Embed Size (px)
Citation preview

1
CS 430 / INFO 430 Information Retrieval
Lecture 11
Latent Semantic Indexing
Extending the Boolean Model
2
Course Administration
Assignment 1
If you have questions about your grading, send me email.
The following are reasonable requests: the wrong files were graded, points were added up wrongly, comments are unclear, etc.
We are not prepared to argue over details of judgment.
If you ask for a regrade, the final grade may be lower than the original!
3
Course Administration
Assignment 2
The assignment has been posted.
The test data is being checked. Look for changes before Saturday evening.
4
Course Administration
Midterm Examination
Wednesday, October 14, 7:30 to 9:00 p.m., Upson B17. Open book.
Laptop computers may be used for lecture slides, notes, readings, etc., but no network connections during the examination.
A sample examination and discussion of the solution will be posted to the Web site.

5
CS 430 / INFO 430 Information Retrieval
Latent Semantic Indexing

6
Latent Semantic Indexing
Objective
Replace indexes that use sets of index terms by indexes that use concepts.
Approach
Map the term vector space into a lower dimensional space, using singular value decomposition.
Each dimension in the new space corresponds to a latent concept in the original data.

7
Deficiencies with Conventional Automatic Indexing
Synonymy: Various words and phrases refer to the same concept (lowers recall).
Polysemy: Individual words have more than one meaning (lowers precision)
Independence: No significance is given to two terms that frequently appear together

8
Example
Query: "IDF in computer-based information look-up"
Index terms for a document: access, document, retrieval, indexing
How can we recognize that information look-up is related to retrieval and indexing?
Conversely, if information has many different contexts in the set of documents, how can we discover that it is an unhelpful term for retrieval?

9
Technical Memo Example: Titles
c1 Human machine interface for Lab ABC computer applications
c2 A survey of user opinion of computer system response time
c3 The EPS user interface management system
c4 System and human system engineering testing of EPS
c5 Relation of user-perceived response time to error measurement
m1 The generation of random, binary, unordered trees
m2 The intersection graph of paths in trees
m3 Graph minors IV: Widths of trees and well-quasi-ordering
m4 Graph minors: A survey
10
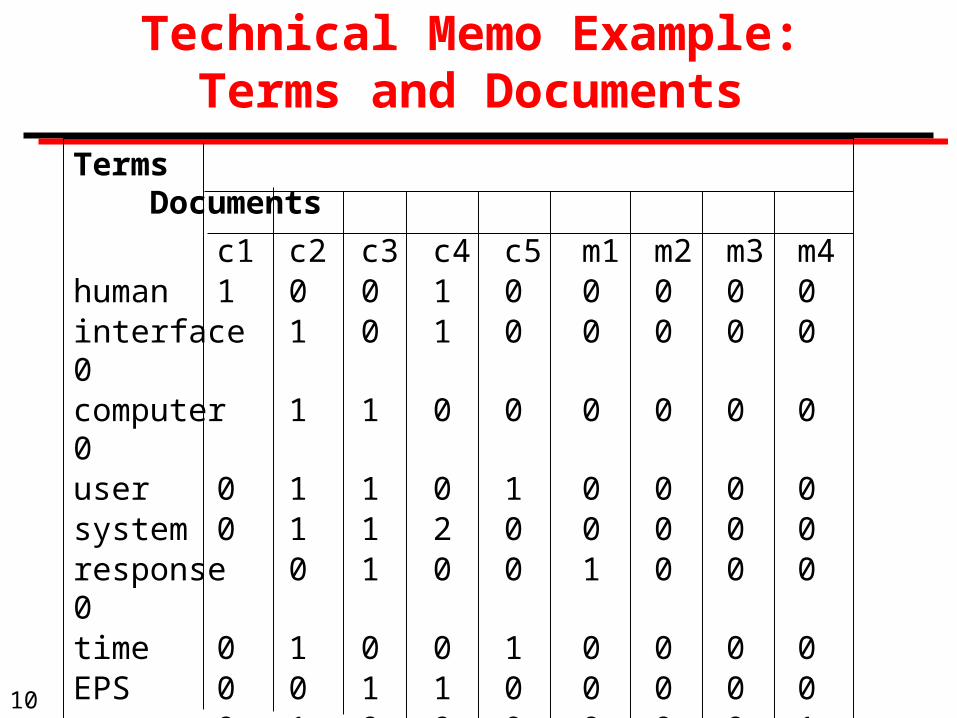
Technical Memo Example: Terms and Documents
Terms Documents
c1 c2 c3 c4 c5 m1 m2 m3 m4human 1 0 0 1 0 0 0 0 0interface 1 0 1 0 0 0 0 0 0computer 1 1 0 0 0 0 0 0 0user 0 1 1 0 1 0 0 0 0system 0 1 1 2 0 0 0 0 0response 0 1 0 0 1 0 0 0 0time 0 1 0 0 1 0 0 0 0EPS 0 0 1 1 0 0 0 0 0survey 0 1 0 0 0 0 0 0 1trees 0 0 0 0 0 1 1 1 0graph 0 0 0 0 0 0 1 1 1minors 0 0 0 0 0 0 0 1 1

11
Technical Memo Example: Query
Query:
Find documents relevant to "human computer interaction"
Simple Term Matching:
Matches c1, c2, and c4Misses c3 and c5
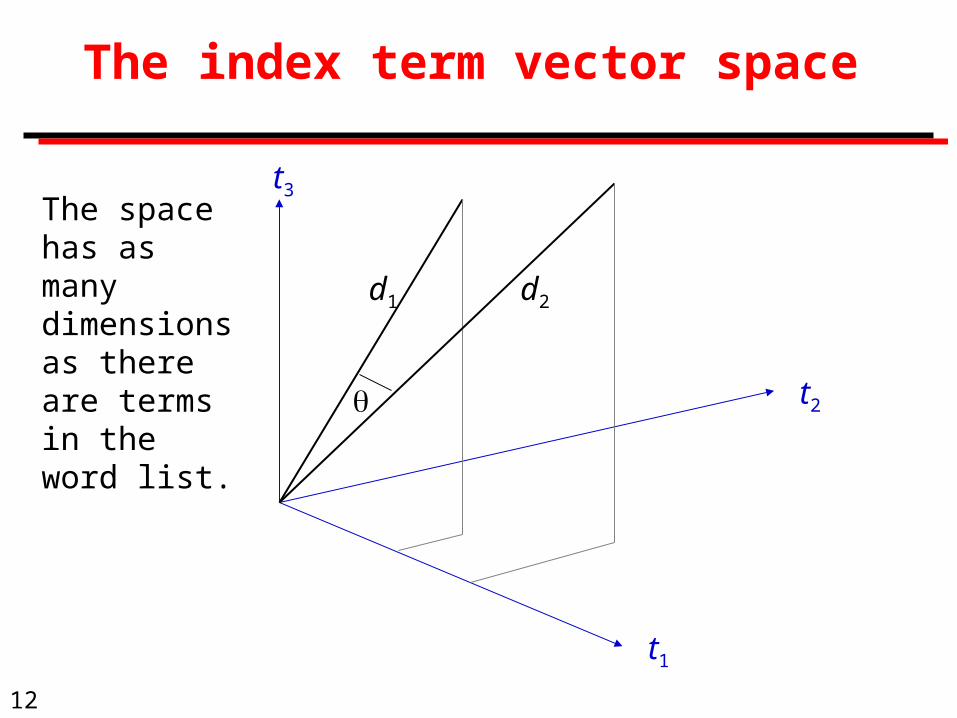
12
t1
t2
t3
d1 d2
The space has as many dimensions as there are terms in the word list.
The index term vector space

13
Models of Semantic Similarity
Proximity models: Put similar items together in some space or structure
• Clustering (hierarchical, partition, overlapping). Documents are considered close to the extent that they contain the same terms. Most then arrange the documents into a hierarchy based on distances between documents. [Covered later in course.]
• Factor analysis based on matrix of similarities between documents (single mode).
• Two-mode proximity methods. Start with rectangular matrix and construct explicit representations of both row and column objects.

14
Selection of Two-mode Factor Analysis
Additional criterion:
Computationally efficient O(N2k3)
N is number of terms plus documentsk is number of dimensions
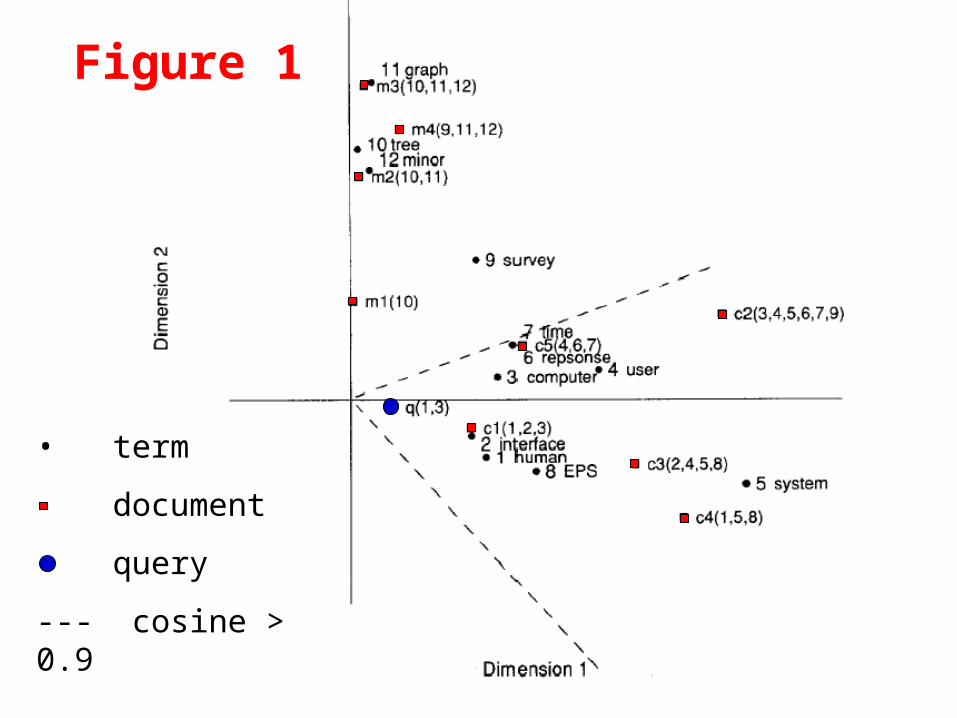
15
Figure 1
• term
document
query
--- cosine > 0.9

16
Mathematical concepts
Singular Value Decomposition
Define X as the term-document matrix, with t rows (number of index terms) and d columns (number of documents).
There exist matrices T, S and D', such that:
X = T0S0D0'
T0 and D0 are the matrices of left and right singular vectorsT0 and D0 have orthonormal columns
S0 is the diagonal matrix of singular values

17
Dimensions of matrices
X = T0
D0'S0
t x d t x m m x dm x m
m is the rank of X < min(t, d)

18
Reduced Rank
Diagonal elements of S0 are positive and decreasing in magnitude. Keep the first k and set the others to zero.
Delete the zero rows and columns of S0 and the corresponding rows and columns of T0 and D0. This gives:
X X = TSD'
Interpretation
If value of k is selected well, expectation is that X retains the semantic information from X, but eliminates noise from synonymy, and recognizes dependence.
~~ ^
^
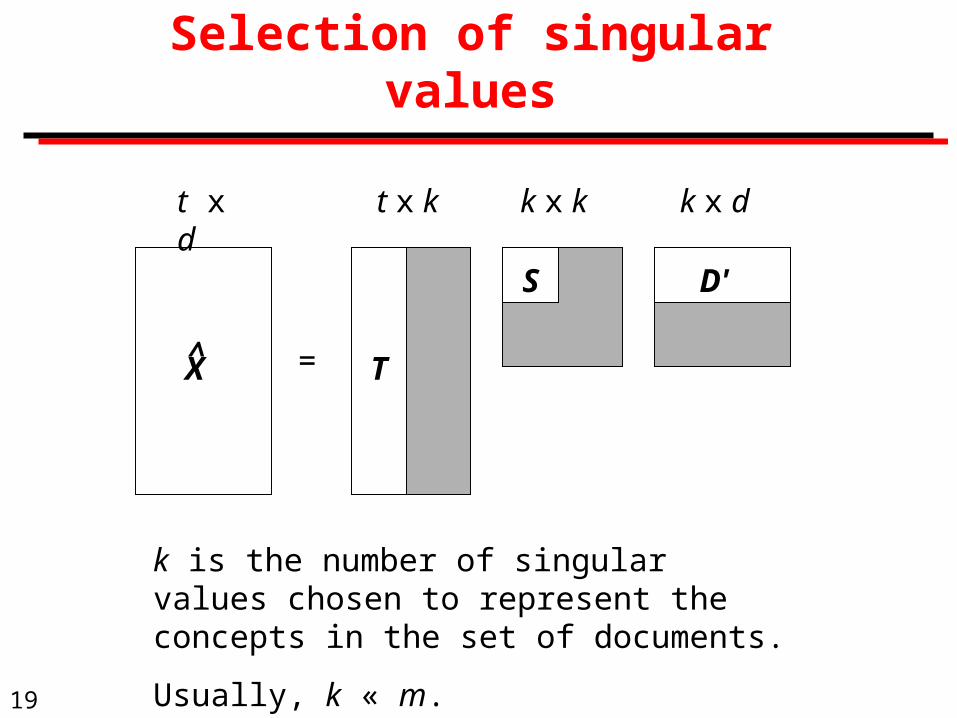
19
Selection of singular values
X =
t x d t x k k x dk x k
k is the number of singular values chosen to represent the concepts in the set of documents.
Usually, k « m.
T
S D'
^

20
Comparing Two Terms
XX' = TSD'(TSD')'
= TSD'DS'T'
= TSS'T Since D is orthonormal
= TS(TS)'
To calculate the i, j cell, take the dot product between the i and j rows of TS
Since S is diagonal, TS differs from T only by stretching the coordinate system
^
^
The dot product of two rows of X reflects the extent to which two terms have a similar pattern of occurrences.
^

21
Comparing Two Documents
X'X = (TSD')'TSD'
= DS(DS)'
To calculate the i, j cell, take the dot product between the i and j columns of DS.
Since S is diagonal DS differs from D only by stretching the coordinate system
^^
The dot product of two columns of X reflects the extent to which two columns have a similar pattern of occurrences.
^

22
Comparing a Term and a Document
Comparison between a term and a document is the value of an individual cell of X.
X = TSD'
= TS(DS)'
where S is a diagonal matrix whose values are the square root of the corresponding elements of S.
^
- -
-
^

23
Technical Memo Example: Query
Terms Query xq
human 1interface 0computer 0user 0system 1response 0time 0EPS 0survey 0trees 1graph 0minors 0
Query: "human system interactions on trees"
In term-document space, a query is represented by xq, a t x 1 vector.
In concept space, a query is represented by dq, a 1 x k vector.

24
Comparing a Query and a Document
A query can be expressed as a vector in the term-document vector space xq.
xqi = 1 if term i is in the query and 0 otherwise.
Let pqj be the inner product of the query xq with document dj in the term-document vector space.
pqj is the jth element in the product of xq'X. ^

25
Comparing a Query and a Document
[pq1 ... pqj ... pqt] = [xq1 xq2 ... xqt]
X̂inner product of query q with document dj
query
document dj is column j of X
^
pq' = xq'X
= xq'TSD'
= xq'T(DS)'
similarity(q, dj) =
^
pqj
|xq| |dj|
cosine of angle is inner product divided by lengths of vectors
Revised October 6, 2004

26
Comparing a Query and a Document
In the reading, the authors treat the query as a pseudo-document in the concept space dq:
dq = xq'TS-1
To compare a query against document j, they extend the method used to compare document i with document j.
Take the jth element of the product of:
dqS and (DS)'
This is the jth element of product of:
xq'T (DS)' which is the same expression as before.
Note that dq is a row vector.Revised October 6, 2004

27
Experimental Results
Deerwester, et al. tried latent semantic indexing on two test collections, MED and CISI, where queries and relevant judgments available.
Documents were full text of title and abstract.
Stop list of 439 words (SMART); no stemming, etc.
Comparison with: (a) simple term matching, (b) SMART, (c) Voorhees method.
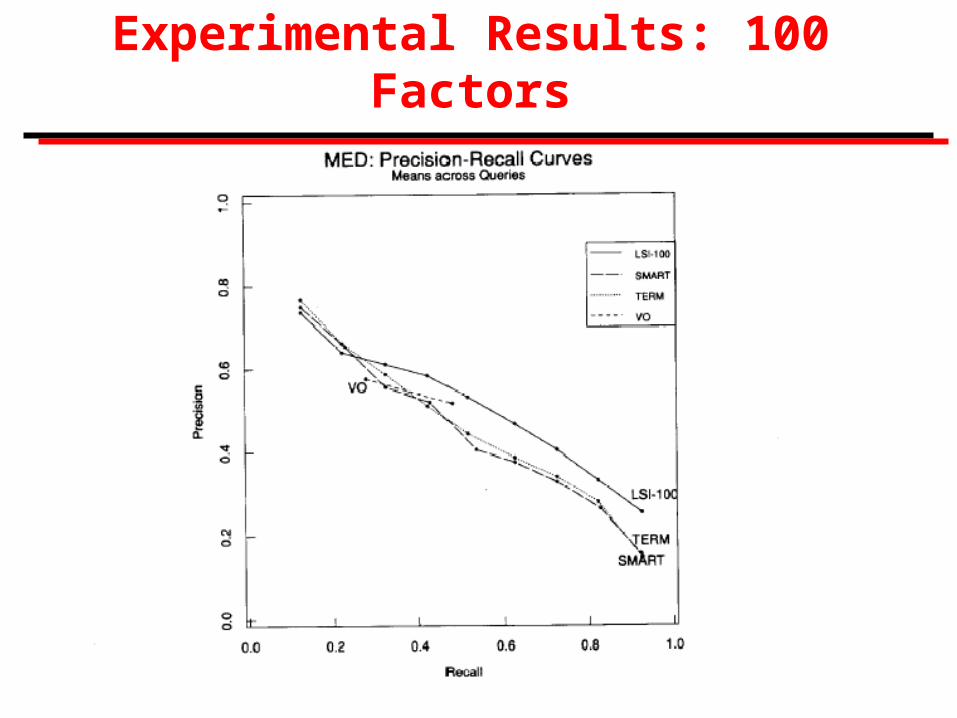
28
Experimental Results: 100 Factors
29
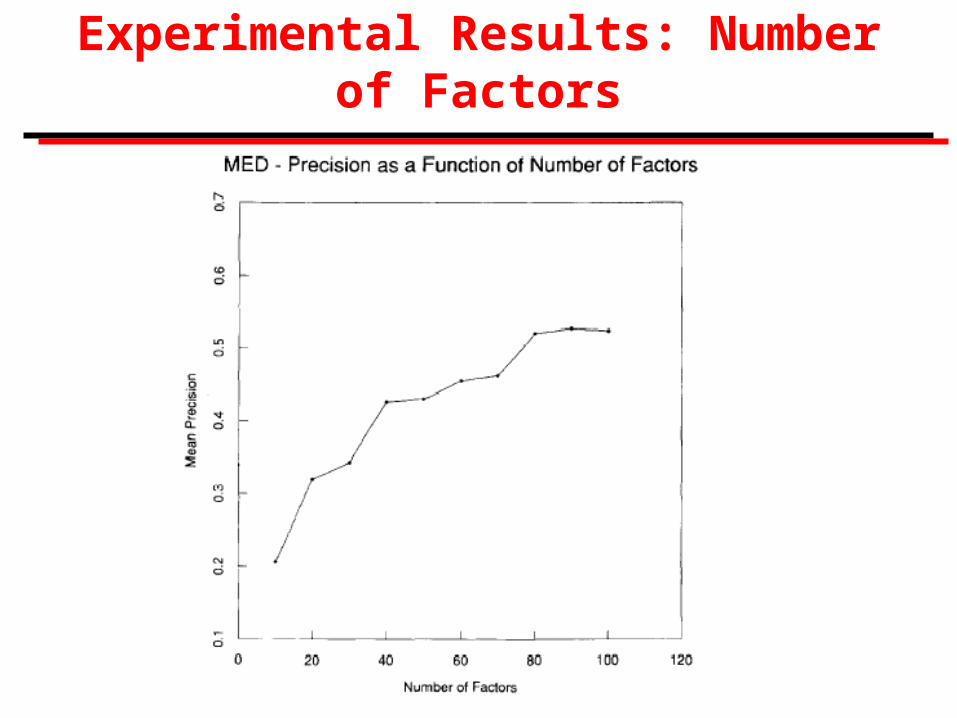
Experimental Results: Number of Factors

30
CS 430 / INFO 430 Information Retrieval
Extending the Boolean Model
31
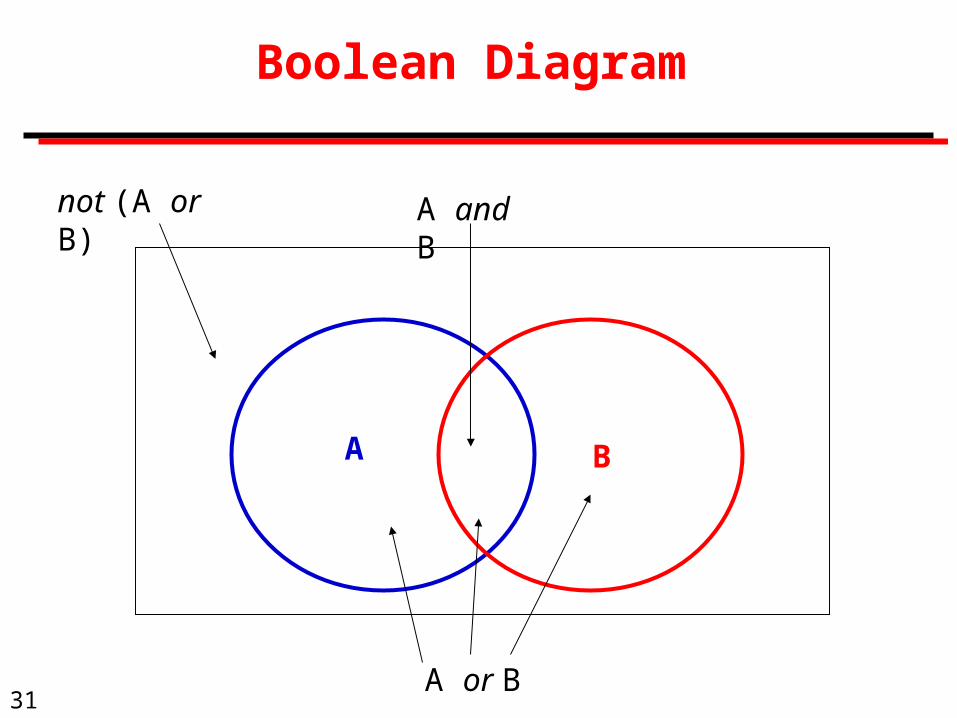
Boolean Diagram
A B
A and B
A or B
not (A or B)

32
Problems with the Boolean model
Counter-intuitive results:
Query q = A and B and C and D and EDocument d has terms A, B, C and D, but not E
Intuitively, d is quite a good match for q, but it is rejected by the Boolean model.
Query q = A or B or C or D or EDocument d1 has terms A, B, C, D and EDocument d2 has term A, but not B, C, D or E
Intuitively, d1 is a much better match than d2, but the Boolean model ranks them as equal.

33
Problems with the Boolean model (continued)
Boolean is all or nothing
• Boolean model has no way to rank documents.
• Boolean model allows for no uncertainty in assigning index terms to documents.
• The Boolean model has no provision for adjusting the importance of query terms.
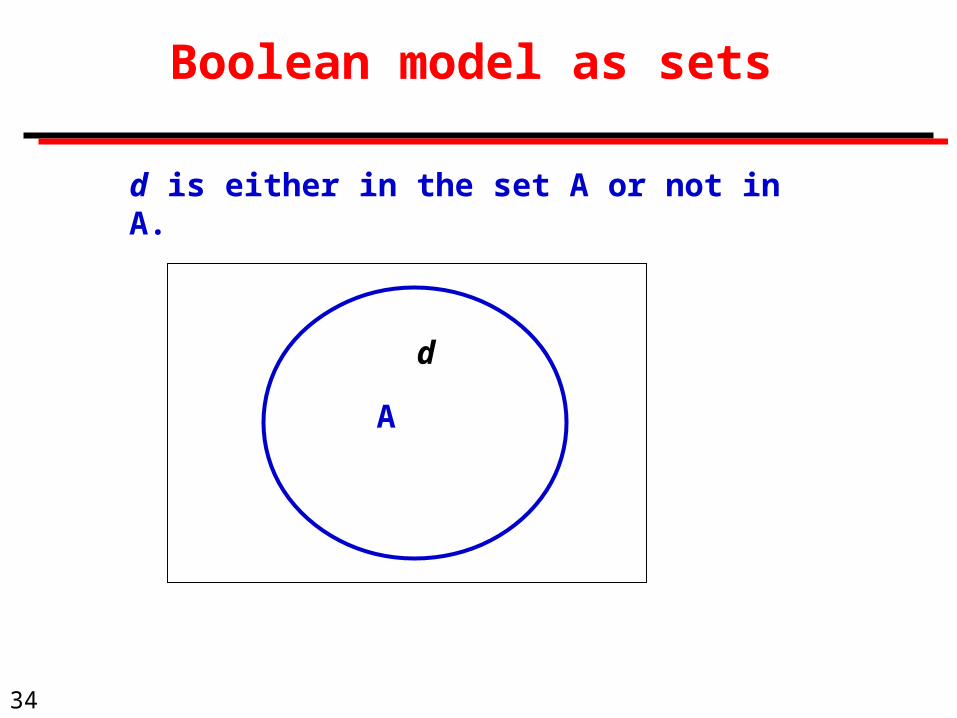
34
Boolean model as sets
A
d
d is either in the set A or not in A.

35
Extending the Boolean model
Term weighting
• Give weights to terms in documents and/or queries.
• Combine standard Boolean retrieval with vector ranking of results
Fuzzy sets
• Relax the boundaries of the sets used in Boolean retrieval

36
Ranking methods in Boolean systems
SIRE (Syracuse Information Retrieval Experiment)
Term weights
• Add term weights to documents
Weights calculated by the standard method of
term frequency * inverse document frequency.
Ranking
• Calculate results set by standard Boolean methods
• Rank results by vector distances

37
Relevance feedback in SIRE
SIRE (Syracuse Information Retrieval Experiment)
Relevance feedback is particularly important with Boolean retrieval because it allow the results set to be expanded
• Results set is created by standard Boolean retrieval
• User selects one document from results set
• Other documents in collection are ranked by vector distance from this document
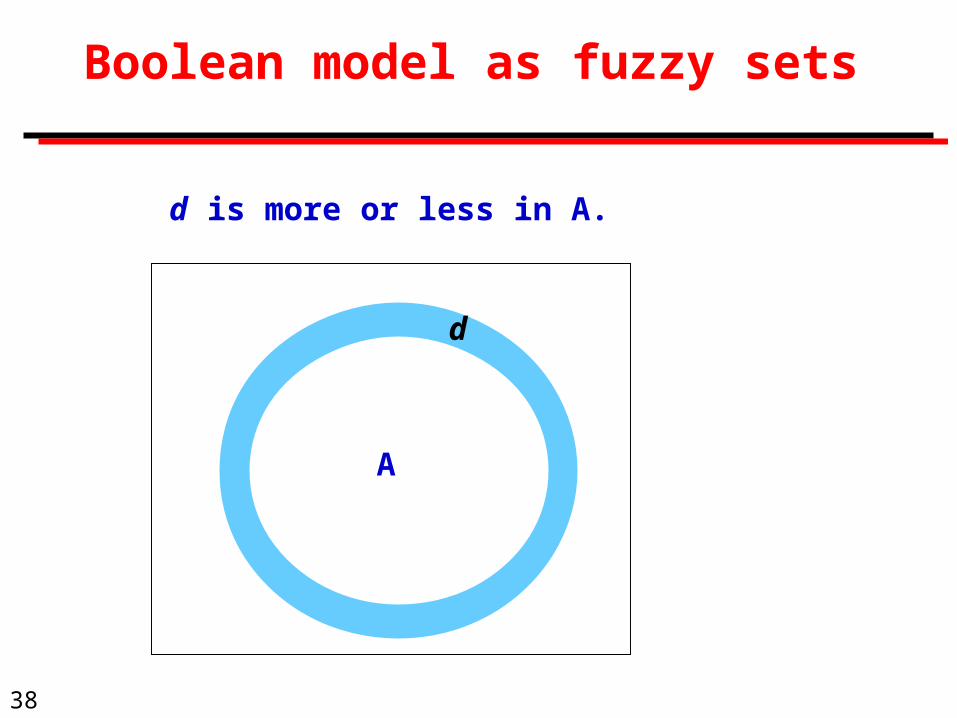
38
Boolean model as fuzzy sets
A
d
d is more or less in A.

39
Basic concept
• A document has a term weight associated with each index term. The term weight measures the degree to which that term characterizes the document.
• Term weights are in the range [0, 1]. (In the standard Boolean model all weights are either 0 or 1.)
• For a given query, calculate the similarity between the query and each document in the collection.
• This calculation is needed for every document that has a non-zero weight for any of the terms in the query.

40
MMM: Mixed Min and Max model
Fuzzy set theory
dA is the degree of membership of an element to set A
intersection (and)
dAB = min(dA, dB)
union (or)
dAB = max(dA, dB)
41
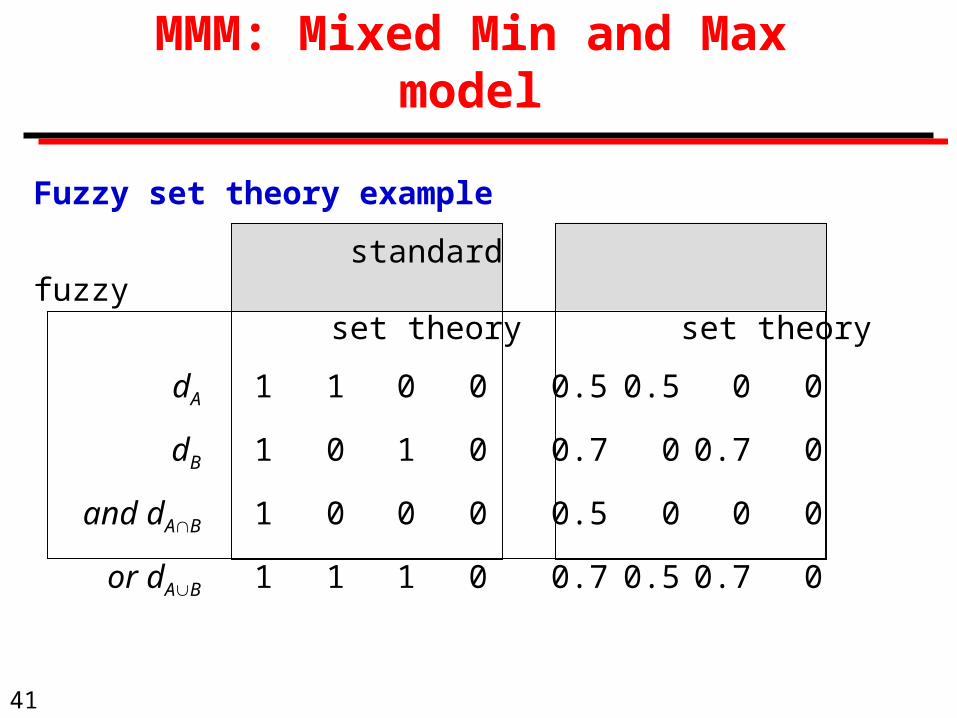
MMM: Mixed Min and Max model
Fuzzy set theory example
standard fuzzy set theory set theory
dA 1 1 0 0 0.5 0.5 0 0
dB 1 0 1 0 0.7 0 0.7 0
and dAB 1 0 0 0 0.5 0 0 0
or dAB 1 1 1 0 0.7 0.5 0.7 0

42
MMM: Mixed Min and Max model
Terms: A1, A2, . . . , An
Document D, with index-term weights: dA1, dA2, . . . , dAn
Qor = (A1 or A2 or . . . or An)
Query-document similarity:
S(Qor, D) = Cor1 * max(dA1, dA2,.. , dAn) + Cor2 * min(dA1, dA2,.. , dAn)
where Cor1 + Cor2 = 1

43
MMM: Mixed Min and Max model
Terms: A1, A2, . . . , An
Document D, with index-term weights: dA1, dA2, . . . , dAn
Qand = (A1 and A2 and . . . and An)
Query-document similarity:
S(Qand, D) = Cand1 * min(dA1,.. , dAn) + Cand2 * max(dA1,.. , dAn)
where Cand1 + Cand2 = 1

44
MMM: Mixed Min and Max model
Experimental values:
Cand1 in range [0.5, 0.8]
Cor1 > 0.2
Computational cost is low. Retrieval performance much improved.

45
Other Models
Paice model
The MMM model considers only the maximum and minimum document weights. The Paice model takes into account all of the document weights. Computational cost is higher than MMM.
P-norm model
Document D, with term weights: dA1, dA2, . . . , dAn
Query terms are given weights, a1, a2, . . . ,an
Operators have coefficients that indicate degree of strictness
Query-document similarity is calculated by considering each document and query as a point in n space.
46
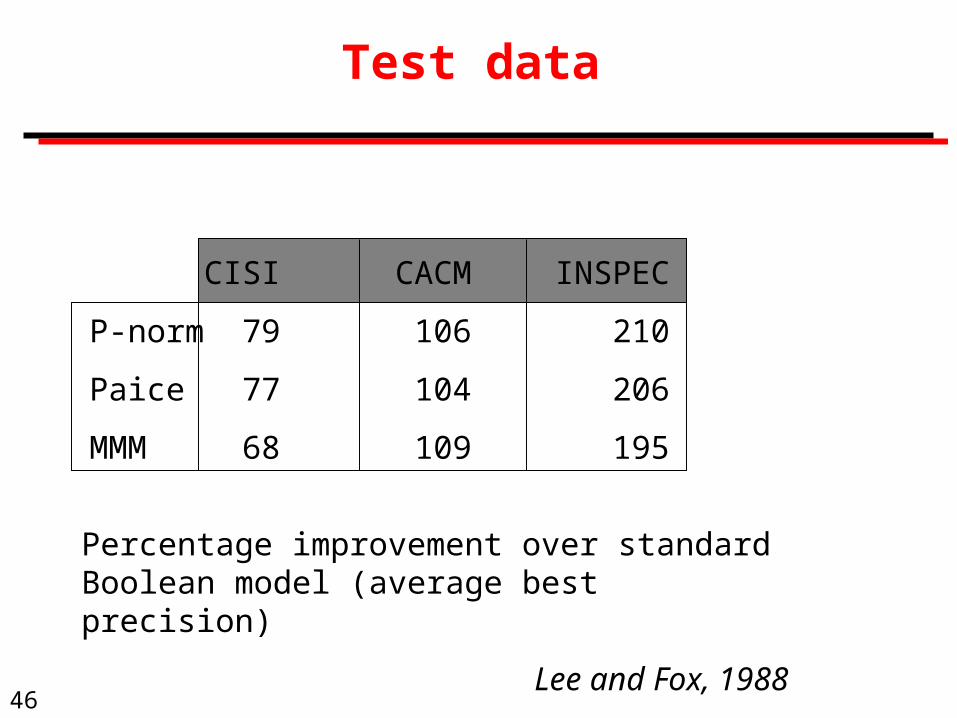
Test data
CISI CACM INSPEC
P-norm 79 106 210
Paice 77 104 206
MMM 68 109 195
Percentage improvement over standard Boolean model (average best precision)
Lee and Fox, 1988

47
Reading
E. Fox, S. Betrabet, M. Koushik, W. Lee, Extended Boolean Models, Frake, Chapter 15
Methods based on fuzzy set concepts





























