Embed Size (px)
Citation preview

7. Unüberwachte Lernverfahren
1. Neuronale Merkmalskarten
2. Explorative Datenanalyse
3. Methoden zur Datenreduktion der Datenpunkte
4. Methoden zur Merkmalsreduktion der Merkmale
Schwenker NI1 141

7.1 Neuronale Merkmalskarten
• Neuron
• Schichten der Großhirnrinde
• Kortikale Säulenarchitektur
• Laterale Hemmung
• Karten im Kortex
Schwenker NI1 142
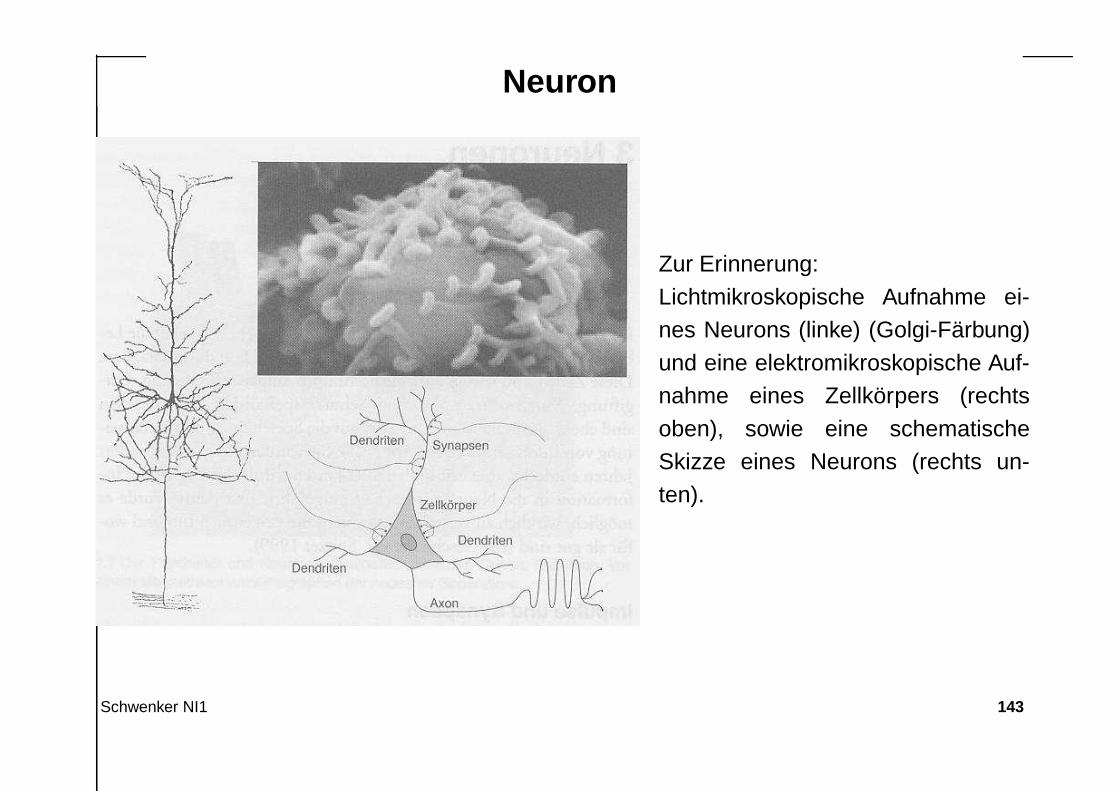
Neuron
Zur Erinnerung:Lichtmikroskopische Aufnahme ei-nes Neurons (linke) (Golgi-Färbung)und eine elektromikroskopische Auf-nahme eines Zellkörpers (rechtsoben), sowie eine schematischeSkizze eines Neurons (rechts un-ten).
Schwenker NI1 143

Schichten der Großhirnrinde
Schichtenstruktur (6 Schichten) derGroßhirnrinde (Kortex):Neuronen mit Dendriten und Axonendurch Golgi-Färbung sichtbar(links).Nissl-Färbung: Nur die Zellkörperder Neuronen sind sichtbar(Mitte).Weigert-Färbung: Sichtbar sind dieNervenfasern (rechts).
Schwenker NI1 144

Kortikale Säulenarchitektur I• Der Kortex weist eine sechsschichtige horizontale
Gliederung auf, insbesondere durch verschiedeneZelltypen.
• Verbindungsstrukur vertikal und horizontal; Verbin-dungen von Pyramidenzellen in Schicht 5 liegen et-wa 0,3 bis 0,5 mm um die vertikale Achse, was einezylindrische Geometrie kortikaler Informationsverar-beitungsmodule nahelegt.
• Ungeklärt ist, ob es sich bei den kortikalen Säulensogar um konkrete anatomische Strukturen oder umabstrakte (momentane) funktionelle Struktur han-delt.
• Die unmittelbaren Nachbarn eines Neurons bildeneine funktionelle Einheit.
• Nachbarneuronen werden leicht erregt.
• Weiter entfernt liegende Neuronen werden über In-terneuronen inhibiert, man spricht von lateraler Inhi-bition.
Schwenker NI1 145

Kortikale Säulenarchitektur II
• Prinzip der kortikalen Säulen: Hierbei sindeigentlich nicht einzelne Neurone gemeint,auch wenn die kortikalen Säulen in der Si-mulation so aufgefasst werden.
• Der gesamte Kortex zeigt diese Säulenar-chitektur.
Schwenker NI1 146

Laterale Inhibition• Center-Surround-Architektur. Jedes Neu-
ron ist mit jedem anderen verbunden.
• Verbindungen zu benachbarten Neuronensind exzitatorisch, weiter entfernt liegendeNeuronen werden inhibiert.
• Oben: Querschnitt durch diese Aktivierung.
• Mitte: Zweidimensionale Darstellung derAktivierung. Wegen der Form wird sie auchmexican hat function genannt.
• Unten: Schematische Anordung der korti-kalen Säulen.
• Die laterale Inhibition bewirkt, dass dasNeuron welches bei einer Eingabe amstärksten aktiviert wird, letztlich nur selbstaktiv bleibt: The winner takes it all
• In der Simulation wird das Neuron be-stimmt, das durch eine Eingabe am stärks-ten aktiviert wurde: Winner detection.
Schwenker NI1 147

Karten im Kortex
Abbildung oben:Motorischer (links) und sensorischer Kortex(rechts).
Abbildung unten:Der auditorische Kortex (genauer das ArealA1) enthält Neuronen, die Töne nach der Fre-quenz sortiert kartenförmig repräsentieren.
Schwenker NI1 148

Abbildung oben:Sensorische Repräsentation der Körperober-fläche bei Hasen (links), Katzen (Mitte) und Af-fen (rechts). Körper ist proportional zur Größeder ihn repräsentierenden Großhirnrinde ge-zeigt.Abbildung unten:Auditorischer Kortex der Fledermaus ist sche-matisch dargestellt (links). Die Verteilung dervon den Neuronen repäsentierten Frequen-zen ist dargestellt (rechts oben). Für Fre-quenzen um 61 kHz ist etwa die Hälfte derNeuronen sensitiv. Signale in diesem Fre-quenzbereich nutzt die Fledermaus um ausder Tonhöheverschiebung des reflektierten Si-gnals die Relativgeschwnidigkeit eines Objek-tes und dem Tier selbst zu bestimmen. Ergeb-nis einer Computersimulation (rechts unten).
Schwenker NI1 149

7.2 Explorative Datenanalyse
1 2 di
12
p
M
i-th feature vector
p-th data point
Probleme
• Viele Datenpunkte.
• Hohe Dimension des Merk-malsraumes.
• Datenpunkte zu Beginn derAnalyse möglicherweisenicht vollständig bekannt.
• Keine Lehrersignale.
Schwenker NI1 150

7.3 Methoden zur Reduktion der Datenpunkte
• Zielsetzung
• Kompetitive Netze, Distanz oder Skalarprodukt
• Selbstorganisierende Merkmalskarten
• Einfache kompetitive Netze und k-means Clusteranalyse
• ART-Netzwerke
• Verwandte Verfahren: Lernende Vektorquantisierung (LVQ)
Schwenker NI1 151

Zielsetzung
• Es soll eine Repräsentation der Eingabedaten bestimmt werden.
• Nicht Einzeldaten, sondern prototypische Repräsentationen sollen berech-net werden (Datenreduktion).
• Ähnliche Daten sollen durch einen Prototypen repäsentiert werden.
• Regionen mit hoher Datendichte sollen duch mehrere Prototypen reprä-sentiert sein.
• Durch spezielle neuronale Netze sollen sich Kartenstrukturen ergeben,d.h. benachbarte Neuronen (Prototypen) auf der Karte sollen durch ähnli-che Eingaben aktiviert werden.
Schwenker NI1 152

Kompetitives neuronales Netz
C
output
weight matrix
input
x
j = argmin || x - c ||k
k
xC
argmin
Schwenker NI1 153

Distanz vs Skalarprodukt zur Gewinnerdetektion
Die Euklidische Norm ist durch das Skalarprodukt im Rn definiert:
‖x‖2 =√
〈x, x〉
Für den Abstand zweier Punkte x, y ∈ Rn gilt demnach:
‖x − y‖22 = 〈x − y, x − y〉 = 〈x, x〉 − 2〈x, y〉 + 〈y, y〉 = ‖x‖2
2 − 2〈x, y〉 + ‖y‖22
Für die Gewinnersuche bei der Eingabe x unter den Neuronen, gegebendurch Gewichtsvektoren c1, . . . , ck und ‖ci‖2 = 1 mit i = 1, . . . , k gilt dannoffenbar:
j∗ = argmaxi〈x, ci〉 ⇐⇒ j∗ = argmini‖x − ci‖2
Schwenker NI1 154

Kohonen’s Selbstorganisierende Karte
Projection
Prototypes
Feature Space 2D Grid with
Neighbourhood Function
Zielsetzung beim SOM-Lernen
• Berechnung von Prototypen im Merkmalsraum, also ci ∈ Rd, die die gegebenen Daten
x ∈ Rd gut repräsentieren.
• Nachbarschaftserhaltende Abbildung der Prototypen ci ∈ Rd auf Gitterpositionen gi auf
ein Gitter im R2 (1D oder 3D Gitter sind auch gebräuchlich).
Schwenker NI1 155

• Kohonen Lernregel: ∆cj = lt · Nt(gj, gj∗) · (x − cj)
• j∗ ist der Gewinner
• Nt(gj, gj∗) eine Nachbarschaftsfunktion.
• gj die Gitterposition des j-ten Neurons
• lt und σt trainingszeitabhängige Lernraten bzw. Nachbarschaftsweitenpa-rameter, die bei wachsender Trainingszeit gegen 0 konvergieren.
• Beispiel: Nt(gj, gj∗) = exp(−‖gj − gj∗‖2/2σ2t )
Schwenker NI1 156

Kohonen Lernalgorithmus
Input: X = x1, . . . , xM ⊂ Rd
1. Wähle r, s ∈ N, eine Clusterzahl k = rs ∈ N, eine Lernrate lt > 0, eineNachbarschaftsfunktion N und max. Lernepochenzahl N . Setze t = 0.
2. Initialisiere Prototypen c1, . . . , ck ∈ Rd (k × d Matrix C)
3. Jeder Prototypen ci auf genau eine Gitterposition gi ∈ 1, . . . , r ×1, . . . , s.
4. repeat
Wähle x ∈ X und t = t + 1j∗ = argmini‖x − ci‖ (winner detection)for all j:
cj = cj + ltNt(gj, gj∗)(x − cj) (update)
5. until t ≥ N
Schwenker NI1 157

SOM-Beispiele
Schwenker NI1 158

Schwenker NI1 159

0 0.5 1 1.5 20
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2Data and original map
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1Sequential training after 300 steps
Schwenker NI1 160

Kompetitives Lernen (Euklidische Distanz)
Input: X = x1, . . . , xM ⊂ Rd
1. Wähle Clusterzahl k ∈ N, eine Lernrate lt > 0 und N . Setze t = 0.
2. Initialisiere Prototypen c1, . . . , ck ∈ Rd (k × d Matrix C)
3. repeat
Wähle x ∈ X und t = t + 1j∗ = argminj‖x − cj‖ (winner detection)cj∗ = cj∗ + lt(x − cj∗) (winner update)
4. until t ≥ N
Schwenker NI1 161

k-means Clusteranalyse
Datenpunkt x ∈ Rd wird dem nächsten Clusterzentrum cj∗ zugeordnet:
j∗ = argminj‖x − cj‖.
Anpassung des Clusterzentrums:
∆cj∗ =1
|Cj∗| + 1(x − cj∗)
Zum Vergleich beim Kompetitiven Lernen
∆cj∗ = lt(x − cj∗)
lt > 0 eine Folge von Lernraten mit∑
t lt = ∞ und∑
t l2t < ∞.Beispiel: lt = 1/t.
Schwenker NI1 162

Beispiel: Kompetitives Lernen
Schwenker NI1 163

ART-Netzwerke
• Adaptive-Resonanz-Theorie (ART) entwickelt von Stephen Grossberg undGail Carpenter
• Hier nur ART1 Architektur
• Erweiterungen: ART 2, ART 3, FuzzyART, ARTMAP
• ART-Netze sind kompetitive Netze
• Besonderheit: ART-Netze sind wachsende Netze, d.h. die Zahl der Neuro-nen kann während des Trainings wachsen (aber nach oben beschränkt);ein Neuron kann allerdings nicht wieder gelöscht werden.
• Spezialität bei den ART 1 Netzen: Die Eingabedaten und die Gewichtsvek-toren (Prototypen) sind binäre Vektoren.
Schwenker NI1 164

ART1 Lernen : Idee
• Inputvektoren und Prototypen ∈ 0, 1d.
• Es wird höchstens der Gewichtsvektor des Gewinnerneurons cj∗ adaptiert.
• Ist die Ähnlichkeit zwischen Inputvektor x und cj∗ zu gering, so definiert xeinen neuen Prototypen und der Gewinnerprototyp cj∗ bleibt unverändert.
• Die Ähnlichkeit wird durch das Skalarprodukt x · cj = 〈x, cj〉 gemessen.
• Schranke für die Mindestähnlichkeit wird durch den sogenannten Vigilanz-parameter gemessen.
• Ist die Ähnlichkeit groß genug, so wird cj∗ durch komponentenweises ANDvon x und cj∗ adaptiert.
• Maximale Zahl von Neuronen wird vorgegeben. Aus dieser Grundidee las-sen sich viele mögliche Algorithmen ableiten.
Schwenker NI1 165

ART1 : Bezeichnungen
• xµ ∈ 0, 1d die Eingabevektoren µ = 1, . . . , M
• ci ∈ 0, 1d die Gewichtsvektoren der Neuronen (Prototypen)
• 1 = (1, 1, . . . , 1) ∈ 0, 1d der Eins-Vektor mit d Einsen.
• k Anzahl der maximal möglichen Neuronen.
• ‖x‖1 =∑d
i=1 xi die l1-Norm (= Anzahl der Einsen).
• % ∈ [0, 1] der Vigilanzparameter.
Schwenker NI1 166

ART1 : Algorithmus
1. Wähle k ∈ N und % ∈ [0, 1].
2. Setze ci = 1 für alle i = 1, . . . , k.
3. WHILE noch ein Muster x vorhanden DOLies x und setze I := 1, . . . , k
REPEATj∗ = argmaxj∈I〈x, cj〉/‖cj‖1 (winner detection)I = I \ j∗
UNTIL I = ∅ ∨ 〈x, cj∗〉 ≥ %‖x‖1
IF 〈x, cj∗〉 ≥ %‖x‖1
THEN cj∗ = x ∧ cj∗ (winner update)ELSE keine Bearbeitung von x
4. END
Schwenker NI1 167

Verwandte Verfahren : LVQ
• Lernende Vektorquantisierung (LVQ) sind überwachte Lernverfahren zurMusterklassifikation.
• LVQ-Verfahren sind heuristische kompetitive Lernverfahren; entwickelt vonTeuvo Kohonen
• Euklidische Distanz zur Berechnung der Ähnlichkeit/Gewinnerermittlung.
• Es wird nur LVQ1 vorgestellt.
• Erweiterungen: LVQ2 und LVQ3 (ggf. Adaptation des 2. Gewinners);OLVQ-Verfahren (neuronenspezifische Lernraten).
Schwenker NI1 168

LVQ1 : AlgorithmusInput: X = (x1, y1), . . . , (xM , yM) ⊂ R
d × Ω hierbei istΩ = 1, . . . , L eine endliche Menge von Klassen(-Labels).
1. Wähle Prototypenzahl k ∈ N, eine Lernrate lt > 0 und N . Setze t = 0.
2. Initialisiere Prototypen c1, . . . , ck ∈ Rd.
3. Bestimme für jeden Protypen ci die Klasse ωi ∈ Ω.
4. repeat
Wähle Paar (x, y) ∈ X und setze t := t + 1j∗ = argmini‖x − ci‖ (winner detection + class from nearest neighbor)if ωj∗ 6= y then ∆ = −1 else ∆ = 1 (correct classification result?)cj∗ = cj∗ + lt∆(x − cj∗) (winner update)
5. until t ≥ N
Schwenker NI1 169

8.4 Methoden zur Reduktion der Merkmale
• Zielsetzung
• Hauptachsentransformation (lineare Merkmalstransformation)
• Neuronale Hauptachsentransformation (Oja und Sanger Netze)
Schwenker NI1 170

Zielsetzung
1 2 di
12
p
M
i-th feature vector
p-th data point
• Einfache kompetitive Netze wie ART, ad-aptive k-means Clusteranalyse und auchLVQ-Netze führen eine Reduktion der Da-tenpunkte auf einige wenige repräsentati-ve Prototypen (diese ergeben sich durchlineare Kombination von Datenpunkten)durch.
• Kohonen’s SOM: Reduktion der Daten-punkte auf Prototypen und gleichzeitig Vi-sualisierung der Prototypen durch nichtli-neare nachbarschaftserhaltende Projekti-on.
• Nun gesucht Reduktion der Datenpunkteauf repräsentative Merkmale, die sich mög-lichst durch lineare Kombination der vor-handenen Merkmale ergeben.
Schwenker NI1 171

Beispieldaten
−30 −20 −10 0 10 20 30−30
−20
−10
0
10
20
30data
• Variation der Daten in Richtung der beiden definierten Merkmale x1 und x2 ist etwa gleichgroß.
• In Richtung des Vektors v1 = (1, 1) ist die Variation der Daten sehr groß.• Orthogonal dazu, in Richtung v2 = (1,−1) ist sie dagegen deutlich geringer.
Schwenker NI1 172

Hauptachsen
• Offensichtlich sind Merkmale in denen die Daten überhaupt nicht variierenbedeutungslos.
• Gesucht ist nun ein Orthonormalsystem (vi)li=1 im R
d mit (l ≤ d), das dieDaten mit möglichst kleinem Rekonstruktionsfehler (bzgl. der quadriertenEuklidischen Norm) bei festem (l < d) erklärt. Dies sind die sogenanntenHauptachsen.
• 1. Hauptachse beschreibt den Vektor v1 ∈ Rd mit der größten Variation
2. Hauptachse den Vektor v2 ∈ Rd mit der zweitgrößten Variation der senk-
recht auf v1 steht.l. Hauptachse ist der Vektor vl ∈ R
d, vl senkrecht auf Vl−1 =linv1, . . . , vl−1 und die Datenpunkte xµ
r mit xµ = xµr +v, v ∈ linvl haben
in Richtung vl die stärkste Variation.
Schwenker NI1 173

Hauptachsentransformation
• Gegeben sei eine Datenmenge mit M Punkten xµ ∈ Rd, als M × d Daten-
matrix X.
• Die einzelnen Merkmale (sind die Spaltenvektoren in der Datenmatrix X)haben den Mittelwert 0. Sonst durchführen.
• Für einen Vektor v ∈ Rd und xµ ∈ X ist 〈v, xµ〉 =
∑di=1 vi ·xµ
i die Projektionvon xµ auf v.
• Für alle Datenpunkte X ist Xv der Vektor mit den Datenprojektionen.
• Es sei nun (vi)di=1 ein Orthonormalsystem in R
d.
• Sei nun l < d. Für x ∈ Rd gilt dann hierbei ist αi = 〈x, vi〉.
x = α1v1 + . . . + αlvl︸ ︷︷ ︸=:x
+αl+1vl+1 + . . . + αdvd
Schwenker NI1 174

• Dann ist der Fehler zwischen x und x
el(x) := ‖x − x‖22 = ‖
d∑
j=l+1
αjvj‖22
• Gesucht wird ein System vi, so dass el möglichst klein ist:
∑
µ
el(xµ) =
∑
µ
⟨ d∑
j=l+1
αµj vj,
d∑
j=l+1
αµj vj
⟩=
∑
µ
d∑
j=l+1
(αµj )2 → min
Dabei ist (αµj )2
(αµj )2 = αµ
j · αµj = (vt
jxµ)((xµ)tvj) = vt
j(xµ(xµ)t)vj
Schwenker NI1 175

Mitteln über alle Muster liefert:
1
M
∑
µ
d∑
j=l+1
vtj(x
µ(xµ)t)vj =d∑
j=l+1
vtj
1
M
∑
µ
(xµ(xµ)t)
︸ ︷︷ ︸=:R
vj
R ist die Korrelationsmatrix der Datenmenge X.
• Es ist damit folgendes Problem zu lösen:
d∑
j=l+1
vtjRvj → min
• Ohne Randbedingungen an die vj ist eine Minimierung nicht möglich.Normierung der vt
jvj = ‖vj‖2 = 1 als Nebenbedingung.
• Minimierung unter Nebenbedingungen (Siehe auch Analysis 2 (multidi-mensionale Analysis), speziell die Anwendungen zum Satz über implizite
Schwenker NI1 176

Funktionen) führt auf die Minimierung der Funktion
ϕ(vl+1, . . . , vd) =
d∑
j=l+1
vtjRvj −
d∑
j=l+1
λj(vtjvj − 1)
mit Lagrange Multiplikatoren λj ∈ R.
• Differenzieren von ϕ nach vj und Nullsetzen liefert:
∂ϕ
∂vj= 2Rvj − 2λvj = 0
• Dies führt direkt auf die Matrixgleichungen
Rvj = λjvj j = l + 1, . . . , d
• Das gesuchte System (vj)dj=1 sind also die Eigenvektoren von R.
Schwenker NI1 177

• R ist symmetrisch und nichtnegativ definit, dh. alle Eigenwerte λj sind reellund nichtnegativ, ferner sind die Eigenvektoren vj orthogonal, wegen derNebenbedingungen sogar orthonormal.
• Vorgehensweise in der Praxis:
– Merkmale auf Mittelwert = 0 transformieren;– Kovarianzmatrix C = X tX berechnen– Eigenwerte λ1, . . . , λd und Eigenvektoren v1, . . . , vd (die Hauptachsen)
von C bestimmen– Daten X auf die d′ ≤ d Hauptachsen projezieren, d.h. X ′ = X · V mit
V = (v1, v2, . . . , vd′). Die Spalten von V sind also die Eigenvektoren vi.– Dies ergibt eine Datenmatrix X ′ mit M Zeilen (Anzahl der Datenpunkte)
und d′ Merkmalen.
Schwenker NI1 178

Hauptachsentransformierte Beispieldaten
−50 −40 −30 −20 −10 0 10 20 30 40−4
−3
−2
−1
0
1
2
3
4PCA−transformierte Datenpunkte, Mittelwert: −1.09e−16 3.6e−16, Standardabweichung: 10.1 0.996
1. PCA Komponente
2. P
CA
Kom
pone
nte
Schwenker NI1 179

Neuronale PCA - Oja-Lernregel
Ausgabe
c
Eingabe
Gewichtsvektor
x
y=xc
Lineares Neuonenmodell mit Oja-Lernregel
• Lineare Verrechnung der Eingabe x und demGewichtsvektor c
y = 〈x, c〉 =n∑
i=1
xici
• Lernregel nach Oja
∆c = lt(yx − y2c) = lty(x − yc)
• Satz von Oja (1985): Gewichtsvektor c kon-vergiert gegen die 1. Hauptachse v1 (bis aufNormierung), hierbei muss gelten: lt → 0 beit → ∞,
∑t lt = ∞ und
∑t l2t < ∞.
Schwenker NI1 180

Neuronale PCA - Sanger-Lernregel
• Verallgemeinerung auf d′ ≤ d lineare Neuronen mit d′ Gewichtsvektor cj.Die Ausgabe des j-ten Neurons ist dabei:
yj = 〈x, cj〉
• Lernregel nach Sanger
∆cij = ltyj(xi −j∑
k=1
ykcik)
• Satz von Sanger (1989): cl konvergiert gegen die Hauptachsen vl (bis aufNormierung). Es muss gelten lt → 0 bei t → ∞,
∑t lt = ∞ und
∑t l2t < ∞.
Schwenker NI1 181

Sanger-Transformierte Beispieldaten
−50 −40 −30 −20 −10 0 10 20 30 40−4
−3
−2
−1
0
1
2
3
4ermittelte Datenpunkte, Mittelwert: −0.0249 0.0157, Standardabweichung: 10.1 0.993
1. PCA Komponente
2. P
CA
Kom
pone
nte
Schwenker NI1 182












![NER Named Entity Recognition Björn Baumann. PG 520: Intelligence Services [Named Entity Recognition]2 09.10.2007 Gliederung 1. Definition & Zielsetzung](https://img.pdfslide.us/doc/110x75/55204d6149795902118b4c86/ner-named-entity-recognition-bjoern-baumann-pg-520-intelligence-services-named-entity-recognition2-09102007-gliederung-1-definition-zielsetzung.jpg)










![Sicherheit mobiler Apps - OWASP · OWASP OWASP Mobile Security Project Seit 2010 [1] Zielsetzung Entwicklung sicherer mobiler Apps Inhalte Threat Model Controls & Design Principles](https://img.pdfslide.us/doc/110x75/605164d0ec773b48515c5bfe/sicherheit-mobiler-apps-owasp-owasp-owasp-mobile-security-project-seit-2010-1.jpg)



