Embed Size (px)
Citation preview

Data Structures and Algorithms
Abstract Data Types

Introduction
Data Type(DT): set of values a variable could have.Ex: an integer number is of the type integer.
• Internal representation: array of bits.
• The need of using DTs:
– To choose an optimal internal representation.– To take the most of the characteristics of a DT.
Ex: arithmetic operations.
• Simple DT, elemental or primitive: integers, floats, booleans and chars.
• Simple associated Operations.Ex: multiply.
1

Introduction (II)
Working with number matrices −→ defining a matrix DT and associated operations (Ex:multiply).
Abstract Data Type(ADT): mathematical model with a set of operations (procedures).
• ADT = a DT generalization.
• Procedures = a generalization of primitive operations.
• Encapsulation o abstraction allow:
– To locate the ADT definition and its operations at the same place.⇒ Specific libraries for an ADT.
– To change the implementation accordingly to the problem.– To facilitate code debugging.– To get a better program structure.
2

Introduction (III)
Ex: ADT matrix −→ traditional implementation or disperse matrices.
• ADT implementation: to translate a type definition into programming languagesentences.A procedure for each ADT operation.
• An implementation has to choose a Data Structure (DS) for the ADT.
• DS built from simple DTs + programming language structured methods(arrays or records).
3

Example
Definning an ADT matrix of integers:
• Matrix of integers≡ array of integer numbers ordered by rows and columns. Thenumber of elements of each row is the same. The number of elements of each columnis the same. An integer number which belongs to a matrix is identified by row andcolumn.
Logic representation:
M =
3 7 94 5 62 3 5
M [1, 2] = 4.
4

Example (II)
• Operations:
– Sum Mat(A,B: Matrix) returns C: Matrix≡ Sums two matrices with the same number of columns and rows. The addition iscarried out adding, element by element, each integer number of matrix A with thecorresponding integer number of matrix B with identical row and column number.
– Multiply Mat(A,B: Matrix) returns C: Matrix≡ multiply two matrices that accomplish . . . .
– Invert Mat(A: Matrix) return C: Matrix≡ if the matrix has inverted one, this is calculated . . . .
5

Example: Implementation
In C language:
#define NUM_FILAS 10#define NUM_COLUMNAS 10
/* Definimos el TAD */typedef int t_matriz[NUM_FILAS][NUM_COLUMNAS];
/* Definimos una variable */t_matriz M;
void Suma_Mat(t_matriz A, t_matriz B, t_matriz C) int i,j;
for (i=0;i<NUM_FILAS;i++)for (j=0;j<NUM_COLUMNAS;j++)
C[i][j] = A[i][j] + B[i][j];
6

Data Structures and Algorithms
Dynamic Memory Management. Pointers

Dynamic Memory Management. Pointers
Definition and creation of a variable on compilation time
In coding and compilation time, variable type and size is defined.
Example
The following definition
int x;
allocates, at the beginning of the execution, a specific space in memory for an integer. It ispossible to access to this memory with the label x.
x
1

In this manner, the following operations are correct:
In code In execution
x=5; x 5
x=x+2; x 7
The situation is the same in more complex structures:
In code In execution Valid instruction
int v[3]; v v[0]=1;
struct float r,i; im;im im.r=5.0;
im.i=3.0;
2

Pointers
The following sentence
int *px;
defines the variable px as a pointer to an integer and not as integer. px can have a memoryaddress to another memory section which can have an interger.
• The operator & allows to recover the memory direction of a variable that already exists inmemory.
• A pointer can take the special value NULL to indicate that it does not point to an accessibleplace.
3

In code In execution Comment
int *px, x=1; px x 1 px is undefined; x cointains 1.
px=&x; px - 1 x In px it is saved the direction of x.
*px=2; px - 2 x x is modified through px.
px=1; px - 2 x ERROR: it is not possible to assign aninteger to px.
px=NULL; px • 2 x px takes value NULL.
*px=1; px • 2 x ERROR: px does not point to an accessibleplace.
4

Pointers and arrays
One of the most important characteristic of the pointers in C language is that they can pointto any position in a more complex structure, like arrays or a struct. In this way, it is allowedthe following sentences:
In code In execution Comment
int *px, v[3]; px v px and the elements of v are undefined.
px=&v[0]; px
v px points to the first array position.
*px=1; px
v 1 The first position of the array is modifiedthrough px.
px=px+1; px
v 1 px points to the second position of thearray.
v[1]=v[0]+*(px-1); px
v 1 2 ?
5

The array definition
int v[3];
can be interpreted in the following manner:
v
The variable v can be seen as a pointer to one or more consecutives memory positions. Inthis way, it is possible the following sentences:
In code In execution Comment
int *px, v[3]; px v px and the elements of v are undefined. Forcommodity, let’s represent v like we did before.
px=v; px
v px points to the first array position.
px[0]=1; px
v 1 The first position of v is modified through px.
6

Variable definition and creation in execution time
Variable type defined in coding and execution time. The allocation of the memory inexecution.
⇒ Memory allocation: functions malloc and calloc allow dynamic memory allocation. Thefunction malloc does not initialize the memory allocated, as it does calloc .
⇒ Memory release: the function free releases previously allocated memory.
⇒ Type size: sizeof returns the number of bytes a type needs.
7

The syntax of malloc and calloc is:
void *malloc(size_t size);void *calloc(size_t nmemb, size_t size);
malloc receives as parameter the number of bytes to allocate and returns a non-typedpointer.calloc receives as parameters the number of elements to allocate and the number of bytesof each element, and returns a non-typed pointer.
The syntax of free is:
void free(void *ptr);
It receives as parameter a pointer to a valid zone of memory.
The syntax of sizeof is:
sizeof(type);
It receives a type as parameter.
8

The following definition:
int *v;
In code Comment
v=(int *)malloc(n*sizeof(int )); An array of n integers is allocated. We forceto the malloc fuction to return a pointer tointeger which is saved in v.
v[0]=1; We index the array as usual.free(v); We release the previous allocated memory.
The information saved is now unaccessible.v[0]=1; ERROR: v is not pointing to a valid zone.
9

Study the following definitions:
int **v,*pv,i,j; /* v es un puntero a uno o mas punteros a enteros. */
The following sentences allow the definition of a squared matrix.
v=(int **)malloc(n*sizeof(int *)); /* Definimos un vector de punteros. */for (i=0; i<n; i++) v[i]=(int *)malloc(n*sizeof(int )); /* Definimos un vector de enteros. */for (j=0; j<n; j++) /* Inicializamos cada fila. */v[i][j]=0;
v=(int **)malloc(n*sizeof(int *)); /* Definimos un vector de punteros. */pv=(int *)malloc(n*n*sizeof(int )); /* Definimos un vector de enteros. */for (i=0; i<n*n; i++)pv[i]=0; /* Inicializamos la matriz. */
for (i=0; i<n; i++) /* Cada componente de v apunta a n posiciones */v[i]=&pv[i*n]; /* consecutivas de pv. */
10

Study the following definitions:
typedef struct int a, b;
tupla;
tupla *t, **tt; /* tt es un vector de apuntadores a tupla. */int *p,i;
In code Comment
t=(tupla *)malloc(sizeof(tupla)); We allocate a record and force to mallocfunction to return a pointer to the pointerwe need.
t->a=0; We modify a record field.p=&t->b; We assign to p the address of a record field,
which is a valid memory zone.*p=0; We modify a record field.free(t); We release the previous allocated memory.*p=0; ERROR: p is not pointing a valid zone.
11

In code Comment
tt=(tupla**)malloc(n*sizeof(tupla*)); We allocate an array of pointers totupla.
t=(tupla*)malloc(n*sizeof(tupla));for (i=0;i<n;i++) tt[i]=&t[i];tt[i]->a=0;tt[i]->b=0;
We allocate a tupla array. Af-terwards, we link each element oftt with an element of t.
12

Arrays as parameters to functions
• The parameter is a pointer to an array.
• To do a copy to a local array each time is too much cost.
• The array is sent by reference.
void f(int *v) ... ...int main()
int p[n];...f(p);...
13

Data Structures and Algorithms
Linear Data Structures

Stacks. Array and linked representation
Definition. A stack is a linear data structure characterized by the way to access to its data:last-in-first-out (LIFO). The access to the elements is only carried out through the top of thestack.
Pn+1 Pn+1
↓ ↑top Pn+1
top Pn Pn top Pn... ... ...
P2 P2 P2
P1 P1 P1
Applications
• Evaluation of arithmetic expressions.
• Recursion management.
1
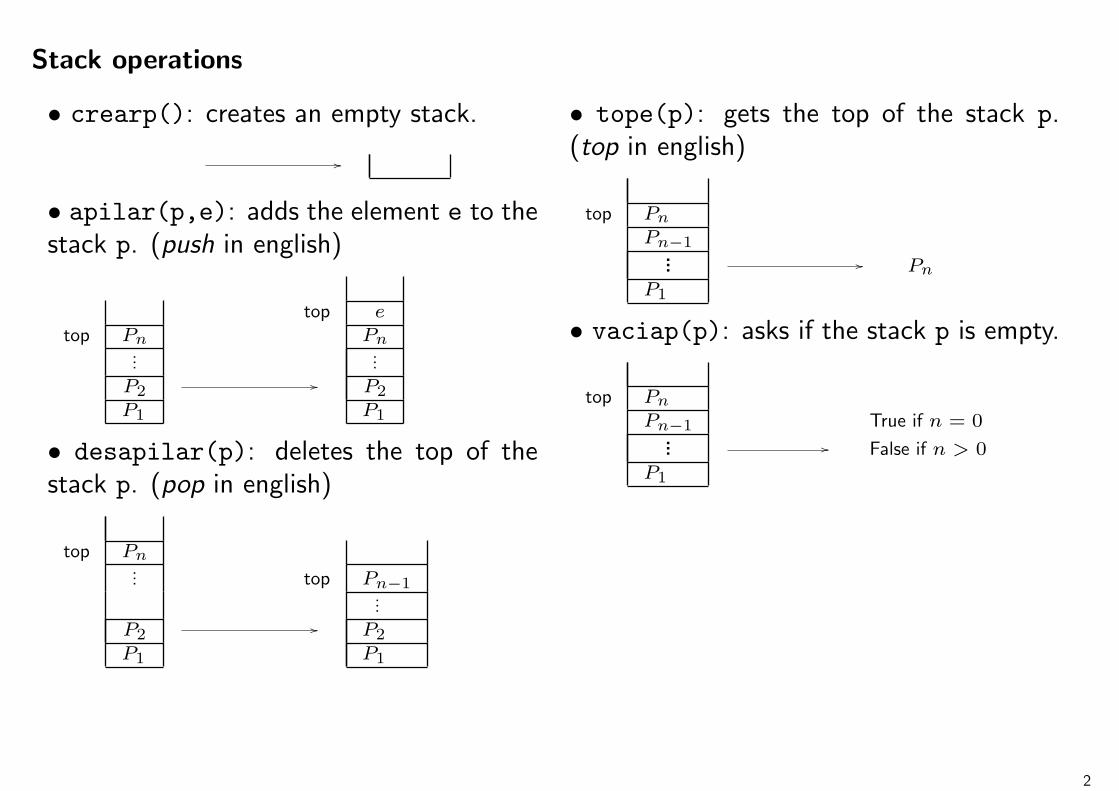
Stack operations
• crearp(): creates an empty stack.
//
• apilar(p,e): adds the element e to thestack p. (push in english)
top etop Pn Pn
......
P2// P2
P1 P1
• desapilar(p): deletes the top of thestack p. (pop in english)
top Pn... top Pn−1
...P2
// P2
P1 P1
• tope(p): gets the top of the stack p.(top in english)
top Pn
Pn−1... // Pn
P1
• vaciap(p): asks if the stack p is empty.
top Pn
Pn−1 True if n = 0... // False if n > 0
P1
2

Stack representation with arrays
0 1 n − 1
P1 P2 · · · Pn
tope
Type definition
#define maxP ... /* Talla maxima de vector. */
typedef struct int v[maxP]; /* Vector definido en tiempo de compilacion. */
/* Trabajamos con pilas de enteros. */int tope; /* Marcador al tope de la pila. */
pila;
3

pila *crearp() pila *p;
p = (pila *) malloc(sizeof(pila)); /* Reservamos memoria para la pila. */p->tope = -1; /* Inicializamos el marcador al tope. */return(p); /* Devolvemos un puntero a la pila creada. */
pila *apilar(pila *p, int e) if (p->tope + 1 == maxP) /* Comprobamos si cabe el elemento. */tratarPilaLlena(); /* Si no cabe hacemos un tratamiento de error. */
else /* Si cabe, entonces */p->tope = p->tope + 1; /* actualizamos el tope e */p->v[p->tope] = e; /* insertamos el elemento. */
return(p); /* Devolvemos un puntero a la pila modificada. */
pila *desapilar(pila *p) p->tope = p->tope - 1; /* Decrementamos el marcador al tope. */return(p); /* Devolvemos un puntero a la pila modificada. */
4

int tope(pila *p) return(p->v[p->tope]); /* Devolvemos el elemento senyalado por tope. */
int vaciap(pila *p) return(p->tope < 0); /* Devolvemos 0 (falso) si la pila no esta vacia, */
/* y 1 (cierto) en caso contrario. */
5

Linked representation with dynamic memory
- Pn Pn−1 · · · P2 P1
::
:•
Type definition
typedef struct _pnodo int e; /* Variable para almacenar un elemento de la pila. */struct _pnodo *sig; /* Puntero al siguiente nodo que contiene un elemento. */
pnodo; /* Tipo nodo. Cada nodo contiene un elemento de la pila. */typedef pnodo pila;
pila *crearp() return(NULL); /* Devolvemos un valor NULL para inicializar */
/* el puntero de acceso a la pila. */
int tope(pila *p) return(p->e); /* Devolvemos el elemento apuntado por p */
6

pila *apilar(pila *p, int e) pnodo *paux;
paux = (pnodo *) malloc(sizeof(pnodo)); /* Creamos un nodo. */paux->e = e; /* Almacenamos el elemento e. */paux->sig = p; /* El nuevo nodo pasa a ser tope de la pila. */return(paux); /* Devolvemos un puntero al nuevo tope. */
pila *desapilar(pila *p) pnodo *paux;
paux = p; /* Guardamos un puntero al nodo a borrar. */p = p->sig; /* El nuevo tope sera el nodo apuntado por el tope actual. */free(paux); /* Liberamos la memoria ocupada por el tope actual. */return(p); /* Devolvemos un puntero al nuevo tope. */
int vaciap(pila *p) return(p == NULL); /* Devolvemos 0 (falso) si la pila no esta vacia, */
/* y 1 (cierto) en caso contrario. */
7

Queues. Array and linked representation
Definition. A queue is a linear data structure characterized by the way to access to its data:first-in-first-out (FIFO). The elements are introduced in the head and extracted from the tail.
pcab pcol
Q1 Q2 · · · Qn ← Qn+1
pcab pcol
Q1 Q2 · · · Qn Qn+1
pcab pcol
Q1 ← Q2 · · · Qn Qn+1
pcab pcol
Q2 · · · Qn Qn+1
Applications
• A processes queue to a specific resource.
• A print queue.
8

Queue operations
• crearq(): creates an empty queue.//
• encolar(q,e): puts an elements e into the tail of the queue q.pcab pcol pcab pcol
Q1 Q2 · · · Qn // Q1 Q2 · · · Qn e
• desencolar(q): deletes the head of the queue q.pcab pcol pcab pcol
Q1 Q2 · · · Qn // Q2 Q3 · · · Qn
• cabeza(q): consults the head element of the queue q.pcab pcol
Q1 Q2 · · · Qn // Q1
• vaciaq(q): consults if the queue q is empty or not.pcab pcol True if n = 0Q1 Q2 · · · Qn // False if n > 0
9

An array representation for queues
0 maxC−1
· · · Q1 Q2 · · · Qn · · ·pcab pcol
Possible cases
0 maxC−1
· · · Q1 Q2 · · · Qn
pcab pcol
0 maxC−1
· · · Qn · · · Q1 Q2 · · ·pcol pcab
10

&%'$
&%'$
BB
BB
HH
XX
0maxC-1
· · ·pcab
pcol&%'$
&%'$
BB
HH
XX
0maxC-1
pcabpcol
¿An empty or full queue?
Type definition
#define maxC ... /* Talla maxima del vector. */
typedef struct int v[maxC]; /* Vector definido en tiempo de compilacion. */int pcab, pcol; /* Marcador a la cabeza y a la cola. */int talla; /* Numero de elementos. */
cola;
11

cola *crearq() cola *q;
q = (cola *) malloc(sizeof(cola)); /* Reservamos memoria para la cola. */q->pcab = 0; /* Inicializamos el marcador a la cabeza. */q->pcol = 0; /* Inicializamos el marcador a la cola. */q->talla = 0; /* Inicializamos la talla. */return(q); /* Devolvemos un puntero a la cola creada. */
cola *encolar(cola *q, int e) if (q->talla == maxC) /* Comprobamos si cabe el elemento. */tratarColaLlena(); /* Si no cabe hacemos un tratamiento de error. */
else /* Si cabe, entonces */q->v[q->pcol] = e; /* guardamos el elemento, */q->pcol = (q->pcol + 1) % maxC; /* incrementamos marcador de cola, */q->talla = q->talla + 1; /* e incrementamos la talla. */
return(q); /* Devolvemos un puntero a la cola modificada. */
12

cola *desencolar(cola *q) q->pcab = (q->pcab + 1) % maxC; /* Avanzamos el marcador de cabeza. */q->talla = q->talla - 1; /* Decrementamos la talla. */return(q); /* Devolvemos un puntero a la cola modificada. */
int cabeza(cola *q) return(q->v[q->pcab]); /* Devolvemos el elemento que hay en cabeza. */
int vaciaq(cola *p) return(q->talla == 0); /* Devolvemos 0 (falso) si la cola */
/* no esta vacia, y 1 (cierto) en caso contrario.*/
13

Linked representation with dynamic memory
pcab - Q1 Q2 · · · Qn−1 Qn
pcol *::
:•
Type definition
typedef struct _cnodo int e; /* Variable para almacenar un elemento de la cola. */struct _cnodo *sig; /* Puntero al siguiente nodo que contiene un elemento. */
cnodo; /* Tipo nodo. Cada nodo contiene un elemento de la cola. */typedef struct
cnodo *pcab, *pcol; /* Punteros a la cabeza y la cola. */ cola;
14

cola *crearq() cola *q;
q = (cola*) malloc(sizeof(cola)); /* Creamos una cola. */q->pcab = NULL; /* Inicializamos a NULL los punteros. */q->pcol = NULL;return(q); /* Devolvemos un puntero a la cola creada.*/
cola *encolar(cola *q, int e) cnodo *qaux;
qaux = (cnodo *) malloc(sizeof(cnodo)); /* Creamos un nodo. */qaux->e = e; /* Almacenamos el elemento e. */qaux->sig = NULL;if (q->pcab == NULL) /* Si no hay nigun elemento, entonces */q->pcab = qaux; /* pcab apunta al nuevo nodo creado, */
else /* y sino, */q->pcol->seg = qaux; /* el nodo nuevo va despues del que apunta pcol. */
q->pcol = qaux; /* El nuevo nodo pasa a estar apuntado por pcol. */return(q); /* Devolvemos un puntero a la cola modificada. */
15

cola *desencolar(cola *q) cnodo *qaux;
qaux = q->pcab; /* Guardamos un puntero al nodo a borrar. */q->pcab = q->pcab->sig; /* Actualizamos pcab. */if (q->pcab == NULL) /* Si la cola se queda vacia, entonces */q->pcol = NULL; /* actualizamos pcol. */
free(qaux); /* Liberamos la memoria ocupada por el nodo. */return(q); /* Devolvemos un puntero a la cola modificada. */
int cabeza(cola *q) return(q->pcab->e); /* Devolvemos el elemento que hay en la cabeza. */
int vaciaq(cola *q) return(q->pcab == NULL); /* Devolvemos 0 (falso) si la cola */
/* no esta vacia, y 1 (cierto) en caso contrario. */
16

Lists. Linked and array representation
Definition. A list is a data structure formed by an object sequence. Each object is referencedby its position in the sequence.
Operations
• crearl(): creates an empty list.1 n
// · · ·
• insertar(l,e,p): inserts e at the position p of the list l. The elements from thisposition until the end are moved one position to the right.
1 p n 1 p p + 1 n + 1
L1 · · · Lp · · · Ln // L1 · · · e Lp · · · Ln
• borrar(l,p): remove the element of the position p of the list l.1 p n 1 p n − 1
L1 · · · Lp · · · Ln // L1 · · · Lp+1 · · · Ln
• recuperar(l,p): returns the element of the position p of the list l.1 p n
L1 · · · Lp · · · Ln // Lp
17

• vacial(l): consults if the list l is empty or not.1 n True if n = 0
L1 · · · Ln // False if n > 0
• fin(l): returns the position that follows the last position of the list l.1 n
L1 · · · Ln // n + 1
• principio(l): returns the first position of the list l.1 n
L1 · · · Ln // 1
• siguiente(l,p): returns the next position of p in the list l.1 p n
L1 · · · Lp · · · Ln // p + 1
18

Array representation of lists
0 n − 1 maxL−1
L1 L2 · · · Ln · · ·ultimo
Type definition
#define maxL ... /* Talla maxima del vector. */
typedef int posicion; /* Cada posicion se referencia con un entero. */typedef struct
int v[maxL]; /* Vector definido en tiempo de compilacion. */posicion ultimo; /* Posicion del ultimo elemento. */
lista;
19

lista *crearl() lista *l
l = (lista *) malloc(sizeof(lista)); /* Creamos la lista. */l->ultimo = -1; /* Inicializamos el marcador al ultimo. */return(l); /* Devolvemos un puntero a la lista creada. */
lista *insertar(lista *l, int e, posicion p) posicion i;
if (l->ultimo == maxL-1) /* Comprobamos si cabe el elemento. */tratarListaLlena(); /* Si no cabe hacemos un tratamiento de error. */
else /* Si cabe, entonces */for (i=l->ultimo; i>=p; i--) /* hacemos un vacio en la posicion p, */
l->v[i+1] = l->v[i];l->v[p] = e; /* guardamos el elemento, */l->ultimo = l->ultimo + 1; /* e incrementamos el marcador al ultimo. */return(l); /* Devolvemos un puntero a la lista modificada. */
20

lista *borrar(lista *l, posicion p) posicion i;
for (i=p; i<l->ultimo; i++) /* Desplazamos los elementos del vector. */l->v[i] = l->v[i+1];
l->ultimo = l->ultimo - 1; /* Decrementamos el marcador al ultimo. */return(l); /* Devolvemos un puntero a la lista modificada. */
int recuperar(lista *l, posicion p) return(l->v[p]); /* Devolvemos el elemento que hay en la posicion p. */
int vacial(lista *l) return(l->ultimo < 0); /* Devolvemos 0 (falso) si la lista */
/* no esta vacia, y 1 (cierto) en caso contrario. */
posicion fin(lista *l) return(l->ultimo + 1); /* Devolvemos la posicion siguiente a la ultima. */
21

posicion principio(lista *l) return(0); /* Devolvemos la primera posicion. */
posicion siguiente(lista *l, posicion p) return(p+1); /* Devolvemos la posicion siguiente a la posicion p. */
22

Linked representation of lists with dynamic memory
We use a sentry node at the beginning of the list to increase the list update performance.
first - L1 · · · Ln−1 Ln
last *::
:•
• First option: given a position p, the element Lp is at the node pointed by p.
p - Lp
· · · : · · ·
• Second option: given a position p, the element Lp is pointed by p->sig.
p - Lp−1 Lp
· · · :: · · ·
23

Type definition
typedef struct _lnodo int e; /* Variable para almacenar un elemento de la lista. */struct _lnodo *sig; /* Puntero al siguiente nodo que contiene un elemento. */
lnodotypedef lnodo *posicion; /* Cada posicion se referencia con un puntero. */typedef struct /* Definimos el tipo lista con un puntero */posicion primero, ultimo; /* al primero y ultimo nodos. */
lista;
lista *crearl() lista *l;
l = (lista *) malloc(sizeof(lista)); /* Creamos una lista. */l->primero = (lnodo *) malloc(sizeof(lnodo)); /* Creamos el centinela */l->primero->sig = NULL;l->ultimo = l->primero;return(l); /* Devolvemos un puntero a la lista creada. */
24

lista *insertar(lista *l, int e, posicion p) posicion q;
q = p->sig; /* Dejamos q apuntando al nodo que se desplaza. */p->sig = (lnodo *) malloc(sizeof(lnodo)); /* Creamos un nodo. */p->sig->e = e; /* Guardamos el elemento. */p->sig->sig = q; /* El sucesor del nuevo nodo esta apuntado por q. */
if (p == l->ultimo) /* Si el nodo insertado ha pasaso a ser el ultimo, */l->ultimo = p->sig; /* actualizamos ultimo. */
return(l); /* Devolvemos un puntero a la lista modificada. */
lista *borrar(lista *l, posicion p) posicion q;
if (p->sig == l->ultimo) /* Si el nodo que borramos es el ultimo, */l->ultimo = p; /* actualizamos ultimo. */
q = p->sig; /* Dejamos q apuntando al nodo a borrar. */p->sig = p->sig->sig; /* p->sig apuntara a su sucesor. */free(q); /* Liberamos la memoria ocupada por el nodo a borrar. */return(l); /* Devolvemos un puntero a la lista modificada. */
25

int recuperar(lista *l, posicion p) return(p->sig->e);/* Devolvemos el elemento que hay en la posicion p. */
int vacial(lista *l) return(l->primero->sig == NULL); /* Devolvemos 0 (falso) si la lista */
/* no esta vacia, y 1 (cierto) en caso contrario. */
posicion fin(lista *l) return(l->ultimo); /* Devolvemos la ultima posicion. */
posicion principio(lista *l) return(l->primero); /* Devolvemos la primera posicion. */
posicion siguiente(lista *l, posicion p) return(p->sig); /* Devolvemos la posicion siguiente a la posicion p. */
26
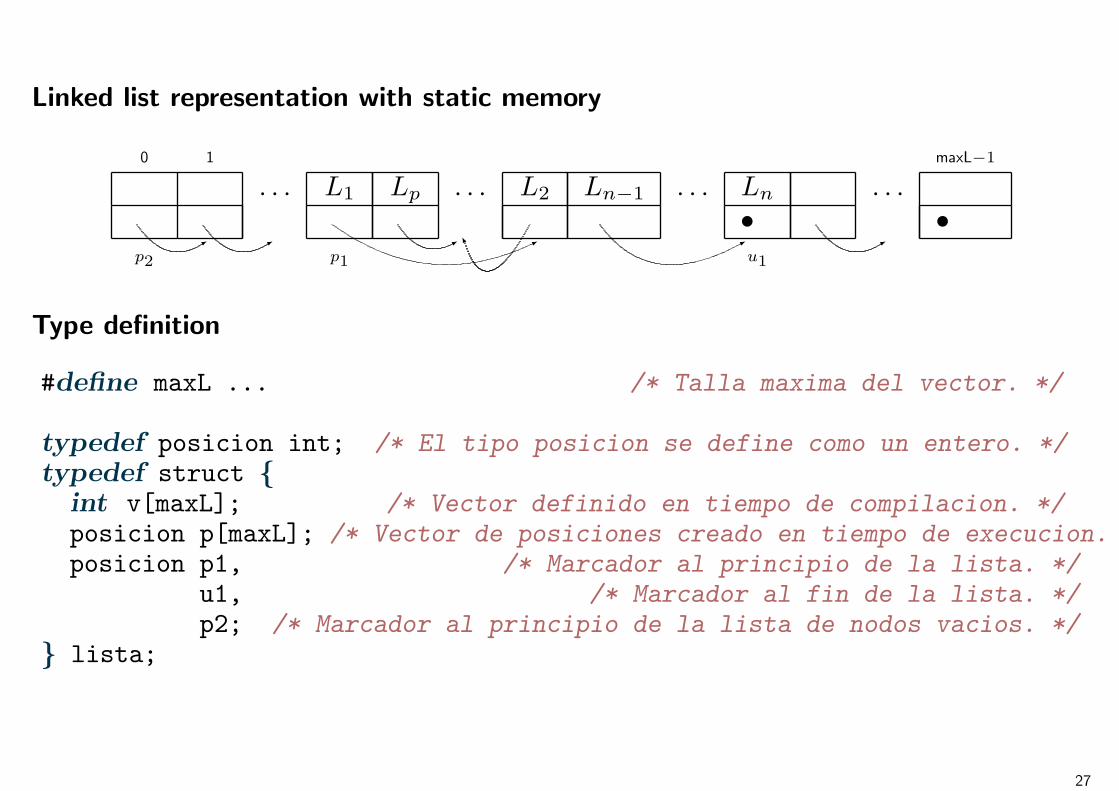
Linked list representation with static memory
0 1 maxL−1
. . . L1 Lp . . . L2 Ln−1 . . . Ln . . .
* * ** K *
•*
•p2 p1 u1
Type definition
#define maxL ... /* Talla maxima del vector. */
typedef posicion int; /* El tipo posicion se define como un entero. */typedef struct
int v[maxL]; /* Vector definido en tiempo de compilacion. */posicion p[maxL]; /* Vector de posiciones creado en tiempo de execucion. */posicion p1, /* Marcador al principio de la lista. */
u1, /* Marcador al fin de la lista. */p2; /* Marcador al principio de la lista de nodos vacios. */
lista;
27

p
. . . . . . Lp . . .
*
Lp = l.v[l.p[p]]
lista *crearl() lista *l;int i;
l = (lista *) malloc(sizeof(lista)); /* Creamos la lista. */l->p1 = 0; /* El nodo 0 es el centinela. */l->u1 = 0;l->p[0] = -1;l->p2 = 1; /* La lista de nodos vacios comienza en el node 1. */for (i=1; i<maxL-1; i++) /* Construimos la lista de nodos vacios. */l->p[i] = i+1;
l->p[maxL-1] = -1; /* El ultimo nodo vacio no senyala a ningun lugar. */return(l); /* Devolvemos un puntero a lista construida. */
28

lista *insertar(lista *l, int e, posicion p) posicion q;
if (l->p2 == -1) /* Si no quedan nodos vacios, */tratarListaLlena(); /* hacemos un tratamiento de error. */
else q = l->p2; /* Dejamos un marcador al primer nodo vacio. */l->p2 = l->p[q]; /* El primer nodo vacio sera el sucesor de q. */l->v[q] = e; /* Guardamos el elemento en el nodo reservado. */l->p[q] = l->p[p]; /* Su sucesor pasa a ser el de la pos. p. */l->p[p] = q; /* El sucesor del nodo apuntado por p pasa a ser q. */if (p == l->u1) /* Si el nodo que hemos insertado pasa a ser el ultimo, */
l->u1 = q; /* actualizamos el marcador u1. */return(l); /* Devolvemos un puntero a la lista modificada. */
29

lista *borrar(lista *l, posicion p) posicion q;
if (l->p[p] == l->u1) /* Si el nodo que borramos es el ultimo, */l->u1 = p; /* actualizamos u1. */
q = l->p[p]; /* Dejamos q senyalando al nodo a borrar. */l->p[p] = l->p[q]; /* El sucesor del nodo senyalado por p pasa a
ser el sucesor del nodo apuntado por q. */l->p[q] = l->p2; /* El nodo que borramos sera el primero de los vacios. */l->p2 = q; /* El principio de la lista de nodos vacios comienza en q. */return(l);
30

Data Structures and Algorithms
Divide and Conquer

“Divide and Conquer” general concept
Given a problem of size of input n:
1. Divide the problem in problems of litter size of input (sub-problems),
2. Solve the sub-problems independently (recursively),
3. Combine the sub-problems solutions to get the original problem solution.
Characteristics
Recursive method.
Cost in the problem division into sub-problems+Cost in the results combination.
Efficient method when the sub-problems are of a similar size of input.
1

Sorting Algorithms
Problem: To sort in an non-decreasing way a set of n integers saved in an array A.
Insertion Sort
Strategy:
1. Two parts in the array: one sorted and one unsorted.
ordenado no ordenado
2. The first element of the unsorted part is selected, and it is inserted in the correspondingposition in the sorted part (and keeping this part sorted).
ordenado
i
no ordenado
no ordenado
ordenado
2

Algorithm: Insertion SortParameters: A: array A[l, . . . , r],
l: index of the first vector position,r: index of the last vector position
void Insert Sort(int *A,int l,int r) int i,j,aux;
for(i=l+1;i<=r;i++)aux=A[i];j=i;
while ((j>l) && (A[j-1]>aux)) A[j]=A[j-1];j--;A[j]=aux;
3

function call: Insertion Sort(A,0,4)
initial array A: 45 14 33 3 560 1 2 3 4
first iteration (i=1,aux=14)
j = 1 33 3 5645 45
j = 0
33 3 5614 45
aux
second iteration (i=2,aux=33)
j = 2 3 5614 45 45
j = 1
3 5614 33 45
aux
4

third iteration (i=3,aux=3)
j = 3 5614 33 45 45
j = 2 5614 33 4533
j = 1 5614 33 4514
j = 0
14 33 563 45
aux
fourth iteration (i=4,aux=56)
j = 4
14 333 45 56
aux
5

Efficiency analysis
Worst case
n∑i=2
(i− 1) =n(n− 1)
2∈ Θ(n
2)
Best case
n∑i=2
1 = n− 1 ∈ Θ(n)
Average case
insert in i: ci =1
i
(2(i− 1) +
i−2∑k=1
k
)=
(i− 1)(i + 2)
2i=
i + 1
2−
1
i
n∑i=2
ci =n∑
i=2
(i + 1
2−
1
i
)=
n2 + 3n
4−Hn ∈ Θ(n
2)
where Hn =∑n
i=11i ∈ Θ(log n)
Temporal cost of “Insert Sort” algorithm =⇒ Ω(n) O(n2)
6

Selection Sort
Characteristics:
Given an array A[1, . . . , N ]
1. Initially, the minimum value is selected and it is put at the first position; i.e., the 1-thlitter element to the position 1.
2. Then, it is selected the minimum value in the sub-sequence A[2, . . . , N ] and it is put inthe second position; i.e., the 2-th litter element to the position 2.
3. Following this procedure with all the i positions of the array, assigning to each one thecorresponding element: the i-th litter.
7

Algorithm: Selection SortParameters: A: array A[l, . . . , r],
l: index to the first vector position,r: index to the last vector position
void Selection Sort(int *A,int l,int r) int i,j,min,aux;
for(i=l;i<r;i++)min=i;
for(j=i+1;j<=r;j++)if (A[j]<A[min])min=j;
aux=A[i];A[i]=A[min];A[min]=aux;
8

An example:
45 56 31433
45 56 31433
1 2 3 40
56 1433 453
33143 45 56
3314 56 453
3314 56 453
i
i
i
i
i
min
min
min
min
9

Efficiency Analysis
Number of comparisons:
n−1∑i=1
n− i =n(n− 1)
2∈ Θ(n2)
Temporal cost of “Selection Sort” algorithm =⇒ Θ(n2)
10

Mergesort
Strategy:
Given an array A[1, . . . , N ]
1. The array is divided in two sub-arrays: A[1, . . . , N2 ] A[N2 + 1, . . . , N ].
2. The sub-arrays are sorted independently .
3. The two sorted sub-arrays are merged getting a sorted array of size N .
11

Example
25 4 6
5 2 64
2 5
1 3
64 1 3
2 6
2 6
5 2 64 1 3 2 6
5 2 4 6 1 3 2 63 4 5 6 7 8
1 3 2 6
62 4 5 1 632
2 2 3 51 6 64
1 2
12
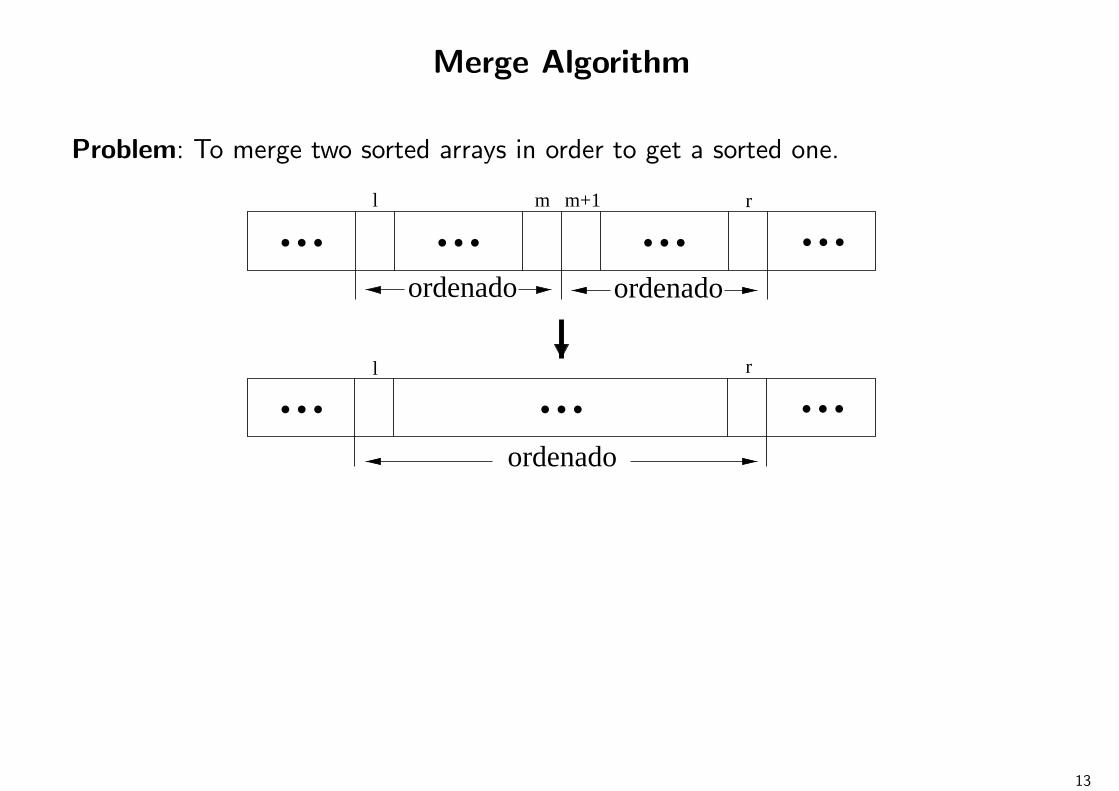
Merge Algorithm
Problem: To merge two sorted arrays in order to get a sorted one.
ordenado
l m m+1 r
ordenado
l r
ordenado
...
... ... ...
...
...
...
13

Algorithm: Merge
Parameters: A: vector A[l, . . . , r],
l: index to the first vector position,
m: index to the position that divides the two sorted parts
r:index to the last vector position
void merge(int *A, int l, int m, int r)int i,j,k, *B;
B = (int *) malloc((r-l+1) * sizeof(int));
i = l; j = m + 1; k = 0;
while ( (i<=m) && (j<=r) )if (A[i] <= A[j])B[k] = A[i];i++;elseB[k] = A[j];j++;k++;
14

while (i<=m)B[k] = A[i];i++;k++;while (j<=r)B[k] = A[j];j++;k++;for(i=l;i<=r;i++)A[i]=B[i-l];
free(B);
Temporal cost of Merge algorithm =⇒ Θ(n).
15

Mergesort Algorithm
Algorithm: MergesortParameters: A: vector A[l, . . . , r],
l: index to the first vector position,r: index to the last vector position
void mergesort(int *A,int l,int r) int m;
if (l<r)m = (int) ((l+r)/2);mergesort(A,l,m);mergesort(A,m+1,r);merge(A,l,m,r);
16

Example
32
47 14
561 4 5
−850
504 5
−86
3561
450
504 5
−86
3
45 56 47 140 1 2 3 5 6
50 3−84
45
0 1
56
32
14 47 −8
4 5
50
6
−84 5
3 50
45 56
472
143
450
(14) mergesort(A,5,5)
0 1 32
47 14 14 450 1 32
5647
(1) mergesort(A,0,3) (11) mergesort(A,4,6)
(6) mergesort(A,2,3) (16) mergesort(A,6,6)
(8) mergesort(A,3,3)(3) mergesort(A,0,0) (4) mergesort(A,1,1)
(2) mergesort(A,0,1)
(5) merge(A,0,0,1) (9) merge(A,2,2,3) (15) merge(A,4,4,5)
(10) merge(A,0,1,3) (17) merge(A,4,5,6)
3−8 45 47140 1 2 3 5 64
5650(18) merge(A,0,3,6)
(7) mergesort(A,2,2)
(12) mergesort(A,4,5)
(13) mergesort(A,4,4)
17

Efficiency cost
For simplicity, let’s say that n is a power of 2:
T (n) =
c1 n = 1
2T (n2) + c2n + c3 n > 1
Solving by substitution:
T (n) = 2T (n
2) + c2n + c3
= 2(2T (n
22) + c2
n
2+ c3) + c2n + c3
= 22T (
n
22) + 2c2n + c3(2 + 1)
= 23T (
n
23) + 3c2n + c3(2
2+ 2 + 1)
= p iterations . . .
= 2pT (
n
2p) + pc2n + c3(2
p−1+ . . . + 2
2+ 2 + 1)
(p = log2 n) = nc1 + c2n log2 n + c3(n− 1) ∈ Θ(n logn)
Temporal cost of “mergesort” algorithm =⇒ Θ(n logn)
18

Balance problem
Let’s see what we get if we divide the original problem, of input size of n, in a sub-problemof size n− 1 and another of size 1.
T (n) =
c1 n = 1T (n− 1) + c2n + c3 n > 1
Solving by substitution:
T (n) = T (n− 1) + c2n + c3
= T (n− 2) + c2n + c2(n− 1) + 2c3
= T (n− 3) + c2n + c2(n− 1) + c2(n− 2) + 3c3
= . . .
= T (1) + c2n + c2(n− 1) + . . . + 2c2 + (n− 1)c3
= c1 + (n− 1)c3 + c2
n∑i=2
i
= c1 + (n− 1)c3 + c2(n + 2)(n− 1)
2∈ Θ(n2)
19

Posible improvements of the algorithm
The use of a classic sorting algorithm for sub-problems of a small size of input.
The use of an additional array to avoid the copy vector process.
20

Sorting by partition: Quicksort
1. Choose as pivot one of the array elements. Permut the elements: those less than the pivotare at A[1, . . . , q], and those greater that the pivot are at A[q + 1, . . . , N ] (partition).
... ...Nq1
2. Apply the same method (repetitively) to each subarray until getting subarrays of size 1, inthis way we get the original array sorted.
...
N
... ...Nq1
... ......q1 q’ q’’
...
...
21

Partition algorithm
Problem: Dividing the array into two parts, and getting that every element of the first partare less or equal than the elements of the second part..
Method: Given an array A[1, . . . , N ]
1. Choose the first element of the array as pivot x = A[1].
2. Using an index i, go (incrementally) from position 1 through A[1, . . . , i] until finding anelement A[i] ≥ x.
3. Using an index j, go (decrementally) from position N through A[j, . . . , N ] until findingan element A[j] ≤ x.
4. Swap A[i] and A[j].
5. While i < j, repeat steps (2,3,4) initializing i and j with their last values.
6. The index j, where 1 ≤ j < N , indicates the position where it is the array divided intotwo parts A[1, . . . , j] A[j + 1, . . . , N ], where every element of A[1, . . . , j] is less or equalthan every element of A[j + 1, . . . , N ]
22

Partition algorithm (II)
int partition(int *A, int l, int r)int i,j,x,aux;
i=l-1; j=r+1; x=A[l];
while(i<j)
doj--;while (A[j]>x);
doi++;while (A[i]<x);
if (i<j)aux=A[i];A[i]=A[j];A[j]=aux;
return(j);
Temporal cost of partition algorithm Θ(n), where n = r − l + 1.
23

Partition algorithm example
j
j
i
i
ji
i j
i
ji
3 3 2 1 4 6 5 7r
x = 5
A[l,...,q] A[q+1,...,r]
5 4 3 7r
3 2 6 1 x = 5
5 3 2 6 4 1 3 7r
3 3 2 6 4 1 5 7r
x = 5
x = 5
x = 53 3 2 6 4 1 5 7r
3 3 2 4 5 7r
1 6 x = 5
3 3 2 1 4 6 5 7r
x = 5
j
q
24

Quicksort algorithm
Algorithm: QuicksortParameters: A: vector A[l, . . . , r],
l: index to the first array position,r: index to the last array position
void quicksort(int *A, int l, int r)int q;
if (l<r)q = partition(A,l,r);quicksort(A,l,q);quicksort(A,q+1,r);
25

Quicksort algorithm example
5 3 2 6 4 1 3 71 2 4 5 6 70 3
3
3 3 2 1 41 2 40
3
3 3 2 1 41 2 40
q=4
6 5 75 6 7
q=1
1 210
(3) partition(A,0,4)
1 210
21
3
3 3 42 4
3
3 3 42 4
q=0
1
32
3
3 44
q=2
3
3 44
3
3 44(12) partition(A,3,4)
q=3
65
7
6 76
7
76
6
q=5
5
(2) quicksort(A,0,4)
quicksort(A,0,7)
(1) partition(A,0,7)
(15) quicksort(A,5,7)
0
1 2
(4) quicksort(A,0,1)
(6) quicksort(A,0,0) (7) quicksort(A,1,1)
10
(8) quicksort(A,2,4)
(10) quicksort(A,2,2)
32
(9) partition(A,2,4)
(11) quicksort(A,3,4)
33
44
(13) quicksort(A,3,3) (14) quicksort(A,4,4)
(16) partition(A,5,7)
5 76 7
55
(17) quicksort(A,5,5)
(19) partition(A,6,7)
q=6
(18) quicksort(A,6,7)
5
6 7
(20) quicksort(A,6,6) (21) quicksort(A,7,7)
7
76
6
6 7
(5) partition(A,0,1)
26

Efficiency analysis
Worst case
T (n) =
c1 n = 1T (n− 1) + c2n + c3 n > 1
=⇒ T (n) ∈ Θ(n2).
Best case
T (n) =
c1 n = 12T (n
2) + c2n + c3 n > 1
=⇒ T (n) ∈ Θ(n logn).
27

Average case
A Subproblems size Probability
...1 n − 1
1 n−1 1n
...1 n − 1
1 n−1 1n
...2 n − 2
2 n−2 1n
...n − 33
3 n−3 1n
. . . . . . . . . . . .
...2n − 2
n−2 2 1n
...n − 1 1
n−1 1 1n
28

T (n) =1n
(T (1) + T (n− 1) +
n−1∑q=1
(T (q) + T (n− q)))
+ Θ(n)
Since T (1) = Θ(1) and, in the worst case, T (n− 1) = O(n2) ,
1n(T (1) + T (n− 1)) =
1n(Θ(1) + O(n2) = O(n)
we can rewrite T (n) as:
T (n) =1n
n−1∑q=1
(T (q) + T (n− q)) + Θ(n)
29

For k = 1, 2, . . . , n− 1 each term T (k) appears once as T (q) and another as T (n− q), so:
T (n) =2n
n−1∑k=1
T (k) + Θ(n)
T (n) =
c1 n ≤ 12n
∑n−1k=1 T (k) + c2n n > 1
By induction ∀ n > 1, T (n) ≤ c3 n log2 n, where c3 = 2c2 + c1, and consequently:=⇒ T (n) ∈ O(n logn)
30

Possible improvements to Quicksort
Solving the subproblems of small sizes with a classic sorting algorithm.
Choosing the pivot randomly among the array values.
In order to solve the median selection, it is possible to use a pseudomedian in the followingway: selecting several elements randomly. One possibility could be, given a subarrayA[l, . . . , r], select three elements: A[l], A[l+r
2 ], A[r].
31

Empirical comparison of the algotihms
32

Search of the k-th smallest element
Problem: Given a set of n integers saved in an array A[1, . . . , N ], find the k-th smallestelement.
Strategy:
1. To use the partition algorithm in order to divide the array into two parts, where everyelement of the first part is less or equal than every element of the second part.
... ...Nq1
2. Due to, once the array is sorted, the k-th smallest element will be allocated at the k, if itis true that 1 ≤ k ≤ q only will be necessary to sort the subarray A[1, . . . , q]; while if, bythe contrary, q < k ≤ N only will be necessary to sort the subarray A[q + 1, . . . , N ].
33

Algorithm: SelectionParamenters: A: array A[0, . . . , n− 1],
n: size of array,k: k value
int selection(int *A, int n, int k)int l,r,q;
l = 0; r = n-1; k = k-1;
while (l<r)q = partition(A,l,r);
if (k<=q)r=q;
elsel=q+1;
return(A[l]);
34

31 23 90 77 52 49 87 600 152 3 5 6 7 8 90 1 4
77 52 49 87 60 31903 5 6 7 8 94
r
r
partition(A,0,9)
52 49 87 60 31903 5 6 7 8 94
77
q=2
52 49 87 60313 5 6 7 84
77
r
52 87 60313 5 6 7 84
77 49
partition(A,3,9)
q=8
313
313
r
seleccion(A,10,4)
2315 020 1
909
partition(A,3,8)
52 87 605 7 84
77 496
q=3
return(31)
35

Efficiency analysis
Worst case:
T (n) =
c1 n = 1T (n− 1) + c2n + c3 n > 1
=⇒ T (n) ∈ Θ(n2)
Best case:
T (n) =
c1 n = 1T (n
2) + c2n + c3 n > 1
Solving by substitution:
36

T (n) = T (n
2) + c2n + c3
= T (n
22) + (n +
n
2)c2 + 2c3
= T (n
23) + c2n(1 +
12
+122
) + 3c3
= p iterations . . .
= T (n
2p) + c2n(1 +
12
+122
+ . . . +1
2p−1) + pc3
= T (n
2p) + c2n
2(2p − 1)2p
+ pc3
(p = log2 n) = c1 + 2c2(n− 1) + c3 log2n ∈ O(n)
Average case: ≈ best case =⇒ T (n) ∈ O(n).
37

Binary search
Problem: Given an array A sorted in non decreasing way of n integers, look for thecorresponding position of the element x.
Strategy:
Given an array A[1. . . n] and an element x:
Take the element in the half of the array A[q], with q=n/2.
If x=A[q] the position looked for is q else:
• If x <A[q] then apply the same criteria to the search in the array A[1. . . q-1].• Si x >A[q] then apply the same criteria to the search in the array A[q+1. . . n].
38

Algorithm: Binary searchParameters: A: array A[l, . . . , r],
l: index to the first array position,r: index to the last array position,x: element to search
int binary search(int *A, int l, int r, int x)int q;
if (l==r)
if (x==A[l]) return(l);
else return(-1);
else q = (int) (l+r)/2;
if (x == A[q]) return(q);
else
if (x < A[q]) return(binary search(A,l,q-1,x));
else return(binary search(A,q+1,r,x));
39

Binary search example
x=1 initial call: binary search(A,0,8,1);
0 1 2 3 4 5 6 7 8
1 3 7 152233415260
↓ q=4
0 1 2 3
1 3 7 15
↓ q=1
0
1
A[0]=1 =⇒ return(0)
40

Efficiency analysis
T (n) =
c1 n = 1T (n
2) + c2 n > 1
Solving by substitution:
T (n) = T (n
2) + c2
= T (n
22) + 2c2
= T (n
23) + 3c2
= p iterations . . .
= T (n
2p) + pc2
(p > log2 n) = c1 + c2 log2n ∈ O(log n)
=⇒ O(log n)
41

The power of a number
Problem: bn, n ≥ 0
Trivial algorithm
Trivial decomposition: bn = b · b · b · · · b · b︸ ︷︷ ︸n
int power(int b, int n)int res, i;
res = 1;
for (i=1; i<=n; i++)res = res * b;
return(res);
=⇒ Algorithm cost O(n).
42

Power of a number: divide and conquer algorithm
Divide and conquer decomposition: bn =
bn2b
n2 if n is even
bn2b
n2b if n is odd
int power(int b, int n)int res, aux;
if (n == 0)res = 1;
elseaux = power(b,n/2);if ((n % 2) == 0)res = aux * aux;
elseres = aux * aux * b;
return(res);
43

Efficiency analysis
T (n) =
c1 n < 1T (n
2) + c2 n ≥ 1
=⇒ T (n) ∈ O(log n).
44

Other D&C algorithms
Binary search in two dimensions (matrix).
Search of a substring in a string.
Finding the minimum in a concave function.
Finding the minimum and maximum in an integer array.
Multiplication of huge integers.
Matrix multiplication.
45

Data Structures and Algorithms
Trees

Definitions
Tree of a type of base T :
1. An empty set is a tree,
2. A node n of type T , with a finite number of disjoint subsets of elements of type T ,called subtrees, is a tree.The node n is called root.
• n is parent of the roots of the subtrees.• The roots of the subtrees are children of n
A
C DB
MK
E F
G H I
J
L
1

Definitions (II)
Path from n1 to nk: succession of nodes of a tree n1, n2, . . . , nk, in which ni is the parentof ni+1 for 1 ≤ i < k.
Length of a path: number of nodes in a path minus 1.There is a path of length zero from any node to itself.
If there is a path from node ni to node nj, then ni is an ancestor of nj, and nj is adescendant or successor of ni.
Proper ancestor or Proper descendant: an ancestor or descendant of a node exceptitself.
In a path n1, n2, . . . , nk; ni is direct ancestor of ni+1, and ni+1 is direct descendant ofni, for 1 ≤ i < k.
2

Definitions (III)
Leaf or terminal node: a node without proper descendants.
Interior node: a node with proper descendants.
Degree of a node: number of direct descendants it has.
Degree of a tree: the maximum degree of all the nodes of the tree.
Level:
1. The root of a tree is at level 1.2. If a node is at level i, then its direct descendants are at level i + 1.
Height of a node: length of the longest path from this node to a leaf.
Height of a tree: height of the root node.
Depth of a node: length of the unique path from the root to this node.
3

Traversing trees
traversing in previous order (preorder).traversing in symmetric order (inorder).traversing in back order (postorder).
Depending on the type of traverse:
if A is empty ⇒ do not carry out action P ;
if A has a unique node ⇒ carry out action P over this node;
if A has root n and subtrees A1, A2, . . . , Ak ⇒• Preorder: carry out action P over n, and, afterwards, traverse in preorder the subtrees
A1, A2, . . . , Ak from left to right.
• Inorder: traverse in inorder the subtree A1, then carry out action P over n, and,afterwards, traverse in inorder the subtrees A2, . . . , Ak from left to right.
• Postorder: traverse in postorder the subtrees A1, A2, . . . , Ak from left to right, and,afterwards, carry out action P over n.
4

Example:
A
C DB
MK
E F
G H I
J
L
Preorder: action P would carry out in the following order: A, B, C, E, G, H, I, F , D,J , K, L, M .
Inorder: action P would carry out in the following order: B, A, G, E, H, I, C, F , K, J ,L, M , D.
Postorder: action P would carry out in the following order: B, G, H, I, E, F , C, K, L,M , J , D, A.
5

Example:
The evaluation of an arithmetic expressions with precedence of operators represented by atree⇒ evaluate first the operands of each operator (postorder traverse).
/
||||
||||
|
BBBB
BBBB
B
×
2222
22+
4444
44
5 6 3 +
2222
22
2 1
⇒ /
1111
11
30 +
4444
44
3 +
2222
22
2 1
⇒
6

⇒ /
>>>>
>>>>
30 +
????
????
3 3
⇒ /
====
====
30 6
⇒ 5
7

Representation of trees
Representation using lists of children
⇒ To form a children list for each node.
Data Structure:
1. Array v with the information of each node.
2. Each element (node) of the array is pointing to a linked list of elements (nodes) whichinforms who their children are.
3. An index to the root.
8

Representation using lists of children: example
109
8
4
1253
7
1 11
62 13
1
123456789
1011121314 ...
/
/
/
/
/
/
/
/
24 6
8
3 5
9 13 1011
/
/
/
/
/
root 12
9

Representation using lists of children (III)
Advantages of this representation:
It’s a simple representation.
Facilitates the operations related to the access of children.
Disadvantages of this representation:
It wastes memory.
The access to the parent of a node is costly.
10

Representation using lists of children (IV)
Exercise: recursive function that prints the indexes of the nodes in preorder.
#define N ...
typedef struct snodeint e;struct snode *next;
node;
typedef struct int root;node *v[N];
tree;
void preorder(tree *T, int n)node *aux;
aux = T->v[n];
printf(" %d ",n);
while (aux != NULL)preorder(T,aux->e);aux = aux->next;
11

Representation of trees (II)
Leftmost child − right sibling representation
For each node, save the following information:
1. key: value of type of base T saved in the node.
2. left child: leftmost child of the node.
3. right sibling: right sibling of the node.
12

Leftmost child − right sibling representation: Example
A
C DB
MK
E F
G H I
J
L
B D
A
C
E JF
G H I L MK
/
/ /
/ / /
/////// /
13

Leftmost child − right sibling representation (III)
A variation that facilitates the access to the parent from a child node: to link the rightmostchild with its parent.
It is necessary to specify, in each node, if the pointer to right sibling is pointing to a siblingor its parent.
Example:
A
C DB
MK
E F
G H I
J
L
B D
A
C
E JF
G H I LK
/
/
/
///// /M
14

Leftmost child − right sibling representation (IV)
Advantages of this representation
Facilitates the operations related to the access to children and parent of a node.
Efficient memory use.
Disadvantages of this representation
The maintenance of the structure is complex.
15

Leftmost child − right sibling representation (V)
Exercise: function that computes recursively the height of a tree.
typedef struct snodechar key[2];struct snode *left;struct snode *right; tree;
int height(tree *T)tree *aux;int maxhsub=0, hsub;
if (T == NULL)return(0);
else if (T->left == NULL)return(0);
elseaux = T->left;while ( aux != NULL)hsub = height(aux);if (hsub > maxhsub)maxhsub = hsub;
aux = aux->right;return(maxhsub + 1);
16

Binary treesBinary tree: finite set of nodes that, either is empty, or is formed by a special node calledroot.The rest of the nodes are grouped into two disjoint binary trees called left subtree and rightsubtree.
A
B C
D E F
Gleft subtree
rightsubtree
root
Example of different binary trees:
G
A
B C
D E F
A
B C
D E F
G
17

Representing binary trees
Representation using arrays
Data structure:
Index to the root.
Array v to save information of each node.
Each element of the array (node), will be a structure with:
1. key: value of the type T saved in the node.2. left child: index to the node which is the left child.3. right child: index to the node which is the right child.
18
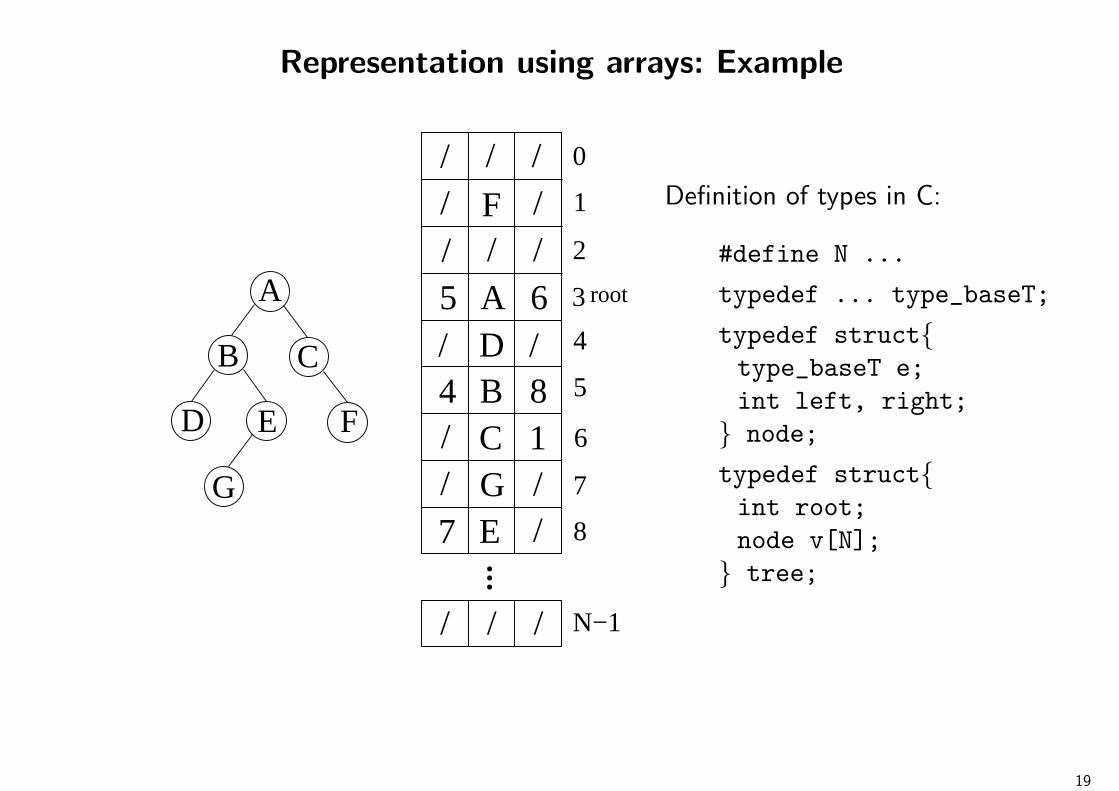
Representation using arrays: Example
A
B C
D E F
G
5 A 6
/ / /
/ / /
/ / /
...
4
5
6
7
8
84 B1C/
// D
3 root
2
1
0
F/ /
E /7G //
N−1
Definition of types in C:
#define N ...
typedef ... type_baseT;
typedef structtype_baseT e;int left, right;
node;
typedef structint root;node v[N];
tree;
19

Representing binary trees (II)
Representation using dynamic memory
For each node, the following information has to be saved:
1. key: value of type T saved in the node.
2. left child: pointer to left child.
3. right child: pointer to right child.
20

Representation using dynamic memory: Example
A
B C
D E F
G
A
B
D E
C
F
G
/
/ //
//
/ /
Definition of types in C:
typedef ... type_baseT;
typedef struct snodetype_baseT e;struct snodo *left, *right;
tree;
21

Representation using dynamic memory (III)⇒ Variation that facilitates the access to parent from a child: in each node, a pointer to itsparent.
A
B C
D E F
G
D
G
/
/ //
//
/ /
/
B C
A
E F
Definition of types in C:
typedef ... type_baseT;typedef struct snodetype_baseT e;struct snode *left, *right, *parent;
tree;
22

Traversing binary trees
As for every tree, we are going to study three ways:
traversing in previous order (preorder)
traversing in symmetric order (inorder)
traversing in back order (postorder)
Preorder(x)if x 6= EMPTY thenActionP(x)Preorder(left(x))Preorder(right(x))
Inorder(x)if x 6= EMPTY thenInorder(left(x))ActionP(x)Inorder(right(x))
Postorder(x)if x 6= EMPTY thenPostorder(left(x))Postorder(right(x))ActionP(x)
Cost ∈ Θ(n), being n the number of nodes of the tree.
23

Traversing binary trees: Implementation
⇒ Representation using dynamic memory.Action P ≡ print the key of the node.
Definition of types in C:
typedef int type_baseT;typedef struct snodetype_baseT e;struct snode *left, *right;
tree;
void preorder(tree *a)if (a != NULL)printf(‘‘ %d ’’,a->e);preorder(a->left);preorder(a->right);
void inorder(tree *a)if (a != NULL)inorder(a->left);printf(‘‘ %d ’’,a->e);inorder(a->right);
void postorder(tree *a)if (a != NULL)postorder(a->left);postorder(a->right);printf(‘‘ %d ’’,a->e);
24

Binary trees: Exercise
A C function that deletes all the leaves of a binary tree, keeping the interior nodes.
tree *delete_leaves(tree *T)if (T == NULL)return(NULL);
else if ( (T->left == NULL) && (T->right == NULL) )free(T);return(NULL);
elseT->left = delete_leaves(T->left);T->right = delete_leaves(T->right);return(T);
25

Complete binary tree
Complete binary tree: binary tree in which all its levels have the maximum number of nodesexcept, may be, the last level.In such a case, the leaves of the last level are leftmost located.
26

Complete binary tree: Representation
The complete binary trees can be represented with an array:
At position 1 is located the root of the tree.
Given a node located at i in the array:
• At position 2i is located its left child.• At position 2i + 1 is located its right child.• At position bi/2c is located its parent if i > 1.
5 6 74
3
1
2
111098
16
7
3
4 2
5 1
10
11
13 19
107 16 3 11 5 41 13 2 191 2 3 4 5 6 7 8 9 10 11
27

Complete binary tree: Exercise
Three C functions that, given a node of a complete binary tree represented using an array,calculate the array position in which it is located the parent node, the left child and the rightchild:
int left(int i)return(2*i);
int right(int i)return((2*i)+1);
int parent(int i)return(i/2);
28

Properties of binary trees
The maximum number of nodes at level i is 2i−1, i ≥ 1.
In a binary tree of i levels there are a maximum of 2i − 1 nodes, i ≥ 1.
In a non empty binary tree, if n0 is the number of leaves and n2 is the number of nodesof degree 2, is true that n0 = n2 + 1.
The height of a complete binary tree that has n nodes is blog2nc.
29

Properties of binary trees: Example
Level
1
2
3
4
height = 3
Maximum nodes per levelLevel 1 20 = 1Level 2 21 = 2Level 3 22 = 4Level 4 23 = 8
Maximum nodes in a tree24 − 1 = 15
Number of leaves (n0)n2 = 7
n0 = n2 + 1 = 7 + 1 = 8Height of a complete binary tree
n = 15blog2nc = blog2 (15)c = 3
30

Data Structures and Algorithms
Sets

General Concepts
Set: group of different elements; each element can be a set or an atom.
Multiset ≡ set with repeated elements.
Representation of sets:
Explicit representation.C = 1, 4, 7, 11
Representation using properties.
C = x ∈ N | x is even
1

Notation
Fundamental relationship: belonging (∈)
• x ∈ A, if x is a member of the set A.• x /∈ A, if x is not a member of the set A.
Size or cardinality: number of elements a set has.
Empty or null set: without any element, ∅.
A ⊆ B or B ⊇ A, if all the elements of A are also elements of B.
Two sets are equal if and only if A ⊆ B and B ⊆ A.
Proper subset: A 6= B and A ⊆ B.
2

Elementary operations on sets
Union of sets: A ∪B,is the set whose elements are elements of A, of B, or of both.
Intersection of two sets: A ∩B,is the set whose elements are elements of, at the same time, of A and B.
Difference of two sets: A−B,is the set shose elements are elements of A and are not elements of B.
3

Dynamic sets
Dynamic set: its elements can vary through time.
Representation of dynamic sets
Its elements will have:
key: the value that identifies the element.
satellite information: additional information of the element.
It may exist a total order relationship between the keys.Ex: the keys are integer or real numbers, words (lexicographic order) etc.
If ∃ a total order → define a minimum and maximum, or previous or successor of an element.
4

Operation on dynamic sets
Given S and x and key(x) = k. It exists two types of operations:
Consulting:
• Search(S,k) → x ∈ S and clave(x) = k.→ null if x /∈ S.
• Empty(S): if S is empty or not.
Possible operations if in S exists a total order relationship between the keys:• Minimum(S): → x with the least key k in S.• Maximum(S): → x with greatest key k in S.• Previous(S,x): → element with the immediate inferior key of x.• Successor(S,x): → element with the immediate superior key of x.
Modifying:
• Insert(S,x): Adds x to S.• Delete(S,x): Removes x from S.• Create(S): Creates S empty.
5

Hash tables
Dictionary: a set that allows, mainly, the following operations: insertion and deletion of anelement, and determination if an element belongs or not to the set.
Direct addressing tables
Direct addressing:
It is advised when the universe U of the possible elements is small.
Each element can be identified with a unique key.
Representation using an array with size equal to the size of the universe |U |.T [0, . . . , | U | −1]: each position k of the array references to the element x with key k.
6

Representation of direct addressing tables
Array of pointers to structures where it is saved the information of the nodes.
Trivial operations of cost O(1):
insert(T,x).
search(T,k).
delete(T,x).
Variation: save the information in the array itself.
The position of the element indicates which its key is.
The need of a technique to distinguish between empty and occupied positions.
7

Representation of direct addressing tables (II)
...
0
1
2
3
4
5
6
7
8
key
2
4
1
M−1
8
information
...
0
1
2
3
4
5
6
7
key information
M−1
1
2
4
8 8
8

Hash tables
Using direct addressing, if the universe U is large:
Impossibility to save the array.
The number of elements is usually small compared with the size of the universe U →wasted space.
⇒ to limit the size of the array T [0, . . . ,M − 1].
Hash tables: the position of x with key k, is obtained with the application of a hashingfunction h over the key k: h(k).
h : K −→ 0, 1, . . . ,M − 1
Table address: each position of the array.x with key k is hashed to the table address h(k).
9

Hash tables (II)
...
0
1
2
3
4
5
6
7
8
M−1
T
k5
k7
k1
K
L
k2
h(k7)
h(k5)
h(k1)
h(k2)
Collision: two or more keys mapped into the same table address.
10

Collision-resolution by chaining
Strategy: the use of a linked list in each table address.
...
k9
0
1
2
3
4
5
6
7
8
M−1
T
k5
k7
k1k2
k4
K
k9
k3
L k6k8
k6 k2
k8k1
k5
k4 k7 k3
11

Collision-resolution by chaining (II)
Given T and x, and key(x) = k, the operations are:
Insert(T,x): inserts the element x in the top of the list pointed by T [h(key(x))].
Search(T,k): searches an element with key k in the list T [h(k)].
Delete(T,x): deletes x from the list with top T [h(key(x))].
12

Analysis of operation costs
Given T with m table addresses and saving n elements ⇒ load factor: α = nm.
Assumption: h(k) can be calculated in O(1).
Insert → O(1).
Search→ O(n).→ Θ(1 + α)
if we have that n = O(m) ⇒ O(1)
Delete → Θ(1 + α) ⇒ O(1)
13

Hashing functions
“Ideal” function → satisfies the simple uniform hashing: each element with equalprobability to be mapped in the m table addresses.
It is difficult to find such a function.
We use functions that hash elements among the table addresses acceptably.
Universe of keys ≡ the set of natural numbers N = 0, 1, 2, . . . .
Representation of keys are natural numbers.Ex: string → to combine the ASCII representation of its characters.
14

Hashing functions: the division method
The key k is transformed to a value between 0 and m− 1:
h(k) = k mod m
Example:If k = 100 and m = 12 → h(100) = 100 mod 12 = 4 → table address 4.If k = 16 and m = 12 → h(16) = 16 mod 12 = 4 → table address 4.
Critic point: the election of m.Good behavior → m prime and not close to a power of 2.Example:To save 2000 strings with α ≤ 3.Minimum table addresses required: 2000/3 = 666,6.m close to 666, prime and not close to a power of 2: 701.
15

Hashing functions: the multiplication method
The key k is transformed to a value between 0 and m− 1 in two steps:
1. Multiply k by a constant in the range 0 < A < 1 and get only the fractional part.
(k ·A) mod 1
2. Multiply the previous value by m, and truncate the result to the closest lower integer(floor).
h(k) = bm (( k ·A) mod 1)c
The value of m is not critic.
To get m as a power of two to facilitate the calculation: m = 2p, p integer.
16

Hashing functions: Examples with strings
To carry out the conversion to a natural number.
String x of n characters (x = x0x1x2 . . . xn−1).
Example of functions based on the division method.
Function 1: to sum the ASCII codes of each character. (it takes the most of all the key)
h(x) = (n−1∑i=0
xi) mod m
Disadvantages:
• m ↑↑, bad distribution of keys.Ex: m = 10007, strings of length ≤ 10 → maximum value of x: 255 · 10 = 2550.Table addresses from 2551 to 10006 empty.
• The order of characters is not considered. h(“spot”)=h(“stop”).
17

Example of functions based on the division method. (II)
Function 2: to use the three first characters as numbers of a particular base (256).
h(x) = (2∑
i=0
xi 256i) mod m
Disadvantages:
• Strings with the first three characters equal → same table address.h(“class”)=h(“clark”)=h(“clan”).
Function 3: Similar to function 2, but considering all the string.
h(x) = (n−1∑i=0
xi 256((n−1)−i)) mod m
Disadvantages:
• A costly h computation.
18

Example of functions based on the multiplication method.
Function 4: to sum the ASCII codes of each character considering that they are numbersof base 2.
h(x) = bm (((n−1∑i=0
xi 2((n−1)−i)) ·A) mod 1) c
19

Examples of functions over strings:Empiric evaluation
Number of elements n = 3975. Number of table addresses m = 2003.
Function 1:
0
2
4
6
8
10
12
14
16
18
20
22
24
26
28
30
32
34
0 250 500 750 1000 1250 1500 1750 2000
elem
ento
por
cub
eta
cubeta
alfa: 1.985; desv.tip: 4.33
1
10
100
1000
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
num
ero
de c
ubet
as
numero de elementos
20

Examples of functions over strings:Empiric evaluation (II)
Function 2:
0
50
100
150
200
250
300
0 250 500 750 1000 1250 1500 1750 2000
elem
ento
s po
r cu
beta
cubeta
alfa: 1.985; desv.tip.: 8.97
1
10
100
1000
0 25 50 75 100 125 150 175 200 225 250 275 300
num
ero
de c
ubet
as
numero de elementos
21

Examples of functions over strings:Empiric evaluation (III)
Function 3:
0
1
2
3
4
5
6
7
8
9
10
0 250 500 750 1000 1250 1500 1750 2000
elem
ento
s po
r cu
beta
cubeta
alfa: 1.985; desv.tip: 1.43
1
10
100
1000
0 1 2 3 4 5 6 7 8 9
num
ero
de c
ubet
as
numero de elementos
22

Examples of functions over strings:Empiric evaluation (IV)
Function 4:
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
0 250 500 750 1000 1250 1500 1750 2000
elem
ento
s po
r cu
beta
cubeta
alfa: 1.985; desv.tip: 1.8
1
10
100
1000
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
num
ero
de c
ubet
as
numero de elementos
23

Examples of functions over strings:Variation of the number of table addresses
Function 3:
m = 2003
0
1
2
3
4
5
6
7
8
9
10
0 250 500 750 1000 1250 1500 1750 2000
elem
ento
s po
r cu
beta
cubeta
alfa: 1.985; desv.tip: 1.43
1
10
100
1000
0 1 2 3 4 5 6 7 8 9
num
ero
de c
ubet
as
numero de elementos
m = 2000
0
5
10
15
20
25
30
35
40
45
50
0 250 500 750 1000 1250 1500 1750 2000
elem
ento
s po
r cu
beta
cubeta
alfa: 1.987; desv.tip: 7.83
1
10
100
1000
0 5 10 15 20 25 30 35 40 45
num
ero
de c
ubet
as
numero de elementos
24

Examples of functions over strings:Variation of the number of table addresses (II)
Function 4:
m = 2003
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
0 250 500 750 1000 1250 1500 1750 2000
elem
ento
s po
r cu
beta
cubeta
alfa: 1.985; desv.tip: 1.8
1
10
100
1000
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
num
ero
de c
ubet
as
numero de elementos
m = 2000
0
2
4
6
8
10
12
14
16
0 250 500 750 1000 1250 1500 1750 2000
elem
ento
s po
r cu
beta
cubeta
alfa: 1.987; desv.tip: 1.8
1
10
100
1000
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
num
ero
de c
ubet
as
numero de elementos
25

Hash tables: Exercise
Definitions:
#define NCUB ...
typedef struct snodechar *pal;struct snode *next;
node;typedef node *Table[NCUB];
Table * T1, * T2, * T3;
/* Creates an empty table */void create_Table(Table * T)
/* Inserts the word w in the table T */void insert(Table * T, char *pal)
/* Returns a pointer to the node which has the wordpal, or NULL if it is not found */node *search(Table * T, char *pal)
26

Hash tables: Exercise (II)
Function that created a table T3 with the elements of the intersection of the tables T1 andT2.
void intersection(Table * T1, Table * T2, Table * T3)int i;node *aux;
create_Table(T3);
for(i=0; i<NCUB; i++)aux = T1[i];
while (aux != NULL)if ( search(T2,aux->pal) != NULL )insert(T3,aux->pal);
aux = aux->next;
27

Binary search trees
Binary search tree: binary tree that could be empty, or accomplishes:
Each node has a unique key (no repeated keys).
For each node n, if its left subtree is not empty, all the keys saved in this subtree aresmaller than the key saved at n.
For each node n, if the right subtree is not empty, all the keys saved in this subtree aregreater than the key saved at n.
Used for representing dictionaries, priority queues, etc.
28

Binary search trees: Examples
YES 9
7
3
18
15
11 21
4
10
7
149
8
NO
7
3
18
15
21
8
16
7
3
18
15
218
19
14
29

Binary search trees representation
Using dynamic variables, each node is a struct:
key: key of the node.
left sibling: pointer to the left sibling.
right sibling: pointer to the right sibling.
9
7
3
18
15
11 21
/
/ //
//
/ /
15
7 18
3 11 21
9
30

Binary search trees representation (II)
Type definition in C:
typedef ... type_baseT;
typedef struct snodetype_baseT key;struct snode *left, *right;
bst;
/
/ //
//
/ /
15
7 18
3 11 21
9
31
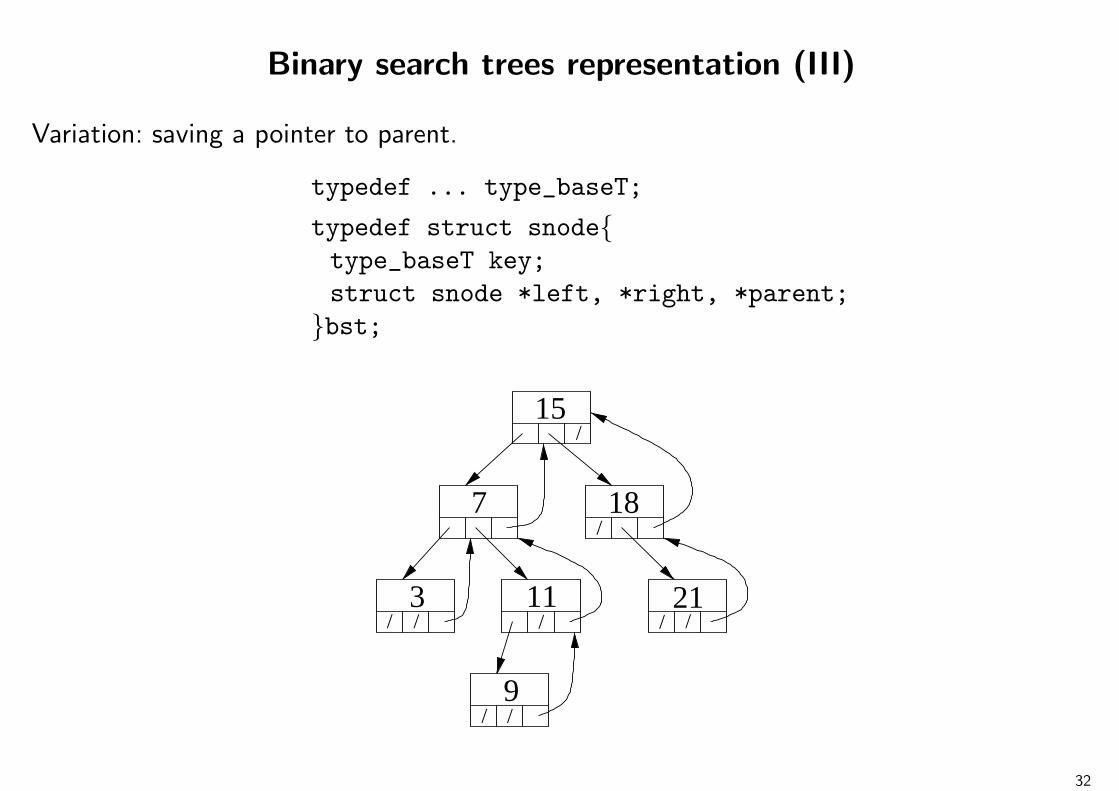
Binary search trees representation (III)
Variation: saving a pointer to parent.
typedef ... type_baseT;
typedef struct snodetype_baseT key;struct snode *left, *right, *parent;
bst;
/
/ //
//
/ /
/15
7
3 11
9
18
21
32

Maximum and minimum height of a bst
Minimum height: O(log n).
Maximum height: O(n).
... ......
logn
...h
Minimum height Maximum height
Notation: Height of a tree = h.
Normally, height of a random bst ∈ O(log n)
33

Traversing binary search trees
3 methods: preorder, inorder and postorder.
Inorder: if the action is, for instance, to print the keys of the node, the keys of the bst aregoing to be printed sorted (increasingly).
void inorder(bst *T)if (T != NULL)inorder(T->left);printf(" %d ",T->key);inorder(T->right);
Exercise: a trace of inorder with the previous tree:
3, 7, 9, 11, 15, 18, 21
34

Searching an element in a bst
The most common operation.
bst *bst_search(bst *T, type_baseT x)while ( (T != NULL) && (x != T->key) )
if (x < T->key)T = T->left;
elseT = T->right;
return(T);
Cost: O(h).
35

Searching an element in a bst (II)
Exercise: recursive version of the previous algorithm.
bst *bst_search(bst *T, type_baseT x)if (T != NULL)
if (x == T->key)return(T);
else if (x < T->key)return(bst_search(T->left,x));else return(bst_search(T->right,x));
return(T);
36
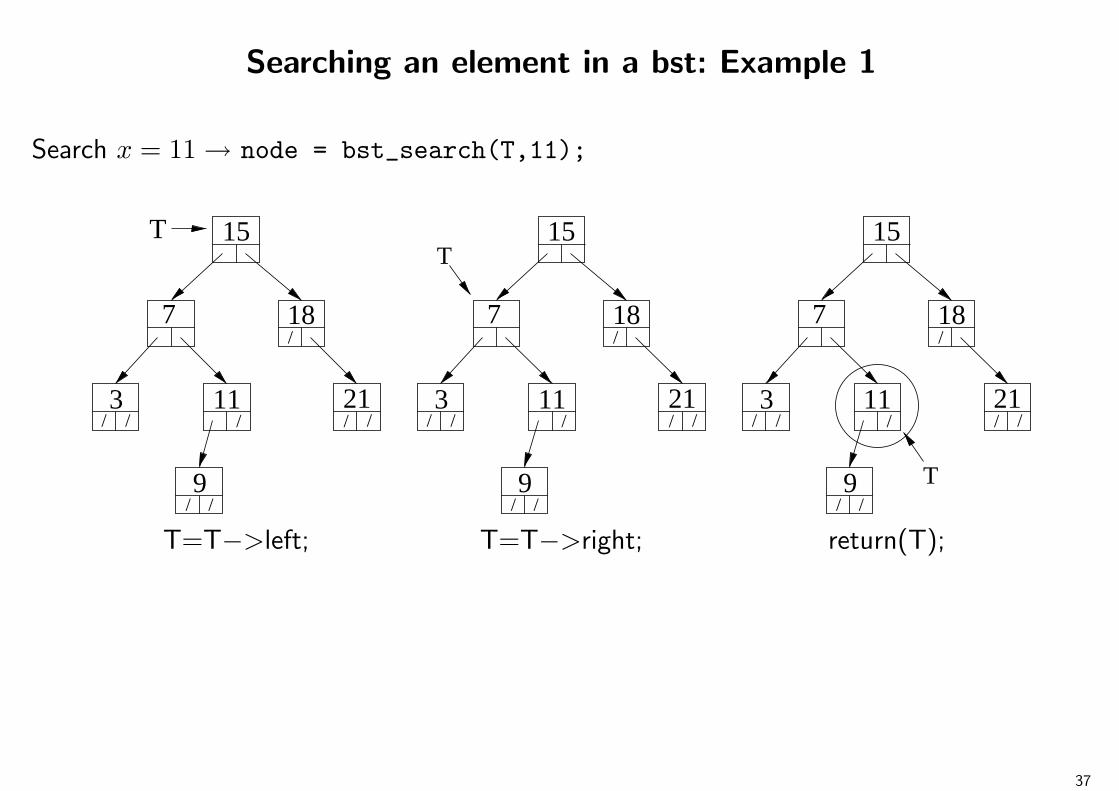
Searching an element in a bst: Example 1
Search x = 11 → node = bst_search(T,11);
/
/ //
//
/ /
15
7 18
3 11 21
9
T
/
/ //
//
/ /
15
7 18
3 11 21
9
T
/
/ //
//
/ /
15
7 18
3 11 21
9 T
T=T−>left; T=T−>right; return(T);
37

Searching an element in a bst: Example 2
Search x = 19 → node = bst_search(T,19);
/
/ //
//
/ /
15
7 18
3 11 21
9
T
T
/
/ //
//
/ /
15
7 18
3 11 21
9
/
/ //
//
/ /
15
7 18
3 11 21
9
T /
/ //
//
/ /
15
7 18
3 11 21
9 T=NULL
T=T−>right; T=T−>right; T=T−>left; return(T);
38

Searching the minimum and maximum
bst *minimum(bst *T)if (T != NULL)while(T->left != NULL)T=T->left;
return(T);
bst *maximum(bst *T)if (T != NULL)while(T->right != NULL)T=T->right;
return(T);
Cost: O(h).
39

Searching an element in a bst: Example
Minimum:
/
/ //
//
/ /
15
7 18
3 11 21
9
T
/
/ //
//
/ /
15
7 18
3 11 21
9
T
/
/ //
//
/ /
15
7 18
3 11 21
9
T
T=T−>left; T=T−>left; return(T);
Maximum:
/
/ //
//
/ /
15
7 18
3 11 21
9
T
/
/ //
//
/ /
15
7 18
3 11 21
9
T
/
/ //
//
/ /
15
7 18
3 11 21
9
T
T=T−>right; T=T−>right; return(T);
40

Inserting an element in a bst
→ to keep the condition of the bst.
Strategy:
1. If the bst is empty → to insert the new node as root.
2. If the bst is not empty:
a) To search the position that corresponds to the new node in the tree. In order to achievethat: to traverse the tree from the root as a searching process.
b) Once the position is located: to insert it in the tree linking it correctly with its parentnode.
Cost: O(h).
41

Inserting an element in a bst (II)
bst *bst_insert(bst *T, bst *node)bst *aux, *aux_parent=NULL;
aux = T;
while (aux != NULL)aux_parent = aux;if (node->key < aux->key)aux = aux->left;
elseaux = aux->right;
if (aux_parent == NULL)return(node);
elseif (node->key < aux_parent->key)aux_parent->left = node;
elseaux_parent->right = node;
return(T);
42

Inserting an element in a bst: Example
Inserting a node of key 10.
/
/ //
//
/ /
15
7 18
3 11 21
9
aux T
/
/ //
//
/ /
15
7 18
3 11 21
9
Taux
aux_parent
/
/ //
//
/ /
15
7 18
3 11 21
9
T
aux
aux_parent
aux parent=aux; aux parent=aux; aux parent=aux;aux=aux->left; aux=aux->right; aux=aux->left;
/
/ //
//
/ /
15
7 18
3 11 21
9
T
aux aux_parent
/
/ /// /
15
7 18
3 11 21
T
//10
/9
aux=null node
aux_parent
aux parent=aux; aux=aux->right; aux parent->right=node; return(T);
43

Deleting an element in a bst
Strategy:
1. If the element to delete has no children (it’s a leaf), it is removed.
2. If the element to delete is an interior node that has one child, it is removed and itsposition is replaced by its only child.
3. If the element to delete is an interior node that has two children, it is removed andits position is replaced by the node of minimum key value of the right subtree (or by themaximum key value of the left subtree).
Cost: O(h).
Exercise: Implement a C function that deletes an element x from the bst.
44
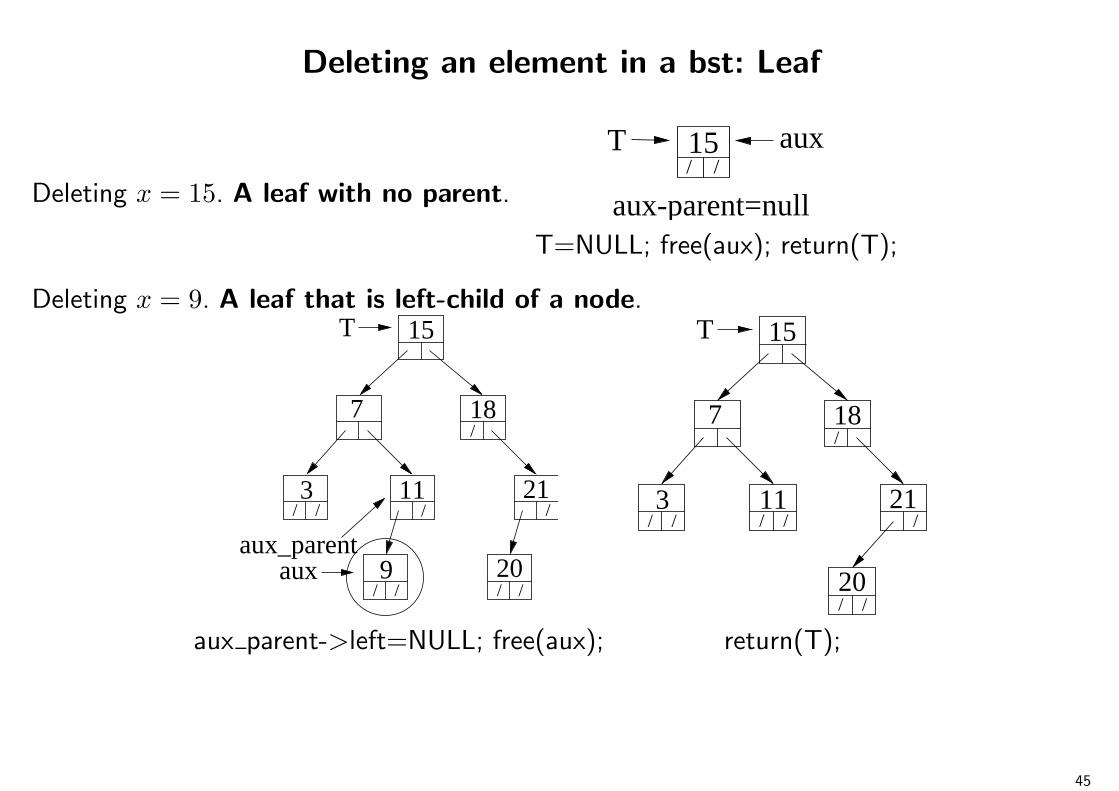
Deleting an element in a bst: Leaf
Deleting x = 15. A leaf with no parent.
15T/ /
aux
aux-parent=nullT=NULL; free(aux); return(T);
Deleting x = 9. A leaf that is left-child of a node.
//9
/
/// /
15
7 18
3 11 21
aux
T
//20
aux_parent/ /3
/
/
15
7 18
11 21
T
/ /
/ /20
aux parent->left=NULL; free(aux); return(T);
45

Deleting an element in a bst: Leaf (II)
Deleting x = 21. A leaf that is right-child of a node.
/
/ //
//
/ /
15
7 18
3 11 21
9
T
aux
aux_parent
/
//
/ /
15
7 18
3 11
9
T
//
aux parent->right = NULL; free(aux); return(T);
46

Deleting an element in a bst: Interior node with just one child
Deleting x = 15. Interior node which is root of a tree and has only one right-child.
/
/ /
15
18
21
T aux/
aux_parent=null T/
/ /
18
21
T=aux->right; free(aux); return(T);
Deleting x = 7. Interior node that being a left-child has an only right-child.
/
/ //
//
15
7 18
11 21
9
/aux
T aux_parent
/11
//9
/
/ /
15
18
21
T
aux parent->left=aux->right; free(aux); return(T);
47
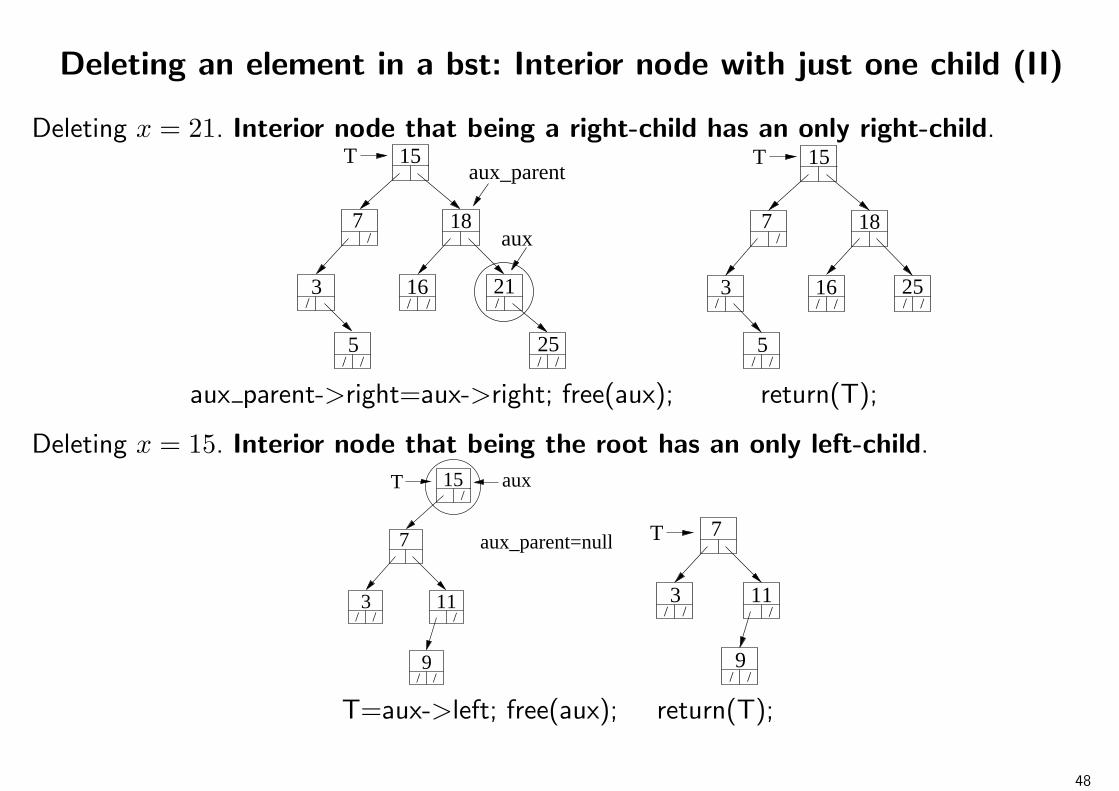
Deleting an element in a bst: Interior node with just one child (II)
Deleting x = 21. Interior node that being a right-child has an only right-child.15
7 18
3 21
T
/
//5
16/
/
/
aux
//25
/
aux_parent
/
15
7 18
3 25
T
/
//5
16/
/
/ /
aux parent->right=aux->right; free(aux); return(T);
Deleting x = 15. Interior node that being the root has an only left-child.
/
//
/ /
15
7
3 11
9
auxT/
aux_parent=null T
/
//
/ /
7
3 11
9
T=aux->left; free(aux); return(T);
48

Deleting an element in a bst: Interior node with just one child (III)
Deleting x = 3. Interior node that being a left-child has an only left-child.
//9
/
/ ///
15
7 18
3 11 21
//1
T
aux
aux_parent
//9
/
/ ///
15
7 18
11 21
T
1/
aux parent->left=aux->left; free(aux); return(T);
Deleting x = 19. Interior node that being right-child has an only left-child.15
7
3
T
/
//5
17
//
/
/
aux
/19
18
aux_parent 15
7
3
T
//5
/
/
//
/17
18
aux parent->right=aux->left; free(aux); return(T);
49

Deleting an element in a bst: Interior node with two children
Deleting x = 18. An interior node with two children and its right-child is the node ofminimum key value of its right subtree.
//5
aux
15
7 18
3 25
T
/17
/
/
/ /
/31
//26
p1
p2=null
aux_parent
//5
//26
15
7
3
T
/17
/
/
/
25
/31
aux->key=p1->key; aux->hder=p1->right; free(p1); return(T);
50

Deleting an element in a bst: Interior node with two children (II)
Deleting x = 10. Interior node with two children and the node of minimum key of itsright subtree is not its right-child.
//26
7 18
3 25
T
16/
/
/ //
aux10
/12
/31
/15
//13
p1
p2
aux_parent=null
//26
/15
//13
7 18
3 25
T
16/
/
/ //
12
/31
aux->key=p1->key; p2->left=p1->right; free(p1); return(T);
51

Binary search trees: Exercise
Recursive function that prints the keys of a bst smaller that a key k.
typedef ... type_baseT;
typedef struct snodetype_baseT key;struct snode *left, *right;
bst;bst *T;
void smaller(bst *T, type_baseT k)if (T != NULL)if (T->key < k)printf(" %d ",T->key);smaller(T->left,k);smaller(T->right,k);;elsesmaller(T->left,k);
→ Cost: O(n).
52

Heaps. Priority queues.
Complete binary tree: binary tree in which all its levels have the maximum number ofnodes except, may be, the last level. In such a case, the leaves of the last level are leftmostlocated.
Heap: set of n elements represented in a complete binary tree that accomplishes thefollowing:for all node i, except the root, the key value of the node i is less or equal to the key valueof the parent of i (the heap property).
53

Representing heaps
→ using the static representation of the complete binary trees:
Position 1 of the array → root of the tree.
Node of position i of the array:
• Position 2i → left-child node of i.• Position 2i + 1 → right-child node of i.• Position bi/2c → parent node if i > 1.
From position bn/2c+ 1 to position n → keys of the leaf nodes.(n is the number of nodes of the complete binary tree)
54

Representing heaps: Example
5 6 74
3
1
2
1098
10
8
2 1
3 14 10 8 9 231 2 3 4 5 6 7 8 9 10
16
14
7 9
4
16 7 4 1
Number of nodes of the heap (size Heap):
14 10 8 9 231 2 3 4 5 6 7 8 9 10
16 7 4 1 ...A
size
size_Heap
55

Heaps: Properties
Using the static representation of a complete binary tree:
A[bi/2c] ≥ A[i], 1 < i ≤ n
Node of maximum key → root.
Each branch is sorted increasingly from the root to the leaves.
Height ∈ Θ(log n).
56

Keeping the heap property
Assume A[i] < A[2i] and/or A[i] < A[2i + 1]
5 6 74
3
1
2
1098
10
2 1
3
16
7 9
8
14
4
→ heapify function: keeps heap property.
To transform sub-tree of a heap. Left and right sub-trees of i are heaps.
57

Keeping heap property: Heapify
void heapify(type_baseT *M, int i)type_baseT aux;int left, right, greater;
left = 2*i;right = 2*i+1;if ( (left <= size_Heap) && (M[left] > M[i]) )greater = left;
elsegreater = i;
if ( (right <= size_Heap) && (M[right] > M[greater]) )greater = right;
if (greater != i)aux = M[i];M[i] = M[greater];M[greater] = aux;
heapify(M,greater);
58

Keeping heap property: Example
→ initial call heapify(M,2)
5 6 74
3
1
2
1098
10
2 1
3
16
7 9
8
4
14 10 9 2316 7 8 14 14M ...
i left right
i
left right
size_Heap
1 2 3 4 5 6 7 8 9 10 size
5 6 7
3
1
1098
10
2 1
3
16
7 9
8
4
14 10 9 2316 7 8 14 14M ...4
2
greater
i greater
i
size_Heap
size 1 2 3 4 5 6 7 8 9 10
59

Keeping heap property: Example(II)
i
5 6 7
3
1
1098
10
2 1
3
16
7 9
8
10 9 2316 7 8 1M ...4
214
4 i
left right
14 4
left right size_Heap
size 10987654321
i
5 6 7
3
1
1098
10
2 1
3
16
7 9
8
10 9 2316 7 8 1M ...4
2
greater
4
14
greater
i 14 4
size_Heap
size 10987654321
60
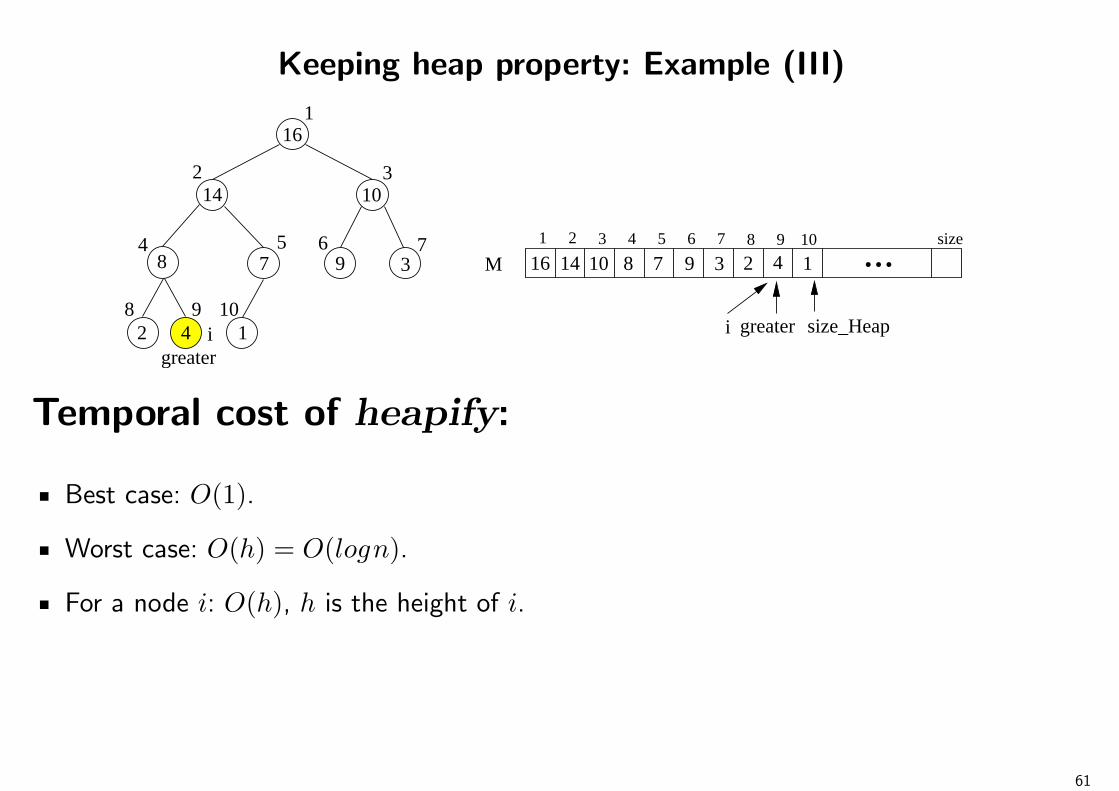
Keeping heap property: Example (III)
greater
5 6 7
3
1
1098
10
2 1
3
16
7 9 10 9 2316 7 4 1M ...4
2
8
14
greater
14 8
i4 i size_Heap
size 10987654321
Temporal cost of heapify:
Best case: O(1).
Worst case: O(h) = O(logn).
For a node i: O(h), h is the height of i.
61

Building a heap: build Heap
Problem: Given a set of n elements in a complete binary tree represented in an array M ,how to transform the array to a heap.
Strategy:
1. The leaves are heaps.
2. To apply heapify over the rest of nodes, starting with the greatest non-leaf index(M [bn/2c]). To descend until the root (M [1]).
void build_Heap(type_baseT *M, int n)int i;
size_Heap = n;
for(i=n/2; i>0; i--)heapify(M,i);
62

Building a heap: Example
9 10 14 8 7162314
5 6 74
3
1
2
1098
9
8
1
4
3
2 16 10
14 7
M1 2 3 4 5 6 7 8 9 10
build Heap(M,10);
63

9 10 14 8 7162314
6 74
3
1
2
1098
9
8
1
4
3
2 16 10
14 7
M
5i
i=greater
1 2 3 4 5 6 7 8 9 10
size_Heap
Heapify(M,5);
9 10 14 8 7162314
5 6 74
3
1
2
1098
9
8
1
4
3
2 16 10
14 7
M1 2 3 4 5 6 7 8 9 10
size_Heap
Heapify(M,5); //
64

9 10 14 8 7162314
6 74
3
1
2
109
9
8
1
4
3
2 16 10
14 7
M
i
i
5
8greater
greater
1 2 3 4 5 6 7 8 109
size_Heap
Heapify(M,4);
6 74
3
1
2
109
9
8
1
4
3
16 10
7
M
i5
8
9 10 8 716314
14
2
14 2
1 2 3 4 5 6 7 8 9 10
size_Heap
Heapify(M,4); //
65

64
3
1
2
109
9
8
1
4
3
16 10
7
M
5
8greater
i
i greater
14
2
9 10 8 716314 14 2
7
1 2 3 4 5 6 7 8 9 10
size_Heap
Heapify(M,3);
64
3
1
2
109
9
1
4
16
7
M
5
88
10
3
9 8 71614 10 3
14
2
14 2
7
1 2 43 5 6 7 8 9 10
size_Heap
Heapify(M,3); //
66

64
3
1
2
109
9
8
1
4
16
7
M
8
5
i
greater
greateri
10
3
9 8 71614 10 3
14
2
14 2
7
1 2 3 4 65 7 8 9 10
size_Heap
Heapify(M,2);
64
3
1
2
109
9
8
4
7
M
8
5
10
3
9 8 74 10 3
16
1
16 1
14
2
214
7
1 2 3 4 5 6 7 8 9 10
size_Heap
heapify(M,2); → heapify(M,5);
67

64
3
1
2
109
9
4
7
M
8
5
10
3
9 8 74 10 3
16
1
16
i
greater
1greateri
14
2 8
14 2
7
1 2 3 4 5 6 7 8 9 10size_Heap
heapify(M,5);
64
3
1
2
109
9
4
1
M
8
5
10
3
9 8 14 10 3
16
7
16 7
14
82
14 2
7
1 2 3 4 5 6 7 8 9 10
size_Heap
heapify(M,5); // → heapify(M,2); //
68

64
3
1
2
109
9
4
1
M
8
5
10
3
9 8 14 10 3
16
7
16 7
14
82
14 2
i
greater
i greater
7
1 2 3 4 5 6 7 8 9 10
size_Heap
heapify(M,1);
64
3
1
2
109
9
1
M
8
5
10
3
9 8 110 3
7
7
14
82
14 216 4
16
4
7
1 2 3 4 5 6 7 8 9 10
size_Heap
heapify(M,1); → Heapify(M,2);
69

64
3
1
2
109
9
1
M
8
5
10
3
9 8 110 3
7
7
14
82
14 216 4
16
4 i
greater
i greater
7
1 2 3 4 5 6 7 8 9 10
size_Heap
heapify(M,2);
64
3
1
2
109
9
1
M
8
5
10
3
9 8 110 3
7
7
82
216
16
14
4
14 4
7
1 2 3 4 5 6 7 8 9 10
size_Heap
heapify(M,2); → Heapify(M,4);
70

64
3
1
2
9
1
M
8
5
10
3
9 8 110 3
7
7
82
216
16
14
4
14 4
i
i greater
greater
9 10
7
1 2 3 4 5 6 7 8 9 10size_Heap
heapify(M,4);
64
3
1
2
9
1
M
8
5
10
3
9 4 110 3
7
7
42
216
16
14
8
14 8
9 10
7
1 2 3 4 5 6 7 8 9 10
size_Heap
heapify(M,4); // → heapify(M,2); // → heapify(M,1); //
71
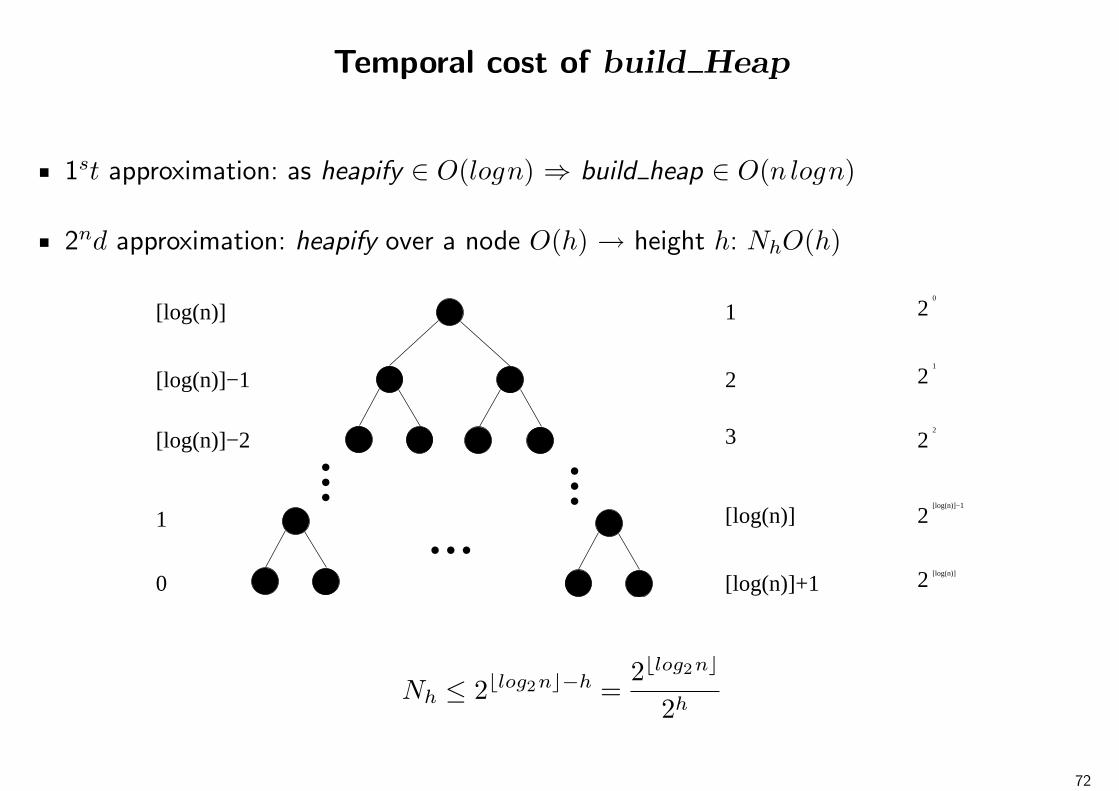
Temporal cost of build Heap
1st approximation: as heapify ∈ O(logn) ⇒ build heap ∈ O(n logn)
2nd approximation: heapify over a node O(h) → height h: NhO(h)
... ......1
0
1
2
3
Nivel (i)Altura (h) Num. maximo de nodos
[log(n)]
[log(n)]−1
[log(n)]−2
[log(n)]
[log(n)]+1
2
2
2
2
2
0
1
2
[log(n)]−1
[log(n)]
Nh ≤ 2blog2nc−h =2blog2nc
2h
72

Temporal cost of build Heap (II)
For each height, heapify over each node.
T (n) =blog2nc∑
h=0
NhO(h) ≤blog2nc∑
h=0
2blog2nc
2hh ≤
log2n∑h=0
2log2n h
2h= n
log2n∑h=0
h
(12
)h
As∑∞
h=0 hxh = x/(1− x)2, if 0 < x < 1, ⇒
n
log2n∑h=0
h
(12
)h
≤ 1/2(1− 1/2)2
n
= 2n ∈ O(n)
73

Heapsort Sorting method
Strategy:
1. build Heap: to transform the array M to a heap.
2. Greatest key always at the root. → swap root with the lat node in the heap → the greatestelement will be located in the last position.
n−1n−2 n
n−1n−2 n
sizeH
M
M
...
...<=
1 2
21
3. To reduce the size of the heap in 1.
sizeHM
n... n−2 n−11 2
4. The root cannot accomplish the heap property → heapify over the root.
sizeH
heapify
Mn−2 n−1 n1 2
74

5. Repeat (2), (3) and (4) until the complete sorting of the array.
75

n−1...
...
...
sizeH
...
MtallaH
...
M
M
tallaH
tallaH
n
...
...
...M
n
n−1
nn−1
Mn−2 n−1 n... n−3
n...
Mn
tallaH
n
n
n
sizeHM
heapify
heapify
1 2
heapify
heapify
n−2
MsizeH
n−2
MsizeH
1 2
1 2
1 2
1 2 3
1 2 3
1 2 3
1 2 3
1
76

Heapsort Sorting method (II)
Function that, given an array M that has n elements M [1, . . . , n], sorts out the array M :
void heapsort(type_baseT *M, int n)int i;type_baseT aux;
build_Heap(M,n);
for (i=n; i>1; i--)aux = M[i];M[i] = M[1];M[1] = aux;size_Heap--;heapify(M,1);
77

Heapsort Sorting method: Example
16 14 10 8 7 9 3 2 4 1
64
3
1
2
9
18
5
10
37
42
16
14
8
9 10
sizeH
i
i
7
1 2 3 4 5 6 7 8 9 10
64
3
1
2
9
8
5
10
37
29
8
4
8 7 9 3 2 4
14
1
1 14 10sizeH
7
161 2 3 4 5 6 7 8 9 10
64
3
1
2
9
8
5
10
37
29
14
8
4
1
14 108 4 7 9 3 2 1sizeH
7
161 2 3 4 5 6 7 8 9 10
M[1]↔ M[i]; heapify(M,1); end iteration i = 10;
78

64
3
1
2
9
8
5
10
37
29
14
8
4
1
14 108 4 7 9 3 2 1sizeH
ii
7
161 2 3 4 5 6 7 8 9 10
64
3
1
2
9
8
5
10
37
2
8
4
108 4 7 9 3 2
1
1
sizeH14 16
7
1 2 3 4 5 6 7 8 9 10
64
3
1
2
8
537
2
4
8 4 7 1 3 2sizeH
14
8
10
9
1
10 9 16
7
1 2 3 4 5 6 7 8 9 10
M[1]↔ M[i]; heapify(M,1); end iteration i = 9;
64
3
1
2
8
537
2
4
8 4 7 1 3 2sizeH
14
8
10
9
1
10 9
i
i
7
161 2 3 4 5 6 7 8 9 10
64
3
1
2
5374
8 4 7 1 3
8 9
1
9
7
2
10 14 16sizeH
21 2 3 4 5 6 7 8 9 10
64
3
1
2
574
8 4 7 1 2
8
1
3
7
9 10 14 16sizeH
9
3
2
1 2 3 4 5 6 7 8 9 10
M[1]↔ M[i]; heapify(M,1); end iteration i = 8;
79

64
3
1
2
574
8
17
9
3
2
8 4 7 1 239 10 16sizeH
14
i
i1 2 3 4 5 6 7 8 9 10
64
3
1
2
574
8
1
3
8 4 7 132 10 1614
2
9sizeH
1 2 3 4 5 6 7 8 9 10
64
3
1
2
524
7
1
3
7 4 2 138 10 1614
8
9sizeH
1 2 3 4 5 6 7 8 9 10
M[1]↔ M[i]; heapify(M,1); end iteration i = 7;
64
3
1
2
524
7
1
3
7 4 2 138 10 1614
8
9sizeH
i
i1 2 3 4 5 6 7 8 9 10
4
3
1
2
524
7 3
7 4 23 10 1614
1
sizeH1 981 2 3 4 5 6 7 8 9 10
4
3
1
2
521
4 3
4 1 23 10 1614
7
sizeH7 981 2 3 4 5 6 7 8 9 10
M[1]↔ M[i]; heapify(M,1); end iteration i = 6;
80

4
3
1
2
521
4 3
4 1 23 10 1614
7
sizeH7 98
i
i1 2 3 4 5 6 7 8 9 10
4
3
1
2
1
4 3
4 13 10 1614
2
982 7sizeH
1 2 3 4 5 6 7 8 9 10
4
3
1
2
1
2 3
2 13 10 1614
4
984 7sizeH
1 2 3 4 5 6 7 8 9 10
M[1]↔ M[i]; heapify(M,1); end iteration i = 5;
4
3
1
2
1
2 3
2 13 10 1614
4
984 7sizeH
i
i1 2 3 4 5 6 7 8 9 10
3
1
22 3
2 43 10 1614
1
981 7sizeH
1 2 3 4 5 6 7 8 9 10
3
1
22 1
2 41 10 1614983 7sizeH
3
1 2 3 4 5 6 7 8 9 10
M[1]↔ M[i]; heapify(M,1); end iteration i = 4;
81

3
1
22 1
3
ii
2 41 10 1614983 7sizeH
1 2 3 4 5 6 7 8 9 10
1
22
1
2 4 10 1614987sizeH
1 31 2 3 4 5 6 7 8 9 10
1
21
2
1 4 10 1614987sizeH
2 31 2 3 4 5 6 7 8 9 10
M[1]↔ M[i]; heapify(M,1); end iteration i = 3;1
21
2
1 4 10 1614987sizeH
2 3
ii
1 2 3 4 5 6 7 8 9 10
11
2 4 10 16149871 3sizeH
1 2 3 4 5 6 7 8 9 10
2 4 10 16149871 31 2 3 4 5 6 7 8 9 10
M[1]↔ M[i]; heapify(M,1);
82

Temporal cost of heapsort
Building a heap: O(n).
n− 1 calls to heapify (of cost O(logn)).
⇒ heapsort ∈ O(n logn).
Only when all the elements are equal the cost of heapsort would be O(n).
83

Priority queues
The common application of a heap.
Priority queue set S of elements, each one with a key (priority).
Associated operations:
• Insert(S,x): inserts x in the set S.• Extract Max(S): deletes and returns the element of S with greatest key.• Maximum(S): return and element of S with greatest key.
⇒ processes management in a shared system.
84

Inserting an element in a heap
Strategy:
1. Expand the size of the heap in 1 (size Heap + 1).
2. Insert the new element in this position of the array (right-most located leaf).
3. Compare the key of the new element with its parent:If the key of the new node is greater → the parent does not accomplish the heap property:
a) Swap the keys.b) if the one which is the parent of the new element does not accomplish the heap property
→ repeat the swapping of the keys until the parent of the new element is greater orequal or the new element is the root.
85

Inserting and element in a heap (II)
Function that inserts the new element of key x (before calling it, we have to check if the sizeof the array allows the insertion):
void insert(type_baseT *M, type_baseT x)int i;
size_Heap++;i = size_Heap;
while ( (i > 1) && (M[i/2] < x) )M[i] = M[i/2];i = i/2;M[i] = x;
86

Inserting and element in a heap: Example
inserting an element of key 15.
64
3
1
2
9
18
5
10
37
42
16
14
8
9 10
sizeH
7
4 116 10 8 7 9 3 2141 2 3 4 5 6 7 8 9 10
1
64
3
1
2
9
8
5
10
37
42
16
14
87
1sizeH
10 i
i
9
1016 14 8 7 9 3 2 41 2 3 4 5 6 7 8 9 10 11
initial tree talla Heap++; i=size Heap;
87

1
64
3
1
2
9
8
5
10
3
42
16
14
87
8 9 3 2 4 1sizeH
107
i
7i
16 14 10 7
9
1 2 3 4 5 6 7 8 9 10 11
1
64
3
1
2
9
8
5
10
3
42
16
8
9
7
16 14 10 8 9 3 2 4 1sizeH
107
7
14
i
i14
1 2 3 4 5 6 7 8 9 10 11
1
64
3
1
2
9
8
5
10
3
42
16
8
9
7
10 8 9 3 2 4 1sizeH
107
7
14
i 15
i16 15 141 2 3 4 5 6 7 8 9 10 11
M[i]=M[i/2]; i=i/2; M[i]=M[i/2]; i=i/2; M[i]=x;
88

Temporal cost of inserting an element in a heap
Cost: number of compares until finding the position of a new element.
Heap of n elements:
• best case: inserting from the beginning at the corresponding position: O(1).• worst case: the element is the maximum → achieving the root: O(logn).
89

Extracting the maximum of a heap
→ the root
Strategy:
1. Get the root value (M [1]).
2. Delete the root by replacing it with the value of the last position of the heap(M [1]=M [size Heap]).Reduce the size of the heap in 1.
3. Apply heapify over the root in order to maintain the heap property.
90

Extracting the maximum of a heap (II)
typy_baseT extract_max(type_baseT *M)type_baseT max;
if (size_Heap == 0)fprintf(stderr,"Empty heap");exit(-1);max = M[1];
M[1] = M[size_Heap];
size_Heap--;
heapify(M,1);
return(max);
91

Extracting the maximum of a heap: Example
64
3
1
2
9
18
5
10
37
42
16
14
8
9 10
size
7
8 7 9 3 2 4 116 14 101 2 3 4 5 6 7 8 9 10
64
3
1
2
9
18
5
10
37
42
16
14
8
9 10
size
7
8 7 9 3 2 4 116 14 101 2 3 4 5 6 7 8 9 10
max=M[1]; M[1]↔ M[size Heap];
92

64
3
1
2
9
8
5
10
37
42
14
8
9
7
8 7 9 3 2 414
1
1 10 sizeH
1 2 3 4 5 6 7 8 9
64
3
1
2
9
8
5
10
37
12
4
9
7
4 7 9 3 2 110 size
14
8
14 81 2 3 4 5 6 7 8 9
size Heap–; heapify(M,1); return(max);
93

Temporal cost of extrating the maximum of a heap
To apply heapify over the root: O(logn).
Extract Max ∈ O(logn).
⇒ heap which represent the priority queue: operations ∈ O(logn).
94

Data structure for disjoint sets: MF-set
Equivalence class of a: subset that contains all the elements related with a (through aequivalence relation).
Equivalence classes → partition of C
Every element of the set appears in an equivalence class.
In order to know if a has an equivalence relation with b ⇒ check out if a and b are in thesame equivalence class.
95

MF-set (II)
MF-set (Merge-Find set): structure of n fixed elements.It is not possible to add or delete elements.Elements organized in equivalence classes.
Subsets identified by representative:- the smallest one.- no matter the element.
If the subset is not modified → same representative.
C
1
23
4
65
12
7 8 910
11
96

MF-set (III)
Operations:
Merge(x,y): x ∈ Sx and y ∈ Sy → union of Sx with Sy.The new subset representative is one of its members, normally the representative of Sx orSy is selected.The subsets Sx and Sy are removed.
Find(x): returns the representative of the equivalence class to which x belongs to.
Applications: grammar inference, equivalence of finite state machines, calculation of expan-sion tree of minimum cost of a non-directional graph, etc.
97

MF-sets representation
Each subset → a tree:
• Node: element information.• The root is the representative.
Tree representation using pointers to the parent: the one pointing itself will be the root.
MF-set: collection of trees (wood).
Each element → number from 1 to n + array M : position i ≡ index of the parent of i.
1
2
3
5
4
6
12 10
8
9
7 11 1M 1291 2 3 4 5 6 7 8 9 10 11 12
1 2 4 4 4 9 10 8 10
98

Operations on MF-sets
Merge
Merge(x,y): to do that the root of the tree points to the root of the other tree.
Assuming that x and y are root (representatives) ⇒ to modificate the pointer of the parentof one of the representatives, O(1).
1
2
3
12 10
4
5 6
8
9
7 11 1M 91 2 3 4 5 6 7 8 9 10 11 12
1 2 10 4 4 9 10 8 10 12
99

Operations on MF-sets
Find
Find(x): using the pointer to the parent, traverse the tree from x to the root.The nodes visited are the search path.
Cost proportional with the depth of the node, O(n).
10
4
5 6
8
9
7 11
1M 91 2 3 4 5 6 7 8 9 10 11 12
1 2 10 4 4 9 10 8 10 12
100

Analysis of the temporal cost
Initial MF-Set: n subsets of one element ⇒ worst sequence of operations:
1. carry out n− 1 Merge operations → unique set of n elements, and
2. carry out m Find operations.
Temporal cost:
n− 1 operations Merge ∈ O(n) → m operations Find ∈ O(mn).
Cost determined by how it is carried out the Merge operation, after k operations Mergecan produce a tree of height k.
⇒ Heuristic techniques in order to improve the cost (reducing the height of the tree).
101

Merge by height or range
Strategy: to merge in order that the root of the shortest tree points to the root of thehighest.
Height of resulting tree: max(h1, h2).
Required to keep the height of each node.
The height of a tree of n elements ≤ blognc.
Cost of m searching operations: O(m logn).
102

4
5 6 10
8
9
7 11
10
4
5 6
8
9
7 11
103

Path compression
Strategy: When an element is being searched, do all nodes of the search path to be directlylinked with the root.
Combining both heuristics, cost of m searching operations: O(mα(m,n)),with α(m,n) ≡ Ackerman inverse function, (slow growing). Normally, α(m,n) ≤ 4.
In practice, with both heuristics ⇒ to do m searching operations has an almost linear costwith m.
10
8
9
7 11
10
8 9 11
7
104

Tries
A kind of search tree.
Application: dictionaries.
Words with common prefixes use the same memory for the prefixes.
Common prefixes compaction ⇒ save of space.
105

Tries (II)
Ex: set pool, prize, preview, prepare, produce, progress
106

Tries: Searching an element
It begins at the root.
From the beginning to the end of the word, character by character is considered.
Chose the edge labeled with the same character.
Each step takes one character and descends one level.
If the word is finished and a leaf has been reached ⇒ found.
If at any time there is no edge with the current character or the word is finished and weare in an internal node ⇒ word not recognized.
Search time proportional to the length of the word −→ very efficient data structure.
107

Tries: Representation
Trie ≡ a kind of finite state machine (FSM).
Representation: transition matrix.
• Rows = states.• Columns = labels.
Each position of the matrix save the next state to transit.
Very efficient temporal cost.
Most of the nodes will have few edges =⇒ a great amount of memory wasted.
108

Balanced trees
Data structures to save elements.
Allow efficient searchs.
Balanced tree: a tree where any leaf are more far away from the root than any other leaf.
Several balance strategies (different definition for more far away).
Different algorithms to update the tree.
109

AVL tree
AVL tree: binary search tree that accomplishes
1. The height of the subtrees of every node differ at maximum in 1.
2. Every subtree is an AVL tree.
Creators: Adelsson, Velskii and Landis.
They are not completely balanced.
Search, insert and delete an element ∈ O(log n).
11
5
84
17
1812
12
17
18
5
8
11
4
110

2-3 trees
2-3 trees: empty tree or a single node or with several nodes that accomplish:
1. Every interior node has 2 or 3 children.
2. Every path from the root to a leaf has the same length.
Internal nodes:p1 k1 p2 k2 p3
• p1: pointer to the first child.• p2: pointer to the second child.• p3: pointer to the third child (if exists).• k1: smallest key of any descendent from the second child.• k2: smallest key if any descendent from the third child.
Leaves: information of the corresponding key.
111

2-3 trees (II)
Example:
112

2-3 trees: Searching
The values in the internal nodes guide the searching.
Begin at the root: k1 and k2 are the two values saved in the root.
• If x < k1, carry on searching in the first child.• If x ≥ k1 and the second node has only 3 children, carry on searching in the second
child.• If x ≥ k1 and the node has 3 children, carry on searching in the second child if x < k2
and in the third child if x ≥ k2.
Apply the strategy to every node that belongs to the search path.
End: a leaf is reached with
• the key x =⇒ element found.• a key different to x =⇒ element not found.
113

B-trees
2-3 trees generalization.
Applications:
• Extern data storage.• Data base indexes management.• Allows to reduce the access to disk in data base queries.
114

B-trees (II)
B tree of n order: search tree n-ary that accomplishes
The root is a leaf or it has a minimum of two children.
Every nodeo, except the root and the leaves, have between dn2e and n children.
Every path from the root to a leaf has the same length.
Every interior node has up to (n− 1) key values and up to m pointers to their children.
The elements are saved in the interior nodes and in the leaves.
A B-tree can be seen as a hierarchical index. The root would be the first indexed level.
115

B-tree (III)
Internal nodes: p1 k1 p2 k2 . . . . . . kn−1 pn
• pi is a pointer to the i-th children, 1 ≤ i ≤ n.• ki are the values of the keys, (k1 < k2 < . . . < kn−1 ) so: all the keys of the subtree p1 are less than k1. For 2 ≤ i ≤ n − 1, all the keys in the subtree pi are greater or equal than ki−1 and
less than ki. All the keys in the subtree pn are greater or equal than kn−1.
116

B-arboles +
B+ tree: B-tree in which all the keys saved in the internal nodes are no useful (only usedfor searching purposes).
All the keys of the internal nodes are duplicated in the leaves.
Advantage: the leaves are sequencially linked and it is possible to access to the informationof the elements without visiting the interior nodes.
Improve the efficiency in some searching methods.
117

Data Structutes and Algorithms
Graphs

Definitions
Graph→ model in order to represent relationships between the elements of a set.
Graph: (V ,E), V is a set of vertices or nodes, with a relationship between them; E is aset of pairs (u,v), u,v ∈ V , called edges or arcs.
Directed graph: the relationship on V is not symmetric. Edge ≡ sorted pair (u,v).
Undirected graph the relationship on V is symmetric. Edge ≡ non-sorted pair u,v, u,v∈ V and u 6=v
1 2
4 5
3
6
1 2
5 4
3
Directed graph G(V , E). Non-directed graph G(V , E).V = 1,2,3,4,5,6 V = 1,2,3,4,5E = (1,2),(1,4),(2,5),(3,5),(3,6),(4,2), E = 1,2,1,5,2,3,2,4,2,5,
(5,4),(6,6) 3,4,4,5
1

Definitions (II)
Path from u ∈ V to v ∈ V : sequence v1, v2, . . . , vk that u = v1, v = vk, and (vi−1,vi)∈ E, for i =2,. . . ,k.Ex: path from 3 to 2 →<3,5,4,2>.
1 2
4 5
3
6
Length of a path: number of edges of a path.
Simple path: path in which all its vertices, except, may be, the first and the last, aredifferent.
2

Definitions (III)
Cycle: simple path v1, v2, . . . , vk that v1 = vk.Ex: <2,5,4,2> is a cycle of length 3.
1 2
4 5
3
6
Loop: cycle of length 1.1 2
4 5
3
6
Acyclic graph: graph without cycles.1 2
4 5
3
6
3

Definitions (IV)
v is adjacent to u if exists an edge (u,v) ∈ E.
In an undirected graph, (u,v) ∈ E relates the nodes u, v.
In a directed graph, (u,v) ∈ E has v as destiny, and u as origin.
Degree of a vertex: number of edges with the node as destination.
In directed graphs exist the out-degree and the in-degree.The degree of the vertex is the sum of in-degree and out-degree.
Degree of a graph: maximum degree of its vertices.
4

Definitions (V)
G′ = (V ′, E′) is a subgraph of G = (V , E) if V ′ ⊆ V and E′ ⊆ E.
Induced subgraph by V ′ ⊆ V : G′ = (V ′,E′) that E′ = (u,v) ∈ E | u,v ∈ V ′.Examples of subgraphs of the slide number 1 graph:
1 2
4 5
1 2
4 5
V ′ = 1,2,4,5 Induced graph byE′ = (1,2),(1,4),(2,5),(5,4) V ′ = 1,2,4,5
5

Definition (VI)
v is reachable from u, is exists a path from u to v.
Am undirected graph is connected is exists a path between a vertex and any other one.
A directed graph with such a property is called strongly connected:
1 2
4 3
If a directed graph is not strongly connected, but if the subjacent graph (without directionin the edges) is connected, the graph is weakly connected.
6

Definitions (VII)
In an undirected graph, the connected components are the equivalence classes followingthe equivalence relation “to be reachable from”.
An undirected graph is unconnected if it is formed by several connected components.
In a directed graph, the strongly connected components, are the equivalence classesfollowing the equivalence relation “to be mutually reachable”.
A directed graph is non-strongly connected if it is formed by several strongly connectedcomponents.
1 2
4 5
3
6
7

Definitions (VIII)
Weighted graph: every edge, or vertex, or both, have a weight.
1 2
4 5
3
6
10
12−1
15
9
8
9
7
8

Introduction to the theory of graphs
problem → representation with graphs → algorithm → computer
The Konigsberg bridges
An island in the center of the river.
Seven bridges that link the different areas.
Problem: to schedule a walk from a point to the same point, crossing all the bridges butonce and only once.
9

The Konigsberg bridges (II)
10

The Konigsberg bridges (III)
11

The Konigsberg bridges (IV)
Translating the problem to graphs:
representing islands and borders with points.
transforming bridges in lines that link the points.
A
C
B
D
New problem: is it possible to draw the figure from a point and come back to the same point,without passing twice over a line and without lifting the pen?
12

The Konigsberg bridges (V)
Euler found out the following rules:
1. A graph formed by vertices of even degree can be traversed in one pass, from a vertex tothe same vertex.
2. A graph with just two vertices of odd degree can be traversed in one pass, but withoutcoming back to the starting vertex.
3. A graph with a number of vertices of odd degree greater that two cannot be traversed injust one pass.
The Konigsberg bridges:
VERTEX DEGREEA 3B 3C 5D 3
⇒ ¡the problem has no solution!
13

Representing graphs: Adjacency lists
G = (V ,E): array of size |V |.
Position i → pointer to a linked list of elements (adjacency list).The elements of the list are the adjacent vertices of i
1 2
5 4
3
2
2
1
2
3
4
5
5
4
4
3
4
1 35
2 5
1 2
1 2
4 5
3
6
2
4
4
6
5
2
5
1
2
3
4
5
6 6
14

Adjacency lists (II)
If G is directed, the sum of the length of the adjacency lists will be |E|.
If G is undirected, the sum of the length of the adjancency lists will be 2|E|.
Spatial cost, directed or not: O(|V |+ |E|).
Proper representation for graphs with |E| less than |V |2.
Disadvantages: if it is needed to check out if an edge (u,v) belongs to E ⇒ search v inthe adjacency list of u.Cost O(Degree(G)) ⊆ O(|V |).
15

Adjacency lists (III)
Representation suitable for weighted graphs.The weight of (u,v) is saved in the node of v of the adjacency list of u.
1 2
4 5
3
6
10
12−1
15
9
8
9
7
1
2
3
4
5
6
4
5
6 155 −1
2 12
4
6
8
7
9
9
2 10
16

Adjacency lists (IV)
C types definition (weighted graphs):
#define MAXVERT ...
typedef struct vertexint node, weight;struct vertex *next;
vert_adj;typedef structint size;vert_adj *adj[MAXVERT];
graph;
17

Representing graphs: Adjacency matrix
G = (V ,E): matrix A of size |V | × |V |.
Value aij of the matrix: aij =
1 if (i,j) ∈ E0 in other case
1 2
5 4
3
1
2
3
4
5
1 2 3 4 51 1
1 1 1 1
1 1
1 1 1
1 1 1
0 0 0
0
0 0 0
0 0
0 0
1 2
4 5
3
6
1
2
3
4
5
1 2 3 4 51 0
0 0 0 1
0 0
1 0 0
0 0 1
0 0 1
0
0 0 1
0 0
0 0
06
6
0
0
0
0 0 0 00
1
1
18

Adjacency matrix (II)
Spatial cost: O(|V |2).
Representation suitable for graphs with a low number of vertices, or dense graphs(|E| ≈ |V | × |V |).
Check if an edge (u,v) belongs to E → consult position A[u][v].Cost O(1).
19

Adjacency matrix (III)
Representing weighted graphs:The weight (i,j) is saved in A[i, j].
aij =
w(i, j) if (i,j) ∈ E0 or ∞ in other case
1 2
4 5
3
6
10
12−1
15
9
8
9
7
1
2
3
4
5
1 2 3 4 50
0 0 0 7
0 0
0 0
0 0 9
0 0 8
0
0 0
0 0
0 0
06
6
0
0
0
0 0 0 00 9
10
−1 15
12
20

Adjacency matrix (IV)
C types definition:
#define MAXVERT ...
typedef structint size;int A[MAXVERT][MAXVERT];
graph;
21

Traversing graphs: depth-first algorithm
→ A generalization of the pre-order method in a tree.
Strategy:
Start from a arbitrary vertex v.
When a new vertex is visited, explore every path that starts from it.Until a path is not finished, the next path is not started.
The exploration of a path is finished when a vertex already visited is reached.
If there were vertices not reachable from v the traverse is uncompleted:select one of them as new starting vertex, and repeat the process.
22

Depth-first traversing algorithm (II)
Recursive strategy: given G = (V , E)
1. Mark all the vertices as unvisited.
2. Chose vertex u as initial point.
3. Mark u as visited.
4. ∀v adjacent to u, (u,v) ∈ E, if v has not been visited, repeat recursively (3) and (4) forv.
Finalize when all reachable nodes from u have been visited.If from u all the nodes are not reachable: back to (2), chose a new unvisited vertex vas starting point, and repeat the process until traversing all the vertices.
23

Depth-first traversing algorithm (III)
→ use a color array (size of input |V |) to indicate if u has been visited (color[u]=YELLOW)or not (color[u]=WHITE):
Algorithm Depth-first(G)for each vertex u ∈ Vcolor[u] = WHITE
end for
for each vertex u ∈ Vif (color[u] = WHITE) Visit node(u)
end for
Algorithm Visit node(u)color[u] = YELLOW
for each vertex v ∈ V adjacent to uif (color[v] = WHITE) Visit node(v)
end for
24
Depth-first traversing algorithm: Example
2
1 4
5
6
3
7
5
6
5
1
2
3
4
5
6 7
4 2
7
7
35 2
3
¡Look out!: the traversing depends on the order in which the vertices in the adjacency listsappear.
25

Depth-first traversing algorithm: Example (II)
2
1 4
5
6
3
7
2
1 4
5
6
3
7u
2
4
5
6
3
7u
1
Depth-First(G) Visit node(1) color[1]=YELLOW
2
4
5
6
3
7
1u
2
4
5
6
3
7
1u
2
4
5
6
3
7
1
u
Visit node(4) color[4]=YELLOW Visit node(6)
26

Depth-first traversing algorithm: Example (III)
2
4
5
3
7
1 6
u
2
4
5
3
7
1 6
u2
4
5
3
7
1 6
u
color[6]=YELLOW Visit node(7) color[7]=YELLOW
2
4
5
3
1 6
7
u
2
4
5
3
7
61
u
2
4
5
3
7
1 6
u
Visit node(3) color[3]=YELLOW Visit node(5)
27

Depth-first traversing algorithm: Example (IV)
2
4
5
3
7
1 6
u
2
4
5
3
7
1 6
u
2
4
5
3
7
1 6
u
color[5]=YELLOW Visit node(2) color[2]=YELLOW
28

Depth-first traversing algorithm: temporal cost
G = (V , E) is represented using adjacency lists.
Visit node is applied only over unvisited vertices → only once over each vertex.
Visit node depends on the number of adjacent vertices that u has (length of adjacencylist).
cost of all calls to Visita node: ∑v∈V
|adj(v)| = Θ(|E|)
Adding the cost associated to the loops of Depth-First: O(|V |).
⇒ Depth-First cost is O(|V |+ |E|).
29

Traversing graphs: breadth-first algorithm
→ Generalization of the tree traversing by levels.
Strategy:
Start from an arbitrary vertex u, visit u and, afterwards, visit every adjacent node to u.
Repeat the process for every adjacent node to u, following the order in which they werevisited.
Cost: O(|V |+ |E|).2
4
5
6
3
7
1
u
30

Least cost paths
G = (V , E) directed and weighted and w(u,v) the weight of each edge.
Weight of a path p =< v0, v1, . . . , vk >: the sum of all the weights of the path:
w(p) =k∑
i=1
w(vi−1, vi)
Minimum weight path from u to v: path with minimum weight among all the pathsfrom u to v, or ∞ if there is no path from u to v.
Length of a path from u to v: weight of a path from u to v.
Shortest path from u to v: Minimum weight path from u to v.
31

Least cost paths (II)
Paths from 1 to 2:1 2
4 3
5
50
10
10
30
20
50
5100
Path Length (weight or cost)
1 250
50
130
3 25
35
130
320
250
4 100
1100
4 220
120
1 5 420
210 10
40
32

Least cost paths (III)
We use a directed weighted graph to represent the communication between cities:
• vertex = city.
• edge (u,v) = road from u to v;the weight associated to the edge is the distance.
Shortest path = the fast way.
Variants in the least cost paths:
• Shortest paths from a vertex to all the other.
• Shortest paths from all the vertex to a particular one.
• Shortest path from a vertex u to a vertex v.
• Shortest paths between every pair of vertices.
33

Dijkstra algorithm
Problem: G = (V , E) directed weighted graph with non-negative weights; given an originvertex s, get the shortest paths to the rest of vertices of V .
If there are negative weights, the solution could be wrong.
Other algorithms allow negative weights, but without cycles of negative weight.
Idea: explote the property that the shortest path between two vertices has shortest pathsbetween the vertices that belong to the path.
34

Dijkstra algorithm (II)
The Dijkstra algorithm keeps these sets:
A set of vertices S that has the vertices whose shortest distant from the origin is known.Initially S = ∅.
A set of vertices Q = V − S that keeps, for every vertex, the shortest distant from thethe origin passing through the vertices that belong to S (Provisional distance).To save provisional distances an array D[1..|V |] is used, where D[i] indicates the provisionaldistant from the origin s to the vertex i.Initially, D[u] = ∞ ∀u ∈ V− s and D[s]= 0.
Besides:
An array P [1..|V |] to recovery the minimum calculated paths.P [i] saves the index to the vertex that precedes to the vertex i in the shortest path froms to i.
35

Dijkstra algorithm (III)
Strategy:
1. Extract from Q the vertex u whose provisional distance D[u] is least.→ this distance is the least possible between the origin vertex s and u.The provisional distances would correspond with the shortest path using vertices from S.⇒ it is no longer possible to find a shortest path from s to u using any other vertex ofthe graph
2. Insert u, to whom the shortest path from s has been calculated, in S (S = S ∪ u).Update the provisional distances of the vertices of Q adjacent to u that improve using thenew path.
3. Repeat 1 and 2 until Q is empty⇒ in D it will be, for every vertex, the shortest distance to the origin.
36

Algorithm Dijkstra(G, w, s)
for each vertex v ∈ V do
D[v] = ∞;
P [v] = NULL;
end for
D[s] = 0; S = ∅; Q = V ;
while Q 6= ∅ do
u = extract min(Q); /∗ following D ∗/S = S ∪ u;for each vertex v ∈ V adjacent to u do
if D[v] > D[u] + w(u,v) then
D[v] = D[u] + w(u,v);
P [v] = u;
end if
end for
end while
37

Dijkstra algorithm: Example
Origin vertex: 1.
Discontinuous line edges = provisional paths from origin to the vertices.
Thick line edges = minimum paths already calculated.
Rest of edges with thin lines.
38

21
5 4
6
5
10
20
3
1040
10
20
55
5
s
S Q u 1 2 3 4 5 6 1,2,3,4,5,6 − D 0 ∞ ∞ ∞ ∞ ∞
P NULL NULL NULL NULL NULL NULL
21
5 4
6
5
10
20
3
1040
10
20
55
5
s
S Q u 1 2 3 4 5 61 2,3,4,5,6 1 D 0 ∞ 40 ∞ 10 5
P NULL NULL 1 NULL 1 1
39

21
5 4
6
5
10
20
3
1040
10
20
55
5
s
S Q u 1 2 3 4 5 61,6 2,3,4,5 6 D 0 25 40 ∞ 10 5
P NULL 6 1 NULL 1 1
21
5 4
6
5
10
20
3
104020
55
5
s
10
S Q u 1 2 3 4 5 61,6,5 2,3,4 5 D 0 25 40 30 10 5
P NULL 6 1 5 1 1
40

21
5 4
6
5
10
20
3
1040
55
5
s
10
20
S Q u 1 2 3 4 5 61,6,5,2 3,4 2 D 0 25 40 30 10 5
P NULL 6 1 5 1 1
21
5 4
6
5
10
20
3
1040
55
5
s
10
20
S Q u 1 2 3 4 5 61,6,5,2,4 3 4 D 0 25 35 30 10 5
P NULL 6 4 5 1 1
41

21
5 4
6
5
10
20
3
1040
55
5
s
10
20
S Q u 1 2 3 4 5 61,6,5,2,4,3 3 D 0 25 35 30 10 5
P NULL 6 4 5 1 1
42





























