Embed Size (px)
Citation preview

UC BERKELEY
IndexedRDD
Ankur Dave���UC Berkeley AMPLab
Efficient Fine-Grained Updates for RDDs

Immutability in Spark
Query: Sequence of data-parallel bulk transformations on RDDs

Immutability in Spark
map task 4
map task 3
map task 2
map task 1
reduce task 4
reduce task 3
reduce task 2
reduce task 1
Wor
ker I
D
Time
Transformations are executed as independent tasks

Immutability in Spark
map task 4
map task 3
map task 2
map task 1
reduce task 4
reduce task 3
reduce task 2
reduce task 1
Wor
ker I
D
Time
map task 2 (retry)
Automatic mid-query fault tolerance

Immutability in Spark
map task 4
map task 3
map task 2 (killed)
map task 1
reduce task 4
reduce task 3
reduce task 2
reduce task 1
Wor
ker I
D
Time
map task 2 (replica)
Automatic straggler mitigation
Task replayability: Repeated task executions must give the same result
Enforced by input immutability and task determinism

The Need for Efficient Updates
1. Local mutable hash table• Partial task failures corrupt local state
2. Local or external database with atomic updates and snapshots (LevelDB, Cassandra)
• Severely limits program generality3. Copy entire data structure on update• Highly wasteful for small updates
Naïve SolutionsMotivation• Spark’s core abstraction is bulk
transformations of immutable datasets (RDDs)
• For batch analytics, immutability enables automatic mid-query fault tolerance and straggler mitigation
• But applications like streaming aggregation depend on efficient fine-grained updates
• Naive solutions involving mutable state sacrifice the advantages of Spark
• Instead, we propose to enable efficient updates without sacrificing immutable semantics
Efficient Updates to Immutable DataAnkur Dave, Joseph Gonzalez, Ion Stoica
username # followers@taylorswift13 48,182,689@ankurdave 206@mejoeyg 81
@taylorswift13: +1 follower
@taylorswift13: +1 follower
Purely Functional Data Structures• Enable efficient updates without
modifying the existing version in any way
• Immutable semantics: Updates return a new copy of the data that internally shares structure with existing copy (similar to copy-on-write snapshot)
• Nodes from old versions are GC’d• Different data structures optimize
different operations (joins, range scans)
Challenges1. Garbage collection:• Tunable branching factor,!
reference counting2. Efficient checkpointing• Incremental checkpoints using data
structure diff3. Aging data out to disk
Evaluation
0.01
0.1
1
10
100
1000
10000
100000
1 10 100 1000 10000 100000 1e+06 1e+07
Tota
l tim
e (m
s)
Read/write size (records)
Read-modify-write scaling, 10M existing elements
hash table with cloningCoW B-tree
LevelDB with snapshotspatricia trie
red-black treehash table (mutable baseline)
Related Work1. Multiversion Concurrency Control2. Copy-on-write B-trees3. Stratified Doubling Array
Streaming Aggregation
Incremental AlgorithmsOld Ranks New RanksGraph Update
+ =

Existing Solutions
map task
Direct mutation:
Problem: Task failures corrupt state
map task (retry)
Time
x = 0, y = 0x = 1, y = 0x = 2, y = 1
map task
def f(row: Row) = { row.x++; row.y++; }

Existing SolutionsAtomic batched database updates:
Problem: Long-lived snapshots are uncommon in databases
Time
Pages taskAds task
def f(row: Row) = { BEGIN; row.x++; row.y++; COMMIT; }
Clicks Ad Views Top Ads
Popular Pages

Existing SolutionsFull copy:
���Problem: Very inefficient for small updates
def f(row: Row) = { val newRow = row.clone(); newRow.x++; newRow.y++; return newRow; }

Immutability(for fault tolerance, straggler mitigation, dataset reusability, parallel recovery, …)
Tradeoff
Fine-grained updates(for streaming aggregation, incremental algorithms, …)
vs.
Can we have both?

Support efficient updates without modifying existing version using structural sharing (fine-grained copy-on-write)
Persistent Data Structures

RDD-based distributed key-value store supporting immutable semantics and efficient updates
IndexedRDD
IndexedRDD (800 LOC)
Spark
PART (1100 LOC)

IndexedRDD
RDD[T] (cached)
Array[T]
Array[T]
Array[T]
Array[T]
IndexedRDD[K,V]
PART[K,V]
PART[K,V]
PART[K,V]
PART[K,V]

class IndexedRDD[K: KeySerializer, V] extends RDD[(K, V)] { // Fine-‐Grained Ops -‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐ def get(k: K): Option[V] def multiget(ks: Array[K]): Map[K, V] def put(k: K, v: V): IndexedRDD[K, V] def multiput(kvs: Map[K, V], merge: (K,V,V) => V): IndexedRDD[K, V] def delete(ks: Array[K]): IndexedRDD[K, V] // Accelerated RDD Ops -‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐ def filter(pred: (K,V) => Boolean): IndexedRDD[K, V] // Specialized Joins -‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐ def fullOuterJoin[V2, W](other: RDD[(K, V2)])(f) : IndexedRDD[K, W]
}
IndexedRDD API

Persistent Adaptive Radix Trees (PART)

Recent work in main-memory indexing for databases
256-ary radix tree (trie) with node compression
V. Leis, A. Kemper, and T. Neumann. The adaptive radix tree: ARTful indexing for main-memory databases. In ICDE 2013.
Adaptive Radix Tree

1. Sorted order traversals (unlike hash tables)
2. Better asymptotic performance than binary search trees for long keys (O(k) vs O(k log n))
3. Very efficient union and intersection operations
4. Predictable performance: no rehashing or rebalancing
Why a Radix Tree?

Adds persistence to the adaptive radix tree using path copying (shadowing) and reference counting
1100 lines of Java
Persistent Adaptive Radix Tree (PART)
old new
…
…
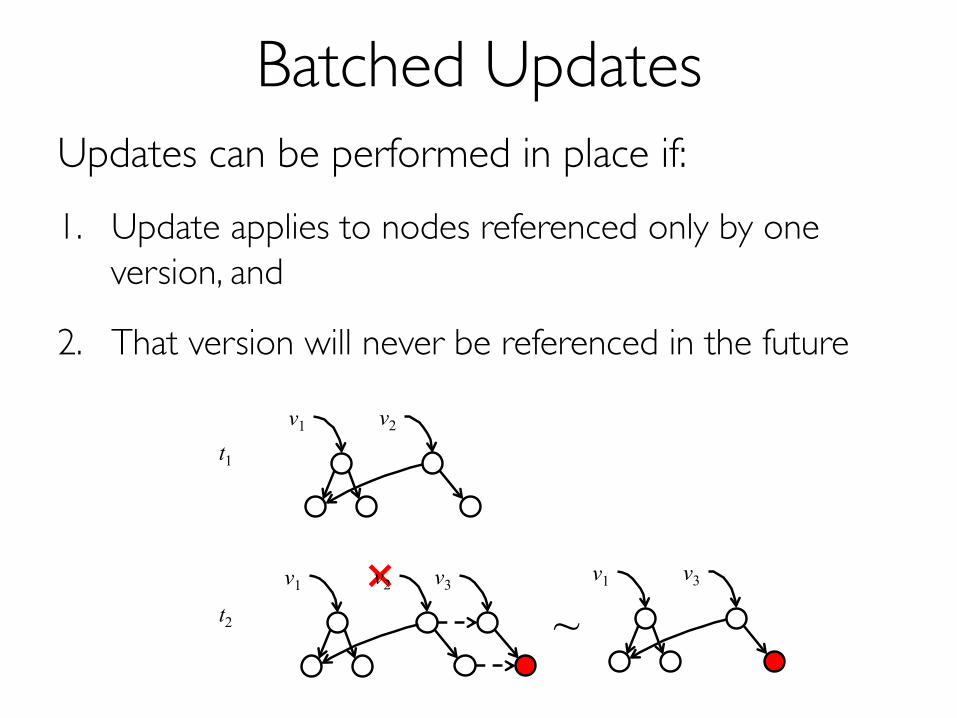
Updates can be performed in place if:1. Update applies to nodes referenced only by one
version, and
2. That version will never be referenced in the future
Batched Updates
×
v1 v2
v1 v3 v1 v3
~
t1
t2
v2

Microbenchmarks
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6
PART (batch size
1K)
PART (batch size
10M)
hash table red-black tree
B-tree
M in
sert
s/s
Insert throughput (single threaded)

Microbenchmarks
0
0.5
1
1.5
2
2.5
M lo
okup
s/s
Lookup throughput
0
5
10
15
20
25
M e
lem
ents
sca
nned
/s
Scan throughput
0
0.2
0.4
0.6
0.8
1
1.2
Mem
ory
usag
e (G
B)
Memory usage

Tree partitioning: minimize number of changed files by segregating frequently-changed nodes from infrequently-changed nodes.
Incremental Checkpointing
frequentlychanging
infrequentlychanging

Incremental Checkpointing

Counting occurrences of 26-character string ids
Synthetic data generated on the slaves (8 r3.2xlarge)
Load with1 billion keys, stream of 100 million keys
Real app: Streaming aggregation

1. GC pauses���Future work: Off-heap storage w/ reference counting
2. Scan performance���Future work: Layout-aware allocator
Limitations

Thanks!
IndexedRDD: https://github.com/amplab/spark-indexedrdd
Use it in your project:
resolvers += "Spark Packages Repo" at "http://dl.bintray.com/spark-‐packages/maven" libraryDependencies += "amplab" % "spark-‐indexedrdd" % "0.1"





























