Embed Size (px)
Citation preview

Spark Meetup #2
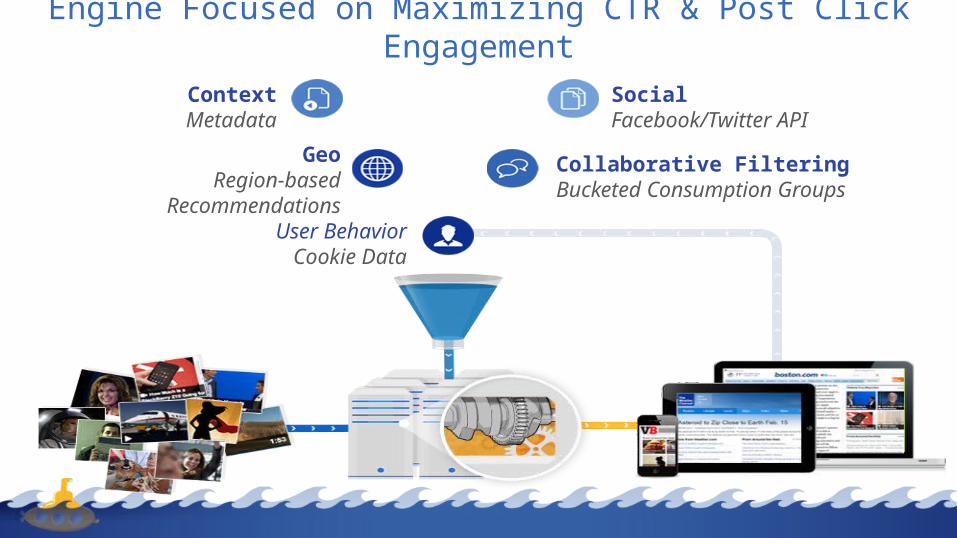
Collaborative FilteringBucketed Consumption Groups
GeoRegion-based
Recommendations
ContextMetadata
SocialFacebook/Twitter API
User BehaviorCookie Data
Engine Focused on Maximizing CTR & Post Click Engagement

Largest Content Discovery and Monetization Network
550MMonthly
Unique Users
240BMonthly
Recommendations
10B+Daily User Events
5TB+Incoming Daily
Data

• Using Spark in production since v0.8• 6 Data Centers across the globe• Dedicated Spark & Cassandra (for spark) cluster consists of
– 5000+ cores with 35TB of RAM memory and ~1PB of SSD local storage, across 2 Data Centers.
• Data must be processed and analyzed in real time, for example:– Real-time, per user content recommendations– Real-time expenditure reports– Automated campaign management– Automated recommendation algorithms calibration– Real-time analytics
What Does it Mean?

SPARK SUMMIT SF 2015Highlights

• Spark DataFrames: Simple and Fast Analysis of Structured Data https://spark-summit.org/2015/events/spark-dataframes-simple-and-fast-analysis-of-structured-data/
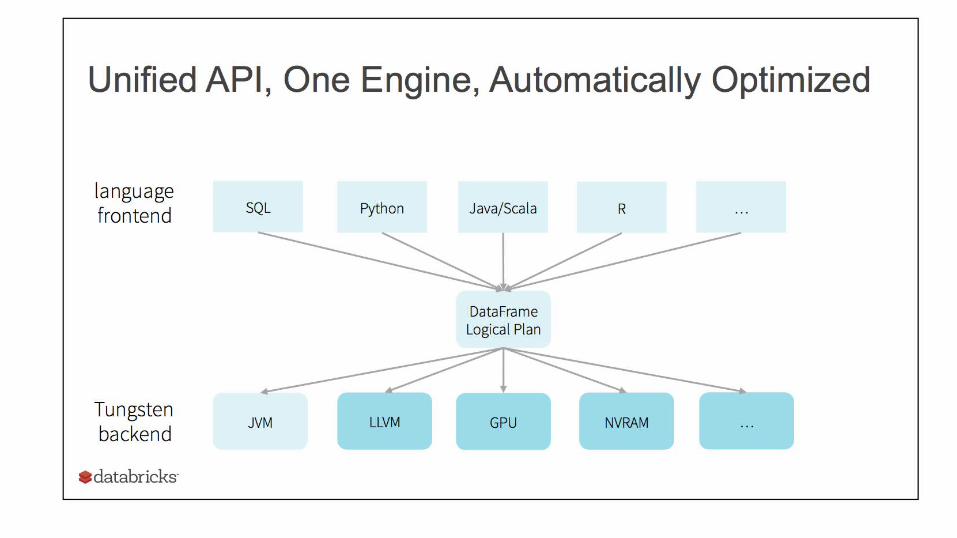
DataFrames

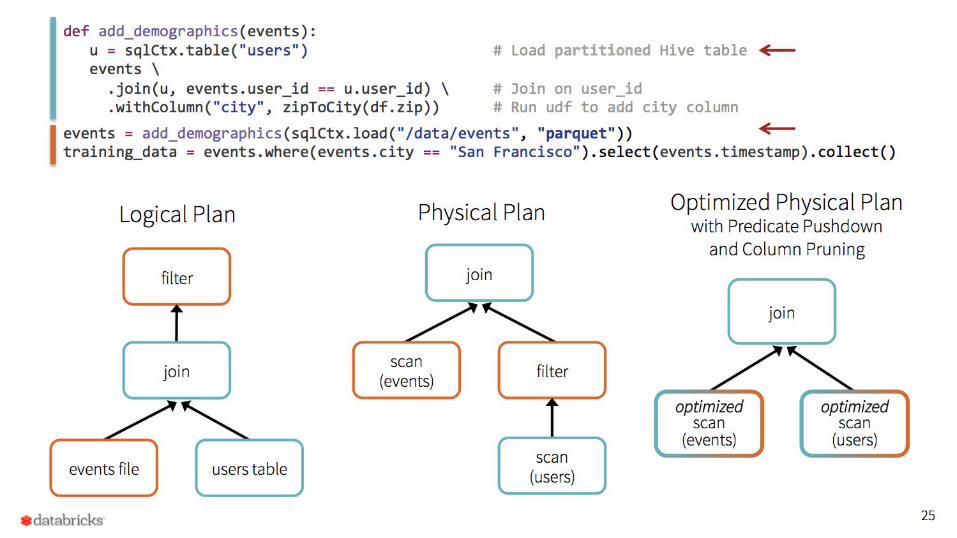

• From DataFrames to Tungsten: A Peek into Spark's Futurehttps://spark-summit.org/2015/events/keynote-9/
• Deep Dive into Project Tungsten: Bringing Spark Closer to Bare Metalhttps://spark-summit.org/2015/events/deep-dive-into-project-tungsten-bringing-spark-closer-to-bare-metal/
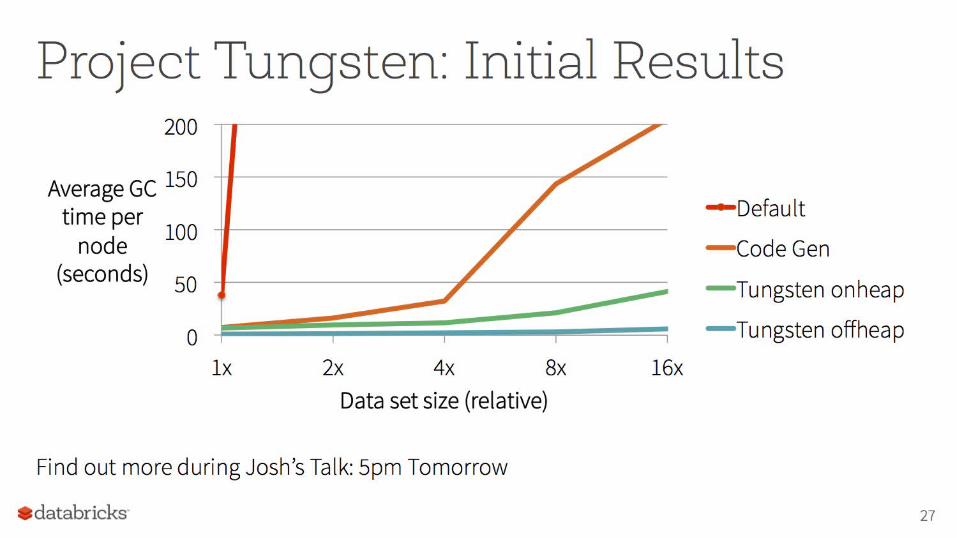
Tungsten

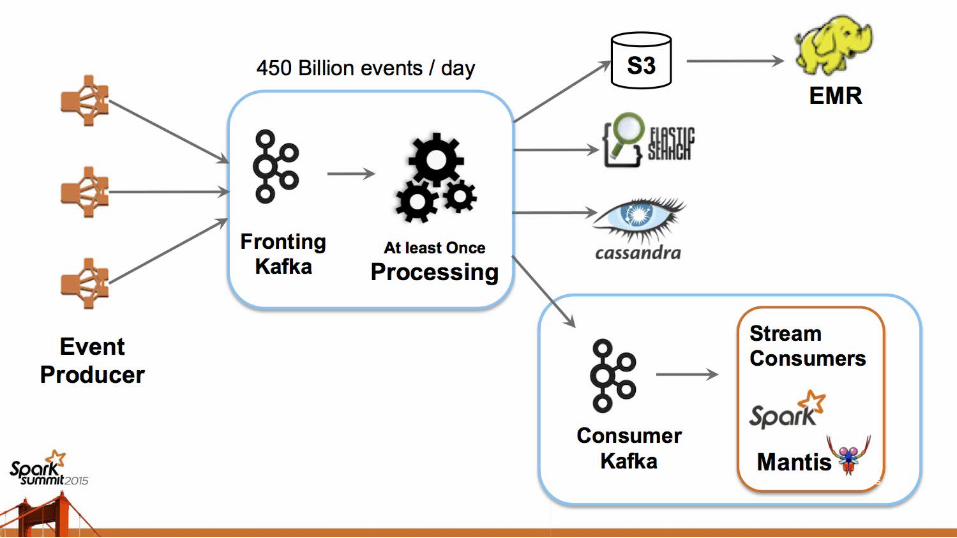
• Spark and Spark Streaming at Netflixhttps://spark-summit.org/2015/events/spark-and-spark-streaming-at-netflix/
Interesting Users’ Experience - Netflix

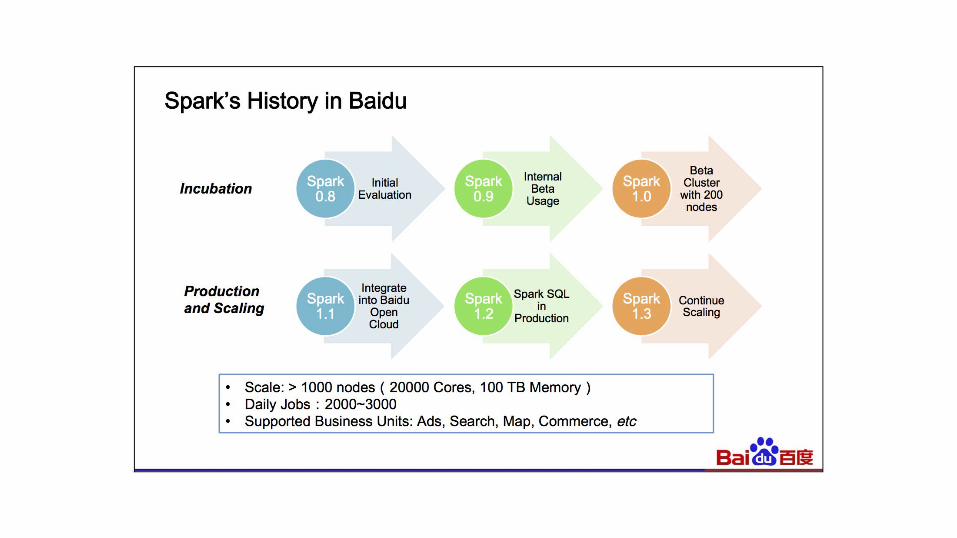
• How Spark Fits into Baidu's Scalehttps://spark-summit.org/2015/events/keynote-10/
Interesting Users’ Experience - Baidu

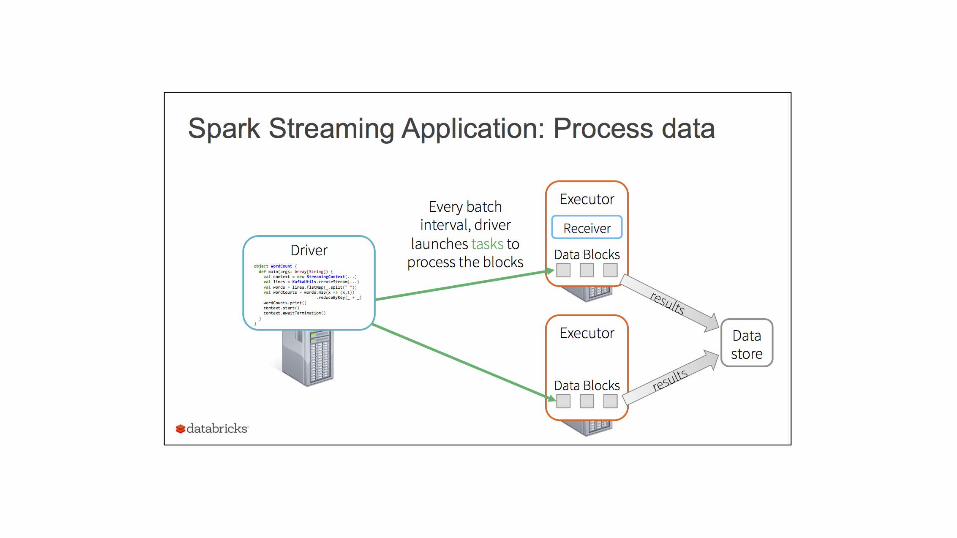
• Recipes for Running Spark Streaming Applications in Productionhttps://spark-summit.org/2015/events/recipes-for-running-spark-streaming-applications-in-production/
Databricks Practical Talks – Spark Streaming
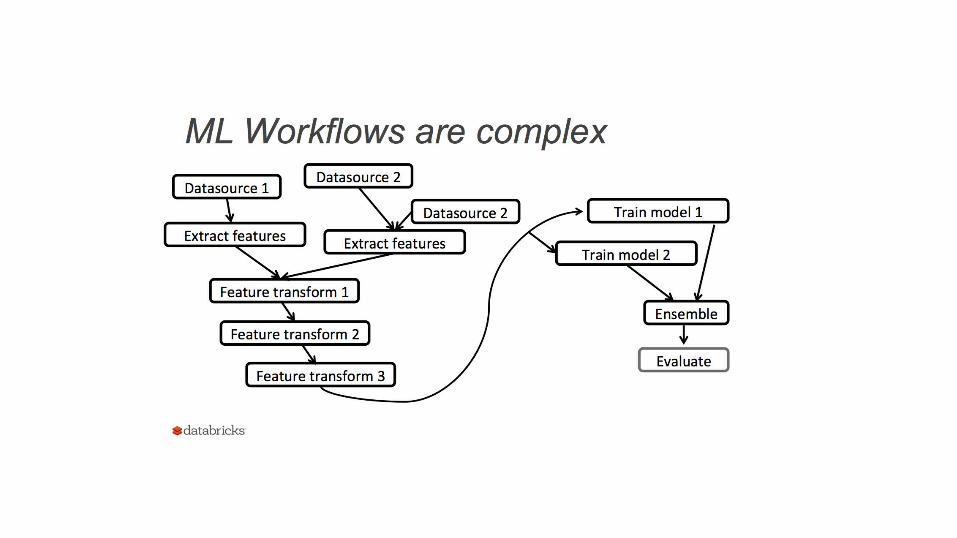
• Building, Debugging, and Tuning Spark Machine Learning Pipelineshttps://spark-summit.org/2015/events/practical-machine-learning-pipelines-with-mllib-2/
Databricks Practical Talks – Machine Learning

• Making Sense of Spark Performancehttps://spark-summit.org/2015/events/making-sense-of-spark-performance/
• Taming GC Pauses for Humongous Java Heaps in Spark Graph Computinghttps://spark-summit.org/2015/events/taming-gc-pauses-for-humongous-java-heaps-in-spark-graph-computing/
• IndexedRDD: Efficient Fine-Grained Updates for RDDshttps://spark-summit.org/2015/events/indexedrdd-efficient-fine-grained-updates-for-rdds/
Performance

• All Spark summit videos and presentations can be found here https://spark-summit.org/2015/
Summary

USING SPARK AND C* TOGETHER FOR DATA ANALYSIS USING DATA FRAMES AND ZEPPELIN
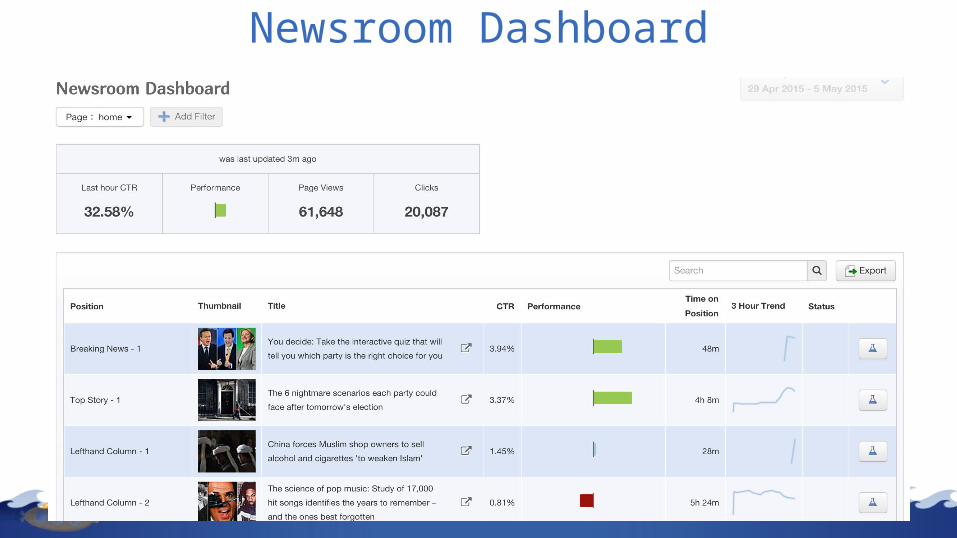
Newsroom Dashboard
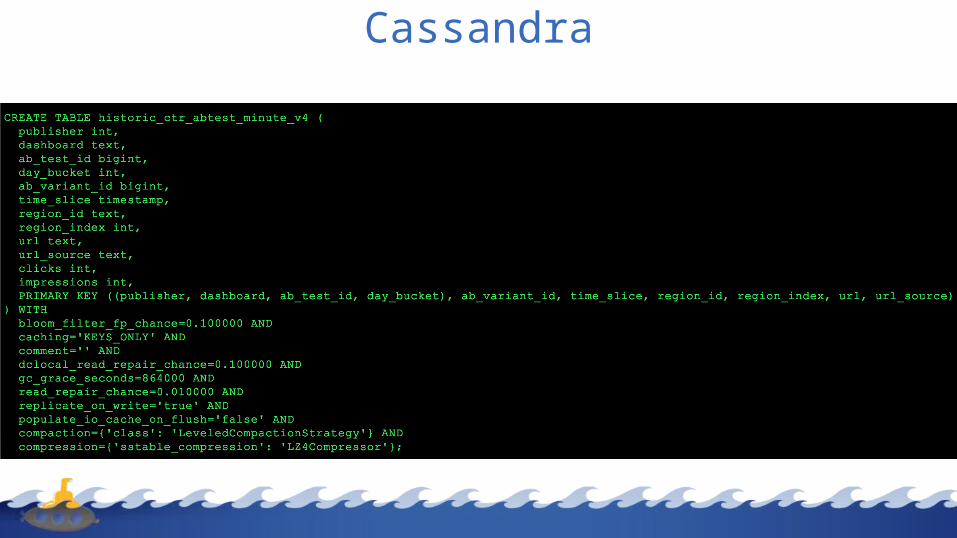
Cassandra

Main Taboola’s framework classes:– CassandraTableSchemaProvider– CassandraDataLoader
Cassandra Table Spark DataFrame

CassandraTableSchemaProviderGetting Cassandra Metadata
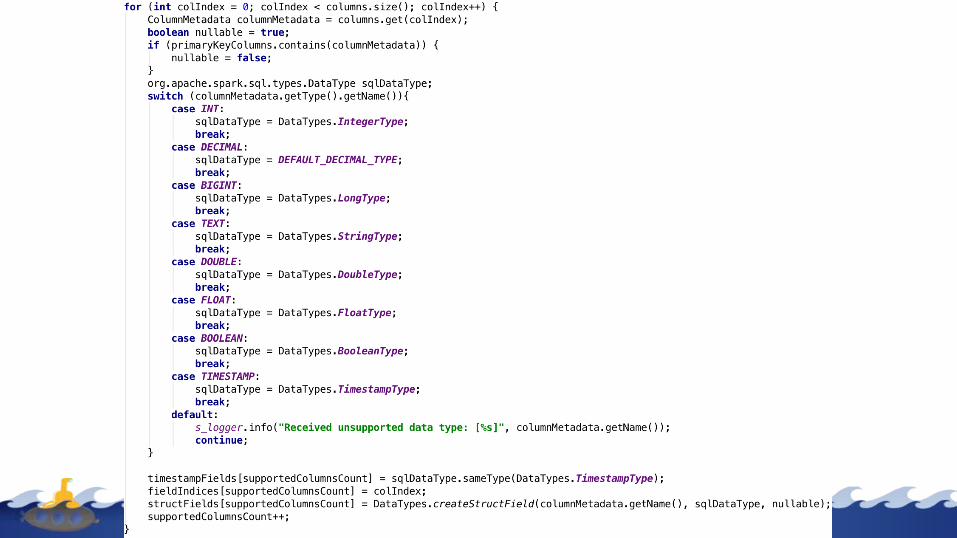
DF From Cassandra

CassandraDataLoader

CassandraDataLoader

Main Taboola’s framework classes:– CassandraTableSchemaProvider– CassandraDataLoader
Cassandra Table Spark DataFrame

Mysql Table Spark DataFrame

Zeppelin
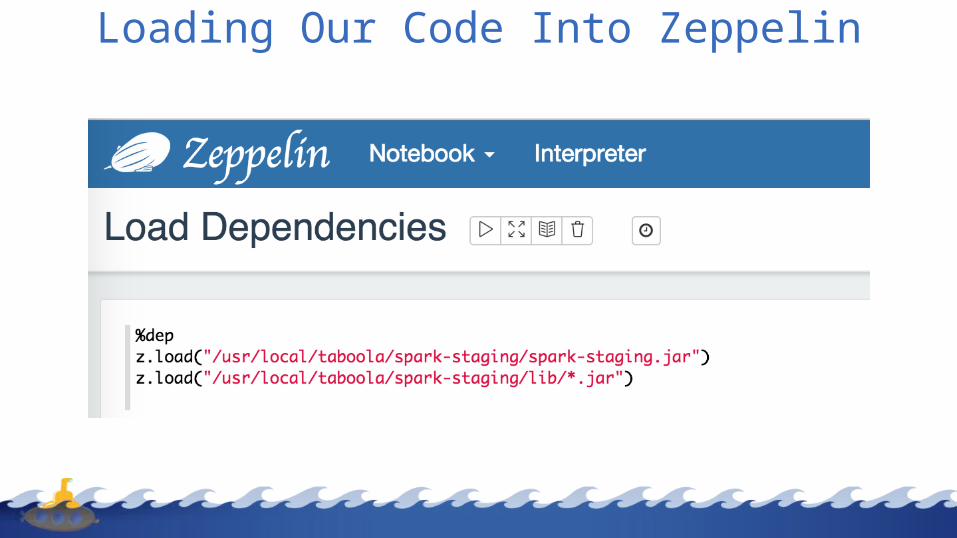
Loading Our Code Into Zeppelin

SparkContext, SQLContext, ZeppelinContext are automatically created and exposed as variable names 'sc', 'sqlContext' and 'z', respectively, both in scala and python environments.
General Variables In Zeppelin
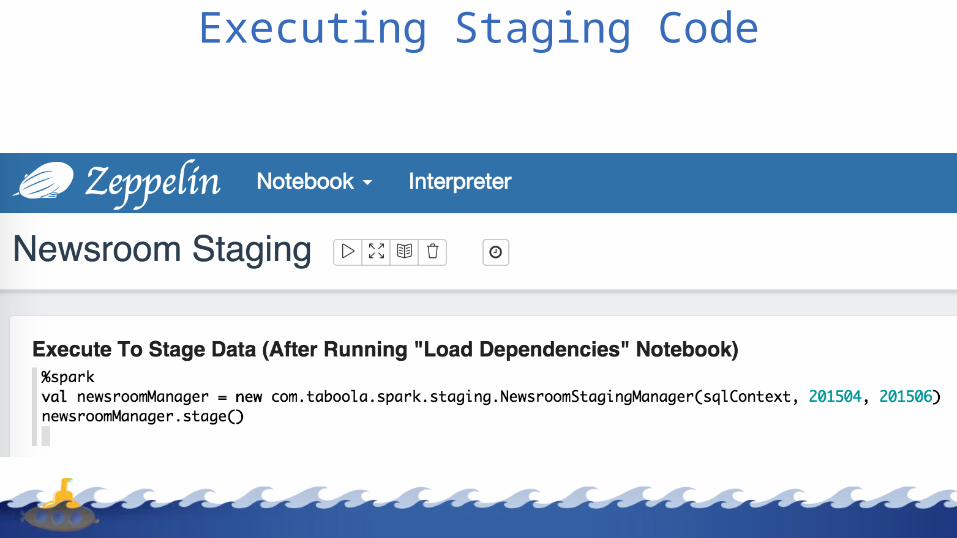
Executing Staging Code
DEMO

• Connect Zeppelin to the cluster (not standalone)
• Load raw sessions data • Run code (python/scala) for algorithmic
analysis
Zeppelin @Taboola - What’s next?