Embed Size (px)
Citation preview

Start From A MapReduce Graph Pattern-recognize Algorithm
Yu LIU
IPL Seminar
2012/05/22

Motivation
• Study the real-word large graph problems – One step of my research on parallel graph algorithms
• Study the graph algorithms and their frameworks – Evaluate different frameworks: MapReduce, Pregel
• Make experiences: other researchers on semantic web asked me about how to parallelize their algorithm
• Find a good problem

A Pattern Matching Problem
• Find the link-patterns in the graphs and extract the data
A B C
GP: A -> B -> C A ->B A -> C …

Background: Semantic Web
• A "web of data"
• Builds on the W3C's Resource Description Framework (RDF)
• http://semanticweb.org/
• Lot’s of graph analysis algorithms are used to organize or retrieve information from the semantic web
• Data intensive graph applications are difficult

Background: Linked Data
• http://www.w3.org/standards/semanticweb/data
• Semantic web uses URIs and RDF to represent structured data(knowledge), called linked data
Part of the Linking Open (LOD) Data Project Cloud Diagram

Background: RDF graph
• http://www.w3.org/TR/2004/REC-rdf-concepts-20040210/
• Resource Description Framework (RDF) data is modeled as a labeled graph that represents a collection of binary relations (triples)
RDF is a collection of triples

A RDF/XML Example
<rdf:RDF
xmlns:rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foo = http://example.com/foo# <!-- namespace -->
>
<foo:Thing>
<foo:name>A Thing</foo:name>
<foo:language rdf:resource="http://downlode.org/rdf/iso-639/languages#en" />
</foo:Thing>
</rdf:RDF>

Recognize the Patterns
• The Linked Open Data (LOD) includes over 31 billion RDF triples interlinked by around 504 million SameAs links (owl:sameAs)
• Retrieving graph patterns from linked data sets is a very time-consuming job.
<rdf:Description rdf:about="#William_Jefferson_Clinton"> <owl:sameAs rdf:resource="#BillClinton"/> </rdf:Description>

An Example
Picture from the paper of Z, LIHUA et al Graph-based Ontology Analysis in the Linked Open Data.

• The problem is
– to find all Connected Components of input data (treated as a undirected graph) to build a list of disjoint sets
– Connected components with same pattern are merged

Current Sequential Algorithm
• Specification
– SameAs Triple : RDF has <X owl:sameAs Y>
– SameAs Instance, SI:= (U, N, D) U is the URI appears in a SameAs Triple <U, owl:sameAs, X> or <X,
owl:sameAs, U>,
N is the number of the distinct SameAs Triples,
D is the label of the data set which includes the instance.
– SameAs Graph, SG:= (V, E, SI)
V is the labels of data sets, E ⊆ (V X V), SI is the same instance

The sequential algorithm (basically DFS) will be very slow on a large data set
Need to query outside database
Picture from the paper of Z, LIHUA et al Graph-based Ontology Analysis in the Linked Open Data.

MapReduce Algorithms of Find Connected Components
• Usually need O(d) rounds of map-reduce, d is the diameter of graph
– J. Lin et al, Design patterns for efficient graph algorithms in MapReduce, MLG’10
– U Kang et al, Patterns on the connected components of terabyte-scale graphs, ICDM’10
– Vibhor Rastogi et al, Finding Connected Components on Map-reduce in Logarithmic Rounds, CoRR’12.

A Naïve O(2Ck)-iter MapReduce Algorithm
• Suppose there are k data sets
• Input data is a set of edges: (URI_X, URI_Y)
• Output data is (URI_X, URI_Y , GP_pttr)
• GP_pttr is a 2Ck bit array e,g., [1,1,0]

An O(2Ck)-iter MapReduce Algorithm
• The simplest case: only considering edges between diffident labeled-datasets
1. Find connected components (cc) between two sets and update each item’s graph pattern
2. Find connected components between each two sets
A B C 1
2
3
4 5

Data Structure
CC sets: (uri_src, [uri_dst] , GP)
A{ ( uri_a1, [], 000) , (uri_a2, [uri_b3], 100) }
B { (uri_b3, [], 000), (uri_b4, [uri_c5], 101) }
C { ((uri_c5, []), 000) }
A B C 1
4 5
3
2
A <->B A <-> C B <-> C
pattern 100 010 001

Forward-Backward Communication
Update CC between two sets:
1. Each cc emit message(s): ( uri_d, uri_s, GP_pttr), where has out-going uri reverse the edge
2. Grouping, e.g., : uri_a1:[ a1, m4, m3], uri_b3:[ b3, m2]
3. Merge: (uri_a1, [], 000) + (uri_a1, [uri_b4,uri_b3],111) -> ( uri_a1, [], 111)
4. If need to update the source cc, then send back messages, e.g., a1 -> b3 : (uri_b3, nil, 111)
D
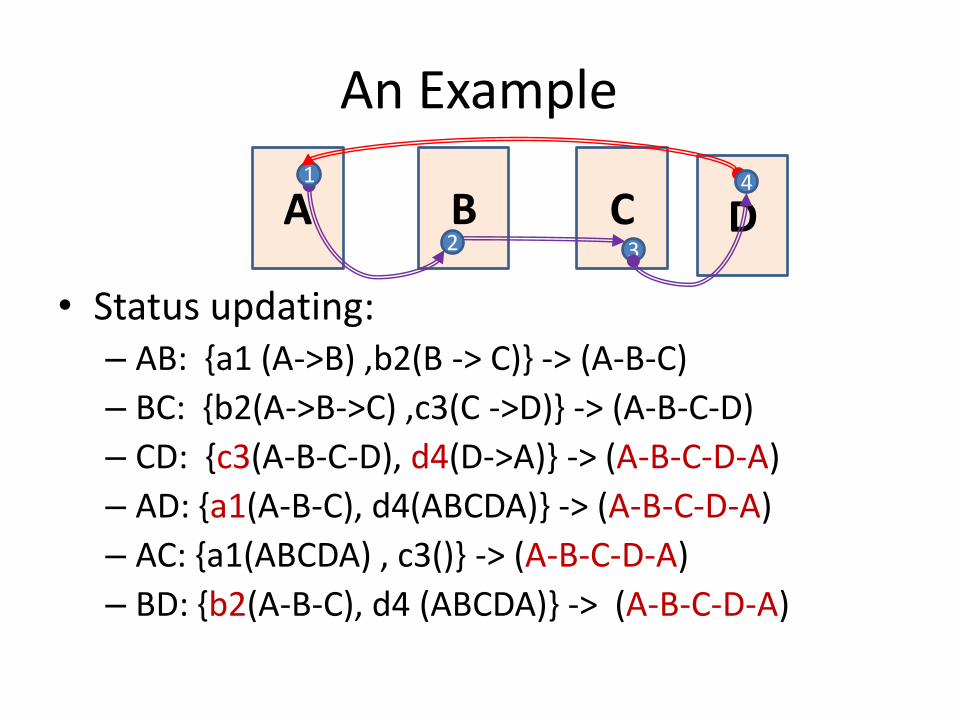
An Example
• Status updating: – AB: {a1 (A->B) ,b2(B -> C)} -> (A-B-C)
– BC: {b2(A->B->C) ,c3(C ->D)} -> (A-B-C-D)
– CD: {c3(A-B-C-D), d4(D->A)} -> (A-B-C-D-A)
– AD: {a1(A-B-C), d4(ABCDA)} -> (A-B-C-D-A)
– AC: {a1(ABCDA) , c3()} -> (A-B-C-D-A)
– BD: {b2(A-B-C), d4 (ABCDA)} -> (A-B-C-D-A)
A B C 1
2 3
4

Complexity
• To update status of each pair of data sets need two passes MapReduce: out-going -> feedback
• For k data sets need 2Ck passes MapReduce
• If there are m edges needs send up to 2(k-1)m messages
• Do not process all data sets but two of them for one time
• Communication can be improved

Also Can Make Similar BSP algorithm
• In [Pregel10]*, a parallel graph framework Pregel is introduced. CC problems can be naturally expressed.
* G. Malewicz et al, Pregel: A System for Large-Scale Graph Processing, SIGMOD’10

Paper Introduction
• CC problem in MapReduce is well studied: – J. Lin et al, Design patterns for efficient graph
algorithms in MapReduce, MLG’10
– U Kang et al, Patterns on the connected components of terabyte-scale graphs, ICDM’10
– Silvio Lattanzi et al, Filtering: A Method for Solving Graph Problems in MapReduce, SPAA’11
– E. Krepska et al, Distributed Processing of Large-Scale Graphs, ICDCN’11
– Finding Connected Components on Map-reduce in Logarithmic Rounds, CoRR’12

Complexity in CoRR’12 Paper
• 3log(n) rounds with high probability, and at most 2(|V| + |E|) communication per round
• Or at most 2log(d) rounds and 3(|V| + |E|) communication per rounds
(n is the number of nodes in the largest component)

Filtering: A Method for Solving Graph Problems in MapReduce
• In this paper they introduced a new approach for processing large scale graph with MapReduce
• The main idea of filtering
“… is to reduce the size of the input in a distributed fashion so that the resulting, much smaller, problem instance can be solved on a single machine. “

Why I Cannot Get Similar Idea One Year Ago?
• My algorithm is a bit similar with the MST algorithm in this paper:

More about SPAA’11 paper
• Strategy of filtering: – Parallel reduce the problem size
– Compute the final answer using the “little” data
– After each filtering-step, the data size should be kept no beyond the main memory
– Complexity analysis
• Examples of algorithms: – unweighted maximal matching problem, maximum
weighted matching problem minimum edge cover problem, minimum cut, find algorithm, …

Find Research problems
• I need finding a good problem to resolve
– What kind of problems are good problems?
• Meaningful
• Not yet resolved
• On one other can do it easily
• Try to resolve real word problems maybe help

The Continued Works
• Study the real word problems such as those on semantic web/linked data : graph indexing, query, contraction, integration and so on.
• Reflect the concrete problems to improve programming pattern/models








![Fast Personalized PageRank on MapReduce...including large scale graph computations [15, 16]. One of the most well known graph computation problems is computing personalized PageRanks](https://img.pdfslide.us/doc/110x75/5f1d9d47d3cd8141252f1060/fast-personalized-pagerank-on-mapreduce-including-large-scale-graph-computations.jpg)




















