Embed Size (px)
Citation preview

Life in the Trenches with ApacheSpark



Who? What?
I work for Kogentix, IncBig Data projects, often with Spark (Core, Streaming, ML)@carsondial on Twitter

Who is the talk for?
People using Apache SparkPeople deciding whether to use Apache SparkPeople who love hearing about Apache SparkWill it get technical? A bit! (but not too much)

Our itinerary:
Good Things!Bad Things!Tips! Tricks! (hopefully the useful section!)Other Frameworks Are Available

Good Things!
Developer-friendly API for batch and streamingSo much faster than MapReduce (in general!)Fits in well with Hadoop EcosystemBatteries included (ML / GraphX / etc.)Tons of Enterprise support

Bad Things!
Spark is not magic pixie dust!Distributed systems are hard!And…well, let's talk about the elephant…

The (Apparent) Motto of ApacheSpark Development:

In Memoriam
This slide is dedicated to all those that created a productionsystem using MLLib just as Spark added ML Pipelines

(and also…)
(btw, if you haven't upgraded to Spark 2.0 yet, be awarethat the change to MurmurHash3 for hashing means you'll
have to retrain all your models that use HashingTF…)

Keeping Up With The Joneses
The Spark development team moves pretty fast, especially fora project in the Hadoop ecosystem
Sometimes Catalyst will fail on a query / job that workedperfectly fine in the previous versionNew features (e.g. KafkaDirectStream/Datasets) can bepushed before they're entirely ready.Sometimes you get big surprises (Hello, StructuredStreaming!)Hadoop distributions can lag (WHERE'S MY SHINY? ITSHOULD HAVE THE SHINY!?)

(cont…)
Not backporting fixes to earlier versions of Spark
e.g. Spark < 2.0 not having support for Kafka 0.9+clients, despite it being a rather useful enterprise-y thing tohave) [SPARK-12177]
Reading the release notes is essential. Yes, I know you doit, but still…

(and yet more…)
API Stability is a big issue
"I want to create a Spark Streaming Solution with Kafkaand Spark 2.0! How should I do it?""Er…"
Hold off on Structured Streaming for now…

ENOUGH NEGATIVITY!
The Spark maintainers are acutely aware of these issuesRecent on-going discussions focussed on improving thingsHurrah!Now, onto tips and tricks

Developers!
Use Scala if you can.Java 8 will preserve your sanity if you have to use Java

Why Not Python?
You will likely take a performance hit with PySparkPython interpreter memory overhead on top of the JVMPickling RDDs and serializing them to Python and back tothe JVMOften lags behind Scala / Java in new features

More Tips
I'm legally mandated mention to not use collect() orgroupByKey() in your code.Be careful with your closures!

Which data structure to use?
Datasets (Catalyst and fancy Encoders!)Dataframes (Catalyst!)RDDs (you're on your own…)Use Kryo serialization when you can if not Encoders

How many partitions should Ihave?
Goldilocks ProblemToo few - not enough parallelismToo many - too much parallelism and lose time inschedulingRemember repartition() is not a free operation

Partition Rule of Thumb
3x cores in your cluster as a baselineExperiment until performance suffers (increase by a factorof <2 each time)gzipped files may not be your friend for partitionsPartitions in streaming often set by streaming source (e.g.Kafka)

Map vs. MapPartitions
.map() works on an element-by-element basis
.mapPartitions() works on a partition basisCan be very helpful when working with heavy objects /connections /etcDon't accidentally consume the iterator!(e.g. converting to a list, using size()/count(), etc)

One more thing
Beware Java!mapPartitions() in Java may bring the entire partitioninto memoryEmbrace Scala, JOIIIIIN USSSSSSS

Streaming Tips
You need to get your processing done within the batchduration.Backpressure!Prefer mapWithState() over updateStateByKey(),as it allows timeouts, modifying state without having toiterate over the entire state spaceSee last year's ATO talk for more streaming tips!

Streaming Sources
Use Apache Kafka if you have an Ops team that cansupport itKinesis if you don't or you can live with the restrictions ofKinesis over Kafka (and you're in AWS)

SparkSQL
Don't rely on JSON schema reflection if you can help itLarge JSON schemas may break Hive(or at least require you to alter things deep in the HiveDDL)Try to push filters down into the source layer when possibleParquet ALL THE THINGSCustom UDFs are (currently) opaque to Catalyst (non-JVMlanguages are even worse here!)

Testing
It's hard! But do it anywayspark-testing-baseMaintained by Holden KarauGreat set of tools for testing RDDs, Dataframes, Datasets,and streaming operations

Test Strategies
Is it correct? (spark-testing-base provides approximatematchers too!)Is it correct under production level loads?Consider a shadow cluster for streaming

Operations
The key to a successful Spark solution.Don't ignore OpsSo many knobs to fiddle with!

Deploying Spark Jobs
Don't rely on spark-submit for too long (do you reallywant users to have to log in to a production server to kickoff a new job?)Use Livy or Spark-Job-Submit as soon as possible to solvewith another layer of indirection!

Upgrading Spark StreamingApplications
Yay! I've turned checkpointing on and I'm super-resilient!Now I'm going to upgrade my app!Why has everything exploded?Checkpointing only works with the same code. Changeanything…and boom.

THIS IS FINE.
Delete checkpoint and it'll workBut…offsets for streaming?Store them in Zookeeper and obtain on start(do you actually need checkpointing in that case? Possiblynot!)

Scheduling Jobs.
OR: We need to talk about Apache Oozie.It can do anything you can throw at it.Providing anything is in a Turing-complete DSL embeddedin XMLWhich can often validate or not, even if written correctly.And a web UI that sometimes rises to the level of'tolerable'

Oozie. Poor Oozie.
But! Less hate!It is not a sexy part of the Hadoop ecosystemIt really can handle almost any scenarioAlso, what if you didn't have to write the XML?

Arbiter
Write your Oozie workflows in YAML100% more hipster-compliantSeriously, up to about 20% less typing and handlesdependencies for you.Try it, and maybe you won't hate Oozie so much

Monitoring
WebUI is great, but perhaps it would be better fed intoyour existing monitoring solution?CODA HALE TO THE RESCUE!Send metrics to CSV, JMX, slf4j, or Graphite

Graphite monitoring
val sparkConf = new spark.SparkConf() .set("spark.metrics.conf.*.sink.graphite.class", "org.apache.spark.metrics.sink.GraphiteSink") .set("spark.metrics.conf.*.sink.graphite.host", graphiteHostName) val sc = new spark.SparkContext(sparkConf)

Monitoring
Also, you're directing all your logs/metrics from yourexecutors and drivers to a central logging system, aren'tyou? And Kafka?Splunk / Datadog / ELK (Elastic, Logstash, Kibana) areyour friendInclude OS metrics too!

Debugging Issues
Spark WebUI is a good place to start for drilling down intotasksThe OS is still important (e.g. memory, OOM killer, Xenhypervisor networking, etc)Distributed systems are hard!

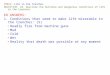
flaaaaaamegraphs
Invented by Brendan Gregg (Netflix, Joyent, Sun)Most common type is on-CPU flamegraphWidth of stack sample is how often that stack sample is onCPU

Spark-flame
Simple and dirty Ansible playbookAttaches to a Spark cluster running on YARNGenerates perf data and pulls back down for flamegraphsOne flamegraph per executor, can be combined into onegraphhttps://github.com/falloutdurham/spark-flame

Flame Graph Search
Interpreter
[libjvm.so]
java/io..
[libjvm.so]
start_thread
Interpreter
[libj..
scala/collection/AbstractIterator:::foreach
[li..
[libjvm..
[libjava.so]
s..
[libjvm.so]
Interpreter
Interpreter
[l..
[lib..
[l..
java
[..
InterpreterInterpr..
Ja..
[..
scala/collection/Iterator$class:::foreach
[libjvm.so]
[li..
[libjvm.so]
java/lang/StrictMat..itable stub
$li..[libjava.so]
[..
Interpreter
org/apach..
[l..
Interpreter
[libjvm.so]
[lib..
Interpreter
Interpreter
call_stub
[libjvm.so]
Interpreter
Interpreter
[libjvm.so]
jav..
java/io..
[libjvm.so]
[li..
[..
InterpreterInterpreter
[..
[libjvm.so]
[li..
Interpreter
Interpreter
scala/collection/generic/Growable$class:::$plus$plus$eq
sc..
java/..
[..
Interpr..
[l..
s..
[..
[..
[..
[..
[l..
[l..
Interpreter
[libjvm.so]
[..
[libjvm.so]
Interpreter
Interpreter

Performance!
How Many Executors Should We Use?How Much Memory Do We Need?What About Garbage Collection?

Executors
Hello Goldilocks again!Small numbers of large executors = long GC pauses, lowparallelismLarge number of small executors = Frequent GC, memoryerrors, other Bad Things

So How Many?
Stay between 3-5 cores per executor64GB is a decent upper memory limit per executorRemember the driver needs memory and cores too!Experiment, experiment, experiment

GC
Use G1GC!Use UI to spot time spent in GC and then turn GC loggingon (or have it on anyway!) Too many major GCs? Increase spark.memory.fraction orExecutor memoryLots of minor GCs? Increase Eden spaceTry other approaches before digging into the GC weeds

Other Frameworks Are Available
Apache Storm / HeronApache FlinkApache ApexApache BeamApache Kafkaaaaaaaaa?

Apache Storm
Low-latency at a level Spark Streaming can't (currently)touchLower-level API (build the DAG yourself, peasant!)Deploying and HA story has not been wonderful in thepast, but is getting much better!Mature and battle-tested at Twitter, Yahoo!, etc.1.0.x series is very solid - lower memory use, much faster.Has slightly undeserved reputation as 'old man' of streamprocessing

Heron
Built by Twitter to work around issues with StormStorm-compatible APIWorks with Apache Mesos (YARN support is coming)Looks very promising as a next-gen Storm(but Apache Storm has also solved a lot of the issuesTwitter did so shrug)

Apache Flink
Higher-level API like SparkBased around streaming rather than Spark's 'batch' focusGetting traction in places like Uber, NetflixDefinitely worth investigating

Apache Apex
Dark Horse of the DAG processing enginesLow-level API like StormFAST.Comes with an amazing array of lego bricks to assembleyour pipelines (want to pipe data from FTP and Splunk intoHBase? Easy with Malhar!)Documentation sometimes lackingUsed by Capital One

Apache Beam
One API to bring them all and in the darkness bind them.Initiative from Google - write your code using the ApacheBeam API and then you can run that code on:Google Cloud DataflowApache SparkApache Flink(more to come)

Apache Beam
In theory, this is great!But…The favoured API is, obviously, Google Cloud Dataflow.Last time I checked, the Apache Spark runner operatedonly in terms of RDDs, thus bypassing Catalyst/Datasetsand all the performance boosts associated with themI'd recommend Beam if you're shopping around for aframework!

Kafkaaaaaaaaaaaa?
Wait, wait, what?Kafka Connect as an alternative to Spark Streaming for ETLKafka Streams for streaming processingHA by using Kafka itself!Streams is very new.Should consider Connect for ETL rather than a Kafka /Spark solution

Finally…
Apache Spark is great!But can require stepping outside the box at scalelots of tuning!test things!monitor things!go do great things!

Zine
Inspired by Julia Evans (@b0rk), I've made a zine!30 copies!Includes bonus material!PDF: http://snappishproductions.com/files/sparklife.pdf

LinksApache Spark
MapWithState
Livy
Spark-Job-Server
Checkpoints
Spark Streaming ATO 2015
Arbiter
Spark-flame