Embed Size (px)
Citation preview

A General Introduction to Lexical Databases
Emmanuel KeuleersDepartment of Experimental Psychology
Ghent University
EMLAR 2015 - Utrecht, April 15-17, 2015
• What can you find in a lexical database?
• How can you find it?

Lexical Databases
• Like a dictionary
• Lexical properties of interest to psycholinguists
• Frequency, orthography, phonology, morphology, syntax, …
• Subjective ratings of those words
• Behavioural responses to those data
Lexical Databases
• No standard: each database has its own format, peculiarities, ...
• Text files, web interfaces, e-mail services, etc ...
• In essence, a lexical database is just a list with a bunch of information about words.

Lexical Databases
• The truth: you'll have to find out where to find something and be prepared to do some processing work.
CELEX: the big and complex
lexical database

History
• Centre for Lexical Information
• Founded in Nijmegen in 1986
• Max Planck Institute for Psycholinguistics & Interfaculty Research Unit for Language and Speech of the University of Nijmegen (now CLS)
• Project ended in 2000
• Three large databases with lexical information for Dutch, English, and German
• Dutch Database
• 124,136 lemmata
• 381,292 wordforms
• 211,389 corpus types
• English Database
• 52,446 lemmata
• 160,594 wordforms
• 220,271 corpus types
• German database
• 51,728 lemmata
• 365,530 wordforms
• 290,712 corpus types

Wordforms, lemmas, and corpus types
• Letter strings, regardless of part of speech
• a walk in the park = to walk slowly = i walk alone = you walk alone
Corpus types

• Letter strings disambiguated for part of speech (and sometimes meaning)
• a walk in the park ≠ to walk slowly ≠ i walk alone ≠ you walk alone
• (walk, noun, singular), (walk, verb, infinitive), (walk, verb, 1p), (walk, verb, 2p)
Wordforms
• Headwords
• (walk, noun): a walk in the park = the long walks
• (walk, verb): I'm walking slowly = i walk alone = he walks too fast
Lemmas

Celex Build Up
• Information from dictionary sources
• Corpus counts or correlation with existing frequency counts
• Almost completely biased towards written language
Dutch Database Sources
• Van Dale's Comprehensive Dictionary of Contemporary Dutch (1984) • 80,000 lemmata
• Word List of the Dutch Language ('Het Groene Boekje') (1954), plus later revisions, including the 1994 spelling reform • 65,000 lemmata
• The most frequent lemmata from the text corpus of the Institute for Dutch Lexicology (INL) 42,380,000 words in all
• 15,000 lemmata

English Database Sources
• Oxford Advanced Learner's Dictionary (1974)• 41,000 lemmata
• Longman Dictionary of Contemporary English (1978)• 53,000 lemmata
German Database Sources
• Bonnlex, supplied by the Institute for Communication Research and Phonetics in Bonn
• Molex, supplied by the Institute for German Language in Mannheim
• Noetic Circle Services (MIT) German spelling lexicon

Dutch Frequency Sources
• INL Corpus (42 million tokens)
• 930 entire fiction and non-fiction books (approx. 30% fiction, 70% non-fiction) published between 1970 and 1988. Newspapers, magazines, children's books, textbooks and specialist literature do not feature in the collection.
English Frequency Sources
• COBUILD/Birmingham corpus (17.9 million tokens)
• 16.6 million tokens from written texts
• 1.3 million tokens from transcribed dialogue

German Frequency Sources
• Mannheimer Korpus I, Mannheimer Korpus II and Bonner Zeitungskorpus 1
• 5.4 million tokens
• written texts like newspapers, fiction and non-fiction
• Freiburger Korpus
• 600,000 tokens
• transcribed speech
• Corpus Types
• Frequency
• Orthography

• Lemma lexica
• Frequency
• Orthography
• Phonology
• Derivational Morphology
• Grammatical information
• Wordform Lexica
• Frequency
• Orthography
• Phonology
• Inflectional Morphology

Frequency
Verb Frequency Deviation Freq/Million
accept 3712 0 207.37
accord 2010 12 112.29
achieve 2121 0 118.49
act 2212 430 123.58
add 4190 0 234.08
agree 3424 0 191.28

Lexicon Form Frequency DeviationFrequency/
million
lemma act 2212 430 123.58
wordform act 269 1233 15.03
wordform acted 92 366 5.14
wordform acting 489 103 27.32
wordform acts 187 80 10.45
wordform act 269 1233 15.03
wordform acted 92 366 5.14
wordform act 269 1233 15.03
wordform acted 92 366 5.14
wordform act 269 1233 15.03
wordform acted 92 366 5.14
wordform acted 92 366 5.14
• Lemma frequency
• Frequency over all wordforms of the lemma
• Wordform frequency
• Deviation == 0 : exact count
• Deviation > 0 : result of disambiguation

• Less than 100 tokens
• Manual disambiguation
• More than 100 tokens
• Disambiguation on a sample of 100 tokens
• Frequency ± deviation = 95 % confidence interval
• No disambiguation for verbal flection
• Frequency divided between forms
• Frequency Deviation > Frequency
• No disambiguation for German
• Frequency divided between forms

• English and German databases have separate fields for written and spoken frequencies
• Spoken frequencies based on very small corpora
• 1.3 million for English
• 0.4 million for German
• What does it mean when an entry in CELEX has a frequency of zero
• Many entries in the database sources were not found in the frequency sources
• A few entries do not come from database sources but are left with a zero frequency after disambiguation
• will have deviation > zero
• Many entries added to CeLex for morphological decomposition of other lemmas have a frequency of zero

Word frequency distributions
Word frequency distributions
word frequency rankthe 1 093 546 1of 540 085 2
and 514 946 3to 483 428 4a 422 334 5in 337 995 6
that 217 376 7it 199 920 8i 198 139 9
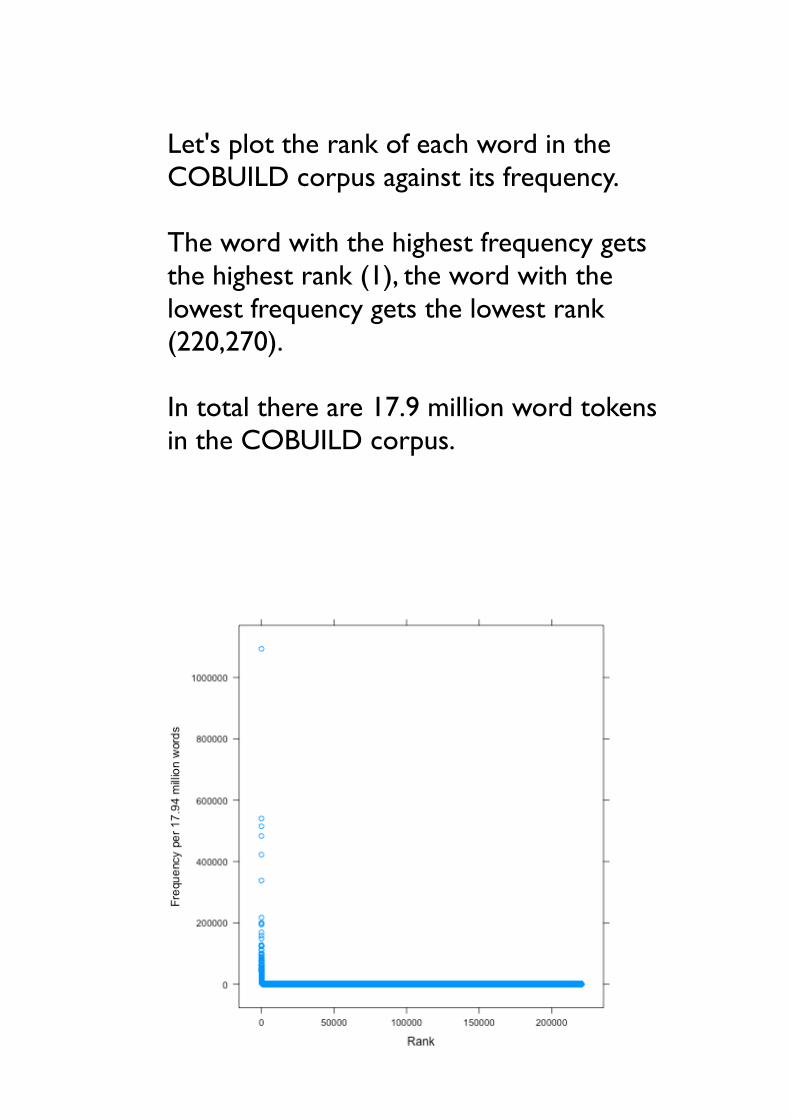
• Let's plot the rank of each word in the COBUILD corpus against its frequency.
• The word with the highest frequency gets the highest rank (1), the word with the lowest frequency gets the lowest rank (220,270).
• In total there are 17.9 million word tokens in the COBUILD corpus.
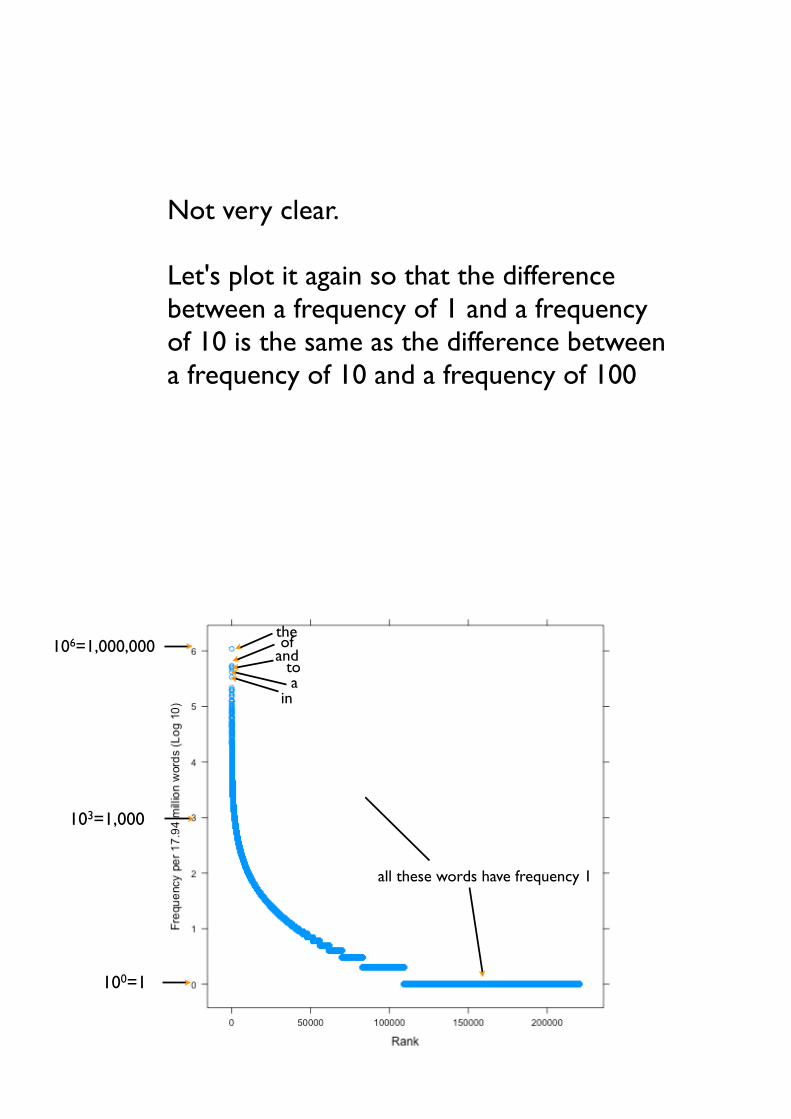
• Not very clear.
• Let's plot it again so that the difference between a frequency of 1 and a frequency of 10 is the same as the difference between a frequency of 10 and a frequency of 100
theof
andto
ina
all these words have frequency 1
106=1,000,000
103=1,000
100=1

• Word frequency lists are composed of very few words with a very high frequency
• Most words (corpus types) occur only once in the corpus!
• The relation between word frequency and rank is log linear.
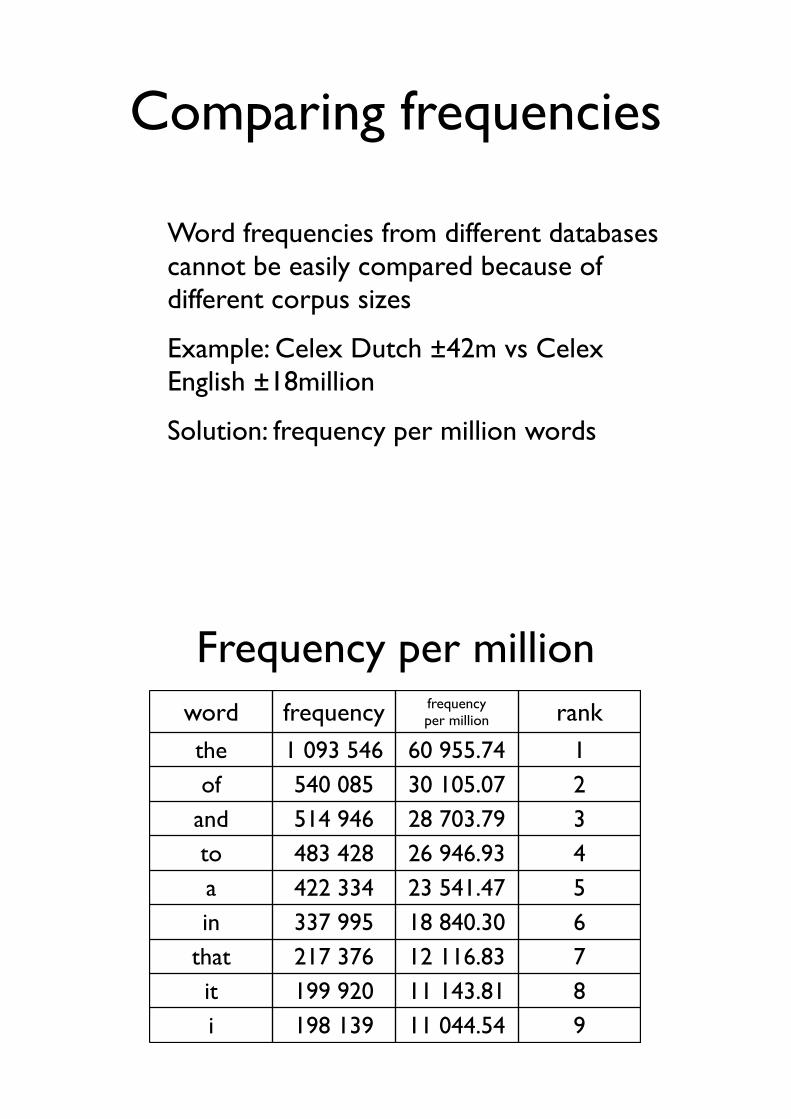
• Word frequencies from different databases cannot be easily compared because of different corpus sizes
• Example: Celex Dutch ±42m vs Celex English ±18million
• Solution: frequency per million words
Comparing frequencies
Frequency per millionword frequency frequency
per million rank
the 1 093 546 60 955.74 1of 540 085 30 105.07 2
and 514 946 28 703.79 3to 483 428 26 946.93 4a 422 334 23 541.47 5in 337 995 18 840.30 6
that 217 376 12 116.83 7it 199 920 11 143.81 8i 198 139 11 044.54 9

• Beware! Some frequency lists contain words with a frequency of 0
• Log10(0) is not something that can be computed
• Solution: always add 1 to the raw frequencies when you are transforming to frequencies per million
Comparing frequencies
Formula
Frequency per million = Raw Frequency +1
(adjusted) Corpus size in million
FPM ('that') = 217 376 +1
17.94
=12116.89
log10(12116.89)=4.08

Zipf ValuesVan Heuven, Mandera, Keuleers, & Brysbaert (2014)
Formula
Freq. per billion = Raw Frequency +1
Corpus size in billion
FPB ('that') = 217 376 +1
.01794
=12116889.63
log10(12116889.63)=7.08
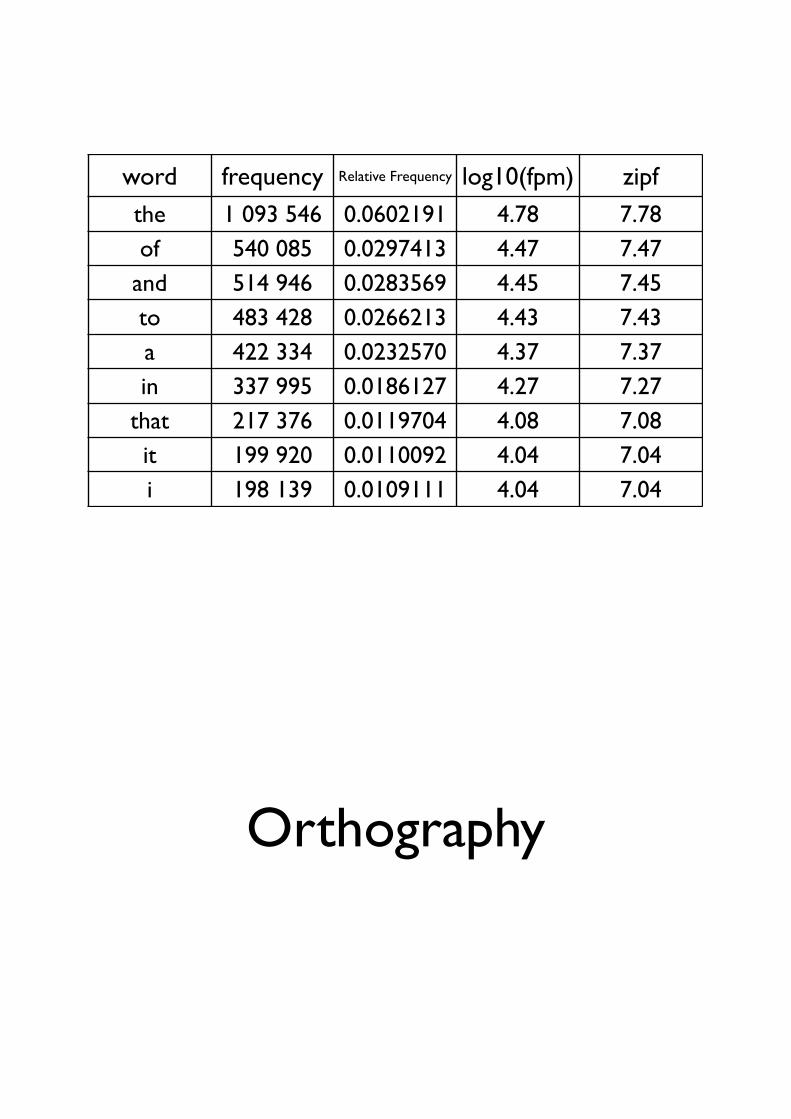
word frequency Relative Frequency log10(fpm) zipf
the 1 093 546 0.0602191 4.78 7.78of 540 085 0.0297413 4.47 7.47
and 514 946 0.0283569 4.45 7.45to 483 428 0.0266213 4.43 7.43a 422 334 0.0232570 4.37 7.37in 337 995 0.0186127 4.27 7.27
that 217 376 0.0119704 4.08 7.08it 199 920 0.0110092 4.04 7.04i 198 139 0.0109111 4.04 7.04
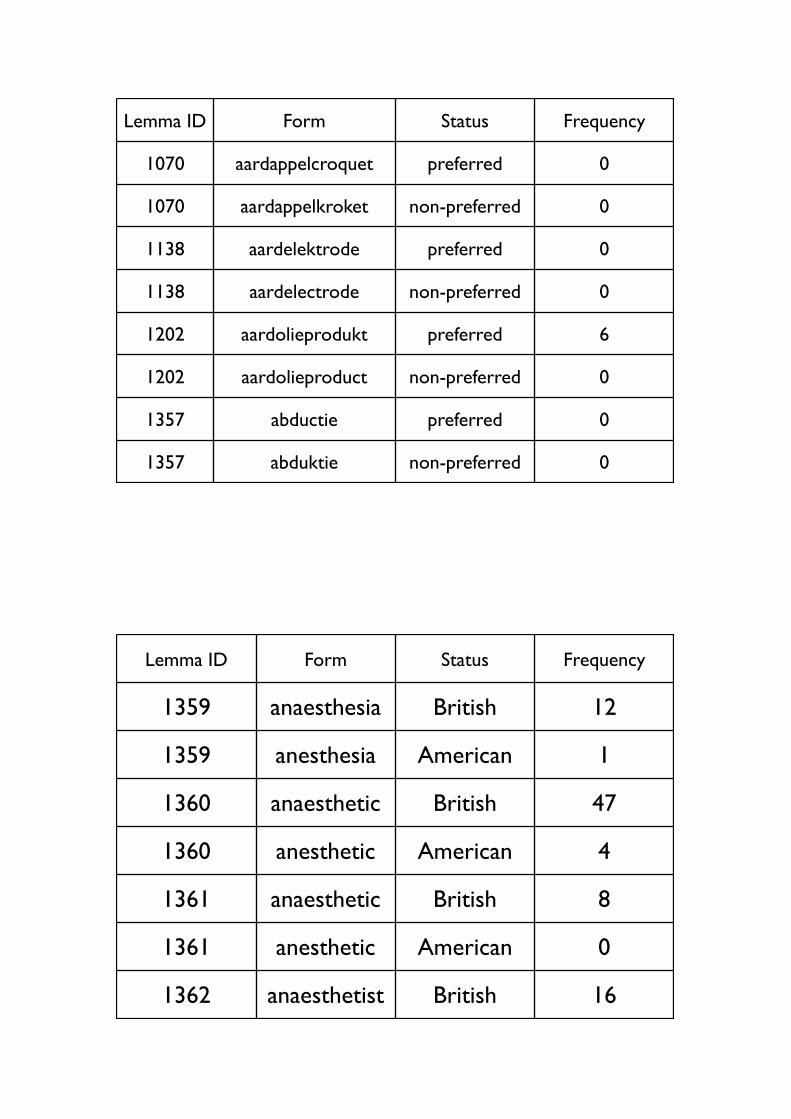
Orthography

• Lemma and wordform lexica list orthographic variants with separate frequencies
• Dutch: preferred, non-preferred, informal
• preferred & non-preferred: in “Groene Boekje”
• informal: non-standard forms occurring at least once in INL corpus
• English: British, American
• British: acceptable for British
• American: occurs only in American
• German
• No orthographic variants
Status
Lemma ID Form Status Frequency
1070 aardappelcroquet preferred 0
1070 aardappelkroket non-preferred 0
1138 aardelektrode preferred 0
1138 aardelectrode non-preferred 0
1202 aardolieprodukt preferred 6
1202 aardolieproduct non-preferred 0
1357 abductie preferred 0
1357 abduktie non-preferred 0
Lemma ID Form Status Frequency
1359 anaesthesia British 12
1359 anesthesia American 1
1360 anaesthetic British 47
1360 anesthetic American 4
1361 anaesthetic British 8
1361 anesthetic American 0
1362 anaesthetist British 16
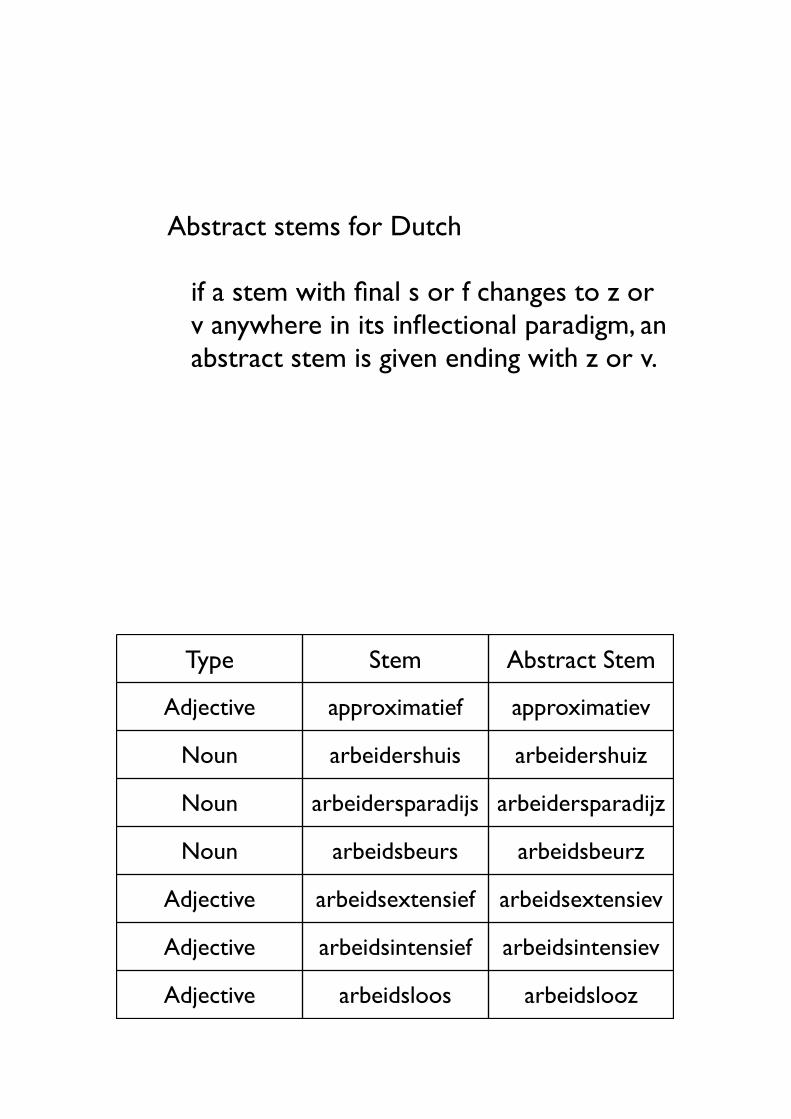
• Abstract stems for Dutch
• if a stem with final s or f changes to z or v anywhere in its inflectional paradigm, an abstract stem is given ending with z or v.
Type Stem Abstract Stem
Adjective approximatief approximatiev
Noun arbeidershuis arbeidershuiz
Noun arbeidersparadijs arbeidersparadijz
Noun arbeidsbeurs arbeidsbeurz
Adjective arbeidsextensief arbeidsextensiev
Adjective arbeidsintensief arbeidsintensiev
Adjective arbeidsloos arbeidslooz

Phonology
• Canonical phonetic transcriptions for written forms
• English: primary and secondary pronunciation
• Dutch, German: no phonetic variants
• Syllabified
• Stress and CV patterns

• IPA-like character sets
• SAM-PA
• CeLex
• CPA
• DISC character set
• one character per phoneme
• no ambiguity
• unreadable
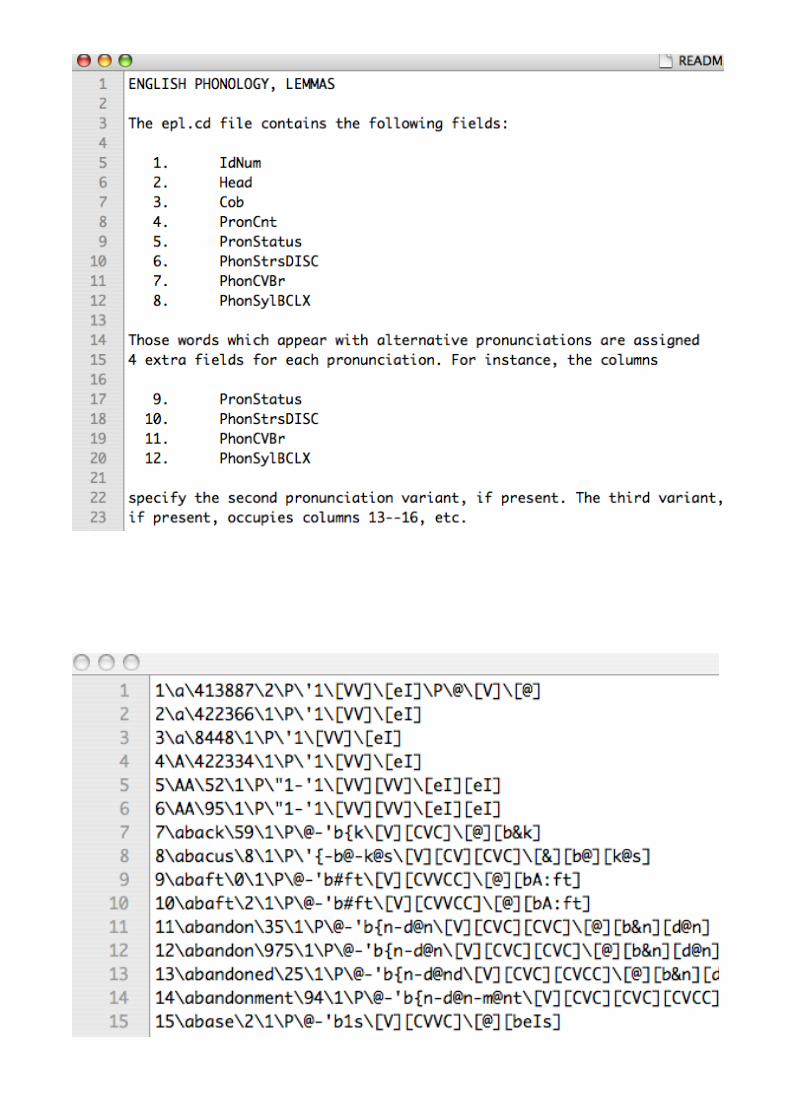
Idnum Spelling Status DISCSyllables
IPAStress CV
42577 sleekness primary sliknIs sliːk-nɪs 10 CCVVC-CVC
42577 sleekness secondary sliknIs sliːk-nəs 10 CCVVC-CVC
42582 sleepily primary slipIlI sliː-pɪ-lɪ 100 CCVV-CV-CV
42582 sleepily secondary slipIlI sliː-pə-lɪ 100 CCVV-CV-CV
42584 sleepiness primary slipInIs sliː-pɪ-nɪs 100 CCVV-CV-CVC
42584 sleepiness secondary slipInIs sliː-pɪ-nəs 100 CCVV-CV-CVC

• Dutch and German
• Separate phonetic trancsriptions for headwords and stems
• English
• First variant is always the primary one, as listed in the English Pronouncing Dictionary
• Newer versions use BBC English and Network English, transcriptions in CeLex are probably RP.
• Phonological transcriptions for morphologically complex Dutch and German stems with indication of morpheme boundaries
• Only with CELEX and CPA character sets

StemPhonological Transcription
Phonetic Transcription
Arbeiter arbait+@r [ar][bai][t@r]
Arbeitsplatz arbait+s#plats [ar][baits][plats]
Arbeitgeber arbait#ge:b+@r[ar][bait][ge:]
[b@r]
arbeitsamkeit arbait#za:m#kait[ar][bait][za:m]
[kait]
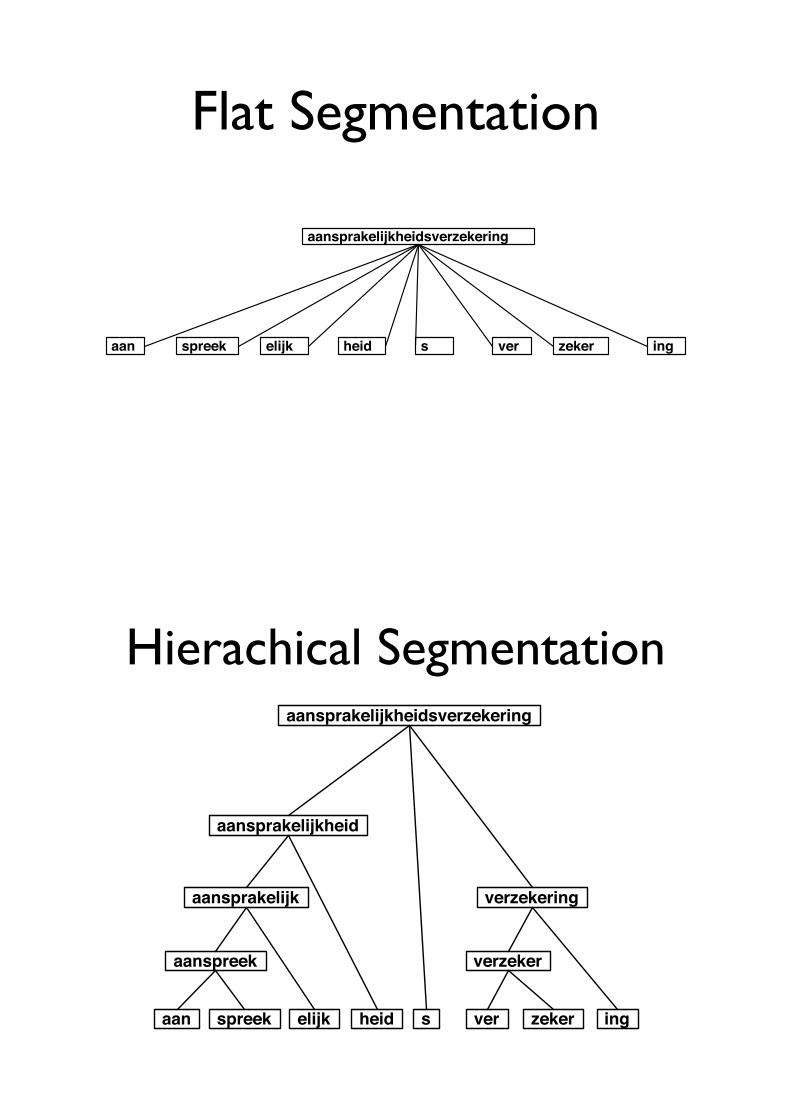
Morphology

• Lemma Morphology
• Morphstatus: indicates if the lemma has a relevant morphological decomposition
• Segmentation
• Immediate, Flat, Hierachical
Immediate Segmentation
aansprakelijkheidsverzekering
aansprakelijkheid s verzekering
aansprakelijkheidsverzekering
aan spreek elijk heid s ver zeker ing
Flat Segmentation
Hierachical Segmentationaansprakelijkheidsverzekering
aansprakelijkheid
aansprakelijk
aanspreek
aan spreek elijk heid s
verzekering
verzeker
ver zeker ing
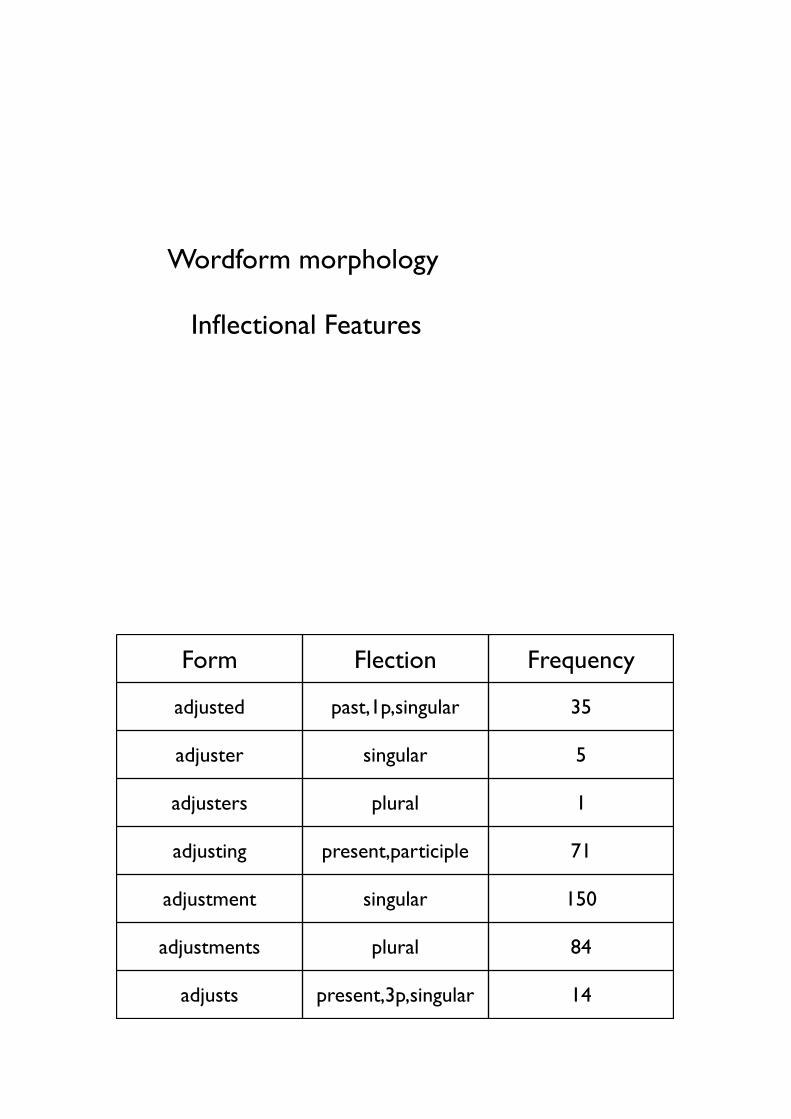
• Wordform morphology
• Inflectional Features
Form Flection Frequency
adjusted past,1p,singular 35
adjuster singular 5
adjusters plural 1
adjusting present,participle 71
adjustment singular 150
adjustments plural 84
adjusts present,3p,singular 14

Grammatical Information
• Syntactic class for lemmas
• Dutch: Expression, Noun, Adjective, Quantifier/Numeral, Verb, Article, Pronoun, Adverb, Preposition, Conjunction, Interjection
• English: Noun, Adjective, Numeral, Verb, Article, Pronoun, Adverb, Preposition, Conjunction, Interjection, Single, Complex, Letter, Abbreviation, Infinitival
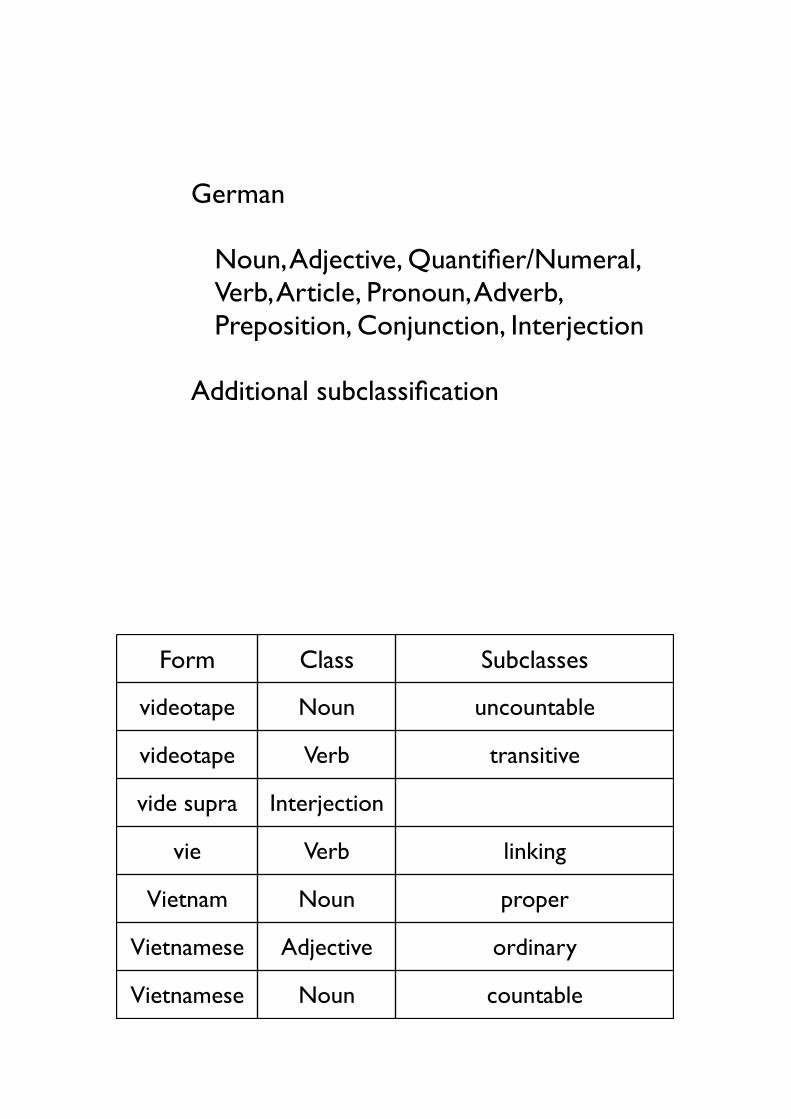
• German
• Noun, Adjective, Quantifier/Numeral, Verb, Article, Pronoun, Adverb, Preposition, Conjunction, Interjection
• Additional subclassification
Form Class Subclasses
videotape Noun uncountable
videotape Verb transitive
vide supra Interjection
vie Verb linking
Vietnam Noun proper
Vietnamese Adjective ordinary
Vietnamese Noun countable

Form Class Subclasses
magnetisch Adjective nonadverbial
magnetiseren Verb lexical intransitive transitivemagnetiseerb
aarAdjective nonadverbial
magnifiek Adjective adverbial
Magyaars Adjective adverbial
maharadja Noun
maharishi Noun
Mahdi Noun
Mahler Noun propername
How to get information from CeLex
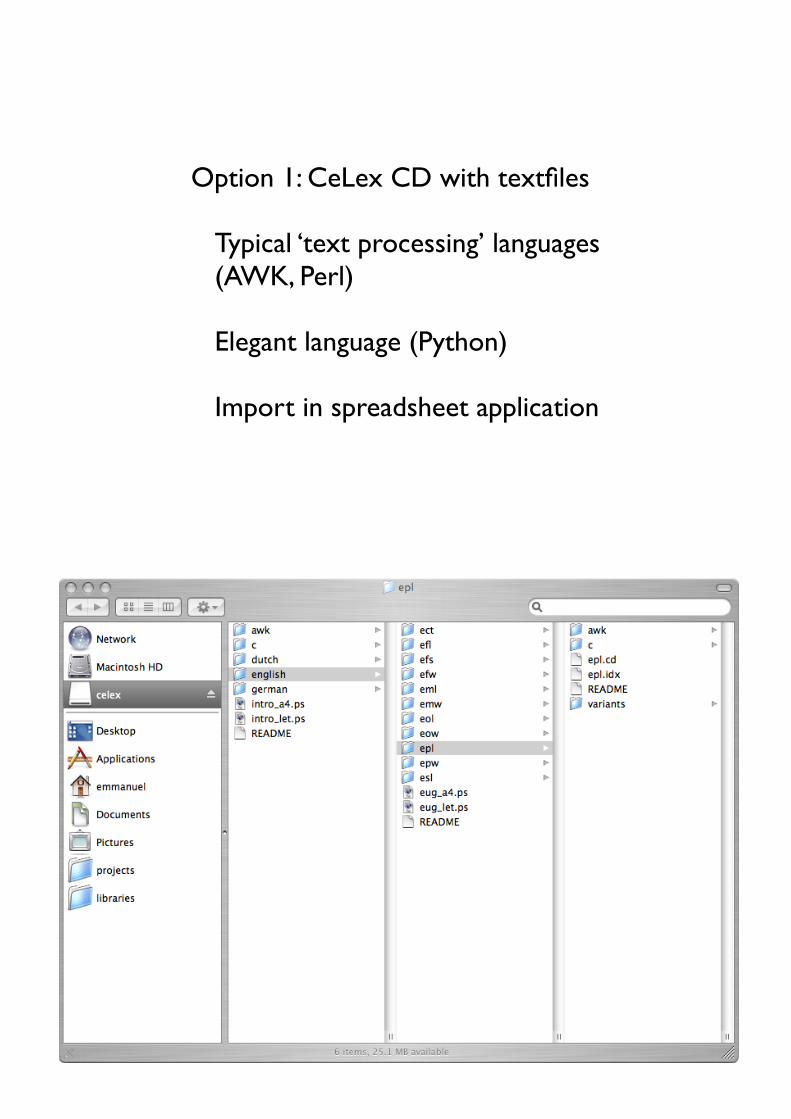
• Option 1: CeLex CD with textfiles
• Typical ‘text processing’ languages (AWK, Perl)
• Elegant language (Python)
• Import in spreadsheet application

• Option 2: Public web interface at MPI (WebCeLex)
• Good tool for selection
• Process with scripting language


Examples

PHONOLOGY, READING ACQUISITION AND DYSLEXIA 15
Words Presented
Per
cen
t C
orr
ect
100K 1M 10M
Training Set
0
10
20
30
40
50
60
70
80
90
100
Feedforward
Untrained Attractor
Trained Attractor
Words Presented
Per
cen
t C
orr
ect
100K 1M 10M
Nonwords
0
10
20
30
40
50
60
70
80
90
100
Feedforward
Untrained Attractor
Trained Attractor
Figure 10. Comparison between the normal reading model, the feedforward model, and the initially untrained
attractor model on the training set (left) and nonword generalization (right).
BAKED). These items were excluded for a pragmatic rea-
son, the need to keep network training times within reason-
able bounds. However, the exclusion of these words raises
questions about the generality of the results we have pre-
sented. One question is whether similar levels of perfor-
mance can be achieved with a larger number of words to be
learned. A second question is whether words with complex
onsets (such STRING) or codas (such as BURST) present
any special challenges. Finally, the properties of En-
glish inflectional morphology create complex orthographic-
phonological mappings for these words. In both the plural
and past tense, the phonological realization of the inflec-
tion is conditioned by the previous phoneme. In both BUDS
and BOOKS, for example, the plural morpheme is spelled
with S. However, whether its pronunciation is voiced (as
in BUDS) or unvoiced (as in BOOKS) depends on the voic-
ing of the preceding phoneme which is itself inconsistently
cued by the orthography. Thus both MOUTH and TENTH
end in TH but differ in voicing; although both form the plu-
ral by adding S in the orthography, the inflections are pro-
nounced differently. The mappings between spelling and
pronunciation for these words are therefore rather complex.
In summary, the words we excluded differ in some respects
from the words in the training corpus and raise additional
challenges for our approach that need to be addressed.
To explore these questions, we conducted a replica-
tion simulation using a much larger corpus. Monosyllables
were extracted from the CELEX electronic corpus (Baayen,
Piepenbrock, & van Rijn, 1993). All items fitting a CC-
CVVCCC template were used, yielding 7,839 words. Most
of the additional words are inflected items. The phonolog-
ical network was expanded from 66 to 88 units to accommo-
date the larger template, and additional orthographic units
were added to fit longer words. Aside from these changes,
no other alterations were made to the model’s architecture,
representations or training regime.
After 10 million trials, the model had correctly learned
99% of the training set, as scored by the strict criterion.
Nonword generalization improved: the model correctly
pronounced 84% of the benchmark nonword set by the strict
criterion, and 90% by the more lax one. The original model
had difficulty pronouncing some nonwords that had few
neighbors in the original training set; for example, it pro-
duced errors on nonwords that look like plurals, such as
SNOCKS and PHOCKS. The larger model, which contains
many plurals, has no difficulty with these items. These re-
sults demonstrate that increasing the size of the training set
not only does not create problems for the model, it facili-
tates performance on nonwords by providing broader cover-
age of the space of orthographic and phonological patterns.
Performance on words with complex onsets or codas
and on inflected words is summarized in Table 4. For
comparison we also examined the performance of a strictly
feedforward network on these items. Both attractor and
feedforward models achieved high levels of performance on
these words, with a slight advantage for the former. The
models’ capacities to generalize were examined by test-
ing them on nonwords with plural or past tense inflections.
Here the attractor network performed significantly better
than the feedforward network. These results are consistent
with the conclusion that the attractor structure is relevant to
learning complex spelling-sound mappings; however, the
learning of the larger corpus proceeded without complica-
tion. The larger model does take significantly longer to
Harm, M. W. & Seidenberg, M. S. (1999). Phonology, reading acquisition, and dyslexia: insights from connectionist models. Psychol Rev, 106(3), 491-528.
[skraIdt] are phonologically filtered; the remaining candidates are submitted to the coreGCM algorithm for evaluation, as described above.
As an illustration of how the model works, Table 2 shows the outcomes it derives forgleed, along with their scores and the analog forms used in deriving each outcome.
To conclude, we feel that a model of this sort satisfies a rigorous criterion for being“analogical”, as it straightforwardly embodies the principle that similar forms influenceone another. The model moreover satisfies the criteria laid out in Section 2.1: it is fullysusceptible to the influence of variegated similarity, and (unless the data accidentally helpit to do so) it utterly ignores the structured-similarity relations that are crucial to our rule-based model.
2.5. Feeding the models
We sought to feed both our rule-based and analogical models a diet of stem/pasttense pairs that would resemble what had been encountered by our experimentalparticipants. We took our set of input forms from the English portion of the CELEXdatabase (Baayen, Piepenbrock, & Gulikers, 1995), selecting all the verbs that had alemma frequency of 10 or greater. In addition, for verbs that show more than one pasttense (like dived/dove), we included both as separate entries (e.g. both dive-dived anddive-dove). The resulting corpus consisted of 4253 stem/past tense pairs, 4035 regularand 218 irregular. Verb forms were listed in a phonemic transcription reflectingAmerican English pronunciation.
A current debate in the acquisition literature (Bybee, 1995; Clahsen & Rothweiler,1992; Marcus, Brinkmann, Clahsen, Wiese, & Pinker, 1995) concerns whether prefixedforms of the same stem (e.g. do/redo/outdo) should be counted separately for purposesof learning. We prepared a version of our learning set from which all prefixed formswere removed, thus cutting its size down to 3308 input pairs (3170 regular, 138irregular), and ran both learning models on both sets. As it turned out, the rule-basedmodel did slightly better on the full set, and the analogical model did slightly better onthe edited set. The results below reflect the performance of each model on its own bestlearning set.
Table 2
Past tenses for gleed derived by the analogical model
Output Score Analogs
gleeded 0.3063 plead, glide, bleat, pleat, bead, greet, glut, need, grade, gloat, and 955 others in our
learning set
gled 0.0833 bleed, lead, breed, read, feed, speed, meet, bottle-feedgleed 0.0175 bid, beat, slit, let, shed, knit, quit, split, fit, hit, and 12 others
gleet 0.0028 lend, build, bend, send, spend
glade 0.0025 eatglode 0.0017 weave, freeze, steal, speak
glud 0.0005 sneak
A. Albright, B. Hayes / Cognition 90 (2003) 119–161132
Albright, A. & Hayes, B. (2003). Rules vs. analogy in English past tenses: A computational/experimental study. Cognition, 90(2), 119-161.

[skraIdt] are phonologically filtered; the remaining candidates are submitted to the coreGCM algorithm for evaluation, as described above.
As an illustration of how the model works, Table 2 shows the outcomes it derives forgleed, along with their scores and the analog forms used in deriving each outcome.
To conclude, we feel that a model of this sort satisfies a rigorous criterion for being“analogical”, as it straightforwardly embodies the principle that similar forms influenceone another. The model moreover satisfies the criteria laid out in Section 2.1: it is fullysusceptible to the influence of variegated similarity, and (unless the data accidentally helpit to do so) it utterly ignores the structured-similarity relations that are crucial to our rule-based model.
2.5. Feeding the models
We sought to feed both our rule-based and analogical models a diet of stem/pasttense pairs that would resemble what had been encountered by our experimentalparticipants. We took our set of input forms from the English portion of the CELEXdatabase (Baayen, Piepenbrock, & Gulikers, 1995), selecting all the verbs that had alemma frequency of 10 or greater. In addition, for verbs that show more than one pasttense (like dived/dove), we included both as separate entries (e.g. both dive-dived anddive-dove). The resulting corpus consisted of 4253 stem/past tense pairs, 4035 regularand 218 irregular. Verb forms were listed in a phonemic transcription reflectingAmerican English pronunciation.
A current debate in the acquisition literature (Bybee, 1995; Clahsen & Rothweiler,1992; Marcus, Brinkmann, Clahsen, Wiese, & Pinker, 1995) concerns whether prefixedforms of the same stem (e.g. do/redo/outdo) should be counted separately for purposesof learning. We prepared a version of our learning set from which all prefixed formswere removed, thus cutting its size down to 3308 input pairs (3170 regular, 138irregular), and ran both learning models on both sets. As it turned out, the rule-basedmodel did slightly better on the full set, and the analogical model did slightly better onthe edited set. The results below reflect the performance of each model on its own bestlearning set.
Table 2
Past tenses for gleed derived by the analogical model
Output Score Analogs
gleeded 0.3063 plead, glide, bleat, pleat, bead, greet, glut, need, grade, gloat, and 955 others in our
learning set
gled 0.0833 bleed, lead, breed, read, feed, speed, meet, bottle-feedgleed 0.0175 bid, beat, slit, let, shed, knit, quit, split, fit, hit, and 12 others
gleet 0.0028 lend, build, bend, send, spend
glade 0.0025 eatglode 0.0017 weave, freeze, steal, speak
glud 0.0005 sneak
A. Albright, B. Hayes / Cognition 90 (2003) 119–161132
Albright, A. & Hayes, B. (2003). Rules vs. analogy in English past tenses: A computational/experimental study. Cognition, 90(2), 119-161.
Stimulus materialsForty-four words were selected from Lexique and 44
matching nonwords were constructed. Selection andconstruction criteria were the same as in Experiment 1,except for the frequencies of the word forms. One listof 22 words had a singular frequency of 16, and a pluralfrequency of 43; the other list had a singular frequencyof 16, and a plural frequency of 4. The two lists of wordswere matched on the number of letters (6.4 and 6.3) andthe number of syllables (1.7 and 1.7). A complete list ofthe words is given in Appendix A (see also Appendix Bfor the nonwords).
ProcedureThe procedure was identical to that described in
Experiment 1, except that in this experiment only thesingular word forms were presented. Because of this,no non-word ended in -s.
Results
Table 2 displays mean reaction time and percentageerror for Experiment 2. Extreme reaction times were re-moved according to the procedure described in Experi-ment 1. In total, 5.5% of the RT data in the subjectsanalysis as well as 4.7% in the item analysis were dis-carded. ANOVAs with one repeated measure revealeda main effect of the frequency of the plural form bothin the analysis over participants (F1(1,14) = 24.09,Mse = 946.06, p < .001) and in the analysis over items(F2(1,21) = 19.57,Mse = 1371.50, p < .001). Participantsresponded faster to singular word forms with high-fre-quency plurals than to singular word forms with low-fre-quency plurals.
Discussion
The main finding of Experiment 2 was the presence ofa base frequency effect when the singular forms werematched on surface frequency. When two singular formshave the same surface frequency but differ in the fre-quency of their plural forms, the singular with the morefrequent plural is processed faster. This result agrees
with Baayen et al.!s findings in Dutch, but deviates fromSereno and Jongman!s findings in English.
So, on the basis of the two experiments reported thusfar, it seems that Dutch and French plurals are pro-cessed in the same way, and both differ significantlyfrom the findings in English. In addition, there is somesuggestive evidence that the Dutch/French pattern couldalso be present in Italian (Baayen et al., 1996) and inSpanish (Dominguez et al., 1999), making the Englishfinding even more isolated. Therefore, we decided to re-peat the Sereno and Jongman experiments.
Experiment 3
A closer look at Sereno and Jongman (1997) revealeda number of methodological differences between thatstudy and all of the other studies. For a start, Serenoand Jongman presented their singular and plural stimuliin two different experiments (their Experiments 2A and2B). This blocked presentation may have encouragedparticipants to ignore the end -s in the experiment withthe plural stimuli. Another problem is that Sereno andJongman!s word frequencies were based on the Browncorpus which only includes one million words. This isa quite limited corpus if we compare it to the Frenchcorpus used in Lexique (31 million tokens) and the En-glish corpus used in Celex (17.9 million tokens). Forthese reasons, we decided to repeat the Sereno and Jong-man experiments, following the same procedure as inour French studies (and in the Dutch studies).
Method
ParticipantsThirty-eight students from Royal Holloway, Univer-
sity of London, took part in the experiment in return forcourse credits. They were all native English-speakers andhad normal or corrected-to-normal vision.
Stimulus materialsThe word stimuli were two lists of 24 nouns drawn
from the Celex database (Baayen, Piepenbrock, & Gul-ikers, 1995), based on a corpus of 16.6 million writtenwords and 1.3 million spoken words. The first list con-sisted of singular dominant items, with an average fre-quency of 25 per million for the singular forms andeight for the plural forms. The second list consisted ofplural dominant items with average frequencies of 9and 26, respectively. The base frequencies (34 vs. 35)did not differ between the lists. The stimuli were furthermatched on the number of letters (6.3 and 6.3) and thenumber of syllables (2 and 2). A complete list of thestimuli is presented in Appendix A. As in Experiment1, two versions of the word list were created, so thateach participant saw only one form of a word.
Table 2Mean reaction time (in ms), standard deviation and percentageerror in Experiment 2
Frequency of thecomplementary form
Presented forms: singular
M SD %ER
High-frequency pluralEx: Ongle [Nail]
540 50 2.1
Low-frequency pluralEx: Frere [Brother]
596 63 3.6
B. New et al. / Journal of Memory and Language 51 (2004) 568–585 573
New, B., Brysbaert, M., Segui, J., Ferrand, L., & Rastle, K. (2004). The processing of singular and plural nouns in French and English. Journal of Memory and Language, 51(4), 568-585.
Appendix A (continued)
Word [in English] Mean reaction time SD Singular frequency Plural frequency
pavilion [bungalow] 491 71 17 4perruque [wig] 536 58 4 2pretre [priest] 635 178 20 13riviere [river] 584 107 34 8sculpteur [sculptor] 625 95 5 3tige [stem] 578 84 12 8torse [chest] 618 113 12 2vallee [valley] 520 76 26 6
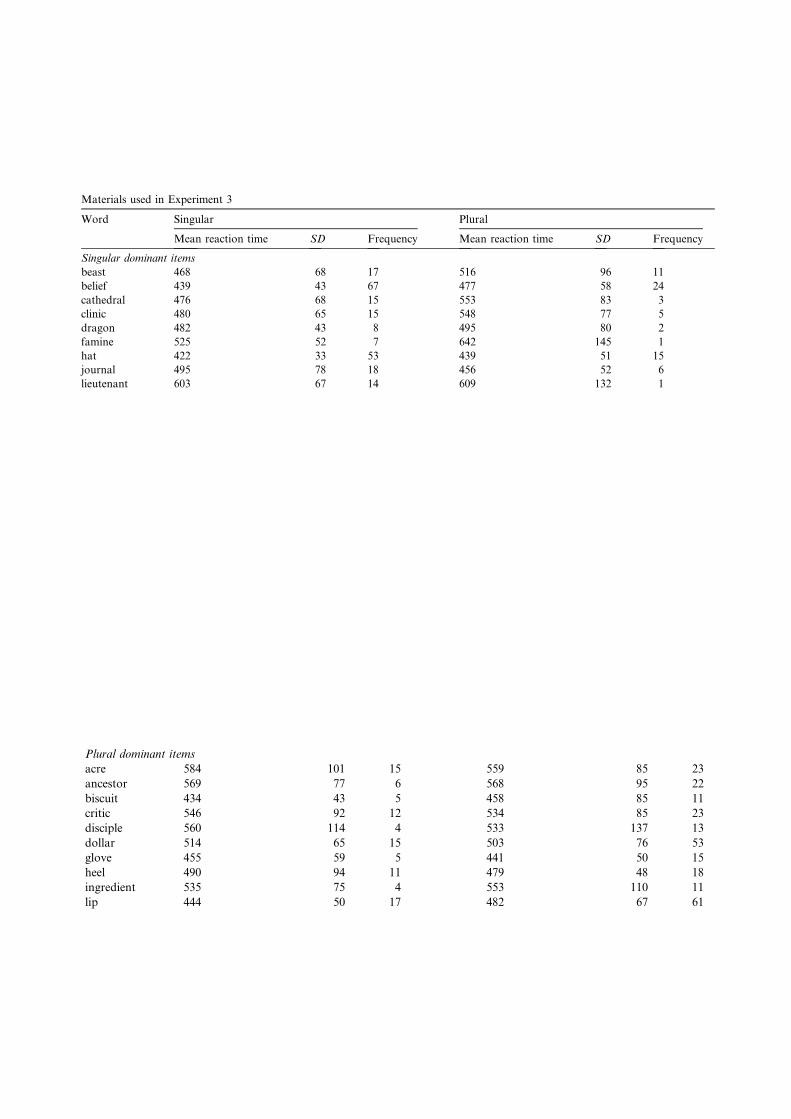
Materials used in Experiment 3
Word Singular Plural
Mean reaction time SD Frequency Mean reaction time SD Frequency
Singular dominant itemsbeast 468 68 17 516 96 11belief 439 43 67 477 58 24cathedral 476 68 15 553 83 3clinic 480 65 15 548 77 5dragon 482 43 8 495 80 2famine 525 52 7 642 145 1hat 422 33 53 439 51 15journal 495 78 18 456 52 6lieutenant 603 67 14 609 132 1monument 547 112 11 588 110 6moustache 519 88 16 547 106 2prophet 532 90 10 606 108 6regiment 586 126 10 572 133 2salad 490 78 16 470 63 4sister 463 59 82 489 52 32studio 450 67 22 498 81 6sum 480 90 32 483 98 17sword 467 73 13 490 78 4talent 473 67 24 506 107 12task 473 68 65 468 74 17texture 433 45 11 490 65 2tribe 478 65 23 505 78 15valley 483 85 49 495 91 7
Plural dominant itemsacre 584 101 15 559 85 23ancestor 569 77 6 568 95 22biscuit 434 43 5 458 85 11critic 546 92 12 534 85 23disciple 560 114 4 533 137 13dollar 514 65 15 503 76 53glove 455 59 5 441 50 15heel 490 94 11 479 48 18ingredient 535 75 4 553 110 11lip 444 50 17 482 67 61molecule 498 57 5 515 83 12neighbour 466 67 19 475 61 31nostril 562 71 2 551 87 10sandal 536 81 1 516 111 8shoe 438 64 14 448 84 65sock 434 56 3 441 64 16soldier 466 35 26 448 42 57
582 B. New et al. / Journal of Memory and Language 51 (2004) 568–585
Appendix A (continued)
Word [in English] Mean reaction time SD Singular frequency Plural frequency
pavilion [bungalow] 491 71 17 4perruque [wig] 536 58 4 2pretre [priest] 635 178 20 13riviere [river] 584 107 34 8sculpteur [sculptor] 625 95 5 3tige [stem] 578 84 12 8torse [chest] 618 113 12 2vallee [valley] 520 76 26 6
Materials used in Experiment 3
Word Singular Plural
Mean reaction time SD Frequency Mean reaction time SD Frequency
Singular dominant itemsbeast 468 68 17 516 96 11belief 439 43 67 477 58 24cathedral 476 68 15 553 83 3clinic 480 65 15 548 77 5dragon 482 43 8 495 80 2famine 525 52 7 642 145 1hat 422 33 53 439 51 15journal 495 78 18 456 52 6lieutenant 603 67 14 609 132 1monument 547 112 11 588 110 6moustache 519 88 16 547 106 2prophet 532 90 10 606 108 6regiment 586 126 10 572 133 2salad 490 78 16 470 63 4sister 463 59 82 489 52 32studio 450 67 22 498 81 6sum 480 90 32 483 98 17sword 467 73 13 490 78 4talent 473 67 24 506 107 12task 473 68 65 468 74 17texture 433 45 11 490 65 2tribe 478 65 23 505 78 15valley 483 85 49 495 91 7
Plural dominant itemsacre 584 101 15 559 85 23ancestor 569 77 6 568 95 22biscuit 434 43 5 458 85 11critic 546 92 12 534 85 23disciple 560 114 4 533 137 13dollar 514 65 15 503 76 53glove 455 59 5 441 50 15heel 490 94 11 479 48 18ingredient 535 75 4 553 110 11lip 444 50 17 482 67 61molecule 498 57 5 515 83 12neighbour 466 67 19 475 61 31nostril 562 71 2 551 87 10sandal 536 81 1 516 111 8shoe 438 64 14 448 84 65sock 434 56 3 441 64 16soldier 466 35 26 448 42 57
582 B. New et al. / Journal of Memory and Language 51 (2004) 568–585

Exercises and practical applications
http://crr.ugent.be/emlar2015














![Using MAUS to Investigate Children’s Production of Lexical ...intro2psycholing.net/ICPhS/papers/ICPhS_2519.pdfSegmentation tool (MAUS) [1]. A search of the databases CINAHL, Scopus,](https://img.pdfslide.us/doc/110x75/5ffb12096481981b1e5eadf1/using-maus-to-investigate-childrenas-production-of-lexical-segmentation-tool.jpg)














