Embed Size (px)
Citation preview

Nikita Shamgunov, CTO and Co-founder of MemSQL
Spark Summit East | Boston | 9 February 2017
The Fast Path to Building Operational Applications with Spark

About Me
Nikita ShamgunovCo-founder and Chief Technology Officer, MemSQL

▪ Every piece of technology is scalable▪ Analyzing data from hundreds of thousands of
machines▪ Delivering immense value in real-time
• Real-time code deployment• Detecting anomalies• A/B testing results
▪ Fundamentally making the business faster by providing data at your fingertips
An Insider’s View at Facebook

Imagine scaling a database on industry standard hardware.
Need 2x the performance? Add 2x the nodes.


▪ About MemSQL▪ Using MemSQL Spark Connector▪ Use Cases and Case Studies
▪ Entity Resolution
Today in My Talk

What is MemSQL?

▪ Scalable and elastic• Petabyte scale• High Concurrency• System of record
▪ Real-time• Operational
▪ Compatible• ETL• Business Intelligence• Kafka• Spark
MemSQL - Hybrid Cloud Data Warehouse
▪ Deployment• Managed service in the
Cloud• On-premises
▪ Community Edition• Unlimited scale• Limited high availability
and security features
MemSQL Confidential9
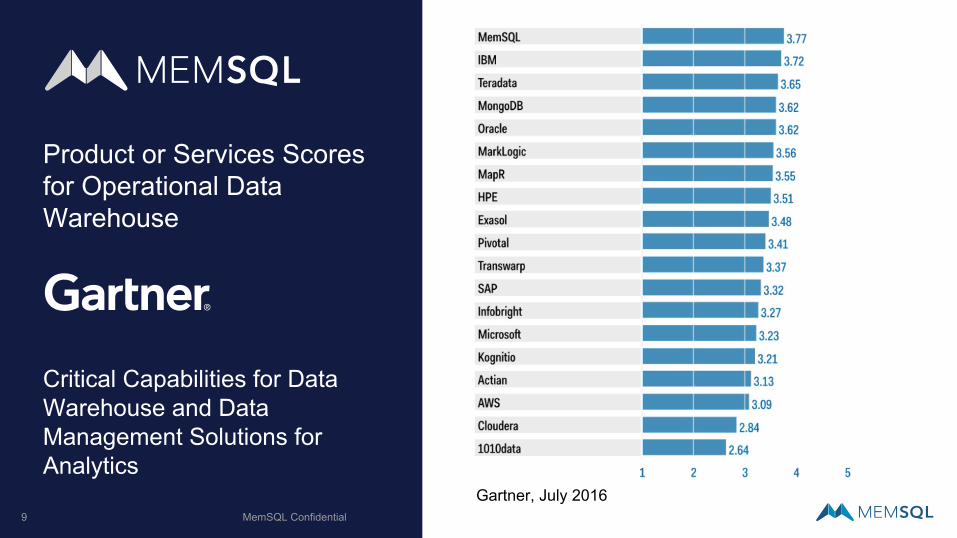
Product or Services Scores for Operational Data Warehouse
Critical Capabilities for Data Warehouse and Data Management Solutions for Analytics
Gartner, July 2016
Keeping Pace
On-demand economy Real-Time Data Predictive Analytics

Understanding MemSQL and Spark
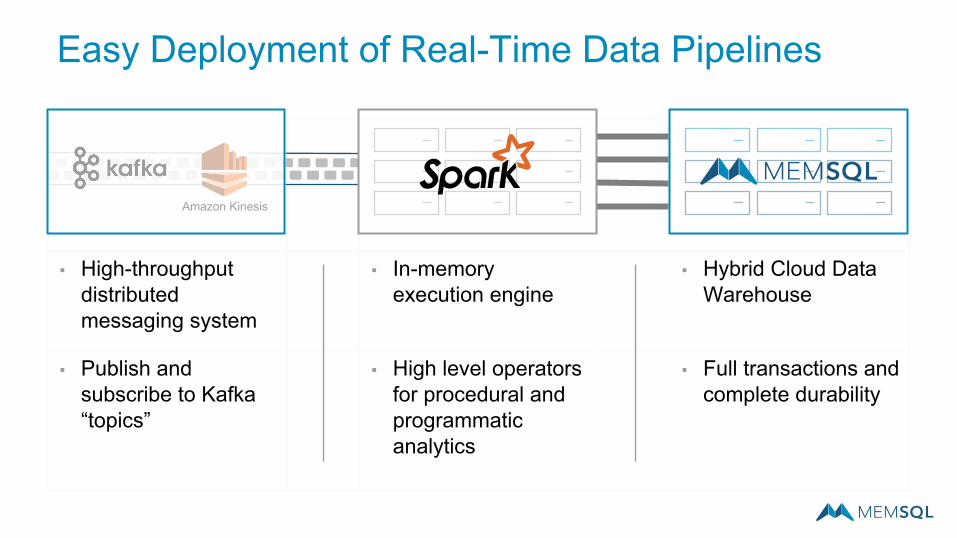
Easy Deployment of Real-Time Data Pipelines
▪ High-throughput distributed messaging system
▪ In-memory execution engine
▪ Hybrid Cloud Data Warehouse
▪ Publish and subscribe to Kafka “topics”
▪ High level operators for procedural and programmatic analytics
▪ Full transactions and complete durability
Amazon Kinesis
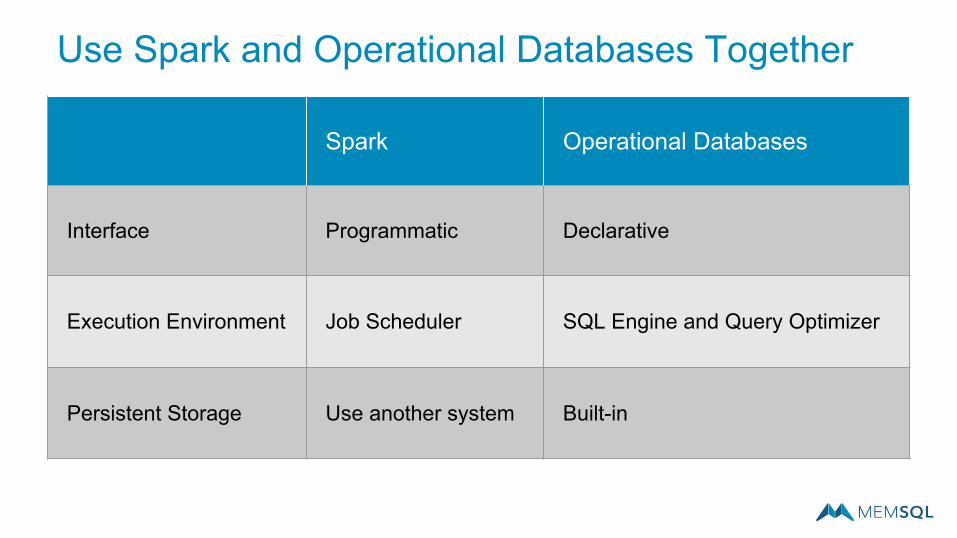
Use Spark and Operational Databases Together
Spark Operational Databases
Interface Programmatic Declarative
Execution Environment Job Scheduler SQL Engine and Query Optimizer
Persistent Storage Use another system Built-in

MemSQL Spark 2 Connector
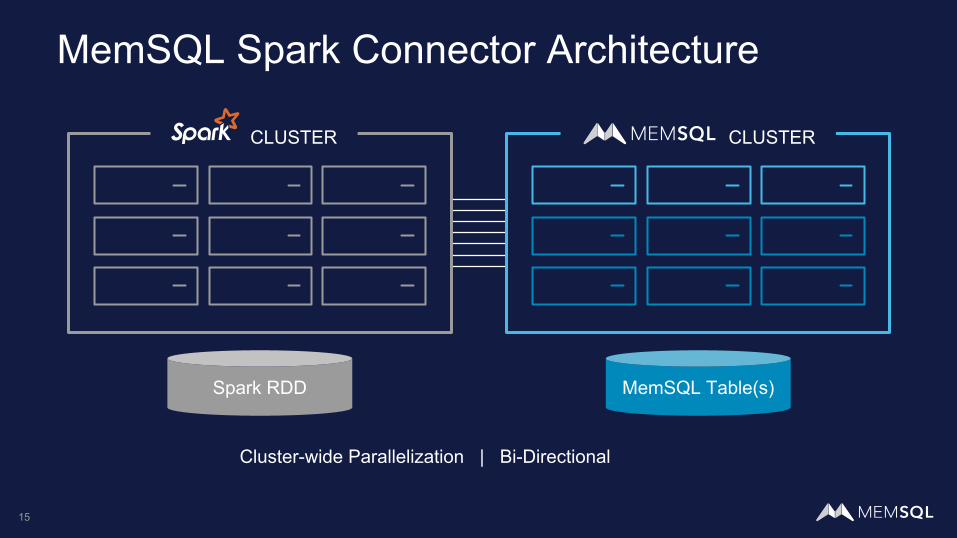
MemSQL Spark Connector Architecture
15
CLUSTERCLUSTER
Spark RDD MemSQL Table(s)
Cluster-wide Parallelization | Bi-Directional

Operationalize Models Built in SparkStream and Event ProcessingExtend MemSQL AnalyticsLive Dashboards and Automated Reports
MemSQL and Spark Use Cases
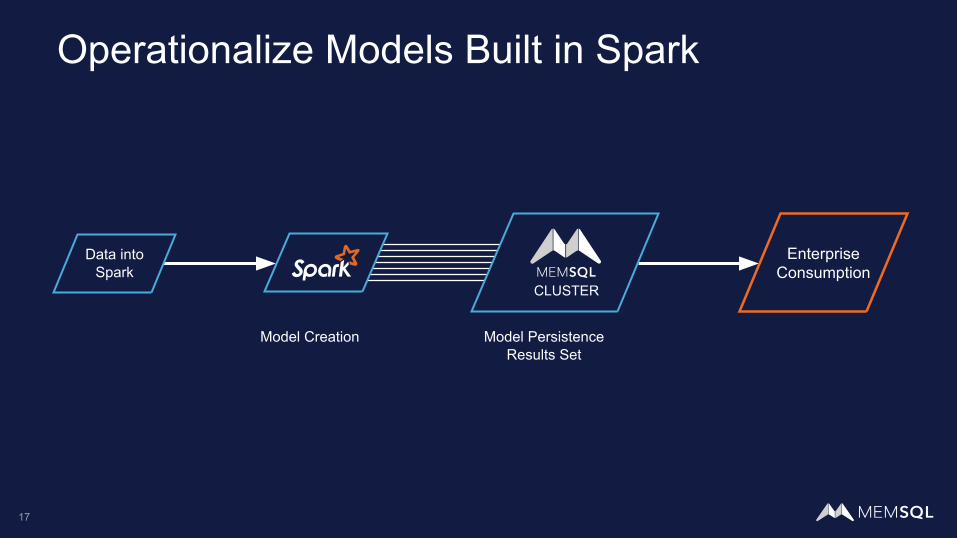
Operationalize Models Built in Spark
17
Enterprise Consumption
Data into Spark
Model Creation Model PersistenceResults Set
CLUSTER
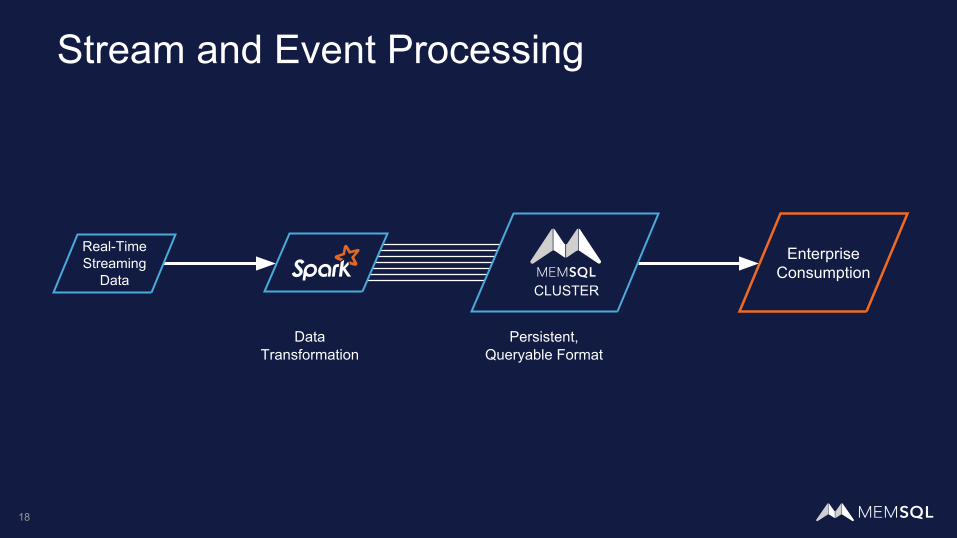
Stream and Event Processing
18
Enterprise Consumption
Real-TimeStreaming
Data
DataTransformation
Persistent,Queryable Format
CLUSTER
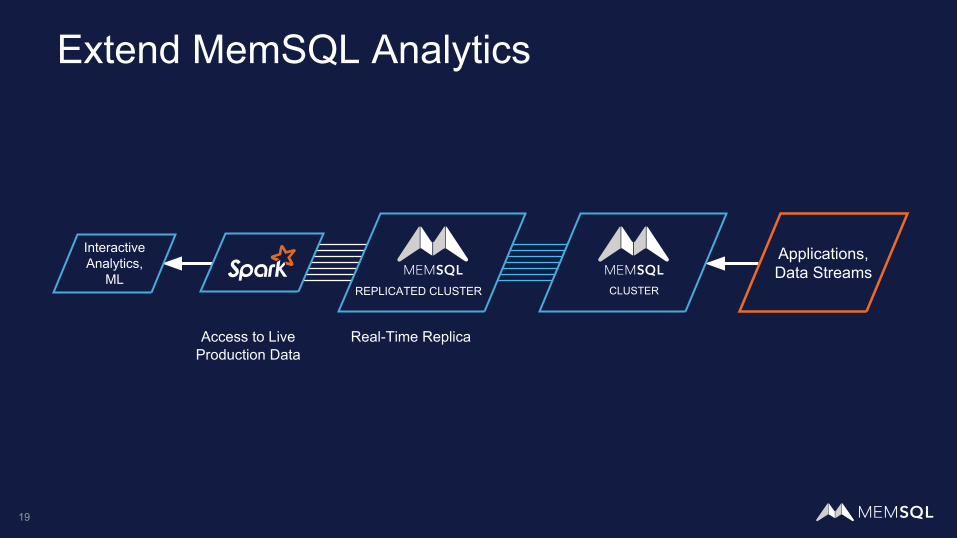
Extend MemSQL Analytics
19
Applications,Data Streams
Interactive Analytics,
ML
Access to LiveProduction Data
CLUSTER
Real-Time Replica
REPLICATED CLUSTER
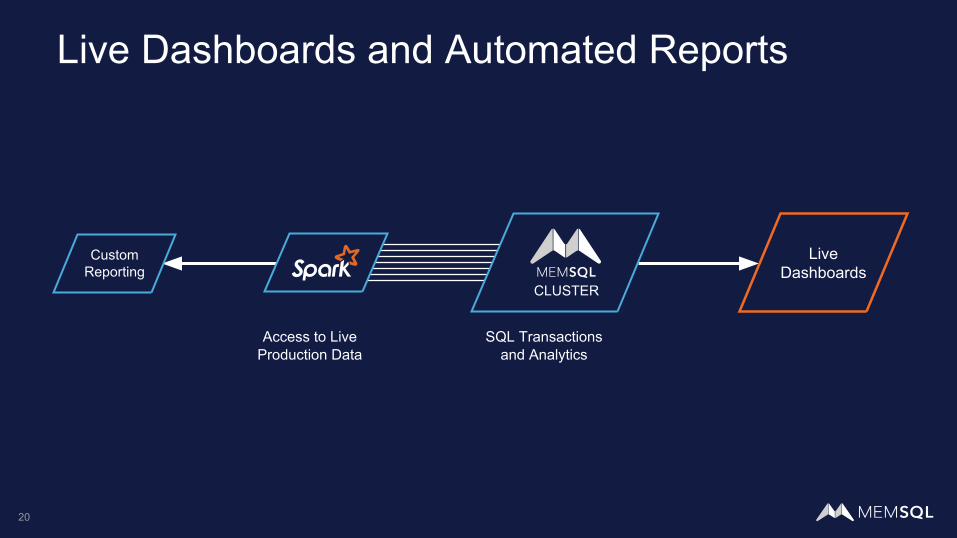
Live Dashboards and Automated Reports
20
LiveDashboards
Custom Reporting
Access to LiveProduction Data
SQL Transactionsand Analytics
CLUSTER

MemSQL Spark Connector via Spark Packages
The memsql-spark-connector is now available via Spark Packages:http://spark-packages.org/https://spark-packages.org/package/memsql/memsql-spark-connectorYou can use it with any Spark command:
> $SPARK_HOME/bin/spark-shell --packages
com.memsql:memsql-connector_2.11:2.0.1
Also available on Mavenhttp://search.maven.org/#artifactdetails%7Ccom.memsql%7Cmemsql-connector_2.11%7C2.0.1%7Cjar
And the Github repositoryhttps://github.com/memsql/memsql-spark-connector

Customer Spark Case Studies

MemSQL Confidential 23
Reducing delay in “freshness of data” from two hours to 10 minutes
+
https://www.enterprisetech.com/2016/12/09/managing-30b-bid-requests/

TECHNICAL BENEFITS
▪ 10x faster data refresh, from hours to minutes
▪ Run ad-hoc queries on log-level data within seconds
THE MANAGE REAL-TIME ARCHITECTURE
REAL-TIMEANALYTICS
Real-Time inputs

MemSQL Confidential25
Goldman Sachs at Kafka Summit April 2016
http://www.confluent.io/kafka-summit-2016-users-real-time-analytics-visualized-with-kafka
Real-Time Analytics Visualized w/ Kafka+Spark+MemSQL+ZoomData

Entity Resolution at Scale

Problem StatementEmployees have many opportunities to take advantage of their insider knowledge and position of trust within a company. This includes:
▪ Preferential treatment to family or friends
▪ Fraud under someone else’s name
In many cases, proximity is one of the most common traits of those they proxy their activities through.
MemSQL can quickly process the massive volume of calculations needed to identify these relationships and iterate on new algorithms.
27
28
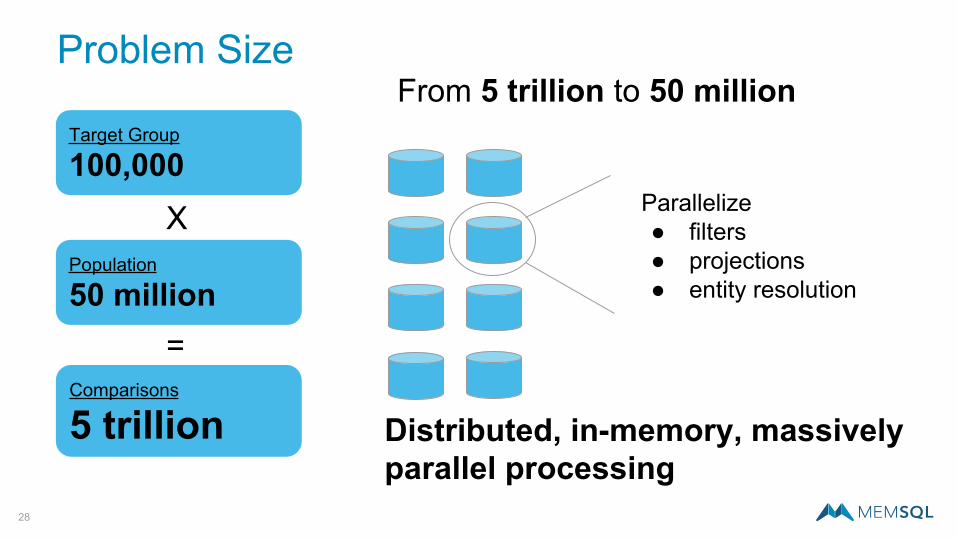
Problem Size
Target Group
100,000
Population
50 million
X
=Comparisons
5 trillion
Parallelize● filters● projections● entity resolution
Distributed, in-memory, massively parallel processing
From 5 trillion to 50 million
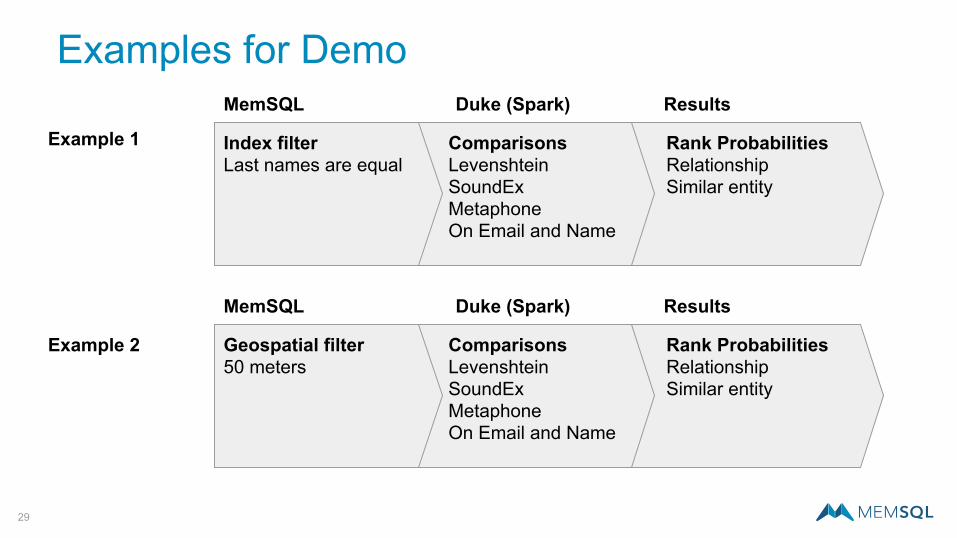
Rank ProbabilitiesRelationshipSimilar entity
ComparisonsLevenshteinSoundExMetaphoneOn Email and Name
Geospatial filter50 meters
Examples for Demo
29
MemSQL Duke (Spark) Results
Rank ProbabilitiesRelationshipSimilar entity
ComparisonsLevenshteinSoundExMetaphoneOn Email and Name
Index filterLast names are equal
MemSQL Duke (Spark) Results
Example 1
Example 2

30
Scalability
Cluster288 cores → 3 mins runtime
Runtime scales linearly with number of cores
8 x c4.8xlarge
Want speed? Add cores!

Cluster size: 8 machines, c4.8xlarge, 36 cores, 60 GB RAM
• 2 leaf nodes per machine, each with 9 partitions• this gives us ~2 cores per partition in the cluster - one core is
going to be at 100% CPU during the computation, the other is used for Spark + Duke + Misc
Cluster Size
31

32
Conclusion
▪ Speed in covering massive search space• In memory (On commodity hardware)• Parallelization
▪ Scales linearly▪ Huge value in running all of this natively in MemSQL

▪ Push down the in-memory, proximity filter to each of the leaves
▪ Leverage indexes▪ Stream results in parallel to Duke Entity Resolution
How does MemSQL do it?
33

▪ Using Metaphone, SoundEx, and Levenshtein algorithms to compare first name, last name and email
▪ Duke supports many more comparisons, and makes it very easy to create new ones
▪ With a training dataset, Duke can use a genetic algorithm to optimize comparator weights
▪ https://github.com/larsga/Duke
Duke Entity Resolution
34

Demo

www.memsql.com
Thank You





























