Embed Size (px)
Citation preview

PERL◦ Introducere
◦ Variabile, cicluri repetitive
◦ Subrutine, lucrul cu fişiere
◦ Vectori, Hash-uri, operatori, substr
Expresii Regulate◦ Ancore
◦ Scurtături
◦ Alternative
◦ Repetiţia
◦ Substituţia
◦ Transliteration
◦ Backreferences

Acronimul este de la Practical Extraction and Reporting Language şi iată care a fost
evoluţia sa în timp:
Apariţie: 1986
Lansare: 1987
Larry Wall: http://www.perl.com

(1) Limbaj de tip SCRIPT (un set de instrucţiuni, care realizează o funcţie). Permite orice începând cu SCRIPTURI simple pentru administrarea de sisteme pâna la aplicaţii sofisticate ale end-user-ilor.
(2) Larry Wall: “Lucrurile uşoare trebuie făcute uşor şi lucrurile dificile trebuie făcute posibile.”
(3) Viteza şi uşurinţa cu care programatorii îşi pot scrie programele.
(4) Programele Perl nu se prăbuşesc niciodată şi pot fi verificate cu built-in debugger-ul (depanatorul incorporat al) limbajului.

(1) Text: Prelucrarea şirurilor se face uşor şi natural datorită caracteristicilor puternice de recunoaştere a şabloanelor
(2) Fişiere: Deschidere, citire şi scriere de fişiere care conţin text şi date liniare
(3) Reţele: Descrierea CLIENTULUI şi SERVERULUI pentru reţelele TCP/IP
(4) Managementul memoriei: garbage colector

(6) Dezvoltarea rapidă a aplicaţiei: Utilizarea librăriei mari de funcţii
(7) Robusteţea: Programele Perl nu se prăbuşesc. Detectarea şi tratarea erorilor, inclusiv asignarea lor sistemului Unix sunt suportate peste tot
(8) Depanator: Perl include un depanator care urmăreşte evaluarea şi inspecţia programelor.

1) Viteza de evaluare şi dimensiunile programelor nu pot concura cu alte limbaje de programare pentru că Perl este scris în C.
2) Programele Perl din biblioteci se schimbă. Utilizarea lor cu timpul este problematică.
3) Nu sunt constrângeri în utilizarea tipurilor, o variabilă putând fi folosită şi ca şir, ca număr sau ca obiect.
4) Perl nu este recomandat pentru scrierea de soft care să rămână secret
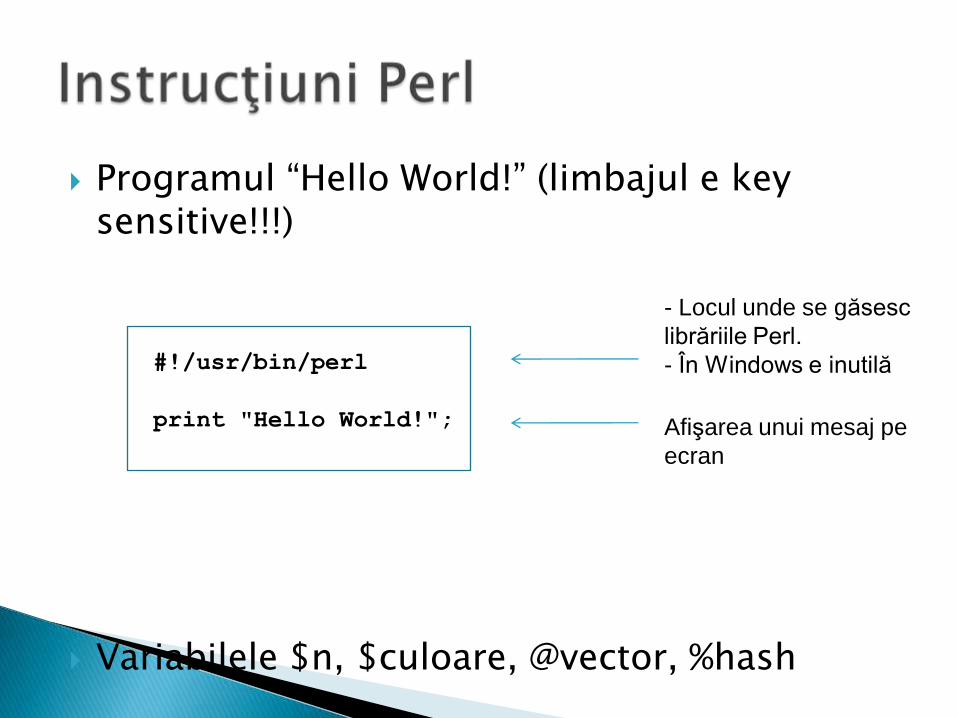
Programul “Hello World!” (limbajul e key sensitive!!!)
Variabilele $n, $culoare, @vector, %hash
#!/usr/bin/perl
print "Hello World!";
- Locul unde se găsesc
librăriile Perl.
- În Windows e inutilă
Afişarea unui mesaj pe
ecran

$culoare = "alb";
$fond = "$culoare de fond";
print $fond;
>alb de fond
$culoare = "alb";
$fond = „$culoare de fond‟;
print $fond;
>$culoare de fond

$n = 5;
$m = '$n';
print "$n * $n ";
print eval(“$n * $n");
print eval("$m * $m");
> 5 * 5 25 25

$x=1; $y = 2;
print "\n",$x+$y,"\n";
print $x.$y;
>3
12
print int rand 1000;
> Un număr întreg între 0 şi 1000

print ”Taxa studenţilor este de \$100.\n”;
> Taxa studentilor este de $100.
print „Taxa studenţilor este de \$100.\n‟;
> Taxa studentilor este de \$100.\n

@v=();
$v[1] = 5;
$v[3] = 7;
for($i=0; $i<=$#v; $i++)
{
if(defined($v[$i]))
{ print $v[$i],“ “; }
}
>5 7
Atenţie {} sunt obligatorii
în while, for, foreach, if, else !!!!

foreach $element(@v)
{print $element, " ";}
sau
print @v;
Ieşirea din ciclu se poate face forţat cu last, next, redo
$i=0; while($i<=10) {$i++; …}
foreach $i(0..10) {…}

HelloName1(“Ionel”, ”Costel”);
HelloName2(“Ionel”, “Costel”);
sub HelloName1
{$name1 = shift; $name2 = shift;
print “Hello $name1!”; print “Hello $name2!”;
}
sub HelloName2
{foreach $name(@_) {print “Hello $name!”;}
}

Citire
my $filename = 'fis.txt';
open FILE, $filename or die "Cannot read '$filename'!";
@continut = <FILE>; echivalent cu
print while(<FILE>); #se foloseste variabila implicita$_
echivalent cu:
print @continut;
echivalent cu:
for($i=0;$i<=$#continut;$i++)
{print $continut[$i],"\n";}

Afişare conţinut
open FILE, $filename or die "Cannot read '$filename': $!";
while(<FILE>)
{
print $_;
}
close FILE;
Operatorul <>
Linia curentă din fişier

my $filename = 'fis.txt';
open FILE, "> $filename" or die "Nu putem citi'$filename': $!";
print FILE "Test";
close FILE;
“>$fisier” => creare + scriere
“>>$fisier” => adăugare

%hash = (“key 1”,”value 1”, “key 2” =>”value 2”);
$hash{“key 3”} = “value 3”;
$hash{1} = “value x”;
foreach $key(sort keys %hash)
{
print "\n$key =>".$hash{$key};
}
if(defined($hash{“key 1”})) {print “Exista!”;}
> key 1 => value 1
key 2 => value 2
key 3 => value 3

Comparare◦ Numere: ==, <=, >=, !=, <, >
◦ Altceva: eq, le, ge, ne, lt, gt
Logici◦ &&, ||, !

$string = "Ana are mere.";
print substr($string,4),"\n";
print substr($string,-4),"\n";
print substr($string,4,3),"\n";
print substr($string,4,-3),"\n";
print substr($string,-4,2),"\n";
>are mere.
ere.
are
are me
er

$string = "Ana are mere.";
print index($string,"re");
print rindex($string,"re");
print index($string,"re“,6);
print rindex($string,"re",7);
>5 10 10 5

Expresiile Regulate ne permit cautarea de «sabloane» in datele noastre. Vom putea: ◦ Verifica ca fiecare propozitie dintr-un fisier incepe cu o
litera mare si se termina cu punct;
◦ Sti de cate ori un nume este specificat intr-o lucrare ;
◦ Vedea daca avem o secventa oarecare de numere in reprezentare zecimala cu lungimea mai mare de cinci
Termenul de Expresie Regulată (Regular Expression notata «RegExp» sau chiar «RE») ◦ se refera la un sablon ce urmeaza regulile unei sintaxe
prezentate in continuare

my $gasit = 0 ;
$_ = ‟‟Nimeni nu vrea sa te raneasca… Numai ca eu mai ranesc oamenii uneori.‟‟ ;
my $sablon = ‟‟oamenii‟‟ ;
foreach my $cuvant (split) {
if ($cuvant eq $sablon) {
$gasit = 1; last;}
}
if ($gasit) {
print ‟‟Succes! Am gasit cuvantul „oamenii‟\n‟‟;
}

$_ = ‟‟Nimeni nu vrea sa te raneasca… Numai ca eu mai ranesc oamenii uneori.‟‟ ;
if ($_ =~ /oamenii/) {
print ‟‟Succes! Am gasit cuvantul „oamenii‟\n‟‟;
}
#echivalent cu
if (/oamenii/) {
print ‟‟Succes! Am gasit cuvantul „oamenii‟\n‟‟;
}

. * ? + [ ] ( ) { } ^ $ | \

Cele doua ancore pe care le avem sunt ^, care apare la inceputul pattern-ului si ancoreazapotrivirea pentru inceputul sirului, si $ care apare la sfarsitul pattern-ului si este ancoratcatre sfarsitul sirului.
Care e semnificaţia lui \.$
Dar a lui ^N

my $silaba = “are”;
$filename = 'fis.txt';
my open FILE, “< $filename” or die "Nu putemciti '$filename': $!";
while(<FILE>)
{
print if /$silaba$/;
}
close FILE;
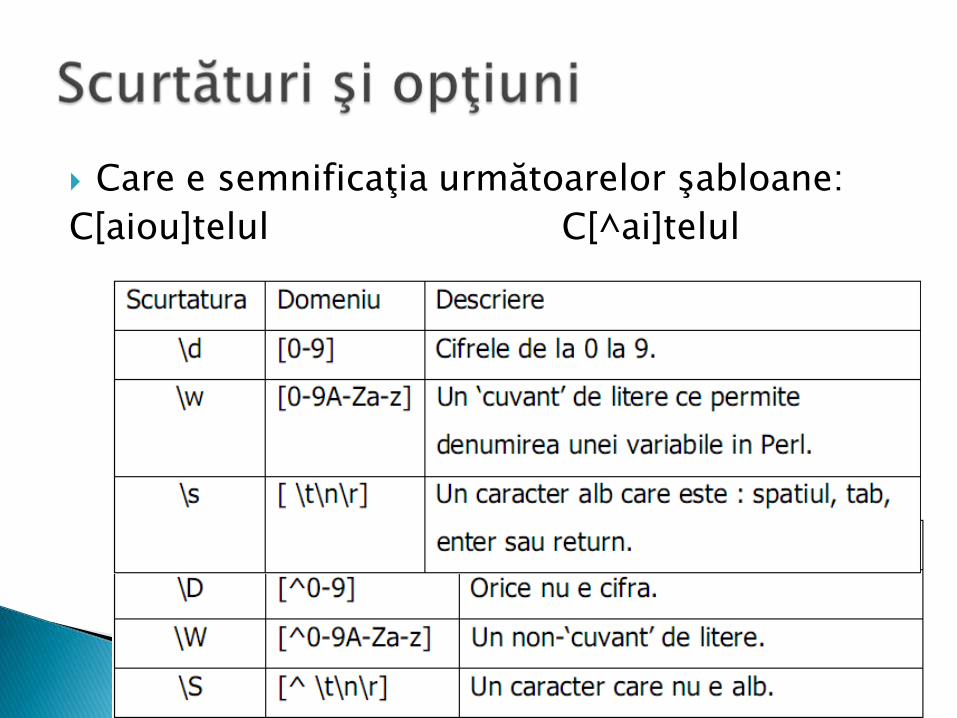
Care e semnificaţia următoarelor şabloane:
C[aiou]telul C[^ai]telul

lui|dumnealui
lu(i|t)
(lui)|(lut)|(luna amara)
lu(i|t|na amara)
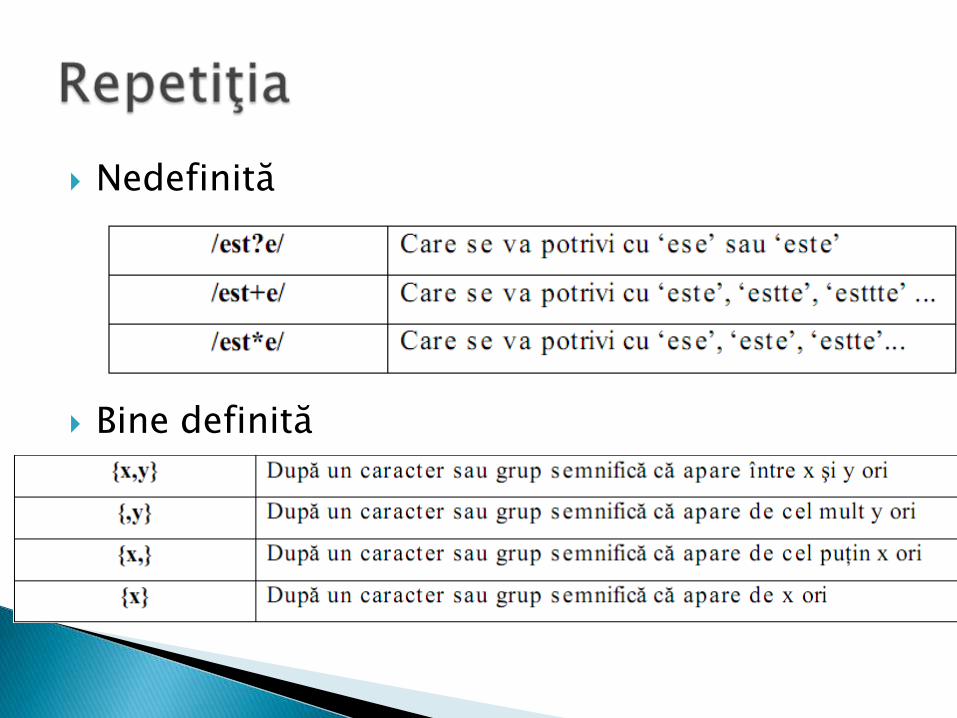
Nedefinită
Bine definită

$sir = “Ana are mere.”;
$sir =~ s/a/1/;
> An1 are mere
$sir =~ s/a/1/g;
>An1 1re mere.
$sir =~ s/a/1/gi;
>1n1 1re mere.

$sir = “Ana are mere.”;
@words = split(“ “, $sir);
foreach $word(@words)
{print $word,”\n”;}>Ana
are
mere.
$sirnou = join(“%”,@words);
Print $sirnou;>Ana%are%mere.

$sir = “Ana are mere.”;
$sir =~ tr/abcdefghij/0123456789/;
print $sir;>An0 0r4 m4r4.
$sir =~ tr/0123456789/abcdefghij/; >Ana are mere.
my $vocale = ($sir =~ tr/aeiou//);
print $vocale;
>5

$string = "Ana are mere.";
if($string =~ /(.*)/)
{ print $1,"\n“;}>Ana are mere.
if($string =~ /(.*) (.*)/)
{ print $1,"\n",$2;}>Ana are
mere.
=> Comportarea de tip Greedy a operatorilor +, *

Eliminarea comportării de tip Greedy:
$string = "Ana are mere.";
if($string =~ /(.*?) (.*)/)
{ print $1,"\n",$2;}
>Ana
are mere.

$string = "Ana are mere.";
while($string =~ /([a-zA-Z]+)/)
{ print $1;}>AnaAnaAnaAnaAnaAnaAnaAnaAnaAnaAna…
while($string =~ /([a-zA-Z]+)/g)
{ print $1,"\n“;}>Ana
are
mere

Implementaţi o structură de întregi implementând operaţiile de bază asupra ei: citire, afişare, element minim, suma elementelor, sortare.
Citirea unei variabile de la tastatură se face ca mai jos:
$n = <STDIN>;
chomp($n);
Rezultatele se vor afişa în fişier.
Elimină <Enter>

Folosind împărţirea pe cuvinte cu split: ◦ Câte rânduri conţine fişierul de lucru?
◦ Câte cuvinte de cel puţin 8 litere avem?
◦ Precizaţi numarul rândurilor care încep cu o vocală.
◦ Număraţi vocalele

Folosind unul fişier text creaţi două proceduri: ◦ Prima de codificare – care va lua conţinutul primului
fişier, îl va codifica şi va pune rezultatul într-un fişier de ieşire;
◦ A doua de decodificare – care va face operaţia inversă procedurii de mai sus.
În final se vor compara fişierul de intrare şi fişierul rezultat în urma decodificării. Sunt ele identice?

Parsaţi fişierul QA_EN.xml
Pentru un id de întrebare afişaţi pe rânduri diferite:◦ source_lang
◦ target_lang
◦ question
<q q_id="0001" source_lang="BG" target_lang="EN">What has forced THE SIMPLIFICATION AND HARMONIZATION OF THE CUSTOM PROCEDURES?</q>
Demo cu extragera q_id-urilor

Extrageţi din întrebări următoarele:◦ Numerele simple şi cele cu virgulă
◦ Datele calendaristice
◦ Cuvintele care încep cu literă mare
◦ Cuvintele cu toate literele mari
◦ Citatele de forma “text”
Număraţile

1) Direct în conturile de la facultate folosind un editor oarecare şi creând fişiere cu extensia .pl sau .cgi. Rularea cu
> perl nume_program.pl
2) În Windows instalând ActivePerl şi Perl Express ca IDE
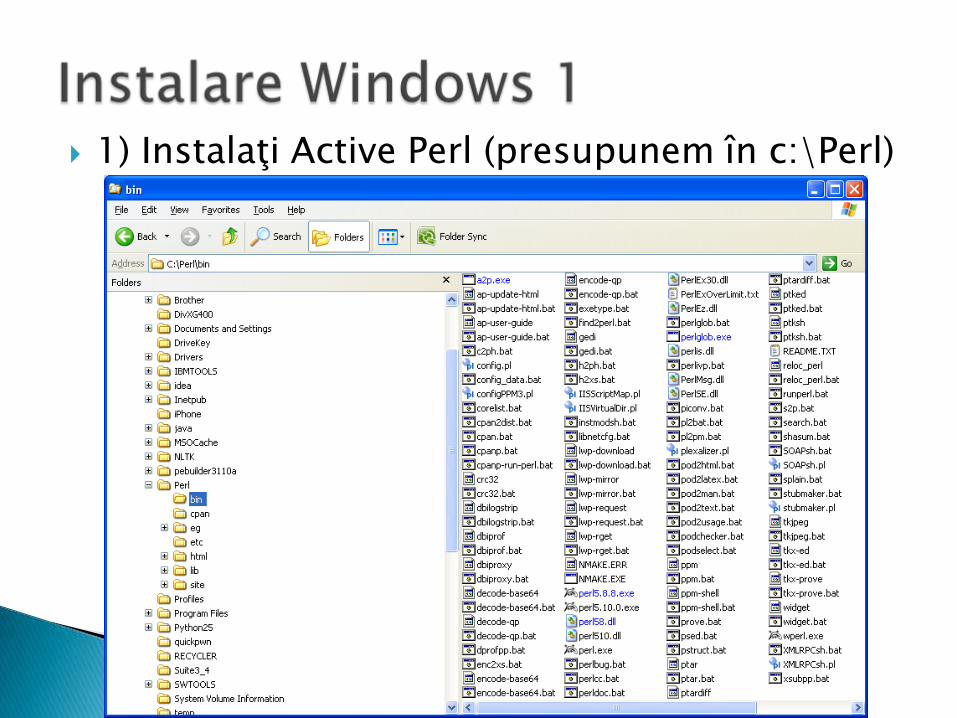
1) Instalaţi Active Perl (presupunem în c:\Perl)
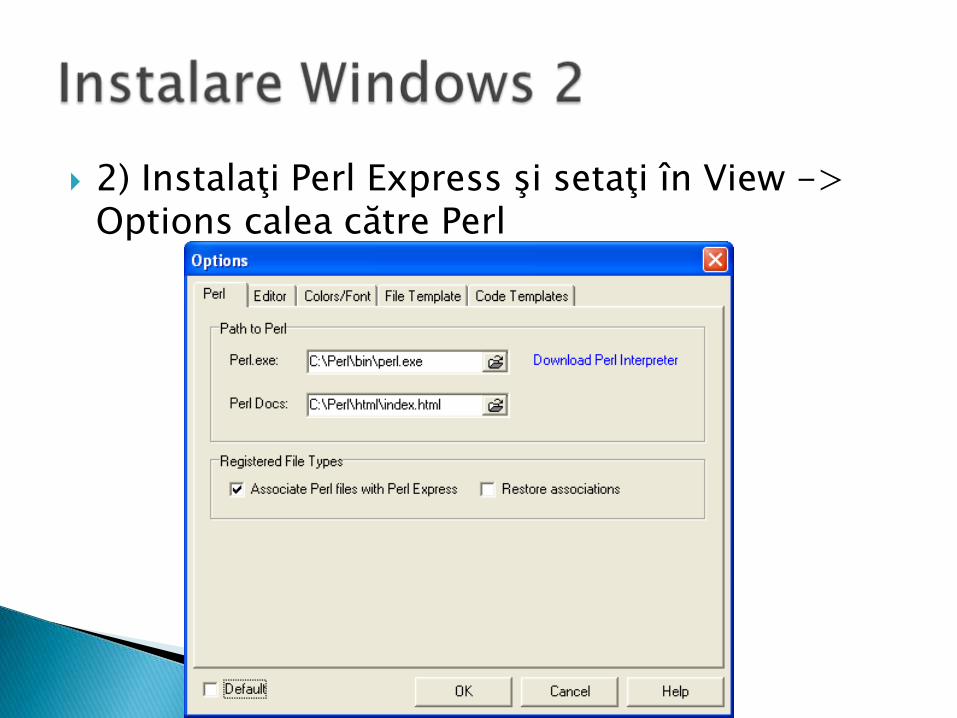
2) Instalaţi Perl Express şi setaţi în View -> Options calea către Perl
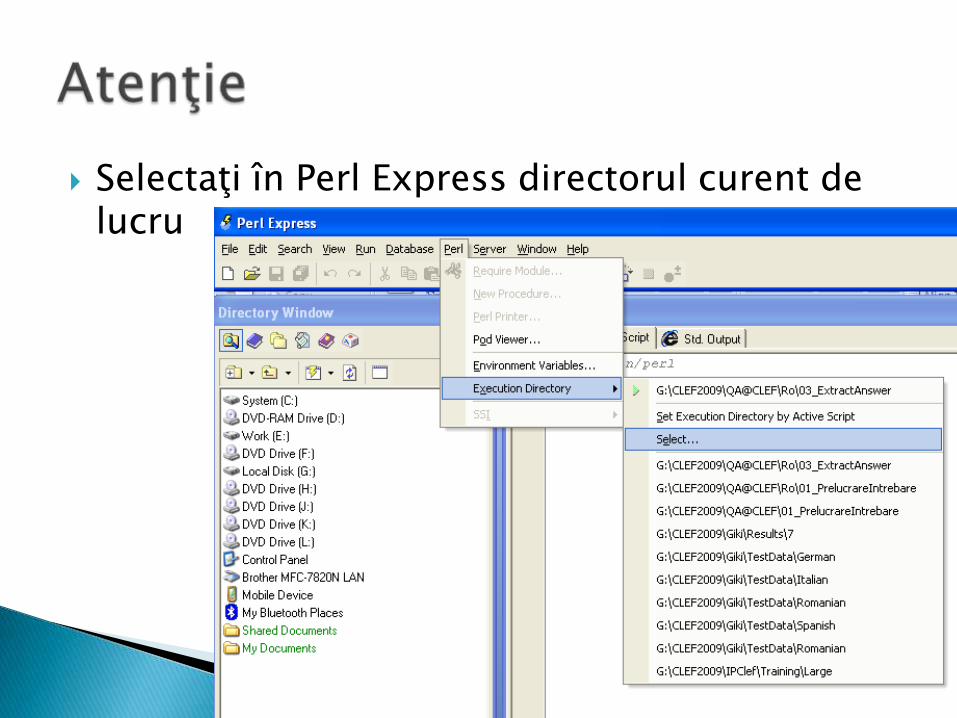
Selectaţi în Perl Express directorul curent de lucru
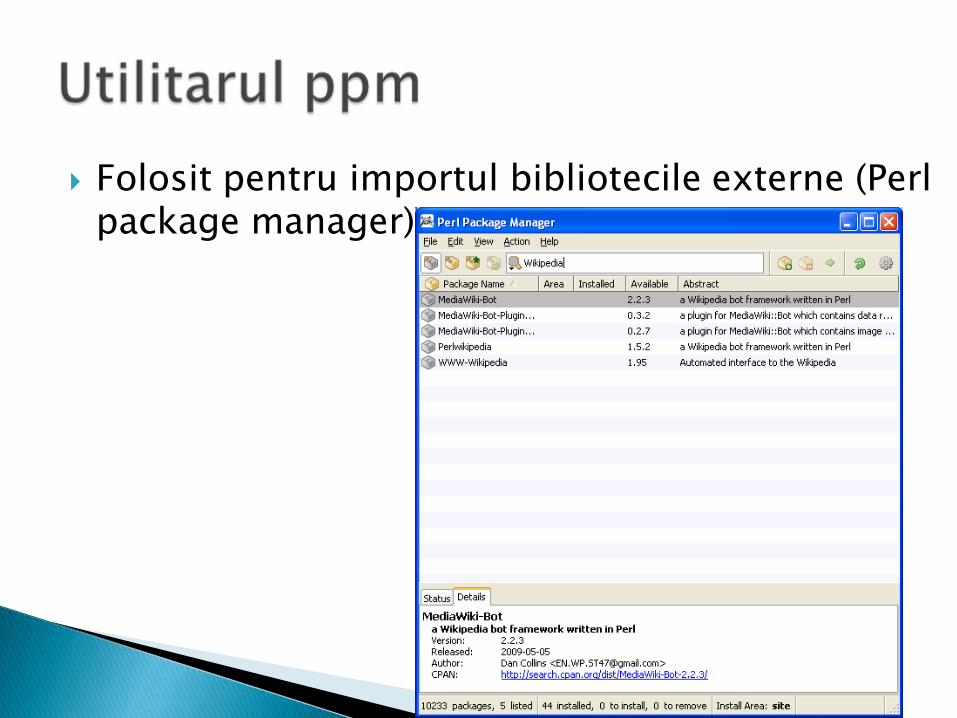
Folosit pentru importul bibliotecile externe (Perl package manager)

Pagina curs PERL http://thor.info.uaic.ro/~adiftene/Scoala/2008/PBR_Perl/
Active Perl http://www.activestate.com/activeperl/
Perl Express http://www.perl-express.com/download.html
Cărţi Perl http://www.unix.org.ua/orelly/
http://www.unix.org.ua/orelly/perl/cookbook/index.htm

#!/usr/bin/perl
use Switch;
$val = 1;
switch($val){
case 1 {print “Numarul 1”}
case “a” {print “Caracterul a”}
case [1..10] {print “Un umar intre 1 si 10”}
else {print “Alta valoare”}
}

Comentariu pe o linie# comentariu
Comentarii pe mai multe linii q^
Comentariu
Pe
Mai
Multe
Linii
^;










![ro ] romanian TrAINEr HANDoUTS roMANIA · Dacă bănui+i că cineva este o victima si aceasta neagă lucrul acesta atunci acţionaţi ca şi când aceasta ar fi o posibilitate. Asiguraţi](https://img.pdfslide.us/doc/110x75/5e3fff5a3fa69e36da797d6c/ro-romanian-trainer-handouts-romania-dacf-bfnuii-cf-cineva-este-o-victima.jpg)




![1victor.muller/Download/BC... · Web viewCapital fix / Active imobilizate [C.f./A.i.]: bunuri care participă la mai multe cicluri de producţie şi nu se consumă la prima utilizare](https://img.pdfslide.us/doc/110x75/5c955b1109d3f2737b8c8019/1-victormullerdownloadbc-web-viewcapital-fix-active-imobilizate-cfai.jpg)














