Embed Size (px)
Citation preview

Teaching AI about human knowledge
Ines Montani Explosion AI

Explosion AI is a digital studio specialising in Artificial Intelligence and Natural Language Processing.
Open-source library for industrial-strength Natural Language Processing
spaCy’s next-generation Machine Learning library for deep learning with text
Data Store coming soon: pre-trained, customisable modelsfor a variety of languages and domains

Machine learning is programming by
example.
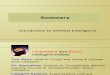
Examples are your source code, training is compilation.
draw examples from the same distribution as the runtime inputs
goal: system’s prediction given some input matches label a human would have assigned
examples
training
predictioninputlabels

How machines “learn”
def train_tagger(examples):
W = defaultdict(lambda: zeros(n_tags))
for (word, prev, next), human_tag in examples:
scores = W[word] + W[prev] + W[next]
guess = scores.argmax()
if guess != human_tag:
for feat in (word, prev, next):
W[feat][guess] -= 1
W[feat][human_tag] += 1
the weights we'll train
if the guess was wrong, adjust weights
get the best-scoring tag
score each tag given weights & context
examples = words, tags, contexts
decrease score for bad tag in this context
increase score for good tag in this context
Example: training a simple part-of-speech tagger with the perceptron algorithm(teach the model to recognise verbs, nouns, etc.)

The bottleneck in AI is data, not algorithms.

Algorithms are general, training data is specific.
data quality, data quantity and accuracy problems are still the biggest problems in AI (Source: The State of AI survey)
you can extract knowledge from all kinds of sources, e.g. sentiment from emoji on Reddit 😍
you usually need at least some data specific to your problem annotated by humans

Where human knowledge in AI really comes from
Images: Amazon Mechanical Turk, depressing.org
Mechanical Turk
human annotators
~$5 per hour
boring tasks
low incentives

Don’t expect great data if you’re boring the shit out of underpaid people.
Why are we “designing around” this?“Taking a HIT: Designing around Rejection, Mistrust, Risk, and Workers’ Experiences in Amazon Mechanical Turk” (McInnis et al., 2016)
data collection needs the same treatment as all other human-facing processes
good UX + purpose + incentives = better quality

UX-driven data collection with active learning
assist human with good UX and task structure
the things that are hard for the computer are usually easy for the human, and vice versa
don’t waste time on what the model already knows, ask human about what the model is most interested in
SOLUTION #1
model human
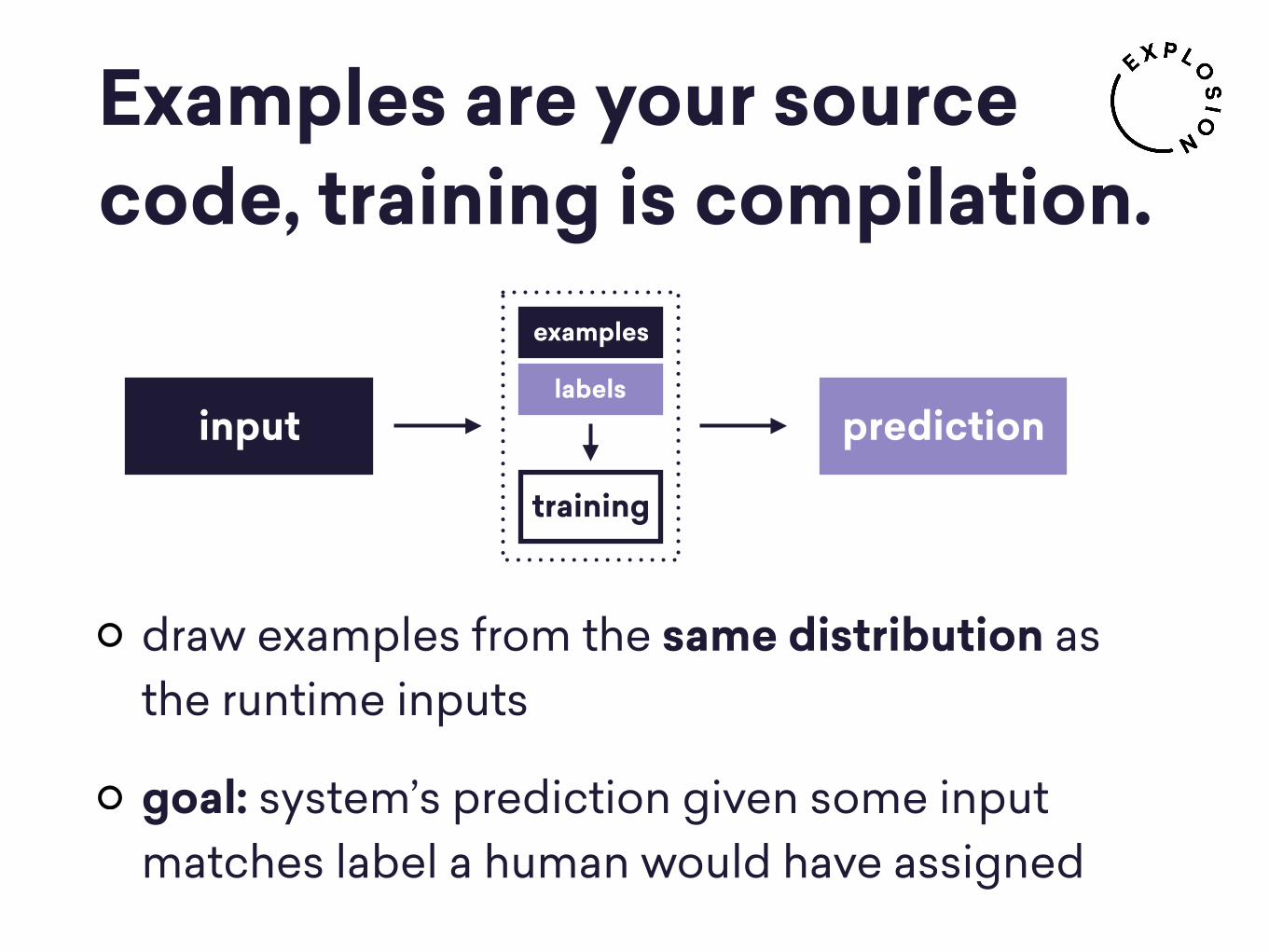
tasks
human annotates all tasks
annotated tasks are used as training
data for model
Batch learning vs. active learning approach to annotation and training
BATCHBATCH
model human
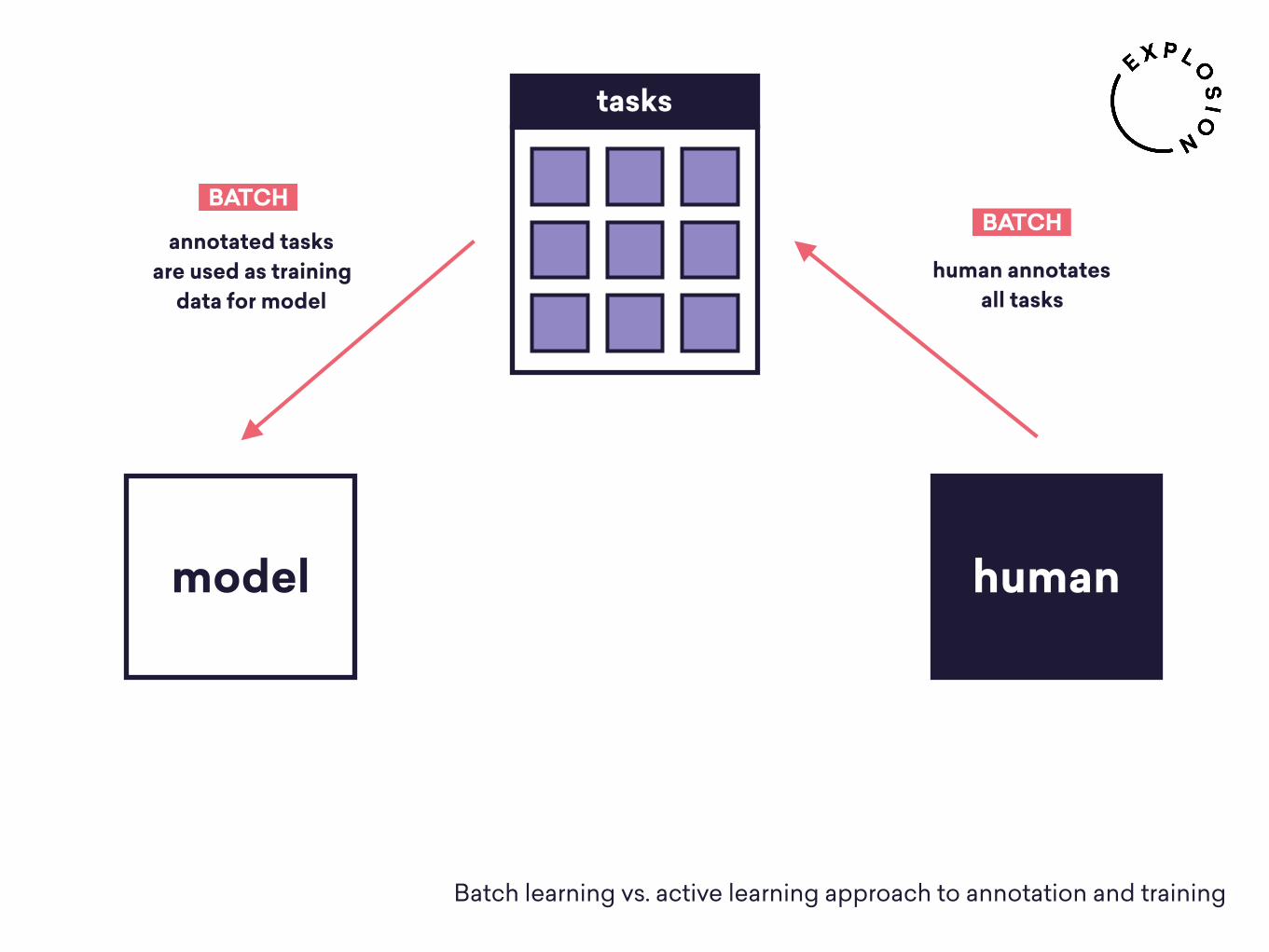
tasks
human annotates all tasks
annotated tasks are used as training
data for model
model chooses one task
human annotates chosen task
annotated single task influences model’s decision on what to ask next
Batch learning vs. active learning approach to annotation and training
BATCHBATCH
ACTIVE

Import knowledge with pre-trained models
start off with general information about the language, the world etc.
fine-tune and improve to fit custom needs
big models can work with little training data
backpropagate error signals to correct model
SOLUTION #2
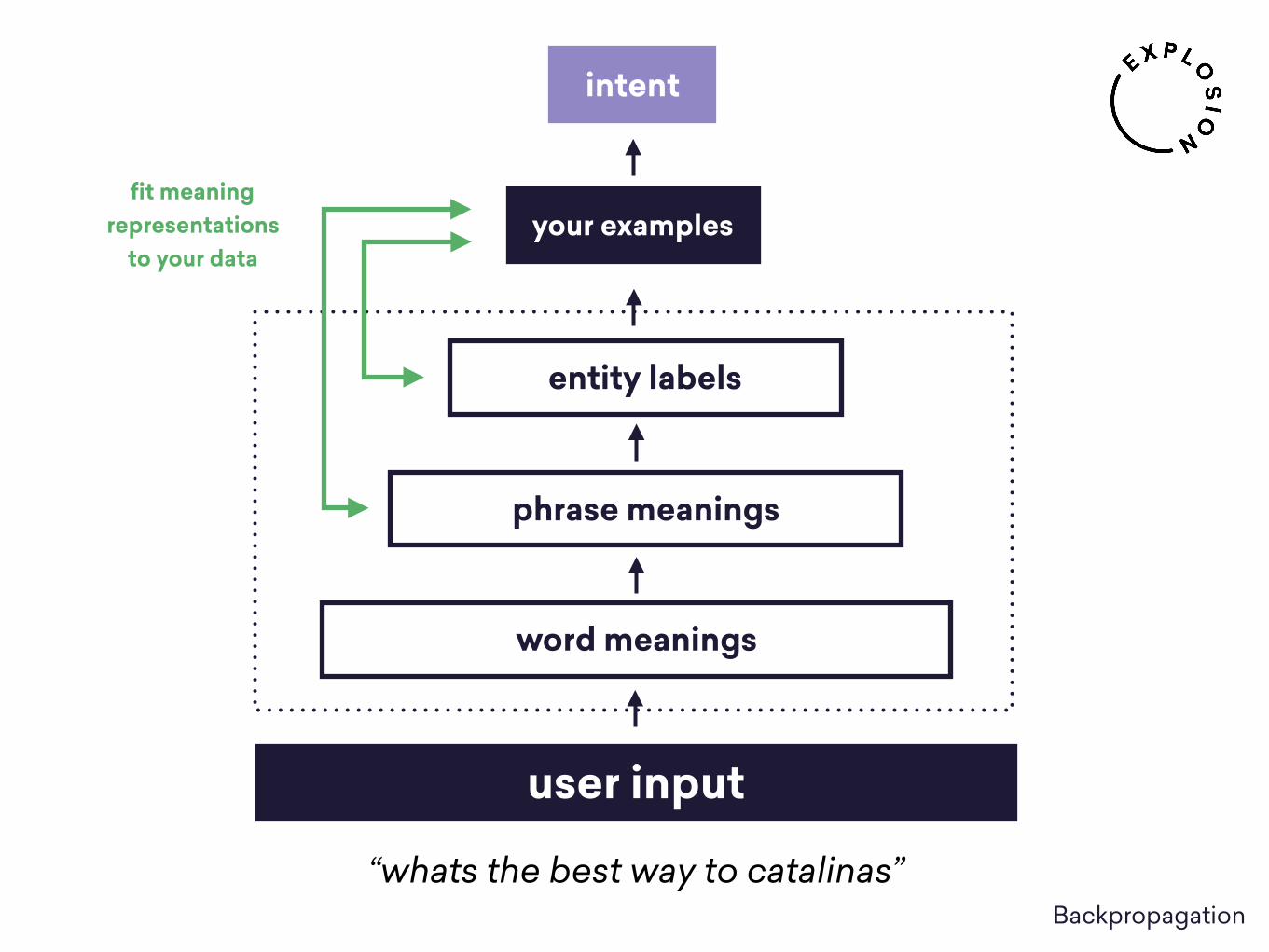
user input
word meanings
entity labels
phrase meanings
intent
your examples
“whats the best way to catalinas”
fit meaning representations
to your data
Backpropagation
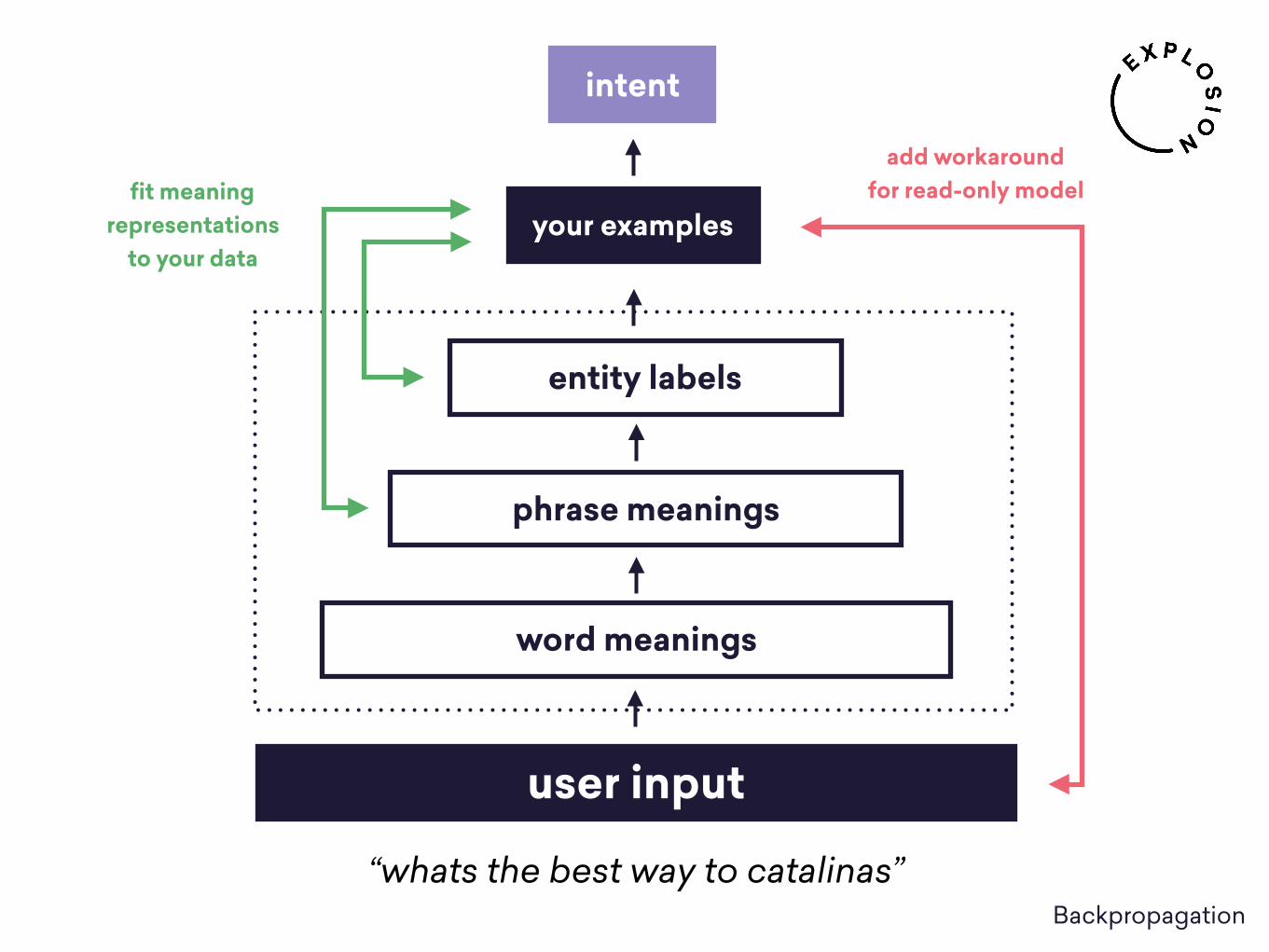
user input
word meanings
entity labels
phrase meanings
intent
your examples
“whats the best way to catalinas”
fit meaning representations
to your data
add workaround for read-only model
Backpropagation

If you don’t own the weights of your model,
you’re missing the point of deep learning.

Deep learning is about reading and writing.
deep learning = learning internal representations to help solve your task.
backpropagate errors on the task you care about to adjust the internal representations
SaaS is great for read-only software – but deep learning needs read and write access

1. AI systems today are no magically smart black boxes. They’re made of annotations and statistics.
2. AI has an HR problem. To improve the technology, we need to fix the way we collect data from humans.
3. AI needs write access. This challenges the current trends towards thin clients and centralised cloud computing.

Thanks!💥 Explosion AI
explosion.ai
📲 Follow us on Twitter@explosion_ai@_inesmontani
@honnibal