Embed Size (px)
Citation preview

On community-standards, data curation and
scholarly communication
Susanna-Assunta Sansone, PhD
@SusannaASansone
BMIR Colloquium, Stanford University, May 5, 2016
Data Consultant, Honorary Academic Editor
Associate Director, Principal Investigator

Philippe Rocca-Serra, PhD Senior Research Lecturer
Alejandra Gonzalez-Beltran, PhD Research Lecturer
Milo Thurston, DPhD Research Software Engineer
Massimiliano Izzo, PhD Research Software Engineer
Peter McQuilton, PhD Knowledge Engineer
Allyson Lister, PhD Knowledge Engineer
Eamonn Maguire, DPhil Software Engineer contractor
David Johnson, PhD Research Software Engineer
Susanna-Assunta Sansone, PhD Centre’s Associate Director, Principal Investigator
…also students and visitors. Interested? Contact us!
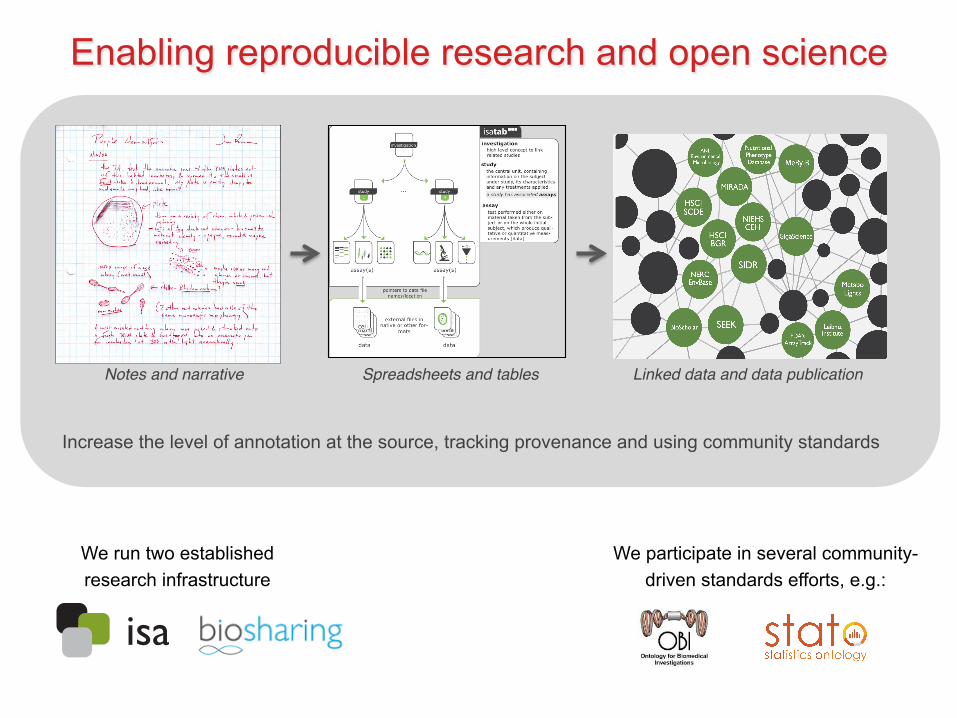
Notes in Lab Books(information for humans)
Spreadsheets and Tables( the compromise)
Facts as RDF statements(information for machines)
Notes and narrative Spreadsheets and tables Linked data and data publication
Notes in Lab Books(information for humans)
Spreadsheets and Tables( the compromise)
Facts as RDF statements(information for machines)
Notes in Lab Books(information for humans)
Spreadsheets and Tables( the compromise)
Facts as RDF statements(information for machines)
Increase the level of annotation at the source, tracking provenance and using community standards
We run two established research infrastructure
We participate in several community-driven standards efforts, e.g.:
Enabling reproducible research and open science

4
medicine
agriculture
bioindustries
environment
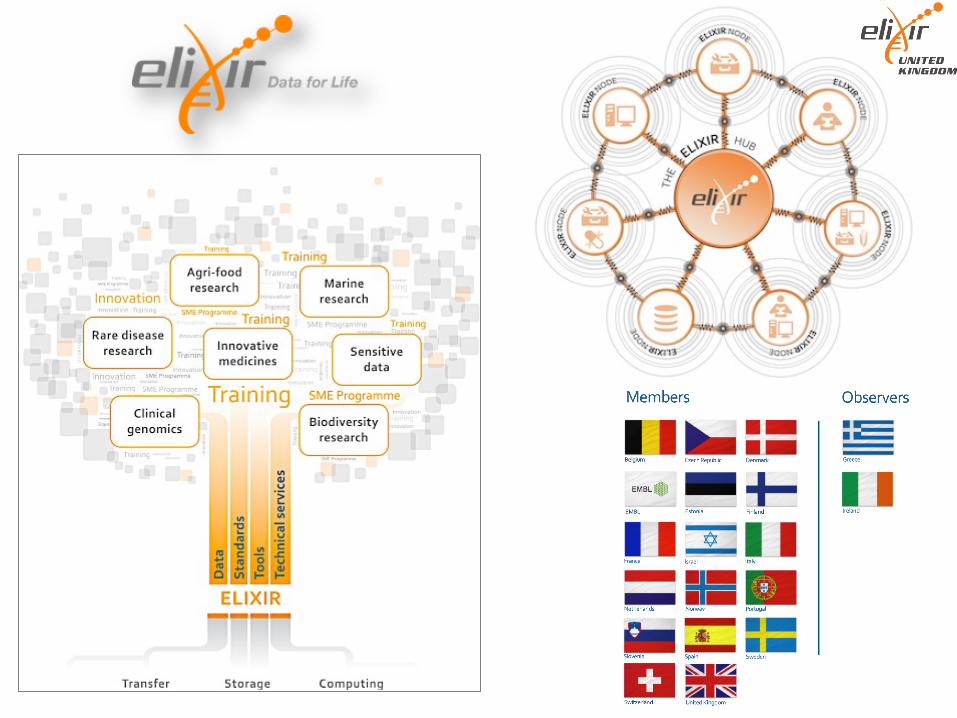
ELIXIRconnectsnationalbioinformaticscentresandEMBL-EBIintoasustainableEuropeaninfrastructureforbiologicalresearchdata
Building a pan-European infrastructure

• Better data better science – role of data journals
• Experimental context – why it matters
• Content standards – potential and challenges
Outline
Credit to

A community mobilization for “openness”
image by Greg Emmerich
http://discovery.urlibraries.org/ https://okfn.org
Open data and methods are a means to do
better science more efficiently
http://pantonprinciples.org
https://creativecommons.org
https://cos.io/

“Over 50% of completed studies in biomedicine do not appear in the published literature….Often because results do not conform to author's hypotheses”
“Only half the health-related studies funded by the European Union between 1998 and 2006 - an expenditure of €6 billion - led to identifiable reports”
Selective reporting: an unfortunate practice
• Small independent efforts, yielding a rich variety of specialty data setso Most of these data (such as null findings) is unpublishedo These dark data hold a potential wealth of knowledge

• Researchers still lack of or insufficient motivationso Focus on big discovery and impact; because they “have to”
• Hypothesis-confirming results get prioritizedo Difficulties with reviews of other results
• Agreements, disagreements and timingo Unclear/lack of data sharing agreements and timing of disclosure
• Loose requirements and monitoring by journals and funderso Publish and release just enough; keep the rest, move to next grant
Selective reporting: why?

• Most researchers are sharing data, and using the data of others
• Direct contact* between researchers (on request) is a common way of sharing data
• Repositories are second most common method of sharing
Kratz JE, Strasser C (2015) Researcher Perspectives on Publication and Peer Review of Data. PLoS ONE 10(2): e0117619.
Current approaches to sharing
* Data associated with published works disappears at a rate of ~17% per year (Vines et al. 2014, doi:10.1016/j.cub.2013.11.014 Datasets not referenced in a manuscript are essentially invisible and data producers do not get appropriate credit for their work

• Outputs are multi-dimensional, diverse, not always well cited / storedo Software, codes, workflows etc.; hard(er) to get hold of
• Data often distributed and fragmented to fit (siloed) databaseso Not contain enough information for others to understand it
• Uneven level of details and annotation across different databaseso Specialized, generalist, public and institutional
• Data curation activities are perceived as time consumingo Collection and harmonization of detailed methods and experimental
steps is done/rushed at publication stage
Shared data is not always understandable, reusable

• Both require significant efforto But transparency is more pragmatic/achievable
• Promoting transparency and reuse helps reproducibility• Access to materials to reduce bias and support
reproducible research:o Methodso Protocolso Codeo Data
Miguel et al. (2014). Promoting transparency in social science research. Science (New York, N.Y.), 343(6166), 30–1. doi:10.1126/science.1245317
Transparency versus reproducibility


A B C D E 1 Group1 Group2 2 Day 0 3 Sodium 139 142 4 Potassium 3.3 4.8 5 Chloride 100 108 6 BUN 18 18 7 Creatine 1.2 1.2 8 Uric acid 5.5* 6.2* 9 Day 7 10 Sodium 140 146 11 Potassium 3.4 5.1 12 Chloride 97 108
S1Sh.cuo
Sharing starts with good metadata…
Credit to: Iain Hrynaszkiewicz

A B C D E 1 Group1 Group2 2 Day 0 3 Sodium 139 142 4 Potassium 3.3 4.8 5 Chloride 100 108 6 BUN 18 18 7 Creatine 1.2 1.2 8 Uric acid 5.5* 6.2* 9 Day 7 10 Sodium 140 146 11 Potassium 3.4 5.1 12 Chloride 97 108
S1Sh.cuo Meaningless column titles
Special characters can cause text mining errors
No units
Unhelpful document name
Undefined abbreviation
Formatting for information that
should be in metadata
….…but this not!
Credit to: Iain Hrynaszkiewicz

A B C D E F 1 Parameter Day Control Treated Units P 2 Sodium 0 139 142 mEq/l 0.82 3 Sodium 7 140 146 mEq/l 0.70 4 Sodium 14 140 158 mEq/l 0.03 5 Sodium 21 143 160 mEq/l 0.02 6 Potassium 0 3.3 4.8 mEq/l 0.06 7 Potassium 7 3.4 5.1 mEq/l 0.07 8 Potassium 14 3.7 4.7 mEq/l 0.10 9 Potassium 21 3.1 3.6 mEq/l 0.52 10 Chloride 0 100 108 mEq/l 0.56 11 Chloride 7 97 108 mEq/l 0.68 12 Chloride 14 101 106 mEq/l 0.79
Table_S1_Shanghai_blood.xls
….this is much clearer!
Credit to: Iain Hrynaszkiewicz

• We need to report sufficient information to reuse the dataset
• We must strike a balance between depth and breadth of information
Without context data is meaningless
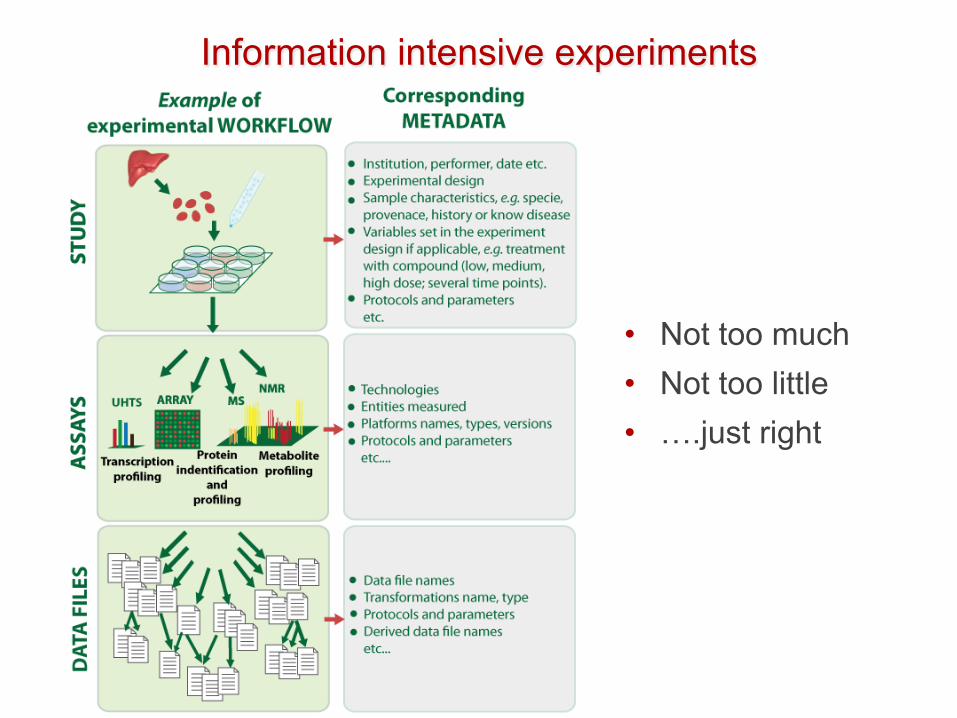
Information intensive experiments
• Not too much • Not too little • ….just right

Seven week old C57BL/6N mice were treated with low-fat diet.
Liver was dissected out, hepatocytes prepared…
From natural language to ‘computable’ concepts
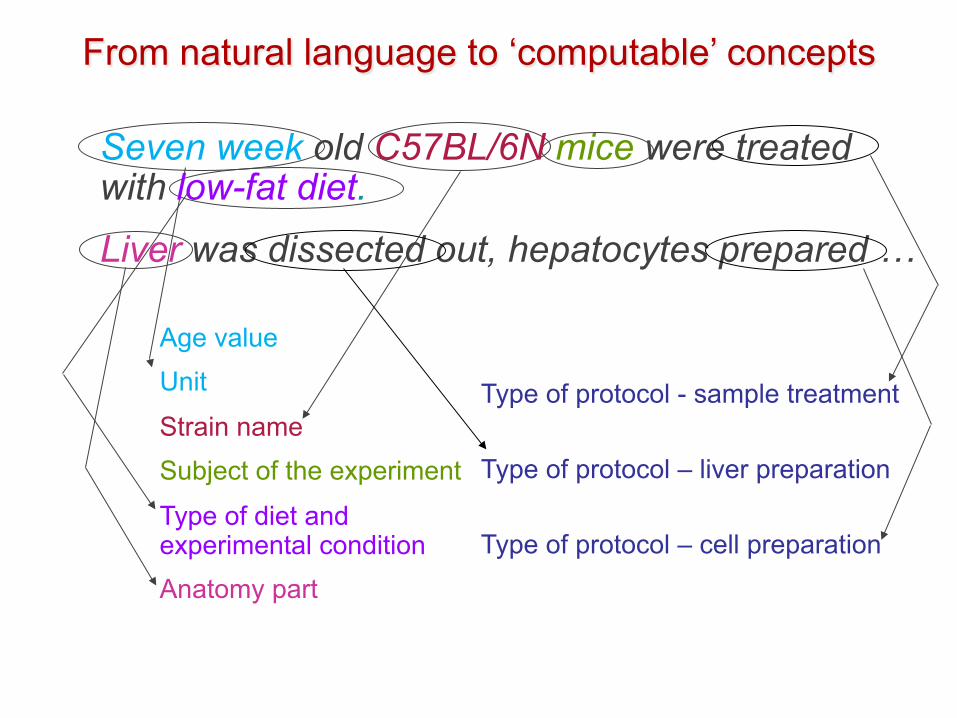
Age value Unit
Strain name Subject of the experiment
Type of diet and experimental condition Anatomy part
Seven week old C57BL/6N mice were treated with low-fat diet.
Liver was dissected out, hepatocytes prepared …
From natural language to ‘computable’ concepts
Type of protocol – cell preparation
Type of protocol - sample treatment
Type of protocol – liver preparation
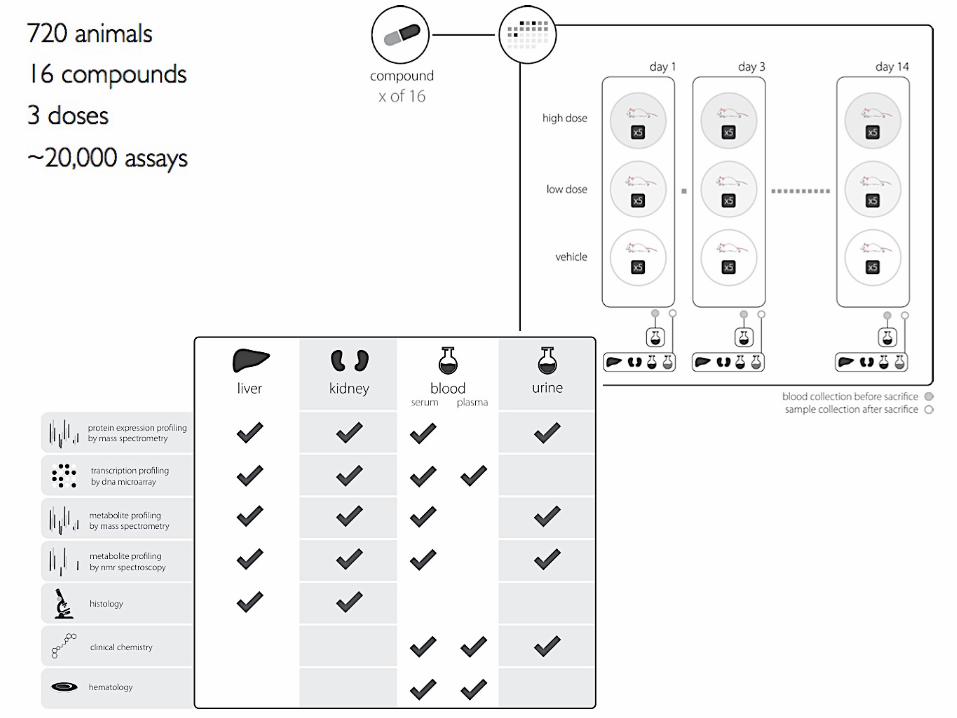
The International Conference on Systems Biology (ICSB), 22-28 August, 2008 Susanna-Assunta Sansone www.ebi.ac.uk/net-project
22
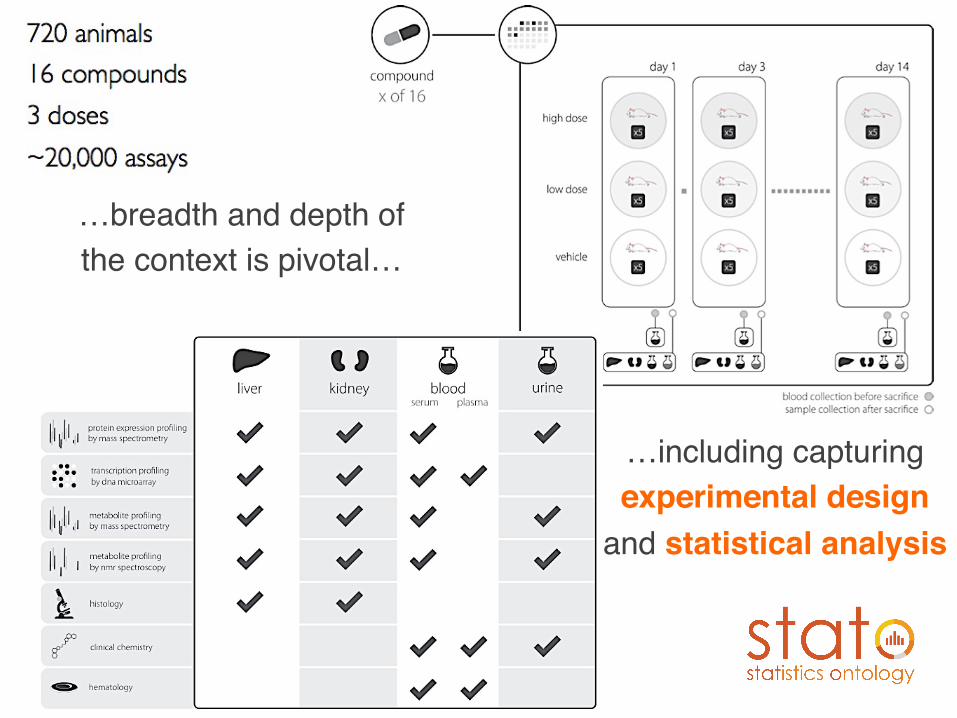
The International Conference on Systems Biology (ICSB), 22-28 August, 2008 Susanna-Assunta Sansone www.ebi.ac.uk/net-project
23
…breadth and depth of the context is pivotal…
…including capturing experimental design
and statistical analysis

Publishers occupy a leverage point, because of importance of formal
publications in the academic incentive structure
Stakeholders mobilizations, old and new driving forces

• More reliable evidence• Supporting journal and society
goals• Supporting expectations of
research community and funding agencies
• Content innovation• More visible and widely
reused publications
Why do publishers care?

• Incentive, credit for sharingo Big and small datao Unpublished datao Long tail of datao Curated aggregation
• Peer review of data• Value of data vs. analysis• Discoverability and reusability
o Complementing community databases
Growing number of data papers and data journals

nature.com/scientificdata Honorary Academic Editor Susanna-Assunta Sansone, PhD Managing Editor Andrew L Hufton, PhD
Editorial Curator Varsha Khodiyar Publisher Iain Hrynaszkiewicz
A new open-access, online-only publication for descriptions of scientifically valuable datasets
Supported by

A new article type
A new category of publication that provides detailed descriptors of scientifically valuable datasets
Mandates open data, without unnecessary restrictions, as a condition of submission

29
Decades old
dataset
Aggregated or curated data
resources
Computationally produced data
productsLarge
consortium dataset
Data from a single
experiment
Data associated with a high
impact analysis article
What does make a good Data Descriptors
Credit to: Andrew Hufton
Res
earc
h pa
pers
D
ata
reco
rds
Dat
a D
escr
ipto
rs
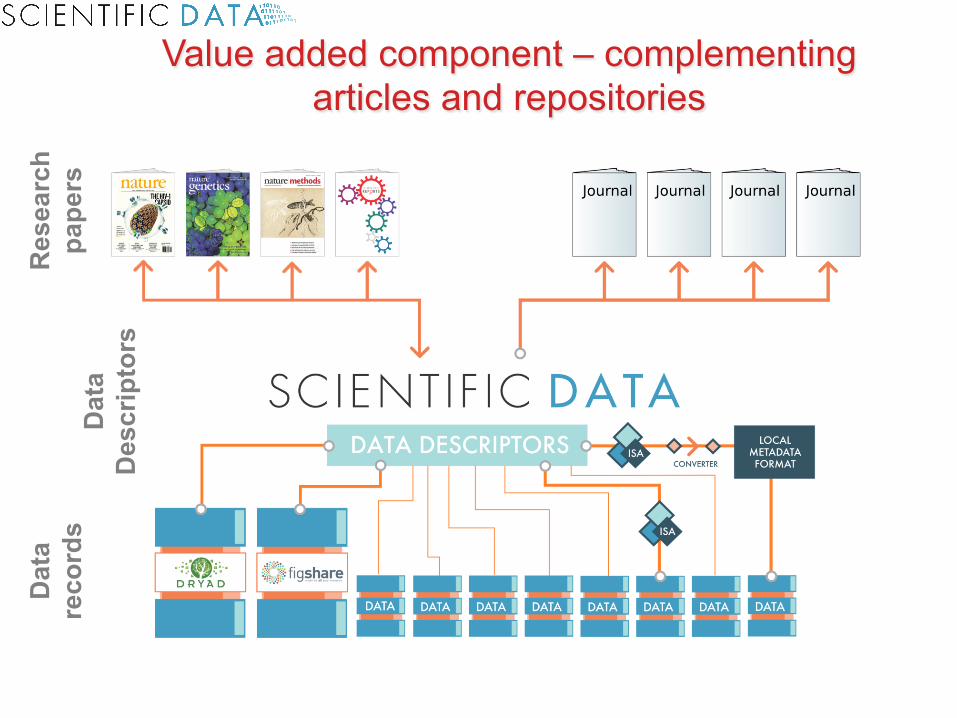
Value added component – complementing articles and repositories

Scientific hypotheses:SynthesisAnalysisConclusions
Methods and technical analyses supporting the quality of the measurements:What did I do to generate the data?How was the data processed?Where is the data?Who did what when
Relation with traditional articles – content

Citation of and links to data files and databases

Experimental metadata or structured component
(in-house curated, machine-readable formats)
Article or narrative component
(PDF and HTML)
Data Descriptors has two components

The Data Curation Editor is responsible for creating and curating the machine-readable structured component• Enables browsing and searching the articles• Facilitates links to related journal articles and repository
records
Curation and discoverability
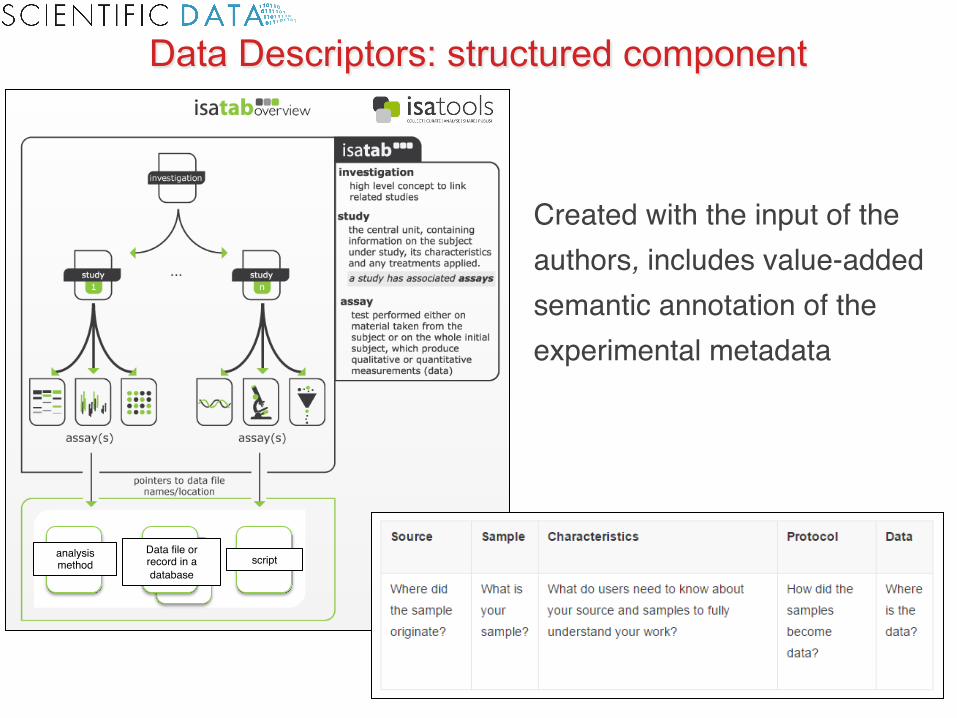
Created with the input of the authors, includes value-added semantic annotation of the experimental metadata
analysis method script
Data file or record in a database
Data Descriptors: structured component
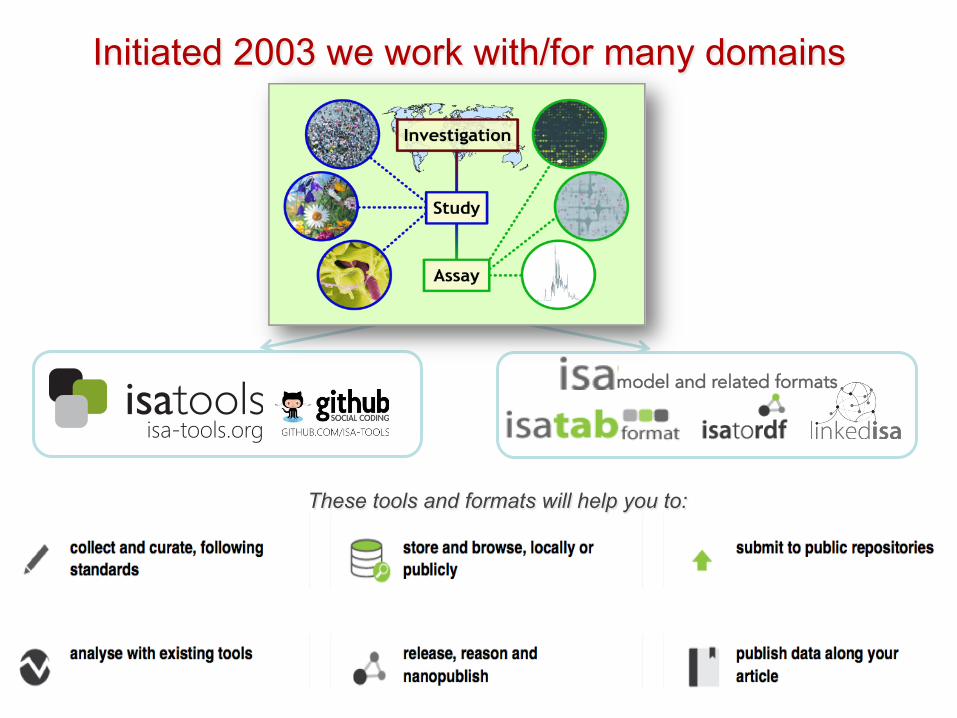
model and related formats
These tools and formats will help you to:
Initiated 2003 we work with/for many domains

The International Conference on Systems Biology (ICSB), 22-28 August, 2008 Susanna-Assunta Sansone www.ebi.ac.uk/net-project
ISA powers data collection, curation resources and repositories, e.g.:
A networked ecosystem
model and related formats
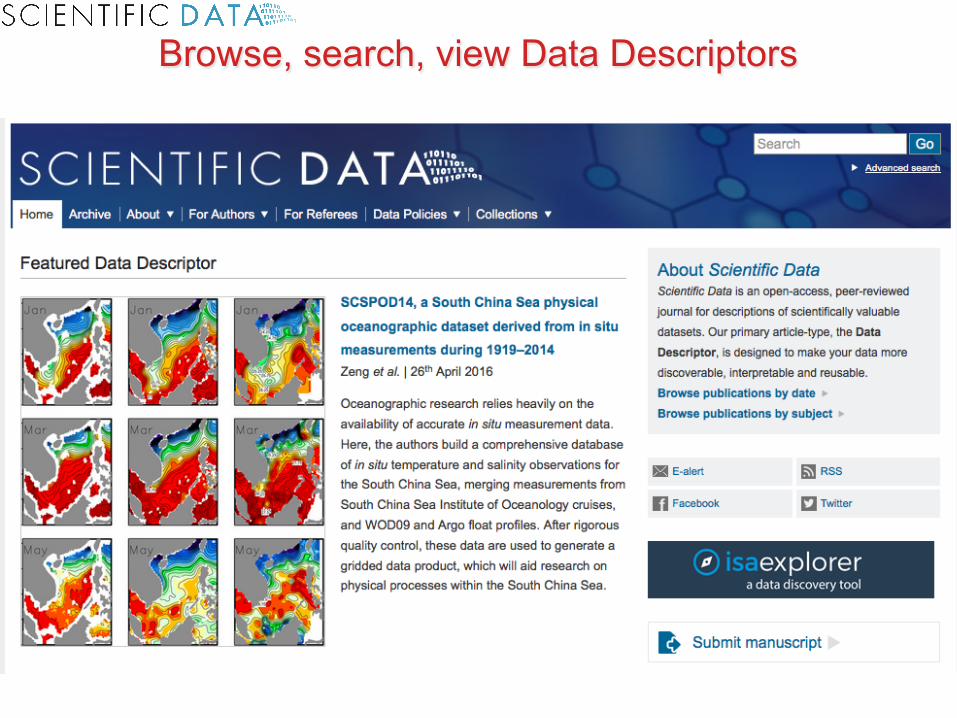
Browse, search, view Data Descriptors


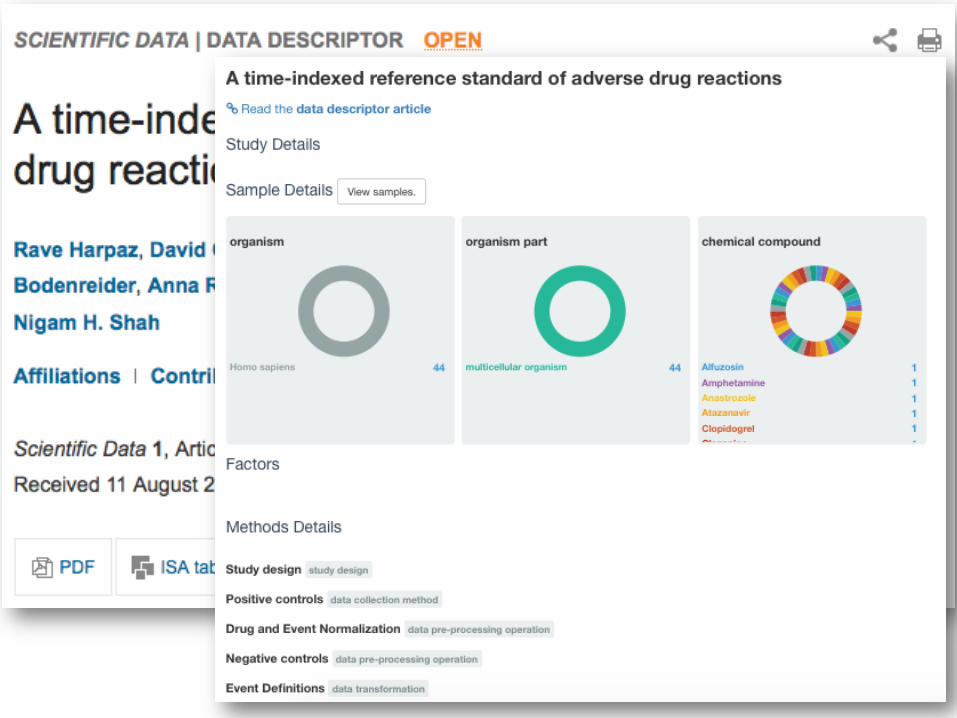

43
Why data papers? Credit for data producers!
Credit to: Varsha Khodiyar

“The Data Descriptor made it easier to use the data, for me it was critical that everything was there…all the technical details like voxel size.”
Professor Daniele Marinazzo
Why data papers? Data reuse is easier!
Credit to: Varsha Khodiyar
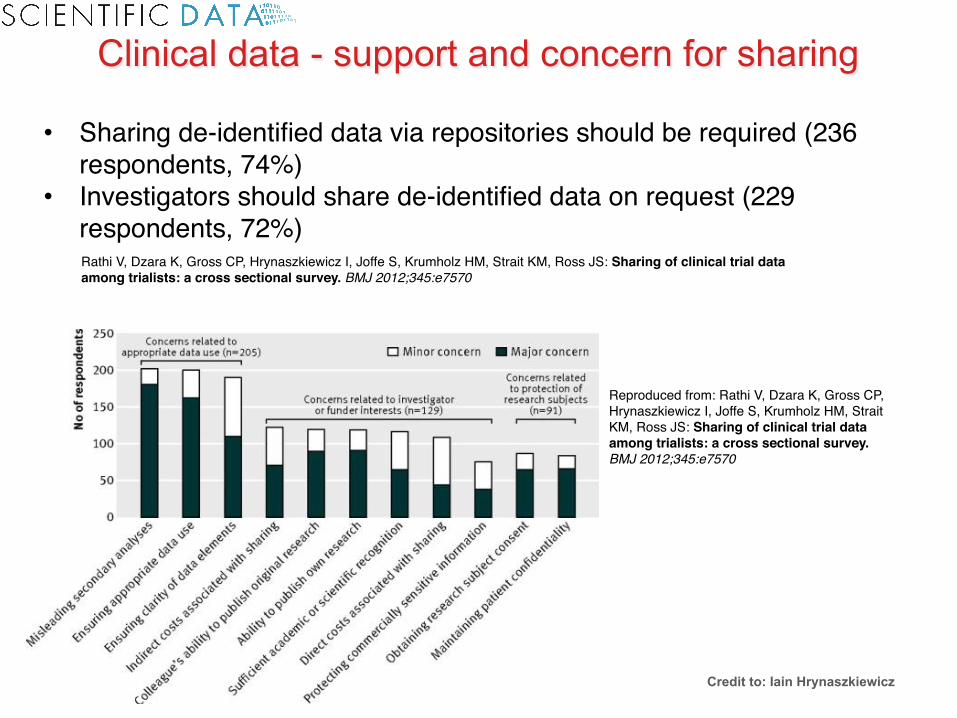
Rathi V, Dzara K, Gross CP, Hrynaszkiewicz I, Joffe S, Krumholz HM, Strait KM, Ross JS: Sharing of clinical trial data among trialists: a cross sectional survey. BMJ 2012;345:e7570
• Sharing de-identified data via repositories should be required (236 respondents, 74%)
• Investigators should share de-identified data on request (229 respondents, 72%)
Clinical data - support and concern for sharing
Credit to: Iain Hrynaszkiewicz
Reproduced from: Rathi V, Dzara K, Gross CP, Hrynaszkiewicz I, Joffe S, Krumholz HM, Strait KM, Ross JS: Sharing of clinical trial data among trialists: a cross sectional survey. BMJ 2012;345:e7570

Better ways to share on request
Credit to: Iain Hrynaszkiewicz
Yale Open Data Access (YODA) & Clinical Study Data Request (CSDR) projects:
• Data Use Agreements (DUAs) • Controlled access environment • Scientific validity of reanalysis checked • Independent governance • Data anonymisation checks
http://yoda.yale.edu/ https://www.clinicalstudydatarequest.com/

Better ways to publish on request
Credit to: Iain Hrynaszkiewicz
• Working group Dec 2014 to produce guidelines1 on publishing descriptions of non-public clinical data
• Goal to connect data on request services with a trusted repository and journal article
• Expected benefits: • Publication and permanence • Peer review – data and article • Discoverability e.g. PubMed • New option for negative/unpublished data? • Robust links with repositories

Key recommendations
• Clinical researchers: Prepare to share on request, with short embargoes
• Repositories: Develop mechanisms to host clinical data non-publicly and manage access requests; collaborate with journals
• Editors and publishers: Check policy compliance for every submission and facilitate peer reviewer access to data; collaborate with repositories
• Sponsors and funders: Partner with trusted repositories and ensure that data access requests are proportionately reviewed without introducing unnecessary barriers
Credit to: Iain Hrynaszkiewicz

Restricted data access Data Descriptor

Restricted data access Data Descriptor

The Data Curation Editor is responsible for creating and curating the machine-readable structured component• Enables browsing and searching the articles• Facilitates links to related journal articles and repository
records
Curation and discoverability

• Better data better science – role of data journals
• Experimental context – why it matters
• Content standards – potential and challenges
Outline
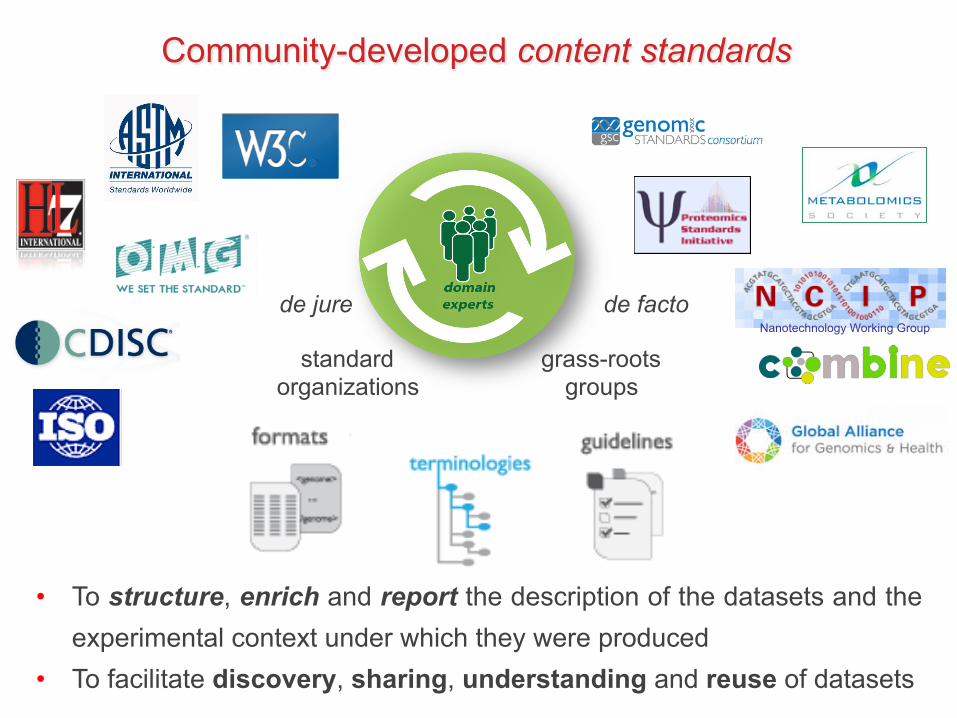
de jure de facto
grass-roots groups
standard organizations
Nanotechnology Working Group
• To structure, enrich and report the description of the datasets and the experimental context under which they were produced
• To facilitate discovery, sharing, understanding and reuse of datasets
Community-developed content standards
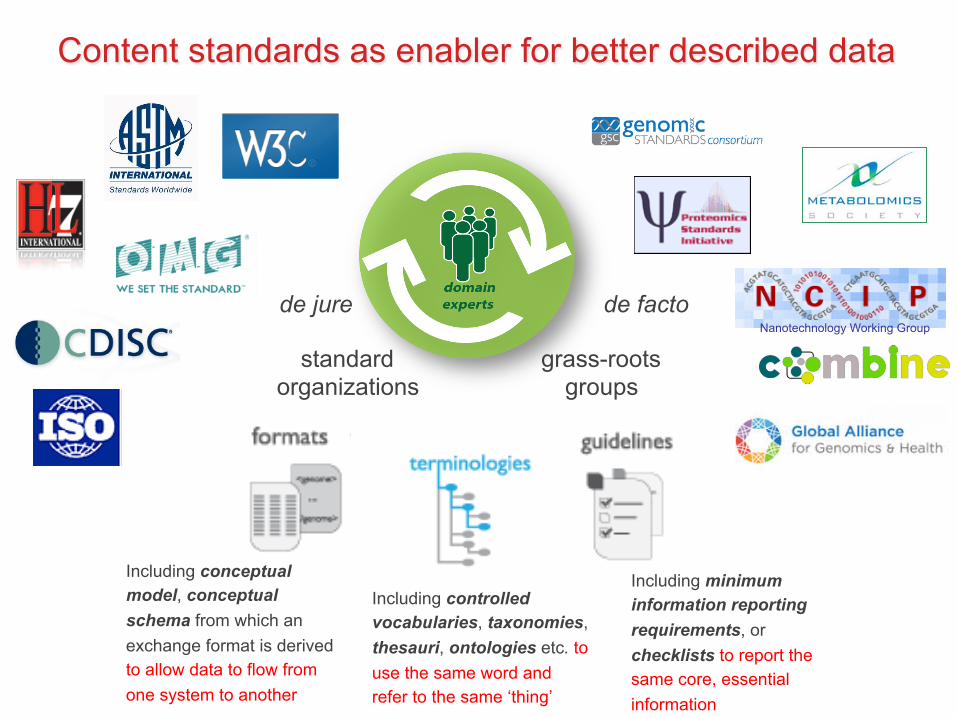
de jure de facto
grass-roots groups
standard organizations
Nanotechnology Working Group
Content standards as enabler for better described data
Including minimum information reporting requirements, or checklists to report the same core, essential information
Including controlled vocabularies, taxonomies, thesauri, ontologies etc. to use the same word and refer to the same ‘thing’
Including conceptual model, conceptual schema from which an exchange format is derived to allow data to flow from one system to another
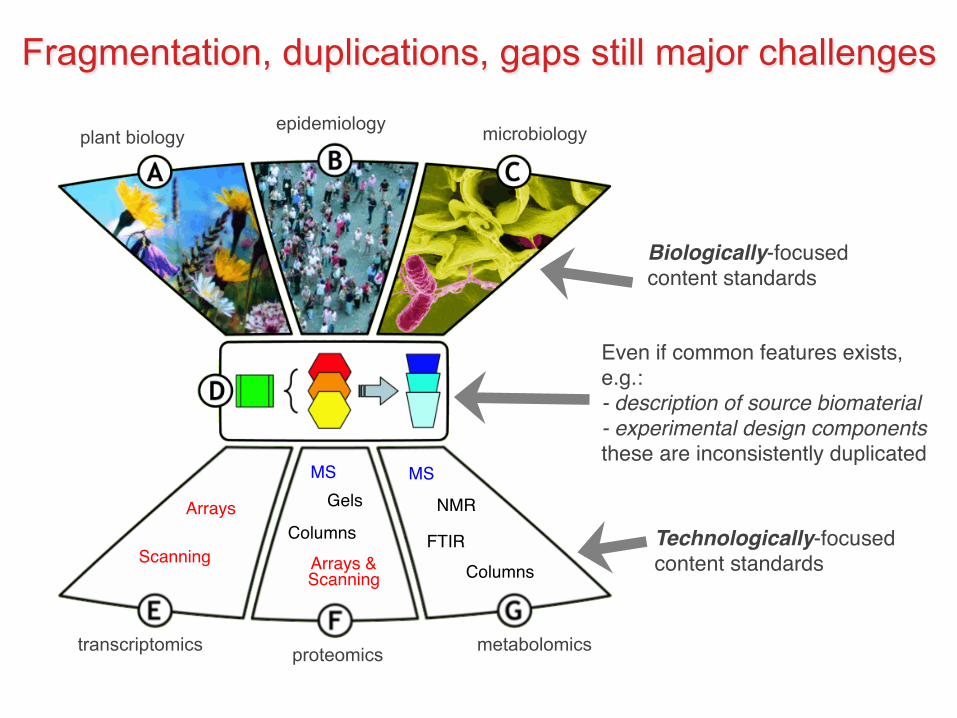
Technologically-focused content standards
Biologically-focused content standards
Even if common features exists, e.g.:- description of source biomaterial- experimental design componentsthese are inconsistently duplicated
Arrays
Scanning Arrays &Scanning
Columns
GelsMS MS
FTIR
NMR
Columns
transcriptomics proteomics metabolomics
plant biology epidemiology microbiology
Fragmentation, duplications, gaps still major challenges
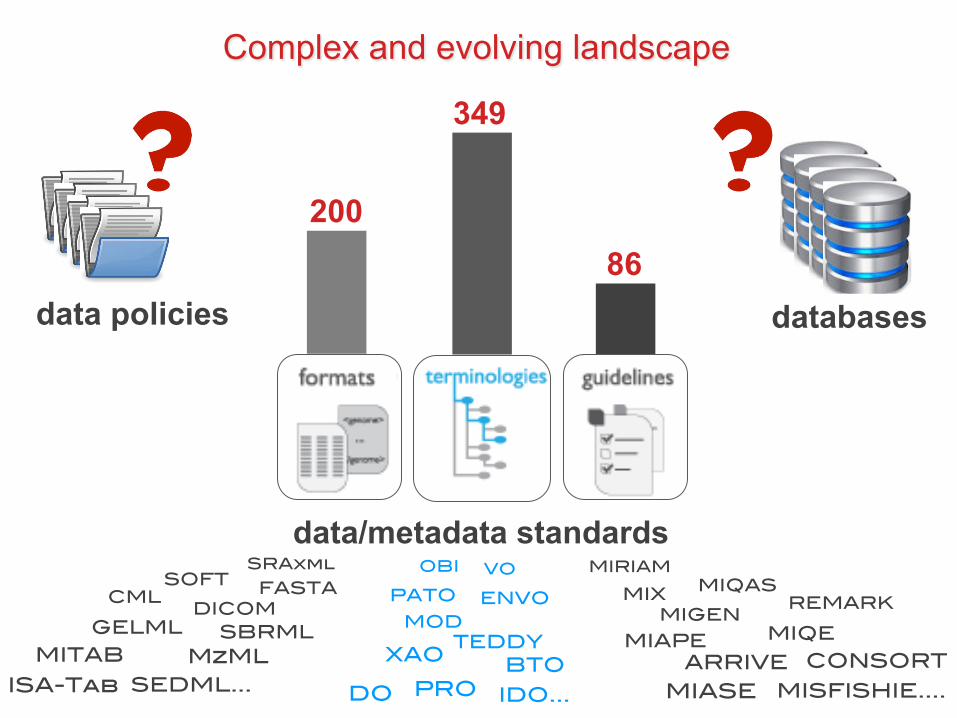
200 86
349
miame!
MIRIAM!MIQAS!MIX!
MIGEN!
ARRIVE!MIAPE!
MIASE!
MIQE!
MISFISHIE….!
REMARK!
CONSORT!
SRAxml!SOFT! FASTA!
DICOM!
MzML!SBRML!
SEDML…!
GELML!
ISA-Tab!
CML!
MITAB!
AAO!CHEBI!
OBI!
PATO! ENVO!MOD!
BTO!IDO…!
TEDDY!
PRO!XAO!
DO
VO!
Complex and evolving landscape
data policies databases
data/metadata standards

Is there a database, implementing standards, where to deposit my
metagenomics dataset?
My funder’s data sharing policy recommends the use of
established standards, but which ones are widely
endorsed and applicable to my toxicological and clinical data?
Am I using the most up-to-date version of this terminology to annotate cell-based assays?
I understand this format has been deprecated; what has been replaced
by and how is leading the work?
Are there databases implementing this exchange format, whose
development we have funded?
What are the mature standards and
standards-compliant databases we should
recommend to our authors?
But how do we help users to make informed decisions?
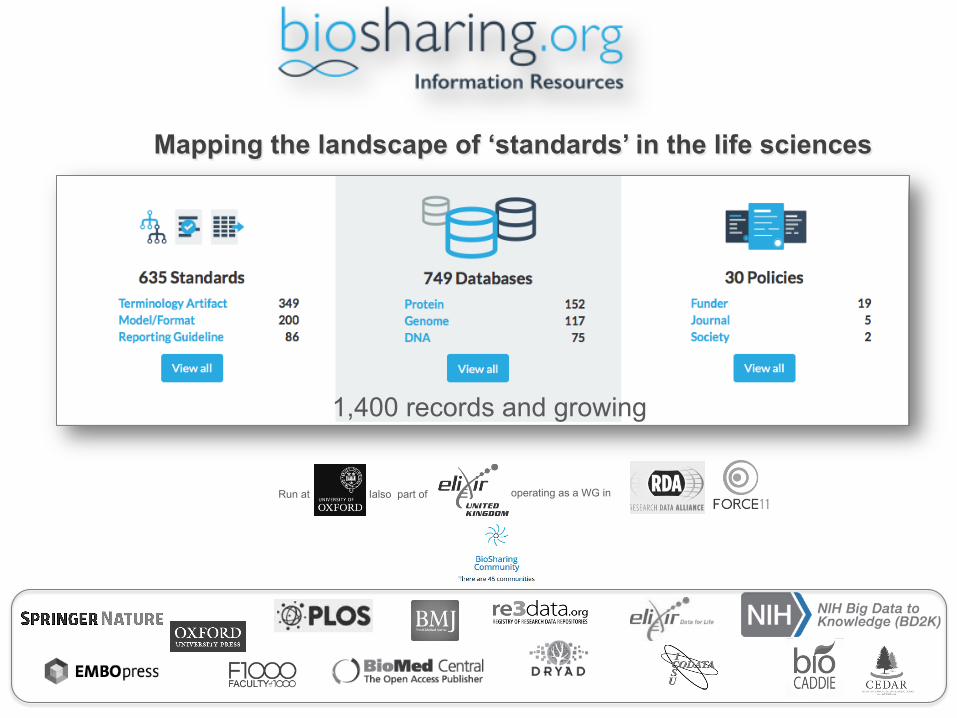
operating as a WG in Run at Ialso part of
Mapping the landscape of ‘standards’ in the life sciences
1,400 records and growing

A web-based, curated and searchable registry ensuring that standards and databases are registered, informative and
discoverable; monitoring development and evolution of standards,
their use in databases and adoption of both in data policies
Mapping the landscape of ‘standards’ in the life sciences
1,400 records and growing
The International Conference on Systems Biology (ICSB), 22-28 August, 2008 Susanna-Assunta Sansone www.ebi.ac.uk/net-project
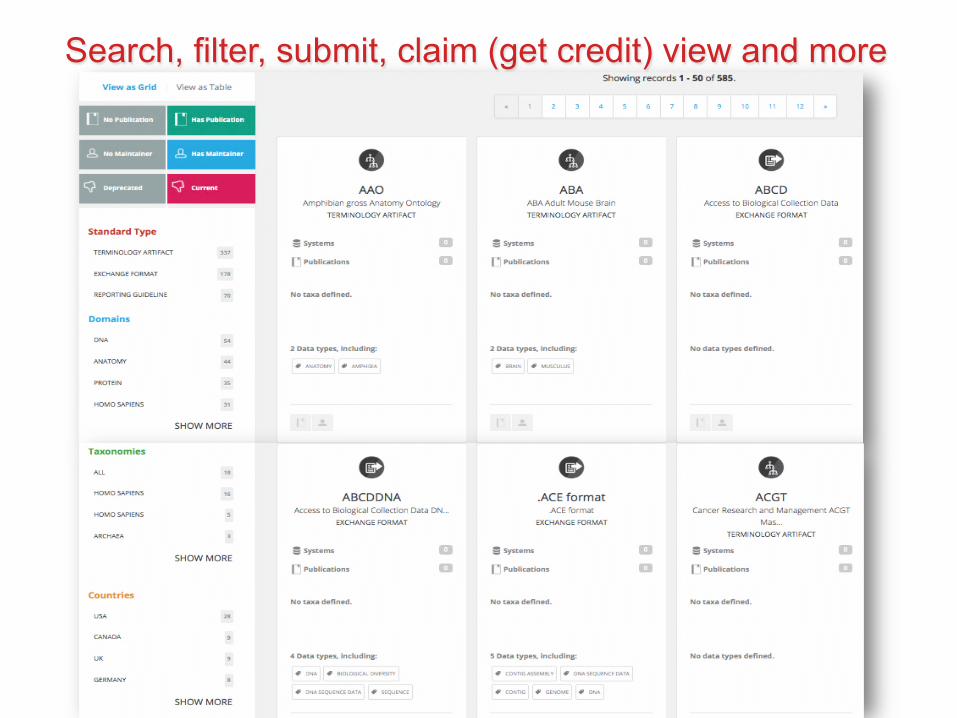
Search, filter, submit, claim (get credit) view and more
The International Conference on Systems Biology (ICSB), 22-28 August, 2008 Susanna-Assunta Sansone www.ebi.ac.uk/net-project
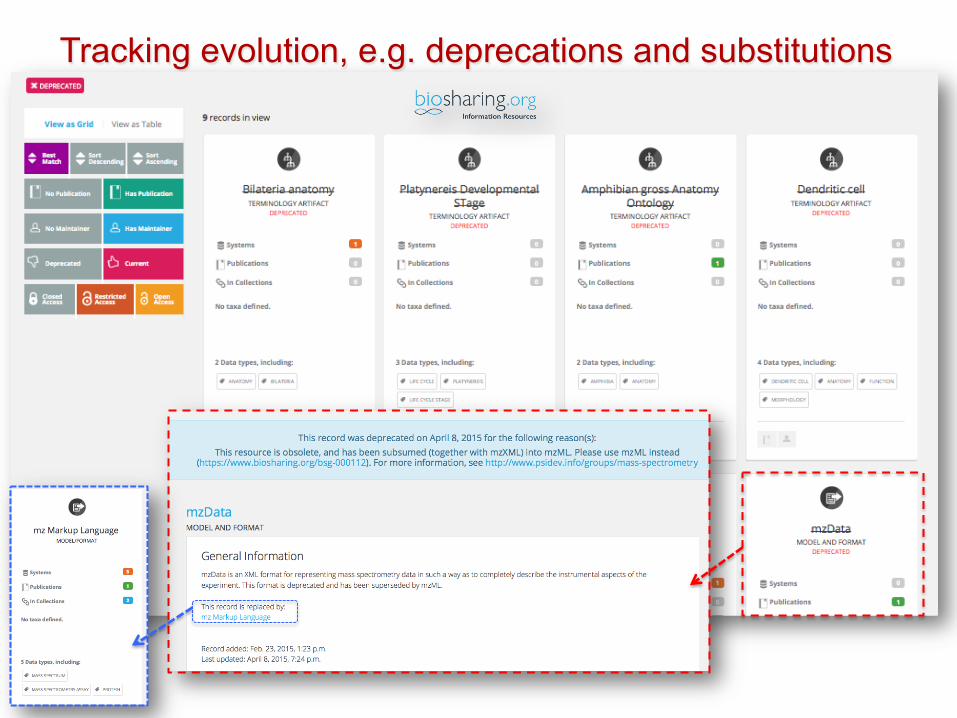
Tracking evolution, e.g. deprecations and substitutions

Powered by curated descriptions of each standard and database records, and their
relations;
Wizard (beta)

Standards and databases recommended by publishers in their data policies

EXPLOREExploration and Reuse
of Datasets through Metadata
ANNOTATEAnnotation of Data with
Metadata
STRUCTUREAuthoring of Metadata
Templates
Metadatatempates
Template authors
define
Metadataacquisition
forms
fill in search,reuse
Scientists
contribute
Metadatarepository
Create a unified framework that researchers in all scientific disciplines can use to create consistent, easily searchable metadata

works to:
• provide information on which metadata elements are needed to create a template for submission to GEO (that also requires compliance to the MIAME reporting requirements)
• serve machine-readable metadata standards, providing provenance for their elements
Goal is to render standards invisible to the researchers
Towards standards-compliant template creation
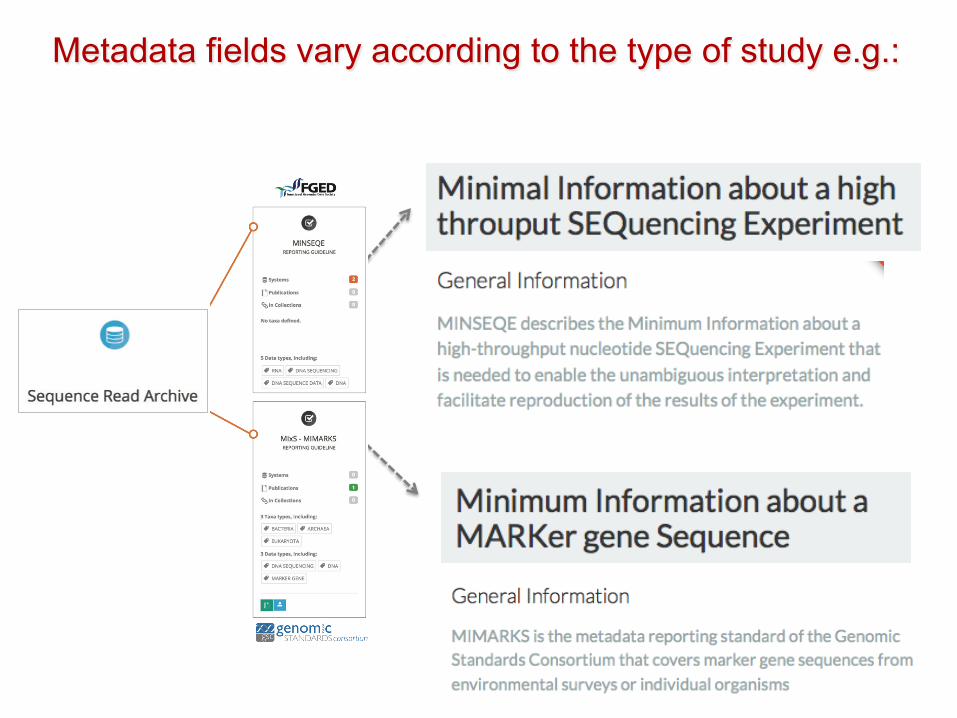
Metadata fields vary according to the type of study e.g.:

Creating standards-derived metadata elements
High-level information about standards, their relations and use by databases
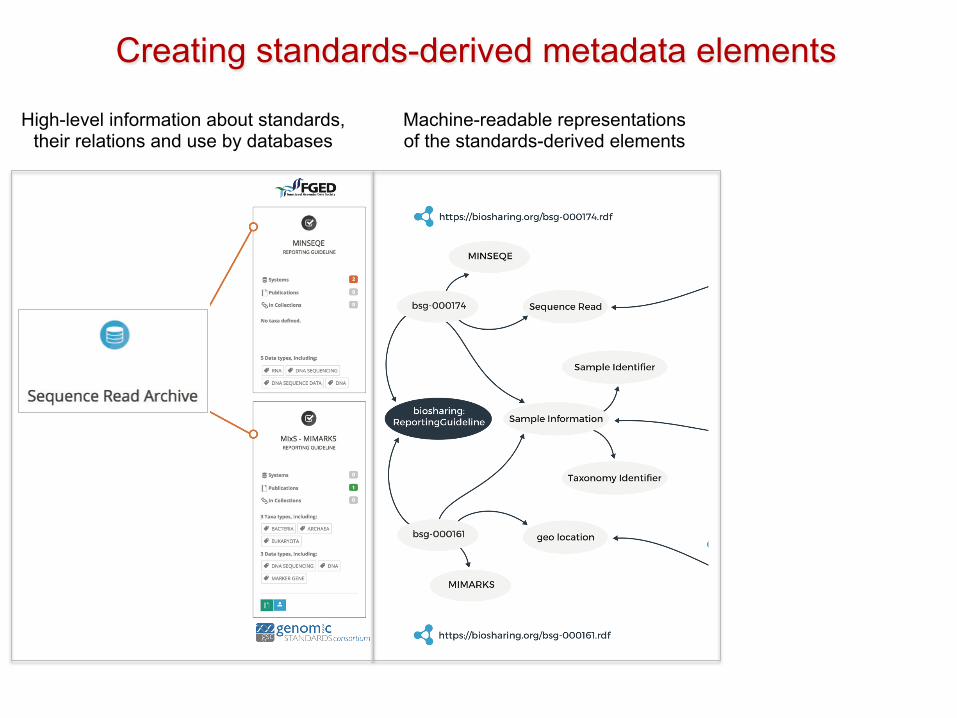
Creating standards-derived metadata elements
High-level information about standards, their relations and use by databases
Machine-readable representations of the standards-derived elements
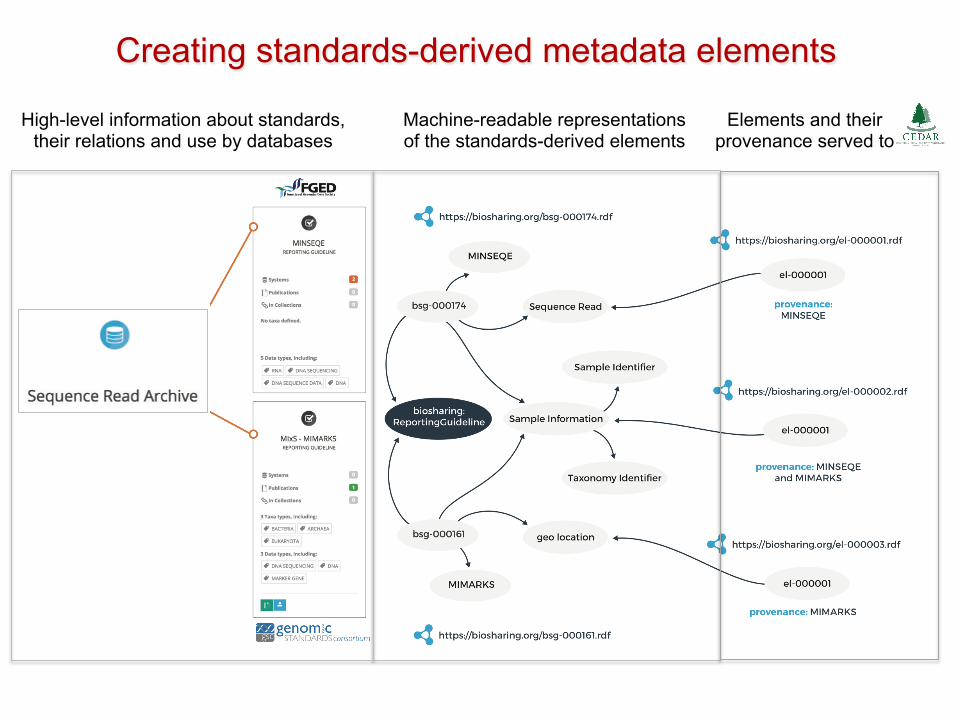
Creating standards-derived metadata elements
High-level information about standards, their relations and use by databases
Machine-readable representations of the standards-derived elements
Elements and their provenance served to

Creating standards-derived metadata elements
High-level information about standards, their relations and use by databases
Machine-readable representations of the standards-derived elements
Elements and their provenance served to

Cross-linking standards to standards and to databases
Model/format formalizing reporting guideline -->
<-- Reporting guideline used by model/format
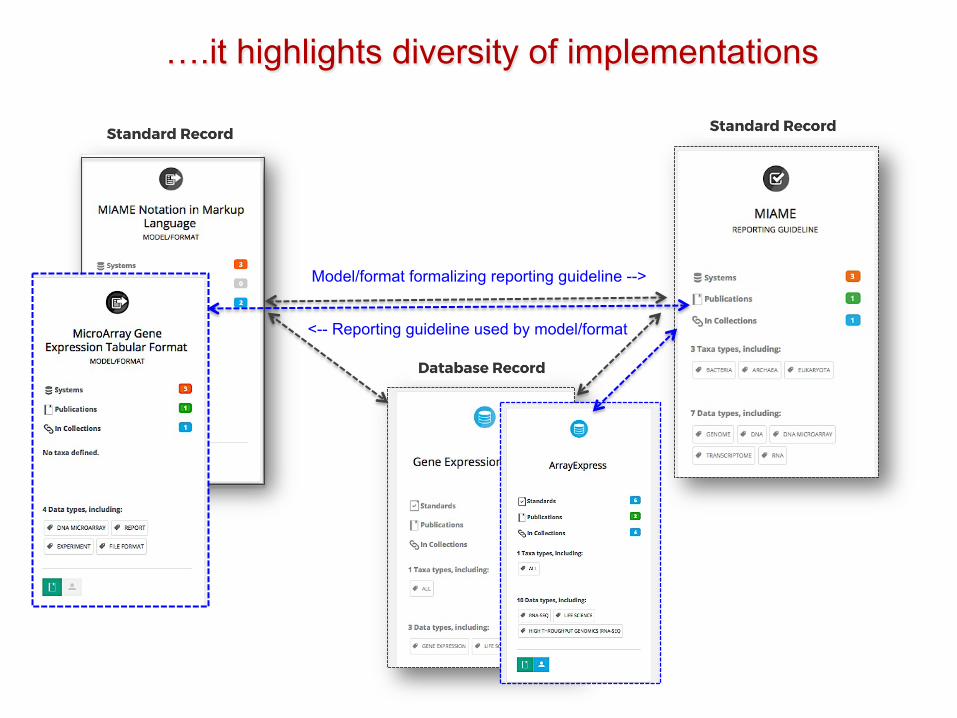
Model/format formalizing reporting guideline -->
<-- Reporting guideline used by model/format
….it highlights diversity of implementations
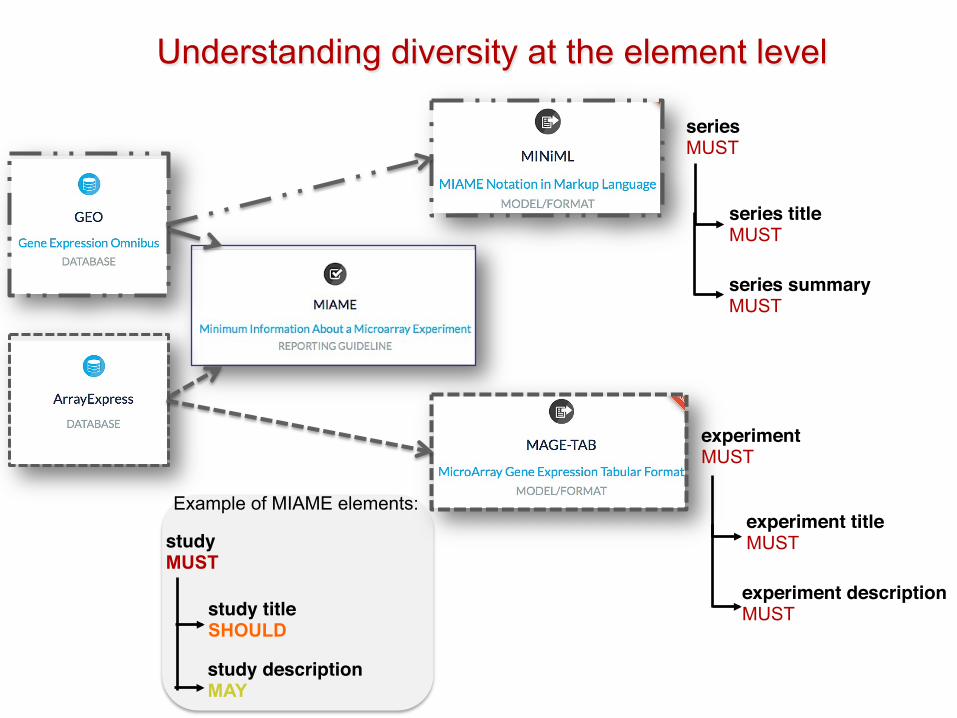
studyMUST
study titleSHOULD
study descriptionMAY
seriesMUST
series titleMUST
series summaryMUST
Example of MIAME elements:
experimentMUST
experiment titleMUST
experiment descriptionMUST
Understanding diversity at the element level
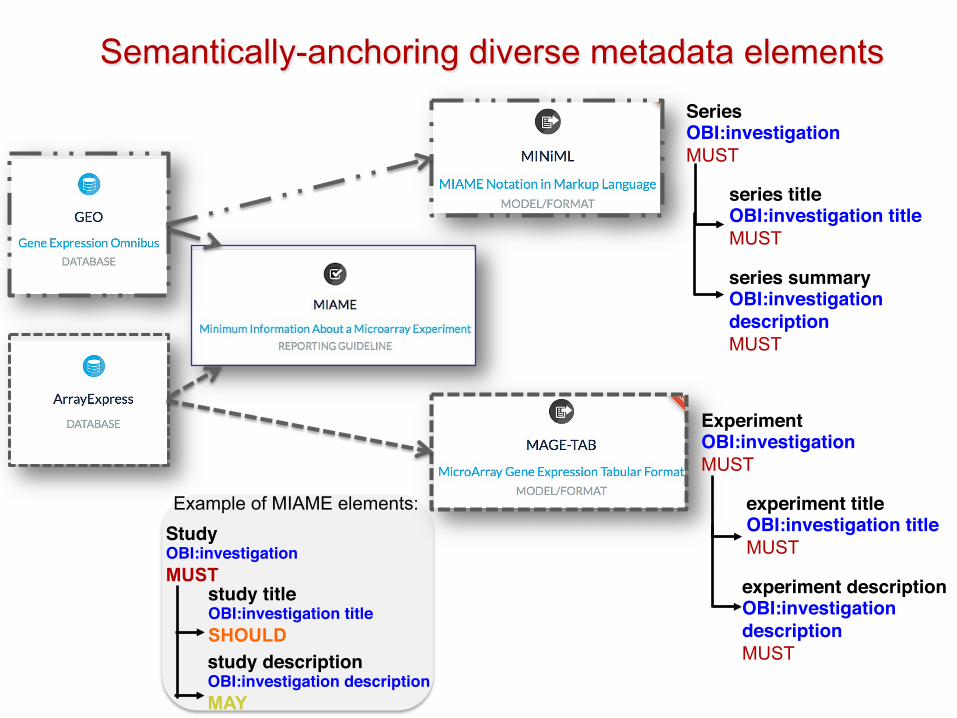
StudyOBI:investigationMUST
study titleOBI:investigation titleSHOULD study descriptionOBI:investigation descriptionMAY
SeriesOBI:investigationMUST
series titleOBI:investigation titleMUST
series summaryOBI:investigation descriptionMUST
Example of MIAME elements:
ExperimentOBI:investigationMUST
experiment titleOBI:investigation titleMUST
experiment descriptionOBI:investigation descriptionMUST
Semantically-anchoring diverse metadata elements

MI checklist document
<MI checklist element>
... <MI checklist element>
… <MI checklist element>
<MI checklist element> <URI>
... <MI checklist element> <URI>
... <MI checklist element> <URI>
1. Element identification 2. Element semantic markup
3. Element requirement formalization (MOSCOW convention)
<MI checklist element> <URI> MUST
... <MI checklist element> <URI> SHOULD
... <MI checklist element> <URI> COULD
4. Element data typing / cardinality
<MI checklist element> <URI> MUST [string] (1..1)
... <MI checklist element> <URI> SHOULD [string] (1..n)
... <MI checklist element> <URI> COULD [date] (0..1)
Bioportal Annotator service from Ontomaton + OBI
Formal representation + serialization
as RDF or JSON
Developing and testing the method

BioSharing also as a mean to disseminate CEDAR templates
E.g. as journals’ data policy are being developed, we work with them to link their policies to the databases and standards they recommend
Link to template

How long to FAIR data as the norm?
If you want to go fast, go alone. !
If you want to go far, go together. !
(African proverb)!





























