Embed Size (px)
Citation preview

A Showcase from the Master in Big Data
Analytics and Social Mining 2015
Andrea GigliEmail: [email protected]
Twitter: @andrgig
08-07-2015

Case 1/6

Building Indicators via Web ScrapingAnalytical Crawling & Text Annotation + Web Search Engines and Information
Retrieval

Goal
�To build a similarity indicator for cities, on the
basis of TripAdvisor.com reviews
�Reviews are related to main city attractions and
not to restaurants or hotels
�Exploit both Tokens and Entities Analysis

Tools
�Python
�HTTrack
�TagMe API
Where we got data (1/2)

Where we got data (2/2)

Cities…

Reducing the weight of frequent
tokens/entities
�Token and Entity frequencies are weigthed by
log N(t) / N
where
�N(t) is the number of reviews where a
token/entity occurs at least one time
�N is the number of reviews
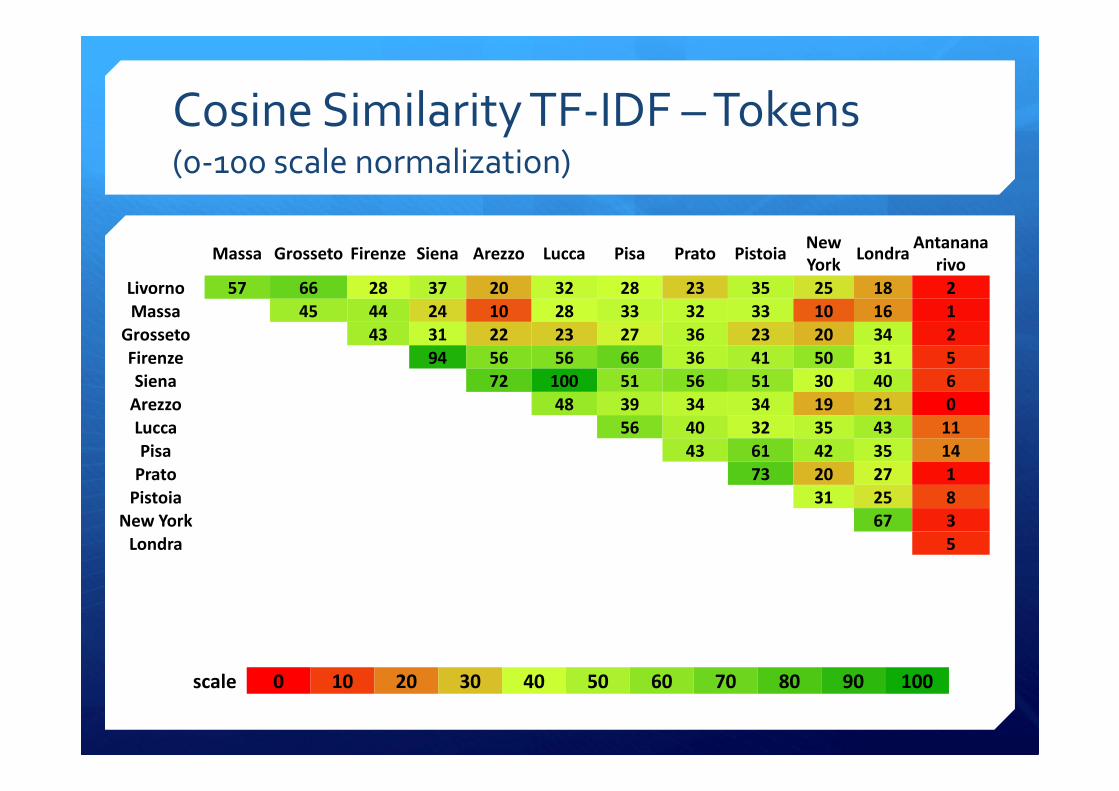
Cosine Similarity TF-IDF – Tokens(0-100 scale normalization)
Massa Grosseto Firenze Siena Arezzo Lucca Pisa Prato PistoiaNew
YorkLondra
Antanana
rivo
Livorno 57 66 28 37 20 32 28 23 35 25 18 2
Massa 45 44 24 10 28 33 32 33 10 16 1
Grosseto 43 31 22 23 27 36 23 20 34 2
Firenze 94 56 56 66 36 41 50 31 5
Siena 72 100 51 56 51 30 40 6
Arezzo 48 39 34 34 19 21 0
Lucca 56 40 32 35 43 11
Pisa 43 61 42 35 14
Prato 73 20 27 1
Pistoia 31 25 8
New York 67 3
Londra 5
scale 0 10 20 30 40 50 60 70 80 90 100
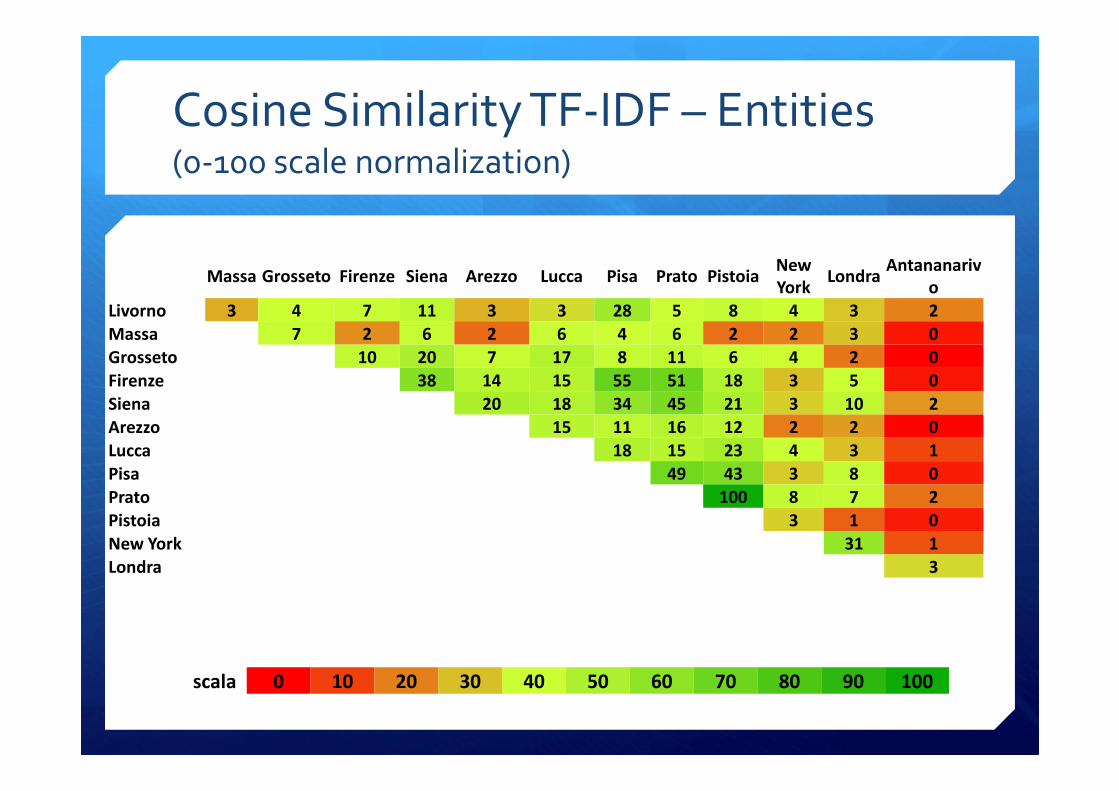
Cosine Similarity TF-IDF – Entities(0-100 scale normalization)
scala 0 10 20 30 40 50 60 70 80 90 100
Massa Grosseto Firenze Siena Arezzo Lucca Pisa Prato PistoiaNew
YorkLondra
Antananariv
o
Livorno 3 4 7 11 3 3 28 5 8 4 3 2
Massa 7 2 6 2 6 4 6 2 2 3 0
Grosseto 10 20 7 17 8 11 6 4 2 0
Firenze 38 14 15 55 51 18 3 5 0
Siena 20 18 34 45 21 3 10 2
Arezzo 15 11 16 12 2 2 0
Lucca 18 15 23 4 3 1
Pisa 49 43 3 8 0
Prato 100 8 7 2
Pistoia 3 1 0
New York 31 1
Londra 3

Case 2/6
Building a Search EngineAnalytical Crawling & Text Annotation + Web Search Engines and Information
Retrieval

Goal
�Collect recipes details from
www.worldrecipes.expo2015.org
�Build a Search Engine for recipes
�Build a simple user interface

Tools
�Python
�HTTrack
�Lucene

Indexation
� Receipt title
� Difficulty
� Ingredients
� Country
� Kcal
� Description
� X persons

Search Engine Output
� The user is able to search for
� Keywords in the Recipe’s title
� Difficulty
� Keywords in the ingredient’s list
� Country
� Optional output
� Recipe’s full description
� Ingredients for n persons

Case 3/6
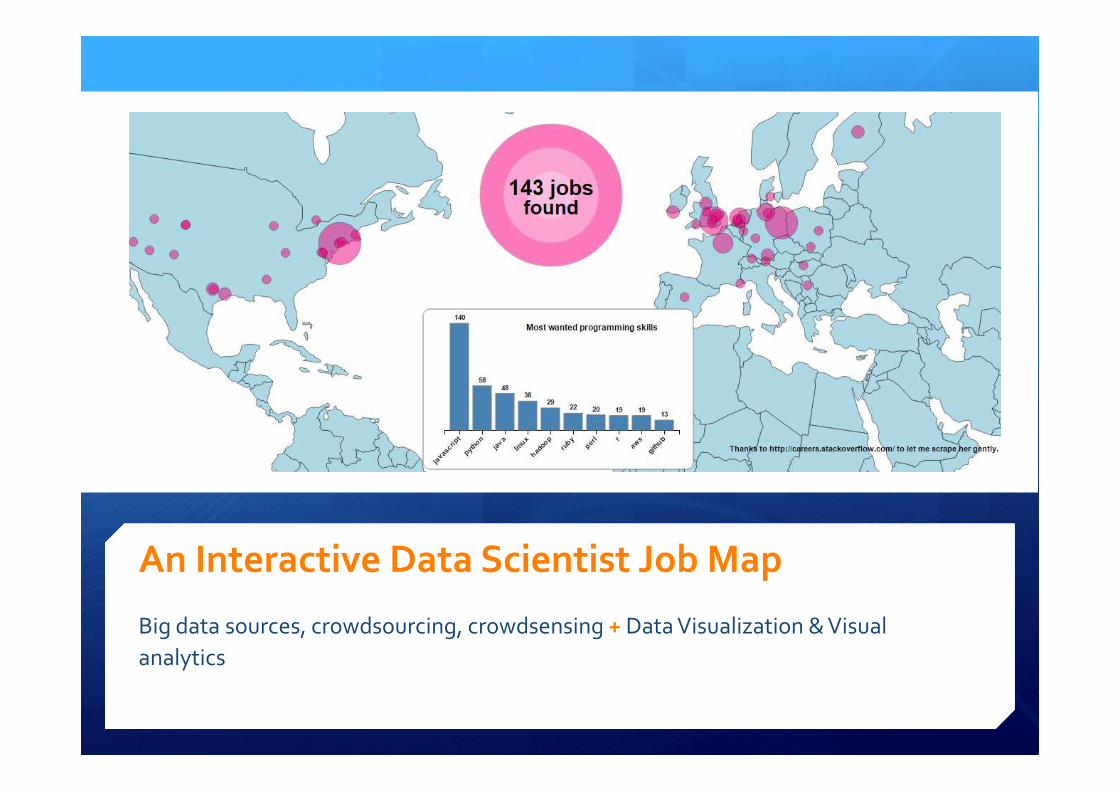
An Interactive Data Scientist Job Map
Big data sources, crowdsourcing, crowdsensing + Data Visualization & Visual
analytics

Goal
�To build a map of the cities offering jobs for Data
Scientists
�To make the map interactive for users
�To show additional info to users

Tools
� Python for
� scraping the web site, data preparation
and data integration
� building the API for querying the DB
� MySQL for storing data
� Jquery and D3.js for visualization
� Xampp for server simulation on PhpMyAdmin

Where we got data (1/2)
Job_url
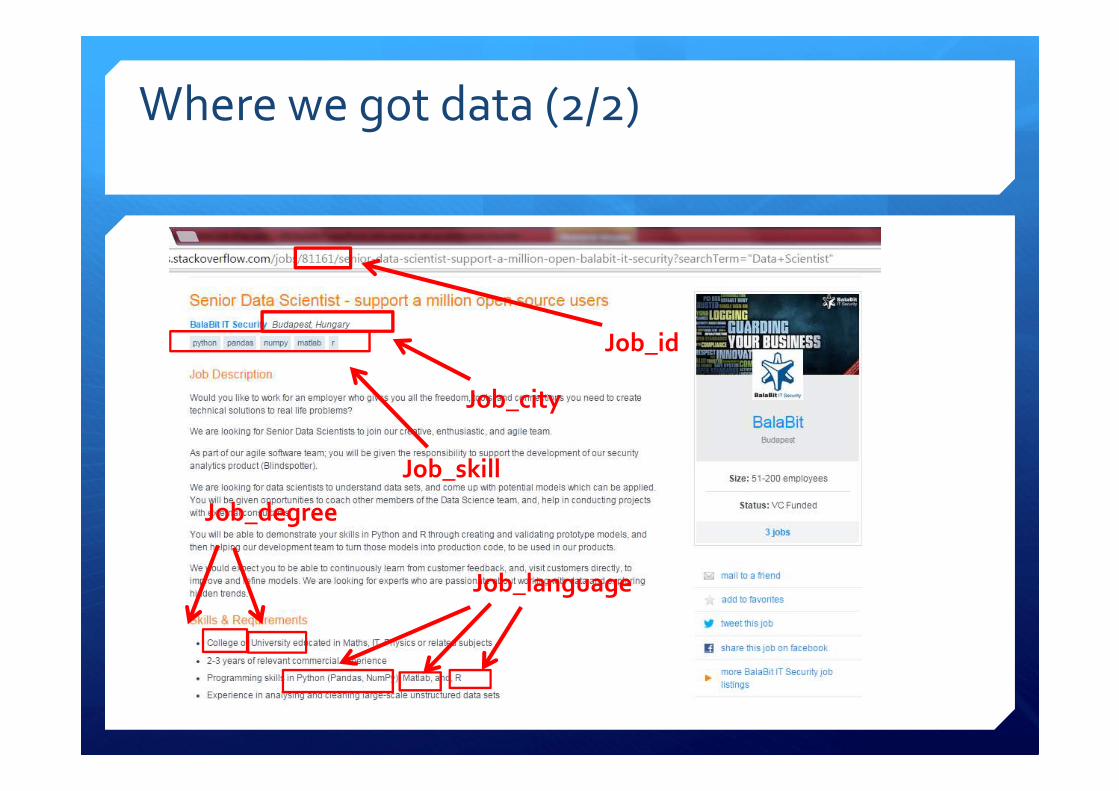
Where we got data (2/2)
Job_id
Job_skill
Job_degree
Job_language
Job_city

Where we stored data
Jobposting Table Joblanguage Table
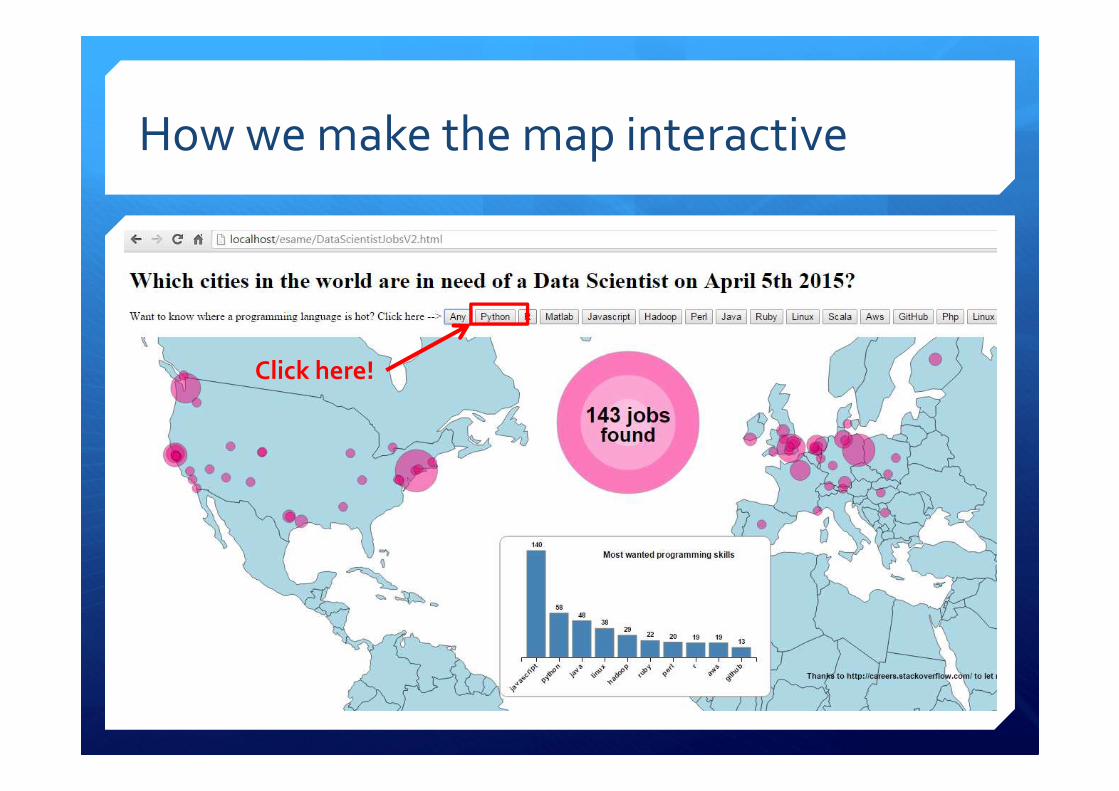
How we make the map interactive
Click here!

Case 4/6

Building a Search Engine Query Recommender
Web Mining & Nowcasting

The goal
Building a query suggestion application exploiting
the information observed on the AOL WebLog.
Constrains:
1) the application relies on observed queries
2) the application must be fast (milliseconds!)

The approach
Exploiting the relation between submitted queries
and clicked URL:
If two queries share “a lot or
URLs” then they are strongly
related to each other

Idea 1/2
Let q(i) be the i-th query and
u(k) be the k-th clicked url.
A Bipartite Graph can be
built such that for each q(i)
belonging to the query set, a
link to a subsequent clicked
url u(k) can be defined
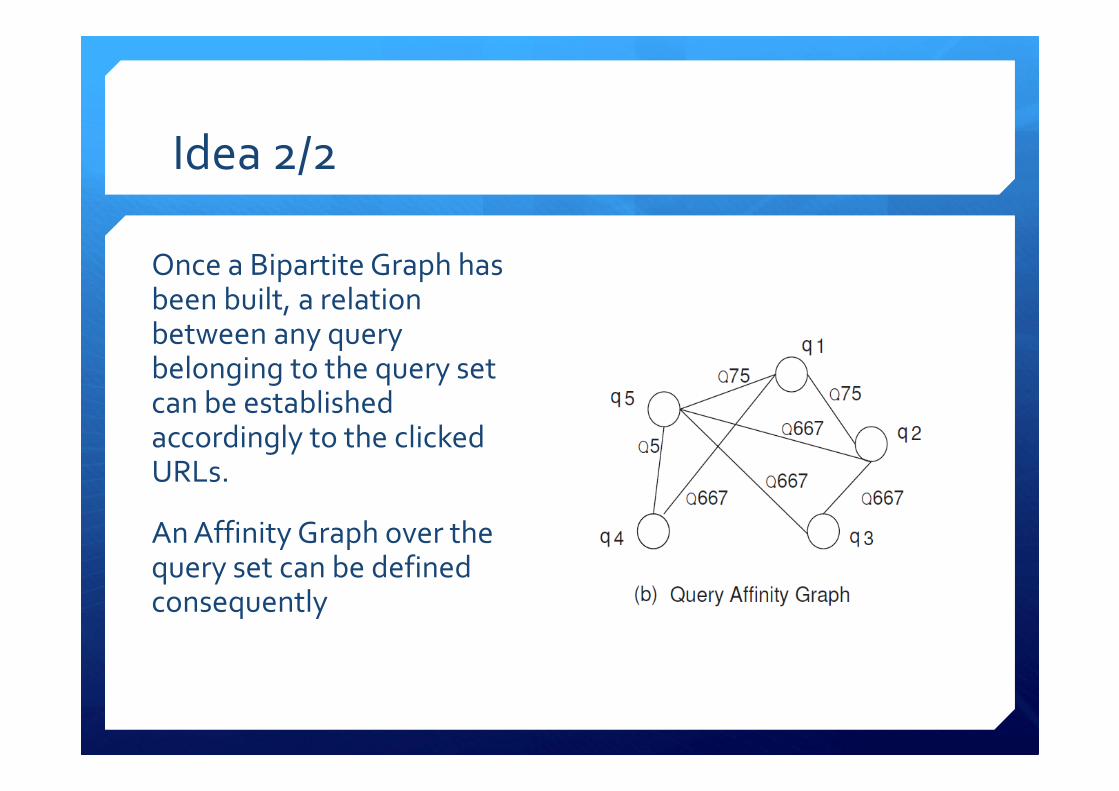
Idea 2/2
Once a Bipartite Graph has been built, a relation between any query belonging to the query set can be established accordingly to the clicked URLs.
An Affinity Graph over the query set can be defined consequently

Weighting the Edges
Tools
�Python
�Bash

Case 5/6

Clustering Users Behavior & Building a TV-Series
Recommendation Engine in Spark
High Performance & Scalable Analytics, NO-SQL Big Data Platforms

The goal
�Clustering users accordingly to the TV series they
watch
�Build a Recommendation System based on the
time spend by user watching a TV series

Tools
�Hadoop HDFS,
Hive
�pySpark, MLlib

Case 6/6

Comparing Machine Learning Algorithms in Text
Mining
Sentiment Analysis and Opinion Mining

The goal
Comparing different Machine Learning Algorithm on
different Text Mining Tasks:
1) Classifying Positive and Negative Reviews
2) Predicting Review Stars
3) Quantifying Sentiment Over Time
4) Detecting Fake Reviews

Tools
�Python 3
�Scikit-Learn
�NLTK

Link to project
�Please follow this link
http://www.slideshare.net/andrgig/saom-
projectwork

Other
Cases

- Social Network Analysis: Static Analysis of Social and Geographic Distances in On-Line Social Networks
- Mobility Data Analysis: Space Dynamics in On-line Social Networks
- Data Journalism: Immigration Stories
What else?






























