Embed Size (px)
Citation preview

Why SparkSecrets of Apache Spark’s Success

This Talk● RDDs● Spark vs InMemory Data Grids (IMDG)● Programming model● Reuse - DRY● Higher level abstraction● Scala● Interactive Shells● Other● Future

About Me● Solution Architect/Dev Manager/Developer/Market Risk
SME at a tier 1 investment bank● 20 years of JVM experience● 2011 - Hadoop + Map Reduce● 2012 - Hive, then Shark● 2013 - Spark, Scala, Play and Spray● 2014 - Spark Streaming, Spark as a compute grid,
Spark ML● 2015 - Independent Apache Spark consultant

Map Reduce
● Good○ High level abstraction (Map and Reduce)○ Distribution and fault tolerance
● Not so Good● Lack abstractions for leveraging distributed memory● Not efficient for iterative algorithms and interactive
data mining (SQL)

Solution - use shared memory
Challenges● not abstracted for general use● fault tolerant and resiliency

Existing In memory solutions
● Distributed shared memory (Coherence, key value stores, database, etc)
● Allow fine grained updated to mutable state● Fault tolerance hard to achieve - requires
replication, logging and checkpointing● network bandwidth < memory bandwidth● substantial storage overheads

Spark RDDs - what’s different● RDD is a read-only, partitioned collection of records● Interface based on coarse grained transformations
(map, filter and join)● Fault tolerance using lineage rather than actual data● if a partition is lost, the RDD has enough information to
recreate it from other RDDs to recompute the partition without requiring replication
● Immutable RDDs
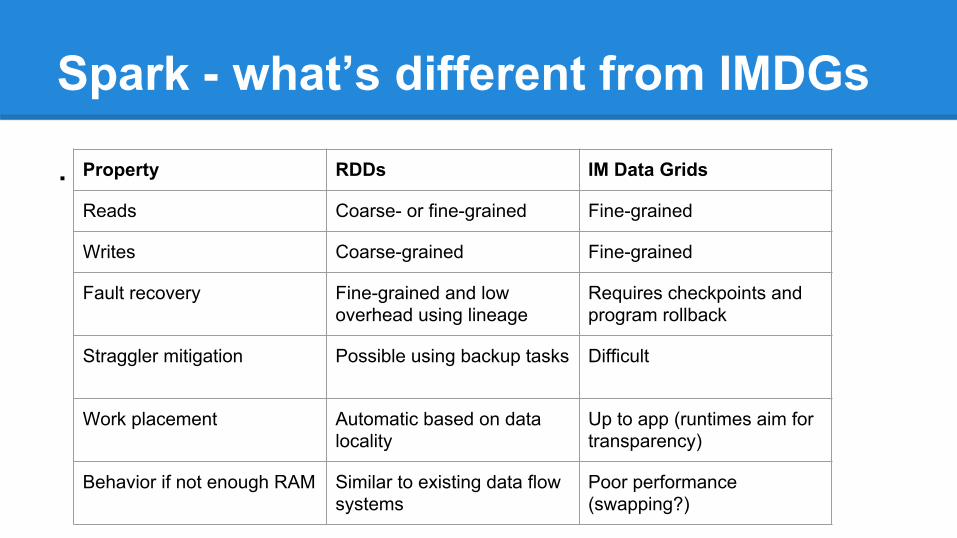
Spark - what’s different from IMDGs
. Property RDDs IM Data Grids
Reads Coarse- or fine-grained Fine-grained
Writes Coarse-grained Fine-grained
Fault recovery Fine-grained and low overhead using lineage
Requires checkpoints and program rollback
Straggler mitigation Possible using backup tasks Difficult
Work placement Automatic based on data locality
Up to app (runtimes aim for transparency)
Behavior if not enough RAM Similar to existing data flow systems
Poor performance (swapping?)

RDDs - what’s different
● only the lost partitions of an RDD need to be recomputed upon failure, and they can be recomputed in parallel on different nodes, without having to roll back the whole program.

RDDs - Straggler Migration
● A second benefit of RDDs is that their immutable nature lets a system mitigate slow nodes (stragglers) by running backup copies of slow tasks as in MapReduce. Backup tasks would be hard to implement with DSM, as the two copies of a task would access the same memory locations and interfere with each other’s updates..

RDD Representation● Set of partitions (“splits”)● List of dependencies on parent RDDs
○ narrow, e.g. map, filter○ wide, e.g. groupBy, require shuffle
● Function to compute a partition given parents● Optional preferred locations● Optional partitioning information

Hadoop RDD
partitions : one per HDFS blockdependencies : nonecompute(partitions) : read corresponding blockpreferred locations : HDFS block locationspartitioner : none

Filtered RDD
partitions : same as parent RDDdependencies : “one-to-one” on parentcompute(partition) : compute parent and filter itpreferred locations(part) : none (ask parent)partitioner = none

Joined RDD
partitions : one per reduce taskdependencies : shuffle on each parentcompute(partition) : read and join shuffled datapreferred locations(part) : none partitioner = HashPartitioner(numTasks)

RDDs - Memory not essential
RDDs degrade gracefully when there is not enough memory to store them, as long as they are only being used in scan-based operations. Partitions that do not fit in RAM can be stored on disk and will provide similar performance to current data-parallel systems.

RDDs - generic abstraction● Coarse grained transformation only are a good fit for
many parallel applications● RDDs efficiently express many programming models -
Map Reduce, SQL, Graph, MLLib● many parallel programs naturally apply the same
operation to many records, making them easy to express
● immutability of RDDs is not an obstacle because one can create multiple RDDs to represent versions of the same dataset


RDDs - persistence and partitioning● Users can control two other aspects of RDDs:
persistence and partitioning. Users can indicate which RDDs they will reuse and choose a storage strategy for them (e.g., in-memory storage). They can also ask that an RDD’s elements be partitioned across machines based on a key in each record. This is useful for placement optimizations, such as ensuring that two datasets that will be joined together are hash-partitioned in the same way

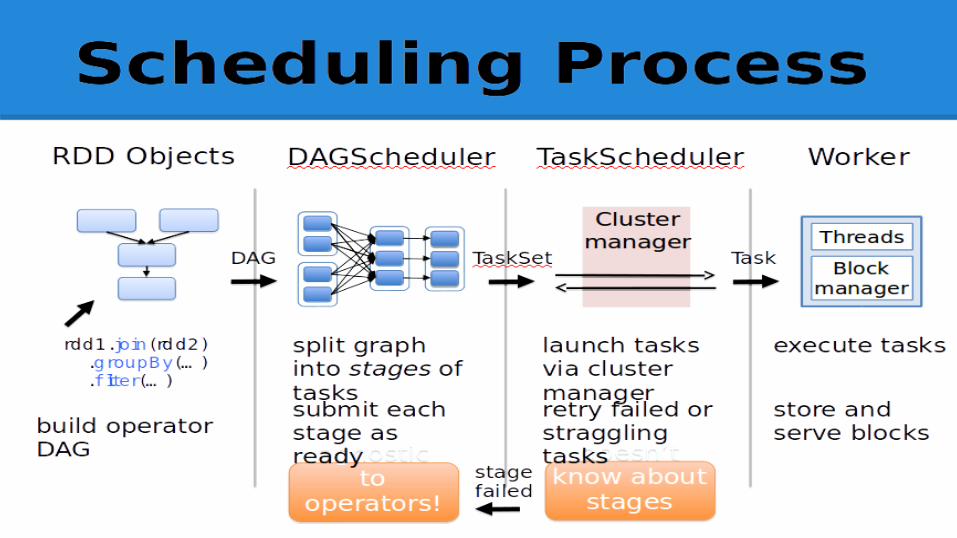
● inspects RDD’s lineage graph to build a DAG of stages to execute. Each stage contains as many pipelined transformations with narrow dependencies as possible.
● The boundaries of the stages are the shuffle operations required for wide dependencies, or any already computed partitions that can shortcircuit the computation of a parent RDD. The scheduler then launches tasks to compute missing partitions from each stage until it has computed the target RDD.
● Cached RDDs not recomputed.● Data locality
Scheduler

Dont reinvent the wheel
● reuse Hadoop APIs - InputOutput formats, codecs
● Hive QL and data types (Serdes)● Hive Server● Spark’s scheduler uses our representation of
RDDs, making it fault tolerant and scalable● Productivity - Spark Shell

● Compatible with JVM ecosystem. Massive legacy codebase in big data
● DSL support Newer Spark API’s are effectively DSL’s
● Concise syntax ● Rapid prototyping, but still type safe ● Thinking functionally Encourages
immutability and good practices
Written in Scala

● Smart team● Dont bite more than what you can chew
(Spark Core, ML + SQL, Streaming next)● Open● Community● Process driven - build automation, test
coverage, api compatibility checks
Other secrets

Don’t use Spark when you need -
● asynchronous finegrained updates to shared state, such as a storage system for a web application or an incremental web crawler. For these applications, it is more efficient to use systems that perform traditional update logging and data checkpointing, such as databases

More to come - Project Tungsten
● Project Tungsten (overcome JVM limitations)○ Memory management and binary processing leveraging application
semantics to manage memory explicitly and eliminate the overhead of JVM object model and garbage collection
○ Cache-aware computation: algorithms and data structures to exploit memory hierarchy
○ Code generation: using code generation to exploit modern compilers and CPUs
● Data Frames○ write less code○ read less data (predicate push down)○ let the optimiser do the hard work

More to come - Data Frames
● write less code● read less data
○ convert to efficient formats○ columnar formats○ use partitioning○ skip data using statistics○ predicate pushdown
● let the optimiser (Catalyst) do the hard work
![Java High Performance Reactive Programmingiproduct.org/.../04/IPT_Reactive_Programming_Java.pdf · Reactive Programming. Functional Programing Reactive Programming [Wikipedia]: a](https://img.pdfslide.us/doc/110x75/5ec60814df097e0643499b13/java-high-performance-reactive-reactive-programming-functional-programing-reactive.jpg)