Embed Size (px)
Citation preview

1
CS 430: Information Discovery
Lecture 11
Latent Semantic Indexing

2
Course Administration
• Comments on Assignment 1.
• Office hours. See correction on web site.

3
Reading
Scott Deerwester, Susan T. Dumais, George W. Furnas, Thomas K. Landauer, Richard Harshman, "Indexing by latent semantic analysis". Journal of the American Society for Information Science, Volume 41, Issue 6, 1990.
http://www3.interscience.wiley.com/cgi-bin/issuetoc?ID=10049584

4
Latent Semantic Indexing
Objective
Replace indexes that use sets of index terms by indexes that use concepts.
Approach
Map the index term vector space into a lower dimensional space, using singular value decomposition.

5
t1
t2
t3
d1 d2
The space has as many dimensions as there are terms in the word list.
The index term vector space

6
Deficiencies with Conventional Automatic Indexing
Synonymy: Various words and phrases refer to the same concept (lowers recall).
Polysemy: Individual words have more than one meaning (lowers precision)
Independence: No significance is given to two terms that frequently appear together

7
Example
Query: "IDF in computer-based information look-up"
Index terms for a document: access, document, retrieval, indexing
How can we recognize that information look-up is related to retrieval and indexing?
Conversely, if information has many different contexts in the set of documents, how can we discover that it is an unhelpful term for retrieval?

8
Models of Semantic Similarity
Proximity models: Put similar items together in some space or structure
• Clustering (hierarchical, partition, overlapping). Documents are considered close to the extent that they contain the same terms. Most then arrange the documents into a hierarchy based on distances between documents. [Covered later in course.]
• Factor analysis based on matrix of similarities between documents (single mode).
• Two-mode proximity methods. Start with rectangular matrix and construct explicit representations of both row and column objects.

9
Selection of Two-mode Factor Analysis
Additional criterion:
Computationally efficient O(N2k3)
N is number of terms plus documentsk is number of dimensions

10
Technical Memo Example: Titles
c1 Human machine interface for Lab ABC computer applications
c2 A survey of user opinion of computer system response time
c3 The EPS user interface management system
c4 System and human system engineering testing of EPS
c5 Relation of user-perceived response time to error measurement
m1 The generation of random, binary, unordered trees
m2 The intersection graph of paths in trees
m3 Graph minors IV: Widths of trees and well-quasi-ordering
m4 Graph minors: A survey

11
Technical Memo Example: Terms and Documents
Terms Documents
c1 c2 c3 c4 c5 m1 m2 m3 m4human 1 0 0 1 0 0 0 0 0interface 1 0 1 0 0 0 0 0 0computer 1 1 0 0 0 0 0 0 0user 0 1 1 0 1 0 0 0 0system 0 1 1 2 0 0 0 0 0response 0 1 0 0 1 0 0 0 0time 0 1 0 0 1 0 0 0 0EPS 0 0 1 1 0 0 0 0 0survey 0 1 0 0 0 0 0 0 1trees 0 0 0 0 0 1 1 1 0graph 0 0 0 0 0 0 1 1 1minors 0 0 0 0 0 0 0 1 1

12
Technical Memo Example: Query
Query:
Find documents relevant to "human computer interaction"
Simple Term Matching:
Matches c1, c2, and c3Misses c4 and c5

13
Figure 1
• term
document
query
--- cosine > 0.9

14
Mathematical concepts
Singular Value Decomposition
Define X as the term-document matrix, with t rows (number of index terms) and n columns (number of documents).
There exist matrices T, S and D', such that:
X = T0S0D0'
T0 and D0 are the matrices of left and right singular vectorsT0 and D0 have orthonormal columns
S0 is the diagonal matrix of singular values

15
Dimensions of matrices
X = T0
D0'S0
t x d t x m m x dm x m
m is the rank of X < min(t, d)

16
Reduced Rank
Diagonal elements of S0 are positive and decreasing in magnitude. Keep the first k and set the others to zero.
Delete the zero rows and columns of S0 and the corresponding rows and columns of T0 and D0. This gives:
X X = TSD'
Interpretation
If value of k is selected well, expectation is that X retains the semantic information from X, but eliminates noise from synonymy and recognizes dependence.
~~ ^
^

17
Selection of singular values
X =
t x d t x k k x dk x k
k is the number of singular values chosen to represent the concepts in the set of documents.
Usually, k « m.
T
S D'
^

18
Comparing Two Terms
XX' = TSD'(TSD')'
= TSD'DS'T'
= TSS'T Since D is orthonormal
= TS(TS)'
To calculate the i, j cell, take the dot product between the i and j rows of TS
Since S is diagonal, TS differs from T only by stretching the coordinate system
^
^
The dot product of two rows of X reflects the extent to which two terms have a similar pattern of occurrences.
^

19
Comparing Two Documents
X'X = (TSD')'TSD'
= DS(DS)'
To calculate the i, j cell, take the dot product between the i and j columns of DS.
Since S is diagonal DS differs from D only by stretching the coordinate system
^^
The dot product of two columns of X reflects the extent to which two columns have a similar pattern of occurrences.
^

20
Comparing a Term and a Document
Comparison between a term and a document is the value of an individual cell of X.
X = TSD'
= TS(DS)'
where S is a diagonal matrix whose values are the square root of the corresponding elements of S.
^
- -
-

21
Technical Memo Example: Query
Terms Query xq
human 1interface 0computer 0user 0system 1response 0time 0EPS 0survey 0trees 1graph 0minors 0
Query: "human system interactions on trees"
In term-document space, a query is represented by xq, a t x 1 vector.
In concept space, a query is represented by dq, a 1 x k vector.

22
Query
Suggested form of dq is:
dq = xq'TS-1
Example of use. To compare a query against document i, take the ith element of the product of DS and dqS, which is the ith element of product of DS and xq'T.
Note that is a dq row vector.

23
Query
Let xq be the vector of terms for a query q.
In the reduced dimensional space, q, is represented by a pseudo-document, dq, at the centroid of the corresponding term points, with appropriate rescaling of the axes.
dq = xq'TS-1

24
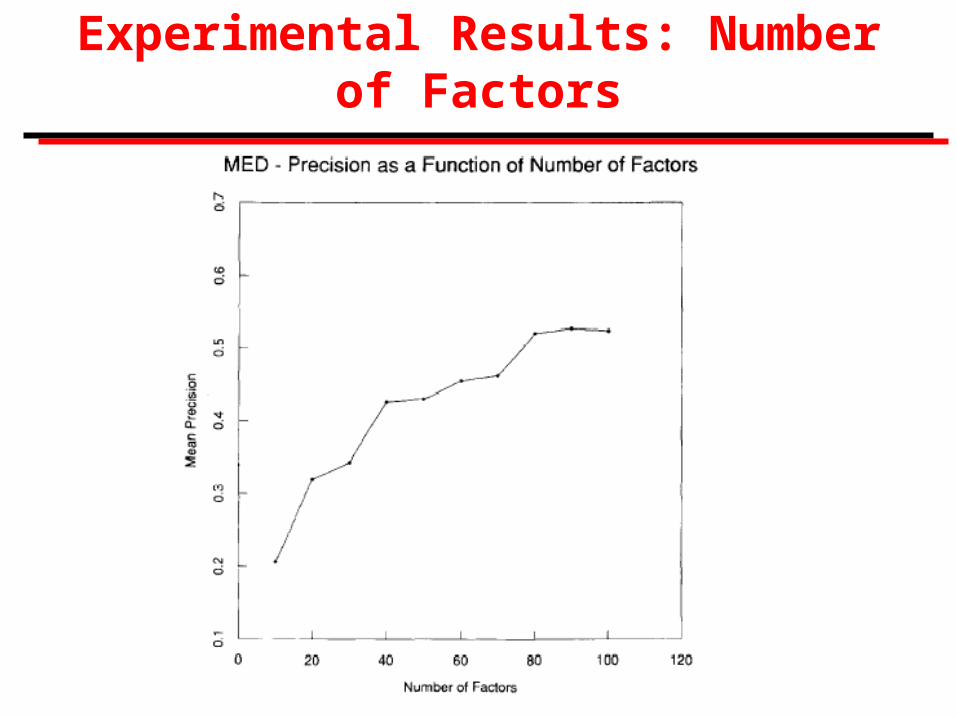
Experimental Results
Deerwester, et al. tried latent semantic indexing on two test collections, MED and CISI, where queries and relevant judgments available.
Documents were full text of title and abstract.
Stop list of 439 words (SMART); no stemming, etc.
Comparison with: (a) simple term matching, (b) SMART, (c) Voorhees method.

25
Experimental Results: 100 Factors
26
Experimental Results: Number of Factors





























