Embed Size (px)
DESCRIPTION
A Probabilistic Model for Classification of Multiple-Record Web Documents. June Tang Yiu-Kai Ng. Overview. Probabilistic Model Bayes decision theory Document and query representations Ranking-function construction Multivariant Statistical Analysis. Approach. - PowerPoint PPT Presentation
Citation preview

A Probabilistic Model for Classification of Multiple-Record
Web Documents
June Tang
Yiu-Kai Ng

Overview
Probabilistic Model– Bayes decision theory– Document and query representations– Ranking-function construction
Multivariant Statistical Analysis

Approach
Constructing a rank function for a probabilistic model based on multivariant statistical analysis
Minimizing expected cost of misclassification Deriving a classification rule Deriving a linear classification rule Deriving a sample linear classification rule
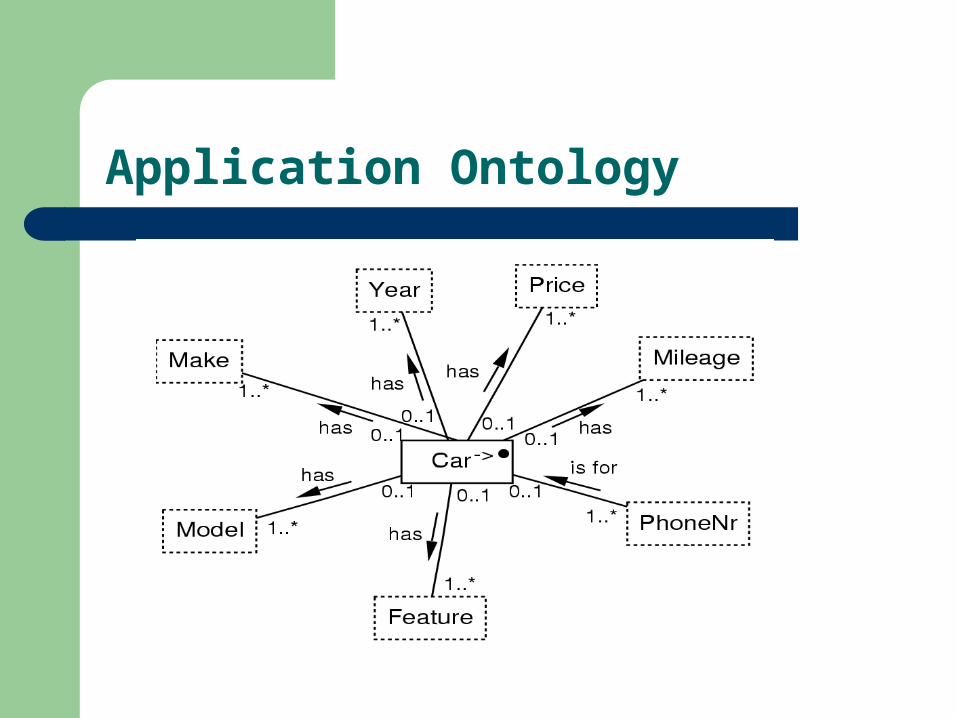
Application Ontology

Document Representation
(Year, Make, Model, Mileage, Price, Feature, PhoneNr)
Total records: 60
(Year:62) (Make:58) (Model:48) (Mileage:12)
(Price:58) (Feature:49) (PhoneNr:33)
(62,58,48,12,58,49,33)
(1.03,0.97,0.80,0.20,0.97,0.82,0.55)

Elementary Concepts
Variables are things that we measure, control, or manipulate in research
Multi-variant analysis considers multiple variables together as a single unit
Normal distribution represents one of the empirically verified elementary "truths about the general nature of reality"

Multivariant Statistical Analysis
Let A be an application ontology
D be a set of Web documents
R be a set of relevant documents
R be a set of irrelevant document
X = (X1, X2, …, Xp) represent a document
be the set of all possible values on which X can take
= 1 2

Expected Cost of Misclassification(ECM)
Here,
Two density functions f1 and f2

Classification Rule

Multivariate Normal Density Functions
Where
Assume that density functions are normal

Document x is classified as relevant if
Linear Classification Rule
Assume that density functions are normal
and 1 , 2 , and are equal

Linear Discrimination Function
Threshold:
?

Parameter Estimations
Suppose we have n1 relevant documents
and n2 irrelevant documents
Such that n1+n2>=p and p is the dimension of vector x

Parameter Estimations (Cont.)

Sample Classification Rule
Document x is classified as relevant if

Misclassification Probabilities
Lachenbruch’s “holdout” procedure
where

Precision Measure
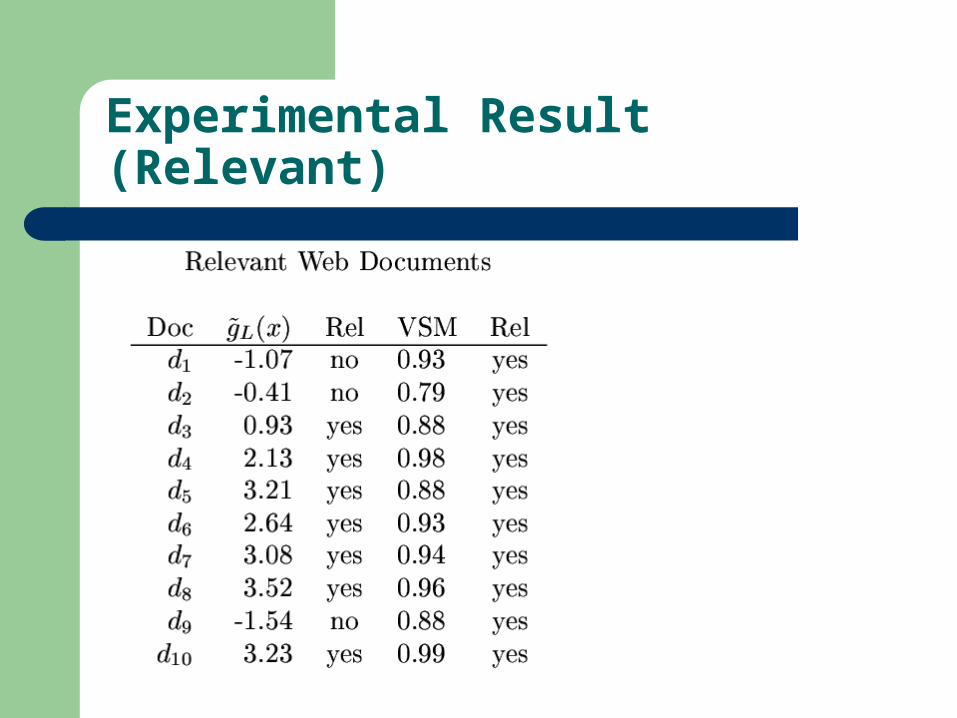
Experimental Result (Relevant)
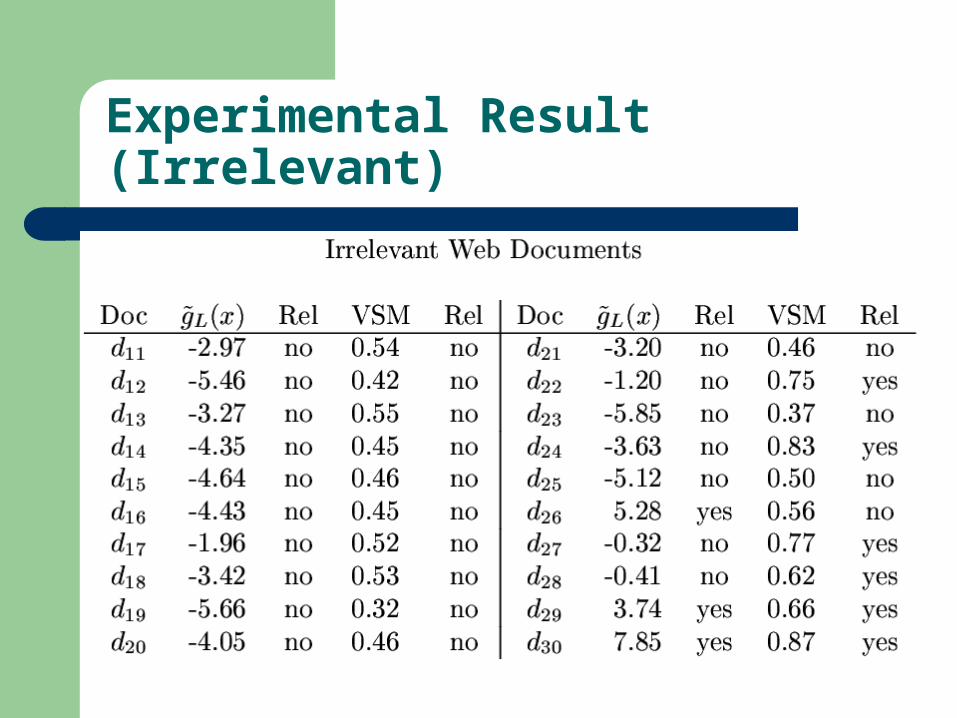
Experimental Result (Irrelevant)

Conclusion
Precision: 85% (VSM: 77.5%) Multivariant Statistical Analysis Extendibility to Multiple Categorization
Classification





























