Embed Size (px)
Citation preview

BIOINFORMATICS at a glance

IMB – Institute for Molecular Bioscience
EMBL Australia Bioinformatics Resource
Genomics Virtual Laboratory – NeCTAR
Australian e-Health Research Centre
ARC Centre of Excellence in Bioinformatics
NCI-Specialised Facility in Bioinformatics
Intersect Australia Ltd
QCIF – Queensland Cyber Infrastructure Foundation
Wound Management Innovation CRC
The University of Auckland
Université de Toulouse
PROOF Centre of Excellence, Canada
Contents2 About QFAB
3 QFAB Solutions
4 QFAB Governance
6 Testimonials
8 QFAB Team
10 QFAB Service
- Next Generation Sequencing
- Genotyping Data
- Microarray Data
- Integrated Systems Biology
- Mass Spectrometry Data
- Cheminformatics
- Biostatistics
- Software and Web Development
- High Performance Computing
- Consulting
- Training
17 Tools & Platforms
- mixOmics
- Systems Biology Platform
- Chemi-Biology Platform
- Genomics Virtual Laboratory
- NCI-SF
- EMBL Australia
18 Case Studies
- Featured project:
The embedded bioinformatician -
QFAB research collaboration
- Southern Cross Univerity -
Plant Science Bioinformatics Support
- Glycoselect statistical pipeline
- ArachnoServer, the world’s
first manually curatable resource for
protein spider toxins
- EBI – Making Australian
Data Discoverable
28 Publications
Foundation Partners
Collaborators
1

QFAB provides scalable and open solutions which enable scientists to extract the greatest value from their research data, across a variety of applications, technologies, and industries.
QFAB can work on specific projects, provide time against an ongoing need or become embedded in your organisation. Our solution will draw on the entire team’s
experience and our broad suite of open source and commercial software and computational systems.
Flexible, rapid and researcher oriented, QFAB has built a reputation for supporting the production of high quality outcomes which deliver those high impact publications or patents faster.
QFAB Solutions
3
TechnologiesWe support evolving technologies used by life science researchers including:
- Pathology/clinical data
- Next generation sequencing: Roche 454 GS-FLX, Illumina HiSeq, LifeTechnologies Solid, Ion Torrent data
- Genotyping: ABI-LifeTechnologies, Illumina, Affymetrix, Agilent
- Microarrays
- Mass spectrometry: SELDI, MALDI, iTRACK
ApplicationsWe design applications to support:
- Molecular biology research
- Biomarker discovery
- Crop science and livestock
- Biodiversity
- Molecular diagnosis
- Drug discovery
- Translational research
- Epidemiology
- Pathway analysis
- Clinical trials
IndustriesWe work with researchers across a number of industries:
- Academic research
- Healthcare
- Pharma R&D
- Clinical research
- Biotechnologies
- Food industry
- Environment
- Biodiversity
- Energy
- Agricultural R&D
About QFAB
Mr Jeremy Barker Chief Executive Officer
What we doHowever you define bioinformatics, as broadly or narrowly as you wish, it fundamentally enables the modern day researcher to handle and analyse large and complex data – the big data challenge - an essential part of understanding biology.
Established in 2007, QFAB focuses on delivering robust, high quality and relevant bioinformatics services for life science researchers to analyse and manage large-scale datasets.
We offer our clients a range of professional services – from contract research, project design and analysis, scientific software development, to designing, deploying and refining the high performance IT infrastructure that is required to support life science informatics.
Our support ranges from experimental design, data capture and mining through to NGS, proteomic and metabolomic analyses. We are also expert in cross-domain integration with clinical data.
QFAB’s training division provides integrated workshops through to customised solutions in all facets of bioinformatics.
We have a strong track record of delivering results which are grounded in the team’s commitment to continuous learning and innovation, ensuring that our clients can trust in the knowledge and integrity of our support.
Who we do it forLife science scientists are our clients. With a focus on client success, our skilled and expert team understands the biological question. We can help you define the appropriate bioinformatics and biostatistics approach and apply the correct analyses to deliver on your project.
By unlocking the full value of your data, QFAB has become a leading provider of bioinformatics services to industry, clinical, applied and academic life science researchers, including the biotechnology, pharmaceutical, clinical and research communities.
We operate nationally and internationally with a commitment to continuous engagement throughout the project.
What we stand forOur highly experienced and skilled team is the foundation of our success. As a team, we are committed to operating ethically, with integrity and respect at all times. We believe that open communication, flexibility and honesty are the keys to successful customer engagement.
Early engagement means we can take the time to understand your goals and help derive the most efficient and cost-effective bioinformatics solutions, while the international experience brought to projects by our team members ensures the application of the relevant tools to the right data to answer your particular questions.
We are the research data specialists: responsive, professional, secure and quality focused.
2

Infectious Disease Research Program at IHBI, which forms part of IHBI’s Cells and Tissue Domain. Ken was appointed to the role of IHBI Deputy Director in 2010. He has worked in the area of mucosal immunology for the past 25 years at the University of Alabama at Birmingham (UAB) and the University of Newcastle prior to moving to QUT. Ken’s current research interests focus on immunity to sexually transmitted infections, in particular Chlamydia trachomatis. His research aims to define and differentiate the immune parameters of immune-mediated inflammatory pathology caused by Chlamydia infection from the immune mechanisms that can protect against chlamydial infection to developing effective chlamydial vaccines.
Associate ProfessorJames HoganQUTJim is an Associate Professor in the Electrical Engineering and Computer Science Faculty at QUT. His research interests include machine learning and its application to cognitive science, and bioinformatics problems and software engineering. Jim’s work is concerned with learning in visual domains with associated text, in the
tradition of the Berkeley L0 project, where he contributed a connectionist synthesis of bottom-up and top-down attentional systems as a model of spatial relations acquisition and processing. Jim also leads development of software internationalisation work within Australia.
Mr Jeremy BarkerQFABJeremy is the founding CEO of QFAB (Queensland Facility for Advanced Bioinformatics) which he joined full time in June 2007. Jeremy is responsible for the overall management of QFAB. He holds postgraduate qualifications in science, commerce and governance and has over 20 years of experience in the management of life science organisations including a number of Board positions for biotechnology companies. In 2007, Jeremy was awarded a Churchill Fellowship to undertake an international study on ‘Management Best Practice in the Delivery of Bioinformatics to Researchers’. He is a member of the Australian Institute of Company Directors.
Dr Andrew LewisGriffith UniversityAndrew is a Senior Research Specialist in eResearch Services at Griffith University. Andrew’s research expertise includes parallel optimisation algorithms for large numerical simulations, including bio-inspired algorithms (particle swarm, ant colony, spatial social networks, evolutionary programming and extremal optimisation), direct search algorithms (simplex and pattern search methods) and gradient descent (quasi-Newton with BFGS update). He specialises in multi-objective optimisation techniques for engineering design, including the application of a variety of algorithms to complex problems, methods of interactive optimisation, automated preference selection in Pareto-optimal sets, extension to many-objective and dynamic environments, and the development of automated, problem-solving frameworks. He also has expertise in parallel, distributed and grid computing methods, including cluster-based, ad hoc grid, distributed, peer-to-peer systems and cloud computing; and advanced visualisation techniques for scientific data analysis.
Mr Peter TurnbullChairmanPeter is a company director and corporate lawyer. Peter’s business interests span many East Asian markets, Europe and the United States. He is currently the Chairman or a Director of various private and unlisted public companies and is a former Director of the Securities and Futures Commission of Hong Kong. Peter has particular expertise in the commercialisation of new technologies, strategic planning, and complex legal, commercial and corporate governance transactions and alternate dispute resolution strategies. He is a recent past-President, and Chairman of Chartered Secretaries Australia, and is a Fellow of the Australian Institute of Company Directors.
Professor Mark RaganIMBMark is the founding head of the Division of Genomics and Computational Biology at the Institute for Molecular Bioscience of The University of Queensland, and Director of the Australian Research Council Centre of Excellence in Bioinformatics. Mark is a Fellow of the Linnean Society of London, and serves on six editorial boards and
seven management and advisory boards in molecular bioscience, informatics and e-Research. He has more than 160 peer-reviewed publications and research interests that include comparative, computational and evolutionary genomics, high-throughput bioinformatics, high-performance computing, and technologies for management and integration of large datasets.
Dr David HansenCSIRODavid is CEO of the Australian e-Health Research Centre. David leads the research programs of the AeHRC, a joint venture between CSIRO and the Queensland Government. Prior to joining CSIRO, David led development of the Sequence Retrieval System (SRS) at LION Bioscience Ltd in Cambridge, UK. SRS is the leading genomic data and tool integration software, and is used by pharmaceutical and biotechnology companies, such as Glaxo Kline-Smith, Celera and Affymetrix, as well as academic institutes, including The European Bioinformatics Institute. David undertook a Bachelor of Science at the University of Queensland in
Chemistry and Computer Science and a PhD in Theoretical Chemistry at the Australian National University.
Dr Wayne Jorgensen Queensland Government Wayne has over 25 years of research experience in parasitology. Wayne has published over 70 research papers in refereed, international journals and over 70 conference papers at national and international conferences. He has written chapters on tick-borne diseases for the Office International des Epizooties, International Livestock Research Institute, Food and Agriculture Organization of the United Nations, Parasitology Journal, and Merck. He is co-editor for Babesiosis in the International Consortium for Tick and Tick-borne Diseases Journal and developed two international patents on poultry coccidiosis vaccines. In 2008 Wayne received the Australia Day award for contribution to Queensland’s Primary Industries.
Professor Ken BeaglyIHBIKen is Deputy Director, Institute of Health and Biomedical Innovation (IHBI). He is a Professor of Immunology at QUT and the leader of the
QFAB Governance
QFAB Specialist Advisory GroupDr Rhys Francis Executive Director,Australian eResearch Infrastructure Council
Dr Gregory HarperDirector, External Engagement,CSIRO
Dr Tim LittlejohnNew Employee Learning Lead, diversity, life sciences,IBM
Warren ParkerCEO, Scion, New Zealand Forest Research Institute, New Zealand
Dr Nadia RosenthalDirector,Australian Regenerative Medicine Institute
54

Testimonials
Professor Glenn King Institute of Molecular Bioscience, The University of Queensland“QFAB has collaborated with us over a number of years to build a world-first spider toxin database that allows us to combine data from publicly available databases including mRNA and protein sequences, 3D structures, and functional information for hundreds of venom proteins. In our most recent project, QFAB worked with us to add a number of new features to the database, including a toxin mass calculator, taxonomic target search, and mechanisms to control the privacy of records. QFAB’s innovative approach and responsiveness has been essential to the success of this project. I am happy to endorse QFAB as a provider of highly effective research data management solutions.”
Dr Roslyn Brandon Co-Founder, President and CEO of Immunexpress (IXP) “Since an initial collaborative project in 2010, IXP has significantly increased its work with QFAB as a contract supplier of bioinformatics services. QFAB undertakes IXP’s genomics multivariate data analytical work – a critical foundation for the development of our novel clinical diagnostic products. IXP is leading the world in applying its patented immune system blood biomarkers to improving the management of sepsis patients and those at risk of sepsis. Sepsis is a life-threatening immune response to infection and is a leading cause of death in Intensive Care Units. QFAB works very effectively with our team to produce results time effectively and cost efficiently. The QFAB project team is a mainstay for our business as our product development processes rely heavily on world-class informatics. We have been very pleased with the quality and responsiveness of QFAB, and I am delighted to provide this testimonial for their client services.”
6
QFAB’s expertise in experimental design and analysis can be applied at any scale, from a simple microarray comparison of differential gene expression, to a full-blown systems biology analysis integrating genomic, proteomic, metabolomic and clinical data.
“QFAB has assigned a successionof its research students and staff to work with our biologists and protein chemists,
helping to design experiments and to interpret the data. As we were doing our research, QFAB was building up a
pool of expertise in wound-healing bioinformatics.” Professor Zee Upton
The embedded bioinformatician
7
Professor Zee UptonWound Management Innovation
Cooperative Research Centre
The Co-Program Leader of the Enabling Technologies Program in the Wound CRC,
Professor Zee Upton, now Assistant Dean of Science at
Queensland University of Technology, says it was clear from the outset that the
CRC was going to need high-order capabilities in bioinformatics to make sense of the huge volumes of DNA, SNP and proteomics data
flowing from its research.In previous projects the bioinformaticians
were not physically co-located with the biological scientist generating the data.
“That didn’t work as well as we hoped,” Professor Upton said.
“We found we needed a bioinformatician with specific expertise in handling
wound-healing data, so QFAB placed one of its researchers
in the CRC for two days a week.”

QFAB Team
Dr Kim-Anh Lê CaoBiostatistician
Ms Roxane LegaieBioinformatician
Dr Xin-Yi ChuaSenior Bioinformatician
Ms Amanda MiottoeResearch Support Specialist
Dr Leo McHughSenior Computational Biologist
Computational Biology Data Specialists
Dr Jeremy ParsonsBioinformatician
Mr Nick RhodesDatabase and Systems Administrator
Mr Pierre ChaumeilBioinformatician
Ms Anne KunertBioinformatician
Ms Sarah WilliamsBioinformatician
98
Senior Management Team
Mr Jeremy BarkerChief Executive Officer
Dr Dominique GorseGeneral Manager
Ms Mathilde DesselleBusiness Development & Marketing Manager
Dr Mark CroweTraining & Outreach Manager
Dr Stephen RuddHead of Computational Biology
“QFAB is a vibrant and dynamic workplace, reflecting the variety of projects that attracted me to QFAB initially. I enjoy the challenge of working for an organisation that is at the cutting edge of bioinformatics and the satisfaction gained from liberating more knowledge or productivity for the customer by applying advanced bioinformatic solutions.” Dr Leo McHugh

1110
Our services include:
QFAB Services QFAB is the research data specialist. We support the bioinformatics requirements of research-intensive universities, institutions and companies and provide secure access to very large databases, dedicated softwares, high-performance computing, terabyte storage, data integration technologies and advanced bioinformatics services. We pride ourselves in developing tailored, relevant bioinformatics solutions to meet research needs to:
> Provide scalable infrastructure to meet future growth
> Enable collaboration between scientists within disparate research areas
> Enable reasoning across data sources
> Develop workflows for easy and efficient data processing, analysis and visualisation.
Next Generation Sequencing Unlock the full value of your next-generation sequencing (NGS) data sets from Illumina HiSeq, Roche 454 GS-FLX and LifeTechnologies Solid and Ion Torrent platforms. QFAB provides tailored bioinformatics services to biologists across the spectrum of computational techniques and services applicable to molecular biology and next generation sequencing. QFAB researchers design and implement custom bioinformatics approaches that are developed in consultation with researchers for specific questions in molecular biology. We can also integrate your genomics data with other omics and clinical datasets.
Our NGS data analysis services include:
De Novo or reference genome assembly and annotation
> Assembly and mapping
> Structural and functional annotation of the genome (ORF detection, assignment of genes,…)
> Samples comparison
Genomic capture
> Mutation and variant detection
> Identification and positioning of known and unknown mutations
> Transcription: Influence of the mutation on the protein functionality
ChipSeq
> Mapping and genes identification
> Comparison if samples regulated by the same transcription factor
Exome
> Listing of identified mutations between the study samples and the reference: SNPs, InDels
> Identification of known mutations by comparing the results to international databases
> Influence of the mutation on the protein functionality
Metagenomics
> Creation of reference database and alignment for or ganisms identification
> Adjustments of interpretation settings
> Taxonomic trees
> Samples comparison
RNAseq and microRNA
RNAseq
> Changes in expression
> Detection of novel splice isoforms or transcripts
> De novo transcriptome assembly
> Mutation detection
Annotation pipeline
> Prediction of coding regions
> Annotation of coding genes, non-coding RNA, tRNA, rRNA, miRNA…
> Repeat identification
> Statistics of annotation and analysis of GC content
1312
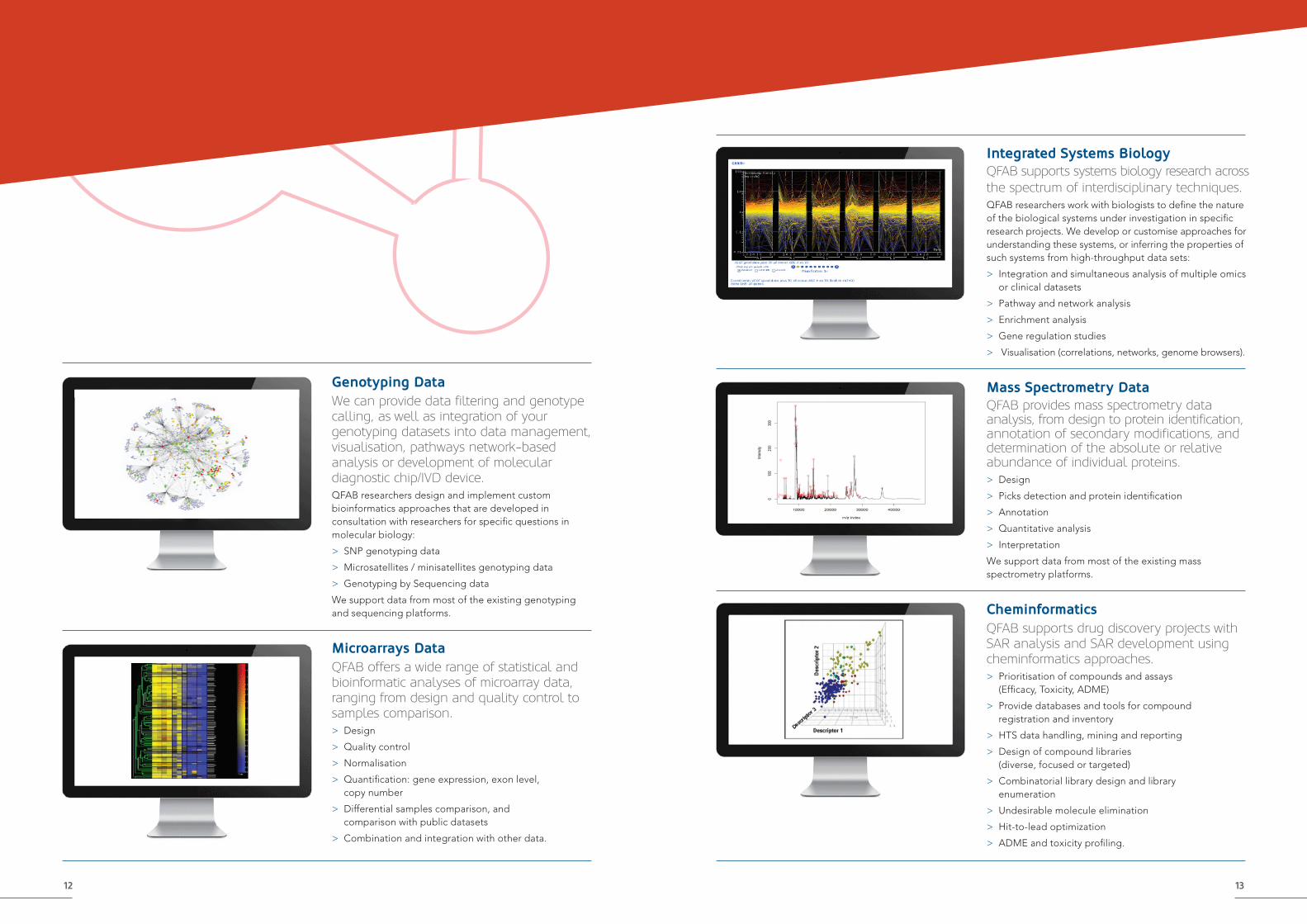
Genotyping DataWe can provide data filtering and genotype calling, as well as integration of your genotyping datasets into data management, visualisation, pathways network-based analysis or development of molecular diagnostic chip/IVD device.QFAB researchers design and implement custom bioinformatics approaches that are developed in consultation with researchers for specific questions in molecular biology:
> SNP genotyping data
> Microsatellites / minisatellites genotyping data
> Genotyping by Sequencing data
We support data from most of the existing genotyping and sequencing platforms.
Microarrays DataQFAB offers a wide range of statistical and bioinformatic analyses of microarray data, ranging from design and quality control to samples comparison.> Design
> Quality control
> Normalisation
> Quantification: gene expression, exon level, copy number
> Differential samples comparison, and comparison with public datasets
> Combination and integration with other data.
Integrated Systems BiologyQFAB supports systems biology research across the spectrum of interdisciplinary techniques.QFAB researchers work with biologists to define the nature of the biological systems under investigation in specific research projects. We develop or customise approaches for understanding these systems, or inferring the properties of such systems from high-throughput data sets:
> Integration and simultaneous analysis of multiple omics or clinical datasets
> Pathway and network analysis
> Enrichment analysis
> Gene regulation studies
> Visualisation (correlations, networks, genome browsers).
Mass Spectrometry DataQFAB provides mass spectrometry data analysis, from design to protein identification, annotation of secondary modifications, and determination of the absolute or relative abundance of individual proteins. > Design
> Picks detection and protein identification
> Annotation
> Quantitative analysis
> Interpretation
We support data from most of the existing mass spectrometry platforms.
CheminformaticsQFAB supports drug discovery projects with SAR analysis and SAR development using cheminformatics approaches.> Prioritisation of compounds and assays (Efficacy, Toxicity, ADME)
> Provide databases and tools for compound registration and inventory
> HTS data handling, mining and reporting
> Design of compound libraries (diverse, focused or targeted)
> Combinatorial library design and library enumeration
> Undesirable molecule elimination
> Hit-to-lead optimization
> ADME and toxicity profiling.

14
High Performance ComputingMr Nick RhodesDatabase and Systems Administrator
QFAB’s HPC services include:
> Hardware access / infrastructure
> Cluster computing
> Cloud computing
> High memory servers.
ConsultingDr Dominique GorseGeneral Manager
Discuss with us the design of your research project, and evaluate bioinformatics analysis and support to be incorporated in your grant proposal. QFAB answers your consulting need on a project basis, on a regular basis (number of days/ week-month-year), as well as through embedded staff model.
QFAB can help scientists with access to the bioinformatics tools and the computational capability needed to meet the challenges of visualising disparate datasets which may use different or no ontologies and, at the social and regulatory levels, the need to maintain patient confidentiality through compliance with clinical records privacy laws. Building on our strengths in understanding and translating the needs of the researcher into the language of the bioinformatician and IT professional, QFAB can work closely with your research team to address both the data management and bioinformatic aspects of your translational research project.
TrainingDr Mark CroweTraining & Outreach Manager
QFAB understands the biological question and can help you unlock the answers from your data through our specialised training programs. We provide a range of flexible modules, courses and workshops designed to suit your needs – ranging from introductory project-focused courses to advanced bioinformatics. Our goal is to improve knowledge diffusion between experimental biologists and bioinformaticians, that is, increase the interaction between developers and users.
Contact QFAB for details of how QFAB can meet your training needs.
For more information on QFAB services, contact us: www.qfab.org
BiostatisticsQFAB provides expert biostatistical services to support the design of biological experiments, biomarker identification, collection and analysis of data from experiments, and the interpretation of that data.QFAB provides tailored data mining services to researchers who want to get more from their datasets. By creating customised data mining solutions, QFAB can assist researchers to get more from their existing data sets. By consulting with QFAB early, QFAB research staff can also provide detailed advice on the best methods for data capture, annotation and storage to maximise the benefits likely to result from the application of data mining techniques.
Our biostatistical services include:
> Combination and integration of multiple datasets types
> Univariate and multivariate analysis
> Power calculation
> Classification
We undertake collaborations in clinical research informatics and research IT services with a growing number of clinical and translational research investigators.
Software and Web DevelopmentResearch computing resources offered by QFAB enable the visualisation and analysis of large biological data sets and to address complex biological problems.QFAB develops custom software tools, data management systems and web interface for life sciences researchers. We support large collaborative research projects where the member groups are based in different locations. We develop online tools for project participants to securely store their own data, access other members’ data and allow real-time communication between collaborative group members.
Our ICT services include:
> Database development
> Web interface to biological databases
> Data analysis web applications.
15

Tools & PlatformsQFAB has a core team of software engineers and biologists who work together to help describe, formulate and build applications to analyse and manage your research data. Our unique tools and platforms include:
MixOmicsThe integration of multiple ‘omics’ analyses enables a better understanding of a biological system as a whole. QFAB’s mixOmics product is an R package dedicated to the exploration and the integration of highly dimensional data sets. MixOmics provides a strong focus on graphical representation, to better understand the relationships between the different types of data and to visualize the correlation structure between different measured entities.
Systems Biology PlatformAnalysis of complex molecular networks which control biological processes requires an integrated, highly capable bioinformatics platform. QFAB has developed a scalable computational environment to analyse, model and infer biomolecular networks. Our platform is unique in Australia, with high-performance hardware and an integrated suite of commercial software linked to curated datasets.
Chemi-Biology PlatformQFAB’s chemi-biology computational platform brings together complementary expertise in infectious disease research and advanced computational methods to accelerate the drug discovery process. The platform aims at increasing the likelihood of discovering successful lead compounds for anti-infective medicine. Unique in Australia, the platform consist of high-performance hardware and an integrated suite of open source and commercial software linked to curated chemical and biological datasets.
Industry CollaborationQFAB provides technical collaboration for:
EMBL Australia Bioinformatics Resource
An online data resource replicating important components of the data and data services provided by the European Bioinformatics Institute (EBI) - to provide Australian scientists with faster access to EBI datasets and expanded collections of Australian data.
http://www.ebi.edu.au/
Genomics Virtual Laboratory (GVL)
The GVL provides Australian researchers with a community of accessible infrastructure, expertise and advocacy that connects genome researchers with massive datasets, sophisticated analysis tools, and large-scale computational infrastructure.
https://www.nectar.org.au/genomics-virtual-laboratory
NCI-SF in Bioinformatics
The National Computational Infrastructure, Specialised Facility (NCI-SF) portal provides information on the hardware, software and services available.
https://ncisf.org/
17

1918
QFAB collaborates with life scientists to help solve important challenges relating to the analysis, management and visualisation of their research data. Read about some of our projects and collaborations.
Indexp. 18 Featured project: The embedded bioinformatician - QFAB research collaborationp. 21 Southern Cross University - Plant Science Bioinformatics Supportp. 23 Glycoselect statistical pipelinep. 24 Arachnoserver, the online data repository for spider toxin research p. 26 EBI – Making Australian Data Discoverable
Case Studies
By Graeme O’Neill
A wound is a complex ecosystem, seething with a diverse population of the patient’s cells, and a complex community of microbes contending to colonise the wound. There is constant communication between them via a molecular intranet.
The Wound Management Innovation Cooperative Research Centre in Brisbane was established in 2010 to explore these processes, and to apply its findings to develop novel treatments to accelerate healing, reduce scarring, and prevent infection.
Every patient is genetically unique, and the microbes vying to colonise their wound will vary according to how and where the wound occurred – it might have been in an operating
theatre, a car accident, a farm accident, or the consequence of necrosis associated with chronic diabetes or a lifetime smoking habit. Over time, the wound’s microbial flora may vary with time, through succession processes.
Fibroblasts and other specialised tissue-repair cells go about their business as the innate and adaptive immune systems’ armies of natural killer cells, macrophages, B cells and T-cells swarm in to mount a coordinated defence of the breach against microbial invaders.
The high-speed DNA sequencers and various microarray technologies required to study the dynamics of these processes over time, generate enormous amounts of data.
The Co-Program Leader of the Enabling Technologies Program in the Wound CRC, Professor Zee Upton, now Assistant Dean of Science at Queensland University of Technology, says it was clear from the outset that the CRC was going to need high-order capabilities in bioinformatics to make sense of the huge volumes of DNA, SNP and proteomics data flowing from its research.
In previous projects the bioinformati-cians were not physically co-located with the biological scientist generating the data. “That didn’t work as well as we hoped,” Professor Upton said. “We found we needed a bioinformatician with specific expertise in handling wound-healing data, so QFAB placed one of its
researchers in the CRC for two days a week.
“Since then, QFAB has assigned a succession of its research students and staff to work with our biologists and protein chemists, helping to design experiments and to interpret the data. As we were doing our research QFAB was building up a pool of expertise in wound-healing bioinformatics.”
And that’s the model QFAB is offering to potential customers for its expertise and facilities. QFAB Chief Executive Officer, Jeremy Barker says the success of biological, medical and pharmaceutical research will depend increasingly on the expertise of bioinformaticians who not only understand the research, but can
help biologists to design experiments and analyse the data to answer the questions posed.
As the cost of purchasing and operating high-speed DNA sequencers has fallen, more research groups have been successful in obtaining ARC infrastructure grants to buy these machines.”Some set out to use the new equipment without really understanding how it can be used,” he said.
“They may have bought the machine after reading a paper in the scientific literature that used the same device. It might describe the methods used to produce the data, and the conclusions, but reveals very little about the assumptions underlying the methodology, which tend to
be project-specific.
“So they bring us this huge data set, saying they want do to this type of analysis, hoping to get a certain result, without fully understanding what they’ve got from the experiment, or how to extract what they want from the dataset.
“That’s where we can help. First, we can explain what their data will allow them do, or how it might allow them to do more than they expected.
“Secondly, we can help by showing them how to do what they really wanted to do, and help them design experiments to produce the type of data they need to answer particular questions. Early engagement saves the costs involved in repeating experiments.
Professor Zee Upton, QUT
Mr Jeremy Barker, CEO, QFAB
Dr Kim-Anh Lê CaoBiostatistician
The embedded bioinformatician - QFAB research collaboration
Featured project: Wound Innovation Management CRC

Brief description of the project
The client is an Australian university research team with broad genomic experience and a special interest in genetics of Australian plants. QFAB is providing a full genomic assembly and analysis service on multiple organisms with direction and focus determined by the client.
Background Recent dramatic cost reductions in shotgun genomic sequencing now enable biologists to cheaply and quickly sample the DNA sequence of an interesting species, or selected
individuals of special interest to their research interests. This “de novo” approach to whole-genome assembly from short shotgun reads is the most economical and fastest path to partial genome reconstruction for novel organisms but it is problematic when attempted without traditional guidance from physical clones or genetic maps. The “de novo” shotgun assembly method leads to fragmented and isolated plant nuclear chromosomal contigs which can be difficult to analyse. QFAB and the client assembled multiple genomes using different DNA assembly programs and then compared
all assemblies against each other and to related species to identify the best product for subsequent genomic analyses.
What were the outcomes?
QFAB fully reconstructed two organelle genomes and partially assembled multiple plant nuclear genomes. Organelle genomes have been shared privately and nuclear genomes for two Australian native species have been assembled and analysed for genes, repeats, microsatellite SSRs, and inter-species similarities. We have also prepared genome size estimates.
Dr Jeremy Parsons, Bioinformatician
Ms Roxane Legaie, Bioinformatician
Barker says QFAB’s expertise in experimental design and bioinformatics analysis can be applied at any scale, from a simple microarray comparison of differential gene expression, to a full-blown systems biology analysis integrating genomic, proteomic, metabolomic and clinical data.
“We engage with a prospective client, discuss what they want, then submit it to our team for a think-tank session on how it might be done with the expertise and resources that we have in-house, and at the client’s end.
“We then go back to the client with a proposal detailing where and how we believe we can help.”
Barker says QFAB has served a variety of clients over the past seven years including CSIRO, Australia’s universities, medical research institutes, state primary industry, fisheries and forestry departments, and private biotech and pharmaceutical companies.
Barker says bioinformatics is moving “at a mile a minute”, so keeping abreast of the changes requires a commitment to ongoing learning as part of the job and an investment in the professional development of QFAB’s team.
Barker says he has seen an example of a research institute’s embedded bioinformatician being rapidly overwhelmed by data. “They have
no reserve time to learn on the job. That is the advantage of having a larger team to draw on.
“Around 60 per cent of QFAB’s recruits are PhDs. Everyone else is at least postgraduate trained, and we have a core of experienced bioinformaticians in senior positions to bring the necessary rigour to project planning.
“You need the depth of experience provided by staff who have worked on other projects before QFAB recruited them.”
“A bioinformatician joining the team may have had experience working on a particular class of cancers, or on viral infections of mangoes, so they’re good with that type of data and have that specialist knowledge as well as the more general bioinformatics skills. “Collectively we can call upon a broad range of expertise within our teams, and ask them what they think about a particular question.
“We apply the team approach to every project, but we like to broaden the discussion on the projects we have on the boil at any point in time, because someone from another team may have an insight into a particularly tricky question.”
Barker says clients can be certain that QFAB will have the best available expertise to do the job -
“We stay up to date with the technologies out there, and the specialised methodologies that go with them, so we will have a pretty good idea which technology is most appropriate for each client’s project.
“The technology changes rapidly, and all bioinformaticians think they can produce a better algorithm than the one described in the latest journal.
“We learn and adapt as need dictates. You don’t always have to reinvent the wheel; often, there is already an algorithm that can do the job. The trick is knowing that the algorithm exists, and how to apply it.”
As for data-crunching power, Barker says the facility has just updated its computer cluster. It has seven nodes built around a 64-core processor, each with 256 gigabits of RAM, and terabyte storage capacities.
“That’s enough for most jobs,” he said. “But if it isn’t, we have access to a supercomputer facility at the University of Queensland that runs a terabyte of RAM, which can handle whole genome comparisons.”
“With these facilities, our broad expertise, and our data-integration abilities, we believe we offer a service beyond the in-house bioinformatics capabilities of any single institution or company in Australia and the Asia Pacific region.”
2120
Southern Cross University - Plant Science Bioinformatics Support
23
Brief description of the project
Implementation of a statistical pipeline in the Glycoselect database for the identification of glycoprotein biomarker signatures.
Background A new high-throughput glycoproteomics technology is being developed by the client to uncover potential glycosylation changes in a complex mix of proteins present in biological fluids such as serum. The input data consists of protein identification as determined by tandem mass spectrometry, together with their binding affinities to a panel of lectins, which indicate the glycan structure. A statistical
pipeline needed to be deployed in the existing Glycoselect database to identify biomarker signatures. One of the challenges was to propose an appropriate methodology to deal with data which include many zero values – many classical statistical approaches (t-test, non parametric test) do not apply in this case.
What were the outcomes? The statistical methodology developed by Lê Cao et al., 2011* was proposed for this project and produced very satisfying results. The pipeline was developed using this methodology and implemented in the R statistical programming language.
An outlier detection step was also
proposed to process the data beforehand and remove potential outliers. The resulting process clearly identified the outliers in the data enabling the researchers to remove these prior to selection of the biomarker panel.
The R script was handed over to the Glycoselect developer to be implemented into the Glycoselect analytical pipeline. The outliner detection methodology including visualisation of the analyses was also provided to the client.
*Lê Cao K.-A., Boitard, S. and Besse, P. (2011). Sparse PLS Discriminant Analysis: biologically relevant feature selection and graphical displays for multiclass problems BMC Bioinformatics, 12:253
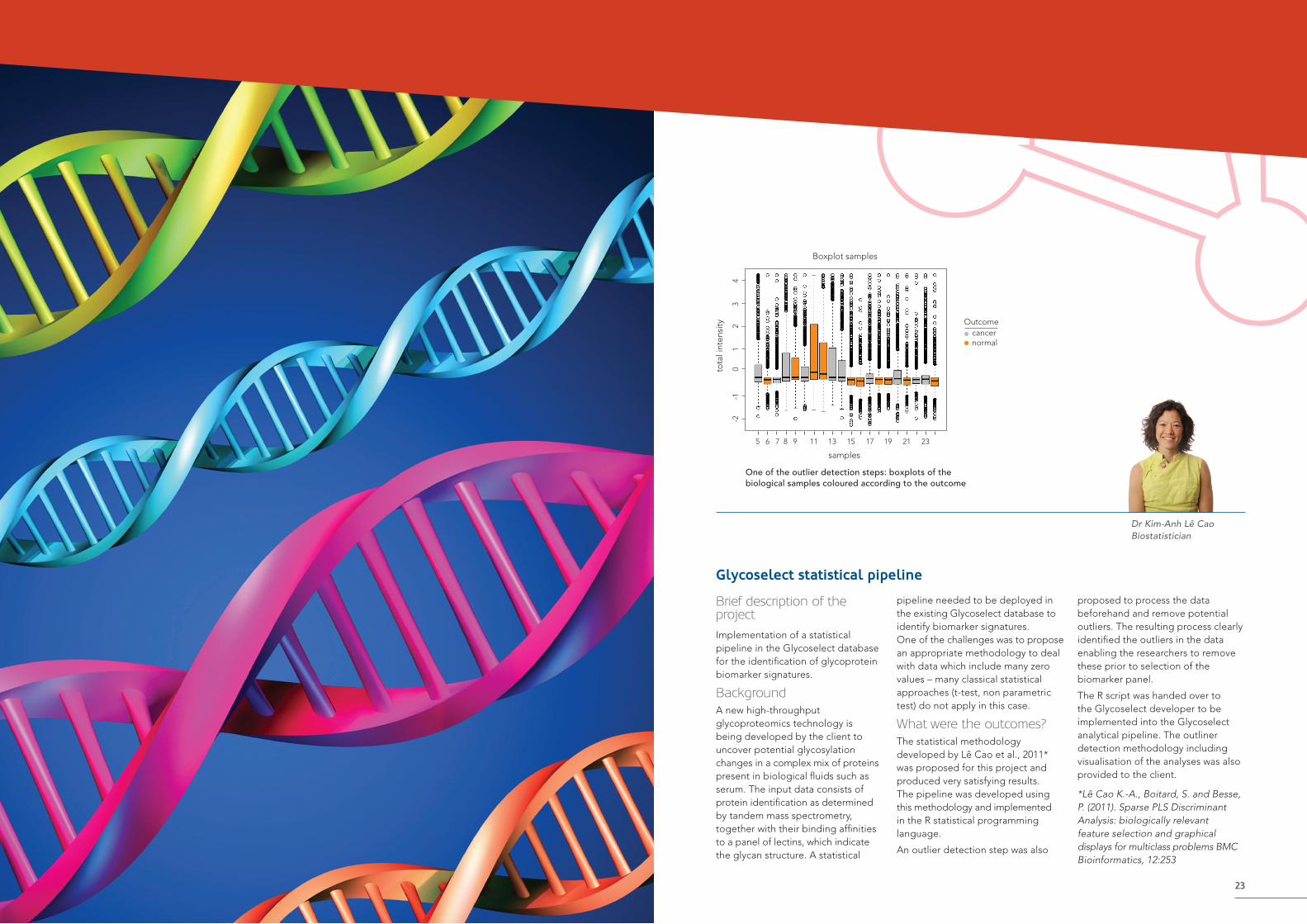
One of the outlier detection steps: boxplots of the biological samples coloured according to the outcome
Dr Kim-Anh Lê CaoBiostatistician
Glycoselect statistical pipeline
Outcomecancernormal
Boxplot samples
samples
tota
l int
ensi
ty
5 6 7 8 9 11 13 15 17 19 21 23
-2
-1
0
1
2
3
4
Brief description of the projectQFAB has worked in collaboration with Professor Glenn King to create Arachnoserver, the online data repository for spider toxin research.
BackgroundHigh impact research requires the wide and clear distribution of results. This can be hampered by bioinformatics web applications, which often suffer from a lack of maintenance, leading to a decline in data currency and subsequent accuracy.
These databases also require that their structure, data, and utility be appropriately modified over time with new discoveries and changes in information priority.
The aim of this project was to develop a robust, extensible and maintainable software architecture that would make ArachnoServer the world’s gold standard online data repository for spider toxin research for years to come.
What were the outcomes? A web application was developed to enable two key functions:
1) Allowing secure manual curation of the toxin records by the expert team led by Professor Glenn King using available literature and patent information.
2) Providing easy and powerful advanced search, browse and view capabilities. ArachnoServer enables neuroscientists, pharmacologists, and toxinologists to explore high quality toxin information and rapidly answer their research questions. Each toxin record is displayed in
2524
a single page and, where available, a toxin’s structure can be dynamically displayed.
The solution chosen for ArachnoServer was to develop a Java Spring Model View Controller (MVC) application that uses a Hibernate Object Relational Mapping (ORM) layer to a MySQL database. Using this architecture, the application and data model can be easily extended or modified, as changes to the data model do not require SQL changes.
Two powerful bioinformatics tools
have been made available through the web interface. First, similarity searches can be made using BLAST. Secondly, signal peptide and propeptide regions in spider-toxin precursors can be predicted using SpiderP, a new tool developed for ArachnoServer.
ArachnoServer has become an international resource that is cross-referenced by the European Bioinformatics Institute’s UniProt knowledge base (UniProtKB).
http://www.arachnoserver.org/
Volker Herzig, David L. A. Wood, Felicity Newell, Pierre-Alain Chaumeil, Quentin Kaas, Greta J. Binford; Graham M. Nicholson; Dominique Gorse; Glenn F. King (2011) ArachnoServer 2.0, an updated online resource for spider toxin sequences and structures. Nucleic Acids Research 39, D653-D657
David LA Wood, Tomas Miljenović, Shuzhi Cai, Robert J Raven, Quentin Kaas, Pierre Escoubas, Volker Herzig, David Wilson and Glenn F King (2009) BMC Genomics 10:375
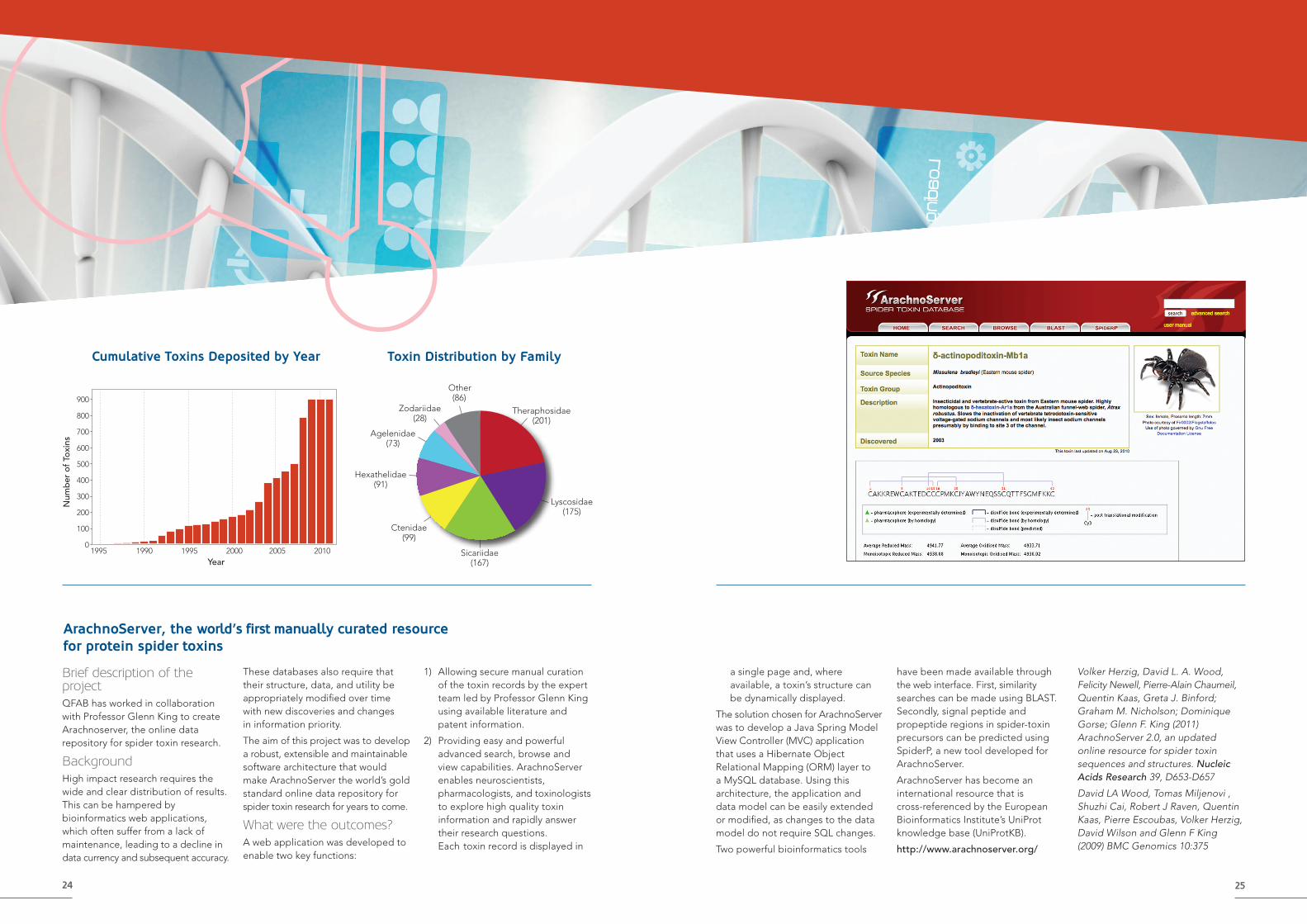
Toxin Distribution by Family
Theraphosidae(201)
Lyscosidae (175)
Sicariidae (167)
Other (86)
Zodariidae (28)
Agelenidae (73)
Ctenidae (99)
Hexathelidae (91)
Cumulative Toxins Deposited by Year
1995 1990 1995 2000 2005 2010
900
800
700
600
500
400
300
200
100
0
Num
ber
of
Toxi
ns
Year
ArachnoServer, the world’s first manually curated resource for protein spider toxins

2726
Brief description of the projectPopulating Research Data Australia with collection descriptions of data held in the European Bioinformatics Institute databanks.
Background The European Bioinformatics Institute (EBI, part of the European Molecular Biology Laboratory, EMBL) provides international access to data in molecular bioscience generated by researchers worldwide, including Australia. In its present state, Australian specific data is difficult to isolate within the EBI databases, particularly for the non-domain user. The establishment of the EMBL Australia Bioinformatics Resource at the University of Queensland has provided the opportunity for linking data of Australian interest deposited at the EBI, to Research Data Australia (RDA), a cohesive repository of research data collections enabling Australian researchers to easily publish, discover, access and use research data.
The aim of this project was to develop a set of software to allow nucleotide and protein sequence data of Australian interest to be discoverable through RDA in the form of collections.
The project was funded by the Australian National Data Service through the DIISRTE Education Infrastructure Fund.
What were the outcomes? In this project, more than 13,000 collection records describing Australian-related content of the EBI nucleotide and protein sequence databases were created. A large effort was made to divide and describe the content of large databases into many smaller datasets that are of potential interest to a wide and varied range of researchers. The collections encompass two types of Australian data: a) data submitted from Australian-based researchers; b) data associated with sets (and subsets thereof) of Australian species.
The link between RDA and the EBI is provided through the use of landing pages that are simple to use and contain structured information useful to non-domain specialists who are unfamiliar with the content of the EBI databases (http://rda.ebi.edu.au). Molecular data of Australian interest that is present on the EBI are now more easily found, accessible and re-usable through RDA (http://researchdata.ands.org.au).
The technical solutions developed for this project were:
> Identification of Australian research institutions: A list of relevant Australian research institutions conducting biological research was compiled. This list includes institutions identified through ARC and NHMRC grant information and having a National Library of Australia (NLA) Party Persistent Identifier. Research institutions were then grouped by states and territories.
Dr Dominique Gorse General Manager
EBI – Making Australian Data Discoverable
> Identification of Australian species: A list of Australian species was sourced from the Atlas of Living Australia through the IBIS taxono my web services (http://www ala.org.au/tools-services/ species-name-services/). These species were assigned to approximately 800 higher level taxonomic ranking groups (eg genus, class, order) using the NCBI taxonomy (http://www.ncbi. nlm.nih.gov/taxonomy). The higher order groupings were selected in consultation with ANDS whilst the NCBI taxonomy was used for species assignment as this taxonomy is used in the EBI databases.
> Extraction of data from EBI databases: Australian species or research institutions were used as query items to interrogate the EBI databases: Uniprot (http://www ebi.ac.uk/uniprot/) for protein sequences and ENA (http:// www.ebi.ac.uk/ena/) for nucleotide
sequences. A Java library was implemented which used EBI hosted web services (http://www. ebi.ac.uk/Tools/webservices/) to query these databases. This library then inserted the extracted data into a MySQL database. Other EBI databases were not interrogated as they either did not contain data that could be definitively identified as Australian, or were not able to be queried using the web services.
> Automatic generation of collections and submission to RDA: Data stored in the MySQL database was converted into ANDS compliant RIF-CS xml (using an ANDS supplied RIF-CS Java library) and made accessible to a RDA harvest data source. More than 13,000 collections were generated.
> Landing page for collections: The landing page is a webpage that is accessible from RDA and acts as a link between RDA and
the primary data housed at the EBI. The webpage lists basic metadata for the collection (eg a short description, synonyms for the collection) as well as displaying a list of records (eg records of DNA or protein sequences) relevant to that collection. It also allows for navigation back to the primary source at EBI and navigation to related collections. The webpage was developed using Java servlets, JSP and JavaScript. The web interface is deployed on an Apache Tomcat web server on an ESX server with RedHat enterprise Linux 5.4.
The software is freely available for download from Scourceforge under the GNU General Public Licence. http://sourceforge.net/projects/ebi-rda-linkage/?source=directory
QFAB staff contact: Dominique Gorse Project Manager
2928
Recent publications in which QFAB has collaborated include:
Muscat GE, Eriksson NA, Byth K, Loi S, Graham D, Jindal S, Davis MJ, Clyne C, Funder JW, Simpson ER, Ragan MA, Kuczek E, Fuller PJ, Tilley WD, Leedman PJ, Clarke CL. (2013). Research Resource: Nuclear Receptors as Transcriptome: Discriminant and Prognostic Value in Breast Cancer. Mol Endocrinol 27(2), 350-365.
Donald M. Gardiner, Megan C. McDonald, Lorenzo Covarelli, Peter S. Solomon, Anca G. Rusu, Mhairi Marshall, Kemal Kazan, Sukumar Chakraborty, Bruce A. McDonald, John M. Manners (2012). Comparative Pathogenomics Reveals Horizontally Acquired Novel Virulence Genes in Fungi Infecting Cereal Hosts. PLoS Pathog Sep, 8(9).
Schroder, K., Irvine, K.M., Taylor, M.S., Bokil, N.J., Lê Cao, K.-A., Masterman, K-A., Labzin, L.I., Semple, C.A., Kapetanovic, R.A., Fairbairn, L., Akalin, A., Faulkner, G.J., Baillie , J.K., Gongora, M., Daub, C.O., Kawaji, H., McLachlan, G.J., Goldman, N., Grimmond, S.M., Carninci, P., Suzuki, H., Hayashizaki, Y., Lenhard, B., Hume, D.A., Sweet, M.J (2012). Conservation and Divergence in Toll-like Receptor 4-regulated gene expression in primary human versus mouse macrophages. Proceedings of the National Academy of Sciences. Proc Natl Acad Sci 109(16), E944 - E953
Yao, F., Coquery, J., & Lê Cao, K.-A. (2012). Independent Principal Component Analysis for biologically meaningful dimension reduction of large biological data sets. BMC bioinformatics, 13(1), 24.
Bauer, D. C., Willadsen, K., Buske, F. A., Lê Cao, K. A., Bailey, T. L., Dellaire, G., & Boden, M. (2011). Sorting the nuclear proteome. Bioinformatics, 27(13), i7-14.
Herzig, V., Wood, D. L., Newell, F., Chaumeil ,P. A., Kaas, Q., Binford, G. J., Nicholson, G. M, Gorse, D., King, G. F. (2011). ArachnoServer 2.0, an updated online resource for spider toxin sequences and structures. [Journal article]. Nucleic acids research, 39(Database issue), D653 - D657.
Lê Cao, K.-A., & LeGall, C. (2011). Integration and variable selection of ‘omics’ data sets with PLS: a survey Journal de la Société Francaise de Statistique, 152(2).
Lê Cao, K. A., Boitard, S., & Besse, P. (2011). Sparse PLS discriminant analysis: biologically relevant
feature selection and graphical displays for multiclass problems. BMC bioinformatics, 12, 253.
Lingwood, B. E., Henry, A. M., d’Emden, M. C., Fullerton, A. M., Mortimer, R. H., Colditz, P. B., Lê Cao, K. A., Callaway, L. K. (2011). Determinants of body fat in infants of women with gestational diabetes mellitus differ with fetal sex. Diabetes Care, 34(12), 2581-2585.
Choi, J., Davis, M. J., Newman, A. F., & Ragan, M. A. (2010). A semantic web ontology for small molecules and their biological targets. J Chem Inf Model, 50(5), 732-741.
Davis, M. J., Sehgal, M. S., & Ragan, M. A. (2010). Automatic, context-specific generation of Gene Ontology slims. [Journal Article Research Support Non-U S Gov’t].
BMC bioinformatics, 11, 498.
Degrelle, S. A., Lê Cao, K. A., Heyman, Y., Everts, R. E., Campion, E., Richard, C., Ducroix-Crépy, C., Tian, X. C., Lewin, H. A., Renard, J. P., Robert-Granié, C., Hue, I. (2010). A small set of extra-embryonic genes defines a new landmark for bovine embryo staging Reproduction 141(1), 79-89.
Lê Cao, K. A., Meugnier, E., & McLachlan, G. J. (2010). Integrative mixture of experts to combine clinical factors and gene markers. Bioinformatics, 26(9), 1192-1198.
Mercer, T. R., Wilhelm, D., Dinger, M.E., Soldà, G., Korbie, D. J., Glazov, E. A., Truong, V., Schwenke, M., Simons, C., Matthaei, K.I., Saint, R., Koopman, P., Mattick, J. S. (2010). Expression of distinct RNAs from 3’
untranslated regions. Nucleic Acids Res, 39((6)), 2393-2403.
Taft, R. J, Simons, C., Nahkuri, S., Oey, H., Korbie, D. J., Mercer, T. R., Holst, J., Ritchie, W., Wong, J. J., Rasko, J. E., Rokhsar, D. S., Degnan, B. M., Mattick, J. S. (2010). Nuclear- localized tiny RNAs are associated with transcription initiation and splice sites in metazoans. Nature Structural & Molecular Biology, 17(8), 1030-U1146.
Shin, C. J., Davis, M. J., & Ragan, M. A. (2009). Towards the mammalian interactome: Inference of a core mammalian interaction set in mouse. Proteomics, 9(23), 5256-5266.
Shin, C. J., Wong, S., Davis, M. J., & Ragan, M. A. (2009). Protein-protein interaction as a predictor of subcellular location. BMC Syst Biol, 3, 28.
Publications
We have supported our client’s successful grant applications worth over $56 million. The intellectual input of the QFAB Team provided clear bioinformatics strategies in their experimental design and valuable outcomes in the analyses.

QFAB BioinformaticsLevel 6, Queensland Bioscience PrecinctThe University of Queensland306 Carmody RoadSt Lucia QLD 4067Australia
T +61 (0)7 3346 2604F +61 (0)7 3346 2101E [email protected]
www.qfab.org



























