Embed Size (px)
Citation preview

2012
Etudiants:
Aurelia ISTRATII
Taylan KUNAL
Luis MACAVILCA
Master 2 – Ingénierie Economique et Financière
01/04/2012
Econométrie de la volatilité et de
la VaR
Modélisation ARCH – GARCH

Table of Contents
I - Constitution d’un portefeuille d’actifs financiers ......................................................................................... 4
I – 1. Représentation graphique des cours : ................................................................................................... 4
I – 2. Représentation graphique des rendements et statistiques descriptives ................................................ 5
II - Modélisation GARCH univariée ................................................................................................................. 9
II – 1. Détermination des paramètres du modèle GARCH (p, q): ................................................................. 9
II – 2. Modélisation des modèles de types ARCH sous la loi normale : ..................................................... 12
II – 2.a Modélisation GARCH (1,2) .................................................................................................. 12
II – 2.b Modélisation IGARCH (1,2) : ............................................................................................... 14
II – 2.c Modélisation EGARCH (1,2) : .............................................................................................. 16
II – 2.d Modélisation GARCH - M(1,1) : .......................................................................................... 18
II – 2.e Résumé des résultats obtenus précédemment : ...................................................................... 21
II – 3. Modélisation des modèle de types ARCH sous la loi de Student : ................................................... 22
II – 3.a Modélisation GARCH (1,2) : ................................................................................................ 22
II – 3.b Modélisation IGARCH (1,2) : ............................................................................................... 24
II – 3.c Modélisation GARCH-M (1,2) : ........................................................................................... 26
II – 3.d Résumé des résultats obtenus précédemment : ...................................................................... 28
III - Calcul de la Value at Risk ........................................................................................................................ 29
III – 1. Presentation de la Value at Risk ...................................................................................................... 29
III – 2. Backtesting ...................................................................................................................................... 29
III – 2.a La couverture non conditionnelle .......................................................................................... 30
III – 2.b Test de Kupiec: ...................................................................................................................... 30
III – 2.c Test de Kupiec pour la modèle EGARCH sous la loi normale et comparaison
avec les rendements ................................................................................................................................. 31
III – 3.d Test de Kupiec pour la modèle IGARCH sous la loi de student et comparaison
avec les rendements : ............................................................................................................................... 32

III – 2.e Choix du modèle de prévision ............................................................................................... 34
IV - Calcul de la Value at Risk Out of Sample ............................................................................................... 35
IV – 1. Prévision glissante sur 250 jours de la Value at Risk Out Sample : ............................................... 35
IV – 2. Backtesting : .................................................................................................................................... 37
V - Prévisions de VaR à 10 jours – tests ex-post ............................................................................................ 41
Conclusion ....................................................................................................................................................... 44
Annexe : Code SAS ......................................................................................................................................... 45

I - Constitution d’un portefeuille d’actifs financiers
L’objectif de notre projet est de proposer des prévisions de VaR sur les rendements d’un
Portefeuille composé de trois actifs bancaires. La Var est une mesure des pertes potentielles d’un
titre ou d’un portefeuille financier. C’est un outil de mesure du risque dont se servent les
investisseurs dans leurs choix stratégiques. Sa modélisation est l’une des problématiques les plus
étudiées en finance car l’enjeu d’une bonne maitrise de la Var est nécessaire dans ce contexte
financier très volatile, de plus en plus imprévisible et sous la menace permanente d’une crise.
Notre choix portera sur trois grandes entreprises françaises de CAC 40 : Société Générale,
Michelin et Danone.
Notre portefeuille est construit de la manière suivante : WSocGen =1/2, WMichelin = ¼, WDanone = ¼.
Les cours de ces trois titres ont été téléchargés depuis http://finance.yahoo.com/.
Pour que notre étude soit fidèle à la réalité, nous prendrons un l’historiques des cours journaliers
sur une période de 9 ans débutant le 1er janvier 2003 et terminant le 29 février 2012.
I – 1. Représentation graphique des cours :

On constate que les titres Michelin et Danone sont relativement corrélés. La crise financière a eu
un impact important sur Société Générale et Michelin, alors que sur Danone l’impact est moins
important, le cours restant à peu près constant dans le temps.
I – 2. Représentation graphique des rendements et statistiques
descriptives
Statistiques descriptives
rend
-0.12
-0.11
-0.10
-0.09
-0.08
-0.07
-0.06
-0.05
-0.04
-0.03
-0.02
-0.01
0.00
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.10
0.11
0.12
0.13
0.14
0.15
0.16
0.17
0.18
0.19
Date
01/01/2003 01/01/2004 01/01/2005 01/01/2006 01/01/2007 01/01/2008 01/01/2009 01/01/2010 01/01/2011 01/01/2012 01/01/2013
Representation graphique des rendements du portefeuille
Moments
N 2356 Sum Weights 2356
Mean 0.00014706 Sum
Observations
0.34646538
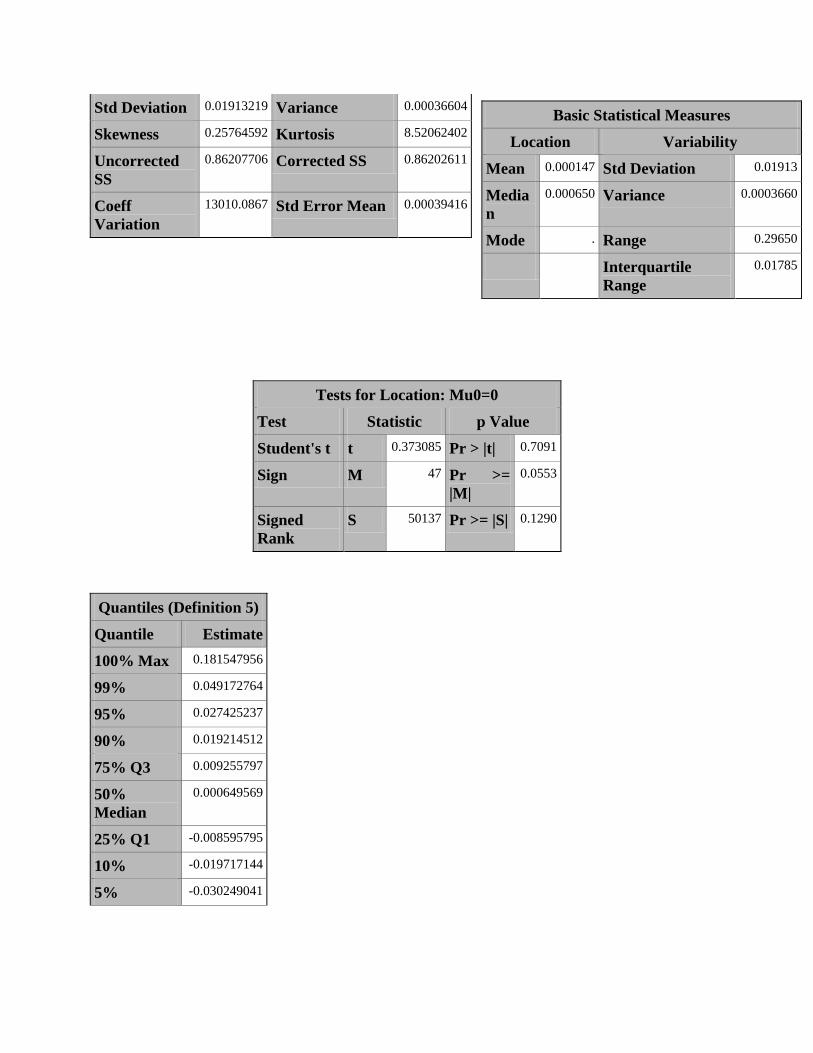
Tests for Location: Mu0=0
Test Statistic p Value
Student's t t 0.373085 Pr > |t| 0.7091
Sign M 47 Pr >=
|M|
0.0553
Signed
Rank
S 50137 Pr >= |S| 0.1290
Quantiles (Definition 5)
Quantile Estimate
100% Max 0.181547956
99% 0.049172764
95% 0.027425237
90% 0.019214512
75% Q3 0.009255797
50%
Median
0.000649569
25% Q1 -0.008595795
10% -0.019717144
5% -0.030249041
Std Deviation 0.01913219 Variance 0.00036604
Skewness 0.25764592 Kurtosis 8.52062402
Uncorrected
SS
0.86207706 Corrected SS 0.86202611
Coeff
Variation
13010.0867 Std Error Mean 0.00039416
Basic Statistical Measures
Location Variability
Mean 0.000147 Std Deviation 0.01913
Media
n
0.000650 Variance 0.0003660
Mode . Range 0.29650
Interquartile
Range
0.01785

Quantiles (Definition 5)
Quantile Estimate
1% -0.055171664
0% Min -0.114947674
Graphiques des statistiques descriptives
Histogram # Boxplot
0.19+* 1 *
.
.
0.13+* 2 *
.* 2 *
.* 1 *
0.07+* 8 0
.** 38 0
.******** 168 0
0.01+************************************************ 1005 +--+--+
.******************************************* 900 +-----+
.********* 171 0
-0.05+** 41 0
.* 13 0
.* 5 *
-0.11+* 1 *
----+----+----+----+----+----+----+----+----+---
* may represent up to 21 counts
Normal Probability Plot
0.19+ *
|
|
0.13+ *
| *
| *
0.07+ *
| ******
| ++********
0.01+ **************
| *************
| +*******++
-0.05++*****
|**
|*
-0.11+*
+----+----+----+----+----+----+----+----+----+----+
-2 -1 0 +1 +2
Extreme Observations
Lowest Highest
Value
Ob
s Value Obs
-0.1149477 2272 0.103861 2247
-0.0946289 2219 0.118188 1472
-0.0945482 2213 0.123055 1888
-0.0938308 1498 0.125352 2269
-0.0835047 1483 0.181548 1153
Missing Values
Missin
g
Value
Coun
t
Percent Of
All
Obs
Missin
g Obs
. 1 0.04 100.00

Interprétations :
Le rendement moyen est de 0.000147 sur la période. Le rendement médian (c’est-à-dire celui
pour lequel 50% des rendements ont été à la fois inférieurs et supérieurs) est de 0.0006495 ce qui
est supérieure à la moyenne des rendements, on a donc l’intuition que les baisses de cours sont
plus conséquentes que les hausses. L’écart-type étant de 0.0191 (plus de 100 fois la moyenne), on
peut considérer que la volatilité des rendements est forte. Le coefficient d’asymétrie est de
0.25764592, il y a donc une symétrie à droite et cela signifie que la moyenne est plus grande que
la médiane.
Le coefficient d’aplatissement est une quantité mesurant l’épaisseur des queues de la distribution,
ce dernier vaut 8.52062402 , ce qui signifie que les queues sont plus épaisses que celles de la loi
normale.
La distribution des rendements du portefeuille ne suit donc pas tout à fait ceux d’une loi normale.

II - Modélisation GARCH univariée
Les modèles de types ARCH « AutoRegressive Conditional Heteroskedasticity » sont utilisés
pour caractériser et modéliser le comportement des séries temporelles dont la volatilité dépend
des innovations passées.
Ces modèles ont été introduit en 1982 par Engle et se divise en plusieurs catégories : GARCH,
GARCH (p,q), NGARCH, IGARCH, EGARCH…
L’utilisation de la méthode ARCH choisie nous permettra de modéliser la volatilité des
rendements des séries constituant notre portefeuille.
On utilise deux types de représentations :
La variance conditionnelle hétéroscédastique :
V(rt+1/ f(t, β) Où β représente un ensemble de variables explicatives ou les propres
observations passées de la série.
La variance non conditionnellement hétéroscédastique :
V(rt+1
II – 1. Détermination des paramètres du modèle GARCH (p, q):
La première étape consiste à déterminer les ordres du modèle où :
p représente le nombre de retard de la partie MA et q le nombre de retard de la partie AR
du processus des rendements du portefeuille.
Pour identifier le nombre de retard sous SAS, on créer la procédure ARIMA qui nous
permet d’identifier, d’estimer puis de prévoir le modèle.

Résultats :
On constate une autocorrélation des rendements. Nous vérifions ensuite l’absence d’autocorrélation par le test du portemanteau.
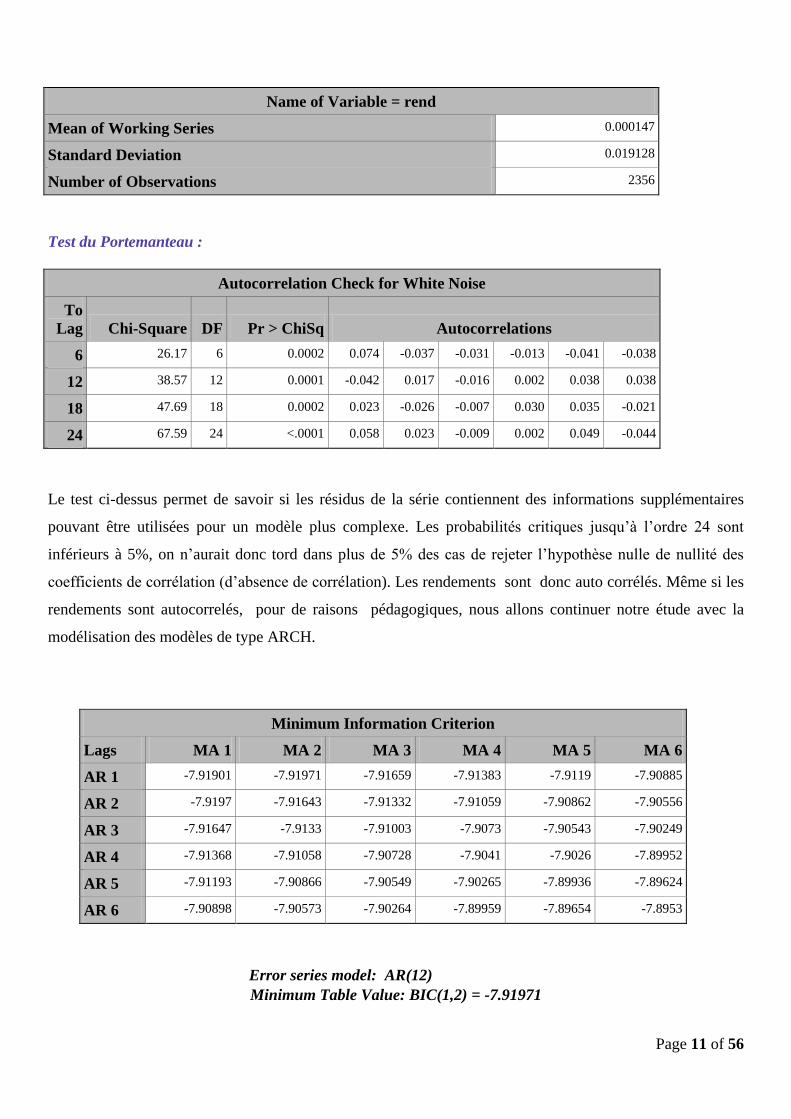
Page 11 of 56
Name of Variable = rend
Mean of Working Series 0.000147
Standard Deviation 0.019128
Number of Observations 2356
Test du Portemanteau :
Autocorrelation Check for White Noise
To
Lag Chi-Square DF Pr > ChiSq Autocorrelations
6 26.17 6 0.0002 0.074 -0.037 -0.031 -0.013 -0.041 -0.038
12 38.57 12 0.0001 -0.042 0.017 -0.016 0.002 0.038 0.038
18 47.69 18 0.0002 0.023 -0.026 -0.007 0.030 0.035 -0.021
24 67.59 24 <.0001 0.058 0.023 -0.009 0.002 0.049 -0.044
Le test ci-dessus permet de savoir si les résidus de la série contiennent des informations supplémentaires
pouvant être utilisées pour un modèle plus complexe. Les probabilités critiques jusqu’à l’ordre 24 sont
inférieurs à 5%, on n’aurait donc tord dans plus de 5% des cas de rejeter l’hypothèse nulle de nullité des
coefficients de corrélation (d’absence de corrélation). Les rendements sont donc auto corrélés. Même si les
rendements sont autocorrelés, pour de raisons pédagogiques, nous allons continuer notre étude avec la
modélisation des modèles de type ARCH.
Minimum Information Criterion
Lags MA 1 MA 2 MA 3 MA 4 MA 5 MA 6
AR 1 -7.91901 -7.91971 -7.91659 -7.91383 -7.9119 -7.90885
AR 2 -7.9197 -7.91643 -7.91332 -7.91059 -7.90862 -7.90556
AR 3 -7.91647 -7.9133 -7.91003 -7.9073 -7.90543 -7.90249
AR 4 -7.91368 -7.91058 -7.90728 -7.9041 -7.9026 -7.89952
AR 5 -7.91193 -7.90866 -7.90549 -7.90265 -7.89936 -7.89624
AR 6 -7.90898 -7.90573 -7.90264 -7.89959 -7.89654 -7.8953
Error series model: AR(12)
Minimum Table Value: BIC(1,2) = -7.91971

Page 12 of 56
Pour modéliser notre processus, on choisit p = 1 et q =2, paramètres optimaux qui minimisent le critère de
Schwarz.
II – 2. Modélisation des modèles de types ARCH sous la loi normale :
II – 2.a Modélisation GARCH (1,2)
Les processus GARCH sont similaires aux processus ARMA usuels dans le sens où le degré q apparaît
comme le degré e » la partie de la moyenne mobile et p comme celui de l’autorégressive ; cela permet
d’introduire des effets d’innovations. La variance conditionnelle est déterminée par le carré des p erreurs
précédentes et des q variances conditionnelles passées.
Dependent
Variable
rend
Ordinary Least Squares Estimates
SSE 0.86202611 DFE 2355
MSE 0.0003660 Root MSE 0.01913
SBC -11949.673 AIC -11955.438
MAE 0.01287403 AICC -11955.436
MAPE 103.654182 HQC -11953.339
Durbin-
Watson
1.8523 Regress R-
Square
0.0000
Total R-Square 0.0000
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Intercep
t
1 -0.000147 0.000394 -0.37 0.7091
WARNING: Optimization cannot improve the function value.
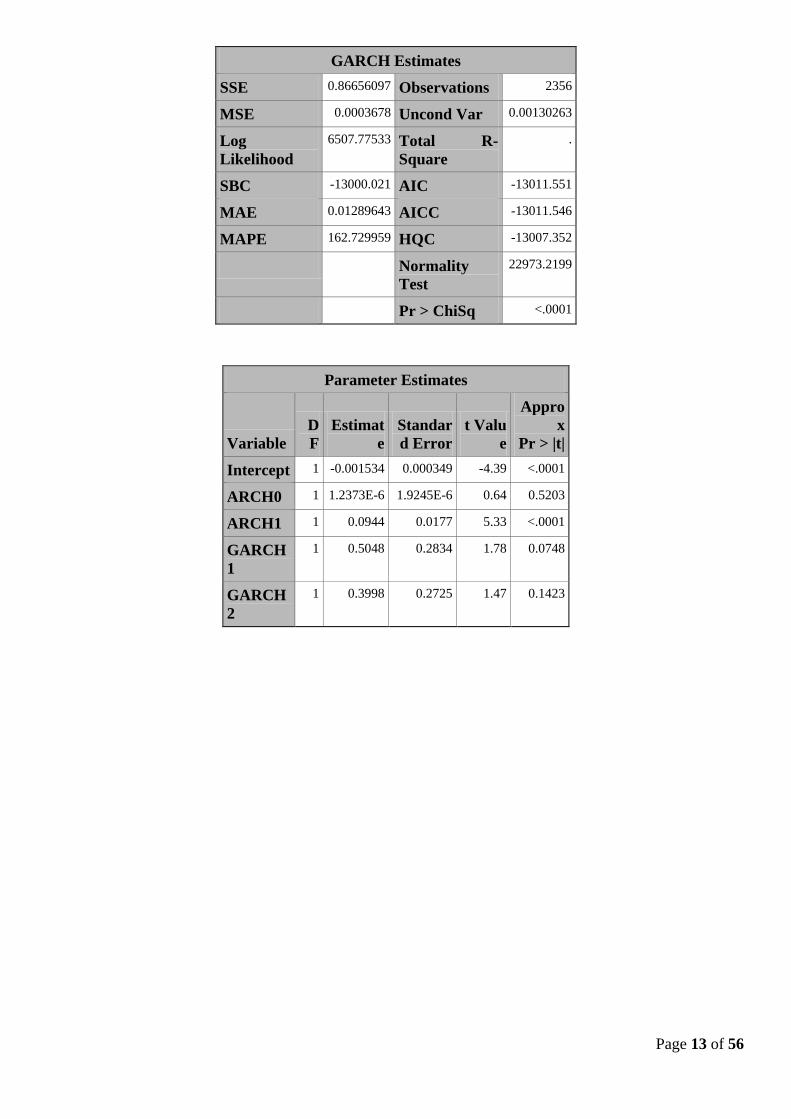
Page 13 of 56
GARCH Estimates
SSE 0.86656097 Observations 2356
MSE 0.0003678 Uncond Var 0.00130263
Log
Likelihood
6507.77533 Total R-
Square
.
SBC -13000.021 AIC -13011.551
MAE 0.01289643 AICC -13011.546
MAPE 162.729959 HQC -13007.352
Normality
Test
22973.2199
Pr > ChiSq <.0001
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Intercept 1 -0.001534 0.000349 -4.39 <.0001
ARCH0 1 1.2373E-6 1.9245E-6 0.64 0.5203
ARCH1 1 0.0944 0.0177 5.33 <.0001
GARCH
1
1 0.5048 0.2834 1.78 0.0748
GARCH
2
1 0.3998 0.2725 1.47 0.1423

Page 14 of 56
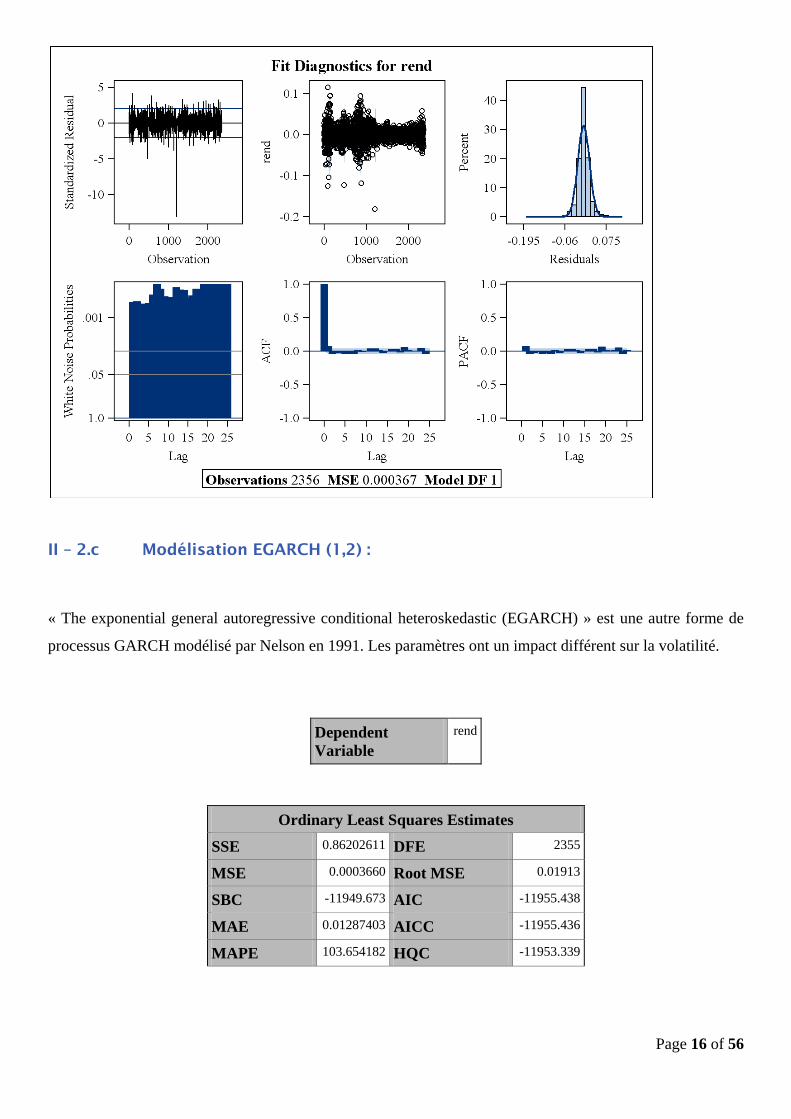
II – 2.b Modélisation IGARCH (1,2) :
« Integrated Generalized Autoregressive Conditional Heteroskedasticity IGARCH” est une version
restrictive du modèle GARCH, où les paramètres persistant sont sommés à un seul et il y’a par conséquent la
présence d’une racine unitaire dans le processus GARCH.
Dependent
Variable
rend
Ordinary Least Squares Estimates
SSE 0.86202611 DFE 2355
MSE 0.0003660 Root MSE 0.01913
SBC -11949.673 AIC -11955.438
MAE 0.01287403 AICC -11955.436
MAPE 103.654182 HQC -11953.339
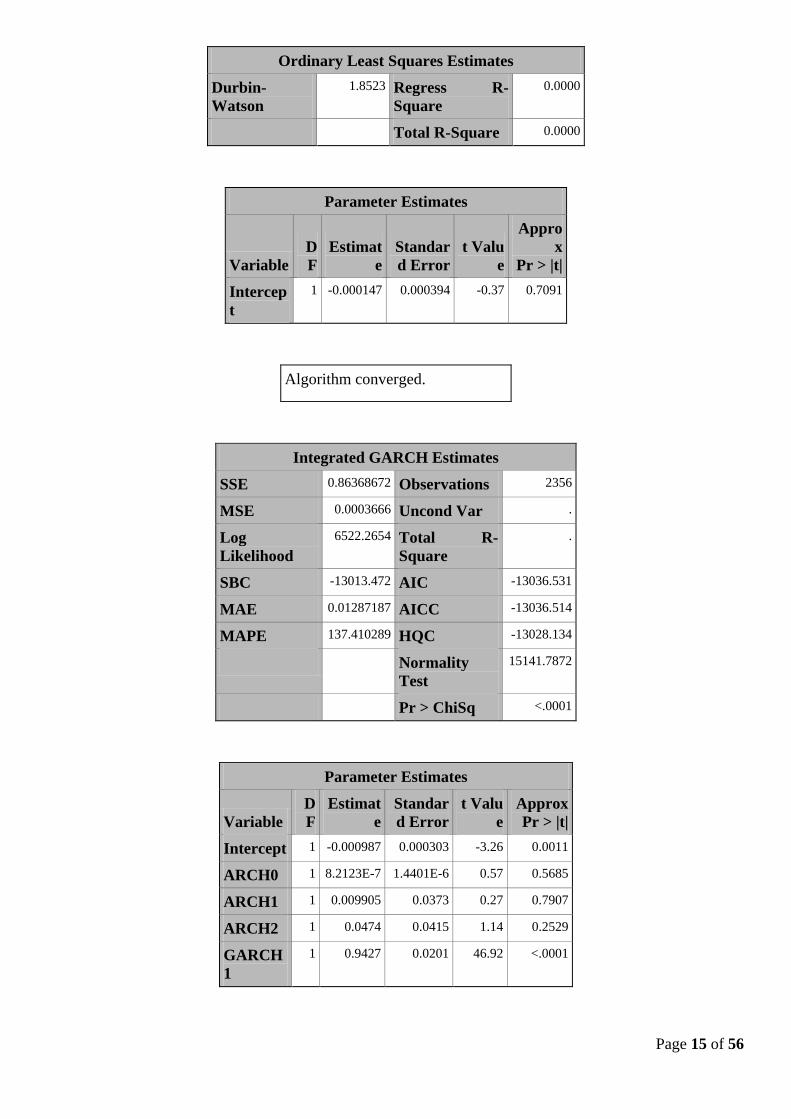
Page 15 of 56
Ordinary Least Squares Estimates
Durbin-
Watson
1.8523 Regress R-
Square
0.0000
Total R-Square 0.0000
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Intercep
t
1 -0.000147 0.000394 -0.37 0.7091
Algorithm converged.
Integrated GARCH Estimates
SSE 0.86368672 Observations 2356
MSE 0.0003666 Uncond Var .
Log
Likelihood
6522.2654 Total R-
Square
.
SBC -13013.472 AIC -13036.531
MAE 0.01287187 AICC -13036.514
MAPE 137.410289 HQC -13028.134
Normality
Test
15141.7872
Pr > ChiSq <.0001
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Approx
Pr > |t|
Intercept 1 -0.000987 0.000303 -3.26 0.0011
ARCH0 1 8.2123E-7 1.4401E-6 0.57 0.5685
ARCH1 1 0.009905 0.0373 0.27 0.7907
ARCH2 1 0.0474 0.0415 1.14 0.2529
GARCH
1
1 0.9427 0.0201 46.92 <.0001
Page 16 of 56
II – 2.c Modélisation EGARCH (1,2) :
« The exponential general autoregressive conditional heteroskedastic (EGARCH) » est une autre forme de
processus GARCH modélisé par Nelson en 1991. Les paramètres ont un impact différent sur la volatilité.
Dependent
Variable
rend
Ordinary Least Squares Estimates
SSE 0.86202611 DFE 2355
MSE 0.0003660 Root MSE 0.01913
SBC -11949.673 AIC -11955.438
MAE 0.01287403 AICC -11955.436
MAPE 103.654182 HQC -11953.339
Page 17 of 56
Ordinary Least Squares Estimates
Durbin-
Watson
1.8523 Regress R-
Square
0.0000
Total R-Square 0.0000
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Intercep
t
1 -0.000147 0.000394 -0.37 0.7091
Algorithm converged.
Exponential GARCH Estimates
SSE 0.86336073 Observations 2356
MSE 0.0003665 Uncond Var .
Log
Likelihood
6545.268 Total R-
Square
.
SBC -13051.712 AIC -13080.536
MAE 0.01287008 AICC -13080.51
MAPE 133.583196 HQC -13070.04
Normality
Test
10835.5532
Pr > ChiSq <.0001

Page 18 of 56
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Intercept 1 -0.000900 0.000247 -3.64 0.0003
EARCH0 0 -0.0198 . . .
EARCH1 1 0.000272 0.0970 0.00 0.9978
EARCH2 1 0.1034 0.0868 1.19 0.2336
EGARCH
1
1 0.9971 0.001371 727.09 <.0001
THETA 1 -0.0138 0.2655 -0.05 0.9586
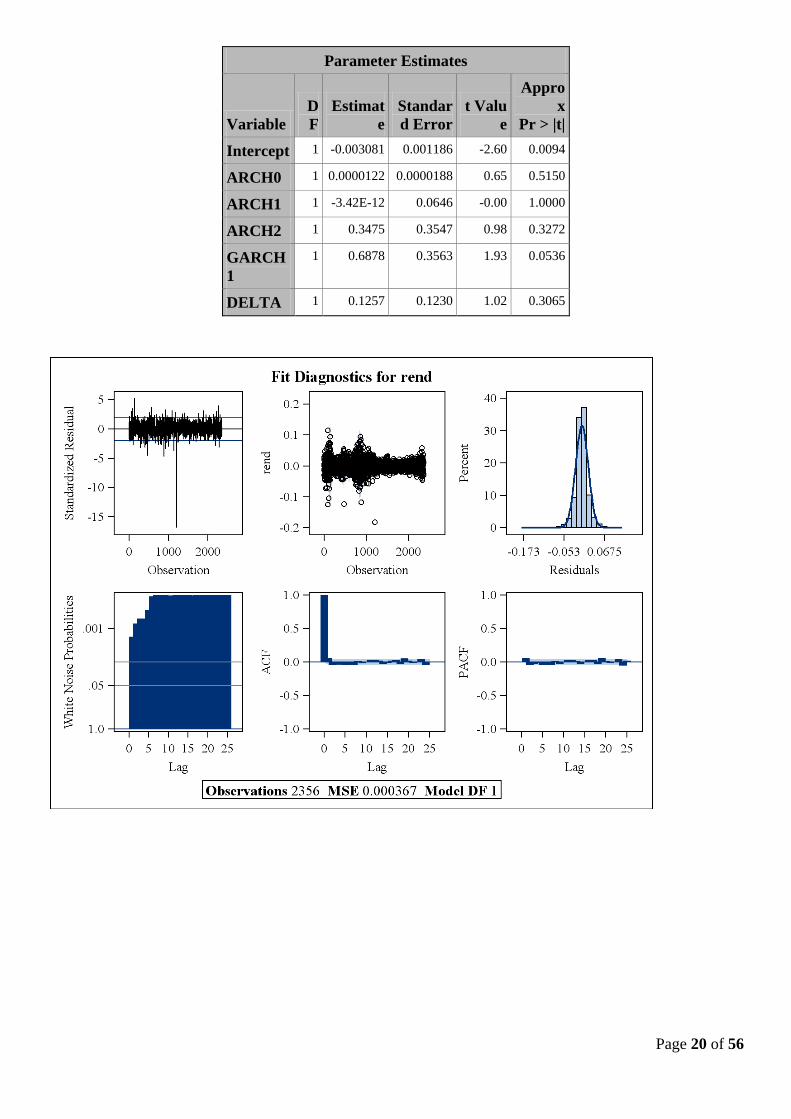
II – 2.d Modélisation GARCH - M(1,1) :
« The GARCH-in-mean (GARCH-M) » modèle ajoute un terme hétéroscédastique dans l’équation de la
moyenne.

Page 19 of 56
Dependent
Variable
rend
Ordinary Least Squares Estimates
SSE 0.86202611 DFE 2355
MSE 0.0003660 Root MSE 0.01913
SBC -11949.673 AIC -11955.438
MAE 0.01287403 AICC -11955.436
MAPE 103.654182 HQC -11953.339
Durbin-
Watson
1.8523 Regress R-
Square
0.0000
Total R-Square 0.0000
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Intercep
t
1 -0.000147 0.000394 -0.37 0.7091
WARNING: Optimization cannot improve the
function value.
GARCH Estimates
SSE 0.85477401 Observations 2356
MSE 0.0003628 Uncond Var .
Log
Likelihood
6424.26049 Total R-
Square
0.0084
SBC -12801.933 AIC -12836.521
MAE 0.01283446 AICC -12836.485
MAPE 163.427422 HQC -12823.926
Normality
Test
112650.587
Pr > ChiSq <.0001
Page 20 of 56
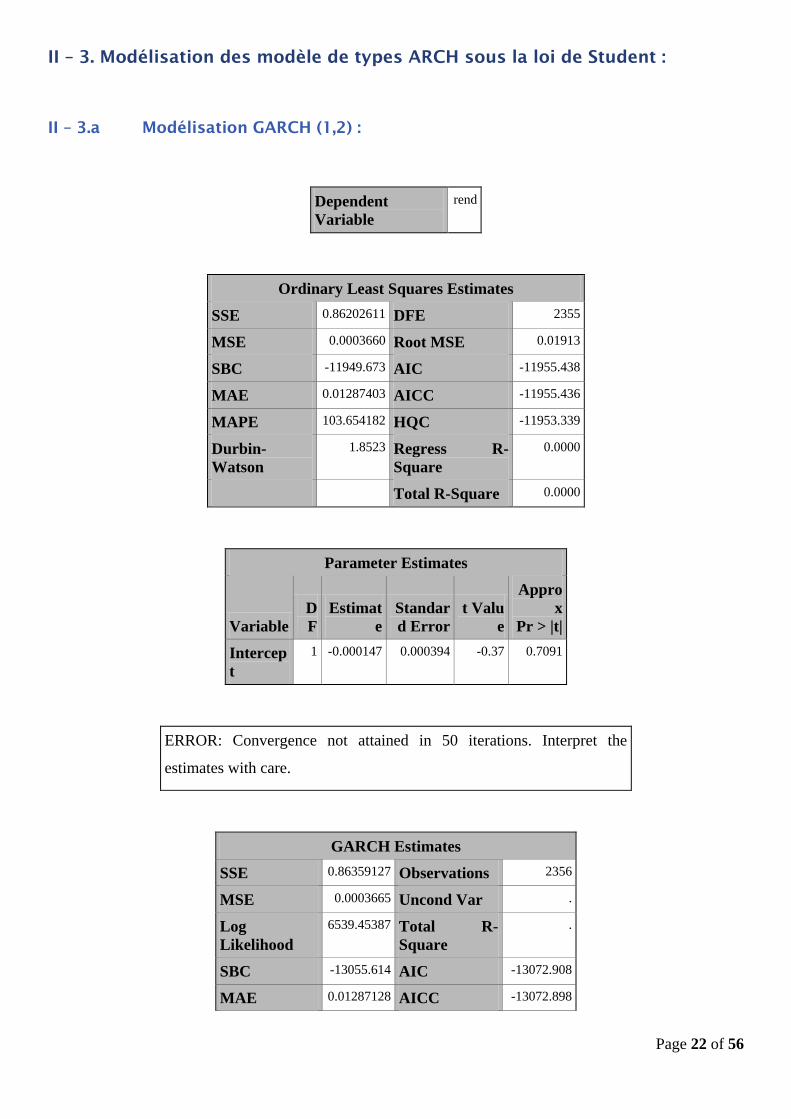
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Intercept 1 -0.003081 0.001186 -2.60 0.0094
ARCH0 1 0.0000122 0.0000188 0.65 0.5150
ARCH1 1 -3.42E-12 0.0646 -0.00 1.0000
ARCH2 1 0.3475 0.3547 0.98 0.3272
GARCH
1
1 0.6878 0.3563 1.93 0.0536
DELTA 1 0.1257 0.1230 1.02 0.3065

Page 21 of 56
II – 2.e Résumé des résultats obtenus précédemment :
Nous remarquons que les résultats d’estimation ne sont pas satisfaisants pour ces modèles, notamment au
niveau de la significativité des variables. Par conséquent, nous allons continuer avec la modélisation des
modèles de type ARCH sous la loi de Student.
Page 22 of 56
II – 3. Modélisation des modèle de types ARCH sous la loi de Student :
II – 3.a Modélisation GARCH (1,2) :
Dependent
Variable
rend
Ordinary Least Squares Estimates
SSE 0.86202611 DFE 2355
MSE 0.0003660 Root MSE 0.01913
SBC -11949.673 AIC -11955.438
MAE 0.01287403 AICC -11955.436
MAPE 103.654182 HQC -11953.339
Durbin-
Watson
1.8523 Regress R-
Square
0.0000
Total R-Square 0.0000
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Intercep
t
1 -0.000147 0.000394 -0.37 0.7091
ERROR: Convergence not attained in 50 iterations. Interpret the
estimates with care.
GARCH Estimates
SSE 0.86359127 Observations 2356
MSE 0.0003665 Uncond Var .
Log
Likelihood
6539.45387 Total R-
Square
.
SBC -13055.614 AIC -13072.908
MAE 0.01287128 AICC -13072.898

Page 23 of 56
GARCH Estimates
MAPE 136.323103 HQC -13066.61
Normality
Test
505209.208
Pr > ChiSq <.0001
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Variable
Label
Intercept 1 -0.000962 0.000204 -4.72 <.0001
ARCH0 1 0.0000164 5.6996E-6 2.88 0.0039
ARCH1 1 0.7087 0.1749 4.05 <.0001
GARCH
1
1 0.2852 0.0899 3.17 0.0015
GARCH
2
1 0.3328 0.0774 4.30 <.0001
TDFI 1 0.3415 0.0335 10.19 <.0001 Inverse of t DF

Page 24 of 56
Les coefficients de l’équation de la variance sont significatifs et positifs. Par conséquent, le modèle GARCH
(1,2) est un modèle candidat.
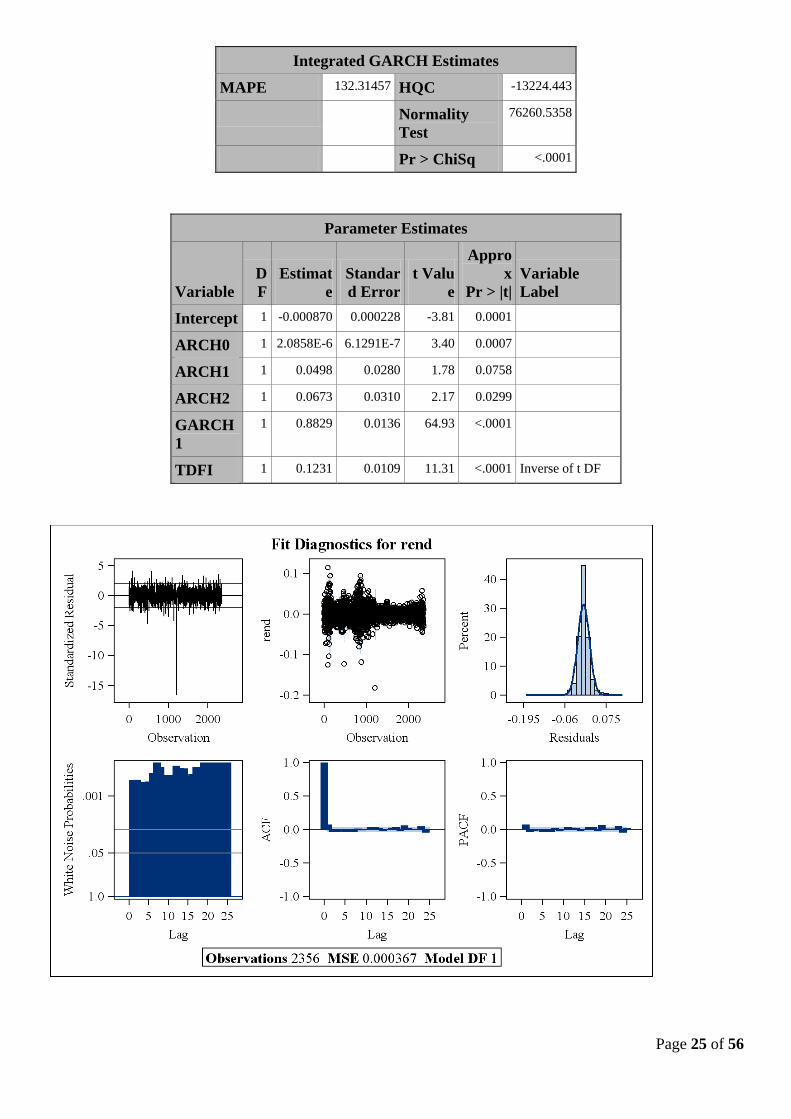
II – 3.b Modélisation IGARCH (1,2) :
Dependent
Variable
rend
Ordinary Least Squares Estimates
SSE 0.86202611 DFE 2355
MSE 0.0003660 Root MSE 0.01913
SBC -11949.673 AIC -11955.438
MAE 0.01287403 AICC -11955.436
MAPE 103.654182 HQC -11953.339
Durbin-
Watson
1.8523 Regress R-
Square
0.0000
Total R-Square 0.0000
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Intercep
t
1 -0.000147 0.000394 -0.37 0.7091
Algorithm
converged.
Integrated GARCH Estimates
SSE 0.86325879 Observations 2356
MSE 0.0003664 Uncond Var .
Log
Likelihood
6622.4695 Total R-
Square
.
SBC -13206.115 AIC -13234.939
MAE 0.01286968 AICC -13234.913
Page 25 of 56
Integrated GARCH Estimates
MAPE 132.31457 HQC -13224.443
Normality
Test
76260.5358
Pr > ChiSq <.0001
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Variable
Label
Intercept 1 -0.000870 0.000228 -3.81 0.0001
ARCH0 1 2.0858E-6 6.1291E-7 3.40 0.0007
ARCH1 1 0.0498 0.0280 1.78 0.0758
ARCH2 1 0.0673 0.0310 2.17 0.0299
GARCH
1
1 0.8829 0.0136 64.93 <.0001
TDFI 1 0.1231 0.0109 11.31 <.0001 Inverse of t DF

Page 26 of 56
Ce modèle est aussi un candidat potentiel intéressant car il apporte une information complémentaire en
termes de modélisation mais aussi sur le comportement de la variance.
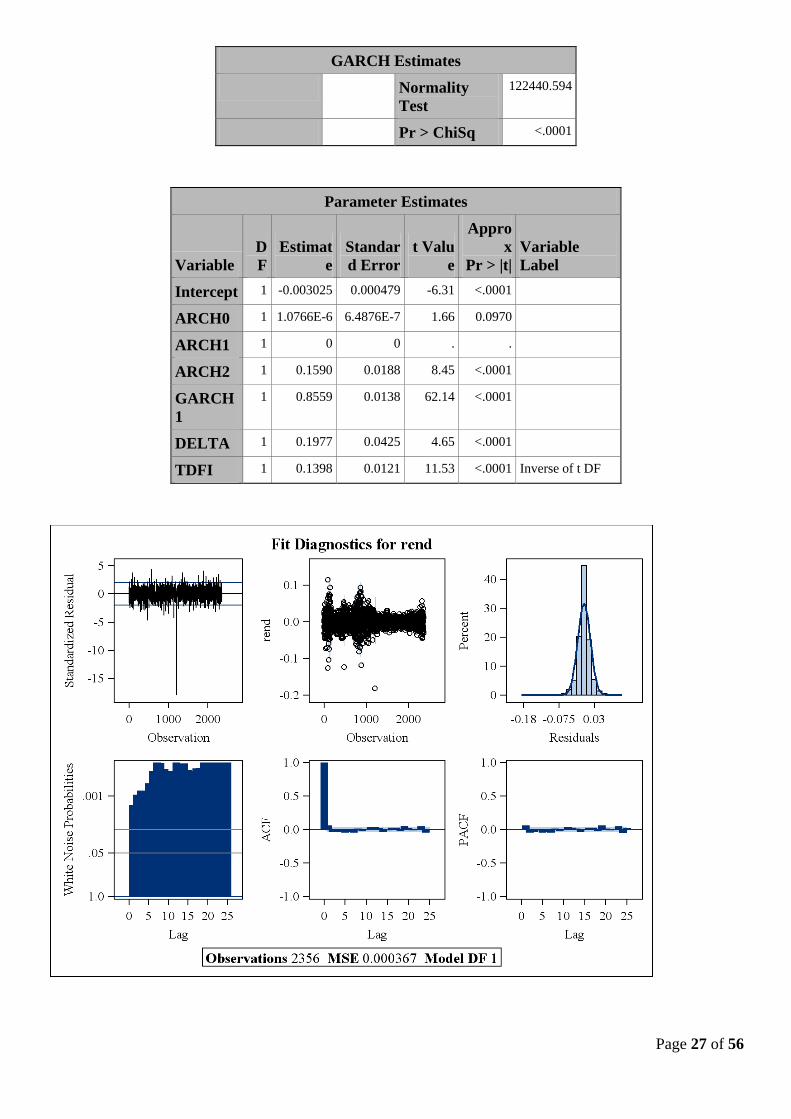
II – 3.c Modélisation GARCH-M (1,2) :
Dependent
Variable
rend
Ordinary Least Squares Estimates
SSE 0.86202611 DFE 2355
MSE 0.0003660 Root MSE 0.01913
SBC -11949.673 AIC -11955.438
MAE 0.01287403 AICC -11955.436
MAPE 103.654182 HQC -11953.339
Durbin-
Watson
1.8523 Regress R-
Square
0.0000
Total R-Square 0.0000
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Intercep
t
1 -0.000147 0.000394 -0.37 0.7091
ERROR: Convergence not attained in 50 iterations. Interpret the
estimates with care.
GARCH Estimates
SSE 0.85366832 Observations 2356
MSE 0.0003623 Uncond Var .
Log
Likelihood
6621.86939 Total R-
Square
0.0097
SBC -13189.386 AIC -13229.739
MAE 0.01283365 AICC -13229.691
MAPE 141.704424 HQC -13215.045
Page 27 of 56
GARCH Estimates
Normality
Test
122440.594
Pr > ChiSq <.0001
Parameter Estimates
Variable
D
F
Estimat
e
Standar
d Error
t Valu
e
Appro
x
Pr > |t|
Variable
Label
Intercept 1 -0.003025 0.000479 -6.31 <.0001
ARCH0 1 1.0766E-6 6.4876E-7 1.66 0.0970
ARCH1 1 0 0 . .
ARCH2 1 0.1590 0.0188 8.45 <.0001
GARCH
1
1 0.8559 0.0138 62.14 <.0001
DELTA 1 0.1977 0.0425 4.65 <.0001
TDFI 1 0.1398 0.0121 11.53 <.0001 Inverse of t DF
Page 28 of 56
L’estimation du modèle GARCH en moyenne est aussi satisfaisante. En effet, le coefficient associé à la
variance conditionnelle dans l’équation de la moyenne est significativement différent de zéro : la variance
conditionnelle est une variable explicative des rentabilités. On peut donc prendre ce modèle en
considération.
II – 3.d Résumé des résultats obtenus précédemment :
Nous allons donc prendre en compte tous les modèles. Nous choisirons le modèle pour lequel les critères
AIC et SBC sont minimisés.
Modélisation SBC AIC Log Likelihood
GARCH -13055.614 -13072.908 6539.454
IGARCH -13206.115 -13234.939 6622.469
GARCH-M -13189.386 -13229.739 6621.869
La modélisation IGARCH minimise au mieux les critères AIC et SBC ! Il semble que le modèle le plus
approprié soit IGARCH (1,2). En effet, il possède le critère d’information le plus faible mais également la
log-vraisemblance la plus élevée. L’avantage du modèle IGARCH est d’être un processus permettant de
rendre compte de la persistance de la variance conditionnelle ce qui est une caractéristique commune des
séries financières en générale.

Page 29 of 56
III - Calcul de la Value at Risk
III – 1. Presentation de la Value at Risk
Cette notion est originaire du secteur de l'assurance. Elle a été importée à la fin des années 1980 sur les
marchés financiers aux États-Unis par la banque Bankers Trust et popularisée par la banque JP Morgan en
1993 et son service (gratuit et public) Riskmetrics puis adoptée sous une forme embryonnaire par le Comité
de Bâle (Bâle II) pour les banques et Solvabilité II pour les assurances.
La VaR d'un portefeuille dépend essentiellement de trois paramètres :
▪ la distribution des résultats des portefeuilles. Souvent cette distribution est supposée normale, mais
beaucoup d'acteurs financiers utilisent des distributions historiques. La difficulté réside dans la taille
de l'échantillon historique : s'il est trop petit, les probabilités de pertes élevées sont peu précises, et
s'il est trop grand, la cohérence temporelle des résultats est perdue (on compare des résultats non
comparables) ;
▪ le niveau de confiance choisi (95 ou 99 % en général). C'est la probabilité que les pertes éventuelles
du portefeuille ou de l'actif ne dépassent pas la Value at Risk, par définition ;
▪ l'horizon temporel choisi. Ce paramètre est très important car plus l'horizon est long plus les pertes
peuvent être importantes. Par exemple, pour une distribution normale des rendements, il faut
multiplier la Value at Risk à un jour par pour avoir la Value at Risk sur jours.
D'une manière générale, la VaR donne une estimation des pertes qui ne devrait pas être dépassée sauf
événement extrême sur un portefeuille pouvant être composé de différentes classes d'actifs.
Pour calculer la VaR il est nécessaire de faire trois hypothèses :
- La normalité des distributions considérées.
- La VaR à N jours est égale à la racine carré de N multiplié par la VaR à un jour.
- Le rendement moyen du titre ou du portefeuille est nul pour la période considérée.
III – 2. Backtesting
Ici nous allons vérifier si les pertes réelles observées ex-post sont en adéquation avec les pertes prévues. On
va donc comparer systématiquement l’historique des prévisions de Value-at-Risk aux rendements.

Page 30 of 56
III – 2.a La couverture non conditionnelle
L’hypothese de couverture non conditionnelle est vérifiée si la probabilité ex-post d’avoir une perte en excès
avec une VaR calculée ex-ante est égale au taux de couverture ( ) 1 ( )b t t
P I E I
Sous cette hypothèse, la variable indicatrice ( )I suit une loi de Bernoulli.
Si la probabilité de violation est supérieure au taux de couverture alors nous sommes face à une sous-
estimation de la VaR.
L’hypothèse de couverture non conditionnelle permet de mesurer la fiabilité de nos calculs de VaR,
autrement dit le nombre de pertes observés qui excèdent la VaR anticipée.
La variable indicatrice ( )t
I est associée à la violation constatée ex-post d’une violation à % en t
( )t
I =1 si 1( )
t tr VaR
( )t
I =0 si 1( )
t tr VaR
III – 2.b Test de Kupiec:
Le test de Kupiec permet de confirmer la fiabilité en fonction du nombre de violations observées par rapport
à la VaR calculée.
Soit / 1
( )t t
VaR la valeur prévue de la VaR pour un taux de couverture de α % et soit ( )t
I son processus
de violation associé.
Pour un taux de couverture de la VaR à α%, le test de couverture non conditionnelle de Kupiec (1995)
admet pour hypothèse nulle :
0( )
tH E I
où It désigne la violation associée à la VaR à une date t. Sous H0 la statistique de ratio de vraisemblance
associée s’écrit :
22 ln (1 ) 2 ln (1 ) ( ) (1)
T N N T N NNLR P N
T

Page 31 of 56
III – 2.c Test de Kupiec pour la modèle EGARCH sous la loi normale et
comparaison avec les rendements
Resultats du test de Kupiec sous la loi normale
Pour une VaR à 5 % nous avons :
T N LR
2357 109 213.59654
T = nombre d’observations
N = nombre des valeurs de la violation à 5% de la VaR normale.
Nous constatons que la statistique LR est largement supérieure au fractile de la loi du Khi –deux : 213.59654
>2(1) 3.84 . Nous rejetons donc l’hypothèse nulle de couverture non conditionnelle.
varN5
-0.19-0.18
-0.17-0.16-0.15
-0.14-0.13
-0.12-0.11-0.10
-0.09-0.08
-0.07-0.06-0.05
-0.04-0.03
-0.02-0.010.00
0.010.02
0.030.040.05
0.060.07
0.080.090.10
0.110.12
Date
01/01/2003 01/01/2004 01/01/2005 01/01/2006 01/01/2007 01/01/2008 01/01/2009 01/01/2010 01/01/2011 01/01/2012 01/01/2013
Graphique de la VaR 1% et 5% sous une loi normale et rendements
PLOT varN5 rend varN1
Page 32 of 56
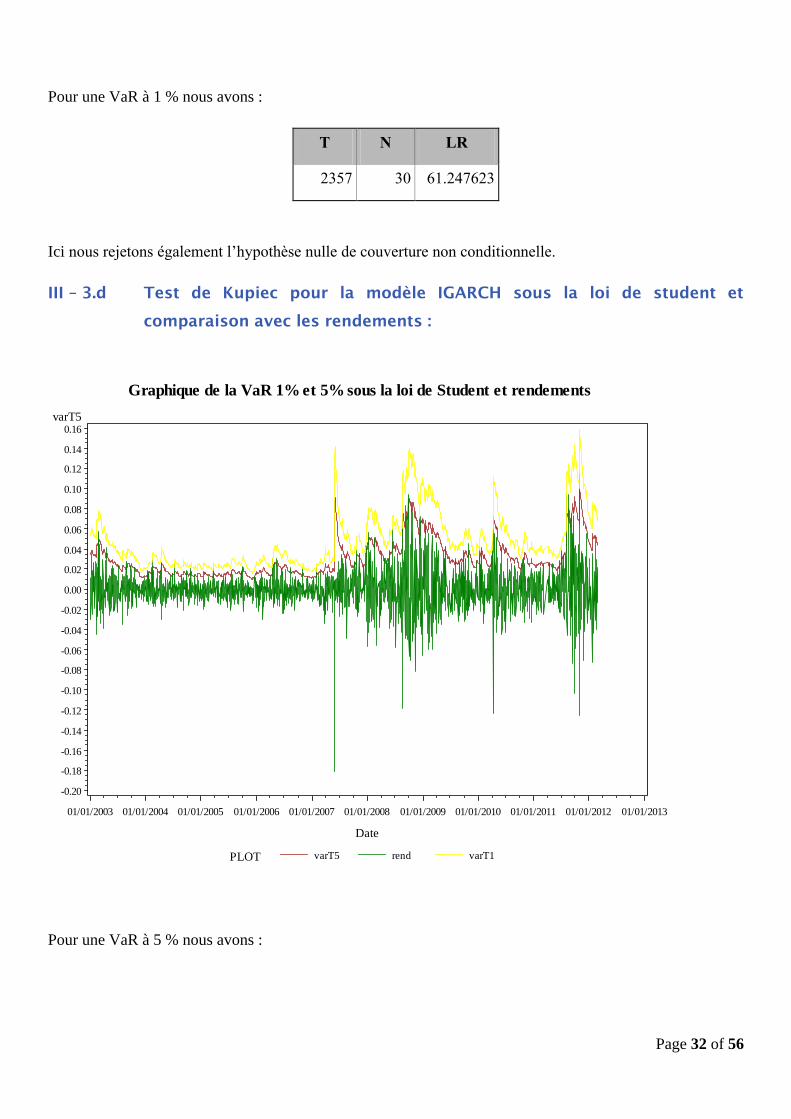
Pour une VaR à 1 % nous avons :
T N LR
2357 30 61.247623
Ici nous rejetons également l’hypothèse nulle de couverture non conditionnelle.
III – 3.d Test de Kupiec pour la modèle IGARCH sous la loi de student et
comparaison avec les rendements :
Pour une VaR à 5 % nous avons :
varT5
-0.20
-0.18
-0.16
-0.14
-0.12
-0.10
-0.08
-0.06
-0.04
-0.02
0.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
0.16
Date
01/01/2003 01/01/2004 01/01/2005 01/01/2006 01/01/2007 01/01/2008 01/01/2009 01/01/2010 01/01/2011 01/01/2012 01/01/2013
Graphique de la VaR 1% et 5% sous la loi de Student et rendements
PLOT varT5 rend varT1

Page 33 of 56
T N LR
2357 89 182.68821
Pour un seuil de 5% nous rejetons l’hypothèse nulle de couverture non conditionnelle.
Pour la VaR à 1% nous obtenons :
T N LR
2357 11 30.390428
Pour un seuil de 5% nous rejetons l’hypothèse nulle de couverture non conditionnelle.
On en conclut que sous cette spécification de la VaR le risque n’est pas sous-estimé.
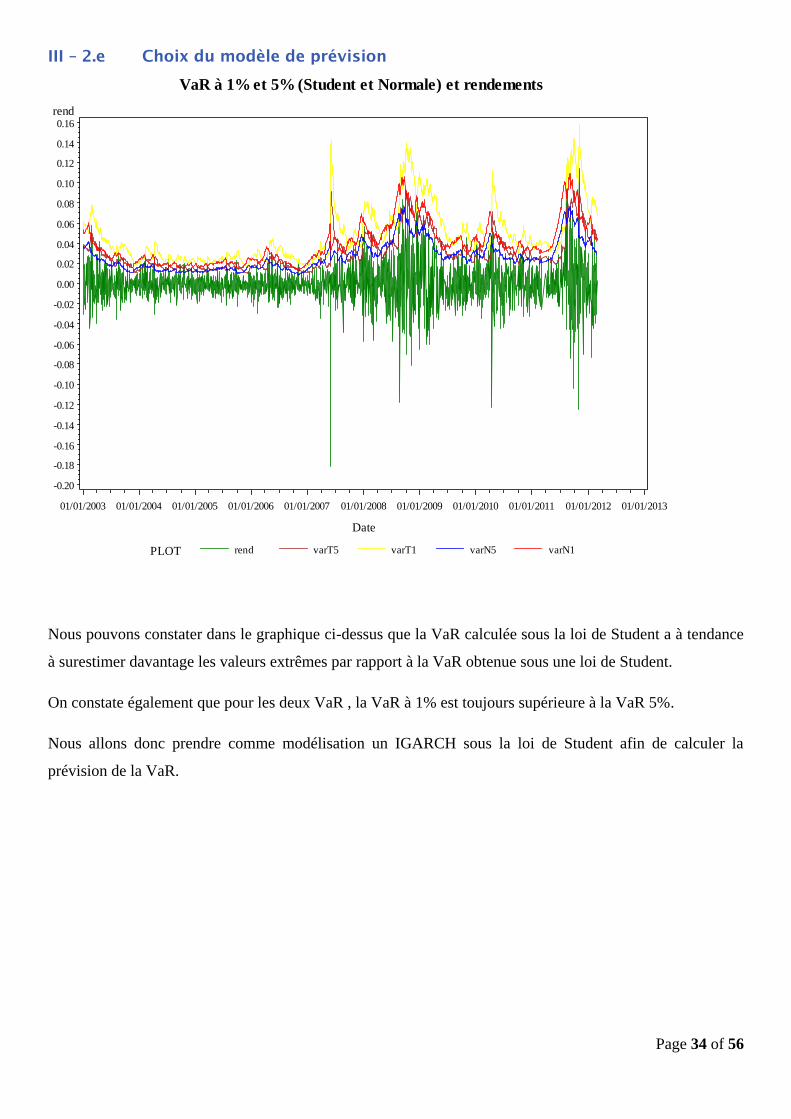
Page 34 of 56
III – 2.e Choix du modèle de prévision
Nous pouvons constater dans le graphique ci-dessus que la VaR calculée sous la loi de Student a à tendance
à surestimer davantage les valeurs extrêmes par rapport à la VaR obtenue sous une loi de Student.
On constate également que pour les deux VaR , la VaR à 1% est toujours supérieure à la VaR 5%.
Nous allons donc prendre comme modélisation un IGARCH sous la loi de Student afin de calculer la
prévision de la VaR.
rend
-0.20
-0.18
-0.16
-0.14
-0.12
-0.10
-0.08
-0.06
-0.04
-0.02
0.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
0.16
Date
01/01/2003 01/01/2004 01/01/2005 01/01/2006 01/01/2007 01/01/2008 01/01/2009 01/01/2010 01/01/2011 01/01/2012 01/01/2013
VaR à 1% et 5% (Student et Normale) et rendements
PLOT rend varT5 varT1 varN5 varN1

Page 35 of 56
IV - Calcul de la Value at Risk Out of Sample
IV – 1. Prévision glissante sur 250 jours de la Value at Risk Out Sample :
La densité de la distribution des pertes et profits peut être différente d’une date à l’autre ce qui complique
l’évaluation de VaR conditionnelle. On définit donc une densité conditionnelle à un ensemble d’information
disponible à la date t, noté W t , cela vas nous permettre de réaliser une prévision de la VaR.
La VaR s’écrit donc :
1( ) ( / )
tt rVaR F
Afin de prévoir la Value at Risk et tester sa validité de cette dernière nous effectuerons nos test sur un
échantillon de 500 observations que nous diviserons en deux parties égale. On réalisera tout d’abord les
prévisions de la VaR sur un échantillon de 250 observations puis sur les 250 autres.
Nous allons réaliser une série de prévision ou of sample sans ré-estimer les paramètres de l’IGARCH. Soit
hT le processus de variance conditionnelle, nous pouvons prévoir les rendements de cette dernière pour la
date T+1 de cette manière :
2
1 0 1 1
ˆ ˆˆ ˆT T T
h h
Sous SAS la fonction Autoreg permettant de calculer l’IGARCH nous permet d’obtenir les estimateurs
convergents des paramètres α0, α1 et β1, issues des modèles ARCH1 et GARCH1.
Résultats obtenus :
Dependent Variable rend

Page 36 of 56
Ordinary Least Squares Estimates
SSE 0.05598808 DFE 251
MSE 0.0002231 Root MSE 0.01494
SBC -1399.1611 AIC -1402.6905
MAE 0.0114064 AICC -1402.6745
MAPE 106.523805 HQC -1401.2703
Durbin-Watson 2.0255 Regress R-Square 0.0000
Total R-Square 0.0000
Parameter Estimates
Variable DF Estimate
Standar
d Error t Value
Approx
Pr > |t|
Intercept 1 -0.001256 0.000941 -1.33 0.1832
Algorithm converged.
Integrated GARCH Estimates
SSE 0.05599912 Observations 252
MSE 0.0002222 Uncond Var .
Log
Likelihood
729.081077 Total R-
Square
.
SBC -1430.515 AIC -1448.1622
MAE 0.01139695 AICC -1447.9183
MAPE 108.31048 HQC -1441.0613
Normality
Test
0.7725
Pr > ChiSq 0.6796
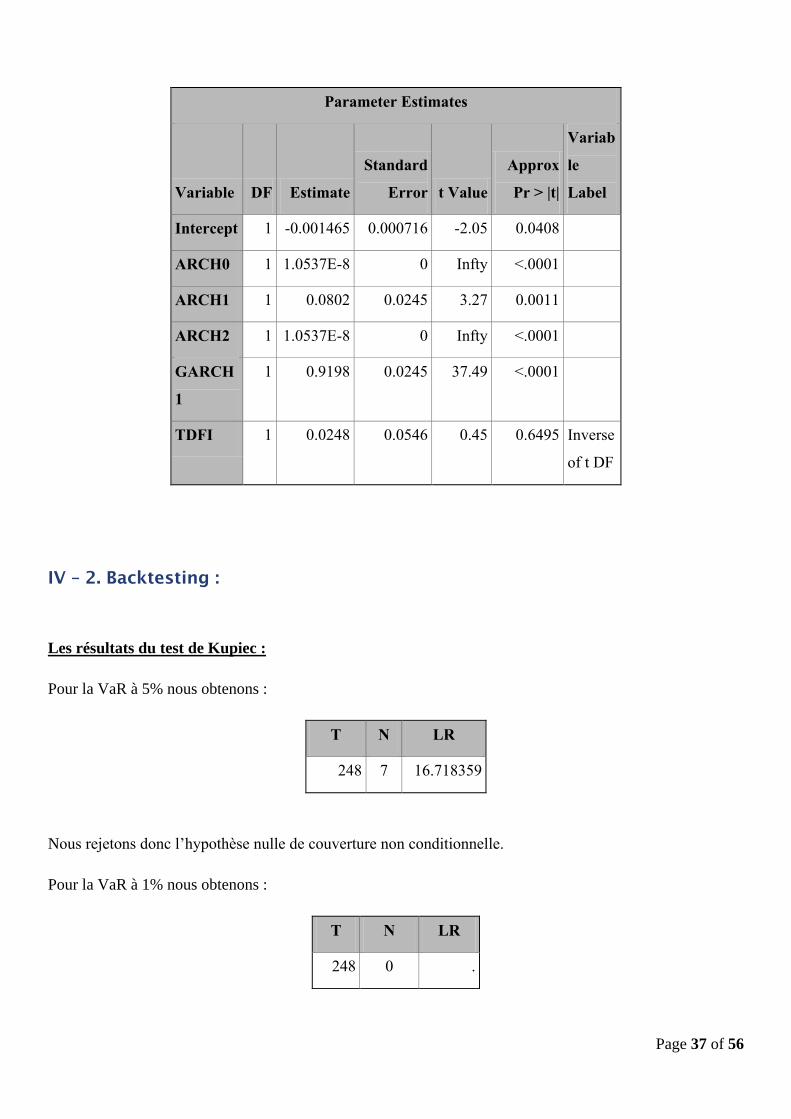
Page 37 of 56
Parameter Estimates
Variable DF Estimate
Standard
Error t Value
Approx
Pr > |t|
Variab
le
Label
Intercept 1 -0.001465 0.000716 -2.05 0.0408
ARCH0 1 1.0537E-8 0 Infty <.0001
ARCH1 1 0.0802 0.0245 3.27 0.0011
ARCH2 1 1.0537E-8 0 Infty <.0001
GARCH
1
1 0.9198 0.0245 37.49 <.0001
TDFI 1 0.0248 0.0546 0.45 0.6495 Inverse
of t DF
IV – 2. Backtesting :
Les résultats du test de Kupiec :
Pour la VaR à 5% nous obtenons :
T N LR
248 7 16.718359
Nous rejetons donc l’hypothèse nulle de couverture non conditionnelle.
Pour la VaR à 1% nous obtenons :
T N LR
248 0 .

Page 38 of 56
Le test de Kupiec n’a pas donné de résultat puisque la somme des valeurs de la violationà 1% de la Value at
Risk normée est nulle.
La violation constaté ex-post de la violation à 1% à la date vaut 0.
Pour faire nos prévisions nous allons r é-estimer le modèle IGARCH à chaque date de Glissement. On peut
s’apercevoir que nous obtenons les mêmes résultats que précédemment.
Parameter Estimates
Variable
D
F Estimate
Standard
Error t Value
Approx
Pr > |t|
Variab
le
Label
Intercept 1 -0.001465 0.000716 -2.05 0.0408
ARCH0 1 1.0537E-8 0 Infty <.0001
ARCH1 1 0.0802 0.0245 3.27 0.0011
ARCH2 1 1.0537E-8 0 Infty <.0001
GARCH1 1 0.9198 0.0245 37.49 <.0001
TDFI 1 0.0248 0.0546 0.45 0.6495 Inverse
of t DF
Nous obtenons les resultats :
0.0000
0.0001
0.0002
0.0003
0.0004
0.0005
0.0006
0.0007
0.0008
Variance Conditionnelle Estimee
01/01/2003 04/01/2003 07/01/2003 10/01/2003 01/01/2004 04/01/2004 07/01/2004 10/01/2004 01/01/2005
Variance Conditionnelle Estimee sur un total de 500 obs
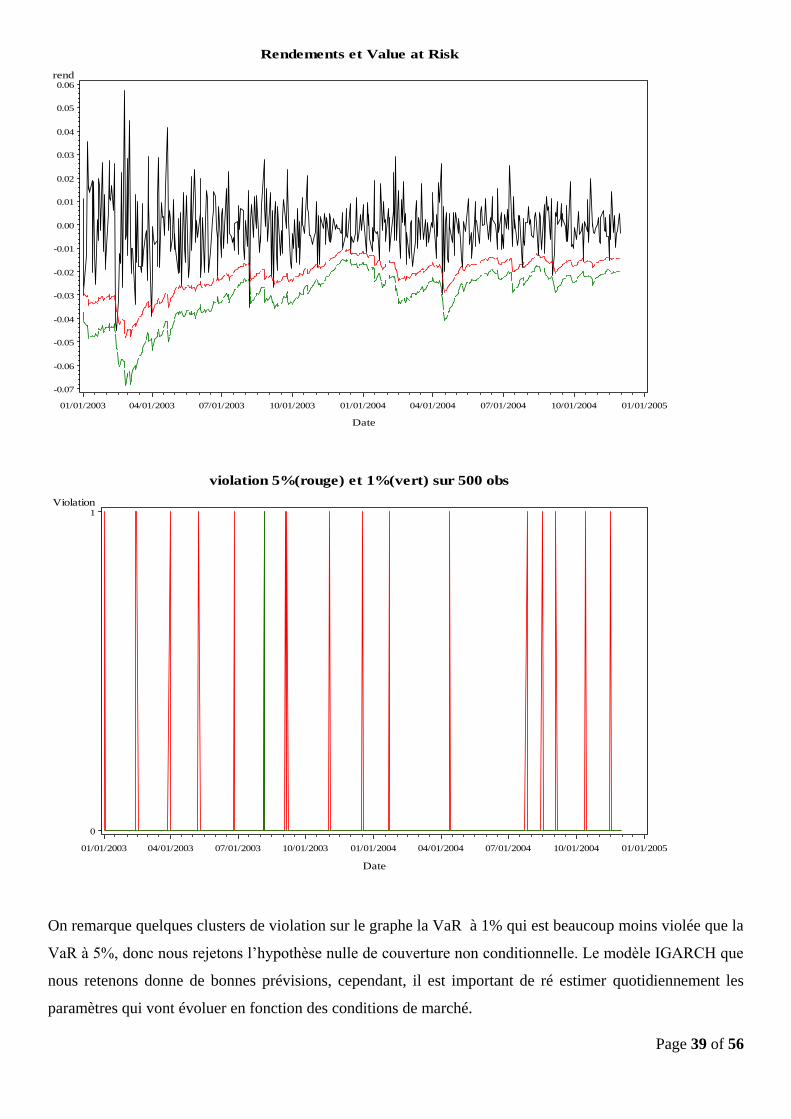
Page 39 of 56
On remarque quelques clusters de violation sur le graphe la VaR à 1% qui est beaucoup moins violée que la
VaR à 5%, donc nous rejetons l’hypothèse nulle de couverture non conditionnelle. Le modèle IGARCH que
nous retenons donne de bonnes prévisions, cependant, il est important de ré estimer quotidiennement les
paramètres qui vont évoluer en fonction des conditions de marché.
rend
-0.07
-0.06
-0.05
-0.04
-0.03
-0.02
-0.01
0.00
0.01
0.02
0.03
0.04
0.05
0.06
Date
01/01/2003 04/01/2003 07/01/2003 10/01/2003 01/01/2004 04/01/2004 07/01/2004 10/01/2004 01/01/2005
Rendements et Value at Risk
Violation
0
1
Date
01/01/2003 04/01/2003 07/01/2003 10/01/2003 01/01/2004 04/01/2004 07/01/2004 10/01/2004 01/01/2005
violation 5%(rouge) et 1%(vert) sur 500 obs

Page 40 of 56
On remarque que la VaR à 5% est très rarement violée, et que celle à 1% ne l’est pas du tout, ce qui
confirme les tests précèdents.
Violation
0
1
Date
11/01/2003 01/01/2004 03/01/2004 05/01/2004 07/01/2004 09/01/2004 11/01/2004 01/01/2005
violation 5% et 1% sur 250 obs Out of Sample
PLOT violation5 violation1

Page 41 of 56
V - Prévisions de VaR à 10 jours – tests ex-post
On peut estimer la VaR à 10 jours à l’aide du modèle grâce aux résultats de Variance Conditionnelle obtenus
à 250 jours. Il faut savoir que la VaR 10 jour est demandée aux institutions financières chaque jour par les
autorités de régulations dans le cadre de Bâle 2.
0.0000
0.0001
0.0002
0.0003
0.0004
0.0005
0.0006
0.0007
0.0008
Variance Conditionnelle Estimee
01/01/2003 04/01/2003 07/01/2003 10/01/2003 01/01/2004 04/01/2004 07/01/2004 10/01/2004 01/01/2005
Variance Conditionnelle Estimee

Page 42 of 56
On constate qu’il n’y a pas de violation à 10 jours, le modèle est assez pertinent sur l’échantillon étudié.
rend
-0.07
-0.06
-0.05
-0.04
-0.03
-0.02
-0.01
0.00
0.01
0.02
0.03
0.04
0.05
0.06
Date
01/01/2003 04/01/2003 07/01/2003 10/01/2003 01/01/2004 04/01/2004 07/01/2004 10/01/2004 01/01/2005
Rendements et VaR
rend
-0.017
-0.016
-0.015
-0.014
-0.013
-0.012
-0.011
-0.010
-0.009
-0.008
-0.007
-0.006
-0.005
-0.004
-0.003
-0.002
-0.001
0.000
0.001
0.002
0.003
0.004
0.005
0.006
0.007
0.008
0.009
0.010
0.011
0.012
t
1 2 3 4 5 6 7 8 9 10
Rendements et VaR 10 jours

Page 43 of 56
Au vu des résultats obtenus nous pouvons estimer que le modèle que nous retenons IGARCH sous une
distribution Student donne des résultats satisfaisants pour mesurer et estimer la volatilité et la VaR sur le
portefeuille constitué.

Page 44 of 56
Conclusion
La VaR est un outil servant à mesurer le risque. Cependant, elle ne donne pas d’indications sur les pertes qui
peuvent apparaître au-delà du seuil de la VaR et de ce fait, cette mesure peut pousser les agents
économiques à sous-estimer le risque.
Des portefeuilles avec la même VaR peuvent ainsi générer des pertes extrêmes très différentes sur lesquelles
la Var ne donne pas d’information (pour cela il faudrait analyser les VaR). De surcroît, la zone des valeurs
extrêmes est celle ou les hypothèses sous-jacentes aux calculs de VaR sont les plus fragiles : le calcul de
VaR s’appuie, à travers la matrice de variance/covariance, sur les corrélations entre actifs ; la stabilité de ces
corrélations n’est pas toujours vérifiée, surtout au-delà du seuil de confiance ; c’est une des raisons pour
lesquelles il est nécessaire, en complément de la VaR, d’évaluer des scénarios de crise (stress tests).
Malgré ses limites, la VaR est largement utilisée et le sera certainement de plus en plus d'autant que cette
utilisation a été validée par les autorités (qui ont toutefois imposé des hypothèses relativement dures).On
constate d'autre part une généralisation du concept qui outre son utilisation dans les grandes banques pour
évaluer le risque des activités de trading, trouve peu à peu sa place dans la gestion de fonds et la trésorerie
d'entreprise.
Par ailleurs la quantification du risque est un souci majeur des acteurs financiers car elle leur permet de
répondre à des interrogations comme « Combien pouvons-nous perdre avec une série financière dans des
conditions de marché normales ou anormales pour un horizon de temps donné ? » La Value at Risk constitue
donc une des méthodes les plus courantes de quantification du risque.

Page 45 of 56
Annexe : Code SAS
/**************************************************************************************
**************************/
/*
*/
/* PROJET DE SAS 1
*/
/*
*/
/* L'objectif de ce travail est de proposer une prévision de la Value at Risk à
un seuil alpha */
/* d'un portefeuille composé de 3 titres. Il s'agit d'estimer differents modeles
GARCH sous differentes */
/* specifications des lois conditionnelles et en déduire les prévisions à partir
d'un echantillon test */
/*
*/
/*
Luis MACAVILCA */
/*
Taylan KUNAL */
/*
Aurelia ISTRATTI */
/*
M2 IEF */
/**************************************************************************************
**************************/
/* Chargement et traitement des données de base */
/*répertoire*/
libname pev "C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data";
/*importer des données à partir de fichier excel*/
proc import datafile ="C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\Data.csv"
out=pev.projet;
run;
/*représentation graphique */
Proc gplot data = pev.projet;
symbol1 interpol=join value=none color=blue;
symbol2 interpol=join value=none color=red;
symbol3 interpol=join value=none color=green;
plot ( DANONE SOCGEN MICHELIN)*Date / LEGEND OVERLAY ;
TITLE "Representation graphique";
run;
ods rtf close;
QUIT;
/*calcul des rendements*/
data pev.projet;
set pev.projet;
rendDANONE=log(DANONE/lag(DANONE));
rendSOCGEN=log(SOCGEN/lag(SOCGEN));
rendMICHELIN=log(MICHELIN/lag(MICHELIN));
/* Pondération */
rend=0.5*rendSOCGEN+0.25*rendMICHELIN+0.25*rendDANONE;
run;
/* Enregistrement du graphique */
proc iml;
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\Graphiques.doc';

Page 46 of 56
/*représentation graphique des rendements */
Proc gplot data = pev.projet;
symbol1 interpol=join value=none color=blue;
plot rend*Date;
TITLE "Representation graphique des rendements du portefeuille";
run;
ods rtf close;
QUIT;
/***************************************************************
*****************************/
/*2*/
proc iml;
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet
VaR\Project\Data\StatDescriptives.doc';
/*Etude de la série obtenue*/
/***************************************************************
*****************************/
/* Statistiques descriptives */
TITLE ' Statistiques Descriptives ';
/*statistique descriptive sur les rendements*/
PROC UNIVARIATE Data=pev.projet plots;
VAR rend;
RUN;
ods rtf close;
QUIT;
proc iml;
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\Identification.doc';
/*Identification des ordres p et q pour la modélisation GARCH*/
title 'Identification des ordres p et q'
proc iml;
/*Estimation pour p et q pour des ordres allant de 1 à 6*/
PROC ARIMA DATA=pev.projet;
identify var = rend MINIC p=(1:6) q=(1:6);
RUN;
QUIT;
ods rtf close;
quit;
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\Test de
Normalite.doc';
/*Test de normalite & stats*/
proc univariate data=pev.projet normal;
var rend;
output out=stats_rlhf normal=stats_test_normalite
probn=sign_test_normalite;
run;
/* Comparaison avec une loi normale de même moyenne et même variance */
PROC UNIVARIATE DATA=pev.projet;
VAR rend;
HISTOGRAM rend;
QQPLOT rend / NORMAL (MU=EST SIGMA=EST);
RUN;
/* Superpose à l'histogramme la courbe représentant une loi normale de mêmes moyenne et
variance */
PROC SGPLOT DATA=pev.projet;
HISTOGRAM rend;
DENSITY rend / TYPE=NORMAL;
QUIT;
ods rtf close;
/* minimisation du critère BIC la procedure SAS retient les
ordres p=1 et q=2*/
/*estimation différents types de GARCH

Page 47 of 56
sous différentes lois (normale, student)
*/
/**************************************************************************************
******/
/****************************Estimation sous loi Normale
**********************************/
/**************************************************************************************
******/
proc iml;
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet
VaR\Project\Data\GARCH_loiNormale.doc';
/*1)Estimation sous loi normale*/
/* Estimation GARCH(1,2) */
title 'Modele GARCH(1,2) sous la loi normale';
proc autoreg data=pev.projet;
model rend = / garch=(q=1,p=2) DIST=NORMAL COVEST=QML;
/*estimation d'une distribution normale par quasi maximum de vriassemblane*/
output out=rstportgarchn r=epsilon cev=condvar ;
run;
/*modélisation INTEGRATED GARCH */
title 'Modele IGARCH(1,2) sous la loi normale' ;
proc autoreg data=pev.projet;
model rend = / garch=( p=1, q=2, type=
integrated)DIST=NORMAL COVEST=QML;
output out=rstportigarchn r=epsilon p=prevision ;
run;
quit;
/*modélisation EXPONENTIAL GARCH */
title ' Modele EGARCH(1,2) sous la loi normale ' ;
proc autoreg data=pev.projet;
model rend = / garch=( p=1, q=2,type= exp) DIST=NORMAL COVEST=QML;
output out=rstportegarchn r=epsilon p=prevision ;
run;
quit;
title 'Modele GARCH-M(1,2) sous la loi normale ' ;
/*modélisation GARCH IN MEAN */
proc autoreg data=pev.projet;
model rend = / garch=( p=1, q=2, mean = sqrt)DIST=NORMAL COVEST=QML;
output out=rstportgarchmn r=epsilon p=prevision alphacli=0.05
lcl=lower ucl=upper;
run;
ods rtf close;
quit;
/**************************************************************************************
******/
/****************************Estimation sous loi de
student**********************************/
/**************************************************************************************
******/
proc iml;
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet
VaR\Project\Data\GARCH_loideStudent.doc';
/* Estimation GARCH(1,2) */
title 'Modele GARCH(1,2)sous loi de Student ';
proc autoreg data=pev.projet;
model rend = / garch=(q=1,p=2) DIST=T;
output out=rstportgarcht r=epsilon cev=condvar ;
run;
/*Note : Il n'est pas possible d'utiliser une modelisation modélisation EGARCH
avec la loi de Student*/
/*modélisation IGARCH */
title 'Modele IGARCH(1,2) sous loi de student ' ;
proc autoreg data=pev.projet;
model rend = / garch=( p=1, q=2, type= integrated)DIST=T;

Page 48 of 56
output out=rstportigarcht r=epsilon p=prevision ;
run;
quit;
/*modélisation GARCH IN MEAN */
title 'Modele GARCH-M(1,2) sous loi de student ' ;
proc autoreg data=pev.projet;
model rend = / garch=( p=1, q=2, mean = sqrt)DIST=t;
output out=rstportgarchmt r=epsilon p=prevision alphacli=0.05
lcl=lower ucl=upper;
run;
quit;
ods rtf close;
quit;
/**************************************************************************************
****/
/**************************************************************************************
****/
/*Calcul de la Var in sample avec la loi normale*/
/**************************************************************************************
****/
/**************************************************************************************
****/
/*Le modèle ARCH optimal sous la loi normale est le modèle EGARCH selon, d'après la
méthode de
minimisation des critères AIC et SBC, nous allons utiliser ce modèle pour modéliser la
VaR avec la loi normale*/
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\VaRNormale IN
SAMPLE.doc';
title ' Modele EGARCH sous une loi normale ';
proc autoreg data=pev.projet;
model rend = / garch=( p=1, q=2,type= exp) DIST=NORMAL COVEST=QML;
output out=pev.valueatrisquenorm r=epsilon cev=condvar p=prevision alphacli=0.05
lcl=lower ucl=upper;
run;
/* Calcul des VaR à 5% et 1%*/
data pev.valueatrisquenorm;
set pev.valueatrisquenorm;
/* on recopie directement la valeur de la constante de l'output*/
/*VaR 5% de l'estimation GARCH = valeurs plus faibles*/
varN5= -0.000900 + sqrt(condvar)*QUANTILE("NORMAL",0.95);
violN5=(rend>varN5);
/*VaR 1% de l'estimation GARCH = valeurs plus faibles*/
varN1= -0.000900 + sqrt(condvar)*QUANTILE("NORMAL",0.99);
violN1=(rend>varN1);
run;
/*représentation de la VaR et rendements*/
proc gplot data = pev.valueatrisquenorm;
symbol1 interpol=join value=none color=blue;
symbol2 interpol=join value=none color=green;
symbol3 interpol=join value=none color=red;
plot varN5*date rend*date varN1*date/LEGEND overlay;
title "Graphique de la VaR 1% et 5% sous une loi normale et rendements";
run;/*On constate que les deux Var sont presque confondues*/
/*on fusionne les tables car la proc autoreg a modifié nos rendements*/
data pev.valueatrisquenorm;
merge pev.valueatrisquenorm pev.projet;
by Date;
run;
title'Test LR de Kupiec pour la var à 5%';
proc iml;
use pev.valueatrisquenorm;
read all into serie;
t=nrow(serie);
n=sum(serie[,15]);/*colonne de la violation à 5% dans valueatrisquenorm*/

Page 49 of 56
NLR5=-2*log(((1-0.05)**(t-n))*((0.05)**n))+2*log(((1-(n/t)**(t-n))*((n/t)**(n))));
print t n NLR5;
run;
quit;
title 'Test LR de Kupiec pour la var à 1%';
proc iml;
use pev.valueatrisquenorm;
read all into serie;
t=nrow(serie);
n=sum(serie[,17]);/*colonne de la violation à 1% dans valueatrisquenorm*/
NLR1=-2*log(((1-0.01)**(t-n))*((0.01)**n))+2*log(((1-(n/t)**(t-n))*((n/t)**(n))));
print t n NLR1;
run;
quit;
ods rtf close;
/**************************************************************************************
****/
/**************************************************************************************
****/
/*Calcul de la Var in sample avec la loi student*/
/**************************************************************************************
****/
/**************************************************************************************
****/
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\VaRStudent IN
SAMPLE.doc';
title 'Modele GARCH(1,2) pour le portefeuille selectionné';
/* Estimation IGARCH(1,2) */
proc autoreg data=pev.projet;
model rend = / garch=( p=1, q=2, type= integrated)DIST=T;
output out=pev.valueatrisquet r=epsilon cev=condvar p=prevision alphacli=0.05
lcl=lower ucl=upper;
run;
/* Calcul des Var à 5% et 1%*/
data pev.valueatrisquet;
set pev.valueatrisquet;
/* on recopie directement la valeur de la constante de l'output et on utilise la valeur
1/TDFI*/
varT5= -0.000870 + sqrt(condvar)*QUANTILE("t",0.95,1/0.1231);
/* TDFI = donne l'inverse de Var=V/(V-2) i.e var de la loi de Student, donc ici 1/0. ~=
*/
/*Le V degré de liberté du Student va être petit car + V est petit et + on met de
kurtosis*/
violT5=(rend>varT5);
/*VaR 5% de l'estimation GARCH = valeurs plus faibles*/
varT1= -0.000870 + sqrt(condvar)*QUANTILE("t",0.99,1/0.1231);
violT1=(rend>varT1);
/*VaR 1% de l'estimation GARCH = valeurs plus faibles*/
run;
/*représentation de la VaR et des rendements dans le temps*/
proc gplot data = pev.valueatrisquet;
symbol1 interpol=join value=none color=brown;
symbol2 interpol=join value=none color=green;
symbol3 interpol=join value=none color=yellow;
plot varT5*date rend*date varT1*date/LEGEND overlay;
title "Graphique de la VaR 1% et 5% sous la loi de Student et rendements";
run;/*On constate que les deux Var sont presque confondues*/
/*on doit fusionner les tables car la proc autoreg a modifié nos rendements*/
proc sort data=pev.valueatrisquet;
by Date;
run;
proc sort data=pev.valueatrisquenorm;
by Date;
run;

Page 50 of 56
proc sort data=pev.projet;
by Date;
run;
data pev.valueatrisquet;
merge pev.valueatrisquet pev.projet;
by Date;
run;
title 'Test LR de Kupiec sur la var à 5%';
proc iml;
use pev.valueatrisquet;
read all into serie;
t=nrow(serie);
n=sum(serie[,15]);/*colonne de la violation à 5% dans valueatrisquenorm*/
TLR5=-2*log(((1-0.05)**(t-n))*((0.05)**n))+2*log(((1-(n/t)**(t-n))*((n/t)**(n))));
print t n TLR5;
run;
quit;
title 'Test LR de Kupiec sur la var à 1%';
proc iml;
use pev.valueatrisquet;
read all into serie;
t=nrow(serie);
n=sum(serie[,17]);/*colonne de la violation à 1% dans valueatrisquenorm*/
TLR1=-2*log(((1-0.01)**(t-n))*((0.01)**n))+2*log(((1-(n/t)**(t-n))*((n/t)**(n))));
print t n TLR1;
run;
quit;
ods rtf close;
quit;
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\Comparaison
resultat.doc';
/*On réunit les VAR dans une même table avec les rendements pour pouvoir les comparer*/
data pev.valueatrisque;
merge pev.valueatrisquet pev.valueatrisquenorm pev.projet;
by Date;
keep date rend varN5 varN1 varT5 varT1;
run;
/*représentation des VaR et les rendements*/
proc gplot data = pev.valueatrisque;
symbol1 interpol=join value=none color=green;
symbol2 interpol=join value=none color=brown;
symbol3 interpol=join value=none color=yellow;
symbol4 interpol=join value=none color=blue;
symbol5 interpol=join value=none color=red;
plot rend*date varT5*date varT1*date varN5*date varN1*date /LEGEND overlay;
title " VaR à 1% et 5% (Student et Normale) et rendements";
run;/*On constate que les deux Var sont presque confondues*/
ods rtf close;
quit;
/**************************************************************************************
****/
/**************************************************************************************
****/
/****************Calcul de la VaR out-of-sample avec la loi
student************************/
/****************VaR OUT OF SAMPLE avec rolling ************************/
/**************************************************************************************
****/
/**************************************************************************************
****/

Page 51 of 56
/*Pour calculer la VaR out of Sample, on a choisi de retenir le modèle optimal IGARCHE
(1,2)
sélectionné par minimisation des critères SBC et AIC. On utilise la loi de Student, car
cette
loi de permet de calculer une VaR qui permet de mieux apréhender les pertes extrèmes.
On va construire une nouvelle table de 250 observations et effectuer des prévisions
roulantes*/
/*IGARCH sur le nouvel échantillon*/
/*calcul des rendements*/
data pev.projet2;
set pev.projet2;
/*Calcul des rendement de chacun des titres*/
rendDANONE=log(DANONE/lag(DANONE));
rendSOCGEN=log(SOCGEN/lag(SOCGEN));
rendMICHELIN=log(MICHELIN/lag(MICHELIN));
/* Pondération */
rend=0.5*rendSOCGEN+0.25*rendMICHELIN+0.25*rendDANONE;
run;
data pev.projet3;/*table de transition*/
set pev.projet;
obs+1;
run;
data pev.projet4;/*table de transition*/
set pev.projet3;
lsp=100;
lsp=lag(lsp)*(1+rend);
if obs=1 then do;
lsp=100;
end;
run;
/*table à utiliser pour faire les Var et les prévisions de VaR*/
DATA pev.Ptf_prev;
SET pev.projet4;
KEEP obs date rend lsp;
WHERE obs > 0;
RUN;
DATA tmp;
SET pev.Ptf_prev;
Where((obs > 0) AND (obs <= 500));
IF Obs > 252 THEN DO;
lsp = .;
rend = .;
END;
RUN;
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\IGARCH Student OUT OF
SAMPLE.doc';
title 'calcul IGARCH(1,2)';
proc autoreg data=tmp;
model rend = / garch=( p=1, q=2, type= integrated)DIST=T;
output out=pev.varprev r=epsilon cev=condvar p=prevision;
run;
ods rtf close;
quit;
/* Macro pour estimer le Igarch sur une période fixe ou glissante */
/** Estimation Rolling **/
%MACRO GARCH_Rolling(datas=, end= , rolling=);
DATA tmp;
SET &datas;
Where((obs >= &end - 251) AND (obs <= &end));
RUN;

Page 52 of 56
/* EGARCH */
PROC autoreg data= tmp NOPRINT;
model rend= / garch=( p=1, q=2, type= integrated)DIST=T;
output out=outvar r=epsilon cev=h_rend;
RUN;
QUIT;
/* Creation de l'indice */
DATA outvar;
SET outvar (KEEP = h_rend) ;
obs + 1;
RUN;
/* Calculer la VaR */
DATA outvar;
SET outvar;
var1 = -0.001465 + sqrt(h_rend)*quantile('T',.01,1/0.0248);
var5 = -0.001465 + sqrt(h_rend)*quantile('T',.05,1/ 0.0248);/*idem*/
obs = obs + (&end-252);
RUN;
DATA Outvar;
MERGE Outvar Tmp(Keep=obs date lsp rend);
RUN;
/* KEEP la derniere VaR calculee */
%IF &rolling=1 %THEN %DO;
DATA outvar;
SET outvar;
WHERE obs = &end;
RUN;
%END;
%MEND;
/*Tester*/
%GARCH_Rolling(datas=pev.Ptf_prev, end=250 , rolling=0);
/** macro pour faire le Rolling sur les 250 out of sample **/
%MACRO Rolling(Base=, start=, end=, option=);
%IF &option= 'rolling' %THEN %DO;
%DO ind = &start %TO &end;
%GARCH_Rolling(datas=&Base, end=&ind , rolling=1);
%IF &ind = &start %THEN %DO;
DATA Rolling;
SET outvar;
RUN;
%END;
%ELSE %DO;
DATA Rolling;
MERGE Rolling outvar;
BY obs;
RUN;
%END;
%END; /* Fin de boucle "do" */
%END;
/* Estimation static */

Page 53 of 56
%ELSE %DO;
%GARCH_Rolling(datas=&Base, end=&end , rolling=0);
DATA Rolling;
SET outvar;
RUN;
%END;
/* Cacluls de la violation */
DATA ROLLING;
SET ROLLING;
/* Violation a 1% */
IF (var1 > rend) THEN
violation1 = 1;
ELSE DO;
violation1 = 0;
END;
/* violation a 5% */
IF (var5 > rend) THEN
violation5 = 1;
ELSE DO;
violation5 = 0;
END;
RUN;
%MEND;
/* Estimation In-Sample */
%Rolling(Base=pev.Ptf_prev, start=1, end=252, option='static');
DATA pev.Var_inSample;
SET Rolling;
RUN;
/* Estimation Out-Of-Sample */
%Rolling(Base=pev.Ptf_prev, start=253, end=500, option='rolling');
DATA pev.Var_outSample;
SET Rolling;
RUN;
/*Test LR de Kupiec sur la var à 5%*/
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\KUPIEC OUT-OF-
SAMPLE.doc';
title ' Test LR Kupiec VaR out of sample à 5%';
proc iml;
use pev.Var_outSample;
read all into serie;
t=nrow(serie);
n=sum(serie[,9]);/*colonne de la violation à 5% dans valueatrisquenorm*/
LR5=-2*log(((1-0.05)**(t-n))*((0.05)**n))+2*log(((1-(n/t)**(t-n))*((n/t)**(n))));
print t n LR5;
run;
quit;
/*Test LR de Kupiec sur la var à 1%*/
title ' Test LR Kupiec VaR out of sample 1%';
proc iml;
use pev.Var_outSample;
read all into serie;
t=nrow(serie);

Page 54 of 56
n=sum(serie[,8]);/*colonne de la violation à 1% dans valueatrisquenorm*/
LR1=-2*log(((1-0.01)**(t-n))*((0.01)**n))+2*log(((1-(n/t)**(t-n))*((n/t)**(n))));
print t n LR1;
run;
quit;
ods rtf close;
quit;
/* Combinaison des resultats */
DATA pev.Var_total;
MERGE pev.Var_inSample pev.Var_outSample;
BY obs;
KEEP obs date lsp rend h_rend var1 var5 violation1 violation5;
RUN;
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\RESULTAT OUT-OF-
SAMPLE.doc';
title 'Variance Conditionnelle Estimée totale 500 observations';
PROC GPLOT DATA = pev.Var_total;
PLOT h_rend*date / VREF=0 HAXIS=axis1 VAXIS=axis2;
SYMBOL1 I=join V=NONE;
AXIS1 LABEL=( H=1 'Variance Conditionnelle Estimee');
AXIS2 LABEL=NONE;
TITLE "Variance Conditionnelle Estimee sur un total de 500 obs";
RUN;
QUIT;
/* représentation graphique*/
PROC GPLOT DATA = pev.Var_total;
SYMBOL1 INTERPOL=join COLOR=BLACK VALUE=NONE;
SYMBOL2 INTERPOL=join COLOR=RED VALUE=NONE LINE=5;
SYMBOL3 INTERPOL=join COLOR=GREEN VALUE=NONE LINE=5;
PLOT rend*date var5*Date var1*date/OVERLAY;
TITLE "Rendements et Value at Risk";
RUN;
QUIT;
title 'Violation sur horizon totale des 500 observations';
PROC GPLOT DATA = pev.Var_total;
SYMBOL1 INTERPOL=join COLOR=RED VALUE=NONE LINE=1;
SYMBOL2 INTERPOL=join COLOR=GREEN VALUE=NONE LINE=1;
PLOT violation5*date
violation1*date / OVERLAY VAXIS=axis1 ;
AXIS1 LABEL=('Violation') ORDER=(0 to 1 by 1);
TITLE "violation 5%(rouge) et 1%(vert) sur 500 obs";
RUN;
QUIT;
title'Violation sur horizon out-of-sample 250 observations';
PROC GPLOT DATA = pev.Var_outsample;
SYMBOL1 INTERPOL=join COLOR=RED VALUE=NONE LINE=1;
SYMBOL2 INTERPOL=join COLOR=GREEN VALUE=NONE LINE=1;
PLOT violation5*date
violation1*date /LEGEND OVERLAY VAXIS=axis1 ;
AXIS1 LABEL=('Violation') ORDER=(0 to 1 by 1);
TITLE "violation 5% et 1% sur 250 obs Out of Sample";
RUN;
ods rtf close;

Page 55 of 56
QUIT;
DATA tmp;
SET pev.Ptf_prev;
Where((obs > 0) AND (obs <= 500));
IF Obs > 252 THEN DO;
lsp = .;
rend = .;
END;
RUN;
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\GLISSEMENT.doc';
TITLE 'Restimation du modele a chaque glissement';
PROC autoreg data= tmp;
model rend= / garch=( p=1, q=2, type= integrated)DIST=T;
output out=outvar r=epsilon cev=h_rend;
run;
ods rtf close;
QUIT;
DATA pev.Var_Prevision;
MERGE Outvar(keep=rend h_rend)
Tmp;
RUN;
DATA pev.Var_Prevision;
SET pev.Var_Prevision;
var1 = -0.001465 + sqrt(h_rend)*quantile('T',.01,1/0.0248);
var5 = -0.001465 + sqrt(h_rend)*quantile('T',.05,1/0.0248);
RUN;
/* Representation graphique */
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\VaR conditionnelle
estimee out-of-sample.doc';
TITLE 'Variance conditionnelle Estimee';
/* Variance Cconditionnelle Estimée*/
PROC GPLOT DATA = pev.Var_prevision;
PLOT h_rend*date / VREF=0 HAXIS=axis1 VAXIS=axis2;
SYMBOL1 I=join V=NONE C=BLUE;
AXIS1 LABEL=( H=1 'Variance Conditionnelle Estimee');
AXIS2 LABEL=NONE;
TITLE "Variance Conditionnelle Estimee";
RUN;
QUIT;
PROC GPLOT DATA = pev.Var_prevision;
SYMBOL1 INTERPOL=join COLOR=BLACK VALUE=NONE;
SYMBOL2 INTERPOL=join COLOR=RED VALUE=NONE LINE=5;
SYMBOL3 INTERPOL=join COLOR=GREEN VALUE=NONE LINE=5;
PLOT rend*date var5*Date var1*date/OVERLAY;
TITLE "Rendements et VaR";
RUN;
QUIT;
ods rtf close;
/* Test ex-poste */
DATA pev.Var_10j;
MERGE pev.Var_prevision(Drop=rend) pev.Ptf_prev(Keep=obs rend);
BY OBS;
RUN;
DATA pev.Var_10j;
SET pev.Var_10j;
WHERE obs >252 AND obs <= 252+10;
RUN;

Page 56 of 56
DATA pev.Var_10j;
SET pev.Var_10j;
/* Violation a 1% */
IF (var1 > rend) THEN
violation1 = 1;
ELSE DO;
violation1 = 0;
END;
/* violation a 5% */
IF (var5 > rend) THEN
violation5 = 1;
ELSE DO;
violation5 = 0;
END;
t+1;
RUN;
ODS RTF file='C:\Users\Luis\Desktop\GARCH\Projet VaR\Project\Data\violation var
10j.doc';
title' Violation sur horizon 10j Out-of-Sample';
PROC GPLOT DATA = pev.Var_10j;
SYMBOL1 INTERPOL=join COLOR=BLACK VALUE=NONE;
SYMBOL2 INTERPOL=join COLOR=RED VALUE=NONE LINE=5;
SYMBOL3 INTERPOL=join COLOR=GREEN VALUE=NONE LINE=5;
PLOT rend*t var5*t var1*t/OVERLAY;
TITLE "Rendements et VaR 10 jours";
RUN;
ODS rtf close;
QUIT;





























