Embed Size (px)
Citation preview

1
Query Language
Baeza-Yates and Navarro
Modern Information Retrieval, 1999
Chapter 4

2
Query Language
Keyword-based Querying» Single-word Queries» Context Queries
– Phrase
– Proximity
» Boolean Queries» Natural Language

3
Query Language (Cont.)
Pattern Matching» Words» Prefixes» Suffixes» Substring» Ranges» Allowing errors» Regular expressions

4
Query Language (Cont.)
Structural Queries» Form-like fixed structures» Hypertext structure » hierarchical structure

5
Structural Queries
(a) form-like fixed structure, (b) hypertext structure, and (c) hierarchical structure
(a) (b) (c)
6
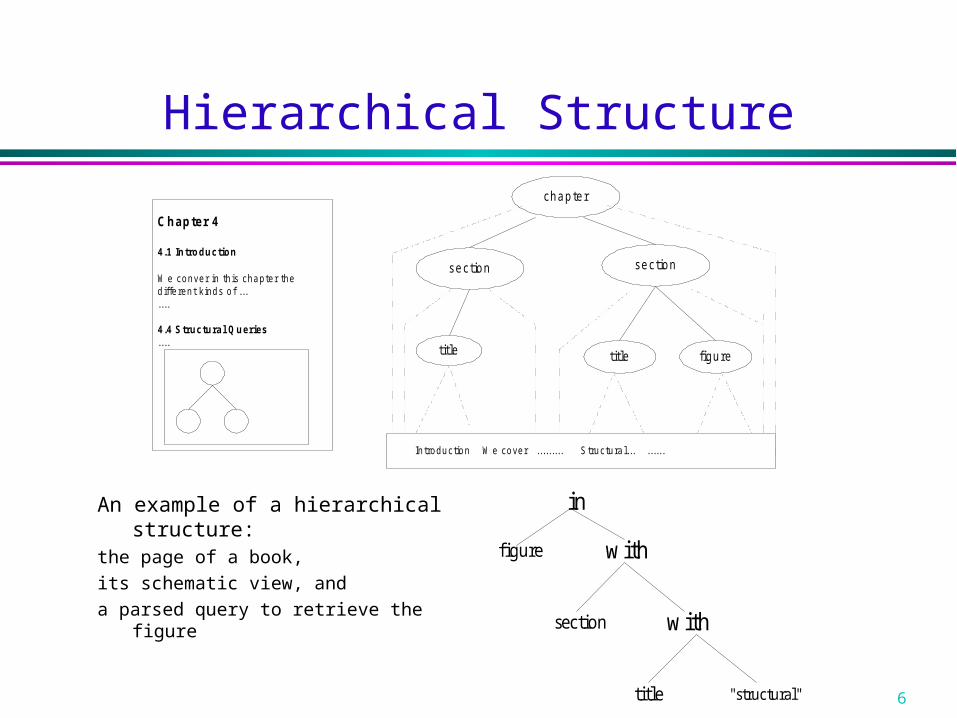
Hierarchical Structure
An example of a hierarchical structure: the page of a book,
its schematic view, and
a parsed query to retrieve the figure
Chapter 4
4.1 Introduction
W e conver in th is chapter thedifferent k inds of .......
4.4 Structural Queries....
chapter
section section
title title figure
In troduction W e cover ......... S tructural... ......
in
figure
section
title
with
with
"structural"

7
The Types of Queries
Boolean queries
fuzzy Boolean
Natural language
structural queries basic queries
proximity
phrases pattern matching
errors
words substrings regular expressions
keywords and context prefixes extended patterns
suffixes

8
Query Operations
Baeza-Yates, 1999
Modern Information Retrieval
Chapter 5

9
Query Modification
Improving initial query formulation» Relevance feedback
– approaches based on feedback information from users
» Local analysis – approaches based on information derived from the set of
documents initially retrieved (called the local set of documents)
» Global analysis– approaches based on global information derived from the
document collection

10
Relevance Feedback
Relevance feedback process» it shields the user from the details of the query reformulation pr
ocess» it breaks down the whole searching task into a sequence of sm
all steps which are easier to grasp» it provides a controlled process designed to emphasize some t
erms and de-emphasize others
Two basic techniques» Query expansion
– addition of new terms from relevant documents
» Term reweighting– modification of term weights based on the user relevance judgem
ent

11
Vector Space Model
Definitionwi,j: the ith term in the vector for document dj
wi,k: the ith term in the vector for query qk
t: the number of unique terms in the data set
t
i
kijikj wwqdsimilarity1
,,),(),,,( ,,2,1 jtjjj wwwd ),,,( ,,2,1 ktkkk wwwq
t
k ktf
tf
itf
tf
ji
idf
idfw
jkk
jk
jkk
ji
1
22}{max
}{max
,
)5.05.0(
)5.05.0(
,
,
,
,

12
Query Expansion and and Term Reweighting for the Vector Model
Ideal situation» CR: set of relevant documents among all documents in the collection
Rocchio (1965, 1971)» R: set of relevant documents, as identified by the user among th
e retrieved documents» S: set of non-relevant documents among the retrieved documen
ts
RjRj Cdj
RCd
j
Ropt d
CNd
Cq
||
1
||
1
Sdj
Rdjm jj
dS
dR
qq||||

13
Rocchio’s Algorithm
Ide_Regular (1971)
Ide_Dec_Hi
Parameters = = =1 >
}|{ SddMaxdqq jjRd
jm j
Sdj
Rdjm jj
ddqq

14
Probabilistic Model
Definition» pi: the probability of observing term ti in the set of relevant do
cuments
» qi: the probability of observing term ti in the set of nonrelevant documents
Initial search assumption» pi is constant for all terms ti (typically 0.5)
» qi can be approximated by the distribution of ti in the whole collection
t
i ii
iiqijij pq
qpwwqdsim
1,, )1(
)1(log),(
iii
i
ii
iii idf
df
N
df
dfN
pq
qpwt
log)(
log)1(
)1(log

15
Term Reweighting for the Probabilistic Model
Robertson and Sparck Jones (1976) With relevance feedback from user
N: the number of documents in the collection
R: the number of relevant documents for query q
ni: the number of documents having term ti
ri: the number of relevant documents having term ti
Document Relevance
DocumentIndexing
+
-
+
ri
R-ri
R
N-ni-R+ri
-
ni-ri
N-R
ni
N-ni
N

16
Initial search assumption» pi is constant for all terms ti (typically 0.5)
» qi can be approximated by the distribution of ti in the whole collection
With relevance feedback from users» pi and qi can be approximated by
» hence the term weight is updated by
)(R
rp i
i )(RN
rnq ii
i
t
i i
iqijij n
nNwwqdsim
1,, log),(
t
i iii
iiiqijij rnrR
rRnNrwwqdsim
1,, ))((
)(log),(
Term Reweighting for the Probabilistic Model (cont.)

17
However, the last formula poses problems for certain small values of R and ri (R=1, ri=0)
Instead of 0.5, alternative adjustments have been propsed
)1
5.0(
R
rp i
i )1
5.0(
RN
rnq ii
i
)1
(
R
rp N
ni
i
i
)1
(
RN
rnq N
nii
i
i
Term Reweighting for the Probabilistic Model (Cont.)

18
Characteristics» Advantage
– the term reweighting is optimal under the asumptions of term independence binary document indexing (wi,q {0,1} and wi,j {0,1})
» Disadvantage– no query expansion is used
– weights of terms in the previous query formulations are also disregarded
– document term weights are not taken into account during the feedback loop
Term Reweighting for the Probabilistic Model (Cont.)

19
Evaluation of relevance feedback
Standard evaluation method is not suitable» (i.e., recall-precision) because the relevant documents used to rew
eight the query terms are moved to higher ranks.
The residual collection method» the set of all documents minus the set of feedback documents pro
vided by the user» because highly ranked documents are removed from the collection
, the recall-precision figures for tend to be lower than the figures for the original query
» as a basic rule of thumb, any experimentation involving relevance feedback strategies should always evaluate recall-precision figures relative to the residual collection
mq
q

20
Automatic Local Analysis
Definition» local document set Dl : the set of documents retrieved by a q
uery
» local vocabulary Vl : the set of all distinct words in Dl
» stemed vocabulary Sl : the set of all distinct stems derived from Vl
Building local clusters» association clusters» metric clusters» scalar clusters

21
Association Clusters
Idea» co-occurrence of stems (or terms) inside documents
– fu,j: the frequency of a stem ku in a document dj
» local association cluster for a stem ku
– the set of k largest values c(ku, kv)
» given a query q, find clusters for the |q| query terms» normalized form
||
1,,),(
D
jjvjuvu ffkkc
),(),(),(
),(),(
vuvvuu
vuvu kkckkckkc
kkckks

22
Metric Clusters
Idea» consider the distance between two terms in the same cluster
Definition» V(ku): the set of keywords which have the same stem form as ku
» distance r(ki, kj)=the number of words between term ku and kv
» normalized form
)( )( ),(
1),(
u vkVi kVj jivu kkr
kkc
|)(||)(|
),(),(
vu
vuvu kVkV
kkckks

23
Scalar Clusters
Idea» two stems with similar neighborhoods have some synonymity
relationships
Definition» cu,v=c(ku, kv)
» vectors of correlation values for stem ku and kv
» scalar association matrix
» scalar clusters– the set of k largest values of scalar association
),,,( ,2,1, tuuuu cccs ),,,( ,2,1, tvvvv cccs
||||,
vu
vuvu
ss
ssS

24
Automatic Global Analysis
A thesaurus-like structure Short history
» Until the beginning of the 1990s, global analysis was considered to be a technique which failed to yield consistent improvements in retrieval performance with general collections
» This perception has changed with the appearance of modern procedures for global analysis

25
Query Expansion based on a Similarity Thesaurus
Idea by Qiu and Frei [1993]» Similarity thesaurus is based on term to term relationships rathe
r than on a matrix of co-occurrence» Terms for expansion are selected based on their similarity to the
whole query rather than on their similarities to individual query terms
Definition» N: total number of documents in the collection» t: total number of terms in the collection
» tfi,j: occurrence frequency of term ki in the document dj
» tj: the number of distinct index terms in the document dj
» itfj : the inverse term frequency for document dj
jj t
titf log

26
Similarity Thesaurus
Each term is associated with a vector
» where wi,j is a weight associated to the index-document pair
The relationship between two terms ku and kv is
» Note that this is a variation of the correlation measure used for computing scalar association matrices
),,,( ,2,1, Niii wwwki
N
k ktf
tf
jtf
tf
ji
itf
itfw
kik
ki
kik
ji
1
22}{max
}{max
,
)5.05.0(
)5.05.0(
,
,
,
,
N
jjvjuvuvu wwkkc
1,,,

27
Term weighting vs. Term concept space
tfij
Term ki
Doc dj tfijTerm ki
Doc dj
t
k ktf
tf
itf
tf
ji
idf
idfw
jkk
jk
jkk
ji
1
22}{max
}{max
,
)5.05.0(
)5.05.0(
,
,
,
,
N
k ktf
tf
jtf
tf
ji
itf
itfw
kik
ki
kik
ji
1
22}{max
}{max
,
)5.05.0(
)5.05.0(
,
,
,
,

28
Query Expansion Procedure with Similarity Thesaurus
1. Represent the query in the concept space by using the representation of the index terms
2. Compute the similarity sim(q,kv) between each term kv and the whole query
3. Expand the query with the top r ranked terms according to sim(q,kv)
uqk
kwqu
qu
,
vuQk
quvqk
uquvv cwkkwkqkqsimuu
,,,),(
qk qu
vqv
uw
kqsimw
,',
),(
29
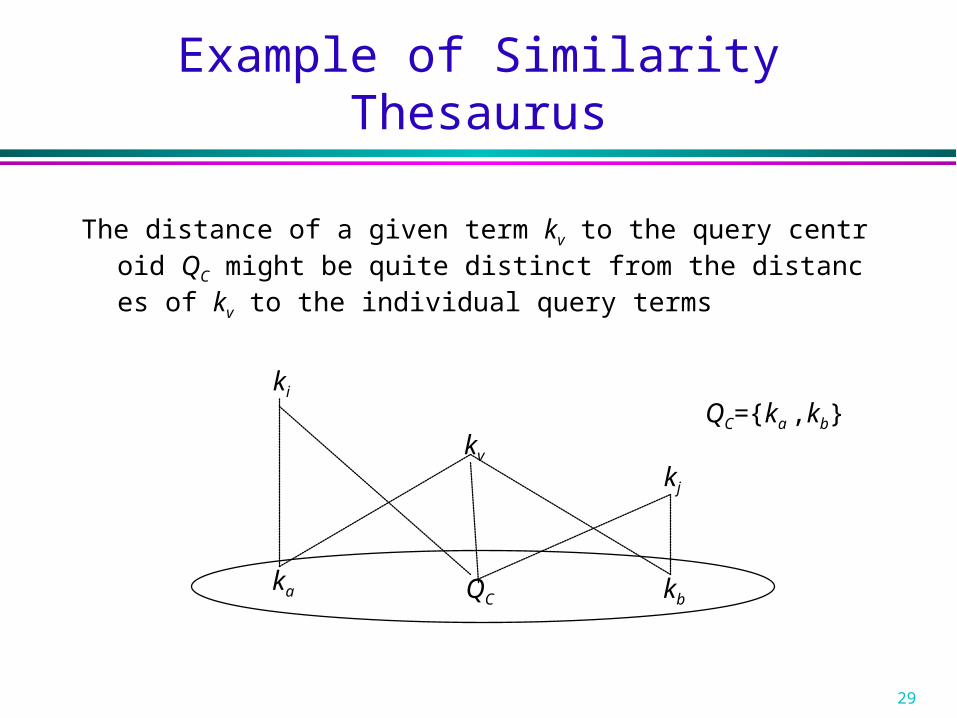
Example of Similarity Thesaurus
The distance of a given term kv to the query centroid QC might be quite distinct from the distances of kv to the individual query terms
ka kb
ki
kj
kv
QC
QC={ka ,kb}

30
Query Expansion based on a Similarity Thesaurus
» A document dj is represented term-concept space by
» If the original query q is expanded to include all the t index terms, then the similarity sim(q, dj) between the document dj and the query q can be computed as
– which is similar to the generalized vector space model
jv u
jvu
dkvu
qkqujvj
dkvjv
qkuquj
cwwdqsim
kwkwdqsim
,,,
,,
),(
),(
jv dk
vjvj kwd ,

31
Query Expansion based on a Statistical Thesaurus
Idea by Crouch and Yang (1992)» Use complete link algorithm to produce small and tight
clusters» Use term discrimination value to select terms for entry into a
particular thesaurus class
Term discrimination value» A measure of the change in space separation which occurs
when a given term is assigned to the document collection

32
Term Discrimination Value
Terms» good discriminators: (terms with positive discrimination values)
– index terms
» indifferent discriminators: (near-zero discrimination values)
– thesaurus class
» poor discriminators: (negative discrimination values)
– term phrases
Document frequency dfk
» dfk >n/10: high frequency term (poor discriminators)
» dfk <n/100: low frequency term (indifferent discriminators)
» n/100 dfk n/10: good discriminator

33
Statistical Thesaurus
Term discrimination value theory» the terms which make up a thesaurus class must be
indifferent discriminators
The proposed approach» cluster the document collection into small, tight clusters» A thesaurus class is defined as the intersection of all the low
frequency terms in that cluster» documents are indexed by the thesaurus classes» the thesaurus classes are weighted by
||
||
1 ,
C
wwt
C
i CiC

34
Discussion
Query expansion » useful» little explored technique
Trends and research issues» The combination of local analysis, global analysis, visual
displays, and interactive interfaces is also a current and important research problem





























