Embed Size (px)
Citation preview

Mehmet Cüneyt GöksuzAnalytics Technical Lead, MEA & [email protected]
DB2 Update Day 2017 in Nordics
Temporal Tables, Transparent Archiving in DB2 for z/OS and IDAA
Disclaimer/Trademarks
© Copyright IBM Corporation 2017. All rights reserved.
U.S. Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp.
THE INFORMATION CONTAINED IN THIS DOCUMENT HAS NOT BEEN SUBMITTED TO ANY FORMAL IBM TEST AND IS DISTRIBUTED AS IS.
THE USE OF THIS INFORMATION OR THE IMPLEMENTATION OF ANY OF THESE TECHNIQUES IS A CUSTOMER RESPONSIBILITY AND
DEPENDS ON THE CUSTOMER’S ABILITY TO EVALUATE AND INTEGRATE THEM INTO THE CUSTOMER’S OPERATIONAL ENVIRONMENT.
WHILE IBM MAY HAVE REVIEWED EACH ITEM FOR ACCURACY IN A SPECIFIC SITUATION, THERE IS NO GUARANTEE THAT THE SAME OR
SIMILAR RESULTS WILL BE OBTAINED ELSEWHERE. ANYONE ATTEMPTING TO ADAPT THESE TECHNIQUES TO THEIR OWN
ENVIRONMENTS DO SO AT THEIR OWN RISK.
ANY PERFORMANCE DATA CONTAINED IN THIS DOCUMENT WERE DETERMINED IN VARIOUS CONTROLLED LABORATORY
ENVIRONMENTS AND ARE FOR REFERENCE PURPOSES ONLY. CUSTOMERS SHOULD NOT ADAPT THESE PERFORMANCE NUMBERS TO
THEIR OWN ENVIRONMENTS AS SYSTEM PERFORMANCE STANDARDS. THE RESULTS THAT MAY BE OBTAINED IN OTHER OPERATING
ENVIRONMENTS MAY VARY SIGNIFICANTLY. USERS OF THIS DOCUMENT SHOULD VERIFY THE APPLICABLE DATA FOR THEIR SPECIFIC
ENVIRONMENT.
Trademarks
IBM, the IBM logo, ibm.com, DB2, and z/OS are trademarks of International Business Machines Corp., registered in many jurisdictions worldwide.
Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the Web at
“Copyright and trademark information” at www.ibm.com/legal/copytrade.shtml.

Agenda
• Data archiving requirements and challenges
• Data archiving solutions for z/OS systems
–Temporal Tables & History Generation
–Transparent Archiving & History Generation
–Overview of IDAA Technology
• Combining Solutions for different usecases
3

Agenda
• Data archiving requirements and challenges
• Data archiving solutions for z/OS systems
–Temporal Tables & History Generation
–Transparent Archiving & History Generation
–Overview of IDAA Technology
• Combining Solutions for different usecases
4
Why retain data for long periods of time?
• Sometimes, due to legal requirements
• Sometimes in support of customer service
We need to
repair
your 2005
vehicle
• Sometimes for analytics purposes
If we analyze more data, we’ll get more
valuable insight…

Data retention’s impact: application performance
• DB2 tables with non-continuously-ascending clustering key (new rows get
inserted throughout table), data retention can increase the CPU cost of data
access
– More recently-inserted rows are often the most frequently accessed, but sets of such
rows will be separated by ever-larger numbers of “old and cold” rows
• Result: more and more DB2 GETPAGEs are required to retrieve the same result
sets, and more GETPAGEs means more CPU
• Even for DB2 table with continuously-ascending clustering key (so newer
rows are concentrated at “end” of table), growth means larger indexes, and
that means more CPU
– A larger index has more levels, leading to more GETPAGEs
– DB2 utilities that process indexes (such as REORG and RUNSTATS) may become
more expensive to run

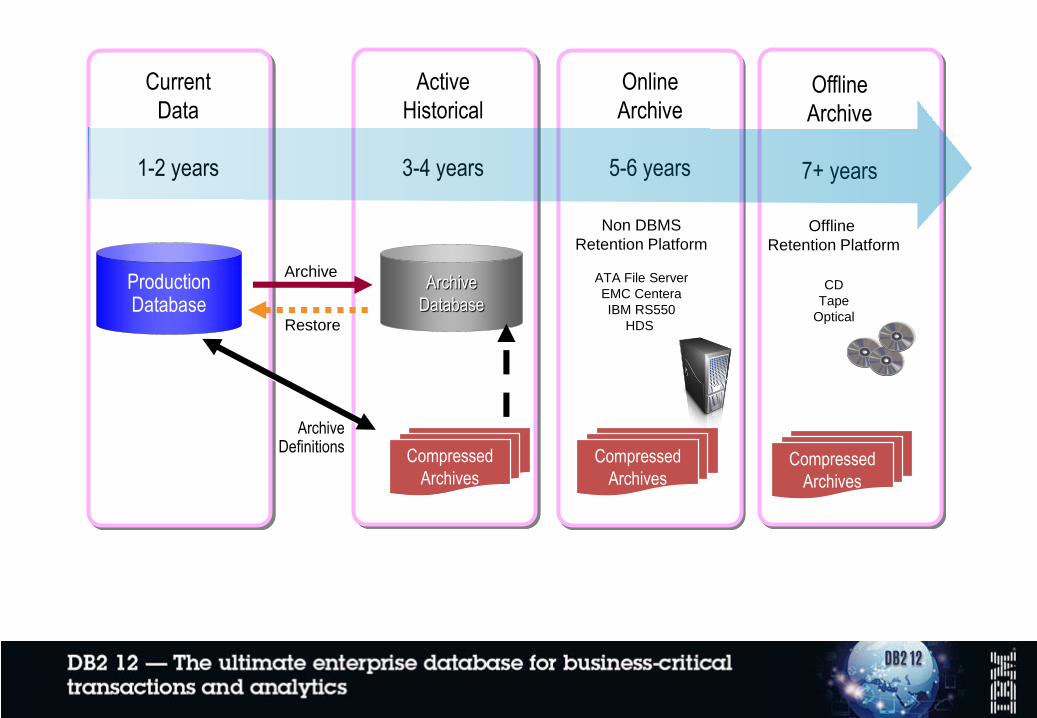
Data retention’s impact: data storage costs
• Storing years of historical data on the high-end disk subsystems typically
used with z Systems can cost a lot of $$$
• A cost-reducing alternative – storing historical data offline, on tape, has
its own problems
– No dynamic query access – data requested for analysis might be restored
to disk overnight, available next day
• Even then, likely that only a subset of data-on-tape would be restored at any
given time
• Is there a better way?
– Yes – several of them!!
Non DBMS
Retention Platform
ATA File Server
EMC Centera
IBM RS550
HDS
Compressed
Archives
Offline
Retention Platform
CD
Tape
Optical
Compressed
Archives
ProductionDatabase
Archive Definitions
Archive
Restore
Archive
Database
Compressed
Archives
Online
Archive
5-6 years
Offline
Archive
7+ years
Current
Data
1-2 years
Active
Historical
3-4 years
8

Agenda
• Data archiving requirements and challenges
• Data archiving solutions for z/OS systems
–Temporal Tables & History Generation
–Transparent Archiving & History Generation
–Overview of IDAA Technology
• Combining Solutions for different usecases
9

DB2 Temporal Tables – Time Travel Query
• One of the major improvements since DB2 10
• The ability for the database to reduce the complexity and amount of coding
needed to implement “versioned” data, data that has different values at
different points in time.
• Data that you need to keep a record of for any given point in time
• Data that you may need to look at for the past, current or future situation
• The ability to support history or auditing queries
• Business Time & System time
DB2 Temporal Tables - History Generation
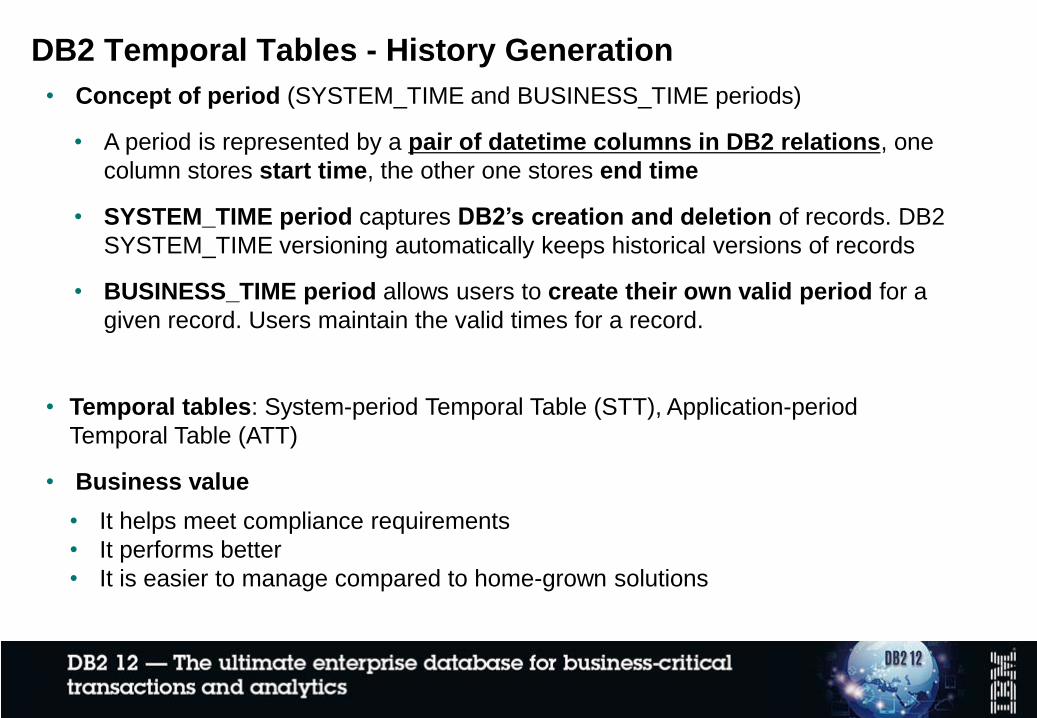
• Concept of period (SYSTEM_TIME and BUSINESS_TIME periods)
• A period is represented by a pair of datetime columns in DB2 relations, one
column stores start time, the other one stores end time
• SYSTEM_TIME period captures DB2’s creation and deletion of records. DB2
SYSTEM_TIME versioning automatically keeps historical versions of records
• BUSINESS_TIME period allows users to create their own valid period for a
given record. Users maintain the valid times for a record.
• Temporal tables: System-period Temporal Table (STT), Application-period
Temporal Table (ATT)
• Business value
• It helps meet compliance requirements
• It performs better
• It is easier to manage compared to home-grown solutions

DB2 Temporal Tables - History Generation
• DML syntax allow query/update/delete data for periods of time
• Period specification with base table reference:
• SELECT … FROM ATT/BTT FOR BUSINESS_TIME AS OF exp/FROM exp1 TO exp2/BETWEEN
exp1 AND exp2 ...;
• SELECT … FROM STT/BTT FOR SYSTEM_TIME AS OF exp/FROM exp1 TO exp2/BETWEEN exp1
AND exp2 ...;
• Period clause with base table reference:
• UPDATE/DELETE FROM ATT/BTT FOR PORTION OF BUSINESS_TIME FROM exp1 TO exp2 ...;
• Bi-temporal
• Inclusion of both System Time and Business Time in row
• Business value
– It helps meet compliance requirements
– It performs better
– It is easier to manage compared to home-grown solutions

Row Maintenance with System Time – History Generation
* T1: INSERT Row A
* T2: UPDATE Row A
* T3: UPDATE Row A
* T4: DELETE Row A
* T5: INSERT Row A
Row A1:T1-T2Row A1:T1-HVRow A2:T2-HV Row A2:T2-T3
Row A1:T1-T2
Row A3:T3-HV Row A3:T3-T4
Row A2:T2-T3
Row A1:T1-T2
Row A4:T5-HV
Base Table History Table
* Notes:
– INSERT has no History Table impact
– The first UPDATE begins a lineage for Row A.
• History Table ST End = Base Table ST Begin (No gap)
• The Base Table ST End is always High Values (HV)
– The second UPDATE deepens the lineage
• No gaps exist across all generations of Row A.
– The DELETE adds to the lineage in the History Table.
• There is no current row (Base Table) after the DELETE
– The second INSERT begins a new row lineage
• There is a gap between the History Table rows and the Base Table
– If all of the above statements happen in the same UOW, there would be no History Table rows
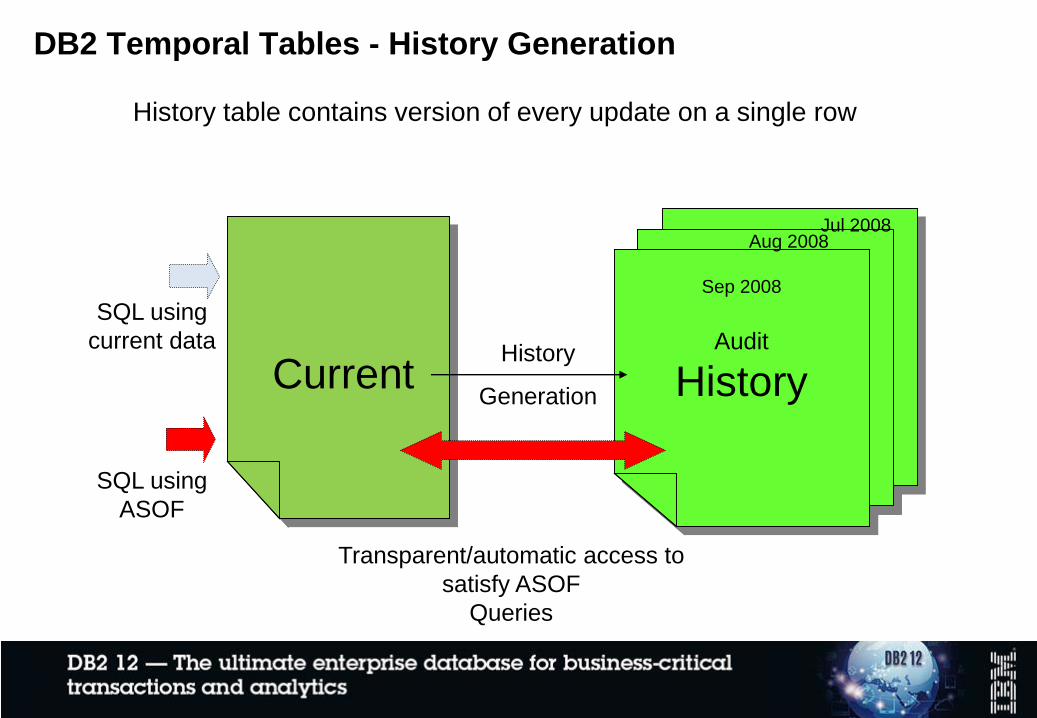
Sep 2008
Audit
HistoryCurrent
Aug 2008Jul 2008
History
Generation
SQL using
current data
SQL using
ASOF
Transparent/automatic access to
satisfy ASOF
Queries
History table contains version of every update on a single row
DB2 Temporal Tables - History Generation
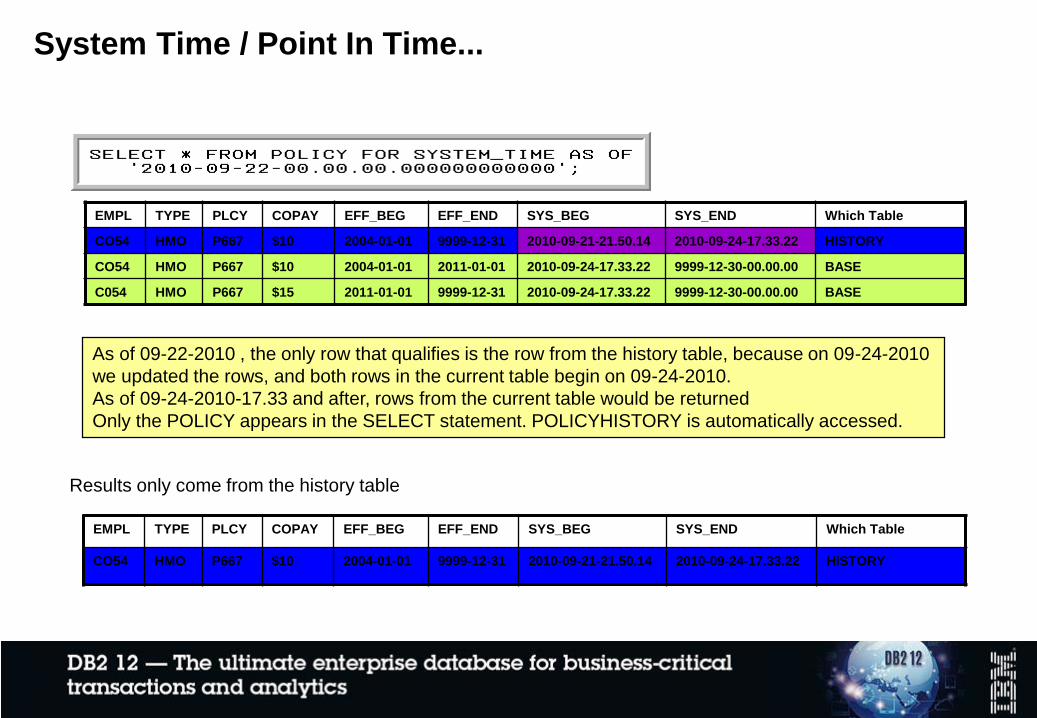
System Time / Point In Time...
EMPL TYPE PLCY COPAY EFF_BEG EFF_END SYS_BEG SYS_END Which Table
CO54 HMO P667 $10 2004-01-01 9999-12-31 2010-09-21-21.50.14 2010-09-24-17.33.22 HISTORY
CO54 HMO P667 $10 2004-01-01 2011-01-01 2010-09-24-17.33.22 9999-12-30-00.00.00 BASE
C054 HMO P667 $15 2011-01-01 9999-12-31 2010-09-24-17.33.22 9999-12-30-00.00.00 BASE
As of 09-22-2010 , the only row that qualifies is the row from the history table, because on 09-24-2010
we updated the rows, and both rows in the current table begin on 09-24-2010.
As of 09-24-2010-17.33 and after, rows from the current table would be returned
Only the POLICY appears in the SELECT statement. POLICYHISTORY is automatically accessed.
Results only come from the history table
EMPL TYPE PLCY COPAY EFF_BEG EFF_END SYS_BEG SYS_END Which Table
CO54 HMO P667 $10 2004-01-01 9999-12-31 2010-09-21-21.50.14 2010-09-24-17.33.22 HISTORY
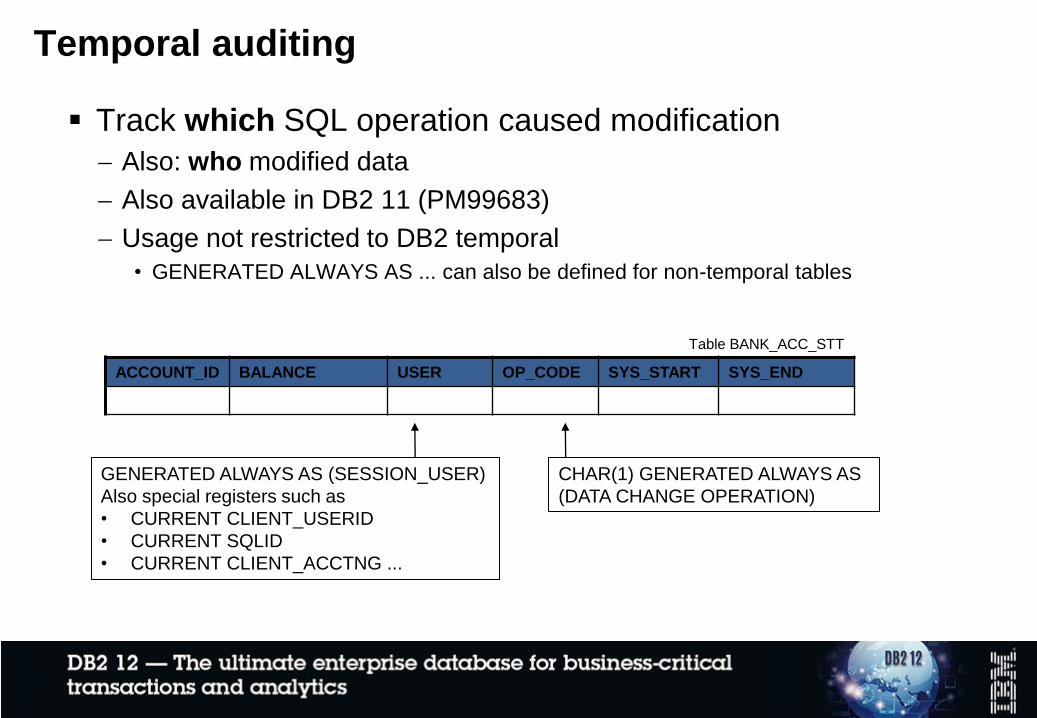
Temporal auditing
Track which SQL operation caused modification
Also: who modified data
Also available in DB2 11 (PM99683)
Usage not restricted to DB2 temporal
• GENERATED ALWAYS AS ... can also be defined for non-temporal tables
ACCOUNT_ID BALANCE USER OP_CODE SYS_START SYS_END
Table BANK_ACC_STT
GENERATED ALWAYS AS (SESSION_USER)
Also special registers such as
• CURRENT CLIENT_USERID
• CURRENT SQLID
• CURRENT CLIENT_ACCTNG ...
CHAR(1) GENERATED ALWAYS AS
(DATA CHANGE OPERATION)
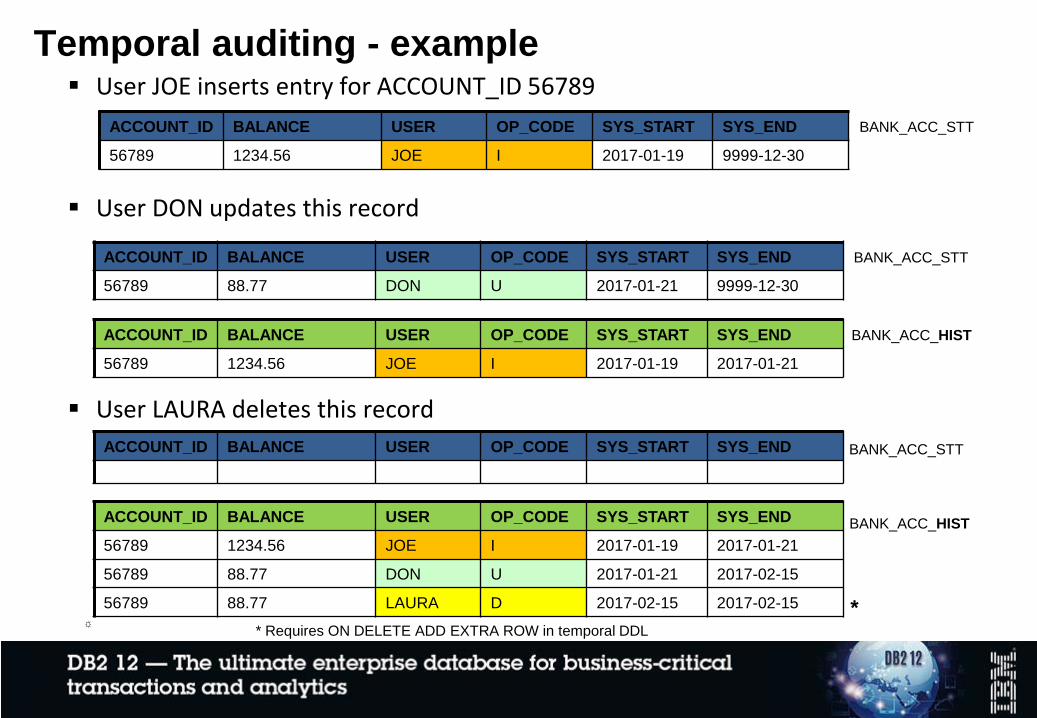
Temporal auditing - example User JOE inserts entry for ACCOUNT_ID 56789
ACCOUNT_ID BALANCE USER OP_CODE SYS_START SYS_END
56789 1234.56 JOE I 2017-01-19 9999-12-30
BANK_ACC_STT
ACCOUNT_ID BALANCE USER OP_CODE SYS_START SYS_END
56789 88.77 DON U 2017-01-21 9999-12-30
User DON updates this record
ACCOUNT_ID BALANCE USER OP_CODE SYS_START SYS_END
56789 1234.56 JOE I 2017-01-19 2017-01-21
BANK_ACC_HIST
ACCOUNT_ID BALANCE USER OP_CODE SYS_START SYS_END
ACCOUNT_ID BALANCE USER OP_CODE SYS_START SYS_END
56789 1234.56 JOE I 2017-01-19 2017-01-21
56789 88.77 DON U 2017-01-21 2017-02-15
56789 88.77 LAURA D 2017-02-15 2017-02-15
BANK_ACC_STT
User LAURA deletes this record
BANK_ACC_STT
BANK_ACC_HIST
** Requires ON DELETE ADD EXTRA ROW in temporal DDL☼

• Both active and history tables with Timestamp(12) can be loaded to the Accelerator
System Time Temporal Query Routing with DB2 12 and IDAA
• Special query rewrite is applied for the following 3 temporal SQL:
• FOR SYSTEM_TIME AS OF expr
• FOR SYSTEM_TIME FROM expr1 TO expr2
• FOR SYSTEM_TIME BETWEEN expr1 AND expr2
• Queries on system temporal tables are routed to the Accelerator when ZPARM
QUERY_ACCEL_OPTIONS is set to 5
5: Allows to run accelerated queries against STT and bi-temporal tables
• All existing offloading criteria have to be met

Can system-time temporal be a form of archiving?
• Yes – it is a “historical” data retention option
– With more-traditional data archiving, you are retaining data that is old but current
(i.e., still in effect as of right now)
– With system-time temporal, you are retaining data that was once, but is no longer,
in effect
• Needs of the business determine which data retention approach is appropriate
for a given situation
– When data previously inserted in a table is changed (updated or deleted), is there
a need to retain a “before” image of a changed row, along with the “from” and “to”
times of the row’s “in effect” period?
• That’s what system-time temporal is for – it lets you see data that WAS current at some
prior point in time

Agenda
• Data archiving requirements and challenges
• Data archiving solutions for z/OS systems
–Temporal Tables & History Generation
–Transparent Archiving & History Generation
–Overview of IDAA Technology
• Combining Solutions for different usecases
2
3

• Querying and managing tables that contain a large amount
of data is a common problem
• Maintaining for performance of a large table is a key pain point
• One known solution is to archive the inactive/cold data
to a different environment
• Challenges on the ease of use and performance
• How to provide easy access to both current and archived data within single
query
• How to make data archiving and access “transparent” with minimum
application changes
Poor Application
PerformanceWhy DB2 Archive Transparency

DB2-managed data archiving – how it’s done
1. DBA creates table (e.g., T1_AR) to be used as archive for table T1
2. DBA tells DB2 to enable archiving for T1, using archive table T1_AR
ALTER TABLE T1 ENABLE ARCHIVE USE T1_AR;
3. Program deletes to-be-archived rows from T1
• If program sets DB2 global variable SYSIBMADM.MOVE_TO_ARCHIVE to ‘Y’, all it has to do is delete from T1 – DB2 will move deleted rows to T1_AR
• The value of a global variable affects only the DB2 thread for which it was set
4. Bind packages appropriately (bind option affects static and dynamic SQL)
• If a program will ALWAYS access ONLY the base table, it should be bound with ARCHIVESENSITIVE(NO)
• If a program will SOMETIMES or ALWAYS access rows in the base table and the associated archive table, it should be bound with ARCHIVESENSITIVE(YES)
• If program sets DB2 global variable SYSIBMADM.GET_ARCHIVE to ‘Y’, and issues SELECT against base table, DB2 will automatically drive that SELECT against associated archive table, too, and will merge results with UNION ALL
• So, with DB2-managed archiving, a program can retrieve data from an archive table without having to reference the archive table
25

DB2-managed data archiving (DB2 11)
• NOT the same thing as system time temporal data
– When versioning (system time) is activated for a table, the “before” images of rows made
“non-current” by update or delete are inserted into an associated history table
– With DB2-managed archiving, rows in an archive table are current in terms of validity –
they are just older than rows in the associated base table (if row age is the archive
criterion)
• When most access is to rows recently inserted into a table, moving older rows to an archive
table can improve performance for newer-row retrieval
• Particularly useful when data clustered by non-continuously-ascending key
• DB2 users are already doing it for several years! – DB2 11 makes it easier
Before DB2-managed data archiving
After DB2-managed data archiving Newer, more
“popular” rows
Older rows, less frequently retrieved
Base table Archive table
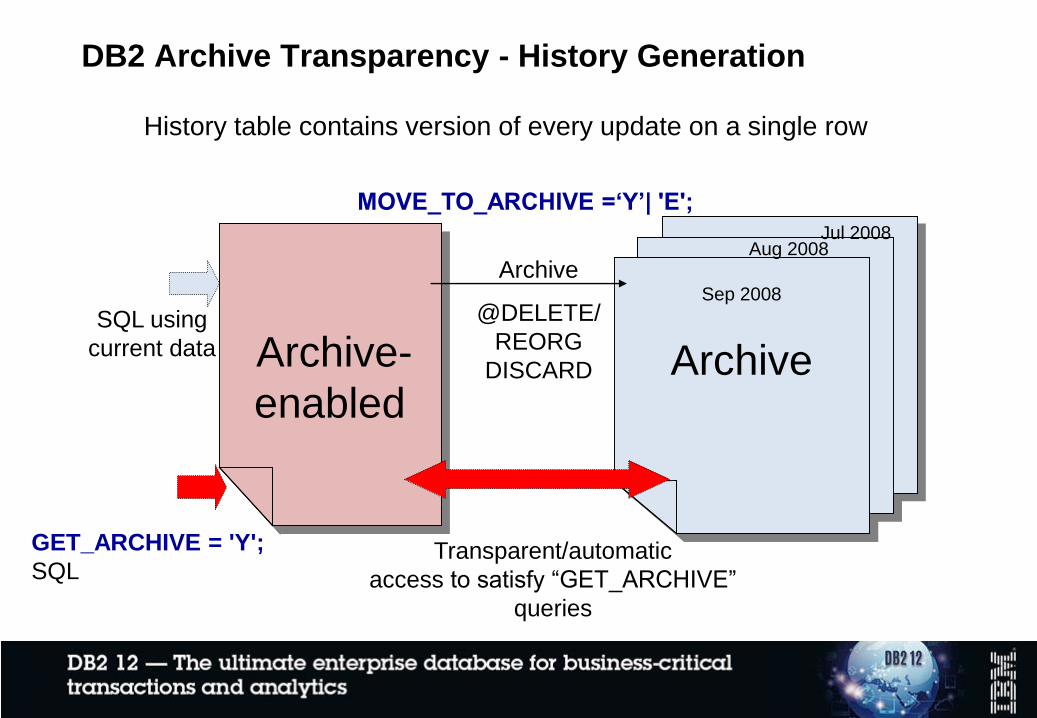
DB2 Archive Transparency - History Generation
Sep 2008
ArchiveArchive-
enabled
Aug 2008Jul 2008
Archive
@DELETE/
REORG
DISCARD
SQL using
current data
GET_ARCHIVE = 'Y';
SQLTransparent/automatic
access to satisfy “GET_ARCHIVE”
queries
History table contains version of every update on a single row
MOVE_TO_ARCHIVE =‘Y’| 'E';

DB2 Transparent archiving – What is new!
Transparent archiving introduced with DB2 11 Enable archiving of deleted rows in separate tables
Similar to temporal / SYSTEM TIME
New with DB2 12: new ZPARM to specify default value for MOVE_TO_ARCHIVE global variable retrofitted to DB2 11 with APAR PI56767
New with DB2 12: allow row change timestamp column to be part of partitioning key can facilitate archiving of archive table to DB2 Analytics Accelerator (on
partition basis)
retrofitted to DB2 11 with APAR PI63830
AND: optimizer improvements in DB2 12 (e.g. UNION ALL) with positive impact on transparent archiving and temporal tables

DB2: temporal (system time) versus archive
• System-time temporal support and DB2-managed archiving cannot be
activated for the same table – use one or the other
• Key differences:
– System-time temporal
• Implemented with a base table and an associated history table
• Rows in the history table are NOT current – they are the “before” images of rows that
were made non-current by DELETE or UPDATE operations targeting the base table
– DB2-managed archiving
• Implemented with a base table and an associated archive table
• Rows in the archive table ARE current – they are just older than the rows in the base
table (assuming that age is the archive criterion)

Agenda
• Data archiving requirements and challenges
• Data archiving solutions for z/OS systems
–Temporal Tables & History Generation
–Transparent Archiving & History Generation
–Overview of IDAA Technology
• Combining Solutions for different usecases
3
0
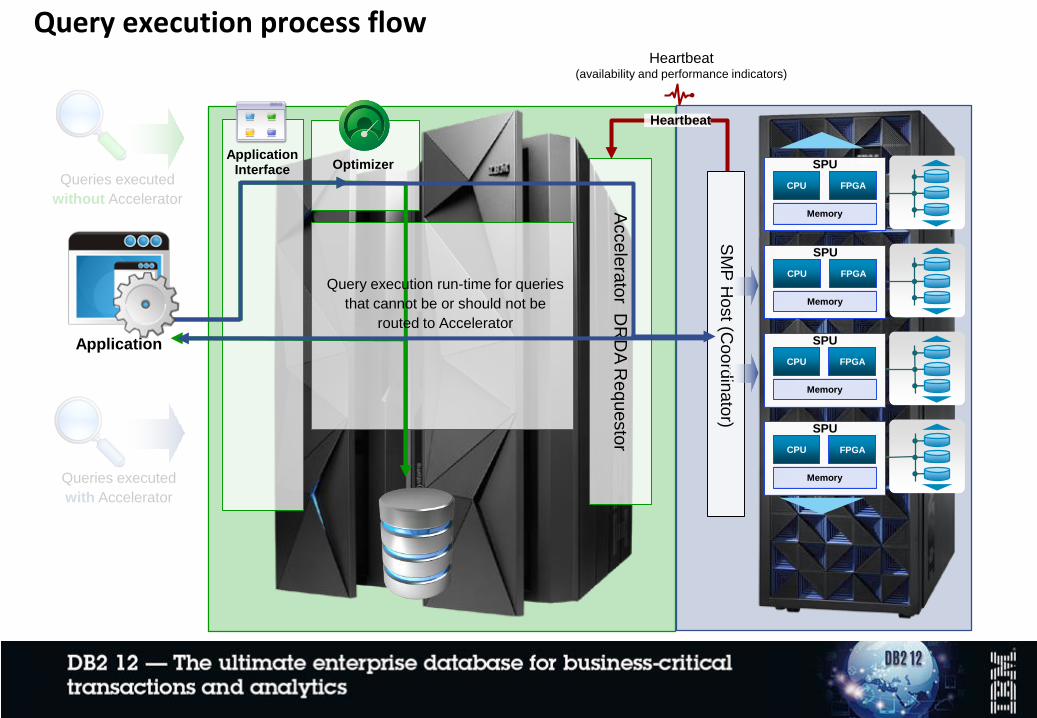
Query execution process flow
Acce
lera
tor D
RD
A R
eq
ue
sto
r
ApplicationInterface
Heartbeat (availability and performance indicators)
SM
P H
ost (C
oord
inato
r)
SPU
Memory
SPU
Memory
SPU
Memory
SPU
Memory
CPU FPGA
CPU FPGA
CPU FPGA
CPU FPGA
Application
Optimizer
Query execution run-time for queries
that cannot be or should not be
routed to Accelerator
SPU
Memory
SPU
Memory
SPU
Memory
SPU
Memory
CPU FPGA
CPU FPGA
CPU FPGA
CPU FPGA
Heartbeat
Queries executed
with Accelerator
Queries executed
without Accelerator
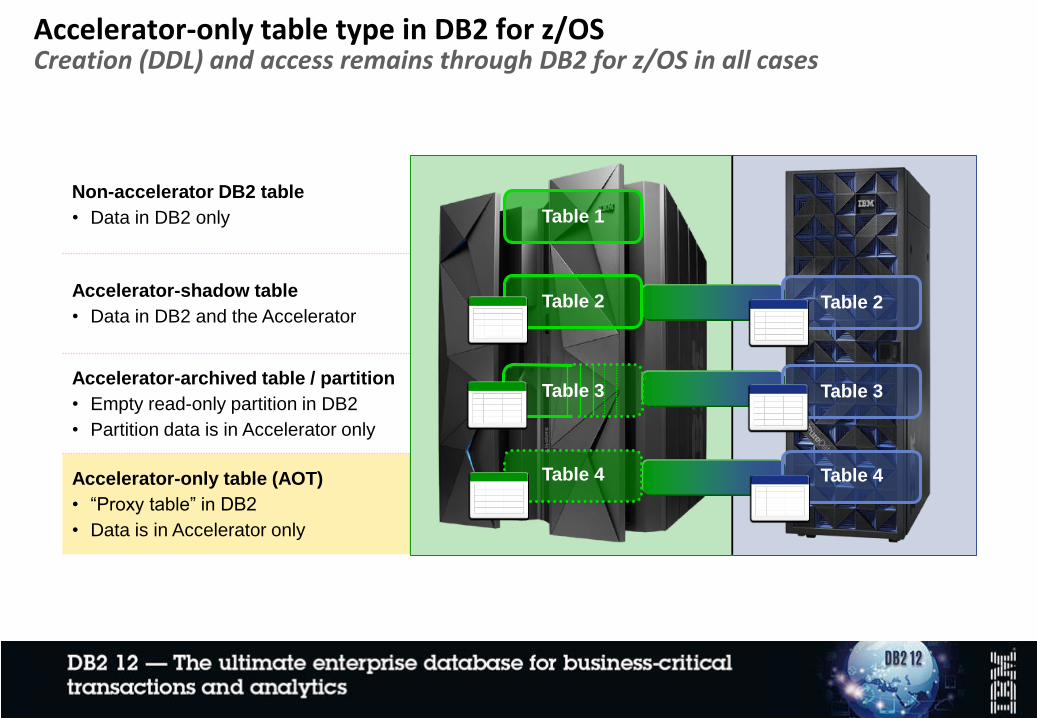
Accelerator-only table type in DB2 for z/OSCreation (DDL) and access remains through DB2 for z/OS in all cases
Non-accelerator DB2 table
• Data in DB2 only
Accelerator-shadow table
• Data in DB2 and the Accelerator
Accelerator-archived table / partition
• Empty read-only partition in DB2
• Partition data is in Accelerator only
Accelerator-only table (AOT)
• “Proxy table” in DB2
• Data is in Accelerator only
Table 1
Table 4
Table 3
Table 2Table 2
Table 4
Table 3

Agenda
• Data archiving requirements and challenges
• Data archiving solutions for z/OS systems
–Temporal Tables & History Generation
–Transparent Archiving & History Generation
–Overview of IDAA Technology
• Combining Solutions for different usecases
3
3

Combining two solutions - DB2-managed archiving and IDAA
1. A base table and its associated archive table can be selected for
acceleration (so both tables will exist on both the front-end DB2 for z/OS
system and the back-end Analytics Accelerator)
2. The archive table can be partitioned, regardless of whether or not the
base table is partitioned (base and associated archive table only have to
be logically – not physically – identical)
3. If archive table is partitioned on a date basis (could require adding
timestamp column to base and archive tables), and if older rows are not
updated, High-Performance Storage Saver can be utilized
• In that case, large majority of archive table’s data would physically exist only on
the Analytics Accelerator
• Timestamp column, if added to base and archive tables to facilitate date-based
partitioning of archive table, can be defined as:
GENERATED ALWAYS FOR EACH ROW ON UPDATE AS ROW CHANGE TIMESTAMP
DB2 will generate a value when a row is moved from base to archive table
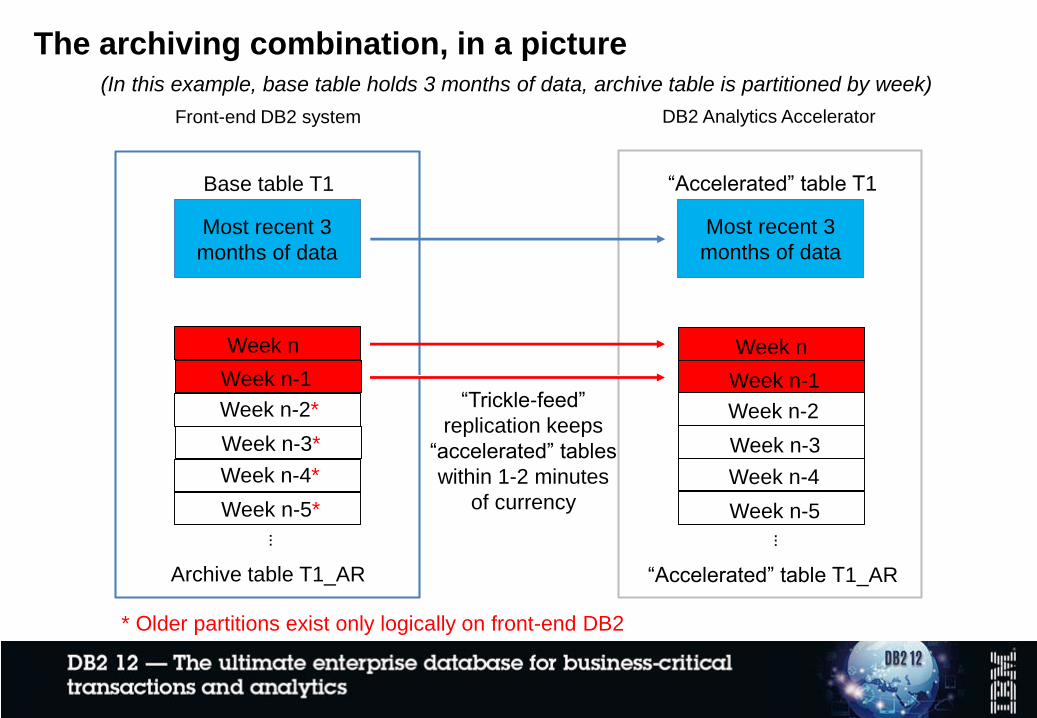
The archiving combination, in a picture
Front-end DB2 system
Base table T1
DB2 Analytics Accelerator
“Accelerated” table T1
……
Archive table T1_AR “Accelerated” table T1_AR
Week n-5*
Week n
Week n-1
Week n-2*
Week n-3*
Week n-4*
Most recent 3
months of data
Most recent 3
months of data
Week n-5
Week n
Week n-1
Week n-2
Week n-3
Week n-4
“Trickle-feed”
replication keeps
“accelerated” tables
within 1-2 minutes
of currency
* Older partitions exist only logically on front-end DB2
(In this example, base table holds 3 months of data, archive table is partitioned by week)
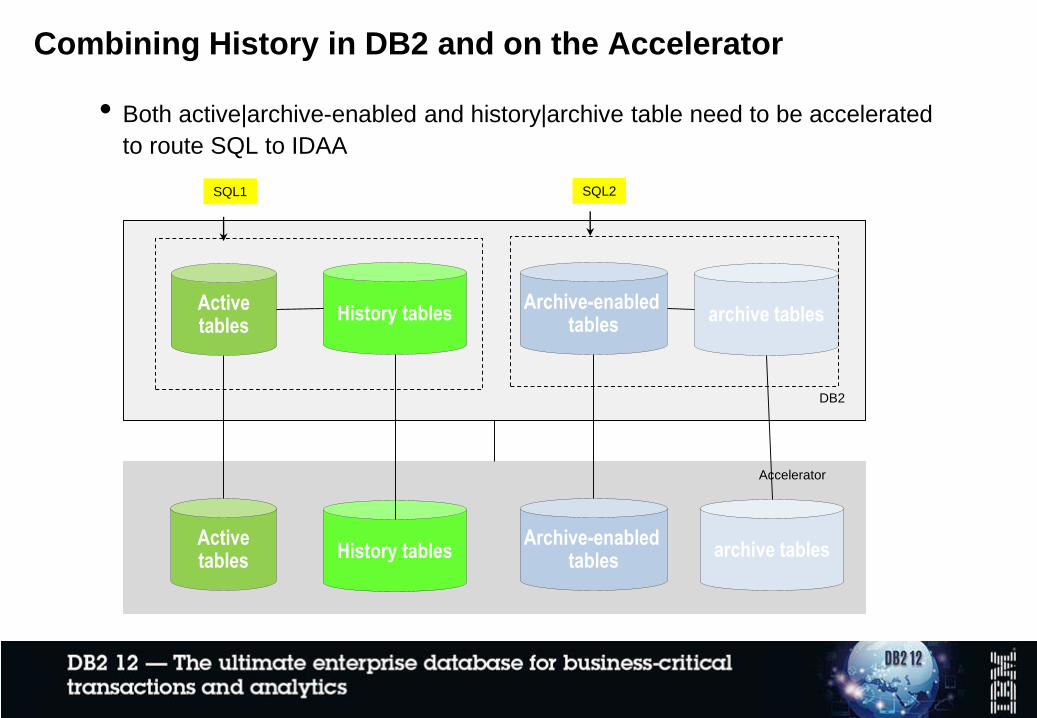
Combining History in DB2 and on the Accelerator
• Both active|archive-enabled and history|archive table need to be accelerated
to route SQL to IDAA
Activetables
History tables
DB2
Accelerator
Activetables History tables
archive tablesArchive-enabled
tables
Archive-enabled tables
archive tables
SQL1 SQL2

Challenges of Typical ETL Processing Today
• Processing pattern
• Move data from original data source(s) through ETL tools or custom transformation
programs to target DW/DM
• Typically, data is stored several times in intermittent staging areas
• Myth: main purpose for ETL
• To make data consumable for end users
• To optimize for performance (star schema)
• Merging and cleansing (making consistent)
• Reality: majority of the ETL processing is generating history data…

Challenges of Typical ETL Processing Today
• Problems with current ETL architecture
• Latency of data typically >1 day, not acceptable any longer
• Amount of data ever increasing -> strectching ETL window even more
• New business requests typically declined if data is not readily available
• Motivation to look into an alternative architecture
• Reduce/Eliminate the latency associated with transformation and movement
• Improve trust in transformed data
• Agile - respond fast to new business requirements including new data elements
• Functionality in DB2 and IDAA can help to implement an alternative ETL
architecture that delivers data with agility, significantly less latency, user
consumable and with great performance
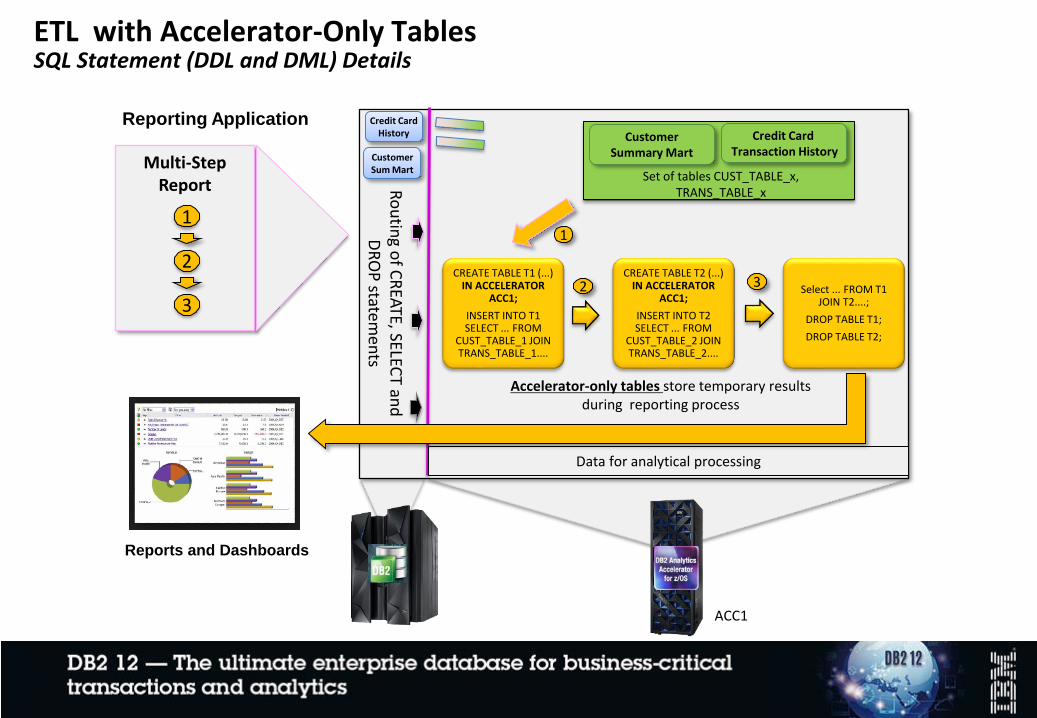
CREATE TABLE T1 (...) IN ACCELERATOR
ACC1;
INSERT INTO T1 SELECT ... FROM
CUST_TABLE_1 JOIN TRANS_TABLE_1....
CREATE TABLE T2 (...) IN ACCELERATOR
ACC1;
INSERT INTO T2 SELECT ... FROM
CUST_TABLE_2 JOIN TRANS_TABLE_2....
Select ... FROM T1 JOIN T2....;
DROP TABLE T1;
DROP TABLE T2;
Accelerator-only tables store temporary results during reporting process
CustomerSummary Mart
Credit Card Transaction History
Set of tables CUST_TABLE_x, TRANS_TABLE_x
Credit CardHistory
CustomerSum Mart
Ro
utin
g of C
REATE, SELEC
T and
D
RO
P statem
ents
ACC1
32
1
Data for analytical processing
Multi-StepReport
Reporting Application
2
3
1
Reports and Dashboards
ETL with Accelerator-Only TablesSQL Statement (DDL and DML) Details

• Transformation logic is often expressed in SQL
• CASE Statements often attach columns just like a join
• Outer Joins attach columns for categorical, key and fact data
• UNIONs append data from multiple applications and/or time periods
• Embedded "Select sum(..) group by“ often used to order and categorize
• Embedded "Select max(...) group by“ often used to order and categorize
• Max(Effective date) is used to group period columns within a category
• Multiple uses of sub-string transform columns into categorical data
• …
• These typical transformations imply opportunities for the data model to
meet reporting requirements
• Why not standardize these transformations and simplify consumability?
Real-time Data Transformation for Data Consumabilityin SQL via VIEWs

• VIEWs can hide SQL complexity from user and contain the intelligence to retrofit
data and simplify access
• Can reflect existing DW/DM schema and keep existing workloads running
• Views can include the transformations necessary to simplify data for end user
consumption
• Rewrite complex SQL within views or..
• Leverage existing database objects (dimensional structures) to transform and
standardize data within the views
• Repetitive transformations from “operational data” to “information» could be
standardized by leveraging data mart modeling techniques
Real-time Data Transformation for Data Consumabilityin SQL via VIEWs

Thank You!





























