Embed Size (px)
Citation preview

1Abstract— In this paper an implementation of a fuzzy adaptive control law to manipulate device of Human-Robot interaction is presented. Mamdani type fuzzy systems are employed to approximate the dynamics of interaction system. An adaptation law is added to controller to compensate for parametric variations and/or uncertainties of the interaction Human-Robot. The theoretical results proposed are illustrated on a PHANToM Premium 1.0 haptic device.
Keywords— Control nonlinear systems, Fuzzy control systems, Adaptive control systems, Haptic interfaces and devices.
I. INTRODUCCIÓN OS SISTEMAS de interacción hombre-máquina, y particularmente sistemas de interacción hombre-robot,
nacen como una necesidad de resolver problemas de inmersión virtual activa (ambientes virtuales dinámicos deformables), para recrear escenarios remotos en la estación del usuario, teleoperar sistemas robóticos complejos ante la existencia de riesgos humanos, establecer plataformas para evaluación biomecánica y entrenamiento, así como sistemas de visualización científica interactiva y simulación de eventos dinámicos complejos [1], [2], [3], [4]. La comunidad científica y académica del área, propone continuamente diversos esquemas y plataformas para lograr metas como las ya descritas, y promueve el diseño a partir de los alcances de la tarea y aplicación. Una plataforma robótica está compuesta por los subsistemas siguientes: i) Electromecánico, ii) Percepción, iii) Comunicación, iv) Decisión y v) Control; la relación entre ellos, las tecnologías de integración y los procedimientos algorítmicos empleados contribuyen en beneficio del desempeño y garantizan eficiencia operativa [5]. Sin embargo, cuando estos sistemas interactúan con fuerzas externas, las condiciones de operación cambian radicalmente y la diferencia se describe a continuación: • Sistema robótico en movimiento libre: no existe presencia
de fuerzas externas (es requerido el control de posición y velocidad).
• Sistema robótico en movimiento restringido: presencia de una superficie de contacto conocida, o calculada en tiempo real en interacción con el efector final (es requerido el control de posición, velocidad y fuerza de contacto).
1 R. Villafuerte, Universidad Autónoma del Estado de Hidalgo (UAEH), Hidalgo, México, [email protected] O. A. Domínguez, Universidad Autónoma del Estado de Hidalgo (UAEH), Hidalgo, México, [email protected] O. González, Instituto Tecnológico Superior del Oriente del Estado de Hidalgo (ITESA), Hidalgo, México, [email protected] M. A. Hoyos, Universidad Autónoma del Estado de Hidalgo (UAEH), Hidalgo, México, [email protected]
En la última década se ha prestado especial atención al diseño, construcción y control de sistemas robóticos que permitan al ser humano interactuar activamente con un ambiente de visualización virtual, incorporando estímulos táctiles y así permitir al ser humano tener una percepción de mundos virtuales recreados a partir de ambientes artificiales y/o reales, [1], [6], [7]. A este tipo de sistemas se les conoce como interfaces hápticas, las cuales están constituidas por un operador humano, un ambiente de visualización virtual y un sistema electromecánico denominado dispositivo háptico, ver Fig 1.
Figura 1. Diagrama a bloques de la interfaz háptica Phantom Premium 1.0.
Las estrategias de control y planificación para cada uno de los casos, consideran en su diseño a la dinámica de fuerzas de interacción y en el mejor de los casos a la incertidumbre presente en la carga en el efector final, en las fuentes de energía empleadas en interfaces electrónicas de potencia, y en presencia de objetos susceptibles de colisión en el espacio de trabajo (ambiente del robot). Los cambios en la dinámica más relevantes corresponden a la tribología articular, y dependen de la fricción dinámica compleja y de las vibraciones mecánicas; estas pueden ser reducidas, compensadas o estabilizadas a través de estrategias de control de movimiento y fuerza [8], [9]. Cuando el sistema robótico tiene contacto con el operador humano, el esquema corresponde a una interfaz háptica, y se asocia a un tipo especial de sistema robótico con movimiento restringido; en estas condiciones la dinámica del humano representa incertidumbre a la dinámica del robot en lazo cerrado, y aunque en condiciones de salud del operador, esta puede ser acotada a través de una estrategia de control robusta, las condiciones no son las mismas bajo condiciones de una discapacidad motriz (movimiento involuntario activo, movimiento espástico, o movimiento pasivo) [10]. En la literatura, se abordan esquemas de diseño e integración de plataformas experimentales con diversos propósitos, que atienden situaciones de este tipo, [11]-[14].
En [15] se presenta una herramienta integral basada en
L
A Simple Implementation of an Intelligent Adaptive Control Systems for Human-Robot Interaction
R. Villafuerte, O. A. Domínguez, O. González and M. A. Hoyos

redes ZigBee para rehabilitación robótica de miembro superior de pacientes con discapacidad motriz como consecuencia de un accidente vascular cerebral, en el que la integración de la percepción propioceptiva de movimiento articular de acuerdo a la biomecánica, permite instrumentar el estado con el propósito de retroalimentar a un sistema robótico, un exoesqueleto, o un robot tipo mayordomo como el empleado en el presente trabajo. Mientras que en [16] se presenta un procedimiento algorítmico y la integración del hardware con el desempeño adecuado para la detección de contacto en un sistema de interacción física hombre-robot. En [17] se hace evidencia del uso del modelo cinemático directo e inverso de posición y diferencial útil en la planificación de movimiento en el espacio operacional y la correspondiente validación cuando la estrategia de control es en el espacio articular. El diseño e implementación de un control neuronal, para un robot redundante de 5 gdl, empleando la dinámica Euler-Lagrange y el término de fuerzas disipativas con los actuadores y reductores de velocidad interconectados. El empleo de un algoritmo de aprendizaje backpropagation para garantizar el seguimiento cartesiano operacional con adecuado desempeño es presentado en [18]. Mientras que en [19] se propone una estrategia de modelado matemático que presenta las condiciones necesarias y suficientes que garantizan pasividad en un sistema robótico. Aunque las técnicas de control clásicas han demostrado tener un buen desempeño en sistemas robóticos bajo condiciones ideales, cuando el sistema robótico en estudio interactúa físicamente con el ambiente, el sistema opera en condiciones de incertidumbre provocando en varios casos un deficiente desempeño. Los sistemas de control borrosos adaptativos ofrecen herramientas y técnicas útiles para mejorar el funcionamiento de esta clase de sistemas en condiciones de incertidumbre [2], [20]. El término borroso o difuso aplicado a la lógica y a la teoría de conjuntos y sistemas procede de la expresión fuzzy sets acuñada por Lofti A. [21]. Una de las primeras implementaciones de la lógica borrosa en el campo del control fue realizado por Assilian y Mamdani [22]-[24], al desarrollar el primer controlador borroso diseñado para una máquina de vapor, en la década de los setentas destacan, además trabajos como [25], [26]. Más tarde, Takagi y Sugeno desarrollan la primera aproximación para construir reglas borrosas a partir de datos de entrenamiento [27], y aunque en un principio no tiene mucha repercusión, fue el punto de partida de la identificación de modelos borrosos [28] y esquemas de control basados en modelos borrosos Takagi Sugeno como la llamada compensación distribuida paralela [29]. Aunque los sistemas Takagi Sugeno se han vuelto muy populares, estos requieren de un modelo dinámico del sistema a estudiar, en contraste con los sistemas Mamdani. Los sistemas borrosos están ganando terreno en el diseño de sistemas de control a tal grado que su aplicación hoy en día se considera relevante. Además, es necesario tomar en cuenta que, los investigadores buscan nuevos campos de aplicación de esta técnica y su vinculación con otras áreas como las redes neuronales [30], [31] el control adaptativo [32]-[37],
extensiones a sistemas no lineales [38]-[40], entre otras. En este artículo se presenta una modificación y una aplicación de los resultados teóricos desarrollados en [41]. A diferencia de los resultados previos, en la presente propuesta se modifica el error de seguimiento filtrado para obtener una ley de control borrosa adaptativa que mejora el desempeño de los sistemas de interacción hombre-robot en tareas de seguimiento, además se presenta la implementación de los resultados teóricos obtenidos sobre un dispositivo háptico PHANToM Premium 1.0. El desempeño apropiado de la interacción hombre-robot es garantizado mediante un análisis de estabilidad del sistema en lazo cerrado en el marco de Lyapunov. El artículo se organiza de la siguiente forma. La descripción del sistema y el planteamiento del problema se presentan en la Sección II. En la Sección III se postulan los resultados principales referentes al diseño del controlador borroso adaptativo y al análisis de estabilidad del sistema en lazo cerrado. Continuando así, en la Sección IV, con la ejemplificación de los resultados propuestos en la sección anterior. Finalmente, en la Sección V se presentan algunas conclusiones y comentarios.
II. FORMULACIÓN DEL PROBLEMA Las estrategias de evaluación de interfaces hombre-robot
existentes, valoran el desempeño del robot en lazo cerrado a un control con movimiento y fuerza planificados, a través de sus variables como posición, velocidad y fuerza; y en el mejor de los casos de la energía y potencia demandadas durante la interacción; esto generalmente implica operar al sistema robótico en condiciones nominales preservando la vida útil de todos y cada uno de sus componentes.
Sin embargo, existen variables ajenas al robot y al operador humano, derivadas principalmente de la interacción entre ellos tanto en tareas de exploración (humano activo en la tarea) o de guiado háptico (humano pasivo en la tarea), que impactan directamente en el desempeño, provocando la ejecución de tareas de forma inadecuada. De ahí la preocupación por el diseño y validación de nuevas estrategias de control para tareas de guiado háptico orientadas a mejorar el funcionamiento de sistemas en condiciones de incertidumbre y favorecer la percepción humana en el uso del robot en tareas de entrenamiento [42].
A. Dinámica de un sistema de interacción hombre-robot La ecuación que describe la dinámica de un robot con el operador humano en el lazo, y con base en la formulación de Euler-Lagrange, es descrita a continuación, H(q) + C(q, ) + G(q) + B = τ + τh, (1) donde H(q) ∈ ℝn×n denota una matriz de fuerzas inerciales, definida positiva y simétrica; C(q, ) ∈ ℝn×n corresponde a la matriz de fuerzas de Coriolis y Centrípetas; G(q) ∈ ℝn modela al vector de fuerzas gravitacionales, B ∈ ℝn×n es una matriz diagonal y definida positiva, cuyas entradas son los coeficientes de fricción viscosa; τ ∈ ℝn corresponde al vector

de par de control, diseñado con base al modelo dinámico; τh = J(q)Tfh representa al par aplicado por el operador humano, distribuido en las articulaciones, y definido a partir de la matriz Jacobiana J(q) del dispositivo háptico o robot; y q ∈ ℝn corresponde a las coordenadas generalizadas, con , ∈ ℝn×1 como las derivadas temporales correspondientes a la velocidad y aceleración articular [8].
B. Control de robot para interacción humana En tareas de guiado háptico, el dispositivo es tratado como un robot manipulador al recibir señales de fuerza y posición como consignas de operación [43]. Debido a la naturaleza no lineal de los robots manipuladores, deben ser considerados sistemas de control sofisticados para satisfacer requerimientos de precisión y rapidez. Las leyes de control aplicadas en tareas de este tipo son no lineales, que se adaptan en línea para compensar las incertidumbres y perturbaciones asociadas al funcionamiento del sistema. La estabilidad es una propiedad que debe poseer una ley de control, para ello una técnica tradicionalmente utilizada en el estudio de estabilidad de robots manipuladores, es el segundo método de Lyapunov o método directo de Lyapunov (Alexandre Mikhailovich Lyapunov, siglo XIX) [5]. Este método determina las propiedades de estabilidad de sistemas a partir de una función escalar asociada con la energía del sistema, y examina su variación temporal. Para las condiciones en un sistema de inte-racción hombre-robot sometido a incertidumbre dinámica en el lazo, la adaptabilidad y con ello la compensación por la realimentación dinámica total es una alternativa deseable como estrategia de control para tareas de guiado háptico local con el humano en el lazo.
C. Forma general del sistema estudiado Considere la dinámica de un robot descrita por la ecuación (1), esta ecuación puede reescribirse como un sistema no lineal con múltiples entradas y múltiples salidas (MIMO, Multiple-Input Multiple-Output), de la forma ( ) = fi(x) + ∑pj 1gij(x)uj, (2)
donde ri , i = 1, … ,p , es el orden relativo del sistema, y = y1, … , yp T es el vector de salida, x = y1, 1, … , y( ), … , yp, p, … , y( ) Tes el vector de
estado el cual se asume disponible para su medición, u =[u1, … , up]T es el vector de entradas de control y fi(x), gij(x), i,j = 1, … ,p son funciones no lineales suaves desconocidas. Note que el sistema (2) puede reescribirse de la forma y(r) = F(x) + G(x)u donde y(r) = [y( ) … y( )]T , F(x) = [f1(x) … fp(x)]T y
G(x) = g11(x) ⋯ g1p(x)⋮ ⋱ ⋮gp1(x) ⋯ gpp(x) . En lo subsecuente se asume que la matriz G(x) es definida positiva. Aunque esto restringe el tipo de sistemas a los cuales se le puede aplicar la presente propuesta, varios sistemas físicos, tales como los sistemas robóticos, cumplen con esta
propiedad. Es claro que el diseño de controladores para la anterior
clase de sistemas resulta una tarea no trivial. Más aún, si las funciones fi(x), gij(x), i,j = 1, … ,p, son desconocidas y el sistema presenta incertidumbres, originadas ya sea por dinámicas no modeladas, perturbaciones, interacción hombre-robot, entre otras.
Es bien conocido que las técnicas de control adaptativo ofrecen una metodología que permite mantener un desempeño consistente en un sistema ante la presencia de incertidumbre. Mientras que, las técnicas borrosas han demostrado ser muy eficientes para aproximar funciones desconocidas [37]. En las secciones siguientes se presenta el desarrollo de un controlador que emplea estas dos técnicas para revelar una manera eficiente de manipular sistemas con dinámica desconocida y expuestos a incertidumbres constantes propias de la interacción hombre-robot.
III. DISEÑO DEL CONTROLADOR BORROSO ADAPTATIVO
En esta sección se presenta el diseño de una ley de control borrosa adaptativa, cuya idea principal parte del razonamiento planteado en [41]. Aquí, el error de seguimiento filtrado es modificado para mejorar el desempeño de los sistemas de interacción hombre-robot en tareas de seguimiento. La modificación radica en incluir términos integrales para ayudar a reducir con mayor rapidez el error en estado estacionario.
Considere un sistema de la forma (2) y sea ( ) =[ ( ) … ( )]T el vector de trayectorias de referencia, donde y (t), i = 1, … ,p, son funciones conocidas, acotadas y ri veces diferenciables, entonces se define el error de seguimiento como: ei(t) = y (t) − yi(t), i = 1, … ,p, (3) y el error de seguimiento filtrado como si(t) = ddt + λi (ri 1) e (t) + αi e (θ)dθ + γi e (θ)dθ dφ ,
(4) con φ ∈ [0, t], λi, αi, γi > 0 para i = 1, … ,p. Note que, si si(t) → 0 cuando t → ∞, entonces cada término del lado derecho de la ecuación (4) también converge asintóticamente a cero. Por lo que, ei(t) → 0 cuando t → ∞, i = 1, … ,p. Así, el desempeño del sistema (2) en tareas de seguimiento, queda determinado por la convergencia asintótica de las si(t).
Por otro lado, derivando la ecuación (4) se tiene que ṡi = vi − fi(x) − ∑pj 1gij(x)uj,i = 1, … ,p, (5)
donde vi = ydi(ri) + βi,ri 1e(ri 1) + ⋯ + βi,1ei, +αiei + γi ei(θ)dθ , con βi,j = (ri 1)!(ri j)!(j 1)! λri , i = 1, … ,p, j = 1, … , ri − 1. Así, definiendo s(t) = [s1(t) … sp(t)]T y

v(t) = [v1(t) … vp(t)]T, la ecuación (5) puede escribirse como ṡ = v − F(x) − G(x)u. (6) Observe que la ley de control no lineal u = G 1(x)(−F(x) + v + K0s), (7) donde K0 ∈ ℝp×p es una matriz definida positiva, estabiliza asintóticamente al sistema (6). Sin embargo la implementación de (7) requiere de un pleno conocimiento de las funciones no lineales F(x) y G(x), lo cual en muchas ocasiones es una tarea no trivial y más aún si la dinámica del sistema cambia constantemente debido a la interacción hombre-robot.
A continuación, se aprovechan las virtudes que ofrecen los sistemas borrosos para aproximar las funciones no lineales F(x) y G(x).
A. Aproximación del sistema MIMO utilizando sistemas borrosos tipo Mamdani
Un sistema borroso de tipo Mamdani se caracteriza por un conjunto de reglas si-entonces con la estructura siguiente Rk: si x1 está en F y … y xn está en ; entonces y(x) está en Ck, k = 1, … ,r, donde r es el número de reglas borrosas, Ck es un conjunto borroso definido en ℝ, y ∈ ℝ es la variable de salida, , … , son conjuntos borrosos asociados a la k − ésima regla y el vector de entradas x = [x1, … , xn]T ∈ ℝ . Los sistemas borrosos de tipo Mamdani han demostrado ser herramientas muy útiles para aproximar funciones no lineales. Al utilizar el fusificador solitón, la operación de producto como motor de inferencia, y el defusificador por centro promedio, la salida final del sistema borroso se obtiene mediante y(x) = ∑rk 1μk(x)dk∑rk 1μk(x) , (8)
donde μk(x) = ∏ni 1μ (xi), μ (xi) es el valor de pertenencia de xi en el conjunto borroso
y dk es el punto en el cual la función de pertenencia Ck alcanza su máximo valor. Observe que, la salida y(x) dada por la ecuación (8) puede reescribirse de la forma y(x) = wT(x)θ. (9) Aquí, θ = [d1, … , dr]T es un vector que agrupa todos los parámetros del consecuente y w(x) = [w1(x), … , wr(x)]T es un conjunto de funciones borrosas base definidas como wk(x) = μk(x)∑rj=1μj(x) , k = 1, … ,r. Cabe mencionar que el sistema borroso se asume bien
definido, es decir, ∑rj 1μj(x) ≠ 0 para todo x ∈ U. Por otro lado,
en [44] se muestra que sistemas borrosos de la forma (9) pueden aproximar funciones no lineales continuas sobre un
conjunto compacto U, con un grado arbitrario de precisión en función del número de reglas borrosas consideradas.
Considere la aproximación de las funciones no lineales fi(x) y gij(x) sobre un conjunto compacto Dx, empleando sistemas de la forma: f x, θfi = wf (x)θfi , i = 1, … ,p,ĝij x, θgij = wg (x)θgij , i,j = 1, … ,p, donde wfi(x) y wgij(x) son vectores de funciones base establecidas por el diseñador, θfi y θgij son los correspondientes vectores de parámetros ajustables de cada sistema borroso. Se definen θ∗ =arg minθfi supx∈Dx fi(x) − f x, θfi , i = 1, … ,p, θg∗ =arg minθgij supx∈Dx gij(x) − ĝij x, θgij , i,j = 1, … ,p, como los parámetros óptimos de θfi y θgij, respectivamente. Note que los parámetros óptimos θ∗ y θg∗ son cantidades constantes introducidas para propósitos de análisis y cuyos valores no son necesarios en la implementación. Se definen los errores de estimación de parámetros θfi = fi∗ − θfi ,θg = g∗ − θgij , y el mínimo error de aproximación, el cual corresponde al error de aproximación obtenido cuando se utilizan los parámetros óptimos, como εfi(x) = fi(x) − f (x, ∗ ),εgij(x) = gij(x) − ĝij(x, g∗ ). Asumiendo que los sistemas borrosos cumplen con el teorema de aproximación universal [32] sobre un conjunto compacto Dx, es decir, el conjunto compacto Dx es lo suficientemente grande como para que las variables de estado x permanezcan a Dx cuando el sistema se encuentra en lazo cerrado, entonces es razonable considerar que el error mínimo de aproximación está acotado para toda x que está en Dx, es decir, |εfi(x)| ≤ εfi(x), εgij(x) ≤ εgij(x), ∀ x ∈ Dx, (10) donde εfi y εgij son constantes dadas. Así, definiendo F(x, θf) = [f (x, θf1), … , f (x, θfp)]T, Ĝ(x, θg) = ĝ11(x, θg11) ⋯ ĝ1p(x, θg1p)⋮ ⋱ ⋮ĝp1(x, θgp1) ⋯ ĝpp(x, θgpp) , εg(x) = εg11(x) ⋯ εg1p(x)⋮ ⋱ ⋮εgp1(x) ⋯ εgpp(x) , εg(x) = εg (x) ⋯ εg (x)⋮ ⋱ ⋮εg (x) ⋯ εg (x) , εf(x) = [εf1(x), … , εfp(x)]T, εf(x) = [εf1(x), … , εfp(x)]T,

θf = [θf1, … , θfp]T, θg = [θg1, … , θgp], θgi = [θg1i , … , θgpi]T. Entonces, es posible establecer lo siguiente F(x) − F(x, θf) = F(x, θf∗) − F(x, θf) + εf(x),G(x) − Ĝ x, θg = Ĝ x, θg∗ − Ĝ x, θg + εg(x). (11)
Así, el resultado siguiente puede ser formulado. Teorema 1 Considere un sistema de la forma (2), donde G(x) es definida positiva. Sean yd (t ), i = 1, … ,p , trayectorias deseadas conocidas, acotadas, ri veces diferenciables cuyas derivadas también son acotadas y conocidas, entonces el control u = uc + ur , (12) con la ley de adaptación = − s, = −Ngi1wgisui, = −η0 ψσ0∥ ∥2 δ, , i = 1, … ,p, (13)
garantizan que los errores de seguimiento (3) converjan asintóticamente a cero. Aquí uc = ĜT(x, θg)[ε0IP + Ĝ(x, θg)ĜT(x, θg)] 1(K0s + v − F(x, θf)), = ψσ0∥ ∥2 δ, , (14)
donde
ψ=12 [sT(Q0 + Q1 + Q2)s + εf (x)Q εf(x) +(εg(x)uc)TQ (εg(x)uc) + u Q u0],
u0=ε0 ε0IP + Ĝ x, θg ĜT x, θg1 (K0s + v − F(x, θf).
Aquí, Q0, Q1, Q2 son matrices de diseño definidas positiva y σ0 = λmin(G(x)). Además, Nf = diag[1 ∕ ηf1,1 ∕ ηf2, ⋯ ,1 ∕ ηfp],Ngi = diag[1 ∕ ηg1i ,1 ∕ ηg2i , ⋯ ,1 ∕ ηgpi], (16) wf = diag[wf , wf , ⋯ , wf ],wgi = diag[wg , wg , ⋯ , wg ], (17)
finalmente ηfi y ηgij son constantes positivas. Demostración 1 Considerando las aproximaciones F(x, θf) y Ĝ(x, θg) , el controlador (7) se remplaza por el siguiente u = Ĝ(x, θg) 1(−F(x, θf) + v + K0s). (18) Dado que los parámetros estimados θg son calculados en línea, no se tiene la certeza de la existencia de la matriz Ĝ(x, θg) 1, por lo que es necesario utilizar la inversa regularizada de Ĝ(x, θg) 1 definida como ĜT(x, θg)[ε0IP + Ĝ(x, θg)ĜT(x, θg)] 1, (19) donde ε0 es un valor constante positivo pequeño e Ip ∈ ℝn×n es la matriz identidad, note que (19) está bien definida aun cuando Ĝ(x, θg) sea singular. Considerando lo anterior, (18) se modifica de la manera siguiente u = ĜT x, θg ε0IP + Ĝ x, θg ĜT x, θg 1 × −F(x, θf) + v + K0s . (20)
A pesar de que la ley de control (20) está bien definida, no se puede garantizar por si sola la estabilización asintótica del sistema (6), principalmente a causa de los errores de aproximación de las funciones F(x) y G(x), y de la aproximación de Ĝ(x, θg) 1 con la inversa regularizada. Por lo que, al control (20) se le agrega el término ur con el objetivo de cancelar los errores de aproximación. Así la ley de control final se propone de la forma (12). Es claro que la adecuada estimación de los parámetros θfi y θgij determinan la eficiente aproximación de las funciones F(x) y G(x); y por consecuencia la efectividad del controlador (12) para estabilizar asintóticamente al sistema (6) para garantizar que el error de seguimiento converja a cero. Sin embargo estos parámetros cambian constantemente a razón de la interacción hombre-robot, por lo que la ley de adaptación paramétrica (13) para mejorar el desempeño del control es propuesta.
A continuación, se presenta una justificación matemática del diseño de la ley de adaptación. La ecuación (6) puede reescribirse como ṡ = v − F(x) − (G(x) − Ĝ(x, θg))u − Ĝ(x, θg)u. (21) Con base en el hecho de que Ĝ(x, θg)ĜT(x, θg)[ε0IP + Ĝ(x, θg)ĜT(x, θg)] 1
=Ip − ε0[ε0IP + Ĝ(x, θg)ĜT(x, θg)] 1 (22) y sustituyendo (12) y uc en una parte de la ecuación (21) se tiene que ṡ= − K0s − (F(x) − F(x, θf)) − G(x) − Ĝ x, θg uc − G(x)ur + u0. (23)
Empleando (11), (23) puede escribirse como ṡ= − K0s − (F(x, θf∗) − F(x, θf)) − εf(x) − εg(x)uc −(Ĝ(x, θg∗) − Ĝ(x, θg))uc − G(x)ur + u0. (24) Por otro lado, observe que F(x, θf∗) − F(x, θf)=wf f, (25) (Ĝ(x, θg∗) − Ĝ(x, θg))uc= ∑pi 1wg g uci, (26)
donde f = [ f1, ⋯ , fp]T, con fi = θfi∗ − θfi y wf definida en (17). Así, sustituyendo (25) y (26) en (24) se tiene que ṡ= − K0s − wf f − ∑pi 1wgi giuci − G(x)ur
−εf(x) − εg(x)uc + u0, (27) multiplicando sT por la izquierda en ambos lados de la ecuación (27) y transponiendo algunos términos, se llega a sTṡ= − sTK0s − f wfs − ∑pi 1 giTwgisuci − sTG(x)ur
−sTεf(x) − sTεg(x)uc + sTu0. (28) Considerando la siguiente función de Lyapunov candidata V(s) = 12 (sTs + f Nf f + ∑pi 1 giTNgi gi + δ2η0), (29)

donde Nf y Ngi están definidas en (16) y η0 es una constante estrictamente positiva. Derivando la función (29) se tiene que
V(s) = sTṡ − θf Nfθf + ∑pi 1θgiT Ng θg + δ η0 , (30)
así sustituyendo (28) en (30) sigue que V(s) = −sTK0s + V ( ) + V ( ), (31) donde V (s) = −θf wfs + Nfθf − ∑pi 1θgiT wgisui + Ngiθgi ,V (s) = −sTG(x)ur − sTεf(x) − sTεg(x)uc + sTu0 + δ η0 . Ahora, sustituyendo f y gi de la ley adaptativa (13) en la primera ecuación anterior, se tiene que V1 = 0. Por otra parte, considerando (10) y usando la desigualdad −2xTy ≤ xTMx +yTM 1y, x, y ∈ ℝn; V ( ) puede escribirse como V ( ) ≤ −sTG(x)ur + ψ + δ η0, (32)
con ψ dada en (15). Por otro lado, empleando la desigualdad de Rayleigh [45] se tiene que G(x)s ψσ0∥s∥ ≥ σ0 ∥ s ∥ ψσ0∥s∥ . (33)
Definiendo ur como en la ecuación (14), se obtiene que sTG(x)ur≥ ψ(σ0∥s∥ )σ0∥s∥ = ψ- ψσ0∥s∥ , Sustituyendo la desigualdad anterior en (32) se tiene que
V ( ) ≤ ψσ0∥s∥ + δ η0, (34)
así sustituyendo dada en (13) V ( ) ≤ 0, por lo tanto V(s) ≤ −sTK0s, como K0 > 0 , entonces V(s) < 0 , por lo tanto s → 0 cuando t → ∞, lo que implica que ei(t) → 0 cuando t → ∞, i =1, … ,p. ∎
IV. IMPLEMENTACIÓN DE LOS RESULTADOS TEÓRICOS
A continuación los resultados teóricos obtenidos en la sección anterior son ilustrados sobre una interfaz háptica PHANToM Premium 1.0 empleando un entorno de simulación como lo es Matlab y directamente sobre la plataforma experimental empleando C++.
A. Interfaz háptica PHANToM Premium 1.0 El PHANToM Premium 1.0 es un dispositivo electrónico
que proporciona una amplia gama de fuerza de trabajo, amplitud de movimiento, rigidez, fuerza y motores para dar cabida a las necesidades específicas de los diferentes proyectos de investigación. Este dispositivo cuenta con realimentación de fuerzas las cuales incorporan estímulos táctiles y así permitir a un usuario “sentir” objetos virtuales en un entorno de simulación [46], ver Fig. 2.
Figura 2. Dispositivo háptico PHANToM Premium 1.0.
Es un dispositivo articulado con 3 grados de libertad que
cuenta con 3 motores de CC y un decodificador óptico con resolución de 1024 pulsos por revolución para cada actuador. La fuerza máxima de implementación es de 8.5N, una inercia de 0.075Kg, fricción de 0.04N y un espacio de trabajo de 0.195 × 0.27 × 0.355m3 en X, Y y Z respectivamente.
B. Modelo dinámico del dispositivo háptico PHANToM
Considere la ecuación dinámica del dispositivo háptico PHANToM propuesta en [8] de la forma (1): h11 0 00 h22 h230 h32 h33
qqq + c11 c12 c13c21 0 c23c31 c32 0 + q1q2q3 + 0g2g3
= τ1τ2τ3 , (35)
donde la matriz de fricción B en el dispositivo es despreciable, h = (0.5l + 0.125l )ma + (0.125l + 0.5l )mc+ 0.125l (4ma + mc)cos (2q )− 0.125(l ma + 4l mc)cos (2q )+ 0.125l (l ma + l mc)cos (q )sin (q )h = l (ma + 0.25mc)h = −0.5l (l ma + l mc)sin (q − q )h = −0.5l (l ma + l mc)sin (q − q )h = 0.25l ma + l mcc = 0.25(−2 sin(q ) [l (4ma + mc) cos(q )+2l (l ma + l mc) sin(q )]q )+0.25 cos(q ) (2l (l ma + l mc) cos(q ))+(l ma + 4l mc)sin (q ))q
c = −0.25(l (4ma + mc)sin (2q ) +4l (l ma + l mc)sin (q )sin (q )q c = −0.125(−4l (l ma + l mc)cos (q )cos (q )−(l ma + 4l mc)sin (2q ))q c = 0.25(l (4ma + mc)sin (2q )−4l (l ma + l mc)sin (q )sin (q )q c = 0.5l (l ma + l mc)cos (q − q )q c = 0.125(−4l (l ma + l mc)cos (q )cos (q )+(l ma + 4l mc)sin (2q ))q c = 0.5l (l ma + l mc)cos(q − q )q
g = 0, g = (l (ma + 0.5mc) + l m )cos (q ) g = (0.5l ma + l mc − l m ) sin(q ).

C. Descripción de la evaluación numérica y experimental de la plataforma de interacción Hombre-Robot
El sistema de interacción hombre-robot propuesto, consiste en evaluar la estrategia de control de movimiento de tipo adaptativo en la interfaz háptica PHANToM Premium 1.0. El dispositivo háptico corresponde a un mayordomo de 3 grados de libertad con baja dinámica inercial y tribológica articular. Al ser modelado como un sistema Euler-Lagrange, es posible diseñar a la estrategia de control basada en las propiedades clásicas de un sistema de esa naturaleza. El desempeño de todos los sub-sistemas garantiza resultados convincentes y permiten demostrar experimentalmente los beneficios de la estrategia de control adaptativo propuesta. La razón de considerar un sistema de lazo cerrado con el operador humano en el lazo de control adaptativo, es la existencia de incertidumbre dinámica que el usuario representa, y los efectos sobre la dinámica inercial, de Coriolis, gravitacional y de fricción articular modeladas y validadas en trabajos publicados previamente. El esquema siguiente, representa la organización de la validación de la plataforma basada en un control borroso de tipo adaptativo para un sistema robótico sujeto a incertidumbre dinámica. Evaluación dela plataforma Movimiento libre SimulaciónExperimetalMovimiento restringido Validaciónexperimental
Movimiento libre: El dispositivo háptico no es sujeto a incertidumbre, el control calcula su señal con base en la dinámica y logra la convergencia de posición y velocidad, así como una estimación del vector de parámetros dinámicos.
Movimiento restringido: En esta etapa de experimentación, se evalúa el desempeño de la ley de control propuesta con el operador humano en el lazo. Intencionadamente, dicho operador perturba en un instante de tiempo a la trayectoria (situación aceptable por las propiedades electromecánicas que el dispositivo háptico posee). Los beneficios de una ley de control adaptativo de alto desempeño, se aprecian ante la presencia de incertidumbre dinámica, y particularmente en los parámetros estimados cuya magnitud evidentemente se incrementa en función de la carga asociada al efector final.
D. Implementación vía simulación
En seguida se presentan la implementación de los resultados teóricos empleando Matlab 2012a y su entorno de programación visual Simulink.
Considere las ecuaciones que describen la dinámica del sistema de interacción hombre-robot (35). Cabe remarcar que para la implementación de la ley de control propuesta aquí, se asume desconocida la dinámica. Observe que el sistema (35) se puede reescribir de la forma (2), es decir,
= − (q)(C(q, ) + G(q))F(x) + H-1(q) τ
G(x) .
Así, x = [q1, q1 , q2, q2, q3, q3]T, u = [τ1, τ2, τ3]T y y =[q1, q2, q3]T. A continuación, se presenta la implementación del Teorema 1, asumiendo desconocida la dinámica del sistema robótico anterior.
La tarea de solución numérica, corresponde a la resolución del sistema de ecuaciones diferenciales que modela al dispositivo háptico PHANToM Premium 1.0, en lazo cerrado con el control borroso adaptativo. Se emplea un algoritmo de integración ODE5 con Matlab, con un paso de integración de 1 milisegundo y con un tiempo de simulación de 10 segundos. Las gráficas que permiten verificar el desempeño de la estrategia de control propuesta corresponden a: i) desempeño en el espacio de trabajo a través del seguimiento de la trayectoria planificada Fig. 3a, ii) convergencia de posición articular Fig. 3b, iii) señal de control Fig. 3c y iv) aproximación de las funciones no lineales propias del dispositivo háptico Fig. 3d. En la tarea de simulación digital no se perturba a la trayectoria, por lo que el resultado promueve la estabilización del dispositivo con el mejor desempeño. Es evidente que las magnitudes en estado estable de la señal de control se encuentran por debajo del 0.25% de la magnitud máxima aceptable para cada actuador. El seguimiento articular permite, vía la cinemática directa de posición, validar al seguimiento operacional; la magnitud del error máximo corresponde a 0.013 radianes. Logrando un excelente desempeño en condiciones ideales (propias de una simulación digital). A continuación se presentan algunas gráficas y estadísticas de la simulación:
TABLA I. DATOS DE LA SIMULACIÓN.
Error articular máximo 0.001 Rad Energía consumida 4.7804e-2 J Magnitud máxima de señal de control 0.0115Nm Máximo valor instantáneo de f1 estimado 5.5e-5
Máximo valor instantáneo de f2estimado 1.04e-4
Máximo valor instantáneo de f3estimado 1.04e-4
Máximo valor instantáneo de f4estimado 1.12e-4
Figura 3a. Seguimiento de la trayectoria planificada.
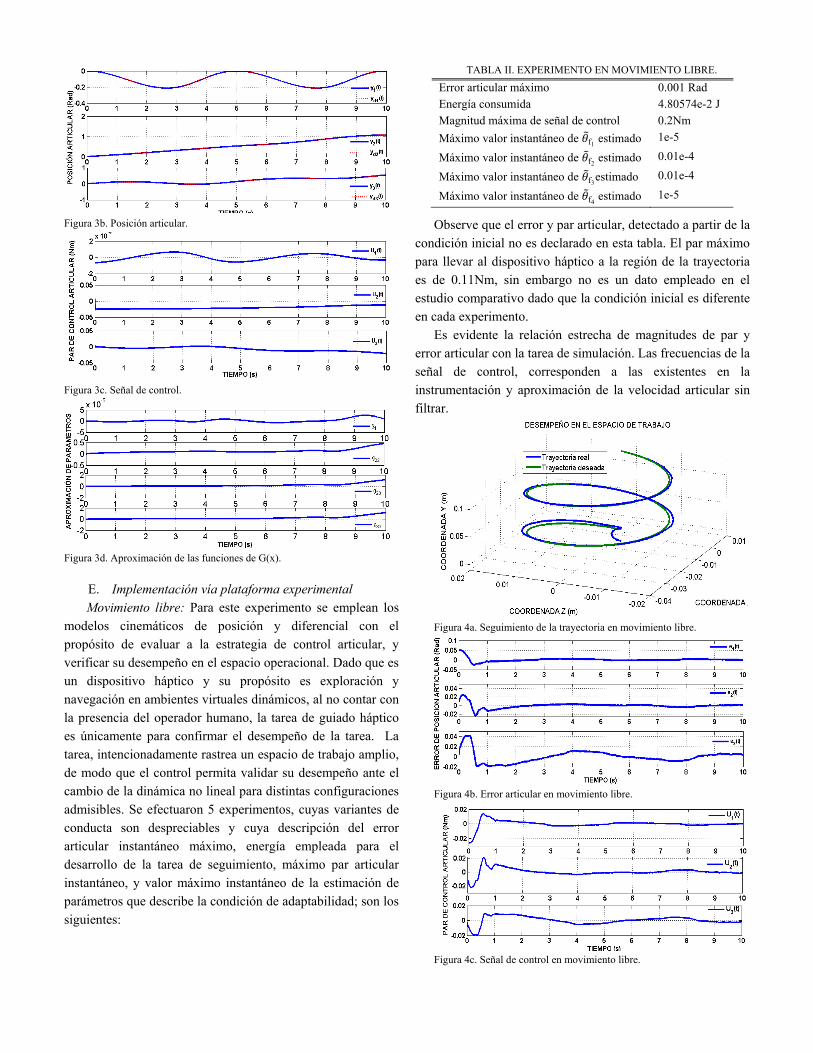
Figura 3b. Posición articular.
Figura 3c. Señal de control.
Figura 3d. Aproximación de las funciones de G(x).
E. Implementación vía plataforma experimental
Movimiento libre: Para este experimento se emplean los modelos cinemáticos de posición y diferencial con el propósito de evaluar a la estrategia de control articular, y verificar su desempeño en el espacio operacional. Dado que es un dispositivo háptico y su propósito es exploración y navegación en ambientes virtuales dinámicos, al no contar con la presencia del operador humano, la tarea de guiado háptico es únicamente para confirmar el desempeño de la tarea. La tarea, intencionadamente rastrea un espacio de trabajo amplio, de modo que el control permita validar su desempeño ante el cambio de la dinámica no lineal para distintas configuraciones admisibles. Se efectuaron 5 experimentos, cuyas variantes de conducta son despreciables y cuya descripción del error articular instantáneo máximo, energía empleada para el desarrollo de la tarea de seguimiento, máximo par articular instantáneo, y valor máximo instantáneo de la estimación de parámetros que describe la condición de adaptabilidad; son los siguientes:
TABLA II. EXPERIMENTO EN MOVIMIENTO LIBRE.
Error articular máximo 0.001 Rad Energía consumida 4.80574e-2 J Magnitud máxima de señal de control 0.2Nm Máximo valor instantáneo de f1 estimado 1e-5
Máximo valor instantáneo de f2 estimado 0.01e-4
Máximo valor instantáneo de f3estimado 0.01e-4
Máximo valor instantáneo de f4 estimado 1e-5
Observe que el error y par articular, detectado a partir de la condición inicial no es declarado en esta tabla. El par máximo para llevar al dispositivo háptico a la región de la trayectoria es de 0.11Nm, sin embargo no es un dato empleado en el estudio comparativo dado que la condición inicial es diferente en cada experimento.
Es evidente la relación estrecha de magnitudes de par y error articular con la tarea de simulación. Las frecuencias de la señal de control, corresponden a las existentes en la instrumentación y aproximación de la velocidad articular sin filtrar.
Figura 4a. Seguimiento de la trayectoria en movimiento libre.
Figura 4b. Error articular en movimiento libre.
Figura 4c. Señal de control en movimiento libre.
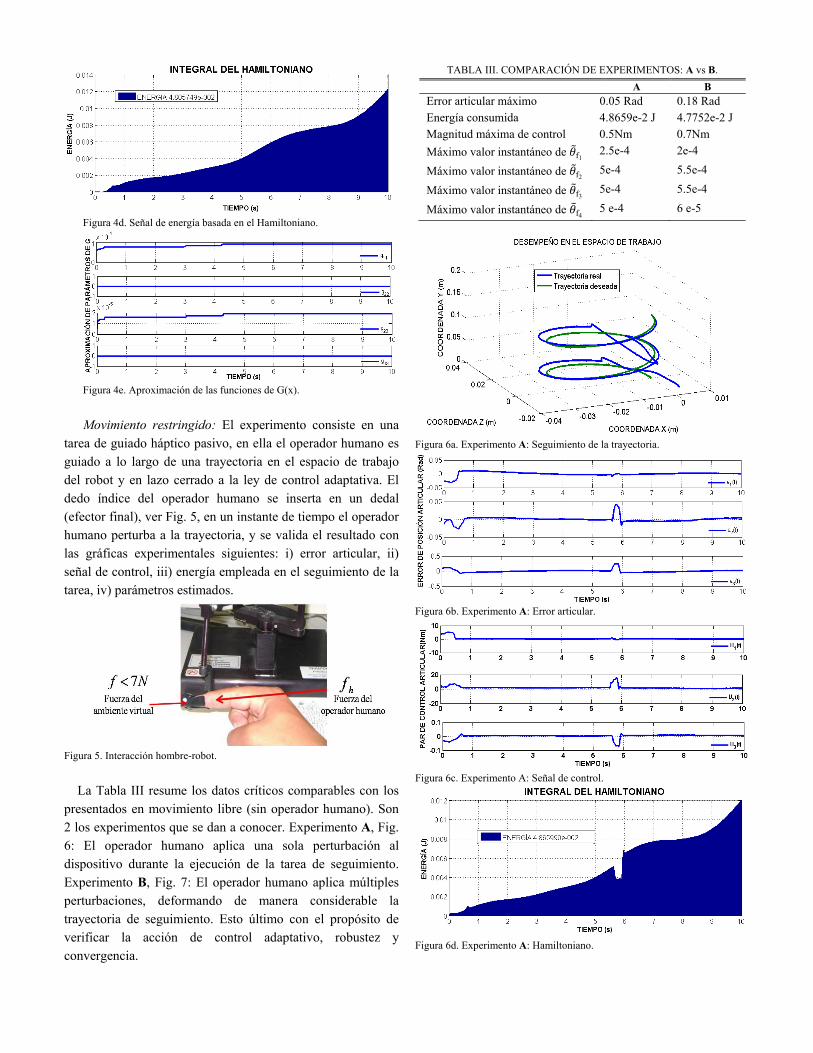
Figura 4d. Señal de energía basada en el Hamiltoniano.
Figura 4e. Aproximación de las funciones de G(x). Movimiento restringido: El experimento consiste en una
tarea de guiado háptico pasivo, en ella el operador humano es guiado a lo largo de una trayectoria en el espacio de trabajo del robot y en lazo cerrado a la ley de control adaptativa. El dedo índice del operador humano se inserta en un dedal (efector final), ver Fig. 5, en un instante de tiempo el operador humano perturba a la trayectoria, y se valida el resultado con las gráficas experimentales siguientes: i) error articular, ii) señal de control, iii) energía empleada en el seguimiento de la tarea, iv) parámetros estimados.
Figura 5. Interacción hombre-robot. La Tabla III resume los datos críticos comparables con los presentados en movimiento libre (sin operador humano). Son 2 los experimentos que se dan a conocer. Experimento A, Fig. 6: El operador humano aplica una sola perturbación al dispositivo durante la ejecución de la tarea de seguimiento. Experimento B, Fig. 7: El operador humano aplica múltiples perturbaciones, deformando de manera considerable la trayectoria de seguimiento. Esto último con el propósito de verificar la acción de control adaptativo, robustez y convergencia.
TABLA III. COMPARACIÓN DE EXPERIMENTOS: A vs B. A B
Error articular máximo 0.05 Rad 0.18 Rad Energía consumida 4.8659e-2 J 4.7752e-2 J Magnitud máxima de control 0.5Nm 0.7Nm Máximo valor instantáneo de f1 2.5e-4 2e-4
Máximo valor instantáneo de f2 5e-4 5.5e-4
Máximo valor instantáneo de f3 5e-4 5.5e-4
Máximo valor instantáneo de f4 5 e-4 6 e-5
Figura 6a. Experimento A: Seguimiento de la trayectoria.
Figura 6b. Experimento A: Error articular.
Figura 6c. Experimento A: Señal de control.
Figura 6d. Experimento A: Hamiltoniano.
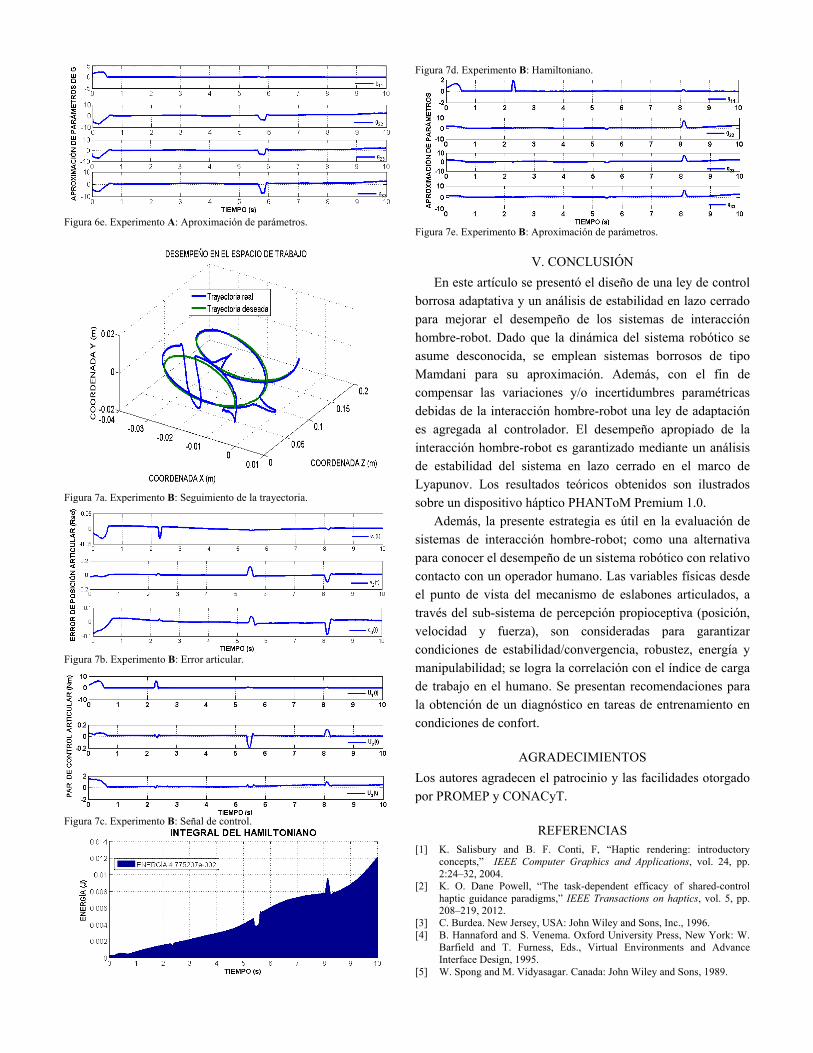
Figura 6e. Experimento A: Aproximación de parámetros.
Figura 7a. Experimento B: Seguimiento de la trayectoria.
Figura 7b. Experimento B: Error articular.
Figura 7c. Experimento B: Señal de control.
Figura 7d. Experimento B: Hamiltoniano.
Figura 7e. Experimento B: Aproximación de parámetros.
V. CONCLUSIÓN En este artículo se presentó el diseño de una ley de control
borrosa adaptativa y un análisis de estabilidad en lazo cerrado para mejorar el desempeño de los sistemas de interacción hombre-robot. Dado que la dinámica del sistema robótico se asume desconocida, se emplean sistemas borrosos de tipo Mamdani para su aproximación. Además, con el fin de compensar las variaciones y/o incertidumbres paramétricas debidas de la interacción hombre-robot una ley de adaptación es agregada al controlador. El desempeño apropiado de la interacción hombre-robot es garantizado mediante un análisis de estabilidad del sistema en lazo cerrado en el marco de Lyapunov. Los resultados teóricos obtenidos son ilustrados sobre un dispositivo háptico PHANToM Premium 1.0.
Además, la presente estrategia es útil en la evaluación de sistemas de interacción hombre-robot; como una alternativa para conocer el desempeño de un sistema robótico con relativo contacto con un operador humano. Las variables físicas desde el punto de vista del mecanismo de eslabones articulados, a través del sub-sistema de percepción propioceptiva (posición, velocidad y fuerza), son consideradas para garantizar condiciones de estabilidad/convergencia, robustez, energía y manipulabilidad; se logra la correlación con el índice de carga de trabajo en el humano. Se presentan recomendaciones para la obtención de un diagnóstico en tareas de entrenamiento en condiciones de confort.
AGRADECIMIENTOS Los autores agradecen el patrocinio y las facilidades otorgado por PROMEP y CONACyT.
REFERENCIAS [1] K. Salisbury and B. F. Conti, F, “Haptic rendering: introductory
concepts,” IEEE Computer Graphics and Applications, vol. 24, pp. 2:24–32, 2004.
[2] K. O. Dane Powell, “The task-dependent efficacy of shared-control haptic guidance paradigms,” IEEE Transactions on haptics, vol. 5, pp. 208–219, 2012.
[3] C. Burdea. New Jersey, USA: John Wiley and Sons, Inc., 1996. [4] B. Hannaford and S. Venema. Oxford University Press, New York: W.
Barfield and T. Furness, Eds., Virtual Environments and Advance Interface Design, 1995.
[5] W. Spong and M. Vidyasagar. Canada: John Wiley and Sons, 1989.

[6] Sepulveda-Cervantes, V. Parra-Vega, and O. A. Dominguez-Ramirez,
“Dynamic coupling haptic suturing based on orthogonal decomposition,” Third Joint Eurohaptics Conference and Symposium on Haptic Interfaces for Virtual Environment and Teleoperator Systems, 2009.
[7] C. Huegel and M. K. OMalley, “Visual versus haptic progressive guidance for training in a virtual dynamic task,” Third Joint Eurohaptics Conference and Symposium on Haptic Interfaces for Virtual Environment and Teleoperator Systems, 2009.
[8] O. A. Domínguez-Ramírez and V. Parra-Vega, “Active haptic interface with purposes of remote training,” Proceedings of the 11th International Conference on Advanced Robotics, vol. 3, pp. 1588–1593, 2003.
[9] F. Daz, O. A. Domínguez-Ramírez, and L. E. Ramos-Velasco, “Sliding computed torque control based on passivity for a haptic device: Phantom premium 1.0,” World Automation Congress (WAC), vol. 1, pp. 24–28, 2012.
[10] J. A. Turijan-Rivera, F. J. Ruz Snchez, O. A. Domínguez-Ramírez, and P. V. V., “Modular platform for haptic guidance in paediatric rehabilitation of upper limb neuromuscular disabilities,” J. L Pons et al (Eds.), Converging Clinical and Engineering Research on Neurorehabilitation Biosystems and Biorobotics, vol. 1, pp. 925–929, 2013.
[11] D. Caldwell, N. Tsagarakis, and A. Wardle, “Mechano-thermo and proprioceptor feedback for integrated haptic feedback,” IEEE International Conference on Robotics and Automation, Alburquerque, pp. 2491–2496, 1997.
[12] G. Grindlay, “Haptic guidance benefits musical motor learning,” Symposium on Haptic Interfaces for Virtual Environments and Teleoperator Systems, 2008.
[13] T. Kotoku, K. Komoriya, and K. Tanie, “A force display system for virtual environments and its evaluation,” Proceedings of IEEE International Workshop on Robot and Human Communication, vol. 1992, pp. 246–251, 1994.
[14] M. M. Boroujeni and A. Meghdari, “Haptic device application in persian calligraphy,” International Conference on Computer and Automation Engineering, 2009.
[15] A. A. Braidot, C. Cifuentes, A. Frizera Neto, M. Frisoli, and A. Santiago, “ZigBee Wearable Sensor Development for Upper Limb Robotics Rehabilitation”, IEEE Latin America Transactions, vol. 11, no. 1, pp. 408-413, FEB. 2013.
[16] L. Mathé, A. Caverzasi, F. Saravia, G. Gomez and J. P. Pedroni, “Detection of Human-Robot Collision Using Kinetic”, IEEE Latin America Transactions, vol. 11, no. 1, pp. 143-148, FEB. 2013 143.
[17] C. A. G. Gutiérrez, J. R. Reséndiz, J. D. M. Santibáñez and G. M. Bobadilla, “A Model and Simulation of a Five-Degree-of-Freedom Robotic Arm for Mechatronic Course”, IEEE Latin America Transactions, vol. 12, no. 2, pp. 78-86, MARCH 2014.
[18] J. Kern , Member, M. Jamett , C. Urrea , and H. Torres, “Development of a neural controller applied in a 5 DOF robot redundant”, Ieee Latin America Transactions, vol. 12, no. 2, pp. 98-106, MARCH 2014.
[19] J. de J. Rubio, A. G. Bravo, J. Pacheco and C. Aguilar, “Passivity Analysis and Modeling of Robotic Arms”, IEEE Latin America Transactions, vol. 12, no. 8, pp. 1389-1397, DECEMBER 2014.
[20] O. Celik and M. O’Malley, “Comparasion of robotics and clinical motor funtion improvement measures for sub-actue stroke patients,” Poc. IEEE Intenational Conference Robotics and Automation (ICRA), pp. 2477–2482, 2008.
[21] L. Zadeh, “Fuzzy sets,” Information and Control, vol. 8, pp. 338–353, 1965.
[22] K. Tanaka and M. Sugeno, “Stability analysis of fuzzy systems using Lyapunov’s direct method,” Proc. NAFIPS’90, vol. 1, pp. 133–136, 1990.
[23] E. Mamdani, “Application of fuzzy algorithms for the control of a dynamic plant,” Proc. IEEE, vol. 121, pp. 1585–1588, 1974.
[24] E. Mamdani and S. Assilian, “An experiment in linguistic synthesis with a fuzzy logic controler,” Int. J. Man-Machine Studies, vol. 7, pp. 1–13, 1975.
[25] R. Tong, “A control engineering review of fuzzy systems,” Automatica, vol. 13, pp. 559–569, 1977.
[26] ——, “Analysis and control of fuzzy systems using finite discrete relations,” International Journal of Control, vol. 27, pp. 431–440, 1978.
[27] T. Takagi and M. Sugeno, “Fuzzy identification of systems and its applications to modeling and control,” IEEE Trans. Syst. Man. Cyber, vol. 15, pp. 116–132, 1985.
[28] M. Sugeno and G. Kang, “Structure identification of fuzzy model,” Fuzzy Sets Systems, vol. 28, pp. 329–346, 1986.
[29] H. Wang, K. Tanaka, and M. Griffin, “Parallel distributed compensation of nonlinear systems by Takagi-Sugeno fuzzy model,” Proc. FUZZ-IEEE/IFES’95, vol. 1, pp. 531–538, 1995.
[30] R. Yang and T. Sun, Neuro-Fuzzy and Soft Computing, 1st ed. Upper Sadle River NJ: Prentice Hall, 1997.
[31] B. Kosko and J. Buress, “Neural networks and fuzzy systems,” J. Acoust. Soc. Am., vol. 103, pp. 3131–3131, 1998.
[32] S. Labiod, M. Boucherit, and T. Guerra, “Adaptive fuzzy control of a class of mimo nonlinear systems,” Fuzzy Sets Systems, vol. 151, pp. 59–77, 2005.
[33] C. Park and Y. Cho, “T-s model based indirect adaptive fuzzy control using online parameter estimation,” IEEE Trans. on Systems, vol. 34, pp. 2293–2301, 2004.
[34] T. Shaocheng, C. Bin, and W. Yongfu, “Fuzzy adaptive output feedback control for mimo nonlinear systems,” Fuzzy Sets Systems, vol. 156, pp. 285–299, 2005.
[35] T. Shaocheng and H. Li, “Fuzzy adaptive sliding-mode control for mimo nonlinear systems,” IEEE Trans. Fuzzy Systems, vol. 11, pp. 354–360, 2003.
[36] T. Shaocheng, T. Wang, and J. Tang, “Fuzzy adaptive output tracking control of nonlinear systems,” Fuzzy Sets Systems, vol. 111, pp. 169–182, 2000.
[37] L. Wang and J. Mendel, “Fuzzy basis functions, universal aproximation, and orthogonal least squares learning,” IEEE Trans. on Neural Networks, vol. 3, pp. 807–814, 1992.
[38] K. Tanaka and M. Sano, “Fuzzy stability criterion of a class of nonlinear systems,” Inform. sci., vol. 71, pp. 3–26, 1993.
[39] H. Wang, K. Tanaka, and M. Griffin, “An analytical framework of fuzzy modeling and control of nonlinear systems: Stability and design issues.” Seatle: Proc. 1995 American Control Conference, 1995, pp. 2272–2276.
[40] ——, “An approach to fuzzy control of nonlinear systems: Stability and design issues,” IEEE Trans. Fuzzy Syst., vol. 4, pp. 14–23, 1996.
[41] S. Labiod, M. Boucherit, and G. T.M., “Adaptive fuzzy control of a class of mimo nonlinear systems,” Fuzzy Sets and Systems, vol. 151, pp. 59–77, 2005.
[42] J. A. Turijan-Rivera, F. A. Machorro-Fernandez, F. J. Ruiz-Sanchez, V. Parra-Vega, and O. A. Dominguez-Ramirez, “Nasa-tlx assessment of modern close loop controllers in haptic guidance for assisted rehabilitation, springer-verlag berlin heidelberg,” Springer-Verlag Berlin Heidelberg: Converging Clinical and Engineering Research on Neurorehabilitation Biosystems and Biorobotics, vol. 1, pp. 243–247, 2013.
[43] D. Feygin, M. Keehner, and F. Tendick, “Haptic guidance: Experimental evaluation of a haptic training method for a perceptual motor skill,” Proceedings of the 10th Symp. On Haptic Interfaces For Virtual Envir. Teleoperator Systs., 2002.
[44] L. Wang, Adaptive Fuzzy Systems and Control: Design and Stability Analysis, 1st ed. Englewood Cliffs, NJ.: Prentice Hall, 1994.
[45] C. Chen, Linear System Theory and Design, 3rd ed. New York: Oxford University Press, 1999.
[46] T. Massie and K. Salisbury, “The phantom haptic interface a dvice for probing virtual objects,” Proceedings of the ASME Winter Annual Meeting, Symposium on Haptic Interfaces for Virtual Environment and Teleoperator Systems, 1994.
Raúl Villafuerte Segura received the B.S. degree in Physics and Mathematics engineering from ESFM-IPN, Mexico City, Mexico in 2004, and the M.S. and the Ph.D. degrees in automatic control from CINVESTAV-IPN, Mexico City, Mexico in 2006 and 2010, respectively. Since 2011, he has been a Professor at the CITIS-UAEH, Hidalgo, Mexico. His research interests include time delay systems, modeling
systems and nonlinear control. He has been member of SNI since 2012 until 2017, level 1.
Omar Arturo Domínguez Ramírez received the Eng degree from the Department of Electrical Engineering at the Technological Institute of Pachuca, Pachuca, Hidalgo, Mexico in 1994; the M.Sc. degree in automatic control from the Postgraduate and Research Division at the Technological Institute of La Laguna, Torreon, Coahuila, Mexico in 1999; and Ph.D. degree in mechatronics from the Department of
Electrical Engineering at CINVESTAV IPN, Mexico city, Mexico in 2005.

He is the director and head of academic and research laboratories, engineering workshops and medical clinics at the Hidalgo State University, leader of the Electronics and Control Group consolidated by PROMEP and the Mexican Secretariat of Public Education, and professor-researcher at Research Center on Information Technologies and Systems-UAEH. He was the Chair of the IEEE/RAS International Symposium on Robotics and Automation (ISRA 2006). His research interests include human robot interaction, medical robotics, haptic interfaces and nonlinear control.
Oscar González Hernández received the Eng degree from the Department of Electronics and Telecommunications Engineering at the Hidalgo State University, Pachuca, Hidalgo, Mexico in 2007; the M.Sc. degree in Automation and Control from the Research Center on Information Technology and Systems at the Hidalgo State University, Pachuca, Hidalgo, Mexico in 2013. He is full professor at
the Higher Technological Institute of the State of Hidalgo East, member of the Automation and Control Group training by PRODEP. His research interests include human robot interaction, fuzzy control and adaptive control.
Miguel Ángel Hoyos León received the B.S. degree in Computer Systems from the UAEH, Hidalgo City, Hidalgo in 2012, and He is currently attending the Master in Automatic Control in CITIS-UAEH, Hidalgo, Mexico. His research interests include fuzzy logic and haptic interfaces.





























