Embed Size (px)
Citation preview

InferenceinBayesiannetworks
Chapter14.4–5
Chapter14.4–51

Outline
♦Exactinferencebyenumeration
♦Exactinferencebyvariableelimination
♦Approximateinferencebystochasticsimulation
♦ApproximateinferencebyMarkovchainMonteCarlo
Chapter14.4–52

Inferencetasks
Simplequeries:computeposteriormarginalP(Xi|E=e)e.g.,P(NoGas|Gauge=empty,Lights=on,Starts=false)
Conjunctivequeries:P(Xi,Xj|E=e)=P(Xi|E=e)P(Xj|Xi,E=e)
Optimaldecisions:decisionnetworksincludeutilityinformation;probabilisticinferencerequiredforP(outcome|action,evidence)
Valueofinformation:whichevidencetoseeknext?
Sensitivityanalysis:whichprobabilityvaluesaremostcritical?
Explanation:whydoIneedanewstartermotor?
Chapter14.4–53

Inferencebyenumeration
Slightlyintelligentwaytosumoutvariablesfromthejointwithoutactuallyconstructingitsexplicitrepresentation
Simplequeryontheburglarynetwork:BE
J
A
M
P(B|j,m)=P(B,j,m)/P(j,m)=αP(B,j,m)=αΣeΣaP(B,e,a,j,m)
RewritefulljointentriesusingproductofCPTentries:P(B|j,m)=αΣeΣaP(B)P(e)P(a|B,e)P(j|a)P(m|a)=αP(B)ΣeP(e)ΣaP(a|B,e)P(j|a)P(m|a)
Recursivedepth-firstenumeration:O(n)space,O(dn)time
Chapter14.4–54

Enumerationalgorithm
functionEnumeration-Ask(X,e,bn)returnsadistributionoverX
inputs:X,thequeryvariable
e,observedvaluesforvariablesE
bn,aBayesiannetworkwithvariables{X}∪E∪Y
Q(X)←adistributionoverX,initiallyempty
foreachvaluexiofXdo
extendewithvaluexiforX
Q(xi)←Enumerate-All(Vars[bn],e)
returnNormalize(Q(X))
functionEnumerate-All(vars,e)returnsarealnumber
ifEmpty?(vars)thenreturn1.0
Y←First(vars)
ifYhasvalueyine
thenreturnP(y|Pa(Y))×Enumerate-All(Rest(vars),e)
elsereturn∑
yP(y|Pa(Y))×Enumerate-All(Rest(vars),ey)
whereeyiseextendedwithY=y
Chapter14.4–55

Evaluationtree
P(j|a).90
P(m|a).70.01
P(m| a)
.05P(j| a)P(j|a)
.90
P(m|a).70.01
P(m| a)
.05P(j| a)
P(b).001
P(e).002
P( e).998
P(a|b,e).95.06
P( a|b, e).05P( a|b,e)
.94P(a|b, e)
Enumerationisinefficient:repeatedcomputatione.g.,computesP(j|a)P(m|a)foreachvalueofe
Chapter14.4–56

Inferencebyvariableelimination
Variableelimination:carryoutsummationsright-to-left,storingintermediateresults(factors)toavoidrecomputation
P(B|j,m)=αP(B) ︸︷︷︸
B
ΣeP(e) ︸︷︷︸
E
ΣaP(a|B,e) ︸︷︷︸
A
P(j|a) ︸︷︷︸
J
P(m|a) ︸︷︷︸
M
=αP(B)ΣeP(e)ΣaP(a|B,e)P(j|a)fM(a)=αP(B)ΣeP(e)ΣaP(a|B,e)fJ(a)fM(a)=αP(B)ΣeP(e)ΣafA(a,b,e)fJ(a)fM(a)=αP(B)ΣeP(e)fAJM(b,e)(sumoutA)=αP(B)fEAJM(b)(sumoutE)=αfB(b)×fEAJM(b)
Chapter14.4–57

Variableelimination:Basicoperations
Summingoutavariablefromaproductoffactors:moveanyconstantfactorsoutsidethesummationaddupsubmatricesinpointwiseproductofremainingfactors
Σxf1×···×fk=f1×···×fiΣxfi+1×···×fk=f1×···×fi×fX
assumingf1,...,fidonotdependonX
Pointwiseproductoffactorsf1andf2:f1(x1,...,xj,y1,...,yk)×f2(y1,...,yk,z1,...,zl)
=f(x1,...,xj,y1,...,yk,z1,...,zl)E.g.,f1(a,b)×f2(b,c)=f(a,b,c)
Chapter14.4–58

Variableeliminationalgorithm
functionElimination-Ask(X,e,bn)returnsadistributionoverX
inputs:X,thequeryvariable
e,evidencespecifiedasanevent
bn,abeliefnetworkspecifyingjointdistributionP(X1,...,Xn)
factors←[];vars←Reverse(Vars[bn])
foreachvarinvarsdo
factors←[Make-Factor(var,e)|factors]
ifvarisahiddenvariablethenfactors←Sum-Out(var,factors)
returnNormalize(Pointwise-Product(factors))
Chapter14.4–59
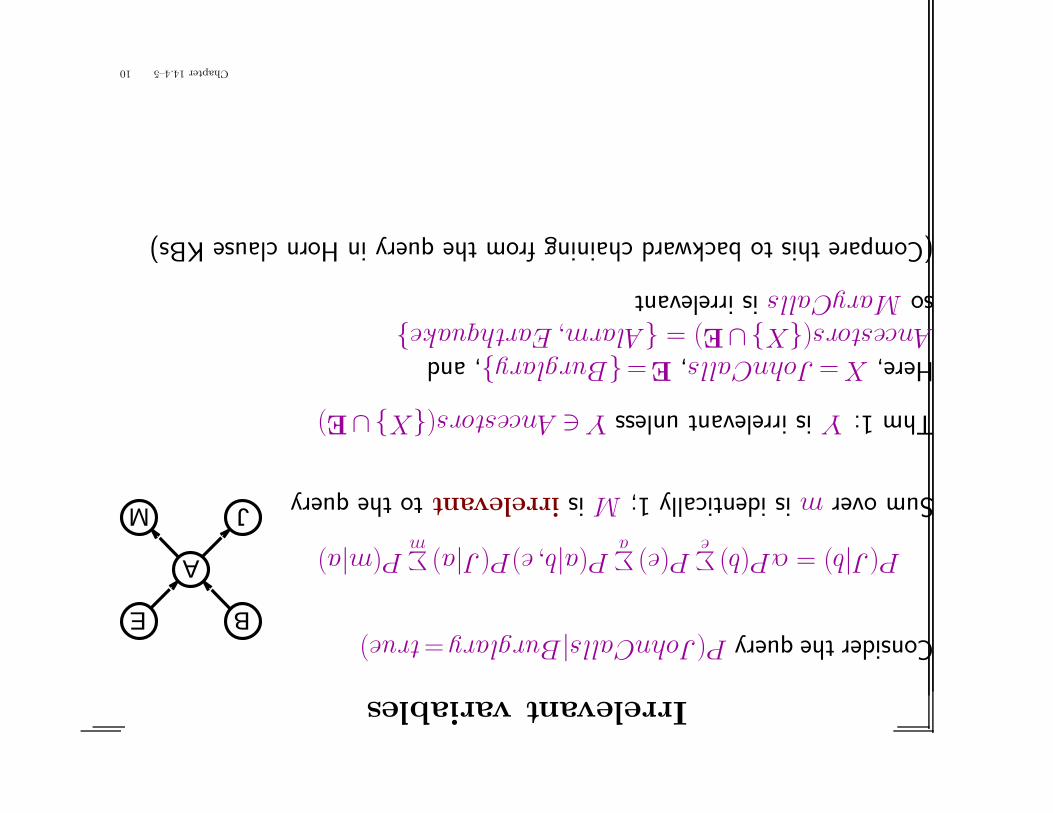
Irrelevantvariables
ConsiderthequeryP(JohnCalls|Burglary=true)BE
J
A
M
P(J|b)=αP(b)∑
eP(e)
∑
aP(a|b,e)P(J|a)
∑
mP(m|a)
Sumovermisidentically1;Misirrelevanttothequery
Thm1:YisirrelevantunlessY∈Ancestors({X}∪E)
Here,X=JohnCalls,E={Burglary},andAncestors({X}∪E)={Alarm,Earthquake}soMaryCallsisirrelevant
(ComparethistobackwardchainingfromthequeryinHornclauseKBs)
Chapter14.4–510
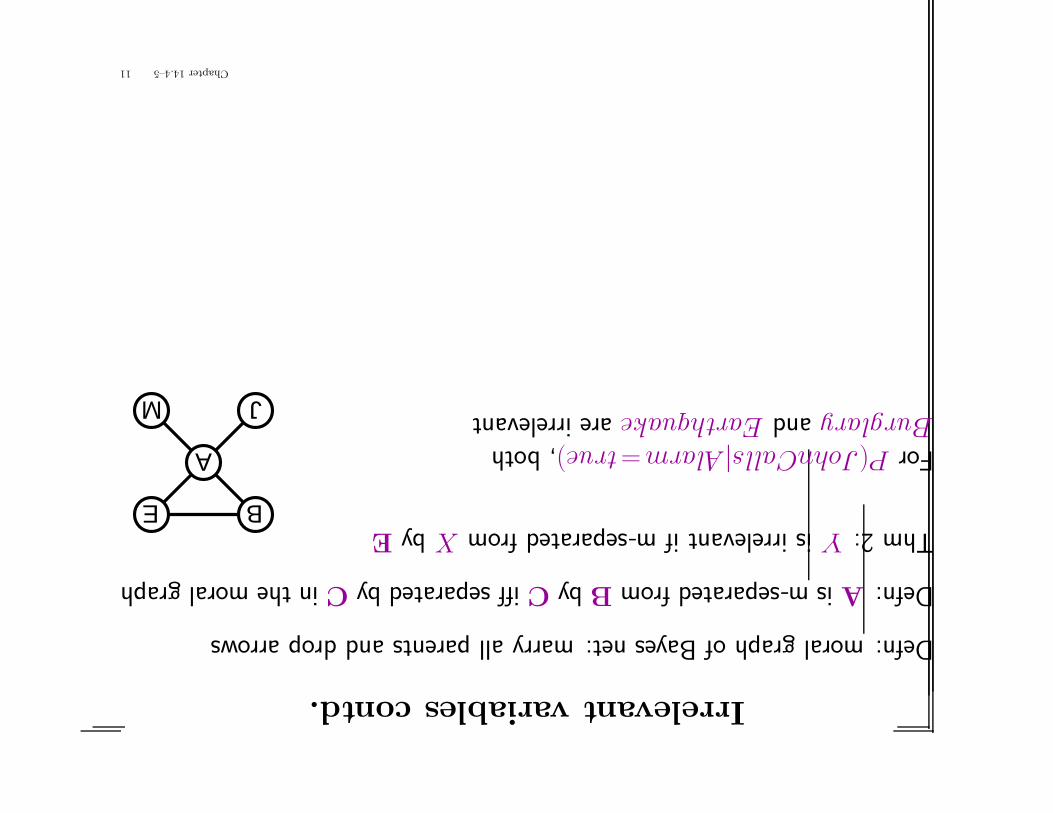
Irrelevantvariablescontd.
Defn:moralgraphofBayesnet:marryallparentsanddroparrows
Defn:Aism-separatedfromBbyCiffseparatedbyCinthemoralgraph
Thm2:Yisirrelevantifm-separatedfromXbyEBE
J
A
M
ForP(JohnCalls|Alarm=true),bothBurglaryandEarthquakeareirrelevant
Chapter14.4–511
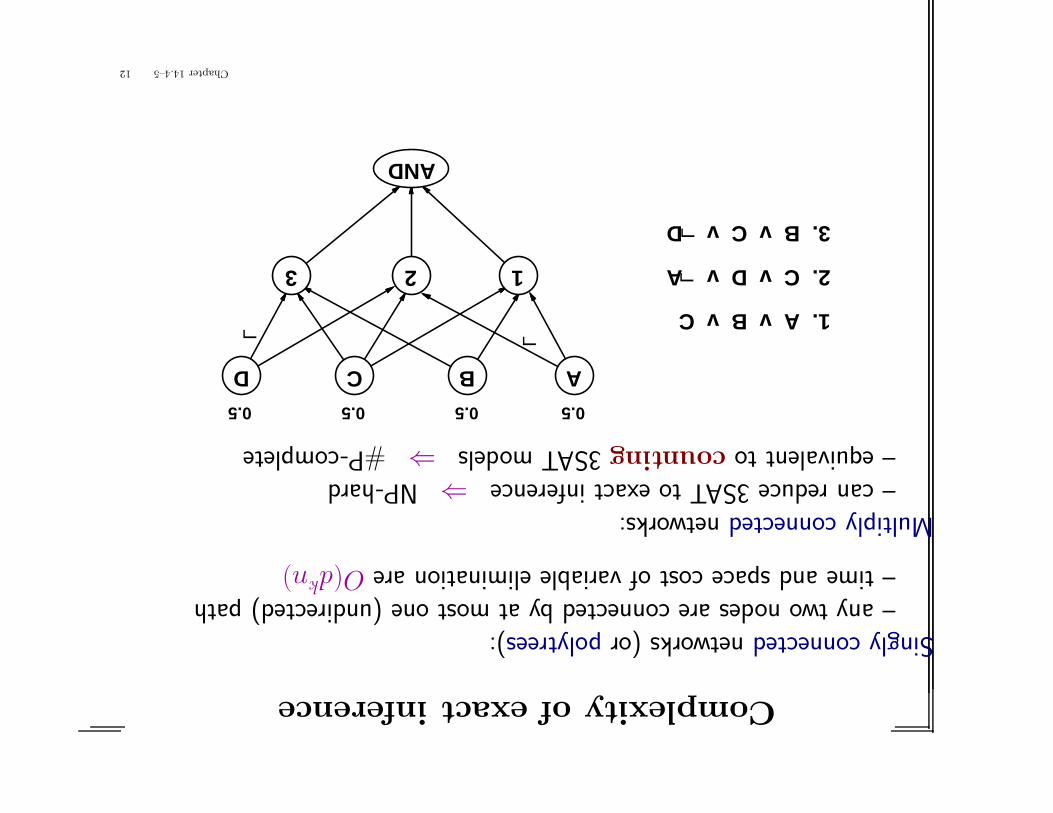
Complexityofexactinference
Singlyconnectednetworks(orpolytrees):–anytwonodesareconnectedbyatmostone(undirected)path–timeandspacecostofvariableeliminationareO(d
kn)
Multiplyconnectednetworks:–canreduce3SATtoexactinference⇒NP-hard–equivalenttocounting3SATmodels⇒#P-complete
ABCD
123
AND
0.50.5 0.5 0.5
L L
LL
1. A v B v C
2. C v D v A
3. B v C v D
Chapter14.4–512

Inferencebystochasticsimulation
Basicidea:1)DrawNsamplesfromasamplingdistributionS
Coin
0.5 2)ComputeanapproximateposteriorprobabilityP3)ShowthisconvergestothetrueprobabilityP
Outline:–Samplingfromanemptynetwork–Rejectionsampling:rejectsamplesdisagreeingwithevidence–Likelihoodweighting:useevidencetoweightsamples–MarkovchainMonteCarlo(MCMC):samplefromastochasticprocess
whosestationarydistributionisthetrueposterior
Chapter14.4–513

Samplingfromanemptynetwork
functionPrior-Sample(bn)returnsaneventsampledfrombn
inputs:bn,abeliefnetworkspecifyingjointdistributionP(X1,...,Xn)
x←aneventwithnelements
fori=1tondo
xi←arandomsamplefromP(Xi|parents(Xi))
giventhevaluesofParents(Xi)inx
returnx
Chapter14.4–514

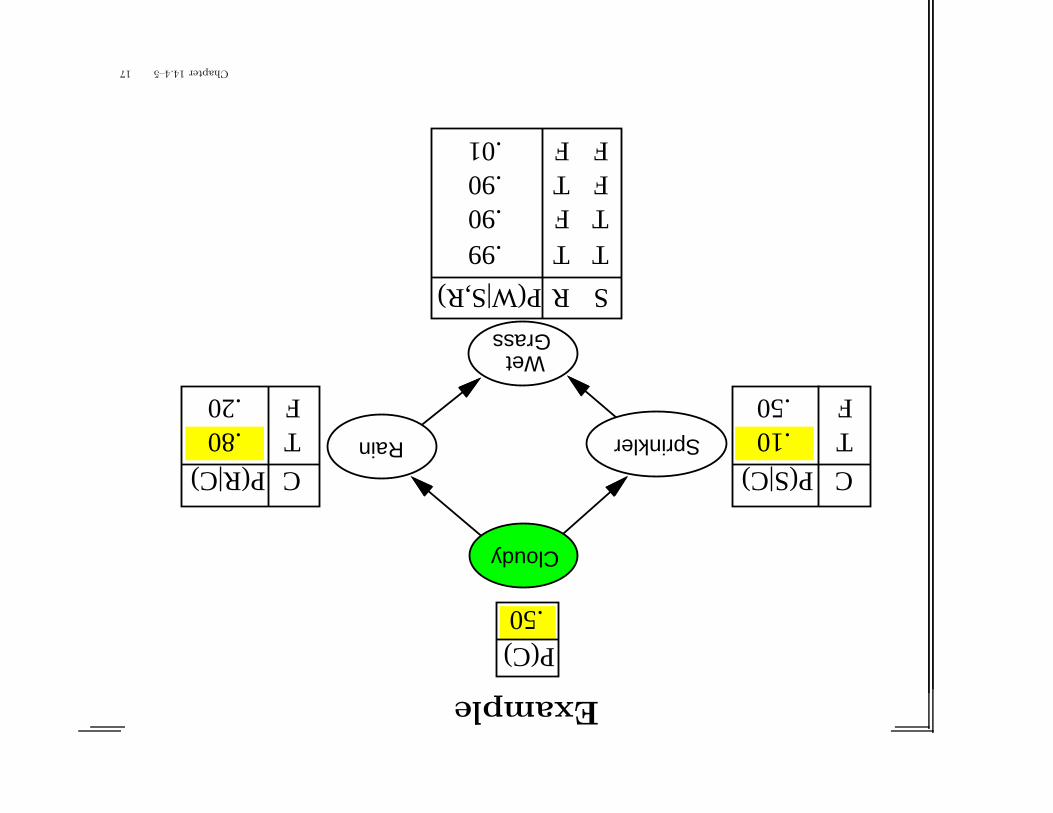
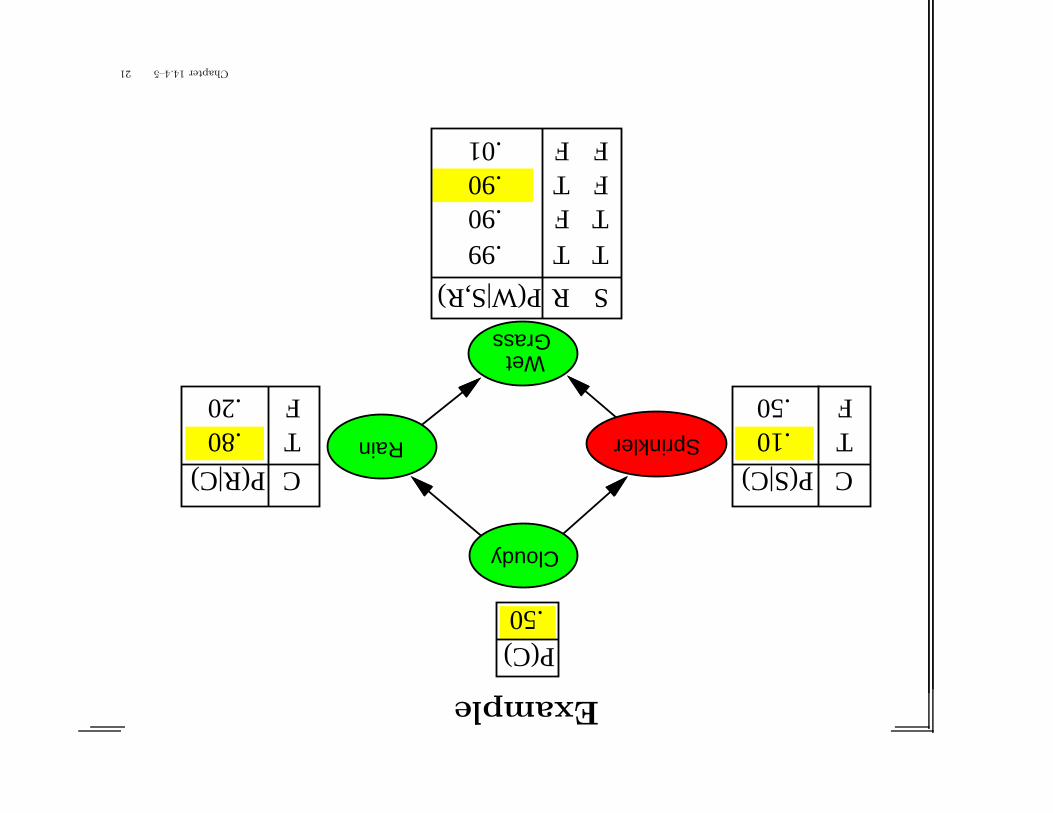
Example
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
Chapter14.4–515

Example
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
Chapter14.4–516
Example
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
Chapter14.4–517

Example
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
Chapter14.4–518

Example
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
Chapter14.4–519

Example
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
Chapter14.4–520
Example
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
Chapter14.4–521

Samplingfromanemptynetworkcontd.
ProbabilitythatPriorSamplegeneratesaparticulareventSPS(x1...xn)=Π
ni=1P(xi|parents(Xi))=P(x1...xn)
i.e.,thetruepriorprobability
E.g.,SPS(t,f,t,t)=0.5×0.9×0.8×0.9=0.324=P(t,f,t,t)
LetNPS(x1...xn)bethenumberofsamplesgeneratedforeventx1,...,xn
Thenwehave
limN→∞
P(x1,...,xn)=limN→∞
NPS(x1,...,xn)/N
=SPS(x1,...,xn)
=P(x1...xn)
Thatis,estimatesderivedfromPriorSampleareconsistent
Shorthand:P(x1,...,xn)≈P(x1...xn)
Chapter14.4–522

Rejectionsampling
P(X|e)estimatedfromsamplesagreeingwithe
functionRejection-Sampling(X,e,bn,N)returnsanestimateofP(X|e)
localvariables:N,avectorofcountsoverX,initiallyzero
forj=1toNdo
x←Prior-Sample(bn)
ifxisconsistentwithethen
N[x]←N[x]+1wherexisthevalueofXinx
returnNormalize(N[X])
E.g.,estimateP(Rain|Sprinkler=true)using100samples27sampleshaveSprinkler=true
Ofthese,8haveRain=trueand19haveRain=false.
P(Rain|Sprinkler=true)=Normalize(〈8,19〉)=〈0.296,0.704〉
Similartoabasicreal-worldempiricalestimationprocedure
Chapter14.4–523

Analysisofrejectionsampling
P(X|e)=αNPS(X,e)(algorithmdefn.)=NPS(X,e)/NPS(e)(normalizedbyNPS(e))≈P(X,e)/P(e)(propertyofPriorSample)=P(X|e)(defn.ofconditionalprobability)
Hencerejectionsamplingreturnsconsistentposteriorestimates
Problem:hopelesslyexpensiveifP(e)issmall
P(e)dropsoffexponentiallywithnumberofevidencevariables!
Chapter14.4–524

Likelihoodweighting
Idea:fixevidencevariables,sampleonlynonevidencevariables,andweighteachsamplebythelikelihooditaccordstheevidence
functionLikelihood-Weighting(X,e,bn,N)returnsanestimateofP(X|e)
localvariables:W,avectorofweightedcountsoverX,initiallyzero
forj=1toNdo
x,w←Weighted-Sample(bn)
W[x]←W[x]+wwherexisthevalueofXinx
returnNormalize(W[X])
functionWeighted-Sample(bn,e)returnsaneventandaweight
x←aneventwithnelements;w←1
fori=1tondo
ifXihasavaluexiine
thenw←w×P(Xi=xi|parents(Xi))
elsexi←arandomsamplefromP(Xi|parents(Xi))
returnx,w
Chapter14.4–525
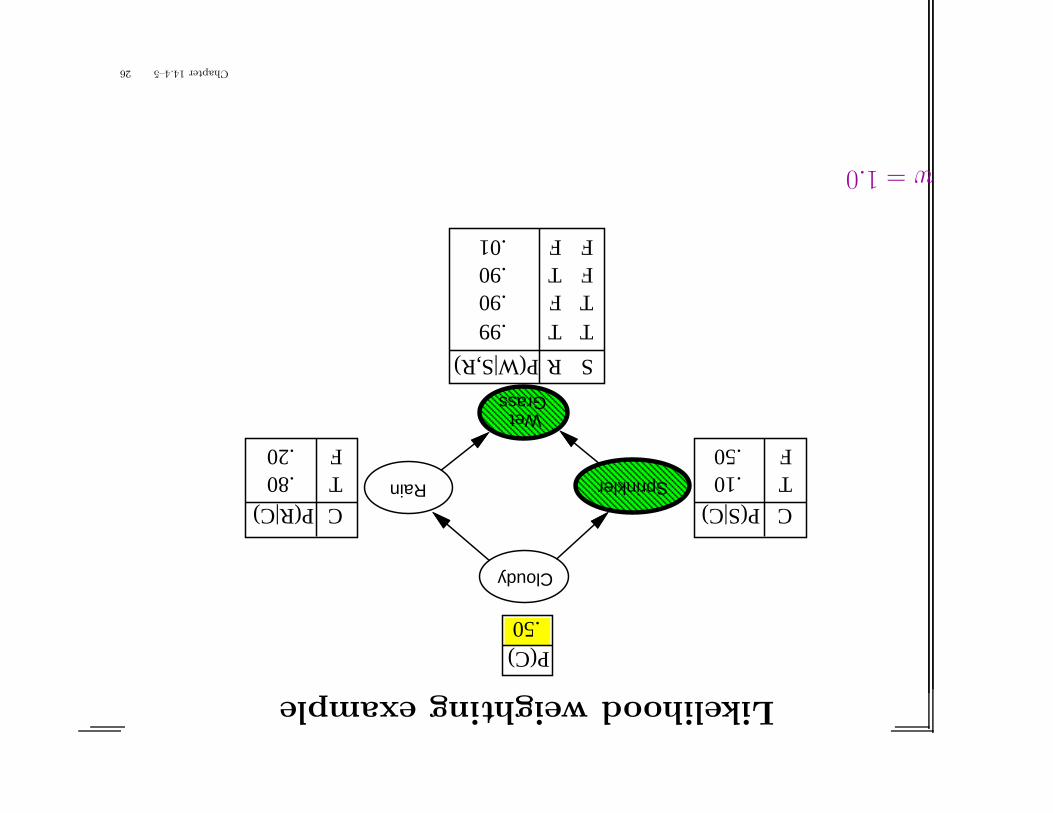
Likelihoodweightingexample
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
w=1.0
Chapter14.4–526

Likelihoodweightingexample
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
w=1.0
Chapter14.4–527

Likelihoodweightingexample
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
w=1.0
Chapter14.4–528
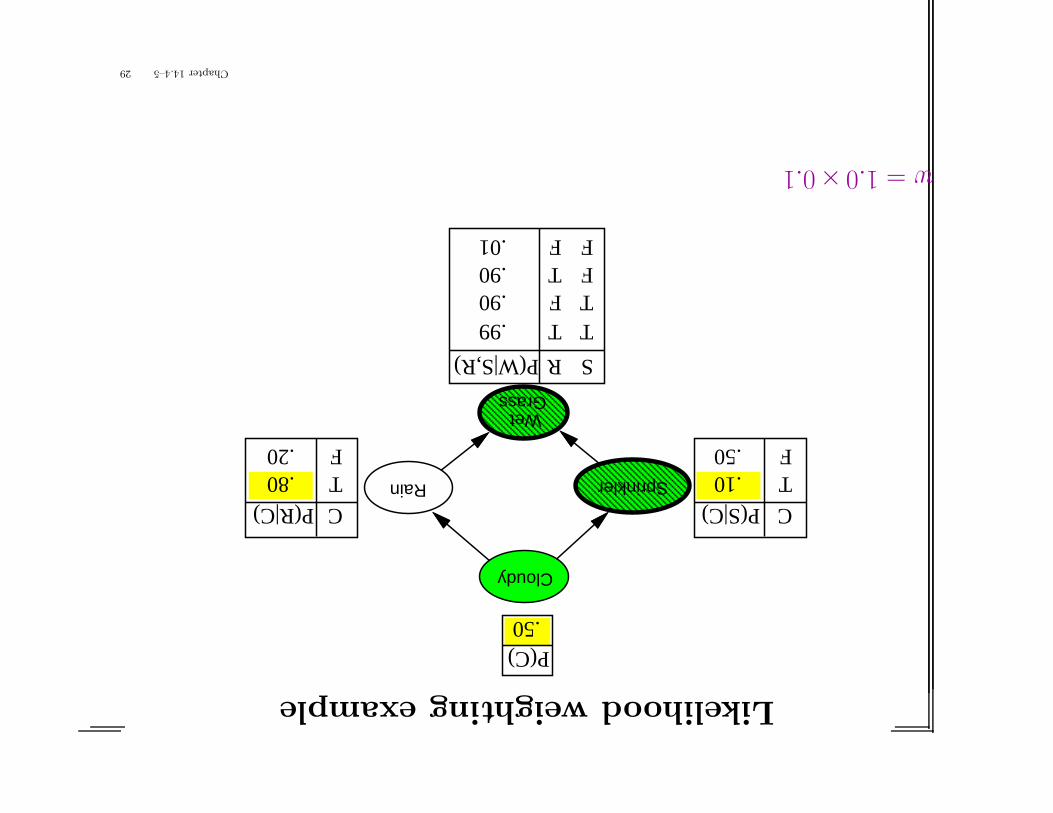
Likelihoodweightingexample
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
w=1.0×0.1
Chapter14.4–529

Likelihoodweightingexample
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
w=1.0×0.1
Chapter14.4–530

Likelihoodweightingexample
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
w=1.0×0.1
Chapter14.4–531
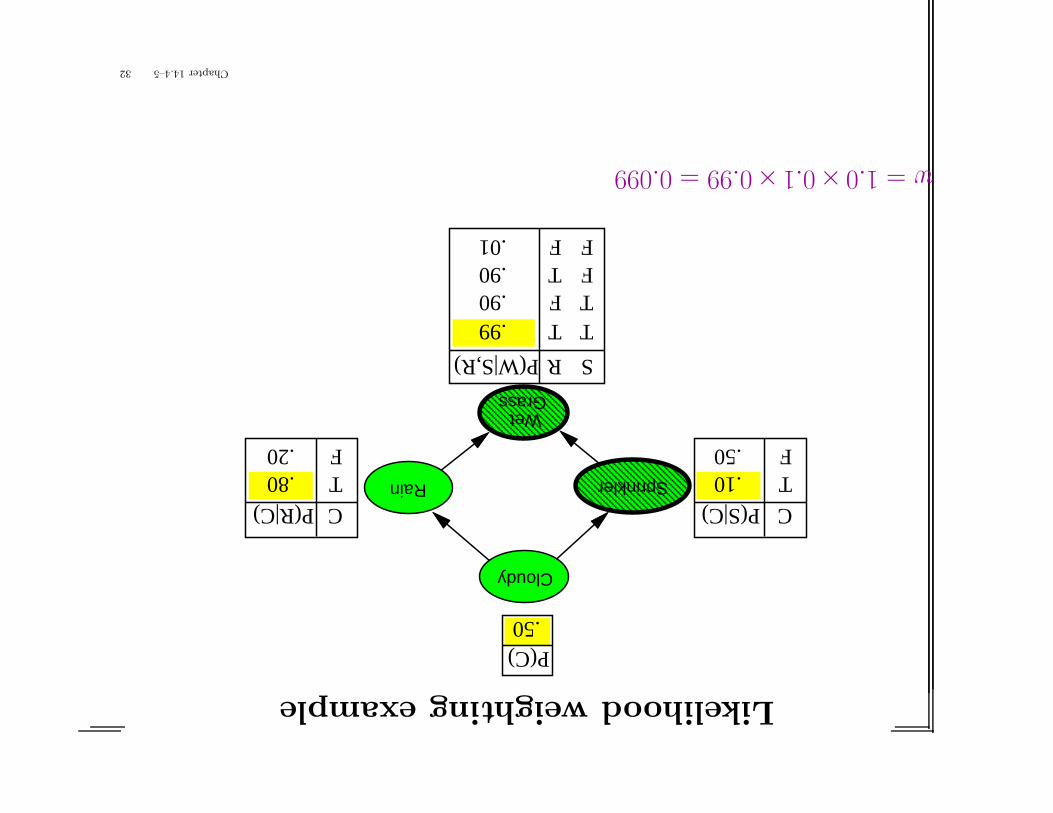
Likelihoodweightingexample
Cloudy
Rain Sprinkler
WetGrass
C
TF
.80
.20
P(R|C) C
TF
.10
.50
P(S|C)
SR
TTTFFTFF
.90
.90
.99
P(W|S,R)
P(C).50
.01
w=1.0×0.1×0.99=0.099
Chapter14.4–532

Likelihoodweightinganalysis
SamplingprobabilityforWeightedSampleis
SWS(z,e)=Πli=1P(zi|parents(Zi))
Note:paysattentiontoevidenceinancestorsonlyCloudy
Rain Sprinkler
WetGrass
⇒somewhere“inbetween”priorandposteriordistribution
Weightforagivensamplez,eisw(z,e)=Π
mi=1P(ei|parents(Ei))
WeightedsamplingprobabilityisSWS(z,e)w(z,e)
=Πli=1P(zi|parents(Zi))Π
mi=1P(ei|parents(Ei))
=P(z,e)(bystandardglobalsemanticsofnetwork)
Hencelikelihoodweightingreturnsconsistentestimatesbutperformancestilldegradeswithmanyevidencevariablesbecauseafewsampleshavenearlyallthetotalweight
Chapter14.4–533

ApproximateinferenceusingMCMC
“State”ofnetwork=currentassignmenttoallvariables.
GeneratenextstatebysamplingonevariablegivenMarkovblanketSampleeachvariableinturn,keepingevidencefixed
functionMCMC-Ask(X,e,bn,N)returnsanestimateofP(X|e)
localvariables:N[X],avectorofcountsoverX,initiallyzero
Z,thenonevidencevariablesinbn
x,thecurrentstateofthenetwork,initiallycopiedfrome
initializexwithrandomvaluesforthevariablesinY
forj=1toNdo
foreachZiinZdo
samplethevalueofZiinxfromP(Zi|mb(Zi))
giventhevaluesofMB(Zi)inx
N[x]←N[x]+1wherexisthevalueofXinx
returnNormalize(N[X])
Canalsochooseavariabletosampleatrandomeachtime
Chapter14.4–534

TheMarkovchain
WithSprinkler=true,WetGrass=true,therearefourstates:
Cloudy
Rain Sprinkler
WetGrass
Cloudy
Rain Sprinkler
WetGrass
Cloudy
Rain Sprinkler
WetGrass
Cloudy
Rain Sprinkler
WetGrass
Wanderaboutforawhile,averagewhatyousee
Chapter14.4–535

MCMCexamplecontd.
EstimateP(Rain|Sprinkler=true,WetGrass=true)
SampleCloudyorRaingivenitsMarkovblanket,repeat.CountnumberoftimesRainistrueandfalseinthesamples.
E.g.,visit100states31haveRain=true,69haveRain=false
P(Rain|Sprinkler=true,WetGrass=true)=Normalize(〈31,69〉)=〈0.31,0.69〉
Theorem:chainapproachesstationarydistribution:long-runfractionoftimespentineachstateisexactlyproportionaltoitsposteriorprobability
Chapter14.4–536

Markovblanketsampling
MarkovblanketofCloudyisCloudy
Rain Sprinkler
WetGrass
SprinklerandRainMarkovblanketofRainis
Cloudy,Sprinkler,andWetGrass
ProbabilitygiventheMarkovblanketiscalculatedasfollows:P(x
′i|mb(Xi))=P(x
′i|parents(Xi))ΠZj∈Children(Xi)P(zj|parents(Zj))
Easilyimplementedinmessage-passingparallelsystems,brains
Maincomputationalproblems:1)Difficulttotellifconvergencehasbeenachieved2)CanbewastefulifMarkovblanketislarge:
P(Xi|mb(Xi))won’tchangemuch(lawoflargenumbers)
Chapter14.4–537

Summary
Exactinferencebyvariableelimination:–polytimeonpolytrees,NP-hardongeneralgraphs–space=time,verysensitivetotopology
ApproximateinferencebyLW,MCMC:–LWdoespoorlywhenthereislotsof(downstream)evidence–LW,MCMCgenerallyinsensitivetotopology–Convergencecanbeveryslowwithprobabilitiescloseto1or0–Canhandlearbitrarycombinationsofdiscreteandcontinuousvariables
Chapter14.4–538





























