Embed Size (px)
Citation preview

Adders
Lecture 12CS301
Administrative
• Read Appendix C.5, C.7-C.10• Program #1 due 10/24

FP Bias
• Infinity is represented asw exponent is all 1sw significand is all 0s
Review
• MUX
• DeMux
• Decoder
• Encoder

Combinational Logic
• Half-Adderw No carry in A B Sum Carry
Out 0 0 0 0 0 1 1 0 1 0 1 0 1 1 0 1
A⊕B AB
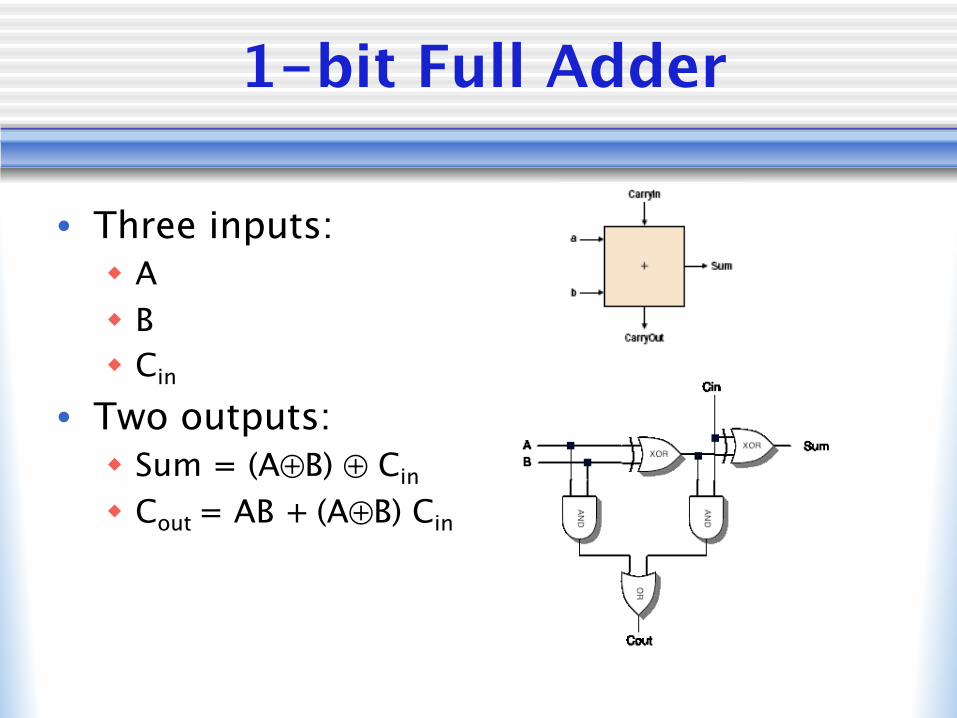
1-bit Full Adder
• Three inputs:w Aw Bw Cin
• Two outputs:w Sum = (A⊕B) ⊕ Cin
w Cout = AB + (A⊕B) Cin
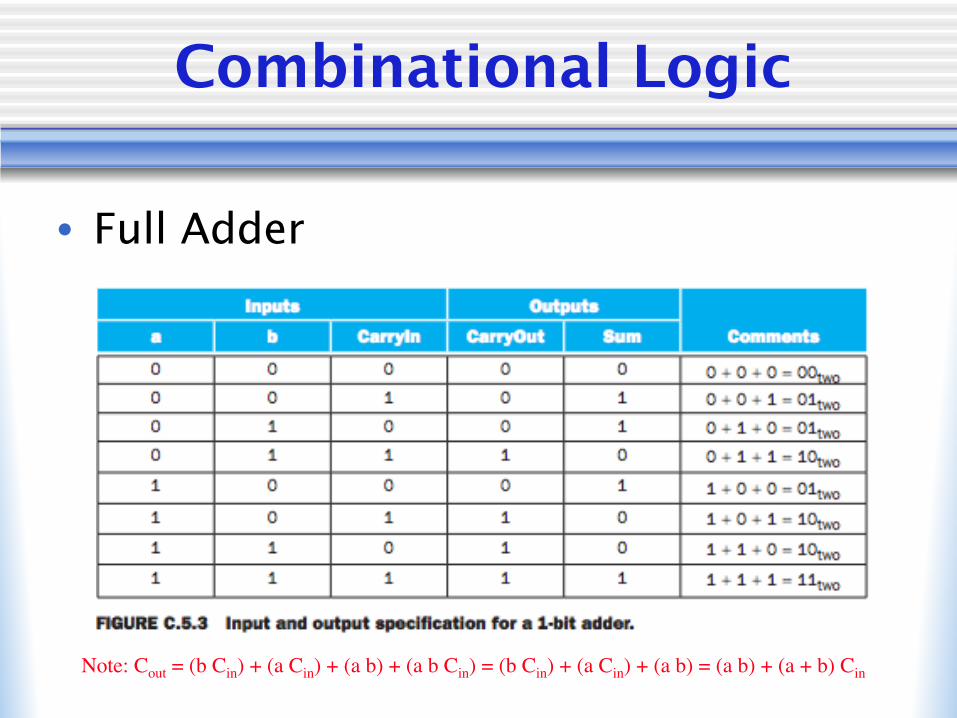
Combinational Logic
• Full Adder
Note: Cout = (b Cin) + (a Cin) + (a b) + (a b Cin) = (b Cin) + (a Cin) + (a b) = (a b) + (a + b) Cin

Ripple Carry Adder
• Construct n-bit adder with n 1-bit adders
• Delay is problem• Faster alternative:
w Carry-lookahead adder

Designing connections
• Problem: Ripple-carry adder is too sloww Each carry must wait for all previous units
to complete execution• Solution:

Designing connections
• Problem: Ripple-carry adder is too sloww Each carry must wait for all previous units
to complete execution• Solution:
w Quickly get information for carriesw Compute carries in parallel

1b Adder
• Three inputs:w Aw Bw Cin
• Two outputs:w Sum = (A⊕B) ⊕ Cin
w Cout = AB + (A⊕B) Cinw Cout = AB + ACin +
BCin

Carry Look-ahead
We already know:ci+1 = (bi � ci) + (ai � ci) + (ai � bi)
= (ai � bi) + ci � (ai + bi)

Carry Look-ahead
We already know:ci+1 = (bi � ci) + (ai � ci) + (ai � bi)
= (ai � bi) + ci � (ai + bi)
= Gi + Ci � PiLet’s calculate ci+1 without waiting for ci
Generate Propagate
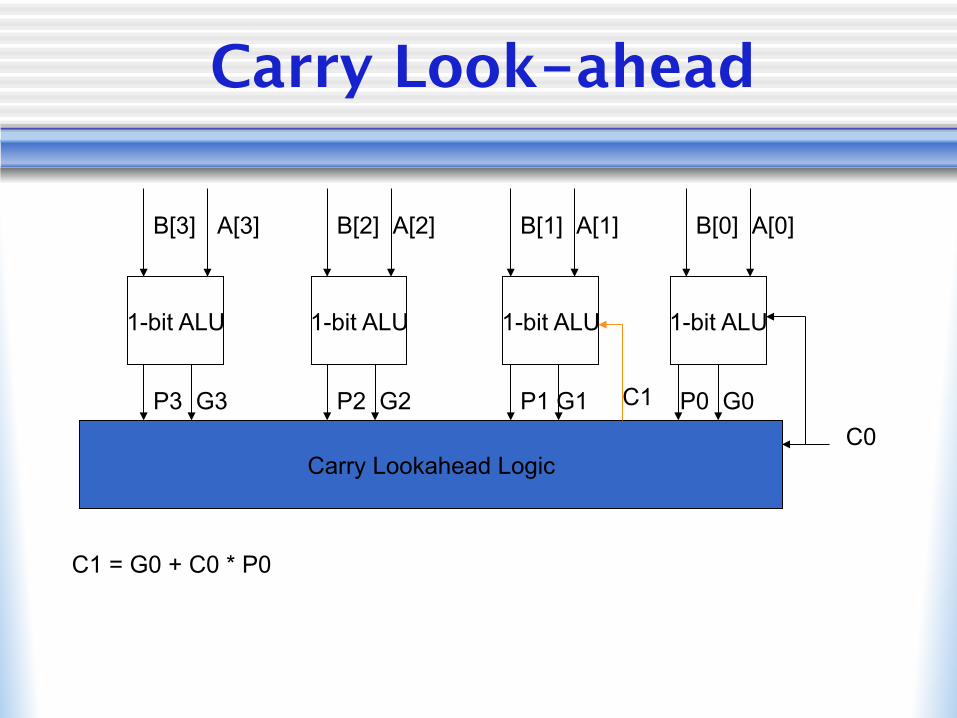
Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
P3 G3 P2 G2 P1 G1 P0 G0
Carry Lookahead Logic C0
C1 = G0 + C0 * P0
C1

Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
P3 G3 P2 G2 P1 G1 P0 G0
Carry Lookahead Logic C0
C1 = G0 + C0 * P0
C1
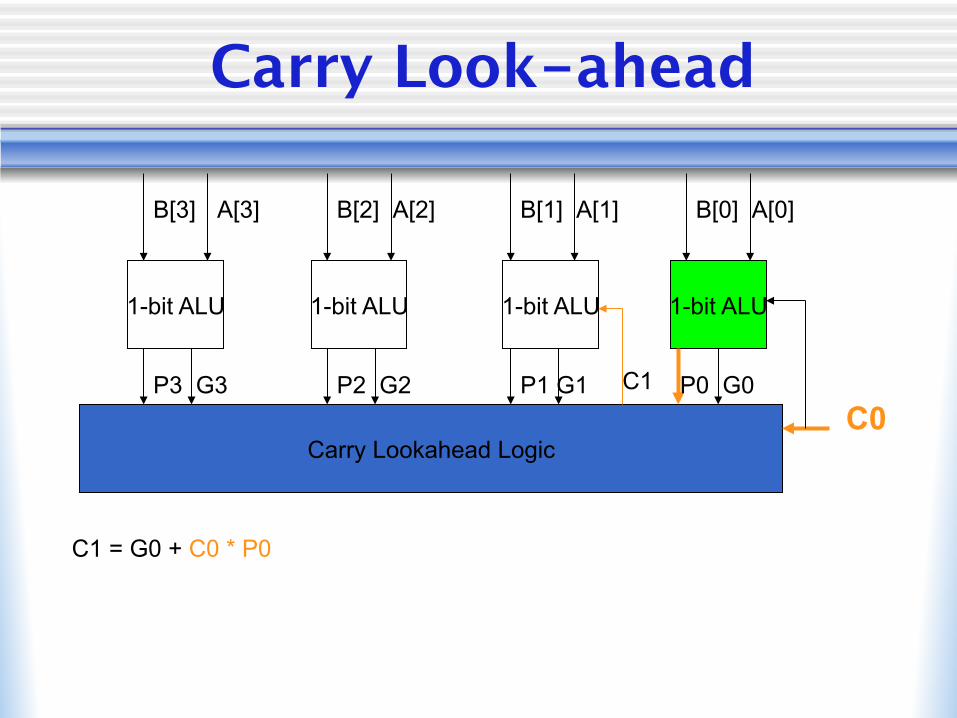
Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Lookahead Logic C0
C1 = G0 + C0 * P0
P3 G3 P2 G2 P1 G1 P0 G0 C1
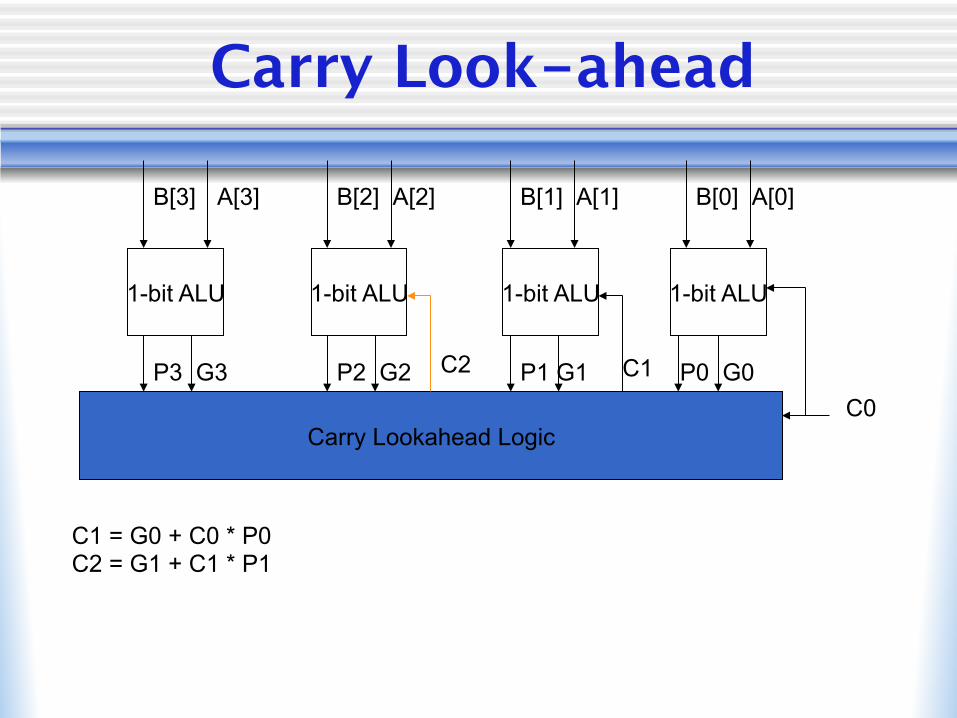
Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Lookahead Logic C0
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2
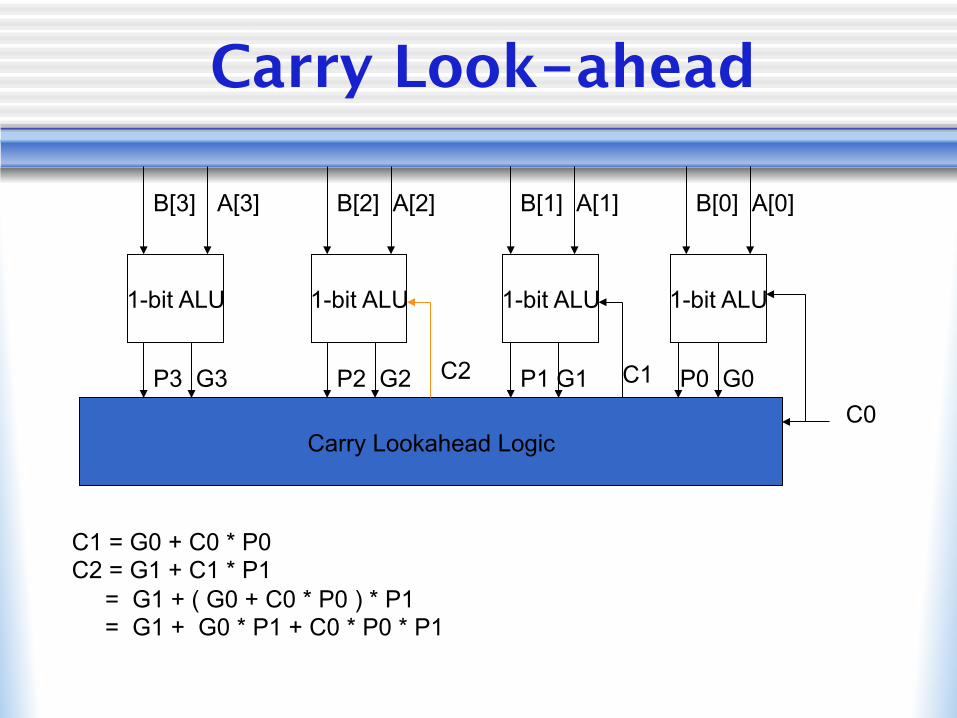
Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Lookahead Logic C0
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1 = G1 + ( G0 + C0 * P0 ) * P1 = G1 + G0 * P1 + C0 * P0 * P1
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2
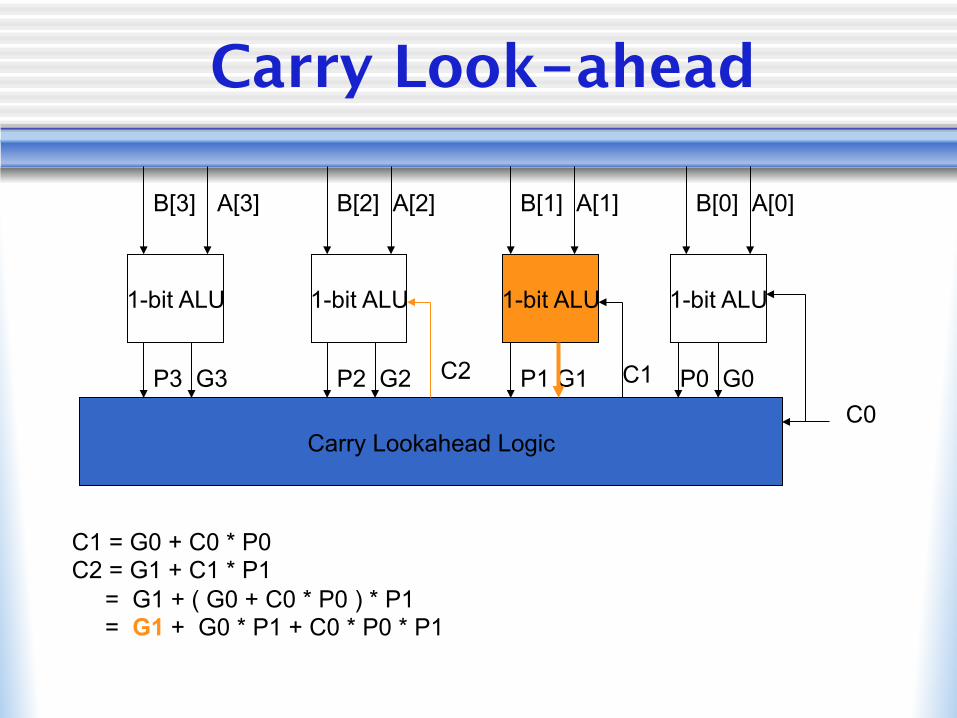
Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Lookahead Logic C0
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1 = G1 + ( G0 + C0 * P0 ) * P1 = G1 + G0 * P1 + C0 * P0 * P1
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2

Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Lookahead Logic C0
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1 = G1 + ( G0 + C0 * P0 ) * P1 = G1 + G0 * P1 + C0 * P0 * P1
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2
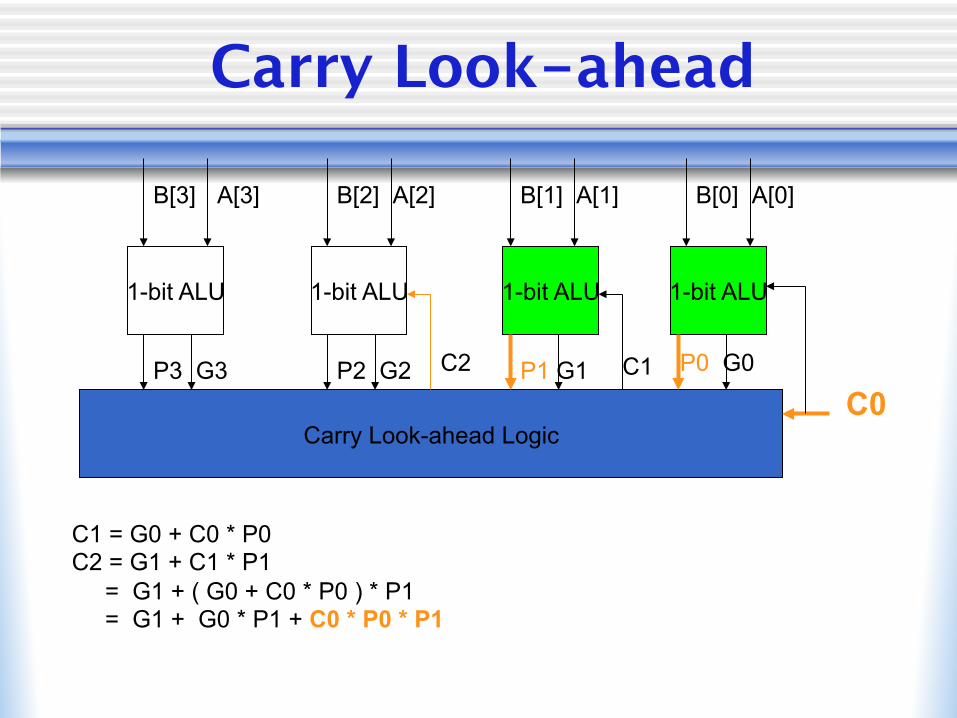
Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Look-ahead Logic C0
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1 = G1 + ( G0 + C0 * P0 ) * P1 = G1 + G0 * P1 + C0 * P0 * P1
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2
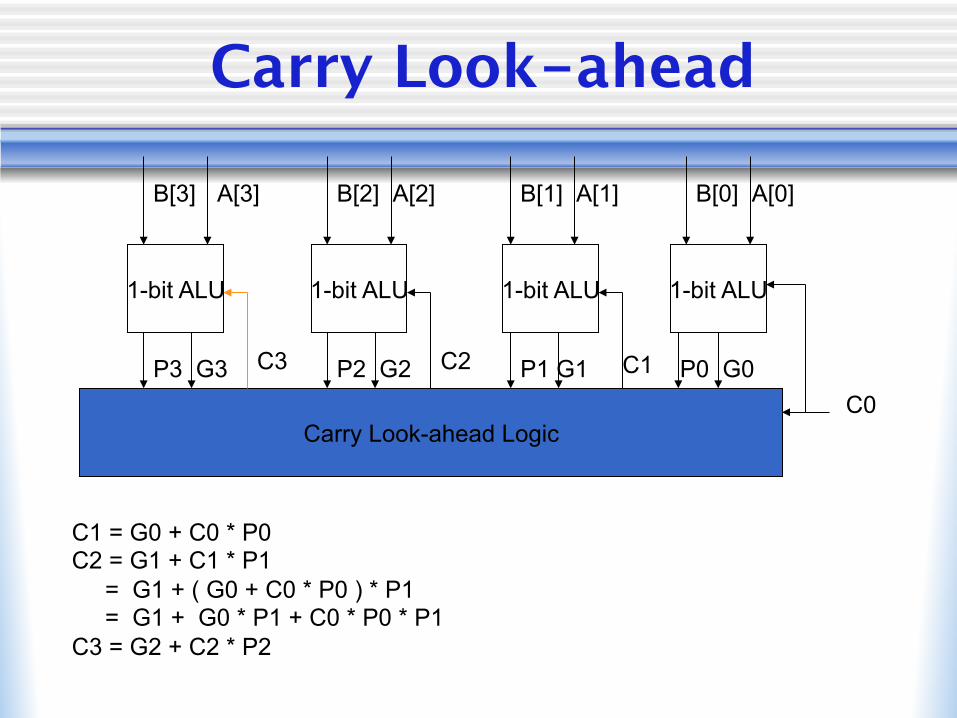
Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Look-ahead Logic C0
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1 = G1 + ( G0 + C0 * P0 ) * P1 = G1 + G0 * P1 + C0 * P0 * P1 C3 = G2 + C2 * P2
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2 C3
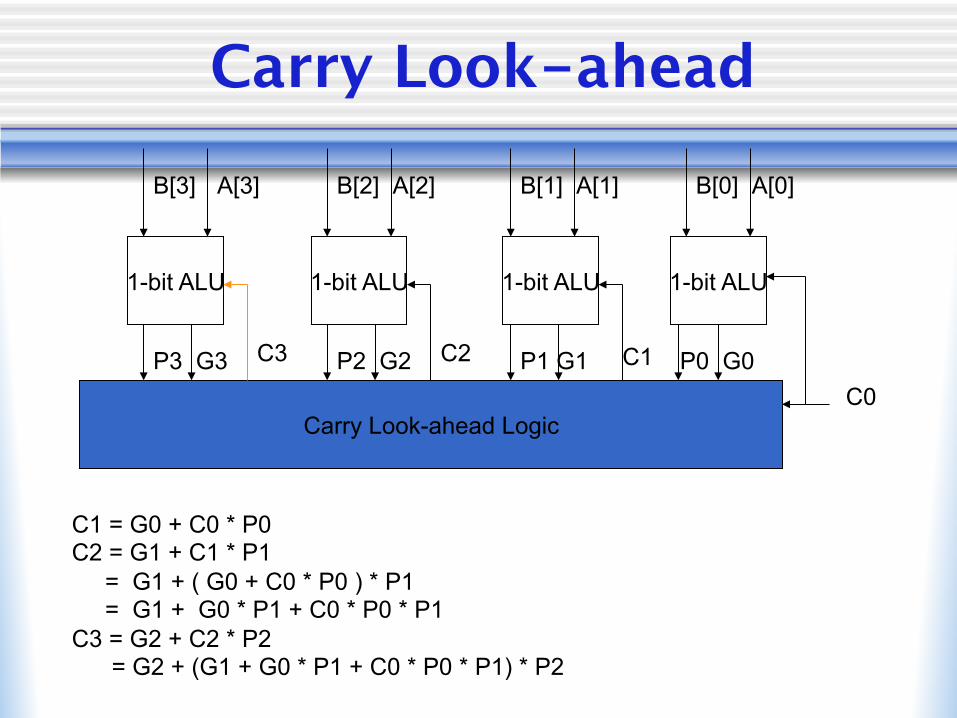
Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Look-ahead Logic C0
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1 = G1 + ( G0 + C0 * P0 ) * P1 = G1 + G0 * P1 + C0 * P0 * P1 C3 = G2 + C2 * P2 = G2 + (G1 + G0 * P1 + C0 * P0 * P1) * P2
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2 C3

Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Look-ahead Logic C0
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1 = G1 + ( G0 + C0 * P0 ) * P1 = G1 + G0 * P1 + C0 * P0 * P1 C3 = G2 + C2 * P2 = G2 + (G1 + G0 * P1 + C0 * P0 * P1) * P2 = G2 + G1 * P2 + G0 * P1 * P2 + C0 * P0 * P1 * P2
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2 C3
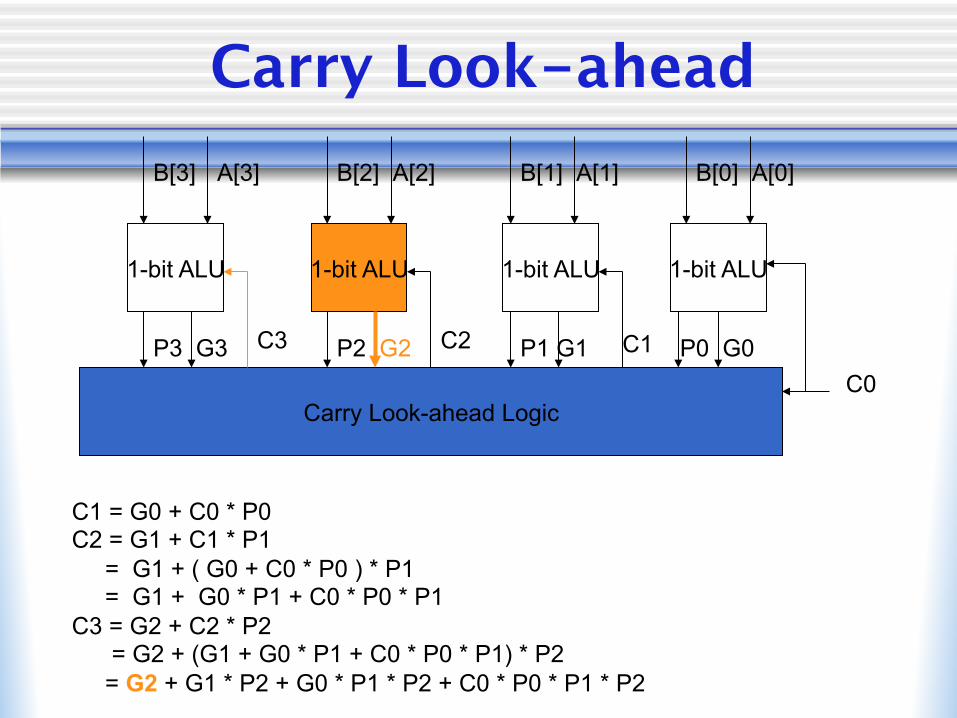
Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Look-ahead Logic C0
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1 = G1 + ( G0 + C0 * P0 ) * P1 = G1 + G0 * P1 + C0 * P0 * P1 C3 = G2 + C2 * P2 = G2 + (G1 + G0 * P1 + C0 * P0 * P1) * P2 = G2 + G1 * P2 + G0 * P1 * P2 + C0 * P0 * P1 * P2
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2 C3

Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Look-ahead Logic C0
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1 = G1 + ( G0 + C0 * P0 ) * P1 = G1 + G0 * P1 + C0 * P0 * P1 C3 = G2 + C2 * P2 = G2 + (G1 + G0 * P1 + C0 * P0 * P1) * P2 = G2 + G1 * P2 + G0 * P1 * P2 + C0 * P0 * P1 * P2
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2 C3

Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Look-ahead Logic C0
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1 = G1 + ( G0 + C0 * P0 ) * P1 = G1 + G0 * P1 + C0 * P0 * P1 C3 = G2 + C2 * P2 = G2 + (G1 + G0 * P1 + C0 * P0 * P1) * P2 = G2 + G1 * P2 + G0 * P1 * P2 + C0 * P0 * P1 * P2
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2 C3
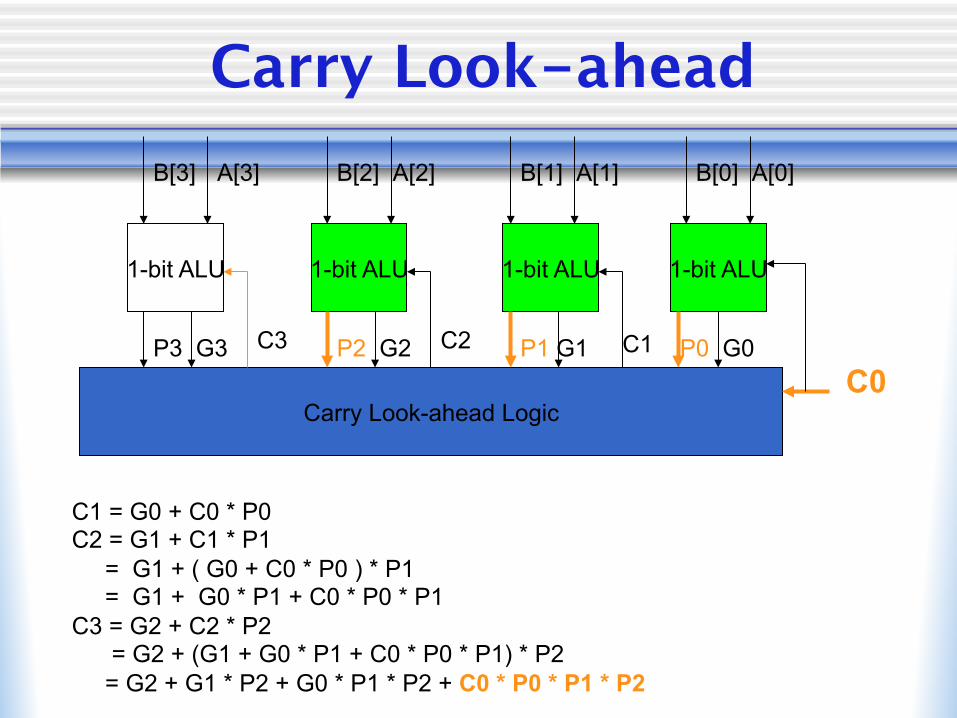
Carry Look-ahead
1-bit ALU 1-bit ALU 1-bit ALU 1-bit ALU
B[3] B[2] B[1] B[0] A[3] A[2] A[1] A[0]
Carry Look-ahead Logic C0
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1 = G1 + ( G0 + C0 * P0 ) * P1 = G1 + G0 * P1 + C0 * P0 * P1 C3 = G2 + C2 * P2 = G2 + (G1 + G0 * P1 + C0 * P0 * P1) * P2 = G2 + G1 * P2 + G0 * P1 * P2 + C0 * P0 * P1 * P2
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2 C3

Why is it Faster?


Why is it Faster?
• 4th bit waits only for p&g to be calculated, not all of the computations from bits 0-2
• Only three levels of computation
w Gi and Piw ANDw OR
C1 = G0 + C0 * P0 C2 = G1 + C1 * P1 = G1 + ( G0 + C0 * P0 ) * P1 = G1 + G0 * P1 + C0 * P0 * P1 C3 = G2 + C2 * P2 = G2 + (G1 + G0 * P1 + C0 * P0 * P1) * P2 = G2 + G1 * P2 + G0 * P1 * P2 + C0 * P0 * P1 * P2
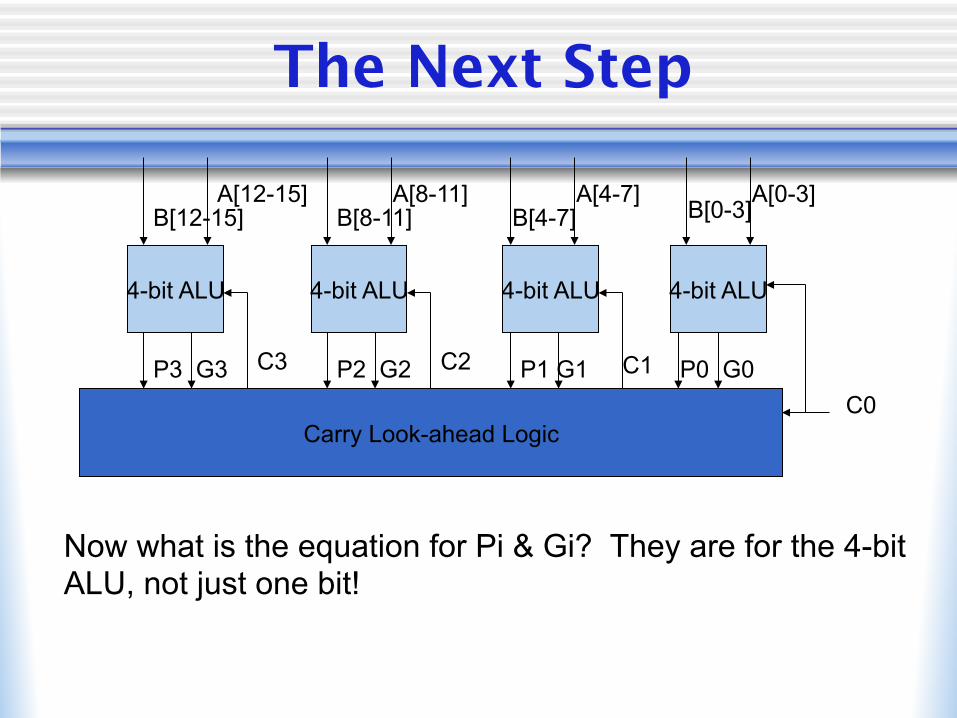
The Next Step
4-bit ALU 4-bit ALU 4-bit ALU 4-bit ALU
B[12-15] B[8-11] B[4-7] B[0-3] A[12-15] A[8-11] A[4-7] A[0-3]
Carry Look-ahead Logic C0
P3 G3 P2 G2 P1 G1 P0 G0 C1 C2 C3
Now what is the equation for Pi & Gi? They are for the 4-bit ALU, not just one bit!
Basic Memory Cells and Sequential Logic

Sequential Logic and Clocks
• Sequential logic retains state• Clocks specify when that state should
be updated• System using clocks called
synchronous
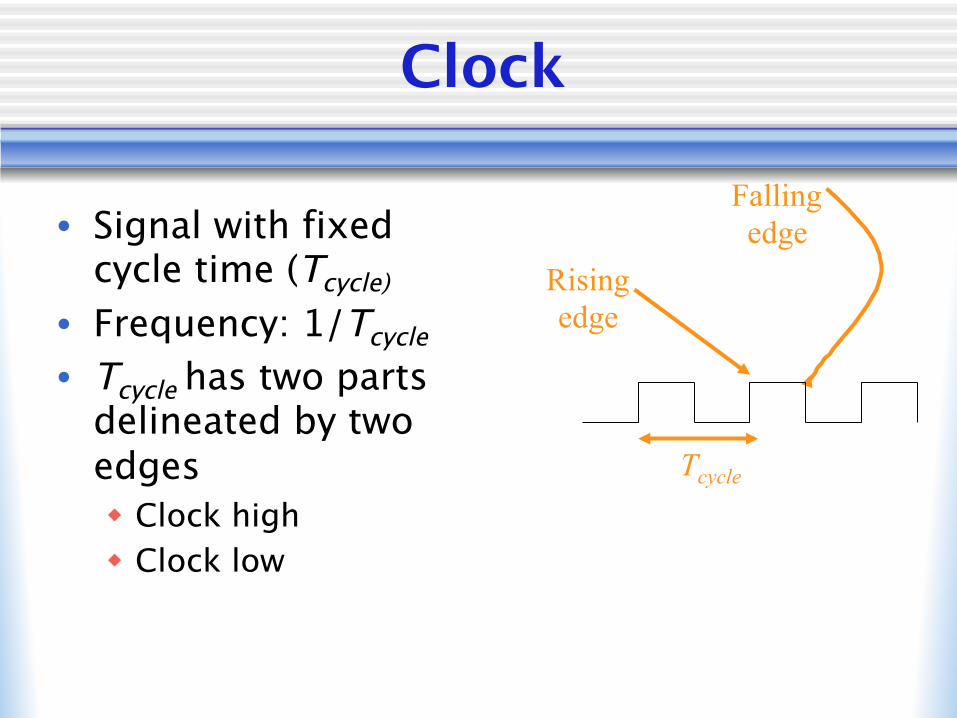
Clock
• Signal with fixed cycle time (Tcycle)
• Frequency: 1/Tcycle• Tcycle has two parts
delineated by two edgesw Clock highw Clock low
Tcycle
Rising edge
Falling edge
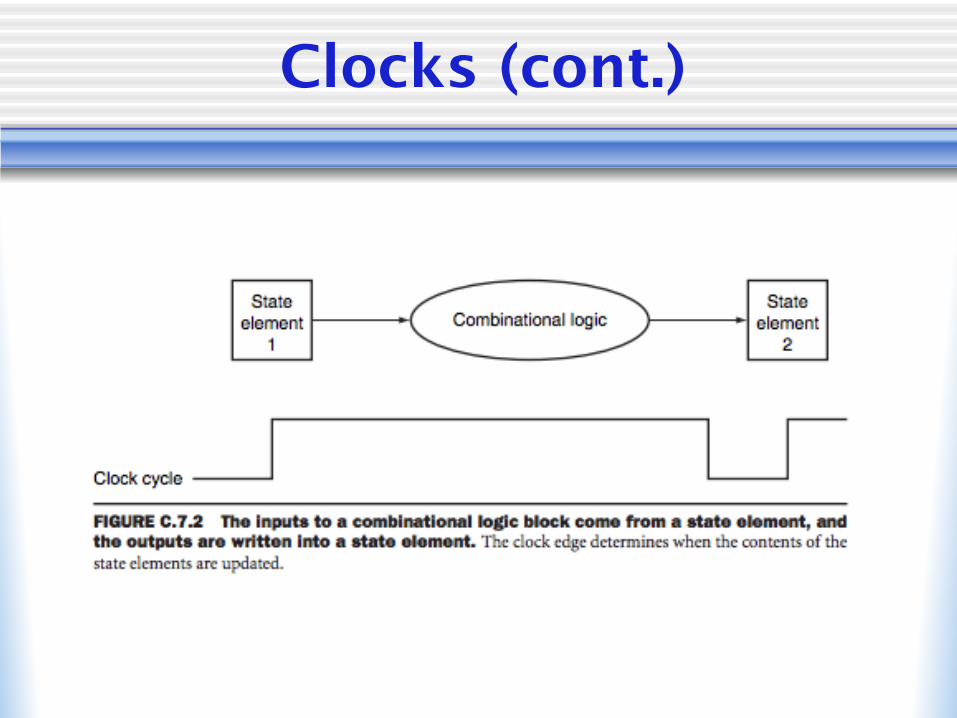
Clocks (cont.)

Memory Elements
• All memory elements store statew Output depends both on inputs and the
value stored inside the memory element• Thus: All logic blocks containing
memory elements contain state and are sequential!
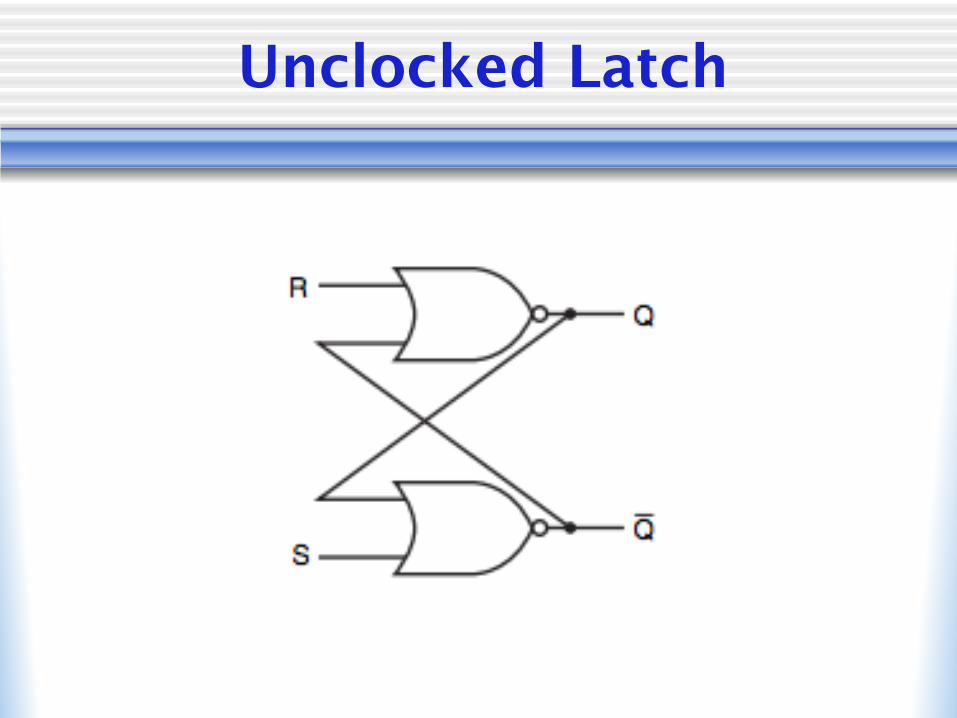
Unclocked Latch

Clocked Latch
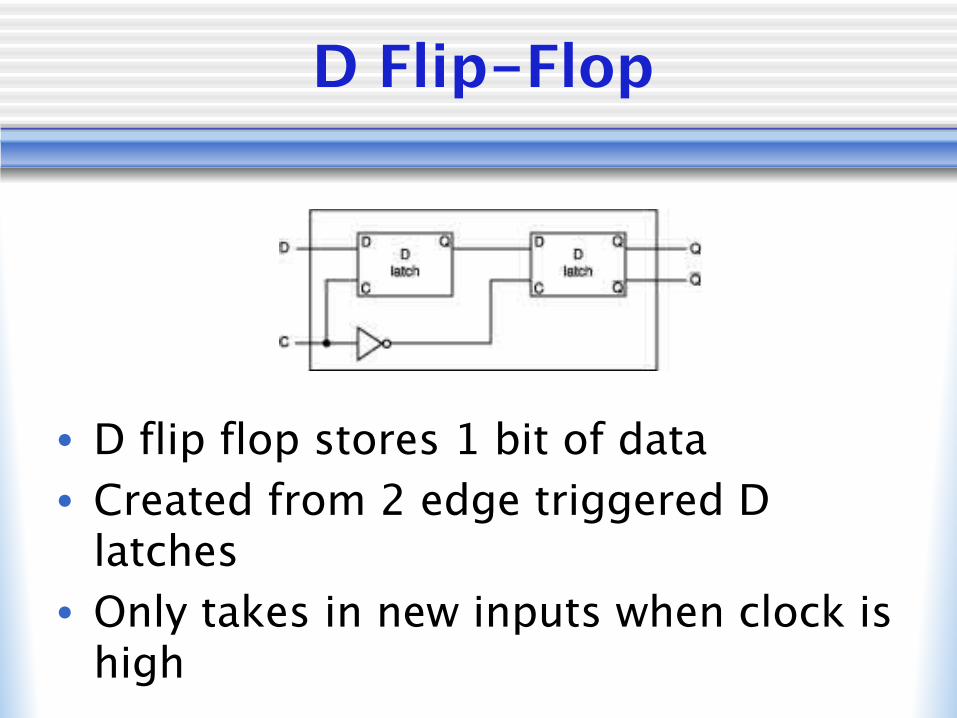
D Flip-Flop
• D flip flop stores 1 bit of data• Created from 2 edge triggered D
latches• Only takes in new inputs when clock is
high

Register
• D flip-flop allows us to store 1 bit• Programmers don’t programming in bits, but
w char = 8 bw integer = 32 bw ...
• String n D flip-flops together to store n bits
4b register implement with D flip-flops
b3 b2 b1 b0

Register Files
• Contains set of registers accessed by register numw Input: register
numberw Output: data in
registern entry register file

Register Files
• Componentsw Array of registers built
from flip-flops• Port
w Access pointw Read port
§ register numw Write port
§ register num, clock, data
2 read ports / 1 write port

Register File:Read Ports

Register File:Write Port

Comparator
• Comparator has three output linesw A<Bw A=Bw A>B

Comparator
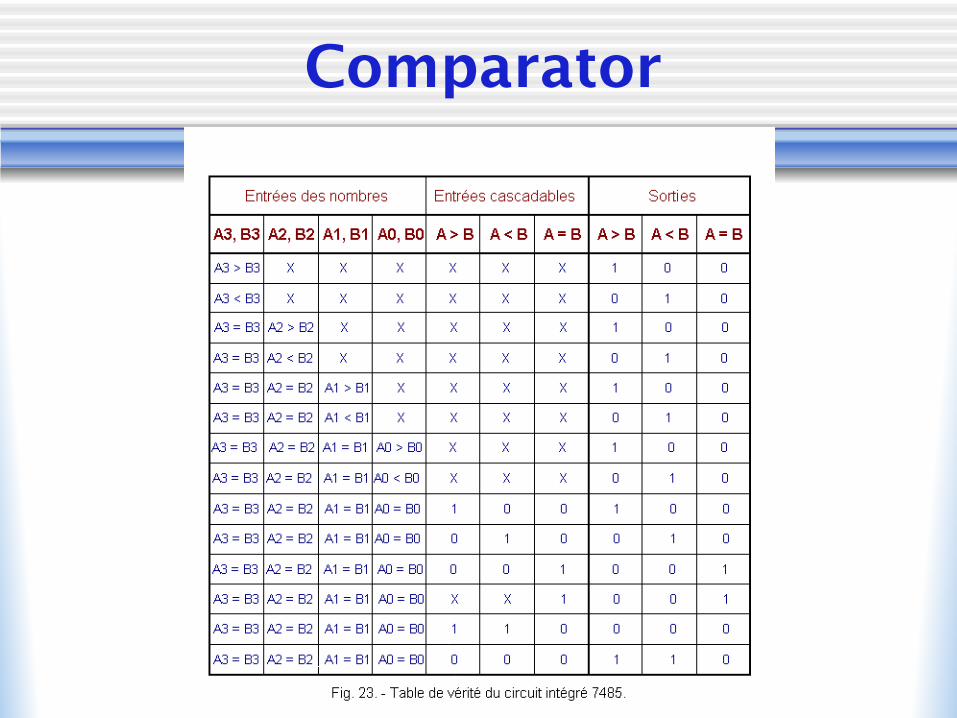
Comparator

Comparator

We Almost Have All the Pieces
• Inverter, AND, OR• Multiplexor and demultiplexor• Decode and encoder• Comparator• Ripple carry adder and carry lookahead adder
w Half and full adder• Register file
w Registersw D flip flop

Arithmetic Logic Unit
• Circuitry that does arithmetic (+/-) and logical operations (AND/OR)
• MIPS has 32b quantities so ALU needs to handle 32b numbers
• Combine 32 1-b ALUs to create 32b ALU
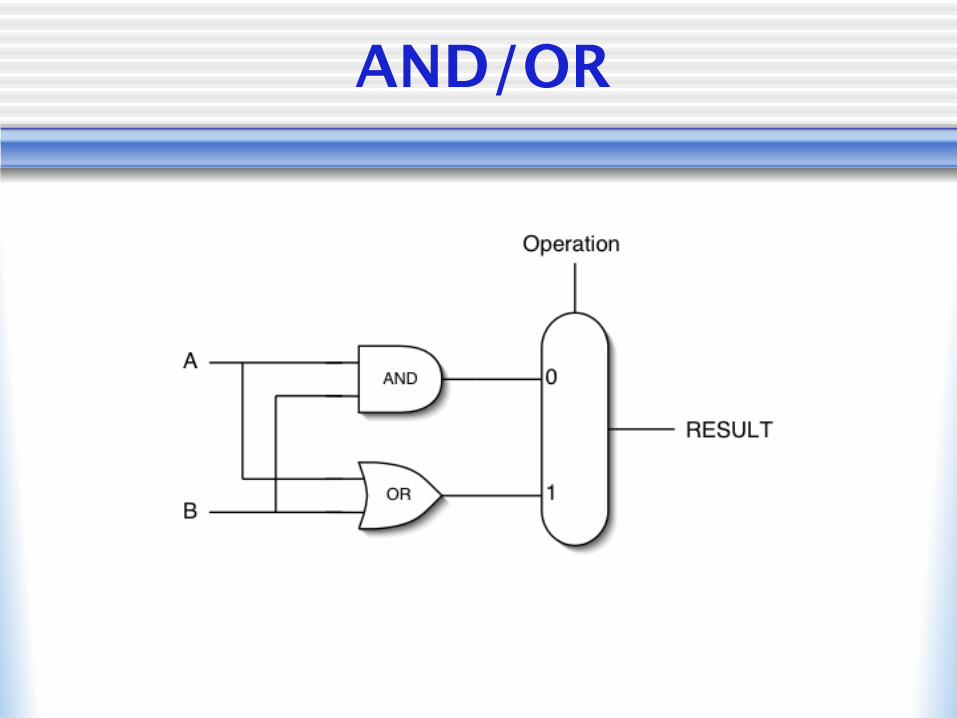
AND/OR
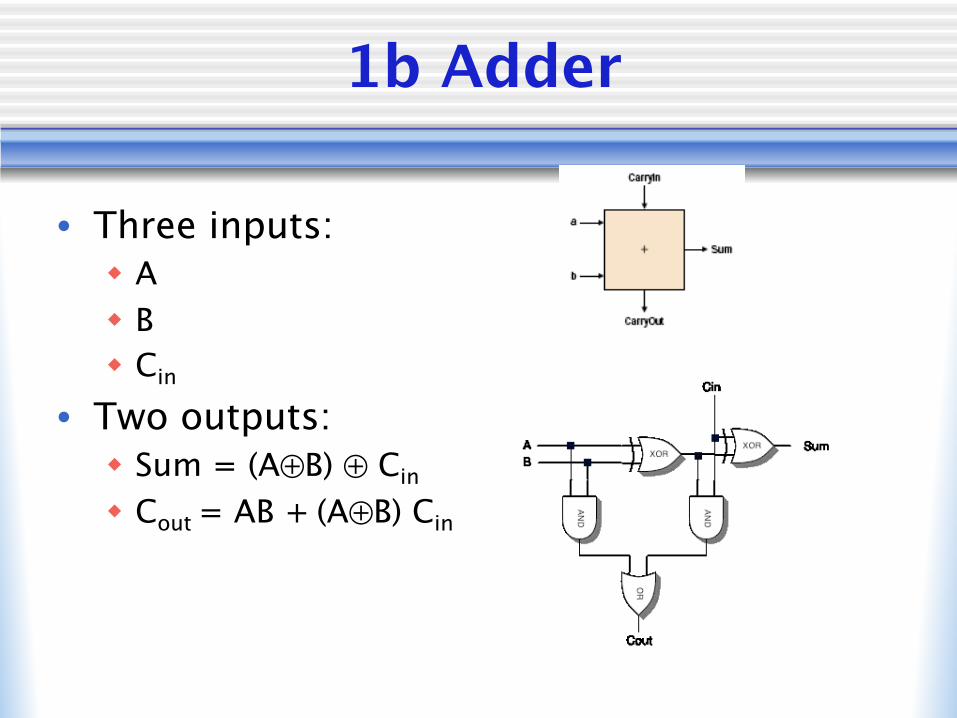
1b Adder
• Three inputs:w Aw Bw Cin
• Two outputs:w Sum = (A⊕B) ⊕ Cin
w Cout = AB + (A⊕B) Cin

1b ALU

32b ALU
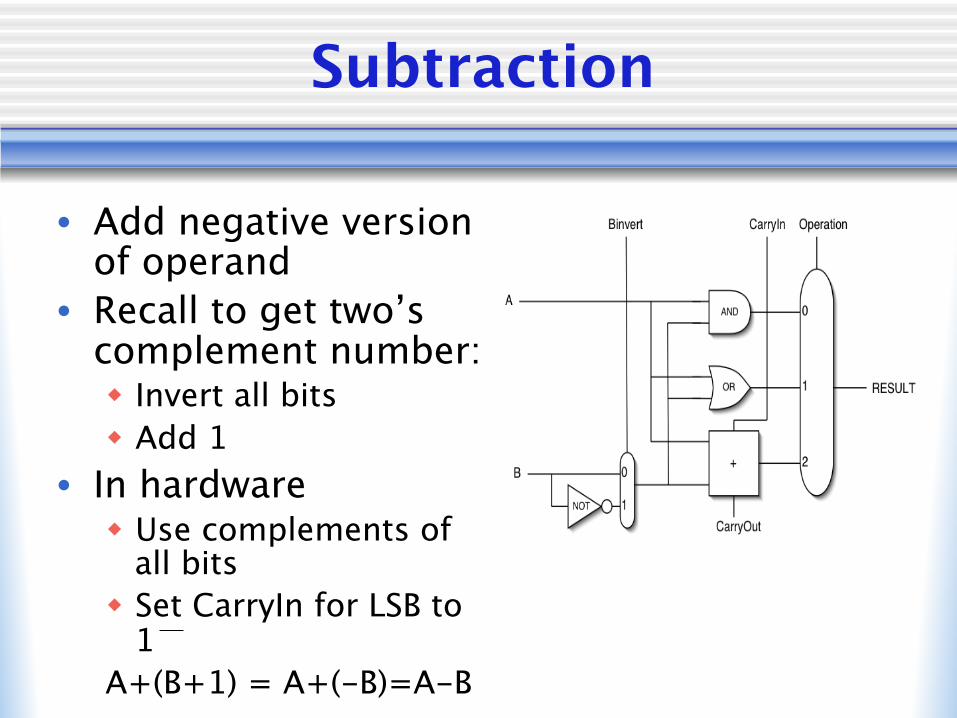
Subtraction
• Add negative version of operand
• Recall to get two’s complement number:w Invert all bitsw Add 1
• In hardwarew Use complements of
all bitsw Set CarryIn for LSB to
1A+(B+1) = A+(-B)=A-B
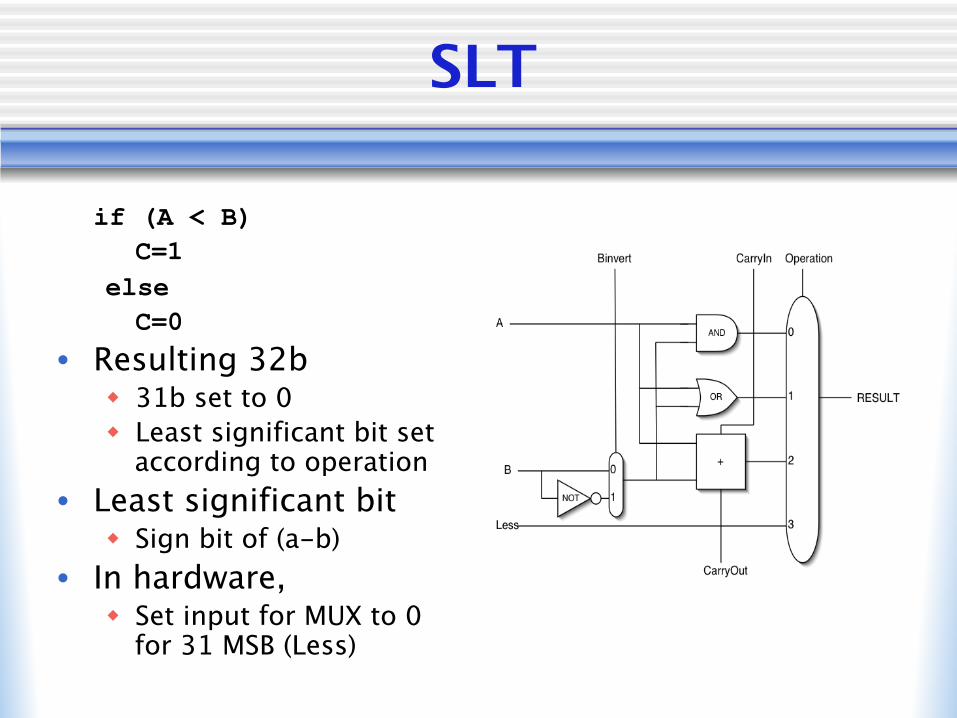
SLT
if (A < B) C=1 else C=0
• Resulting 32bw 31b set to 0w Least significant bit set
according to operation• Least significant bit
w Sign bit of (a-b)• In hardware,
w Set input for MUX to 0 for 31 MSB (Less)
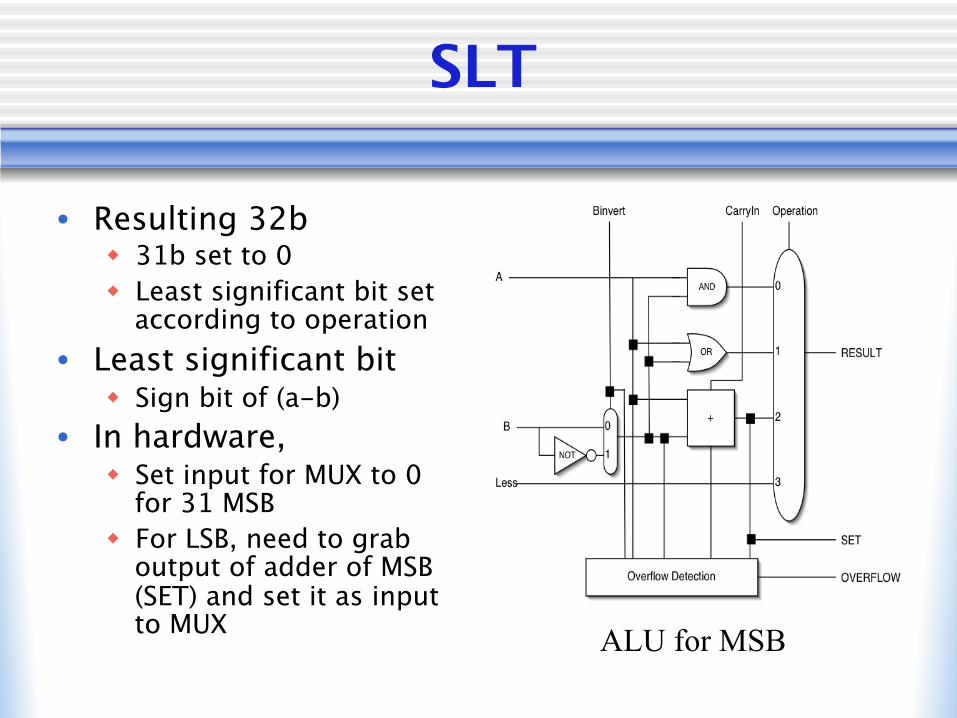
SLT
• Resulting 32bw 31b set to 0w Least significant bit set
according to operation• Least significant bit
w Sign bit of (a-b)• In hardware,
w Set input for MUX to 0 for 31 MSB
w For LSB, need to grab output of adder of MSB (SET) and set it as input to MUX ALU for MSB

32b ALU w/ SLT
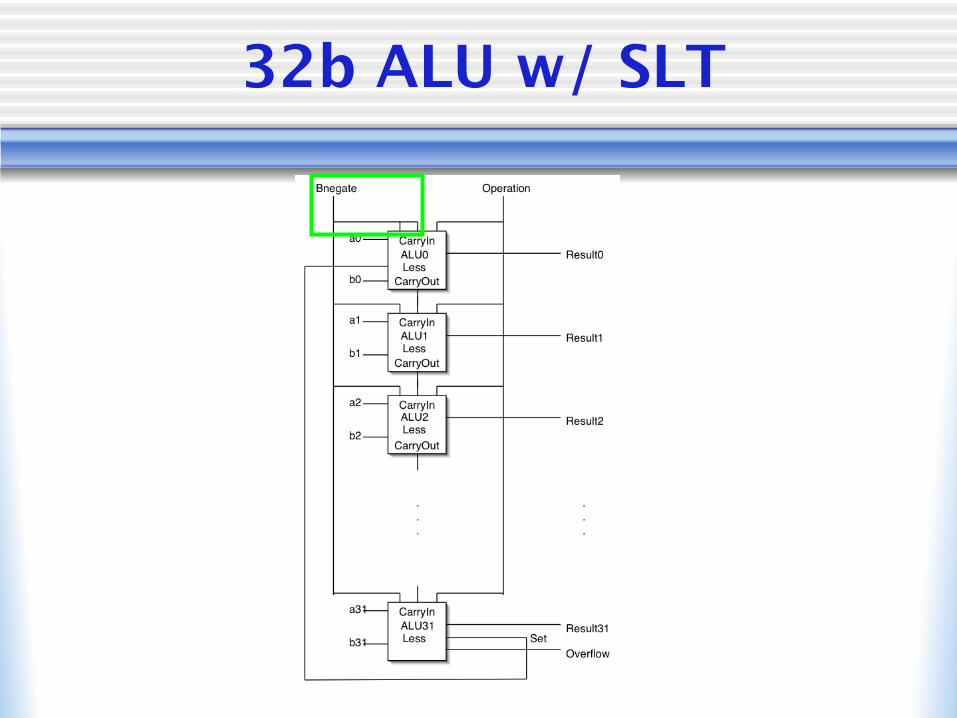
32b ALU w/ SLT
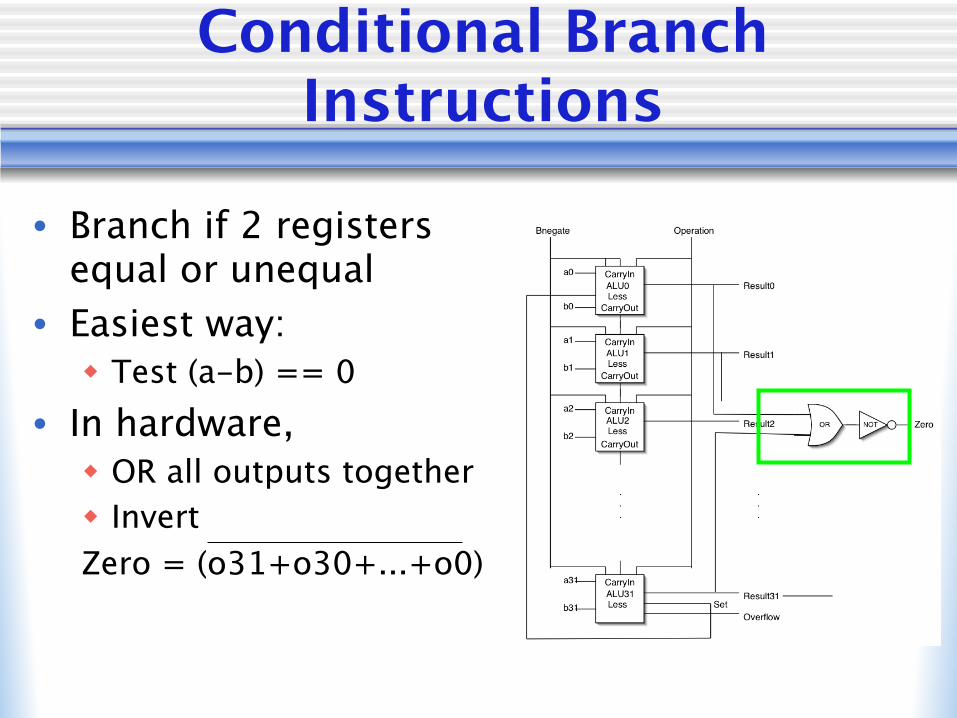
Conditional Branch Instructions
• Branch if 2 registers equal or unequal
• Easiest way:w Test (a-b) == 0
• In hardware,w OR all outputs togetherw InvertZero = (o31+o30+...+o0)

Review: ALU
• AND/OR• Addition/
Subtraction• SLT• Conditional
branches

What More Do We Need?
• Multiplication• Division





















![Arithmetic Circuits 3 - KFUPM · Presentation Outline Carry Lookahead Adder BCD Adder Binary Multiplier Carry-Save Adders in Multipliers. ... BCD Adder 4 A [3:0] 4 B [3:0] C out C](https://img.pdfslide.us/doc/110x75/5f4e251bbf3d40066f1e07a0/arithmetic-circuits-3-kfupm-presentation-outline-carry-lookahead-adder-bcd-adder.jpg)






