Embed Size (px)
Citation preview

Addressing the Data Deluge: the Structuring, Sharing, and Preserving of
Scientific Experiment Data
Beth Plale
Sangmi Lee
Scott Jensen
Yiming Sun
Computer Science Dept.
Indiana University

The Data DelugeComputational science is increasingly data intense and
getting more so. Why? More complex computations:
– Nested model runs– Linked models– Finer resolution
More sources of data products – Observational data products
• Streaming continuously from hundreds of sensor and network sources, scaling to thousands
• Large archives – Annotations– Model configuration parameters– Output results– Model data– Statistical data (e.g., data mining)

Problem
Computational scientists are reaching their limit on ability to manage data products associated with investigations– Scientist can touch hundreds to thousands of data
products in single investigation
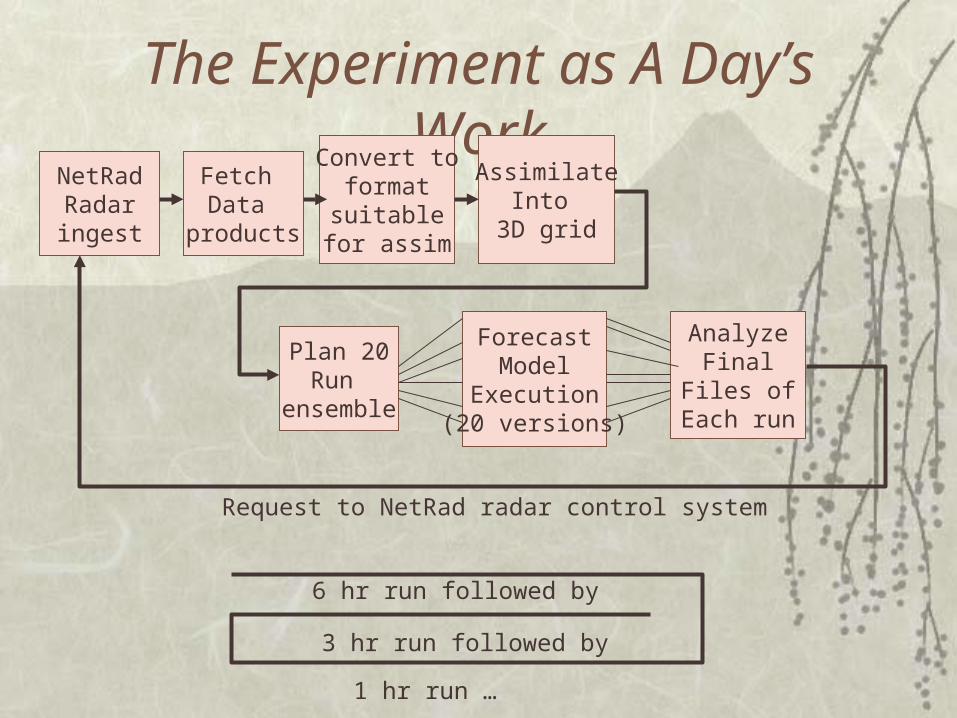
The Experiment as A Day’s WorkNetRadRadaringest
Fetch Data
products
ForecastModel
Execution(20 versions)
Convert toformat
suitablefor assim
Plan 20Run
ensemble
AnalyzeFinal
Files ofEach run
Request to NetRad radar control system
AssimilateInto
3D grid
6 hr run followed by
3 hr run followed by
1 hr run …

Why not just put up a metadata database and let them come?
The King’s solution. Burdens users (people or programs) with:
– Knowing where database is located– Knowing the schema of the database– Initiating all the communication with database– Generating all metadata– Knowing precisely how to write the queries.
We can’t afford the King’s solution - we have to be more aggressive if our solution is to be widely used.

Who are our users? (psst…scientists)
Users don’t want to write precise SQL– That is, learn the nuances of a relational schema
Users won’t hand-code metadata Scientists don’t want to have to think about
hierarchies of files, versions, or replicas. They want to run experiments and do their science.
Scientists use Google - they know searching can be fast and flexible - far more flexible than
% find . -n “03052005:1300:25:30.nc” -print

myLEAD: an ‘active’ metadata catalog
If we’re going to have half a chance of being widely used, it is going to be us that reaches 3/4’s of the way across the gulf. Our users reach the other 1/4:– Easy query “writing”– Automated metadata generation– Transparent structure management– Transparent versioning management– Expressive query writing

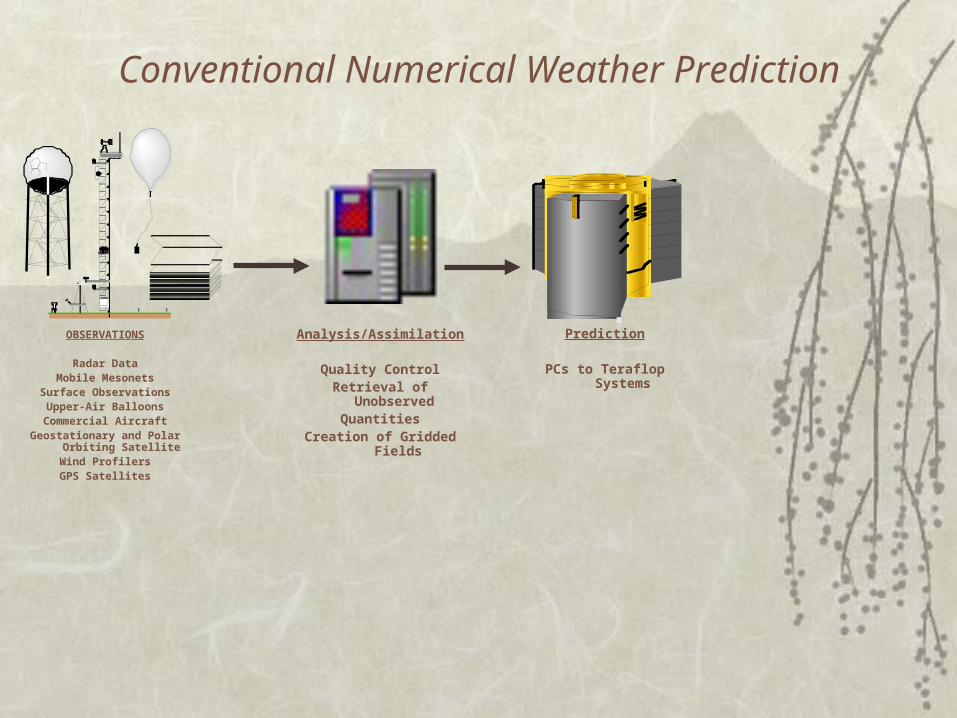
Conventional Numerical Weather Prediction
OBSERVATIONS
Radar DataMobile Mesonets
Surface ObservationsUpper-Air Balloons
Commercial AircraftGeostationary and Polar Orbiting
SatelliteWind ProfilersGPS Satellites

OBSERVATIONS
Radar DataMobile Mesonets
Surface ObservationsUpper-Air Balloons
Commercial AircraftGeostationary and Polar Orbiting
SatelliteWind ProfilersGPS Satellites
Analysis/Assimilation
Quality ControlRetrieval of Unobserved
QuantitiesCreation of Gridded Fields
Conventional Numerical Weather Prediction
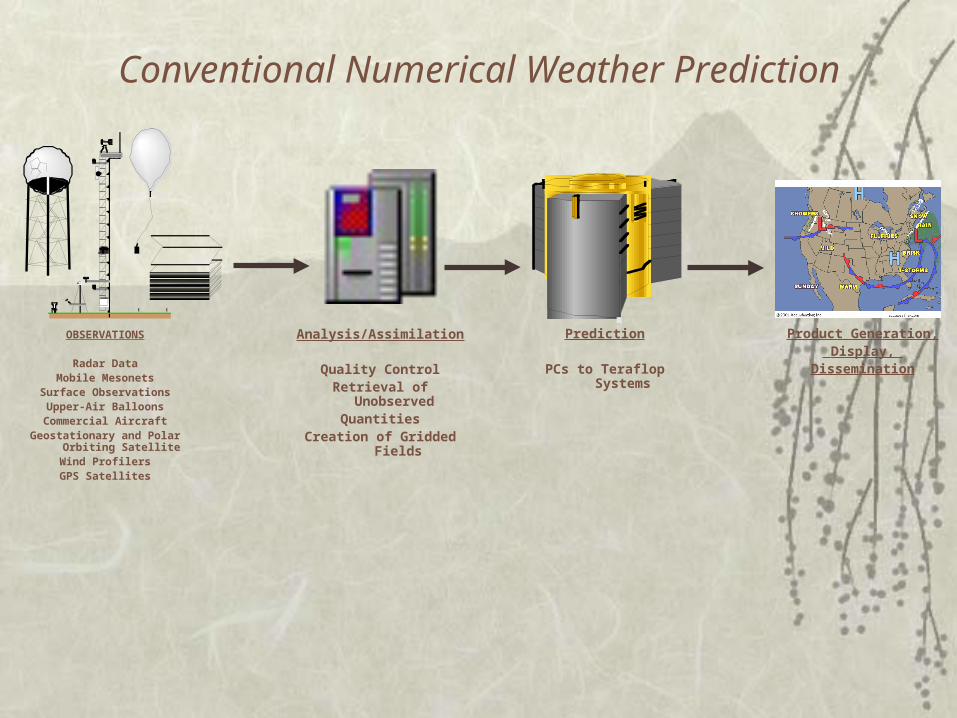
Analysis/Assimilation
Quality ControlRetrieval of Unobserved
QuantitiesCreation of Gridded Fields
Prediction
PCs to Teraflop Systems
Conventional Numerical Weather Prediction
OBSERVATIONS
Radar DataMobile Mesonets
Surface ObservationsUpper-Air Balloons
Commercial AircraftGeostationary and Polar Orbiting
SatelliteWind ProfilersGPS Satellites
Analysis/Assimilation
Quality ControlRetrieval of Unobserved
QuantitiesCreation of Gridded Fields
Prediction
PCs to Teraflop Systems
Product Generation, Display,
Dissemination
Conventional Numerical Weather Prediction
OBSERVATIONS
Radar DataMobile Mesonets
Surface ObservationsUpper-Air Balloons
Commercial AircraftGeostationary and Polar Orbiting
SatelliteWind ProfilersGPS Satellites
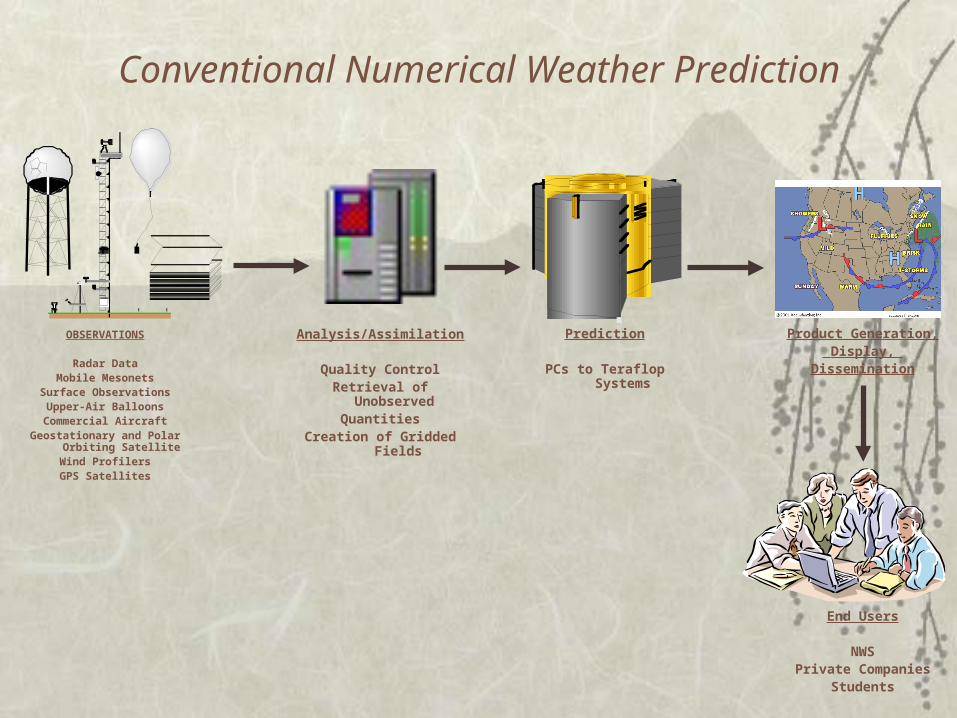
Analysis/Assimilation
Quality ControlRetrieval of Unobserved
QuantitiesCreation of Gridded Fields
Prediction
PCs to Teraflop Systems
Product Generation, Display,
Dissemination
End Users
NWSPrivate Companies
Students
Conventional Numerical Weather Prediction
OBSERVATIONS
Radar DataMobile Mesonets
Surface ObservationsUpper-Air Balloons
Commercial AircraftGeostationary and Polar Orbiting
SatelliteWind ProfilersGPS Satellites

Analysis/Assimilation
Quality ControlRetrieval of Unobserved
QuantitiesCreation of Gridded Fields
Prediction
PCs to Teraflop Systems
Product Generation, Display,
Dissemination
End Users
NWSPrivate Companies
Students
Conventional Numerical Weather Prediction
OBSERVATIONS
Radar DataMobile Mesonets
Surface ObservationsUpper-Air Balloons
Commercial AircraftGeostationary and Polar Orbiting
SatelliteWind ProfilersGPS Satellites
The process is entirely serialand pre-scheduled: no response
to weather!
The process is entirely serialand pre-scheduled: no response
to weather!

Analysis/Assimilation
Quality ControlRetrieval of Unobserved
QuantitiesCreation of Gridded Fields
Prediction
PCs to Teraflop Systems
Product Generation, Display,
Dissemination
End Users
NWSPrivate Companies
Students
The LEAD Vision: No Longer Serial or Static
OBSERVATIONS
Radar DataMobile Mesonets
Surface ObservationsUpper-Air Balloons
Commercial AircraftGeostationary and Polar Orbiting
SatelliteWind ProfilersGPS Satellites
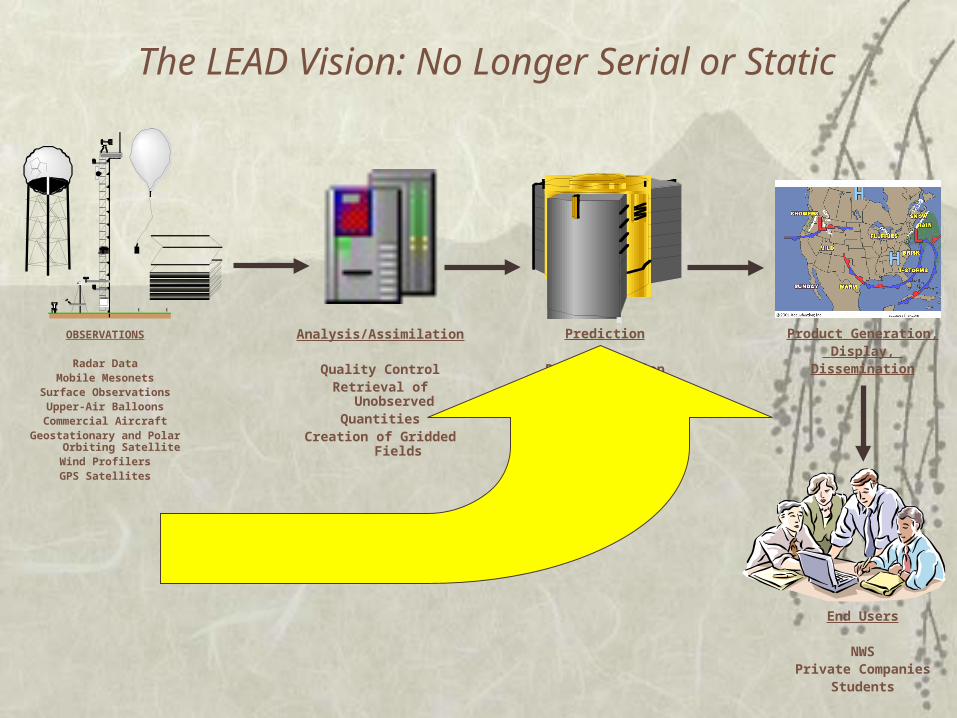
Analysis/Assimilation
Quality ControlRetrieval of Unobserved
QuantitiesCreation of Gridded Fields
Prediction
PCs to Teraflop Systems
Product Generation, Display,
Dissemination
End Users
NWSPrivate Companies
Students
The LEAD Vision: No Longer Serial or Static
OBSERVATIONS
Radar DataMobile Mesonets
Surface ObservationsUpper-Air Balloons
Commercial AircraftGeostationary and Polar Orbiting
SatelliteWind ProfilersGPS Satellites
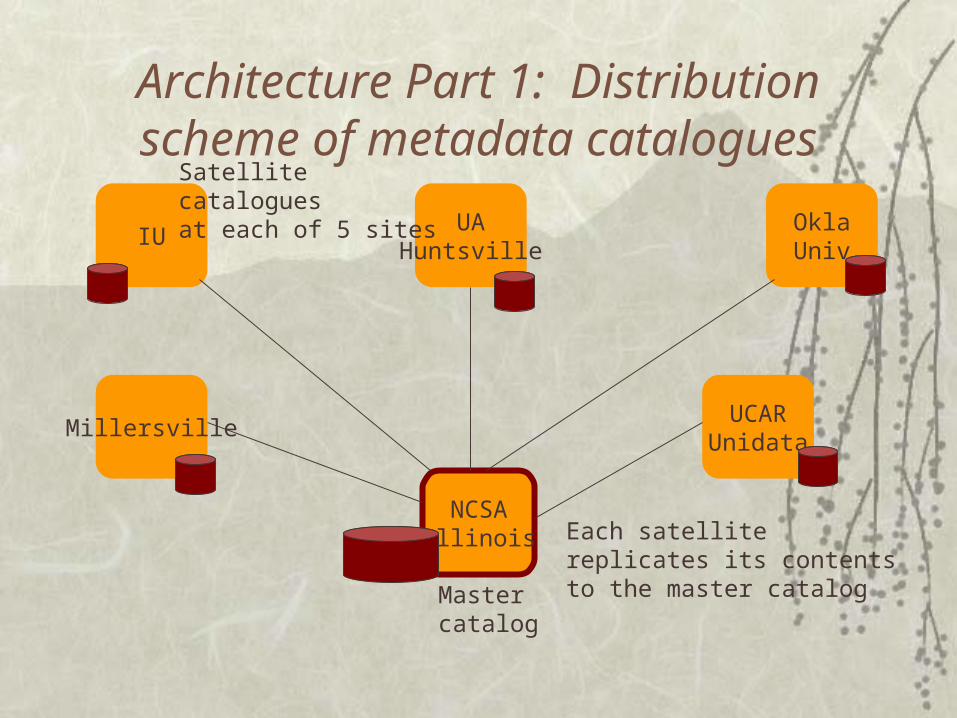
Architecture Part 1: Distribution scheme of metadata catalogues
IU
NCSAIllinois
UAHuntsville
MillersvilleUCAR
Unidata
OklaUniv
Master catalog
Satellite cataloguesat each of 5 sites
Each satellitereplicates its contentsto the master catalog
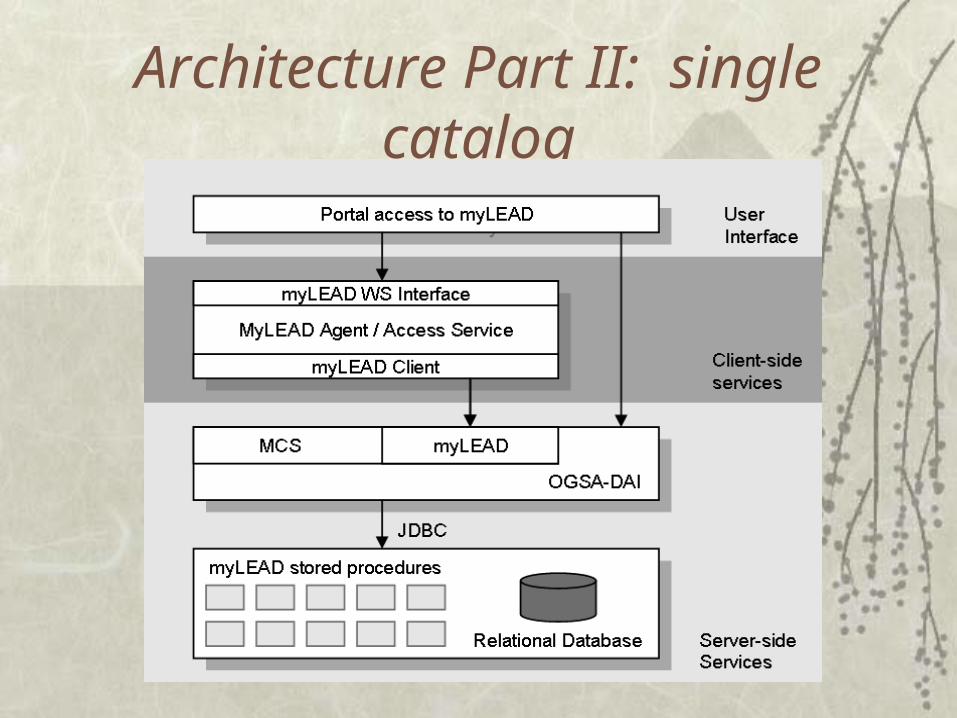
Architecture Part II: single catalog

Providing higher level functionality:
Structure, sharing, preservation, querying

Preservation
Sh
arin
gStructure
Depth 2: searchable
Depth 3: browsable
Do
es
no
t kn
ow
e
xist
en
ce
Flat structure
Tempo
rary
data
pro
duct
Versioning through time
Increasing levels of access
Increasing levelsof transparency
Axes of Functionality

Higher-level functionality: transparent structure
Structure -- creating structure in metadata catalog transparent to user, based on knowledge of control flow– Why? Want to hide as structure so user’s don’t
need to learn it and abide by it, but– Structure gives user more attributes to query on

Hurricane Ivan
SE OK quadrant
Vortice study 98-00
Input data sets
WRF output
Hurricane Ivan
SE OK quadrant
Vortice study 98-00
Workflow templates
150.nc
Input data sets
Hurricane Ivan
SE OK quadrant
Vortice study 98-00
ftp://storageserver.org/file1998o768
Bob’s workspace (Dec 04) Bob’s workspace (Feb 05) Bob’s workspace (Mar 05)
Physical data storage
Table of collection
Table of file
Table of User
Metadata Catalog
Experim-Dec04
Experim-Feb05
Experim-Dec04
Experim-Feb05
001.nc. . .
WRF output filesPublished results
Capturing process in the structure

Example Query: contains structure, but only vaguely
LeadQuery:
SELECT TARGET = collection
WHERE collection.date = “February 20, 2005”
WITHIN experiment.name = “mytest1” and
CONTAINS (file.type = “GOES” or file.type = “Eta”) and
file.geoProperty = “precipitation”
RECURSIVE
ResultSet:
TARGET_ONLY
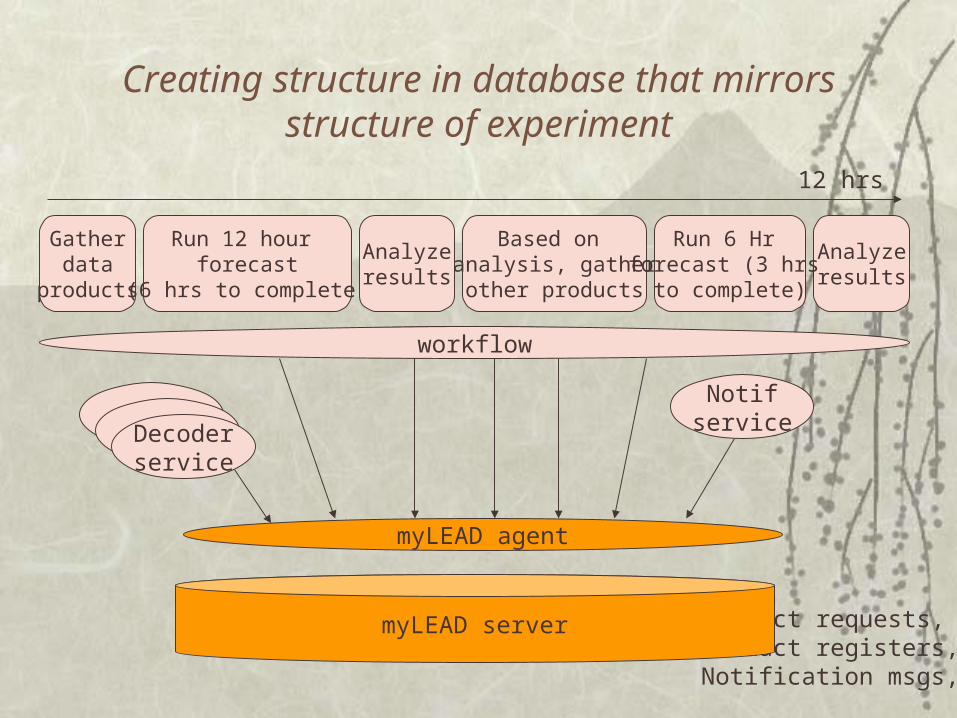
Creating structure in database that mirrors structure of experiment
workflow
myLEAD agent
Product requests,Product registers,Notification msgs,
myLEAD server
Gatherdata
products
workflow
Run 12 hour forecast
(6 hrs to complete)
Analyzeresults
Based on analysis, gatherother products
Analyzeresults
Run 6 Hr forecast (3 hrs
to complete)
12 hrs
Decoderservice
Notifservice

Higher level functionality: sharing
Depth-0: participant (P) is unaware that experiment data (E) owned by user (U) exists
Depth-1: P is aware that E exists Depth-2: P can search E Depth-3: P can browse the content of E Depth-4: P can access E and its contents Depth-5: P can remove and write E


Experimental evaluation

Experiment environment
myLEAD client: dual processor Dell PowerEdge 6400 Xeon server (700 MHz Pentium III), 2GF RAM, 100 GB Raid 5, RedHat 7.2, JDK 1.4.2
myLEAD server: dual processor 2.0 MHz Opterons, 16BGRAM, GENTOO Linux, OGSA-DAI 3.0, Globus MCS 3.1, mysql 5.0.
LAN: 1Gbps switched Ethernet
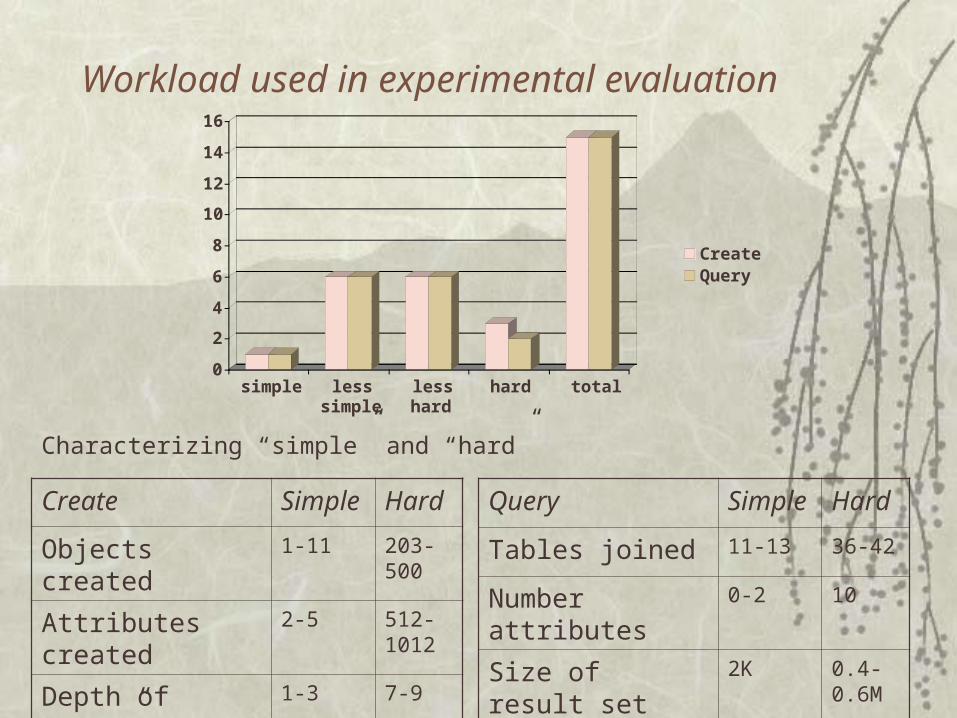
Workload used in experimental evaluation
0
2
4
6
8
10
12
14
16
simple lesssimple
lesshard
hard total
CreateQuery
Create Simple Hard
Objects created 1-11 203-500
Attributes created 2-5 512-1012
Depth of “tree” 1-3 7-9
Query Simple Hard
Tables joined 11-13 36-42
Number attributes 0-2 10
Size of result set 2K 0.4-0.6M
Characterizing “simple” and “hard”
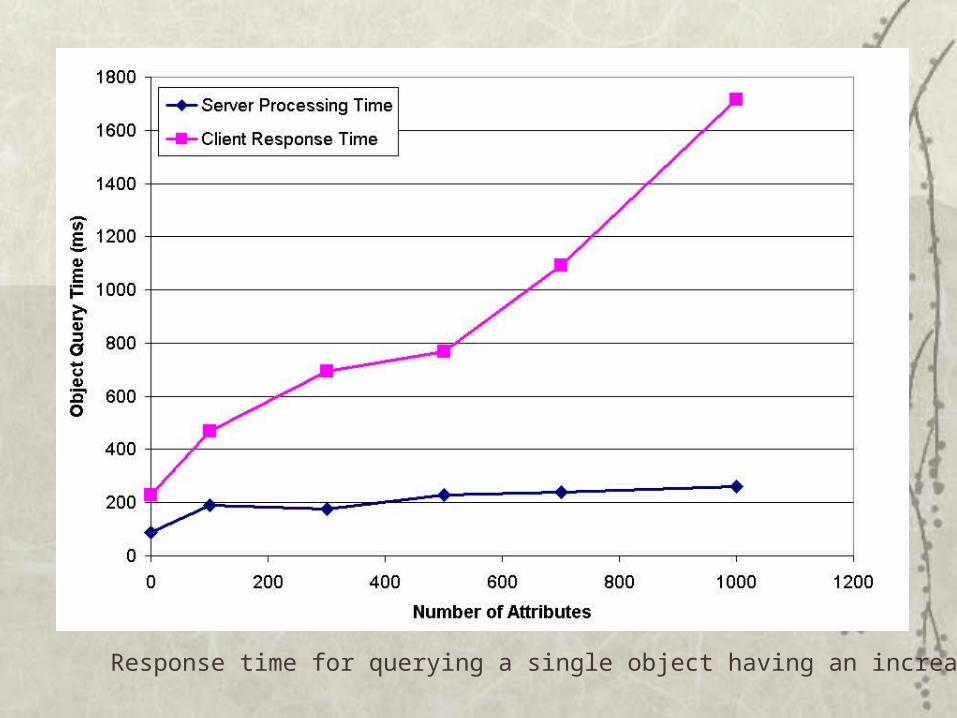
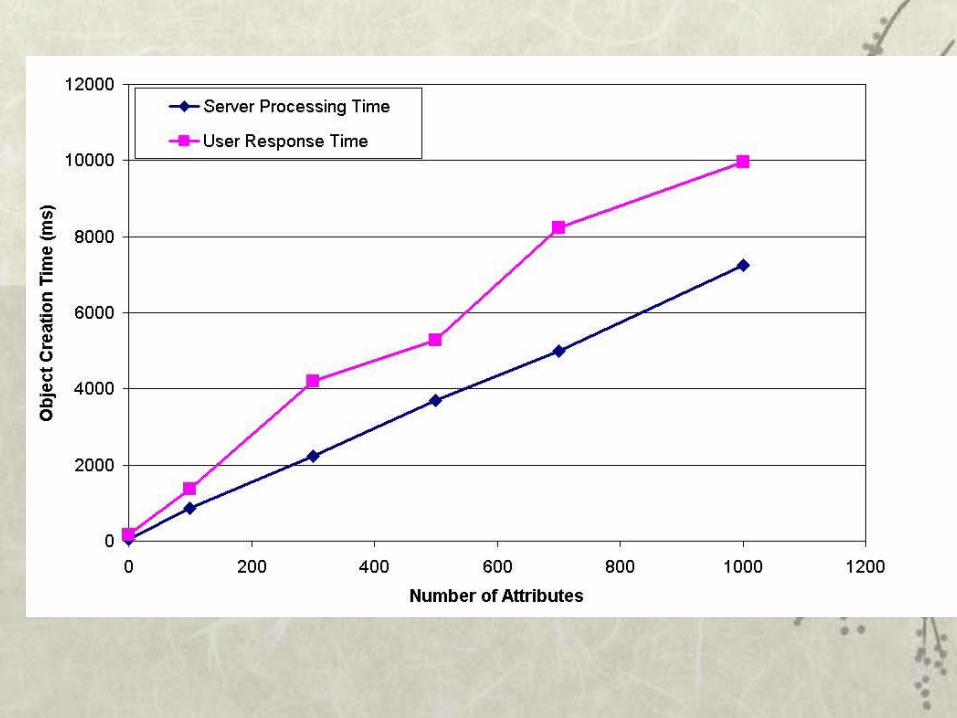
Response time for querying a single object having an increasing

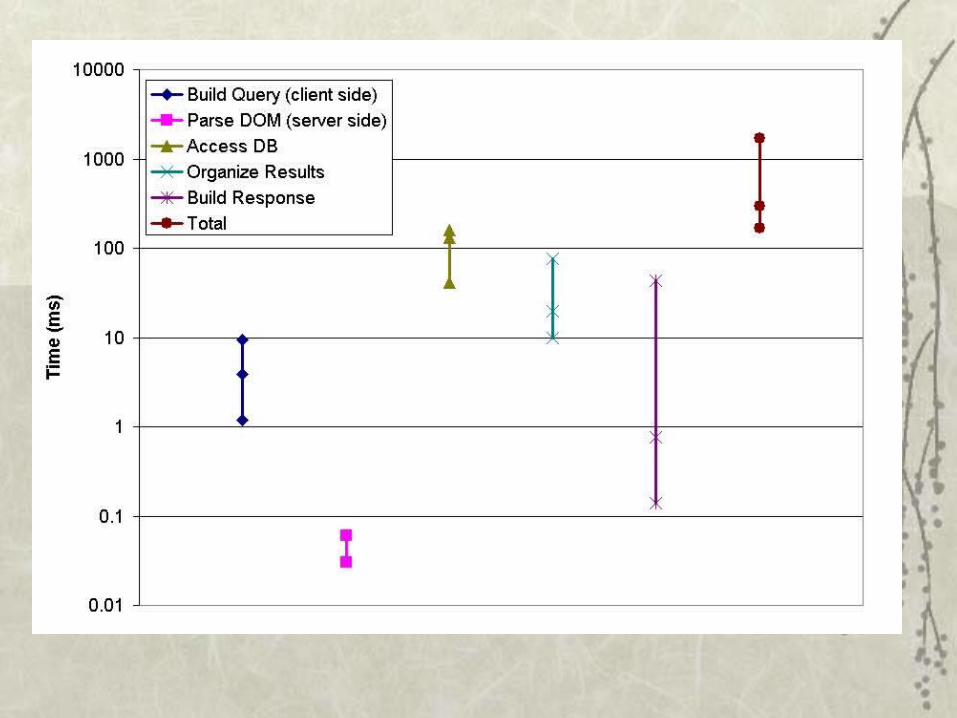

Related Work myGrid
– Intelligent Systems for Molecular Biology 2003
mySpace– UK e-Science All Hands Meeting 2003
NEESgrid metadata catalog– NEESGrid technical report 2004
Roma personal metadata service – Mobile Networks and Applications 2002
Presto Document System – User Interface Software and Technology 1999
Semantic File Systems– SOSP 1991


The end

Seeds of solution in Internet? Internet has proven the utility of user-oriented view towards
information space management– Search, tag: browser, bookmarks– Publish: blogs, web page tools
But web not completely appropriate. Web is– Single-writer, multiple reader, and– Search-and-download.
Apply concept of user-oriented view to managing data space Want ability to work locally.
– myLEAD: tool to help an investigator make sense of, and operate in, the vast information space that is computational science (e.g., mesoscale meteorology.)





























