Embed Size (px)
Citation preview

Adaptive streaming of MPEG-based audio/video content overwireless networksCitation for published version (APA):Burza, M., Kang, J., & Stok, van der, P. D. V. (2006). Adaptive streaming of MPEG-based audio/video contentover wireless networks. Journal of Multimedia, 2(2), 17-27.
Document status and date:Published: 01/01/2006
Document Version:Publisher’s PDF, also known as Version of Record (includes final page, issue and volume numbers)
Please check the document version of this publication:
• A submitted manuscript is the version of the article upon submission and before peer-review. There can beimportant differences between the submitted version and the official published version of record. Peopleinterested in the research are advised to contact the author for the final version of the publication, or visit theDOI to the publisher's website.• The final author version and the galley proof are versions of the publication after peer review.• The final published version features the final layout of the paper including the volume, issue and pagenumbers.Link to publication
General rightsCopyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright ownersand it is a condition of accessing publications that users recognise and abide by the legal requirements associated with these rights.
• Users may download and print one copy of any publication from the public portal for the purpose of private study or research. • You may not further distribute the material or use it for any profit-making activity or commercial gain • You may freely distribute the URL identifying the publication in the public portal.
If the publication is distributed under the terms of Article 25fa of the Dutch Copyright Act, indicated by the “Taverne” license above, pleasefollow below link for the End User Agreement:www.tue.nl/taverne
Take down policyIf you believe that this document breaches copyright please contact us at:[email protected] details and we will investigate your claim.
Download date: 06. Mar. 2020

Adaptive Streaming of MPEG-basedAudio/Video Content over Wireless Networks
Marek Burza, Jeffrey Kang, Peter van der StokPhilips Research, High Tech Campus 31, 5656 AE Eindhoven, The Netherlands
E-mail: {Marek.Burza, Jeffrey.Kang, Peter.van.der.Stok}@philips.com
Abstract— This paper describes a method for robust stream-ing of combined MPEG audio/video content (encoded eitherwith MPEG-2 or MPEG-4/H.264) over in-home wireless net-works. We make use of currently used content distributionformat (MPEG Transport Stream) and network protocols(either RTP or TCP/HTTP). The transmitted bit-rate isconstantly adapted to the available network bandwidth, suchthat audio and video artifacts caused by packet loss areavoided. Bit-rate adaptation is achieved by using a packetscheduling technique called I-Frame Delay (IFD), whichperforms priority-based frame dropping upon insufficientbandwidth. We show an implementation using RTP andan implementation using TCP. Measurements on a real-lifedemonstrator set-up demonstrate the effectiveness of ourapproach.
Index Terms— adaptive video streaming, wireless networks,MPEG, H.264, I-Frame Delay
I. INTRODUCTION
In-home networks are becoming more and more com-mon in consumer households. They connect together thedifferent electronic devices in the home from the CE,mobile and PC domains, with which different digitalcontent is stored and viewed. Such in-home networkstypically consist of wired and wireless segments. Espe-cially wireless networks are popular due to the ease ofinstallation. However, wireless networks cannot alwaysdeliver the bandwidth needed for transporting the de-sired content. This is because wireless networks offera lower bandwidth than wired networks, and very of-ten this bandwidth has to be shared between multiplestreams. Furthermore, the wireless network bandwidthoften exhibits an unpredictable and fluctuating behav-ior. This is mainly caused by reflections and obstacles,roaming portable devices, and disturbances from otherdevices (e.g. neighboring wireless networks, microwaves).Other network technologies, e.g. power-line, also exhibitsimilar stochastic behavior under interference. For streamswith real-time requirements, such as audio/video (A/V),insufficient network bandwidth causes data loss and theassociated artifacts, such as blocky distortions in theimage and disturbances in the audio. This is clearlyunacceptable for the end user.
The problem of bandwidth sharing can be addressedby several QoS (Quality-of-Service) techniques such asprioritization and bandwidth reservation, and access con-trol mechanisms. In this paper, we address the secondproblem, namely that of fluctuating bandwidth for au-dio/video streaming. A technique is presented to stream
the A/V content over the network, whereby the amountof data transmitted by the sender is dynamically adaptedto the available bandwidth by selectively dropping data.In this way the perceived quality of the A/V streamis dynamically adjusted according to the quality of thenetwork link. Our solution can be implemented using RTP(Real-time Transport Protocol) and TCP (TransmissionControl Protocol).
This paper is organized as follows. Section II lists somerelated work. Section III describes our adaptive streamingtechnique and its implementations. Experimental resultsare presented in Section IV. This paper ends with con-clusions and final remarks.
This paper is an extension of earlier publication sub-mitted to IFIP/IEEE International Conference on Man-agement of Multimedia and Mobile Networks and Ser-vices [1]. Additional work included here covers extensionof the demonstator server and presented algorithm to han-dle also the streams encoded with MPEG-4/H.264 codec(in Section III-E), results of experiments for streams withH.264 content previously done only for streams withMPEG-2 content (in Section IV) and evaluation of picturequality delivered by our algorithm (in Section IV-C).
II. RELATED WORK
Most work in literature concentrates around streamingof video only, whereas we also consider audio, which isstreamed together with the video stream. Most users aremore sensitive to audio than to video artifacts, thereforethese should be avoided. Different approaches have beenproposed for adaptively streaming video over wirelessnetworks. These solutions can be categorized by:
• Scalable video. The original video is encoded inseparate layers, where a base layer contains videoof acceptable quality, and one or more enhancementlayers enhance the quality of the base layer. Adap-tation is done by dropping enhancement layers incase of insufficient bandwidth. As long as the baselayer can be transmitted without loss, no artifactswill occur. Examples of this approach can be foundin [2][3][4].
• Transcoding/transrating. Here the original bit-rate ofthe video is adaptively changed to a different bit-rate depending on the available bandwidth, e.g. bydynamically changing the quantization parameters.Examples of such solutions are found in [5][6].
JOURNAL OF MULTIMEDIA, VOL. 2, NO. 2, APRIL 2007 17
© 2007 ACADEMY PUBLISHER

Figure 1. Architecture of the streaming use case.
Figure 2. Protocol and format encapsulation.
• Frame dropping. Complete frames are dropped incase of insufficient bandwidth, examples are foundin [7][8].
Our adaptation technique falls into the last category andis called I-Frame Delay (IFD), previously reported in [9].This paper extends this by including audio. IFD is ascheduling technique which drops MPEG video frameswhen detecting insufficient bandwidth, thereby favoring I-and P-frames over B-frames. Artifacts are avoided as longas only B-frames are dropped. The result is a decreasedvideo frame rate. The perceived quality here is lower thane.g. scalable video [10] or transrating, however IFD hasthe lowest cost in the implementation, and is able to reactquickly to the changing conditions. Most MPEG decoderimplementations are able to decode the resulting stream.Furthermore, the decision to perform adaptation is basedon send buffer fullness, instead of relying on feedbackfrom the receiver for bandwidth estimation. Therefore noreceiver modifications are necessary. The work of [11]resembles ours the most, dealing with adaptive streamingof MPEG Transport Streams by means of frame drop-ping. However, this approach relies on specific receiverfeedback about the network status. Furthermore, sincethe feedback arrives periodically, the beginning of anabrupt bandwidth drop can often not be handled in time,leading to a short burst of lost packets (and hence frames).Lastly, only RTP streaming is considered, whereas we alsoconsider TCP.
III. ADAPTIVE STREAMING OF MPEG TRANSPORT
STREAMS
In this paper, we focus on the home scenario wherecontent is entering the home from a content provider viaADSL, cable or satellite, then possibly stored on a homestorage server and further distributed over a local networkwithin the home (Figure 1). The content can be deliveredeither with use of HTTP or RTP protocol which transportsdistribution format. Here the most common distribution
format is MPEG Transport Stream (TS) [12], which cancontain video encoded with a variety of different codecs(i.e. MPEG-2 and H.264 that we focus on). Thereforewe will further discuss adaptive streaming of MPEG TS.Figure 2 illistrates encapsulation of protocols and formats.
Section III-A shortly introduces the problem addressedlater on with our video sheduling technique. Section III-B describes our IFD adaptive video scheduling technique.Sections III-C and III-D explain how this technique canbe applied on Transport Streams using RTP and TCP.Section III-E will describe the challenges faced andsolutions found when applying IFD to streams with H.264content.
A. Problem description
Streaming video over a network often faces limitedbandwidth as the network link is usually shared betweenmultiple applications. Moreover, if the video is transmit-ted over wireless networks (e.g. IEEE 802.11), then asidefrom sharing the logical link, the physical medium thatthe link is using is also shared between different standards(e.g. DECT phones, Bluetooth, ZigBee) and is subject tointerference (such as multipath interference or microwaveovens).
When available bandwidth is insufficient for transmis-sion of a video stream, the viewer will experience adisruption of the viewing experience. Since the defaultbehaviour of a network stack in case of insufficient band-width is to drop packets at the moment of congestion, thedisruption of frames (artifacts) will be random: missingparts of a frame, mixed frames, misplaced fragments ofthe picture, etc.
B. I-Frame Delay
I-Frame Delay (IFD) is a scheduling technique foradaptive streaming of MPEG video. The basic idea isthat scheduler will drop video frames when the trans-mission buffer is full and overflow is imminent due toinsufficient bandwidth, to reduce the transmitted bit-rate.The algorithm is characterized by the following: 1) bufferfullness is indicated by the number of frames currentlyin the buffer (not the number of bytes), 2) less importantframes (B-frames) are dropped in favor of more importantframes (I- and P-frames), 3) the transmission of I-framesis delayed when conditions are bad but as little as possibleomitted, even if they are out-of-date w.r.t. the display time,because they can still be used to decode subsequent inter-predicted frames1.
The IFD mechanism is based on two parts: 1) duringparsing and packetization of the stream into network pack-ets, the stream is analyzed and the packets are tagged witha priority number reflecting the frame type (I/P/B)2, and2) during transmission, packets are dropped by the IFD
1We assume that out-of-date frames are still decoded and only thrownaway by the renderer, rather than thrown away already before decoding.
2Since there may be multiple consecutive B-frames between two P-frames, we use different tags to distinguish between them.
18 JOURNAL OF MULTIMEDIA, VOL. 2, NO. 2, APRIL 2007
© 2007 ACADEMY PUBLISHER

10 12121212 122111111 11 2 0
SW
11Outgoing packets
Incomingpackets
C
Non−video packets
Figure 3. Network packets in the IFD buffer.
scheduler when the bandwidth is insufficient. Non-videopackets are given a priority number not recognizable bythe IFD scheduler, which therefore will never drop them.The size of the IFD buffer should be big enough tohold a number of frames. The minimum required sizeis two frames, one to hold the frame currently beingsent (denoted as S), and one currently waiting to be sent(denoted as W ). Increasing the IFD buffer size permitsmore intelligent decisions on which frames to be dropped,at the cost of increased latency and memory usage.Figure 3 depicts an example of the buffer filling. Thenumbers represent the priority numbers of the packets. Inthis example the IFD-related priority numbers are 10 andhigher. The packets with priority number 12 belong to theS frame, and the packets with number 11 belong to the W
frame. Currently a packet from an incoming frame C isabout to enter the buffer. As can be seen, it is possible tointerleave video packets with non-video packets (prioritynumbers 0 and 2). When a packet belonging to C triesto enter the IFD buffer and both S and W are full, theIFD scheduler will decide to drop a frame (in C or W ),based on the priority numbers. No artifacts will occur ifonly B-frames are dropped, because no subsequent framesdepend on them. When the network conditions are suchthat also P-frames are dropped, then the GOP (Group ofPictures) is said to be disturbed and the remainder of theGOP is also dropped. This causes the effect of the imagebeing temporarily frozen, the duration of which dependson the GOP size. For an IFD buffer capable of holdingtwo frames, the frame dropping algorithm is shown inFigure 4.
C. RTP implementation
This section describes our adaptive streaming approachusing RTP. We first present a method for encapsulating TSpackets into RTP packets, such that they can be used byIFD. This does not come without consequences, as will beexplained. We then describe our streamer implementation.
1) IFD-friendly RTP encapsulation: For RTP encapsu-lation of TS packets we adhere to RFC2250 [13]. It statesthat a RTP packet contains a number of TS packets (188bytes each). Each RTP packet does not need to containan equal number of TS packets, however the commonapproach is to encapsulate 7 TS packets into one RTPpacket. Together with some protocol headers, the packetsize stays just below the MTU (Maximum TransmissionUnit) of 1500 bytes (Ethernet), which avoids packetfragmentation. The problem of such RTP packets is thatthey are dropped by IFD as a whole, and they may contain
procedure BUFFER ENQUEUE(C)if Disturbed GOP == True then
if C is of type I then � New GOP is encounteredDisturbed GOP = False � Reset disturbed GOP flag
end ifend ifif Disturbed GOP == True then
Discard C � Discard rest of disturbed GOPreturn
end ifif W is empty then
Store C in W
elseif C is of type I then
Overwrite W with C
else if C is of type B thenDiscard C
else if W is of type I or P thenDiscard C
if C was of type P then � Discarded frame is P-frameDisturbed GOP = True � Set disturbed GOP flag
end ifelse
Overwrite W with C
end ifend if
end procedure
Figure 4. Pseudocode for IFD algorithm with buffer of two frames.
audio, video and data TS packets, or packets belongingto multiple frames. Therefore we need to make sure thatvideo and non-video packets are split up in different RTPpackets, and the same goes for video packets belonging todifferent frames. Re-ordering of TS packets is unwanteddue to timing dependencies and efficiency (e.g. buffermemory usage) considerations, therefore we can achievethe splitting by simply finalizing packets earlier. Duringparsing, TS packets are gathered into RTP packets. A RTPpacket is finalized if one of the following conditions ismet:
1) The RTP packet contains 7 TS packets.2) The next TS packet has a different TS PID (Packet
Identifier) than its predecessor, and one of them hasthe video PID.
3) The next TS packet and its predecessor both havethe video PID, but the next packet starts a new videoframe.
Figure 5(a) shows the result of the common encapsula-tion scheme for an example TS packet sequence. TheTS packets are denoted with their type (Audio, Video,Data). For video packets also their frame numbers arementioned. All packet boundaries are exactly 7 TS packetsapart. Figure 5(b) shows the packet boundaries obtainedwith our encapsulation scheme. Boundary number 2 is theresult of the first rule (maximum of 7 packets reached).Boundaries 1, 3, 4, 6 and 7 are the result of rule 2(switching between video and non-video). Boundary 5 isthe result of crossing a frame boundary (rule 3).
Compared to the common encapsulation scheme, pars-ing of the TS packets down to the video elementary streamlevel is required for finding the picture start codes in videopackets to identify the start of each frame and the frametype. In many cases the start of a new frame is alignedwith the start of a TS packet. This is the ideal situation and
JOURNAL OF MULTIMEDIA, VOL. 2, NO. 2, APRIL 2007 19
© 2007 ACADEMY PUBLISHER

A V1 V1 V1 V1 V1 V1 V1 V1 V1 A V2 V2 V2 V3 V3D D V3 V3 V3
A V1 V1 V1 V1 V1 V1 V1 V1 V1 A V2 V2 V2 V3 V3D D V3 V3 V3
1 42 3 5 6 7
(b)
7
(a)
Figure 5. Example of RTP packet encapsulation: (a) common scheme,(b) IFD-friendly scheme.
a clean separator can be placed between two TS packetsto separate two frames. However, there are cases wherethe frame start and TS packet start are not aligned:
1) In some cases, the picture start code is locatedhalfway a TS packet, which means that this packetbelongs to two different frames. In this case thereare a number of options for setting the RTP packetboundary: 1) split up this packet into two TSpackets and add stuffing, 2) keep this packet withthe previous frame, 3) keep this packet with thenew frame. For efficiency reasons (no increased bit-rate and no copying/modification of TS headers) wedid not go for option 1. Options 2 and 3 differin which part of a frame will be dropped. Withoption 2 the start of the new frame will be lostif the previous frame is dropped, while with option3 the last part of the previous frame will be lost ifthe new frame is dropped. In our experience, mostdecoders handle the latter situation better, thereforewe choose option 3.
2) Sometimes the picture start code is split over twoTS video packets. Detecting this situation entailsa higher complexity, because two video packetshave to be scanned at a time, with the additionalpossibility that they are interleaved with audio anddata packets. Failing to detect this situation mayresult in two frames being tagged as if they areone. If a B-frame is followed by a P-frame, thenalso the latter is tagged as a B-frame, and may bedropped as well.
The occurrence of the above situations depends on howthe video stream is packetized into Packetized ElementaryStream (PES) packets, before it is multiplexed in theTransport Stream together with audio data. From ourexperience with broadcast streams two methods are mostoften used: 1) each PES packet contains a single frame,2) each PES packet contains a GOP. The above miss-alignment situations do not occur when a PES packetcontains a frame, because the start of a PES packet isalways at the start of a TS packet. They might occur often,though, when each PES packet contains a GOP.
2) IFD overhead: As can be seen from Figure 5, ourIFD-friendly encapsulation scheme results in more andsmaller RTP packets. Smaller packets have more over-head, which means that the wireless network is used lessefficiently. Considering an average size of a RTP packetconsisting of NTS per RTP TS packets, we define theencapsulation efficiency Eencap as a measure to express
0
20000
40000
60000
80000
100000
7 6 5 4 3 2 1
Num
ber
of R
TP
pac
kets
# TS packets per RTP packet
RTP packet size distribution
(a)
0
50000
100000
150000
200000
250000
300000
350000
400000
7 6 5 4 3 2 1
Num
ber
of R
TP
pac
kets
# TS packets per RTP packet
RTP packet size distribution
(b)
Figure 6. Example RTP packet size distribution for high (a) and low(b) encapsulation efficiency.
how well a stream can be encapsulated, that is, how closeNTS per RTP is to the optimal number of 7:
Eencap =NTS per RTP
7× 100% (1)
Our experience with typical Transport Streams yields val-ues for Eencap ranging from 37.4% to 85.8% for MPEG-2 and 59.9% to 76.5% for H.264. Figure 6 shows thedistribution of RTP packet sizes for example sequenceswith a high and a low encapsulation efficiency.
One source of overhead of having smaller packetsis the protocol headers (e.g. RTP, IP), as the packetpayload is relatively smaller. An analysis of the headeroverhead resulted in numbers ranging from 0.92% to8.42% (MPEG-2) and from 1.63% to 3.56% (H.264) forour example streams. Another source of overhead comesfrom the fact that the maximum theoretical throughput atthe 802.11 MAC layer degrades with decreasing packetsize (a theoretical analysis can be found in [14]). Fig-ure 7 depicts the relation between NTS per RTP and themaximum throughput. We define the throughput penaltyas the relative drop in throughput with an average RTPpacket size NTS per RTP compared to the throughputwith the maximum packet size of 7 (Eencap = 100%).For the example sequences we used, a throughput penaltywas found ranging from 6.1% to 47.0% for MPEG-2 andfrom 15.7% to 28.5% for H.264. It is therefore imperativeto obtain a high encapsulation efficiency. This dependson how the packets have been multiplexed. The best is
20 JOURNAL OF MULTIMEDIA, VOL. 2, NO. 2, APRIL 2007
© 2007 ACADEMY PUBLISHER
0
5
10
15
20
25
30
35
40
1 2 3 4 5 6 7
Thr
ough
put (
Mb/
s)
# TS packets per RTP packet
Maximum theoretical throughput for 802.11
802.11a / 802.11g (no RTS/CTS)802.11b, long preamble
802.11b, short preamble802.11g (RTS/CTS)
Figure 7. Maximum theoretical throughput for 802.11.
MPEG−2Transport Stream
TS filereader packetizer
RTP RTP sender
RTPscheduler
Network
Send_packet()
Figure 8. RTP sender architecture.
to have as few transitions between video and non-videopackets as possible. Since video packets make up mostof the stream, we can then achieve the highest possiblenumber of RTP packets of the maximum size (such as inFigure 6(a)).
3) Implementation: We implemented IFD as part of aRTP/RTSP server application running on a Linux PC, thestreaming part of which is shown in Figure 8. The TS filereader reads TS packets from a MPEG Transport Streamfile and sends it to the RTP packetizer, which encapsulatesthe TS packets into RTP packets according to the methoddescribed earlier. The target transmission times (TTT) ofthe packets are determined by the file reader from the PCR(Program Clock Reference) values (following the DLNAguidelines [15]). The RTP packetizer then translates theTTT to RTP timestamps and inserts the proper RTPheaders. The resulting RTP packets are given to the RTPsender. This component is responsible for buffering theRTP packets for transmission. For the correct pacing ofthe transmission, the RTP scheduler examines the RTPtimestamps of the RTP packets and tells the RTP senderto send the packets at the right time. IFD packet taggingis done by the RTP packetizer, and the dropping isimplemented in the RTP sender. Audio and data packetsare tagged with a priority number which is not recognizedas video frames by IFD; they thus will never be dropped.In this way the audio is almost never interrupted at thereceiver output.
D. TCP implementation
The main drawback of using RTP streaming is thatIFD must be supported by each wireless node (e.g. anaccess point) in the network, not only at the sender. This
MPEG−2Transport Stream
IFDdropper
TS filereader
TScollector
TCPsender
Network
IFD buffer
Figure 9. TCP sender architecture.
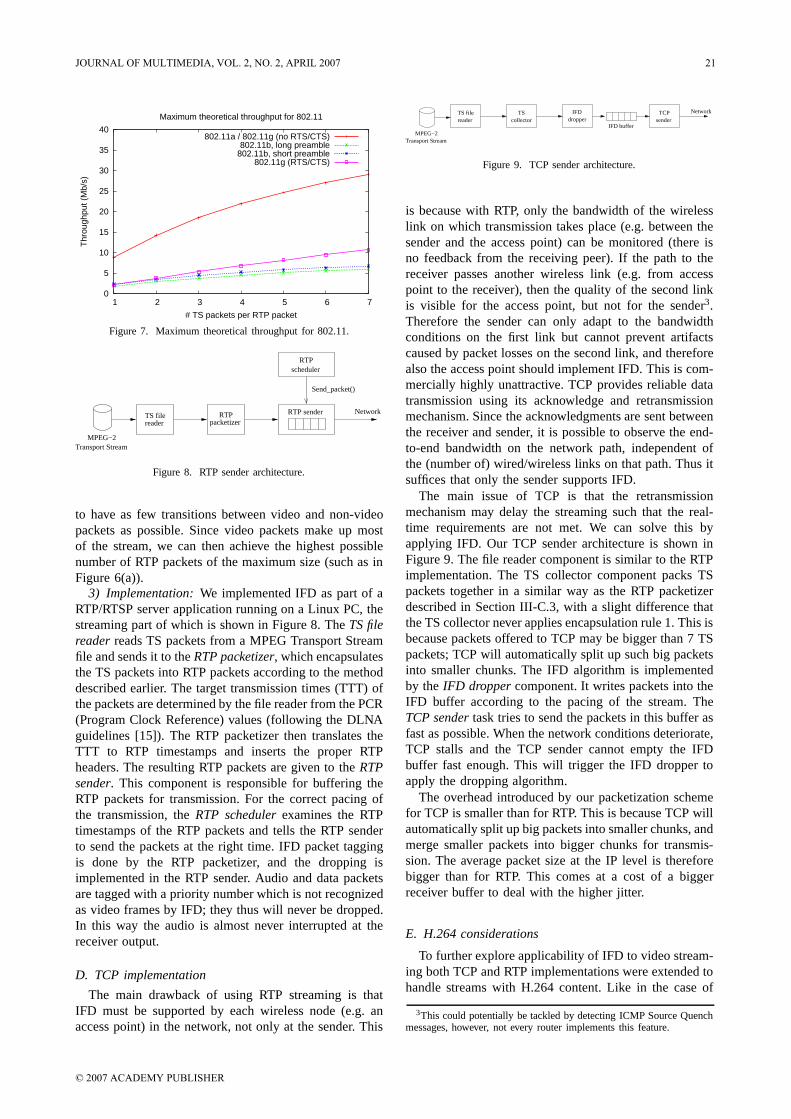
is because with RTP, only the bandwidth of the wirelesslink on which transmission takes place (e.g. between thesender and the access point) can be monitored (there isno feedback from the receiving peer). If the path to thereceiver passes another wireless link (e.g. from accesspoint to the receiver), then the quality of the second linkis visible for the access point, but not for the sender3.Therefore the sender can only adapt to the bandwidthconditions on the first link but cannot prevent artifactscaused by packet losses on the second link, and thereforealso the access point should implement IFD. This is com-mercially highly unattractive. TCP provides reliable datatransmission using its acknowledge and retransmissionmechanism. Since the acknowledgments are sent betweenthe receiver and sender, it is possible to observe the end-to-end bandwidth on the network path, independent ofthe (number of) wired/wireless links on that path. Thus itsuffices that only the sender supports IFD.
The main issue of TCP is that the retransmissionmechanism may delay the streaming such that the real-time requirements are not met. We can solve this byapplying IFD. Our TCP sender architecture is shown inFigure 9. The file reader component is similar to the RTPimplementation. The TS collector component packs TSpackets together in a similar way as the RTP packetizerdescribed in Section III-C.3, with a slight difference thatthe TS collector never applies encapsulation rule 1. This isbecause packets offered to TCP may be bigger than 7 TSpackets; TCP will automatically split up such big packetsinto smaller chunks. The IFD algorithm is implementedby the IFD dropper component. It writes packets into theIFD buffer according to the pacing of the stream. TheTCP sender task tries to send the packets in this buffer asfast as possible. When the network conditions deteriorate,TCP stalls and the TCP sender cannot empty the IFDbuffer fast enough. This will trigger the IFD dropper toapply the dropping algorithm.
The overhead introduced by our packetization schemefor TCP is smaller than for RTP. This is because TCP willautomatically split up big packets into smaller chunks, andmerge smaller packets into bigger chunks for transmis-sion. The average packet size at the IP level is thereforebigger than for RTP. This comes at a cost of a biggerreceiver buffer to deal with the higher jitter.
E. H.264 considerations
To further explore applicability of IFD to video stream-ing both TCP and RTP implementations were extended tohandle streams with H.264 content. Like in the case of
3This could potentially be tackled by detecting ICMP Source Quenchmessages, however, not every router implements this feature.
JOURNAL OF MULTIMEDIA, VOL. 2, NO. 2, APRIL 2007 21
© 2007 ACADEMY PUBLISHER

MPEG-2, the H.264 content was encapsulated in MPEGTransport Stream together with audio. The choice of thecodec was dictated by the high interest with H.264 inboth scientific comunity and industry. Its features and therecognition it gets suggest that it is a viable successor toMPEG-2. For this reason it was important to investigatethe performance of IFD with H.264 streams.
Although there are differences between the two stan-dards, the H.264 standard keeps many of the MPEG-2 notions: it still distinguishes I, P and B frames, andencoding of the frames is in principle the same.
Prior to implementation it was necessary to perform asimple sanity check if IFD can be at all applied. Majorbenefit of IFD is that it allows to cope with bandwidthdrop by dropping B-frames without introducing artifacts.Therefore, applying IFD depends on the contribution ofB-frames to the size of the stream - if it is significantthen it is reasonable to apply IFD to use the bandwidthgain. After checking our example streams with MPEG-2 content it was concluded that the contribution of B-frames is between 30% and 55% (which means that it ispossible to save the same amount of bandwidth in caseof network congestion). The same check for our examplestreams with H.264 content yielded results between 20%and 35% for SD streams and 40%-48% for HD content.This is still significant, even though it is somewhat lessthan in MPEG-2.
The high compression factor of the H.264 codec canbe attributed to several features it supports. Many ofthese features are new in H.264 and were not includedin MPEG-2 before. Because of these differences betweenthese two standards, it was necessary to look closer atthose features as they could have a negative impact onthe possible application of IFD to H.264.
IFD relies only on extraction of frames (beginning andend or length of a frame) and detection of their type. That,in turn, depends on features related to the structure of thebitstream with frame-wise granularity and classificationof the frames, which limits the scope of the featuresconsidered to the following list (for a complete list offeatures one can refer to [16] or [17]):
• Indication of frame boundaries. There are two waysto detect a beginning of a new frame in H.264. Oneway is to scan bitstream and detect an Access UnitDelimiter (AUD) indicating a beginning of a newframe. However, AUD is an optional element of asequence. Another way is to parse headers of all top-level parsing units (Network Abstraction Layer units,NAL units) in the bitstream and checking valuesfrom the headers against a set of conditions definedby the standard.
• Variable Length Compression. If parsing of headersis necessary then this can introduce overhead throughkeeping storage and the analysis of the values in theheaders. H.264 uses Exponential-Golomb encodingfor these values, which requires more computingthan for the encoding used in MPEG-2.
• Less strict inter-frame dependencies. Often, B-
frames are a closer approximation to neighbouringB-frames than more distant I- or P-frames. Thereforeto enhance video quality and compression ratio itwas allowed to make B-frames dependant on otherB-frames. The result of this is that some B-framesare more important than others.
• New frame types. H.264 introduces new frame types- SI and SP, which allow to introduce custom en-try points for the purpose of random access andenhanced resilience. They basically duplicate thecontent of another frame - for example an SI frameduplicates another SP frame but allows the decoderto recover in case preceding frames were lost, or, incase we have two SP frames they introduce switchingpoints between two streams (more information canbe found in [18]).
• GOP-related issues. H.264 does not have an explicitcounterpart of Group-of-Pictures structure knownfrom MPEG-2. Instead, it has a concept of Instan-taneous Decoding Refresh (IDR) picture, which canbe considered as a counterpart of a beginning of aGOP.
One challenging feature is related to the detection offrames. In our research we are using Transport Streamsand the standard defines that if H.264 bitstream in encap-sulated in TS then AUD units are mandatory. In this caseframe detection is simple and requires only a detection ofthe AUD units, it requires only scanning for a particularfour byte long sequence in the bitstream (the test setused during this research consisted only of sequenceswith AUD units). We are also able to handle a situationwhere AUD units are absent. In this case the server hasto do more detailed parsing of the sequence (it has to berobust enough for sequences with arbitrary slice ordering,consecutive frames of the same type etc.) and has tomanage necessary data for parsing and detection.
Parsing of a H.264 bitstream and frame detection inabsence of the AUD units can be a resource consumingprocess. One reason for this would be storage and lookupof values from previously parsed headers, but a moresignificant reason is the encoding used in the H.264. Toavoid sending any unnecessary data even in the controlpart, it was decided to use variable length encoding(Exponential-Golomb) with bit alignment (not a bytealignment) and not to use any leap values. The fact thatno leap values are used (like length of a header or aparsing unit) makes it impossible to skip values that areof no interest - everything needs to be parsed. This can ofcourse require some CPU cycles, but by an experiment itwas established that the cost is minimal. For Pentium 41.7GHz with Windows XP the detection of frames byusing the slice encoded info adds only about 0.192%processing time per frame as compared to the detectionbased on the Access Unit Delimiters and for MIPS in aset-top-box running Linux the difference is 0.032% (bothvalues measured for a 2 Mb/s stream).
The next feature that might pose problems is using B-frames as reference frames. In this case it is necessary
22 JOURNAL OF MULTIMEDIA, VOL. 2, NO. 2, APRIL 2007
© 2007 ACADEMY PUBLISHER

to distinguish between ”more” and ”less” important B-frames. Tagging a priority to frames is no longer equiva-lent to their type only. In general, that could require pars-ing and analysis of a sequence to be even more detailed.Fortunately, the parsing unit (NAL) header holds a fieldwhich indicates whether given unit is referenced or not -this can aid the detection of referenced B-frames withoutadding much complexity to the decision algorithm. Theway the field is used, reflects the level of dependencyon given unit, for example - I-frame receives value 2, P-frame 1 and unreferenced B-frame 0. Again, our test setincluded sequences without B-frames as reference frames.
Another new feature is the introduction of new frametypes, SP and SI. Although their role is slightly differentthen of the P- and I-frame, their priority can remainthe same, which allows using the same tags and leavingdecision algorithm unchanged.
In MPEG-2, it used to be possible that B-frames at thebeginning of GOP were referencing frames from previousGOP (so-called open GOP). This, however, was limitedto a GOP boundary. In H.264, to enable management ofreference buffers a concept of Instantaneous DecodingRefresh (IDR) picture was introduced. Only I-frames canbe IDR frames, and - when encountered - such frameindicates that all reference frames should be marked asunused. Therefore, even though H.264 does not recognizeformally a notion of GOP, it still keeps this functionality.
The IFD also handles situations where GOP is dis-turbed by dropping P- or I-frame. I this case all followingframes are dropped until beginning of the next GOP. Thereason for this is to drop frames that depend on a missingframe (these frames would be displayed with artifacts).H.264 does not have a notion of GOP, but fortunatelyit is possible to detect a boundary beyond which thereis no reference made. The boundary is an IDR-frame.Thanks to that, also this IFD feature remains valid forH.264 - IFD algorithm only requires different source ofinformation used in the decision. Long distances betweenIDR-frames might be then the only problem. However, fora broadcast content the distance is supposed to be short toavoid sparse recovery points; trick-play for stored contentrequires that as well. Otherwise, a mechanism analysingreferences between frames would have to be in place inorder to detect when a dropped frame is not referencedanymore. A trade-off is possible: dropping can simplybe continued until next I-frame or IDR-frame, which, incase of sparsely distributed IDR-frames, would mean thatdropping I- or P-frame would result in longer periodswhen the picture is frozen.
IV. EXPERIMENTAL RESULTS
This section presents some experimental results in twoscenarios. The first one involves a stationary receiverattached to a TV. In this scenario (Section IV-A), the wire-less network is disturbed by turning on a microwave. Thesecond scenario (Section IV-B) involves a mobile receiver,which is moved away from the access point, causing thebandwidth to drop. We used a 802.11g wireless access
Microwave
Receiver (STB)
Sender (PC) TV+ routerAccess point
MPEG−2 TS
Figure 10. Experimental set-up with stationary receiver.
point and PCMCIA wireless adapters. IFD is implementedin the sender. The experiments were conducted in an officeenvironment with a WLAN infrastructure, which causessome additional interference with our own network.
A. Stationary receiver with microwave disturbance
The set-up for this scenario is shown in Figure 10.The sender PC has a wireless connection to the accesspoint, which is connected via wired Ethernet to a set-top-box. The nearby (at appr. 2 m) microwave introducesthe disturbance. For this experiment we used a 10 Mb/sMPEG-2 sequence (with phy-rate set to 54 Mb/s) and4 Mb/s H.264 sequence (with phy-rate set to 24 Mb/s).The GOP size in both cases is 15 and the GOP structureis IBBP. During the experiment, the microwave wasturned on 45 seconds after the stream started, for a periodof 1 minute, and the output video and audio qualitywas observed on the TV. With the microwave off, theaudio and video were streamed without problems. Duringthe period when the microwave was on, the experimentwithout IFD exhibited artifacts in the video and frequentinterruptions in the audio. With IFD turned on, the audiowas never interrupted, and the video frame rate was ob-servably reduced, however no artifacts were seen. Similarobservations were made both for the RTP and the TCPimplementation. Since the wireless network conditionsmay vary over time, the experiments were repeated anumber of times.
Measurements were performed to determine thedropped frames and their types. For both types of streams(MPEG-2 and H.264) we first ran an experiment withthe TCP sender (Figure 9) without IFD, where the IFDdropper was configured to drop all incoming packets whenthe IFD buffer is full (tail-drop). The dropped framesat the sender side are shown in Figure 11 (a) and (c).The observations for MPEG-2 and H.264 were similar.As can be seen, almost no frames were dropped whenthe microwave was off. When the microwave was on,frames from all types were dropped (including I- andP-frames, consistent with the observed artifacts). Notethat actually only some packets belonging to these frameswere dropped, and not the complete frames. We considera frame with one or more packets missing as droppedbecause typical decoders will throw away incompleteframes anyway (including I- and P-frames, leading toartifacts). With IFD turned on, it can be seen that no I-frames were dropped (Figure 11 (b) and (d)). Most of the
JOURNAL OF MULTIMEDIA, VOL. 2, NO. 2, APRIL 2007 23
© 2007 ACADEMY PUBLISHER

I
P
B
0 500 1000 1500 2000 2500 3000
Fra
me
type
Frame number
Dropped frames
(a)
I
P
B
0 500 1000 1500 2000 2500 3000
Fra
me
type
Frame number
Dropped frames
(b)
I
P
B
0 500 1000 1500 2000 2500 3000
Fra
me
type
Frame number
Dropped frames
(c)
I
P
B
0 500 1000 1500 2000 2500 3000
Fra
me
type
Frame number
Dropped frames
(d)
Figure 11. Dropped frames under microwave disturbance (TCP): (a)MPEG-2 without IFD, (b) MPEG-2 with IFD, (c) H.264 without IFD,(d) H.264 with IFD.
I
P
B
0 500 1000 1500 2000 2500 3000
Fra
me
type
Frame number
Dropped frames
(a)
I
P
B
0 500 1000 1500 2000 2500 3000
Fra
me
type
Frame number
Dropped frames
(b)
Figure 12. Dropped frames with IFD under microwave disturbance(RTP): (a) MPEG-2, (b) H.264.
dropped frames were B-frames. It can be seen that alsosome P-frames had to be dropped, causing the droppingof the rest of the disturbed GOPs. Considering our GOPsize, dropping a disturbed GOP may cause the image to befrozen up to roughly half a second. This effect is reducedif the GOP size is smaller.
The results for the RTP implementation are shown inFigure 12. As can be seen, in this experiment only B-frames were dropped.
B. Mobile receiver
In this experiment we used a 8 Mb/s MPEG-2 sequence(with phy-rate set to 54 Mb/s) and 4 Mb/s H.264 se-quence (with phy-rate set to 24 Mb/s). The sequence wasstreamed along two wireless links from the sender PC tothe laptop (see Figure 13). After the stream started, wewalked away with the laptop from the access point untilhalfway the sequence, then turned around and walkedback to the starting position. This experiment was onlydone with the TCP implementation, because for RTP welacked IFD on the access point for adapting the streamon the second link.
With IFD off, it was observed that while walking away,the audio and video were first streamed with no problems,followed by a short period with artifacts, then followedagain by a period without problems. This is caused bythe automatic reduction of the transmission rate by the
24 JOURNAL OF MULTIMEDIA, VOL. 2, NO. 2, APRIL 2007
© 2007 ACADEMY PUBLISHER

Sender (PC) Receiver (laptop)+ router
Access point
MPEG−2 TS
Figure 13. Experimental set-up with mobile receiver.
access point when the signal strength decreased. Hencethe artifacts were caused during the transitions. This effectcan also be seen in Figure 14 (a) and (c) from the shortbursts of dropped frames. When we reached a certaindistance where the required bandwidth could not be sus-tained anymore, the receiver output exhibited continuousartifacts. With IFD on, we observed that during transitionsthe image showed a short freeze (caused by droppinga P-frame and the subsequent frames in the disturbedGOP). There were no blocking artifacts and no audiointerruptions. As can be seen from Figure 14 (b) and(d), the dropped frames were limited to B-frames andP-frames.
C. Picture quality delivered with IFD
Additionally, to confirm that IFD delivers better qualitythan standard scheduling mechanism we performed anexperiment using scenario from Figure 10 where thesequences were recorded as delivered on receiver side andthe Peak Signal-to-Noise Ratio (PSNR) was calculatedagainst the original sequence.
The experiment was done for both MPEG-2 and H.264.The bandwidth was continuously suppressed to a valuejust above the bitrate of the sequence to ensure a bigenough measurement sample (total number of frames sentwas 3370). Limitation of bandwidth was done with useof the Token Bucket Filter (TBF) - a queuing mechanismavailable on Linux, which can be used for traffic control(the reason for using it, is to be able to arbitrarilyconfigure available bandwidth). For MPEG-2, a 10 Mb/ssequence was used. Bandwidth was set to 10.5 Mb/s andno additional interference was introduced. Similarly, forH.264 we used a 4 Mb/s sequence with bandwidth limitedto 4.2 Mb/s.
The PSNR values were obtained by comparing YUVfiles decoded from original and recorded sequences withffmpeg decoder. In case of missing frames this transcodercopies most recent one so the number of frames andtiming still matches the original - which is consistent withobservations we made during playback of the streamedvideo. The results of these experiments are presented intwo sets - one presents how many frames were disturbedduring transmission (Table I) and another presents averagePSNR (Table II). Note: The average PSNR was calculatedfor disturbed frames only.
In both cases - MPEG-2 and H.264 - we can observethat the number of disturbed frames is reduced by similarfactor when IFD is used. Also, in both cases the qualityof the disturbed frames is better - this can be attributed to
I
P
B
0 500 1000 1500 2000 2500 3000
Fra
me
type
Frame number
Dropped frames
(a)
I
P
B
0 500 1000 1500 2000 2500 3000
Fra
me
type
Frame number
Dropped frames
(b)
I
P
B
0 500 1000 1500 2000 2500 3000
Fra
me
type
Frame number
Dropped frames
(c)
I
P
B
0 500 1000 1500 2000 2500 3000
Fra
me
type
Frame number
Dropped frames
(d)
Figure 14. Dropped frames with roaming receiver (TCP): (a) MPEG-2without IFD, (b) MPEG-2 with IFD, (c) H.264 without IFD, (d) H.264with IFD.
JOURNAL OF MULTIMEDIA, VOL. 2, NO. 2, APRIL 2007 25
© 2007 ACADEMY PUBLISHER

Without IFD With IFD
MPEG-2 54.58% 8.21%H.264 83.26% 39.85%
TABLE I.PERCENTAGE OF DISTURBED FRAMES.
Without IFD With IFD
MPEG-2 22.40 24.14H.264 19.56 25.60
TABLE II.AVERAGE PSNR OF DISTURBED FRAMES.
the fact that for IFD there are no artifacts in the disturbedframes - they are simply repeated frames.
V. CONCLUSIONS
In this paper, we have shown a method for adaptivestreaming of audio/video content over wireless networkswhile using standard content distribution formats andnetwork protocols. With I-Frame Delay as the underlyingbit-rate adaptation mechanism, we are able to streamartifact-free video even under degrading network con-ditions. Moreover, it allows to reduce the number ofaffected frames and this together artifact-free transmissionit results in a higher picture quality. Our solution isimplemented at the sender side only, no modifications areneeded at the receiver side. We also found out that IFDis flexible enough to be applied to both MPEG-2 as wellas H.264 (and possibly also to other video codecs whennecessary adaptation is made). It is possible to apply IFDin combination with RTP as well as TCP. We proposeda packet encapsulation scheme which makes it possibleto separate video TS packets from non-video packetsand packets belonging to different frames, such that theresulting packets can be fed into the IFD scheduler.The effectiveness of IFD in case of network bandwidthfluctuations was shown by means of measurements on areal-life demonstrator set-up.
Our RTP packet encapsulation scheme results in onaverage smaller network packets, which entails someoverhead in network efficiency. This overhead is depen-dent on the encapsulation efficiency of the streams. ForTCP this overhead is considerably smaller.
IFD is effective against bandwidth fluctuations, whichmay be severe but only last a short period of time. Incase of long-term bandwidth drops (e.g. due to multiplecontending streams), the perceived quality of the IFDsolution seriously degrades because frames are constantlydropped. Such bandwidth problems are better handled bysolutions such as transrating.
ACKNOWLEDGMENT
We would like to thank Thierry Walrant and EwoutBrandsma for their valuable input to this work, and the
reviewers for their detailed comments.
REFERENCES
[1] J. Kang, M. Burza, P. van der Stok. Adaptive Streaming ofCombined Audio/Video Content over Wireless Networks.In Proceedings 9th IFIP/IEEE International Conferenceon Management of Multimedia and Mobile Networks andServices, 2006
[2] D. Wu, Y. Hou and Y.-Q. Zhang. Scalable Video Codingand Transport over Broadband Wireless Networks. In Pro-ceedings of the IEEE, vol. 89, no. 1, 2001.
[3] M. Domanski, A. Luczak and S. Mackowiak. Spatio-temporal Scalability for MPEG Video Coding. In IEEETransactions on Circuits and Systems for Video Technol-ogy, vol. 10, 2000.
[4] H. Radha, M. van der Schaar and Y. Chen. The MPEG-4Fine-Grained Scalable Video Coding Method for Multime-dia Streaming over IP. In IEEE Transactions on Multime-dia, vol. 3, no. 1, 2001.
[5] Kwang-deok Seo, Sang-hee Lee, Jae-kyoon Kim and Jong-seog Koh. Rate-control algorithm for fast bit-rate con-version transcoding. In IEEE Transactions on ConsumerElectronics, vol. 46, no. 4, 2000.
[6] P. Assuncao and M. Ghanbari. A frequency-domain videotranscoder for dynamic bit-rate reduction of MPEG-2 bitstreams. In IEEE Transactions on circuits and systems forvideo technology, vol. 8, no. 8, 1998.
[7] Yantian Lu and Kenneth J. Christensen. Using SelectiveDiscard to Improve Real-Time Video Quality on an Eth-ernet Local Area Network. In International Journal ofNetwork Management, Volume 9, Issue 2, 1999.
[8] Ricardo N. Vaz, Mario S. Nunes. Selective Discard forVideo Streaming over IP Networks. In Proceedings of the7th Conference on Computer Networks (CRC2004), 2004.
[9] Sergei Kozlov, Peter van der Stok, Johan Lukkien. Adap-tive Scheduling of MPEG Video Frames during Real-TimeWireless Video Streaming. In Proceedings of WoWMoM,2005.
[10] Reinder Haakma, Dmitri Jarnikov, Peter van der Stok.Perceived quality of wirelessly transported videos. In Dy-namic and Robust Streaming in and between ConnectedConsumer-Electronic Devices, Philips Research Book Se-ries, vol. 3. Springer, 2005.
[11] SangHoon Park, Seungjoo Lee, JongWon Kim. Network-adaptive high definition MPEG-2 streaming over IEEE802.11a WLAN using frame-based prioritized packetiza-tion. In Proceedings of the 3
rd ACM international work-shop on Wireless mobile applications and services onWLAN hotspots (WMASH), 2005.
[12] ISO/IEC 13818-1:2000(E). Information technology −
Generic coding of moving pictures and associated audioinformation: System.
[13] D. Hoffman, G. Fernando, V. Goyal and M. Civan-lar. RFC2250: RTP Payload Format for MPEG1/MPEG2Video.
[14] Jangeun Jun, Pushkin Peddabachagari and Mihail Sichitiu.Theoretical Maximum Throughput of IEEE 802.11 andits Applications. In Proceedings of the 2nd IEEE Interna-tional Symposium on Network Computing and Applications(NCA’03), 2003.
[15] Digital Living Network Alliance. Home Networked DeviceInteroperability Guidelines, Version 1.5, 25-10-2005.
[16] T. Wiegand, G. J. Sullivan, G. Bjontegaard, A. Luthra.Overview of the H.264 / AVC Video Coding Standard.IEEE Transactions on Circuits and Systems for VideoTechnology, July 2003
[17] H.264: Advanced video coding for generic audiovisualservices. ITU-T, March 2005
26 JOURNAL OF MULTIMEDIA, VOL. 2, NO. 2, APRIL 2007
© 2007 ACADEMY PUBLISHER

[18] E. Setton, B. Girod. Rate-Distortion Analysis and Stream-ing of SP and SI Frames. IEEE Transactions on Circuitsand Systems for Video Technology, vol. 16, no. 6, pp. 733-743, 2006
Marek Burza was born in Tarnow, Poland. He receivedhis M.Sc. degree in Computer Science from the WrocławUniversity of Technology in 2002. He then joinedSiemens Mobile Communications Dept. as a SWdeveloper and a project leader. In 2005 he moved toPhilips Research and had worked on streaming platformsfor multicore processors and location services in wirelesssensor networks. His recent research is devoted toQuality-of-Service for networked multi-media streaming.
Jeffrey Kang was born in Taipei, Taiwan. He receivedhis M.Sc. degree in Electrical Engineering from theDelft University of Technology in 1999. He then joinedPhilips Research as a research scientist, where he hasworked on various projects related to hardware/softwarecommunication, streaming models and interfaces, andrapid system prototyping. His recent research interestsinclude (wireless) networked multi-media streaming andQuality-of-Service. He currently works at the InnovationLab of Philips Customer Electronics.
Peter van der Stok holds a M.Sc (1973) and aPh.D. (1982) degree in physics from the Universityof Amsterdam. He has worked from 1973 till 1989 atCERN where he became responsible for the operatingsystem software of the distributed control system of theLEP accelerator. He worked from 1989 at EindhovenUniversity where he is associate professor. His maininterests are distributed fault-tolerant real-time systems.Since September 2000 he works for 90% of histime at Philips Research on the subject of In-HomeDigital Networks and more recently on Wireless SensorNetworks.
JOURNAL OF MULTIMEDIA, VOL. 2, NO. 2, APRIL 2007 27
© 2007 ACADEMY PUBLISHER






![Multimedia Human-Centric Networking: Concepts, Technologies … · 2019-03-04 · 4 AVC [Puri et al. 2004], MPEG Dynamic Adaptive Streaming over HTTP (MPEG-DASH) [Sodagar 2011], and](https://img.pdfslide.us/doc/110x75/5f2bae284a70f710ae1b1270/multimedia-human-centric-networking-concepts-technologies-2019-03-04-4-avc-puri.jpg)


![Intel® Media Accelerator Reference Software...6. HTML5 Zone [Chrome* Browser, Microsoft* Internet Explorer] 7. Adaptive Streaming [MPEG-DASH] 8. Capture Card [USB/Yuan] 2.3 Operating](https://img.pdfslide.us/doc/110x75/5fb24b6fe9eec0017f601fa9/intel-media-accelerator-reference-software-6-html5-zone-chrome-browser.jpg)



















