. Requirement-centric traceability for changeimpact analysis: A case study. In International Conference on SoftwareProcess, pages 100–111, 2008.
[111] E. Liddy. Natural language processing. Encyclopedia of Library and Infor-mation Science. Marcel Decker, 2nd edition, 2001.
[112] J. Lin, L. Chan, J. Cleland-Huang, R. Settimi, J. Amaya, G. Bedford,B. Berenbach, O. B Khadra, D. Chuan, and X. Zou. Poirot: A distributedtool supporting enterprise-wide automated traceability. In Proceedings ofthe 14th International Conference on Requirements Engineering, pages363–364, 2006.
[113] M. Lindvall, R. Feldmann, G. Karabatis, Z. Chen, and V. Janeja. Searchingfor relevant software change artifacts using semantic networks. In Proceed-ings of the Symposium on Applied Computing, pages 496–500, 2009.
[114] M. Lormans, H-G. Gross, A. van Deursen, R. van Solingen, and A. Ste-houwer. Monitoring requirements coverage using reconstructed views: Anindustrial case study. In Procedings of the 13th Working Conference onReverse Engineering, pages 275–284, 2006.
[115] M. Lormans and A. van Deursen. Can LSI help reconstructing requirementstraceability in design and test? In Proceedings of the 10th European Con-ference on Software Maintenance and Reengineering, pages 45–54, 2006.
[116] M. Lormans, A. Van Deursen, and H-G. Gross. An industrial case studyin reconstructing requirements views. Empirical Software Engineering,13(6):727–760, 2008.
[117] A. Mahmoud and N. Niu. Using semantics-enabled information retrieval inrequirements tracing: An ongoing experimental investigation. In Proceed-ings of the International Computer Software and Applications Conference,pages 246–247, 2010.
[118] A. Mahmoud and N. Niu. Source code indexing for automated tracing. InProceeding of the 6th International Workshop on Traceability in Emergingforms of Software Engineering, pages 3–9, 2011.
[119] C. Manning, P. Raghavan, and H. Schütze. Introduction to informationretrieval. Cambridge University Press, 2008.
[120] A. Marcus and J. Maletic. Recovering documentation-to-source-code trace-ability links using latent semantic indexing. In Proceedings of the Interna-tional Conference on Software Engineering, pages 125–135, 2003.

Bibliography 105
[121] A. Marcus, J. Maletic, and A. Sergeyev. Recovery of traceability links be-tween software documentation and source code. International Journal ofSoftware Engineering and Knowledge Engineering, 15(5):811–836, 2005.
[122] A. Marcus, A. Sergeyev, V. Rajlich, and J. I. Maletic. An information re-trieval approach to concept location in source code. In Proceedings of the11th Working Conference on Reverse Engineering, pages 214–223, 2004.
[123] A. Marcus, X. Xie, and D. Poshyvanyk. When and how to visualize trace-ability links? In Proceedings of the 3rd International Workshop on Trace-ability in Emerging Forms of Software Engineering, pages 56–61, 2005.
[124] M. Maron and J. Kuhns. On relevance, probabilistic indexing and informa-tion retrieval. Journal of the ACM, 7(3):216–244, 1960.
[125] C. McMillan, D. Poshyvanyk, and M. Revelle. Combining textual and struc-tural analysis of software artifacts for traceability link recovery. In Proceed-ings of the International Workshop on Traceability in Emerging Forms ofSoftware Engineering, pages 41–48, 2009.
[126] M. Miles and M. Huberman. Qualitative data analysis: An expandedsourcebook. Sage Publications, 2nd edition, 1994.
[127] P. Morville. Ambient findability: What we find changes who we become.O’Reilly Media, 2005.
[128] J. Natt och Dag, V. Gervasi, S. Brinkkemper, and B. Regnell. Speedingup requirements management in a product software company: Linking cus-tomer wishes to product requirements through linguistic engineering. InProceedings of the 12th International Requirements Engineering Confer-ence, pages 283–294, 2004.
[129] J. Natt och Dag, B. Regnell, P. Carlshamre, M. Andersson, and J. Karlsson.A feasibility study of automated natural language requirements analysis inmarket-driven development. Requirements Engineering, 7(1):20–33, 2002.
[130] J. Natt och Dag, T. Thelin, and B. Regnell. An experiment on linguistic toolsupport for consolidation of requirements from multiple sources in market-driven product development. Empirical Software Engineering, 11(2):303–329, 2006.
[131] R. Oliveto. Traceability management meets information retrieval methods:Strengths and limitations. PhD thesis, University of Salerno, 2008.
[132] R. Oliveto, M. Gethers, D. Poshyvanyk, and A. De Lucia. On the equiv-alence of information retrieval methods for automated traceability link re-covery. In International Conference on Program Comprehension, pages68–71, 2010.

106 Recovering from a Decade: A Systematic Review of Information . . .
[133] T. Olsson. Software information management in requirements and test doc-umentation. Licentiate thesis, Lund University, 2002.
[134] S. Park, H. Kim, Y. Ko, and J. Seo. Implementation of an efficient require-ments analysis supporting system using similarity measure techniques. In-formation and Software Technology, 42(6):429–438, 2000.
[135] A. G Parvathy, B. G Vasudevan, and R. Balakrishnan. A comparative studyof document correlation techniques for traceability analysis. In Proceedingsof the 10th International Conference on Enterprise Information Systems,Information Systems Analysis and Specification, pages 64–69, 2008.
[136] K. Petersen, R. Feldt, S. Mujtaba, and M. Mattsson. Systematic mappingstudies in software engineering. In Proceedings of the 12th InternationalConference on Evaluation and Assessment in Software Engineering, pages71–80, 2008.
[137] K. Pohl, G. Böckle, and F. van der Linden. Software product line engineer-ing: foundations, principles, and techniques. Birkhäuser, 2005.
[138] J. Ponte and B. Croft. A language modeling approach to information re-trieval. In Proceedings of the 21st Annual International SIGIR Conferenceon Research and Development in Information Retrieval, pages 275–281,1998.
[139] D. Port, A. Nikora, J. Hihn, and L. Huang. Experiences with text mininglarge collections of unstructured systems development artifacts at JPL. InProceedings of the 33rd International Conference on Software Engineering,pages 701–710, 2011.
[140] J. Randolph. Free-marginal multirater Kappa (multirater K[free]): An alter-native to Fleiss’ fixed-marginal multirater Kappa. In Joensuu Learning andInstruction Symposium, 2005.
[141] S. Robertson. The probability ranking principle in IR. Journal of Docu-mentation, 33(4):294–304, 1977.
[142] S. Robertson and J. Robertson. Mastering the requirements process.Addison-Wesley Professional, 1999.
[143] S. Robertson and H. Zaragoza. The probabilistic relevance framework:BM25 and beyond. Foundation and Trends in Information Retrieval,3(4):333–389, 2009.
[144] S. E. Robertson and S. Jones. Relevance weighting of search terms. Journalof the American Society for Information Science, 27(3):129–146, 1976.

Bibliography 107
[145] J. Rocchio. Relevance feedback in information retrieval. In G. Salton,editor, The SMART Retrieval System: Experiments in Automatic DocumentProcessing, pages 313–323. Prentice-Hall, 1971.
[146] P. Runeson, M. Alexandersson, and O. Nyholm. Detection of duplicatedefect reports using natural language processing. In Proceedings of the 29thInternational Conference on Software Engineering, pages 499–510, 2007.
[147] P. Runeson, M. Höst, A. Rainer, and B. Regnell. Case study research insoftware engineering: Guidelines and examples. Wiley, 2012.
[148] G. Sabaliauskaite, A. Loconsole, E. Engström, M. Unterkalmsteiner,B. Regnell, P. Runeson, T. Gorschek, and R. Feldt. Challenges in aligningrequirements engineering and verification in a large-scale industrial con-text. In Requirements Engineering: Foundation for Software Quality, pages128–142, 2010.
[149] G. Salton and C. Buckley. Term-weighting approaches in automatic textretrieval. Information Processing and Management, 24(5):513–523, 1988.
[150] G. Salton, A. Wong, and C. Yang. A vector space model for automaticindexing. Commununications of the ACM, 18(11):613–620, 1975.
[151] W. Scacchi. Understanding the requirements for developing open sourcesoftware systems. IEEE Software, 149(1):24–39, 2002.
[152] R. Settimi, J. Cleland-Huang, O. Ben Khadra, J. Mody, W. Lukasik, andC. DePalma. Supporting software evolution through dynamically retrievingtraces to UML artifacts. In Proceedings of the 7th International Workhopon Principles of Software Evolution, pages 49–54, 2004.
[153] F. Shull, J. Carver, S. Vegas, and N. Juristo. The role of replications in em-pirical software engineering. Empirical Software Engineering, 13(2):211–218, 2008.
[154] A. Singhal. Modern information retrieval: A brief overview. Data Engi-neering Bulletin, 24(2):1–9, 2001.
[155] A. Smeaton and D. Harman. The TREC experiments and their impact oneurope. Journal of Information Science, 23(2):169–174, 1997.
[156] G. Spanoudakis, A. d’Avila-Garcez, and A. Zisman. Revising rules to cap-ture requirements traceability relations: A machine learning approach. InProceedings of the 15th International Conference in Software Engineeringand Knowledge Engineering, 2003.

108 Recovering from a Decade: A Systematic Review of Information . . .
[157] G. Spanoudakis, A. Zisman, E. Pérez-Miñana, and P. Krause. Rule-basedgeneration of requirements traceability relations. Journal of Systems andSoftware, 72(2):105–127, 2004.
[158] K. Spärck Jones, S. Walker, and S. E. Robertson. A probabilistic modelof information retrieval: Development and comparative experiments. Infor-mation Processing and Management, 36(6):779–808, 2000.
[159] A. Stone and P. Sawyer. Using pre-requirements tracing to investigaterequirements based on tacit knowledge. In Proceedings of the 1st Inter-national Conference on Software and Data Technologies, pages 139–144,2006.
[160] H. Sultanov and J. Huffman Hayes. Application of swarm techniques torequirements engineering: Requirements tracing. In Proceedings of the18th International Requirements Engineering Conference, pages 211–220,2010.
[161] S. Sundaram, J. Huffman Hayes, and A. Dekhtyar. Baselines in require-ments tracing. In Proceedings of the Workshop on Predictor Models inSoftware Engineering, pages 1–6, 2005.
[162] S. Sundaram, J. Huffman Hayes, A. Dekhtyar, and A. Holbrook. Assessingtraceability of software engineering artifacts. Requirements Engineering,15(3):313–335, 2010.
[163] M. Torchiano and F. Ricca. Impact analysis by means of unstructuredknowledge in the context of bug repositories. In Proceedings of the Inter-national Symposium on Empirical Software Engineering and Measurement,pages 47:1–47:4, 2010.
[164] H. Turtle and B. Croft. Evaluation of an inference network-based retrievalmodel. Transactions on Information Systems, 9(3):187–222, 1991.
[165] B. Van Rompaey and S. Demeyer. Establishing traceability links betweenunit test cases and units under test. In Proceedings of the 13th EuropeanConference on Software Maintenance and Reengineering, pages 209–218,2009.
[166] E. Voorhees. TREC: experiment and evaluation in information retrieval.MIT Press, 2005.
[167] X. Wang, G. Lai, and C. Liu. Recovering relationships between documen-tation and source code based on the characteristics of software engineering.Electronic Notes in Theoretical Computer Science, 243:121–137, 2009.

Bibliography 109
[168] S. Winkler. Trace retrieval for evolving artifacts. In Proceedings of theInternational Workshop on Traceability in Emerging Forms of Software En-gineering, pages 49–56, 2009.
[169] S. Winkler and J. Pilgrim. A survey of traceability in requirements en-gineering and model-driven development. Software & Systems Modeling,9(4):529–565, 2010.
[170] C. Wohlin, P. Runeson, M. Höst, M. Ohlsson, B. Regnell, and A. Wess-lén. Experimentation in software engineering: A practical guide. Springer,2012.
[171] S. Yadla, J. Huffman Hayes, and A. Dekhtyar. Tracing requirements to de-fect reports: An application of information retrieval techniques. Innovationsin Systems and Software Engineering, 1:116–124, 2005.
[172] R. Yin. Case study research: Design and methods. Sage Publications, 3rdedition, 2003.
[173] C. Zhai. A brief review of information retrieval models. Technical report,University of Illinois at Urbana-Champaign, 2007.
[174] C. Zhai. Statistical language models for information retrieval: A criticalreview. Foundations and Trends in Information Retrieval, 2(3):137–213,2008.
[175] C. Zhai and J. Lafferty. Model-based feedback in the language modelingapproach to information retrieval. In Proceedings of the 10th InternationalConference on Information and Knowledge Management, pages 403–410,2001.
[176] W. Zhao, L. Zhang, Y. Liu, J. Luo, and J. S. Sun. Understanding how therequirements are implemented in source code. In Proceedings of the Asia-Pacific Software Engineering Conference, pages 68–77, 2003.
[177] X. Zhou and H. Yu. A clustering-based approach for tracing object-orienteddesign to requirement. In Proceedings of the 10th International Confer-ence on Fundamental Approaches to Software Engineering, pages 412–422,2007.
[178] X. Zou, R. Settimi, and J. Cleland-Huang. Phrasing in dynamic require-ments trace retrieval. In Proceedings of the International Computer Soft-ware and Applications Conference, pages 265–272, 2006.
[179] X. Zou, R. Settimi, and J. Cleland-Huang. Evaluating the use of projectglossaries in automated trace retrieval. In Proceedings of the InternationalConference on Software Engineering Research and Practice, pages 157–163, 2008.

110 Recovering from a Decade: A Systematic Review of Information . . .
[180] X. Zou, R. Settimi, and J. Cleland-Huang. Improving automated require-ments trace retrieval: A study of term-based enhancement methods. Empir-ical Software Engineering, 15(2):119–146, 2010.

PAPER II
INDUSTRIAL COMPARABILITYOF STUDENT ARTIFACTS INTRACEABILITY RECOVERY
RESEARCH - ANEXPLORATORY SURVEY
Abstract
About a hundred studies on traceability recovery have been published in softwareengineering fora. In roughly half of them, software artifacts developed by studentshave been used as input. To what extent student artifacts differ from industrialcounterparts has not been fully explored in the literature. We conducted a sur-vey among authors of studies on traceability recovery, including both academicsand practitioners, to explore their perspectives on the matter. Our results indi-cate that a majority of authors consider software artifacts originating from studentprojects to be only partly representative to industrial artifacts. Moreover, only fewrespondents validated student artifacts for industrial representativeness. Further-more, our respondents made suggestions for improving the description of artifactsets used in studies by adding contextual, domain-specific and artifact-centric in-formation. Example suggestions include adding descriptions of processes used forartifact development, meaning of traceability links, and the structure of artifacts.Our findings call for further research on characterization and validation of softwareartifacts to support aggregation of results from empirical studies.
Markus Borg, Krzysztof Wnuk, and Dietmar Pfahl, In Proceedings of the 16thEuropean Conference on Software Maintenance and Reengineering, 2012

112 Industrial comparability of student artifacts in traceability recovery . . .
1 Introduction
To advance both the state-of-art and state-of-practice in software engineering, em-pirical studies (i.e., surveys, experiments, case studies) have to be conducted [7,20]. In order to investigate the cause-effect relationships of introducing new meth-ods, techniques or tools in software engineering, controlled experiments are com-monly used as the research method. Despite the benefits resulting from the con-trolled environment that can be created in this fixed research design [19, 24],controlled experiments are expensive due to the involvement of human subjects.Therefore, controlled experiments are often conducted with university students -and not with engineers working in industry.
Several researchers have studied the differences between using students andpractitioners as subjects in software engineering studies, since the inadequate choiceof subjects might be a considerable threat to the validity of the study results [8].A number of publications report that the differences are only minor, thus usingstudents is reasonable under certain circumstances [2,8,9,14,23]. Senior students,representing the next generation of professional software engineers, are relativelyclose to the population of interest in studies aiming at emulating professional be-havior [14]. Further, for relatively small tasks, trained students have been shownto perform comparably to practitioners in industry [8, 23].
However, the question whether software artifacts (referred to as only ‘artifacts’in this paper) produced by students should be used in empirical studies has beenless explored. How useful are results from such studies when it comes to general-izability to industrial contexts? Using student artifacts is often motivated by lowavailability of industrial artifacts due to confidentiality issues. A qualification ofthe validity of student artifacts is particularly important for the domain of trace-ability recovery, since student artifacts frequently have been used for tool evalua-tions [5, 6, 18]. Since several software maintenance tasks (such as change impactanalysis and regression testing) depend on up-to-date traceability information [12],it is fundamental to understand the nature of experimental artifact sets.
Furthermore, as presented in more detail in Section II, the reported charac-terization of artifact sets used as input to experiments on traceability recovery istypically insufficient. According to Jedlitschka et al., inadequate reporting of em-pirical research commonly impedes integration of study results into a commonbody of knowledge [13]. This applies also to traceability recovery research. First,insufficient reporting makes it harder to assess the validity of results using studentartifacts (even if artifacts have been made available elsewhere). Second, it hindersaggregation of empirical results, particularly when closed industrial artifact setshave been used (that never can be made available).
In this paper, we present a study exploring differences between Natural Lan-guage (NL) artifacts originating from students and practitioners. We conducted aquestionnaire-based survey of researchers with experience in doing experimentson traceability recovery using Information Retrieval (IR) approaches. The survey

2 Background and Related Work 113
builds upon results from a literature study, which will be published in full detailelsewhere.
This paper is structured as follows. Section 2 presents background, includinga short overview of related work on IR-based traceability recovery and using stu-dents in software engineering experiments. Section 3 presents the research designand how the survey was conducted. In Section 4 we present and analyze our re-sults in comparison to the literature. Section 5 describes threats to validity. Finally,Section 6 concludes the paper and discusses future work.
2 Background and Related Work
Using students as subjects in empirical software engineering studies has been con-sidered as reasonable by several researchers [2, 8, 9, 14, 23]. Kitchenham et al.claim that students are the next generation of software professionals and that theyare relatively close to the population of interest (practitioners) [14]. Kuzniarz etal. concluded that students are good subjects under certain circumstances and pro-poses a classification of the possible types of students used in an experiment [15].Svahnberg et al. investigated if students understand the way how industry acts inthe context of requirements selection [23].
Höst et al. investigated the incentives and experience of subjects in experi-ments and proposed a classification scheme in relation to the outcome of an ex-periment [9]. Although Höst et al. distinguished between artificial artifacts (suchas produced by students during a course) and industrial artifacts as part of the in-centives in the proposed classification, guidelines on how to assess the two typesof artifacts are not provided in this work. Moreover, none of the mentioned stud-ies investigate whether artifacts produced by students are comparable to artifactsproduced in industry and how possible discrepancies could be assessed.
Several empirical studies on traceability recovery were conducted using stu-dent subjects working on artifacts originating from student projects. De Luciaet al. evaluated the usefulness of supported traceability recovery in a study with150 students in 17 software development projects at the University of Salerno [6].They also conducted a controlled experiment with 32 students using student ar-tifacts [5]. Natt och Dag et al. conducted another controlled experiment in anacademic setting, where 45 students were solving tracing tasks on artifacts pro-duced by students [18].
During the last decade, several researchers proposed expressing the traceabil-ity challenge, i.e., identifying related artifacts, as an IR problem [1, 5, 17]. Theapproach suggests traceability links based on textual similarity between artifacts,since text in NL is the common format of information representation in softwaredevelopment [17]. The underlying assumption is that developers use similar lan-guage when referring to the same functionality across artifacts.

114 Industrial comparability of student artifacts in traceability recovery . . .
Figure 1: Origin of artifacts used in IR-based traceability recovery evalua-tions. Artifact sets in darker grey are available at COEST (A=MODIS, B=CM-1,C=Waterloo, D=EasyClinic).
Artifact set Artifact types Origin / Domain Size (#artifacts)A MODIS Requirements NASA / 48
EmbeddedB CM-1 Requirements NASA / 555
EmbeddedC Waterloo Requirements 23 student 23 x ~75
projectsD EasyClinic Requirements Student 160
code, test cases project
Table 1: Publicly available artifact sets at COEST (Oct 23, 2011).
In an ongoing literature review, we have identified 59 publications on IR-basedtraceability recovery of NL artifacts. Figure 1 shows the reported origin of artifactsused in evaluations of traceability recovery tools, classified as industrial artifacts,open source artifacts, university (artifacts developed in university projects, role ofdevelopers unspecified) or student (deliverables from student projects). Severalpublications use artifacts from more than one category, some do not report theorigin of the artifacts used for evaluations. As Figure 1 shows, a majority of theartifacts originate from an academic environment, i.e. they have been developedin university or student projects.
The Center of Excellence for Software Traceability (COEST) has collected andpublished four artifact sets (see Table 1), that constitute the de-facto benchmarksfor IR-based traceability recovery research. In Figure 1, darker grey color repre-sents artifact sets available at COEST. Among the 59 identified publications, themost frequently used artifact sets in traceability recovery studies are EasyClinic(marked with a letter D, 10 publications), CM-1 (B, 9 publications) and MODIS(A, 6 publications).

3 Research Design 115
In 2005, Huffman Hayes and Dekhtyar proposed “A framework for comparingrequirements tracing experiments” [10]. The framework focuses on developing,conducting and analyzing experiments, but also suggests information about arti-facts and contexts that are worth reporting. They specifically say that the averagesize of an artifact is of interest, but that it rarely is specified in research papers.Furthermore, they propose characterizing the quality of the artifacts and the im-portance of both the domain and object of study (on a scale from convenience tosafety-critical).
Moreover, even though the framework was published in 2005, our review ofthe literature revealed that artifact sets often are presented in rudimentary fashionin the surveyed papers. The most common way to characterize artifact sets inthe surveyed papers is to report its origins together with a brief description ofthe functionality of the related system, its size and the types of artifacts included.Size is reported as the number of artifacts and the number of traceability linksbetween them. This style of reporting was applied in 49 of the 59 publications(83%). Only three publications thoroughly describe the context and process usedwhen the artifacts were developed. For example, Lormans et al. well describe thecontext of their case study at LogicaCMG [16].
Apart from mentioning size and number of links, some publications presentmore detail regarding the artifacts. Six publications report descriptive statistics ofindividual artifacts, including average size and number of words. Being even moredetailed, Huffman Hayes et al. reported two readability measures to characterizeartifact sets, namely Flesch Reading Ease and Flesch-Kincaid Grade Level [11].Another approach was proposed by De Lucia et al. [5]. They reported subjectivelyassessed quality of different artifact types, in addition to the typical size measures.As stressed by Jedlitschka et al. proper reporting of traceability recovery studiesis important, since inadequate reporting of empirical research commonly impedesintegration of study results into a common body of knowledge [13].
3 Research Design
This section presents the research questions, the research methodology, and thedata collection procedures used in our study. The study is an exploratory follow-upto the ongoing literature review mentioned in Section 2. Table 5 presents the re-search questions governing this study. The research questions investigate whetherthe artifacts used in the reported studies are considered comparable to their indus-trial counterparts by our respondents. Moreover, the questions aim at exploringhow to support assessing the comparability by augmenting the descriptions of theused artifacts.
For this study, we chose a questionnaire-based survey as the tool to collect em-pirical data, since it helps reaching a large number of respondents from geograph-ically diverse locations [21]. Also, a survey provides flexibility and is convenient

116 Industrial comparability of student artifacts in traceability recovery . . .
Research question Aim Example answerRQ1 When used as ex-
periment inputs,how comparable areartifacts producedby students to theirindustrial counterparts?
Understand to what de-gree respondents, bothin academia and indus-try, consider industrialand student artifacts tobe comparable.
“As a rule, the ed-ucational artifactsare simpler.”
RQ2 How are artifactsvalidated before be-ing used as input toexperiments?
Survey if and how stu-dent artifacts are val-idated before experi-ments are conducted.
“Our validation wasbased on expertopinion.”
RQ3 Is the typically reportedcharacterization of arti-fact sets sufficient?
Do respondents, both inacademia and industry,consider that the waynatural language arti-facts are described isgood enough.
“I would argue thatit should also becharacterized by theprocess by it wasdeveloped.”
RQ4 How could artifacts bedescribed to better sup-port aggregation of em-pirical results?
Explore whether thereare ways to improve theway natural languageartifacts are presented.
“The artifactsshould be com-bined with a taskthat is of principalcognitive nature.”
RQ5 How could the dif-ference between arti-facts originating fromindustrial and studentprojects be measured?
Investigate if thereare any measures thatwould be particularlysuitable to compareindustrial and studentartifacts.
“The main differ-ence is the ver-bosity.”
Table 2: Research questions of the study. All questions are related to the contextof traceability recovery studies.

3 Research Design 117
to both researchers and participants [7]. The details in relation to survey designand data collection are outlined in the section that follows.
3.1 Survey design
Since the review of literature resulted in a substantial body of knowledge on IR-based approaches to traceability recovery, we decided to use the authors of theidentified publications as our sample population. Other methods to recover trace-ability have been proposed, including data mining [22] and ontology-based re-covery [25], however the majority of traceability recovery publications apply IRtechniques. Furthermore, it is well-known that IR is sensitive to the input dataused in evaluations [4].
The primary aim of this study was to explore researchers’ views on the compa-rability between NL artifacts produced by students and practitioners. We restrictedthe sample to authors with documented experience, i.e., published peer-reviewedresearch articles, of using either student or industrial artifact sets in IR-based trace-ability recovery studies. Consequently, we left out authors who exclusively usedartifacts from the open source domain.
The questionnaire was constructed through a brainstorming session with theauthors, using the literature review as input. To adapt the questions to the respon-dents regarding the origin of the artifacts used, three versions of the questionnairewere created:
• STUD. A version for authors of published studies on traceability recoveryusing student artifacts. This version was most comprehensive since it con-tained more questions. Thus it was sent to authors, if at least one publicationusing student artifacts had been identified.
• UNIV. A version for authors using artifacts originating from university pro-jects. This version included a clarifying question on whether the artifactswere developed by students or not, followed by the same detailed questionsabout student artifacts as in version STUD. This question was used to filterout answers related to student artifacts.
• IND. A subset of STUD, sent to authors who only had published traceabilityrecovery studies using industrial artifacts.
We piloted the questionnaire using five senior software engineering researchers,including a native English speaker. The three versions of the questionnaire werethen refined, the final versions are presented in the Appendix. The mapping be-tween research questions and questions in the questionnaire is presented in Table 3.

118 Industrial comparability of student artifacts in traceability recovery . . .
Research questions Questionnaire questionsRQ1 QQ1, QQ4, QQ6RQ2 QQ4, QQ5RQ3 QQ2RQ4 QQ3RQ5 QQ4, QQ7
Table 3: Mapping between research questions and the questionnaire. QQ4 wasused as a filter.
Figure 2: Survey response rate.
3.2 Survey execution and analysis
The questionnaires were distributed via email, sent to the set of authors describedin Section 3.1. As Figure 2 depicts, in total 90 authors were identified. We wereable to send emails that appeared to reach 75 (83%) of them. Several mails re-turned with no found recipient and in some cases no contact information was avail-able. In those few cases we tried contacting current colleagues; nevertheless thereremained 15 authors (17%) we did not manage to send emails successfully. Themails were sent between September 27 and October 12, 2011. After one week,reminders were sent to respondents who had not yet answered the survey.
24 authors (32%) responded to our emails; however four responses did notcontain answers to the survey questions. Among them, two academics referred toother colleagues more suitable to answer the questionnaire (all however alreadyincluded in our sample) and two practitioners claimed to be too disconnected fromresearch to be able to answer with a reasonable effort. Thus, the final set of com-plete answers included 20 returned questionnaires. This yielded a response rate of27%.
The survey answers were analyzed by descriptive statistics and qualitative cat-egorization of the answers. The results and the analysis are presented in Section 4.

4 Results and Analysis 119
Figure 3: Current main affiliation of respondents.
STUD UNIV INDAcademics 8 2 2Practitioners 3 0 5Total 11 2 7
Table 4: Mapping between research questions and the questionnaire. QQ4 wasused as a filter.
4 Results and Analysis
In this section, the results from the survey of authors are presented and discussed.
4.1 Demographics and sample characterization
For the 20 authors of publications on IR-based traceability recovery who answeredthe questionnaire, Figure 3 depicts the distribution of practitioners and academicsbased on current main affiliation. 40% of the respondents are currently working inindustry. Our respondents represent all combinations of academics and practition-ers from Europe, North America and Asia. Table 4 presents how many answers wereceived per questionnaire version. Both respondents answering UNIV reportedthat students had developed the artifacts in their university projects (QQ4), thus atleast twelve of the respondents had experience with student artifacts in traceabilityrecovery experiments.
4.2 Representativeness of student artifacts (RQ1)
In this subsection, we present the view of our respondents on the representative-ness of software artifacts produced by students. In this case, we investigated ifour respondents agree with the statement that software artifacts produced by stu-dents are representative of software artifacts produced in industry (see QQ1, andQQ6 filtered by QQ4 in the Appendix). QQ6 overlaps QQ1 by targeting specific

120 Industrial comparability of student artifacts in traceability recovery . . .
publications. To preserve the anonymity of the respondents, the analyses of thequestions are reported together.
Figure 4 shows survey answers to the statement “Software artifacts producedby students (used as input in traceability experiments) are representative of soft-ware artifacts produced in industry” (QQ1). Black color represents answers frompractitioners, grey color answers from academics. Half of the respondents fully orpartly disagree to the statement. Academics answered this question with a higherdegree of consensus than practitioners. No respondent totally agreed to the state-ment.
Several respondents decided to comment on the comparability of student ar-tifacts. Two of them, both practitioners answering QQ1 with ‘4’, pointed outthat trained students actually might produce NL artifacts of higher quality thanengineers in industry. One of them clarified: “In industry, there are a lot of un-trained ‘professionals’ who, due to many reasons including time constraints, pro-duce ‘flawed’ artifacts”. Another respondent answered QQ1 with ‘2’, but stressedthat certain student projects could be comparable to industrial counterparts, for in-stance in the domain of web applications. On the other hand, he explained, wouldthey not at all be comparable for domains with many process requirements suchas finance and aviation. Finally, one respondent mentioned the wider diversity ofindustrial artifacts, compared to artifacts produced by students: “I’ve seen ridicu-lously short requirements in industry (5 words only) and very long ones of multipleparagraphs. Students would be unlikely to create such monstrous requirements!”and also added “Student datasets are MUCH MUCH smaller (perhaps 50-100 ar-tifacts compared to several thousands)”.
Three of our respondents mentioned the importance of understanding the in-centives of the developers of the artifacts. This result confirms the findings by Höstet al. [9]. The scope and lifetime of student artifacts are likely to be much differentfor industrial counterparts. Another respondent (academic) supported this claimand also stressed the importance of the development context: “The vast majority[of student artifacts] are developed for pedagogical reasons - not for practical rea-sons. That is, the objective is not to build production code, but to teach students.”According to one respondent (practitioner), both incentives and development con-texts are playing an important role also in industry: “Industrial artifacts are createdand evolved in a tension between regulations, pressing schedule and lacking mo-tivation /—/ some artifacts are created because mandated by regulations, but noone ever reads them again, other artifacts are part of contracts and are, therefore,carefully formulated and looked through by company lawyers etc.”
These results are not surprising, and lead to the conclusion that NL artifactsproduced by students are understood to be less complex than their industrial coun-terparts. However, put in the light of related work outlined in Section 2, the resultscan lead to interesting interpretations. As presented in Figure 1, experiments ontraceability recovery frequently use artifacts developed by students as input. Also,as presented in Table 1, two of four publicly available artifact sets at COEST orig-
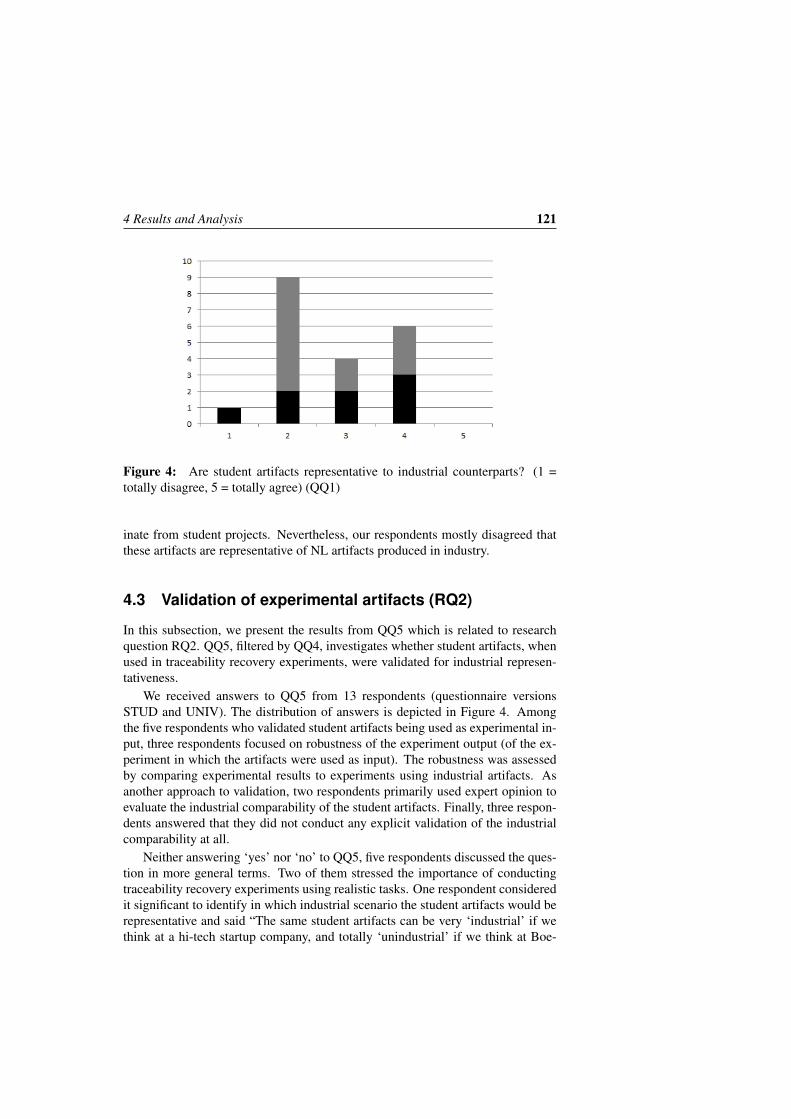
4 Results and Analysis 121
Figure 4: Are student artifacts representative to industrial counterparts? (1 =totally disagree, 5 = totally agree) (QQ1)
inate from student projects. Nevertheless, our respondents mostly disagreed thatthese artifacts are representative of NL artifacts produced in industry.
4.3 Validation of experimental artifacts (RQ2)
In this subsection, we present the results from QQ5 which is related to researchquestion RQ2. QQ5, filtered by QQ4, investigates whether student artifacts, whenused in traceability recovery experiments, were validated for industrial represen-tativeness.
We received answers to QQ5 from 13 respondents (questionnaire versionsSTUD and UNIV). The distribution of answers is depicted in Figure 4. Amongthe five respondents who validated student artifacts being used as experimental in-put, three respondents focused on robustness of the experiment output (of the ex-periment in which the artifacts were used as input). The robustness was assessedby comparing experimental results to experiments using industrial artifacts. Asanother approach to validation, two respondents primarily used expert opinion toevaluate the industrial comparability of the student artifacts. Finally, three respon-dents answered that they did not conduct any explicit validation of the industrialcomparability at all.
Neither answering ‘yes’ nor ‘no’ to QQ5, five respondents discussed the ques-tion in more general terms. Two of them stressed the importance of conductingtraceability recovery experiments using realistic tasks. One respondent consideredit significant to identify in which industrial scenario the student artifacts would berepresentative and said “The same student artifacts can be very ‘industrial’ if wethink at a hi-tech startup company, and totally ‘unindustrial’ if we think at Boe-

122 Industrial comparability of student artifacts in traceability recovery . . .
Figure 5: Were the student artifacts validated for industrial comparability? (QQ5)
ing”. Another respondent claimed that they had focused on creating an as generaltracing task as possible.
Only a minority of researchers who used student artifacts to evaluate IR-basedtraceability recovery explicitly answered with ‘yes’ to this question, suggestingthat it is no widespread common practice. Considering the questionable compara-bility of artifacts produced by students, confirmed by QQ1, this finding is remark-able. Simply assuming that there is an industrial context where the artifacts wouldbe representative might not be enough. The validation that actually takes placeappears to be ad-hoc, thus some form of supporting guidelines would be helpful.
4.4 Adequacy of artifact characterization (RQ3)In this subsection, we present the results from asking our respondents whether thetypical way of characterizing artifacts used in experiments (mainly size and num-ber of correct traceability links) is sufficient. In Figure 6, we present answers toQQ2 which is related to RQ3. Black color represents practitioners, grey color aca-demics. Two respondents (both academics) considered this to be a fully sufficientcharacterization. The distribution of the rest of the answers, both for practitionersand academics, shows mixed opinions.
Respondents answering with ‘1’ (totally insufficient) to QQ2 motivated theiranswers by claiming: simple link existence being too rudimentary, complexityof artifact sets must be presented and the meaning of traceability links should beclarified. On the other hand, seven respondents answered with ‘4’ or ‘5’ (5=fullysufficient). Their motivations included: tracing effort is most importantly propor-tional to the size of the artifact set and experiments based on textual similaritiesare reliable. However, two respondents answering with ‘4’ also stated that infor-mation density and language are important factors and that the properties of thetraceability links should not be missed.
More than 50% of all answers to QQ2 were marking options ‘1’, ‘2’ or ‘3’.Thus a majority of the respondents answering this question either disagree with
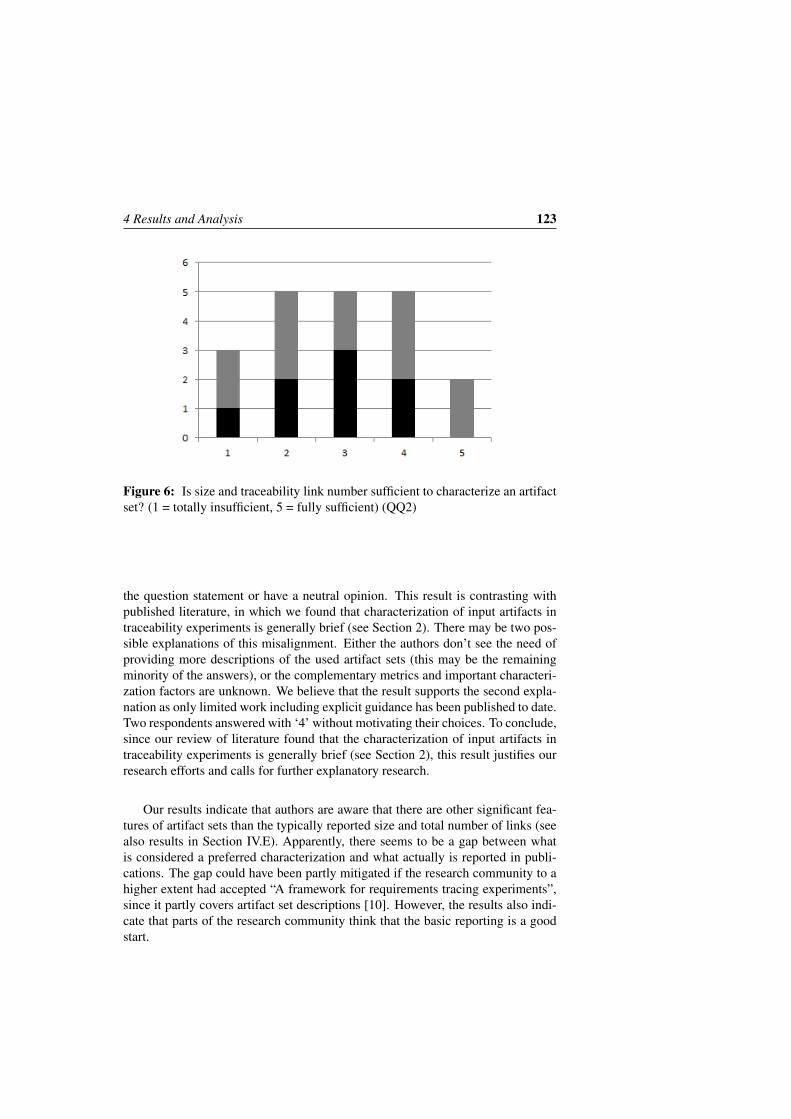
4 Results and Analysis 123
Figure 6: Is size and traceability link number sufficient to characterize an artifactset? (1 = totally insufficient, 5 = fully sufficient) (QQ2)
the question statement or have a neutral opinion. This result is contrasting withpublished literature, in which we found that characterization of input artifacts intraceability experiments is generally brief (see Section 2). There may be two pos-sible explanations of this misalignment. Either the authors don’t see the need ofproviding more descriptions of the used artifact sets (this may be the remainingminority of the answers), or the complementary metrics and important characteri-zation factors are unknown. We believe that the result supports the second expla-nation as only limited work including explicit guidance has been published to date.Two respondents answered with ‘4’ without motivating their choices. To conclude,since our review of literature found that the characterization of input artifacts intraceability experiments is generally brief (see Section 2), this result justifies ourresearch efforts and calls for further explanatory research.
Our results indicate that authors are aware that there are other significant fea-tures of artifact sets than the typically reported size and total number of links (seealso results in Section IV.E). Apparently, there seems to be a gap between whatis considered a preferred characterization and what actually is reported in publi-cations. The gap could have been partly mitigated if the research community to ahigher extent had accepted “A framework for requirements tracing experiments”,since it partly covers artifact set descriptions [10]. However, the results also indi-cate that parts of the research community think that the basic reporting is a goodstart.

124 Industrial comparability of student artifacts in traceability recovery . . .
4.5 Improved characterization (RQ4)In this section we provide results for the RQ4, exploring ways to improve theway NL artifacts are reported, addressed by QQ3. Eleven respondents, six aca-demics and five practitioners, suggested explicit enhancements to artifact set char-acterization, other respondents answered more vaguely. Those suggestions arecollected and organized below into the three classes Contextual (describes the en-vironment of the artifact development), Link-related (describes properties of trace-ability links) and Artifact-centric (describes the artifacts). In total, 23 aspects toadditionally characterize artifacts were suggested.
Contextual aspects:
• Domain from which the artifacts originate
• Process used when artifact was developed (agile/spiral/waterfall etc., ver-sioning, safety regulations)
• When in the product lifecycle the artifacts were developed
• Maturity/evolution of the artifacts (years in operation, #reviews, #updates)
• Role and personality of the developer of the artifacts
• Number of stakeholders/users of the artifacts
• Tasks that are related to the artifact set
Link-related aspects:
• Meaning of a traceability link (depends on, satisfies, based on, verifies etc.)
• Typical usage of traceability links
• Values and costs of traceability links (Value of correct link, cost of estab-lishing link, establishing false link, missing link)
• Person who created the golden standard of links (practitioners, researchers,students, and their incentives)
• Quality of the golden standard of traceability links
• Link density
• Distribution of inbound/outbound links

4 Results and Analysis 125
Artifact-centric aspects:
• Size of individual artifacts
• Language (Natural, formal)
• Complexity of artifacts
• Verbosity of artifacts
• Artifact redundancy/overlap
• Artifact granularity (Full document/chapter/page/ section etc.)
• Quality/maturity of artifact (#defects reported, draft/reviewed/released)
• Structure/format of artifact (structured/semi-structured/unstructured infor-mation)
• Information density
As our survey shows, several authors have ideas about additional artifact setfeatures that would be meaningful to report. Thus most authors both are of theopinion that artifact sets should be better characterized, and also have suggestionsfor how it could be done. Still, despite also being stressed in Huffman Hayes andDekhtyars framework from 2005, it has not reached the publications. However, wecollected many requests for “what” to describe, but little input on the “how” (i.e.‘what’ = state complexity / ‘how’ = how to measure complexity?). This discrep-ancy can be partly responsible for the insufficient artifact set characterizations.A collection of how different aspects might be measured, tailored for reportingartifact sets used in traceability recovery studies, appears to be a desirable compo-sition.
One might argue that several of the suggested aspects are not applicable to stu-dent projects. This is in line with both what Höst et al. [9] and our respondentsstated, purpose and lifecycle of student artifacts are rarely representative for indus-trial settings. Thus, aspects such as maturity, evolution and stakeholders usuallyare unfeasible to measure. Again, this indicates that artifacts originating from stu-dent projects might be too trivial, resulting in little more empirical evidence thanproofs-of-concept.
4.6 Measuring student/industrial artifacts (RQ5)
In this section, we present results in relation to RQ5, concerning the respondents’opinions about how differences between NL artifacts developed by students andindustrial practitioners can be assessed. QQ7, filtered by QQ4, provides answersto this question.

126 Industrial comparability of student artifacts in traceability recovery . . .
A majority of the respondents of STUD and UNIV commented on the chal-lenge of measuring differences between artifacts originating from industrial andstudent projects. Only four respondents explicitly mentioned suitable aspects toinvestigate. Two of them suggested looking for differences in quality, such asmaintainability, extensibility and ambiguities. One respondent stated that the maindifferences are related to complexity (students use more trivial terminology). Onthe other hand, one academic respondent instead claimed that “In fact artifact writ-ten by students are undoubtedly the most verbose and better argued since theirevaluation certainly depends on the quality of the documentation”. Yet anotherrespondent, a practitioner, answered that the differences are minor.
Notably, one respondent to QQ7 warned about trying to measure differencesamong artifacts, motivated by the great diversity in industry. According to the re-spondent, there is no such thing as an average artifact. “What is commonly called‘requirements’ in industry can easily be a 1-page business plan or a 15-volumesrequirements specification of the International Space Station”, the respondent ex-plained.
To summarize, the results achieved for QQ7 confirm our expectations that mea-suring the comparability is indeed a challenging task. Obviously, there is no simplemeasure to aim for. This is also supported by QQ5, the few validations of studentartifacts that the respondents reported utilized only expert opinion or replicationswith industrial artifacts.
5 Threats to Validity
This section provides a discussion of the threats to validity in relation to researchdesign and data collection phases as well as in relation to results from the study.The discussion of the threats to validity is based on the classification proposed byWohlin et al. [24], focusing on threats to construct, internal and external validity.
Construct validity is concerned with the relation between the observations dur-ing the study and the theories in which the research is grounded. The exact for-mulations of the questions in the used questionnaire are crucial in survey researchas misunderstanding or misinterpreting the questions can happen. We alleviatedthis threat to construct validity by revising the questionnaire by an independentreviewer (except the authors of the paper who also revised the questions) who isa native English speaker and writer. To further minimize threats to construct va-lidity, a pilot study was conducted on five senior researchers in software engineer-ing. Still, the subjectivity of the data provided by our respondents can negativelyinfluence the interpretability of the results. Due to a relatively low number ofdata points, the mono-operational bias threat to construct validity is not fully ad-dressed. The anonymity of respondents was not guaranteed as the survey was sentvia email; this leaves the evaluation apprehension threat unaddressed. Since theresearch is exploratory, the experimenter expectancies threat to construct validity

6 Discussion and Concluding Remarks 127
is minimized. Finally, the literature survey conducted as the first step of the studyhelps to address the mono-method threat to construct validity, which however stillrequires further research to fully alleviate it.
Internal validity concerns confounding factors that can affect the causal re-lationship between the treatment and the outcome. By performing the review ofthe questionnaire questions, the instrumentation threat to internal validity was ad-dressed. On the other hand, the selection bias can still threaten the internal validityas the respondents were not randomly selected. We have measured the time neededto answer the survey in the pilot study; therefore the maturation threat to internalvalidity is alleviated. Finally, the selection threat to internal validity should bementioned here since respondents of the survey were volunteers who, according toWohlin et al., are not representative for the whole populations [24].
External validity concerns the ability to generalize the results of the study toindustrial practice. We have selected a survey research method in order to targetmore potential respondents from various countries, companies and research groupsand possibly generate more results [7]. Still, the received number of responses islow and thus not a strong basis for extensive generalizations of our findings. How-ever, the external validity of the results achieved is acceptable when consideringthe exploratory nature of this study.
6 Discussion and Concluding Remarks
We have conducted an exploratory survey of the comparability of artifacts used inIR-based traceability recovery experiments, originating from industrial and studentprojects. Our sample of authors of related publications confirms that artifacts de-veloped by students are only partially comparable to industrial counterparts. Nev-ertheless, it commonly happens that student artifacts used as input to experimentalresearch are not validated with regards to their industrial representativeness.
Our results show that, typically, artifact sets are only rudimentarily described,despite the experimental framework proposed by Huffman Hayes and Dekhtyar in2005. We found that a majority of authors of traceability recovery publicationsthink that artifact sets are inadequately characterized. Interestingly, a majority ofthe authors explicitly suggested features of artifact sets they would prefer to see re-ported. Suggestions include general aspects such as contextual information duringartifact development and artifact-centric measures. Also, domain-specific (link-related) aspects were proposed, specifically applicable to traceability recovery.
The explanatory part of this study, should be followed by an in-depth studyvalidating the proposals made by the respondents and aim at making the proposalsmore operational. This in turn could lead to characterization schemes that help as-sess the generalizability of study results using student artifacts. The results couldcomplement Huffman Hayes and Dekhtyars framework [10] or be used as an em-pirical foundation of a future revision. Moreover, studies similar to this one should

128 Industrial comparability of student artifacts in traceability recovery . . .
Figure 7: Risks involved in different combinations of subjects and artifacts intraceability recovery studies.
be conducted for other application domains where student artifacts frequently areused as input to experimental software engineering, such as regression testing, costestimation and model-driven development.
Clearly, researchers need to be careful when designing traceability recoverystudies. Previous research has shown that using students as experimental subjectsis reasonable [2, 8, 9, 14, 23]. However, according to our survey, the validity of us-ing student artifacts is uncertain. Unfortunately, industrial artifacts are hard to getaccess to. Furthermore, even with access to industrial artifacts, researchers mightnot be permitted to show them to students. And even with that permission, stu-dents might lack the domain knowledge necessary to be able to work with them.Figure 7 summarizes general risks involved in different combinations of subjectsand artifacts in traceability recovery studies. The most realistic option, conduct-ing studies on practitioners working with industrial artifacts, is unfortunately oftenhard to accomplish with a large enough number of subjects. Instead, several pre-vious studies used students solving tasks involving industrial artifacts [3, 12] orartifacts developed in student projects [5, 6, 18]. However, these two experimentalsetups introduce threats either related to construct validity or external validity. Thelast option, conducting studies with practitioners working with student artifacts,has not been attempted. We plan to further explore the possible combinations infuture work.
Acknowledgement
Thanks go to the respondents of the survey. This work was funded by the Indus-trial Excellence Center EASE – Embedded Applications Software Engineering1.Special thanks go to David Callele for excellent language-related comments.
1http://ease.cs.lth.se

6 Discussion and Concluding Remarks 129
Appendix
Questionnaire Used in versionsQQ1 Would you agree with the statement: “Software artifacts produced by
students (used as input in traceability experiments) are representative ofsoftware artifacts produced in industry?”
STUD / UNIV /IND
(Please select one number. 1 = totally disagree, 5 = totally agree)1—2—3—4—5
QQ2 Typically, datasets containing software artifacts used as input to trace-ability experiments are characterized by size and number of correcttraceability links. Do you consider this characterization as sufficient?Please explain why you hold this opinion. (Please select one number.
STUD / UNIV /IND
(Please select one number. 1 = totally disagree, 5 = totally agree)1—2—3—4—5
QQ3 What would be a desirable characterization of software artifacts to en-able comparison (for example between software artifacts developed bystudents and industrial practitioners)?
STUD / UNIV /IND
QQ4 In your experiment, you used software artifacts developed in the univer-sity project [NAME OF PROJECT]. Were the software artifacts devel-oped by students?
UNIV
QQ5 Did you evaluate whether the software artifacts used in your study wererepresentative of industrial artifacts? If you did, how did you performthis evaluation?
STUD / UNIV
QQ6 How representative were the software artifacts you used in your exper-iment of industrial software artifacts? What was the same? What wasdifferent?
STUD / UNIV
QQ7 How would you measure the difference between software artifacts de-veloped by students and software artifacts developed by industrial prac-titioners?
STUD / UNIV
Table 5: Research questions of the study. All questions are related to the contextof traceability recovery studies.

130 Industrial comparability of student artifacts in traceability recovery . . .
Bibliography[1] G. Antoniol, G. Canfora, G. Casazza, A. De Lucia, and E. Merlo. Recover-
ing traceability links between code and documentation. In Transactions onSoftware Engineering, volume 28, pages 970–983, 2002.
[2] P. Berander. Using students as subjects in requirements prioritization. InProdeedings of the International Symposium on Empirical Software Engi-neering, pages 167–176, August 2004.
[3] M. Borg and D. Pfahl. Do better IR tools improve the accuracy of engi-neers’ traceability recovery? In Proceedings of the International Workshopon Machine Learning Technologies in Software Engineering, pages 27–34,2011.
[4] C. Borgman. From Gutenberg to the global information infrastructure: Ac-cess to information in the networked world. MIT Press, 2003.
[5] A. De Lucia, F. Fasano, R. Oliveto, and G. Tortora. Recovering traceabilitylinks in software artifact management systems using information retrievalmethods. Transactions on Software Engineering and Methodology, 16(4),2007.
[6] A. De Lucia, R. Oliveto, and G. Tortora. Assessing IR-based traceabilityrecovery tools through controlled experiments. Empirical Software Engi-neering, 14(1):57–92, 2009.
[7] S. Easterbrook, J. Singer, M. Storey, and D. Damian. Selecting empiri-cal methods for software engineering research. In F. Shull, J. Singer, andD. Sjöberg, editors, Guide to Advanced Empirical Software Engineering,pages 285–311. Springer, 2008.
[8] M Höst, B. Regnell, and C. Wohlin. Using students as subjects: A com-parative study of students and professionals in lead-time impact assessment.Empirical Software Engineering, 5(3):201–214, 2000.
[9] M. Höst, C. Wohlin, and T. Thelin. Experimental context classification: In-centives and experience of subjects. In Proceedings of the 27th internationalconference on Software engineering, pages 470–478, 2005.
[10] J. Huffman Hayes and A. Dekhtyar. A framework for comparing require-ments tracing experiments. Interational Journal of Software Engineeringand Knowledge Engineering, 15(5):751–781, 2005.
[11] J. Huffman Hayes, A. Dekhtyar, and S. Sundaram. Advancing candidate linkgeneration for requirements tracing: The study of methods. Transactions onSoftware Engineering, 32(1):4–19, 2006.

Bibliography 131
[12] J. Huffman Hayes, A. Dekhtyar, S. Sundaram, A. Holbrook, S. Vadlamudi,and A. April. REquirements TRacing on target (RETRO): improving soft-ware maintenance through traceability recovery. Innovations in Systems andSoftware Engineering, 3(3):193–202, 2007.
[13] A. Jedlitschka, M. Ciolkowski, and D. Pfahl. Reporting experiments in soft-ware engineering. In F. Shull, J. Singer, and D. Sjöberg, editors, Guide toAdvanced Empirical Software Engineering, pages 201–228. Springer, Lon-don, 2008.
[14] B. Kitchenham, S. Pfleeger, L Pickard, P. Jones, D. Hoaglin, K. El Emam,and J. Rosenberg. Preliminary guidelines for empirical research in soft-ware engineering. Transactions on Software Engineering and Methodology,28(8):721–734, 2002.
[15] L. Kuzniarz, M. Staron, and C. Wohlin. Students as study subjects in soft-ware engineering experimentation. In Proceedings of the 3rd Conference onSoftware Engineering Research and Practise in Sweden, 2003.
[16] M. Lormans, H-G. Gross, A. van Deursen, R. van Solingen, and A. Ste-houwer. Monitoring requirements coverage using reconstructed views: Anindustrial case study. In Procedings of the 13th Working Conference on Re-verse Engineering, pages 275–284, 2006.
[17] A. Marcus and J. Maletic. Recovering documentation-to-source-code trace-ability links using latent semantic indexing. In Proceedings of the Interna-tional Conference on Software Engineering, pages 125–135, 2003.
[18] J. Natt och Dag, T. Thelin, and B. Regnell. An experiment on linguistic toolsupport for consolidation of requirements from multiple sources in market-driven product development. Empirical Software Engineering, 11(2):303–329, 2006.
[19] B. Robson. Real world research. Blackwell, 2nd edition, 2002.
[20] P. Runeson and M. Höst. Guidelines for conducting and reporting casestudy research in software engineering. Empirical Software Engineering,14(2):131–164, 2009.
[21] J. Singer, S. Sim, and T. Lethbridge. Software engineering data collectionfor field studies. In F. Shull, J. Singer, and D. Sjöberg, editors, Guide toAdvanced Empirical Software Engineering, pages 9–34. Springer, 2008.
[22] G. Spanoudakis, A. d’Avila-Garcez, and A. Zisman. Revising rules to cap-ture requirements traceability relations: A machine learning approach. InProceedings of the 15th International Conference in Software Engineeringand Knowledge Engineering, 2003.

132 Industrial comparability of student artifacts in traceability recovery . . .
[23] M. Svahnberg, A. Aurum, and C. Wohlin. Using students as subjects: Anempirical evaluation. In Proceedings of the 2nd International Symposium onEmpirical Software Engineering and Measurement, pages 288–290, 2008.
[24] C. Wohlin, P. Runeson, M. Höst, M. Ohlsson, B. Regnell, and A. Wesslén.Experimentation in software engineering: An introduction. Kluwer Aca-demic Publications, 1st edition, 1999.
[25] Y. Zhang, R. Witte, J. Rilling, and V. Haarslev. Ontological approach forthe semantic recovery of traceability links between software artefacts. IETSoftware, 2(3):185–203, 2008.

PAPER III
EVALUATION OFTRACEABILITY RECOVERY IN
CONTEXT: A TAXONOMYFOR INFORMATIONRETRIEVAL TOOLS
Abstract
Background: Development of complex, software intensive systems generates largeamounts of information. Several researchers have developed tools implementinginformation retrieval (IR) approaches to suggest traceability links among artifacts.Aim: We explore the consequences of the fact that a majority of the evaluationsof such tools have been focused on benchmarking of mere tool output. Method:To illustrate this issue, we have adapted a framework of general IR evaluations toa context taxonomy specifically for IR-based traceability recovery. Furthermore,we evaluate a previously proposed experimental framework by conducting a studyusing two publicly available tools on two datasets originating from developmentof embedded software systems. Results: Our study shows that even though bothdatasets contain software artifacts from embedded development, the characteris-tics of the two datasets differ considerably, and consequently the traceability out-comes. Conclusions: To enable replications and secondary studies, we suggestthat datasets should be thoroughly characterized in future studies on traceabilityrecovery, especially when they can not be disclosed. Also, while we conclude thatthe experimental framework provides useful support, we argue that our proposedcontext taxonomy is a useful complement. Finally, we discuss how empirical ev-idence of the feasibility of IR-based traceability recovery can be strengthened infuture research.

134 Evaluation of Traceability Recovery in Context: A Taxonomy for . . .
Markus Borg, Per Runeson, and Lina Brodén, In Proceedings of the 16th Interna-tional Conference on Evaluation and Assessment in Software Engineering, 2012
1 Introduction
Large-scale software development generates large amounts of information. En-abling software engineers to efficiently navigate the document space of the de-velopment project is crucial. One typical way to structure the information withinthe software engineering industry is to maintain traceability, defined as “the abil-ity to describe and follow the life of a requirement, in both a forward and back-ward direction” [18]. This is widely recognized as an important factor for efficientsoftware engineering as it supports activities such as verification, change impactanalysis, program comprehension, and software reuse [2].
Several researchers have proposed using information retrieval (IR) techniquesto support maintenance of traceability information [10, 23, 28, 29]. Traceabilitycan be maintained between any software artifacts, i.e., any piece of informationproduced and maintained during software development. Textual content in naturallanguage (NL) is the common form of information representation in software en-gineering [31]. Tools implementing IR-based traceability recovery suggest trace-ability links based on textual similarities, for example between requirements andtest cases. However, about 50% of the evaluations have been conducted using oneof the four datasets available at the Center of Excellence for Software Traceability(COEST)1 [6]. Consequently, especially the CM-1 and EasyClinic datasets haveturned into de-facto benchmarks of IR-based traceability recovery, further ampli-fied by “traceability challenges” issued by the Traceability in Emerging Forms ofSoftware Engineering (TEFSE) workshop series.
Developing a repository of benchmarks for traceability research is a centralpart of COEST’s vision, and thus has been discussed in several publications [4, 7,12, 13]. As another contribution supporting benchmarking efforts and evaluationsin general, Huffman Hayes et al. proposed an experimental framework for require-ments tracing [21]. It is known that benchmarks can advance tool and technologydevelopment, which for instance has been the case for the Text REtrieval Confer-ence (TREC), driving large-scale evaluations of IR methodologies [42]. On theother hand, benchmarking introduces a risk of over-engineering IR techniques onspecific datasets. TREC enables generalizability by providing very large amountsof texts, but is still limited to certain domains such as news articles. Whether itis possible for the research community on traceability in software engineering tocollect and distribute a similarly large dataset is an open question. Runeson et al.have discussed the meaning of benchmarks, however in relation to software test-ing [39]. They stress that researchers should first consider what the goal of thebenchmarking is, and that a benchmark is a selected case that should be analyzed
1COEST, http://www.coest.org/

2 Background and Related work 135
in its specific context. Consequently, as a benchmark is not an “average situation”,they advocate that benchmarks should be studied with a qualitative focus ratherthan with the intention to reach statistical generalizability.
To enable categorization of evaluations of IR-based traceability recovery, in-cluding benchmarking studies, we adapted Ingwersen and Järvelins frameworkof IR evaluation contexts [24] into a taxonomy of IR-based traceability recoveryevaluations. Within this context taxonomy, described in detail in Section 2, typ-ical benchmarking studies belong to the innermost context. In the opposite endof the context taxonomy, the outermost evaluation context, industrial case studiesreside. Furthermore, we add a dimension of study environment to the context tax-onomy, to better reflect the external validity of the studied project, and its softwareartifacts.
To illustrate the context taxonomy with an example, and to evaluate the exper-imental framework proposed by Huffman Hayes et al. [21], we have conducteda quasi-experiment using the tools RETRO [23] and ReqSimile [35], using twosets of proprietary software artifacts as input. This constitutes a replication of ear-lier evaluations of RETRO [14,44], as well as an extension considering both toolsand input data. Also, we describe how it would be possible to extend this study be-yond the innermost level of the context taxonomy, i.e., moving beyond technology-oriented evaluation contexts. Finally, we discuss concrete ways to strengthen theempirical evidence of IR-based traceability tools in relation to findings and sug-gestions by Falessi et al. [16], Runeson et al. [39], and Borg et al. [5, 6].
The paper is organized as follows. Section 2 gives a short overview of relatedwork on IR-based traceability recovery in software engineering, while Section 3describes our context taxonomy. Section 4 presents the research methodology,and the frameworks our experimentation follows. Section 4 presents the resultsfrom the experiments. In Section 6 we discuss the implications of our results, thevalidity threats of our study, and evaluations of IR-based traceability recovery ingeneral. Finally, Section 7 presents conclusions and suggests directions of futureresearch.
2 Background and Related work
During the last decade, several researchers proposed expressing traceability re-covery as an IR problem. Proposed tools aim to support software engineers bypresenting candidate traceability links ranked by textual similarities. The query istypically the textual content of a software artifact you want to link to other arti-facts. Items in the search result can be either relevant or irrelevant, i.e., correct orincorrect traceability links are suggested.
In 2000, Antoniol et al. did pioneering work on traceability recovery whenthey used the standard Vector Space Model (VSM) [40] and the binary indepen-dence model [37] to suggest links between source code and documentation in

136 Evaluation of Traceability Recovery in Context: A Taxonomy for . . .
natural language [1]. Marcus and Maletic introduced Latent Semantic Indexing(LSI) [11] to recover traceability in 2003 [31]. Common to those papers is thatthey have a technical focus and do not go beyond reporting precision-recall graphs.
Other studies reported evaluations of traceability recovery tools using humans.Huffman Hayes et al. developed a traceability recovery tool named RETRO andevaluated it using 30 student subjects [23]. The students were divided into twogroups, one working with RETRO and the other working manually. Studentsworking with the tool finished a requirements tracing task faster and with a higherrecall than the manual group, the precision however was lower. Natt och Daget al. developed the IR-based tool ReqSimile to support market-driven require-ments engineering and evaluated it in a controlled experiment with 23 student sub-jects [35]. They reported that subjects supported by ReqSimile completed trace-ability related tasks faster than subjects working without any tool support. DeLucia et al. conducted a controlled experiment with 32 students on the usefulnessof tool-supported traceability recovery [9] and also observed 150 students in 17software development projects [10]. In line with previous findings, they foundthat subjects using their tool completed a task, related to tracing various softwareartifacts, faster and more accurately than subjects working manually. They con-cluded that letting students use IR-based tool support is helpful when maintenanceof traceability information is a process requirement.
Several previous publications have contributed to advancing the research onIR-based traceability recovery, either by providing methodological advice, or bymapping previous research. Huffman Hayes and Dekhtyar published a frameworkintended to advance reporting and conducting of empirical experiments on trace-ability recovery [21]. However, the framework has unfortunately not been appliedfrequently in previous evaluations, and the quality of reporting varies [6]. Anotherpublication that offers structure to IR-based traceability recovery, also by Huff-man Hayes et al., distinguishes between studies of methods (are the tools capableof providing accurate results fast?) and studies of human analysts (how do humansuse the tool output?) [22]. These categories are in line with experimental guide-lines by Wohlin et al. [48], where the types of experiments in software engineeringare referred to as either technology-oriented or human-oriented. Moreover, Huff-man Hayes et al. propose assessing the accuracy of tool output, wrt. precisionand recall, according to quality intervals named Acceptable, Good, and Excellent,based on the first author’s practical experience of requirements tracing. Also dis-cussing evaluation methodology, a recent publication by Falessi et al. proposesseven empirical principles for evaluating the performance of IR techniques [16].Their work covers study design, statistical guidelines, and interpretation of results.Also, they present implementation strategies for the seven principles, and exem-plify them in a study on industrial software artifacts originating from an Italiancompany.
Going beyond the simplistic measures of precision and recall is necessary toevolve IR tools [27], thus measures such as Mean Average Precision (MAP) [30],

3 Derivation of Context Taxonomy 137
Figure 1: The Integrated Cognitive Research Framework by Ingwersen andJärvelin [24], a framework for IR evaluations in context.
and Discounted Cumulative Gain (DCG) [26] have been proposed. To addressthis matter in the specific domain of IR-based traceability, a number of so calledsecondary measures have been proposed. Sundaram et al. developed DiffAR,DiffMR, Lag, and Selectivity [45] to assess the quality of generated candidate links.
In the general field of IR research, Ingwersen and Järvelin argue that IR is al-ways evaluated in a context [24]. Their work extends the standard methodology ofIR evaluation, the Laboratory Model of IR Evaluation developed in the Cranfieldtests in the 60s [8], challenged for its unrealistic lack of user involvement [27].Ingwersen and Järvelin proposed a framework, The Integrated Cognitive ResearchFramework, consisting of four integrated evaluation contexts, as presented in Fig-ure 1. The innermost IR context, referred to by Ingwersen and Järvelin as “thecave of IR evaluation”, is the most frequently studied level, but also constitutesthe most simplified context. The seeking context, “drifting outside the cave”, isused to study how users find relevant information among the information that isactually retrieved. The third context, the work task context introduces evaluationswhere the information seeking is part of a bigger work task. Finally, in the outer-most realm, the socio-organizational & cultural context, Ingwersen and Järvelinargue that socio-cognitive factors are introduced, that should be studied in naturalfield experiments or studies, i.e., in-vivo evaluations are required. Moreover, theypropose measures for the different evaluation contexts [24]. However, as thosemeasures and the evaluation framework in itself are general and not tailored forneither software engineering nor traceability recovery, we present an adaptation inSection 3.
3 Derivation of Context Taxonomy
Based on Ingwersen and Järvelin’s framework [24], we introduce a four-level con-text taxonomy in which evaluations of IR-based traceability recovery can be con-ducted, see Table 1. Also, we extend it by a dimension of evaluation environmentsmotivated by our previous study [6], i.e., proprietary, open source, or university,as depicted in Figure 2. The figure also shows how the empirical evaluations pre-

138 Evaluation of Traceability Recovery in Context: A Taxonomy for . . .
sented in Section 2 map to the taxonomy. Note that several previous empiricalevaluations of IR-based traceability recovery have used software artifacts from theopen source domain, however, none of them were mentioned in Section 2.
We refer to the four integrated contexts as the retrieval context (Level 1), theseeking context (Level 2), the work task context (Level 3), and the project context(Level 4). Typical benchmarking experiments [1, 16, 31], similar to what is con-ducted within TREC, reside in the innermost retrieval context. Accuracy of tooloutput is measured by the standard IR-measures precision, recall, and F-score (de-fined in Section 4.2. In order to enable benchmarks in the seeking context, userstudies or secondary measures are required [22, 45]. In both the two innermostcontexts, traceability recovery evaluations are dominated by quantitative analysis.On the other hand, to study the findability offered by IR tools in the seeking con-text, defined as “the degree to which a system or environment supports navigationand retrieval” [34], researchers must introduce human subjects in the evaluations.
Regarding evaluations in the work task context, human subjects are necessary.Typically, IR-based traceability recovery in this context has been evaluated usingcontrolled experiments with student subjects [9, 23, 35]. To assess the usefulnessof tool support in work tasks involving traceability recovery, realistic tasks suchas requirements tracing, change impact analysis, and test case selection should bestudied in a controlled, in-vitro environment. Finally, in the outermost project con-text, the effect of deploying IR-based traceability recovery tools should be studiedin-vivo in software development projects. Due to the typically low level of con-trol in such study environments, a suitable evaluation methodology is a case study.An alternative to industrial in-vivo evaluations is to study student developmentprojects, as De Lucia et al. [10] have done. In the work task context both quan-titative and qualitative studies are possible, but in the project context qualitativeanalysis dominates. As applied researchers we value technology-oriented evalu-ations in the retrieval and seeking contexts, however, our end goal is to study IRtools in the full complexity of an industrial environment.
4 Method
We base discussions on the context taxonomy in Section 6 on a concrete studyof traceability recovery. This section describes the definition, design and settingsof the experimentation, organized into the four phases definition, planning, re-alization and interpretation as specified in the experimental framework by Huff-man Hayes and Dekhtyar [21]. Also, our work followed the general experimentalguidelines by Wohlin et al. [48]. According to the proposed context taxonomy inFigure 2, our experiment is an evaluation conducted in the retrieval context, i.e., inthe cave, using datasets from two industrial contexts.

4 Method 139
EvaluationContext
Description Evaluationmethodol-ogy
Examplemeasures
Level 4: Projectcontext
Evaluations in a socio-organizational context. TheIR tool is studied when usedby engineers within the fullcomplexity of an in-vivosetting.
Case studies Project met-rics, tool us-age
Level 3: Worktask context
Humans complete real worktasks, but in an in-vitro setting.Goal of evaluation is to assessthe casual effect of an IR toolwhen completing a task.
Controlledexperi-ments, casestudies
Work taskresults, timespent
Level 2: Seek-ing context
A seeking context with a focuson how the human finds relevantinformation among what was re-trieved by the system.
Technology-orientedexperiments
Usability,MAP, DCG,DiffAR, Lag
Level 1: Re-trieval context
A strict retrieval context, perfor-mance is evaluated wrt. the ac-curacy of a set of search results.
Benchmarks Precision,recall,F-measure
Table 1: Four integrated levels of context in IR-based traceability recovery eval-uations.
4.1 Phase I: DefinitionThe definition phase presents the scope of the experimentation and describes thecontext. We entitle the study a quasi-experiment since there is no randomizationin the selection of data sets nor IR tools.
Experiment Definition
The goal of the quasi-experiment is to evaluate traceability recovery tools in thecontext of embedded development, with the purpose of reporting results usingproprietary software artifacts. The quality focus is to evaluate precision and recallof tools from the perspective of a researcher who wants to evaluate how existingapproaches to traceability recovery perform in a specific industrial context.
Industrial Context
The software artifacts in the industrial dataset are collected from a large multi-national company active in the power and automation sector. The context of thespecific development organization within the company is safety critical embedded

140 Evaluation of Traceability Recovery in Context: A Taxonomy for . . .
Figure 2: Contexts and environments in evaluations of IR-based traceability re-covery. The numbers refer to references. Note that the publication by Sundaramet al. [45] contains both an evaluation in an industrial environment, as well as anevaluation in the university environment.
development in the domain of industrial control systems. The number of devel-opers is in the magnitude of hundreds; a project has typically a length of 12-18months and follows an iterative stage-gate project management model. The soft-ware is certified to a Safety Integrity Level (SIL) of 2 as defined by IEC 61508 [25],corresponding to a risk reduction factor of 1,000,000-10,000,000 for continuousoperation. There are process requirements on maintenance of traceability infor-mation, especially between requirements and test cases. The software develop-ers regularly perform tasks requiring traceability information, for instance whenperforming change impact analysis. Requirements and tests are predominantlyspecified in English NL text.
Characterization of Datasets
The first dataset used in our experiment originates from a project in the NASAMetrics Data Program, publicly available at COEST as the CM-1 dataset. Thedataset specifies parts of a data processing unit and consists of 235 high-levelrequirements and 220 corresponding low-level requirements specifying detaileddesign. 361 traceability links between the requirement abstraction levels have beenmanually verified, out of 51 700 possible links. Items in the dataset have links tozero, one or many other items. This dataset is a de-facto benchmark of IR-basedtraceability recovery [6], thus we conduct a replication of previous evaluations.

4 Method 141
Number of traceability links: 225Characteristic Requirements Test Case DescriptionsItems 224 218Words 4 813 6 961Words/Item 21.5 31.9Avg. word length 6.5 7.0Unique words 817 850Gunning Fog Index 10.7 14.2Flesch Reading Ease 33.7 14.8
Table 2: Descriptive statistics of the industrial data
Number of traceability links: 361Characteristic High-level Reqs. Low-level Reqs.Items 235 220Words 5 343 17 448Words/Items 22.7 79.3Avg. word length 5.2 5.1Unique words 1 056 2 314Gunning Fog Index 7.5 10.9Flesch Reading Ease 67.3 59.6
Table 3: Descriptive statistics of the NASA data
The second dataset, referred to as the industrial data, consists of 225 require-ments describing detailed design. These requirements are verified by 220 corre-sponding test case descriptions. The golden standard of 225 links was provided bythe company, containing one link per requirement to a specific test case descrip-tion. Thus, the link structure is different to the NASA data. The total number ofcombinatorial links is 49 500.
Both the NASA and the industrial datasets are bipartite, i.e., there exist onlylinks between two subsets of software artifacts. Descriptive statistics of the datasets,calculated using the Advanced Text Analyzer at UsingEnglish.com2, are presentedin Tables 2 and 3. Calculating Gunning Fog Index [19] as a complexity metric forrequirement specifications written in English has been proposed by Farbey [17].The second complexity metric reported in Tables 2 and 3 is the Flesch ReadingEase. Wilson et al. have previously calculated and reported it for requirementspecifications from NASA [47]. Both datasets are considered large according tothe framework of Huffman Hayes and Dekhtyar [21], even though we would preferto label them very small.
2http://www.usingenglish.com/members/text-analysis/

142 Evaluation of Traceability Recovery in Context: A Taxonomy for . . .
4.2 Phase II: Planning
This section describes the traceability recovery tools and the experimental design.
Description of Tools
We selected two IR-based traceability recovery tools for our experiment. Require-ments Tracing on Target (RETRO) was downloaded from the library of OpenSource Software from NASA’s Goddard Space Flight Center3, however only bi-naries were available. Source code and binaries of ReqSimile was downloadedfrom the source code repository SourceForge4.
RETRO, developed by Huffman Hayes et al., is a tool that supports softwaredevelopment by tracing textual software engineering artifacts [23]. The tool weused implements VSM with features having term frequency-inverse document fre-quency weights. Similarities are calculated as the cosine of the angle betweenfeature vectors [3]. RETRO also implements a probabilistic retrieval model. Fur-thermore, the tool supports relevance feedback from users using the Standard Ro-chio feedback. Stemming is done as a preprocessing step and stop word removalis optional according to the settings in the tool. Later versions of RETRO also im-plement LSI, but were not available for our experiments. We used RETRO versionV.BETA, Release Date February 23, 2006.
ReqSimile, developed by Natt och Dag et al., is a tool with the primary pur-pose to provide semi-automatic support to requirements management activitiesthat rely on finding semantically similar artifacts [35]. Examples of such activitiesare traceability recovery and duplicate detection. The tool was intended to supportthe dynamic nature of market-driven requirements engineering. ReqSimile alsoimplements VSM and cosine similarities. An important difference to RETRO isthe feature weighting; terms are weighted as 1 + log2(freq) and no inverse doc-ument frequencies are considered. Stop word removal and stemming is done aspreprocessing steps. In our experimentation, we used version 1.2 of ReqSimile.
To get yet another benchmark for comparisons, a tool was implemented usinga naïve tracing approach as suggested by Menzies et al. [32]. The Naïve toolcalculates the number of terms shared by different artifacts, and produces rankedlists of candidate links accordingly. This process was done without any stop wordremoval or stemming.
Experimental Design
The quasi-experiment has two independent variables: the IR-based traceabilityrecovery tool used and the input dataset. The first one has three factors: RETRO,ReqSimile and Naïve as explained in Section 4.2. The second independent variable
3http://opensource.gsfc.nasa.gov/projects/RETRO/4http://reqsimile.sourceforge.net/

4 Method 143
has two factors: Industrial and NASA as described in Section 4.1. Consequently,six test runs were required to get a full factorial design.
IR-based traceability recovery tools are in the innermost evaluation contextevaluated by verifying how many suggested links above a certain similarity thresh-old are correct, compared to a hand-crafted gold standard of correct links. Then,as presented in Figure 2, the laboratory model of IR evaluation is applied, thusrecall and precision constitute our dependent variables. Recall and precision mea-sure both the percentage of correct links recovered by a tool, and the amount offalse positives. The aggregate measure F-score was also calculated, defined as theharmonic mean of precision and recall [3]:
F = 2 ∗ precision ∗ recallprecision + recall
Our null hypotheses, guiding the data analysis, are stated below. Performanceis considered wrt. recall and precision.
NH1 The two tools implementing the vector space model, RETRO and ReqSim-ile, show equivalent performance.
NH2 Performance differences between the tools show equivalent patterns on theNASA and Industrial datasets.
NH3 RETRO and ReqSimile do not perform better than the Naïve tool.
4.3 Phase III: Realization
This section describes how the data was converted to valid input formats, and theactual tool usage.
Preprocessing of Datasets
Preprocessing the datasets was required since RETRO and ReqSimile use differ-ent input formats. The NASA dataset was available in a clean textual format andcould easily be converted. The industrial data was collected as structured Mi-crosoft Word documents including references, diagrams, revision history etc. Wemanually extracted the textual content and removed all formatting.
Experimental Procedure
Conducting the experiment consisted of six test runs combining all tools anddatasets. In RETRO, two separate projects were created and the tool was run usingdefault settings. We did not have access to neither a domain specific thesaurus nora list of stop words. Relevance feedback using the standard Rochio method wasnot used. The Trace All command was given to calculate all candidate links, nofiltering was done in the tool.

144 Evaluation of Traceability Recovery in Context: A Taxonomy for . . .
ReqSimile does not offer any configuration of the underlying IR models. Thetwo input datasets were separated in two projects. After configuring the driversof the database connections, the commands Fetch requirements and Preprocessrequirements were given and the lists of candidate links were presented in theCandidate requirements tab.
The Naïve tool uses the same input format as RETRO. The tool does not havea graphical user interface, and was executed from a command-line interface.
5 Results and InterpretationThis section presents the results from our six test runs.
5.1 Phase IV: InterpretationHuffman Hayes and Dekhtyar define the interpretation context as “the environ-ment/circumstances that must be considered when interpreting the results of anexperiment” [21]. We conduct our evaluation in the retrieval context as describedin Section 3. Due to the small number of datasets studied, our hypotheses are notstudied in a strict statistical context.
The precision-recall graphs and the plotted F-scores are used as the basis forour comparisons. All hypotheses do to some extent concern the concept of equiv-alence, which we study qualitatively in the resulting graphs. However, presentingmore search results than a user would normally consider adds no value to a tool.We focus on the top ten search results, in line with recommendations from previ-ous research [33,43,46], and common practise in web search engines. The stars inFigures 3 and 4 indicate candidate link lists of length 10.
The first null hypothesis stated that the two tools implementing the VSM showequivalent performance. Figures 3 and 5 show that RETRO and ReqSimile pro-duce candidate links of equivalent quality, the stars are even partly overlapping.However, Figures 4 and 6 show that RETRO outperforms ReqSimile on the NASAdataset. As a result, the first hypothesis is rejected; the two IR-based traceabilityrecovery tools RETRO and ReqSimile, both implementing VSM, do not performequivalently.
The second null hypothesis stated that performance differences between thetools show equivalent patterns on the both datasets. The first ten datapoints of theprecision-recall graphs, representing search hits of candidate links with lengthsfrom 1 to 10, show linear quality decreases for both datasets. Graphs for the in-dustrial data starts with higher recall values for short candidate lists, but dropsfaster to precision values of 5% compared to the NASA data. The Naïve tool per-forms better on the industrial data than on the NASA data, and the recall valuesincrease at a higher pace, passing 50% at candidate link lists of length 10. Thesecond hypothesis is rejected; the tools show different patterns on the industrialdataset and the NASA dataset.

6 Discussion 145
Figure 3: Precision-recall graph for the Industrial dataset. The stars show candi-date link lists of length 10.
Figure 4: Precision-recall graph for the NASA dataset. The stars show candidatelink lists of length 10.
The third null hypothesis, RETRO and ReqSimile do not perform better thanthe Naïve tool, is also rejected. Our results show that the Naïve tool, just compar-ing terms without any preprocessing, does not reach the recall and precision of thetraceability recovery tools implementing VSM. RETRO and ReqSimile performbetter than the Naïve tool.
6 Discussion
In this section, the results from the quasi-experiment and related threats to validityare discussed. Furthermore, we discuss how we could conduct evaluations in outercontextual levels based on this study, and we discuss how to advance evaluationsof IR-based traceability recovery in general.

146 Evaluation of Traceability Recovery in Context: A Taxonomy for . . .
Figure 5: F-Score for the Industrial dataset. The X-axis shows the length ofcandidate link lists considered.
Figure 6: F-Score for the NASA dataset. The X-axis shows the length of candi-date link lists considered.
6.1 Implication of Results
The IR-based traceability recovery tools RETRO and ReqSimile perform equiv-alently on the industrial dataset and similarly on the NASA data. From readingdocumentation and code of RETRO and ReqSimile, it was found that the toolsconstruct different feature vectors. RETRO, but not ReqSimile, takes the inversedocument frequency of terms into account when calculating feature weights. Con-sequently, terms overly frequent in the document set are not down-weighted asmuch in ReqSimile as in RETRO. This might be a major reason why RETRO gen-erally performs better than ReqSimile in our quasi-experiment, even without theuse of optional stop word removal. This shows that the construction of feature vec-tors is important to report when classifying traceability recovery tools, an aspectthat often is omitted when reporting overviews of the field.
Our experimentation was conducted on two bipartite datasets of different na-ture. The NASA data has a higher density of traceability links and also a morecomplex link structure. RETRO and ReqSimile both perform better on the indus-trial dataset. The average amount of words of this dataset is fewer than in theNASA dataset, the reason for better IR performance is rather the less complex linkstructure. Not surprisingly, the performance of the traceability recovery is heav-ily dependant on the dataset used as input. Before there is a general large-scaledataset available for benchmarking, traceability recovery research would benefitfrom understanding various types of software artifacts. Especially for proprietarydatasets used in experiments, characterization of both industrial context and the

6 Discussion 147
dataset itself must be given proper attention.As mentioned in Section 1, our quasi-experiment is partly a replication of stud-
ies conducted by Sundaram et al. [44], and Dekhtyar et al. [14]. Our results ofusing RETRO on the NASA dataset are similar, but not identical. Most likely,we have not applied the same version of the tool. Implementation of IR solutionsforces developers to make numerous minor design decisions, i.e., details of thepreprocessing steps, order of computations, numerical precision etc. Such minorvariations can cause the differences in tool output we observe, thus version controlof tools is important and should be reported.
6.2 Validity Threats
This section contains a discussion on validity threats to help define the creditabilityof the conclusions [48]. We focus on construct, internal and external validity.
Threats to construct validity concern the relationship between theory and ob-servation. Tracing errors include both errors of inclusion and errors of exclusion.By measuring both recall and precision, the retrieval performance of a tool is wellmeasured. However, the simplifications of the laboratory model of IR evaluationhave been challenged [27]. There is a threat that recall and precision are not effi-cient measures of the overall usefulness of traceability tools. The question remainswhether the performance differences, when put in a context with a user and a task,will have any practical significance. However, we have conducted a pilot studyon RETRO and ReqSimile on a subset of the NASA dataset to explore this matter,and the results suggest that subjects supported by a slightly better tool also produceslightly better output [5].
Threats to internal validity can affect the independent variable without the re-searcher’s knowledge and threat the conclusion about causal relationships betweentreatment and outcome. The first major threat comes from the manual preprocess-ing of data, which might introduce errors. Another threat is that the downloadedtraceability recovery tools were incorrectly used. This threat was addressed byreading associated user documentation and running pilot runs on smaller datasetpreviously used in our department.
External validity concerns the ability to generalize from the findings. Thebipartite datasets are not comparable to a full-size industrial documentation spaceand the scalability of the approach is not fully explored. However, a documentationspace might be divided into smaller parts by filtering artifacts by system module,type, development team etc., thus also smaller datasets are interesting to study.
On the other hand, there is a risk that the industrial dataset we collected isa very special case, and that the impact of datasets on the performance of trace-ability recovery tools normally is much less. The specific dataset was selected indiscussion with the company, to be representative and match our requirements onsize and understandability. It could also be the case that the NASA dataset is notrepresentative to compare RETRO and ReqSimile. The NASA data has been used

148 Evaluation of Traceability Recovery in Context: A Taxonomy for . . .
in controlled experiments of RETRO before, and the tool might be fine-tuned tothis specific dataset. Consequently, RETRO and ReqSimile must be compared onmore datasets to enable firm conclusions.
6.3 Advancing to outer levels
The evaluation we have conducted resides in the innermost retrieval context of thetaxonomy described in Section 3. Thus, by following the experimental frameworkby Huffman Hayes et al. [21], and by using proprietary software artifacts as input,our contribution of empirical evidence can be classified as a Level 1 evaluation inan industrial environment, as presented in Figure 7. By adhering to the experimen-tal framework, we provided enough level of detail in the reporting to enable futuresecondary studies to utilize our results.
Building upon our experiences from the quasi-experiment, we outline a possi-ble research agenda to move the empirical evaluations in a more industry relevantdirection. Based on our conducted Level 1 study, we could advance to outer levelsof the context taxonomy. Primarily, we need to go beyond precision-recall graphs,i.e., step out of “the cave of IR evaluation”. For example, we could introduce DCGas a secondary measure to analyze how the traceability recovery tools support find-ing relevant information among retrieved candidate links, repositioning our studyas path A shows in the Figure 7.
However, our intention is to study how software engineers interact with theoutput from IR-based traceability recovery tools, in line with what we initiallyhave explored in a pilot study [5]. Based on our experimental experiences, a futurecontrolled experiment should be conducted with more subjects, and preferably notonly students. An option would be to construct a realistic work task, using theindustrial dataset as input, and run the experiment in a classroom setting. Such aresearch design could move a study as indicated by path B in Figure 7. Finally,to reach the outermost evaluation context as path C shows, we would need tostudy a real project with real engineers, or possibly settle for a student project.An option would be to study the information seeking involved in the state-of-practice change impact analysis process at the company from where the industrialdataset originates. The impact analysis work task involves traceability recovery,but currently the software engineers have to complete it without dedicated toolsupport.
6.4 Advancing traceability recovery evaluations in gen-eral
Our experiences from applying the experimental framework proposed by Huff-man Hayes and Dekhtyar [21] are positive. The framework provided structure tothe experiment design activity, and also it encouraged detailed reporting. As aresult, it supports comparisons between experimental results, replications of re-

6 Discussion 149
ported experiments, and it supports secondary studies to aggregate empirical ev-idence. However, as requirements tracing constitutes an IR problem (for a givenartifact, relations to others are to be identified), it must be evaluated according tothe context of the user as argued by Ingwersen and Järvelin [24]. The experimentalframework includes “interpretation context”, but it does not cover this aspect of IRevaluation. Consequently, we claim that our context taxonomy fills a purpose, asa complement to the more practical experimental guidelines offered by HuffmanHayes and Dekhtyar’s framework [21].
While real-life proprietary artifacts are advantageous for the relevance of theresearch, the disadvantage is the lack of accessibility for validation and replicationpurposes. Open source artifacts offer in that sense a better option for advancingthe research. However, there are two important aspects to consider. Firstly, opensource development models tend to be different compared to proprietary devel-opment. For example, wikis and change request databases are more importantthan requirements documents or databases [41]. Secondly, there are large varia-tions within open source software contexts, as there is within proprietary contexts.Hence, it is critical that research matches pairs of open source and proprietarysoftware, as proposed by Robinson and Francis [38], based on several character-istics, and not only their being open source or proprietary. This also holds forgeneralization from studies from one domain to the other, as depicted in Figure 7.
Despite the context being critical, also evaluations in the innermost evalua-tion context can advance IR-based traceability recovery research, in line with thebenchmarking discussions by Runeson et al. [39] and suggestions by members ofthe COEST [7, 12, 13]. Runeson et al. refer to the automotive industry, and arguethat even though benchmarks of crash resistance are not representative to all typesof accidents, there is no doubt that such tests have been a driving force in makingcars safer. The same is true for the TREC conferences as mentioned in Section 1.Thus, the traceability community should focus on finding a series of meaningfulbenchmarks, including contextual information, rather than striving to collect a sin-gle large set of software artifacts to “rule them all”. Regarding size however, suchbenchmarks should be considerably larger that the de-facto benchmarks used to-day. The same benchmark discussion is active within the research community onenterprise search, where it has been proposed to extract documents from compa-nies that no longer exist, e.g., Enron [20], an option that might be possible also insoftware engineering.
Runeson et al. argue that a benchmark should not aim at statistical general-ization, but a qualitative method of analytical generalization. Falessi et al. onthe other hand, bring attention to the value of statistical hypothesis testing of tooloutput [16]. They reported a technology-oriented experiment in the seeking con-text (including secondary measures), and presented experimental guidelines in theform of seven empirical principles. However, the principles they proposed focuson the innermost contexts of the taxonomy in Figure 2, i.e., evaluations withouthuman subjects. Also, since the independence between datapoints on a precision-

150 Evaluation of Traceability Recovery in Context: A Taxonomy for . . .
Figure 7: Our quasi-experiment, represented by a square, mapped to the taxon-omy. Paths A-C show options to advance towards outer evaluation contexts, whilethe dashed arrow represents the possibility to generalize between environments asdiscussed by Robinson and Francis [38].
recall curve for a specific dataset is questionable, we argue that the result fromeach dataset instead should be treated as a single datapoint, rather than applyingthe cross-validation approach proposed by Falessi et al. As we see it, statisticalanalysis turns meaningful in the innermost evaluation contexts when we have ac-cess to sufficient numbers of independent datasets. On the other hand, when con-ducting studies on human subjects, stochastic variables are inevitably introduced,making statistical methods necessary tools.
Research on traceability recovery has the last decade, with a number of ex-ceptions, focused more on tool improvements and less on sound empirical eval-uations [6]. Since several studies suggest that further modifications of IR-basedtraceability recovery tools will only result in minor improvements [15, 36, 45], thevital next step is instead to assess the applicability of the IR approach in an indus-trial setting. The strongest empirical evidence on the usefulness of IR-based trace-ability recovery tools comes from a series of controlled experiments in the worktask context, dominated by studies using student subjects [5, 9, 23, 35]. Conse-quently, to strengthen empirical evaluations of IR-based traceability recovery, weargue that contributions must be made along two fronts. Primarily, in-vivo evalua-tions should be conducted, i.e., industrial case studies in a project context. In-vivostudies on the general feasibility of the IR-based approach are conspicuously ab-sent despite more than a decade of research. Thenceforth, meaningful benchmarksto advance evaluations in the two innermost evaluation contexts should be col-lected by the traceability community.
7 Conclusions and Future Work
We propose a context taxonomy for evaluations of IR-based traceability recovery,consisting of four integrated levels of evaluation contexts (retrieval, seeking, work

7 Conclusions and Future Work 151
task, and project context), and an orthogonal dimension of study environments(university, open source, proprietary environment). To illustrate our taxonomy, weconducted an evaluation of the framework for requirements tracing experimentsby Huffman Hayes and Dekhtyar [21].
Adhering to the framework, we conducted a quasi-experiment with two toolsimplementing VSM, RETRO and ReqSimile, on proprietary software artifactsfrom two embedded development projects. The results from the experiment showthat the tools performed equivalently on the dataset with a low density of traceabil-ity links. However, on the dataset with a more complex link structure, RETRO out-performed ReqSimile. An important difference between the tools is that RETROtakes the inverse document frequency of terms into account when representing ar-tifacts as feature vectors. We suggest that information about feature vectors shouldget more attention when classifying IR-based traceability recovery tools in the fu-ture, as well as version control of the tools. Furthermore, our research confirmsthat input software artifacts is an important factor in traceability experiments. Re-search on traceability recovery should focus on exploring different industrial con-texts and characterize the data in detail, since replications of experiments on closeddata are unlikely.
Following the experimental framework supported our study by providing struc-ture and practical guidelines. However, it lacks a discussion on the evaluation con-texts highlighted by our context taxonomy. On the other hand, when combined,the experimental framework and the context taxonomy offer a valuable platform,both for conducting and discussing, evaluations of IR-based traceability recovery.
As identified by other researchers, the widely used measures recall and pre-cision are not enough to compare the results from tracing experiments [22]. Thelaboratory model of IR evaluation has been questioned for its lack of realism, basedon progress in research on the concept of relevance and information seeking [27].Critics claim that real human users of IR systems introduce non-binary, subjectiveand dynamic relevance, which affect the overall IR process. Our hope is that ourproposed context taxonomy can be used to direct studies beyond “the cave” of IRevaluation, and motivate more industrial case studies in the future.
AcknowledgementThis work was funded by the Industrial Excellence Center EASE – EmbeddedApplications Software Engineering5. Special thanks go to the company providingthe proprietary dataset.
5http://ease.cs.lth.se

152 Evaluation of Traceability Recovery in Context: A Taxonomy for . . .
Bibliography
[1] G. Antoniol, G. Canfora, G. Casazza, and A. De Lucia. Information retrievalmodels for recovering traceability links between code and documentation. InConference on Software Maintenance, pages 40–49, 2000.
[2] G. Antoniol, G. Canfora, A. De Lucia, and E. Merlo. Recovering code todocumentation links in OO systems. In Proceedings of the 6th Working Con-ference on Reverse Engineering, pages 136–144, 1999.
[3] R. Baeza-Yates and B. Ribeiro-Neto. Modern information retrieval.Addison-Wesley, 1999.
[4] E. Ben Charrada, D. Caspar, C. Jeanneret, and M. Glinz. Towards a bench-mark for traceability. In Proceedings of the 12th International Workshop onPrinciples on Software Evolution, pages 21–30, 2011.
[5] M. Borg and D. Pfahl. Do better IR tools improve the accuracy of engi-neers’ traceability recovery? In Proceedings of the International Workshopon Machine Learning Technologies in Software Engineering, pages 27–34,2011.
[6] M. Borg, K. Wnuk, and D. Pfahl. Industrial comparability of student artifactsin traceability recovery research - an exploratory survey. In Proceedings ofthe 16th European Conference on Software Maintenance and Reengineering,pages 181–190, 2012.
[7] J. Cleland-Huang, A. Czauderna, A. Dekhtyar, O. Gotel, J. Huffman Hayes,E. Keenan, J. Maletic, D. Poshyvanyk, Y. Shin, A. Zisman, G. Antoniol,B. Berenbach, A. Egyed, and P. Mäder. Grand challenges, benchmarks, andTraceLab: Developing infrastructure for the software traceability researchcommunity. In Proceedings of the 6th International Workshop on Traceabil-ity in Emerging Forms of Software Engineering, 2011.
[8] C. Cleverdon. The significance of the Cranfield tests on index languages. InProceedings of the 14th Annual International SIGIR Conference on Researchand Development in Information Retrieval, pages 3–12, 1991.
[9] A. De Lucia, F. Fasano, R. Oliveto, and G. Tortora. Recovering traceabilitylinks in software artifact management systems using information retrievalmethods. Transactions on Software Engineering and Methodology, 16(4),2007.
[10] A. De Lucia, R. Oliveto, and G. Tortora. Assessing IR-based traceabilityrecovery tools through controlled experiments. Empirical Software Engi-neering, 14(1):57–92, 2009.

Bibliography 153
[11] S. Deerwester, S. Dumais, G. Furnas, T. Landauer, and R. Harshman. Index-ing by latent semantic analysis. Journal of the American Society for Infor-mation Science, 41(6):391–407, 1990.
[12] A. Dekhtyar and J. Huffman Hayes. Good benchmarks are hard to find:Toward the benchmark for information retrieval applications in software en-gineering. Proceedings of the International Conference on Software Mainte-nance, 2006.
[13] A. Dekhtyar, J. Huffman Hayes, and G. Antoniol. Benchmarks for traceabil-ity? In Proceedings of the International Symposium on Grand Challenges inTraceability, 2007.
[14] A. Dekhtyar, J. Huffman Hayes, and J. Larsen. Make the most of your time:How should the analyst work with automated traceability tools? In Pro-ceedings of the 3rd International Workshop on Predictor Models in SoftwareEngineering, 2007.
[15] D. Falessi, G. Cantone, and G. Canfora. A comprehensive characterization ofNLP techniques for identifying equivalent requirements. In Proceedings ofthe International Symposium on Empirical Software Engineering and Mea-surement, 2010.
[16] D. Falessi, G. Cantone, and G. Canfora. Empirical principles and an indus-trial case study in retrieving equivalent requirements via natural languageprocessing techniques. Transactions on Software Engineering, 2011.
[17] B. Farbey. Software quality metrics: considerations about requirements andrequirement specifications. Information and Software Technology, 32(1):60–64, 1990.
[18] O. Gotel and C. Finkelstein. An analysis of the requirements traceabilityproblem. In Proceedings of the First International Conference on Require-ments Engineering, pages 94–101, 1994.
[19] R. Gunning. Technique of clear writing - Revised edition. McGraw-Hill,1968.
[20] D. Hawking. Challenges in enterprise search. In Proceedings of the 15thAustralasian database conference, pages 15–24, 2004.
[21] J. Huffman Hayes and A. Dekhtyar. A framework for comparing require-ments tracing experiments. Interational Journal of Software Engineeringand Knowledge Engineering, 15(5):751–781, 2005.
[22] J. Huffman Hayes, A. Dekhtyar, and S. Sundaram. Advancing candidate linkgeneration for requirements tracing: The study of methods. Transactions onSoftware Engineering, 32(1):4–19, 2006.

154 Evaluation of Traceability Recovery in Context: A Taxonomy for . . .
[23] J. Huffman Hayes, A. Dekhtyar, S. Sundaram, A. Holbrook, S. Vadlamudi,and A. April. REquirements TRacing on target (RETRO): improving soft-ware maintenance through traceability recovery. Innovations in Systems andSoftware Engineering, 3(3):193–202, 2007.
[24] P. Ingwersen and K. Järvelin. The turn: Integration of information seekingand retrieval in context. Springer, 2005.
[25] International Electrotechnical Commission. IEC 61508 ed 2.0, Electrical/-Electronic/Programmable electronic safety-related systems, 2010.
[26] K. Järvelin and J. Kekäläinen. IR evaluation methods for retrieving highlyrelevant documents. In Proceedings of the 23rd Annual International ACMSIGIR Conference on Research and Development in Information Retrieval,pages 41–48, 2000.
[27] J. Kekäläinen and K. Järvelin. Evaluating information retrieval systems un-der the challenges of interaction and multidimensional dynamic relevance.Proceedings of the COLIS 4 Conference, pages 253—270, 2002.
[28] J. Lin, L. Chan, J. Cleland-Huang, R. Settimi, J. Amaya, G. Bedford,B. Berenbach, O. B Khadra, D. Chuan, and X. Zou. Poirot: A distributedtool supporting enterprise-wide automated traceability. In Proceedings ofthe 14th International Conference on Requirements Engineering, pages 363–364, 2006.
[29] M. Lormans, H-G. Gross, A. van Deursen, R. van Solingen, and A. Ste-houwer. Monitoring requirements coverage using reconstructed views: Anindustrial case study. In Procedings of the 13th Working Conference on Re-verse Engineering, pages 275–284, 2006.
[30] C. Manning, P. Raghavan, and H. Schütze. Introduction to information re-trieval. Cambridge University Press, 2008.
[31] A. Marcus and J. Maletic. Recovering documentation-to-source-code trace-ability links using latent semantic indexing. In Proceedings of the Interna-tional Conference on Software Engineering, pages 125–135, 2003.
[32] T. Menzies, D. Owen, and J. Richardson. The strangest thing about software.Computer, 40(1):54–60, 2007.
[33] G. Miller. The magical number seven, plus or minus two: Some limits on ourcapacity for processing information. The Psychological Review, 63:81–97,1956.
[34] P. Morville. Ambient findability: What we find changes who we become.O’Reilly Media, 2005.

Bibliography 155
[35] J. Natt och Dag, T. Thelin, and B. Regnell. An experiment on linguistic toolsupport for consolidation of requirements from multiple sources in market-driven product development. Empirical Software Engineering, 11(2):303–329, 2006.
[36] R. Oliveto, M. Gethers, D. Poshyvanyk, and A. De Lucia. On the equivalenceof information retrieval methods for automated traceability link recovery. InInternational Conference on Program Comprehension, pages 68–71, 2010.
[37] S. E. Robertson and S. Jones. Relevance weighting of search terms. Journalof the American Society for Information Science, 27(3):129–146, 1976.
[38] B. Robinson and P. Francis. Improving industrial adoption of software engi-neering research: A comparison of open and closed source software. In Pro-ceedings of the International Symposium on Empirical Software Engineeringand Measurement, pages 21:1–21:10, 2010.
[39] P. Runeson, M. Skoglund, and E. Engström. Test benchmarks: What is thequestion? In Proceedings of the International Conference on Software Test-ing Verification and Validation Workshop, pages 368–371, 2008.
[40] G. Salton, A. Wong, and C. Yang. A vector space model for automatic in-dexing. Commununications of the ACM, 18(11):613–620, 1975.
[41] W. Scacchi. Understanding the requirements for developing open sourcesoftware systems. IEEE Software, 149(1):24–39, 2002.
[42] A. Smeaton and D. Harman. The TREC experiments and their impact oneurope. Journal of Information Science, 23(2):169–174, 1997.
[43] K. Spärck Jones, S. Walker, and S. E. Robertson. A probabilistic model of in-formation retrieval: Development and comparative experiments. InformationProcessing and Management, 36(6):779–808, 2000.
[44] S. Sundaram, J. Huffman Hayes, and A. Dekhtyar. Baselines in requirementstracing. In Proceedings of the Workshop on Predictor Models in SoftwareEngineering, pages 1–6, 2005.
[45] S. Sundaram, J. Huffman Hayes, A. Dekhtyar, and A. Holbrook. Assess-ing traceability of software engineering artifacts. Requirements Engineering,15(3):313–335, 2010.
[46] T. Welsh, K. Murphy, T. Duffy, and D. Goodrum. Accessing elaborationson core information in a hypermedia environment. Educational TechnologyResearch and Development, 41(2):19–34, 1993.

156 Evaluation of Traceability Recovery in Context: A Taxonomy for . . .
[47] W. Wilson, L. Rosenberg, and L. Hyatt. Automated analysis of requirementspecifications. In Proceedings of the 19th international conference on Soft-ware engineering, pages 161–171, 1997.
[48] C. Wohlin, P. Runeson, M. Höst, M. Ohlsson, B. Regnell, and A. Wesslén.Experimentation in software engineering: An introduction. Kluwer Aca-demic Publications, 1st edition, 1999.

PAPER IV
DO BETTER IR TOOLSIMPROVE THE ACCURACY OFENGINEERS’ TRACEABILITY
RECOVERY?
Abstract
Large-scale software development generates an ever-growing amount of informa-tion. Multiple research groups have proposed using approaches from the domain ofInformation Retrieval (IR) to recover traceability. Several enhancement strategieshave been initially explored using the laboratory model of IR evaluation for per-formance assessment. We conducted a pilot experiment using printed candidatelists from the tools RETRO and ReqSimile to investigate how different qualitylevels of tool output affect the tracing accuracy of engineers. Statistical testing ofequivalence, commonly used in medicine, has been conducted to analyze the data.The low number of subjects in this pilot experiment resulted neither in statisticallysignificant equivalence nor difference. While our results are not conclusive, thereare indications that it is worthwhile to investigate further into the actual value ofimproving tool support for semi-automatic traceability recovery. For example, ourpilot experiment showed that the effect size of using RETRO versus ReqSimile isof practical significance regarding precision and F-measure. The interpretation ofthe effect size regarding recall is less clear. The experiment needs to be replicatedwith more subjects and on varying tasks to draw firm conclusions.
Markus Borg, and Dietmar Pfahl, In Proceedings of the International Workshopon Machine Learning Technologies in Software Engineering, 2011

158 Do Better IR Tools Improve the Accuracy of Engineers’ Traceability . . .
1 Introduction
Development and maintenance of software often result in information overload.Knowledge workers are in general forced to spend more and more time to extractuseful information. Maintaining traceability links between software artifacts isone approach to structure the information space of software development projects.Introducing information taxonomies and manually maintaining links is, however,an approach that does not scale very well. As a result, several researchers haveproposed to support traceability recovery with tools based on IR methods, utilizingthe fact that artifacts often have textual content in natural language.
Traceability recovery tools are generally evaluated by verifying how many sug-gested links above a certain similarity threshold are correct compared to a hand-crafted set of correct links. The laboratory model of IR evaluation is applied tocalculate the measures recall and precision, sometimes extended by a harmonicmean, the F-measure. Recall and precision are commonly reported using graphs,like the one shown in Figure 4. The “X” in Figure 4 marks the recall and precisionvalues of RETRO [13] and ReqSimile [16] for the first ten links proposed by thesetools. For “X”, the recall and precision values of RETRO are 50% respectively60% larger than those of ReqSimile. RETRO is a well-known traceability recov-ery tool. ReqSimile is a research tool developed at Lund University for the purposeto support information retrieval in the context of market-driven requirements en-gineering. However, since the real question is to what extent tools like RETROand ReqSimile actually help engineers in performing traceability recovery tasks,one may wonder whether it is worthwhile to keep hunting for recall-precision im-provements of traceability recovery tools.
To tackle this questions, we conducted a controlled experiment with 8 sub-jects to study how tool support affects the tracing process performed by engineers.The purpose of our experiment was to explore how the output from two traceabil-ity recovery tools, RETRO and ReqSimile, impacted a task requiring traceabilityinformation.
We analyzed our results using a test of equivalence, trying to prove that onetreatment is indistinguishable from another. In equivalence testing, the null hy-pothesis is formulated such that the statistical test is a proof of similarity i.e.,checking whether the tracing accuracies of engineers using different tools differby more than a tolerably small amount ∆ [20]. Our null hypothesis is the follow-ing:Hypothesis: The engineers’ accuracy of traceability recovery supported by RETROdiffers by more than ∆ compared to that supported by ReqSimile.
The alternative hypothesis is that the difference between the engineers’ ac-curacies is smaller than ∆, which implies that the treatments can be consideredequivalent. Accuracy is expressed in terms of recall and precision.

2 Related work 159
2 Related work
The last decade, several researchers proposed semi-automatic support to the taskof traceability recovery. For example, traceability recovery tools have been de-veloped implementing techniques based on algebraic or probabilistic models [1],data mining [23] and machine learning [19]. Several researchers have expressedthe tracing task as an IR problem. The query in such a tool is typically the soft-ware artifact you want to link to other artifacts. The answer to a query is normallya ranked list of artifact suggestions, most often sorted by the level of textual sim-ilarity. The ranked list is analogous to the output of search engines used on theweb. Items in the list can be either relevant or irrelevant for the given task.
In 2000, Antoniol et al. did pioneering work on traceability recovery whenthey used the standard vector space model (VSM) and probabilistic models to sug-gest links between source code and documentation in natural language [1]. Mar-cus and Maletic introduced Latent Semantic Indexing (LSI), another vector spaceapproach, to recover traceability in 2003 [15]. Their work showed that LSI canachieve good results without the need for stemming, which is fundamental in VSMand the probabilistic models. The same year Spanoudakis et al. used a machinelearning approach to establish traceability links [19]. By generating traceabilityrules from a set of artifacts given by the user, links were derived in the documentset. Zhang et al. proposed automatic ontology population for traceability recov-ery [23]. They developed a text mining system to semantically analyze softwaredocuments. Concepts discovered by the system were used to populate a documen-tation ontology, which was then aligned with a source code ontology to establishtraceability links.
Common to those papers is that they have a technical focus and present noor limited evaluations using software engineers solving real tasks. The major-ity of the published evaluations of traceability tools do not go beyond reportingrecall-precision graphs or other measures calculated without human involvement.Exceptions include studies comparing subjects working with tool support to man-ual control groups. Huffman Hayes et al. developed a traceability recovery toolnamed RETRO and evaluated it using 30 student subjects [13]. The students weredivided into two groups, one working with RETRO and the other working man-ually. Students working with the tool finished a requirements tracing task fasterand with a higher recall than the manual group, the precision however was lower.De Lucia et al. conducted a controlled experiment with 32 students on the useful-ness of supported traceability recovery [9]. They found that subjects using theirtool completed a task related to tracing various software artifacts faster and moreaccurately than subjects working manually, i.e. without any support from a ded-icated traceability recovery tool. In another study, De Lucia et. al observed 150students in 17 software development projects and concluded that letting them useIR-based tool support is helpful when maintenance of traceability information is aprocess requirement [10]. An experiment similar to ours was conducted by Cud-

160 Do Better IR Tools Improve the Accuracy of Engineers’ Traceability . . .
deback et. al, using students and student artifacts [8]. They had 26 subjects vetcandidate requirements traceability matrices (RTMs) of varying accuracy. Theyconcluded that subjects receiving the most inaccurate RTMs drastically improvedthem and that subjects in general balanced recall and precision.
Several researchers proposed ways to obtain better tool output, either by en-hancing existing tools implementing standard IR techniques, or by exploring newor combined approaches. Using a thesaurus to deal with synonymy is one pro-posed enhancement strategy explored by different researchers [12, 18]. Zou et al.investigated term based improvement strategies such as including a part-of-speechtagger to extract key phrases and using a project glossary to weight certain termshigher [24]. Recently, Cleland-Huang et al. [6] and Asuncion et al. [2] used amachine learning approach, Latent Direchlet Allocation, to trace requirements.Furthermore, Chen has done preliminary work on combining IR-methods and textmining in a traceability recovery tool and reported improved results [5].
Even though enhancements lead to better tool outputs in certain cases, theirgeneral applicability and the benefit they generate for engineers performing a spe-cific task remain uncertain. Oliveto et al. studied the impact of using four dif-ferent methods for traceability recovery. In their empirical study, VSM, LSI andthe Jensen-Shannon method resulted in almost equivalent results wrt. tracing ac-curacy [17]. LDA however, while not resulting in better accuracy, was able tocapture different features than the others. As far as we know, no studies exceptCuddeback et. al [8], have been published comparing how different quality levelsof tool output impact of an engineer in a specific traceability task. If more em-pirical studies with humans were available, one could conduct a meta-analysis toinvestigate this matter. Since this is not the case, our approach is instead to com-pare in an experimental setting the effect of using support tools with differentlyaccurate outputs on traceability tasks performed by humans.
3 Experimental Setup
This section describes the definition, design and setting of the experiment, follow-ing the general guidelines by Wohlin et al. [22]. An overview of our experimentalsetup is shown in Figure 1.
3.1 Experiment Definition and Context
The goal of the experiment was to study the tool-supported traceability recoveryprocess of engineers, for the purpose of evaluating the impact of traceability re-covery tools’ accuracies, with respect to the engineers’ accuracy of traceability re-covery, from the perspective of a researcher evaluating whether quality variationsbetween IR tool outputs significantly affect the tracing accuracy of engineers.

3 Experimental Setup 161
Figure 1: Overview of the experimental setup
3.2 Subjects and Experimental Setting
The experiment was executed at Lund University, Sweden. Eight subjects involvedin software engineering research participated in the study. Six subjects were doc-toral students, two subjects were senior researchers. Most subjects had industrialexperience of software development.
The experiment was conducted in a classroom setting, the subjects worked in-dividually. Each subject was randomly seated and supplied with a laptop with twoelectronic documents containing the artifacts that were to be traced in PDF format.Each subject also received a printed list per artifact to trace, containing candidatelinks as described in section 3.5. Four subjects received lists with candidate linksgenerated by RETRO, the other four received candidate lists generated by ReqSim-ile. The lists were distributed randomly. The subjects received a pen, a two-pageinstruction, an answer sheet and a debriefing questionnaire. The subjects weresupposed to navigate the PDF documents as they preferred, using the candidatelink lists as support. All individual requirements were clickable as bookmarks,and keyword searching using the Find tool of their PDF viewer was encouraged.
3.3 Task and Description of the Dataset
It was decided to reuse a publicly available dataset and a task similar to previoustracing experiments to enable comparison to old results. The task, in which trace-ability recovery was required, was to estimate impact of a change request on theCM-1 dataset. For twelve given requirements, the subjects were asked to identifyrelated requirements on a lower abstraction level. The task was given a realis-tic scenario involving time pressure, by having the subjects assume they shouldpresent their results in a meeting 45 minutes later. Before the actual experiment

162 Do Better IR Tools Improve the Accuracy of Engineers’ Traceability . . .
Figure 2: Histograms showing the link densities of CM-1 (left) and the subsetused as the experimental sample (right).
started, the subjects were given a warm-up exercise to become familiar with thedocument structure and the candidate link lists.
The CM-1 data is a publicly available1 set of requirements with complete trace-ability information. The data originates from a project in the NASA Metrics DataProgram and has been used in several traceability experiments before [13, 14, 24].The dataset specifies parts of a data processing unit and consists of 235 high-levelrequirements and 220 corresponding low-level requirements specifying detaileddesign. Many-to-many relations exist between abstraction levels. The link den-sity of CM-1 and the representative subset used in the experiment are presented inFigure 2. This figure depicts histograms with the X-axis representing the numberof low-level requirements related to one high-level requirement. Due to the ratherunintuitive nature of the dataset, having many unlinked system requirements, thesubjects received a hint saying that “Changes to system requirements normally im-pact zero, one or two design items. Could be more, but more than five would reallybe exceptional”.
Descriptive statistics of CM-1, including two commonly reported text com-plexity measures, are presented in Table 1. Farbey proposed calculating GunningFog Index as a complexity metric for requirement specifications written in En-glish [11]. The second complexity metric reported is the Flesch Reading Ease, pre-viously reported by Wilson et al. for requirement specifications from NASA [21].
3.4 Decription of the ToolsRETRO, developed by Huffman Hayes et al., is a tool that supports software devel-opment by tracing textual software engineering artifacts [13]. The tool generatesRTMs using standard information retrieval techniques. The evolution of RETROaccelerated when NASA analysts working on independent verification and valida-tion projects showed interest in the tool. The version of the software we used im-plements VSM with features having term frequency-inverse document frequency
1www.coest.org

3 Experimental Setup 163
Number of traceability links: 361Characteristic High-level Reqs. Low-level Reqs.Items 235 220Words 5 343 17 448Words/Items 22.7 79.3Avg. word length 5.2 5.1Unique words 1 056 2 314Gunning Fog Index 7.5 10.9Flesch Reading Ease 67.3 59.6
Table 1: Statistics of the CM-1 data, calculated using the Text Content Analyzeron UsingEnglish.com.
weights. Similarities are calculated as the cosine of the angle between featurevectors [3]. Stemming is done as a preprocessing step by default. For stop wordremoval, an external file must be provided, a feature we did not use. We used theRETRO version V.BETA, Release Date February 23, 2006.
ReqSimile, developed by Natt och Dag et al., is a tool with the primary pur-pose to provide semi-automatic support to requirements management activitiesthat rely on finding semantically similar artifacts [16]. Examples of such activitiesare traceability recovery and duplicate detection. The tool was intended to supportthe dynamic nature of market-driven requirements engineering. ReqSimile alsoimplements VSM and cosine similarities. An important difference to RETRO isthe feature weighting; terms are weighted as 1 + log2(freq) and no inverse docu-ment frequencies are considered. Preprocessing steps in the tool include stop wordremoval and stemming. We used version 1.2 of ReqSimile.
3.5 Experimental Variables
In the context of the proposed experiment, the independent variable was the qual-ity of the tool output given to the subjects. For each item to trace, i.e. for eachhigh-level requirement, entire candidate link lists generated by the tools using de-fault settings were used. No filtering was applied in the tools. The output variedbetween 47 and 170 items, i.e. each item representing a low-level requirement. Anexample of part of such a list is presented in Figure 3, showing high-level require-ment SRS5.14.1.6 and the top part of a list of candidate low-level requirements andtheir cosine similarities. The two tools RETRO [13] and ReqSimile [16] are fur-ther described in Section 3.4. RETRO has outperformed ReqSimile wrt. accuracyof tool output in a previous experiment on the CM-1 dataset [4].
The lists were printed with identical formatting to ensure the same presenta-tion. Thus, the independent variable was given two treatments, printed lists of can-didate links ranked by RETRO (Treatment RETRO), and printed lists of candidatelinks ranked by ReqSimile (Treatment ReqSimile). The recall-precision graphs

164 Do Better IR Tools Improve the Accuracy of Engineers’ Traceability . . .
Figure 3: Example of top part of a candidate link list.
for the two tools on the experiment sample are presented in Figure 4, extendedby the accuracy of the tracing results, i.e. the answer sets returned by subjects asdescribed in Section 4.
The dependent variable, the outcome observed in the study, was the accuracyof the tracing result. Accuracy was measured in terms of recall, precision andF-measure. Recall measures the percentage of correct links traced by a subject,while precision measures the percentage of traced links that were actually correct.The F-measure is the harmonic mean of recall and precision. The time spent on thetask was limited to 45 minutes, creating realistic time pressure. We also recordedthe number of requirements traced by the subjects.
3.6 Experiment Design and Procedure
A completely randomized design was chosen. The experiment was conductedduring one single session. The design was balanced, i.e. both treatments, RETROand ReqSimile, were assigned to the same number of subjects. The two treatmentwere given to the subjects at random. Each subject received the same tasks and hadnot studied the system previously. When the 45 minutes had passed, the subjectswere asked to answer a debriefing questionnaire.
3.7 Statistical Analysis
The null hypothesis was formulated as existence of a difference in the outcomesbigger than ∆. ∆ defines the interval of equivalence, i.e., the interval where varia-tion is considered to have no practical value. For this pilot study, we decided to set∆ to 0.05 for both recall, precision and F-measure. This means that finishing thetask with 0.05 better or worse recall and precision does not have a practical value.
The two one-sided test (TOST) is the most basic form of equivalence testingused to compare two treatments. Confidence intervals for the difference between

4 Results and Data Analysis 165
Figure 4: Recall-Precision graph for RETRO and ReqSimile for requirementstracing (our sample). The ’X’-symbols mark candidate link lists of length 10.Overall accuracy of answer sets returned by subjects is presented as circles, thediameter represents the relative number of links in the answer set. For a picturewhere also tool output is presented with relative sizes, see Figure 5.
two treatments must be defined. In a TOST analysis, a (1 - 2α)100% confidenceinterval is constructed [20]. We selected α = 0.05, thus we reject the null hypothe-ses that the outcomes of the treatments differ by at least ∆, if the 90% confidenceinterval for the difference is completely confined within the endpoints -∆ and +∆.The 90% confidence intervals are calculated as follows:
point_estimate_outcomeRETRO − point_estimate_outcomeReqSimile ±2.353
√std_dev2RETRO + std_dev2ReqSimile
4 Results and Data Analysis
The experiment had no dropouts and as a result we collected 8 valid answer sheetsand debriefing questionnaires. The answer sets were compared to the gold standardavailable for the datasets and the corresponding values for recall (Rc), precision(Pr) and F-measure (F) were calculated. The descriptive statistics for Rc, Pr, F, andthe number of requirements traced are presented in Table 2. We also calculatedthe effect sizes using Cohen’s d (cf. last column in Table 2). Results from thequestionnaire are shown in Table 3.
Most subjects experienced the task as challenging and did not have enoughtime to finish. The list of common acronyms provided to assist the subjects, aswas done in a previous case study using the CM-1 dataset [13], was not consideredenough to appropriately understand the domain. Generally, the subjects considered

166 Do Better IR Tools Improve the Accuracy of Engineers’ Traceability . . .
the printed candidate link lists as supportive and would prefer having tool supportif performing a similar task in the future.
Table 4 characterizes the tool outputs of RETRO and ReqSimile as well asthe tracing results provided by the subjects participating in the experiment. Theupper part of the table shows the data for the treatment with RETRO, the lowerpart that for the treatment with ReqSimile. Each row in the table provides thefollowing data: the ID of the high-level requirement (Req. ID), the number oflow-level requirements suggested by the tool (#Links), the cosine similarities ofthe first and last link in the list of suggested low-level requirements (Sim. 1st link,Sim. last link), and for each subject (A to H) the number of reported links and theassociated recall and precision (Sub. A: # / Rc / Pr). Bold values represent fullyaccurate answers. A hyphen indicates that a subject did not provide any data onthat high-level requirement. IDs of high-level requirements printed in italics haveno associated low-level requirements links, thus a correct answer would have beento report 0 links. For those requirements we define rc and pr equal to 1 if a subjectactually reported 0 links, otherwise rc and pr equal 0. When subjects reported0 links for high-level requirements that actually have low-level requirements, wedefine rc and pr equal to 0.
The number of high-level requirements the subjects had time to investigate dur-ing the experiment varied between three and twelve. On average, RETRO subjectsinvestigated eight items and ReqSimile subjects investigated 8.75. All subjects ap-parently proceeded in the order the requirements were presented to them. Sincesubjects A and E investigated only three and four high-level requirements respec-tively, they clearly focused on quality rather than coverage. However, the precisionof their tracing results does not reflect this focus. The mean recall for subjects sup-ported by RETRO was higher than for subjects supported by ReqSimile, and alsothe mean precision. The standard deviations were however high, as expected whenusing few subjects. Not surprisingly, subjects reporting more links in their answerset reached higher recall values.
The debriefing questionnaire was also used to let subjects briefly describe theirtracing strategies. Most subjects expressed focus on the top of the candidate lists.One subject reported the strategy of investigating the top 10 suggestions. Twosubjects reported comparing similarity values and investigating candidate linksuntil the first “big drop”. Two subjects investigated links on the candidate listsuntil several in a row were clearly incorrect. Only one subject explicitly reportedconsidering links after position 10. This subject investigated the first ten links,then every second until position 20, then every third until the 30th suggestion.This proved to be a a time-consuming approach and the resulting answer set wasthe smallest in the experiment. The strategies explained by the subjects are in linewith our expectation that presenting more than 10 candidate links per requirementadds little value.
As Figure 4 shows, a naïve strategy of just picking the first one or two candi-date links returned by the tools would in most cases result in better accuracy than

4 Results and Data Analysis 167
Figure 5: Circle diameters show relative number of links in answer sets. Tooloutput is plotted for candidate link lists of length from 1 to 6.
the subjects achieved. Also, there is a trend that subjects supported by RETROhanded in more accurate answer sets. Pairwise comparison of subjects orderedaccording to accuracy, i.e. B to E, A to F, C to G, D to H, indicates that the betteraccuracy of RETRO actually spills over to the subjects’ tracing result.
Figure 5 shows relative sizes of answer sets returned by both human subjectsand the tools, presenting how the number of tool suggestions grows linearly. Themajority of human answer sets contained between one or two links per require-ment, comparable to tools generating one or two candidate links.
The 90% confidence intervals of the differences between RETRO and ReqSim-ile are presented in Figure 6. Since none of the 90% confidence intervals of recall,precision, and F-measure are covered by the interval of equivalence, there is nostatistically significant equivalence of the engineers’ accuracies of traceability re-covery, when using our choice of ∆. For completeness, we also did differencetesting with the null hypothesis: The engineers’ accuracy of traceability recoverysupported by RETRO is equal to that supported by ReqSimile. This null hypoth-esis could not be rejected neither by a two-sided T-test nor a two-sided Wilcoxonrank-sum test with α=0.05. Consequently, there were no statistically significantdifferences on the engineers’ accuracies of traceability recovery when supportedby candidate link lists from different tools.
Our tests of significance are accompanied by effect-size statistics. Effect sizeis expressed as the difference between the means of the two samples divided bythe root mean square of the variances of the two samples. On the basis of the effectsize indices proposed by Cohen, effects greater or equal 0.5 are considered to be of

168 Do Better IR Tools Improve the Accuracy of Engineers’ Traceability . . .
TREATMENT Reqs. Traced (number)Mean Median Std. Dev. Eff. Size
RETRO 8.00 8.50 2.74ReqSimile 8.75 10.0 3.70 -0.230
RecallMean Median Std. Dev. Eff. Size
RETRO 0.237 0.237 0.109ReqSimile 0.210 0.211 0.118 0.232
PrecisionMean Median Std. Dev. Eff. Size
RETRO 0.328 0.325 0.058ReqSimile 0.247 0.225 0.077 1.20
F-MeasureMean Median Std. Dev. Eff. Size
RETRO 0.267 0.265 0.092ReqSimile 0.218 0.209 0.116 0.494
Table 2: Descriptive statistics of experimental results.
medium size, while effect sizes greater or equal than 0.8 are considered large [7].The effect sizes for precision and F-measure are high and medium respectively.Most researchers would consider them as being of practical significance. For re-call, the effect size is too small to say anything conclusive.
5 Threats to Validity
The entire experiment was done during one session, lowering the risk of matura-tion. The total time for the experiment was less than one hour to help subjects keepfocused. As the answers in the debriefing questionnaire suggests, it is likely thatdifferent subjects had different approaches to the process of artifact tracing, andthe chosen approach might have influenced the outcome more than the differenttreatments. This is a threat to the internal validity. The fully randomized experi-ment design was one way to mitigate such effects. Future replications should aimat providing more explicit guidance to the subjects.
A possible threat to construct validity is that using printed support when tracingsoftware artifacts is not representing how engineers would actually interact withthe supporting IR tools, but it straightens the internal validity.
The CM-1 dataset used in the experiment, has been used in several previoustracing experiments and case studies. The dataset is not comparable to a large-scaleindustrial documentation space but is a representative subset. The CM-1 datasetoriginates from a NASA project, and is probably the most referenced dataset forrequirements tracing. The subjects all do research in software engineering, most

5 Threats to Validity 169
QUESTIONS(1=Strongly agree, 5=Strongly disagree) RETRO ReqSimile1. I had enough time to finish the task. 4.0 3.32. The list of acronyms gave me enoughunderstanding of the domain to completethe task. 4.3 3.83. The objectives of the task wereperfectly clear to me. 2.5 1.54. I experienced no major difficulties inperforming the task. 3.3 4.35. The tool output (proposed links) reallysupported my task. 2.3 2.06. If I was performing a similar taskin the future, I would want to use asoftware tool to assist. 2.3 1.8
Table 3: Results from the debriefing questionnaire. All questions were answeredusing a five-level Likert item. The means for each group are shown.
Figure 6: Differences in recall, precision and F-measure between RETRO andReqSimile. The horizontal T-shaped bars depict confidence intervals. The intervalof equivalence is the grey-shaded area.

170 Do Better IR Tools Improve the Accuracy of Engineers’ Traceability . . .
TreatmentR
ET
RO
Req.ID
#Links
Sim.
Sim.
Sub.ASub.B
Sub.CSub.D
1stlinklastlink
#/R
c/Pr
#/R
c/Pr
#/R
c/Pr
#/R
c/Pr
SRS5.1.3.5
1340.551
0.0191
/1/1
1/1
/13
/1/0.33
1/1
/1SR
S5.1.3.9116
0.1800.005
4/0.2
/0.251
/0/0
1/0
/02
/0/0
SRS5.12.1.11
1560.151
0.0042
/0/0
2/0
/02
/0/0
1/0
/0SR
S5.12.1.8125
0.2540.005
2/0.5
/0.50
/0/0
3/0.5
/0.330
/0/0
SRS5.14.1.6
1010.280
0.006-
1/0
/01
/0.25/1
3/0.25
/0.33SR
S5.14.1.8117
0.1730.005
-1
/0/0
0/0
/01
/0/0
SRS5.18.4.3
470.136
0.009-
2/1
/0.53
/1/0.3
2/1
/0.5SR
S5.19.1.10135
0.1400.004
--
1/0
/01
/0/0
SRS5.19.1.2.1
1010.151
0.006-
-0
/0/0
2/1
/0.5SR
S5.2.1.3127
0.3290.005
--
3/0.67
/0.674
/0.67/0.5
SRS5.9.1.1
1630.206
0.003-
-2
/0/0
-SR
S5.9.1.9159
0.2400.005
--
--
TreatmentR
eqSimile
Req.ID
#Links
Sim.
Sim.
Sub.ESub.F
Sub.GSub.H
1stlinklastlink
#/R
c/Pr
#/R
c/Pr
#/R
c/Pr
#/R
c/Pr
SRS5.1.3.5
1450.568
0.0043
/1/0.33
4/1
/0.252
/1/0.5
1/1
/1SR
S5.1.3.9142
0.3180.029
1/0
/02
/0/0
3/0
/01
/0/0
SRS5.12.1.11
1660.315
0.0291
/0/0
1/0
/02
/0/0
0/1
/1SR
S5.12.1.8111
0.3350.022
-0
/0/0
1/0
/04
/0.5/0.25
SRS5.14.1.6
1340.397
0.021-
4/0.25
/0.253
/0.25/0.33
2/0.25
/0.5SR
S5.14.1.8170
0.3970.029
-2
/0/0
2/0
/02
/0/0
SRS5.18.4.3
1430.259
0.021-
3/1
/0.331
/1/1
1/0
/0SR
S5.19.1.10160
0.3400.025
-2
/0/0
0/1
/13
/0/0
SRS5.19.1.2.1
1460.433
0.021-
-2
/0/0
3/1
/0.66SR
S5.2.1.3151
0.6190.018
--
2/0.66
/11
/0.33/1
SRS5.9.1.1
1670.341
0.019-
-2
/0/0
0/1
/1SR
S5.9.1.9157
0.5270.018
--
1/0
/01
/1/1
Table4:
Characterization
oftooloutputsand
tracingresults
providedby
thesubjects
participatingin
theexperim
ent.

6 Discussion and Future Work 171
have also worked as software developers in industry. Since the dataset is complex,dealing with embedded development in a safety critical domain, it was challeng-ing for the subjects to fully understand the information they received to performtheir task. In that regard, the subjects are comparable to newly employed softwareengineers in industry. This limits the generalizability of the experimental results,as software engineers normally would be more knowledgeable.
6 Discussion and Future Work
The results of the pilot experiment are inconclusive. The low number of sub-jects did not enable us to collect strong empirical evidence. The equivalence test(TOST) did not reject difference and the difference test (two-sided T-test) did notreject similarity. Thus, in this experiment, neither the evidence against equalitynor difference was strong enough to reject either null hypothesis.
Although not statistically significant, we could see a trend that subjects sup-ported with the better tool performed more accurately. Somewhat surprisingly, theprecision of the subjects was not higher than that of the results the tools produced.For our specific task, with a time pressure, just using the tool output would gen-erally be better than letting our subjects solve the task, using the tool output assupport. One could argue that our subjects actually made the results worse. Onedirection of future research could be to explore under which circumstances this isthe case.
Our experiment is in line with the finding of Cuddeback et. al [8], stating thatsubjects seem to balance recall and precision. We observed this trend in a verydifferent experimental setup. Foremost, our task was to trace a subset of artifactsunder time pressure using printed candidate link lists as support, as opposed to veta complete RTM without time pressure using a tool. Other differences include:types of subjects and artifacts, and a sparser golden standard RTM.
Is it meaningful to study a tracing task with subjects that are not very knowl-edgeable in the domain? Embedded software development in the space industryis not easy to simulate in a classroom setting. Yet there is a need to understandthe return on investment of improved accuracy of IR tools in support of traceabil-ity recovery. Controlled experiments can be one step forward. Our ambition is toreplicate this pilot experiment using a larger number of student subjects, to explorewhether any statistically significant results appear.
Recall and precision of traceability recovery tools are not irrelevant measures,but the main focus of research should be broader. For example, Figure 4 shows thatthe accuracy of RETRO is clearly better than that that of ReqSimile. However, theeffect of using RETRO in a specific traceability recovery task is not that clear, asour pilot experiment suggests. Therefore, our future work aims at moving closerto research about information access, especially to the sub-domain of enterprisesearch, where more holistic approaches are explored. For example, we think that

172 Do Better IR Tools Improve the Accuracy of Engineers’ Traceability . . .
assessing quality aspects such as findability in the software engineering contextwould mature the traceability recovery research.
AcknowledgementsThis work was funded by the Industrial Excellence Center EASE - EmbeddedApplications Software Engineering2. Parts of this work were funded by the Excel-lence Center at Linköping-Lund in Information Technology (ELLIIT).
2http://ease.cs.lth.se

Bibliography 173
Bibliography
[1] G. Antoniol, G. Canfora, G. Casazza, and A. De Lucia. Information retrievalmodels for recovering traceability links between code and documentation. InConference on Software Maintenance, pages 40–49, 2000.
[2] H. Asuncion, A. Asuncion, and R. Taylor. Software traceability with topicmodeling. In Proceedings of the International Conference on Software En-gineering, pages 95–104, 2010.
[3] R. Baeza-Yates and B. Ribeiro-Neto. Modern information retrieval.Addison-Wesley, 1999.
[4] L. Brodén. Requirements traceability recovery: A study of available tools.Master thesis, Lund University, http://sam.cs.lth.se/ExjobGetFile?id=377,2011.
[5] X. Chen. Extraction and visualization of traceability relationships betweendocuments and source code. In Proceedings of the International Conferenceon Automated Software Engineering, pages 505–509, 2010.
[6] J. Cleland-Huang, A. Czauderna, M. Gibiec, and J. Emenecker. A machinelearning approach for tracing regulatory codes to product specific require-ments. In Proceedings International Conference on Software Engineering,pages 155–164, 2010.
[7] J. Cohen. Statistical power analysis for the behavioral sciences. Routledge,1988.
[8] D. Cuddeback, A. Dekhtyar, and J. Huffman Hayes. Automated require-ments traceability: The study of human analysts. In Proceedings of the 18thInternational Requirements Engineering Conference, pages 231–240, 2010.
[9] A. De Lucia, F. Fasano, R. Oliveto, and G. Tortora. Recovering traceabilitylinks in software artifact management systems using information retrievalmethods. Transactions on Software Engineering and Methodology, 16(4),2007.
[10] A. De Lucia, R. Oliveto, and G. Tortora. Assessing IR-based traceabilityrecovery tools through controlled experiments. Empirical Software Engi-neering, 14(1):57–92, 2009.
[11] B. Farbey. Software quality metrics: considerations about requirements andrequirement specifications. Information and Software Technology, 32(1):60–64, 1990.

174 Do Better IR Tools Improve the Accuracy of Engineers’ Traceability . . .
[12] J. Huffman Hayes, A. Dekhtyar, and S. Sundaram. Advancing candidate linkgeneration for requirements tracing: The study of methods. Transactions onSoftware Engineering, 32(1):4–19, 2006.
[13] J. Huffman Hayes, A. Dekhtyar, S. Sundaram, A. Holbrook, S. Vadlamudi,and A. April. REquirements TRacing on target (RETRO): improving soft-ware maintenance through traceability recovery. Innovations in Systems andSoftware Engineering, 3(3):193–202, 2007.
[14] A. Mahmoud and N. Niu. Using semantics-enabled information retrieval inrequirements tracing: An ongoing experimental investigation. In Proceed-ings of the International Computer Software and Applications Conference,pages 246–247, 2010.
[15] A. Marcus and J. Maletic. Recovering documentation-to-source-code trace-ability links using latent semantic indexing. In Proceedings of the Interna-tional Conference on Software Engineering, pages 125–135, 2003.
[16] J. Natt och Dag, V. Gervasi, S. Brinkkemper, and B. Regnell. A linguistic-engineering approach to large-scale requirements management. IEEE Softw.,22(1):32–39, 2005.
[17] R. Oliveto, M. Gethers, D. Poshyvanyk, and A. De Lucia. On the equivalenceof information retrieval methods for automated traceability link recovery. InInternational Conference on Program Comprehension, pages 68–71, 2010.
[18] R. Settimi, J. Cleland-Huang, O. Ben Khadra, J. Mody, W. Lukasik, andC. DePalma. Supporting software evolution through dynamically retrievingtraces to UML artifacts. In Proceedings of the 7th International Workhop onPrinciples of Software Evolution, pages 49–54, 2004.
[19] G. Spanoudakis, A. d’Avila-Garcez, and A. Zisman. Revising rules to cap-ture requirements traceability relations: A machine learning approach. InProceedings of the 15th International Conference in Software Engineeringand Knowledge Engineering, 2003.
[20] S. Wellek. Testing statistical hypotheses of equivalence. Chapman and Hall,2003.
[21] W. Wilson, L. Rosenberg, and L. Hyatt. Automated analysis of requirementspecifications. In Proceedings of the 19th international conference on Soft-ware engineering, pages 161–171, 1997.
[22] C. Wohlin, P. Runeson, M. Höst, M. Ohlsson, B. Regnell, and A. Wesslén.Experimentation in software engineering: An introduction. Kluwer Aca-demic Publications, 1st edition, 1999.

Bibliography 175
[23] Y. Zhang, R. Witte, J. Rilling, and V. Haarslev. Ontological approach forthe semantic recovery of traceability links between software artefacts. IETSoftware, 2(3):185–203, 2008.
[24] X. Zou, R. Settimi, and J. Cleland-Huang. Improving automated require-ments trace retrieval: A study of term-based enhancement methods. Empiri-cal Software Engineering, 15(2):119–146, 2010.





























