Embed Size (px)
Citation preview

MULTIMODAL FUSION: A THEORY AND APPLICATIONS
By
YANG PENG
A DISSERTATION PRESENTED TO THE GRADUATE SCHOOLOF THE UNIVERSITY OF FLORIDA IN PARTIAL FULFILLMENT
OF THE REQUIREMENTS FOR THE DEGREE OFDOCTOR OF PHILOSOPHY
UNIVERSITY OF FLORIDA
2017

© 2017 Yang Peng

To my parents, sisters and girlfriend

ACKNOWLEDGMENTS
It has been more than five years since I first arrived at University of Florida. I spent
some of my best years being a Gator and a CISE Ph.D. student. In this journey, I must
thank a lot of people who have not only helped me along the way but also guided me
through the hardest times.
I thank my advisor, Prof. Daisy Zhe Wang for her guidance, ideas and encouragement.
It has been a great honor to be her student. I have learned a lot from her, such as her
passion and her rigorous academic attitude. I am also grateful for both the financial and
moral support from her.
I am grateful to Prof. Shigang Chen, Prof. Sartaj Sahni, Prof. Sanjay Ranka and
Prof. Tan Wong for serving as my Ph.D. committee members and their precious time and
constructive opinions.
I am also thankful to my lab mates, especially Dr. Kun Li, Dr. Christan Grant, Dr.
Morteza Shahriari Nia, Dr. Yang Chen, Xiaofeng Zhou, Sean Goldberg, Miguel Rodríguez,
Dihong Gong and Ali Sadeghian, for their help, collaboration and insightful suggestions.
Finally, it is the support of my family which allows me to pursue the Ph.D. degree
from the beginning to the end. It is the company of my girlfriend which got me through
the hardest moments in the last three years. Without them, I wouldn’t imagine I can
overcome so many difficulties along this journey.
My research is partially supported by DARPA under FA8750-12-2-0348 and a
generous gift from Pivotal.
4

TABLE OF CONTENTSpage
ACKNOWLEDGMENTS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
LIST OF TABLES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
LIST OF FIGURES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
ABSTRACT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
CHAPTER
1 INTRODUCTION . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.1 Applications . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.1.1 Fact Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161.1.2 Word Sense Disambiguation . . . . . . . . . . . . . . . . . . . . . . 171.1.3 Information Retrieval . . . . . . . . . . . . . . . . . . . . . . . . . . 171.1.4 Knowledge Base Completion . . . . . . . . . . . . . . . . . . . . . . 18
1.2 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181.3 Outline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2 THEORY . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
2.1 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.2 Correlative Relation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.3 Complementary Relation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.4 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.4.1 Why Multimodal Fusion Works . . . . . . . . . . . . . . . . . . . . 252.4.2 How to Design Multimodal Fusion Algorithms . . . . . . . . . . . . 25
3 STREAMING FACT EXTRACTION . . . . . . . . . . . . . . . . . . . . . . . . 27
3.1 System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 293.1.1 Entity Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.1.2 Wikipedia Citation . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.1.3 Slot Filling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323.1.4 Constraints and Inference . . . . . . . . . . . . . . . . . . . . . . . 33
3.2 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343.3 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4 SCALABLE IMAGE RETRIEVAL . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404.3 System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.3.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 424.3.2 Distributed Clustering Algorithms . . . . . . . . . . . . . . . . . . . 42
5

4.3.2.1 Distributed approximate K-Means . . . . . . . . . . . . . 434.3.2.2 Distributed hierarchical K-Means . . . . . . . . . . . . . . 43
4.4 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 444.4.1 Datasets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.4.1.1 Oxford . . . . . . . . . . . . . . . . . . . . . . . . . . . . 454.4.1.2 ImageNet . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.4.2 Performance of Mahout K-Means, d-AKM and d-HKM . . . . . . . 454.4.3 Performance on Large Datasets . . . . . . . . . . . . . . . . . . . . 46
4.4.3.1 Different subsets . . . . . . . . . . . . . . . . . . . . . . . 474.4.3.2 Different cluster numbers . . . . . . . . . . . . . . . . . . 48
5 MULTIMODAL ENSEMBLE FUSION . . . . . . . . . . . . . . . . . . . . . . . 49
5.1 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 495.1.1 Word Sense Disambiguation . . . . . . . . . . . . . . . . . . . . . . 495.1.2 Information Retrieval . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.2 Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 515.2.1 Ensemble Fusion Model . . . . . . . . . . . . . . . . . . . . . . . . 525.2.2 Ensemble Approaches . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.2.2.1 Linear rule . . . . . . . . . . . . . . . . . . . . . . . . . . 535.2.2.2 Maximum rule . . . . . . . . . . . . . . . . . . . . . . . . 545.2.2.3 Logistic regression . . . . . . . . . . . . . . . . . . . . . . 54
5.2.3 Applications (Individual Approaches and Implementation) . . . . . 555.2.3.1 Disambiguation . . . . . . . . . . . . . . . . . . . . . . . . 555.2.3.2 Retrieval . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5.3 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 565.3.1 Datasets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.3.1.1 UIUC-ISD . . . . . . . . . . . . . . . . . . . . . . . . . . 575.3.1.2 Google-MM . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.3.2 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 585.3.2.1 Word sense disambiguation . . . . . . . . . . . . . . . . . 585.3.2.2 Information retrieval . . . . . . . . . . . . . . . . . . . . . 58
5.4 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 605.4.1 Correlation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 605.4.2 Complementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 605.4.3 Early Fusion vs Ensemble Fusion . . . . . . . . . . . . . . . . . . . 62
6 KNOWLEDGE BASE COMPLETION . . . . . . . . . . . . . . . . . . . . . . . 63
6.1 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 666.1.1 Knowledge Base Construction . . . . . . . . . . . . . . . . . . . . . 666.1.2 Inference and Learning . . . . . . . . . . . . . . . . . . . . . . . . . 676.1.3 Question Answering . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
6.2 System Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 686.2.1 Ensemble Fusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
6.3 Web-Based Question Answering . . . . . . . . . . . . . . . . . . . . . . . . 70
6

6.3.1 WebQA Pipeline . . . . . . . . . . . . . . . . . . . . . . . . . . . . 716.3.1.1 Question generation . . . . . . . . . . . . . . . . . . . . . 716.3.1.2 Data collection . . . . . . . . . . . . . . . . . . . . . . . . 746.3.1.3 Answer extraction . . . . . . . . . . . . . . . . . . . . . . 756.3.1.4 Answer ranking . . . . . . . . . . . . . . . . . . . . . . . . 76
6.3.2 Offline Training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 766.3.2.1 Template selection . . . . . . . . . . . . . . . . . . . . . . 766.3.2.2 Query-driven snippet filtering . . . . . . . . . . . . . . . . 786.3.2.3 Feature extraction . . . . . . . . . . . . . . . . . . . . . . 796.3.2.4 Classification . . . . . . . . . . . . . . . . . . . . . . . . . 80
6.4 Rule Inference . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 816.4.1 Rules . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 816.4.2 Ordinary Rule Inference . . . . . . . . . . . . . . . . . . . . . . . . 826.4.3 Augmented Rule Inference . . . . . . . . . . . . . . . . . . . . . . . 82
6.4.3.1 Length-1 rules . . . . . . . . . . . . . . . . . . . . . . . . 836.4.3.2 Length-2 rules . . . . . . . . . . . . . . . . . . . . . . . . 836.4.3.3 Query-driven optimization . . . . . . . . . . . . . . . . . . 84
6.5 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 856.5.1 Datasets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 866.5.2 WebQA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
6.5.2.1 Question template selection . . . . . . . . . . . . . . . . . 876.5.2.2 Overall performance . . . . . . . . . . . . . . . . . . . . . 896.5.2.3 Performance with snippet filtering . . . . . . . . . . . . . 906.5.2.4 Efficiency . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
6.5.3 Rule Inference . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 936.5.4 Ensemble Fusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
7 CONCLUSIONS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
REFERENCES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
BIOGRAPHICAL SKETCH . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
7

LIST OF TABLESTable page
3-1 The set of slot names. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3-2 Server specifications. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3-3 Document chunk distribution. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3-4 Sampled accuracy of the results of the extracted facts. . . . . . . . . . . . . . . 35
3-5 Recall measure: generic slot names like Affiliate had the most recall, comparedto less popular slot names e.g. DateOfDeath. . . . . . . . . . . . . . . . . . . . 36
3-6 Accuracy measure: accuracy of AffiliateOf was the best and Affiliate appliedpoorly due to ambiguity of being an affiliate of somebody/something. . . . . . . 36
4-1 The time complexity of one iteration of Mahout K-Means (d-KM), d-AKM andd-HKM. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4-2 Dataset specifics. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5-1 The accuracy of image-only, text-only, linear rule fusion, maximum rule fusionand logistic regression fusion on UIUC-ISD dataset for WSD. . . . . . . . . . . 58
5-2 Retrieval quality (MAP) of image-only, text-only, early fusion, linear rule fusion,maximum rule fusion and logistic regression fusion on the Google-MM datasetfor IR. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5-3 The coverage, average precision (AP) and average recall (AR) of different approacheson WSD for keyword “bass”. Coverage refers to the percentage of the documentseach approach can effectively disambiguate. . . . . . . . . . . . . . . . . . . . . 61
6-1 Example relations, templates, queries, questions and snippets. . . . . . . . . . . 72
6-2 Overall KBC performance for 8 relations with all snippets. Comparison betweenour system and previous work [1] (denoted as West in the table) are also explained.MAP (mean average precision) measures the KBC performance. Numbers inbold indicate the best results for individual relations. . . . . . . . . . . . . . . . 88
6-3 KBC performance with snippet filtering for different numbers of snippets. Theexperiments are run on our system evaluated with 10 snippets, 20 snippets, 30snippets and all snippets. Performance of previous work [1] is denoted as West.Performance is measured by MAP. . . . . . . . . . . . . . . . . . . . . . . . . . 90
6-4 Average running time of our system using query-driven snippet filtering for relationwasBornIn with 3 questions. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
6-5 KBC performance of OrdRI vs AugRI (measured by MAP). . . . . . . . . . . . 93
8

6-6 KBC performance of individual approaches and ensemble fusion (measured byMAP). WebQA is conducted with 30 snippets. . . . . . . . . . . . . . . . . . . . 93
9

LIST OF FIGURESFigure page
2-1 Examples selected from UIUC-ISD dataset [2] for keyword “bass”. The left figureshows a document carrying sense “bass (fish)” and the right figure shows anotherdocument carrying sense “bass (instrument)”. Photo courtesy of Kate Saenko. . 23
2-2 Examples selected from UIUC-ISD dataset [2] for sense “bass (fish)”. Photocourtesy of Kate Saenko. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3-1 Streaming fact extraction system architecture. . . . . . . . . . . . . . . . . . . . 30
4-1 The process of building the BoVW model. Reprinted with permission from GoogleImages, https://images.google.com/ (October 20, 2017). . . . . . . . . . . . . . 40
4-2 The top-down hierarchical K-Means. . . . . . . . . . . . . . . . . . . . . . . . . 44
4-3 Running time of different algorithms on Oxford dataset. . . . . . . . . . . . . . 46
4-4 Performance comparison between AKM and HKM with larger cluster numbers.Note: k refers to a thousand in the figure. . . . . . . . . . . . . . . . . . . . . . 47
4-5 Experiments on Large Datasets. Note: k refers to a thousand in the figures. . . 48
5-1 The ensemble fusion model. Photo courtesy of Kate Saenko. . . . . . . . . . . . 53
5-2 IR: per-query detailed result. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
6-1 The query-driven knowledge base system pipeline. . . . . . . . . . . . . . . . . . 69
6-2 The web-based question answering system. . . . . . . . . . . . . . . . . . . . . . 71
6-3 An example rule. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
6-4 Single-literal processing. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
6-5 Two-literal processing. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6-6 The KBC performance results for three relations with different numbers of questions.k is the number of selected questions. The KBC performance is measured byMAP. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
6-7 The average running time of WebQA with different numbers of questions forrelation wasBornIn. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
10

Abstract of Dissertation Presented to the Graduate Schoolof the University of Florida in Partial Fulfillment of theRequirements for the Degree of Doctor of Philosophy
MULTIMODAL FUSION: A THEORY AND APPLICATIONS
By
Yang Peng
December 2017
Chair: Daisy Zhe WangMajor: Computer Science
As data grows larger and larger nowadays, Big Data and Data Science are becoming
more and more prominent in Computer Science. In Data Science, not only the volume of
data is important for research, but also the variety of data has drawn a lot of attention
from researchers. In recent years, we have seen more and more complex datasets with
multiple kinds of data. For example, Wikipedia is a huge dataset with unstructured text,
semi-structured documents, structured knowledge and images. We call a dataset with
different types of data as a multimodal dataset. This dissertation focuses on employing
multimodal fusion on multimodal data to improve performance for various tasks, as well as
providing scalability and high efficiency.
In this dissertation, I first introduce the concepts of multimodal datasets and
multimodal fusion, and then different applications for multimodal fusion, such as
information extraction, word sense disambiguation, information retrieval and knowledge
base completion. Multimodal fusion is the use of algorithms to combine information from
different kinds of data with the purpose of achieving better performance. Multimodal
datasets studied in this dissertation include images, unstructured text and structured facts
in knowledge bases.
I present the correlative and complementary relations between different modalities
and propose a theory on multimodal fusion based on this observation. Previous work
usually focused on exploiting the correlation between different modalities at the feature
11

level and ignored the complementary relation between modalities. Early fusion and late
fusion have been used as two schemes to combine multimodal data, but little explanation
about how to effectively design multimodal fusion algorithms has been discussed. In
this dissertation, I discuss multimodal fusion from a deeper perspective, explain why
multimodal fusion works and analyze how to design multimodal fusion algorithms to
improve performance for tasks based on the correlative and complementary relations on
different multimodal datasets.
We then present the multimodal ensemble fusion model to combine images and text
for a few applications, including word sense disambiguation and information retrieval.
In our ensemble fusion model, text processing and image processing are conducted on
text and images separately and different fusion algorithms are employed to effectively
combine the results. The ensemble fusion model can effectively exploit the correlative and
complementary relations between images and text to improve performance. Experimental
results demonstrate ensemble approaches outperform image-only and text-only approaches.
We build a query-driven knowledge base completion system based on multimodal
fusion with web-based question answering and rule inference to combine information from
the Web and knowledge bases. We design a novel web-based question answering system to
extract facts from the Web with multimodal features and an effective question template
selection algorithm, which can achieve better performance with much fewer questions
than previous work. We build an augmented rule inference engine to infer new facts using
logical rules learned from knowledge bases and web-based question answering. We design
different fusion algorithms to combine web-based question answering and rule inference
to achieve high performance. We use a few query-driven optimization techniques, such as
query-driven snippet filtering, to improve the efficiency of the whole system.
Scalability and efficiency are also important aspects in this dissertation. We employ
streaming processing for fact extraction, which can efficiently process terabytes of text
data in less than one hour on a single machine. We implement a scalable image retrieval
12

system over millions of images using distributed systems and map-reduce, which can run
much faster than previous work. For knowledge base completion, query-driven techniques
are applied to improve system efficiency.
13

CHAPTER 1INTRODUCTION
The four Vs (volume, variety, velocity, and veracity) are the most important topics
in Data Science. In recent years, we have not only observed larger and larger datasets,
but also more and more complex datasets with different types of data. For example,
Wikipedia [3] is a huge dataset with unstructured text, semi-structured documents,
structured knowledge and images. We call this kind of dataset as a multimodal dataset.
This dissertation focuses on employing different kinds of data to improve performance and
provide scalability and high efficiency for different tasks.
Multimodal fusion is the use of algorithms to combine information from multiple
modalities. The objective of multimodal fusion is usually achieving better task performance
than single-modality approaches. Multimodal datasets may contain various kinds of data,
such as text, images, videos, audios, articles, news, blogs and XML documents. The
challenge of multimodal fusion is how to effectively and efficiently combine data of
different sources and natures.
With abundant multimodal data available on the Internet from 2000s, researchers
have developed many fusion algorithms and models to integrate data of multiple
modalities for various tasks, such as event detection in multimedia analysis. There are
two major fusion schemes divided by levels of fusion [4] used in previous work: early fusion
and late fusion. The most widely used strategy, is to fuse the information at the feature
level, which is known as early fusion or feature fusion. The other approach is decision level
fusion which fuses multiple modalities at the decision level, which is also known as late
fusion or ensemble fusion. The early fusion can utilize the correlation between multiple
features from different modalities at an early stage, while the late fusion strategy is more
flexible in terms of feature representations and learning algorithms for different modalities
and more scalable in terms of the number of modalities [4].
14

Although previous work utilize these two fusion schemes, they seldom discuss
why multimodal fusion works and how we can combine multimodal data to achieve
better performance. In this dissertation, we propose a theory about multimodal data
and multimodal fusion and discuss multimodal fusion from a deeper perspective in
Chapter 2. I explain why multimodal fusion works by analyzing the correlative and
complementary relations among different modalities. With correlative and complementary
relations, multimodal data can either provide additional information or emphasize the
same information, hence multimodal fusion can utilize these two relations to improve
performance for different applications. We analyze how to improve performance with
correlative and complementary relations for different applications on different multimodal
datasets.
To demonstrate our theory, we present the multimodal ensemble fusion model to
combine images and text for a few applications including word sense disambiguation
and information retrieval in Chapter 5. Our ensemble fusion model can capture the
complementary relation between image processing and text processing to improve
performance, while previous work focus on early fusion based on feature correlation.
In our ensemble fusion model, text processing and image processing are conducted on text
and images separately and various fusion algorithms are used to combine their results.
Experimental results demonstrate ensemble fusion approaches outperform image-only and
text-only approaches.
We present a query-driven multimodal fusion system with multimodal fusion for
knowledge base completion in Chapter 6. The knowledge base completion system
combines both web-based question answering and rule inference to utilize information from
unstructured text and strucutured knowledge bases. The web-based question answering
applies early fusion to combine features extracted from both the unstrcutured Web
and structured knowledge bases. We design novel multimodal features and an effective
question template selection algorithm for question answering, which can achieve better
15

performance with much fewer questions than previous work. We build an augmented
rule inference system with pre-learned logical rules, existing facts in knowledge bases and
web-based question answering. Then late fusion approaches are employed to combine rule
inference and web-based question answering to further improve knowledge base completion
performance. Query-driven optimization techniques are employed to improve the running
time of the whole system pipeline and provide fast responses to user queries.
Scalability and efficiency are also important aspects in this dissertation. We design
and implement a streaming processing system for the fact extraction task on terabytes
of text data, which can efficiently finish in less than one hour based on two layers of
filters. And I introduce how to implement a scalable image retrieval system on top
of Hadoop to efficiently process over millions of images. We design two distributed
clustering algorithms using Hadoop and Map-Reduce, which can run much faster than
previous work. Query-driven techniques are also employed to speed up the knowledge base
completion pipeline on-the-fly.
In the following sections of this chapter, I briefly discuss the applications studied in
this dissertation and our contributions.
1.1 Applications
In this section, the applications studied in this dissertation are briefly introduced,
including fact extraction, word sense disambiguation, information retrieval and knowledge
base completion. Only general definitions and descriptions about these applications are
presented here to give readers a brief introduction to them.
1.1.1 Fact Extraction
Fact extraction is the task to extract unknown structured facts for a knowledge base
from a source dataset, which is often an unstructured text dataset [5]. A knowledge base
(KB) is a data store with entities, attributes, relations and facts, usually stored in the
triple store format. The knowledge base we work on is the Wikipedia [3] knowledge base.
Wikipedia.org [3] is the largest online resource for free information and is maintained by
16

a small number of volunteer editors. The site contains over 5 million English articles.
However, these pages can easily be neglected, becoming out of date. Any news-worthy
event may require an update of several pages. To address this issue of stale articles, we
automatically extract facts from outside datasets to update Wikipedia [3].
1.1.2 Word Sense Disambiguation
Words in natural languages tend to have multiple senses, for example, the word
“crane” may refer to a type of bird or a type of machine. The problem of determining
which sense of a word is used in a sentence is called word sense disambiguation (WSD)
[6, 7]. WSD was first formulated as a distinct computational task during the early days of
machine translation in the 1940s, making it one of the oldest problems in computational
linguistics. Different kinds of methods have been introduced to solve WSD, including
knowledge-based approaches, supervised and unsupervised machine learning models and
other machine learning techniques [6, 7].
1.1.3 Information Retrieval
Information retrieval is the activity of obtaining relevant information to a query from
a collection of documents (usually textual documents). It involves many research topics,
such as document representation models, similarity metric, indexing, relevance feedback,
reranking, and so on. The bag-of-words model is commonly used to represent textual
documents in information retrieval and natural language processing. In this model, a
textual document or sentence is represented as a bag or a set of its words in an order-less
and grammar-free manner. The frequency vectors or occurrence vectors of words are
treated as features in this model. Image retrieval [8] is the search for desired images from
an image dataset based on queries from users. Content-based image retrieval (CBIR),
which emerged in 1990s, is a special case of image retrieval, where the queries are images
and the search process is based on visual content of images rather than textual captions or
image labels.
17

1.1.4 Knowledge Base Completion
Over the past few years, massive amounts of world knowledge have been accumulated
in publicly available knowledge bases, such as Freebase [9], NELL [10] and YAGO [11].
Yet despite their seemingly huge size, these knowledge bases are greatly incomplete. For
example, over 70% of people included in Freebase [9] have no known place of birth, and
99% have no known ethnicity. Knowledge base completion (KBC) is the task to fill in the
gaps in knowledge bases in a targeted way. The difference between fact extraction and
knowledge base completion is the former extracts unknown facts from outside datasets,
which may involve unknown entities, while KBC links existing entities in knowledge bases.
1.2 Contributions
We implement a streaming processing system for the fact extraction task on terabytes
of text data, which can efficiently complete the task in less than one hour on a single
machine. We design two layers of filters to efficiently eliminate unnecessary documents
for fact extraction. We implement a rule-based pattern matching algorithm to effectively
extract facts from raw text.
We implement a scalable image retrieval system on Hadoop to efficiently handle
millions of images using limited resources. We design two distributed clustering algorithms
using Map-Reduce and Hadoop to build the bag-of-visual-words model much faster than
previous work.
We propose a new theory about multimodal fusion based on the observation of the
correlative and complementary relations between different modalities. We explain why
multimodal fusion works by analyzing the correlative and complementary relations. We
discuss how to improve performance for different applications based on correlative and
complementary relations on multimodal datasets.
We present the multimodal ensemble fusion model to combine images and text for
word sense disambiguation and information retrieval. We design three ensemble fusion
approaches which can achieve better performance than single-modality approaches.
18

We implement a query-driven multimodal fusion system for knowledge base
completion by combining question answering and rule inference to utilize unstructured
text and structured knowledge. We design a web-based question answering system with
early fusion, which can achieve better performance than previous work using much
fewer questions. We build a rule inference system based on logical facts, existing facts
in knowledge bases and web-based question answering. We design different approaches
to effectively combine rule inference and question answering to achieve better KBC
performance. We use query-driven optimization techniques to improve system efficiency
and provide fast responses to user queries.
1.3 Outline
First, I introduce the theory on multimodal fusion based on the correlative and
complementary relations between multiple modalities in Chapter 2. Second, the streaming
fact extraction system is presented in Chapter 3 and the scalable image retrieval system
is introduced in Chapter 4. Third, the ensemble fusion model combining images and text
for disambiguation and retrieval are presented in Chapter 5. Finally, the query-driven
pipeline with multimodal fusion of unstructured and structured data for knowledge base
completion is introduced in Chapter 6. In Chapter 7, conclusions of my dissertation are
explained.
19

CHAPTER 2THEORY
Although previous work utilize early fusion and late fusion schemes, they seldom
discuss why multimodal fusion works and how we can combine multimodal data to achieve
better performance. Most of previous approaches are only interested in the correlative
relation among multiple modalities, while they ignore the complementary relation.
In this chapter, we propose a theory on multimodal fusion to explain the benefit
of employing multimodal fusion and how to use multimodal fusion to achieve better
performance than single-modality approaches. First, we explain the correlative and
complementary relations among multiple modalities, which have not been discovered or
studied by previous work. These two relations reveal the potential of using multimodal
fusion to achieve better performance than single-modality approaches. Second, we explain
why multimodal fusion works and how to design multimodal fusion algorithms based on
these two relations.
To simplify the scenario, we only use two modalities (images and text) and word sense
disambiguation (WSD) as an example application to explain the correlative relation and
complementary relation among multiple modalities. These two relations extend to many
other applications such as information retrieval and knowledge base completion, as shown
in later chapters.
2.1 Related Work
Researchers in the multimedia analysis community have developed many multimodal
machine learning models [4] to integrate data of multiple modalities, including text,
images, audios and videos, for multimedia analysis tasks, such as event detection. There
are two major fusion schemes divided by levels of fusion: early fusion and late fusion.
The most widely used strategy, is to fuse the information at the feature level, which
is also known as early fusion [4]. The other approach is late fusion or decision level
fusion, which fuses multiple modalities in the semantic space at the decision level [4].
20

Current approaches mostly focus on developing a unified representation model for multiple
modalities and then employ existing classification methods on the unified representation.
In the machine learning community, with deep learning gaining much popularity in
recent years, there have been efforts in exploiting deep learning for multimodal learning
[12, 13]. In [12], Ngiam et al. proposed the bimodal deep Boltzmann machine and the
bimodal deep autoencoder to fuse features of multiple modalities for multimodal fusion
and cross-modal learning. Deep Boltzmann machine was also employed in [13] to fuse
features of images and text.
For word sense disambiguation, there have been several research projects on using
images and text to improve disambiguation accuracy [14, 15]. In [14], May et al. combined
the image space and text space directly and applied a modified version of Yarowsky
algorithm [16] on the combined space to solve WSD. But this naive combination of two
spaces might not capture the deep or complex correlations between the image space
and text space, which might lead to poor accuracy. In [15], Saenko et al. assumed the
features of one modality are independent of sense given the other modality, then used
LDA to model the probability distributions of senses given images and text separately, and
combined these two distributions using a sum rule. Although the linear rule in Chapter 5
and the sum rule in [15] may look similar, the ideologies and motivations behind them
are quite different. The goal of the sum rule in [15] is to model the joint probability
distribution of senses given both images and text under the independence assumption,
while our goal of the linear rule approach is to capture the complementary relationship
between images and text in the ensemble fusion framework, where text processing and
image processing are conducted first and then the linear rule is used to combine the results
of them to achieve higher quality.
For information retrieval, Rasiwasia et al. [17] proposed several state-of-the-art
approaches to achieve cross-modal information retrieval. The first approach was
correlation matching, which aimed to map the different feature spaces for images and
21

text to the same feature space based on correlation analysis of these two spaces. The
second approach was semantic matching, which represented images and text with the same
semantic concepts using multi-class logistic regression. This work motivated us to discover
the correlative relation among multiple modalities. Wu et al. [18] proposed the super
kernel fusion method to combine multimodal features optimally for image categorization.
Zhu et al. [19] preprocessed embedded text in images to get weighted distance and
combined the distance with visual cues for further classification for images. Bruno et al.
[20] proposed preference-based representation to completely abstract multimedia content
for efficient processing. In [21], the proposed cross-reference-based fusion strategy for video
search used late fusion technique, by hierarchically combining ranked results from different
modalities, which can be considered as a special discrete case of the linear rule in our
model. Fusion techniques have been used in other research areas. For example, [22, 23]
proposed risk analysis approaches for chemical toxicity assessment on multiple limited
and uncertain data sources. However, their approaches are not directly applicable to our
applications since our work focuses on fusing information from deterministic multimodal
data.
Previous work didn’t discover the complementary and correlative relations between
modalities or explain why multimodal fusion works. They mostly focused on using the
early fusion scheme by developing unified representation models from multiple modalities
based on the correlative relation, and then using classification techniques on top of the
unified representation models to solve different tasks. However, we propose a theory on
multimodal fusion to explain the benefit of employing multimodal fusion and how to
design multimodal fusion algorithms to achieve better performance than single-modality
approaches, based on both the complementary and correlative relations, which are first
discovered and studied by us.
22

2.2 Correlative Relation
The data from different modalities tend to contain same or similar semantic
information and correlate with each other. For word sense disambiguation, the correlative
relation between text and images means images and textual sentences of the same
documents tend to contain semantic information describing the same objects or concepts.
For example, the image and textual sentence in Figure 2-1(A) both refer to the sense
“bass (fish)”, while the image and sentence in Figure 2-1(B) both describe the sense “bass
(instrument)”.
A “fish of florida: rock sea bass” B “l.a. kidwell musical instruments - product(bass 006)”
Figure 2-1. Examples selected from UIUC-ISD dataset [2] for keyword “bass”. The leftfigure shows a document carrying sense “bass (fish)” and the right figure showsanother document carrying sense “bass (instrument)”. Photo courtesy of KateSaenko.
Because information from different modalities have this correlative relation, they tend
to be correlated in the feature spaces as well. Then it is possible to conduct correlation
analysis to construct a unified feature space across multiple modalities to represent
multimodal documents. Previous research papers [12, 13, 17] exploit the correlative
relation to develop a unified representation model for multimodal documents, although
most of them did not identify this correlative relation explicitly.
In the late fusion scheme, images and text also display certain correlation at the
decision level. For example, some images and textual sentences are classified to the same
23

senses correctly in the experiments for WSD. But the late fusion scheme obviously cannot
exploit the correlation of images and text at the feature level.
2.3 Complementary Relation
Data from multiple modalities are complementary to each other by containing
different semantic information. For example, in the word sense disambiguation case,
textual sentences contain more useful and relevant information for disambiguation in some
documents, while images contain more useful information in other ones. For example, in
Figure 2-2(A), the sentence “portfolio 2” contains little information to disambiguate senses
for “bass”, while the image depicts the “bass (fish)” object. In Figure 2-2(B), the image is
rather complex and shows a lot of foreground objects, including a person, a boat, a fish,
a lake and trees, while the textual sentence contains cues which can be directly used to
disambiguate, such as “fishing”, “lake” and “catch”.
A “portfolio 2” B “lake fork fishing guide, bass guide - guaran-tees bass catch”
Figure 2-2. Examples selected from UIUC-ISD dataset [2] for sense “bass (fish)”. Photocourtesy of Kate Saenko.
On the other way, if we process data from multiple modalities separately, the
results from these approaches are also complementary to each other. Let’s use image
processing and text processing for instance. Image processing and text processing are
also complementary to each other. For some documents text processing generates correct
results, while for others image processing generates correct results. The reasons are
24

twofold: first, the semantic information in images and text are complementary to each
other; second, text processing usually has high precision but low recall, while image
processing has low precision but high recall.
In word sense disambiguation, the Yarowsky algorithm [16] we use to disambiguate
textual sentences, has high confidence of its disambiguation results, but frequently fails to
disambiguate a lot of unseen documents. On the other hand, the image disambiguation
using SVM classification has lower precision but higher recall because it can disambiguate
all the unseen documents but with lower confidence. Text retrieval and image retrieval
have the similar complementary relationship to each other. After using inverted indexing
to index textual data, the text retrieval has high precision but low recall due to the sparse
representation of short textual sentences. But image retrieval has high recall but low
precision, due to its dense and noisy representation of images. This observation motivated
us to design our ensemble fusion model to combine the results of text processing and
image processing, which is explained in Chapter 5.
2.4 Discussion
2.4.1 Why Multimodal Fusion Works
Complementary and correlative relations can be both leveraged in multimodal
processing tasks such as word sense disambiguation to achieve high performance. They
usually co-exist inside the same datasets, while they are probably presented in different
documents. These two relations reveal the potential of using multimodal fusion to achieve
higher quality than single-modality approaches, since multimodal data can either provide
additional information or emphasize the same information.
2.4.2 How to Design Multimodal Fusion Algorithms
The goal of multimodal fusion is to achieve higher performance than single-modality
approaches. The advantage of using multimodal fusion, as discussed above, is the ability
to exploit the correlative and complementary relations between different modalities. To
design effective multimodal fusion algorithms, we need to first examine the relationship
25

(correlative relation, complementary relation, or both) between different modalities in
multimodal data. Then we need to determine which fusion scheme (early fusion, late
fusion or both), can effectively capture the relationship between modalities in the data.
The last step is to design specific algorithms for early fusion or late fusion.
26

CHAPTER 3STREAMING FACT EXTRACTION
Wikipedia.org is the largest online resource for free information and is maintained by
a small number of volunteer editors. The website is estimated to have nearly 365 million
readers worldwide. It contains over 5 million english articles; these pages can easily be
neglected, becoming out of date. Any news-worthy event may require an update of several
pages. To address this issue of stale articles, we create a system that reads in a stream of
diverse web documents and recommends facts to be added to specified Wikipedia pages.
We developed a three-stage streaming system that creates models of Wikipedia pages,
filters out irrelevant documents and extracts facts that are relevant to Wikipedia pages.
The systems is evaluated over a 500M page web corpus and 139 Wikipedia pages. Our
results show a promising framework for fast fact extraction from arbitrary web pages for
Wikipedia.
An important part of keeping WP usable is to include new and current content.
Presently, there is considerable time lag between the publication of an event and its
citation in WP. The median time lag for a sample of about 60K web pages cited by WP
articles in the living people category is over a year and the distribution has a long and
heavy tail [5]. Such stale entries are the norm in any large reference work because the
number of humans maintaining the reference is far fewer than the number of entities.
Reducing latency keeps WP relevant and helpful to its users. Given an entity page,
such as wiki/Boris_Berezovsky_(businessman), possible citations may come from a
variety of sources. Notable news may be derived from newspapers, tweets, blogs and a
variety of different sources include Twitter, Facebook, Blogs, arxiv, etc. However, the
actual citable information is a small percentage of the total documents that appear on the
web. To help WP editors, a system is needed to parse through terabytes of documents and
select facts that can be recommended to particular WP pages.
27

Previous approaches are able to find relevant documents given a list of WP entities
as query nodes [24–28]. Entities of three categories (person, organization and facility) are
considered. This work involves processing large sets of documents to determine which facts
may contain references to a WP entity. This problem becomes increasingly more difficult
when we look to extract relevant facts from each document. Each relevant document
must now be parsed and processed to determine if a sentence or paragraph is worth being
cited. Discovering facts across the Internet that are relevant and citable to the WP entities
is a non-trivial task. Here we produce an example sentence from a webpage: “Boris
Berezovsky, who made his fortune in Russia in the 1990s, passed away March 2013.”
After parsing the sentence, we must first note that there are two entities named ‘Boris
Berezovsky’ in WP; one a businessman and the other a pianist. Any extraction needs to
take this into account and employ a viable distinguishing policy (entity resolution). Then,
we match the sentence to find a topic such as DateOfDeath valued at March 2013. Each
of these operations is expensive, so an efficient framework is necessary to execute these
operations at web scale.
In this section, we introduce an efficient fact extraction system or given WP entities
from a time-ordered document stream. Fact extraction is defined as follows: match each
sentence to the generic sentence structure of subject — verb — adverbial/complement.
The subject represents the entity (WP entity) and the verb is the relation type (slot) we
are interested in (e.g. Table 3-1). The third component, adverbial/complement, represents
the value of the associated slot. In our example sentence, the entity of the sentence is
Boris Berezovsky and the slot we extract is DateOfDeath with a slot value of March 2013.
The resulting extraction containing an entity, slot name and slot value is a fact.
Our system contains three main components. First, we pre-process the data and
build models representing the WP query entities. Next, we use the models to filter a large
stream of documents so they only contain candidate citations. Lastly, we process sentences
from candidate extractions and return slot values. Overall, we contribute the following:
28

Table 3-1. The set of slot names.Person Facility OrganizationAffiliateAssociateOfContact_Meet_PlaceTime Affiliate AffiliateAwardsWon Contact_Meet_Entity TopMembersDateOfDeath FoundedByTitlesFounderOfEmployeeOf
• Introduce a method to build models of WP name variations;
• Build a system to filter large numbers of diverse documents using a natural languageprocessing rule-based extraction system;
• Extract, infer and filter entity-slot-value triples of information to be added to KB.
Our system extracts hundreds of thousand facts from 5TB multimodal text data,
including blogs, news, forum posts, tweets, Wikipedia. The multimodal text data has been
preprocessed and annotated using natural language processing tools, thus multimodal
fusion is not the major problem here. In this chapter, I focus on discussing the streaming
system handling large datasets and the pattern matching algorithm extracting missing
facts for Wikipedia.
3.1 System
In this section, I introduce the main components of the streaming fact extraction
system. Our system is built with a pipeline style architecture giving it the advantage to
run each section separately to allow stream processing without blocking the data flow of
components (Figure 3-1). The three logical components are Model for entity resolution
purposes, Wikipedia Citation to annotate cite-worthy documents, and Slot Filling to
generate the actual slot values.
To discover facts for a single WP entity, the first step is to extract aliases of the
entity. We extract several name variations from the Wikipedia.org API and from the WP
entity page. Also, if the entity type is person, we can change the order of user names to
29
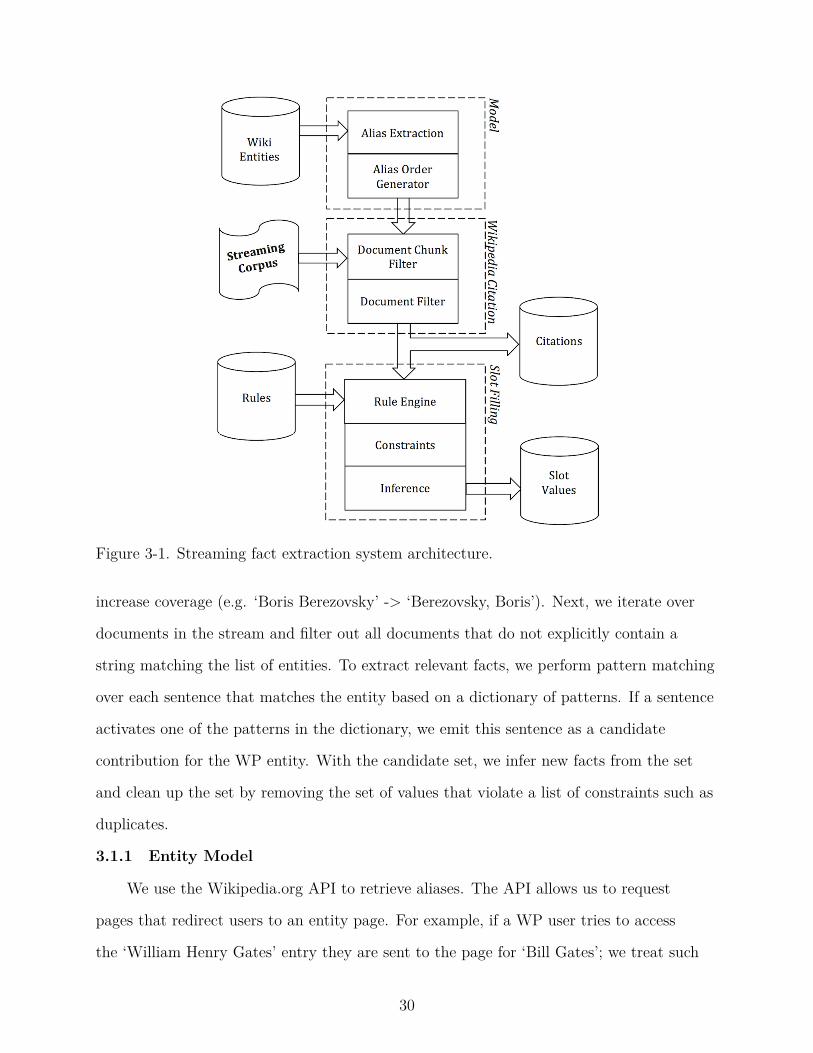
Figure 3-1. Streaming fact extraction system architecture.
increase coverage (e.g. ‘Boris Berezovsky’ -> ‘Berezovsky, Boris’). Next, we iterate over
documents in the stream and filter out all documents that do not explicitly contain a
string matching the list of entities. To extract relevant facts, we perform pattern matching
over each sentence that matches the entity based on a dictionary of patterns. If a sentence
activates one of the patterns in the dictionary, we emit this sentence as a candidate
contribution for the WP entity. With the candidate set, we infer new facts from the set
and clean up the set by removing the set of values that violate a list of constraints such as
duplicates.
3.1.1 Entity Model
We use the Wikipedia.org API to retrieve aliases. The API allows us to request
pages that redirect users to an entity page. For example, if a WP user tries to access
the ‘William Henry Gates’ entry they are sent to the page for ‘Bill Gates’; we treat such
30

redirects as aliases. To extract more aliases, we parse the HTML source of a WP entity
page. Using regular expressions, we extract the bold phrases of the initial paragraph as
aliases. This method provides several inline aliases from the wiki page. In WP page for
the businessman ‘Boris Berezovski’, there is a mention of ‘Boris Abramovich Berezovsky’
given in bold in the wiki page which obtained by regular expression extraction.
We pass the full set of person entities through rules for generating alternate name
orders. This module produces various forms of expressing entity names and titles. For
example, ‘Bill Gates’ can be written as ‘Gates, Bill’. This allows the system to capture
various notation forms of aliases that appear in text documents.
3.1.2 Wikipedia Citation
The goal of this step is to use the models created to discover a set of documents that
are relevant to the WP entity. As a stream of documents comes in, we first perform a
string matching between the model aliases and document text. We use this technique as a
first filter with confidence, because previous work states non-mentioning documents have
a low chance of being citable in Wikipedia. Given our large number of aliases, we can be
confident that if an alias does not appear in a document it does not need to be cited.
Our system streams in documents in the form of chunk files. Each chunk file contains
thousands of documents. This corpus of documents is processed by a two-layer filter
system referred to as Document Chunk Filter and Document Filter. The purpose of these
filters is to reduce I/O cost while generating slot values for various entities. Document
Chunk Filter removes the chunk files that do not contain a mention of any of the desired
entities. Each chunk file may contain thousands of documents and each document is
expensive to process. The Document Filter removes documents that do not contain a
mention of an entity. This two-level filter allows us to perform detailed slower processing
over a smaller set of documents. Not all chunk files contain mentions of the entities, so
filtering out large chunk files early saves I/O and processing costs. Document Chunk
Filter discards non-mentioning chunk files and promotes chunk files as soon as an entity
31

mention is found. The document filter additionally notes the sentences that contain entity
mentions. This data is passed to the Slot Filling system.
3.1.3 Slot Filling
Streaming Slot Filling (SSF) extracts fact values from sentences according to a list of
patterns. Table 3-1 lists the slot relationships that we look to extract. In Figure 3-1, we
refer to this task as Slot Filling. SSF reads documents filtered by the Wikipedia Citation
step and fetches and tags sentences containing WP entities. All entities are extracted
from the document using a natural language processing tool. In the next section, we
describe how WP entities are matched against the set of patterns. Following, we discuss
our approach to inference over the extracted facts.
A pattern is a template of a fact to be extracted and added to a WP entity. Patterns
are used to find and extract facts from text. A pattern P is represented as a five-tuple
P = {p1, p2, p3, p4, p5}. The first value, p1 represents the type of entity. These entity
types are in the set {FAC, ORG, PER} where FAC represents a type of facility, ORG
represents an organization and PER represents a person. p2 represents a slot name. A list
of slot names is presented in Table 3-1. The third element p3 is the pattern content, i.e.
a string found in the sentence that identifies a slot name. The extractor looks specifically
for pattern content. The pattern evaluator uses a direction (left or right) found in p4 to
explore sentence. The final element p5 represents the slot value of a pattern. The type of
slot value may be the entity type labeled by the named entity extractor, a noun phrase
(NP) tagged by a part of speech tagger or a phrase described in the pattern list.
3.1.4 Constraints and Inference
Our dataset contains some duplicate webpages, webpage texts with similar content,
and some of the entity tags are incomplete. This causes some duplicates or highly similar
content in the extracted list. We implement a filter to remove duplicates or the fact
extractions that match patterns that are general and highly susceptible to be noisy. The
data contains duplicates and incorrect extractions. We define rules to read ordered sets
32

of facts to sanitize the output. The input is processed in time order, in a tuple-at-a-time
fashion to allow rules to discover noisy slots that appears in close proximity. We define
two classes of rules: deduplication and inference rules.
The output contains many duplicate entries. As we read the list of extracted slots we
create rules to define ‘duplicate’. Duplicates can be present in a window of rows; we use a
window size of 2, meaning we only use adjacent rows. Two rows are duplicates if they have
the same exact extraction or if the rows have the same slot name and a similar slot value
or if the extracted sentence for a specific slot types come from the same sentence.
New slots can be deduced from existing slots by defining inference rules. For example,
two slots for the task are FounderOf and FoundedBy. A safe assumption is these slot
names are biconditional logical connectives with the entities and slot values. Therefore,
we can express a rule ‘X FounderOf Y <=> Y FoundedBy X’ , where X and Y are single
unique entities. Additionally, we found that the slot names Contact_Meet_PlaceTime
could be inferred as Contact_Meet_Entity, if the Entity was a FAC and the extracted
sentence contained an additional ORG/FAC tag. We also remove erroneous slots that have
extractions that are thousands of characters in length or tool small. Errors of extracting
long sentences can typically be attributed to poor sentence parsing of web documents. We
have some valid ‘small’ extractions. For example, a comma may separate a name and a
title (e.g. “John, Professor at MIT”). But such extraction rules can be particularly noisy,
so we check to see if the extracted values have good entity values.
3.2 Evaluation
We evaluate the effectiveness of extracting slot values for 139 entities. We look at the
baseline coverage for entities and slot names we present in a 500M page snapshot of the
English web. We estimate the precision and recall of our extractions over several extracted
facts.
Our system was developed on a 32-core server described in Table 3-2. Each document
is annotated using a name entity extraction and in document coreference. A bundle of
33

documents are serialized into chunks and encrypted. The total size of the data after
compression and encryption is 4.5TB. Data is ordered into 11952 date-hour buckets ranged
from 2011-10-05-00 (5th of October 2011, 12am) until 2013-02- 13-23 (13th of February
2013, 11pm). The first four months of data (October 2011 - February 2012) is for training
purposes, and we use this portion for rule and pattern creation and tuning. The data set
contains text from several web page types as listed in Table 3-3.
We develop 172 extraction patterns covering each slot-name/entity-type combinations.
Out of the 500M documents and 139 entities we found 158,052 documents containing
query entities, 17,885 unique extracted slot values for 8 different slots. We did not get any
results from 31 entities and 4 slots.
Table 3-2. Server specifications.Spec Details
Processor 32 core AMD OpteronTM 6272OS CentOS release 6.4 final
Software stack GCC version 4.4.7, Java 1.7.0.25, Scala 2.9.2, SBT 0.12.3RAM 64GBDrives 2x2.7TB disks, 6Gbps, 7200RPM
Table 3-3. Document chunk distribution.Document type # DocumentsArxiv 10988Classified 34887Forum 77674Linking 12947Mainstream News 141936Memetracker 4137News 280629Review 6347Social 688848Weblog 740987
In Table 3-4 we performed two samples of a baseline and estimate the correctness of
the extractions. The first was addressing the overall performance measures of the system,
e.g. precision and recall. The latter experiment was performed over an enhanced version of
34

Table 3-4. Sampled accuracy of the results of the extracted facts.Correct Incorrect entity
nameIncorrect value
Sampling #1 55% 17% 27%Sampling #2 54% 15% 31%
the system; we included the aliases from WP API, the alias generation process, and some
additional patterns. We produced accuracies in range of 54% and 55%. We classify the
errors into two sets, incorrect entities and incorrect extractions. We found 15% and 17%
incorrect entity names and we identified 27% and 30% incorrect value extracted across all
entities and slot types. The majority of errors were regarding poor slot value extraction
patterns and incomplete aliases.
After enhancing the system via better and more extraction patterns we provide more
detailed statistics, as displayed in Table 3-5 and Table 3-6. Table 3-5 shows the recall
for each slot name. Entities can have different coverages across the entire Web. Some
of them were more popular (‘William H. Gates’) or less well known such as (‘Stevens
Cooperative School’). Similarly, slot names have various coverages, for example, Affiliate is
more probable across the entities when compared to AwardsWon. The slot name Affiliate
was extracted the most number of times; AwardsWon contained the next fewest with 38
instances found.
Table 3-5. Recall measure: generic slot names like Affiliate had the most recall, comparedto less popular slot names e.g. DateOfDeath.
Slot name Instances found Entity coverageAffiliate 108598 80AssociateOf 25278 106AwardsWon 38 14Contact_Meet_Entity 191 8Contact_Meet_PlaceTime 5974 109DateOfDeath 87 14EmployeeOf 75 16FoundedBy 326 30FounderOf 302 29Titles 26823 118TopMembers 314 26
35

Table 3-6. Accuracy measure: accuracy of AffiliateOf was the best and Affiliate appliedpoorly due to ambiguity of being an affiliate of somebody/something.Slot name Correct Wrong entity Incorrect valueAffiliate 1% 95% 5%AssociateOf 63.6% 9.1% 27.3%AwardsWon 10% 10% 80%Contact_Meet_Entity 21% 42% 37%Contact_Meet_PlaceTime 5% 20% 85%DateOfDeath 29.6% 71% 25%EmployeeOf 5% 30% 65%FoundedBy 62% 17% 21%FounderOf 50% 0% 50%Titles 55% 0% 45%TopMembers 33% 17% 50%
An Affiliate relationship can be defined in three general ways [29]:
• A relationship consisting solely of the two groups interacting in a specific eventcontext is not enough evidence to constitute a religious/political affiliation;
• Former political or religious affiliations are correct responses for this slot;
• Any relation that is not of parent-child form; a suborganization is not an affiliate itsparent organization but rather a Memberof.
Affiliate is a generic slot name; extracting affiliate relationships is difficult because the
actual relationship must be determined. Our patterns for this relationship led to noisy
results.
However, less ambiguous slot names (AssociateOf) obtained higher accuracy but we
have lower recall. We developed patterns that explicitly expressed these relationships, but
we did not create enough patterns to express all forms of those slot names.
Table 3-6 addresses the relative accuracy measure per slot value. AssociateOf has the
highest accuracy with 63.6%, while Affiliate, Contact_Meet_PlaceTime and EmployeeOf
have the lowest accuracies of 1%, 1% and 5% accuracy respectively.
3.3 Discussion
Table 3-5 shows the distribution of extracted slot names. The number of extraction
between slot names vary greatly. Some slots naturally have more results than other slots.
36

For example, DateOfDeath and CauseOfDeath have some of the fewest entities, because
only a few entities are deceased.
Some patterns use common words as part of their patterns causing more extractions.
For example, Affiliate looks for common words (like and, with) as part of the pattern
content. These words are more common than dead, died or founded in other patterns.
Some of the entities are popular and appear at a greater frequency in the data set. For
example, a ‘Corn Belt Power Cooperative’ Google search results in 86,800 documents,
while ‘William H. Gates’ returns 3,880,000 documents. We observed that more than half
of the entities appear in less than 10 documents in the data set; a large portion have
appeared only once. This significant change in coverage supports the viability of our
search and filter schemes.
The system pipeline architecture is an efficient method of processing the stream of
data. Each hour of in the corpus contains and average of 380 MB of compressed data. It
takes and hour for the system to extract facts from 140-hour worth of data from the KBA
corpus.
For more details about this project, please refer to our papers [30, 31].
37

CHAPTER 4SCALABLE IMAGE RETRIEVAL
In this dissertation, one of the major problem we studied is the multimodal
information retrieval on images and text. The ensemble fusion model for multimodal
information retrieval is further explained in Chapter 5.
As the number of images grows rapidly on the Internet, the scalability of image
retrieval systems becomes a significant issue. The remaining sections in this chapter focus
on the scalability issue of image retrieval on millions of images, since text retrieval usually
is very efficient on millions of titles using existing technologies. In this chapter, we propose
two distributed clustering algorithms to scale up the bag-of-visual-words model on millions
of images and billions of visual features by leveraging distributed systems.
Image retrieval is the search for desired images from an image dataset according to
queries from users. Content-based image retrieval (CBIR), which emerged in 1990s, is
a special case of image retrieval, where the queries are images and the search process is
based on the visual content of images rather than textual captions or image labels. In the
following sections, the term ‘image retrieval’ specifically refers to CBIR, since our focus is
to solve the image retrieval problem based on visual content on large-scale datasets.
Huge image datasets of terabytes or even petabytes have been generated from
the Internet. For example, ImageNet [32], an open image dataset for computer science
research, contains over 20 million images. And social networks, such as Facebook and
Twitter, can generate over petabytes of images everyday. Comparing all the images in
an existing dataset to the query images is not a scalable solution. Thus indexing is a
necessary step to handle large-scale image datasets. In order to index images, they should
be represented as vectors, similar to the bag-of-words model in information retrieval.
With this motivation, the bag-of-visual-words model was designed in the computer vision
community [33, 34] to represent images in ‘visual words’ vectors. Existing indexing
38

approaches in information retrieval, such as inverted indexing, can be directly applied on
the ‘visual words’ vectors.
Since the building process of the bag-of-visual-words model requires a lot of time
on large image datasets, we designed two distributed clustering algorithms to scale up
the building process of the bag-of-visual-words model by utilizing the state-of-the-art
distributed systems.
4.1 Background
The bag-of-visual-words (BoVW) model first appeared in early 2000s [33] and
has been widely used in the computer vision community for tasks such as category
classification [35] and image retrieval [34]. BoVW can represent one image as a histogram
of independent visual words in vector format. Visual words are generated by applying
clustering on local features of images. Then we can use indexing approaches to index the
visual words vectors of images. The process to build the bag-of-visual-words model on an
image dataset is described in Figure 4-1.
In the feature extraction step, local features, such as interest points or local patches,
are extracted from images. We have chosen SIFT (Scale-Invariant Fast Transform)
features, which are invariant to scale, rotation and illumination, making SIFT [36] an ideal
candidate for the bag-of-visual-words model.
After feature extraction, a clustering algorithm is used to divide features into different
clusters. Researchers [33–35] have commonly used K-Means clustering for its simplicity
and rapid convergence, but previous work [34] pointed out K-Means cannot scale up with
a large number of clusters. Even a distributed K-Means, such as Mahout K-Means, fails
to scale up with large numbers of clusters. Thus we have implemented two distributed
clustering algorithms on Hadoop to overcome this issue.
After the clustering step, clusters are treated as independent visual words and finally
a visual vocabulary is formed with these visual words. Then for a given image, the local
39

Figure 4-1. The process of building the BoVW model. Reprinted with permission fromGoogle Images, https://images.google.com/ (October 20, 2017).
features are quantized by assigning the closest visual words to them, to create a histogram
of visual words. For example, the cat image is represented as (1, 3, 2, 2)T in Figure 4-1.
To handle millions of images and billions of features, state-of-the-art distributed
systems were employed for both scalability and stability in our algorithms. All the
time-consuming steps, such as feature extraction, vocabulary construction and image
representation, are run on Hadoop [37]. Mahout [38], an open-source scalable machine
learning library, provides a distributed K-Means implementation on top of Hadoop, which
we also utilized in our distributed hierarchical K-Means. Solr [39], an information retrieval
server based on Lucene [40], is used for indexing and searching.
4.2 Related Work
In recent years, some of the research efforts in image retrieval community have been
focusing on developing scalable algorithms for image retrieval. For example, in [41],
Perronnin et al. applied compressed Fisher kernel framework instead of the BoVW model
to obtain better retrieval quality, and the compressed Fisher kernel framework was more
40

efficient than the non-compressed version. In [42], Deng et al. proposed a hierarchical
semantic indexing to handle large-scale similarity learning for images. The proposed
learning approach was fundamentally parallelizable and as a result scales more easily
than previous work, as stated in their paper. These previous work focus on designing new
algorithms to improve retrieval quality without spending too much time for the retrieval
process, while what we did was to scale up an existing mature BoVW model.
A few projects have used Hadoop as a distributed platform to process image search in
parallel. Hadoop was used to parallelize feature extraction, indexing and searching in [43]
by Gu and Gao. In [44], Yin and Liu first built a database of image features using SURF
(Speeded Up Robust Features) algorithm and LSH (Locality-Sensitive Hashing) and then
performed the search on Hadoop in a parallel way. In [45], Premchaiswadi et al. proposed
a similarity metric between images and performed parallel similarity computation between
the query image and existing images using Map-Reduce on Hadoop. Grace et al. [46]
employed Hadoop Map-Reduce to extract features, compute similarity scores and rank
the images based on similarity scores on medical datasets. Most of the related work listed
above employed Hadoop Map-Reduce to parallelize the search process of finding similar
images, while in our projects we used Hadoop as the platform to accelerate the building
process of the BoVW model.
4.3 System
To process a large number of images at high speed, the BoVW model is built in
parallel on top of Hadoop. After encoding images with visual words, the size of the visual
words vectors is significantly smaller than the original image dataset, usually less than
0.1%. A Solr server can then be deployed to handle the indexing and searching quite
efficiently without requiring significant resources. In our experiments, the image searching
process is very fast, ususally costing less than a few seconds.
Someone may argue the BoVW building process can be conducted offline, so scaling
up the building process is not necessary. However, people usually need to run the BoVW
41

building processes many times to tune the vocabulary size, i.e. the number of visual
words. And a slow approach may take a few days to finish on large datasets with large
numbers of visual words, while a fast approach only costs a few hours in the same
scenario, as shown in experiments.
4.3.1 Overview
Since a single-node cluster and multi-processing cannot deal with such many images,
we employed a Hadoop cluster to provide scalability and stability for our system. The
feature extraction and image representation both fit the data-parallel scheme of the
Map-Reduce paradigm, hence straight-forward to be parallelized on the Hadoop using
Map-Reduce. Lire [47] is used to extract 128-dimensional SIFT features from images.
The bottleneck of the system is the vocabulary construction step, because it involves
iterative clustering algorithms to generate visual words from large numbers of local
features. As shown in related work [33–35], K-Means was used as the default clustering
algorithm to generate visual words for its fast convergence and good performance.
However, the performance of K-Means, even a distributed Mahout K-Means, deteriorates
quickly as the number of clusters increases. Thus we have designed and implemented
distributed approximate K-Means (d-AKM) and distributed hierarchical K-Means
(d-HKM) algorithms on Hadoop to solve this problem. While both d-AKM and d-HKM
run much faster than Mahout K-Means, d-AKM has better running time performance
than d-HKM for smaller cluster numbers and d-HKM works better for larger cluster
numbers, as demonstrated in experiments.
4.3.2 Distributed Clustering Algorithms
Since the most time consuming step of each iteration in these three algorithms is the
assignment step, where the features are assigned to their corresponding nearest clusters.
Let’s assume that each HDFS block in Hadoop can hold s features and the Hadoop cluster
has sufficient resources, then the time complexity of one iteration of Mahout K-Means
42

(d-KM) on the Hadoop is O(s × k). The complexities of these three algorithms for one
iteration are shown in Table 4-1.
Table 4-1. The time complexity of one iteration of Mahout K-Means (d-KM), d-AKM andd-HKM.
Algorithm d-KM d-AKM d-HKMComplexity O(s× k) O(p%s× k) O(s× sqrt(k))
4.3.2.1 Distributed approximate K-Means
In the d-AKM, we have applied an approximate process using a randomized k-d tree
forest to find the nearest cluster centroid for each feature, as introduced in [48–50]. The
d-AKM is parallelized using Map-Reduce on Hadoop. Let’s assume the d-AKM uses at
most p%k comparisons for each feature when searching for its closest cluster centroid
among k clusters, then the running time complexity for one iteration of d-AKM is reduced
to O(p%s×k). The time complexity of k-d tree building is O(k× logk) [48], which is much
smaller than O(p%s× k), since s is usually much larger than k and logk.
4.3.2.2 Distributed hierarchical K-Means
The d-HKM is shown in Figure 4-2. At the top layer, a single Mahout K-Means is
applied to divide the feature dataset into kt clusters parallelly on Hadoop. At the bottom
layer, for each cluster of the kt clusters, a single Mahout K-Means is applied to divide
this cluster into kb clusters in parallel. All the bottom-level Mahout K-Means clustering
processes run in parallel with the total number of clusters k = kt × kb.
At the top level, the running time complexity of one iteration of Mahout K-Means
is O(s × kt). At the bottom level, for each Mahout K-Means, the time complexity
of one iteration is O(s × kb). Assuming we have m bottom-level Mahout K-Means
clustering running at the same time, the running time complexity of one iteration of all
the bottom-level K-Means processes is O(s × kb × kt/m) = O(s × k/m). Thus, when kt,
kb and m are close to each other, the time complexity of one iteration of both the top-level
and the bottom-level clustering processes could be O(s× sqrt(k)).
43

Figure 4-2. The top-down hierarchical K-Means.
In addition, the number of iterations is also positively related to the number of
clusters. The d-AKM usually converges with a similar number of iterations as Mahout
K-Means. For the d-HKM, both top-level and bottom-level K-Means converges with
smaller numbers of iterations compared to Mahout K-Means. In conclusion, both d-HKM
and d-AKM should run much faster than Mahout K-Means.
4.4 Evaluation
The Oxford dataset and ImageNet dataset were used to evaluate the running
time performance of our system, especially the distributed clustering algorithms. The
44

experiments were run on the Pivotal Analytics Workbench (AWB) and Amazon Web
Services (AWS).
4.4.1 Datasets
4.4.1.1 Oxford
The Oxford building dataset, provided by University of Oxford [34], contains 5062
images about different landmark buildings in Oxford Campus searched from Flickr.
4.4.1.2 ImageNet
The two training datasets of the ImageNet Large Scale Visual Recognition Challenge
2014 (ILSVRC14) [51] were used to provide a large dataset of 185GB with over 1.7 million
images and over 230 million features.
The specifics of the 4 datasets are shown in Table 4-2.
Table 4-2. Dataset specifics.Dataset Image # Image size Feature # Feature sizeOxford 5,062 2.2GB 2,734,105 3.0GBImageNet 1,737,734 185.0GB 230,428,057 260.6GB
4.4.2 Performance of Mahout K-Means, d-AKM and d-HKM
This section compares the performance of Mahout K-Means (denoted as d-KM in
the figures), d-AKM and d-HKM with different cluster numbers. Note performance is
equivalent to running time in this chapter. In all the experiments listed in this chapter,
the maximum number of comparisons conducted in each iteration for d-AKM is 5% of the
number of clusters, and kt, kb and m are roughly the same for d-HKM.
The first experiment is to compare the running time of Mahout K-Means, d-HKM
and d-AKM on the Oxford dataset with small cluster numbers on AWB, as shown in
Figure 4-3. The running time of d-KM increases almost linearly with the number of
clusters, while d-AKM and d-HKM are very flat. d-AKM performs better than d-HKM
because d-HKM has very large overhead, due to its two-layer setup and multi-threading
mechanism. When the cluster number increases to 10k, the running time of d-KM
45

Figure 4-3. Running time of different algorithms on Oxford dataset.
increases to over 1000 minutes, demonstrating Mahout K-Means cannot scale up with
large cluster numbers.
A second experiment to compare d-AKM and d-HKM on the Oxford dataset with
larger cluster numbers is shown in Figure 4-4. The running time of d-AKM increases
almost linearly with the number of clusters, while the running time of d-HKM is quite flat
as the cluster number increases, since d-HKM has better running time complexity than
d-AKM for large cluster numbers.
4.4.3 Performance on Large Datasets
The ImageNet dataset was used for testing the performance of the building process
of the BoVW model on large numbers of images. Since d-HKM has better running time
complexity than d-AKM and Mahout K-Means with regard to the numbers of clusters,
d-HKM was used for vocabulary construction in all the experiments shown in this section.
46

Figure 4-4. Performance comparison between AKM and HKM with larger cluster numbers.Note: k refers to a thousand in the figure.
4.4.3.1 Different subsets
There are two groups of subsets generated from ImageNet: the first group with
20GB, 40GB, 60GB, 80GB and 100GB; the second group with 5GB, 10GB, 20GB,
30GB and 47GB. The experiments on the first group were run with 10,000 clusters and
300 containers using AWS, as shown in Figure 4-5(A). The experiments on the second
group were run with 2,500 clusters and 2,000 containers on Pivotal AWB, as shown in
Figure 4-5(B).
With sufficient resources, the running time of the building process of BoVW grows
sublinearly to the dataset size on Hadoop, as shown in Figure 4-5(B). But with limited
resources, the running time of our approach grows almost linearly to the dataset size on
Hadoop, as shown in Figure 4-5(A). But even with only 300 containers, our approach still
can process 100GB image data with 10k visual words in less than 9 hours.
47

A Group 1 with 10k visual words and 300 containers B Group 2 with 2.5k visual words and 2000 contain-ers
C 20GB with 300 containers
Figure 4-5. Experiments on Large Datasets. Note: k refers to a thousand in the figures.
4.4.3.2 Different cluster numbers
The number of clusters has significant influence on the running time of the vocabulary
construction and image representation steps. Several experiments has been conducted on
a 20GB dataset with different cluster numbers from 10k to 90k using 300 containers on
AWS as shown in Figure 4-5(C). The performance of our system is sublinear, very close to
sqrt(k), in the number of clusters with d-HKM for vocabulary construction. It can process
20GB with 90k clusters in less than 4 hours, which is quite fast with only 300 containers.
48

CHAPTER 5MULTIMODAL ENSEMBLE FUSION
In this chapter, we propose a multimodal ensemble fusion model to demonstrate
the theory explained in Chapter 2, by combining the results of text-only processing
(disambiguation or retrieval) and image-only processing (disambiguation or retrieval)
to achieve better quality than them. Our ensemble fusion model is designed to capture
the complementary relation and correlative relation between images and text. Different
ensemble approaches, including the linear rule, the maximum rule and logistic regression,
are used to combine the results from methods using single-modality data. Experimental
results on the UIUC-ISD dataset and the Google-MM dataset show our ensemble fusion
model outperforms approaches using only single modality for disambiguation and retrieval.
Word sense disambiguation (WSD) and information retrieval (IR) are used as tasks
to demonstrate the effectiveness of our ensemble fusion model. We employ several existing
algorithms and models in WSD and IR in our ensemble fusion model, including the
unsupervised Yarowsky algorithm [16] for text disambiguation and the inverted indexing
provided by Solr [39] for indexing and searching. For disambiguation, the results from text
disambiguation and image disambiguation are senses with confidence scores. For retrieval,
the results from text retrieval and image retrieval are similarity scores between documents
to queries.
5.1 Related Work
Related work on multimodal fusion has been introduced in Chapter 2.1. This section
focuses on explaining previous work related to information retrieval and word sense
disambiguation.
5.1.1 Word Sense Disambiguation
Words in natural languages tend to have multiple senses, for example, the word crane
may refer to a type of bird or a type of machine. The problem of determining which
sense of a word is used in a sentence is called word sense disambiguation (WSD). WSD
49

was first formulated as a distinct computational task during the early days of machine
translation in the 1940s, making it one of the oldest problems in computational linguistics.
Different kinds of methods [6, 7] have been introduced to solve WSD, including supervised
approaches, unsupervised approaches and knowledge-based approaches. While most of the
existing approaches exploit only textual information, very limited research efforts have
been conducted on multimodal data for word sense disambiguation [14, 15].
For supervised approaches, many supervised statistical algorithms [6, 7] have been
employed for WSD, including decision list, decision tree, Naive Bayesian, Neural Networks
and Support Vector Machines. However, it is unrealistic to manually label a very large
collection of textual data, which is the major limitation of the supervised approaches.
Unsupervised approaches [6, 7], on the other hand, do not require a large labeled dataset,
which enables them to overcome the knowledge acquisition bottleneck, i.e. the lack of
large data collections with manual annotations. But unsupervised approaches have a
major disadvantage that they do not exploit any knowledge inventory or dictionary of
real-world senses. Knowledge-based methods, which utilize knowledge resources (e.g.
dictionaries, ontologies, etc.), provide a better trade-off between disambiguation accuracy
and computational costs than supervised and unsupervised methods. One of the famous
unsupervised algorithms, Yarowsky algorithm [16] is employed in our ensemble fusion
model for text disambiguation.
5.1.2 Information Retrieval
Information retrieval is the activity of obtaining relevant information to a query from
a collection of documents (usually textual documents). It involves many research topics,
such as document representation models, similarity metric, indexing, relevance feedback,
reranking, and so on. The bag-of-words model is commonly used to represent textual
documents in information retrieval and natural language processing. In this model, a
textual document or sentence is represented as a bag or a set of its words in an order-less
50

and grammar-free manner. The frequency vectors or occurrence vectors of words are
treated as features in this model.
Image retrieval is the search for desired images from an image dataset according to
queries from users [8]. Content-based image retrieval (CBIR), which emerged in 1990s,
is a special case of image retrieval, where the queries are images and the search process
is based on visual content of images rather than textual captions or image labels. Image
retrieval borrows many existing algorithms and technologies from information retrieval.
For CBIR task, the most popular approach uses the bag-of-visual-words model
[33] with local features like SIFT [36] features for representing images. Similar to the
bag-of-words model, the bag-of-visual-words model is designed to represent images as
a frequency or occurrence vectors of “visual words”. The extracted local features from
images are quantized into a dictionary of visual words, with which each image can further
be represented by a histogram of visual words. Visual words are generated offline by
clustering from local features of images [33]. Thus techniques in information retrieval can
be easily borrowed and applied to CBIR, and the model has been proven effective and
efficient [34, 52].
One of the most important indexing algorithms, the inverted indexing algorithm
is used for indexing and searching images and text in our model. For each word, the
inverted index stores a list of documents in which the word appears. Inverted indexing
can provide fast full-text document search, hence is widely applied in the document
information retrieval community. Our implementation for image retrieval utilizes the
bag-of-visual-words model and inverted indexing.
5.2 Model
In our ensemble fusion model, text processing and image processing are conducted
on text and images separately and a fusion algorithm is used to combine the results. For
disambiguation, the results from text disambiguation and image disambiguation are senses
with confidence scores. For retrieval, the results from text retrieval and image retrieval are
51

similarity scores between documents and queries. The details of the model and different
ensemble approaches are explained below.
5.2.1 Ensemble Fusion Model
In the ensemble fusion model, images and text are first processed separately to
provide decision-level results. Then the results are combined using different approaches,
including the linear rule, the maximum rule and logistic regression classification, to
generate the final results.
Let’s use score to denote the results from text processing and image processing.
For disambiguation, score refers to the confidences scores (c1, c2, c3, .., cn)T of senses
(s1, s2, s3, .., sn)T . For retrieval, score refers to the similarity score of a document to the
query document. The process of our ensemble fusion model is shown in Figure 5-1.
Let’s simplify the scenario for word sense disambiguation: say for one keyword w with
two senses s1 and s2, and a document d with one image i and a textual sentence t, the
image classifier generates (s1, ci1) and (s2, ci2), and the text classifier generates (s1, ct1)
and (s2, ct2), where ci1, ci2, ct1 and ct2 denoting the confidence scores of senses s1 and s2
generated by image disambiguation and text disambiguation respectively. Confidence
scores are normalized into [0, 1] interval. The sense with the higher confidence score
between s1 and s2 is used as the disambiguated sense annotation for the word w.
Let’s also formulate the retrieval problem: say for a document d with one image i and
a textual sentence t in the data collection, the image retrieval generates similarity score
scorei and the text retrieval returns similarity score scoret.
Our ensemble model is simple but powerful. The experimental results demonstrate
the effectiveness of our model. In addition, the model can be viewed as a general
framework for multimodal fusion, where you can come up with new fusion approaches
to combine the results from text processing and image processing, or new text processing
and image processing methods. It also can be expanded to more modalities, such as audios
and videos, beyond only images and text.
52

Probabilistic Ensemble Fusion (Linear Rule,Max Rule, Logistic Regression)
Text Processing(Yarowsky, Bag-of-Words)
Image Processing(SVM, Bag-of-Visual-Words)
scoret scorei
scoref
Largemouth bass fishing tips
Figure 5-1. The ensemble fusion model. Photo courtesy of Kate Saenko.
5.2.2 Ensemble Approaches
We proposed rule-based and classification-based approaches to combine the results
from image processing and text processing. There are two rule-based approaches,
linear rule fusion and maximum rule fusion. Logistic regression is employed as a
classification-based fusion approach in our model.
5.2.2.1 Linear rule
The linear rule fusion uses a weight λ to combine the scores from image processing
and text processing. For disambiguation, the fused confidence scores for s1 and s2 are:
cf1 = λ× ci1 + (1− λ)× ct1 (5–1)
53

cf2 = λ× ci2 + (1− λ)× ct2 (5–2)
λ = Accuracyi/(Accuracyi + Accuracyt) (5–3)
λ is calculated by dividing the accuracy of image disambiguation by the sum of accuracy
of text and image disambiguation on the validation datasets.
For retrieval, the fused similarity score for d is:
scoref = λ× scorei + (1− λ)× scoret (5–4)
λ = APi/(APi + APt) (5–5)
λ is calculated by dividing the AP (average precision) of image retrieval by the sum of the
AP of text and image retrieval on training queries.
5.2.2.2 Maximum rule
The maximum rule selects the highest confidence score or similarity score from text
processing and image processing. For disambiguation, the maximum rule chooses the
sense s with the highest confidence score c from (s1, ci1), (s2, ci2), (s1, ct1) and (s2, ct2). For
example, with (s1, 0.45) and (s2, 0.55) from image classification and (s1, 0.91) and (s2, 0.09)
from text classification, we choose s1 as the output sense for the document d according to
the maximum rule, because the text classification outputs the highest confidence score 0.91
for sense s1. For retrieval, the maximum rule simply chooses the larger score from scorei
and scoret as the final score scoref .
5.2.2.3 Logistic regression
For logistic regression, confidence scores and similarity scores are used as features
to train the logistic regression classifier. For disambiguation, confidence scores from two
modalities, ci1, ci2, ct1 and ct2, are used to train the logistic regression classifier on the
validation datasets. For retrieval, similarity scores, returned by training queries, are used
to train the logistic regression classifier to determine if a document is relevant or similar
to the query. Then the logistic regression classifier is used to classify the documents to get
54

the final results. And the confidence scores of the logistic regression are used as the final
confidence scores for WSD or the final similarity scores for IR. Logistic regression is chosen
for its non-linear transformation of the confidence scores or similarity scores compared to
rule-based approaches.
5.2.3 Applications (Individual Approaches and Implementation)
5.2.3.1 Disambiguation
For text disambiguation, the unsupervised Yarowsky algorithm [16] is implemented.
The iterative Yarowsky algorithm starts with a small set of seed rules to disambiguate
senses and a large untagged corpus. In each iteration, the algorithm first applies known
rules to untagged samples and learns a set of new rules from newly tagged samples.
This process is repeated until all training samples are tagged, and the learned rules are
arranged in descending order of confidence scores, which are determined by the numbers of
samples supporting the rules. When given an unseen testing sample, the algorithm returns
the first rule matching the testing sample in the ordered list and the confidence score of
the matched rule.
For image disambiguation, we use SIFT [36] to extract local features and the
bag-of-visual-words model [33] to represent images. Then, a SVM (Support Vector
Machine) classifier is trained on the bag-of-visual-words vectors to classify images. The
SVM model is a supervised classification model, the goal of which is to construct a set
of hyperplanes in the high-dimensional feature space with the intuition of maximizing
the margins between different hyperplanes [53]. Both the image disambiguation and the
text disambiguation generate sense annotations along with confidence scores for testing
samples. The image classifier and text classifier are trained on training datasets.
For text disambiguation, the Yarowsky algorithm [16] implementation is written in
C++ and the pseudo probability distribution is implemented over the Yarowsky classifier
using Python. For image disambiguation, OpenCV is used to extract SIFT features from
images, the K-Means from Python scikit-learn is used to generate visual words, and
55

the multi-class SVM implementation from Python scikit-learn is used to disambiguate
images. The ensemble fusion model uses the logistic regression implementation with L2
regularization from Python scikit-learn.
5.2.3.2 Retrieval
In our implementation, Solr [39], a web server based on Lucene, is deployed to handle
indexing and searching for textual data and image data with inverted indexing and tf-idf
weighting. The textual sentences are represented using bag-of-words model and the
images are represented using the bag-of-visual-words model [33]. Both text and images are
represented as vectors, which makes them straight-forward to be indexed and searched by
Solr.
The cosine similarity with tf-idf weighting on the word vectors or visual word
vectors is used as similarity metric for documents (images and textual sentences). The
cosine similarity scores between documents and a query document are used to rank the
documents by Solr. The tf-idf (term frequency-inverse document frequency) weight is a
numerical weight often used in information retrieval and text mining, to evaluate how
important a word is to a document in a corpus. Given a query document, the sentence and
the image are transformed into their proper representation vectors and then searched by
Solr separately. Solr returns the ranked lists of documents with similarity scores for both
text retrieval and image retrieval.
For text retrieval, the bag-of-words model is used to represent textual sentences.
For image retrieval, LIRE, a Java library for image processing, is used to extract SIFT
features. The bag-of-visual-words model is implemented in Java using distributed K-Means
algorithms. Solr provides indexing and searching for both images and text. We use the
logistic regression implementation with ridge regularization from Weka for fusion.
5.3 Evaluation
Experiments were run on the UIUC-ISD dataset [2] and the Google-MM dataset to
test the performance of the three fusion approaches used in our ensemble fusion model.
56

Results demonstrated these three fusion approaches achieve higher quality than the
text-only and image-only methods.
5.3.1 Datasets
5.3.1.1 UIUC-ISD
The multimodal UIUC-ISD dataset [2] is used to test the accuracy of the text-only
disambiguation (Yarowsky algorithm), the image-only disambiguation (the SVM classifier)
and the three fusion approaches in our ensemble fusion model for WSD. There are three
keywords “bass”, “crane” and “squash” in the dataset. For each keyword, we selected two
core senses. There are 1691 documents for “bass”, 1194 documents for “crane” and 673
documents for “squash”.
We have constructed a training dataset, a validation dataset and a testing dataset for
each keyword. The training dataset is used to train the image and text classifiers. The
validation data is used to train the logistic regression classifier and select the linear weight
λ based on the accuracy of the image disambiguation and text disambiguation on the
validation dataset. The testing dataset is used to evaluate the fusion algorithms and to
demonstrate that by using multimodal fusion, we can get higher disambiguation accuracy
compared to methods using single modality.
5.3.1.2 Google-MM
The Google-MM dataset is used to evaluate the retrieval quality of image-only
retrieval, text-only retrieval and these three fusion approaches in our ensemble fusion
model for information retrieval. We have crawled 2,209 multimodal documents using
Google Images with 20 object categories (airplane, cat, dog, etc.) and 14 landmarks (Big
Ben, Eiffel Tower, The Taj Mahal, etc.). Each document is composed of one title and
one image. For each category or landmark, we have prepared one query for training and
one query for testing, with each query containing a few keywords and one image. For
each training or testing query, the ground truth results are provided for retrieval quality
evaluation.
57

5.3.2 Results
5.3.2.1 Word sense disambiguation
The experimental results for WSD on the UIUC-ISD dataset are shown in Table 5-1.
From the table, the accuracy of the three fusion methods is much higher than the
image-only and text-only methods on “bass” and “crane”. For “bass”, the ensemble
approaches improved the accuracy from 0.565 to 0.871. For “crane”, the maximum rule
approach improved the accuracy from 0.642 to 0.808. For “squash”, because the accuracy
of text-only disambiguation is low (0.188), we could not get much additional information
from the text-only disambiguation. Therefore the accuracy of the three fusion approaches
for “squash” is quite similar to the image-only classification.
Table 5-1. The accuracy of image-only, text-only, linear rule fusion, maximum rule fusionand logistic regression fusion on UIUC-ISD dataset for WSD.
Image Text Linear-Rule Max-Rule Log-Regbass 0.565 0.365 0.871 0.871 0.871crane 0.642 0.333 0.800 0.808 0.775squash 0.754 0.188 0.768 0.754 0.754
5.3.2.2 Information retrieval
The experimental results for information retrieval on the Google-MM dataset are
shown in Table 5-2. The retrieval quality is measured by the mean average precision
(MAP) of all 34 testing queries. From Table 5-2, all the three fusion approaches achieve
higher MAP than image-only and text-only retrieval. While image-only retrieval has
0.125 MAP and text-only retrieval has 0.761 MAP, the linear rule fusion achieves 0.802
MAP, the maximum rule fusion achieves 0.788 MAP and the logistic regression reaches
0.798 MAP. For the naive early fusion where we combine text words and visual words
directly as introduced in [14], MAP is 0.187, slightly higher than image only MAP. The
reasons why we have significantly lower image-only MAP are: 1) the most of the searched
images have noisy backgrounds, or incomplete coverage of the object; 2) we only use the
bag-of-visual-words model and cosine distance to calculate the similarity score, without
58

Table 5-2. Retrieval quality (MAP) of image-only, text-only, early fusion, linear rulefusion, maximum rule fusion and logistic regression fusion on the Google-MMdataset for IR.
Image Text Early fusion Linear-Rule Max-Rule Log-Reg0.125 0.761 0.187 0.802 0.788 0.798
Figure 5-2. IR: per-query detailed result.
complex techniques, since our focus is on the ensemble fusion part. The reasons why the
naive early fusion has very low MAP are: 1) the images and textual sentences are usually
not quite correlated; 2) the image feature space has much more dimensions than the text
feature space, which leads very low impact of the text features to the retrieval results.
Figure 5-2 shows the detailed per-query image result for IR. We can see that the three
fusion models have very close performance, while the naive early fusion of text and visual
words has low MAP for all 34 queries.
By combining the results of image-only and text-only processing under an ensemble
fusion framework, we can achieve higher performance compared to methods using only
single modality. In cases where image processing and text processing are reliable to
some extent, such as “bass” and “crane” in Table 5-1, the fusion model can improve the
performance to a great extent. Even in cases where one of the single-modality methods
59

has very poor performance, the fusion model can still generate results as good as or even
slightly better than the best results from any single-modality processing methods, such
as “squash” in Table 5-1. More analysis about our ensemble fusion model and fusion
approaches is presented below.
5.4 Discussion
In this section, we discuss how our ensemble fusion model captures the correlative
and complementary relations between images and text to achieve higher quality compared
to single-modality approaches. The differences between early fusion and ensemble fusion
models are also compared.
5.4.1 Correlation
Images and text display certain correlation at the decision level. For WSD, if image
processing and text processing generate the same sense annotation for one document,
the linear rule fusion, the maximum rule fusion and the logistic regression fusion will
usually generate the same sense annotation as image processing and text processing for
this document, according to our experimental results. For IR, if image retrieval and text
retrieval generate high similarity scores for one document, the linear rule fusion, the
maximum rule fusion and the logistic regression fusion would generate high similarity
scores for this document as well, according to our experimental results. Thus, although
our ensemble fusion model cannot capture the correlation between images and text at the
feature level, it can capture the correlation at the decision level.
5.4.2 Complementation
Although our ensemble fusion model can capture the correlation between images
and text at the decision level, this is not the main reason why we can improve the
quality, since in this case our model just generates consistent results as image-only and
text-only processing. However, the ability to capture the complementary relation between
image-only and text-only processing helps our model to generate more good results
compared to image-only and text-only processing. The average precision and average
60

recall of image-only processing, text-only processing and three ensemble fusion approaches
on WSD for keyword “bass” are shown in Table 5-3, as an example to illustrate the
complementary relation between image processing and text processing.
Table 5-3. The coverage, average precision (AP) and average recall (AR) of differentapproaches on WSD for keyword “bass”. Coverage refers to the percentage ofthe documents each approach can effectively disambiguate.
Image Text Linear-Rule Max-Rule Log-RegCoverage 1.000 0.376 1.000 1.000 1.000AP 0.522 0.857 0.862 0.862 0.859AR 0.636 0.297 0.884 0.884 0.893
Text processing usually has high precision but low recall, as shown in Table 5-3. For
example, Yarowsky classifier works well when the testing sentences contain patterns that
have been discovered in training datasets. It will generate very high confidence scores
for the correct senses in most cases, for example, (s1, 1.0) and (s2, 0.0) or (s1, 0.95) and
(s2, 0.05), with s1 usually being the correct sense. However for the sentences that do
not contain known patterns, Yarowsky classifier would fail to disambiguate between two
senses and output (s1, 0.0) and (s2, 0.0). Similar to text disambiguation, the text retrieval
also has high precision and low recall, because inverted indexing works well for textual
sentences which contain query keywords. For those sentences which do not contain query
keywords, the text retrieval can not return them as relevant results, thus causing recall to
drop.
On the other hand, image processing has high recall but low precision, as shown
in Table 5-3. For disambiguation, the image SVM classification can disambiguate all
images, but it is less accurate due to the noisy image data and image representation.
Hence image disambiguation generates less confident results, for example, (s1, 0.55) and
(s2, 0.45) or (s1, 0.60) and (s2, 0.40), with s1 possibly to be a wrong label. Image retrieval
also generate lower similarity scores for documents than text retrieval because of the noisy
representation of images. And since each image may contain hundreds or thousands of
61

local features, the image representation is more dense, so image retrieval has better recall
compared to text retrieval.
Hence, for documents in which the text processing works, the results of these three
fusion approaches in our ensemble fusion model would be consistent with text processing,
since the text processing outputs results with very high confidence scores or similarity
scores. For other documents in which the text processing fails, the results of these three
fusion approaches in the ensemble fusion model would be consistent with the image
processing because text processing returns no useful information for these documents.
Therefore, our ensemble fusion model can increase both precision and recall by taking
advantage of both text processing and image processing and avoiding their drawbacks in
the meantime.
5.4.3 Early Fusion vs Ensemble Fusion
Images and text have correlative and complementary relations between each other,
as we have discussed in prior sections. Early fusion can capture the correlative relation
between images and text at the feature level, while ensemble fusion can capture the
complementary relation at the decision level. Whether we should use early fusion or
ensemble fusion is dependent on the nature of the multimodal datasets.
In our multimodal datasets, the images and textual sentences are mostly complementary
to each other, which corroborates the fact that our ensemble fusion model can achieve
better quality than image-only and text-only approaches. On the other hand, the
correlative relation between images and text is not commonly found in the the documents,
which explains why the naive early fusion fails to improve retrieval quality. Since the
early fusion approaches use correlation analysis methods to fuse features from different
modalities, which aim to maximize the correlation effect between images and text in the
combined feature space, they are not expected to achieve very good results on the datasets
we used.
62

CHAPTER 6KNOWLEDGE BASE COMPLETION
A knowledge base (KB) is usually a data store of structured information about
entities, relations and facts. In recent years, huge knowledge bases, such as Freebase [9],
NELL [10] and YAGO [11], have been constructed to host massive amounts of knowledge
acquired from real-world datasets. Despite their huge size, these knowledge bases are
greatly incomplete. For example, Freebase [9] contains over 112 million entities and 388
million facts, while over 70% of people included in Freebase have no known place of birth
and 99% have no known ethnicity. Therefore, knowledge base completion has drawn a lot
of attention from researchers.
Formally speaking, knowledge base completion (KBC) is the task to fill in the gaps
in knowledge bases in a targeted way. Facts inside KBs are usually represented in triple
format as <subject, relation, object>, for example <Marvin_Minsky1 , wasBornIn,
New_York_City>. A knowledge base completion query can be formulated as <subject,
relation, ?>, which means given the subject and relation, what is the corresponding object
value(s)?
Knowledge bases can be constructed by iteratively extracting new information
from large datasets (usually text corpora) [9–11]. However, this is not the ideal solution
for KBC, because creating large datasets requires a lot of processing time and human
labor and the running time of knowledge base construction is usually too long. Inference
and learning in knowledge bases have been utilized in recent years for knowledge base
completion [54–57]. But learning effective, expressive and scalable models inside knowledge
bases is challenging [56, 57].
1 Marvin Lee Minsky (August 9, 1927 – January 24, 2016) was an American cognitivescientist concerned largely with research of artificial intelligence (AI), co-founder ofthe Massachusetts Institute of Technology’s AI laboratory, and author of several textsconcerning AI and philosophy. https://en.wikipedia.org/wiki/Marvin_Minsky.
63

Previous approaches for knowledge base completion ususally either utilize only
unstructured textual information, or only the structured information inside knowledge
bases. However, structured information, such as entity types and entity-to-entity
relatedness, can help fact/knowledge extraction tasks based on unstructured datasets.
On the other hand, approaches using strucutured information in KBs can benefit
by incorporating unstructured textual information, since knowledge bases are highly
incomplete. And fusing two different approaches with different types of datasets can
further help improve performance, because they have complementary strengthes and
weaknesses [58]. Another common problem of previous work is they are all batch-oriented
systems and they cannot prvoide fast real-time responses to user queries at query time.
In this chapter, we propose a query-driven knowledge base completion system
combining rule inference and question answering and fusing unstructured text and
knowledge bases. To our best knowledge, our system is the first system providing
query-time knowledge base completion and leveraging both unstructured and structured
data in depth.
We employ web-based question answering (WebQA) to solve knowledge base
completion for its flexibility and effectiveness based on the massive unstructured textual
information available on the Web. We design novel multimodal features and an effective
question template selection algorithm for WebQA, which can achieve better performance
with much fewer questions than previous work [1]. WebQA fuses unstructured textual
snippets and structured information from knowledge bases to extract features and uses
entity type information to filter out incorrect candidate answers. Our question answering
system exploits some similar techniques used in [1, 59], but we pursue both effectiveness
and efficiency and provide real-time responses to user queries.
Horn-clause logical rules are used in our system to infer new facts for KBC queries.
These rules are pre-learned by previous work [60] through ontological path finding.
However, only using existing facts in knowledge bases fail to match the premises of rules
64

to effectively infer new facts of interest in many cases, because knowledge bases are highly
incomplete. We employ WebQA to first extract missing premise facts from the Web and
then use rule inference to get answers for KBC queries. By combininig WebQA and logical
rules learned from knowledge bases, our augmented rule inference system can achieve
better KBC performance than only using existing information in knowledge bases.
We use ensemble fusion to combine augmented rule inference and web-based question
answering to further improve KBC performance. As discussed in previous work [58] by
Peng et al., approaches on different datasets display complementary relation between
each other, which can provide complementary information to improve performance by
combining them together. We use a few ensemble approaches to fuse the results of rule
inference and question answering, including linear rule, maximum rule, sum rule and
logistic regression. Experiments demonstrate significant performance gain after using
ensemble fusion.
We design a few query-driven approaches to eliminate unnecessary computations
and reduce the running time of our system on-the-fly. We implement the query-driven
snippet filtering component in WebQA, which can greatly reduce the number of snippets
for processing and improve the running time of the WebQA pipeline. For augmented rule
inference, we only use WebQA for rules of which premises are missing inside knowledge
bases and confidence thresholds to choose the most reliable results from WebQA to reduce
running time on-the-fly. We also use query-driven optimization to avoid unnecessary
WebQA queries in augmented rule inference.
Our contributions are shown below:
• We propose an effective and efficient KBC system by combining rule inference andweb-based question answering with the massive information available on the Weband in the knowledge bases. Our system fuses both unstructured data from the Weband structured information from knowledge bases in depth.
• We design and implement a web-based question answering (WebQA) system toextract missing facts from the unstructured Web with effective multimodal features
65

and question template selection, which can achieve better performance with muchfewer questions than previous work [1].
• We build an augmented rule inference system leveraging logical rules, existingstructured facts in knowledge bases and our web-based question answering system,to infer missing facts for KBC queries.
• We apply ensemble fusion to effectively combine question answering and ruleinference to achieve high KBC performance.
• To improve efficiency, we employ a set of query-driven techniques for WebQA andrule inference to reduce the running time for user queries on-the-fly.
• Extensive experiments have been conducted to demonstrate the effectiveness andefficiency of our system.
6.1 Related Work
Although huge knowledge bases have been constructed from large datasets, they
are far from complete as shown above. There are a few approaches to fill in missing
information from different research directions. In this section, we briefly discuss related
work on knowledge base construction, inference and learning inside knowledge bases and
question answering.
6.1.1 Knowledge Base Construction
Huge knowledge bases have been constructed since mid-2000s [9–11]. Most knowledge
bases use iterative construction processes to learn extractors, rules and facts from large
datasets [10, 11]. Some knowledge bases employ human workers to manually add new
information [9].
TAC KBP [61] and TREC KBA [5] are the two most famous annual competitions for
knowledge base construction. The goal of them is to develop and evaluate technologies
for building and populating knowledge bases from unstructured text. Most of these
methods process each document in turn, extracting as many facts as possible by using
named-entity linkage and (supervised) relation extraction methods. Summaries of the
standard approaches in TAC KBP and TREC KBA are given by Ji and Grishman [28],
Weikum and Theobald [62] and Frank et al. [63].
66

Manual KB construction/population is not a feasible approach because of its long
response time and intense human labor cost. Iterative KB construction requires very
long processing time to learn new extractors, rules and facts on large datasets [11].
Constructing knowledge bases on new datasets is not scalable because creating large
datasets is time-consuming and involves intense human labor, and construction processes
usually take very long time to finish, e.g. a fast streaming system by Morteza et al.
[30, 31] for TREC KBA still needs hours to process 5TB text data in one pass. Another
disadvantage of knowledge base construction is it can not guarantee to extract the missing
facts users are looking for in a targeted way, as knowledge base completion queries require.
6.1.2 Inference and Learning
Inference and statistical learning have been utilized in recent years for knowledge base
completion [54–57]. Logical rule inference has been widely used for inferring new facts in
knowledge bases [60]. Richardson and Domingos proposed the Markov Logic Networks
[54] for inference based on logical rules and graphical models. However, batch inference in
Markov Logic Networks is very time-consuming and unscalable for large knowledge bases.
Information inside knowledge bases can be structured as massive graphs of entities
and relations. Entities are treated as nodes and relations are treated as edges in
the knowledge graphs. Random walks in knowledge graphs have been utilized for
knowledge base completion for its scalability [55, 56]. Recent work [57, 64, 65] learned
embedded representations of entities and relations in the knowledge bases and used these
representations to infer missing facts. But learning expressive, scalable and effective
models can be challenging [56, 57].
Inference and learning in knowledge bases are restricted to the information only
available inside knowledge bases. To make the problem more difficult, information in
knowledge bases are highly incomplete. In our system, we combine web-based question
answering and logical rules to build a rule inference system to achieve better KBC
performance than using only information inside knowledge bases.
67

6.1.3 Question Answering
Open-domain question answering (QA) has been popular for a long time. QA returns
exact answers to natural language questions posed by users. Since 1999, a specialized
track related to QA has been introduced into the annual competition held at the Text
Retrieval Conference [66]. Web-based QA systems are highly scalable and are among the
top performing systems in TREC-10 [67]. Such systems issue simple reformulations of the
questions as queries to a search engine, and rank the repeatedly occurring N-grams in the
top snippets as answers based on named entity recognition (NER) and heuristic answer
type checking.
In our system, we implement web-based question answering as a subsystem to solve
knowledge base completion for its scalability, flexibility and effectiveness based on the
massive information available on the Web. We first formulate knowledge base completion
tasks to natural language questions, search these questions on the Web using search
engines and extract answers from crawled data. Our main focus is not developing better
QA systems, but rather addressing the issue of how to use and adapt such systems for
knowledge base completion. In [1], West et al. proposed different question templates
based on relations of entities and utilized existing in-house question answering systems for
knowledge base completion. We design our own question templates and a novel template
selection algorithm which can greatly reduce the number of questions, while maintaining
high performance. Our system uses some similar techniques such as entity linking and
type filtering shown in [1, 59], but we pursue both effectiveness and efficiency in WebQA,
provide real-time responses to user queries and study multimodal fusion of unstructured
text and structured knowledge in depth.
6.2 System Overview
As stated earlier, we propose a query-driven knowledge base completion system with
multimodal fusion of unstructured text and structured knowledge. Our system combines
rule inference and web-based question answering using ensemble fusion. The web-based
68

Figure 6-1. The query-driven knowledge base system pipeline.
question answering system utilizes structured knowledge from KBs to help extract facts
from the textual snippets returned by the Web. The rule inference system combines logical
rules, existing facts in knowledge bases and web-based question answering to infer missing
facts.
Our system pipeline is illustrated in Figure 6-1. The same KBC query <subject,
relation, ?> is passed to two different components (rule inference and question answering)
and processed separately by these two components. These two components produce ranked
candidate answers with confidence scores. Their results are finally fused by the ensemble
fusion component.
In question answering and rule inference, multimodal information from text and KBs
are also fused together to achieve high performance. The WebQA system first transforms
KBC queries to natural language questions and extracts candidate answers from textual
snippets searched by these questions on the Web. It then links candidate answers to
entities in KBs, utilizes entity category information and relation schema information to
filter out incorrect candidate answers, and employs entity-to-entity relatedness and entity
69

descriptions inside KBs for feature extraction. The augmented rule inference system uses
logical rules pre-learned based on the information inside KBs, existing facts inside KBs
and WebQA to infer missing facts.
We apply the multimodal ensemble fusion model similar to the model explained in
[58]. We tested different ensemble fusion approaches, including maximum rule, linear rule,
sum rule and logistic regression. The empirical results demonstrate sum rule is better in
most cases.
6.2.1 Ensemble Fusion
We applied ensemble fusion to combine rule inference and web-based question
answering. Our ensemble fusion model is similar to the model explained in Chapter 5. We
tested different ensemble fusion approaches, including maximum rule, linear rule, sum rule
(simply adding confidence scores for the same candidate answers together) and logistic
regression, similar to approaches in Chapter 5. The empirical results demonstrate sum rule
is best in most cases.
6.3 Web-Based Question Answering
In this section, we explain the web-based question answering system (WebQA) for
knowledge base completion by fusing both unstructured data from the Web and structured
information from knowledge bases. WebQA employs question templates to generate
multiple natural language questions for each knowledge base completion query. Then
textual snippets are crawled by searching these questions on the Web via search engines.
Different from traditional question answering systems, we utilize entity linking to collect
candidate answers from snippets. Candidate answers with incorrect entity types for KBC
queries are discarded. Various features are extracted for candidate answers by fusing
information from both the unstructured snippets and structured knowledge in KBs. Then
we rank the candidate answers by probability scores generated from classification on their
features. Our system exploits some similar techniques used in [1, 59], but we pursue both
effectiveness and efficiency in our system and provide real-time responses to user queries.
70

Figure 6-2. The web-based question answering system.
Compared to previous work [1] using question answering for KBC, we design effective
question templates to achieve high performance with much fewer questions. We propose a
greedy algorithm to automatically learn question templates for transforming KBC queries
to natural language questions. We conduct query-driven snippet filtering to reduce the
number of snippets for processing, which greatly improves the running time performance
of WebQA. While previous work used batch-oriented question answering systems [1, 59],
WebQA can provide real-time responses to user queries on the fly. We design novel and
effective features through early fusion [4] of information from unstructured text and
structured knowledge bases. Experimental results demonstrate both the effectiveness and
efficiency of WebQA.
6.3.1 WebQA Pipeline
In this section, we use <Marvin_Minsky, wasBornIn, ?> as an example query and the
correct answer to this query is New_York_City. More similar examples for 4 relations are
shown in Table 6-1.
There are four major components in the query-driven WebQA system, including
question generation, data collection, answer extraction and answer ranking. The system
pipeline is illustrated in Figure 6-2. In this section, we briefly explain the design and
implementation of these components.
6.3.1.1 Question generation
Structured queries are transformed into natural language questions using selected
question templates, as shown in Table 6-1. Each relation has multiple corresponding
71

question templates. For example, for relation wasBornIn, we use born, birth and birthplace
as its templates. Then for <Marvin_Minsky, wasBornIn, ?>, the corresponding questions
are “Marvin Minsky born”, “Marvin Minsky birth”, “Marvin Minsky birthplace”.
Table 6-1. Example relations, templates, queries, questions and snippets.Relation Templates Question examples Top snippetswasBornIn born, birth,
birthplace, childbirth,delivered, delivery,etc.
<Marvin_Minsky,wasBornIn, ?>:Marvin Minsky born,Marvin Minsky birth,Marvin Minsky birth-place, etc.
Marvin Lee Minsky was born inNew York City, to an eye surgeonfather, Henry, and to a mother,Fannie ...Marvin Minsky - A.M. TuringAward Winner, BIRTH: New YorkCity, August 9, 1927. DEATH:Boston, January 24, 2016 ...
isMarriedTo married, marriage,spouse, husband,wife, love, etc.
<Ryan_Block,isMarriedTo, ?>:Ryan Block married,Ryan Block marriage,Ryan Block spouse,etc.
Jul 15, 2014 ... Ryan Block,formerly of Engadget and now atAOL .... More famous for being mar-ried to Veronica Belmont IMHO...Spouse(s), Veronica Belmont. RyanBlock (born June 25, 1982) is aSan Francisco-based technologyentrepreneur. He was ...
hasChild child, children, kid,son, daughter,offspring, etc.
<Julia_Foster,hasChild, ?>:Julia Foster child,Julia Foster children,Julia Foster kid, etc.
Mother Love - Ben Fogle and hismother Julia Foster ... A shyand introverted child, he often feltoverwhelmed ...Children, Ben Fogle, Emily and Bill.Julia Foster (born 2 August 1943) isan English stage, screen and televisionactress. Born in ...
isCitizenOf citizenship,nationality, country,citizen, nation,national, etc.
<Ruth_Dyson,isCitizenOf, ?>:Ruth Dyson citizen-ship,Ruth Dyson national-ity,Ruth Dyson country,etc.
Nationality, New Zealand. Politicalparty, Labour Party ... Ruth SuzanneDyson (born 11 August 1957) is aNew Zealand politician ...Ruth Suzanne Dyson (born 11August 1957) is a New Zealandpolitician ... so Dyson’s familyfrequently moved around the coun-try.
72

For each relation, we design multiple question templates. The benefit of using
multiple question templates is it can increase the chance of finding true answers by
crawling more snippets with different questions and improve the KBC performance. As
demonstrated by experiments, multiple questions can provide higher KBC performance
than any single question.
Templates with multiple words tend to generate long questions, which may return
many noisy snippets without true answers by search engines. On the contrary, search
engines are better at finding relevant snippets to short questions. Based on this
observation, we design question templates by selecting single words with their meanings
close to the semantic meanings of relations. For example, for relation wasBornIn, born,
birthplace and birth are selected as templates, and for relation isMarriedTo, single words
such as marriage and spouse are selected as templates. More examples are listed in
Table 6-1.
In previous work [1], West et al. utilized information from other relations about
entities to augment the questions for a given relation. For example, for query <Frank_Zappa,
mother, ?>, one example question generated by their templates is “Frank Zappa mother
Baltimore”, with Baltimore being the birthplace of Frank_Zappa. However, the major
problem of their templates is search engines may get confused at the focus of their
questions. For example, for question “Frank Zappa mother Baltimore”, search engines
may find it hard to determine whether it is asking about “Frank Zappa mother” or “Frank
Zappa Baltimore”, and then return snippets related to Frank_Zappa and Baltimore
instead of the mother of Frank_Zappa. As shown in experiments, our system can achieve
better completion performance with much fewer questions than previous work [1].
Issuing all possible questions with all templates to search engines is problematic for
two reasons. First, its computational cost is too high. Processing each question involves
significant computational resources, such as CPU time and web searches. Especially web
searches require a lot of time waiting for responses from search engines. Moreover, more
73

questions return more snippets and entity linking on a large number of snippets is also
very time-consuming. Second, the KBC performance may deteriorate with more questions.
Not all questions are equally good. Some questions have better KBC performance than
others. So by asking all possible questions, we are likely to get more false answers, which
affects the performance of answer ranking. And through experiments, we find out with
only a few questions, we can get better or equivalent performance compared to using all
possible questions. We propose a greedy question template selection algorithm to select
a small subset of question templates which achieves highest KBC performance for each
relation.
6.3.1.2 Data collection
We search the natural language questions on the Web using search engines and crawl
the snippets returned by search engines to extract missing information for KBC queries.
A snippet is a small piece or fragment of text belonging to the document which search
engines find relevant to the queries. Thus, a snippet usually contains relevant information
excerpted from the original document. For query <Marvin_Minsky, wasBornIn, ?>,
a top snippet we crawled from the Web is “Marvin Lee Minsky was born in New York
City, to an eye surgeon father, Henry, and to a mother, Fannie ...,” which contains the
correct answer New_York_City. Examples of top snippets for more KBC queries are
shown in Table 6-1. We also conduct query-driven snippet filtering to effectively reduce
the number of snippets for processing at next steps and maintain high KBC performance
in the meantime.
Snippets are chosen over whole documents for a few reasons. First, snippets are
generated by search engines with the goal of excerpting useful information for questions
from original documents. So, answers to questions should exist in snippets in most cases.
Second, snippets are very short while documents are much larger, thus we can save a lot
of processing time by conducting entity linking on snippets instead of whole documents.
Third, crawling original documents would launch additional HTTP connections and cost a
74

lot of time waiting for responses from different web servers. We crawl up to 50 snippets for
each question and hundreds of snippets for each KBC query. To reduce time waiting for
responses from search engines for each relation, multithreading is employed to parallelize
the snippet crawling step with multiple questions.
However, entity linking on hundreds of snippets is still very time-consuming and far
from being able to provide real-time responses to user queries. Therefore, we implement
query-driven snippet filtering to select best snippets for candidate answer extraction and
ranking. Clearly not all snippets contain useful information to answer KBC queries.
Processing hundreds of snippets for each KBC query is also expensive in terms of
computational cost. Thus, we implement a query-driven snippet filtering component
to automatically select top snippets to extract candidate answers for knowledge base
completion.
6.3.1.3 Answer extraction
Noun phrases are extracted from the snippets and then treated as candidate answers.
Then candidate answers are linked to entities in Wikipedia [3] and Yago [11]. Entity
linking is the task to link entity mentions in text with their corresponding entities in
a knowledge base [68]. Linking candidate answers in snippets to entities in knowledge
bases has several remarkable advantages [59]. First, redundancy among candidate answers
is automatically reduced. Second, the types of a candidate answer can be effortlessly
determined by its corresponding entity in knowledge bases. Third, we can develop
semantic features for candidate answer ranking by utilizing the rich semantic information
about entities in knowledge bases.
Since entity linking is beyond the scope of this paper, please refer to a survey paper
[68] for more information. An open-source entity linking tool, TagMe [69, 70] is employed
in our system to accomplish the entity linking task. We parallelize the entity linking
process using multithreading to reduce running time waiting for responses from the TagMe
server [70].
75

After linking candidate answers discovered in the snippets to entities in knowledge
bases, candidate answers with incorrect entity types for KBC queries are discarded. For
example, the query <Marvin_Minsky, wasBornIn, ?> is looking for candidate answers
of type city rather than person. In the snippet “Marvin Lee Minsky was born in New
York City, to an eye surgeon father, Henry, and to a mother, Fannie ...”, the entity
Henry_Minsky, which is the father of Marvin_Minsky, is discarded because of wrong
entity types. This type filtering step greatly reduces the number of candidate answers for
ranking and thus helps improve answer ranking quality.
6.3.1.4 Answer ranking
After obtaining a set of eligible candidate answers with correct entity types from
snippets, various features are developed for candidate answers and classification is
applied on their features for ranking. For example, both Boston and New_York_City are
extracted as candidate answers for <Marvin_Minsky, wasBornIn, ?> from the snippet
”Marvin Minsky - A.M. Turing Award Winner, BIRTH: New York City, August 9, 1927.
DEATH: Boston, January 24, 2016 ... ”.
For feature extraction, we design six features to combine information from unstructured
snippets and structured knowledge in KBs. For classification, three classification
algorithms, SVM, logistic regression and decision tree, have been tested and two
approaches, resampling and cost weighting, have been applied to solve the issue of
imbalanced training datasets. The probability scores from classification results are used
to rank the candidate answers. We develop features for candidate answers based on
information from both unstructured textual snippets and structured knowledge bases and
apply classification on these features of candidate answers.
6.3.2 Offline Training
6.3.2.1 Template selection
Issuing all possible questions to search engines is problematic for two reasons.
First, its computational cost is too high. Processing each question involves significant
76

computational resources, such as CPU time and web searches. Especially web searches
require a lot of time waiting for responses from search engines. Moreover, more questions
return more snippets and entity linking on a large number of snippets is also very
time-consuming. Second, the KBC performance may deteriorate with more questions.
Not all questions are equally good. Some questions have better KBC performance than
others. So by asking all possible questions, we are likely to get more false answers, which
affects the performance of answer ranking. And through experiments, we find out with
only a few questions, we can get better or equivalent performance compared to using all
possible questions.
According to previous work [1], greedy selection is the best selection strategy. In [1],
West et al. first evaluated each question template on training datasets and then greedily
selected the top-performing question templates. However, this is not the most effective
approach in our case. We observe that some top-performing question templates produce
mostly overlapping results. So we propose a different greedy algorithm to learn the best
set of question templates as shown in Algorithm 6.1.
Algorithm 6.1. Greedy selection algorithm
T = {t1, t2, ..., tn}: the set of n question templates
Q = ∅: current selected question templates
QS = ∅: the set of different sets of question templates
for i = 1; i <= n; i++ do
Select tj from T such that Q∪{tj} has the highest performance for all possible t in T
Q = Q ∪ {tj}
QS = QS ∪ {Q}
T = T − {tj}
end for
Select Qm from QS with the highest performance and smallest size
return Qm
77

Our greedy algorithm aims to select the question template tj from T which works best
with existing templates in Q, instead of just choosing the template with best performance
among all remaining templates in T . When i = 1, our greedy algorithm selects the
question template with highest KBC performance. When i = 2, instead of selecting the
second best question template, our algorithm selects the question template which works
best with the first selected question. The algorithm goes on to select next questions in the
same way. After collecting a series of different sets of question templates, we choose the
set of templates which achieves highest KBC performance among all possible sets with the
smallest number of templates.
The advantage of our greedy selection algorithm is by choosing templates which work
best together, we can avoid computing the exponential combinations of question templates
and quickly find the optimal set of question templates, which can greatly reduce the
number of questions to be asked for KBC queries. As shown in experiments, our system
can achieve quite good performance with two or three question templates compared to
using all questions.
6.3.2.2 Query-driven snippet filtering
To reduce the number of snippets for processing, we propose a query-driven snippet
filtering algorithm to select snippets most likely containing information relevant to
knowledge base completion queries. An important observation is not all top snippets
ranked by search engines contain useful information for KBC queries. For example, for
question “Marvin Minsky born”, some of the top snippets returned by search engines focus
on general information about Marvin_Minsky rather than the birthplace of him. To solve
this problem, we rerank the snippets by classification on features of them and select top
snippets in the reranked list for candidate answer extraction.
The features we used for classification on snippets are:
• The original rank of a snippet returned by a search engine.
78

• A boolean indicator about whether the keyword in question templates appearing inthe snippet or not, e.g. whether born appearing in snippets returned by searchingthe question “Marvin Minsky born”.
• How many words of entity names appearing in the snippet. For instance, if “Marvin”and “Minsky” both appear inside the snippet for question “Marvin Minsky born”,the value of this feature is 2.
Clearly these features are designed to select snippets, which not only are originally
high-ranking snippets returned by search engines, but also contain information about
question keywords and subject entities.
A logistic regression classifier is trained on training datasets to classify snippets and
confidence scores of them are used for snippet reranking. The original training datasets are
highly imbalanced, because the number of positive samples is much smaller than negative
samples. We resolve this issue by conducting resampling on these biased training datasets
to generate new balanced datasets for training classifiers.
6.3.2.3 Feature extraction
In previous work [58, 71], Peng et al. explained multimodal data can provide
additional information or emphasize the same information among multiple modalities,
and thus multimodal fusion can usually achieve better performance than single-modality
approaches. In our system, we adopt the early fusion scheme, which combines information
from multiple modalities at the feature level [4, 58, 71]. Both unstructured textual
snippets from the Web and structured knowledge from KBs are fused together to produce
various effective features in our system. For each candidate answer, we extract 6 features
as shown below.
• The feature snippet count represents the number of snippets in which a candidateanswer appears. This feature is straightforward to understand, because correctanswers are expected to appear more frequently than false candidate answers acrosssnippets.
• The feature average rank calculates the average rank of the snippets in which thecandidate answer appears. Search engines aim to rank most relevant snippets to thetop of the ranked list of retrieved snippets for queries. The smaller the average rank,the more likely the candidate answer is correct.
79

• The feature keyword count is the number of times question keywords appearingtogether with the candidate answer in snippets. For question “Marvin Minsky born”,born is the question keyword and Marvin_Minsky is the subject entity. We findout snippets containing question keywords are usually useful snippets and trueanswers are more likely to co-occur with question keywords than false answers. Soif a candidate answer appears frequently together with question keywords, it isconsidered likely to be correct.
• The feature context distance measures the similarity between the context of thecandidate answer in snippets and the Wikipedia abstract of the subject entity. Eachentity has a short abstract describing the most important information about theentity in Wikipedia. The context of a candidate answer is the set of words appearingin the neighborhoods of it in the snippets. This feature is calculated by the cosinedistance between the bag-of-words vectors of the context of the candidate answerand the abstract of the subject entity.
• The feature abstract distance measures the similarity between the Wikipediaabstracts of the candidate answer and the subject entity. It is calculated as thecosine distance between the bag-of-words vectors of these two abstracts. The correctanswer and the subject entity of a KBC query should be related to each other, whichmeans the context distance and abstract distance between them should be quitesmall in the bag-of-words vector space.
• The relatedness between the candidate answer and the subject entity measures thesemantic relevance of these two entities based on only the structured informationinside knowledge bases. The entity relatedness implementation is provided by TagMe[70].
As shown above, these six features combine information from both unstructured
textual snippets and structured knowledge bases. The major advantage of applying
multimodal fusion at the feature level is that multimodal features can provide more
information than using only textual snippets or knowledge bases.
6.3.2.4 Classification
The features of candidate answers are classified using pre-trained classifiers and
corresponding probability scores are used to rank the candidate answers. However,
classification on candidate answers is challenging because of the highly imbalanced training
datasets, which is not dealt with in previous work [1, 59]. The training datasets usually
contain 30+ times more negative samples than positive samples, making the training
datasets extremely biased.
80

We employed two approaches, resampling and cost-weighting, to solve the issue of
imbalanced training. The resampling approach samples the existing training datasets
to create new balanced datasets with equal numbers of positive samples and negative
samples. The cost-weighting approach assigns higher costs to false negatives, which forces
the classifiers to get higher recall. After using resampling and cost-weighting, we usually
get classifiers with 20% to 40% larger PRC (area under precision-recall curve) than regular
classifiers.
Three different classification techniques have been utilized in our system, logistic
regression [1], decision tree [59] and support vector machines. Through extensive
experiments, logistic regression usually performs more steadily than the other two
classifiers for most relations.
6.4 Rule Inference
We build an augmented rule inference (AugRI) system with logical rules, existing
facts in knowledge bases and web-based question answering to infer new facts of interest.
We compare the performance of augmented rule inference with ordinary rule inference.
The ordinary rule inference (OrdRI) system uses only existing facts in knowledge bases.
6.4.1 Rules
We choose logical rule inference to infer missing facts based on structured information
inside knowledge bases for its expressiveness and efficiency. The rules we use are
horn-clause rules pre-learned by previous work [60]. A Horn clause is a disjunction of
literals. An example horn-clause rule is shown in Figure 6-3.
In Figure 6-3, the premise isMarriedTo(x, y) ∧ hasChild(y, z) is called body and the
conclusion hasChild(x, z) is called head. Each rule has a confidence score indicating its
validness. There are two kinds of rules divided by the numbers of literals in their bodies,
length-1 rules (e.g. isMarriedTo(x, y) =⇒ isMarriedTo(y, x)) and length-2 rules (e.g.
isMarriedTo(x, y) ∧ hasChild(y, z) =⇒ hasChild(x, z)).
81

Figure 6-3. An example rule.
6.4.2 Ordinary Rule Inference
The rules learned by previous work [60] contain noisy and incorrect ones which we
eliminated before inference. We also discarded rules which have very low confidence and
support, since processing these rules cannot produce meaningful results. We store the facts
in knowledge bases as triples in database tables.
Ordinary rule inference only uses existing facts inside knowledge bases. It is run
by executing corresponding SQL queries for all rules in parallel using multi-threading,
which is very fast. If a fact can be infered by one or more rules, we must combine the
results from multiple rules. We tested a few fusion approaches, including maximum rule
(choosing the highest score), sum rule (adding all corresponding scores together) and
logistic regression (based on features such as average confidence score and total number of
rules by which the fact is infered). The sum rule works best in validation datasets. Notice
that the confidence score of an infered fact could exceed 1.0, which is allowed since the
confidence scores are only used to rank the candidate answers.
6.4.3 Augmented Rule Inference
Ordinary rule inference has low performance because many body literals of rules are
missing, for knowledge bases are highly incomplete. So in order to increase performance of
rule inference, we use WebQA to find missing literal values of rule bodies and use them to
82

infer missing facts. We follow the query-driven scheme to decide when to use WebQA. For
these literals already existing in knowledge bases, we use them directly to avoid running
expensive WebQA queries. Only for these literals not existing inside knowledge bases, we
choose WebQA to find their values from the Web. Experimental results show AugRI can
achieve better performance than OrdRI.
6.4.3.1 Length-1 rules
An example of the inference process of a single literal is shown in Figure 6-4.
The single-literal processing works for length-1 rules, such as diedIn(x, y) =⇒
wasBornIn(x, y). For a candidate answer y, the confidence score from this rule is
score(wasBornIn(x, y)) = score(diedIn(x, y)) × scorer. If diedIn(x,y) exists inside
knowledge bases, its confidence score is 1. Otherwise, its confidence score is the score
returned by WebQA. scorer is the confidence score of this rule.
Figure 6-4. Single-literal processing.
6.4.3.2 Length-2 rules
The inference process of two literals is shown in Figure 6-5. In Figure 6-5, we first
get a list of candidate y values for the first literal and then for each of the y value, we
execute a single-literal processing step for the second literal. Then all these z values with
83

confidence scores are output for final ranking. Two-literal processing works for length-2
rules.
To calculate the confidence scores of infered facts for length-2 rules, we propose a
method called sum of products. The intuition behind this method is very straight-forward.
For example, for a KBC query <x, hasChild, ?>, we use the rule isMarriedTo(x, y) ∧
hasChild(y, z) =⇒ hasChild(x, z) to infer hasChild(x,z). The rule isMarriedTo(x, y) ∧
hasChild(y, z) =⇒ hasChild(x, z) itself has a confidence score scorer. The
confidence score for hasChild(x,z) generated by this rule is score(isMarriedTo(x, y)) ×
score(hasChild(x, z))× scorer. Then we sum up the confidence scores generated by all the
available intermediate y values by which hasChild(x,z) is infered, and use the sum value as
the confidence score of this infered fact. To fuse results from multiple rules, we follow the
same method in ordinary rule inference.
Figure 6-5. Two-literal processing.
6.4.3.3 Query-driven optimization
Usually a KBC query has only a few true answers (less than 4 in most cases). For a
length-2 rule, if single-literal processing for the first literal generates m candidate answers
and the second one generates n candidate answers in average for each intermediate y
value, then we get m × n candidate answers in total, of which most are wrong answers.
84

Two-literal processing would issue m + 1 WebQA queries for each rule, which is very
time-consuming. Although we use multi-threading to parallelize the rule inference
process, issuing all the available WebQA queries is not efficient. Another disadvantage is
low-confidence results from the first step would generate many incorrect candidate answers
at the second step.
In order to improve KBC performance and system efficiency, we use two parameters
to filter the candidate answers generated by WebQA for the first literal, the confidence
threshold and the number of answers to pass to the second step of two-literal processing.
If the confidence score of a candidate answer for the first literal is smaller than the
threshold, we discard it. And we only pass at most top k answers to the next step. We
learned the best parameters by empirically running experiments with different sets of
parameters. We also terminate some WebQA queries if they have waited very long time
for responses from web servers.
6.5 Evaluation
In this section, we demonstrate the effectiveness and efficiency of our system
through extensive experiments. We first introduce our datasets for training and testing.
Experiments have been conducted to evaluate the KBC performance of our system under
different circumstances. We also discuss the efficiency of the WebQA system and show it
can provide real-time responses to user queries.
For KBC performance, we evaluate the quality of answer rankings. Mean average
precision (MAP) is used as the evaluation metric. For a KBC query, the average precision
is defined as AP = (∑n
k=1 p(k)× r(k))/n, where k is the rank in the sequence of candidate
answers, n is the number of candidate answers, p(k) is the precision at cut-off k in the
ranked list and r(k) is the change in recall from candidate answers k − 1 to k. Averaging
over all queries yields the mean average precision (MAP).
85

6.5.1 Datasets
To evaluate our system, we extracted facts from Yago [11, 72] as training and testing
datasets. Yago [11, 72] is a huge semantic knowledge base, derived from Wikipedia,
WordNet and GeoNames. Currently, Yago has knowledge of more than 10 million entities
(like persons, organizations, cities, etc.) and contains more than 120 million facts about
these entities. The whole Yago knowledge base can be downloaded from Yago website2 .
We consider 8 relations from Yago (diedIn, graduatedFrom, hasAcademicAdvisor,
hasCapital, hasChild, isCitizenOf, isMarriedTo and wasBornIn) for testing our system.
To collect training and testing data, we make the local closed-world assumption, which
assumes if Yago has a non-empty set of objects O for a given subject-relation pair, then O
contains all the ground-truth objects for this subject-relation pair. For each relation, we
randomly sampled 500 subjects and corresponding objects from Yago for training and 100
subjects and corresponding objects for testing. For some relations, there are no rules or
reliable rules available, so we did not conduct rule inference for them.
6.5.2 WebQA
Logistic regression was chosen as the classification method for WebQA. To balance
training datasets, we tested both resampling and cost-weighting and selected the
better one for different relations separately. We first evaluate the KBC performance of
WebQA with different numbers of questions selected by Algorithm 6.1. Then we show
experimental results for the overall KBC performance of our system for 8 relations. These
experiments used all snippets crawled by searching selected questions on the Web. Lastly,
we conducted experiments to examine the performance of WebQA with top snippets
selected by query-driven snippet filtering.
2 http://www.mpi-inf.mpg.de/departments/databases-and-information-systems/research/yago-naga/yago/downloads/.
86

Figure 6-6. The KBC performance results for three relations with different numbers ofquestions. k is the number of selected questions. The KBC performance ismeasured by MAP.
6.5.2.1 Question template selection
As discussed earlier, issuing all possible questions for each KBC query is not efficient
and sometimes deteriorates the answer ranking quality. We designed Algorithm 6.1, the
greedy selection algorithm, to select a few questions which can achieve considerably good
performance compared to using all possible questions. For experiments, we designed
several question templates for each relation and run the greedy learning algorithm with
different numbers of questions. For demonstration, we present experimental results for
three relations (hasChild, isCitizenOf and isMarriedTo) with typical results in Figure 6-6.
For relation isMarriedTo, the KBC performance of our system boosts from 0.45
to 0.52 when the number of questions increases from 1 to 3, then decreases with more
questions. For relation isCitizenOf, the KBC performance increases from 0.35 to 0.45 when
the number of questions grows from 1 to 3, then keeps unchanged with more questions.
87

Table 6-2. Overall KBC performance for 8 relations with all snippets. Comparisonbetween our system and previous work [1] (denoted as West in the table) arealso explained. MAP (mean average precision) measures the KBC performance.Numbers in bold indicate the best results for individual relations.
Relation Perf. (Ours) Question # (Ours) Perf. (West) Question # (West)wasBornIn 0.75 2 0.67 8hasChild 0.24 2 0.18 8
isMarriedTo 0.52 3 0.50 8isCitizenOf 0.45 3 0.93 32
diedIn 0.43 3 N/A N/AhasCapital 0.52 2 N/A N/A
graduatedFrom 0.25 2 N/A N/AhasAcademicAdvisor 0.21 2 N/A N/A
For relation hasChild, the best KBC performance was achieved at 0.24 with 2 questions.
After adding more questions, the performance gradually decreases to 0.22.
As we explained earlier, when k = 1, the greedy algorithm selects the question
template with highest performance. In Figure 6-6, we can see multiple questions have
higher MAP than the best single question. Another important observation from the results
is using all questions does not guarantee to improve KBC performance compared to a
few questions. For relation isMarriedTo and hasChild, the performance with 6 questions
are lower than 2 or 3 questions. The reason is with more questions, especially low-quality
questions, false answers will be more likely ranked top in the ranked list of candidate
answers. For all 8 relations we examined, with only two or three questions selected by the
greedy algorithm, we can achieve the highest KBC performance.
The experimental results in Figure 6-6 demonstrate our greedy algorithm can
effectively select very few questions to achieve high KBC performance compared to using
all possible questions. And it is significant because we can use much fewer questions
for KBC and hence improve running time performance of the whole pipeline with fewer
questions and fewer snippets crawled from them.
88

6.5.2.2 Overall performance
For each relation, we discovered the smallest set of question templates which can
achieve the highest KBC performance based on experiments shown above. Using these sets
of question templates, we conducted experiments to evaluate WebQA for all 8 relations.
These experiments used all snippets crawled from the Web.
West et al. designed their own question templates and exploited an in-house question
answering system [1]. Their system is the only system found by us, which used web-based
question answering for knowledge base completion. We compare the KBC performance
of our system with their system for 4 relations, wasBornIn, hasChild, isMarriedTo and
isCitizenOf. The results are demonstrated in Table 6-2.
For three relations wasBornIn, hasChild and isMarriedTo, our system can achieve
better performance than previous work [1] with much fewer questions, as shown in
Table 6-2. This is due to a few reasons. First, we design better templates than previous
work as discussed above. Second, we fuse information from both the unstructured text
and structured knowledge bases to design features, while previous work only uses textual
information to rank candidate answers.
Only for relation isCitizenOf, our system fails to match previous work. The possible
reason is, previous work [1] checks facts for top 100K entities searched by Google, while
we randomly select 100 subject entities from millions of entities in Yago, which means
these entities we examined could be mostly rare entities, which are not appearing in the
Internet as frequently as those in previous work [1]. As we found out in experiments, the
major problem causing low KBC performance for isCitizenOf in WebQA is the missing
citizenship information for rare entities.
We have demonstrated through experiments that our system can achieve good
performance with much fewer questions than previous work [1]. However, there are
still some issues with web-based question answering. First, popular entities have more
89

Table 6-3. KBC performance with snippet filtering for different numbers of snippets. Theexperiments are run on our system evaluated with 10 snippets, 20 snippets, 30snippets and all snippets. Performance of previous work [1] is denoted as West.Performance is measured by MAP.
Relation 10 snippets 20 snippets 30 snippets All snippets WestwasBornIn 0.70 0.71 0.70 0.75 0.67hasChild 0.21 0.21 0.24 0.24 0.18
isMarriedTo 0.48 0.50 0.51 0.52 0.50isCitizenOf 0.39 0.40 0.41 0.45 0.93
diedIn 0.31 0.38 0.40 0.43 N/AhasCapital 0.45 0.48 0.51 0.52 N/A
graduatedFrom 0.19 0.22 0.22 0.25 N/AhasAcademicAdvisor 0.10 0.16 0.18 0.21 N/A
useful information crawled from the Web than rare entities. Second, web-based question
answering works poorly at some relations, such as graduatedFrom and hasChild.
6.5.2.3 Performance with snippet filtering
To reduce the number of snippets for processing, we apply query-driven snippet
filtering to select useful snippets which most likely contain relevant information to queries.
While improving system efficiency, we want to demonstrate through experiments, selecting
a subset of the snippets by query-driven snippet filtering does not cause severe loss of
answer ranking quality. So we conducted a few experiments with different numbers of
snippets and compare their KBC performance with experiments using all snippets and
previous work [1]. The experiments here used the same sets of questions templates as the
experiments above. The results are shown in Table 6-3.
For all the 8 relations we tested, the performance of our system using snippet filtering
with 20 or 30 snippets decreases very little compared to using all snippets, usually with
less than 0.04 loss in MAP. And for relation hasChild, our system achieves the same MAP
with 30 snippets as all snippets. Compared to previous work [1], our system still achieves
better performance for relation wasBornIn, isMarriedTo and hasChild after using snippet
filtering. It’s safe to say our system can still achieve better performance than previous
work [1] after snippet filtering.
90

6.5.2.4 Efficiency
In our WebQA pipeline, question generation and answer ranking are very fast, usually
costing only a few milliseconds. The bottleneck of our system is data collection and
answer extraction, which involve web searches and server inquiries. Compared to previous
work [1, 59], WebQA has two advantages. First, WebQA needs much fewer questions to
achieve high KBC performance than previous work [1]. Second, we conduct query-driven
snippet filtering to select only a small subset of all snippets to reduce the workload of
entity linking.
A sequential pipeline without parallelization usually costs a few minutes to finish.
So we employed multithreading to parallelize snippet crawling and entity linking, in
order to reduce the time waiting for responses from search engines and web servers. A
parallelized pipeline achieves about 10x speedups in terms of total running time compared
to a sequential pipeline. However, parallelization alone cannot provide real-time responses
to user queries, because too many connections are maintained for hundreds of snippets
and web servers process many queries from other users simultaneously. Thus, we conduct
query-driven snippet filtering to effectively reduce the number of snippets while maintain
high KBC performance.
To evaulate the running time of our pipeline, the experiments were run on a single
machine with a 3.1GHZ four-core CPU and 4GB memory. The running time varies
with multiple environment factors such as network congestion and server speed. So we
calculated average running time through extensive experiments with different queries.
The number of questions has an important impact on the running time of our
pipeline, since it crawls more snippets with more questions. Experimental results for
evaluating the running time of our system with different numbers of questions for relation
wasBornIn with 30 snippets for each question are shown in Figure 6-7. The results for
other relations are smiliar to wasBornIn. From Figure 6-7, the running time of WebQA
grows almost linearly as the number of questions increases. Since our system needs much
91

Figure 6-7. The average running time of WebQA with different numbers of questions forrelation wasBornIn.
fewer questions compared to previous work [1], it is definitely more efficient under the
same circumstances.
Query-driven snippet filtering is conducted to further improve the running time
by reducing the number of snippets. Experimental results of our system using snippet
filtering with different numbers of snippets are shown in Table 6-4. With 3 questions, we
need to crawl up to 3× 50 = 150 snippets per query. Using snippet filteirng, we can reduce
the number of snippets from 150 to 20/30 without sacrificing too much quality as shown in
Table 6-4. The running time is about 3 seconds when the number of snippets decreases to
20/30, which is less than 25% of the time when using all snippets. In conclusion, WebQA
can provide real-time responses to user queries on-the-fly, since it only spends a few
seconds for each query.
Table 6-4. Average running time of our system using query-driven snippet filtering forrelation wasBornIn with 3 questions.
Snippet number 20 30 50 150Time (seconds) 3.1 3.2 4.1 12.5
92

Table 6-5. KBC performance of OrdRI vs AugRI (measured by MAP).OrdRI AugRI
wasBornIn 0.12 0.49hasChild 0.22 0.24
isCitizenOf 0.08 0.53diedIn 0.20 0.30
graduatedFrom 0.06 0.17isMarriedTo 0.96 0.96
Table 6-6. KBC performance of individual approaches and ensemble fusion (measured byMAP). WebQA is conducted with 30 snippets.
WebQA AugRI WebQA + AugRIwasBornIn 0.70 0.49 0.82hasChild 0.24 0.24 0.40
isCitizenOf 0.41 0.53 0.55diedIn 0.40 0.30 0.47
graduatedFrom 0.22 0.17 0.30isMarriedTo 0.51 0.96 0.96
hasAcademicAdvisor 0.18 N/A N/AhasCapital 0.51 N/A N/A
6.5.3 Rule Inference
We have conducted a series of experiments for two different rule inference systems,
ordinary rule inference (OrdRI) and augmented rule inference (AugRI) for 6 relations. The
experimental results are shown in Table 6-5. As shown in Table 6-5, we can see ordinary
rule inference (OrdRI) has low MAP for 5 relations. Only for relation isMarriedTo,
OrdRI gets the same performance as AugRI. The reason is knowledge bases are highly
incomplete, hence many literals in rule bodies cannot are missing. And after using WebQA
to augment rule inference, we can see improvements of performance over all relations,
especially large improvements for relation graduatedFrom (200%+), diedIn (50%+),
isCitizenOf (550%+) and wasBornIn (300%+). The performance of AugRI is still not high
enough for two reasons. First, knowledge bases are highly incomplete. Second, WebQA
is not very reliable for some relations and hence would generate low-confidence candidate
answers.
93

6.5.4 Ensemble Fusion
We have conducted experiments to compare the KBC performance of WebQA, AugRI
and ensemble fusion of WebQA and AugRI (WebQA + AugRI). The experimental results
are shown in Table 6-6. The ensemble fusion approach achieves higher performance than
WebQA and rule inference for most relations. For relation diedIn and graduatedFrom, the
KBC performance of ensemble fusion improved by over 0.07 MAP compared to WebQA
and AugRI. For relation wasBornIn, ensemble fusion improved KBC performance by
0.12. For relation hasChild, ensemble fusion achieved nearly 70% improvement of KBC
performance than WebQA and AugRI. In conclusion, multimodal fusion generates very
high KBC performance for many relations by exploiting the complementary relation
between WebQA and AugRI.
We use multi-threading to parallelize the rule inference and web-based question
answering. Our whole system runs very fast in average (e.g. costing only 4̃-5 seconds for
relation isCitizenOf), because threshold filtering effectively avoids unnecessary WebQA
operations. However, for some queries issuing a lot of WebQA operations, it could take
dozens of seconds to finish in worst cases.
94

CHAPTER 7CONCLUSIONS
This dissertation focuses on utilizing different kinds of data by multimodal fusion to
improve performance and providing scalability and high efficiency for different tasks. I
introduce multimodal datasets and multimodal fusion for different applications, including
word sense disambiguation, information retrieval and knowledge base completion.
Multimodal fusion is the use of algorithms to combine information from different kinds of
data with the purpose of achieving better performance than single-modality approaches.
Multimodal datasets studied in this dissertation include images, unstructured text and
structured facts from knowledge bases.
Scalability and efficiency are two important aspects in this dissertation. We first
present the streaming processing system for fact extraction on terabytes of text data,
which can efficiently finish in less than one hour based on two layers of filters on a single
machine with limited computation resources. Then we introduce how to implement a
scalable image retrieval system on top of Hadoop to efficiently process millions of images.
We design two distributed clustering algorithms using Hadoop and Map-Reduce, which
can run much faster than previous work. We also use query-driven optimization techniques
to improve KBC system efficiency and provide fast responses to user queries.
We propose a theory about multimodal fusion based on the observation of the
correlative and complementary relations between different modalities. With correlative
and complementary relations, multimodal data can either provide additional information
or emphasize the same information, hence multimoal fusion can utilize these two relations
to improve task performance. Previous work usually focus on exploiting the correlation
between different modalities at the feature level and ignore the complementary relation
between different modalities. In this dissertation, I discuss multimodal fusion from a
deeper perspective, explain why multimodal fusion works and analyze how to improve
95

performance for different tasks based on correlative and complementary relations on
multimodal datasets.
We present the multimodal ensemble fusion model for word sense disambiguation and
information retrieval as an example to explain our theory. The multimodal datasets for
these two applications display mostly the complementary relation between images and
text. And image processing and text processing are also complementary to each other.
Our multimodal ensemble fusion model can utilze the complementary relation between
images and text to achieve better performance than image-only and text-only approaches.
We design a query-driven system with multimodal fusion for knowledge base
completion by combining web-based question answering and rule inference to fuse
unstructured text and structured knowledge. In different phases of the pipeline,
information from multiple modalities are fused to exploit both complementary and
correlative relations of multimodal data. The web-based question answering applies early
fusion to combine features extracted from both the unstrcutured Web and structured
knowledge bases. We design novel multimodal features and an effective question template
selection algorithm for question answering, which can achieve better performance with
much fewer questions than previous work. We implement the query-driven snippet filtering
algorithm, which can greatly reduce the number of snippets for processing and reduce
the running time. We build an augmented rule inference system utilizing web-based
question answering, pre-learned logical rules from knowledge bases and existing facts in
knowledge bases to infer new facts for KBC queries. Query-driven optimization techniques
are used to reduce the runtime of augmented rule inference. Then late fusion approaches
are employed to combine rule inference and web-based question answering to further
improve knowledge base completion performance. Query-driven optimization techniques
are employed to improve the running time performance of the whole system pipeline and
provide fast responses to user queries.
96

REFERENCES
[1] R. West, E. Gabrilovich, K. Murphy, S. Sun, R. Gupta, and D. Lin, “Knowledgebase completion via search-based question answering,” in Proceedings of the 23rdinternational conference on World wide web. ACM, 2014, pp. 515–526.
[2] “Uiuc-isd dataset,” http://vision.cs.uiuc.edu/isd/, accessed: 2017-04-05.
[3] “Wikipedia,” https://www.wikipedia.org/, accessed: 2017-04-05.
[4] P. K. Atrey, M. A. Hossain, A. El Saddik, and M. S. Kankanhalli, “Multimodal fusionfor multimedia analysis: a survey,” Multimedia systems, vol. 16, no. 6, pp. 345–379,2010.
[5] J. R. Frank, M. Kleiman-Weiner, D. A. Roberts, F. Niu, C. Zhang, C. Ré, andI. Soboroff, “Building an entity-centric stream filtering test collection for trec 2012,”DTIC Document, Tech. Rep., 2012.
[6] R. Navigli, “Word sense disambiguation: A survey,” ACM Computing Surveys(CSUR), vol. 41, no. 2, p. 10, 2009.
[7] E. Agirre and P. Edmonds, Word sense disambiguation: Algorithms and applications.Springer Science & Business Media, 2007, vol. 33.
[8] R. Datta, D. Joshi, J. Li, and J. Z. Wang, “Image retrieval: Ideas, influences, andtrends of the new age,” ACM Computing Surveys (Csur), vol. 40, no. 2, p. 5, 2008.
[9] K. Bollacker, C. Evans, P. Paritosh, T. Sturge, and J. Taylor, “Freebase: acollaboratively created graph database for structuring human knowledge,” in Proceed-ings of the 2008 ACM SIGMOD international conference on Management of data.AcM, 2008, pp. 1247–1250.
[10] A. Carlson, J. Betteridge, B. Kisiel, B. Settles, E. R. Hruschka Jr, and T. M.Mitchell, “Toward an architecture for never-ending language learning.” in AAAI,vol. 5, 2010, p. 3.
[11] F. M. Suchanek, G. Kasneci, and G. Weikum, “Yago: a core of semantic knowledge,”in Proceedings of the 16th international conference on World Wide Web. ACM, 2007,pp. 697–706.
[12] J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng, “Multimodal deeplearning,” in Proceedings of the 28th international conference on machine learning(ICML-11), 2011, pp. 689–696.
[13] N. Srivastava and R. R. Salakhutdinov, “Multimodal learning with deep boltzmannmachines,” in Advances in neural information processing systems, 2012, pp. 2222–2230.
97

[14] W. May, S. Fidler, A. Fazly, S. Dickinson, and S. Stevenson, “Unsuperviseddisambiguation of image captions,” in Proceedings of the First Joint Conferenceon Lexical and Computational Semantics-Volume 1: Proceedings of the main con-ference and the shared task, and Volume 2: Proceedings of the Sixth InternationalWorkshop on Semantic Evaluation. Association for Computational Linguistics, 2012,pp. 85–89.
[15] K. Saenko and T. Darrell, “Filtering abstract senses from image search results,” inAdvances in Neural Information Processing Systems, 2009, pp. 1589–1597.
[16] D. Yarowsky, “Unsupervised word sense disambiguation rivaling supervised methods,”in Proceedings of the 33rd annual meeting on Association for Computational Linguis-tics. Association for Computational Linguistics, 1995, pp. 189–196.
[17] N. Rasiwasia, J. Costa Pereira, E. Coviello, G. Doyle, G. R. Lanckriet, R. Levy, andN. Vasconcelos, “A new approach to cross-modal multimedia retrieval,” in Proceedingsof the 18th ACM international conference on Multimedia. ACM, 2010, pp. 251–260.
[18] Y. Wu, E. Y. Chang, K. C.-C. Chang, and J. R. Smith, “Optimal multimodal fusionfor multimedia data analysis,” in Proceedings of the 12th annual ACM internationalconference on Multimedia. ACM, 2004, pp. 572–579.
[19] Q. Zhu, M.-C. Yeh, and K.-T. Cheng, “Multimodal fusion using learned text conceptsfor image categorization,” in Proceedings of the 14th ACM international conference onMultimedia. ACM, 2006, pp. 211–220.
[20] E. Bruno, J. Kludas, and S. Marchand-Maillet, “Combining multimodal preferencesfor multimedia information retrieval,” in Proceedings of the international workshop onWorkshop on multimedia information retrieval. ACM, 2007, pp. 71–78.
[21] S. Wei, Y. Zhao, Z. Zhu, and N. Liu, “Multimodal fusion for video search reranking,”IEEE Transactions on Knowledge and Data Engineering, vol. 22, no. 8, pp. 1191–1199, 2010.
[22] L. Yang and D. Neagu, “Toxicity risk assessment from heterogeneous uncertain datawith possibility-probability distribution,” in Fuzzy Systems (FUZZ), 2013 IEEEInternational Conference on. IEEE, 2013, pp. 1–8.
[23] L. Yang, D. Neagu, M. T. Cronin, M. Hewitt, S. J. Enoch, J. C. Madden, andK. Przybylak, “Towards a fuzzy expert system on toxicological data qualityassessment,” Molecular Informatics, vol. 32, no. 1, pp. 65–78, 2013.
[24] P. McNamee, V. Stoyanov, J. Mayfield, T. Finin, T. Oates, T. Xu, D. W. Oard, andD. Lawrie, “Hltcoe participation at tac 2012: Entity linking and cold start knowledgebase construction.” in TAC, 2012.
98

[25] J. Dalton and L. Dietz, “Bi-directional linkability from wikipedia to documents andback again: Umass at trec 2012 knowledge base acceleration track,” DTIC Document,Tech. Rep., 2012.
[26] L. Bonnefoy, V. Bouvier, and P. Bellot, “A weakly-supervised detection of entitycentral documents in a stream,” in Proceedings of the 36th international ACM SIGIRconference on Research and development in information retrieval. ACM, 2013, pp.769–772.
[27] K. Balog and H. Ramampiaro, “Cumulative citation recommendation: Classificationvs. ranking,” in Proceedings of the 36th international ACM SIGIR conference onResearch and development in information retrieval. ACM, 2013, pp. 941–944.
[28] H. Ji and R. Grishman, “Knowledge base population: Successful approaches andchallenges,” in Proceedings of the 49th Annual Meeting of the Association for Com-putational Linguistics: Human Language Technologies-Volume 1. Association forComputational Linguistics, 2011, pp. 1148–1158.
[29] J. Ellis, “Tac kbp 2013 slot descriptions,” TAC KBP, 2013.
[30] M. S. Nia, C. E. Grant, Y. Peng, D. Z. Wang, and M. Petrovic, “Streaming factextraction for wikipedia entities at web-scale.” in FLAIRS Conference, 2014.
[31] M. S. Nia, C. Grant, Y. Peng, D. Z. Wang, and M. Petrovic, “University of floridaknowledge base acceleration notebook,” The Twenty-Second Text REtrieval Confer-ence (TREC 2013).
[32] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scalehierarchical image database,” in Computer Vision and Pattern Recognition, 2009.CVPR 2009. IEEE Conference on. IEEE, 2009, pp. 248–255.
[33] J. Sivic, A. Zisserman et al., “Video google: A text retrieval approach to objectmatching in videos.” in iccv, vol. 2, no. 1470, 2003, pp. 1470–1477.
[34] J. Philbin, O. Chum, M. Isard, J. Sivic, and A. Zisserman, “Object retrieval withlarge vocabularies and fast spatial matching,” in Computer Vision and PatternRecognition, 2007. CVPR’07. IEEE Conference on. IEEE, 2007, pp. 1–8.
[35] L. Fei-Fei and P. Perona, “A bayesian hierarchical model for learning natural scenecategories,” in Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEEComputer Society Conference on, vol. 2. IEEE, 2005, pp. 524–531.
[36] D. G. Lowe, “Object recognition from local scale-invariant features,” in Computervision, 1999. The proceedings of the seventh IEEE international conference on, vol. 2.Ieee, 1999, pp. 1150–1157.
[37] “Apache hadoop,” https://hadoop.apache.org/, accessed: 2017-04-05.
[38] “Apache mahout,” https://mahout.apache.org/, accessed: 2017-04-05.
99

[39] “Apache solr,” http://lucene.apache.org/solr/, accessed: 2017-04-05.
[40] “Apache lucene,” http://lucene.apache.org/, accessed: 2017-04-05.
[41] F. Perronnin, Y. Liu, J. Sánchez, and H. Poirier, “Large-scale image retrieval withcompressed fisher vectors,” in Computer Vision and Pattern Recognition (CVPR),2010 IEEE Conference on. IEEE, 2010, pp. 3384–3391.
[42] J. Deng, A. C. Berg, and L. Fei-Fei, “Hierarchical semantic indexing for large scaleimage retrieval,” in Computer Vision and Pattern Recognition (CVPR), 2011 IEEEConference on. IEEE, 2011, pp. 785–792.
[43] C. Gu and Y. Gao, “A content-based image retrieval system based on hadoopand lucene,” in Cloud and Green Computing (CGC), 2012 Second InternationalConference on. IEEE, 2012, pp. 684–687.
[44] D. Yin and D. Liu, “Content-based image retrial based on hadoop,” MathematicalProblems in Engineering, vol. 2013, 2013.
[45] W. Premchaiswadi, A. Tungkatsathan, S. Intarasema, and N. Premchaiswadi,“Improving performance of content-based image retrieval schemes using hadoopmapreduce,” in High Performance Computing and Simulation (HPCS), 2013 Interna-tional Conference on. IEEE, 2013, pp. 615–620.
[46] R. K. Grace, R. Manimegalai, and S. S. Kumar, “Medical image retrieval systemin grid using hadoop framework,” in Computational Science and ComputationalIntelligence (CSCI), 2014 International Conference on, vol. 1. IEEE, 2014, pp.144–148.
[47] M. Lux and S. A. Chatzichristofis, “Lire: lucene image retrieval: an extensible javacbir library,” in Proceedings of the 16th ACM international conference on Multimedia.ACM, 2008, pp. 1085–1088.
[48] C. Silpa-Anan and R. Hartley, “Optimised kd-trees for fast image descriptormatching,” in Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEEConference on. IEEE, 2008, pp. 1–8.
[49] M. Muja and D. Lowe, “Fast approximate nearest neighbors with automaticalgorithm configuration,” in VISAPP, 2009.
[50] M. Muja and D. G. Lowe, “Scalable nearest neighbor algorithms for high dimensionaldata,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36,no. 11, pp. 2227–2240, 2014.
[51] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang,A. Karpathy, A. Khosla, M. Bernstein et al., “Imagenet large scale visual recognitionchallenge,” International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252,2015.
100

[52] J. Yang, Y.-G. Jiang, A. G. Hauptmann, and C.-W. Ngo, “Evaluatingbag-of-visual-words representations in scene classification,” in Proceedings of theinternational workshop on Workshop on multimedia information retrieval. ACM,2007, pp. 197–206.
[53] C. Cortes and V. Vapnik, “Support-vector networks,” Machine learning, vol. 20, no. 3,pp. 273–297, 1995.
[54] M. Richardson and P. Domingos, “Markov logic networks,” Machine learning, vol. 62,no. 1, pp. 107–136, 2006.
[55] H. Tong, C. Faloutsos, and J.-Y. Pan, “Fast random walk with restart and itsapplications,” 2006.
[56] N. Lao, T. Mitchell, and W. W. Cohen, “Random walk inference and learning in alarge scale knowledge base,” in Proceedings of the Conference on Empirical Methodsin Natural Language Processing. Association for Computational Linguistics, 2011,pp. 529–539.
[57] M. Nickel, V. Tresp, and H.-P. Kriegel, “A three-way model for collective learning onmulti-relational data,” in Proceedings of the 28th international conference on machinelearning (ICML-11), 2011, pp. 809–816.
[58] Y. Peng, X. Zhou, D. Z. Wang, I. Patwa, D. Gong, and C. Fang, “Multimodalensemble fusion for disambiguation and retrieval,” IEEE MultiMedia, 2016.
[59] H. Sun, H. Ma, W.-t. Yih, C.-T. Tsai, J. Liu, and M.-W. Chang, “Open domainquestion answering via semantic enrichment,” in Proceedings of the 24th InternationalConference on World Wide Web. ACM, 2015, pp. 1045–1055.
[60] Y. Chen, S. Goldberg, D. Z. Wang, and S. S. Johri, “Ontological pathfinding,” inProceedings of the 2016 International Conference on Management of Data. ACM,2016, pp. 835–846.
[61] H. Ji, R. Grishman, H. T. Dang, K. Griffitt, and J. Ellis, “Overview of the tac 2010knowledge base population track,” in Third Text Analysis Conference (TAC 2010),vol. 3, no. 2, 2010, pp. 3–3.
[62] G. Weikum and M. Theobald, “From information to knowledge: harvesting entitiesand relationships from web sources,” in Proceedings of the twenty-ninth ACMSIGMOD-SIGACT-SIGART symposium on Principles of database systems. ACM,2010, pp. 65–76.
[63] J. R. Frank, S. J. Bauer, M. Kleiman-Weiner, D. A. Roberts, N. Tripuraneni,C. Zhang, C. Re, E. Voorhees, and I. Soboroff, “Evaluating stream filtering for entityprofile updates for trec 2013 (kba track overview),” DTIC Document, Tech. Rep.,2013.
101

[64] A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko, “Translatingembeddings for modeling multi-relational data,” in Advances in neural informationprocessing systems, 2013, pp. 2787–2795.
[65] R. Socher, D. Chen, C. D. Manning, and A. Ng, “Reasoning with neural tensornetworks for knowledge base completion,” in Advances in neural information process-ing systems, 2013, pp. 926–934.
[66] E. M. Voorhees et al., “The trec-8 question answering track report.” in Trec, vol. 99,1999, pp. 77–82.
[67] E. Brill, J. J. Lin, M. Banko, S. T. Dumais, A. Y. Ng et al., “Data-intensive questionanswering.” in TREC, vol. 56, 2001, p. 90.
[68] W. Shen, J. Wang, and J. Han, “Entity linking with a knowledge base: Issues,techniques, and solutions,” IEEE Transactions on Knowledge and Data Engineering,vol. 27, no. 2, pp. 443–460, 2015.
[69] P. Ferragina and U. Scaiella, “Fast and accurate annotation of short texts withwikipedia pages,” IEEE software, vol. 29, no. 1, pp. 70–75, 2012.
[70] “Tagme,” https://sobigdata.d4science.org/web/tagme/, accessed: 2017-04-05.
[71] Y. Peng, D. Z. Wang, I. Patwa, D. Gong, and C. V. Fang, “Probabilistic ensemblefusion for multimodal word sense disambiguation,” in Multimedia (ISM), 2015 IEEEInternational Symposium on. IEEE, 2015, pp. 172–177.
[72] “Yago official website,” http://www.mpi-inf.mpg.de/departments/databases-and-information-systems/research/yago-naga/yago/, accessed: 2017-04-05.
102

BIOGRAPHICAL SKETCH
Yang Peng received his Bachelor of Science degree in computer science at Nanjing
University, Nanjing, China in June 2012. He has been pursuing Ph.D. degree in computer
science at University of Florida since Fall 2012. His research interests involve Data
Science, Big Data, Knowledge Bases and Multimodal Fusion. He has worked on a few
projects on large data processing, information extraction, information retrieval, word
sense disambiguation and knowledge base completion. He has served as a session chair for
IEEE ISM, a reviewer for WWW and an external reviewer for SIGMOD, VLDB, VLDB
Journal, IJCAI, ICDE, and so on. He also worked as a software engineering intern at
Google Photos team in Fall 2016.
103






















![with Holistic 3D Motion Understanding arXiv:1806.10556v2 ... · arXiv:1806.10556v2 [cs.CV] 15 Aug 2018. 2 Zhenheng Yang Peng Wang Yang Wang Wei Xu Ram Nevatia ... a very far object](https://img.pdfslide.us/doc/110x75/5f3265597b968e10975ab9ce/with-holistic-3d-motion-understanding-arxiv180610556v2-arxiv180610556v2.jpg)






