Embed Size (px)
Citation preview

QBer Crowd Based Coding and Harmonization using Linked Data
Rinke Hoekstra and Albert Meroño-Peñuela

The problem we’re trying to solve…
• Many interesting datasets are messy, incomplete and incorrect
• Data analysis requires clean data
• Cleaning data involves careful interpretation and study
• Values and variables in the data are replaced with (more) standard terms (coding)
• Cross-dataset analyses requires a further data harmonization step
• This ‘data preparation’ step can take up to 60% of the total work
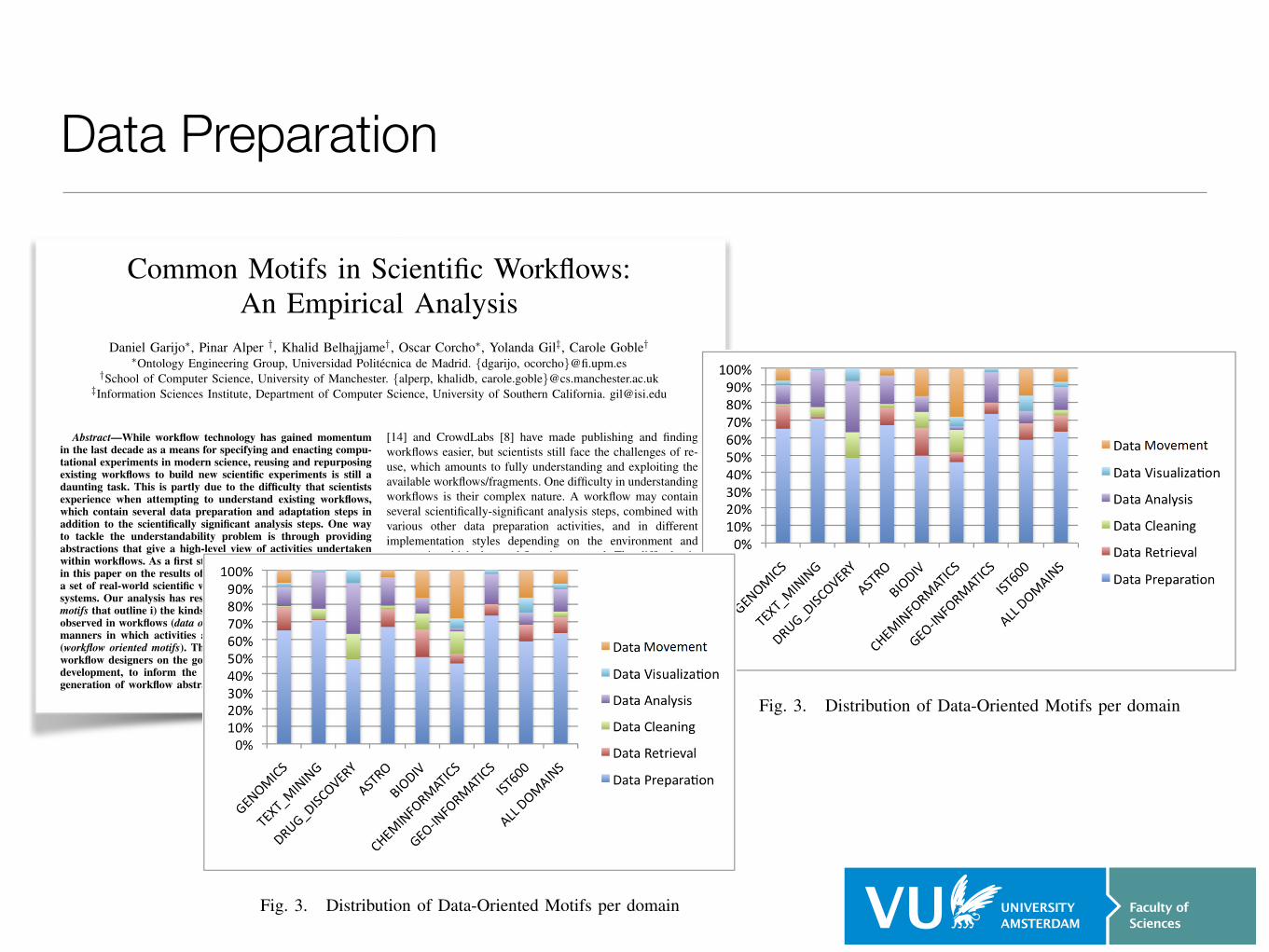
Data Preparation
Common Motifs in Scientific Workflows:An Empirical Analysis
Daniel Garijo⇤, Pinar Alper †, Khalid Belhajjame†, Oscar Corcho⇤, Yolanda Gil‡, Carole Goble†⇤Ontology Engineering Group, Universidad Politecnica de Madrid. {dgarijo, ocorcho}@fi.upm.es
†School of Computer Science, University of Manchester. {alperp, khalidb, carole.goble}@cs.manchester.ac.uk‡Information Sciences Institute, Department of Computer Science, University of Southern California. [email protected]
Abstract—While workflow technology has gained momentumin the last decade as a means for specifying and enacting compu-tational experiments in modern science, reusing and repurposingexisting workflows to build new scientific experiments is still adaunting task. This is partly due to the difficulty that scientistsexperience when attempting to understand existing workflows,which contain several data preparation and adaptation steps inaddition to the scientifically significant analysis steps. One wayto tackle the understandability problem is through providingabstractions that give a high-level view of activities undertakenwithin workflows. As a first step towards abstractions, we reportin this paper on the results of a manual analysis performed overa set of real-world scientific workflows from Taverna and Wingssystems. Our analysis has resulted in a set of scientific workflow
motifs that outline i) the kinds of data intensive activities that areobserved in workflows (data oriented motifs), and ii) the differentmanners in which activities are implemented within workflows(workflow oriented motifs). These motifs can be useful to informworkflow designers on the good and bad practices for workflowdevelopment, to inform the design of automated tools for thegeneration of workflow abstractions, etc.
I. INTRODUCTION
Scientific workflows have been increasingly used in the lastdecade as an instrument for data intensive scientific analysis.In these settings, workflows serve a dual function: first asdetailed documentation of the method (i. e. the input sourcesand processing steps taken for the derivation of a certaindata item) and second as re-usable, executable artifacts fordata-intensive analysis. Workflows stitch together a varietyof data manipulation activities such as data movement, datatransformation or data visualization to serve the goals of thescientific study. The stitching is realized by the constructsmade available by the workflow system used and is largelyshaped by the environment in which the system operates andthe function undertaken by the workflow.
A variety of workflow systems are in use [10] [3] [7] [2]serving several scientific disciplines. A workflow is a softwareartifact, and as such once developed and tested, it can beshared and exchanged between scientists. Other scientists canthen reuse existing workflows in their experiments, e.g., assub-workflows [17]. Workflow reuse presents several advan-tages [4]. For example, it enables proper data citation andimproves quality through shared workflow development byleveraging the expertise of previous users. Users can alsore-purpose existing workflows to adapt them to their needs[4]. Emerging workflow repositories such as myExperiment
[14] and CrowdLabs [8] have made publishing and findingworkflows easier, but scientists still face the challenges of re-use, which amounts to fully understanding and exploiting theavailable workflows/fragments. One difficulty in understandingworkflows is their complex nature. A workflow may containseveral scientifically-significant analysis steps, combined withvarious other data preparation activities, and in differentimplementation styles depending on the environment andcontext in which the workflow is executed. The difficulty inunderstanding causes workflow developers to revert to startingfrom scratch rather than re-using existing fragments.
Through an analysis of the current practices in scientificworkflow development, we could gain insights on the creationof understandable and more effectively re-usable workflows.Specifically, we propose an analysis with the following objec-tives:
1) To reverse-engineer the set of current practices in work-flow development through an analysis of empirical evi-dence.
2) To identify workflow abstractions that would facilitateunderstandability and therefore effective re-use.
3) To detect potential information sources and heuristicsthat can be used to inform the development of tools forcreating workflow abstractions.
In this paper we present the result of an empirical analysisperformed over 177 workflow descriptions from Taverna [10]and Wings [3]. Based on this analysis, we propose a catalogueof scientific workflow motifs. Motifs are provided through i)a characterization of the kinds of data-oriented activities thatare carried out within workflows, which we refer to as data-oriented motifs, and ii) a characterization of the different man-ners in which those activity motifs are realized/implementedwithin workflows, which we refer to as workflow-orientedmotifs. It is worth mentioning that, although important, motifsthat have to do with scheduling and mapping of workflowsonto distributed resources [12] are out the scope of this paper.
The paper is structured as follows. We begin by providingrelated work in Section II, which is followed in Section III bybrief background information on Scientific Workflows, and thetwo systems that were subject to our analysis. Afterwards wedescribe the dataset and the general approach of our analysis.We present the detected scientific workflow motifs in SectionIV and we highlight the main features of their distribution
Fig. 3. Distribution of Data-Oriented Motifs per domain
Fig. 4. Distribution of Data Preparation motifs per domain
databases and shipping data to necessary locations for analysis.The impact of the environmental difference of Wings and
Taverna on the workflows is also observed in the workflow-oriented motifs (Figure 7). Stateful invocations motifs are notpresent in Wings workflows, as all steps are handled by adedicated workflow scheduling framework and the details arehidden from the workflow developers. In Taverna, the work-flow developer is responsible for catering for various differentinvocation requirements of 3rd party services, which mayinclude stateful invocations requiring execution of multipleconsecutive steps in order to undertake a single function.
Regarding workflow-oriented motifs, Figure 8 shows thatHuman-interaction steps are increasingly used in scientificworkflows, especially in the Biodiversity and Cheminformat-ics domains. Human interactions in Taverna workflows arehandled either through external tools (e.g., Google Refine),facilitated via a human-interaction plug-in, or through simplelocal scripts (e.g., selection of configuration values frommulti-choice lists). We have observed that non-trivial humaninteractions involving external tooling require a large numberof workflow steps dedicated to deploying or configuring theexternal tools, resulting in very large and complex workflows.Wings workflows do not support human interaction steps.
Finally, the large proportion of the combination of Compos-ite Workflows and Atomic Workflows motif in Figure 8 shows
Fig. 5. Data Preparation Motifs in the Genomics Workflows
Fig. 6. Data-Oriented Motifs in the Genomics Workflows
that the use of sub-workflows is an established best practicefor modularizing functionality.
VI. DISCUSSION
Our analysis shows that the nature of the environment inwhich a workflow system operates can bring-about obstaclesagainst the re-usability of workflows.
A. Obfuscation of Scientific WorkflowsData-intensive scientific analysis could be large and com-
plex with several processing steps corresponding to differentphases of data analysis performed over various kinds of data.This complexity is exacerbated when the workflow operates inan open environment, like Taverna’s, and composes multiplethird party services supporting different data formats andprotocols. In such cases the workflow contains additional stepsfor coping with different format and protocol requirements.This obfuscation of the workflow burdens the documentationfunction and creates difficulty for the workflow re-user sci-entists, who seeks to have a complete understanding of thefunction and the details of the workflow that they are re-usingin order to be able make scientific claims with their workflowbased studies.
Obfuscation is caused by the abundance of data preparationsteps, data movement operations and multi-step stateful invo-cations. One way to overcome obfuscation is to encapsulate
Fig. 3. Distribution of Data-Oriented Motifs per domain
Fig. 4. Distribution of Data Preparation motifs per domain
databases and shipping data to necessary locations for analysis.The impact of the environmental difference of Wings and
Taverna on the workflows is also observed in the workflow-oriented motifs (Figure 7). Stateful invocations motifs are notpresent in Wings workflows, as all steps are handled by adedicated workflow scheduling framework and the details arehidden from the workflow developers. In Taverna, the work-flow developer is responsible for catering for various differentinvocation requirements of 3rd party services, which mayinclude stateful invocations requiring execution of multipleconsecutive steps in order to undertake a single function.
Regarding workflow-oriented motifs, Figure 8 shows thatHuman-interaction steps are increasingly used in scientificworkflows, especially in the Biodiversity and Cheminformat-ics domains. Human interactions in Taverna workflows arehandled either through external tools (e.g., Google Refine),facilitated via a human-interaction plug-in, or through simplelocal scripts (e.g., selection of configuration values frommulti-choice lists). We have observed that non-trivial humaninteractions involving external tooling require a large numberof workflow steps dedicated to deploying or configuring theexternal tools, resulting in very large and complex workflows.Wings workflows do not support human interaction steps.
Finally, the large proportion of the combination of Compos-ite Workflows and Atomic Workflows motif in Figure 8 shows
Fig. 5. Data Preparation Motifs in the Genomics Workflows
Fig. 6. Data-Oriented Motifs in the Genomics Workflows
that the use of sub-workflows is an established best practicefor modularizing functionality.
VI. DISCUSSION
Our analysis shows that the nature of the environment inwhich a workflow system operates can bring-about obstaclesagainst the re-usability of workflows.
A. Obfuscation of Scientific WorkflowsData-intensive scientific analysis could be large and com-
plex with several processing steps corresponding to differentphases of data analysis performed over various kinds of data.This complexity is exacerbated when the workflow operates inan open environment, like Taverna’s, and composes multiplethird party services supporting different data formats andprotocols. In such cases the workflow contains additional stepsfor coping with different format and protocol requirements.This obfuscation of the workflow burdens the documentationfunction and creates difficulty for the workflow re-user sci-entists, who seeks to have a complete understanding of thefunction and the details of the workflow that they are re-usingin order to be able make scientific claims with their workflowbased studies.
Obfuscation is caused by the abundance of data preparationsteps, data movement operations and multi-step stateful invo-cations. One way to overcome obfuscation is to encapsulate

We do this repeatedly for the same datasets!
Big datasets…
• NAPP, Mosaic, IPUMS etc. solve this for large datasets
• But this is very expensive
• And the results are not mutually compatible
• Or worse… the compatibility is contested

What QBer does…
• Empower individual researchers to
• Code and harmonize individual datasets according to best practices of the community (e.g. HISCO, SDMX, Worldbank, etc.) or against their colleagues
• Share their own code lists with fellow researchers
• Align code lists across datasets
• Publish their standards-compliant datasets on a Structured Data Hub
We use web-based linked data to grow a giant graph of interconnected datasets
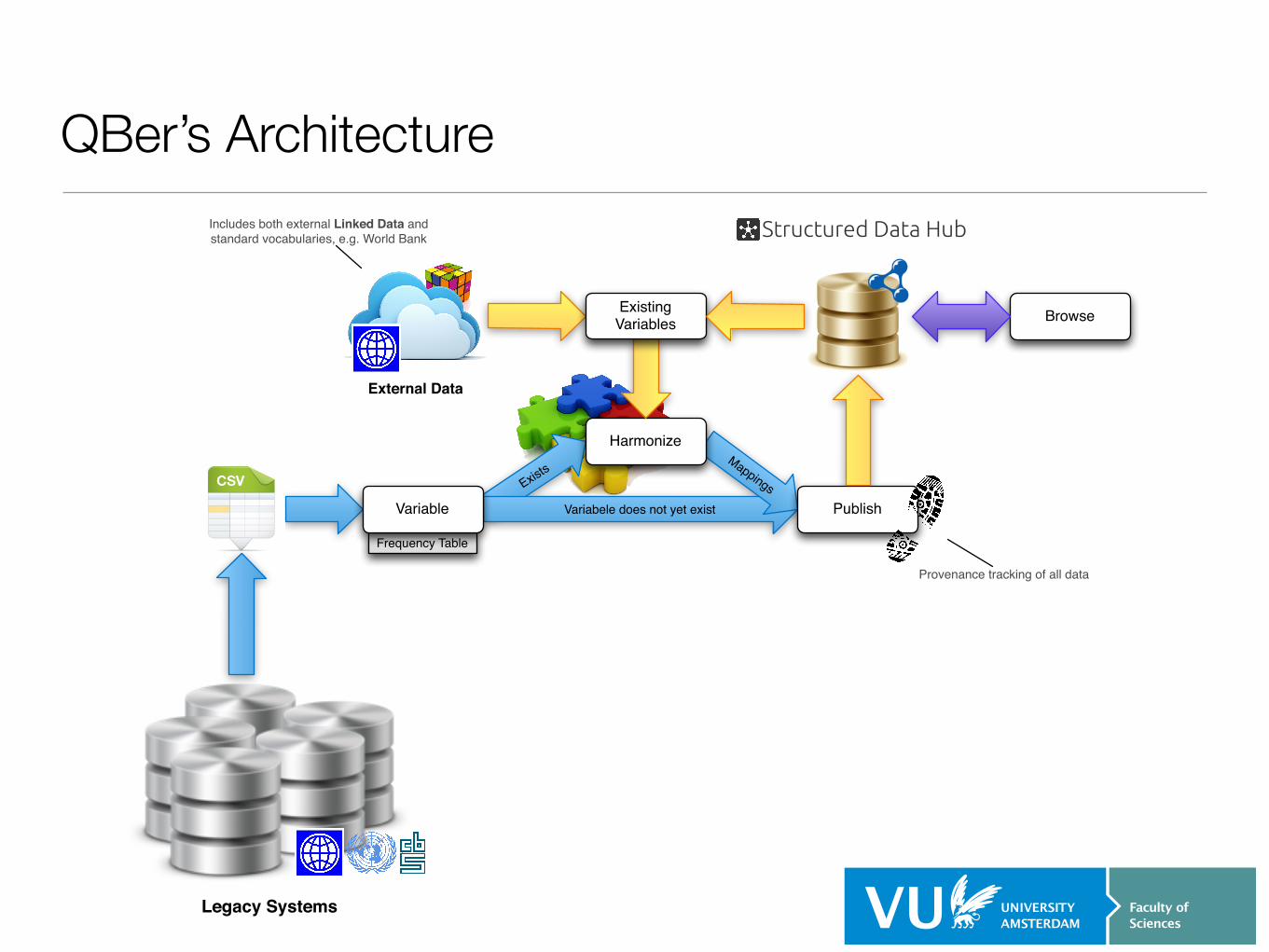
QBer’s Architecture
Exists
Frequency Table
Variabele does not yet existVariable
Mappings
Publish
Harmonize
Includes both external Linked Data and standard vocabularies, e.g. World Bank Structured Data Hub
External Data
Existing Variables
Provenance tracking of all data
Legacy Systems
Browse

What you just saw
• Uploading of micro data dataset and extraction of variables and value frequencies
• Gleaning of known variables and code lists from the Web
• Mapping of variable values to codes (while preserving the originals!)
• Publishing of dataset structure as Linked Data
• Provenance of all assertions to the SDH traceable to time and person
• Collaborative growing of a graph of interconnected datasets

Future benefits
• Automatic extraction of interesting data across datasets
• Opportunities for large scale cross-dataset studies
• Crowd-based production of code lists and mappings
• Reuse other people’s work (or stand on the shoulders of giants)
• No disposable research






























