Embed Size (px)
Citation preview

DRBD é um amigo!

What is DRBD?
• DRBD is a block device designed as a building block to form HA clusters.
• This is done by mirroring a whole block device via an assigned network.
• DRBD can be understand as network based RAID1.
• T uses DRBD-8.2, S uses DRBD-8.4(may change in the future).
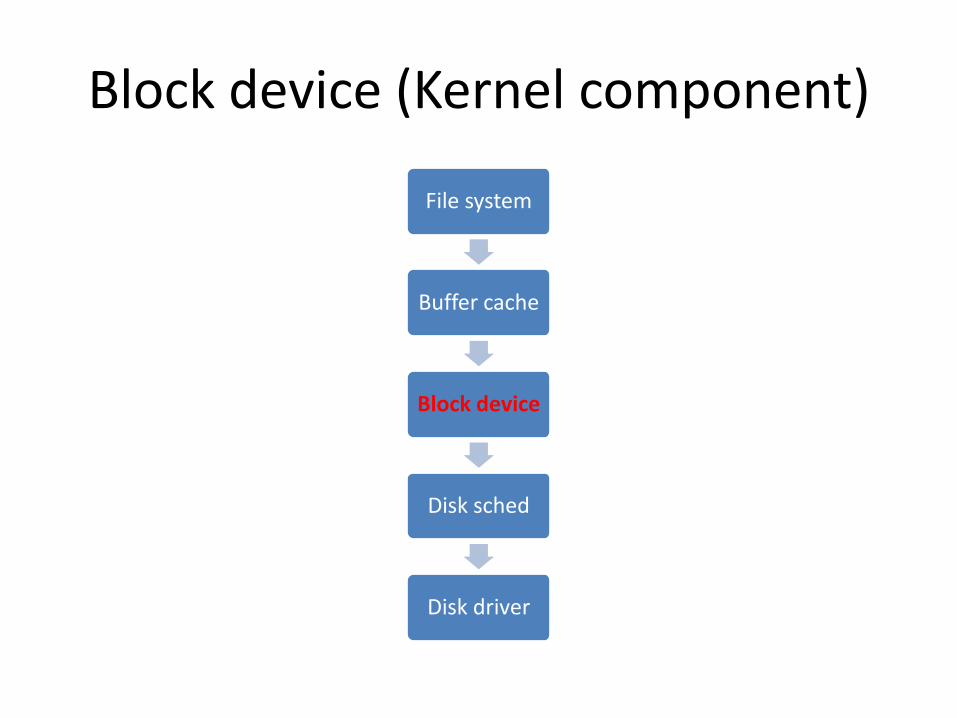
Block device (Kernel component)
File system
Buffer cache
Block device
Disk sched
Disk driver
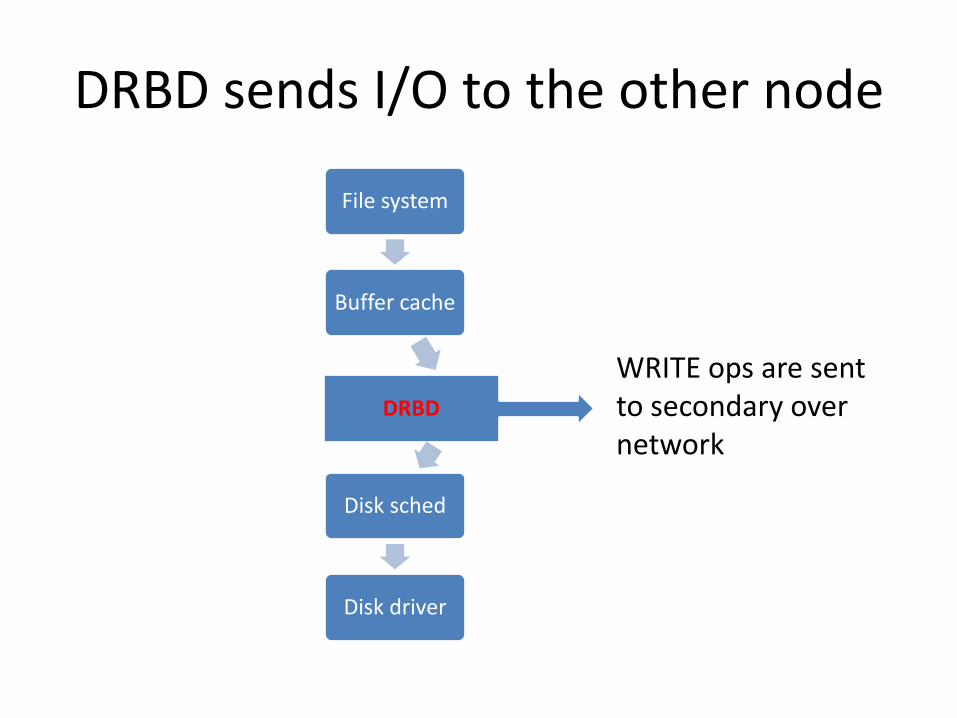
DRBD sends I/O to the other node
File system
Buffer cache
DRBD
Disk sched
Disk driver
WRITE ops are sent to secondary over network
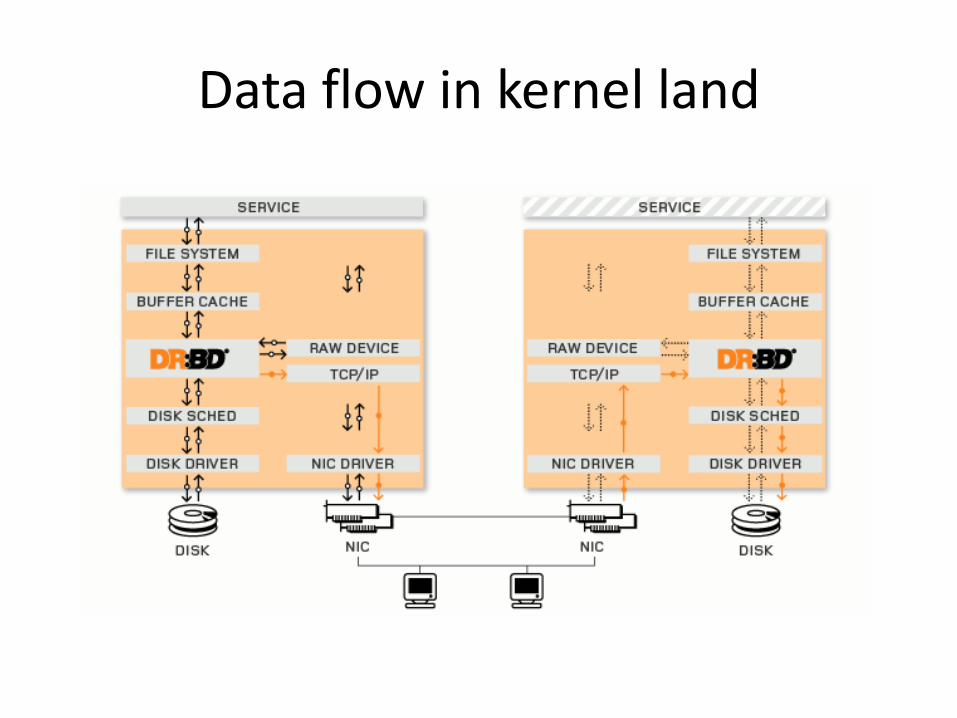
Data flow in kernel land

How to set up DRBD
• Prepare DRBD partitions
• Create setup files/etc/drbd.conf (DRBD-8.2)/etc/drbd.d/global_common.conf (DRBD-8.4)/etc/drbd.d/r0.res,r1.res (DRBD-8.4)
• Start DRBD sync

DRBD settings
• In DRBD-8.2, all the settings are in /etc/drbd.conf
• In DRBD-8.4, global settings in /etc/drbd.d/global_common.confresource level settings in /etc/drbd.d/r<N>.res
• Sample: http://www.drbd.org/users-guide/re-drbdconf.html
• HA1 and HA2 have the identical DRBD config files• Usage-count (always no)• Protocol (C WRITE completes when reached the other node as
well)• Sync rate (100MB/sec for sync no need for 10Gb NIC)• Partition name (device minor # for /dev/drbdN)• Node name / IP address / port number

Sampe drbd.conf (1)
• global {• usage-count no;• }• common {• net {• protocol C;• }• syncer {• rate 100M;• }• }

Sample drbd.conf (2)
• resource r0 {• protocol C;• on Machine-HA1 { (must match what “uname –n” says on HA1)• device /dev/drbd1;• disk /dev/disk/by-label/XX;• address 10.0.128.17:7788;• }• on Machine-HA2 { (must match what “uname –n” says on HA2)• device /dev/drbd1;• disk /dev/disk/by-label/XX;• address 10.0.128.18:7788;• }• }
• [root@Machine-HA2 ~]# uname -n• Machine-HA2• [root@Machine-HA2 ~]#

Resource and Role
• In DRBD, every resource (partition) has a role, which may be primary or secondary.
• A primary DRBD device can be used for any read/write operations.
• A DRBD secondary device can NOT be used for any read/write operations.
• Secondary only receives WRITEs from primary.

Connection state
• DRBD always uses bond1HA1: 10.0.128.17 (ping drbd1)HA2: 10.0.128.18 (ping drbd2)

Monitor DRBD (1)Healthy state
Shutdown bond1

Monitor DRBD (2)
Enabled bond1 again
DRBD became WFC status (Waiting For Connection)

Nothing can separate DRBD

Nada pode separar DRBD

What causes DRBD problems
There are 3 types of problems.
1. Network error (bond1)
Outdated
2. Disk error (disk error or filesystem error)
Diskless
3. Role change without sync(typically caused by multiple host reboots)
Inconsistent

1. Network problem
• When bond1 stops working between HA1 and HA2, DRBD devices on standby node becomes Outdated
How to fix?
• Fix the network issue at first.
• Then DRBD will fix automatically.
• Without heartbeat, you may need manual intervention.

Healthy State

Bond1 stopped (ifdown bond1)
CS (connection Status) becomes WFConnection (Waiting For Connection).
ST (Status) becomes Unknown on peer side.
DS (Disk Status) becomes Outdated on secondary devices.

How to fix
• Find where the problem is. It can be bond1 on HA1 or bond1 on HA2, or the network cable.
• Fix the network issue.
• Then the DRBD problem will be fixed automatically.
• If heartbeat is NOT running, DRBD may not be fixed automatically.

Disk I/O error on secondary
• DRBD device will be Detached automatically upon disk error.
• drbd.confResource r0 {
disk {on-io-error detach;
}}

Disk I/O error on secondary
• Upon disk error, drbdadm detach <res> will run.
Secondary devices become Diskless state. After fixing the disk issue,
You need to attach drbdadm attach all
If the internal data on the disk is broken, sync will run from UpToDate
device to the peer.

• Fix the disk issue at first.
• Then run drbdadm attach all
• Sync may run.
Disk I/O error on secondary

Disk I/O error on primary
• If disk I/O error happened on primary, Primary DRBD devices become Diskless.

Disk I/O error on primary• Fix the disk issue at first. Then run
drbdadm attach all on the bad node.
• Sync will run from UpToDate (secondary) to Inconsistent (Primary).

• Attach/Detach attaches/detaches lower disks
• Connect/Disconnect connect-to/disconnect-from peer node
• Primary/Secondary define the role of resource
• Invalidate invalidate the data
• Pre-DRBD-8.4
drbdadm -- --discard-my-data connect <res>DRBD-8.4
drbdadm connect --discard-my-data <res> discard data on the resource

How to check if split-brain happens
• Once SB happens, you seeSplit-Brain detected, dropping connection!In /var/log/messages
• When SB happens, at least one node becomes StandAlone. The peer can be WFConnectionor StandAlone too.
• If SB happens, you need to discard data on one node.

Sample plan to fix SB (1)
1. Take hostbackup
2. Identify the bad host
3. Identify which are primary and secondary (DRBD)
4. Stop DBservice heartbeat stop (HA1/HA2)make sure DRBD partitions are not mounted

Sample plan to fix SB (2)
• drbdadm disconnect all (HA1 / HA2)
• drbdadm secondary all (HA1 / HA2)
• drbdadm disconnect all (HA1 / HA2)
• drbdadm -- --discard-my-data connect all(only on bad host)
• drbdadm connect all (good host)
• drbdadm connect all (bad host)

Sample plan to fix SB (3)
5. Start heartbeat on the good host to make it Primary.

How to use nzhostbackup
• When DB is online, run nzhostback by NZ user
• Use destination /nzscratch if available
• In Mustang, /nzscratch may not be available. You can use /var/tmp/. Don’t use /nz/ or /export/home/nz to store backup files.
• Use date and host (ha1 or ha2) name for the backup filename

It does not take long (5~10min)
• Run nzhostbakup when db is online
• $ nzhostbackup /nzscratch/backup.2013-09-08-ha2.1
• Starting host backup. System state is 'online'.
• Pausing the system ...
• Checkpointing host catalog ...
• Archiving system catalog ...
• Resuming the system ...
• Host backup completed successfully. System state is 'online'.
• $

nzhostrestore (1)
• $ nzhostrestore /nzscratch/backup.2013-09-08-ha2.1
• Starting host restore
• nzhostrestore command: nzhostrestore /nzscratch/backup.2013-09-08-ha2.1
• Extracting host data archive ...
• Restore host data archived Sun Sep 8 08:40:10 EDT 2013? (y/n) [n] y
• Stopping the system ...
• Starting topology restore ...
• Stopping the system ...
• Warning: The restore will now rollback spu data to Sun Sep 8 08:40:10 EDT 2013.
• This operation cannot be undone. Ok to proceed? (y/n) [n]

nzhostrestore (2)
• This operation cannot be undone. Ok to proceed? (y/n) [n] y
• Installing system catalog to '/nz/data.1.0' ...
• Starting the system in host restore mode...
• Synchronizing data on spus ...
• ......................................................................................................................................................done.
• Stopping the system ...
• Restore complete. You can now start the system using 'nzstart'.
• $

What if db cannot be online?
• You can run nzhostrestore when DB is Stopped.
•

• $ nzstate
• System state is 'Stopped'.
• [nz@NZ80641-H2 ~]$ mv /nz/data.1.0 /tmp/
• [nz@NZ80641-H2 ~]$ nzstart
• WARNING: Cannot determine data directory: free space check skipped
• WARNING: Unrecognized limit item: nice
• WARNING: Unrecognized limit item: nice
• WARNING: Search domain 'nzlab.ibm.com' appears multiple times in /etc/resolv.conf.upstream
• WARNING: Contents of /etc/localtime and zone file /usr/share/zoneinfo/Europe/London are not the same
• WARNING: System timezone is 'EDT', but
• /etc/sysconfig/clock 'ZONE' is '' (UTC)
• nzstart: Error: '/nz/data' is not a valid data directory
• $

• $ nzhostrestore /nzscratch/backup.2013-09-08-ha2.1
• mkdir: cannot create directory `/nz/data': File exists
• $ ls -l /nz/data
• lrwxrwxrwx 1 nz nz 13 May 9 13:46 /nz/data -> /nz/data.1.0/
• $ rm /nz/data
• $ ls -l /nz/data
• ls: /nz/data: No such file or directory
• $ nzhostrestore /nzscratch/backup.2013-09-08-ha2.1
• Starting host restore
• nzhostrestore command: nzhostrestore /nzscratch/backup.2013-09-08-ha2.1
• Extracting host data archive ...
• Unable to determine catalog version of data directory at /nz/data, hence exiting. If you are sure that catalog versions of current and that of the archived data directory are same, use the command-line switch -catverok to skip this check.
• NPS system is not running.
• Error, see /nz/kit.dbg.6.0.8.P12/log/nzhostrestore/nzhostrestore.17548.2013-09-08.log
• $

• $ nzhostrestore /nzscratch/backup.2013-09-08-ha2.1 -catverok
• Starting host restore
• nzhostrestore command: nzhostrestore /nzscratch/backup.2013-09-08-ha2.1
• Extracting host data archive ...
• Restore host data archived Sun Sep 8 08:40:10 EDT 2013? (y/n) [n] y
• Stopping the system ...
• NPS system is not running.
• Starting topology restore ...
• Stopping the system ...
• Warning: The restore will now rollback spu data to Sun Sep 8 08:40:10 EDT 2013.
• This operation cannot be undone. Ok to proceed? (y/n) [n] y
• Installing system catalog to '/nz/data' ...
• Starting the system in host restore mode...
• Synchronizing data on spus ...
• .....................................................................................................................................................done.
• Stopping the system ...
• Restore complete. You can now start the system using 'nzstart'.
• $

What is backup file?
• TAR GZIP’ed of /nz/data.1.0 directory• $ cd /nz
• $ tar zcf /tmp/yyy.tgz data
• $ nzhostrestore /tmp/yyy.tgz (which command works)





























