Embed Size (px)
Citation preview

2016/4/27
[論文紹介]Beyond Ranking: Optimizing Whole-Page Presentation
(WSDM2016)by Yue Wang, Dawei Yin, Luo Jie, Pengyuan Wang,
Makoto Yamada, Yi Chang, Qiaozhu Mei
ヤフー株式会社
山本 浩司

P2概要
• WSDM2016 Best paper
• 筆頭著者の米Yahooでのインターン時の研究
• 検索結果ページの良さを最適化するためにページのpresentation(表示方法) を考慮する手法
• 従来のランキングを決める問題を拡張

P3一昔前の検索結果ページ(SERP)
• 10件のWeb検索結果: “10 blue links”
• “Probability ranking principle”[36]
• ユーザが上から順に見ていく前提
• レレバンシ (関連度)の高い順に上から並べて表示したときに最適
• より注目されるポジションに重要な結果を配置
credit: slides by the authors
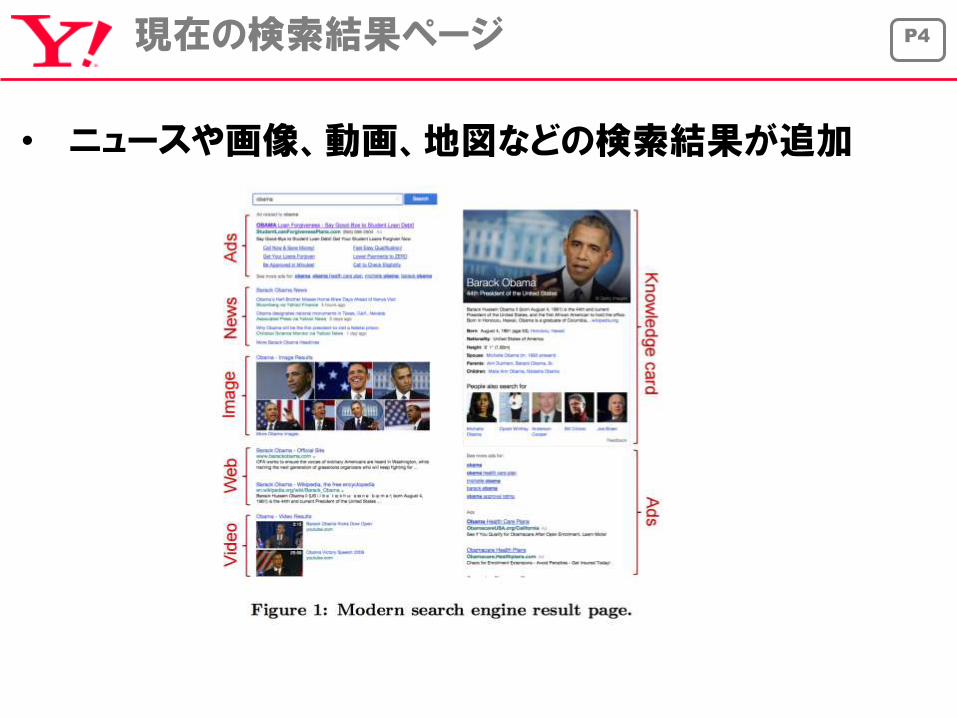
P4現在の検索結果ページ
• ニュースや画像、動画、地図などの検索結果が追加

P5背景:ユーザインタラクションの変化
• 人間の目は自然とグラフィカルな部分に引きつけられる
• 画像、動画などの検索結果が注視されやすい(vertical bias)
• その近くの検索結果も注視されやすい
→ ユーザは検索結果を必ずしも上から順に見ていない
• 種類の異なる結果が混在
• 上から順に関連度の高いものを出せばいいというわけではない
→ ページ全体としてのユーザの満足度の推定が難しくなっている
Credit: Matthew Campion. Eye tracking study:
Google results with videos. 2013/9.
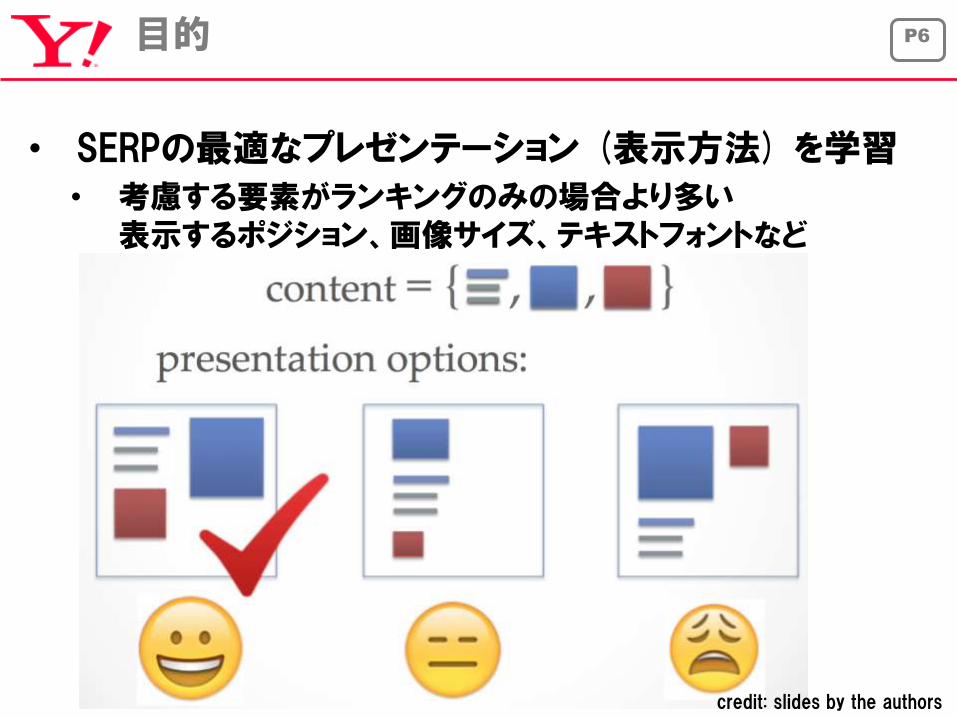
P6目的
• SERPの最適なプレゼンテーション (表示方法) を学習
• 考慮する要素がランキングのみの場合より多い表示するポジション、画像サイズ、テキストフォントなど
credit: slides by the authors

P7提案手法の枠組み
• ページプレゼンテーションの良さの指標は、ユーザの満足度とする
• 満足度のスコアリング関数を学習Q(content, presentation) = satisfaction
• 学習した関数を用いて、検索結果に対し、満足度を最大化するようなプレゼンテーションを予測presentation* = argmax Q(content, presentation)
credit: slides by the authors
presentation
presentation
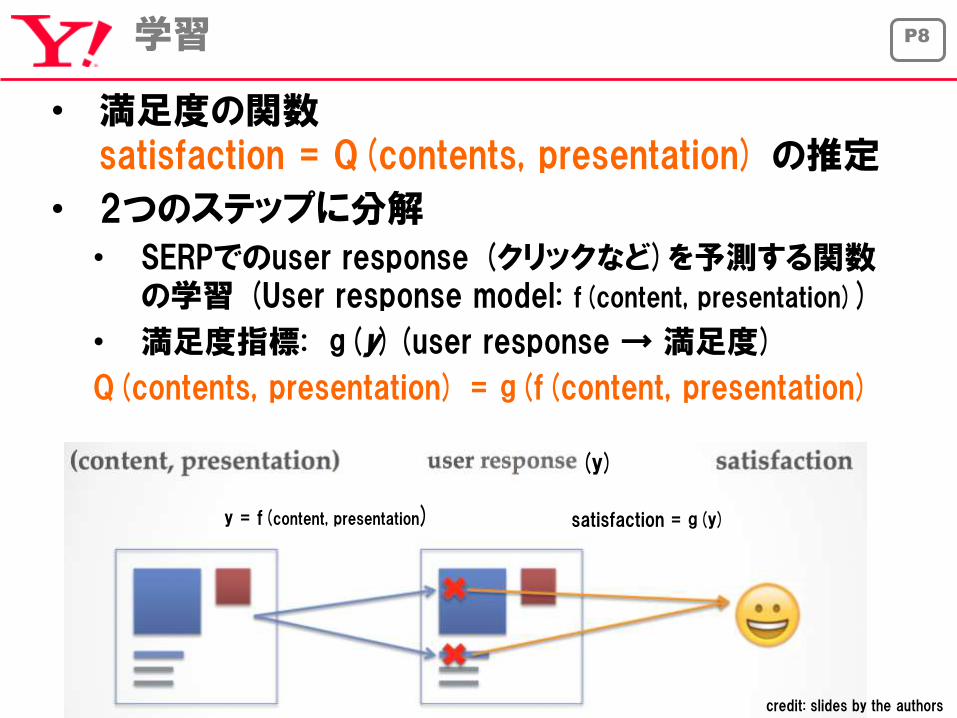
P8学習
• 満足度の関数satisfaction = Q(contents, presentation) の推定
• 2つのステップに分解
• SERPでのuser response (クリックなど)を予測する関数の学習 (User response model: f(content, presentation))
• 満足度指標: g(y)(user response → 満足度)
Q(contents, presentation) = g(f(content, presentation)
credit: slides by the authors
y = f(content, presentation)
(y)
satisfaction = g(y)

P9サーチエンジンの既存手法による選択バイアス
• データ収集時の注意点:通常の検索トラフィックを Q(contents, presentation ) の学習に使えない
• 通常のサーチエンジンは決定的 (deterministic) にcontentをページに表示
• つまり、contentに対してpresentationがユニークに決まっている
credit: slides by the authors
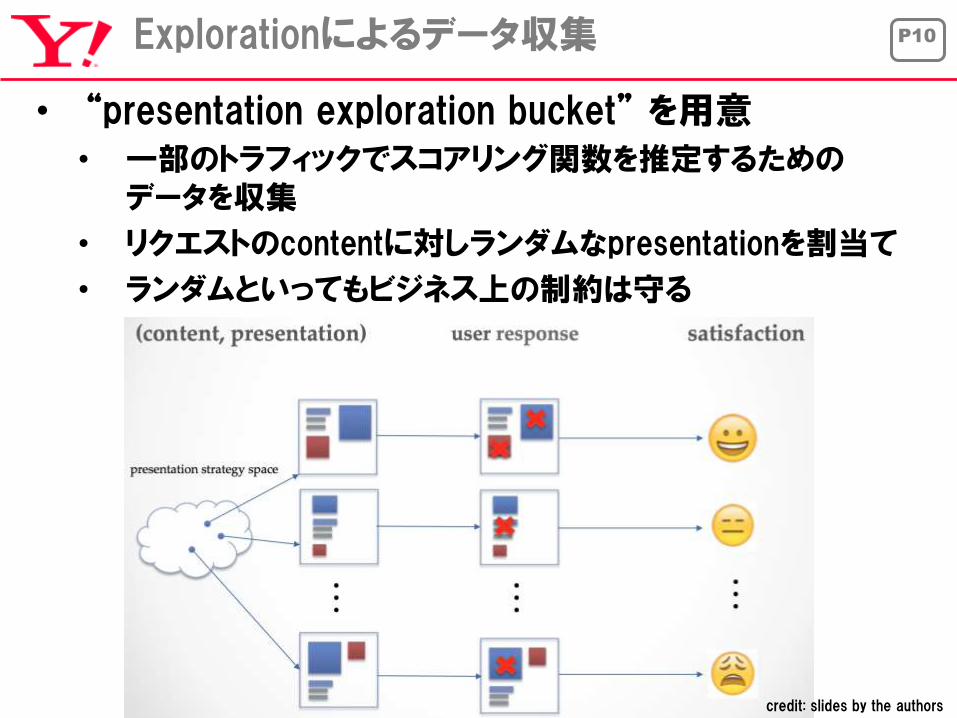
P10Explorationによるデータ収集
• “presentation exploration bucket” を用意
• 一部のトラフィックでスコアリング関数を推定するためのデータを収集
• リクエストのcontentに対しランダムなpresentationを割当て
• ランダムといってもビジネス上の制約は守る
credit: slides by the authors

P11user response model
• 2つのモデルを使用
• Quadratic Feature model• 素性ベクトル: コンテンツ x、プレゼンテーション p (ポジション)、
コンテンツとプレゼンテーションの組み合わせ素性
• Gradient Boosted Decision Tree Model• Gradient boosted decision tree [18]を使ったモデル
y = aTx + bTp + x T W p + c
p* = argmax Q(x, p)p p
= argmax θTp
y = hGBDT (x, p)
p* = argmax Q (x, p)p
(subject to constraints on p)
(subject to constraints on p)
コンテンツ プレゼンテーション 組み合わせ
Q(x, p) = g(y)
(user response y を予測)
(gは満足度指標 )
(user response y を予測)
Q(x, p) = g(y)

P12素性
• Content features
• クエリとその検索結果に関する情報を含むlearning to rankでよく使われる素性
• 比較のため [23] の素性と同じものを使用
• Presentation features
• 本研究で新規に導入した、表示方法についての素性

P13Content features
• Global result set features• 返ってきたすべての結果からの素性
• 各バーティカルのコンテンツの有用性を示す
• Query features• クエリのunigram, bigram, 共起統計量などの語彙素性
• クエリクラシファイアの出力や、実績ベースのクエリ素性など
• Corpus level features• 各バーティカルやWeb検索のドキュメントに関する、クエリとは独立な素性
• 実績CTRやユーザの嗜好など
• Search result features• 各検索結果からの素性
• 個々の結果のレレバンシスコアやランキング素性
• いくつかのバーティカル固有のメタ素性も抽出
• 映画バーティカル: 映画のポスターが使えるか、映画が公開中か、などニュースバーティカル: 過去数時間でヒットした記事数

P14Presentation features
• Binary indicators
• ポジション素性
• Categorical features
• マルチメディアタイプ (テキスト or 画像) や、テキストの書体
• Numerical features
• グラフィカルなアイテムの明るさやコントラストなど
• Other features
• User responseに影響を与えるような要素についての素性例:"グラフィカルアイテムのすぐ上にあるテキストアイテム"
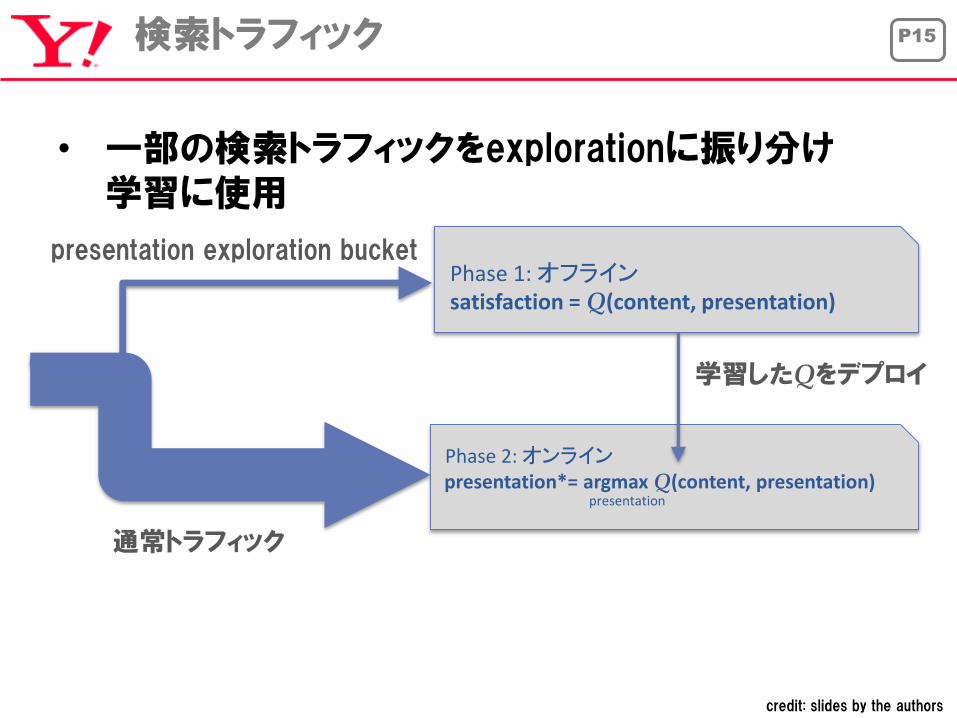
P15検索トラフィック
• 一部の検索トラフィックをexplorationに振り分け学習に使用
Phase 1: オフラインsatisfaction = Q(content, presentation)
presentation*= argmaxQ(content, presentation)presentation
Phase 2: オンライン
通常トラフィック
presentation exploration bucket
学習したQをデプロイ
credit: slides by the authors

P16米Yahoo! Search での実験
• Presentation exploration bucketで探索的にデータ収集
• 2013年の800万page view
• 1-6月を学習データ、7-12月をテストデータ
• 4つのバーティカル
• ニュース、ショッピング、ローカルビジネス (レストランなど)
• 評価指標: click-skip 指標
• ランキングの各アイテムを上から見ていき、• アイテムがクリックされてたら: +1,
• クリックされず、それより下のアイテムがクリックされてたら: -1
の総和
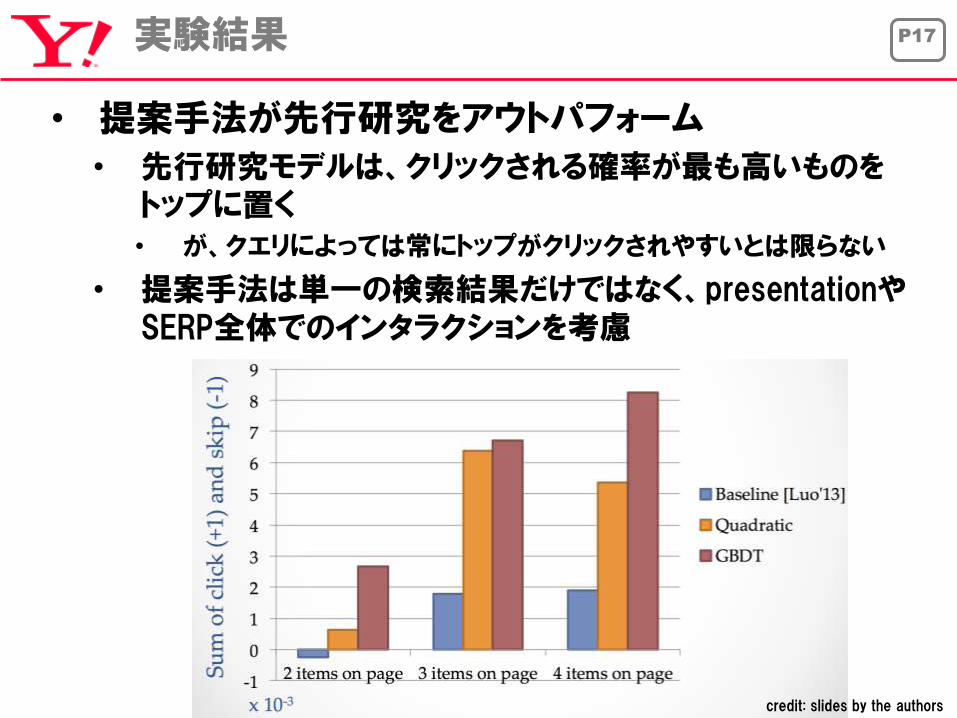
P17実験結果
• 提案手法が先行研究をアウトパフォーム
• 先行研究モデルは、クリックされる確率が最も高いものをトップに置く• が、クエリによっては常にトップがクリックされやすいとは限らない
• 提案手法は単一の検索結果だけではなく、presentationやSERP全体でのインタラクションを考慮
credit: slides by the authors

P18まとめ
• Whole-page presentation optimization(ページ全体での表示最適化) を新たな問題として定式化
• 従来のドキュメントのランキングを拡張したもの
• Federated search の検索結果の最適な表示を求める手法を提案
• 実験で手法の有効性を示した

情報開示先ラベルを入力してください
ありがとうございました





























