Embed Size (px)
Citation preview

RenjinAlexander Bertrambedatadriven
TU DortmundDepartment of Computer Science20.01.2012

Agenda
• Brief intro to R
• Motivation for Renjin
• Renjin’s Design
• Performance
• Optimization and the Compiler

Brief Intro to R
• Lingua franca for statistical computing
• R is used by ~ 250,000 analysts worldwide (some say up to 2 million)
• Over 3,500 contributed packages in wide variety of specializations
• Most new statistical techniques are published with R source code

Motivations for Developing Renjin
• Existing R interpreter is an excellent tool for ad hoc analysis – however:
• Difficult to implement certain use cases specific to our consulting business:
▫ Incorporate our R scripts into larger applications for clients (e.g. BI tools)
▫ Make our R scripts available via web interface
▫ Run user provided scripts in sandbox
▫ Develop SaaS tools based on R

Existing Interpreter
• Developed in C
• Extensive use of globals; one interpreter per process
• No layer of abstraction between data and algorithms; all code operates directly on pointers

Opportunties in the JVM
• Growth of Platforms-as-a-Service: Google AppEngine, Heroku, Amazon Beanstalk
• Big Data frameworks: Hadoop, Mahout
• State of the art VM: GC, JIT, etc

Renjin Design Principles
• Performance is best achieved through well-designed abstraction, not hand-coded assembly
• Focus on core statistical functionality and delegate to state-of-the art implementations in other fields, e.g.:
▫ Garbage collection
▫ Character encoding
▫ Database access
▫ Web servers

R developers have alreadyrevolutionized statistical computing: is it fair to expect them to develop
best-of-bread garbage collectors, VM, web servers, and database systems ??

Renjin Implementation
• Parser is ported directly (via Bison-Java)
• Primitive functions (700+) mostly rewritten into natural Java/OO style
• Extensive unit test coverage enables experimentation

Renjin Compared
• Others are seeking to overcome similar shortcomings in R with other approaches:
▫ RevoR
▫ Bigmemory
• Renjin, in contrast, attempts to fix problems in core
▫ Pros: bigger opportunities in the long-term
▫ Cons: riskier, incompatibilities with packages written in C

Examples of Extension Points
R File Functions
Apache VFS
OSHadoop
DFSAmazon
S3
Renjin Vector API
Math & Data Functions
Mem-backed
Rolling buffer backed
JDBC

Primitive implementations
• Primitive implementation is the bulk of the work
• Uses declarative annotations in combination with code generation; several advantages:
▫ Boilerplate auto generated
▫ Optimizations can be globally applied
▫ Provides information to the compiler about types

Primitive Annotations @Primitive("==") @Recycle public static boolean equalTo(double x, double y) { return x == y; } @Primitive("==") @Recycle(false) public static boolean equalTo(Symbol x, Symbol y) { return x == y; } @Primitive("==") @Recycle public static boolean equalTo(String x, String y) { return x.equals(y); }

Aside: Data structures
• R has several OO systems:
▫ S3 function dispatch
▫ S4 objects
▫ Rproto
• However, most R packages simply reuse base vector & list types to organize data
▫ Pro: high degree of interoperability
▫ Con: can be difficult to organize large systems

Aside: R Data Structures
Atomic Vectors:• null• logical• Integer• double• complex• character• raw
Other• symbol• environment*
variables storage for a lexical scope, can be reused as map
• promise
Lists• null• list• expression• pairlist• language - function call
• dotexp - list of promises
Attributesclass – determines function dispatchnames – gives names to list elementsdim – lends a matrix/array shape to vectors/lists
All R values can have attributes, some are “special”
* mutable

Aside: Example of R data structure
data.frame
x <- 1:100
y <- 100:1
frame <- list(x, y)
attr(frame, "class") <- "data.frame"
attr(frame, "names") <- c("x", "y")

Aside: Data structures
• Renjin defines these data structures as interfaces
• Currently, the only implementations are array-backed, but this design opens the possibility of alternate implementations:
▫ Backed by a database cursor
▫ Rolling buffer over text file, etc
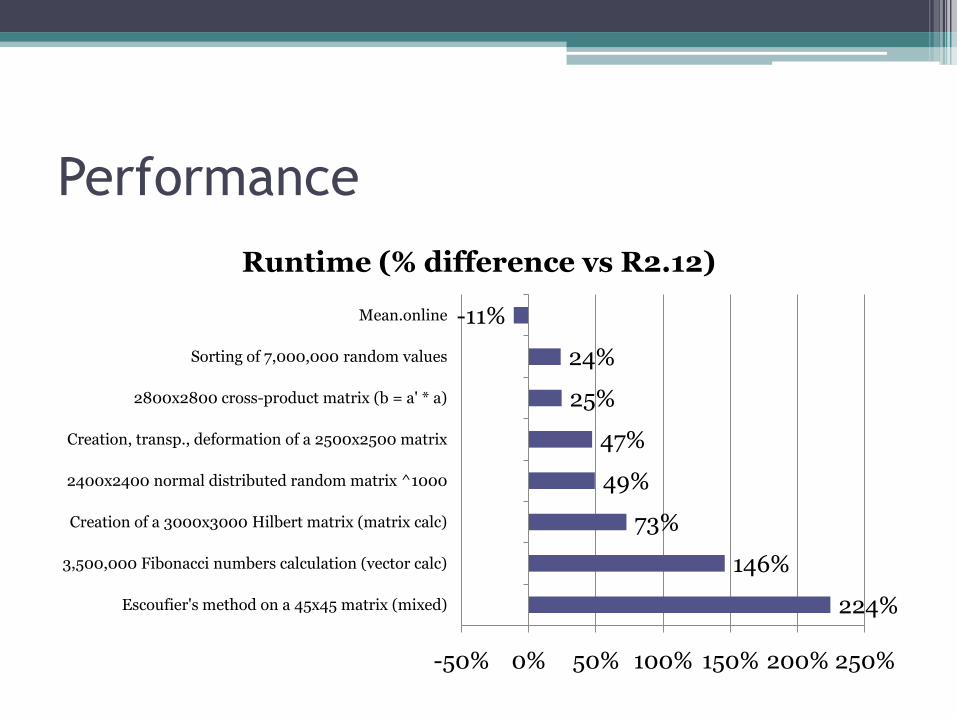
Performance
224%
146%
73%
49%
47%
25%
24%
-11%
-50% 0% 50% 100% 150% 200% 250%
Escoufier's method on a 45x45 matrix (mixed)
3,500,000 Fibonacci numbers calculation (vector calc)
Creation of a 3000x3000 Hilbert matrix (matrix calc)
2400x2400 normal distributed random matrix ^1000
Creation, transp., deformation of a 2500x2500 matrix
2800x2800 cross-product matrix (b = a' * a)
Sorting of 7,000,000 random values
Mean.online
Runtime (% difference vs R2.12)

Performance Wins
– Bloom filterBASE
EN
V
Methods
EN
V
Utils
EN
V
grDevices
EN
V
Stats
EN
V
survey
EN
V
GLOBAL
EN
V
Call to length(x) at
this scope requires checking all parent scopes for a variable length with a function
value

Performance Wins
– Bloom filterBASE
EN
V
Methods
EN
V
Utils
EN
V
grDevices
EN
V
Stats
EN
V
survey
EN
V
GLOBAL
EN
V
Call to length(x) at
this scope requires checking all parent scopes for a variable length with a function
value
To avoid expensive lookups to the HashMap at eachframe, we:• Assign each symbol a single bit in 32-bit integer• Maintain an OR-d mask at each level in the tree• We only check the HashMap if the symbol’s bit is
set

Potential Sources of Performance
Gains (1/2)• Primitives (How fast can we compute the svd of
a huge matrix?)
▫ Parallelization
▫ Algorithmic improvements
Cache-awareness
▫ Byte code optimizations (c.f. Soot)
▫ JVM-level optimization (e.g. SSE instruction sets)

Potential Sources of Performance
Gains (2/2)• Performance of R language code
▫ Translation to JVM byte code (and benefit from JVM’s optimizations)
▫ Avoiding vector-boxing of scalars
▫ Copy-on-write optimization
▫ Parallelization

Building the Compiler
• Direct translation of R code to byte code yields only marginal performance gains – will require optimization to deliver signficiant speedups

Aside: The R language from a
compiler-writer’s perspective• Very functional
• Lazy and impure
• Access to calling frames
• Multimethod dispatch
• Computing on the language

R Language Fun – Very functional
• Everything is actually a function
double <- function(x) x*2
g <- function(f) f(3)
g(double)
`if` <- function(condition, a, b) 42
if(FALSE) 1 else 2; # evaluates to 42
`(` <- function(x) stop('foo!')
2 * (x + 1) # throws foo

R Language Fun – Lazy and Impure
f <- function(a, b) b + a
x <- 1
f(x<-2, x) # evaluates to 3
g <- function(x) deparse(substitute(x))
g(sin(x)) # evaluates to “sin(x)”

R Language Fun – Access to calling
frames
f <- function() assign("x", 42, envir=parent.frame())
g <- function() {
x <- 1
f()
x
}
g() # evaluates to 42

R Language Fun – Multimethod
dispatch
x <- list(2,14)
class(x) <- "version"
y <- list(2,12)
class(y) <- "version"
`<.version` <- function(a,b) (a[[1]] < b[[1]]) || (a[[1]] == b[[1]] && a[[2]] < b[[2]])
x < y # false
y < x # true

R Language Fun – Computing on the
language
f <- function(a,b) a + b
body(f)[[1]] <- `-`
f(0,2) # -2

Design choices
• How much of the language to change?▫ Can’t reasonably allow developers to redefine if, (), {}, etc
▫ What about missing(x), quote(x), assign() ?
• When to compile?▫ AOT – more time to optimize▫ JIT – much more information
• Do ask developers to provide cues/ guidance?▫ Maybe special blocks where only a subset of language
features are supported?▫ Type annotations? New syntax for typing arguments?

Compiling in-depth
• Typical under-performing fragment:
mean.online <- function(x) {
xbar <- x[1]
for(n in 2:length(x)) {
xbar <- ((n – 1) * xbar + x[n]) / n
}
xbar
}

Translation to IRmean.online <- function(x) {
xbar <- x[1]
for(n in seq(2,length(x)) {
xbar <- ((n – 1) *
xbar + x[n]) / n
}
xbar
}
0: xbar ← primitive<[>(x, 1.0)
1: τ₃ ← Δ length(x)d
2: τ₄ ← Δ seq(2.0, τ₃)3: Λ0 ← 0
4: τ₂ ← primitive<length>(τ₄)L0 5: if Λ0 >= τ₂ goto L3 else L1
L1 6: n ← τ₄[Λ0]7: τ₅ ← primitive<->(n, 1.0)
8: τ₆ ← primitive<*>(τ₅, xbar)9: τ₇ ← primitive<[>(x, n)
10: τ₈ ← primitive<+>(τ₆, τ₇)11: xbar ← primitive</>(τ₈, n)
L2 12: Λ0 ← increment counter Λ0
13: goto L0
L3 14: return xbar

Just-in-time Compiling
• Implementing the full language in the IR-based interpreter is difficult;
• May stick with the AST-based interpreter, wait till we hit big loop
• At that point, compile to JVM byte code
• Let’s look at the example again…
![arXiv:1103.1216v2 [astro-ph.IM] 18 Oct 2011 - TU Dortmund...tDept. of Physics, TU Dortmund University, D-44221 Dortmund, Germany uDept. of Physics, University of Alberta, Edmonton,](https://img.pdfslide.us/doc/110x75/613163fb1ecc51586944b4c2/arxiv11031216v2-astro-phim-18-oct-2011-tu-dortmund-tdept-of-physics.jpg)




























