Embed Size (px)
Citation preview

Unsupervised Extraction of Attributes and
Their Values from Product Description
Keiji Shinzato and Satoshi Sekine
Rakuten Institute of Technology
17th Oct. 2013
The 6th International Joint Conference on Natural Language Processing

2
What is Rakuten?
• Biggest e-commerce company in Japan.
• B2B2C model.
• Statistics:
– # of merchants: 40K+
– # of products: 100M+
– # of product categories: 40K+
• Product page is categorized into a single product
category by a merchant.
• Product info. offered by merchants is described
by various kind of methods.
– Not well organized :-(

3
Examples of product pages (wine category)
Table
Itemizations
Product data is offered by merchants using various methods.

4
Examples of product pages (wine category)
Product data is offered by merchants using various methods.
Full texts

5
Goal
• Develop an unsupervised methodology for
constructing structured data from full texts.
Attribute Value
Color Red
Production area
Italy, Tuscany
Grape variety
Merlot, Cabernet sauvignon, Petit verdot,
Cabernet franc
Vintage 2010
Volume 750ml
Full texts
(Unstructured data) Structured data

6
Unsupervised information extraction
• Distant supervision [Mintz+ 2009]
– Construct an annotated corpus using an existing
Knowledge Base (KB).
– Train a model from the constructed corpus.
Hiroshi Mikitani is founder and CEO of
the online marketing company Rakuten .
Training data for founder-company
information extraction
Founder:
Hiroshi Mikitani
Machine learning
Extraction model

7
Problem of existing KBs
• Wikipedia
– Infobox is not tailored towards e-commerce.
• Freebase
– Only available in English.
– Attribute and values are limited even in English.
Production area
Grape variety
Winery
Attributes in the infobox for the
wine article in Wikipedia.
Attributes for users seeking
their favorite wines.
Vintage
Gap
1. Construct KB for product information extraction.
2. Remove false-positive and false-negative annotations in
the automatically constructed corpous.

8
Agenda
• Background
• Overview of our approach
– Knowledge base induction
– Training data construction
– Extraction model training
– Product page structuring
• Experiments
• Conclusion and future work

9
Overview of our approach
Input: Product pages in the category C
Pages for model construction Pages that we want to structure
Winery: Bodegas Carchelo
Type: Medium body
Grape: Monastrell 40%, Syrah 40%,
Cabernet Sauvignon 20%
Type Red
Country Italy / Tuscany
Grape Sangiovese
Year 2011
Pages including
tables or itemizations
Unstructured pages

10
Overview of our approach
Input: Product pages in the category C
Pages for model construction Pages including
tables or itemizations
Unstructured pages
1. Knowledge
base induction
Knowledge base(KB)
<attr1, value1>
<attr2, value2>
<attr1, value3>
:
Pages that we want to structure
Annotated pages
2. Training data
construction
3. Extraction
model training
Extraction
model
4. Product page
structuring
Output:
Structured data

11
KB induction – Extraction of attribute and its value -
• Attribute acquisition:
– Assumption: Expressions that are often located in
table headers can be considered as attributes.
– Extract expressions enclosed by <TH> tags.
• Attribute value extraction:
– Extract attribute-value using regular expression
patterns [Yoshinaga and Torisawa 2006].
– Store <attr., val.> in the KB along with the number of
merchants that use it in tables or itemizations.
Merchant frequency (MF)
<Production area, France> (29),
<Region, Italy> (13)

12
KB induction - Attribute synonym discovery -
• Assumption: Attributes can be seen as
synonyms of one another if
– they are not included in the same structured data, and
– they share an identical popular value.
• Regard attribute pairs satisfying the conditions as
synonyms.
• Aggregate similar pairs of attribute synonyms by
computing cosine measure.
Non
synonym
<Alcohol, 15 degree>
<Temperature, 15 degree> Synonym
<Production area, France>
<Region, France>
(Country, Region, Production area) (Production area, Region),
(Country, Production area)

13
ぶどう品種
(Grape variety)
内容量
(Volume)
産地
(Production area)
生産者
(Producer)
タイプ
(Type)
ブドウ品種,
(Grape variety)
葡萄品種,
(Grape variety)
使用品種,
(Usage variety)
品種
(Variety)
容量
(Content)
原産地呼称AOC,
(Appellations of origin)
原産地,
(Region of origin)
国,
(Country)
生産地域,
(Production region)
地域,
(Region)
生産地
(Production region)
製造元,
(Manufacturer)
生産者名
(Name of producers)
シャルドネ [59]
(Chardonnay) 750ML [147]
フランス [45]
(France)
ファルネーゼ [9]
(Farnese)
辛口 [34]
(Dry)
メルロー [36]
(Merlot)
720ML [64] イタリア [30]
(Italy)
マス デ モニストロル [4]
(Mas de Monistrol)
赤 [24]
(Red)
シラー [29]
(Syrah)
375ML [49] スペイン [30]
(Spain)
ルロワ [3]
(Leroy)
白 [23]
(White)
リースリング [29]
(Riesling)
500ML [41] チリ [25]
(Chile)
M. シャプティエ [3]
(M. Chapoutier)
フルボディ [23]
(Full body)
グルナッシュ [22]
(Grenache)
1500ML [22] ボルドー [22]
(Bordeaux)
マストロベラルディーノ [3]
(Mastroberardino)
やや甘口 [15]
(Slightly sweet)

14
Overview of our approach
Input: Product pages in the category C
Pages for model construction Pages including
tables or itemizations
Unstructured pages
1. Knowledge
base induction
Knowledge base(KB)
<attr1, value1>
<attr2, value2>
<attr1, value3>
:
Pages that we want to structure
Annotated pages
2. Training data
construction
3. Extraction
model training
Extraction
model
4. Product page
structuring
Output:
Structured data

15
Training data construction
• Simple longest string matching between full texts
and attribute-values in KB.
• Problems in automatic annotation:
– Incorrect annotation (false-positive)
• The flavor of the <grape_variety> grape </grape_variety> is quite
a little.
– Missing annotation (false-negative)
• Chateau Talbot is a famous winery in <production_area> France
</production_area>.

16
Incorrect annotation filtering
• Assumption: Attribute values with low MFs in
structured data and high MFs in unstructured
data are likely to be incorrect.
NM … # of merchants offering a product in a category. MS … # of merchants offering structured data in a category. MFD (v) … # of merchants describing the value v in full texts. MFS (v) … # of merchants describing the value v in structure data.
𝑆𝑐𝑜𝑟𝑒 𝑣 =𝑀𝐹𝐷(𝑣) 𝑁𝑀
𝑀𝐹𝑆(𝑣) 𝑀𝑆
Likeliness of occurring the value v in structured data.
Likeliness of occurring the value v in full texts.
We regard attribute values with scores greater than 30 as incorrect,
and remove sentences including such values from the corpus.

17
Missing annotation filtering
• Induce frequently occurred token sequences in
attribute values with PrefixSpan [Pei+ 2001].
• Remove sentences containing a string that is not
annotated and matches an induced pattern.
– Chateau Talbot is a famous winery in <production_area>
France </production_area>.
Pattern: [chateau] [ANY_TOKEN]
<Winery, Chateau Lanessan>
<Winery, Chateau Fontareche>
<Winery, Chateau Latour>

18
Overview of our approach
Input: Product pages in the category C
Pages for model construction Pages including
tables or itemizations
Unstructured pages
1. Knowledge
base induction
Knowledge base(KB)
<attr1, value1>
<attr2, value2>
<attr1, value3>
:
Pages that we want to structure
Annotated pages
2. Training data
construction
3. Extraction
model training
Extraction
model
4. Product page
structuring
Output:
Structured data

19
Extraction model training
• Algorithm: Conditional random fields [Lafferty+ 2001]
• Chunk tag: Start/End (IOBES) model [Sekine+ 1998]
• Features:
– Token: Surface form of the token.
– Base: Base form of the token.
– PoS: Part-of-Speech tag of the token.
– Char. type: Types of characters in the token.
– Prefix: Double character prefix of the token.
– Suffix: Double character suffix of the token.
– The above features of ±3 tokens surrounding the token.
They are frequently employed in the task of Japanese NER.

20
Overview of our approach
Input: Product pages in the category C
Pages for model construction Pages including
tables or itemizations
Unstructured pages
1. Knowledge
base induction
Knowledge base(KB)
<attr1, value1>
<attr2, value2>
<attr1, value3>
:
Pages that we want to structure
Annotated pages
2. Training data
construction
3. Extraction
model training
Extraction
model
4. Product page
structuring
Output:
Structured data

21
Agenda
• Background
• Overview of our approach
– Knowledge base induction
– Training data construction
– Extraction model training
– Product page structuring
• Experiments
• Conclusion and future work

22
Experiments
• Evaluation of KB
– Extracted attributes
– Aggregated attribute synonyms
– Extracted attribute-values
• Evaluation of the quality of annotated corpora
• Evaluation of extraction models

23
Experimental setting
• Category:
– Selected major eight categories in Rakuten.
• Wine, T-shirts, Printer ink, Shampoo, Golf ball, and others.
• Attribute:
– Selected the top eight attributes in each category
according to the merchant frequencies of the attributes.
• Training dataset:
– Randomly picked up 100K sentences for each category.
• Evaluation dataset:
– Tailored annotated corpus comprising 1,776 product
pages gathered from the categories.

24
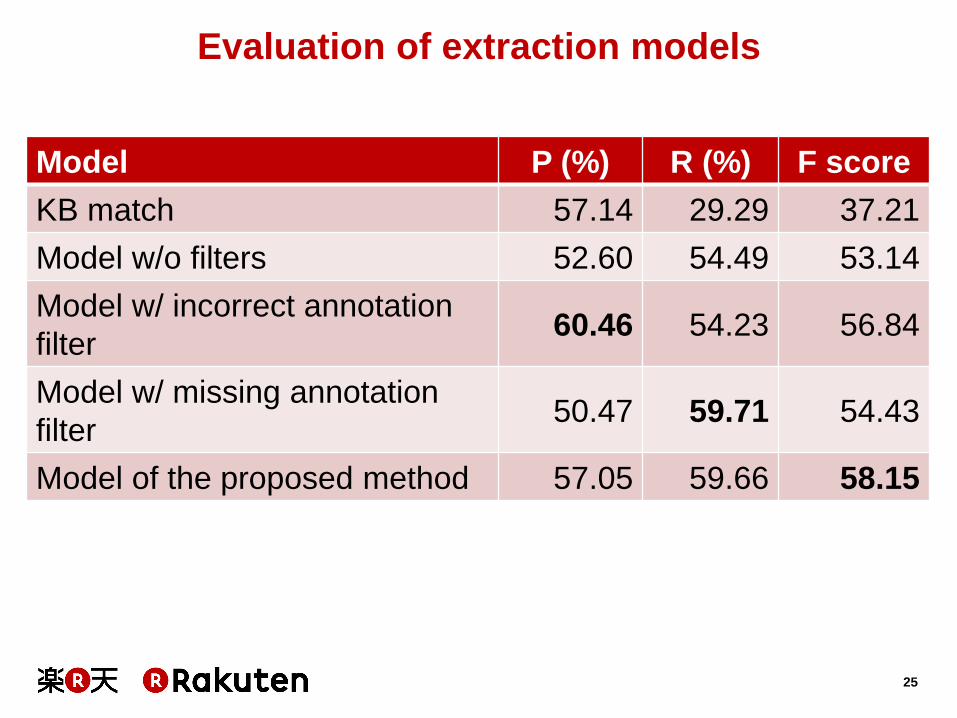
Compared models
• KB match:
– Matching attribute values in KB, and then filtering out
problematic annotations.
• Model w/o filters:
– Training models based on a corpus where the both
filters are not applied.
• Model w/ incorrect annotation filter:
– Training models based on a corpus where only the
filter for incorrect annotations is applied.
• Model w/ missing annotation filter:
– Training models based on a corpus where only the
filter for missing annotations is applied.
25
Evaluation of extraction models
Model P (%) R (%) F score
KB match 57.14 29.29 37.21
Model w/o filters 52.60 54.49 53.14
Model w/ incorrect annotation
filter 60.46 54.23 56.84
Model w/ missing annotation
filter 50.47 59.71 54.43
Model of the proposed method 57.05 59.66 58.15

26
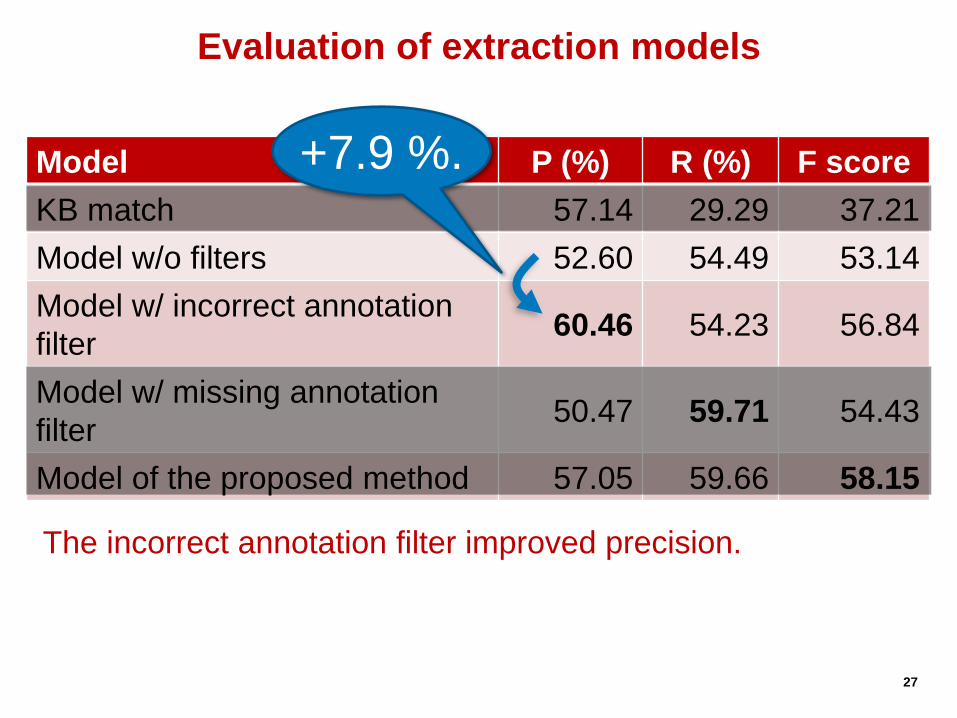
Model P (%) R (%) F score
KB match 57.14 29.29 37.21
Model w/o filters 52.60 54.49 53.14
Model w/ incorrect annotation
filter 60.46 54.23 56.84
Model w/ missing annotation
filter 50.47 59.71 54.43
Model of the proposed method 57.05 59.66 58.15
Evaluation of extraction models +30.4 %.
Recall was dramatically improved.
⇒ Contexts surrounding a value and patterns of
⇒ tokens in a value are successfully captured.
27
Model P (%) R (%) F score
KB match 57.14 29.29 37.21
Model w/o filters 52.60 54.49 53.14
Model w/ incorrect annotation
filter 60.46 54.23 56.84
Model w/ missing annotation
filter 50.47 59.71 54.43
Model of the proposed method 57.05 59.66 58.15
Evaluation of extraction models
+7.9 %.
The incorrect annotation filter improved precision.

28
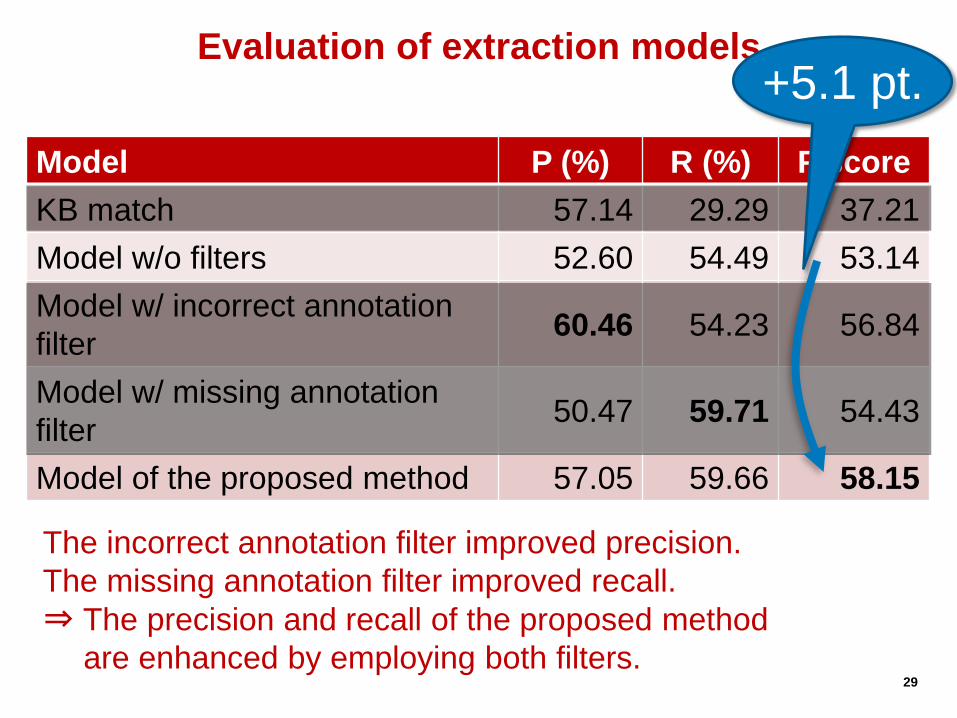
Model P (%) R (%) F score
KB match 57.14 29.29 37.21
Model w/o filters 52.60 54.49 53.14
Model w/ incorrect annotation
filter 60.46 54.23 56.84
Model w/ missing annotation
filter 50.47 59.71 54.43
Model of the proposed method 57.05 59.66 58.15
Evaluation of extraction models +5.2 %.
The incorrect annotation filter improved precision.
The missing annotation filter improved recall.
29
Model P (%) R (%) F score
KB match 57.14 29.29 37.21
Model w/o filters 52.60 54.49 53.14
Model w/ incorrect annotation
filter 60.46 54.23 56.84
Model w/ missing annotation
filter 50.47 59.71 54.43
Model of the proposed method 57.05 59.66 58.15
Evaluation of extraction models +5.1 pt.
The incorrect annotation filter improved precision.
The missing annotation filter improved recall.
⇒ The precision and recall of the proposed method
⇒ are enhanced by employing both filters.

30
Error trend
• Randomly selected 50 attribute values judged as
incorrect in wine and shampoo categories.
Type # of err.
Automatic annotation 36
Incorrect KB entry 23
Over generation by learned patterns 15
Extraction from unrelated regions 12
Others 14

31
Automatic annotation error
• 土壌が<産地>ボルドー</産地>のポムロールと非常に似ている。
• <成分>ヒアルロン酸</成分> 以上の保水力がある。
• <タイプ>白</タイプ>カビチーズに合わせるとより楽しめます。
• 輸出は全体の<アルコール>10%</アルコール>程度。
Soil is very similar with ones in Pomerol region of <production_area>
Bordeaux </production_area>.
<type>White</type> mold cheese will enhance the taste of the wine.
The amount of exports is approximately <alcohol>10 %</alcohol> of
the total.
It has a higher water-holding ability <constituent> than hyaluronan
</constituent> has.

32
Related work
• Product information extraction
– (Semi-) Supervised methodology [Ghani+ 2006, Probst+
2007, Davidov+ 2010, Bakalov+ 2011, Putthividhya+ 2011]
⇒ Training data or initial seeds are required.
– Unsupervised methodology [Yoshinaga+ 2006, Dalvi+ 2009,
Gulhane+ 2010, Mauge+ 2012, Bing+ 2012]
⇒ Not for full texts or limited to the size of texts.
• Unsupervised NER / Unsupervised IE
– Many attempts based on distant supervision [Nadeau+
2006, Whitelaw+ 2008, Nothman+ 2008, Mintz+ 2009, Ritter+
2011]
⇒ Wikipedia and Freebase are resources.

33
Conclusion and future work
• Distant supervision based approach for extracting
attributes and their values from product pages.
– Construction of knowledge base.
– Remove false-positive and false-negative annotations
from automatically constructed corpus.
• Evaluated the performance of KB induction,
automatic annotation, and extraction models
under multiple categories.
• Future work
– Improve the annotation quality by considering contexts.
– Construct KB with wide coverage and high quality.

34
Thank you for your kind attention !





























