Embed Size (px)
DESCRIPTION
3D video streaming
Citation preview

1
3D VIDEO STREAMING
Report by: Ashok Banjara
Roll No.-13EC64R21
Design and Simulation Lab
Telecommunication Systems Engineering
Department of E & ECE, IIT Kharagpur

2
CONTENTS
S. No. Topic Name Page Number
1) Abstract………………………………………………………………………………………………………………. 3
2) Introduction………………………………………………………………………………………………………… 4
3) State of the art...…………………………………………………………………………………………………. 8
a. Three-dimensional video formats…………………………………………………………………. 8
b. Three-dimensional video coding……………………………………………………………………. 13
c. Transport protocols………………………………………………………………………………………. 15
d. Adaptive streaming……………………………………………………………………………………….. 17
e. P2P streaming……………………………………………………………………………………………….. 17
4) Conclusions………………………………………………………………………………………………………….. 19
5) References……………………………………………………………………………………………………………. 20

3
ABSTRACT
Three-dimensional (3-D) video is the next natural step in the evolution of digital media technologies.
Stereoscopic TV broadcasts have already begun in frame-compatible format for stereoscopic 3D. Recent
3-D autostereoscopic displays can display multitier video with up to 200 views. While it is possible to
broadcast 3-D stereo video (two views) over digital TV platforms today, streaming over Internet Protocol
(IP) provides a more flexible approach for distribution of stereo and free-view 3-D media to home and
mobile with different connection bandwidths and different 3-D displays. 3D video is destined to be
available in homes and mobile devices. The natural next step is to deliver 3D content in the form of
multiview video (MVV) that enables a natural glasses-free 3D experience. Unfortunately, the number of
views needed to drive multiview displays varies depending on the price vs. quality trade-off. Therefore,
the bitrate requirement of MVV content changes according to users’ display technology, making
transmission over fixed bit rate channels inefficient. IP provides a flexible transport mechanism for 3D
content; however, well known problems such as fluctuations in available link capacity and varying
transmission delays pose challenges to 3D video services over the Internet.

4
1. INTRODUCTION
Stereoscopic 3D has had a significant impact on the movie industry, and public interest in 3D content
has increased over the last decade. At present, broadcast standards exist for stereoscopic 3D in a frame
compatible format, where frames are subsampled to keep the size the same as in conventional 2D
video. Although frame compatible formats have created a seamless solution for transmission of
stereoscopic 3D video, there are serious drawbacks with this approach. First, the perceived visual quality
can be inferior compared to 2D video because the resolution of individual views is lower. Second, the
necessity of wearing glasses is a burden on viewers. There are alternative solutions that use lenticular
sheet technology; however, such autostereoscopic displays have sweet spots, which are narrow and
difficult to keep aligned all the time. With wide availability of low cost stereo cameras, 3-D displays, and
broadband communication options, 3-D media is destined to move from the movie theater to home and
mobile platforms. Finally, the viewing angle of stereoscopic 3D is fixed to a single point of view, and
users do not have the free-view capability that presents a scene from different perspectives. Therefore,
3D is destined to be available in homes and mobile devices in the form of multiview video (MVV).
In the near term, popular 3-D media will most likely be in the form of stereoscopic and multiview video
with associated spatial audio. Transmission of 3-D media, via broadcast or on-demand, to end users with
varying 3-D display terminals (e.g., TV, laptop, and mobile devices) and bandwidths is one of the biggest
challenges to bring 3-D media to the home and mobile devices.
Multiview displays allow users to experience natural depth perception without wearing special glasses
and can present a scene from multiple angles. With each additional view, it is possible to cover a wider
range until the display’s limitation is reached. Therefore, the required number to drive multiview auto-
stereoscopic displays is not fixed but depends on the display technology (based on the price vs. quality
trade-off). The requirement to transmit varying numbers of views according to users’ display capability
is a key challenge in the transmission of MVV contents because the traditional broadcast standards such
as digital video broadcasting (DVB) operate over fixed bit rate channels, assuming that there exists an
upper bound for the bit rate of the content. This is not the case with multiview video.
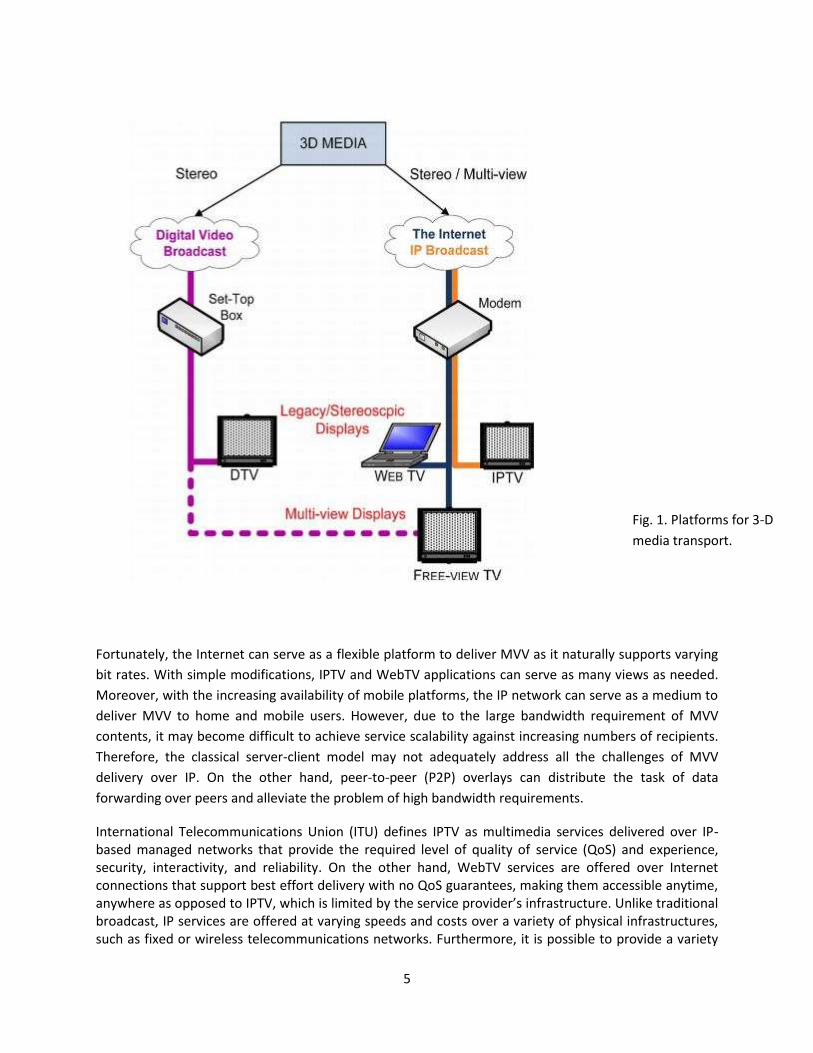
There are two main platforms for 3-D video delivery: digital television (DTV) platforms and the Internet
Protocol (IP) platform, as depicted in Fig. 1. There are already broadcasters, who started 3DTV
broadcasts using a DTV platform. For example, digital video broadcasting (DVB) is a suite of open
standards for DTV, which has already been used to broadcast stereo video using frame-compatible
formats. However, DTV platforms are not well suited to transmit multiview content with variable
number of views to accommodate different 3-D display technologies. On the other hand, the IP
platform, with applications such as IPTV and WebTV, provides a more flexible channel to transmit as
many views as required by the user display terminal and at a quality level allowed by the bandwidth of
each user.
5
Fortunately, the Internet can serve as a flexible platform to deliver MVV as it naturally supports varying
bit rates. With simple modifications, IPTV and WebTV applications can serve as many views as needed.
Moreover, with the increasing availability of mobile platforms, the IP network can serve as a medium to
deliver MVV to home and mobile users. However, due to the large bandwidth requirement of MVV
contents, it may become difficult to achieve service scalability against increasing numbers of recipients.
Therefore, the classical server-client model may not adequately address all the challenges of MVV
delivery over IP. On the other hand, peer-to-peer (P2P) overlays can distribute the task of data
forwarding over peers and alleviate the problem of high bandwidth requirements.
International Telecommunications Union (ITU) defines IPTV as multimedia services delivered over IP-based managed networks that provide the required level of quality of service (QoS) and experience, security, interactivity, and reliability. On the other hand, WebTV services are offered over Internet connections that support best effort delivery with no QoS guarantees, making them accessible anytime, anywhere as opposed to IPTV, which is limited by the service provider’s infrastructure. Unlike traditional broadcast, IP services are offered at varying speeds and costs over a variety of physical infrastructures, such as fixed or wireless telecommunications networks. Furthermore, it is possible to provide a variety
Fig. 1. Platforms for 3-D
media transport.

6
of service architectures such as server–client (unicast) or peer-to peer (multicast) using different transport protocol options, such as HTTP/TCP or RTP/UDP, over the IP platform. Hence, 3-D video encoding methods that offer functionalities such as rate scalability, resolution scalability, view scalability, view selectivity, and packet-loss resilience, without a significant sacrifice from encoding efficiency become a key requirement in order to take full advantage of the flexibility that the IP platform provides. In order to provide the best end-to-end quality of user experience, 3-D video encoding methods and transport mechanisms must be jointly optimized, considering the available network rate, the end-user display terminal, and possibly the human perception of stereoscopy. IP does not guarantee quality of service and poses serious challenges to video streaming applications
that must deliver time-sensitive multimedia content at a desired quality of experience (QoE). Adaptive
streaming is a key technology to handle IP artifacts such as varying link capacity as it can match source
video rate to available capacity. Rate adaptation is more essential in P2P video streaming because peers
have limited upload capacities, making connections more prone to rate fluctuations.
At present, 3DTV can be considered the logical next step for complementing HDTV to incorporate 3D
perception into the viewing experience. Multiview Video (MVV) systems have gained significant interest
recently, particularly in terms of view synthesis approaches. View synthesis usually falls in two
categories: Geometry-Based Rendering (GBR) and Image-Based Rendering (IBR). Typically, GBR exploits
the 3D geometric texture knowledge of the scene, which requires 3D models of the objects. However,
such models require millions of polygons, complex lighting models, extensive texture mapping, and
great computational cost. IBR techniques have received attention as an attractive alternative to GBR for
view synthesis. Instead of 3D geometric primitives, a collection of images are used to generate other
images. Among a variety of IBR techniques, the Layered Depth Image (LDI) is one of the most efficient
synthesizing view methods for complex 3D scenes.
An extension of LDI representation called Layered Depth Video (LDV) has been proposed as a 3D video data representation. LDV is considered suitable associated 3D video data representation that provides one full or central view as a main layer, and additional enhancement layers that include residual texture and depth data to represent the side views. LDV is then both a derivative of and an alternative to Multiview Video-plus-Depth (MVD) representation: it only transmits one full view (with associated residual data) over the channel, and afterwards, the non-transmitted side views are generated by view synthesis as a view transfer between the central and side views. The central view is then projected onto side views by IBR. The problem, however, in that every pixel does not necessarily exist in every view, which results in the occurrence of holes when the central view is projected. View synthesis then exposes the parts of the scene that are occluded in the central view and make them visible in the side views. This is a process known as “disocclusion”. One way of dealing with these disocclusions would be to rely on pre-processing the depth video to allow the reduction of depth data discontinuities in a way that decreases the disocclusions. However, this would mean introducing filtering-induced distortion to the depth video, which would reduce the user’s original depth perception. It is possible to remove disocclusions by considering more complex multi-dimensional data representations, such as LDV data representation, that allow the storage of additional depth and color values for pixels that are occluded in the central view. This extra data provides the necessary information to fill in disoccluded areas in rendered, novel views.

7
One solution suggested by Tauber et al. consists of combining IBR with inpainting techniques to deal with large disocclusions, due to the natural similarity between damaged holes inpaintings and disocclusions in view synthesis. Image inpainting, also known as image completion, fills in pixels in a large missing region with the information derived from the pixels that surround it. A more recent research direction is to consider a combination of DVB and IP platforms to deliver multiview video (MVV) in order to provide free-view TV/video experience. The DVB channel provides a dedicated platform that can be used for transmitting stereoscopic media in frame-compatible format wrapped in MPEG-2 transport stream, but is constrained by the physical channel bandwidth to allow transmitting MVV. The IP platform is more flexible in terms of bandwidth but is not reliable. Server–client or peer-to-peer (P2P) streaming over IP can be used standalone or to supplement the DVB (to deliver additional views) in order to provide free-view 3-D experience.

8
2. STATE OF THE ART
A. Three-Dimensional Video Formats To support 3DTV system requirements, many 3D video data representation have been investigated in
terms of their complexity, efficiency, and functionality according to the following general requirements:
• can utilize as many existing delivery infrastructure and media as possible,
• require minimal change to device components,
• backwards compatibility - it is unacceptable for 3D services to impair existing devices,
• can support a wide range of display devices and allow for future extension,
• are high quality.
Current 3-D video formats can be classified as stereoscopic and multiview as depicted in Fig. 2.
Stereoscopic systems are the most well-known and simple acquisition techniques for 3D video data
representation. Stereoscopic video can provide a 3D impression by using left and right videos as a pair,
thereby creating a stereo camera system, while a monoscopic 2D video cannot. A pair of 2D videos is
acquired: one for the left eye, and the other for the right. As a generalization of stereo video, MVV can
be considered an extension of the stereo video data representation to a higher number of views.
Common stereo video formats are frame-compatible and full resolution (sequential) formats. There are
also depth based representations, which are often preferred for efficient transmission of multiview
video as the number of views increases. Frame-compatible stereo video formats have been developed
to provide 3DTV services over the existing digital TV broadcast infrastructures. They employ pixel
subsampling in order to keep the frame size and rate the same with that of 2-D video.
Fig. 2.Three-dimensional video formats and coding options for fixed-rate and rate-adaptive streaming.

9
Common subsampling patterns include side by side, top and bottom, line interleaved, and
checkerboard. Side-by-side format applies horizontal subsampling to the left and right views, reducing
horizontal resolution by 50%. The subsampled frames are then put together side by side. Likewise, top
and-bottom format vertically subsamples the left and right views, and stitches them over–under. In the
line interleaved format, the left and right views are again subsampled vertically, but put together in an
interleaved fashion. Checkerboard format subsamples left and right views in an offset grid pattern and
multiplexes them into a single frame in a checkerboard layout. Among these formats, side by side and
top and bottom are selected as mandatory for broadcast by the latest HDMI specification 1.4a.
Fig. 3. Multiplexing stereo video
Frame packing, which is the mandatory format for movie and game content in the HDMI specification
version 1.4a, stores frames of left and right views sequentially, without any change in resolution. This
format, which supports full HD stereo video, requires, in the worst case, twice as much bandwidth of
monocular video. The extra bandwidth requirement may be kept around 50% if we use the multiview
video coding (MVC) standard, which is selected by the Blu-Ray Disc Association as the coding format for
3-D video.
Multiview autostereoscopic displays project multiple views into the viewing zone at the same time
essentially, the consecutive views act like stereo pairs (Fig. 4). As a result, head motion parallax viewing
can be supported within practical limits, but the amount of data to be processed and transmitted
increases significantly compared to using conventional stereo data or 2D video. The development of a
wide range of multiview autostereoscopic displays and MVV applications increases the number of
output video needs. Users can therefore choose their own viewpoint (e.g. Super bowl XXXV sport event,

10
bullet time effect, etc). Advanced 3D video applications like this require a 3D video format that can
render a continuum of output views or a very large number of different output views at the decoder
side. MVV formats are still not sufficient to support such requirements without extensively increasing
the number of input views and consequently the bandwidth.
Fig. 4. Efficient support of multiview autostereoscopic displays based on MVV content.
Video-plus-depth data representation has been introduced to overcome this issue. It can respond to the
stereoscopic vision needs at the receiver side as shown in Fig. 5, and at the same time decrease
dramatically the transmission bandwidth compared to the conventional stereo video data
representation. Initially studied in the computer vision field, the video-plus-depth format provides a
regular 2D video enriched with its associated depth video (see Fig. 6).
Fig. 5. Efficient support of stereo autostereoscopic displays based on video-plus-depth content.

11
Fig. 6. Texture picture and its associated depth map.
The 2D video provides the texture information, the color intensity, and the structure of the scene, while
the depth video represents the -distance per-pixel between the optical center of the camera and a 3D
point in the visual scene. Hereafter, the 2D video may be denoted as texture video in opposition to the
depth video.
Great effort has been made to estimate depth information from multiple 2D video inputs. Thanks to
recent advances in semiconductor processes, it is possible to directly capture depth video using a time-
of-flight (TOF) camera, also known as a depth camera. The TOF camera is based on TOF technology that
measures the distance between the camera and the scene in real time. This camera emits infrared light
that is reflected by the environment and then comes back to the camera’s sensor. The traveling time of
the light is then measured for each pixel of the sensor and used to compute the depth of the scene. The
depth video can be regarded as a monochromatic texture-less video signal. Generally, the depth data is
quantized with 8 bits, i.e., the closest point is associated with the value 255 and the most distant point is
associated the value 0. With that, the depth video is specified as a smoothed gray level representation.
At the client side, the second color video corresponding to the second view is reconstructed from the
transmitted video-plus-depth data by means of depth image based rendering (DIBR) techniques. The
ability to generate a stereoscopic video from video-plus-depth data at the receiver side is an extended
functionality compared to conventional stereo video data representation. Consequently, the 3D
impression can be adjusted and customized after transmission. However, because view-synthesis-
induced artifacts increase dramatically with the distance of the rendered viewpoint, video-plus-depth
can support only a very limited continuum around the available original view. To overcome this issue,
MPEG started an activity developing a 3D video standard that would support these requirements. This
standard is based on a video-plus-depth (MVD) format as shown in Fig. 7. Video-plus-depth data is
combined with multiview video (MVV) data to form the MVD format, which consists of multiple 2D
videos, each of which has an associated depth video.

12
Fig. 7. Efficient support of multiview autostereoscopic displays based on MVD content.
The final step in this process is rendering multiple intermediate views from the received data by DIBR. At
this point, the central and side views are fully processed and transmitted. As an alternative to fully
transmitting the side views in addition to the central view, LDV can decrease redundancies between the
views by only considering the central view as the main layer and some residual data as enhancement
layers. This new representation can deliver targets high-quality, high-resolution images with lower
bitrates than those deliver by MVD.
We will describe residual layer generation within a three video camera system composed of one central
and two side views (left and right), as illustrated in Fig. 7. The generation process can be separated into
two main parts. First, the central view is transferred to each side view by DIBR using the given depth
video. This process is called as 3D warping.
Fig. 8. 3D image warping: Projection of a 3D point on two image planes in homogeneous coordinates

13
Next, by subtraction, it is possible to determine which parts of the side views are covered in the central
view. These are then assigned as residual data for texture and depth and transmitted while the rest is
omitted. This process includes a function for mapping points from the central view (the reference image
plane) to the side views (the targeted image plane) as illustrated in Fig. 8 and Fig. 9.
Fig. 9. Advanced LDV-based 3DTV concept; Pos: viewpoint, R: right eye, L:left eye, V: view/image, D:
depth, RV: Residual Video Layer, RD: Residual Depth Layer.
B. Three-Dimensional Video Coding The method of choice for 3-D video encoding should depend on the transport option and raw video
format. For example, for transmission of stereo video over fixed bandwidth broadcast channels, a
nonscalable monocular video codec, such as H.264/AVC, can be used to encode stereo video in one of
frame-compatible formats. Adaptive streaming of stereo and MVV in sequential or multiview-plus-depth
formats have two main options.
1. Simulcast encoding: encode each view and/or depth map independently using a scalable or
nonscalable monocular video codec, which enables streaming each view over separate
channels; and clients can request as many views as their 3-D displays require without worrying
about inter-view dependencies.

14
2. Dependent encoding: encode views using MVC to decrease the overall bit rate by exploiting the
inter-view redundancies. We note that, in this case, special inter-view prediction structures
must be employed to enable view-scalable and view-selective adaptive streaming.
It is also possible to exploit features of the human visual system (HVS) to achieve more efficient
compression by degrading the quality of one of the views without introducing noticeable artifacts. This
approach is known as asymmetric coding. We review some common encoding options for adaptive
streaming of 3-D video in more detail below.
1) Simulcast View Coding Using SVC: Simulcast coding using the SVC standard refers to producing
scalable 3-D video, where each view is encoded independently. Here, two approaches can be
followed for scalability: either all views can be coded scalable, or some views can be coded
scalable using SVC and others can be coded nonscalable using H.264/AVC.
The SVC, which is an annex of the advanced video coding (AVC) standard, provides spatial,
temporal, and quality scalability. SVC provides temporal scalability through the usage of
hierarchical prediction structures, whereas spatial and quality scalability are supported by
multilayer coding. Quality scalability is supported in two modes: coarse-grained scalability (CGS)
and medium grained scalability (MGS). CGS, also called layer-based scalability, is based on the
multilayer concept of SVC, meaning that rate adaptation should be performed on complete
layer basis. However, MGS concept allows any enhancement layer network abstraction layer
(NAL) unit, to be discarded from a quality scalable bit stream in decreasing ‘quality_id’ order,
providing packet based scalability. Also, it is possible to fragment an MGS layer into multiple
sublayers by grouping zigzag scanned transform coefficients and in this way increase the
number of rate adaptation points.
2) Multiview Extension of H.264/AVC: MVC aims to offer high compression efficiency for MVV by
exploiting interview redundancies. It is based on the high profile of H.264/AVC, and features
hierarchical B-pictures and flexible prediction structures. In one extreme, each frame can be
predicted only from frames of the same view, which is simulcast coding. In another extreme,
frame prediction spans all views, which is called full prediction, at the cost of complex
dependency hierarchy. A simplified prediction scheme is proposed that restricts inter-view
prediction to only anchor pictures, and still achieves similar RD performances. An illustration of
prediction structures for a video with five views is depicted in Fig. 10. In MVC, it is important to
perform proper illumination compensation either by preprocessing or by weighted inter-view
prediction within the coding loop. Also, large disparity or different camera calibration among
views may adversely affect the performance of MVC.
Although there has been some work on scalable MVC, they either utilize a subset of scalability
options or MVC prediction schemes. Current implementation of the reference MVC software
(JMVC 7.0) offers only temporal and view scalability, but no quality or resolution scalability.
Effect of scalability options on subjective quality of MVV is a current research area and the
results are very likely to be dependent on the content and/or 3-D display.

15
Fig. 10.Prediction structures for asymmetric MVC encoding. (a) Full prediction scheme. (b)
Simplified prediction scheme.
3) Multiview-Plus-Depth Coding: In this option, selected views and associated depth maps can be
either simulcast or dependently encoded using nonscalable or scalable codecs. It is also possible
to exploit correlations between the texture video and associated depth maps. For example, SVC
is employed to compress texture videos and associated depth maps jointly, where up to 0.97-dB
gain is achieved for the coded depth maps, compared with the simulcast scheme.
4) Asymmetric Stereoscopic Video Coding: Naturally, stereoscopic video requires higher bit rates
than monocular video. Another method to decrease the overall transmission rate is to exploit
the human visual system, which is known to tolerate lack of high-frequency components in one
of the views. Hence, one of the views may be presented at a lower quality without degrading
the 3-D video perception. This is similar to what is being done with monocular video in which
the chrominance channels can be represented using fewer bits than the luminance, because
human eye is less perceptive to changes in color. In asymmetric MVC coding, where alternating
views are coded at high and low quality, the inter-view dependencies should be carefully
constructed. Fig. 10 depicts a scheme in which the views are predicted only from high-quality
views in order to achieve better prediction.
C. Transport Protocols Being the de facto reliable transport protocol of the Internet, the Transmission Control Protocol (TCP) is
the first that comes to mind when to send data over IP. But it may be unsuitable to use TCP for
streaming live video with a strict end-to-end delay constraint, due to TCP’s lack of control on delay and

16
its rapidly changing transmission rate. On the other hand, TCP is the easiest choice for streaming stored
media, with its built-in congestion control, reliable transmission, and firewall friendliness, making it the
most used transport protocol to stream stored media over the Internet. Popular video distribution sites,
such as YouTube, Vimeo, and Metacafe, use HTTP over TCP to stream video to clients. Moreover, it has
been shown that using TCP for streaming video provides good performance when the available network
bandwidth is about twice the maximum video rate, with a few seconds pre-roll delay.
An alternative to streaming video over TCP is UDP, which does not accommodate TCP’s built-in
congestion control and reliable, in order packet delivery, leaving their implementations to the
application layer. Since congestion control is crucial for the stability of the Internet, it should be
implemented by the applications using UDP, which is not a straightforward task. Moreover, UDP is not
firewall friendly, thanks to its connectionless nature. For these reasons, UDP is not as popular as TCP for
streaming video over the Internet, used by media streaming servers such as Windows Media Server. On
the other hand, video conferencing systems such as Skype and Vidyo utilize UDP for media delivery;
however, they base their fail over scenarios on TCP.
The datagram congestion control protocol (DCCP) is a new transport protocol, implementing
bidirectional unicast connections of congestion-controlled, unreliable datagrams, which accommodates
a choice of modular congestion control mechanisms, to be selected at connection startup. DCCP is
designed for applications like streaming media, which does not prefer to use TCP due to arbitrary long
delays that can be introduced by reliable in-order delivery and congestion control, and which does not
like to implement the complex congestion control mechanism that is absent in UDP. It has been shown
that DCCP outperforms TCP under congestion when a video streaming scenario is considered. Moreover,
the performance of streaming video over DCCP in heterogeneous networks is compared with UDP and
the stream control transmission protocol (SCTP); and it is concluded that DCCP achieves better results
than SCTP and UDP. Real-time transport protocol (RTP) is an application layer protocol enabling end-to-
end delivery of media services. RTP defines a packetization format that identifies the payload type,
orders data packets, and provides timestamps to be used in media playout. RTP is typically run on top of
UDP, and may easily be used with DCCP or SCTP, but a framing mechanism is required in case it is used
over TCP. RTP is usually used together with the real-time transport control protocol (RTCP), which
monitors transmission statistics and QoS information. These transport protocols, shown in Fig. 11, can
be easily adopted in 3-D video streaming with little or no change at all.
Fig. 11.Streaming protocol stacks
When a 3-D multicast scenario is considered, the views that compose the video are usually transmitted
over separate multicast channels, so that the clients can subscribe to as many channels as they want,

17
depending on their download capacity or display characteristics. For 3-D unicast, multiplexing all views
on a single connection may utilize the available network better in case a TCP compatible congestion
control scheme is used and the views are encoded at unequal rates. This is because TCP compatible
congestion control schemes tend to divide available bandwidth equally among connections sharing the
same bottleneck link. When unequal rates are allocated to views that are sent over separate network
connections, views demanding lower rates will be overprovisioned while the ones with high bit rate
requirements will not get the network share they need. It should be noted that each video packet
should carry a view identifier, as implemented by the MVC, so the receiver can distinguish the packets of
one view from the other, in case of using a single connection. If multiplexing views on a single
connection to overcome this fairness issue is not an option, then each view with high bit rate may be
split over multiple connections for fairness.
D. Adaptive Streaming For adaptive streaming, a mechanism should exist to estimate the network conditions so as to adapt the
video rate accordingly, in order to optimize the received video quality. This estimation can be performed
by requesting receiver buffer occupancy status information to prevent buffer underflow/overflow or by
combining the receiver buffer status with bandwidth estimation. A virtual network buffer between the
sender and the receiver is employed together with end-to-end delay constraints to adapt the video
transmitted, while the same virtual network buffer algorithm is also utilized to implement source rate
control and congestion control jointly. Packets may be sent depending on their RD values. In case DCCP
is used, with the TCP friendly rate control (TFRC) congestion control method selected, the TFRC rate
calculated by DCCP can be utilized by the sender to estimate the available network rate. When the video
is streamed over TCP, an average of the transmission rate can be used to determine the available
network bandwidth.
How to adapt the video rate to the available bandwidth depends on the encoding characteristics of the
views. One or more views can be encoded multiple times with varying bit rates, where the sender can
switch between these streams according to the network conditions. Alternatively, in HTTP live
streaming, the client selects from a number of streams containing the same material encoded at a
variety of data rates in order to adapt to the available network rate. A more elegant solution is encoding
views once with multiple layers using SVC and switching between these layers. Another video
adaptation scheme is real-time encoding with source rate control. Even SVC encoding can be performed
in real time. However, real-time encoding of MVV is difficult due to high computational requirements as
the number of views grows.
E. P2P Streaming The server–client unicast streaming model is not scalable by its nature, that is, it is difficult to serve an
increasing number of clients without expanding the bandwidth capacity or creating a large content
distribution network (CDN). The most important advantage of P2P solutions over traditional server–
client architecture is scalable media distribution. These solutions aim to reduce the bandwidth
requirement of the server by utilizing the network capacity of the clients, now called peers.

18
In theory, it is possible to originate only a single copy from a source and duplicate the packets along the
path to different peers at the network layer. This could have been the best solution for the scalability
problem but unfortunately multicasting at the network layer has not been implemented. Current P2P
solutions use overlay networks in which the data are redirected to another peer by the application at
the edge platforms and multiple copies of the data traverse the IP network. It is evident that relying on
peers that may leave the network or stop data transmission anytime has its drawbacks but there are
already successful P2P video applications that have managed to solve such issues. It is possible to
examine these solutions under two extremes: tree-based (structured) and mesh-based (unstructured)
solutions.

19
3. CONCLUSIONS
We review three adaptive streaming solutions for distribution of 3-D media. The first, asymmetric streaming can be utilized for displays with limited number of views, such as five views or less. We note that the visual experiments on asymmetric coding have been conducted so far on short video clips, and some experts claim viewing asymmetric-coded stereo video over longer periods may cause eye fatigue, which needs to be studied further. If this is the case, asymmetric streaming only during periods of congestion may be more desirable. The second and third methods, streaming using MVD and selective streaming, respectively, are intended for displays that support more views, such as 5–200 views. Selective streaming requires tracking a viewer’s head position; hence it is applicable in case of a single user with a head tracking 3-D display. Thus, adaptive streaming using the MVD representation seems to be better suited for general purpose multiview video applications with more than five views. Broadcast of stereoscopic 3-D media over digital TV platforms has already started. However, these platforms cannot provide sufficient bandwidth to broadcast multiview video due to physical channel limitations. Hence, we foresee that, in the medium term, multiview video services will be developed using the second method and these services will be deployed over the IP platform using various architectures, including server–client and P2P.

20
4. REFERENCES
C. Göktug Gürler and Murat Tekalp, Koç University, “Peer-to-peer system design for adaptive 3D
video streaming”, IEEE Commun. Mag., vol. 51, no. 5, 2013, pp. 108-114.
Gürler, C.G. ; Dept. of Comput. Eng., Koc Univ., Istanbul, Turkey ; Görkemli, . ; Saygili,
G. ; Tekalp, A.M.,“Flexible Transport of 3-D Video Over Networks”, Proceedings of the IEEE, vol.
99, no. 4, 2011, pp. 694-707.
Ismaël Daribo and Hideo Saito, “A Novel Inpainting- ased Layered Depth Video for 3DTV,” IEEE
Transactions on Broadcasting, vol. 57, no. 2, June 2011
K. Muller, A. Smolic, K. Dix, P. Kauff, and T. Wiegand, “Reliabilitybased generation and view
synthesis in layered depth video,” inProc. IEEE Workshop Multimedia Signal Process. (MMSP),
Cairns, Queensland, Australia, Oct. 2008, pp. 34–39.





























